⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Uni-Gaussians: Unifying Camera and Lidar Simulation with Gaussians for Dynamic Driving Scenarios
Authors:Zikang Yuan, Yuechuan Pu, Hongcheng Luo, Fengtian Lang, Cheng Chi, Teng Li, Yingying Shen, Haiyang Sun, Bing Wang, Xin Yang
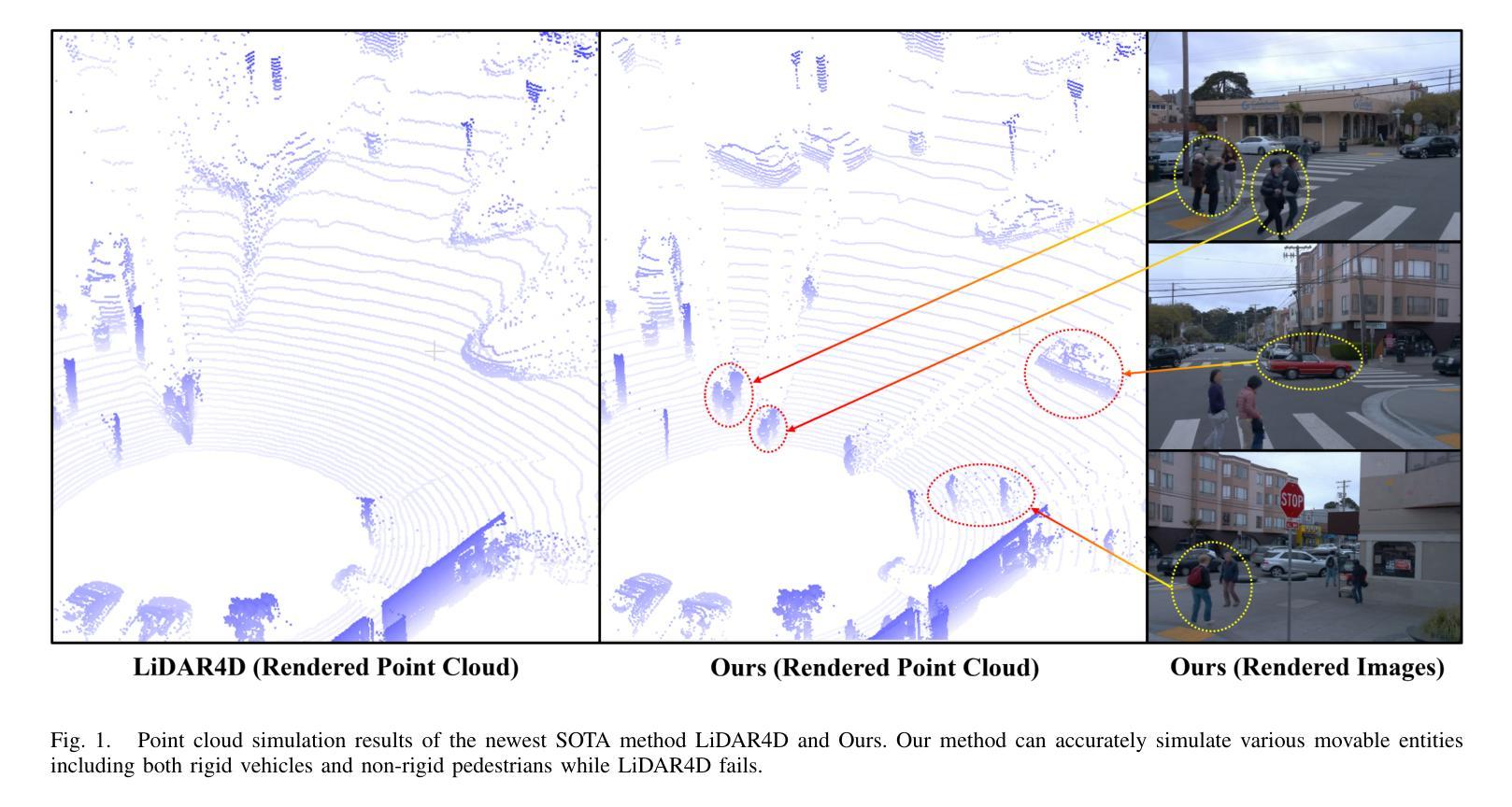
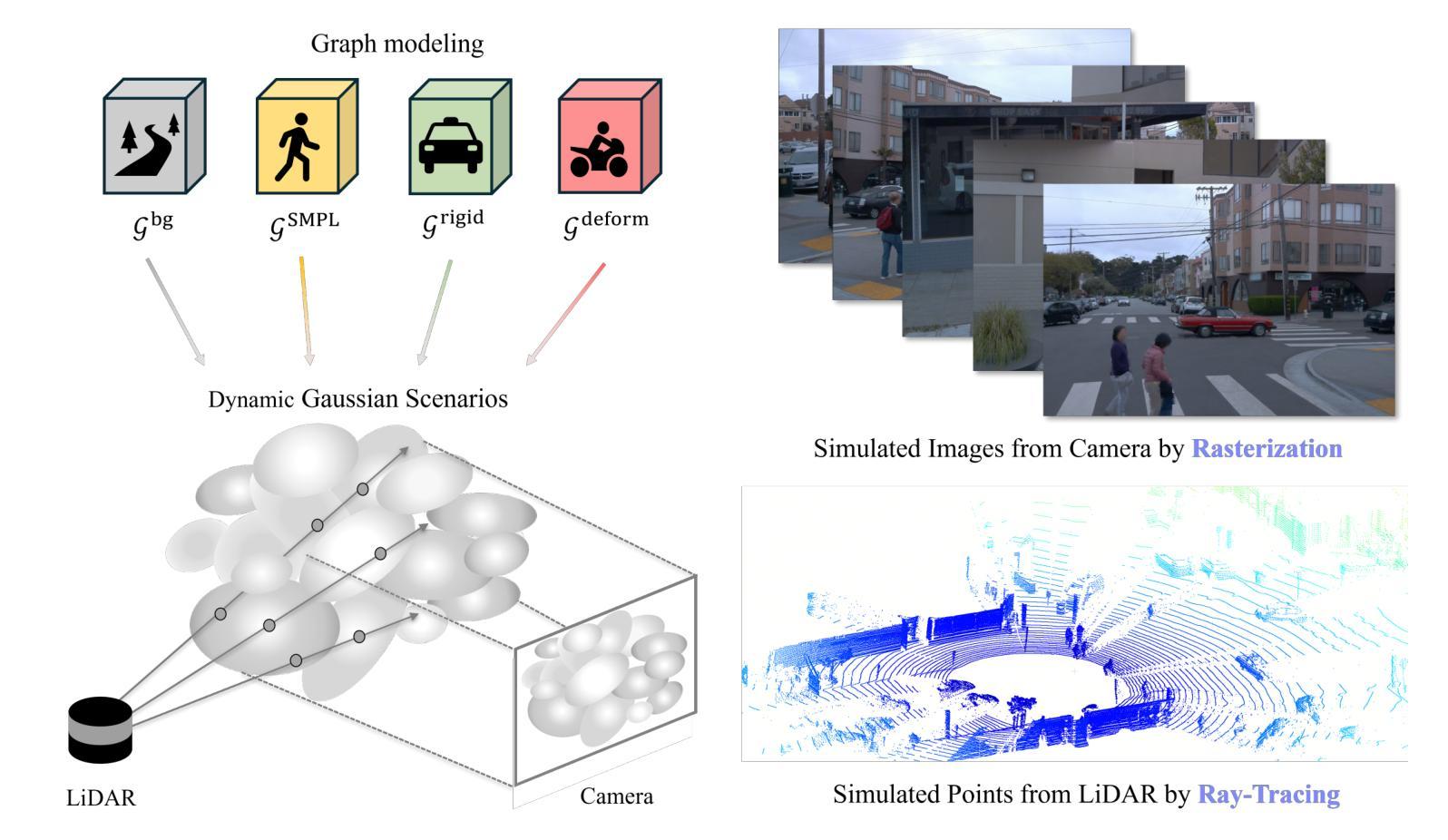
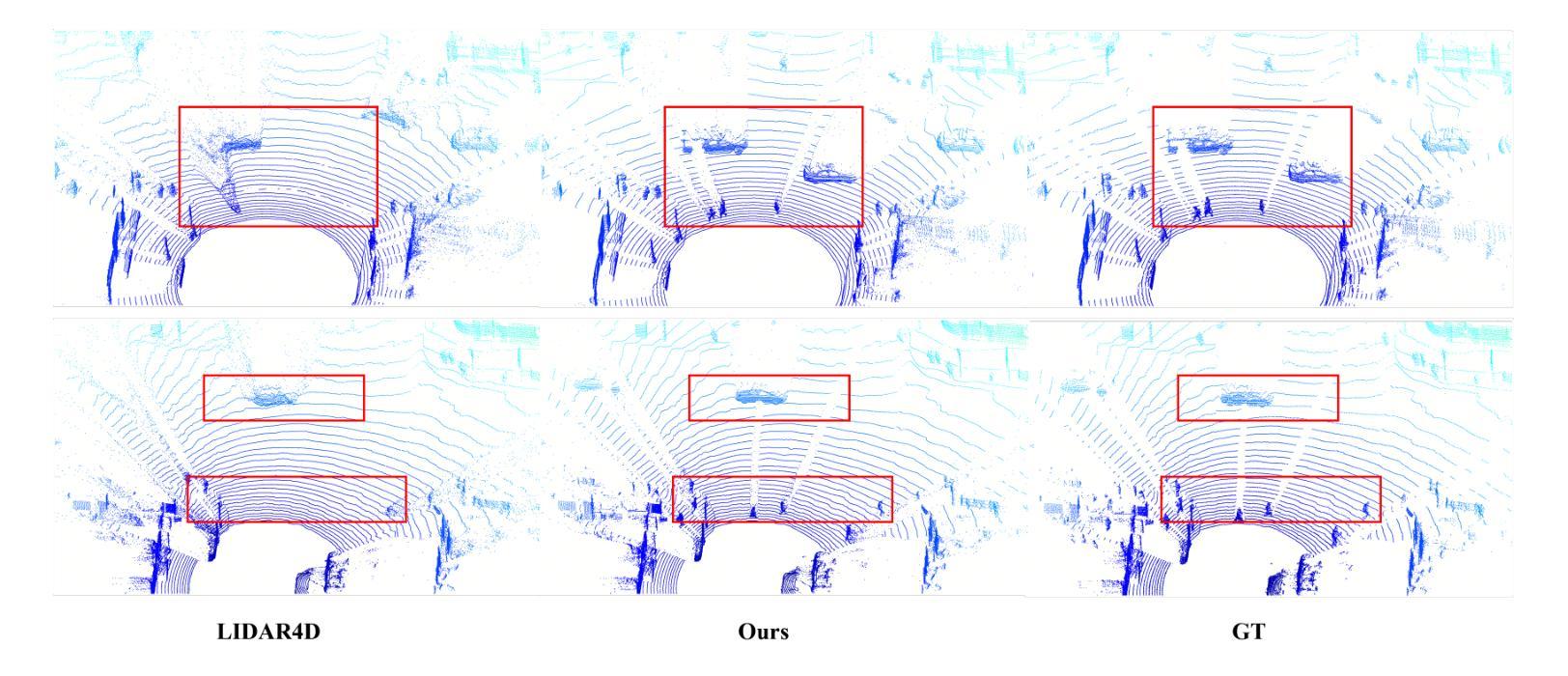
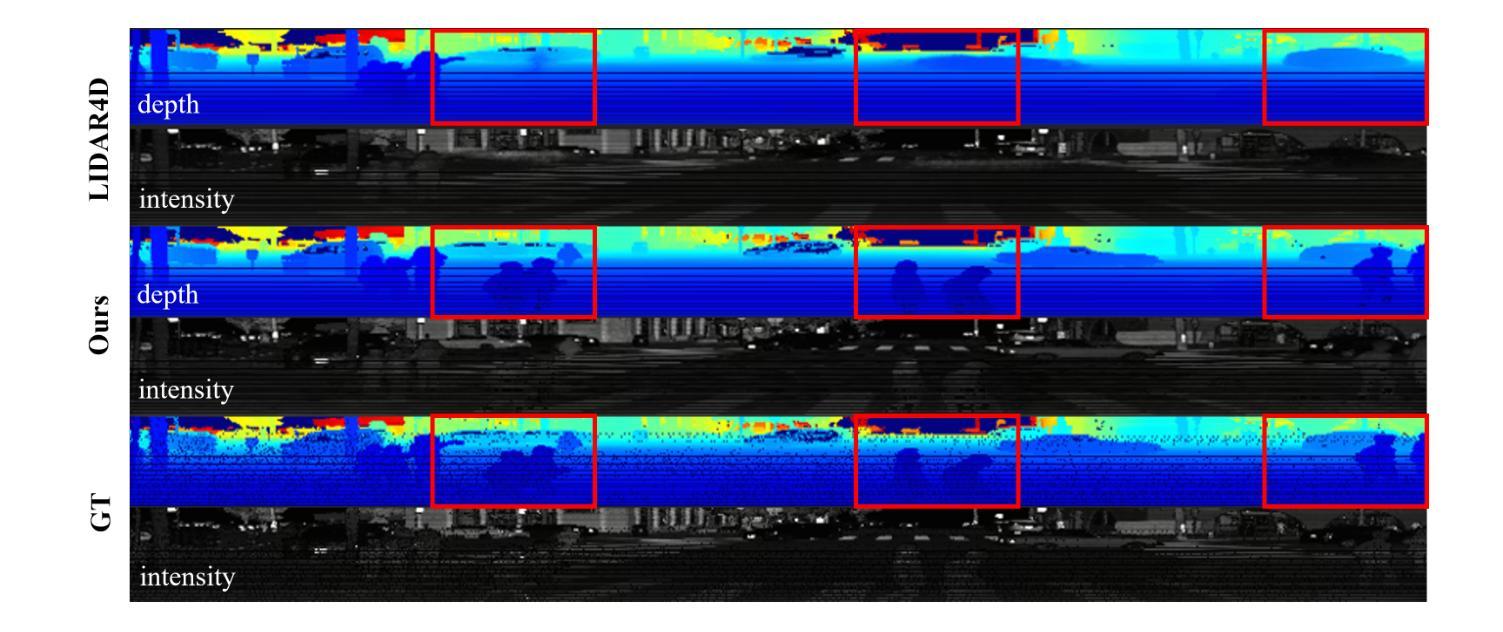
Ensuring the safety of autonomous vehicles necessitates comprehensive simulation of multi-sensor data, encompassing inputs from both cameras and LiDAR sensors, across various dynamic driving scenarios. Neural rendering techniques, which utilize collected raw sensor data to simulate these dynamic environments, have emerged as a leading methodology. While NeRF-based approaches can uniformly represent scenes for rendering data from both camera and LiDAR, they are hindered by slow rendering speeds due to dense sampling. Conversely, Gaussian Splatting-based methods employ Gaussian primitives for scene representation and achieve rapid rendering through rasterization. However, these rasterization-based techniques struggle to accurately model non-linear optical sensors. This limitation restricts their applicability to sensors beyond pinhole cameras. To address these challenges and enable unified representation of dynamic driving scenarios using Gaussian primitives, this study proposes a novel hybrid approach. Our method utilizes rasterization for rendering image data while employing Gaussian ray-tracing for LiDAR data rendering. Experimental results on public datasets demonstrate that our approach outperforms current state-of-the-art methods. This work presents a unified and efficient solution for realistic simulation of camera and LiDAR data in autonomous driving scenarios using Gaussian primitives, offering significant advancements in both rendering quality and computational efficiency.
