⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
Authors:Yingshuang Zou, Yikang Ding, Chuanrui Zhang, Jiazhe Guo, Bohan Li, Xiaoyang Lyu, Feiyang Tan, Xiaojuan Qi, Haoqian Wang
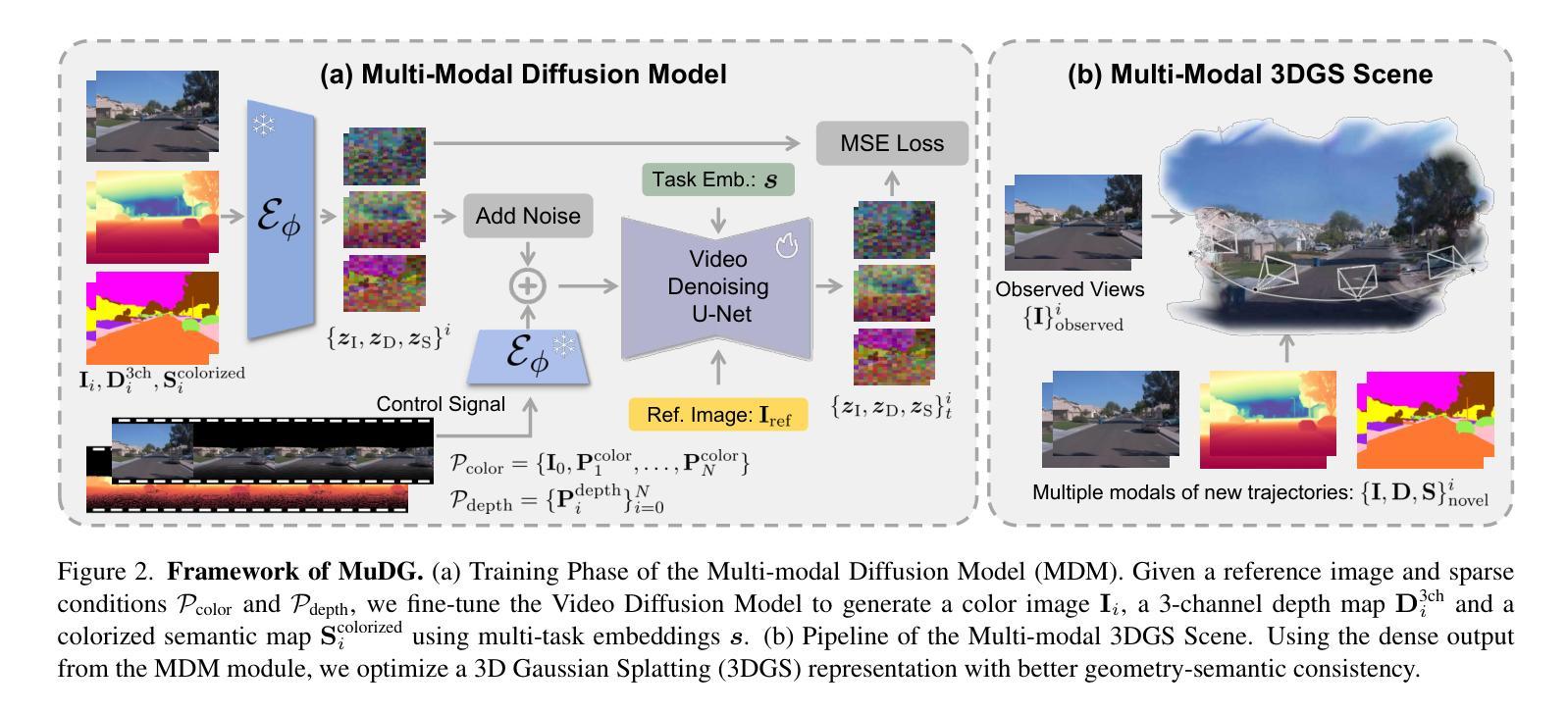
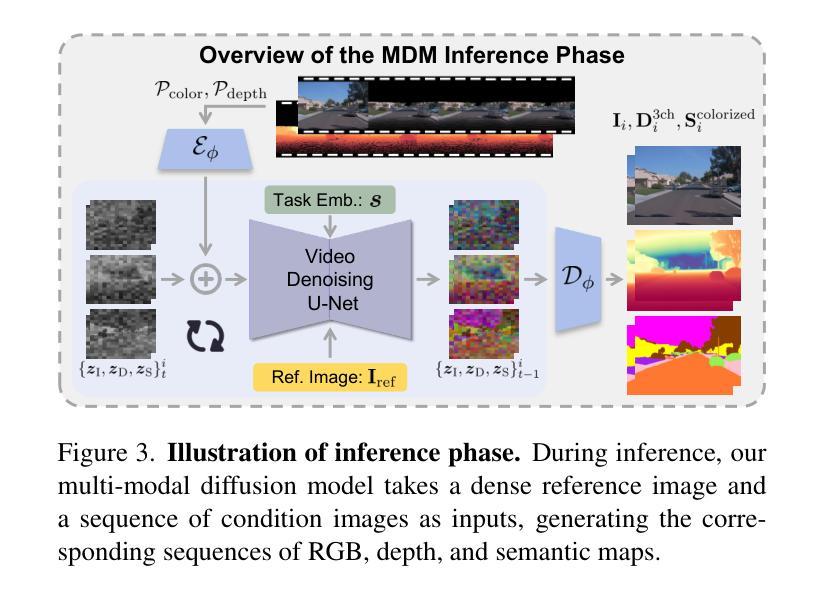
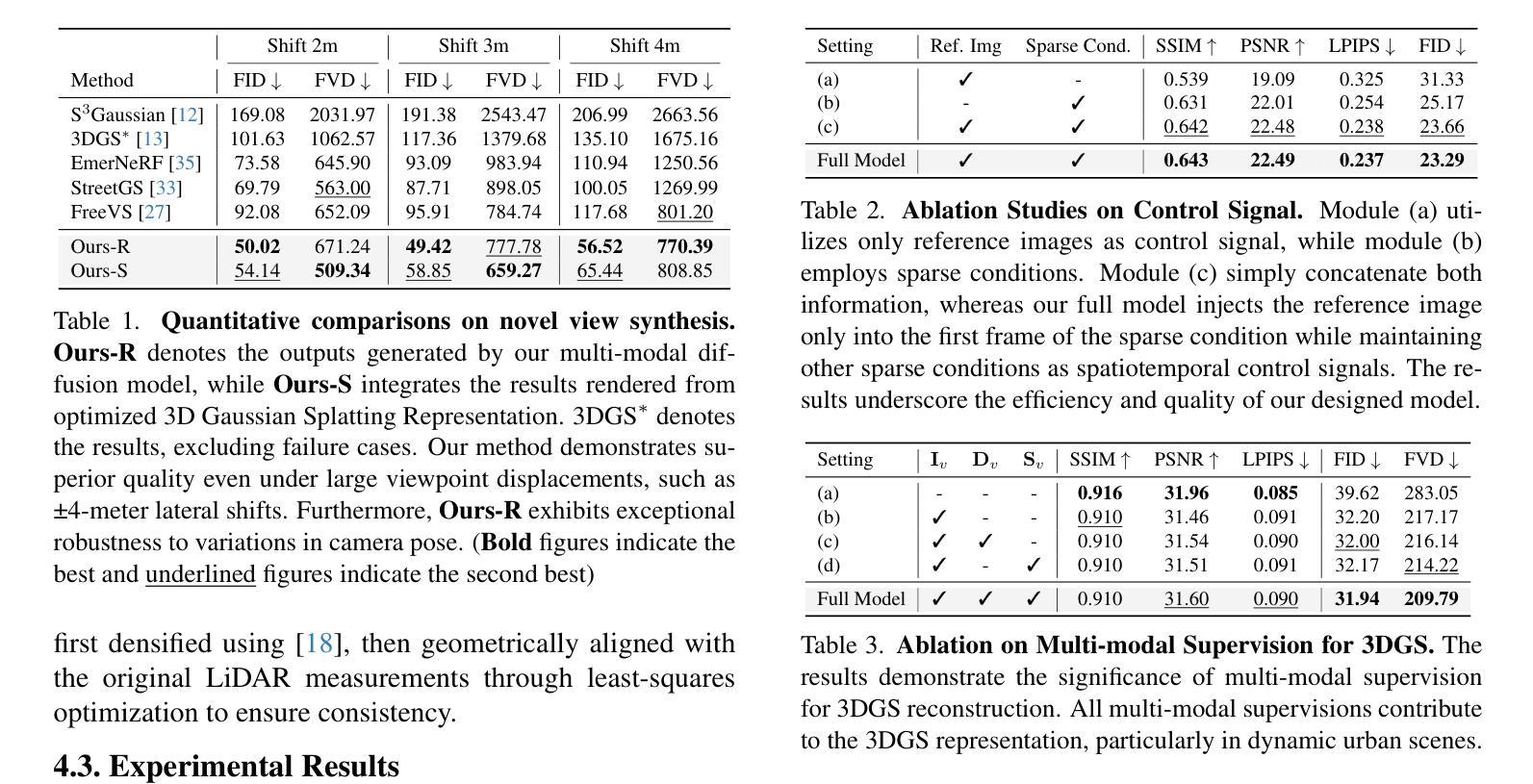
Recent breakthroughs in radiance fields have significantly advanced 3D scene reconstruction and novel view synthesis (NVS) in autonomous driving. Nevertheless, critical limitations persist: reconstruction-based methods exhibit substantial performance deterioration under significant viewpoint deviations from training trajectories, while generation-based techniques struggle with temporal coherence and precise scene controllability. To overcome these challenges, we present MuDG, an innovative framework that integrates Multi-modal Diffusion model with Gaussian Splatting (GS) for Urban Scene Reconstruction. MuDG leverages aggregated LiDAR point clouds with RGB and geometric priors to condition a multi-modal video diffusion model, synthesizing photorealistic RGB, depth, and semantic outputs for novel viewpoints. This synthesis pipeline enables feed-forward NVS without computationally intensive per-scene optimization, providing comprehensive supervision signals to refine 3DGS representations for rendering robustness enhancement under extreme viewpoint changes. Experiments on the Open Waymo Dataset demonstrate that MuDG outperforms existing methods in both reconstruction and synthesis quality.
