⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
PersonaBooth: Personalized Text-to-Motion Generation
Authors:Boeun Kim, Hea In Jeong, JungHoon Sung, Yihua Cheng, Jeongmin Lee, Ju Yong Chang, Sang-Il Choi, Younggeun Choi, Saim Shin, Jungho Kim, Hyung Jin Chang
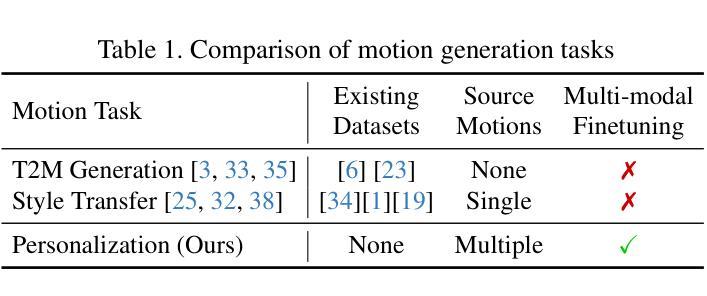
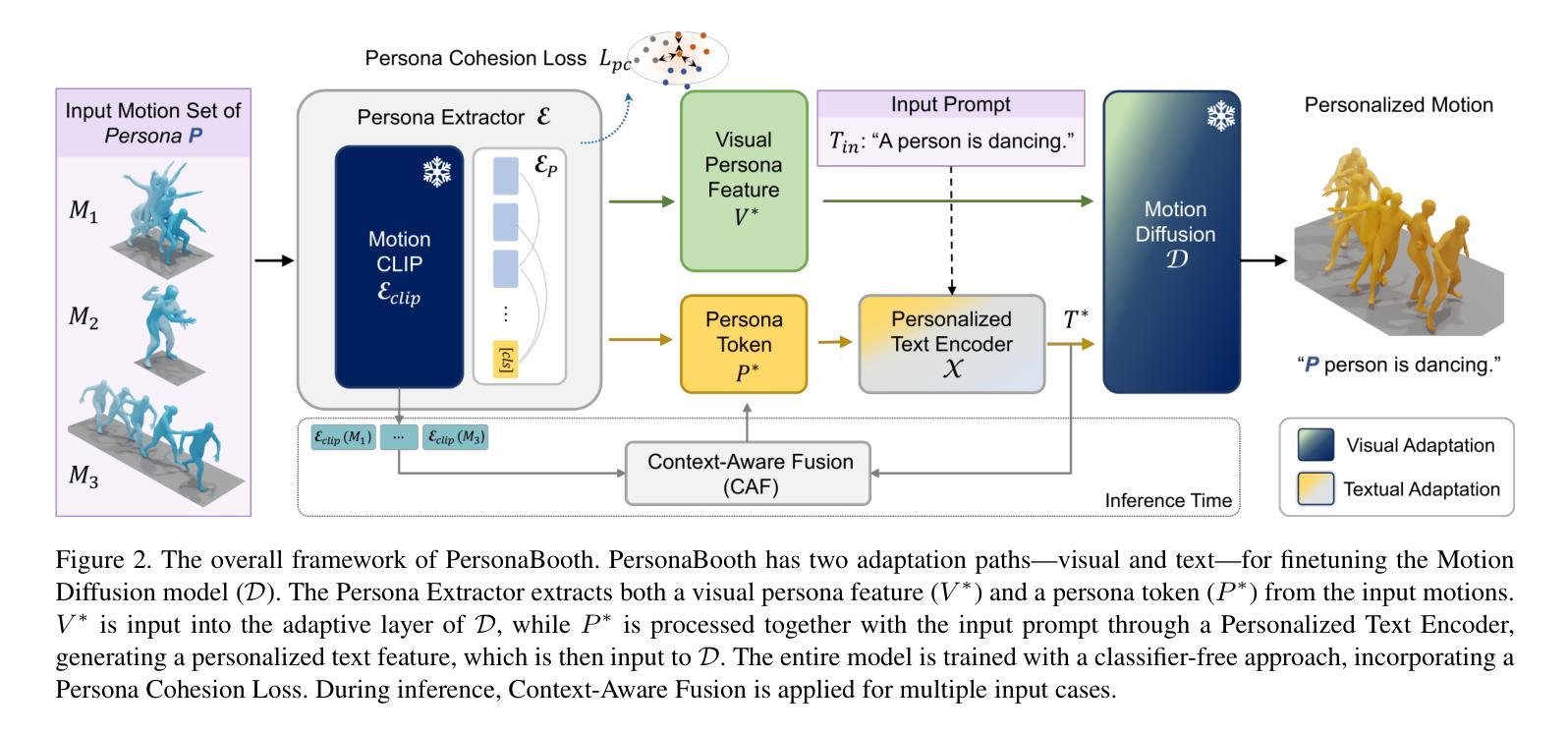
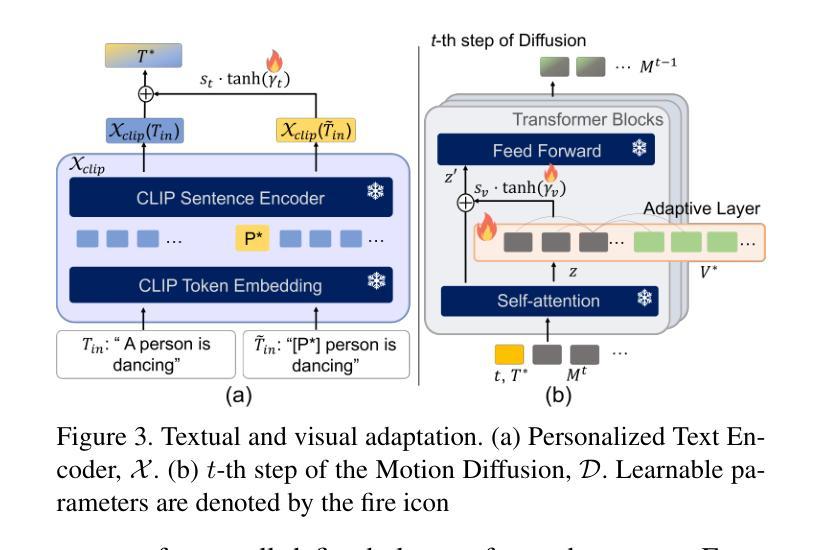
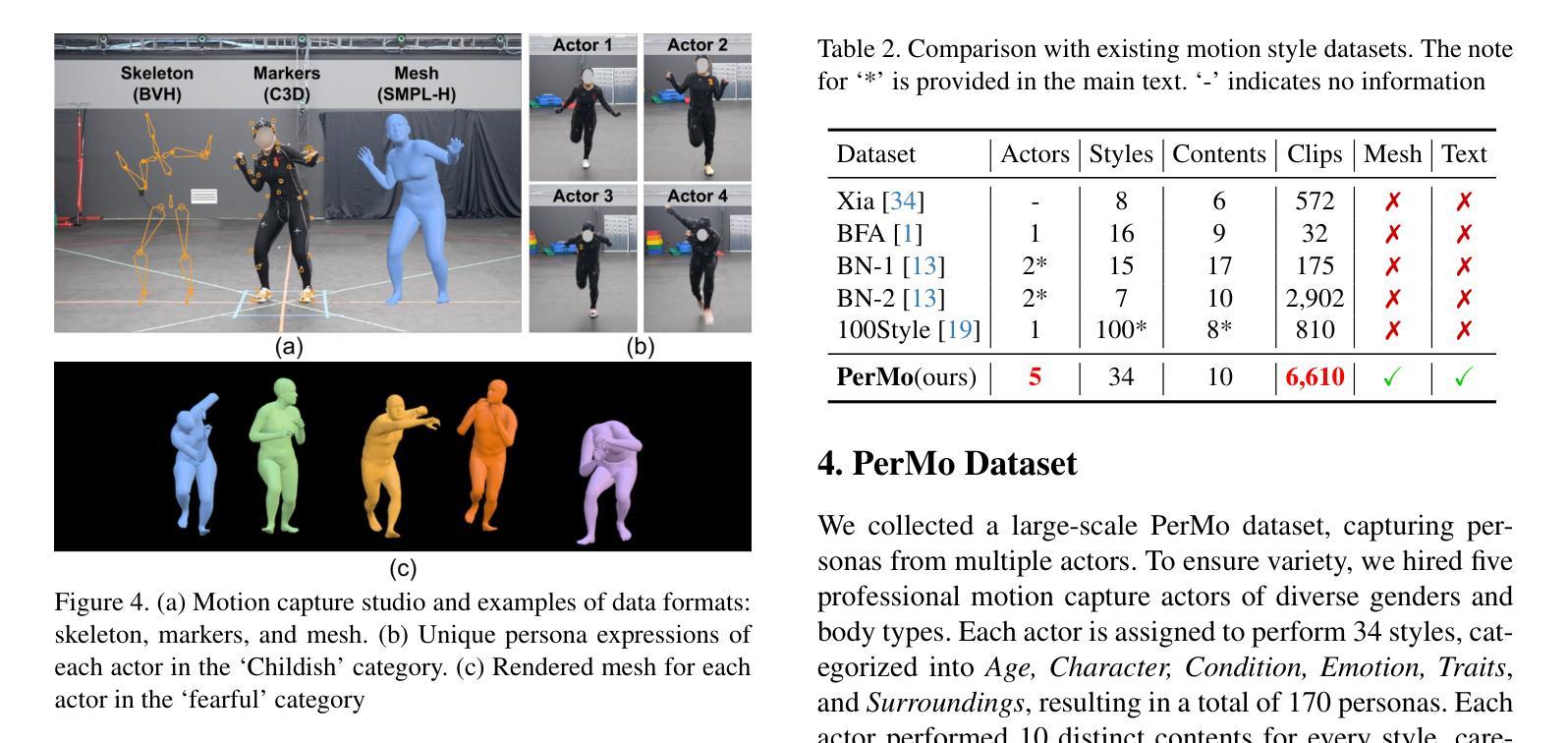
