⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Memory-enhanced Retrieval Augmentation for Long Video Understanding
Authors:Huaying Yuan, Zheng Liu, Minhao Qin, Hongjin Qian, Y Shu, Zhicheng Dou, Ji-Rong Wen
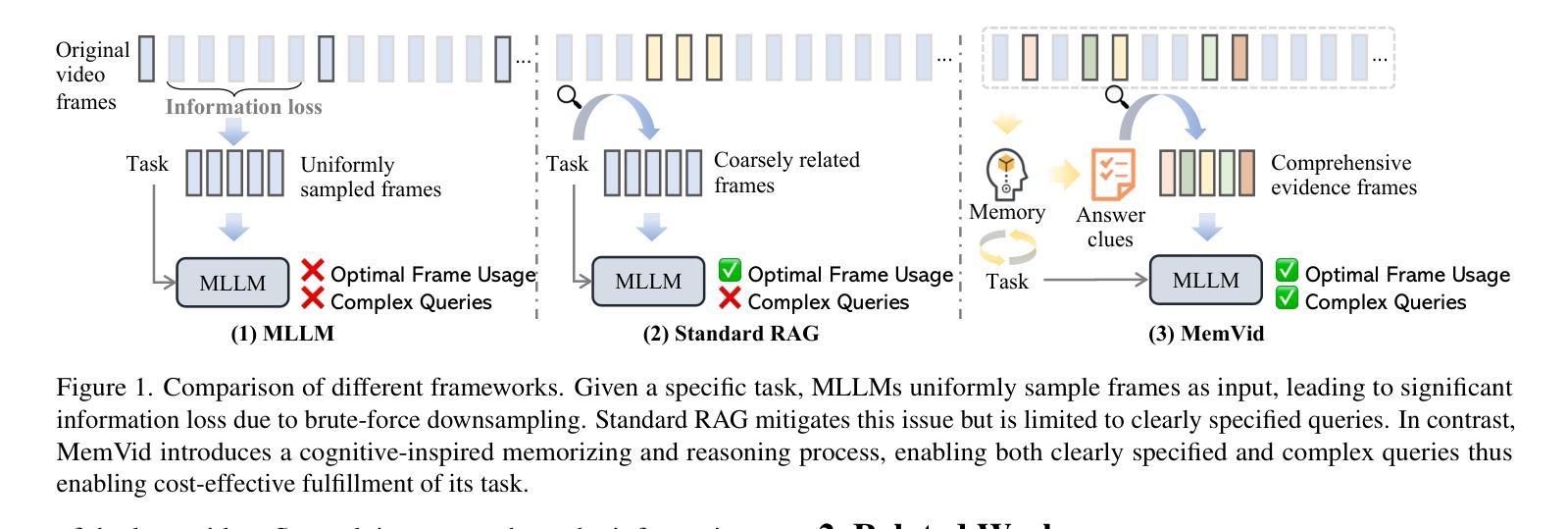
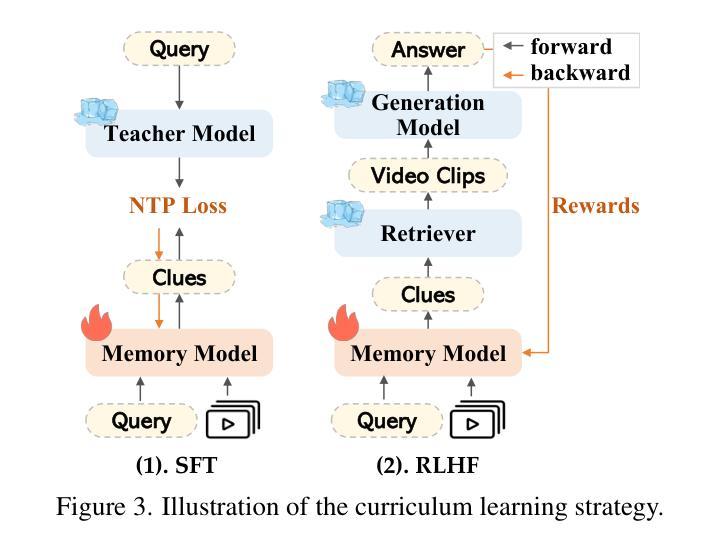
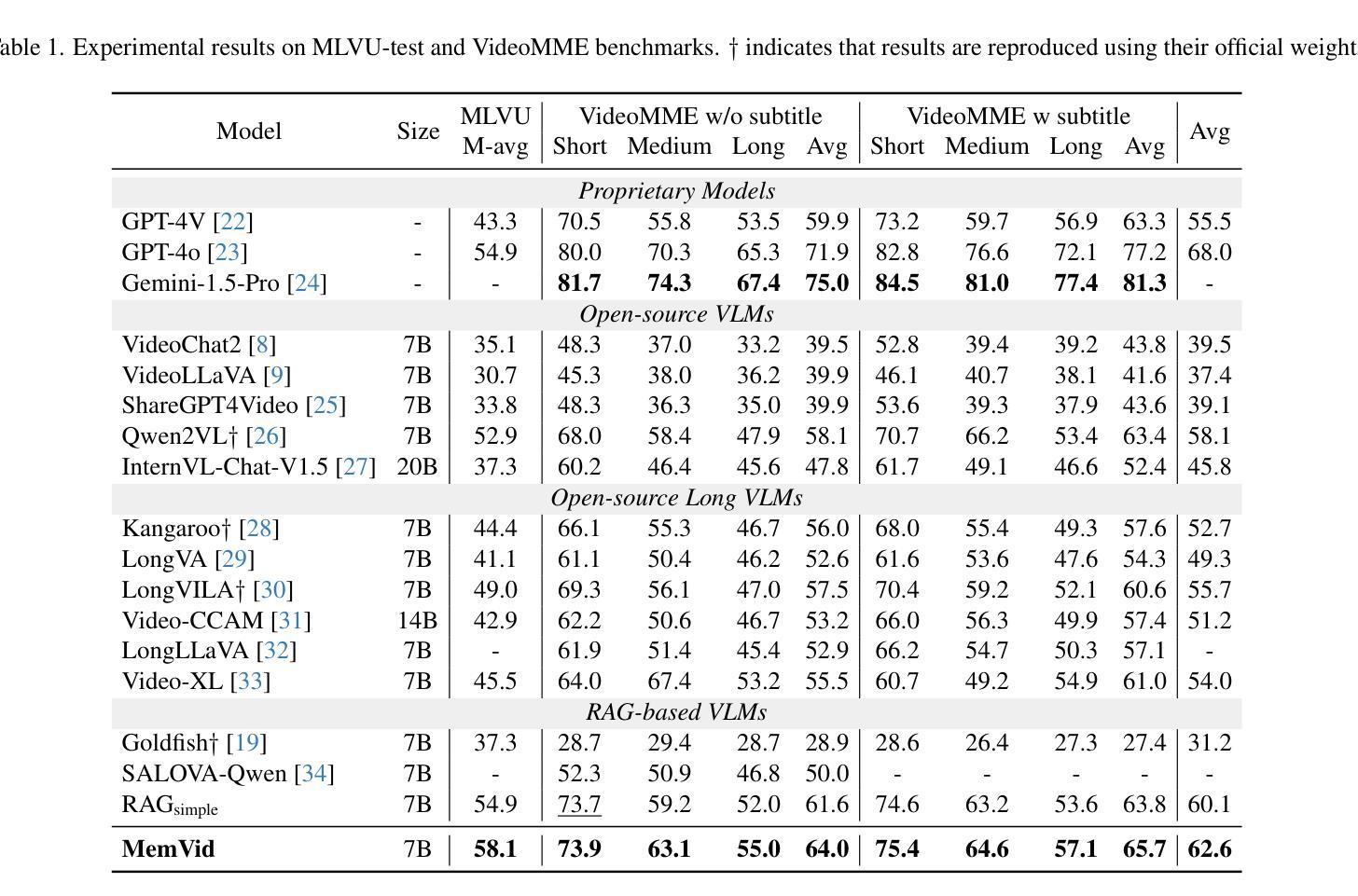
Retrieval-augmented generation (RAG) shows strong potential in addressing long-video understanding (LVU) tasks. However, traditional RAG methods remain fundamentally limited due to their dependence on explicit search queries, which are unavailable in many situations. To overcome this challenge, we introduce a novel RAG-based LVU approach inspired by the cognitive memory of human beings, which is called MemVid. Our approach operates with four basics steps: memorizing holistic video information, reasoning about the task’s information needs based on the memory, retrieving critical moments based on the information needs, and focusing on the retrieved moments to produce the final answer. To enhance the system’s memory-grounded reasoning capabilities and achieve optimal end-to-end performance, we propose a curriculum learning strategy. This approach begins with supervised learning on well-annotated reasoning results, then progressively explores and reinforces more plausible reasoning outcomes through reinforcement learning. We perform extensive evaluations on popular LVU benchmarks, including MLVU, VideoMME and LVBench. In our experiment, MemVid significantly outperforms existing RAG-based methods and popular LVU models, which demonstrate the effectiveness of our approach. Our model and source code will be made publicly available upon acceptance.
检索增强生成(RAG)在解决长视频理解(LVU)任务方面显示出强大的潜力。然而,传统的RAG方法由于其依赖于明确的搜索查询而从根本上受到限制,这在许多情况下是不可用的。为了克服这一挑战,我们引入了一种受人类认知记忆启发的新型基于RAG的LVU方法,称为MemVid。我们的方法有四个基本步骤:记忆整体视频信息,基于记忆对任务信息需求进行推理,根据信息需求检索关键时刻,并专注于检索到的时刻以产生最终答案。为了提高系统的基于记忆推理的能力并实现端到端的最佳性能,我们提出了一种课程学习策略。该方法首先从经过良好注释的推理结果开始进行有监督学习,然后通过强化学习逐步探索和强化更合理的推理结果。我们在流行的LVU基准测试上进行了广泛评估,包括MLVU、VideoMME和LVBench。在我们的实验中,MemVid显著优于现有的基于RAG的方法和流行的LVU模型,这证明了我们的方法的有效性。我们的模型和源代码将在接受后公开发布。
论文及项目相关链接
Summary
本文提出了一种基于记忆的视频理解方法MemVid,它通过模拟人类的认知记忆过程来解决长视频理解任务。该方法包括四个步骤:记忆整体视频信息、基于任务需求进行推理、根据需求检索关键时刻,以及专注于检索到的时刻生成最终答案。为提高系统的记忆推理能力并实现端到端的优化性能,本文提出了一种课程学习策略,从监督学习开始,逐步探索并强化更合理的推理结果。实验表明,MemVid在流行的长视频理解基准测试中显著优于现有的基于检索增强生成的方法和流行模型。
