⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
FCaS: Fine-grained Cardiac Image Synthesis based on 3D Template Conditional Diffusion Model
Authors:Jiahao Xia, Yutao Hu, Yaolei Qi, Zhenliang Li, Wenqi Shao, Junjun He, Ying Fu, Longjiang Zhang, Guanyu Yang
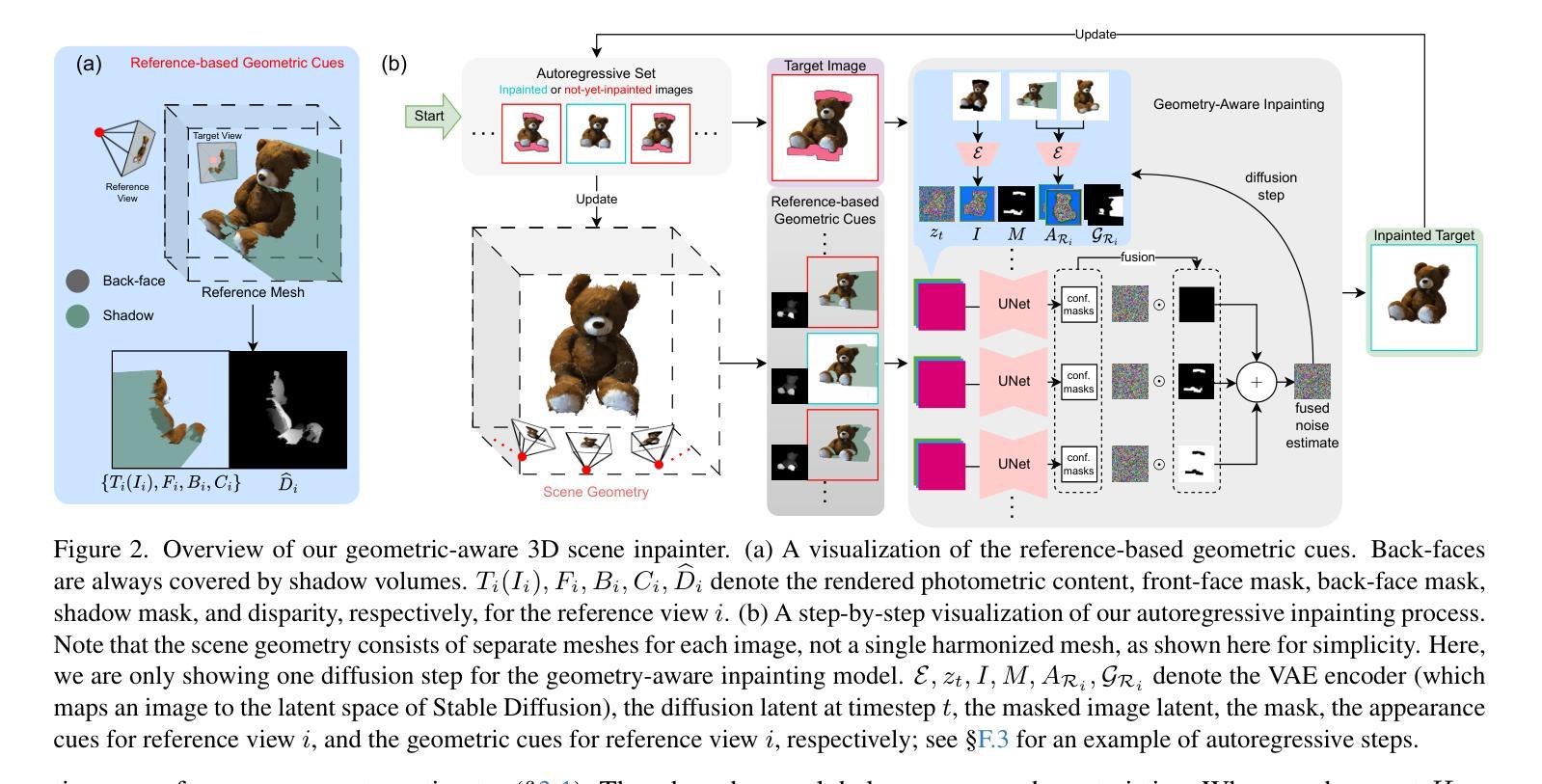
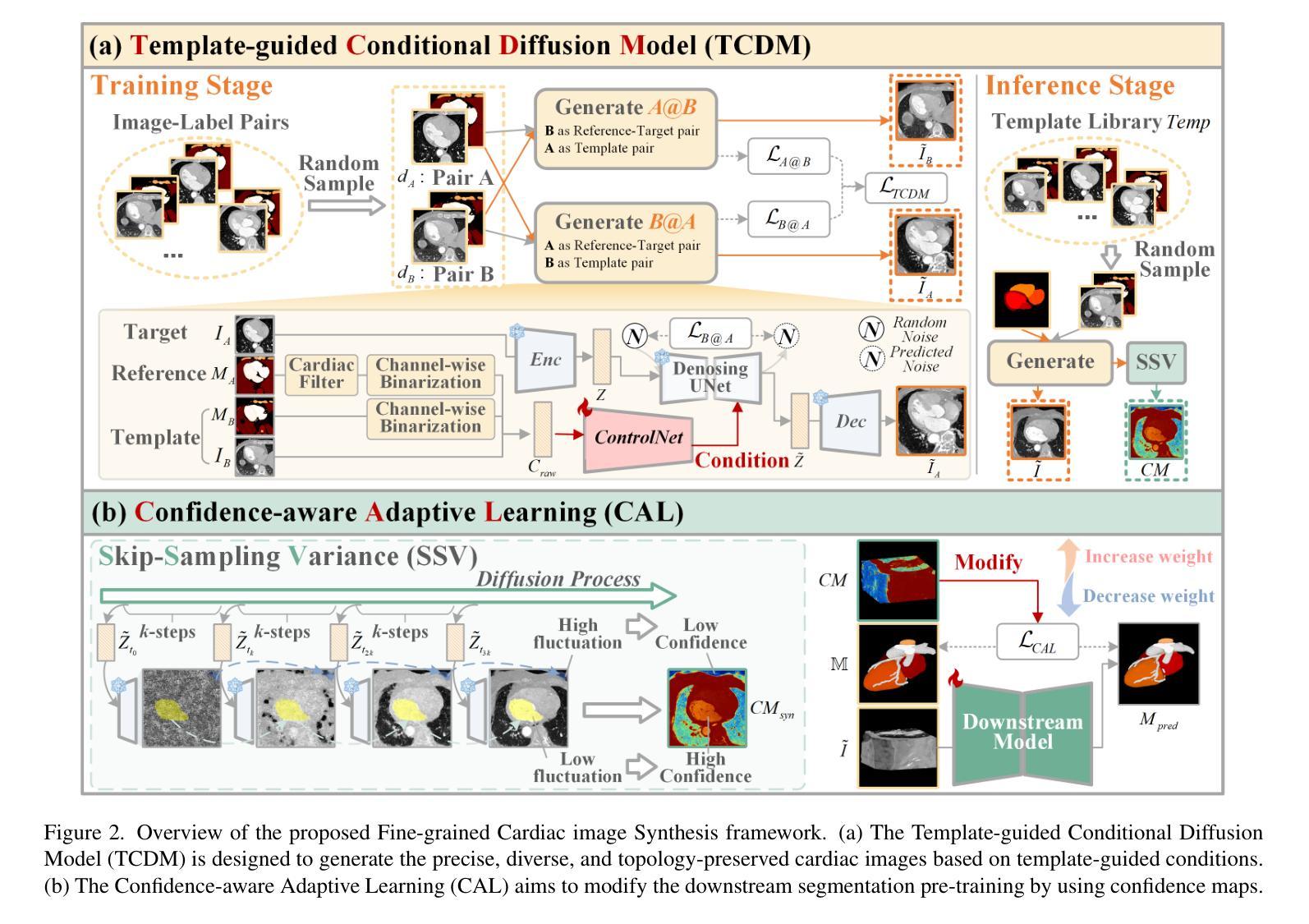
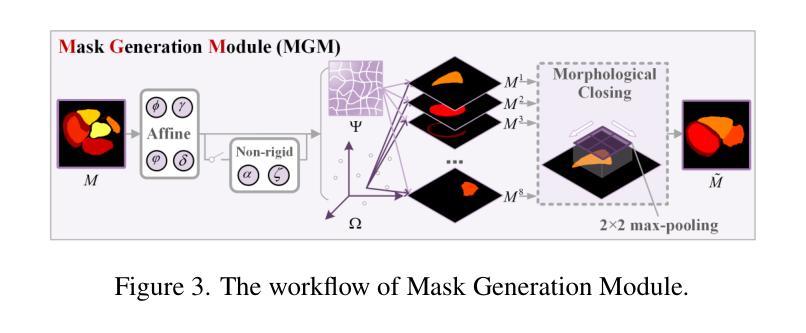
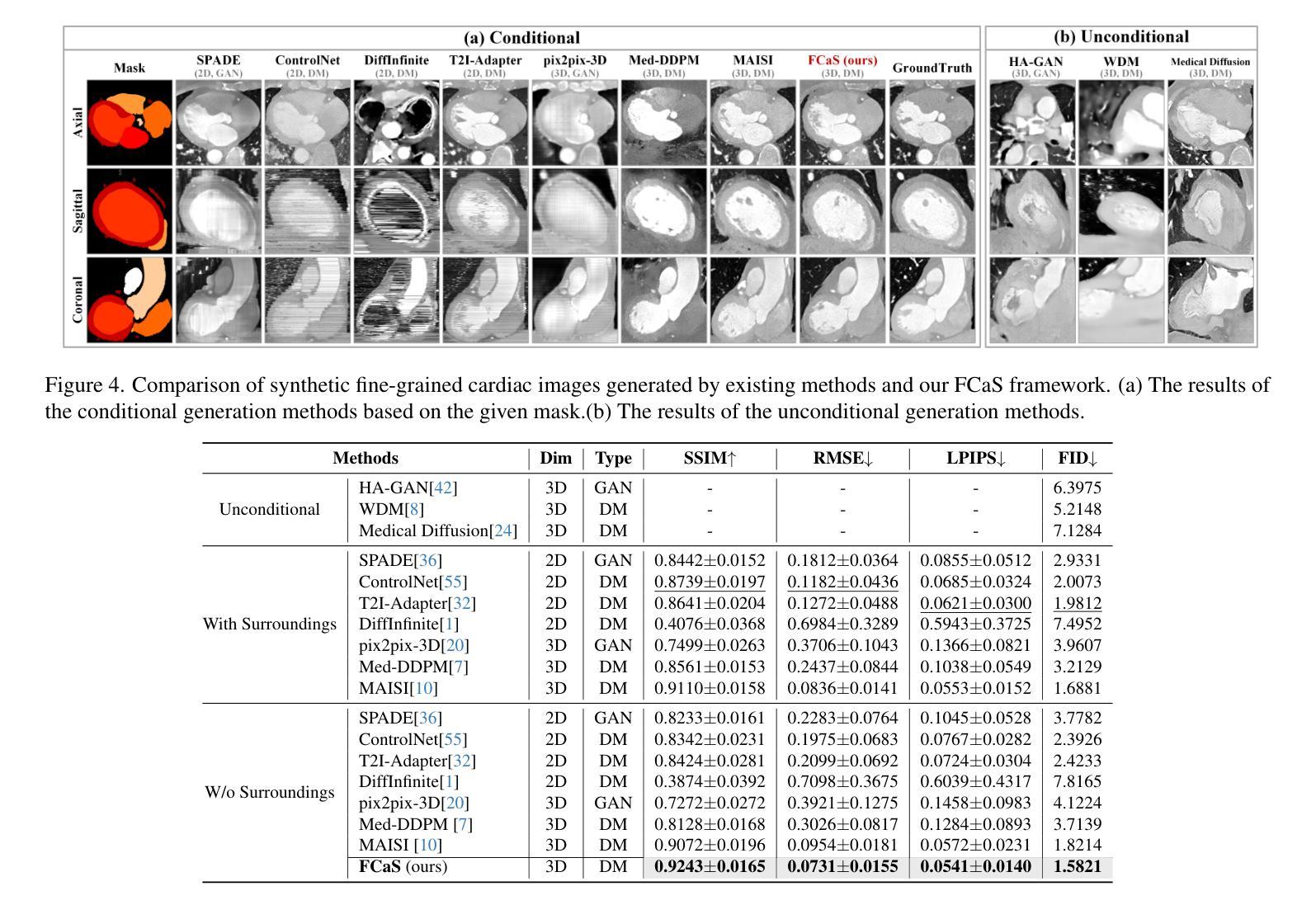
Solving medical imaging data scarcity through semantic image generation has attracted significant attention in recent years. However, existing methods primarily focus on generating whole-organ or large-tissue structures, showing limited effectiveness for organs with fine-grained structure. Due to stringent topological consistency, fragile coronary features, and complex 3D morphological heterogeneity in cardiac imaging, accurately reconstructing fine-grained anatomical details of the heart remains a great challenge. To address this problem, in this paper, we propose the Fine-grained Cardiac image Synthesis(FCaS) framework, established on 3D template conditional diffusion model. FCaS achieves precise cardiac structure generation using Template-guided Conditional Diffusion Model (TCDM) through bidirectional mechanisms, which provides the fine-grained topological structure information of target image through the guidance of template. Meanwhile, we design a deformable Mask Generation Module (MGM) to mitigate the scarcity of high-quality and diverse reference mask in the generation process. Furthermore, to alleviate the confusion caused by imprecise synthetic images, we propose a Confidence-aware Adaptive Learning (CAL) strategy to facilitate the pre-training of downstream segmentation tasks. Specifically, we introduce the Skip-Sampling Variance (SSV) estimation to obtain confidence maps, which are subsequently employed to rectify the pre-training on downstream tasks. Experimental results demonstrate that images generated from FCaS achieves state-of-the-art performance in topological consistency and visual quality, which significantly facilitates the downstream tasks as well. Code will be released in the future.
通过语义图像生成解决医学成像数据稀缺问题近年来已引起广泛关注。然而,现有方法主要集中在生成整个器官或大型组织结构,对于具有精细结构(如心脏)的器官显示有限的有效性。由于严格的地形一致性、脆弱的冠状动脉特征和心脏成像中复杂的3D形态异质性,精确重建心脏等精细解剖结构仍然是一个巨大的挑战。针对此问题,本文提出了基于三维模板条件扩散模型的精细心脏图像合成(FCaS)框架。FCaS利用模板引导条件扩散模型(TCDM)通过双向机制实现精确的心脏结构生成。该模型通过模板指导提供目标图像的精细拓扑结构信息。同时,我们设计了一个可变形掩膜生成模块(MGM),以缓解生成过程中高质量和多样化参考掩膜的稀缺性。此外,为了减轻由不精确合成图像引起的混淆,我们提出了一种自信度自适应学习(CAL)策略,以促进下游分割任务的预训练。具体来说,我们引入跳过采样方差(SSV)估计来获得置信图,然后用于校正下游任务的预训练。实验结果表明,从FCaS生成的图像在拓扑一致性和视觉质量方面达到了最新性能水平,这极大地促进了下游任务。未来我们将发布相关代码。
论文及项目相关链接
PDF 16 pages, 9 figures
摘要
本文提出一种基于三维模板条件扩散模型的精细心脏图像合成(FCaS)框架,以解决医学成像中精细心脏结构重建的挑战。通过模板引导的条件扩散模型(TCDM)实现心脏结构的精确生成,通过双向机制利用模板提供的目标图像的精细拓扑结构信息。同时设计了一个可变形掩膜生成模块(MGM),以缓解生成过程中高质量和多样化参考掩膜的稀缺问题。此外,为了减轻由合成图像不精确引起的混淆,本文提出了一种基于信心的自适应学习(CAL)策略,促进下游分割任务的预训练。通过引入跳过采样方差(SSV)估计得到置信图,用于修正下游任务的预训练。实验结果表明,FCaS生成的图像在拓扑一致性和视觉质量方面达到了领先水平,极大地促进了下游任务。
关键见解
- FCaS框架是基于三维模板条件扩散模型提出的,旨在解决医学成像中精细心脏结构重建的挑战。
- 通过模板引导的条件扩散模型(TCDM)和双向机制实现心脏结构的精确生成。
- 设计了一个可变形掩膜生成模块(MGM),以应对生成过程中高质量和多样化参考掩膜的稀缺问题。
- 引入基于信心的自适应学习(CAL)策略,通过跳过采样方差(SSV)估计得到置信图,修正下游任务的预训练。
- 实验结果展示了FCaS在拓扑一致性和视觉质量方面的卓越性能。
- FCaS显著促进了下游任务,如医学图像分割等。
- 未来将发布相关代码。
点此查看论文截图

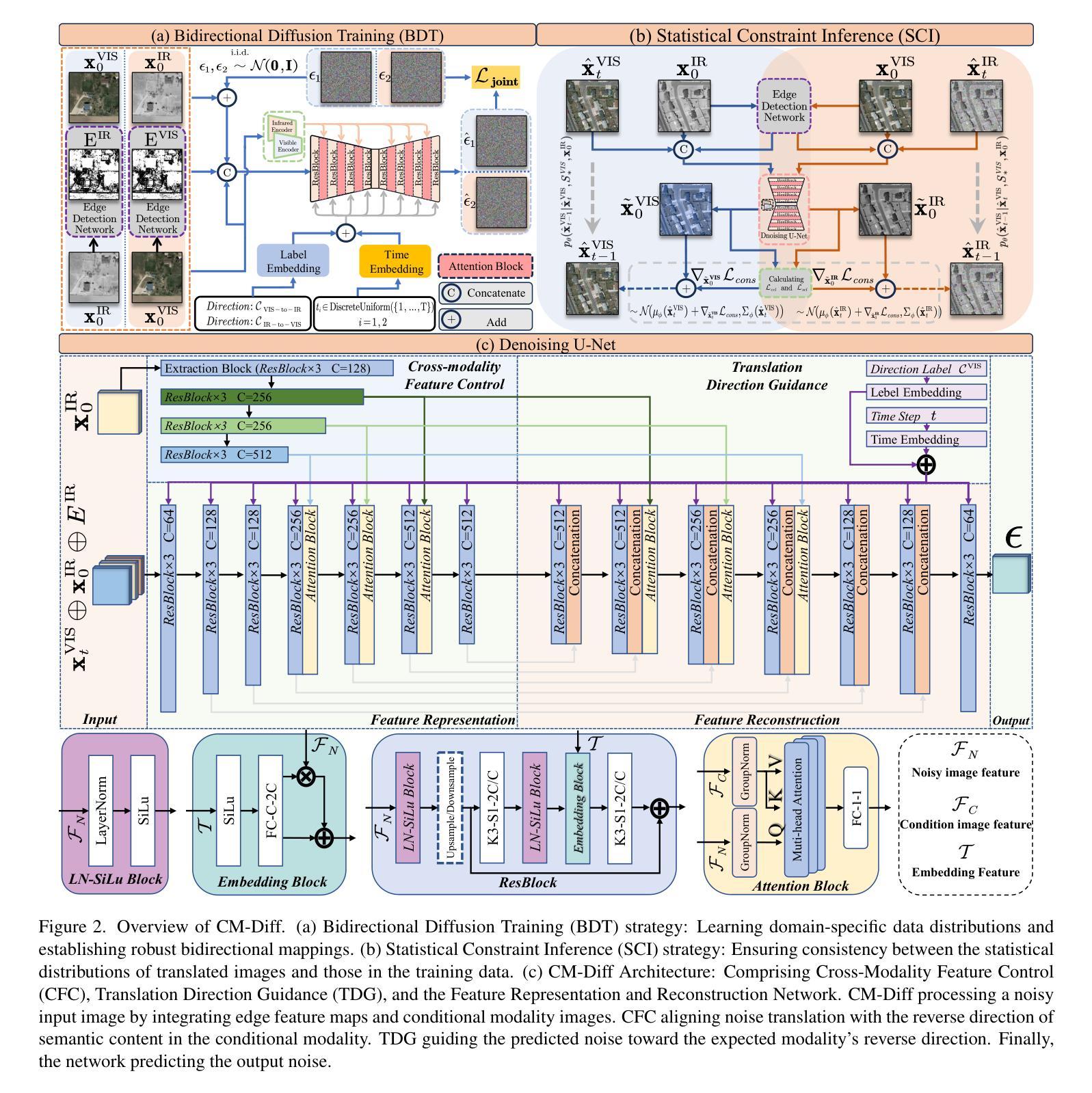
CM-Diff: A Single Generative Network for Bidirectional Cross-Modality Translation Diffusion Model Between Infrared and Visible Images
Authors:Bin Hu, Chenqiang Gao, Shurui Liu, Junjie Guo, Fang Chen, Fangcen Liu
The image translation method represents a crucial approach for mitigating information deficiencies in the infrared and visible modalities, while also facilitating the enhancement of modality-specific datasets. However, existing methods for infrared and visible image translation either achieve unidirectional modality translation or rely on cycle consistency for bidirectional modality translation, which may result in suboptimal performance. In this work, we present the cross-modality translation diffusion model (CM-Diff) for simultaneously modeling data distributions in both the infrared and visible modalities. We address this challenge by combining translation direction labels for guidance during training with cross-modality feature control. Specifically, we view the establishment of the mapping relationship between the two modalities as the process of learning data distributions and understanding modality differences, achieved through a novel Bidirectional Diffusion Training (BDT) strategy. Additionally, we propose a Statistical Constraint Inference (SCI) strategy to ensure the generated image closely adheres to the data distribution of the target modality. Experimental results demonstrate the superiority of our CM-Diff over state-of-the-art methods, highlighting its potential for generating dual-modality datasets.
图像转换方法对于减轻红外和可见模态中的信息缺失至关重要,同时有助于增强特定模态的数据集。然而,现有的红外和可见图像转换方法要么实现单向模态转换,要么依赖于循环一致性进行双向模态转换,这可能导致性能不佳。在这项工作中,我们提出了跨模态转换扩散模型(CM-Diff),用于同时建模红外和可见模态的数据分布。我们通过结合训练过程中的转换方向标签进行引导以及控制跨模态特征来解决这一挑战。具体来说,我们将建立两个模态之间的映射关系视为学习过程数据分布和理解模态差异的过程,通过一种新的双向扩散训练(BDT)策略来实现。此外,我们提出了一种统计约束推断(SCI)策略,以确保生成的图像紧密符合目标模态的数据分布。实验结果证明了我们的CM-Diff相较于最先进的方法具有优越性,凸显了其生成双模态数据集的潜力。
论文及项目相关链接
Summary
该文提出了一种跨模态翻译扩散模型(CM-Diff),该模型可以同时建模红外和可见模态的数据分布。通过结合翻译方向标签进行训练指导以及跨模态特征控制来解决这一挑战。通过新的双向扩散训练(BDT)策略来建立两种模态之间的映射关系,并提出统计约束推断(SCI)策略以确保生成的图像紧密符合目标模态的数据分布。实验结果表明,CM-Diff相较于现有方法具有优越性,具有生成双模态数据集的潜力。
Key Takeaways
- 跨模态翻译扩散模型(CM-Diff)可以同时建模红外和可见模态的数据分布。
- 该模型通过结合翻译方向标签进行训练指导,以提高性能。
- 双向扩散训练(BDT)策略用于建立两种模态之间的映射关系。
- 统计约束推断(SCI)策略确保生成的图像符合目标模态的数据分布。
- CM-Diff模型在实验中表现出优越性。
- CM-Diff模型有助于增强模态特定数据集,并减轻信息缺陷。
点此查看论文截图

