⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
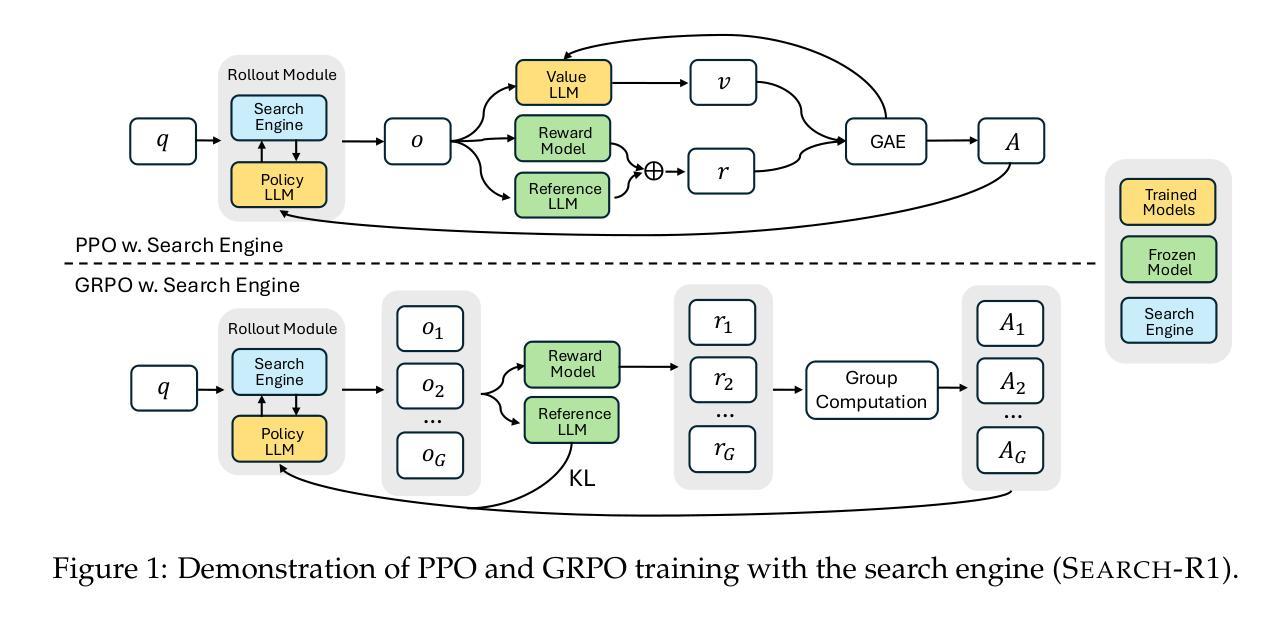
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Authors:Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, Jiawei Han
Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Retrieval augmentation and tool-use training approaches where a search engine is treated as a tool lack complex multi-turn retrieval flexibility or require large-scale supervised data. Prompting advanced LLMs with reasoning capabilities during inference to use search engines is not optimal, since the LLM does not learn how to optimally interact with the search engine. This paper introduces Search-R1, an extension of the DeepSeek-R1 model where the LLM learns – solely through reinforcement learning (RL) – to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM rollouts with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 26% (Qwen2.5-7B), 21% (Qwen2.5-3B), and 10% (LLaMA3.2-3B) over SOTA baselines. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.
在大规模语言模型(LLM)中进行有效的推理和文本生成,高效获取外部知识和最新信息至关重要。检索增强和工具使用训练方法中,将搜索引擎视为工具缺乏复杂的多轮检索灵活性,或者需要大规模监督数据。在推理过程中提示具备推理能力的先进LLM使用搜索引擎并不理想,因为LLM并没有学习如何最优地与搜索引擎进行交互。本文介绍了Search-R1,它是DeepSeek-R1模型的扩展,其中LLM通过强化学习(RL)自主学习,在逐步推理过程中自主生成(多个)搜索查询,并进行实时检索。Search-R1通过多轮搜索交互优化LLM的推出,利用检索令牌屏蔽进行稳定的RL训练和一个简单的基于结果奖励函数。在七个问答数据集上的实验表明,相较于SOTA基线,Search-R1提高了Qwen2.5-7B的26%、Qwen2.5-3B的21%和LLaMA3.2-3B的10%的性能。本文还提供了关于强化学习优化方法、LLM选择和响应长度动力学的实证见解。代码和模型检查点可通过https://github.com/PeterGriffinJin/Search-R1获取。
论文及项目相关链接
PDF 16 pages
Summary
本文介绍了Search-R1模型,它是DeepSeek-R1模型的扩展。该模型使大型语言模型(LLM)能够自主学习与搜索引擎进行多轮搜索交互,以实时检索方式生成多个搜索查询。通过强化学习(RL)训练,Search-R1优化了LLM的推理过程,并提供了关于RL优化方法、LLM选择和响应长度动态的实证见解。实验结果表明,Search-R1在七个问答数据集上的性能较现有技术提高了26%、21%和10%。
Key Takeaways
- Search-R1模型是DeepSeek-R1的扩展,使LLM能够自主学习与搜索引擎进行多轮搜索交互。
- 该模型通过强化学习(RL)训练,使LLM能够自主生成多个搜索查询,以实时检索方式进行推理。
- Search-R1优化了LLM的推理过程,通过检索到的令牌屏蔽来实现稳定的RL训练。
- 响应长度动力学在检索增强推理中很重要,Search-R1对此进行了深入研究。
- 实证分析表明,Search-R1在多个问答数据集上的性能较现有技术显著提高。
- 该模型的代码和模型检查点已公开发布,可供研究使用。
点此查看论文截图

Reinforcement Learning is all You Need
Authors:Yongsheng Lian
Inspired by the success of DeepSeek R1 in reasoning via reinforcement learning without human feedback, we train a 3B language model using the Countdown Game with pure reinforcement learning. Our model outperforms baselines on four of five benchmarks, demonstrating improved generalization beyond its training data. Notably, response length does not correlate with reasoning quality, and while “aha moments” emerge, they do not always yield correct answers. These findings highlight the potential of RL-only training for reasoning enhancement and suggest future work on refining reward structures to bridge emergent insights with accuracy.
受DeepSeek R1通过无需人类反馈的强化学习进行推理的成功启发,我们采用纯强化学习的方法,使用倒计时游戏对3B语言模型进行训练。该模型在五个基准测试中的四个上超越了基线水平,表现出在训练数据之外的改进泛化能力。值得注意的是,响应长度并不与推理质量相关,虽然会出现“顿悟时刻”,但并不总能得出正确答案。这些发现突显了仅使用强化学习进行推理增强的潜力,并建议未来的工作是对奖励结构进行细化,以将突发见解与准确性相结合。
论文及项目相关链接
PDF 15 pages, 2 figures
Summary
基于DeepSeek R1通过强化学习进行推理的成功,我们训练了一个规模为3B的语言模型,采用纯强化学习的Countdown Game方法。模型在五个基准测试中有四个表现超越基线,展现出超越训练数据的泛化能力。响应长度并不与推理质量相关,“顿悟时刻”的出现并不总能带来正确答案。这些发现突显出仅使用强化学习进行推理增强的潜力,并建议未来改进奖励结构以弥合新兴见解与准确性之间的鸿沟。
Key Takeaways
- 使用纯强化学习训练了一个规模为3B的语言模型,在五个基准测试中表现优异。
- 模型展现出超越训练数据的泛化能力。
- 响应长度并不与推理质量直接相关。
- 模型在推理过程中会出现“顿悟时刻”,但并不总能得出正确答案。
- 仅使用强化学习进行推理增强具有潜力。
- 需要改进奖励结构以更好地结合新兴见解与准确性。
- 研究强调了强化学习在推动语言模型推理能力方面的作用。
点此查看论文截图

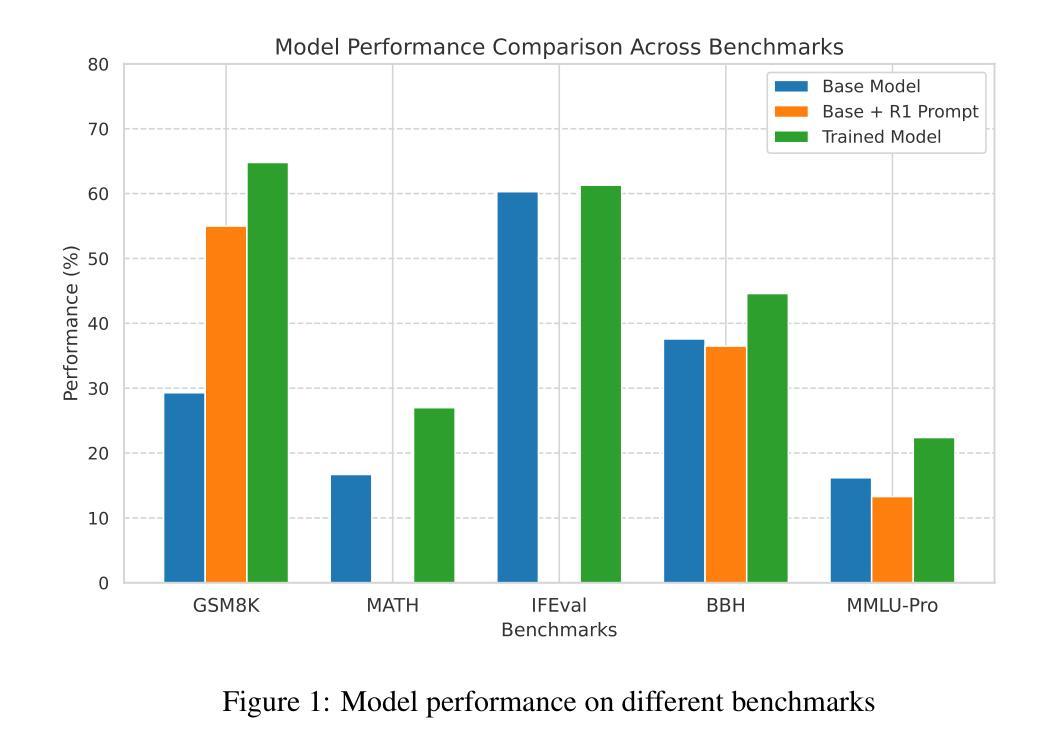

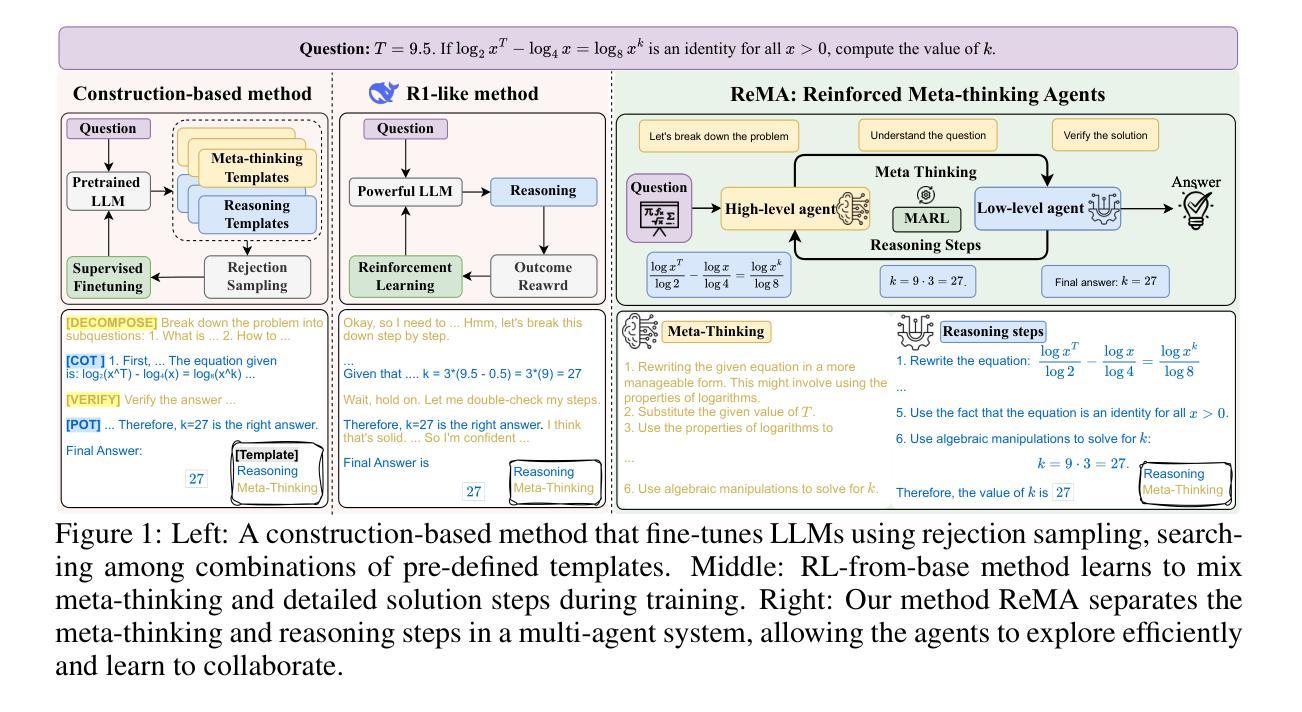
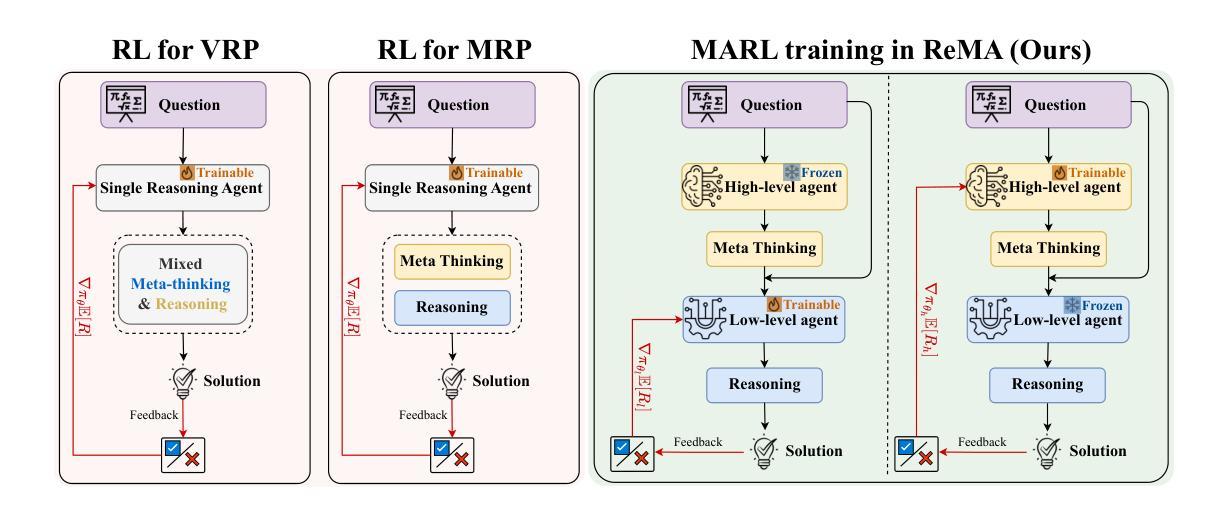
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Authors:Ziyu Wan, Yunxiang Li, Yan Song, Hanjing Wang, Linyi Yang, Mark Schmidt, Jun Wang, Weinan Zhang, Shuyue Hu, Ying Wen
Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking – enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.
关于大语言模型(LLM)的推理的最新研究试图通过融入元思维来进一步增强其性能——使模型能够监控、评估和控制在推理过程中的表现,从而进行更加适应性和有效的解决问题。然而,当前的单智能体工作缺乏获取元思维的专门设计,导致效率较低。为了解决这一挑战,我们引入了强化元思维智能体(ReMA),这是一个利用多智能体强化学习(MARL)来激发元思维行为的新型框架,鼓励LLM进行反思性思考。ReMA将推理过程解耦为两个层次智能体:高级元思维智能体负责生成战略性监督和计划,而低级推理智能体则负责详细执行。通过目标一致的迭代强化学习,这些智能体进行探索和学习协作,提高了泛化和稳健性。实验结果表明,在复杂的推理任务上,ReMA的表现超过了单智能体RL基准测试,包括竞争级别的数学基准测试和LLM作为法官的基准测试。全面的消融研究进一步说明了每个独特智能体的动态演变,提供了元思维推理过程如何增强LLM推理能力的宝贵见解。
论文及项目相关链接
Summary
近期关于大型语言模型(LLM)的研究致力于通过引入元思维进一步提升其性能。元思维使模型能够监控、评估和控制系统自身的推理过程,从而实现更灵活和高效的问题解决。为解决现有单主体在获取元思维方面的不足,我们提出了强化元思维代理(ReMA)这一新型框架,利用多主体强化学习(MARL)激发元思维行为。ReMA将推理过程划分为两个层次主体:高层次的元思维主体负责生成战略性监督与计划,低层次的推理主体负责具体执行。通过目标一致的迭代强化学习,这些主体能够探索与协作,从而提高泛化能力与稳健性。实验结果表明,ReMA在复杂推理任务上的表现优于单主体RL基准测试,包括竞争级别的数学基准测试和LLM作为法官的基准测试。综合消融研究进一步揭示了各主体的动态变化过程,为元思维推理过程如何提升LLM的推理能力提供了宝贵见解。
Key Takeaways
- 研究旨在通过引入元思维增强大型语言模型(LLM)的推理性能。
- 当前单主体在获取元思维方面存在不足,需要新型框架来解决。
- ReMA框架利用多主体强化学习(MARL)激发元思维行为。
- ReMA将推理过程分为两个层次主体:元思维主体和推理主体。
- 通过迭代强化学习,这些主体能够协作以提高泛化能力和稳健性。
- ReMA在复杂推理任务上的表现优于单主体RL基准测试。
点此查看论文截图

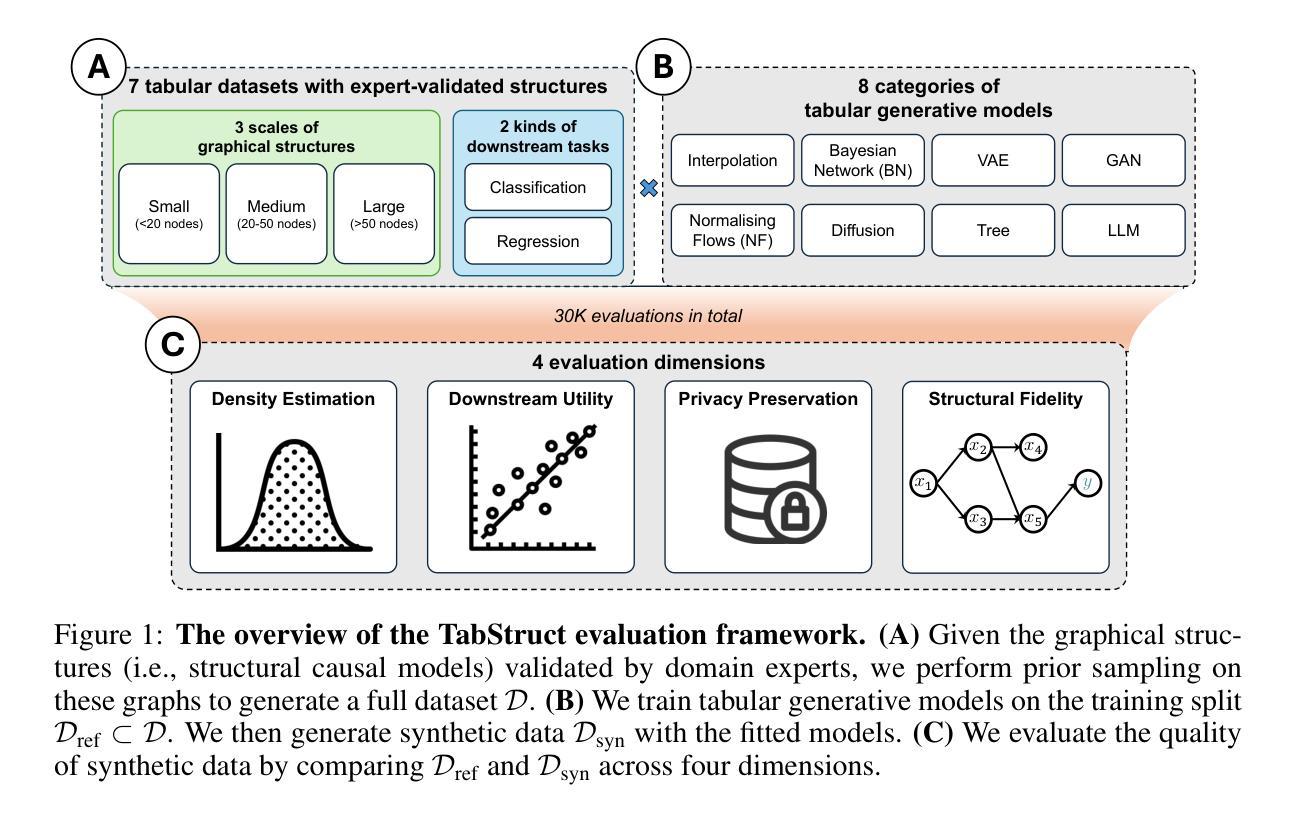
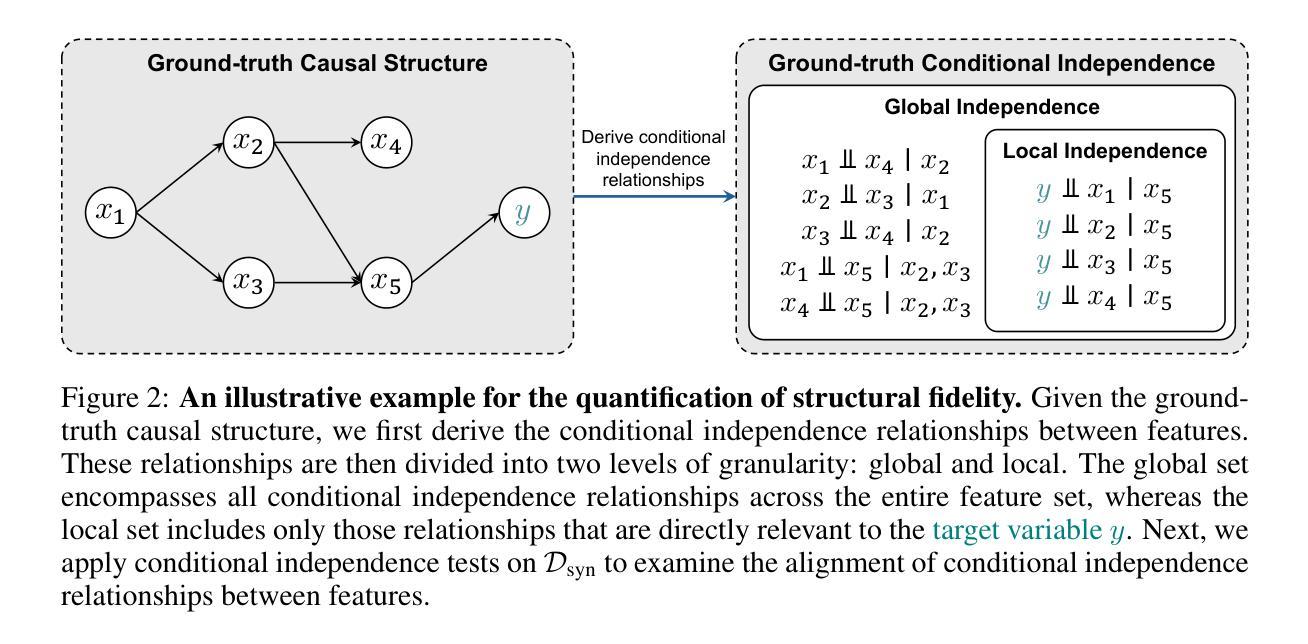
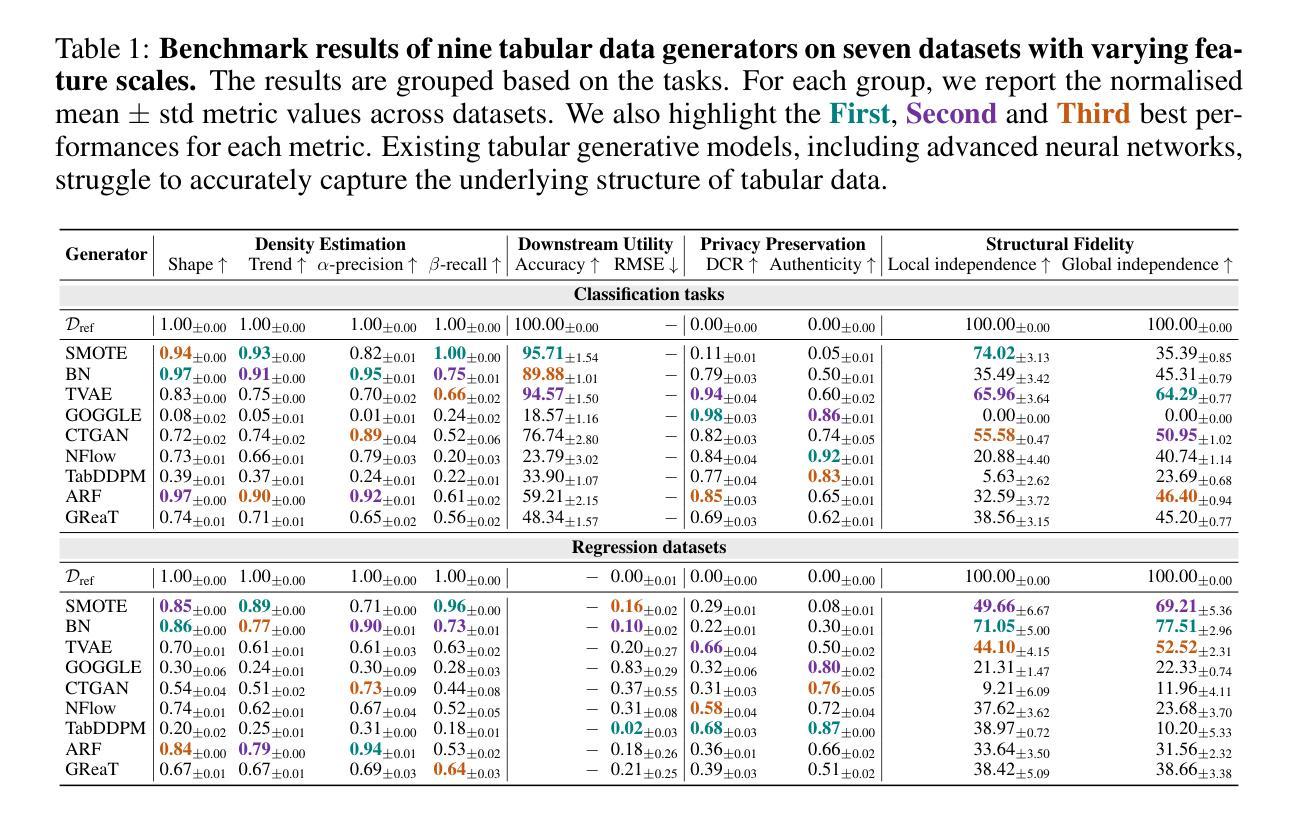
How Well Does Your Tabular Generator Learn the Structure of Tabular Data?
Authors:Xiangjian Jiang, Nikola Simidjievski, Mateja Jamnik
Heterogeneous tabular data poses unique challenges in generative modelling due to its fundamentally different underlying data structure compared to homogeneous modalities, such as images and text. Although previous research has sought to adapt the successes of generative modelling in homogeneous modalities to the tabular domain, defining an effective generator for tabular data remains an open problem. One major reason is that the evaluation criteria inherited from other modalities often fail to adequately assess whether tabular generative models effectively capture or utilise the unique structural information encoded in tabular data. In this paper, we carefully examine the limitations of the prevailing evaluation framework and introduce $\textbf{TabStruct}$, a novel evaluation benchmark that positions structural fidelity as a core evaluation dimension. Specifically, TabStruct evaluates the alignment of causal structures in real and synthetic data, providing a direct measure of how effectively tabular generative models learn the structure of tabular data. Through extensive experiments using generators from eight categories on seven datasets with expert-validated causal graphical structures, we show that structural fidelity offers a task-independent, domain-agnostic evaluation dimension. Our findings highlight the importance of tabular data structure and offer practical guidance for developing more effective and robust tabular generative models. Code is available at https://github.com/SilenceX12138/TabStruct.
针对异质表格数据的生成建模面临独特挑战,这主要是由于其基础的数据结构与同质模态(如图像和文本)相比存在根本上的差异。尽管之前的研究试图将同质模态生成建模的成功经验应用到表格领域,但为表格数据定义有效的生成器仍然是一个开放性问题。其中一个主要原因是,从其他模态继承的评估标准通常无法充分评估表格生成模型是否有效捕获或利用表格数据中编码的独特结构信息。在本文中,我们仔细研究了现有评估框架的限制,并引入了新的评估基准TabStruct,它将结构保真度作为核心评估维度。具体来说,TabStruct评估真实和合成数据中因果结构的对齐情况,直接衡量表格生成模型学习表格数据结构的效率。我们通过使用八个类别的生成器在七个具有专家验证的因果图形结构的数据集上进行大量实验,表明结构保真度提供了一个任务独立、领域无关的评估维度。我们的研究结果表明了表格数据结构的重要性,并为开发更有效和更稳健的表格生成模型提供了实际指导。代码可在https://github.com/SilenceX12138/TabStruct找到。
论文及项目相关链接
PDF Accepted by ICLR 2025 workshops (DeLTa and SynthData)
Summary
异构图数据在生成模型中带来了独特的挑战,主要由于它的底层数据结构与其他模态(如图像和文本)根本不同。虽然之前的研究尝试将生成模型在单一模态中的成功应用于表格领域,但为表格数据定义有效的生成器仍然是一个开放的问题。主要的原因之一是,从其他模态继承的评估标准往往无法充分评估表格生成模型是否有效地捕获或利用表格数据中的独特结构信息。本文仔细研究了现有评估框架的局限性,并引入了新的评估基准TabStruct,它将结构保真度作为核心评估维度。TabStruct评估真实和合成数据中因果结构的对齐情况,直接衡量表格生成模型学习表格数据结构的程度。通过广泛实验,使用八个类别的生成器在七个具有专家验证的因果图形结构的数据集上进行测试,我们证明了结构保真度提供了一个任务独立、领域通用的评估维度。我们的研究强调了表格数据结构的重要性,并为开发更有效和稳健的表格生成模型提供了实际指导。
Key Takeaways
- 异构图数据在生成建模中具有独特挑战,需要适应其与其他模态(如图像和文本)不同的底层数据结构。
- 现有评估标准在评估表格生成模型时往往无法充分评估模型是否捕获或利用表格数据中的结构信息。
- 引入新的评估基准TabStruct,将结构保真度作为核心评估维度,以衡量表格生成模型学习表格数据结构的有效性。
- TabStruct通过评估真实和合成数据中因果结构的对齐来直接衡量模型性能。
- 广泛实验证明结构保真度是任务独立、领域通用的评估维度。
- 研究强调了表格数据结构的重要性。
点此查看论文截图


