⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
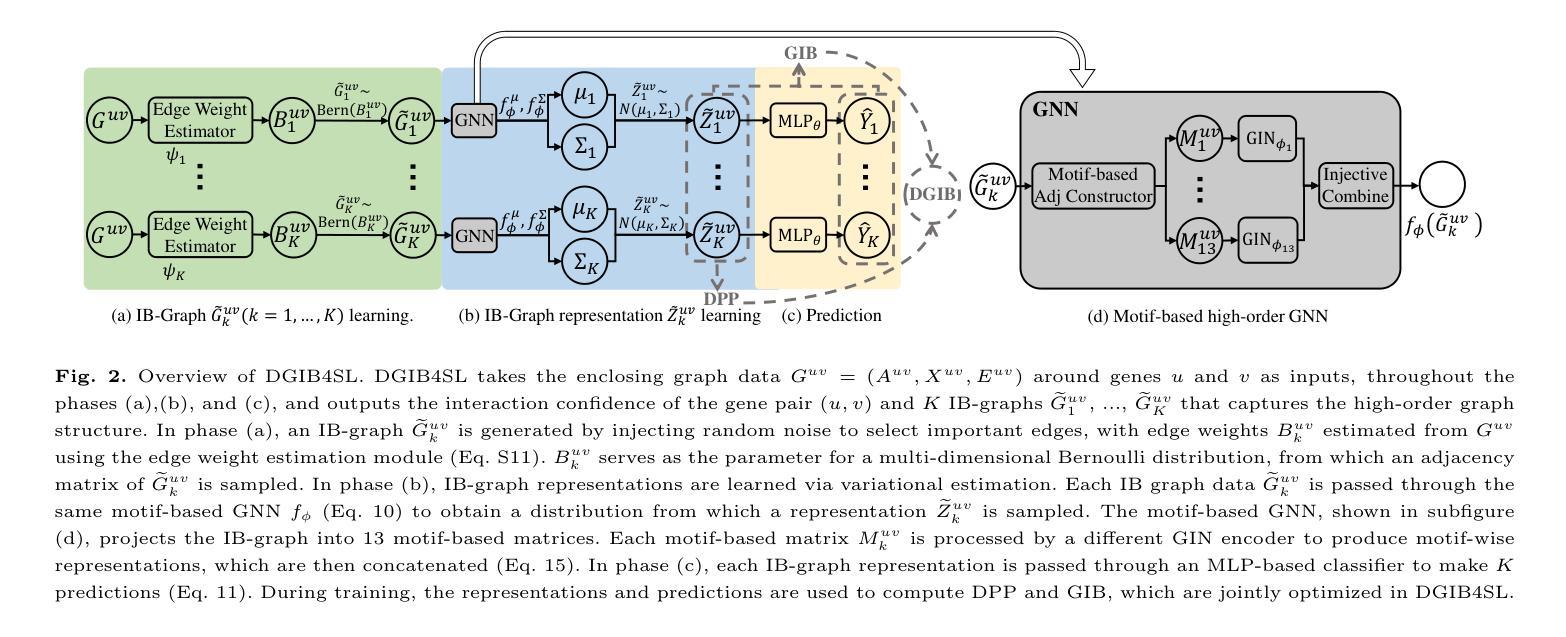
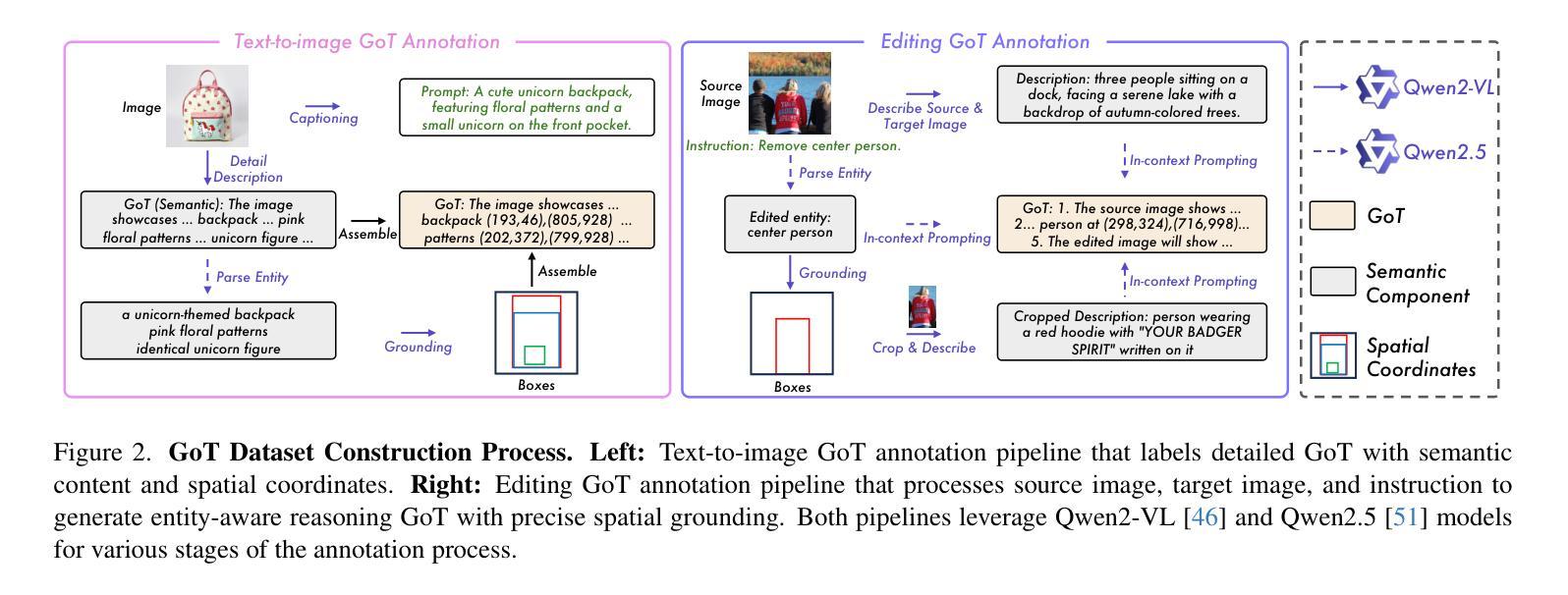
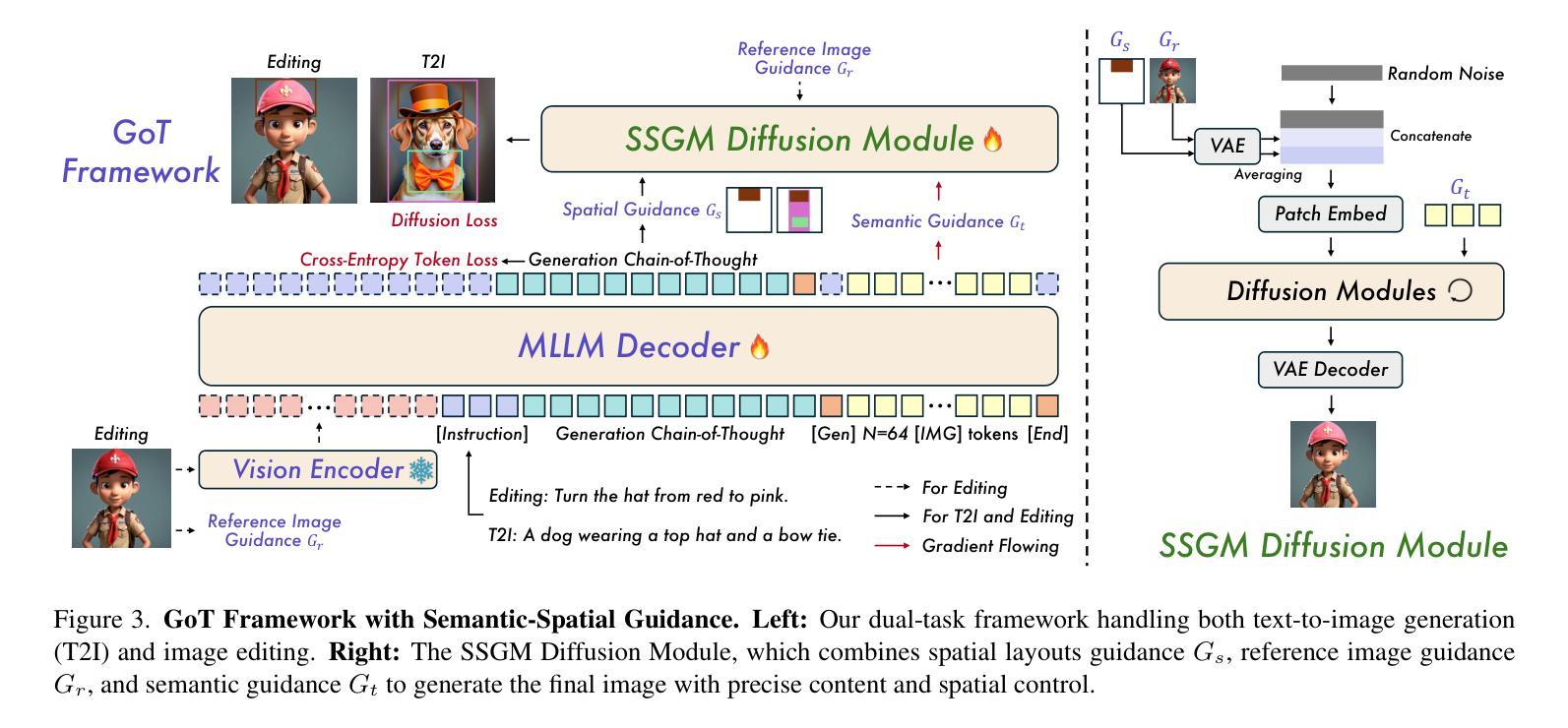
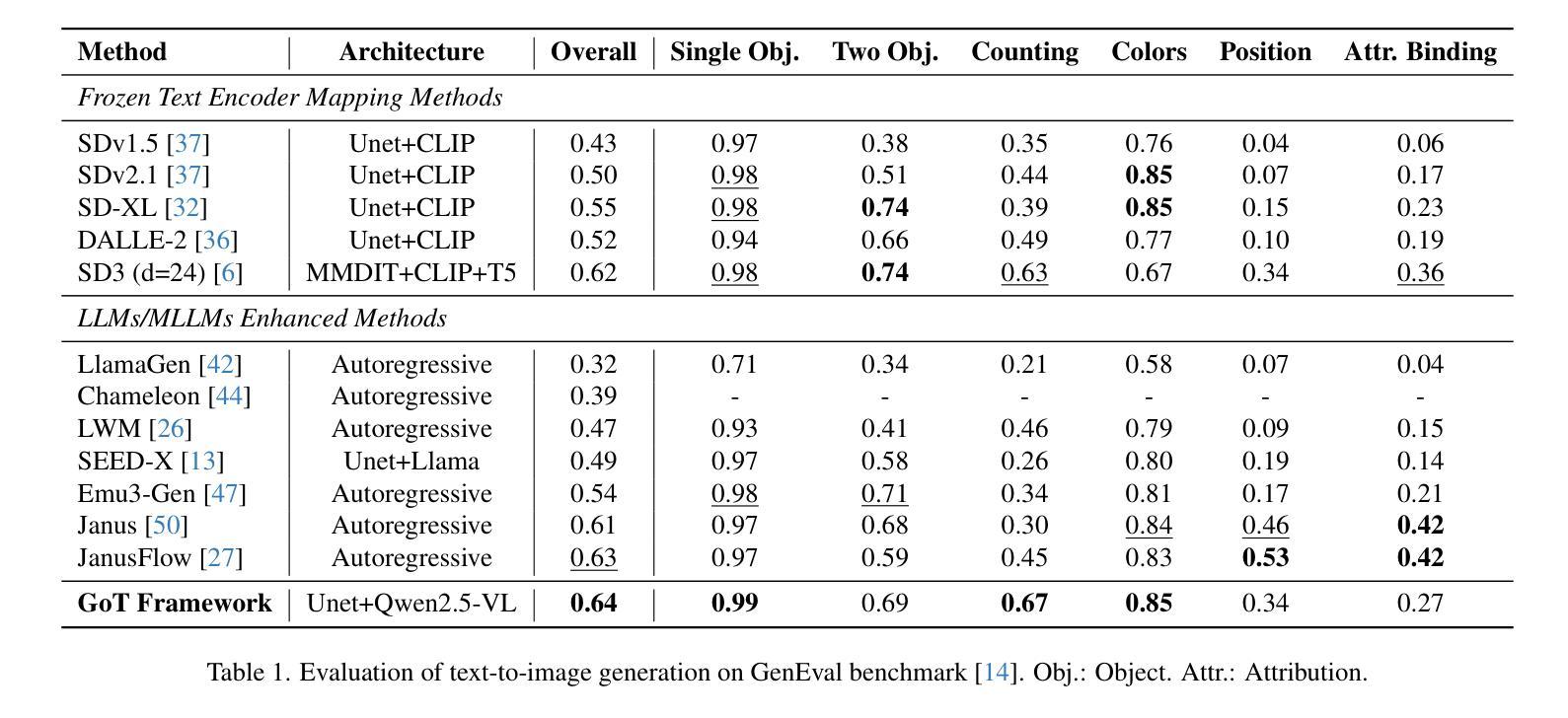
GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing
Authors:Rongyao Fang, Chengqi Duan, Kun Wang, Linjiang Huang, Hao Li, Shilin Yan, Hao Tian, Xingyu Zeng, Rui Zhao, Jifeng Dai, Xihui Liu, Hongsheng Li
Current image generation and editing methods primarily process textual prompts as direct inputs without reasoning about visual composition and explicit operations. We present Generation Chain-of-Thought (GoT), a novel paradigm that enables generation and editing through an explicit language reasoning process before outputting images. This approach transforms conventional text-to-image generation and editing into a reasoning-guided framework that analyzes semantic relationships and spatial arrangements. We define the formulation of GoT and construct large-scale GoT datasets containing over 9M samples with detailed reasoning chains capturing semantic-spatial relationships. To leverage the advantages of GoT, we implement a unified framework that integrates Qwen2.5-VL for reasoning chain generation with an end-to-end diffusion model enhanced by our novel Semantic-Spatial Guidance Module. Experiments show our GoT framework achieves excellent performance on both generation and editing tasks, with significant improvements over baselines. Additionally, our approach enables interactive visual generation, allowing users to explicitly modify reasoning steps for precise image adjustments. GoT pioneers a new direction for reasoning-driven visual generation and editing, producing images that better align with human intent. To facilitate future research, we make our datasets, code, and pretrained models publicly available at https://github.com/rongyaofang/GoT.