近期,辐射场方面的突破极大地推动了自主驾驶中的3D场景重建和新型视角合成(NVS)的发展。然而,仍存在一些关键限制:基于重建的方法在训练轨迹的显著视点偏差下表现出显著的性能下降,而基于生成的技术则难以维持时间连贯性和精确的场景可控性。为了克服这些挑战,我们提出了MuDG,这是一个创新框架,它将多模式扩散模型与高斯喷溅(GS)相结合,用于城市场景重建。MuDG利用聚合的激光雷达点云、RGB和几何先验条件来调控多模式视频扩散模型,合成逼真的RGB、深度和语义输出,用于新颖视角。这一合成管道实现了前馈NVS,无需计算密集的单场景优化,提供全面的监督信号,以在极端视点变化下提高渲染的鲁棒性,细化3DGS表示。在Open Waymo数据集上的实验表明,MuDG在重建和合成质量方面都优于现有方法。
论文及项目相关链接
Summary
近期,辐射场技术的突破显著推动了自动驾驶中的3D场景重建和新型视角合成(NVS)的发展。然而,仍存在关键局限:基于重建的方法在训练轨迹的显著视角偏差下性能大幅下降,而基于生成的技术则在时间连贯性和精确场景可控性方面面临挑战。为克服这些难题,我们提出了MuDG框架,它结合了多模态扩散模型和高斯拼贴(GS)进行城市场景重建。MuDG利用聚合的激光雷达点云、RGB和几何先验来条件化多模态视频扩散模型,为新型视角合成逼真的RGB、深度和语义输出。这一合成管道实现了前馈NVS,无需计算密集的场景优化,为增强3DGS表示的渲染稳健性提供了全面的监督信号,在极端视角变化下表现尤为出色。在Open Waymo数据集上的实验表明,MuDG在重建和合成质量方面均优于现有方法。
Key Takeaways
- 辐射场技术的最新突破已经显著推动了3D场景重建和新型视角合成在自动驾驶领域的发展。
- 当前方法存在局限性,基于重建的方法在视角偏差较大时性能下降,而基于生成的方法在保持时间连贯性和场景精确可控性方面存在挑战。
- MuDG框架结合了多模态扩散模型和高斯拼贴(GS)进行城市场景重建,旨在克服现有方法的局限性。
- MuDG利用LiDAR点云、RGB和几何先验信息,为新型视角合成逼真的RGB、深度和语义输出。
- 合成管道实现了前馈NVS,无需密集的场景优化计算,提供了全面的监督信号,以改进3D表示并增强渲染稳健性。
- MuDG在多种数据集上的实验表现优于现有方法,特别是在处理极端视角变化时。
点此查看论文截图

4D LangSplat: 4D Language Gaussian Splatting via Multimodal Large Language Models
Authors:Wanhua Li, Renping Zhou, Jiawei Zhou, Yingwei Song, Johannes Herter, Minghan Qin, Gao Huang, Hanspeter Pfister
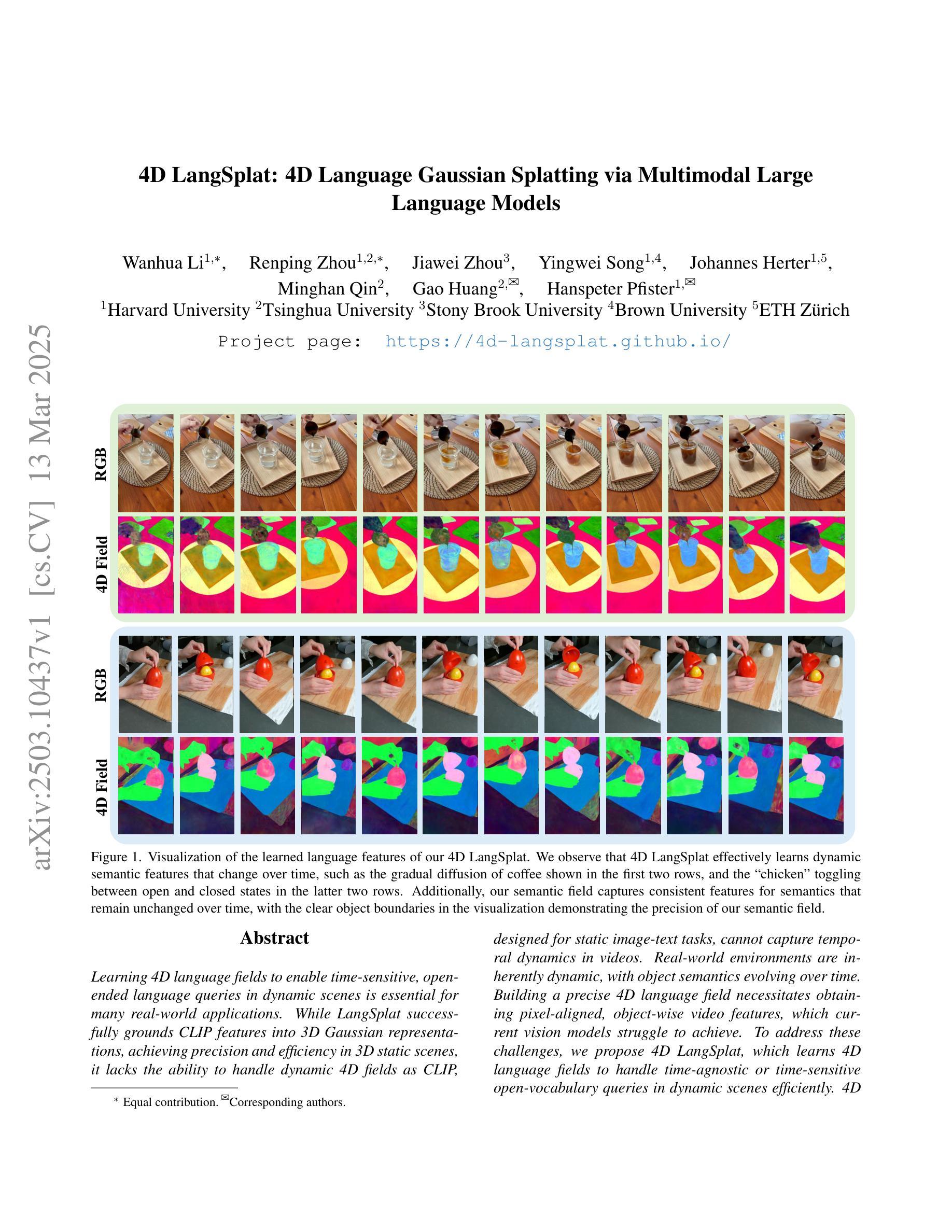
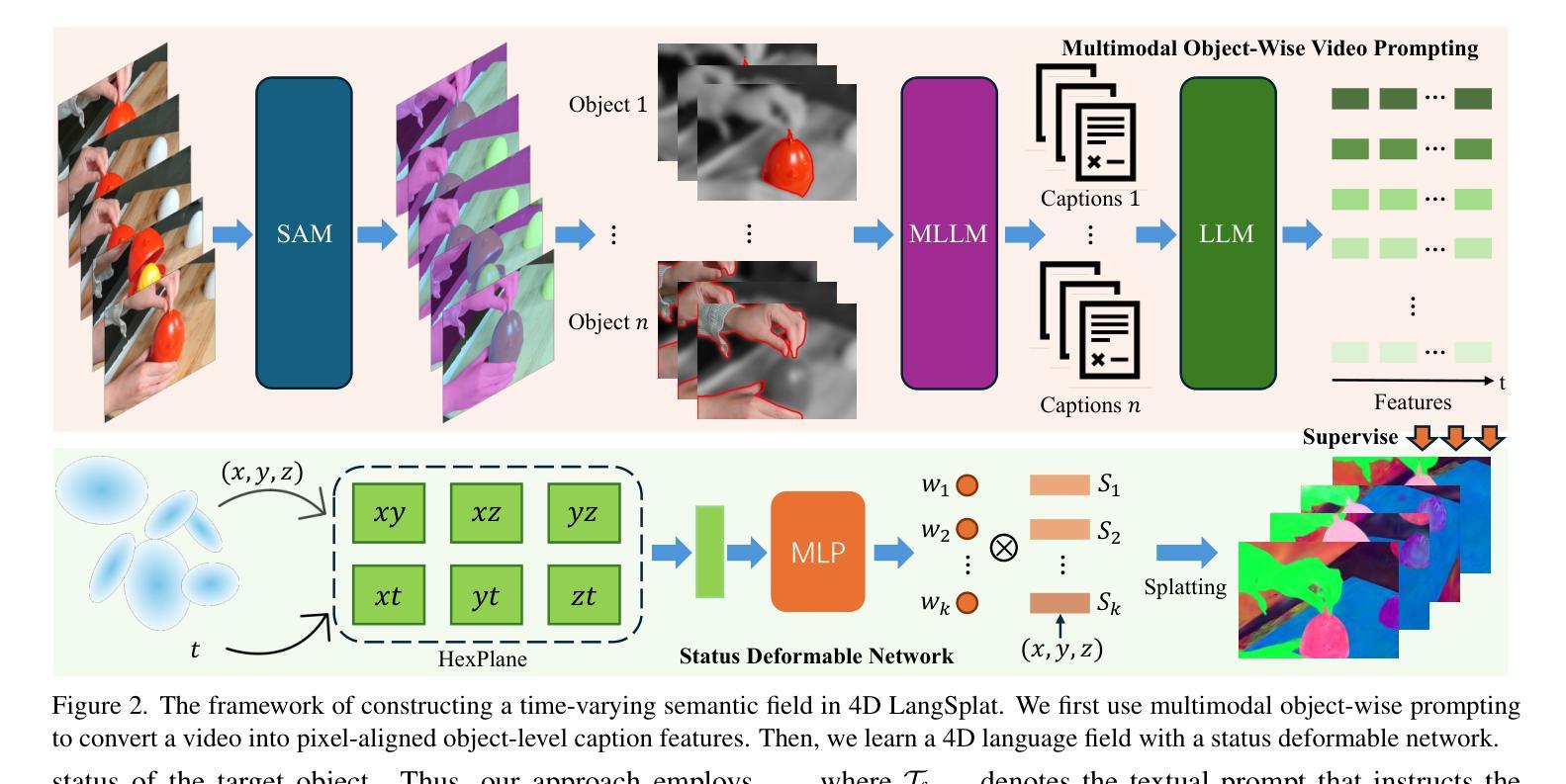
Learning 4D language fields to enable time-sensitive, open-ended language queries in dynamic scenes is essential for many real-world applications. While LangSplat successfully grounds CLIP features into 3D Gaussian representations, achieving precision and efficiency in 3D static scenes, it lacks the ability to handle dynamic 4D fields as CLIP, designed for static image-text tasks, cannot capture temporal dynamics in videos. Real-world environments are inherently dynamic, with object semantics evolving over time. Building a precise 4D language field necessitates obtaining pixel-aligned, object-wise video features, which current vision models struggle to achieve. To address these challenges, we propose 4D LangSplat, which learns 4D language fields to handle time-agnostic or time-sensitive open-vocabulary queries in dynamic scenes efficiently. 4D LangSplat bypasses learning the language field from vision features and instead learns directly from text generated from object-wise video captions via Multimodal Large Language Models (MLLMs). Specifically, we propose a multimodal object-wise video prompting method, consisting of visual and text prompts that guide MLLMs to generate detailed, temporally consistent, high-quality captions for objects throughout a video. These captions are encoded using a Large Language Model into high-quality sentence embeddings, which then serve as pixel-aligned, object-specific feature supervision, facilitating open-vocabulary text queries through shared embedding spaces. Recognizing that objects in 4D scenes exhibit smooth transitions across states, we further propose a status deformable network to model these continuous changes over time effectively. Our results across multiple benchmarks demonstrate that 4D LangSplat attains precise and efficient results for both time-sensitive and time-agnostic open-vocabulary queries.
学习四维语言场,以实现动态场景中的时间敏感型开放式语言查询,对于许多现实世界应用至关重要。虽然LangSplat成功地将CLIP特性融入三维高斯表示,实现了在三维静态场景中的精度和效率,但它无法处理动态四维场,因为CLIP是为静态图像文本任务设计的,无法捕捉视频中的时间动态。现实世界的环境本质上是动态的,物体语义会随时间演变。构建精确的四维语言场必须获得像素对齐的、面向对象的视频特征,而当前视觉模型很难做到这一点。为了应对这些挑战,我们提出了四维LangSplat,它学习四维语言场,以高效地处理动态场景中的时间无关或时间敏感型开放式词汇查询。四维LangSplat绕过从视觉特征中学习语言场的方法,而是直接从通过面向对象的视频字幕生成文本中学习。具体来说,我们提出了一种多模态面向对象的视频提示方法,包括视觉和文本提示,可以引导多模态大型语言模型(MLLMs)为视频中的对象生成详细、时间连贯的高质量字幕。这些字幕使用大型语言模型进行编码,生成高质量句子嵌入,然后作为像素对齐的、面向对象的特征监督,通过共享嵌入空间实现开放式词汇文本查询。我们认识到四维场景中的对象在状态之间呈现出平滑过渡,因此进一步提出了一种状态可变形网络,以有效地对这些随时间变化的连续变化进行建模。我们在多个基准测试上的结果表明,四维LangSplat对于时间敏感型和时间无关型的开放式词汇查询都达到了精确和高效的结果。
论文及项目相关链接
PDF CVPR 2025. Project Page: https://4d-langsplat.github.io
Summary
本文介绍了学习4D语言字段的重要性,该语言字段可以处理动态场景中的时间敏感或无时间敏感的开放词汇查询。为解决当前模型在动态视频处理上的不足,提出了一种名为“四维朗思平板”(4D LangSplat)的方法。它采用对象级别的视频提示来指导大型多媒体语言模型(MLLMs)生成高质量的详细描述对象视频内容的文本字幕。该文本被转换为高质量的句子嵌入,作为像素对齐的对象特定特征监督,为通过共享嵌入空间进行开放式文本查询提供了便利。进一步采用了一种状态可变形网络,有效建模对象在连续时间内变化的特征变化。结果证明了该方法在不同标准上的准确性和高效性。
