⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Versatile Multimodal Controls for Whole-Body Talking Human Animation
Authors:Zheng Qin, Ruobing Zheng, Yabing Wang, Tianqi Li, Zixin Zhu, Minghui Yang, Ming Yang, Le Wang
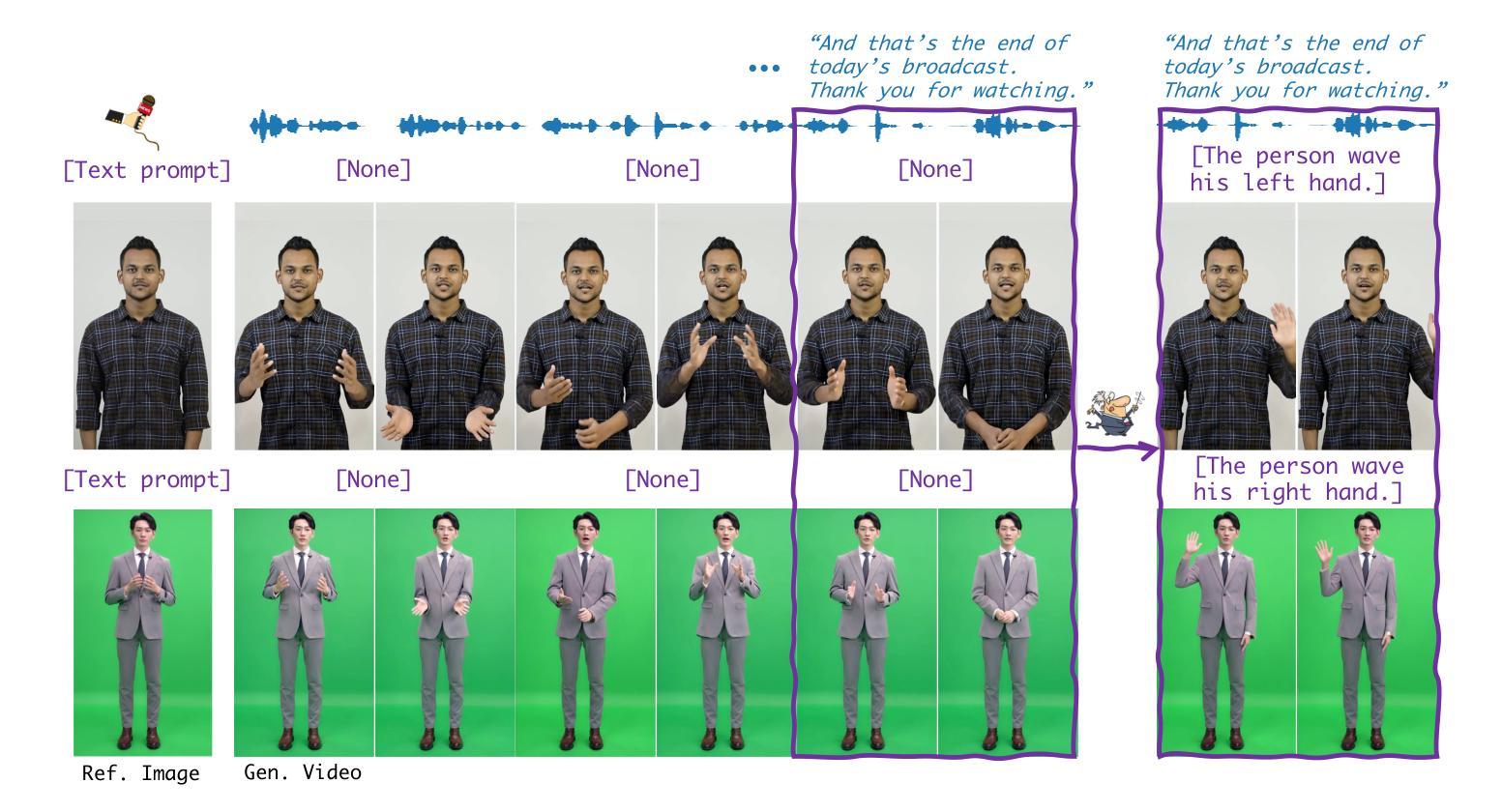
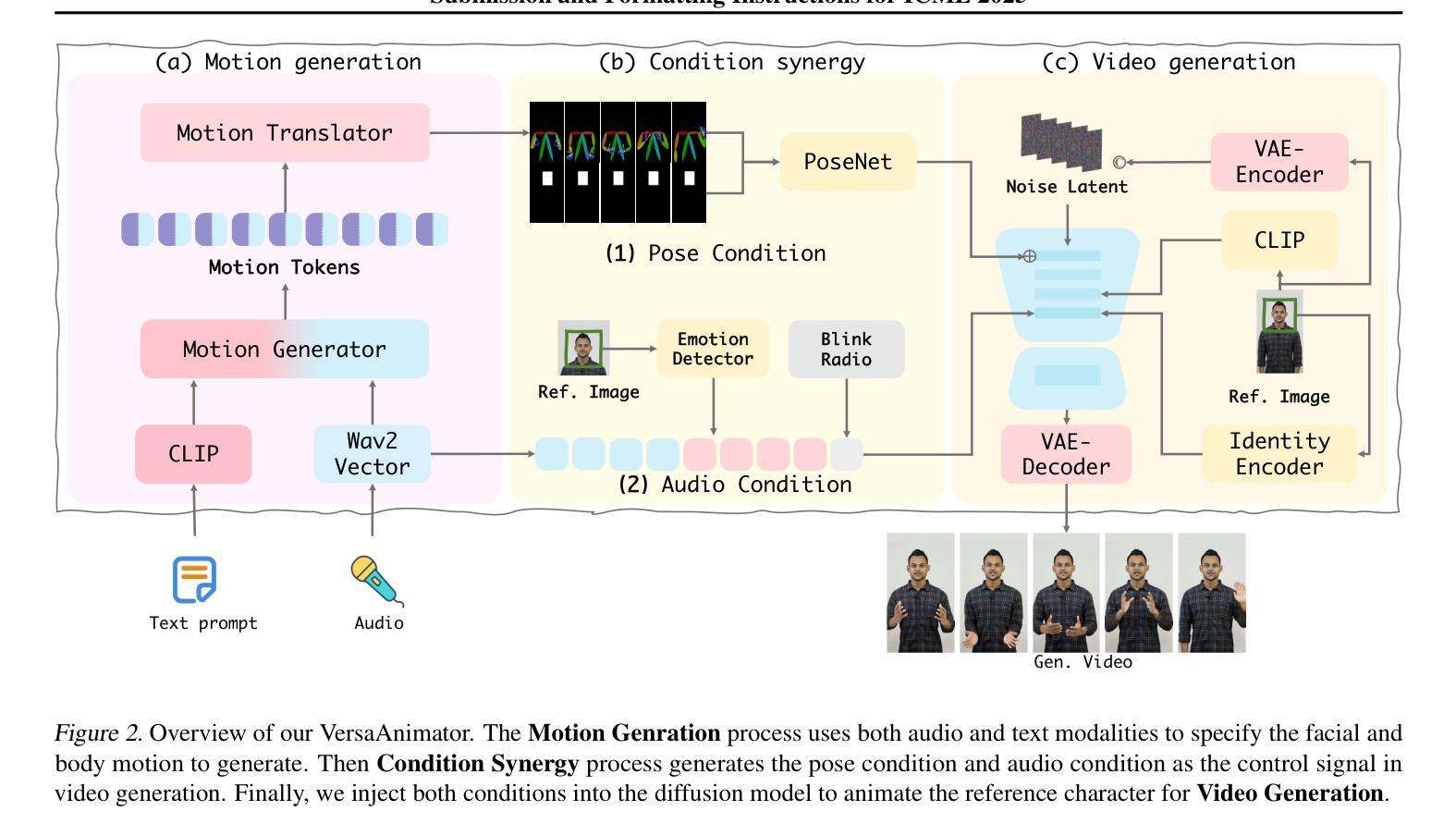
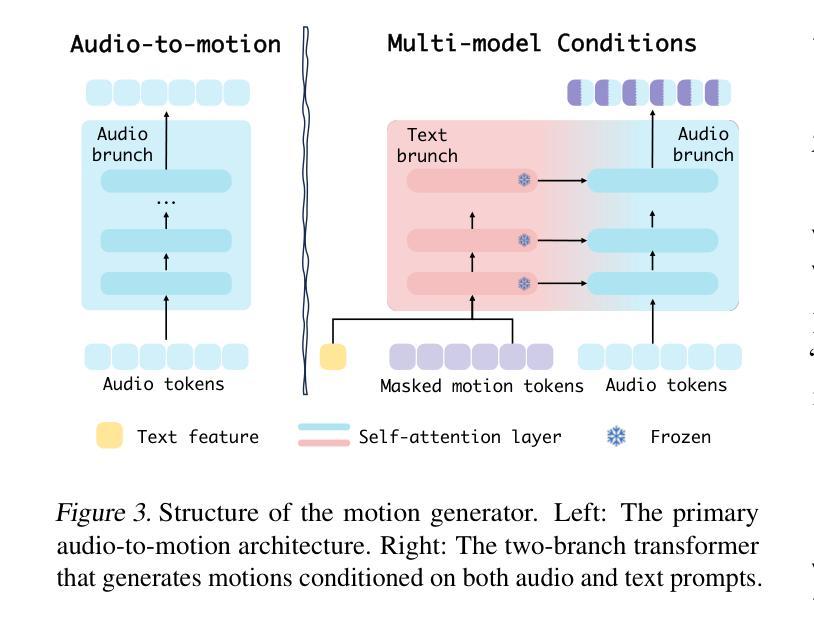
Human animation from a single reference image shall be flexible to synthesize whole-body motion for either a headshot or whole-body portrait, where the motions are readily controlled by audio signal and text