⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Patch-Wise Hypergraph Contrastive Learning with Dual Normal Distribution Weighting for Multi-Domain Stain Transfer
Authors:Haiyan Wei, Hangrui Xu, Bingxu Zhu, Yulian Geng, Aolei Liu, Wenfei Yin, Jian Liu
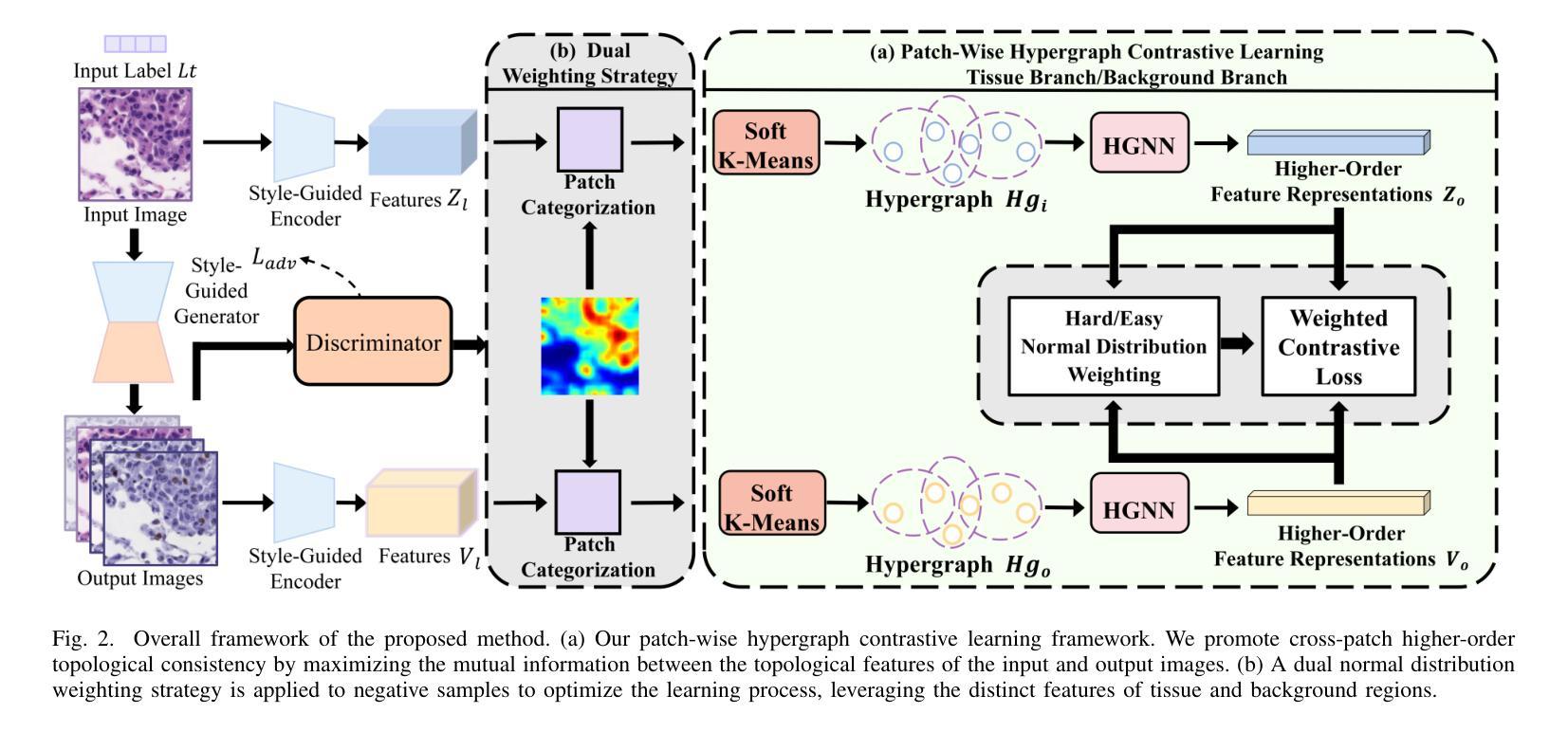
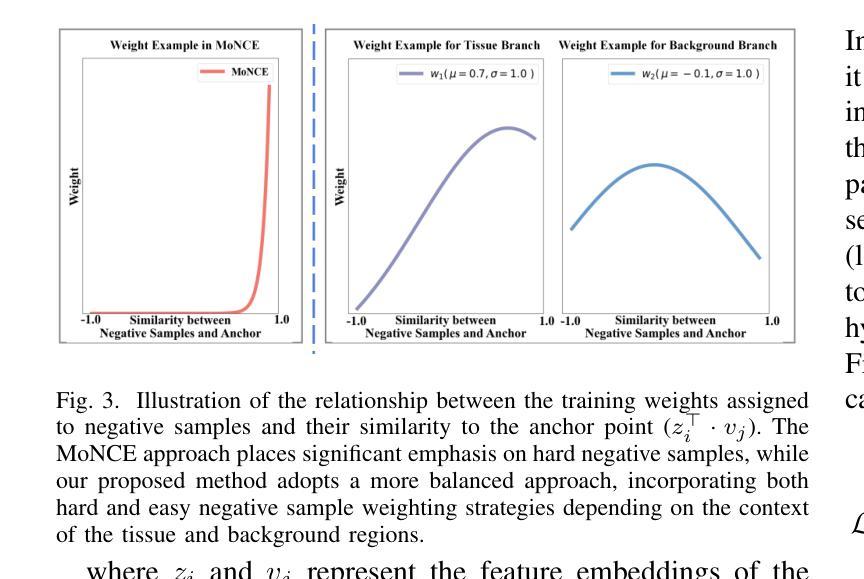
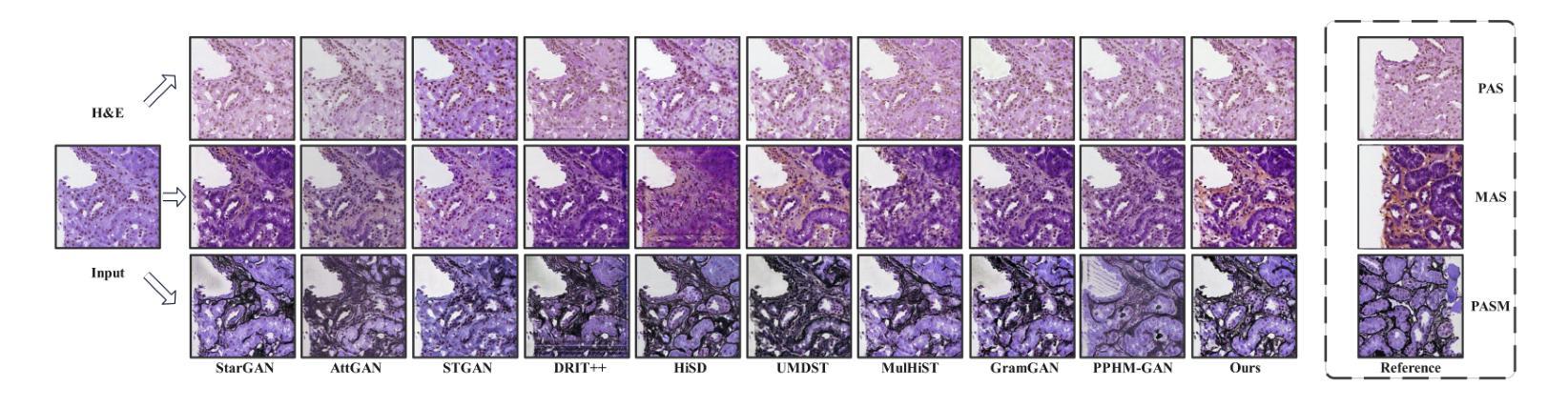
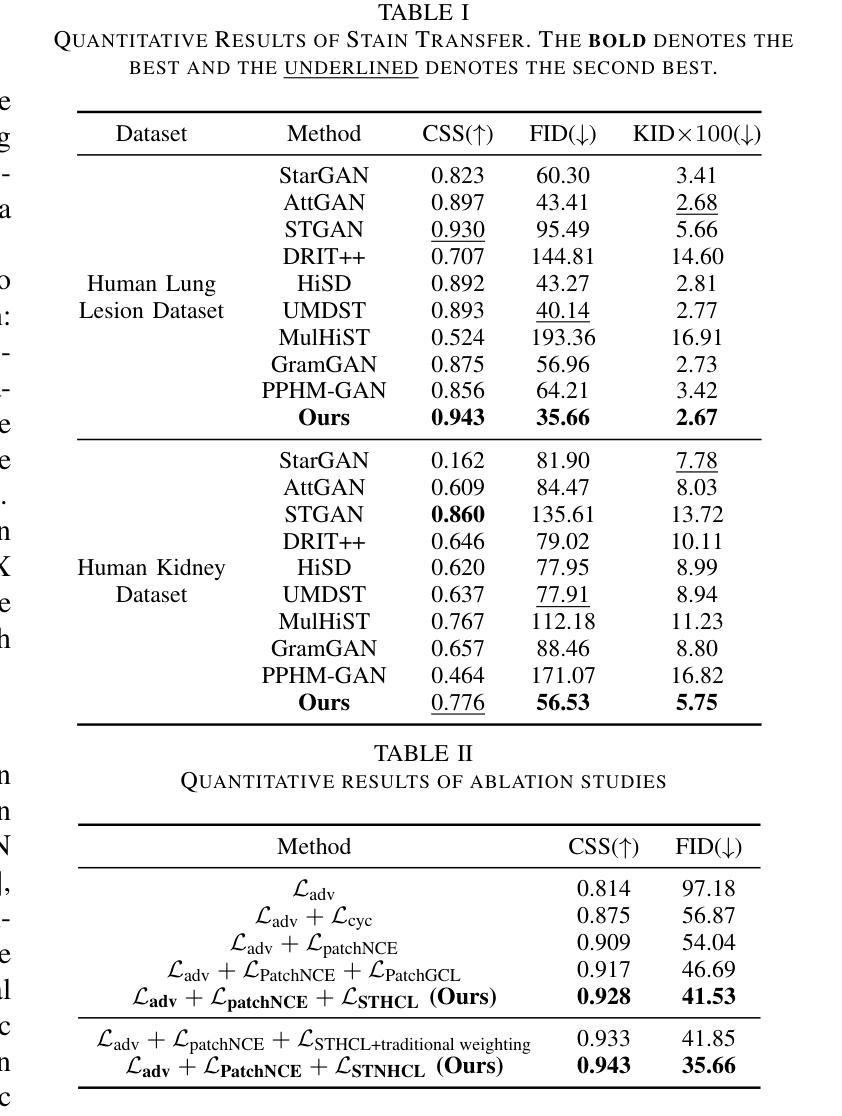
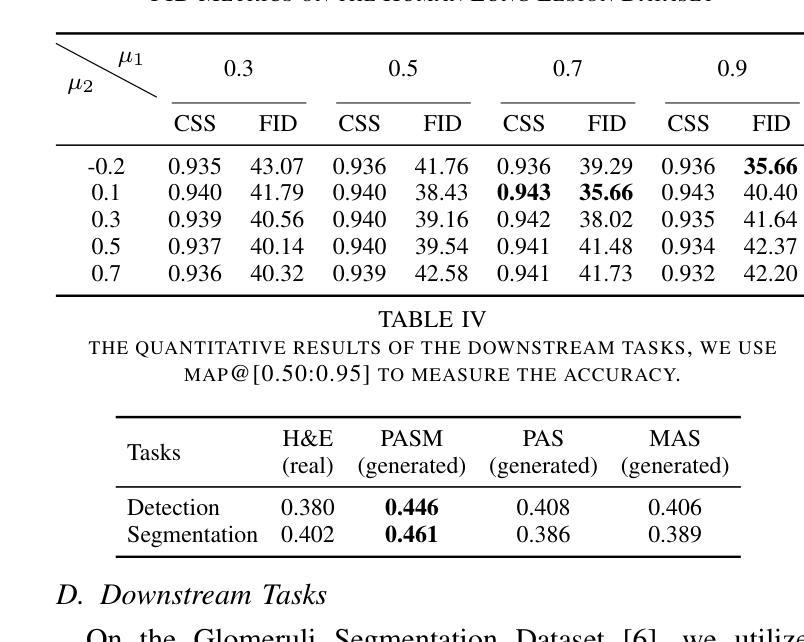
Virtual stain transfer leverages computer-assisted technology to transform the histochemical staining patterns of tissue samples into other staining types. However, existing methods often lose detailed pathological information due to the limitations of the cycle consistency assumption. To address this challenge, we propose STNHCL, a hypergraph-based patch-wise contrastive learning method. STNHCL captures higher-order relationships among patches through hypergraph modeling, ensuring consistent higher-order topology between input and output images. Additionally, we introduce a novel negative sample weighting strategy that leverages discriminator heatmaps to apply different weights based on the Gaussian distribution for tissue and background, thereby enhancing traditional weighting methods. Experiments demonstrate that STNHCL achieves state-of-the-art performance in the two main categories of stain transfer tasks. Furthermore, our model also performs excellently in downstream tasks. Code will be made available.
