⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Revealing Unintentional Information Leakage in Low-Dimensional Facial Portrait Representations
Authors:Kathleen Anderson, Thomas Martinetz
We evaluate the information that can unintentionally leak into the low dimensional output of a neural network, by reconstructing an input image from a 40- or 32-element feature vector that intends to only describe abstract attributes of a facial portrait. The reconstruction uses blackbox-access to the image encoder which generates the feature vector. Other than previous work, we leverage recent knowledge about image generation and facial similarity, implementing a method that outperforms the current state-of-the-art. Our strategy uses a pretrained StyleGAN and a new loss function that compares the perceptual similarity of portraits by mapping them into the latent space of a FaceNet embedding. Additionally, we present a new technique that fuses the output of an ensemble, to deliberately generate specific aspects of the recreated image.
我们通过对神经网络的低维输出可能无意间泄露的信息进行评估,从意图仅描述面部肖像抽象属性的特征向量中重构输入图像。重构过程使用对图像编码器的黑箱访问,该编码器生成特征向量。与之前的工作不同,我们利用有关图像生成和面部相似性的最新知识,实施了一种超越当前技术的方法。我们的策略使用预训练的StyleGAN和一个新的损失函数,通过将肖像映射到FaceNet嵌入的潜在空间来比较肖像的感知相似性。此外,我们还提出了一种新技术,该技术融合了组合的输出,以故意生成重构图像的特定方面。
论文及项目相关链接
Summary
基于给定的文本摘要描述信息无意识地泄漏到神经网络的低维输出中,通过重构仅意图描述面部肖像的抽象属性的特征向量来评估这些信息。重构使用了图像编码器的黑箱访问来生成特征向量。除了以前的工作外,我们还利用最新的图像生成和面部相似性知识来实现优于当前最先进技术的方法。我们的策略使用了预训练的StyleGAN和新开发的损失函数来通过将它们映射到FaceNet嵌入的潜在空间中比较肖像的感知相似性。此外,我们还提出了一种融合组合的新技术,有意识地生成重构图像的特定属性。这一技术和分析能够准确反映出当前研究工作的新颖性和重要性。
