⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
6D Object Pose Tracking in Internet Videos for Robotic Manipulation
Authors:Georgy Ponimatkin, Martin Cífka, Tomáš Souček, Médéric Fourmy, Yann Labbé, Vladimir Petrik, Josef Sivic
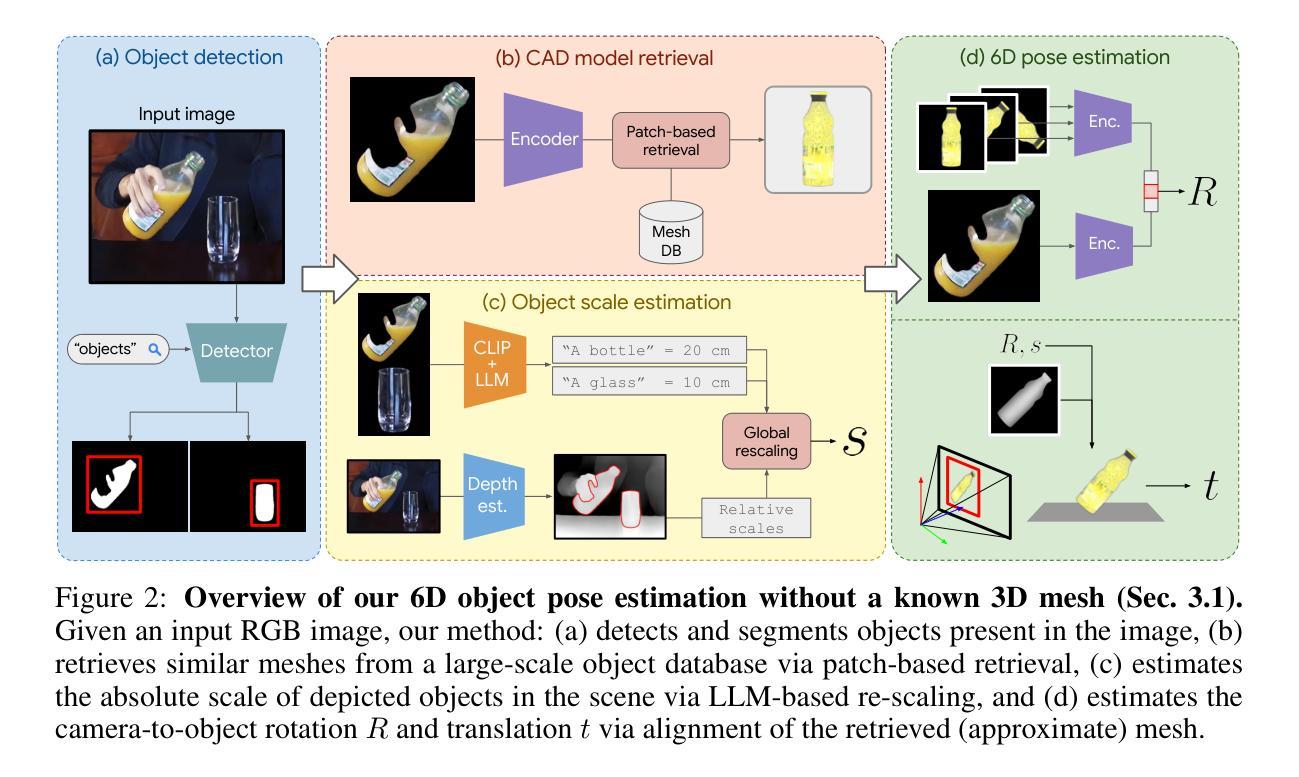
We seek to extract a temporally consistent 6D pose trajectory of a manipulated object from an Internet instructional video. This is a challenging set-up for current 6D pose estimation methods due to uncontrolled capturing conditions, subtle but dynamic object motions, and the fact that the exact mesh of the manipulated object is not known. To address these challenges, we present the following contributions. First, we develop a new method that estimates the 6D pose of any object in the input image without prior knowledge of the object itself. The method proceeds by (i) retrieving a CAD model similar to the depicted object from a large-scale model database, (ii) 6D aligning the retrieved CAD model with the input image, and (iii) grounding the absolute scale of the object with respect to the scene. Second, we extract smooth 6D object trajectories from Internet videos by carefully tracking the detected objects across video frames. The extracted object trajectories are then retargeted via trajectory optimization into the configuration space of a robotic manipulator. Third, we thoroughly evaluate and ablate our 6D pose estimation method on YCB-V and HOPE-Video datasets as well as a new dataset of instructional videos manually annotated with approximate 6D object trajectories. We demonstrate significant improvements over existing state-of-the-art RGB 6D pose estimation methods. Finally, we show that the 6D object motion estimated from Internet videos can be transferred to a 7-axis robotic manipulator both in a virtual simulator as well as in a real world set-up. We also successfully apply our method to egocentric videos taken from the EPIC-KITCHENS dataset, demonstrating potential for Embodied AI applications.