Key Takeaways
- MemVid是一种基于记忆的视频理解方法,适用于长视频理解任务。
- MemVid方法包括四个基本步骤:记忆视频信息、推理任务需求、检索关键时刻和生成答案。
- 为提高系统性能,提出了一种课程学习策略,结合监督学习和强化学习。
- MemVid在多个长视频理解基准测试中表现出显著优势。
- MemVid显著提高了基于检索增强生成的方法的性能。
- 该模型和源代码在接受后将公开发布。
点此查看论文截图


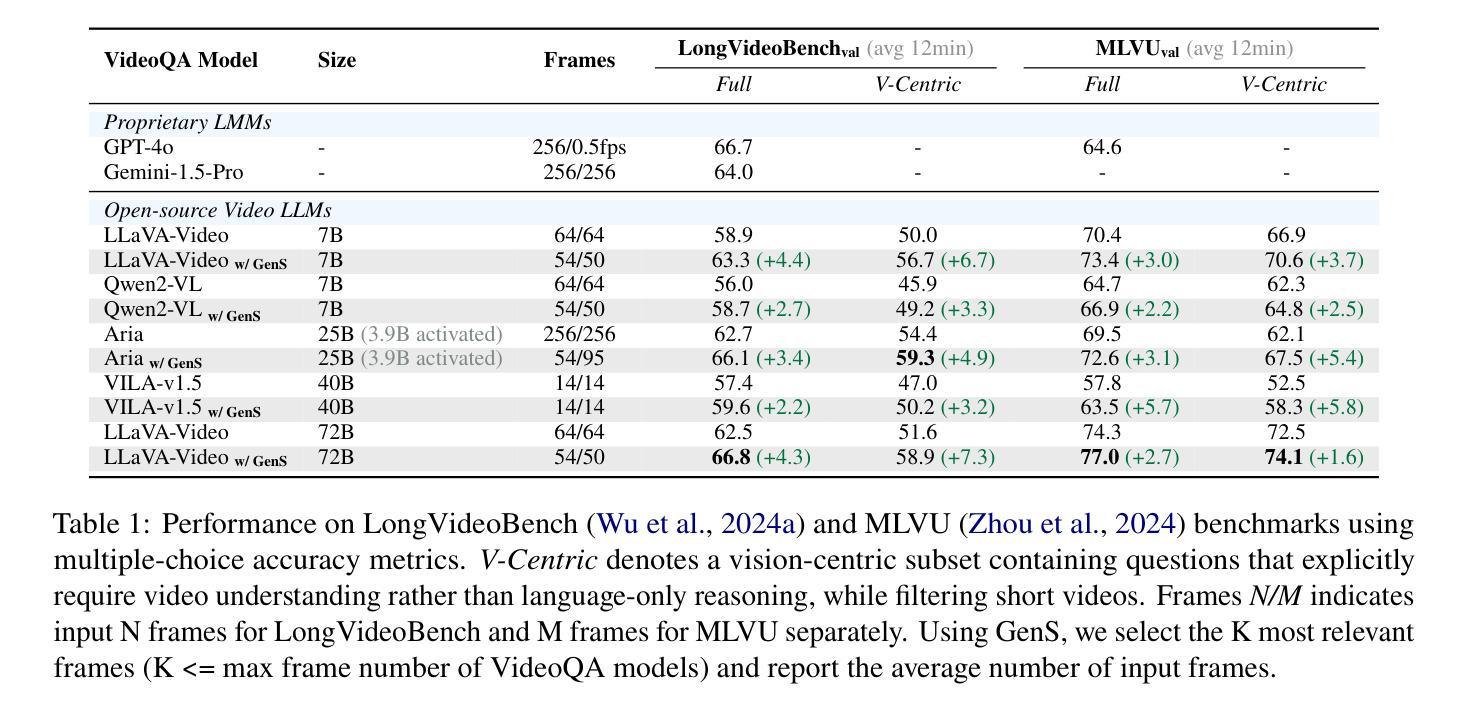
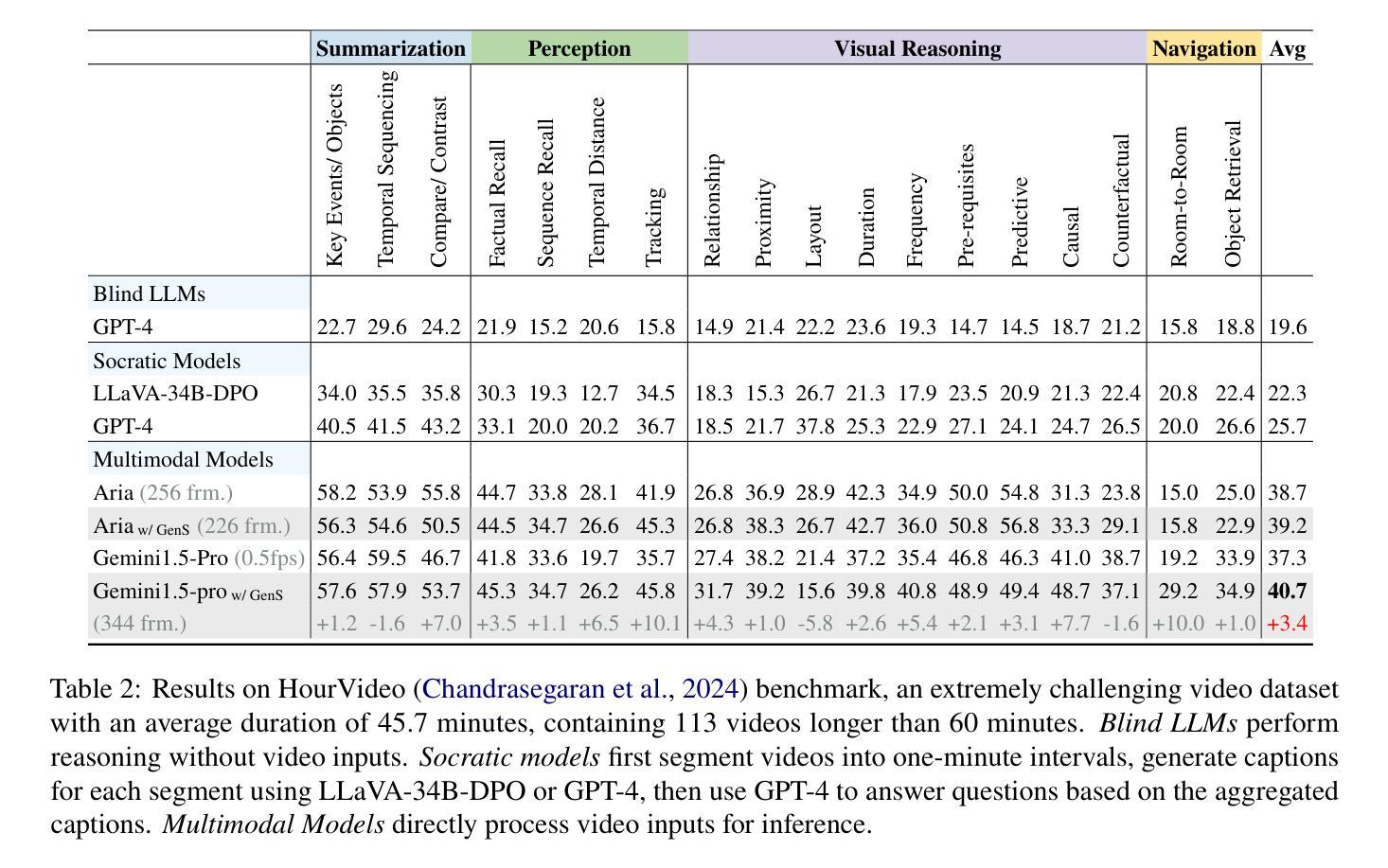
Generative Frame Sampler for Long Video Understanding
Authors:Linli Yao, Haoning Wu, Kun Ouyang, Yuanxing Zhang, Caiming Xiong, Bei Chen, Xu Sun, Junnan Li
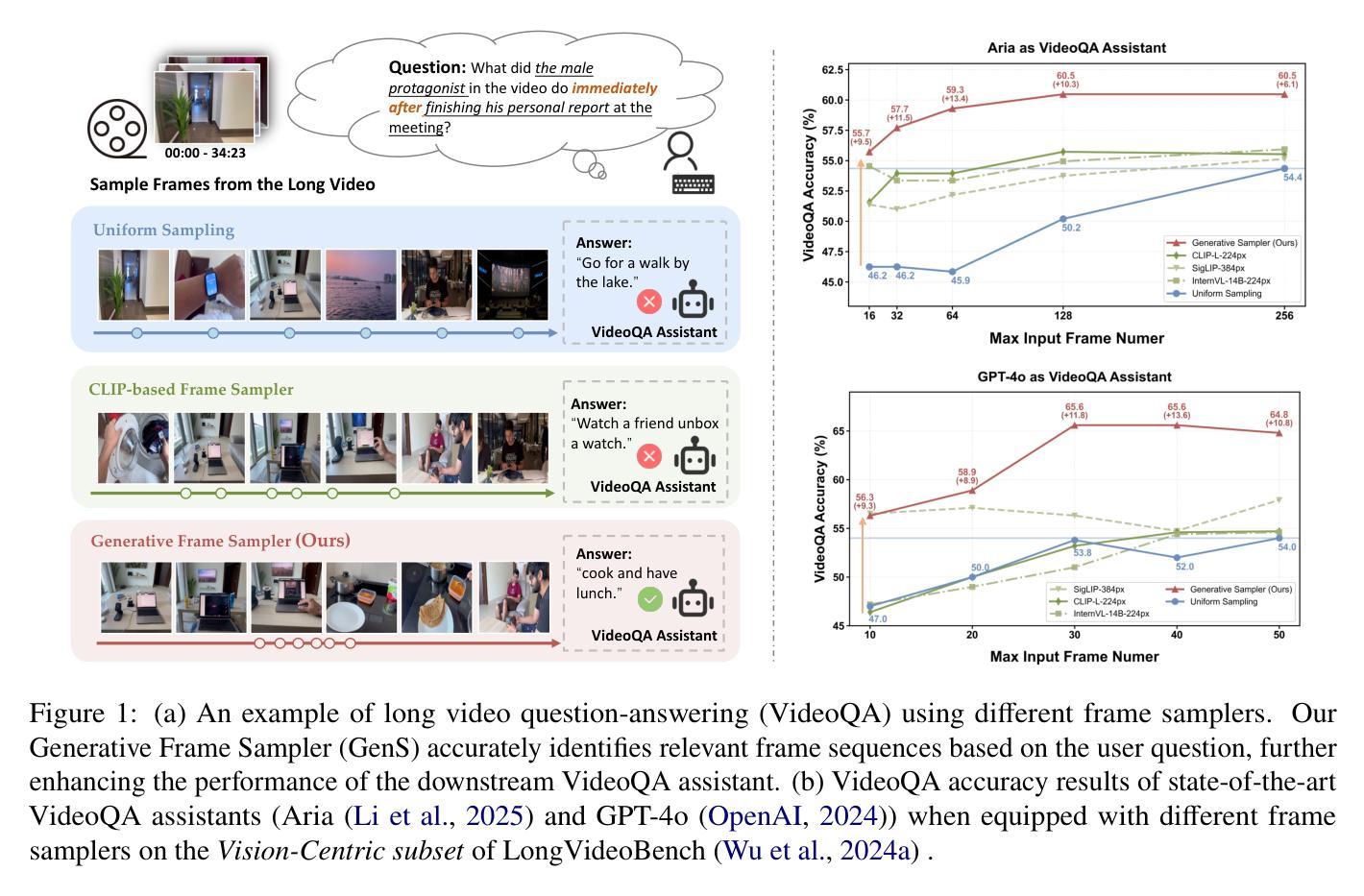
Despite recent advances in Video Large Language Models (VideoLLMs), effectively understanding long-form videos remains a significant challenge. Perceiving lengthy videos containing thousands of frames poses substantial computational burden. To mitigate this issue, this paper introduces Generative Frame Sampler (GenS), a plug-and-play module integrated with VideoLLMs to facilitate efficient lengthy video perception. Built upon a lightweight VideoLLM, GenS leverages its inherent vision-language capabilities to identify question-relevant frames. To facilitate effective retrieval, we construct GenS-Video-150K, a large-scale video instruction dataset with dense frame relevance annotations. Extensive experiments demonstrate that GenS consistently boosts the performance of various VideoLLMs, including open-source models (Qwen2-VL-7B, Aria-25B, VILA-40B, LLaVA-Video-7B/72B) and proprietary assistants (GPT-4o, Gemini). When equipped with GenS, open-source VideoLLMs achieve impressive state-of-the-art results on long-form video benchmarks: LLaVA-Video-72B reaches 66.8 (+4.3) on LongVideoBench and 77.0 (+2.7) on MLVU, while Aria obtains 39.2 on HourVideo surpassing the Gemini-1.5-pro by 1.9 points. We will release all datasets and models at https://generative-sampler.github.io.
尽管最近在视频大型语言模型(VideoLLMs)方面取得了进展,但有效地理解长视频仍然是一个巨大的挑战。处理包含数千帧的冗长视频带来了巨大的计算负担。为了缓解这个问题,本文介绍了生成帧采样器(GenS),这是一个与VideoLLMs集成的即插即用模块,可促进高效的长视频感知。基于轻量级的VideoLLM,GenS利用其固有的视觉语言功能来识别与问题相关的帧。为了促进有效检索,我们构建了GenS-Video-150K,这是一个大规模的视频指令数据集,具有密集的帧相关性注释。大量实验表明,GenS持续提升了各种VideoLLMs的性能,包括开源模型(Qwen2-VL-7B、Aria-25B、VILA-40B、LLaVA-Video-7B/72B)和专有助理(GPT-4o、Gemini)。配备GenS后,开源VideoLLMs在长篇视频基准测试上取得了令人印象深刻的最先进结果:LLaVA-Video-72B在LongVideoBench上达到66.8(+4.3),在MLVU上达到77.0(+2.7),而Aria在HourVideo上获得39.2,超越了Gemini-1.5-pro的1.9分。我们将在https://generative-sampler.github.io发布所有数据集和模型。
