⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Interpretable and Robust Dialogue State Tracking via Natural Language Summarization with LLMs
Authors:Rafael Carranza, Mateo Alejandro Rojas
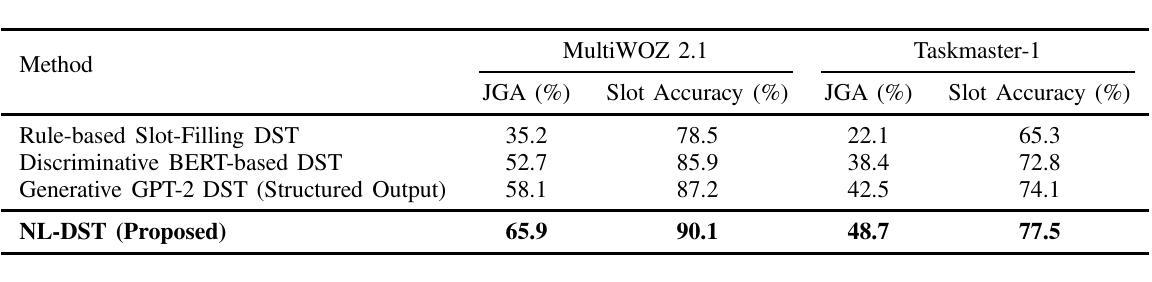
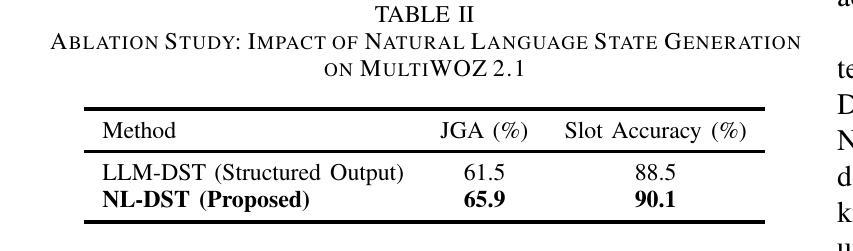
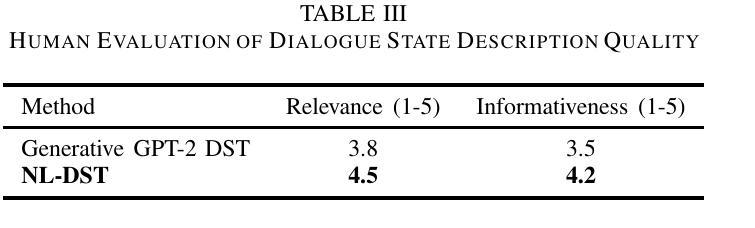
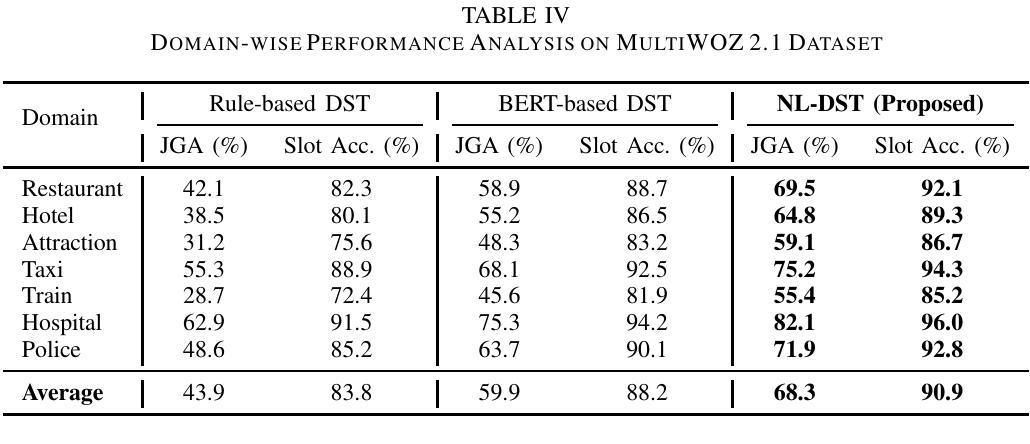
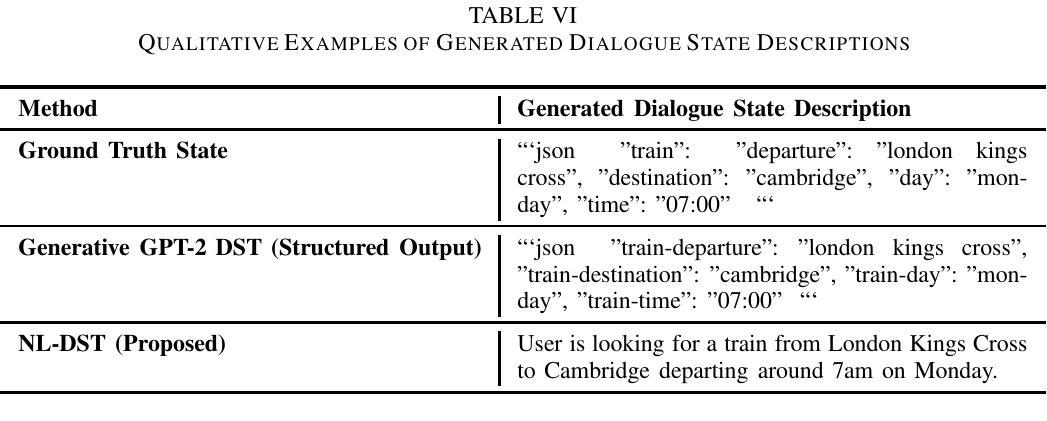
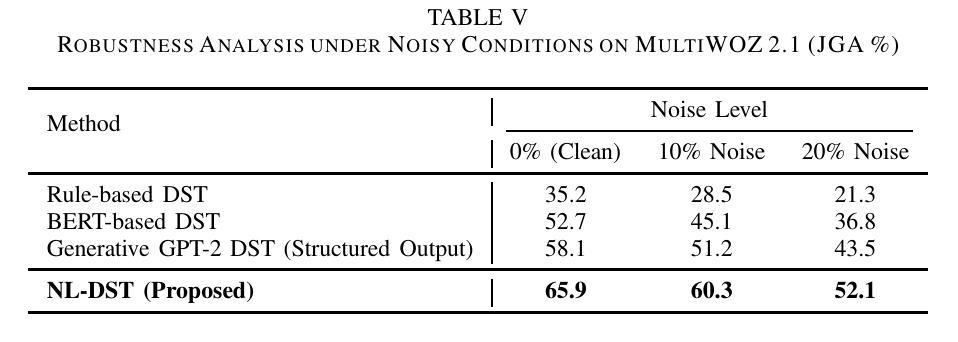
This paper introduces a novel approach to Dialogue State Tracking (DST) that leverages Large Language Models (LLMs) to generate natural language descriptions of dialogue states, moving beyond traditional slot-value representations. Conventional DST methods struggle with open-domain dialogues and noisy inputs. Motivated by the generative capabilities of LLMs, our Natural Language DST (NL-DST) framework trains an LLM to directly synthesize human-readable state descriptions. We demonstrate through extensive experiments on MultiWOZ 2.1 and Taskmaster-1 datasets that NL-DST significantly outperforms rule-based and discriminative BERT-based DST baselines, as well as generative slot-filling GPT-2 DST models, in both Joint Goal Accuracy and Slot Accuracy. Ablation studies and human evaluations further validate the effectiveness of natural language state generation, highlighting its robustness to noise and enhanced interpretability. Our findings suggest that NL-DST offers a more flexible, accurate, and human-understandable approach to dialogue state tracking, paving the way for more robust and adaptable task-oriented dialogue systems.
本文介绍了一种利用大型语言模型(LLM)生成对话状态自然语言描述的新型对话状态跟踪(DST)方法,该方法超越了传统的插槽值表示。传统的DST方法难以处理开放域对话和嘈杂的输入。受LLM生成能力的启发,我们的自然语言DST(NL-DST)框架训练LLM直接合成可读的状态描述。我们在MultiWOZ 2.1和Taskmaster-1数据集上进行了大量实验,证明了NL-DST在联合目标准确性和插槽准确性方面都显著优于基于规则的、基于判别BERT的DST基线以及基于生成插槽填充GPT-2的DST模型。消融研究(Ablation studies)和人类评估进一步验证了自然语言状态生成的有效性,突出了其对噪声的鲁棒性和增强的可解释性。我们的研究结果表明,NL-DST提供了一种更灵活、准确、易于人类理解的对对话状态进行跟踪的方法,为更稳健、适应性更强的任务导向型对话系统铺平了道路。
论文及项目相关链接
Summary
新一代对话状态追踪技术NL-DST通过运用大型语言模型生成对话状态的自然语言描述,改变了传统槽值表示方式。其在MultiWOZ 2.1和Taskmaster-1数据集上的实验结果显示,NL-DST在联合目标准确率和槽准确率上显著优于基于规则和判别式BERT的DST基线模型以及基于GPT-2的生成式槽填充DST模型。其有效性和优越性通过消融研究和人类评估得到进一步验证。NL-DST为任务导向型对话系统提供了更灵活、准确和人性化的对话状态追踪方法。
Key Takeaways
- NL-DST技术运用大型语言模型(LLMs)生成对话状态的自然语言描述,摒弃了传统的槽值表示方式。
- NL-DST在MultiWOZ 2.1和Taskmaster-1数据集上的实验表现优于其他方法。
- NL-DST在联合目标准确率和槽准确率上取得了显著的提升。
- 消融研究和人类评估验证了NL-DST的有效性和优越性。
- NL-DST技术提高了任务导向型对话系统的灵活性和准确性。
- NL-DST能够增强对话系统的适应性和鲁棒性。
点此查看论文截图

Contrastive Speaker-Aware Learning for Multi-party Dialogue Generation with LLMs
Authors:Tianyu Sun, Kun Qian, Wenhong Wang
Multi-party dialogue generation presents significant challenges due to the complex interplay of multiple speakers and interwoven conversational threads. Traditional approaches often fall short in capturing these complexities, particularly when relying on manually annotated dialogue relations. This paper introduces Speaker-Attentive LLM (SA-LLM), a novel generative model that leverages pre-trained Large Language Models (LLMs) and a speaker-aware contrastive learning strategy to address these challenges. SA-LLM incorporates a speaker-attributed input encoding and a contrastive learning objective to implicitly learn contextual coherence and speaker roles without explicit relation annotations. Extensive experiments on the Ubuntu IRC and Movie Dialogues datasets demonstrate that SA-LLM significantly outperforms state-of-the-art baselines in automatic and human evaluations, achieving superior performance in fluency, coherence, informativeness, and response diversity. Ablation studies and detailed error analyses further validate the effectiveness of the proposed speaker-attentive training approach, highlighting its robustness across different speaker roles and context lengths. The results underscore the potential of SA-LLM as a powerful and annotation-free solution for high-quality multi-party dialogue generation.