确保自动驾驶车辆的安全需要全面模拟多传感器数据,包括来自相机和激光雷达传感器的输入,以及在不同动态驾驶场景中的应用。利用收集的原始传感器数据模拟这些动态环境的神经渲染技术已经成为一种主要方法。虽然基于NeRF的方法可以统一表示场景,实现相机和激光雷达的渲染数据,但它们受到密集采样导致的渲染速度慢的阻碍。相反,基于高斯涂抹的方法使用高斯原始数据进行场景表示,并通过光栅化实现快速渲染。然而,这些基于光栅化的技术在模拟非线性光学传感器时遇到了困难。这一局限性限制了它们对针孔相机以外传感器的适用性。为了解决这些挑战,实现对动态驾驶场景的统一表示,本研究提出了一种新型混合方法。我们的方法利用光栅化进行图像数据渲染,同时使用高斯光线追踪进行激光雷达数据渲染。在公共数据集上的实验结果表明,我们的方法优于当前最先进的方法。本研究提出了一种统一且高效的解决方案,利用高斯原始数据模拟自动驾驶场景中的相机和激光雷达数据,在渲染质量和计算效率方面都取得了重大进展。
论文及项目相关链接
PDF 10 pages
Summary
本文提出一种针对自主驾驶场景中相机和激光雷达数据模拟的混合方法。该方法利用rasterization进行图像数据渲染,同时使用高斯射线追踪进行激光雷达数据渲染,实现了对动态驾驶场景的统⼀表示。该方法在公共数据集上的实验结果表明,该方法优于当前的最优方法,为自主驾驶场景中的相机和激光雷达数据模拟提供了统⼀、高效的解决方案,同时在渲染质量和计算效率方面取得了显著的进步。
Key Takeaways
- 自主车辆安全需要全面模拟多传感器数据,包括相机和激光雷达。
- 神经网络渲染技术已成为模拟动态环境的主要方法。
- NeRF方法能统一表示相机和激光雷达的场景,但渲染速度慢。
- 高斯Splatting方法使用高斯原始数据进行快速渲染,但难以准确建模非线性光学传感器。
- 提出了一种混合方法,利用rasterization进行图像数据渲染,使用高斯射线追踪进行激光雷达数据渲染。
- 该方法在公共数据集上的实验表现优于当前最优方法。
点此查看论文截图


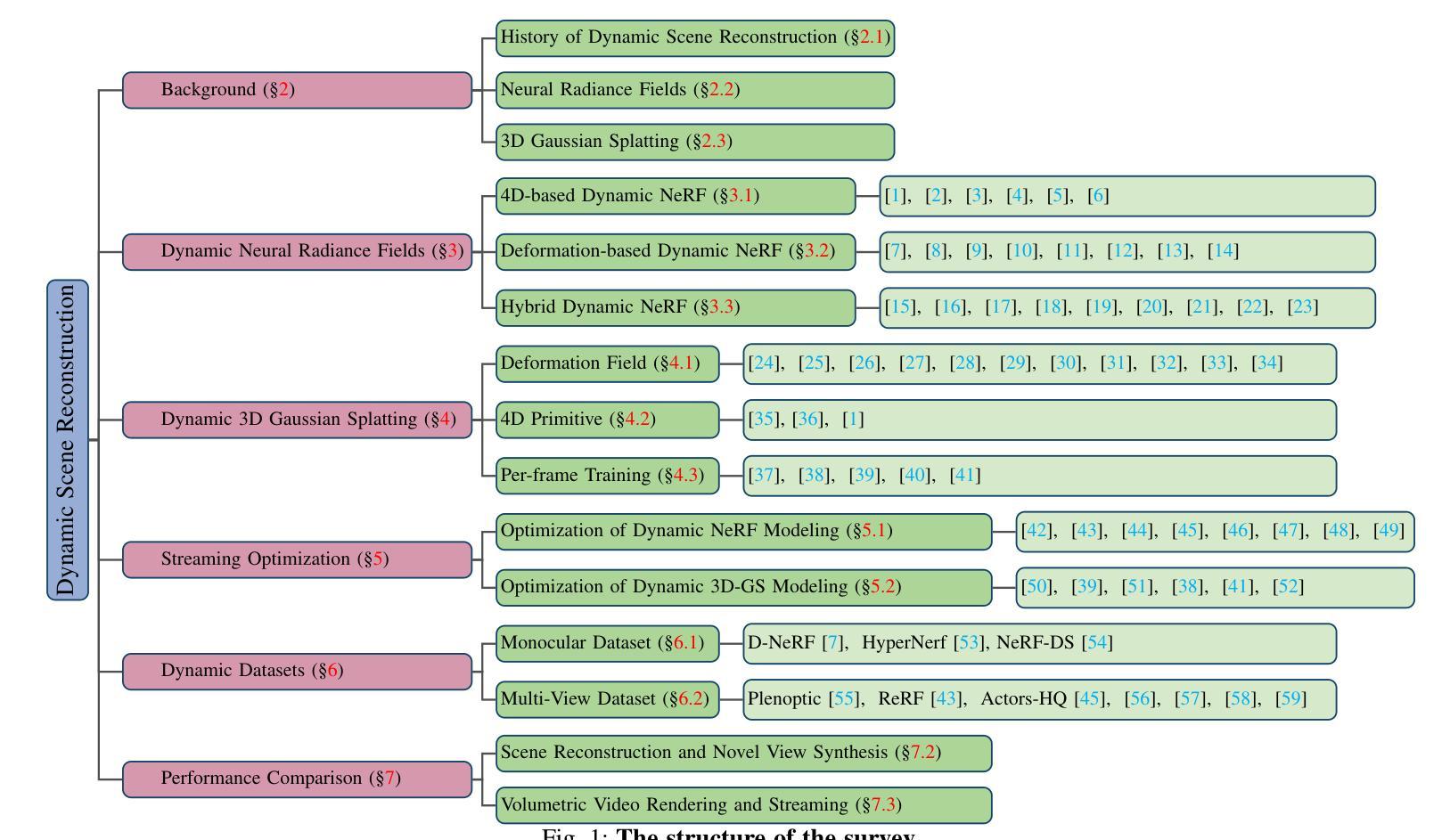
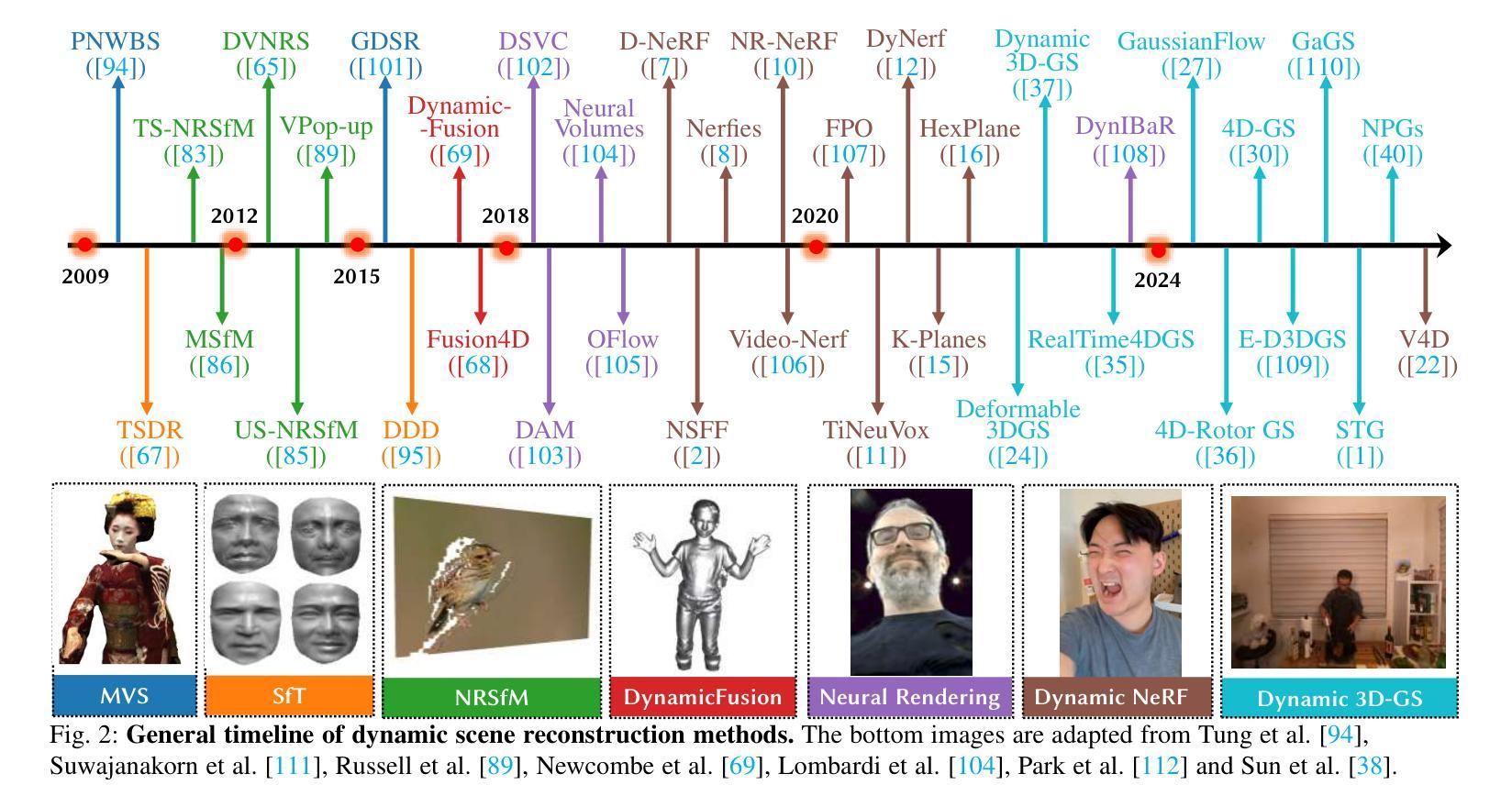
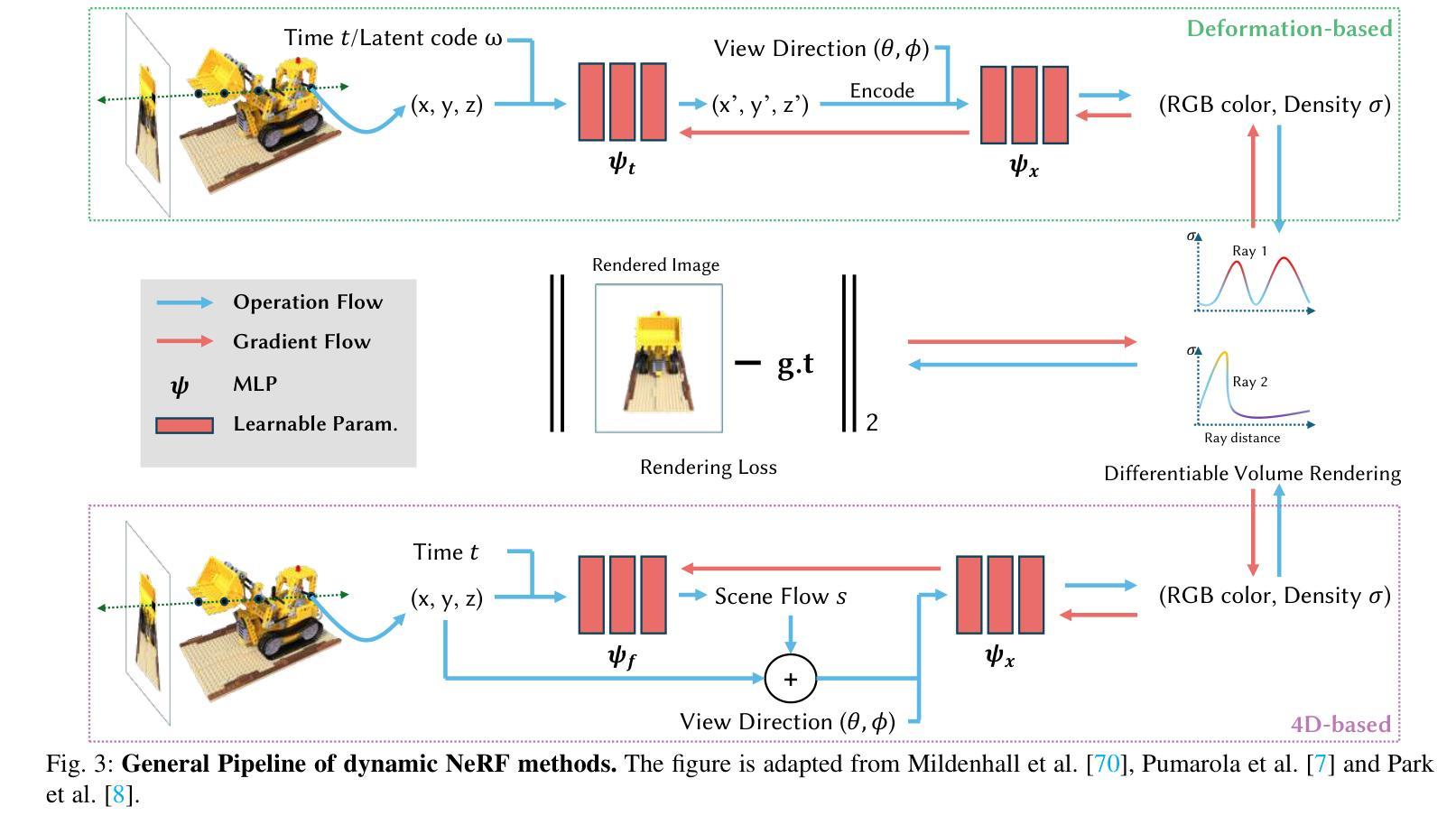
Dynamic Scene Reconstruction: Recent Advance in Real-time Rendering and Streaming
Authors:Jiaxuan Zhu, Hao Tang
Representing and rendering dynamic scenes from 2D images is a fundamental yet challenging problem in computer vision and graphics. This survey provides a comprehensive review of the evolution and advancements in dynamic