⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
Imaging Ultrafast Dynamical Diffraction wavefronts of femtosecond laser-induced lattice distortions inside crystalline semiconductors
Authors:Angel Rodríguez-Fernández, Jan-Etienne Pudell, Roman Shayduk, Wonhyuk Jo, James Wrigley, Johannes Möller, Peter Zalden, Alexey Zozulya, Jörg Hallmann, Anders Madsen, Pablo Villanueva-Perez, Zdenek Matej, Thies J. Albert, Dominik Kaczmarek, Klaus Sokolowski-Tinten, Antonowicz Jerzy, Ryszard Sobierajski, Rahimi Mosafer, Oleksii I. Liubchenko, Javier Solis, Jan Siegel
Material processing with femtosecond lasers has attracted enormous attention because of its potential for technology and industry applications. In parallel, time-resolved x-ray diffraction has been successfully used to study ultrafast structural distortion dynamics in semiconductor thin films. Gracing incident x-ray geometry has been also used to look to distortion dynamics, but this technique is only sensitive to the surface of bulk materials with a limited temporal resolution. However, ‘real-world’ processing applications deal mostly with bulk materials, which prevent the use of such techniques. For processing applications, a fast and depth-sensitive probe is needed. To address this, we present a novel technique based on ultrafast dynamical diffraction (UDD) capable of imaging transient strain distributions inside bulk crystals upon single-pulse excitation. This pump-probe technique provides a complete picture of the temporal evolution of ultrafast distortion depth profiles. Our measurements were obtained in a thin crystalline Si wafer upon single pulse femtosecond optical excitation revealing that even below the melting threshold strong lattice distortions appear on ps time scales due to the formation and propagation of high-amplitude strain waves into the bulk.
材料使用飞秒激光处理因其技术和工业应用潜力而备受关注。同时,时间分辨X射线衍射已成功应用于研究半导体薄膜中的超快结构畸变动力学。尽管入射X射线几何结构也被用于观察畸变动力学,但这种技术仅对体材料表面敏感,且时间分辨率有限。然而,现实世界的处理应用大多涉及体材料,这使得这些技术的使用受到限制。为了应对这一问题,我们提出了一种基于超快动态衍射(UDD)的新技术,能够在单脉冲激发下对体晶体内部的瞬态应变分布进行成像。这种泵浦探针技术提供了超快畸变深度分布的时间演化的完整图像。我们的测量是在单晶硅薄片中进行的,通过对单脉冲飞秒光学激发发现,即使在低于熔化阈值的情况下,由于高振幅应变波的形成和向体材料的传播,皮秒时间内也会出现强烈的晶格畸变。
论文及项目相关链接
Summary
本研究关注飞秒激光材料加工技术及其在半导体薄膜中的超快结构畸变动力学研究。针对现有技术无法对块状材料进行深度敏感探测的问题,提出了一种基于超快动态衍射(UDD)的新型成像技术,该技术能够在单脉冲激发下成像晶体内部的瞬态应变分布,为加工应用提供了快速且深度敏感的探测手段。实验结果表明,在单脉冲飞秒光学激发下,即使在熔点以下,硅晶圆薄片也会出现强晶格畸变,表现为高振幅应变波在体材料中的形成和传播。
Key Takeaways
- 飞秒激光材料加工技术因其潜在的技术和工业应用而备受关注。
- 时间分辨X射线衍射已成功应用于研究半导体薄膜中的超快结构畸变动力学。
- 现有技术难以处理块状材料的深度敏感探测。
- 提出了一种基于超快动态衍射(UDD)的新型成像技术,该技术可以成像晶体内部的瞬态应变分布。
- 该技术为加工应用提供了快速且深度敏感的探测手段。
- 实验结果表明,在单脉冲飞秒光学激发下,硅晶圆薄片出现强晶格畸变。
点此查看论文截图

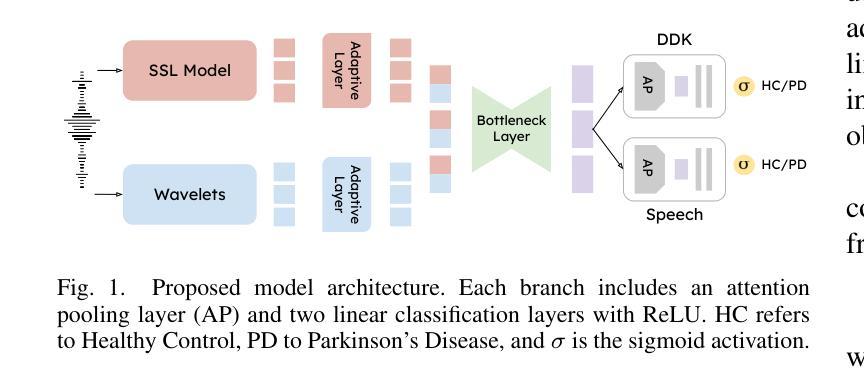
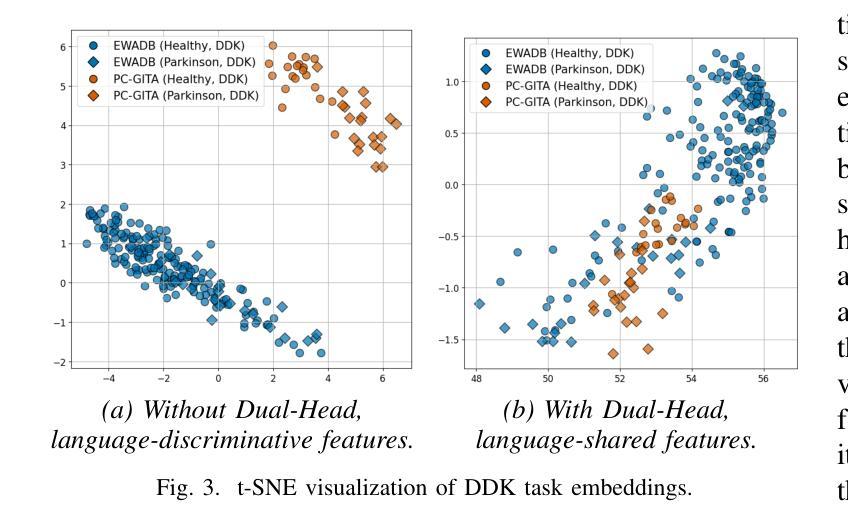
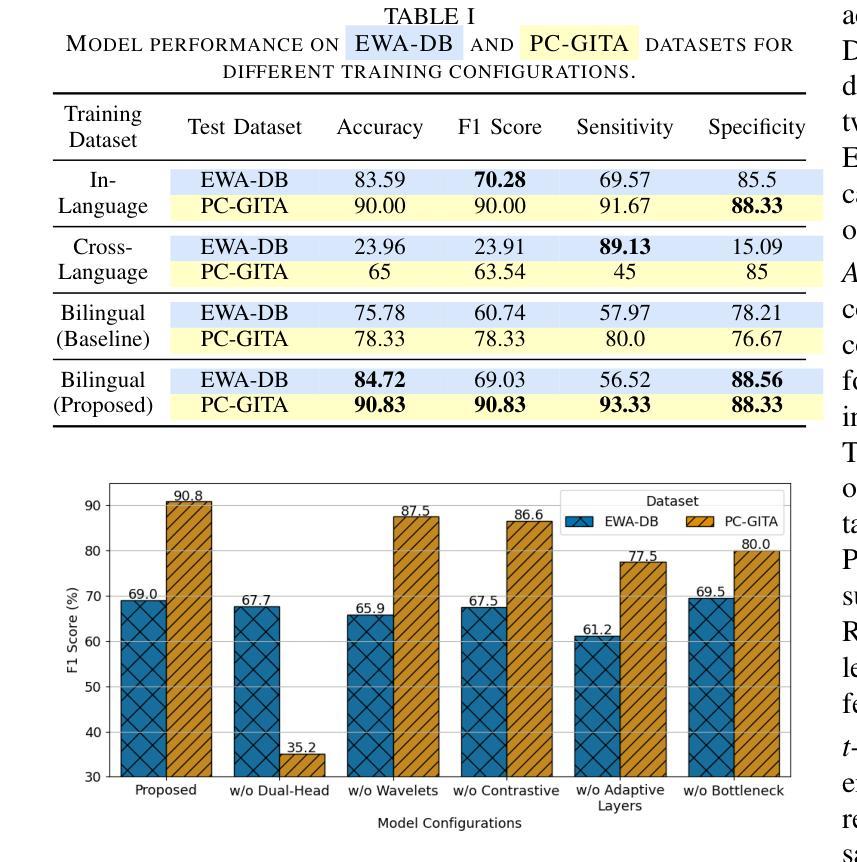
Bilingual Dual-Head Deep Model for Parkinson’s Disease Detection from Speech
Authors:Moreno La Quatra, Juan Rafael Orozco-Arroyave, Marco Sabato Siniscalchi
This work aims to tackle the Parkinson’s disease (PD) detection problem from the speech signal in a bilingual setting by proposing an ad-hoc dual-head deep neural architecture for type-based binary classification. One head is specialized for diadochokinetic patterns. The other head looks for natural speech patterns present in continuous spoken utterances. Only one of the two heads is operative accordingly to the nature of the input. Speech representations are extracted from self-supervised learning (SSL) models and wavelet transforms. Adaptive layers, convolutional bottlenecks, and contrastive learning are exploited to reduce variations across languages. Our solution is assessed against two distinct datasets, EWA-DB, and PC-GITA, which cover Slovak and Spanish languages, respectively. Results indicate that conventional models trained on a single language dataset struggle with cross-linguistic generalization, and naive combinations of datasets are suboptimal. In contrast, our model improves generalization on both languages, simultaneously.
本文旨在解决双语环境下的帕金森病(PD)语音信号检测问题。为此,我们提出了一种基于类型二分类的专用双头深度神经网络架构。一个头专门用于处理连续语音中的发音运动模式,另一个头则用于寻找自然语音模式。根据输入的性质,只有其中一个头处于工作状态。语音表示是从自监督学习(SSL)模型和小波变换中提取的。我们利用自适应层、卷积瓶颈和对比学习来减少跨语言之间的差异。我们的解决方案在两个不同的数据集EWA-DB和PC-GITA上进行了评估,这两个数据集分别涵盖了斯洛伐克语和西班牙语。结果表明,在单一语言数据集上训练的常规模型在跨语言泛化方面存在困难,而单纯的数据集组合效果并不理想。相比之下,我们的模型可以同时改善两种语言的泛化能力。
论文及项目相关链接
PDF Accepted at ICASSP 2025 - Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses
Summary
帕金森病(PD)检测在双语环境下的语音信号研究提出了一种专门针对类型化二元分类的双头深度神经网络架构。一头专注于连续语音中的自然语音模式,另一头专注于发音运动模式。根据输入类型选择激活相应的头部。该研究使用自监督学习模型和小波变换提取语音特征,并利用自适应层、卷积瓶颈和对比学习来减少语言间的差异。在斯洛伐克和西班牙语数据集上的评估结果表明,单一语言模型的跨语言泛化能力有限,而本模型在两种语言上的泛化能力均有提升。
Key Takeaways
- 针对双语环境下的帕金森病(PD)检测问题,提出了双头深度神经网络架构。
- 双头架构分别专注于发音运动模式与自然语音模式。
- 使用自监督学习模型和小波变换提取语音特征。
- 通过自适应层、卷积瓶颈和对比学习减少语言间的差异。
- 在斯洛伐克和西班牙语数据集上的评估表明单一语言模型的跨语言泛化能力受限。
- 提出的模型在两种语言上的泛化能力有所提升。
点此查看论文截图

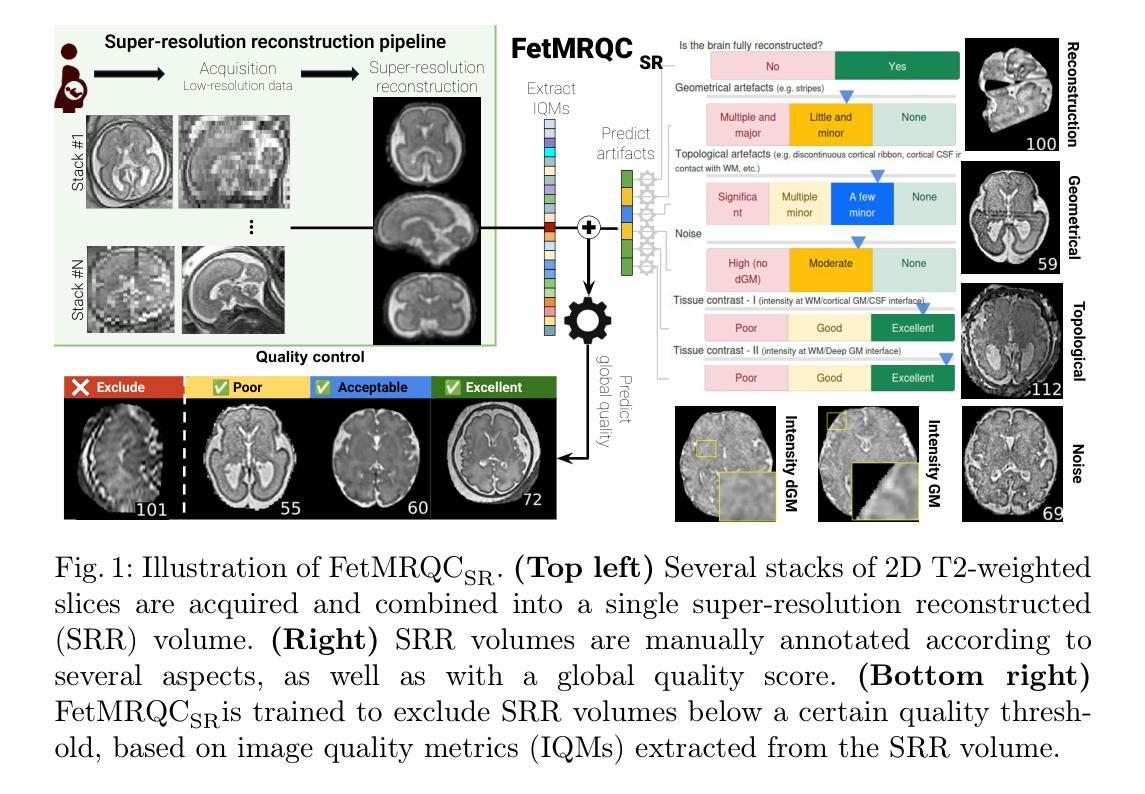
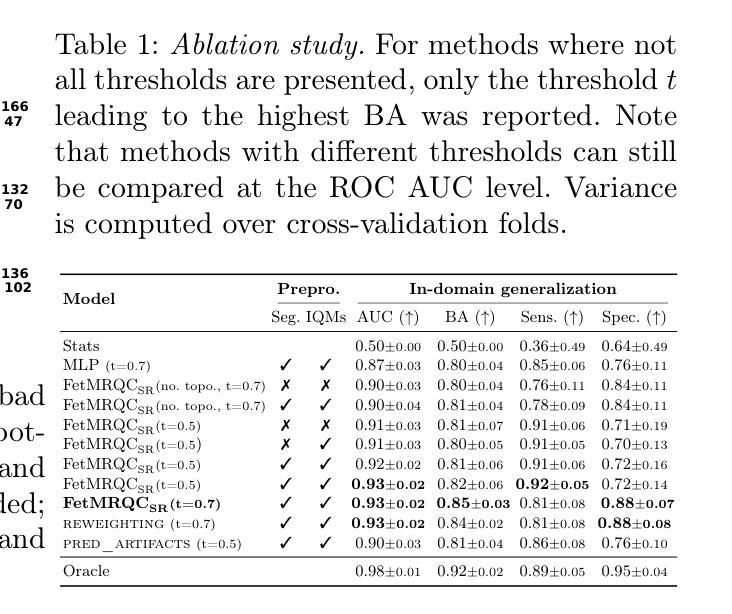
Automatic quality control in multi-centric fetal brain MRI super-resolution reconstruction
Authors:Thomas Sanchez, Vladyslav Zalevsky, Angeline Mihailo, Gerard Martí Juan, Elisenda Eixarch, Andras Jakab, Vincent Dunet, Mériam Koob, Guillaume Auzias, Meritxell Bach Cuadra
Quality control (QC) has long been considered essential to guarantee the reliability of neuroimaging studies. It is particularly important for fetal brain MRI, where acquisitions and image processing techniques are less standardized than in adult imaging. In this work, we focus on automated quality control of super-resolution reconstruction (SRR) volumes of fetal brain MRI, an important processing step where multiple stacks of thick 2D slices are registered together and combined to build a single, isotropic and artifact-free T2 weighted volume. We propose FetMRQC${SR}$, a machine-learning method that extracts more than 100 image quality metrics to predict image quality scores using a random forest model. This approach is well suited to a problem that is high dimensional, with highly heterogeneous data and small datasets. We validate FetMRQC${SR}$ in an out-of-domain (OOD) setting and report high performance (ROC AUC = 0.89), even when faced with data from an unknown site or SRR method. We also investigate failure cases and show that they occur in $45%$ of the images due to ambiguous configurations for which the rating from the expert is arguable. These results are encouraging and illustrate how a non deep learning-based method like FetMRQC$_{SR}$ is well suited to this multifaceted problem. Our tool, along with all the code used to generate, train and evaluate the model will be released upon acceptance of the paper.
质量控制(QC)被认为是保证神经影像学研究可靠性的关键因素已经很久了。对于胎儿脑部MRI来说尤其重要,因为与成人成像相比,其采集和图像处理技术标准化程度较低。在这项工作中,我们专注于胎儿脑部MRI的超分辨率重建(SRR)体积的自动质量控制,这是一个重要的处理步骤,其中多个厚的2D切片堆叠在一起注册,并组合成一个单一、各向同性且无伪影的T2加权体积。我们提出了一种名为FetMRQC_{SR}的机器学习方法,该方法提取了超过100个图像质量指标,并使用随机森林模型预测图像质量分数。这种方法非常适合于高维、数据高度异质和小数据集的问题。我们在域外(OOD)环境中验证了FetMRQC_{SR},并报告了高性能(ROC AUC = 0.89),即使在面对来自未知站点或SRR方法的数据时也是如此。我们还调查了失败的情况,并表明这些失败发生在45%的图像中,主要是由于配置模糊,专家的评分存在争议。这些结果令人鼓舞,并说明了像FetMRQC_{SR}这样的非深度学习方法如何适应这个多面问题。我们的工具以及用于生成、训练和评估模型的所有代码将在论文被接受后发布。
论文及项目相关链接
PDF 11 pages, 3 figures; Submitted to MICCAI 2025
摘要
本文关注胎儿脑部MRI的超分辨率重建(SRR)体积的自动化质量控制。提出一种名为FetMRQC_{SR}的机器学习方法,通过提取超过100个图像质量指标,使用随机森林模型预测图像质量分数。该方法适用于高维、数据高度异质且数据集较小的问题。在领域外(OOD)环境下验证了FetMRQC_{SR}的性能,即使面对来自未知站点或SRR方法的数据,也表现出较高的性能(ROC AUC = 0.89)。研究发现,45%的图像存在失败案例,主要由于模糊配置导致专家评分存在争议。本文工具及所有用于生成、训练和评估模型的代码将在论文被接受后发布。
关键见解
- 质量控制在神经成像研究中至关重要,尤其在胎儿脑部MRI中,其采集和图像处理技术较成人成像标准化程度较低。
- 本文关注胎儿脑部MRI的超级分辨率重建(SRR)的质量控制。
- 提出一种名为FetMRQC_{SR}的机器学习方法,通过提取超过100个图像质量指标预测图像质量分数。
- 该方法在非深度学习的背景下表现良好,适用于高维、数据高度异质的问题。
- 在领域外环境下验证性能良好(ROC AUC = 0.89),在不同数据源下具有良好的泛化能力。
- 发现失败案例占45%,主要是由于图像配置模糊导致专家评分的不确定性。
- 该工具和代码将在论文被接受后公开发布。
点此查看论文截图

