⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
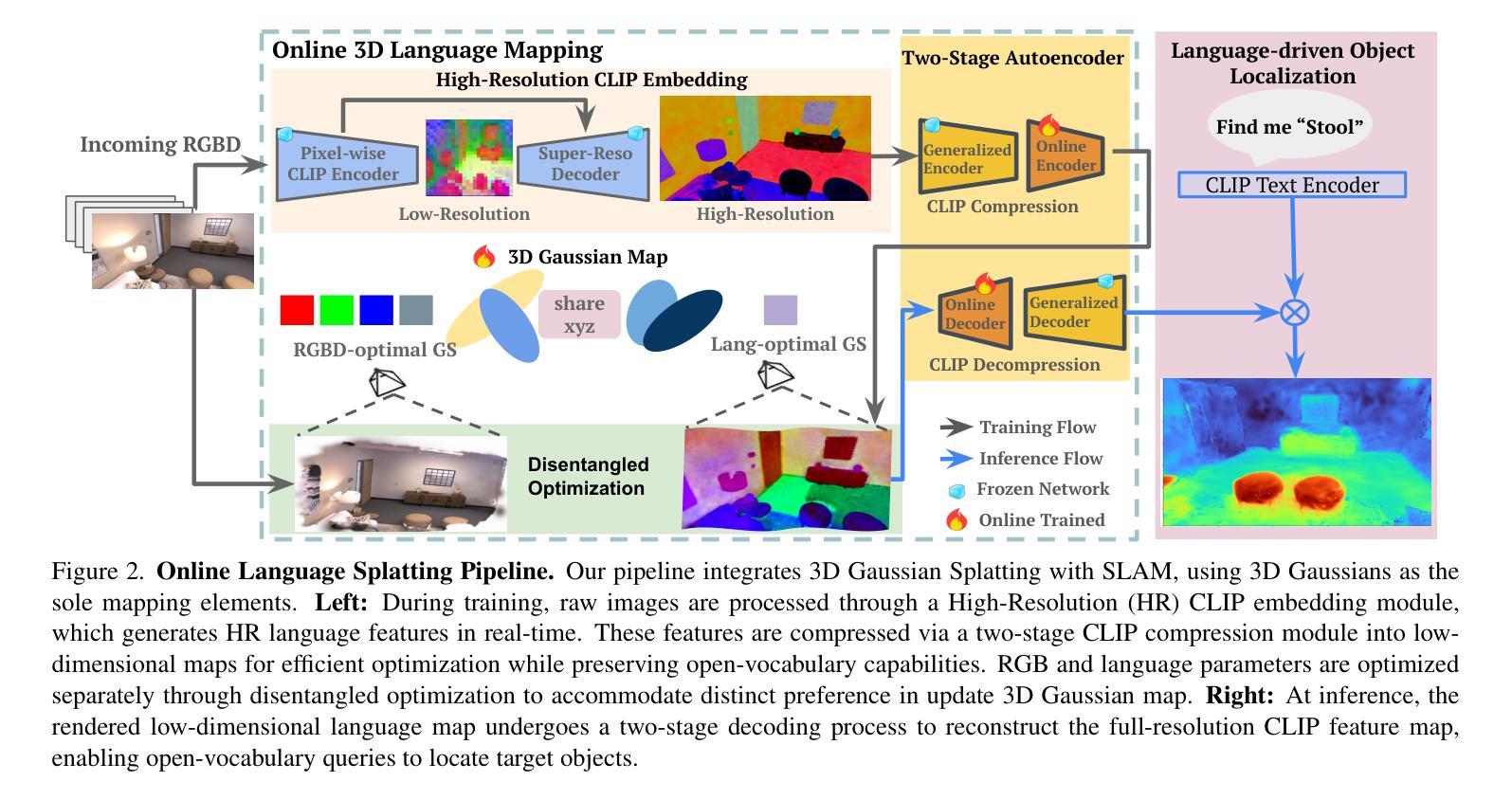
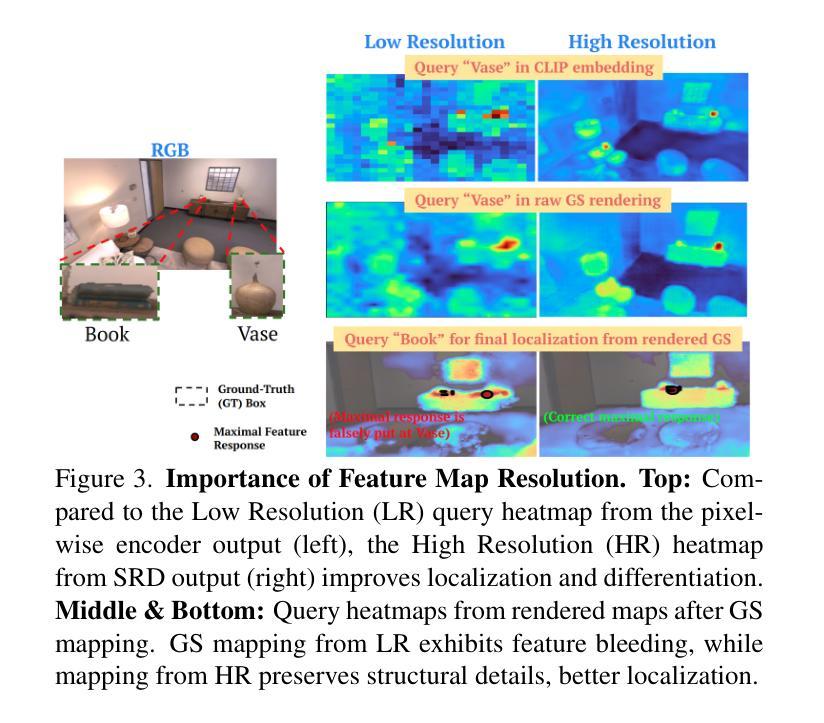
Online Language Splatting
Authors:Saimouli Katragadda, Cho-Ying Wu, Yuliang Guo, Xinyu Huang, Guoquan Huang, Liu Ren
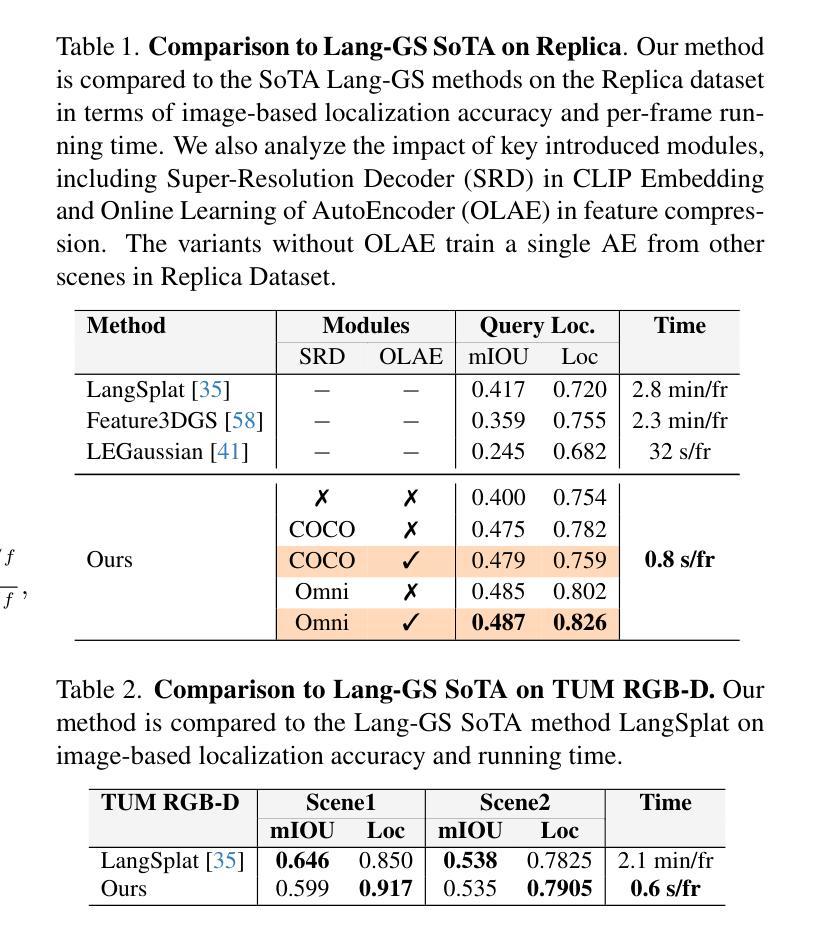
To enable AI agents to interact seamlessly with both humans and 3D environments, they must not only perceive the 3D world accurately but also align human language with 3D spatial representations. While prior work has made significant progress by integrating language features into geometrically detailed 3D scene representations using 3D Gaussian Splatting (GS), these approaches rely on computationally intensive offline preprocessing of language features for each input image, limiting adaptability to new environments. In this work, we introduce Online Language Splatting, the first framework to achieve online, near real-time, open-vocabulary language mapping within a 3DGS-SLAM system without requiring pre-generated language features. The key challenge lies in efficiently fusing high-dimensional language features into 3D representations while balancing the computation speed, memory usage, rendering quality and open-vocabulary capability. To this end, we innovatively design: (1) a high-resolution CLIP embedding module capable of generating detailed language feature maps in 18ms per frame, (2) a two-stage online auto-encoder that compresses 768-dimensional CLIP features to 15 dimensions while preserving open-vocabulary capabilities, and (3) a color-language disentangled optimization approach to improve rendering quality. Experimental results show that our online method not only surpasses the state-of-the-art offline methods in accuracy but also achieves more than 40x efficiency boost, demonstrating the potential for dynamic and interactive AI applications.
为了实现人工智能代理无缝地与人类和三维环境进行交互,它们不仅需要准确感知三维世界,还需要将人类语言与三维空间表示对齐。尽管先前的尝试通过将语言特征整合到具有几何细节的三维场景表示中,使用三维高斯拼贴(GS)取得了重大进展,但这些方法依赖于针对每个输入图像的密集计算离线预处理语言特征,对新环境的适应性有限。在这项工作中,我们引入了在线语言拼贴技术,这是第一个实现在线、接近实时的三维几何空间系统(3DGS)内的开放词汇语言映射的框架,无需预先生成的语言特征。主要挑战在于如何将高维语言特征有效地融合到三维表示中,同时平衡计算速度、内存使用、渲染质量和开放词汇能力。为此,我们创新地设计了:(1)一个高分辨率CLIP嵌入模块,能够在每帧内以18毫秒的速度生成详细的语音特征图;(2)一个两阶段在线自编码器,能将CLIP特征的维度从768压缩到15个维度同时保留开放词汇功能;(3)一种色彩与语言分离的优化方法以提高渲染质量。实验结果表明,我们的在线方法不仅超越了最新离线方法的准确性,还实现了超过40倍的性能提升,展示了其在动态和交互式人工智能应用中的潜力。
论文及项目相关链接
Summary
本文介绍了一种在线语言映射框架,名为在线语言喷绘,能够在3DGS-SLAM系统内实现近实时的开放词汇语言映射,而无需预先生成语言特征。通过设计高效的CLIP嵌入模块、两阶段在线自动编码器及颜色语言分离优化方法,实现了高维语言特征在3D环境中的高效融合,提高了渲染质量和开放词汇能力,显著提升了AI交互的智能和效率。
Key Takeaways
- 在线语言喷绘框架实现了在3DGS-SLAM系统中的在线、近实时的开放词汇语言映射。
- 高效融合高维语言特征到3D环境,提升了AI的智能交互能力。
- 通过设计高分辨率CLIP嵌入模块,生成详细的语言特征图。
- 两阶段在线自动编码器压缩了高维CLIP特征,同时保持开放词汇能力。
- 颜色语言分离优化方法提高了渲染质量。
- 在线方法不仅在准确性上超越现有离线方法,而且实现了超过40倍的性能提升。
点此查看论文截图