虚拟染色转移技术利用计算机辅助技术将组织样本的组化染色模式转化为其他染色类型。然而,现有方法由于受循环一致性假设的限制,往往会丢失详细的病理信息。为了应对这一挑战,我们提出了基于超图的STNHCL(斑点级对比学习方法)。STNHCL通过超图模型捕捉斑点间的高阶关系,确保输入和输出图像之间高阶拓扑的一致性。此外,我们引入了一种新型负样本加权策略,利用鉴别器热图根据高斯分布对组织和背景应用不同的权重,从而增强传统加权方法。实验表明,STNHCL在染色转移任务的两个主要类别中均达到了最佳性能,并且在下游任务中也表现出色。代码将公开提供。
论文及项目相关链接
Summary
基于计算机技术的虚拟染色转移方法能将组织样本的染色模式转换为其他染色类型。针对现有方法因循环一致性假设的限制而丢失详细病理信息的问题,我们提出了基于超图的局部对比学习方法STNHCL。STNHCL通过超图建模捕捉局部之间的高阶关系,确保输入和输出图像之间的高阶拓扑一致性。此外,我们还引入了新型负样本加权策略,利用鉴别器热图根据高斯分布对组织和背景应用不同的权重,从而改进传统加权方法。实验表明,STNHCL在染色转移任务的两个主要类别中均达到最佳性能,并在下游任务中表现出色。代码即将发布。
Key Takeaways
- 虚拟染色转移利用计算机技术转换组织样本的染色模式。
- 现有方法因循环一致性假设的限制,易丢失详细病理信息。
- STNHCL方法通过超图建模捕捉局部之间的高阶关系,确保输入和输出图像之间的高阶拓扑一致性。
- 引入新型负样本加权策略,改进传统加权方法。
- STNHCL在染色转移任务的两个主要类别中表现最佳。
- STNHCL不仅适用于染色转移任务,还在下游任务中表现出色。
点此查看论文截图

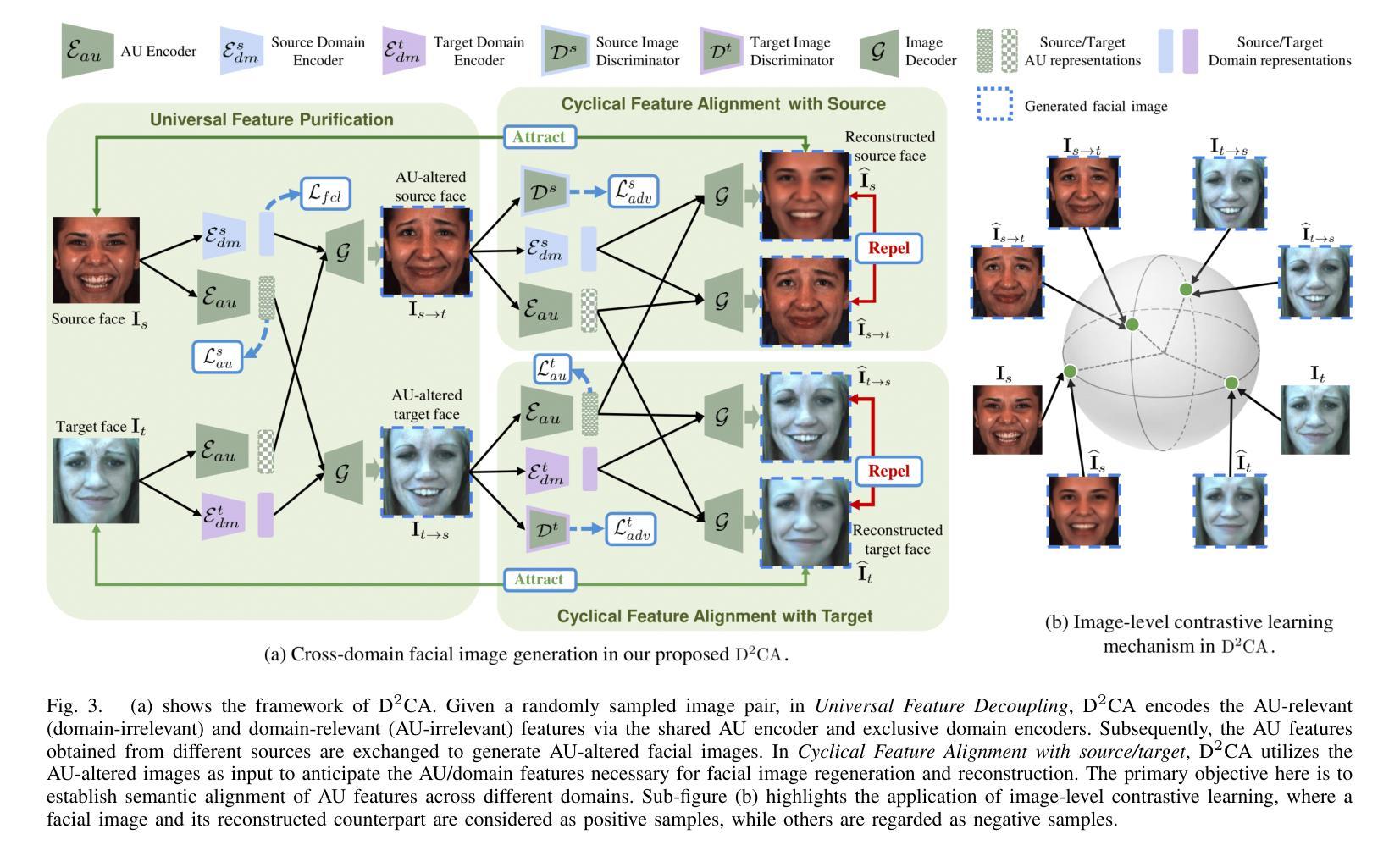
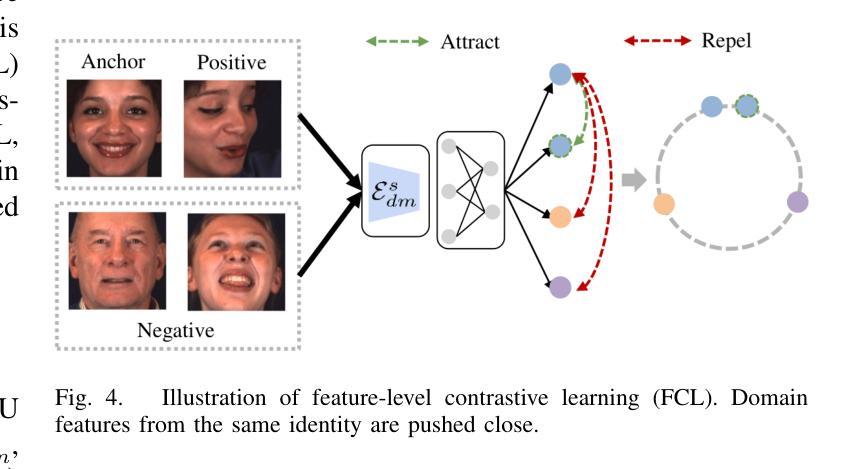
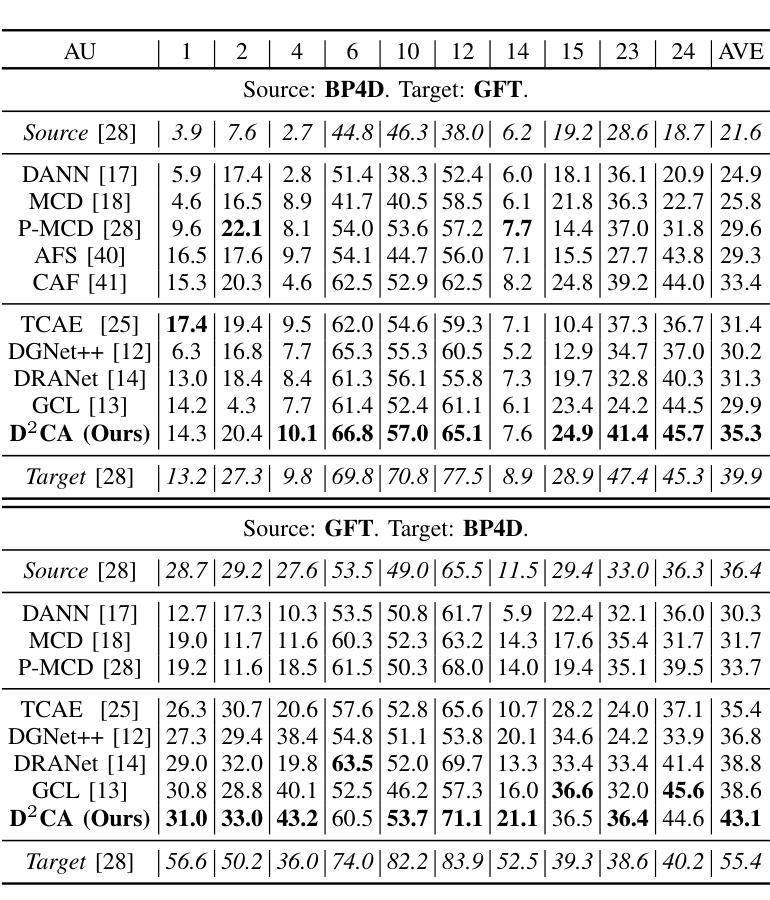
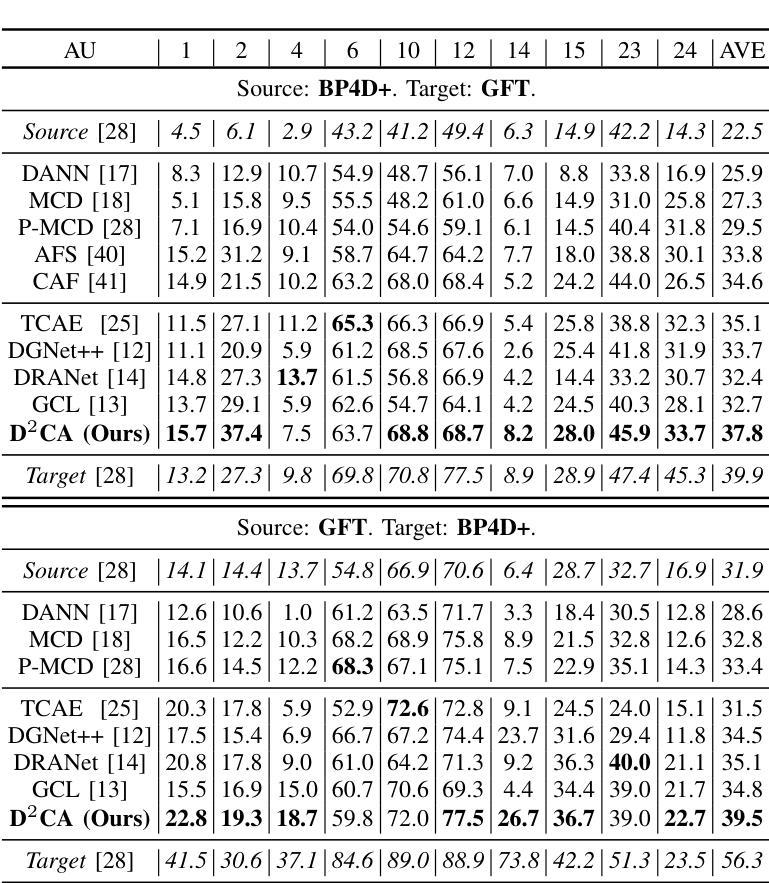
Decoupled Doubly Contrastive Learning for Cross Domain Facial Action Unit Detection
Authors:Yong Li, Menglin Liu, Zhen Cui, Yi Ding, Yuan Zong, Wenming Zheng, Shiguang Shan, Cuntai Guan
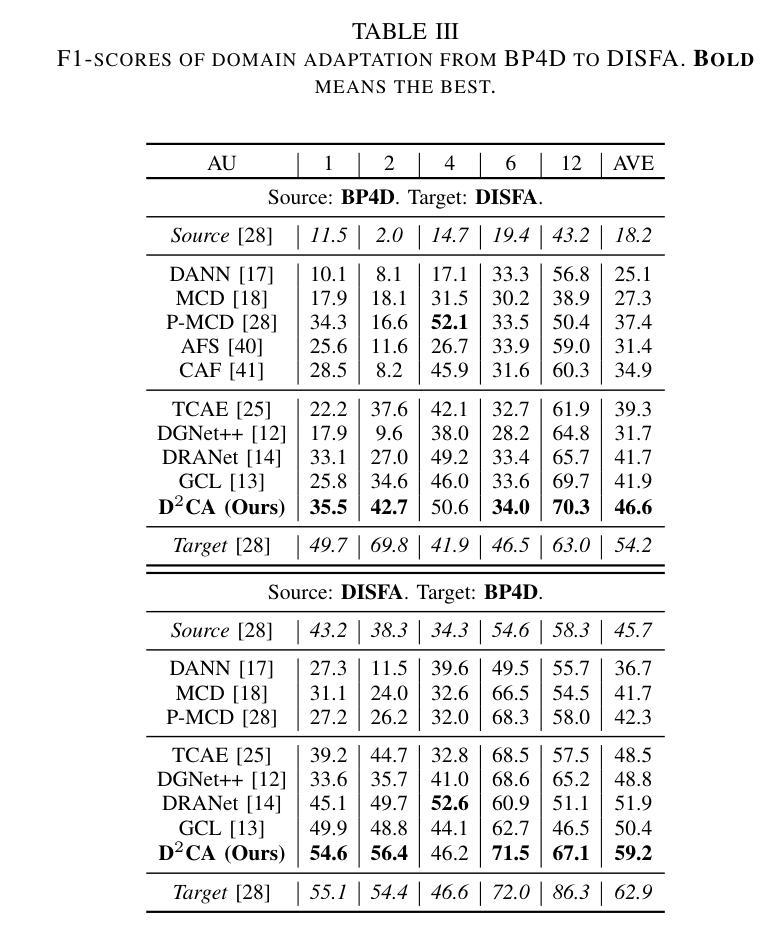
Despite the impressive performance of current vision-based facial action unit (AU) detection approaches, they are heavily susceptible to the variations across different domains and the cross-domain AU detection methods are under-explored. In response to this challenge, we propose a decoupled doubly contrastive adaptation (D$^2$CA) approach to learn a purified AU representation that is semantically aligned for the source and target domains. Specifically, we decompose latent representations into AU-relevant and AU-irrelevant components, with the objective of exclusively facilitating adaptation within the AU-relevant subspace. To achieve the feature decoupling, D$^2$CA is trained to disentangle AU and domain factors by assessing the quality of synthesized faces in cross-domain scenarios when either AU or domain attributes are modified. To further strengthen feature decoupling, particularly in scenarios with limited AU data diversity, D$^2$CA employs a doubly contrastive learning mechanism comprising image and feature-level contrastive learning to ensure the quality of synthesized faces and mitigate feature ambiguities. This new framework leads to an automatically learned, dedicated separation of AU-relevant and domain-relevant factors, and it enables intuitive, scale-specific control of the cross-domain facial image synthesis. Extensive experiments demonstrate the efficacy of D$^2$CA in successfully decoupling AU and domain factors, yielding visually pleasing cross-domain synthesized facial images. Meanwhile, D$^2$CA consistently outperforms state-of-the-art cross-domain AU detection approaches, achieving an average F1 score improvement of 6%-14% across various cross-domain scenarios.