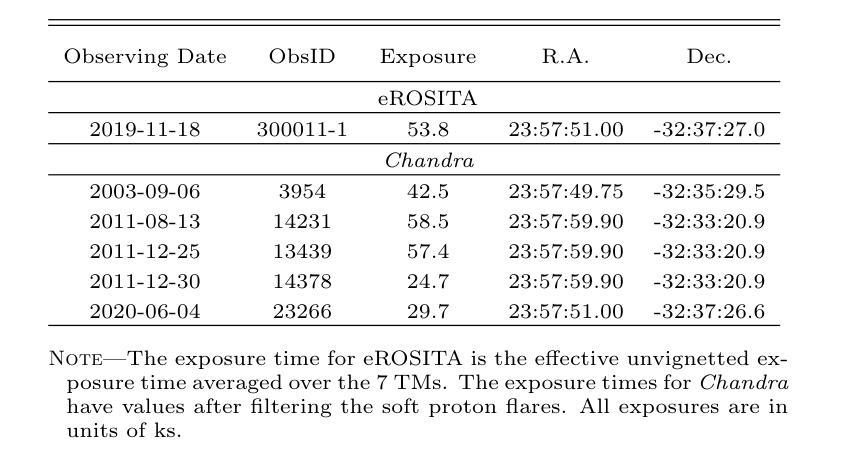
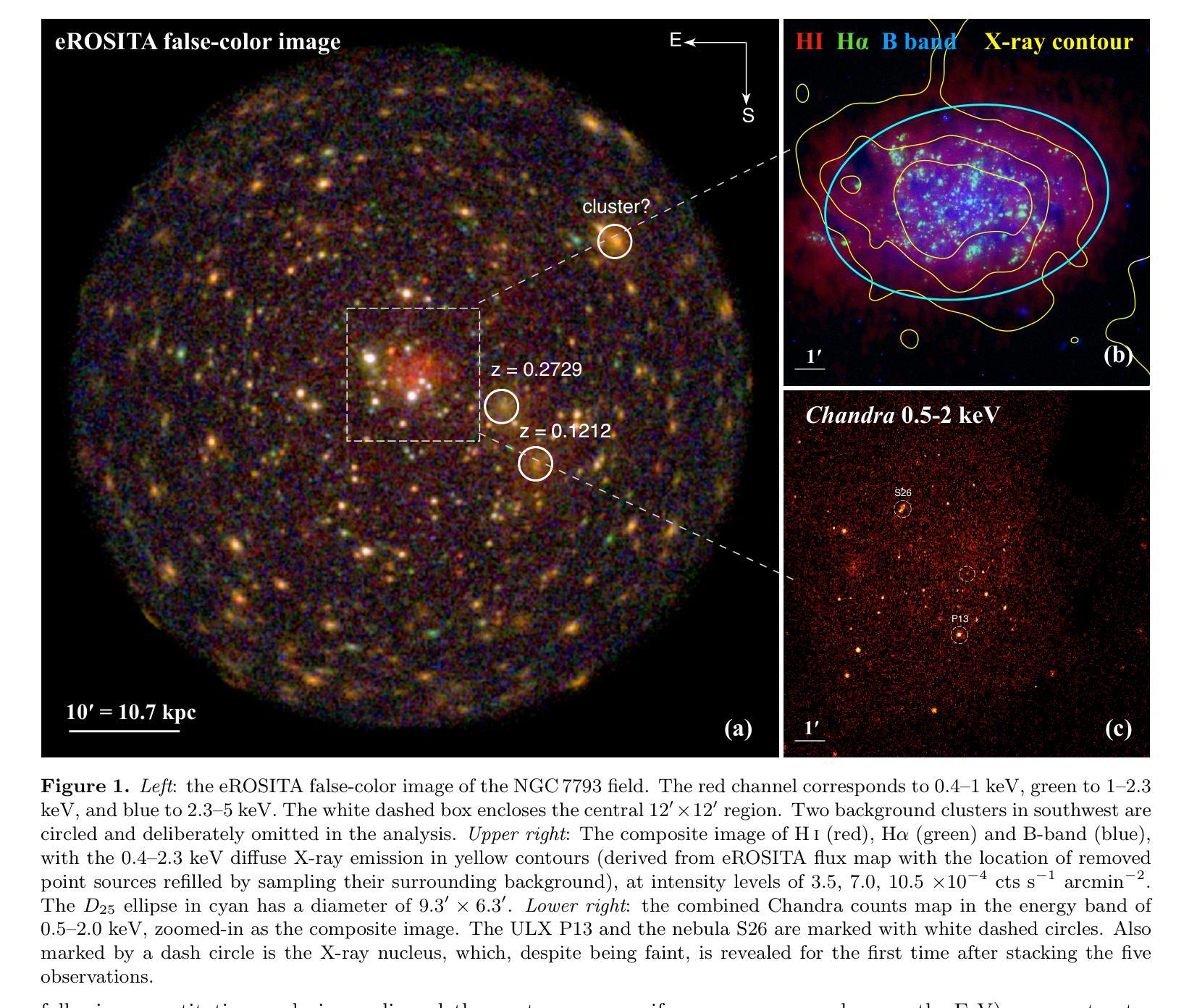
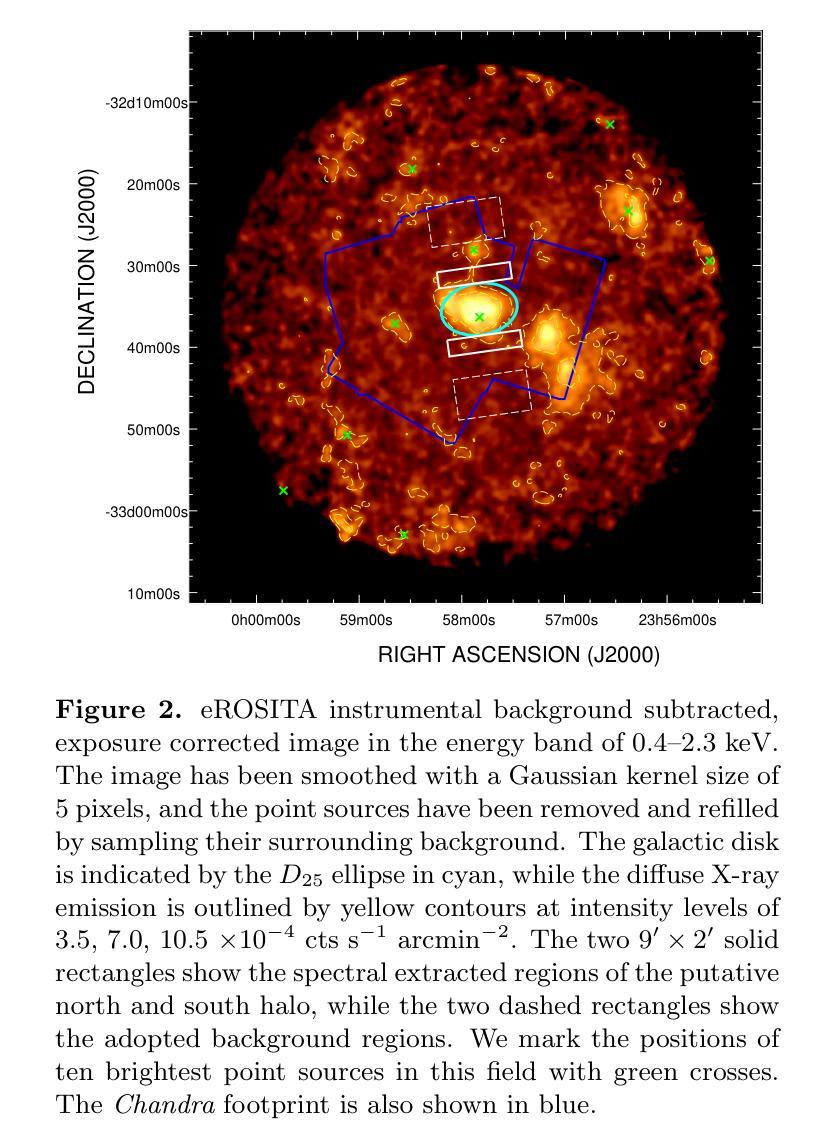
Probing the Hot Gaseous Halo of the Low-mass Disk Galaxy NGC 7793 with eROSITA and Chandra
Authors:Lin He, Zhiyuan Li, Meicun Hou, Min Du, Taotao Fang, Wei Cui
Galaxy formation models predict that local galaxies are surrounded by hot X-ray-emitting halos, which are technically difficult to detect due to their extended and low surface brightness nature. Previous X-ray studies have mostly focused on disk galaxies more massive than the Milky Way, with essentially no consensus on the halo X-ray properties at the lower mass end. We utilize the early-released eROSITA and archival Chandra observations to analyze the diffuse X-ray emission of NGC7793, a nearby spiral galaxy with an estimated stellar mass of only $3.2\times 10^9$ $M_{\odot}$. We find evidence for extraplanar hot gas emission from both the radial and vertical soft X-ray intensity profiles, which spreads up to a galactocentric distance of $\sim$ 6 kpc, nearly 30 $%$ more extended than its stellar disk. Analysis of the eROSITA spectra indicates that the hot gas can be characterized by a temperature of $0.18^{+0.02}_{-0.03}$ keV, with 0.5–2 keV unabsorbed luminosity of $1.3\times 10^{38}$ erg $s^{-1}$. We compare our results with the IllustrisTNG simulations and find overall consistence on the disk scale, whereas excessive emission at large radii is predicted by TNG50. This work provides the latest detection of hot corona around a low-mass galaxy, putting new constrains on state-of-the-art cosmological simulations. We also verify the detectability of hot circumgalactic medium around even low-mass spirals with future high-resolution X-ray spectrometer such as the Hot Universe Baryon Surveyor.
星系形成模型预测,局部星系周围存在发射X射线的热晕,由于其延展性和低表面亮度,技术上很难检测到。之前的X射线研究主要集中于质量大于银河系的盘状星系,对于低质量端星系晕的X射线特性基本无共识。我们利用早期发布的eROSITA观测数据和存档的Chandra观测数据来分析NGC7793的漫射X射线发射情况。NGC7793是附近的一个螺旋星系,其恒星质量估计仅为$3.2\times 10^9$ $M_{\odot}$。我们发现径向和垂直软X射线强度分布都有平面外的热气体发射证据,它扩展到离中心约6kpc的距离,比其恒星盘延伸了约30%。对eROSITA光谱的分析表明,热气体特征温度约为$0.18^{+0.02}_{-0.03}$ keV,未吸收的0.5-2 keV光度为$1.3\times 10^{38}$ erg s$^{-1}$。我们将我们的结果与IllustrisTNG模拟进行了比较,发现在磁盘尺度上总体一致,而TNG50预计在较大半径处会出现过多的发射。这项工作提供了低质量星系周围热冕的最新检测,对最新的宇宙学模拟提出了新的约束。我们还验证了即使对于低质量螺旋星系,未来高分辨率X射线光谱仪(如Hot Universe Baryon Surveyor)也可以检测到围绕其周围的热宇宙介质。
论文及项目相关链接
PDF 17 pages, 7 figures, 1 table, accepted for publication in ApJ
摘要
本摘要基于星系形成模型预测,本地星系周围存在难以检测的热X射线发射晕。先前的研究主要关注质量高于银河系的大型盘星系,而对低质量星系的晕X射线特性尚无共识。本研究利用早期发布的eROSITA和存档的Chandra观测数据,分析了NGC7793这一邻近螺旋星系的弥散X射线发射。该星系的恒星质量估计仅为$3.2\times 10^9$ $M_{\odot}$。我们发现来自径向和垂直软X射线强度分布的证据显示存在热气体发射,其扩展至距离中心约6kpc的地方,几乎比其恒星盘延伸了30%。对eROSITA光谱的分析表明,热气体可以通过温度约为$0.18^{+0.02}_{-0.03}$ keV的特质来表征,未吸收在0.5–2 keV之间的光度约为 $1.3\times 10^{38}$ erg $s^{-1}$。我们的结果与IllustrisTNG模拟大致一致,但TNG50在大半径处预测过度发射。这项研究为低质量星系周围热晕的最新检测提供了证据,对最新的宇宙学模拟提出了新的约束。此外,我们还验证了未来使用高分辨率X射线光谱仪(如Hot Universe Baryon Surveyor)检测低质量螺旋星系周围热环周介质的可能性。
Key Takeaways
- 星系形成模型预测本地星系周围存在难以检测的热X射线发射晕。
- 先前研究主要集中在质量较大的盘星系上,而对低质量星系的晕X射线特性了解较少。
- 利用eROSITA和Chandra观测数据,发现低质量螺旋星系NGC7793存在热气体发射证据。
- 热气体延伸超出恒星盘范围,近至中心距离约6kpc处。
- eROSITA光谱分析揭示热气体温度约为$0.18^{+0.02}_{-0.03}$ keV。
- 与模拟结果对比显示,大半径处的发射在TNG50模型中预测得较多。
点此查看论文截图

AI-assisted Early Detection of Pancreatic Ductal Adenocarcinoma on Contrast-enhanced CT
Authors:Han Liu, Riqiang Gao, Sasa Grbic
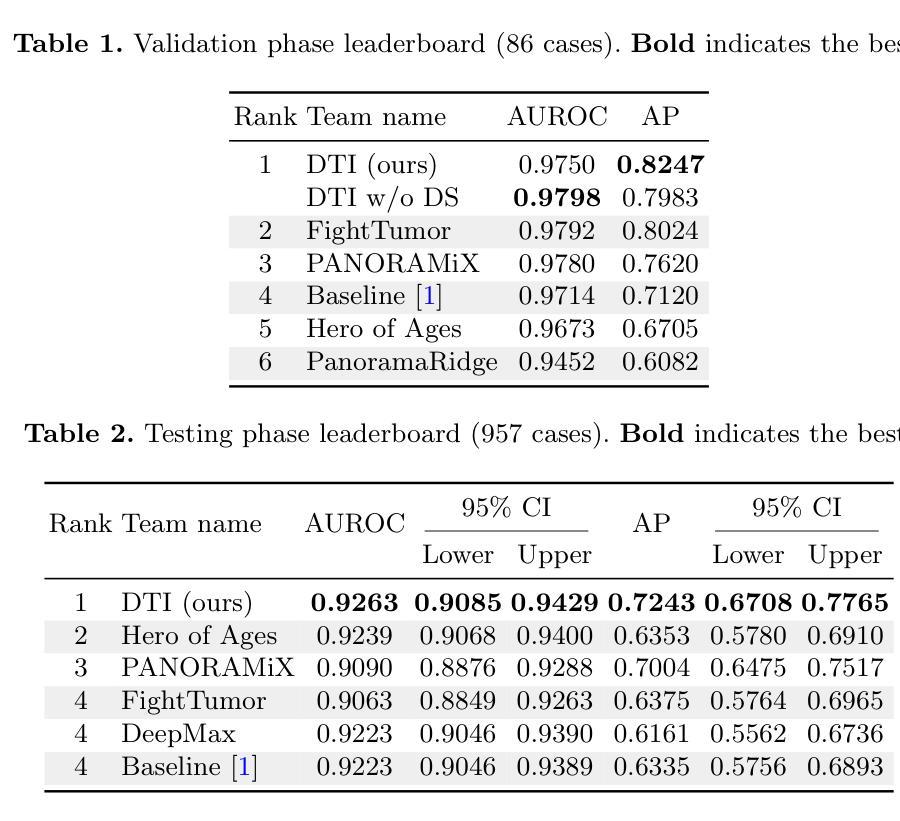
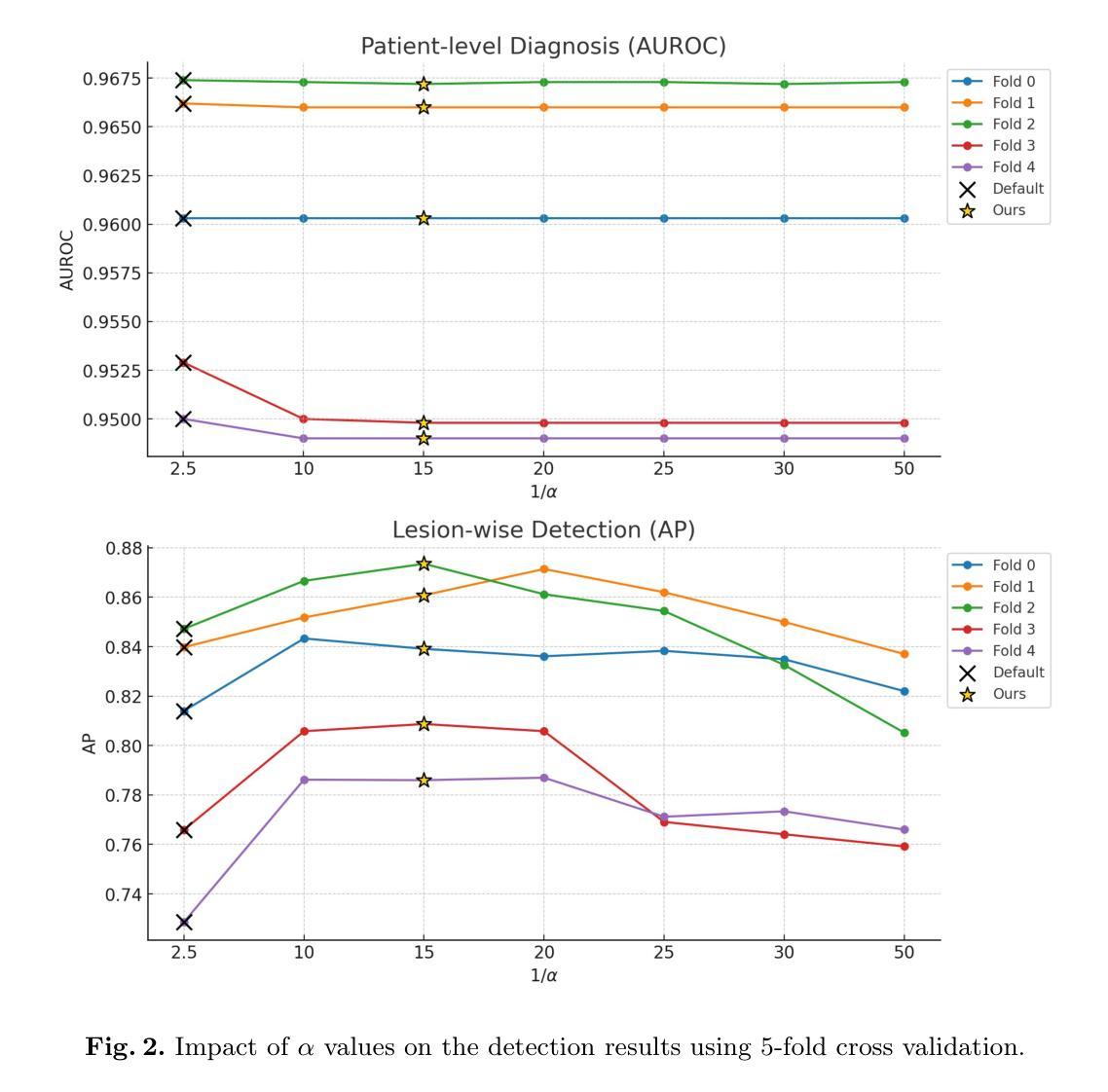
Pancreatic ductal adenocarcinoma (PDAC) is one of the most common and aggressive types of pancreatic cancer. However, due to the lack of early and disease-specific symptoms, most patients with PDAC are diagnosed at an advanced disease stage. Consequently, early PDAC detection is crucial for improving patients’ quality of life and expanding treatment options. In this work, we develop a coarse-to-fine approach to detect PDAC on contrast-enhanced CT scans. First, we localize and crop the region of interest from the low-resolution images, and then segment the PDAC-related structures at a finer scale. Additionally, we introduce two strategies to further boost detection performance: (1) a data-splitting strategy for model ensembling, and (2) a customized post-processing function. We participated in the PANORAMA challenge and ranked 1st place for PDAC detection with an AUROC of 0.9263 and an AP of 0.7243. Our code and models are publicly available at https://github.com/han-liu/PDAC_detection.
胰腺癌导管腺癌(PDAC)是胰腺癌最常见且最具有侵袭性的类型之一。然而,由于早期和疾病特异性症状缺乏,大多数PDAC患者在疾病进展阶段才被诊断出来。因此,早期发现PDAC对于改善患者生活质量和扩大治疗选择至关重要。在这项工作中,我们开发了一种从粗到细的PDAC检测方法来检测增强CT扫描中的胰腺癌。首先,我们从低分辨率图像中定位和裁剪感兴趣区域,然后在更精细的尺度上分割与PDAC相关的结构。此外,我们还引入了两种策略来进一步提高检测性能:(1)用于模型集成的数据拆分策略,(2)定制的后处理功能。我们参加了PANORAMA挑战赛,在PDAC检测方面获得第一名,AUROC为0.9263,AP为0.7243。我们的代码和模型可在https://github.com/han-liu/PDAC_detection上公开访问。
论文及项目相关链接
PDF 1st place in the PANORAMA Challenge (Team DTI)
Summary
胰腺导管腺癌(PDAC)是胰腺癌中最常见且最具有侵袭性的类型之一。由于早期和特定疾病症状缺乏,大多数PDAC患者在疾病进展到晚期时才被诊断出来。因此,早期发现PDAC对于改善患者生活质量和扩大治疗选择至关重要。本研究采用由粗到精的方法,在增强CT扫描中检测PDAC。首先,我们从低分辨率图像中定位并裁剪感兴趣区域,然后在更精细的尺度上分割与PDAC相关的结构。此外,我们还引入了两种策略来进一步提高检测性能:一是模型集成的数据拆分策略,二是定制的后处理功能。我们参加了PANORAMA挑战赛,在PDAC检测方面获得第一名,AUROC为0.9263,AP为0.7243。我们的代码和模型可在公开访问网站上找到:公开链接。
Key Takeaways
- 胰腺导管腺癌(PDAC)是胰腺癌中常见且具有侵袭性的类型,早期发现对改善患者生活质量和扩大治疗选择至关重要。
- 研究采用由粗到精的方法检测PDAC,先在低分辨率图像中定位并裁剪感兴趣区域,再在更精细的尺度上分割相关结构。
- 为提高检测性能,引入了模型集成的数据拆分策略和定制的后处理功能。
- 在PANORAMA挑战赛中,PDAC检测获得第一名,显示出所提出方法的有效性和优越性。
- 该研究提供的代码和模型可供公开访问,便于其他研究者使用和学习。
- AUROC(Area Under the Receiver Operating Characteristic Curve)为0.9263,表明模型的高准确性和良好的诊断能力。
点此查看论文截图

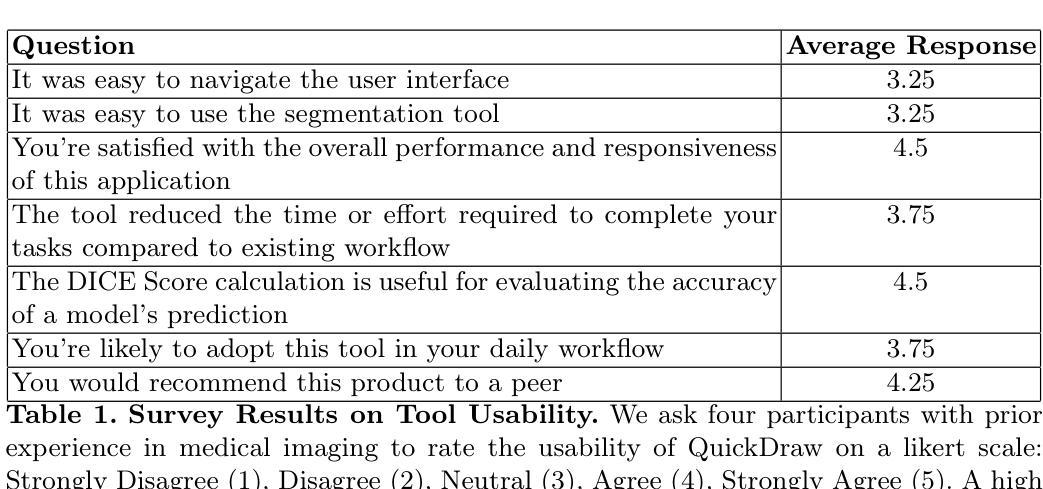
QuickDraw: Fast Visualization, Analysis and Active Learning for Medical Image Segmentation
Authors:Daniel Syomichev, Padmini Gopinath, Guang-Lin Wei, Eric Chang, Ian Gordon, Amanuel Seifu, Rahul Pemmaraju, Neehar Peri, James Purtilo
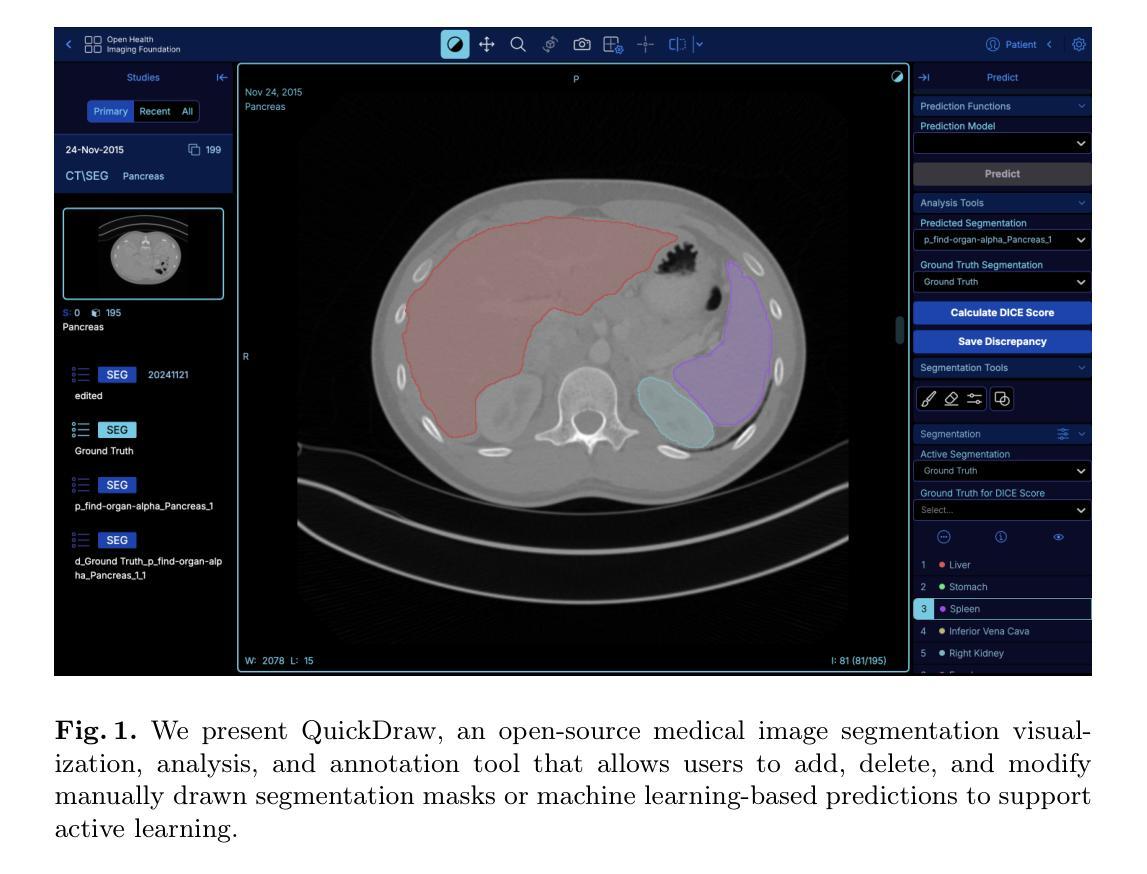
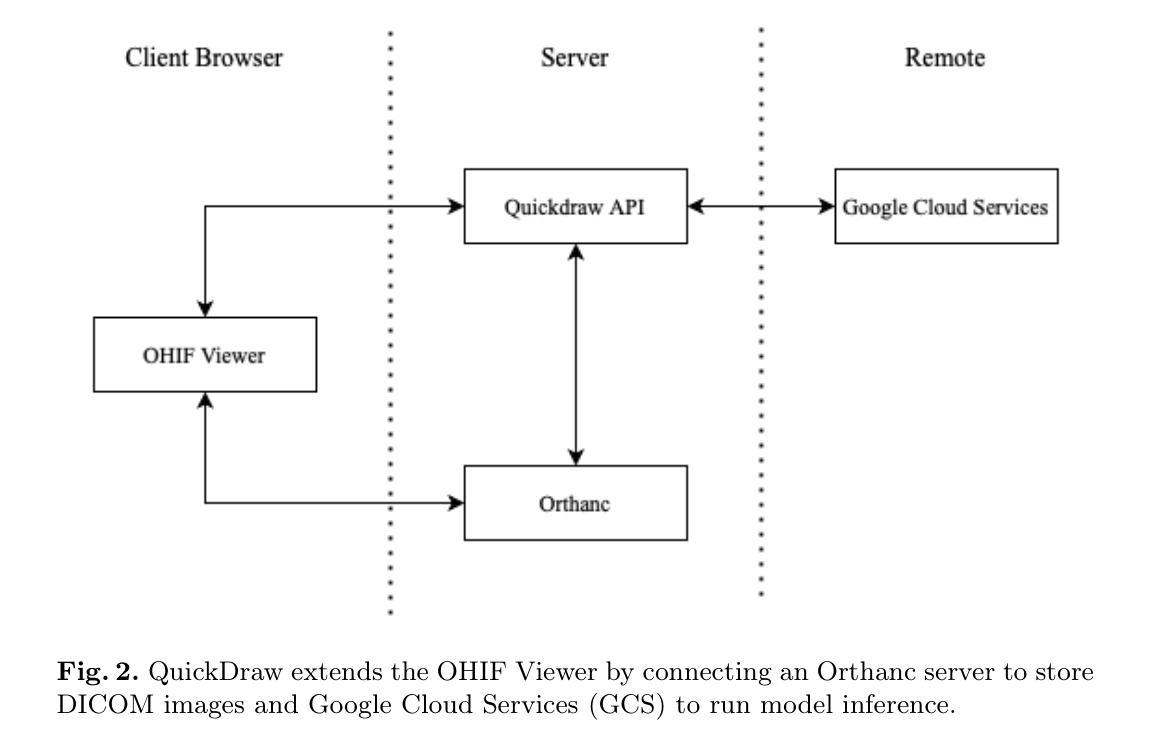
Analyzing CT scans, MRIs and X-rays is pivotal in diagnosing and treating diseases. However, detecting and identifying abnormalities from such medical images is a time-intensive process that requires expert analysis and is prone to interobserver variability. To mitigate such issues, machine learning-based models have been introduced to automate and significantly reduce the cost of image segmentation. Despite significant advances in medical image analysis in recent years, many of the latest models are never applied in clinical settings because state-of-the-art models do not easily interface with existing medical image viewers. To address these limitations, we propose QuickDraw, an open-source framework for medical image visualization and analysis that allows users to upload DICOM images and run off-the-shelf models to generate 3D segmentation masks. In addition, our tool allows users to edit, export, and evaluate segmentation masks to iteratively improve state-of-the-art models through active learning. In this paper, we detail the design of our tool and present survey results that highlight the usability of our software. Notably, we find that QuickDraw reduces the time to manually segment a CT scan from four hours to six minutes and reduces machine learning-assisted segmentation time by 10% compared to prior work. Our code and documentation are available at https://github.com/qd-seg/quickdraw
分析CT扫描、MRI和X光射线对疾病的诊断和治疗至关重要。然而,从这样的医学图像中检测和识别异常是一个耗时的过程,需要专家分析,并且容易受观察者之间的差异影响。为了缓解这些问题,已经引入了基于机器学习模型的自动化图像分割技术来显著降低成本。尽管近年来在医学图像分析方面取得了重大进展,但许多最新模型从未应用于临床环境,因为最先进的模型不容易与现有的医学图像查看器接口连接。为了解决这些局限性,我们提出了QuickDraw,这是一个用于医学图像可视化和分析的开源框架,允许用户上传DICOM图像并运行现成的模型来生成3D分割蒙版。此外,我们的工具允许用户编辑、导出和评估分割蒙版,通过主动学习迭代改进最先进的模型。在本文中,我们详细介绍了工具的设计,并提供了调查结果,以突出我们软件的可用性。值得注意的是,我们发现QuickDraw将手动分割CT扫描的时间从四个小时减少到六分钟,与使用先前工作相比将机器学习辅助分割时间减少了10%。我们的代码和文档可在https://github.com/qd-seg/quickdraw找到。
论文及项目相关链接
PDF The first two authors contributed equally. The last three authors advised equally. This work has been accepted to the International Conference on Human Computer Interaction (HCII) 2025
Summary
医疗图像分析对于疾病的诊断和治疗至关重要,但手动分析耗费时间且存在观察者间差异。机器学习模型可自动化图像分割降低成本,但现有模型难以与医疗图像查看器整合。QuickDraw开源框架解决此问题,允许上传DICOM图像并使用现成模型生成3D分割蒙版,支持编辑、导出和评估蒙版,通过主动学习迭代改进模型。本研究详细阐述设计并展示软件可用性调查结果,发现QuickDraw可大幅减少手动分割CT扫描时间,并降低机器学习辅助分割时间。
Key Takeaways
- 医疗图像分析对疾病诊断和治疗至关重要,但存在耗时和观察者间差异问题。
- 机器学习模型可自动化医疗图像分割,降低成本。
- 现有模型难以与医疗图像查看器整合,存在应用障碍。
- QuickDraw框架解决此问题,支持DICOM图像上传和现成模型使用。
- QuickDraw允许生成3D分割蒙版,并支持编辑、导出和评估。
- 通过主动学习,可迭代改进模型。
- QuickDraw大幅减少手动分割CT扫描时间,并降低机器学习辅助分割时间。
点此查看论文截图

