⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment
Authors:Katrin Renz, Long Chen, Elahe Arani, Oleg Sinavski
Integrating large language models (LLMs) into autonomous driving has attracted significant attention with the hope of improving generalization and explainability. However, existing methods often focus on either driving or vision-language understanding but achieving both high driving performance and extensive language understanding remains challenging. In addition, the dominant approach to tackle vision-language understanding is using visual question answering. However, for autonomous driving, this is only useful if it is aligned with the action space. Otherwise, the model’s answers could be inconsistent with its behavior. Therefore, we propose a model that can handle three different tasks: (1) closed-loop driving, (2) vision-language understanding, and (3) language-action alignment. Our model SimLingo is based on a vision language model (VLM) and works using only camera, excluding expensive sensors like LiDAR. SimLingo obtains state-of-the-art performance on the widely used CARLA simulator on the Bench2Drive benchmark and is the winning entry at the CARLA challenge 2024. Additionally, we achieve strong results in a wide variety of language-related tasks while maintaining high driving performance.
将大型语言模型(LLM)集成到自动驾驶中,旨在提高通用性和可解释性,已经引起了人们的广泛关注。然而,现有方法往往集中在驾驶或视觉语言理解上,而实现高驾驶性能和广泛的语言理解仍然具有挑战性。此外,解决视觉语言理解的主要方法是使用视觉问答。然而,对于自动驾驶来说,只有将其与动作空间对齐时才有用。否则,模型的答案可能与其行为不一致。因此,我们提出了一种能够处理三种不同任务模型:即(1)闭环驾驶、(2)视觉语言理解和(3)语言动作对齐。我们的模型SimLingo基于视觉语言模型(VLM),仅使用相机工作,不包括昂贵的传感器,如激光雷达。SimLingo在广泛使用的CARLA模拟器上的Bench2Drive基准测试中获得了最先进的性能,并在CARLA挑战2024中获得了第一名。此外,我们在多种语言相关任务中取得了强劲的结果,同时保持了高驾驶性能。
论文及项目相关链接
PDF CVPR 2025. 1st Place @ CARLA Challenge 2024. Challenge tech report (preliminary version of SimLingo): arXiv:2406.10165
Summary
大型语言模型(LLM)在自动驾驶中的应用已经引起了广泛关注,有助于提高通用性和可解释性。然而,现有方法常常集中在驾驶或视觉语言理解方面,实现高驾驶性能和广泛的语言理解仍然具有挑战性。为此,本文提出了一种可以处理三种不同任务(闭环驾驶、视觉语言理解和语言行为对齐)的模型SimLingo。该模型基于视觉语言模型(VLM),仅使用相机工作,不使用昂贵的传感器如激光雷达。SimLingo在广泛使用的CARLA模拟器上的Bench2Drive基准测试中取得了最新性能,并在CARLA挑战赛中获得了第一名。同时,该模型在各种语言相关任务中也取得了显著成果,同时保持了较高的驾驶性能。
Key Takeaways
- 大型语言模型(LLM)在自动驾驶中的集成旨在提高通用性和可解释性。
- 当前方法在实现高驾驶性能和广泛的语言理解方面存在挑战。
- SimLingo模型能够处理闭环驾驶、视觉语言理解和语言行为对齐三种任务。
- SimLingo基于视觉语言模型(VLM),仅使用相机,不使用昂贵的传感器。
- SimLingo在CARLA模拟器的Bench2Drive基准测试中取得了最新性能。
- SimLingo在CARLA挑战赛中获得了第一名。
点此查看论文截图

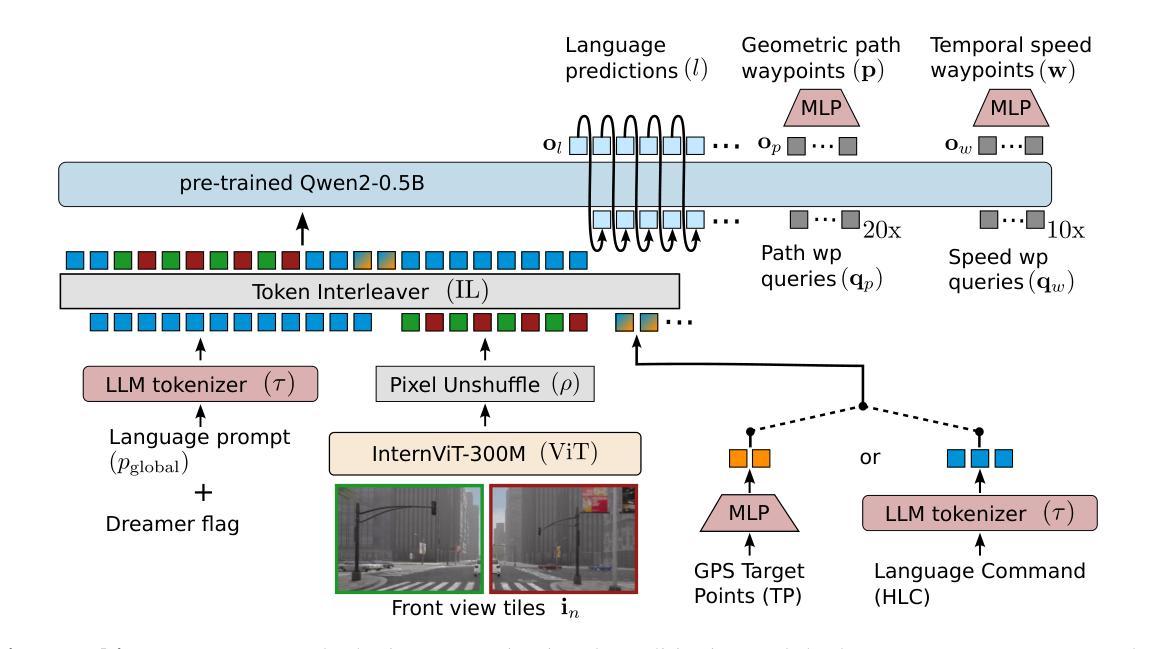

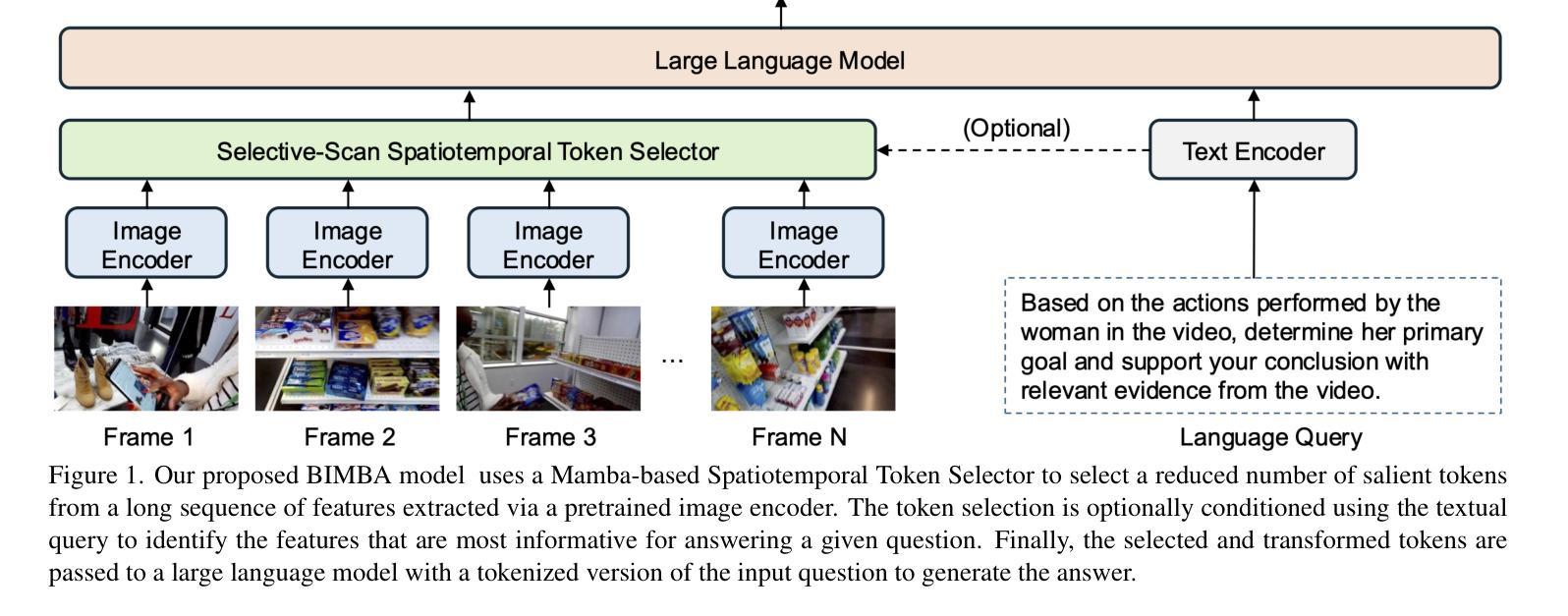
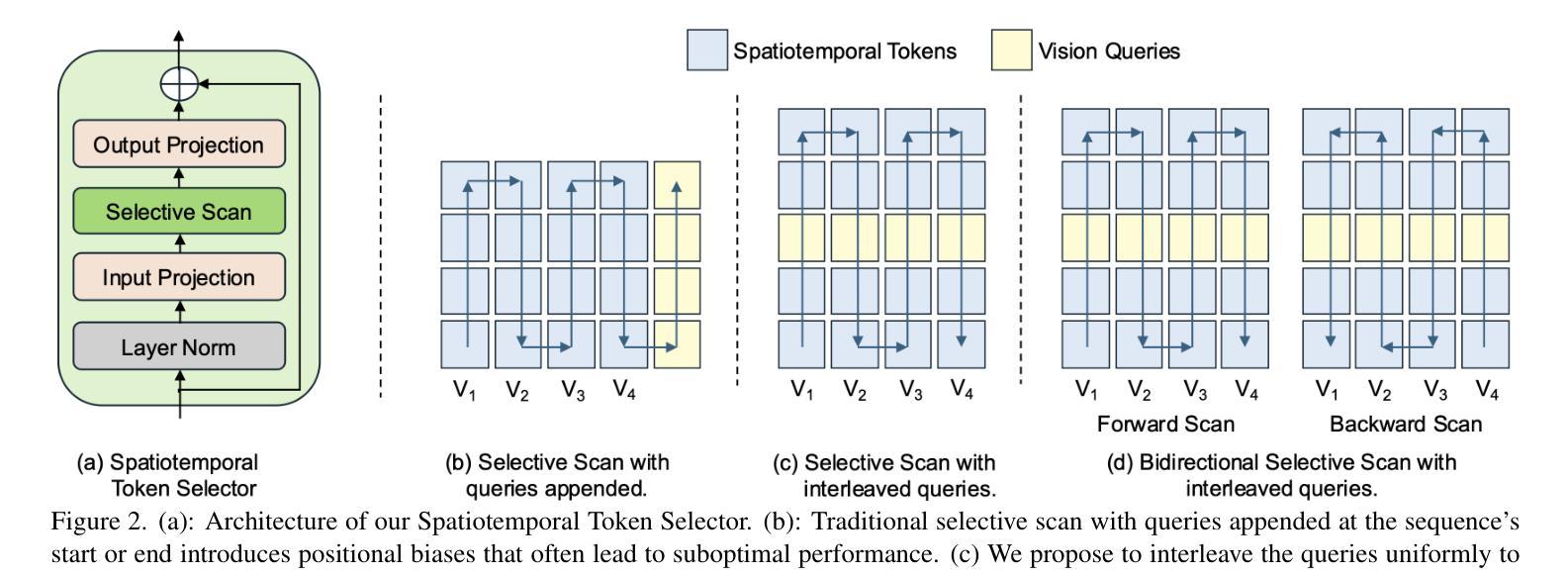
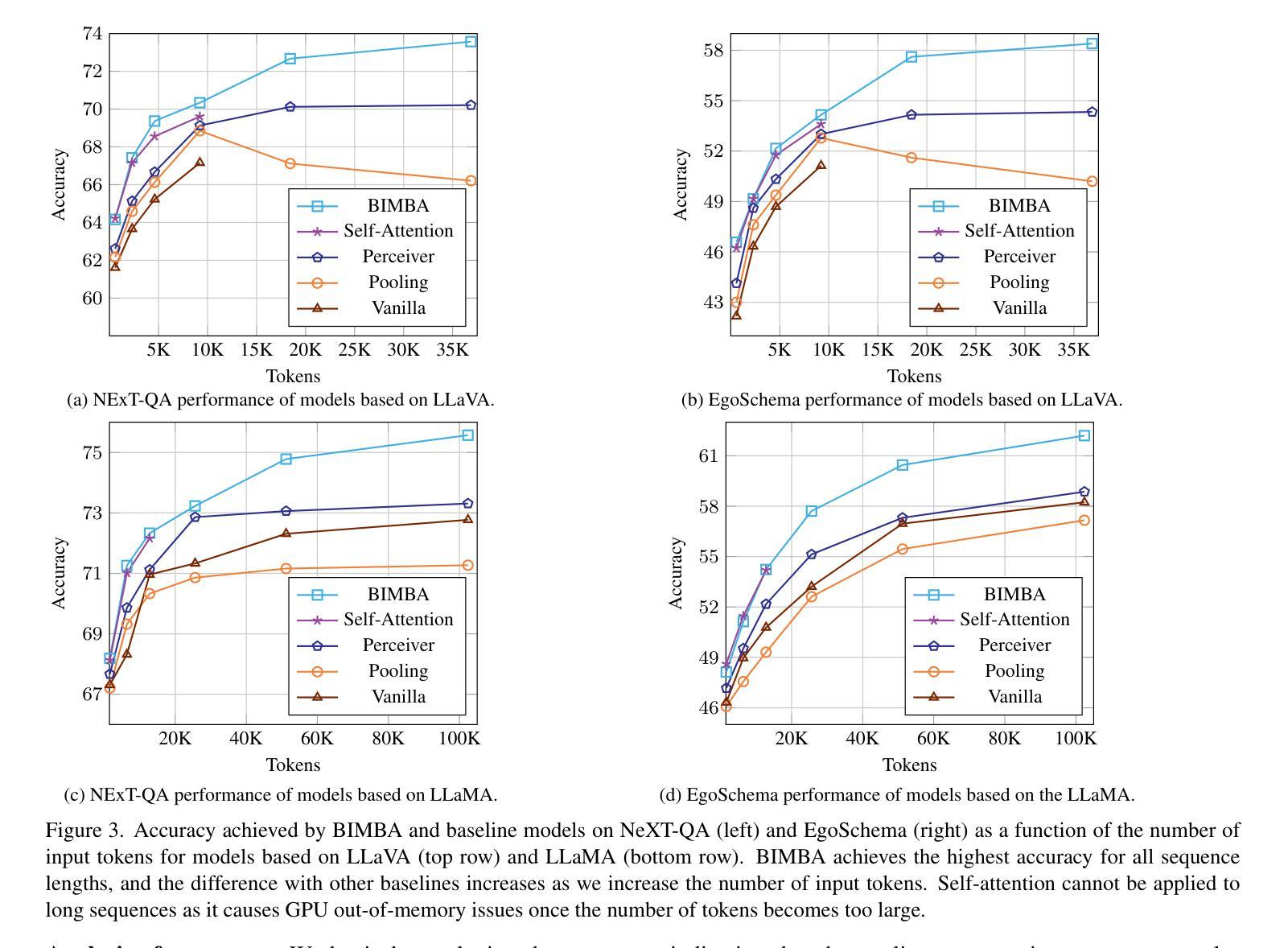
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Authors:Md Mohaiminul Islam, Tushar Nagarajan, Huiyu Wang, Gedas Bertasius, Lorenzo Torresani
Video Question Answering (VQA) in long videos poses the key challenge of extracting relevant information and modeling long-range dependencies from many redundant frames. The self-attention mechanism provides a general solution for sequence modeling, but it has a prohibitive cost when applied to a massive number of spatiotemporal tokens in long videos. Most prior methods rely on compression strategies to lower the computational cost, such as reducing the input length via sparse frame sampling or compressing the output sequence passed to the large language model (LLM) via space-time pooling. However, these naive approaches over-represent redundant information and often miss salient events or fast-occurring space-time patterns. In this work, we introduce BIMBA, an efficient state-space model to handle long-form videos. Our model leverages the selective scan algorithm to learn to effectively select critical information from high-dimensional video and transform it into a reduced token sequence for efficient LLM processing. Extensive experiments demonstrate that BIMBA achieves state-of-the-art accuracy on multiple long-form VQA benchmarks, including PerceptionTest, NExT-QA, EgoSchema, VNBench, LongVideoBench, and Video-MME. Code, and models are publicly available at https://sites.google.com/view/bimba-mllm.
视频问答(VQA)在长视频中面临的关键挑战是从大量冗余帧中提取相关信息并对长距离依赖进行建模。自注意力机制为序列建模提供了一般解决方案,但当应用于长视频中大量时空令牌时,其成本是巨大的。大多数先前的方法依赖于压缩策略来降低计算成本,例如通过稀疏帧采样减少输入长度,或通过时空池化压缩传递给大型语言模型(LLM)的输出序列。然而,这些简单的方法过度代表了冗余信息,并且经常错过重要事件或快速发生的时空模式。在这项工作中,我们引入了BIMBA,一种用于处理长格式视频的高效状态空间模型。我们的模型利用选择性扫描算法来学习从高维视频中选择关键信息并将其转换为减少的令牌序列以进行高效的LLM处理。大量实验表明,BIMBA在多个长格式VQA基准测试中实现了最先进的准确性,包括PerceptionTest、NExT-QA、EgoSchema、VNBench、LongVideoBench和视频MME。代码和模型可在https://sites.google.com/view/bimba-mllm公开访问。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文主要介绍了针对长视频中的视频问题回答(VQA)挑战,提出了一种新的高效状态空间模型BIMBA。该模型利用选择性扫描算法从高维视频中选择关键信息,并将其转换为减少的令牌序列,以便高效的大型语言模型处理。实验表明,BIMBA在多个长格式VQA基准测试中实现了最先进的准确性。
Key Takeaways
- VQA在长视频上面临提取相关信息和建模长范围依赖性的关键挑战。
- 自注意力机制为序列建模提供了通用解决方案,但应用于长视频的众多时空令牌时计算成本高昂。
- 之前的策略如稀疏帧采样和时空池化以降低计算成本,但可能过度代表冗余信息并错过重要事件或快速发生的时空模式。
- BIMBA模型是一个高效的状态空间模型,用于处理长格式视频。
- BIMBA利用选择性扫描算法从高维视频中选择关键信息。
- BIMBA在多个长格式VQA基准测试中实现了最先进的准确性。
点此查看论文截图

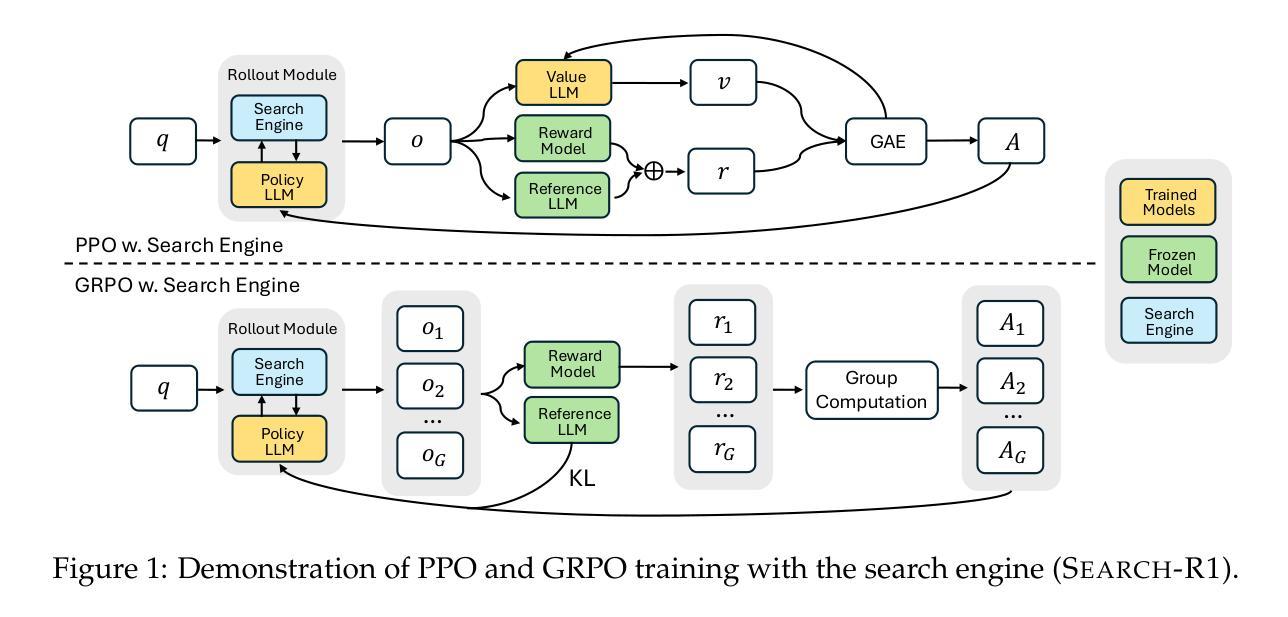
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Authors:Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, Jiawei Han
Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Retrieval augmentation and tool-use training approaches where a search engine is treated as a tool lack complex multi-turn retrieval flexibility or require large-scale supervised data. Prompting advanced LLMs with reasoning capabilities during inference to use search engines is not optimal, since the LLM does not learn how to optimally interact with the search engine. This paper introduces Search-R1, an extension of the DeepSeek-R1 model where the LLM learns – solely through reinforcement learning (RL) – to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM rollouts with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 26% (Qwen2.5-7B), 21% (Qwen2.5-3B), and 10% (LLaMA3.2-3B) over SOTA baselines. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.
在大规模语言模型(LLM)中进行有效的推理和文本生成,获取外部知识和最新信息是关键。尽管检索增强和工具使用训练的方法将搜索引擎视为工具,但它们在复杂的多轮检索灵活性方面有所不足或需要大量监督数据。在推理过程中提示具有推理能力的先进LLM使用搜索引擎并不理想,因为LLM并没有学习如何最优地与搜索引擎进行交互。本文介绍了Search-R1,它是DeepSeek-R1模型的扩展,其中LLM通过强化学习(RL)自主学习,在逐步推理过程中自主生成(多个)搜索查询并进行实时检索。Search-R1通过多轮搜索交互优化LLM的滚动操作,利用检索令牌屏蔽进行稳定的RL训练和一个简单的基于结果奖励函数。在七个问答数据集上的实验表明,Search-R1相较于最先进基线提高了26%(Qwen2.5-7B)、21%(Qwen2.5-3B)和10%(LLaMA3.2-3B)的性能。本文还深入探讨了强化学习优化方法、LLM选择和检索增强推理中的响应长度动态。代码和模型检查点可访问于:https://github.com/PeterGriffinJin/Search-R1。
论文及项目相关链接
PDF 16 pages
Summary
本论文提出Search-R1模型,该模型是大规模语言模型(LLM)的一种扩展,通过强化学习(RL)自主学习在实时检索中进行多轮搜索查询。Search-R1优化了LLM的推理过程,通过多轮搜索交互、检索到的令牌掩码用于稳定的RL训练以及简单的结果导向奖励函数来实现。实验结果显示,Search-R1在七个问答数据集上的性能较现有技术提高了26%(Qwen2.5-7B)、21%(Qwen2.5-3B)和10%(LLaMA3.2-3B)。同时,本论文还对RL优化方法、LLM选择和响应长度动态等进行了实证分析。代码和模型检查点可在指定网址下载。
Key Takeaways
- Search-R1模型是LLM的一种扩展,采用强化学习(RL)自主学习进行多轮搜索查询。
- 该模型通过实时检索、多轮搜索交互等方式优化LLM推理过程。
- Search-R1通过检索到的令牌掩码实现稳定的RL训练。
- 该模型采用简单的结果导向奖励函数。
- 实验结果显示,Search-R1在多个问答数据集上的性能显著提升。
- 本论文提供了关于RL优化方法、LLM选择和响应长度动态的实证分析。
点此查看论文截图

