⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Electromyography-Informed Facial Expression Reconstruction for Physiological-Based Synthesis and Analysis
Authors:Tim Büchner, Christoph Anders, Orlando Guntinas-Lichius, Joachim Denzler
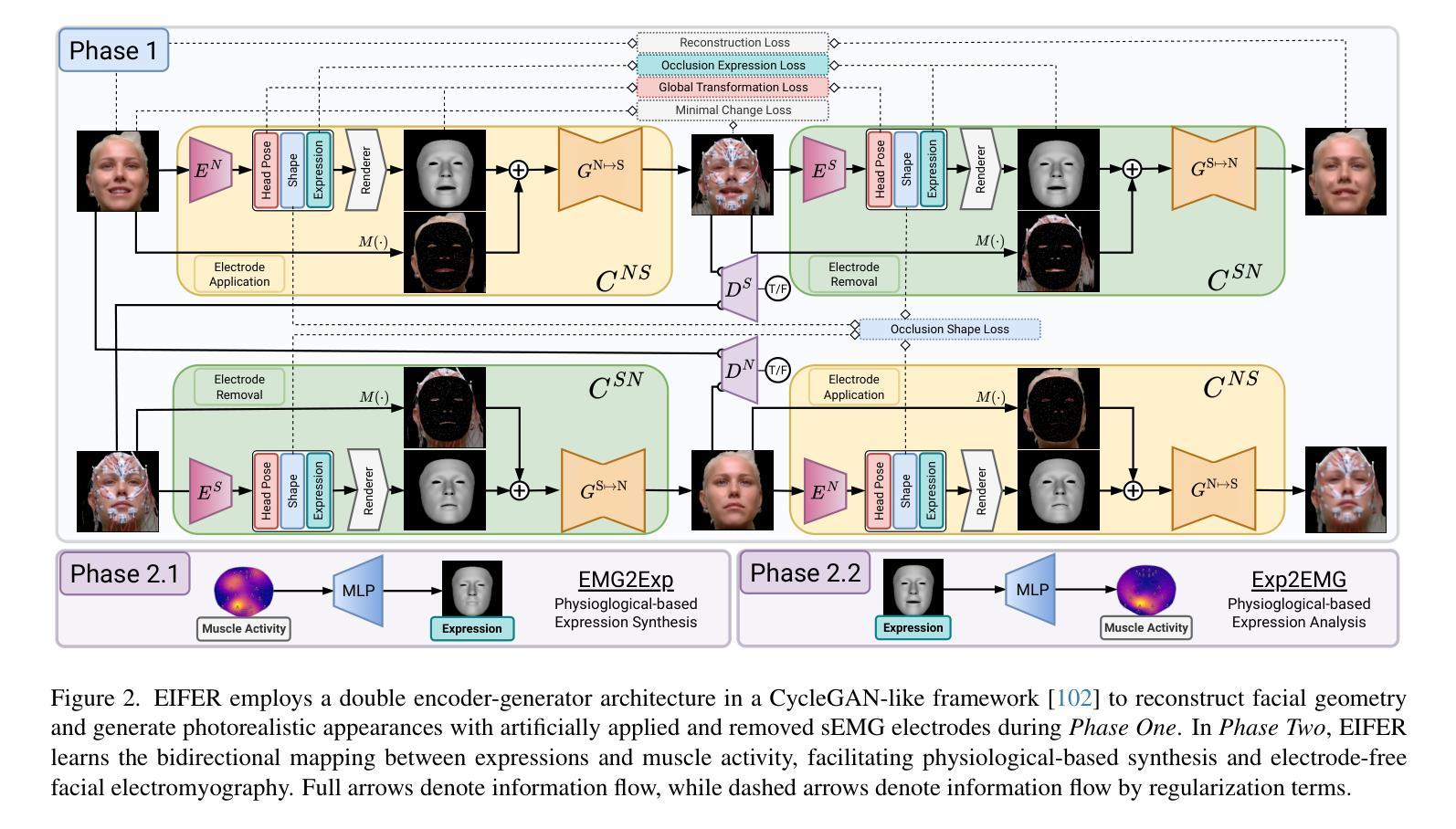
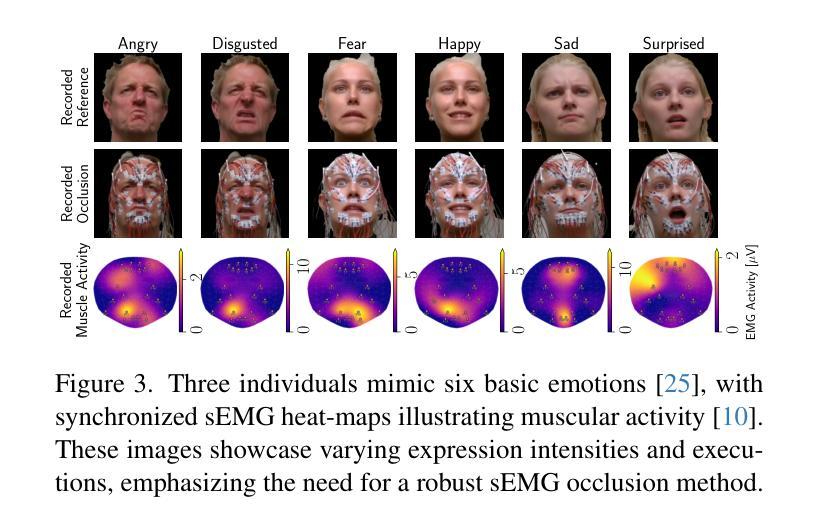
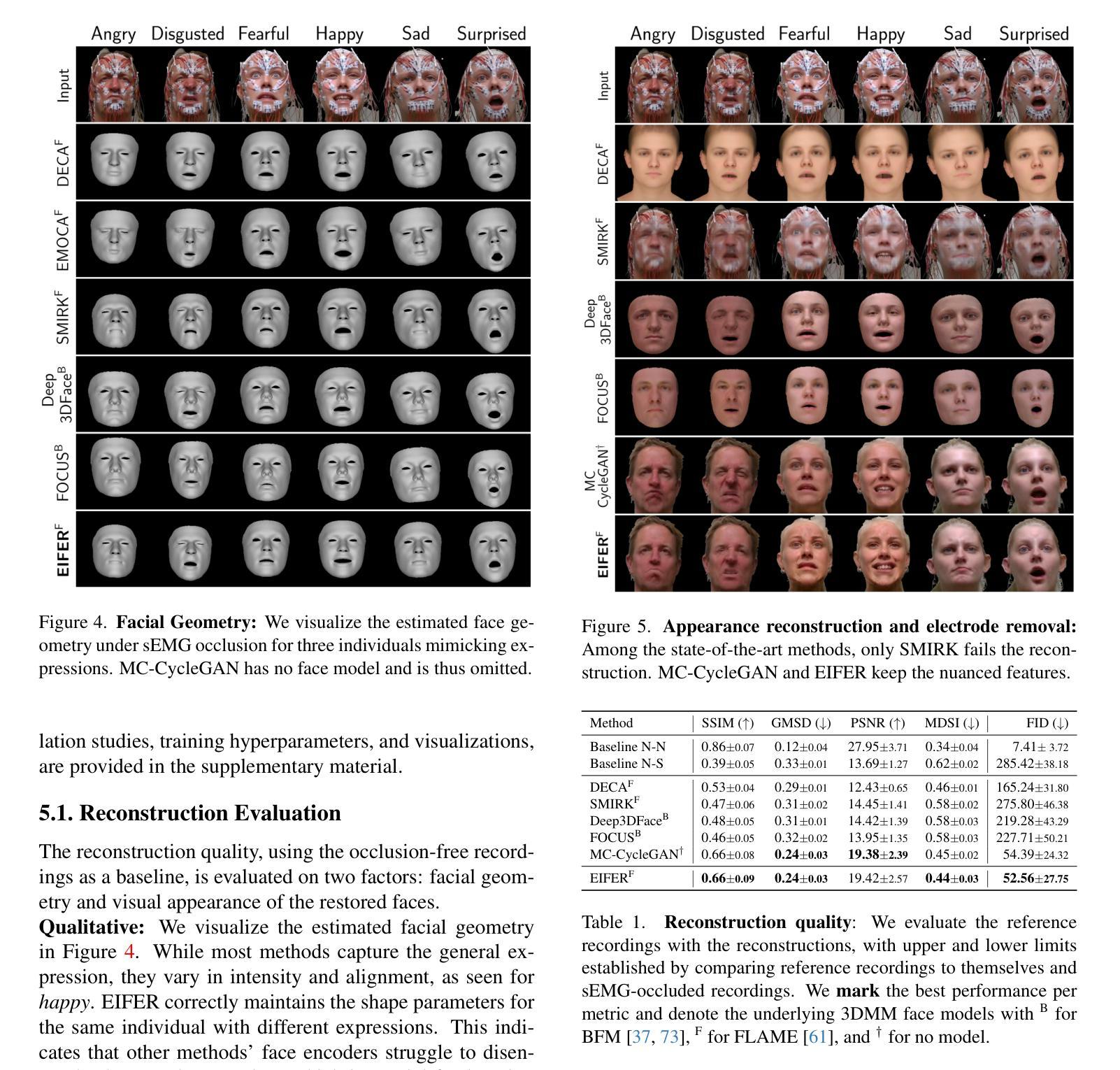
The relationship between muscle activity and resulting facial expressions is crucial for various fields, including psychology, medicine, and entertainment. The synchronous recording of facial mimicry and muscular activity via surface electromyography (sEMG) provides a unique window into these complex dynamics. Unfortunately, existing methods for facial analysis cannot handle electrode occlusion, rendering them ineffective. Even with occlusion-free reference images of the same person, variations in expression intensity and execution are unmatchable. Our electromyography-informed facial expression reconstruction (EIFER) approach is a novel method to restore faces under sEMG occlusion faithfully in an adversarial manner. We decouple facial geometry and visual appearance (e.g., skin texture, lighting, electrodes) by combining a 3D Morphable Model (3DMM) with neural unpaired image-to-image translation via reference recordings. Then, EIFER learns a bidirectional mapping between 3DMM expression parameters and muscle activity, establishing correspondence between the two domains. We validate the effectiveness of our approach through experiments on a dataset of synchronized sEMG recordings and facial mimicry, demonstrating faithful geometry and appearance reconstruction. Further, we synthesize expressions based on muscle activity and how observed expressions can predict dynamic muscle activity. Consequently, EIFER introduces a new paradigm for facial electromyography, which could be extended to other forms of multi-modal face recordings.