论文及项目相关链接
Summary
该文针对长视频理解问题,提出了一种名为Generative Frame Sampler(GenS)的插件模块,该模块可与VideoLLM集成,以实现对长视频的快速感知。GenS基于轻量级VideoLLM构建,利用其固有的视觉语言功能识别与问题相关的帧。同时,为了促进有效检索,构建了大型视频指令数据集GenS-Video-150K,其中包含密集的帧相关性注释。实验表明,GenS能显著提高各种VideoLLM的性能,包括开源模型和专有助手。特别是LLaVA-Video-72B在长视频基准测试上取得了66.8的优异成绩,提高了4.3个点。
Key Takeaways
- 提出了一种名为Generative Frame Sampler(GenS)的模块,用于解决长视频理解中的计算负担问题。
- GenS模块可以集成到现有的VideoLLM中,以提高对长视频的感知效率。
- GenS利用轻量级VideoLLM的固有视觉语言功能来识别与问题相关的帧。
- 构建了一个大型视频指令数据集GenS-Video-150K,用于训练和评估长视频理解模型。
- GenS在各种基准测试中表现出显著提高的性能,包括开源模型LLaVA-Video-72B和Aria等。
- LLaVA-Video-72B在长视频基准测试上的表现达到最新水平,相较于基准测试有明显的性能提升。
点此查看论文截图

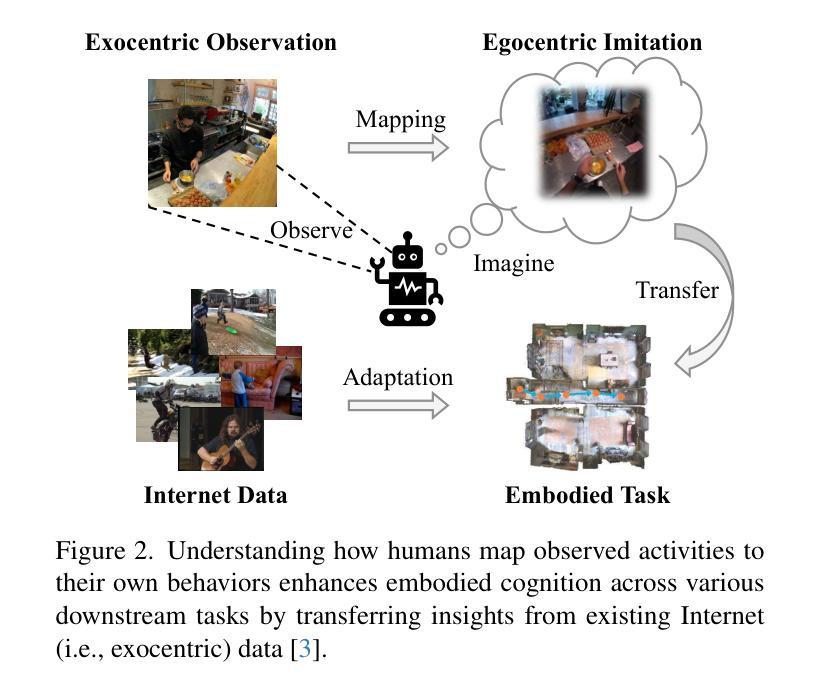
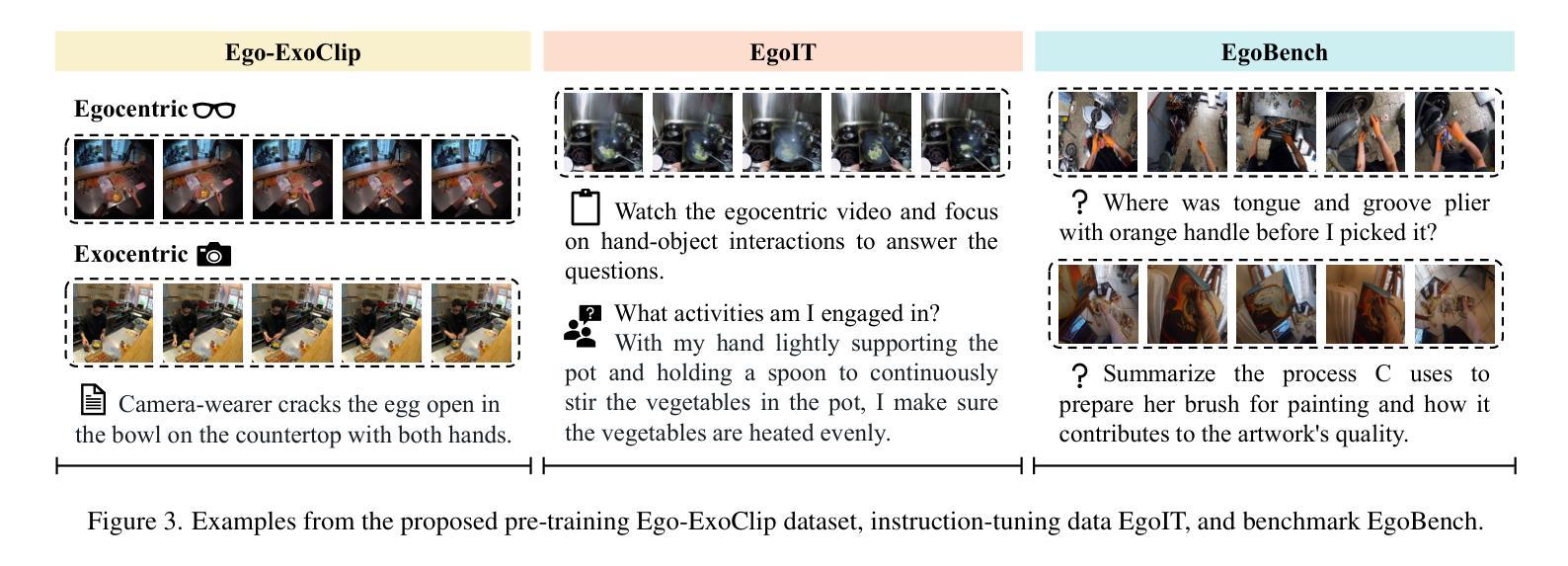
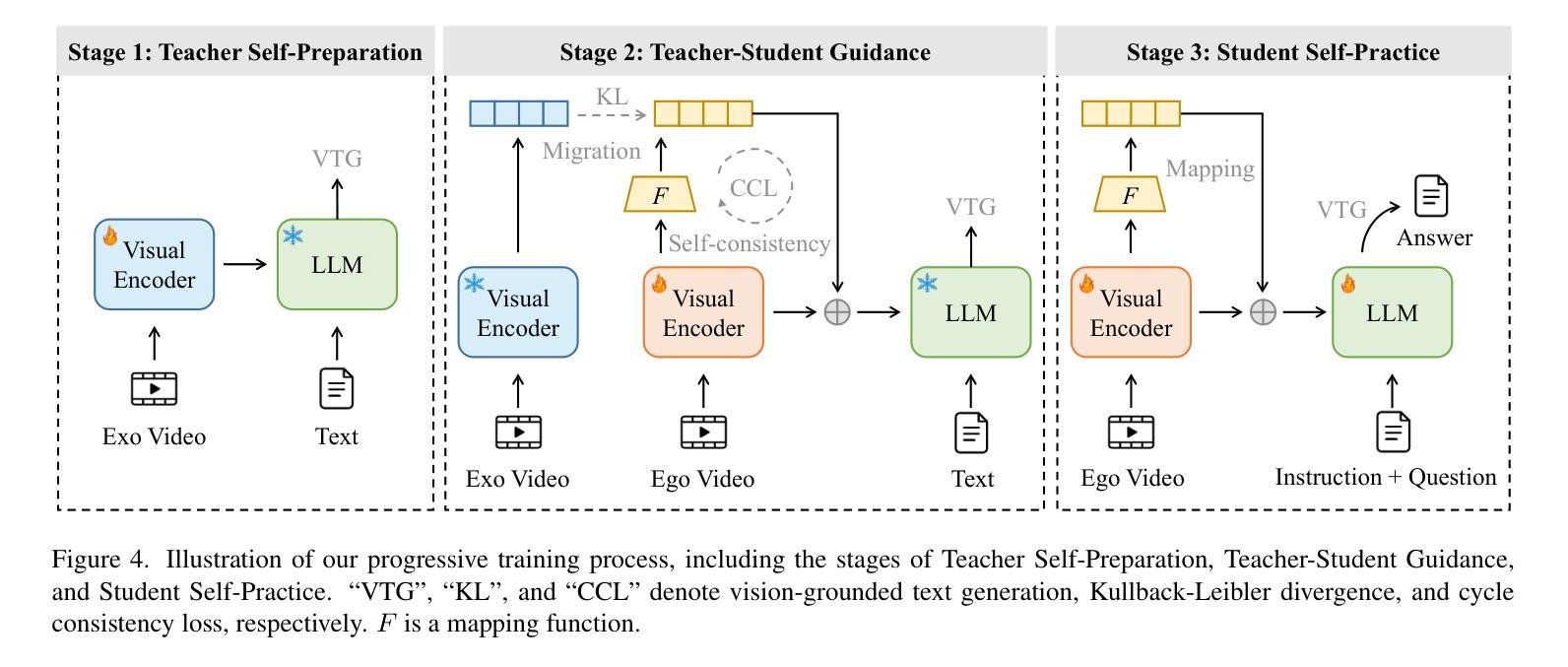
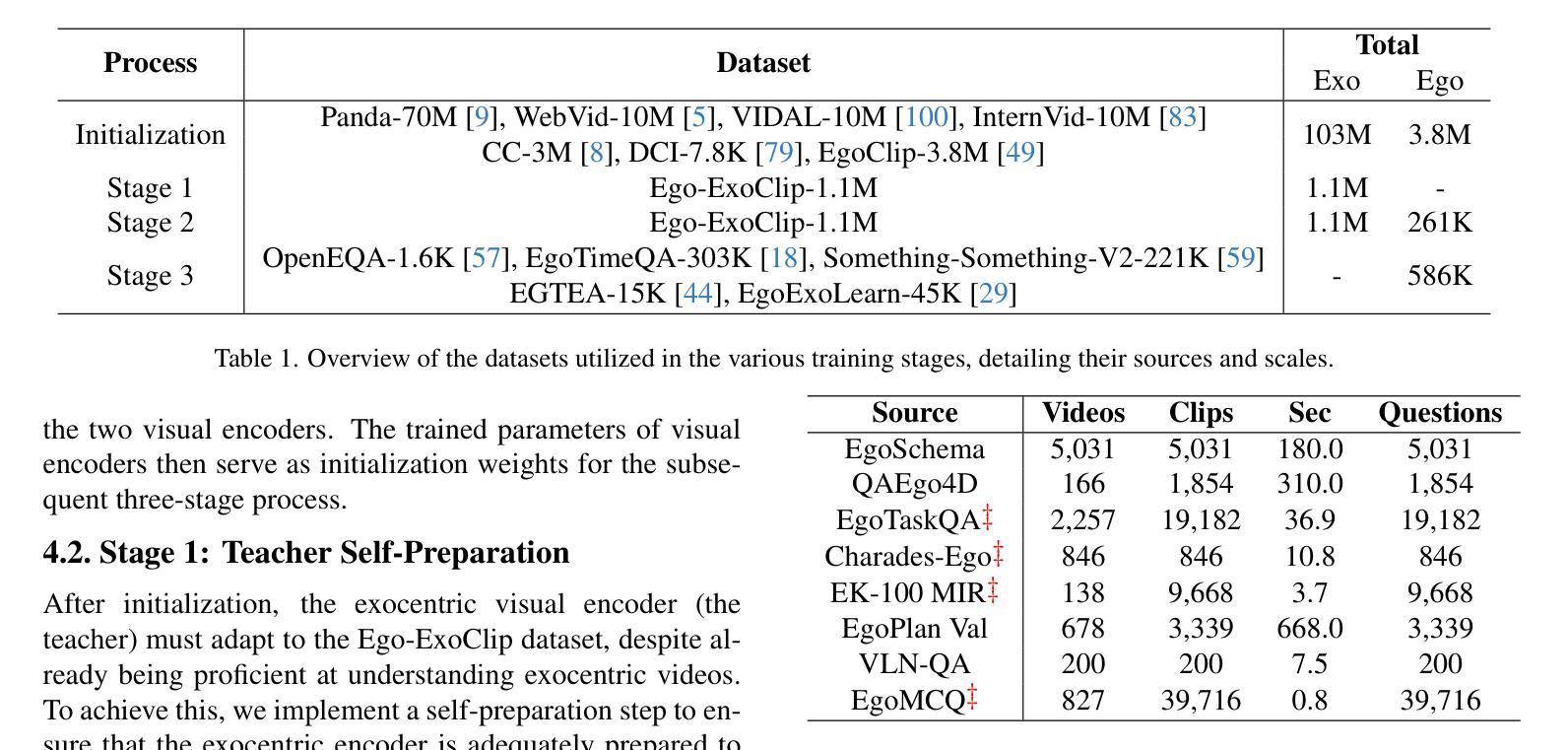
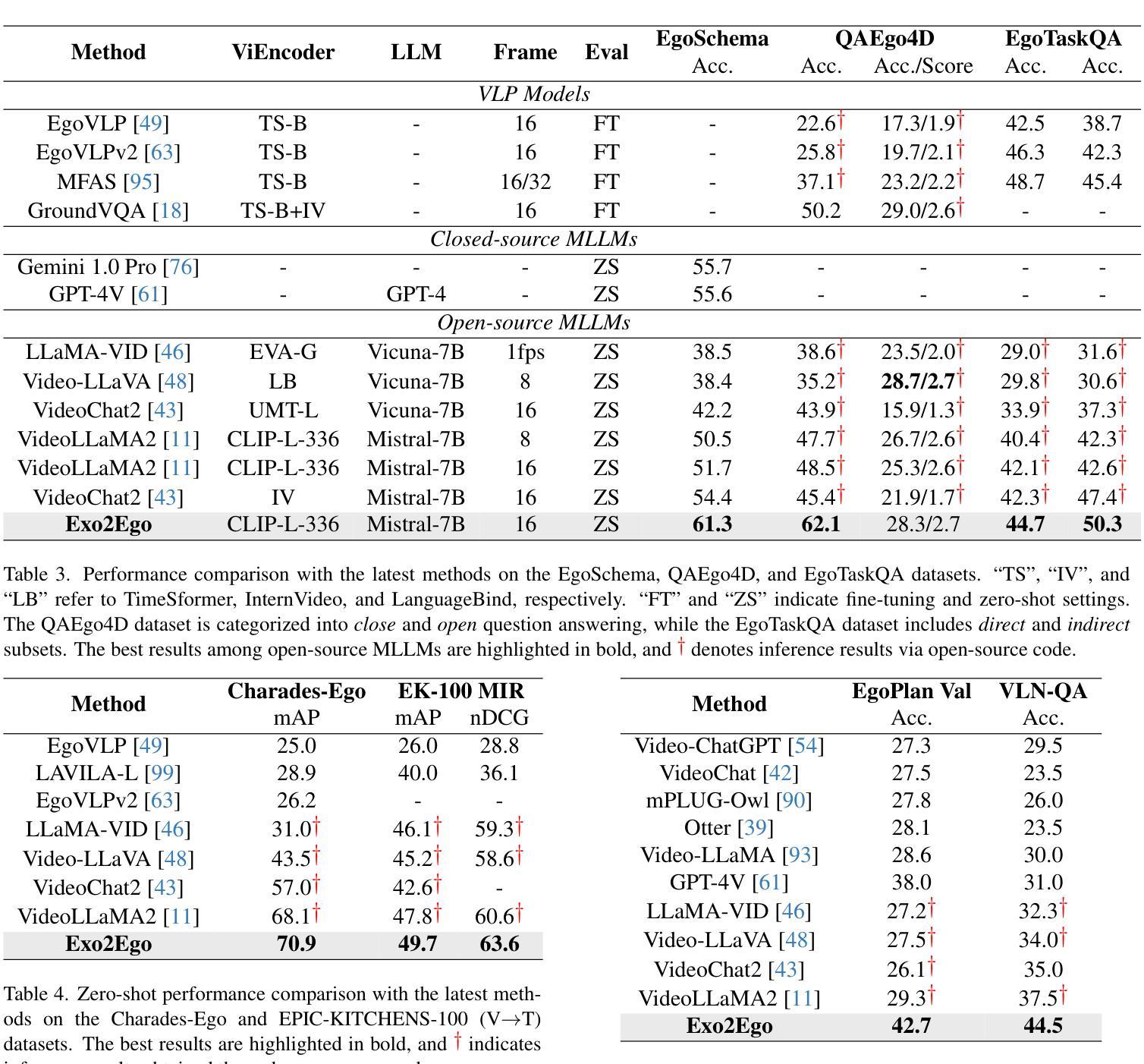
Exo2Ego: Exocentric Knowledge Guided MLLM for Egocentric Video Understanding
Authors:Haoyu Zhang, Qiaohui Chu, Meng Liu, Yunxiao Wang, Bin Wen, Fan Yang, Tingting Gao, Di Zhang, Yaowei Wang, Liqiang Nie
AI personal assistants, deployed through robots or wearables, require embodied understanding to collaborate effectively with humans. Current Multimodal Large Language Models (MLLMs) primarily focus on third-person (exocentric) vision, overlooking the unique aspects of first-person (egocentric) videos. Additionally, high acquisition costs limit data size, impairing MLLM performance. To address these challenges, we propose learning the mapping between exocentric and egocentric domains, leveraging the extensive exocentric knowledge within existing MLLMs to enhance egocentric video understanding. To this end, we introduce Ego-ExoClip, a pre-training dataset comprising 1.1M synchronized ego-exo clip-text pairs derived from Ego-Exo4D. Our approach features a progressive training pipeline with three stages: Teacher Self-Preparation, Teacher-Student Guidance, and Student Self-Practice. Additionally, we propose an instruction-tuning data EgoIT from multiple sources to strengthen the model’s instruction-following capabilities, along with the EgoBench benchmark comprising eight different tasks for thorough evaluation. Extensive experiments across diverse egocentric tasks reveal that existing MLLMs perform inadequately in egocentric video understanding, while our model significantly outperforms these leading models.