Key Takeaways
- 学习四维语言字段对于处理动态场景中的时间敏感和无时间敏感的开放词汇查询至关重要。
- 当前模型在处理动态视频时面临困难,无法捕捉对象的语义变化。
点此查看论文截图
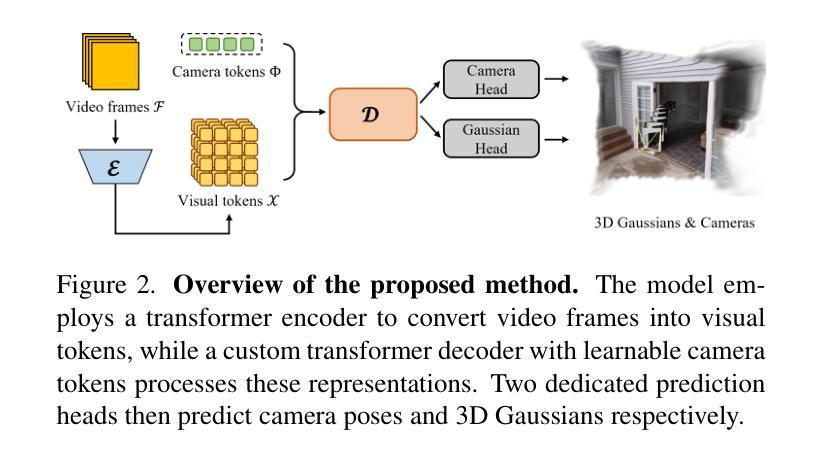
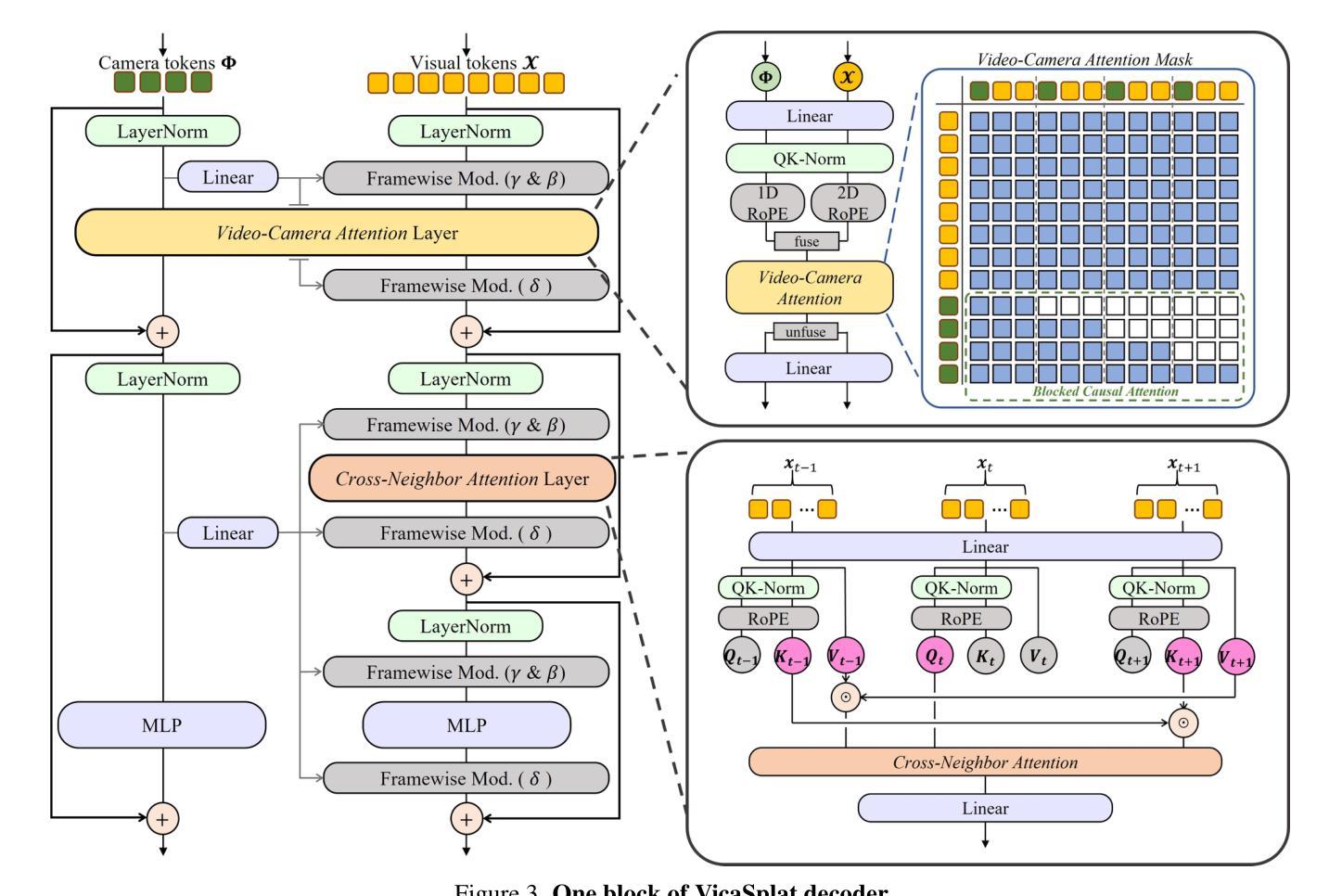
VicaSplat: A Single Run is All You Need for 3D Gaussian Splatting and Camera Estimation from Unposed Video Frames
Authors:Zhiqi Li, Chengrui Dong, Yiming Chen, Zhangchi Huang, Peidong Liu
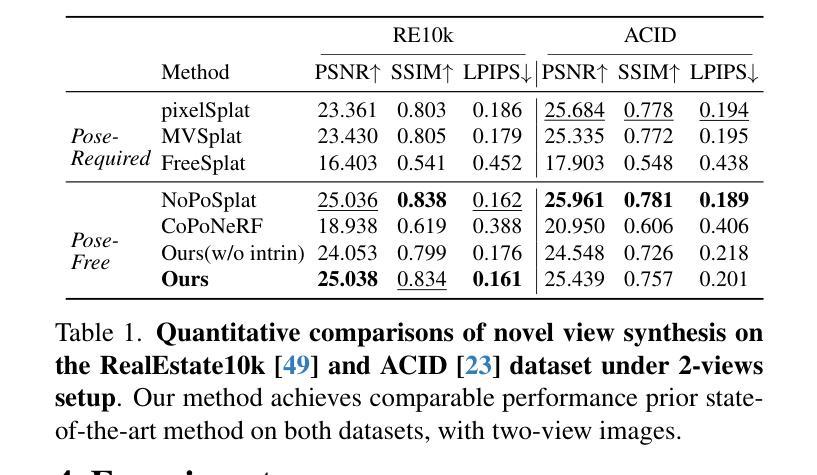
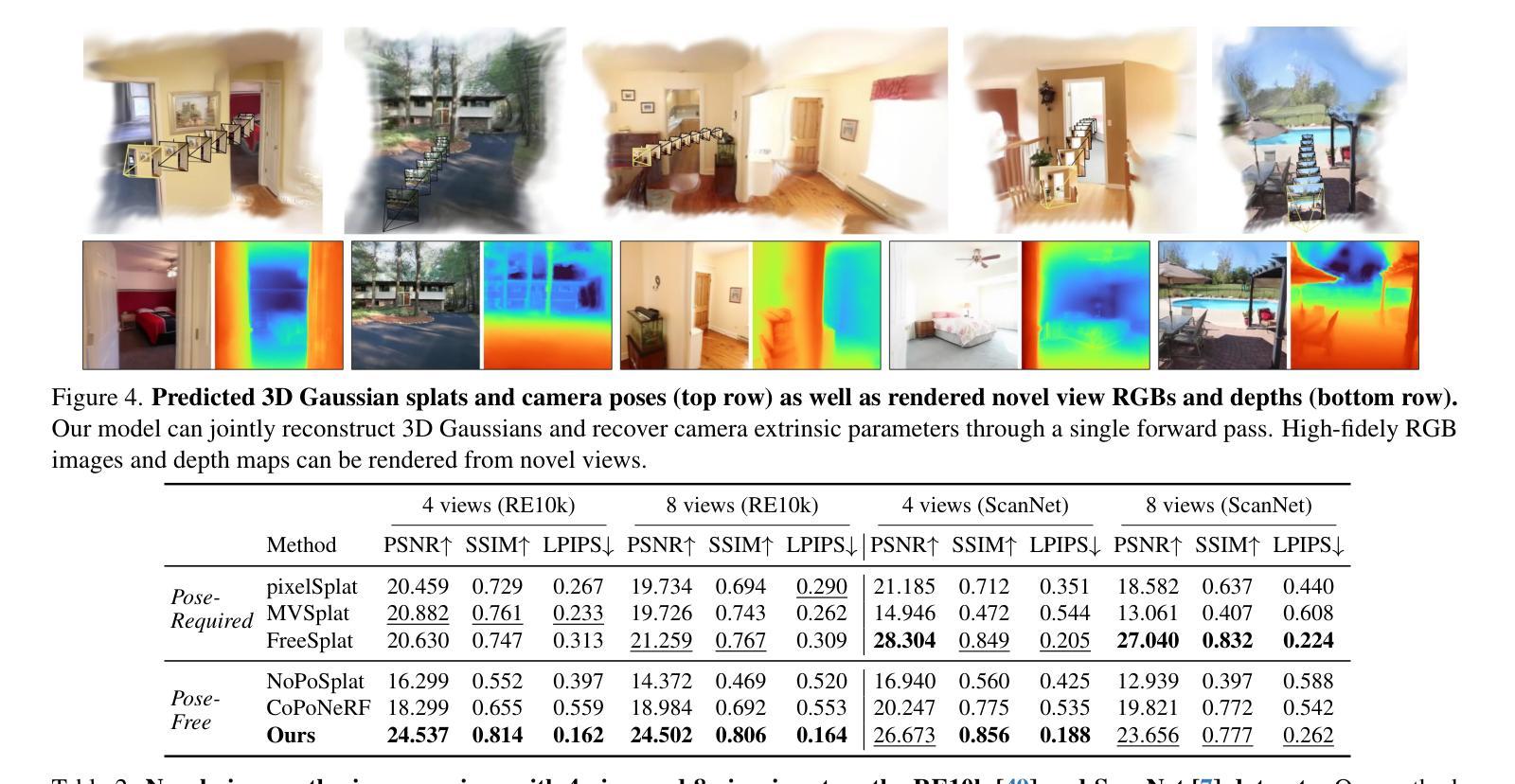
We present VicaSplat, a novel framework for joint 3D Gaussians reconstruction and camera pose estimation from a sequence of unposed video frames, which is a critical yet underexplored task in real-world 3D applications. The core of our method lies in a novel transformer-based network architecture. In particular, our model starts with an image encoder that maps each image to a list of visual tokens. All visual tokens are concatenated with additional inserted learnable camera tokens. The obtained tokens then fully communicate with each other within a tailored transformer decoder. The camera tokens causally aggregate features from visual tokens of different views, and further modulate them frame-wisely to inject view-dependent features. 3D Gaussian splats and camera pose parameters can then be estimated via different prediction heads. Experiments show that VicaSplat surpasses baseline methods for multi-view inputs, and achieves comparable performance to prior two-view approaches. Remarkably, VicaSplat also demonstrates exceptional cross-dataset generalization capability on the ScanNet benchmark, achieving superior performance without any fine-tuning. Project page: https://lizhiqi49.github.io/VicaSplat.
我们提出了VicaSplat,这是一个新颖的框架,用于从一系列未摆姿势的视频帧中联合重建3D高斯并估计相机姿态,这是现实世界3D应用中一个关键但尚未被充分研究的任务。我们的方法的核心在于一种新型的基于transformer的网络架构。具体来说,我们的模型从一个图像编码器开始,它将每张图像映射到一系列视觉令牌。所有视觉令牌都与附加的插入的可学习相机令牌连接在一起。所获得的令牌之间在定制的transformer解码器中进行充分的通信。相机令牌从来自不同视角的视觉令牌中提取特征,并进一步对其进行调制以注入视角相关的特征。然后可以通过不同的预测头估计出3D高斯地图和相机姿态参数。实验表明,对于多视角输入,VicaSplat超过了基线方法,实现了与现有两视角方法相当的性能。值得注意的是,VicaSplat在ScanNet基准测试上也表现出了出色的跨数据集泛化能力,无需微调即可实现卓越性能。项目页面:https://lizhiqi49.github.io/VicaSplat。
论文及项目相关链接
摘要
本文介绍了VicaSplat这一新型框架,该框架可从一系列未定位的视频帧中联合进行3D高斯分布重建和相机姿态估计,这是现实世界中3D应用中的一个关键但尚未充分探索的任务。该方法的核心在于基于transformer的网络架构。模型通过图像编码器将每幅图像映射到一系列视觉令牌,并将这些令牌与额外的可学习相机令牌相结合。这些令牌在一个定制的transformer解码器内进行全面交流。相机令牌从来自不同视图的视觉令牌中提取特征,并对其进行智能调节以注入视角相关的特征。最后通过不同的预测头估计出3D高斯分布和相机姿态参数。实验表明,VicaSplat在多视图输入上超过了基线方法,并实现了与前两个视图方法相当的性能。此外,VicaSplat在ScanNet数据集上也展现出了卓越的跨数据集泛化能力,并且在不进行微调的情况下取得了优越的性能。
关键见解
- VicaSplat是一个针对从视频帧序列进行3D高斯分布重建和相机姿态估计的新型框架。
- 方法核心在于基于transformer的网络架构,包括图像编码器和定制的transformer解码器。
- 通过相机令牌注入视角相关的特征,实现跨不同视图的特征融合。
- VicaSplat通过不同的预测头估计出3D高斯分布和相机姿态参数。
- 实验结果表明,该框架在多视图输入上性能卓越。
- VicaSplat实现了强大的跨数据集泛化能力,在ScanNet数据集上表现优异。
- 项目页面提供了更多详细信息:链接。
点此查看论文截图

ROODI: Reconstructing Occluded Objects with Denoising Inpainters
Authors:Yeonjin Chang, Erqun Dong, Seunghyeon Seo, Nojun Kwak, Kwang Moo Yi
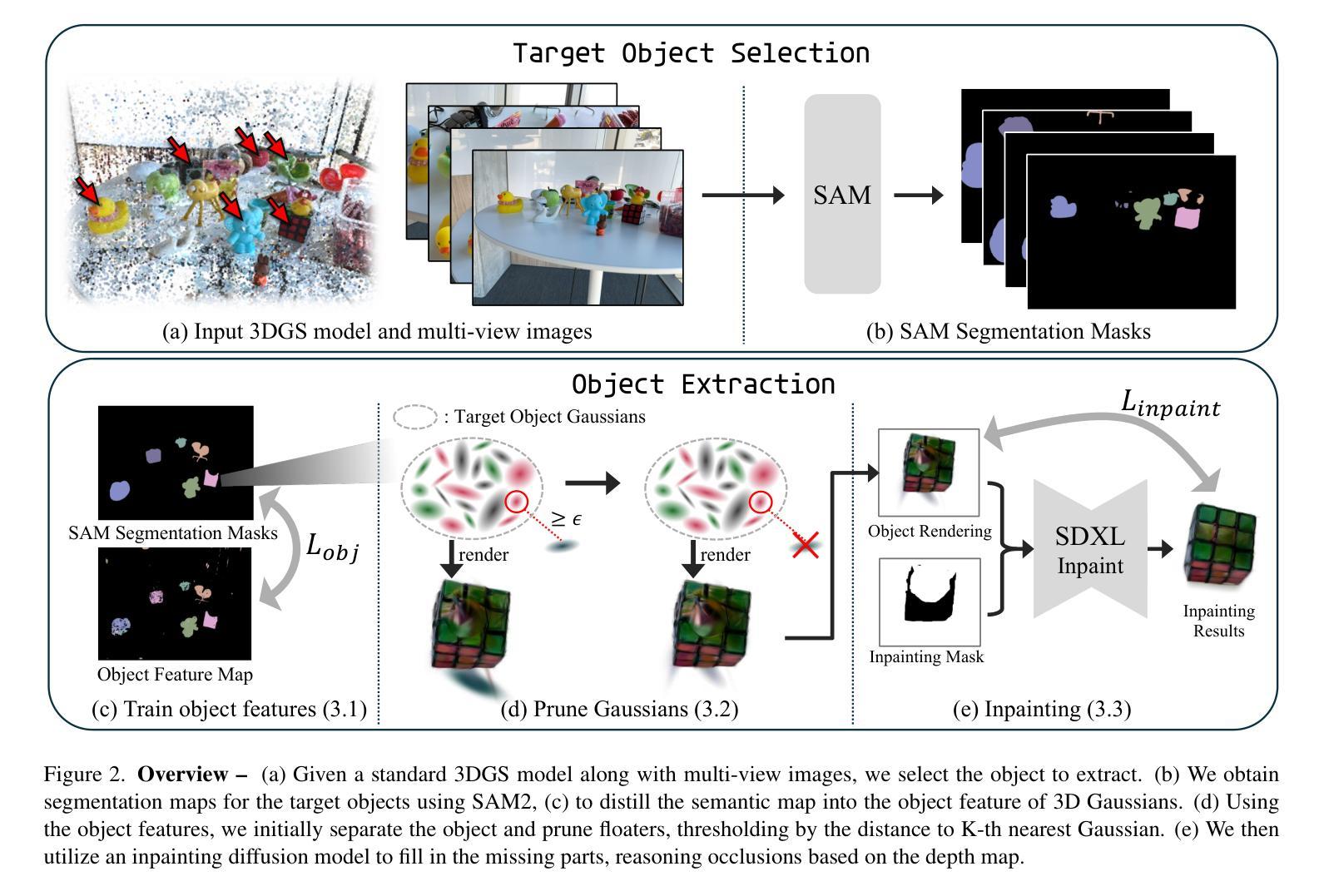
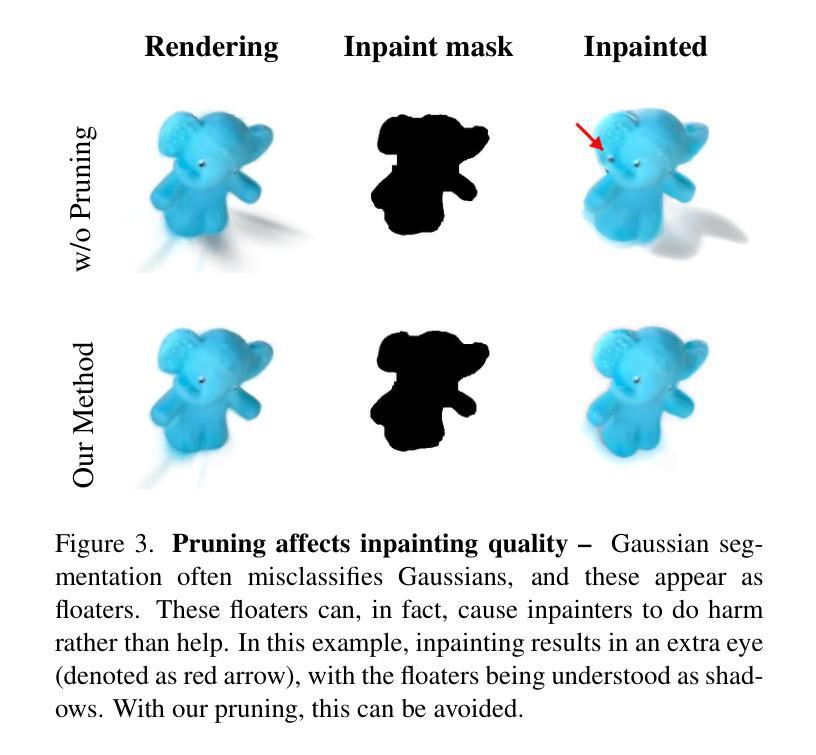
While the quality of novel-view images has improved dramatically with 3D Gaussian Splatting, extracting specific objects from scenes remains challenging. Isolating individual 3D Gaussian primitives for each object and handling occlusions in scenes remain far from being solved. We propose a novel object extraction method based on two key principles: (1) being object-centric by pruning irrelevant primitives; and (2) leveraging generative inpainting to compensate for missing observations caused by occlusions. For pruning, we analyze the local structure of primitives using K-nearest neighbors, and retain only relevant ones. For inpainting, we employ an off-the-shelf diffusion-based inpainter combined with occlusion reasoning, utilizing the 3D representation of the entire scene. Our findings highlight the crucial synergy between pruning and inpainting, both of which significantly enhance extraction performance. We evaluate our method on a standard real-world dataset and introduce a synthetic dataset for quantitative analysis. Our approach outperforms the state-of-the-art, demonstrating its effectiveness in object extraction from complex scenes.