Key Takeaways
- 通过重构图像从特征向量中评估信息泄漏问题。
- 使用黑箱访问图像编码器生成特征向量进行重构。
- 结合最新知识,在面部肖像的图像生成方面表现超越当前最先进的技术。
- 利用预训练的StyleGAN和新的损失函数,通过映射到FaceNet嵌入的潜在空间来比较肖像感知相似性。
- 提出一种融合组合的新技术,旨在生成图像的特定属性。
- 该方法提高了肖像重构的质量和准确性。
点此查看论文截图

Posterior-Mean Denoising Diffusion Model for Realistic PET Image Reconstruction
Authors:Yiran Sun, Osama Mawlawi
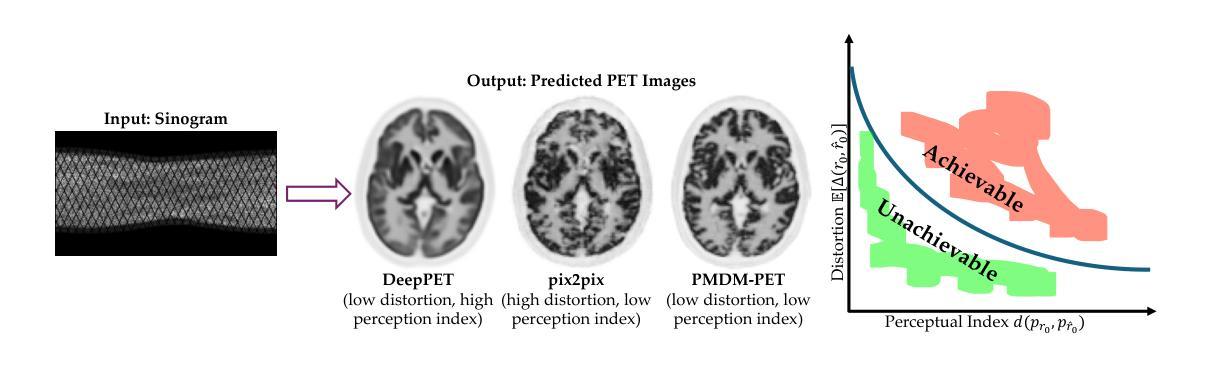
Positron Emission Tomography (PET) is a functional imaging modality that enables the visualization of biochemical and physiological processes across various tissues. Recently, deep learning (DL)-based methods have demonstrated significant progress in directly mapping sinograms to PET images. However, regression-based DL models often yield overly smoothed reconstructions lacking of details (i.e., low distortion, low perceptual quality), whereas GAN-based and likelihood-based posterior sampling models tend to introduce undesirable artifacts in predictions (i.e., high distortion, high perceptual quality), limiting their clinical applicability. To achieve a robust perception-distortion tradeoff, we propose Posterior-Mean Denoising Diffusion Model (PMDM-PET), a novel approach that builds upon a recently established mathematical theory to explore the closed-form expression of perception-distortion function in diffusion model space for PET image reconstruction from sinograms. Specifically, PMDM-PET first obtained posterior-mean PET predictions under minimum mean square error (MSE), then optimally transports the distribution of them to the ground-truth PET images