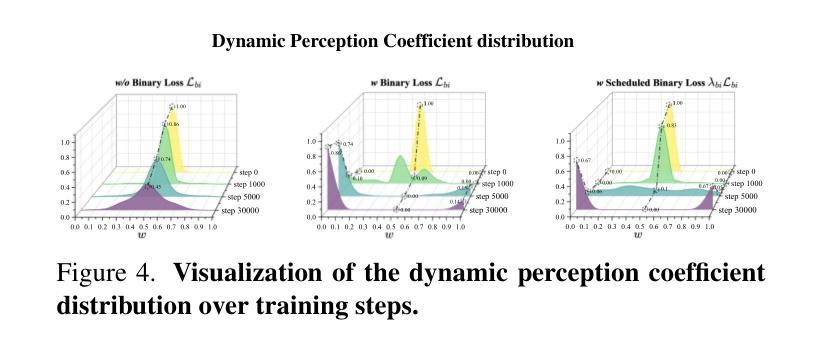
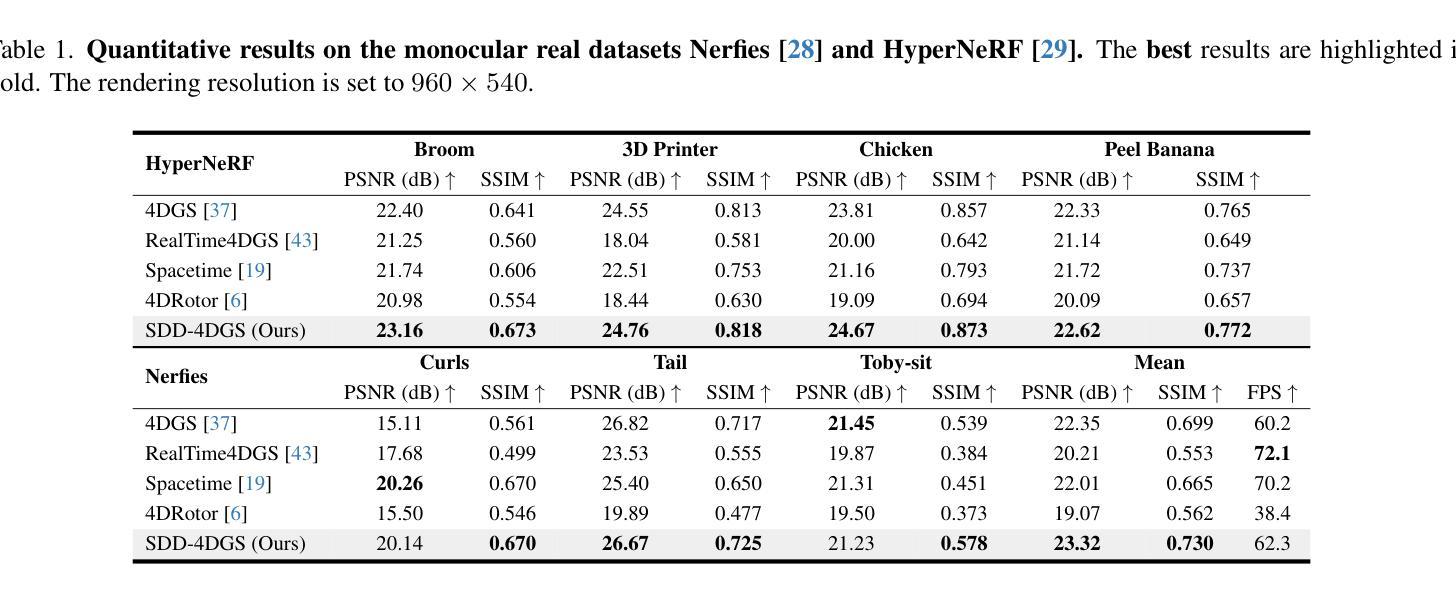
SDD-4DGS: Static-Dynamic Aware Decoupling in Gaussian Splatting for 4D Scene Reconstruction
Authors:Dai Sun, Huhao Guan, Kun Zhang, Xike Xie, S. Kevin Zhou
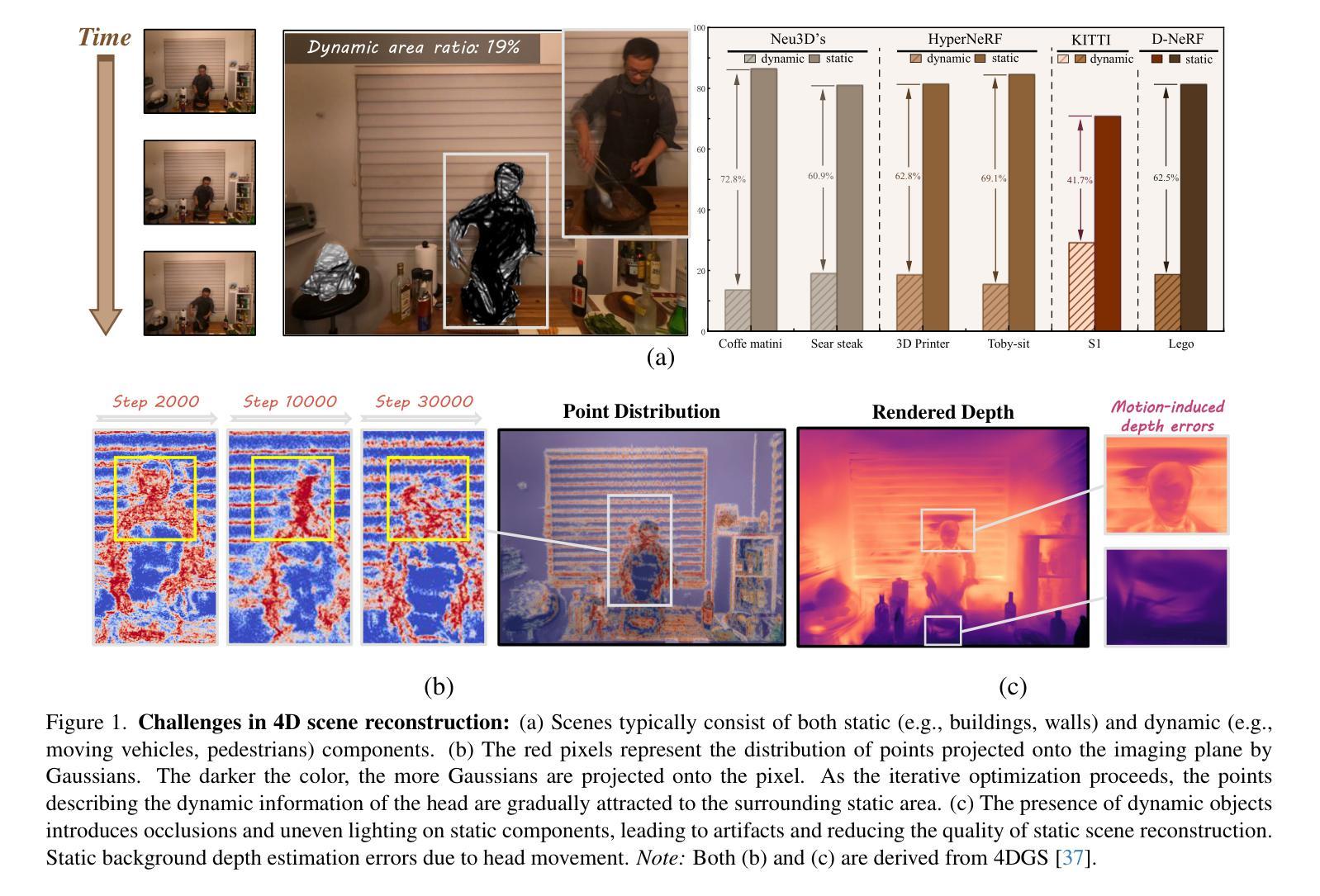
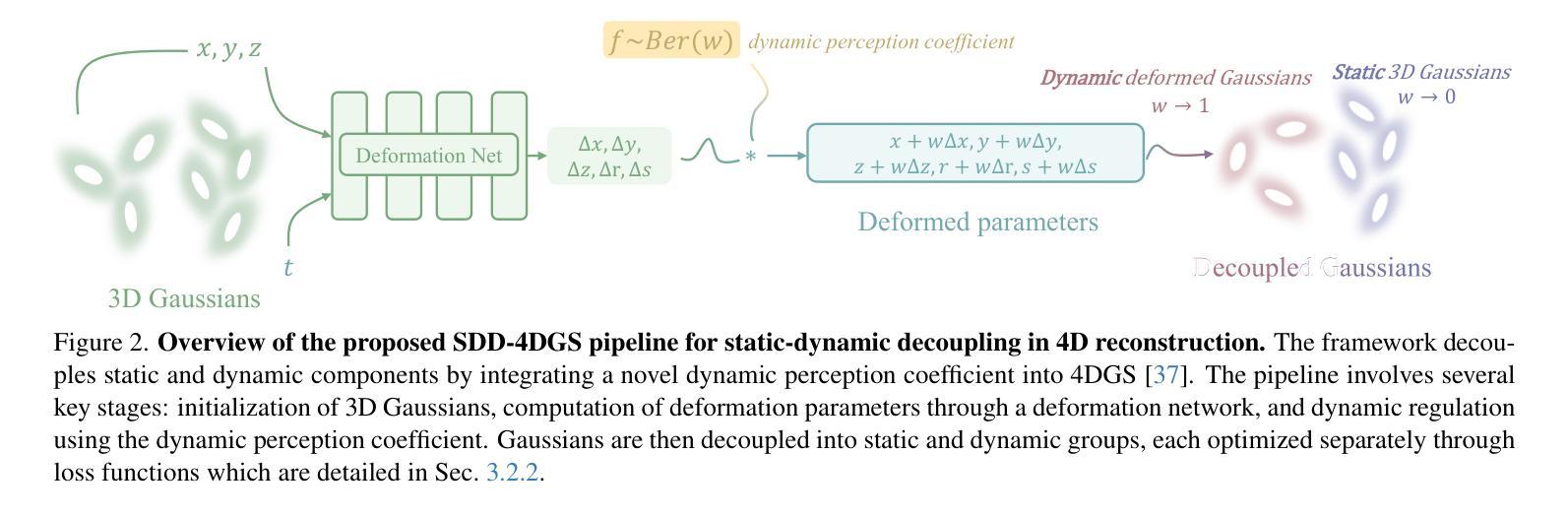
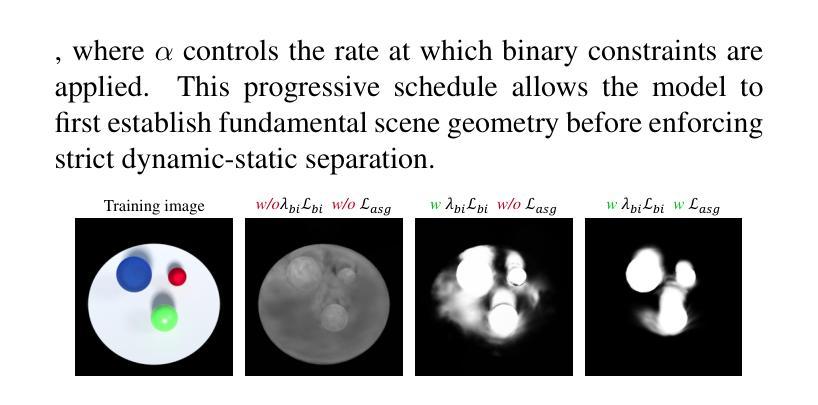
Dynamic and static components in scenes often exhibit distinct properties, yet most 4D reconstruction methods treat them indiscriminately, leading to suboptimal performance in both cases. This work introduces SDD-4DGS, the first framework for static-dynamic decoupled 4D scene reconstruction based on Gaussian Splatting. Our approach is built upon a novel probabilistic dynamic perception coefficient that is naturally integrated into the Gaussian reconstruction pipeline, enabling adaptive separation of static and dynamic components. With carefully designed implementation strategies to realize this theoretical framework, our method effectively facilitates explicit learning of motion patterns for dynamic elements while maintaining geometric stability for static structures. Extensive experiments on five benchmark datasets demonstrate that SDD-4DGS consistently outperforms state-of-the-art methods in reconstruction fidelity, with enhanced detail restoration for static structures and precise modeling of dynamic motions. The code will be released.
场景中的动态和静态组件通常表现出不同的属性,然而大多数4D重建方法都是不加区分地对待它们,导致两种情况下的性能都不佳。这项工作引入了SDD-4DGS,这是基于高斯涂抹技术的静态-动态解耦4D场景重建的第一个框架。我们的方法建立在新型的概率动态感知系数上,该系数自然地融入到高斯重建流程中,能够实现静态和动态组件的自适应分离。通过精心设计的实现策略来实现这一理论框架,我们的方法有效地促进了动态元素的运动模式的学习,同时保持静态结构的几何稳定性。在五个基准数据集上的广泛实验表明,SDD-4DGS在重建保真度方面始终优于最先进的方法,为静态结构提供了增强的细节恢复和动态运动的精确建模。代码将发布。
论文及项目相关链接
Summary
本文提出了SDD-4DGS,一个基于高斯展布的静态动态解耦4D场景重建框架。该框架通过自然集成新型概率动态感知系数,实现了静态和动态组件的自适应分离。通过精心设计的实现策略,该方法能有效学习动态元素的运动模式,同时保持静态结构的几何稳定性。在五个基准数据集上的实验表明,SDD-4DGS在重建保真度上始终优于最新方法,对静态结构的细节恢复增强,对动态运动的建模精确。
Key Takeaways
- SDD-4DGS是首个针对静态动态解耦的4D场景重建框架。
- 该方法基于高斯展布,通过自然集成概率动态感知系数,实现静态和动态组件的自适应分离。
- 精心设计的实现策略,使得方法能有效学习动态元素的运动模式,同时保持静态结构的几何稳定性。
- 在五个基准数据集上的实验表明SDD-4DGS性能优越。
- SDD-4DGS在重建保真度上优于现有最新方法。
- 该方法增强了静态结构的细节恢复和动态运动的建模精确性。
- 代码将会公开。
点此查看论文截图


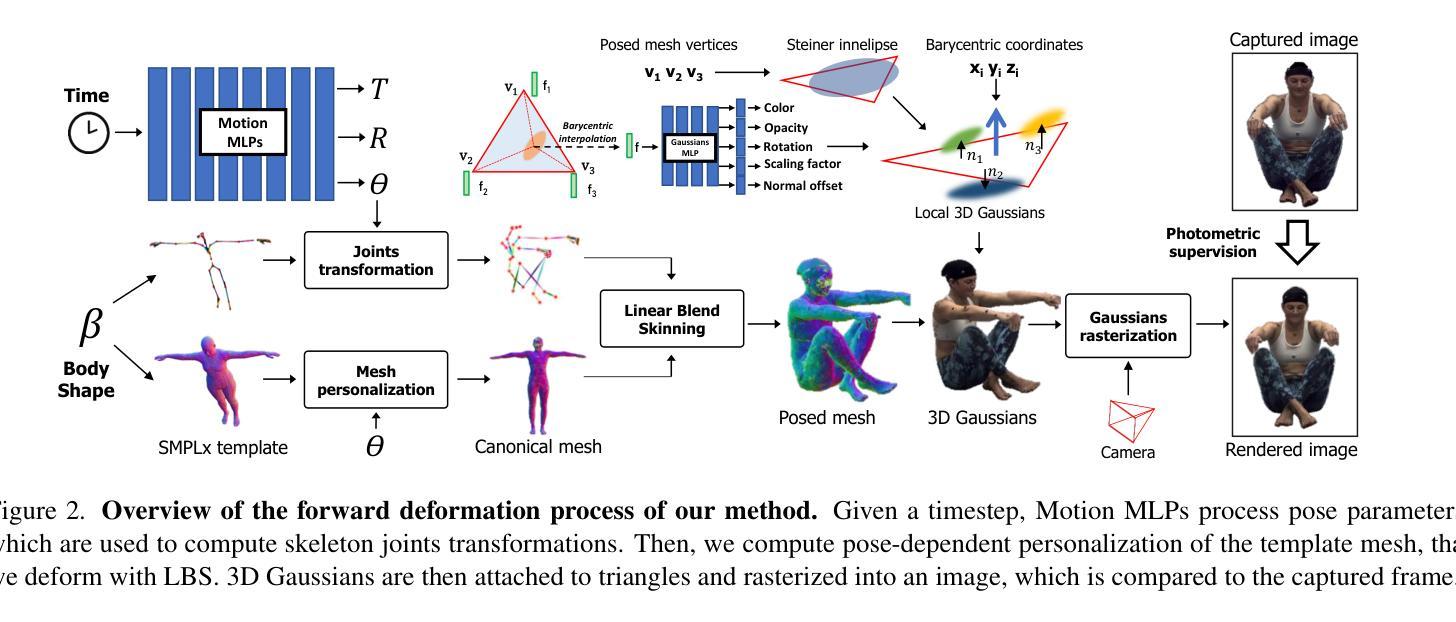
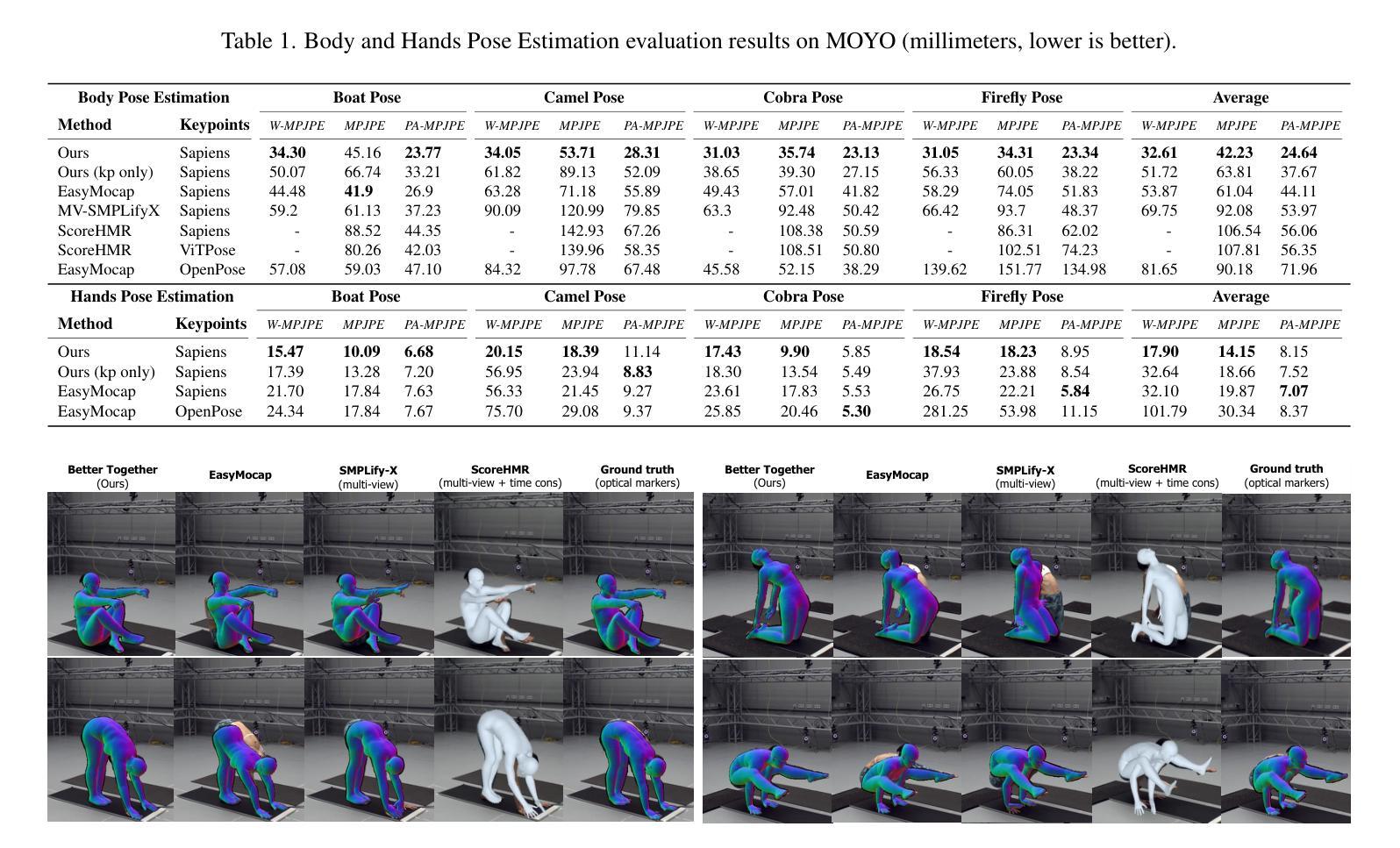
Better Together: Unified Motion Capture and 3D Avatar Reconstruction
Authors:Arthur Moreau, Mohammed Brahimi, Richard Shaw, Athanasios Papaioannou, Thomas Tanay, Zhensong Zhang, Eduardo Pérez-Pellitero
We present Better Together, a method that simultaneously solves the human pose estimation problem while reconstructing a photorealistic 3D human avatar from multi-view videos. While prior art usually solves these problems separately, we argue that joint optimization of skeletal motion with a 3D renderable body model brings synergistic effects, i.e. yields more precise motion capture and improved visual quality of real-time rendering of avatars. To achieve this, we introduce a novel animatable avatar with 3D Gaussians rigged on a personalized mesh and propose to optimize the motion sequence with time-dependent MLPs that provide accurate and temporally consistent pose estimates. We first evaluate our method on highly challenging yoga poses and demonstrate state-of-the-art accuracy on multi-view human pose estimation, reducing error by 35% on body joints and 45% on hand joints compared to keypoint-based methods. At the same time, our method significantly boosts the visual quality of animatable avatars (+2dB PSNR on novel view synthesis) on diverse challenging subjects.
我们提出了一种名为“Better Together”的方法,该方法能够同时解决人体姿态估计问题,并从多视角视频中重建出逼真的3D人体化身。虽然先前的研究通常分别解决这两个问题,但我们主张,对骨骼运动与3D可渲染身体模型进行联合优化可以产生协同效应,即可以获得更精确的动作捕捉和实时渲染化身时提高的视觉质量。为了实现这一点,我们引入了一种新型动画化身,它在个性化网格上配备了3D高斯模型,并提出使用时间相关的多层感知器(MLPs)来优化运动序列,以提供准确且时间一致的姿态估计。我们首先对我们的方法进行了具有挑战性的瑜伽动作评估,并展示了在多视角人体姿态估计方面的最新技术准确性。与基于关键点的方法相比,我们的方法在身体关节上减少了35%的错误,在手部关节上减少了45%的错误。同时,我们的方法在多样且具有挑战性的主题上显著提高了动画化身的视觉质量(在新型视图合成上提高了2dB PSNR)。
论文及项目相关链接
PDF 14 pages, 6 figures
Summary
该摘要提出了一种名为“Better Together”的方法,该方法可同时解决人体姿态估计问题并从多角度视频重建逼真的三维人类角色。文章指出传统技术往往分别解决这两个问题,但联合优化骨骼运动与三维可渲染人体模型可以产生协同效果,即实现更精确的动作捕捉和角色实时渲染的视觉质量提升。为达成此目标,文章引入了一种新型可动画角色,在个性化网格上设置三维高斯分布,并提出使用时间依赖多层感知器优化动作序列,以提供准确且时间一致的姿态估计。文章首先在高难度瑜伽动作上评估此方法,并在多视角人体姿态估计上展现出卓越准确性,在关节点上较基于关键点的方法减少35%的误差。同时,此方法在可动画角色的视觉质量上有显著提升(在新视角合成上提高2dB PSNR),适用于各种挑战对象。
Key Takeaways
- 提出了一种名为“Better Together”的方法,可同时解决人体姿态估计和三维角色重建问题。
- 通过联合优化骨骼运动和三维可渲染人体模型,实现了更精确的动作捕捉和更高的角色实时渲染质量。
- 引入了一种新型可动画角色,使用个性化网格和三维高斯分布。
- 使用时间依赖多层感知器优化动作序列,提供准确且时间一致的姿态估计。
- 在高难度瑜伽动作上评估方法,多视角人体姿态估计表现出卓越准确性。
- 较之基于关键点的方法,在关节点上减少了35%的误差。
- 方法显著提高可动画角色的视觉质量(新视角合成上提高2dB PSNR)。
点此查看论文截图