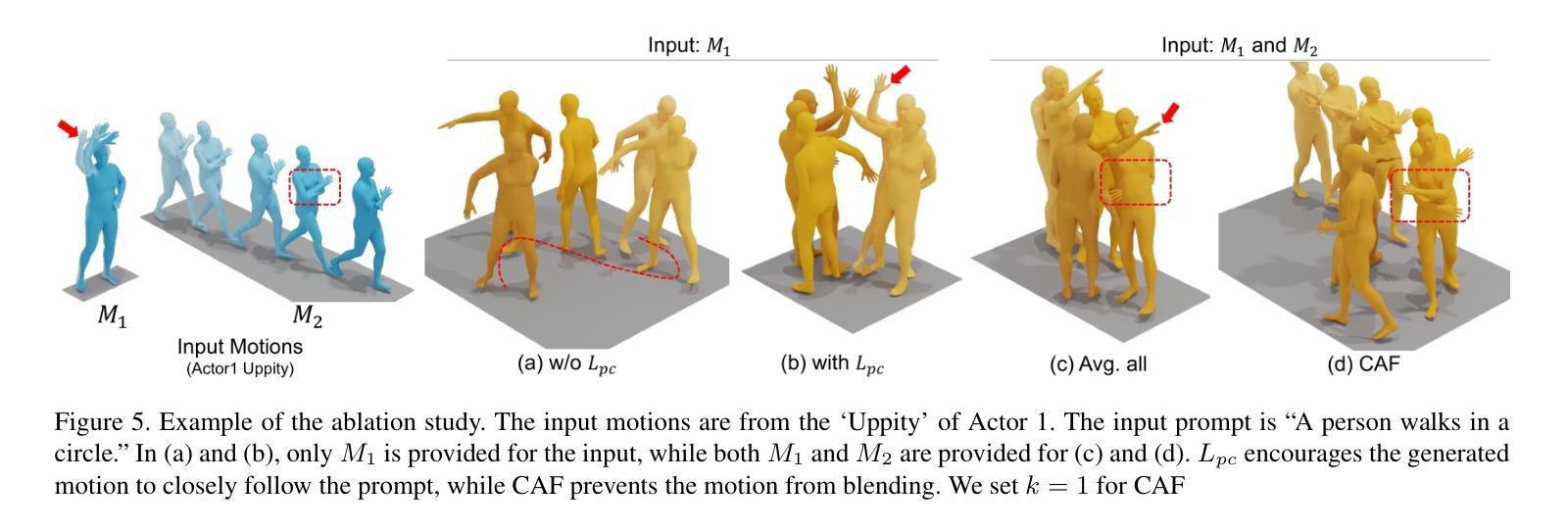
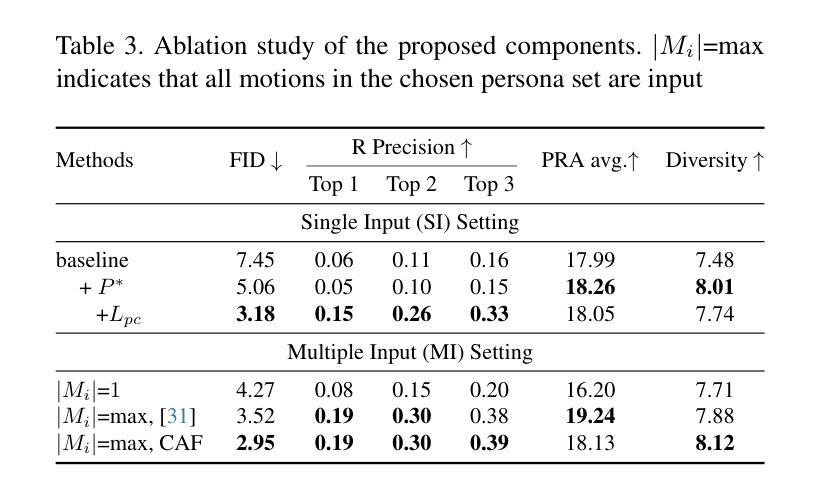
This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
本文介绍了动作个性化这一新任务,该任务利用包含个性的多种基本动作,根据文本描述生成个性化的动作。为了支持这项新任务,我们引入了一个名为PerMo(PersonaMotion)的大规模动作数据集,它捕捉了多个角色的独特个性。我们还提出了一种预训练运动扩散模型的多模态微调方法,该方法被称为PersonaBooth。PersonaBooth解决了两个主要挑战:一是以个性为中心的PerMo数据集与缺乏个性特定数据的预训练数据集之间的显著分布差距;二是从内容多变的动作中捕捉一致个性的难度。为了解决数据集分布差距的问题,我们引入了个性令牌来接受新的个性特征,并在微调过程中进行文本和视觉的多模态适应。