⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
LVAgent: Long Video Understanding by Multi-Round Dynamical Collaboration of MLLM Agents
Authors:Boyu Chen, Zhengrong Yue, Siran Chen, Zikang Wang, Yang Liu, Peng Li, Yali Wang
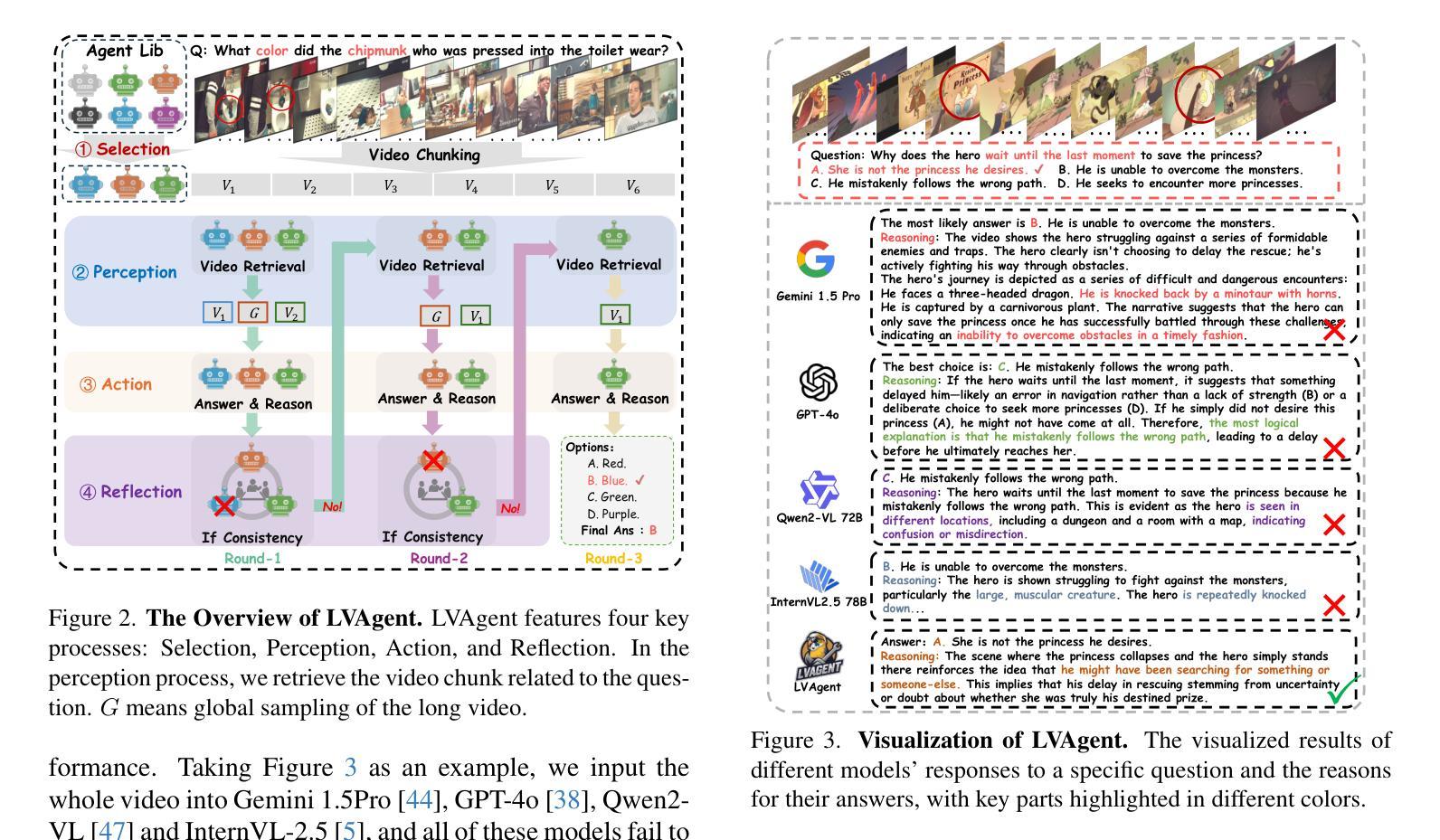
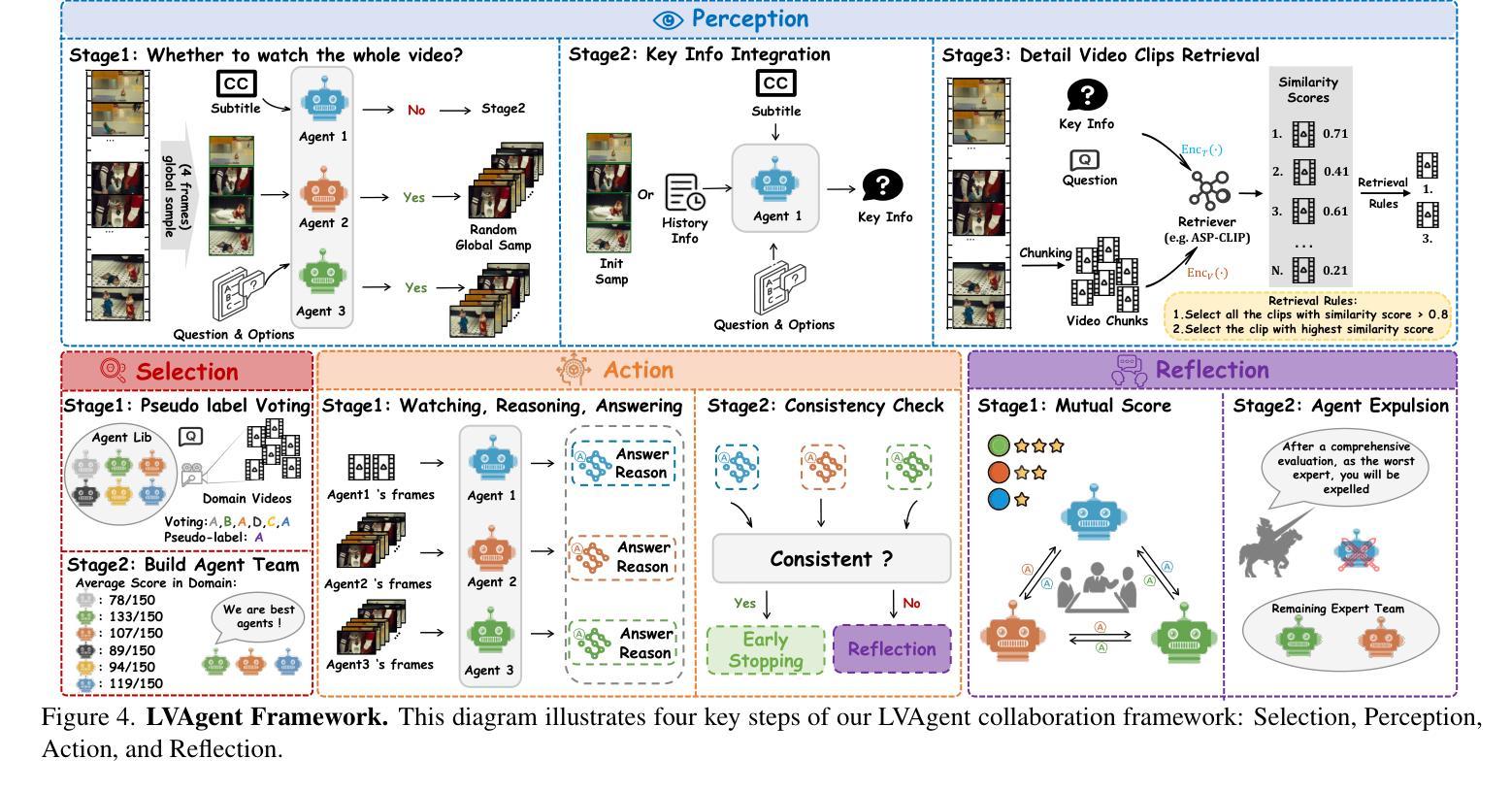
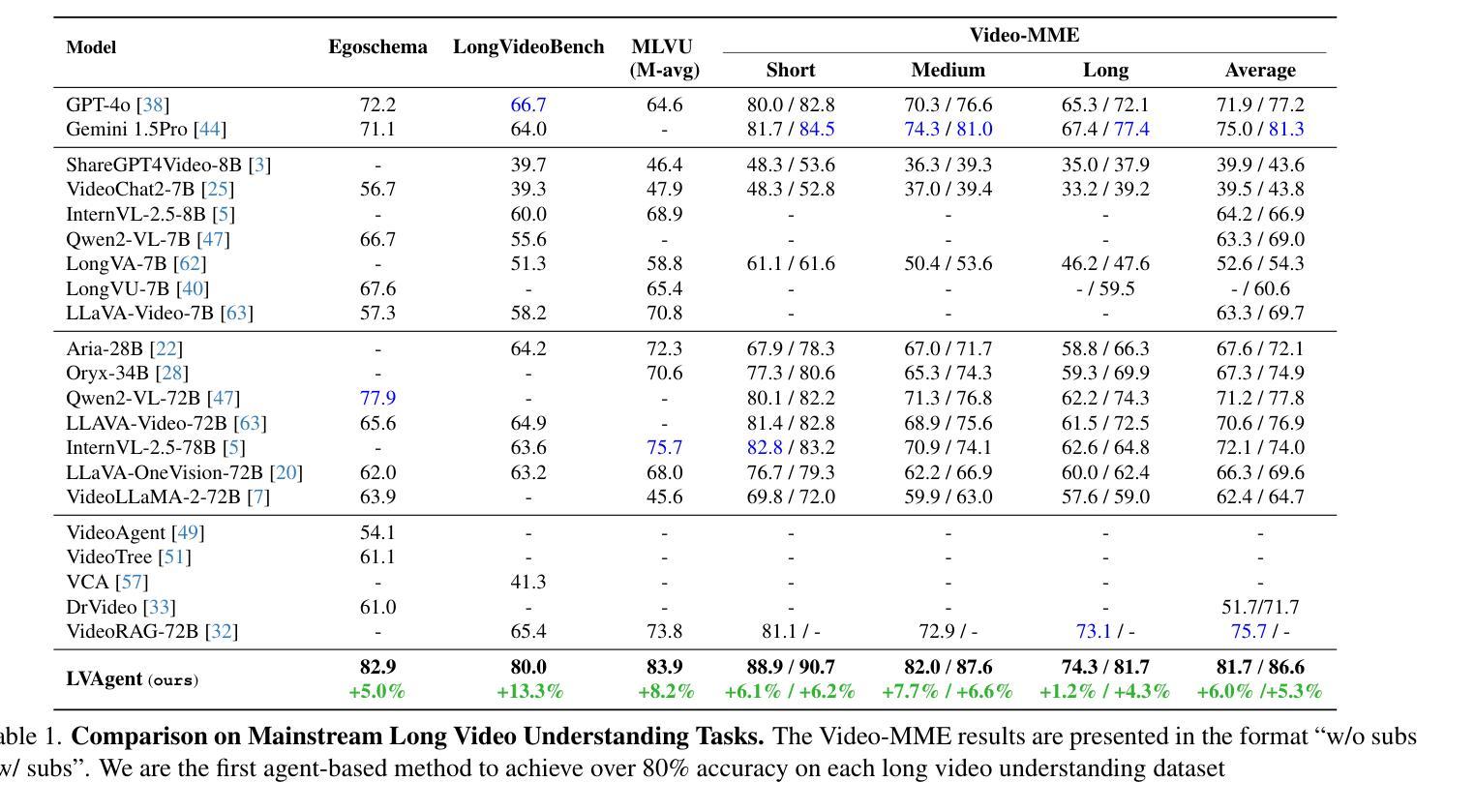
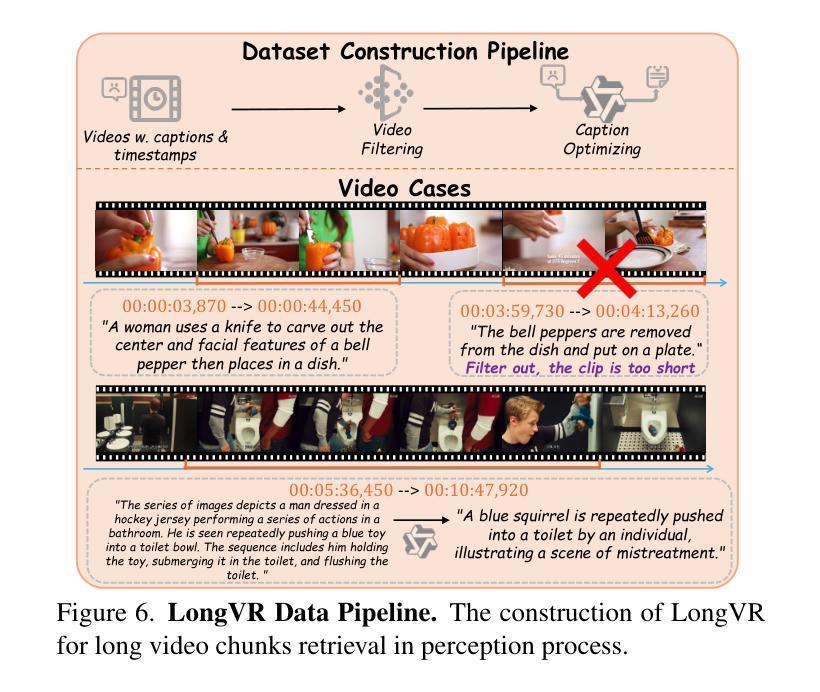
Existing Multimodal Large Language Models (MLLMs) encounter significant challenges in modeling the temporal context within long videos. Currently, mainstream Agent-based methods use external tools (e.g., search engine, memory banks, OCR, retrieval models) to assist a single MLLM in answering long video questions. Despite such tool-based support, a solitary MLLM still