⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Everything Can Be Described in Words: A Simple Unified Multi-Modal Framework with Semantic and Temporal Alignment
Authors:Xiaowei Bi, Zheyuan Xu
Long Video Question Answering (LVQA) is challenging due to the need for temporal reasoning and large-scale multimodal data processing. Existing methods struggle with retrieving cross-modal information from long videos, especially when relevant details are sparsely distributed. We introduce UMaT (Unified Multi-modal as Text), a retrieval-augmented generation (RAG) framework that efficiently processes extremely long videos while maintaining cross-modal coherence. UMaT converts visual and auditory data into a unified textual representation, ensuring semantic and temporal alignment. Short video clips are analyzed using a vision-language model, while automatic speech recognition (ASR) transcribes dialogue. These text-based representations are structured into temporally aligned segments, with adaptive filtering to remove redundancy and retain salient details. The processed data is embedded into a vector database, enabling precise retrieval of dispersed yet relevant content. Experiments on a benchmark LVQA dataset show that UMaT outperforms existing methods in multimodal integration, long-form video understanding, and sparse information retrieval. Its scalability and interpretability allow it to process videos over an hour long while maintaining semantic and temporal coherence. These findings underscore the importance of structured retrieval and multimodal synchronization for advancing LVQA and long-form AI systems.
长视频问答(LVQA)具有挑战性,因为它需要时序推理和大规模多模态数据处理。现有方法在从长视频中检索跨模态信息时面临困难,尤其是当相关细节稀疏分布时。我们引入了UMaT(统一多模态文本),这是一种增强检索生成(RAG)框架,能够高效处理极长的视频,同时保持跨模态一致性。UMaT将视觉和听觉数据转换为统一的文本表示,确保语义和时序对齐。短视频片段使用视觉语言模型进行分析,而自动语音识别(ASR)则转录对话。这些基于文本的表示被结构化成时序对齐的片段,通过自适应过滤去除冗余,保留重要细节。处理过的数据嵌入到向量数据库中,能够实现分散但相关内容精确检索。在基准LVQA数据集上的实验表明,UMaT在多模态融合、长格式视频理解和稀疏信息检索方面优于现有方法。其可扩展性和可解释性允许其处理超过一小时的视频,同时保持语义和时序一致性。这些发现强调了结构化检索和多模态同步在推动LVQA和长格式AI系统发展中的重要性。
论文及项目相关链接
Summary
长视频问答(LVQA)面临时间推理和大规模多模态数据处理的需求挑战。现有方法难以从长视频中检索跨模态信息,尤其当相关细节分布稀疏时。我们推出UMaT(统一多模态文本),一个检索增强生成(RAG)框架,能够高效处理极长视频并保持跨模态一致性。UMaT将视觉和听觉数据转化为统一文本表示,确保语义和时间对齐。它分析短视频片段使用视觉语言模型,自动语音识别(ASR)转录对话。这些基于文本的表示被结构化成时间对齐的片段,通过自适应过滤去除冗余并保留重要细节。处理过的数据嵌入向量数据库,能精确检索分散但相关的内容。在基准LVQA数据集上的实验表明,UMaT在多模态融合、长视频理解和稀疏信息检索方面优于现有方法。其可扩展性和可解释性可处理超过一小时的视频,同时保持语义和时间一致性。
Key Takeaways
- 长视频问答(LVQA)需要处理大规模多模态数据,面临时间推理和跨模态信息检索的挑战。
- UMaT是一个RAG框架,能高效处理极长视频并维持跨模态一致性。
- UMaT将视觉和听觉数据转化为统一文本表示,确保语义和时间对齐。
- UMaT通过结构化为时间对齐的片段,并利用自适应过滤来处理长视频中的冗余和关键信息。
- UMaT使用向量数据库进行数据处理和存储,能精确检索分散但相关的内容。
- UMaT在基准LVQA数据集上的表现优于现有方法,尤其在多模态融合、长视频理解和稀疏信息检索方面。
- UMaT具备可扩展性和可解释性,可处理超过一小时的视频内容。
点此查看论文截图



An Exhaustive Evaluation of TTS- and VC-based Data Augmentation for ASR
Authors:Sewade Ogun, Vincent Colotte, Emmanuel Vincent
Augmenting the training data of automatic speech recognition (ASR) systems with synthetic data generated by text-to-speech (TTS) or voice conversion (VC) has gained popularity in recent years. Several works have demonstrated improvements in ASR performance using this augmentation approach. However, because of the lower diversity of synthetic speech, naively combining synthetic and real data often does not yield the best results. In this work, we leverage recently proposed flow-based TTS/VC models allowing greater speech diversity, and assess the respective impact of augmenting various speech attributes on the word error rate (WER) achieved by several ASR models. Pitch augmentation and VC-based speaker augmentation are found to be ineffective in our setup. Jointly augmenting all other attributes reduces the WER of a Conformer-Transducer model by 11% relative on Common Voice and by up to 35% relative on LibriSpeech compared to training on real data only.
近年来,通过文本到语音(TTS)或语音转换(VC)生成合成数据来增强自动语音识别(ASR)系统的训练数据已经变得非常流行。几项作品已经证明了使用这种增强方法可以改进ASR性能。然而,由于合成语音的多样性较低,简单地结合合成数据和真实数据往往不能产生最佳结果。在这项工作中,我们利用最近提出的基于流的TTS/VC模型,允许更大的语音多样性,并评估增强各种语音属性对多个ASR模型实现的单词错误率(WER)的相应影响。在我们的设置中,发现音调增强和基于VC的演讲者增强效果不佳。联合增强所有其他属性可以降低Common Voice上Conformer-Transducer模型的相对WER 11%,与仅在真实数据上进行训练相比,LibriSpeech上的相对WER可降低高达35%。
论文及项目相关链接
摘要