scene representation and rendering, with a particular emphasis on recent progress in Neural Radiance Fields based and 3D Gaussian Splatting based reconstruction methods. We systematically summarize existing approaches, categorize them according to their core principles, compile relevant datasets, compare the performance of various methods on these benchmarks, and explore the challenges and future research directions in this rapidly evolving field. In total, we review over 170 relevant papers, offering a broad perspective on the state of the art in this domain.
从二维图像表示和渲染动态场景是计算机视觉和图形学中的一个基本且具挑战性的问题。这篇综述全面回顾了动态场景表示和渲染的演变和进展,特别强调了基于神经辐射场和基于三维高斯涂抹技术的重建方法的最新进展。我们系统地总结了现有方法,根据其核心原理进行分类,整理了相关数据集,比较了这些方法在这些基准测试上的性能,并探讨了这一快速演进领域的挑战和未来研究方向。总共回顾了超过1 7 0篇相关论文,为这一领域的最新进展提供了广泛的视角。
论文及项目相关链接
PDF 20 pages, 6 figures
Summary
本文综述了动态场景表示和渲染的研究进展,重点介绍了基于神经辐射场和3D高斯贴图技术的重建方法的最新进展。文章系统总结了现有方法,按核心原理进行分类,整理了相关数据集,对比了各方法在基准测试上的性能,并探讨了该领域的挑战和未来研究方向。本文共评述了170多篇相关论文,为当前该领域的技术状态提供了宏观视角。
Key Takeaways
- 介绍了动态场景表示和渲染的基本问题与挑战。
- 强调了基于神经辐射场和3D高斯贴图的重建方法的最新进展。
- 系统总结了现有方法,并按核心原理进行了分类。
- 整理了相关数据集,为研究者提供了便利。
- 对比了不同方法在基准测试上的性能。
- 指出该领域的挑战和未来研究方向。
点此查看论文截图

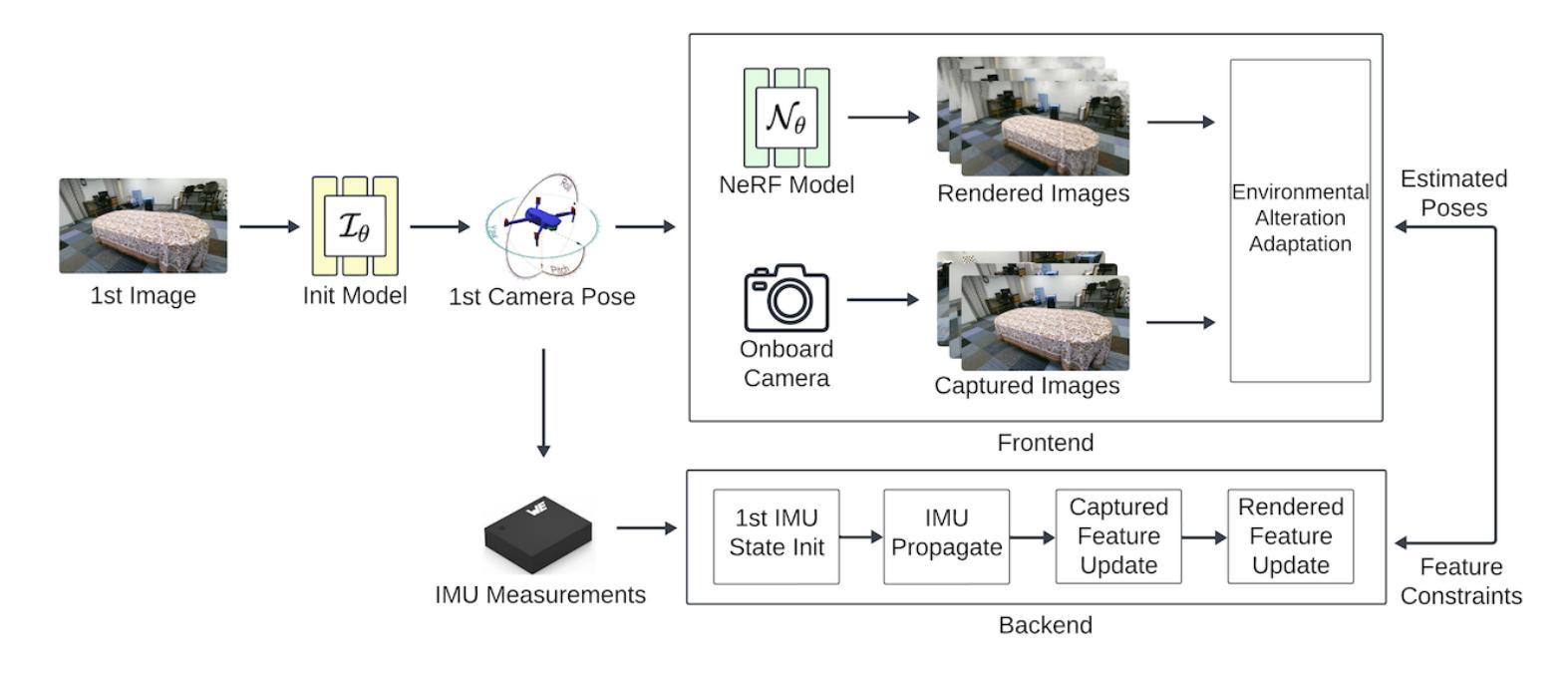
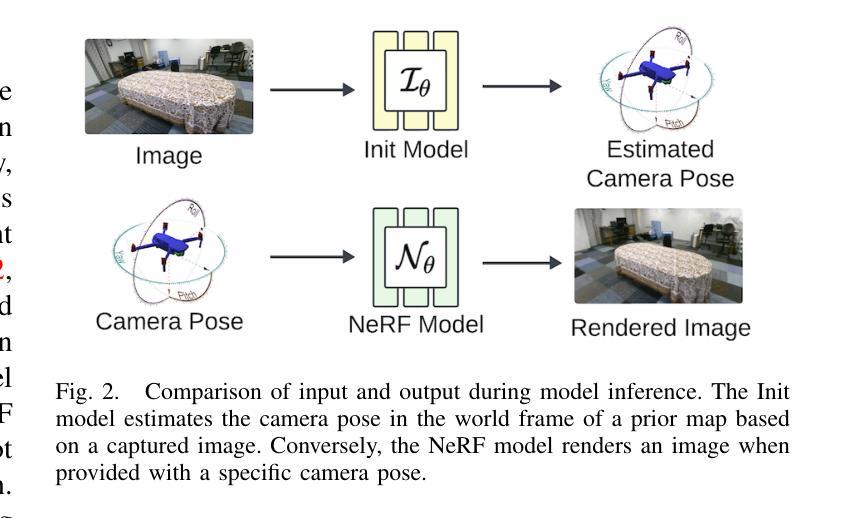
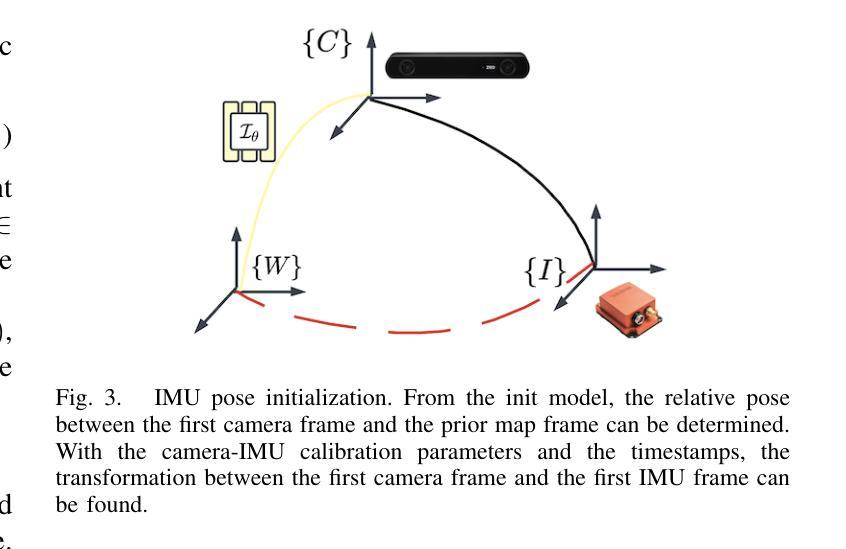
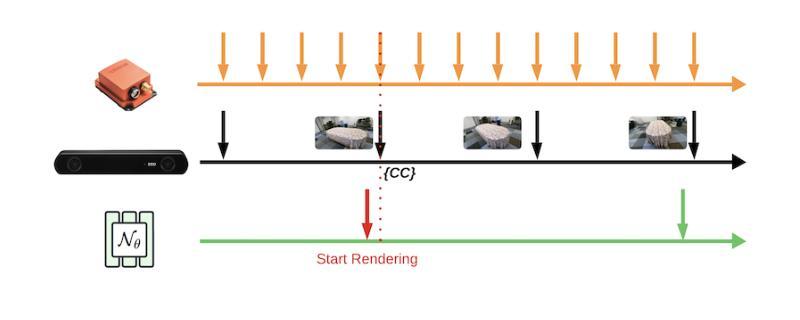
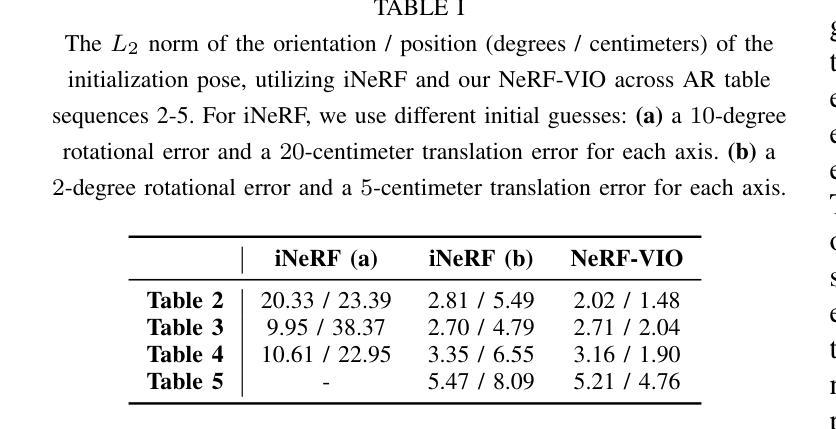
NeRF-VIO: Map-Based Visual-Inertial Odometry with Initialization Leveraging Neural Radiance Fields
Authors:Yanyu Zhang, Dongming Wang, Jie Xu, Mengyuan Liu, Pengxiang Zhu, Wei Ren
A prior map serves as a foundational reference for localization in context-aware applications such as augmented reality (AR). Providing valuable contextual information about the environment, the prior map is a vital tool for mitigating drift. In this paper, we propose a map-based visual-inertial localization algorithm (NeRF-VIO) with initialization using neural radiance fields (NeRF). Our algorithm utilizes a multilayer perceptron model and redefines the loss function as the geodesic distance on (SE(3)), ensuring the invariance of the initialization model under a frame change within (\mathfrak{se}(3)). The evaluation demonstrates that our model outperforms existing NeRF-based initialization solution in both accuracy and efficiency. By integrating a two-stage update mechanism within a multi-state constraint Kalman filter (MSCKF) framework, the state of NeRF-VIO is constrained by both captured images from an onboard camera and rendered images from a pre-trained NeRF model. The proposed algorithm is validated using a real-world AR dataset, the results indicate that our two-stage update pipeline outperforms MSCKF across all data sequences.