我们旨在从互联网教学视频中提取出被操作物体的时间上一致的6D姿态轨迹。这对于当前的6D姿态估计方法来说是一个具有挑战性的设置,因为存在不受控制的捕获条件、微妙但动态的物体运动,以及不清楚被操作物体的精确网格。为了解决这些挑战,我们做出了以下贡献。首先,我们开发了一种新方法,可以在不了解物体本身的情况下,估计输入图像中任何物体的6D姿态。该方法通过以下步骤进行:(i)从大规模模型数据库中检索与所描绘物体相似的CAD模型,(ii)将检索到的CAD模型与输入图像进行6D对齐,(iii)确定物体相对于场景的绝对尺度。其次,我们通过仔细跟踪视频帧中的检测物体,从互联网视频中提取平滑的6D物体轨迹。然后,通过轨迹优化将提取的物体轨迹转移到机器人操纵器的配置空间。第三,我们在YCB-V、HOPE-Video数据集以及手动注释了近似6D物体轨迹的新教学视频数据集上,全面评估并剥离了我们的6D姿态估计方法。我们证明了与现有的最先进的RGB 6D姿态估计方法相比,我们的方法具有显著改进。最后,我们展示了从互联网视频估计的6D物体运动可以转移到7轴机器人操纵器,不仅在虚拟模拟器中,而且在真实世界设置中也是如此。我们还成功地将我们的方法应用于EPIC-KITCHENS数据集中的第一人称视频,展示了嵌入式人工智能应用的可能性。
论文及项目相关链接
PDF Accepted to ICLR 2025. Project page available at https://ponimatkin.github.io/wildpose/
Summary