使用文本转语音(TTS)或语音转换(VC)生成合成数据来增强自动语音识别(ASR)系统的训练数据已逐渐成为近年来的热门趋势。多项研究证明,使用这种增强方法可以提高ASR的性能。然而,由于合成语音的多样性较低,单纯地将合成数据与真实数据相结合往往无法获得最佳效果。本研究利用最新提出的基于流的TTS/VC模型,该模型允许更大的语音多样性,并评估增强各种语音属性对词错误率(WER)的影响。在我们的设置中,音调增强和基于VC的说话人增强效果不佳。联合增强所有其他属性可使Conformer-Transducer模型的WER在Common Voice上相对降低11%,在LibriSpeech上相对降低高达35%,与仅使用真实数据进行训练相比。
要点
- 合成数据增强ASR训练数据逐渐流行,能提高ASR性能。
- 单纯结合合成数据和真实数据并不总能获得最佳结果。
- 利用基于流的TTS/VC模型,该模型允许更大的语音多样性。
- 评估了增强各种语音属性对WER的影响。
- 音调增强和基于VC的说话人增强在特定设置下效果不佳。
- 联合增强所有其他属性可显著提高ASR性能,相对降低WER。
点此查看论文截图


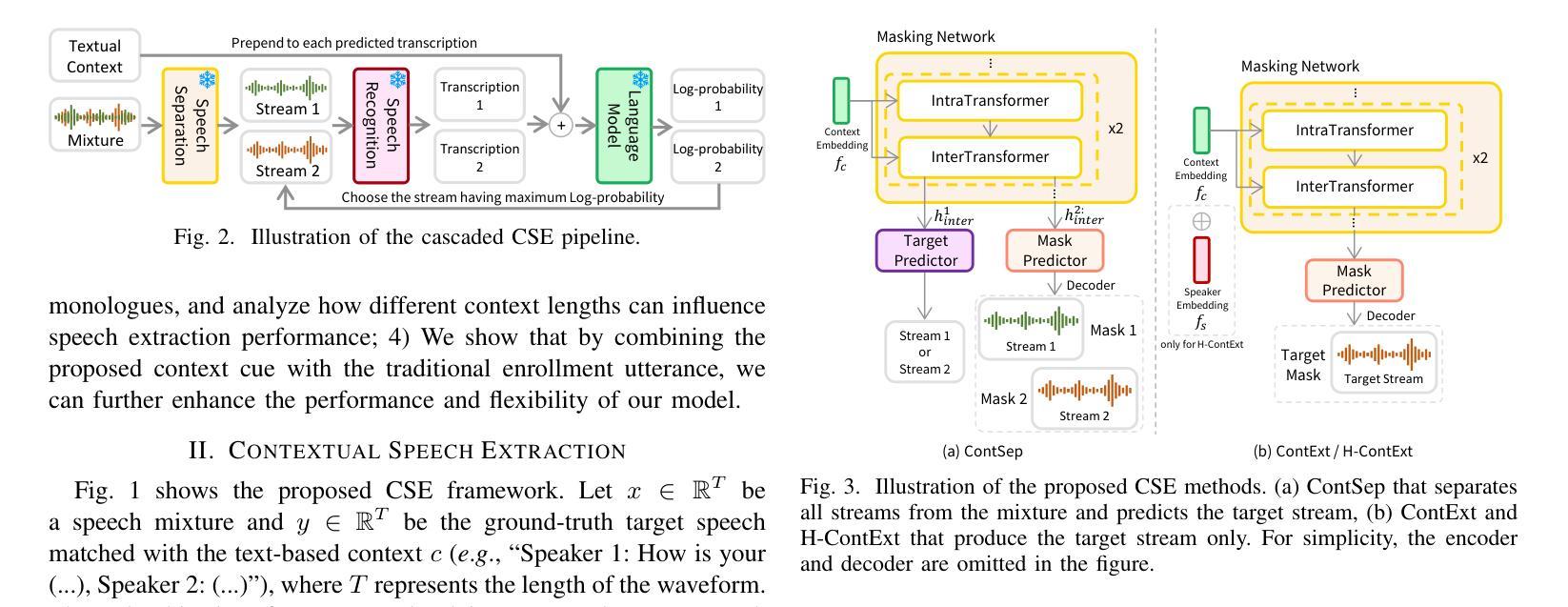
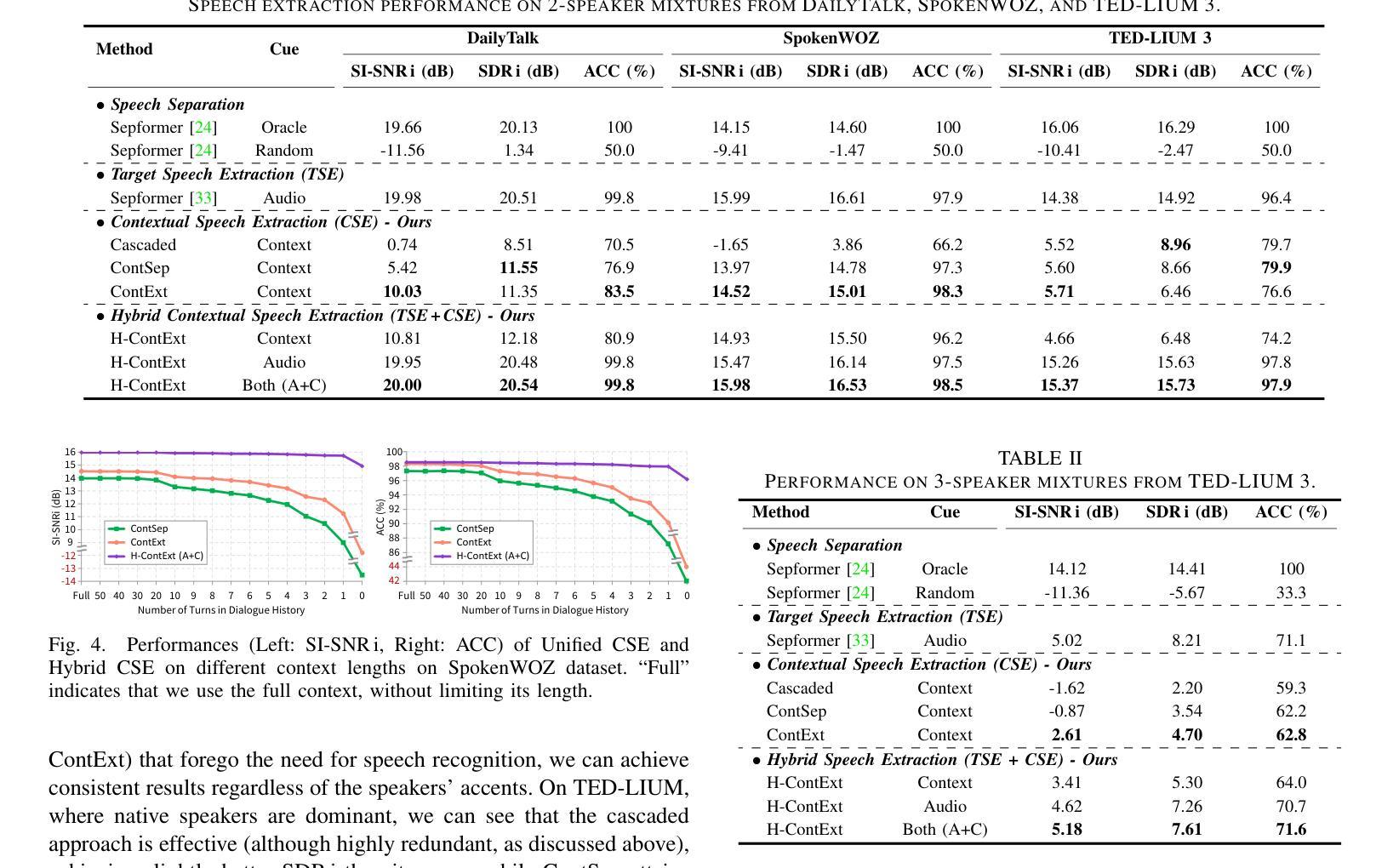
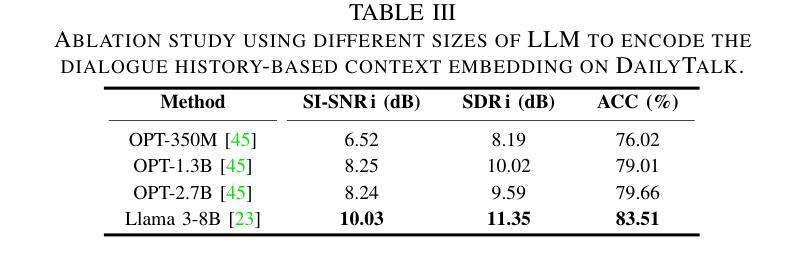
Contextual Speech Extraction: Leveraging Textual History as an Implicit Cue for Target Speech Extraction
Authors:Minsu Kim, Rodrigo Mira, Honglie Chen, Stavros Petridis, Maja Pantic
In this paper, we investigate a novel approach for Target Speech Extraction (TSE), which relies solely on textual context to extract the target speech. We refer to this task as Contextual Speech Extraction (CSE). Unlike traditional TSE methods that rely on pre-recorded enrollment utterances, video of the target speaker’s face, spatial information, or other explicit cues to identify the target stream, our proposed method requires only a few turns of previous dialogue (or monologue) history. This approach is naturally feasible in mobile messaging environments where voice recordings are typically preceded by textual dialogue that can be leveraged implicitly. We present three CSE models and analyze their performances on three datasets. Through our experiments, we demonstrate that even when the model relies purely on dialogue history, it can achieve over 90 % accuracy in identifying the correct target stream with only two previous dialogue turns. Furthermore, we show that by leveraging both textual context and enrollment utterances as cues during training, we further enhance our model’s flexibility and effectiveness, allowing us to use either cue during inference, or combine both for improved performance. Samples and code available on https://miraodasilva.github.io/cse-project-page .
在本文中,我们研究了一种针对目标语音提取(TSE)的新型方法,该方法仅依赖文本上下文来提取目标语音。我们将此任务称为上下文语音提取(CSE)。与传统的TSE方法不同,这些方法依赖于预先录制的注册话语、目标说话人的面部视频、空间信息或其他明确的线索来识别目标流,我们提出的方法只需要前几轮对话(或独白)历史。这种方法在移动消息环境中自然而然地可行,语音记录通常先于文本对话,可以隐性利用。我们提出了三种CSE模型,并在三个数据集上对其性能进行了分析。通过实验,我们证明即使模型仅依赖于对话历史,在仅使用前两轮对话的情况下,也可以实现超过90%的正确识别目标流的准确率。此外,我们还表明,通过在训练过程中利用文本上下文和注册话语作为线索,可以进一步提高模型的灵活性和有效性,使我们能够在推理过程中使用任一线索,或结合两者以提高性能。相关样本和代码可通过https://miraodasilva.github.io/cse-project-page获取。
论文及项目相关链接
PDF Accepted to ICASSP 2025
Summary:
本文提出了一种新的目标语音提取方法——上下文语音提取(CSE),该方法仅依赖于文本上下文来提取目标语音,适用于移动通讯环境下的文本对话和声音数据的无缝交互场景。相较于传统的目标语音提取方法,该方法无需预录的注册语音、目标说话人的面部视频、空间信息或其他明确线索,仅依赖对话历史即可实现超过90%的准确识别。此外,研究还展示了结合文本上下文和注册语音作为线索进行训练的方法,提高了模型的灵活性和有效性,可在推理过程中单独使用或结合两种线索实现更佳性能。该方法的样品和代码可访问[https://miraodasilva.github.io/cse-project-page了解详细信息]。
Key Takeaways:
- 论文提出了一种新的目标语音提取方法——上下文语音提取(CSE)。
- 该方法仅依赖于文本上下文进行目标语音提取。
- 对比传统方法,新方法无需预录的注册语音等明确线索,仅依赖对话历史即可实现高准确识别。
- 新方法在实验中的准确识别率超过90%。
- 研究展示了结合文本上下文和注册语音作为训练线索的方法,提高模型的灵活性和有效性。
- 模型可以在推理过程中使用单一线索或结合两种线索,实现更佳性能。
点此查看论文截图

Prompt2LVideos: Exploring Prompts for Understanding Long-Form Multimodal Videos
Authors:Soumya Shamarao Jahagirdar, Jayasree Saha, C V Jawahar
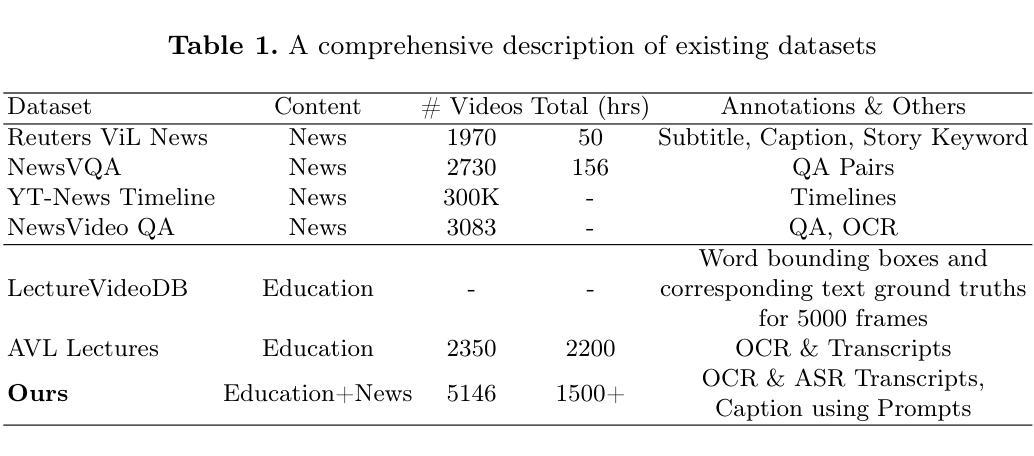
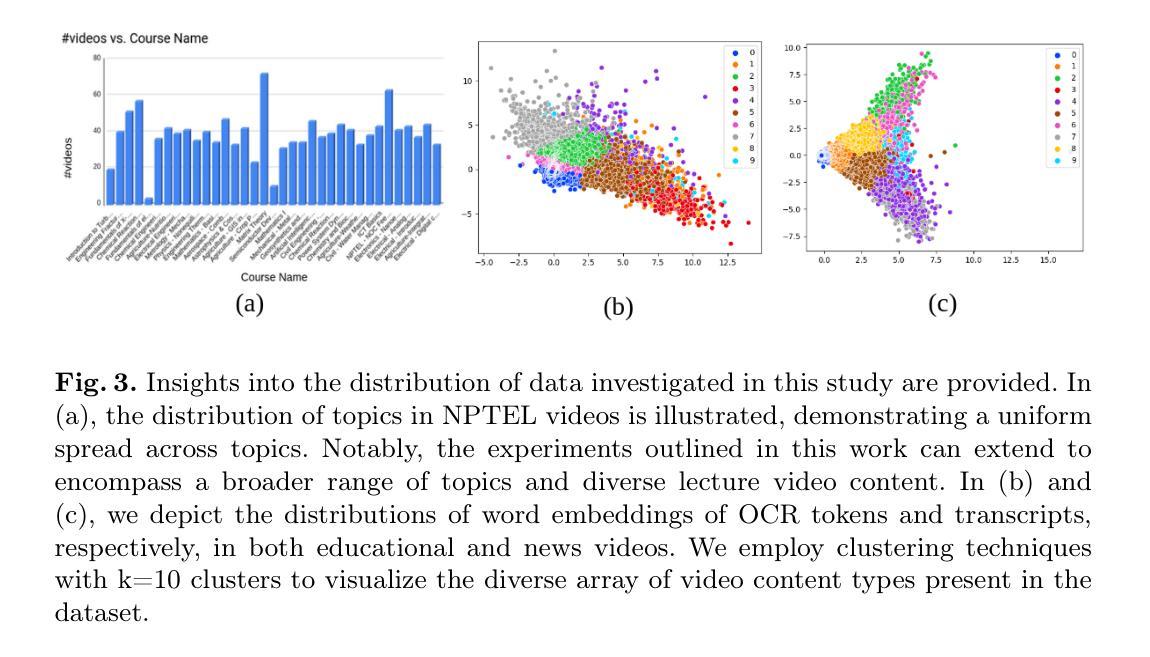
Learning multimodal video understanding typically relies on datasets comprising video clips paired with manually annotated captions. However, this becomes even more challenging when dealing with long-form videos, lasting from minutes to hours, in educational and news domains due to the need for more annotators with subject expertise. Hence, there arises a need for automated solutions. Recent advancements in Large Language Models (LLMs) promise to capture concise and informative content that allows the comprehension of entire videos by leveraging Automatic Speech Recognition (ASR) and Optical Character Recognition (OCR) technologies. ASR provides textual content from audio, while OCR extracts textual content from specific frames. This paper introduces a dataset comprising long-form lectures and news videos. We present baseline approaches to understand their limitations on this dataset and advocate for exploring prompt engineering techniques to comprehend long-form multimodal video datasets comprehensively.
