⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-14 更新
Evaluating Visual Explanations of Attention Maps for Transformer-based Medical Imaging
Authors:Minjae Chung, Jong Bum Won, Ganghyun Kim, Yujin Kim, Utku Ozbulak
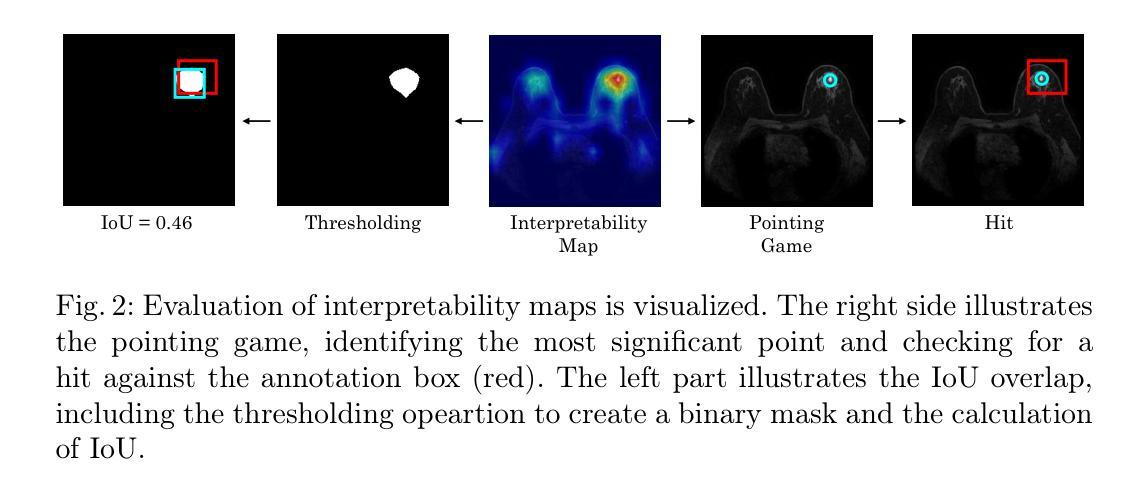
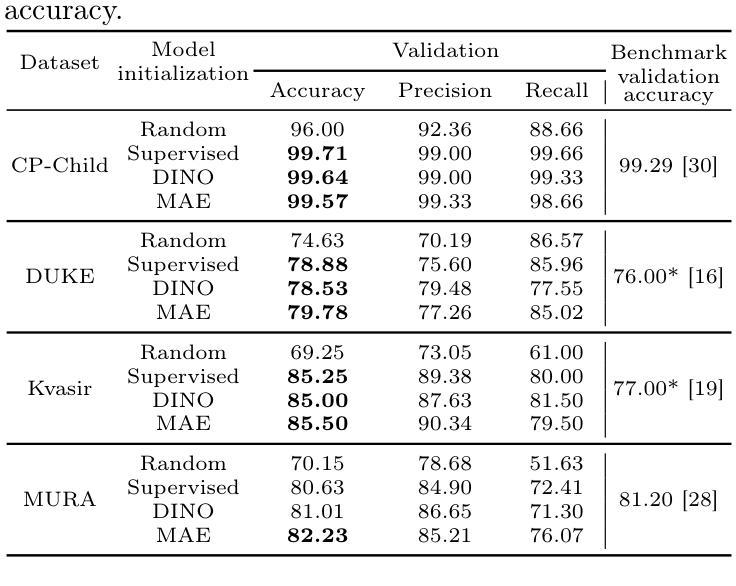
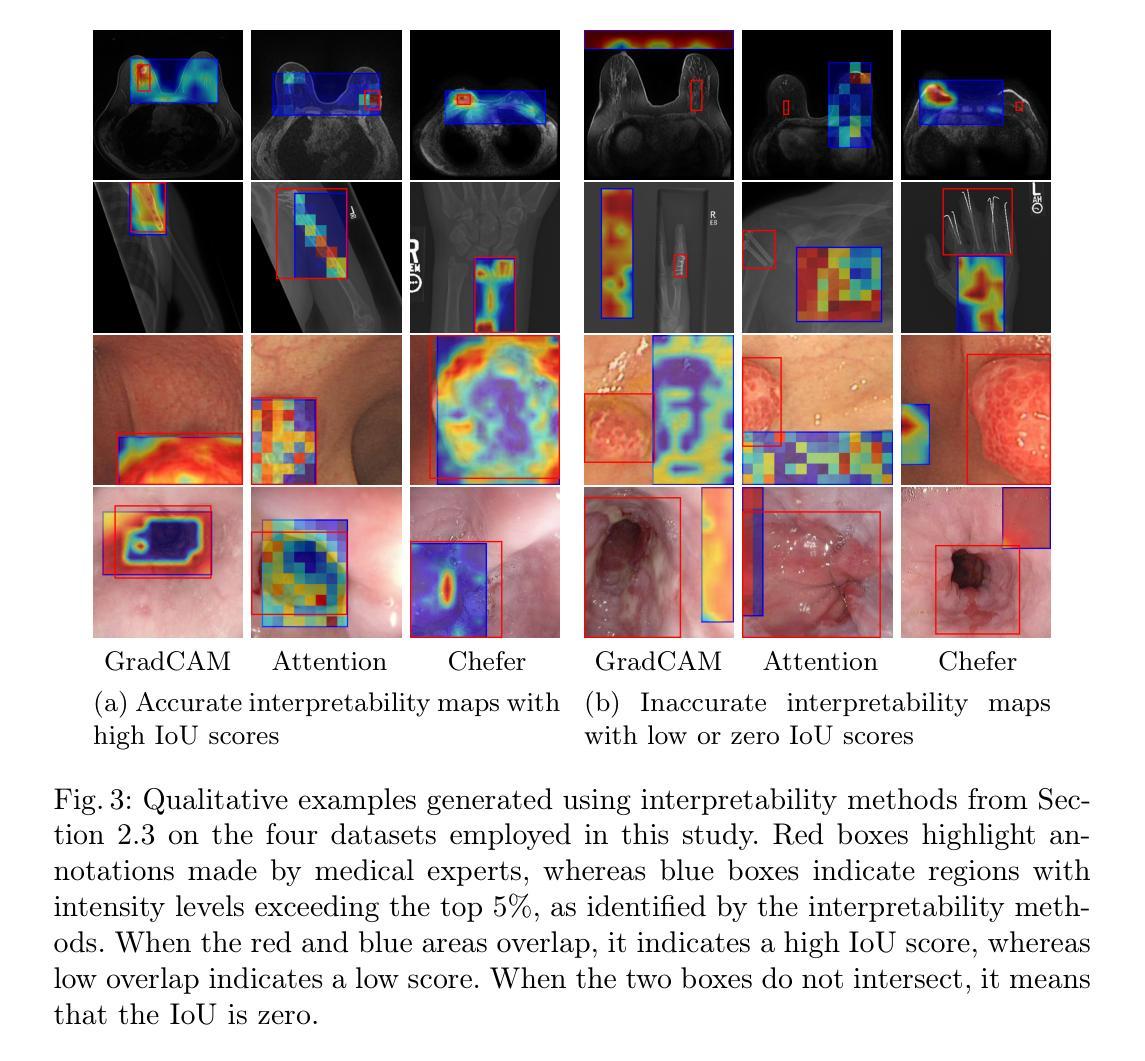
Although Vision Transformers (ViTs) have recently demonstrated superior performance in medical imaging problems, they face explainability issues similar to previous architectures such as convolutional neural networks. Recent research efforts suggest that attention maps, which are part of decision-making process of ViTs can potentially address the explainability issue by identifying regions influencing predictions, especially in models pretrained with self-supervised learning. In this work, we compare the visual explanations of attention maps to other commonly used methods for medical imaging problems. To do so, we employ four distinct medical imaging datasets that involve the identification of (1) colonic polyps, (2) breast tumors, (3) esophageal inflammation, and (4) bone fractures and hardware implants. Through large-scale experiments on the aforementioned datasets using various supervised and self-supervised pretrained ViTs, we find that although attention maps show promise under certain conditions and generally surpass GradCAM in explainability, they are outperformed by transformer-specific interpretability methods. Our findings indicate that the efficacy of attention maps as a method of interpretability is context-dependent and may be limited as they do not consistently provide the comprehensive insights required for robust medical decision-making.
尽管视觉Transformer(ViTs)在医学影像问题中展现出卓越的性能,但它们仍面临与早期架构(如卷积神经网络)类似的解释性问题。最近的研究努力表明,视觉Transformer的决策过程中的注意力地图有可能通过识别影响预测的区域来解决解释性问题,特别是在使用自监督学习进行预训练的模型中。在这项工作中,我们将注意力地图的视觉解释与其他常用于医学影像问题的方法进行比较。为此,我们采用了四个不同的医学影像数据集,涉及(1)结肠息肉、(2)乳房肿瘤、(3)食道炎症和(4)骨折及硬件植入物的识别。通过在大规模数据集上进行各种有监督和自监督预训练的ViT实验,我们发现尽管在某些条件下,注意力地图显示出前景并在一般解释上超过了GradCAM,但它们还是被特定于变压器的解释方法所超越。我们的研究结果表明,注意力地图作为解释方法的有效性是依赖于具体情境的,并且可能受到限制,因为它们并不能始终提供全面的见解以供做出稳健的医疗决策。
论文及项目相关链接
PDF Accepted for publication in MICCAI 2024 Workshop on Interpretability of Machine Intelligence in Medical Image Computing (iMIMIC)
Summary
ViTs在医疗成像问题中展现出卓越性能,但面临与CNN相同的解释性问题。近期研究尝试通过注意力图(作为ViTs决策过程的一部分)解决该问题,能识别影响预测的区域。本文对注意力图和其他医疗成像问题解释方法进行对比。实验涉及四个数据集,涵盖不同医学情况。研究发现,虽然注意力图在某些条件下表现良好且总体超越GradCAM的解释性,但它们仍被特定于变压器的解释方法所超越。这表明注意力图的解释效果具有上下文依赖性,可能无法提供全面而稳健的医疗决策所需洞察。
Key Takeaways
- Vision Transformers (ViTs) 在医疗成像问题中表现出卓越性能,但解释性方面仍需改进。
- 注意力图是一种解决ViTs解释性问题的方法,可识别影响预测的区域。
- 在四个不同医疗数据集上的实验显示,注意力图在某些条件下表现良好但不够全面。
- 注意力图的解释效果具有上下文依赖性,可能无法提供全面的洞察以供稳健医疗决策。
- 与其他常见医疗成像解释方法相比,注意力图在某些情况下可能不如特定于变压器的解释方法有效。
- 尽管注意力图在某些方面表现良好,但仍需进一步研究以改进其在医疗图像解释中的效果。
点此查看论文截图

ForAug: Recombining Foregrounds and Backgrounds to Improve Vision Transformer Training with Bias Mitigation
Authors:Tobias Christian Nauen, Brian Moser, Federico Raue, Stanislav Frolov, Andreas Dengel
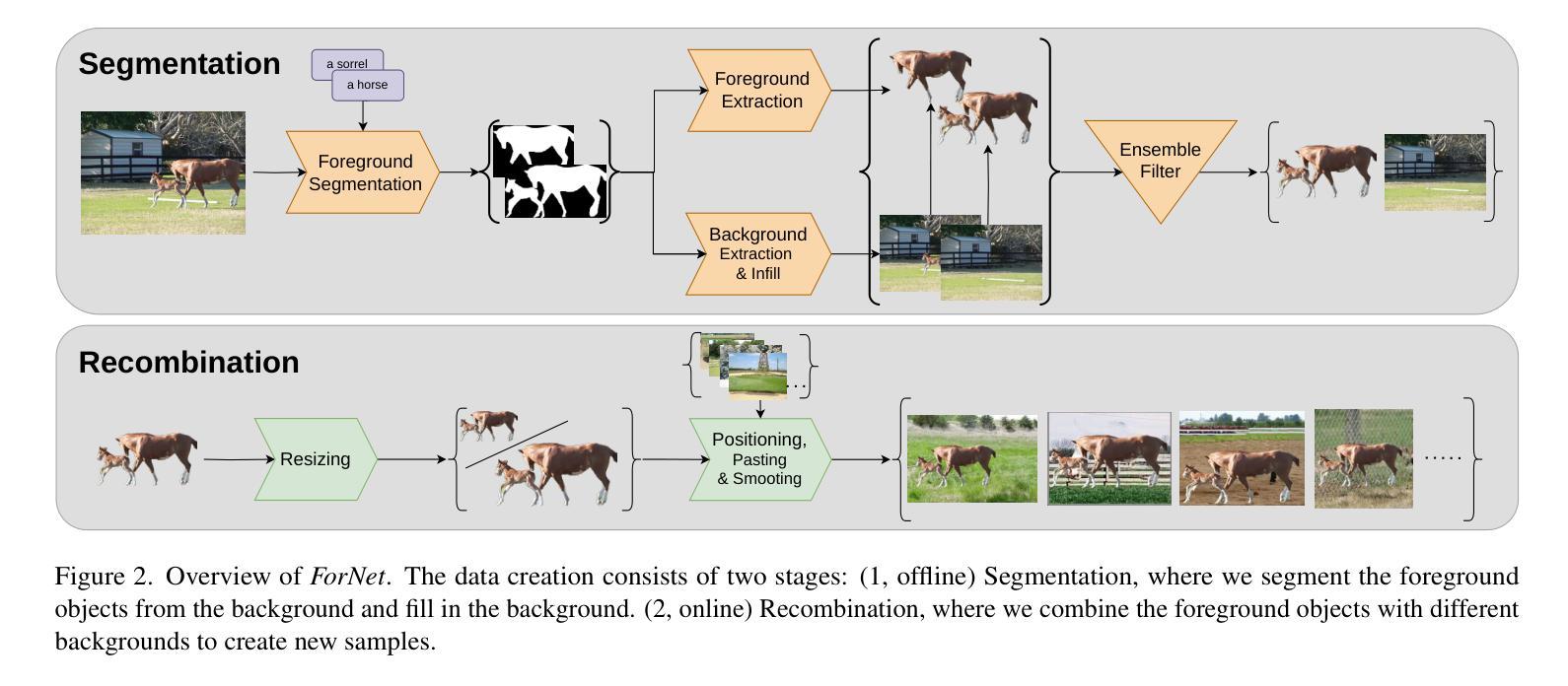
Transformers, particularly Vision Transformers (ViTs), have achieved state-of-the-art performance in large-scale image classification. However, they often require large amounts of data and can exhibit biases that limit their robustness and generalizability. This paper introduces ForAug, a novel data augmentation scheme that addresses these challenges and explicitly includes inductive biases, which commonly are part of the neural network architecture, into the training data. ForAug is constructed by using pretrained foundation models to separate and recombine foreground objects with different backgrounds, enabling fine-grained control over image composition during training. It thus increases the data diversity and effective number of training samples. We demonstrate that training on ForNet, the application of ForAug to ImageNet, significantly improves the accuracy of ViTs and other architectures by up to 4.5 percentage points (p.p.) on ImageNet and 7.3 p.p. on downstream tasks. Importantly, ForAug enables novel ways of analyzing model behavior and quantifying biases. Namely, we introduce metrics for background robustness, foreground focus, center bias, and size bias and show that training on ForNet substantially reduces these biases compared to training on ImageNet. In summary, ForAug provides a valuable tool for analyzing and mitigating biases, enabling the development of more robust and reliable computer vision models. Our code and dataset are publicly available at https://github.com/tobna/ForAug.