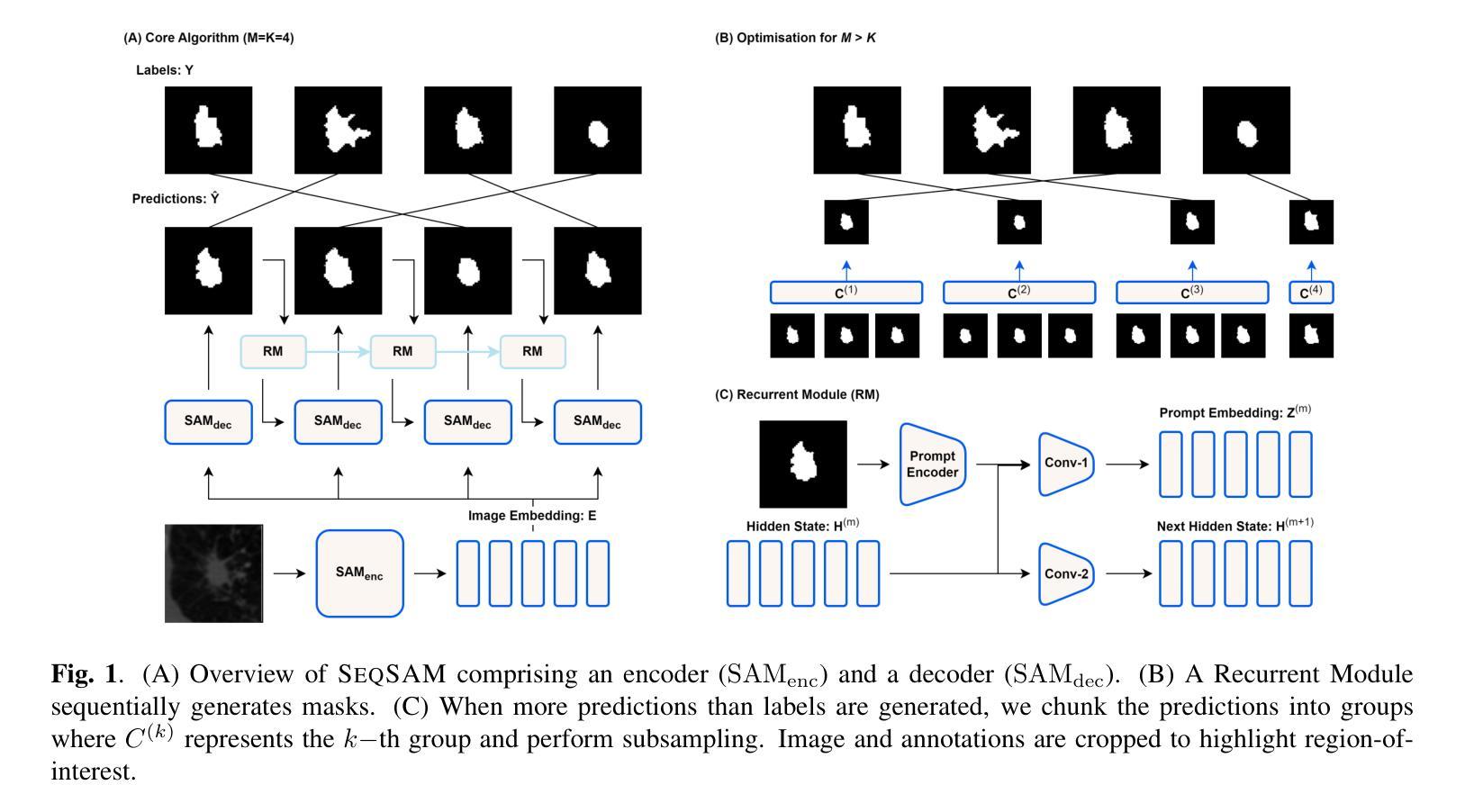
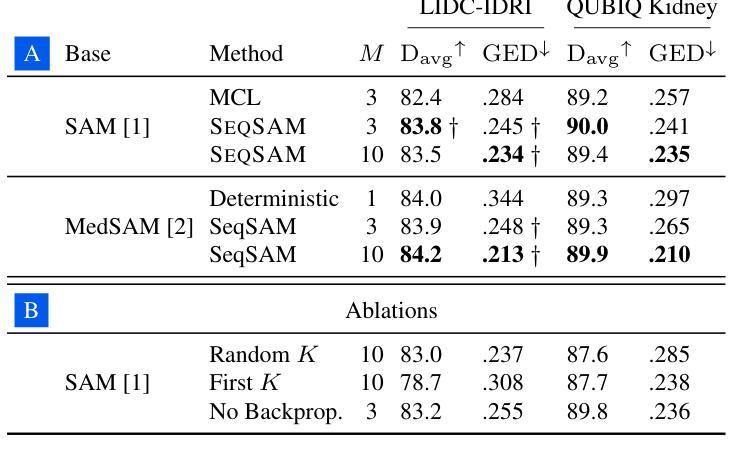
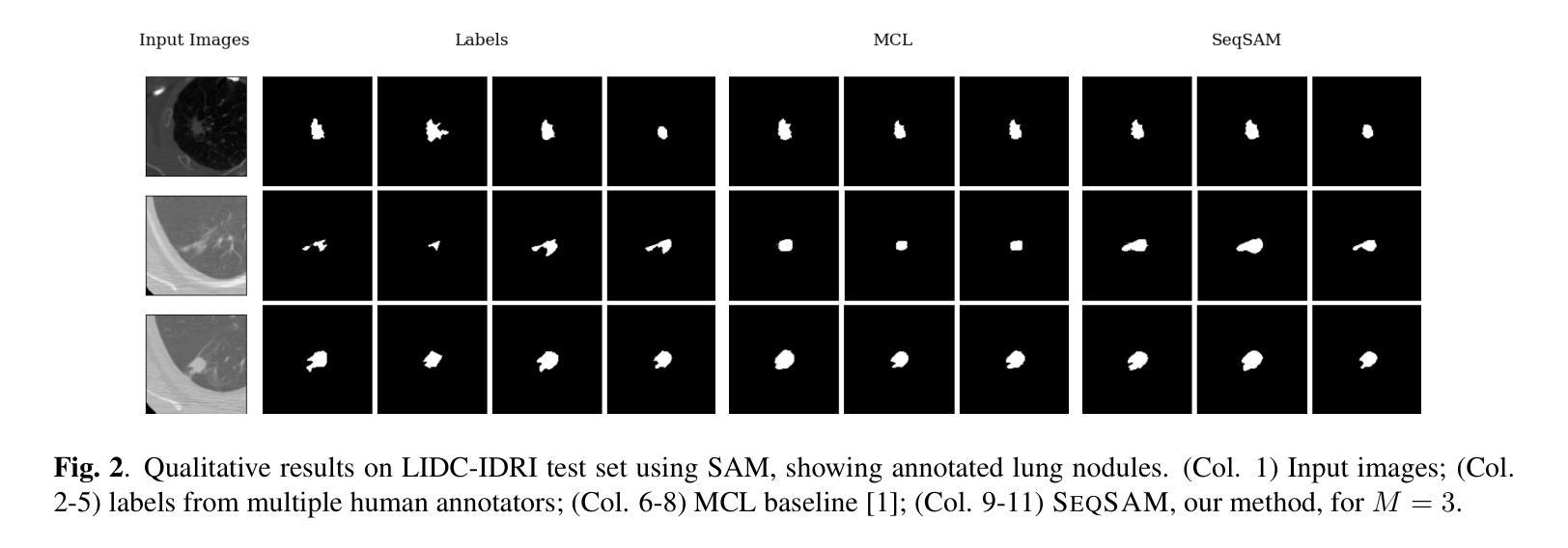
SeqSAM: Autoregressive Multiple Hypothesis Prediction for Medical Image Segmentation using SAM
Authors:Benjamin Towle, Xin Chen, Ke Zhou
Pre-trained segmentation models are a powerful and flexible tool for segmenting images. Recently, this trend has extended to medical imaging. Yet, often these methods only produce a single prediction for a given image, neglecting inherent uncertainty in medical images, due to unclear object boundaries and errors caused by the annotation tool. Multiple Choice Learning is a technique for generating multiple masks, through multiple learned prediction heads. However, this cannot readily be extended to producing more outputs than its initial pre-training hyperparameters, as the sparse, winner-takes-all loss function makes it easy for one prediction head to become overly dominant, thus not guaranteeing the clinical relevancy of each mask produced. We introduce SeqSAM, a sequential, RNN-inspired approach to generating multiple masks, which uses a bipartite matching loss for ensuring the clinical relevancy of each mask, and can produce an arbitrary number of masks. We show notable improvements in quality of each mask produced across two publicly available datasets. Our code is available at https://github.com/BenjaminTowle/SeqSAM.
预训练分割模型是分割图像的强大且灵活的工具。最近,这一趋势已扩展到医学成像领域。然而,由于对象边界不清晰和标注工具引起的错误,这些方法通常只为给定的图像生成单一预测结果,忽略了医学图像中的固有不确定性。多选择学习是一种通过多个学习预测头生成多个掩膜的技术。然而,由于稀疏的胜者全取损失函数使得一个预测头很容易过于占主导地位,因此不能轻易扩展到比其初始预训练超参数更多的输出,从而不能保证生成的每个掩膜的医学相关性。我们引入了SeqSAM,这是一种受RNN启发的生成多个掩膜的顺序方法,它使用二分匹配损失确保每个掩膜的医学相关性,并且可以生成任意数量的掩膜。我们在两个公开数据集上显示出生成的每个掩膜质量的显著提高。我们的代码在https://github.com/BenjaminTowle/SeqSAM上提供。
论文及项目相关链接
PDF Accepted to ISBI 2025
Summary
预训练分割模型在图像分割中具有强大和灵活的工具优势,尤其在医学影像领域。然而,由于医学图像中的模糊对象边界和标注工具引起的误差,这些方法通常只为给定图像生成单一预测结果,忽略了医学图像中的固有不确定性。SeqSAM是一种生成多个掩膜的序贯方法,它受到RNN的启发,使用二分匹配损失确保每个掩膜的临床相关性,并能生成任意数量的掩膜。在公开数据集上,SeqSAM生成的掩膜质量显著提高。
Key Takeaways
- 预训练分割模型在图像分割中具有显著优势,尤其在医学图像领域。
- 由于医学图像的模糊边界和标注工具误差,现有的方法忽略了图像中的不确定性。
- Multiple Choice Learning方法通过多个学习预测头生成多个掩膜。
- SeqSAM是一种序贯方法,受到RNN启发,可以生成任意数量的掩膜。
- SeqSAM使用二分匹配损失确保每个掩膜的临床相关性。
- 在公开数据集上,SeqSAM生成的掩膜质量显著提高。
点此查看论文截图

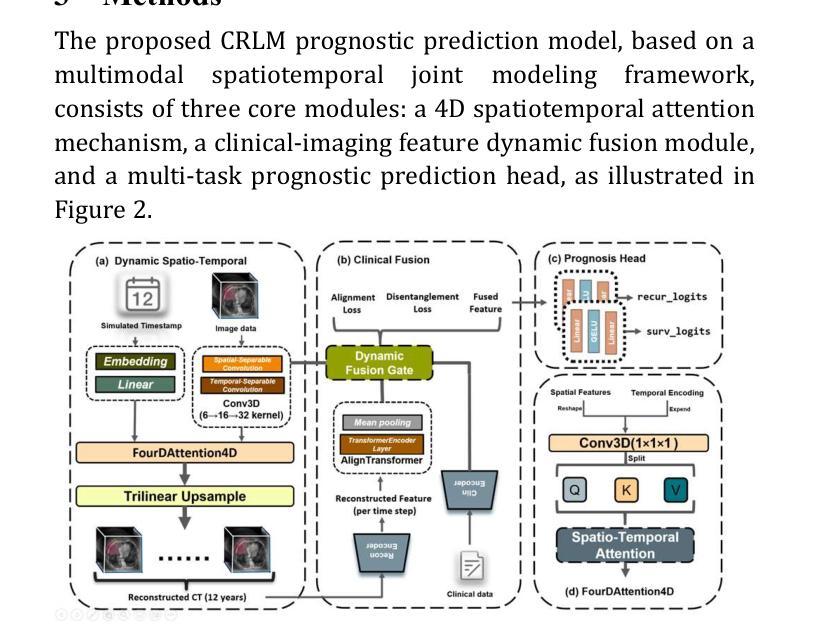
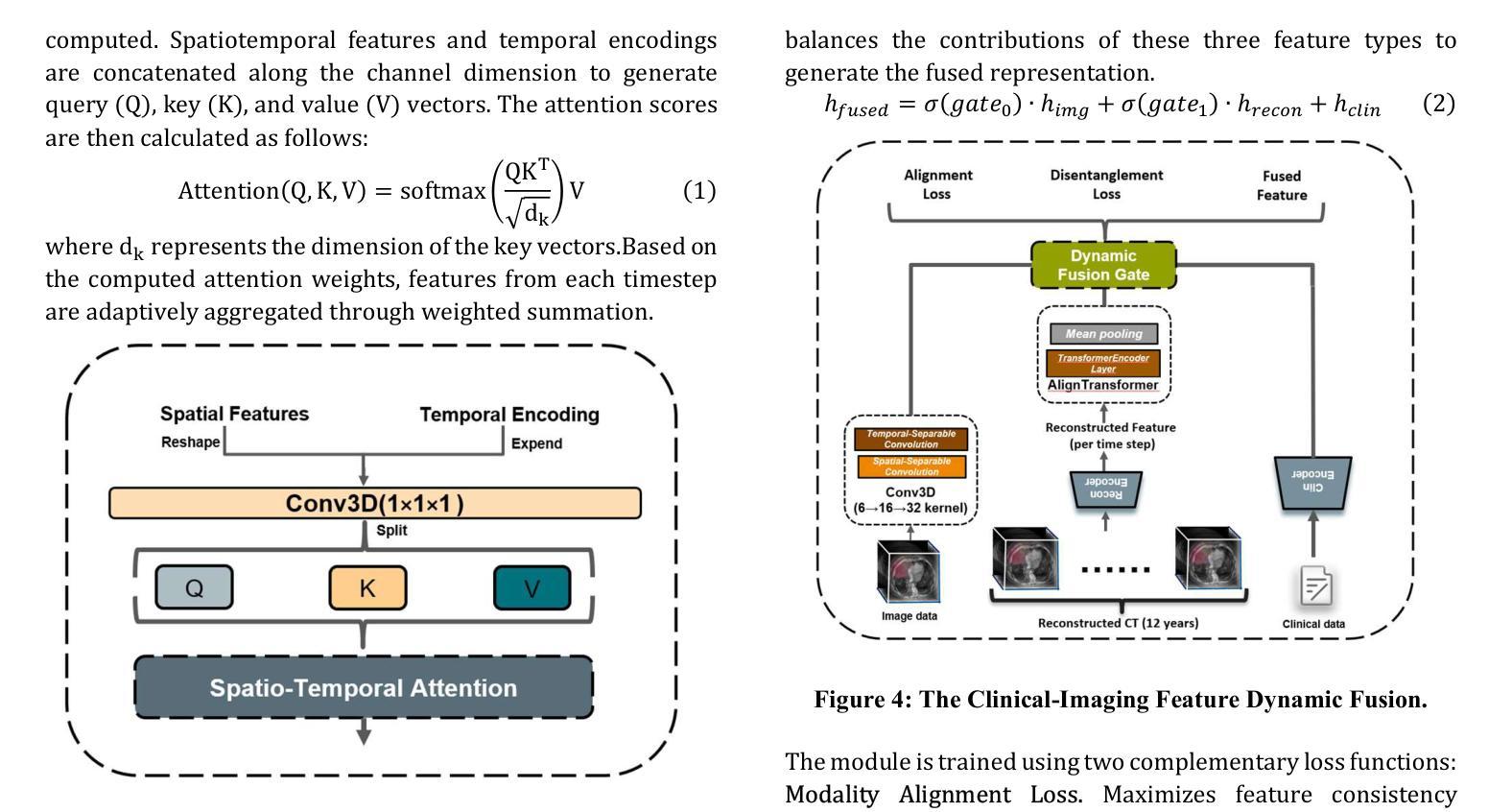
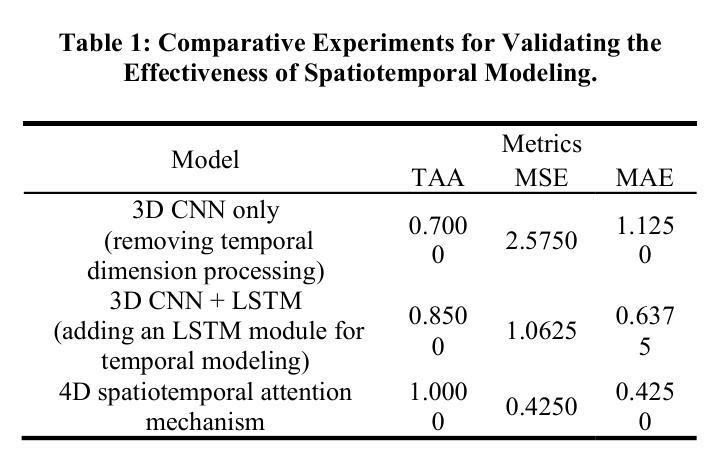
4D-ACFNet: A 4D Attention Mechanism-Based Prognostic Framework for Colorectal Cancer Liver Metastasis Integrating Multimodal Spatiotemporal Features
Authors:Zesheng Li, Wei Yang, Yan Su, Yiran Zhu, Yuhan Tang, Haoran Chen, Chengchang Pan, Honggang Qi
Postoperative prognostic prediction for colorectal cancer liver metastasis (CRLM) remains challenging due to tumor heterogeneity, dynamic evolution of the hepatic microenvironment, and insufficient multimodal data fusion. To address these issues, we propose 4D-ACFNet, the first framework that synergistically integrates lightweight spatiotemporal modeling, cross-modal dynamic calibration, and personalized temporal prediction within a unified architecture. Specifically, it incorporates a novel 4D spatiotemporal attention mechanism, which employs spatiotemporal separable convolution (reducing parameter count by 41%) and virtual timestamp encoding to model the interannual evolution patterns of postoperative dynamic processes, such as liver regeneration and steatosis. For cross-modal feature alignment, Transformer layers are integrated to jointly optimize modality alignment loss and disentanglement loss, effectively suppressing scale mismatch and redundant interference in clinical-imaging data. Additionally, we design a dynamic prognostic decision module that generates personalized interannual recurrence risk heatmaps through temporal upsampling and a gated classification head, overcoming the limitations of traditional methods in temporal dynamic modeling and cross-modal alignment. Experiments on 197 CRLM patients demonstrate that the model achieves 100% temporal adjacency accuracy (TAA), with performance significantly surpassing existing approaches. This study establishes the first spatiotemporal modeling paradigm for postoperative dynamic monitoring of CRLM. The proposed framework can be extended to prognostic analysis of multi-cancer metastases, advancing precision surgery from “spatial resection” to “spatiotemporal cure.”
对于结直肠癌肝转移(CRLM)的术后预后预测,由于肿瘤的异质性、肝脏微环境的动态演变以及多模态数据融合的不足,仍然面临挑战。为了解决这些问题,我们提出了4D-ACFNet框架,该框架协同整合了轻量级时空建模、跨模态动态校准和个性化时序预测的统一架构。具体来说,它融入了一种新颖的4D时空注意力机制,采用时空可分离卷积(减少41%的参数数量)和虚拟时间戳编码,以模拟术后动态过程的年度演变模式,如肝脏再生和脂肪肝变性等。为了进行跨模态特征对齐,集成了Transformer层以联合优化模态对齐损失和分解损失,有效地抑制了临床影像数据中尺度不匹配和冗余干扰。此外,我们设计了一个动态预后决策模块,通过时序上采样和门控分类头生成个性化的年度复发风险热图,克服了传统方法在时序动态建模和跨模态对齐方面的局限性。在197名CRLM患者上的实验表明,该模型的时间邻接精度(TAA)达到100%,性能显著超越了现有方法。本研究为CRLM的术后动态监测建立了首个时空建模范式。所提出的框架可扩展到多癌转移的预后分析,推动精准手术从“空间切除”发展到“时空治愈”。
论文及项目相关链接
PDF 8 pages,6 figures,2 tables,submitted to the 33rd ACM International Conference on Multimedia(ACM MM 2025)
摘要
本文提出了一个名为4D-ACFNet的框架,旨在解决结直肠癌肝转移(CRLM)术后预后预测的难题。该框架通过整合轻量级时空建模、跨模态动态校准和个性化时序预测,克服了肿瘤异质性、肝脏微环境动态演变和多模态数据融合不足的问题。它通过引入4D时空注意力机制和虚拟时间戳编码,对术后动态过程(如肝再生和脂肪变性)的年际演变模式进行建模。同时,通过整合Transformer层优化模态对齐损失和分离损失,有效抑制了临床与成像数据中的尺度不匹配和冗余干扰。此外,设计了一个动态预后决策模块,通过时序上采样和门控分类头生成个性化的年际复发风险热图,克服了传统方法在时序动态建模和跨模态对齐方面的局限性。在197名CRLM患者上的实验表明,该模型达到100%的时间邻接精度(TAA),性能显著优于现有方法。该研究为CRLM的术后动态监测建立了首个时空建模范例,并且该框架可扩展到多癌转移的预后分析,推动精准手术从“空间切除”向“时空治愈”发展。
关键见解
- 4D-ACFNet框架被提出,整合了轻量级时空建模、跨模态动态校准和个性化时序预测。
- 引入4D时空注意力机制和虚拟时间戳编码,对术后动态过程的年际演变进行建模。
- 通过Transformer层优化模态对齐,减少临床与成像数据中的尺度不匹配和冗余干扰。
- 设计了动态预后决策模块,生成个性化复发风险热图,克服传统方法的局限性。
- 模型在197名CRLM患者上达到100%的时间邻接精度(TAA)。
- 研究为CRLM的术后动态监测建立了首个时空建模范例。
点此查看论文截图