肌肉活动与产生的面部表情之间的关系对心理学、医学和娱乐等多个领域都至关重要。通过表面肌电图(sEMG)同步记录面部表情和肌肉活动,为这些复杂动态提供了一个独特的窗口。然而,现有的面部分析方法无法处理电极遮挡问题,导致它们无效。即使使用同一人无遮挡的参考图像,表情强度和执行的差异也无法匹配。我们的电生理学启发下的面部表情重建(EIFER)方法是一种采用对抗方式在sEMG遮挡下忠实还原面部的新方法。我们通过结合三维可变形模型(3DMM)和通过参考记录进行神经无配对图像到图像的翻译,来解耦面部几何形状和视觉外观(如皮肤纹理、光照、电极等)。然后,EIFER学习3DMM表情参数与肌肉活动之间的双向映射,在两个领域之间建立对应关系。我们通过同步sEMG记录和面部表情的数据集进行实验,验证了我们的方法的有效性,展示了忠实的几何和外观重建。此外,我们根据肌肉活动合成表情,并探讨观察到的表情如何预测动态肌肉活动。因此,EIFER为面部肌电图引入了新的范式,可以扩展到其他形式的多模式面部记录。
论文及项目相关链接
PDF Accepted at CVPR 2025, 41 pages, 37 figures, 8 tables
Summary
本文介绍了肌肉活动与面部表情之间的关键关系,并指出其在心理学、医学和娱乐等领域的重要性。文章提出了一种新型的电肌图引导面部表情重建(EIFER)方法,能够在表面肌电图(sEMG)遮挡的情况下恢复面部图像。通过结合三维可变形模型(3DMM)和神经非配对图像到图像的翻译,该方法能够解耦面部几何形状和视觉外观,并通过双向映射学习肌肉活动与面部表情参数之间的对应关系。实验验证表明,该方法在同步sEMG记录和面部表情模仿数据集上具有良好的几何形状和外观重建效果。此外,该方法还能根据肌肉活动合成表情,并根据观察到的表情预测动态肌肉活动。因此,EIFER为面部电肌图研究带来了新的范式,可扩展到其他多模态面部记录形式。
Key Takeaways
- 肌肉活动与面部表情的关系在心理学、医学和娱乐等领域具有重要意义。
- 现有面部分析方法无法处理电极遮挡问题,导致分析失效。
- EIFER方法结合3DMM和神经非配对图像翻译技术,能够在sEMG遮挡的情况下恢复面部图像。
- EIFER方法通过双向映射学习肌肉活动与面部表情参数之间的对应关系。
- 实验验证了EIFER方法在几何形状和外观重建上的有效性。
- EIFER能合成基于肌肉活动的表情,并预测动态肌肉活动。
点此查看论文截图

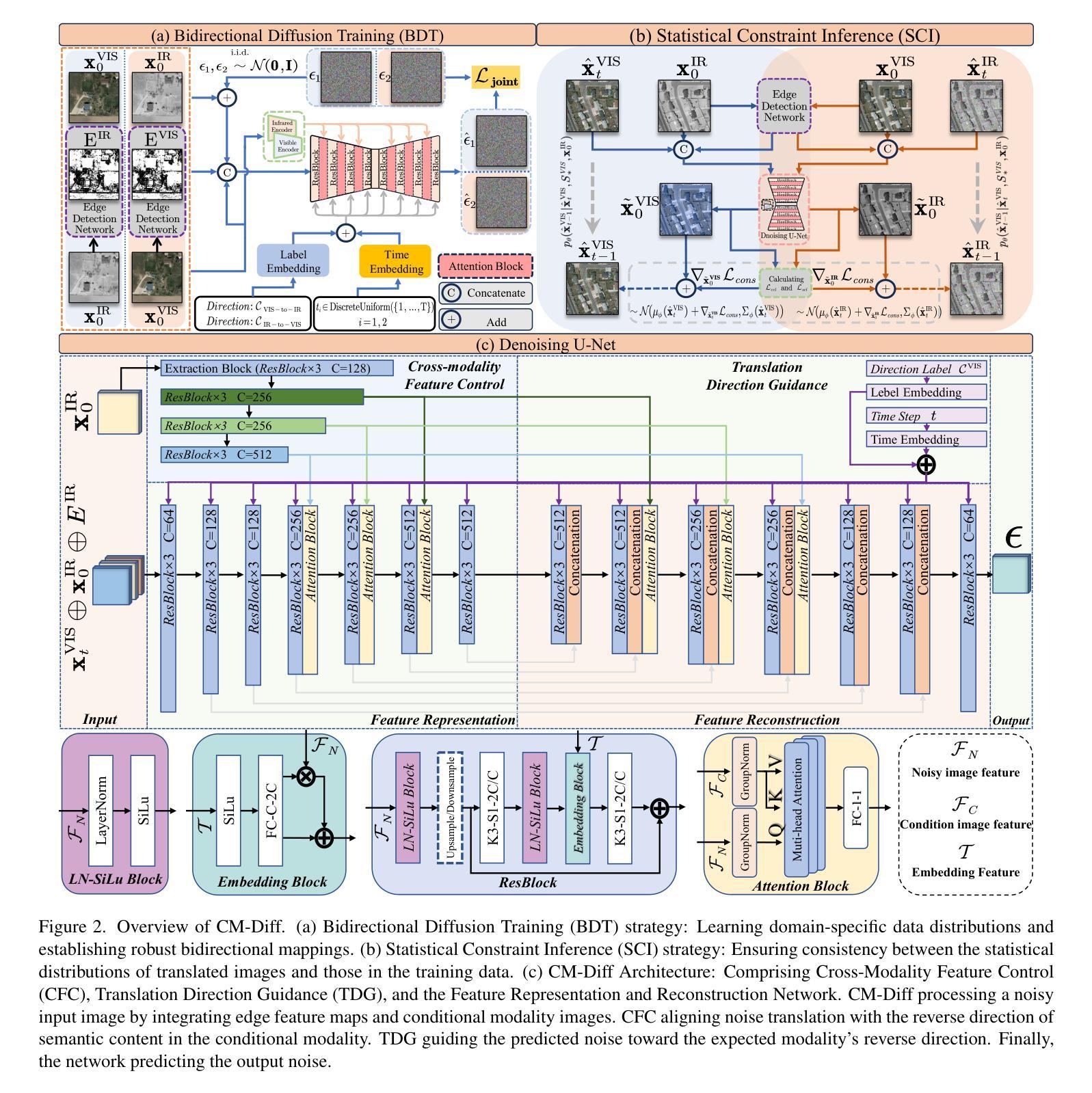
CM-Diff: A Single Generative Network for Bidirectional Cross-Modality Translation Diffusion Model Between Infrared and Visible Images
Authors:Bin Hu, Chenqiang Gao, Shurui Liu, Junjie Guo, Fang Chen, Fangcen Liu
The image translation method represents a crucial approach for mitigating information deficiencies in the infrared and visible modalities, while also facilitating the enhancement of modality-specific datasets. However, existing methods for infrared and visible image translation either achieve unidirectional modality translation or rely on cycle consistency for bidirectional modality translation, which may result in suboptimal performance. In this work, we present the cross-modality translation diffusion model (CM-Diff) for simultaneously modeling data distributions in both the infrared and visible modalities. We address this challenge by combining translation direction labels for guidance during training with cross-modality feature control. Specifically, we view the establishment of the mapping relationship between the two modalities as the process of learning data distributions and understanding modality differences, achieved through a novel Bidirectional Diffusion Training (BDT) strategy. Additionally, we propose a Statistical Constraint Inference (SCI) strategy to ensure the generated image closely adheres to the data distribution of the target modality. Experimental results demonstrate the superiority of our CM-Diff over state-of-the-art methods, highlighting its potential for generating dual-modality datasets.
图像转换方法对于弥补红外和可见光模式中的信息缺失至关重要,同时也有助于增强特定模式的数据集。然而,现有的红外和可见图像转换方法要么实现单向模式转换,要么依赖于循环一致性进行双向模式转换,这可能导致性能不佳。在这项工作中,我们提出了跨模态转换扩散模型(CM-Diff),以同时模拟红外和可见光模态的数据分布。我们通过结合训练过程中的翻译方向标签进行引导,以及跨模态特征控制来解决这一挑战。具体来说,我们将建立两种模式之间的映射关系视为学习过程数据分布和理解模式差异的过程,通过一种新的双向扩散训练(BDT)策略来实现。此外,我们提出了一种统计约束推理(SCI)策略,以确保生成的图像紧密符合目标模态的数据分布。实验结果证明了我们的CM-Diff相较于最先进的方法具有优越性,凸显了其生成双模态数据集的潜力。
论文及项目相关链接
摘要
该研究提出了一种跨模态翻译扩散模型(CM-Diff),该模型能够同时对红外和可见模态的数据分布进行建模,解决了现有图像翻译方法在红外和可见光图像翻译方面存在的单向模态翻译或依赖于循环一致性进行双向模态翻译的问题。该研究通过结合翻译方向标签进行训练指导以及跨模态特征控制来解决这一挑战。通过采用双向扩散训练(BDT)策略,建立两种模态之间的映射关系,理解和利用模态差异。同时,提出统计约束推理(SCI)策略,确保生成的图像紧密符合目标模态的数据分布。实验结果表明,CM-Diff相较于现有先进方法具有优越性,具有生成双模态数据集的潜力。
要点
- 跨模态翻译扩散模型(CM-Diff)解决了红外和可见模态信息缺失的问题,同时增强了模态特定数据集。
- 现有图像翻译方法存在单向或依赖于循环一致性的双向模态翻译的问题,而CM-Diff能同时进行双向翻译。
- CM-Diff通过结合翻译方向标签进行训练指导以及跨模态特征控制来解决挑战。
- 采用双向扩散训练(BDT)策略建立两种模态的映射关系,理解和利用模态差异。
- CM-Diff采用统计约束推理(SCI)策略,确保生成的图像符合目标模态的数据分布。
- 实验证明CM-Diff在生成双模态数据集方面表现优异,超过现有方法。
- CM-Diff的潜在应用包括改善模态转换的性能、扩充数据集、增强跨模态通信等。
点此查看论文截图

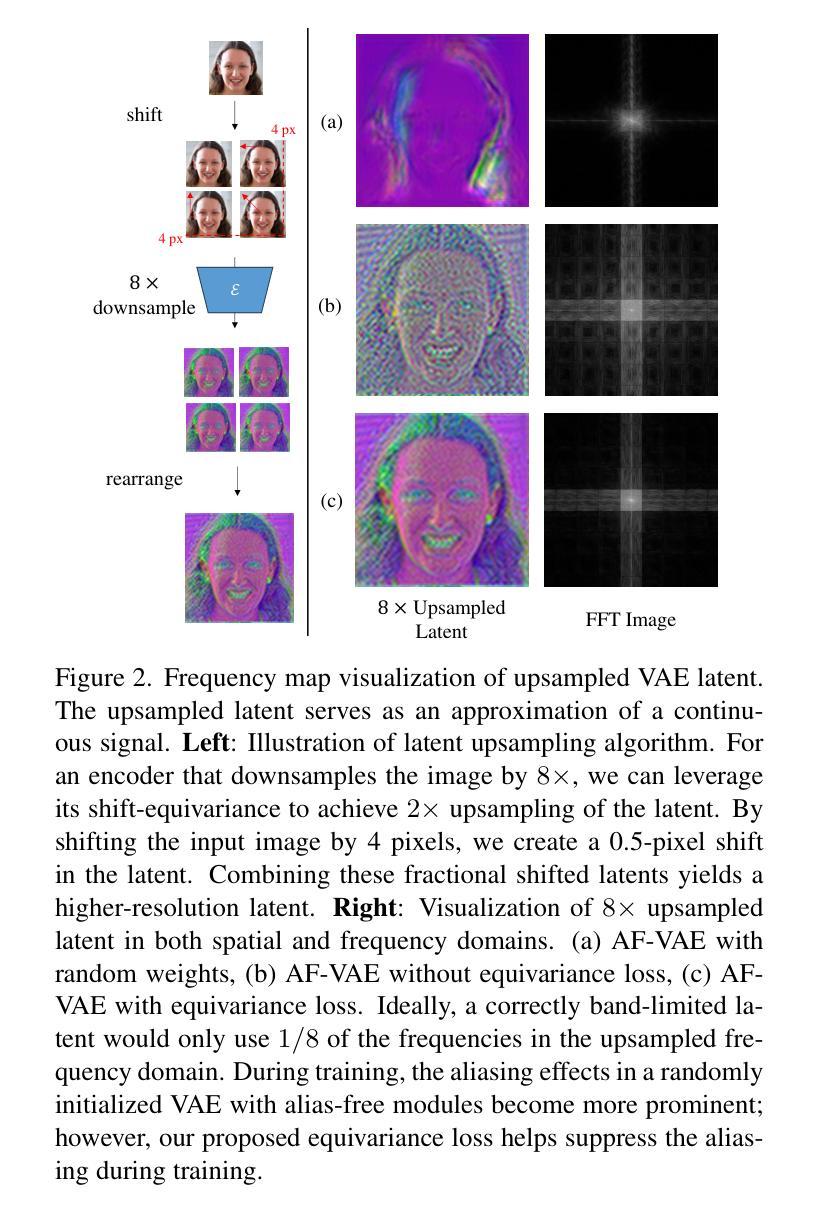
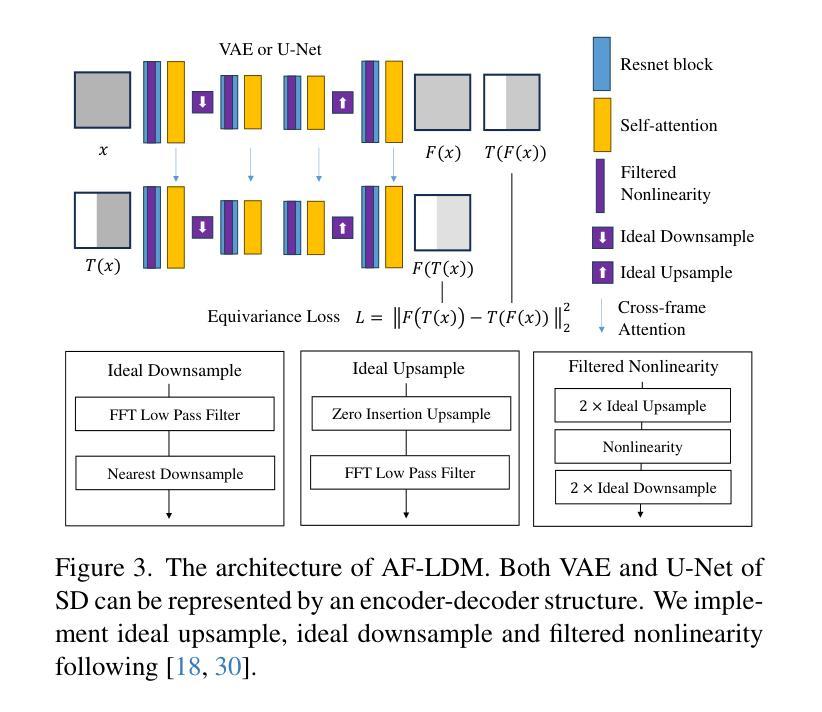
Alias-Free Latent Diffusion Models:Improving Fractional Shift Equivariance of Diffusion Latent Space
Authors:Yifan Zhou, Zeqi Xiao, Shuai Yang, Xingang Pan
Latent Diffusion Models (LDMs) are known to have an unstable generation process, where even small perturbations or shifts in the input noise can lead to significantly different outputs. This hinders their applicability in applications requiring consistent results. In this work, we redesign LDMs to enhance consistency by making them shift-equivariant. While introducing anti-aliasing operations can partially improve shift-equivariance, significant aliasing and inconsistency persist due to the unique challenges in LDMs, including 1) aliasing amplification during VAE training and multiple U-Net inferences, and 2) self-attention modules that inherently lack shift-equivariance. To address these issues, we redesign the attention modules to be shift-equivariant and propose an equivariance loss that effectively suppresses the frequency bandwidth of the features in the continuous domain. The resulting alias-free LDM (AF-LDM) achieves strong shift-equivariance and is also robust to irregular warping. Extensive experiments demonstrate that AF-LDM produces significantly more consistent results than vanilla LDM across various applications, including video editing and image-to-image translation. Code is available at: https://github.com/SingleZombie/AFLDM