当前图像生成和编辑方法主要将文本提示作为直接输入进行处理,而没有对视觉构图和明确操作进行推理。我们提出了思维链生成(GoT)这一新颖范式,通过明确的语言推理过程来生成和编辑图像,然后再输出图像。这种方法将传统的文本到图像生成和编辑转变为以推理为指导的框架,分析语义关系和空间布局。我们定义了GoT的公式,并构建了大规模GoT数据集,包含超过900万个样本,详细的推理链捕捉了语义-空间关系。为了利用GoT的优势,我们实现了一个统一框架,集成了Qwen2.5-VL进行推理链生成,通过我们新颖的语义-空间指导模块增强端到端扩散模型。实验表明,我们的GoT框架在生成和编辑任务上都取得了卓越的性能,显著优于基准线。此外,我们的方法还实现了交互式视觉生成,让用户能够明确修改推理步骤,进行精确图像调整。GoT开创了推理驱动视觉生成和编辑的新方向,生成的图像更好地符合人类意图。为了方便未来研究,我们在https://github.com/rongyaofang/GoT公开了我们的数据集、代码和预训练模型。
论文及项目相关链接
PDF Dataset and models are released in https://github.com/rongyaofang/GoT
Summary
本文提出了基于生成式思维链(Generation Chain-of-Thought,GoT)的图像生成与编辑新范式。该方法通过明确的自然语言推理过程来指导图像生成与编辑,实现了对语义关系和空间布局的分析。为此,研究团队构建了大规模GoT数据集,并开发了结合Qwen2.5-VL推理链生成与扩散模型的统一框架,其中融入新型语义空间引导模块。实验表明,GoT框架在生成与编辑任务上表现卓越,显著优于基准模型。此外,GoT支持交互式视觉生成,使用户可精确调整图像细节。该研究为推理驱动视觉生成与编辑开创了新方向。
Key Takeaways
- 引入生成式思维链(GoT)新范式,用于图像生成与编辑。
- GoT通过自然语言推理过程指导图像生成与编辑,涉及语义关系和空间布局分析。
- 构建大规模GoT数据集,包含超过900万样本,详细记录推理链中的语义空间关系。
- 开发出结合Qwen2.5-VL与扩散模型的统一框架,并融入语义空间引导模块。
- 实验显示GoT框架在生成与编辑任务上表现优异,显著超越基准模型。
- GoT支持交互式视觉生成,允许用户精确调整图像细节。
点此查看论文截图

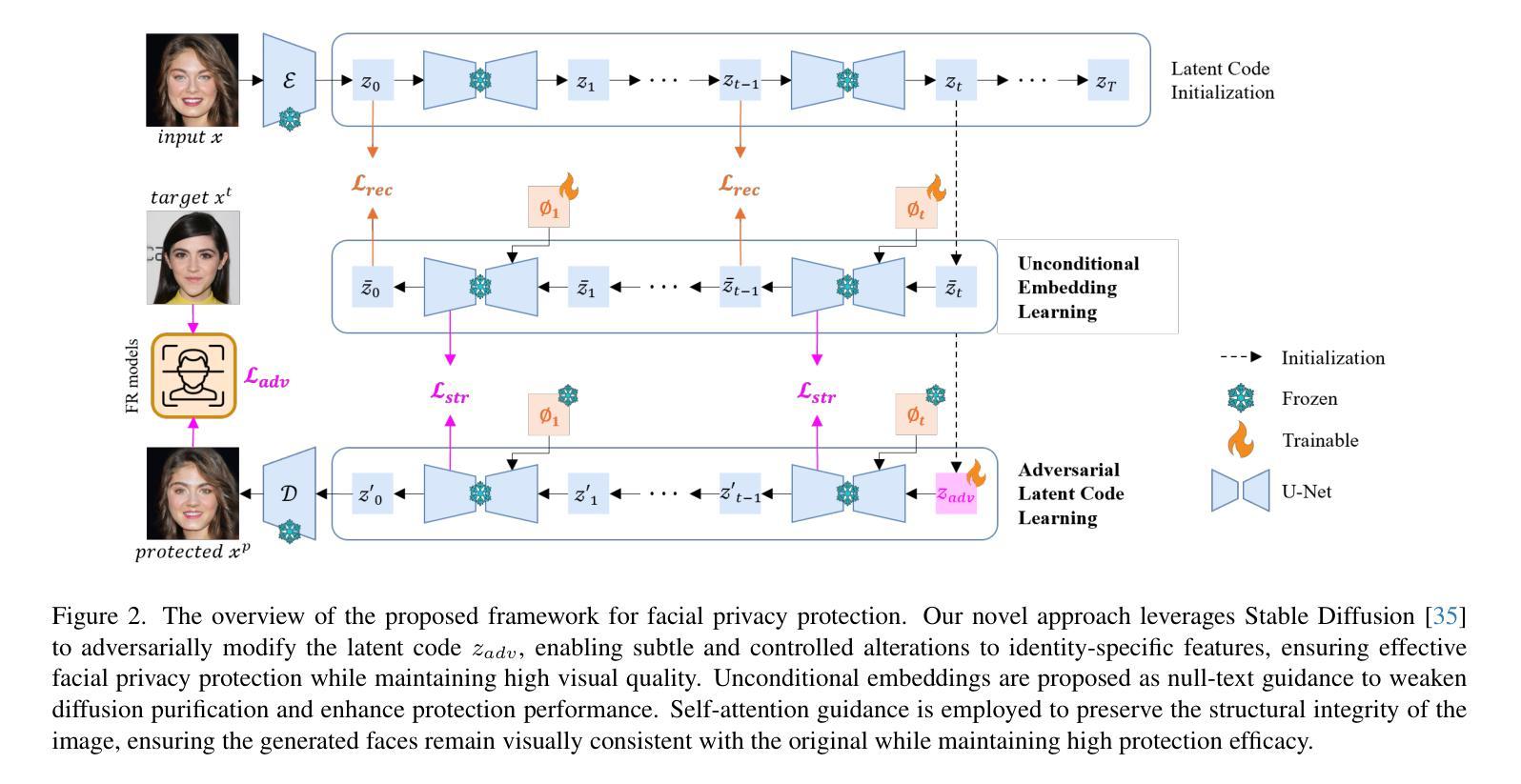
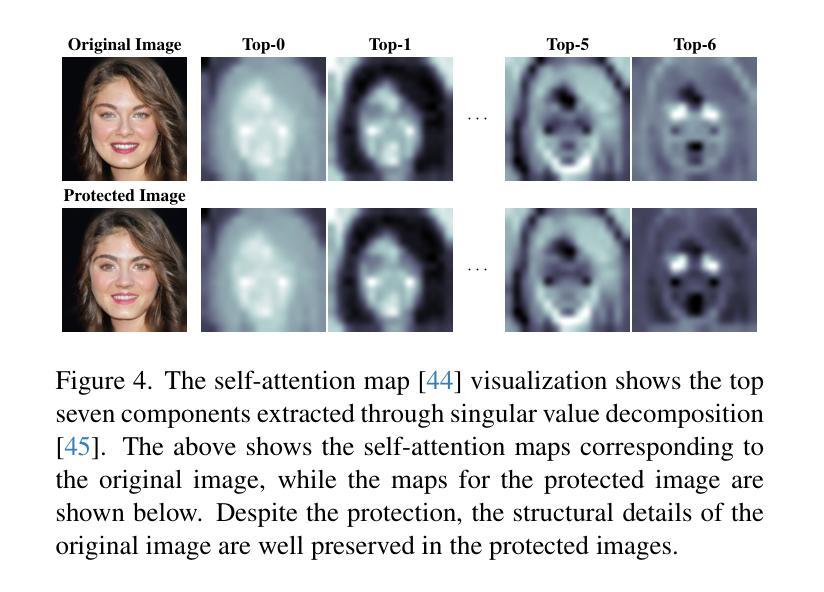
Enhancing Facial Privacy Protection via Weakening Diffusion Purification
Authors:Ali Salar, Qing Liu, Yingli Tian, Guoying Zhao
The rapid growth of social media has led to the widespread sharing of individual portrait images, which pose serious privacy risks due to the capabilities of automatic face recognition (AFR) systems for mass surveillance. Hence, protecting facial privacy against unauthorized AFR systems is essential. Inspired by the generation capability of the emerging diffusion models, recent methods employ diffusion models to generate adversarial face images for privacy protection. However, they suffer from the diffusion purification effect, leading to a low protection success rate (PSR). In this paper, we first propose learning unconditional embeddings to increase the learning capacity for adversarial modifications and then use them to guide the modification of the adversarial latent code to weaken the diffusion purification effect. Moreover, we integrate an identity-preserving structure to maintain structural consistency between the original and generated images, allowing human observers to recognize the generated image as having the same identity as the original. Extensive experiments conducted on two public datasets, i.e., CelebA-HQ and LADN, demonstrate the superiority of our approach. The protected faces generated by our method outperform those produced by existing facial privacy protection approaches in terms of transferability and natural appearance.
随着社交媒体的快速发展,个人肖像照片的共享日益普遍,由于大规模监控的自动人脸识别(AFR)系统的能力,这带来了严重的隐私风险。因此,保护面部隐私免受未经授权的人脸识别系统的识别至关重要。受新兴扩散模型生成能力的启发,最近的方法采用扩散模型生成对抗性人脸图像来进行隐私保护。然而,它们受到扩散净化效果的影响,导致保护成功率(PSR)较低。在本文中,我们首先提出学习无条件嵌入,以增加对抗性修改的学习能力,然后使用它们来指导对抗性潜在代码的修改,以减弱扩散净化效果。此外,我们整合了身份保持结构,以保持原始和生成图像之间的结构一致性,使人类观察者能够认出生成图像与原始图像具有相同的身份。在CelebA-HQ和LADN两个公开数据集上进行的广泛实验证明了我们方法的优越性。由我们的方法生成的受保护的人脸在可转移性和自然外观方面优于现有面部隐私保护方法生成的人脸。
论文及项目相关链接
Summary
社交媒体上个人肖像照片的广泛分享带来了严重的隐私风险,因为自动面部识别(AFR)系统可以进行大规模监控。保护面部隐私免受未经授权的AFR系统侵扰至关重要。受新兴扩散模型生成能力的启发,最近的方法采用扩散模型生成对抗性面部图像以实现隐私保护,但它们受到扩散净化效应的影响,导致保护成功率(PSR)较低。本文首先提出学习无条件嵌入,以增加对抗性修改的学习容量,然后利用它们来指导对抗性潜在代码的修改,以削弱扩散净化效应。此外,我们整合了一种身份保留结构,以保持原始图像和生成图像之间的结构一致性,使人类观察者能够识别生成图像与原始图像具有相同的身份。在CelebA-HQ和LADN两个公开数据集上进行的广泛实验证明了我们方法的有效性。我们的方法生成的受保护人脸在传输性和自然外观方面优于现有面部隐私保护方法生成的人脸。
Key Takeaways
- 社交媒体上个人肖像的广泛分享引发了由于自动面部识别(AFR)系统的隐私风险。
- 扩散模型被用于生成对抗性面部图像以实现隐私保护,但存在扩散净化效应,导致保护成功率较低。
- 提出学习无条件嵌入以提高对抗性修改的学习容量,并削弱扩散净化效应。
- 整合身份保留结构,保持原始和生成图像之间的结构一致性。
- 方法在CelebA-HQ和LADN数据集上的实验表现优越,生成的受保护人脸在传输性和自然外观方面优于现有方法。
- 该方法能有效对抗未经授权的AFR系统,提高面部隐私保护效果。
点此查看论文截图


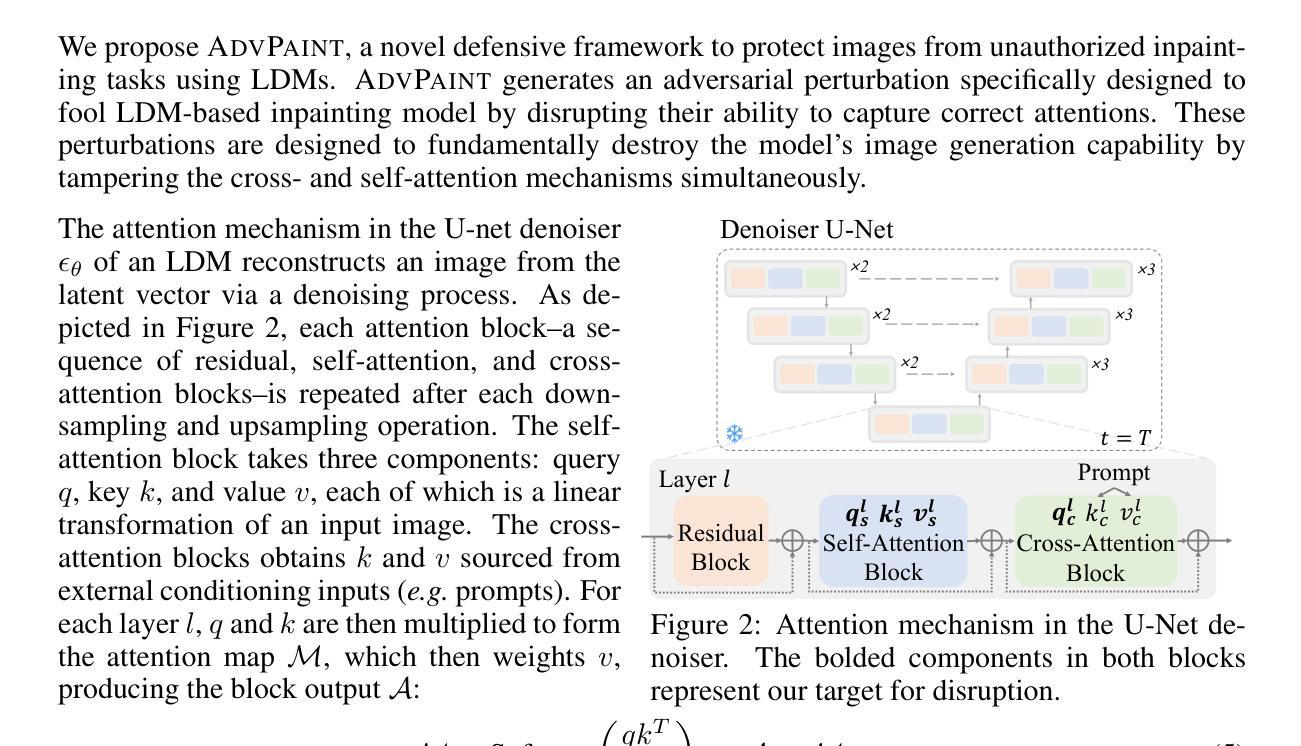
AdvPaint: Protecting Images from Inpainting Manipulation via Adversarial Attention Disruption
Authors:Joonsung Jeon, Woo Jae Kim, Suhyeon Ha, Sooel Son, Sung-eui Yoon
The outstanding capability of diffusion models in generating high-quality images poses significant threats when misused by adversaries. In particular, we assume malicious adversaries exploiting diffusion models for inpainting tasks, such as replacing a specific region with a celebrity. While existing methods for protecting images from manipulation in diffusion-based generative models have primarily focused on image-to-image and text-to-image tasks, the challenge of preventing unauthorized inpainting has been rarely addressed, often resulting in suboptimal protection performance. To mitigate inpainting abuses, we propose ADVPAINT, a novel defensive framework that generates adversarial perturbations that effectively disrupt the adversary’s inpainting tasks. ADVPAINT targets the self- and cross-attention blocks in a target diffusion inpainting model to distract semantic understanding and prompt interactions during image generation. ADVPAINT also employs a two-stage perturbation strategy, dividing the perturbation region based on an enlarged bounding box around the object, enhancing robustness across diverse masks of varying shapes and sizes. Our experimental results demonstrate that ADVPAINT’s perturbations are highly effective in disrupting the adversary’s inpainting tasks, outperforming existing methods; ADVPAINT attains over a 100-point increase in FID and substantial decreases in precision.