offers only a partial understanding of long videos, resulting in limited performance. In order to better address long video tasks, we introduce LVAgent, the first framework enabling multi-round dynamic collaboration of MLLM agents in long video understanding. Our methodology consists of four key steps: 1. Selection: We pre-select appropriate agents from the model library to form optimal agent teams based on different tasks. 2. Perception: We design an effective retrieval scheme for long videos, improving the coverage of critical temporal segments while maintaining computational efficiency. 3. Action: Agents answer long video-related questions and exchange reasons. 4. Reflection: We evaluate the performance of each agent in each round of discussion and optimize the agent team for dynamic collaboration. The agents iteratively refine their answers by multi-round dynamical collaboration of MLLM agents. LVAgent is the first agent system method that outperforms all closed-source models (including GPT-4o) and open-source models (including InternVL-2.5 and Qwen2-VL) in the long video understanding tasks. Our LVAgent achieves an accuracy of 80% on four mainstream long video understanding tasks. Notably, on the LongVideoBench dataset, LVAgent improves accuracy by up to 14.3% compared with SOTA.
现有的多模态大型语言模型(MLLMs)在建模长视频中的时间上下文时面临重大挑战。目前,主流的基于代理的方法使用外部工具(如搜索引擎、记忆库、OCR、检索模型)来协助单个MLLM回答长视频问题。尽管有基于工具的支持,单个MLLM仍然只能对长视频进行部分理解,导致性能有限。为了更好地解决长视频任务,我们引入了LVAgent,这是第一个使多轮动态协作的MLLM代理能够参与长视频理解的框架。我们的方法包括四个关键步骤:1.选择:我们从模型库中预先选择合适的代理,根据不同的任务形成最优代理团队。