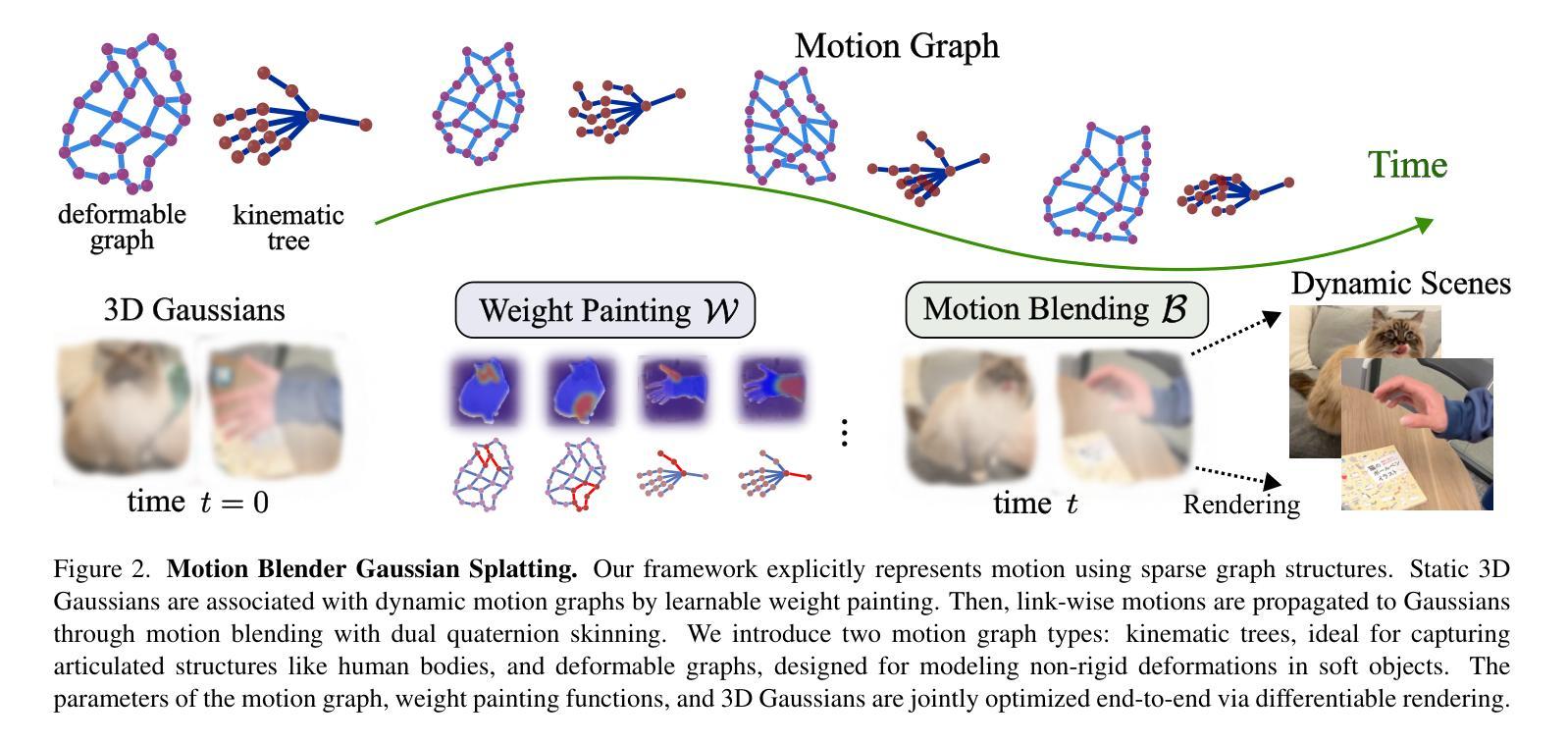
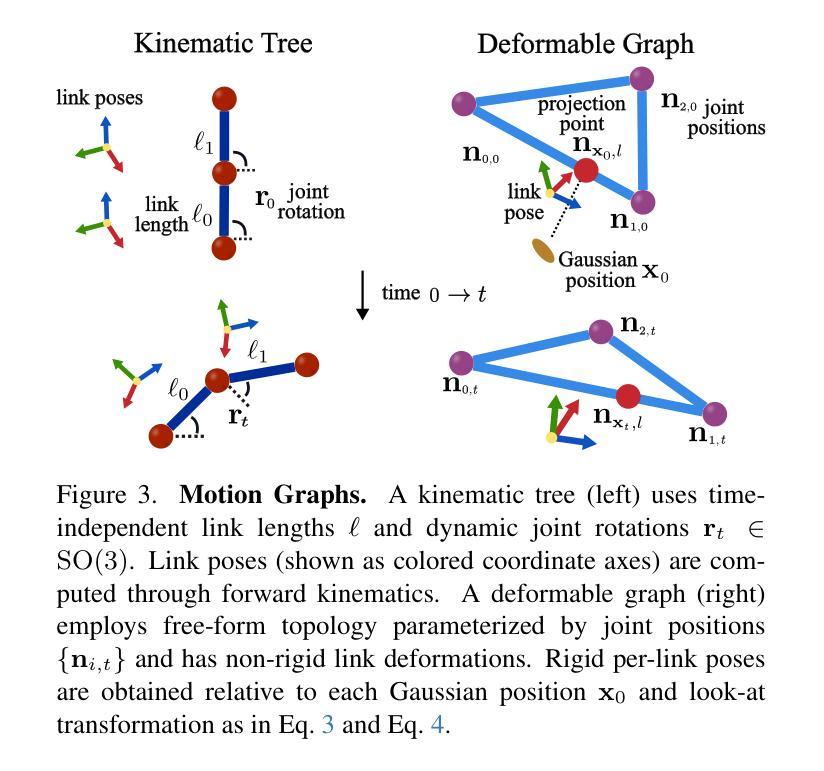
Motion Blender Gaussian Splatting for Dynamic Reconstruction
Authors:Xinyu Zhang, Haonan Chang, Yuhan Liu, Abdeslam Boularias
Gaussian splatting has emerged as a powerful tool for high-fidelity reconstruction of dynamic scenes. However, existing methods primarily rely on implicit motion representations, such as encoding motions into neural networks or per-Gaussian parameters, which makes it difficult to further manipulate the reconstructed motions. This lack of explicit controllability limits existing methods to replaying recorded motions only, which hinders a wider application. To address this, we propose Motion Blender Gaussian Splatting (MB-GS), a novel framework that uses motion graph as an explicit and sparse motion representation. The motion of graph links is propagated to individual Gaussians via dual quaternion skinning, with learnable weight painting functions determining the influence of each link. The motion graphs and 3D Gaussians are jointly optimized from input videos via differentiable rendering. Experiments show that MB-GS achieves state-of-the-art performance on the iPhone dataset while being competitive on HyperNeRF. Additionally, we demonstrate the application potential of our method in generating novel object motions and robot demonstrations through motion editing. Video demonstrations can be found at https://mlzxy.github.io/mbgs.
高斯绘制技术已成为重建动态场景的高保真工具。然而,现有方法主要依赖于隐式运动表示,如将运动编码到神经网络或每个高斯参数中,这使得进一步操作重建的运动变得困难。这种缺乏明确的可控性限制了现有方法只能回放记录的运动,阻碍了更广泛的应用。针对这一问题,我们提出了Motion Blender Gaussian Splatting(MB-GS)这一新框架,它使用运动图作为明确且稀疏的运动表示。图链接的运动通过双重四元数蒙皮传播到各个高斯分布中,可学习的权重绘制函数决定了每个链接的影响。运动图和3D高斯分布通过可微分渲染从输入视频中进行联合优化。实验表明,MB-GS在iPhone数据集上达到了最先进的性能,同时在HyperNeRF上具有很强的竞争力。此外,我们还通过运动编辑展示了该方法在生成新型物体运动和机器人演示方面的应用潜力。视频演示可在https://mlzxy.github.io/mbgs查看。
论文及项目相关链接
Summary
高斯点扩展(Gaussian Splatting)在动态场景的高保真重建中显示出强大的能力。但现有方法主要依赖隐式运动表示,如将运动编码到神经网络或每个高斯参数中,这使得难以进一步操控重建的运动。为解决此问题,本文提出Motion Blender Gaussian Splatting(MB-GS)框架,采用运动图作为显式且稀疏的运动表示。图链接的运动通过双重四元数蒙皮传播到各个高斯分布上,并由可学习的权重绘制函数决定每个链接的影响。从输入视频中联合优化运动图和三维高斯分布通过可微分渲染技术。实验表明,MB-GS在iPhone数据集上实现了最佳性能,同时在HyperNeRF上表现良好。此外,本文展示了该方法在生成新型物体运动和机器人演示中的潜力。视频演示可在https://mlzxy.github.io/mbgs查看。
Key Takeaways
- 高斯点扩展是一种强大的动态场景重建工具。
- 现有方法主要依赖隐式运动表示,限制了运动的进一步操控。
- MB-GS框架采用运动图作为显式且稀疏的运动表示来解决这一问题。
- 运动图链接的运动通过双重四元数蒙皮传播到高斯分布上。
- MB-GS在iPhone数据集上实现最佳性能,同时在HyperNeRF上表现良好。
- 该方法可应用于生成新型物体运动和机器人演示。
点此查看论文截图