扩散模型在生成高质量图像方面的出色能力,当被恶意对手误用时,构成了重大威胁。特别是,我们假设恶意对手正在利用扩散模型进行图像修复任务,例如用名人替换特定区域。虽然现有的保护图像免受基于扩散的生成模型操纵的方法主要集中在图像到图像和文本到图像的任务上,但防止未经授权的图像修复的挑战很少得到重视,往往导致保护性能不佳。为了缓解图像修复滥用的情况,我们提出了ADVPAINT这一新型防御框架,它生成对抗性扰动,有效地破坏了对手的图像修复任务。ADVPAINT针对目标扩散修复模型中的自注意力块和交叉注意力块,干扰语义理解和图像生成过程中的交互。ADVPAINT还采用两阶段扰动策略,根据对象周围扩大的边界框划分扰动区域,提高了在各种形状和大小的面具下的稳健性。我们的实验结果表明,ADVPAINT的扰动在破坏对手的图像修复任务方面非常有效,优于现有方法;ADVPAINT的FID得分提高了超过100点,精确度也大幅下降。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
扩散模型在生成高质量图像方面具有出色能力,但一旦被恶意对手滥用,就会构成重大威胁。现有方法主要关注基于扩散的生成模型中的图像到图像和文本到图像任务的图像保护,很少解决防止未经授权的补全挑战,导致保护性能不佳。为此,我们提出了ADVPAINT,这是一种新的防御框架,通过生成对抗性扰动来有效破坏对手的图像补全任务。ADVPAINT针对目标扩散补全模型中的自我和跨注意力块,以分散语义理解和生成图像时的提示交互。ADVPAINT还采用两阶段扰动策略,根据对象周围扩大的边界框划分扰动区域,提高了对各种形状和大小不同掩码的鲁棒性。实验结果表明,ADVPAINT的扰动在破坏对手的图像补全任务方面非常有效,优于现有方法,并在FID上实现了超过100点的提高,同时在精度上也有大幅下降。
Key Takeaways
- 扩散模型生成高质量图像的能力如果被恶意对手滥用,将会带来严重威胁。
- 现有方法主要关注基于扩散的生成模型中的图像到图像和文本到图像任务的保护,对防止未经授权的补全挑战解决不足。
- ADVPAINT是一种新的防御框架,通过生成对抗性扰动来有效破坏对手的图像补全任务。
- ADVPAINT针对目标扩散补全模型中的自我和跨注意力块进行干扰。
- ADVPAINT采用两阶段扰动策略来提高对各种形状和大小不同掩码的鲁棒性。
- 实验结果表明,ADVPAINT在破坏对手的图像补全任务方面非常有效,优于现有方法。
点此查看论文截图


Investigating and Improving Counter-Stereotypical Action Relation in Text-to-Image Diffusion Models
Authors:Sina Malakouti, Adriana Kovashka
Text-to-image diffusion models consistently fail at generating counter-stereotypical action relationships (e.g., “mouse chasing cat”), defaulting to frequent stereotypes even when explicitly prompted otherwise. Through systematic investigation, we discover this limitation stems from distributional biases rather than inherent model constraints. Our key insight reveals that while models fail on rare compositions when their inversions are common, they can successfully generate similar intermediate compositions (e.g., “mouse chasing boy”). To test this hypothesis, we develop a Role-Bridging Decomposition framework that leverages these intermediates to gradually teach rare relationships without architectural modifications. We introduce ActionBench, a comprehensive benchmark specifically designed to evaluate action-based relationship generation across stereotypical and counter-stereotypical configurations. Our experiments validate that intermediate compositions indeed facilitate counter-stereotypical generation, with both automatic metrics and human evaluations showing significant improvements over existing approaches. This work not only identifies fundamental biases in current text-to-image systems but demonstrates a promising direction for addressing them through compositional reasoning.
文本到图像的扩散模型在生成反刻板动作关系(例如“老鼠追猫”)时持续失败,即使在明确提示下也默认采用频繁出现的刻板印象。通过系统调查,我们发现这一局限性源于分布偏见,而非固有的模型约束。我们的关键见解是,虽然模型在常见反转的情况下无法处理罕见的组合,但它们可以成功生成类似的中间组合(例如,“老鼠追孩子”)。为了验证这一假设,我们开发了一个角色桥接分解框架,利用这些中间结构来逐步教授罕见的关系,无需进行架构修改。我们引入了ActionBench,这是一个专门设计的全面基准测试,用于评估刻板和非刻板配置中的基于动作的关系生成。我们的实验验证了中间组合确实有助于反刻板生成,自动指标和人类评估均显示对现有方法的显著改善。这项工作不仅识别了当前文本到图像系统的基础偏见,而且展示了一个通过组合推理解决它们的充满希望的方向。
论文及项目相关链接
Summary
文本到图像扩散模型在生成反刻板动作关系(如“老鼠追逐猫”)时持续失败,即使明确提示也是如此,这主要是由于分布偏见而非模型本身的限制。研究发现,模型在反转罕见组合时失败,但能成功生成类似的中间组合(如“老鼠追逐男孩”)。为了测试这一假设,研究者开发了一种基于角色转换分解的框架,通过中间状态逐步学习罕见关系,无需对架构进行修改。同时,他们引入了ActionBench基准测试,专门用于评估基于动作的关系生成在刻板和非刻板配置下的表现。实验证明,中间组合确实有助于生成反刻板动作,在自动评估和人工评估中都显示出对现有方法的显著改进。这项研究不仅揭示了当前文本到图像系统的基础偏见,还展示了通过组合推理解决这些问题的有前途的方向。
Key Takeaways
- 文本到图像扩散模型在生成反刻板动作关系时存在失败现象。
- 失败的原因被归结为分布偏见,而非模型本身的限制。
- 模型在生成罕见组合时遇到困难,但能成功生成类似的中间组合。
- 提出了一种基于角色转换分解的框架,通过中间状态逐步学习罕见关系。
- 引入了ActionBench基准测试,用于评估文本到图像系统在处理动作关系生成方面的性能。
- 实验表明,中间组合有助于生成反刻板动作,并在评估中显示出显著改进。
点此查看论文截图


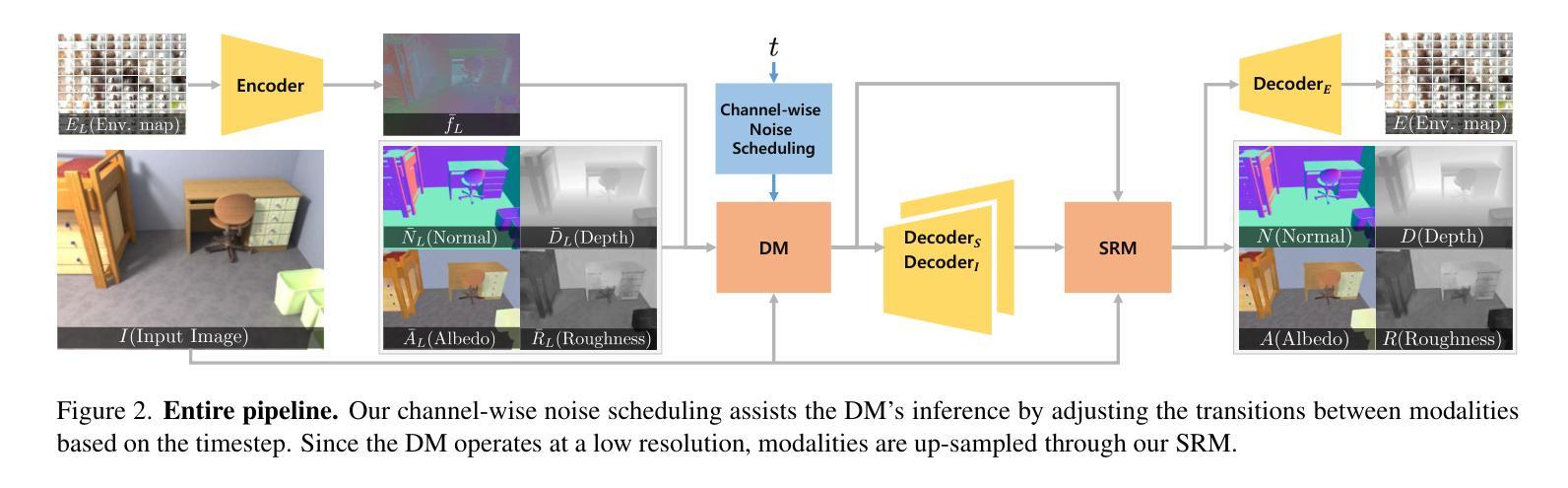
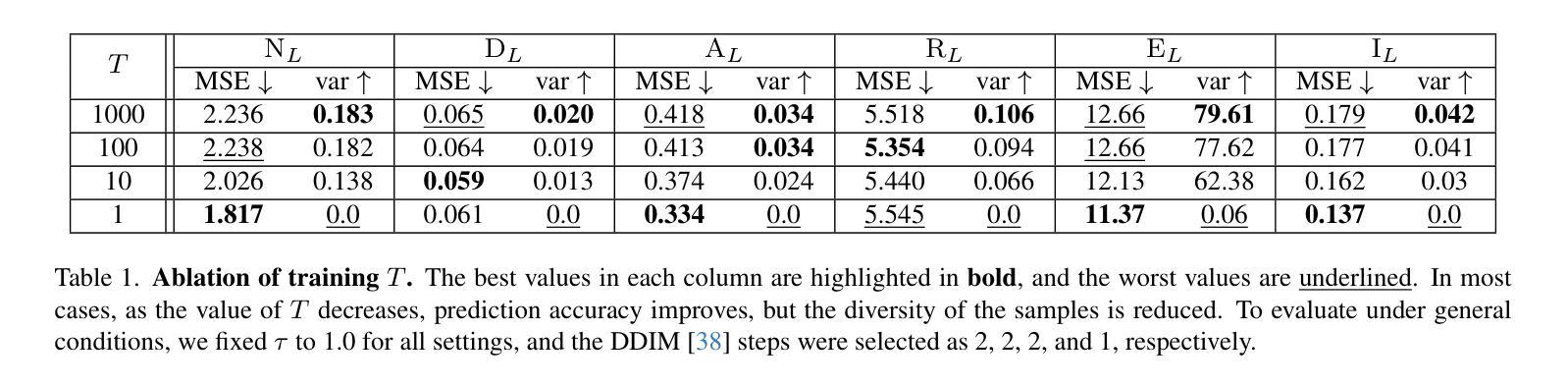
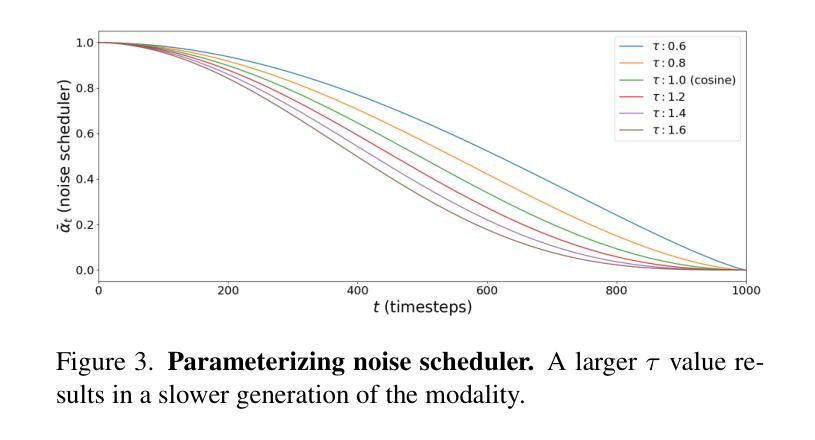
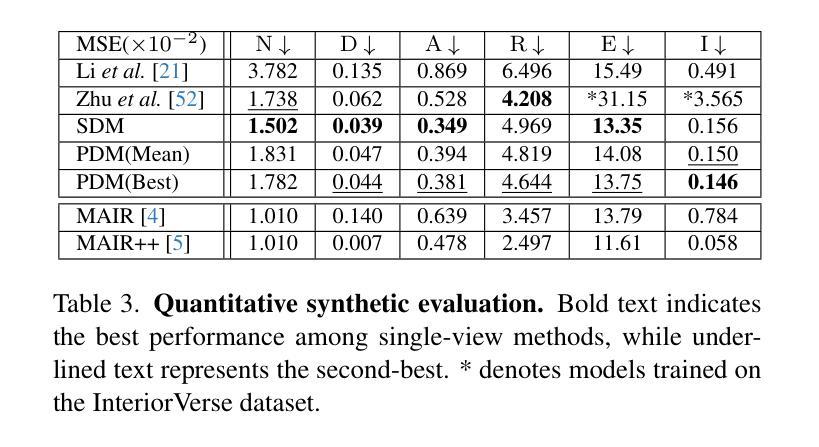
Channel-wise Noise Scheduled Diffusion for Inverse Rendering in Indoor Scenes
Authors:JunYong Choi, Min-Cheol Sagong, SeokYeong Lee, Seung-Won Jung, Ig-Jae Kim, Junghyun Cho
We propose a diffusion-based inverse rendering framework that decomposes a single RGB image into geometry, material, and lighting. Inverse rendering is inherently ill-posed, making it difficult to predict a single accurate solution. To address this challenge, recent generative model-based methods aim to present a range of possible solutions. However, finding a single accurate solution and generating diverse solutions can be conflicting. In this paper, we propose a channel-wise noise scheduling approach that allows a single diffusion model architecture to achieve two conflicting objectives. The resulting two diffusion models, trained with different channel-wise noise schedules, can predict a single highly accurate solution and present multiple possible solutions. The experimental results demonstrate the superiority of our two models in terms of both diversity and accuracy, which translates to enhanced performance in downstream applications such as object insertion and material editing.