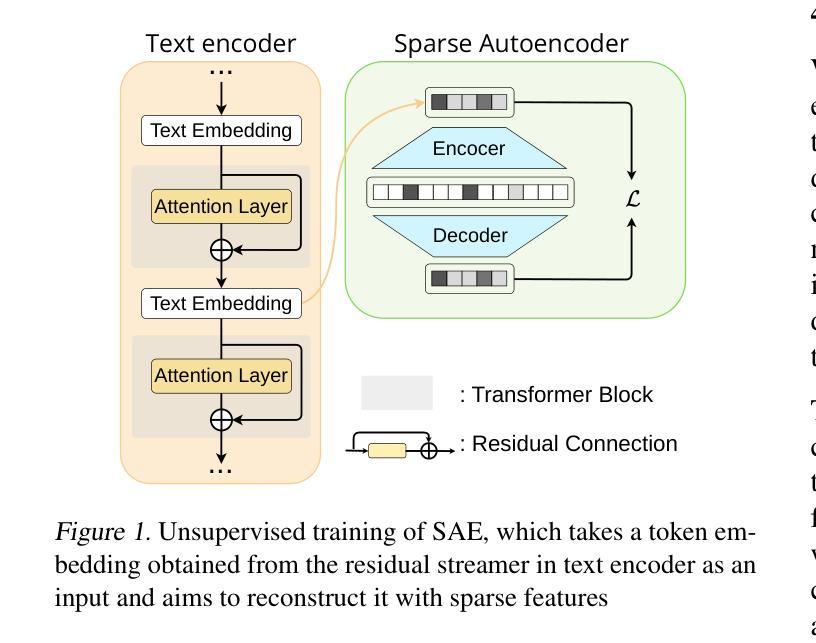
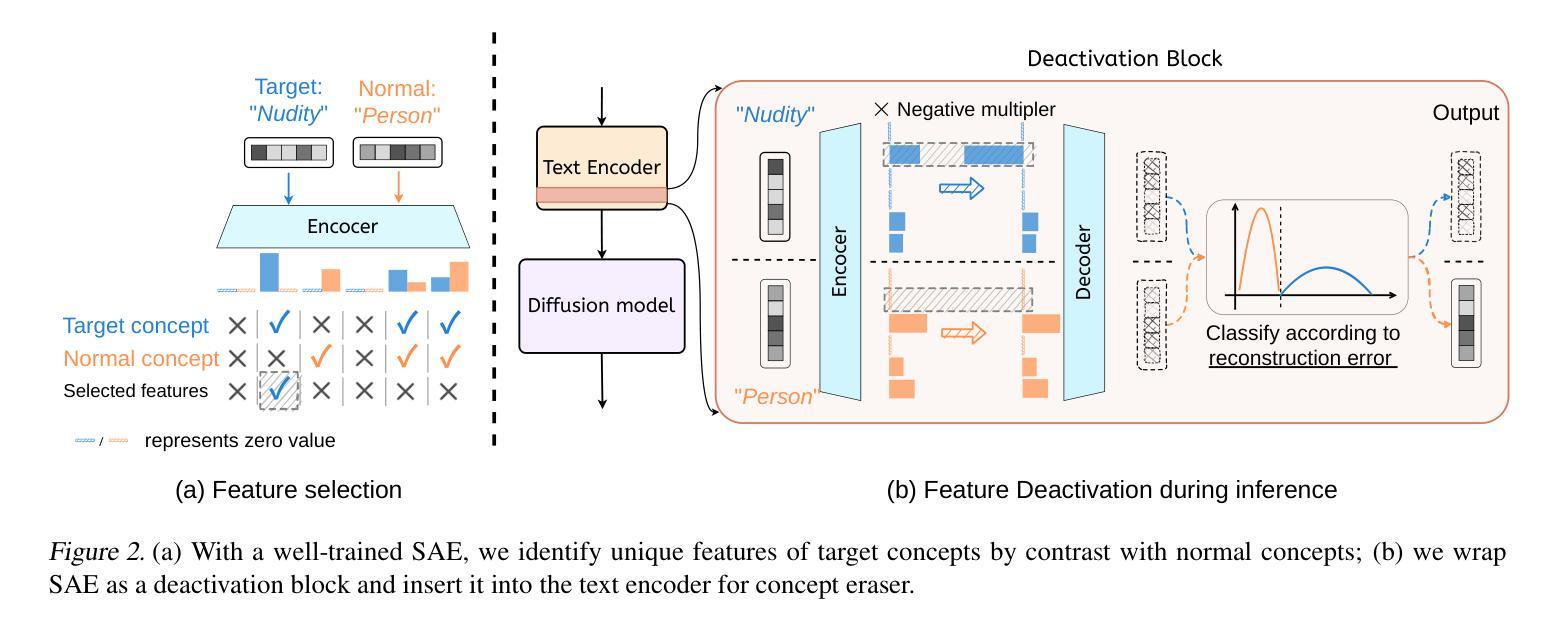
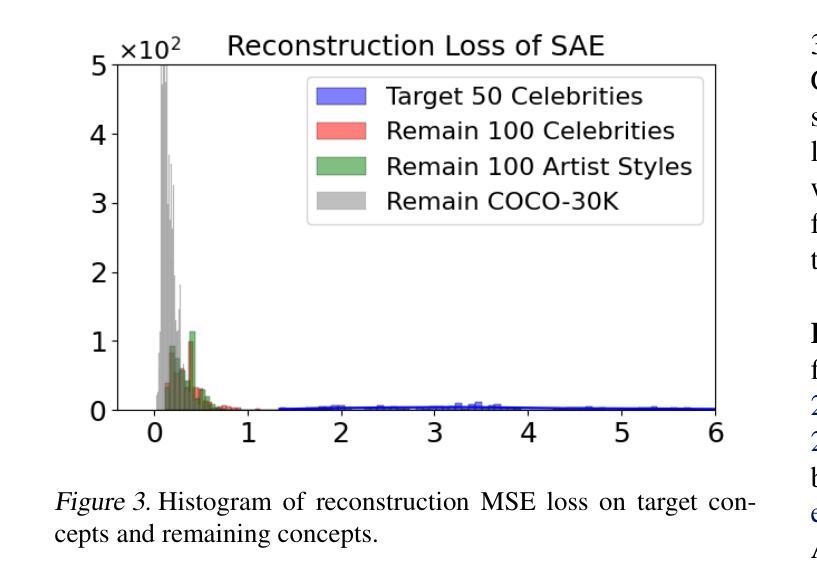
Sparse Autoencoder as a Zero-Shot Classifier for Concept Erasing in Text-to-Image Diffusion Models
Authors:Zhihua Tian, Sirun Nan, Ming Xu, Shengfang Zhai, Wenjie Qu, Jian Liu, Kui Ren, Ruoxi Jia, Jiaheng Zhang
Text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images but also raise people’s concerns about generating harmful or misleading content. While extensive approaches have been proposed to erase unwanted concepts without requiring retraining from scratch, they inadvertently degrade performance on normal generation tasks. In this work, we propose Interpret then Deactivate (ItD), a novel framework to enable precise concept removal in T2I diffusion models while preserving overall performance. ItD first employs a sparse autoencoder (SAE) to interpret each concept as a combination of multiple features. By permanently deactivating the specific features associated with target concepts, we repurpose SAE as a zero-shot classifier that identifies whether the input prompt includes target concepts, allowing selective concept erasure in diffusion models. Moreover, we demonstrate that ItD can be easily extended to erase multiple concepts without requiring further training. Comprehensive experiments across celebrity identities, artistic styles, and explicit content demonstrate ItD’s effectiveness in eliminating targeted concepts without interfering with normal concept generation. Additionally, ItD is also robust against adversarial prompts designed to circumvent content filters. Code is available at: https://github.com/NANSirun/Interpret-then-deactivate.
文本到图像(T2I)扩散模型在生成高质量图像方面取得了显著的进步,但也引发了人们对生成有害或误导性内容的担忧。虽然已提出广泛的方法在不重新训练的情况下消除不需要的概念,但它们会无意中降低正常生成任务的性能。在这项工作中,我们提出了“解释然后停用”(ItD)这一新框架,能够在T2I扩散模型中实现精确的概念移除,同时保留整体性能。ItD首先采用稀疏自动编码器(SAE)来解释每个概念是多个特征的组合。通过永久停用与目标概念相关的特定特征,我们将SAE重新定位为一种零样本分类器,用于确定输入提示是否包含目标概念,从而在扩散模型中实现选择性概念删除。此外,我们证明ItD可以很容易地扩展到删除多个概念,而无需进一步训练。在名人身份、艺术风格和明确内容方面的综合实验证明了ItD在消除目标概念方面的有效性,而不会干扰正常的概念生成。此外,ItD还能有效对抗旨在绕过内容过滤器的对抗性提示。代码可在:https://github.com/NANSirun/Interpret-then-deactivate获取。
论文及项目相关链接
PDF 25 pages
Summary
文本生成图像(T2I)扩散模型在生成高质量图像方面取得了显著进展,但也引发了人们对生成有害或误导性内容的担忧。尽管已经提出了许多方法来消除不需要的概念,而无需从头开始重新训练,但它们会无意中降低正常生成任务的性能。在这项工作中,我们提出了一个名为“解释后停用”(ItD)的新框架,可以在T2I扩散模型中实现精确的概念移除,同时保留整体性能。ItD首先使用稀疏自动编码器(SAE)来解释每个概念是多个特征的组合。通过永久停用与目标概念相关的特定特征,我们重新使用SAE作为零射击分类器,确定输入提示是否包含目标概念,从而在扩散模型中选择性地消除概念。此外,我们证明了ItD可以轻松地扩展到消除多个概念,无需进一步训练。在名人身份、艺术风格和明确内容方面的综合实验证明了ItD在消除目标概念方面的有效性,而不会干扰正常的概念生成。此外,ItD对设计用于绕过内容过滤器的对抗性提示也具有鲁棒性。相关代码已发布在:https://github.com/NANSirun/Interpret-then-deactivate。
Key Takeaways
- T2I扩散模型虽然能生成高质量图像,但存在生成有害或误导性内容的风险。
- 现有方法在去除非必要概念时可能会影响模型的正常生成任务性能。
- 提出的ItD框架利用稀疏自动编码器(SAE)解释概念并停用特定特征,实现精确的概念移除同时保留整体性能。
- ItD能够选择性地消除单个或多个概念,无需进一步训练模型。
- 实验证明ItD在消除目标概念的同时不影响正常概念生成的有效性。
- ItD对对抗性提示具有鲁棒性,能有效防止绕过内容过滤器。
点此查看论文截图

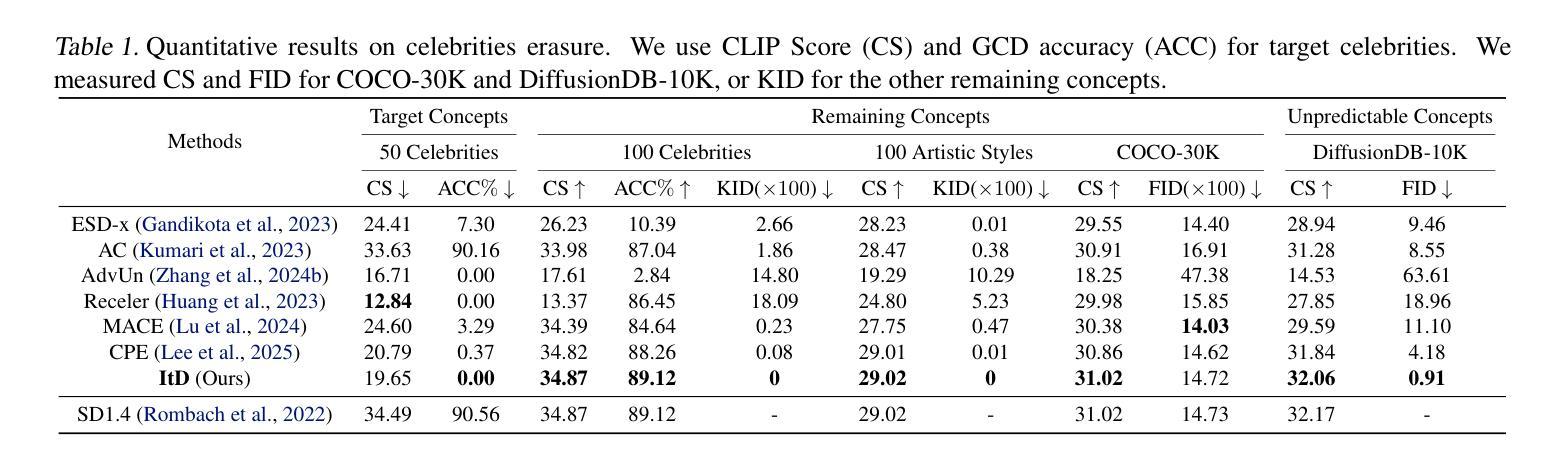
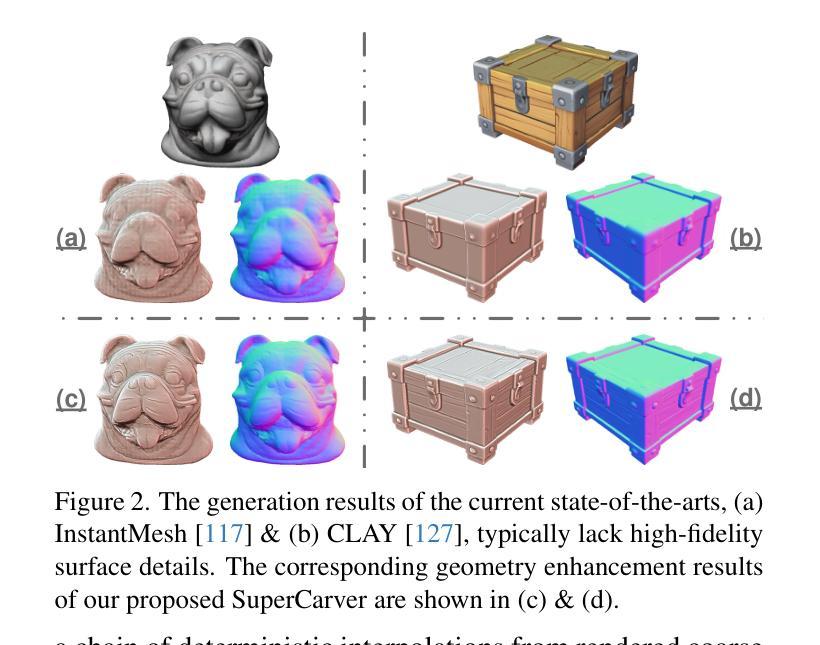
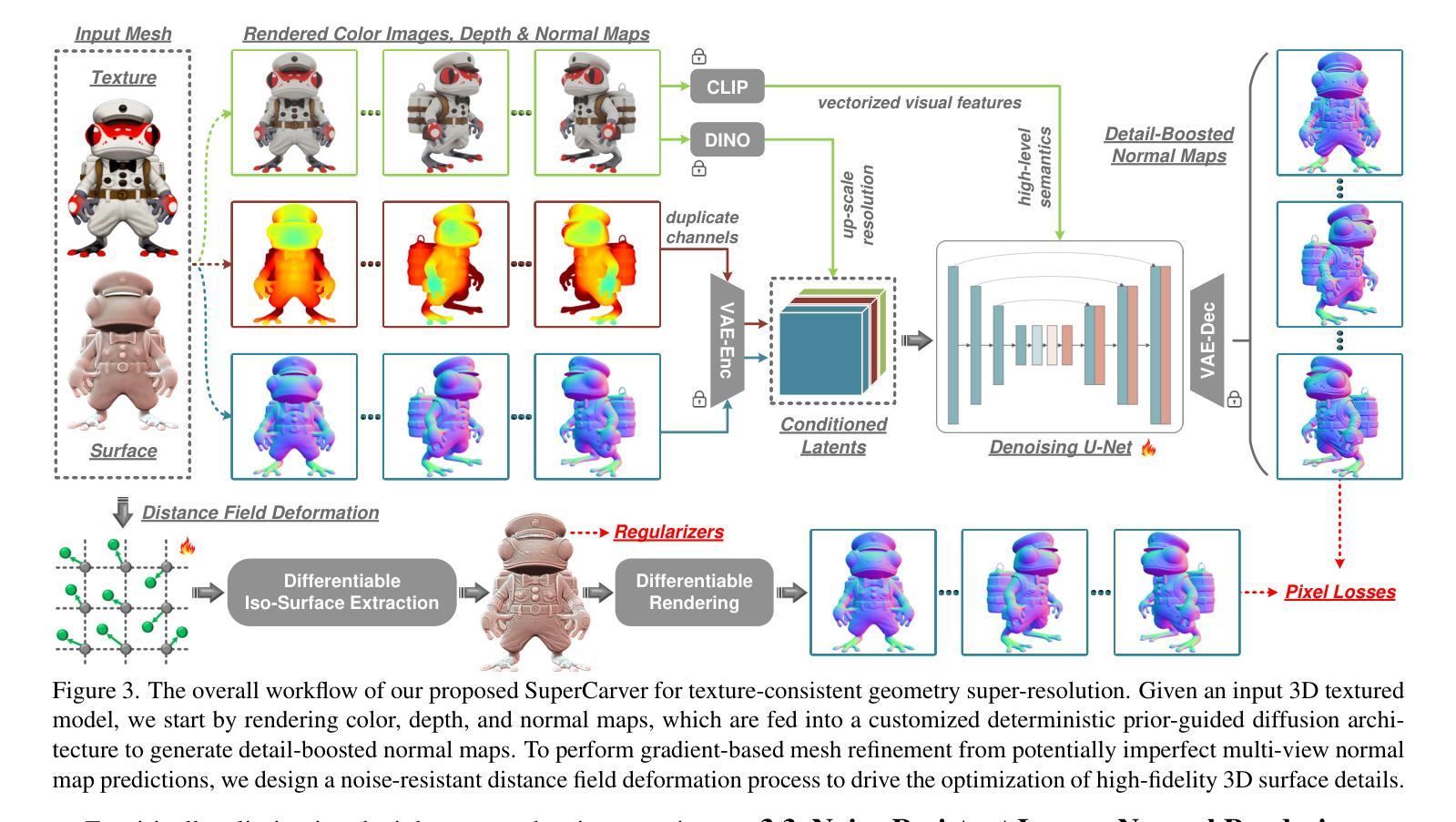
SuperCarver: Texture-Consistent 3D Geometry Super-Resolution for High-Fidelity Surface Detail Generation
Authors:Qijian Zhang, Xiaozheng Jian, Xuan Zhang, Wenping Wang, Junhui Hou
Traditional production workflow of high-precision 3D mesh assets necessitates a cumbersome and laborious process of manual sculpting by specialized modelers. The recent years have witnessed remarkable advances in AI-empowered 3D content creation. However, although the latest state-of-the-arts are already capable of generating plausible structures and intricate appearances from images or text prompts, the actual mesh surfaces are typically over-smoothing and lack geometric details. This paper introduces SuperCarver, a 3D geometry super-resolution framework particularly tailored for adding texture-consistent surface details to given coarse meshes. Technically, we start by rendering the original textured mesh into the image domain from multiple viewpoints. To achieve geometric detail generation, we develop a deterministic prior-guided normal diffusion model fine-tuned on a carefully curated dataset of paired low-poly and high-poly normal renderings. To optimize mesh structures from potentially imperfect normal map predictions, we design a simple yet effective noise-resistant inverse rendering scheme based on distance field deformation. Extensive experiments show that SuperCarver generates realistic and expressive surface details as depicted by specific texture appearances, making it a powerful tool for automatically upgrading massive outdated low-quality assets and shortening the iteration cycle of high-quality mesh production in practical applications.
传统的高精度3D网格资产生产流程需要专业建模师进行繁琐而耗时的手动雕塑。近年来,AI赋能的3D内容创作领域取得了显著进展。然而,尽管最新的先进技术已经能够从图像或文本提示中生成合理的结构和复杂的外貌,但实际的网格表面通常过于平滑,缺乏几何细节。本文介绍了SuperCarver,这是一个3D几何超分辨率框架,特别用于为给定的粗糙网格添加纹理一致的表面细节。
技术上,我们首先从多个视点将原始纹理网格渲染到图像域。为了实现几何细节生成,我们开发了一个确定性先验引导的正常扩散模型,该模型在精心挑选的低多边形和高多边形正常渲染配对数据集上进行微调。为了从可能不完美的法线映射预测结果优化网格结构,我们设计了一种简单有效的抗噪声逆向渲染方案,基于距离场变形。大量实验表明,SuperCarver能够生成与特定纹理外观相符的现实和表达性表面细节,使其成为自动升级大量过时低质量资产、缩短高质量网格制作迭代周期的强大工具。
论文及项目相关链接
Summary
本文介绍了一个名为SuperCarver的3D几何超分辨率框架,该框架特别设计用于为给定的粗糙网格添加纹理一致的表面细节。通过从多个视点将原始纹理网格渲染到图像域,并结合确定性先验引导的正常扩散模型,在精心挑选的低多边形和高多边形正常渲染数据集上进行微调,以生成几何细节。同时,设计了一种简单有效的抗噪声逆向渲染方案,基于距离场变形优化网格结构。SuperCarver能够生成逼真的表面细节,缩短高质量网格生产的迭代周期,是升级大量旧的低质量资产的有力工具。
Key Takeaways
- SuperCarver框架用于为给定的粗糙网格添加纹理一致的表面细节。
- 通过从多个视点渲染原始纹理网格到图像域来实现细节生成。
- 结合确定性先验引导的正常扩散模型,在特定数据集上进行微调以生成几何细节。
- 设计了一种基于距离场变形的抗噪声逆向渲染方案来优化网格结构。
- SuperCarver能够生成逼真的表面细节,特别适合升级旧的低质量资产。
- 该框架缩短了高质量网格生产的迭代周期。
点此查看论文截图


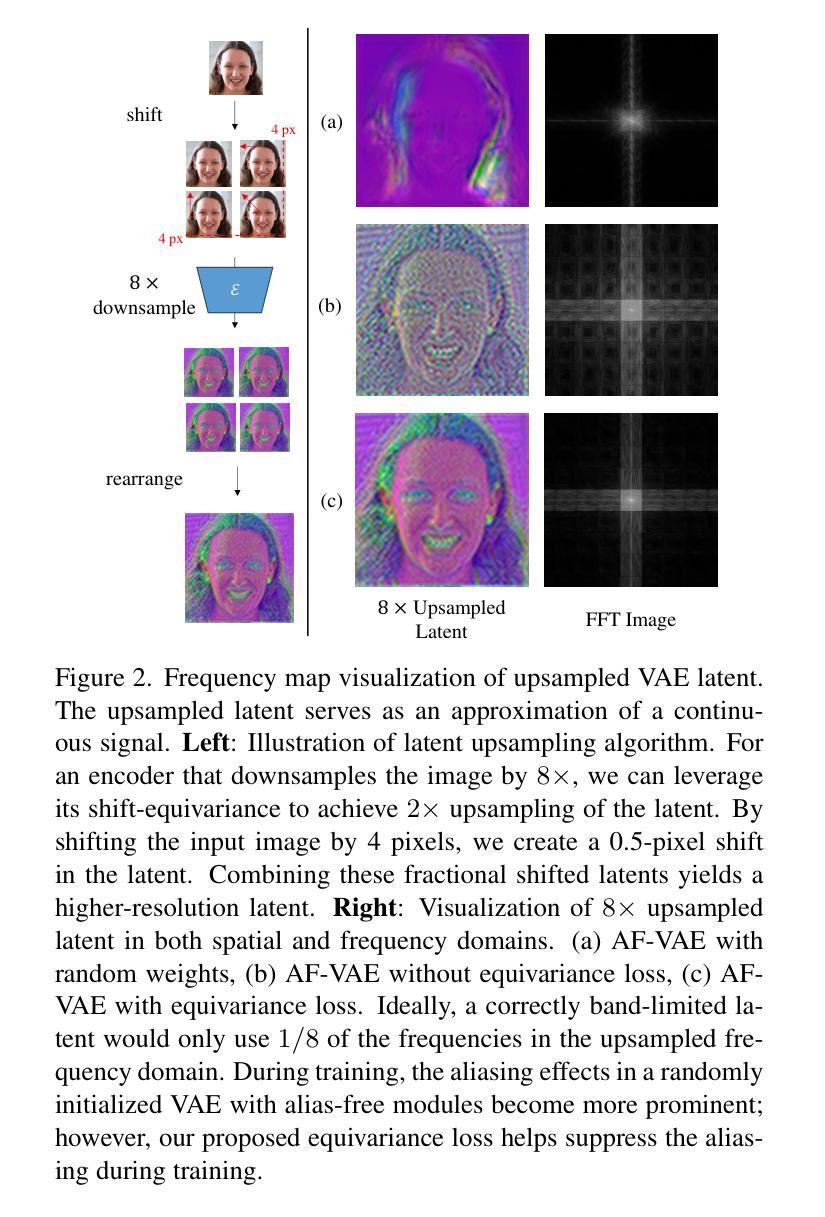
Alias-Free Latent Diffusion Models:Improving Fractional Shift Equivariance of Diffusion Latent Space
Authors:Yifan Zhou, Zeqi Xiao, Shuai Yang, Xingang Pan
Latent Diffusion Models (LDMs) are known to have an unstable generation process, where even small perturbations or shifts in the input noise can lead to significantly different outputs. This hinders their applicability in applications requiring consistent results. In this work, we redesign LDMs to enhance consistency by making them shift-equivariant. While introducing anti-aliasing operations can partially improve shift-equivariance, significant aliasing and inconsistency persist due to the unique challenges in LDMs, including 1) aliasing amplification during VAE training and multiple U-Net inferences, and 2) self-attention modules that inherently lack shift-equivariance. To address these issues, we redesign the attention modules to be shift-equivariant and propose an equivariance loss that effectively suppresses the frequency bandwidth of the features in the continuous domain. The resulting alias-free LDM (AF-LDM) achieves strong shift-equivariance and is also robust to irregular warping. Extensive experiments demonstrate that AF-LDM produces significantly more consistent results than vanilla LDM across various applications, including video editing and image-to-image translation. Code is available at: https://github.com/SingleZombie/AFLDM
潜在扩散模型(LDMs)的生成过程不稳定,输入噪声的微小扰动或变化都可能导致显著不同的输出。这阻碍了它们在需要一致结果的应用中的适用性。在这项工作中,我们重新设计了LDMs,通过使其具有平移等变性来增强一致性。虽然引入抗混叠操作可以部分改善平移等变性,但由于LDM中的独特挑战,仍然存在严重的混叠和不一致性,包括1)在VAE训练和多U-Net推理过程中的混叠放大,以及2)本质上缺乏平移等变性的自注意力模块。为了解决这些问题,我们重新设计了注意力模块以实现平移等变性,并提出了一种等效性损失,该损失有效地抑制了连续域中特征的频率带宽。由此产生的无混叠LDM(AF-LDM)实现了强大的平移等变性,并且对不规则变形具有鲁棒性。大量实验表明,AF-LDM在各种应用中产生的结果比原始LDM更加一致,包括视频编辑和图像到图像的翻译。代码可在:https://github.com/SingleZombie/AFLDM访问。
论文及项目相关链接
Summary
本文主要关注潜在扩散模型(Latent Diffusion Models,简称LDMs)的一致性问题。为了提高模型在不同应用中的稳定性和一致性,研究人员对其进行重新设计以提高其位移等价性。研究探讨了如何优化反混叠操作及重构注意模块以增加模型的一致性并克服特定的模型挑战。该研究成果以一个改进版命名为别名无LDM(AF-LDM),在视频编辑和图像到图像翻译等应用中表现显著优于常规LDM。代码已公开于GitHub上。
Key Takeaways
- LDM具有不稳定的生成过程,对输入噪声的微小变化反应敏感,可能导致输出结果的巨大差异。这限制了其在实际应用中的适用性。
- 为了提高LDM的一致性,研究人员通过设计使其具有位移等价性来改进模型。这有助于模型在不同情境下生成更稳定的结果。
- 反混叠操作的部分引入有助于增强模型的位移等价性,但LDM的固有挑战仍可能导致混叠和不一致性。这些挑战包括在VAE训练期间的混叠放大和多个U-Net推断等。
- LDM中的自注意力模块本质上缺乏位移等价性,因此研究人员重新设计了注意力模块以解决这一问题。
- 为了更有效地提高一致性,研究人员提出了一种等价损失函数,用于抑制连续域中的特征频率带宽。这一改进有助于AF-LDM实现更稳定的性能。
- AF-LDM在视频编辑和图像到图像翻译等应用中表现出显著优势,相较于常规LDM能生成更一致的结果。这表明AF-LDM在实际应用中具有更高的稳定性和可靠性。
点此查看论文截图

