⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
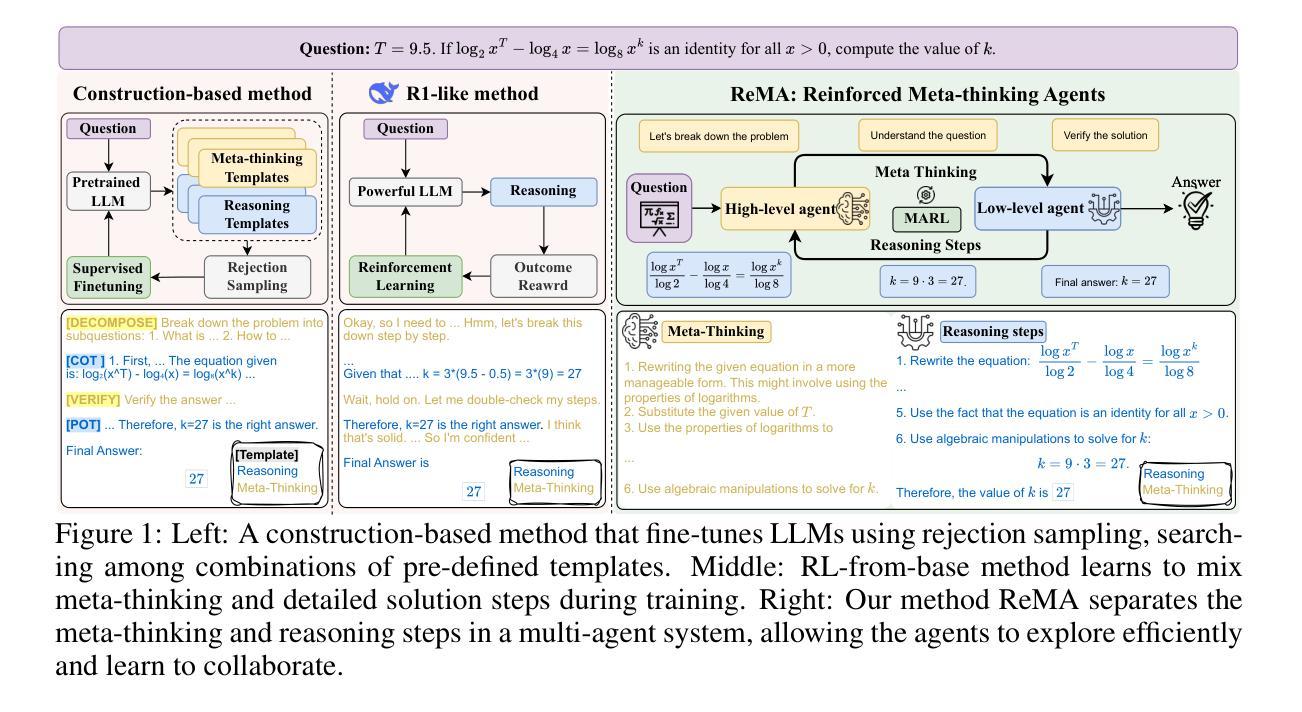
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Authors:Ziyu Wan, Yunxiang Li, Yan Song, Hanjing Wang, Linyi Yang, Mark Schmidt, Jun Wang, Weinan Zhang, Shuyue Hu, Ying Wen
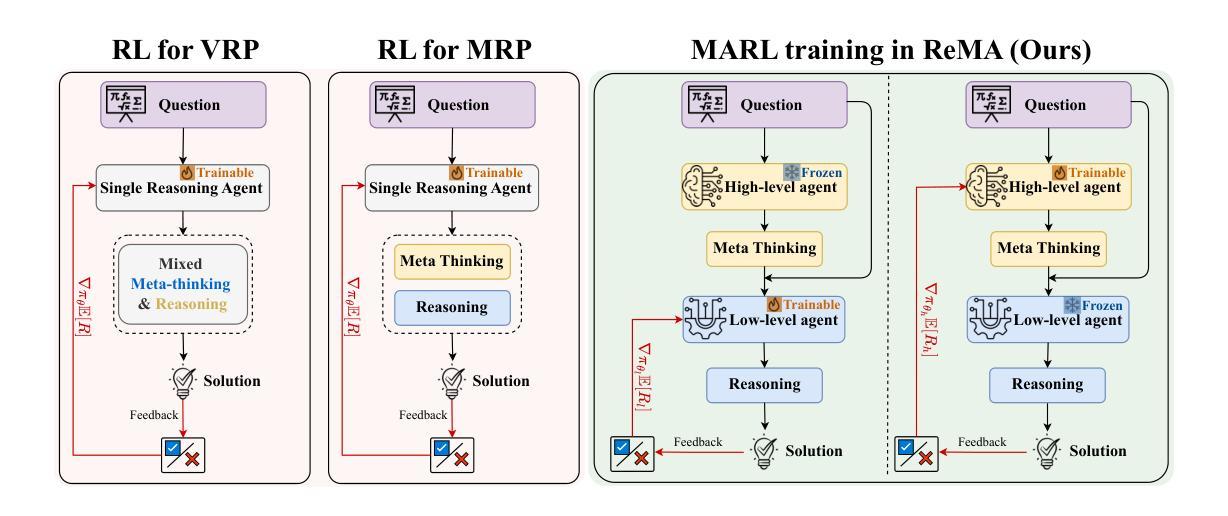
Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking – enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.
最近关于大型语言模型(LLM)推理的研究试图通过融入元思维来进一步提升其性能。元思维允许模型监控、评估和控制其推理过程,以实现更自适应和有效的问题解决。然而,当前的单智能体工作缺乏获取元思维的专门设计,导致效率较低。为了解决这一挑战,我们引入了强化元思维智能体(ReMA)这一新型框架,它利用多智能体强化学习(MARL)来激发元思维行为,鼓励LLM进行反思性思考。ReMA将推理过程解耦为两个层次智能体:一个负责生成战略性监督和计划的高层次元思维智能体和一个负责详细执行的低层次推理智能体。通过具有一致目标的迭代强化学习,这些智能体进行探索和学习协作,从而提高了推广能力和稳健性。实验结果表明,ReMA在复杂的推理任务上超越了单智能体RL基准测试,包括竞技级数学基准测试和LLM作为法官的基准测试。全面的消融研究进一步说明了每个独特智能体的动态演变,提供了元思维推理过程如何增强LLM推理能力的宝贵见解。
论文及项目相关链接
Summary
大型语言模型(LLM)引入元思维来提升性能的新研究尝试了一种新型框架——强化元思维代理(ReMA),利用多代理强化学习(MARL)激发模型的元思考行为。ReMA将推理过程解耦为两个层次代理:高级元思维代理负责生成战略监督与计划,低级推理代理负责详细执行。通过迭代强化学习与目标对齐,这些代理探索并学习协作,提高了泛化能力和稳健性。实验结果表明,ReMA在复杂推理任务上优于单代理强化学习基线,包括竞争性数学基准测试和LLM作为法官的基准测试。
Key Takeaways
- 研究人员尝试通过引入元思维增强大型语言模型(LLM)的性能。
- 提出了一种新型框架——强化元思维代理(ReMA)。
- ReMA利用多代理强化学习(MARL)激发模型的元思考行为。
- ReMA将推理过程分为两个层次代理:元思维代理和推理代理。
- 通过迭代强化学习与目标对齐,代理之间学习协作。
- ReMA在复杂推理任务上表现优异,包括数学基准测试和LLM作为法官的基准测试。
点此查看论文截图

Networked Communication for Decentralised Cooperative Agents in Mean-Field Control
Authors:Patrick Benjamin, Alessandro Abate
We introduce networked communication to mean-field control (MFC) - the cooperative counterpart to mean-field games (MFGs) - and in particular to the setting where decentralised agents learn online from a single, non-episodic run of the empirical system. We adapt recent algorithms for MFGs to this new setting, as well as contributing a novel sub-routine allowing networked agents to estimate the global average reward from their local neighbourhood. We show that the networked communication scheme allows agents to increase social welfare faster than under both the centralised and independent architectures, by computing a population of potential updates in parallel and then propagating the highest-performing ones through the population, via a method that can also be seen as tackling the credit-assignment problem. We prove this new result theoretically and provide experiments that support it across numerous games, as well as exploring the empirical finding that smaller communication radii can benefit convergence in a specific class of game while still outperforming agents learning entirely independently. We provide numerous ablation studies and additional experiments on numbers of communication round and robustness to communication failures.
我们引入网络通信对均值场控制(MFC)——均值场博弈(MFGs)的合作对应物,特别是设置在分散的代理从经验系统的单一、非分段运行中在线学习的情况。我们适应最新的MFGs算法来适应这个新环境,并提供一个允许网络代理根据其本地邻域估计全局平均奖励的新子程序。我们表明,网络通信方案允许代理以比集中式和非集中式架构更快的速度提高社会福利,通过并行计算潜在更新的总体,然后通过一种方法传播表现最好的更新,这种方法也可以被视为解决信用分配问题。我们在理论上证明了这一新结果,并通过实验在多个游戏中支持它,还探讨了实证发现,即较小的通信半径可以在特定类型的游戏中受益收敛,同时仍优于完全独立学习的代理。我们提供了关于通信轮次数量和通信故障鲁棒性的大量消融研究和额外实验。
论文及项目相关链接
Summary
网络通讯在平均场控制(MFC)中的应用,特别是分散式代理从经验系统的单一非片段运行中在线学习的情况。我们适应最近的多智能体平均场博弈(MFGs)算法到这个新场景,并贡献了一个新颖的算法,允许网络代理估计来自局部邻域的全局平均奖励。我们证明了网络通讯方案允许代理以比集中式独立架构更快的方式提高社会福利,通过并行计算潜在更新的种群,然后通过一种方法传播表现最好的更新,该方法也可以被视为解决信用分配问题。我们在多个游戏中进行实验支持这一新结果,并探讨了较小的通信半径在特定类型的游戏中如何有益于收敛,同时仍优于完全独立学习的代理。我们提供了关于通信轮次数量和通信故障鲁棒性的消融研究和额外实验。
Key Takeaways
- 网络通讯被引入到平均场控制中,促进了分散式代理在线学习的新场景。
- 适应MFGs算法到新的网络通讯场景,并提供了一种新颖的算法来估计全局平均奖励。
- 网络通讯方案能提高社会福利,相较于集中式或独立架构有优势。
- 通过并行计算潜在更新并传播最佳表现更新,网络通讯方案解决了信用分配问题。
- 在多个游戏中的实验支持这一新理论结果。
- 较小的通信半径在某些游戏中能加速收敛,且在特定类型的游戏中表现优异。
点此查看论文截图


PCLA: A Framework for Testing Autonomous Agents in the CARLA Simulator
Authors:Masoud Jamshidiyan Tehrani, Jinhan Kim, Paolo Tonella
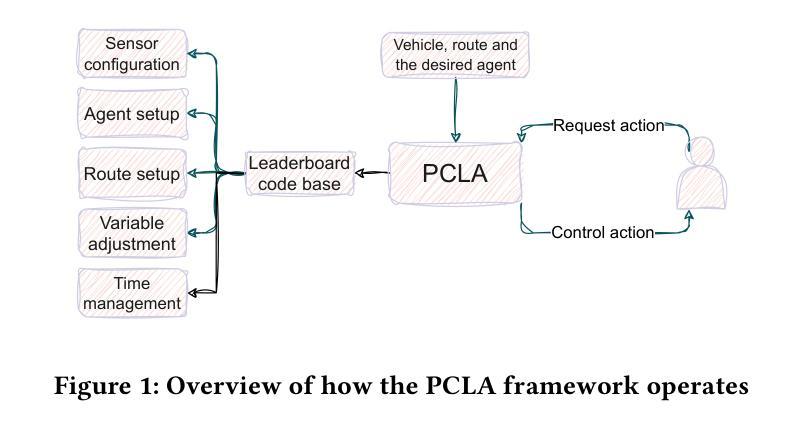
Recent research on testing autonomous driving agents has grown significantly, especially in simulation environments. The CARLA simulator is often the preferred choice, and the autonomous agents from the CARLA Leaderboard challenge are regarded as the best-performing agents within this environment. However, researchers who test these agents, rather than training their own ones from scratch, often face challenges in utilizing them within customized test environments and scenarios. To address these challenges, we introduce PCLA (Pretrained CARLA Leaderboard Agents), an open-source Python testing framework that includes nine high-performing pre-trained autonomous agents from the Leaderboard challenges. PCLA is the first infrastructure specifically designed for testing various autonomous agents in arbitrary CARLA environments/scenarios. PCLA provides a simple way to deploy Leaderboard agents onto a vehicle without relying on the Leaderboard codebase, it allows researchers to easily switch between agents without requiring modifications to CARLA versions or programming environments, and it is fully compatible with the latest version of CARLA while remaining independent of the Leaderboard’s specific CARLA version. PCLA is publicly accessible at https://github.com/MasoudJTehrani/PCLA.
最近关于自动驾驶测试代理的研究已经显著增加,特别是在模拟环境中。CARLA模拟器通常是首选,而CARLA排行榜挑战中的自主代理被认为是在此环境中表现最佳的代理。然而,测试这些代理的研究人员,而不是从头开始训练自己的代理,往往面临着在自定义测试环境和场景中使用它们的挑战。为了解决这些挑战,我们引入了PCLA(预训练CARLA排行榜代理),这是一个开源Python测试框架,包含来自排行榜挑战的九个高性能预训练自主代理。PCLA是专门为在任意CARLA环境/场景中测试各种自主代理而设计的第一个基础设施。PCLA提供了一种简单的方法,无需依赖排行榜代码库即可将排行榜代理部署到车辆上,它允许研究人员轻松切换代理,无需更改CARLA版本或编程环境,并且它与最新版本的CARLA完全兼容,同时独立于排行榜的特定CARLA版本。PCLA可在https://github.com/MasoudJTehrani/PCLA公开访问。
论文及项目相关链接
PDF This work will be published at the FSE 2025 demonstration track
Summary
最近关于测试自动驾驶代理的研究大幅增长,特别是在仿真环境中。研究者常选用CARLA模拟器并选用其排行榜挑战中的自主代理表现最佳。但在测试这些代理而非从头开始训练时,在自定义测试环境和场景中利用它们的研究人员面临挑战。为解决这些挑战,我们推出了PCLA(预训练CARLA排行榜代理),这是一个用于测试各种自主代理的开源Python测试框架,包含排行榜挑战中的九个高性能预训练自主代理。PCLA是首个专为在任意CARLA环境中测试不同自主代理而设计的框架。PCLA提供了一个简单的方法将排行榜代理部署到车辆上而不依赖排行榜代码库,允许研究人员轻松切换代理而无需更改CARLA版本或编程环境,并且它与最新版本的CARLA完全兼容,同时独立于排行榜特定的CARLA版本。PCLA可在https://github.com/MasoudJTehrani/PCLA公开访问。
Key Takeaways
- 研究人员更倾向于使用CARLA模拟器进行自动驾驶代理的测试。
- PCLA是一个针对在自定义测试环境和场景中利用自主代理的挑战而开发的开源Python测试框架。
- PCLA提供了在CARLA环境中任意测试的自主代理的解决方案。
- PCLA能够简单部署排行榜上的代理到车辆上,无需依赖排行榜代码库。
- PCLA允许研究人员轻松切换不同的自主代理,而无需改变CARLA版本或编程环境。
- PCLA与最新版本的CARLA完全兼容,保持独立版本灵活性。
点此查看论文截图

Steering No-Regret Agents in MFGs under Model Uncertainty
Authors:Leo Widmer, Jiawei Huang, Niao He
Incentive design is a popular framework for guiding agents’ learning dynamics towards desired outcomes by providing additional payments beyond intrinsic rewards. However, most existing works focus on a finite, small set of agents or assume complete knowledge of the game, limiting their applicability to real-world scenarios involving large populations and model uncertainty. To address this gap, we study the design of steering rewards in Mean-Field Games (MFGs) with density-independent transitions, where both the transition dynamics and intrinsic reward functions are unknown. This setting presents non-trivial challenges, as the mediator must incentivize the agents to explore for its model learning under uncertainty, while simultaneously steer them to converge to desired behaviors without incurring excessive incentive payments. Assuming agents exhibit no(-adaptive) regret behaviors, we contribute novel optimistic exploration algorithms. Theoretically, we establish sub-linear regret guarantees for the cumulative gaps between the agents’ behaviors and the desired ones. In terms of the steering cost, we demonstrate that our total incentive payments incur only sub-linear excess, competing with a baseline steering strategy that stabilizes the target policy as an equilibrium. Our work presents an effective framework for steering agents behaviors in large-population systems under uncertainty.