prompts. This is hard for most existing methods as they only support producing pre-specified head or half-body motion aligned with audio inputs. In this paper, we propose a versatile human animation method, i.e., VersaAnimator, which generates whole-body talking human from arbitrary portrait images, not only driven by audio signal but also flexibly controlled by text prompts. Specifically, we design a text-controlled, audio-driven motion generator that produces whole-body motion representations in 3D synchronized with audio inputs while following textual motion descriptions. To promote natural smooth motion, we propose a code-pose translation module to link VAE codebooks with 2D DWposes extracted from template videos. Moreover, we introduce a multi-modal video diffusion that generates photorealistic human animation from a reference image according to both audio inputs and whole-body motion representations. Extensive experiments show that VersaAnimator outperforms existing methods in visual quality, identity preservation, and audio-lip synchronization.
从单一参考图像生成的人脸动画应该能够灵活地合成头部特写或全身肖像的全身运动,这些运动可以通过音频信号和文字提示轻松控制。对于大多数现有方法而言,这很难实现,因为它们仅支持生成与音频输入对齐的预设头部或半身运动。在本文中,我们提出了一种通用的人脸动画方法,即VersaAnimator。它可以从任意肖像图像生成全身说话的人脸动画,不仅由音频信号驱动,还通过文字提示灵活控制。具体来说,我们设计了一个文本控制、音频驱动的动效生成器,它能在3D环境中产生与音频输入同步的全身运动表示,同时遵循文本动作描述。为了促进自然流畅的动作,我们提出了一个编码姿势转换模块,将VAE代码本与从模板视频中提取的2DDW姿势相联系。此外,我们引入了一种多模式视频扩散方法,根据参考图像、音频输入和全身运动表示生成逼真的人脸动画。大量实验表明,VersaAnimator在视觉质量、身份保留和音频-嘴唇同步方面优于现有方法。
论文及项目相关链接
Summary
本文提出了一种通用的人类动画方法VersaAnimator,能够从任意肖像图像生成全身动态人类动画。该方法不仅由音频信号驱动,还灵活地通过文本提示进行控制。通过设计文本控制、音频驱动的动作生成器,产生与音频输入同步的全身动作表示。同时,引入编码姿态翻译模块和多模态视频扩散技术,实现自然流畅的动作生成和照片级真实感的人类动画。
Key Takeaways