我们提出了一种基于扩散的逆向渲染框架,该框架可以将单个RGB图像分解为几何、材质和光照。逆向渲染本质上是病态的,因此很难预测单个准确解。为了解决这一挑战,最近的基于生成模型的方法旨在提出一系列可能的解决方案。然而,找到单个准确解并生成多种解决方案可能会存在冲突。在本文中,我们提出了一种通道噪声调度方法,允许单个扩散模型架构实现两个相互冲突的目标。通过用不同通道噪声调度训练的两种扩散模型,可以预测单个高度准确的解决方案,并呈现多种可能的解决方案。实验结果表明,我们的两种模型在多样性和准确性方面都表现出卓越的性能,这转化为下游应用如对象插入和材料编辑的性能提升。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文提出了一种基于扩散模型的逆向渲染框架,可将单个RGB图像分解为几何、材质和光照信息。逆向渲染本质上是病态问题,难以预测单一准确解。针对这一问题,本文提出了通道噪声调度方法,使单一扩散模型架构同时实现两个相互冲突的目标:预测单一高度准确的解和呈现多种可能的解。实验结果表明,通过不同的通道噪声调度训练的两种扩散模型在多样性和准确性方面表现优越,进而在物体插入和材料编辑等下游应用中表现出色。
Key Takeaways
- 提出了一种基于扩散模型的逆向渲染框架,可将图像分解为几何、材质和光照信息。
- 逆向渲染是病态问题,难以获得单一准确解。
- 通道噪声调度方法使单一扩散模型能同时实现预测单一高度准确的解和呈现多种可能的解这两个相互冲突的目标。
- 通过不同的通道噪声调度训练的两种扩散模型在多样性和准确性方面表现优越。
- 该方法在实验应用中实现了高度准确的解生成和多种解的呈现。
- 这种方法能提高下游应用的性能,如物体插入和材料编辑等。
点此查看论文截图




VideoMerge: Towards Training-free Long Video Generation
Authors:Siyang Zhang, Harry Yang, Ser-Nam Lim
Long video generation remains a challenging and compelling topic in computer vision. Diffusion based models, among the various approaches to video generation, have achieved state of the art quality with their iterative denoising procedures. However, the intrinsic complexity of the video domain renders the training of such diffusion models exceedingly expensive in terms of both data curation and computational resources. Moreover, these models typically operate on a fixed noise tensor that represents the video, resulting in predetermined spatial and temporal dimensions. Although several high quality open-source pretrained video diffusion models, jointly trained on images and videos of varying lengths and resolutions, are available, it is generally not recommended to specify a video length at inference that was not included in the training set. Consequently, these models are not readily adaptable to the direct generation of longer videos by merely increasing the specified video length. In addition to feasibility challenges, long-video generation also encounters quality issues. The domain of long videos is inherently more complex than that of short videos: extended durations introduce greater variability and necessitate long-range temporal consistency, thereby increasing the overall difficulty of the task. We propose VideoMerge, a training-free method that can be seamlessly adapted to merge short videos generated by pretrained text-to-video diffusion model. Our approach preserves the model’s original expressiveness and consistency while allowing for extended duration and dynamic variation as specified by the user. By leveraging the strengths of pretrained models, our method addresses challenges related to smoothness, consistency, and dynamic content through orthogonal strategies that operate collaboratively to achieve superior quality.
长视频生成仍然是计算机视觉领域一个具有挑战性和吸引力的主题。在多种视频生成方法中,基于扩散的模型以其迭代去噪程序达到了最先进的品质。然而,视频领域的固有复杂性使得这类扩散模型的训练在数据整理和计算资源方面极为昂贵。此外,这些模型通常在一个代表视频的固定噪声张量上运行,导致预先确定的空间和时间维度。尽管有几个高质量的开源预训练视频扩散模型,它们可以在不同长度和分辨率的图像和视频上进行联合训练,但通常不建议在推理阶段指定未在训练集中包含的视频长度。因此,这些模型并不易于仅通过增加指定的视频长度来直接生成更长的视频。除了可行性挑战外,长视频生成还面临质量问题。长视频领域的复杂性本质上高于短视频:更长的持续时间引入了更大的可变性和必要的长期时间一致性,从而增加了任务的总体难度。我们提出了VideoMerge,这是一种无需训练的方法,可以无缝地适应合并由预训练文本到视频扩散模型生成的短视频。我们的方法保留了模型的原始表达力和一致性,同时允许用户指定的扩展持续时间和动态变化。通过利用预训练模型的优势,我们的方法通过协同工作的正交策略解决了与平滑度、一致性和动态内容相关的挑战,从而实现优质效果。
论文及项目相关链接
Summary
本文探讨了基于扩散模型的长视频生成问题。尽管扩散模型在视频生成方面取得了先进的质量,但由于视频域的固有复杂性和训练成本高昂,其应用受到限制。此外,现有模型通常操作固定噪声张量表示的视频,导致空间和时间维度预定,难以适应直接生成更长的视频。为此,提出了VideoMerge方法,这是一种无需训练的方法,可无缝适应合并由预训练文本到视频扩散模型生成短视频,允许用户指定扩展的持续时间和动态变化,同时保留模型的原始表达力和一致性。
Key Takeaways
- 扩散模型在长视频生成方面表现出卓越性能,但存在复杂性和高成本挑战。
- 现有模型通常操作固定噪声张量,限制了视频生成的空间和时间维度。
- 尽管存在高质量的开源预训练视频扩散模型,但不建议在推理阶段指定未在训练集中包含的视频长度。
- 直接生成更长的视频面临适应性和质量挑战,需要保持长时间序列的一致性和动态内容。
- VideoMerge方法是一种无需训练的方法,可合并短视频以生成长视频。
- VideoMerge方法允许用户指定扩展的持续时间和动态变化,同时保留模型的原始表达力和一致性。
点此查看论文截图

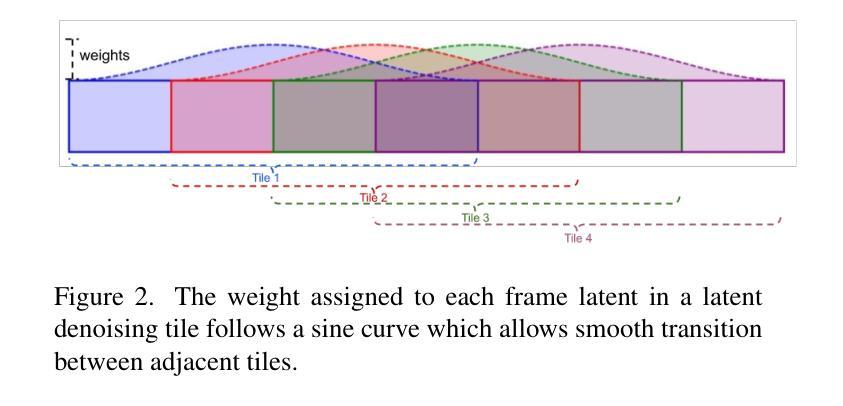




Shaping Inductive Bias in Diffusion Models through Frequency-Based Noise Control
Authors:Thomas Jiralerspong, Berton Earnshaw, Jason Hartford, Yoshua Bengio, Luca Scimeca
Diffusion Probabilistic Models (DPMs) are powerful generative models that have achieved unparalleled success in a number of generative tasks. In this work, we aim to build inductive biases into the training and sampling of diffusion models to better accommodate the target distribution of the data to model. For topologically structured data, we devise a frequency-based noising operator to purposefully manipulate, and set, these inductive biases. We first show that appropriate manipulations of the noising forward process can lead DPMs to focus on particular aspects of the distribution to learn. We show that different datasets necessitate different inductive biases, and that appropriate frequency-based noise control induces increased generative performance compared to standard diffusion. Finally, we demonstrate the possibility of ignoring information at particular frequencies while learning. We show this in an image corruption and recovery task, where we train a DPM to recover the original target distribution after severe noise corruption.