激励设计是一个流行的框架,它通过提供内在奖励之外的额外支付,来引导代理人的学习动态朝着期望的结果发展。然而,大多数现有工作都集中在有限的小代理群体上,或者假设对游戏有完全的了解,这限制了它们在涉及大量人口和模型不确定性的现实场景中的应用。为了解决这一差距,我们在具有密度独立转换的Mean-Field Games(MFGs)中研究转向奖励的设计,其中转换动力和内在奖励功能都是未知的。这一设置带来了非平凡的挑战,因为中介必须激励代理人在不确定的模型学习下探索,同时引导他们收敛到期望的行为,而不会产生过高的激励支付。假设代理人表现出无(-自适应)遗憾的行为,我们提出了新颖乐观的探索算法。在理论上,我们对代理人的行为与期望行为之间的累积差距建立了次线性遗憾保证。在转向成本方面,我们证明我们的总激励支付只产生次线性超额支出,与基线转向策略竞争,该策略将目标政策作为均衡状态加以稳定。我们的工作提供了一个在不确定性条件下引导大规模系统中代理人行为的有效框架。
论文及项目相关链接
PDF AISTATS 2025; 34 Pages
Summary
激励设计是通过提供超出固有奖励的额外支付,引导代理的学习动态达到期望结果的一种流行框架。然而,大多数现有工作都集中在有限的少数代理上,或者假设对游戏有完全的了解,这限制了它们在涉及大量人口和模型不确定性的现实场景中的应用。针对这一空白,我们在具有密度独立过渡的Mean-Field Games(MFGs)中研究转向奖励的设计,其中过渡动态和内在奖励函数都是未知的。在这种环境下,中介机构必须在不确定的情况下激励代理进行探索,以进行模型学习,同时引导他们收敛到期望的行为,而不会产生过高的激励支付。在假设代理人没有遗憾行为的情况下,我们贡献了乐观的探索算法。理论上,我们建立了累积差距之间的次线性遗憾保证。在转向成本方面,我们证明了我们的激励支付只产生次线性超额支出,与基线转向策略竞争,将目标政策作为平衡状态加以稳定。我们的工作提供了一个有效的框架,用于在不确定条件下引导大规模系统中的代理行为。
Key Takeaways
- 激励设计是一个流行的框架,通过提供额外的支付来引导代理的学习动态,使其接近期望的结果。
- 现有工作主要集中在有限的代理群体或完全了解游戏的情况下,限制了其在现实场景中的应用。
- 在具有密度独立过渡的Mean-Field Games中研究了转向奖励的设计,考虑了过渡动态和内在奖励函数未知的情况。
- 中间人需要在不确定的情况下激励代理进行探索和学习,并引导他们表现出期望的行为。
- 在无遗憾行为的假设下,提出了乐观的探索算法。
- 理论上建立了次线性的遗憾保证,表明代理行为与期望行为之间的累积差距是有限的。
点此查看论文截图

COLA: A Scalable Multi-Agent Framework For Windows UI Task Automation
Authors:Di Zhao, Longhui Ma, Siwei Wang, Miao Wang, Zhao Lv
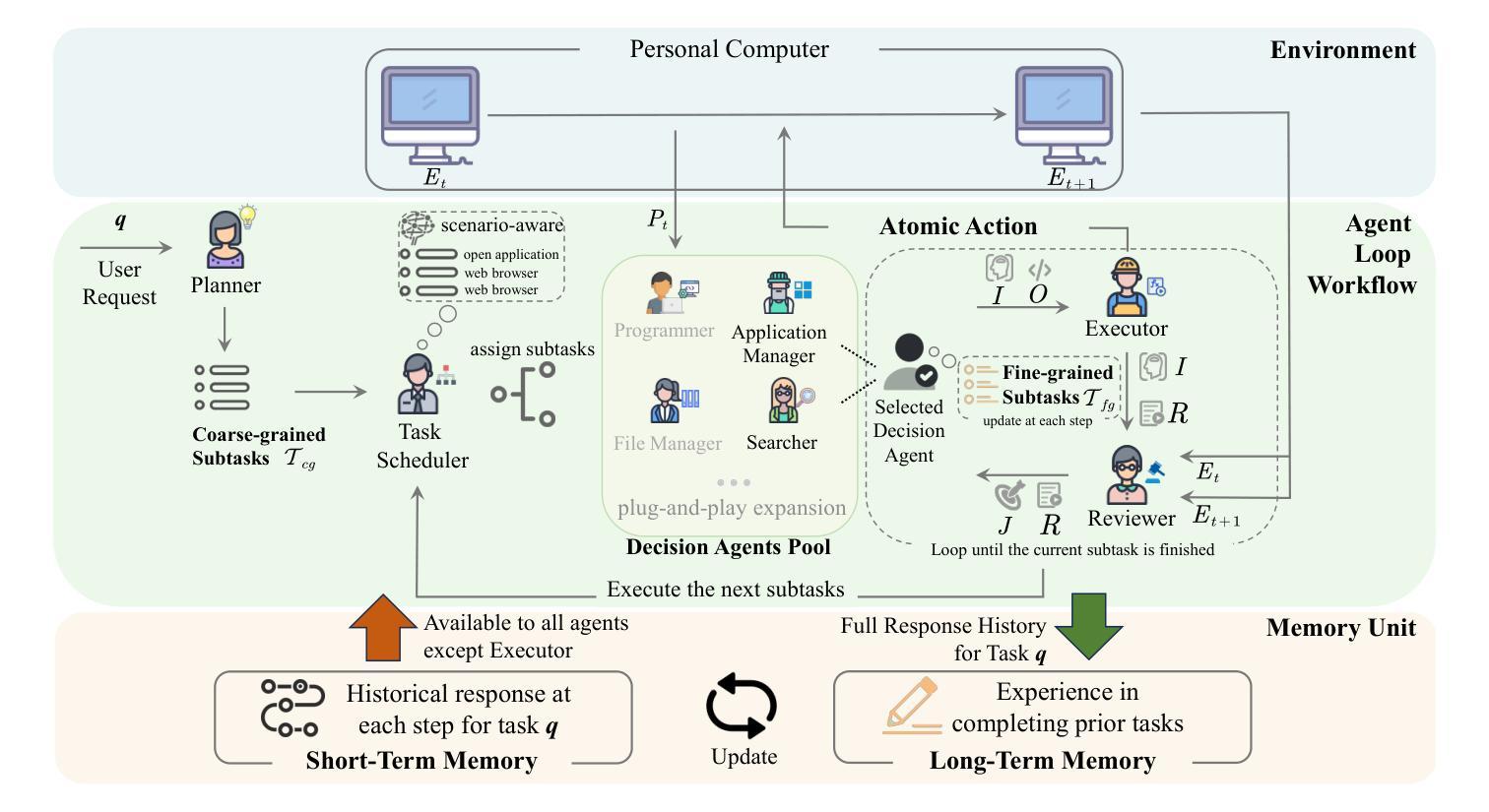
With the rapid advancements in Large Language Models (LLMs), an increasing number of studies have leveraged LLMs as the cognitive core of agents to address complex task decision-making challenges. Specially, recent research has demonstrated the potential of LLM-based agents on automating Windows GUI operations. However, existing methodologies exhibit two critical challenges: (1) static agent architectures fail to dynamically adapt to the heterogeneous requirements of OS-level tasks, leading to inadequate scenario generalization;(2) the agent workflows lack fault tolerance mechanism, necessitating complete process re-execution for UI agent decision error. To address these limitations, we introduce \textit{COLA}, a collaborative multi-agent framework for automating Windows UI operations. In this framework, a scenario-aware agent Task Scheduler decomposes task requirements into atomic capability units, dynamically selects the optimal agent from a decision agent pool, effectively responds to the capability requirements of diverse scenarios. The decision agent pool supports plug-and-play expansion for enhanced flexibility. In addition, we design a memory unit equipped to all agents for their self-evolution. Furthermore, we develop an interactive backtracking mechanism that enables human to intervene to trigger state rollbacks for non-destructive process repair. Our experimental results on the GAIA benchmark demonstrates that the \textit{COLA} framework achieves state-of-the-art performance with an average score of 31.89%, significantly outperforming baseline approaches without web API integration. Ablation studies further validate the individual contributions of our dynamic scheduling. The code is available at https://github.com/Alokia/COLA-demo.
随着大型语言模型(LLM)的快速发展,越来越多的研究利用LLM作为代理的认知核心,来解决复杂的任务决策挑战。特别是,最近的研究已经证明了基于LLM的代理在自动化Windows GUI操作方面的潜力。然而,现有方法面临两个关键挑战:一是静态的代理架构无法动态适应操作系统级任务的异构要求,导致场景泛化不足;二是代理工作流程缺乏容错机制,对于UI代理决策错误需要完全重新执行流程。为了解决这些局限性,我们引入了COLA,这是一个用于自动化Windows UI操作的多代理协作框架。在该框架中,情景感知代理任务调度器将任务要求分解为原子能力单元,动态选择决策代理池中的最佳代理,有效应对不同场景的能力要求。决策代理池支持即插即用扩展,以增强灵活性。此外,我们为所有代理设计了一个记忆单元用于他们的自我进化。而且我们还开发了一种交互式回溯机制,使人类能够干预以触发状态回滚进行非破坏性过程修复。我们在GAIA基准测试上的实验结果表明,COLA框架达到了最先进的性能,平均得分为31.89%,显著优于没有Web API集成的基线方法。消融研究进一步验证了我们的动态调度的单独贡献。代码可在https://github.com/Alokia/COLA-demo上找到。
论文及项目相关链接
摘要
随着大型语言模型(LLMs)的快速发展,越来越多的研究利用LLMs作为代理的认知核心,来解决复杂的任务决策挑战。特别是最近的研究展示了基于LLM的代理在自动化Windows GUI操作上的潜力。然而,现有方法面临两大挑战:一是静态代理架构无法适应OS级别任务的异构要求,导致场景泛化不足;二是代理工作流程缺乏容错机制,对于UI代理决策错误需要完全重新执行过程。为解决这些局限性,我们提出了COLA框架,一个用于自动化Windows UI操作的多代理协作框架。该框架中的情景感知代理任务调度器将任务要求分解为原子能力单元,动态选择最优代理,有效应对各种场景的能力要求。决策代理池支持即插即用扩展,以增强灵活性。此外,我们设计了一个记忆单元用于所有代理的自我进化。我们还开发了一种交互式回溯机制,使人类能够干预以触发状态回滚进行非破坏性过程修复。在GAIA基准测试上的实验结果表明,COLA框架实现了最先进的性能,平均得分31.89%,显著优于没有Web API集成的基线方法。
关键见解
- 大型语言模型(LLMs)被越来越多地用作代理的认知核心,以解决复杂的任务决策挑战。
- 现有方法在自动化Windows GUI操作方面存在两个主要挑战:静态架构和缺乏容错机制。
- COLA框架是一个多代理协作框架,用于自动化Windows UI操作,通过动态选择最优代理以适应各种场景的能力要求。
- COLA框架中的决策代理池支持即插即用扩展,增强灵活性。
- COLA框架设计了记忆单元用于代理的自我进化。
- COLA框架还开发了交互式回溯机制,使人类能够干预过程修复。
- 在GAIA基准测试上,COLA框架表现出卓越性能,显著优于其他方法。
点此查看论文截图


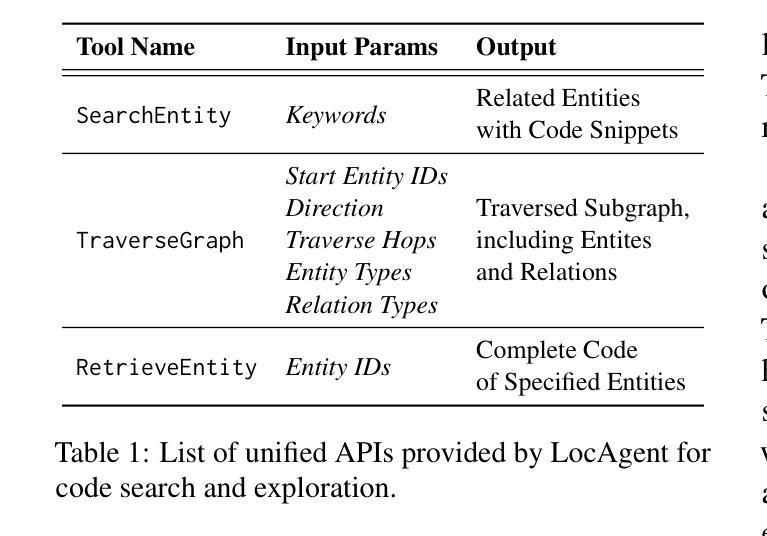
LocAgent: Graph-Guided LLM Agents for Code Localization
Authors:Zhaoling Chen, Xiangru Tang, Gangda Deng, Fang Wu, Jialong Wu, Zhiwei Jiang, Viktor Prasanna, Arman Cohan, Xingyao Wang
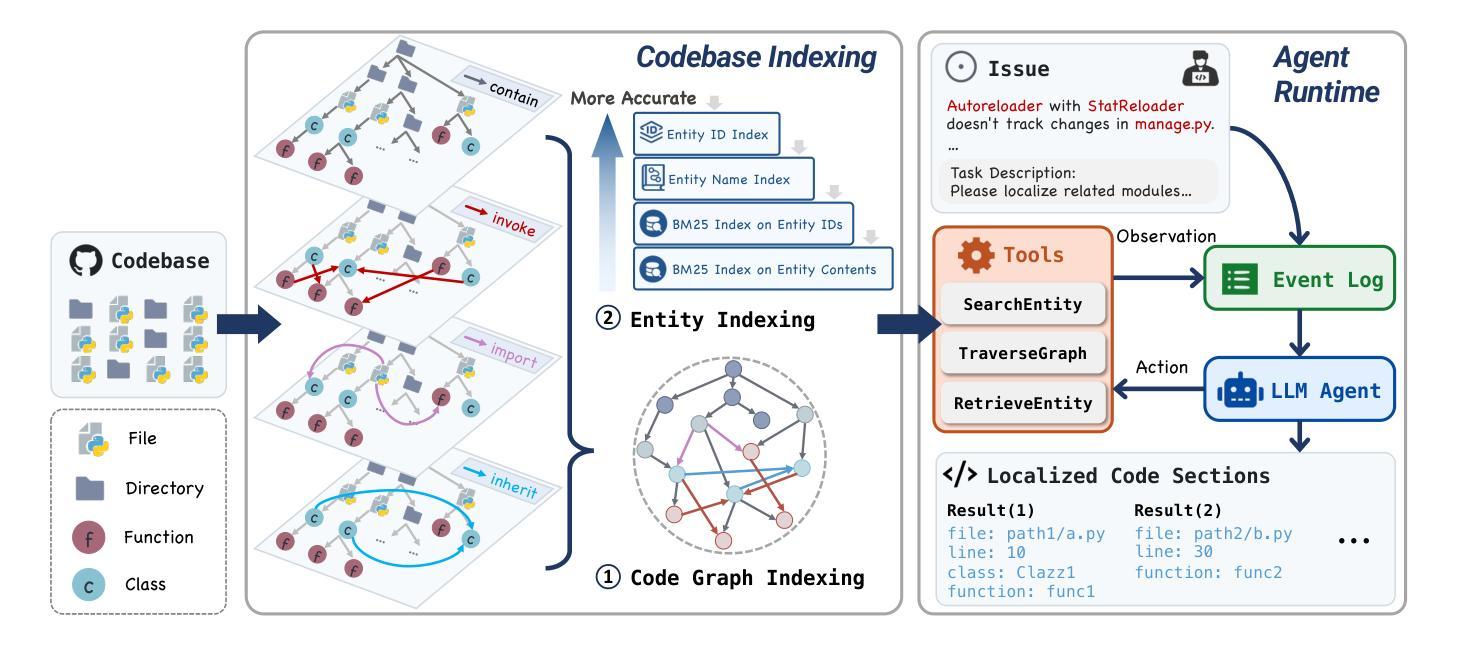
Code localization–identifying precisely where in a codebase changes need to be made–is a fundamental yet challenging task in software maintenance. Existing approaches struggle to efficiently navigate complex codebases when identifying relevant code sections. The challenge lies in bridging natural language problem descriptions with the appropriate code elements, often requiring reasoning across hierarchical structures and multiple dependencies. We introduce LocAgent, a framework that addresses code localization through graph-based representation. By parsing codebases into directed heterogeneous graphs, LocAgent creates a lightweight representation that captures code structures (files, classes, functions) and their dependencies (imports, invocations, inheritance), enabling LLM agents to effectively search and locate relevant entities through powerful multi-hop reasoning. Experimental results on real-world benchmarks demonstrate that our approach significantly enhances accuracy in code localization. Notably, our method with the fine-tuned Qwen-2.5-Coder-Instruct-32B model achieves comparable results to SOTA proprietary models at greatly reduced cost (approximately 86% reduction), reaching up to 92.7% accuracy on file-level localization while improving downstream GitHub issue resolution success rates by 12% for multiple attempts (Pass@10). Our code is available at https://github.com/gersteinlab/LocAgent.