潜在扩散模型(LDMs)的生成过程不稳定,即使输入噪声出现微小的扰动或变化,也可能导致输出结果显著不同。这阻碍了它们在需要一致结果的应用中的适用性。在这项工作中,我们通过使模型具有平移等变性来重新设计LDMs,以增强其一致性。虽然引入抗混叠操作可以部分提高平移等变性,但由于LDM中独特的挑战,仍然存在严重的混叠和不一致性,包括1)在VAE训练期间和多个U-Net推断期间的混叠放大,以及2)本质上缺乏平移等变性的自注意力模块。为了解决这些问题,我们重新设计了注意力模块以实现平移等变性,并提出了一种等变性损失,有效地抑制了连续域中特征频率带宽。由此产生的无混叠LDM(AF-LDM)实现了强大的平移等变性,并且对不规则扭曲也具有鲁棒性。大量实验表明,AF-LDM在各种应用中产生的结果比原始LDM更加一致,包括视频编辑和图像到图像的翻译。代码可在此处找到:https://github.com/SingleZombie/AFLDM
论文及项目相关链接
Summary
本文介绍了潜在扩散模型(LDMs)在生成过程中的不稳定性问题,并针对该问题提出了一种改进方法,即通过设计别名免费潜在扩散模型(AF-LDM)来实现更强的等变性。为了解决LDM面临的特定挑战,如变分自编码器训练中的别名放大和多U-Net推理问题,以及自注意力模块本身缺乏等变性,该研究重新设计了注意力模块并提出了等变性损失来抑制连续域中的特征频率带宽。实验结果证明,AF-LDM在各种应用中表现优于原始LDM,实现了更一致的生成结果。
Key Takeaways
- LDMs存在生成过程不稳定的问题,导致输入噪声的小扰动或变化可能导致显著不同的输出。
- 为提高一致性,研究者提出了AF-LDM模型以增强其等变性。
- 通过引入抗混叠操作,AF-LDM能够部分改善等变性。然而,由于LDM面临的特定挑战,仍存在显著的混叠和不一致性。
- LDM的挑战包括变分自编码器训练中的别名放大问题以及多个U-Net推理过程中出现的问题。此外,其自注意力模块本质上缺乏等变性也是问题所在。对此提出了两种解决方案:重新设计注意力模块以实现等变性,并引入等变性损失来抑制特征频率带宽。这些措施旨在消除别名影响并提高模型的稳健性。
点此查看论文截图



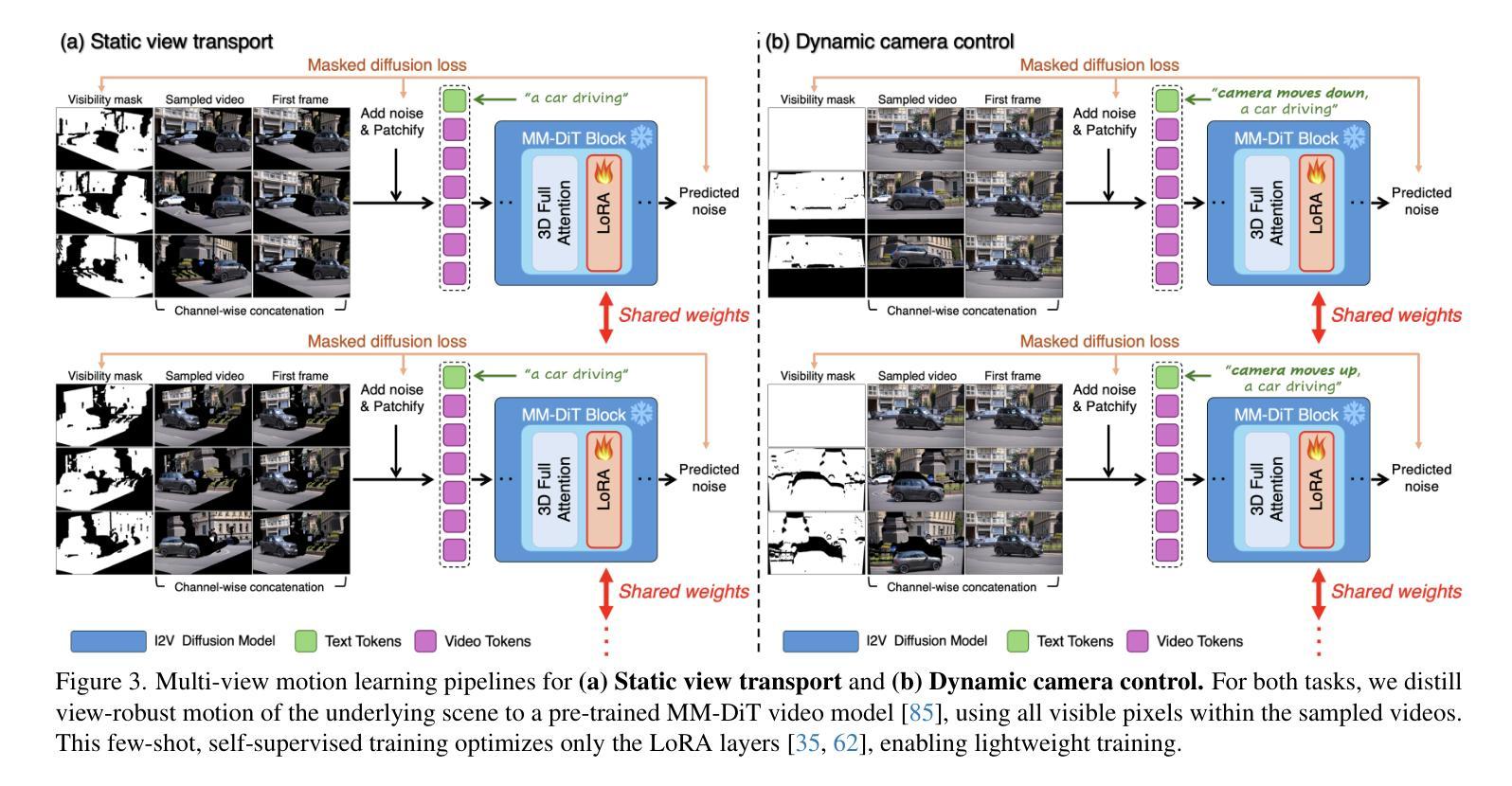
Reangle-A-Video: 4D Video Generation as Video-to-Video Translation
Authors:Hyeonho Jeong, Suhyeon Lee, Jong Chul Ye
We introduce Reangle-A-Video, a unified framework for generating synchronized multi-view videos from a single input video. Unlike mainstream approaches that train multi-view video diffusion models on large-scale 4D datasets, our method reframes the multi-view video generation task as video-to-videos translation, leveraging publicly available image and video diffusion priors. In essence, Reangle-A-Video operates in two stages. (1) Multi-View Motion Learning: An image-to-video diffusion transformer is synchronously fine-tuned in a self-supervised manner to distill view-invariant motion from a set of warped videos. (2) Multi-View Consistent Image-to-Images Translation: The first frame of the input video is warped and inpainted into various camera perspectives under an inference-time cross-view consistency guidance using DUSt3R, generating multi-view consistent starting images. Extensive experiments on static view transport and dynamic camera control show that Reangle-A-Video surpasses existing methods, establishing a new solution for multi-view video generation. We will publicly release our code and data. Project page: https://hyeonho99.github.io/reangle-a-video/
我们介绍Reangle-A-Video,这是一个从单个输入视频生成同步多视角视频的统一框架。不同于主流方法在大型4D数据集上训练多视角视频扩散模型,我们的方法将多视角视频生成任务重新构建为视频到视频的翻译,利用公开可用的图像和视频扩散先验。本质上,Reangle-A-Video分为两个阶段。(1)多视角运动学习:以自监督的方式同步微调图像到视频扩散转换器,从一组扭曲的视频中提炼出视角不变的运动。(2)多视角一致图像到图像的翻译:输入视频的第一帧在推理时间跨视角一致性指导下扭曲和填充,生成多视角一致的开始图像。关于静态视角传输和动态摄像机控制的广泛实验表明,Reangle-A-Video超越了现有方法,为多视角视频生成建立了新的解决方案。我们将公开发布我们的代码和数据。项目页面:https://hyeonho99.github.io/reangle-a-video/
论文及项目相关链接
PDF Project page: https://hyeonho99.github.io/reangle-a-video/
Summary
Reangle-A-Video框架能够从单一输入视频生成同步多视角视频。它采用视频到视频的翻译方式,利用公开可用的图像和视频扩散先验知识,不同于主流在大型4D数据集上训练多视角视频扩散模型的方法。Reangle-A-Video分为两个阶段:多视角运动学习和多视角一致图像到图像的翻译。通过同步自监督方式微调图像到视频扩散转换器,从一组变形视频中提取视图不变的运动。在输入视频的第一帧中,采用跨视角一致性指导生成多视角一致起始图像。实验表明,Reangle-A-Video在静态视角转换和动态摄像机控制上超越了现有方法,为多视角视频生成提供了新的解决方案。
Key Takeaways
- Reangle-A-Video是一个从单一输入视频生成同步多视角视频的框架。
- 它采用视频到视频的翻译方式,利用图像和视频扩散先验知识。
- 该方法通过两个阶段进行:多视角运动学习和多视角一致图像到图像的翻译。
- 通过同步自监督方式提取视图不变的运动。
- 生成多视角一致起始图像时采用了跨视角一致性指导。
- Reangle-A-Video在静态和动态视角转换上表现出超越现有方法的效果。
点此查看论文截图


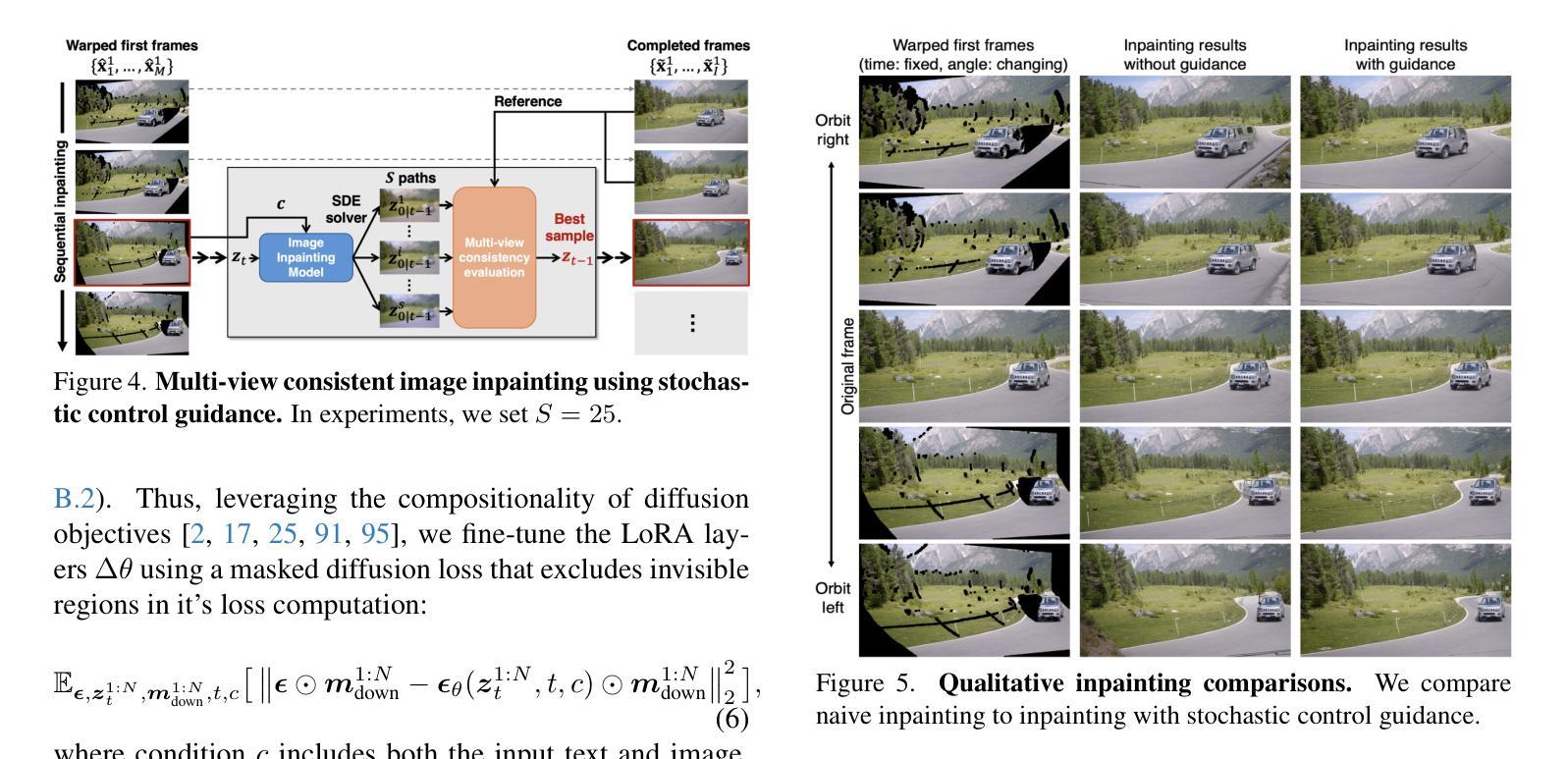

Are ECGs enough? Deep learning classification of cardiac anomalies using only electrocardiograms
Authors:Joao D. S. Marques, Arlindo L. Oliveira
Electrocardiography (ECG) is an essential tool for diagnosing multiple cardiac anomalies: it provides valuable clinical insights, while being affordable, fast and available in many settings. However, in the current literature, the role of ECG analysis is often unclear: many approaches either rely on additional imaging modalities, such as Computed Tomography Pulmonary Angiography (CTPA), which may not always be available, or do not effectively generalize across different classification problems. Furthermore, the availability of public ECG datasets is limited and, in practice, these datasets tend to be small, making it essential to optimize learning strategies. In this study, we investigate the performance of multiple neural network architectures in order to assess the impact of various approaches. Moreover, we check whether these practices enhance model generalization when transfer learning is used to translate information learned in larger ECG datasets, such as PTB-XL and CPSC18, to a smaller, more challenging dataset for pulmonary embolism (PE) detection. By leveraging transfer learning, we analyze the extent to which we can improve learning efficiency and predictive performance on limited data. Code available at https://github.com/joaodsmarques/Are-ECGs-enough-Deep-Learning-Classifiers .