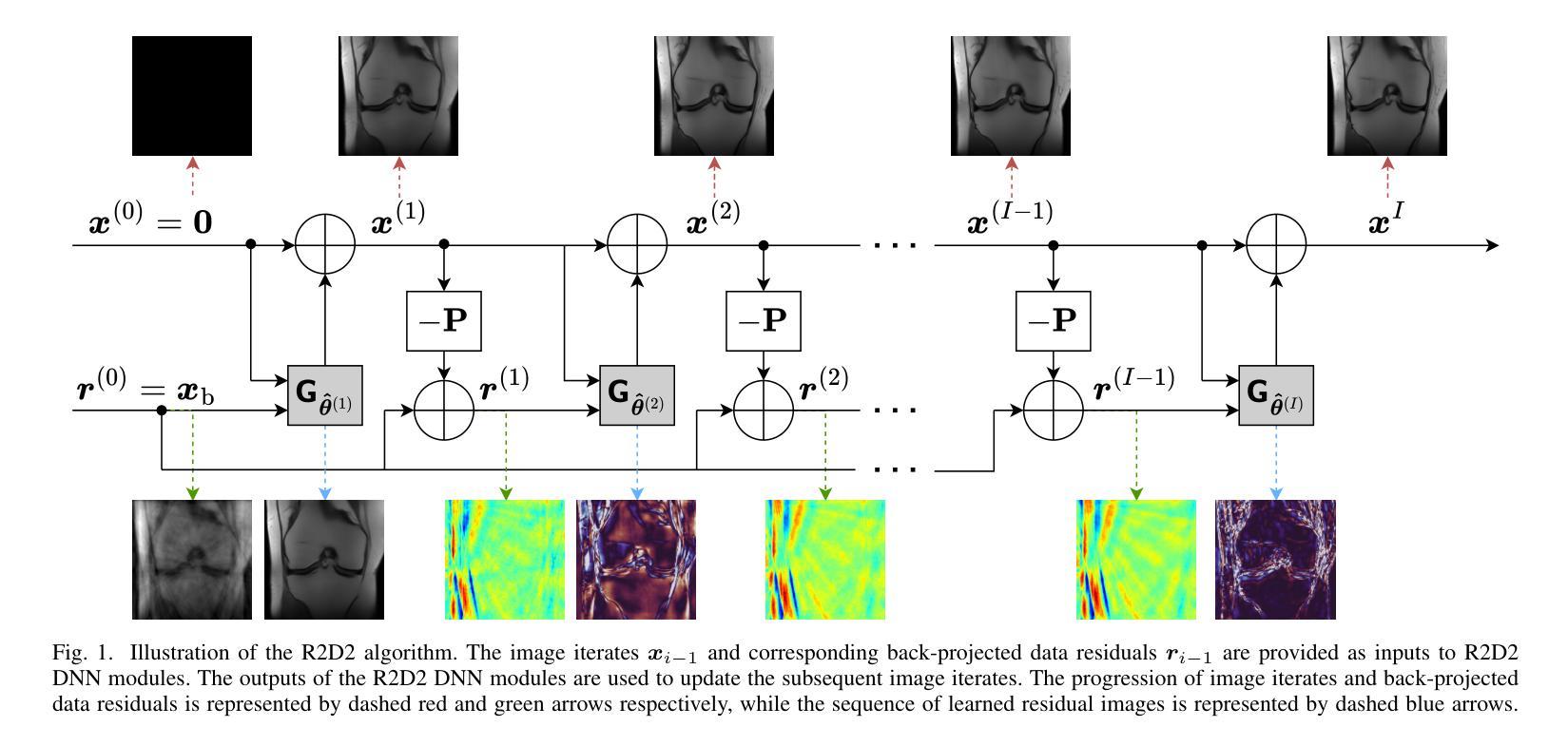
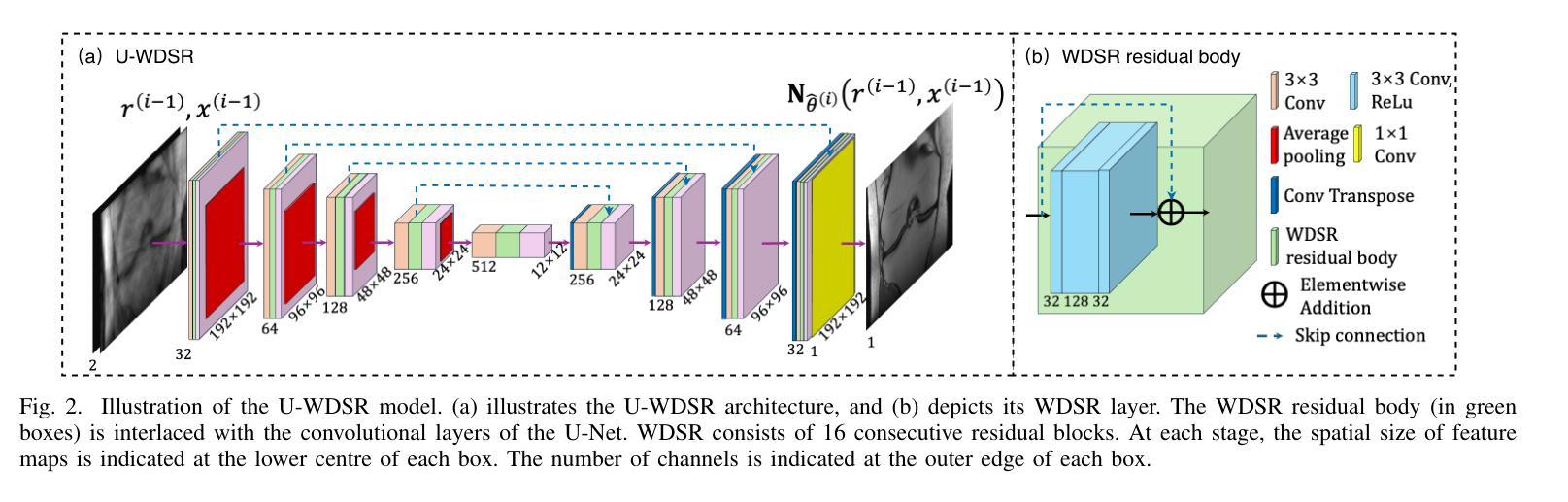
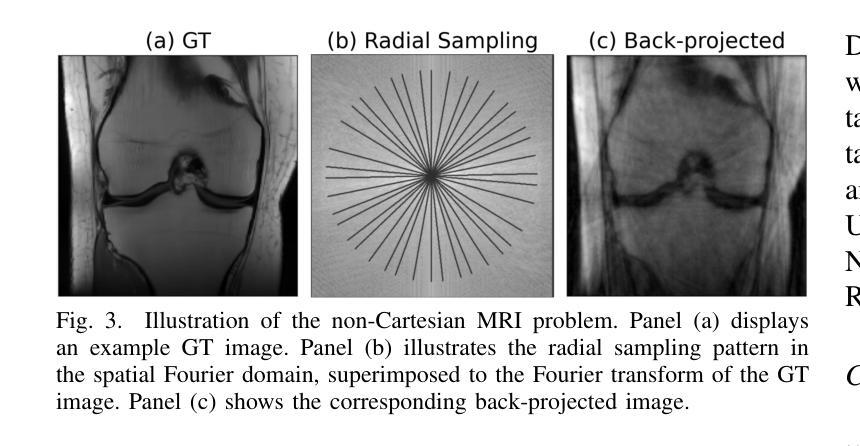
The R2D2 Deep Neural Network Series for Scalable Non-Cartesian Magnetic Resonance Imaging
Authors:Yiwei Chen, Amir Aghabiglou, Shijie Chen, Motahare Torki, Chao Tang, Ruud B. van Heeswijk, Yves Wiaux
We introduce the R2D2 Deep Neural Network (DNN) series paradigm for fast and scalable image reconstruction from highly-accelerated non-Cartesian k-space acquisitions in Magnetic Resonance Imaging (MRI). While unrolled DNN architectures provide a robust image formation approach via data-consistency layers, embedding non-uniform fast Fourier transform operators in a DNN can become impractical to train at large scale, e.g in 2D MRI with a large number of coils, or for higher-dimensional imaging. Plug-and-play approaches that alternate a learned denoiser blind to the measurement setting with a data-consistency step are not affected by this limitation but their highly iterative nature implies slow reconstruction. To address this scalability challenge, we leverage the R2D2 paradigm that was recently introduced to enable ultra-fast reconstruction for large-scale Fourier imaging in radio astronomy. R2D2’s reconstruction is formed as a series of residual images iteratively estimated as outputs of DNN modules taking the previous iteration’s data residual as input. The method can be interpreted as a learned version of the Matching Pursuit algorithm. A series of R2D2 DNN modules were sequentially trained in a supervised manner on the fastMRI dataset and validated for 2D multi-coil MRI in simulation and on real data, targeting highly under-sampled radial k-space sampling. Results suggest that a series with only few DNNs achieves superior reconstruction quality over its unrolled incarnation R2D2-Net (whose training is also much less scalable), and over the state-of-the-art diffusion-based “Decomposed Diffusion Sampler” approach (also characterised by a slower reconstruction process).
我们引入了R2D2深度神经网络(DNN)系列范式,用于从磁共振成像(MRI)中高度加速的非笛卡尔k空间采集快速且可扩展的图像重建。虽然展开的DNN架构通过数据一致性层提供了稳健的图像形成方法,但在大规模情况下,例如在具有大量线圈的二维MRI或更高维成像中,在DNN中嵌入非均匀快速傅里立叶变换算子进行训练可能不切实际。交替使用对测量设置盲目的学习去噪器和数据一致性步骤的即插即用方法不受此限制,但它们的高度迭代性质意味着重建速度较慢。为了应对这一可扩展性挑战,我们利用R2D2范式,该范式最近被引入到天文无线电中的大规模傅里叶成像以进行超快速重建。R2D2的重建是由一系列残差图像组成,这些残差图像是DNN模块的输出,以之前的迭代数据残差作为输入而迭代估计得出。该方法可解释为匹配追踪算法的学习版本。R2D2 DNN模块系列以监督方式在fastMRI数据集上进行训练,并针对高度欠采样的径向k空间采样在模拟和真实数据上进行2D多线圈MRI验证。结果表明,只有少数DNN的系列达到了优于其展开的R2D2-Net(其训练也不太可扩展)以及优于最先进的基于扩散的“分解扩散采样器”方法的重建质量(该方法也以其较慢的重建过程为特征)。
论文及项目相关链接
PDF 13 pages, 10 figures
Summary
本文介绍了基于R2D2深度神经网络(DNN)系列的范式,用于从高度加速的非笛卡尔k空间采集中进行快速且可伸缩的磁共振成像(MRI)图像重建。该范式解决了在具有大量线圈的二维MRI或更高维度成像中,将非均匀快速傅里叶变换算子嵌入DNN中进行大规模训练的不实用性。通过利用R2D2范式,实现了快速重建,该范式的重建形式是一系列残差图像的迭代估计,这些估计作为DNN模块的输出来获得前一次迭代的剩余数据作为输入。一系列R2D2 DNN模块在fastMRI数据集上进行监督训练,并在模拟和真实数据上对二维多线圈MRI进行验证,针对高度欠采样的径向k空间采样。结果表明,仅包含少数DNN的系列实现优于其未展开的R2D2-Net版本(其训练也不太可扩展),并且优于最先进的基于扩散的“分解扩散采样器”方法(其特征在于较慢的重建过程)。
Key Takeaways
- 引入R2D2 Deep Neural Network (DNN)系列范式,用于快速和可伸缩的图像重建。
- 解决在大型傅里叶成像中将非均匀快速傅里叶变换嵌入DNN进行大规模训练的不实用性问题。
- R2D2范式的重建是一系列基于DNN模块输出的残差图像的迭代估计。
- R2D2范式可以理解为匹配追踪算法的学习版本。
- R2D2 DNN模块在fastMRI数据集上进行监督训练。
- R2D2系列在模拟和真实数据的二维多线圈MRI验证中表现优越。
点此查看论文截图

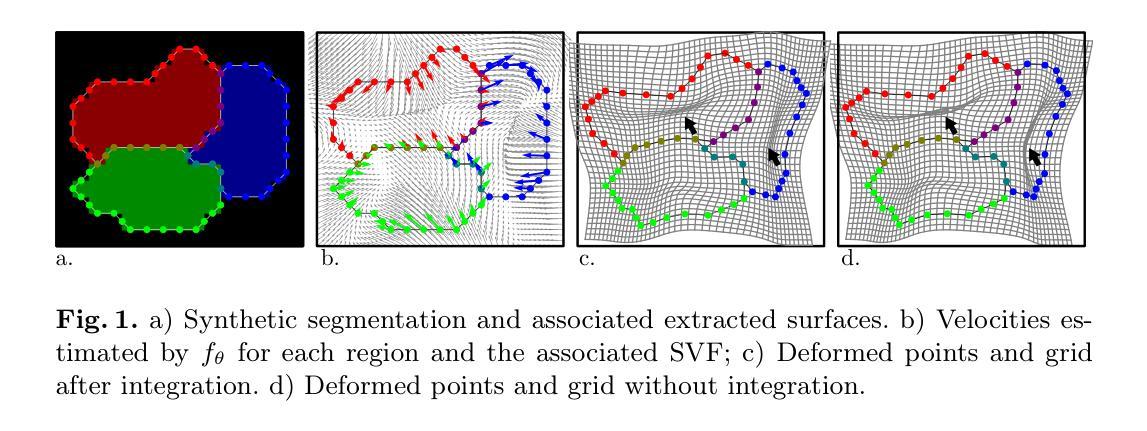
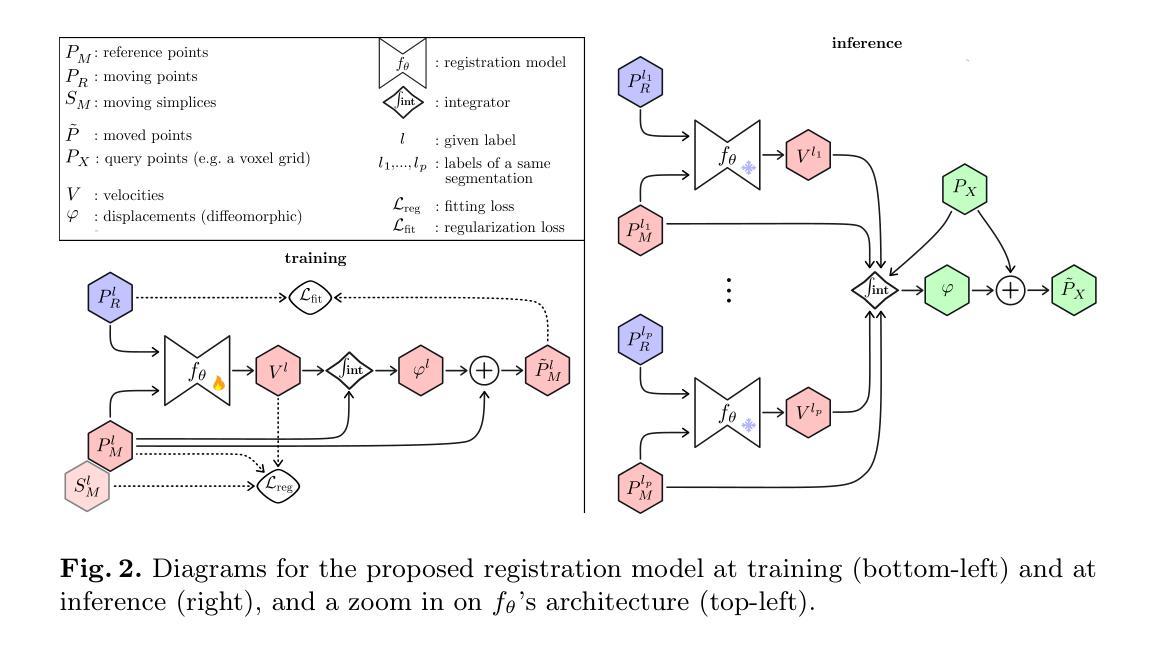
NimbleReg: A light-weight deep-learning framework for diffeomorphic image registration
Authors:Antoine Legouhy, Ross Callaghan, Nolah Mazet, Vivien Julienne, Hojjat Azadbakht, Hui Zhang
This paper presents NimbleReg, a light-weight deep-learning (DL) framework for diffeomorphic image registration leveraging surface representation of multiple segmented anatomical regions. Deep learning has revolutionized image registration but most methods typically rely on cumbersome gridded representations, leading to hardware-intensive models. Reliable fine-grained segmentations, that are now accessible at low cost, are often used to guide the alignment. Light-weight methods representing segmentations in terms of boundary surfaces have been proposed, but they lack mechanism to support the fusion of multiple regional mappings into an overall diffeomorphic transformation. Building on these advances, we propose a DL registration method capable of aligning surfaces from multiple segmented regions to generate an overall diffeomorphic transformation for the whole ambient space. The proposed model is light-weight thanks to a PointNet backbone. Diffeomoprhic properties are guaranteed by taking advantage of the stationary velocity field parametrization of diffeomorphisms. We demonstrate that this approach achieves alignment comparable to state-of-the-art DL-based registration techniques that consume images.
本文介绍了NimbleReg,这是一个轻量级的深度学习(DL)框架,用于利用多个分割解剖区域的表面表示进行微分同胚图像配准。深度学习已经彻底改变了图像配准,但大多数方法通常依赖于繁琐的网格表示,导致硬件密集型模型。现在低成本即可获得的可靠精细分割通常用于引导对齐。虽然已有轻量级方法用边界表面表示分割,但它们缺乏将多个区域映射融合到整体微分同胚变换中的机制。基于这些进展,我们提出了一种深度学习配准方法,该方法能够将多个分割区域的表面对齐,以生成整个环境空间的整体微分同胚变换。所提模型得益于PointNet骨干网而实现轻量化。通过利用微分同胚的稳态速度场参数化,保证了微分同胚属性。我们证明,该方法实现的配准效果与消耗图像的最新深度学习配准技术相当。
论文及项目相关链接
PDF submitted in MICCAI 2025 conference
Summary
本文介绍了NimbleReg,这是一个基于深度学习的轻量化图像注册框架,它利用多个分割解剖区域的表面表示来进行微分同胚图像注册。该方法基于PointNet骨干网构建轻量化模型,利用表面表示法融合多个区域映射,生成整个环境的微分同胚变换。这种方法在保证对齐质量的同时,更加轻量化和高效。
Key Takeaways
- NimbleReg是一个基于深度学习的图像注册框架,适用于微分同胚图像注册。
- 该方法利用多个分割解剖区域的表面表示进行图像注册。
- NimbleReg采用轻量化模型设计,基于PointNet骨干网。
- 该方法融合了多个区域映射,生成了整个环境的微分同胚变换。
- 微分同胚属性通过利用微分同胚的稳态速度场参数化来保证。
- 实验结果表明,该方法实现了与基于图像的深度学习方法相当的对齐效果。
点此查看论文截图

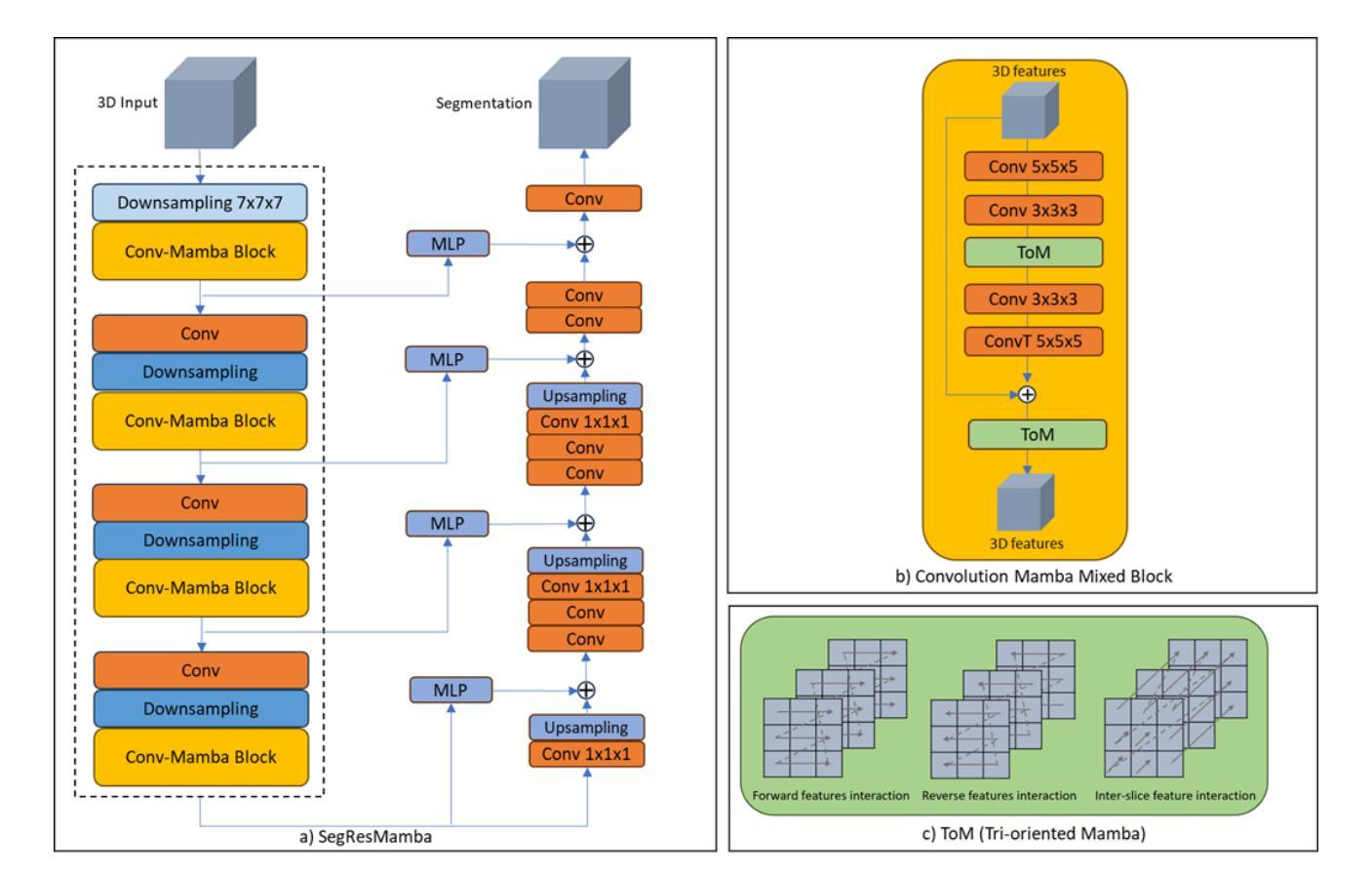
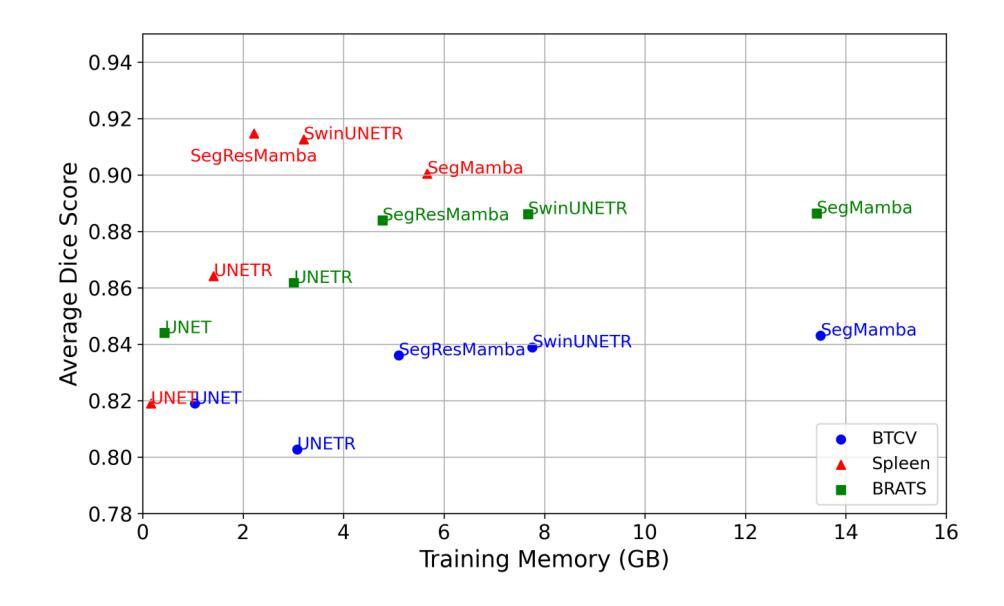
SegResMamba: An Efficient Architecture for 3D Medical Image Segmentation
Authors:Badhan Kumar Das, Ajay Singh, Saahil Islam, Gengyan Zhao, Andreas Maier
The Transformer architecture has opened a new paradigm in the domain of deep learning with its ability to model long-range dependencies and capture global context and has outpaced the traditional Convolution Neural Networks (CNNs) in many aspects. However, applying Transformer models to 3D medical image datasets presents significant challenges due to their high training time, and memory requirements, which not only hinder scalability but also contribute to elevated CO$_2$ footprint. This has led to an exploration of alternative models that can maintain or even improve performance while being more efficient and environmentally sustainable. Recent advancements in Structured State Space Models (SSMs) effectively address some of the inherent limitations of Transformers, particularly their high memory and computational demands. Inspired by these advancements, we propose an efficient 3D segmentation model for medical imaging called SegResMamba, designed to reduce computation complexity, memory usage, training time, and environmental impact while maintaining high performance. Our model uses less than half the memory during training compared to other state-of-the-art (SOTA) architectures, achieving comparable performance with significantly reduced resource demands.
Transformer架构凭借其能够建模长距离依赖关系并捕捉全局上下文的能力,在深度学习领域开启了一种新的范式,并且在许多方面都超越了传统的卷积神经网络(CNN)。然而,将Transformer模型应用于3D医学图像数据集存在巨大的挑战,因为其训练时间长和内存要求高的特点不仅阻碍了可扩展性,还导致了CO₂排放足迹增加。这促使人们探索能够维持甚至提高性能的同时更高效且环保的替代模型。结构化状态空间模型(SSMs)的最新进展有效地解决了Transformer的一些固有局限性,特别是其高内存和计算需求。受这些进展的启发,我们提出了一个高效的医学成像3D分割模型SegResMamba,旨在降低计算复杂度、内存使用、训练时间以及对环境的影响,同时保持高性能。与其他最先进的架构相比,我们的模型在训练期间使用的内存减少了一半以上,并以显著降低的资源需求实现了相当的性能。
论文及项目相关链接
Summary
本文介绍了Transformer架构在深度学习领域中的新范式,其能够建模长距离依赖关系并捕获全局上下文,已在许多方面超越了传统的卷积神经网络(CNNs)。然而,将Transformer模型应用于3D医学图像数据集时,存在训练时间长、内存要求高等挑战,这不仅阻碍了可扩展性,还导致了二氧化碳足迹的增加。因此,研究人员开始探索能够维持或提高性能同时更具效率和环保的替代模型。最近的结构状态空间模型(SSMs)的进步有效地解决了Transformer的一些固有局限性,特别是其高内存和计算需求。受这些进步的启发,本文提出了一种高效的医学成像3D分割模型SegResMamba,旨在降低计算复杂度、内存使用、训练时间和环境影响,同时保持高性能。该模型在训练期间使用的内存不到其他先进架构的一半,同时实现了相当的性能,并显著降低了资源需求。
Key Takeaways
- Transformer架构具有建模长距离依赖和捕获全局上下文的能力,在深度学习领域开辟了新的范式。
- 将Transformer模型应用于3D医学图像数据集时存在挑战,如训练时间长、内存要求高。
- 这些挑战导致二氧化碳足迹增加,需要探索更高效、环保的替代模型。
- 结构状态空间模型(SSMs)的最新进展解决了Transformer的一些局限性。
- SegResMamba模型是一种高效的医学成像3D分割模型,旨在降低计算复杂度、内存使用、训练时间和环境影响,同时保持良好的性能。
- SegResMamba模型在训练期间使用的内存显著少于其他先进架构。
点此查看论文截图