distribution. Experimental results demonstrate that PMDM-PET not only generates realistic PET images with possible minimum distortion and optimal perceptual quality but also outperforms five recent state-of-the-art (SOTA) DL baselines in both qualitative visual inspection and quantitative pixel-wise metrics PSNR (dB)/SSIM/NRMSE.
正电子发射断层扫描(PET)是一种功能成像技术,能够可视化各种组织中的生物化学和生理过程。最近,深度学习(DL)方法在直接将辛图映射到PET图像上取得了显著进展。然而,基于回归的DL模型往往会产生过于平滑的重建结果,缺乏细节(即低失真、低感知质量),而基于GAN和基于后验采样的似然模型则往往在预测中引入不需要的伪影(即高失真、高感知质量),限制了它们在临床上的适用性。为了实现稳健的感知-失真权衡,我们提出了后验均值去噪扩散模型(PMDM-PET),这是一种新方法,建立在最近建立的数学理论上,探索扩散模型空间中感知-失真函数的封闭形式表达式,用于从辛图重建PET图像。具体来说,PMDM-PET首先以最小均方误差(MSE)获得后验均值PET预测,然后将其分布最优地传输到真实PET图像分布。实验结果表明,PMDM-PET不仅生成了具有可能最小失真和最佳感知质量的现实PET图像,而且在定性和定量像素级指标上都优于五种最新的最先进的DL基线方法,包括峰值信噪比(PSNR)(dB)/结构相似性度量(SSIM)/归一化均方根误差(NRMSE)。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
基于正电子发射断层扫描(PET)成像技术,本文提出了一种新型的图像重建方法——后均值去噪扩散模型(PMDM-PET)。该方法结合了扩散模型空间中的感知失真函数的闭式表达式,旨在实现PET图像从正弦图重建过程中的稳健感知失真权衡。实验结果表明,PMDM-PET不仅生成了具有最小失真和最佳感知质量的现实PET图像,而且在视觉定性检查和像素级指标PSNR(分贝)/SSIM/NRMSE方面均优于五种最新的深度学习方法。
Key Takeaways
- PET是一种功能成像技术,可以可视化各种组织的生物化学反应和生理过程。
- 基于深度学习的直接从正弦图映射到PET图像的方法已经取得了显著进展。
- 回归型深度学习模型可能会产生过于平滑的图像,缺乏细节;而基于GAN和基于后验采样的模型则可能在预测中引入不希望的伪影。
- 提出了一种新型的PET图像重建方法——后均值去噪扩散模型(PMDM-PET)。
- PMDM-PET旨在实现感知失真权衡,通过探索扩散模型空间中的感知失真函数的闭式表达式来实现。
- 实验结果表明,PMDM-PET在生成具有最小失真和最佳感知质量的现实PET图像方面优于五种最新的深度学习方法。
点此查看论文截图

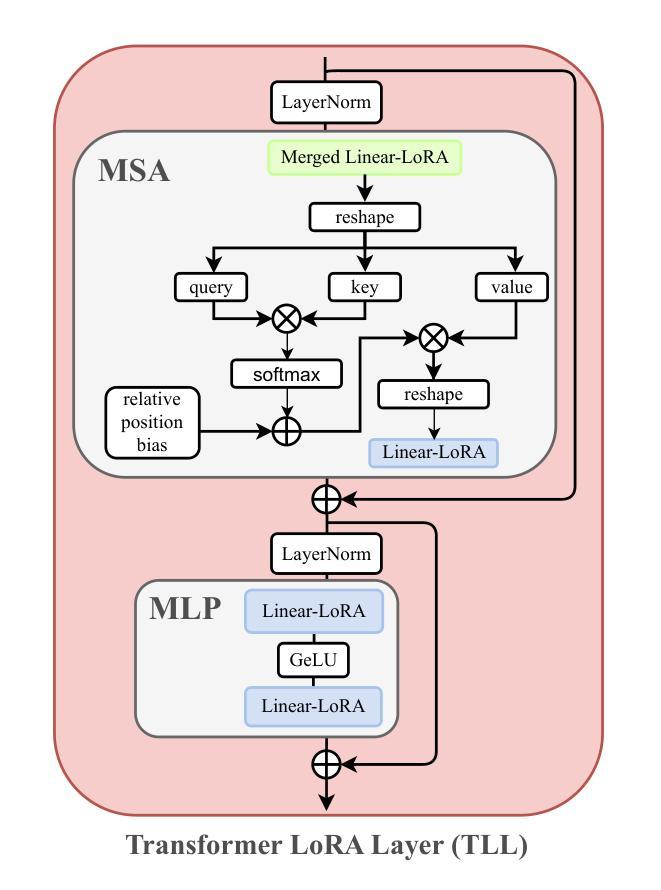
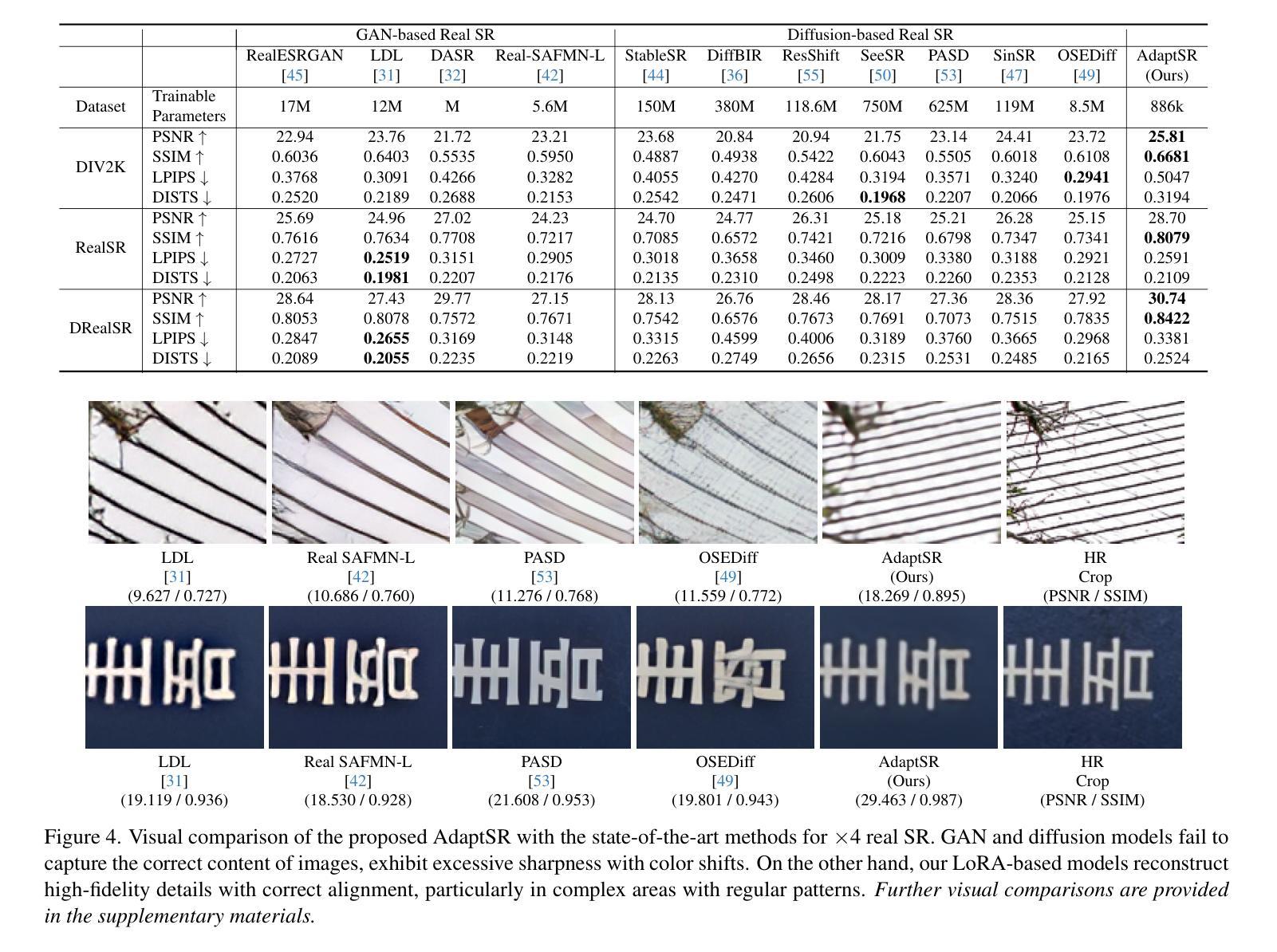
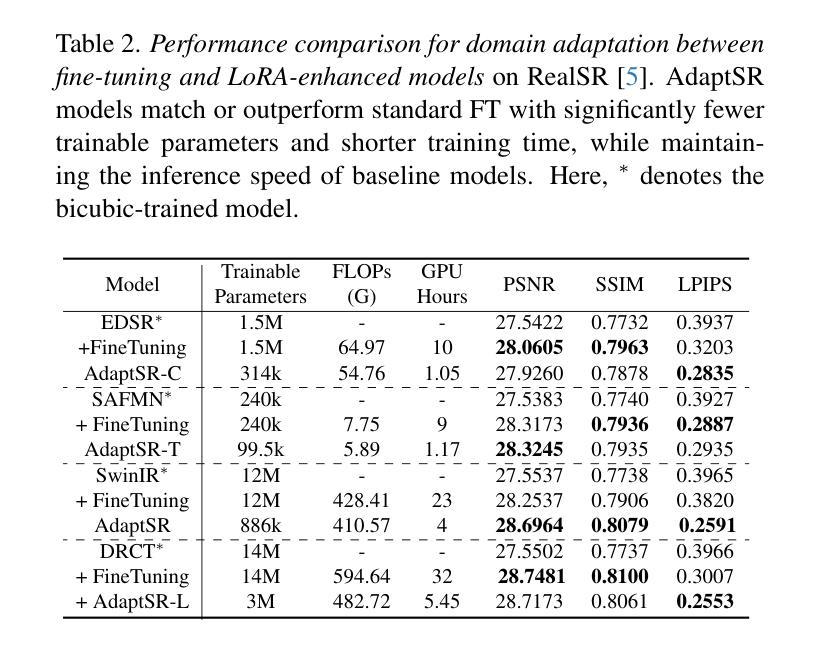
AdaptSR: Low-Rank Adaptation for Efficient and Scalable Real-World Super-Resolution