尽管当前基于视觉的面部动作单元(AU)检测方法的性能令人印象深刻,但它们极易受到不同领域之间的差异影响,而且跨域AU检测方法的研究仍然不足。针对这一挑战,我们提出了一种解耦双重对比适应(D$^2$CA)方法,旨在学习纯化的AU表示,该表示在源域和目标域之间进行语义对齐。具体来说,我们将潜在表示分解为与AU相关和与AU不相关的组件,目的是专门促进AU相关子空间内的适应。为了实现特征解耦,D$^2$CA通过评估跨域场景中合成面部质量(当AU或领域属性被修改时)来训练分解AU和领域因素。为了进一步加强特征解耦,特别是在AU数据多样性有限的场景中,D$^2$CA采用了一种双重对比学习机制,包括图像和特征级别的对比学习,以确保合成面部的质量并减少特征模糊性。这一新框架实现了AU相关因素和领域相关因素的自动学习分离,它能够实现跨域面部图像合成的直观、比例特定控制。大量实验表明,D$^2$CA在成功解耦AU和领域因素方面非常有效,能够生成视觉上令人愉悦的跨域合成面部图像。同时,D$^2$CA在多种跨域场景中始终优于最先进的跨域AU检测方法,平均F1分数提高了6%-14%。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Image Processing 2025. A novel and elegant feature decoupling method for cross-domain facial action unit detection
摘要
提出了一种基于解耦双重对比适应(D$^2$CA)的方法,用于学习纯净的面部动作单元(AU)表示,该表示在源域和目标域之间语义对齐。方法通过分解潜在表示来专注于AU相关的子空间内的适配。D$^2$CA通过评估跨域场景中合成面部质量来训练特征解耦,当修改AU或域属性时。为进一步强化特征解耦,特别是在AU数据多样性有限的场景中,D$^2$CA采用双重对比学习机制,包括图像和特征级别的对比学习,确保合成面部质量并减少特征模糊。实验表明,D$^2$CA在成功解耦AU和域因素方面表现优异,产生视觉上令人满意的跨域合成面部图像。与最先进的跨域AU检测方法进行对比,D$^2$CA在各种跨域场景下平均F1得分提高了6%~14%。
关键见解
- 当前基于视觉的面部动作单元(AU)检测方法对域之间的差异非常敏感,而跨域AU检测方法的研究相对较少。
- 提出了一种名为D$^2$CA的解耦双重对比适应方法,专注于学习针对源域和目标域的语义对齐的纯净AU表示。
- D$^2$CA通过分解潜在表示来解耦AU相关和AU不相关的成分,以促进AU相关子空间内的适配。
- 通过评估在跨域场景中修改AU或域属性时的合成面部质量来进行特征解耦训练。
- D$^2$CA采用双重对比学习机制来提高特征解耦的效果,特别是在AU数据多样性有限的场景中。
- D$^2$CA能自动学习并专门分离AU相关和域相关的因素,实现对跨域面部图像合成的直观、尺度特定控制。
点此查看论文截图


3D Medical Imaging Segmentation on Non-Contrast CT
Authors:Canxuan Gang, Yuhan Peng
This technical report analyzes non-contrast CT image segmentation in computer vision. It revisits a proposed method, examines the background of non-contrast CT imaging, and highlights the significance of segmentation. The study reviews representative methods, including convolutional-based and CNN-Transformer hybrid approaches, discussing their contributions, advantages, and limitations. The nnUNet stands out as the state-of-the-art method across various segmentation tasks. The report explores the relationship between the proposed method and existing approaches, emphasizing the role of global context modeling in semantic labeling and mask generation. Future directions include addressing the long-tail problem, utilizing pre-trained models for medical imaging, and exploring self-supervised or contrastive pre-training techniques. This report offers insights into non-contrast CT image segmentation and potential advancements in the field.
这篇技术报告分析了计算机视觉中的非对比CT图像分割,重新审视了一种方法,探讨了非对比CT成像的背景,并强调了分割的重要性。该研究复习了代表性的方法,包括基于卷积和CNN-Transformer混合方法,并讨论了其贡献、优点和局限性。在各种分割任务中,nnUNet表现出最先进的性能。报告探讨了所提出方法与现有方法之间的关系,并强调全局上下文建模在语义标记和蒙版生成中的作用。未来的研究方向包括解决长尾问题、利用医学影像的预训练模型和探索自监督或对比预训练技术。本报告深入探讨了非对比CT图像分割以及该领域的潜在进展。
论文及项目相关链接
PDF tech report
Summary
本技术报告探讨了计算机视觉中非对比CT图像分割的分析。报告回顾了一种方法,介绍了非对比CT成像的背景,并强调了分割的重要性。报告评述了具有代表性的方法,包括基于卷积和CNN-Transformer混合方法,并讨论了其贡献、优点和局限性。报告还探讨了新方法之间的关系,强调了全局上下文建模在语义标注和掩膜生成中的作用。未来研究方向包括解决长尾问题、利用预训练模型进行医学影像分析以及探索自监督或对比预训练技术。本报告为深入了解非对比CT图像分割以及该领域的潜在进展提供了宝贵见解。
Key Takeaways
- 报告详细分析了非对比CT图像分割在计算机视觉中的重要性。
- 介绍了非对比CT成像的背景,并回顾了现有方法的背景。
- 评述了基于卷积和CNN-Transformer混合方法的代表性方法。
- nnUNet在各种分割任务中表现出卓越的性能。
- 强调了全局上下文建模在语义标注和掩膜生成中的关键作用。
- 提出了未来研究方向,包括解决长尾问题、利用预训练模型以及探索自监督或对比预训练技术。
点此查看论文截图

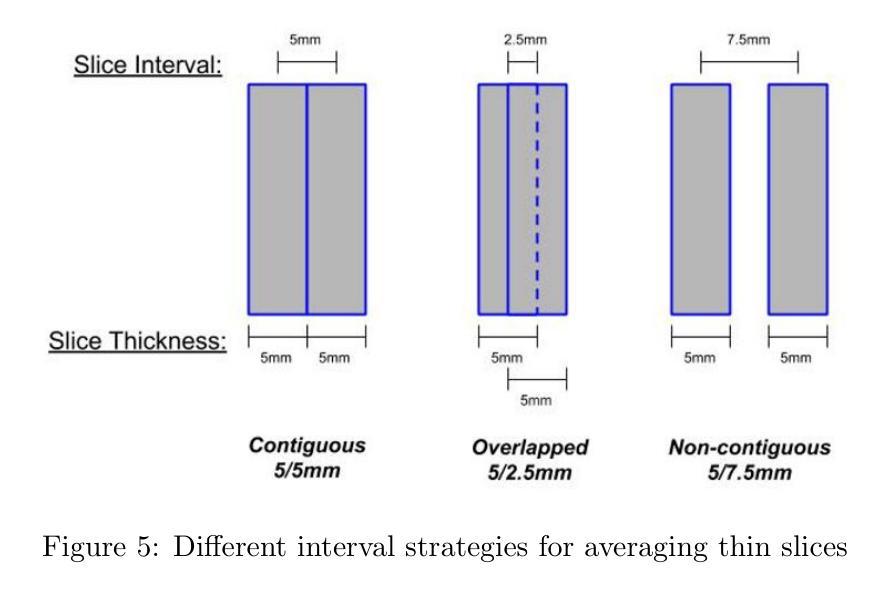
CL-MVSNet: Unsupervised Multi-view Stereo with Dual-level Contrastive Learning
Authors:Kaiqiang Xiong, Rui Peng, Zhe Zhang, Tianxing Feng, Jianbo Jiao, Feng Gao, Ronggang Wang
Unsupervised Multi-View Stereo (MVS) methods have achieved promising progress recently. However, previous methods primarily depend on the photometric consistency assumption, which may suffer from two limitations: indistinguishable regions and view-dependent effects, e.g., low-textured areas and reflections. To address these issues, in this paper, we propose a new dual-level contrastive learning approach, named CL-MVSNet. Specifically, our model integrates two contrastive branches into an unsupervised MVS framework to construct additional supervisory signals. On the one hand, we present an image-level contrastive branch to guide the model to acquire more context awareness, thus leading to more complete depth estimation in indistinguishable regions. On the other hand, we exploit a scene-level contrastive branch to boost the representation ability, improving robustness to view-dependent effects. Moreover, to recover more accurate 3D geometry, we introduce an L0.5 photometric consistency loss, which encourages the model to focus more on accurate points while mitigating the gradient penalty of undesirable ones. Extensive experiments on DTU and Tanks&Temples benchmarks demonstrate that our approach achieves state-of-the-art performance among all end-to-end unsupervised MVS frameworks and outperforms its supervised counterpart by a considerable margin without fine-tuning.