人工智能个人助理通过机器人或可穿戴设备部署,需要实体理解才能与人类有效协作。当前的多模态大型语言模型(MLLM)主要关注第三人称(离心)视觉,忽视了第一人称(自我中心)视频的独特方面。此外,高昂的采集成本限制了数据量,影响了MLLM的性能。为了应对这些挑战,我们提出了学习离心和自我中心领域之间的映射,利用现有的MLLMs中的丰富离心知识来增强自我中心视频的理解能力。为此,我们引入了Ego-ExoClip预训练数据集,包含从Ego-Exo4D派生的110万同步自我中心-离心剪辑文本对。我们的方法采用分阶段训练管道,包括三个阶段:教师自我准备、教师学生指导和学生自我实践。此外,我们从多个来源提出了指令调整数据EgoIT,以加强模型的指令执行能力,以及包含八个不同任务的EgoBench基准测试集进行全面评估。在多种自我中心任务上的广泛实验表明,现有的MLLM在自我中心视频理解方面表现不足,而我们的模型在这些领先模型中表现出显著优势。
论文及项目相关链接
PDF Project: https://egovisiongroup.github.io/Exo2Ego.github.io/
Summary
AI个人助理在机器人或可穿戴设备上的实现需要身临其境的理解来与人类有效协作。当前的多模态大型语言模型(MLLMs)主要关注第三人称(外部视角)的视觉,忽略了第一人称(个人视角)视频的独特性。为了解决数据获取成本高、影响MLLM性能的问题,我们提出了学习外部视角和内部视角领域之间的映射关系的方法,利用现有的MLLMs中的外部视角知识来增强内部视角的视频理解。为此,我们引入了Ego-ExoClip预训练数据集,包含从Ego-Exo4D派生的110万对同步的个人与外部剪辑文本。我们的方法采用分阶段训练管道,包括教师自我准备、教师-学生指导和学生的自我实践三个阶段。此外,我们还提出了来自多个来源的指令调整数据EgoIT,以加强模型的指令执行能力,以及包含八个不同任务的EgoBench基准测试集进行全面评估。实验表明,现有的MLLM在内部视角视频理解方面表现不佳,而我们的模型则显著优于这些领先模型。
Key Takeaways
- AI个人助理需要身临其境的理解来与人类协作。
- 当前的多模态大型语言模型主要关注第三人称视觉,忽视第一人称视频的独特性。
- 提出学习外部视角和内部视角领域之间的映射关系的方法。
- 引入Ego-ExoClip预训练数据集,包含同步的个人与外部剪辑文本。
- 采用分阶段训练管道,包括教师自我准备、教师-学生指导和学生的自我实践阶段。
- 提出指令调整数据EgoIT,加强模型的指令执行能力。
点此查看论文截图

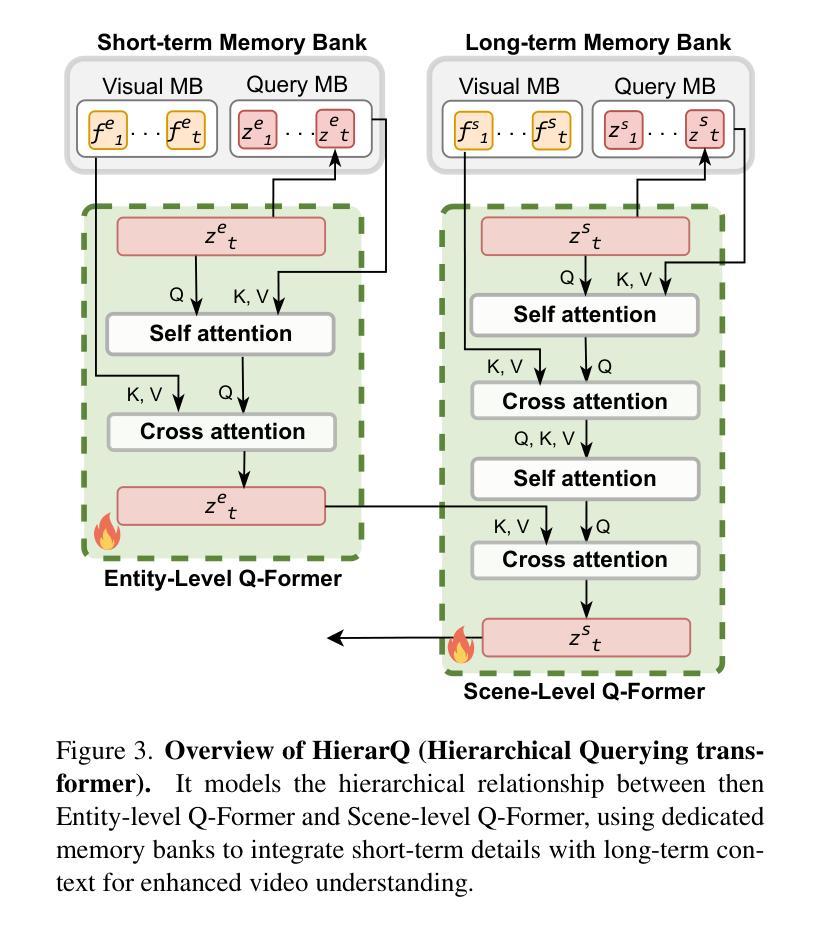
HierarQ: Task-Aware Hierarchical Q-Former for Enhanced Video Understanding
Authors:Shehreen Azad, Vibhav Vineet, Yogesh Singh Rawat
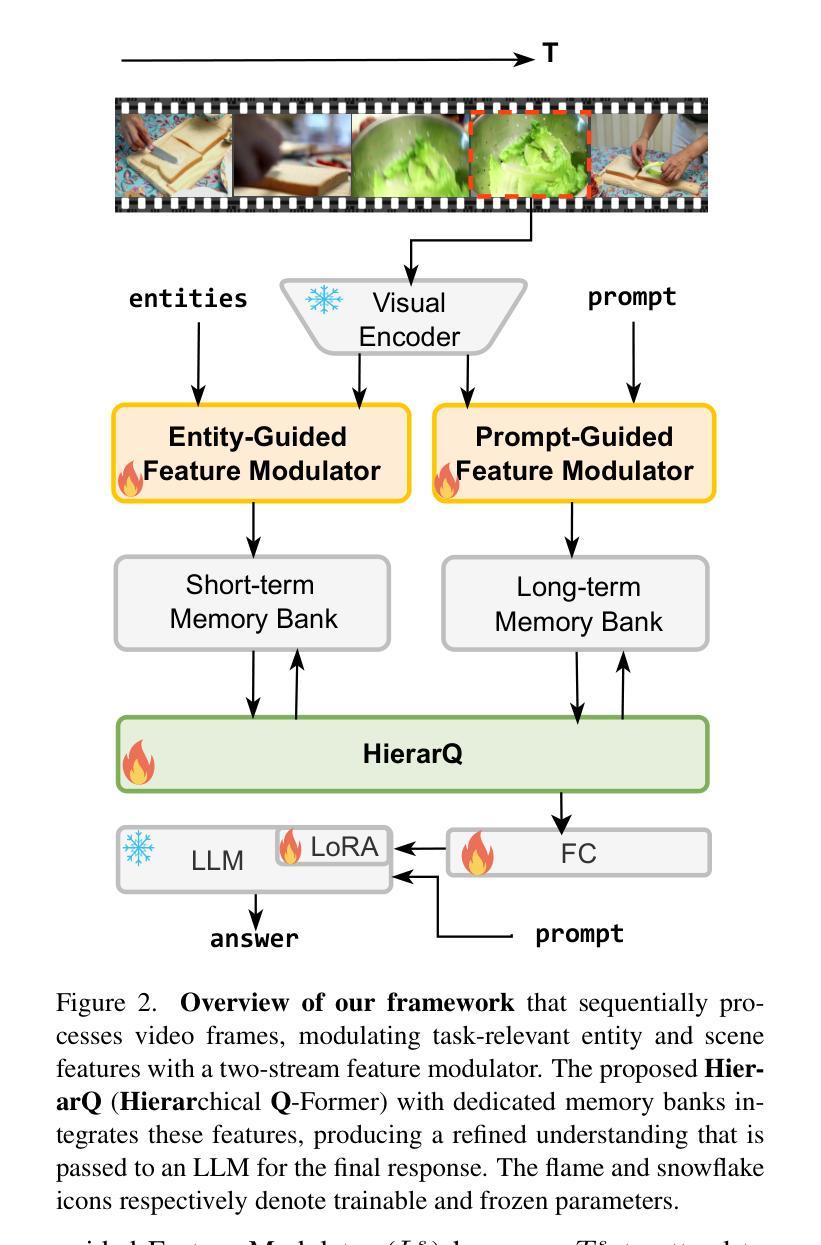
Despite advancements in multimodal large language models (MLLMs), current approaches struggle in medium-to-long video understanding due to frame and context length limitations. As a result, these models often depend on frame sampling, which risks missing key information over time and lacks task-specific relevance. To address these challenges, we introduce HierarQ, a task-aware hierarchical Q-Former based framework that sequentially processes frames to bypass the need for frame sampling, while avoiding LLM’s context length limitations. We introduce a lightweight two-stream language-guided feature modulator to incorporate task awareness in video understanding, with the entity stream capturing frame-level object information within a short context and the scene stream identifying their broader interactions over longer period of time. Each stream is supported by dedicated memory banks which enables our proposed Hierachical Querying transformer (HierarQ) to effectively capture short and long-term context. Extensive evaluations on 10 video benchmarks across video understanding, question answering, and captioning tasks demonstrate HierarQ’s state-of-the-art performance across most datasets, proving its robustness and efficiency for comprehensive video analysis.
尽管多模态大型语言模型(MLLMs)有所进展,但当前的方法在中长视频理解方面仍面临挑战,这是由于帧和上下文长度的限制所导致的。因此,这些模型通常依赖于帧采样,这有可能在时间上错过关键信息,并且缺乏特定任务的关联性。为了解决这些挑战,我们引入了 HierarQ,这是一个基于任务感知的分层 Q-Former 框架,它按顺序处理帧,从而绕过对帧采样的需求,同时避免 LLM 的上下文长度限制。我们引入了一个轻量级的双流语言引导特征调制器,将任务感知融入视频理解中,实体流在短语境中捕获帧级对象信息,场景流则识别它们在更长时间内的更广泛的交互。每个流都由专用内存库支持,这使得我们提出的分层查询变压器(HierarQ)可以有效地捕获短期和长期上下文。在10个视频基准测试上的广泛评估,包括视频理解、问答和字幕任务,证明了 HierarQ 在大多数数据集上的最新性能,证明了其在综合视频分析中的稳健性和效率。
论文及项目相关链接
PDF Accepted in CVPR 2025
Summary
该文指出,尽管多模态大型语言模型(MLLMs)有所进展,但在中等至长视频理解方面仍存在挑战,受限于帧和上下文长度。因此,现有模型常依赖帧采样,这可能遗漏关键信息且缺乏任务相关性。为应对这些挑战,提出一种任务感知的分层Q-Former框架(HierarQ),该框架可顺序处理帧,无需帧采样,同时避免LLM的上下文长度限制。通过引入轻量级双流语言引导特征调制器实现任务感知的视频理解,实体流捕获短上下文内的帧级对象信息,场景流识别较长时间内的更广泛交互。每条流都有专用内存银行,支持分层查询变压器(HierarQ)有效捕获短期和长期上下文。在10个视频基准测试上的广泛评估表明,HierarQ在大多数数据集上表现最佳,证明了其在综合视频分析中的稳健性和效率。
Key Takeaways
- 当前的多模态大型语言模型在中等至长视频理解上存有限制,主要因为帧和上下文长度的制约。
- 现有模型常依赖帧采样,这可能造成关键信息的遗漏,并且缺乏任务特异性。
- 提出一种任务感知的分层Q-Former框架(HierarQ),能顺序处理帧,绕过帧采样的需要。
- HierarQ框架避免了大型语言模型的上下文长度限制。
- 通过引入轻量级双流语言引导特征调制器实现任务感知的视频理解,包括实体流和场景流。
- 实体流捕获短上下文内的帧级对象信息,场景流识别更广泛的长期交互。
点此查看论文截图

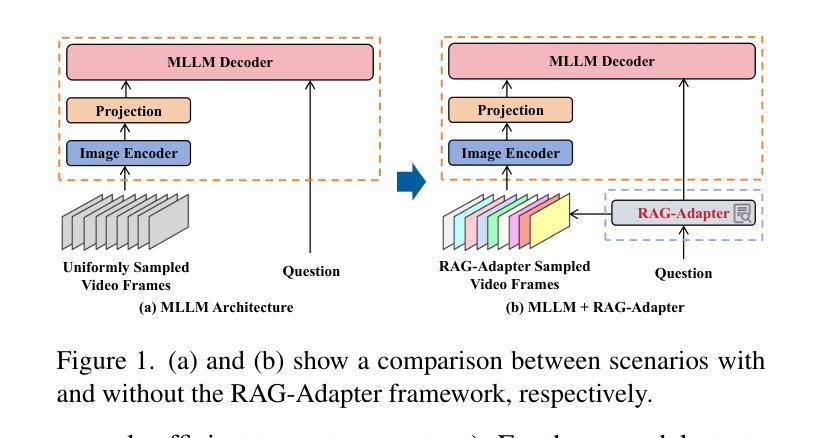
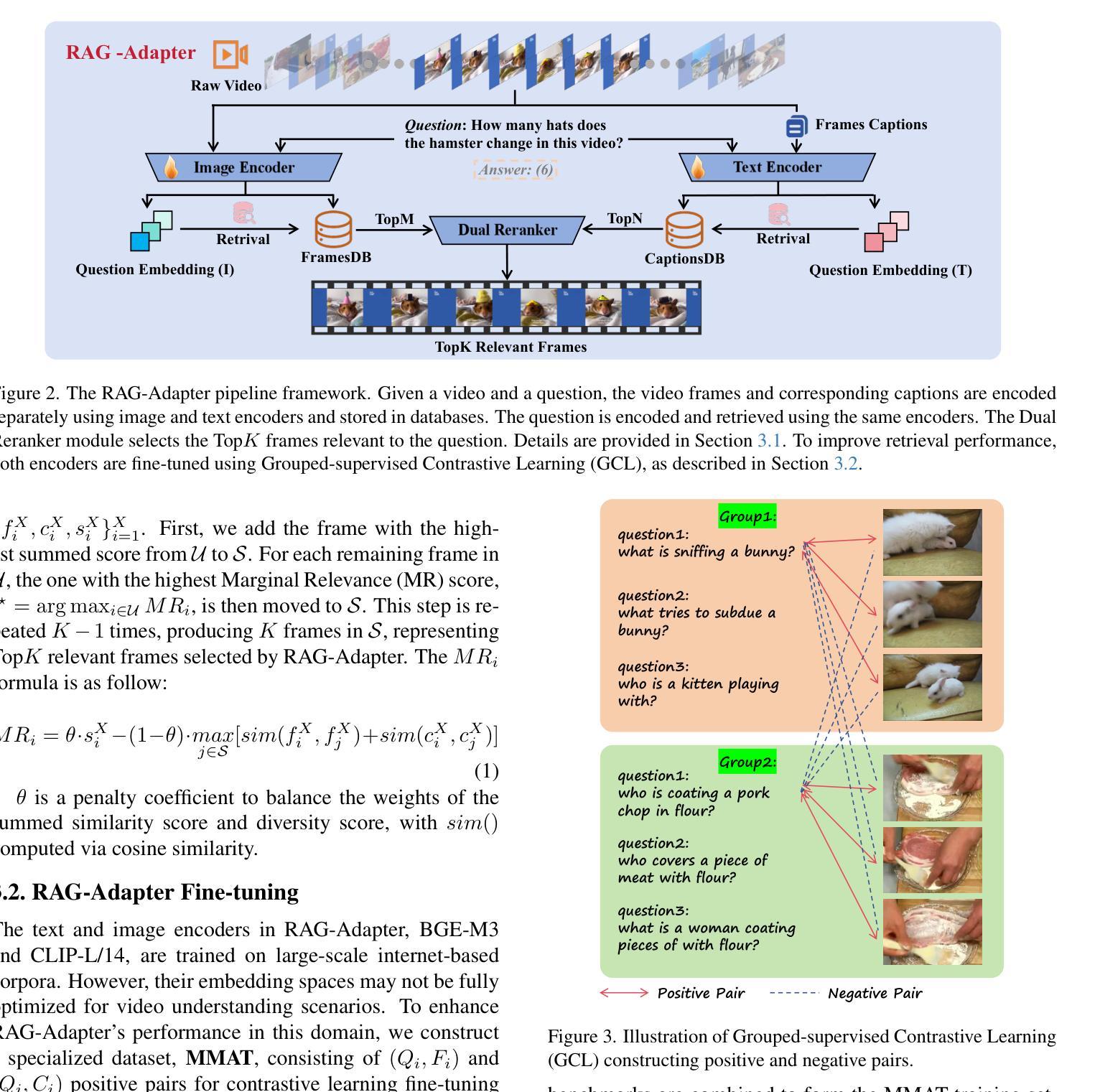
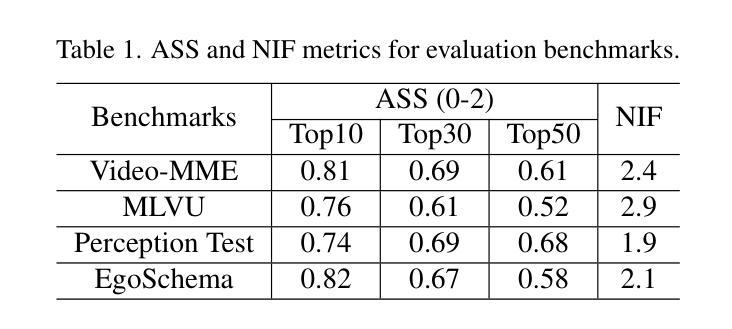
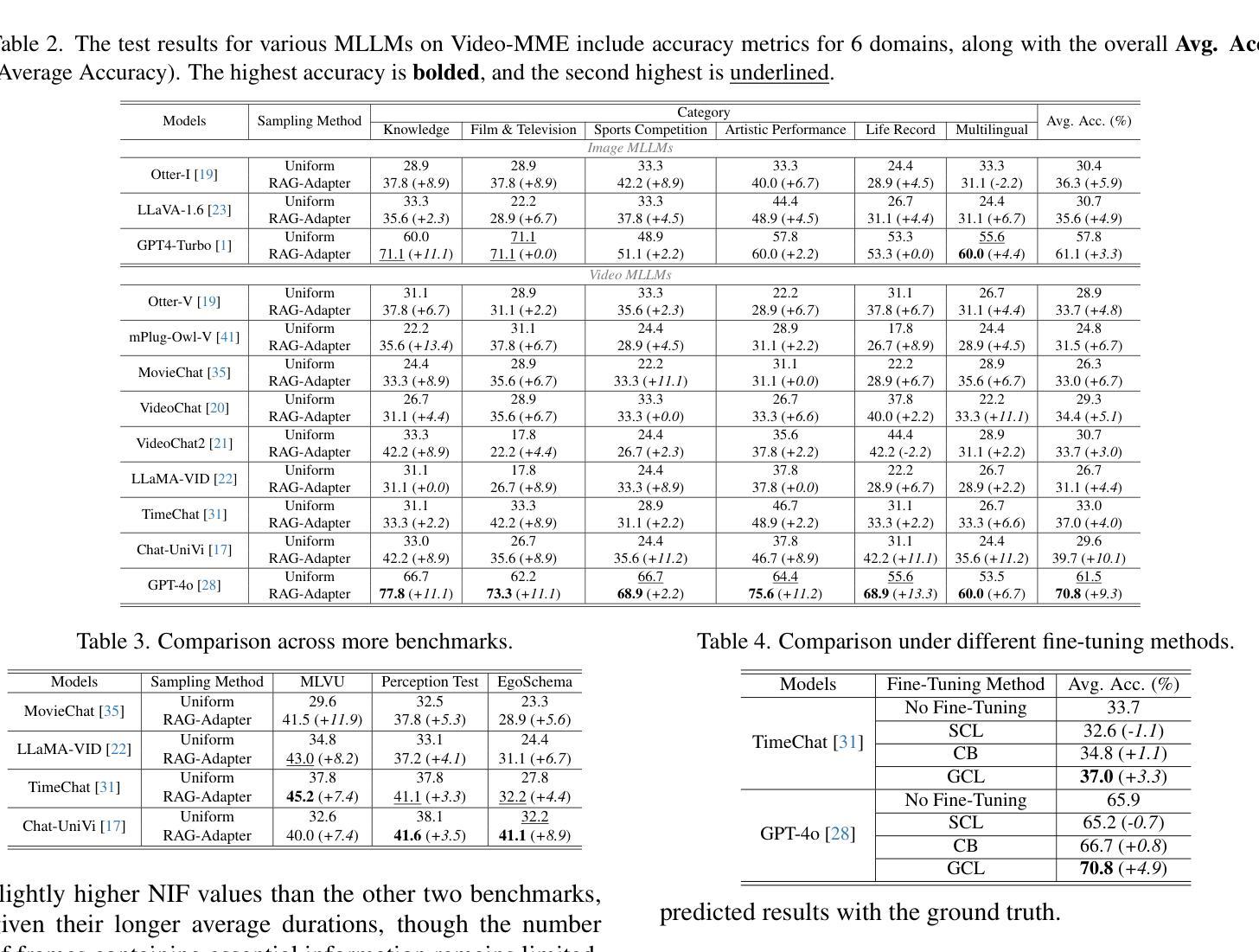
RAG-Adapter: A Plug-and-Play RAG-enhanced Framework for Long Video Understanding
Authors:Xichen Tan, Yunfan Ye, Yuanjing Luo, Qian Wan, Fang Liu, Zhiping Cai
Multi-modal Large Language Models (MLLMs) capable of video understanding are advancing rapidly. To effectively assess their video comprehension capabilities, long video understanding benchmarks, such as Video-MME and MLVU, are proposed. However, these benchmarks directly use uniform frame sampling for testing, which results in significant information loss and affects the accuracy of the evaluations in reflecting the true abilities of MLLMs. To address this, we propose RAG-Adapter, a plug-and-play framework that reduces information loss during testing by sampling frames most relevant to the given question. Additionally, we introduce a Grouped-supervised Contrastive Learning (GCL) method to further enhance sampling effectiveness of RAG-Adapter through fine-tuning on our constructed MMAT dataset. Finally, we test numerous baseline MLLMs on various video understanding benchmarks, finding that RAG-Adapter sampling consistently outperforms uniform sampling (e.g., Accuracy of GPT-4o increases by 9.3 percent on Video-MME), providing a more accurate testing method for long video benchmarks.