2.感知:我们为长视频设计了有效的检索方案,提高了关键时间段的覆盖率,同时保持了计算效率。3.行动:代理回答与长视频相关的问题并交流理由。4.反思:我们评估每个代理在每轮讨论中的表现,优化代理团队进行动态协作。通过MLLM代理的多轮动态协作,代理们可以迭代优化答案。LVAgent是第一个在长视频理解任务中表现优于所有闭源模型(包括GPT-4o)和开源模型(包括InternVL-2.5和Qwen2-VL)的代理系统方法。我们的LVAgent在四个主流的长视频理解任务中达到了80%的准确率。值得注意的是,在LongVideoBench数据集上,LVAgent与SOTA相比,准确率提高了高达14.3%。
论文及项目相关链接
Summary
本文介绍了针对长视频理解的挑战,现有单一的多模态大型语言模型(MLLMs)难以充分理解长视频内容。为此,提出了LVAgent框架,通过多轮动态协作多个MLLM代理来提高长视频任务性能。LVAgent包括选择、感知、行动和反思四个关键步骤,能有效回答长视频相关问题并进行动态优化。LVAgent在主流长视频理解任务上实现了80%的准确率,相较于其他模型有明显提升。
Key Takeaways
- 长视频理解面临挑战,单一多模态大型语言模型(MLLMs)难以充分理解内容。
- LVAgent框架通过多轮动态协作多个MLLM代理解决此问题。
- LVAgent包括选择、感知、行动和反思四个关键步骤。
- LVAgent能有效回答长视频相关问题,并优化代理团队动态协作。
- LVAgent在主流长视频理解任务上实现80%准确率。
- LVAgent相较于其他模型,包括GPT-4o、InternVL-2.5和Qwen2-VL等,性能有所提升。
点此查看论文截图