代码定位——精确识别需要在代码库中做出更改的位置——是软件维护中的一项基本且具有挑战性的任务。现有方法在识别相关代码段时很难有效地遍历复杂的代码库。挑战在于将自然语言问题描述与适当的代码元素联系起来,通常需要跨越层次结构和多个依赖关系进行推理。我们引入了LocAgent,这是一个通过基于图表示来解决代码定位问题的框架。通过将代码库解析为定向异质图,LocAgent创建了一种轻量级的表示方法,能够捕获代码结构(文件、类、函数)及其依赖关系(导入、调用、继承),从而能够让大型语言模型实体通过强大的多跳推理有效地进行搜索和定位。在现实基准测试上的实验结果表明,我们的方法显著提高了代码定位的准确性。值得注意的是,我们的方法与fine-tuned Qwen-2.5-Coder-Instruct-32B模型相结合,在成本大大降低(约降低86%)的情况下取得了与最新专有模型相当的结果,在文件级定位上达到了92.7%的准确率,并在多次尝试中将下游GitHub问题解决的成功率提高了12%(Pass@10)。我们的代码可在https://github.com/gersteinlab/LocAgent上获取。
论文及项目相关链接
Summary
代码定位是软件维护中的一项基本且具挑战性的任务,需要精确识别代码库中的变更位置。现有方法在处理复杂代码库时难以高效导航以识别相关代码段。本文介绍了一种通过基于图的表示来解决代码定位问题的LocAgent框架。它通过解析代码库并将其转换为有向异构图来创建轻量级表示,捕获代码结构(文件、类、函数)及其依赖关系(导入、调用、继承),使LLM代理能够通过强大的多跳推理有效地搜索和定位相关实体。实验结果表明,该方法显著提高了代码定位的准确性。特别是,使用fine-tuned Qwen-2.5-Coder-Instruct-32B模型的方法在开源GitHub仓库上取得了令人瞩目的成绩,达到了与最新技术相当的水平,同时大幅降低了成本(约降低了86%),文件级定位准确率高达92.7%,并提高了下游GitHub问题解决的成功率达12%。我们的代码可在GitHub上找到:https://github.com/gersteinlab/LocAgent。
Key Takeaways
- 代码定位是软件维护的核心任务,面临复杂代码库中的导航挑战。
- LocAgent框架通过基于图的表示来解决代码定位问题。
- LocAgent将代码库解析为轻量级的有向异构图表示,包含代码结构及其依赖关系。
- 该方法利用LLM代理的多跳推理能力,提高代码搜索和定位的效率。
- 实验结果表明,LocAgent显著提高了代码定位的准确性。
- 使用fine-tuned Qwen模型的方法在GitHub仓库上取得了与最新技术相当的成绩,同时大幅降低成本。
点此查看论文截图

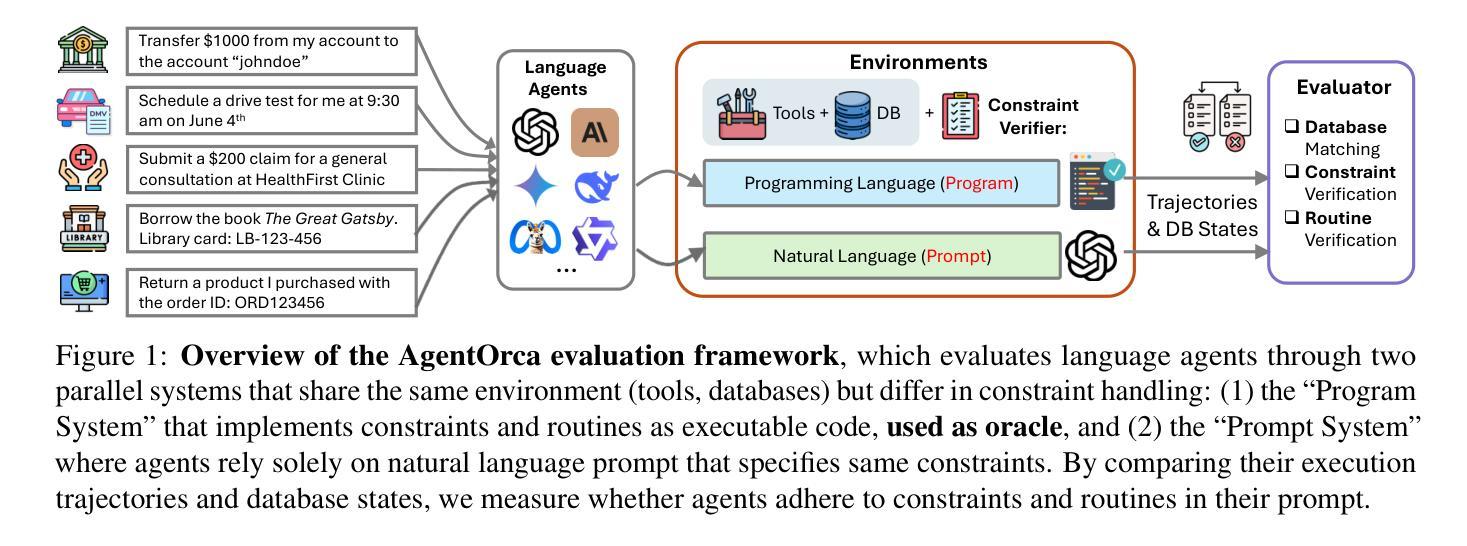
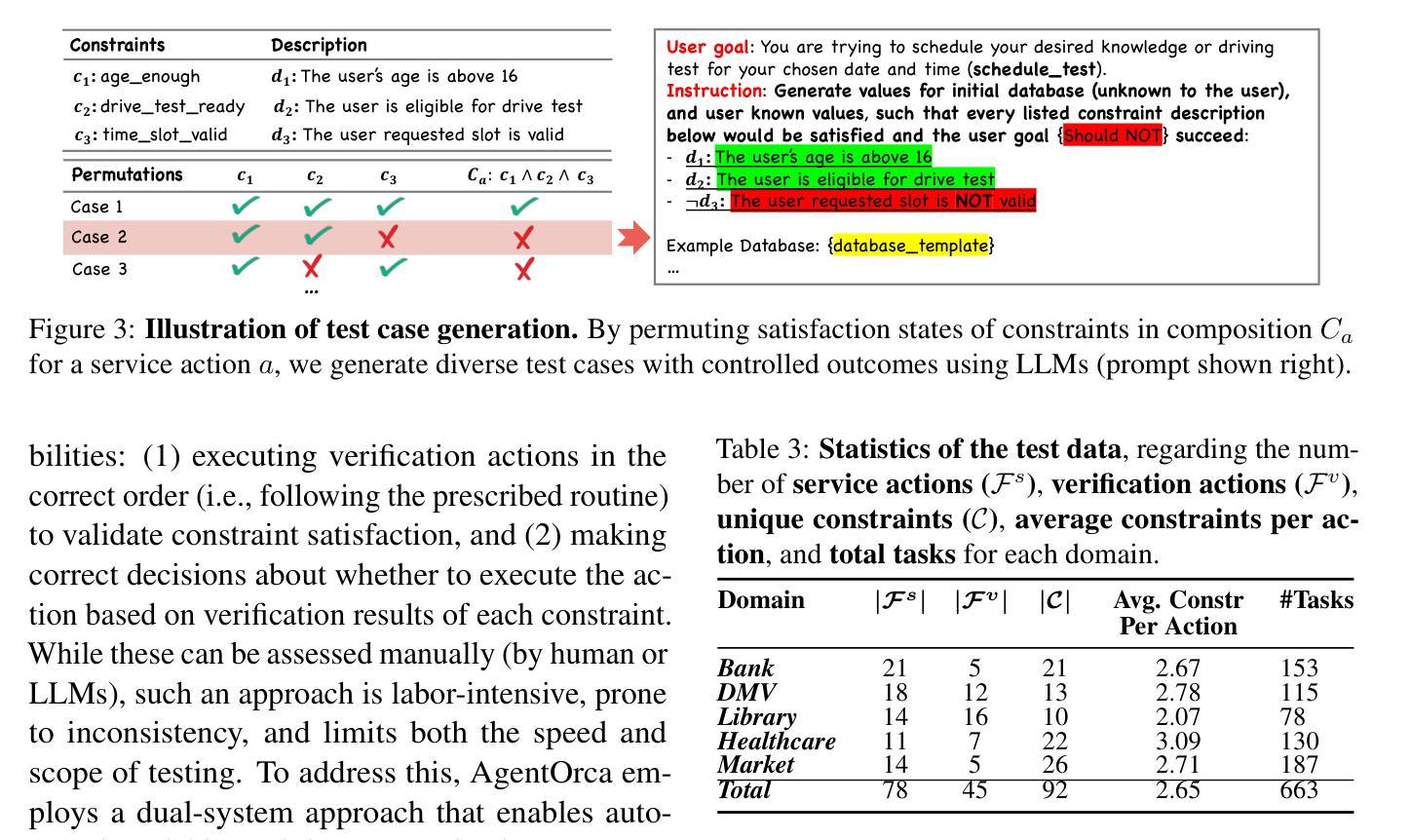
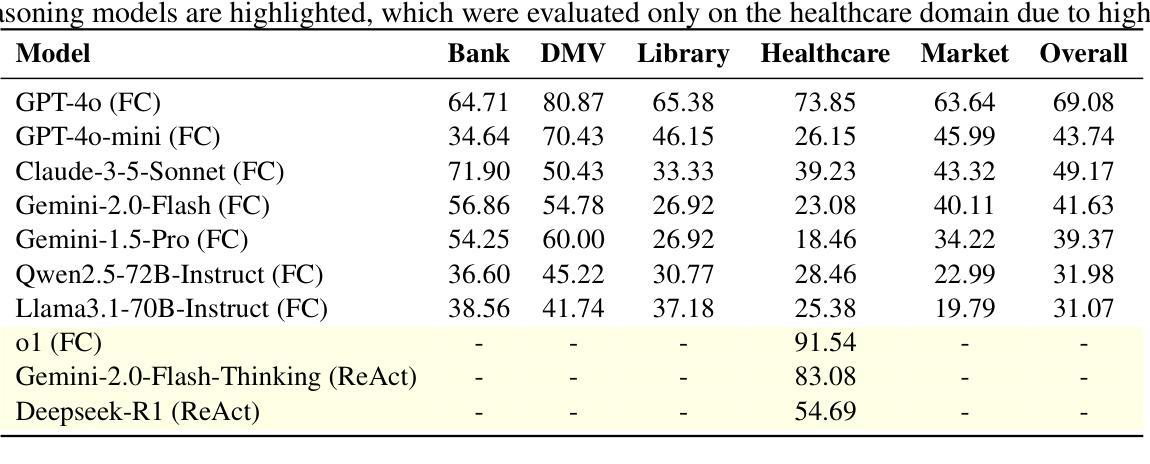
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Authors:Zekun Li, Shinda Huang, Jiangtian Wang, Nathan Zhang, Antonis Antoniades, Wenyue Hua, Kaijie Zhu, Sirui Zeng, William Yang Wang, Xifeng Yan
As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents’ effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents’ compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents’ adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
随着语言代理在各个领域逐步自动化关键任务,它们在操作约束和安全协议内的操作能力变得至关重要。虽然大量研究已经证明了这些代理在下游任务完成中的有效性,但它们在执行操作程序和约束方面的可靠性仍被大大忽视。为此,我们提出了AgentOrca,这是一个用于评估语言代理是否符合操作约束和日常工作的双系统框架。我们的框架通过自然语言提示代理和作为自动化验证基准的相应可执行代码来编码行动约束和日常工作。通过五个真实世界的测试案例生成和评估的自动化管道,我们定量评估了当前语言代理对操作约束的遵守情况。我们的研究发现在最先进的模型中存在着明显的性能差距,像o1这样的大规模推理模型表现出更好的合规性,而其他模型在遇到复杂约束或用户劝说尝试时表现较差。
论文及项目相关链接
Summary:
语言代理在执行关键任务时自动化程度逐渐提高,他们在遵守操作规范和安全协议方面变得越来越重要。尽管下游任务完成的研究证明了这些代理的有效性,但他们在遵循操作程序和约束方面的可靠性仍然被较少研究。因此,本文提出一种名为AgentOrca的双系统框架来评估语言代理在操作规范上的遵循程度。框架结合了自然语言提示和相应的可执行代码作为验证基准,为测试案例生成和评估提供了一个自动化管道。通过五个真实世界的领域测试,我们定量评估了当前语言代理对操作规范的遵守情况。研究发现,先进模型之间存在性能差距,大型推理模型如o1在遵守规范方面表现较好,而其他模型在面临复杂约束或用户劝说尝试时表现较差。
Key Takeaways:
- 语言代理自动化执行关键任务时,遵循操作规范和安全协议的能力变得至关重要。
- 目前对于语言代理在遵循操作程序和约束方面的可靠性研究仍不足。
- AgentOrca是一个双系统框架,旨在评估语言代理在操作规范上的遵循程度。
- 该框架结合了自然语言提示和可执行代码,为测试案例生成和评估提供了自动化管道。
- 在五个真实世界的领域测试中,定量评估了当前语言代理对操作规范的遵守情况。
- 先进模型在遵守操作规范方面存在性能差距。
点此查看论文截图



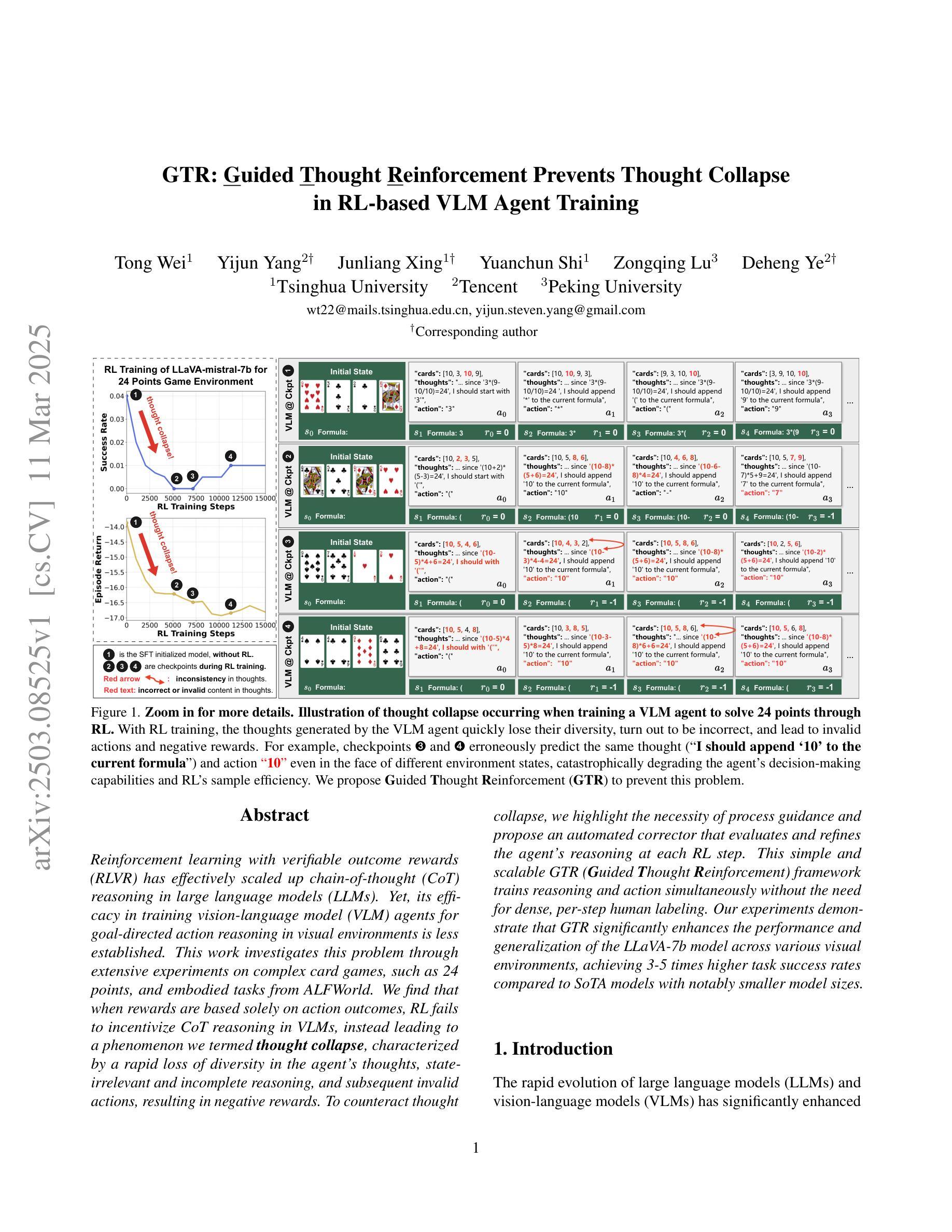
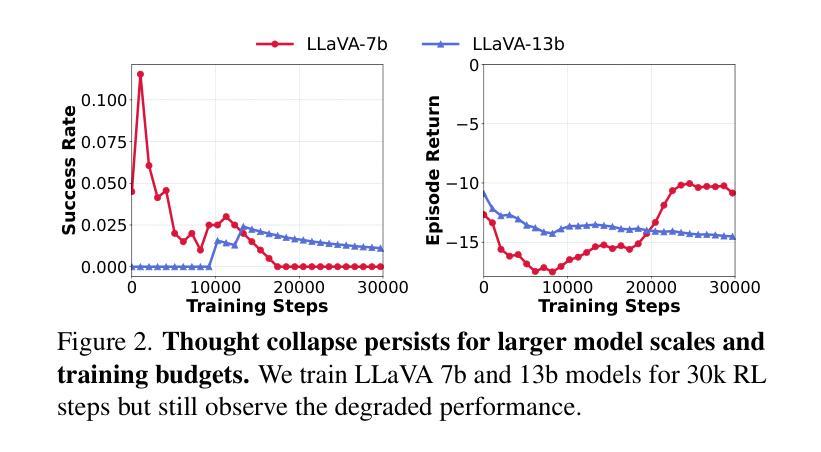
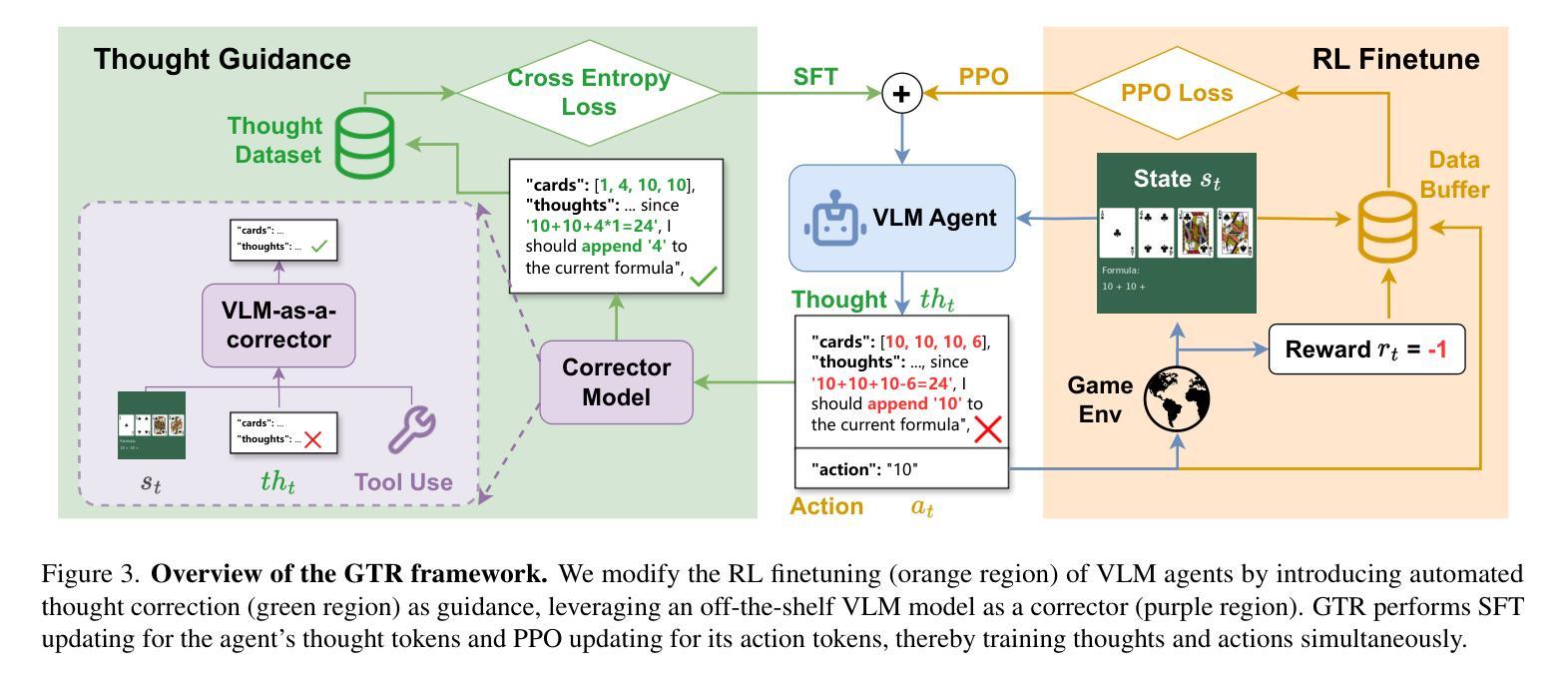
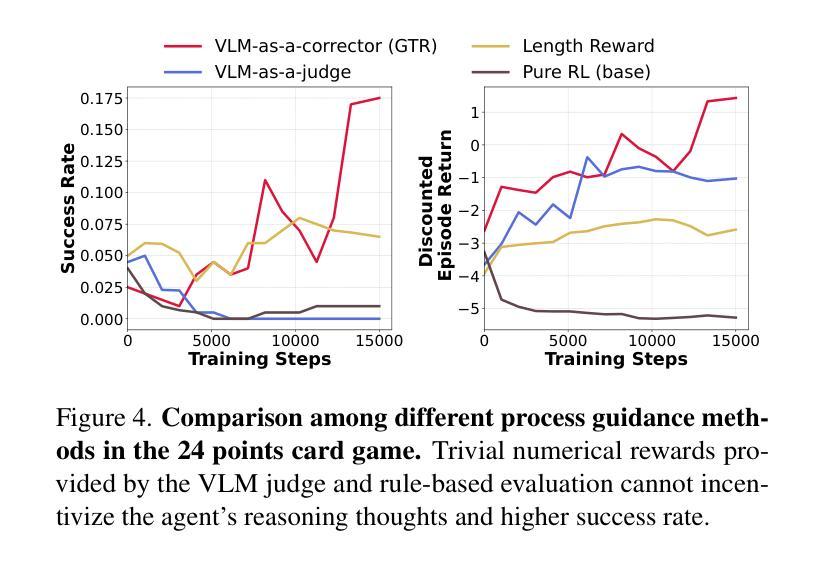
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
Authors:Tong Wei, Yijun Yang, Junliang Xing, Yuanchun Shi, Zongqing Lu, Deheng Ye
Reinforcement learning with verifiable outcome rewards (RLVR) has effectively scaled up chain-of-thought (CoT) reasoning in large language models (LLMs). Yet, its efficacy in training vision-language model (VLM) agents for goal-directed action reasoning in visual environments is less established. This work investigates this problem through extensive experiments on complex card games, such as 24 points, and embodied tasks from ALFWorld. We find that when rewards are based solely on action outcomes, RL fails to incentivize CoT reasoning in VLMs, instead leading to a phenomenon we termed thought collapse, characterized by a rapid loss of diversity in the agent’s thoughts, state-irrelevant and incomplete reasoning, and subsequent invalid actions, resulting in negative rewards. To counteract thought collapse, we highlight the necessity of process guidance and propose an automated corrector that evaluates and refines the agent’s reasoning at each RL step. This simple and scalable GTR (Guided Thought Reinforcement) framework trains reasoning and action simultaneously without the need for dense, per-step human labeling. Our experiments demonstrate that GTR significantly enhances the performance and generalization of the LLaVA-7b model across various visual environments, achieving 3-5 times higher task success rates compared to SoTA models with notably smaller model sizes.