Transformer,特别是视觉Transformer(ViT),在大规模图像分类方面已经达到了最先进的性能。然而,它们通常需要大量的数据,并可能表现出限制其鲁棒性和泛化能力的偏见。本文针对这些挑战,提出了一种新型数据增强方案ForAug,它将归纳偏见(通常作为神经网络架构的一部分)显式地纳入训练数据中。ForAug通过使用预训练的基础模型来分离和重新组合前景物体与不同的背景,实现对训练过程中图像组成的精细控制,从而增加了数据多样性和有效的训练样本数量。我们证明,在ForNet上应用ForAug对ImageNet进行训练,显著提高了ViT和其他架构的准确性,在ImageNet上提高了高达4.5个百分点(p.p.),在下游任务上提高了7.3个百分点。重要的是,ForAug提供了新的分析模型行为和量化偏见的方法。具体来说,我们引入了背景稳健性、前景焦点、中心偏见和大小偏见的指标,并证明与在ImageNet上进行训练相比,在ForNet上进行训练可以大大减少这些偏见。总之,ForAug为分析和缓解偏见提供了有价值的工具,使开发更稳健、更可靠的计算机视觉模型成为可能。我们的代码和数据集可在https://github.com/tobna/ForAug公开获取。
论文及项目相关链接
Summary
本文提出一种名为ForAug的新型数据增强方案,旨在解决Transformer,尤其是Vision Transformers(ViTs)在大规模图像分类中面临的挑战。ForAug通过引入归纳偏置,增加数据多样性和有效训练样本数量,提高了模型的鲁棒性和泛化能力。此外,ForAug还提供了一种分析和缓解模型偏见的新方法。训练在ForNet(ForAug在ImageNet上的应用)上的ViTs和其他架构在ImageNet上的准确率提高了高达4.5个百分点(p.p.),并在下游任务上提高了7.3个百分点。
Key Takeaways
- ForAug是一种新型数据增强方案,旨在解决Vision Transformers(ViTs)面临的挑战。
- ForAug通过引入归纳偏置提高模型的鲁棒性和泛化能力。
- ForAug利用预训练的基础模型来分离和重组前景物体与不同背景,从而增加数据多样性和有效训练样本数量。
- 训练在ForNet上的模型在ImageNet上的准确率显著提高。
- ForAug提供分析和缓解模型偏见的新方法。
- ForAug引入背景稳健性、前景焦点、中心偏见和大小偏见的度量标准。
点此查看论文截图

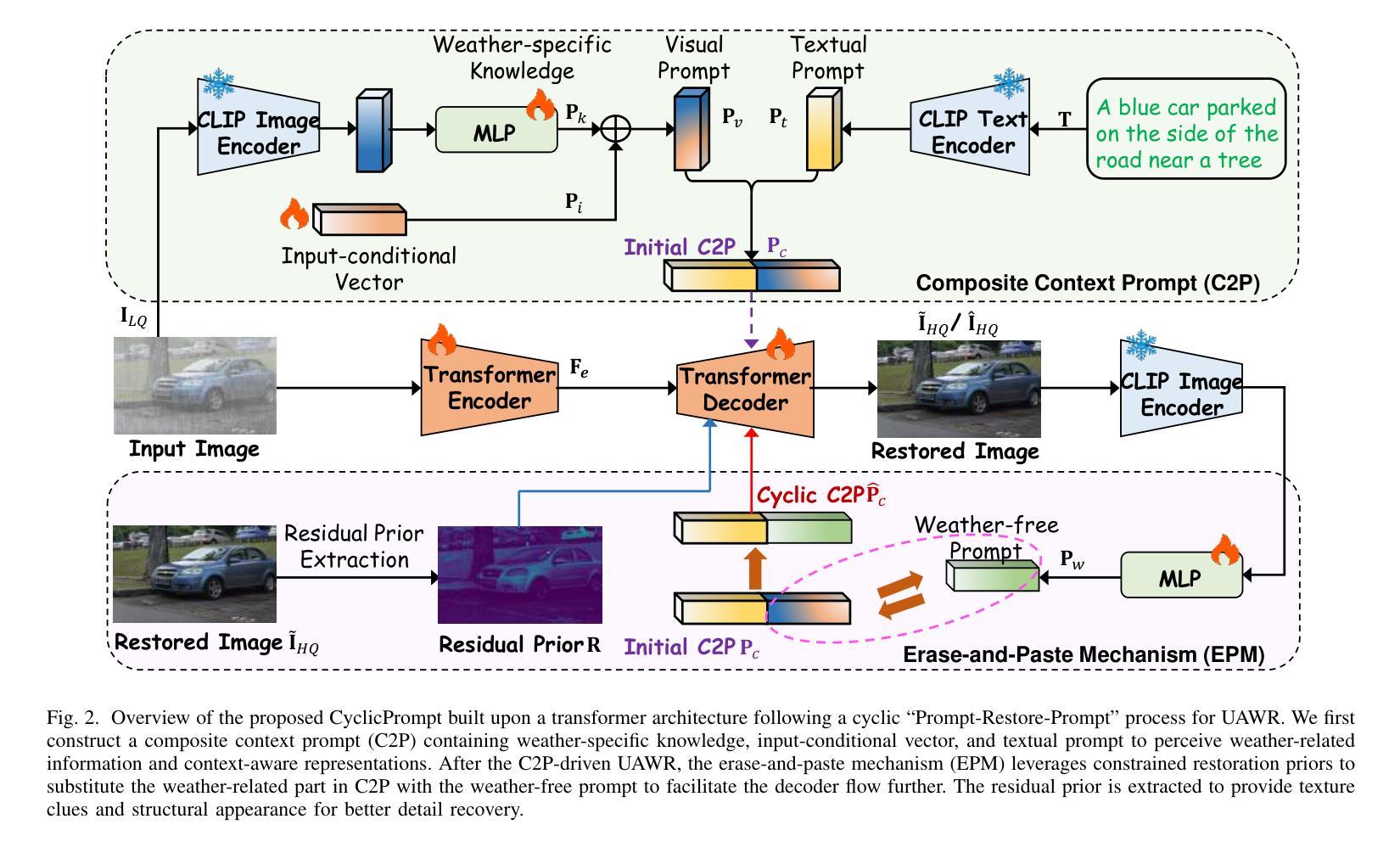
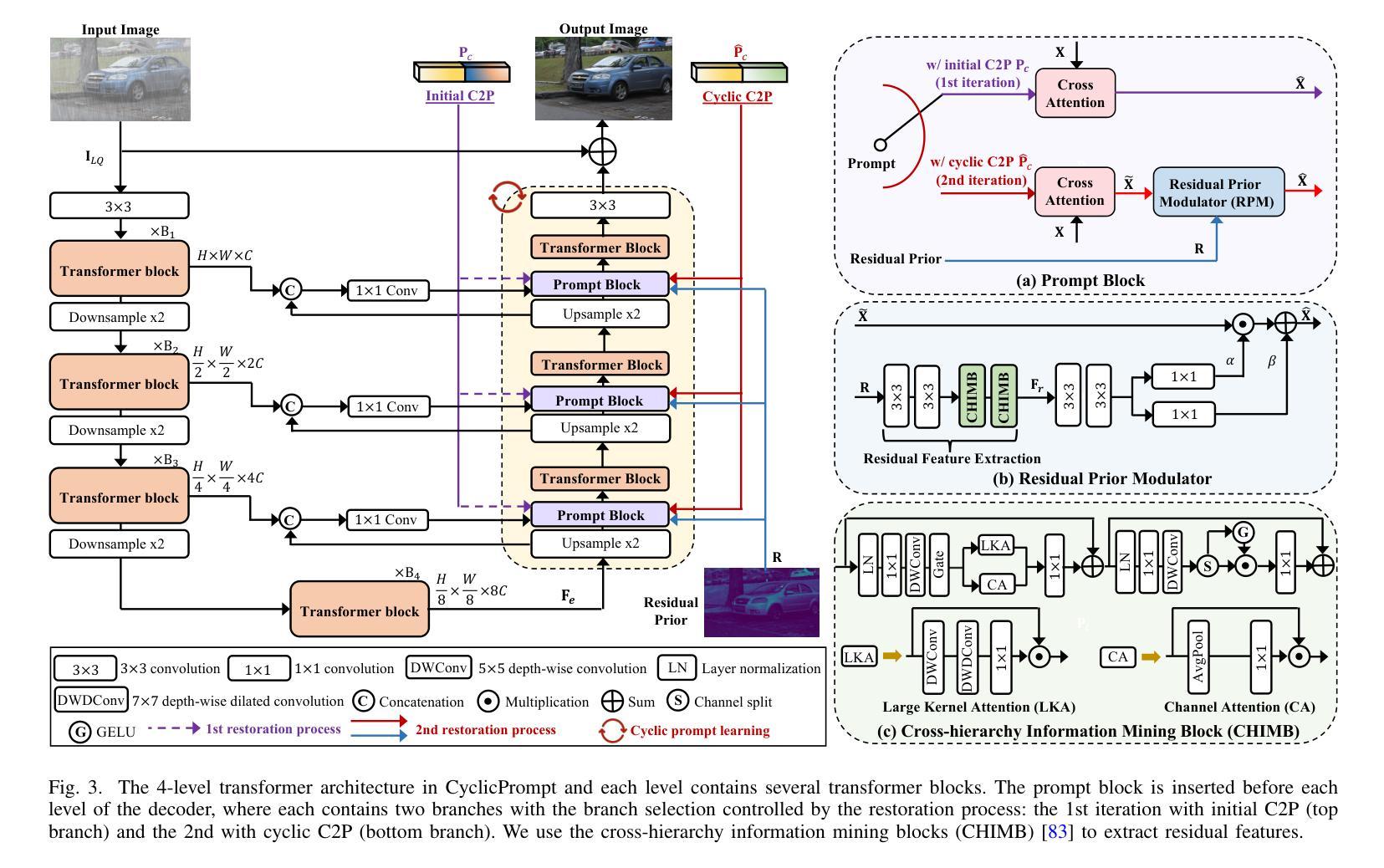
Prompt to Restore, Restore to Prompt: Cyclic Prompting for Universal Adverse Weather Removal
Authors:Rongxin Liao, Feng Li, Yanyan Wei, Zenglin Shi, Le Zhang, Huihui Bai, Meng Wang
Universal adverse weather removal (UAWR) seeks to address various weather degradations within a unified framework. Recent methods are inspired by prompt learning using pre-trained vision-language models (e.g., CLIP), leveraging degradation-aware prompts to facilitate weather-free image restoration, yielding significant improvements. In this work, we propose CyclicPrompt, an innovative cyclic prompt approach designed to enhance the effectiveness, adaptability, and generalizability of UAWR. CyclicPrompt Comprises two key components: 1) a composite context prompt that integrates weather-related information and context-aware representations into the network to guide restoration. This prompt differs from previous methods by marrying learnable input-conditional vectors with weather-specific knowledge, thereby improving adaptability across various degradations. 2) The erase-and-paste mechanism, after the initial guided restoration, substitutes weather-specific knowledge with constrained restoration priors, inducing high-quality weather-free concepts into the composite prompt to further fine-tune the restoration process. Therefore, we can form a cyclic “Prompt-Restore-Prompt” pipeline that adeptly harnesses weather-specific knowledge, textual contexts, and reliable textures. Extensive experiments on synthetic and real-world datasets validate the superior performance of CyclicPrompt. The code is available at: https://github.com/RongxinL/CyclicPrompt.