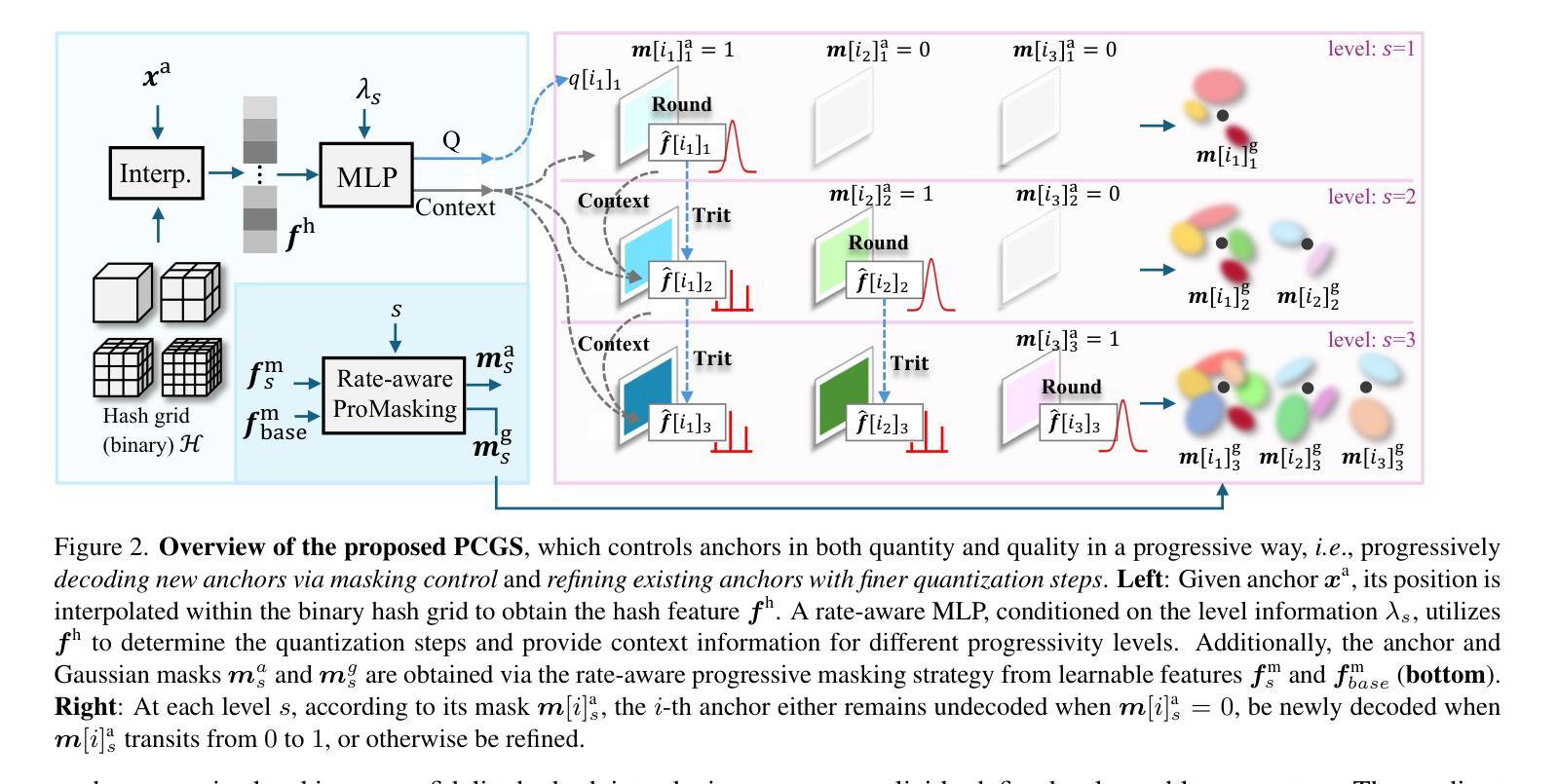
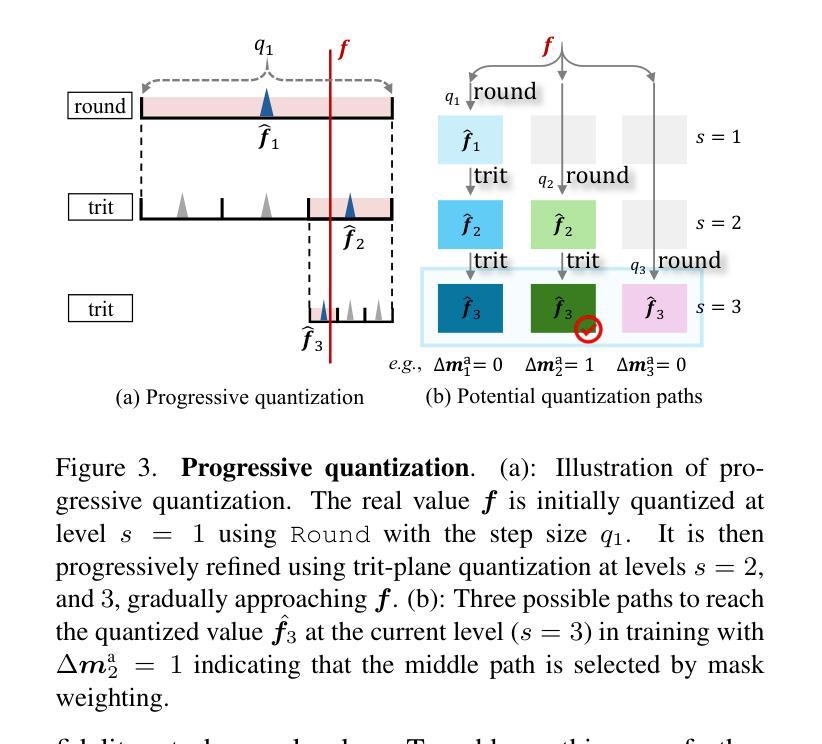
PCGS: Progressive Compression of 3D Gaussian Splatting
Authors:Yihang Chen, Mengyao Li, Qianyi Wu, Weiyao Lin, Mehrtash Harandi, Jianfei Cai
3D Gaussian Splatting (3DGS) achieves impressive rendering fidelity and speed for novel view synthesis. However, its substantial data size poses a significant challenge for practical applications. While many compression techniques have been proposed, they fail to efficiently utilize existing bitstreams in on-demand applications due to their lack of progressivity, leading to a waste of resource. To address this issue, we propose PCGS (Progressive Compression of 3D Gaussian Splatting), which adaptively controls both the quantity and quality of Gaussians (or anchors) to enable effective progressivity for on-demand applications. Specifically, for quantity, we introduce a progressive masking strategy that incrementally incorporates new anchors while refining existing ones to enhance fidelity. For quality, we propose a progressive quantization approach that gradually reduces quantization step sizes to achieve finer modeling of Gaussian attributes. Furthermore, to compact the incremental bitstreams, we leverage existing quantization results to refine probability prediction, improving entropy coding efficiency across progressive levels. Overall, PCGS achieves progressivity while maintaining compression performance comparable to SoTA non-progressive methods. Code available at: github.com/YihangChen-ee/PCGS.
3D高斯混合技术(3DGS)在新视角合成方面达到了令人印象深刻的渲染保真度和速度。然而,其庞大的数据量对实际应用构成了重大挑战。虽然已提出了许多压缩技术,但由于它们缺乏渐进性,它们在按需应用时无法有效地利用现有比特流,导致资源浪费。为了解决这个问题,我们提出了PCGS(3D高斯混合的渐进压缩),通过自适应控制高斯(或锚点)的数量和质量,为实现按需应用的有效渐进性。具体来说,在数量方面,我们引入了一种渐进掩码策略,该策略在细化现有锚点的同时逐步加入新的锚点,以提高保真度。在质量方面,我们提出了一种渐进量化方法,通过逐步减小量化步长来实现对高斯属性的更精细建模。此外,为了压缩增量比特流,我们利用现有的量化结果来优化概率预测,提高渐进层次上的熵编码效率。总体而言,PCGS在保持与当前最先进的非渐进方法相当的压缩性能的同时实现了渐进性。代码可在github.com/YihangChen-ee/PCGS找到。
论文及项目相关链接
PDF Project Page: https://yihangchen-ee.github.io/project_pcgs/ Code: https://github.com/YihangChen-ee/PCGS
Summary
3DGS渲染技术以其高质量和速度优势应用于虚拟视图合成领域,但其数据量巨大的问题限制了实际应用。为此,我们提出了PCGS方法,采用自适应控制高斯数量和质量的方式实现渐进式压缩,以支持按需应用。通过渐进掩码策略和渐进量化方法优化数量和质量,并利用现有量化结果提高概率预测精度,提升编码效率。PCGS在保持与现有非渐进方法相当的压缩性能的同时实现了渐进式编码。
Key Takeaways
- 3DGS用于虚拟视图合成,但数据量巨大限制了实际应用。
- PCGS方法旨在解决此问题,通过自适应控制高斯数量和质量实现渐进式压缩。
- 采用渐进掩码策略优化高斯数量,渐进量化方法优化质量。
- 利用现有量化结果提高概率预测精度,提升编码效率。
- PCGS在保持与现有非渐进方法相当的压缩性能的同时实现了渐进式编码。
- PCGS有望提高按需应用的资源利用效率。
点此查看论文截图

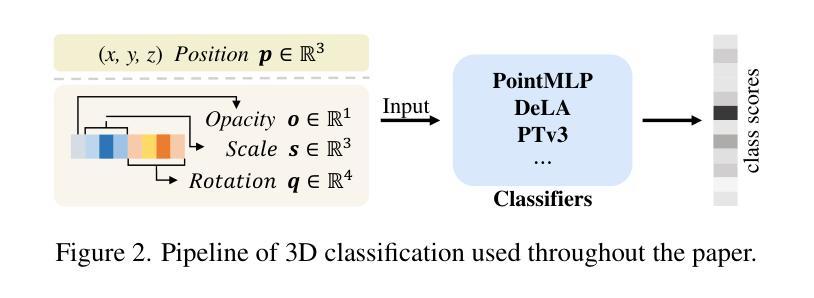
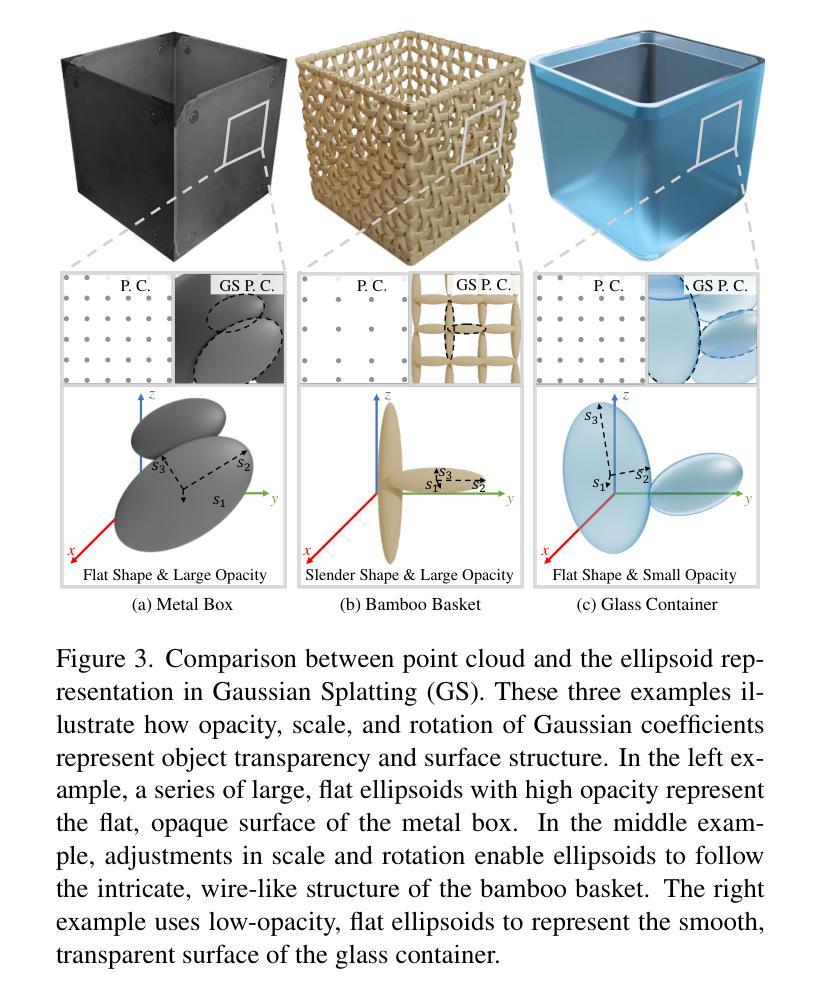
Mitigating Ambiguities in 3D Classification with Gaussian Splatting
Authors:Ruiqi Zhang, Hao Zhu, Jingyi Zhao, Qi Zhang, Xun Cao, Zhan Ma
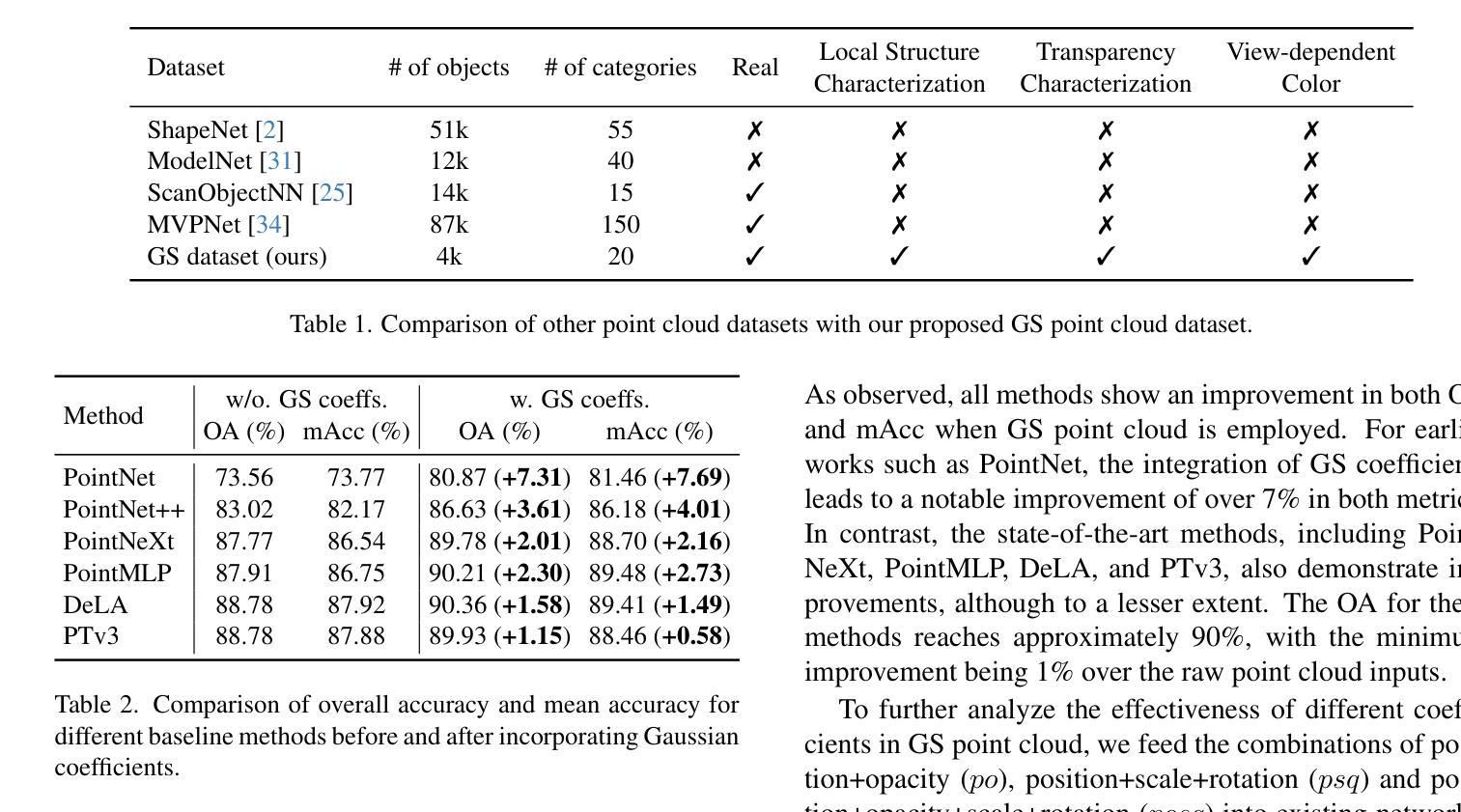
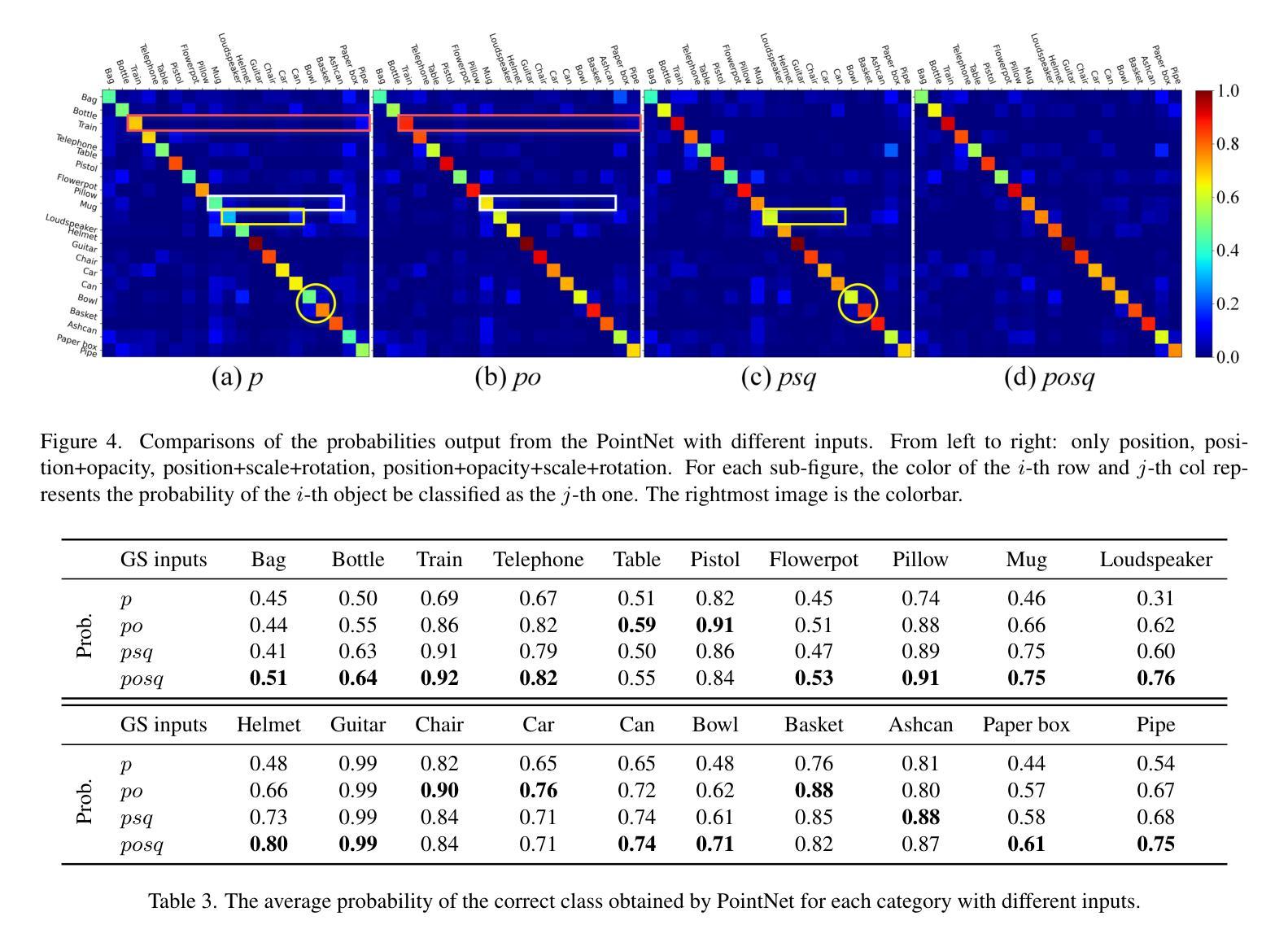
3D classification with point cloud input is a fundamental problem in 3D vision. However, due to the discrete nature and the insufficient material description of point cloud representations, there are ambiguities in distinguishing wire-like and flat surfaces, as well as transparent or reflective objects. To address these issues, we propose Gaussian Splatting (GS) point cloud-based 3D classification. We find that the scale and rotation coefficients in the GS point cloud help characterize surface types. Specifically, wire-like surfaces consist of multiple slender Gaussian ellipsoids, while flat surfaces are composed of a few flat Gaussian ellipsoids. Additionally, the opacity in the GS point cloud represents the transparency characteristics of objects. As a result, ambiguities in point cloud-based 3D classification can be mitigated utilizing GS point cloud as input. To verify the effectiveness of GS point cloud input, we construct the first real-world GS point cloud dataset in the community, which includes 20 categories with 200 objects in each category. Experiments not only validate the superiority of GS point cloud input, especially in distinguishing ambiguous objects, but also demonstrate the generalization ability across different classification methods.
三维点云输入的3D分类是3D视觉中的一个基本问题。然而,由于点云表示的离散性和材料描述不足,在区分线状和平坦表面以及透明或反射物体时存在歧义。为了解决这些问题,我们提出了基于高斯喷溅(GS)的点云3D分类。我们发现GS点云中的尺度和旋转系数有助于表征表面类型。具体来说,线状表面由多个细长的高斯椭球组成,而平坦表面则由几个扁平的高斯椭球组成。此外,GS点云中的不透明度代表了物体的透明特性。因此,利用GS点云作为输入,可以减少基于点云的3D分类中的歧义。为了验证GS点云输入的有效性,我们构建了社区中第一个真实世界的GS点云数据集,其中包括20个类别,每个类别有200个对象。实验不仅验证了GS点云输入的优越性,特别是在区分模糊对象方面,而且证明了其在不同分类方法中的泛化能力。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
GS点云(Gaussian Splatting)能够有效解决3D点云分类中的表面模糊问题。该方法通过利用点云中的尺度与旋转系数区分线状或平面表面,同时使用点云的透明度特性来识别透明或反射物体。为验证其有效性,建立了首个真实世界的GS点云数据集,实验结果显示GS点云输入在区分模糊物体上具有优势,且在不同分类方法中具有良好的泛化能力。
Key Takeaways
- GS点云基于高斯分布解决了点云离散性和描述不足的问题。
- 通过尺度与旋转系数区分线状或平面表面。
- 点云的透明度特性有助于识别透明或反射物体。
- 建立首个真实世界的GS点云数据集,包含20个类别、每个类别200个对象。
- 实验验证了GS点云在区分模糊物体上的优越性。
- GS点云输入在不同分类方法中具有良好的泛化能力。
点此查看论文截图