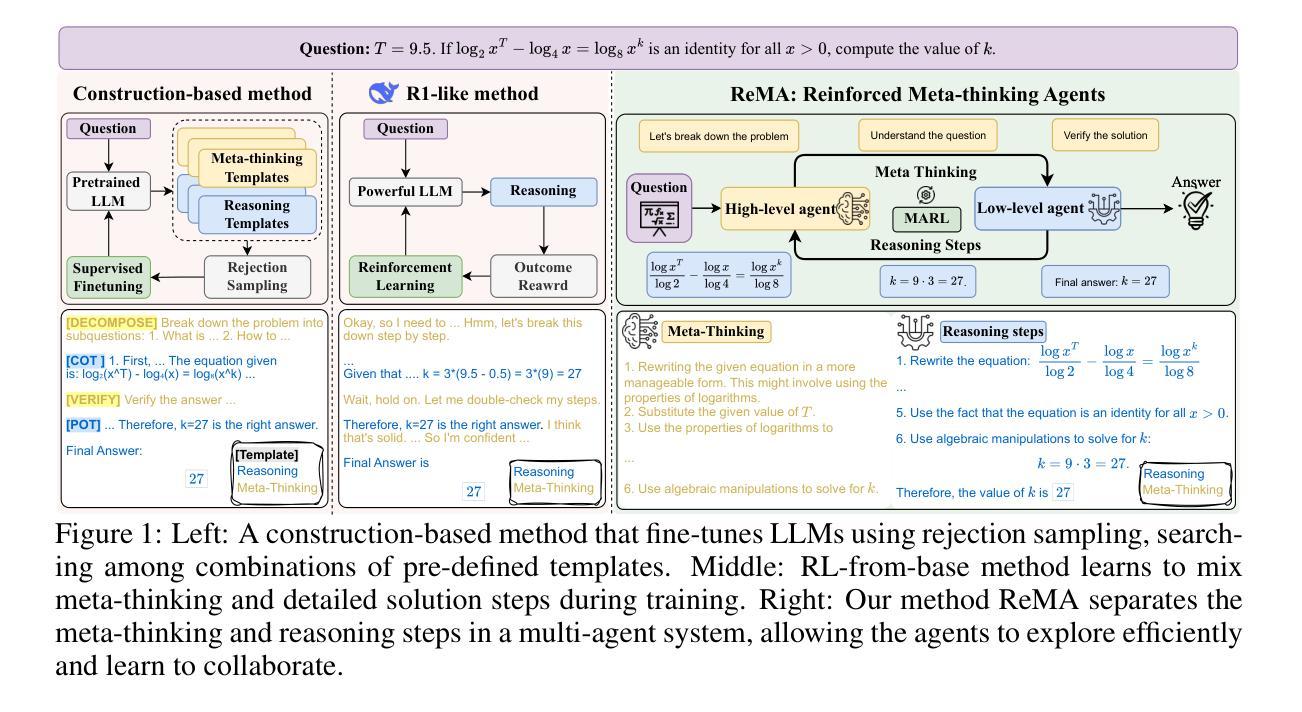
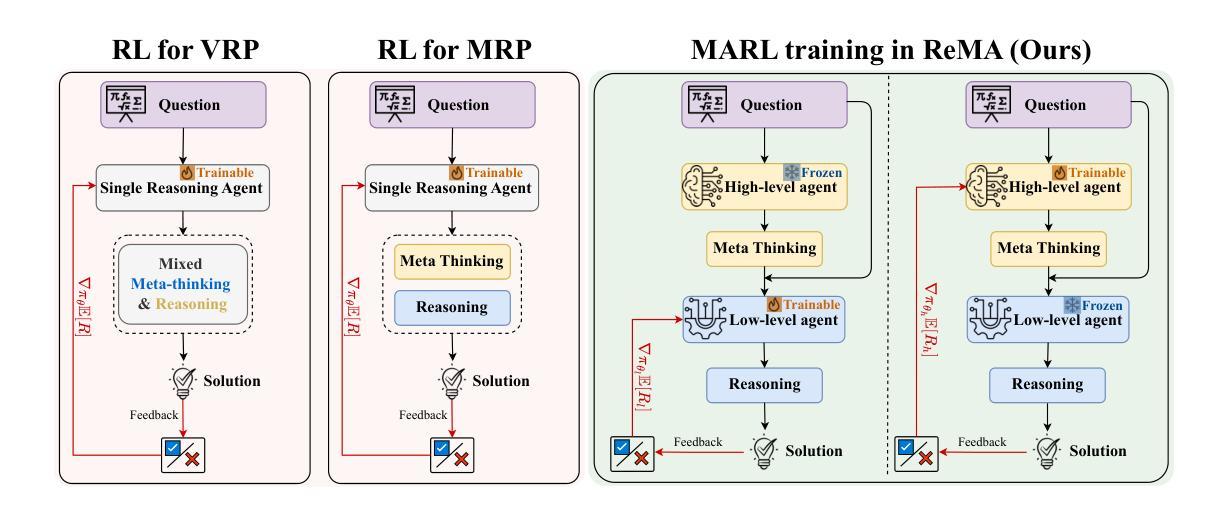
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Authors:Ziyu Wan, Yunxiang Li, Yan Song, Hanjing Wang, Linyi Yang, Mark Schmidt, Jun Wang, Weinan Zhang, Shuyue Hu, Ying Wen
Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking – enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.
近期关于大语言模型(LLM)推理的研究,旨在通过融入元思维来进一步提升其性能。元思维能够让模型监控、评估和控制系统自身的推理过程,从而实现更加适应性和高效的问题解决。然而,现有的单智能体研究缺乏获取元思维的专门设计,导致效果不佳。为解决这一挑战,我们提出了强化元思维智能体(ReMA)这一新型框架,利用多智能体强化学习(MARL)来激发元思维行为,鼓励LLM进行反思性思考。ReMA将推理过程解耦为两个层次化的智能体:一个高层次的元思维智能体,负责生成战略性监督和计划;一个低层次的推理智能体,负责详细执行。通过目标一致的迭代强化学习,这些智能体探索和学习协作,实现了更好的泛化能力和稳健性。实验结果表明,ReMA在复杂的推理任务上超越了单智能体RL基准测试,包括竞争级别的数学基准测试和LLM作为法官的基准测试。全面的消融研究进一步说明了每个独特智能体的动态演化过程,为元思维推理过程如何增强LLM的推理能力提供了宝贵的见解。
论文及项目相关链接
Summary
大型语言模型(LLM)引入元思维以增强其性能,但现有单一模型设计在获取元思维方面存在局限性。为此,我们提出强化元思维代理(ReMA)框架,利用多代理强化学习(MARL)激发元思维行为。ReMA将推理过程分为两个层次代理:高级元思维代理负责战略监督与计划,低级推理代理负责详细执行。通过目标对齐的迭代强化学习,这些代理能够探索与协作,从而提高泛化与稳健性。实验结果显示,ReMA在复杂推理任务上优于单一代理RL基线,包括竞争性数学基准测试和LLM作为法官的基准测试。
Key Takeaways
- LLM引入元思维以增强性能,面临单一模型设计获取元思维的局限性。
- 提出ReMA框架,利用MARL激发元思维行为。
- ReMA将推理过程分为高级元思维代理和低级推理代理。
- 通过目标对齐的迭代强化学习,代理能够探索与协作。
- ReMA在复杂推理任务上表现优越,包括数学和LLM判断任务。
- 消融研究展示了不同代理在元思维推理过程中的动态变化。
- 元思维增强LLM的推理能力。
点此查看论文截图

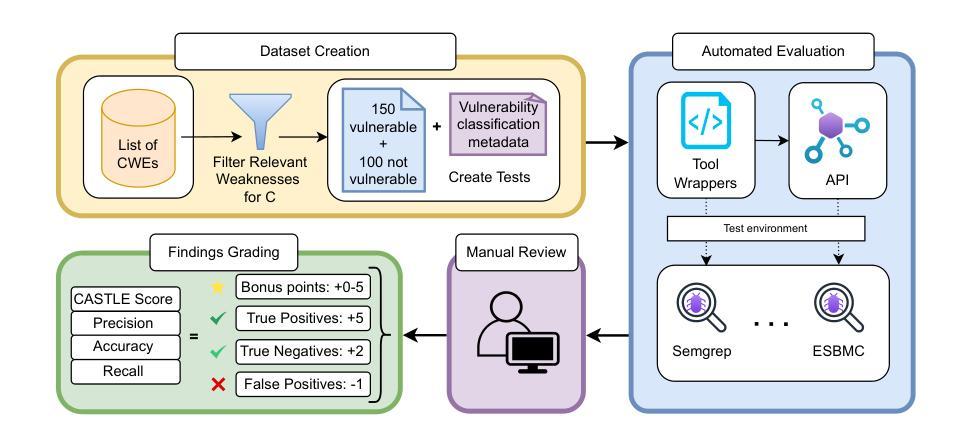
CASTLE: Benchmarking Dataset for Static Code Analyzers and LLMs towards CWE Detection
Authors:Richard A. Dubniczky, Krisztofer Zoltán Horvát, Tamás Bisztray, Mohamed Amine Ferrag, Lucas C. Cordeiro, Norbert Tihanyi
Identifying vulnerabilities in source code is crucial, especially in critical software components. Existing methods such as static analysis, dynamic analysis, formal verification, and recently Large Language Models are widely used to detect security flaws. This paper introduces CASTLE (CWE Automated Security Testing and Low-Level Evaluation), a benchmarking framework for evaluating the vulnerability detection capabilities of different methods. We assess 13 static analysis tools, 10 LLMs, and 2 formal verification tools using a hand-crafted dataset of 250 micro-benchmark programs covering 25 common CWEs. We propose the CASTLE Score, a novel evaluation metric to ensure fair comparison. Our results reveal key differences: ESBMC (a formal verification tool) minimizes false positives but struggles with vulnerabilities beyond model checking, such as weak cryptography or SQL injection. Static analyzers suffer from high false positives, increasing manual validation efforts for developers. LLMs perform exceptionally well in the CASTLE dataset when identifying vulnerabilities in small code snippets. However, their accuracy declines, and hallucinations increase as the code size grows. These results suggest that LLMs could play a pivotal role in future security solutions, particularly within code completion frameworks, where they can provide real-time guidance to prevent vulnerabilities. The dataset is accessible at https://github.com/CASTLE-Benchmark.
识别源代码中的漏洞至关重要,特别是在关键软件组件中。现有的方法,如静态分析、动态分析、形式化验证和最近出现的大型语言模型,被广泛用于检测安全漏洞。本文介绍了CASTLE(CWE自动化安全测试和低级评估),这是一个用于评估不同方法漏洞检测能力的基准测试框架。我们使用包含25个常见CWE的250个手工制作的小型基准程序数据集,评估了13种静态分析工具、1LLM和2种形式化验证工具。我们提出了CASTLE分数,一种新的评估指标,以确保公平比较。我们的结果表明了关键差异:ESBMC(一种形式化验证工具)虽然能最小化误报,但在模型检查之外的漏洞,如弱加密或SQL注入等方面存在困难。静态分析器存在较高的误报率,增加了开发者的手动验证工作。大型语言模型在CASTLE数据集中表现优异,特别是在识别小代码片段中的漏洞方面。然而,随着代码量的增长,其准确性会下降,幻觉现象也会增多。这些结果表明,大型语言模型在未来的安全解决方案中可能会发挥关键作用,特别是在代码补全框架中,它们可以提供实时指导以防止漏洞。数据集可在https://github.com/CASTLE-Benchmark上获取。
论文及项目相关链接
Summary:
本文介绍了一个名为CASTLE的基准测试框架,用于评估源代码漏洞检测工具的性能。通过对多种静态分析工具、大型语言模型和形式验证工具的综合评估,发现不同工具在检测不同种类的公共弱点方面具有显著区别。大型语言模型在处理小型代码片段时表现良好,但随着代码量的增长,其准确性下降,出现更多的误判。本文结果对未来安全解决方案中的大型语言模型角色有重要影响。
Key Takeaways:
- CASTLE框架用于评估源代码漏洞检测工具的性能。
- 评估了多种静态分析工具、大型语言模型和形式验证工具。
- 发现形式验证工具ESBMC在减少误报方面表现良好,但在检测某些特定漏洞方面存在困难。
- 静态分析工具虽然会出现高误报率,增加了开发者的手动验证工作负担。
- 大型语言模型在处理小型代码片段时表现出良好的识别漏洞能力,但随着代码规模的增大,其准确性下降,产生更多的幻觉结果。
- 大型语言模型在未来安全解决方案中可能扮演重要角色,特别是在代码补全框架中提供实时指导以防止漏洞。
点此查看论文截图


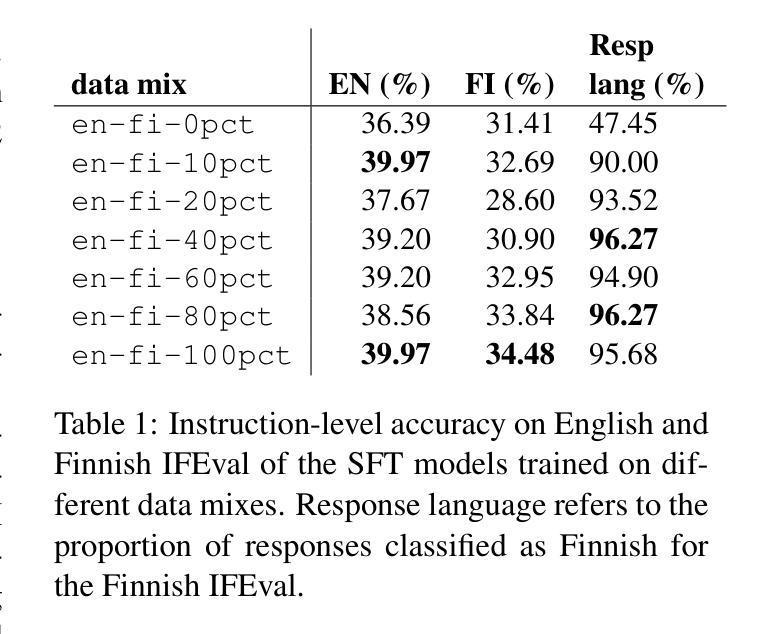
Got Compute, but No Data: Lessons From Post-training a Finnish LLM
Authors:Elaine Zosa, Ville Komulainen, Sampo Pyysalo
As LLMs gain more popularity as chatbots and general assistants, methods have been developed to enable LLMs to follow instructions and align with human preferences. These methods have found success in the field, but their effectiveness has not been demonstrated outside of high-resource languages. In this work, we discuss our experiences in post-training an LLM for instruction-following for English and Finnish. We use a multilingual LLM to translate instruction and preference datasets from English to Finnish. We perform instruction tuning and preference optimization in English and Finnish and evaluate the instruction-following capabilities of the model in both languages. Our results show that with a few hundred Finnish instruction samples we can obtain competitive performance in Finnish instruction-following. We also found that although preference optimization in English offers some cross-lingual benefits, we obtain our best results by using preference data from both languages. We release our model, datasets, and recipes under open licenses at https://huggingface.co/LumiOpen/Poro-34B-chat-OpenAssistant
随着大型语言模型(LLM)在聊天机器人和通用助理中越来越受欢迎,已经开发了一些方法使LLM能够遵循指令并与人类偏好保持一致。这些方法在该领域已经取得了成功,但它们在非高资源语言环境中的有效性尚未得到证明。在这项工作中,我们分享了我们在为英语和芬兰语进行指令遵循训练大型语言模型后的经验。我们使用一种多语言的大型语言模型,将指令和偏好数据集从英语翻译成芬兰语。我们在英语和芬兰语中进行指令调整和偏好优化,并评估了该模型在这两种语言中的指令遵循能力。我们的结果表明,只需几百个芬兰语指令样本,我们就可以在芬兰语的指令遵循方面取得具有竞争力的性能。我们还发现,尽管英语中的偏好优化提供了一些跨语言的好处,但我们通过使用两种语言的偏好数据获得了最佳结果。我们在https://huggingface.co/LumiOpen/Poro-34B-chat-OpenAssistant下以开放许可证发布我们的模型、数据集和配方。
论文及项目相关链接
PDF 7 pages
Summary
本摘要介绍LLM在自然语言处理中的应用及其所面临的挑战,特别是如何适应人类偏好。通过对英文和芬兰语的训练数据和模型的评估结果进行了讨论,表明LLM能够遵循指令并具有跨文化能力。最佳实践是使用两种语言的偏好数据,并且仅通过数百个芬兰指令样本即可获得具有竞争力的性能。
Key Takeaways
- LLMs在聊天机器人和通用助理方面日益普及,开发人员为此开发出能使LLM遵循指令和适应人类偏好的方法。这些方法已经在高资源语言领域表现出其效果,但在其他语言领域尚未得到验证。
- 通过使用多语言LLM将指令和偏好数据集从英语翻译成芬兰语,实现了对英语的训练和优化后,对模型在芬兰语中的指令遵循能力进行了评估。结果显示少量芬兰语指令样本就能获得具有竞争力的性能。
- 虽然英语偏好优化提供了一些跨语言优势,但使用两种语言的偏好数据才能获得最佳结果。这表明LLM的性能可以通过适应多种语言的偏好数据来进一步提高。
点此查看论文截图