本文旨在从互联网教学视频中提取出操作对象的时空一致的6D姿态轨迹,这是一个对当前的6D姿态估计方法充满挑战的任务。为解决这些挑战,本文提出了一系列贡献:首先,开发了一种新方法,可以在无需了解对象先验知识的情况下估计输入图像中任何对象的6D姿态;其次,通过仔细跟踪检测到的对象并优化轨迹,从互联网视频中提取平滑的6D对象轨迹;最后,将提取的轨迹应用于机器人操纵器的配置空间,并在虚拟仿真器和现实环境中进行了验证。本文的方法在多个数据集上实现了显著的改进,并成功应用于互联网视频和第一人称视频,展示了在人工智能嵌入式应用中的潜力。
Key Takeaways
- 本文的目标是提取互联网教学视频中操作对象的6D姿态轨迹。
- 当前的方法可以在无需对象先验知识的情况下估计输入图像中的任何对象的6D姿态。
- 通过从大型模型数据库中检索与显示对象相似的CAD模型,实现了6D对齐和绝对尺度的确定。
- 从互联网视频中提取平滑的6D对象轨迹,通过仔细跟踪检测到的对象并优化轨迹实现。
- 提取的轨迹通过轨迹优化被重定向到机器人操纵器的配置空间。
- 在多个数据集上的评估证明了该方法相较于现有技术的显著改进。
- 成功将该方法应用于互联网视频和第一人称视频,展示了在人工智能嵌入式应用中的潜力。
点此查看论文截图

A Hierarchical Semantic Distillation Framework for Open-Vocabulary Object Detection
Authors:Shenghao Fu, Junkai Yan, Qize Yang, Xihan Wei, Xiaohua Xie, Wei-Shi Zheng
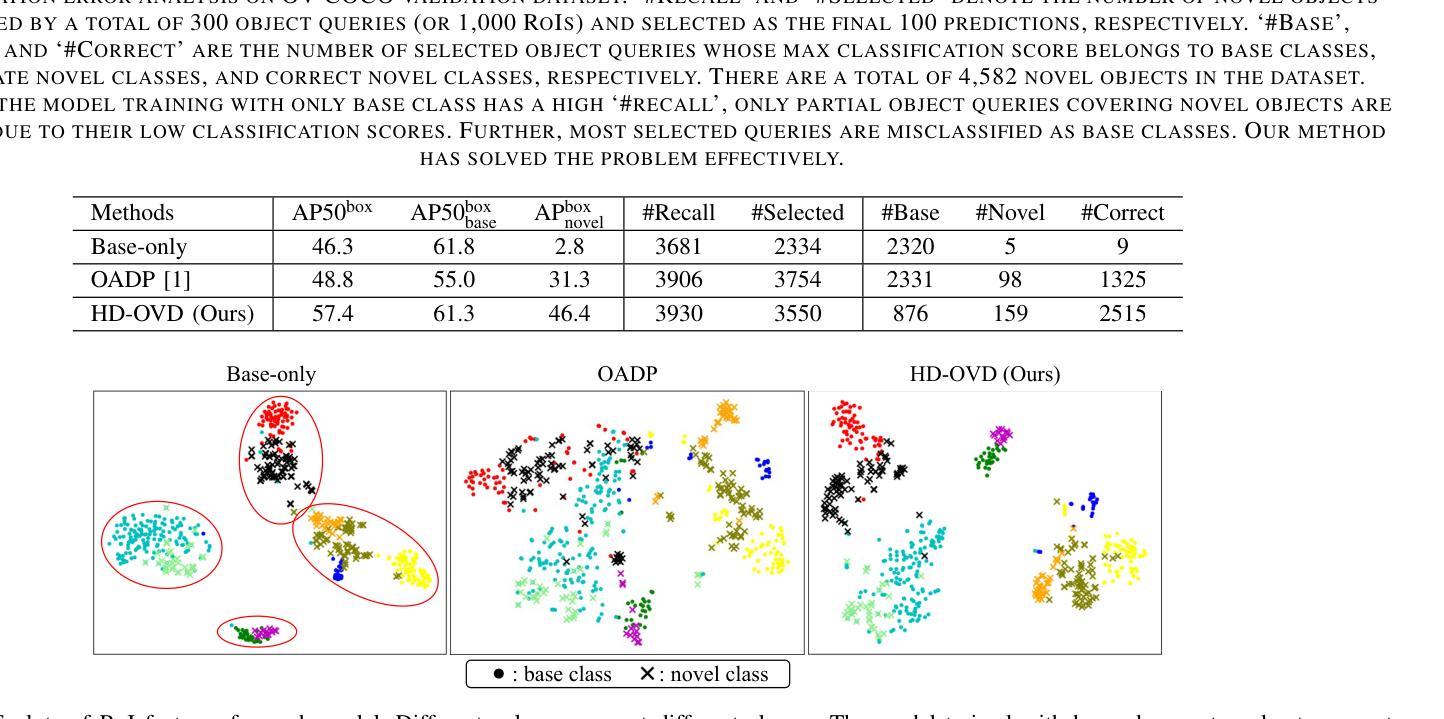
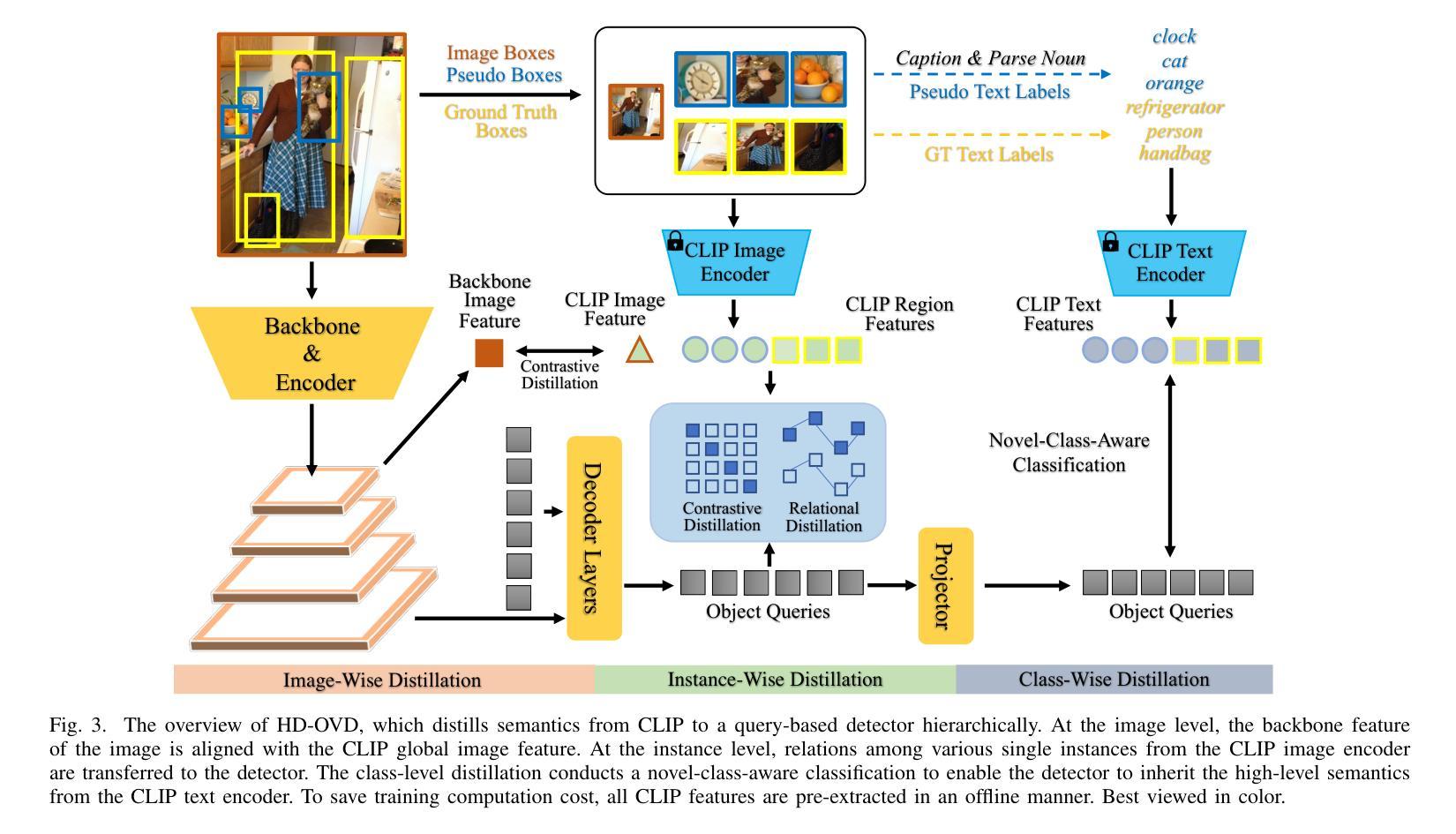
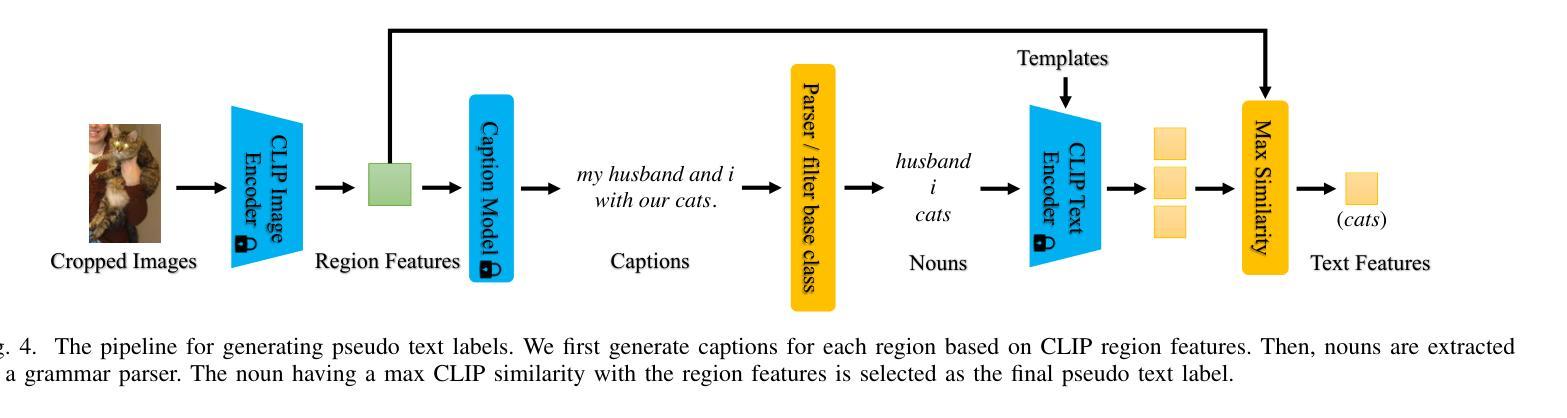
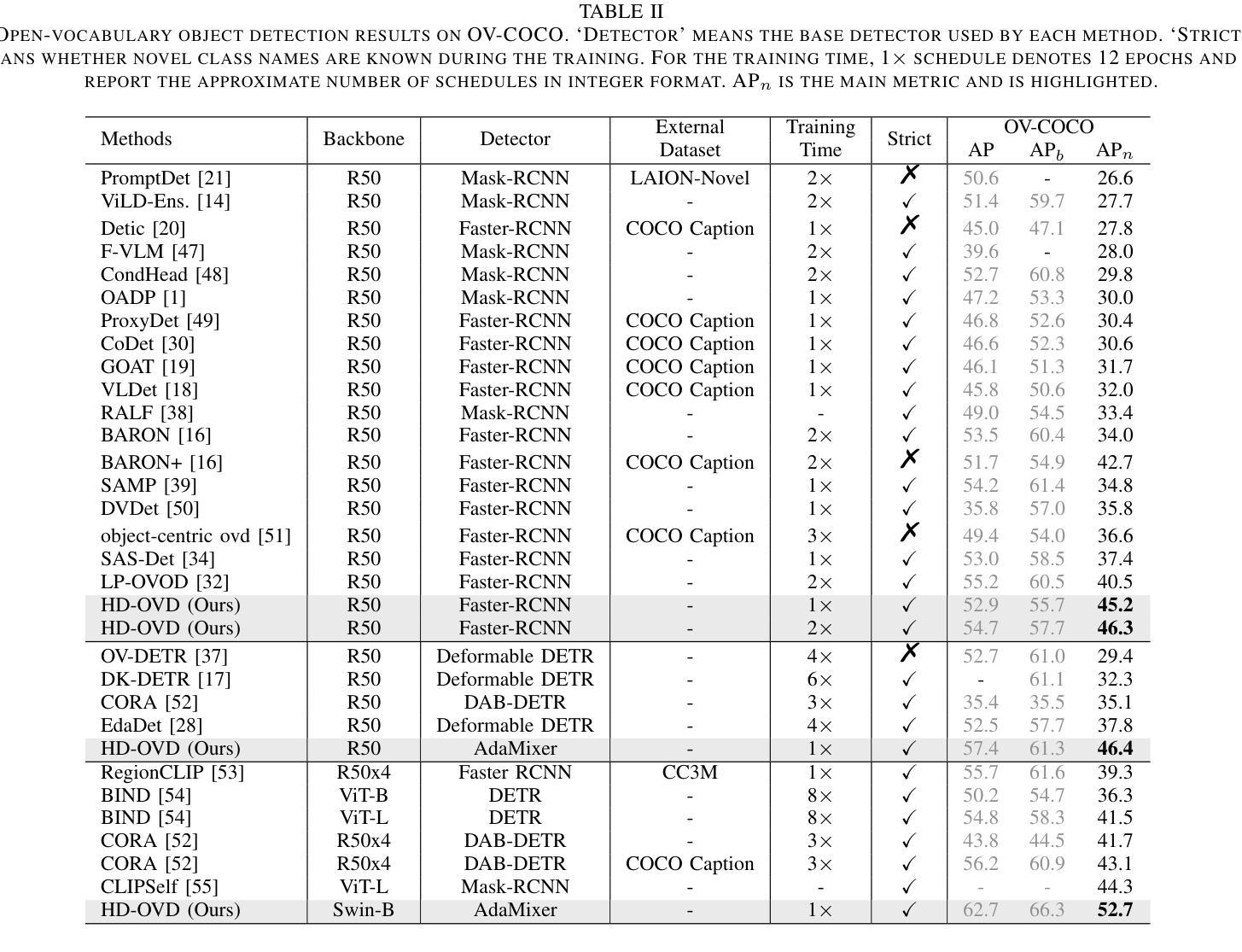
Open-vocabulary object detection (OVD) aims to detect objects beyond the training annotations, where detectors are usually aligned to a pre-trained vision-language model, eg, CLIP, to inherit its generalizable recognition ability so that detectors can recognize new or novel objects. However, previous works directly align the feature space with CLIP and fail to learn the semantic knowledge effectively. In this work, we propose a hierarchical semantic distillation framework named HD-OVD to construct a comprehensive distillation process, which exploits generalizable knowledge from the CLIP model in three aspects. In the first hierarchy of HD-OVD, the detector learns fine-grained instance-wise semantics from the CLIP image encoder by modeling relations among single objects in the visual space. Besides, we introduce text space novel-class-aware classification to help the detector assimilate the highly generalizable class-wise semantics from the CLIP text encoder, representing the second hierarchy. Lastly, abundant image-wise semantics containing multi-object and their contexts are also distilled by an image-wise contrastive distillation. Benefiting from the elaborated semantic distillation in triple hierarchies, our HD-OVD inherits generalizable recognition ability from CLIP in instance, class, and image levels. Thus, we boost the novel AP on the OV-COCO dataset to 46.4% with a ResNet50 backbone, which outperforms others by a clear margin. We also conduct extensive ablation studies to analyze how each component works.