心电图(ECG)是诊断多种心脏异常的重要工具:它提供了宝贵的临床见解,同时经济实惠、快速,并在许多环境中都可使用。然而,在目前的文献中,心电图分析的作用往往不明确:许多方法要么依赖于可能并不可用的其他成像模式,例如计算机断层扫描肺动脉造影术(CTPA),要么在不同的分类问题中不能有效地通用。此外,公共心电图数据集的可获得性有限,实际上这些数据集往往很小,因此必须优化学习策略。在这项研究中,我们调查了多种神经网络架构的性能,以评估各种方法的影响。此外,我们还检查了当使用迁移学习将在大规模心电图数据集中学习到的信息(如PTB-XL和CPSC18)迁移到较小但更具挑战性的肺栓塞(PE)检测数据集时,这些实践是否提高了模型的通用性。通过利用迁移学习,我们分析了在有限数据上,我们能提高多少学习效率和预测性能。相关代码可通过以下链接获取:https://github.com/joaodsmarques/Are-ECGs-enough-Deep-Learning-Classifiers。(以供参考)(请以实际网站内容为准)
论文及项目相关链接
Summary
心电图(ECG)是诊断多种心脏异常的重要工具,具有经济、快速、可在多种环境中使用的优势。然而,现有文献中关于心电图分析的角色往往不明确,许多方法依赖于可能无法始终获得的附加成像模式,如计算机断层扫描肺动脉造影术(CTPA),或者不能有效地在不同分类问题中推广。此外,公开的心电图数据集有限,且在实践中这些数据集往往很小,因此需要优化学习策略。本研究旨在评估多种神经网络架构的性能,并检查这些实践在提高模型泛化能力方面的作用,特别是在使用迁移学习将在大规模心电图数据集中学习的信息转移到较小的、更具挑战性的肺栓塞检测数据集时。通过利用迁移学习,我们分析了在有限数据上提高学习效率和预测性能的可行性。
Key Takeaways
- 心电图是诊断心脏异常的重要工具,具有广泛的应用和经济性优势。
- 当前文献中心电图分析的角色存在不明确性,许多方法依赖于其他成像模式或难以在不同分类问题中推广。
- 公共心电图数据集有限且实际应用中往往规模较小,需要优化学习策略。
- 本研究评估了多种神经网络架构的性能以提高模型泛化能力。
- 研究重点之一是使用迁移学习在大规模心电图数据集中学习的信息转移到小规模数据集上的能力。
- 利用迁移学习可改善有限数据上的学习效率和预测性能。
点此查看论文截图

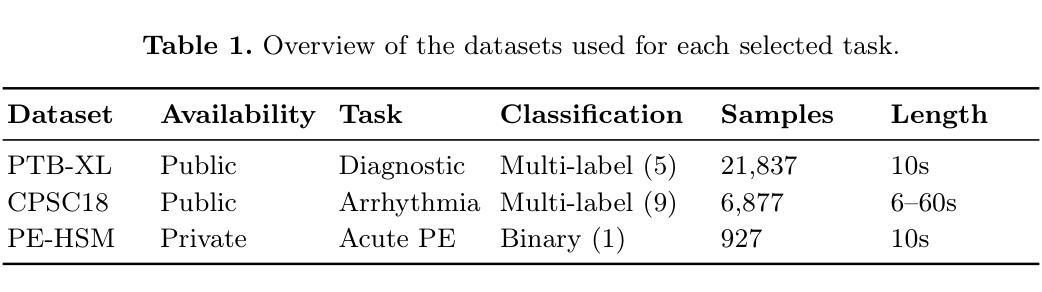
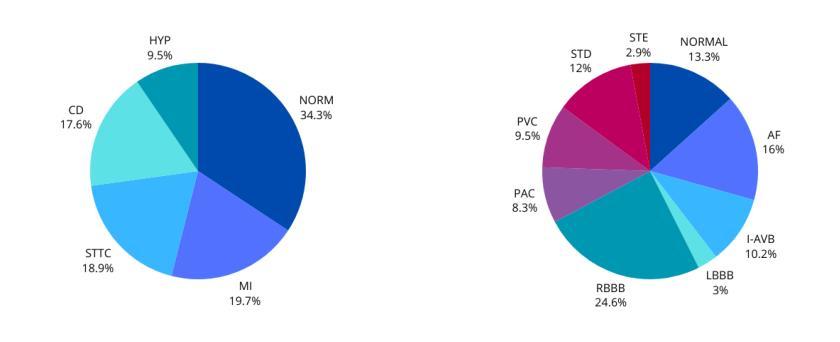
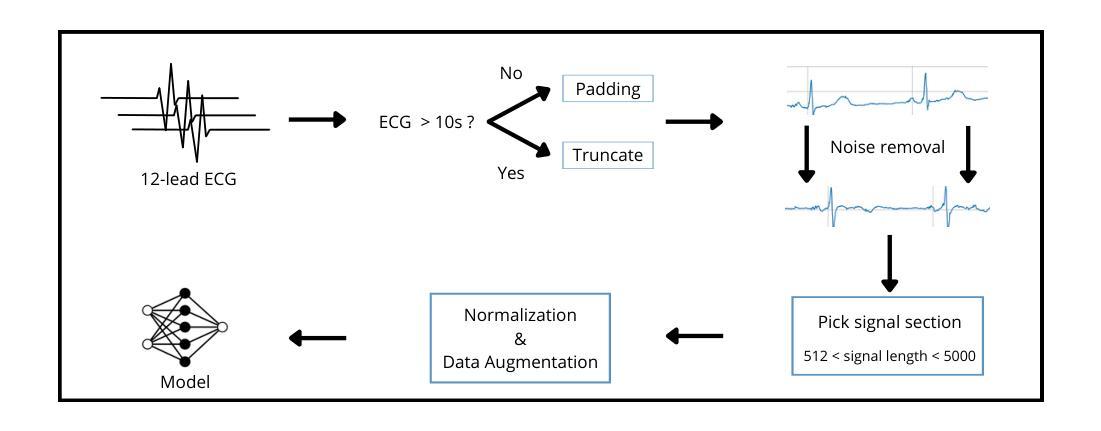
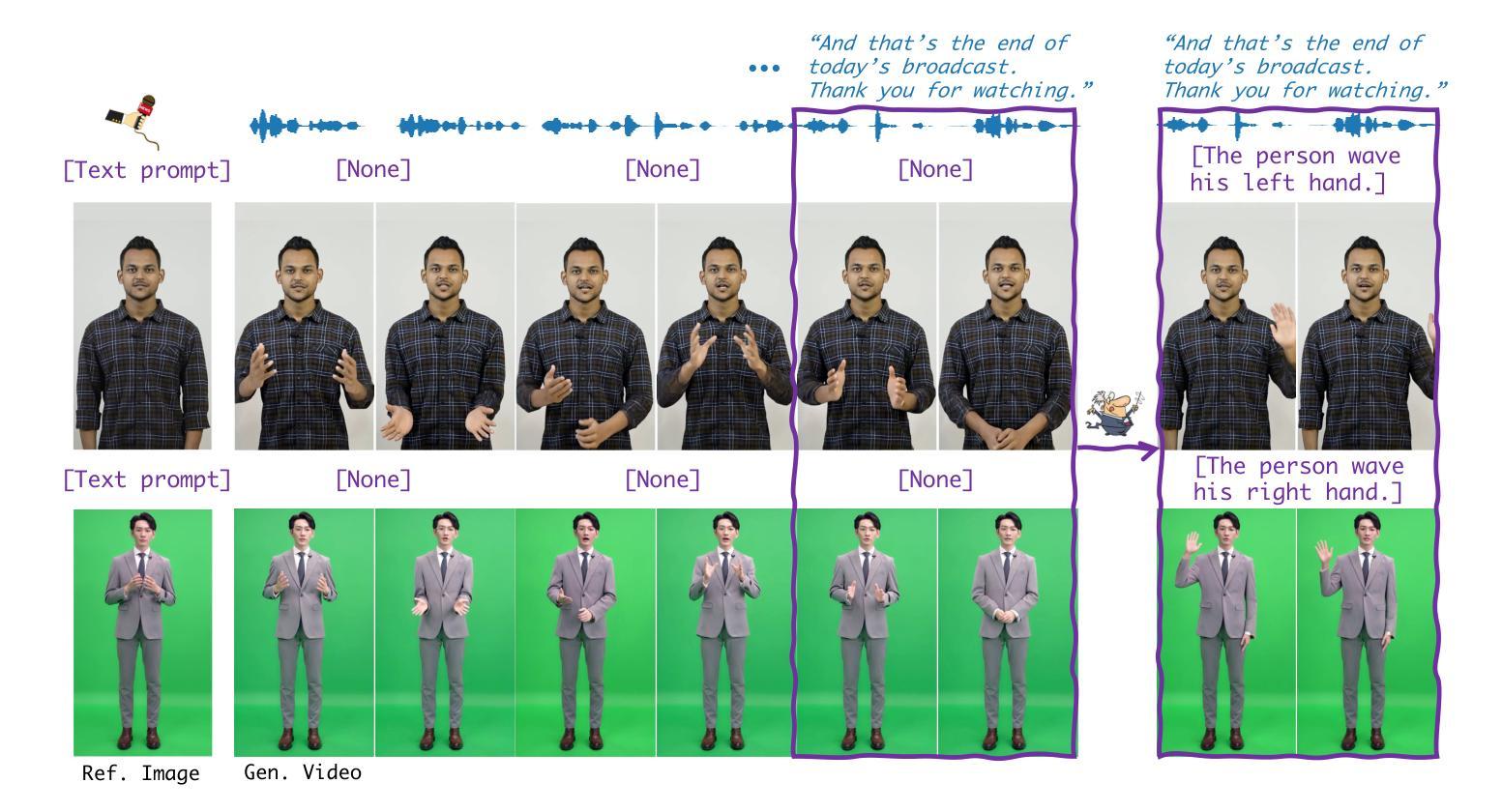
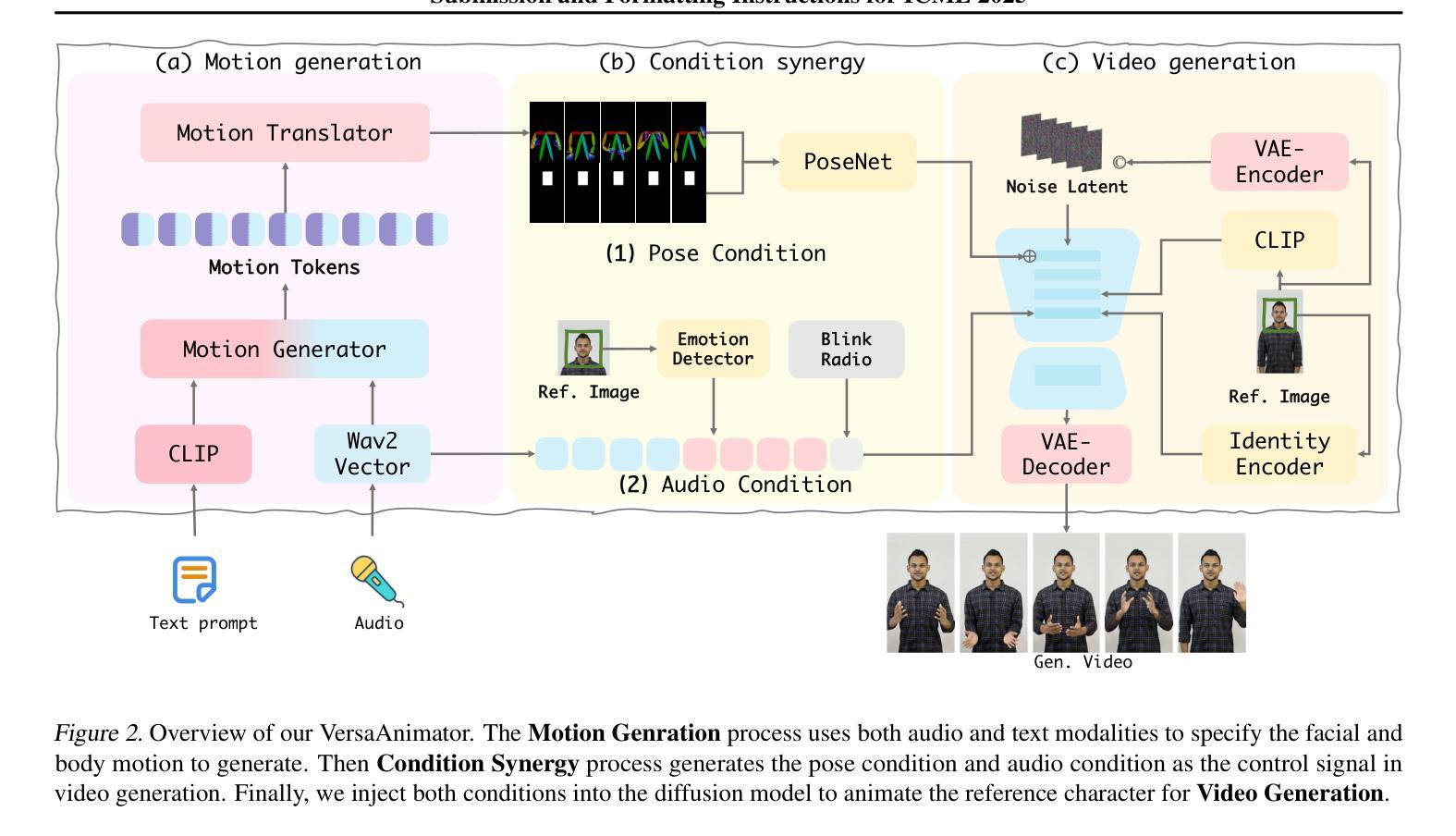
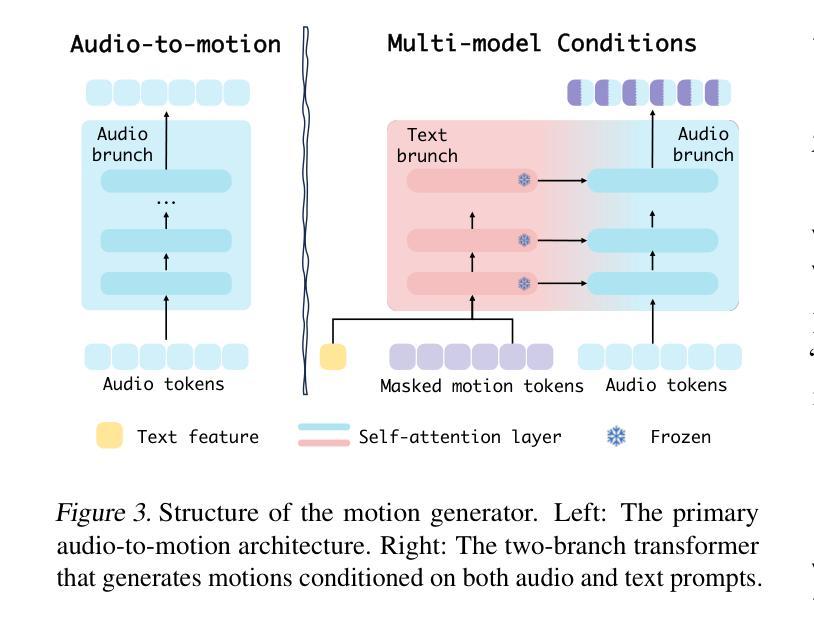
Versatile Multimodal Controls for Whole-Body Talking Human Animation
Authors:Zheng Qin, Ruobing Zheng, Yabing Wang, Tianqi Li, Zixin Zhu, Minghui Yang, Ming Yang, Le Wang
Human animation from a single reference image shall be flexible to synthesize whole-body motion for either a headshot or whole-body portrait, where the motions are readily controlled by audio signal and text prompts. This is hard for most existing methods as they only support producing pre-specified head or half-body motion aligned with audio inputs. In this paper, we propose a versatile human animation method, i.e., VersaAnimator, which generates whole-body talking human from arbitrary portrait images, not only driven by audio signal but also flexibly controlled by text prompts. Specifically, we design a text-controlled, audio-driven motion generator that produces whole-body motion representations in 3D synchronized with audio inputs while following textual motion descriptions. To promote natural smooth motion, we propose a code-pose translation module to link VAE codebooks with 2D DWposes extracted from template videos. Moreover, we introduce a multi-modal video diffusion that generates photorealistic human animation from a reference image according to both audio inputs and whole-body motion representations. Extensive experiments show that VersaAnimator outperforms existing methods in visual quality, identity preservation, and audio-lip synchronization.