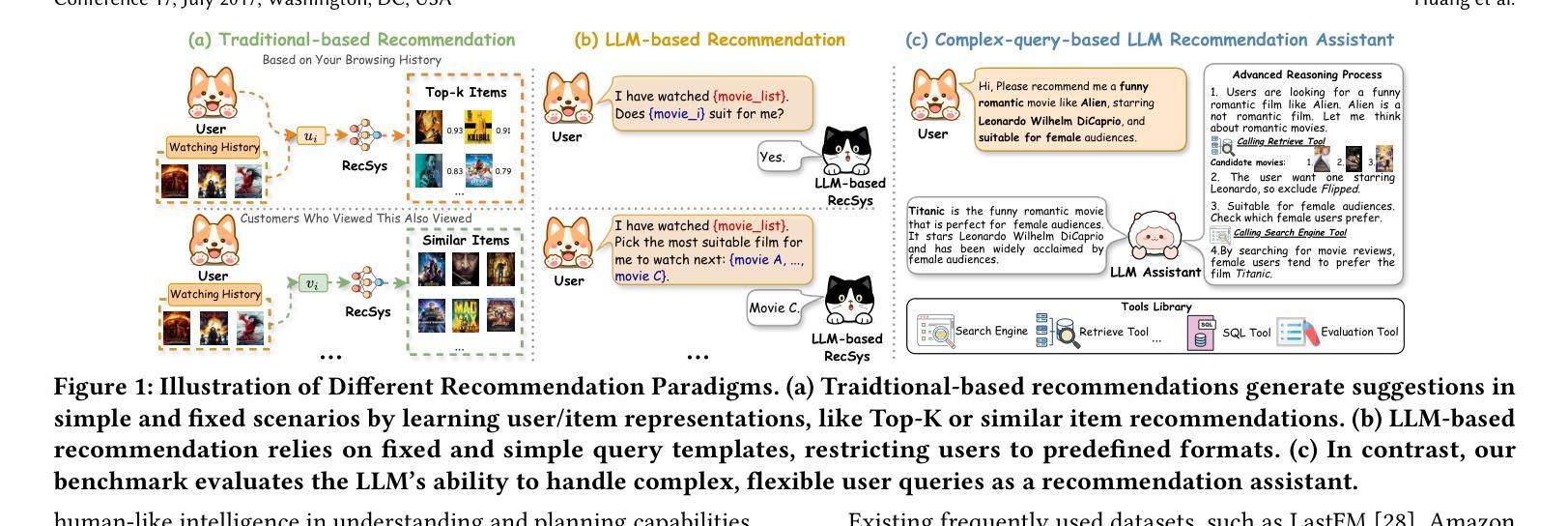
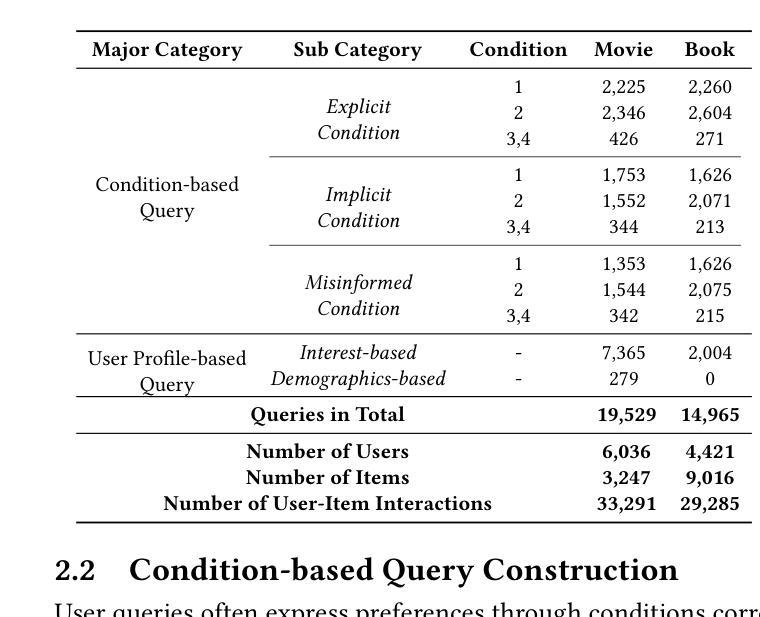
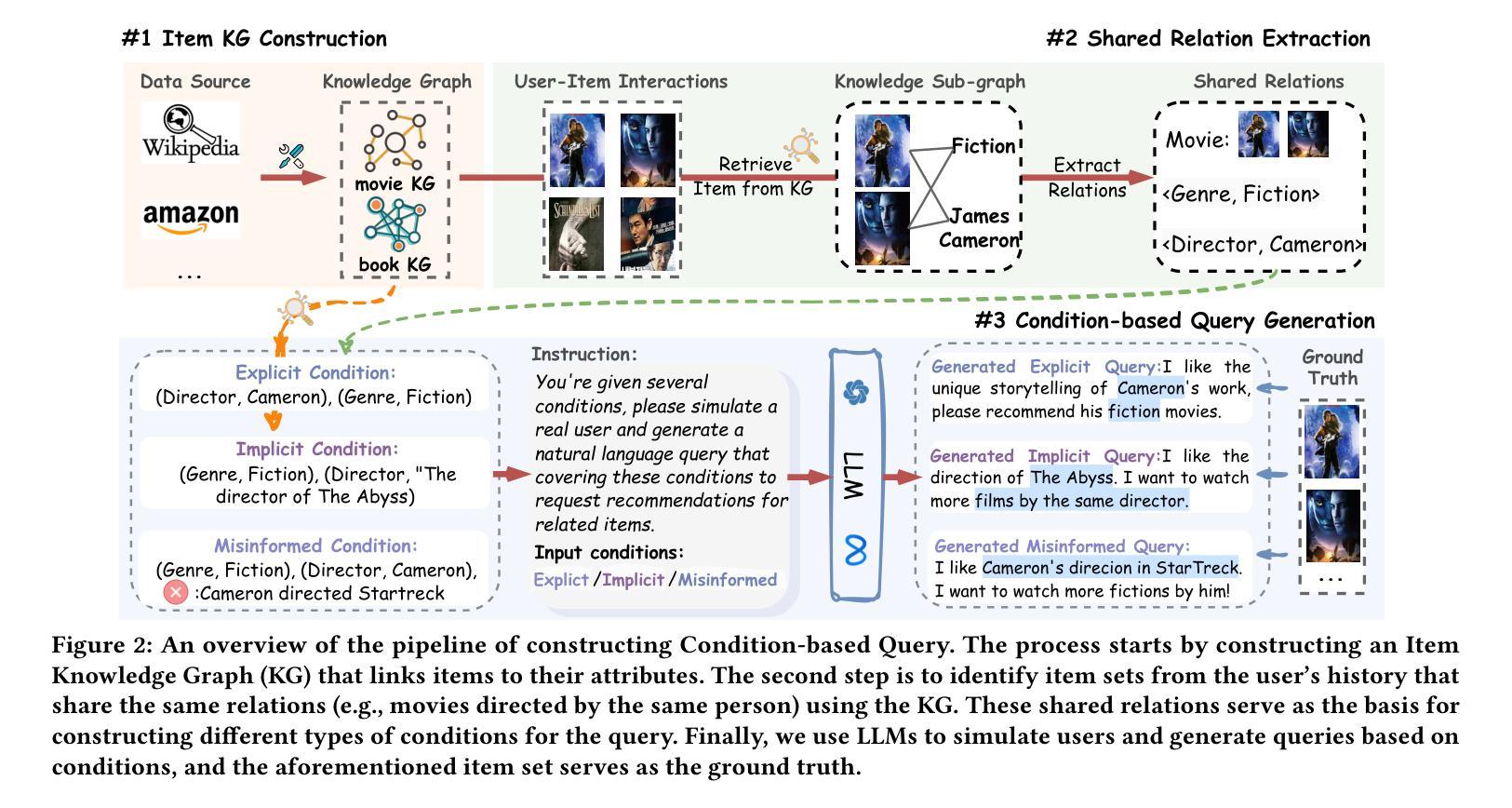
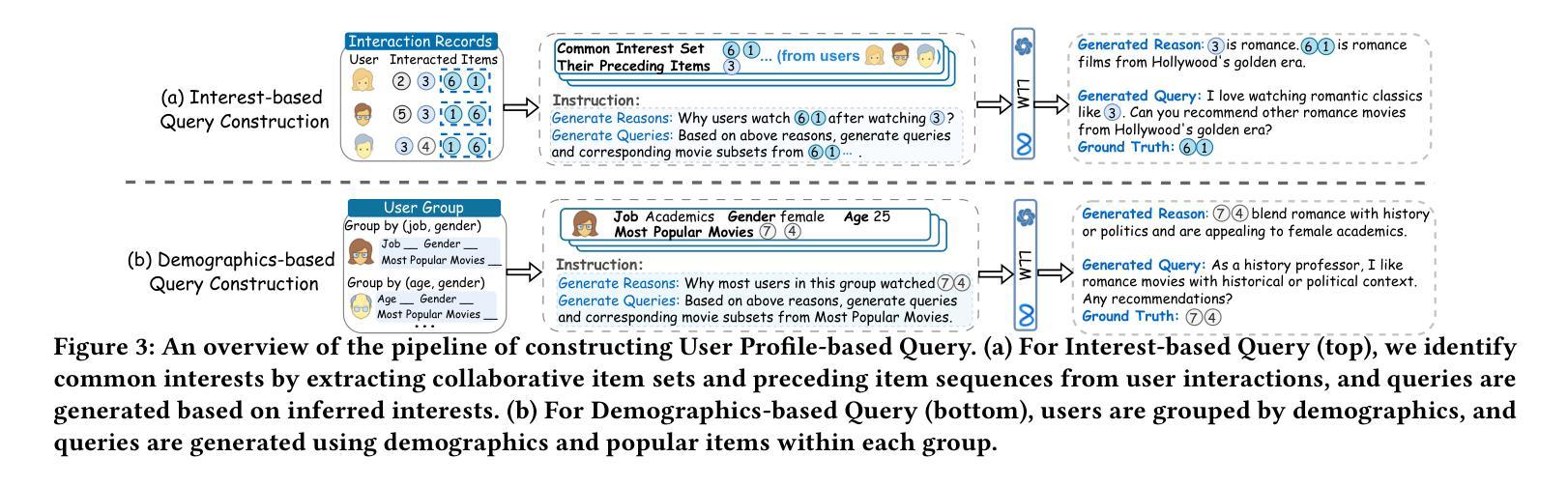
Towards Next-Generation Recommender Systems: A Benchmark for Personalized Recommendation Assistant with LLMs
Authors:Jiani Huang, Shijie Wang, Liang-bo Ning, Wenqi Fan, Shuaiqiang Wang, Dawei Yin, Qing Li
Recommender systems (RecSys) are widely used across various modern digital platforms and have garnered significant attention. Traditional recommender systems usually focus only on fixed and simple recommendation scenarios, making it difficult to generalize to new and unseen recommendation tasks in an interactive paradigm. Recently, the advancement of large language models (LLMs) has revolutionized the foundational architecture of RecSys, driving their evolution into more intelligent and interactive personalized recommendation assistants. However, most existing studies rely on fixed task-specific prompt templates to generate recommendations and evaluate the performance of personalized assistants, which limits the comprehensive assessments of their capabilities. This is because commonly used datasets lack high-quality textual user queries that reflect real-world recommendation scenarios, making them unsuitable for evaluating LLM-based personalized recommendation assistants. To address this gap, we introduce RecBench+, a new dataset benchmark designed to access LLMs’ ability to handle intricate user recommendation needs in the era of LLMs. RecBench+ encompasses a diverse set of queries that span both hard conditions and soft preferences, with varying difficulty levels. We evaluated commonly used LLMs on RecBench+ and uncovered below findings: 1) LLMs demonstrate preliminary abilities to act as recommendation assistants, 2) LLMs are better at handling queries with explicitly stated conditions, while facing challenges with queries that require reasoning or contain misleading information. Our dataset has been released at https://github.com/jiani-huang/RecBench.git.
推荐系统(RecSys)在现代各种数字平台上得到广泛应用,并引起了广泛关注。传统的推荐系统通常只关注固定和简单的推荐场景,难以推广到交互式范式中的新和未见过的推荐任务。最近,大型语言模型(LLM)的进展彻底改变了RecSys的基础架构,推动其进化为更智能、更交互的个性化推荐助手。然而,大多数现有研究依赖于固定的任务特定提示模板来生成推荐并评估个性化助手的性能,这限制了对其能力的全面评估。这是因为常用的数据集缺乏反映真实世界推荐场景的高质量文本用户查询,因此不适合评估基于LLM的个性化推荐助手。为了弥补这一差距,我们推出了RecBench +,这是一个新的数据集基准,旨在评估LLM时代LLM处理复杂的用户推荐需求的能力。RecBench+包含涵盖硬条件和软偏好以及不同难度级别的各种查询。我们在RecBench+上对常用的LLM进行了评估,并发现了以下发现:1)LLM初步具备作为推荐助手的能力;2)LLM在处理明确陈述的条件查询时表现较好,而在需要推理或包含误导信息的查询时面临挑战。我们的数据集已在https://github.com/jiani-huang/RecBench.git发布。
论文及项目相关链接
Summary
该文介绍了推荐系统(RecSys)在现代数字平台中的广泛应用,并指出传统推荐系统在新兴的互动型推荐任务上存在着局限性。随着大型语言模型(LLMs)的发展,推荐系统正朝着智能化和个性化方向发展。然而,现有的研究大多依赖于固定的任务特定提示模板来生成推荐并评估个性化助理的性能,这限制了对其能力的全面评估。为此,文章引入了一个新的数据集基准测试RecBench+,旨在评估LLM在复杂用户推荐需求方面的能力。RecBench+包含了不同难度层次的查询,既涵盖硬条件也涵盖软偏好。对常用的LLMs在RecBench+上的评估发现,LLMs有初步作为推荐助理的能力,在处理明确条件的查询时表现较好,但在需要推理或含有误导信息的查询时面临挑战。
Key Takeaways
- 推荐系统(RecSys)在现代数字平台中广泛应用,但传统系统在处理新兴互动型推荐任务时存在局限性。
- 大型语言模型(LLMs)的发展推动了推荐系统的智能化和个性化发展。
- 现有研究依赖固定任务特定提示模板来评估个性化助理的性能,这限制了全面评估。
- 引入新的数据集基准测试RecBench+,旨在评估LLM在复杂用户推荐需求上的能力。
- RecBench+包含了涵盖硬条件和软偏好的不同难度层次的查询。
- LLMs有初步作为推荐助理的能力。
点此查看论文截图

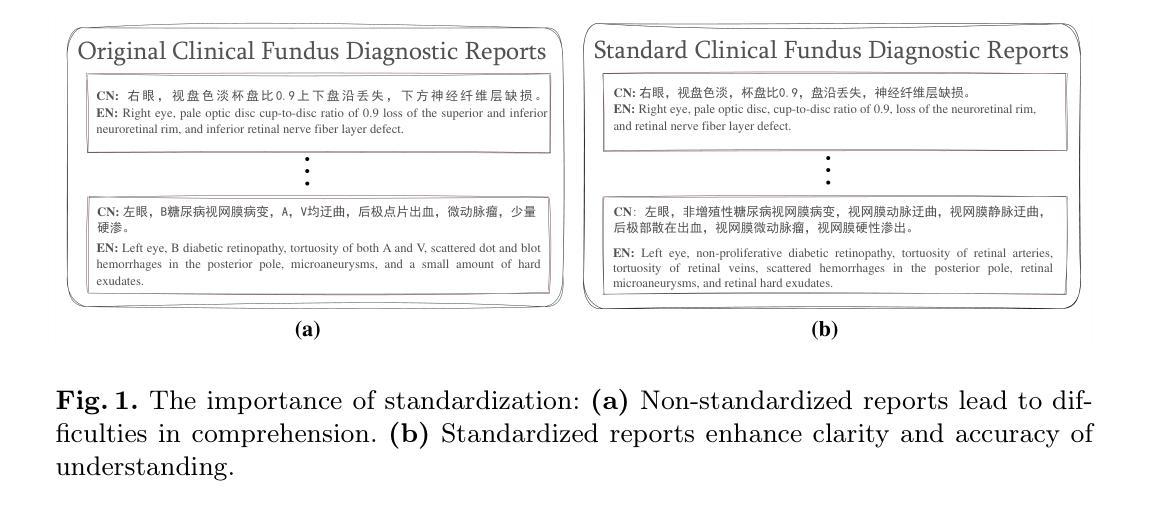
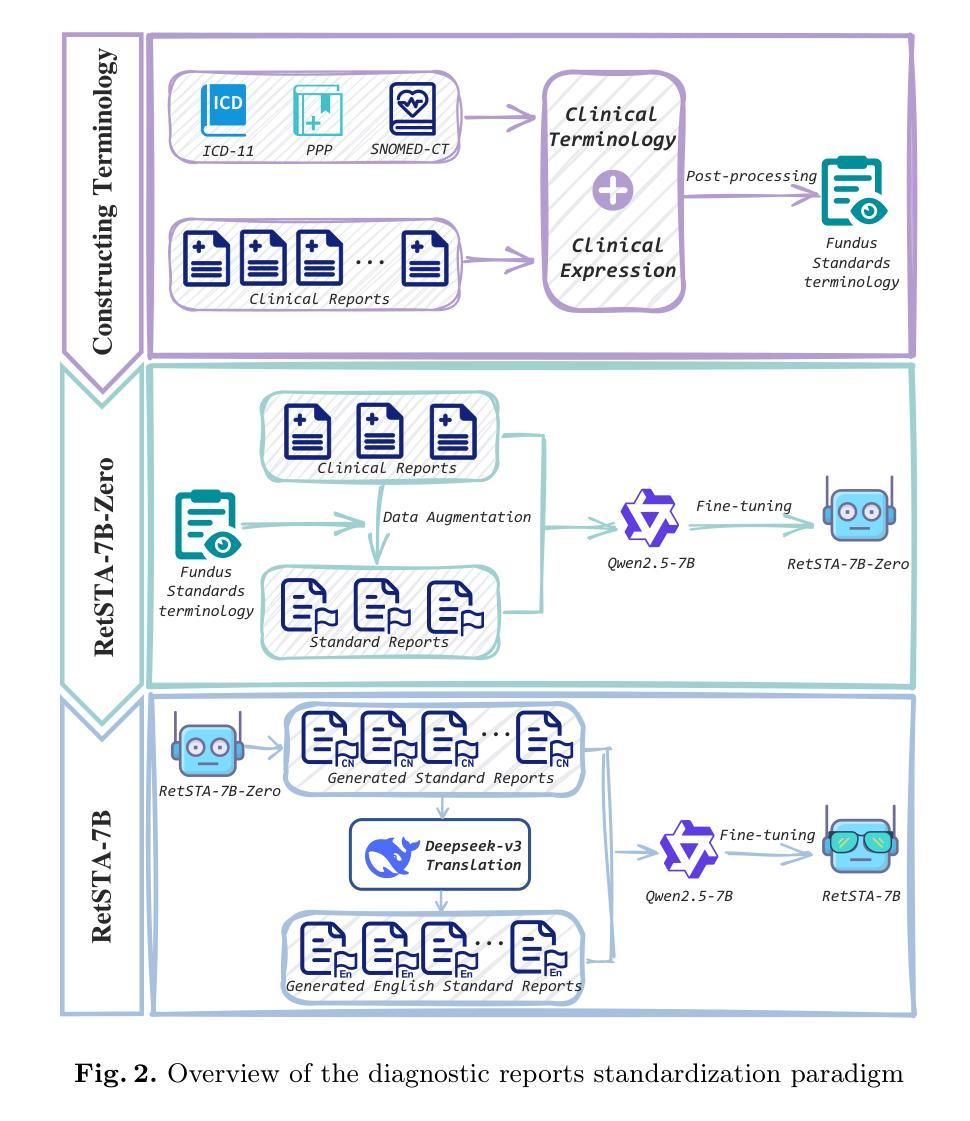
RetSTA: An LLM-Based Approach for Standardizing Clinical Fundus Image Reports
Authors:Jiushen Cai, Weihang Zhang, Hanruo Liu, Ningli Wang, Huiqi Li
Standardization of clinical reports is crucial for improving the quality of healthcare and facilitating data integration. The lack of unified standards, including format, terminology, and style, is a great challenge in clinical fundus diagnostic reports, which increases the difficulty for large language models (LLMs) to understand the data. To address this, we construct a bilingual standard terminology, containing fundus clinical terms and commonly used descriptions in clinical diagnosis. Then, we establish two models, RetSTA-7B-Zero and RetSTA-7B. RetSTA-7B-Zero, fine-tuned on an augmented dataset simulating clinical scenarios, demonstrates powerful standardization behaviors. However, it encounters a challenge of limitation to cover a wider range of diseases. To further enhance standardization performance, we build RetSTA-7B, which integrates a substantial amount of standardized data generated by RetSTA-7B-Zero along with corresponding English data, covering diverse complex clinical scenarios and achieving report-level standardization for the first time. Experimental results demonstrate that RetSTA-7B outperforms other compared LLMs in bilingual standardization task, which validates its superior performance and generalizability. The checkpoints are available at https://github.com/AB-Story/RetSTA-7B.
临床报告的标准化对于提高医疗保健质量并促进数据整合至关重要。在临床眼底诊断报告中,由于缺乏统一的格式、术语和风格等标准,存在巨大的挑战。这给大型语言模型(LLM)理解数据增加了难度。为了解决这个问题,我们构建了一个双语标准术语集,包含眼底临床术语和临床诊断中常用的描述。接着,我们建立了两个模型,即RetSTA-7B-Zero和RetSTA-7B。RetSTA-7B-Zero在模拟临床场景的增强数据集上进行微调,表现出强大的标准化行为。然而,它在覆盖更广泛的疾病方面遇到了挑战。为了进一步提高标准化性能,我们构建了RetSTA-7B,它集成了由RetSTA-7B-Zero生成的标准化数据以及相应的英语数据,覆盖多种复杂的临床场景,首次实现了报告级别的标准化。实验结果表明,RetSTA-7B在双语标准化任务上优于其他比较的大型语言模型,验证了其卓越的性能和通用性。相关关键点代码可在以下网址找到:https://github.com/AB-Story/RetSTA-7B。
论文及项目相关链接
Summary
临床报告标准化对于提高医疗保健质量和促进数据整合至关重要。缺乏统一的标准,包括格式、术语和风格,是临床眼底诊断报告中的一个巨大挑战,这也增加了大型语言模型(LLM)理解数据的难度。为解决这一问题,我们构建了一个包含眼底临床术语和临床诊断中常用描述的双语标准术语。随后,我们建立了两个模型:RetSTA-7B-Zero和RetSTA-7B。RetSTA-7B-Zero在模拟临床场景的增强数据集上进行微调,表现出强大的标准化行为,但覆盖的疾病范围有限。为进一步增强标准化性能,我们构建了RetSTA-7B,集成了由RetSTA-7B-Zero生成的标准化数据及其对应的英文数据,覆盖多种复杂的临床场景,首次实现了报告级别的标准化。实验结果表明,RetSTA-7B在双语标准化任务上的表现优于其他对比的LLM,验证了其卓越的性能和泛化能力。
Key Takeaways
- 临床报告标准化对医疗保健质量的提高和数据整合的促进具有关键作用。
- 缺乏统一的标准,如格式、术语和风格,是临床眼底诊断报告的主要挑战之一。
3.双语标准术语的创建是解决这一挑战的重要步骤,包含了眼底临床术语和临床诊断中的常用描述。 - RetSTA-7B-Zero模型展示了强大的标准化能力,但在疾病覆盖范围上有所限制。
- RetSTA-7B模型通过集成大量标准化数据,扩展了疾病覆盖范围,并首次实现了报告级别的标准化。
- 实验结果证明RetSTA-7B在双语标准化任务上的表现优于其他LLM。
点此查看论文截图