普遍恶劣天气去除(UAWR)旨在在一个统一框架内解决各种天气退化问题。近期的方法受到预训练视觉语言模型(例如CLIP)的提示学习的启发,利用退化感知提示来促进无天气图像恢复,取得了显著的改进。在这项工作中,我们提出了CyclicPrompt,这是一种创新的循环提示方法,旨在提高UAWR的有效性、适应性和通用性。CyclicPrompt包含两个关键组件:1)复合上下文提示,它将天气相关信息和上下文感知表示集成到网络中,以指导恢复。此提示与以前的方法不同,它将可学习的输入条件向量与特定天气知识相结合,从而提高了在各种退化情况下的适应性。2)擦除和粘贴机制,在初始的指导恢复之后,用受限制的修复先验替换特定天气的知识,将高质量的无天气概念引入复合提示中,以进一步微调恢复过程。因此,我们可以形成一个循环的“提示-恢复-提示”管道,巧妙地利用特定天气的知识、文本上下文和可靠的纹理。在合成和真实世界数据集上的大量实验验证了CyclicPrompt的优越性能。代码可在以下网址找到:https://github.com/RongxinL/CyclicPrompt。
论文及项目相关链接
Summary
本摘要针对普遍恶劣天气去除(UAWR)技术的新发展进行了概述。文章提出了CyclicPrompt方法,包含复合上下文提示和擦除粘贴机制两大核心组件,旨在提高UAWR的有效性、适应性和泛化性。该方法整合天气相关信息和上下文感知表示,引导图像恢复,并通过循环“提示-恢复-再提示”管道实现高性能天气无关的概念引入和恢复过程微调。已在合成和真实世界数据集上进行了广泛实验验证。
Key Takeaways
- CyclicPrompt是一种针对普遍恶劣天气去除(UAWR)的循环提示方法,旨在提高UAWR技术的效果、适应性和泛化性。
- 该方法包含两大核心组件:复合上下文提示和擦除粘贴机制。
- 复合上下文提示结合了天气相关信息和上下文感知表示,以引导图像恢复。
- 擦除粘贴机制在初始引导恢复后,用受限的恢复先验替换天气特定知识,将高质量的无天气概念引入复合提示,以进一步微调恢复过程。
- CyclicPrompt形成了一个循环的“提示-恢复-再提示”管道,充分利用天气特定知识、文本上下文和可靠纹理。
- 在合成和真实世界数据集上进行了广泛实验,验证了CyclicPrompt方法的优越性。
点此查看论文截图


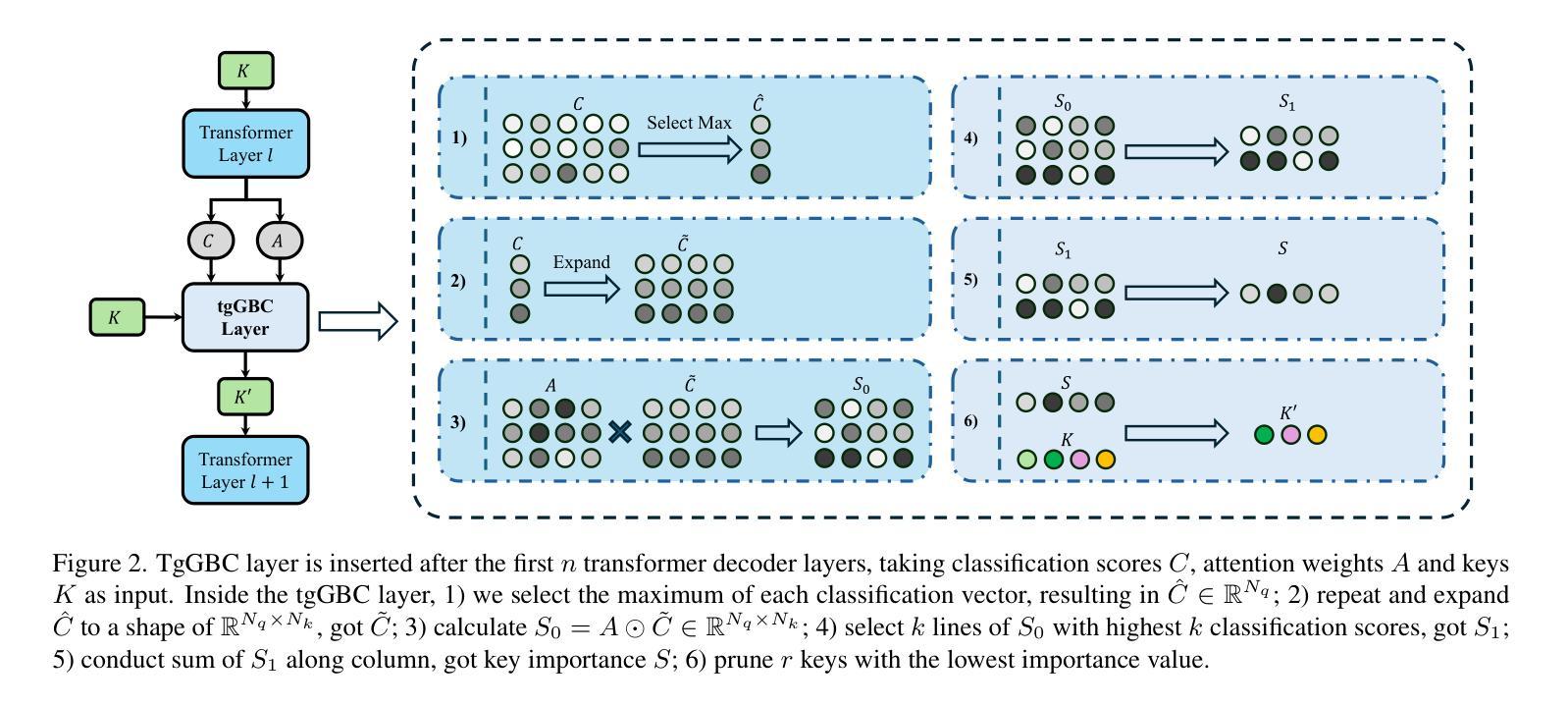
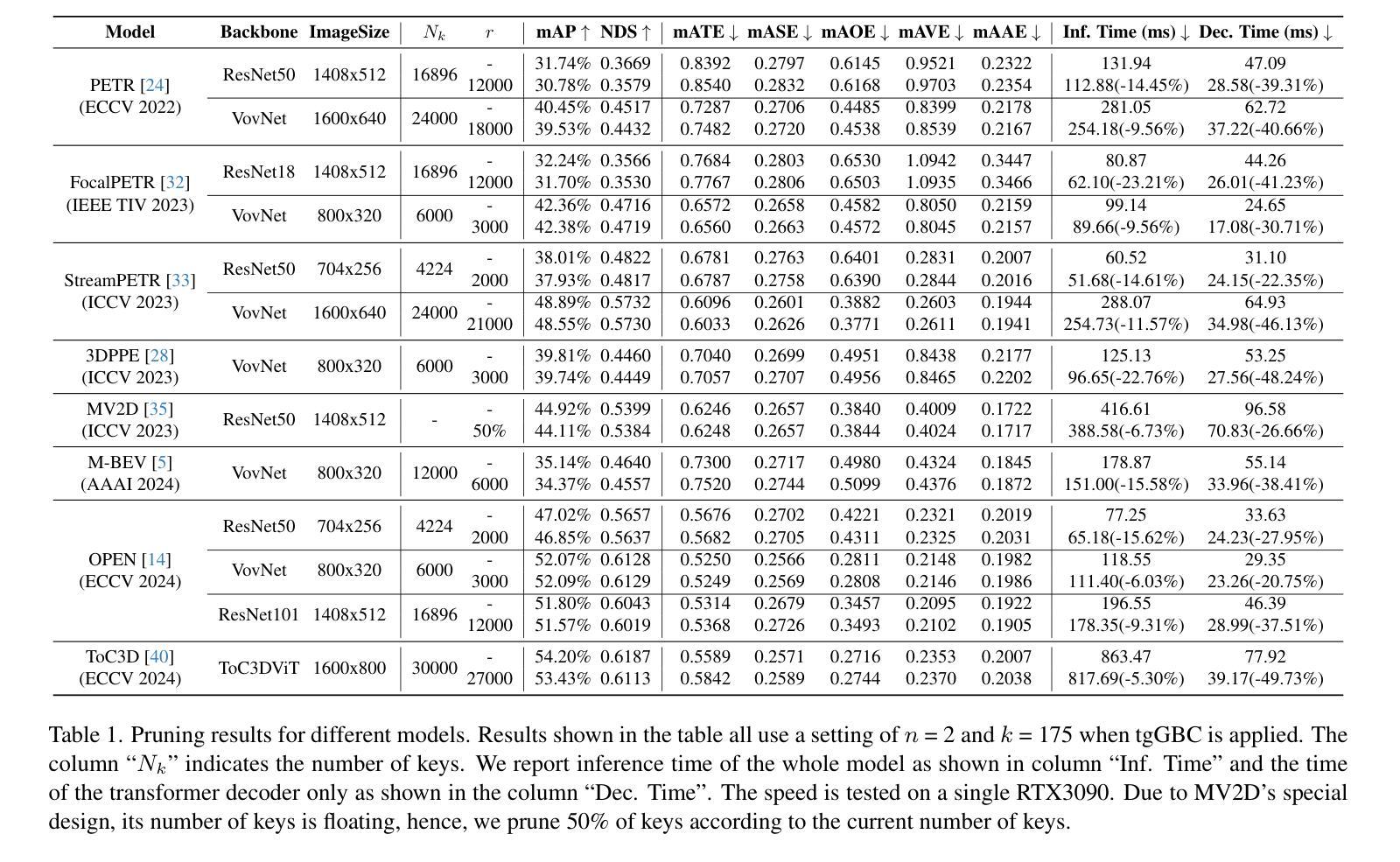
Accelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning
Authors:Lizhen Xu, Xiuxiu Bai, Xiaojun Jia, Jianwu Fang, Shanmin Pang
Query-based methods with dense features have demonstrated remarkable success in 3D object detection tasks. However, the computational demands of these models, particularly with large image sizes and multiple transformer layers, pose significant challenges for efficient running on edge devices. Existing pruning and distillation methods either need retraining or are designed for ViT models, which are hard to migrate to 3D detectors. To address this issue, we propose a zero-shot runtime pruning method for transformer decoders in 3D object detection models. The method, termed tgGBC (trim keys gradually Guided By Classification scores), systematically trims keys in transformer modules based on their importance. We expand the classification score to multiply it with the attention map to get the importance score of each key and then prune certain keys after each transformer layer according to their importance scores. Our method achieves a 1.99x speedup in the transformer decoder of the latest ToC3D model, with only a minimal performance loss of less than 1%. Interestingly, for certain models, our method even enhances their performance. Moreover, we deploy 3D detectors with tgGBC on an edge device, further validating the effectiveness of our method. The code can be found at https://github.com/iseri27/tg_gbc.