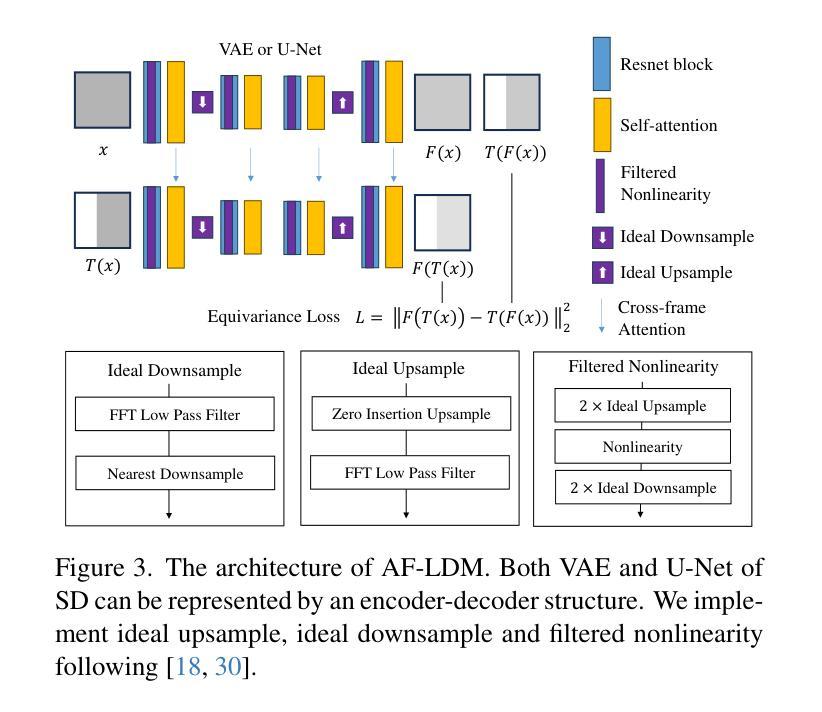


Diff-CL: A Novel Cross Pseudo-Supervision Method for Semi-supervised Medical Image Segmentation
Authors:Xiuzhen Guo, Lianyuan Yu, Ji Shi, Na Lei, Hongxiao Wang
Semi-supervised learning utilizes insights from unlabeled data to improve model generalization, thereby reducing reliance on large labeled datasets. Most existing studies focus on limited samples and fail to capture the overall data distribution. We contend that combining distributional information with detailed information is crucial for achieving more robust and accurate segmentation results. On the one hand, with its robust generative capabilities, diffusion models (DM) learn data distribution effectively. However, it struggles with fine detail capture, leading to generated images with misleading details. Combining DM with convolutional neural networks (CNNs) enables the former to learn data distribution while the latter corrects fine details. While capturing complete high-frequency details by CNNs requires substantial computational resources and is susceptible to local noise. On the other hand, given that both labeled and unlabeled data come from the same distribution, we believe that regions in unlabeled data similar to overall class semantics to labeled data are likely to belong to the same class, while regions with minimal similarity are less likely to. This work introduces a semi-supervised medical image segmentation framework from the distribution perspective (Diff-CL). Firstly, we propose a cross-pseudo-supervision learning mechanism between diffusion and convolution segmentation networks. Secondly, we design a high-frequency mamba module to capture boundary and detail information globally. Finally, we apply contrastive learning for label propagation from labeled to unlabeled data. Our method achieves state-of-the-art (SOTA) performance across three datasets, including left atrium, brain tumor, and NIH pancreas datasets.
半监督学习利用无标签数据的见解来提高模型的泛化能力,从而减少了对大量有标签数据集的依赖。现有的大多数研究集中在有限样本上,无法捕捉整体数据分布。我们认为,将分布信息与详细信息相结合对于实现更稳健和准确的分割结果至关重要。一方面,扩散模型(DM)具有强大的生成能力,能够有效地学习数据分布。然而,它在捕捉细节方面存在困难,导致生成的图像细节误导。将DM与卷积神经网络(CNNs)相结合,使DM能够学习数据分布,而后者则校正细节。虽然CNN捕捉完整的高频细节需要大量的计算资源,并容易受到局部噪声的影响。另一方面,鉴于有标签和无标签数据来自同一分布,我们认为无标签数据中与有标签数据的整体类别语义相似的区域很可能属于同一类别,而相似性极小的区域则不太可能属于同一类别。这项工作从分布角度引入了一个半监督医学图像分割框架(Diff-CL)。首先,我们提出了一种扩散和卷积分割网络之间的跨伪监督学习机制。其次,我们设计了一个高频mamba模块,以全局捕获边界和详细信息。最后,我们应用对比学习,实现从有标签数据到无标签数据的标签传播。我们的方法在左心房、脑肿瘤和NIH胰腺数据集上的表现均达到最新水平。
论文及项目相关链接
Summary
半监督学习通过利用无标签数据的见解提高模型泛化能力,减少依赖大量有标签数据集。本研究结合分布信息和细节信息对于实现更稳健和准确的分割结果至关重要。扩散模型有效学习数据分布,但难以捕捉精细细节。将其与卷积神经网络结合,前者学习数据分布而后者校正细节。本研究从分布角度引入半监督医学图像分割框架(Diff-CL),提出交叉伪监督学习机制、设计高频mamba模块以全局捕获边界和细节信息,并采用对比学习进行标签从有标签数据向无标签数据的传播。该方法在左心房、脑肿瘤和NIH胰腺数据集上均达到最新技术水平。
Key Takeaways
- 半监督学习利用无标签数据提升模型泛化能力。
- 扩散模型与卷积神经网络的结合能互补各自的优势,提高图像分割的准确性。
- 扩散模型擅长学习数据分布,而卷积神经网络擅长捕捉精细细节。
- 提出了一种新的半监督医学图像分割框架(Diff-CL),包含交叉伪监督学习机制和高频mamba模块。
- 高频mamba模块能够全局捕获边界和细节信息。
- 对比学习用于标签从有标签数据向无标签数据的传播。
- 该方法在多个数据集上达到了最新技术水平。
点此查看论文截图

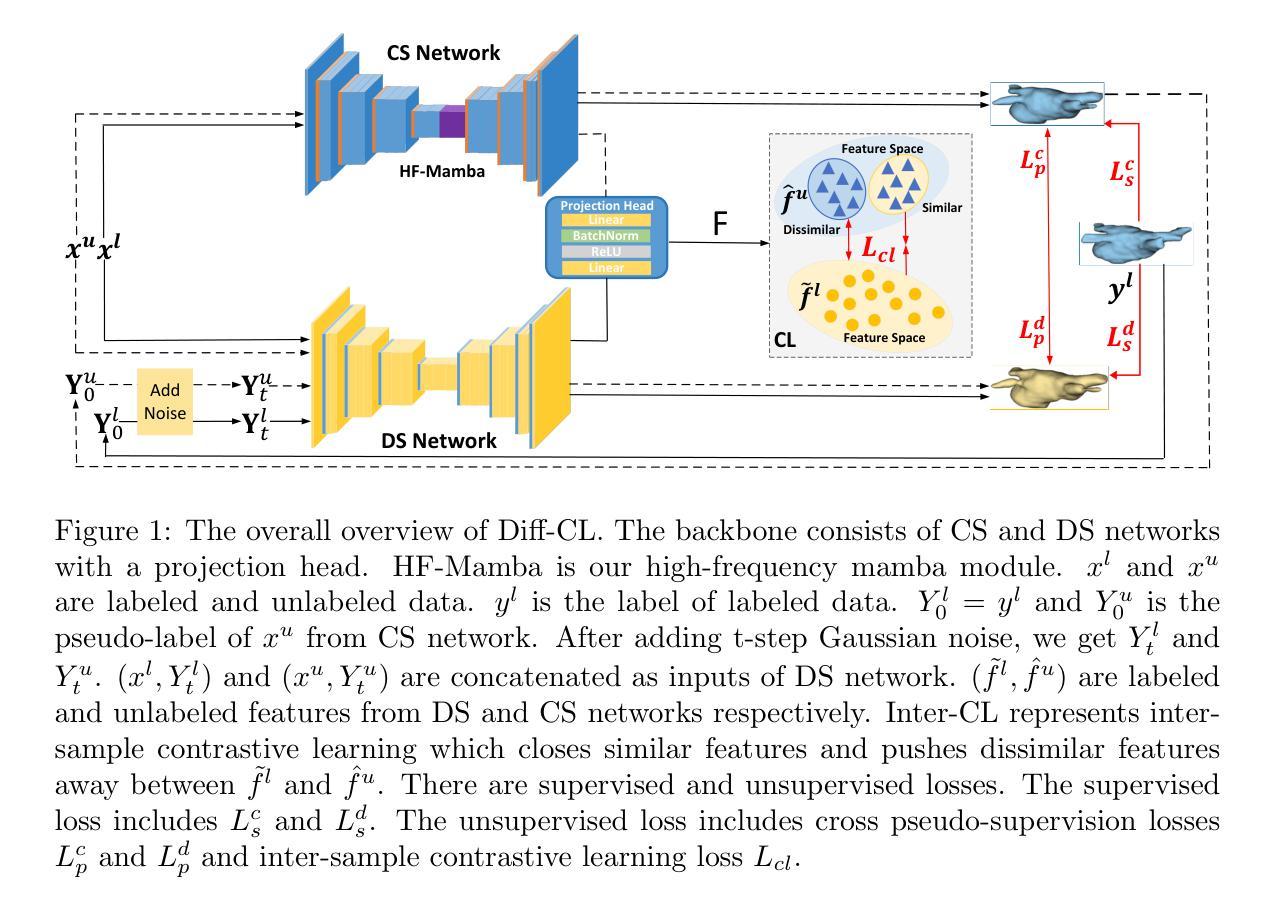
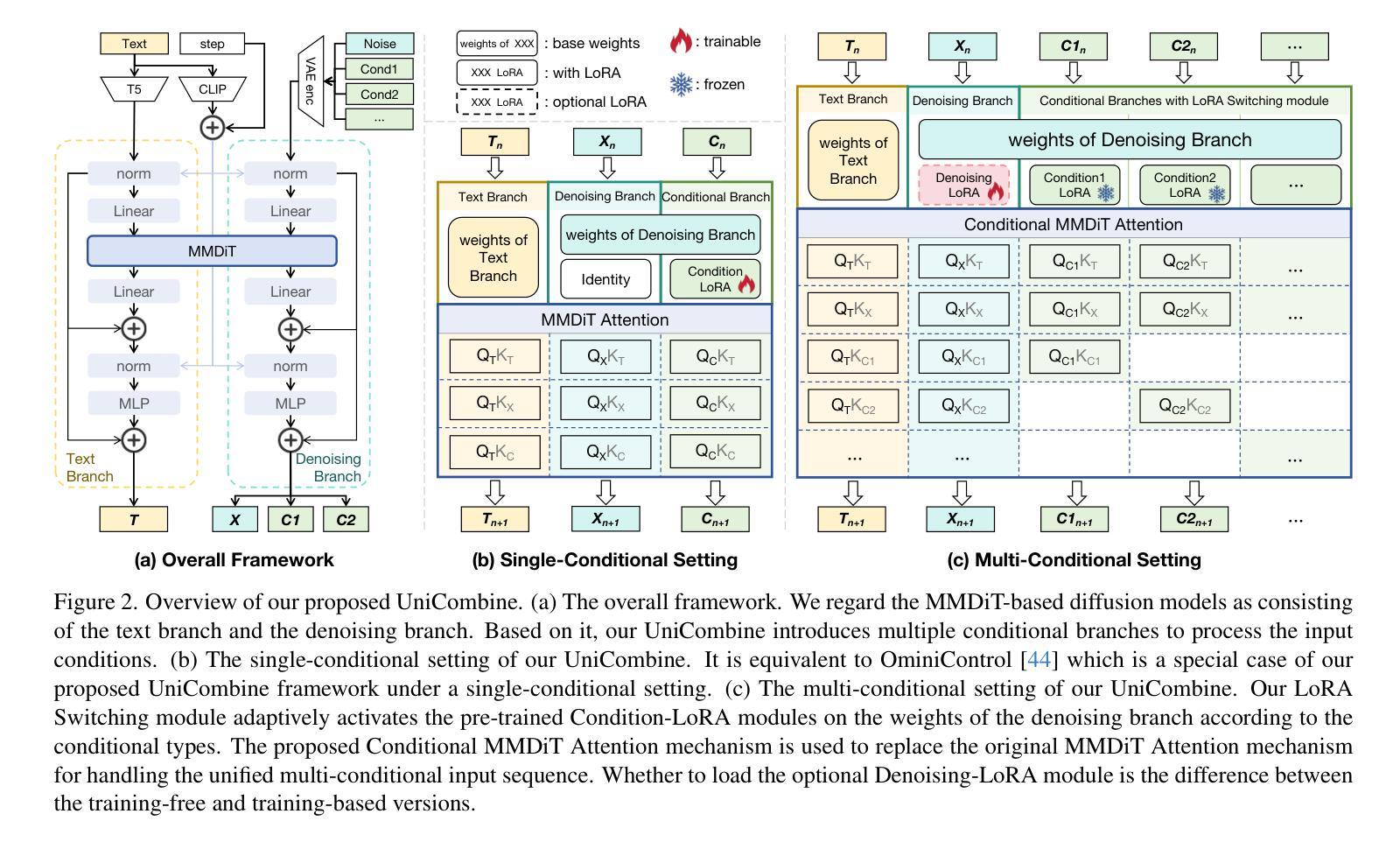
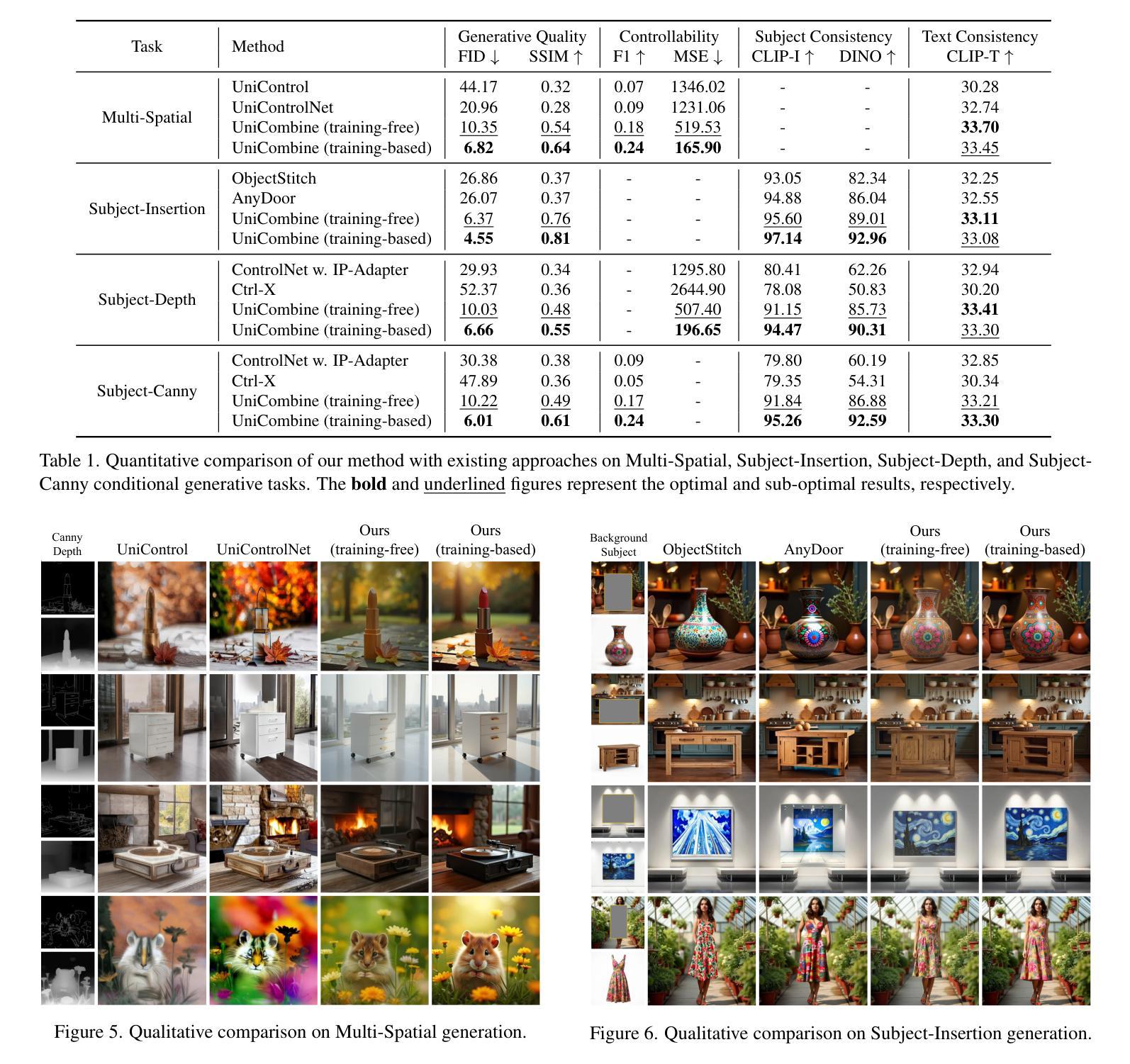
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Authors:Haoxuan Wang, Jinlong Peng, Qingdong He, Hao Yang, Ying Jin, Jiafu Wu, Xiaobin Hu, Yanjie Pan, Zhenye Gan, Mingmin Chi, Bo Peng, Yabiao Wang
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
随着扩散模型在图像生成领域的快速发展,对更强大、更灵活的可控框架的需求也在增加。尽管现有方法可以在文本提示之外引导生成,但如何在保持与所有条件一致的同时有效地结合多个条件输入仍然是一个未解决的问题。为了解决这一挑战,我们引入了UniCombine,这是一个基于DiT的多条件可控生成框架,能够处理任何条件组合,包括但不限于文本提示、空间地图和主题图像。具体来说,我们引入了一种新型的Conditional MMDiT Attention机制,并融入了一个可训练的LoRA模块,来构建免训练的和基于训练的两个版本。此外,我们提出了一个新的流程来构建SubjectSpatial200K数据集,这是专为多条件生成任务设计的第一个数据集,涵盖主题驱动和空间对齐的条件。在多种条件下的生成实验结果表明,我们的方法具有出色的通用性和强大的能力,性能处于业界领先水平。
论文及项目相关链接
Summary
随着扩散模型在图像生成领域的快速发展,对更强大、更灵活的可控框架的需求不断增加。现有方法虽能指导超越文本提示的生成,但如何在保持所有条件一致性的同时,有效结合多个条件输入仍是一个挑战。为此,我们推出了UniCombine,一个基于DiT的多条件可控生成框架,能够处理各种条件组合,包括但不限于文本提示、空间地图和主题图像。
Key Takeaways
- 扩散模型在图像生成领域的应用快速发展,对更先进、多功能的可控框架需求增加。
- 现有方法在结合多个条件输入时面临挑战,难以保持所有条件的一致性。
- UniCombine是一个基于DiT的多条件可控生成框架,能够处理各种条件组合。
- 引入了新型的Conditional MMDiT Attention机制,并结合可训练的LoRA模块,构建无需训练或基于训练的两个版本。
- 提出了构建SubjectSpatial200K数据集的新流程,这是专门为多条件生成任务设计的第一个数据集,涵盖主题驱动和空间对齐的条件。
- 实验结果表明,UniCombine方法在多种条件下的生成能力具有出色的通用性和强大性能。
点此查看论文截图