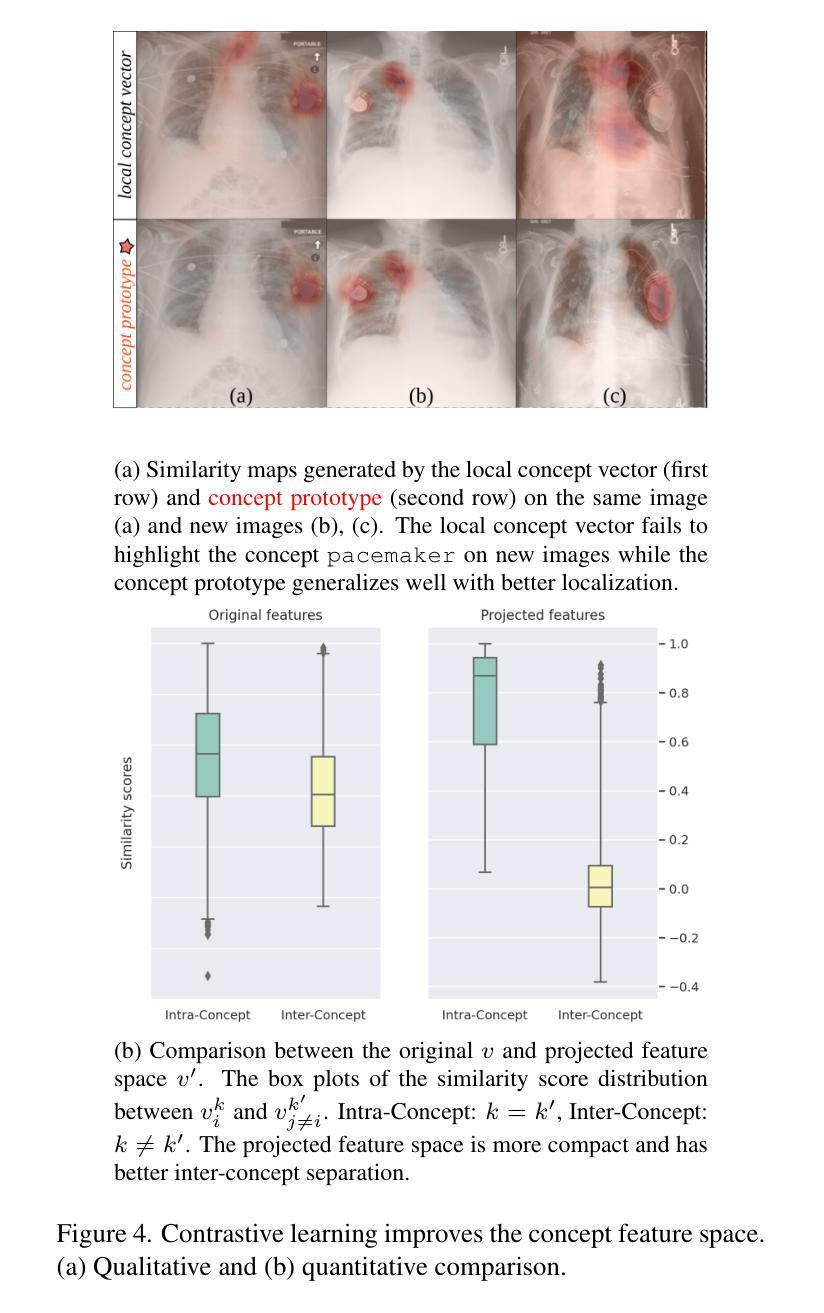
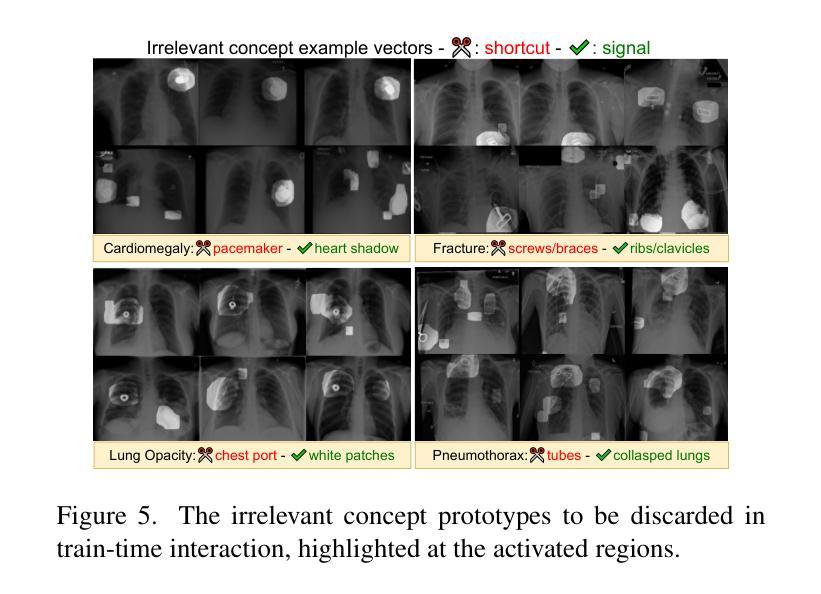
Interactive Medical Image Analysis with Concept-based Similarity Reasoning
Authors:Ta Duc Huy, Sen Kim Tran, Phan Nguyen, Nguyen Hoang Tran, Tran Bao Sam, Anton van den Hengel, Zhibin Liao, Johan W. Verjans, Minh-Son To, Vu Minh Hieu Phan
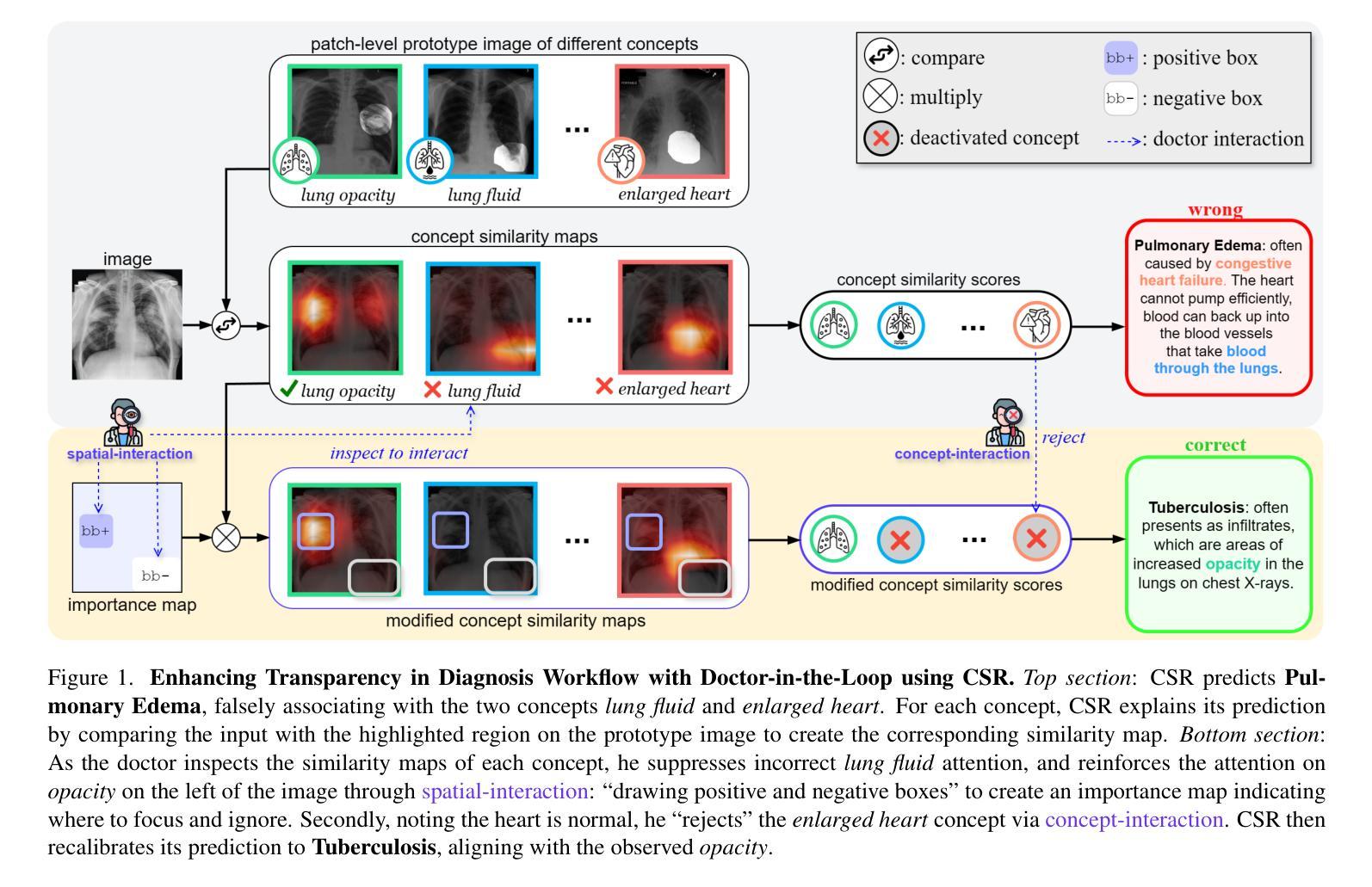
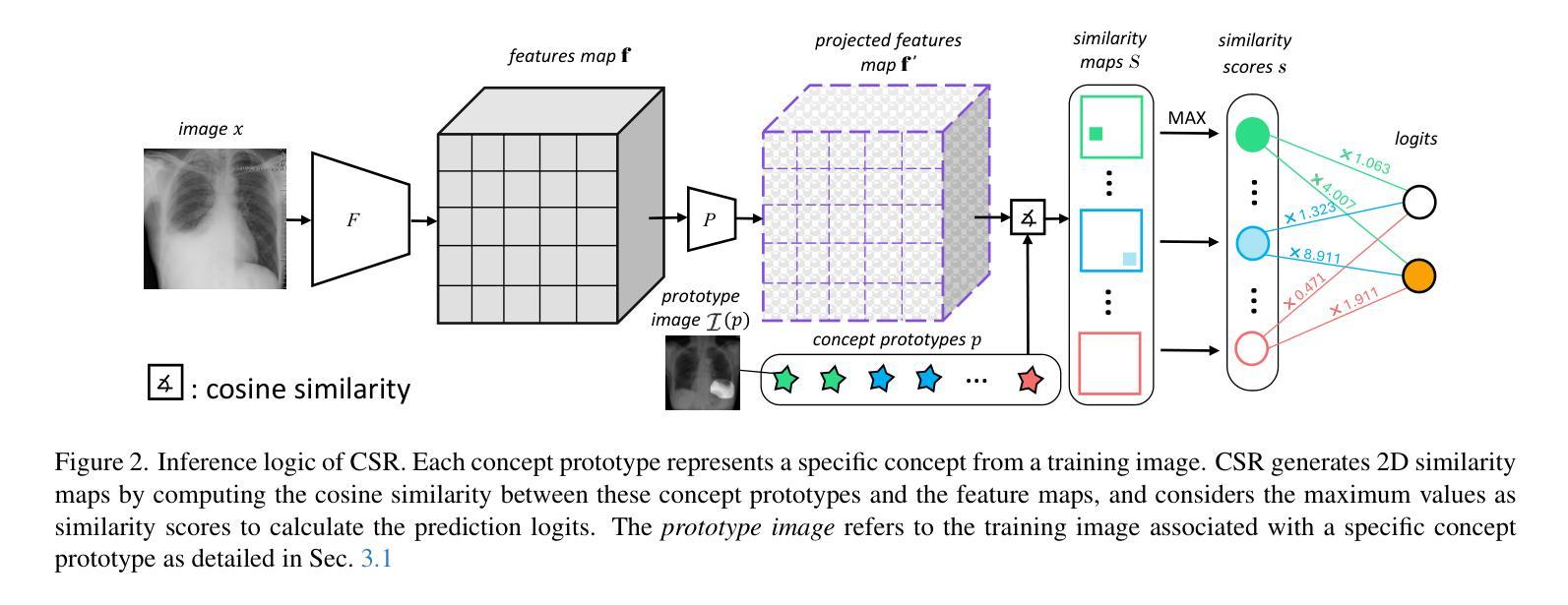
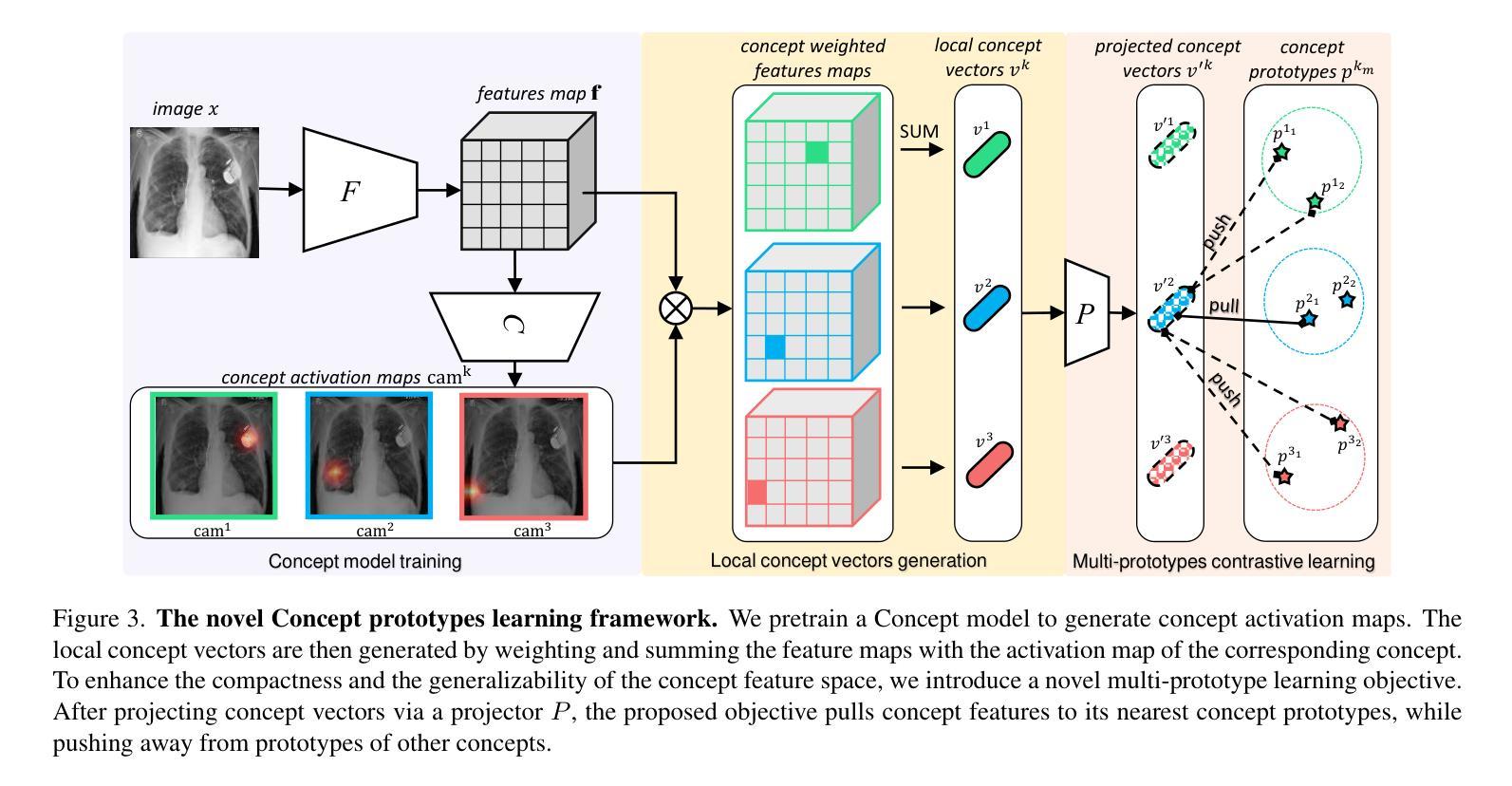
The ability to interpret and intervene model decisions is important for the adoption of computer-aided diagnosis methods in clinical workflows. Recent concept-based methods link the model predictions with interpretable concepts and modify their activation scores to interact with the model. However, these concepts are at the image level, which hinders the model from pinpointing the exact patches the concepts are activated. Alternatively, prototype-based methods learn representations from training image patches and compare these with test image patches, using the similarity scores for final class prediction. However, interpreting the underlying concepts of these patches can be challenging and often necessitates post-hoc guesswork. To address this issue, this paper introduces the novel Concept-based Similarity Reasoning network (CSR), which offers (i) patch-level prototype with intrinsic concept interpretation, and (ii) spatial interactivity. First, the proposed CSR provides localized explanation by grounding prototypes of each concept on image regions. Second, our model introduces novel spatial-level interaction, allowing doctors to engage directly with specific image areas, making it an intuitive and transparent tool for medical imaging. CSR improves upon prior state-of-the-art interpretable methods by up to 4.5% across three biomedical datasets. Our code is released at https://github.com/tadeephuy/InteractCSR.
解读和干预模型决策的能力对于在临床工作流程中采用计算机辅助诊断方法具有重要意义。最近的概念方法将模型预测与可解释的概念联系起来,并修改其激活分数以与模型进行交互。然而,这些概念存在于图像层面,阻碍了模型确定概念激活的确切区域。基于原型的方法则从训练图像块中学习表示,并将其与测试图像块进行比较,使用相似度得分进行最终类别预测。然而,解释这些图像块的潜在概念可能具有挑战性,通常需要进行事后猜测。为了解决这个问题,本文引入了新型的概念相似性推理网络(CSR),它提供了(i)图像块级别的原型和内在概念解释,(ii)空间交互性。首先,所提出的CSR通过在图像区域上为每个概念提供原型来提供局部解释。其次,我们的模型引入了新型的空间级别交互,允许医生直接与特定的图像区域进行交互,使其成为医学影像的直观和透明工具。CSR在三个生物医学数据集上改进了最先进的可解释方法,提高了高达4.5%。我们的代码已发布在https://github.com/tadeephuy/InteractCSR。
论文及项目相关链接
PDF Accepted CVPR2025
Summary
医学图像领域中的概念相似性推理网络(CSR)结合了概念级和补丁级的解释方法,提高了模型决策的可解释性和干预能力。CSR实现了概念与图像区域的联系,为医生提供了直观和透明的诊断工具。该模型在三个生物医学数据集上的表现优于现有解释方法。
Key Takeaways
- 医学图像诊断中的模型决策需要可解释性和可干预性。
- 概念级方法有助于解释模型预测,但难以定位具体激活区域。
- 补丁级方法通过图像区域学习表示,但解释底层概念具有挑战性。
- CSR网络结合了概念级和补丁级的解释方法,提供局部解释和内在概念解读。
- CSR网络实现了空间级别的交互,使医生能够直接与特定图像区域互动。
- CSR网络提高了模型在三个生物医学数据集上的表现。
点此查看论文截图

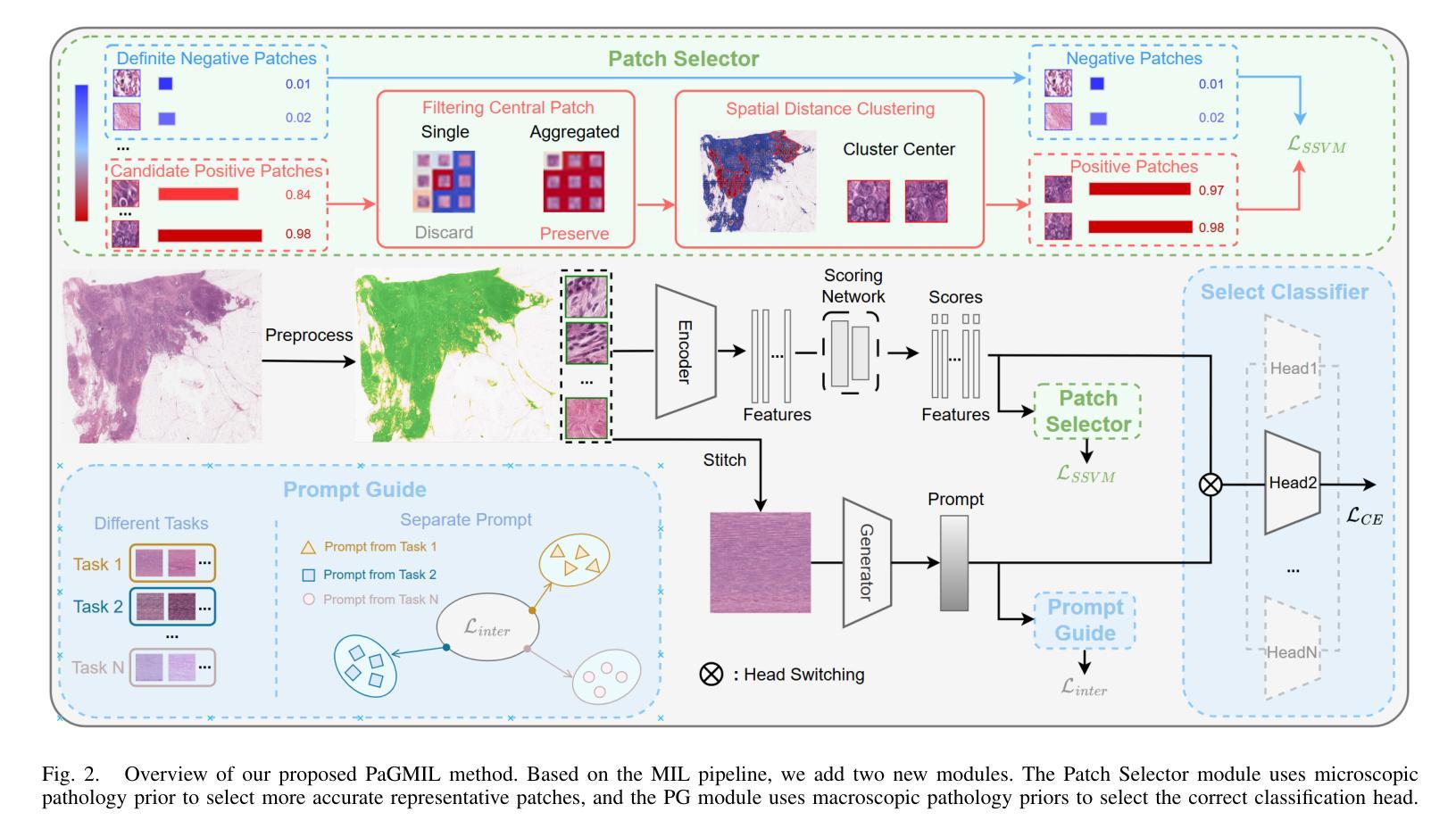
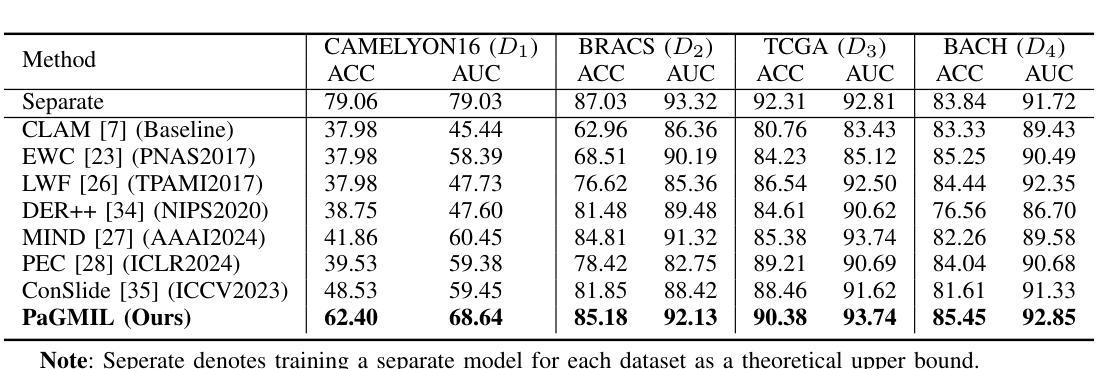
Pathological Prior-Guided Multiple Instance Learning For Mitigating Catastrophic Forgetting in Breast Cancer Whole Slide Image Classification
Authors:Weixi Zheng, Aoling Huang. Jingping Yuan, Haoyu Zhao, Zhou Zhao, Yongchao Xu, Thierry Géraud
In histopathology, intelligent diagnosis of Whole Slide Images (WSIs) is essential for automating and objectifying diagnoses, reducing the workload of pathologists. However, diagnostic models often face the challenge of forgetting previously learned data during incremental training on datasets from different sources. To address this issue, we propose a new framework PaGMIL to mitigate catastrophic forgetting in breast cancer WSI classification. Our framework introduces two key components into the common MIL model architecture. First, it leverages microscopic pathological prior to select more accurate and diverse representative patches for MIL. Secondly, it trains separate classification heads for each task and uses macroscopic pathological prior knowledge, treating the thumbnail as a prompt guide (PG) to select the appropriate classification head. We evaluate the continual learning performance of PaGMIL across several public breast cancer datasets. PaGMIL achieves a better balance between the performance of the current task and the retention of previous tasks, outperforming other continual learning methods. Our code will be open-sourced upon acceptance.
在病理学领域,智能地对全片图像(Whole Slide Images,简称WSI)进行诊断对于实现诊断和客观化诊断的自动化、减轻病理学家的工作量至关重要。然而,诊断模型在针对来自不同来源的数据集进行增量训练时,常常面临遗忘先前学习数据的挑战。为了解决这个问题,我们提出了一种新的框架PaGMIL,旨在缓解乳腺癌WSI分类中的灾难性遗忘问题。我们的框架在常见的MIL模型架构中引入了两个关键组件。首先,它利用微观病理先验知识来选择更准确和多样化的代表性补丁用于MIL。其次,它为每个任务训练了单独的分类头,并使用宏观病理先验知识,将缩略图作为提示指南(Prompt Guide,简称PG)来选择适当的分类头。我们在多个公共乳腺癌数据集上评估了PaGMIL的连续学习效果。PaGMIL在平衡当前任务性能和保留先前任务知识方面表现更好,优于其他连续学习方法。代码将在验收后开源。
论文及项目相关链接
PDF ICASSP2025(Oral)
Summary
本文介绍了一种新的框架PaGMIL,用于解决组织病理学全幻灯片图像(WSIs)智能诊断中的灾难性遗忘问题。通过引入微观和宏观病理先验知识,该框架优化了多实例学习(MIL)模型架构,并提升了乳腺癌WSI分类的连续学习能力。实验表明,PaGMIL在不同公共乳腺癌数据集上的持续学习性能表现优异,实现了当前任务性能与先前任务保留之间的平衡,并优于其他持续学习方法。
Key Takeaways
- 智能诊断全幻灯片图像(WSIs)在组织病理学中的重要性。
- 现有诊断模型在增量训练时面临灾难性遗忘的挑战。
- PaGMIL框架通过引入微观病理先验知识来选择更准确和多样化的代表性补丁,优化多实例学习(MIL)模型架构。
- PaGMIL使用宏观病理先验知识训练单独的任务分类头,并使用缩略图作为提示指南来选择适当的分类头。
- PaGMIL在多个公共乳腺癌数据集上进行了评估,实现了当前任务与先前任务之间的平衡。
- PaGMIL的持续学习性能优于其他方法。
点此查看论文截图