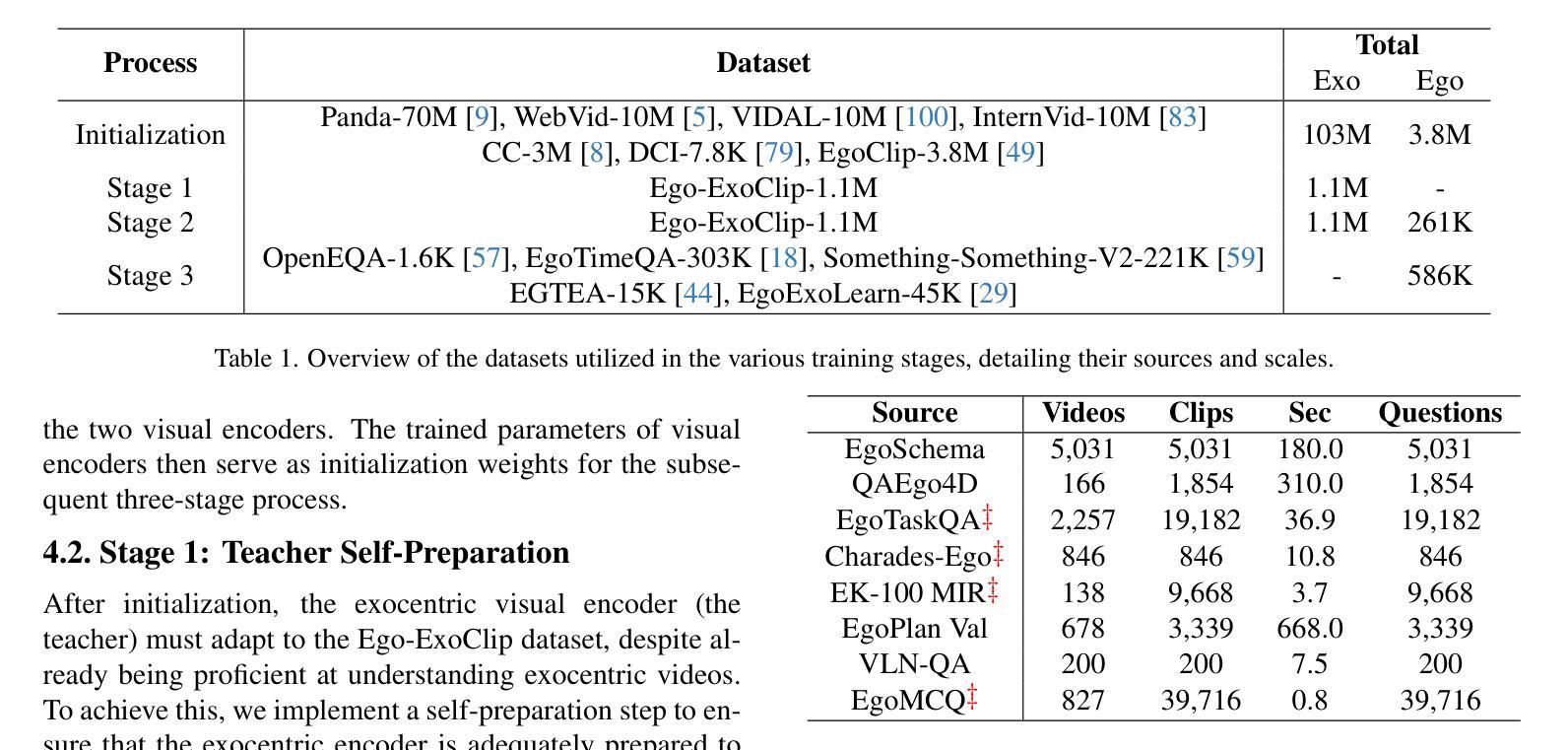
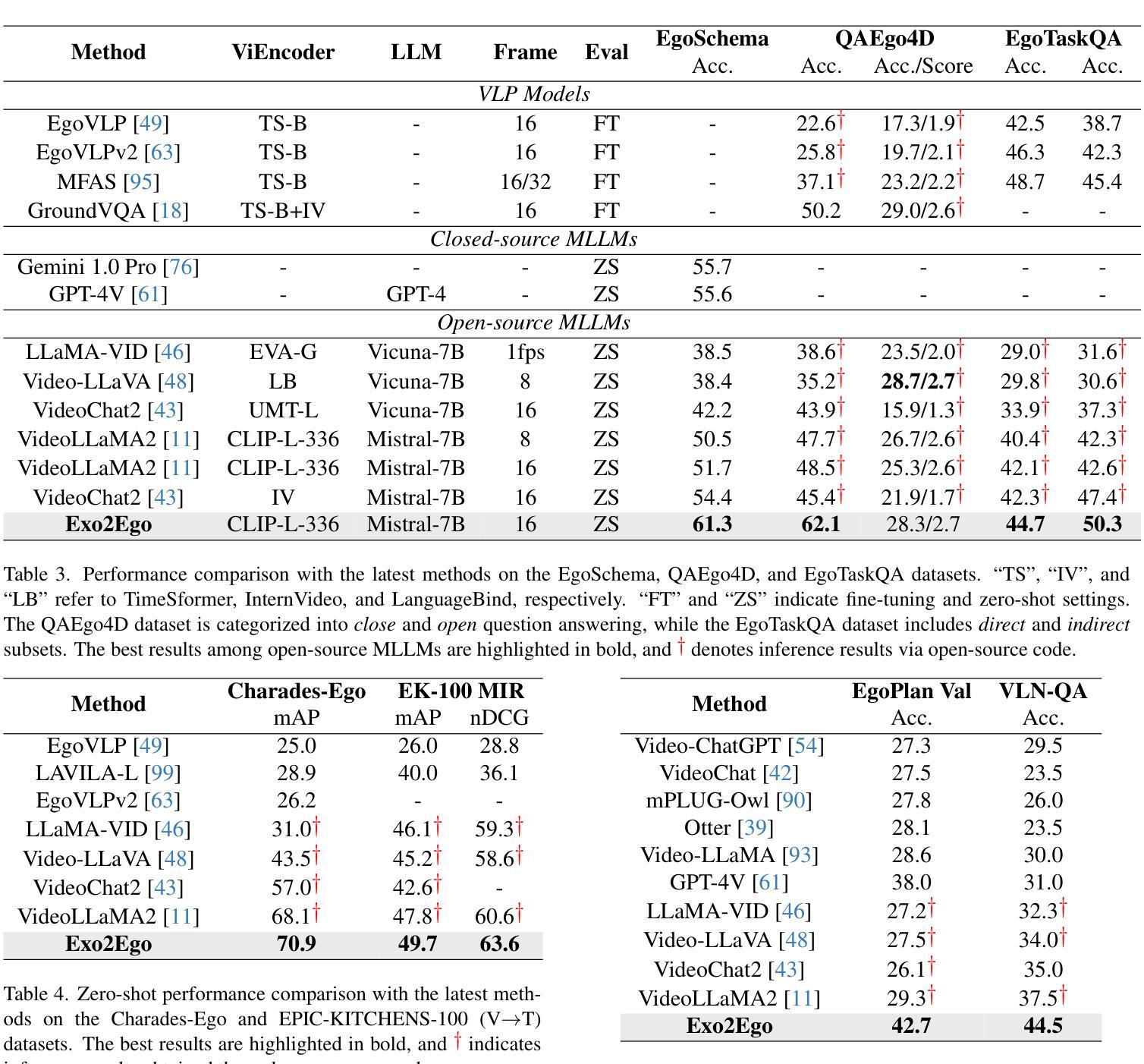
Exo2Ego: Exocentric Knowledge Guided MLLM for Egocentric Video Understanding
Authors:Haoyu Zhang, Qiaohui Chu, Meng Liu, Yunxiao Wang, Bin Wen, Fan Yang, Tingting Gao, Di Zhang, Yaowei Wang, Liqiang Nie
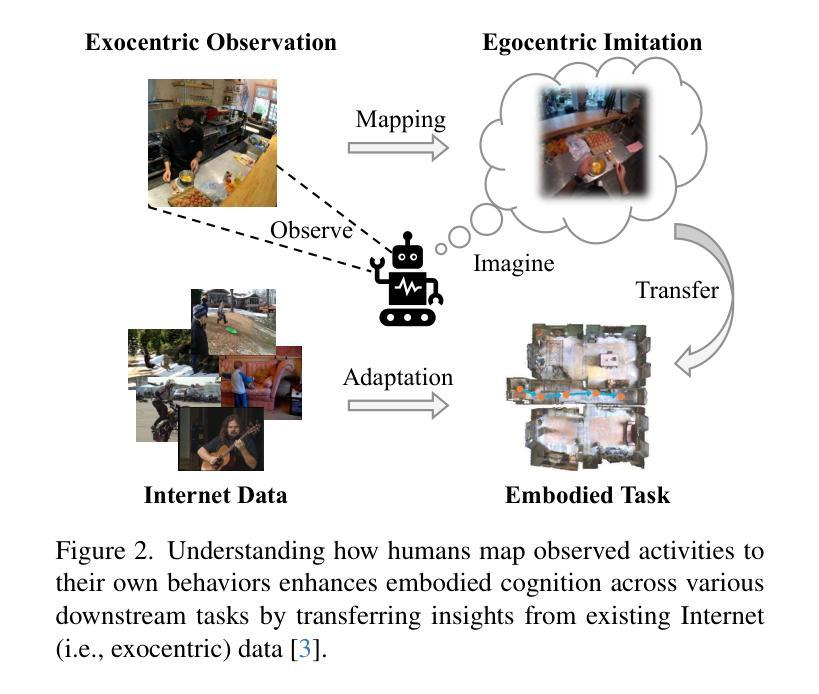
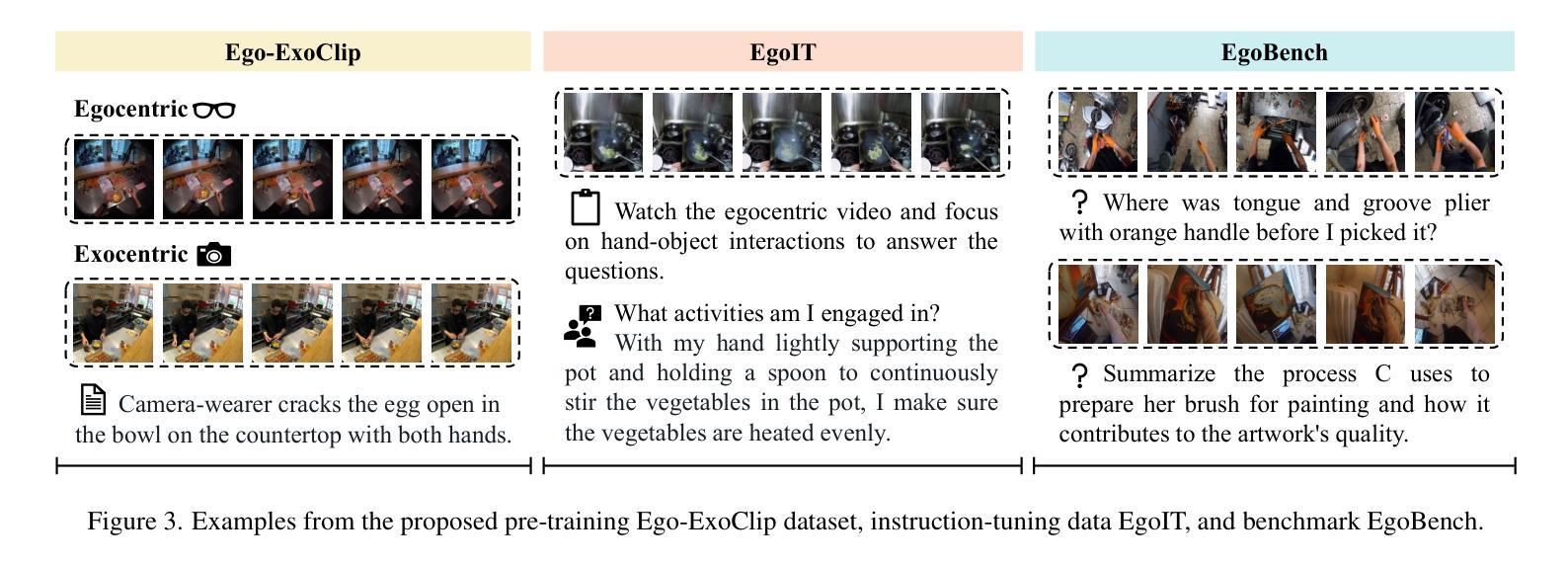
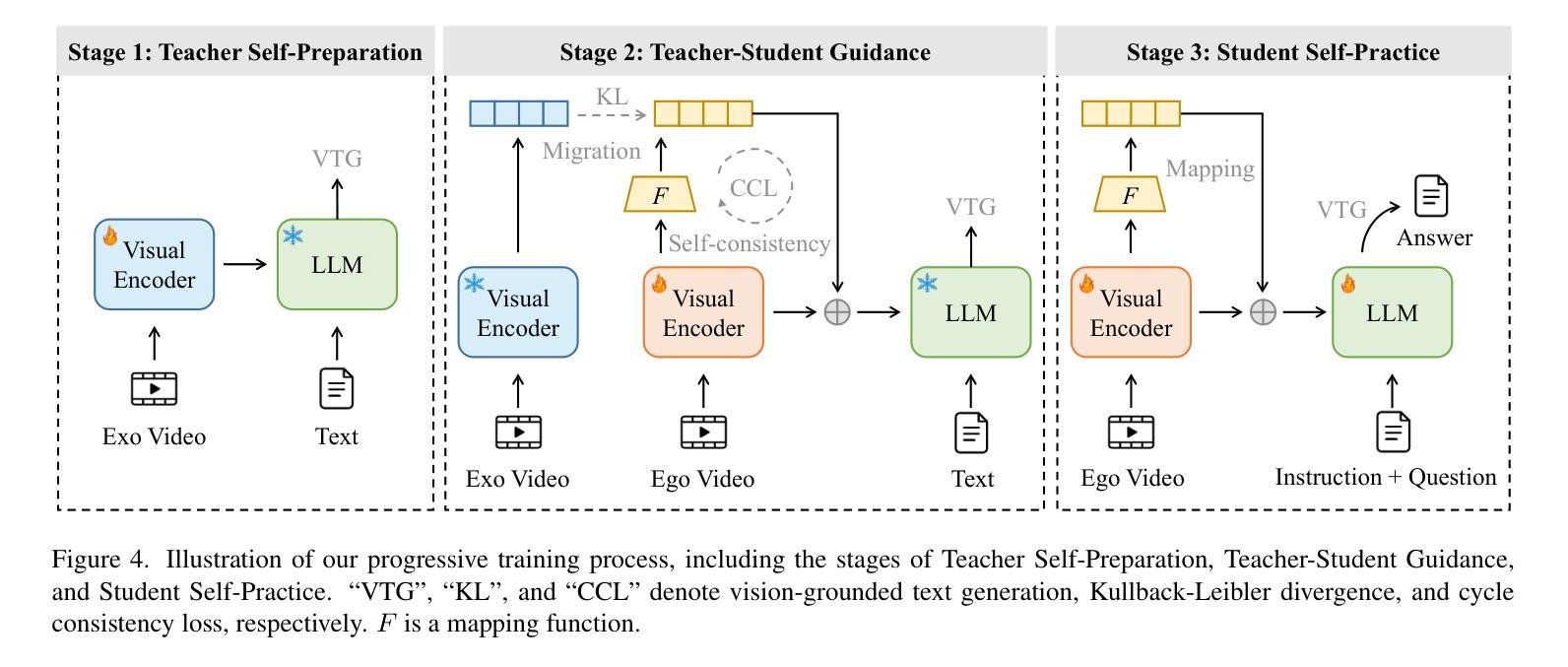
AI personal assistants, deployed through robots or wearables, require embodied understanding to collaborate effectively with humans. Current Multimodal Large Language Models (MLLMs) primarily focus on third-person (exocentric) vision, overlooking the unique aspects of first-person (egocentric) videos. Additionally, high acquisition costs limit data size, impairing MLLM performance. To address these challenges, we propose learning the mapping between exocentric and egocentric domains, leveraging the extensive exocentric knowledge within existing MLLMs to enhance egocentric video understanding. To this end, we introduce Ego-ExoClip, a pre-training dataset comprising 1.1M synchronized ego-exo clip-text pairs derived from Ego-Exo4D. Our approach features a progressive training pipeline with three stages: Teacher Self-Preparation, Teacher-Student Guidance, and Student Self-Practice. Additionally, we propose an instruction-tuning data EgoIT from multiple sources to strengthen the model’s instruction-following capabilities, along with the EgoBench benchmark comprising eight different tasks for thorough evaluation. Extensive experiments across diverse egocentric tasks reveal that existing MLLMs perform inadequately in egocentric video understanding, while our model significantly outperforms these leading models.
通过机器人或可穿戴设备部署的人工智能个人助理,需要实体理解才能与人类有效协作。当前的多模态大型语言模型(MLLM)主要关注第三人称(外视)视角,忽略了第一人称(内视)视频的独特方面。此外,高昂的采集成本限制了数据量,影响了MLLM的性能。为了应对这些挑战,我们提出了学习外视和内视领域之间的映射关系,利用现有MLLM中的大量外视知识来增强对内视视频的理解。为此,我们引入了Ego-ExoClip预训练数据集,包含从Ego-Exo4D派生的110万同步的ego-exo剪辑文本对。我们的方法采用分阶段训练管道,包括三个阶段:教师自我准备、教师学生指导和学生自我实践。此外,我们从多个来源提出了用于加强模型指令跟随能力的指令调整数据EgoIT,以及包含八个不同任务的EgoBench基准测试集进行全面评估。在多种第一人称任务的广泛实验表明,现有的MLLM在内视视频理解方面表现不佳,而我们的模型显著优于这些领先模型。
论文及项目相关链接
PDF Project: https://egovisiongroup.github.io/Exo2Ego.github.io/
Summary
机器人或可穿戴设备上的AI个人助理需要身体感知来与人类有效协作。当前的多模态大型语言模型(MLLM)主要关注第三人称视角(外部视角)的视野,忽略了第一人称视角(内部视角)的独特性。此外,高昂的采集成本限制了数据量,影响了MLLM的性能。为解决这些挑战,本文提出了学习外部视角和内部视角领域之间的映射关系的方法,利用现有的MLLM中的外部视角知识增强内部视角视频的理解能力。为此,引入了Ego-ExoClip预训练数据集,包含从Ego-Exo4D派生的110万同步自我外部剪辑文本对。我们的方法采用分阶段训练管道,包括教师自我准备、教师学生指导和学生自我实践三个阶段。此外,还提出了来自多个来源的指令调整数据EgoIT,以加强模型的指令执行能力,以及包含八个不同任务的EgoBench基准测试用于全面评估。大量实验表明,现有MLLM在内部视角视频理解方面表现不足,而我们的模型显著优于这些领先模型。
Key Takeaways
- AI个人助理需要身体感知来与人类协作。
- 当前MLLM主要关注第三人称视角(外部视角),忽略第一人称视角(内部视角)。
- 数据采集成本高限制了MLLM的性能提升。
- 提出学习外部视角和内部视角领域映射的方法。
- 引入Ego-ExoClip预训练数据集用于增强内部视角视频理解能力。
- 采用分阶段训练管道来提升模型性能。
点此查看论文截图

Teaching LLMs How to Learn with Contextual Fine-Tuning
Authors:Younwoo Choi, Muhammad Adil Asif, Ziwen Han, John Willes, Rahul G. Krishnan
Prompting Large Language Models (LLMs), or providing context on the expected model of operation, is an effective way to steer the outputs of such models to satisfy human desiderata after they have been trained. But in rapidly evolving domains, there is often need to fine-tune LLMs to improve either the kind of knowledge in their memory or their abilities to perform open ended reasoning in new domains. When human’s learn new concepts, we often do so by linking the new material that we are studying to concepts we have already learned before. To that end, we ask, “can prompting help us teach LLMs how to learn”. In this work, we study a novel generalization of instruction tuning, called contextual fine-tuning, to fine-tune LLMs. Our method leverages instructional prompts designed to mimic human cognitive strategies in learning and problem-solving to guide the learning process during training, aiming to improve the model’s interpretation and understanding of domain-specific knowledge. We empirically demonstrate that this simple yet effective modification improves the ability of LLMs to be fine-tuned rapidly on new datasets both within the medical and financial domains.
提示大型语言模型(LLM)或提供预期的模型操作上下文,是引导此类模型的输出以满足人类需求的有效方法,这些模型在训练后。但在快速发展的领域中,通常需要微调LLM,以改善其内存中的知识类型或在新的领域进行开放式推理的能力。当人类学习新概念时,我们常常通过把我们正在研究的新材料与之前已经学过的概念联系起来来学习。为此,我们提出的问题是:“提示能否帮助我们教会LLM如何学习”。在这项工作中,我们研究了一种指令微调的新泛化方法,称为上下文微调,以微调LLM。我们的方法利用指令提示来模仿人类在学习和解决问题中的认知策略,以指导训练过程中的学习过程,旨在提高模型对特定领域知识的解释和理解能力。我们从实证上证明,这种简单而有效的改进提高了LLM在新数据集上的快速微调能力,无论是在医疗领域还是金融领域。
论文及项目相关链接
PDF ICLR 2025
Summary
通过对大型语言模型(LLMs)进行提示或提供操作预期模型上下文,可以有效引导模型训练后的输出以满足人类的需求。然而,在快速发展的领域中,往往需要微调LLM,以提高其记忆中的知识或在新领域进行开放式推理的能力。本文研究了一种名为“上下文微调”的新型指令微调方法,通过设计模仿人类学习和问题解决认知策略的指令提示来指导学习过程,旨在提高模型对特定领域知识的理解和解释能力。实验证明,这种简单而有效的方法能够改进LLM在新数据集上的快速微调能力,尤其是在医疗和金融领域。
Key Takeaways
- 通过提示大型语言模型(LLMs)可有效引导模型输出以满足人类需求。
- 在快速发展的领域中,需要微调LLM以适应新知识和新领域。
- 上下文微调是一种新型的指令微调方法,通过设计模仿人类学习和问题解决认知策略的指令提示来指导学习过程。
- 上下文微调方法旨在提高模型对特定领域知识的理解和解释能力。
- 上下文微调能够改进LLM在新数据集上的快速微调能力。
- 这种方法在医疗和金融领域取得了实证效果。
点此查看论文截图