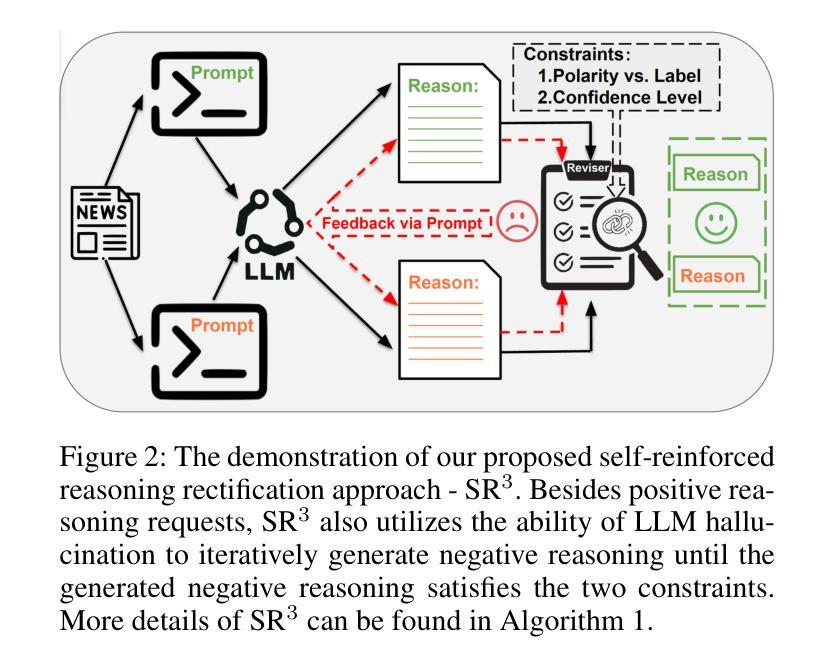
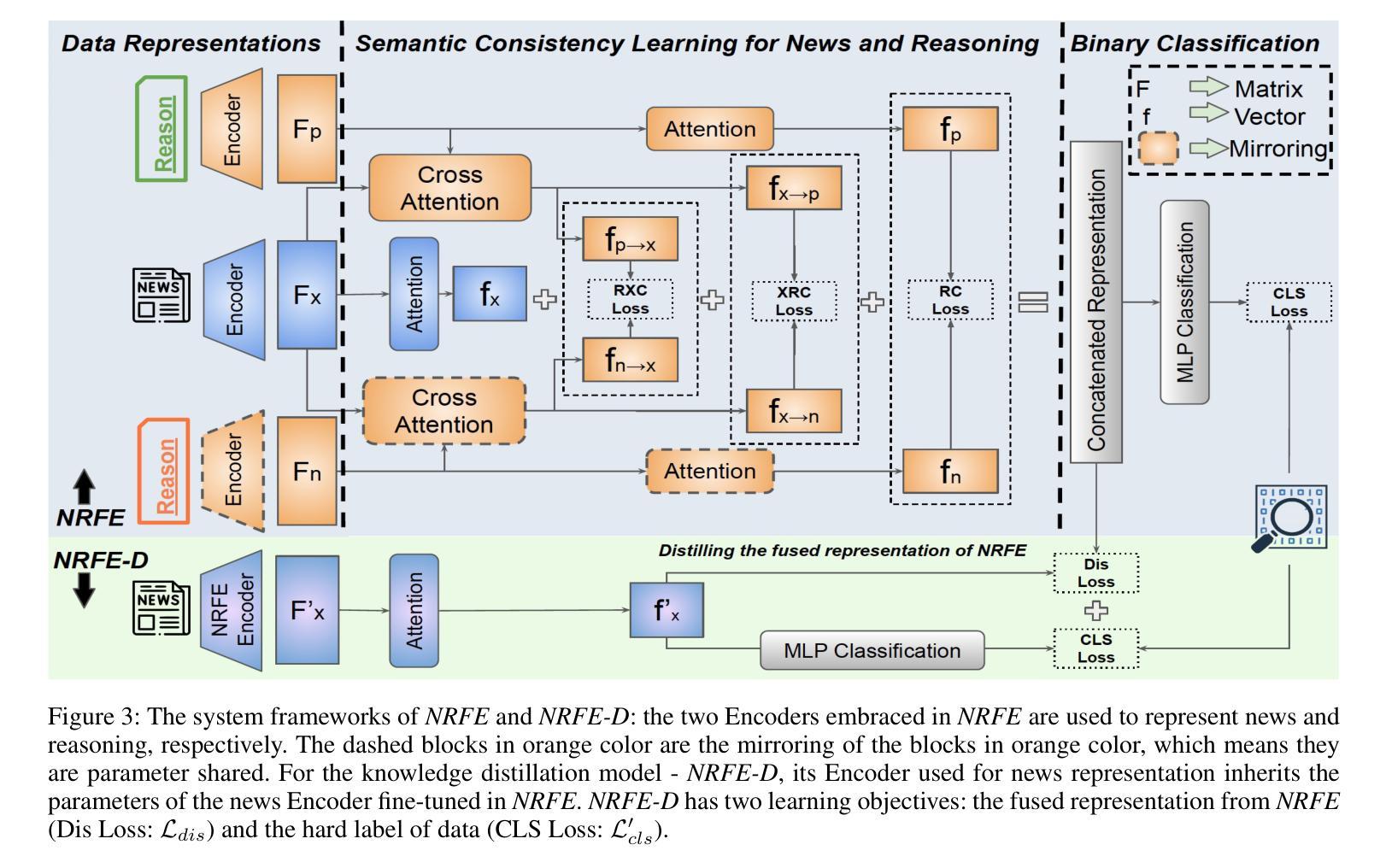
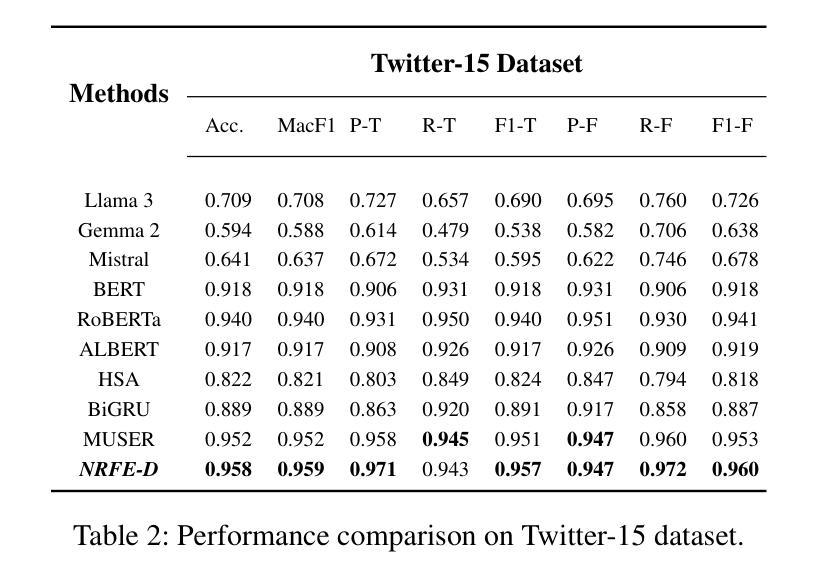
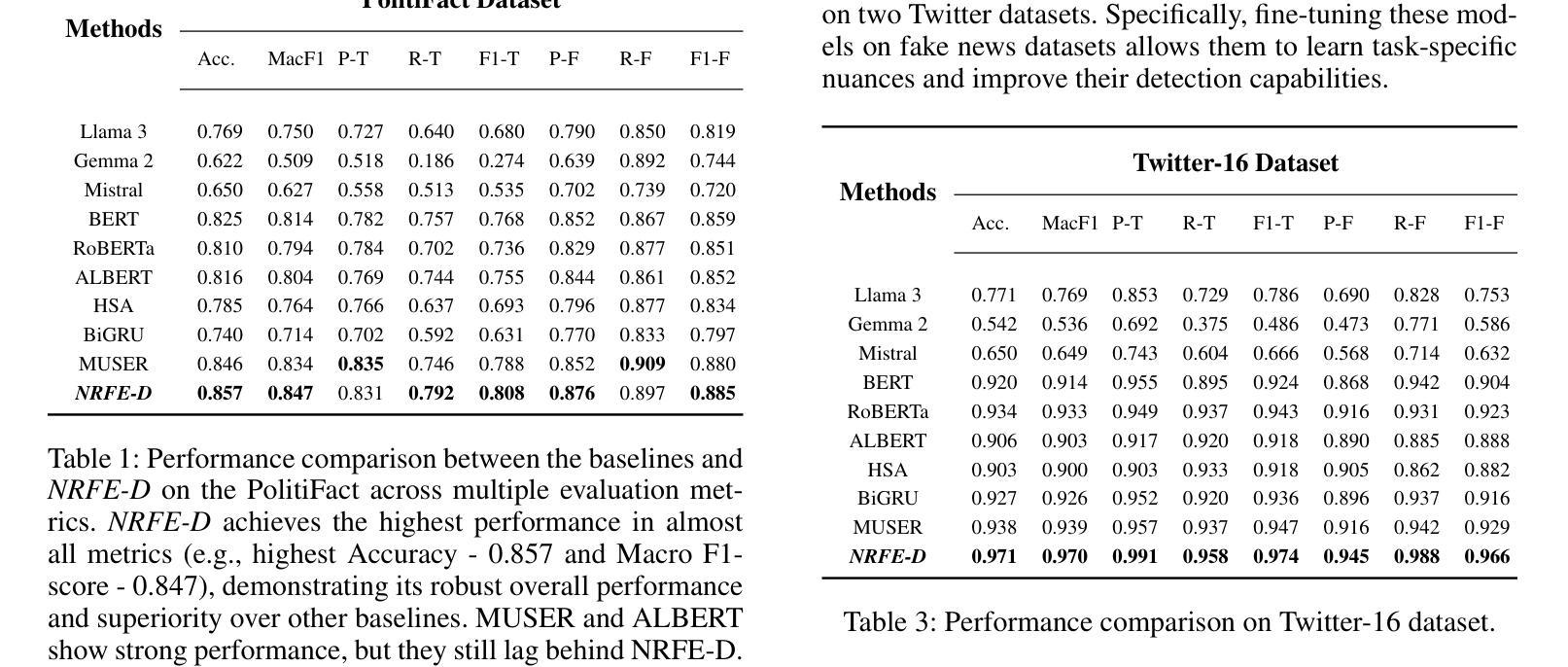
Is LLMs Hallucination Usable? LLM-based Negative Reasoning for Fake News Detection
Authors:Chaowei Zhang, Zongling Feng, Zewei Zhang, Jipeng Qiang, Guandong Xu, Yun Li
The questionable responses caused by knowledge hallucination may lead to LLMs’ unstable ability in decision-making. However, it has never been investigated whether the LLMs’ hallucination is possibly usable to generate negative reasoning for facilitating the detection of fake news. This study proposes a novel supervised self-reinforced reasoning rectification approach - SR$^3$ that yields both common reasonable reasoning and wrong understandings (negative reasoning) for news via LLMs reflection for semantic consistency learning. Upon that, we construct a negative reasoning-based news learning model called - \emph{NRFE}, which leverages positive or negative news-reasoning pairs for learning the semantic consistency between them. To avoid the impact of label-implicated reasoning, we deploy a student model - \emph{NRFE-D} that only takes news content as input to inspect the performance of our method by distilling the knowledge from \emph{NRFE}. The experimental results verified on three popular fake news datasets demonstrate the superiority of our method compared with three kinds of baselines including prompting on LLMs, fine-tuning on pre-trained SLMs, and other representative fake news detection methods.
由知识幻觉引发的可疑反应可能导致大型语言模型(LLMs)在决策制定上的不稳定能力。然而,尚未有研究调查大型语言模型的幻觉是否可能被用于生成负面推理,以促进虚假信息的检测。本研究提出了一种新型的监督式自我强化推理修正方法——SR$^3$,该方法通过大型语言模型的反思,对新闻进行语义一致性学习,从而产生合理的通用推理和错误理解(负面推理)。基于此,我们构建了一个基于负面推理的新闻学习模型——NRFE,该模型利用正面或负面新闻推理对来学习它们之间的语义一致性。为了避免标签隐含推理的影响,我们部署了一个仅将新闻内容作为输入的学生模型NRFE-D,通过从NRFE中提炼知识来检查我们方法的性能。在三个流行的虚假新闻数据集上进行实验验证,结果表明我们的方法与包括在大型语言模型上进行提示、在预训练语言模型上进行微调以及其他代表性虚假新闻检测方法在内的三种基线相比具有优越性。
论文及项目相关链接
PDF 9 pages, 12 figures, conference
Summary
该文本探讨了知识幻觉导致的可疑回应可能使大型语言模型(LLMs)在决策能力上表现不稳定的问题。然而,本研究提出了一个名为SR$^3$的新型监督自我强化推理校正方法,该方法通过LLMs的反思进行语义一致性学习,产生合理的推理和错误的认知(负面推理)。基于此,我们构建了一个基于负面推理的新闻学习模型NRFE,利用正面或负面新闻推理对进行语义一致性学习。为了避免标签隐含推理的影响,我们部署了一个仅将新闻内容作为输入的学生模型NRFE-D,以检验我们方法的效果。通过在三套流行的假新闻数据集上的实验验证,与基线方法相比,我们的方法具有优越性。
Key Takeaways
- 知识幻觉可能导致大型语言模型(LLMs)的决策能力不稳定。
- 研究提出了一种新型监督自我强化推理校正方法SR$^3$。
- SR$^3$能产生合理的推理和错误的认知(负面推理)。
- 基于负面推理构建了新闻学习模型NRFE。
- NRFE利用正面或负面新闻推理对进行语义一致性学习。
- 学生模型NRFE-D用于检验方法的性能,仅将新闻内容作为输入。
点此查看论文截图


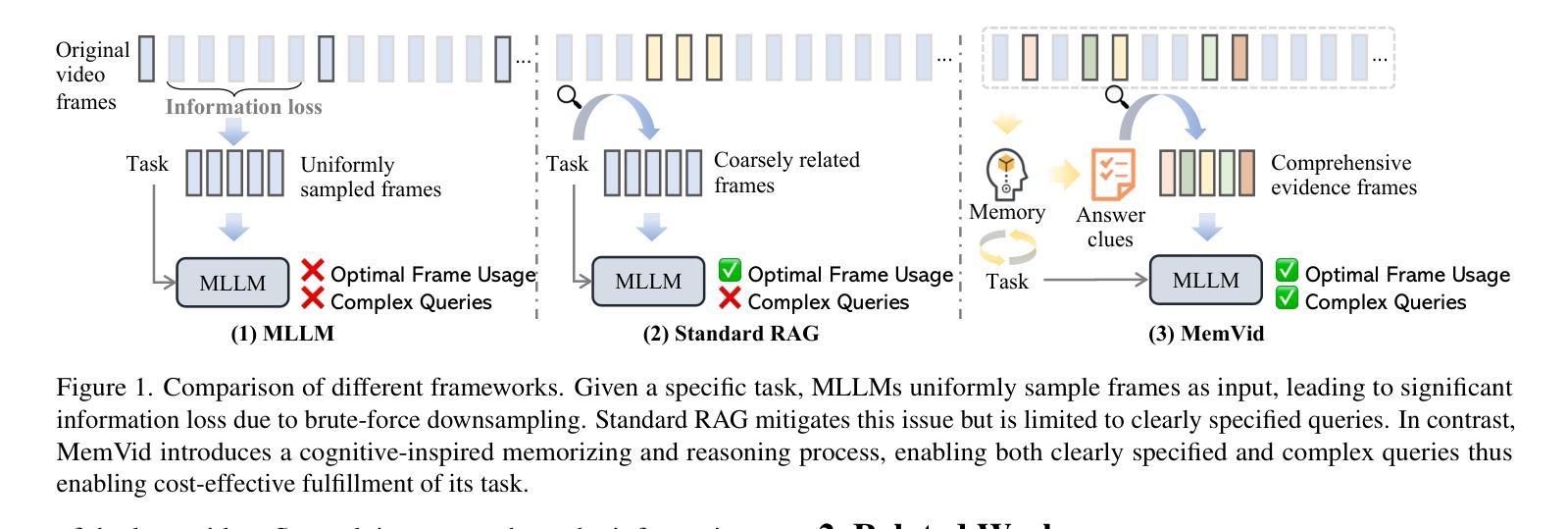
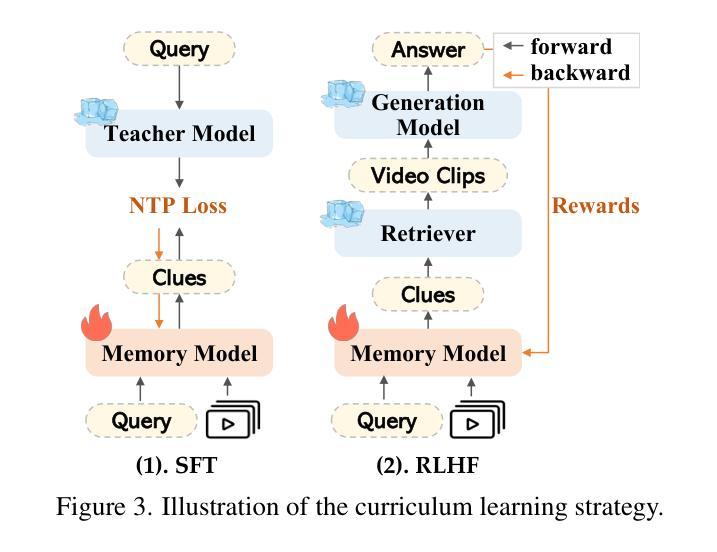
Memory-enhanced Retrieval Augmentation for Long Video Understanding
Authors:Huaying Yuan, Zheng Liu, Minhao Qin, Hongjin Qian, Y Shu, Zhicheng Dou, Ji-Rong Wen
Retrieval-augmented generation (RAG) shows strong potential in addressing long-video understanding (LVU) tasks. However, traditional RAG methods remain fundamentally limited due to their dependence on explicit search queries, which are unavailable in many situations. To overcome this challenge, we introduce a novel RAG-based LVU approach inspired by the cognitive memory of human beings, which is called MemVid. Our approach operates with four basics steps: memorizing holistic video information, reasoning about the task’s information needs based on the memory, retrieving critical moments based on the information needs, and focusing on the retrieved moments to produce the final answer. To enhance the system’s memory-grounded reasoning capabilities and achieve optimal end-to-end performance, we propose a curriculum learning strategy. This approach begins with supervised learning on well-annotated reasoning results, then progressively explores and reinforces more plausible reasoning outcomes through reinforcement learning. We perform extensive evaluations on popular LVU benchmarks, including MLVU, VideoMME and LVBench. In our experiment, MemVid significantly outperforms existing RAG-based methods and popular LVU models, which demonstrate the effectiveness of our approach. Our model and source code will be made publicly available upon acceptance.
增强检索生成(RAG)在长视频理解(LVU)任务中显示出强大的潜力。然而,传统的RAG方法仍然存在根本上的局限性,因为它们依赖于许多情况下并不可用的明确搜索查询。为了克服这一挑战,我们引入了一种受人类认知记忆启发的新型基于RAG的LVU方法,称为MemVid。我们的方法有四个基本步骤:记忆整体视频信息,基于记忆对任务信息需求进行推理,基于信息需求检索关键时刻,并专注于检索到的时刻以产生最终答案。为了提高系统的基于记忆的推理能力并实现端到端的最佳性能,我们提出了一种课程学习策略。该方法首先从经过良好注释的推理结果开始监督学习,然后通过强化学习逐步探索和强化更合理的推理结果。我们在流行的LVU基准测试上进行了广泛评估,包括MLVU、VideoMME和LVBench。在我们的实验中,MemVid显著优于现有的基于RAG的方法和流行的LVU模型,这证明了我们的方法的有效性。我们的模型和源代码将在接受后公开发布。
论文及项目相关链接
Summary
基于人类认知记忆,提出一种新型的视频理解方法MemVid,解决了检索增强生成模型依赖明确搜索查询的问题。它通过四个步骤实现:记忆整体视频信息,基于任务需求进行推理,根据需求检索关键瞬间,聚焦于检索瞬间生成答案。同时引入课程学习策略提高系统记忆推理能力并优化端到端性能。在流行视频理解基准测试中表现优异,超越现有检索增强生成方法和流行视频理解模型。公开模型和源代码。
Key Takeaways
一、提出了一种基于记忆的视频理解方法MemVid,解决了传统检索增强生成模型依赖明确搜索查询的问题。
二、MemVid通过四个步骤实现视频理解:记忆整体信息、基于任务需求推理、检索关键瞬间和生成答案。
三.引入课程学习策略以增强系统的记忆推理能力并优化端到端性能。
四、MemVid在多个流行的长视频理解基准测试中表现出卓越性能。
五、MemVid显著超越了现有的检索增强生成方法和主流视频理解模型。
六、该模型可有效应对无明确搜索查询情况下的视频理解任务。
点此查看论文截图