采用3D高斯贴图技术,全景图像的质量得到了极大提高,但从场景中提取特定物体仍然具有挑战性。隔离每个物体的单个3D高斯基本体并处理场景中的遮挡问题仍有待解决。我们提出了一种基于两个关键原则的新物体提取方法:(1)以物体为中心,剔除无关的基本体;(2)利用生成式补全技术来弥补遮挡造成的观测缺失。对于剔除操作,我们通过分析基本体的局部结构,利用K近邻法只保留相关的基本体。对于补全操作,我们采用现成的基于扩散的补全工具,结合遮挡推理,利用整个场景的3D表示。我们的研究发现,剔除和补全之间的协同作用至关重要,二者都能显著提高提取性能。我们在标准现实世界数据集上评估了我们的方法,并引入了一个合成数据集进行定量分析。我们的方法优于当前最新技术,证明了其在复杂场景中提取物体的有效性。
论文及项目相关链接
PDF Project page: https://yeonjin-chang.github.io/ROODI/
Summary
本文提出一种基于三维高斯分裂技术的新物体提取方法,该方法针对场景中特定物体的提取挑战进行了优化。该方法包括两个关键原则:一是以物体为中心,剔除无关的原语;二是利用生成补全技术补偿因遮挡造成的观测缺失。通过K近邻分析原语局部结构进行剔除,并结合场景的三维表示和扩散式补全技术处理遮挡问题。该方法在真实和合成数据集上的表现均优于现有技术,显著提高了从复杂场景中提取物体的性能。
Key Takeaways
- 3D Gaussian Splatting技术虽在生成新视角图像方面取得了显著进步,但场景中的特定物体提取仍然面临挑战。
- 剔除无关原语并利用生成补全技术补偿遮挡是本文提出的新物体提取方法的关键。
- 通过K近邻分析原语的局部结构来进行剔除,以提高提取性能。
- 利用场景的三维表示结合扩散式补全技术处理遮挡问题。
- 剔除和补全之间的协同作用对于提高物体提取性能至关重要。
- 在真实和合成数据集上的实验表明,该方法在复杂场景中的物体提取性能优于现有技术。
点此查看论文截图




GS-SDF: LiDAR-Augmented Gaussian Splatting and Neural SDF for Geometrically Consistent Rendering and Reconstruction
Authors:Jianheng Liu, Yunfei Wan, Bowen Wang, Chunran Zheng, Jiarong Lin, Fu Zhang
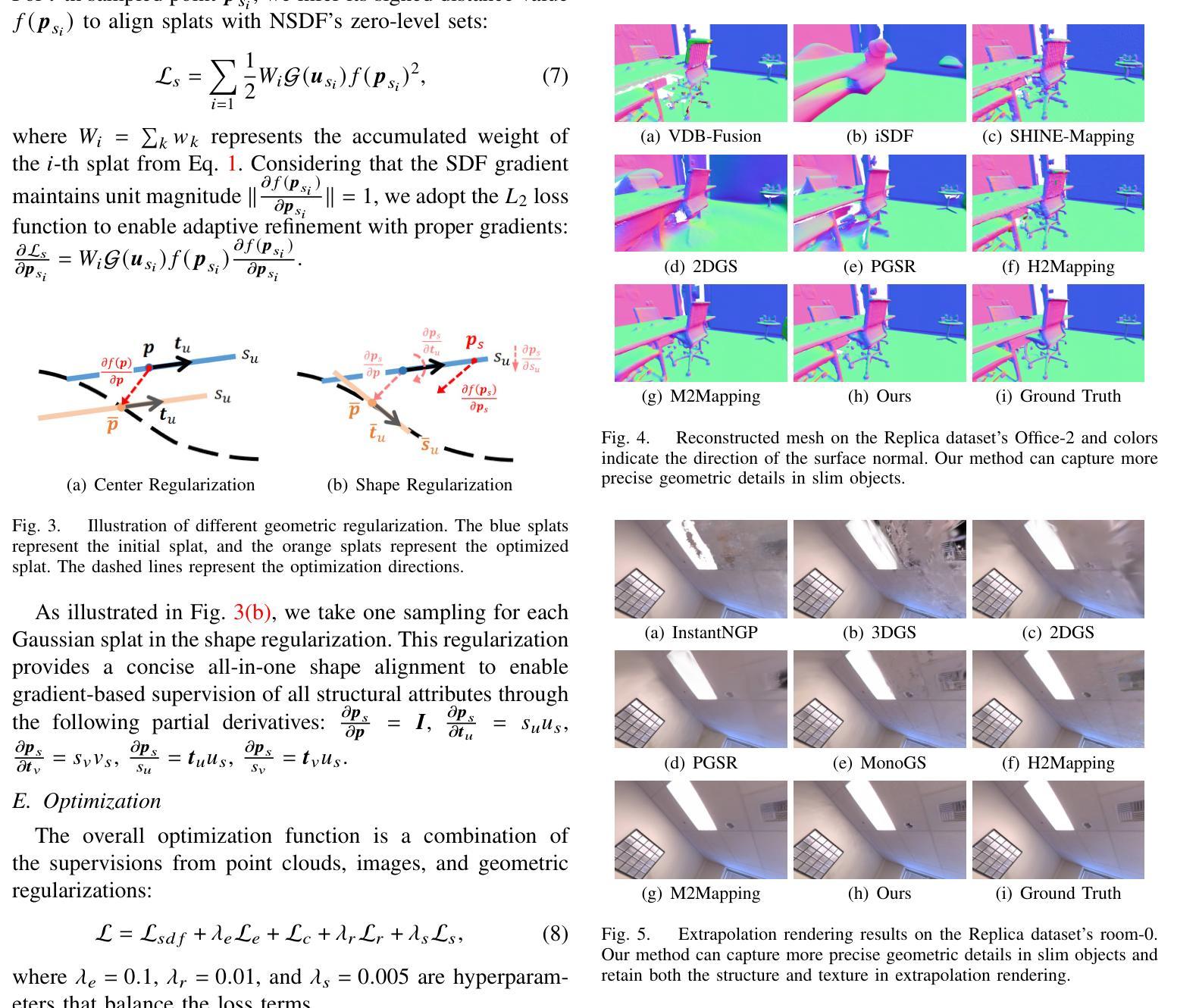
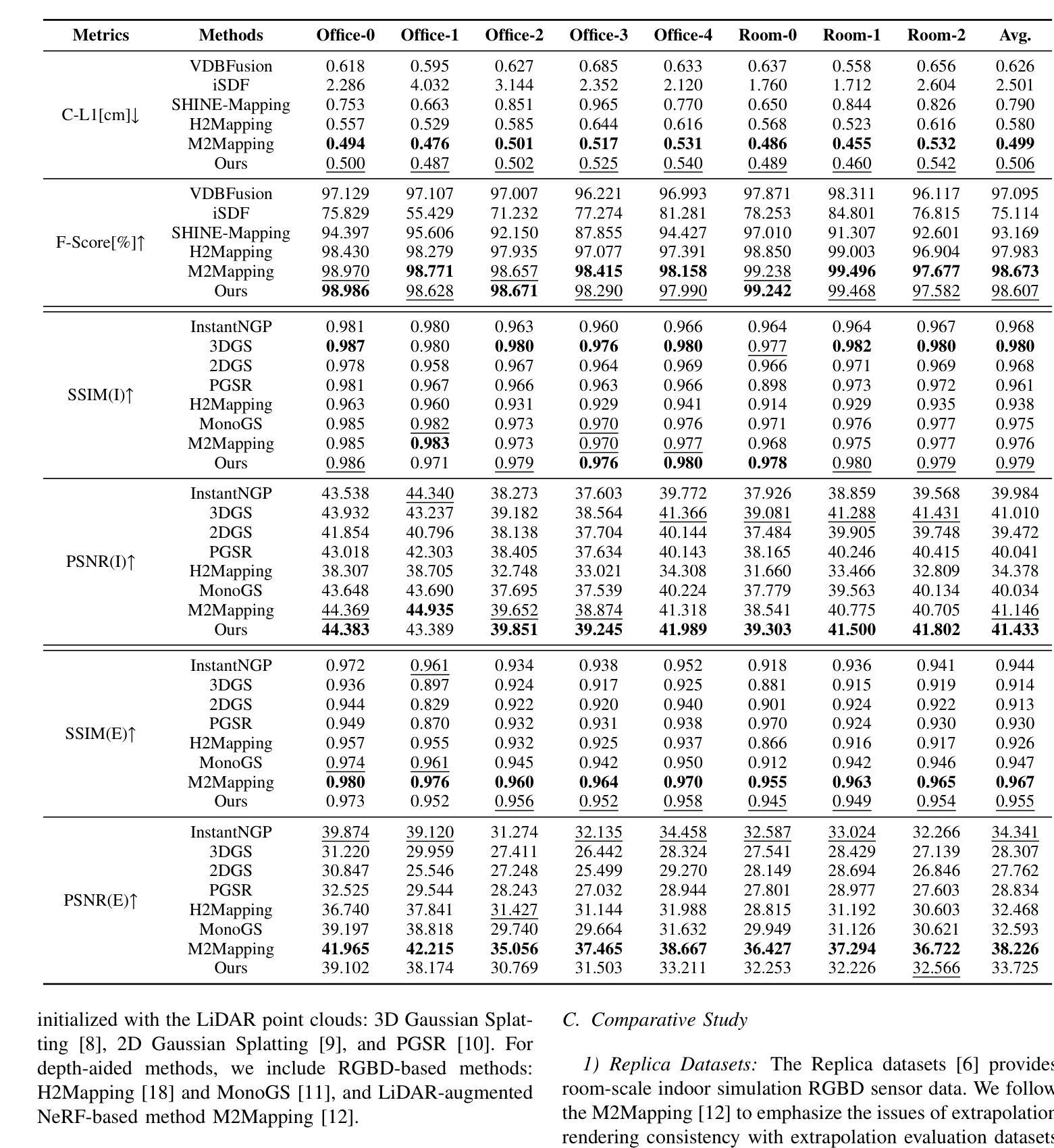
Digital twins are fundamental to the development of autonomous driving and embodied artificial intelligence. However, achieving high-granularity surface reconstruction and high-fidelity rendering remains a challenge. Gaussian splatting offers efficient photorealistic rendering but struggles with geometric inconsistencies due to fragmented primitives and sparse observational data in robotics applications. Existing regularization methods, which rely on render-derived constraints, often fail in complex environments. Moreover, effectively integrating sparse LiDAR data with Gaussian splatting remains challenging. We propose a unified LiDAR-visual system that synergizes Gaussian splatting with a neural signed distance field. The accurate LiDAR point clouds enable a trained neural signed distance field to offer a manifold geometry field, This motivates us to offer an SDF-based Gaussian initialization for physically grounded primitive placement and a comprehensive geometric regularization for geometrically consistent rendering and reconstruction. Experiments demonstrate superior reconstruction accuracy and rendering quality across diverse trajectories. To benefit the community, the codes will be released at https://github.com/hku-mars/GS-SDF.