从单一参考图像进行的人脸动画应该能够灵活地合成头部特写或全身肖像的整体运动,这些运动可以由音频信号和文字提示轻松控制。这对大多数现有方法来说是非常困难的,因为它们仅支持生成与音频输入对齐的预设头部或半身运动。在本文中,我们提出了一种通用的人脸动画方法,即VersaAnimator,它可以从任意的肖像图像生成全身说话的人脸动画,不仅由音频信号驱动,还可以灵活地由文字提示控制。具体来说,我们设计了一个文本控制的、音频驱动的运动生成器,该生成器能够产生与音频输入同步的全身运动表示(在3D中),同时遵循文本运动描述。为了促进自然流畅的运动,我们提出了一个编码姿态转换模块,用于将VAE代码本与从模板视频中提取的2DDW姿态联系起来。此外,我们引入了一种多模态视频扩散技术,该技术可以根据参考图像、音频输入和全身运动表示生成逼真的人脸动画。大量实验表明,VersaAnimator在视觉质量、身份保留和音频与嘴唇同步方面优于现有方法。
论文及项目相关链接
Summary
单参考图像的人像动画可以灵活合成全身动作,无论是头像还是全身肖像,动作都可以通过音频信号和文字提示轻松控制。大多数现有方法仅支持生成与音频输入对齐的预设头部或半身动作,难以实现全身动作的灵活控制。本文提出了一种通用的人像动画方法VersaAnimator,可以从任意肖像图像生成全身动作,不仅由音频信号驱动,还能通过文字提示灵活控制。此方法结合了文本控制、音频驱动的运动生成器,产生与音频输入同步的全身动作表示,并通过模板视频提取的DWposes与VAE代码本的转换模块,实现自然流畅的动作生成。同时引入了多模态视频扩散技术,根据参考图像、音频输入和全身动作表示生成逼真的动画。实验表明,VersaAnimator在视觉质量、身份保留和音频唇同步方面优于现有方法。
Key Takeaways
- 人像动画可以从单参考图像生成全身动作,包括头部和全身肖像。
- 动作可以通过音频信号和文字提示灵活控制。
- 现有方法仅支持预设的头部或半身动作与音频输入对齐,难以实现全身动作的灵活控制。
- 提出了一种通用的人像动画方法VersaAnimator,能生成与音频输入同步的全身动作表示。
- 通过模板视频提取的DWposes与VAE代码本的转换模块实现自然流畅的动作生成。
- 引入了多模态视频扩散技术,提高了动画的逼真度。
- VersaAnimator在视觉质量、身份保留和音频唇同步方面优于现有方法。
点此查看论文截图


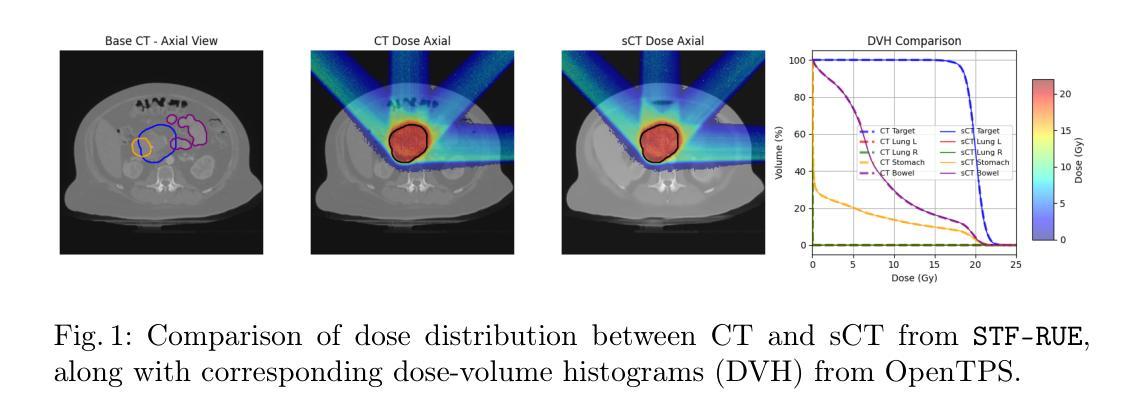
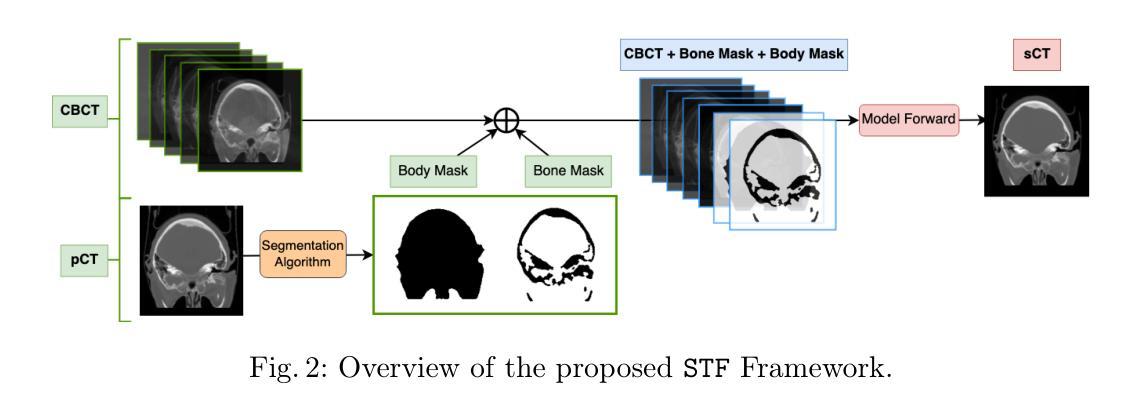
Segmentation-Guided CT Synthesis with Pixel-Wise Conformal Uncertainty Bounds
Authors:David Vallmanya Poch, Yorick Estievenart, Elnura Zhalieva, Sukanya Patra, Mohammad Yaqub, Souhaib Ben Taieb
Accurate dose calculations in proton therapy rely on high-quality CT images. While planning CTs (pCTs) serve as a reference for dosimetric planning, Cone Beam CT (CBCT) is used throughout Adaptive Radiotherapy (ART) to generate sCTs for improved dose calculations. Despite its lower cost and reduced radiation exposure advantages, CBCT suffers from severe artefacts and poor image quality, making it unsuitable for precise dosimetry. Deep learning-based CBCT-to-CT translation has emerged as a promising approach. Still, existing methods often introduce anatomical inconsistencies and lack reliable uncertainty estimates, limiting their clinical adoption. To bridge this gap, we propose STF-RUE, a novel framework integrating two key components. First, STF, a segmentation-guided CBCT-to-CT translation method that enhances anatomical consistency by leveraging segmentation priors extracted from pCTs. Second, RUE, a conformal prediction method that augments predicted CTs with pixel-wise conformal prediction intervals, providing clinicians with robust reliability indicator. Comprehensive experiments using UNet++ and Fast-DDPM on two benchmark datasets demonstrate that STF-RUE significantly improves translation accuracy, as measured by a novel soft-tissue-focused metric designed for precise dose computation. Additionally, STF-RUE provides better-calibrated uncertainty sets for synthetic CT, reinforcing trust in synthetic CTs. By addressing both anatomical fidelity and uncertainty quantification, STF-RUE marks a crucial step toward safer and more effective adaptive proton therapy. Code is available at https://anonymous.4open.science/r/cbct2ct_translation-B2D9/.