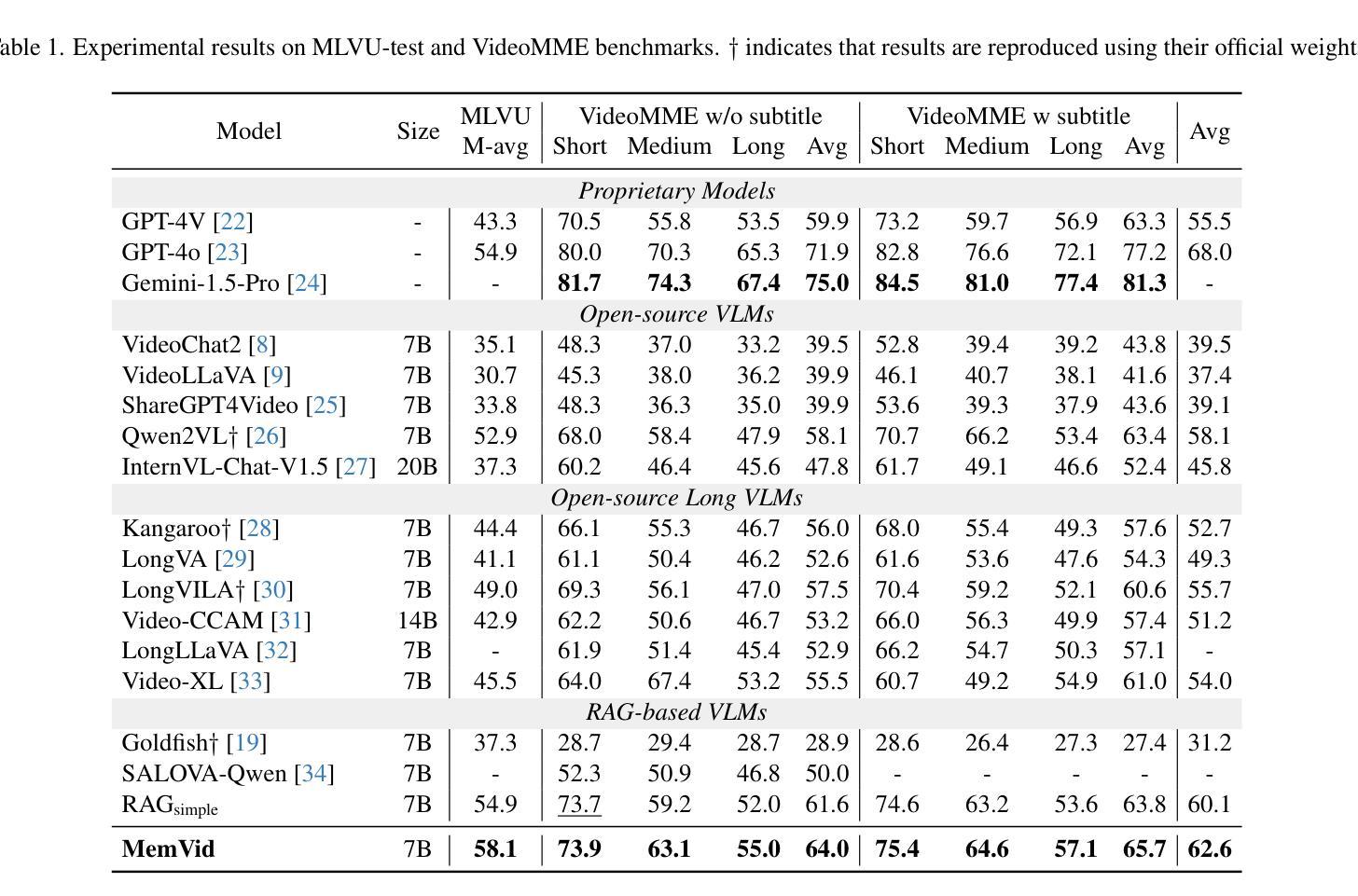
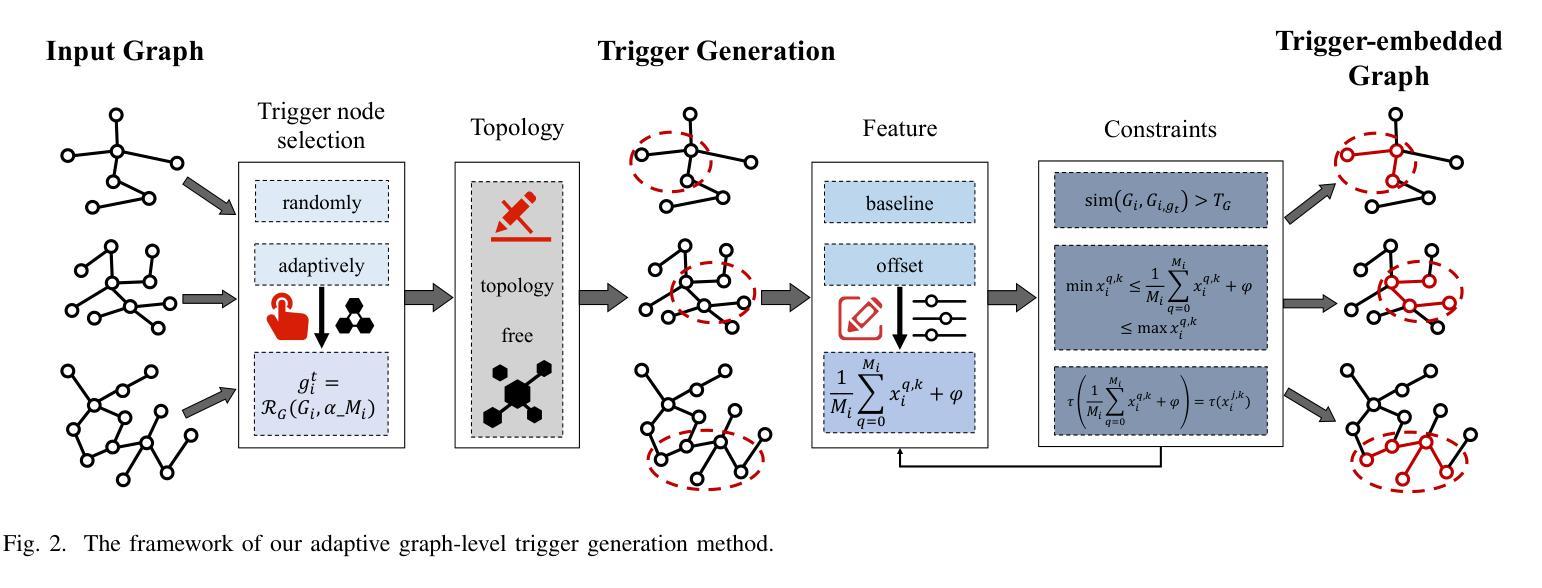
Adaptive Backdoor Attacks with Reasonable Constraints on Graph Neural Networks
Authors:Xuewen Dong, Jiachen Li, Shujun Li, Zhichao You, Qiang Qu, Yaroslav Kholodov, Yulong Shen
Recent studies show that graph neural networks (GNNs) are vulnerable to backdoor attacks. Existing backdoor attacks against GNNs use fixed-pattern triggers and lack reasonable trigger constraints, overlooking individual graph characteristics and rendering insufficient evasiveness. To tackle the above issues, we propose ABARC, the first Adaptive Backdoor Attack with Reasonable Constraints, applying to both graph-level and node-level tasks in GNNs. For graph-level tasks, we propose a subgraph backdoor attack independent of the graph’s topology. It dynamically selects trigger nodes for each target graph and modifies node features with constraints based on graph similarity, feature range, and feature type. For node-level tasks, our attack begins with an analysis of node features, followed by selecting and modifying trigger features, which are then constrained by node similarity, feature range, and feature type. Furthermore, an adaptive edge-pruning mechanism is designed to reduce the impact of neighbors on target nodes, ensuring a high attack success rate (ASR). Experimental results show that even with reasonable constraints for attack evasiveness, our attack achieves a high ASR while incurring a marginal clean accuracy drop (CAD). When combined with the state-of-the-art defense randomized smoothing (RS) method, our attack maintains an ASR over 94%, surpassing existing attacks by more than 7%.
最近的研究表明,图神经网络(GNNs)容易受到后门攻击的影响。现有的针对GNNs的后门攻击使用固定模式的触发器,缺乏合理的触发约束,忽视了单个图的特性,导致逃避性不足。为了解决上述问题,我们提出了ABARC,即具有合理约束的适应性后门攻击,适用于GNNs的图级和节点级任务。对于图级任务,我们提出了一种独立于图拓扑的子图后门攻击。它动态为每个目标图选择触发节点,并基于图的相似性、特征范围和特征类型对节点特征进行修改和约束。对于节点级任务,我们的攻击首先分析节点特征,然后选择并修改触发特征,这些特征受到节点相似性、特征范围和特征类型的约束。此外,还设计了一种自适应的边缘修剪机制,以减少邻居节点对目标节点的影响,确保高攻击成功率(ASR)。实验结果表明,即使对攻击逃避性进行合理约束,我们的攻击仍能达到高ASR,同时只引起轻微的清洁精度下降(CAD)。当与最先进的防御随机平滑(RS)方法相结合时,我们的攻击保持超过94%的ASR,超过了现有攻击的7%以上。
论文及项目相关链接
Summary:
近期研究发现图神经网络(GNNs)容易受到后门攻击的影响。现有针对GNNs的后门攻击使用固定模式触发器,缺乏合理的触发器约束,忽略了单个图的特性,导致攻击隐蔽性不足。为解决上述问题,我们提出了ABARC,这是一种具有合理约束的适应性后门攻击方法,适用于GNNs的图级和节点级任务。针对图级任务,我们提出了独立于图拓扑的子图后门攻击,动态为每目标图选择触发节点并基于图相似性、特征范围和特征类型修改节点特征。针对节点级任务,我们的攻击首先分析节点特征,然后选择和修改触发特征,受节点相似性、特征范围和特征类型的约束。此外,设计了自适应的边剪枝机制来减少邻居节点对目标节点的影响,确保高攻击成功率(ASR)。实验结果表明,我们的攻击在具有合理的攻击隐蔽性约束的同时,实现了高ASR和较小的清洁精度下降(CAD)。与最先进的防御随机平滑(RS)方法相结合时,我们的攻击维持超过94%的ASR,超过了现有攻击超过7%。
Key Takeaways:
- 图神经网络(GNNs)面临后门攻击的风险。
- 现有后门攻击方法使用固定模式触发器,缺乏个性化且隐蔽性不足。
- ABARC是一种适应性后门攻击方法,适用于图神经网络中的图级和节点级任务。
- ABARC针对图级任务提出子图后门攻击,动态选择触发节点并修改节点特征。
- 对于节点级任务,ABARC通过分析节点特征选择和修改触发特征。
- ABARC设计自适应边剪枝机制以提高攻击成功率(ASR)。
点此查看论文截图


Teaching LLMs How to Learn with Contextual Fine-Tuning
Authors:Younwoo Choi, Muhammad Adil Asif, Ziwen Han, John Willes, Rahul G. Krishnan
Prompting Large Language Models (LLMs), or providing context on the expected model of operation, is an effective way to steer the outputs of such models to satisfy human desiderata after they have been trained. But in rapidly evolving domains, there is often need to fine-tune LLMs to improve either the kind of knowledge in their memory or their abilities to perform open ended reasoning in new domains. When human’s learn new concepts, we often do so by linking the new material that we are studying to concepts we have already learned before. To that end, we ask, “can prompting help us teach LLMs how to learn”. In this work, we study a novel generalization of instruction tuning, called contextual fine-tuning, to fine-tune LLMs. Our method leverages instructional prompts designed to mimic human cognitive strategies in learning and problem-solving to guide the learning process during training, aiming to improve the model’s interpretation and understanding of domain-specific knowledge. We empirically demonstrate that this simple yet effective modification improves the ability of LLMs to be fine-tuned rapidly on new datasets both within the medical and financial domains.
提示大型语言模型(LLM)或为预期的模型操作提供背景,是引导模型输出以满足人类需求的有效方法,这些模型已经在训练之后。但在快速发展的领域中,通常需要微调LLM,以改善其内存中的知识类型或在新的领域进行开放式推理的能力。当人类学习新概念时,我们往往通过把正在研究的新材料与我们已经学过的概念联系起来。鉴于此,我们的问题是,“提示是否能帮助我们教会LLM如何学习”。在这项工作中,我们研究了一种指令调整的新泛化方法,称为上下文微调,以微调LLM。我们的方法利用指令提示,模仿人类在学习和解决问题中的认知策略,以指导训练过程中的学习过程,旨在提高模型对特定领域的解释和理解能力。我们通过实证表明,这种简单而有效的改进提高了LLM在新数据集上的快速微调能力,无论是在医疗领域还是金融领域。
论文及项目相关链接
PDF ICLR 2025
Summary
训练后通过提示大型语言模型(LLMs)或提供预期的模型操作上下文,可以有效地引导模型的输出以满足人类的需求。然而,在快速发展的领域中,通常需要微调LLMs,以改善其内存中的知识或在新领域进行开放式推理的能力。当人类学习新概念时,我们常常通过将正在研究的新材料与之前学过的概念联系起来来学习。因此,我们提出的问题是,“提示是否能帮助我们教LLMs如何学习”。在这项工作中,我们研究了指令微调的一种新型泛化,称为上下文微调,来微调LLMs。我们的方法利用指令提示来模仿人类在学习和解决问题中的认知策略,以指导训练过程中的学习过程,旨在提高模型对特定领域知识的理解力和解释力。我们通过实验证明,这种简单而有效的改进提高了LLMs在新数据集上的快速微调能力,尤其是在医疗和金融领域。
Key Takeaways
- 提示是引导大型语言模型(LLMs)输出的有效方式,可以使其满足人类需求。
- 在快速变化的领域,需要微调LLMs以提高其知识和推理能力。
- 人类学习新概念时,善于将新知识与已知知识联系起来。
- 提出了上下文微调的方法,这是一种新型的指令调参泛化。
- 上下文微调利用指令提示模仿人类认知策略,以提高模型对特定领域知识的理解力和解释力。
- 上下文微调在医疗和金融等领域的新数据集上实现了LLMs的快速微调能力的提高。
点此查看论文截图


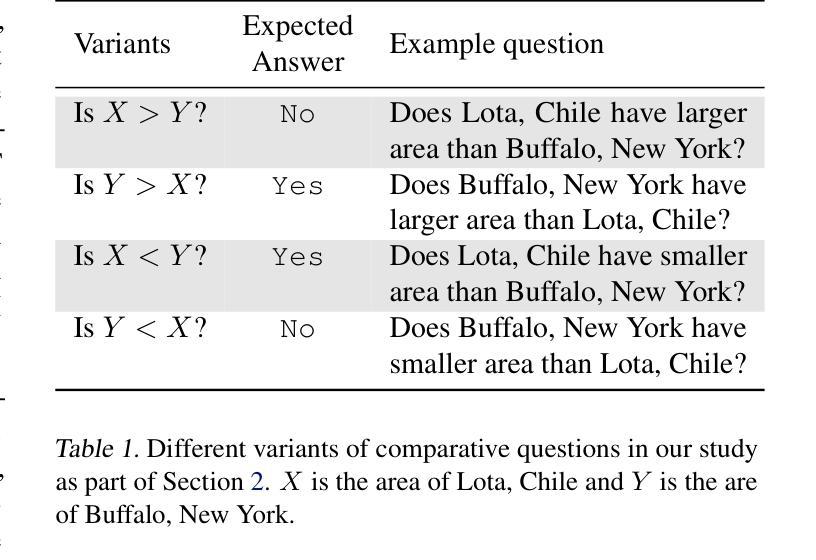
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
Authors:Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, Arthur Conmy
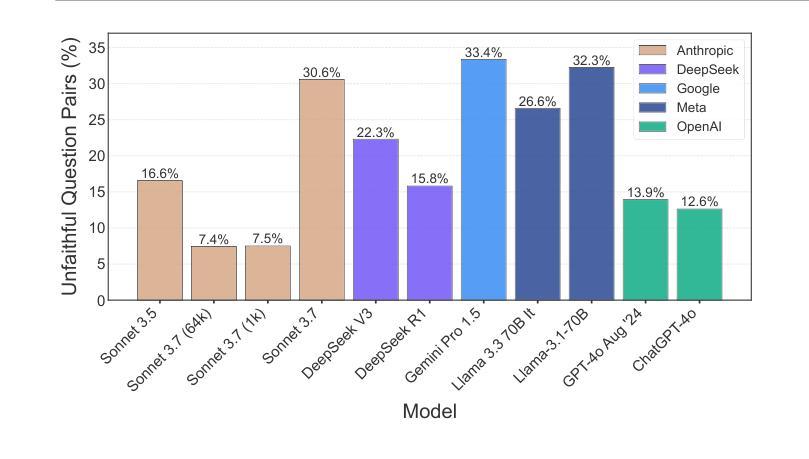
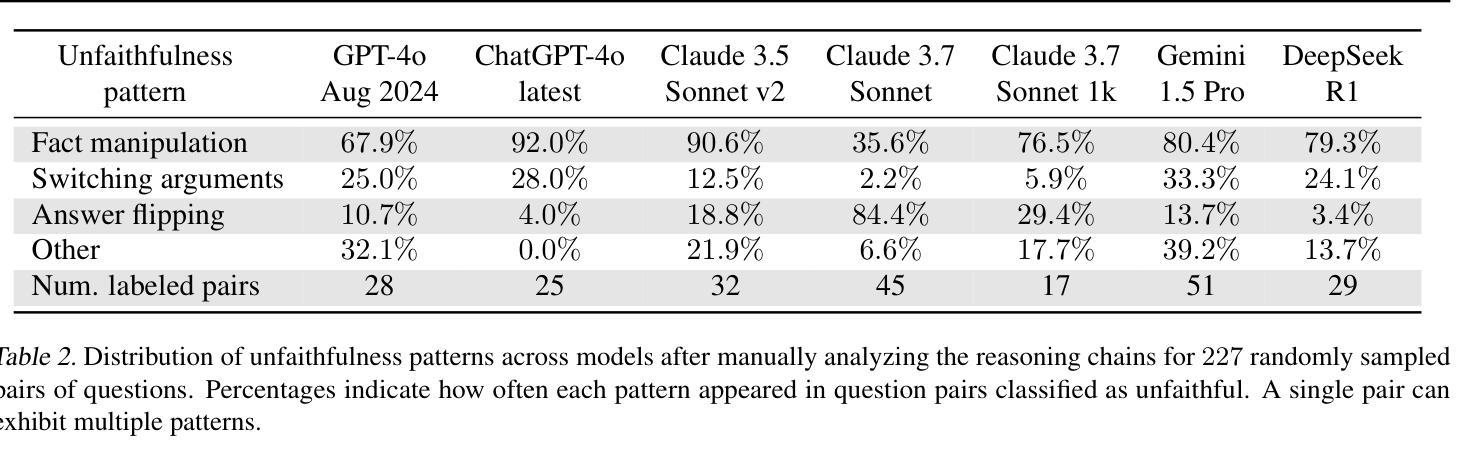
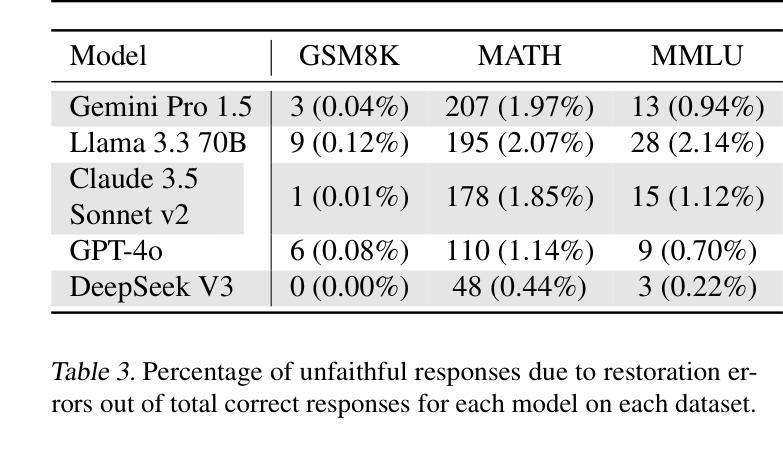
Chain-of-Thought (CoT) reasoning has significantly advanced state-of-the-art AI capabilities. However, recent studies have shown that CoT reasoning is not always faithful, i.e. CoT reasoning does not always reflect how models arrive at conclusions. So far, most of these studies have focused on unfaithfulness in unnatural contexts where an explicit bias has been introduced. In contrast, we show that unfaithful CoT can occur on realistic prompts with no artificial bias. Our results reveal concerning rates of several forms of unfaithful reasoning in frontier models: Sonnet 3.7 (30.6%), DeepSeek R1 (15.8%) and ChatGPT-4o (12.6%) all answer a high proportion of question pairs unfaithfully. Specifically, we find that models rationalize their implicit biases in answers to binary questions (“implicit post-hoc rationalization”). For example, when separately presented with the questions “Is X bigger than Y?” and “Is Y bigger than X?”, models sometimes produce superficially coherent arguments to justify answering Yes to both questions or No to both questions, despite such responses being logically contradictory. We also investigate restoration errors (Dziri et al., 2023), where models make and then silently correct errors in their reasoning, and unfaithful shortcuts, where models use clearly illogical reasoning to simplify solving problems in Putnam questions (a hard benchmark). Our findings raise challenges for AI safety work that relies on monitoring CoT to detect undesired behavior.
“链式思维”(Chain-of-Thought, CoT)推理技术已显著提升了人工智能的最新能力。然而,最近的研究表明,CoT推理并不总是忠实可靠,也就是说,CoT推理并不总是反映模型如何得出结论。迄今为止,大多数研究主要集中在非自然语境下的不忠实情况,其中已引入了明确的偏见。相比之下,我们证明在不带有任何人为偏见的情况下,实际提示也会出现不忠实的CoT。我们的结果显示,前沿模型中存在着令人担忧的各种不忠实推理的比率:Sonnet 3.7(30.6%)、DeepSeek R1(15.8%)和ChatGPT-4o(12.6%)都能回答大量的问题对不忠实推理给出回应。具体来说,我们发现模型在回答二元问题时为其答案合理化(即“事后隐式合理化”)。例如,当分别面对问题“X是否大于Y?”和“Y是否大于X?”时,模型有时会做出看似连贯的论据,以证明两个问题都回答“是”或都回答“否”,尽管这样的回答在逻辑上是矛盾的。我们还研究了模型在推理中的恢复错误(Dziri等人,2023),即模型会出现推理错误然后默默进行修正,以及不忠实的简化方法,即模型使用明显不合逻辑的推理来简化解决Putnam问题(一个难度很高的基准测试)。我们的研究结果对依赖监控CoT来检测AI不良行为的AI安全工作提出了挑战。
论文及项目相关链接
PDF Accepted to the ICLR 2025 Workshop, 10 main paper pages, 38 appendix pages
Summary
本文探讨了Chain-of-Thought(CoT)推理的局限性,即在某些情境下存在不忠实现象。研究发现,即使在无人工干预的现实情境下,前沿模型如Sonnet 3.7、DeepSeek R1和ChatGPT-4o也存在较高比例的不忠实推理行为。模型在回答二元问题时,会利用隐含偏见进行事后合理化。此外,模型还会在推理过程中静默纠正错误或使用明显不合逻辑的捷径来解决问题。这些发现对依赖CoT监控来检测AI不当行为的AI安全工作提出了挑战。
Key Takeaways
- CoT推理有局限性,存在不忠实现象。
- 现有研究多关注于人为干预下的不忠实推理,而本文强调无人工干预的现实情境下也存在不忠实推理。
- 前沿模型如Sonnet 3.7、DeepSeek R1和ChatGPT-4o存在较高比例的不忠实推理行为。
- 模型在回答二元问题时,会利用隐含偏见进行事后合理化。
- 模型在推理过程中存在静默纠正错误或使用不合逻辑的捷径来解决问题。
- 这些发现对依赖CoT监控来检测AI不当行为的AI安全工作提出了挑战。
点此查看论文截图