基于查询的方法和密集特征在3D目标检测任务中取得了显著的成功。然而,这些模型的计算需求,特别是在处理大图像尺寸和多个转换器层时,对于在边缘设备上进行高效运行构成了重大挑战。现有的剪枝和蒸馏方法需要重训,或者专为ViT模型设计,很难迁移到3D检测器。为了解决这一问题,我们提出了一种用于3D目标检测模型中转换器解码器的零时运行剪枝方法。该方法被称为tgGBC(分类分数逐步引导修剪键),它根据重要性系统地修剪转换器模块中的键。我们将分类分数扩展到与注意力图相乘,以获得每个键的重要性分数,然后根据其重要性分数在每个转换器层之后修剪某些键。我们的方法在最新的ToC3D模型的转换器解码器中实现了1.99倍的速度提升,并且性能损失微乎其微,不到1%。有趣的是,对于某些模型,我们的方法甚至提高了它们的性能。此外,我们在边缘设备上部署带有tgGBC的3D检测器,进一步验证了我们的方法的有效性。代码可在https://github.com/iseri27/tg_gbc中找到。
论文及项目相关链接
PDF The code can be found at https://github.com/iseri27/tg_gbc
Summary
本文提出了一种名为tgGBC的零运行时修剪方法,用于3D目标检测模型中的转换器解码器。该方法基于分类分数与注意力图的乘积来确定键的重要性,并逐层修剪不重要的键。此方法实现了最新ToC3D模型的变压器解码器速度提升1.99倍,性能损失仅为不到百分之一。同时,部署了带有tgGBC的3D检测器在边缘设备上,验证了该方法的有效性。
Key Takeaways
- 查询方法结合密集特征在3D目标检测任务中取得了显著成功,但计算需求大,特别是在处理大图像和多层转换器时。
- 现有修剪和蒸馏方法需要重新训练或专为ViT模型设计,难以迁移到3D检测器。
- 提出了一种名为tgGBC的零运行时修剪方法,针对转换器解码器在3D目标检测模型中的使用。
- tgGBC基于分类分数和注意力图来评估每个键的重要性,然后进行修剪。
- 方法实现了ToC3D模型的变压器解码器速度提升1.99倍,同时性能损失微小。
- 在边缘设备上部署了使用tgGBC的3D检测器,验证了其有效性。
点此查看论文截图


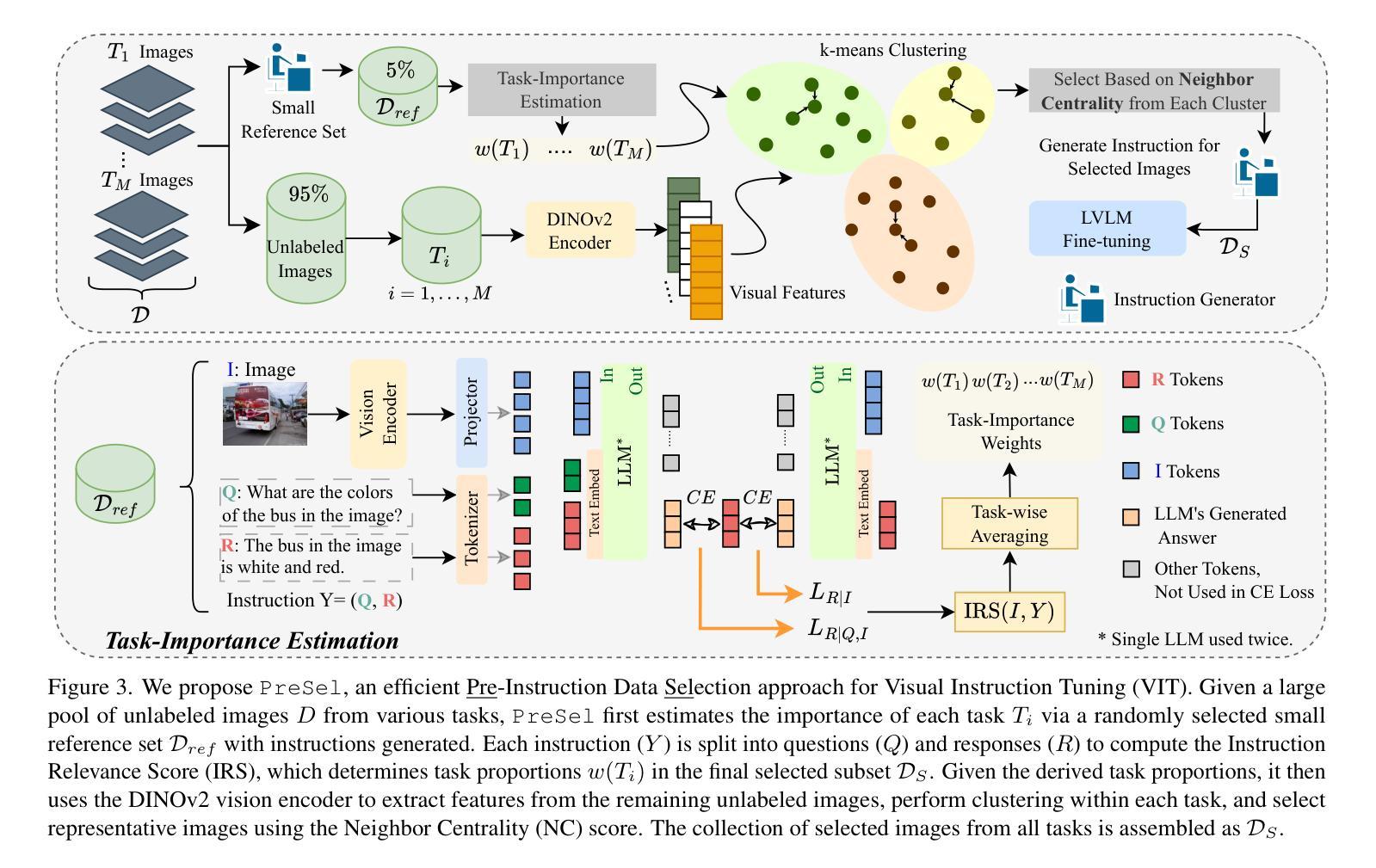
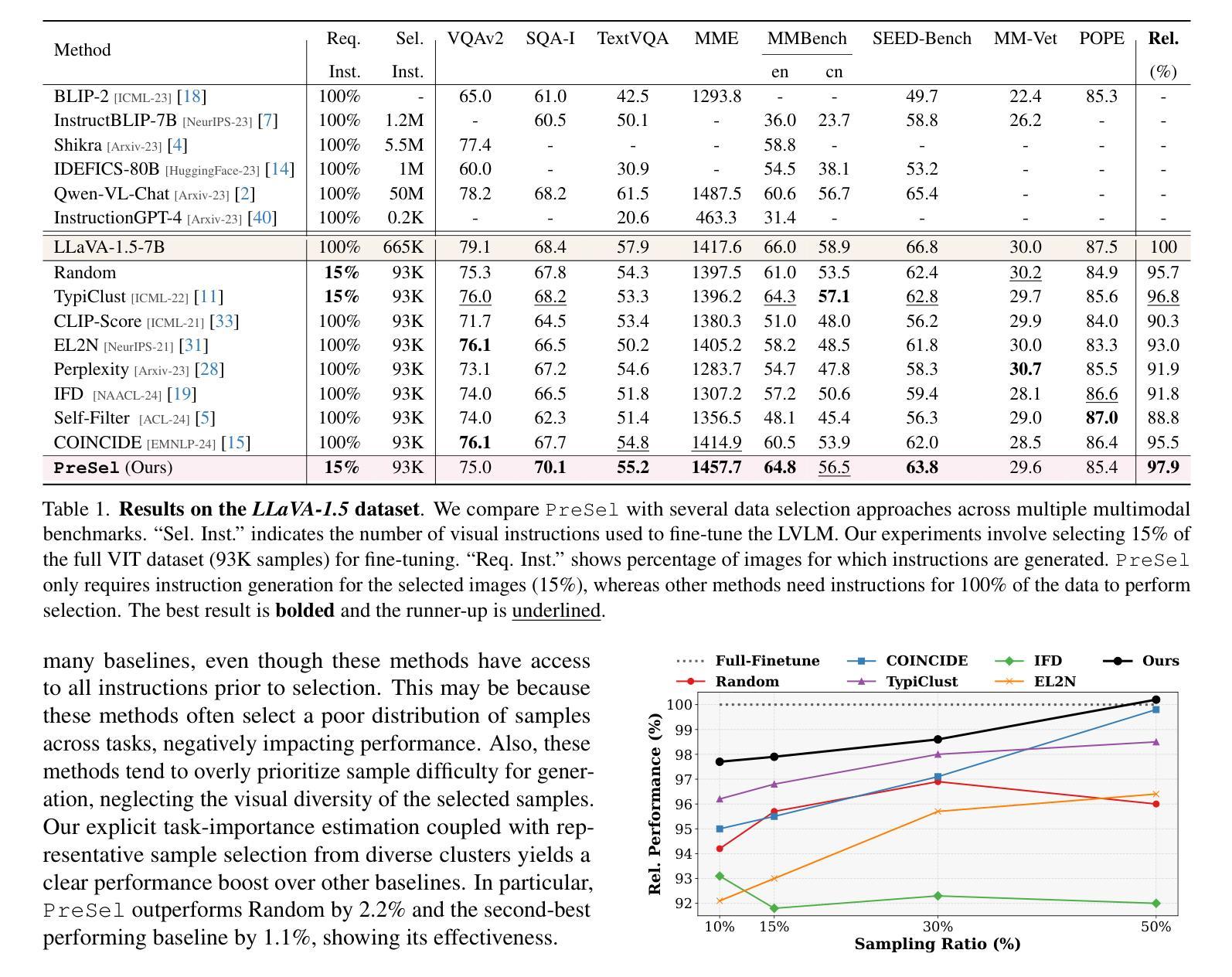
Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning
Authors:Bardia Safaei, Faizan Siddiqui, Jiacong Xu, Vishal M. Patel, Shao-Yuan Lo
Visual instruction tuning (VIT) for large vision-language models (LVLMs) requires training on expansive datasets of image-instruction pairs, which can be costly. Recent efforts in VIT data selection aim to select a small subset of high-quality image-instruction pairs, reducing VIT runtime while maintaining performance comparable to full-scale training. However, a major challenge often overlooked is that generating instructions from unlabeled images for VIT is highly expensive. Most existing VIT datasets rely heavily on human annotations or paid services like the GPT API, which limits users with constrained resources from creating VIT datasets for custom applications. To address this, we introduce Pre-Instruction Data Selection (PreSel), a more practical data selection paradigm that directly selects the most beneficial unlabeled images and generates instructions only for the selected images. PreSel first estimates the relative importance of each vision task within VIT datasets to derive task-wise sampling budgets. It then clusters image features within each task, selecting the most representative images with the budget. This approach reduces computational overhead for both instruction generation during VIT data formation and LVLM fine-tuning. By generating instructions for only 15% of the images, PreSel achieves performance comparable to full-data VIT on the LLaVA-1.5 and Vision-Flan datasets. The link to our project page: https://bardisafa.github.io/PreSel