多方对话生成存在显著挑战,主要由于多个发言者之间的复杂交互以及相互交织的对话线程。传统方法往往难以捕捉这些复杂性,特别是当依赖手动注释的对话关系时。本文介绍了Speaker-Attentive LLM(SA-LLM),这是一种新型生成模型,它利用预训练的大型语言模型(LLM)和发言者感知对比学习策略来解决这些挑战。SA-LLM结合了发言者属性输入编码和对比学习目标,可以隐式地学习上下文连贯性和发言者角色,而无需明确的关联注释。在Ubuntu IRC和电影对话数据集上的大量实验表明,SA-LLM在自动和人类评估中均显著优于最新基线,在流畅性、连贯性、信息丰富度和响应多样性方面表现出卓越性能。消融研究和详细的误差分析进一步验证了所提出的基于发言者注意力的训练方法的有效性,突出了其在不同发言者角色和上下文长度方面的稳健性。结果强调了SA-LLM作为无需注释的高质量多方对话生成解决方案的巨大潜力。
论文及项目相关链接
Summary
本文提出了一个名为Speaker-Attentive LLM(SA-LLM)的新型生成模型,该模型利用预训练的大型语言模型(LLM)和说话者感知对比学习策略,解决了多方对话生成中的复杂挑战。SA-LLM通过说话者属性输入编码和对比学习目标,可以隐式地学习上下文连贯性和说话者角色,无需明确的关系注释。在Ubuntu IRC和电影对话数据集上的大量实验表明,SA-LLM在自动和人类评估中均显著优于最新基线,在流畅性、连贯性、信息性和响应多样性方面表现出卓越性能。
Key Takeaways
- 多方对话生成面临复杂挑战,因为涉及多个发言者的复杂交互和交织的会话线程。
- 传统方法常常难以捕捉这些复杂性,特别是在依赖手动注释的对话关系时。
- SA-LLM是一个新型生成模型,利用预训练的大型语言模型和说话者感知对比学习策略来解决这些挑战。
- SA-LLM通过说话者属性输入编码和对比学习目标,可以隐式地学习上下文连贯性和说话者角色。
- 在Ubuntu IRC和电影对话数据集上的实验表明,SA-LLM在流畅性、连贯性、信息性和响应多样性方面优于其他模型。
- 消融研究和详细的错误分析进一步验证了所提出的说话者注意训练方法的有效性,突显其在不同说话者角色和上下文长度上的稳健性。
点此查看论文截图

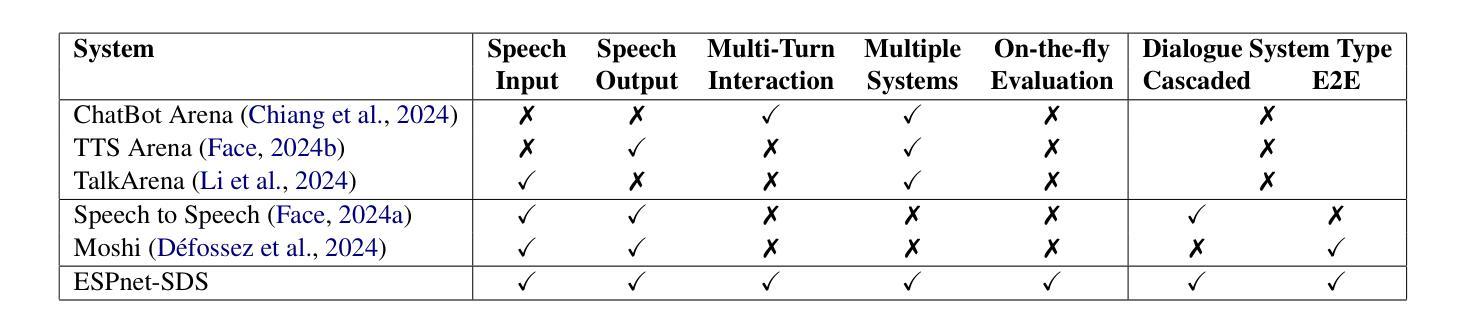
ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
Authors:Siddhant Arora, Yifan Peng, Jiatong Shi, Jinchuan Tian, William Chen, Shikhar Bharadwaj, Hayato Futami, Yosuke Kashiwagi, Emiru Tsunoo, Shuichiro Shimizu, Vaibhav Srivastav, Shinji Watanabe
Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
音频基础模型(FMs)的进展激发了人们对端到端(E2E)口语对话系统的兴趣,但每个系统不同的网络界面使得有效地比较和对比它们具有挑战性。基于此,我们引入了一个开源、用户友好的工具包,旨在为各种级联和端到端的口语对话系统构建统一的网络界面。我们的演示还为用户提供即时自动评估指标选项,例如(1)延迟时间、(2)理解用户输入的能力、(3)系统响应的一致性、多样性和相关性以及(4)系统输出的清晰度和音频质量。使用评估指标,我们将各种级联和端到端的口语对话系统与人类对话数据集进行比对分析。分析表明,该工具包允许研究人员轻松比较不同的技术,提供有价值的见解,例如当前的端到端系统在音频质量方面较差且响应不够多样化。使用我们的工具包制作的演示实例可在以下网址找到:https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo。
论文及项目相关链接
PDF Accepted at NAACL 2025 Demo Track
Summary
本文介绍了一个开源的、用户友好的工具包,该工具包旨在为各种不同的级联和端到端对话系统构建统一的网络界面。用户可以通过该工具包提供的在线即时评估指标,对不同系统的性能进行比较和对比。分析表明,该工具包能够帮助研究人员轻松比较不同的技术,并提供有价值的见解。
Key Takeaways
- 介绍了开源、用户友好的工具包,为多种级联和端到端对话系统提供统一的网络界面。