Authors:Cansu Korkmaz, Nancy Mehta, Radu Timofte
Recovering high-frequency details and textures from low-resolution images remains a fundamental challenge in super-resolution (SR), especially when real-world degradations are complex and unknown. While GAN-based methods enhance realism, they suffer from training instability and introduce unnatural artifacts. Diffusion models, though promising, demand excessive computational resources, often requiring multiple GPU days, even for single-step variants. Rather than naively fine-tuning entire models or adopting unstable generative approaches, we introduce AdaptSR, a low-rank adaptation (LoRA) framework that efficiently repurposes bicubic-trained SR models for real-world tasks. AdaptSR leverages architecture-specific insights and selective layer updates to optimize real SR adaptation. By updating only lightweight LoRA layers while keeping the pretrained backbone intact, it captures domain-specific adjustments without adding inference cost, as the adapted layers merge seamlessly post-training. This efficient adaptation not only reduces memory and compute requirements but also makes real-world SR feasible on lightweight hardware. Our experiments demonstrate that AdaptSR outperforms GAN and diffusion-based SR methods by up to 4 dB in PSNR and 2% in perceptual scores on real SR benchmarks. More impressively, it matches or exceeds full model fine-tuning while training 92% fewer parameters, enabling rapid adaptation to real SR tasks within minutes.