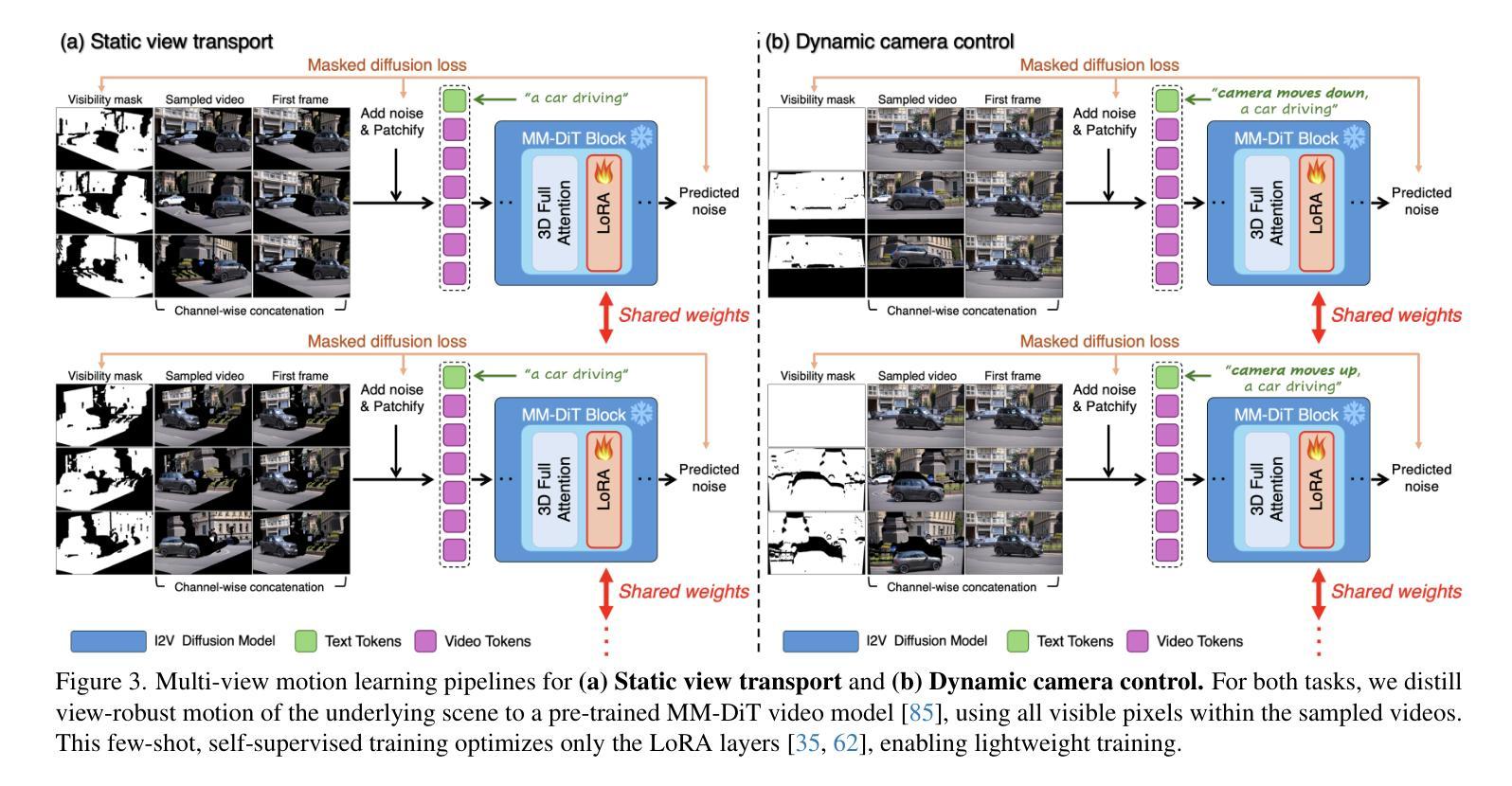
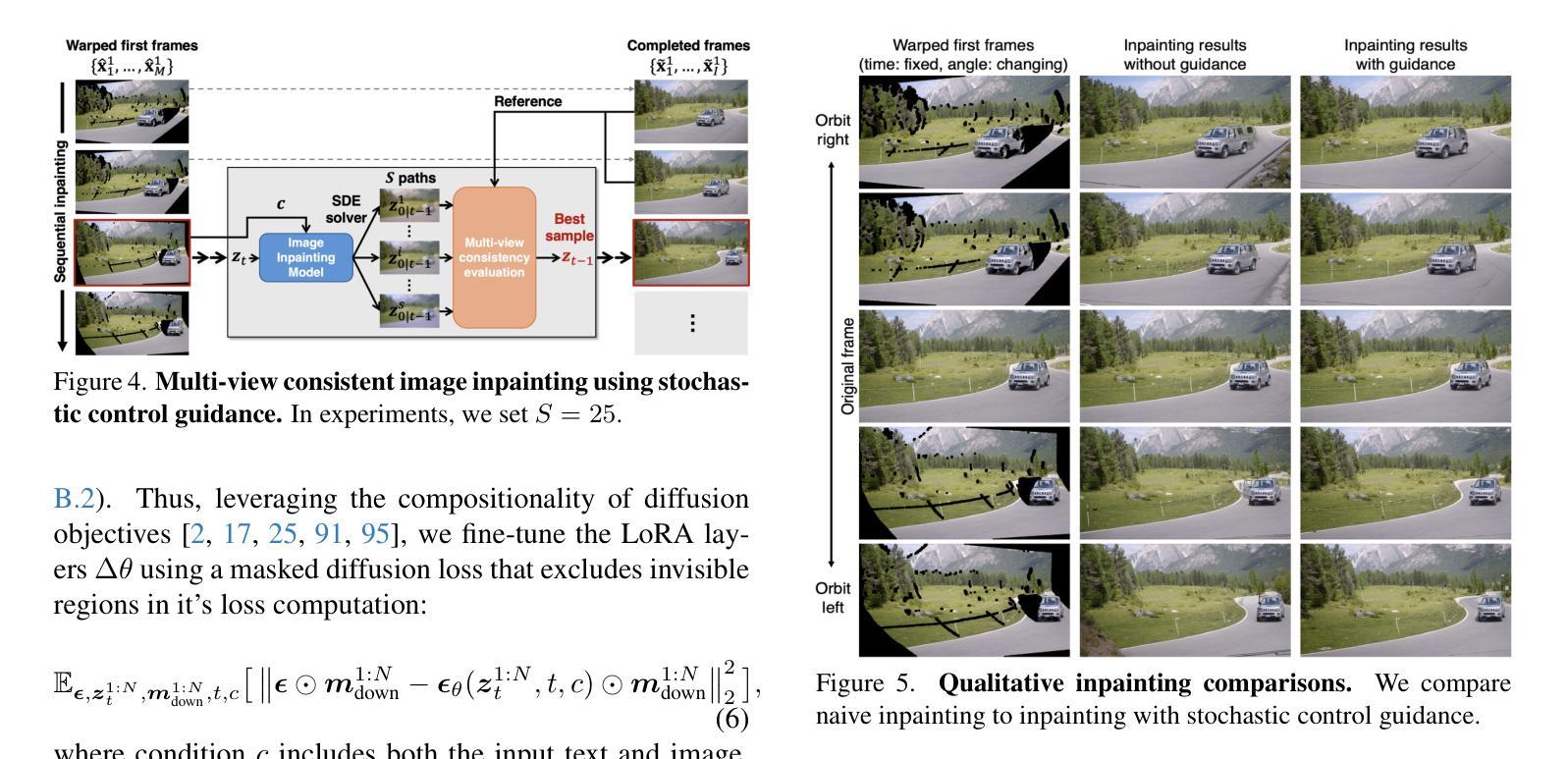
Reangle-A-Video: 4D Video Generation as Video-to-Video Translation
Authors:Hyeonho Jeong, Suhyeon Lee, Jong Chul Ye
We introduce Reangle-A-Video, a unified framework for generating synchronized multi-view videos from a single input video. Unlike mainstream approaches that train multi-view video diffusion models on large-scale 4D datasets, our method reframes the multi-view video generation task as video-to-videos translation, leveraging publicly available image and video diffusion priors. In essence, Reangle-A-Video operates in two stages. (1) Multi-View Motion Learning: An image-to-video diffusion transformer is synchronously fine-tuned in a self-supervised manner to distill view-invariant motion from a set of warped videos. (2) Multi-View Consistent Image-to-Images Translation: The first frame of the input video is warped and inpainted into various camera perspectives under an inference-time cross-view consistency guidance using DUSt3R, generating multi-view consistent starting images. Extensive experiments on static view transport and dynamic camera control show that Reangle-A-Video surpasses existing methods, establishing a new solution for multi-view video generation. We will publicly release our code and data. Project page: https://hyeonho99.github.io/reangle-a-video/
我们介绍了Reangle-A-Video,这是一个从单个输入视频生成同步多视角视频的统一框架。不同于主流方法在大型4D数据集上训练多视角视频扩散模型,我们的方法将多视角视频生成任务重新定位为视频到视频的翻译,并利用可公开获取的图像和视频扩散先验。本质上,Reangle-A-Video分为两个阶段。第一阶段是多视角运动学习:以自监督的方式同步微调图像到视频扩散转换器,从一组变形视频中提取视角不变的运动。第二阶段是多视角一致图像到图像的翻译:输入视频的第一帧在推理时间跨视角一致性指导下被变形和填充到各种相机视角,使用DUSt3R生成多视角一致的首帧图像。在静态视角传输和动态相机控制方面的广泛实验表明,Reangle-A-Video超越了现有方法,为多视角视频生成建立了新的解决方案。我们将公开发布我们的代码和数据。项目页面:https://hyeonho99.github.io/reangle-a-video/。
论文及项目相关链接
PDF Project page: https://hyeonho99.github.io/reangle-a-video/
Summary
本文介绍了Reangle-A-Video框架,该框架能够从单一输入视频生成同步多视角视频。不同于主流方法在大型4D数据集上训练多视角视频扩散模型,Reangle-A-Video将多视角视频生成任务重新定义为视频到视频的翻译,并利用公开可用的图像和视频扩散先验。其核心操作分为两个阶段:首先是多视角运动学习,通过自监督方式同步微调图像到视频扩散转换器,从一组变形视频中提取视角不变的运动;其次是多视角一致图像到图像的翻译,将输入视频的第一帧在推理时间下进行跨视角一致性指导,变形并填充成各种相机视角,生成多视角一致的开始图像。实验表明,Reangle-A-Video在静态视角传输和动态相机控制方面超越了现有方法,为多视角视频生成提供了新的解决方案。
Key Takeaways
- Reangle-A-Video是一个统一框架,可以从单一输入视频生成同步多视角视频。
- 与主流方法不同,Reangle-A-Video将多视角视频生成重新定义为视频到视频的翻译任务。
- 该方法利用图像和视频扩散先验。
- Reangle-A-Video操作分为两个阶段:多视角运动学习和多视角一致图像到图像的翻译。
- 通过自监督方式同步微调图像到视频扩散转换器,提取视角不变的运动。
- 在推理时间下,利用跨视角一致性指导生成多视角一致的开始图像。
- 实验表明,Reangle-A-Video在静态视角传输和动态相机控制方面表现优异,为多视角视频生成提供了新的解决方案。
点此查看论文截图



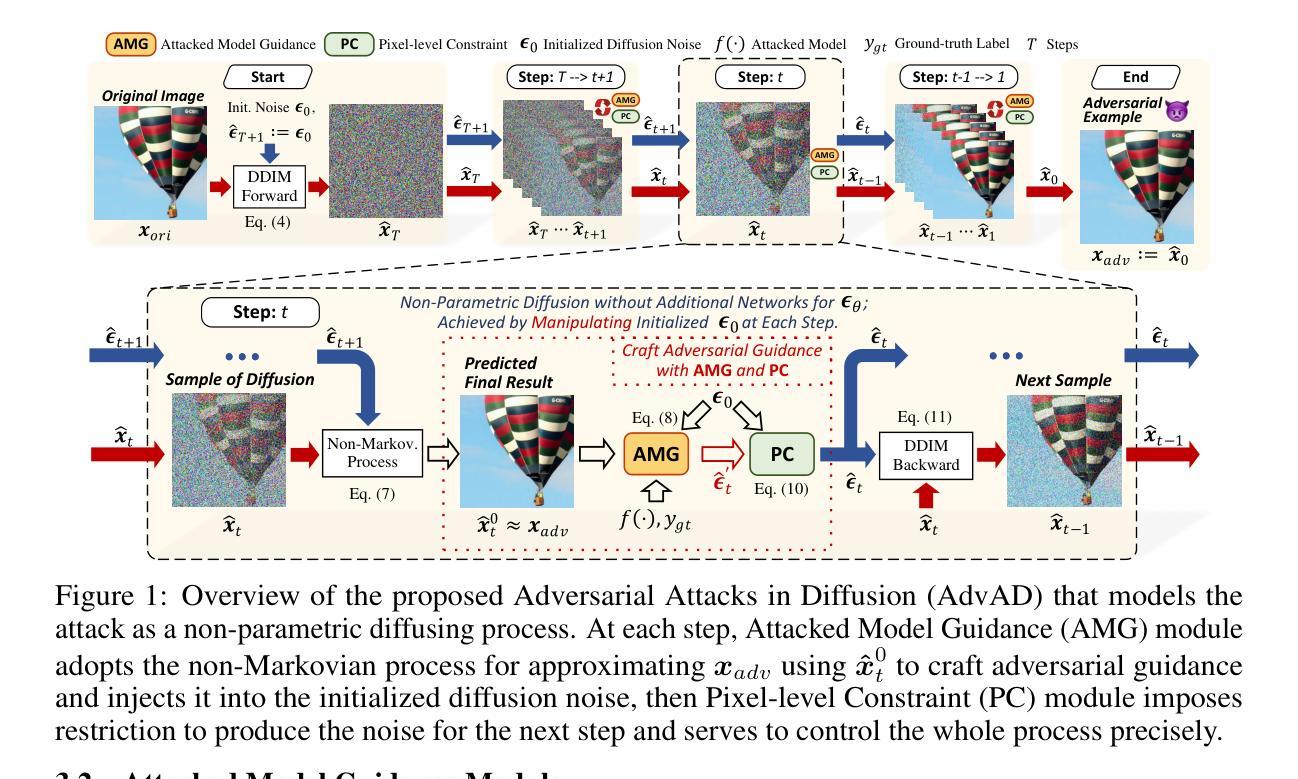
AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks
Authors:Jin Li, Ziqiang He, Anwei Luo, Jian-Fang Hu, Z. Jane Wang, Xiangui Kang
Imperceptible adversarial attacks aim to fool DNNs by adding imperceptible perturbation to the input data. Previous methods typically improve the imperceptibility of attacks by integrating common attack paradigms with specifically designed perception-based losses or the capabilities of generative models. In this paper, we propose Adversarial Attacks in Diffusion (AdvAD), a novel modeling framework distinct from existing attack paradigms. AdvAD innovatively conceptualizes attacking as a non-parametric diffusion process by theoretically exploring basic modeling approach rather than using the denoising or generation abilities of regular diffusion models requiring neural networks. At each step, much subtler yet effective adversarial guidance is crafted using only the attacked model without any additional network, which gradually leads the end of diffusion process from the original image to a desired imperceptible adversarial example. Grounded in a solid theoretical foundation of the proposed non-parametric diffusion process, AdvAD achieves high attack efficacy and imperceptibility with intrinsically lower overall perturbation strength. Additionally, an enhanced version AdvAD-X is proposed to evaluate the extreme of our novel framework under an ideal scenario. Extensive experiments demonstrate the effectiveness of the proposed AdvAD and AdvAD-X. Compared with state-of-the-art imperceptible attacks, AdvAD achieves an average of 99.9$%$ (+17.3$%$) ASR with 1.34 (-0.97) $l_2$ distance, 49.74 (+4.76) PSNR and 0.9971 (+0.0043) SSIM against four prevalent DNNs with three different architectures on the ImageNet-compatible dataset. Code is available at https://github.com/XianguiKang/AdvAD.
难以察觉的对抗性攻击旨在通过向输入数据添加难以察觉的扰动来欺骗深度神经网络(DNNs)。之前的方法通常通过整合常见的攻击模式与专门设计的基于感知的损失或生成模型的能力来改善攻击的难以察觉性。在本文中,我们提出了扩散模型中的对抗性攻击(AdvAD),这是一种不同于现有攻击模式的新型建模框架。AdvAD创新地将攻击概念化为非参数扩散过程,通过理论探索基本的建模方法,而不是使用常规扩散模型的降噪或生成能力,这需要神经网络。在每一步中,我们使用仅受攻击模型构建的更为微妙但有效的对抗性指导,无需任何额外的网络,这逐渐引导扩散过程的最终状态从原始图像到期望的难以察觉的对抗性示例。基于所提出的非参数扩散过程的坚实理论基础,AdvAD实现了高攻击效果和难以察觉性,并且具有本质上更低的总体扰动强度。此外,还提出了增强版AdvAD-X,以在理想场景下评估我们新框架的极限。大量实验证明了所提出的AdvAD和AdvAD-X的有效性。与最新的难以察觉的攻击相比,AdvAD在针对具有三种不同架构的四种深度神经网络的ImageNet兼容数据集上,实现了平均99.9%(+ 17.3%)的攻击成功率(ASR),同时具有1.34(- 0.97)的L2距离,49.74(+ 4.76)的峰值信号噪声比(PSNR)和0.9971(+ 0.0043)的结构相似性度量(SSIM)。代码可在https://github.com/XianguiKang/AdvAD获得。
论文及项目相关链接
PDF Accept by NeurIPS 2024. Please cite this paper using the following format: J. Li, Z. He, A. Luo, J. Hu, Z. Wang, X. Kang*, “AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks”, the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, Canada, Dec 9-15, 2024. Code: https://github.com/XianguiKang/AdvAD
摘要
本文提出一种名为AdvAD的新型攻击框架,将攻击概念化为非参数扩散过程,不同于现有的攻击范式。该方法在理论上探索基本的建模方法,不使用常规扩散模型的去噪或生成能力,而是通过微妙的对抗性指导逐步引导扩散过程的结束,从原始图像到期望的几乎无法察觉的对抗性示例。AdvAD在坚实的非参数扩散过程理论基础上,实现了高攻击效果和难以察觉的特性,具有内在更低的总体扰动强度。此外,还提出了增强版AdvAD-X来评估理想场景下的新型框架极限。实验证明,与最先进的难以察觉的攻击相比,AdvAD在针对四个流行DNN的ImageNet兼容数据集上,平均攻击成功率提高17.3%,L2距离降低0.97,峰值信噪比提高4.76,结构相似性指数提高0.0043。
关键见解
- AdvAD是一种新型的攻击框架,将攻击概念化为非参数扩散过程。
- 该方法不依赖于常规扩散模型的去噪或生成能力。
- AdvAD通过微妙的对抗性指导逐步引导扩散过程。
- 该方法在理论上探索基本的建模方法,实现高攻击效果和难以察觉的特性。
- AdvAD具有内在更低的总体扰动强度。
- 提出了增强版AdvAD-X来评估框架的极限。
- 实验证明,与现有技术相比,AdvAD在攻击成功率、L2距离、峰值信噪比和结构相似性指数等方面表现出优势。
点此查看论文截图

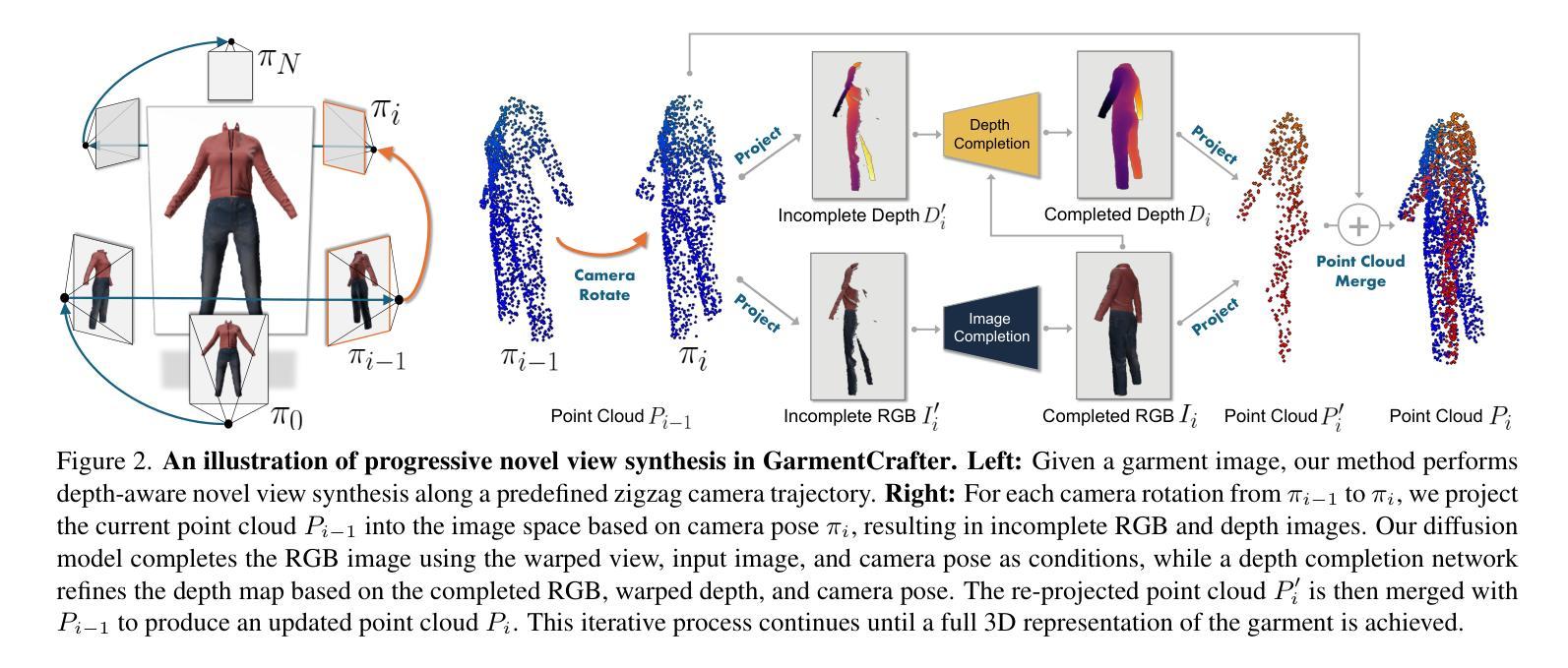
GarmentCrafter: Progressive Novel View Synthesis for Single-View 3D Garment Reconstruction and Editing
Authors:Yuanhao Wang, Cheng Zhang, Gonçalo Frazão, Jinlong Yang, Alexandru-Eugen Ichim, Thabo Beeler, Fernando De la Torre
We introduce GarmentCrafter, a new approach that enables non-professional users to create and modify 3D garments from a single-view image. While recent advances in image generation have facilitated 2D garment design, creating and editing 3D garments remains challenging for non-professional users. Existing methods for single-view 3D reconstruction often rely on pre-trained generative models to synthesize novel views conditioning on the reference image and camera pose, yet they lack cross-view consistency, failing to capture the internal relationships across different views. In this paper, we tackle this challenge through progressive depth prediction and image warping to approximate novel views. Subsequently, we train a multi-view diffusion model to complete occluded and unknown clothing regions, informed by the evolving camera pose. By jointly inferring RGB and depth, GarmentCrafter enforces inter-view coherence and reconstructs precise geometries and fine details. Extensive experiments demonstrate that our method achieves superior visual fidelity and inter-view coherence compared to state-of-the-art single-view 3D garment reconstruction methods.
我们介绍了GarmentCrafter,这是一种新方法,使非专业用户能够从单视图图像创建和修改3D服装。虽然最近图像生成的进步促进了2D服装设计,但对于非专业用户来说,创建和编辑3D服装仍然具有挑战性。现有的单视图3D重建方法通常依赖于预训练的生成模型,根据参考图像和相机姿态合成新视图,但它们缺乏跨视图的一致性,无法捕捉不同视图之间的内部关系。在本文中,我们通过渐进的深度预测和图像扭曲来近似新视图,以解决这一挑战。随后,我们训练了一个多视图扩散模型,以根据不断变化的相机姿态,完成被遮挡和未知的服装区域。通过联合推断RGB和深度,GarmentCrafter强制实施跨视图一致性,并重建精确几何和精细细节。大量实验表明,与最先进的单视图3D服装重建方法相比,我们的方法实现了更高的视觉保真度和跨视图一致性。
论文及项目相关链接
PDF Project Page: https://humansensinglab.github.io/garment-crafter/
Summary
GarmentCrafter是一种新方法,能够让非专业用户从单视角图像创建和修改3D服装。尽管最近图像生成技术的进步促进了2D服装设计,但为非营利用户创建和编辑3D服装仍然具有挑战性。现有单视图3D重建方法通常依赖于预训练的生成模型来根据参考图像和相机姿态合成新视图,但它们缺乏跨视图的一致性,无法捕捉不同视图之间的内部关系。本研究通过渐进的深度预测和图像扭曲来近似新视图,然后训练一个多视图扩散模型,以根据不断变化的相机姿态完成被遮挡和未知的服装区域。通过联合推断RGB和深度,GarmentCrafter强制跨视图一致性并重建精确的几何形状和细节。实验表明,与最先进的单视图3D服装重建方法相比,我们的方法实现了更高的视觉保真度和跨视图一致性。
Key Takeaways
- GarmentCrafter是一种面向非专业用户的3D服装设计新方法。
- 现有单视图3D重建方法存在跨视图一致性缺失的问题。
- 通过渐进的深度预测和图像扭曲来近似新视图是GarmentCrafter解决挑战的关键步骤。
- 多视图扩散模型根据相机姿态完成被遮挡和未知的服装区域。
- GarmentCrafter通过联合推断RGB和深度信息来强制跨视图一致性。
- GarmentCrafter在精确重建几何形状和细节方面表现出色。
点此查看论文截图