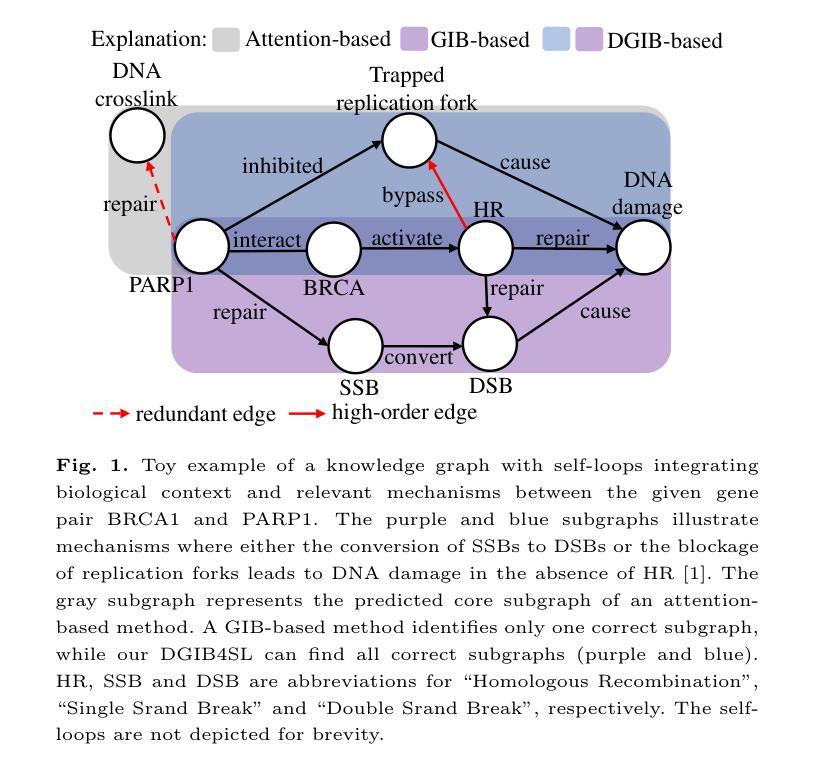
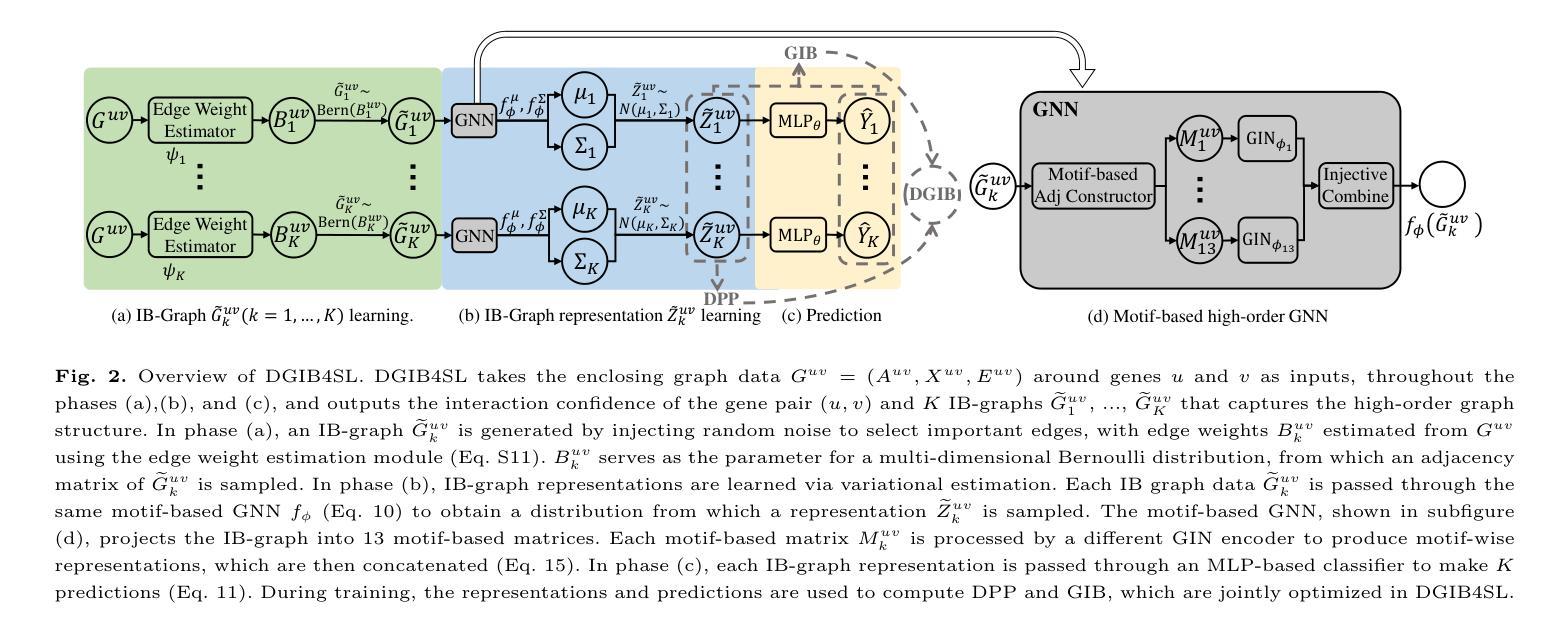
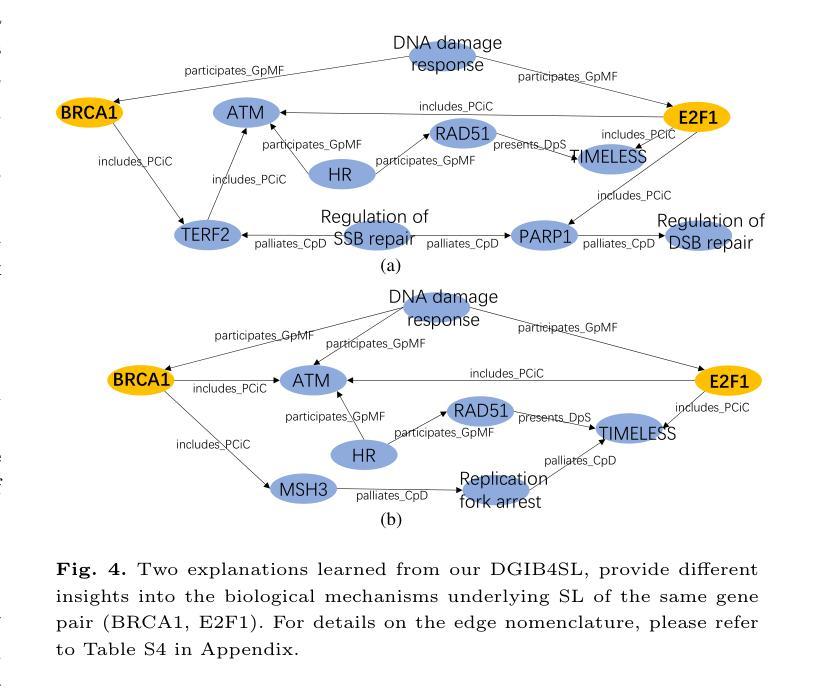
Interpretable High-order Knowledge Graph Neural Network for Predicting Synthetic Lethality in Human Cancers
Authors:Xuexin Chen, Ruichu Cai, Zhengting Huang, Zijian Li, Jie Zheng, Min Wu
Synthetic lethality (SL) is a promising gene interaction for cancer therapy. Recent SL prediction methods integrate knowledge graphs (KGs) into graph neural networks (GNNs) and employ attention mechanisms to extract local subgraphs as explanations for target gene pairs. However, attention mechanisms often lack fidelity, typically generate a single explanation per gene pair, and fail to ensure trustworthy high-order structures in their explanations. To overcome these limitations, we propose Diverse Graph Information Bottleneck for Synthetic Lethality (DGIB4SL), a KG-based GNN that generates multiple faithful explanations for the same gene pair and effectively encodes high-order structures. Specifically, we introduce a novel DGIB objective, integrating a Determinant Point Process (DPP) constraint into the standard IB objective, and employ 13 motif-based adjacency matrices to capture high-order structures in gene representations. Experimental results show that DGIB4SL outperforms state-of-the-art baselines and provides multiple explanations for SL prediction, revealing diverse biological mechanisms underlying SL inference.
合成致死性(Synthetic Lethality, SL)是一种具有潜力的癌症治疗基因交互作用。最近的SL预测方法将知识图谱(KG)融入图神经网络(GNN),并应用注意力机制提取局部子图作为目标基因对的解释。然而,注意力机制通常缺乏准确性,通常只为每个基因对生成一个解释,并且无法在解释中确保可靠的高阶结构。为了克服这些局限性,我们提出了基于知识图谱的合成致死性多样图信息瓶颈(DGIB4SL)方法。该方法为同一基因对生成多个忠实解释,并有效地编码高阶结构。具体来说,我们引入了一种新颖的DGIB目标,将行列式点过程(DPP)约束集成到标准IB目标中,并使用13个基于基序的邻接矩阵来捕获基因表示中的高阶结构。实验结果表明,DGIB4SL优于最新的基线方法,为SL预测提供了多个解释,揭示了SL推断背后的多种生物机制。
论文及项目相关链接
Summary
合成致死性(SL)是癌症治疗中有前景的基因交互作用。为克服现有SL预测方法中的注意力机制缺乏忠实度、通常只为基因对生成单一解释以及无法确保解释中可靠的高阶结构等问题,我们提出了基于知识图谱的图神经网络DGIB4SL,为同一基因对生成多个忠实解释,并有效编码高阶结构。
Key Takeaways
- 合成致死性(SL)在癌症治疗中是重要的基因交互。
- 现有SL预测方法结合知识图谱和图神经网络,但注意力机制常缺乏忠实度。
- DGIB4SL方法通过引入新颖的DGIB目标,整合行列式点过程(DPP)约束到标准IB目标中,解决现有方法的局限性。
- DGIB4SL使用13个基于模式的邻接矩阵来捕捉基因表示中的高阶结构。
- DGIB4SL相比最新技术基线表现出更好的性能。
- DGIB4SL为SL预测提供多个解释,揭示合成致死性推断背后的多种生物机制。
点此查看论文截图

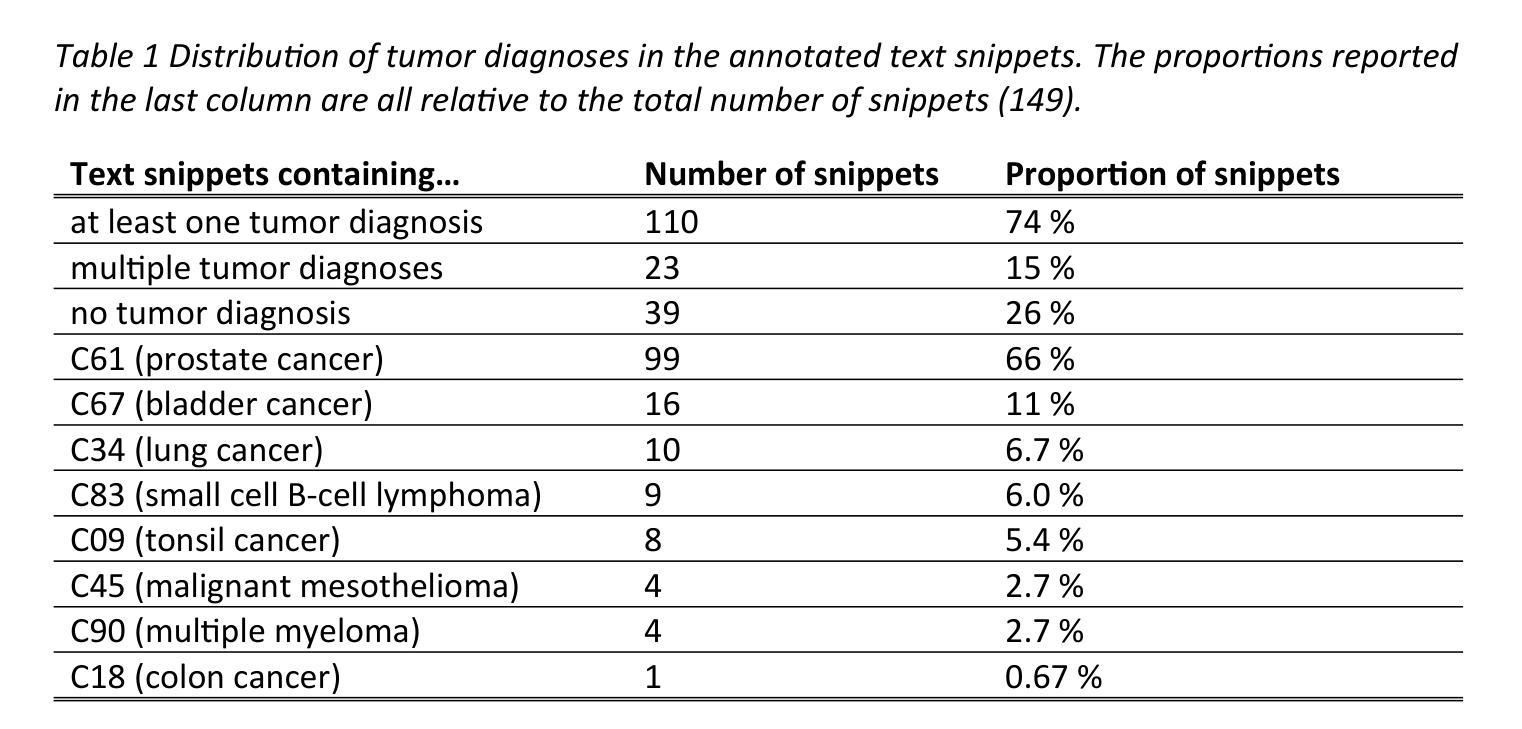
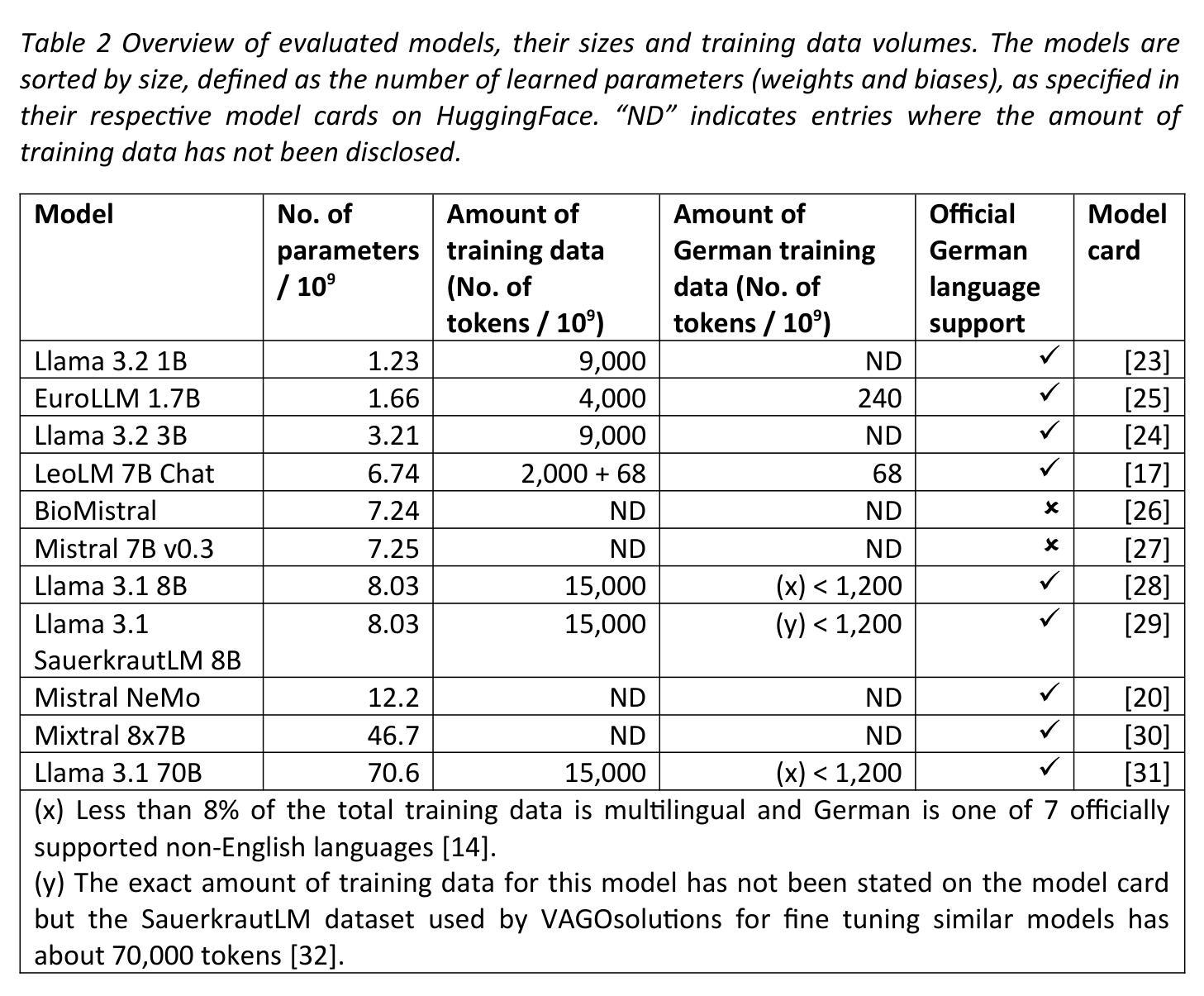
Can open source large language models be used for tumor documentation in Germany? – An evaluation on urological doctors’ notes
Authors:Stefan Lenz, Arsenij Ustjanzew, Marco Jeray, Torsten Panholzer
Tumor documentation in Germany is largely done manually, requiring reading patient records and entering data into structured databases. Large language models (LLMs) could potentially enhance this process by improving efficiency and reliability. This evaluation tests eleven different open source LLMs with sizes ranging from 1-70 billion model parameters on three basic tasks of the tumor documentation process: identifying tumor diagnoses, assigning ICD-10 codes, and extracting the date of first diagnosis. For evaluating the LLMs on these tasks, a dataset of annotated text snippets based on anonymized doctors’ notes from urology was prepared. Different prompting strategies were used to investigate the effect of the number of examples in few-shot prompting and to explore the capabilities of the LLMs in general. The models Llama 3.1 8B, Mistral 7B, and Mistral NeMo 12 B performed comparably well in the tasks. Models with less extensive training data or having fewer than 7 billion parameters showed notably lower performance, while larger models did not display performance gains. Examples from a different medical domain than urology could also improve the outcome in few-shot prompting, which demonstrates the ability of LLMs to handle tasks needed for tumor documentation. Open source LLMs show a strong potential for automating tumor documentation. Models from 7-12 billion parameters could offer an optimal balance between performance and resource efficiency. With tailored fine-tuning and well-designed prompting, these models might become important tools for clinical documentation in the future. The code for the evaluation is available from https://github.com/stefan-m-lenz/UroLlmEval. We also release the dataset as a new valuable resource that addresses the shortage of authentic and easily accessible benchmarks in German-language medical NLP.
在德国,肿瘤记录工作大多以手动方式进行,需要阅读患者病历并将数据输入结构化数据库。大型语言模型(LLMs)有潜力通过提高效率和可靠性来增强这一流程。本次评估对三种肿瘤记录基本任务(识别肿瘤诊断、分配ICD-10代码和提取首次诊断日期)上使用了从1亿到70亿模型参数不等的十一个不同开源LLMs进行了测试。为了评估这些任务上的LLMs性能,准备了一份基于泌尿科匿名医生笔记的注释文本片段数据集。使用了不同的提示策略来研究少量示例提示中示例数量的影响,并探索LLMs的一般能力。Llama 3.1 8B、Mistral 7B和Mistral NeMo 12B等模型在这些任务中表现相当出色。拥有较少训练数据或参数少于7亿的模型表现明显较差,而大型模型并没有显示出性能提升。来自泌尿科以外的其他医学领域的例子也可以在少量提示中改善结果,这证明了LLMs处理肿瘤记录所需任务的能力。开源LLMs在自动肿瘤记录方面显示出强大的潜力。参数在7亿到12亿之间的模型可能在性能和资源效率之间达到最佳平衡。通过有针对性的微调(fine-tuning)和精心设计提示,这些模型未来可能成为临床记录的重要工具。评估的代码可从https://github.com/stefan-m-lenz/UroLlmEval获取。我们还公开了数据集,作为解决德国医疗NLP领域中真实和易于访问基准测试数据短缺问题的新有价值资源。
论文及项目相关链接
PDF 48 pages, 5 figures
Summary
本文探讨了大型语言模型(LLMs)在肿瘤记录自动化方面的潜力。通过对11种不同规模(从1亿到70亿参数)的开源LLMs进行评价,发现它们在肿瘤诊断识别、ICD-10代码分配和首次诊断日期提取等任务中表现出良好的性能。模型参数在7-12亿之间的模型在性能和资源效率之间达到平衡。通过精细调整和精心设计提示,这些模型有望在未来成为临床文档管理的重要工具。数据集已发布,以解决德语医疗NLP领域真实和可访问基准数据的短缺问题。
Key Takeaways
- 大型语言模型(LLMs)有潜力提高德国肿瘤记录过程的效率和可靠性。
- 对11种不同规模和开源的LLMs进行了评价,包括不同任务和模型性能的比较。
- Llama 3.1 8B、Mistral 7B和Mistral NeMo 12B等模型在评估任务中表现良好。
- 模型参数在7-12亿之间可能在性能和资源效率之间达到最佳平衡。
- 通过精细调整和精心设计提示,这些模型可应用于临床文档管理。
- 模型的性能不仅取决于模型本身的规模和训练数据,还受到提示策略和领域差异的影响。
点此查看论文截图