无监督多视图立体(MVS)方法最近取得了有希望的进展。然而,之前的方法主要依赖于光度一致性假设,这可能会面临两个局限性:不可区分区域和视图相关效应,例如低纹理区域和反射。为了解决这些问题,本文提出了一种新的双级对比学习方法,名为CL-MVSNet。具体来说,我们的模型将两个对比分支集成到无监督MVS框架中,以构建额外的监督信号。一方面,我们提出了一个图像级对比分支,以指导模型获取更多的上下文意识,从而导致不可区分区域中更完整的深度估计。另一方面,我们利用场景级对比分支来提高表示能力,增强对视图相关效应的鲁棒性。此外,为了恢复更准确的3D几何结构,我们引入了L0.5光度一致性损失,这鼓励模型更多地关注准确点,同时减轻不理想点的梯度惩罚。在DTU和Tanks&Temples基准测试上的大量实验表明,我们的方法在端到端的无监督MVS框架中实现了最先进的性能,并且在未经微调的情况下大幅超越了其有监督的同类产品。
论文及项目相关链接
PDF Accpetd by ICCV2023
Summary
本文提出了一种新的基于对比学习的无监督多视角立体(MVS)方法,名为CL-MVSNet。该方法通过引入图像级和场景级的对比学习分支,增强了模型的上下文感知能力和表征能力,从而提高了在区分不明显区域和受视角影响区域的鲁棒性。同时,通过引入L0.5光度一致性损失,恢复了更准确的3D几何结构。在DTU和Tanks&Temples基准测试上的实验表明,该方法在端到端的无监督MVS框架中达到了最新技术水平,并且在没有微调的情况下显著超越了其有监督的同类方法。
Key Takeaways
- CL-MVSNet是一种基于对比学习的无监督多视角立体(MVS)方法。
- 该方法通过引入图像级对比学习分支,提高了模型在区分不明显区域的深度估计的完整性。
- 通过引入场景级对比学习分支,增强了模型的表征能力,提高了对受视角影响区域的鲁棒性。
- L0.5光度一致性损失的引入有助于恢复更准确的3D几何结构。
- 在DTU和Tanks&Temples基准测试上,CL-MVSNet达到了最新技术水平。
- 该方法在无监督环境下显著超越了其有监督的同类方法,且无需微调。
点此查看论文截图

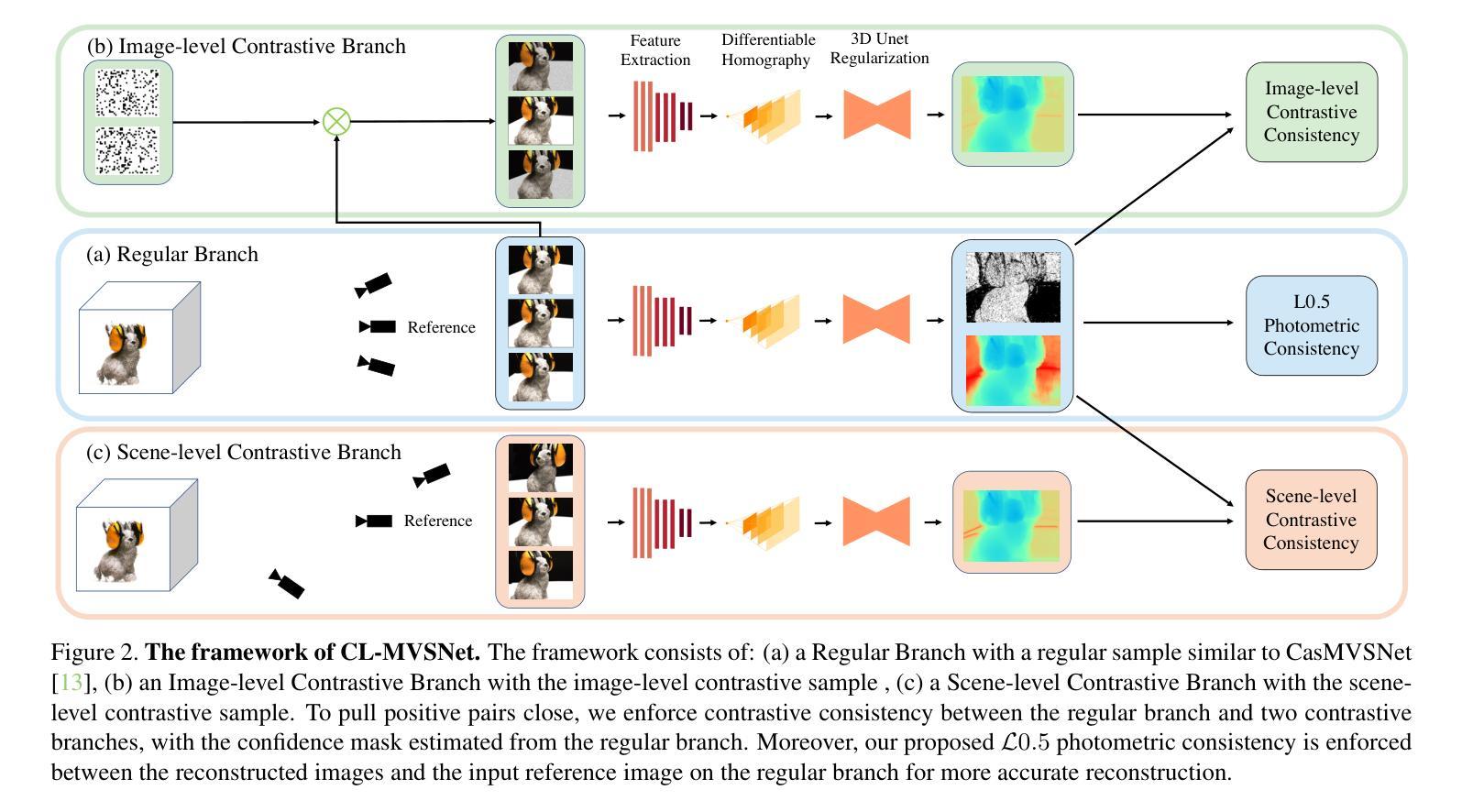
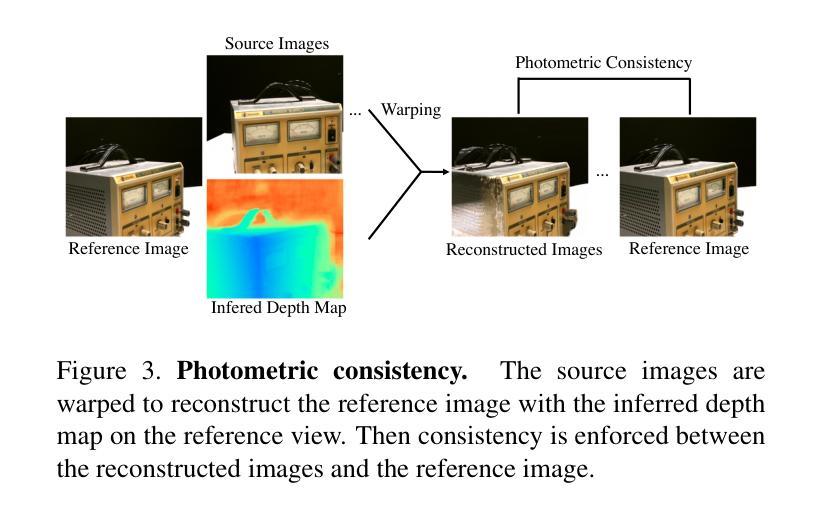

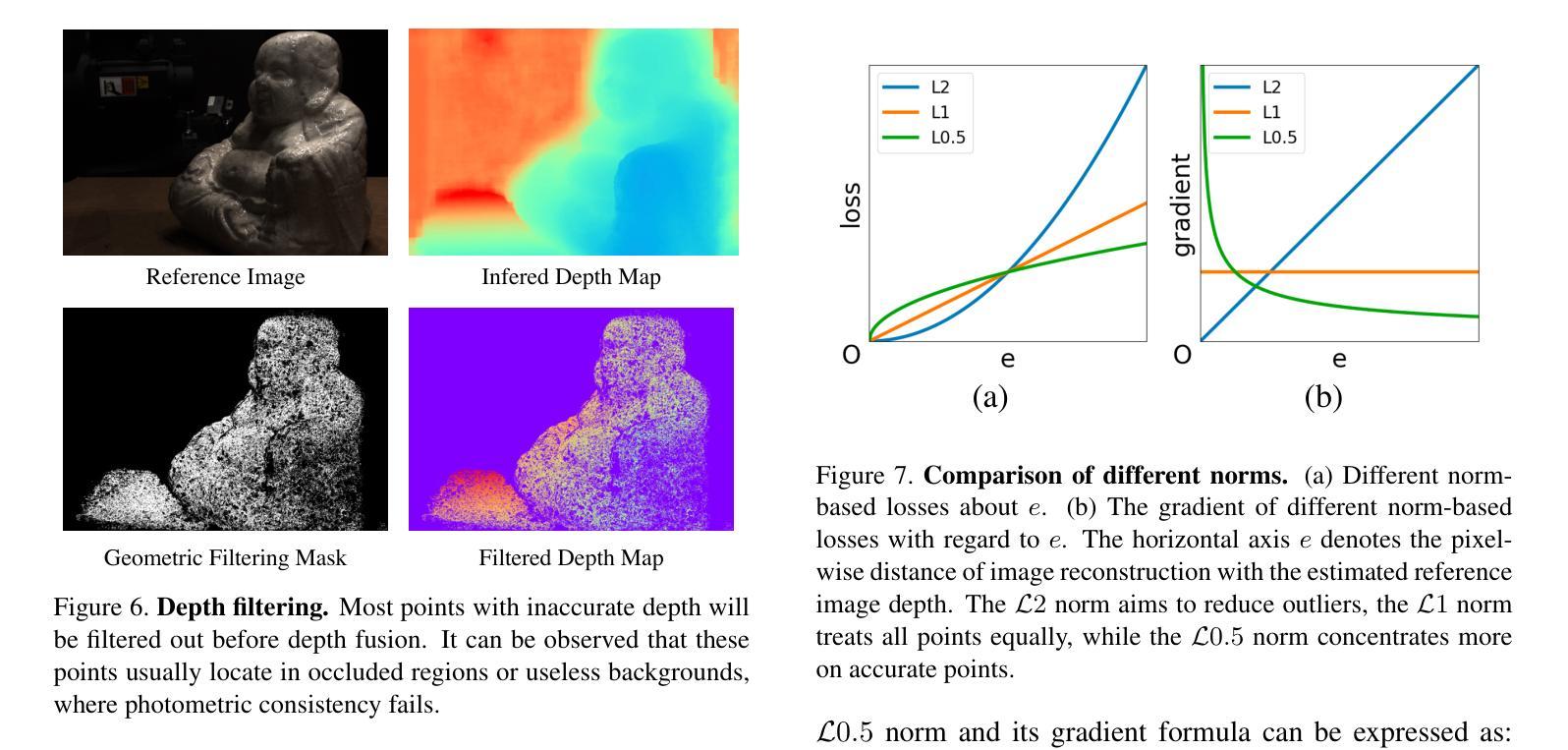
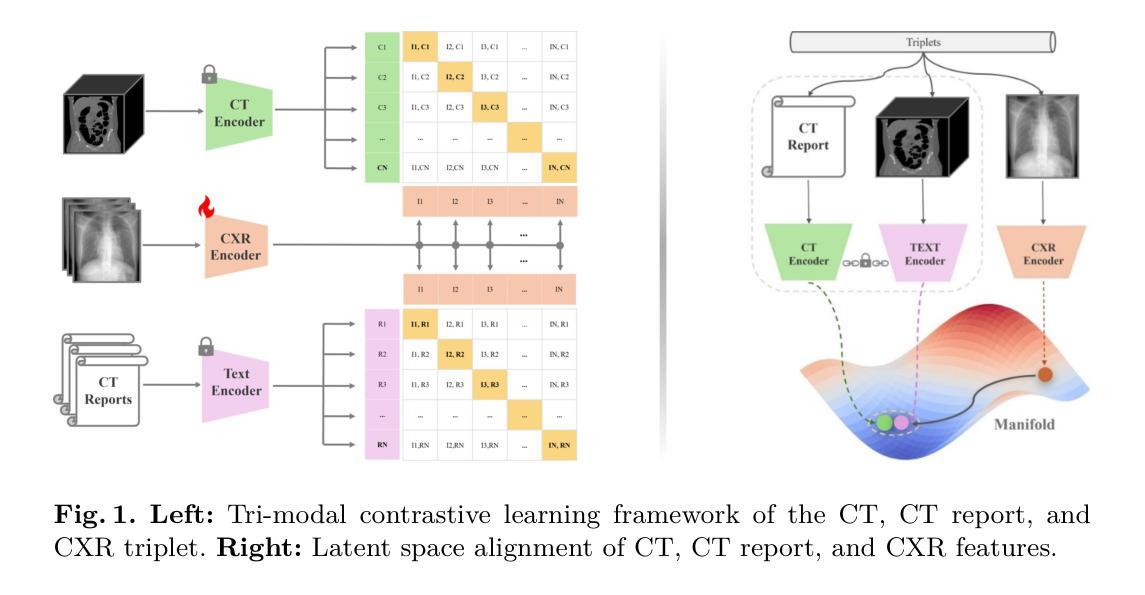
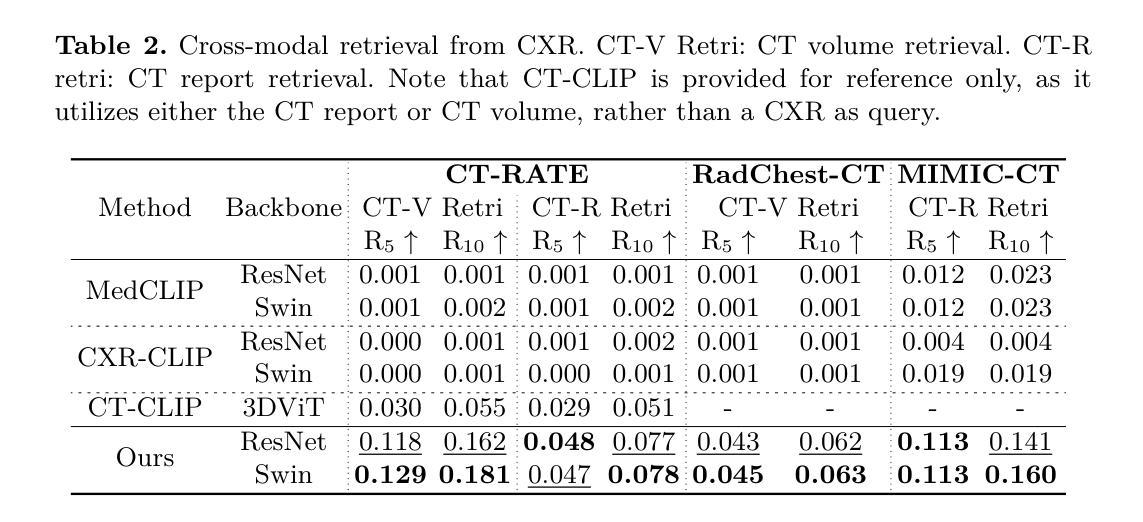
X2CT-CLIP: Enable Multi-Abnormality Detection in Computed Tomography from Chest Radiography via Tri-Modal Contrastive Learning
Authors:Jianzhong You, Yuan Gao, Sangwook Kim, Chris Mcintosh