为了捕捉一致的个性,我们采用对比学习技术,增强同一人格样本之间的内部凝聚力。此外,我们还引入了一种上下文感知融合机制,以最大限度地整合来自多个输入动作的个性线索。PersonaBooth在动作风格转换方法上表现出卓越的性能,为动作个性化树立了新的基准。
论文及项目相关链接
Summary
文本介绍了Motion Personalization这一新任务,即通过文本描述生成与个性化动作对齐的动作。为此任务,引入了一个新的大规模动作数据集PerMo(PersonaMotion),该数据集捕捉了多个角色的独特个性。同时,提出了一种对预训练运动扩散模型PersonaBooth的多模态微调方法。该方法解决了两个主要挑战:一是缺乏个性化数据的PerMo数据集与预训练数据集之间的分布差距显著;二是从内容多变的动作中捕捉一致角色的难度。为缩小数据集分布差距,引入了角色令牌以接受新角色特征,并在微调过程中进行文本和视觉的多模态适应。为捕捉一致的角色,采用对比学习技术增强同一角色样本之间的内部凝聚力。此外,还引入了上下文感知融合机制,以最大化来自多个输入动作的角色线索的融合。PersonaBooth在动作风格转换方法中表现卓越,为运动个性化树立了新标杆。
Key Takeaways
- 引入了Motion Personalization任务,旨在通过文本描述生成与个性化动作对齐的动作。
- 介绍了新的大规模运动数据集PerMo(PersonaMotion),用于捕捉多个角色的独特个性。
- 提出了对预训练运动扩散模型PersonaBooth的多模态微调方法,以支持Motion Personalization任务。
- PersonaBooth解决了数据分布差距和从内容多变的动作中捕捉一致角色的挑战。
- 通过引入角色令牌和对比学习技术来缩小数据集分布差距并增强角色样本之间的内部凝聚力。
- 采用了上下文感知融合机制,以最大化角色线索的融合。
点此查看论文截图