Uni-Gaussians: Unifying Camera and Lidar Simulation with Gaussians for Dynamic Driving Scenarios
Authors:Zikang Yuan, Yuechuan Pu, Hongcheng Luo, Fengtian Lang, Cheng Chi, Teng Li, Yingying Shen, Haiyang Sun, Bing Wang, Xin Yang
Ensuring the safety of autonomous vehicles necessitates comprehensive simulation of multi-sensor data, encompassing inputs from both cameras and LiDAR sensors, across various dynamic driving scenarios. Neural rendering techniques, which utilize collected raw sensor data to simulate these dynamic environments, have emerged as a leading methodology. While NeRF-based approaches can uniformly represent scenes for rendering data from both camera and LiDAR, they are hindered by slow rendering speeds due to dense sampling. Conversely, Gaussian Splatting-based methods employ Gaussian primitives for scene representation and achieve rapid rendering through rasterization. However, these rasterization-based techniques struggle to accurately model non-linear optical sensors. This limitation restricts their applicability to sensors beyond pinhole cameras. To address these challenges and enable unified representation of dynamic driving scenarios using Gaussian primitives, this study proposes a novel hybrid approach. Our method utilizes rasterization for rendering image data while employing Gaussian ray-tracing for LiDAR data rendering. Experimental results on public datasets demonstrate that our approach outperforms current state-of-the-art methods. This work presents a unified and efficient solution for realistic simulation of camera and LiDAR data in autonomous driving scenarios using Gaussian primitives, offering significant advancements in both rendering quality and computational efficiency.
确保自动驾驶车辆的安全需要对多传感器数据进行全面的仿真,这涵盖了来自摄像机和激光雷达传感器的输入,并涵盖各种动态驾驶场景。利用收集的原始传感器数据模拟这些动态环境的神经渲染技术已成为一种主要方法。虽然基于NeRF的方法可以统一表示场景,对来自相机和激光雷达的渲染数据进行统一呈现,但由于密集采样,其渲染速度较慢。相反,基于高斯涂抹的方法使用高斯原始模型进行场景表示,并通过光栅化实现快速渲染。然而,这些基于光栅化的技术在模拟非线性光学传感器时遇到了困难。这一局限性限制了它们对针孔相机以外的传感器的适用性。为了解决这些挑战,实现对动态驾驶场景的基于高斯原始模型进行统一表示,本研究提出了一种新型混合方法。我们的方法使用光栅化进行图像数据渲染,同时使用高斯光线追踪进行激光雷达数据渲染。在公开数据集上的实验结果表明,我们的方法优于当前最先进的其它方法。本研究提出了一种使用高斯原始模型对自动驾驶场景中的相机和激光雷达数据进行逼真模拟的统一高效解决方案,在渲染质量和计算效率方面都取得了重大进展。
论文及项目相关链接
PDF 10 pages
Summary
本文探讨了在自动驾驶车辆的安全性保障中,如何利用神经网络渲染技术模拟多传感器数据的问题。文章提出了一个混合方法,使用栅格化进行图像数据渲染,同时采用高斯射线追踪进行激光雷达数据渲染。该方法实现了对动态驾驶场景的统一表示,并在公共数据集上的实验结果表明,该方法在渲染质量和计算效率方面均取得了显著的进展。
Key Takeaways
- 自主车辆的安全性需要全面模拟多传感器数据,包括相机和激光雷达传感器在各种动态驾驶场景下的输入。
- 神经网络渲染技术已成为模拟这些动态环境的主要方法,其中基于NeRF的方法可以统一表示场景并为相机和激光雷达提供渲染数据,但渲染速度较慢。
- 高斯摊铺法使用高斯原始场景表示并实现快速渲染,但在建模非线性光学传感器方面存在困难。
- 提出了一个混合方法,结合栅格化和高斯射线追踪来渲染图像数据和激光雷达数据。
- 该方法实现了对动态驾驶场景的统一表示,并显著提高了渲染质量和计算效率。
- 实验结果表明,该方法在公共数据集上的性能优于当前的最先进方法。
点此查看论文截图