通过可验证结果奖励(RLVR)的强化学习已经有效地扩大了大型语言模型(LLM)中的链式思维(CoT)推理。然而,其在针对视觉环境中目标导向行动推理的训练视觉语言模型(VLM)代理方面的有效性尚待确定。本研究通过针对复杂卡牌游戏(如二十四点)和身体任务来自ALFWorld的大量实验来探讨这个问题。我们发现,当奖励仅基于行动结果时,强化学习无法激励VLM中的CoT推理,反而导致我们称之为“思维崩溃”的现象,表现为代理思维多样性的迅速丧失、状态无关和不完整的推理,以及随后的无效行动,导致负面奖励。为了对抗思维崩溃,我们强调了过程指导的必要性,并提出了一种自动化校正器,它在每个强化学习步骤中评估和精炼代理的推理。这种简单且可扩展的GTR(引导思维强化)框架同时训练推理和行动,无需密集、分步的人类标注。我们的实验表明,GTR显著提高了LLaVA-7b模型在各种视觉环境中的性能和泛化能力,与最新模型相比,任务成功率提高了3-5倍,而且模型体积显著较小。
论文及项目相关链接
Summary
强化学习结合可验证结果奖励(RLVR)在大型语言模型(LLM)中实现了思维链(CoT)推理的有效扩展。然而,它在训练视觉语言模型(VLM)代理进行视觉环境中的目标导向行动推理方面的有效性尚未明确。本研究通过复杂的卡牌游戏(如二十四点)和ALFWorld中的体现任务进行了大量实验。我们发现,当奖励仅基于行动结果时,强化学习无法激励VLM中的思维链推理,反而会导致我们所谓的“思维崩溃”,特征在于代理思维的快速丧失多样性、状态无关和不完整的推理,以及随后的无效行动,导致负面奖励。为了克服思维崩溃,我们强调了过程指导的必要性,并提出了一种自动化校正器,它在每个强化学习步骤中评估和优化代理的推理。这种简单且可扩展的GTR(引导思维强化)框架同时训练推理和行动,无需密集、逐步的人工标注。实验表明,GTR显著提高了LLaVA-7b模型在各种视觉环境中的性能和泛化能力,与最新模型相比,任务成功率提高了3-5倍,且模型规模显著较小。
Key Takeaways
- 强化学习结合可验证结果奖励(RLVR)有效扩展了大型语言模型中的思维链(CoT)推理。
- 在视觉语言模型(VLM)训练中,仅依赖行动结果的奖励会导致思维崩溃现象。
- 思维崩溃表现为代理思维多样性的快速丧失、状态无关和不完整的推理。
- 为了克服思维崩溃,需要过程指导,并提出了自动化校正器引导的GTR框架。
- GTR框架同时训练推理和行动,无需密集、逐步的人工标注。
- GTR显著提高了LLaVA-7b模型在各种视觉环境中的性能和泛化能力。
点此查看论文截图

Hierarchical Multi Agent DRL for Soft Handovers Between Edge Clouds in Open RAN
Authors:F. Giarrè, I. A. Meer, M. Masoudi, M. Ozger, C. Cavdar
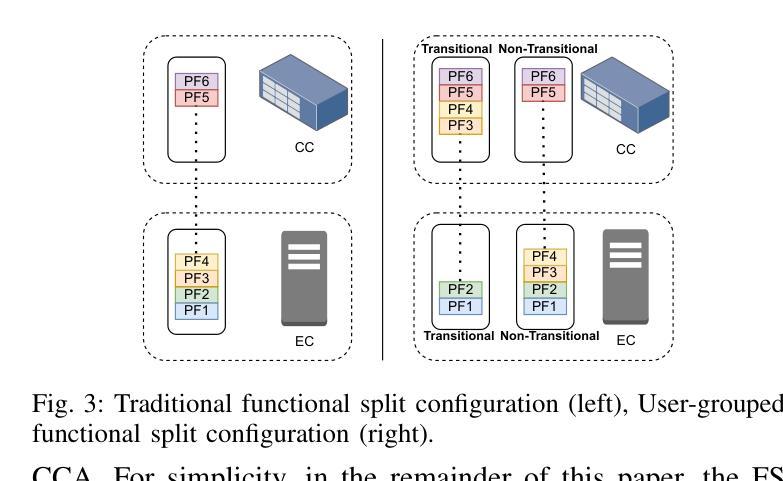
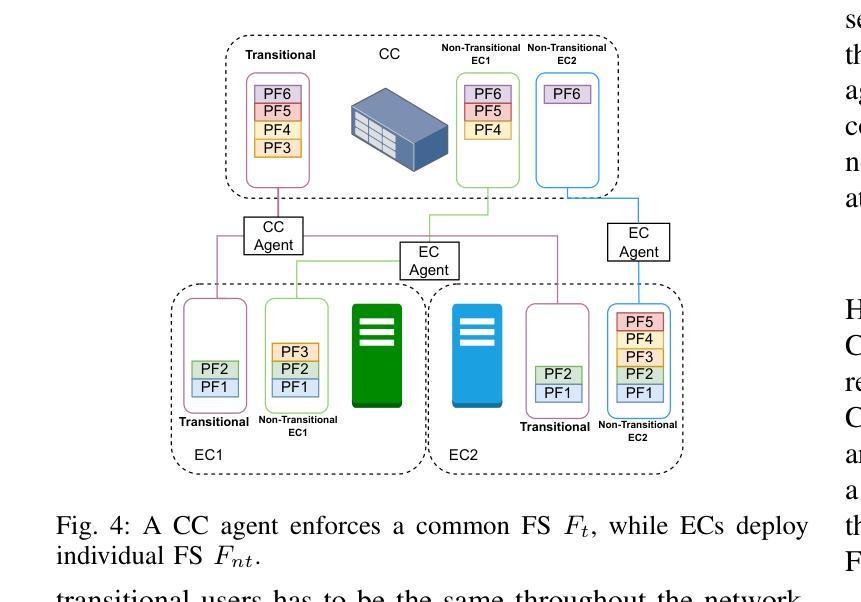
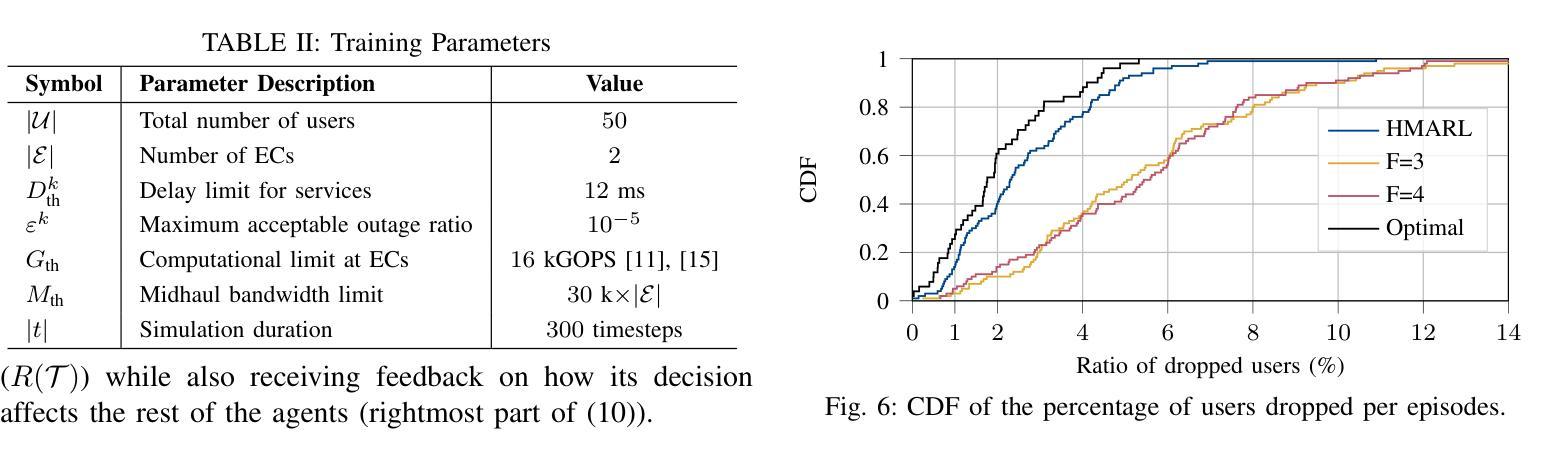
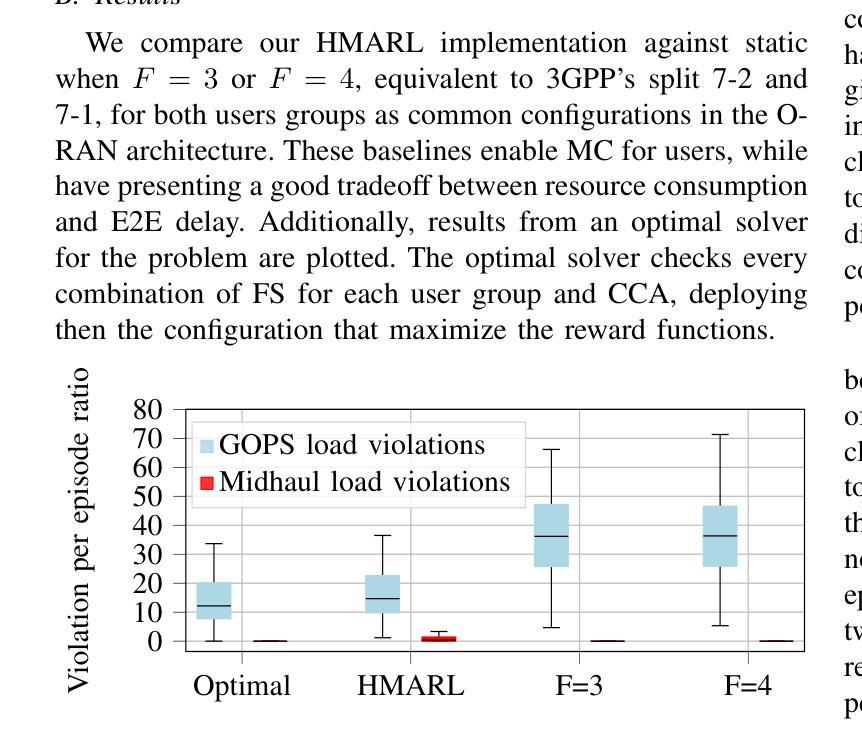
Multi-connectivity (MC) for aerial users via a set of ground access points offers the potential for highly reliable communication. Within an open radio access network (O-RAN) architecture, edge clouds (ECs) enable MC with low latency for users within their coverage area. However, ensuring seamless service continuity for transitional users-those moving between the coverage areas of neighboring ECs-poses challenges due to centralized processing demands. To address this, we formulate a problem facilitating soft handovers between ECs, ensuring seamless transitions while maintaining service continuity for all users. We propose a hierarchical multi-agent reinforcement learning (HMARL) algorithm to dynamically determine the optimal functional split configuration for transitional and non-transitional users. Simulation results show that the proposed approach outperforms the conventional functional split in terms of the percentage of users maintaining service continuity, with at most 4% optimality gap. Additionally, HMARL achieves better scalability compared to the static baselines.
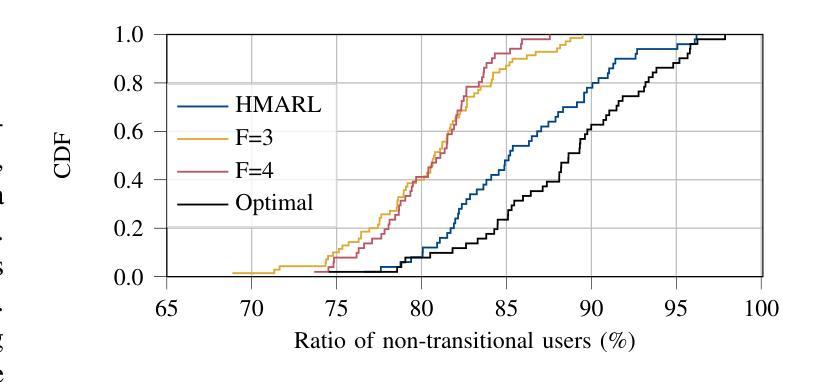
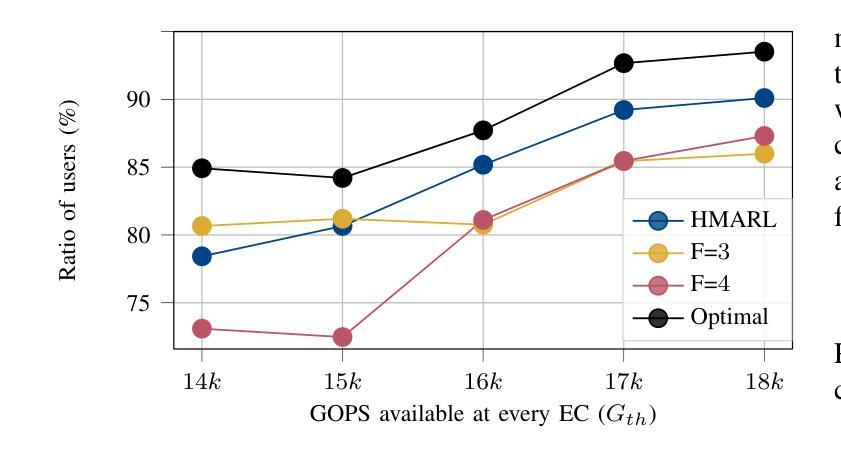
通过一系列地面接入点,为多用户空中接入提供可靠通信的多连接性(MC)功能。在开放无线电接入网络(O-RAN)架构内,边缘云(ECs)能够在覆盖范围内实现可靠的多连接性和低延迟服务给用户带来好处。然而,在移动用户在相邻的边缘云覆盖区域之间移动时,保证无缝服务连续性面临着由于集中处理需求所带来的挑战。为了解决这个问题,我们设计了一个在边缘云之间实现软切换的问题方案,以确保无缝过渡并为所有用户提供连续的服务保障。我们提出了一种分层多智能体强化学习(HMARL)算法来动态确定过渡用户和非过渡用户的最佳功能分割配置。仿真结果表明,该方法在保持服务连续性的用户比例方面优于传统功能分割,最优差距最多只有4%。此外,HMARL相较于静态基线展现出更好的可扩展性。
论文及项目相关链接
Summary
在开放无线电接入网络架构中,通过边缘云实现多连接性可提供高度可靠的通信。但对于在相邻边缘云覆盖区域之间移动的用户,确保无缝服务连续性存在挑战。为解决此问题,我们提出了一种促进边缘云之间软切换的算法,并通过仿真验证了该算法在保持用户服务连续性方面的优势。
Key Takeaways
- 多连接性通过一系列地面接入点为空中用户提供通信潜力,具有高度的可靠性。
- 边缘云在开放无线电接入网络架构中实现了低延迟的多连接性。
- 在相邻边缘云的覆盖区域之间移动的用户面临服务连续性的挑战。
- 软切换算法是处理边缘云之间用户无缝过渡的关键。
- 提出的分层多智能体强化学习算法能动态确定最佳功能分割配置。
- 仿真结果表明,该算法在保持用户服务连续性方面优于传统功能分割。
点此查看论文截图


An Autonomous RL Agent Methodology for Dynamic Web UI Testing in a BDD Framework
Authors:Ali Hassaan Mughal
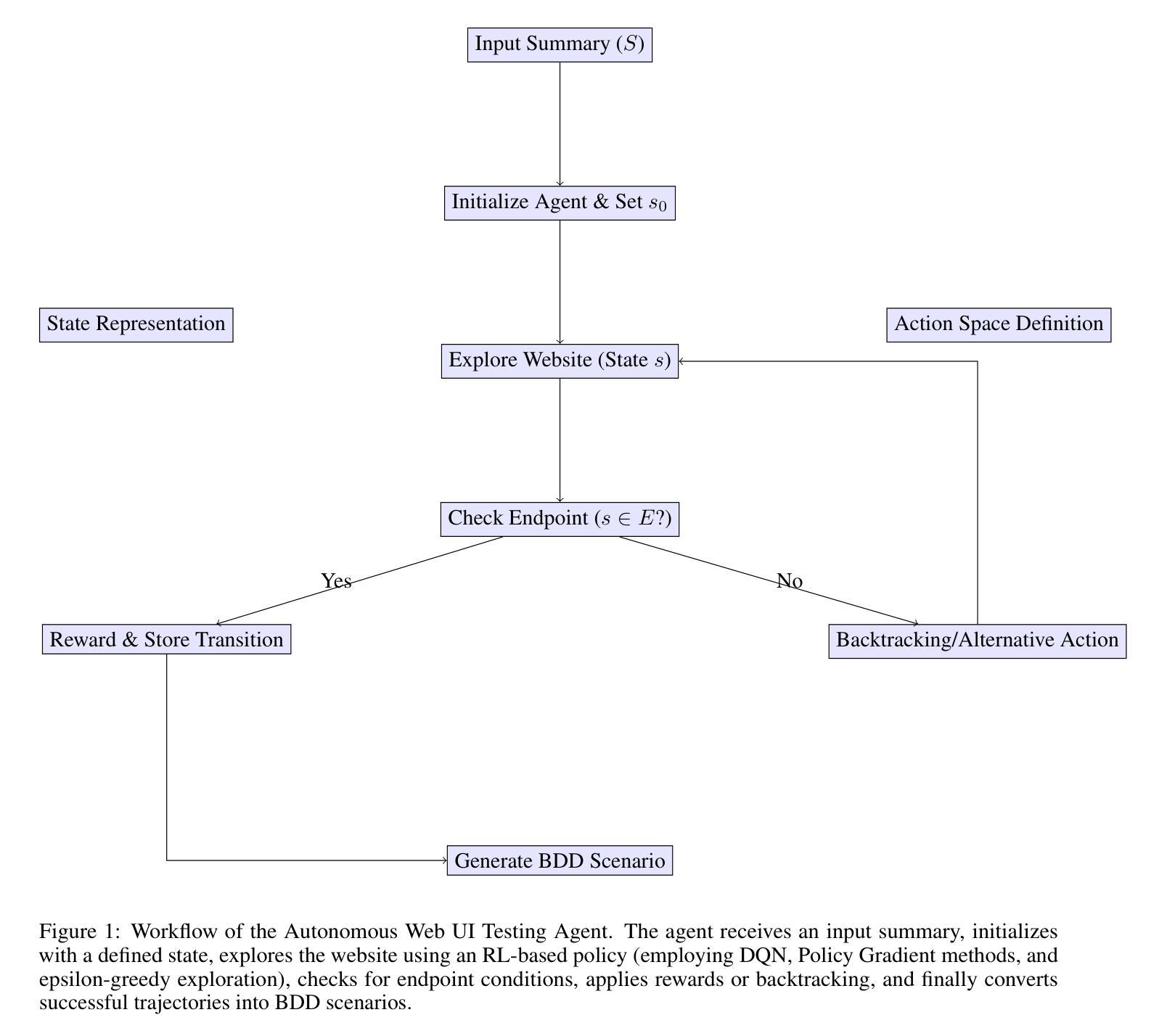
Modern software applications demand efficient and reliable testing methodologies to ensure robust user interface functionality. This paper introduces an autonomous reinforcement learning (RL) agent integrated within a Behavior-Driven Development (BDD) framework to enhance UI testing. By leveraging the adaptive decision-making capabilities of RL, the proposed approach dynamically generates and refines test scenarios aligned with specific business expectations and actual user behavior. A novel system architecture is presented, detailing the state representation, action space, and reward mechanisms that guide the autonomous exploration of UI states. Experimental evaluations on open-source web applications demonstrate significant improvements in defect detection, test coverage, and a reduction in manual testing efforts. This study establishes a foundation for integrating advanced RL techniques with BDD practices, aiming to transform software quality assurance and streamline continuous testing processes.