多模态大型语言模型(MLLMs)在视频理解方面正在迅速发展。为了有效地评估其视频理解能力,提出了长视频理解基准测试,如Video-MME和MLVU等。然而,这些基准测试直接使用统一的帧采样进行测试,导致大量信息丢失,影响评估的准确性,无法真正反映MLLMs的能力。为了解决这一问题,我们提出了RAG-Adapter,这是一个即插即用的框架,通过采样与给定问题最相关的帧来减少测试过程中的信息丢失。此外,我们还引入了一种分组监督对比学习(GCL)方法,通过在我们构建的MMAT数据集上进行微调,进一步提高RAG-Adapter的采样效果。最后,我们在各种视频理解基准测试上对多个基准MLLMs进行了测试,发现RAG-Adapter采样始终优于均匀采样(例如,GPT-4o在Video-MME上的准确率提高9.3%),为长视频基准测试提供了更准确的测试方法。
论文及项目相关链接
PDF 37 pages, 36 figures
Summary
多模态大型语言模型(MLLMs)在视频理解方面迅速进步,但现有视频理解基准测试(如Video-MME和MLVU)采用均匀帧采样,导致信息丢失并影响评估准确性。为解决此问题,我们提出RAG-Adapter框架,通过采样与问题最相关的帧来减少测试中的信息丢失。此外,我们引入分组监督对比学习方法(GCL)来提升RAG-Adapter的采样效果。在多个视频理解基准测试中测试显示,RAG-Adapter采样方法表现优于均匀采样,如GPT-4o在Video-MME上的准确率提高9.3%。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视频理解方面进展迅速。
- 目前视频理解基准测试存在信息丢失问题。
- RAG-Adapter框架通过采样与问题最相关的帧来减少测试中的信息丢失。
- 引入分组监督对比学习方法(GCL)提升RAG-Adapter的采样效果。
- RAG-Adapter采样方法表现优于均匀采样。
- 在不同视频理解基准测试中,使用RAG-Adapter框架的MLLMs表现更优秀。
点此查看论文截图

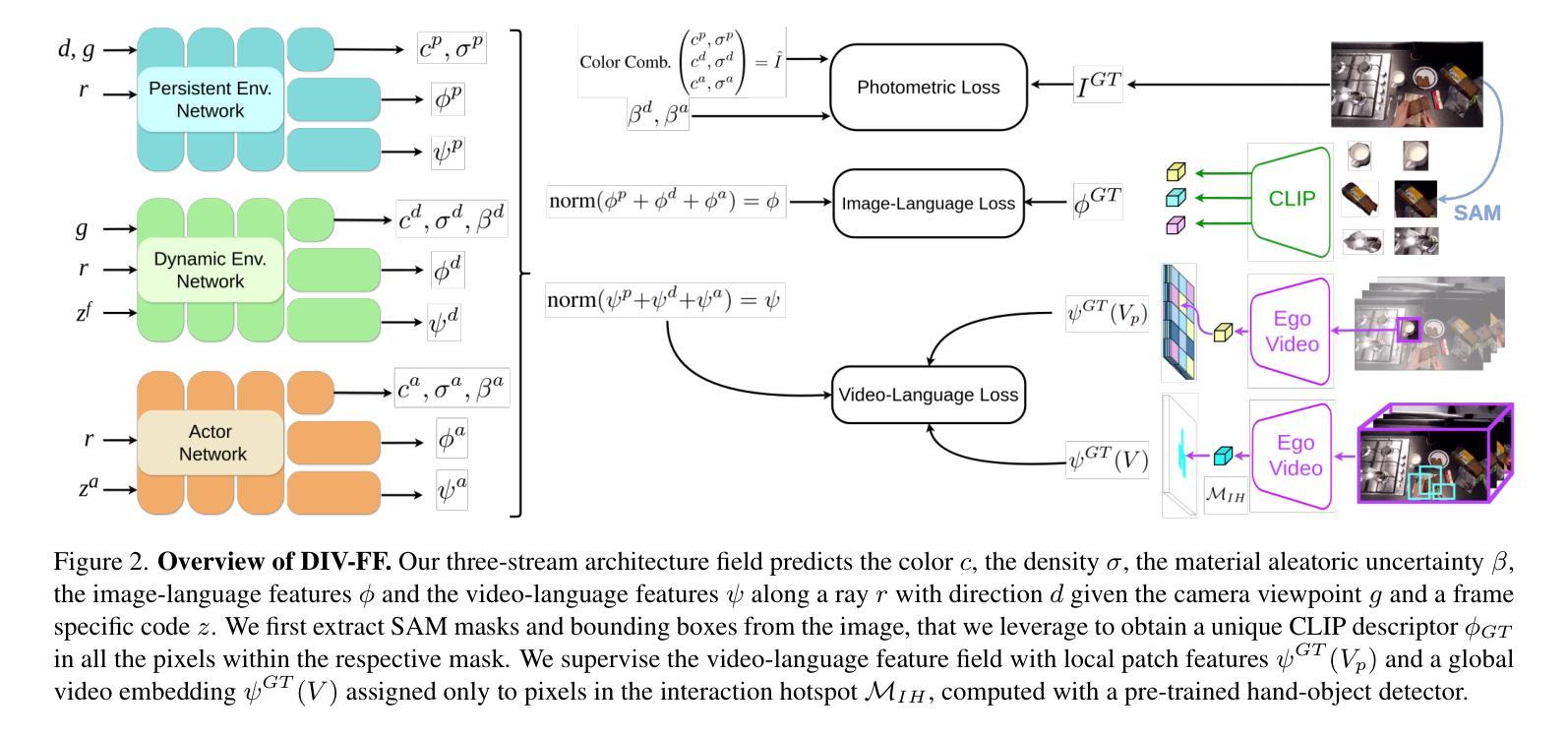
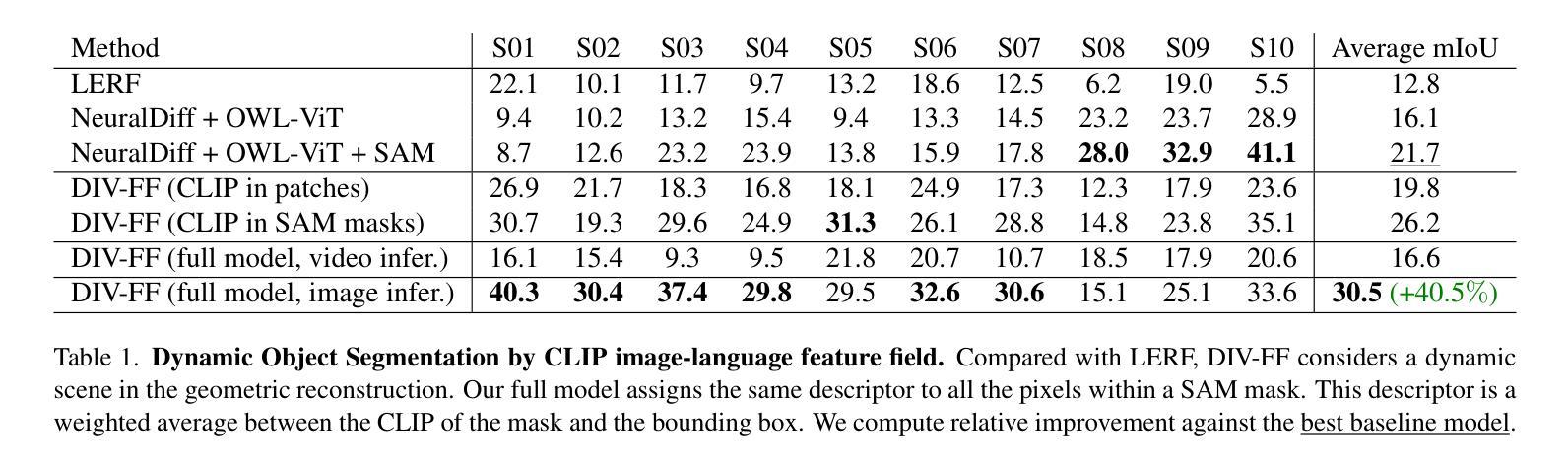
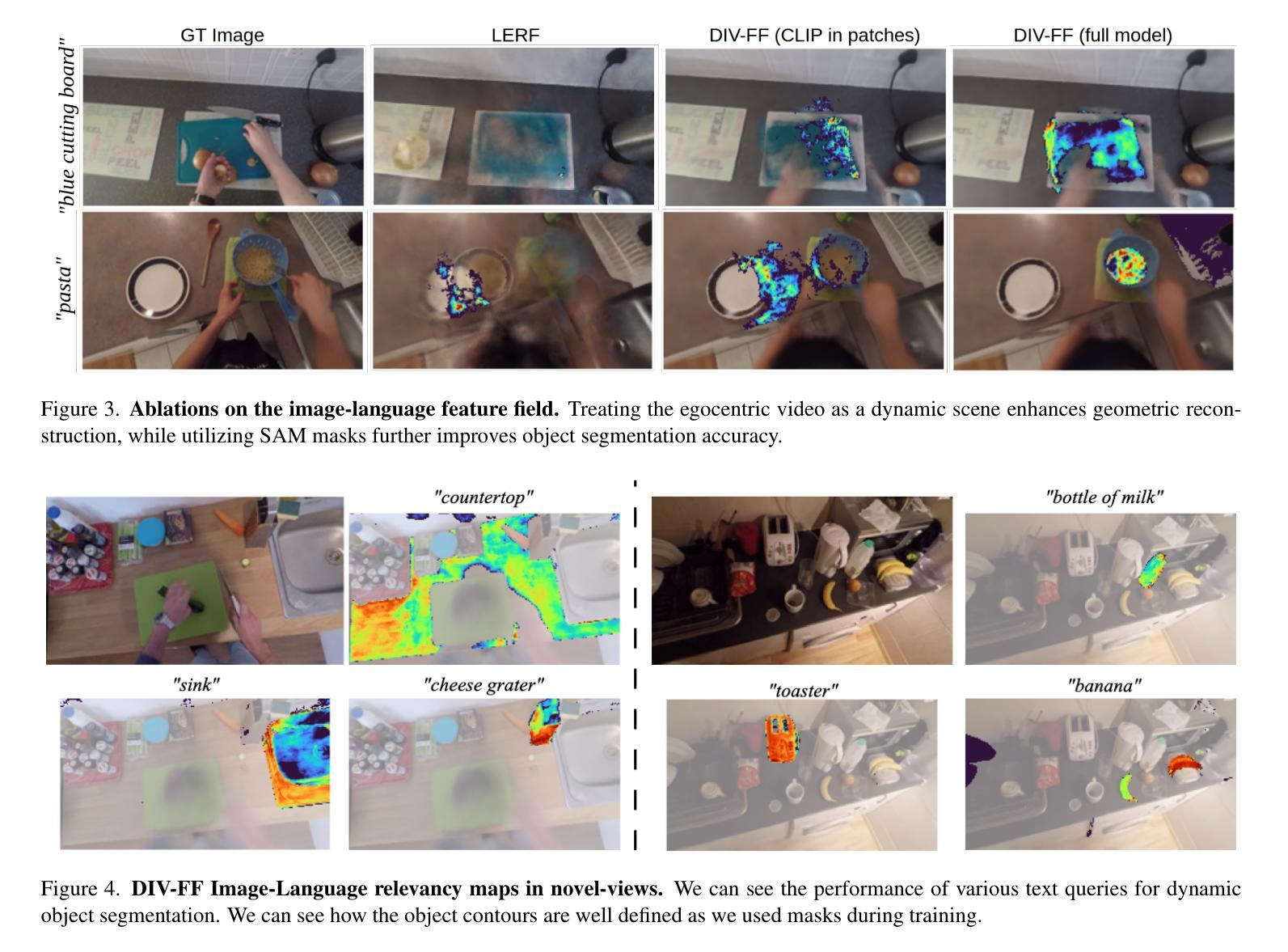
DIV-FF: Dynamic Image-Video Feature Fields For Environment Understanding in Egocentric Videos
Authors:Lorenzo Mur-Labadia, Josechu Guerrero, Ruben Martinez-Cantin
Environment understanding in egocentric videos is an important step for applications like robotics, augmented reality and assistive technologies. These videos are characterized by dynamic interactions and a strong dependence on the wearer engagement with the environment. Traditional approaches often focus on isolated clips or fail to integrate rich semantic and geometric information, limiting scene comprehension. We introduce Dynamic Image-Video Feature Fields (DIV FF), a framework that decomposes the egocentric scene into persistent, dynamic, and actor based components while integrating both image and video language features. Our model enables detailed segmentation, captures affordances, understands the surroundings and maintains consistent understanding over time. DIV-FF outperforms state-of-the-art methods, particularly in dynamically evolving scenarios, demonstrating its potential to advance long term, spatio temporal scene understanding.