数字孪生对自动驾驶和人工智能实体的发展具有重要意义。然而,实现高粒度表面重建和高保真渲染仍然是一个挑战。高斯斑点法虽可提供高效的逼真渲染,但在机器人应用中,由于碎片化的原始数据和稀疏的观察数据,其在处理几何不一致性方面存在困难。现有的依赖于渲染约束的正则化方法往往在复杂环境中失效。此外,如何将稀疏的激光雷达数据与高斯斑点法有效结合仍然是一个挑战。我们提出了一种统一的激光雷达视觉系统,该系统将高斯斑点法与神经有向距离场相结合。准确的激光雷达点云能够使经过训练的神经有向距离场提供流形几何场,这促使我们提供一种基于SDF的高斯初始化,用于物理基础的原始位置放置和全面的几何正则化,以实现几何一致的渲染和重建。实验表明,该方法在多种轨迹上的重建精度和渲染质量均表现优越。为了造福社区,相关代码将在[https://github.com/hku-mars/GS-SDF上发布。]
论文及项目相关链接
Summary
数字孪生在自动驾驶和人工智能领域扮演重要角色,但实现高粒度表面重建和高保真渲染仍存在挑战。高斯贴图技术虽然能进行逼真的渲染,但在机器人应用中因几何不一致性和稀疏观测数据导致的问题却令人头疼。目前依赖渲染派生约束的正则化方法,在复杂环境中常常失效。同时,如何将稀疏的激光雷达数据与高斯贴图技术有效结合也是一个难题。本研究提出一种统一的激光雷达视觉系统,该系统将高斯贴图技术与神经网络距离场相融合。准确的激光雷达点云数据为训练神经网络提供了几何场数据,基于此,我们提出了基于距离场的初始高斯设置和全面的几何正则化方法,以实现几何一致的渲染和重建。实验证明,该方法在多种轨迹上的重建精度和渲染质量均表现优越。相关代码已发布至GitHub(https://github.com/hku-mars/GS-SDF)。
Key Takeaways
- 数字孪生在自动驾驶和人工智能领域有重要作用,但实现高粒度表面重建和高保真渲染仍存在挑战。
- 高斯贴图技术虽然在机器人应用中能够进行逼真的渲染,但存在几何不一致性和稀疏观测数据的问题。
- 目前依赖渲染派生约束的正则化方法在复杂环境中常常失效。
- 激光雷达数据与高斯贴图技术的结合是一大挑战。
- 本研究提出了一种统一的激光雷达视觉系统,融合了高斯贴图技术与神经网络距离场技术。
- 该系统利用准确的激光雷达点云数据训练神经网络,并基于此提出了基于距离场的初始高斯设置和全面的几何正则化方法。
点此查看论文截图




3D Student Splatting and Scooping
Authors:Jialin Zhu, Jiangbei Yue, Feixiang He, He Wang
Recently, 3D Gaussian Splatting (3DGS) provides a new framework for novel view synthesis, and has spiked a new wave of research in neural rendering and related applications. As 3DGS is becoming a foundational component of many models, any improvement on 3DGS itself can bring huge benefits. To this end, we aim to improve the fundamental paradigm and formulation of 3DGS. We argue that as an unnormalized mixture model, it needs to be neither Gaussians nor splatting. We subsequently propose a new mixture model consisting of flexible Student’s t distributions, with both positive (splatting) and negative (scooping) densities. We name our model Student Splatting and Scooping, or SSS. When providing better expressivity, SSS also poses new challenges in learning. Therefore, we also propose a new principled sampling approach for optimization. Through exhaustive evaluation and comparison, across multiple datasets, settings, and metrics, we demonstrate that SSS outperforms existing methods in terms of quality and parameter efficiency, e.g. achieving matching or better quality with similar numbers of components, and obtaining comparable results while reducing the component number by as much as 82%.
最近,3D高斯拼接(3DGS)为新型视角合成提供了新的框架,并在神经渲染和相关应用中引发了新的研究热潮。由于3DGS正在成为许多模型的基础组件,因此对3DGS本身的任何改进都能带来巨大的好处。为此,我们旨在改进3DGS的基本范式和公式。我们认为,作为一种未归一化的混合模型,它既不需要是高斯分布也不需要是拼接。随后,我们提出了一种新的混合模型,由灵活的Student’s t分布组成,包括正向(拼接)和负向(挖掘)密度。我们将我们的模型命名为学生拼接和挖掘,或SSS。在提高表达性的同时,SSS也给学习带来了新的挑战。因此,我们还提出了一种新的有原则性的采样优化方法。通过跨多个数据集、设置和指标的综合评估比较,我们证明了SSS在质量和参数效率方面优于现有方法,例如在使用相似数量的组件时达到匹配或更好的质量,并在减少组件数量的同时获得相当的结果,最多可达82%。
论文及项目相关链接
Summary
点此查看论文截图

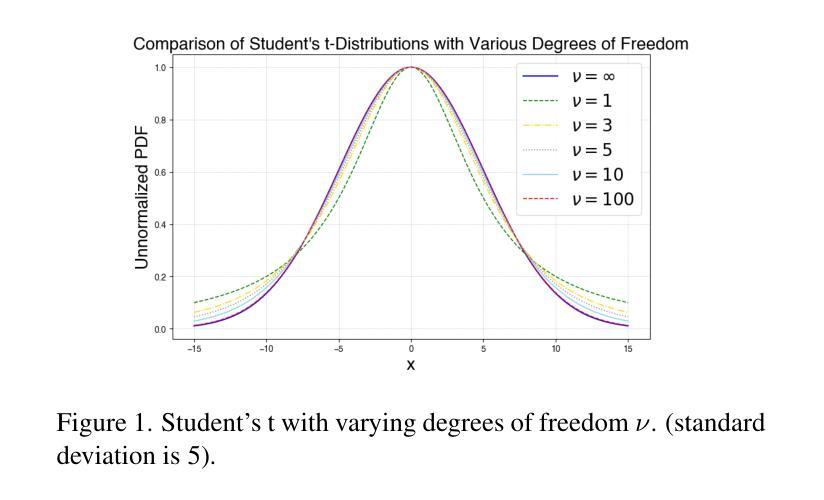

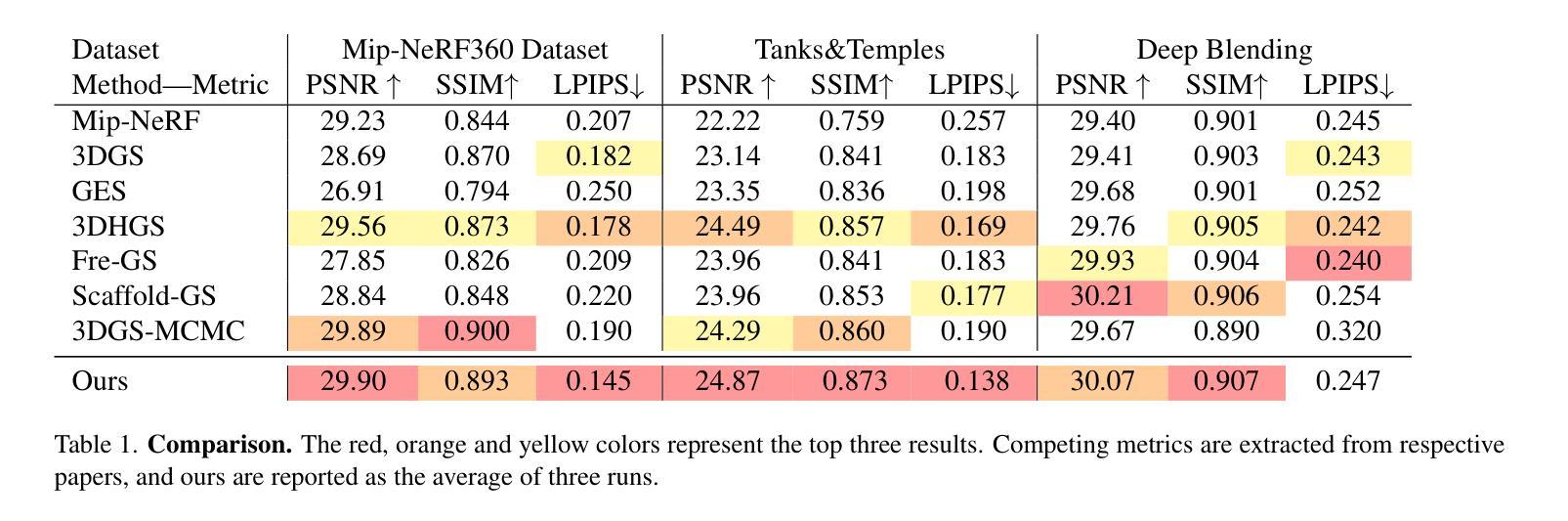
GaussHDR: High Dynamic Range Gaussian Splatting via Learning Unified 3D and 2D Local Tone Mapping
Authors:Jinfeng Liu, Lingtong Kong, Bo Li, Dan Xu
High dynamic range (HDR) novel view synthesis (NVS) aims to reconstruct HDR scenes by leveraging multi-view low dynamic range (LDR) images captured at different exposure levels. Current training paradigms with 3D tone mapping often result in unstable HDR reconstruction, while training with 2D tone mapping reduces the model’s capacity to fit LDR images. Additionally, the global tone mapper used in existing methods can impede the learning of both HDR and LDR representations. To address these challenges, we present GaussHDR, which unifies 3D and 2D local tone mapping through 3D Gaussian splatting. Specifically, we design a residual local tone mapper for both 3D and 2D tone mapping that accepts an additional context feature as input. We then propose combining the dual LDR rendering results from both 3D and 2D local tone mapping at the loss level. Finally, recognizing that different scenes may exhibit varying balances between the dual results, we introduce uncertainty learning and use the uncertainties for adaptive modulation. Extensive experiments demonstrate that GaussHDR significantly outperforms state-of-the-art methods in both synthetic and real-world scenarios.