先验地图在上下文感知应用(如增强现实(AR))中作为定位的基础参考。它提供了有关环境的宝贵上下文信息,是减轻漂移的重要工具。在本文中,我们提出了一种基于地图的视觉惯性定位算法(NeRF-VIO),该算法使用神经辐射场(NeRF)进行初始化。我们的算法采用多层感知器模型,并将损失函数重新定义为SE(3)上的测地线距离,确保初始化模型在se(3)内框架变化下的不变性。评估表明,我们的模型在准确性和效率方面都优于现有的基于NeRF的初始化解决方案。通过在多状态约束卡尔曼滤波器(MSCKF)框架内集成两阶段更新机制,NeRF-VIO的状态受到来自车载相机的捕获图像和来自预训练的NeRF模型的渲染图像的共同约束。使用真实的AR数据集对提出的算法进行了验证,结果表明我们的两阶段更新管道在所有数据序列上的表现均优于MSCKF。
论文及项目相关链接
Summary
本文提出一种基于地图的视觉惯性定位算法(NeRF-VIO),利用神经网络辐射场(NeRF)进行初始化。算法采用多层感知器模型,将损失函数定义为SE(3)上的测地线距离,确保初始化模型的frame变化下的不变性。评估显示,该模型在准确性和效率方面均优于现有NeRF初始化解决方案。通过在一个多状态约束卡尔曼滤波器(MSCKF)框架内整合两阶段更新机制,NeRF-VIO的状态受到来自车载相机捕获的图像和预先训练的NeRF模型渲染的图像的共同约束。使用真实世界的AR数据集验证了所提算法,结果显示我们的两阶段更新管道在所有数据序列上都优于MSCKF。
Key Takeaways
- 本文提出了一种基于地图的视觉惯性定位算法NeRF-VIO,利用NeRF进行初始化,为AR等应用提供重要环境上下文信息。
- 算法采用多层感知器模型,重新定义损失函数为SE(3)上的测地线距离,确保初始化模型在frame变化下的不变性。
- 评估显示,NeRF-VIO在准确性和效率方面优于现有NeRF初始化解决方案。
- NeRF-VIO整合了两阶段更新机制,约束来自相机捕获和NeRF模型渲染的图像。
- 所提算法在真实世界的AR数据集上进行了验证。
- 结果显示,NeRF-VIO的两阶段更新管道在定位精度上优于多状态约束卡尔曼滤波器(MSCKF)。
点此查看论文截图

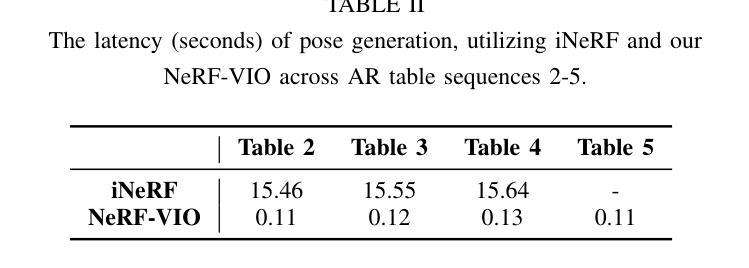
Geometry-Aware Diffusion Models for Multiview Scene Inpainting
Authors:Ahmad Salimi, Tristan Aumentado-Armstrong, Marcus A. Brubaker, Konstantinos G. Derpanis
In this paper, we focus on 3D scene inpainting, where parts of an input image set, captured from different viewpoints, are masked out. The main challenge lies in generating plausible image completions that are geometrically consistent across views. Most recent work addresses this challenge by combining generative models with a 3D radiance field to fuse information across a relatively dense set of viewpoints. However, a major drawback of these methods is that they often produce blurry images due to the fusion of inconsistent cross-view images. To avoid blurry inpaintings, we eschew the use of an explicit or implicit radiance field altogether and instead fuse cross-view information in a learned space. In particular, we introduce a geometry-aware conditional generative model, capable of multi-view consistent inpainting using reference-based geometric and appearance cues. A key advantage of our approach over existing methods is its unique ability to inpaint masked scenes with a limited number of views (i.e., few-view inpainting), whereas previous methods require relatively large image sets for their 3D model fitting step. Empirically, we evaluate and compare our scene-centric inpainting method on two datasets, SPIn-NeRF and NeRFiller, which contain images captured at narrow and wide baselines, respectively, and achieve state-of-the-art 3D inpainting performance on both. Additionally, we demonstrate the efficacy of our approach in the few-view setting compared to prior methods.