- VersaAnimator能从单张参考图像生成全身动态人类动画。
- 该方法支持通过音频信号和文本提示控制动画。
- 文本控制的动作生成器能生成与音频输入同步的全身动作表示。
- 编码姿态翻译模块连接了VAE代码本和从模板视频提取的2D DWposes。
- 多模态视频扩散技术用于生成具有照片级真实感的动画。
- 实验显示,VersaAnimator在视觉质量、身份保留和音频唇形同步方面优于现有方法。
点此查看论文截图


Talking to GDELT Through Knowledge Graphs
Authors:Audun Myers, Max Vargas, Sinan G. Aksoy, Cliff Joslyn, Benjamin Wilson, Tom Grimes
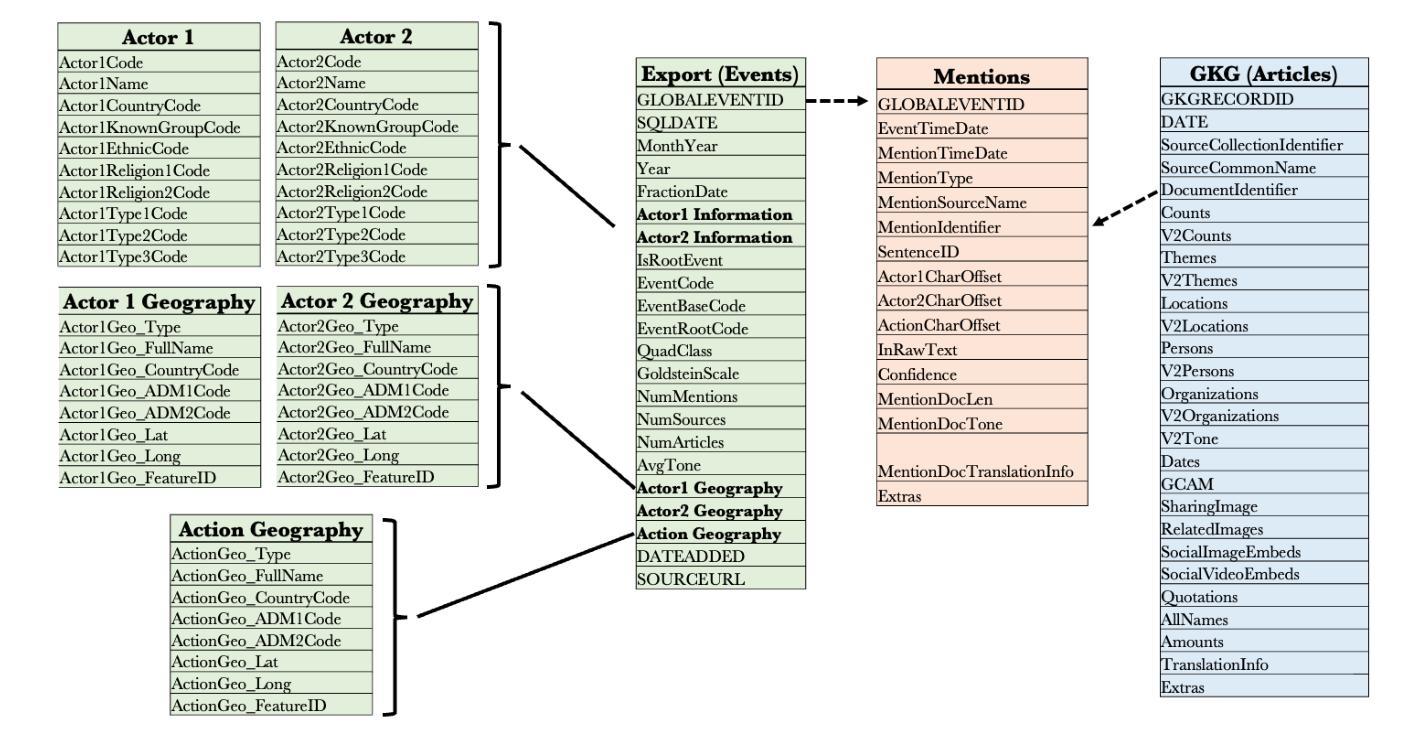
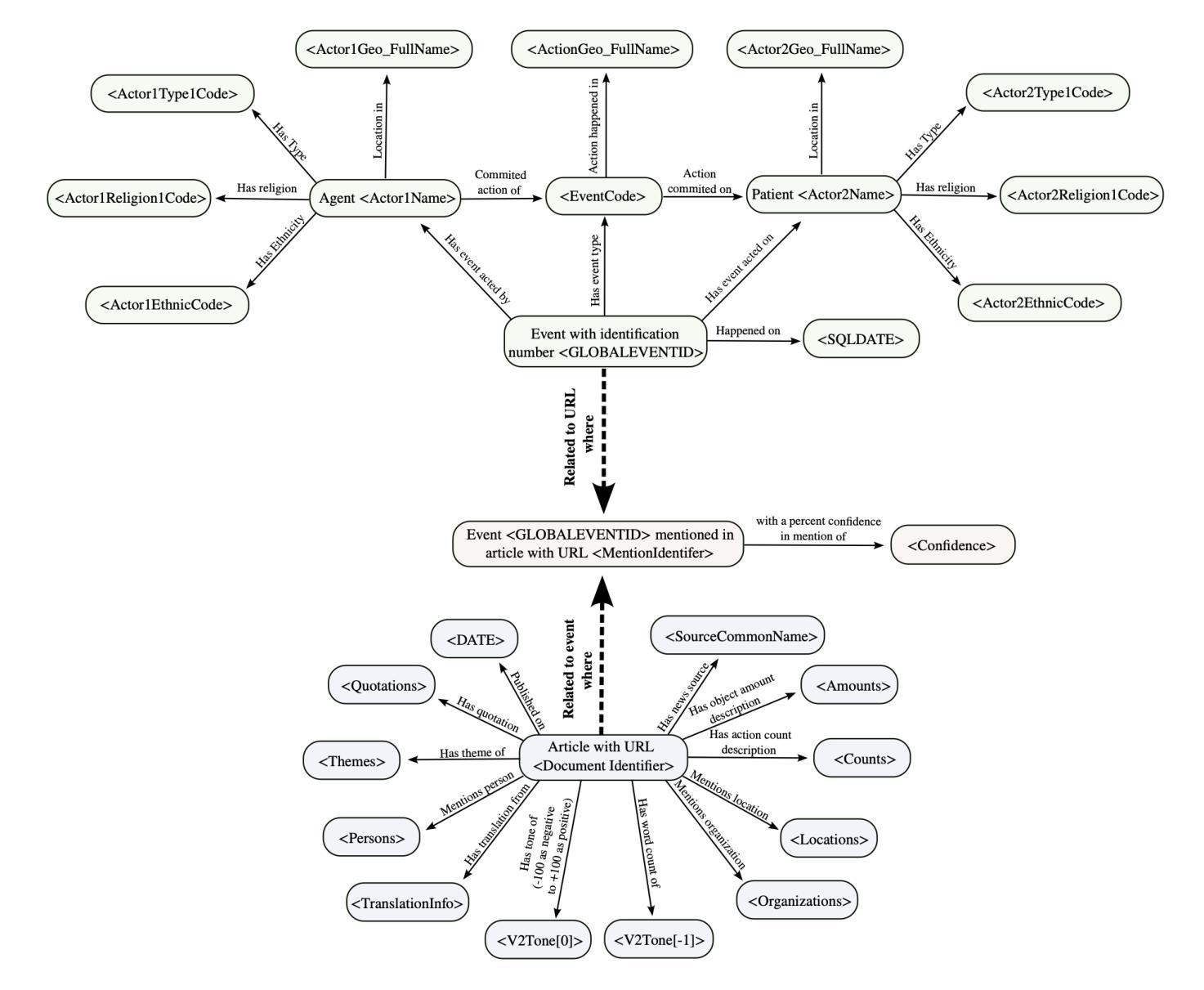
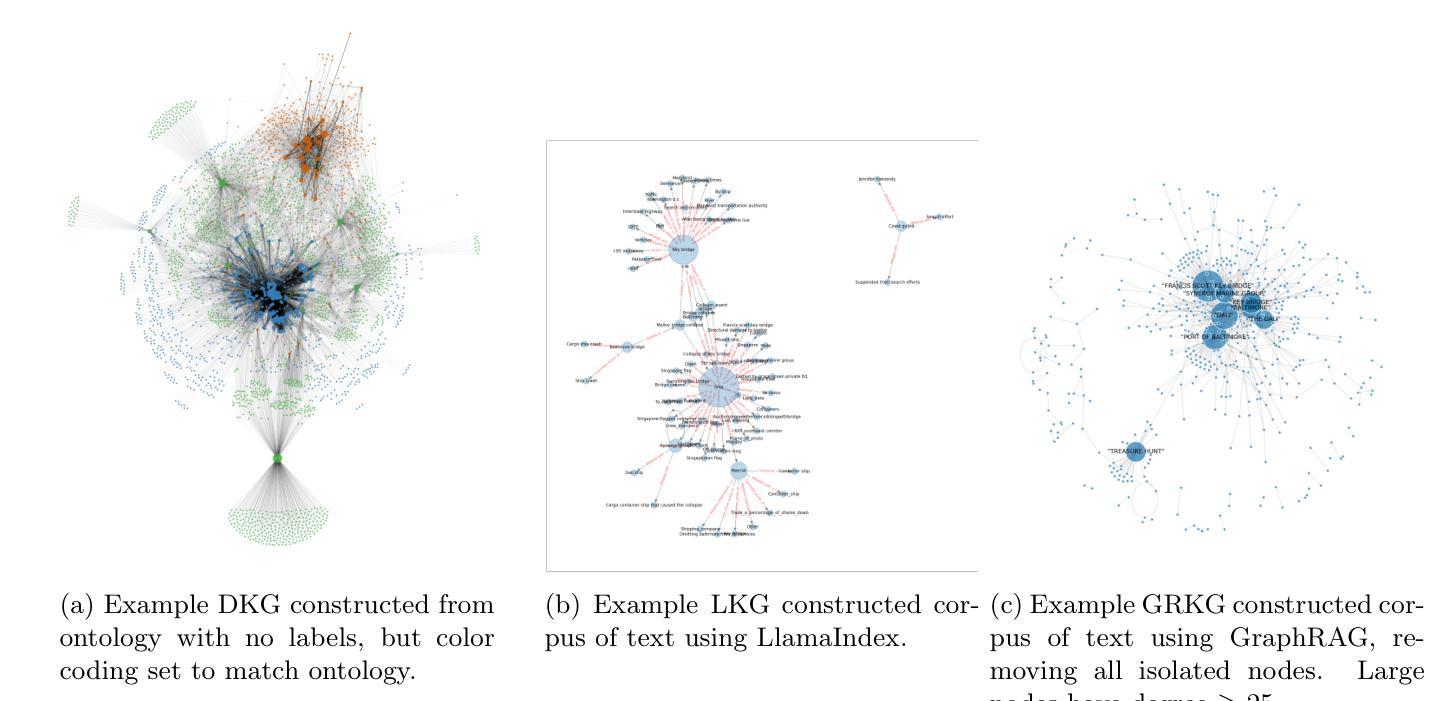
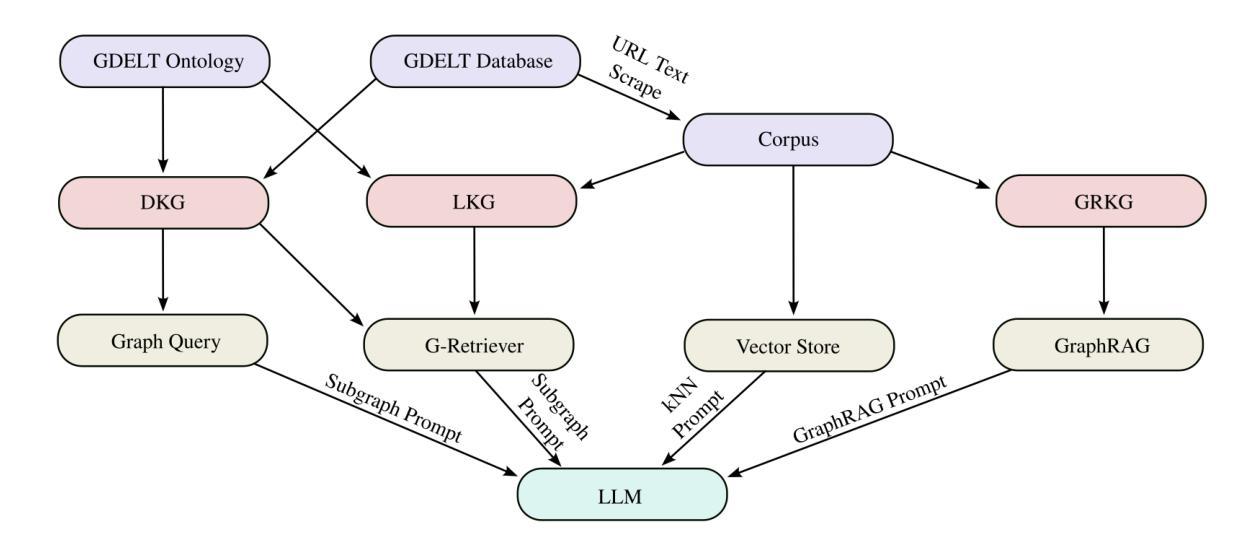
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