扩散概率模型(DPMs)是强大的生成模型,在多个生成任务中取得了无与伦比的成功。在这项工作中,我们的目标是在扩散模型的训练和采样过程中构建归纳偏置,以更好地适应要建模的数据的目标分布。对于拓扑结构数据,我们设计了一个基于频率的噪声操作符,以故意操作并设置这些归纳偏置。我们首先表明,适当地操作噪声正向过程可以使DPM专注于分布学习的特定方面。我们表明,不同的数据集需要不同的归纳偏置,与标准扩散相比,适当的基于频率的噪声控制会提高生成性能。最后,我们展示了在学习时忽略特定频率信息的可能性。我们在图像损坏和恢复任务中展示了这一点,在该任务中,我们训练DPM在严重噪声损坏后恢复原始目标分布。
论文及项目相关链接
PDF Published as workshop paper at DeLTa and FPI workshops, ICLR 2025
Summary
本文介绍了扩散概率模型(DPMs),一种强大的生成模型,旨在通过引入归纳偏见来改善数据目标分布与模型之间的匹配程度。对于拓扑结构数据,本文设计了一种基于频率的噪声操作器来故意操纵并设置这些归纳偏见。通过适当操纵噪声前向过程,DPMs可以专注于分布学习的特定方面。不同数据集需要不同的归纳偏见,而适当的基于频率的噪声控制可提高生成性能,与标准扩散相比。此外,本文展示了在学习时忽略特定频率信息的可能性,并在图像损坏和恢复任务中进行了演示,训练DPM在严重噪声损坏后恢复原始目标分布。
Key Takeaways
- 扩散概率模型(DPMs)是一种强大的生成模型,能够在多种生成任务中取得前所未有的成功。
- 对于拓扑结构数据,引入归纳偏见可以改善数据目标分布与模型之间的匹配程度。
- 基于频率的噪声操作器被设计来故意操纵设置这些归纳偏见。
- 通过适当操纵噪声前向过程,DPMs可以专注于分布学习的特定方面,从而提高生成模型的性能。
- 不同数据集需要不同的归纳偏见,而基于频率的噪声控制是一种有效的改进方法。
- 在学习时可以忽略特定频率信息,这在图像损坏和恢复任务中得到了验证。
点此查看论文截图


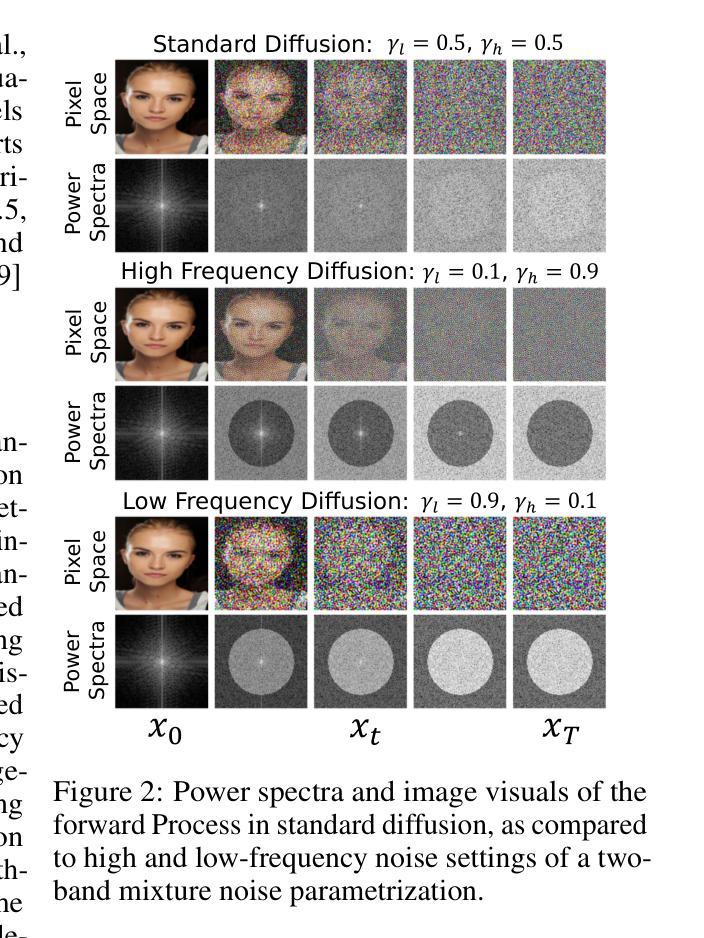
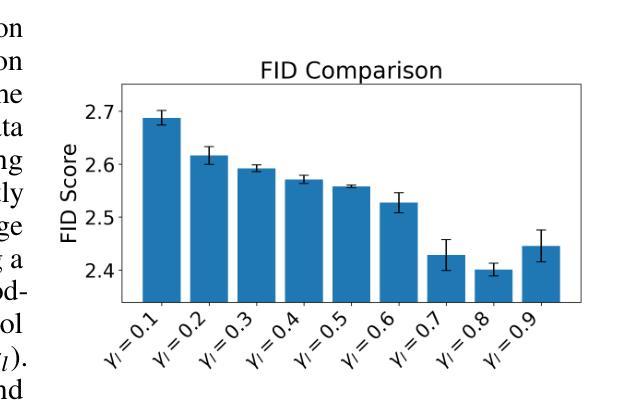
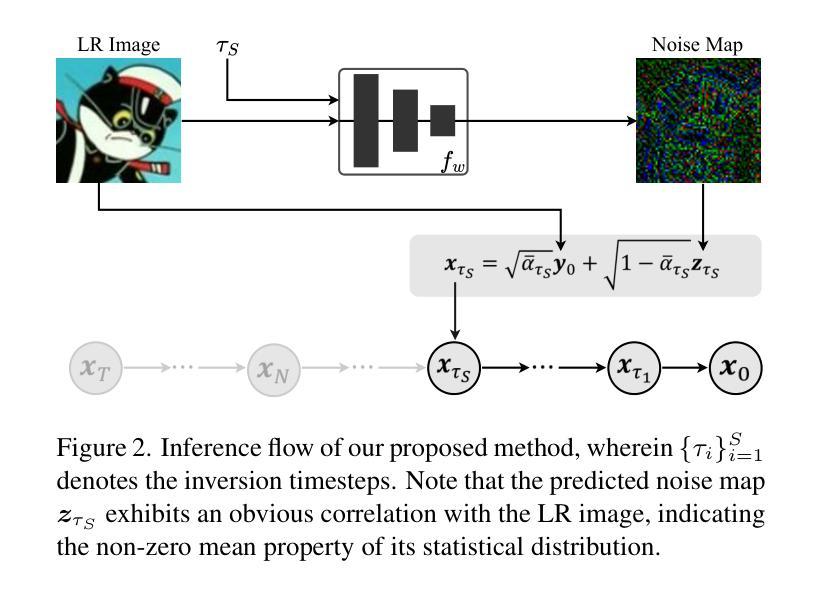
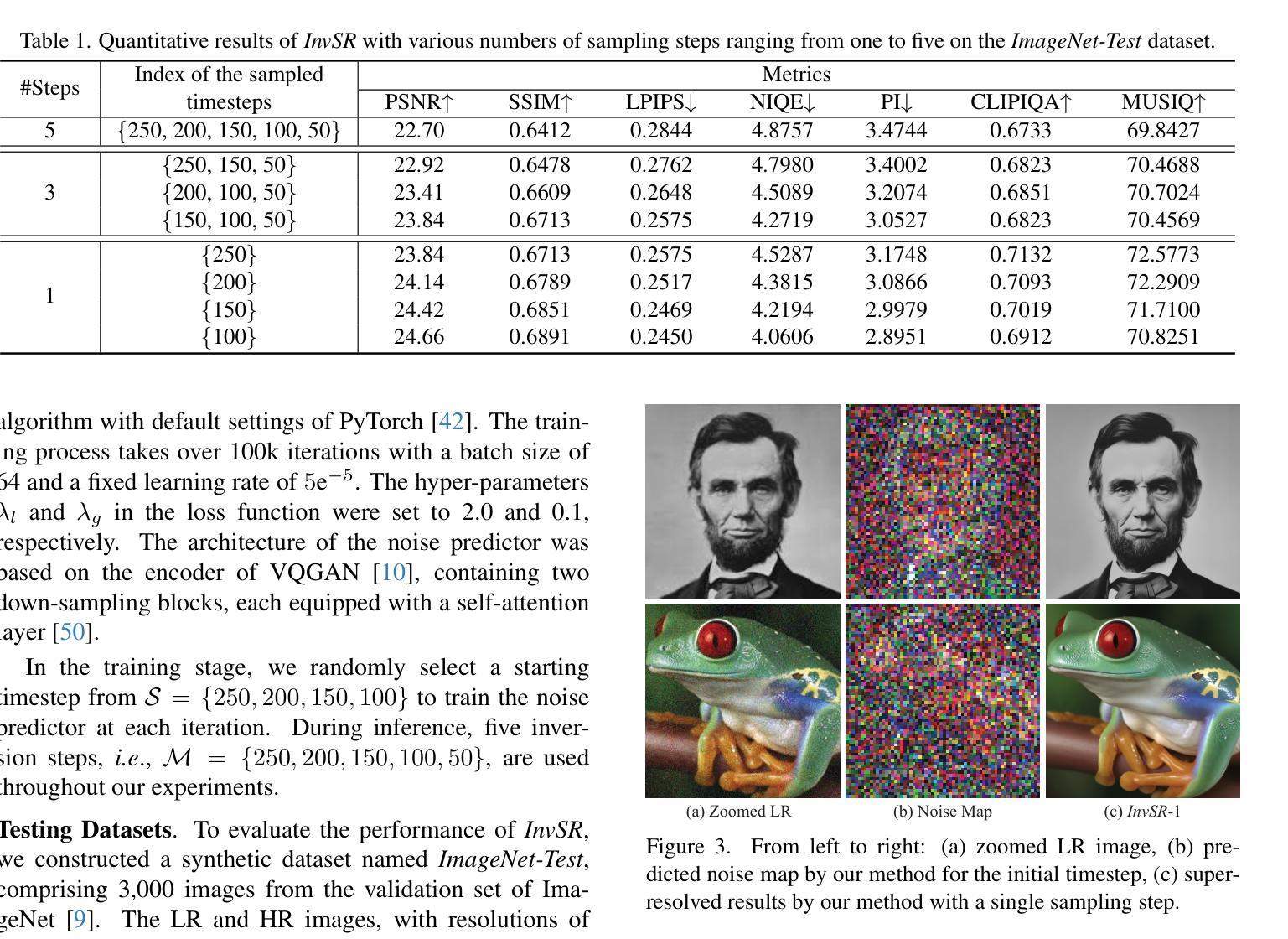
Arbitrary-steps Image Super-resolution via Diffusion Inversion
Authors:Zongsheng Yue, Kang Liao, Chen Change Loy
This study presents a new image super-resolution (SR) technique based on diffusion inversion, aiming at harnessing the rich image priors encapsulated in large pre-trained diffusion models to improve SR performance. We design a Partial noise Prediction strategy to construct an intermediate state of the diffusion model, which serves as the starting sampling point. Central to our approach is a deep noise predictor to estimate the optimal noise maps for the forward diffusion process. Once trained, this noise predictor can be used to initialize the sampling process partially along the diffusion trajectory, generating the desirable high-resolution result. Compared to existing approaches, our method offers a flexible and efficient sampling mechanism that supports an arbitrary number of sampling steps, ranging from one to five. Even with a single sampling step, our method demonstrates superior or comparable performance to recent state-of-the-art approaches. The code and model are publicly available at https://github.com/zsyOAOA/InvSR.
本研究提出了一种基于扩散反转的新型图像超分辨率(SR)技术,旨在利用预训练的大型扩散模型中封装的丰富图像先验知识来提高SR性能。我们设计了一种局部噪声预测策略,以构建扩散模型的中间状态,作为起始采样点。我们的方法的核心是一个深度噪声预测器,用于估计正向扩散过程的最佳噪声图。一旦训练完成,该噪声预测器可用于部分初始化沿扩散轨迹的采样过程,生成理想的高分辨率结果。与现有方法相比,我们的方法提供了一种灵活高效的采样机制,支持从一到五任意的采样步骤数。即使只有一个采样步骤,我们的方法也表现出与最新先进方法相当或更优的性能。代码和模型可在https://github.com/zsyOAOA/InvSR上公开获得。
论文及项目相关链接
PDF Accepted by CVPR 2025. Project: https://github.com/zsyOAOA/InvSR
Summary
本研究提出了一种基于扩散反演的新图像超分辨率(SR)技术,旨在利用大型预训练扩散模型中封装的丰富图像先验知识,以提高SR性能。设计了一种局部噪声预测策略,构建了扩散模型的中间状态,作为采样起始点。方法的核心是一个深度噪声预测器,用于估计前向扩散过程的最佳噪声图。一旦训练完成,该噪声预测器可用于沿扩散轨迹部分初始化采样过程,生成理想的高分辨率结果。与现有方法相比,该方法提供了灵活高效的采样机制,支持从一到五步的任意采样步骤数。即使只有一个采样步骤,该方法也表现出优于或相当于最近先进方法的性能。模型和代码已公开在https://github.com/zsyOAOA/InvSR上提供。
Key Takeaways
- 本研究提出了一种基于扩散反演的图像超分辨率技术。
- 利用大型预训练扩散模型的图像先验知识来提高超分辨率性能。
- 设计了局部噪声预测策略,构建了扩散模型的中间状态作为采样起始点。
- 深度噪声预测器用于估计前向扩散过程的最佳噪声图。
- 方法支持任意数量的采样步骤,包括从一到五步。
- 单步采样即可达到或超越现有先进方法的性能。
点此查看论文截图

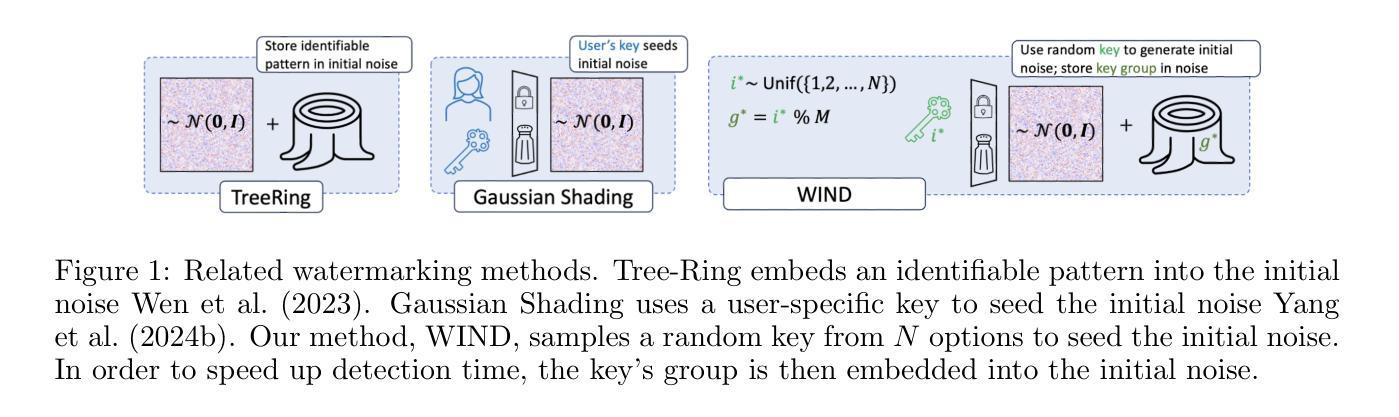
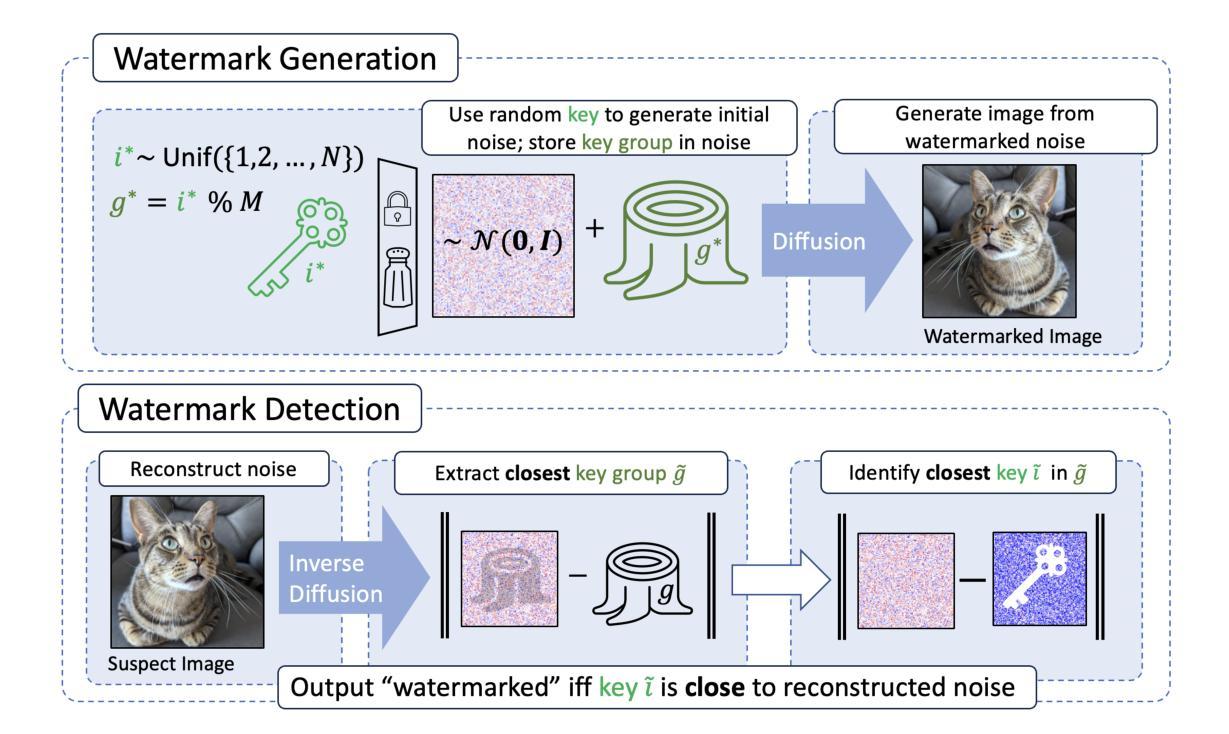
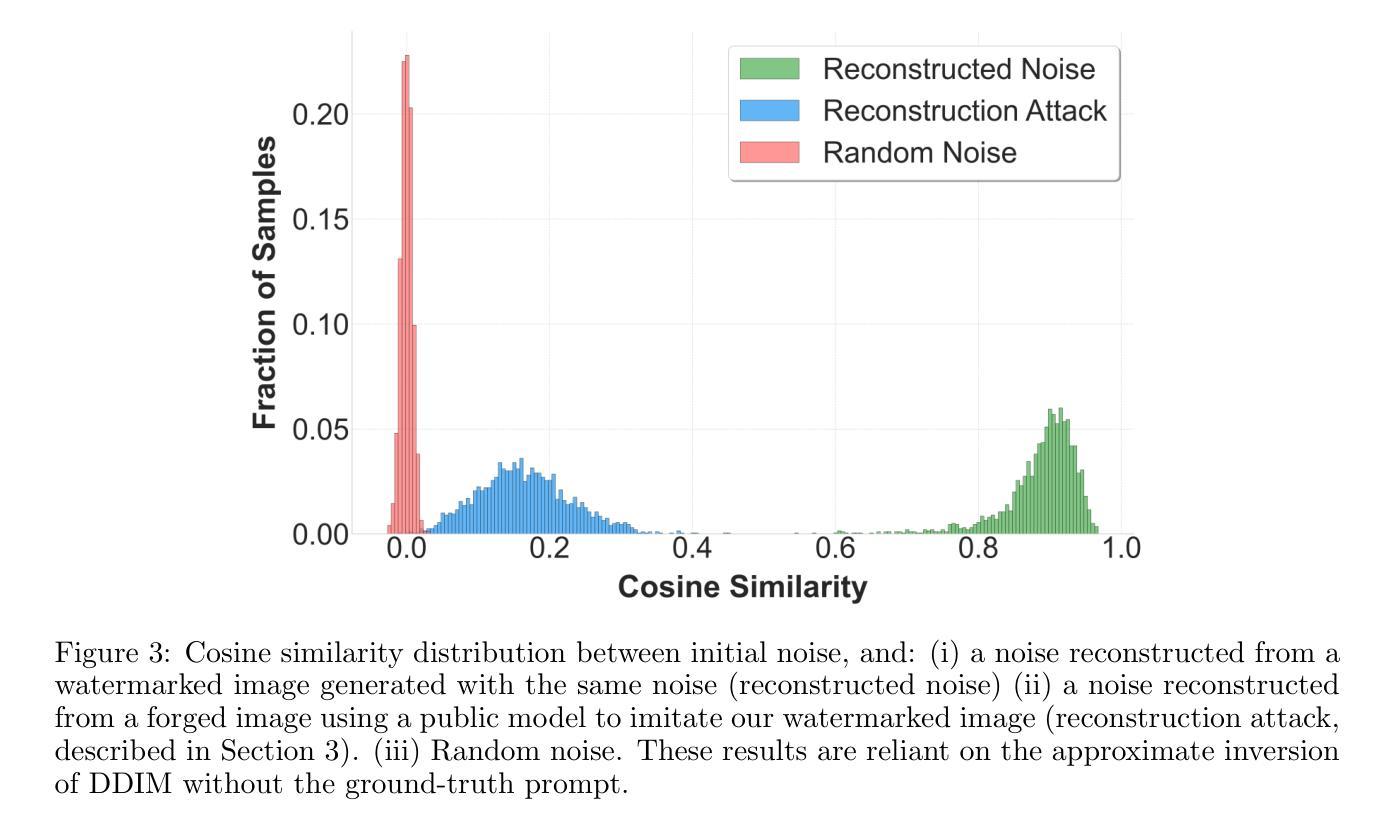
Hidden in the Noise: Two-Stage Robust Watermarking for Images
Authors:Kasra Arabi, Benjamin Feuer, R. Teal Witter, Chinmay Hegde, Niv Cohen