Computed tomography (CT) is a key imaging modality for diagnosis, yet its clinical utility is marred by high radiation exposure and long turnaround times, restricting its use for larger-scale screening. Although chest radiography (CXR) is more accessible and safer, existing CXR foundation models focus primarily on detecting diseases that are readily visible on the CXR. Recently, works have explored training disease classification models on simulated CXRs, but they remain limited to recognizing a single disease type from CT. CT foundation models have also emerged with significantly improved detection of pathologies in CT. However, the generalized application of CT-derived labels on CXR has remained illusive. In this study, we propose X2CT-CLIP, a tri-modal knowledge transfer learning framework that bridges the modality gap between CT and CXR while reducing the computational burden of model training. Our approach is the first work to enable multi-abnormality classification in CT, using CXR, by transferring knowledge from 3D CT volumes and associated radiology reports to a CXR encoder via a carefully designed tri-modal alignment mechanism in latent space. Extensive evaluations on three multi-label CT datasets demonstrate that our method outperforms state-of-the-art baselines in cross-modal retrieval, few-shot adaptation, and external validation. These results highlight the potential of CXR, enriched with knowledge derived from CT, as a viable efficient alternative for disease detection in resource-limited settings.
计算机断层扫描(CT)是诊断的关键成像方式,但其临床应用受到高辐射暴露和长时间处理时间的限制,限制了其在大规模筛查中的使用。虽然胸部放射摄影(CXR)更容易获取且更安全,但现有的CXR基础模型主要关注在CXR上易于观察到的疾病检测。最近,已有研究开始探索在模拟的CXR上进行疾病分类模型训练,但它们仅限于从CT图像中识别单一疾病类型。也出现了基于CT的基础模型,以显著改善CT中的病理检测。然而,将CT衍生的标签推广到CXR的通用应用仍然具有挑战性。本研究中,我们提出了X2CT-CLIP,这是一个三模态知识迁移学习框架,它缩小了CT和CXR之间的模态差距,同时降低了模型训练的计算负担。我们的方法是通过从3D CT体积和相关放射学报告转移知识到CXR编码器,利用精心设计的潜在空间中的三模态对齐机制,实现了使用CXR在CT上进行多异常分类的首项工作。在三个多标签CT数据集上的广泛评估表明,我们的方法在跨模态检索、少样本适应和外部验证方面均优于最新基线。这些结果突显了CXR的潜力,通过从CT中获取知识,可作为资源有限环境中疾病检测的可行高效替代方案。
论文及项目相关链接
PDF 11 pages, 1 figure, 5 tables
Summary
该研究表明,针对计算机断层扫描(CT)和胸部放射线检查(CXR)的双模态知识迁移学习框架被提出,用以解决CT检查的高辐射暴露和长时间等待结果的问题。该研究提出了一种新的方法X2CT-CLIP,该方法通过精心设计三模态对齐机制,在潜在空间中实现了从CT体积和相关的放射学报告向CXR编码器的知识迁移。实验证明,该方法在多标签CT数据集上的表现优于现有技术,具有跨模态检索、少样本适应和外部验证的潜力。这标志着使用CXR结合从CT中获得的知识在资源受限环境中进行疾病检测的一种高效可行的替代方案。
Key Takeaways
- 该研究提出了X2CT-CLIP框架,旨在解决CT检查的高辐射和长时间等待问题。
- X2CT-CLIP是一个三模态知识迁移学习框架,可以缩短模型训练的计算负担。
- 该方法首次实现了使用CXR进行多异常性分类的CT技术。
- 通过精心设计三模态对齐机制,在潜在空间中实现了从CT体积和相关放射学报告向CXR编码器的知识迁移。
- 在多标签CT数据集上的实验证明,X2CT-CLIP在跨模态检索、少样本适应和外部验证方面表现出优异性能。
- 研究结果强调了结合CXR和从CT获得的知识在资源受限环境中进行疾病检测的潜力。
点此查看论文截图