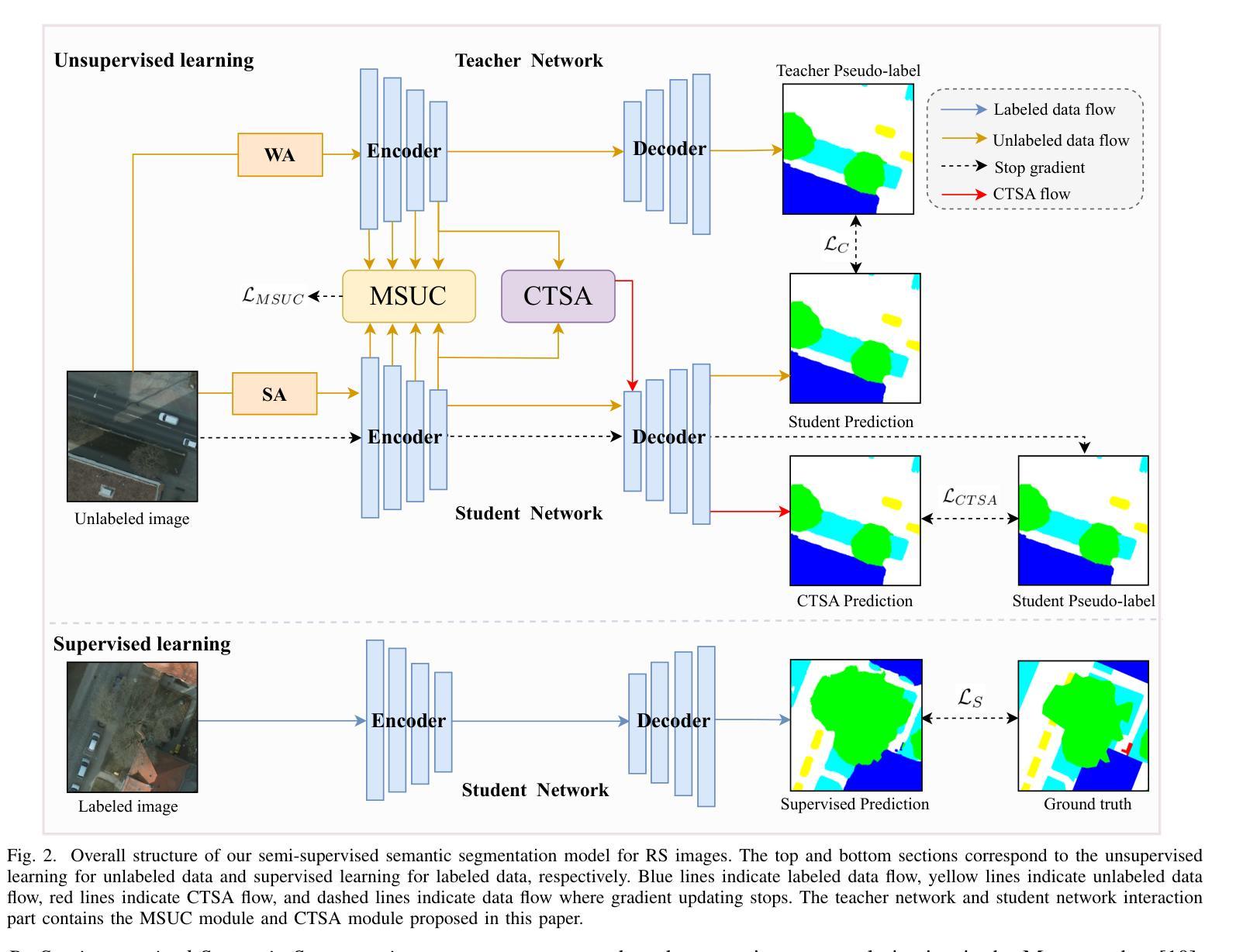
Semi-supervised Semantic Segmentation for Remote Sensing Images via Multi-scale Uncertainty Consistency and Cross-Teacher-Student Attention
Authors:Shanwen Wang, Xin Sun, Changrui Chen, Danfeng Hong, Jungong Han
Semi-supervised learning offers an appealing solution for remote sensing (RS) image segmentation to relieve the burden of labor-intensive pixel-level labeling. However, RS images pose unique challenges, including rich multi-scale features and high inter-class similarity. To address these problems, this paper proposes a novel semi-supervised Multi-Scale Uncertainty and Cross-Teacher-Student Attention (MUCA) model for RS image semantic segmentation tasks. Specifically, MUCA constrains the consistency among feature maps at different layers of the network by introducing a multi-scale uncertainty consistency regularization. It improves the multi-scale learning capability of semi-supervised algorithms on unlabeled data. Additionally, MUCA utilizes a Cross-Teacher-Student attention mechanism to guide the student network, guiding the student network to construct more discriminative feature representations through complementary features from the teacher network. This design effectively integrates weak and strong augmentations (WA and SA) to further boost segmentation performance. To verify the effectiveness of our model, we conduct extensive experiments on ISPRS-Potsdam and LoveDA datasets. The experimental results show the superiority of our method over state-of-the-art semi-supervised methods. Notably, our model excels in distinguishing highly similar objects, showcasing its potential for advancing semi-supervised RS image segmentation tasks.
半监督学习为遥感(RS)图像分割提供了一个吸引人的解决方案,减轻了劳动密集型的像素级标签的负担。然而,遥感图像带来了独特的挑战,包括丰富的多尺度特征和高的类间相似性。为了解决这些问题,本文提出了一种新型的半监督多尺度不确定性与交叉教师学生注意力(MUCA)模型,用于遥感图像语义分割任务。具体来说,MUCA通过引入多尺度不确定性一致性正则化,约束网络不同层特征图之间的一致性。它提高了半监督算法在未标记数据上的多尺度学习能力。此外,MUCA利用跨教师学生注意力机制来引导学生网络,通过教师网络的互补特征构建更具区分性的特征表示。这一设计有效地结合了弱增强和强增强(WA和SA),进一步提高了分割性能。为了验证我们模型的有效性,我们在ISPRS-Potsdam和LoveDA数据集上进行了大量实验。实验结果表明,我们的方法优于最新的半监督方法。值得注意的是,我们的模型在区分高度相似物体方面表现出色,展示了其在推进半监督遥感图像分割任务方面的潜力。
论文及项目相关链接
Summary
半监督学习为遥感图像分割提供了一种有吸引力的解决方案,减轻了劳动力密集的像素级标注的负担。针对遥感图像的多尺度特征和类间高相似性的挑战,本文提出了一种新的半监督Multi-Scale Uncertainty and Cross-Teacher-Student Attention(MUCA)模型。MUCA通过引入多尺度不确定性一致性正则化,提高了半监督算法在未标记数据上的多尺度学习能力。同时,MUCA利用跨教师学生注意力机制引导学生网络构建更具辨识度的特征表示。实验表明,该方法在ISPRS-Potsdam和LoveDA数据集上表现优异,尤其是在区分高度相似物体方面展现潜力。
Key Takeaways
- 半监督学习是解决遥感图像分割中劳动力密集标注问题的一种有效方法。
- 遥感图像具有多尺度特征和类间高相似性的挑战。
- MUCA模型通过多尺度不确定性一致性正则化提高半监督算法在未标记数据上的多尺度学习能力。
- MUCA模型利用跨教师学生注意力机制,引导学生网络构建更具辨识度的特征表示。
- 模型结合了弱增强和强增强,进一步提高分割性能。
- 在ISPRS-Potsdam和LoveDA数据集上的实验验证了MUCA模型的有效性。
点此查看论文截图

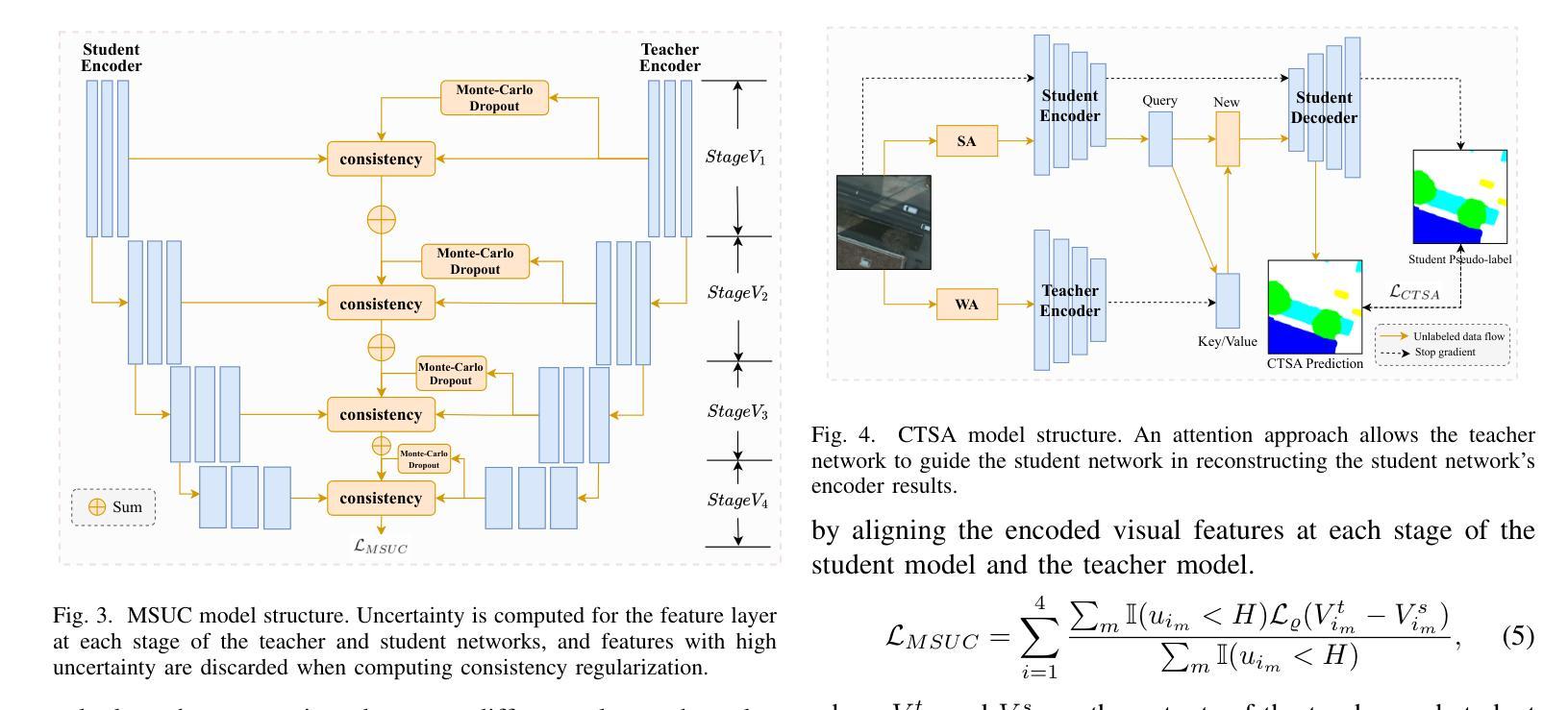

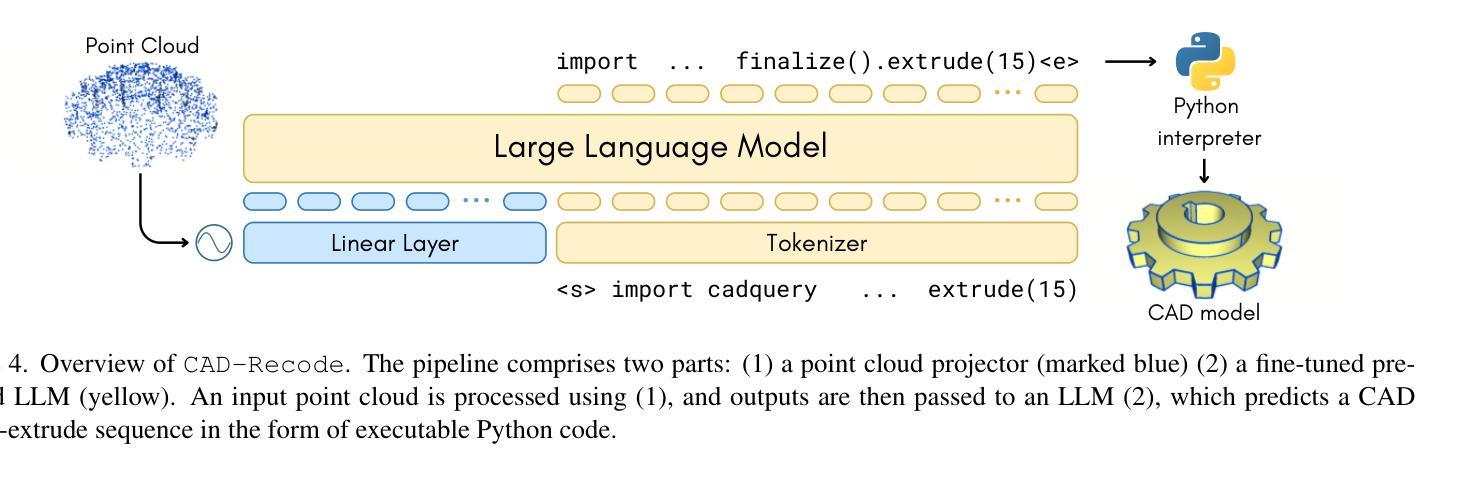
CAD-Recode: Reverse Engineering CAD Code from Point Clouds
Authors:Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, Djamila Aouada
Computer-Aided Design (CAD) models are typically constructed by sequentially drawing parametric sketches and applying CAD operations to obtain a 3D model. The problem of 3D CAD reverse engineering consists of reconstructing the sketch and CAD operation sequences from 3D representations such as point clouds. In this paper, we address this challenge through novel contributions across three levels: CAD sequence representation, network design, and training dataset. In particular, we represent CAD sketch-extrude sequences as Python code. The proposed CAD-Recode translates a point cloud into Python code that, when executed, reconstructs the CAD model. Taking advantage of the exposure of pre-trained Large Language Models (LLMs) to Python code, we leverage a relatively small LLM as a decoder for CAD-Recode and combine it with a lightweight point cloud projector. CAD-Recode is trained on a procedurally generated dataset of one million CAD sequences. CAD-Recode significantly outperforms existing methods across the DeepCAD, Fusion360 and real-world CC3D datasets. Furthermore, we show that our CAD Python code output is interpretable by off-the-shelf LLMs, enabling CAD editing and CAD-specific question answering from point clouds.
计算机辅助设计(CAD)模型通常是通过依次绘制参数化草图并应用CAD操作来获得的三维模型。3D CAD逆向工程的问题在于从点云等3D表示中重建草图和CAD操作序列。在本文中,我们通过三个方面的新贡献来解决这一挑战:CAD序列表示、网络设计和训练数据集。特别是,我们将CAD草图挤压序列表示为Python代码。所提出的CAD-Recode将点云转换为Python代码,执行该代码即可重建CAD模型。利用预训练的的大型语言模型(LLM)对Python代码的暴露,我们利用一个较小的LLM作为CAD-Recode的解码器,并将其与一个轻量级的点云投影仪相结合。CAD-Recode是在程序生成的一百万个CAD序列数据集上进行训练的。在DeepCAD、Fusion360和现实世界CC3D数据集中,CAD-Recode显著优于现有方法。此外,我们展示了我们的CAD Python代码输出能被市面上的LLM解释,从而能够有点云进行CAD编辑和针对CAD的问题回答。
论文及项目相关链接
Summary
这篇论文探讨了计算机三维辅助设计(CAD)的逆向工程问题,通过三个方面的创新贡献来解决这个问题:CAD序列表示、网络设计和训练数据集。论文将CAD草图挤压序列表示为Python代码,并提出CAD-Recode方法,将点云转化为Python代码,执行后可重建CAD模型。利用预训练的的大型语言模型(LLM)对Python代码的暴露,结合小型LLM解码器和轻量级点云投影仪,在CAD-Recode训练了一千万个CAD序列的程序生成数据集上表现出显著的性能。CAD-Recode在深CAD、Fusion360和现实世界CC3D数据集上的表现均优于现有方法。此外,论文展示的CAD Python代码输出能被市面上的LLM解释,使得从点云中进行CAD编辑和回答CAD相关问题成为可能。
Key Takeaways
- 该论文解决了计算机三维辅助设计(CAD)的逆向工程问题,旨在从三维表示(如点云)重建草图和设计操作序列。
- 创新性地使用Python代码表示CAD草图挤压序列,提出CAD-Recode方法,将点云转化为可执行的Python代码以重建CAD模型。
- 利用预训练的大型语言模型(LLM)结合轻量级点云投影仪进行解码。
- CAD-Recode在大型程序生成数据集上进行训练,性能显著优于现有方法。
- CAD-Recode输出的Python代码具有可解释性,便于CAD编辑和回答相关问题。
- 该方法具有广泛的应用前景,可应用于不同领域的三维模型重建和编辑。
点此查看论文截图

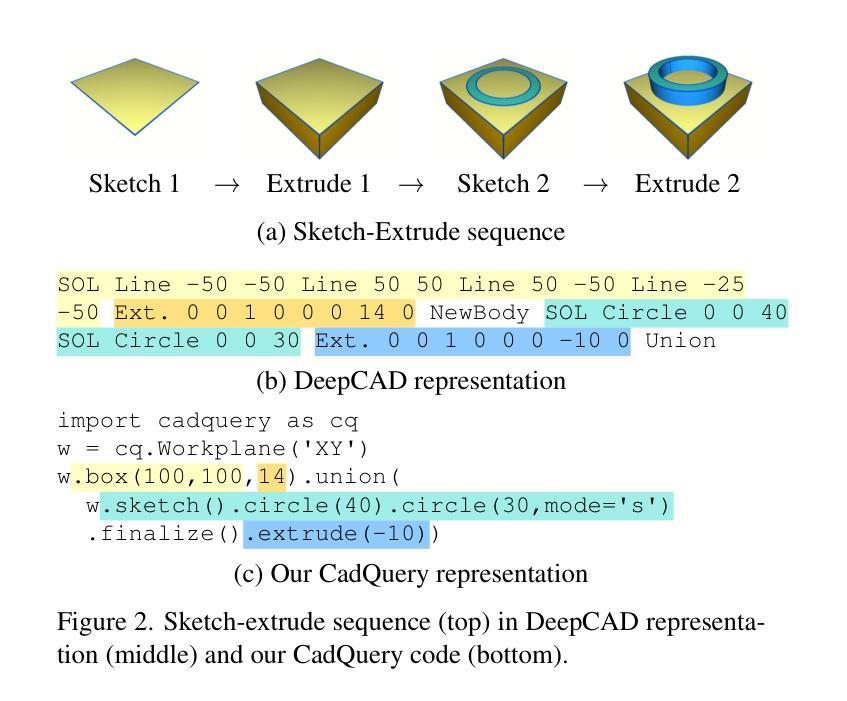
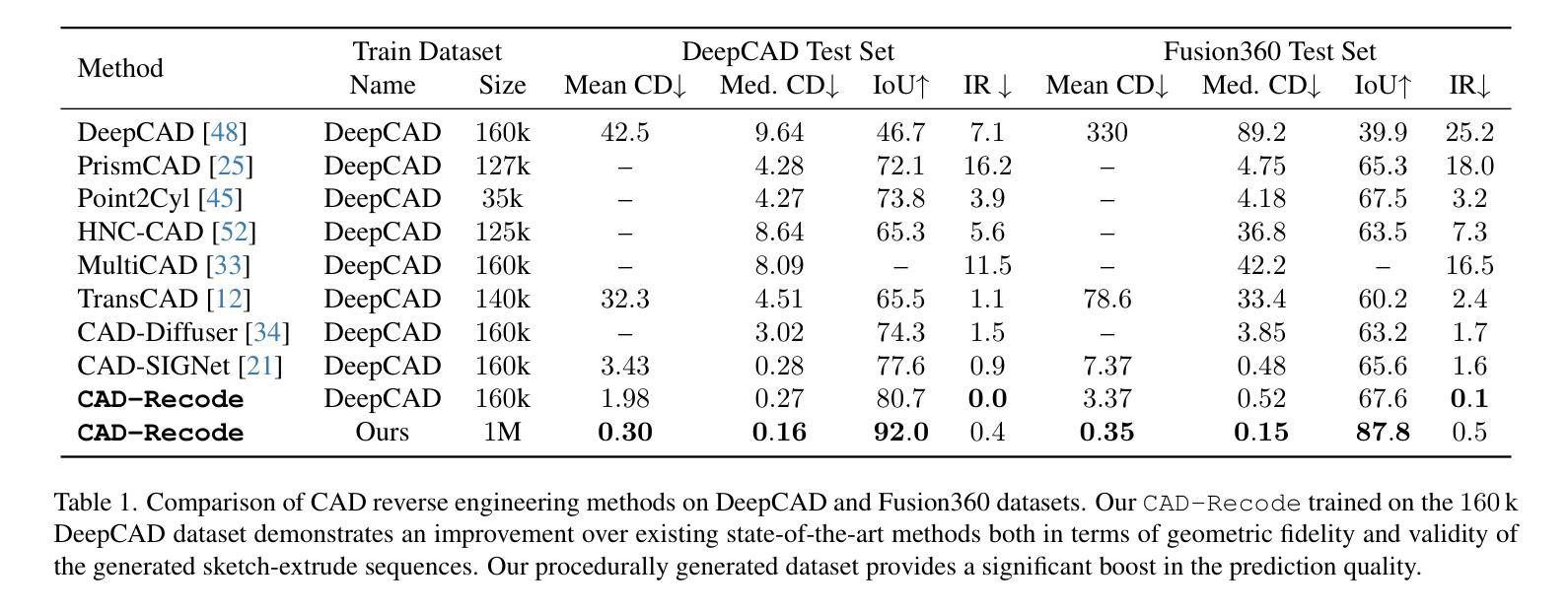
CAD-Assistant: Tool-Augmented VLLMs as Generic CAD Task Solvers
Authors:Dimitrios Mallis, Ahmet Serdar Karadeniz, Sebastian Cavada, Danila Rukhovich, Niki Foteinopoulou, Kseniya Cherenkova, Anis Kacem, Djamila Aouada
We propose CAD-Assistant, a general-purpose CAD agent for AI-assisted design. Our approach is based on a powerful Vision and Large Language Model (VLLM) as a planner and a tool-augmentation paradigm using CAD-specific tools. CAD-Assistant addresses multimodal user queries by generating actions that are iteratively executed on a Python interpreter equipped with the FreeCAD software, accessed via its Python API. Our framework is able to assess the impact of generated CAD commands on geometry and adapts subsequent actions based on the evolving state of the CAD design. We consider a wide range of CAD-specific tools including a sketch image parameterizer, rendering modules, a 2D cross-section generator, and other specialized routines. CAD-Assistant is evaluated on multiple CAD benchmarks, where it outperforms VLLM baselines and supervised task-specific methods. Beyond existing benchmarks, we qualitatively demonstrate the potential of tool-augmented VLLMs as general-purpose CAD solvers across diverse workflows.
我们提出CAD助手,这是一个用于人工智能辅助设计的通用CAD代理。我们的方法基于强大的视觉和大语言模型(VLLM)作为规划器,并使用CAD特定工具进行工具增强范式。CAD助手通过生成动作来解决多模式用户查询,这些动作在配备FreeCAD软件的Python解释器上迭代执行,通过其Python API进行访问。我们的框架能够评估生成的CAD命令对几何形状的影响,并根据CAD设计的不断变化状态调整后续动作。我们考虑了广泛的CAD特定工具,包括草图图像参数化器、渲染模块、2D横截面生成器和其他专业例行程序。CAD助手在多个CAD基准测试上进行了评估,表现出优于VLLM基准线和有监督的特定任务方法。除了现有的基准测试外,我们还从定性角度展示了工具增强型VLLM在多样化工作流程中的通用CAD求解器的潜力。
论文及项目相关链接
Summary
基于强大的视觉和大型语言模型(VLLM)以及CAD特定工具的辅助设计助手CAD-Assistant提出。CAD-Assistant能够通过Python解释器上的迭代执行动作响应多模态用户查询,并配备FreeCAD软件通过其Python API访问。该框架能够评估生成的CAD命令对几何结构的影响,并根据CAD设计的不断演变状态调整后续操作。CAD-Assistant包括草图图像参数化器、渲染模块、二维横截面生成器和其他特定例行程序在内的多种CAD特定工具。在多个CAD基准测试中评估了CAD-Assistant的性能,相较于VLLM基准测试和特定任务监督学习方法有更好的表现。此外,我们定性展示了工具增强型VLLM在多样化工作流程中的通用CAD求解潜力。
Key Takeaways
- CAD-Assistant是一个基于强大的视觉和大型语言模型(VLLM)的通用CAD辅助工具。
- 它采用工具增强范式,使用CAD特定工具响应多模态用户查询。
- CAD-Assistant能够通过Python解释器执行动作,并配备FreeCAD软件通过其Python API访问。
- 该框架可以评估生成的CAD命令对设计几何结构的影响,并适应性地调整后续操作。
- CAD-Assistant包括多种CAD特定工具,如草图图像参数化器、渲染模块和二维横截面生成器等。
- 在多个CAD基准测试中,CAD-Assistant表现出优越的性能,优于VLLM基准测试和特定任务监督学习方法。
点此查看论文截图