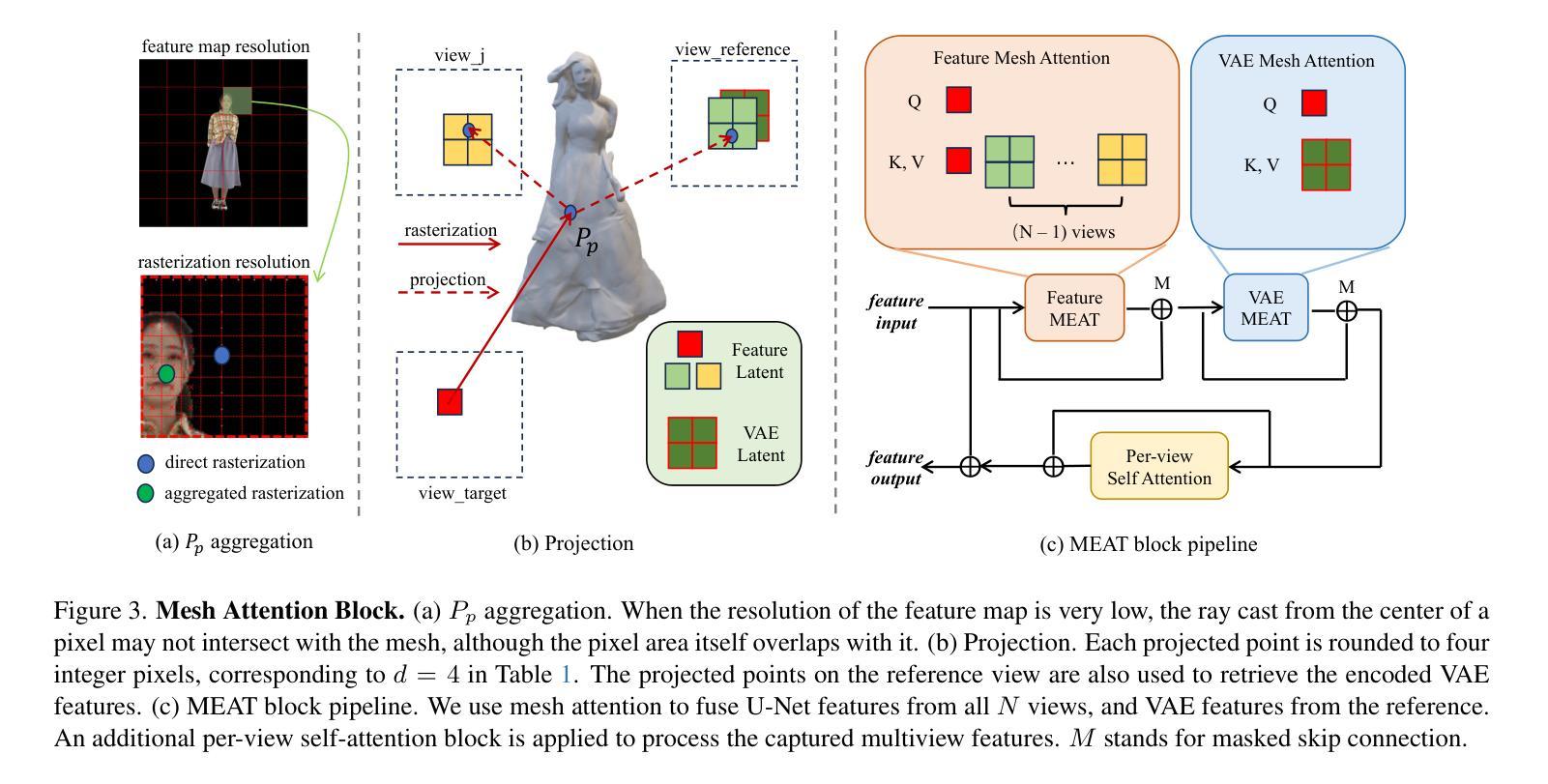
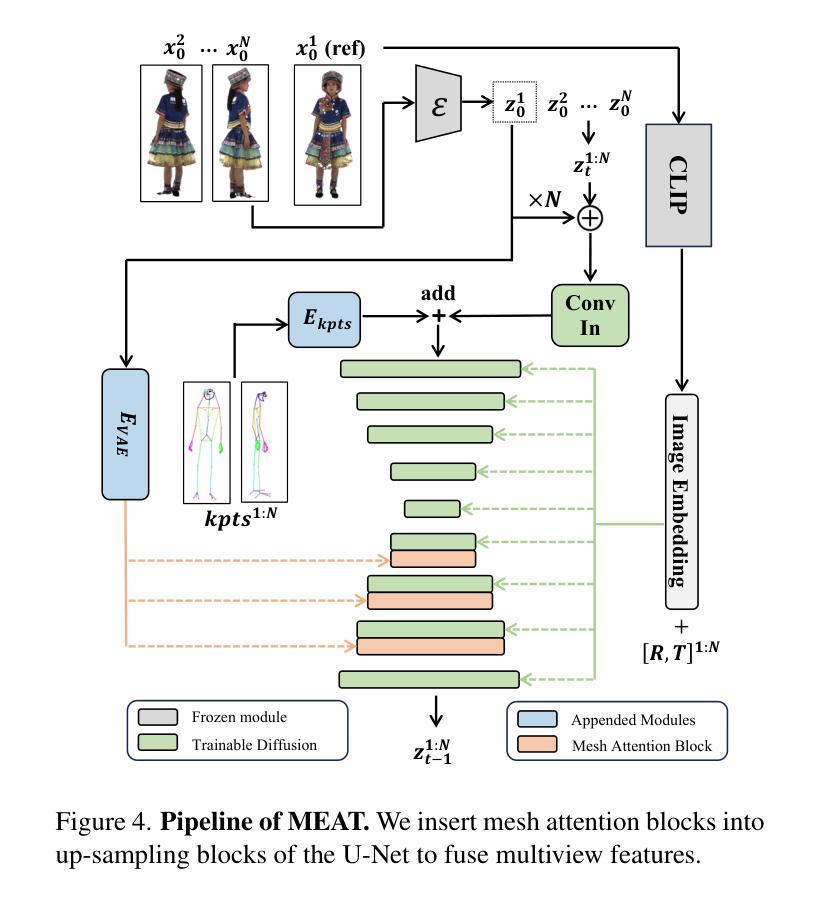
MEAT: Multiview Diffusion Model for Human Generation on Megapixels with Mesh Attention
Authors:Yuhan Wang, Fangzhou Hong, Shuai Yang, Liming Jiang, Wayne Wu, Chen Change Loy
Multiview diffusion models have shown considerable success in image-to-3D generation for general objects. However, when applied to human data, existing methods have yet to deliver promising results, largely due to the challenges of scaling multiview attention to higher resolutions. In this paper, we explore human multiview diffusion models at the megapixel level and introduce a solution called mesh attention to enable training at 1024x1024 resolution. Using a clothed human mesh as a central coarse geometric representation, the proposed mesh attention leverages rasterization and projection to establish direct cross-view coordinate correspondences. This approach significantly reduces the complexity of multiview attention while maintaining cross-view consistency. Building on this foundation, we devise a mesh attention block and combine it with keypoint conditioning to create our human-specific multiview diffusion model, MEAT. In addition, we present valuable insights into applying multiview human motion videos for diffusion training, addressing the longstanding issue of data scarcity. Extensive experiments show that MEAT effectively generates dense, consistent multiview human images at the megapixel level, outperforming existing multiview diffusion methods.
多视角扩散模型在一般物体的图像到3D生成中取得了显著的成功。然而,当应用于人类数据时,现有方法尚未取得令人满意的结果,这主要是因为将多视角注意力扩展到高分辨率面临的挑战。在本文中,我们在兆像素级别探索了人类多视角扩散模型,并引入了一种名为网格注意力的解决方案,以实现在1024x1024分辨率下的训练。以穿衣人体网格作为中心粗糙几何表示,所提出的网格注意力利用光线追踪和投影建立直接跨视图坐标对应关系。这种方法在保持跨视图一致性的同时,大大降低了多视角注意力的复杂性。在此基础上,我们设计了一个网格注意力块,并与关键点条件相结合,创建了专门针对人类的多视角扩散模型MEAT。此外,我们还提供了将多视角人类运动视频应用于扩散训练的宝贵见解,解决了长期存在的数据稀缺问题。大量实验表明,MEAT能够在兆像素级别有效地生成密集、一致的多视角人类图像,优于现有的多视角扩散方法。
论文及项目相关链接
PDF CVPR 2025. Code https://github.com/johannwyh/MEAT Project Page https://johann.wang/MEAT/
Summary
多视角扩散模型在通用对象的三维生成图像中取得了显著成功,但在处理人类数据时仍面临挑战。本文探索了在百万像素级别上的人类多视角扩散模型,并提出了一种名为网格注意力的解决方案,以实现1024x1024分辨率的训练。该解决方案利用着装人体网格作为基本的粗糙几何表示,通过光线追踪和投影建立跨视图坐标的对应关系。在此基础上,我们开发了网格注意力模块,并与关键点条件相结合,创建了特定于人类的多视角扩散模型MEAT。此外,我们还提供了利用多视角人类运动视频进行扩散训练的见解,解决了长期存在的数据稀缺问题。实验表明,MEAT能够在百万像素级别生成密集、一致的多视角人类图像,优于现有的多视角扩散方法。
Key Takeaways
- 多视角扩散模型在通用对象的三维生成图像中表现良好,但在处理人类数据时面临挑战。
- 网格注意力解决方案被提出来解决在更高分辨率(如1024x1024)下的人类多视角扩散模型的训练问题。
- 网格注意力利用人体网格作为基本几何表示,通过光线追踪和投影实现跨视图坐标的对应关系。
- 网格注意力模块与关键点条件相结合,创建了特定于人类的多视角扩散模型MEAT。
- MEAT能够在百万像素级别生成密集、一致的多视角人类图像,性能优于现有方法。
- 本文还提供了利用多视角人类运动视频进行扩散训练的见解,有助于解决数据稀缺的问题。
点此查看论文截图



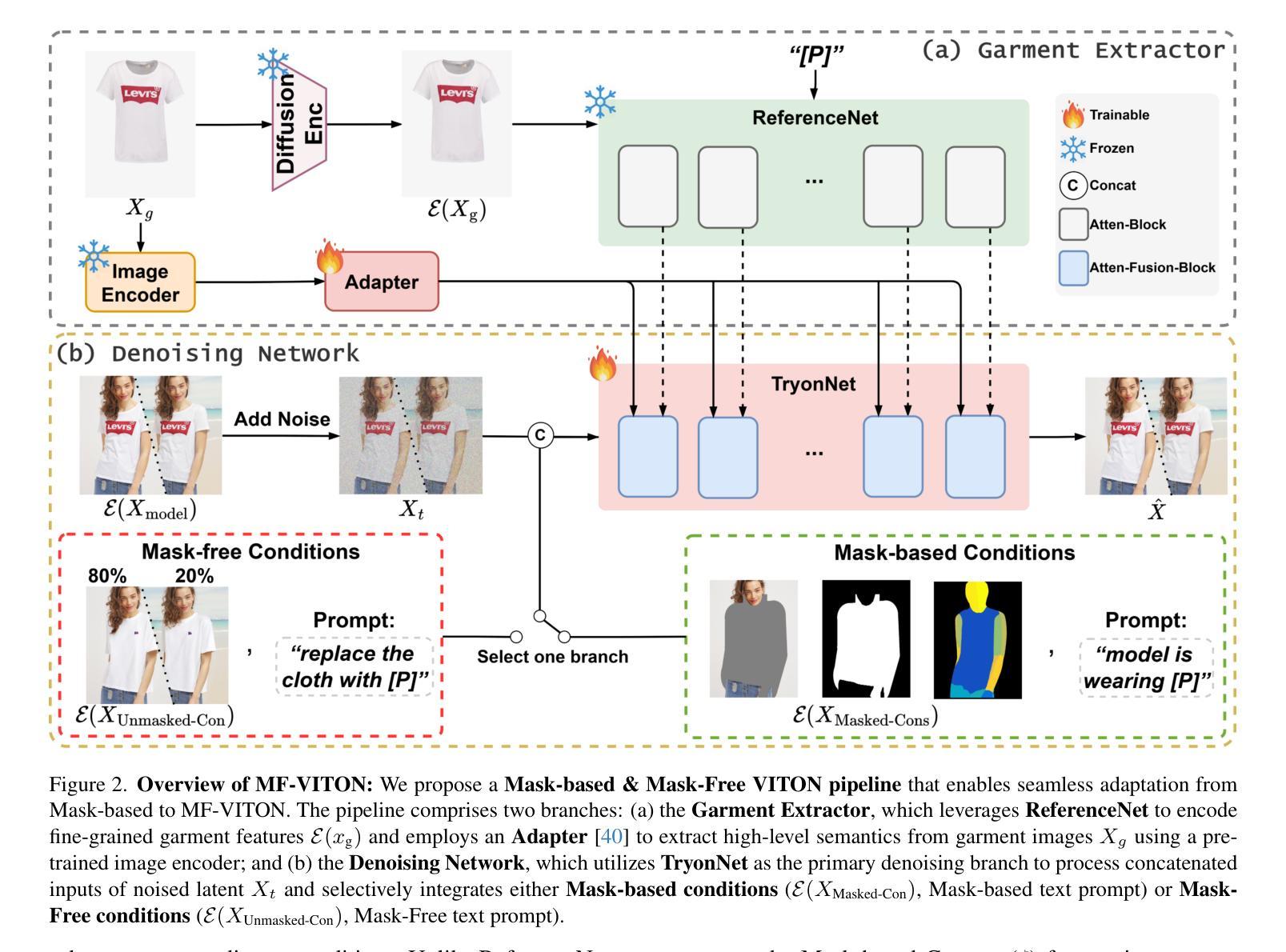
MF-VITON: High-Fidelity Mask-Free Virtual Try-On with Minimal Input
Authors:Zhenchen Wan, Yanwu xu, Dongting Hu, Weilun Cheng, Tianxi Chen, Zhaoqing Wang, Feng Liu, Tongliang Liu, Mingming Gong
Recent advancements in Virtual Try-On (VITON) have significantly improved image realism and garment detail preservation, driven by powerful text-to-image (T2I) diffusion models. However, existing methods often rely on user-provided masks, introducing complexity and performance degradation due to imperfect inputs, as shown in Fig.1(a). To address this, we propose a Mask-Free VITON (MF-VITON) framework that achieves realistic VITON using only a single person image and a target garment, eliminating the requirement for auxiliary masks. Our approach introduces a novel two-stage pipeline: (1) We leverage existing Mask-based VITON models to synthesize a high-quality dataset. This dataset contains diverse, realistic pairs of person images and corresponding garments, augmented with varied backgrounds to mimic real-world scenarios. (2) The pre-trained Mask-based model is fine-tuned on the generated dataset, enabling garment transfer without mask dependencies. This stage simplifies the input requirements while preserving garment texture and shape fidelity. Our framework achieves state-of-the-art (SOTA) performance regarding garment transfer accuracy and visual realism. Notably, the proposed Mask-Free model significantly outperforms existing Mask-based approaches, setting a new benchmark and demonstrating a substantial lead over previous approaches. For more details, visit our project page: https://zhenchenwan.github.io/MF-VITON/.
最新的虚拟试穿(VITON)技术进展,在强大的文本到图像(T2I)扩散模型的推动下,显著提高了图像的真实感和服装细节保留。然而,现有方法往往依赖于用户提供的蒙版,由于输入的不完美,引入了复杂性和性能下降,如图1(a)所示。为了解决这一问题,我们提出了无蒙版VITON(MF-VITON)框架,该框架仅使用单人图像和目标服装实现真实的虚拟试穿,无需辅助蒙版。我们的方法引入了一个新颖的两阶段流程:(1)我们利用现有的基于蒙版的VITON模型合成高质量数据集。该数据集包含人员图像和相应服装的多样化、真实的配对,并增加了不同的背景以模拟真实场景。(2)在生成的数据集上对预训练的基于蒙版模型进行微调,实现了无需蒙版的服装转移。这一阶段简化了输入要求,同时保持了服装纹理和形状的真实性。我们的框架在服装转移准确性和视觉真实性方面达到了最新水平。值得注意的是,所提出的无蒙版模型显著优于现有的基于蒙版方法,设定了新的基准,并在之前的方法中显示出巨大的领先优势。更多细节,请访问我们的项目页面:https://zhenchenwan.github.io/MF-VITON/。
论文及项目相关链接
PDF The project page is available at: https://zhenchenwan.github.io/MF-VITON/
Summary
最新进展的虚拟试穿(VITON)技术已显著提高图像真实感和服装细节保留度,得益于强大的文本到图像(T2I)扩散模型。为克服现有方法依赖用户提供的遮罩所带来的复杂性和性能下降问题,我们提出了无遮罩VITON(MF-VITON)框架,仅使用单人图像和目标服装实现逼真的虚拟试穿。通过引入两阶段管道,利用基于遮罩的VITON模型合成高质量数据集并进行微调,消除对辅助遮罩的需求,简化输入要求的同时保持服装纹理和形状保真度。MF-VITON框架在服装转移准确性和视觉逼真度方面达到最新水平,显著优于现有基于遮罩的方法。
Key Takeaways
- 最新VITON技术提高了图像真实感和服装细节保留度,借助T2I扩散模型推动发展。
- 现有VITON方法依赖用户提供的遮罩,导致复杂性和性能下降。
- MF-VITON框架实现无遮罩的虚拟试穿,仅使用单人图像和目标服装。
- MF-VITON通过两阶段管道引入高质量数据集合成和模型微调。
- 第一阶段利用基于遮罩的VITON模型合成多样化、逼真的个人图像和对应服装图像。
- 第二阶段对预训练的基于遮罩的模型进行微调,实现无遮罩的服装转移。
点此查看论文截图

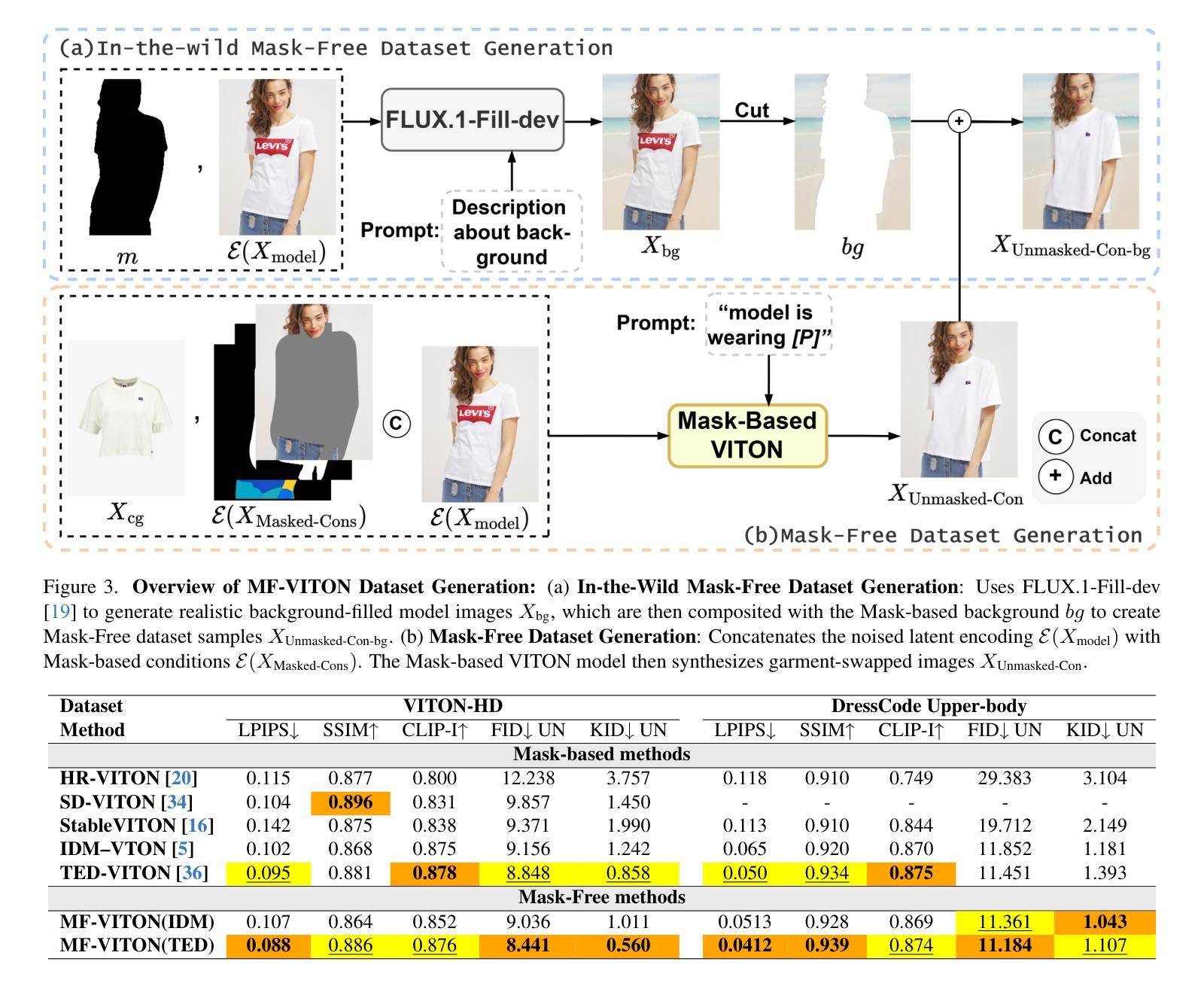
Layton: Latent Consistency Tokenizer for 1024-pixel Image Reconstruction and Generation by 256 Tokens
Authors:Qingsong Xie, Zhao Zhang, Zhe Huang, Yanhao Zhang, Haonan Lu, Zhenyu Yang
Image tokenization has significantly advanced visual generation and multimodal modeling, particularly when paired with autoregressive models. However, current methods face challenges in balancing efficiency and fidelity: high-resolution image reconstruction either requires an excessive number of tokens or compromises critical details through token reduction. To resolve this, we propose Latent Consistency Tokenizer (Layton) that bridges discrete visual tokens with the compact latent space of pre-trained Latent Diffusion Models (LDMs), enabling efficient representation of 1024x1024 images using only 256 tokens-a 16 times compression over VQGAN. Layton integrates a transformer encoder, a quantized codebook, and a latent consistency decoder. Direct application of LDM as the decoder results in color and brightness discrepancies. Thus, we convert it to latent consistency decoder, reducing multi-step sampling to 1-2 steps for direct pixel-level supervision. Experiments demonstrate Layton’s superiority in high-fidelity reconstruction, with 10.8 reconstruction Frechet Inception Distance on MSCOCO-2017 5K benchmark for 1024x1024 image reconstruction. We also extend Layton to a text-to-image generation model, LaytonGen, working in autoregression. It achieves 0.73 score on GenEval benchmark, surpassing current state-of-the-art methods. Project homepage: https://github.com/OPPO-Mente-Lab/Layton
图像符号化(Image tokenization)在视觉生成和多模态建模方面取得了显著进展,尤其是在与自回归模型结合使用时。然而,当前的方法在平衡效率和保真度方面面临挑战:高分辨率图像重建需要大量符号或需要通过减少符号来妥协关键细节。为解决此问题,我们提出了Latent Consistency Tokenizer(Layton),它将离散视觉符号与预训练潜在扩散模型(LDM)的紧凑潜在空间相结合,仅使用256个符号就能有效地表示1024x1024的图像,这是VQGAN的16倍压缩。Layton集成了变压器编码器、量化代码本和潜在一致性解码器。直接使用LDM作为解码器会导致颜色和亮度差异。因此,我们将其转换为潜在一致性解码器,将多步采样减少到1-2步,实现直接像素级的监督。实验证明Layton在高保真重建方面的优势,在MSCOCO-2017 5K基准的1024x1024图像重建中,重建Frechet Inception Distance达到10.8。我们还把Layton扩展到文本到图像生成模型LaytonGen,采用自回归方式工作。它在GenEval基准测试中达到0.73分,超过了当前先进的方法。项目主页:https://github.com/OPPO-Mente-Lab/Layton
论文及项目相关链接
Summary
本文介绍了Latent Consistency Tokenizer(Layton)的研究,该技术在图像标记化方面取得了显著进展,实现了高效且高保真度的图像重建。通过将离散视觉标记与预训练的Latent Diffusion Models(LDM)的潜在空间相结合,Layton能够使用较少的标记表示高分辨率图像。此外,研究还提出了一个潜在一致性解码器,以改进颜色与亮度的差异问题。实验结果证明了Layton在高保真重建任务中的优越性,并且扩展到文本到图像生成模型LaytonGen,实现了自动回归。
Key Takeaways
- Layton通过结合离散视觉标记和预训练的Latent Diffusion Models(LDM)的潜在空间,实现了图像标记化的显著进展。
- Layton能够使用较少的标记(仅256个标记)表示1024x1024的高分辨率图像,实现了高效的图像表示。
- 提出的潜在一致性解码器改善了颜色与亮度的差异问题。
- Layton在高保真重建任务中表现出优越性,其Frechet Inception Distance在MSCOCO-2017 5K基准测试中达到了优秀的表现。
- Layton扩展到了文本到图像生成模型LaytonGen,实现了自动回归功能。
- LaytonGen在GenEval基准测试中取得了较高的得分,超过了当前的主流方法。
点此查看论文截图