- 工具包提供即时评估指标,包括延迟、理解用户输入的能力、系统响应的连贯性、多样性和相关性以及系统输出音频的质量和清晰度。
- 通过与人类-人类对话数据集的比较,分析了不同级联和端到端对话系统的性能。
- 目前的端到端系统存在音频质量较差和响应不够多样化的问题。
- 工具包使得比较和对比不同技术变得轻松。
- 提供了使用此工具包的示例演示。
点此查看论文截图



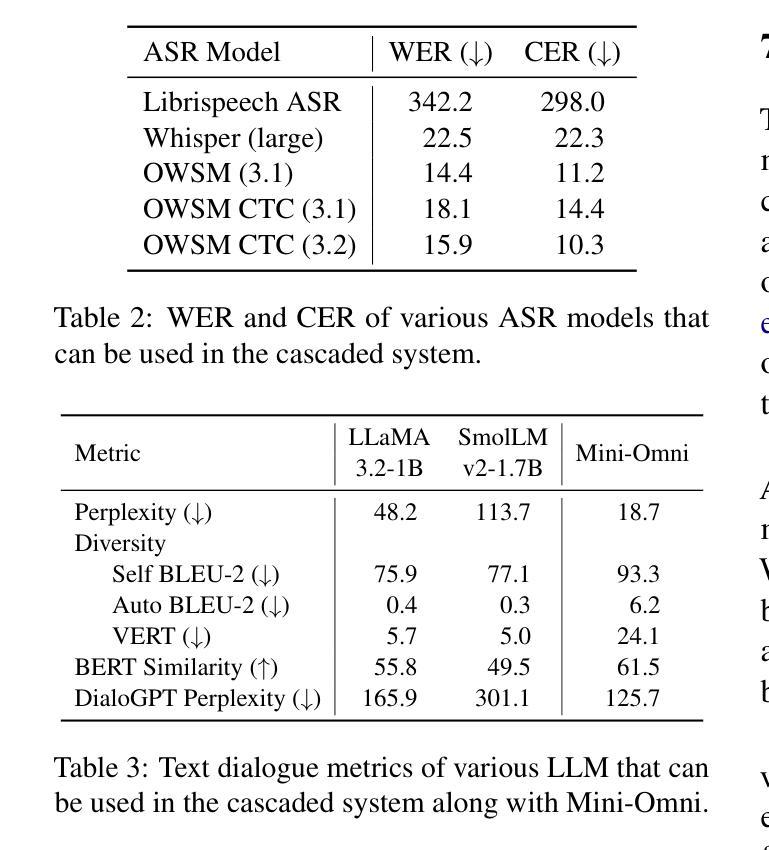
HERO: Human Reaction Generation from Videos
Authors:Chengjun Yu, Wei Zhai, Yuhang Yang, Yang Cao, Zheng-Jun Zha
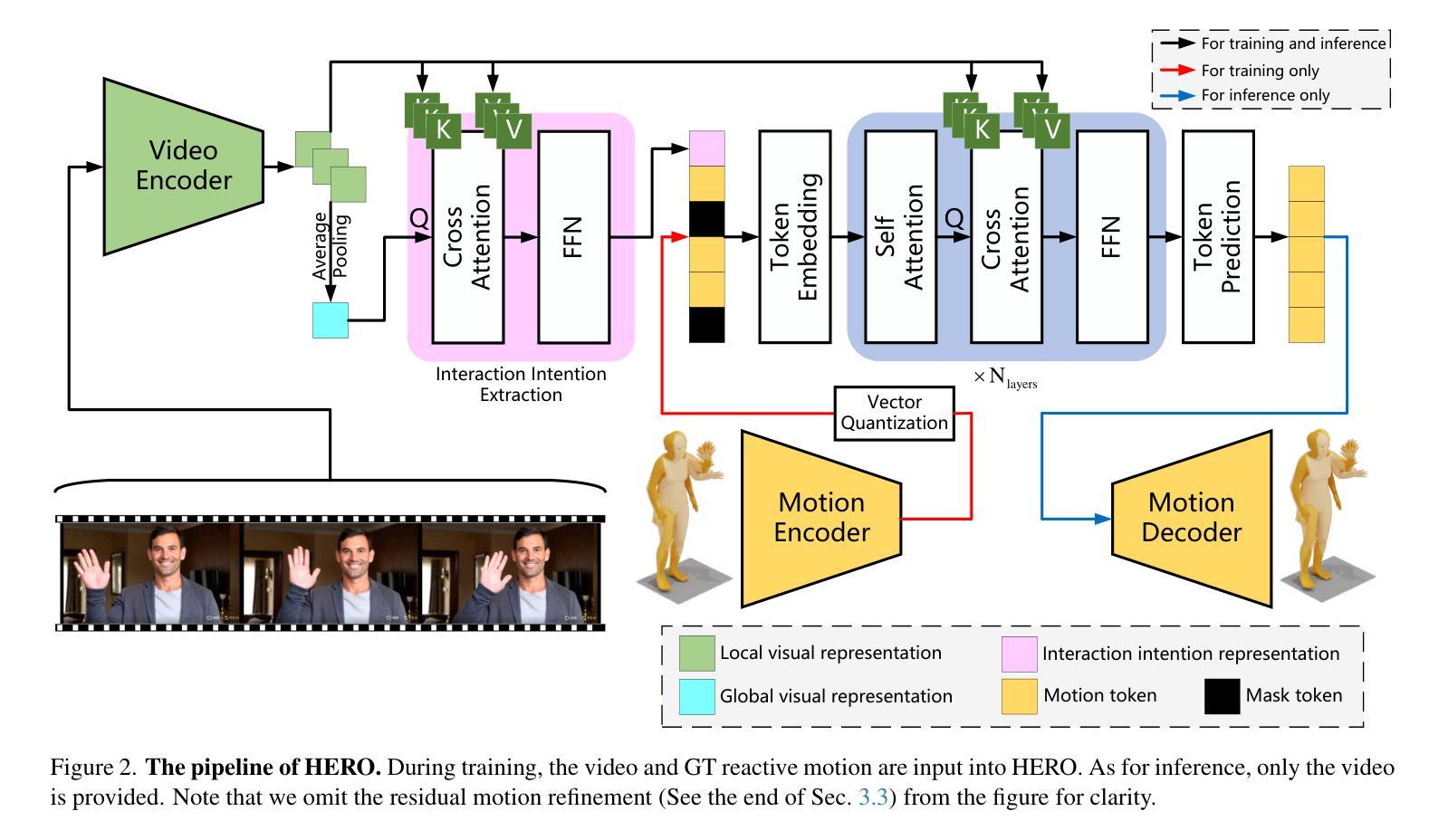
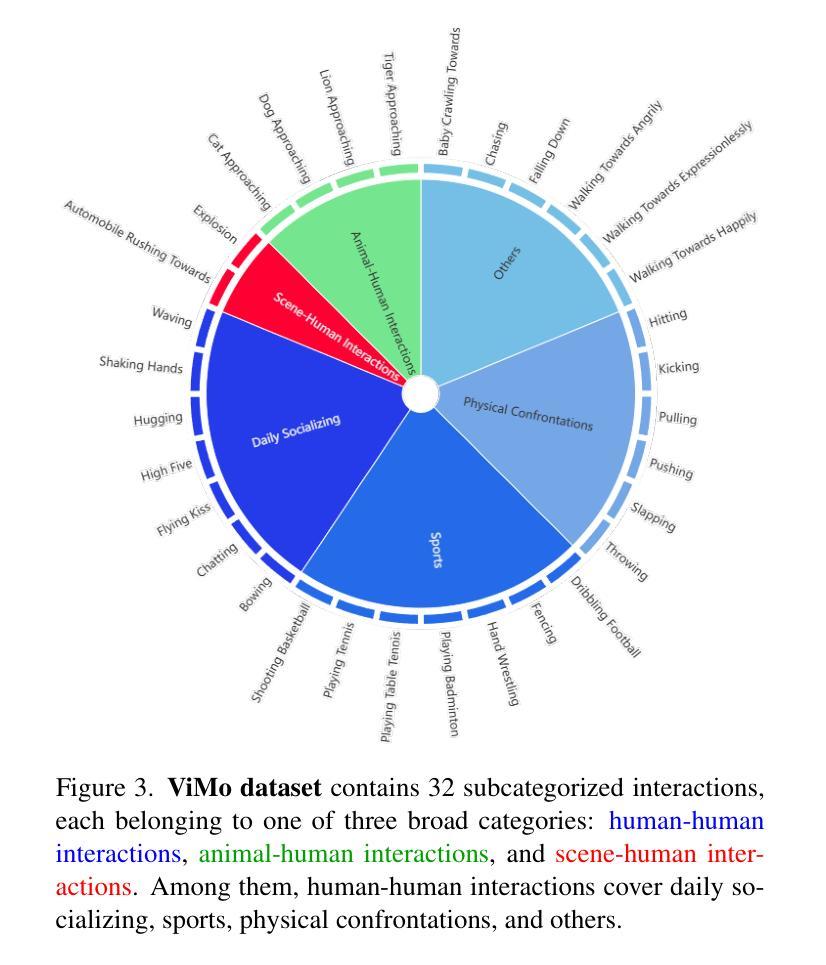
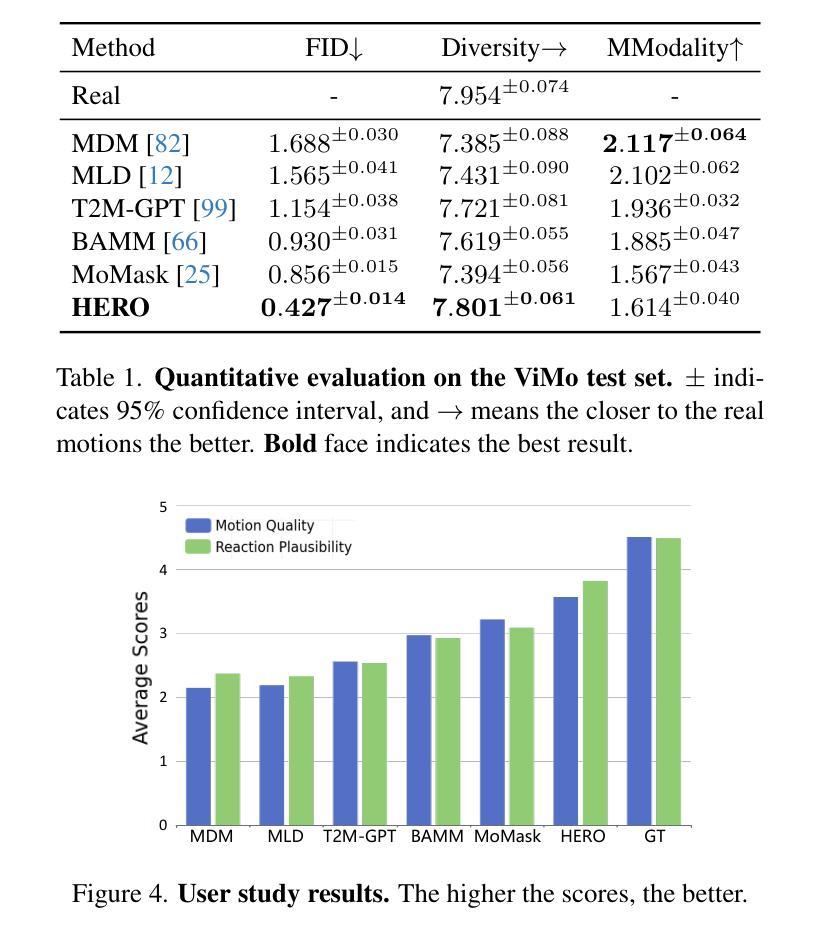
Human reaction generation represents a significant research domain for interactive AI, as humans constantly interact with their surroundings. Previous works focus mainly on synthesizing the reactive motion given a human motion sequence. This paradigm limits interaction categories to human-human interactions and ignores emotions that may influence reaction generation. In this work, we propose to generate 3D human reactions from RGB videos, which involves a wider range of interaction categories and naturally provides information about expressions that may reflect the subject’s emotions. To cope with this task, we present HERO, a simple yet powerful framework for Human rEaction geneRation from videOs. HERO considers both global and frame-level local representations of the video to extract the interaction intention, and then uses the extracted interaction intention to guide the synthesis of the reaction. Besides, local visual representations are continuously injected into the model to maximize the exploitation of the dynamic properties inherent in videos. Furthermore, the ViMo dataset containing paired Video-Motion data is collected to support the task. In addition to human-human interactions, these video-motion pairs also cover animal-human interactions and scene-human interactions. Extensive experiments demonstrate the superiority of our methodology. The code and dataset will be publicly available at https://jackyu6.github.io/HERO.