高动态范围(HDR)新颖视图合成(NVS)旨在利用在不同曝光级别下捕获的多视图低动态范围(LDR)图像重建HDR场景。当前使用3D色调映射的训练模式往往会导致HDR重建不稳定,而使用2D色调映射的训练则降低了模型对LDR图像的拟合能力。此外,现有方法中所使用的全局色调映射器会阻碍HDR和LDR表示的学习。为了解决这些挑战,我们提出了GaussHDR,它通过3D高斯喷涂技术统一了3D和2D局部色调映射。具体来说,我们为3D和2D色调映射设计了残差局部色调映射器,该映射器以额外的上下文特征作为输入。然后,我们在损失级别上提出了结合来自3D和2D局部色调映射的两种LDR渲染结果。最后,我们认识到不同场景在双重结果之间可能存在不同的平衡,因此引入了不确定性学习并使用不确定性进行自适应调制。大量实验表明,GaussHDR在合成场景和真实世界场景中均显著优于最先进的方法。
论文及项目相关链接
PDF This paper is accepted by CVPR 2025. Project page is available at https://liujf1226.github.io/GaussHDR
Summary
本文提出一种名为GaussHDR的方法,旨在通过结合3D和2D局部色调映射技术,实现高动态范围(HDR)场景的重构。该方法通过3D高斯平铺技术统一了这两种色调映射,设计了一种接受附加上下文特征输入的残差局部色调映射器。在损失层面结合了来自3D和2D局部色调映射的双重LDR渲染结果,并引入不确定性学习来适应不同场景的需求。实验表明,GaussHDR在合成和真实场景中都显著优于现有方法。
Key Takeaways
- GaussHDR结合了3D和2D局部色调映射技术,旨在实现HDR场景的稳定重构。
- 现有训练模式在HDR重建时存在不稳定问题,而GaussHDR通过结合两种色调映射技术解决了这一问题。
- GaussHDR设计了一种接受附加上下文特征输入的残差局部色调映射器。
- 方法在损失层面结合了来自3D和2D局部色调映射的双重LDR渲染结果。
- GaussHDR引入了不确定性学习,以应对不同场景中双重结果之间的不同平衡。
- 实验表明,GaussHDR在合成和真实场景中均显著优于当前主流方法。
- GaussHDR能够提高模型的容量,更好地适应LDR图像的拟合。
点此查看论文截图


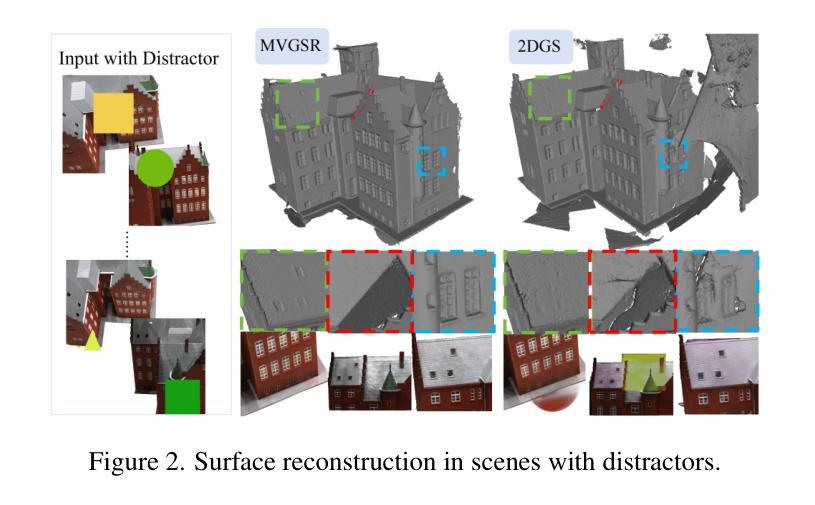
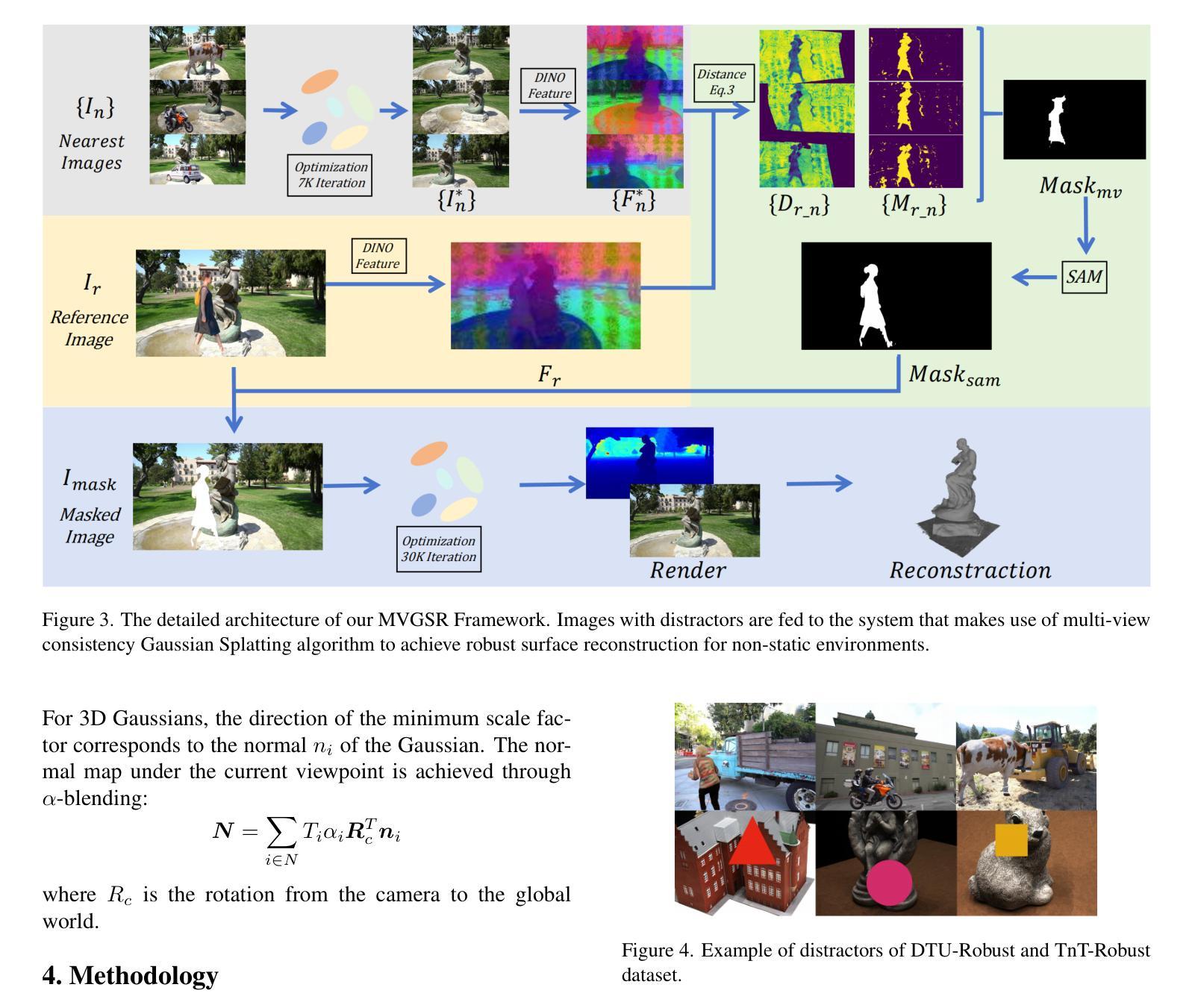
MVGSR: Multi-View Consistency Gaussian Splatting for Robust Surface Reconstruction
Authors:Chenfeng Hou, Qi Xun Yeo, Mengqi Guo, Yongxin Su, Yanyan Li, Gim Hee Lee
3D Gaussian Splatting (3DGS) has gained significant attention for its high-quality rendering capabilities, ultra-fast training, and inference speeds. However, when we apply 3DGS to surface reconstruction tasks, especially in environments with dynamic objects and distractors, the method suffers from floating artifacts and color errors due to inconsistency from different viewpoints. To address this challenge, we propose Multi-View Consistency Gaussian Splatting for the domain of Robust Surface Reconstruction (\textbf{MVGSR}), which takes advantage of lightweight Gaussian models and a {heuristics-guided distractor masking} strategy for robust surface reconstruction in non-static environments. Compared to existing methods that rely on MLPs for distractor segmentation strategies, our approach separates distractors from static scene elements by comparing multi-view feature consistency, allowing us to obtain precise distractor masks early in training. Furthermore, we introduce a pruning measure based on multi-view contributions to reset transmittance, effectively reducing floating artifacts. Finally, a multi-view consistency loss is applied to achieve high-quality performance in surface reconstruction tasks. Experimental results demonstrate that MVGSR achieves competitive geometric accuracy and rendering fidelity compared to the state-of-the-art surface reconstruction algorithms. More information is available on our project page (https://mvgsr.github.io).
3D高斯融合(3DGS)因其高质量渲染能力、超快训练和推理速度而受到广泛关注。然而,当我们将其应用于表面重建任务,尤其是在动态物体和干扰物存在的环境中,该方法会因从不同视角的不一致性而出现浮动伪影和颜色错误。为了应对这一挑战,我们提出了针对稳健表面重建领域的多视角一致性高斯融合(MVGSR)。该方法利用轻量级高斯模型和启发式引导干扰物遮挡策略,在非静态环境中实现稳健的表面重建。与现有依赖MLP进行干扰物分割策略的方法相比,我们的方法通过比较多视角特征一致性来区分干扰物和静态场景元素,从而在训练早期就能精确获取干扰物遮挡。此外,我们引入了一种基于多视角贡献的修剪度量来重置透射率,有效减少浮动伪影。最后,应用多视角一致性损失,以实现表面重建任务的高性能。实验结果表明,与最新表面重建算法相比,MVGSR在几何精度和渲染保真度方面达到竞争力水平。更多信息请访问我们的项目页面(https://mvgsr.github.io)。
论文及项目相关链接
PDF project page https://mvgsr.github.io
摘要
基于高效的高斯模型及多视角一致性算法,本研究针对非静态环境中的鲁棒表面重建提出一种新的策略Multi-View Consistency Gaussian Splatting(MVGSR)。在具有动态物体与干扰物的环境下,针对现有的基于3DGS的表面重建技术的局限性问题(如视角不一致造成的漂浮伪影及色彩错误),本文创新性地利用特征一致性识别干扰物的机制、修复对目标数据的视角冲突导致的几何表面及重建着色差异等表面重建任务中的关键问题。相较于依赖MLPs的干扰物分割策略,MVGSR在训练初期就能通过对比多视角特征一致性分离出干扰物与静态场景元素。同时引入了基于多视角贡献的重置透光率的方法来降低漂浮伪影的出现频率,确保了重建表面的质量。实验结果表明,MVGSR在几何精度和渲染保真度方面达到了先进的表面重建算法水平。更多详细信息可参见项目主页。总体来说,此研究工作主要展示了全新的角度分离方法和精准的几何精度处理技术对目标数据进行合理的分解、分离与重建工作的重要性。如需更多细节信息,请访问项目主页进行了解。
关键见解
- 3DGS在高质量渲染、超快训练和推理速度方面备受关注。但在表面重建任务中,特别是在动态对象和干扰物的环境中,存在由于视角不一致导致的浮动伪影和颜色错误的问题。
- 提出了一种新的鲁棒表面重建策略——MVGSR(多视角一致性高斯飞溅法)。利用轻量化高斯模型和启发式引导的干扰物掩蔽策略来解决非静态环境中的表面重建问题。此方法在早期训练阶段就通过比较多视角特征一致性来分离干扰物和静态场景元素。相较于依赖MLPs的干扰物分割策略更具优势。
点此查看论文截图


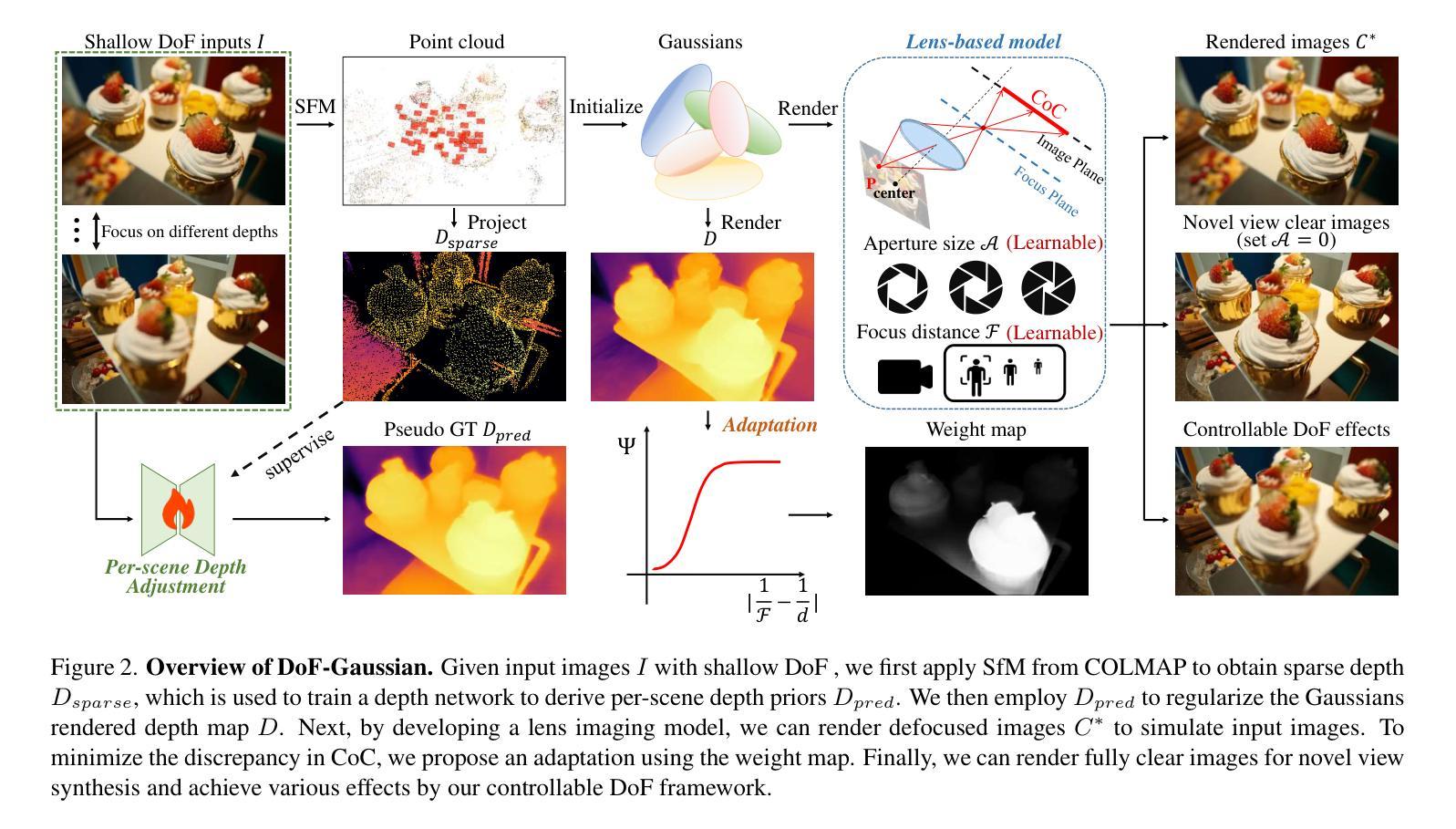
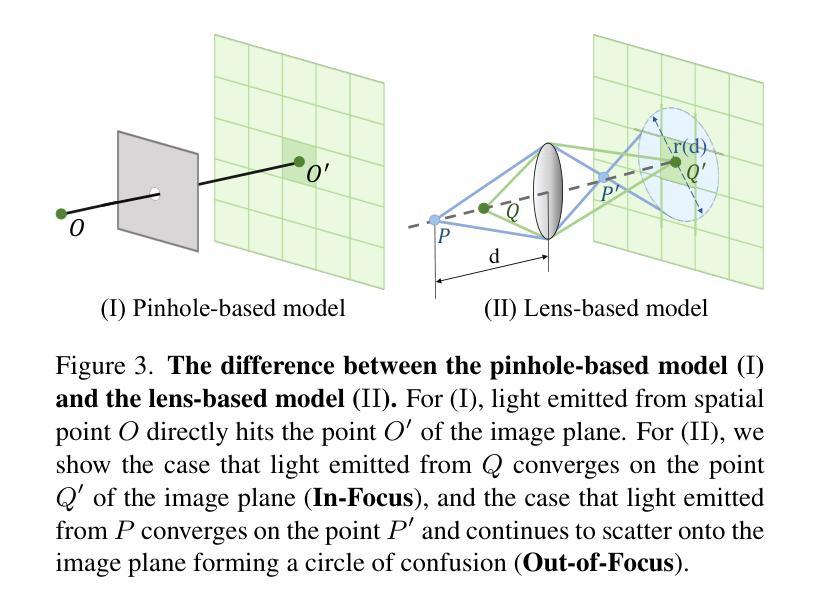
DoF-Gaussian: Controllable Depth-of-Field for 3D Gaussian Splatting
Authors:Liao Shen, Tianqi Liu, Huiqiang Sun, Jiaqi Li, Zhiguo Cao, Wei Li, Chen Change Loy
Recent advances in 3D Gaussian Splatting (3D-GS) have shown remarkable success in representing 3D scenes and generating high-quality, novel views in real-time. However, 3D-GS and its variants assume that input images are captured based on pinhole imaging and are fully in focus. This assumption limits their applicability, as real-world images often feature shallow depth-of-field (DoF). In this paper, we introduce DoF-Gaussian, a controllable depth-of-field method for 3D-GS. We develop a lens-based imaging model based on geometric optics principles to control DoF effects. To ensure accurate scene geometry, we incorporate depth priors adjusted per scene, and we apply defocus-to-focus adaptation to minimize the gap in the circle of confusion. We also introduce a synthetic dataset to assess refocusing capabilities and the model’s ability to learn precise lens parameters. Our framework is customizable and supports various interactive applications. Extensive experiments confirm the effectiveness of our method. Our project is available at https://dof-gaussian.github.io.