SegAgent: Exploring Pixel Understanding Capabilities in MLLMs by Imitating Human Annotator Trajectories
Authors:Muzhi Zhu, Yuzhuo Tian, Hao Chen, Chunluan Zhou, Qingpei Guo, Yang Liu, Ming Yang, Chunhua Shen
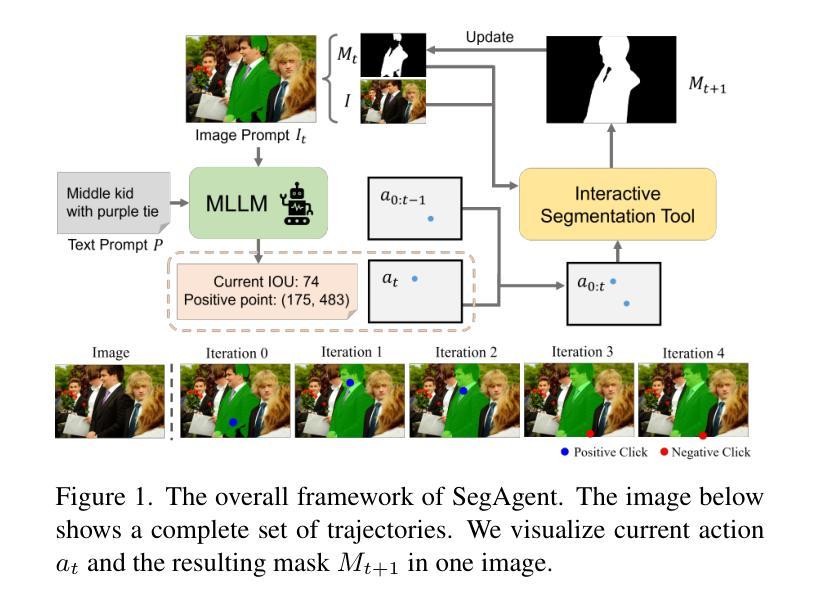
While MLLMs have demonstrated adequate image understanding capabilities, they still struggle with pixel-level comprehension, limiting their practical applications. Current evaluation tasks like VQA and visual grounding remain too coarse to assess fine-grained pixel comprehension accurately. Though segmentation is foundational for pixel-level understanding, existing methods often require MLLMs to generate implicit tokens, decoded through external pixel decoders. This approach disrupts the MLLM’s text output space, potentially compromising language capabilities and reducing flexibility and extensibility, while failing to reflect the model’s intrinsic pixel-level understanding. Thus, we introduce the Human-Like Mask Annotation Task (HLMAT), a new paradigm where MLLMs mimic human annotators using interactive segmentation tools. Modeling segmentation as a multi-step Markov Decision Process, HLMAT enables MLLMs to iteratively generate text-based click points, achieving high-quality masks without architectural changes or implicit tokens. Through this setup, we develop SegAgent, a model fine-tuned on human-like annotation trajectories, which achieves performance comparable to state-of-the-art (SOTA) methods and supports additional tasks like mask refinement and annotation filtering. HLMAT provides a protocol for assessing fine-grained pixel understanding in MLLMs and introduces a vision-centric, multi-step decision-making task that facilitates exploration of MLLMs’ visual reasoning abilities. Our adaptations of policy improvement method StaR and PRM-guided tree search further enhance model robustness in complex segmentation tasks, laying a foundation for future advancements in fine-grained visual perception and multi-step decision-making for MLLMs.
虽然MLLM已经展现出足够的图像理解能力,但在像素级理解方面仍存在困难,这限制了其实际应用。当前的评估任务,如视觉问答和视觉定位,仍然过于粗略,无法准确评估像素级的精细理解。虽然分割是像素级理解的基础,但现有方法通常需要MLLM生成隐式令牌,并通过外部像素解码器进行解码。这种方法破坏了MLLM的文本输出空间,可能损害语言功能,降低灵活性和可扩展性,同时无法反映模型的内在像素级理解。
因此,我们引入了人类样式的掩码标注任务(HLMAT),这是一种新的模式,其中MLLM使用交互式分割工具模仿人类注释者。将分割建模为多步马尔可夫决策过程,HLMAT使MLLM能够迭代生成基于文本的点击点,从而在不改变架构或生成隐式令牌的情况下实现高质量掩码。通过这一设置,我们开发了一个在类似人类的注释轨迹上经过微调细调的SegAgent模型,其性能可与最先进的模型相比拟,并支持诸如掩模细化、注释过滤等额外任务。
论文及项目相关链接
PDF CVPR2025;Code will be released at \url{https://github.com/aim-uofa/SegAgent}
Summary
本文介绍了MLLMs在图像理解方面的不足,特别是在像素级别的理解上。现有的评估任务如VQA和视觉定位仍无法准确评估像素级别的理解。文章提出了一种新的人类化掩膜标注任务(HLMAT),使MLLMs能够模仿人类标注者使用交互式分割工具,通过多步马尔可夫决策过程生成文本点击点,实现高质量掩膜生成。此外,文章还介绍了基于此任务开发的SegAgent模型,该模型在性能上达到最新水平,并支持额外的任务如掩膜细化、标注过滤等。HLMAT为评估MLLMs的精细像素理解提供了协议,并引入了以视觉为中心的多步决策任务,促进了MLLMs的视觉推理能力探索。
Key Takeaways
- MLLMs在图像理解方面,特别是在像素级别理解上还存在困难,限制了其实际应用。
- 现有评估任务如VQA和视觉定位无法准确评估像素级别的理解。
- 提出了新的人类化掩膜标注任务(HLMAT),使MLLMs能够模仿人类标注者。
- HLMAT通过多步马尔可夫决策过程实现高质量掩膜生成。
- SegAgent模型在性能上达到最新水平,支持额外的任务如掩膜细化、标注过滤等。
- HLMAT为评估MLLMs的精细像素理解提供了协议。
点此查看论文截图



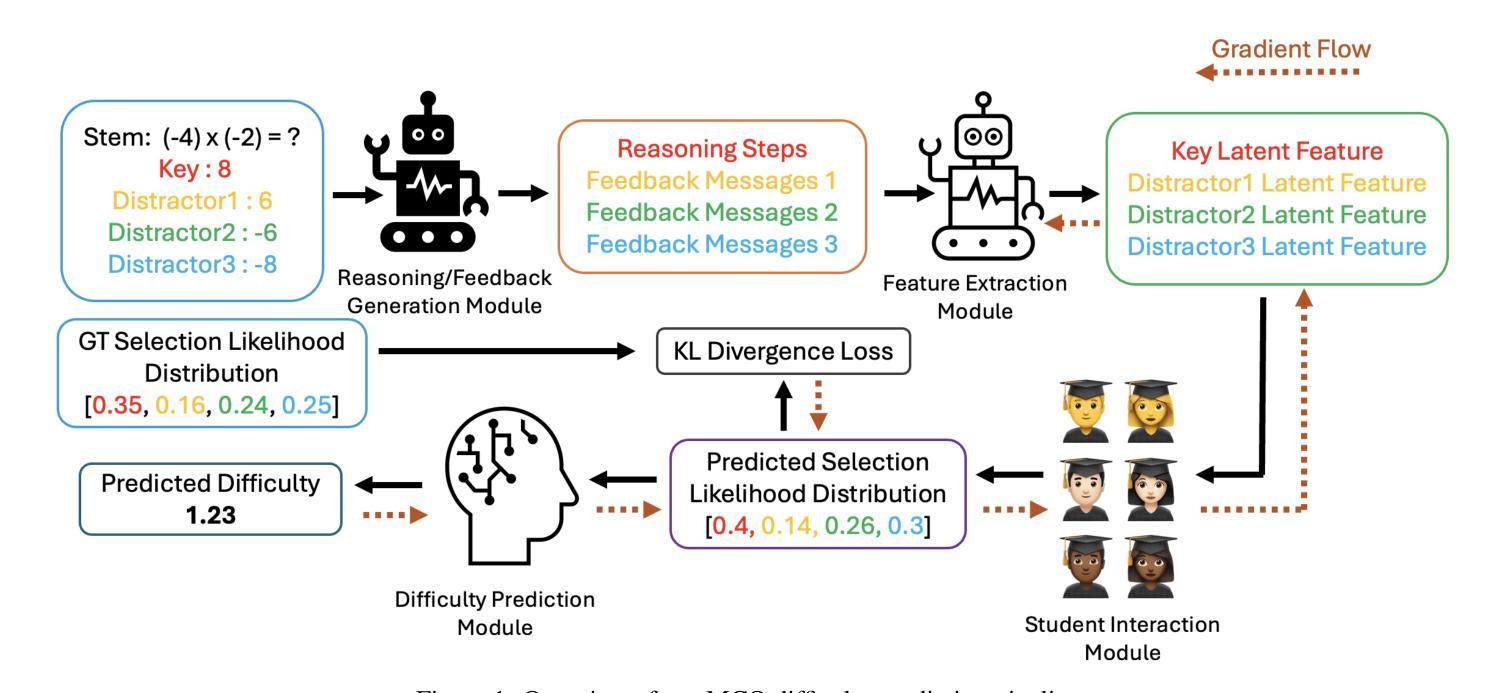
Reasoning and Sampling-Augmented MCQ Difficulty Prediction via LLMs
Authors:Wanyong Feng, Peter Tran, Stephen Sireci, Andrew Lan
The difficulty of multiple-choice questions (MCQs) is a crucial factor for educational assessments. Predicting MCQ difficulty is challenging since it requires understanding both the complexity of reaching the correct option and the plausibility of distractors, i.e., incorrect options. In this paper, we propose a novel, two-stage method to predict the difficulty of MCQs. First, to better estimate the complexity of each MCQ, we use large language models (LLMs) to augment the reasoning steps required to reach each option. We use not just the MCQ itself but also these reasoning steps as input to predict the difficulty. Second, to capture the plausibility of distractors, we sample knowledge levels from a distribution to account for variation among students responding to the MCQ. This setup, inspired by item response theory (IRT), enable us to estimate the likelihood of students selecting each (both correct and incorrect) option. We align these predictions with their ground truth values, using a Kullback-Leibler (KL) divergence-based regularization objective, and use estimated likelihoods to predict MCQ difficulty. We evaluate our method on two real-world \emph{math} MCQ and response datasets with ground truth difficulty values estimated using IRT. Experimental results show that our method outperforms all baselines, up to a 28.3% reduction in mean squared error and a 34.6% improvement in the coefficient of determination. We also qualitatively discuss how our novel method results in higher accuracy in predicting MCQ difficulty.
选择题难度是教育评估中的关键因素。预测选择题的难度具有挑战性,因为这需要理解选择正确答案的复杂性和错误选项的迷惑性。在本文中,我们提出了一种新的两阶段方法来预测选择题的难度。首先,为了更好地估计每个选择题的复杂性,我们使用大型语言模型(LLM)来增加解答每个选项所需的推理步骤。我们不仅使用选择题本身,而且使用这些推理步骤作为输入来预测难度。其次,为了捕捉错误选项的迷惑性,我们从分布中抽取知识层次来反映学生在回答选择题时的差异。这个设置灵感来自于项目反应理论(IRT),它使我们能够估计学生选择每个选项(无论是正确还是错误)的可能性。我们使用基于Kullback-Leibler(KL)散度的正则化目标来对齐这些预测与他们的真实值,并使用估计的可能性来预测选择题的难度。我们在两个真实的数学选择题和回答数据集上评估了我们的方法,这些数据的真实难度值是通过IRT估计得出的。实验结果表明,我们的方法优于所有基线方法,平均平方误差降低了28.3%,决定系数提高了34.6%。我们还从定性角度讨论了我们的新方法在预测选择题难度方面为何能带来更高的准确性。
论文及项目相关链接
Summary
本文提出了一种预测选择题难度的新颖两阶段方法。首先,为了更好地估计每个选择题的复杂度,使用大型语言模型来增强解答每个选项所需的推理步骤。然后,利用知识水平的分布来捕捉干扰项的可信程度,以应对不同学生对选择题反应的不同。通过基于Kullback-Leibler散度的正则化目标对齐这些预测与其真实值,并利用估计的可能性来预测选择题的难度。实验结果表明,该方法优于所有基线方法,均方误差降低了28.3%,决定系数提高了34.6%。
Key Takeaways
- 选择题的难度是教育评估中的关键因素。
- 预测选择题难度具有挑战性,因为它涉及理解正确选项的复杂性和干扰项的可信程度。
- 提出一种新颖的两阶段方法来预测选择题的难度。
- 使用大型语言模型增强推理步骤,以更好地估计每个选择题的复杂度。
- 利用知识水平的分布来捕捉干扰项的可信程度,以应对学生的不同反应。
- 方法通过基于Kullback-Leibler散度的正则化目标进行预测,并实验验证了其优越性。
点此查看论文截图

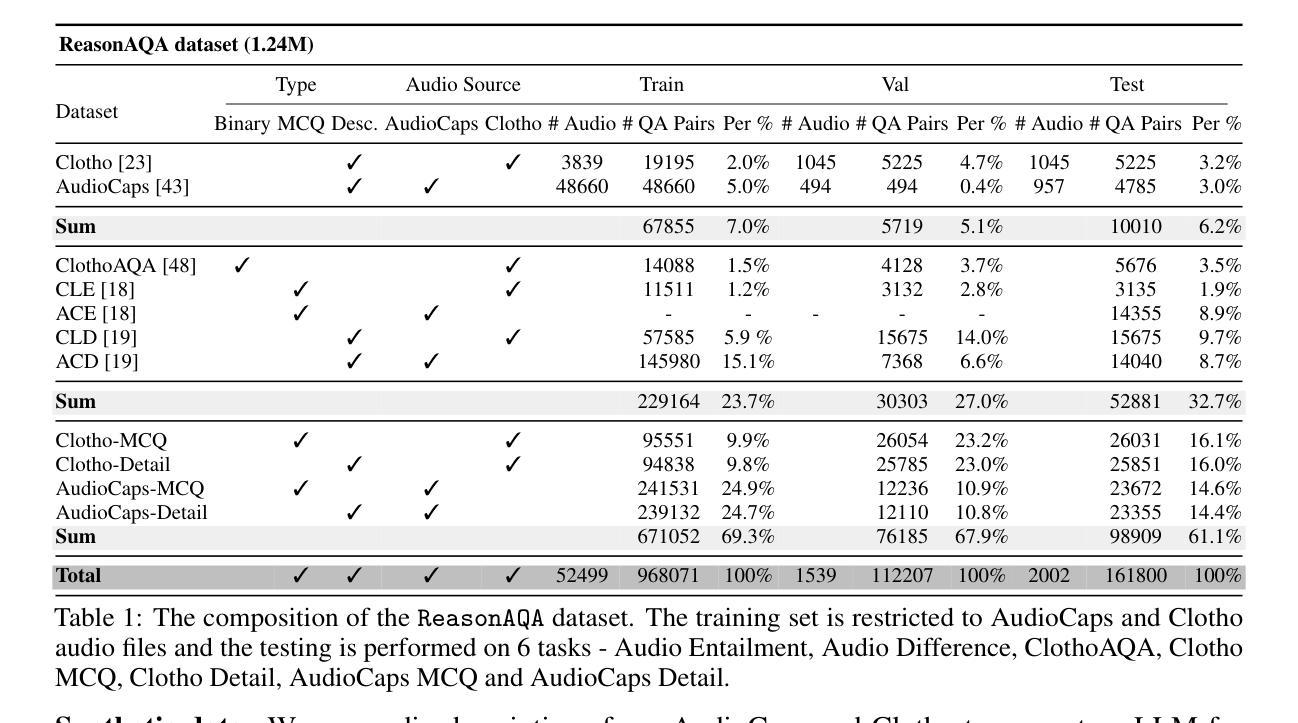
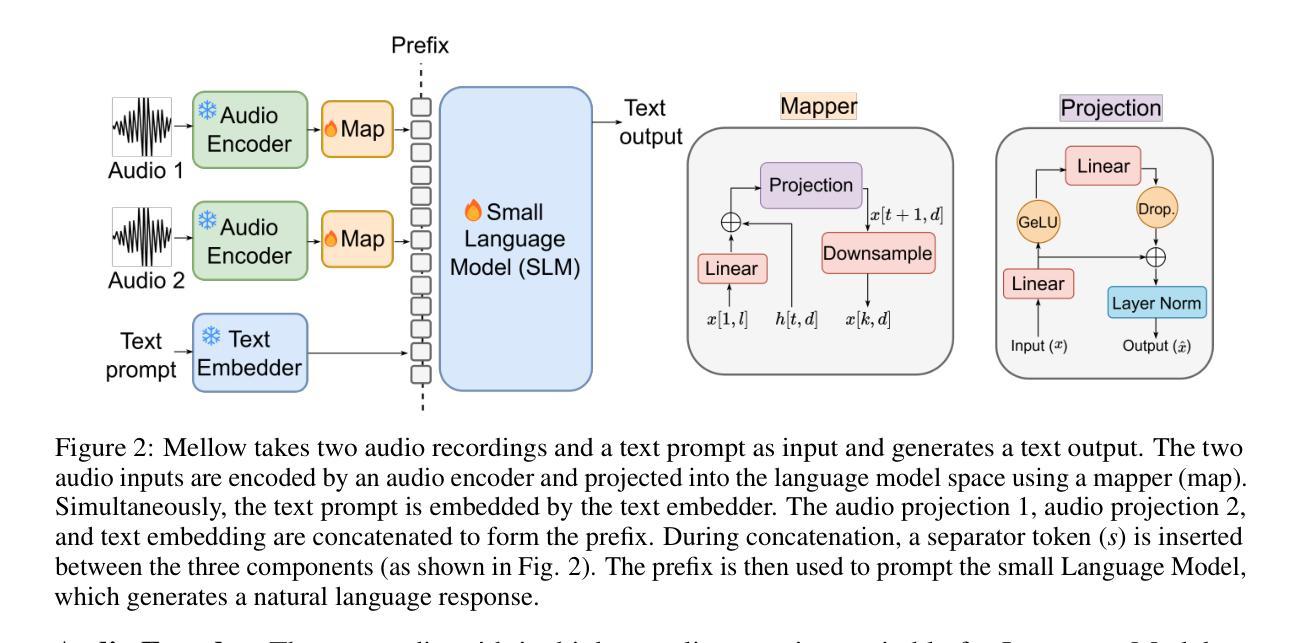
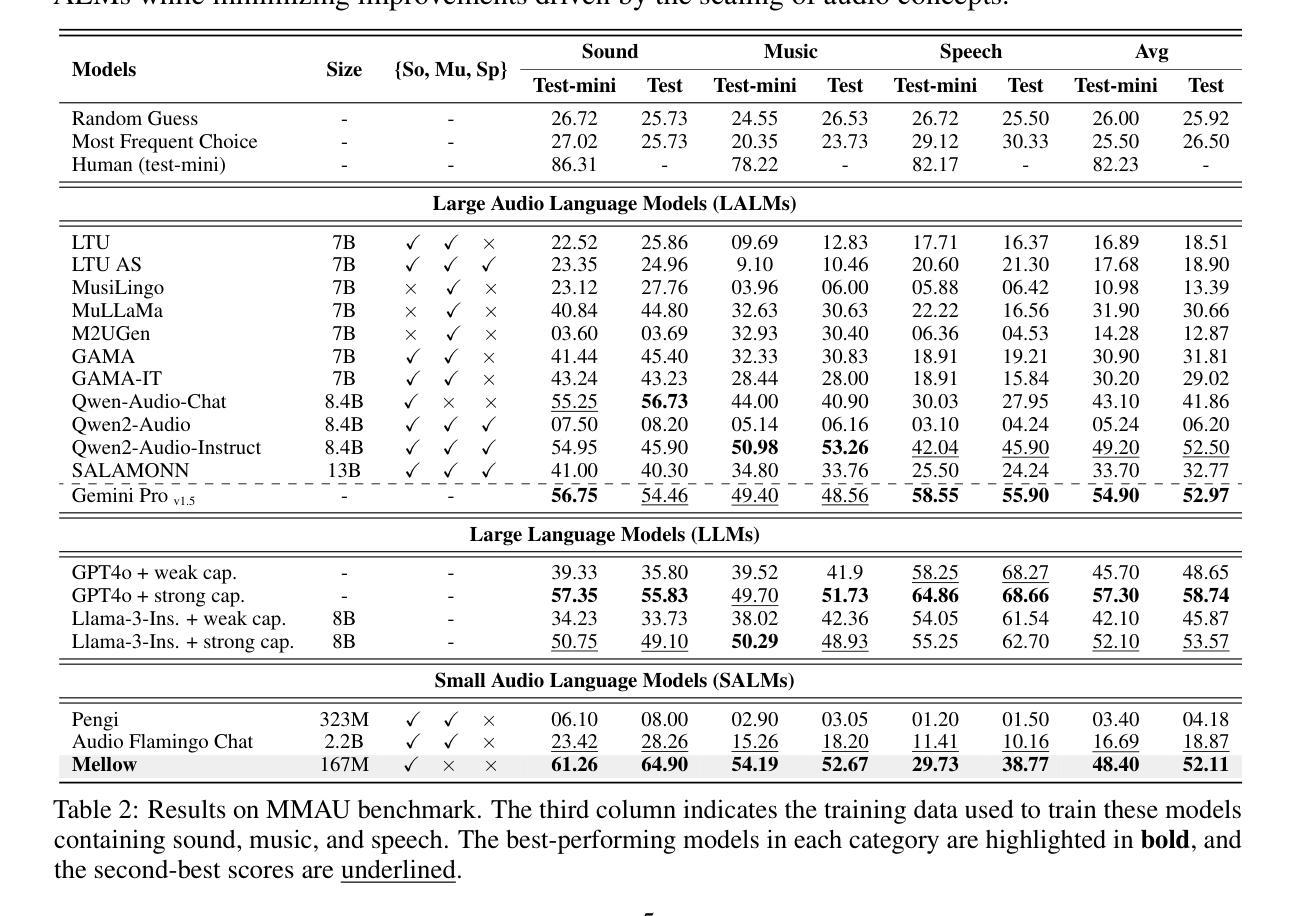
Mellow: a small audio language model for reasoning
Authors:Soham Deshmukh, Satvik Dixit, Rita Singh, Bhiksha Raj
Multimodal Audio-Language Models (ALMs) can understand and reason over both audio and text. Typically, reasoning performance correlates with model size, with the best results achieved by models exceeding 8 billion parameters. However, no prior work has explored enabling small audio-language models to perform reasoning tasks, despite the potential applications for edge devices. To address this gap, we introduce Mellow, a small Audio-Language Model specifically designed for reasoning. Mellow achieves state-of-the-art performance among existing small audio-language models and surpasses several larger models in reasoning capabilities. For instance, Mellow scores 52.11 on MMAU, comparable to SoTA Qwen2 Audio (which scores 52.5) while using 50 times fewer parameters and being trained on 60 times less data (audio hrs). To train Mellow, we introduce ReasonAQA, a dataset designed to enhance audio-grounded reasoning in models. It consists of a mixture of existing datasets (30% of the data) and synthetically generated data (70%). The synthetic dataset is derived from audio captioning datasets, where Large Language Models (LLMs) generate detailed and multiple-choice questions focusing on audio events, objects, acoustic scenes, signal properties, semantics, and listener emotions. To evaluate Mellow’s reasoning ability, we benchmark it on a diverse set of tasks, assessing on both in-distribution and out-of-distribution data, including audio understanding, deductive reasoning, and comparative reasoning. Finally, we conduct extensive ablation studies to explore the impact of projection layer choices, synthetic data generation methods, and language model pretraining on reasoning performance. Our training dataset, findings, and baseline pave the way for developing small ALMs capable of reasoning.
多模态音频语言模型(ALM)能够理解和推理音频和文本。通常,推理性能与模型大小相关,最好的结果是由超过8亿参数的模型实现的。然而,尽管边缘设备有潜在的应用,但之前的工作并未探索使小型音频语言模型执行推理任务的可能性。为了弥补这一空白,我们引入了专为推理而设计的小型音频语言模型“Mellow”。Mellow在现有小型音频语言模型中实现了最先进的性能,并在推理能力方面超越了某些更大的模型。例如,Mellow在MMAU上的得分为52.11,与当前最佳水平的Qwen2 Audio(得分为52.5)相当,同时使用参数少50倍,并且在数据(音频小时数)的训练上减少了60倍。为了训练Mellow,我们引入了ReasonAQA数据集,该数据集旨在提高模型的音频基础推理能力。它包含现有数据集(占30%)和合成数据(占70%)的混合。合成数据集来源于音频描述数据集,大型语言模型(LLM)会生成专注于音频事件、对象、声学场景、信号属性、语义和听众情绪的具体和多项选择题。为了评估Mellow的推理能力,我们在一组多样化的任务上对其进行了基准测试,评估其在内部数据和外部数据上的表现,包括音频理解、演绎推理和比较推理。最后,我们进行了广泛的消融研究,以探讨投影层选择、合成数据生成方法和语言模型预训练对推理性能的影响。我们的训练数据集、研究结果和基线为开发能够推理的小型ALM铺平了道路。
论文及项目相关链接
PDF Checkpoint and dataset available at: https://github.com/soham97/mellow
Summary
本文介绍了针对小型音频语言模型的推理任务的研究。研究人员推出了Mellow模型,该模型在小型音频语言模型上实现了最先进的性能,并在某些推理能力方面超越了较大的模型。Mellow的设计针对特定任务进行了优化,采用了一种新的数据集ReasonAQA进行训练,该数据集由现有数据集和合成数据集组成。合成数据集是通过音频描述数据集和大型语言模型生成的,用于生成关于音频事件的详细和多选择题。Mellow在各种任务上进行了评估,包括音频理解、推理等。
Key Takeaways
- 多模态音频语言模型(ALMs)能理解并处理音频和文本。
- 模型的推理性能与模型大小有关,大型模型表现更佳。
- 目前尚未有研究探索小型音频语言模型的推理任务,尽管这在边缘设备上有潜在应用。
- Mellow是一个专为推理设计的小型音频语言模型,实现了最先进的性能。
- Mellow在MMAU上的得分与SoTA Qwen2 Audio相当,但使用了50倍更少的参数,并在更少的数据(音频小时数)上进行训练。
- ReasonAQA数据集的引入,该数据集由现有数据集和合成数据集组成,旨在提高模型的音频基础推理能力。
- 合成数据集是通过音频描述数据集和大型语言模型生成的,包含关于音频事件的详细和多选择题。
点此查看论文截图