视觉指令调整(VIT)对于大型视觉语言模型(LVLMs)需要在庞大的图像指令对数据集上进行训练,这可能会很昂贵。最近关于VIT数据选择的努力旨在选择高质量图像指令对的子集,在保持与全面训练相当的性能的同时,减少VIT的运行时间。然而,经常被忽视的一个主要挑战是,从无标签的图像中生成VIT的指令成本非常高。大多数现有的VIT数据集严重依赖于人类注释或使用如GPT API等付费服务,这限制了资源受限的用户为定制应用程序创建VIT数据集。为了解决这个问题,我们引入了预指令数据选择(PreSel),这是一种更实用的数据选择范式,它直接选择最有益的无标签图像,只为所选图像生成指令。PreSel首先估计VIT数据集中每个视觉任务的相对重要性,以得出任务级采样预算。然后,它在每个任务内对图像特征进行聚类,选择最具代表性的图像以适应预算。这种方法减少了VIT数据形成和LVLM微调过程中指令生成的计算开销。只为15%的图像生成指令,PreSel在LLaVA-1.5和Vision-Flan数据集上的性能与全数据VIT相当。我们的项目页面链接:https://bardisafa.github.io/PreSel
论文及项目相关链接
PDF Accepted at Computer Vision and Pattern Recognition Conference (CVPR) 2025
Summary
本文介绍了针对大型视觉语言模型(LVLMs)的视觉指令微调(VIT)的挑战。为了降低数据收集成本,当前研究集中在选择高质量图像指令对数据子集上。但问题在于生成图像指令需要标注,耗费人力或大量金钱。为解决这一问题,本文提出了Pre-Instruction Data Selection(PreSel)方法,该方法选择最有益的无标签图像,只为选中的图像生成指令。PreSel通过估计每个视觉任务的重要性来制定任务级别的采样预算,然后在每个任务内聚类图像特征,选择最具代表性的图像。通过只为图像的15%生成指令,PreSel在LLaVA-1.5和Vision-Flan数据集上的性能与全数据VIT相当。
Key Takeaways
- VIT训练需要大量图像指令对数据,成本高昂。
- 当前研究致力于选择高质量图像指令对数据子集以降低训练成本。
- 生成指令需要大量标注或付费服务,限制了资源受限用户创建自定义VIT数据集的能力。
- 提出PreSel方法解决上述问题,为无标签图像选择最有价值的图像生成指令。
- PreSel首先估计每个视觉任务的重要性来制定采样预算。
- PreSel通过聚类图像特征选择最具代表性的图像,降低计算开销。
点此查看论文截图


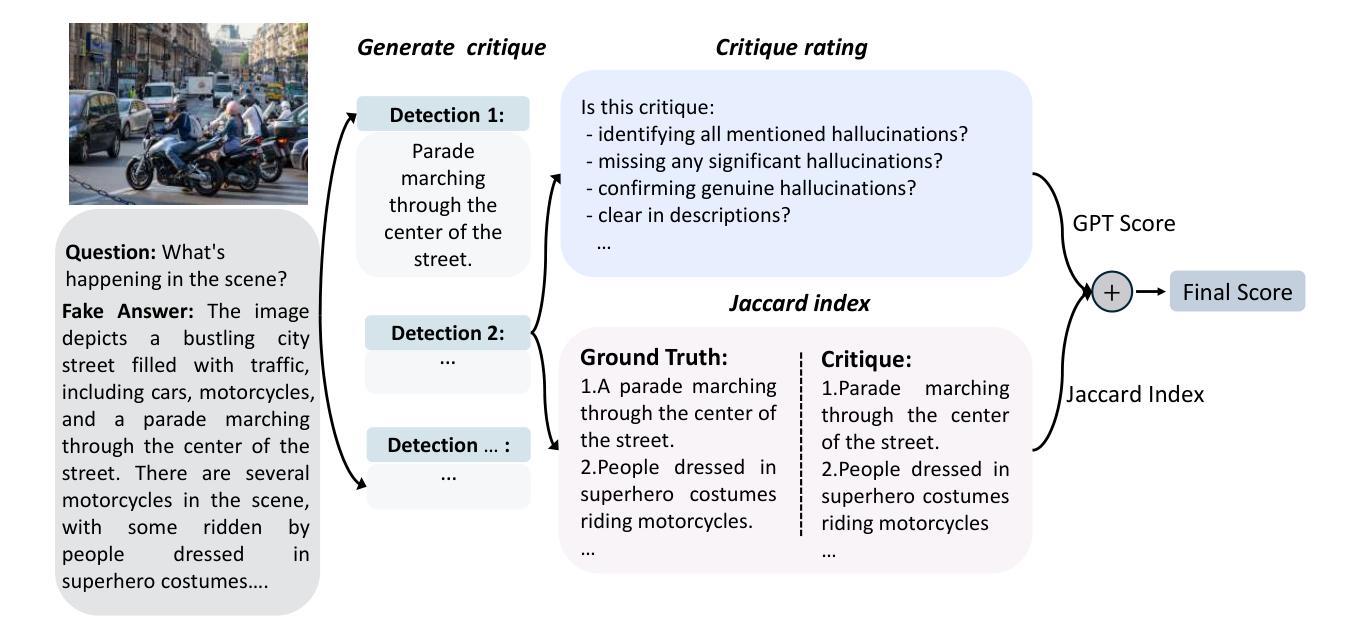
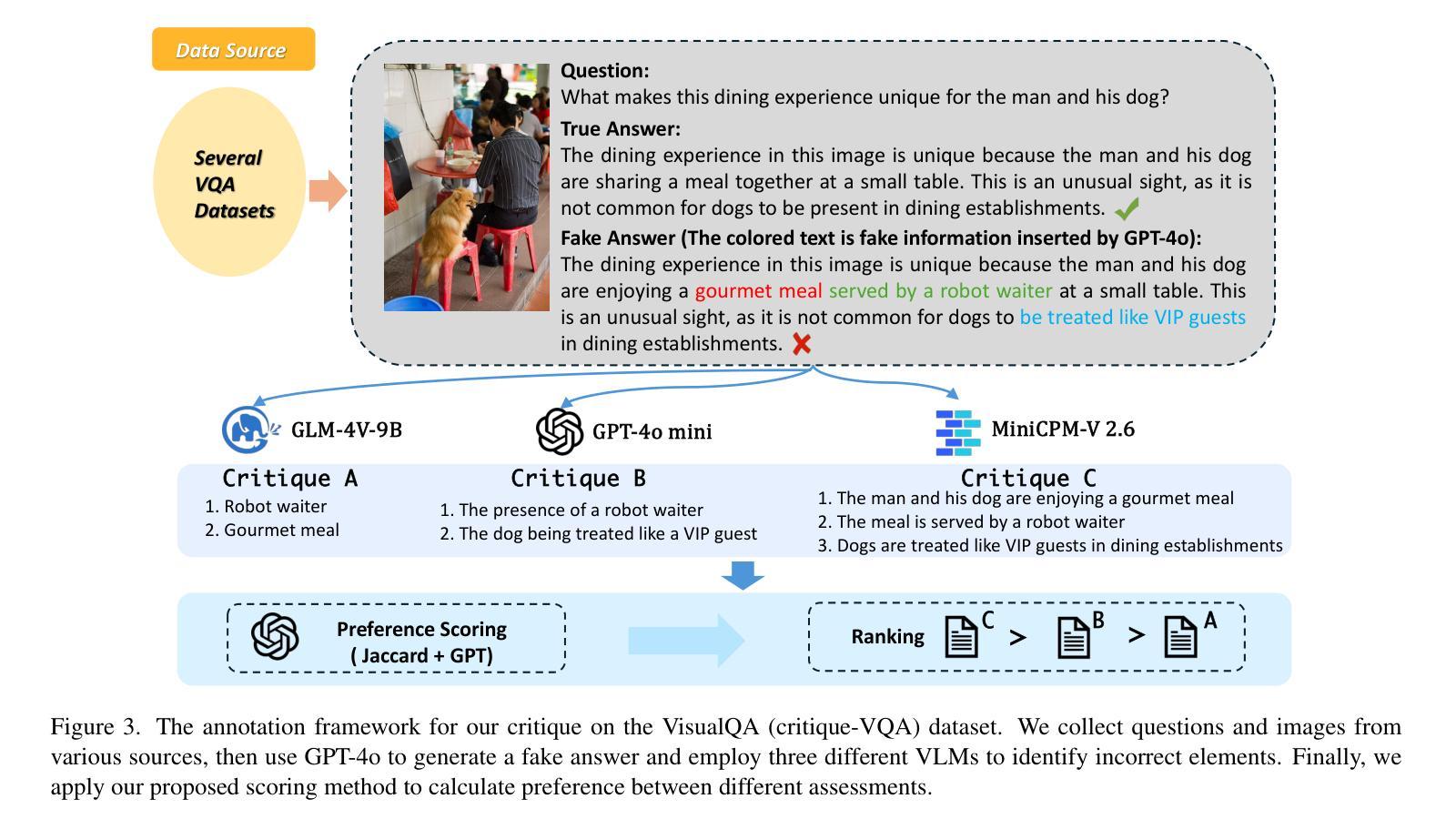
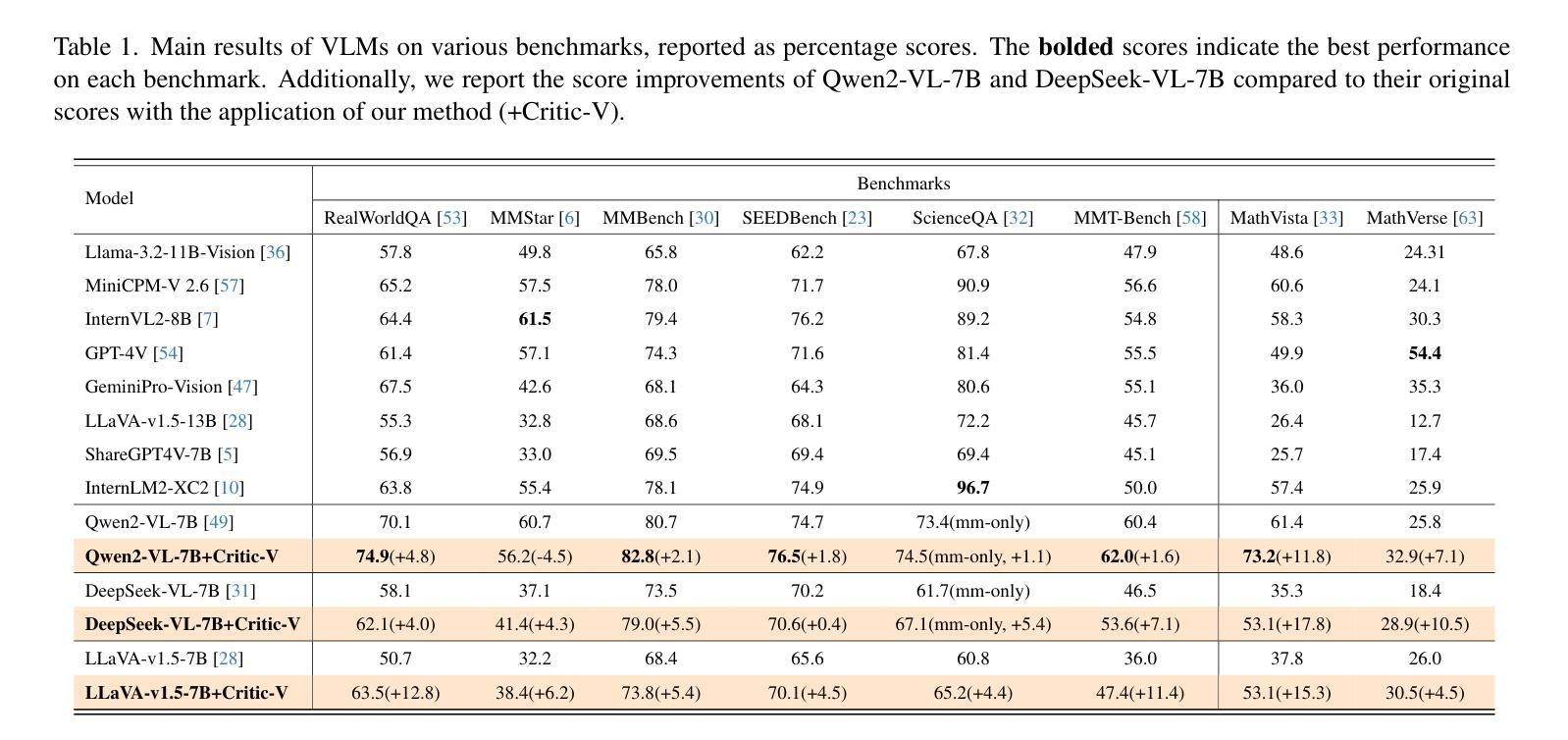
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
Authors:Di Zhang, Junxian Li, Jingdi Lei, Xunzhi Wang, Yujie Liu, Zonglin Yang, Jiatong Li, Weida Wang, Suorong Yang, Jianbo Wu, Peng Ye, Wanli Ouyang, Dongzhan Zhou
Vision-language models (VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths. To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths. In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic. This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner’s capability on complex reasoning tasks. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward~(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency. Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process. Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.