学习多模态视频理解通常依赖于由视频片段和手动注释的标题组成的数据集。然而,在处理教育和新领域的长视频时,由于需要更多具有专业知识的注释者,这变得更加具有挑战性,这些视频时长从几分钟到几小时不等。因此,需要自动解决方案。最近的大型语言模型(LLM)的进步显示出能够捕捉简洁且信息丰富的内容,利用自动语音识别(ASR)和光学字符识别(OCR)技术,通过理解整个视频的内容实现视频的理解。ASR从音频中提供文本内容,而OCR则从特定帧中提取文本内容。本文介绍了一个包含长讲座和新闻视频的数据集。我们介绍了在这个数据集上理解其局限性的基线方法,并提倡探索提示工程技术,以全面理解长形式的多模态视频数据集。
论文及项目相关链接
PDF CVIP 2024
Summary
随着长视频内容的普及,特别是在教育和新闻领域,手动标注视频内容的任务变得越来越复杂和耗时。因此,需要自动化解决方案。本文引入了一种包含长讲座和新闻视频的数据集,并探讨了如何利用大型语言模型(LLMs)自动识别和识别视频内容的技术,为理解长视频提供了有效的工具。文章主张采用提示工程技术,以便更全面地理解长格式的多模态视频数据集。这一技术在教育技术和人工智能领域的应用潜力巨大。本文基于自动语音识别(ASR)和光学字符识别(OCR)技术实现了从视频音频和视频帧中提取文本内容的目标。
Key Takeaways
- 长格式视频在教育和新闻领域的需求增长导致了对自动化解决方案的需求,以简化手动标注视频内容的任务。
- 大型语言模型(LLMs)在理解长格式多模态视频内容方面具有潜力。
- 自动语音识别(ASR)和光学字符识别(OCR)技术被用于从视频中提取文本内容。
- ASR能够从视频音频中提取文本内容,而OCR则从特定的视频帧中提取文本信息。
- 本文介绍了包含长讲座和新闻视频的数据集,并提出了基准方法来理解其在该数据集上的局限性。
点此查看论文截图



Enhancing Multilingual Language Models for Code-Switched Input Data
Authors:Katherine Xie, Nitya Babbar, Vicky Chen, Yoanna Turura
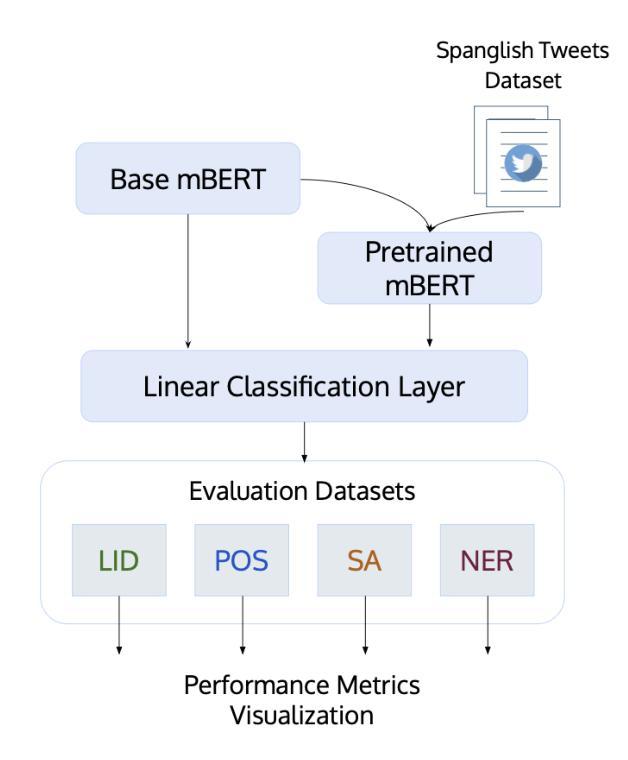
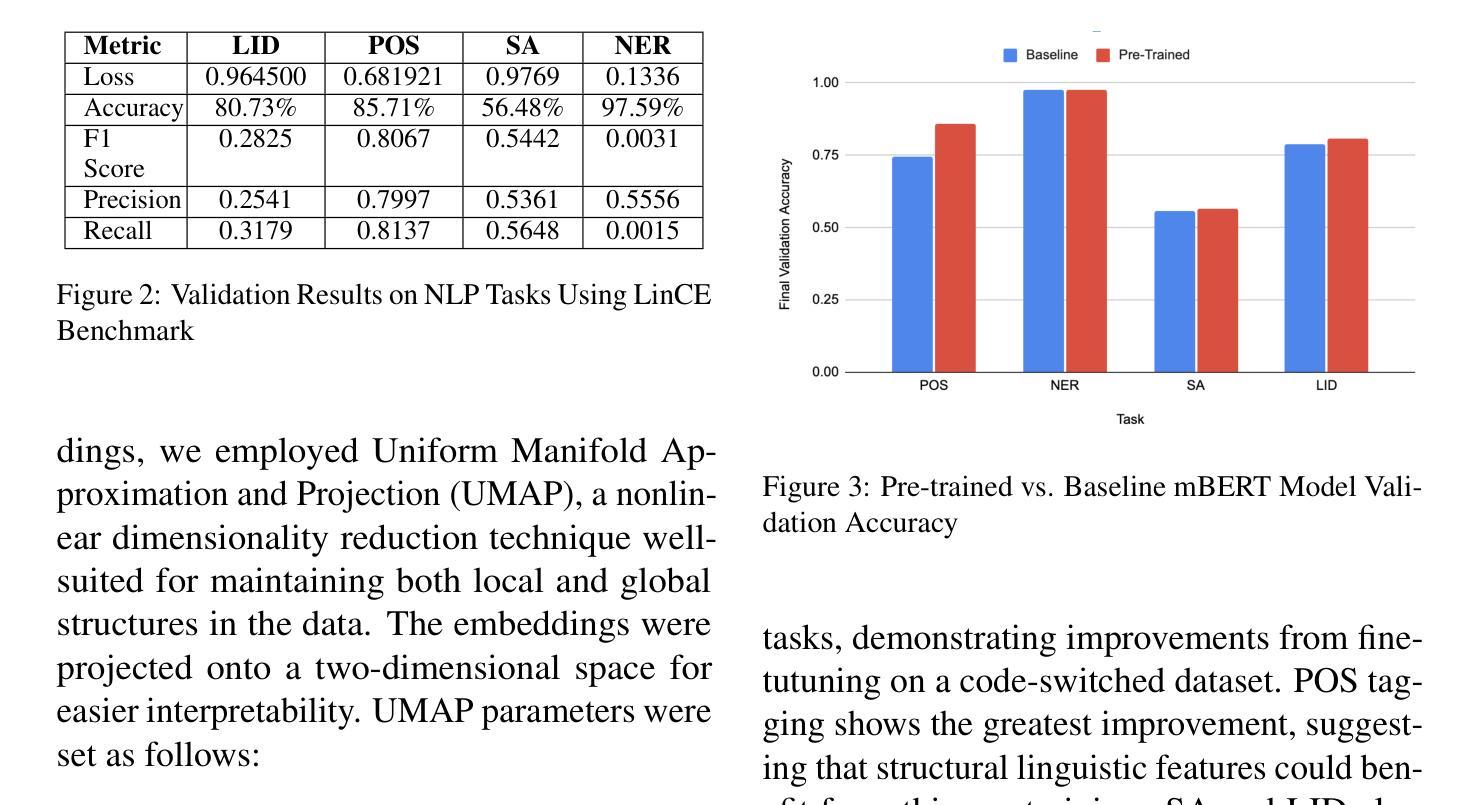
Code-switching, or alternating between languages within a single conversation, presents challenges for multilingual language models on NLP tasks. This research investigates if pre-training Multilingual BERT (mBERT) on code-switched datasets improves the model’s performance on critical NLP tasks such as part of speech tagging, sentiment analysis, named entity recognition, and language identification. We use a dataset of Spanglish tweets for pre-training and evaluate the pre-trained model against a baseline model. Our findings show that our pre-trained mBERT model outperforms or matches the baseline model in the given tasks, with the most significant improvements seen for parts of speech tagging. Additionally, our latent analysis uncovers more homogenous English and Spanish embeddings for language identification tasks, providing insights for future modeling work. This research highlights potential for adapting multilingual LMs for code-switched input data in order for advanced utility in globalized and multilingual contexts. Future work includes extending experiments to other language pairs, incorporating multiform data, and exploring methods for better understanding context-dependent code-switches.