以自我为中心的视频中的环境理解对于机器人技术、增强现实和辅助技术等领域的应用是一个重要步骤。这些视频的特点是动态交互性强,强烈依赖于佩戴者与环境的互动。传统方法往往侧重于孤立的片段或无法整合丰富的语义和几何信息,从而限制了场景的理解。我们引入了动态图像视频特征场(DIV FF)框架,该框架将自我中心场景分解为持久性、动态性和基于演员的成分,同时整合图像和视频语言特征。我们的模型能够实现详细的分割,捕捉负担能力,理解周围环境,并随时间保持一致的理解。DIV-FF在动态演化场景中表现出优于最新技术方法的性能,展示了它在长期时空场景理解方面的潜力。
论文及项目相关链接
Summary:
动态图像视频特征场(DIV FF)框架能够分解以自我为中心的场景为持久性、动态性和基于演员的部分,同时整合图像和视频语言特征,实现详细分割、捕捉负担、理解周围环境和长期一致的理解。与传统的环境理解方法相比,DIV FF在动态演化场景中表现优越。
Key Takeaways:
- 环境理解在机器人技术、增强现实和辅助技术等领域具有关键作用。
- 以自我为中心的视频具有动态交互性和对佩戴者与环境互动的高度依赖性。
- 传统方法常集中在孤立的片段上,或者无法整合丰富的语义和几何信息,限制了场景的理解。
- DIV FF框架将自我为中心的环境分解为不同的组件并整合图像和视频语言特征。
- DIV FF框架可实现详细分割、捕捉负担和理解周围环境的能力。
- DIV FF框架在长期时空场景理解方面具有潜力。
点此查看论文截图

Prompt2LVideos: Exploring Prompts for Understanding Long-Form Multimodal Videos
Authors:Soumya Shamarao Jahagirdar, Jayasree Saha, C V Jawahar
Learning multimodal video understanding typically relies on datasets comprising video clips paired with manually annotated captions. However, this becomes even more challenging when dealing with long-form videos, lasting from minutes to hours, in educational and news domains due to the need for more annotators with subject expertise. Hence, there arises a need for automated solutions. Recent advancements in Large Language Models (LLMs) promise to capture concise and informative content that allows the comprehension of entire videos by leveraging Automatic Speech Recognition (ASR) and Optical Character Recognition (OCR) technologies. ASR provides textual content from audio, while OCR extracts textual content from specific frames. This paper introduces a dataset comprising long-form lectures and news videos. We present baseline approaches to understand their limitations on this dataset and advocate for exploring prompt engineering techniques to comprehend long-form multimodal video datasets comprehensively.
学习多模态视频理解通常依赖于由与手动注释的标题配对构成的视频剪辑数据集。然而,在处理教育和新领域的持续时间从几分钟到几小时的长视频时,由于需要大量有专业知识的主注释者,这一要求变得更具挑战性。因此,对自动解决方案的需求应运而生。基于最新进展的大型语言模型(LLM)承诺捕捉简洁而富有信息的内容,利用自动语音识别(ASR)和光学字符识别(OCR)技术,通过对整个视频进行推断以实现理解。ASR提供了来自音频的文本内容,而OCR从特定帧中提取文本内容。本文介绍了一个包含长讲座和新闻视频的数据集。我们介绍了基线方法,以了解他们在该数据集上的局限性,并倡导探索提示工程技术以全面理解长格式多模态视频数据集。
论文及项目相关链接
PDF CVIP 2024
Summary
本文探讨了在教育和新闻领域中对长视频(从几分钟到几小时不等)进行多模态理解所面临的挑战。文章指出,现有的手动标注数据集无法满足长视频的需求,需要更多具有专业知识的标注者参与。文章还介绍了大型语言模型(LLM)的进展,它可以利用自动语音识别(ASR)和光学字符识别(OCR)技术捕捉视频中的关键信息。本文还引入了一个包含长讲座和新闻视频的数据集,并探讨了基于该数据集的基准方法的局限性,并提倡探索提示工程技术来全面理解长视频多模态数据集。
Key Takeaways
- 学习多模态视频理解通常依赖于包含视频剪辑和手动注释字幕的数据集。
- 处理教育和新闻领域中的长视频面临挑战,需要更多具有专业知识的标注者参与。
- 大型语言模型(LLM)可以捕捉视频中的关键信息,利用ASR和OCR技术。
- 文章引入了一个包含长讲座和新闻视频的数据集。
- 基准方法在处理此类数据集时存在局限性。
- 需要探索提示工程技术来优化大型语言模型在长视频多模态理解方面的性能。
点此查看论文截图



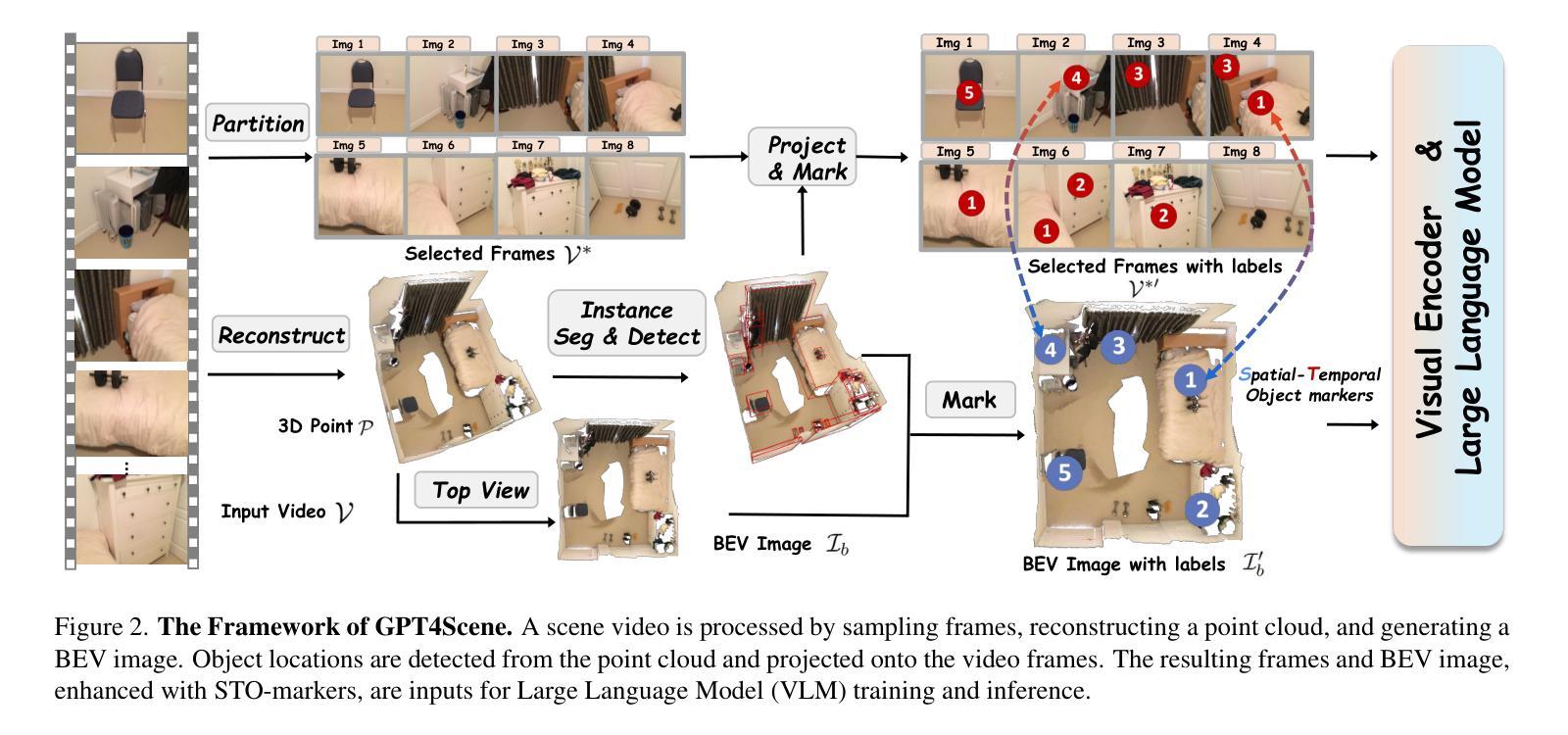
GPT4Scene: Understand 3D Scenes from Videos with Vision-Language Models
Authors:Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, Hengshuang Zhao
In recent years, 2D Vision-Language Models (VLMs) have made significant strides in image-text understanding tasks. However, their performance in 3D spatial comprehension, which is critical for embodied intelligence, remains limited. Recent advances have leveraged 3D point clouds and multi-view images as inputs, yielding promising results. However, we propose exploring a purely vision-based solution inspired by human perception, which merely relies on visual cues for 3D spatial understanding. This paper empirically investigates the limitations of VLMs in 3D spatial knowledge, revealing that their primary shortcoming lies in the lack of global-local correspondence between the scene and individual frames. To address this, we introduce GPT4Scene, a novel visual prompting paradigm in VLM training and inference that helps build the global-local relationship, significantly improving the 3D spatial understanding of indoor scenes. Specifically, GPT4Scene constructs a Bird’s Eye View (BEV) image from the video and marks consistent object IDs across both frames and the BEV image. The model then inputs the concatenated BEV image and video frames with markers. In zero-shot evaluations, GPT4Scene improves performance over closed-source VLMs like GPT-4o. Additionally, we prepare a processed video dataset consisting of 165K text annotation to fine-tune open-source VLMs, achieving state-of-the-art performance on all 3D understanding tasks. Surprisingly, after training with the GPT4Scene paradigm, VLMs consistently improve during inference, even without object marker prompting and BEV image as explicit correspondence. It demonstrates that the proposed paradigm helps VLMs develop an intrinsic ability to understand 3D scenes, which paves the way for a seamless approach to extending pre-trained VLMs for 3D scene understanding.