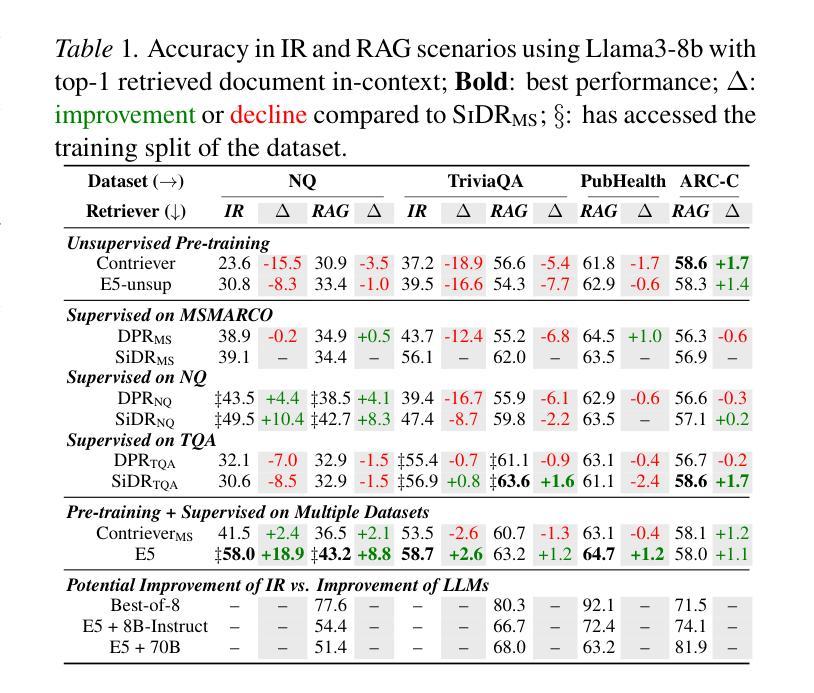
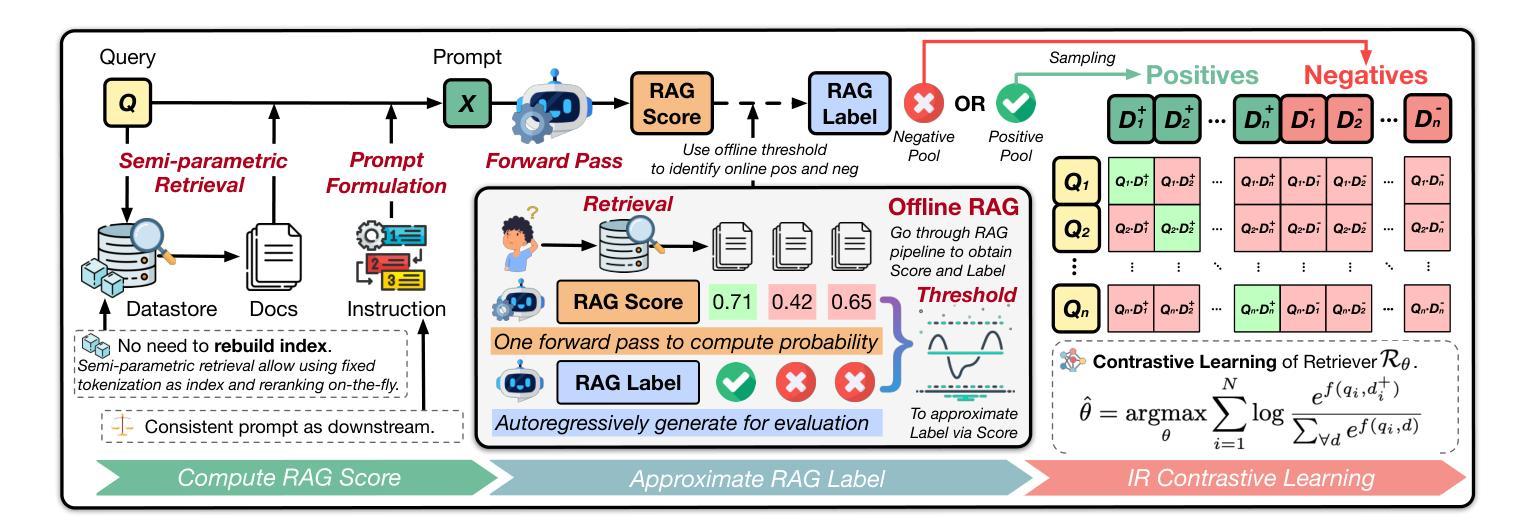
OpenRAG: Optimizing RAG End-to-End via In-Context Retrieval Learning
Authors:Jiawei Zhou, Lei Chen
In this paper, we analyze and empirically show that the learned relevance for conventional information retrieval (IR) scenarios may be inconsistent in retrieval-augmented generation (RAG) scenarios. To bridge this gap, we introduce OpenRAG, a RAG framework that is optimized end-to-end by tuning the retriever to capture in-context relevance, enabling adaptation to the diverse and evolving needs. Extensive experiments across a wide range of tasks demonstrate that OpenRAG, by tuning a retriever end-to-end, leads to a consistent improvement of 4.0% over the original retriever, consistently outperforming existing state-of-the-art retrievers by 2.1%. Additionally, our results indicate that for some tasks, an end-to-end tuned 0.2B retriever can achieve improvements that surpass those of RAG-oriented or instruction-tuned 8B large language models (LLMs), highlighting the cost-effectiveness of our approach in enhancing RAG systems.
本文分析和实证表明,传统信息检索(IR)场景中学习的相关性可能在检索增强生成(RAG)场景中不一致。为了弥合这一差距,我们引入了OpenRAG,这是一个通过调整检索器来捕获上下文相关性的端到端优化的RAG框架,能够适应多样且不断发展的需求。在多个任务上的广泛实验表明,通过端到端调整检索器,OpenRAG在原始检索器的基础上实现了4.0%的持续改进,并且始终优于现有的最先进的检索器,领先了2.1%。此外,我们的结果表明,对于某些任务,端到端调整的0.2B检索器的改进甚至超过了面向RAG或指令调整的8B大型语言模型(LLM),这突显了我们方法在增强RAG系统中的成本效益。
论文及项目相关链接
Summary
本文提出并分析传统的信息检索场景在检索增强生成(RAG)场景中可能存在的不一致性。为了弥补这一差距,引入了OpenRAG框架,通过端到端优化检索器来捕捉上下文相关性,适应多样化和不断发展的需求。实验证明,OpenRAG相较于原始检索器有4.0%的一致性提升,相较于现有的先进检索器有2.1%的提升。此外,对于某些任务,端到端优化的较小规模检索器的改进甚至超过了面向RAG或指令优化的超大规模语言模型(LLM),突显了增强RAG系统成本效益的优势。
Key Takeaways
- 传统的信息检索场景在检索增强生成(RAG)场景中可能存在不一致性。
- OpenRAG是一个优化的RAG框架,旨在通过端到端优化检索器来解决上述问题。
- OpenRAG框架通过捕捉上下文相关性,适应了多样化和不断发展的需求。
- 实验结果显示,OpenRAG相较于原始检索器有显著提升。
- OpenRAG相较于现有先进检索器也有显著优势。
- 对于某些任务,优化后的较小规模检索器的改进甚至超过了大型语言模型(LLM)。
点此查看论文截图

GPT-PPG: A GPT-based Foundation Model for Photoplethysmography Signals
Authors:Zhaoliang Chen, Cheng Ding, Saurabh Kataria, Runze Yan, Minxiao Wang, Randall Lee, Xiao Hu
This study introduces a novel application of a Generative Pre-trained Transformer (GPT) model tailored for photoplethysmography (PPG) signals, serving as a foundation model for various downstream tasks. Adapting the standard GPT architecture to suit the continuous characteristics of PPG signals, our approach demonstrates promising results. Our models are pre-trained on our extensive dataset that contains more than 200 million 30s PPG samples. We explored different supervised fine-tuning techniques to adapt our model to downstream tasks, resulting in performance comparable to or surpassing current state-of-the-art (SOTA) methods in tasks like atrial fibrillation detection. A standout feature of our GPT model is its inherent capability to perform generative tasks such as signal denoising effectively, without the need for further fine-tuning. This success is attributed to the generative nature of the GPT framework.
本研究介绍了一种针对光体积描记法(PPG)信号的新型应用,即生成式预训练转换器(GPT)模型,该模型为各种下游任务提供了基础模型。通过调整标准GPT架构以适应PPG信号的连续特性,我们的方法显示出有前景的结果。我们的模型在包含超过2000万份30秒PPG样本的庞大数据集上进行预训练。我们探索了不同的监督微调技术,以使我们的模型适应下游任务,从而在诸如心房颤动检测等任务的性能上达到或超越了当前最新技术水平。我们的GPT模型的一个突出特点是,它具有执行生成任务(如信号去噪)的固有能力,并且不需要进一步的微调。这一成功归因于GPT框架的生成性质。
论文及项目相关链接
Summary
本研究介绍了一种针对光体积脉搏波信号(PPG)的新型生成预训练转换器(GPT)模型的应用,该模型可作为各种下游任务的基础模型。通过调整标准GPT架构以适应PPG信号的连续特性,该研究展现出令人鼓舞的结果。该模型在包含超过20亿个30秒PPG样本的大规模数据集上进行预训练。研究还探索了不同的监督微调技术,使模型能够适应下游任务,在房颤检测等任务中的性能达到或超越了当前最先进的水平。GPT模型的一个突出特点是其固有的生成任务能力,如信号去噪,无需进一步微调。
Key Takeaways
- 研究人员成功将生成预训练转换器(GPT)模型应用于光体积脉搏波信号(PPG)。
- GPT模型经过微调以适应下游任务,如房颤检测,性能卓越。
- 模型在大型数据集上进行预训练,包含超过20亿个PPG样本。
- GPT模型的生成性质使其能够执行生成任务,如信号去噪。
- 此研究为多种下游任务提供了基础模型。
- 模型连续适应性强,能够适应PPG信号的连续特性。
点此查看论文截图

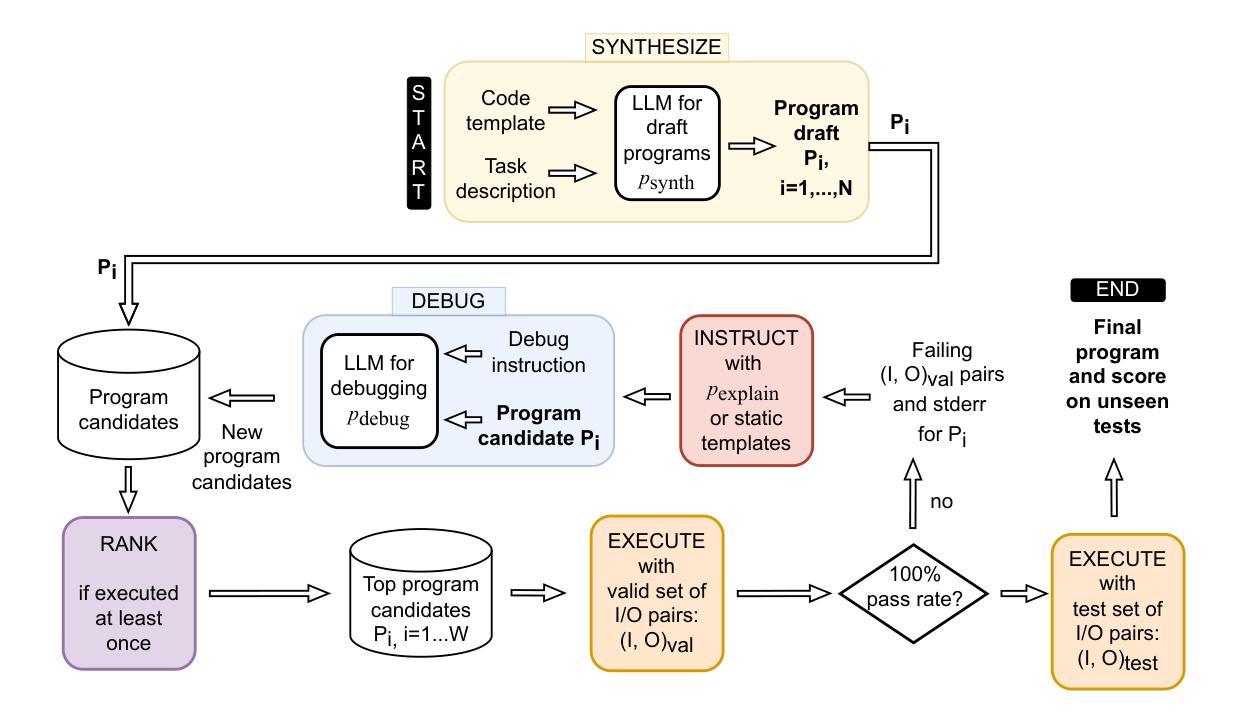
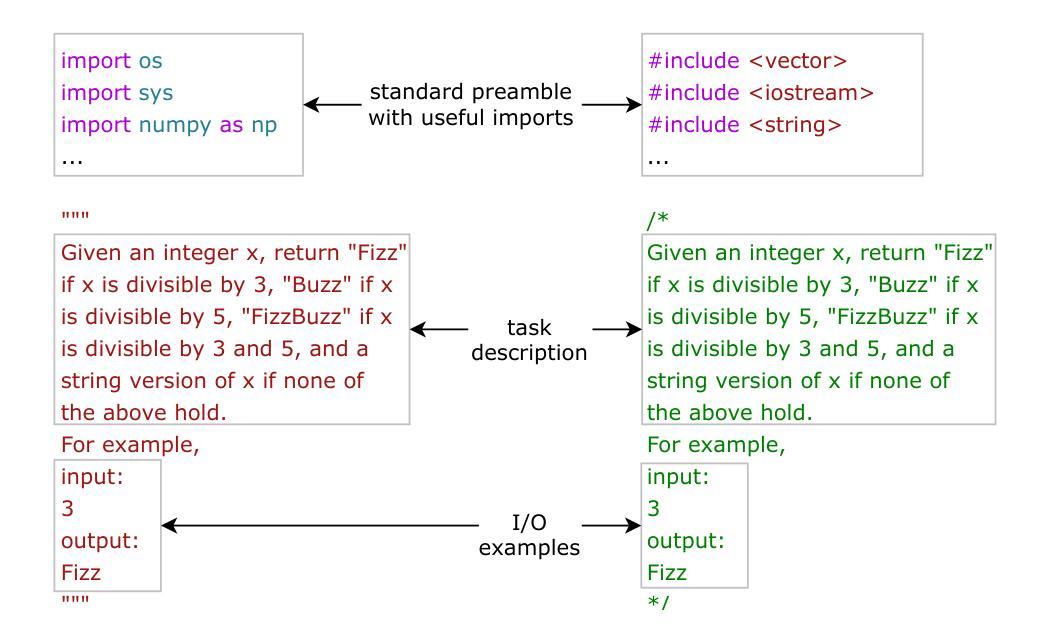
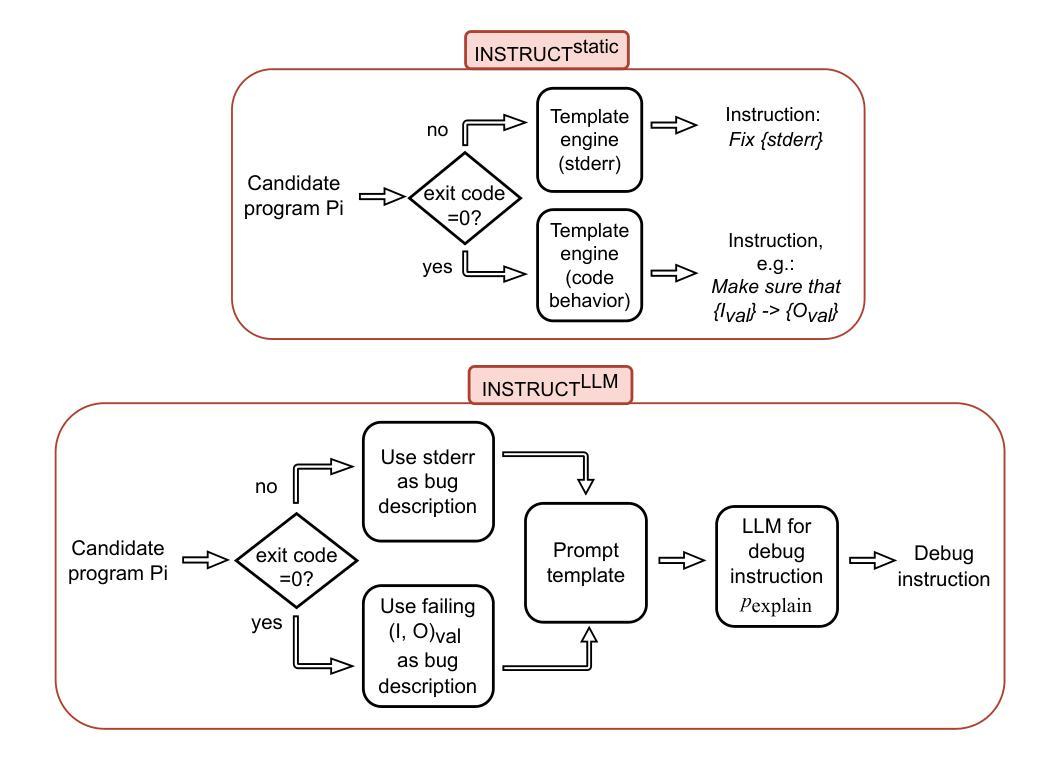
Fully Autonomous Programming using Iterative Multi-Agent Debugging with Large Language Models
Authors:Anastasiia Grishina, Vadim Liventsev, Aki Härmä, Leon Moonen
Program synthesis with Large Language Models (LLMs) suffers from a “near-miss syndrome”: the generated code closely resembles a correct solution but fails unit tests due to minor errors. We address this with a multi-agent framework called Synthesize, Execute, Instruct, Debug, and Repair (SEIDR). Effectively applying SEIDR to instruction-tuned LLMs requires determining (a) optimal prompts for LLMs, (b) what ranking algorithm selects the best programs in debugging rounds, and (c) balancing the repair of unsuccessful programs with the generation of new ones. We empirically explore these trade-offs by comparing replace-focused, repair-focused, and hybrid debug strategies. We also evaluate lexicase and tournament selection to rank candidates in each generation. On Program Synthesis Benchmark 2 (PSB2), our framework outperforms both conventional use of OpenAI Codex without a repair phase and traditional genetic programming approaches. SEIDR outperforms the use of an LLM alone, solving 18 problems in C++ and 20 in Python on PSB2 at least once across experiments. To assess generalizability, we employ GPT-3.5 and Llama 3 on the PSB2 and HumanEval-X benchmarks. Although SEIDR with these models does not surpass current state-of-the-art methods on the Python benchmarks, the results on HumanEval-C++ are promising. SEIDR with Llama 3-8B achieves an average pass@100 of 84.2%. Across all SEIDR runs, 163 of 164 problems are solved at least once with GPT-3.5 in HumanEval-C++, and 162 of 164 with the smaller Llama 3-8B. We conclude that SEIDR effectively overcomes the near-miss syndrome in program synthesis with LLMs.
使用大型语言模型(LLM)进行程序合成时,存在一种“近似综合征”:生成的代码与正确解决方案非常相似,但由于微小错误而无法通过单元测试。我们通过一个名为“合成、执行、指令、调试和修复(SEIDR)”的多智能体框架来解决这个问题。将SEIDR有效应用于指令调整LLM,需要确定(a)针对LLM的最佳提示,(b)在调试轮中选择最佳程序的排名算法,以及(c)平衡不成功程序的修复和新程序的生成。我们通过比较以替换为重点、以修复为重点以及混合调试策略,实证地探索了这些权衡。我们还评估了词典选择法和锦标赛选拔法以在每一代中挑选候选者。在程序合成基准测试第二版(PSB2)上,我们的框架优于常规使用OpenAI Codex而不进行修复阶段以及传统的遗传编程方法。SEIDR在单独使用LLM时表现出色,在PSB2的C++和Python中分别解决了至少一次实验的18个问题和20个问题。为了评估通用性,我们在PSB2和HumanEval-X基准测试上使用了GPT-3.5和Llama 3。尽管使用这些模型的SEIDR在Python基准测试上并未超越当前的最先进方法,但在HumanEval-C++上的结果具有希望。使用Llama 3-8B的SEIDR达到平均通过率为84.2%。在所有SEIDR运行中,GPT-3.5在HumanEval-C++中至少解决了一次以上其中的所有问题中的至少解决过有答案的前置题(pass@100)有十六分之三(即至少解决了十六题中的十六题),较小的Llama 3-8B解决了一六二题中的十六题以上。我们得出结论,SEIDR有效地克服了使用LLM进行程序合成时的近失误问题。
论文及项目相关链接
PDF Accepted for publication in ACM Trans. Evol. Learn. Optim., February 2025. arXiv admin note: text overlap with arXiv:2304.10423
摘要
基于大型语言模型(LLM)的程序合成受到“近似综合征”的影响,即生成的代码虽然与正确解决方案相似,但由于细微错误而无法通过单元测试。为解决这一问题,我们提出了一个名为SEIDR(合成、执行、指令、调试和修复)的多智能体框架。有效应用SEIDR到指令调整LLM需要确定(a)LLM的最佳提示,(b)在调试轮次中选择最佳程序的排名算法,以及(c)平衡不成功程序的修复与新生成的程序之间的平衡。我们通过比较注重替换、注重修复和混合调试策略来实证探索这些权衡。我们还评估了词典选择和锦标赛选择来排列每一代的候选人。在程序合成基准测试2(PSB2)上,我们的框架优于常规使用OpenAI Codex而不进行修复阶段以及传统的遗传编程方法。SEIDR优于单独使用LLM,在PSB2上解决C++的18个问题和Python的20个问题。为了评估通用性,我们在PSB2和HumanEval-X基准测试上使用了GPT-3.5和Llama 3。虽然SEIDR与这些模型的结合在Python基准测试上并未超越当前最先进的方法,但在HumanEval-C++上的结果很有希望。使用Llama 3-8B的SEIDR达到平均通过率为84.2%。在所有SEIDR运行中,GPT-3.5在HumanEval-C++中至少解决了一次的163个问题和较小的Llama 3-8B解决的至少一次的162个问题。我们得出结论,SEIDR有效地克服了基于LLM的程序合成的近似综合征问题。
关键见解
- SEIDR框架解决了基于大型语言模型(LLM)的程序合成中的“近似综合征”问题,即通过生成的代码虽近似正确解但无法通过单元测试的问题。
- SEIDR应用的关键要素包括确定最佳提示、选择排名算法的调试轮次中最佳程序的策略,以及平衡修复与生成新程序之间的策略。
- 通过比较不同的调试策略(如注重替换、注重修复和混合策略),实证探索了这些权衡。
- SEIDR在程序合成基准测试上的表现优于常规方法和遗传编程方法。
- SEIDR在不同的大型语言模型(如GPT-3.5和Llama 3)上的表现显示出良好的通用性,尤其在HumanEval-C++上的结果有潜力。
- SEIDR使用Llama 3-8B在HumanEval-C++的基准测试中达到的平均通过率为84.2%,显示出其有效性。
点此查看论文截图