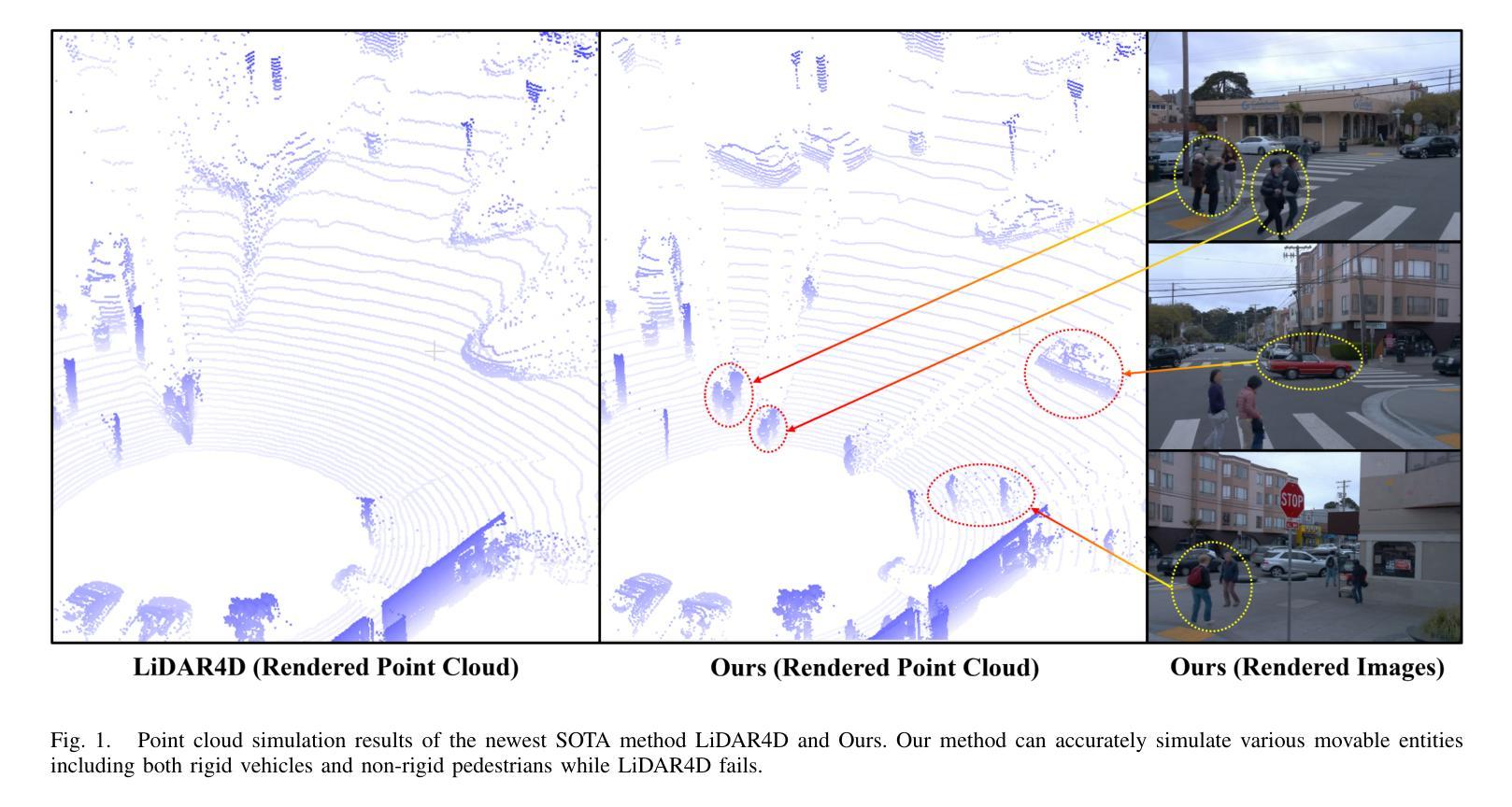

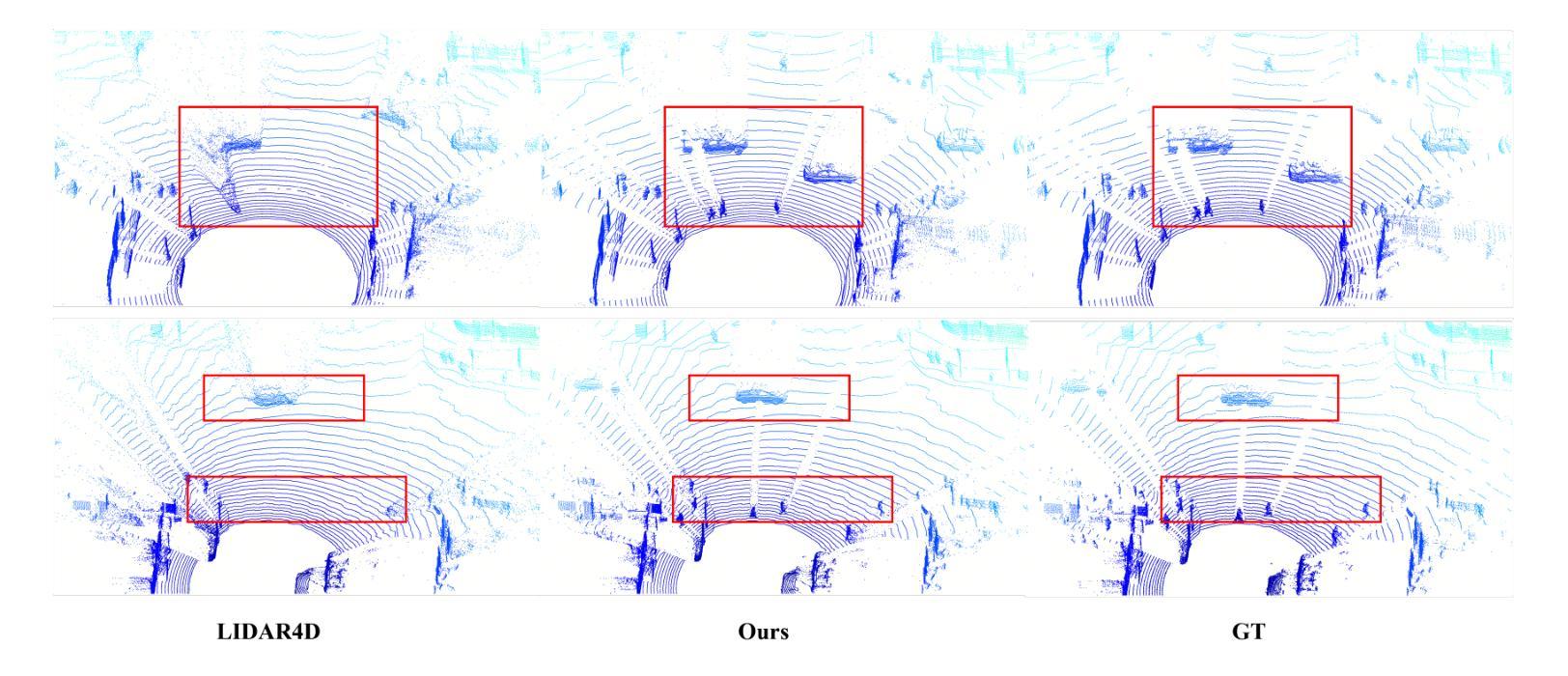
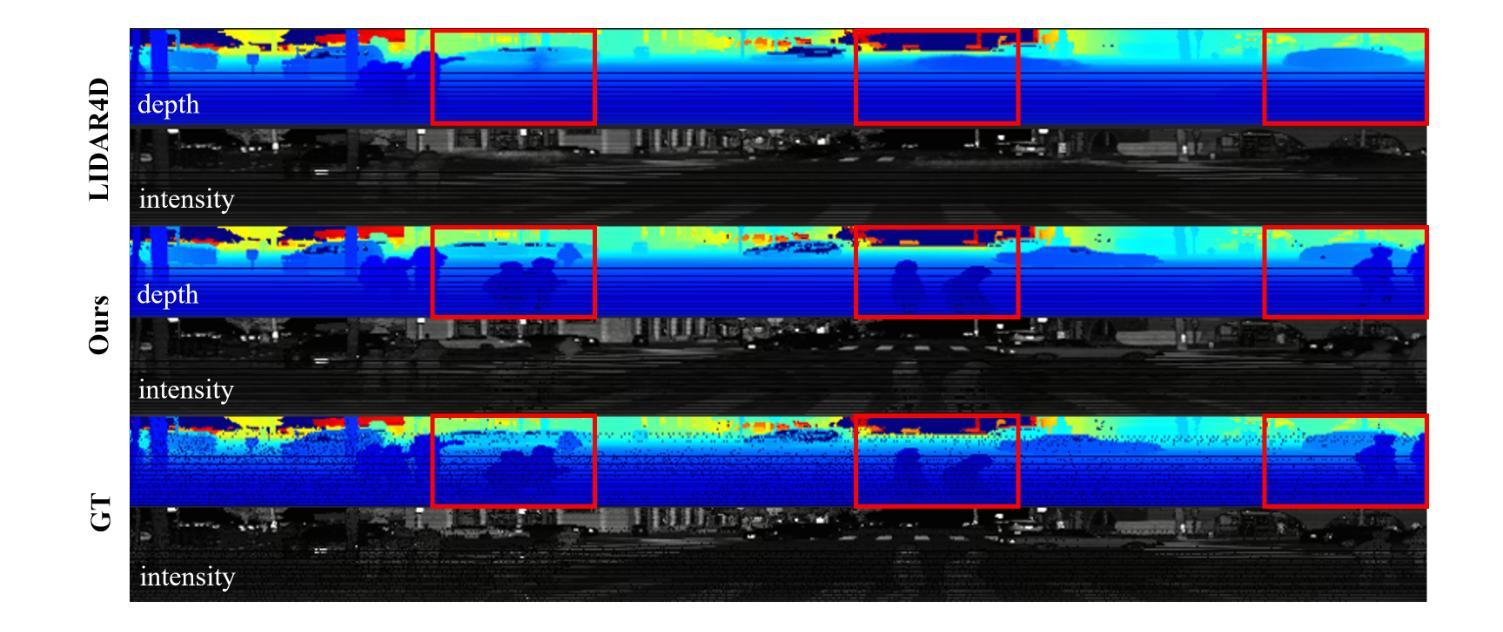

ELECTRA: A Symmetry-breaking Cartesian Network for Charge Density Prediction with Floating Orbitals
Authors:Jonas Elsborg, Luca Thiede, Alán Aspuru-Guzik, Tejs Vegge, Arghya Bhowmik
We present the Electronic Tensor Reconstruction Algorithm (ELECTRA) - an equivariant model for predicting electronic charge densities using “floating” orbitals. Floating orbitals are a long-standing idea in the quantum chemistry community that promises more compact and accurate representations by placing orbitals freely in space, as opposed to centering all orbitals at the position of atoms. Finding ideal placements of these orbitals requires extensive domain knowledge though, which thus far has prevented widespread adoption. We solve this in a data-driven manner by training a Cartesian tensor network to predict orbital positions along with orbital coefficients. This is made possible through a symmetry-breaking mechanism that is used to learn position displacements with lower symmetry than the input molecule while preserving the rotation equivariance of the charge density itself. Inspired by recent successes of Gaussian Splatting in representing densities in space, we are using Gaussians as our orbitals and predict their weights and covariance matrices. Our method achieves a state-of-the-art balance between computational efficiency and predictive accuracy on established benchmarks.
我们提出了电子张量重建算法(ELECTRA)——一种利用“浮动”轨道预测电子电荷密度的等价模型。浮动轨道是量子化学界长期以来的一个理念,它通过让轨道在空间中自由放置(而不是将所有轨道都置于原子的位置),从而提供更为紧凑和准确的表示。然而,寻找这些轨道的理想位置需要大量的专业知识,这迄今为止一直阻碍了它的广泛应用。我们通过训练一个笛卡尔张量网络来预测轨道位置以及轨道系数来解决这一问题。这是通过一个对称破坏机制实现的,该机制用于学习具有比输入分子更低对称性的位置位移,同时保留电荷密度本身的旋转等价性。受到最近高斯平铺法在空间密度表示方面成功的启发,我们使用高斯函数作为我们的轨道,并预测其权重和协方差矩阵。我们的方法在既定的基准测试上实现了计算效率和预测精度之间的最佳平衡。
论文及项目相关链接
PDF 8 pages, 3 figures, 1 table
摘要
本文介绍了电子张量重建算法(ELECTRA),这是一种利用“浮动”轨道预测电子电荷密度的等价模型。浮动轨道是量子化学界长期以来的一个理念,它通过让轨道在空间中自由放置,而不是将所有轨道定位在原子位置,从而提供更紧凑和准确的表示。然而,找到这些轨道的理想位置需要大量的领域知识,这至今阻碍了其广泛应用。我们采用数据驱动的方法,训练笛卡尔张量网络来预测轨道位置和轨道系数。这是通过一个对称破坏机制实现的,该机制可以学习具有比输入分子更低对称性的位置位移,同时保持电荷密度的旋转等价性。受到高斯平铺法在空间中表示密度的最新成功的启发,我们使用高斯作为我们的轨道,并预测其权重和协方差矩阵。我们的方法在既定的基准测试上实现了计算效率和预测精度之间的最佳平衡。
要点
- 介绍了Electronic Tensor Reconstruction Algorithm(ELECTRA)算法。
- ELECTRA利用浮动轨道理念预测电子电荷密度。
- 浮动轨道允许轨道在空间中自由放置,提高表示的精度和紧凑性。
- 通过数据驱动方法,通过训练笛卡尔张量网络来预测轨道位置和轨道系数。
- 对称破坏机制使模型能够学习位置位移,同时保持电荷密度的旋转等价性。
- 受到高斯平铺法的启发,使用高斯作为轨道,并预测其权重和协方差矩阵。
点此查看论文截图


MVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Authors:Kaiqiang Xiong, Ying Feng, Qi Zhang, Jianbo Jiao, Yang Zhao, Zhihao Liang, Huachen Gao, Ronggang Wang
3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
从单张图像进行3D人体重建是一个具有挑战性的问题,已在文献中进行了专门研究。最近,一些方法采用扩散模型进行引导,通过分数蒸馏采样(SDS)优化3D表示,或者生成一张后视图图像以辅助重建。然而,这些方法往往会产生不满意的伪影(例如由于多视图的不一致先验导致的扁平化人体结构或过度平滑的结果),并且在现实世界的野外环境中推广时遇到困难。在本研究中,我们提出了“MVD-HuGaS”,它通过多视图人体扩散模型,实现从单张图像进行自由视角的3D人体渲染。我们首先使用增强的多视图扩散模型从单张参考图像生成多视图图像,该模型在高质量的3D人体数据集上进行微调,以融入3D几何先验和人体结构先验。为了从稀疏生成的多视图图像中推断出用于重建的准确相机姿态,我们引入了对齐模块,以促进3D高斯和相机姿态的联合优化。此外,我们提出了基于深度的面部失真减轻模块,以细化生成的面部区域,从而提高重建的整体保真度。最后,利用细化后的多视图图像及其准确的相机姿态,MVD-HuGaS优化目标人体的3D高斯分布,以实现高保真自由视角渲染。在Thuman2.0和2K2K数据集上的广泛实验表明,所提出的MVD-HuGaS在单视图3D人体渲染上达到了最先进的性能。
论文及项目相关链接
Summary
本文提出一种基于多视角扩散模型MVD-HuGaS的单图像自由视角三维人体渲染方法。该方法通过增强多视角扩散模型生成参考图像的多视角图像,结合3D几何先验和人体结构先验进行优化。引入对齐模块推断稀疏多视角图像的准确相机姿态,提出基于深度的面部失真减轻模块优化面部区域。最终,利用优化后的多视角图像和准确的相机姿态,MVD-HuGaS优化目标人体的三维高斯分布,实现高保真自由视角渲染。在Thuman2.0和2K2K数据集上的实验表明,该方法在单视角三维人体渲染上取得了最新性能。
Key Takeaways
- 提出了一种新的基于多视角扩散模型(MVD-HuGaS)的三维人体渲染方法。
- 通过增强多视角扩散模型生成参考图像的多视角图像,并融入3D几何和人体结构先验。
- 引入对齐模块,可以从稀疏生成的多视角图像推断准确的相机姿态。
- 提出基于深度的面部失真减轻模块,用于优化面部区域的生成效果。
- 利用优化后的多视角图像和准确的相机姿态,优化了目标人体的三维高斯分布。
- MVD-HuGaS在单视角三维人体渲染方面达到了最新性能。
点此查看论文截图




REArtGS: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints
Authors:Di Wu, Liu Liu, Zhou Linli, Anran Huang, Liangtu Song, Qiaojun Yu, Qi Wu, Cewu Lu
Articulated objects, as prevalent entities in human life, their 3D representations play crucial roles across various applications. However, achieving both high-fidelity textured surface reconstruction and dynamic generation for articulated objects remains challenging for existing methods. In this paper, we present REArtGS, a novel framework that introduces additional geometric and motion constraints to 3D Gaussian primitives, enabling high-quality textured surface reconstruction and generation for articulated objects. Specifically, given multi-view RGB images of arbitrary two states of articulated objects, we first introduce an unbiased Signed Distance Field (SDF) guidance to regularize Gaussian opacity fields, enhancing geometry constraints and improving surface reconstruction quality. Then we establish deformable fields for 3D Gaussians constrained by the kinematic structures of articulated objects, achieving unsupervised generation of surface meshes in unseen states. Extensive experiments on both synthetic and real datasets demonstrate our approach achieves high-quality textured surface reconstruction for given states, and enables high-fidelity surface generation for unseen states. Codes will be released within the next four months and the project website is at https://sites.google.com/view/reartgs/home.
关节型物体作为人类生活中常见的实体,其3D表示在各种应用中扮演着至关重要的角色。然而,对于现有方法来说,实现关节型物体的高保真纹理表面重建和动态生成仍然具有挑战性。在本文中,我们提出了REArtGS,一个引入3D高斯原始几何和动作约束的新型框架,能够实现关节型物体的高质量纹理表面重建和生成。具体而言,给定关节型物体的任意两种状态的多视角RGB图像,我们首先引入无偏符号距离场(SDF)指导来规范高斯不透明度场,增强几何约束并提高表面重建质量。然后,我们为受关节型物体运动结构约束的3D高斯建立可变形场,实现未见状态的表面网格的无监督生成。在合成和真实数据集上的大量实验表明,我们的方法实现了给定状态的高质量纹理表面重建,并为未见状态实现了高保真表面生成。代码将在未来四个月内发布,项目网站地址为:https://sites.google.com/view/reartgs/home。
论文及项目相关链接
PDF 11pages, 6 figures
摘要
REArtGS框架引入额外的几何和运动约束到3D高斯原始模型,实现对关节型对象的高质量纹理表面重建和生成。通过多视角RGB图像,对关节型对象的任意两种状态进行无偏带符号距离场(SDF)引导,规范高斯不透明度场,提高几何约束,改善表面重建质量。建立关节型对象的变形场,实现未见状态的表面网格无监督生成。在合成和真实数据集上的大量实验证明,该方法实现了给定状态的高质量纹理表面重建,并为未见状态实现了高保真表面生成。
要点
- REArtGS框架用于关节型对象的3D表示中,实现高质量纹理表面重建和生成。
- 通过引入额外的几何和运动约束到3D高斯原始模型,提高表面重建质量。
- 使用多视角RGB图像,对关节型对象的任意两种状态进行无偏带符号距离场(SDF)引导。
- 建立关节型对象的变形场,实现未见状态的表面网格无监督生成。
- 该方法在合成和真实数据集上均表现出优异性能,实现了给定状态的高质量纹理表面重建。
- 该方法还为未见状态实现了高保真表面生成。
- 将在未来四个月内发布代码,项目网站为[网站链接]。
点此查看论文截图




DoF-Gaussian: Controllable Depth-of-Field for 3D Gaussian Splatting
Authors:Liao Shen, Tianqi Liu, Huiqiang Sun, Jiaqi Li, Zhiguo Cao, Wei Li, Chen Change Loy
Recent advances in 3D Gaussian Splatting (3D-GS) have shown remarkable success in representing 3D scenes and generating high-quality, novel views in real-time. However, 3D-GS and its variants assume that input images are captured based on pinhole imaging and are fully in focus. This assumption limits their applicability, as real-world images often feature shallow depth-of-field (DoF). In this paper, we introduce DoF-Gaussian, a controllable depth-of-field method for 3D-GS. We develop a lens-based imaging model based on geometric optics principles to control DoF effects. To ensure accurate scene geometry, we incorporate depth priors adjusted per scene, and we apply defocus-to-focus adaptation to minimize the gap in the circle of confusion. We also introduce a synthetic dataset to assess refocusing capabilities and the model’s ability to learn precise lens parameters. Our framework is customizable and supports various interactive applications. Extensive experiments confirm the effectiveness of our method. Our project is available at https://dof-gaussian.github.io.
近期三维高斯拼贴(3D-GS)的进展在表示三维场景和实时生成高质量、新颖视图方面取得了显著的成功。然而,3D-GS及其变种假设输入图像是基于针孔成像捕获的,并且完全在焦点上。这一假设限制了其适用性,因为现实世界中的图像通常具有较浅的景深(DoF)。在本文中,我们介绍了DoF-Gaussian,这是一种可控景深的三维高斯拼贴方法。我们基于几何光学原理开发了一种基于镜头的成像模型来控制景深效应。为了确保场景几何的准确性,我们根据场景调整了深度先验知识,并应用了失焦到聚焦的适应来减少模糊圆之间的间隙。我们还引入了一个合成数据集来评估重新对焦能力和模型学习精确镜头参数的能力.我们的框架是定制化的,支持各种交互式应用程序。大量实验证实了我们方法的有效性。我们的项目可在https://dof-gaussian.github.io找到。
论文及项目相关链接
PDF CVPR 2025
Summary
该论文针对三维高斯点扩展(3D-GS)的最新进展进行了深入研究,并提出了一个新的可控深度视野方法——DoF-Gaussian。论文引入了基于几何光学原理的镜头成像模型来控制深度视野效应,并结合场景深度先验进行深度调整,实现了从失焦到聚焦的适应。此外,论文还引入了一个合成数据集来评估模型的重新聚焦能力和精确镜头参数的学习能力。该框架具有良好的可定制性,支持各种交互式应用,并通过广泛的实验验证了其有效性。
Key Takeaways
- 论文针对三维高斯点扩展(3D-GS)技术进行了改进,解决了其在处理真实世界图像时存在的局限性。
- 引入了一种新的可控深度视野方法——DoF-Gaussian,该方法基于几何光学原理的镜头成像模型来控制深度视野效应。
- 结合场景深度先验进行深度调整,以实现从失焦到聚焦的适应。
- 引入合成数据集用于评估模型的重新聚焦能力和精确镜头参数的学习能力。
- 该框架具有良好的可定制性,适用于各种交互式应用。
- 实验结果证明了该方法的有效性。
点此查看论文截图