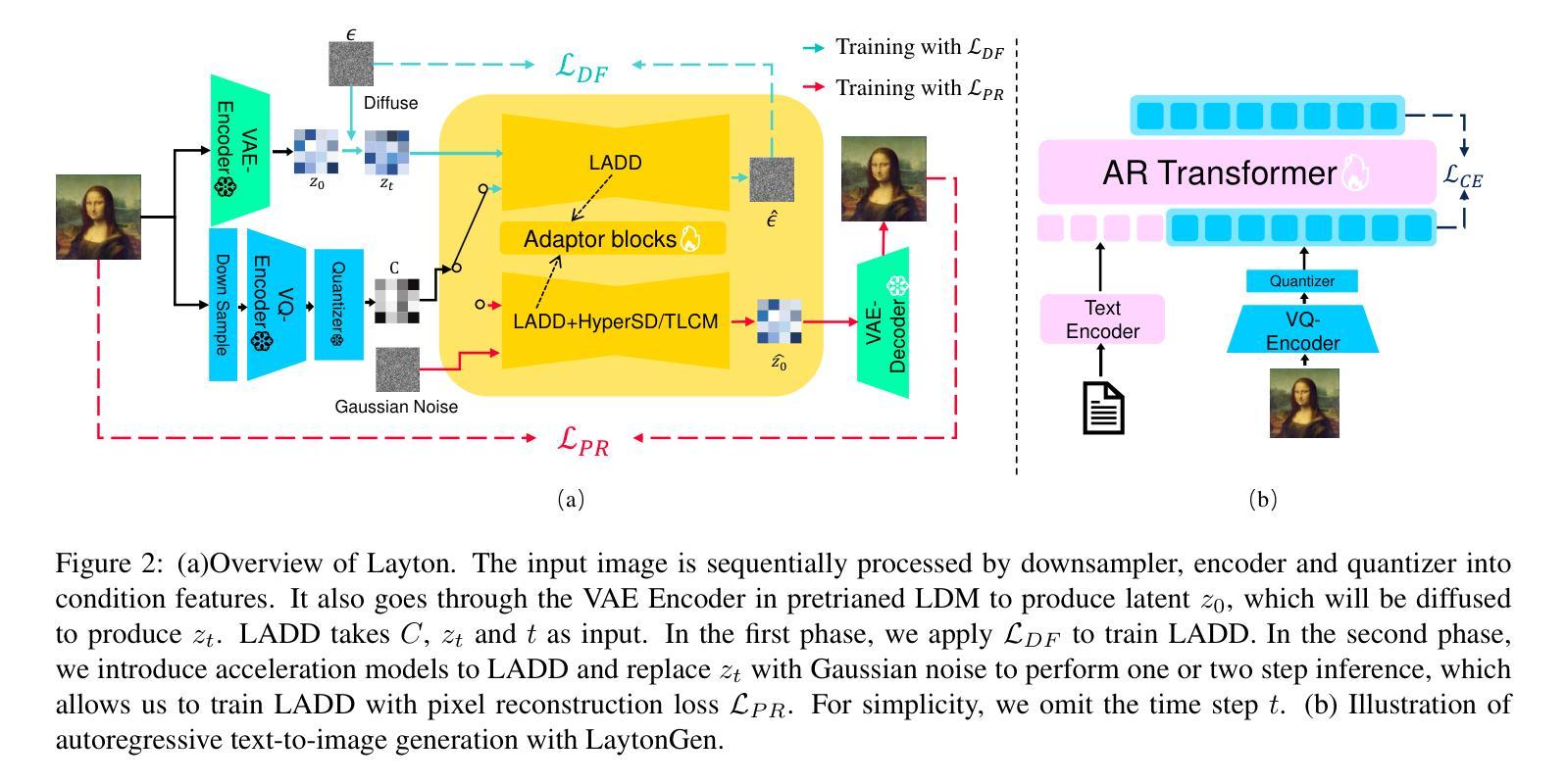


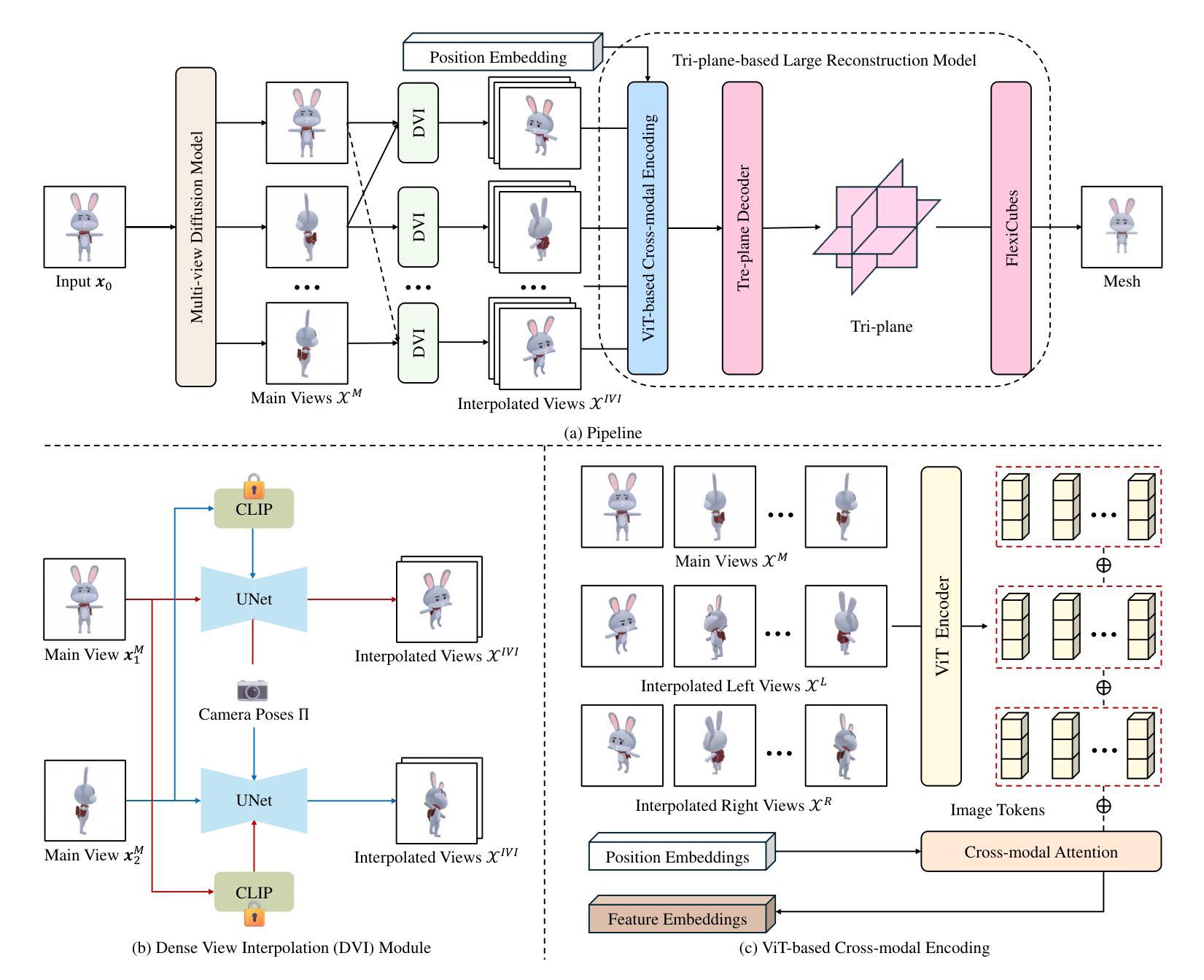
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Authors:Zhiyuan Wu, Xibin Song, Senbo Wang, Weizhe Liu, Jiayu Yang, Ziang Cheng, Shenzhou Chen, Taizhang Shang, Weixuan Sun, Shan Luo, Pan Ji
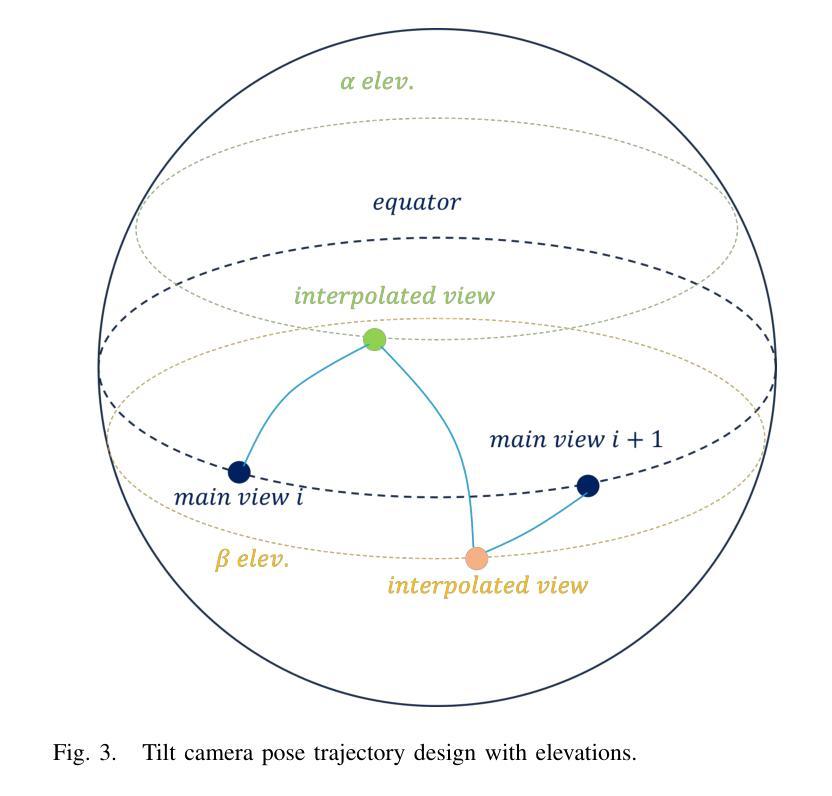
3D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
从单视图图像进行3D对象重建是计算机视觉中的一项基本任务,具有广泛的应用。最近的大型重建模型(LRMs)的进展表明,利用2D扩散模型生成的多视图图像提取3D内容具有巨大潜力。然而,仍存在挑战,因为2D扩散模型往往难以生成具有强烈多视图一致性的密集图像,而LRMs在3D重建过程中往往会放大这些不一致性。解决这些问题对于实现高质量和高效的3D重建至关重要。在本文中,我们提出了CDI3D,这是一个前馈框架,旨在实现高效、高质量的图片到3D生成以及视角插值。为了解决上述挑战,我们提议将基于2D扩散的视图插值集成到LRM管道中,以提高生成网格的质量和一致性。具体来说,我们的方法引入了一个密集视图插值(DVI)模块,它合成由2D扩散模型生成的主视图之间的插值图像,有效地使输入视图密集化,提高了多视图的一致性。我们还设计了一个倾斜的相机姿态轨迹来捕捉不同海拔和角度的视图。随后,我们采用基于三面网的网格重建策略,从这些插值和原始视图中提取稳健的令牌,从而生成具有出色纹理和几何形状的高质量3D网格。大量实验表明,我们的方法在多个基准测试上显著优于之前的最先进方法,生成的3D内容具有增强的纹理保真度和几何准确性。
论文及项目相关链接
Summary
本文提出了一种高效的、高质量的图像到三维生成框架CDI3D,用于解决二维扩散模型产生的密集图像多视角一致性差的问题,及其在大型重建模型(LRMs)中放大这些问题的问题。文章引入了一种名为Dense View Interpolation(DVI)的模块,用于合成由二维扩散模型生成的主视图之间的插值图像,提高生成网格的质量和一致性。同时采用倾斜相机姿态轨迹捕获不同高度和角度的视图,并使用基于三角平面的网格重建策略从插值和原始视图中提取稳健的标记,生成高质量的三维网格。实验表明,该方法在多个基准测试中显著优于现有方法,生成的三维内容具有增强的纹理保真度和几何准确性。
Key Takeaways
- 介绍了二维扩散模型在生成密集图像时面临的多视角一致性挑战。
- 提出了一种高效的、高质量的图像到三维生成框架CDI3D,旨在解决上述问题并实现高质量的3D重建。
- 引入了Dense View Interpolation(DVI)模块来合成插值图像,提高生成网格的一致性和质量。
- 通过采用倾斜相机姿态轨迹和基于三角平面的网格重建策略,增强了生成的3D内容的纹理和几何质量。
点此查看论文截图


Learning Few-Step Diffusion Models by Trajectory Distribution Matching
Authors:Yihong Luo, Tianyang Hu, Jiacheng Sun, Yujun Cai, Jing Tang
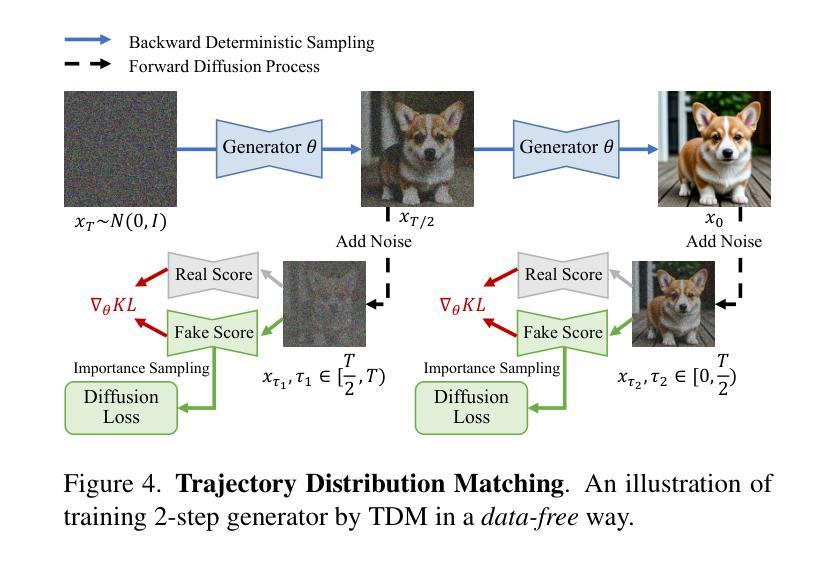
Accelerating diffusion model sampling is crucial for efficient AIGC deployment. While diffusion distillation methods – based on distribution matching and trajectory matching – reduce sampling to as few as one step, they fall short on complex tasks like text-to-image generation. Few-step generation offers a better balance between speed and quality, but existing approaches face a persistent trade-off: distribution matching lacks flexibility for multi-step sampling, while trajectory matching often yields suboptimal image quality. To bridge this gap, we propose learning few-step diffusion models by Trajectory Distribution Matching (TDM), a unified distillation paradigm that combines the strengths of distribution and trajectory matching. Our method introduces a data-free score distillation objective, aligning the student’s trajectory with the teacher’s at the distribution level. Further, we develop a sampling-steps-aware objective that decouples learning targets across different steps, enabling more adjustable sampling. This approach supports both deterministic sampling for superior image quality and flexible multi-step adaptation, achieving state-of-the-art performance with remarkable efficiency. Our model, TDM, outperforms existing methods on various backbones, such as SDXL and PixArt-$\alpha$, delivering superior quality and significantly reduced training costs. In particular, our method distills PixArt-$\alpha$ into a 4-step generator that outperforms its teacher on real user preference at 1024 resolution. This is accomplished with 500 iterations and 2 A800 hours – a mere 0.01% of the teacher’s training cost. In addition, our proposed TDM can be extended to accelerate text-to-video diffusion. Notably, TDM can outperform its teacher model (CogVideoX-2B) by using only 4 NFE on VBench, improving the total score from 80.91 to 81.65. Project page: https://tdm-t2x.github.io/
加速扩散模型的采样对于高效的AIGC部署至关重要。虽然基于分布匹配和轨迹匹配的扩散蒸馏方法能够将采样减少到一步,但在文本到图像生成等复杂任务上表现不足。少步骤生成在速度和质量之间提供了更好的平衡,但现有方法面临着持续的权衡:分布匹配缺乏多步骤采样的灵活性,而轨迹匹配往往产生次优的图像质量。为了弥补这一差距,我们提出了通过轨迹分布匹配(TDM)学习少步骤扩散模型,这是一种结合分布匹配和轨迹匹配优点的统一蒸馏范式。我们的方法引入了一个无数据的分数蒸馏目标,在分布层面使学生的轨迹与教师对齐。此外,我们开发了一个采样步骤感知的目标,该目标能够在不同的步骤中解耦学习目标,从而实现更可调整的采样。该方法既支持确定性的采样以获得优质的图像,又支持灵活的多步骤适应,以卓越的效率实现了最先进的性能。我们的TDM模型在各种backbone上超越了现有方法,如SDXL和PixArt-α,在1024分辨率的真实用户偏好上表现出超越其教师的质量,同时大大降低了训练成本。具体来说,我们的方法将PixArt-α蒸馏成一个4步生成器,在500次迭代和2个A800小时内完成了训练,仅为教师训练成本的0.01%。此外,我们提出的TDM可以扩展到加速文本到视频的扩散。值得注意的是,TDM能够在VBench上仅使用4个NFE超越其教师模型(CogVideoX-2B),总分数从80.91提高到81.65。项目页面:https://tdm-t2x.github.io/
论文及项目相关链接
PDF Project page: https://tdm-t2x.github.io/
Summary
本文介绍了加速扩散模型采样的重要性,并提出了一种新的扩散模型蒸馏方法——轨迹分布匹配(TDM)。该方法结合了分布匹配和轨迹匹配的优势,通过引入无数据评分蒸馏目标和采样步骤感知目标,实现了在复杂任务如文本到图像生成中的高效性能。TDM方法支持确定性采样以提供高质量的图像,并可实现灵活的多步适应。在多个基准测试上,TDM表现出卓越的性能和效率,显著降低了训练成本。此外,TDM还可扩展应用于文本到视频的扩散任务,并能在某些情况下超越其教师模型。
Key Takeaways
- 加速扩散模型采样对高效的AIGC部署至关重要。
- 现有方法如分布匹配和轨迹匹配在复杂任务上存在局限。
- TDM方法结合了分布匹配和轨迹匹配的优势,提高了采样速度和图像质量。
- TDM引入了无数据评分蒸馏目标和采样步骤感知目标,实现了灵活的多步适应和高质量图像生成。
- TDM在多个基准测试上表现出卓越的性能和效率,显著降低了训练成本。
- TDM可应用于文本到视频的扩散任务,并能在某些情况下超越其教师模型。
- TDM方法在多种背景模型上均表现优异,如SDXL和PixArt-$\alpha$。
点此查看论文截图



Adding Additional Control to One-Step Diffusion with Joint Distribution Matching
Authors:Yihong Luo, Tianyang Hu, Yifan Song, Jiacheng Sun, Zhenguo Li, Jing Tang
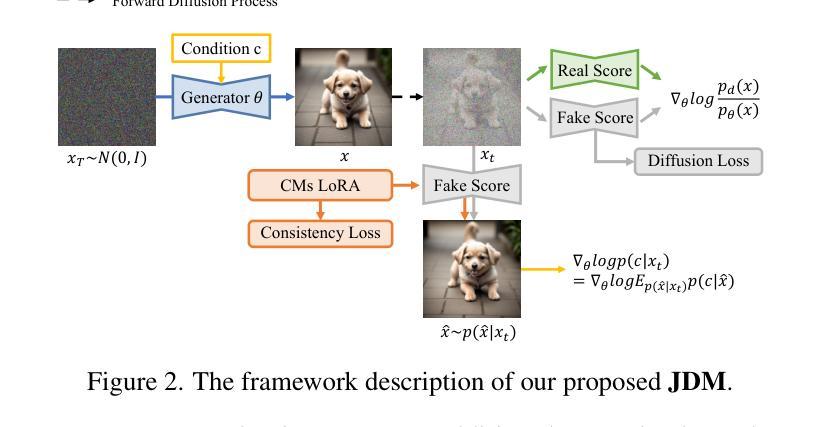
While diffusion distillation has enabled one-step generation through methods like Variational Score Distillation, adapting distilled models to emerging new controls – such as novel structural constraints or latest user preferences – remains challenging. Conventional approaches typically requires modifying the base diffusion model and redistilling it – a process that is both computationally intensive and time-consuming. To address these challenges, we introduce Joint Distribution Matching (JDM), a novel approach that minimizes the reverse KL divergence between image-condition joint distributions. By deriving a tractable upper bound, JDM decouples fidelity learning from condition learning. This asymmetric distillation scheme enables our one-step student to handle controls unknown to the teacher model and facilitates improved classifier-free guidance (CFG) usage and seamless integration of human feedback learning (HFL). Experimental results demonstrate that JDM surpasses baseline methods such as multi-step ControlNet by mere one-step in most cases, while achieving state-of-the-art performance in one-step text-to-image synthesis through improved usage of CFG or HFL integration.
扩散蒸馏技术已经通过变分评分蒸馏等方法实现了一步生成,但将蒸馏模型适应于新兴的新控制因素,例如新型结构约束或最新用户偏好,仍然具有挑战性。传统方法通常需要修改基础扩散模型并重新蒸馏,这一过程既计算密集又耗时。为了应对这些挑战,我们引入了联合分布匹配(JDM),这是一种最小化图像条件联合分布之间反向KL散度的新型方法。通过推导可行上界,JDM将保真度学习与条件学习解耦。这种不对称的蒸馏方案使我们的一步学生模型能够处理教师模型未知的控制因素,促进了改进的无分类器引导(CFG)使用和无缝集成人类反馈学习(HFL)。实验结果表明,在大多数情况下,JDM仅需一步即可超越多步ControlNet等基线方法,同时在利用CFG或HFL集成的一步文本到图像合成中达到最新技术水平。
论文及项目相关链接
Summary
扩散蒸馏虽然通过诸如变分评分蒸馏等方法实现了一步生成,但在适应新兴的新控制因素方面,如新的结构约束或最新的用户偏好,仍存在挑战。常规方法通常需要修改基础扩散模型并重新蒸馏,这一过程计算量大且耗时。为解决这些挑战,我们提出了联合分布匹配(JDM)这一新方法,它通过最小化图像条件联合分布之间的逆向KL散度来优化。JDM通过推导可行上界,将保真度学习与条件学习解耦。这种对称的蒸馏方案使一步生成模型能够处理教师模型未知的控制因素,并促进了无分类器引导和无缝集成人类反馈学习的改进。实验结果表明,在大多数情况下,JDM仅需一步即可超越多步ControlNet等基线方法,并通过改进的无分类器引导或人类反馈学习的集成,实现了一步文本到图像合成的最佳性能。
Key Takeaways
- 扩散蒸馏实现了一步生成,但适应新控制因素仍有挑战。
- 常规方法修改基础扩散模型并重新蒸馏,过程计算量大且耗时。
- 联合分布匹配(JDM)提出最小化图像条件联合分布之间的逆向KL散度来优化。
- JDM通过可行上界解耦保真度学习与条件学习。
- JDM使一步生成模型能够处理教师模型未知的控制因素。
- JDM促进了无分类器引导和无缝集成人类反馈学习的改进。
点此查看论文截图