代码切换或在单个对话中使用多种语言,对多语言语言模型在自然语言处理任务上提出了挑战。本研究旨在调查预训练多语言BERT(mBERT)在代码切换数据集上是否能在关键的自然语言处理任务(如词性标注、情感分析、命名实体识别和语言识别等)上提高模型性能。我们使用西班牙语和英语混合推文的数据集进行预训练,并对预训练模型与基线模型进行评估。我们的研究结果表明,预训练mBERT模型在给定的任务上表现优于或等于基线模型,其中词性标注的改进最为显著。此外,我们的潜在分析揭示了用于语言识别任务的更统一的英语和西班牙语嵌入,为未来建模工作提供了见解。该研究强调了为适应代码切换输入数据的多语言语言模型在全球化和多语言环境的高级应用中的潜力。未来的工作包括将实验扩展到其他语言对、融入多种形式的数据,并探索更好地理解上下文相关代码切换的方法。
论文及项目相关链接
Summary
预训练的多语言BERT模型(mBERT)在代码切换数据集上进行训练,可以改善其在自然语言处理任务上的性能,如词性标注、情感分析、实体命名识别和语言识别等。本研究使用西班牙英语推特数据集进行预训练,并与基线模型进行评估。结果显示,预训练的mBERT模型在给定任务上的表现优于或等同于基线模型,尤其在词性标注方面最为显著。此外,潜在分析发现英语和西班牙语的语言识别任务嵌入更为一致,为未来的建模工作提供了启示。本研究突显了为适应代码切换输入数据的多语言语言模型在全球化、多语言环境中的潜在应用。未来的研究方向包括扩展到其他语言对、融入多种形式的数据和探索理解上下文相关代码切换的方法。
Key Takeaways
- 代码切换对于多语言语言模型在自然语言处理任务上构成挑战。
- 预训练多语言BERT模型(mBERT)在代码切换数据集上可以改进模型在自然语言处理任务上的性能。
- 使用西班牙英语推特数据集进行预训练评估,显示预训练模型在多个任务上优于基线模型。
- 词性标注任务的改进最为显著。
- 潜在分析发现英语和西班牙语的嵌入一致性更高,有助于语言识别任务。
- 适应代码切换输入数据的多语言语言模型在全球化、多语言环境中具有潜在应用价值。
点此查看论文截图

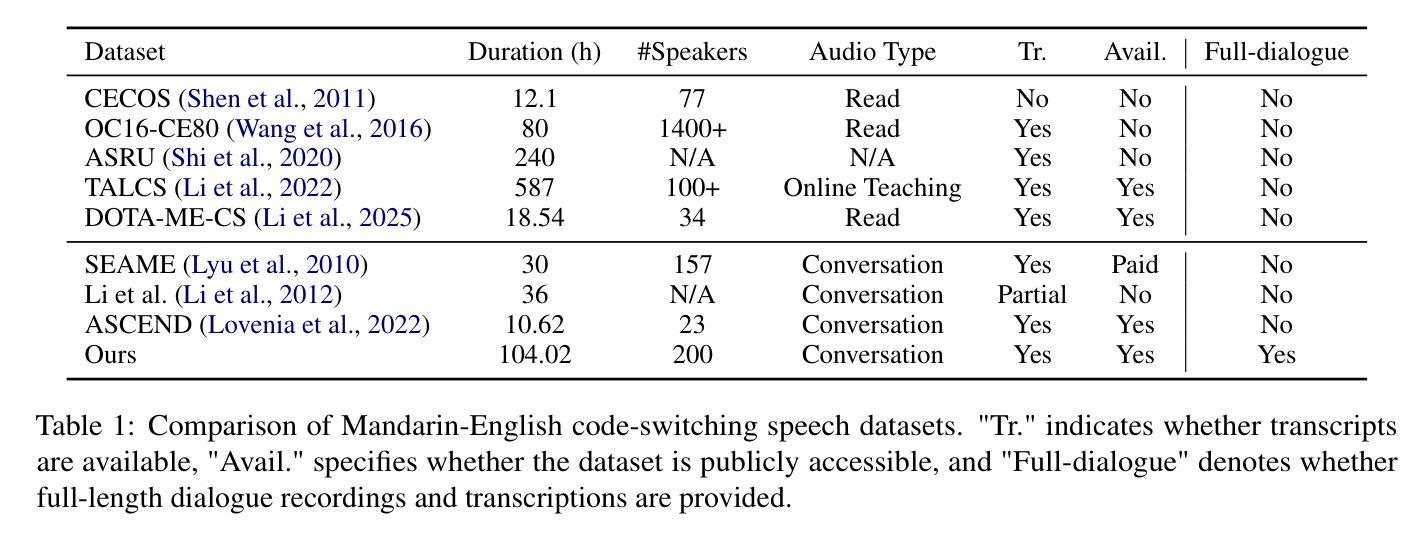
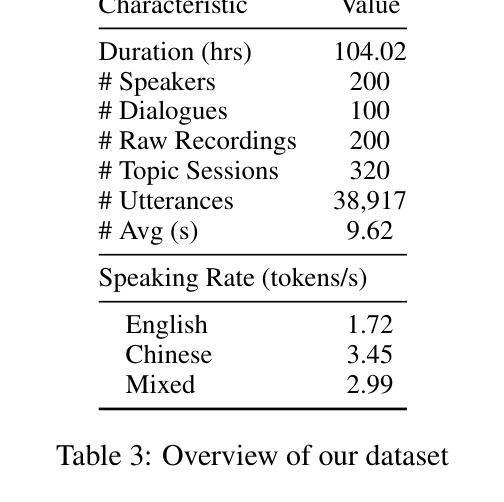
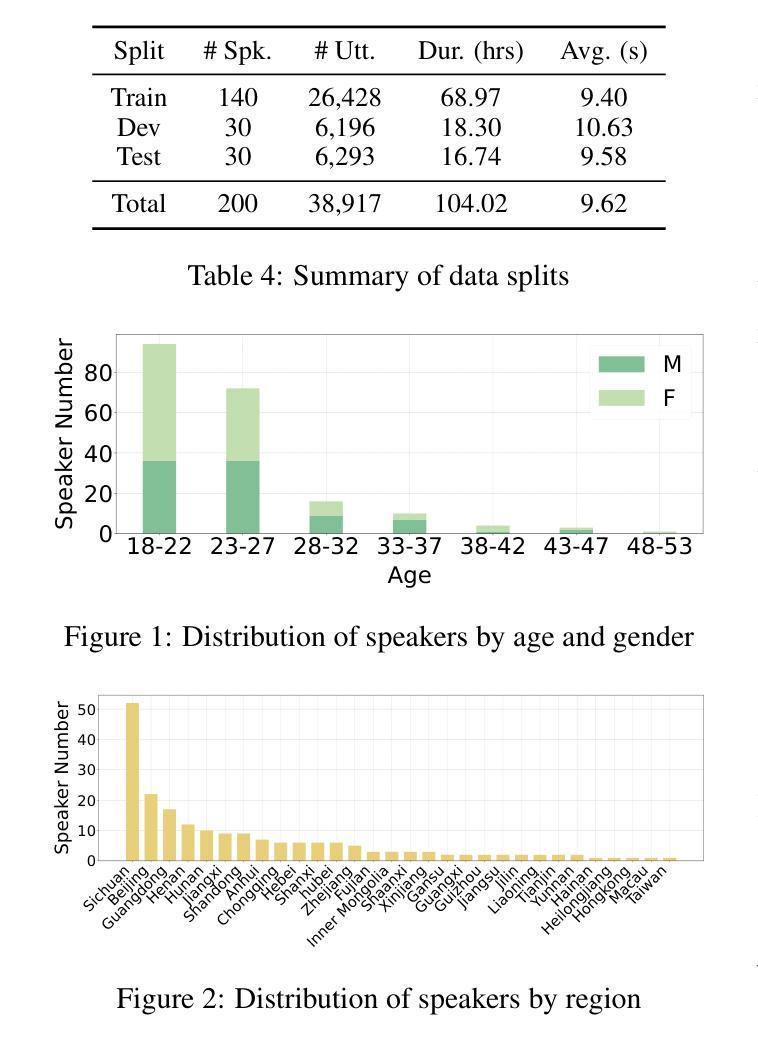
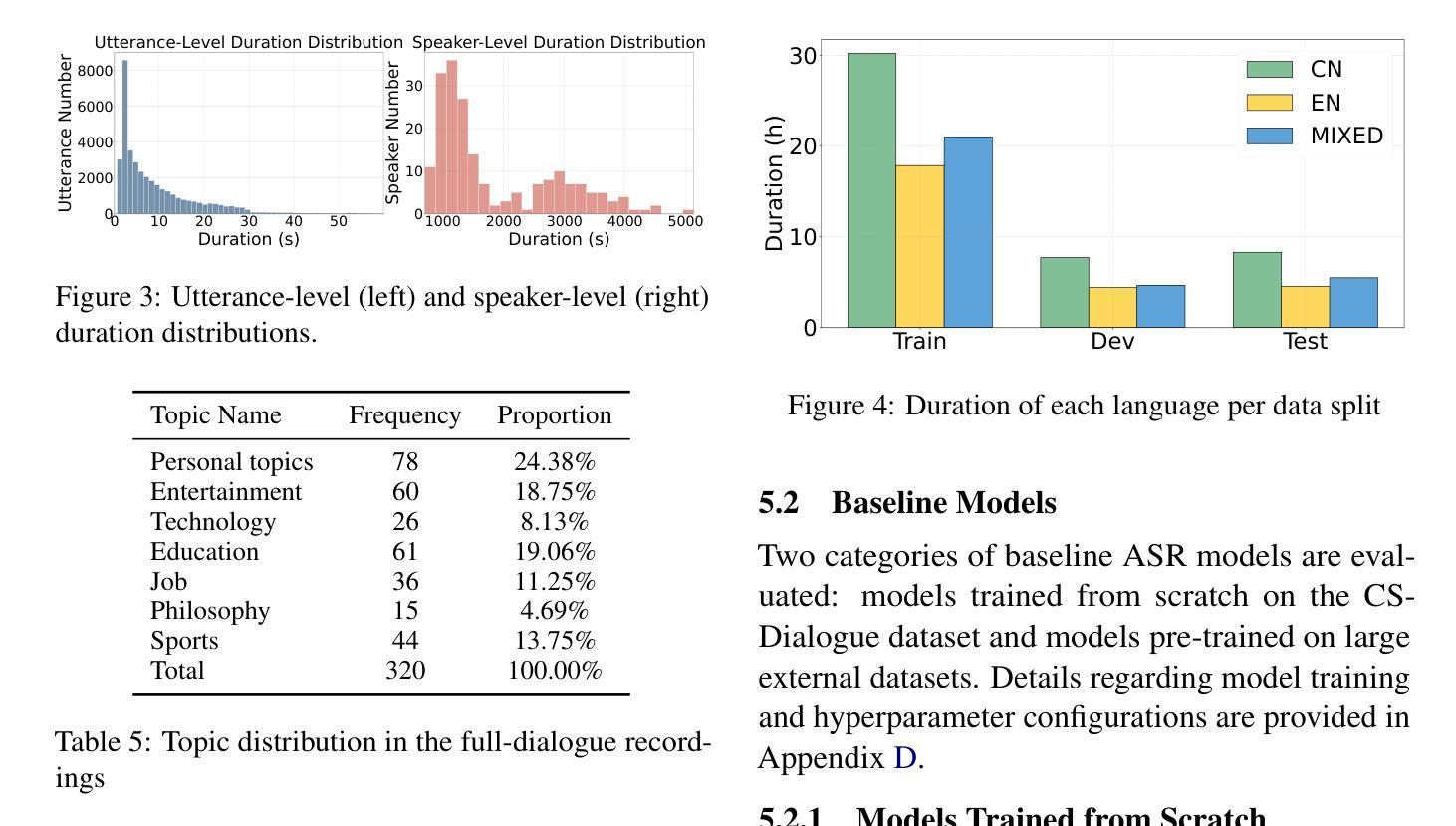
CS-Dialogue: A 104-Hour Dataset of Spontaneous Mandarin-English Code-Switching Dialogues for Speech Recognition
Authors:Jiaming Zhou, Yujie Guo, Shiwan Zhao, Haoqin Sun, Hui Wang, Jiabei He, Aobo Kong, Shiyao Wang, Xi Yang, Yequan Wang, Yonghua Lin, Yong Qin
Code-switching (CS), the alternation between two or more languages within a single conversation, presents significant challenges for automatic speech recognition (ASR) systems. Existing Mandarin-English code-switching datasets often suffer from limitations in size, spontaneity, and the lack of full-length dialogue recordings with transcriptions, hindering the development of robust ASR models for real-world conversational scenarios. This paper introduces CS-Dialogue, a novel large-scale Mandarin-English code-switching speech dataset comprising 104 hours of spontaneous conversations from 200 speakers. Unlike previous datasets, CS-Dialogue provides full-length dialogue recordings with complete transcriptions, capturing naturalistic code-switching patterns in continuous speech. We describe the data collection and annotation processes, present detailed statistics of the dataset, and establish benchmark ASR performance using state-of-the-art models. Our experiments, using Transformer, Conformer, and Branchformer, demonstrate the challenges of code-switching ASR, and show that existing pre-trained models such as Whisper still have the space to improve. The CS-Dialogue dataset will be made freely available for all academic purposes.