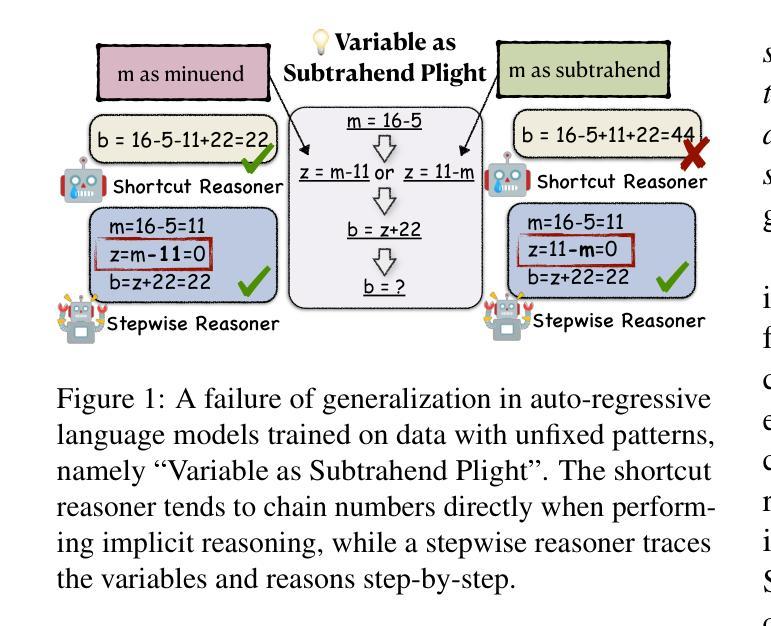
Implicit Reasoning in Transformers is Reasoning through Shortcuts
Authors:Tianhe Lin, Jian Xie, Siyu Yuan, Deqing Yang
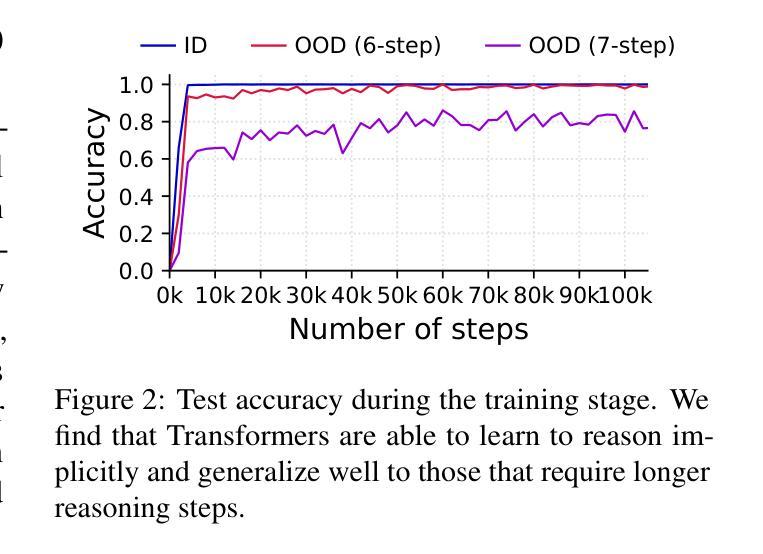
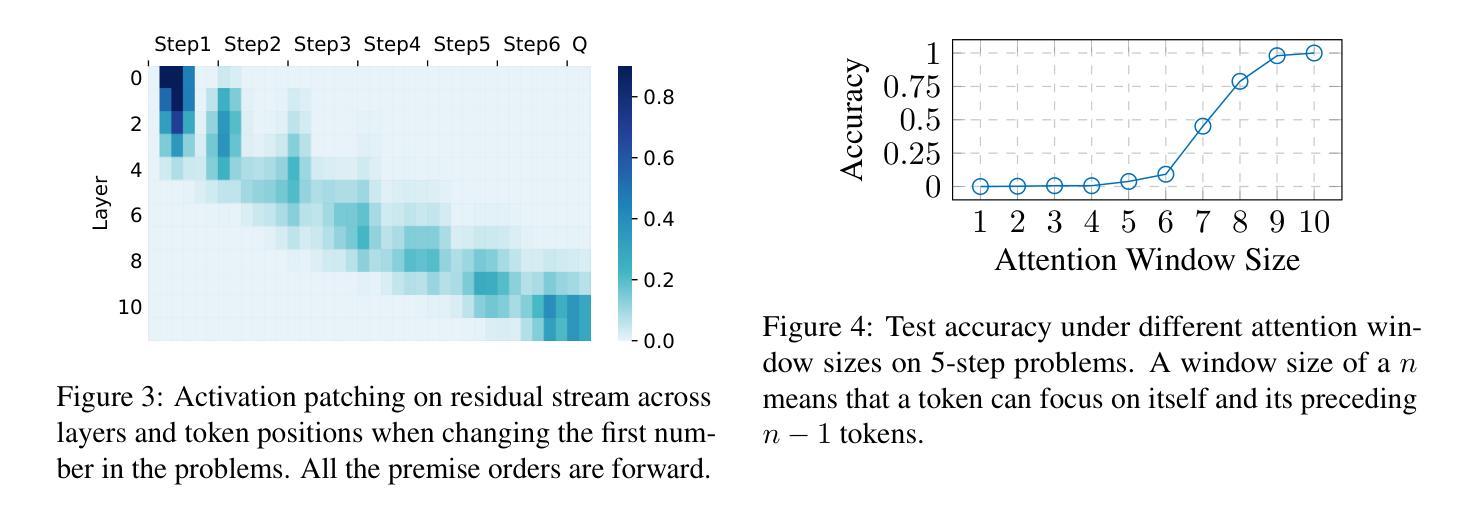
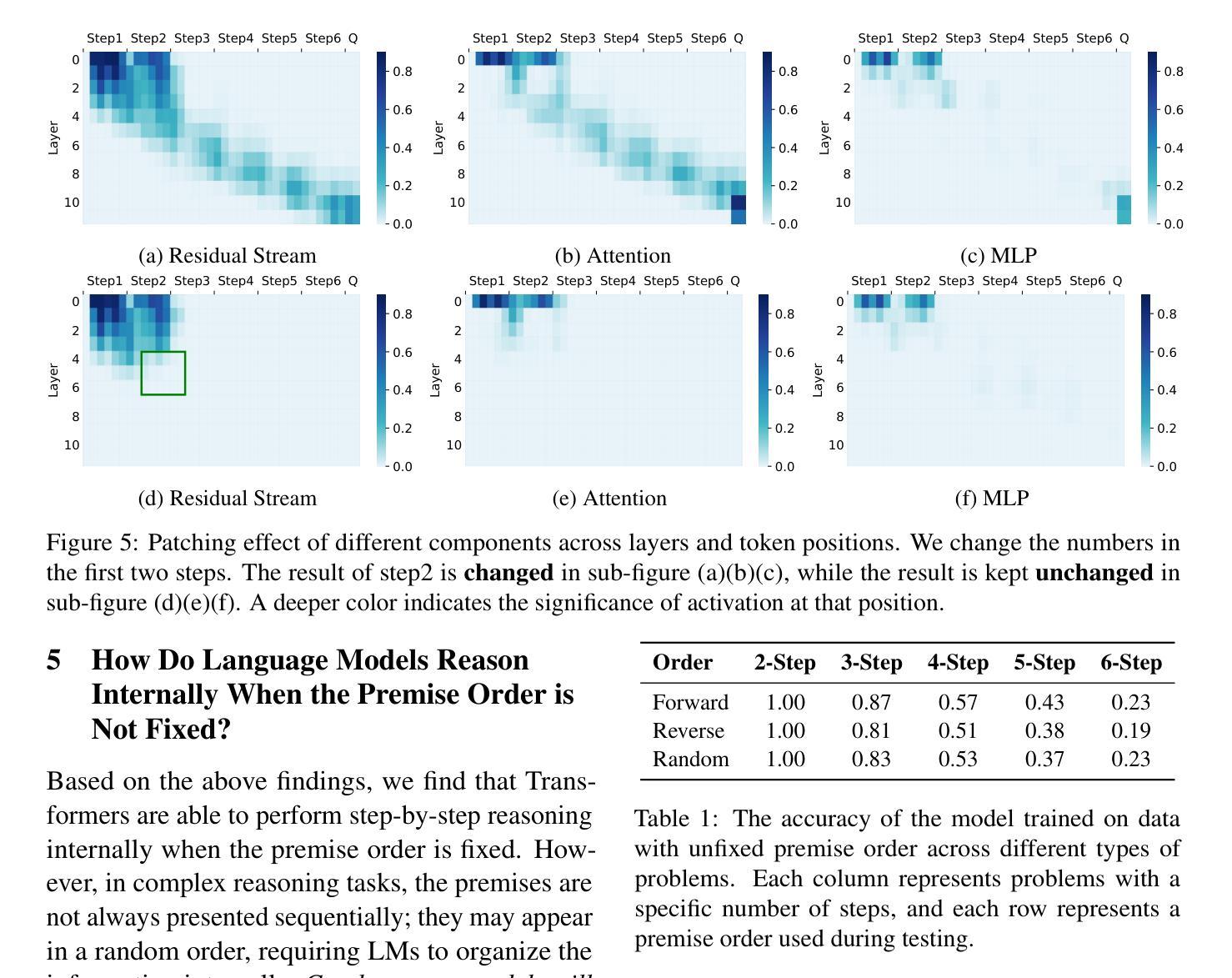
Test-time compute is emerging as a new paradigm for enhancing language models’ complex multi-step reasoning capabilities, as demonstrated by the success of OpenAI’s o1 and o3, as well as DeepSeek’s R1. Compared to explicit reasoning in test-time compute, implicit reasoning is more inference-efficient, requiring fewer generated tokens. However, why does the advanced reasoning capability fail to emerge in the implicit reasoning style? In this work, we train GPT-2 from scratch on a curated multi-step mathematical reasoning dataset and conduct analytical experiments to investigate how language models perform implicit reasoning in multi-step tasks. Our findings reveal: 1) Language models can perform step-by-step reasoning and achieve high accuracy in both in-domain and out-of-domain tests via implicit reasoning. However, this capability only emerges when trained on fixed-pattern data. 2) Conversely, implicit reasoning abilities emerging from training on unfixed-pattern data tend to overfit a specific pattern and fail to generalize further. Notably, this limitation is also observed in state-of-the-art large language models. These findings suggest that language models acquire implicit reasoning through shortcut learning, enabling strong performance on tasks with similar patterns while lacking generalization.
测试时的计算正成为一种新兴的模式,用于增强语言模型的复杂多步推理能力,OpenAI的o1和o3以及DeepSeek的R1的成功演示了这一点。与测试时计算中的显式推理相比,隐式推理的推理效率更高,生成的标记更少。然而,为什么先进的推理能力无法在隐式推理风格中产生呢?在这项工作中,我们从零开始训练GPT-2,使其适应精选的多步数学推理数据集,并进行分析实验,以研究语言模型在多步任务中进行隐式推理的表现。我们的研究发现:1)语言模型可以通过隐式推理进行逐步推理,并在域内和域外测试中实现高准确性。但这种能力仅在训练固定模式数据时出现。2)相反,从训练非固定模式数据中出现的隐式推理能力往往倾向于过度适应特定模式,而无法进一步推广。值得注意的是,这一局限性也被观察到存在于最先进的自然语言模型中。这些发现表明,语言模型通过捷径学习获得隐式推理能力,能够在具有相似模式的任务上表现出强大的性能,但却缺乏泛化能力。
论文及项目相关链接
Summary
本文探讨了测试时计算(test-time compute)这一新兴范式在增强语言模型复杂多步推理能力方面的应用。通过对GPT-2进行训练和实验分析,研究发现在固定模式数据上训练的语言模型可以通过隐式推理实现逐步推理,并在域内和域外测试中获得高准确性。然而,在非标定模式数据上训练的模型往往会出现过度拟合特定模式的情况,缺乏进一步的泛化能力。这表明语言模型的隐式推理能力是通过捷径学习获得的,能够在具有相似模式的任务上表现出色,但缺乏泛化能力。
Key Takeaways
- 测试时计算是一种新兴范式,用于增强语言模型的复杂多步推理能力。
- 隐式推理相比显式推理更推理高效,需要生成的标记更少。
- 语言模型在固定模式数据上训练后,可以通过隐式推理进行逐步推理,并在测试中获得高准确性。
- 在非标定模式数据上训练的模型会出现过度拟合特定模式的情况,缺乏泛化能力。
- 隐式推理能力是通过捷径学习获得的,能够在具有相似模式的任务上表现出色。
- 在不同领域(如数学)的隐式推理研究中发现了类似的语言模型限制和局限。这种泛化能力不足的问题可能影响语言模型在其他复杂任务上的表现。
点此查看论文截图

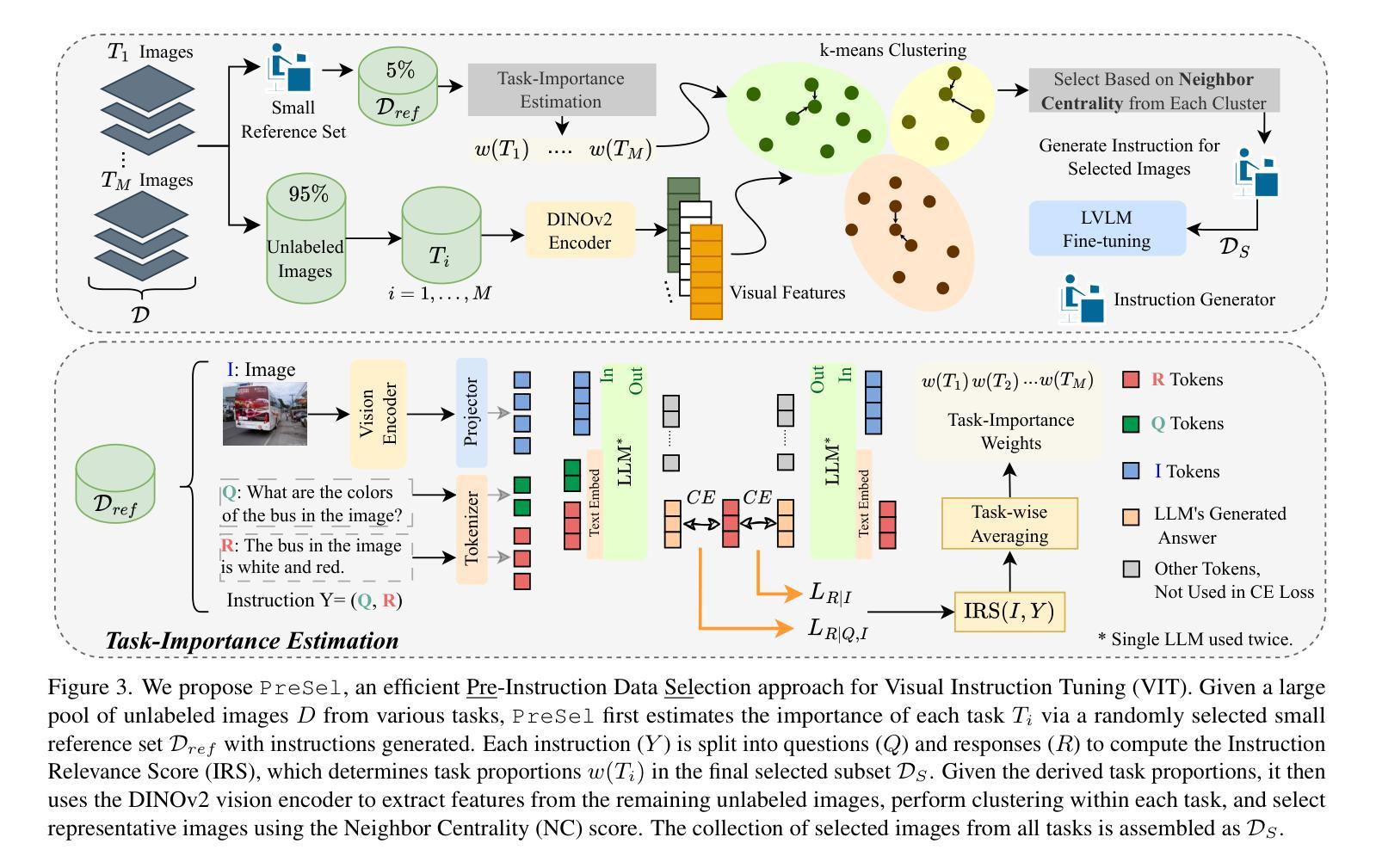
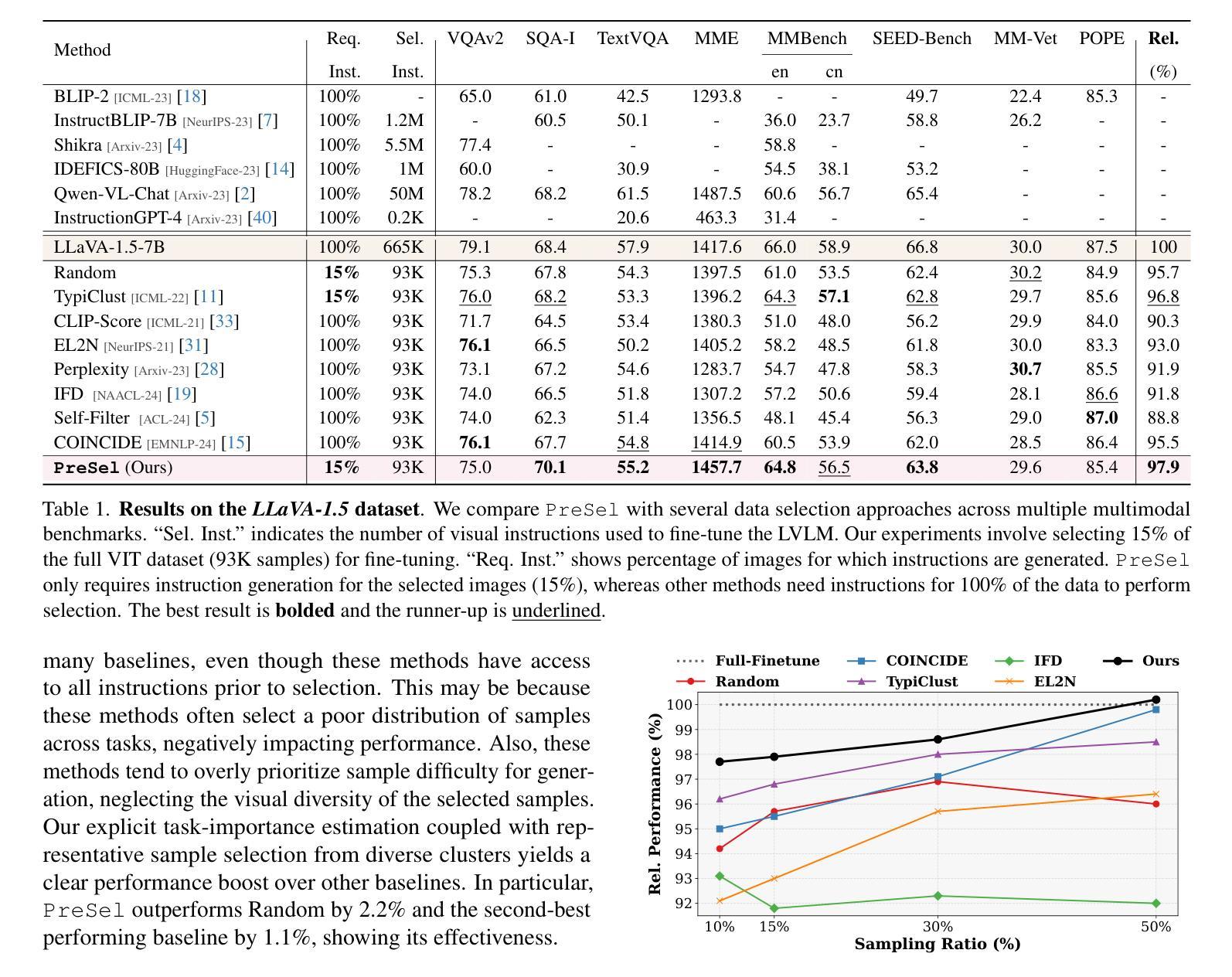
Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning
Authors:Bardia Safaei, Faizan Siddiqui, Jiacong Xu, Vishal M. Patel, Shao-Yuan Lo
Visual instruction tuning (VIT) for large vision-language models (LVLMs) requires training on expansive datasets of image-instruction pairs, which can be costly. Recent efforts in VIT data selection aim to select a small subset of high-quality image-instruction pairs, reducing VIT runtime while maintaining performance comparable to full-scale training. However, a major challenge often overlooked is that generating instructions from unlabeled images for VIT is highly expensive. Most existing VIT datasets rely heavily on human annotations or paid services like the GPT API, which limits users with constrained resources from creating VIT datasets for custom applications. To address this, we introduce Pre-Instruction Data Selection (PreSel), a more practical data selection paradigm that directly selects the most beneficial unlabeled images and generates instructions only for the selected images. PreSel first estimates the relative importance of each vision task within VIT datasets to derive task-wise sampling budgets. It then clusters image features within each task, selecting the most representative images with the budget. This approach reduces computational overhead for both instruction generation during VIT data formation and LVLM fine-tuning. By generating instructions for only 15% of the images, PreSel achieves performance comparable to full-data VIT on the LLaVA-1.5 and Vision-Flan datasets. The link to our project page: https://bardisafa.github.io/PreSel
视觉指令调优(VIT)对于大型视觉语言模型(LVLM)需要在大量的图像指令对数据集上进行训练,这可能会很昂贵。近期关于VIT数据选择的努力旨在选择一小部分高质量的图像指令对,在减少VIT运行时间的同时保持与全规模训练相当的性能。然而,经常被忽视的一个主要挑战是,从未标记的图像中生成指令的成本非常高。大多数现有的VIT数据集严重依赖于人工注释或如GPT API之类的付费服务,这限制了资源有限的用户创建用于自定义应用程序的VIT数据集。为了解决这一问题,我们引入了预指令数据选择(PreSel),这是一种更实用的数据选择模式,它直接选择最有益的无标签图像,只为所选图像生成指令。PreSel首先估计VIT数据集中每个视觉任务的相对重要性,以得出任务级采样预算。然后,它在每个任务内对图像特征进行聚类,选择最具代表性的图像以符合预算。这种方法减少了VIT数据形成和LVLM微调过程中的指令生成计算开销。只为15%的图像生成指令,PreSel在LLaVA-1.5和Vision-Flan数据集上的性能与全数据VIT相当。我们的项目页面链接:https://bardisafa.github.io/PreSel
论文及项目相关链接
PDF Accepted at Computer Vision and Pattern Recognition Conference (CVPR) 2025
摘要
视觉指令微调(VIT)需要大量图像-指令对数据集对大型视觉语言模型(LVLMs)进行训练,成本较高。最新研究致力于选择高质量的图像-指令对数据子集,以在保持性能的同时减少VIT的运行时间。然而,经常被忽视的一个挑战是从无标签图像中生成指令的成本高昂。大多数现有的VIT数据集严重依赖于人工注释或有偿服务(如GPT API),这限制了资源受限的用户创建自定义应用的VIT数据集。为解决此问题,我们引入了预指令数据选择(PreSel)这一更实际的数据选择范式,该范式直接选择最有益的无标签图像,只为所选图像生成指令。PreSel首先估计VIT数据集中每个视觉任务的重要性,以导出任务特定的采样预算。然后它在每个任务中对图像特征进行聚类,选择最具代表性的图像来使用预算。这种方法减少了在形成VIT数据和微调LVLM期间的指令生成计算开销。只为图像的15%生成指令,PreSel在LLaVA-1.5和Vision-Flan数据集上的性能与全数据VIT相当。项目链接:https://bardisafa.github.io/PreSel。
关键见解
- VIT需要大量的图像-指令对数据集进行训练,成本高昂。
- 最新研究致力于选择高质量的图像-指令对数据子集,以减少运行时间并保持性能。
- 生成指令的成本是从无标签图像中生成指令的一个挑战。
- 大多数现有方法高度依赖于人工注释或有偿服务,限制了资源受限用户的自定义应用。
- PreSel直接选择最有益的无标签图像,并为所选图像生成指令,降低计算开销。
- PreSel通过估计每个视觉任务的重要性来导出任务特定的采样预算,选择最具代表性的图像。
- 仅对少量图像生成指令,PreSel的性能与全数据VIT相当。
点此查看论文截图