从低分辨率图像中恢复高频细节和纹理仍然是超分辨率(SR)中的一项基本挑战,特别是在现实世界退化复杂且未知的情况下。虽然基于GAN的方法增强了真实性,但它们存在训练不稳定的问题,并引入了不自然的伪影。尽管扩散模型很有前景,但它们需要大量的计算资源,即使是单步变体,也通常需要多个GPU天。我们并没有微调整个模型或采用不稳定的生成方法,而是引入了AdaptSR,这是一种低秩适应(LoRA)框架,它能有效地将用于现实世界任务的立方SR模型重新用于实际应用。AdaptSR利用特定的架构见解和选择性的层更新来优化真实的SR适应。它只更新轻量级的LoRA层,同时保持预训练的骨干部分不变,从而捕获特定领域的调整,同时不增加推理成本,因为适应的层在训练后无缝融合。这种高效的适应不仅减少了内存和计算需求,而且使得在轻量级硬件上进行现实世界的SR成为可能。我们的实验表明,在真实SR基准测试中,AdaptSR在PSNR上比基于GAN和扩散的SR方法高出4分贝左右,感知分数提高约2%。更引人注目的是,它与完全模型微调相匹配或超过它,同时训练参数减少了92%,能够在几分钟内快速适应真实SR任务。
论文及项目相关链接
PDF 11 pages including 3 pages of references, 7 figures and 7 tables
Summary
本文介绍了针对超分辨率(SR)任务中从低分辨率图像恢复高频细节和纹理的挑战,提出了一种名为AdaptSR的低秩适应(LoRA)框架。该框架能够高效地将基于双三次插值的SR模型用于真实世界任务,通过架构特定见解和选择性层更新进行优化。AdaptSR通过仅更新轻量级的LoRA层,同时保持预训练的主干网络不变,捕获特定领域的调整,而不增加推理成本。这种方法不仅降低了内存和计算要求,而且使得在轻量级硬件上进行真实世界的SR成为可能。实验表明,AdaptSR在真实SR基准测试中优于基于GAN和扩散的SR方法,峰值信噪比(PSNR)高达4dB,感知得分提高2%。更重要的是,它可与全模型微调相匹敌,同时训练参数减少92%,可在几分钟内快速适应真实SR任务。
Key Takeaways
- 面临从低分辨率图像恢复高频细节和纹理的超分辨率(SR)挑战。
- GAN方法虽然增强了真实性,但存在训练不稳定和引入不自然伪影的问题。
- 扩散模型虽然前景广阔,但需要巨大的计算资源,即使是单步变体也需要多次GPU天。
- 提出了一种名为AdaptSR的低秩适应(LoRA)框架,能够高效地将SR模型用于真实世界任务。
- AdaptSR通过更新轻量级LoRA层并保留预训练的主干网络来优化适应。
- 该方法降低了内存和计算要求,使得在轻量级硬件上进行真实世界的SR成为可能。
- AdaptSR在真实SR基准测试中表现出优异的性能,优于基于GAN和扩散的SR方法。
点此查看论文截图