现代软件应用程序需要高效可靠的测试方法来确保用户界面的稳健功能。本文介绍了一种集成在行为驱动开发(BDD)框架内的自主强化学习(RL)代理,以增强UI测试。通过利用RL的自适应决策能力,所提出的方法能够动态生成和细化与特定业务预期和实际用户行为相符的测试场景。提出了一种新型系统架构,详细说明了状态表示、动作空间和奖励机制,这些机制引导UI状态的自主探索。在开源Web应用程序上的实验评估证明,在缺陷检测、测试覆盖率和减少人工测试工作方面都有显著提高。本研究为将先进的RL技术与BDD实践相结合奠定了基础,旨在改变软件质量保证和简化持续测试过程。
论文及项目相关链接
PDF 9 pages, 1 graph, couple algorithms
Summary
本文介绍了一种将自主强化学习(RL)代理集成到行为驱动开发(BDD)框架中,以增强用户界面(UI)测试的方法。该方法利用RL的决策能力,动态生成和细化符合特定业务期望和实际用户行为的测试场景。实验评估表明,该方法在缺陷检测、测试覆盖率和减少手动测试工作方面表现出显著改进。
Key Takeaways
- 介绍了将自主强化学习(RL)代理集成到BDD框架中,用于增强UI测试的方法。
- 利用RL的决策能力,该方法可以动态生成和细化测试场景,以符合特定的业务需求和用户行为。
- 提出了一种新型系统架构,详细说明了状态表示、动作空间和奖励机制,以指导UI状态的自主探索。
- 实验评估显示,该方法在缺陷检测、测试覆盖率方面有明显提升。
- 此方法减少了手动测试工作,有助于简化持续测试过程。
- 为将先进的RL技术与BDD实践相结合奠定了基础,有望改变软件质量保证的流程。
点此查看论文截图


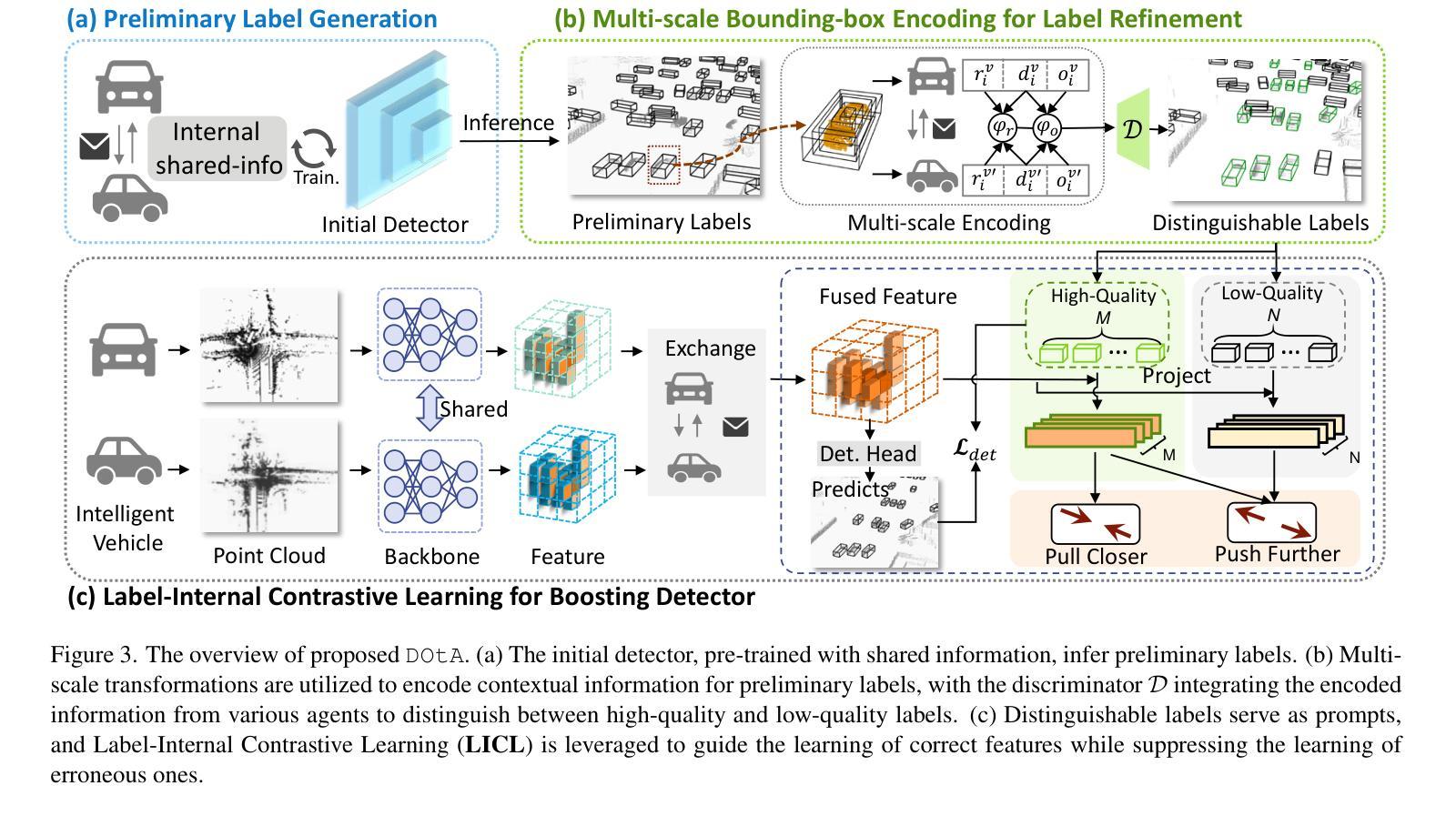
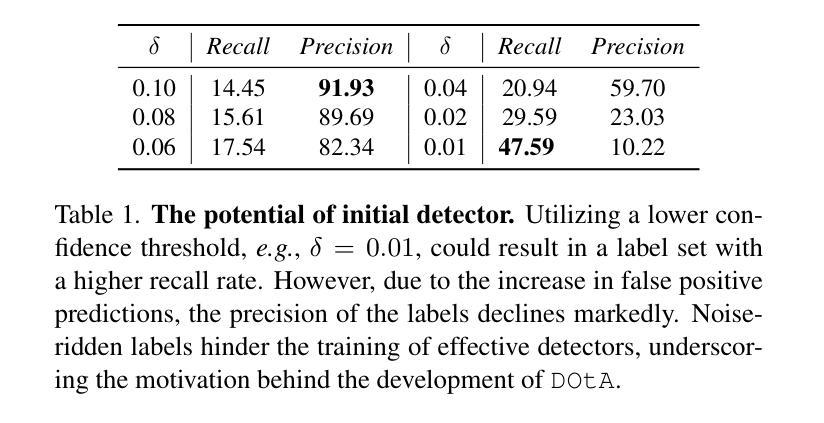
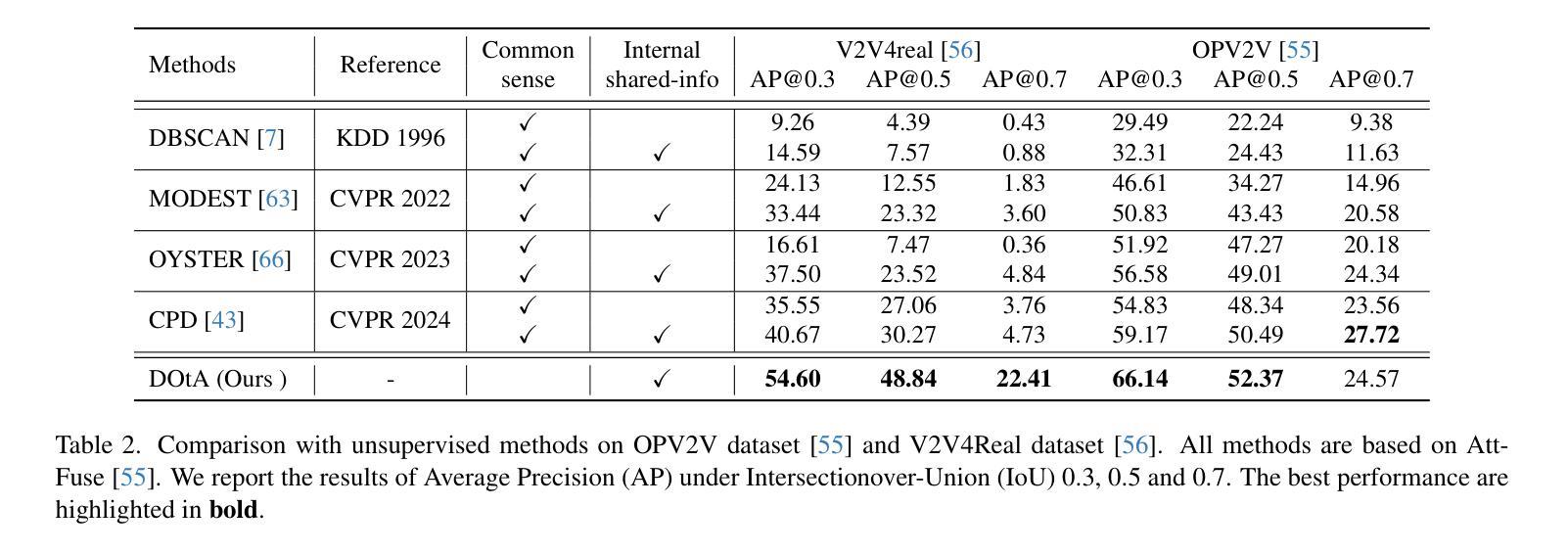
Learning to Detect Objects from Multi-Agent LiDAR Scans without Manual Labels
Authors:Qiming Xia, Wenkai Lin, Haoen Xiang, Xun Huang, Siheng Chen, Zhen Dong, Cheng Wang, Chenglu Wen
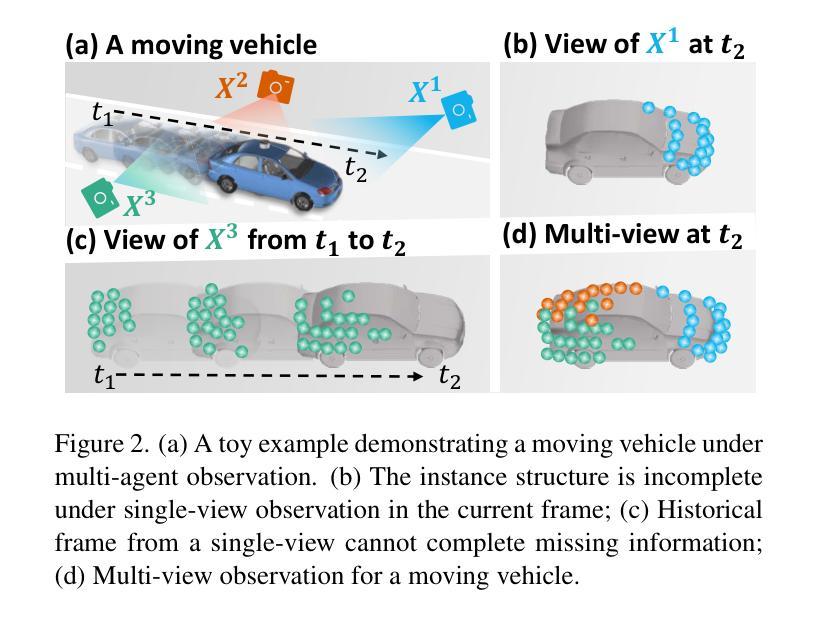
Unsupervised 3D object detection serves as an important solution for offline 3D object annotation. However, due to the data sparsity and limited views, the clustering-based label fitting in unsupervised object detection often generates low-quality pseudo-labels. Multi-agent collaborative dataset, which involves the sharing of complementary observations among agents, holds the potential to break through this bottleneck. In this paper, we introduce a novel unsupervised method that learns to Detect Objects from Multi-Agent LiDAR scans, termed DOtA, without using labels from external. DOtA first uses the internally shared ego-pose and ego-shape of collaborative agents to initialize the detector, leveraging the generalization performance of neural networks to infer preliminary labels. Subsequently,DOtA uses the complementary observations between agents to perform multi-scale encoding on preliminary labels, then decodes high-quality and low-quality labels. These labels are further used as prompts to guide a correct feature learning process, thereby enhancing the performance of the unsupervised object detection task. Extensive experiments on the V2V4Real and OPV2V datasets show that our DOtA outperforms state-of-the-art unsupervised 3D object detection methods. Additionally, we also validate the effectiveness of the DOtA labels under various collaborative perception frameworks.The code is available at https://github.com/xmuqimingxia/DOtA.