As the quality of image generators continues to improve, deepfakes become a topic of considerable societal debate. Image watermarking allows responsible model owners to detect and label their AI-generated content, which can mitigate the harm. Yet, current state-of-the-art methods in image watermarking remain vulnerable to forgery and removal attacks. This vulnerability occurs in part because watermarks distort the distribution of generated images, unintentionally revealing information about the watermarking techniques. In this work, we first demonstrate a distortion-free watermarking method for images, based on a diffusion model’s initial noise. However, detecting the watermark requires comparing the initial noise reconstructed for an image to all previously used initial noises. To mitigate these issues, we propose a two-stage watermarking framework for efficient detection. During generation, we augment the initial noise with generated Fourier patterns to embed information about the group of initial noises we used. For detection, we (i) retrieve the relevant group of noises, and (ii) search within the given group for an initial noise that might match our image. This watermarking approach achieves state-of-the-art robustness to forgery and removal against a large battery of attacks.
随着图像生成器的质量不断提高,深度伪造成为社会热议的话题。图像水印允许模型所有者对其AI生成的内容进行检测和标注,从而减轻其造成的伤害。然而,当前最先进的水印技术仍然容易受到伪造和删除攻击的影响。这种脆弱性部分是由于水印会破坏生成图像的分布,从而无意间泄露有关水印技术的信息。在这项工作中,我们首先展示了一种基于扩散模型的初始噪声的无失真水印方法。然而,检测水印需要比较重建的图像初始噪声与所有先前使用的初始噪声。为了解决这些问题,我们提出了一种用于高效检测的两阶段水印框架。在生成阶段,我们使用生成的傅里叶模式增强初始噪声以嵌入关于我们所用初始噪声组的信息。对于检测阶段,我们(i)检索相关的噪声组,(ii)在给定的组内搜索可能与我们的图像匹配的初始噪声。这种水印方法达到了对抗大量攻击的伪造和删除操作的最新鲁棒性水平。
论文及项目相关链接
Summary
本文介绍了图像水印技术在防止深度伪造图像方面的应用及其面临的挑战。针对当前图像水印技术易被篡改和移除的问题,提出了一种基于扩散模型的无需变形的图像水印方法。通过利用扩散模型的初始噪声进行水印嵌入与检测,实现了一种两阶段的水印检测框架,有效提高水印检测的效率和鲁棒性。该方法能有效抵抗多种攻击手段,达到业界领先水平。
Key Takeaways
- 图像水印技术允许模型所有者对其AI生成的内容进行检测和标记,有助于缓解深度伪造图像带来的危害。
- 当前图像水印技术面临易被篡改和移除的问题,部分原因在于水印会干扰生成图像的分布,从而泄露水印技术信息。
- 基于扩散模型的初始噪声进行图像水印是一种无需变形的解决方案。
- 提出了一种两阶段的水印检测框架,通过生成时增加初始噪声的傅立叶模式,嵌入关于初始噪声组的信息,以提高检测效率。
- 水印检测分为两个阶段:首先检索相关的噪声组,然后在给定的噪声组内搜索可能与图像匹配的初始噪声。
- 该方法实现了对多种攻击的高鲁棒性,达到业界领先水平。
点此查看论文截图


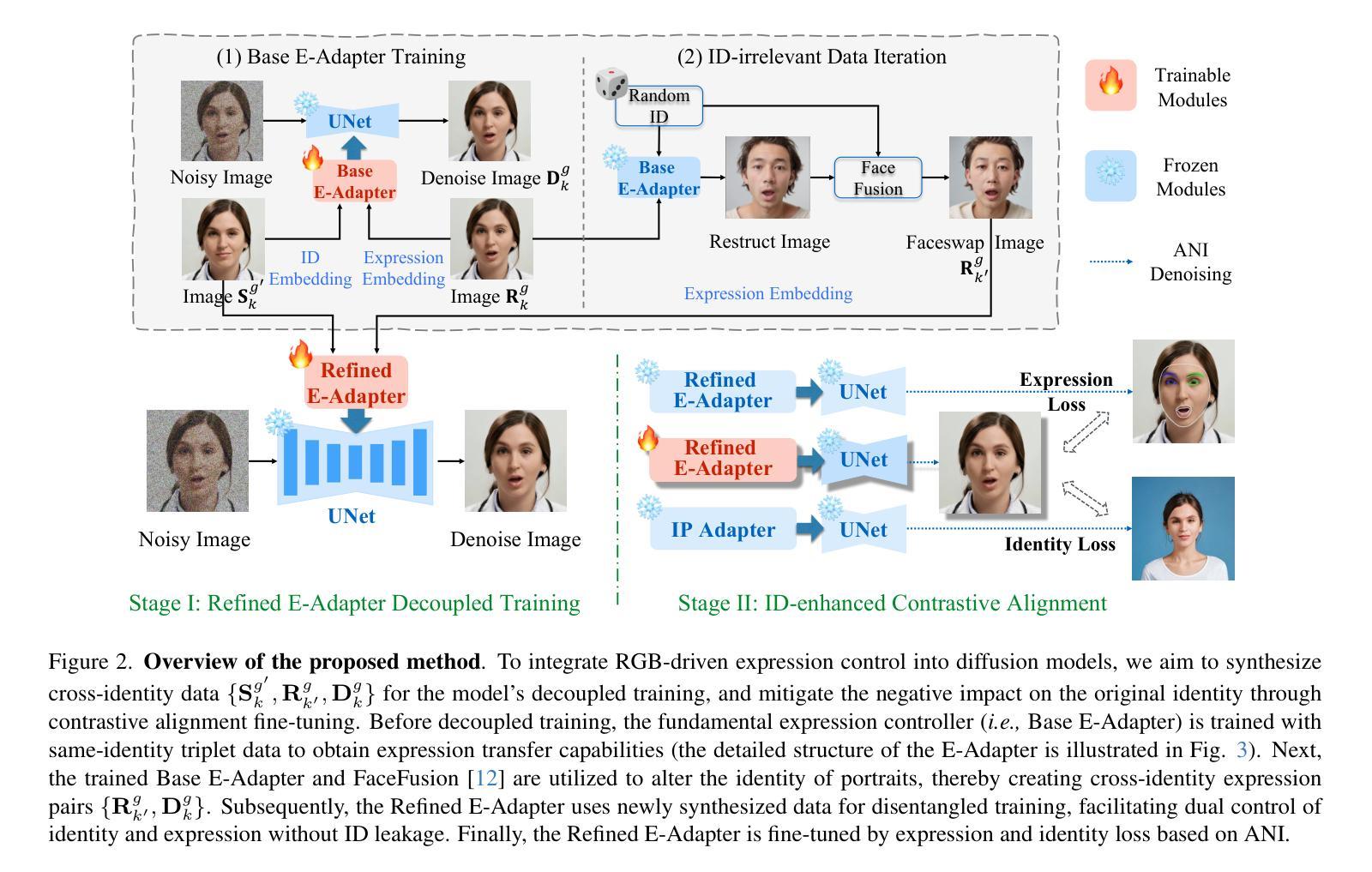
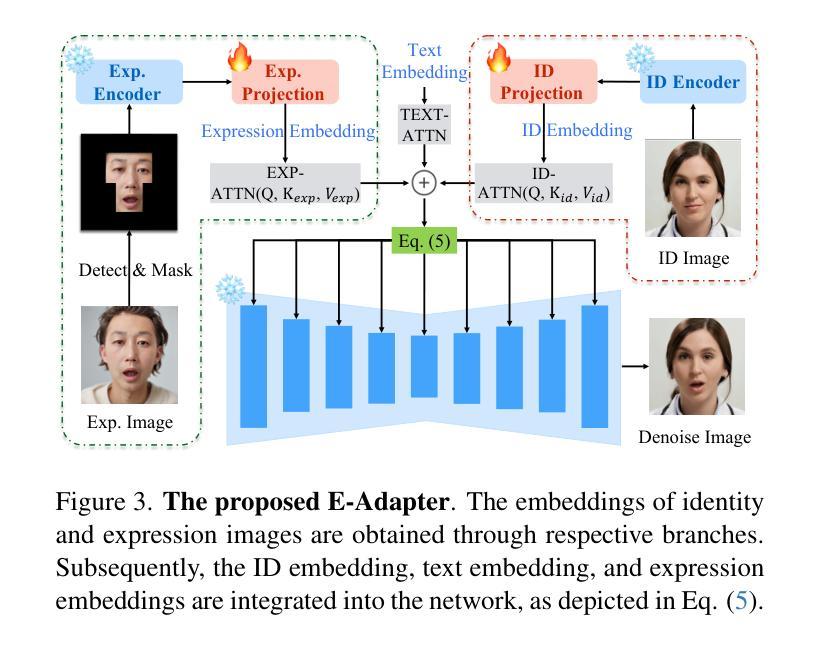
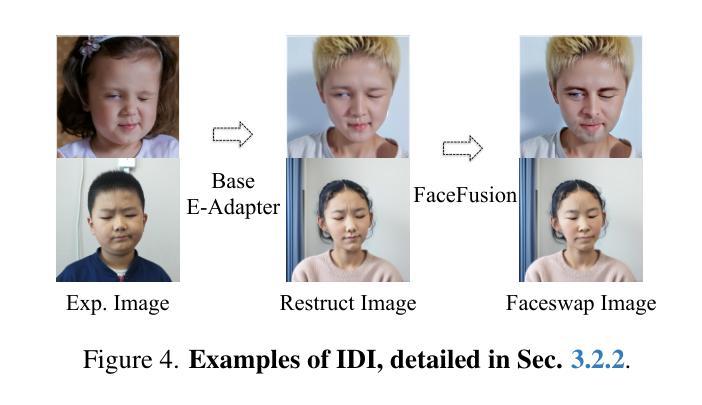
EmojiDiff: Advanced Facial Expression Control with High Identity Preservation in Portrait Generation
Authors:Liangwei Jiang, Ruida Li, Zhifeng Zhang, Shuo Fang, Chenguang Ma
This paper aims to bring fine-grained expression control while maintaining high-fidelity identity in portrait generation. This is challenging due to the mutual interference between expression and identity: (i) fine expression control signals inevitably introduce appearance-related semantics (e.g., facial contours, and ratio), which impact the identity of the generated portrait; (ii) even coarse-grained expression control can cause facial changes that compromise identity, since they all act on the face. These limitations remain unaddressed by previous generation methods, which primarily rely on coarse control signals or two-stage inference that integrates portrait animation. Here, we introduce EmojiDiff, the first end-to-end solution that enables simultaneous control of extremely detailed expression (RGB-level) and high-fidelity identity in portrait generation. To address the above challenges, EmojiDiff adopts a two-stage scheme involving decoupled training and fine-tuning. For decoupled training, we innovate ID-irrelevant Data Iteration (IDI) to synthesize cross-identity expression pairs by dividing and optimizing the processes of maintaining expression and altering identity, thereby ensuring stable and high-quality data generation. Training the model with this data, we effectively disentangle fine expression features in the expression template from other extraneous information (e.g., identity, skin). Subsequently, we present ID-enhanced Contrast Alignment (ICA) for further fine-tuning. ICA achieves rapid reconstruction and joint supervision of identity and expression information, thus aligning identity representations of images with and without expression control. Experimental results demonstrate that our method remarkably outperforms counterparts, achieves precise expression control with highly maintained identity, and generalizes well to various diffusion models.