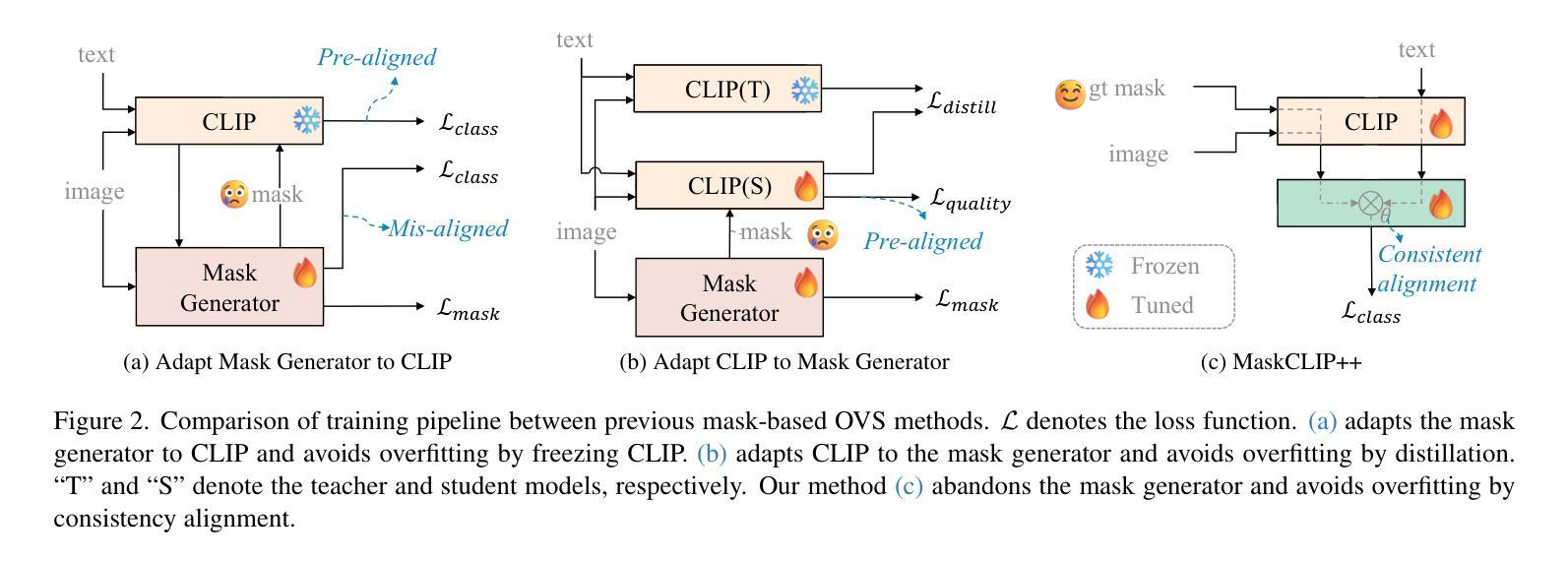
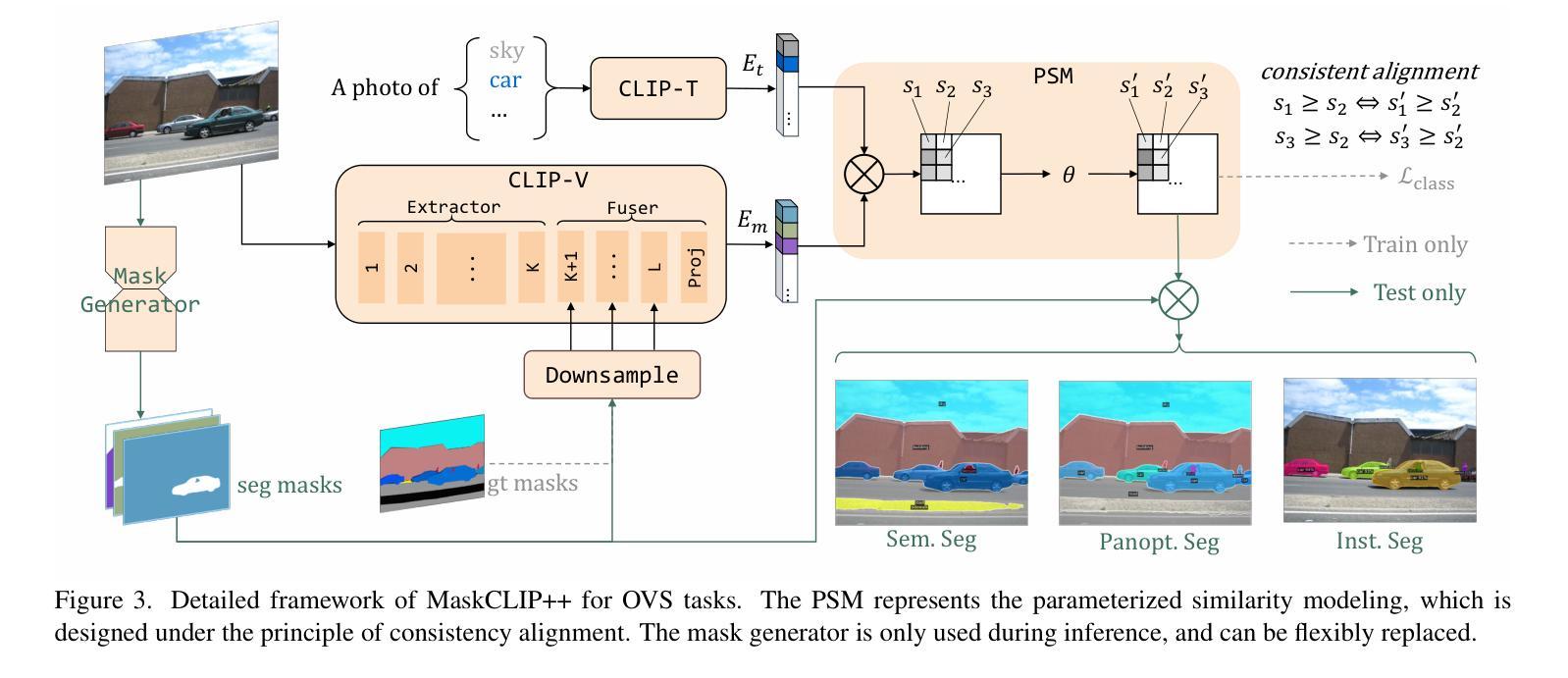
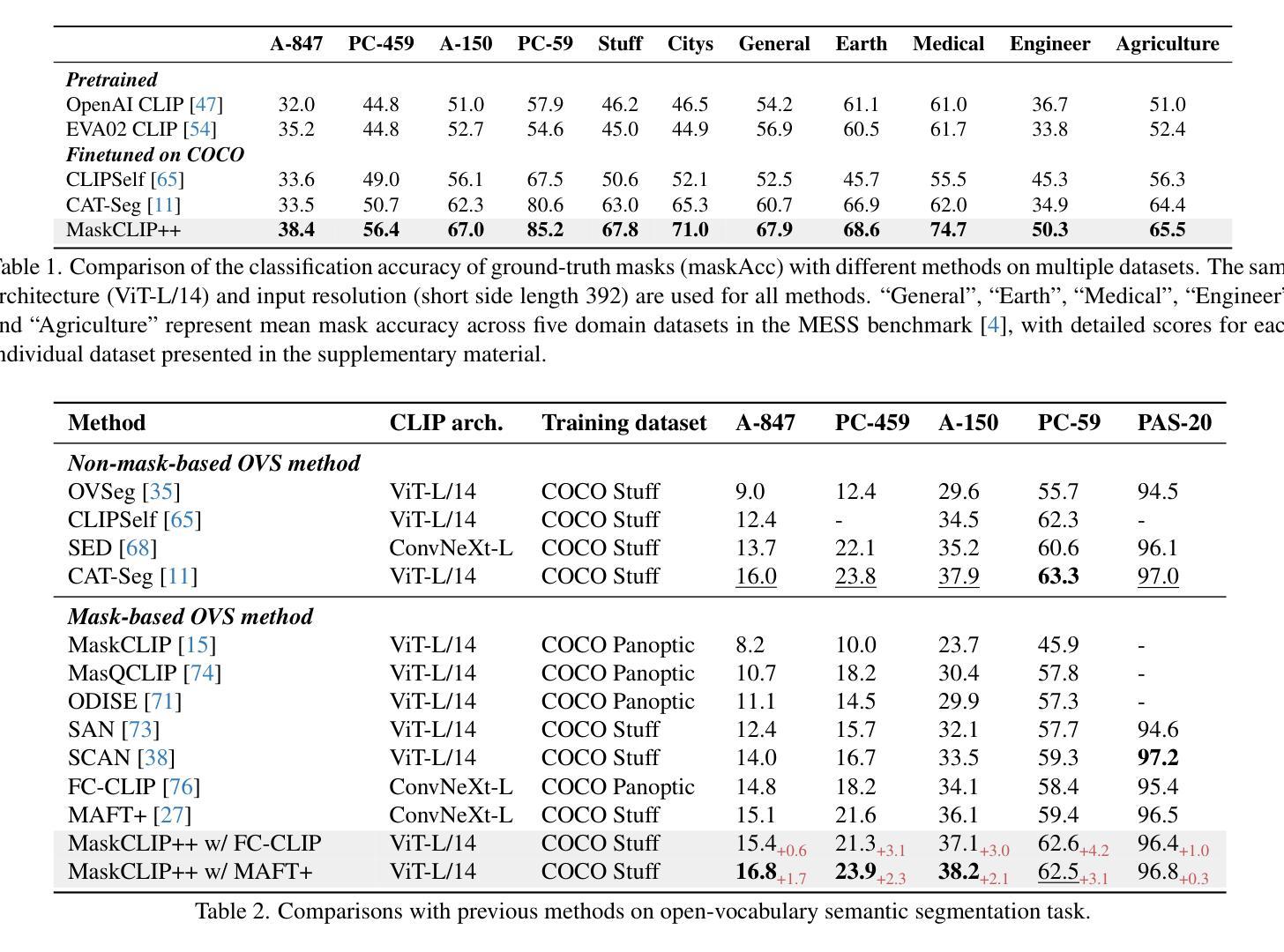
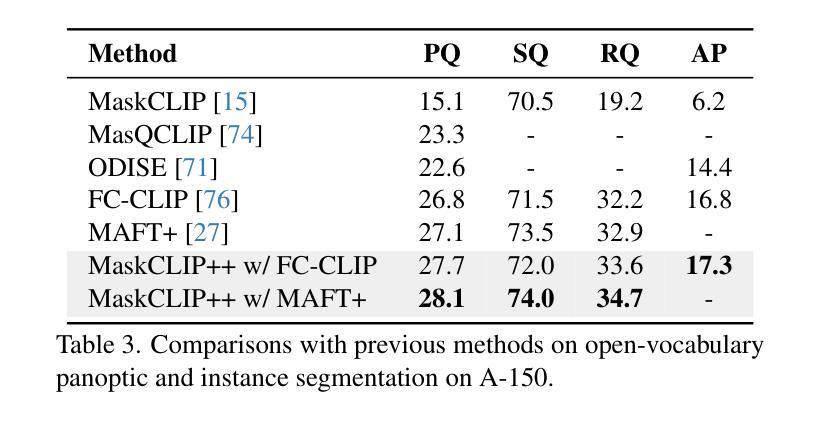
High-Quality Mask Tuning Matters for Open-Vocabulary Segmentation
Authors:Quan-Sheng Zeng, Yunheng Li, Daquan Zhou, Guanbin Li, Qibin Hou, Ming-Ming Cheng
Open-vocabulary image segmentation has been advanced through the synergy between mask generators and vision-language models like Contrastive Language-Image Pre-training (CLIP). Previous approaches focus on generating masks while aligning mask features with text embeddings during training. In this paper, we observe that relying on generated low-quality masks can weaken the alignment of vision and language in regional representations. This motivates us to present a new fine-tuning framework, named MaskCLIP++, which uses ground-truth masks instead of generated masks to enhance the mask classification capability of CLIP. Due to the limited diversity of image segmentation datasets with mask annotations, we propose incorporating a consistency alignment principle during fine-tuning, which alleviates categorical bias toward the fine-tuning dataset. After low-cost fine-tuning, MaskCLIP++ significantly improves the mask classification performance on multi-domain datasets. Combining with the mask generator in previous state-of-the-art mask-based open vocabulary segmentation methods, we achieve performance improvements of +1.7, +2.3, +2.1, +3.1, and +0.3 mIoU on the A-847, PC-459, A-150, PC-59, and PAS-20 datasets, respectively. Code is avaliable at https://github.com/HVision-NKU/MaskCLIPpp .
开放词汇图像分割已经通过掩膜生成器和视觉语言模型(如对比语言图像预训练CLIP)之间的协同作用得到了发展。之前的方法侧重于生成掩膜,并在训练过程中将掩膜特征与文本嵌入进行对齐。在本文中,我们观察到依赖生成的低质量掩膜会削弱区域表示中的视觉和语言对齐。这促使我们提出了一种新的微调框架,名为MaskCLIP++,它使用真实掩膜而不是生成的掩膜,以提高CLIP的掩膜分类能力。由于带有掩膜标注的图像分割数据集多样性有限,我们提出了在微调过程中引入一致性对齐原则,这减轻了对微调数据集的类别偏见。经过低成本的微调后,MaskCLIP++在多域数据集上的掩膜分类性能得到了显著提升。与先前最先进的基于掩膜的开放词汇分割方法中的掩膜生成器相结合,我们在A-847、PC-459、A-150、PC-59和PAS-20数据集上的mIoU分别提高了+1.7、+2.3、+2.1、+3.1和+0.3。代码可在https://github.com/HVision-NKU/MaskCLIPpp上找到。
论文及项目相关链接
PDF Revised version according to comments from reviewers of ICLR2025
Summary
论文提出了一种新的微调框架MaskCLIP++,采用真实掩膜代替生成掩膜以增强CLIP的掩膜分类能力。为提高模型在多领域数据集的掩膜分类性能,论文还提出了一种一致性对齐原则。MaskCLIP++与当前先进的基于掩膜的开放词汇分割方法相结合,在多个数据集上实现了性能提升。
Key Takeaways
- MaskCLIP++使用真实掩膜代替生成掩膜进行训练,以提高模型对图像区域表示的视觉和语言对齐能力。
- 一致性对齐原则用于缓解模型对微调数据集的类别偏见,适用于图像分割数据集掩膜标注有限的情况。
- MaskCLIP++通过低成本的微调显著提高了掩膜分类性能,在多领域数据集上的表现得到了显著提升。
- 结合先前先进的基于掩膜的开放词汇分割方法,MaskCLIP++在A-847、PC-459、A-150、PC-59和PAS-20数据集上的性能分别提升了+1.7、+2.3、+2.1、+3.1和+0.3 mIoU。
- 该研究提供的MaskCLIP++代码已公开,可供研究人员使用。
- MaskCLIP++的方法可应用于图像分割任务中的开放词汇场景,具有广泛的应用前景。
点此查看论文截图

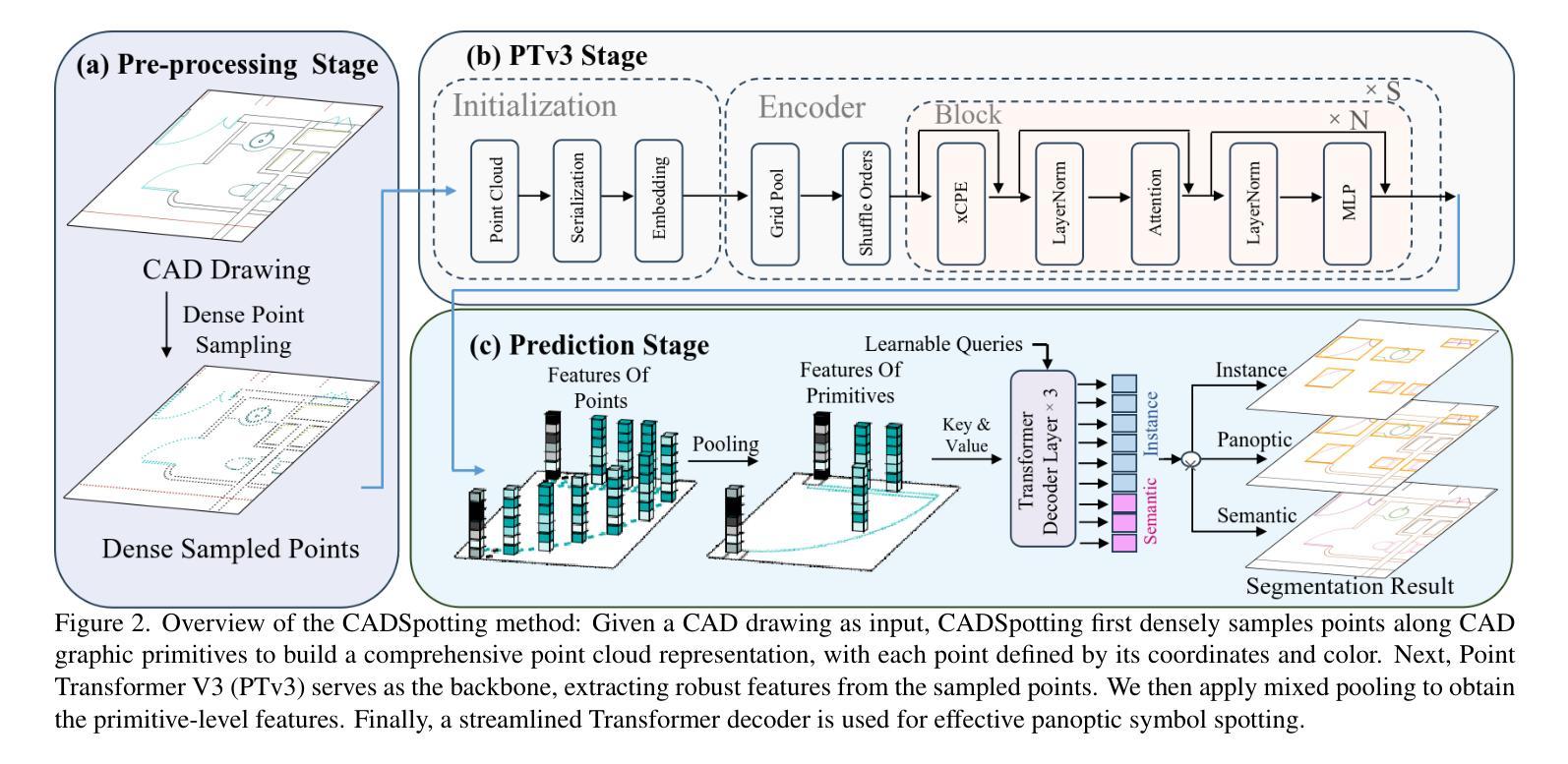
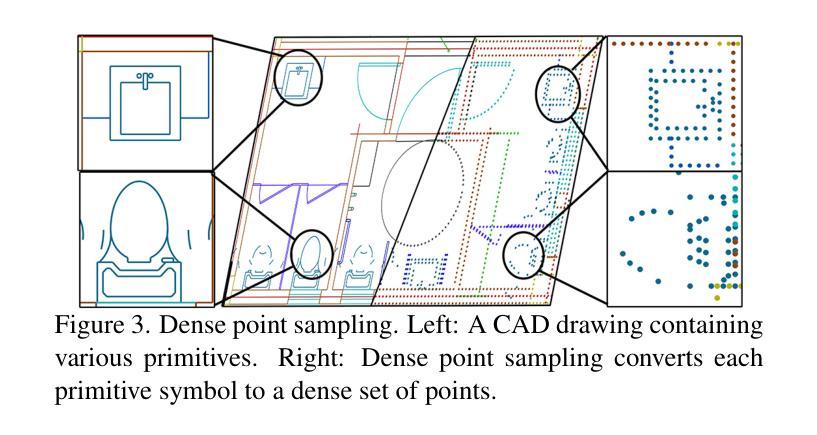
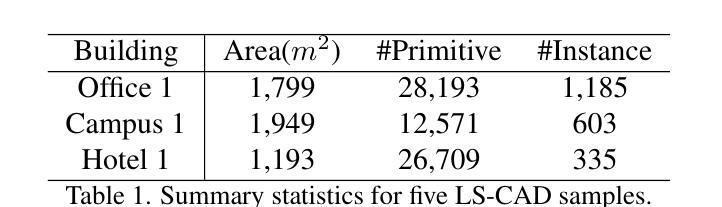
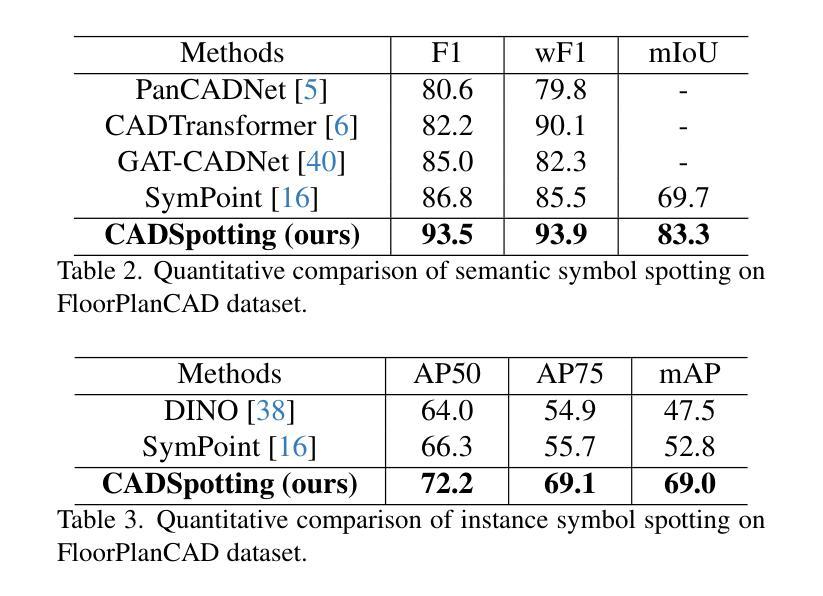
CADSpotting: Robust Panoptic Symbol Spotting on Large-Scale CAD Drawings
Authors:Jiazuo Mu, Fuyi Yang, Yanshun Zhang, Mingqian Zhang, Junxiong Zhang, Yongjian Luo, Lan Xu, Yujiao Shi, Yingliang Zhang
We introduce CADSpotting, an effective method for panoptic symbol spotting in large-scale architectural CAD drawings. Existing approaches struggle with symbol diversity, scale variations, and overlapping elements in CAD designs. CADSpotting overcomes these challenges by representing primitives through densely sampled points with attributes like coordinates and colors, using a unified 3D point cloud model for robust feature learning. To enable accurate segmentation in large, complex drawings, we further propose a novel Sliding Window Aggregation (SWA) technique, combining weighted voting and Non-Maximum Suppression (NMS). Moreover, we introduce LS-CAD, a new large-scale CAD dataset to support our experiments, with each floorplan covering around 1,000 square meters, significantly larger than previous benchmarks. Experiments on FloorPlanCAD and LS-CAD datasets show that CADSpotting significantly outperforms existing methods. We also demonstrate its practical value through automating parametric 3D reconstruction, enabling interior modeling directly from raw CAD inputs.
我们介绍了CADSpotting,这是一种在大型建筑CAD图纸中进行全景符号识别的高效方法。现有方法在符号多样性、尺度变化和CAD设计中的重叠元素方面存在困难。CADSpotting通过统一使用密集采样点云模型进行稳健的特征学习,这些点带有坐标和颜色等属性,克服了这些挑战。为了在大型复杂图纸中实现准确分割,我们进一步提出了一种新颖的滑动窗口聚合(SWA)技术,该技术结合了加权投票和非最大抑制(NMS)。此外,我们引入了LS-CAD这一新的大规模CAD数据集来支持我们的实验,每个平面图覆盖约一千平方米,远超之前的基准测试集。在FloorPlanCAD和LS-CAD数据集上的实验表明,CADSpotting在性能上显著优于现有方法。我们还通过自动参数化三维重建展示了其实用价值,能够直接从原始CAD输入进行室内建模。
论文及项目相关链接
PDF 18pages, 14 figures, Project web-page: https://dgeneai.github.io/cadspotting-pages/
Summary
CADSpotting方法能有效解决大规模建筑CAD绘图中的全景符号识别问题。现有方法面临符号多样性、尺度变化和CAD设计中的重叠元素等挑战。CADSpotting通过统一使用三维点云模型表示原始图形中的密集采样点(包含坐标和颜色等属性),克服这些难题。为实现大型复杂绘图的精确分割,研究团队进一步提出新颖的滑动窗口聚合技术(SWA),结合加权投票和非极大值抑制(NMS)。此外,研究团队推出新的大规模CAD数据集LS-CAD以支持实验,每个平面图约覆盖一千平方米,远超之前的基准测试集。在FloorPlanCAD和LS-CAD数据集上的实验表明,CADSpotting显著优于现有方法,并能通过自动化参数化三维重建,实现从原始CAD输入中进行内部建模。
Key Takeaways
- CADSpotting能有效解决大型建筑CAD绘图中的全景符号识别难题。
- 现有方法面临符号多样性、尺度变化和重叠元素的挑战。
- CADSpotting使用统一的三维点云模型表示原始图形,有助于克服上述难题。
- 研究团队提出滑动窗口聚合技术(SWA),以提高大型复杂绘图的精确分割能力。
- CADSpotting结合加权投票和非极大值抑制(NMS)。
- 研究团队推出新的大规模CAD数据集LS-CAD,用于支持实验,每个平面图覆盖面积远超之前的基准测试集。
点此查看论文截图