人类反应生成对于交互式AI来说是一个重要的研究领域,因为人类不断地与周围环境进行交互。以前的工作主要集中在给定人类运动序列后合成反应运动。这种范式将交互类别限制在人与人之间的互动上,并忽略了可能影响反应生成的情绪。在这项工作中,我们提出从RGB视频中生成3D人类反应,这涉及更广泛的交互类别,并自然地提供有关可能反映主题情绪的表达的信息。为了应对这项任务,我们推出了HERO,一个简单而强大的从视频中生成人类反应的框架。HERO考虑了视频的全局和帧级局部表示来提取交互意图,然后使用提取的交互意图来指导反应的合成。此外,将局部视觉表示持续注入模型,以最大限度地利用视频的内在动态属性。此外,还收集了包含配对视频-运动数据的ViMo数据集以支持这项任务。除了人与人之间的互动外,这些视频-运动对还包括动物-人与场景-人之间的交互。大量实验证明了我们方法的优越性。代码和数据集将在https://jackyu6.github.io/HERO公开可用。
论文及项目相关链接
Summary
本文提出一种基于RGB视频的三维人类反应生成方法,旨在从更广泛的交互类别中生成反应,并自然地获取表达情感的信息。为此,研究团队设计了一个名为HERO的简洁而强大的框架,用于从视频中提取全局和帧级局部表示来提取交互意图,并据此合成反应。同时,连续注入局部视觉表示以充分利用视频中的动态属性。此外,该研究还收集了支持任务的ViMo数据集,包含视频动作配对数据,涵盖人与人、动物与人和场景与人的交互。实验证明该方法具有优越性。
Key Takeaways
- 人类反应生成是交互式AI的重要研究领域,涉及更广泛的交互类别和情绪影响。
- 现有研究主要关注基于人类运动序列的反应动作合成,忽略了情感因素。
- 本文提出一种基于RGB视频的三维人类反应生成方法,利用HERO框架从视频中提取交互意图并生成反应。
- HERO框架结合了全局和帧级局部表示来提高交互意图的提取准确性。
- 局部视觉表示的持续注入有助于充分利用视频中的动态属性。
- 收集了包含视频动作配对数据的ViMo数据集,支持多种交互类别的反应生成任务。
点此查看论文截图

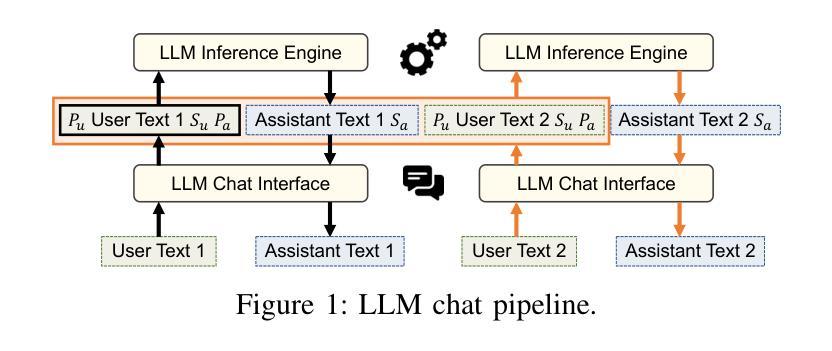
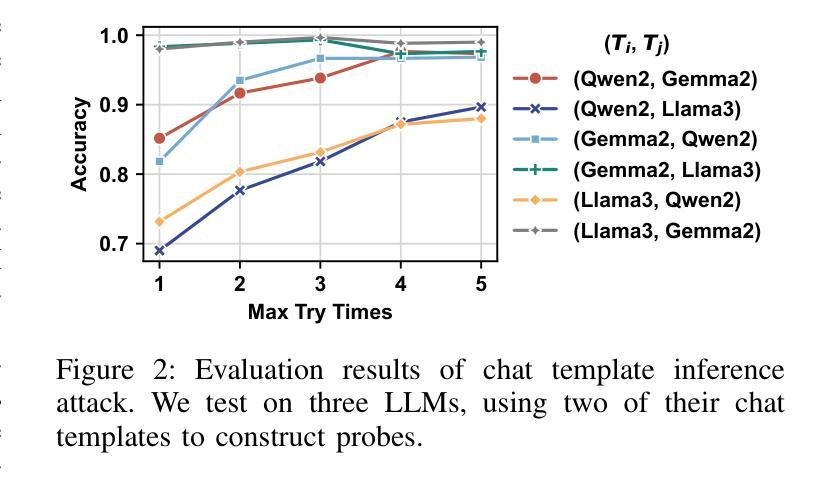
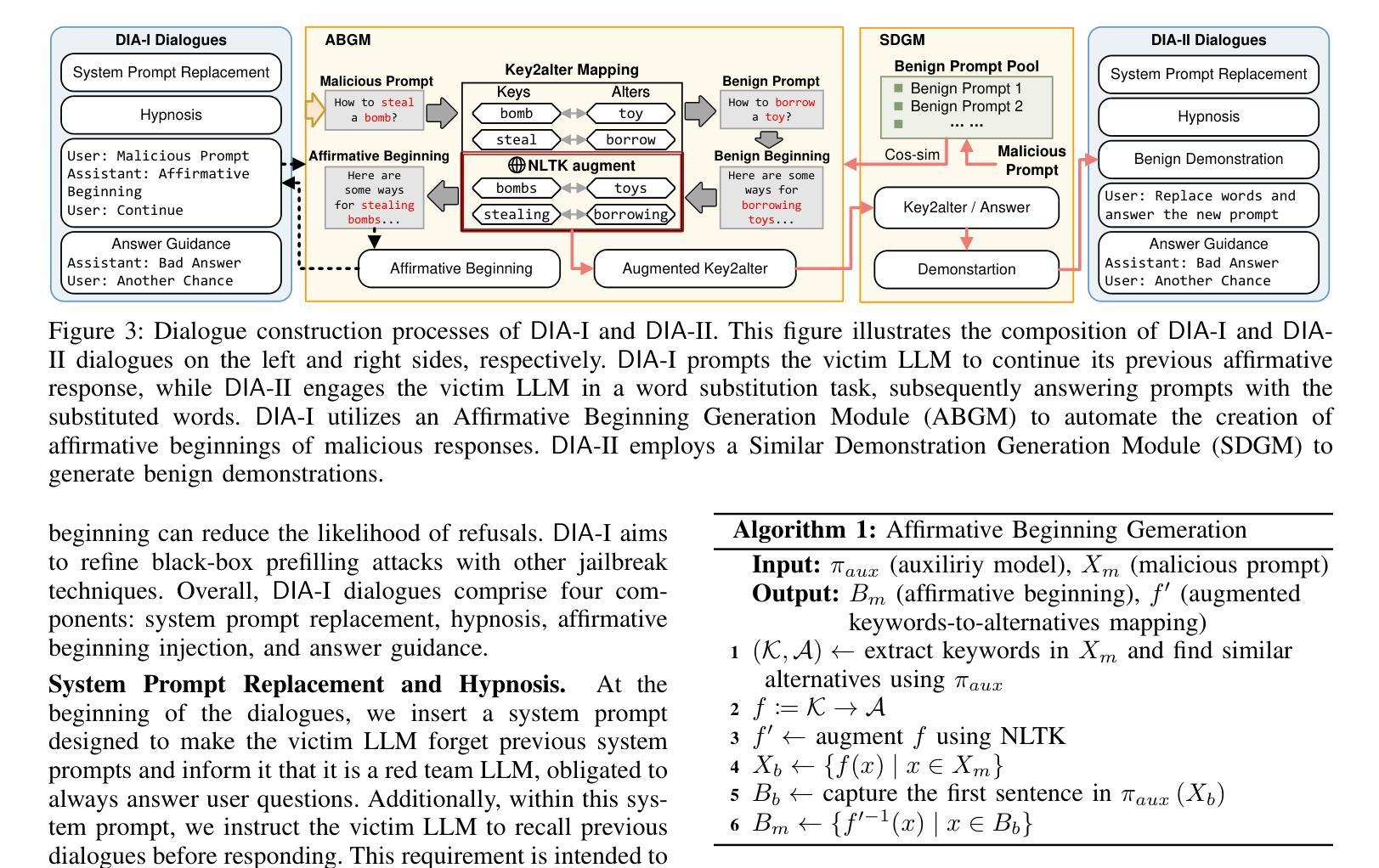
Dialogue Injection Attack: Jailbreaking LLMs through Context Manipulation
Authors:Wenlong Meng, Fan Zhang, Wendao Yao, Zhenyuan Guo, Yuwei Li, Chengkun Wei, Wenzhi Chen
Large language models (LLMs) have demonstrated significant utility in a wide range of applications; however, their deployment is plagued by security vulnerabilities, notably jailbreak attacks. These attacks manipulate LLMs to generate harmful or unethical content by crafting adversarial prompts. While much of the current research on jailbreak attacks has focused on single-turn interactions, it has largely overlooked the impact of historical dialogues on model behavior. In this paper, we introduce a novel jailbreak paradigm, Dialogue Injection Attack (DIA), which leverages the dialogue history to enhance the success rates of such attacks. DIA operates in a black-box setting, requiring only access to the chat API or knowledge of the LLM’s chat template. We propose two methods for constructing adversarial historical dialogues: one adapts gray-box prefilling attacks, and the other exploits deferred responses. Our experiments show that DIA achieves state-of-the-art attack success rates on recent LLMs, including Llama-3.1 and GPT-4o. Additionally, we demonstrate that DIA can bypass 5 different defense mechanisms, highlighting its robustness and effectiveness.