TrackGS: Optimizing COLMAP-Free 3D Gaussian Splatting with Global Track Constraints
Authors:Dongbo Shi, Shen Cao, Lubin Fan, Bojian Wu, Jinhui Guo, Renjie Chen, Ligang Liu, Jieping Ye
While 3D Gaussian Splatting (3DGS) has advanced ability on novel view synthesis, it still depends on accurate pre-computaed camera parameters, which are hard to obtain and prone to noise. Previous COLMAP-Free methods optimize camera poses using local constraints, but they often struggle in complex scenarios. To address this, we introduce TrackGS, which incorporates feature tracks to globally constrain multi-view geometry. We select the Gaussians associated with each track, which will be trained and rescaled to an infinitesimally small size to guarantee the spatial accuracy. We also propose minimizing both reprojection and backprojection errors for better geometric consistency. Moreover, by deriving the gradient of intrinsics, we unify camera parameter estimation with 3DGS training into a joint optimization framework, achieving SOTA performance on challenging datasets with severe camera movements.
尽管3D高斯拼接(3DGS)在新型视图合成方面具备高级能力,但它仍然依赖于难以获取且易出错的事先计算好的相机参数。之前的COLMAP-Free方法通过使用局部约束优化相机姿态,但在复杂场景中经常表现不佳。为了解决这一问题,我们引入了TrackGS,它通过特征轨迹对多视图几何进行全局约束。我们选择与每条轨迹相关的高斯,并将其训练和重新缩放到无穷小的尺寸,以保证空间精度。我们还提出最小化重投影和反向投影误差,以更好地实现几何一致性。此外,通过推导内参的梯度,我们将相机参数估计与3DGS训练统一到一个联合优化框架中,在具有剧烈相机运动的挑战数据集上实现了SOTA性能。
论文及项目相关链接
Summary
该摘要提到,尽管三维高斯膨胀法(3DGS)在新型视角合成方面具有卓越的能力,但其仍然依赖于难以获取且易受噪声干扰的预先计算的相机参数。为此,文章引入了TrackGS,它结合了特征轨迹来全局约束多视角几何。通过选择每个轨迹相关的高斯并进行训练和缩放至无穷小的尺寸,以确保空间精度。同时,最小化重投影和反向投影误差以实现更好的几何一致性。此外,通过推导内参的梯度,将相机参数估计与三维高斯膨胀训练结合到一个联合优化框架中,实现在具有严重相机运动的挑战数据集上的卓越性能。
Key Takeaways
- TrackGS结合了特征轨迹进行全局的多视角几何约束,以提高空间精度。
- 通过选择每个轨迹相关的高斯并进行训练和缩放至无穷小尺寸来处理噪声问题。
- 同时优化重投影和反向投影误差以改善几何一致性。
- 相机参数估计与三维高斯膨胀训练的联合优化提高了挑战数据集的优异性能。
- 该方法实现了对具有严重相机运动的数据集的有效处理。
- 该方法解决了先前COLMAP-Free方法在复杂场景中的优化问题。
点此查看论文截图




AutoOcc: Automatic Open-Ended Semantic Occupancy Annotation via Vision-Language Guided Gaussian Splatting
Authors:Xiaoyu Zhou, Jingqi Wang, Yongtao Wang, Yufei Wei, Nan Dong, Ming-Hsuan Yang
Obtaining high-quality 3D semantic occupancy from raw sensor data remains an essential yet challenging task, often requiring extensive manual labeling. In this work, we propose AutoOcc, an vision-centric automated pipeline for open-ended semantic occupancy annotation that integrates differentiable Gaussian splatting guided by vision-language models. We formulate the open-ended semantic occupancy reconstruction task to automatically generate scene occupancy by combining attention maps from vision-language models and foundation vision models. We devise semantic-aware Gaussians as intermediate geometric descriptors and propose a cumulative Gaussian-to-voxel splatting algorithm that enables effective and efficient occupancy annotation. Our framework outperforms existing automated occupancy annotation methods without human labels. AutoOcc also enables open-ended semantic occupancy auto-labeling, achieving robust performance in both static and dynamically complex scenarios. All the source codes and trained models will be released.
从原始传感器数据获取高质量3D语义占用仍然是一项基本且具有挑战性的任务,通常需要大量的人工标注。在这项工作中,我们提出了AutoOcc,这是一个以视觉为中心的开放式语义占用注释自动化管道,它集成了由视觉语言模型引导的可微高斯涂抹技术。我们将开放式语义占用重建任务制定为通过结合视觉语言模型和基础视觉模型的注意力图来自动生成场景占用。我们设计语义感知高斯作为中间几何描述符,并提出累积高斯到体素涂抹算法,以实现有效和高效的占用注释。我们的框架在不需要人工标签的情况下,优于现有的自动占用注释方法。AutoOcc还实现了开放式语义占用的自动标注,在静态和动态复杂场景中均表现出稳健的性能。所有源代码和训练过的模型都将被发布。
论文及项目相关链接
Summary
本研究提出了AutoOcc,一个以视觉为中心的自动化管道,用于开放式语义占用标注。该管道结合了可微分的Gaussian splatting和视觉语言模型,自动化生成场景占用信息。通过设计语义感知的Gaussians作为中间几何描述符,以及提出一种累积的Gaussian-to-voxel splatting算法,实现了有效且高效的占用标注。AutoOcc框架在无需人工标签的情况下,超越了现有的自动化占用标注方法,并实现了开放式语义占用的自动标注,在静态和动态复杂场景中均表现出稳健性能。
Key Takeaways
- 本研究提出了一种新的自动化管道AutoOcc,用于开放式语义占用标注。
- 该管道集成了可微分的Gaussian splatting和视觉语言模型,以自动化生成场景占用信息。
- 通过设计语义感知的Gaussians作为中间几何描述符,提高了标注的准确性和效率。
- 提出了一种累积的Gaussian-to-voxel splatting算法,实现了有效且高效的占用标注。
- AutoOcc框架在无需人工标签的情况下,超越了现有的自动化占用标注方法。
- 该框架能够实现开放式语义占用的自动标注,具有广泛的应用前景。
点此查看论文截图






Generalized and Efficient 2D Gaussian Splatting for Arbitrary-scale Super-Resolution
Authors:Du Chen, Liyi Chen, Zhengqiang Zhang, Lei Zhang
Implicit Neural Representation (INR) has been successfully employed for Arbitrary-scale Super-Resolution (ASR). However, INR-based models need to query the multi-layer perceptron module numerous times and render a pixel in each query, resulting in insufficient representation capability and computational efficiency. Recently, Gaussian Splatting (GS) has shown its advantages over INR in both visual quality and rendering speed in 3D tasks, which motivates us to explore whether GS can be employed for the ASR task. However, directly applying GS to ASR is exceptionally challenging because the original GS is an optimization-based method through overfitting each single scene, while in ASR we aim to learn a single model that can generalize to different images and scaling factors. We overcome these challenges by developing two novel techniques. Firstly, to generalize GS for ASR, we elaborately design an architecture to predict the corresponding image-conditioned Gaussians of the input low-resolution image in a feed-forward manner. Each Gaussian can fit the shape and direction of an area of complex textures, showing powerful representation capability. Secondly, we implement an efficient differentiable 2D GPU/CUDA-based scale-aware rasterization to render super-resolved images by sampling discrete RGB values from the predicted continuous Gaussians. Via end-to-end training, our optimized network, namely GSASR, can perform ASR for any image and unseen scaling factors. Extensive experiments validate the effectiveness of our proposed method.
隐式神经网络表示(INR)已成功应用于任意尺度超分辨率(ASR)。然而,基于INR的模型需要多次查询多层感知器模块,并在每次查询中呈现一个像素,导致表示能力和计算效率不足。最近,高斯喷涂(GS)在3D任务的视觉质量和渲染速度方面显示出其相对于INR的优势,这激励我们探索是否可以使用GS进行ASR任务。然而,直接将GS应用于ASR具有极大的挑战性,因为原始的GS是一种基于优化的方法,通过过度拟合每个单一场景,而在ASR中,我们的目标是学习一个可以推广到不同图像和缩放因子的模型。我们通过开发两种新技术来克服这些挑战。首先,为了将GS推广到ASR,我们精心设计了一种架构,以前馈方式预测输入低分辨率图像对应的图像条件高斯分布。每个高斯分布都能适应复杂纹理区域的形状和方向,显示出强大的表示能力。其次,我们实现了一种高效的可微分2D GPU/CUDA基尺度感知光栅化,通过从预测的持续高斯分布中采样离散RGB值来呈现超分辨率图像。通过端到端的训练,我们优化的网络,即GSASR,可以对任何图像和未见的缩放因子执行ASR。大量的实验验证了我们的方法的有效性。
论文及项目相关链接
Summary
本文探讨了将高斯贴图(GS)技术应用于任意尺度超分辨率(ASR)任务的挑战及解决方案。针对GS在ASR应用中的优化问题,提出了两种新技术:一是设计了一种前馈网络架构,用于预测输入低分辨率图像的条件高斯分布;二是实现了高效的二维GPU/CUDA可微分尺度感知渲染技术,用于从预测的高斯分布中采样生成超分辨率图像。实验结果验证了所提出方法的有效性。
Key Takeaways
- INR在ASR任务中的应用面临计算效率和表示能力不足的问题。
- GS在视觉质量和渲染速度方面在3D任务中表现出优势,但在ASR任务中直接应用具有挑战性。
- 为克服挑战,提出了两种新技术:设计前馈网络架构预测低分辨率图像的条件高斯分布,并实现高效的尺度感知渲染技术。
- 所提出的方法通过端到端训练,能够针对任意图像和未见过的缩放因子进行ASR。
点此查看论文截图






Locality-aware Gaussian Compression for Fast and High-quality Rendering
Authors:Seungjoo Shin, Jaesik Park, Sunghyun Cho
We present LocoGS, a locality-aware 3D Gaussian Splatting (3DGS) framework that exploits the spatial coherence of 3D Gaussians for compact modeling of volumetric scenes. To this end, we first analyze the local coherence of 3D Gaussian attributes, and propose a novel locality-aware 3D Gaussian representation that effectively encodes locally-coherent Gaussian attributes using a neural field representation with a minimal storage requirement. On top of the novel representation, LocoGS is carefully designed with additional components such as dense initialization, an adaptive spherical harmonics bandwidth scheme and different encoding schemes for different Gaussian attributes to maximize compression performance. Experimental results demonstrate that our approach outperforms the rendering quality of existing compact Gaussian representations for representative real-world 3D datasets while achieving from 54.6$\times$ to 96.6$\times$ compressed storage size and from 2.1$\times$ to 2.4$\times$ rendering speed than 3DGS. Even our approach also demonstrates an averaged 2.4$\times$ higher rendering speed than the state-of-the-art compression method with comparable compression performance.
我们提出了LocoGS,这是一个基于局部感知的3D高斯展开(3DGS)框架,它利用3D高斯的空间连贯性对体积场景进行紧凑建模。为此,我们首先分析了3D高斯属性的局部连贯性,并提出了一种新型的局部感知的3D高斯表示方法,该方法使用具有最小存储要求的神经场表示法有效地编码局部连贯的高斯属性。基于这种新型表示方法,LocoGS经过精心设计,配备了密集初始化、自适应球面谐波带宽方案以及针对不同高斯属性的不同编码方案等额外组件,以最大化压缩性能。实验结果表明,我们的方法在具有代表性的真实世界3D数据集上,相较于现有的紧凑高斯表示方法,提高了渲染质量,同时实现了从54.6倍到96.6倍的压缩存储大小和从2.1倍到2.4倍的渲染速度提升。即使与具有类似压缩性能的最先进压缩方法相比,我们的方法也表现出了平均高出2.4倍的渲染速度。
论文及项目相关链接
PDF Accepted to ICLR 2025. Project page: https://seungjooshin.github.io/LocoGS
Summary
本文介绍了LocoGS,一种基于空间感知的3D高斯融合(3DGS)框架。它通过利用3D高斯的空间一致性,实现了对体积场景的有效建模。通过引入局部感知的3D高斯表示法,实现了对局部一致的高斯属性的高效编码,从而在保证渲染质量的同时降低了存储需求。该框架还包括密集初始化、自适应球面谐波带宽方案等组件,用于进一步优化压缩性能。实验结果表明,相较于现有方法,LocoGS在真实世界数据集上实现了更高的渲染质量,同时压缩存储大小减少了54.6倍至96.6倍,渲染速度提高了2.1倍至2.4倍。相较于其他同类方法,其在相近压缩性能下渲染速度提高了平均2.4倍。
Key Takeaways
- LocoGS是一种基于空间感知的3D高斯融合框架,用于体积场景的紧凑建模。
- 引入局部感知的3D高斯表示法,实现对局部一致的高斯属性的高效编码。
- 通过神经网络场表示法实现最小存储需求的有效编码。
- LocoGS包括密集初始化、自适应球面谐波带宽方案等组件以优化压缩性能。
- 实验结果显示LocoGS在真实世界数据集上实现高渲染质量,显著优于现有方法。
- LocoGS在压缩存储和渲染速度方面均有显著提升,压缩比达到54.6倍至96.6倍,渲染速度提高2.1倍至2.4倍。
点此查看论文截图



FAST-Splat: Fast, Ambiguity-Free Semantics Transfer in Gaussian Splatting
Authors:Ola Shorinwa, Jiankai Sun, Mac Schwager
We present FAST-Splat for fast, ambiguity-free semantic Gaussian Splatting, which seeks to address the main limitations of existing semantic Gaussian Splatting methods, namely: slow training and rendering speeds; high memory usage; and ambiguous semantic object localization. We take a bottom-up approach in deriving FAST-Splat, dismantling the limitations of closed-set semantic distillation to enable open-set (open-vocabulary) semantic distillation. Ultimately, this key approach enables FAST-Splat to provide precise semantic object localization results, even when prompted with ambiguous user-provided natural-language queries. Further, by exploiting the explicit form of the Gaussian Splatting scene representation to the fullest extent, FAST-Splat retains the remarkable training and rendering speeds of Gaussian Splatting. Precisely, while existing semantic Gaussian Splatting methods distill semantics into a separate neural field or utilize neural models for dimensionality reduction, FAST-Splat directly augments each Gaussian with specific semantic codes, preserving the training, rendering, and memory-usage advantages of Gaussian Splatting over neural field methods. These Gaussian-specific semantic codes, together with a hash-table, enable semantic similarity to be measured with open-vocabulary user prompts and further enable FAST-Splat to respond with unambiguous semantic object labels and $3$D masks, unlike prior methods. In experiments, we demonstrate that FAST-Splat is 6x to 8x faster to train, achieves between 18x to 51x faster rendering speeds, and requires about 6x smaller GPU memory, compared to the best-competing semantic Gaussian Splatting methods. Further, FAST-Splat achieves relatively similar or better semantic segmentation performance compared to existing methods. After the review period, we will provide links to the project website and the codebase.
我们提出了用于快速、无歧义的语义高斯展布(Semantic Gaussian Splatting)的FAST-Splat方法,旨在解决现有语义高斯展布方法的主要局限性,包括:训练和渲染速度慢、内存使用率高以及语义对象定位模糊。我们采用自下而上的方法推导FAST-Splat,克服封闭集语义蒸馏的局限性,实现开放集(开放词汇表)语义蒸馏。最终,这个关键方法使得FAST-Splat在接收到模糊的用户提供自然语言查询时,仍能提供精确语义对象定位结果。此外,通过充分利用高斯展布场景表示的显式形式,FAST-Splat保留了高斯展布在训练和渲染方面的出色速度。具体来说,现有的语义高斯展布方法将语义蒸馏到单独的神经网络场或利用神经网络模型进行降维,而FAST-Splat直接在每个高斯上增加特定的语义代码,保留了高斯展布在训练、渲染和内存使用方面的优势,相对于神经网络场方法。这些特定于高斯语义代码与哈希表相结合,使用户能够使用开放词汇表提示来测量语义相似性,并进一步使FAST-Splat能够响应出明确的语义对象标签和三维掩码,不同于先前的方法。在实验方面,我们证明了FAST-Splat的训练速度是最佳竞争语义高斯展布方法的6倍至8倍,渲染速度达到18倍至51倍,并且所需的GPU内存减少了大约6倍。此外,FAST-Splat相较于现有方法取得了相当或更好的语义分割性能。评审期过后,我们将提供项目网站和代码库的链接。
论文及项目相关链接
Summary
本文介绍了FAST-Splat方法,它是一种快速、无歧义语义高斯混合技术,旨在解决现有语义高斯混合方法的主要局限性,包括训练与渲染速度慢、内存使用高以及语义对象定位模糊。FAST-Splat采取自下而上的方法,摒弃了封闭集语义蒸馏的局限性,实现了开放集(开放词汇表)语义蒸馏。该方法能精确进行语义对象定位,即使面对用户提供的模糊自然语言查询也能应对。同时,FAST-Splat充分利用高斯混合场景表示的显式形式,保持了高斯混合在训练与渲染速度上的优势。相比于现有的神经场方法,FAST-Splat直接对每一个高斯进行特定语义编码,从而在训练、渲染和内存使用方面保持了优势。实验表明,FAST-Splat的训练速度是现有方法的6至8倍,渲染速度达到18至51倍的提升,GPU内存使用减少约6倍。同时,FAST-Splat的语义分割性能与现有方法相当或更好。
Key Takeaways
- FAST-Splat解决了现有语义高斯混合方法的训练与渲染速度慢的问题。
- FAST-Splat通过实现开放集语义蒸馏解决了封闭集方法的局限性。
- FAST-Splat能精确处理模糊的自然语言查询并进行语义对象定位。
- FAST-Splat通过利用高斯混合的优势提高了训练和渲染速度。
- 与现有的神经场方法相比,FAST-Splat具有更高效的内存使用和更快的运行速度。
- FAST-Splat通过为每个高斯分配特定的语义编码增强了语义性能。
点此查看论文截图