开放词汇对象检测(OVD)的目标是检测超出训练注解的对象,检测器通常与预训练的视觉语言模型(例如CLIP)对齐,以继承其通用识别能力,从而使检测器能够识别新的或未知的对象。然而,以前的工作是直接与CLIP进行特征空间对齐,未能有效地学习语义知识。在我们的工作中,我们提出了一个名为HD-OVD的分层语义蒸馏框架,以构建全面的蒸馏过程,从三个方面利用CLIP模型的通用知识。在HD-OVD的第一层级中,检测器通过建模视觉空间中单个对象之间的关系,从CLIP图像编码器中学习精细的实例级语义。此外,我们引入了文本空间新颖类感知分类,以帮助检测器从CLIP文本编码器中吸收高度通用的类级语义,这代表了第二层级。最后,通过图像级的对比蒸馏,包含多个对象及其上下文在内的丰富图像级语义也被提炼出来。得益于三个层级的精心语义蒸馏,我们的HD-OVD从CLIP中继承了在实例、类和图像级别上的通用识别能力。因此,我们在OV-COCO数据集上将新颖AP提高到46.4%,使用ResNet50骨干网,明显超越其他方法。我们还进行了广泛的消融研究,分析每个组件的效果。
论文及项目相关链接
PDF Accepted to TMM 2025
Summary:
本文介绍了开放词汇对象检测(OVD)的新方法,旨在检测超出训练注释的对象。针对以往方法未能有效学习语义知识的问题,本文提出了一个层次化的语义蒸馏框架HD-OVD。该框架通过三个层次来利用CLIP模型的通用知识:在视觉空间中建模单个对象之间的关系来学习细粒度实例级语义;引入文本空间中的新型类别感知分类,以获取可泛化的类别级语义;通过图像级的对比蒸馏来提取包含多个对象及其上下文信息的图像级语义。实验结果表明,该方法提高了开放词汇对象检测的性能,在OV-COCO数据集上的新型AP达到了46.4%,并超过了其他方法。
Key Takeaways:
- 开放词汇对象检测(OVD)的目标在于检测超出训练注释的对象。
- 以往方法直接对齐特征空间,未能有效学习语义知识。
- 提出了层次化的语义蒸馏框架HD-OVD,包含三个层次:实例级、类别级和图像级。
- HD-OVD利用CLIP模型的通用知识,通过建模对象关系、新型类别感知分类和图像级对比蒸馏来提取语义知识。
- 在OV-COCO数据集上,HD-OVD方法的新型AP达到了46.4%,并超过了其他方法。
- 进行了大量的消融研究,分析了每个组件的作用。
点此查看论文截图


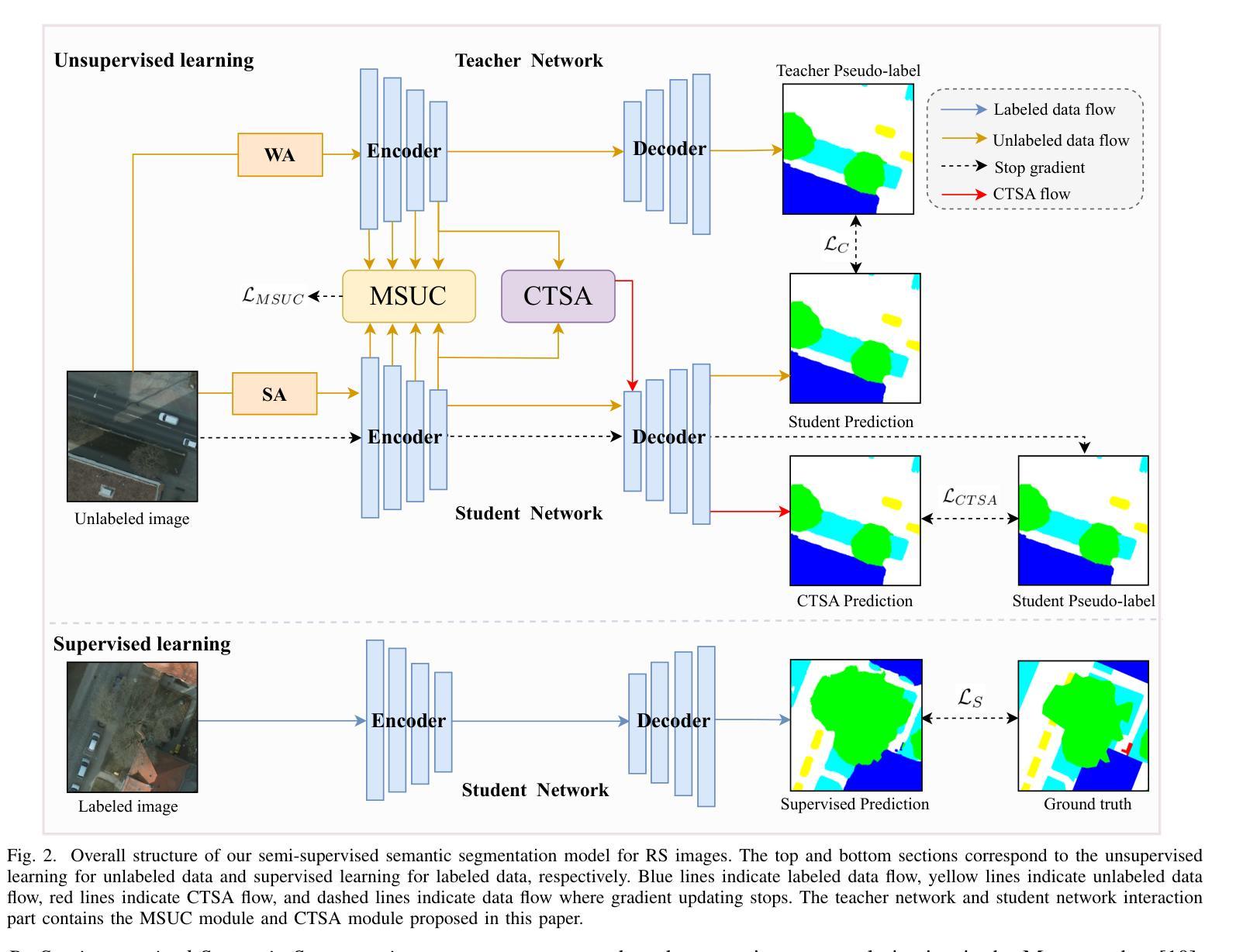
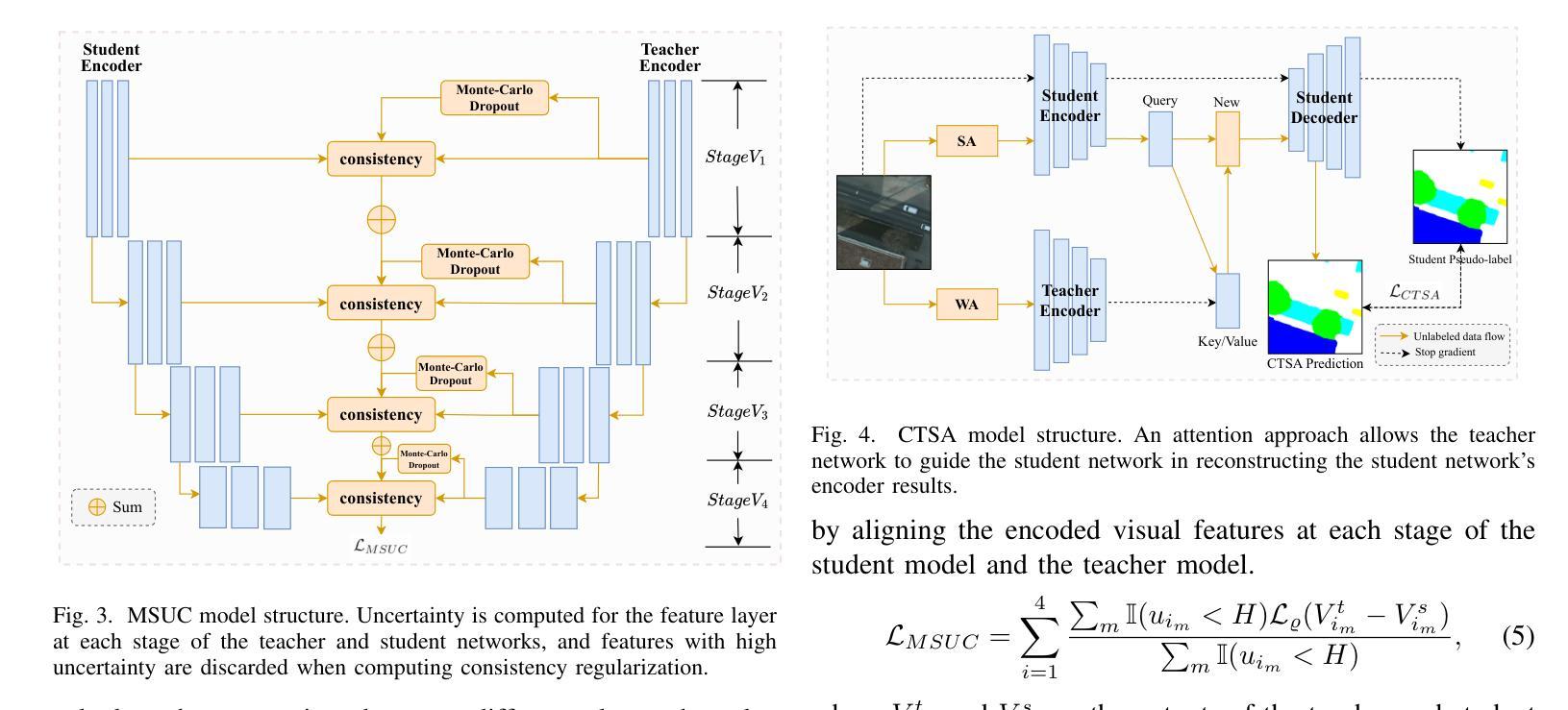
Semi-supervised Semantic Segmentation for Remote Sensing Images via Multi-scale Uncertainty Consistency and Cross-Teacher-Student Attention