质子疗法中的准确剂量计算依赖于高质量CT图像。计划CT(pCT)作为剂量计划的参考,而锥形束CT(CBCT)在自适应放射治疗(ART)中用于生成改进剂量计算的sCT。尽管CBCT具有成本低、辐射暴露优势小等优点,但它存在严重的伪影和图像质量差的问题,因此不适合进行精确的剂量测定。基于深度学习的CBCT-to-CT转换已成为一种有前途的方法。然而,现有方法往往引入解剖结构不一致性,且缺乏可靠的不确定性估计,限制了其在临床上的应用。为了弥补这一差距,我们提出了STF-RUE,这是一个结合了关键组件的新框架。首先,STF是一种受分割指导的CBCT-to-CT转换方法,它通过利用从pCT中提取的分割先验知识来提高解剖结构的一致性。其次,RUE是一种符合预测的方法,它为预测的CT配备像素级的预测间隔,为临床医生提供可靠的可靠性指标。在两项基准数据集上使用UNet++和Fast-DDPM进行的综合实验表明,STF-RUE在新型软组织针对性指标衡量下显著提高翻译精度,该指标专为精确剂量计算而设计。此外,STF-RUE为合成CT提供更好的校准不确定性集,增强了对合成CT的信任。通过解决解剖结构忠实度和不确定性量化问题,STF-RUE标志着自适应质子疗法朝着更安全、更有效的方向迈出了重要一步。代码可在https://anonymous.4open.science/r/cbct2ct_translation-B2D9/找到。
论文及项目相关链接
PDF MICCAI 2025 Conference Submission. Follows the required LNCS format. 12 pages including references. Contains 4 figures and 1 table
Summary
质子治疗中的精确剂量计算依赖于高质量的CT图像。在适应性放射治疗(ART)中,锥束CT(CBCT)被用于生成sCT以改进剂量计算,尽管其成本较低且辐射暴露减少,但其图像质量存在严重缺陷,不适宜进行精确剂量测定。深度学习在CBCT到CT的翻译上展现出潜力,但现有方法常带来解剖结构不一致性和缺乏可靠的不确定性估计,限制了其临床应用。本研究提出了STF-RUE框架,该框架结合了两项关键技术,提升了质子治疗的精准度和可靠性。
Key Takeaways
* CBCT虽有助于剂量计算但存在严重图像质量缺陷问题,对精准放射治疗效果有影响。
* 当前用于处理CBCT到CT翻译的深度学习技术面临解剖结构不一致性和不确定性估计的挑战。
* STF-RUE框架通过集成两项关键技术解决了上述问题,包括基于分割引导的CBCT到CT翻译方法和基于一致性预测的可靠性指标估计方法。
* STF-RUE显著提高了翻译精度和可靠性指标,改善了合成CT的不确定性校准,对质子治疗安全有效性具有关键性影响。这一研究成果已经通过实验验证。
点此查看论文截图

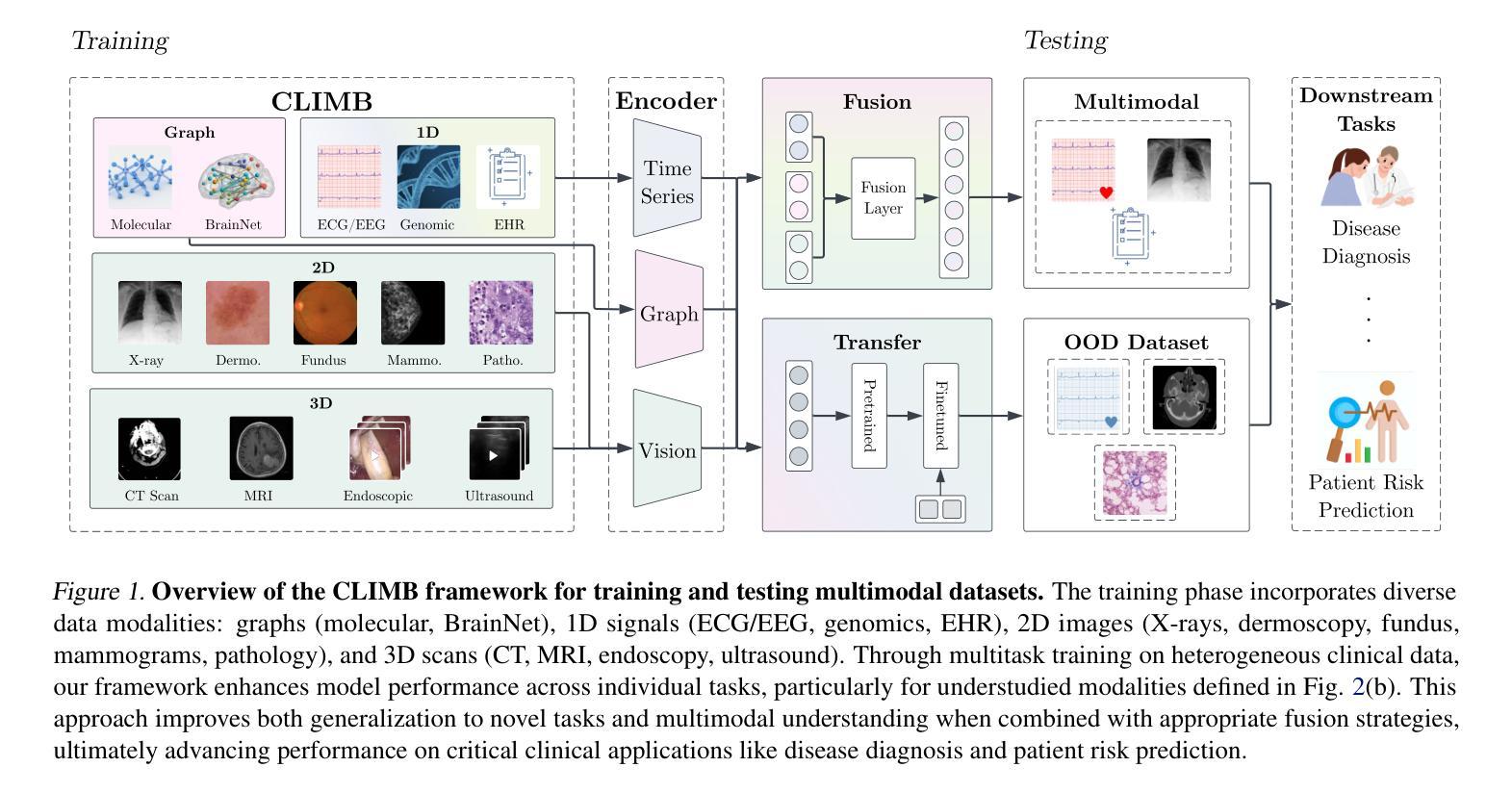
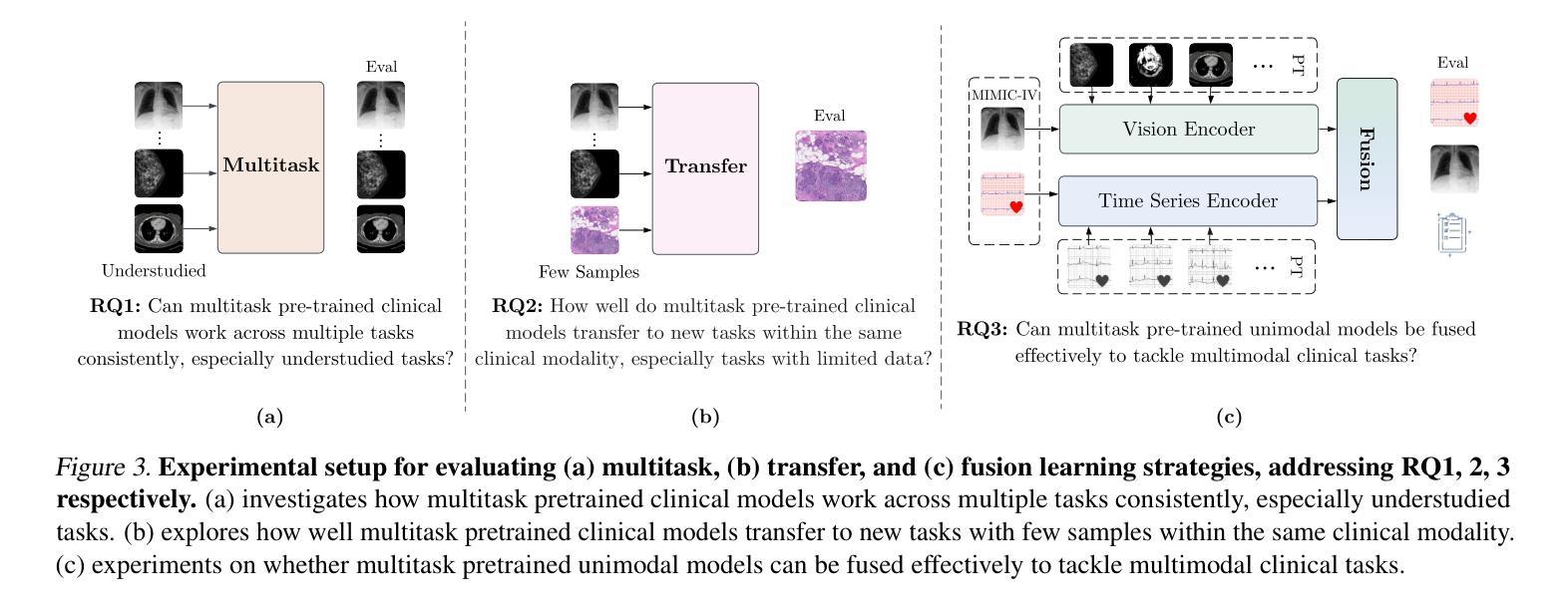
Data Foundations for Large Scale Multimodal Clinical Foundation Models
Authors:Wei Dai, Peilin Chen, Malinda Lu, Daniel Li, Haowen Wei, Hejie Cui, Paul Pu Liang
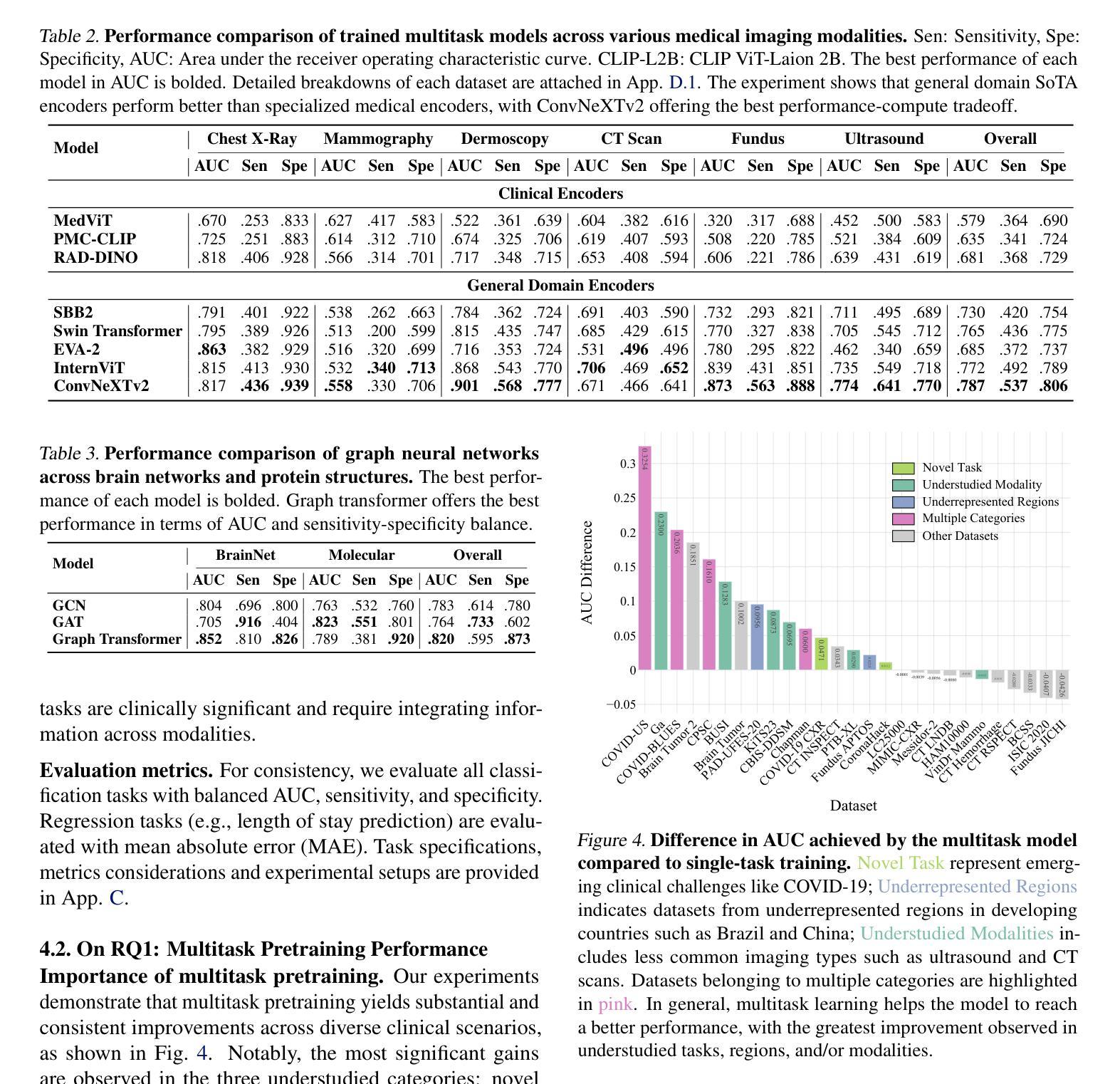
Recent advances in clinical AI have enabled remarkable progress across many clinical domains. However, existing benchmarks and models are primarily limited to a small set of modalities and tasks, which hinders the development of large-scale multimodal methods that can make holistic assessments of patient health and well-being. To bridge this gap, we introduce Clinical Large-Scale Integrative Multimodal Benchmark (CLIMB), a comprehensive clinical benchmark unifying diverse clinical data across imaging, language, temporal, and graph modalities. CLIMB comprises 4.51 million patient samples totaling 19.01 terabytes distributed across 2D imaging, 3D video, time series, graphs, and multimodal data. Through extensive empirical evaluation, we demonstrate that multitask pretraining significantly improves performance on understudied domains, achieving up to 29% improvement in ultrasound and 23% in ECG analysis over single-task learning. Pretraining on CLIMB also effectively improves models’ generalization capability to new tasks, and strong unimodal encoder performance translates well to multimodal performance when paired with task-appropriate fusion strategies. Our findings provide a foundation for new architecture designs and pretraining strategies to advance clinical AI research. Code is released at https://github.com/DDVD233/climb.