Self-Ensembling Gaussian Splatting for Few-Shot Novel View Synthesis
Authors:Chen Zhao, Xuan Wang, Tong Zhang, Saqib Javed, Mathieu Salzmann
3D Gaussian Splatting (3DGS) has demonstrated remarkable effectiveness in novel view synthesis (NVS). However, 3DGS tends to overfit when trained with sparse views, limiting its generalization to novel viewpoints. In this paper, we address this overfitting issue by introducing Self-Ensembling Gaussian Splatting (SE-GS). We achieve self-ensembling by incorporating an uncertainty-aware perturbation strategy during training. A $\mathbf{\Delta}$-model and a $\mathbf{\Sigma}$-model are jointly trained on the available images. The $\mathbf{\Delta}$-model is dynamically perturbed based on rendering uncertainty across training steps, generating diverse perturbed models with negligible computational overhead. Discrepancies between the $\mathbf{\Sigma}$-model and these perturbed models are minimized throughout training, forming a robust ensemble of 3DGS models. This ensemble, represented by the $\mathbf{\Sigma}$-model, is then used to generate novel-view images during inference. Experimental results on the LLFF, Mip-NeRF360, DTU, and MVImgNet datasets demonstrate that our approach enhances NVS quality under few-shot training conditions, outperforming existing state-of-the-art methods. The code is released at: https://sailor-z.github.io/projects/SEGS.html.
3D高斯融合(3DGS)在新型视角合成(NVS)中表现出显著的效果。然而,当使用稀疏视角进行训练时,3DGS容易出现过拟合,限制了其在新型观点上的泛化能力。在本文中,我们通过引入自集成高斯融合(SE-GS)来解决过拟合问题。我们在训练过程中采用了一种感知不确定性的扰动策略来实现自集成。Δ模型和Σ模型在可用图像上联合训练。Δ模型根据训练步骤中的渲染不确定性进行动态扰动,生成具有微小计算开销的多种扰动模型。在整个训练过程中,最小化Σ模型与这些扰动模型之间的差异,形成稳健的3DGS模型集合。这个集合由Σ模型表示,然后用于推理过程中的新型视角图像生成。在LLFF、Mip-NeRF360、DTU和MVImgNet数据集上的实验结果表明,我们的方法在提高少量训练条件下的NVS质量方面优于现有的最先进的方法。代码发布在:https://sailor-z.github.io/projects/SEGS.html。
论文及项目相关链接
Summary
本文解决了在稀疏视图训练下,3D高斯采样(3DGS)存在的过拟合问题,限制了其在新型视角上的泛化能力。通过引入自集成高斯采样(SE-GS)解决了这一问题。在训练过程中采用了一种感知不确定性的扰动策略来实现自集成。同时训练了Δ模型和Σ模型,Δ模型根据渲染不确定性进行动态扰动,生成多种扰动模型且计算开销小。通过最小化Σ模型和这些扰动模型之间的差异,形成稳健的3DGS模型集合。在LLFF、Mip-NeRF360、DTU和MVImgNet数据集上的实验结果表明,该方法在少量训练样本的情况下提高了新型视图合成的质量,优于现有最先进的方法。代码已发布在:[链接地址]。
Key Takeaways
- 3DGS在新型视图合成(NVS)中表现出显著的有效性。
- 在稀疏视图训练下,3DGS存在过拟合问题,限制了其泛化能力。
- 引入SE-GS方法来解决这一过拟合问题。
- 通过感知不确定性的扰动策略实现自集成训练。
- 同时训练Δ模型和Σ模型,其中Δ模型动态扰动以生成多种模型。
- 通过最小化Σ模型和扰动模型间的差异,形成稳健的模型集合。
- 在多个数据集上的实验结果表明SE-GS方法提高了NVS质量,优于现有方法。
点此查看论文截图






Fast Feedforward 3D Gaussian Splatting Compression
Authors:Yihang Chen, Qianyi Wu, Mengyao Li, Weiyao Lin, Mehrtash Harandi, Jianfei Cai
With 3D Gaussian Splatting (3DGS) advancing real-time and high-fidelity rendering for novel view synthesis, storage requirements pose challenges for their widespread adoption. Although various compression techniques have been proposed, previous art suffers from a common limitation: for any existing 3DGS, per-scene optimization is needed to achieve compression, making the compression sluggish and slow. To address this issue, we introduce Fast Compression of 3D Gaussian Splatting (FCGS), an optimization-free model that can compress 3DGS representations rapidly in a single feed-forward pass, which significantly reduces compression time from minutes to seconds. To enhance compression efficiency, we propose a multi-path entropy module that assigns Gaussian attributes to different entropy constraint paths for balance between size and fidelity. We also carefully design both inter- and intra-Gaussian context models to remove redundancies among the unstructured Gaussian blobs. Overall, FCGS achieves a compression ratio of over 20X while maintaining fidelity, surpassing most per-scene SOTA optimization-based methods. Our code is available at: https://github.com/YihangChen-ee/FCGS.
随着3D高斯融合(3DGS)在实时和高保真渲染新视角合成方面的进展,其存储需求挑战了其广泛应用的可行性。虽然已提出了各种压缩技术,但现有技术存在一种常见限制:对于任何现有的3DGS,都需要针对每个场景进行优化以实现压缩,这使得压缩过程缓慢。为了解决这一问题,我们引入了快速压缩的3D高斯融合(FCGS)模型,这是一个无需优化的模型,可以在单个前馈传递中快速压缩3DGS表示,将压缩时间从数分钟大幅缩短至数秒。为了提高压缩效率,我们提出了多路熵模块,它将高斯属性分配给不同的熵约束路径,以在大小和保真度之间取得平衡。我们还精心设计了高斯内外上下文模型,以消除非结构化高斯块之间的冗余。总体而言,FCGS在保持高保真度的同时实现了超过20倍的压缩比,超越了大多数基于场景的先进优化方法。我们的代码可通过以下网址获取:FCGS链接。
论文及项目相关链接
PDF Project Page: https://yihangchen-ee.github.io/project_fcgs/ Code: https://github.com/yihangchen-ee/fcgs/
Summary
3D高斯渲染技术(3DGS)为实时和高保真渲染新型视图合成提供了机会,但存储需求限制了其广泛应用。为应对压缩难题,现有多种压缩技术但都需要场景优化。我们提出了快速压缩3D高斯渲染(FCGS)模型,实现了无需优化的单通道前馈压缩,将压缩时间从分钟缩短到秒。通过多路径熵模块和精心设计的内外高斯上下文模型,实现了高保真下的超过20倍的压缩比,超越多数场景优化方法。代码已公开。
Key Takeaways
- 3DGS技术在实时和高保真渲染领域具有潜力,但存储需求限制了其应用。
- 现有压缩技术需要场景优化,导致压缩效率低下。
- FCGS模型实现了快速、无需优化的单通道前馈压缩。
- FCGS通过多路径熵模块平衡大小与保真度。
- 精心设计的内外高斯上下文模型消除了高斯数据块间的冗余信息。
- FCGS实现了超过20倍的压缩比,同时保持高保真度。
点此查看论文截图




EVA-Gaussian: 3D Gaussian-based Real-time Human Novel View Synthesis under Diverse Multi-view Camera Settings
Authors:Yingdong Hu, Zhening Liu, Jiawei Shao, Zehong Lin, Jun Zhang
Feed-forward based 3D Gaussian Splatting methods have demonstrated exceptional capability in real-time novel view synthesis for human models. However, current approaches are confined to either dense viewpoint configurations or restricted image resolutions. These limitations hinder their flexibility in free-viewpoint rendering across a wide range of camera view angle discrepancies, and also restrict their ability to recover fine-grained human details in real time using commonly available GPUs. To address these challenges, we propose a novel pipeline named EVA-Gaussian for 3D human novel view synthesis across diverse multi-view camera settings. Specifically, we first design an Efficient Cross-View Attention (EVA) module to effectively fuse cross-view information under high resolution inputs and sparse view settings, while minimizing temporal and computational overhead. Additionally, we introduce a feature refinement mechianism to predict the attributes of the 3D Gaussians and assign a feature value to each Gaussian, enabling the correction of artifacts caused by geometric inaccuracies in position estimation and enhancing overall visual fidelity. Experimental results on the THuman2.0 and THumansit datasets showcase the superiority of EVA-Gaussian in rendering quality across diverse camera settings. Project page: https://zhenliuzju.github.io/huyingdong/EVA-Gaussian.
基于前馈的3D高斯拼贴法在人形模型实时生成新颖视角的合成中表现出卓越的能力。然而,当前的方法仅限于密集的视点配置或受限的图像分辨率。这些局限性阻碍了它们在广泛相机视角差异上的自由视角渲染的灵活性,并限制了它们在常用GPU上实时恢复精细粒度人类细节的能力。为了应对这些挑战,我们提出了一种名为EVA-Gaussian的用于多种不同视图设置下的3D人类新颖视角合成的管道。具体来说,我们首先设计了一个高效的跨视图注意力(EVA)模块,以在高分辨率输入和稀疏视图设置下有效地融合跨视图信息,同时最小化时间和计算开销。此外,我们引入了一种特征细化机制来预测3D高斯属性并为每个高斯分配一个特征值,从而纠正因位置估计中的几何误差引起的伪影并增强整体视觉逼真度。在THuman2.0和THumansit数据集上的实验结果表明,EVA-Gaussian在不同相机设置下的渲染质量上具有优势。项目页面:https://zhenliuzju.github.io/huyingdong/EVA-Gaussian 。
论文及项目相关链接
Summary
本文提出一种名为EVA-Gaussian的3D人体视角合成新方法,用于处理多种复杂场景下的新型视点渲染问题。它通过高效跨视图注意力模块(EVA)融合不同视角信息,在高分辨率输入和稀疏视图设置下实现有效融合,同时降低时间和计算开销。此外,还引入特征优化机制以预测3D高斯属性并为其分配特征值,修正因位置估计几何误差引起的伪影,提高整体视觉逼真度。在THuman2.0和THumansit数据集上的实验表明,EVA-Gaussian在不同相机设置下的渲染质量表现卓越。
Key Takeaways
- EVA-Gaussian方法解决了现有3D高斯混色方法在实时人体模型新视角合成中的局限性。
- 提出Efficient Cross-View Attention(EVA)模块,有效融合跨视角信息,适用于高分辨输入和稀疏视图设置。
- 引入特征优化机制,预测3D高斯属性并分配特征值,修正位置估计几何误差引起的伪影。
- 方法在THuman2.0和THumansit数据集上表现出卓越的渲染质量。
- EVA-Gaussian提高了自由视角渲染的灵活性和能力,可在广泛的角度差异下恢复精细的人类细节。
- 方法在常见GPU上实现实时精细人类细节恢复。
点此查看论文截图




RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
Authors:Jaidev Shriram, Alex Trevithick, Lingjie Liu, Ravi Ramamoorthi
We introduce RealmDreamer, a technique for generating forward-facing 3D scenes from text descriptions. Our method optimizes a 3D Gaussian Splatting representation to match complex text prompts using pretrained diffusion models. Our key insight is to leverage 2D inpainting diffusion models conditioned on an initial scene estimate to provide low variance supervision for unknown regions during 3D distillation. In conjunction, we imbue high-fidelity geometry with geometric distillation from a depth diffusion model, conditioned on samples from the inpainting model. We find that the initialization of the optimization is crucial, and provide a principled methodology for doing so. Notably, our technique doesn’t require video or multi-view data and can synthesize various high-quality 3D scenes in different styles with complex layouts. Further, the generality of our method allows 3D synthesis from a single image. As measured by a comprehensive user study, our method outperforms all existing approaches, preferred by 88-95%. Project Page: https://realmdreamer.github.io/
我们介绍了RealmDreamer技术,这是一种从文本描述生成正面3D场景的方法。我们的方法优化了一个3D高斯飞溅表示,使用预训练的扩散模型来匹配复杂的文本提示。我们的关键见解是利用基于初始场景估计的二维填充扩散模型,为3D蒸馏过程中的未知区域提供低方差监督。此外,我们从深度扩散模型中汲取几何蒸馏,赋予高保真几何形状以灵感,以填充模型的样本为条件。我们发现优化的初始化至关重要,并提供了一种进行初始化的原则性方法。值得注意的是,我们的技术不需要视频或多视角数据,并能合成各种不同风格、布局复杂的高质量3D场景。此外,我们的方法具有很强的通用性,可以从单张图像中进行3D合成。根据全面的用户研究测量,我们的方法优于所有现有方法,被偏好率为88-95%。项目页面:https://realmdreamer.github.io/(域名已作调整)。
论文及项目相关链接
PDF Published at 3DV 2025
Summary
RealDreamer技术能通过文本描述生成面向前方的3D场景。该技术优化3D高斯混合表示,以匹配复杂的文本提示,并借助预训练的扩散模型实现。其关键在于利用初始场景估计的2D补全扩散模型,为3D蒸馏过程中的未知区域提供低方差监督。同时,结合深度扩散模型的几何蒸馏,赋予高保真几何以初始样本的样式。研究发现优化初始化至关重要,并提供了一种原则性的方法来实现。该方法具有通用性,无需视频或多视角数据,并能合成不同风格、复杂布局的高质量3D场景。经综合用户研究测试,该方法优于现有技术,用户满意度达88-95%。
Key Takeaways
- RealDreamer能从文本描述生成面向前方的3D场景。
- 技术核心是优化3D高斯混合表示,匹配文本提示。
- 利用2D补全扩散模型提供低方差监督,辅助3D蒸馏过程。
- 结合深度扩散模型的几何蒸馏,增加场景的高保真度。
- 研究的重点是优化初始化的重要性,并提供了实现原则性方法。
- 该技术无需视频或多视角数据,能合成多种高质量3D场景。
- 通过用户研究验证,RealDreamer在性能上优于现有技术,用户满意度高。
点此查看论文截图