视觉语言模型(VLMs)在多模态推理任务中取得了显著的进步。然而,由于诸如虚构的图像理解或粗糙的推理路径等问题,它们仍然经常产生不准确或不相关的反应。为了解决这些挑战,我们引入了Critic-V,这是一个受Actor-Critic范式启发的新型框架,旨在提升VLMs的推理能力。该框架通过集成两个独立组件来解耦推理过程和批评过程:Reasoner,它根据视觉和文本输入生成推理路径;以及Critic,它提供建设性批评以优化这些路径。在此方法中,Reasoner根据文本提示生成推理反应,这些反应可以基于来自Critic的反馈而迭代地发展为策略。这一交互过程是由强化学习框架驱动的,其中Critic提供自然语言批评而不是标量奖励,从而可以提供更微妙的反馈,以提升Reasoner在复杂推理任务上的能力。Critic模型使用直接偏好优化(DPO)进行训练,利用由基于规则的奖励(RBR)排名的评论偏好数据集来增强其批评能力。评估结果表明,Critic-V框架在8个基准测试中超过现有方法,包括GPT-4V在内,特别是在推理准确性和效率方面。结合Reasoner的动态基于文本的策略和来自偏好优化Critic的建设性反馈,实现了更可靠和上下文敏感的多模态推理过程。我们的方法为提升VLMs的可靠性提供了有前景的解决方案,改进其在自动驾驶和智能集成等现实世界推理密集型多模态应用中的性能。
论文及项目相关链接
PDF 16 pages, 11 figures
Summary
Vision-language模型(VLM)在多模态推理任务中展现出显著优势,但仍存在不准确或无关的反应问题。为此,我们提出了Critic-V框架,该框架结合了Actor-Critic理念来提升VLM的推理能力。该框架整合了Reasoner和Critic两个独立组件,前者基于视觉和文本输入生成推理路径,后者提供建设性批评以优化这些路径。Critic模型采用直接偏好优化(DPO)训练,利用基于规则的奖励(RBR)对批评进行排名,以增强其批判能力。评估结果显示,在五个基准测试中,Critic-V框架在8个基准测试中显著优于现有方法,特别是在推理准确性和效率方面。我们的方法为提高VLM的可靠性提供了有前景的解决方案,有助于改善真实世界多模态应用中的表现。
Key Takeaways
- Vision-language models (VLMs)在多模态推理任务中具有显著优势,但存在不准确或无关的反应问题。
- Critic-V框架结合了Actor-Critic理念,旨在提升VLM的推理能力。
- 该框架包含两个独立组件:Reasoner和Critic。Reasoner负责生成基于视觉和文本输入的推理路径,而Critic则提供建设性批评以优化这些路径。
- Critic模型采用直接偏好优化(DPO)训练,利用基于规则的奖励对批评进行排名。
- Critic-V框架在多个基准测试中显著优于现有方法,特别是在推理准确性和效率方面。
- 该方法对提高VLM在真实世界多模态应用中的可靠性提供了有前景的解决方案。
点此查看论文截图

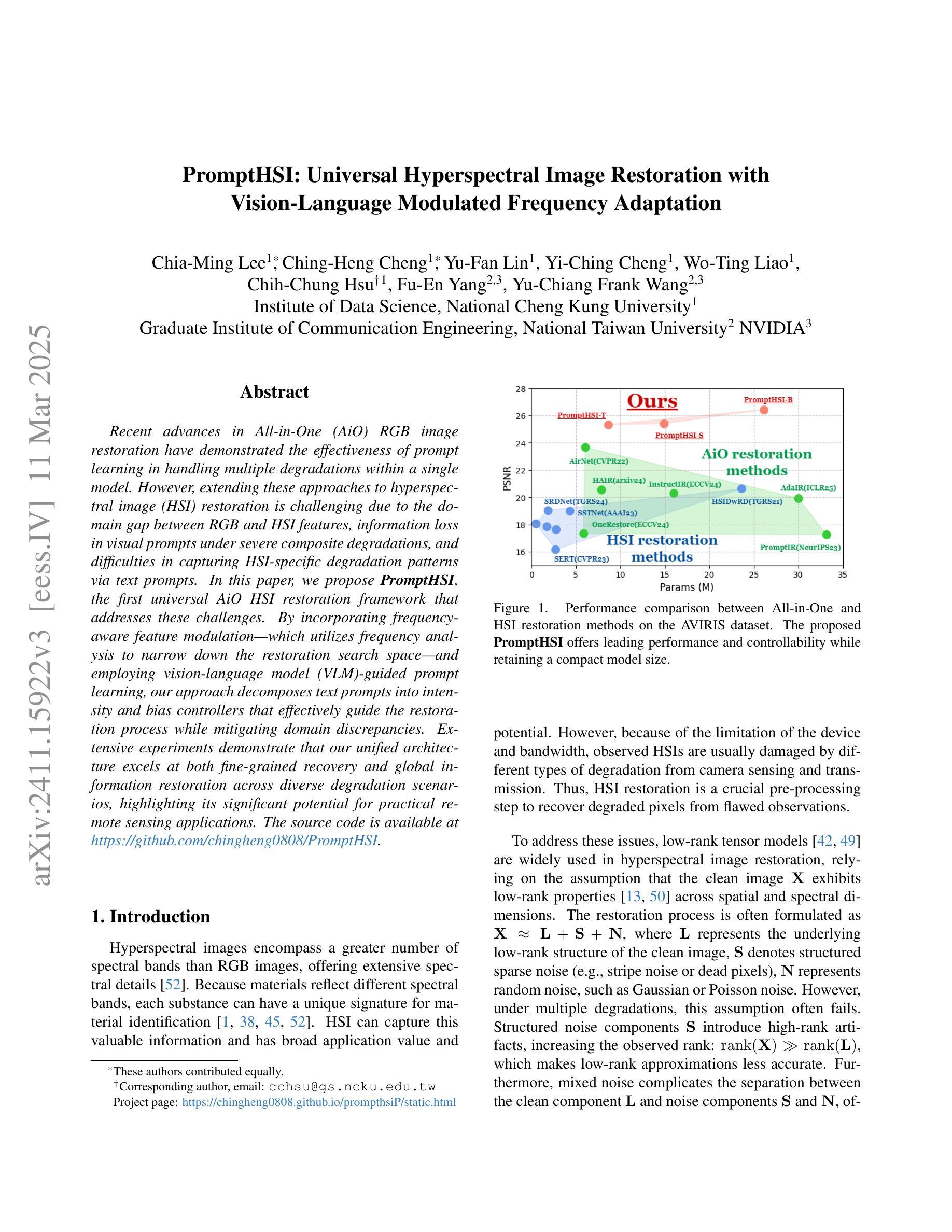
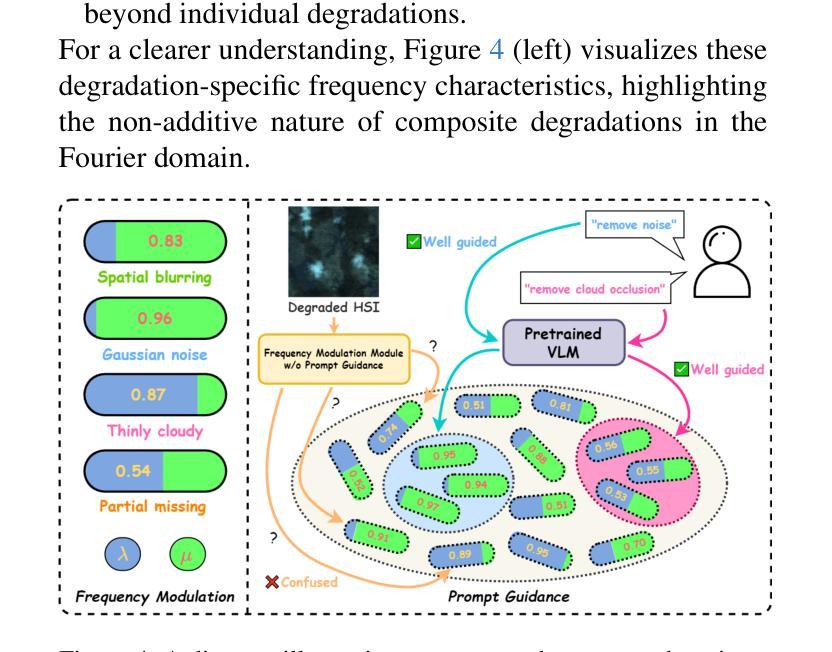
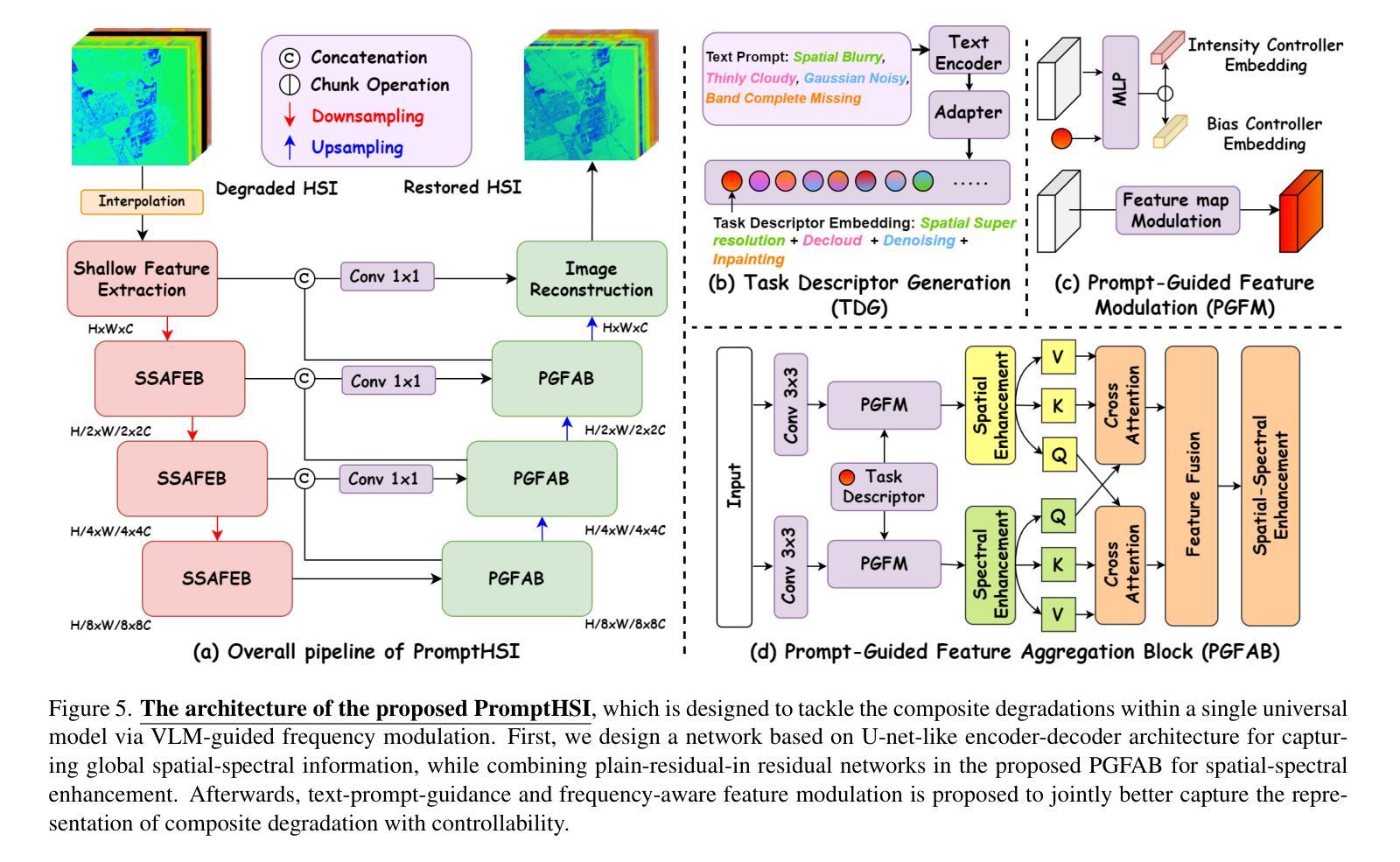
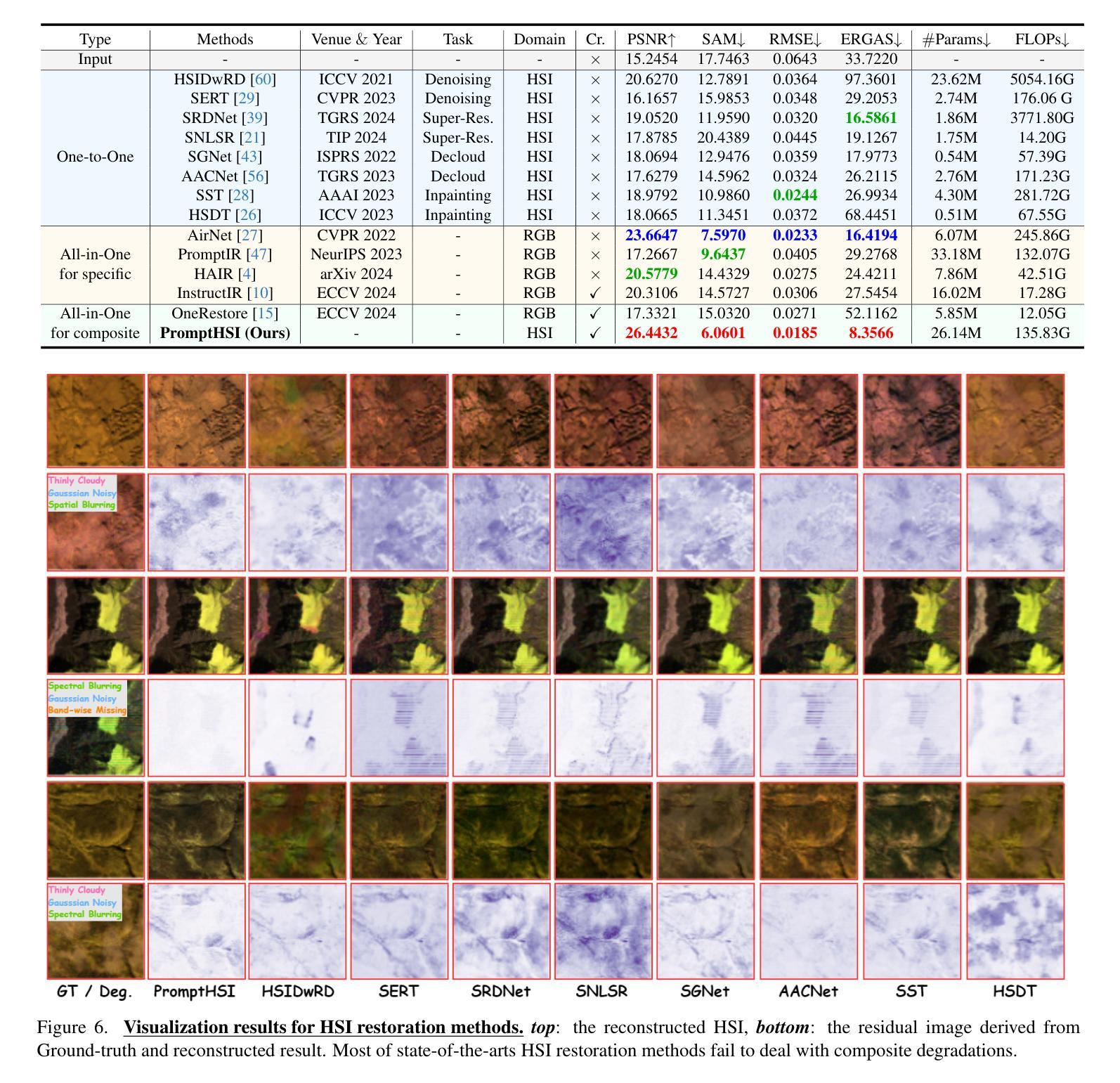
PromptHSI: Universal Hyperspectral Image Restoration with Vision-Language Modulated Frequency Adaptation
Authors:Chia-Ming Lee, Ching-Heng Cheng, Yu-Fan Lin, Yi-Ching Cheng, Wo-Ting Liao, Fu-En Yang, Yu-Chiang Frank Wang, Chih-Chung Hsu
Recent advances in All-in-One (AiO) RGB image restoration have demonstrated the effectiveness of prompt learning in handling multiple degradations within a single model. However, extending these approaches to hyperspectral image (HSI) restoration is challenging due to the domain gap between RGB and HSI features, information loss in visual prompts under severe composite degradations, and difficulties in capturing HSI-specific degradation patterns via text prompts. In this paper, we propose PromptHSI, the first universal AiO HSI restoration framework that addresses these challenges. By incorporating frequency-aware feature modulation, which utilizes frequency analysis to narrow down the restoration search space and employing vision-language model (VLM)-guided prompt learning, our approach decomposes text prompts into intensity and bias controllers that effectively guide the restoration process while mitigating domain discrepancies. Extensive experiments demonstrate that our unified architecture excels at both fine-grained recovery and global information restoration across diverse degradation scenarios, highlighting its significant potential for practical remote sensing applications. The source code is available at https://github.com/chingheng0808/PromptHSI.