近年来,临床人工智能的进步在许多临床领域都取得了显著的成效。然而,现有的基准测试和模型主要局限于少数几种模态和任务,这阻碍了能够全面评估患者健康和福祉的大规模多模态方法的发展。为了弥补这一差距,我们引入了临床大规模综合多模态基准测试(CLIMB),这是一个统一了成像、语言、时间和图形等多种临床数据模式的综合临床基准测试。CLIMB包含了跨越二维成像、三维视频、时间序列、图形和多模态数据的共达四千五百一十万患者样本数据,总计十九亿字节数据分布。通过广泛的实证研究,我们证明了多任务预训练能够在缺乏研究的领域里显著提高性能,超声波分析中的提升率高达百分之二十九,心电图分析中达到百分之二十三于单任务学习之上。在CLIMB上进行预训练还能有效提高模型对新任务的泛化能力,强大的单模态编码器性能在与任务适当的融合策略结合时,能很好地转化为多模态性能。我们的研究为新的架构设计和预训练策略提供了基础,以推动临床人工智能研究的发展。相关代码已发布在https://github.com/DDVD233/climb上。
论文及项目相关链接
Summary
本文主要介绍了临床人工智能的最新进展及多模态方法的局限性,为此提出了一种大规模的多模态临床基准测试(CLIMB),涵盖了图像、语言、时序和图等多种临床数据模态。通过多任务预训练,CLIMB在超声和心电图分析等领域取得了显著的提升效果。此外,CLIMB还为临床人工智能研究提供了新的架构设计和预训练策略的基础。
Key Takeaways
- 临床人工智能在多个领域取得显著进展,但多模态方法的开发受限。
- 提出了一种新的临床基准测试CLIMB,涵盖多种临床数据模态。
- CLIMB包含4.51百万患者样本,总计19.01太字节的数据。
- 多任务预训练在CLIMB上能显著提升模型性能,特别是在超声和心电图分析领域。
- 预训练有助于模型对新任务的适应能力。
- 强大的单模态编码器性能,在配合适当的融合策略时,能取得良好的多模态性能。
点此查看论文截图



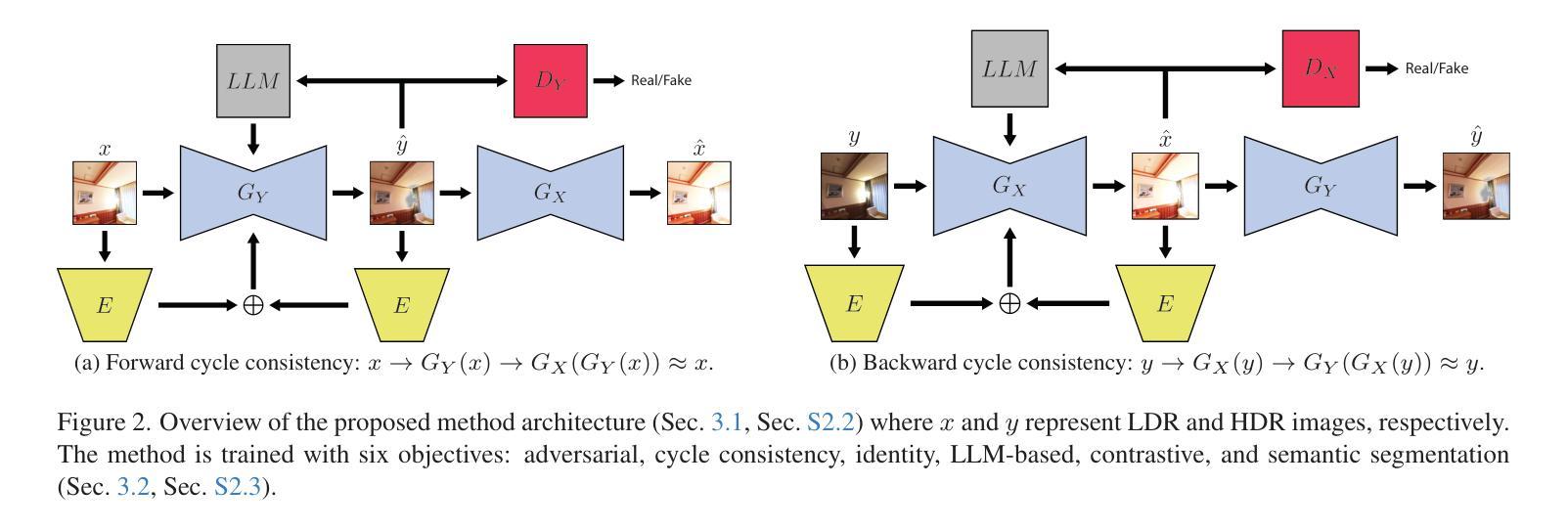
LLM-HDR: Bridging LLM-based Perception and Self-Supervision for Unpaired LDR-to-HDR Image Reconstruction
Authors:Hrishav Bakul Barua, Kalin Stefanov, Lemuel Lai En Che, Abhinav Dhall, KokSheik Wong, Ganesh Krishnasamy
The translation of Low Dynamic Range (LDR) to High Dynamic Range (HDR) images is an important computer vision task. There is a significant amount of research utilizing both conventional non-learning methods and modern data-driven approaches, focusing on using both single-exposed and multi-exposed LDR for HDR image reconstruction. However, most current state-of-the-art methods require high-quality paired {LDR,HDR} datasets for model training. In addition, there is limited literature on using unpaired datasets for this task, that is, the model learns a mapping between domains, i.e., {LDR,HDR}. This paper proposes LLM-HDR, a method that integrates the perception of Large Language Models (LLM) into a modified semantic- and cycle-consistent adversarial architecture that utilizes unpaired {LDR,HDR} datasets for training. The method introduces novel artifact- and exposure-aware generators to address visual artifact removal and an encoder and loss to address semantic consistency, another under-explored topic. LLM-HDR is the first to use an LLM for the {LDR,HDR} translation task in a self-supervised setup. The method achieves state-of-the-art performance across several benchmark datasets and reconstructs high-quality HDR images. The official website of this work is available at: https://github.com/HrishavBakulBarua/LLM-HDR
将低动态范围(LDR)图像翻译成高动态范围(HDR)图像是一项重要的计算机视觉任务。许多研究都利用传统的非学习方法和现代的数据驱动方法,专注于使用单曝光和多曝光的LDR进行HDR图像重建。然而,目前大多数最先进的方法都需要高质量成对的{LDR,HDR}数据集进行模型训练。此外,关于使用非配对数据集进行此任务的文献很少,也就是说,模型在两个领域之间进行映射学习,即{LDR,HDR}。本文提出了LLM-HDR方法,它将大型语言模型(LLM)的感知能力集成到一个经过修改的语义和循环一致的对抗性架构中,该架构利用非配对的{LDR,HDR}数据集进行训练。该方法引入了新型的去伪影和曝光感知生成器来解决视觉伪影去除问题,以及一个解决语义一致性的编码器和损失函数,这是另一个尚未深入探讨的主题。LLM-HDR是第一个在自我监督设置中使用LLM进行{LDR,HDR}翻译任务的方法。该方法在多个基准数据集上实现了最先进的性能,并重建了高质量HDR图像。该工作的官方网站地址为:https://github.com/HrishavBakulBarua/LLM-HDR
论文及项目相关链接
Summary:本文提出一种将低动态范围(LDR)图像翻译成高动态范围(HDR)图像的新方法,即LLM-HDR。该方法利用大型语言模型(LLM)感知能力,采用无配对数据集的语义一致性循环对抗架构进行训练。引入新颖的伪影感知和曝光感知生成器解决视觉伪影去除问题,并通过编码器和损失解决语义一致性问题。LLM-HDR首次在自监督设置中利用LLM进行LDR到HDR的翻译任务,实现了跨多个基准数据集的卓越性能,并能重建高质量HDR图像。
Key Takeaways:
- LLM-HDR是一种新的低动态范围(LDR)到高动态范围(HDR)图像翻译方法。
- 该方法结合了大型语言模型(LLM)的感知能力进行图像翻译。
- LLM-HDR采用无配对数据集的语义一致性循环对抗架构进行训练。
- 该方法引入了伪影感知和曝光感知生成器以解决视觉伪影去除问题。
- LLM-HDR首次在自监督设置中使用LLM进行HDR图像重建。
- LLM-HDR实现了跨多个基准数据集的卓越性能。
点此查看论文截图


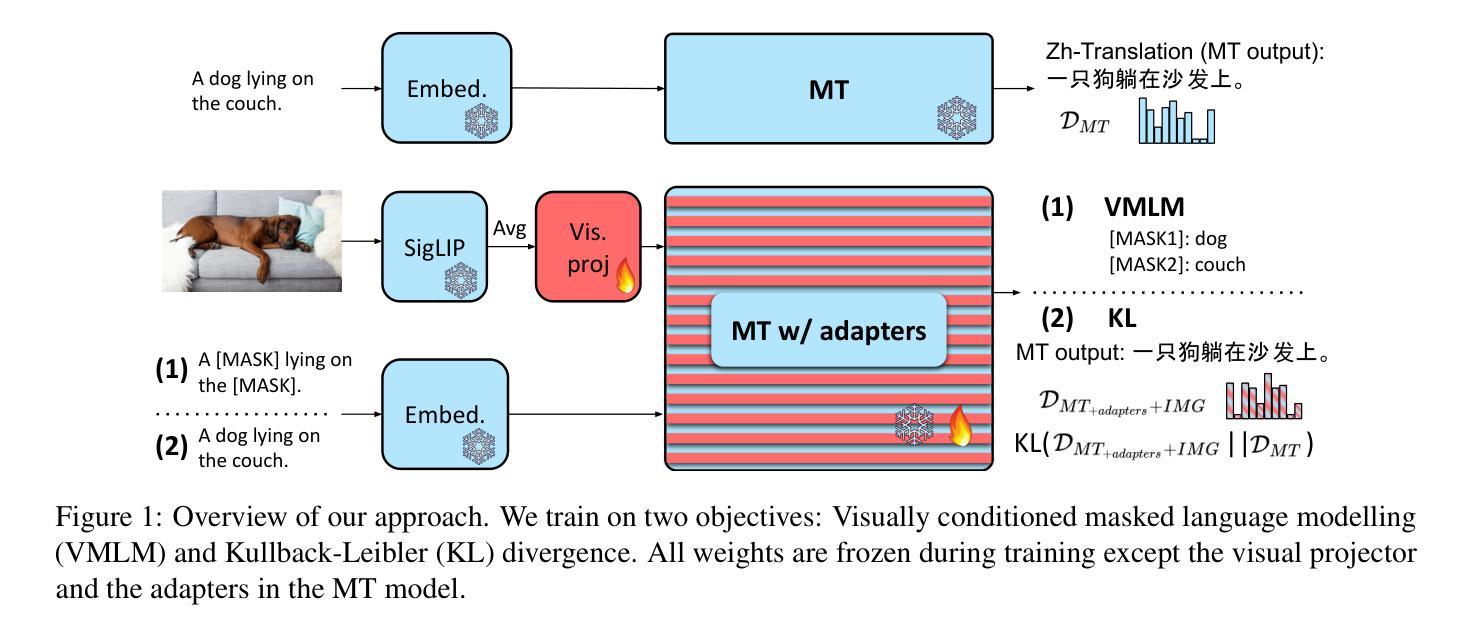
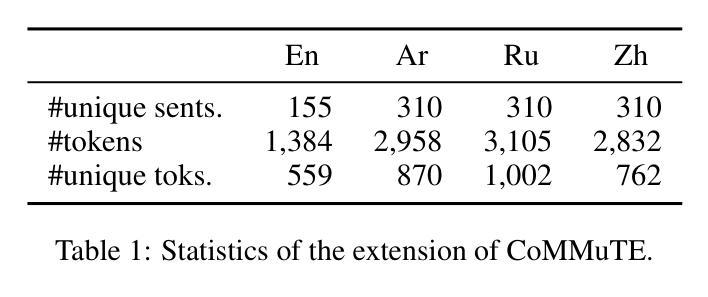
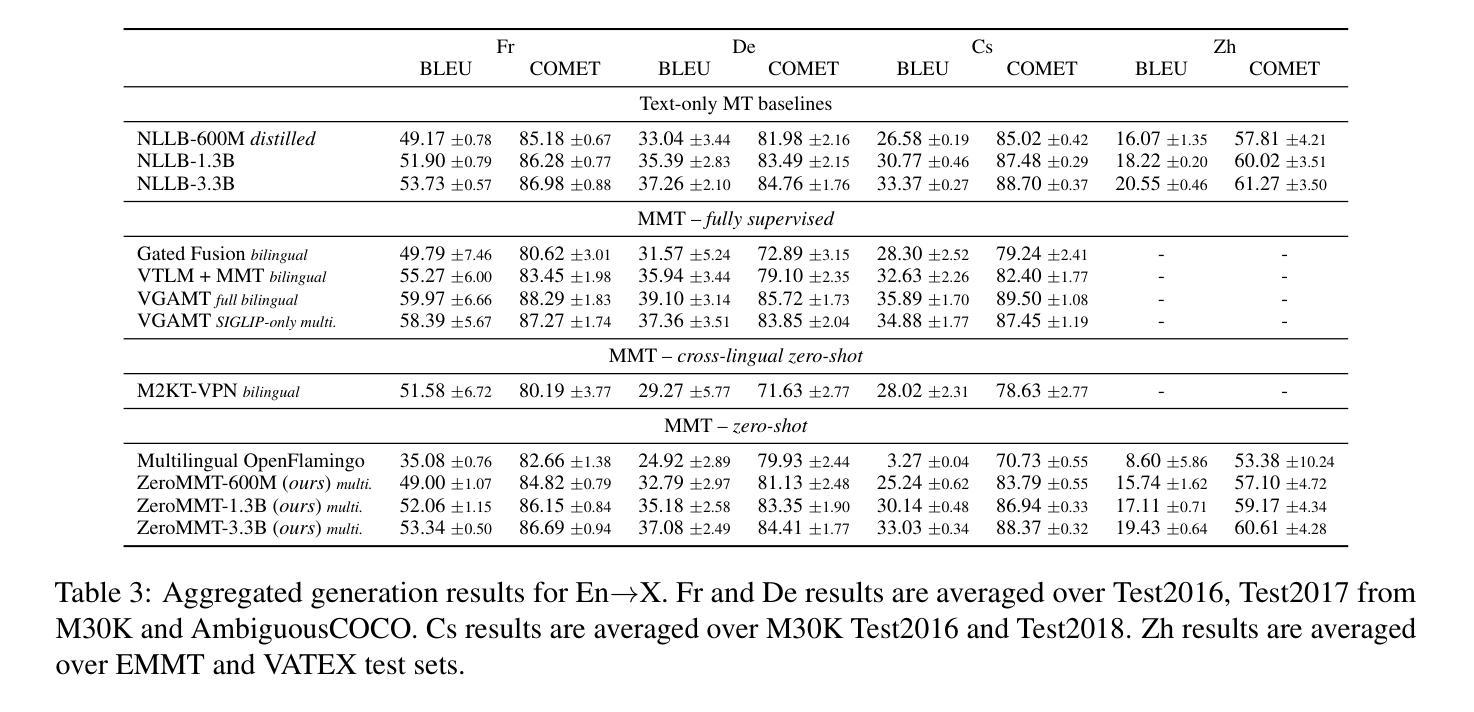
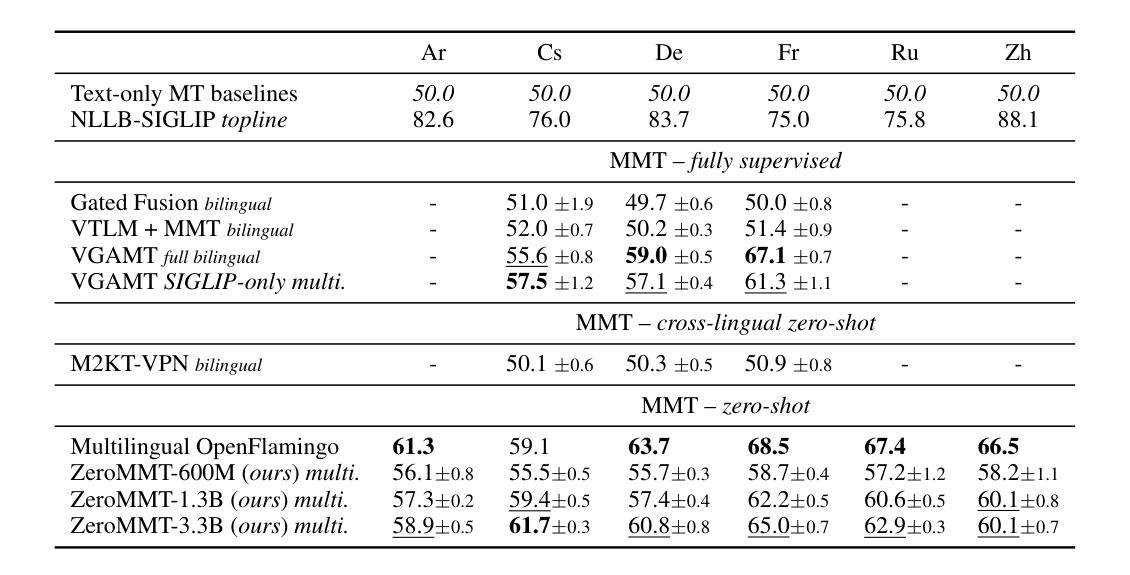
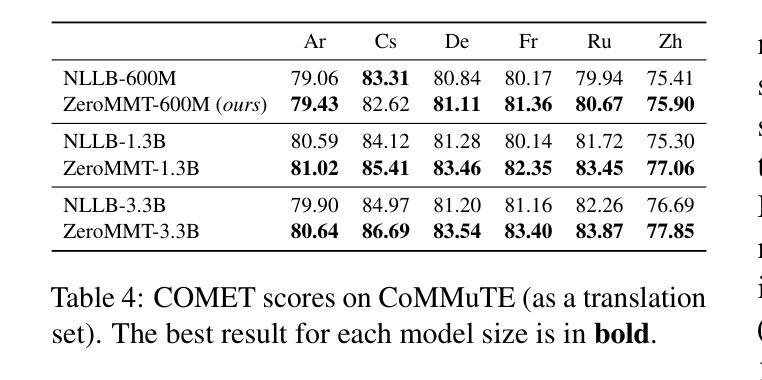
Towards Zero-Shot Multimodal Machine Translation
Authors:Matthieu Futeral, Cordelia Schmid, Benoît Sagot, Rachel Bawden