近期三维高斯描点(3D-GS)的进展在表示三维场景和实时生成高质量、新颖视图方面取得了显著的成功。然而,3D-GS及其变体假设输入图像是基于针孔成像捕获的,并且完全在焦点内。这一假设限制了其适用性,因为现实世界的图像通常具有较浅的景深(DoF)。在本文中,我们介绍了DoF-Gaussian,这是一种可控景深的三维高斯描点方法。我们基于几何光学原理开发了一种基于镜头的成像模型来控制景深效应。为确保场景几何的准确性,我们根据场景调整了深度优先事项,并采用了失焦到聚焦的适应方法来减小模糊圆之间的间隙。我们还引入了一个合成数据集来评估重新聚焦能力和模型学习精确镜头参数的能力。我们的框架可定制且支持各种交互应用程序。大量实验证实了我们方法的有效性。我们的项目可在https://dof-gaussian.github.io找到。
论文及项目相关链接
PDF CVPR 2025
Summary
3D高斯插值(3D-GS)的最新进展在表示3D场景和实时生成高质量、新颖视图方面取得了显著的成功。然而,该方法和其变体假设输入图像是基于针孔成像并完全聚焦的,这限制了其在现实世界中的应用,因为真实图像往往具有较浅的景深(DoF)。本文介绍了一种可控景深的方法DoF-Gaussian,用于3D-GS。我们基于几何光学原理开发了一种透镜成像模型来控制DoF效应。为确保场景几何的准确性,我们根据场景调整了深度先验知识,并应用了失焦到聚焦的适应来减少模糊圆圈的差距。我们还引入了一个合成数据集来评估我们的方法的重新聚焦能力和学习精确镜头参数的能力。我们的框架支持各种交互式应用,并通过广泛的实验验证了其有效性。
Key Takeaways
- 3D-GS在表示3D场景和生成高质量视图方面表现出显著成功。
- 现有方法假设输入图像完全基于针孔成像并聚焦,限制了其在现实场景的应用。
- DoF-Gaussian方法解决了上述问题,通过透镜成像模型控制景深效应。
- 该方法结合场景深度先验知识,确保场景几何的准确性。
- 通过失焦到聚焦的适应,减少了模糊差距。
- 引入合成数据集用于评估重新聚焦能力和模型学习精确镜头参数的能力。
点此查看论文截图


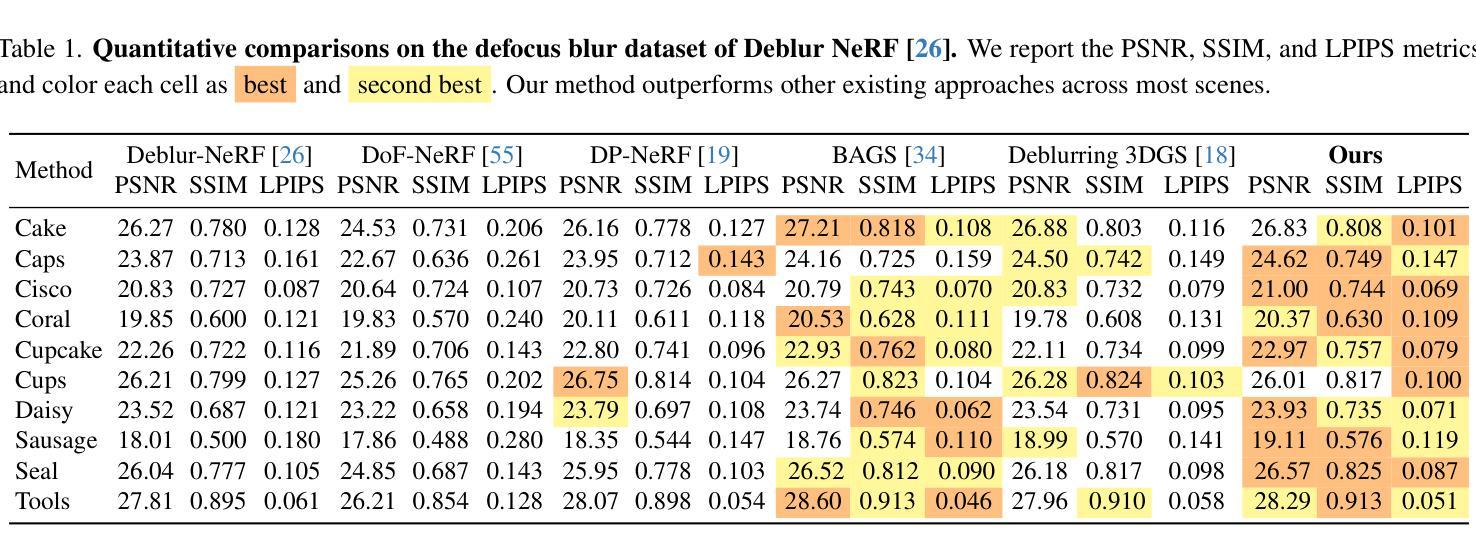
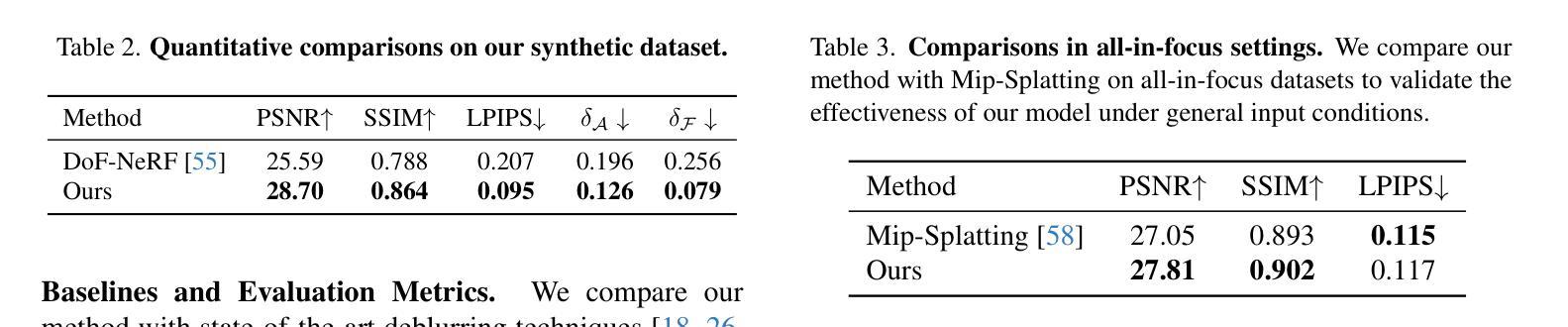
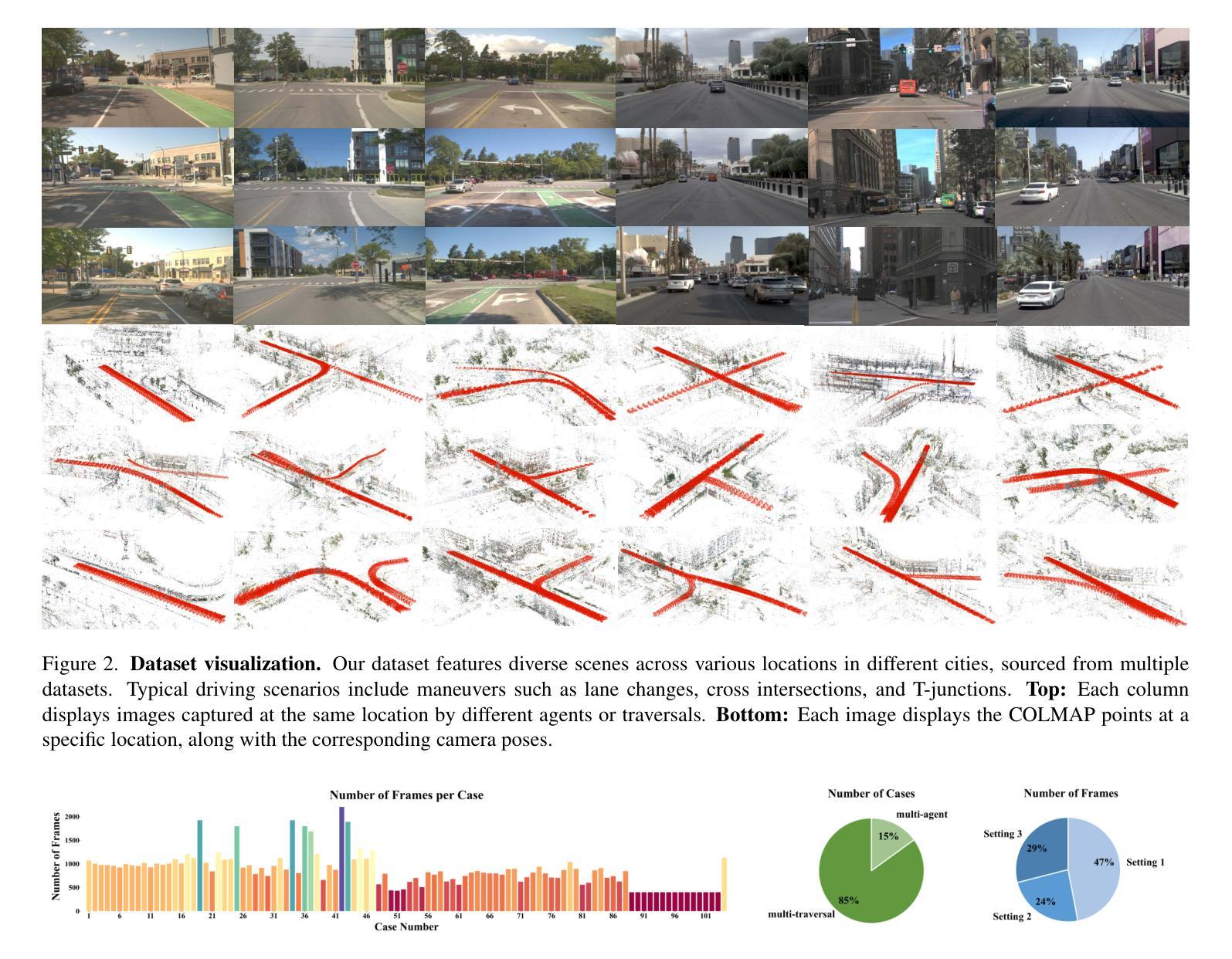
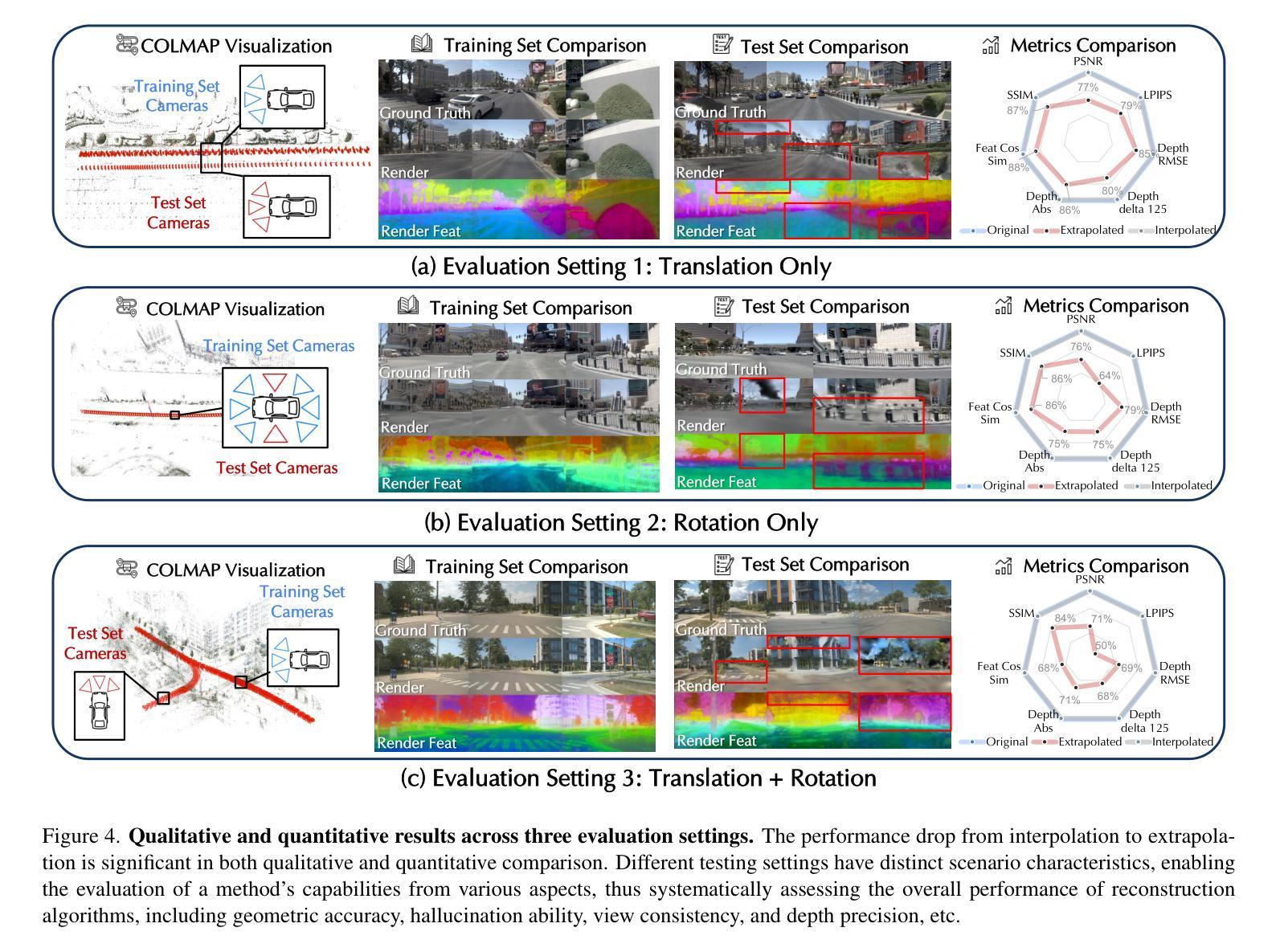
Extrapolated Urban View Synthesis Benchmark
Authors:Xiangyu Han, Zhen Jia, Boyi Li, Yan Wang, Boris Ivanovic, Yurong You, Lingjie Liu, Yue Wang, Marco Pavone, Chen Feng, Yiming Li
Photorealistic simulators are essential for the training and evaluation of vision-centric autonomous vehicles (AVs). At their core is Novel View Synthesis (NVS), a crucial capability that generates diverse unseen viewpoints to accommodate the broad and continuous pose distribution of AVs. Recent advances in radiance fields, such as 3D Gaussian Splatting, achieve photorealistic rendering at real-time speeds and have been widely used in modeling large-scale driving scenes. However, their performance is commonly evaluated using an interpolated setup with highly correlated training and test views. In contrast, extrapolation, where test views largely deviate from training views, remains underexplored, limiting progress in generalizable simulation technology. To address this gap, we leverage publicly available AV datasets with multiple traversals, multiple vehicles, and multiple cameras to build the first Extrapolated Urban View Synthesis (EUVS) benchmark. Meanwhile, we conduct both quantitative and qualitative evaluations of state-of-the-art NVS methods across different evaluation settings. Our results show that current NVS methods are prone to overfitting to training views. Besides, incorporating diffusion priors and improving geometry cannot fundamentally improve NVS under large view changes, highlighting the need for more robust approaches and large-scale training. We will release the data to help advance self-driving and urban robotics simulation technology.