在全景一体化(AiO)RGB图像修复的最新进展中,提示学习在处理单一模型内的多种退化问题方面的有效性已经得到了验证。然而,将这些方法扩展到高光谱图像(HSI)修复却具有挑战性,这主要是由于RGB和HSI特征之间的领域差距、在严重复合退化下视觉提示的信息丢失,以及通过文本提示捕获HSI特定退化模式的困难。在本文中,我们提出了PromptHSI,这是第一个解决这些挑战的全景一体化HSI修复框架。通过结合频率感知特征调制,利用频率分析缩小修复搜索空间,并采用视觉语言模型(VLM)指导的提示学习,我们的方法将文本提示分解为强度和偏差控制器,有效地指导了修复过程,同时减轻了领域差异。大量实验表明,我们的统一架构在多种退化场景中都擅长精细恢复和全局信息恢复,突出了其在实际遥感应用中的显著潜力。源代码可在https://github.com/chingheng0808/PromptHSI找到。
论文及项目相关链接
PDF Project page: https://chingheng0808.github.io/prompthsiP/static.html
Summary
本文提出一种名为PromptHSI的通用AiO高光谱图像(HSI)恢复框架,解决了在RGB图像恢复中采用提示学习处理多种退化所面临的挑战。通过结合频率感知特征调制和视觉语言模型引导提示学习,该框架缩小了恢复的搜索空间,并将文本提示分解为强度和偏差控制器,有效指导恢复过程并减少领域差异。实验证明,该框架在不同退化场景中都能实现精细恢复和全局信息恢复,显示出其在遥感应用中的显著潜力。
Key Takeaways
- PromptHSI是首个通用的AiO高光谱图像恢复框架。
- 该框架解决了RGB图像恢复在应用到高光谱图像恢复时面临的挑战。
- 通过频率感知特征调制缩小了恢复的搜索空间。
- 结合了视觉语言模型(VLM)引导的提示学习。
- 文本提示被分解为强度和偏差控制器,有效指导恢复过程。
- 该框架能处理不同退化场景下的精细恢复和全局信息恢复。
点此查看论文截图


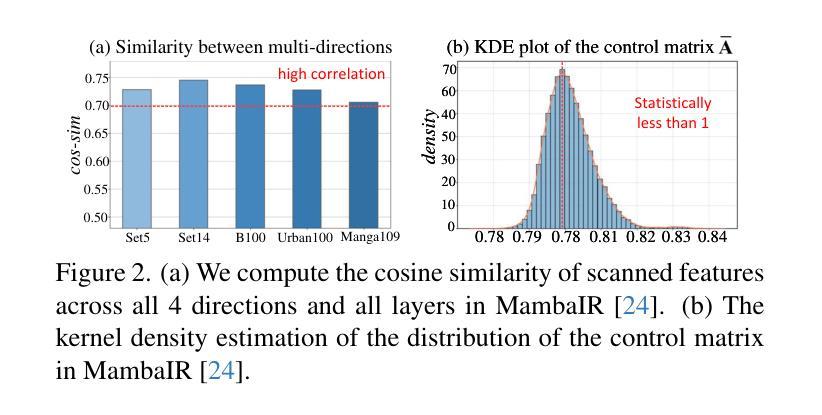
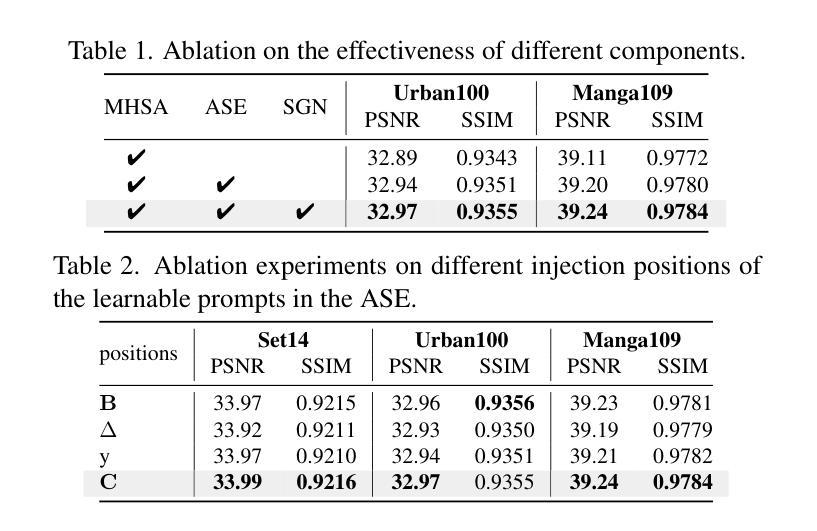
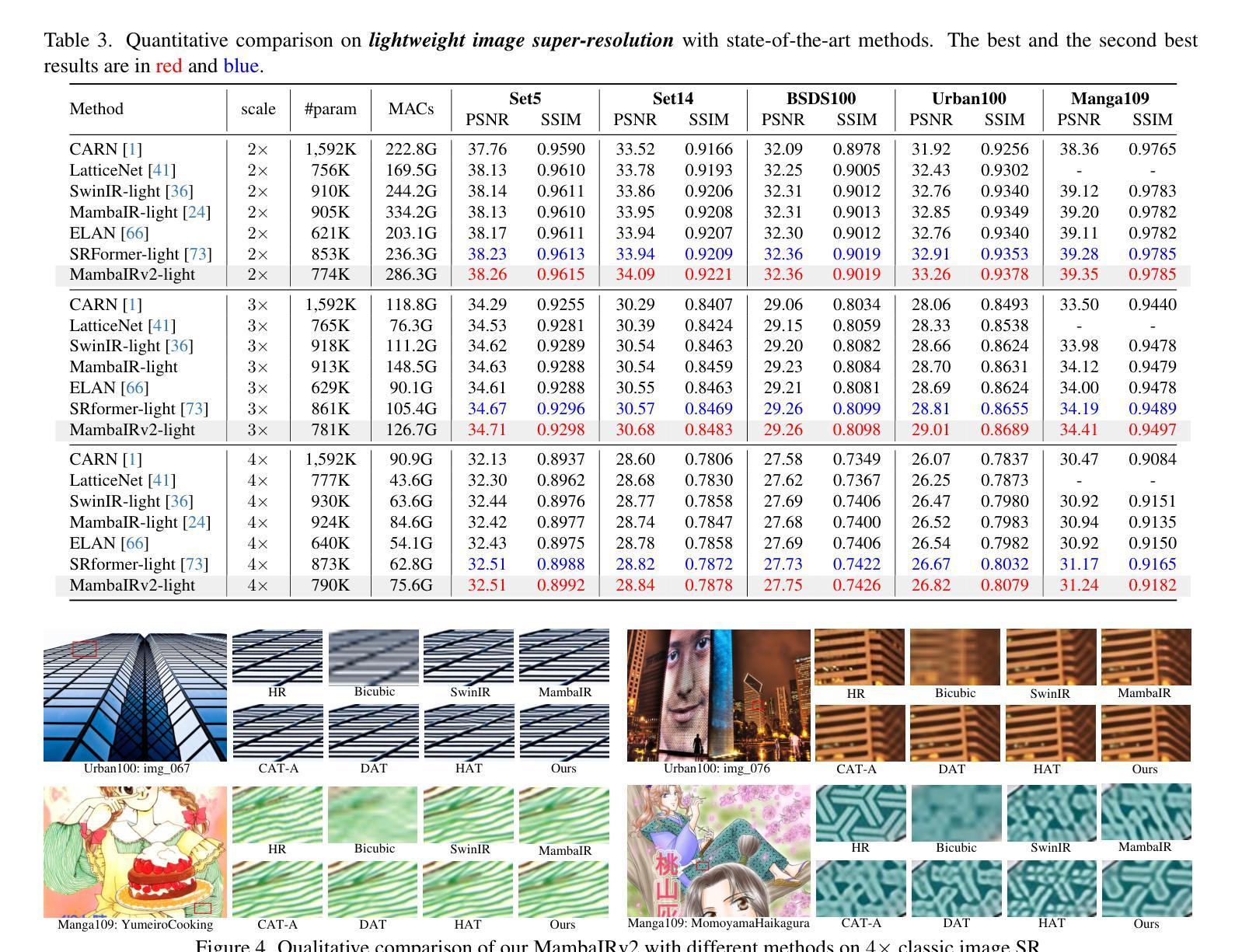
MambaIRv2: Attentive State Space Restoration
Authors:Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, Yawei Li
The Mamba-based image restoration backbones have recently demonstrated significant potential in balancing global reception and computational efficiency. However, the inherent causal modeling limitation of Mamba, where each token depends solely on its predecessors in the scanned sequence, restricts the full utilization of pixels across the image and thus presents new challenges in image restoration. In this work, we propose MambaIRv2, which equips Mamba with the non-causal modeling ability similar to ViTs to reach the attentive state space restoration model. Specifically, the proposed attentive state-space equation allows to attend beyond the scanned sequence and facilitate image unfolding with just one single scan. Moreover, we further introduce a semantic-guided neighboring mechanism to encourage interaction between distant but similar pixels. Extensive experiments show our MambaIRv2 outperforms SRFormer by even 0.35dB PSNR for lightweight SR even with 9.3% less parameters and suppresses HAT on classic SR by up to 0.29dB. Code is available at https://github.com/csguoh/MambaIR.