Current multimodal machine translation (MMT) systems rely on fully supervised data (i.e models are trained on sentences with their translations and accompanying images). However, this type of data is costly to collect, limiting the extension of MMT to other language pairs for which such data does not exist. In this work, we propose a method to bypass the need for fully supervised data to train MMT systems, using multimodal English data only. Our method, called ZeroMMT, consists in adapting a strong text-only machine translation (MT) model by training it on a mixture of two objectives: visually conditioned masked language modelling and the Kullback-Leibler divergence between the original and new MMT outputs. We evaluate on standard MMT benchmarks and the recently released CoMMuTE, a contrastive benchmark aiming to evaluate how well models use images to disambiguate English sentences. We obtain disambiguation performance close to state-of-the-art MMT models trained additionally on fully supervised examples. To prove that our method generalizes to languages with no fully supervised training data available, we extend the CoMMuTE evaluation dataset to three new languages: Arabic, Russian and Chinese. We further show that we can control the trade-off between disambiguation capabilities and translation fidelity at inference time using classifier-free guidance and without any additional data. Our code, data and trained models are publicly accessible.
当前的多模态机器翻译(MMT)系统依赖于完全监督的数据(即模型在具有翻译和相应图像的句子上进行训练)。然而,这种类型的数据收集成本很高,限制了MMT在其他没有此类数据存在的语言配对中的扩展。在这项工作中,我们提出了一种方法,绕过对完全监督数据训练MMT系统的需求,仅使用多模态英语数据。我们的方法称为ZeroMMT,通过对强大的纯文本机器翻译(MT)模型进行适应,以两个目标进行训练:视觉条件下的掩码语言建模和原始与新的MMT输出之间的Kullback-Leibler散度。我们在标准MMT基准测试和最近发布的CoMMuTE上进行了评估,CoMMuTE是一个对比基准测试,旨在评估模型使用图像对英文句子进行消歧的能力。我们获得的消歧性能接近在完全监督示例上训练的最新MMT模型。为了证明我们的方法可以推广到没有完全监督训练数据可用的语言,我们将CoMMuTE评估数据集扩展到三种新语言:阿拉伯语、俄语和中文。我们进一步表明,我们可以在推理时间使用无分类器引导和无需任何额外数据的情况下,控制消歧能力和翻译忠实度之间的权衡。我们的代码、数据和训练模型可公开访问。
论文及项目相关链接
PDF NAACL 2025 (Findings)
Summary
本文提出了一种不需要全监督数据训练多模态机器翻译系统的方法,名为ZeroMMT。该方法通过训练强大的纯文本机器翻译模型,实现两种目标混合:视觉条件下的掩码语言建模和原始与新型多模态翻译输出之间的Kullback-Leibler散度。评估结果显示,该方法在标准多模态翻译基准测试集和最新发布的旨在评估模型如何利用图像消除英语句子歧义的对比基准测试集CoMMuTE上的表现接近使用全监督示例训练的多模态翻译模型的最先进水平。此外,为了证明该方法可以推广到没有全监督训练数据可用的语言,我们将CoMMuTE评估数据集扩展到了三种新语言:阿拉伯语、俄语和中文。同时,我们还展示了在推理时间,我们可以通过无分类器引导的方式,无需任何额外数据来控制消除歧义能力和翻译忠实度之间的权衡。
Key Takeaways
- 当前的多模态机器翻译系统依赖于全监督数据,成本高昂且限制了其在没有此类数据的语言对的扩展。
- 提出了一种名为ZeroMMT的方法,通过训练强大的纯文本机器翻译模型来适应多模态翻译,无需全监督数据。
- ZeroMMT方法结合了两种目标:视觉条件下的掩码语言建模和原始与新型多模态翻译输出之间的Kullback-Leibler散度。
- 在标准多模态翻译基准测试集和CoMMuTE评估数据集上,ZeroMMT的表现接近最先进水平。
- ZeroMMT方法可以推广到没有全监督训练数据的语言,如阿拉伯语、俄语和中文。
- 通过无分类器引导的方式,可以在推理时间控制消除歧义能力和翻译忠实度之间的权衡。
点此查看论文截图

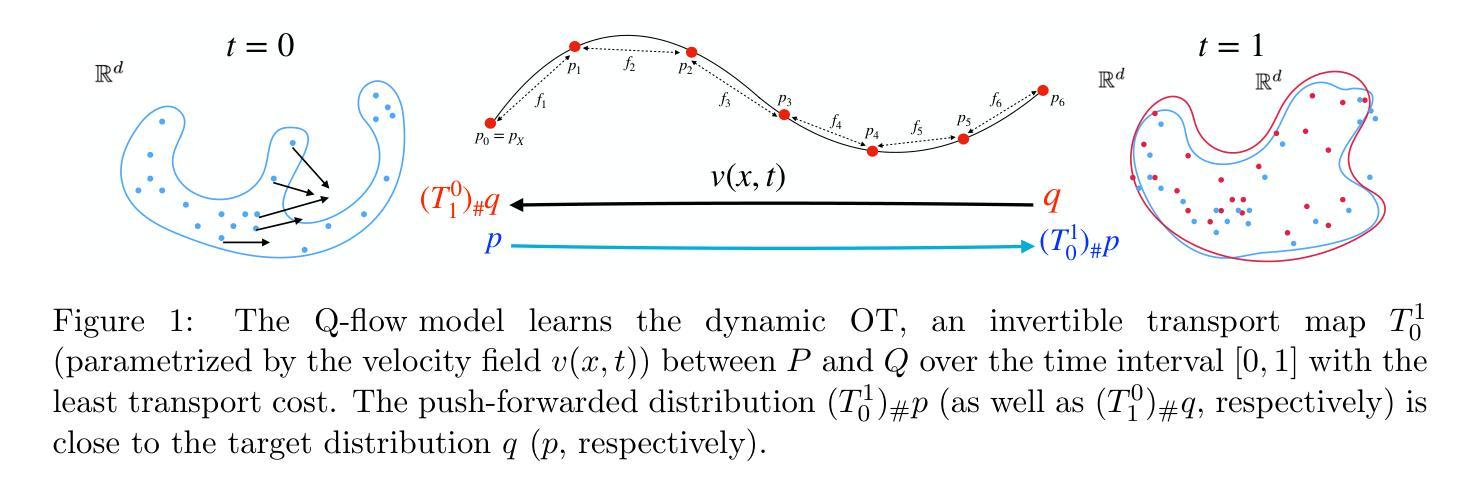
Computing high-dimensional optimal transport by flow neural networks
Authors:Chen Xu, Xiuyuan Cheng, Yao Xie
Computing optimal transport (OT) for general high-dimensional data has been a long-standing challenge. Despite much progress, most of the efforts including neural network methods have been focused on the static formulation of the OT problem. The current work proposes to compute the dynamic OT between two arbitrary distributions $P$ and $Q$ by optimizing a flow model, where both distributions are only accessible via finite samples. Our method learns the dynamic OT by finding an invertible flow that minimizes the transport cost. The trained optimal transport flow subsequently allows for performing many downstream tasks, including infinitesimal density ratio estimation (DRE) and domain adaptation by interpolating distributions in the latent space. The effectiveness of the proposed model on high-dimensional data is demonstrated by strong empirical performance on OT baselines, image-to-image translation, and high-dimensional DRE.
计算通用高维数据的最优传输(OT)一直是一个长期存在的挑战。尽管取得了诸多进展,但包括神经网络方法在内的大多数努力都集中在OT问题的静态公式上。当前的工作提出了一种通过优化流模型来计算两个任意分布$P$和$Q$之间的动态OT的方法,这两个分布只能通过有限样本访问。我们的方法通过学习动态OT,找到一个可逆流,以最小化传输成本。训练后的最优传输流随后可执行许多下游任务,包括无穷小密度比率估计(DRE)和通过潜在空间中的分布插值进行域适应。所提出模型在高维数据上的有效性已通过OT基准测试、图像到图像的翻译和高维DRE的强大实证性能得到证明。
论文及项目相关链接
PDF Accepted by AISTATS 2025
Summary
本文提出了动态最优传输(OT)的计算方法,用于计算两个任意分布P和Q之间的动态OT。该方法通过优化流模型来学习动态OT,其中两个分布仅通过有限样本访问。训练后的最优传输流可以进行许多下游任务,包括无穷密度比率估计(DRE)和域适应,通过在潜在空间中对分布进行插值。该模型在高维数据上的有效性通过在对OT基线、图像到图像的翻译和高维DRE上的强大经验表现得到证明。
Key Takeaways
- 本文提出了计算两个任意分布间动态最优传输(OT)的方法。
- 该方法通过优化流模型来学习动态OT。
- 分布仅通过有限样本进行访问。
- 训练后的最优传输流可以进行多种下游任务,如无穷密度比率估计(DRE)和域适应。
- 插值在潜在空间中的分布有助于提高模型的性能。
- 模型在高维数据上的有效性得到了强有力的实证证明。
点此查看论文截图