在这项工作中,我们研究了各种基于检索的再生(RAG)方法,以了解每种方法在问答分析中的优缺点。为了获得这种理解,我们使用了全球事件、语言和语调(GDELT)数据集的一个案例研究子集以及从在线新闻文章中抓取的大量原始文本语料库。为了从文本语料库中检索信息,我们实施了传统的向量存储RAG以及基于最新大型语言模型(LLM)的方法,用于自动构建知识图谱和检索相关的子图。除了这些语料库方法外,我们还开发了一种基于本体构建知识图谱(KGs)的新框架,该框架直接从GDELT中提取信息,并利用GDELT的底层模式创建全球事件的结构化表示。为了从基于本体的知识图谱中检索相关信息,我们实现了直接图查询和最新的图检索方法。我们在问答任务中比较了每种方法的性能。我们发现,虽然我们的基于本体的知识图谱对于问答很有价值,但自动提取相关子图具有挑战性。相比之下,虽然LLM生成的知识图谱能够捕捉事件摘要,但往往缺乏一致性和可解释性。我们的研究结果表明了本体和LLM在知识图谱构建中的协同作用所带来的好处,并提出了朝着这一目标发展的建议途径。
论文及项目相关链接
Summary
该文本研究了多种基于检索的增强再生(RAG)方法,通过问答分析来了解每种方法的长处和短板。文中使用全球事件语言语调的数据库(GDELT)数据集的一个案例研究子集以及从在线新闻文章中抓取的大量原始文本语料库来进行研究。