本文旨在实现肖像生成中的精细表情控制,同时保持高保真身份。这是一个挑战,因为表情和身份之间存在相互干扰:(i)精细表情控制信号不可避免地会引入与外观相关的语义(例如面部轮廓和比例),这会影响生成的肖像的身份;(ii)即使是粗粒度的表情控制也会导致面部变化,损害身份,因为它们都作用于面部。以前的生成方法主要依赖于粗控制信号或集成肖像动画的两阶段推理,无法解决这些限制。在这里,我们引入了EmojiDiff,这是第一个端到端的解决方案,能够在肖像生成中同时控制极其详细的表情(RGB级别)和高保真身份。为了解决上述挑战,EmojiDiff采用了涉及解耦训练和微调的两阶段方案。对于解耦训练,我们创新了ID无关数据迭代(IDI),通过分离和优化保持表情和改变身份的过程,合成跨身份表情对,从而确保稳定且高质量的数据生成。使用此数据训练模型,我们可以有效地将从表情模板中的精细表情特征与其他外来信息(例如身份、皮肤)分离。接下来,我们进行了ID增强对比对齐(ICA)的进一步微调。ICA实现了身份和表情信息的快速重建和联合监督,从而对齐有和无表情控制图像的身份表示。实验结果表明,我们的方法显著优于同行,实现了精确的表情控制,同时高度保持身份,并且能很好地适应各种扩散模型。
论文及项目相关链接
Summary
本文提出了一种名为EmojiDiff的端到端解决方案,旨在实现肖像生成中的精细表情控制和高保真身份保持。该方法采用两阶段方案,包括解耦训练和微调,解决了表情与身份之间相互干扰的问题。通过创新性的ID-irrelevant Data Iteration(IDI)方法,合成跨身份的表情对,确保在保持表情的同时改变身份,从而确保稳定高质量的数据生成。随后,通过ID-enhanced Contrast Alignment(ICA)进行进一步微调,实现身份和表情信息的快速重建和联合监督,使带有和不带表情控制的图像身份表示对齐。实验结果证明,该方法显著优于同类产品,实现了精确的表情控制和高度的身份保持,并能很好地应用于各种扩散模型。
Key Takeaways
- 本文旨在实现肖像生成中的精细表情控制与高保真身份保持,解决表情与身份相互干扰的问题。
- 提出了名为EmojiDiff的端到端解决方案,采用两阶段方案(解耦训练和微调)。
- 通过ID-irrelevant Data Iteration(IDI)方法,合成跨身份的表情对,确保数据生成的稳定性和高质量。
- ID-enhanced Contrast Alignment(ICA)用于进一步微调,实现身份和表情信息的快速重建和联合监督。
- 该方法实现了精确的表情控制,高度保持了身份,并具有良好的泛化能力,适用于各种扩散模型。
- 实验结果证明该方法显著优于其他同类产品。
点此查看论文截图

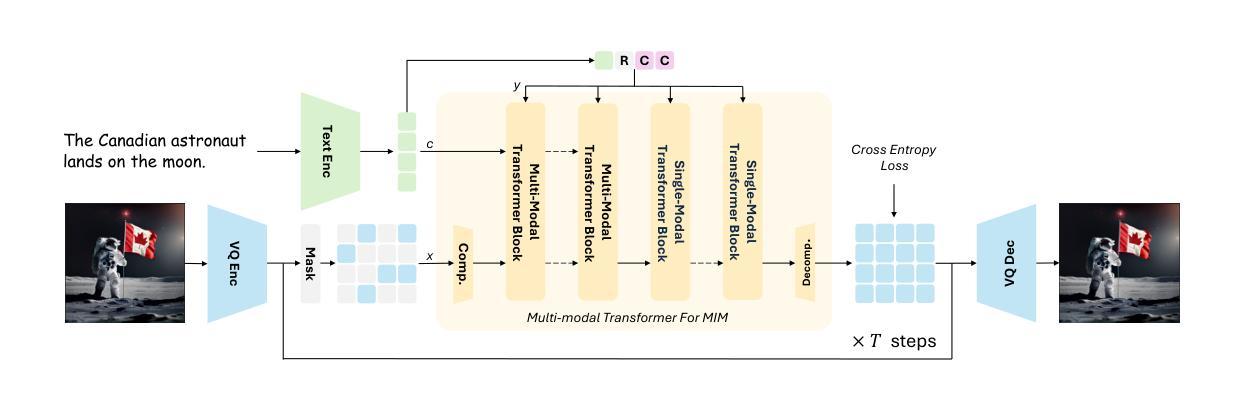
Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
Authors:Jinbin Bai, Tian Ye, Wei Chow, Enxin Song, Xiangtai Li, Zhen Dong, Lei Zhu, Shuicheng Yan
We present Meissonic, which elevates non-autoregressive masked image modeling (MIM) text-to-image to a level comparable with state-of-the-art diffusion models like SDXL. By incorporating a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions, Meissonic substantially improves MIM’s performance and efficiency. Additionally, we leverage high-quality training data, integrate micro-conditions informed by human preference scores, and employ feature compression layers to further enhance image fidelity and resolution. Our model not only matches but often exceeds the performance of existing models like SDXL in generating high-quality, high-resolution images. Extensive experiments validate Meissonic’s capabilities, demonstrating its potential as a new standard in text-to-image synthesis. We release a model checkpoint capable of producing $1024 \times 1024$ resolution images.
我们推出了Meissonic,它将非自回归掩膜图像建模(MIM)的文本到图像的水平提升到了与SDXL等最先进的扩散模型相当的水平。通过融入一系列架构创新、先进的定位编码策略和优化采样条件,Meissonic大大提高了MIM的性能和效率。此外,我们还利用高质量的训练数据,结合人类偏好分数所提供的微观条件,并采用特征压缩层,以进一步提高图像的保真度和分辨率。我们的模型不仅达到了现有模型如SDXL的性能水平,而且在生成高质量、高分辨率图像方面往往表现更佳。大量实验验证了Meissonic的能力,表明了它在文本到图像合成领域的潜力,有望成为一种新标准。我们发布了一个可以生成$1024 \times 1024$分辨率图像的模型检查点。
论文及项目相关链接
PDF Accepted to ICLR 2025. Codes and Supplementary Material: https://github.com/viiika/Meissonic
Summary
Meissonic模型通过引入一系列架构创新、先进的定位编码策略以及优化采样条件,大幅提升了非自回归掩盖图像建模(MIM)的文本转图像能力,使其与如SDXL等先进扩散模型相媲美。借助高质量训练数据、人类偏好得分指导的微条件以及特征压缩层,Meissonic不仅达到了现有模型如SDXL的性能,而且在生成高质量、高分辨率图像方面更胜一筹。
Key Takeaways
- Meissonic模型提高了非自回归掩盖图像建模(MIM)的文本转图像能力。
- 通过引入一系列架构创新和先进的定位编码策略,Meissonic实现了性能提升。