真实感模拟器对于以视觉为中心的自动驾驶汽车的训练和评估至关重要。其核心是新型视图合成(NVS),这是一种能够生成多种未见观点以适应自动驾驶汽车广泛且连续的姿态分布的关键能力。最近的辐射场进展,如3D高斯绘图板,实现了实时速度的逼真渲染,并已广泛应用于模拟大规模驾驶场景。然而,它们的性能通常使用插值设置进行评估,其中训练和测试观点的关联度很高。相比之下,外推(extrapolation)研究则很少进行探索,即测试视图与训练视图有很大差异,这在通用仿真技术的进步方面构成了一个限制。为了弥补这一差距,我们利用具有多次遍历、多辆车和多摄像头的公开自动驾驶数据集建立了第一个外推城市视图合成(EUVS)基准。同时,我们在不同的评估环境下对最先进的新型视图合成方法进行了定量和定性的评估。结果表明,当前的新型视图合成方法容易过度拟合训练视图。此外,引入扩散先验知识和改进几何结构并不能从根本上改善大视角变化下的新型视图合成技术,这凸显了需要更稳健的方法和大规模训练数据。我们将发布这些数据以帮助推进自动驾驶和城市机器人仿真技术的发展。
论文及项目相关链接
PDF Project page: https://ai4ce.github.io/EUVS-Benchmark/
Summary
本文强调真实感模拟器对以视觉为中心的自动驾驶汽车(AVs)训练和评估的重要性。核心在于视点合成(NVS),它能生成多样的未见过视点以适应AVs的广泛和连续姿态分布。虽然使用辐射场的新进展如3D高斯拼贴可以在实时速度下实现逼真的渲染,但现有的评估方法主要使用插值设置,训练视图和测试视图高度相关。为了解决这个问题,本文建立了一个名为“Extrapolated Urban View Synthesis (EUVS)”的基准测试平台,该平台利用公开可用的自动驾驶汽车数据集进行构建。同时,对最先进的NVS方法进行了不同评估环境的定量和定性评估。结果显示,当前NVS方法容易过度拟合训练视图,在大视角变化下融入扩散先验和改进几何并不能从根本上改善NVS,这突显了需要更稳健的方法和大规模训练数据的重要性。
Key Takeaways
- 真实感模拟器对自动驾驶汽车的训练和评估至关重要。
- 真实感模拟器的核心能力是视点合成(NVS),可以生成多样的未见过视点。
- 当前NVS方法主要使用插值设置进行评估,存在对训练视图的过度拟合问题。
- EUVS基准测试平台利用公开可用的自动驾驶汽车数据集进行构建,旨在解决现有评估方法的不足。
- 评估结果显示,当前NVS方法在处理大视角变化时存在局限性。
- 融合扩散先验和改进几何在解决大视角变化下的NVS问题时效果有限。
点此查看论文截图

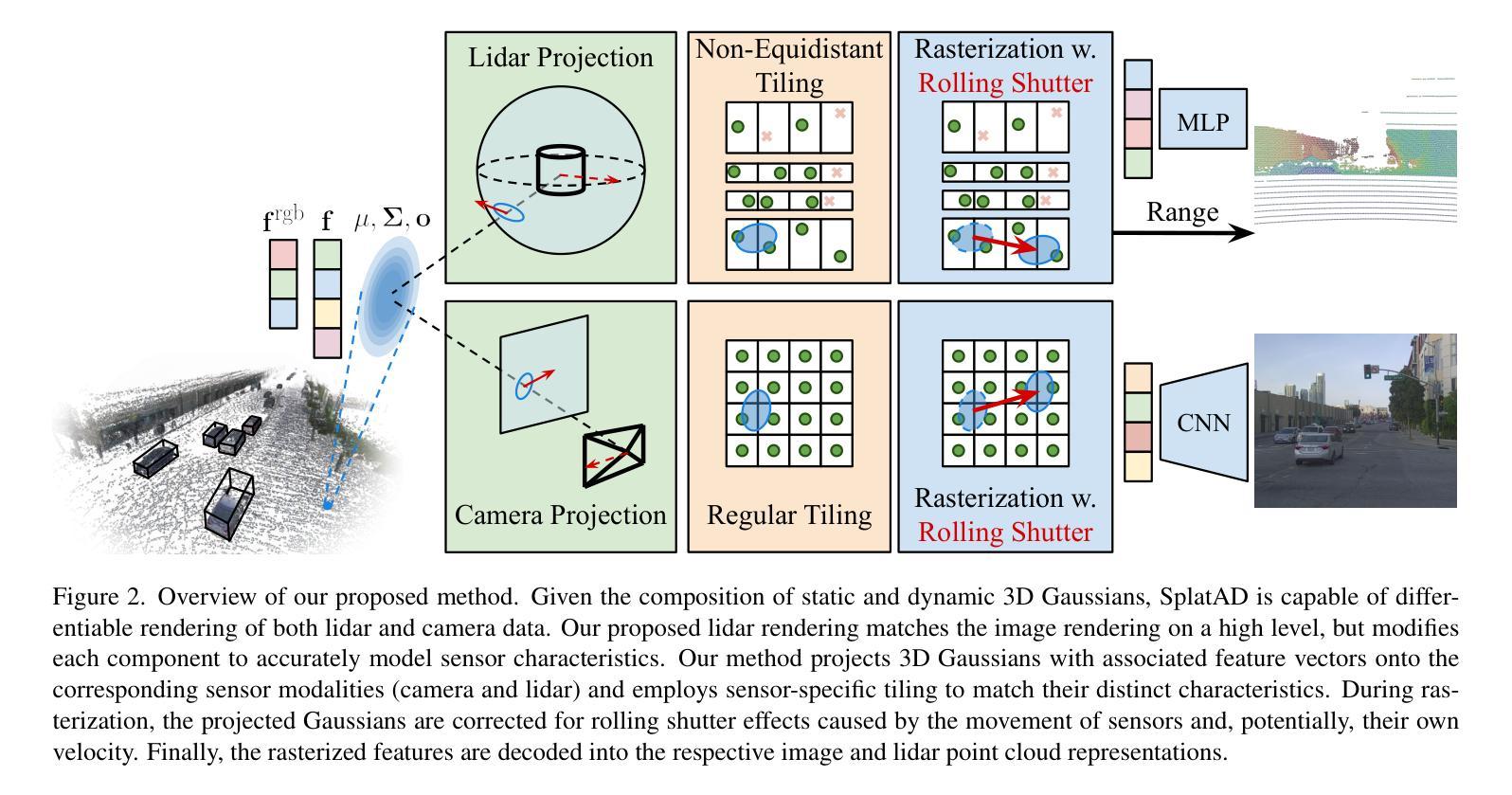
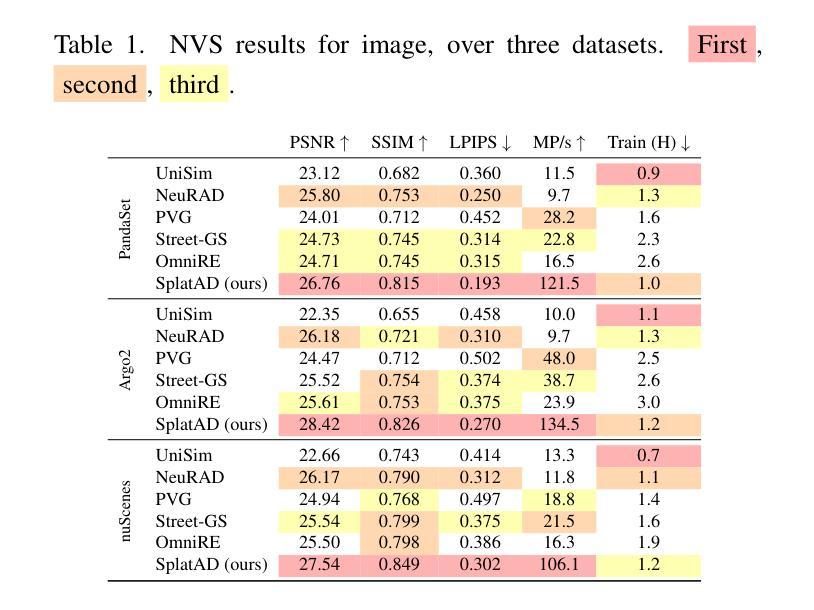
SplatAD: Real-Time Lidar and Camera Rendering with 3D Gaussian Splatting for Autonomous Driving
Authors:Georg Hess, Carl Lindström, Maryam Fatemi, Christoffer Petersson, Lennart Svensson
Ensuring the safety of autonomous robots, such as self-driving vehicles, requires extensive testing across diverse driving scenarios. Simulation is a key ingredient for conducting such testing in a cost-effective and scalable way. Neural rendering methods have gained popularity, as they can build simulation environments from collected logs in a data-driven manner. However, existing neural radiance field (NeRF) methods for sensor-realistic rendering of camera and lidar data suffer from low rendering speeds, limiting their applicability for large-scale testing. While 3D Gaussian Splatting (3DGS) enables real-time rendering, current methods are limited to camera data and are unable to render lidar data essential for autonomous driving. To address these limitations, we propose SplatAD, the first 3DGS-based method for realistic, real-time rendering of dynamic scenes for both camera and lidar data. SplatAD accurately models key sensor-specific phenomena such as rolling shutter effects, lidar intensity, and lidar ray dropouts, using purpose-built algorithms to optimize rendering efficiency. Evaluation across three autonomous driving datasets demonstrates that SplatAD achieves state-of-the-art rendering quality with up to +2 PSNR for NVS and +3 PSNR for reconstruction while increasing rendering speed over NeRF-based methods by an order of magnitude. See https://research.zenseact.com/publications/splatad/ for our project page.
确保自主机器人(如自动驾驶汽车)的安全需要在各种驾驶场景中进行广泛的测试。仿真是一种以成本效益高和可扩展的方式开展此类测试的关键要素。神经渲染方法很受欢迎,因为它们可以以数据驱动的方式从收集的日志中构建仿真环境。然而,现有的用于相机和激光雷达数据传感器现实渲染的神经辐射场(NeRF)方法存在渲染速度低的问题,限制了它们在大规模测试中的应用。虽然3D高斯拼贴(3DGS)可以实现实时渲染,但当前的方法仅限于相机数据,而无法呈现对自动驾驶至关重要的激光雷达数据。为了解决这些局限性,我们提出了SplatAD,这是基于3DGS的第一种用于相机和激光雷达数据动态场景现实实时渲染的方法。SplatAD使用专门构建的算法准确建模关键传感器特定现象,如滚降效应、激光雷达强度和激光雷达射线中断,以优化渲染效率。在三个自动驾驶数据集上的评估表明,SplatAD实现了最先进的渲染质量,在NVS和重建方面分别提高了+2 PSNR和+3 PSNR,同时提高了NeRF方法的渲染速度一个数量级。有关我们的项目页面,请访问:[https://research.zenseact.com/publications/splatad/]
论文及项目相关链接
Summary
为自主机器人如自动驾驶汽车进行测试,需要跨多种驾驶场景进行大量测试。仿真是一种经济高效且可扩展的测试方式。神经渲染方法能够从收集的数据日志中以数据驱动的方式构建仿真环境。然而,现有的神经辐射场(NeRF)方法在处理和渲染相机和激光雷达数据时速度较慢,不适用于大规模测试。而3D高斯喷射技术(3DGS)可以实现实时渲染,但仅限于相机数据,无法渲染对自动驾驶至关重要的激光雷达数据。为解决这些问题,我们提出了SplatAD,这是一种基于3DGS的实时渲染动态场景的方法,既适用于相机数据也适用于激光雷达数据。SplatAD准确模拟了滚动快门效应、激光雷达强度和激光雷达射线丢失等关键传感器特性。在三个自动驾驶数据集上的评估表明,SplatAD的渲染质量达到业界最佳水平,渲染速度比基于NeRF的方法提高了一个数量级。
Key Takeaways
- 自主机器人的安全性需要通过多样场景的广泛测试来确保。
- 仿真测试是经济高效且可扩展的测试方式。
- 神经渲染方法能够从数据日志构建仿真环境。
- 现有的NeRF方法在处理和渲染相机和激光雷达数据时存在低渲染速度的问题。
- 3DGS技术可实现相机数据的实时渲染,但无法处理激光雷达数据。
- SplatAD是基于3DGS的方法,能实时渲染动态场景,适用于相机和激光雷达数据。
点此查看论文截图