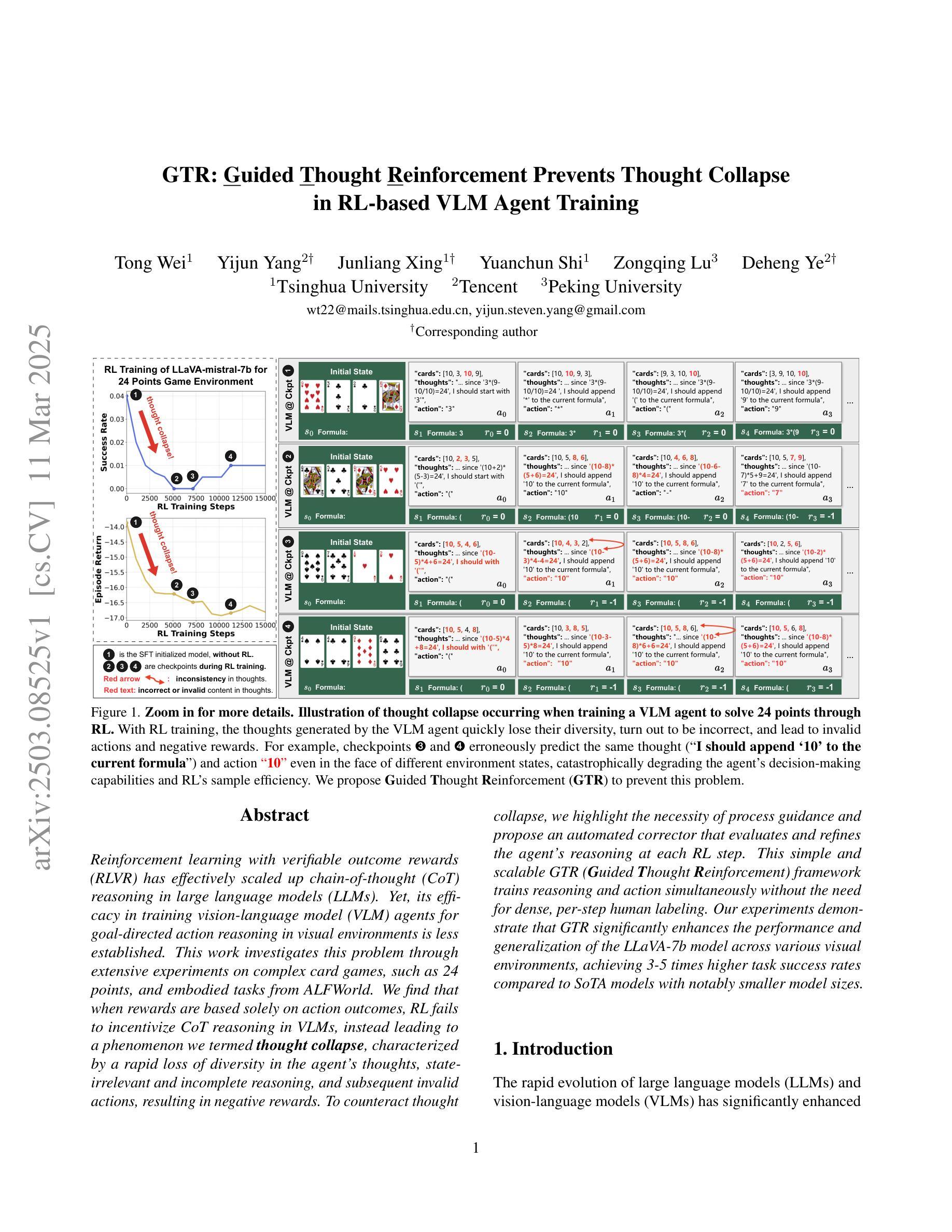
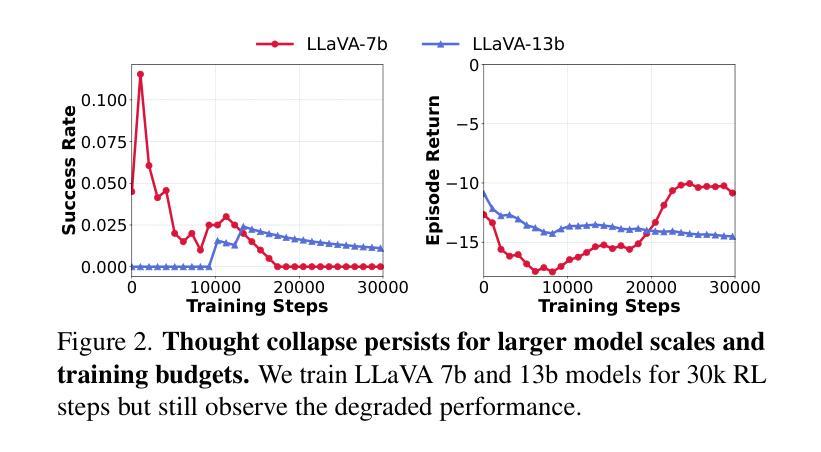
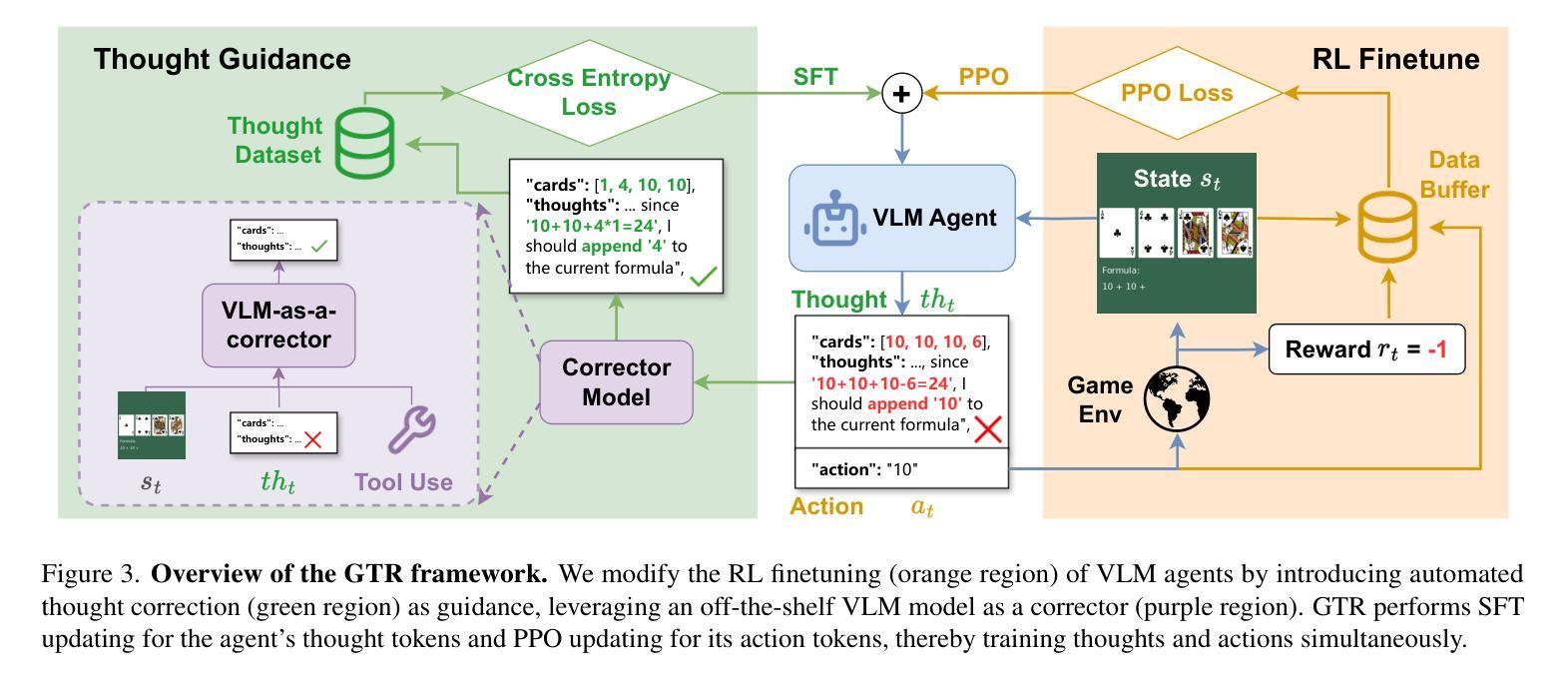
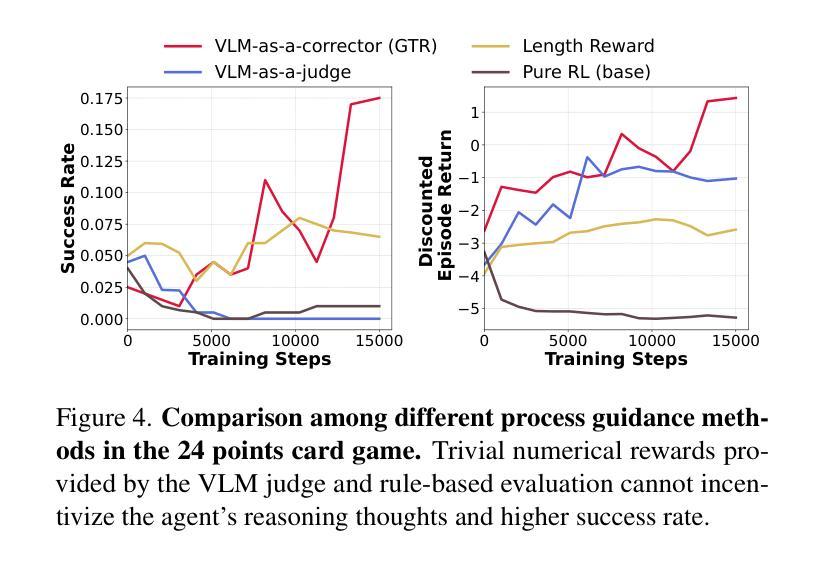
GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
Authors:Tong Wei, Yijun Yang, Junliang Xing, Yuanchun Shi, Zongqing Lu, Deheng Ye
Reinforcement learning with verifiable outcome rewards (RLVR) has effectively scaled up chain-of-thought (CoT) reasoning in large language models (LLMs). Yet, its efficacy in training vision-language model (VLM) agents for goal-directed action reasoning in visual environments is less established. This work investigates this problem through extensive experiments on complex card games, such as 24 points, and embodied tasks from ALFWorld. We find that when rewards are based solely on action outcomes, RL fails to incentivize CoT reasoning in VLMs, instead leading to a phenomenon we termed thought collapse, characterized by a rapid loss of diversity in the agent’s thoughts, state-irrelevant and incomplete reasoning, and subsequent invalid actions, resulting in negative rewards. To counteract thought collapse, we highlight the necessity of process guidance and propose an automated corrector that evaluates and refines the agent’s reasoning at each RL step. This simple and scalable GTR (Guided Thought Reinforcement) framework trains reasoning and action simultaneously without the need for dense, per-step human labeling. Our experiments demonstrate that GTR significantly enhances the performance and generalization of the LLaVA-7b model across various visual environments, achieving 3-5 times higher task success rates compared to SoTA models with notably smaller model sizes.
强化学习与可验证结果奖励(RLVR)已在大型语言模型(LLM)中有效地扩展了思维链(CoT)推理。然而,其在针对视觉环境中目标导向行动推理训练视觉语言模型(VLM)代理方面的有效性尚未明确建立。本研究通过复杂的卡牌游戏(如二十四点)和身体任务(来自ALFWorld)的大量实验来解决这个问题。我们发现,当奖励仅仅基于行动结果时,强化学习无法激励VLM中的思维链推理,反而导致我们称之为“思维崩溃”的现象,特点是代理思维的迅速丧失多样性、状态无关和不完整的推理,以及随后的无效行动,导致负面奖励。为了对抗思维崩溃,我们强调了过程指导的必要性,并提出了一种自动化校正器,它在每个强化学习步骤中评估和精炼代理的推理。这种简单且可扩展的GTR(引导思维强化)框架同时训练推理和行动,无需密集、逐步的人工标注。我们的实验表明,GTR显著提高了LLaVA-7b模型在各种视觉环境中的性能和泛化能力,与最新模型相比,任务成功率提高了3-5倍,而且模型大小显著更小。
论文及项目相关链接
Summary:强化学习结合可验证结果奖励(RLVR)在大型语言模型(LLM)中的链式思维(CoT)推理已经取得了有效进展。然而,其在训练视觉语言模型(VLM)代理进行视觉环境中的目标导向行动推理方面的有效性尚未明确。本研究通过复杂的卡牌游戏和ALFWorld中的实体任务实验,发现仅基于行动结果的奖励会导致强化学习无法激励VLM中的CoT推理,出现我们称之为“思维崩溃”的现象。为解决这一问题,我们强调了过程指导的必要性,并提出一种自动化校正器,在强化学习的每一步评估并改进代理的推理。这种简单且可扩展的GTR(引导思维强化)框架同时训练推理和行动,无需密集的每一步人工标注。实验表明,GTR显著提高了LLaVA-7b模型在各种视觉环境中的性能和泛化能力,相较于最先进模型的任务成功率提高了3-5倍,且模型体积更小。
Key Takeaways:
- 强化学习结合可验证结果奖励(RLVR)能够提升大型语言模型(LLM)中的链式思维(CoT)推理能力。
- 在视觉语言模型(VLM)中,仅依赖行动结果的奖励会导致强化学习无法有效激励推理思维,出现“思维崩溃”现象。
- 为解决思维崩溃问题,需要引入过程指导,提出一种自动化校正器来评估并改进代理的每一步推理。
- GTR(引导思维强化)框架能同时训练推理和行动,无需密集的每一步人工标注。
- GTR框架在多种视觉环境中显著提高模型的性能和泛化能力。
- 与现有先进模型相比,GTR框架的任务成功率提高了3-5倍。
点此查看论文截图

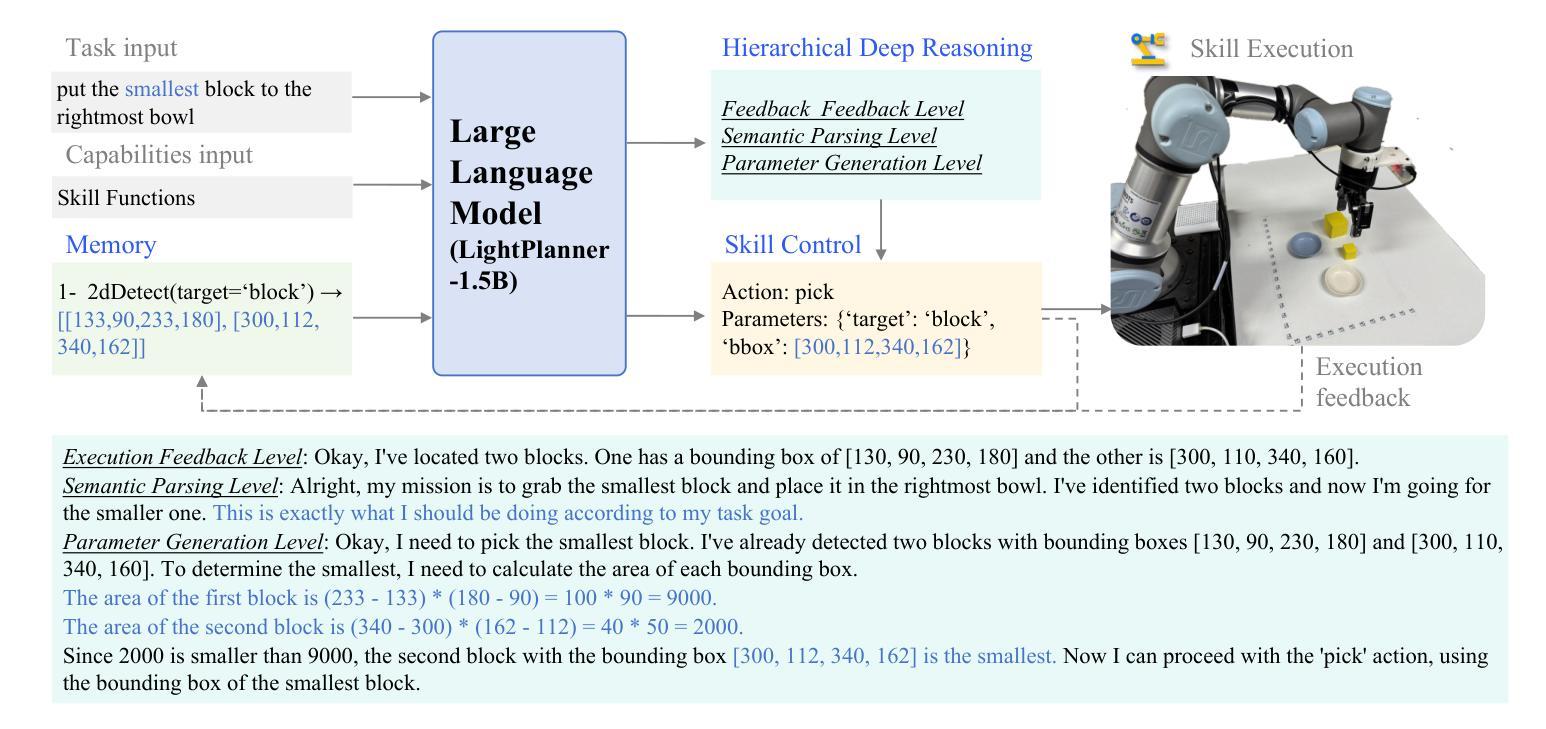
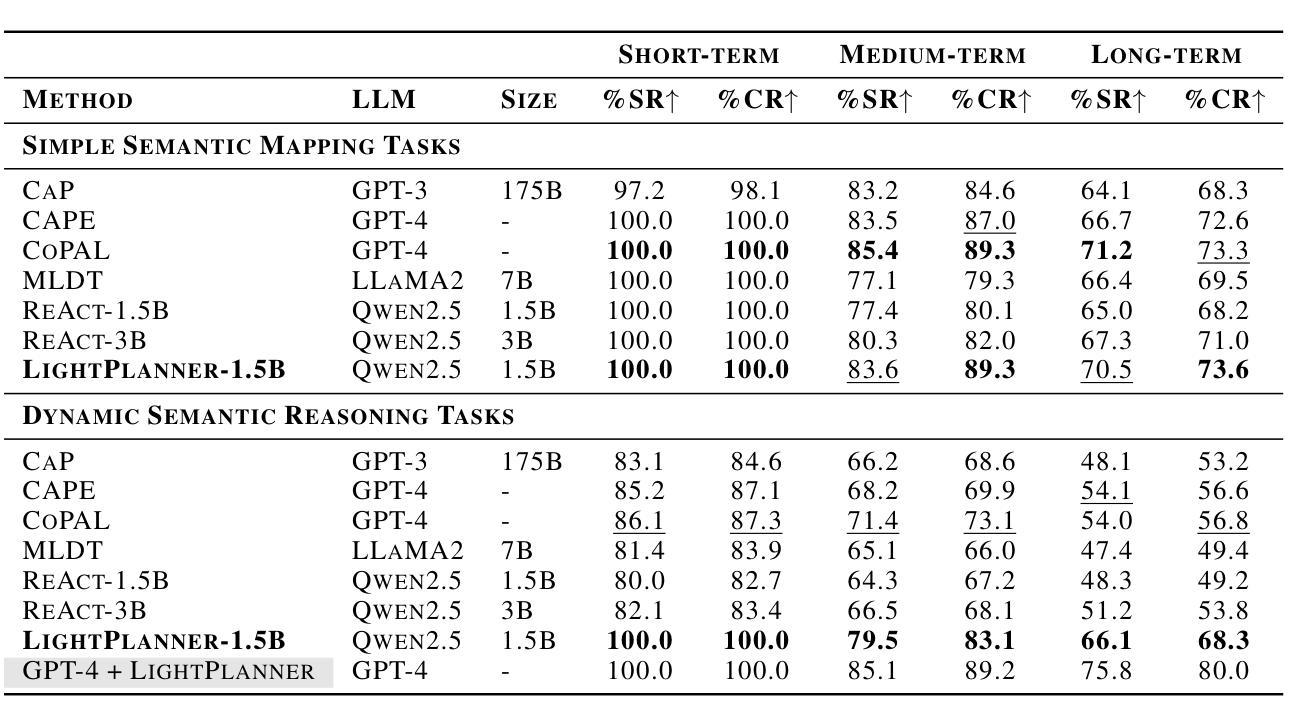
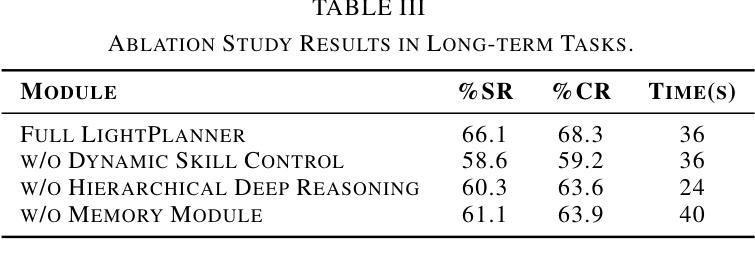
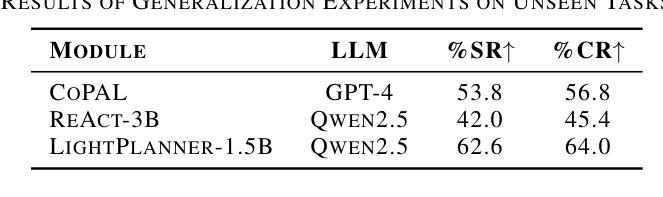
LightPlanner: Unleashing the Reasoning Capabilities of Lightweight Large Language Models in Task Planning
Authors:Weijie Zhou, Yi Peng, Manli Tao, Chaoyang Zhao, Honghui Dong, Ming Tang, Jinqiao Wang
In recent years, lightweight large language models (LLMs) have garnered significant attention in the robotics field due to their low computational resource requirements and suitability for edge deployment. However, in task planning – particularly for complex tasks that involve dynamic semantic logic reasoning – lightweight LLMs have underperformed. To address this limitation, we propose a novel task planner, LightPlanner, which enhances the performance of lightweight LLMs in complex task planning by fully leveraging their reasoning capabilities. Unlike conventional planners that use fixed skill templates, LightPlanner controls robot actions via parameterized function calls, dynamically generating parameter values. This approach allows for fine-grained skill control and improves task planning success rates in complex scenarios. Furthermore, we introduce hierarchical deep reasoning. Before generating each action decision step, LightPlanner thoroughly considers three levels: action execution (feedback verification), semantic parsing (goal consistency verification), and parameter generation (parameter validity verification). This ensures the correctness of subsequent action controls. Additionally, we incorporate a memory module to store historical actions, thereby reducing context length and enhancing planning efficiency for long-term tasks. We train the LightPlanner-1.5B model on our LightPlan-40k dataset, which comprises 40,000 action controls across tasks with 2 to 13 action steps. Experiments demonstrate that our model achieves the highest task success rate despite having the smallest number of parameters. In tasks involving spatial semantic reasoning, the success rate exceeds that of ReAct by 14.9 percent. Moreover, we demonstrate LightPlanner’s potential to operate on edge devices.
近年来,由于机器人领域对计算资源的要求较低且适合边缘部署,轻量级的大型语言模型(LLMs)已经引起了广泛的关注。然而,在任务规划方面,尤其是在涉及动态语义逻辑推理的复杂任务中,轻量级LLMs的表现并不理想。为了解决这一局限性,我们提出了一种新型的任务规划器LightPlanner,它通过充分利用轻量级LLM的推理能力,提高其在复杂任务规划中的性能。与传统的使用固定技能模板的规划器不同,LightPlanner通过参数化函数调用控制机器人动作,并动态生成参数值。这种方法允许精细的技能控制,并在复杂场景中提高了任务规划的成功率。此外,我们还引入了分层深度推理。在生成每个动作决策步骤之前,LightPlanner会充分考虑三个层次:动作执行(反馈验证)、语义解析(目标一致性验证)和参数生成(参数有效性验证)。这确保了后续动作控制的正确性。此外,我们加入了一个记忆模块来存储历史动作,从而减少了上下文长度,提高了长期任务的规划效率。我们在LightPlan-40k数据集上训练了LightPlanner-1.5B模型,该数据集包含4万个涉及任务中行动步骤的动作控制指令,涵盖的任务涉及行动步骤在2至13之间。实验表明,尽管我们的模型参数数量最少,但我们的模型仍然达到了最高的任务成功率。在涉及空间语义推理的任务中,成功率超过了ReAct模型14.9个百分点。此外,我们还展示了LightPlanner在边缘设备上的潜力。
论文及项目相关链接
Summary
本文介绍了针对轻量化大型语言模型(LLMs)在机器人任务规划中的性能不足问题,提出了一种新型任务规划器LightPlanner。LightPlanner通过参数化函数调用控制机器人动作,并引入层次化深度推理和记忆模块,提高了轻量级LLMs在复杂任务规划中的性能。实验证明,LightPlanner模型在任务成功率上表现优异,尤其是涉及空间语义推理的任务。
Key Takeaways
- 轻量化大型语言模型(LLMs)在机器人任务规划中受到关注,但在涉及动态语义逻辑推理的复杂任务中表现不佳。
- 提出了一种新型任务规划器LightPlanner,通过参数化函数调用控制机器人动作,提高轻量级LLMs在复杂任务规划中的性能。
- LightPlanner引入层次化深度推理,确保后续动作控制正确性。
- LightPlanner包含记忆模块,用于存储历史动作,提高长期任务的规划效率。
- LightPlanner-1.5B模型在LightPlan-40k数据集上训练,实验证明其任务成功率表现优异。
- 在涉及空间语义推理的任务中,LightPlanner成功率超过ReAct达14.9%。
点此查看论文截图