- Meissonic模型使用了优化采样条件,进一步提升了效率。
- 高质量训练数据、人类偏好得分指导的微条件以及特征压缩层的应用增强了图像的保真度和分辨率。
- Meissonic模型达到了甚至超越了现有模型如SDXL的性能。
- Meissonic模型能够通过广泛实验验证其能力,显示出在文本转图像合成方面的潜力。
点此查看论文截图


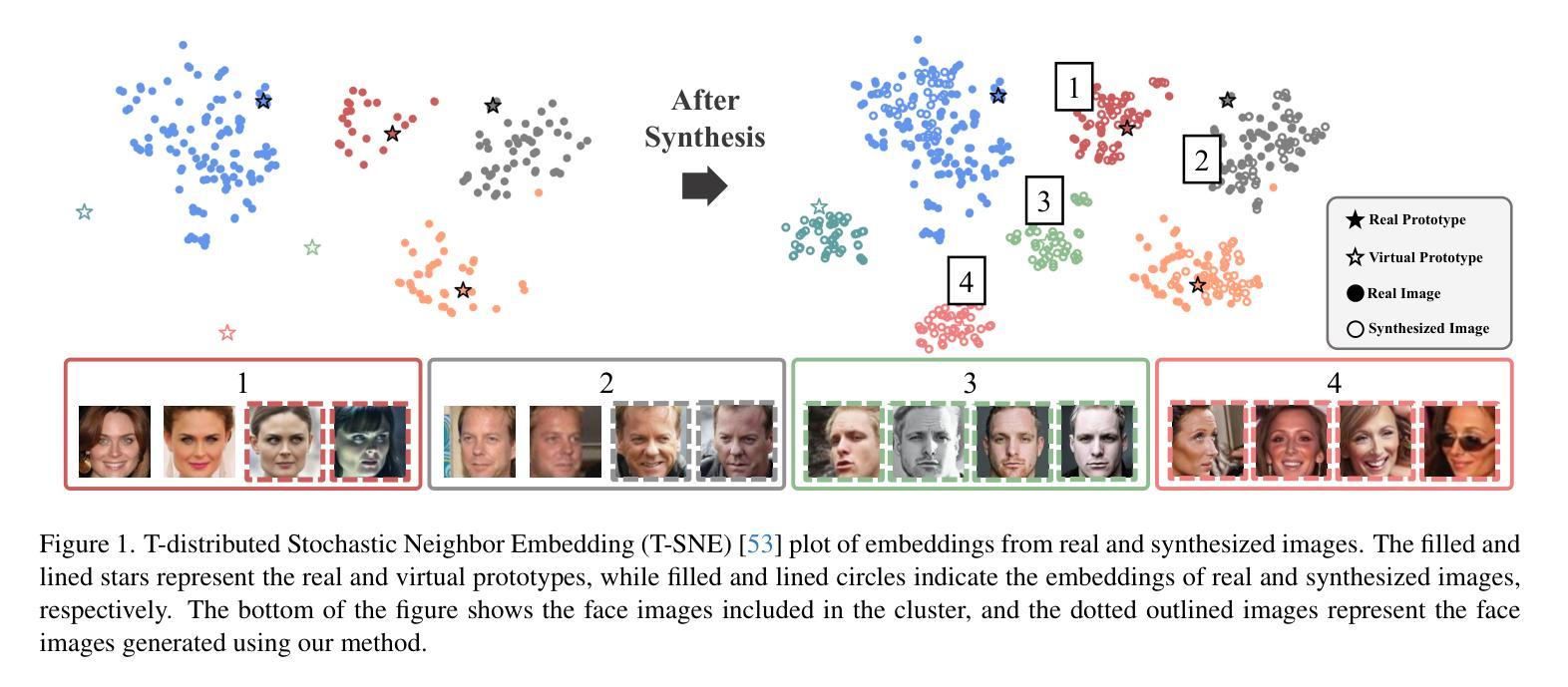
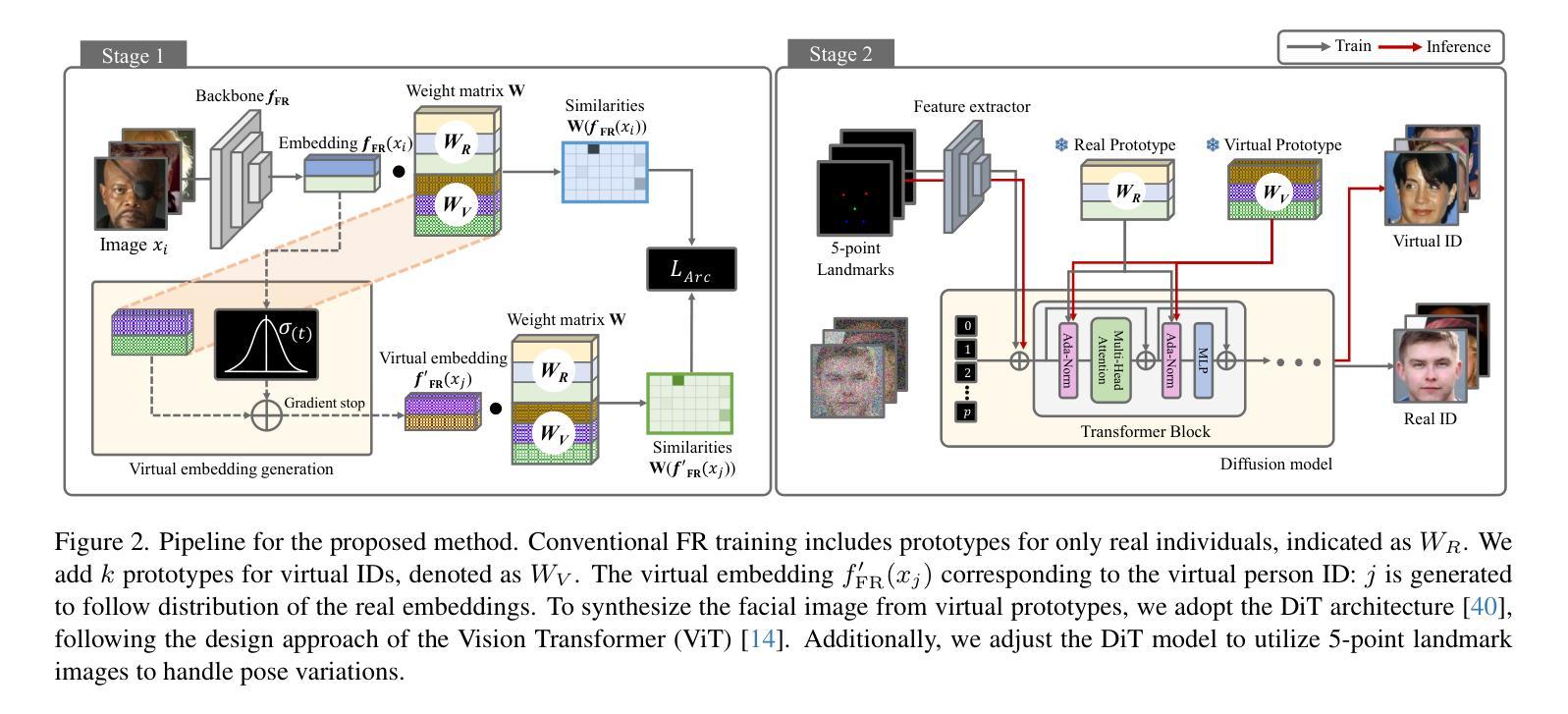
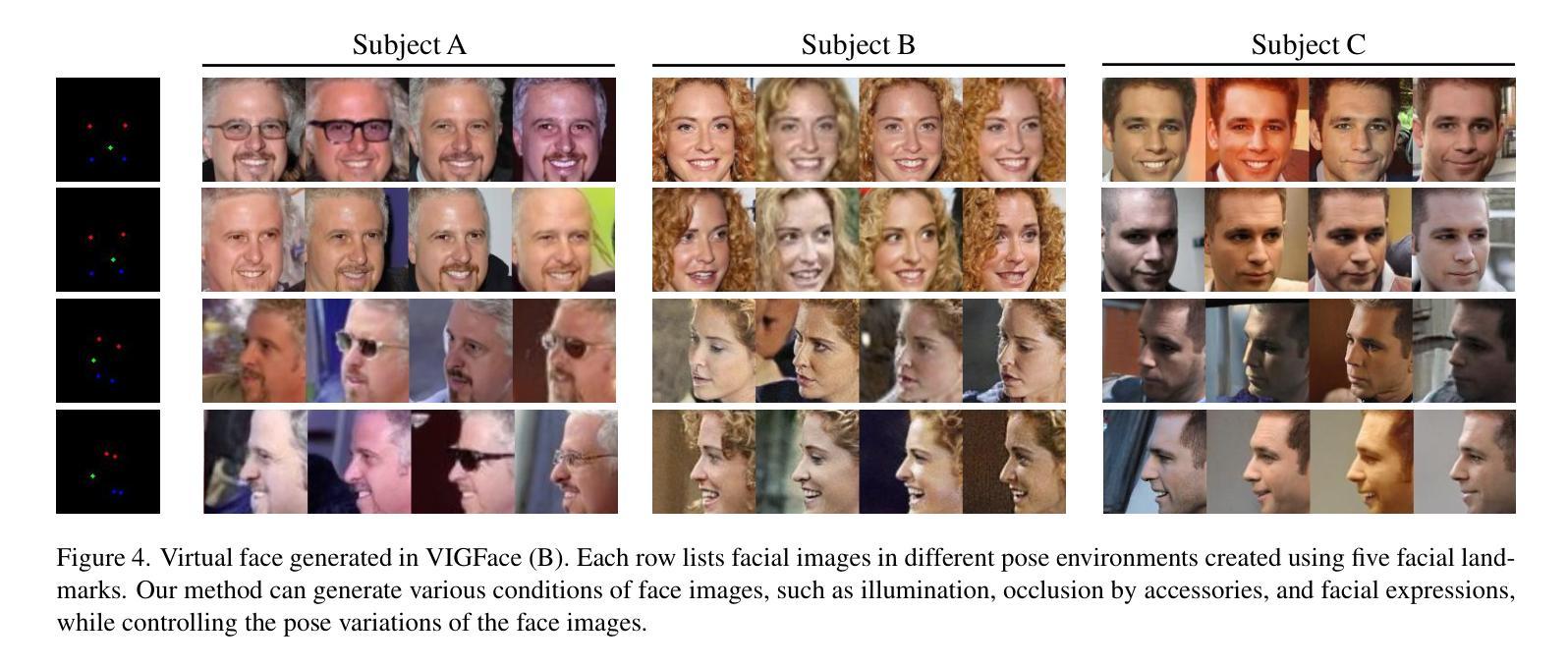
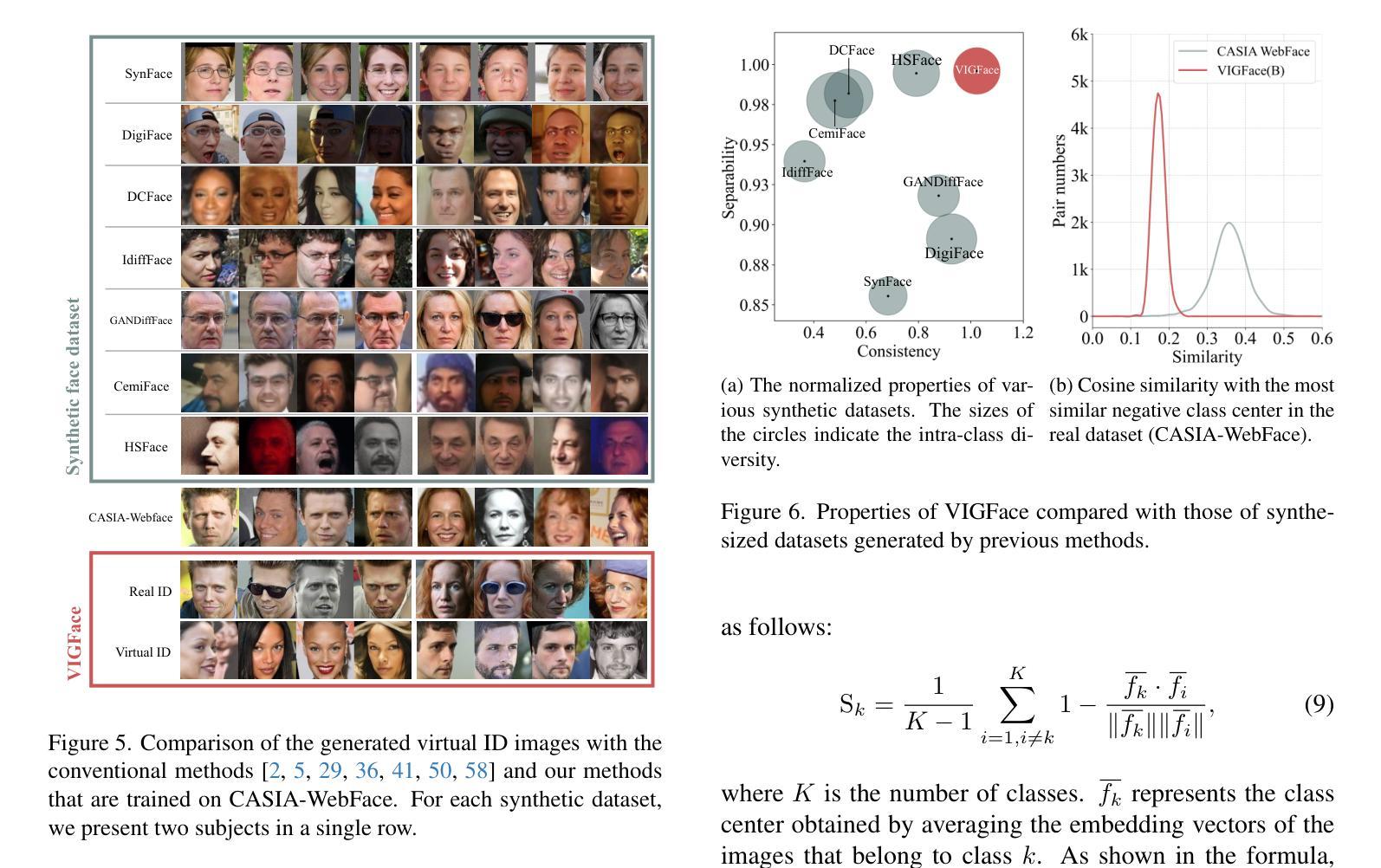
VIGFace: Virtual Identity Generation for Privacy-Free Face Recognition
Authors:Minsoo Kim, Min-Cheol Sagong, Gi Pyo Nam, Junghyun Cho, Ig-Jae Kim
Deep learning-based face recognition continues to face challenges due to its reliance on huge datasets obtained from web crawling, which can be costly to gather and raise significant real-world privacy concerns. To address this issue, we propose VIGFace, a novel framework capable of generating synthetic facial images. Our idea originates from pre-assigning virtual identities in the feature space. Initially, we train the face recognition model using a real face dataset and create a feature space for both real and virtual identities, where virtual prototypes are orthogonal to other prototypes. Subsequently, we train the diffusion model based on the established feature space, enabling it to generate authentic human face images from real prototypes and synthesize virtual face images from virtual prototypes. Our proposed framework provides two significant benefits. Firstly, it shows clear separability between existing individuals and virtual face images, allowing one to create synthetic images with confidence and without concerns about privacy and portrait rights. Secondly, it ensures improved performance through data augmentation by incorporating real existing images. Extensive experiments demonstrate the superiority of our virtual face dataset and framework, outperforming the previous state-of-the-art on various face recognition benchmarks.
基于深度学习的人脸识别仍然面临着挑战,因为它依赖于从网络爬虫获得的大量数据集,这些数据集的收集成本高昂,并引发了现实世界中的重大隐私担忧。为了解决这一问题,我们提出了VIGFace框架,该框架能够生成合成面部图像。我们的想法源于在特征空间预先分配虚拟身份。首先,我们使用真实面部数据集训练人脸识别模型,并为真实和虚拟身份创建特征空间,其中虚拟原型与其他原型正交。随后,我们基于建立的特征空间训练扩散模型,使其能够从真实原型生成真实的人脸图像,并从虚拟原型合成虚拟人脸图像。我们提出的框架提供了两个重要优势。首先,它实现了现有个体和虚拟人脸图像之间的清晰可分离性,使人们能够自信地创建合成图像,无需担心隐私和肖像权问题。其次,通过融入真实存在的图像,它确保了通过数据增强提高性能。大量实验证明,我们的虚拟人脸数据集和框架优于各种人脸识别基准测试上的先前最新技术。
论文及项目相关链接
PDF Please refer to version 3 if you are citing this paper. Major updates: (1)Test utilities updated: use AdaFace code. (2)Training method updated: AdaFace+IR-SE50
Summary
本文提出了一种新型的面貌识别框架VIGFace,它利用深度学习技术生成合成面部图像,以解决依赖网络爬虫获取的大量真实面部图像数据所带来的挑战。该框架通过在特征空间预先分配虚拟身份来生成虚拟面部原型,训练扩散模型以生成真实和虚拟面部图像。该框架具有两个主要优势:一是能够在现有个体和虚拟面部图像之间实现清晰的分离,为创建合成图像提供了信心,消除了对隐私和肖像权的担忧;二是通过引入真实的现有图像,实现了数据增强,提高了性能。实验证明,该虚拟面部数据集和框架优于当前先进的方法,在各种面部识别基准测试中表现优异。
Key Takeaways
- VIGFace框架解决了深度学习在面部识别中依赖大量真实数据的问题,通过生成合成面部图像减少了成本和对隐私的担忧。
- 该框架利用特征空间预先分配虚拟身份来生成虚拟面部原型,这些原型与真实原型正交。
- 扩散模型基于已建立的特性空间进行训练,可以生成真实和虚拟的面部图像。
- VIGFace框架能够确保现有个体和虚拟面部图像之间的清晰分离,提高了创建合成图像的可靠性和安全性。
- 通过引入真实现有图像进行增强,提高了数据多样性和性能。
- 实验证明,VIGFace框架在多种面部识别基准测试中表现优于现有技术。
点此查看论文截图