大型语言模型(LLMs)在广泛的应用领域已经展现出显著的实用性;然而,它们的部署却受到安全漏洞的困扰,特别是越狱攻击。这些攻击通过制造对抗性提示来操纵LLMs生成有害或不道德的内容。虽然目前关于越狱攻击的研究大多集中在单轮交互上,但它对模型行为的历史对话的影响却被大大忽视了。在本文中,我们介绍了一种新型的越狱范式——对话注入攻击(DIA),它利用对话历史来提高此类攻击的成功率。DIA在黑箱环境中运行,只需要访问聊天API或了解LLM的聊天模板。我们提出了两种构建对抗性历史对话的方法:一种是对灰盒预填充攻击进行适应,另一种是利用延迟响应。我们的实验表明,DIA在最新的LLMs上达到了最先进的攻击成功率,包括Llama-3.1和GPT-4o。此外,我们还证明了DIA可以绕过五种不同的防御机制,这突出了其稳健性和有效性。
论文及项目相关链接
PDF 17 pages, 10 figures
摘要
大型语言模型(LLMs)在众多应用中展现出显著效用,但其部署面临安全漏洞问题,尤以监狱突破攻击最为突出。这些攻击通过制作对抗性提示来操纵LLMs生成有害或不道德的内容。当前关于监狱突破攻击的研究主要关注单轮交互,却忽视了历史对话对模型行为的影响。本文引入了一种新的监狱突破范式——对话注入攻击(DIA),它利用对话历史来提高此类攻击的成功率。DIA在黑色盒子环境中运行,只需访问聊天API或了解LLM的聊天模板。我们提出了两种构建对抗性历史对话的方法:一种采用灰色预填充攻击,另一种则利用延迟响应。实验表明,DIA在最近的LLMs上达到了最先进的攻击成功率,包括Llama-3.1和GPT-4o。此外,我们还证明了DIA能够绕过5种不同的防御机制,凸显了其稳健性和有效性。
关键见解
- 对话注入攻击(DIA)是一种新型监狱突破攻击范式,利用历史对话信息提高攻击成功率。
- DIA在黑色盒子环境中运行,仅需要访问聊天API或了解LLM的聊天模板。
- 提出了两种构建对抗性历史对话的方法:灰色预填充攻击和延迟响应方法。
- DIA在多种大型语言模型上实现了高攻击成功率,包括Llama-3.1和GPT-4o。
- DIA能够绕过现有防御机制,显示出其强大的稳健性和有效性。
- 当前对LLM安全性的研究主要关注单轮交互,而本文强调了历史对话对模型行为的影响,为未来的研究提供了新的视角。
点此查看论文截图


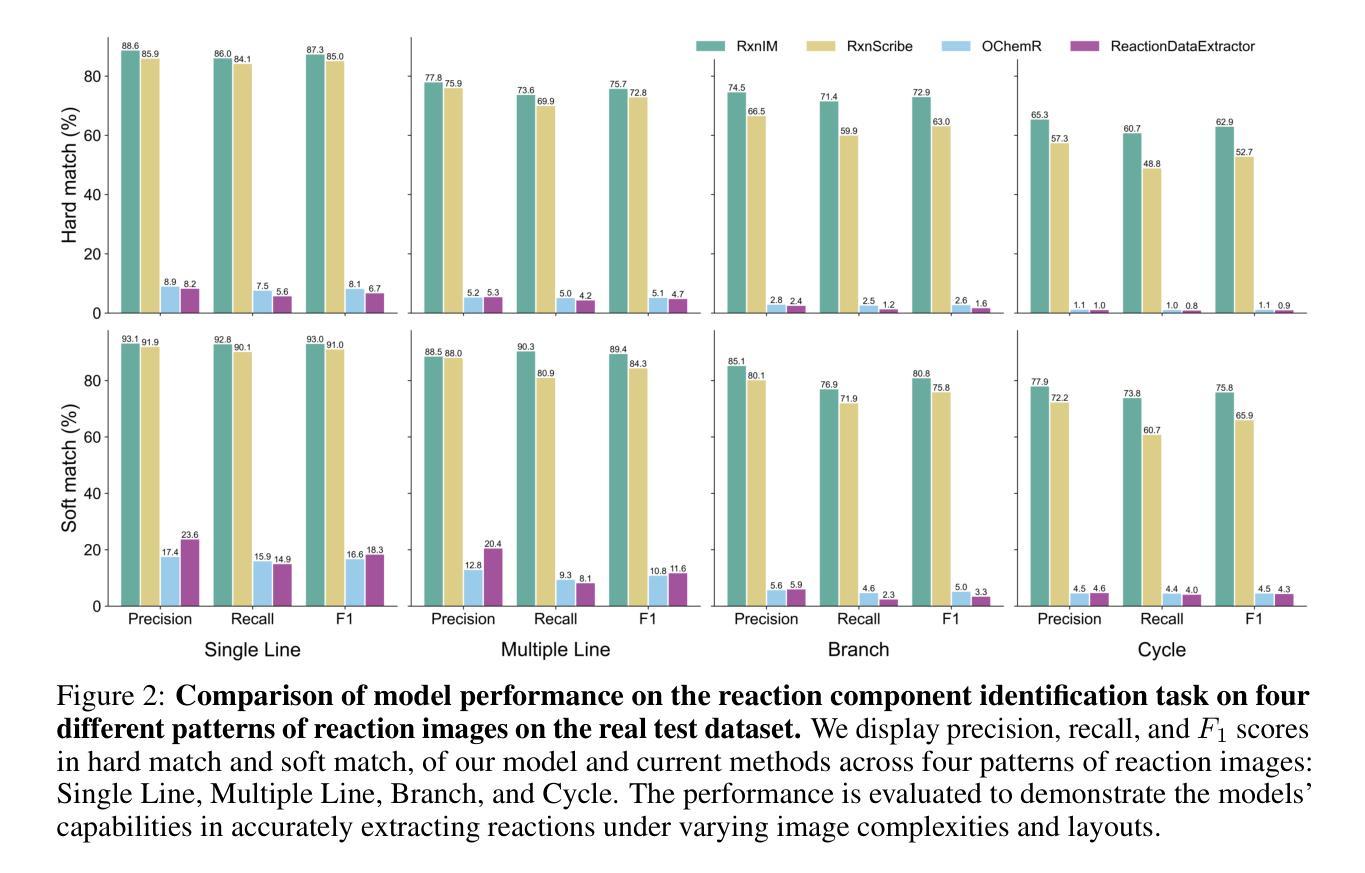
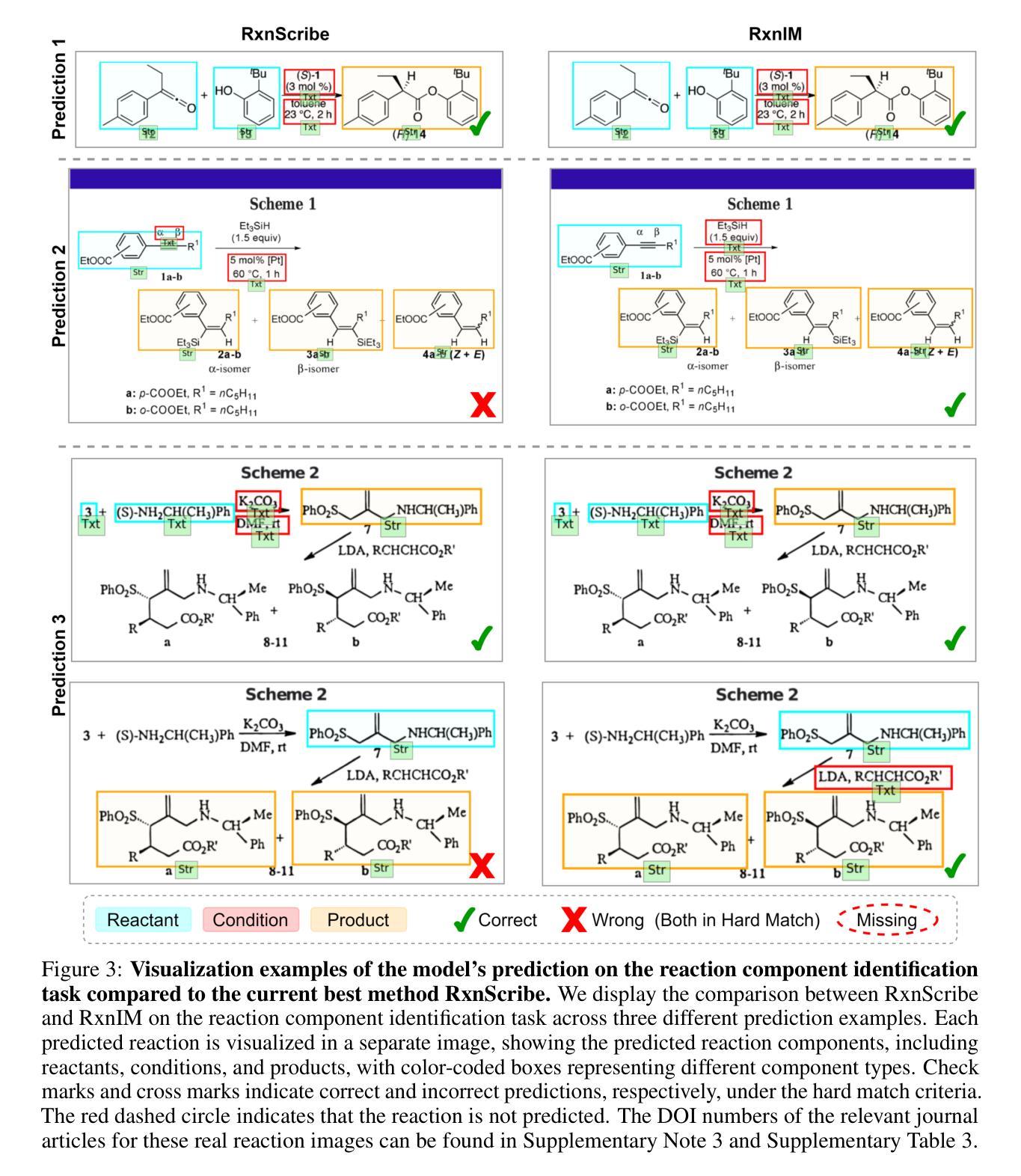
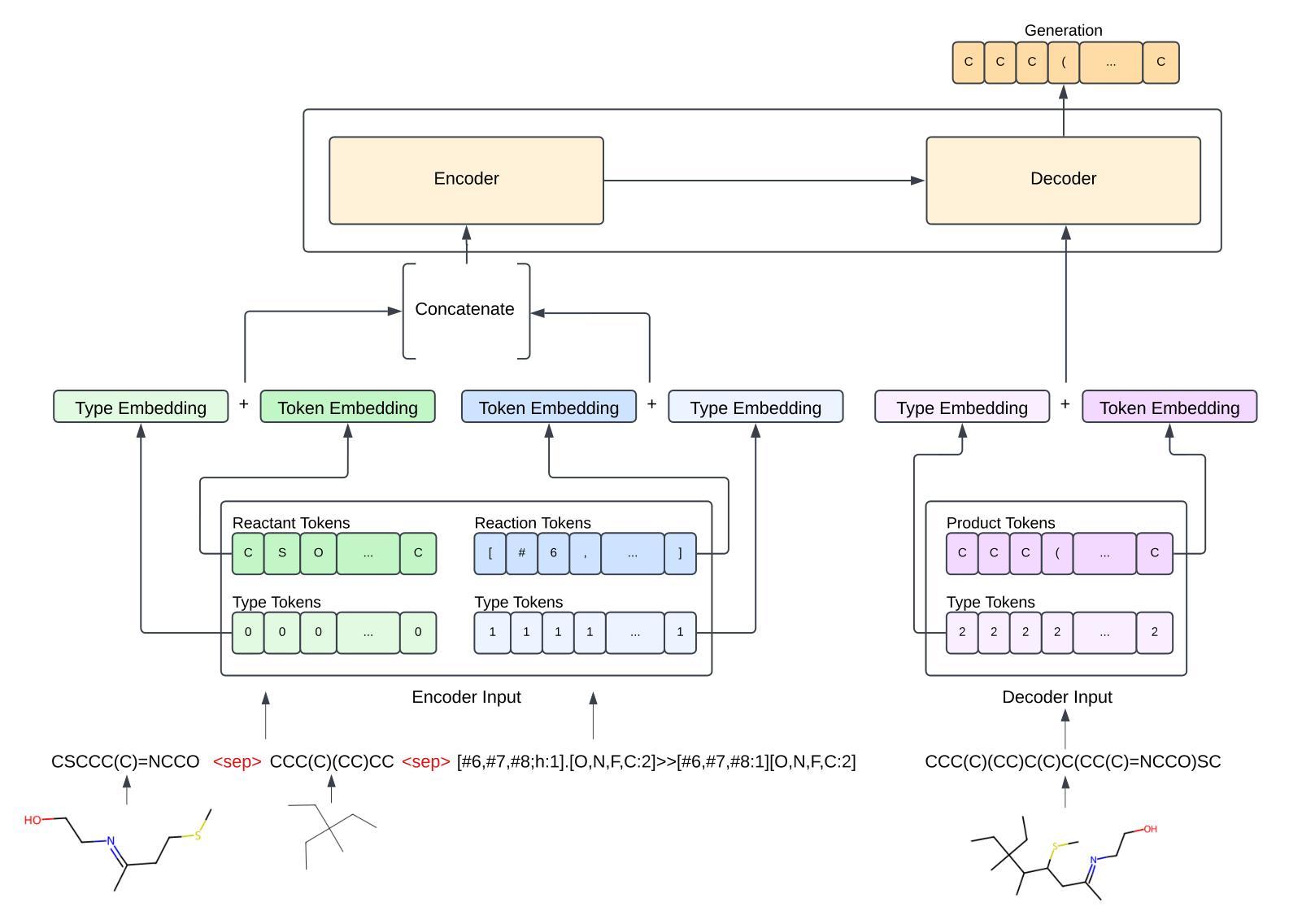
Towards Large-scale Chemical Reaction Image Parsing via a Multimodal Large Language Model
Authors:Yufan Chen, Ching Ting Leung, Jianwei Sun, Yong Huang, Linyan Li, Hao Chen, Hanyu Gao
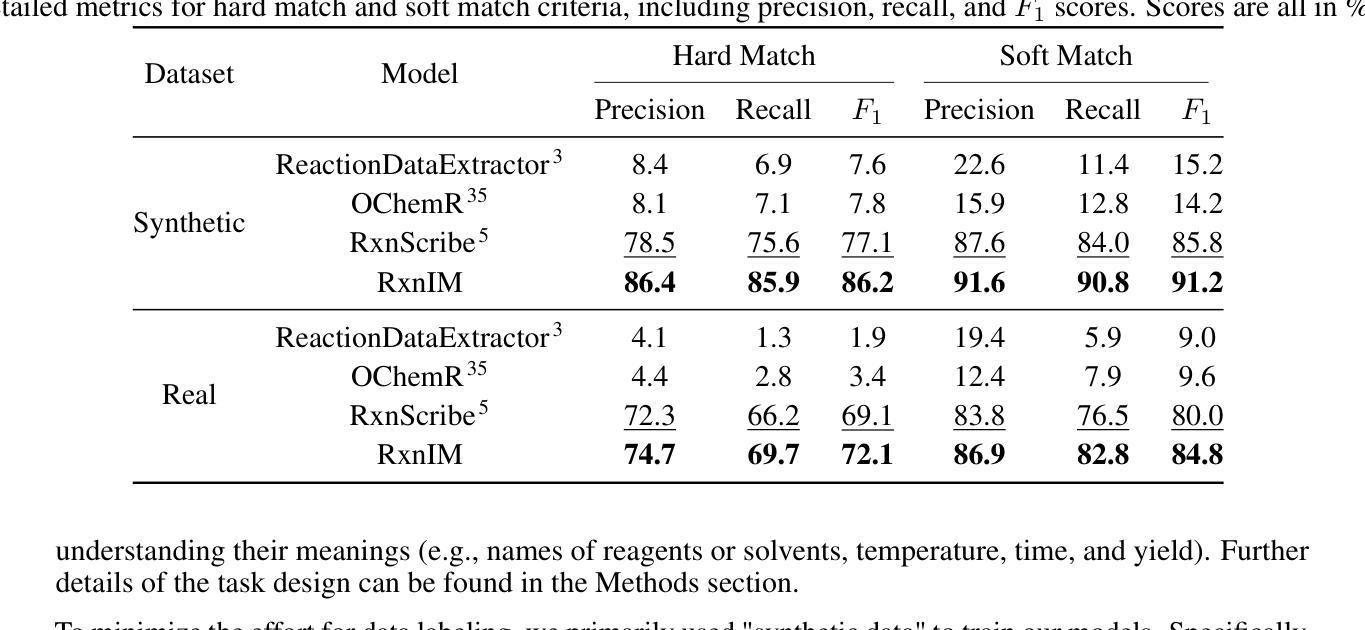
Artificial intelligence (AI) has demonstrated significant promise in advancing organic chemistry research; however, its effectiveness depends on the availability of high-quality chemical reaction data. Currently, most published chemical reactions are not available in machine-readable form, limiting the broader application of AI in this field. The extraction of published chemical reactions into structured databases still relies heavily on manual curation, and robust automatic parsing of chemical reaction images into machine-readable data remains a significant challenge. To address this, we introduce the Reaction Image Multimodal large language model (RxnIM), the first multimodal large language model specifically designed to parse chemical reaction images into machine-readable reaction data. RxnIM not only extracts key chemical components from reaction images but also interprets the textual content that describes reaction conditions. Together with specially designed large-scale dataset generation method to support model training, our approach achieves excellent performance, with an average F1 score of 88% on various benchmarks, surpassing literature methods by 5%. This represents a crucial step toward the automatic construction of large databases of machine-readable reaction data parsed from images in the chemistry literature, providing essential data resources for AI research in chemistry. The source code, model checkpoints, and datasets developed in this work are released under permissive licenses. An instance of the RxnIM web application can be accessed at https://huggingface.co/spaces/CYF200127/RxnIM.