本文重点关注3D场景补全,即输入图像集中的部分从不同视角拍摄并被屏蔽。主要挑战在于生成在几何上跨视图一致的合理图像补全。最近的工作通过结合生成模型与3D辐射场来融合相对密集视点集的信息来解决这一挑战。然而,这些方法的一个主要缺点是它们通常由于跨视图图像的不一致融合而产生模糊图像。为了避免模糊的补全,我们完全摒弃了显式或隐式的辐射场的使用,而是在学习空间中融合跨视图信息。特别是,我们引入了一种几何感知条件生成模型,它能够在基于参考的几何和外观线索下实现多视图一致的补全。我们的方法与现有方法相比的一个主要优势是,它能够在有限的视图数量下进行遮罩场景的补全(即少视图补全),而之前的方法则需要相对较大的图像集来进行其3D模型拟合步骤。从经验上讲,我们在两个数据集SPIn-NeRF和NeRFiller上评估并比较了我们的场景中心补全方法,这两个数据集分别包含了窄视场和宽视场的图像,并且在两者上都实现了最先进的3D补全性能。此外,我们还证明了与先前方法相比,在少视图情况下我们的方法的有效性。
论文及项目相关链接
PDF Our project page is available at https://geomvi.github.io
Summary
本文专注于3D场景补全,针对输入图像集中从不同视角捕获的部分被遮挡的问题。主要挑战在于生成在不同视角下几何一致的合理图像补全。虽然最近的工作通过结合生成模型与3D辐射场来融合跨视角的信息,但它们常常因跨视角图像的不一致性融合而产生模糊图像。为了避免产生模糊的补全图像,本文放弃了显式或隐式的辐射场的使用,而是在学习空间中融合跨视角的信息。我们引入了一个基于几何条件的生成模型,利用参考的几何和外观线索进行多视角一致的补全。相比于现有方法,我们的方法能在有限的视角下进行场景补全,而之前的方法则需要大量的图像集来进行3D模型拟合。我们在两个数据集上评估并比较了我们的场景中心补全方法,分别是SPIn-NeRF和NeRFiller,这两个数据集包含窄视角和宽视角的图像,我们在两者上都实现了最先进的3D补全性能。此外,我们还展示了与先前方法相比,在少量视角设置下的有效性。
Key Takeaways
- 本文专注于3D场景补全,挑战在于生成在不同视角下几何一致的合理图像补全。
- 最近的方法结合生成模型与3D辐射场进行信息融合,但常产生模糊图像。
- 本文为避免模糊图像,在学习空间中融合跨视角信息,并引入基于几何条件的生成模型。
- 相比现有方法,本文方法在有限视角下进行场景补全。
- 在两个数据集SPIn-NeRF和NeRFiller上实现了先进的3D补全性能。
- 引入的方法在少量视角设置下相比先前方法更有效。
点此查看论文截图

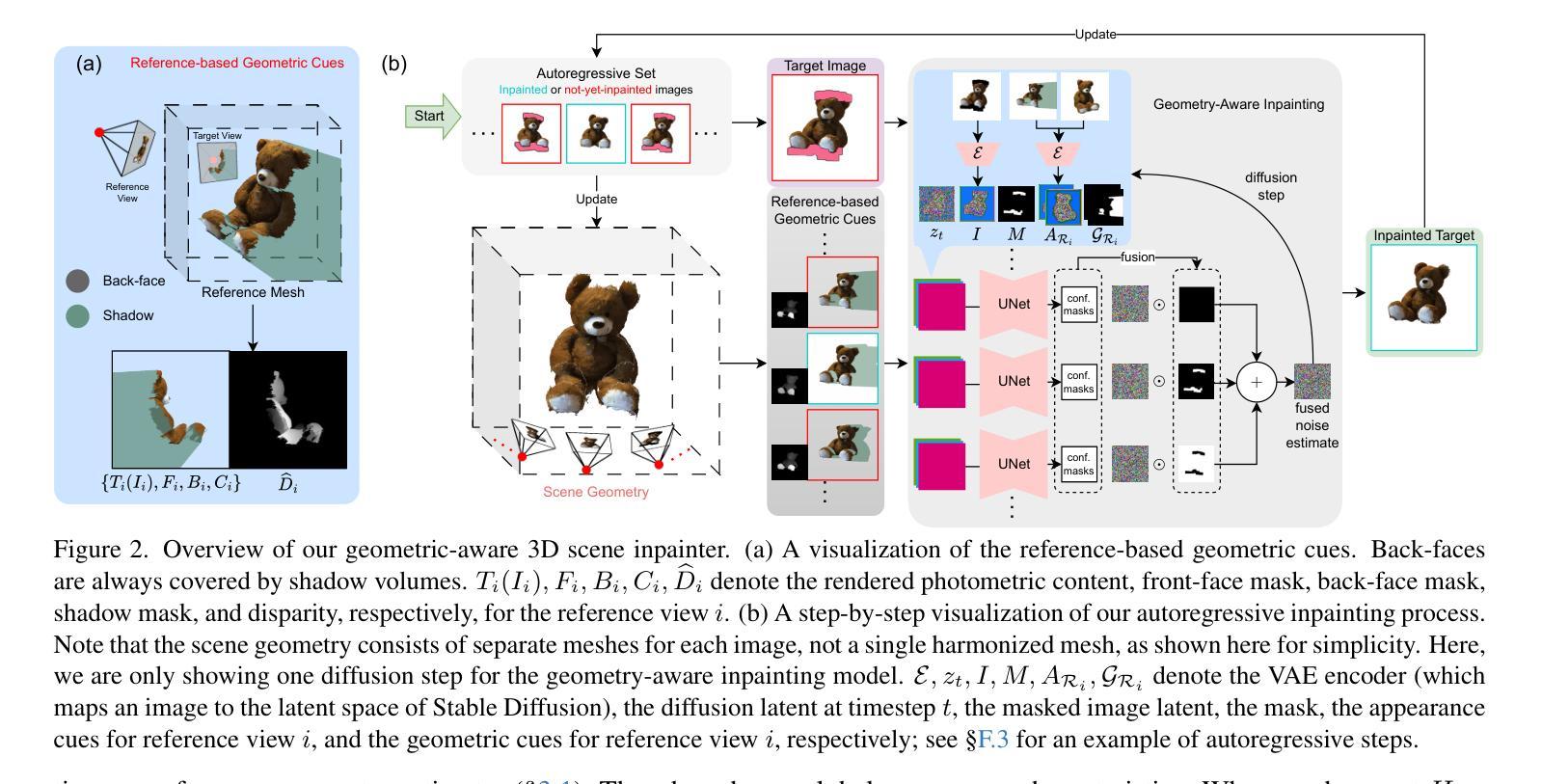
6DGS: Enhanced Direction-Aware Gaussian Splatting for Volumetric Rendering
Authors:Zhongpai Gao, Benjamin Planche, Meng Zheng, Anwesa Choudhuri, Terrence Chen, Ziyan Wu
Novel view synthesis has advanced significantly with the development of neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS). However, achieving high quality without compromising real-time rendering remains challenging, particularly for physically-based ray tracing with view-dependent effects. Recently, N-dimensional Gaussians (N-DG) introduced a 6D spatial-angular representation to better incorporate view-dependent effects, but the Gaussian representation and control scheme are sub-optimal. In this paper, we revisit 6D Gaussians and introduce 6D Gaussian Splatting (6DGS), which enhances color and opacity representations and leverages the additional directional information in the 6D space for optimized Gaussian control. Our approach is fully compatible with the 3DGS framework and significantly improves real-time radiance field rendering by better modeling view-dependent effects and fine details. Experiments demonstrate that 6DGS significantly outperforms 3DGS and N-DG, achieving up to a 15.73 dB improvement in PSNR with a reduction of 66.5% Gaussian points compared to 3DGS. The project page is: https://gaozhongpai.github.io/6dgs/
随着神经网络辐射场(NeRF)和三维高斯涂抹(3DGS)的发展,新型视图合成技术已经取得了重大进展。然而,在不损害实时渲染的前提下实现高质量仍然是一个挑战,特别是在基于物理的射线追踪和视角依赖效果方面。最近,N维高斯(N-DG)引入了一种6维空间角表示法,以更好地融入视角依赖效果,但高斯表示和控制方案并不理想。在本文中,我们重新审视了6D高斯,并引入了6维高斯涂抹(6DGS),它增强了颜色和透明度表示,并利用6D空间中的额外方向信息对高斯控制进行了优化。我们的方法与3DGS框架完全兼容,通过更好地建模视角依赖效果和细节,显著改进了实时辐射场渲染。实验表明,6DGS在PSNR上相较于3DGS和高斯-N维方法取得了显著的优势,实现了高达15.73分贝的改进,同时高斯点减少了66.5%。项目页面为:链接。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