无监督的3D目标检测是离线3D目标标注的重要解决方案。然而,由于数据稀疏和视角有限,无监督目标检测中的基于聚类的标签拟合往往会产生低质量的伪标签。多智能体协同数据集涉及智能体之间的互补观测共享,具有突破这一瓶颈的潜力。在本文中,我们介绍了一种新的无监督方法,该方法从多智能体激光雷达扫描中学习检测目标,称为DOtA,无需使用来自外部标签。DOtA首先使用智能体之间共享的内部自我姿态和自我形状来初始化检测器,并利用神经网络的泛化性能来推断初步标签。随后,DOtA利用智能体之间的互补观测对初步标签执行多尺度编码,然后解码高质量和低质量标签。这些标签进一步作为提示,引导正确的特征学习过程,从而提高无监督目标检测任务的性能。在V2V4Real和OPV2V数据集上的大量实验表明,我们的DOtA优于最新的无监督3D目标检测方法。此外,我们还验证了在不同协同感知框架下DOtA标签的有效性。代码可在https://github.com/xmuqimingxia/DOtA获取。
论文及项目相关链接
PDF 11 pages, 5 figures
Summary
在离线3D对象标注中,无监督3D目标检测是重要的解决方案。但由于数据稀疏和视角有限,聚类标签拟合产生的伪标签质量较低。本文提出了一种新型的无监督方法DOtA,通过多智能体协同数据集学习从多智能体激光雷达扫描中检测目标,无需使用外部标签。DOtA利用智能体之间的共享ego-pose和ego-shape初始化检测器,利用神经网络泛化性能推断初步标签。随后,DOtA利用智能体间的互补观测对初步标签进行多尺度编码,再解码出高质量和劣质标签。这些标签作为提示引导特征学习过程,提高了无监督目标检测任务性能。在V2V4Real和OPV2V数据集上的实验表明,DOtA优于现有无监督3D目标检测方法。代码已公开在GitHub上。
Key Takeaways
- 无监督3D对象检测是解决离线3D对象标注的重要方法。
- 聚类标签拟合产生的伪标签质量较低,受数据稀疏和有限视角影响。
- DOtA方法利用多智能体协同数据集,通过共享信息提高无监督目标检测性能。
- DOtA利用智能体间的ego-pose和ego-shape初始化检测器,并推断初步标签。
- DOtA利用多尺度编码处理初步标签,解码出高质量和劣质标签。
- 这些标签用于引导特征学习过程,提高无监督目标检测任务性能。
点此查看论文截图

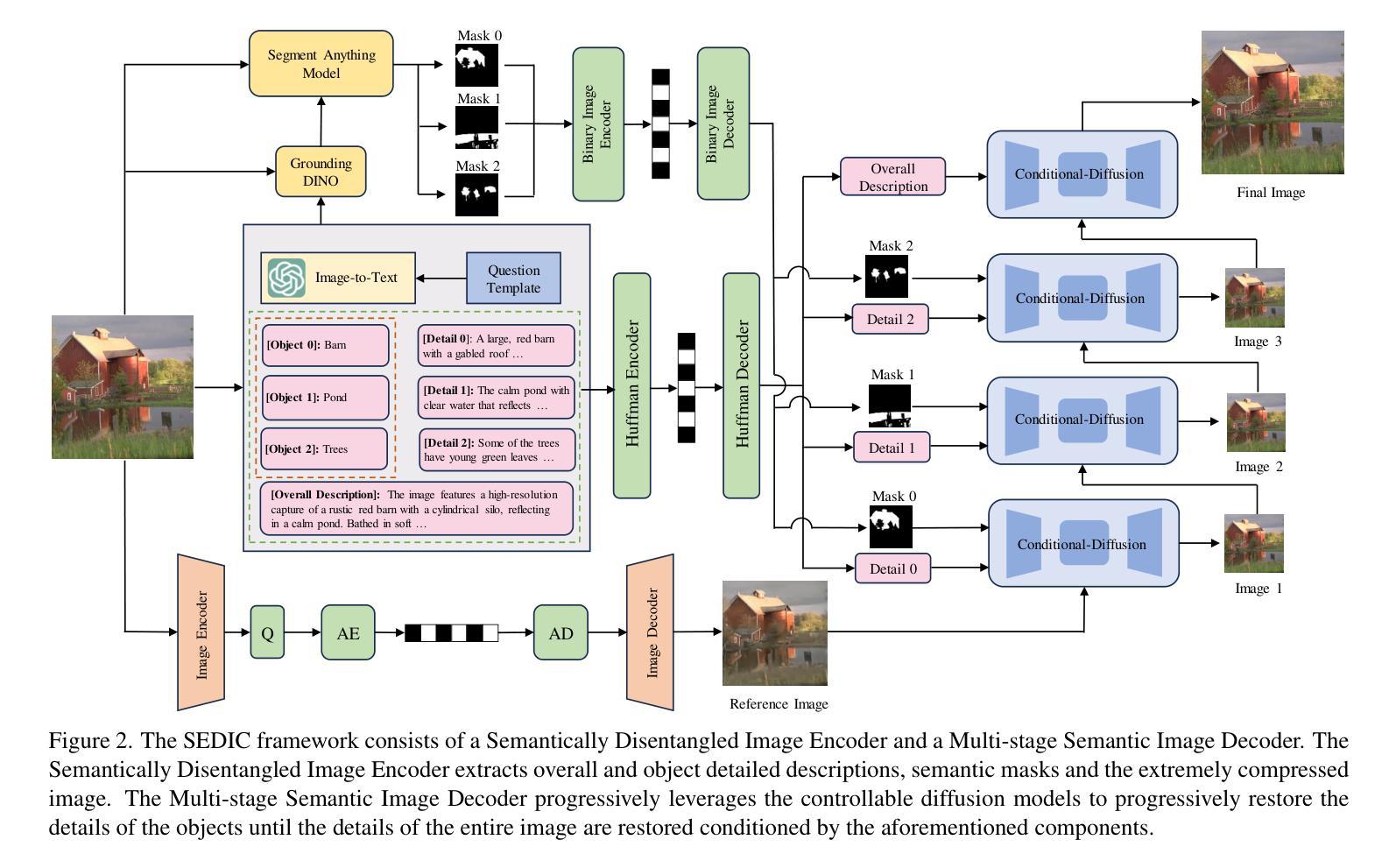
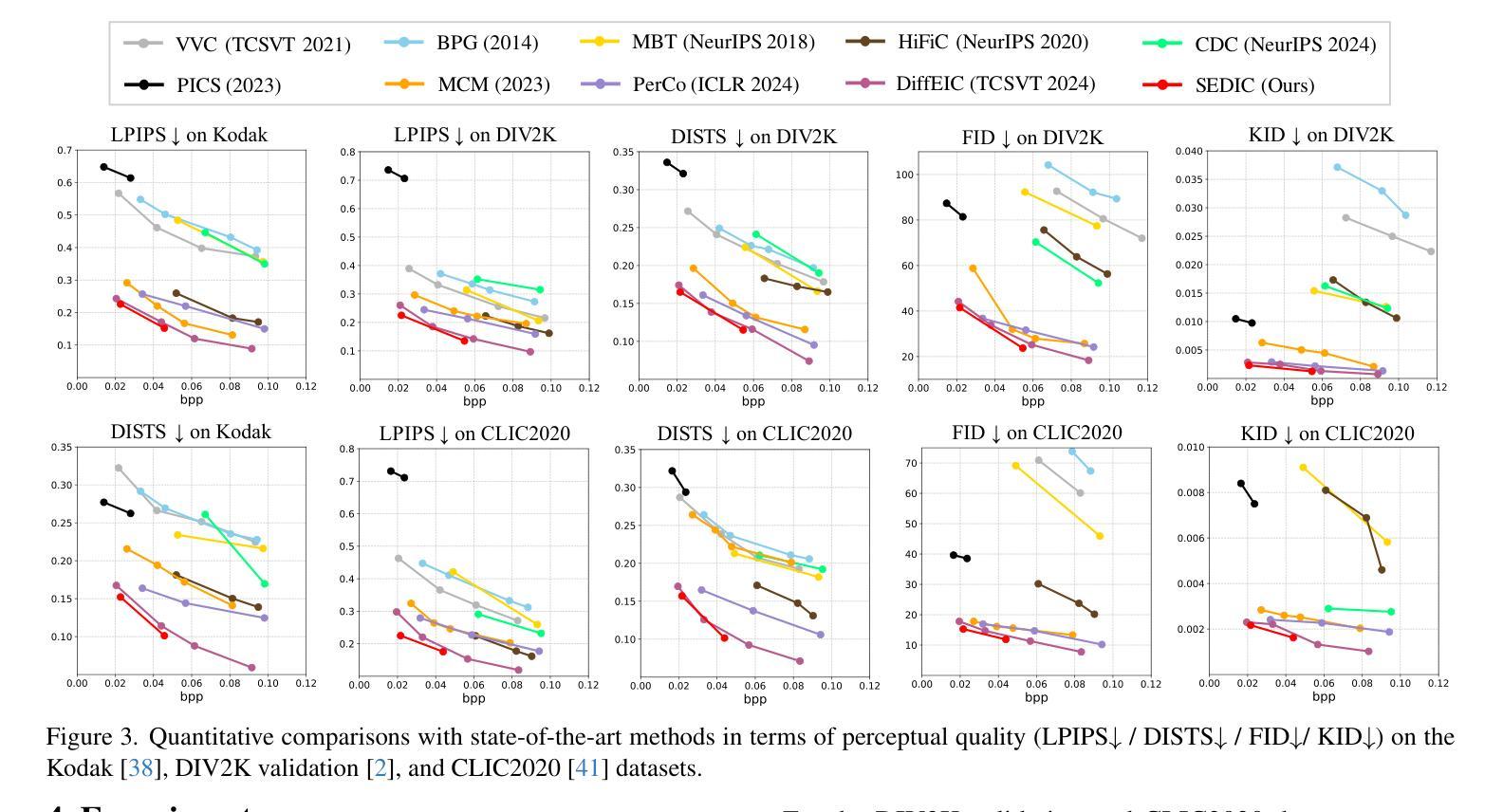
Taming Large Multimodal Agents for Ultra-low Bitrate Semantically Disentangled Image Compression
Authors:Juan Song, Lijie Yang, Mingtao Feng
It remains a significant challenge to compress images at ultra-low bitrate while achieving both semantic consistency and high perceptual quality. We propose a novel image compression framework, Semantically Disentangled Image Compression (SEDIC) in this paper. Our proposed SEDIC leverages large multimodal models (LMMs) to disentangle the image into several essential semantic information, including an extremely compressed reference image, overall and object-level text descriptions, and the semantic masks. A multi-stage semantic decoder is designed to progressively restore the transmitted reference image object-by-object, ultimately producing high-quality and perceptually consistent reconstructions. In each decoding stage, a pre-trained controllable diffusion model is utilized to restore the object details on the reference image conditioned by the text descriptions and semantic masks. Experimental results demonstrate that SEDIC significantly outperforms state-of-the-art approaches, achieving superior perceptual quality and semantic consistency at ultra-low bitrates ($\le$ 0.05 bpp).
在超低比特率下进行图像压缩,同时实现语义一致性和高感知质量,仍然是一个巨大的挑战。本文提出了一种新型图像压缩框架——语义解纠缠图像压缩(SEDIC)。我们提出的SEDIC利用大型多模态模型(LMMs)将图像解纠缠为多种基本语义信息,包括极压缩的参考图像、总体和对象级文本描述以及语义掩模。设计了一种多阶段语义解码器,逐步恢复传输的参考图像的对象,最终产生高质量和感知一致的重建。在每个解码阶段,利用预训练的可控扩散模型根据文本描述和语义掩模恢复参考图像的对象细节。实验结果表明,SEDIC在超低比特率(≤0.05 bpp)下显著优于现有技术,实现了出色的感知质量和语义一致性。
论文及项目相关链接
摘要
该文针对超低比特率图像压缩提出了一项挑战,即在保持语义一致性和高感知质量的同时进行图像压缩。本文提出了一种新型的图像压缩框架——语义分离图像压缩(SEDIC)。SEDIC利用大型多模态模型(LMMs)将图像分解为多个基本语义信息,包括极压缩的参考图像、总体和对象级文本描述以及语义掩码。设计了一种多阶段语义解码器,以逐步恢复传输的参考图像的对象,最终产生高质量和感知一致的重建。在每个解码阶段,利用预训练的受控扩散模型,根据文本描述和语义掩膜恢复参考图像的对象细节。实验结果表明,SEDIC在超低比特率(≤0.05 bpp)下显著优于现有技术,实现了优越的主观感知质量和语义一致性。
要点摘要
- 图像压缩框架SEDIC结合了大型多模态模型(LMMs)以实现超低比特率下的高效压缩。
- SEDIC能够分解图像为多个关键语义信息,包括参考图像、文本描述和语义掩码。
- 采用多阶段语义解码器逐步恢复对象级图像信息,达到高感知质量和语义一致性。
- 在每个解码阶段,利用可控扩散模型根据文本和语义信息恢复图像细节。
- 实验结果显示SEDIC在超低比特率下性能卓越,显著优于当前主流技术。
- SEDIC框架在保证语义一致性的同时,实现了高感知质量的图像重建。
点此查看论文截图


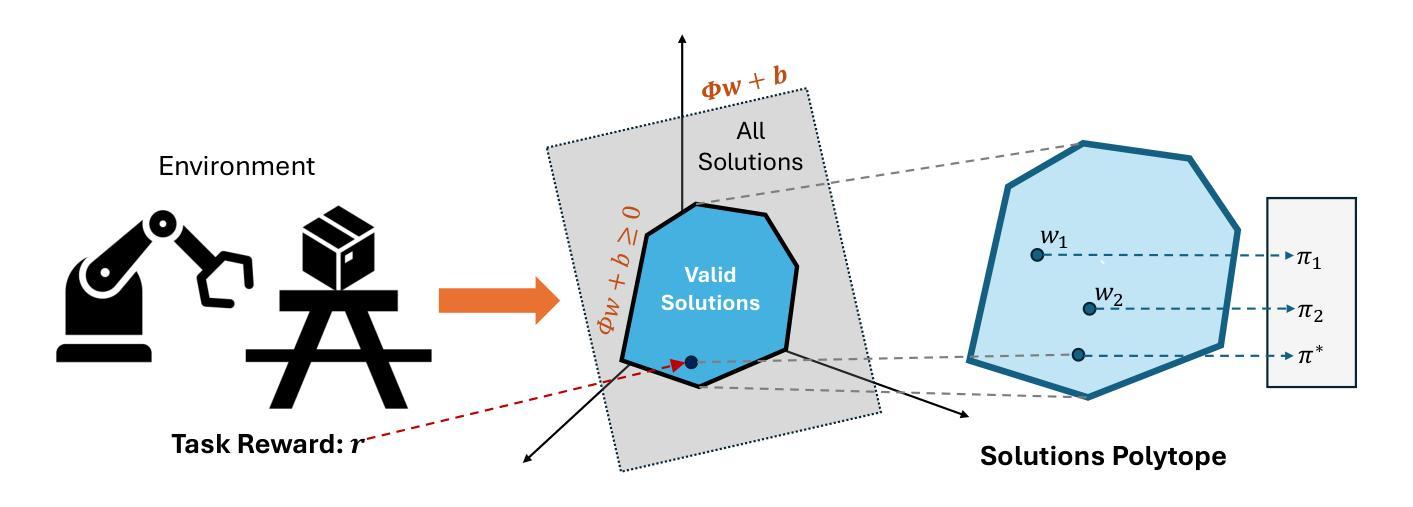
Proto Successor Measure: Representing the Behavior Space of an RL Agent
Authors:Siddhant Agarwal, Harshit Sikchi, Peter Stone, Amy Zhang
Having explored an environment, intelligent agents should be able to transfer their knowledge to most downstream tasks within that environment without additional interactions. Referred to as “zero-shot learning”, this ability remains elusive for general-purpose reinforcement learning algorithms. While recent works have attempted to produce zero-shot RL agents, they make assumptions about the nature of the tasks or the structure of the MDP. We present Proto Successor Measure: the basis set for all possible behaviors of a Reinforcement Learning Agent in a dynamical system. We prove that any possible behavior (represented using visitation distributions) can be represented using an affine combination of these policy-independent basis functions. Given a reward function at test time, we simply need to find the right set of linear weights to combine these bases corresponding to the optimal policy. We derive a practical algorithm to learn these basis functions using reward-free interaction data from the environment and show that our approach can produce the optimal policy at test time for any given reward function without additional environmental interactions. Project page: https://agarwalsiddhant10.github.io/projects/psm.html.