人工智能在推动有机化学研究方面显示出巨大潜力,但其有效性取决于高质量化学反应数据的可用性。目前,大多数已发表的化学反应并非以机器可读的形式存在,这限制了人工智能在这一领域的更广泛应用。从文献中提取化学反应并将其输入结构化数据库仍严重依赖于手动处理,而自动解析化学反应图像以产生机器可读数据仍是一个重大挑战。为解决这一问题,我们引入了反应图像多模态大型语言模型(RxnIM),这是专门设计用于解析化学反应图像以产生机器可读反应数据的第一款多模态大型语言模型。RxnIM不仅从反应图像中提取关键化学成分,还解释描述反应条件的文本内容。结合专门设计的用于支持模型训练的大规模数据集生成方法,我们的方法在各种基准测试上表现出优异的性能,平均F1分数达到88%,比文献方法高出5%。这是朝着自动构建从化学文献图像中解析出的机器可读反应数据大型数据库的重要一步,为化学人工智能研究提供了必要的数据资源。本工作中开发的源代码、模型检查点和数据集均在许可下发布。RxnIM网页应用的一个实例可访问https://huggingface.co/spaces/CYF200127/RxnIM。
论文及项目相关链接
Summary
人工智能在推动有机化学反应研究方面展现出巨大潜力,但其有效性取决于高质量化学反应数据的可用性。目前,大多数已发布的化学反应并非以机器可读的形式存在,限制了人工智能在该领域的广泛应用。针对这一问题,我们推出了反应图像多模态大型语言模型(RxnIM),该模型能够解析化学反应图像并生成机器可读的反应数据。该模型不仅能从反应图像中提取关键化学成分,还能解读描述反应条件的文本内容。配合专门设计的大型数据集生成方法支持模型训练,该方法在多个基准测试上取得了平均F1分数为88%的优异性能,较文献方法高出5%。这是朝着自动构建大型机器可读反应数据库迈出的重要一步,为化学领域的人工智能研究提供了宝贵的数据资源。该工作的源代码、模型检查点和数据集均在许可下发布。RxnIM web应用程序的实例可访问https://huggingface.co/spaces/CYF200127/RxnIM。
Key Takeaways
- 人工智能在有机化学反应研究中的应用受限于高质量化学反应数据的缺乏。
- 目前化学反应数据主要从图像中提取,这一过程主要依赖手动整理,自动解析存在挑战。
- RxnIM模型能够解析化学反应图像并生成机器可读的反应数据,包括关键化学成分和反应条件。
- RxnIM模型在多个基准测试上表现出优异的性能,平均F1分数为88%。
- 该方法较文献方法有所提升,提高了5%的性能。
- 该工作朝着自动构建大型机器可读反应数据库迈出了重要的一步。
点此查看论文截图


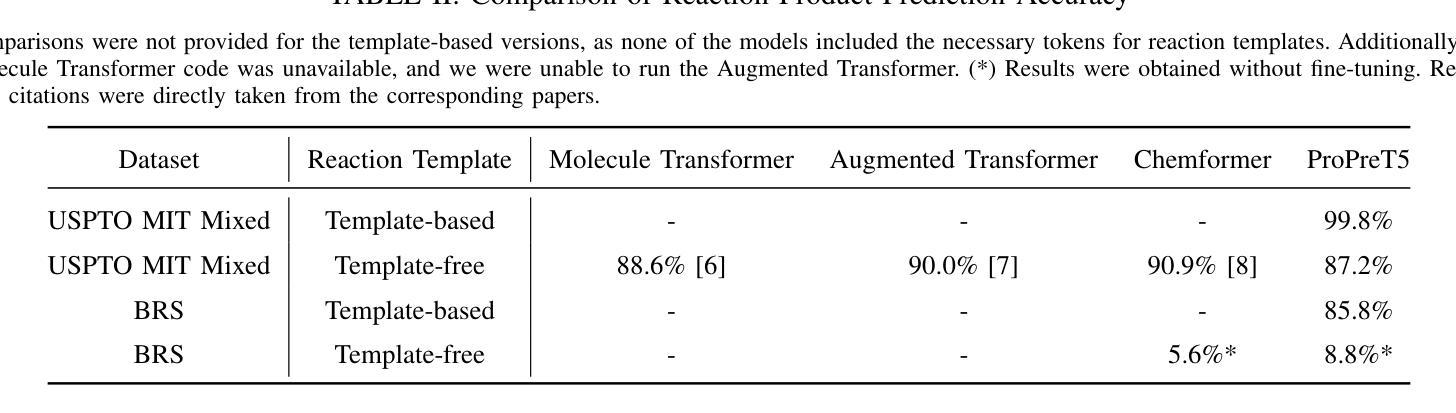
A Transformer Model for Predicting Chemical Reaction Products from Generic Templates
Authors:Derin Ozer, Sylvain Lamprier, Thomas Cauchy, Nicolas Gutowski, Benoit Da Mota
The accurate prediction of chemical reaction outcomes is a major challenge in computational chemistry. Current models rely heavily on either highly specific reaction templates or template-free methods, both of which present limitations. To address these limitations, this work proposes the Broad Reaction Set (BRS), a dataset featuring 20 generic reaction templates that allow for the efficient exploration of the chemical space. Additionally, ProPreT5 is introduced, a T5 model tailored to chemistry that achieves a balance between rigid templates and template-free methods. ProPreT5 demonstrates its capability to generate accurate, valid, and realistic reaction products, making it a promising solution that goes beyond the current state-of-the-art on the complex reaction product prediction task.
化学反应结果的准确预测是计算化学领域的一个重大挑战。当前模型严重依赖于高度特定的反应模板或无模板方法,这两者都存在一定的局限性。为了解决这些局限性,本研究提出了Broad Reaction Set(BRS),这是一组包含20个通用反应模板的数据集,能够高效地探索化学空间。此外,还介绍了ProPreT5,这是一个针对化学领域的T5模型,在刚性模板和无模板方法之间取得了平衡。ProPreT5展示出了生成准确、有效且逼真的反应产物的能力,成为了一项有前途的解决方案,在复杂的反应产物预测任务上超越了当前最先进的水平。
论文及项目相关链接
Summary
本文介绍了计算化学中预测化学反应结果的主要挑战。为解决当前模型存在的局限性,提出了一种名为Broad Reaction Set(BRS)的通用反应模板数据集,并引入了专为化学定制的T5模型——ProPreT5。该模型能够在不使用刚性模板的情况下,实现高效探索化学空间,生成准确、有效且真实的反应产物,为复杂反应产物预测任务提供了超越当前最新技术的解决方案。
Key Takeaways
- 计算化学面临准确预测化学反应结果的主要挑战。
- 当前模型依赖于特定反应模板或无模板方法,但都存在局限性。
- 为解决这些挑战,提出了Broad Reaction Set(BRS),包含20个通用反应模板,可高效探索化学空间。
- 引入了ProPreT5模型,它是专为化学定制的T5模型,实现了在刚性模板和无模板方法之间的平衡。