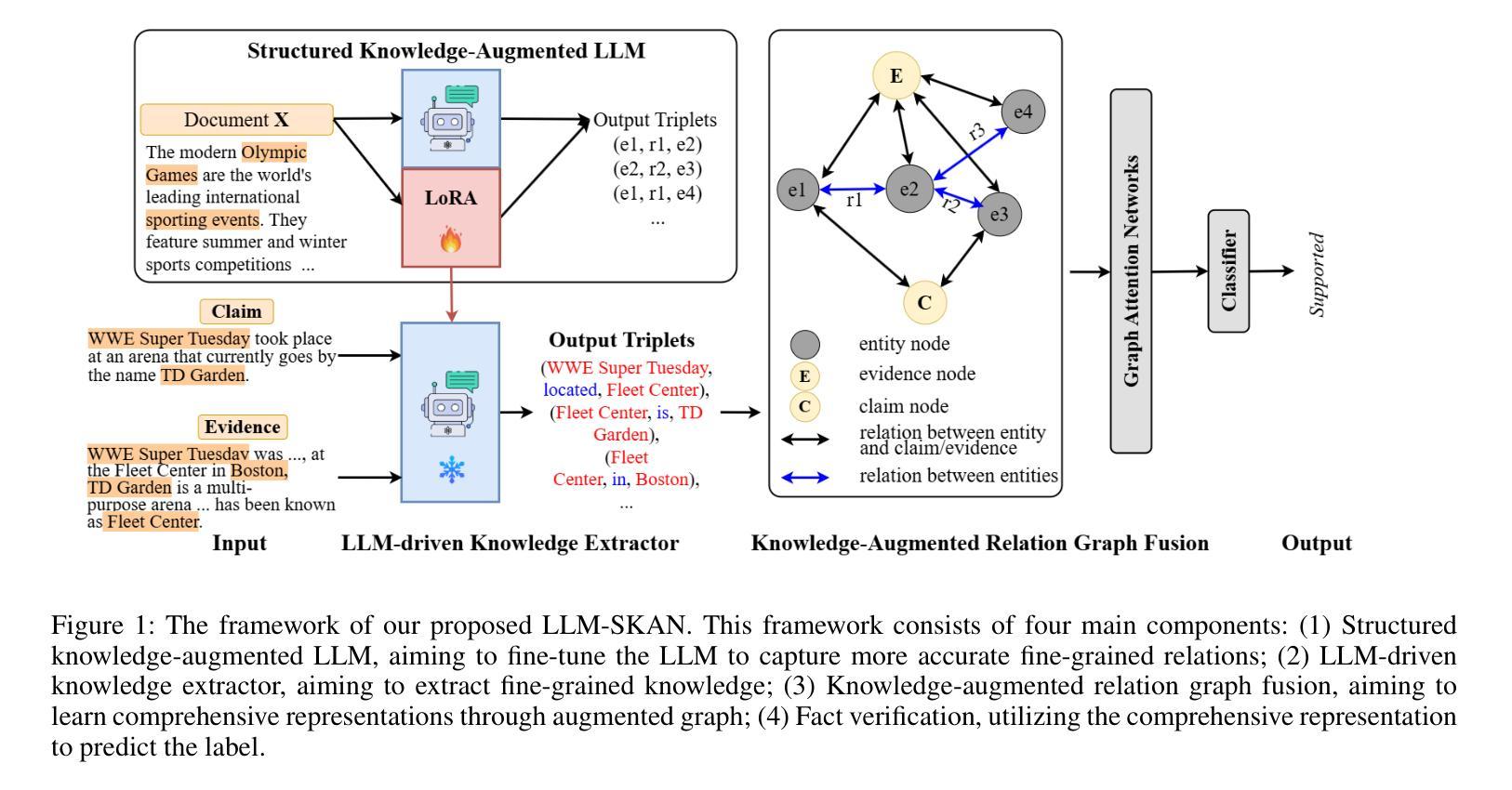
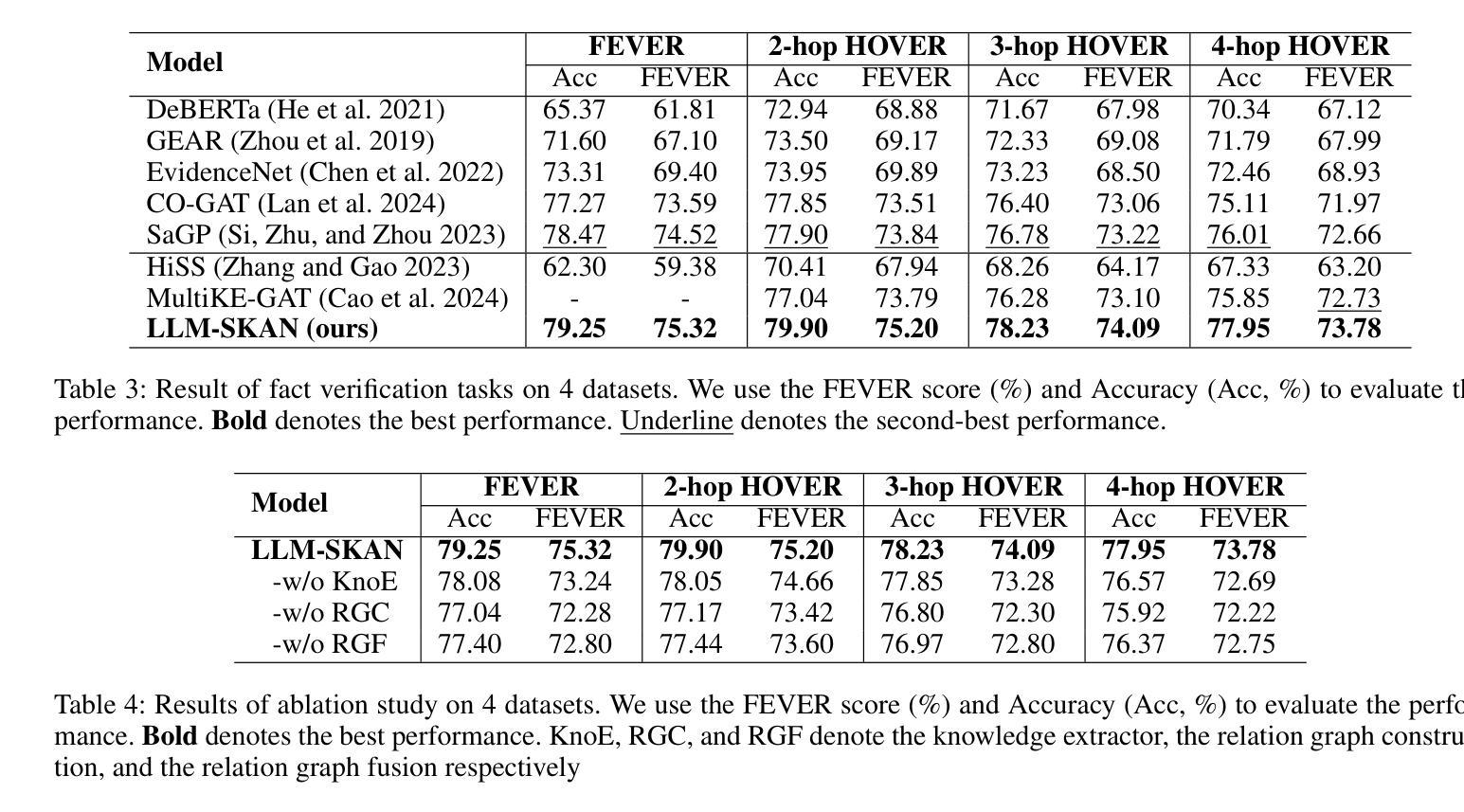
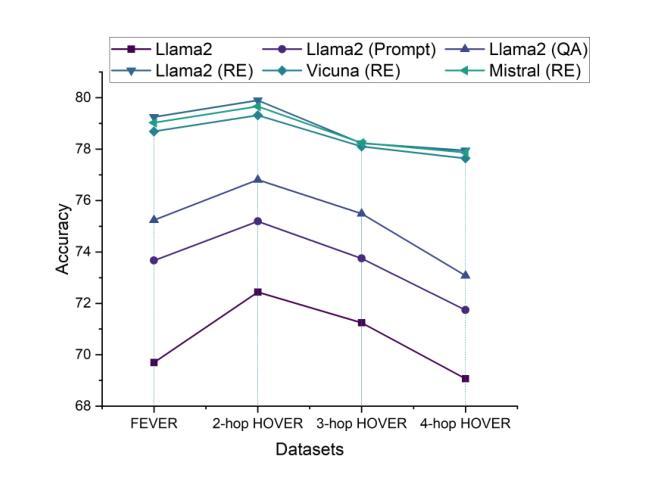
Enhancing Multi-Hop Fact Verification with Structured Knowledge-Augmented Large Language Models
Authors:Han Cao, Lingwei Wei, Wei Zhou, Songlin Hu
The rapid development of social platforms exacerbates the dissemination of misinformation, which stimulates the research in fact verification. Recent studies tend to leverage semantic features to solve this problem as a single-hop task. However, the process of verifying a claim requires several pieces of evidence with complicated inner logic and relations to verify the given claim in real-world situations. Recent studies attempt to improve both understanding and reasoning abilities to enhance the performance, but they overlook the crucial relations between entities that benefit models to understand better and facilitate the prediction. To emphasize the significance of relations, we resort to Large Language Models (LLMs) considering their excellent understanding ability. Instead of other methods using LLMs as the predictor, we take them as relation extractors, for they do better in understanding rather than reasoning according to the experimental results. Thus, to solve the challenges above, we propose a novel Structured Knowledge-Augmented LLM-based Network (LLM-SKAN) for multi-hop fact verification. Specifically, we utilize an LLM-driven Knowledge Extractor to capture fine-grained information, including entities and their complicated relations. Besides, we leverage a Knowledge-Augmented Relation Graph Fusion module to interact with each node and learn better claim-evidence representations comprehensively. The experimental results on four common-used datasets demonstrate the effectiveness and superiority of our model.
随着社交平台的高速发展,加剧了错信息的传播,这激发了事实核查的研究。近期的研究倾向于利用语义特征来解决这个问题,把它作为一个单跳任务来处理。然而,验证一个声明的过程需要多个证据,这些证据在内部逻辑和关联上非常复杂,才能在现实情境中对给定的声明进行验证。近期的研究试图提高理解和推理能力来提升性能,但它们忽视了实体之间的关键关系,这些关系有助于模型更好地理解并促进预测。为了强调关系的重要性,我们借助大型语言模型(LLM),考虑到它们出色的理解能力。与其他将LLM用作预测器的方法不同,我们将其用作关系提取器,根据实验结果,它们在理解而非推理方面表现更好。因此,为了解决上述挑战,我们提出了一种新的基于大型语言模型的结构化知识增强网络(LLM-SKAN)进行多跳事实核查。具体来说,我们利用LLM驱动的知识提取器来捕捉精细信息,包括实体和他们的复杂关系。此外,我们还借助知识增强关系图融合模块来与每个节点进行交互,并全面学习更好的声明-证据表示。在四个常用数据集上的实验结果表明了我们模型的有效性和优越性。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary:随着社交平台快速发展,谣言传播问题加剧,促使了事实核查研究的重要性日益增加。最近研究倾向于利用语义特征解决这一问题,但现实情况中的核查需要多方证据和复杂逻辑。为提高模型理解和推理能力,本文利用大型语言模型(LLM)的优秀理解能力,将其作为关系提取器,提出一种基于LLM的结构化知识增强网络(LLM-SKAN)进行多跳事实核查。通过LLM驱动的知识提取器捕捉实体及其复杂关系,并结合知识增强关系图融合模块,提高模型性能。实验结果表明该模型在四个常用数据集上的有效性和优越性。
Key Takeaways:
- 社交平台快速发展加剧了谣言传播,引发了对事实核查研究的关注。
- 最近研究倾向于利用语义特征解决事实核查问题,但现实情况中的核查过程复杂,需要多方证据和复杂逻辑。
- 大型语言模型(LLM)具有出色的理解能力,本文将其作为关系提取器来强化模型的推理能力。
- 提出一种新型结构化知识增强网络(LLM-SKAN)用于多跳事实核查。
- LLM-SKAN通过LLM驱动的知识提取器捕捉实体及其复杂关系,提高模型性能。
- 知识增强关系图融合模块能增强模型的交互能力和对索赔证据的综合理解。
点此查看论文截图