语言交替(CS)是指在单次对话中两个或多个语言之间的交替,这对自动语音识别(ASR)系统提出了重大挑战。现有的汉语-英语交替数据集通常在规模、自发性和缺乏带有转录的全长对话录音等方面存在局限性,阻碍了为现实世界的对话场景开发稳健的ASR模型。本文介绍了CS-Dialogue,这是一个新的大规模汉语-英语交替语音数据集,包含来自200名发言人的104小时自发对话。与以前的数据集不同,CS-Dialogue提供了带有完整转录的全长对话录音,捕捉连续语音中的自然语言交替模式。我们描述了数据收集和注释过程,给出了数据集的详细统计信息,并使用最新模型建立了ASR性能基准。我们的实验使用了Transformer、Conformer和Branchformer,展示了语言交替ASR的挑战性,并表明现有的预训练模型(如Whisper)仍有改进空间。CS-Dialogue数据集将免费供所有学术用途使用。
论文及项目相关链接
总结
该论文介绍了CS-Dialogue数据集,这是一个大规模的、涵盖普通话与英语交替使用现象的大型数据集。其中包含来自200名说话者的104小时自然对话录音,并附有完整转录。该数据集解决了现有普通话-英语交替使用数据集大小有限、缺乏自发性及完整对话录音的问题,有助于开发适用于真实对话场景的稳健语音识别模型。论文描述了数据收集与标注过程,提供了数据集的详细统计信息,并使用前沿模型建立了基准语音识别性能。实验表明,现有的预训练模型如Whisper在普通话-英语交替使用的语音识别上仍有提升空间。CS-Dialogue数据集将免费用于所有学术用途。
关键见解
- CS-Dialogue是首个大规模的普通话-英语交替使用语音数据集,包含104小时的自发对话录音和完整转录。
- 数据集解决了现有普通话-英语交替使用数据集大小有限、缺乏自发性及完整对话记录的问题。
- 数据集有助于开发适用于真实对话场景的稳健语音识别模型。
- 论文描述了数据收集与标注流程,并提供了详细的统计数据。
- 使用Transformer、Conformer和Branchformer等先进模型建立的基准语音识别性能表明了现有的预训练模型在处理普通话-英语交替使用的语音识别时面临的挑战。
- 实验结果显示,现有的预训练模型如Whisper仍有改进空间。
- CS-Dialogue数据集将供所有学术用途免费使用。
点此查看论文截图


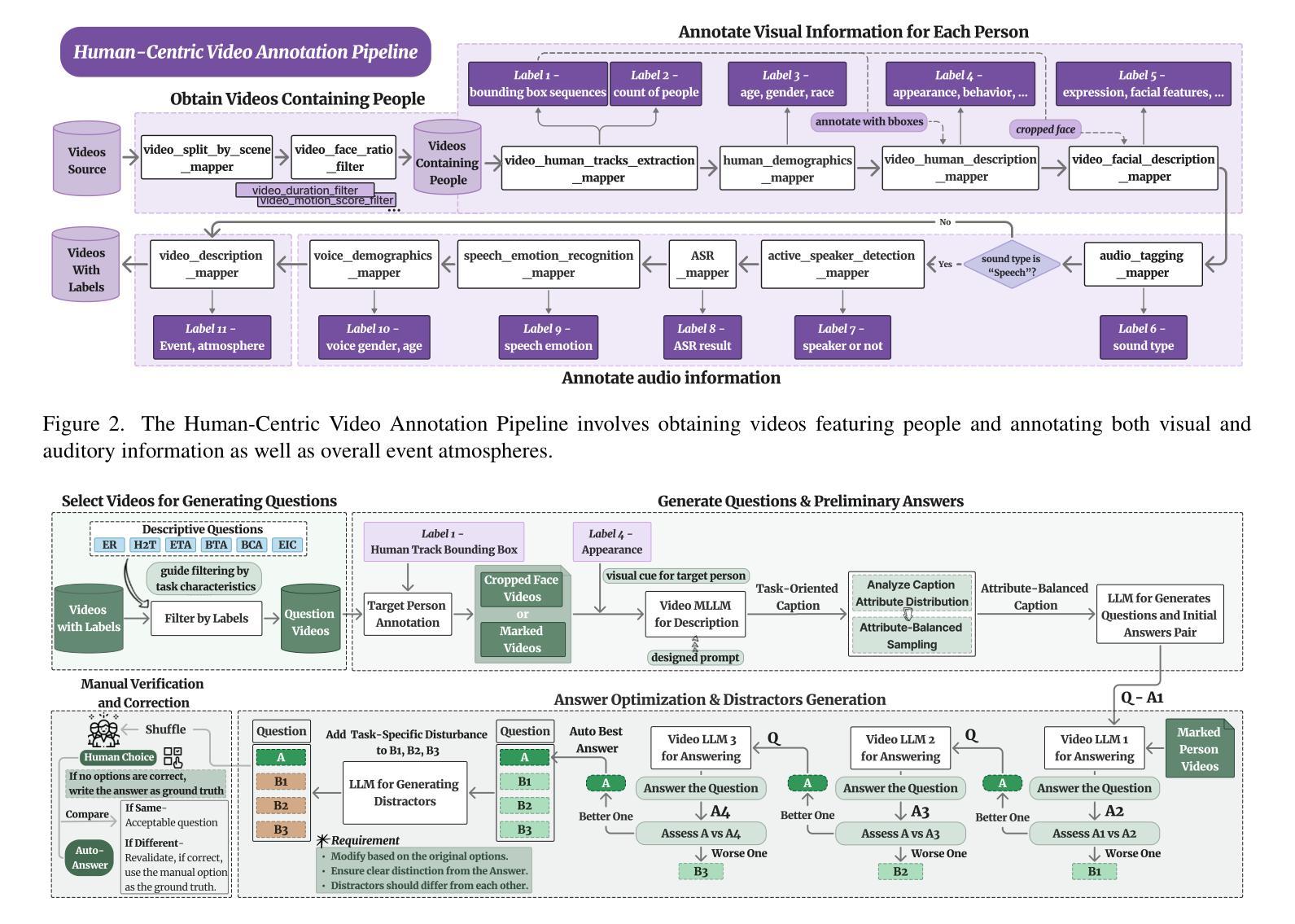
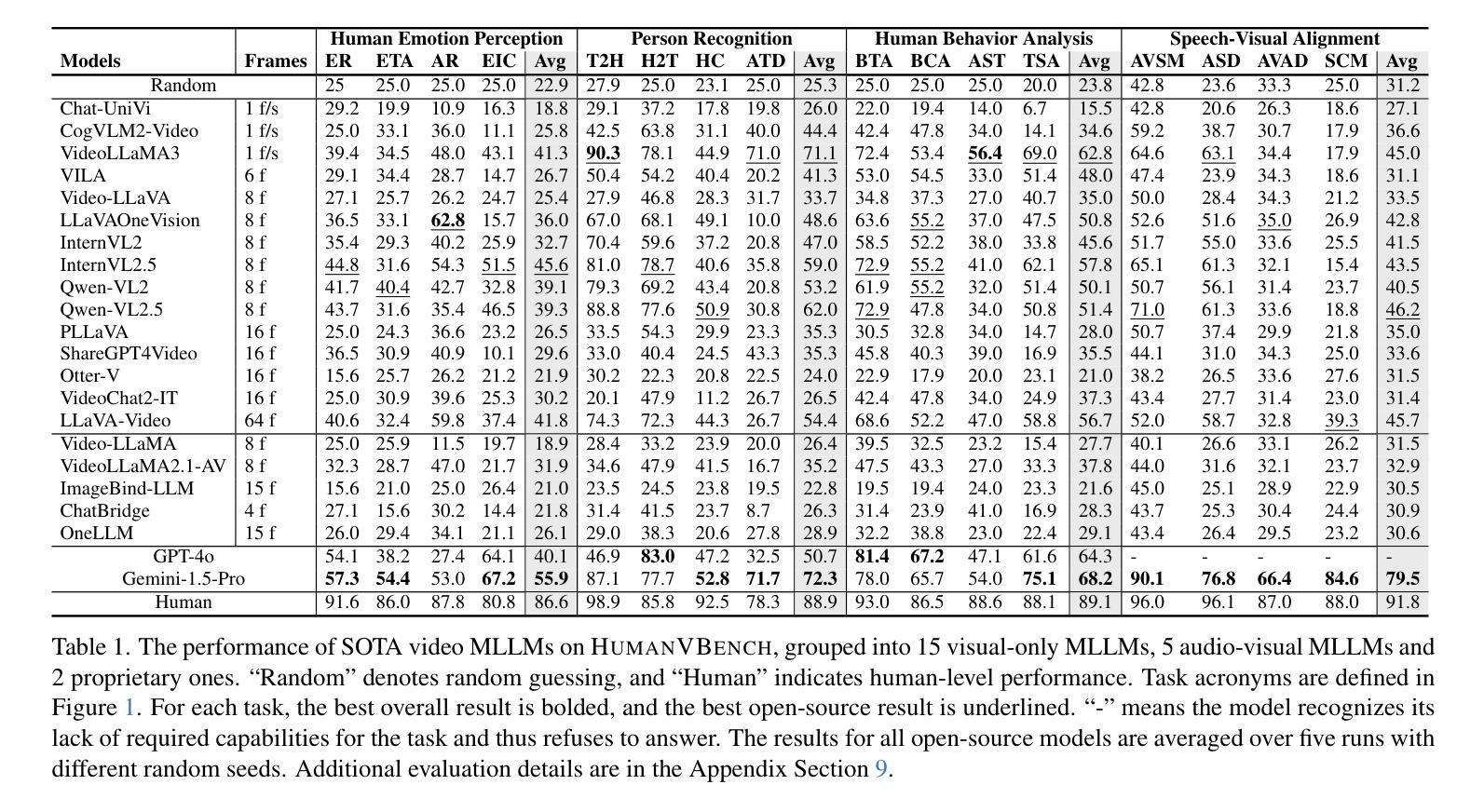
HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
Authors:Ting Zhou, Daoyuan Chen, Qirui Jiao, Bolin Ding, Yaliang Li, Ying Shen
In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech-visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 16 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 22 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and emotion perception, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.