近年来,二维视觉语言模型(VLMs)在图文理解任务中取得了显著进展。然而,它们在三维空间理解方面的表现,对于体现智能至关重要,仍然有限。最近的进展利用三维点云和多视角图像作为输入,取得了有前景的结果。然而,我们提出探索一种基于纯粹视觉的解决方案,该方案受到人类感知的启发,仅依赖视觉线索进行三维空间理解。
论文及项目相关链接
PDF Project page: https://gpt4scene.github.io/
Summary
本文探讨了二维视觉语言模型(VLMs)在三维空间理解上的局限性,并介绍了一种基于视觉提示的新方法GPT4Scene,用于改善VLMs在三维室内场景理解方面的表现。GPT4Scene通过建立鸟瞰图(BEV)和对象标记技术构建全局局部对应关系,从而提高模型的零样本评估性能。此外,通过处理过的包含文本注释的视频数据集进行微调,使得模型在三维理解任务上表现卓越。最重要的是,GPT4Scene训练后的模型能够在推理时即使没有明确的提示也能理解三维场景,展现出其内在的三维场景理解能力。
Key Takeaways
- 二维视觉语言模型(VLMs)在三维空间理解方面存在局限性。
- GPT4Scene是一种新的视觉提示方法,旨在改善VLMs在三维室内场景理解上的性能。
- GPT4Scene通过建立鸟瞰图(BEV)和对象标记技术,建立全局局部对应关系。
- GPT4Scene能提高模型的零样本评估性能。
- 处理过的视频数据集用于微调模型,使其在三维理解任务上表现卓越。
- GPT4Scene训练后的模型能够在推理时即使没有明确的提示也能理解三维场景。
点此查看论文截图

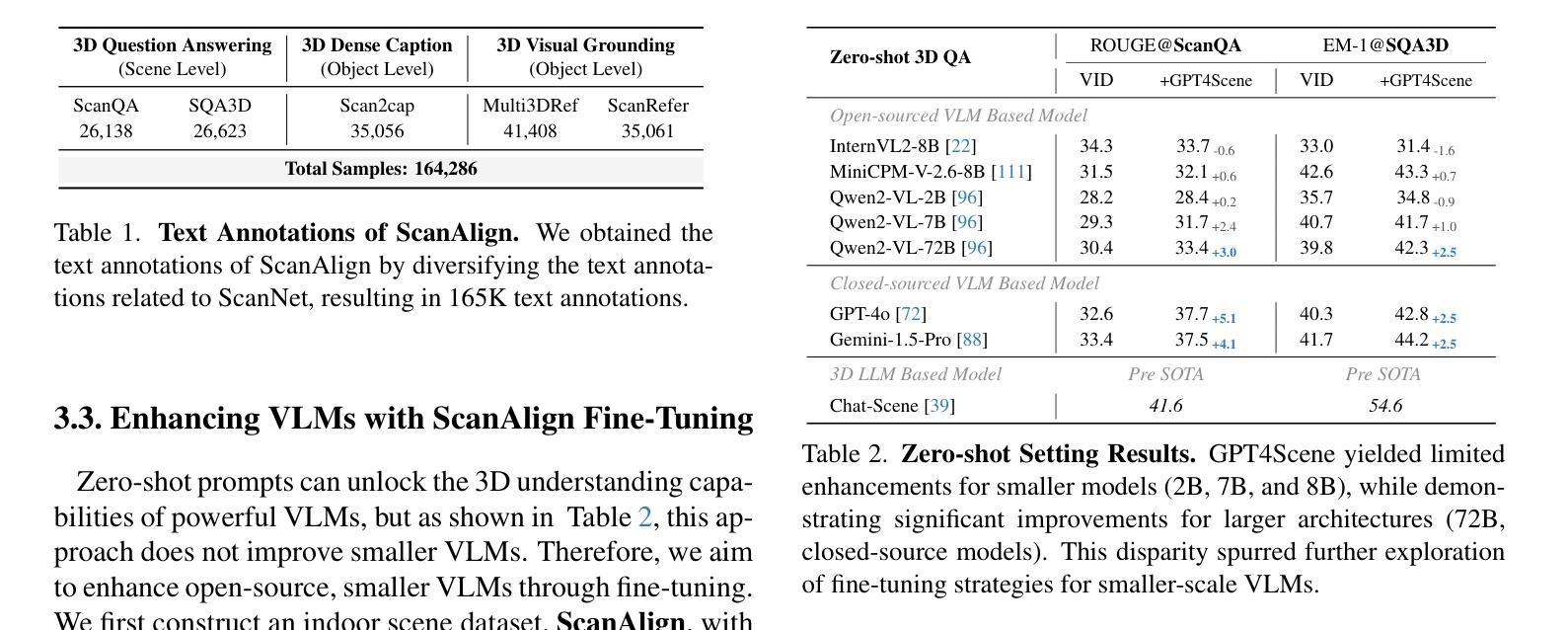
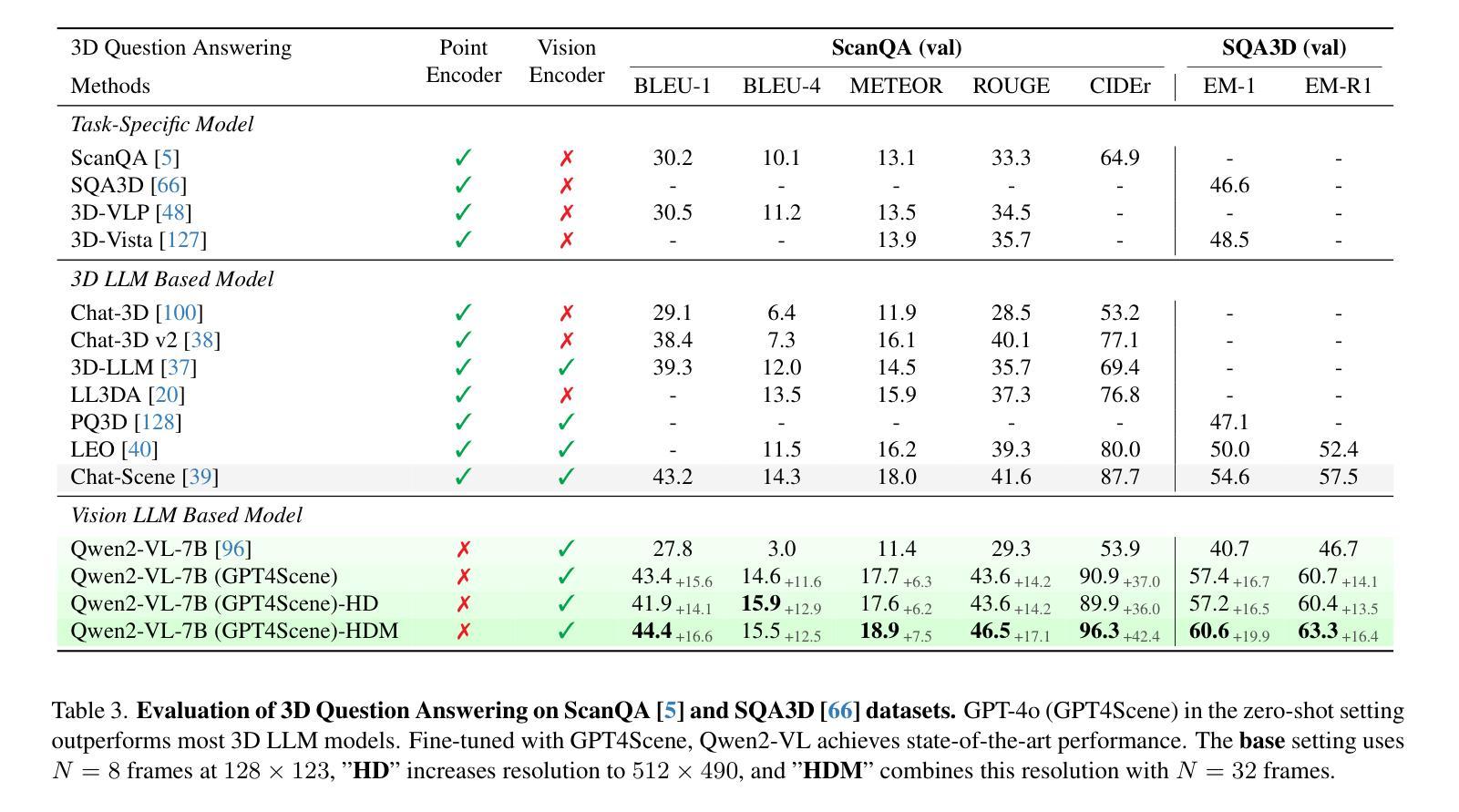
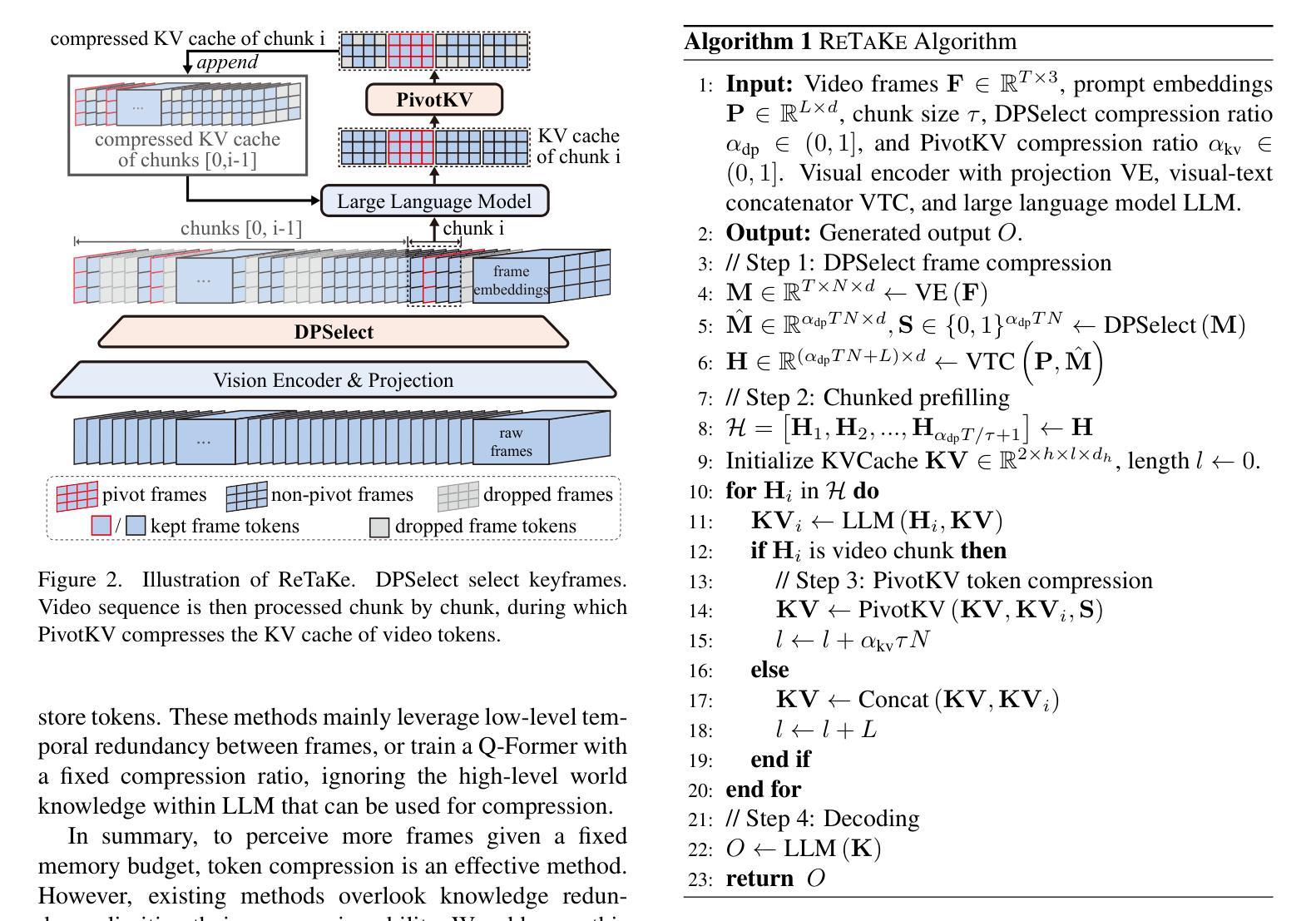
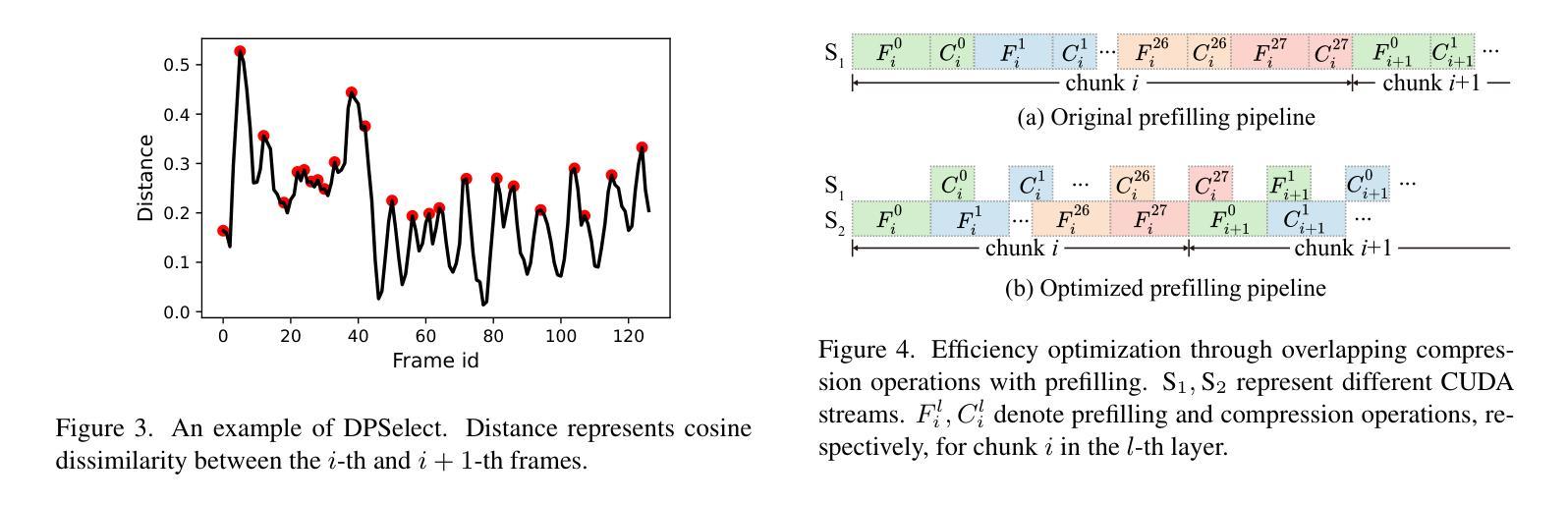
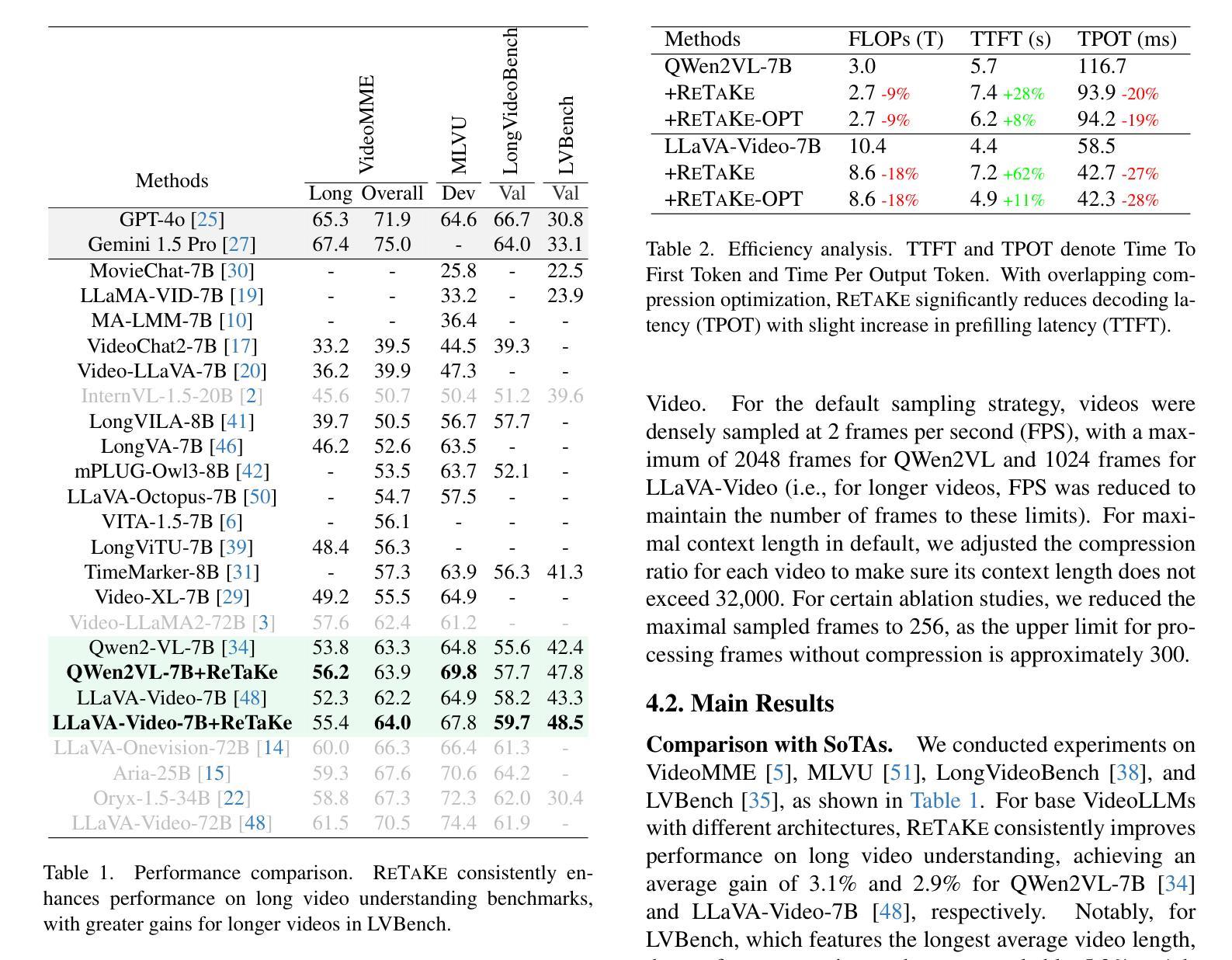
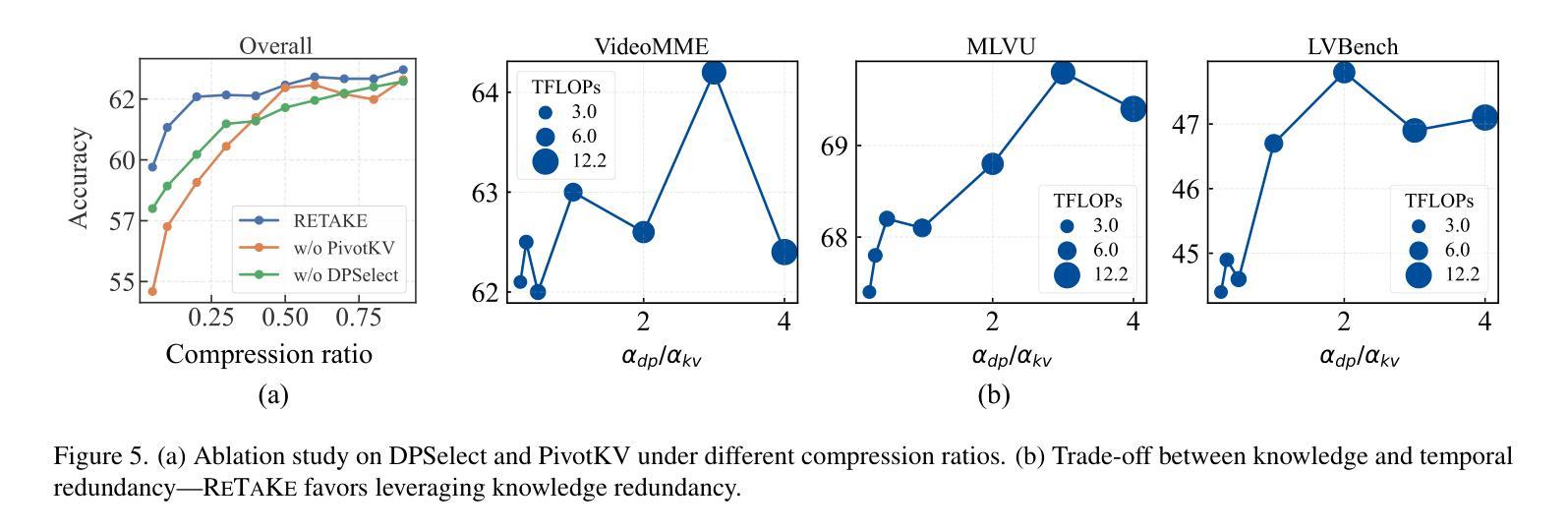
ReTaKe: Reducing Temporal and Knowledge Redundancy for Long Video Understanding
Authors:Xiao Wang, Qingyi Si, Jianlong Wu, Shiyu Zhu, Li Cao, Liqiang Nie
Video Large Language Models (VideoLLMs) have achieved remarkable progress in video understanding. However, existing VideoLLMs often inherit the limitations of their backbone LLMs in handling long sequences, leading to challenges for long video understanding. Common solutions either simply uniformly sample videos’ frames or compress visual tokens, which focus primarily on low-level temporal visual redundancy, overlooking high-level knowledge redundancy. This limits the achievable compression rate with minimal loss. To this end. we introduce a training-free method, $\textbf{ReTaKe}$, containing two novel modules DPSelect and PivotKV, to jointly model and reduce both temporal visual redundancy and knowledge redundancy for long video understanding. Specifically, DPSelect identifies keyframes with local maximum peak distance based on their visual features, which are closely aligned with human video perception. PivotKV employs the obtained keyframes as pivots and conducts KV-Cache compression for the non-pivot tokens with low attention scores, which are derived from the learned prior knowledge of LLMs. Experiments on benchmarks VideoMME, MLVU, and LVBench, show that ReTaKe can support 4x longer video sequences with minimal performance loss (<1%) and outperform all similar-size VideoLLMs with 3%-5%, even surpassing or on par with much larger ones. Our code is available at https://github.com/SCZwangxiao/video-ReTaKe