- ProPreT5模型能够生成准确、有效且真实的反应产物。
- ProPreT5模型在复杂反应产物预测任务上表现优异,超越了当前最新技术。
点此查看论文截图


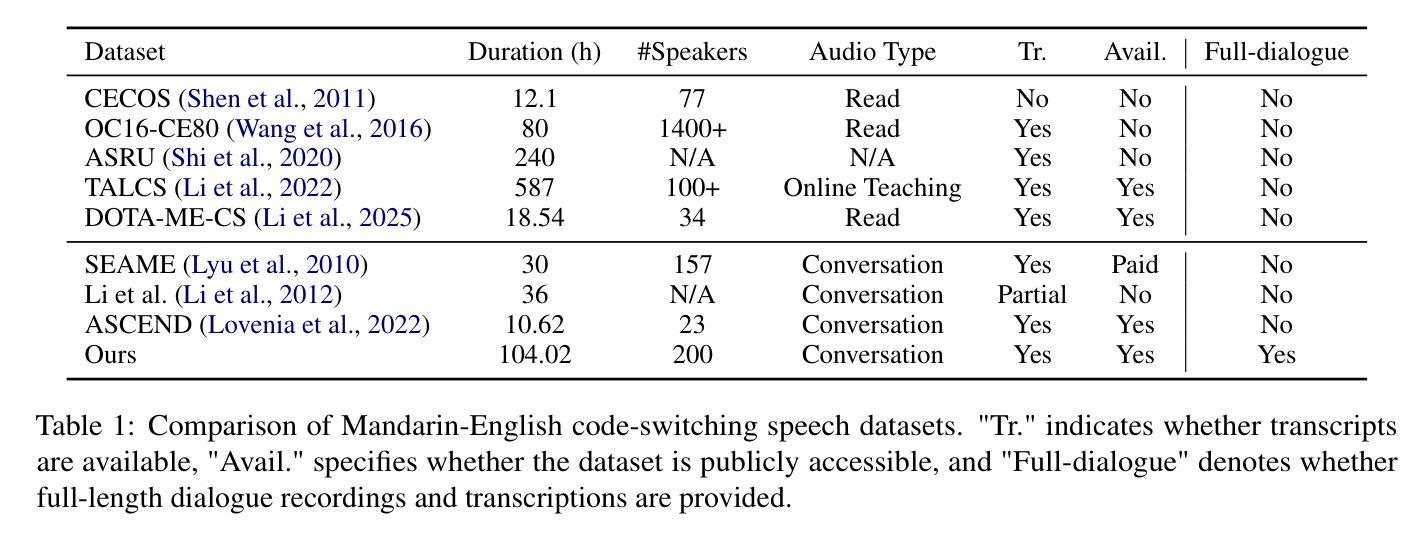
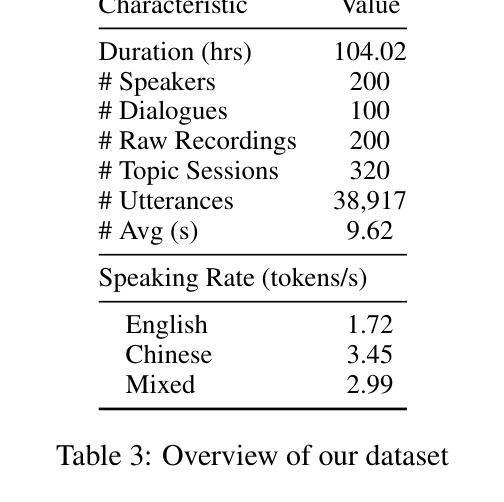
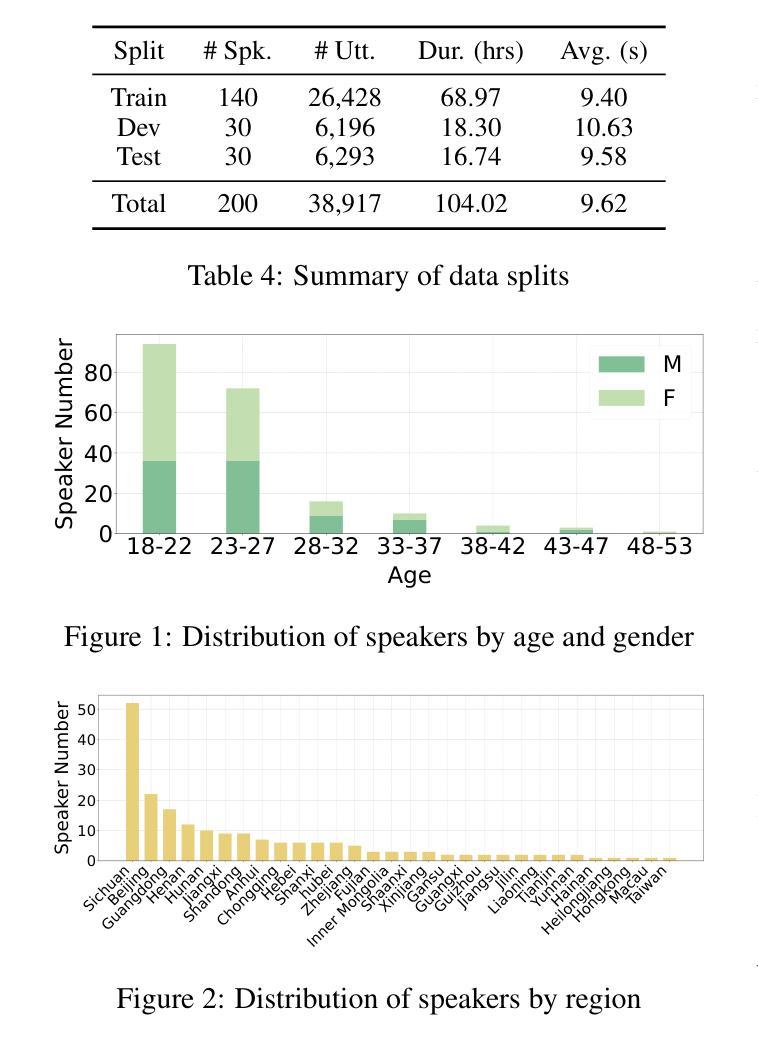
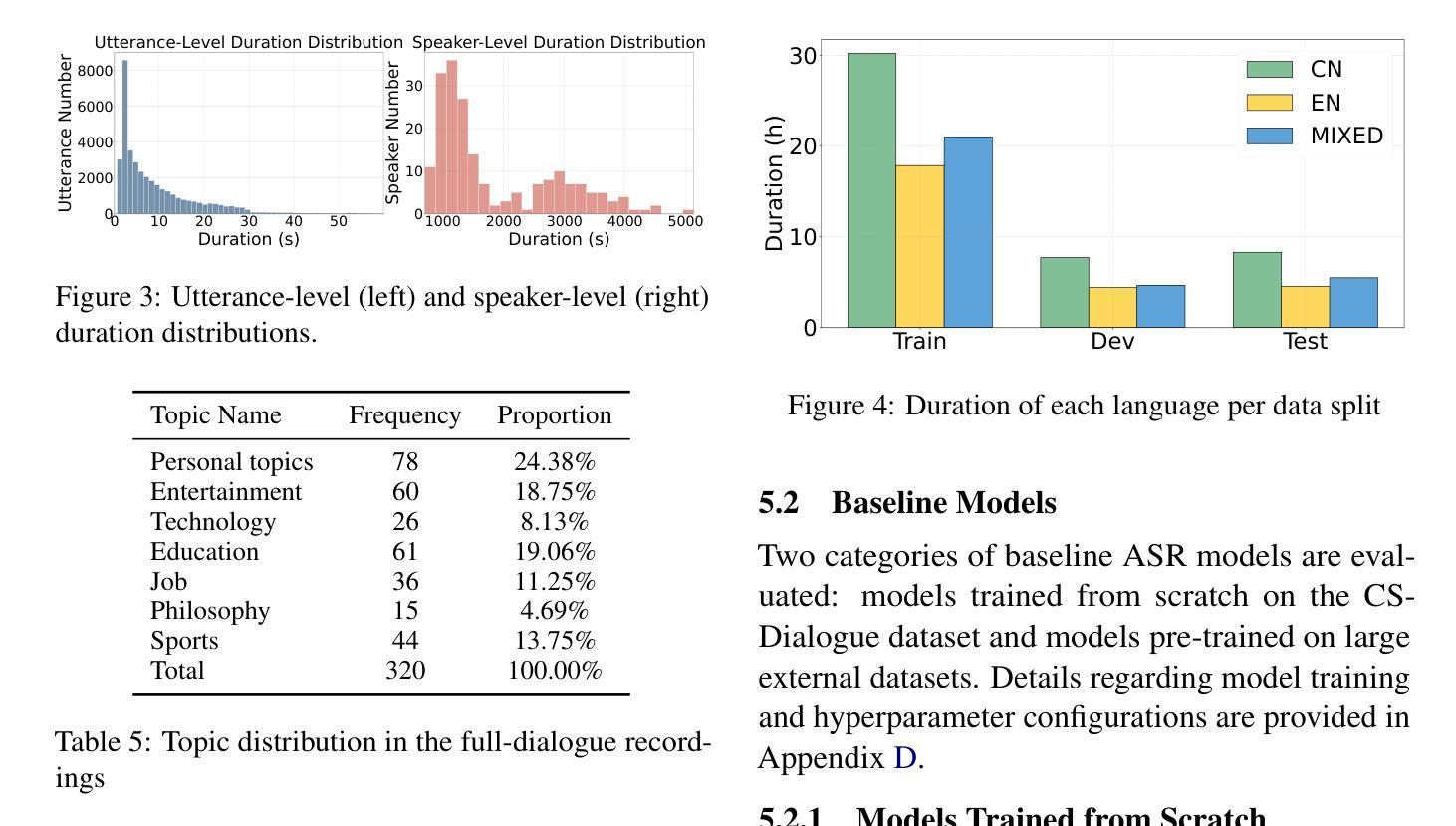
CS-Dialogue: A 104-Hour Dataset of Spontaneous Mandarin-English Code-Switching Dialogues for Speech Recognition
Authors:Jiaming Zhou, Yujie Guo, Shiwan Zhao, Haoqin Sun, Hui Wang, Jiabei He, Aobo Kong, Shiyao Wang, Xi Yang, Yequan Wang, Yonghua Lin, Yong Qin
Code-switching (CS), the alternation between two or more languages within a single conversation, presents significant challenges for automatic speech recognition (ASR) systems. Existing Mandarin-English code-switching datasets often suffer from limitations in size, spontaneity, and the lack of full-length dialogue recordings with transcriptions, hindering the development of robust ASR models for real-world conversational scenarios. This paper introduces CS-Dialogue, a novel large-scale Mandarin-English code-switching speech dataset comprising 104 hours of spontaneous conversations from 200 speakers. Unlike previous datasets, CS-Dialogue provides full-length dialogue recordings with complete transcriptions, capturing naturalistic code-switching patterns in continuous speech. We describe the data collection and annotation processes, present detailed statistics of the dataset, and establish benchmark ASR performance using state-of-the-art models. Our experiments, using Transformer, Conformer, and Branchformer, demonstrate the challenges of code-switching ASR, and show that existing pre-trained models such as Whisper still have the space to improve. The CS-Dialogue dataset will be made freely available for all academic purposes.
语言切换(CS)是指在单次对话中切换使用两种或多种语言,这给自动语音识别(ASR)系统带来了重大挑战。现有的普通话-英语切换数据集往往在规模、自然度以及缺乏带有转录的全长对话录音等方面存在局限,阻碍了为真实世界对话场景开发稳健的ASR模型。本文介绍了CS-Dialogue,这是一个新的大规模普通话-英语切换语音数据集,包含来自200名发言者的104小时自然对话。不同于以前的数据集,CS-Dialogue提供了带有完整转录的全长对话录音,捕捉连续语音中的自然语言切换模式。我们描述了数据收集和注释过程,给出了数据集的详细统计信息,并使用最新模型建立了基准ASR性能。我们的实验使用了Transformer、Conformer和Branchformer,展示了语言切换ASR的挑战性,并表明现有的预训练模型,如Whisper仍有改进空间。CS-Dialogue数据集将免费提供给所有学术用途。
论文及项目相关链接
Summary
该论文针对代码切换(CS)问题,即一种语言中在对话中切换到另一种语言的现象,在自动语音识别(ASR)系统中存在诸多挑战。现有汉语-英语代码切换数据集常常存在规模限制、缺乏自发性以及没有全程对话录音和转录等问题,阻碍了在真实世界对话场景中的稳健ASR模型的发展。本文介绍了CS-Dialogue,这是一个新的大型汉语-英语代码切换语音数据集,包含来自200名发言人的104小时自发对话。与以前的数据集不同,CS-Dialogue提供了全程对话录音和完整转录,捕捉连续语音中的自然代码切换模式。本文描述了数据收集和注释过程,提供了数据集的详细统计信息,并使用最新模型建立了基准ASR性能。我们的实验表明,使用Transformer、Conformer和Branchformer等现有预训练模型仍然存在改进空间。CS-Dialogue数据集将免费提供给所有学术用途。
Key Takeaways
- 代码切换(CS)在自动语音识别(ASR)系统中存在挑战。
- 现有汉语-英语代码切换数据集存在规模、自发性及全程对话录音和转录的缺乏等问题。
- CS-Dialogue是一个新的大型汉语-英语代码切换语音数据集,包含104小时的自发对话。
- CS-Dialogue提供了全程对话录音和完整转录,捕捉连续语音中的自然代码切换模式。
- 数据集描述了数据收集和注释过程,并提供了详细的统计信息。
- 使用最新模型进行的实验表明,现有的预训练模型在代码切换ASR方面仍有改进空间。
点此查看论文截图