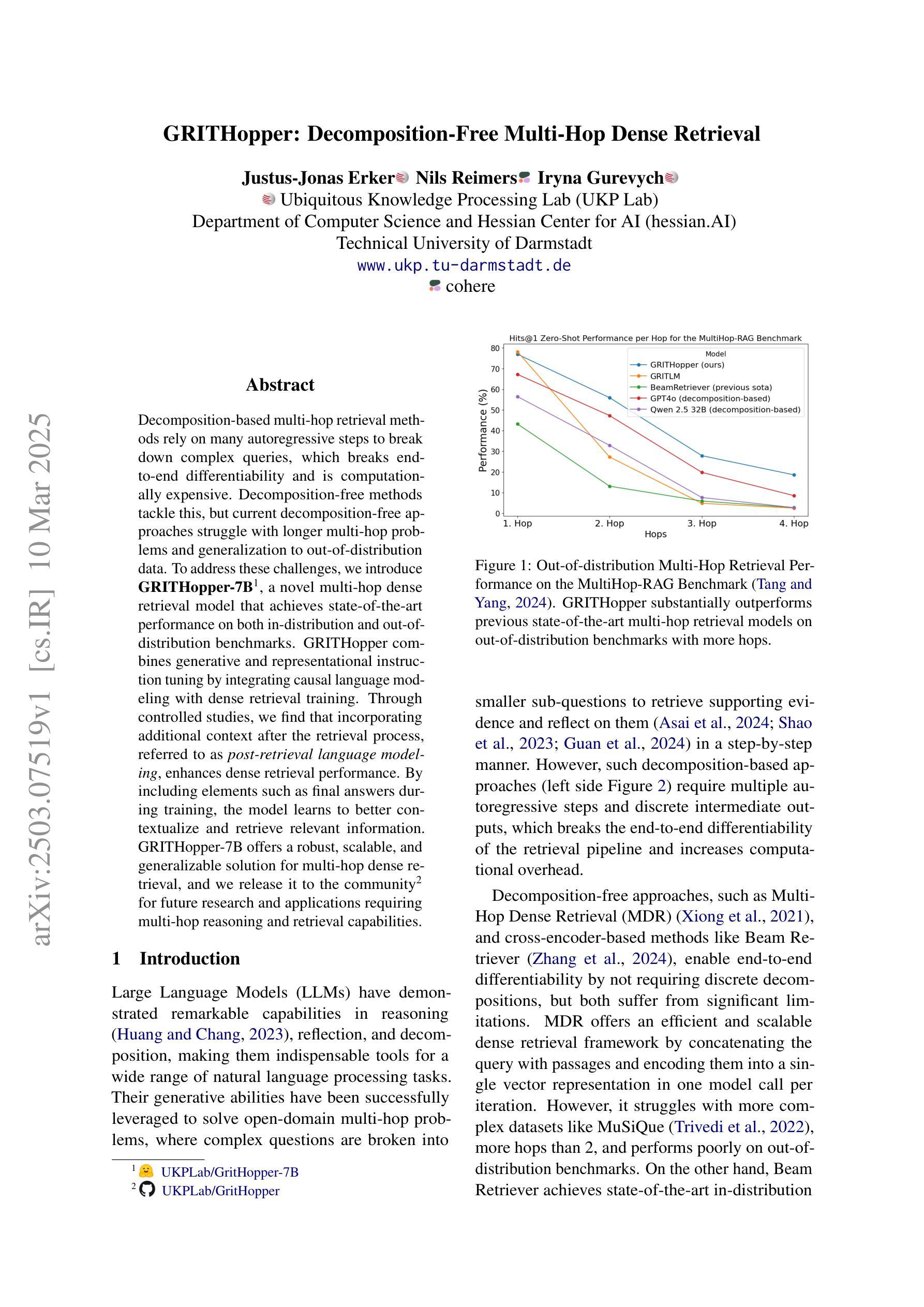
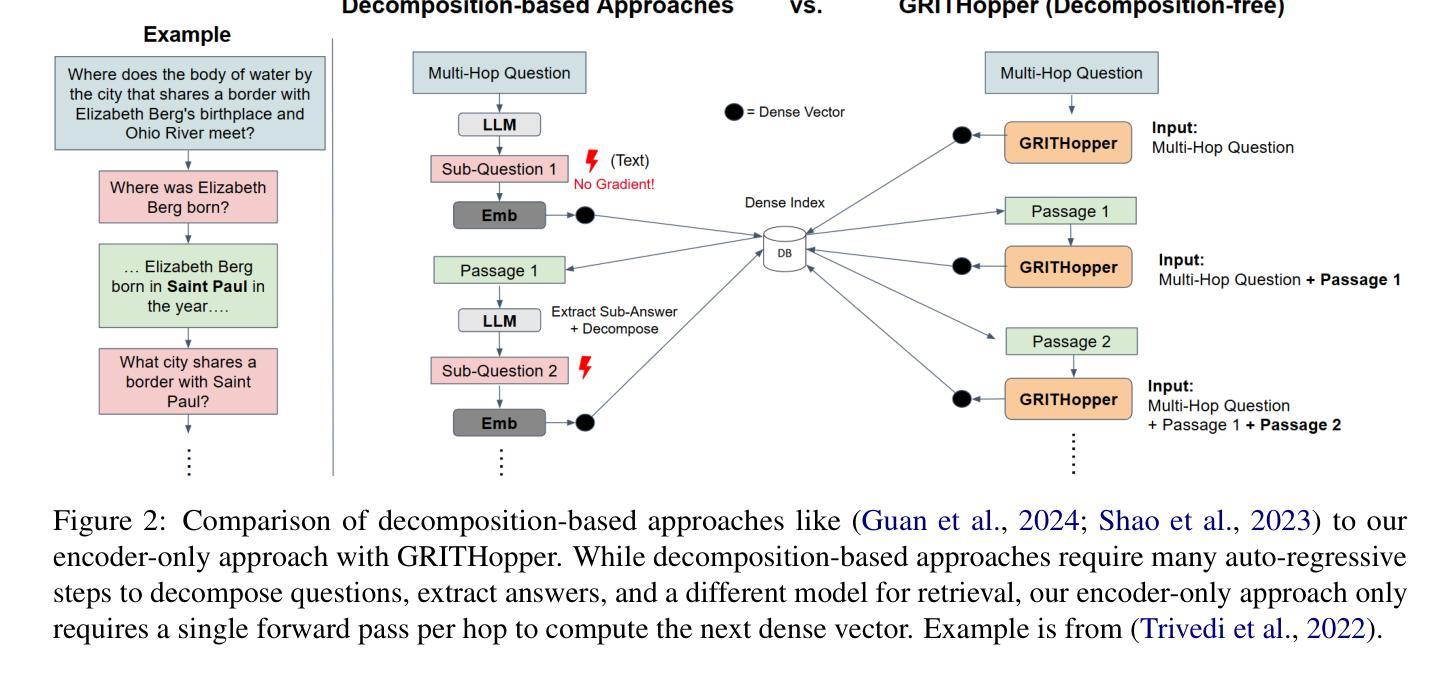
GRITHopper: Decomposition-Free Multi-Hop Dense Retrieval
Authors:Justus-Jonas Erker, Nils Reimers, Iryna Gurevych
Decomposition-based multi-hop retrieval methods rely on many autoregressive steps to break down complex queries, which breaks end-to-end differentiability and is computationally expensive. Decomposition-free methods tackle this, but current decomposition-free approaches struggle with longer multi-hop problems and generalization to out-of-distribution data. To address these challenges, we introduce GRITHopper-7B, a novel multi-hop dense retrieval model that achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks. GRITHopper combines generative and representational instruction tuning by integrating causal language modeling with dense retrieval training. Through controlled studies, we find that incorporating additional context after the retrieval process, referred to as post-retrieval language modeling, enhances dense retrieval performance. By including elements such as final answers during training, the model learns to better contextualize and retrieve relevant information. GRITHopper-7B offers a robust, scalable, and generalizable solution for multi-hop dense retrieval, and we release it to the community for future research and applications requiring multi-hop reasoning and retrieval capabilities.
基于分解的多跳检索方法依赖于许多自回归步骤来分解复杂查询,这破坏了端到端的可区分性,并且计算成本高昂。无分解的方法解决了这个问题,但当前的无分解方法在处理较长的多跳问题和泛化到分布外数据时遇到困难。为了解决这些挑战,我们引入了GRITHopper-7B,这是一种新型的多跳密集检索模型,在分布内和分布外的基准测试中均实现了最新性能。GRITHopper通过结合因果语言建模和密集检索训练,实现了生成和代表性指令调整。通过对照研究,我们发现,在检索过程后融入额外的上下文,即所谓的后检索语言建模,可以增强密集检索的性能。通过在训练中加入最终答案等元素,模型学会了更好地上下文化和检索相关信息。GRITHopper-7B为多跳密集检索提供了稳健、可扩展和通用的解决方案,我们将其发布给社区,以供未来研究和需要多跳推理和检索能力的应用使用。
论文及项目相关链接
PDF Under Review at ACL Rolling Review (ARR)
Summary
基于分解的多跳检索方法依赖多个自回归步骤来分解复杂查询,这破坏了端到端的可区分性,并且计算成本高昂。无分解方法解决了这一问题,但当前的无分解方法对于较长的多跳问题和泛化到离群数据方面存在挑战。为解决这些挑战,我们推出了GRITHopper-7B,一种新型多跳密集检索模型,在内外分布基准测试上均实现了卓越性能。GRITHopper通过整合因果语言建模与密集检索训练,实现了生成性和代表性指令调整。通过对照研究,我们发现,在检索过程后增加额外的上下文,即所谓的后检索语言建模,可以增强密集检索的性能。通过在训练中包含最终答案等元素,模型学会了更好地上下文化和检索相关信息。GRITHopper-7B为需要多跳推理和检索能力的未来研究与应用提供了稳健、可扩展和通用的解决方案。
Key Takeaways
- 基于分解的多跳检索方法存在端到端不可区分性和计算成本高昂的问题。
- 无分解方法解决了这一问题,但在处理较长多跳问题和泛化到离群数据方面存在挑战。
- GRITHopper-7B是一个新型多跳密集检索模型,具有强大的性能和广泛的应用前景。
- GRITHopper结合了生成性和代表性指令调整,通过整合因果语言建模与密集检索训练实现高性能。
- 后检索语言建模能增强密集检索性能。
- 在训练中加入最终答案等元素使模型能更精准地上下文化和检索相关信息。
点此查看论文截图

CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Authors:Yuxuan Luo, Jiaqi Tang, Chenyi Huang, Feiyang Hao, Zhouhui Lian
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader’s \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader’s efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.
中国书法作为联合国教科文组织(UNESCO)遗产,仍然具有计算上的挑战性,原因在于视觉模糊和文化复杂性。现有的AI系统无法对其复杂的脚本进行语境化理解,这主要是因为标注数据有限以及视觉语义对齐不佳。我们提出了CalliReader,这是一种视觉语言模型(VLM),它通过三项创新解决了中文书法的语境化问题(CC$^2$):(1)字符级切片,用于精确字符提取和排序;(2)CalliAlign用于视觉文本符号压缩和对齐;(3)嵌入指令调整(e-IT)用于改善对齐并解决数据稀缺问题。我们还建立了CalliBench,这是第一个全页书法语境化的基准测试,解决了之前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅显和幻觉。进行了大量实验和用户研究,验证了CalliReader在页级书法识别和解释方面优于其他最先进的方法,甚至优于专业书法家,在提高准确性的同时减少了幻觉。与推理模型的比较突显了准确识别作为可靠理解先决条件的重要性。定量分析验证了CalliReader的效率;对文档和真实世界的基准测试评估证明了其稳健的泛化能力。
论文及项目相关链接
PDF 11 pages
Summary
本文介绍了中文书法作为联合国教科文组织遗产所面临的计算挑战,包括视觉模糊和文化复杂性。现有的AI系统因缺乏注释数据和视觉语义对齐不良而无法适应复杂的脚本上下文。提出了一种新型的视觉语言模型CalliReader,它通过三个创新解决了中文书法上下文化问题:字符级切片技术用于精确字符提取和排序,CalliAlign用于视觉文本令牌压缩和对齐,嵌入指令调整e-IT用于改进对齐并解决数据稀缺问题。此外建立了首个全页书法上下文基准测试CalliBench,解决了以往OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅显和幻觉现象。通过广泛的实验和用户研究验证了CalliReader在页级书法识别和解释方面优于其他先进方法和专业人士,在保持高准确性的同时降低了幻觉现象。与推理模型的比较突显了准确识别作为可靠理解先决条件的重要性。定量分析验证了CalliReader的效率,对文档和真实世界的基准测试评估证明了其稳健的泛化能力。
Key Takeaways
- 中文书法作为联合国教科文组织遗产,面临视觉模糊和文化复杂性的计算挑战。
- 现有AI系统在处理中文书法时存在困难,主要是因为缺乏注释数据和视觉语义对齐不良。
- CalliReader是一种新型的视觉语言模型,通过三个创新解决了中文书法上下文化问题:字符级切片技术、CalliAlign和嵌入指令调整e-IT。
- CalliBench作为首个全页书法上下文基准测试,解决了以往OCR和VQA方法中的关键问题和缺陷。
- CalliReader在页级书法识别和解释方面优于其他先进方法和专业人士,且具有较高的准确性和效率。
- 与推理模型的比较突显了准确识别对于可靠理解的先决条件的重要性。
点此查看论文截图

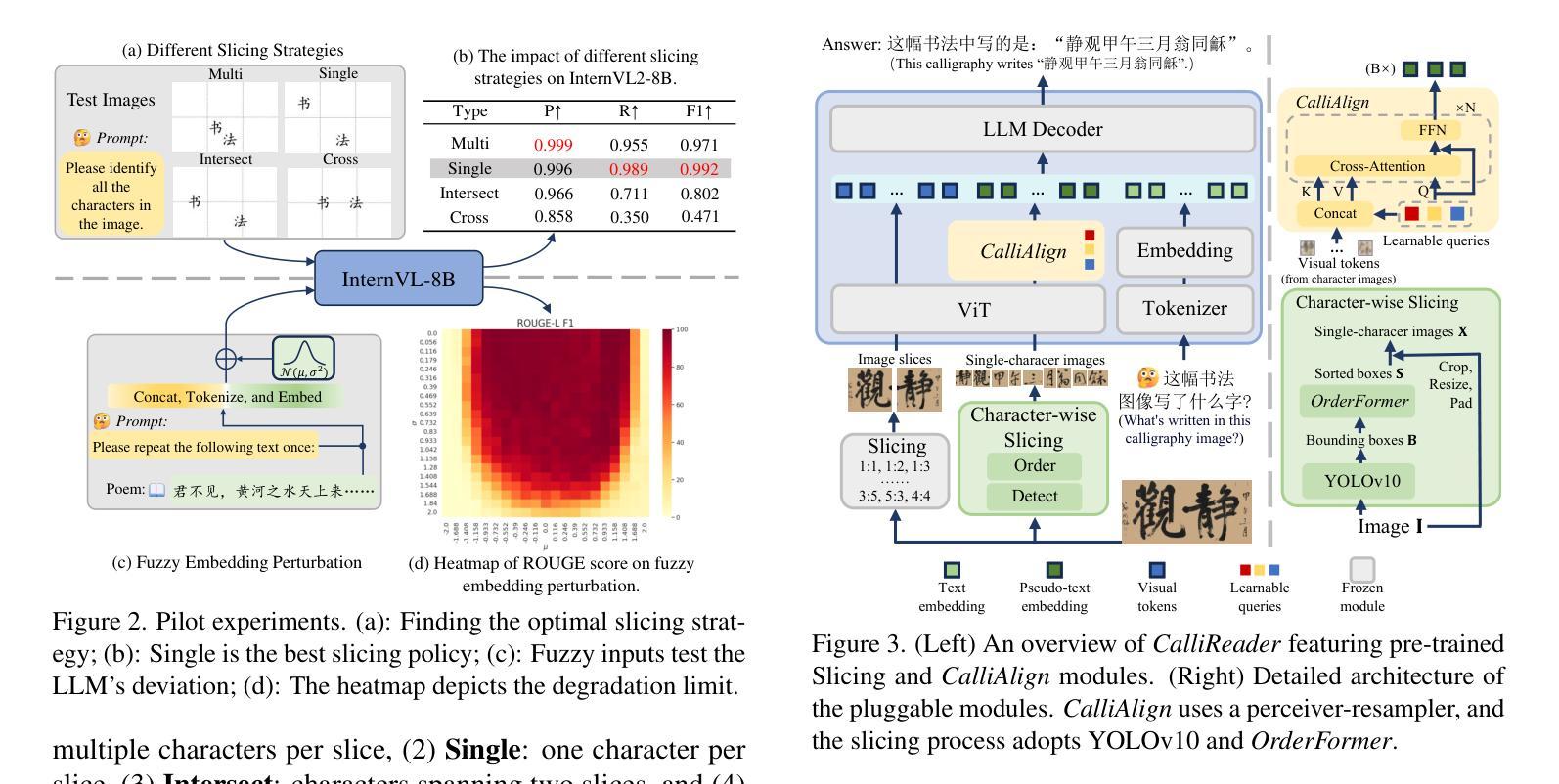
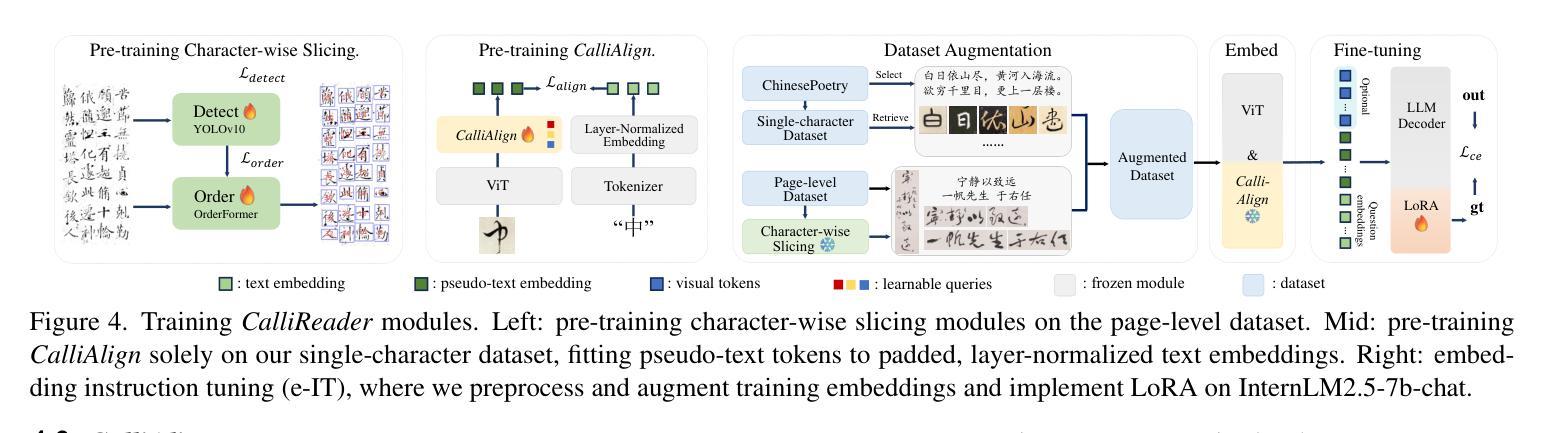