视频大语言模型(VideoLLMs)在视频理解方面取得了显著的进步。然而,现有的VideoLLMs通常继承了其主干LLMs在处理长序列时的局限性,这给长视频理解带来了挑战。常见的解决方案要么简单地统一采样视频帧,要么压缩视觉令牌,这些解决方案主要关注低级别的时序视觉冗余,而忽略了高级知识的冗余。这限制了可实现的压缩率,并伴随有较多损失。为此,我们引入了一种无需训练的方法ReTaKe,包含两个新模块DPSelect和PivotKV,以联合建模并减少时序视觉冗余和知识冗余,以实现长视频理解。具体来说,DPSelect基于视觉特征识别具有局部最大峰值距离的关键帧,这与人类视频感知紧密相连。PivotKV将获得的关键帧作为基准点,并使用KV-Cache压缩注意力得分较低的非基准令牌,这些令牌来源于LLMs学到的先验知识。在VideoMME、MLVU和LVBench等基准测试上的实验表明,ReTaKe可以在性能损失极小(<1%)的情况下支持4倍更长的视频序列,并优于所有类似规模的VideoLLMs(高出3%-5%),甚至超越或等同于更大的模型。我们的代码可在https://github.com/SCZwangxiao/video-ReTaKe找到。
论文及项目相关链接
PDF Rewrite the methods section. Add more ablation studies and results in LongVideoBench
Summary
视频大型语言模型(VideoLLMs)在视频理解方面取得了显著进展,但在处理长序列视频时存在挑战。现有方法主要关注低级别的时间视觉冗余,而忽视高级别知识冗余。为解决此问题,本文提出一种无需训练的方法ReTaKe,包含DPSelect和PivotKV两个新模块,联合建模并减少时间视觉冗余和知识冗余,以提高长视频理解的效果。
Key Takeaways
- VideoLLMs在视频理解方面取得显著进展,但在处理长序列视频时存在挑战。
- 现有方法主要关注低级别的时间视觉冗余,忽视高级别知识冗余。
- ReTaKe方法包含DPSelect和PivotKV两个新模块,旨在联合建模并减少时间视觉冗余和知识冗余。
- DPSelect基于视觉特征识别关键帧,与人的视频感知紧密对齐。
- PivotKV使用获得的关键帧作为基准点,对低关注度非基准点标记进行KV-Cache压缩。
- 实验结果表明,ReTaKe方法可以支持更长的视频序列,性能损失极小,优于类似大小的VideoLLMs,甚至超过或与大模型相当。
点此查看论文截图


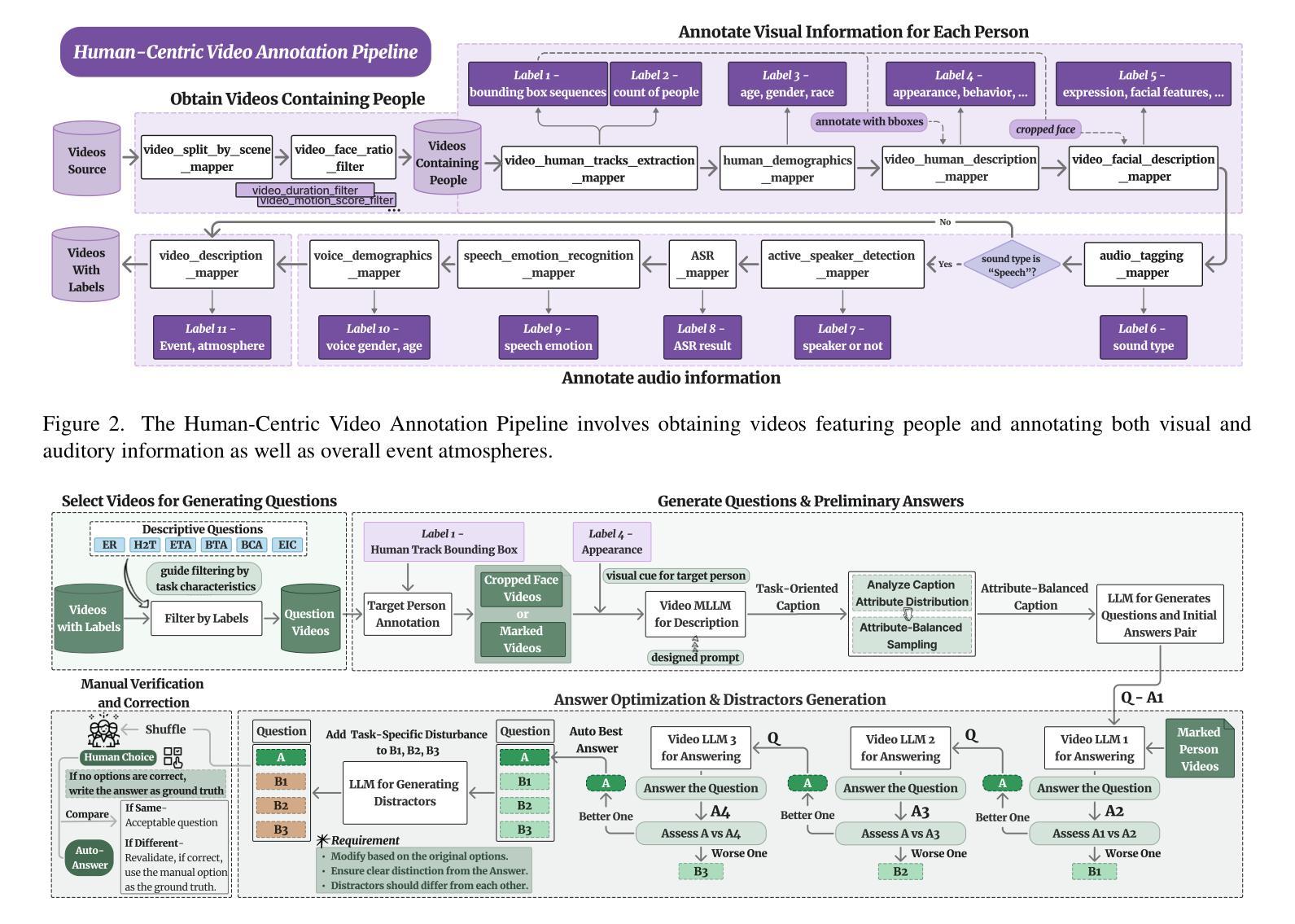
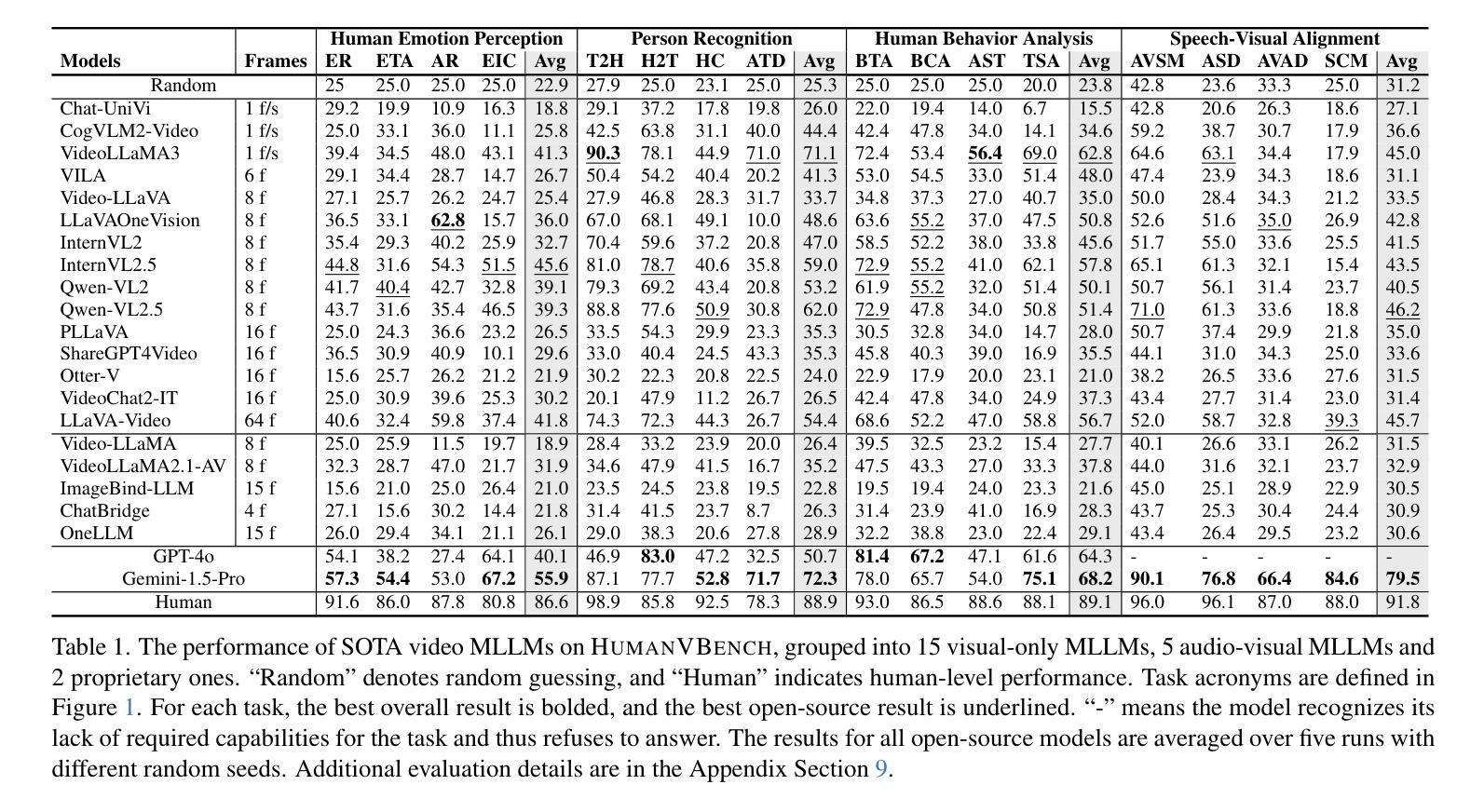
HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
Authors:Ting Zhou, Daoyuan Chen, Qirui Jiao, Bolin Ding, Yaliang Li, Ying Shen
In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech-visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 16 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 22 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and emotion perception, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.
在多模态大型语言模型(MLLMs)领域,实现以人类为中心的视频理解仍然是一个巨大的挑战。现有的基准测试主要强调对象和动作识别,往往忽视了视频内容中人类情绪、行为和语音视觉对齐的细微差别。我们推出了HumanVBench,这是一个精心设计的创新基准测试,旨在弥补视频MLLMs评估中的这些差距。HumanVBench包含16个精心设计的任务,探索两个主要维度:内在情绪和外在表现,涵盖静态和动态、基本和复杂,以及单模态和跨模态方面。HumanVBench使用两个先进的自动化管道进行视频注释和包含干扰项的QA生成,利用多种最新技术优化基准数据合成和质量评估,减少对人类注释的依赖,专门针对以人类为中心的多模态属性。对22个最新视频MLLM的全面评估显示,当前性能存在显著局限,尤其在跨模态和情感感知方面,这强调了进一步改进以实现更人性化的理解的必要性。HumanVBench开源,以促进视频MLLM的未来发展和实际应用。
论文及项目相关链接
PDF 22 pages, 23 figures, 7 tables
Summary
HumanVBench是针对视频理解领域的多模态大型语言模型(MLLMs)提出的新型基准测试平台。该平台着重关注现有基准测试未能覆盖的人的情绪、行为和语音视觉对齐等细节方面。它包含精心设计的十六项任务,涉及情感认知和行为表现等方面,旨在弥补现有视频理解技术的短板。同时,该平台还提供了两个先进的自动化管道,用于视频标注和包含干扰项的QA生成,旨在减少人工标注依赖,并推动视频MLLMs的进步。然而,现有技术的表现仍有限,特别是在跨模态和情感感知方面有较大不足。该基准测试平台面向开源社区开放。
Key Takeaways
- HumanVBench针对视频理解的基准测试缺乏关注人的情感和行为等细节问题,提出了新的评价标准和方法。
- 它包括十六项任务,涵盖了情感和行为的内在和外在表现等多个方面。
- HumanVBench设计了两个自动化管道来优化视频标注和QA生成过程,减少人工干预的需求。
- 当前视频MLLMs在跨模态和情感感知方面存在显著局限性。
- HumanVBench强调未来在视频MLLMs领域的进步和实际应用前景。
- HumanVBench的开源特性将促进社区对其贡献和发展。
点此查看论文截图