在多模态大型语言模型(MLLMs)领域,实现以人类为中心的视频理解仍然是一个巨大的挑战。现有的基准测试主要强调对象和动作识别,往往忽视了视频内容中人类情绪、行为和语音视觉对齐的细微差别。我们推出了HumanVBench,这是一个精心设计的基准测试,旨在弥补视频MLLMs评估中的这些差距。HumanVBench包含16个精心设计的任务,探索两个主要维度:内在情绪和外在表现,涵盖静态和动态、基本和复杂,以及单模态和跨模态方面。HumanVBench使用先进的自动化管道进行视频标注和包含干扰项的QA生成,利用多种最新技术优化基准数据合成和质量评估,减少对人类标注的依赖,专门面向以人类为中心的多模态属性。对22个最新视频MLLMs的综合评估显示,当前性能存在显著局限,特别是在跨模态和情感感知方面,这强调了对进一步改进实现更人性化的理解的必要性。HumanVBench开源,以促进视频MLLMs的未来发展和实际应用。
论文及项目相关链接
PDF 22 pages, 23 figures, 7 tables
Summary
在多媒体大型语言模型领域,实现以人类为中心的视频理解是一项挑战。现有的基准测试主要侧重于物体和动作识别,忽视了人类情绪、行为和视频内容中语音视觉对齐的细微差别。我们推出HumanVBench基准测试,以弥补这些评估差距。HumanVBench包含16项精心设计的任务,探索内在情感和外在表现两个主要维度,涵盖静态和动态、基本和复杂,以及单模态和跨模态方面。利用两个先进的自动化管道进行视频标注和包含干扰项的QA生成,HumanVBench利用多种最新技术简化基准测试数据合成和质量评估,减少人工标注的依赖,针对以人为中心的多模态属性定制。对22个最新视频多媒体语言模型的全面评估显示,在跨模态和情感感知方面存在显著局限性,强调需要进一步改进以实现更人性化的理解。HumanVBench已开源,以促进视频多媒体语言模型的未来发展和实际应用。
Key Takeaways
- Human-centric video understanding remains a challenge in Multimodal Large Language Models (MLLMs).
- 现有基准测试主要关注物体和动作识别,忽视了人类情绪、行为和语音视觉对齐的细微差别。
- HumanVBench基准测试包含16项任务,探索内在情感和外在表现两个主要维度。
- HumanVBench利用自动化管道进行视频标注和QA生成,以减少人工标注的依赖。
- 跨模态和情感感知是当前多媒体语言模型在视频理解方面的显著局限性。
- HumanVBench已开源,以促进视频多媒体语言模型的未来发展。
点此查看论文截图

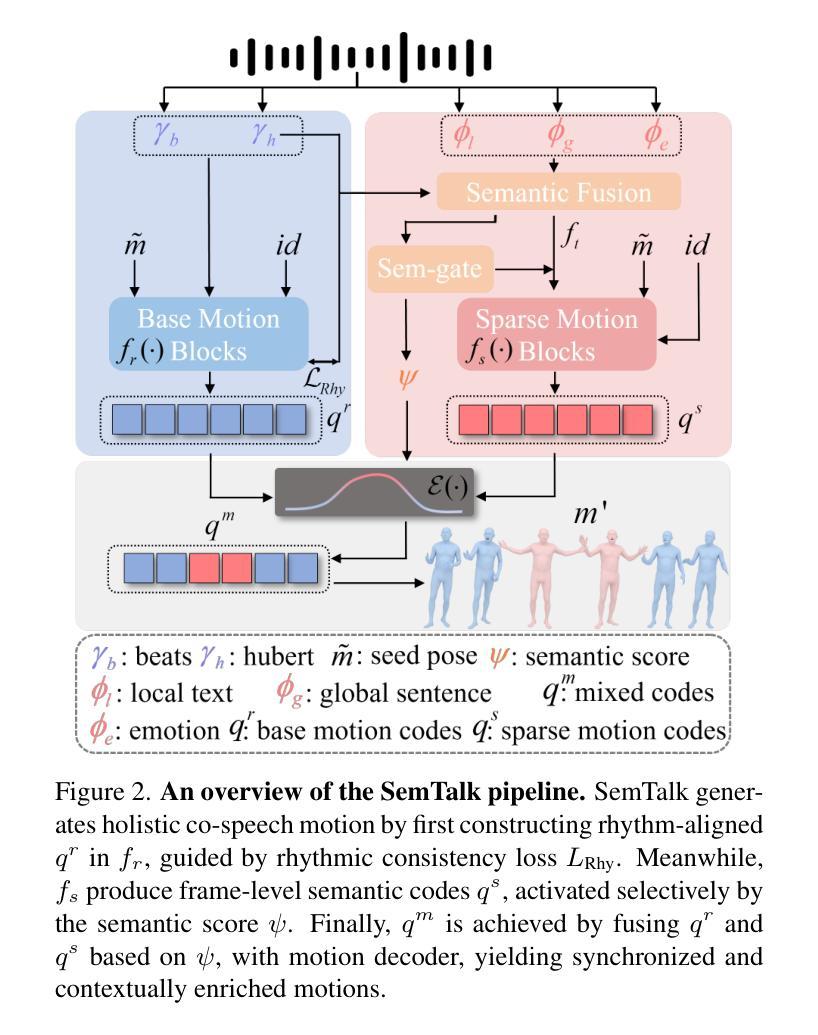
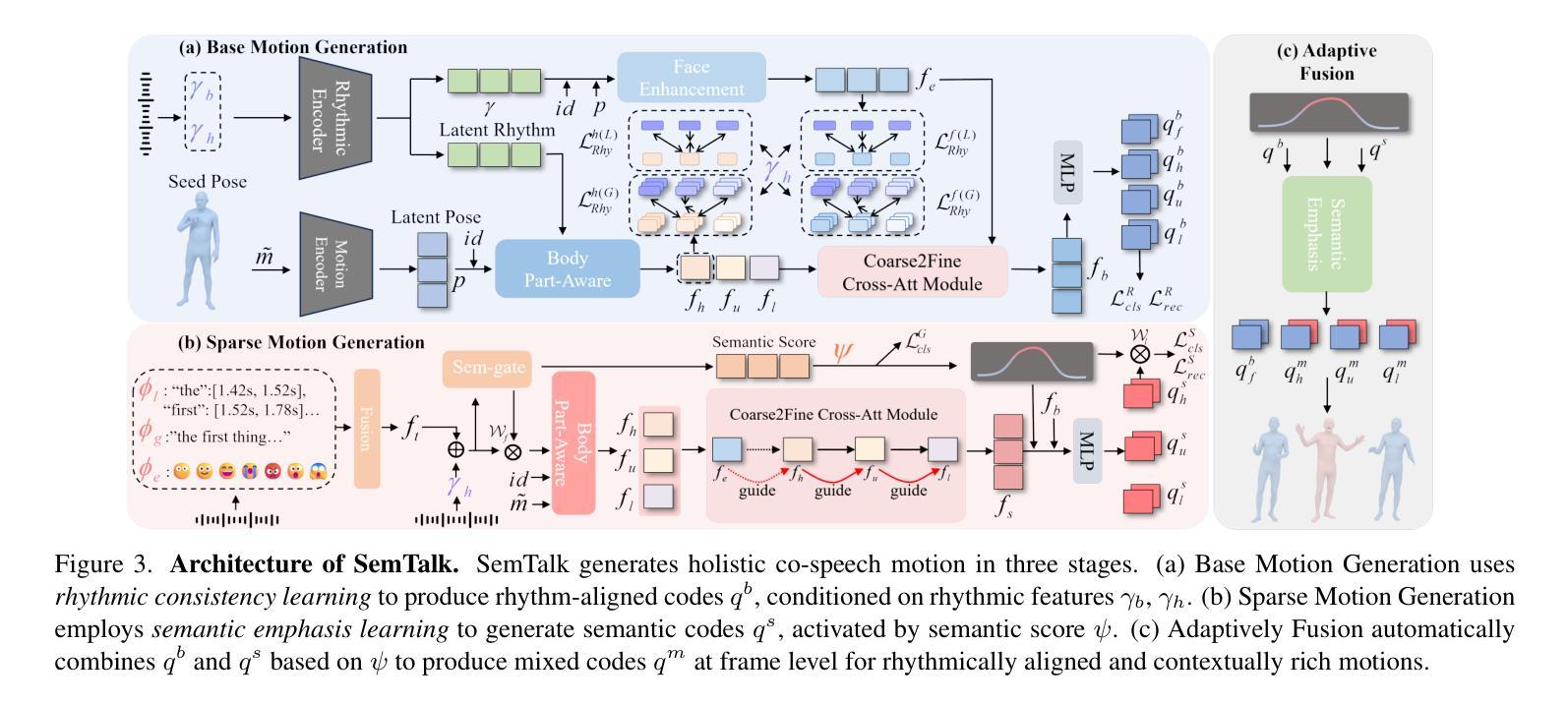
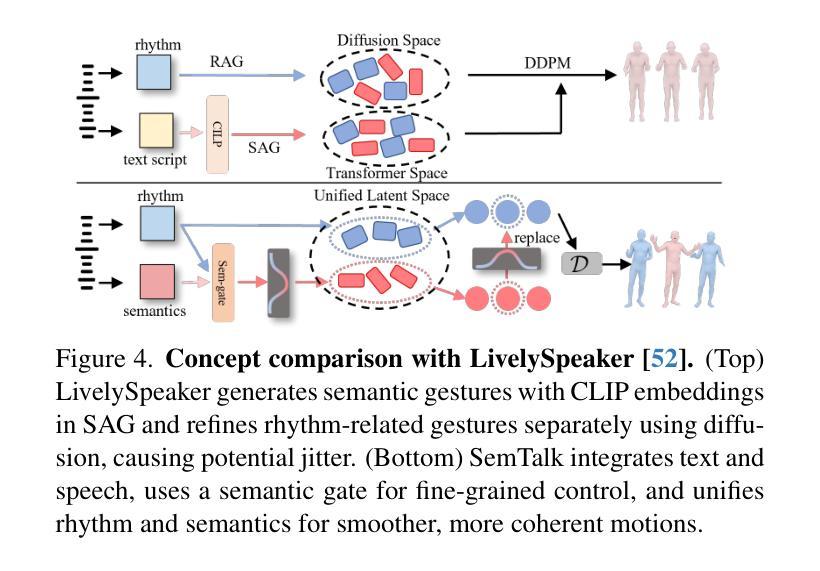
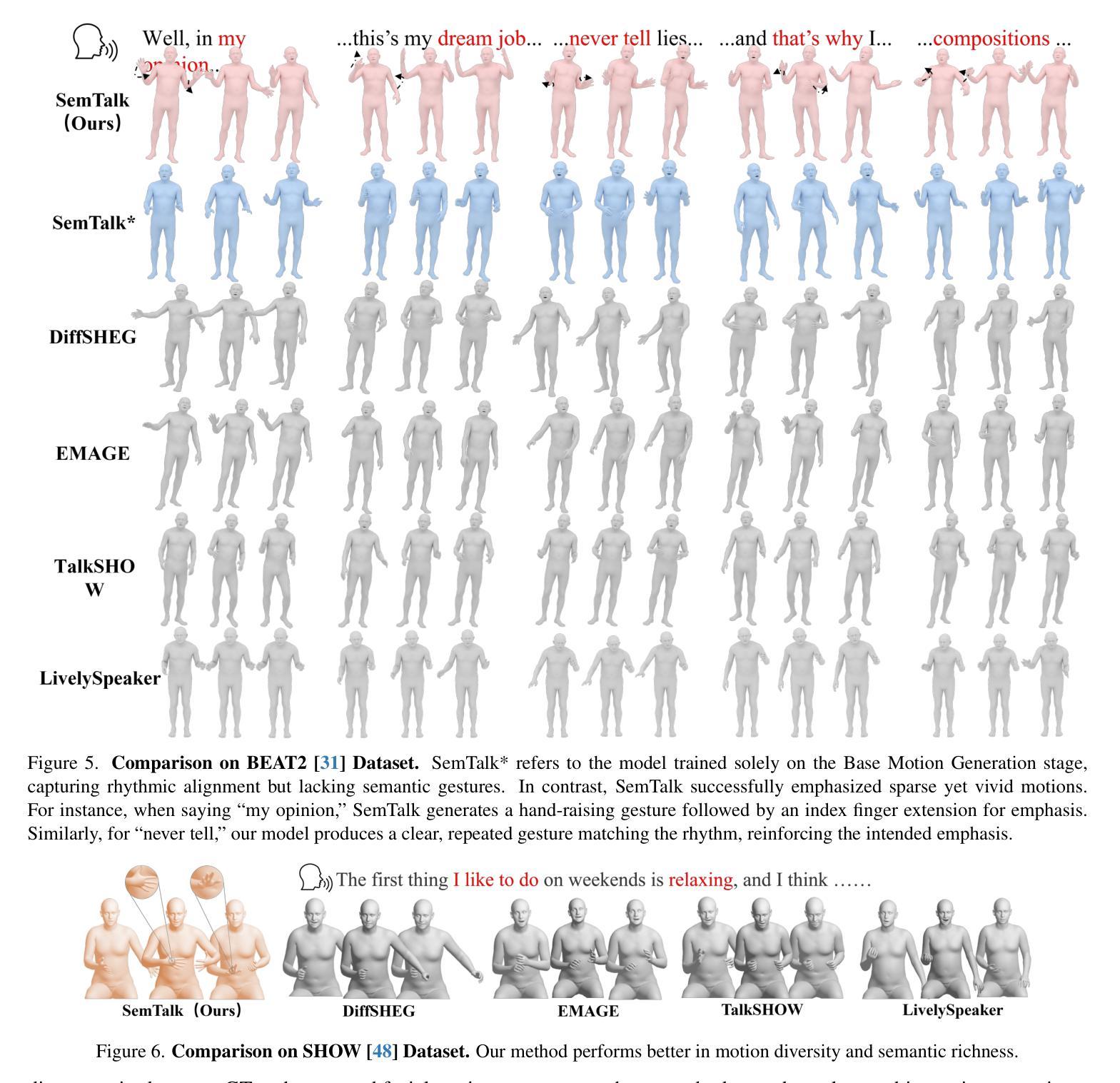
SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
Authors:Xiangyue Zhang, Jianfang Li, Jiaxu Zhang, Ziqiang Dang, Jianqiang Ren, Liefeng Bo, Zhigang Tu
A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn base motions and sparse motions, and then adaptively fuse them. In particular, coarse2fine cross-attention module and rhythmic consistency learning are explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion.
良好的协同语音动作生成离不开常见的节奏动作和罕见但必要的语义动作的仔细融合。在这项工作中,我们提出了用于整体协同语音动作生成的SemTalk方法,具有帧级语义强调。我们的关键见解是分别学习基础动作和稀疏动作,然后自适应地融合它们。特别是,我们探索了coarse2fine交叉注意力模块和节奏一致性学习来建立与节奏相关的基本动作,确保与语音节奏同步的手势有一个连贯的基础。随后,设计语义强调学习来生成具有语义感知的稀疏动作,侧重于帧级语义线索。最后,为了将稀疏动作融入基础动作中,生成具有语义强调的协同语音手势,我们进一步利用学习得到的语义分数进行自适应合成。在两项公共数据集上的定性和定量比较表明,我们的方法优于现有技术,提供高质量的协同语音动作,在稳定的基础动作上增加了语义丰富性。