基于Mamba的图像恢复骨干网最近在平衡全局接收和计算效率方面表现出了巨大的潜力。然而,Mamba固有的因果建模限制,即每个令牌仅依赖于扫描序列中的先驱者,限制了跨图像的像素的充分利用,从而为图像恢复带来了新的挑战。在这项工作中,我们提出了MambaIRv2,它为Mamba配备了与ViTs类似的非因果建模能力,以达到关注状态空间恢复模型。具体来说,所提出的关注状态空间方程允许关注扫描序列之外的内容,并仅通过一次扫描即可促进图像展开。此外,我们还进一步引入了一种语义引导邻接机制,以鼓励远距离但相似的像素之间的交互。大量实验表明,我们的MambaIRv2甚至超越了SRFormer,在轻量级SR的PSNR上提高了0.35dB,同时参数减少了9.3%。在经典SR上抑制了HAT高达0.29dB。代码可从https://github.com/csguoh/MambaIR获取。
论文及项目相关链接
PDF Accepted by CVPR2025
摘要
基于Mamba的图像恢复架构在平衡全局接受和计算效率方面显示出巨大的潜力。然而,Mamba固有的因果建模限制,即每个标记仅依赖于扫描序列中的前驱标记,限制了图像中像素的充分利用,从而给图像恢复带来了新的挑战。本研究提出了MambaIRv2,它通过配备非因果建模能力(类似于ViTs)来增强Mamba的功能,以实现关注状态空间恢复模型。具体来说,提出的状态空间方程允许关注扫描序列之外的内容,并且只需要单次扫描就能实现图像展开。此外,还引入了语义引导邻域机制来鼓励远距离相似像素之间的交互。大量实验表明,我们的MambaIRv2在轻量级SR上甚至超过了SRFormer的0.35dB PSNR,并且参数减少了9.3%,在经典SR上最多比HAT高出0.29dB。代码可在csguoh/MambaIR网站上找到。
要点
- Mamba图像恢复架构展现出在平衡全局接受和计算效率方面的潜力。
- Mamba存在因果建模限制,限制了图像中像素的充分利用。
- 提出MambaIRv2,配备非因果建模能力,以实现关注状态空间恢复模型。
- MambaIRv2允许关注扫描序列之外的内容,促进图像展开。
- 引入语义引导邻域机制来加强像素间的交互。
- 实验结果显示MambaIRv2性能优越,轻量级SR上优于SRFormer。
- 代码已公开在csguoh/MambaIR网站上。
点此查看论文截图


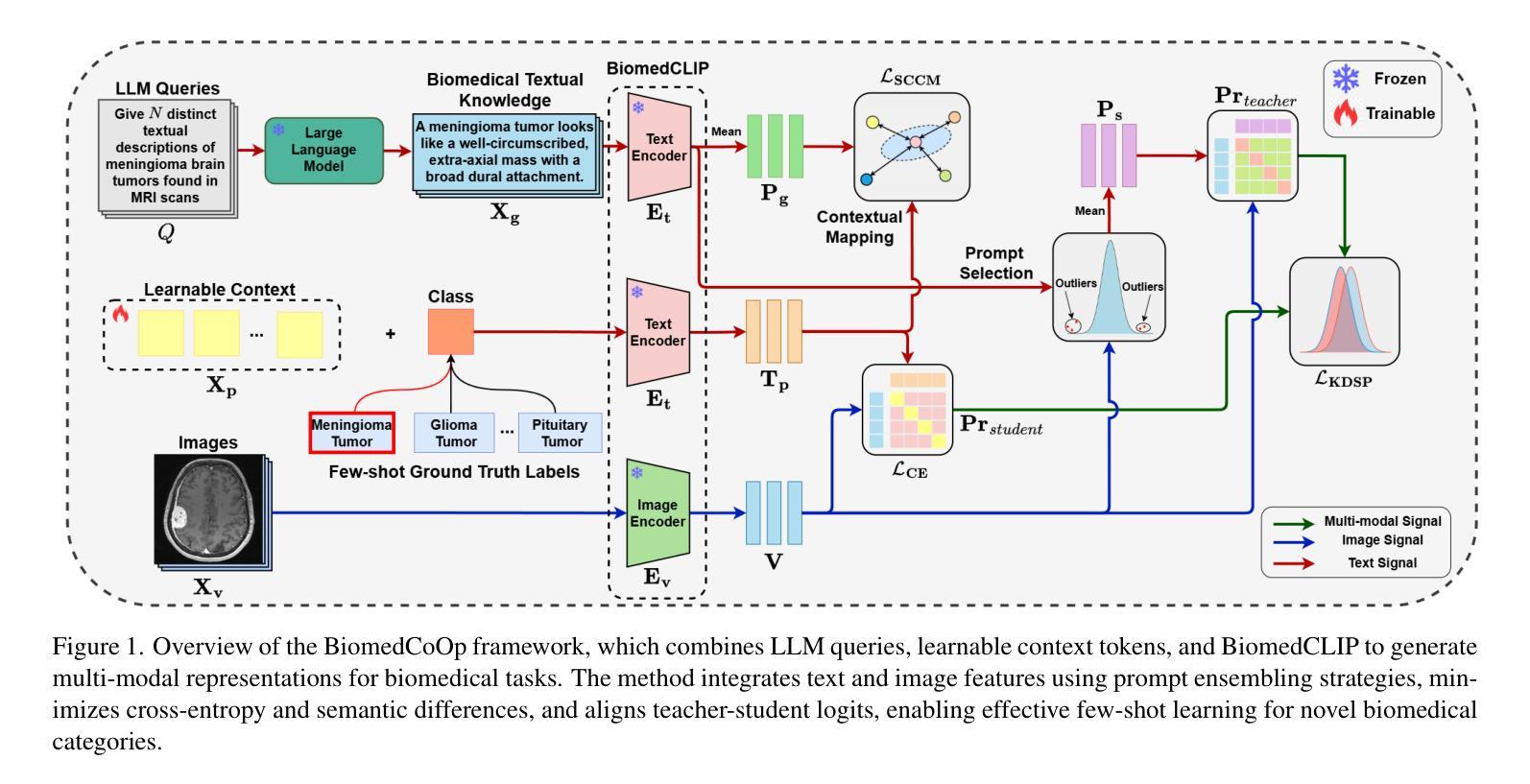
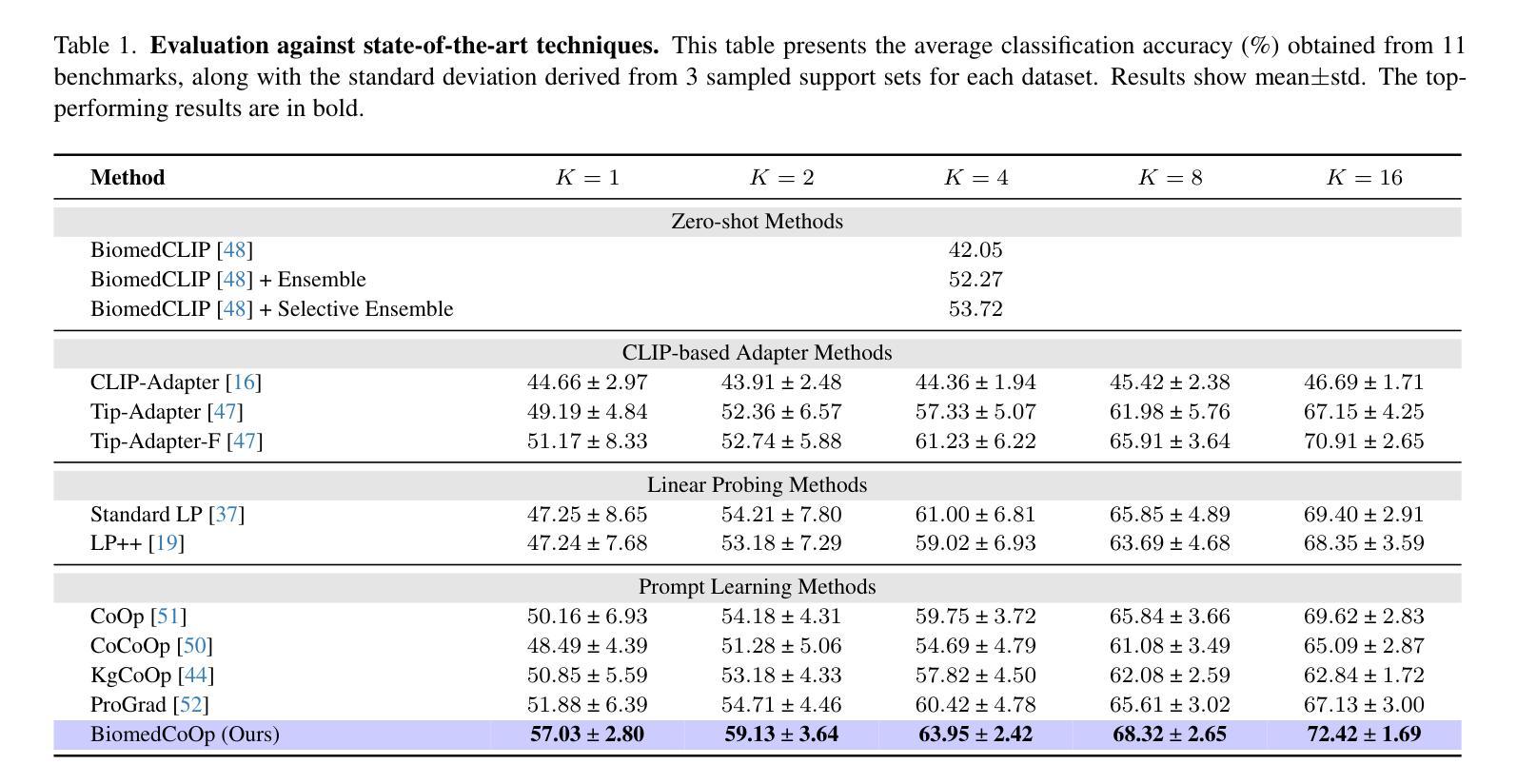
BiomedCoOp: Learning to Prompt for Biomedical Vision-Language Models
Authors:Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, Yiming Xiao
Recent advancements in vision-language models (VLMs), such as CLIP, have demonstrated substantial success in self-supervised representation learning for vision tasks. However, effectively adapting VLMs to downstream applications remains challenging, as their accuracy often depends on time-intensive and expertise-demanding prompt engineering, while full model fine-tuning is costly. This is particularly true for biomedical images, which, unlike natural images, typically suffer from limited annotated datasets, unintuitive image contrasts, and nuanced visual features. Recent prompt learning techniques, such as Context Optimization (CoOp) intend to tackle these issues, but still fall short in generalizability. Meanwhile, explorations in prompt learning for biomedical image analysis are still highly limited. In this work, we propose BiomedCoOp, a novel prompt learning framework that enables efficient adaptation of BiomedCLIP for accurate and highly generalizable few-shot biomedical image classification. Our approach achieves effective prompt context learning by leveraging semantic consistency with average prompt ensembles from Large Language Models (LLMs) and knowledge distillation with a statistics-based prompt selection strategy. We conducted comprehensive validation of our proposed framework on 11 medical datasets across 9 modalities and 10 organs against existing state-of-the-art methods, demonstrating significant improvements in both accuracy and generalizability. The code is publicly available at https://github.com/HealthX-Lab/BiomedCoOp.
关于视觉语言模型(如CLIP)的最新进展在视觉任务的自监督表示学习中取得了重大成功。然而,将VLMs有效地适应到下游应用中仍然具有挑战性,因为它们的准确度通常依赖于耗时且需要专业知识的提示工程,而全模型的微调成本高昂。这对于生物医学图像尤其如此,与天然图像不同,生物医学图像通常受限于标注数据集、图像对比度不够直观以及微妙的视觉特征。最近的提示学习技术(如CoOp)旨在解决这些问题,但在通用性方面仍然有所不足。同时,针对生物医学图像分析的提示学习探索仍然非常有限。在这项工作中,我们提出了BiomedCoOp,这是一种新型的提示学习框架,能够实现BiomedCLIP的高效适应,以进行准确且高度通用的生物医学图像分类。我们的方法通过利用与大语言模型(LLM)的平均提示集合的语义一致性以及基于统计的提示选择策略的知识蒸馏,实现了有效的提示上下文学习。我们在跨越9种模态和10个器官的11个医学数据集上对所提出的框架进行了全面的验证,与现有的最先进的方法相比,准确性和通用性均显示出显著的提升。代码公开在:https://github.com/HealthX-Lab/BiomedCoOp。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
基于CLIP等视觉语言模型(VLMs)的最新进展,在自我监督表示学习方面取得了显著的成功。然而,将其有效地适应下游应用仍然具有挑战性,特别是对于生物医学图像而言。本文提出了BiomedCoOp,一种新颖的提示学习框架,能够实现准确且高度通用的少数生物医学图像分类的模型适配。它通过利用大语言模型(LLMs)的平均提示集合的语义一致性以及基于统计的提示选择策略进行知识蒸馏,实现了有效的提示上下文学习。经过广泛的验证,与现有的最新方法相比,BiomedCoOp在准确性和通用性方面都取得了显著的改进。
Key Takeaways
- VLMs如CLIP在自我监督表示学习方面取得了显著成功,但在适应下游应用方面面临挑战。
- 提示工程是VLMs在特定任务中应用的关键因素,通常需要大量时间和专业知识。
- 针对生物医学图像分析的特定挑战(如有限注释数据集、不直观的图像对比和微妙的视觉特征),现有的方法如CoOp仍有待改进。
- BiomedCoOp是一种新颖的提示学习框架,通过结合语义一致性、平均提示集合和基于统计的提示选择策略进行知识蒸馏,实现了高效的生物医学图像分类模型适配。
- 在涵盖多种医学数据集、模态和器官的大规模验证中,BiomedCoOp相对于现有技术显示出更高的准确性和通用性。
点此查看论文截图