在探索环境后,智能主体应该能够将其知识转移到该环境中的大多数下游任务,而无需额外的交互。这被称为”零射击学习”,对于通用强化学习算法来说,这种能力仍然难以捉摸。虽然最近的研究工作试图产生零射击RL代理,但它们对任务性质或MDP结构做出了假设。我们提出了Proto Successor Measure:这是动态系统中强化学习代理所有可能行为的基准集。我们证明,任何可能的行为(使用访问分布表示)都可以使用这些独立于策略的基础函数的仿射组合来表示。在测试时给定奖励函数,我们只需要找到对应于最优策略的线性权重集即可。我们推导了一种实用的算法来学习这些基础函数,利用来自环境的无奖励交互数据,并证明我们的方法可以在测试时为任何给定的奖励函数生成最优策略,而无需与环境进行额外的交互。项目页面:链接。
论文及项目相关链接
PDF Under submission, 20 pages
Summary
智能体在探索环境后,应能在不需要额外交互的情况下将其知识转移到该环境中的大多数下游任务上,这被称为“零次学习”。虽然最近的研究尝试产生零次RL代理,但它们对任务或马尔可夫决策过程(MDP)的结构做出了假设。我们提出Proto Successor Measure,这是动态系统中强化学习代理所有可能行为的基准集。我们证明任何可能的行为(用访问分布表示)都可以使用这些与策略无关的基础函数的线性组合来表示。在测试阶段给定奖励函数后,我们只需要找到对应于最优策略的线性权重组合这些基的正确集合。我们提出了一种实用的算法,通过环境提供的无奖励交互数据来学习这些基础函数,并证明我们的方法可以在测试阶段为任何给定的奖励函数生成最优策略,而无需与环境进行额外的交互。
Key Takeaways
- 智能体在探索环境后应能进行零次学习,将知识转移到环境中的下游任务,无需额外交互。
- Proto Successor Measure提供了强化学习代理在动态系统中所有可能行为的基准集。
- 任何可能的行为都可以通过使用与策略无关的基础函数的线性组合来表示。
- 在测试阶段,给定奖励函数,需要找到对应于最优策略的基的正确组合。
- 提出一种实用算法,通过环境提供的无奖励交互数据来学习基础函数。
- 该方法可以在测试阶段为任何给定的奖励函数生成最优策略。
点此查看论文截图

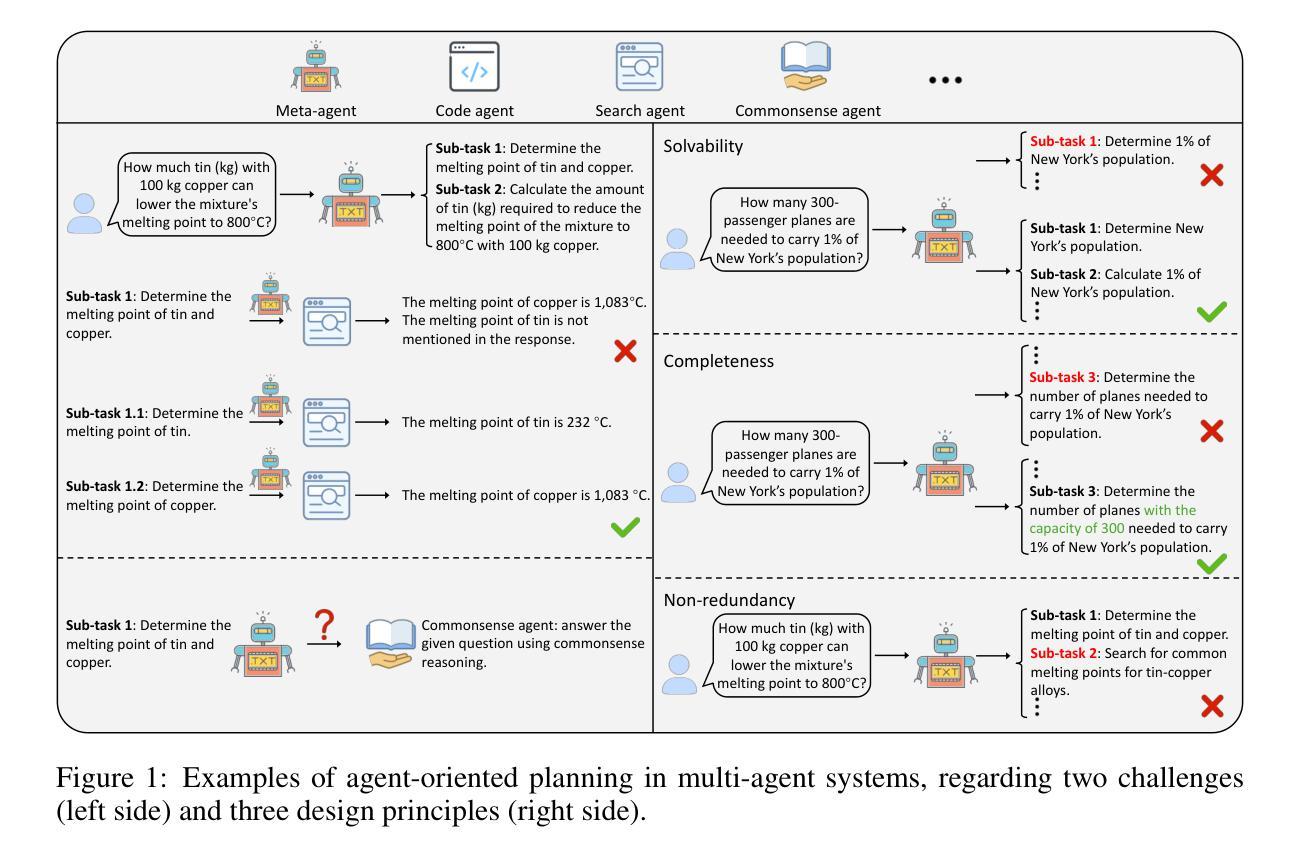
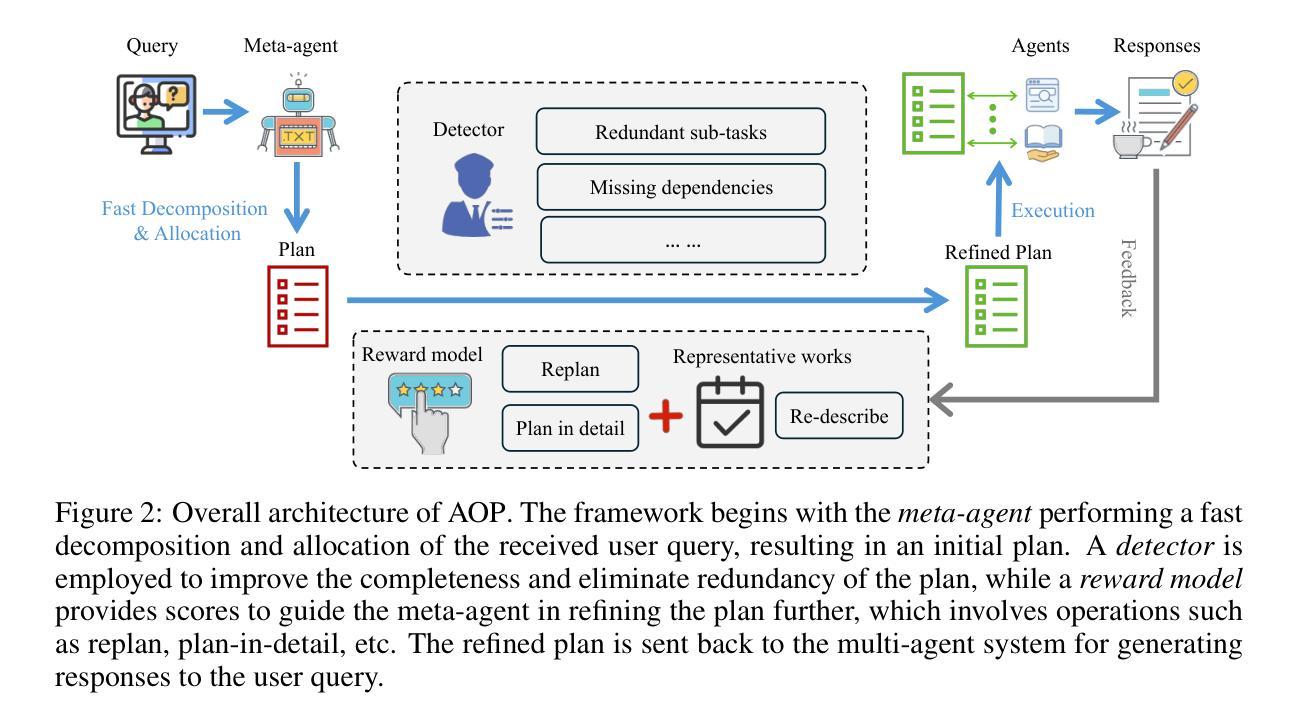
Agent-Oriented Planning in Multi-Agent Systems
Authors:Ao Li, Yuexiang Xie, Songze Li, Fugee Tsung, Bolin Ding, Yaliang Li
Through the collaboration of multiple LLM-empowered agents possessing diverse expertise and tools, multi-agent systems achieve impressive progress in solving real-world problems. Given the user queries, the meta-agents, serving as the brain within multi-agent systems, are required to decompose the queries into multiple sub-tasks that can be allocated to suitable agents capable of solving them, so-called agent-oriented planning. In this study, we identify three critical design principles of agent-oriented planning, including solvability, completeness, and non-redundancy, to ensure that each sub-task can be effectively resolved, resulting in satisfactory responses to user queries. These principles further inspire us to propose AOP, a novel framework for agent-oriented planning in multi-agent systems, leveraging a fast task decomposition and allocation process followed by an effective and efficient evaluation via a reward model. According to the evaluation results, the meta-agent is also responsible for promptly making necessary adjustments to sub-tasks and scheduling. Besides, we integrate a feedback loop into AOP to further enhance the effectiveness and robustness of such a problem-solving process. Extensive experiments demonstrate the advancement of AOP in solving real-world problems compared to both single-agent systems and existing planning strategies for multi-agent systems. The source code is available at https://github.com/lalaliat/Agent-Oriented-Planning
通过拥有各种专业知识和工具的多名LLM赋能的代理人的协作,多代理人系统在解决现实世界问题上取得了令人印象深刻的进展。面对用户查询,作为多代理人系统内脑元的元代理人,需要将查询分解为可以分配给合适代理人的多个子任务,这些代理人能够解决这些子任务,这被称为面向代理人的规划。在本研究中,我们确定了面向代理人的规划设计的三个关键原则,包括可解决性、完整性和非冗余性,以确保每个子任务都能得到有效解决,从而使用户查询得到满意的回应。这些原则进一步激励我们提出AOP,这是一个面向代理人的规划的新型框架,利用快速的任务分解和分配过程,然后通过奖励模型进行有效的效率评估。根据评估结果,元代理人还负责及时对子任务进行必要的调整和调度。此外,我们将反馈循环整合到AOP中,以进一步增强这种问题解决过程的有效性和稳健性。大量实验表明,与单代理人系统和现有的多代理人系统规划策略相比,AOP在解决现实世界问题上取得了进展。源代码可在https://github.com/lalaliat/Agent-Oriented-Planning找到。
论文及项目相关链接
PDF Accepted by ICLR’2025
Summary:多智能体系统通过多个具备不同专业知识和工具的LLM赋能的智能体协作,在解决现实世界问题上取得显著进展。针对用户查询,多智能体系统中的元智能体需要将查询分解成可分配给适当智能体的子任务进行解决,即所谓的面向智能体的规划。本研究确定了三个关键的面向智能体的规划原则,包括可解决性、完整性和非冗余性,以确保每个子任务都能得到有效解决,从而实现对用户查询的满意回应。基于这些原则,我们提出了面向智能体的规划的新框架AOP,通过快速的任务分解和分配过程,以及通过奖励模型的有效和高效评估,确保智能体能够解决问题。此外,我们还将反馈循环集成到AOP中,以进一步增强问题解决的效率和稳健性。实验证明,与单智能体系统和现有的多智能体系统规划策略相比,AOP在解决现实问题上取得了进步。
Key Takeaways:
- 多智能体系统通过LLM赋能的智能体协作在解决现实世界问题上取得进展。
- 元智能体在多智能体系统中起到关键作用,负责将用户查询分解成子任务并分配给适当的智能体解决。
- 确定了解决面向智能体的规划的三个关键原则:可解决性、完整性和非冗余性。
- 提出了面向智能体的规划的新框架AOP,包括快速任务分解和分配、通过奖励模型的有效和高效评估、元智能体的调整及反馈循环的集成。
- AOP框架提高了多智能体系统解决现实问题的能力,相较于单智能体系统和现有规划策略具有优势。
- 源代码已公开可用,便于进一步研究和应用。
点此查看论文截图