Taming Large Multimodal Agents for Ultra-low Bitrate Semantically Disentangled Image Compression
Authors:Juan Song, Lijie Yang, Mingtao Feng
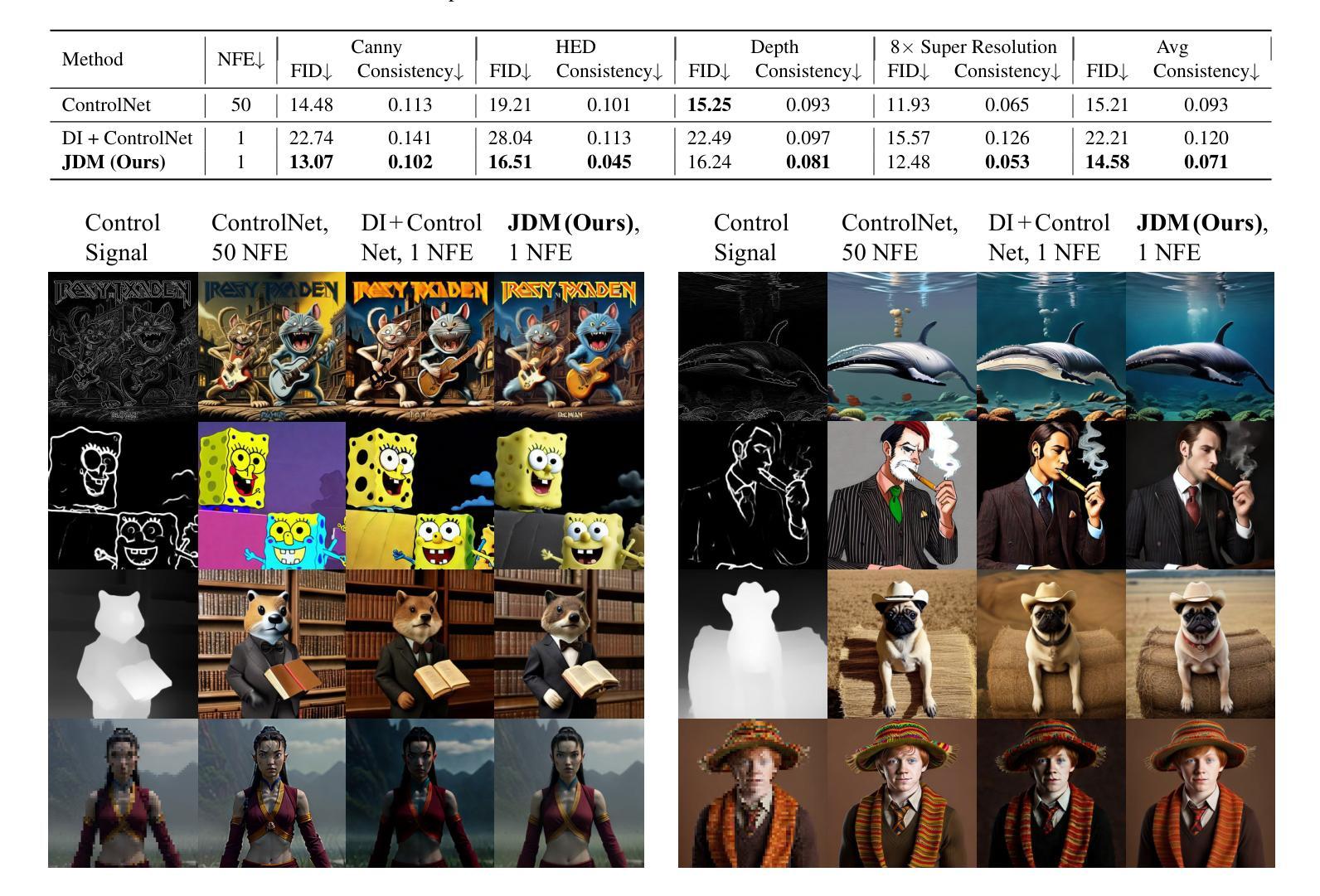
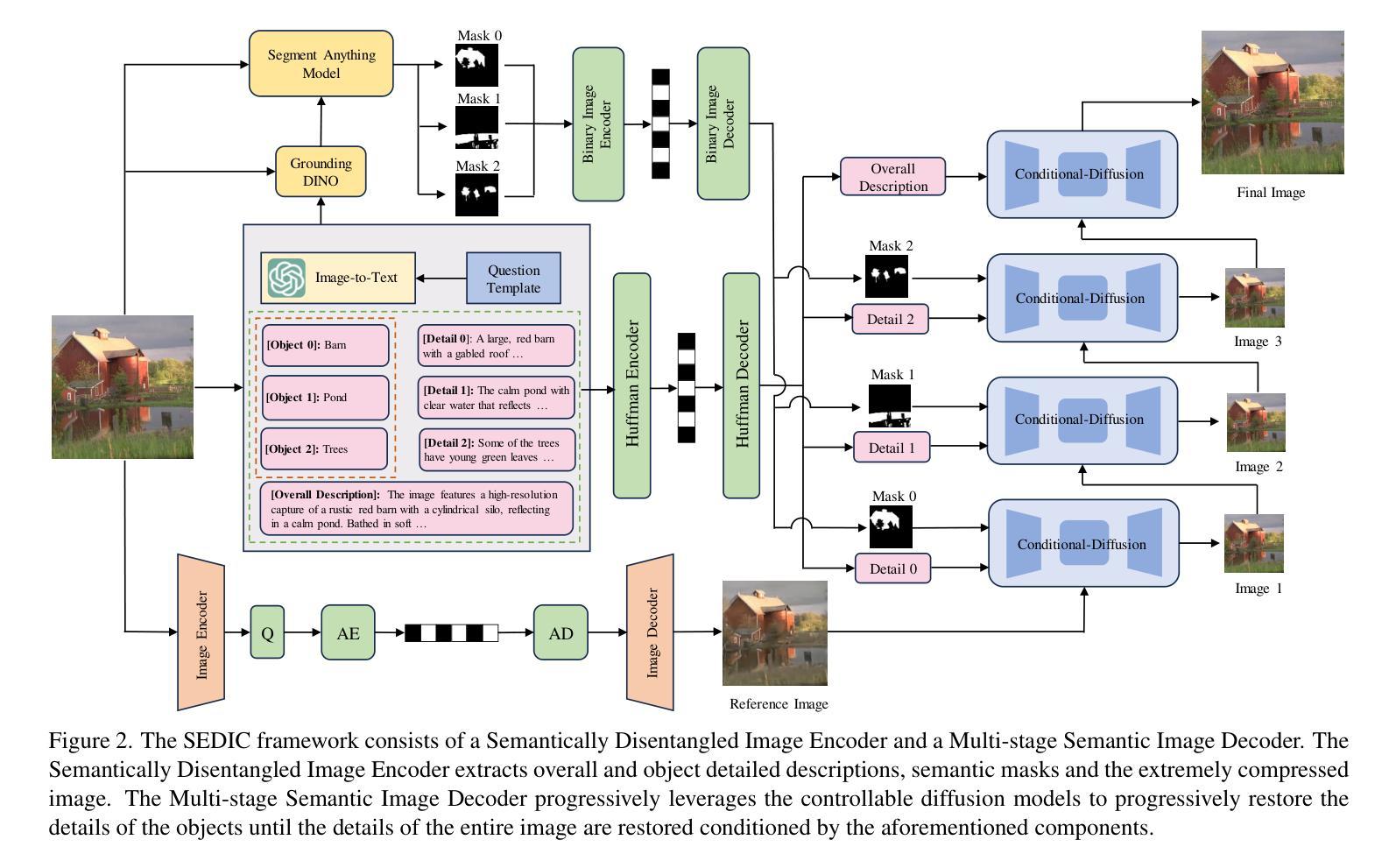
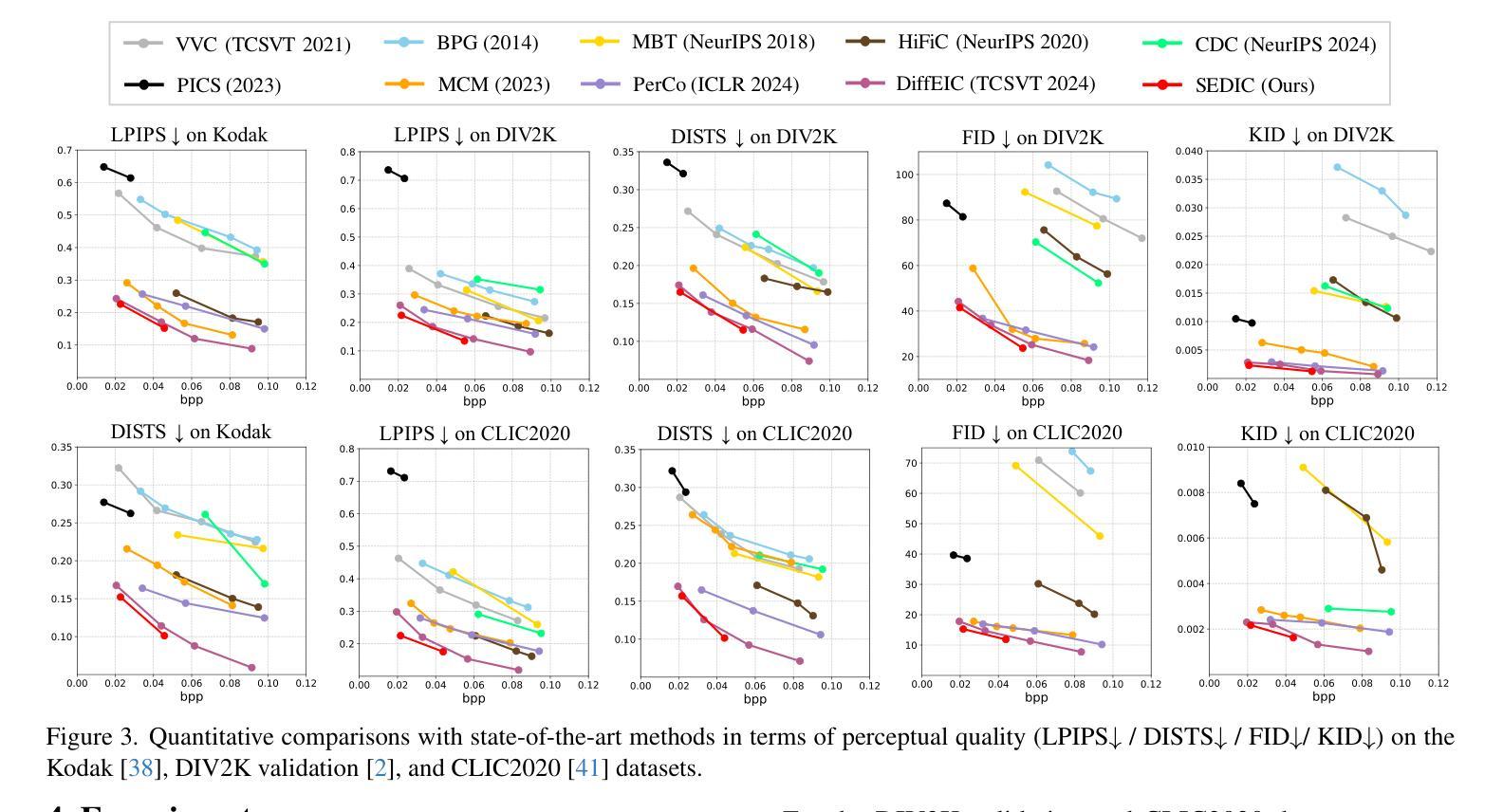
It remains a significant challenge to compress images at ultra-low bitrate while achieving both semantic consistency and high perceptual quality. We propose a novel image compression framework, Semantically Disentangled Image Compression (SEDIC) in this paper. Our proposed SEDIC leverages large multimodal models (LMMs) to disentangle the image into several essential semantic information, including an extremely compressed reference image, overall and object-level text descriptions, and the semantic masks. A multi-stage semantic decoder is designed to progressively restore the transmitted reference image object-by-object, ultimately producing high-quality and perceptually consistent reconstructions. In each decoding stage, a pre-trained controllable diffusion model is utilized to restore the object details on the reference image conditioned by the text descriptions and semantic masks. Experimental results demonstrate that SEDIC significantly outperforms state-of-the-art approaches, achieving superior perceptual quality and semantic consistency at ultra-low bitrates ($\le$ 0.05 bpp).
在超低比特率下对图像进行压缩,同时实现语义一致性和高感知质量仍然是一个重大挑战。本文提出了一种新型图像压缩框架——语义分离图像压缩(SEDIC)。我们提出的SEDIC利用大型多模态模型(LMMs)将图像分解为多种基本语义信息,包括极度压缩的参考图像、总体和对象级文本描述以及语义掩码。设计了一个多阶段语义解码器,以逐步恢复传输的参考图像的对象,最终产生高质量和感知一致的重建。在每个解码阶段,利用预训练的可控扩散模型根据文本描述和语义掩膜恢复参考图像的对象细节。实验结果表明,SEDIC在超低比特率(≤0.05 bpp)下显著优于现有技术,实现了出色的感知质量和语义一致性。
论文及项目相关链接
Summary
本文提出了一种新型的图像压缩框架——语义分离图像压缩(SEDIC),该框架利用大型多模态模型(LMMs)将图像分解为多个基本语义信息,包括高度压缩的参考图像、整体和对象级别的文本描述以及语义掩码。设计了一个多阶段语义解码器,以逐步恢复传输的参考图像的对象,最终产生高质量和感知一致的重建图像。在每个解码阶段,利用预训练的可控扩散模型根据文本描述和语义掩膜恢复对象细节。实验结果表明,SEDIC在超低比特率下显著优于现有技术,实现了优越的主观感知质量和语义一致性。
Key Takeaways
- 提出了一种新的图像压缩框架SEDIC,利用大型多模态模型进行图像分解。
- SEDIC能够将图像分解为多个基本语义信息,包括参考图像、文本描述和语义掩码。
- 设计了多阶段语义解码器,可逐步恢复并重建高质量和感知一致的图像。
- 在每个解码阶段,使用预训练的可控扩散模型根据文本和语义信息恢复对象细节。
- SEDIC在超低比特率下实现优越性能,达到了≤0.05 bpp。
- 实验结果表明,SEDIC在语义一致性和高感知质量方面显著优于现有技术。
点此查看论文截图


Autoregressive Image Generation with Vision Full-view Prompt
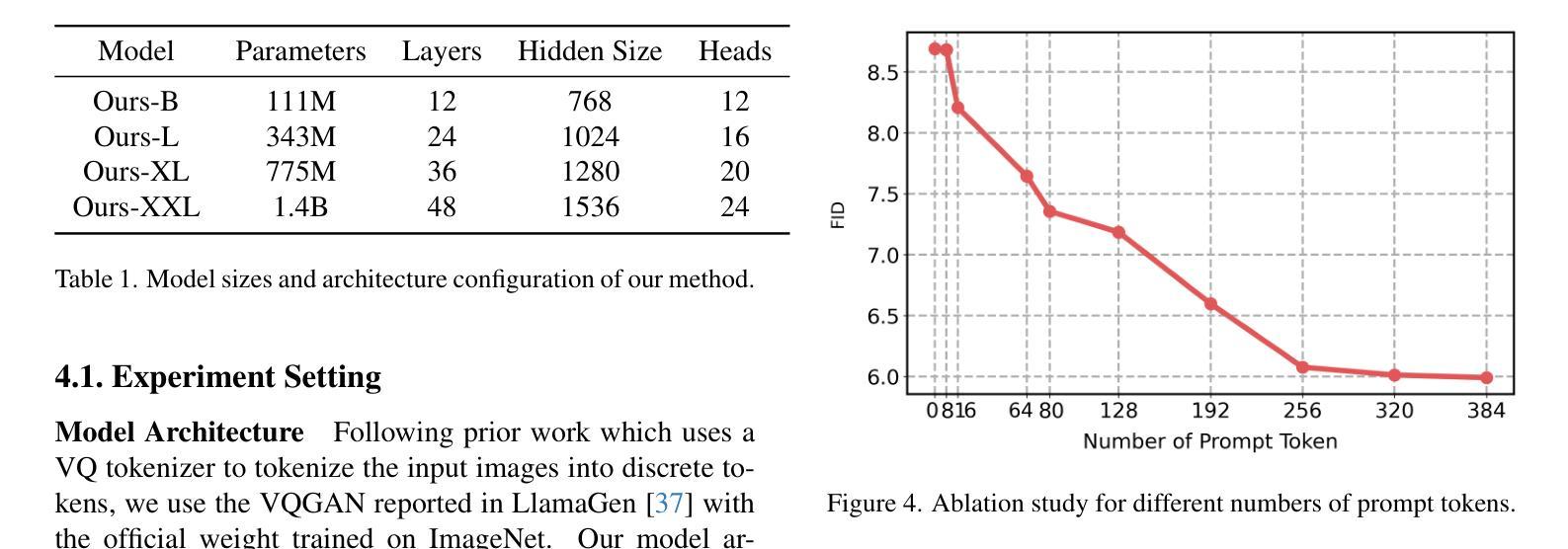
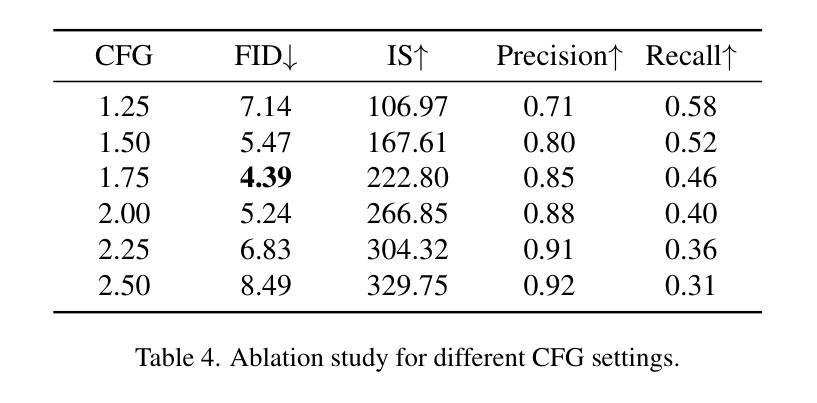
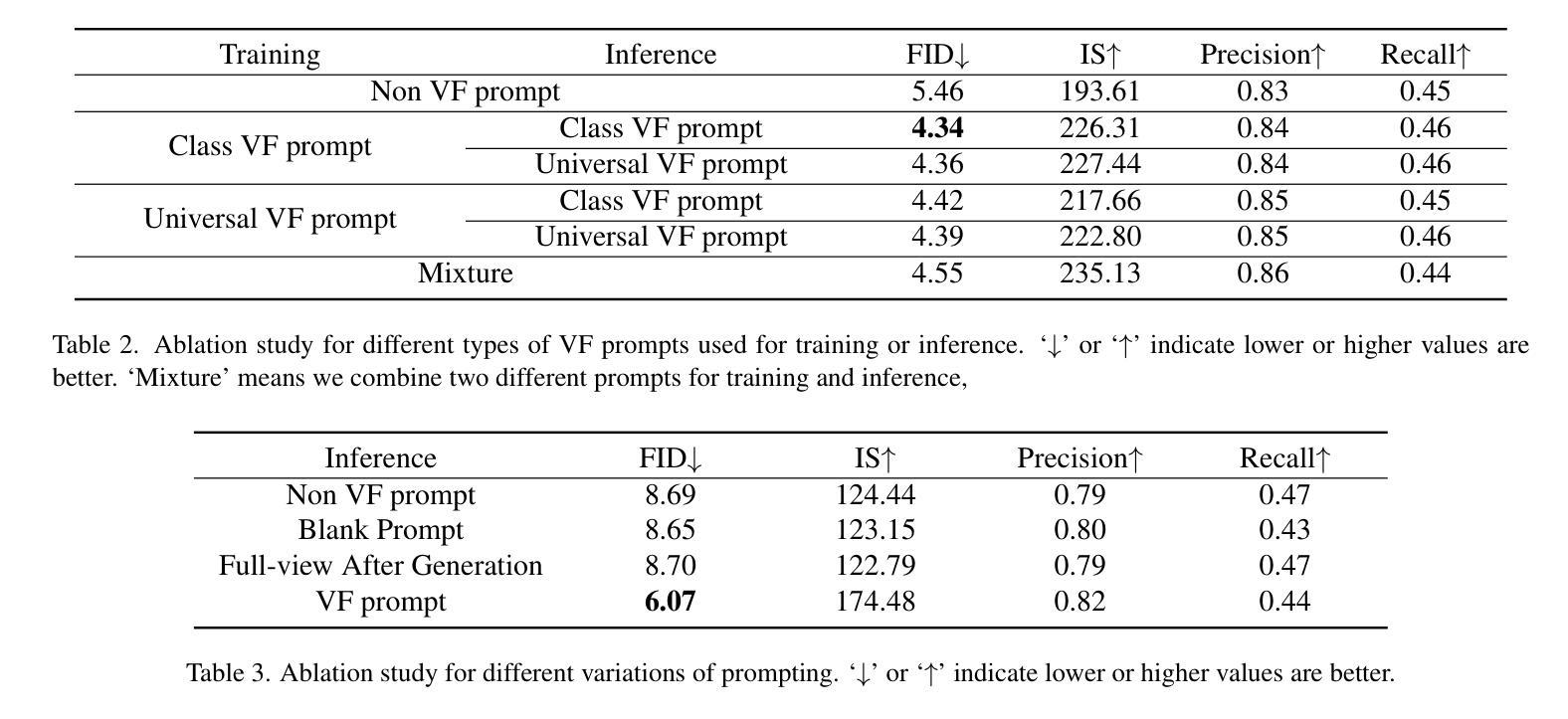
Authors:Miaomiao Cai, Guanjie Wang, Wei Li, Zhijun Tu, Hanting Chen, Shaohui Lin, Jie Hu
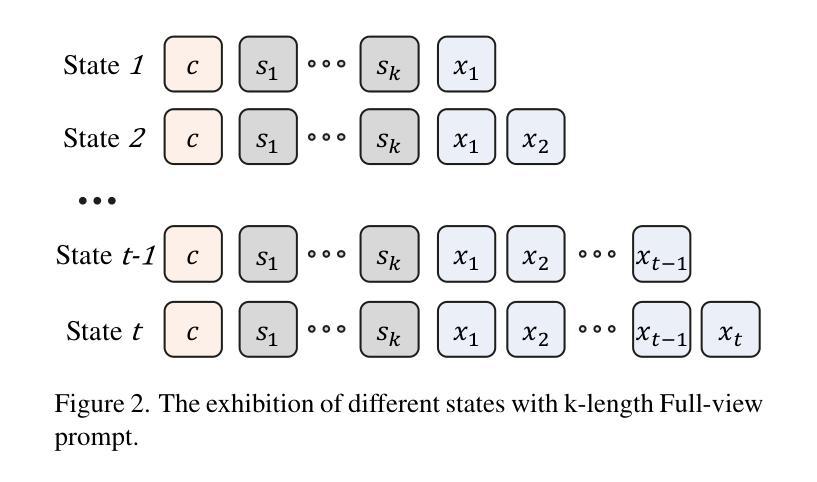
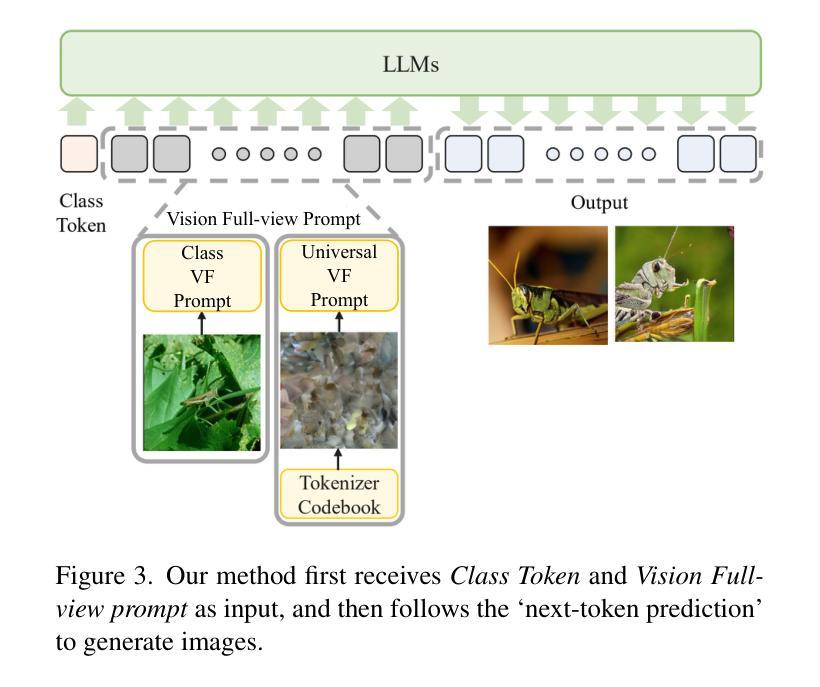
In autoregressive (AR) image generation, models based on the ‘next-token prediction’ paradigm of LLMs have shown comparable performance to diffusion models by reducing inductive biases. However, directly applying LLMs to complex image generation can struggle with reconstructing the image’s structure and details, impacting the generation’s accuracy and stability. Additionally, the ‘next-token prediction’ paradigm in the AR model does not align with the contextual scanning and logical reasoning processes involved in human visual perception, limiting effective image generation. Prompt engineering, as a key technique for guiding LLMs, leverages specifically designed prompts to improve model performance on complex natural language processing (NLP) tasks, enhancing accuracy and stability of generation while maintaining contextual coherence and logical consistency, similar to human reasoning. Inspired by prompt engineering from the field of NLP, we propose Vision Full-view prompt (VF prompt) to enhance autoregressive image generation. Specifically, we design specialized image-related VF prompts for AR image generation to simulate the process of human image creation. This enhances contextual logic ability by allowing the model to first perceive overall distribution information before generating the image, and improve generation stability by increasing the inference steps. Compared to the AR method without VF prompts, our method shows outstanding performance and achieves an approximate improvement of 20%.
在自回归(AR)图像生成中,基于大型语言模型(LLM)的“下一个令牌预测”范式的模型通过减少归纳偏见表现出了与扩散模型相当的性能。然而,直接将大型语言模型应用于复杂图像生成会面临重建图像结构和细节的挑战,从而影响生成的准确性和稳定性。此外,自回归模型中的“下一个令牌预测”范式并不符合人类视觉感知所涉及的环境扫描和逻辑推理过程,限制了有效的图像生成。作为一种引导大型语言模型的关键技术,提示工程利用专门设计的提示来改善模型在复杂自然语言处理(NLP)任务上的性能,提高生成的准确性和稳定性,同时保持上下文连贯和逻辑一致性,类似于人类推理。受自然语言处理领域提示工程的启发,我们提出Vision Full-view prompt(VF提示)来增强自回归图像生成。具体来说,我们为AR图像生成设计了专门化的图像相关VF提示,以模拟人类图像创建的过程。这通过允许模型在生成图像之前先感知整体分布信息,增强了上下文逻辑能力,并通过增加推理步骤提高了生成的稳定性。与没有VF提示的AR方法相比,我们的方法表现出卓越的性能,并实现了大约20%的改进。
论文及项目相关链接
Summary
基于自然语言处理领域的提示工程技术,本文提出一种名为Vision Full-view prompt(VF提示)的方法,用于增强自回归图像生成的效果。通过设计专门的图像相关VF提示,模拟人类图像创建过程,增强自回归图像生成的上下文逻辑能力,并在增加推理步骤的情况下提高生成稳定性,实现了相较于没有VF提示的AR方法约20%的性能提升。
Key Takeaways
- 自回归(AR)图像生成中,基于大型语言模型(LLM)的“下一个令牌预测”范式在减少归纳偏见方面表现出与扩散模型相当的性能。
- 直接应用LLMs于复杂图像生成面临重建图像结构和细节的挑战,影响生成的准确性和稳定性。
- “下一个令牌预测”范式不符合人类视觉感知涉及的上文扫描和逻辑推理过程,限制了有效的图像生成。
- 提示工程技术通过专门设计的提示来改善LLMs在复杂自然语言处理任务上的性能,维持上下文连贯性和逻辑一致性,类似于人类推理。
- 借鉴自然语言处理的提示工程技术,提出Vision Full-view prompt(VF提示)以增强自回归图像生成。
- VF提示通过模拟人类图像创建过程,允许模型先感知整体分布信息再生成图像,增强了上下文逻辑能力。
点此查看论文截图