Authors:Shanwen Wang, Xin Sun, Changrui Chen, Danfeng Hong, Jungong Han
Semi-supervised learning offers an appealing solution for remote sensing (RS) image segmentation to relieve the burden of labor-intensive pixel-level labeling. However, RS images pose unique challenges, including rich multi-scale features and high inter-class similarity. To address these problems, this paper proposes a novel semi-supervised Multi-Scale Uncertainty and Cross-Teacher-Student Attention (MUCA) model for RS image semantic segmentation tasks. Specifically, MUCA constrains the consistency among feature maps at different layers of the network by introducing a multi-scale uncertainty consistency regularization. It improves the multi-scale learning capability of semi-supervised algorithms on unlabeled data. Additionally, MUCA utilizes a Cross-Teacher-Student attention mechanism to guide the student network, guiding the student network to construct more discriminative feature representations through complementary features from the teacher network. This design effectively integrates weak and strong augmentations (WA and SA) to further boost segmentation performance. To verify the effectiveness of our model, we conduct extensive experiments on ISPRS-Potsdam and LoveDA datasets. The experimental results show the superiority of our method over state-of-the-art semi-supervised methods. Notably, our model excels in distinguishing highly similar objects, showcasing its potential for advancing semi-supervised RS image segmentation tasks.
半监督学习为遥感(RS)图像分割提供了一个吸引人的解决方案,以减轻劳动密集型的像素级标注的负担。然而,遥感图像带来了独特的挑战,包括丰富的多尺度特征和高的类间相似性。为了解决这些问题,本文提出了一种新型的半监督多尺度不确定性与跨教师学生注意力(MUCA)模型,用于遥感图像语义分割任务。具体来说,MUCA通过引入多尺度不确定性一致性正则化,约束网络不同层特征图之间的一致性。它提高了半监督算法在未标注数据上的多尺度学习能力。此外,MUCA利用跨教师学生注意力机制来引导学生网络,通过教师网络的互补特征构建更具判别力的特征表示。这一设计有效地结合了弱增强和强增强(WA和SA),进一步提升了分割性能。为了验证我们模型的有效性,我们在ISPRS-Potsdam和LoveDA数据集上进行了大量实验。实验结果表明,我们的方法优于最新的半监督方法。值得注意的是,我们的模型在区分高度相似物体方面表现出色,展示了其在推进半监督遥感图像分割任务方面的潜力。
论文及项目相关链接
Summary
半监督学习为遥感图像分割提供了一种吸引人的解决方案,减轻了劳动密集型的像素级标注负担。本文提出一种新型半监督多尺度不确定性及跨教师学生注意力模型(MUCA),用于遥感图像语义分割任务。MUCA通过引入多尺度不确定性一致性正则化,约束网络不同层特征图的一致性,提高半监督算法在未标注数据上的多尺度学习能力。此外,MUCA利用跨教师学生注意力机制引导学生网络构建更具区分性的特征表示。实验结果表明,该方法在ISPRS-Potsdam和LoveDA数据集上表现出优异性能,尤其在区分高度相似物体方面展现潜力。
Key Takeaways
- 半监督学习对于遥感图像分割是一种有效的解决方案,能够减轻对大量标注数据的依赖。
- 本文提出的MUCA模型结合了多尺度不确定性和跨教师学生注意力机制。
- MUCA通过引入多尺度不确定性一致性正则化,提高模型在不同尺度的学习能力。
- 跨教师学生注意力机制有助于增强模型的表征能力,通过结合教师的互补特征来引导学生网络。
- 模型整合了弱增强和强增强,进一步提升了分割性能。
- 在ISPRS-Potsdam和LoveDA数据集上的实验验证了MUCA模型的优越性。
点此查看论文截图