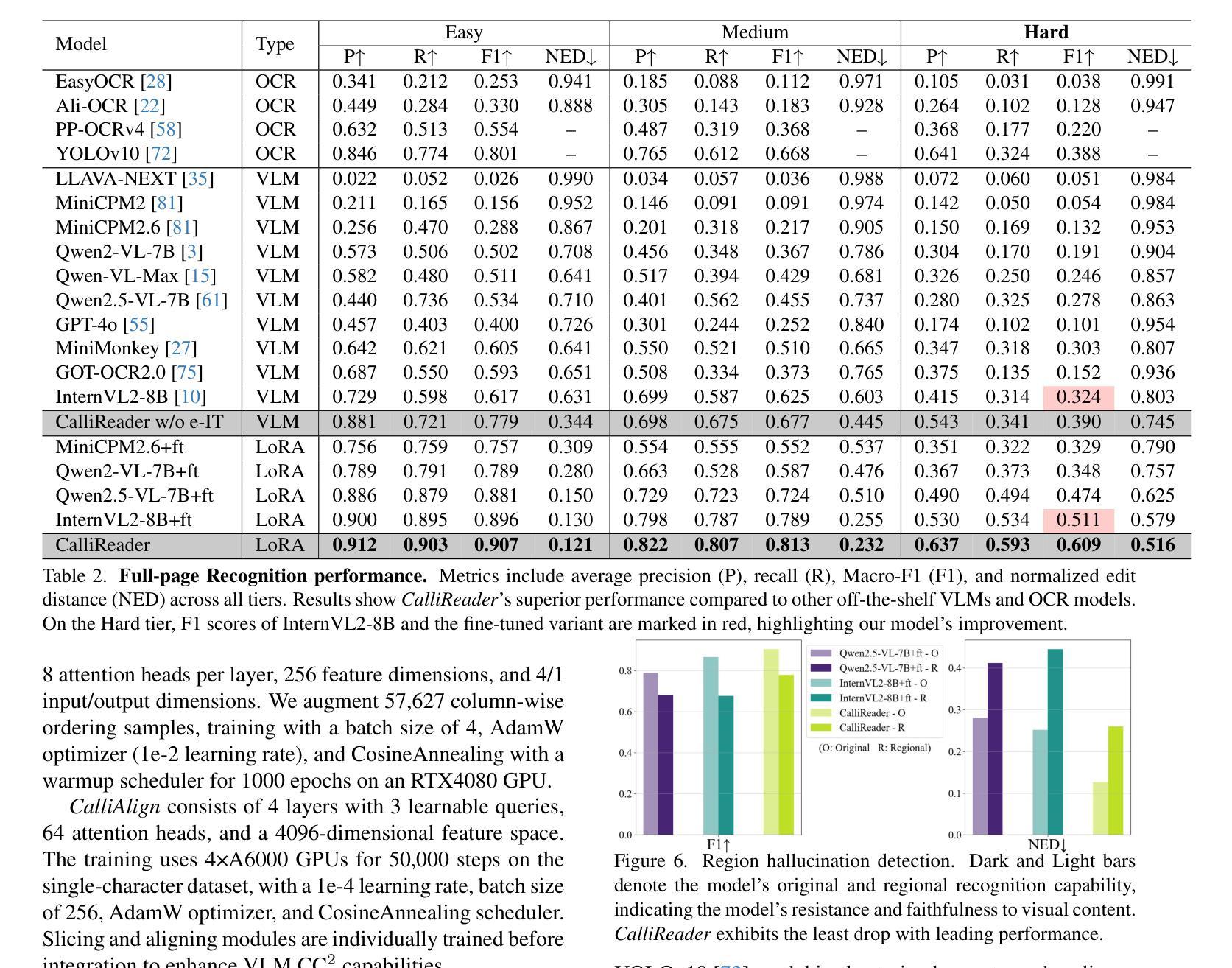
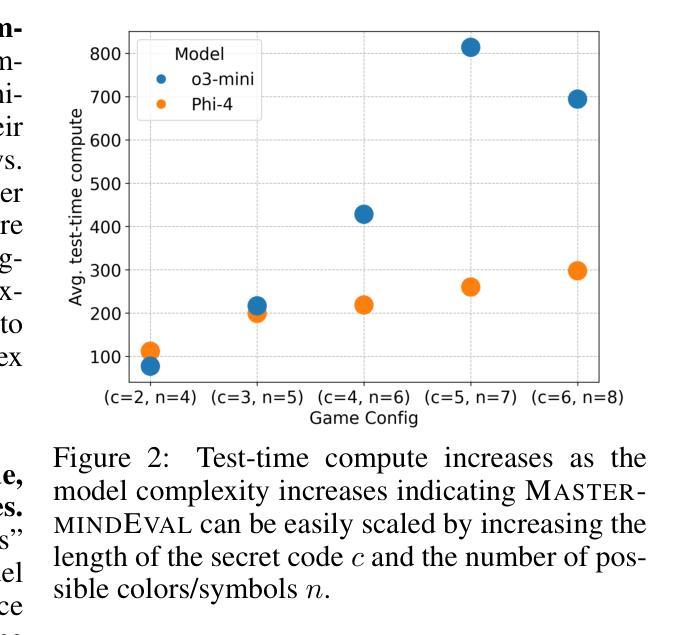
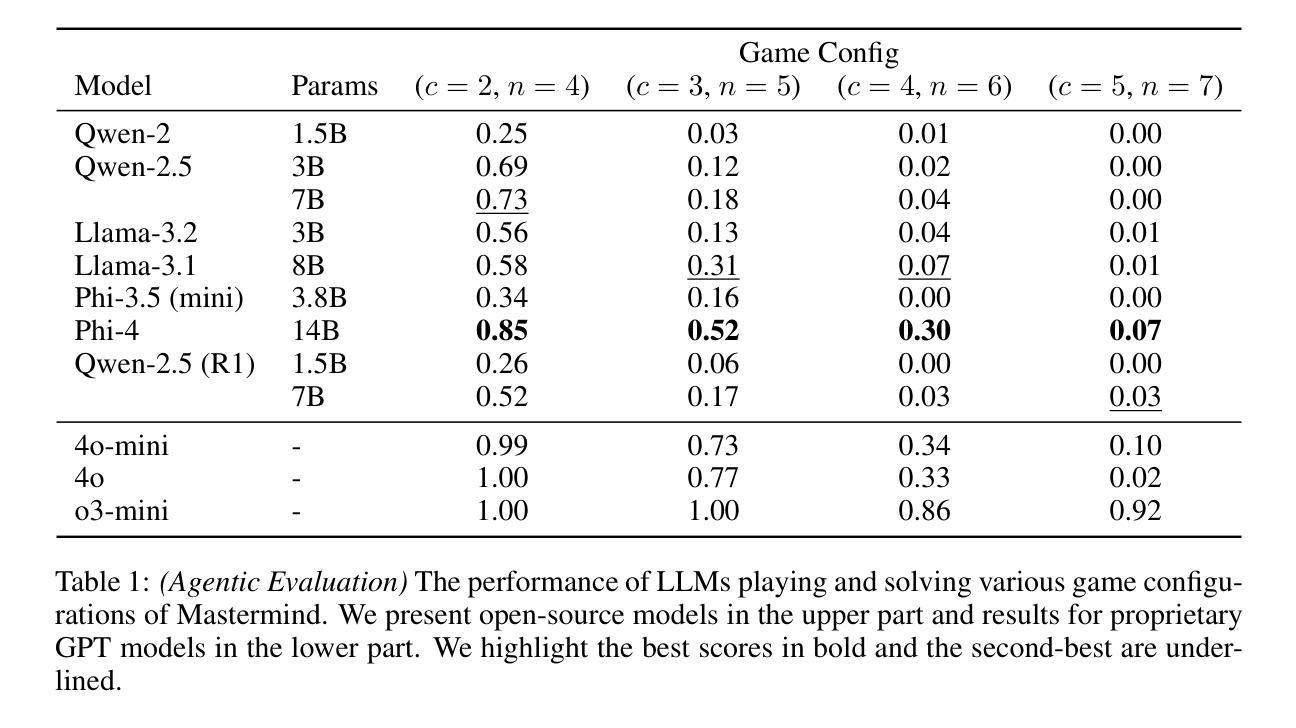
MastermindEval: A Simple But Scalable Reasoning Benchmark
Authors:Jonas Golde, Patrick Haller, Fabio Barth, Alan Akbik
Recent advancements in large language models (LLMs) have led to remarkable performance across a wide range of language understanding and mathematical tasks. As a result, increasing attention has been given to assessing the true reasoning capabilities of LLMs, driving research into commonsense, numerical, logical, and qualitative reasoning. However, with the rapid progress of reasoning-focused models such as OpenAI’s o1 and DeepSeek’s R1, there has been a growing demand for reasoning benchmarks that can keep pace with ongoing model developments. In this paper, we introduce MastermindEval, a simple, scalable, and interpretable deductive reasoning benchmark inspired by the board game Mastermind. Our benchmark supports two evaluation paradigms: (1) agentic evaluation, in which the model autonomously plays the game, and (2) deductive reasoning evaluation, in which the model is given a pre-played game state with only one possible valid code to infer. In our experimental results we (1) find that even easy Mastermind instances are difficult for current models and (2) demonstrate that the benchmark is scalable to possibly more advanced models in the future Furthermore, we investigate possible reasons why models cannot deduce the final solution and find that current models are limited in deducing the concealed code as the number of statement to combine information from is increasing.
近期大型语言模型(LLM)的最新进展在各种语言理解和数学任务中取得了显著的成绩。因此,人们越来越关注评估LLM的真正推理能力,推动了常识、数值、逻辑和定性推理的研究。然而,随着以OpenAI的o1和DeepSeek的R1等为代表的推理重点模型的快速发展,对能与当前模型发展同步的推理基准测试的需求也在增长。在本文中,我们介绍了MastermindEval,这是一个受棋盘游戏《猜密码》启发的简单、可扩展和可解释的演绎推理基准测试。我们的基准测试支持两种评估范式:(1)代理评估,即模型自主玩游戏;(2)演绎推理评估,即给模型一个预先玩过的游戏状态,只有一个可能的正确密码需要推断。在我们的实验结果中,我们(1)发现即使是简单的《猜密码》实例对当前的模型来说也是困难的,(2)证明该基准测试在未来可以扩展到更先进的模型。此外,我们还调查了模型无法推断最终解决方案的可能原因,并发现随着需要从陈述中结合信息数量的增加,当前模型在推断隐藏密码方面存在局限性。
论文及项目相关链接
PDF 9 pages, 2 figures, 4 tables. In: ICLR 2025 Workshop on Reasoning and Planning for Large Language Models
Summary
大型语言模型(LLM)的最新进展在各种语言理解和数学任务上取得了显著的成绩,引发了人们对评估其真正推理能力的关注,推动了常识、数值、逻辑和定性推理的研究。为此,人们迫切需要与模型发展同步的推理基准测试。本文介绍了MastermindEval,一个简单、可扩展、可解释的推理基准测试,其灵感来自猜谜游戏Mastermind。该基准测试支持两种评估范式:一是模型自主玩游戏,二是推理评估,即模型根据给定的游戏状态进行推理。实验结果表明,即使是简单的猜谜实例对当前的模型来说也是困难的,并且该基准测试可以扩展到未来的更高级模型。当前模型的局限性在于,随着需要组合的信息数量的增加,它们无法推断出最终的答案。
Key Takeaways
- LLM的最新进展在各种语言理解和数学任务上表现出色,引发了对评估其真正推理能力的关注。
- 迫切需要与模型发展同步的推理基准测试。
- 介绍了MastermindEval,一个简单、可扩展、可解释的推理基准测试,灵感来自猜谜游戏Mastermind。
- MastermindEval支持两种评估范式:模型自主玩游戏和推理评估。
- 实验表明,即使是简单的猜谜实例对当前的模型来说也是困难的。
- MastermindEval可以扩展到未来的更高级模型。
点此查看论文截图

The Lazy Student’s Dream: ChatGPT Passing an Engineering Course on Its Own
Authors:Gokul Puthumanaillam, Melkior Ornik
This paper presents a comprehensive investigation into the capability of Large Language Models (LLMs) to successfully complete a semester-long undergraduate control systems course. Through evaluation of 115 course deliverables, we assess LLM performance using ChatGPT under a “minimal effort” protocol that simulates realistic student usage patterns. The investigation employs a rigorous testing methodology across multiple assessment formats, from auto-graded multiple choice questions to complex Python programming tasks and long-form analytical writing. Our analysis provides quantitative insights into AI’s strengths and limitations in handling mathematical formulations, coding challenges, and theoretical concepts in control systems engineering. The LLM achieved a B-grade performance (82.24%), approaching but not exceeding the class average (84.99%), with strongest results in structured assignments and greatest limitations in open-ended projects. The findings inform discussions about course design adaptation in response to AI advancement, moving beyond simple prohibition towards thoughtful integration of these tools in engineering education. Additional materials including syllabus, examination papers, design projects, and example responses can be found at the project website: https://gradegpt.github.io.
本文全面探讨了大型语言模型(LLM)成功完成一学期本科控制系统课程的能力。通过对115份课程交付成果的评价,我们采用ChatGPT评估LLM性能,遵循模拟现实学生使用模式的“最小努力”协议。调查采用严格的测试方法,涵盖多种评估形式,从自动评分的多项选择题到复杂的Python编程任务和长篇分析写作。我们的分析提供了关于AI在处理控制系统工程中的数学公式、编程挑战和理论概念的优点和局限性的定量见解。LLM取得了B级表现(82.24%),接近但未达到班级平均水平(84.99%),结构化作业成绩最佳,开放式项目成绩局限性最大。这些发现引发了关于适应AI发展的课程设计适应的讨论,超越简单的禁令,朝着在工程教育中深思熟虑地整合这些工具的方向发展。附加材料包括教学大纲、试卷、设计项目和示例答案,可在项目网站找到:https://gradegpt.github.io。
论文及项目相关链接
Summary
本文探讨了大型语言模型(LLM)在完成学期长的控制工程系本科生课程方面的能力。通过对使用ChatGPT在模拟真实学生使用模式的“最小努力”协议下完成的115份课程成果进行评价,该研究采用严格的测试方法,涵盖多种评估形式,从自动批改的选择题到复杂的Python编程任务和长格式分析写作。分析提供了关于人工智能在处理控制系工程中的数学公式、编程挑战和理论概念的优点和局限性的定量见解。LLM的表现达到了B级水平(82.24%),接近但未超过班级平均水平(84.99%),在结构化作业中的表现最佳,而在开放式项目中的表现最为受限。这些发现引发了关于适应人工智能发展的课程设计的讨论,推动人们超越简单的禁令,开始思考如何整合这些工具在工程教育中发挥作用。更多材料可以在项目网站上找到:https://gradegpt.github.io。
Key Takeaways
以下是关于该文本的关键见解:
- 大型语言模型(LLM)在完成控制工程系本科生课程方面的能力得到了全面研究。
- 通过使用ChatGPT进行模拟真实学生使用模式的测试,对LLM的表现进行了评价。
- 研究采用了多种评估形式的严格测试方法,包括自动批改的选择题、Python编程任务和长格式分析写作。
- LLM在处理控制系工程中的数学公式、编程挑战和理论概念方面表现出优点和局限性。
- LLM的成绩达到了B级水平,接近班级平均水平,但并未超过。
- LLM在结构化作业中的表现最佳,而在开放式项目中的表现受限。
点此查看论文截图




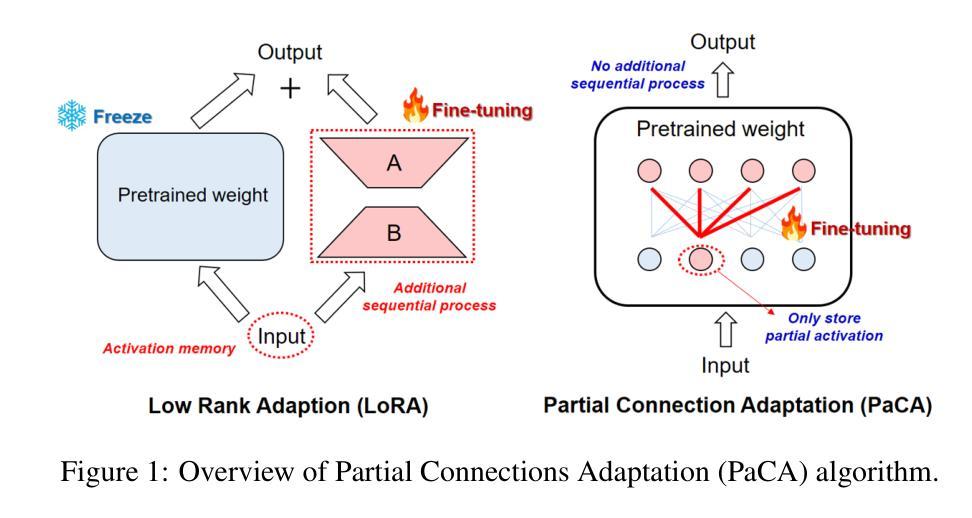
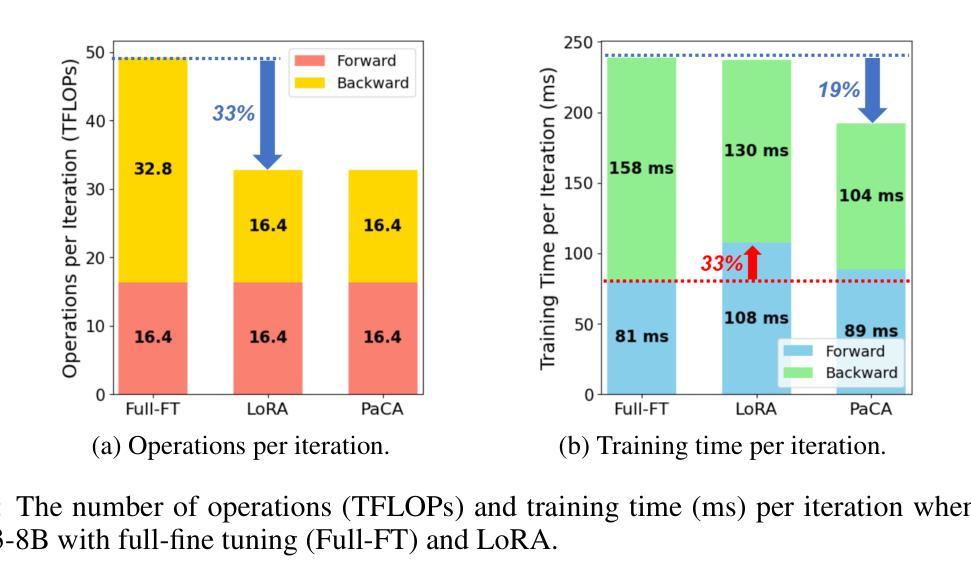
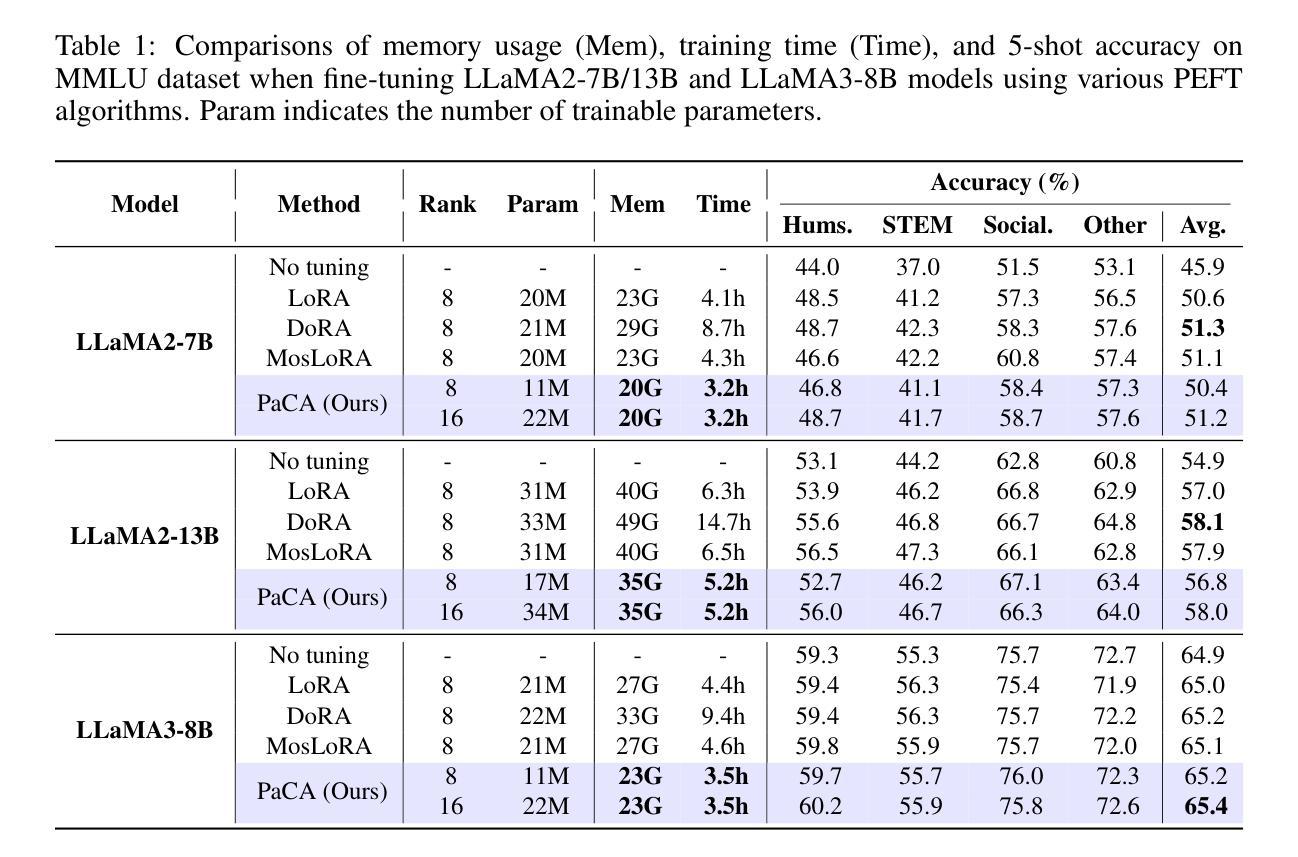
PaCA: Partial Connection Adaptation for Efficient Fine-Tuning
Authors:Sunghyeon Woo, Sol Namkung, Sunwoo Lee, Inho Jeong, Beomseok Kim, Dongsuk Jeon
Prior parameter-efficient fine-tuning (PEFT) algorithms reduce memory usage and computational costs of fine-tuning large neural network models by training only a few additional adapter parameters, rather than the entire model. However, the reduction in computational costs due to PEFT does not necessarily translate to a reduction in training time; although the computational costs of the adapter layers are much smaller than the pretrained layers, it is well known that those two types of layers are processed sequentially on GPUs, resulting in significant latency overhead. LoRA and its variants merge low-rank adapter matrices with pretrained weights during inference to avoid latency overhead, but during training, the pretrained weights remain frozen while the adapter matrices are continuously updated, preventing such merging. To mitigate this issue, we propose Partial Connection Adaptation (PaCA), which fine-tunes randomly selected partial connections within the pretrained weights instead of introducing adapter layers in the model. PaCA not only enhances training speed by eliminating the time overhead due to the sequential processing of the adapter and pretrained layers but also reduces activation memory since only partial activations, rather than full activations, need to be stored for gradient computation. Compared to LoRA, PaCA reduces training time by 22% and total memory usage by 16%, while maintaining comparable accuracy across various fine-tuning scenarios, such as fine-tuning on the MMLU dataset and instruction tuning on the Oasst1 dataset. PaCA can also be combined with quantization, enabling the fine-tuning of large models such as LLaMA3.1-70B. In addition, PaCA enables training with 23% longer sequence and improves throughput by 16% on both NVIDIA A100 GPU and INTEL Gaudi2 HPU compared to LoRA. The code is available at https://github.com/WooSunghyeon/paca.
之前的参数高效微调(PEFT)算法通过仅训练少量额外的适配器参数,而不是对整个模型进行训练,从而减少了微调大型神经网络模型的内存使用和计算成本。然而,由于PEFT导致的计算成本降低并不一定转化为训练时间的减少。尽管适配器层的计算成本远小于预训练层,众所周知,这两种类型的层在GPU上是顺序处理的,这会导致显著的延迟开销。LoRA及其变体在推理过程中将低阶适配器矩阵与预训练权重合并,以避免延迟开销,但在训练过程中,预训练权重保持冻结状态,而适配器矩阵不断更新,这阻止了合并。为了缓解这个问题,我们提出了部分连接适配(PaCA),它在预训练权重内微调随机选择的部分连接,而不是在模型中引入适配器层。PaCA不仅通过消除由于适配器层和预训练层的顺序处理而产生的时间开销,提高了训练速度,而且减少了激活内存,因为只需要存储部分激活值,而不是完整的激活值来进行梯度计算。与LoRA相比,PaCA减少了22%的训练时间和16%的总内存使用量,同时在各种微调场景(如使用MMLU数据集进行微调和使用Oasst1数据集进行指令调整)中保持相当的准确性。PaCA还可以与量化相结合,实现对大型模型(如LLaMA3.1-70B)的微调。此外,PaCA使用NVIDIA A100 GPU和INTEL Gaudi2 HPU时,支持23%更长的序列训练,并提高了16%的吞吐量相比LoRA。代码可在https://github.com/WooSunghyeon/paca找到。
论文及项目相关链接
Summary
本文介绍了一种名为Partial Connection Adaptation(PaCA)的新方法,用于改进现有的参数高效微调(PEFT)算法。该方法通过微调预训练权重中的部分连接,避免了引入额外的适配器层,从而提高训练速度和减少内存使用。相较于传统的LoRA方法,PaCA能够减少训练时间和总内存使用,同时保持相当的精度。此外,PaCA还可以与量化结合,支持大规模模型的微调,并能提高序列长度处理能力和吞吐量。
Key Takeaways
- PaCA是一种改进的PEFT方法,通过微调预训练权重中的部分连接,避免引入额外的适配器层。
- PaCA提高了训练速度,减少了因适配器层和预训练层顺序处理导致的延迟开销。
- PaCA降低了激活内存的使用,因为只需存储部分激活,而不是完整的激活,以供梯度计算。
- PaCA相较于LoRA,能够减少训练时间22%和总内存使用16%,同时保持相似的精度。
- PaCA支持在多种微调场景(如MMLU数据集上的微调、Oasst1数据集上的指令微调)中使用。
- PaCA可与量化结合,使大规模模型的微调成为可能,如LLaMA3.1-70B。
点此查看论文截图