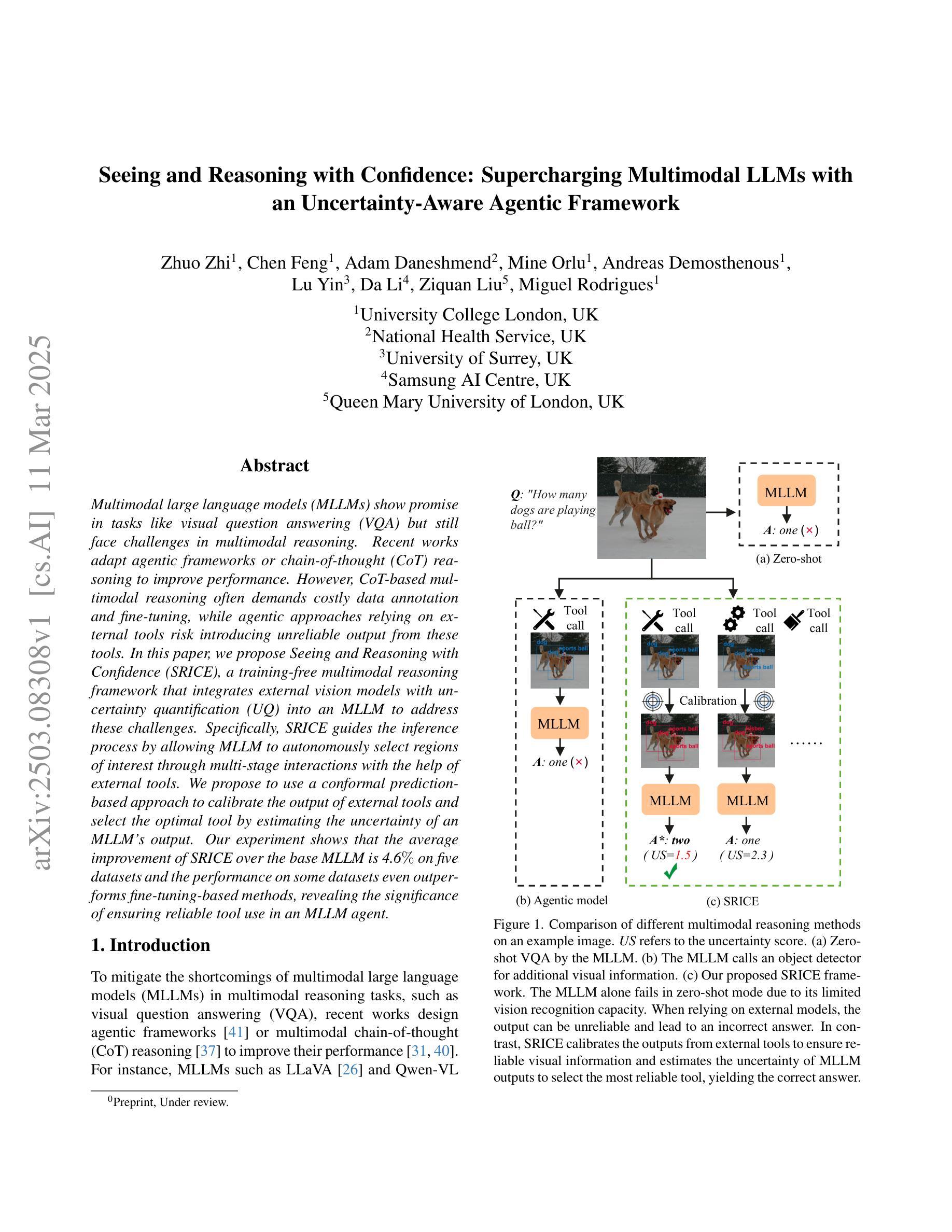
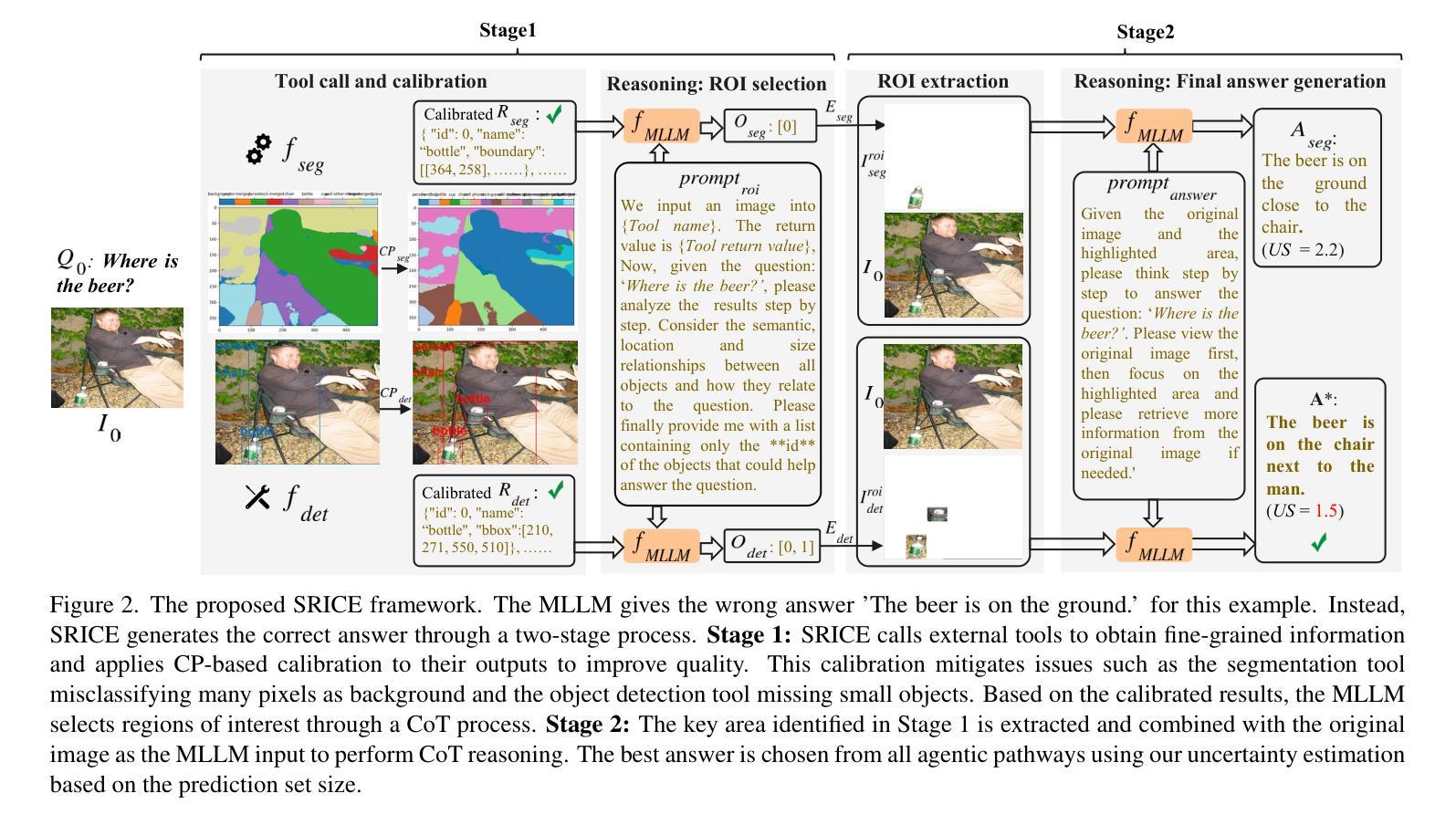
Seeing and Reasoning with Confidence: Supercharging Multimodal LLMs with an Uncertainty-Aware Agentic Framework
Authors:Zhuo Zhi, Chen Feng, Adam Daneshmend, Mine Orlu, Andreas Demosthenous, Lu Yin, Da Li, Ziquan Liu, Miguel R. D. Rodrigues
Multimodal large language models (MLLMs) show promise in tasks like visual question answering (VQA) but still face challenges in multimodal reasoning. Recent works adapt agentic frameworks or chain-of-thought (CoT) reasoning to improve performance. However, CoT-based multimodal reasoning often demands costly data annotation and fine-tuning, while agentic approaches relying on external tools risk introducing unreliable output from these tools. In this paper, we propose Seeing and Reasoning with Confidence (SRICE), a training-free multimodal reasoning framework that integrates external vision models with uncertainty quantification (UQ) into an MLLM to address these challenges. Specifically, SRICE guides the inference process by allowing MLLM to autonomously select regions of interest through multi-stage interactions with the help of external tools. We propose to use a conformal prediction-based approach to calibrate the output of external tools and select the optimal tool by estimating the uncertainty of an MLLM’s output. Our experiment shows that the average improvement of SRICE over the base MLLM is 4.6% on five datasets and the performance on some datasets even outperforms fine-tuning-based methods, revealing the significance of ensuring reliable tool use in an MLLM agent.
多模态大型语言模型(MLLMs)在视觉问答(VQA)等任务中显示出巨大的潜力,但在多模态推理方面仍面临挑战。近期的研究采用代理框架或思维链(CoT)推理来提高性能。然而,基于思维链的多模态推理通常需要昂贵的数据标注和微调,而依赖外部工具的代理方法则存在引入这些工具不可靠输出的风险。针对这些挑战,本文提出了“信心满满的看见与推理”(SRICE)这一无需训练的多模态推理框架。SRICE通过将外部视觉模型与不确定性量化(UQ)集成到MLLM中来解决这些挑战。具体来说,SRICE通过引导推理过程,使MLLM能够借助外部工具自主选择合适的感兴趣区域进行多阶段交互。我们提出了一种基于适配预测的方法对外部工具的输出进行校准,并通过估计MLLM输出的不确定性来选择最佳工具。实验表明,SRICE相较于基础MLLM在五个数据集上的平均改进率为4.6%,并且在某些数据集上的性能甚至超过了微调方法,这表明在MLLM代理中确保可靠的工具使用具有重要意义。
论文及项目相关链接
Summary
基于多模态大型语言模型(MLLMs)在视觉问答(VQA)等任务中的潜力,本文提出了Seeing and Reasoning with Confidence(SRICE)框架,这是一个无需训练的多模态推理框架。它集成了外部视觉模型与不确定性量化(UQ),解决了现有挑战。SRICE通过多阶段交互自主选取感兴趣区域,并使用外部工具辅助推理过程。同时,采用基于共识预测的方法校准外部工具的输出,通过估计MLLM的输出不确定性来选择最佳工具。实验表明,SRICE在五个数据集上的平均改进比基础MLLM提高了4.6%,在某些数据集上的性能甚至超过了微调方法,突显了在MLLM代理中确保可靠工具使用的重要性。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉问答(VQA)等任务中具有潜力,但仍面临多模态推理的挑战。
- 现有方法如基于代理框架和链式思维(CoT)推理的方法虽能提升性能,但存在数据标注成本高和依赖外部工具带来的不确定性问题。
- SRICE框架是一种无需训练的多模态推理框架,集成了外部视觉模型与不确定性量化(UQ)。
- SRICE通过多阶段交互自主选取感兴趣区域,引导推理过程。
- 采用共识预测方法校准外部工具输出,通过估计MLLM输出不确定性来选择最佳工具。
- 实验显示SRICE在多个数据集上的性能优于基础MLLM,甚至在某些数据集上超过微调方法。
点此查看论文截图
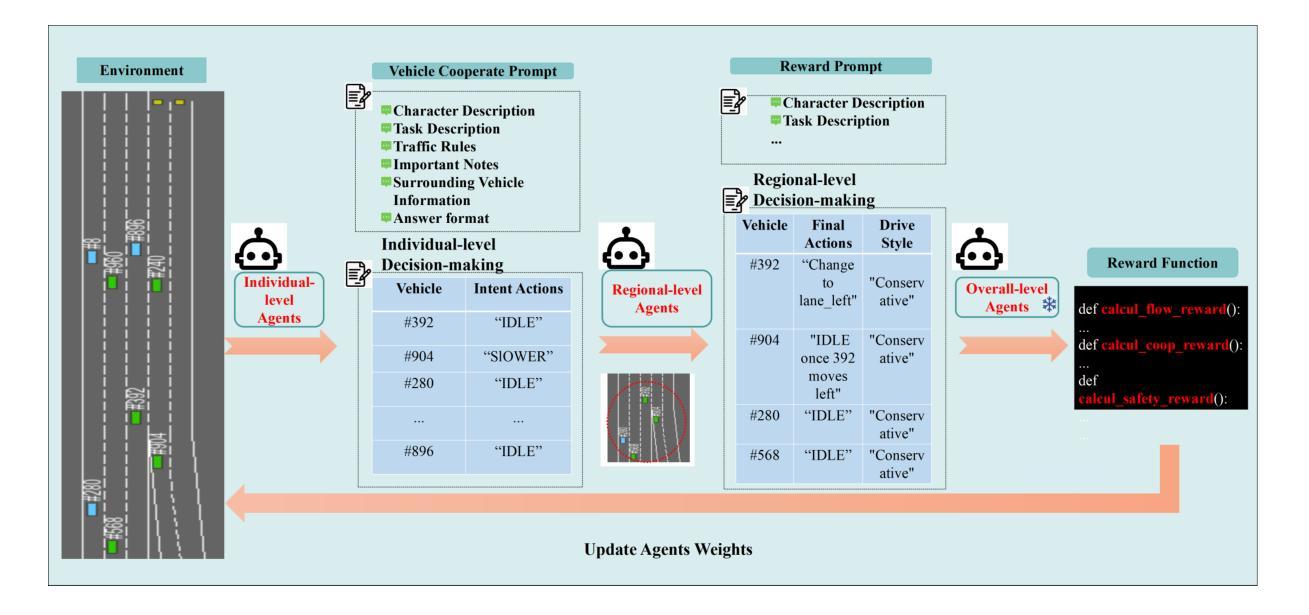
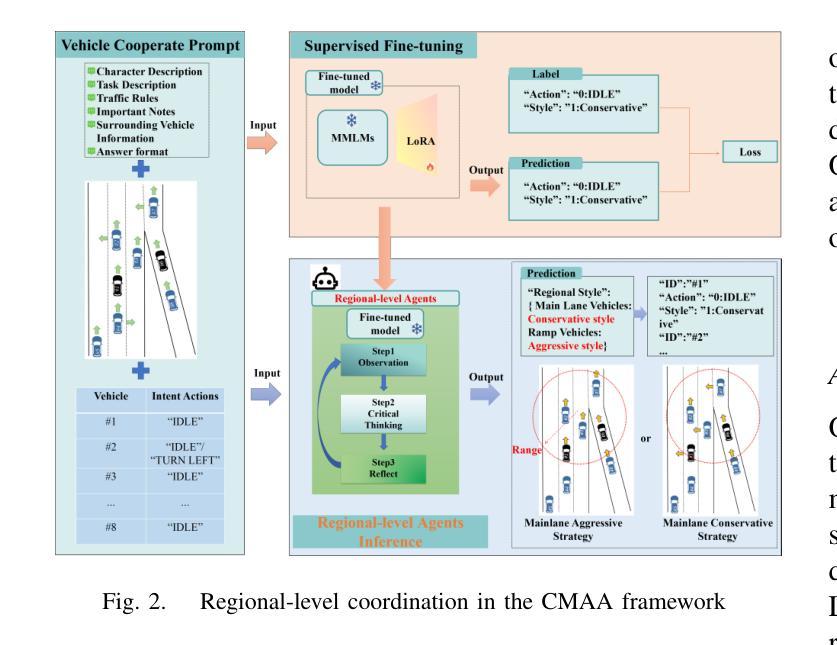
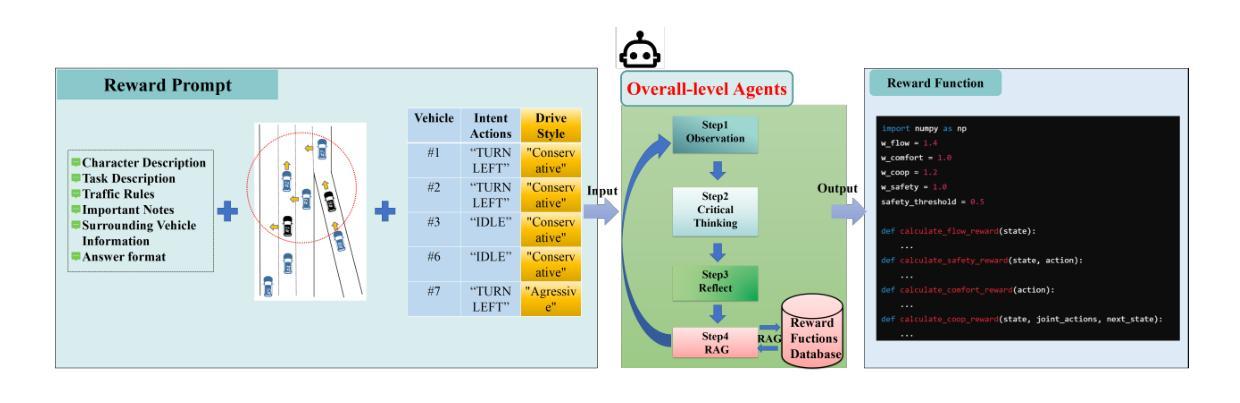
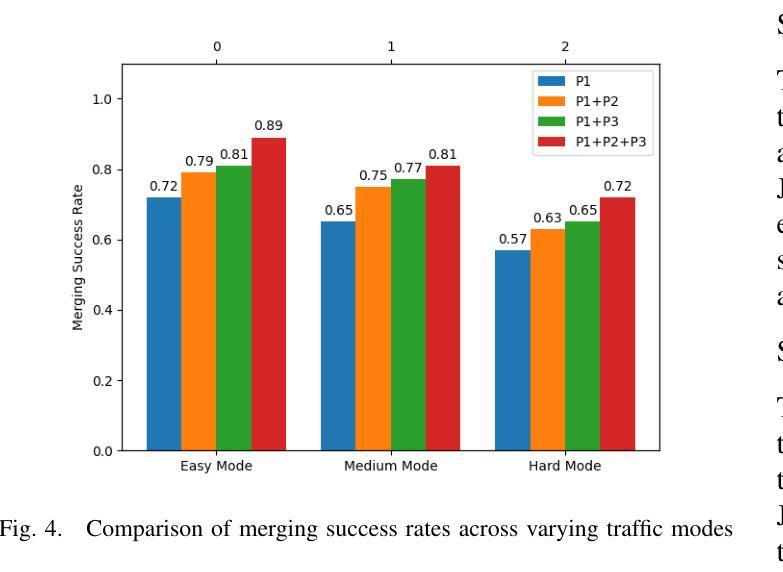
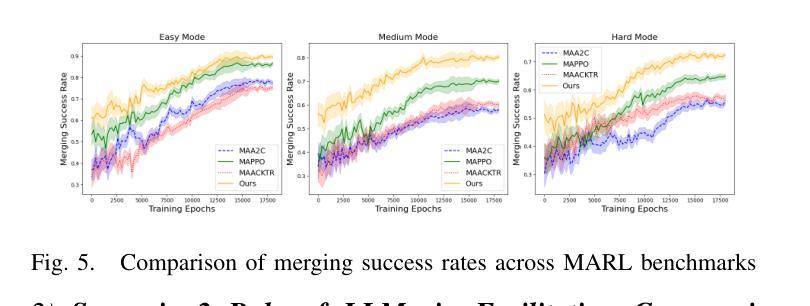
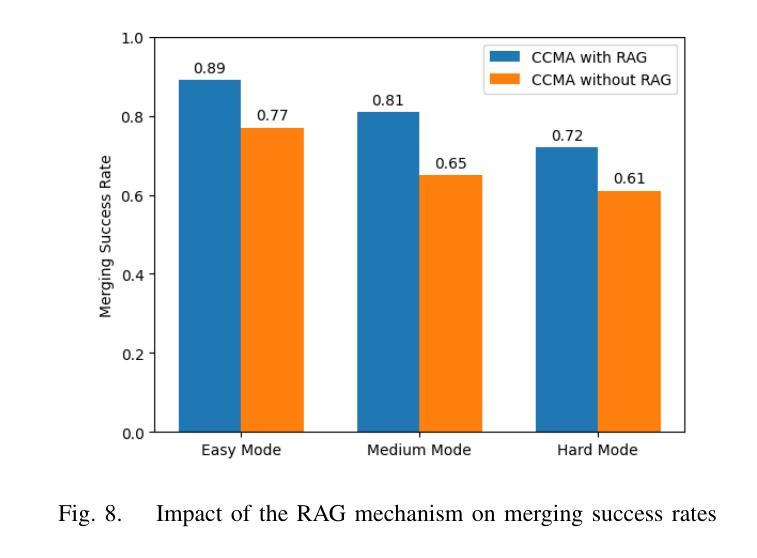
A Cascading Cooperative Multi-agent Framework for On-ramp Merging Control Integrating Large Language Models
Authors:Miao Zhang, Zhenlong Fang, Tianyi Wang, Qian Zhang, Shuai Lu, Junfeng Jiao, Tianyu Shi
Traditional Reinforcement Learning (RL) suffers from replicating human-like behaviors, generalizing effectively in multi-agent scenarios, and overcoming inherent interpretability issues.These tasks are compounded when deep environment understanding, agent coordination and dynamic optimization are required. While Large Language Model (LLM) enhanced methods have shown promise in generalization and interoperability, they often neglect necessary multi-agent coordination. Therefore, we introduce the Cascading Cooperative Multi-agent (CCMA) framework, integrating RL for individual interactions, a fine-tuned LLM for regional cooperation, a reward function for global optimization, and the Retrieval-augmented Generation mechanism to dynamically optimize decision-making across complex driving scenarios. Our experiments demonstrate that the CCMA outperforms existing RL methods, demonstrating significant improvements in both micro and macro-level performance in complex driving environments.
传统强化学习(RL)在复制人类行为、在多智能体场景中的有效泛化以及解决固有的可解释性问题方面存在困难。当需要深入了解环境、智能体协调和动态优化时,这些任务更为复杂。虽然大型语言模型(LLM)增强方法在泛化和互操作性方面显示出潜力,但它们往往忽视了必要的多智能体协调。因此,我们引入了级联合作多智能体(CCMA)框架,该框架整合了用于个体交互的RL、用于区域合作的微调LLM、用于全局优化的奖励函数以及增强生成机制,以在复杂的驾驶场景中动态优化决策。我们的实验表明,CCMA在复杂驾驶环境中,无论是在微观还是宏观层面,都优于现有的RL方法,表现出显著的性能改进。
论文及项目相关链接
Summary
传统强化学习(RL)在模拟人类行为、多智能体场景中的有效泛化以及解决固有的可解释性问题方面存在挑战。当需要深度环境理解、智能体协调和动态优化时,这些任务更加复杂。虽然大型语言模型(LLM)增强方法在泛化和互操作性方面显示出潜力,但它们往往忽略了必要的多智能体协调。因此,我们引入了级联合作多智能体(CCMA)框架,整合RL进行个体交互、对区域合作进行微调LLM、用于全局优化的奖励函数以及增强生成的检索机制,以在复杂的驾驶场景中动态优化决策。实验表明,CCMA在微观和宏观性能上均优于现有RL方法,在复杂驾驶环境中表现出显著改进。
Key Takeaways
- 传统强化学习(RL)在模拟人类行为、多智能体场景中的泛化以及解决可解释性问题方面存在挑战。
- 为解决这些问题,提出了级联合作多智能体(CCMA)框架。
- CCMA框架结合了RL、大型语言模型(LLM)、奖励函数和检索增强生成机制。
- RL用于个体交互,LLM用于区域合作,奖励函数用于全局优化。
- CCMA框架在复杂的驾驶场景中表现出优异的性能,显著优于现有的RL方法。
- 实验结果证明了CCMA在微观和宏观层面上的改进。
点此查看论文截图


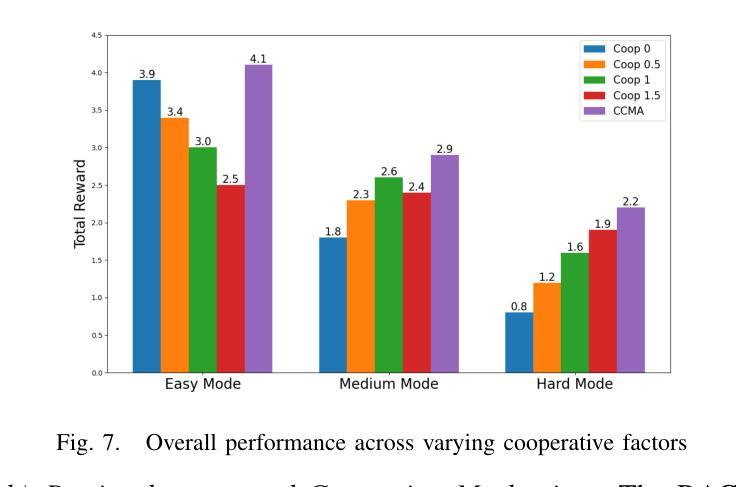
ProtTeX: Structure-In-Context Reasoning and Editing of Proteins with Large Language Models
Authors:Zicheng Ma, Chuanliu Fan, Zhicong Wang, Zhenyu Chen, Xiaohan Lin, Yanheng Li, Shihao Feng, Jun Zhang, Ziqiang Cao, Yi Qin Gao
Large language models have made remarkable progress in the field of molecular science, particularly in understanding and generating functional small molecules. This success is largely attributed to the effectiveness of molecular tokenization strategies. In protein science, the amino acid sequence serves as the sole tokenizer for LLMs. However, many fundamental challenges in protein science are inherently structure-dependent. The absence of structure-aware tokens significantly limits the capabilities of LLMs for comprehensive biomolecular comprehension and multimodal generation. To address these challenges, we introduce a novel framework, ProtTeX, which tokenizes the protein sequences, structures, and textual information into a unified discrete space. This innovative approach enables joint training of the LLM exclusively through the Next-Token Prediction paradigm, facilitating multimodal protein reasoning and generation. ProtTeX enables general LLMs to perceive and process protein structures through sequential text input, leverage structural information as intermediate reasoning components, and generate or manipulate structures via sequential text output. Experiments demonstrate that our model achieves significant improvements in protein function prediction, outperforming the state-of-the-art domain expert model with a twofold increase in accuracy. Our framework enables high-quality conformational generation and customizable protein design. For the first time, we demonstrate that by adopting the standard training and inference pipelines from the LLM domain, ProtTeX empowers decoder-only LLMs to effectively address diverse spectrum of protein-related tasks.
在分子科学领域,大型语言模型取得了引人注目的进展,特别是在理解和生成功能性小分子方面。这一成功在很大程度上归功于分子标记策略的效用。在蛋白质科学领域,氨基酸序列被视为大型语言模型的唯一标记器。然而,蛋白质科学中的许多基本挑战本质上是结构依赖的。缺乏结构感知标记显著限制了大型语言模型在全面生物分子理解和多模式生成方面的能力。为了应对这些挑战,我们引入了一种新型框架ProtTeX,它将蛋白质序列、结构和文本信息标记为统一的离散空间。这种创新的方法通过仅通过下一个标记预测范式来联合训练大型语言模型,促进多模式蛋白质推理和生成。ProtTeX使通用的大型语言模型能够通过顺序文本输入感知和处理蛋白质结构,利用结构信息作为中间推理成分,并通过顺序文本输出生成或操作结构。实验表明,我们的模型在蛋白质功能预测方面取得了显著改进,优于最先进的领域专家模型,准确性提高了两倍。我们的框架能够实现高质量的结构生成和可定制的蛋白质设计。首次展示了通过采用大型语言模型领域的标准训练和推理管道,ProtTeX赋能仅解码的大型语言模型有效解决各种蛋白质相关任务。
论文及项目相关链接
PDF 26 pages, 9 figures
Summary
大型语言模型在分子科学领域取得了显著进展,特别是在理解和生成功能性小分子方面。本文提出一种新型框架ProtTeX,将蛋白质序列、结构和文本信息统一到一个离散空间中,实现蛋白质的多模态推理和生成。该框架通过序列文本输入使通用大型语言模型能够感知和处理蛋白质结构,利用结构信息作为中间推理成分,并通过序列文本输出生成或操作结构。实验表明,该模型在蛋白质功能预测方面取得了显著改进,并实现了高质量的构象生成和可定制的蛋白质设计。
Key Takeaways
- 大型语言模型在分子科学领域取得显著进展,特别是在理解和生成功能性小分子方面。
- 蛋白质科学中的许多基本挑战是固有地结构依赖的。
- 现有大型语言模型在处理蛋白质结构时存在局限性。
- ProtTeX框架通过统一离散空间实现蛋白质序列、结构和文本信息的处理。
- ProtTeX框架使通用大型语言模型能够感知和处理蛋白质结构。
- 该框架在蛋白质功能预测方面取得了显著改进,并实现了高质量的构象生成。
点此查看论文截图