论文及项目相关链接
PDF 11 pages, 8 figures
Summary
本文提出一种名为SemTalk的协同语音运动生成方法,该方法融合了常规节奏运动和罕见但重要的语义运动。通过分别学习基础运动和稀疏运动,然后自适应地融合它们。采用coarse2fine交叉注意力模块和节奏一致性学习来建立与节奏相关的基础运动,确保手势与语音节奏的同步。此外,设计了语义强调学习来生成具有语义意识的稀疏运动,重点关注帧级语义线索。最后,通过自适应合成将稀疏运动融入基础运动,生成具有语义强调的协同语音手势。本文方法在两个公共数据集上的表现优于现有技术,生成了高质量且语义丰富的协同语音运动。
Key Takeaways
- 协同语音运动生成需要融合常规节奏运动和语义运动。
- 提出SemTalk方法,分别学习基础运动和稀疏运动,并自适应融合。
- 采用coarse2fine交叉注意力模块建立与语音节奏相关的基础运动。
- 语义强调学习用于生成帧级语义线索的稀疏运动。
- 通过自适应合成将稀疏运动融入基础运动。
- 方法在公共数据集上表现优异,生成高质量且语义丰富的协同语音运动。
点此查看论文截图

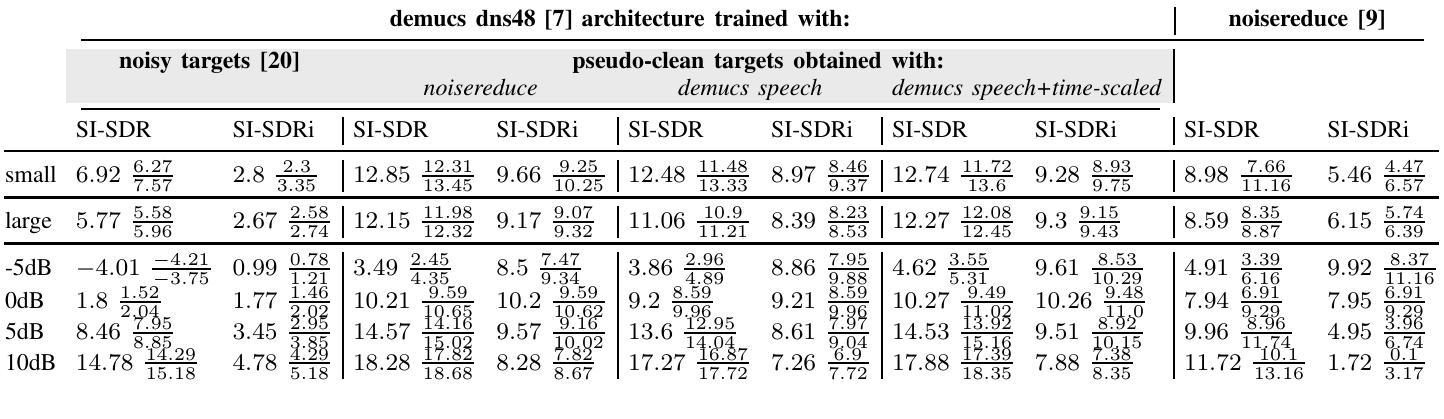
Biodenoising: Animal Vocalization Denoising without Access to Clean Data
Authors:Marius Miron, Sara Keen, Jen-Yu Liu, Benjamin Hoffman, Masato Hagiwara, Olivier Pietquin, Felix Effenberger, Maddie Cusimano
Animal vocalization denoising is a task similar to human speech enhancement, which is relatively well-studied. In contrast to the latter, it comprises a higher diversity of sound production mechanisms and recording environments, and this higher diversity is a challenge for existing models. Adding to the challenge and in contrast to speech, we lack large and diverse datasets comprising clean vocalizations. As a solution we use as training data pseudo-clean targets, i.e. pre-denoised vocalizations, and segments of background noise without a vocalization. We propose a train set derived from bioacoustics datasets and repositories representing diverse species, acoustic environments, geographic regions. Additionally, we introduce a non-overlapping benchmark set comprising clean vocalizations from different taxa and noise samples. We show that that denoising models (demucs, CleanUNet) trained on pseudo-clean targets obtained with speech enhancement models achieve competitive results on the benchmarking set. We publish data, code, libraries, and demos at https://earthspecies.github.io/biodenoising/.