新型视图合成技术通过神经网络辐射场(NeRF)和三维高斯涂抹(3DGS)取得了显著进展,但如何在保证高质量的同时实现实时渲染仍是挑战。本文提出一种基于六维高斯涂抹(6DGS)的方法,优化了颜色和透明度表示,并利用六维空间中的额外方向信息优化了高斯控制。该方法与三维高斯涂抹框架兼容,能更有效地模拟视图相关效应和细节,显著提高了实时辐射场渲染效果。实验表明,6DGS显著优于其他方法。
Key Takeaways
- NeRF与视图相关的新型合成技术在近年来发展显著,但实现高质量实时渲染仍是挑战。
- 引入六维高斯涂抹(6DGS)方法,该方法优化了颜色和透明度表示。
- 6DGS利用六维空间中的额外方向信息,实现高斯控制优化。
- 6DGS与现有三维高斯涂抹框架兼容,可大幅提高实时辐射场渲染效果。
- 相比其他方法,6DGS在PSNR上有显著改进,最高可达15.73dB。
- 与现有技术相比,6DGS可减少高达66.5%的高斯点使用。
点此查看论文截图

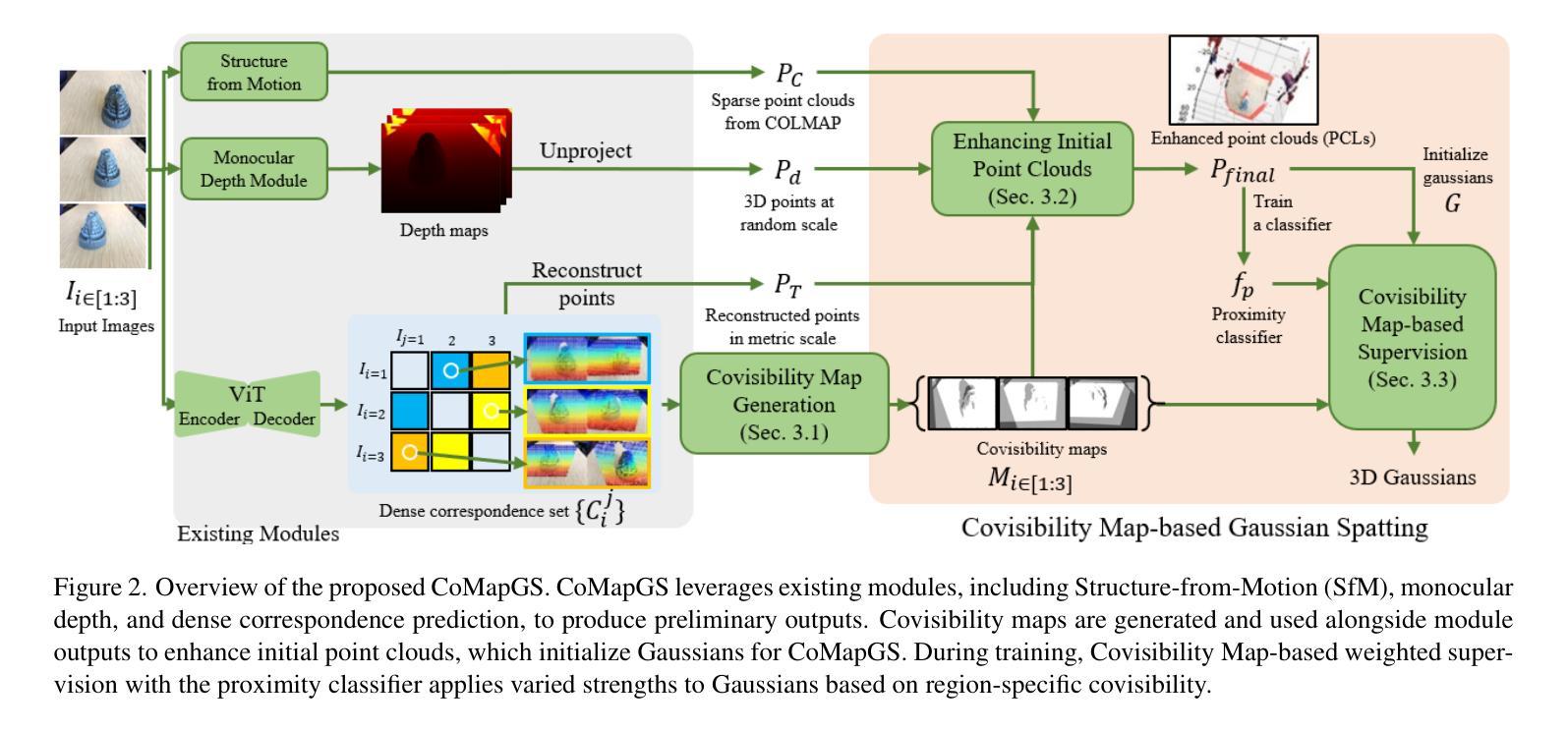
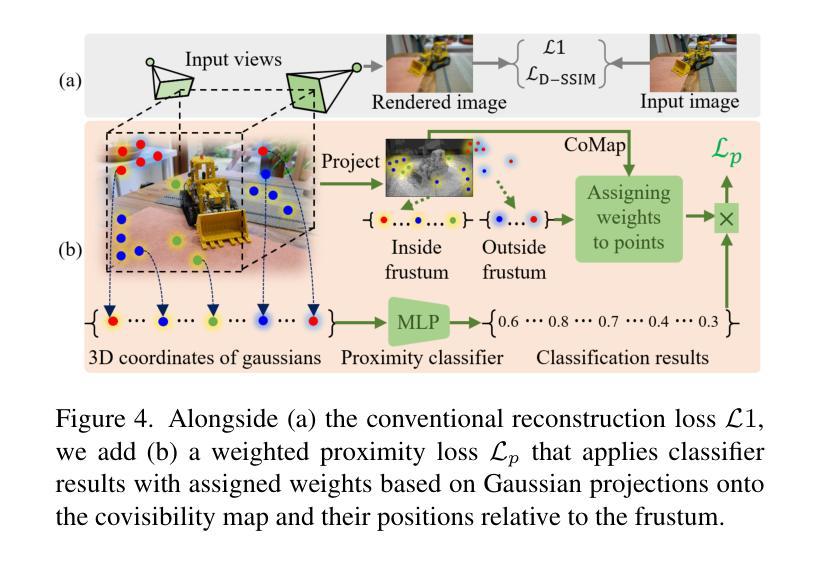
CoMapGS: Covisibility Map-based Gaussian Splatting for Sparse Novel View Synthesis
Authors:Youngkyoon Jang, Eduardo Pérez-Pellitero
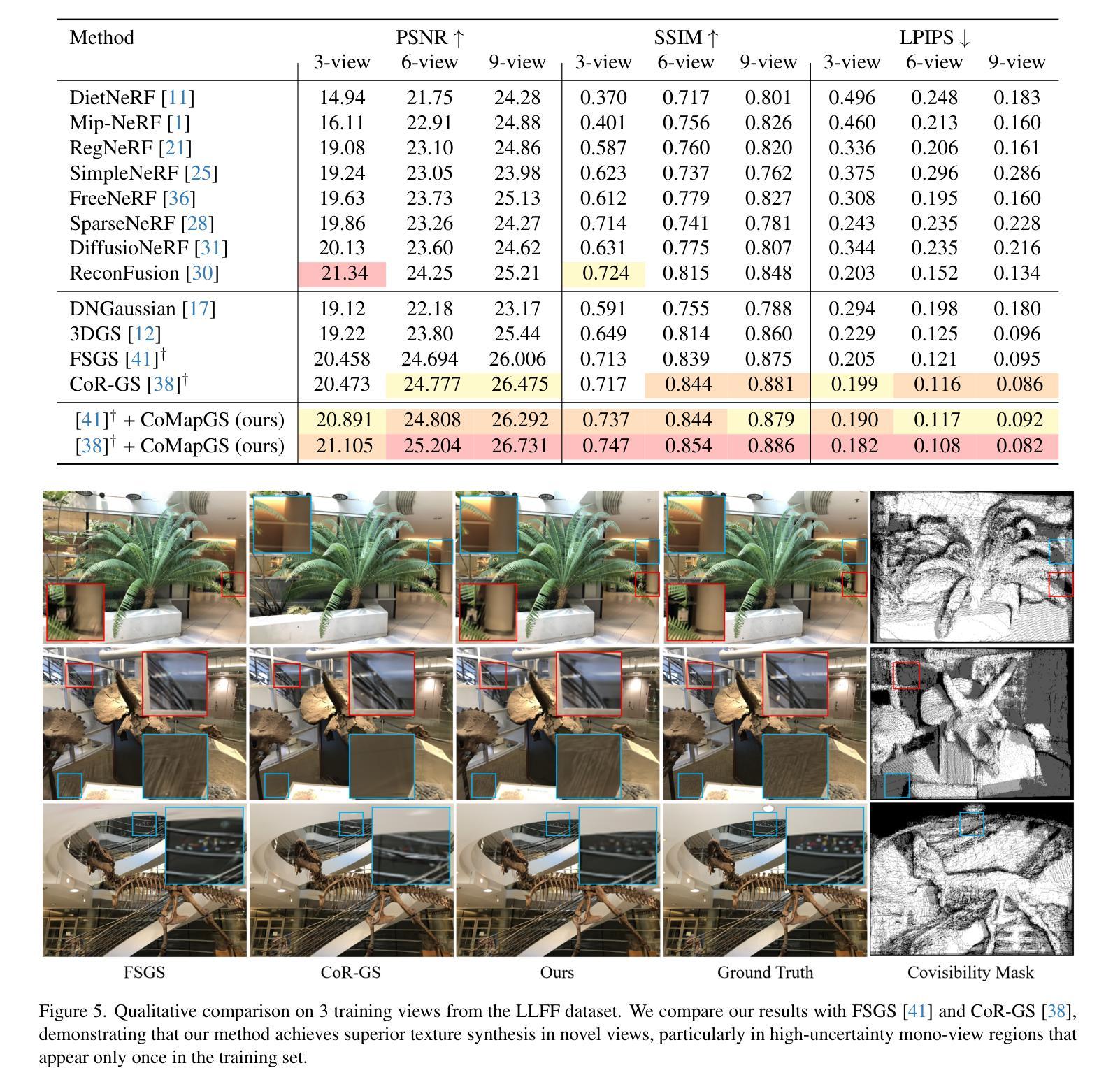
We propose Covisibility Map-based Gaussian Splatting (CoMapGS), designed to recover underrepresented sparse regions in sparse novel view synthesis. CoMapGS addresses both high- and low-uncertainty regions by constructing covisibility maps, enhancing initial point clouds, and applying uncertainty-aware weighted supervision with a proximity classifier. Our contributions are threefold: (1) CoMapGS reframes novel view synthesis by leveraging covisibility maps as a core component to address region-specific uncertainty levels; (2) Enhanced initial point clouds for both low- and high-uncertainty regions compensate for sparse COLMAP-derived point clouds, improving reconstruction quality and benefiting few-shot 3DGS methods; (3) Adaptive supervision with covisibility-score-based weighting and proximity classification achieves consistent performance gains across scenes with various sparsity scores derived from covisibility maps. Experimental results demonstrate that CoMapGS outperforms state-of-the-art methods on datasets including Mip-NeRF 360 and LLFF.
我们提出了基于可见性地图的高斯拼贴(CoMapGS),旨在恢复稀疏新颖视角合成中表现不足的稀疏区域。CoMapGS通过构建可见性地图、增强初始点云、应用基于接近度的分类器的带权重的不确定性感知监督来解决高不确定性和低不确定性区域的问题。我们的贡献有三点:(1)CoMapGS利用可见性地图作为核心组件,重新定义了新颖视角的合成,以解决特定区域的不确定性水平问题;(2)增强初始点云,对低不确定性和高不确定性区域进行补偿,弥补稀疏COLMAP衍生的点云,提高重建质量,有利于少镜头3DGS方法;(3)基于可见性得分的加权和接近度分类的自适应监督,在来自不同可见性地图的稀疏场景上实现了性能的一致性提升。实验结果表明,在包括Mip-NeRF 360和LLFF数据集上,CoMapGS优于最新方法。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文提出基于可见性地图的高斯拼贴法(CoMapGS),旨在恢复稀疏的新型视图合成中的未充分表示区域。CoMapGS通过构建可见性地图、增强初始点云、应用不确定性的加权监督及邻近分类器,解决了高不确定性和低不确定性区域的问题。其贡献在于三个方面:首先,CoMapGS利用可见性地图作为核心组件,解决区域特定的不确定性水平,重新定义了新型视图合成;其次,增强初始点云以提高低高不确定性区域的重建质量,并有利于少数3DGS方法;最后,自适应监督与基于可见性得分的加权和邻近分类实现跨场景的持续性能提升,根据可见性地图得出不同的稀疏度得分。实验结果表明,CoMapGS在Mip-NeRF 360和LLFF等数据集上的性能优于现有技术。
Key Takeaways
- CoMapGS旨在恢复稀疏新型视图合成中的未充分表示区域。
- CoMapGS通过构建可见性地图解决高、低不确定性区域的问题。
- CoMapGS利用可见性地图作为核心组件,重新定义了新型视图合成。
- 增强初始点云以提高重建质量,并优化少数3DGS方法。
- 自适应监督与基于可见性得分的加权和邻近分类实现跨场景的持续性能提升。
- CoMapGS在Mip-NeRF 360和LLFF等数据集上的性能优于现有技术。
点此查看论文截图