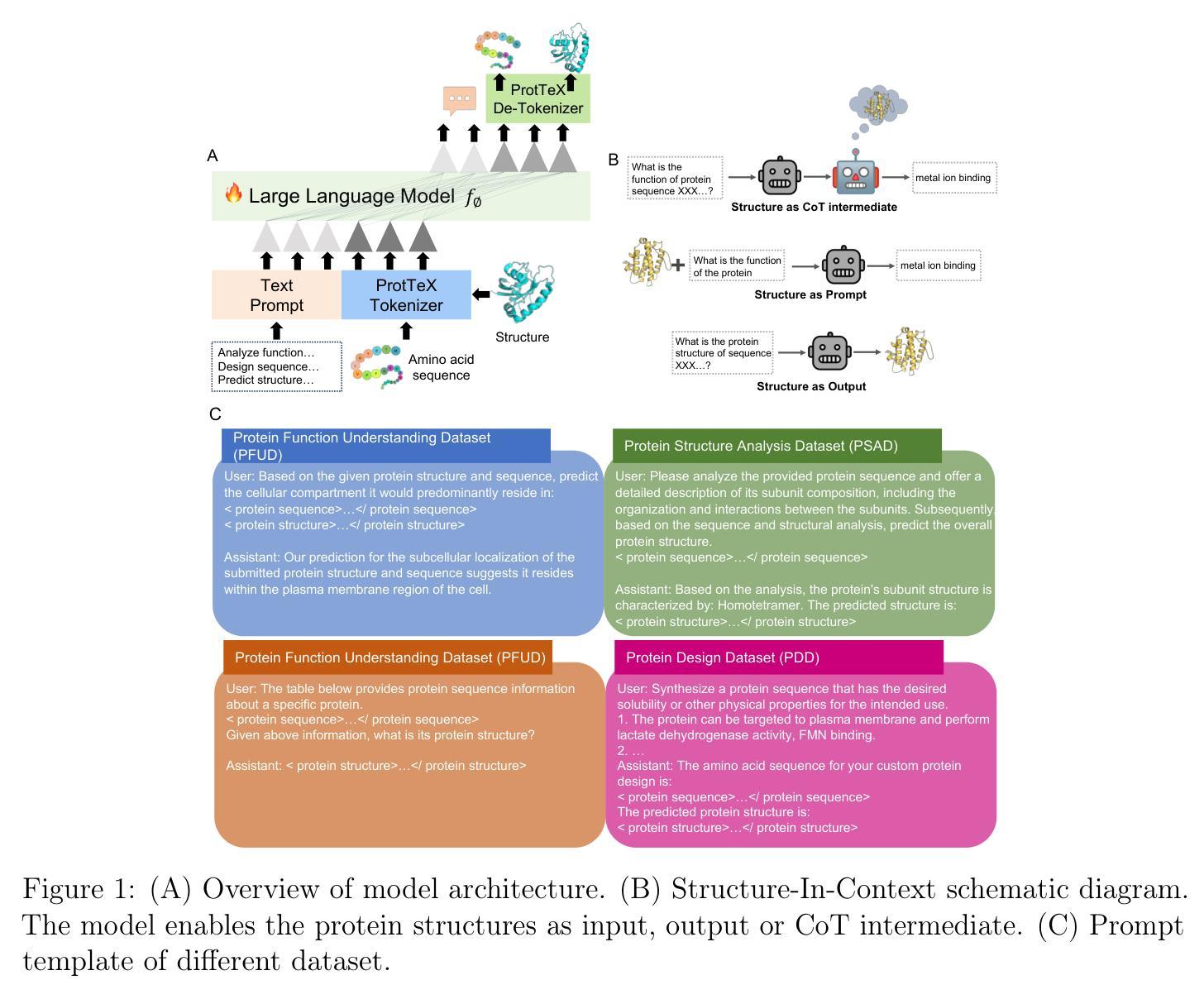
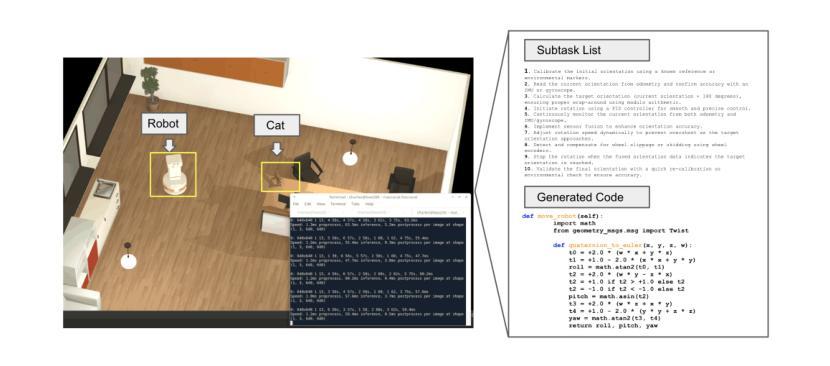
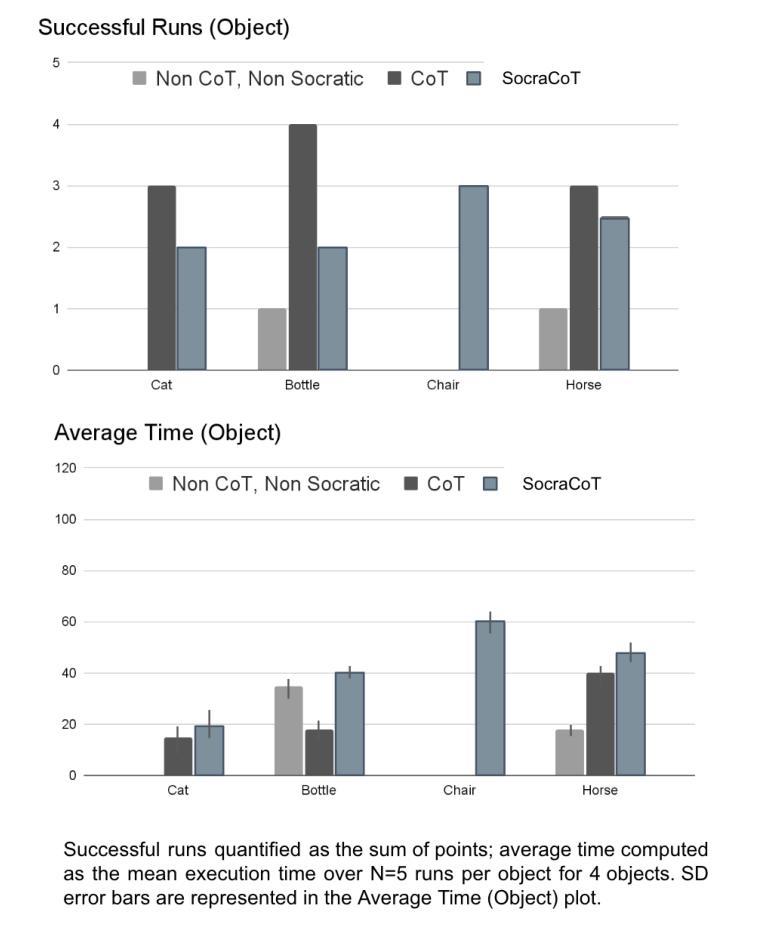
Investigating the Effectiveness of a Socratic Chain-of-Thoughts Reasoning Method for Task Planning in Robotics, A Case Study
Authors:Veronica Bot, Zheyuan Xu
Large language models (LLMs) have demonstrated unprecedented capability in reasoning with natural language. Coupled with this development is the emergence of embodied AI in robotics. Despite showing promise for verbal and written reasoning tasks, it remains unknown whether LLMs are capable of navigating complex spatial tasks with physical actions in the real world. To this end, it is of interest to investigate applying LLMs to robotics in zero-shot learning scenarios, and in the absence of fine-tuning - a feat which could significantly improve human-robot interaction, alleviate compute cost, and eliminate low-level programming tasks associated with robot tasks. To explore this question, we apply GPT-4(Omni) with a simulated Tiago robot in Webots engine for an object search task. We evaluate the effectiveness of three reasoning strategies based on Chain-of-Thought (CoT) sub-task list generation with the Socratic method (SocraCoT) (in order of increasing rigor): (1) Non-CoT/Non-SocraCoT, (2) CoT only, and (3) SocraCoT. Performance was measured in terms of the proportion of tasks successfully completed and execution time (N = 20). Our preliminary results show that when combined with chain-of-thought reasoning, the Socratic method can be used for code generation for robotic tasks that require spatial awareness. In extension of this finding, we propose EVINCE-LoC; a modified EVINCE method that could further enhance performance in highly complex and or dynamic testing scenarios.
大型语言模型(LLMs)在自然语言推理方面表现出了前所未有的能力。与此同时,机器人领域也出现了嵌入式的AI。尽管LLMs在言语和书面推理任务中显示出潜力,但我们仍不清楚它们是否能在现实世界中执行复杂的空间任务。因此,将LLMs应用于机器人的零样本学习场景十分令人感兴趣,并且不需要精细调整,这一特性能够极大地改善人机交互、降低计算成本,并消除与机器人任务相关的低级编程任务。为了探究这一问题,我们将GPT-4(Omni)与Webots引擎中的模拟Tiago机器人相结合,进行物体搜索任务。我们评估了三种基于思维链(CoT)的子任务列表生成策略的有效性,这三种策略按严谨性递增的顺序排列:(1)非CoT/非苏格拉底方法(SocraCoT),(2)仅CoT,(3)SocraCoT。我们的绩效衡量标准是任务完成的比例和执行时间(N=20)。初步结果表明,结合思维链推理,苏格拉底方法可用于生成机器人任务的代码,这些任务需要空间感知能力。在此基础上,我们提出了EVINCE-LoC;一种改进的EVINCE方法,可能进一步提高在高度复杂或动态测试场景中的性能。
论文及项目相关链接
Summary
大型语言模型(LLM)结合机器人实体AI展现出自然语言的推理能力。然而,对于是否能在无微调情况下,实现机器人零射击学习场景中的复杂空间任务,仍然未知。研究通过GPT-4(Omni)与Webots引擎中的模拟Tiago机器人进行对象搜索任务来探索这个问题。初步结果表明,结合思维链推理,苏格拉底方法可用于生成机器人任务的代码,这些任务需要空间感知。据此,研究提出了EVINCE-LoC方法,可进一步提升复杂和动态测试场景中的性能。
Key Takeaways
- 大型语言模型结合机器人实体AI具有自然语言的推理能力。
- 目前对于LLM在零射击学习场景中完成复杂空间任务的能力仍不清楚。
- 研究通过GPT-4(Omni)在Webots引擎中的模拟Tiago机器人进行对象搜索任务以探索此问题。
- 初步结果表明,结合思维链推理,苏格拉底方法可用于生成需要空间感知的机器人任务代码。
- 研究提出了EVINCE-LoC方法,旨在提高在复杂和动态测试场景中的机器人任务性能。
- 性能评估是通过任务完成比例和执行时间(N=20)来进行的。
点此查看论文截图

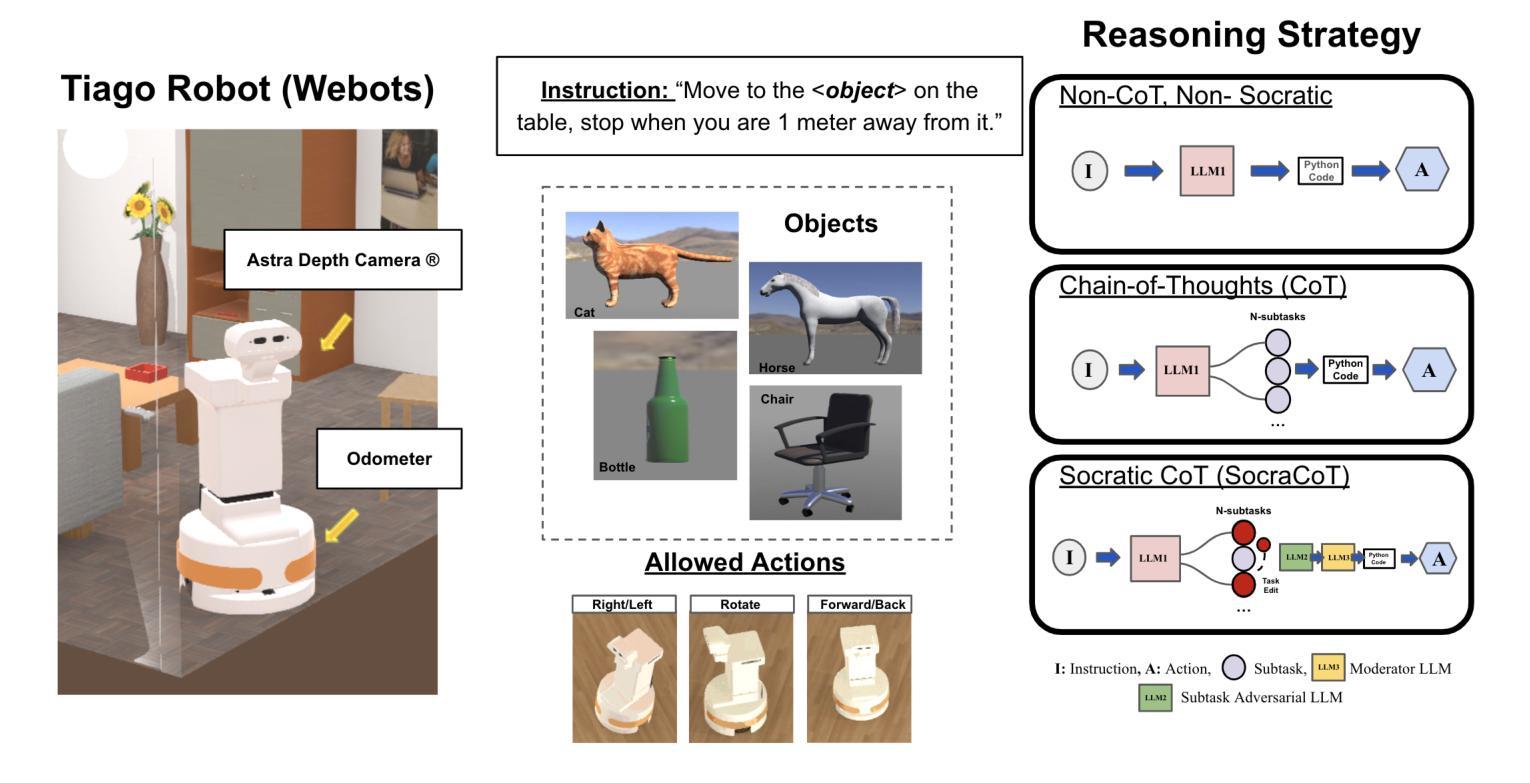
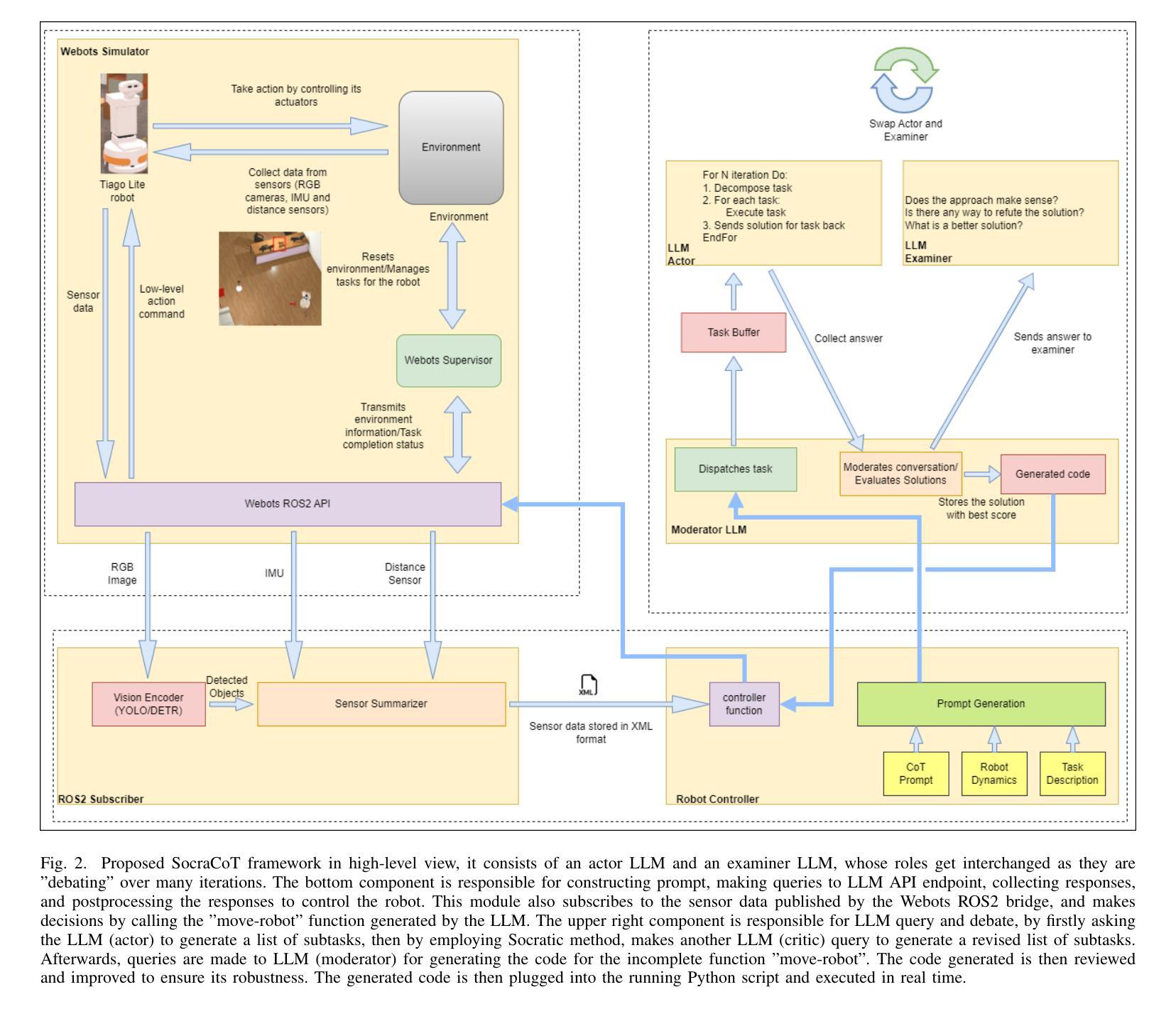

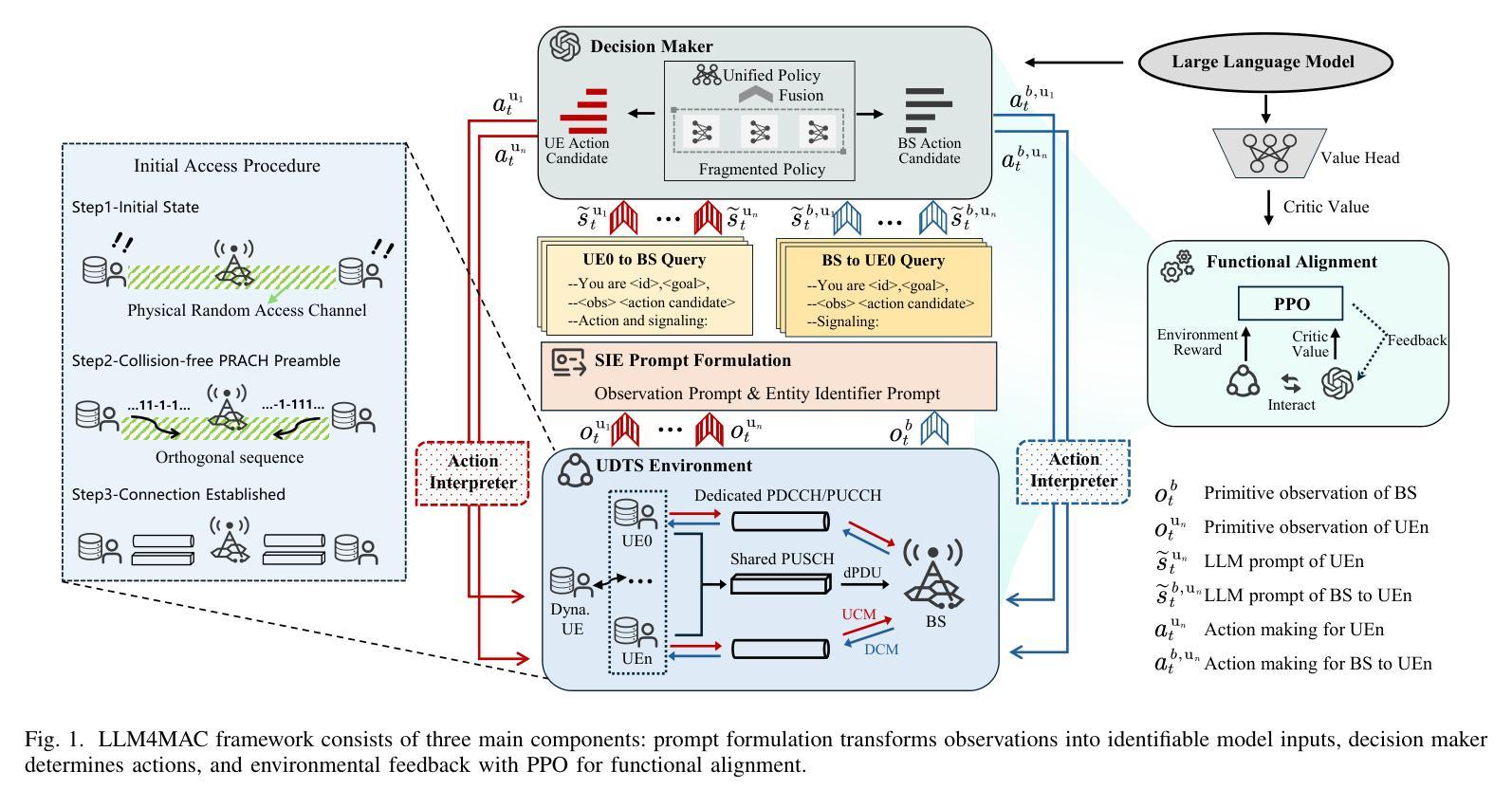
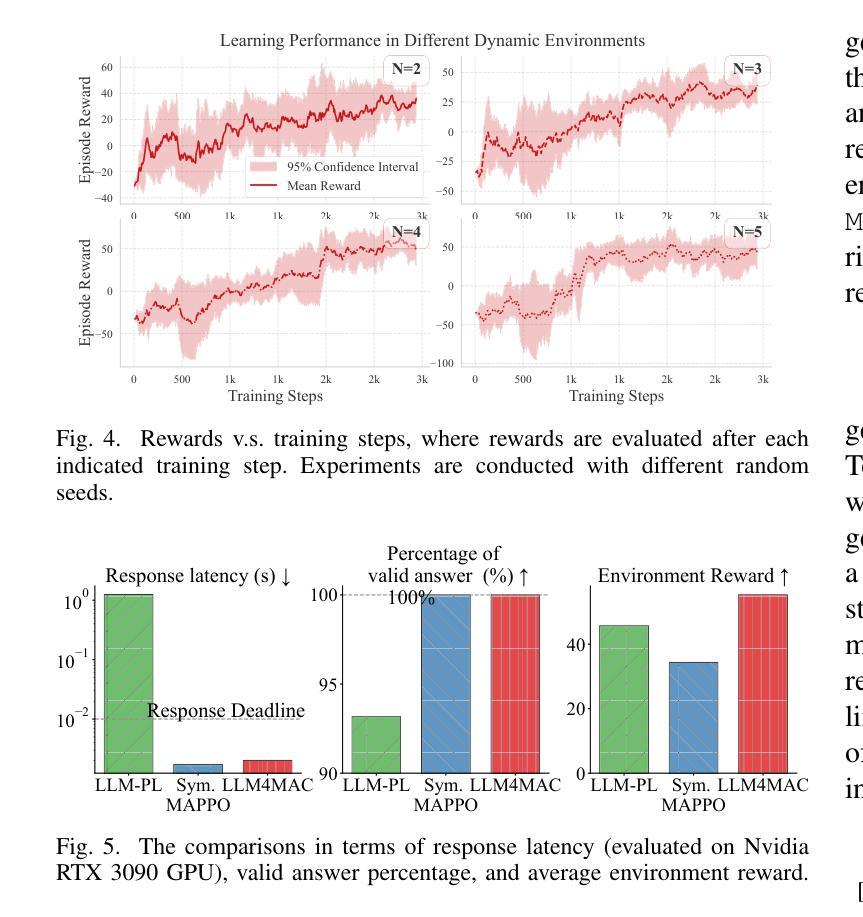
LLM4MAC: An LLM-Driven Reinforcement Learning Framework for MAC Protocol Emergence
Authors:Renxuan Tan, Rongpeng Li, Zhifeng Zhao
With the advent of 6G systems, emerging hyper-connected ecosystems necessitate agile and adaptive medium access control (MAC) protocols to contend with network dynamics and diverse service requirements. We propose LLM4MAC, a novel framework that harnesses large language models (LLMs) within a reinforcement learning paradigm to drive MAC protocol emergence. By reformulating uplink data transmission scheduling as a semantics-generalized partially observable Markov game (POMG), LLM4MAC encodes network operations in natural language, while proximal policy optimization (PPO) ensures continuous alignment with the evolving network dynamics. A structured identity embedding (SIE) mechanism further enables robust coordination among heterogeneous agents. Extensive simulations demonstrate that on top of a compact LLM, which is purposefully selected to balance performance with resource efficiency, the protocol emerging from LLM4MAC outperforms comparative baselines in throughput and generalization.
随着6G系统的出现,新兴的超互联生态系统需要灵活和自适应的介质访问控制(MAC)协议来应对网络动态变化和各种服务需求。我们提出了LLM4MAC这一新型框架,它利用强化学习范式中的大型语言模型(LLM)来驱动MAC协议的生成。我们将上行数据传输调度重新构建为语义泛化的部分可观察马尔可夫游戏(POMG),LLM4MAC用自然语言编码网络操作,而近端策略优化(PPO)确保与不断变化的网络动态持续对齐。结构化身份嵌入(SIE)机制进一步实现了异质智能体之间的稳健协调。大量模拟表明,经过精心挑选以平衡性能和资源效率的小型LLM,LLM4MAC协议在吞吐量和泛化方面均优于对比基线。
论文及项目相关链接
PDF 5 pages, 5 figures
Summary
随着6G系统的出现,需要灵活自适应的媒体接入控制(MAC)协议应对网络动态和各种服务需求。提出LLM4MAC框架,利用大型语言模型(LLMs)在强化学习范式中驱动MAC协议涌现。通过将有源数据上传调度重新定义为语义广义部分可观察马尔可夫博弈(POMG),LLM4MAC以自然语言编码网络操作,同时近端策略优化(PPO)确保与不断变化网络动态的持续对齐。结构化身份嵌入(SIE)机制进一步实现不同代理之间的稳健协调。模拟显示,在紧凑型LLM上,LLM4MAC协议在吞吐量和泛化能力方面超越了对比基线。
Key Takeaways
- 6G系统需要灵活自适应的MAC协议应对网络动态和服务需求的多样性。
- LLM4MAC框架利用大型语言模型和强化学习范式来驱动MAC协议的涌现。
- LLM4MAC通过将有源数据上传调度定义为语义广义POMG来处理网络操作。
- PPO确保与不断变化网络动态的持续对齐。
- 结构化身份嵌入(SIE)机制用于不同代理之间的稳健协调。
- LLM4MAC在紧凑型LLM的基础上,通过模拟显示出其在吞吐量和泛化能力方面的优越性。
- LLM4MAC协议具备高效资源利用的性能。
点此查看论文截图