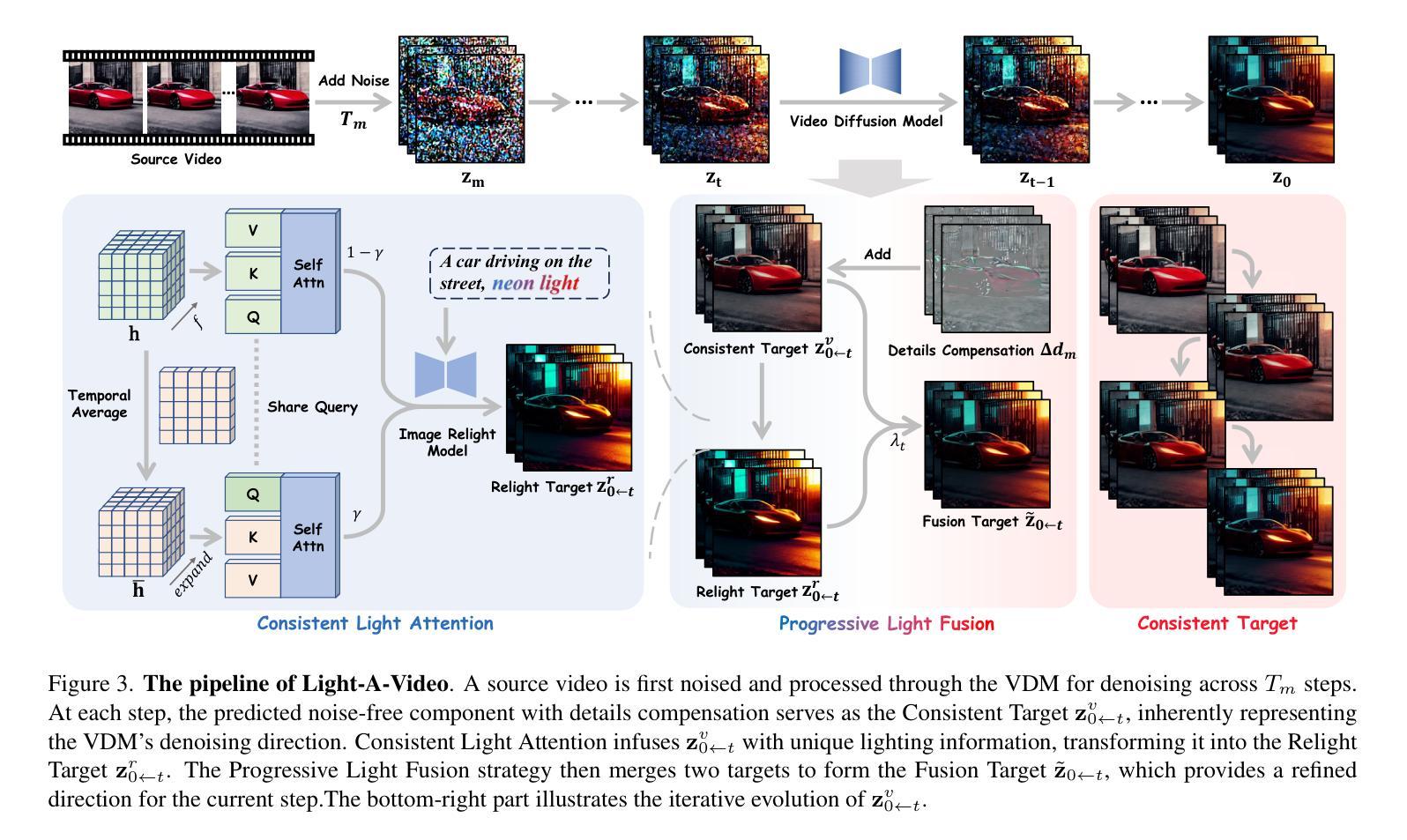
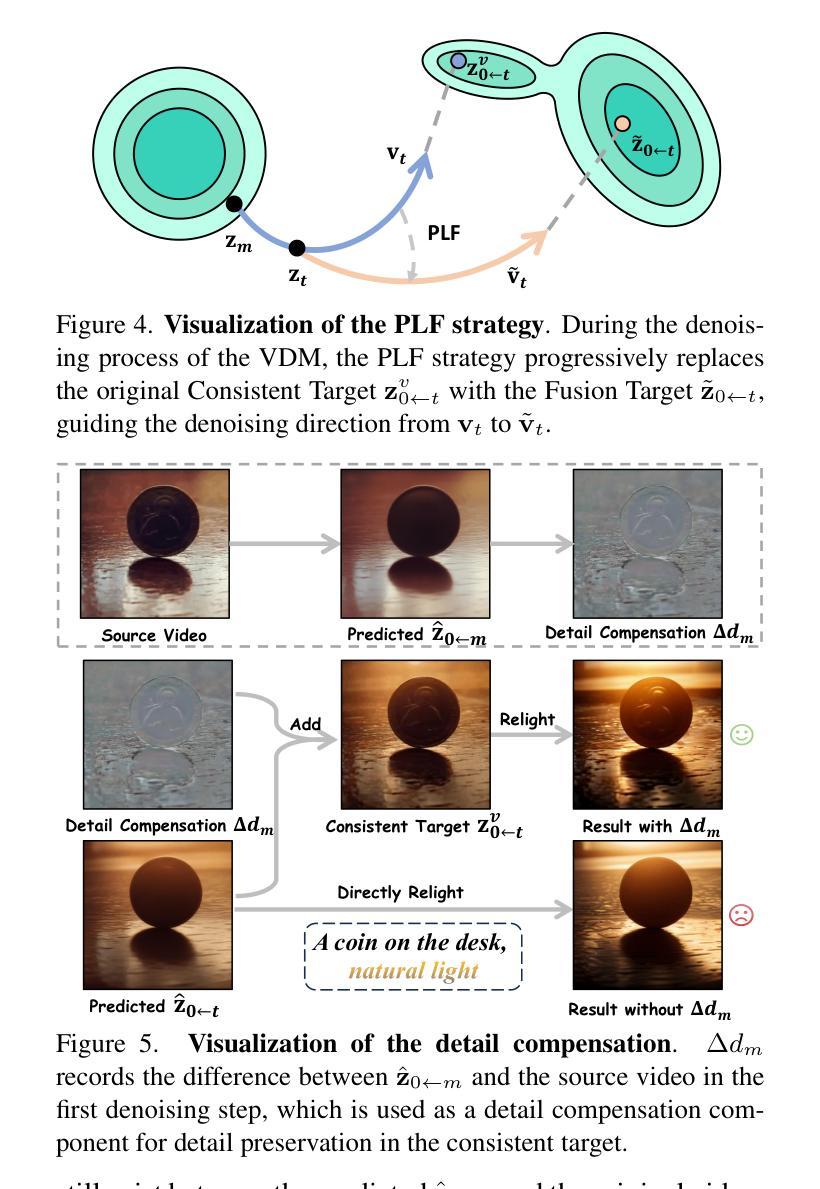
Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
Authors:Yujie Zhou, Jiazi Bu, Pengyang Ling, Pan Zhang, Tong Wu, Qidong Huang, Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Anyi Rao, Jiaqi Wang, Li Niu
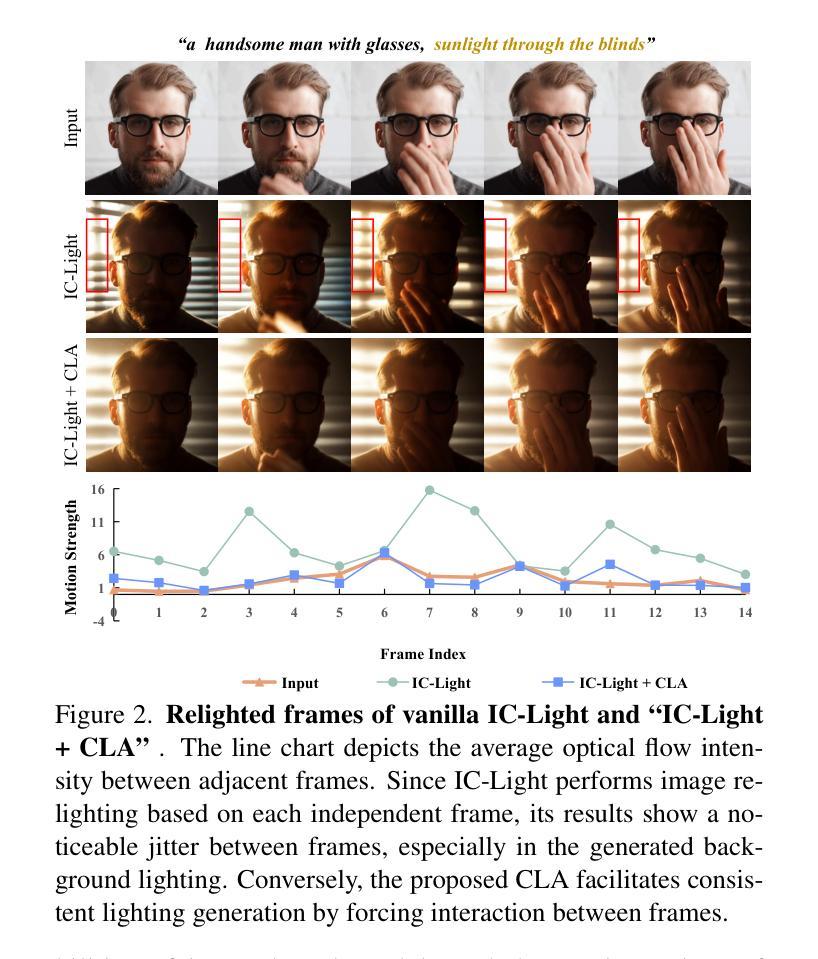
Recent advancements in image relighting models, driven by large-scale datasets and pre-trained diffusion models, have enabled the imposition of consistent lighting. However, video relighting still lags, primarily due to the excessive training costs and the scarcity of diverse, high-quality video relighting datasets. A simple application of image relighting models on a frame-by-frame basis leads to several issues: lighting source inconsistency and relighted appearance inconsistency, resulting in flickers in the generated videos. In this work, we propose Light-A-Video, a training-free approach to achieve temporally smooth video relighting. Adapted from image relighting models, Light-A-Video introduces two key techniques to enhance lighting consistency. First, we design a Consistent Light Attention (CLA) module, which enhances cross-frame interactions within the self-attention layers of the image relight model to stabilize the generation of the background lighting source. Second, leveraging the physical principle of light transport independence, we apply linear blending between the source video’s appearance and the relighted appearance, using a Progressive Light Fusion (PLF) strategy to ensure smooth temporal transitions in illumination. Experiments show that Light-A-Video improves the temporal consistency of relighted video while maintaining the relighted image quality, ensuring coherent lighting transitions across frames. Project page: https://bujiazi.github.io/light-a-video.github.io/.
近期,由于大规模数据集和预训练扩散模型的推动,图像补光模型的发展已经实现了连贯的照明。然而,视频补光仍然滞后,主要是由于训练成本过高和多样、高质量视频补光数据集的稀缺。简单地将图像补光模型逐帧应用会导致几个问题:光源不一致和补光外观不一致,导致生成的视频出现闪烁。在这项工作中,我们提出了Light-A-Video,这是一种无需训练的、实现时间平滑视频补光的方法。Light-A-Video从图像补光模型中汲取灵感,引入了两种关键技术来提高照明的一致性。首先,我们设计了一个一致的光注意力(CLA)模块,它增强了图像补光模型的自注意力层中的跨帧交互,以稳定背景光源的生成。其次,利用光线传输独立的物理原理,我们采用渐进式光融合(PLF)策略,对源视频的外观和补光的外观进行线性混合,以确保照明的时间过渡平滑。实验表明,Light-A-Video提高了补光视频的时间一致性,同时保持了补光图像的质量,确保了跨帧的照明过渡连贯。项目页面:https://bujiazi.github.io/light-a-video.github.io/。
论文及项目相关链接
PDF Project Page: https://bujiazi.github.io/light-a-video.github.io/
Summary
本文介绍了基于图像重照明模型的视频重照明技术的新进展。由于大规模数据集和预训练扩散模型的推动,图像重照明技术已经能够实现一致性的照明。然而,视频重照明仍存在训练成本过高、高质量视频重照明数据集稀缺的问题。简单地将图像重照明模型逐帧应用于视频会导致光源不一致和重照明外观不一致的问题,生成的视频会出现闪烁。本文提出了一种名为Light-A-Video的方法,该方法无需训练即可实现时间平滑的视频重照明。它引入了两种关键技术来提高照明一致性:一是设计了一致的灯光注意力模块,增强图像重照明模型中自注意力层的跨帧交互,稳定背景光源的生成;二是利用光线传输的独立物理原理,采用渐进光融合策略,对源视频的外观和重照明外观进行线性混合,确保照明的时间过渡平滑。实验表明,Light-A-Video在保持重照明图像质量的同时,提高了重照明视频的时空一致性。
Key Takeaways
- 近期图像重照明模型的进展为视频重照明提供了基础,但需要解决训练成本和数据集稀缺的问题。
- 简单应用图像重照明模型于视频会导致光源和外观不一致,造成视频闪烁。
- Light-A-Video是一种无需训练的视频重照明方法,通过引入一致的灯光注意力模块和渐进光融合策略来提高照明一致性。
- 一致的灯光注意力模块增强了跨帧交互,稳定背景光源生成。
- 渐进光融合策略确保照明的时间过渡平滑。
- Light-A-Video在保持重照明图像质量的同时,提高了重照明视频的时空一致性。
点此查看论文截图

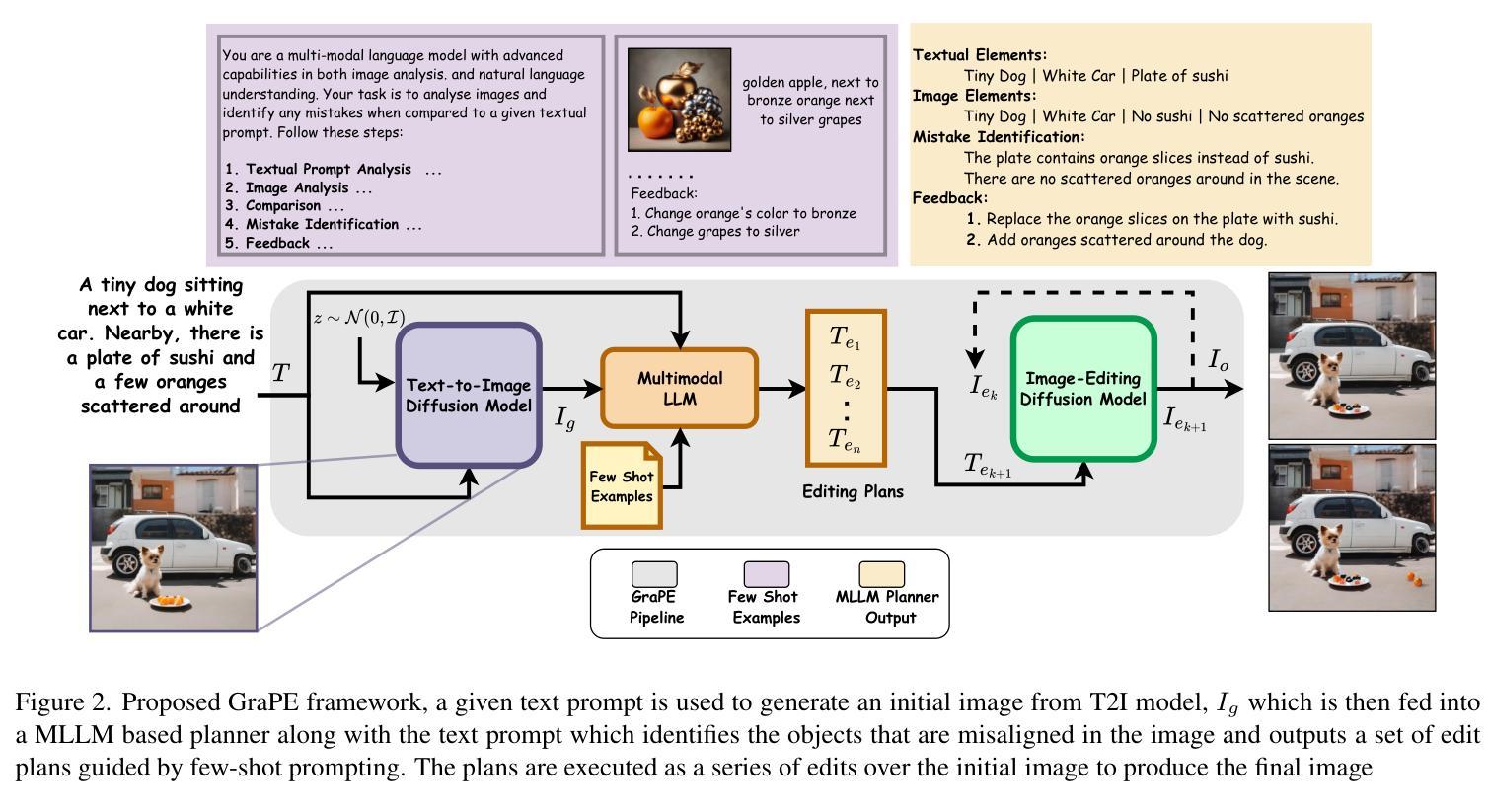
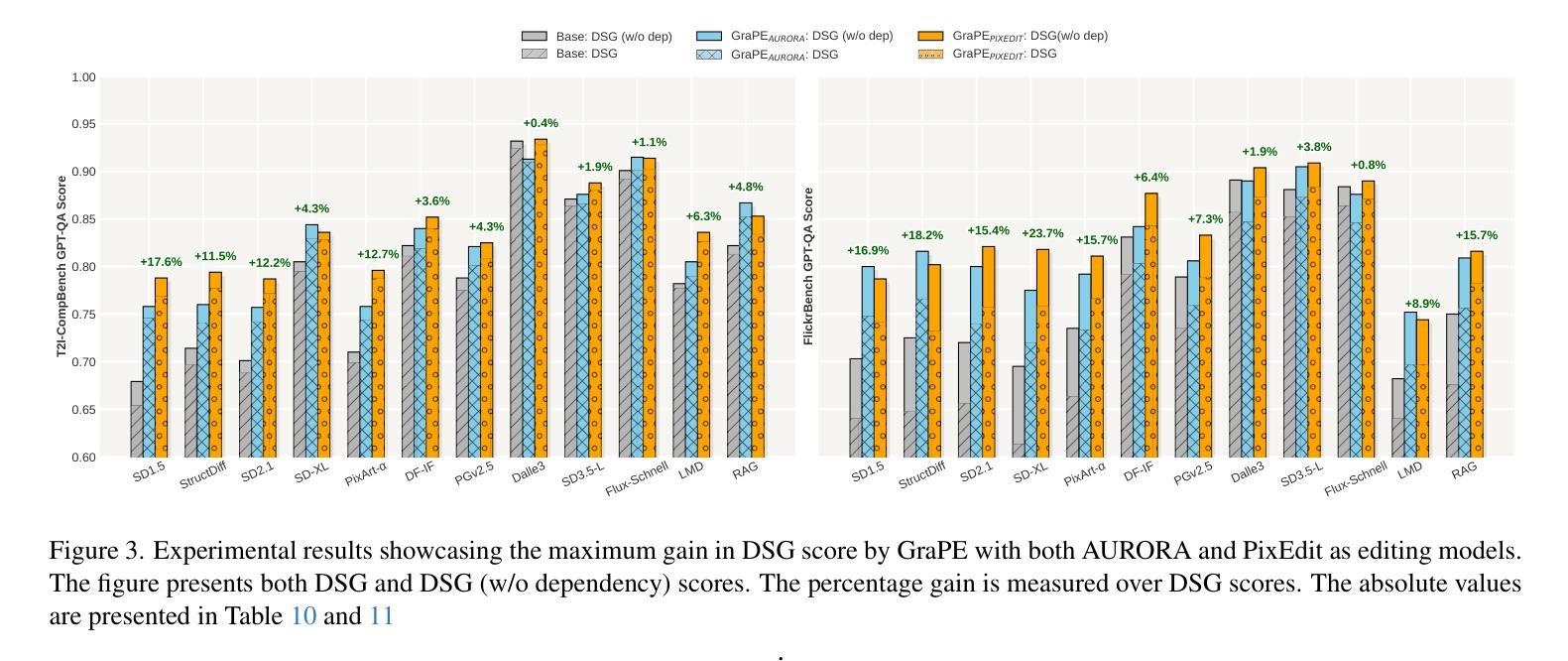
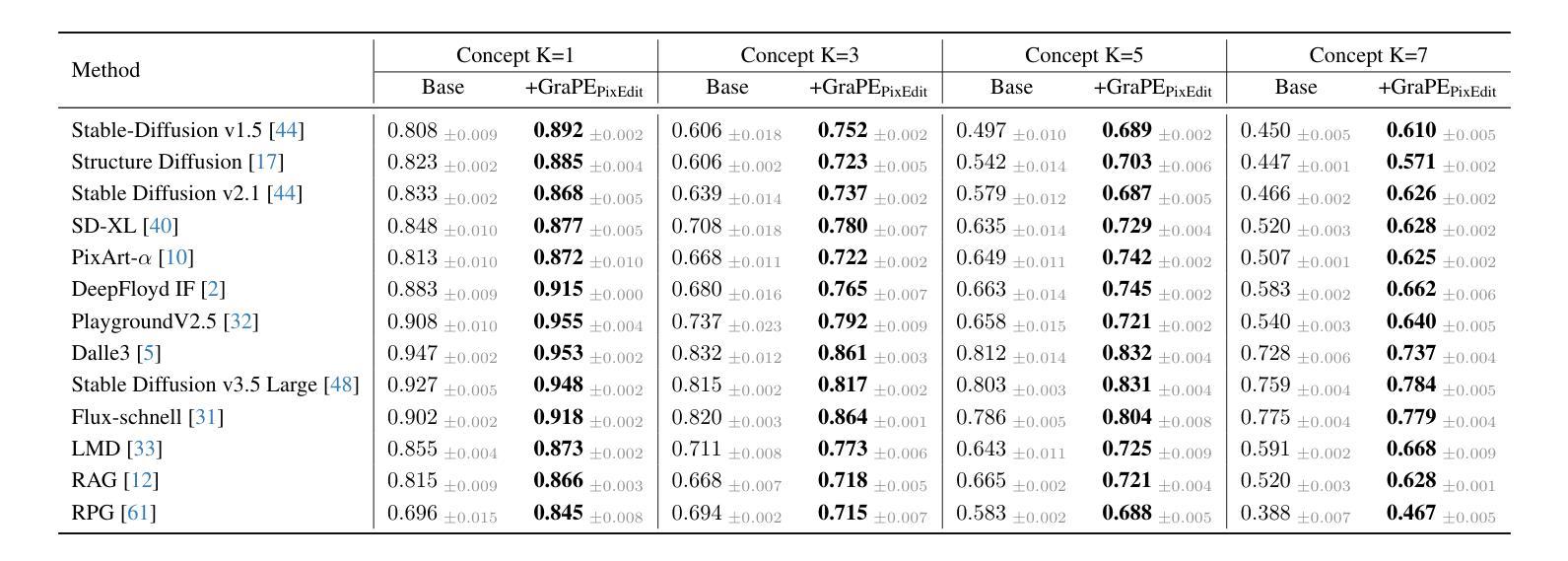
GraPE: A Generate-Plan-Edit Framework for Compositional T2I Synthesis
Authors:Ashish Goswami, Satyam Kumar Modi, Santhosh Rishi Deshineni, Harman Singh, Prathosh A. P, Parag Singla
Text-to-image (T2I) generation has seen significant progress with diffusion models, enabling generation of photo-realistic images from text prompts. Despite this progress, existing methods still face challenges in following complex text prompts, especially those requiring compositional and multi-step reasoning. Given such complex instructions, SOTA models often make mistakes in faithfully modeling object attributes, and relationships among them. In this work, we present an alternate paradigm for T2I synthesis, decomposing the task of complex multi-step generation into three steps, (a) Generate: we first generate an image using existing diffusion models (b) Plan: we make use of Multi-Modal LLMs (MLLMs) to identify the mistakes in the generated image expressed in terms of individual objects and their properties, and produce a sequence of corrective steps required in the form of an edit-plan. (c) Edit: we make use of an existing text-guided image editing models to sequentially execute our edit-plan over the generated image to get the desired image which is faithful to the original instruction. Our approach derives its strength from the fact that it is modular in nature, is training free, and can be applied over any combination of image generation and editing models. As an added contribution, we also develop a model capable of compositional editing, which further helps improve the overall accuracy of our proposed approach. Our method flexibly trades inference time compute with performance on compositional text prompts. We perform extensive experimental evaluation across 3 benchmarks and 10 T2I models including DALLE-3 and the latest – SD-3.5-Large. Our approach not only improves the performance of the SOTA models, by upto 3 points, it also reduces the performance gap between weaker and stronger models. $\href{https://dair-iitd.github.io/GraPE/}{https://dair-iitd.github.io/GraPE/}$
文本到图像(T2I)生成在扩散模型的推动下取得了重大进展,能够实现从文本提示生成逼真的图像。尽管如此,现有方法仍然面临遵循复杂文本提示的挑战,尤其是那些需要组合和多步推理的提示。面对这样的复杂指令,当前顶尖模型在忠实建模物体属性以及它们之间的关系时经常出错。在这项工作中,我们提出了一种替代的T2I合成范式,将复杂的多步生成任务分解为三个步骤:(a)生成:我们首先使用现有的扩散模型生成一个图像;(b)规划:我们利用多模态大型语言模型(MLLMs)来识别生成图像中单个对象及其属性的错误,并产生一系列以编辑计划形式存在的校正步骤。(c)编辑:我们利用现有的文本引导图像编辑模型,按序在生成的图像上执行我们的编辑计划,以获得忠实于原始指令的理想图像。我们的方法之所以强大,是因为它具有模块化性质、无需训练,并且可以应用于任何图像生成和编辑模型的组合。作为额外的贡献,我们还开发了一个能够进行组合编辑的模型,这有助于进一步提高我们提出的方法的整体准确性。我们的方法灵活地平衡了组合文本提示的推理时间与性能。我们在三个基准测试和十个T2I模型(包括DALLE-3和最新的SD-3.5-Large)上进行了广泛的实验评估。我们的方法不仅提高了SOTA模型高达3个点的性能,还缩小了强弱模型之间的性能差距。详情请访问:[https://dair-iitd.github.io/GraPE/]
论文及项目相关链接
摘要
文本转图像(T2I)生成领域借助扩散模型取得了显著进展,能够基于文本提示生成逼真的图像。然而,现有方法在处理复杂文本提示时仍面临挑战,特别是在涉及组合和多步推理的情况下。针对复杂指令,现有顶尖模型在忠实建模物体属性和它们之间的关系时经常出错。本研究提出了一种新的T2I合成范式,将复杂的多步生成任务分解为三个步骤:生成、计划和编辑。首先,利用现有扩散模型生成图像;其次,运用多模态大型语言模型(MLLMs)识别图像中单个对象及其属性的错误,并生成修正步骤序列;最后,借助文本引导的图像编辑模型,按修正步骤对生成图像进行编辑,得到忠实于原始指令的图像。本研究的优势在于其模块化特性、无需训练,且可应用于任何图像生成和编辑模型的组合。此外,还开发了一个能够进行组合编辑的模型,进一步提高整体准确性,并灵活地在推理时间和性能之间权衡。在三个基准测试和十个T2I模型(包括DALLE-3和最新的SD-3.5-Large)上的广泛实验评估表明,该方法不仅提高了现有顶尖模型性能,减少了高达3个点,还缩小了强弱模型之间的性能差距。
关键见解
- 文本转图像(T2I)生成领域虽然取得了显著进展,但在处理复杂文本提示时仍面临挑战。
- 现有顶尖模型在忠实建模物体属性和它们之间的关系时经常出错。
- 本研究提出了一种新的T2I合成范式,包括生成、计划和编辑三个步骤。
- 所提出的方法利用多模态大型语言模型(MLLMs)识别图像中的错误,并生成修正步骤序列。
- 借助文本引导的图像编辑模型按修正步骤进行编辑,得到忠实于原始指令的图像。
- 该方法具有模块化特性、无需训练,且可灵活应用于不同的图像生成和编辑模型组合。
- 研究还开发了能够进行组合编辑的模型,提高了整体准确性,并通过灵活调整推理时间来实现性能优化。
点此查看论文截图