该研究实现了传统的向量存储RAG以及基于最新大型语言模型(LLM)的方法,用于自动构建知识图谱并检索相关子图。此外,还开发了一种基于本体构建知识图谱的新框架,该框架利用GDELT的底层模式创建全球事件的结构化表示。为了从基于本体的知识图谱中检索相关信息,该研究实现了直接图形查询和最新的图形检索方法。比较了各种方法在问答任务中的表现,发现基于本体的知识图谱对于问答任务有价值,但自动提取相关子图具有挑战性;而LLM生成的知识图谱虽然能够捕捉事件摘要,但常常缺乏一致性和可解释性。研究结果建议采用本体和LLM知识图谱构建的协同方法。
Key Takeaways
- 研究了多种基于检索的增强再生(RAG)方法,用于问答分析。
- 通过使用GDELT数据集和在线新闻文章语料库来评估各种方法。
- 实现了基于向量存储的RAG方法和基于大型语言模型(LLM)的方法,用于自动构建知识图谱并检索相关子图。
- 开发了一种基于本体构建知识图谱的新框架,利用GDELT的底层模式来创建结构化表示。
- 通过直接图形查询和最新的图形检索方法从基于本体的知识图谱中检索信息。
- 比较了各种方法在问答任务中的表现,发现基于本体的知识图谱对于问答有价值,但自动提取相关子图具有挑战性。
点此查看论文截图