动物发声去噪与人类语音增强任务类似,已经得到了较为充分的研究。然而,与之相比,动物发声去噪包含了更多样化的声音产生机制和录音环境,这给现有模型带来了更大的挑战。除了这些挑战之外,与语音不同,我们还缺乏包含清晰发声的大型多样化数据集。作为解决方案,我们使用伪清洁目标作为训练数据,即预去噪发声和无发声的背景噪声片段。我们提出了一个基于生物声学数据集和存储库的训练集,这些数据集涵盖了多种物种、声学环境和地理区域。此外,我们还引入了一个不包含重叠的基准测试集,其中包括来自不同分类群组的清洁发声和噪声样本。我们证明,使用语音增强模型获得的伪清洁目标进行训练的去噪模型(如demucs和CleanUNet)在基准测试集上取得了具有竞争力的结果。我们在https://earthspecies.github.io/biodenoising/发布数据、代码、库和演示。
论文及项目相关链接
PDF 5 pages, 2 tables
Summary
本文介绍了动物声音去噪任务面临的挑战和解决方案。由于动物声音产生机制和录音环境多样,现有模型难以应对。为解决此问题,研究团队使用伪清洁目标作为训练数据,并引入生物声学数据集和代表不同物种、声学环境和地理区域的存储库构建训练集。此外,他们还推出一个包含不同税种清洁发声和噪声样本的非重叠基准测试集。通过训练伪清洁目标上的去噪模型,如demucs和CleanUNet,在基准测试集上取得了具有竞争力的结果。相关数据和代码已发布在https://earthspecies.github.io/biodenoising/上。
Key Takeaways
- 动物声音去噪与人类语音增强类似,但面临更高的声音多样性和缺乏大型多元清洁发声数据集挑战。
- 为解决数据缺乏问题,研究团队使用伪清洁目标和背景噪声作为训练数据。
- 研究团队构建了一个包含多种物种、声学环境和地理区域的训练集。
- 引入非重叠基准测试集,包含清洁发声和噪声样本。
- 基于伪清洁目标的去噪模型(如demucs和CleanUNet)在基准测试集上表现良好。
- 该研究团队提供了动物声音去噪的数据集、代码库和演示。
点此查看论文截图


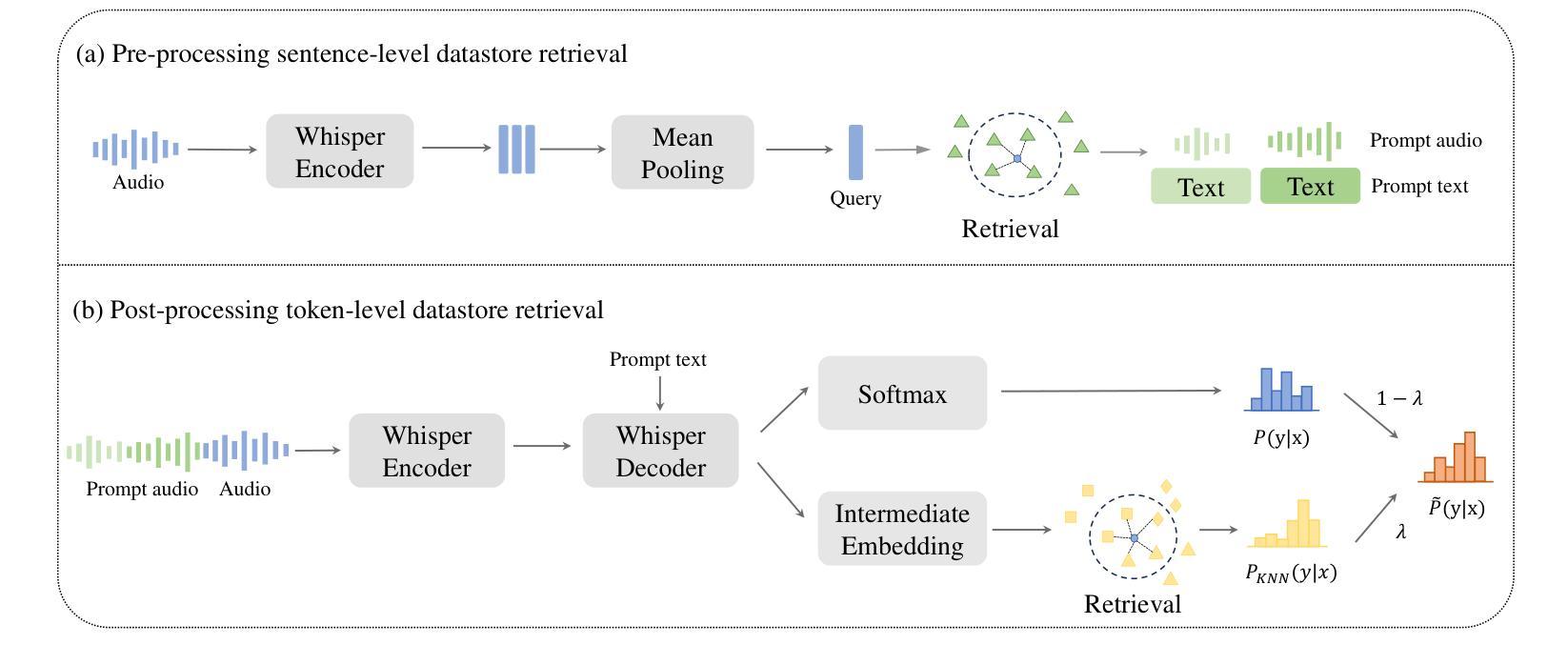
M2R-Whisper: Multi-stage and Multi-scale Retrieval Augmentation for Enhancing Whisper
Authors:Jiaming Zhou, Shiwan Zhao, Jiabei He, Hui Wang, Wenjia Zeng, Yong Chen, Haoqin Sun, Aobo Kong, Yong Qin
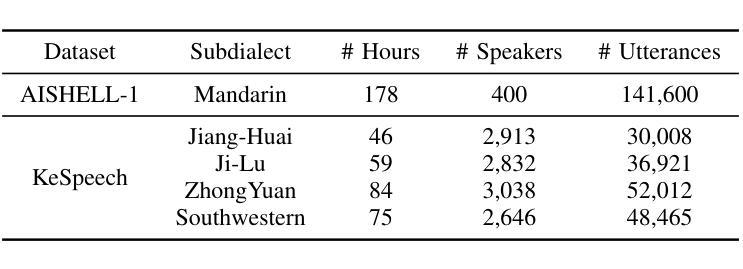
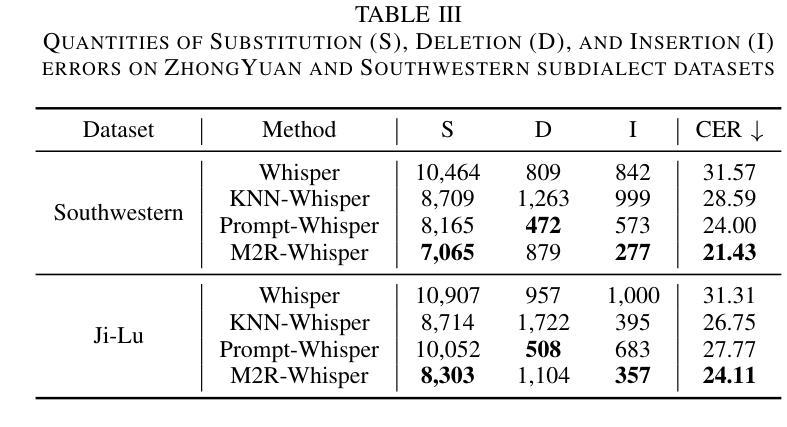
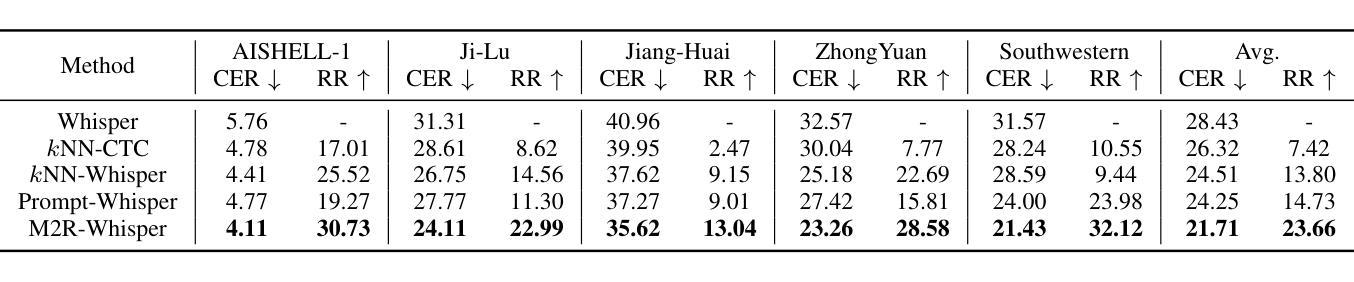
State-of-the-art models like OpenAI’s Whisper exhibit strong performance in multilingual automatic speech recognition (ASR), but they still face challenges in accurately recognizing diverse subdialects. In this paper, we propose M2R-whisper, a novel multi-stage and multi-scale retrieval augmentation approach designed to enhance ASR performance in low-resource settings. Building on the principles of in-context learning (ICL) and retrieval-augmented techniques, our method employs sentence-level ICL in the pre-processing stage to harness contextual information, while integrating token-level k-Nearest Neighbors (kNN) retrieval as a post-processing step to further refine the final output distribution. By synergistically combining sentence-level and token-level retrieval strategies, M2R-whisper effectively mitigates various types of recognition errors. Experiments conducted on Mandarin and subdialect datasets, including AISHELL-1 and KeSpeech, demonstrate substantial improvements in ASR accuracy, all achieved without any parameter updates.
当前最先进的模型,如OpenAI的Whisper,在多语种自动语音识别(ASR)方面表现出强大的性能,但它们在识别多样的次方言方面仍面临挑战。在本文中,我们提出了M2R-whisper,这是一种新型的多阶段多尺度检索增强方法,旨在增强低资源环境下的ASR性能。我们的方法基于上下文学习(ICL)和检索增强技术,在预处理阶段采用句子级ICL来利用上下文信息,同时在后处理步骤中集成基于标记的k近邻(kNN)检索,以进一步优化最终的输出分布。通过协同结合句子级和标记级检索策略,M2R-whisper有效地减轻了各种类型的识别错误。在包括AISHELL-1和KeSpeech在内的普通话和次方言数据集上进行的实验表明,ASR准确率得到了显著提高,所有这些改进都没有更新任何参数。
论文及项目相关链接
PDF Accepted by ICASSP 2025, oral
Summary
M2R-whisper是一种针对低资源环境下的多语种自动语音识别(ASR)性能提升的新方法。它结合了上下文学习(ICL)和检索增强技术,采用多阶段多尺度的策略,在预处理阶段利用句子级别的ICL来利用上下文信息,并在后处理阶段采用基于token的k近邻(kNN)检索技术进一步优化输出结果分布。此方法可有效减轻各类识别错误,通过中英文的对照实验验证了其在不同方言口音数据集上的性能提升。
Key Takeaways
- M2R-whisper旨在增强低资源环境下的多语种自动语音识别(ASR)性能。
- 该方法结合了上下文学习(ICL)和检索增强技术。
- M2R-whisper采用多阶段多尺度的策略,包括预处理和后处理步骤。
- 预处理阶段采用句子级别的ICL以利用上下文信息。
- 后处理阶段使用基于token的k近邻(kNN)检索技术进一步优化输出结果分布。
- M2R-whisper能够有效减轻各类识别错误。
点此查看论文截图