⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
Cognitive-Mental-LLM: Leveraging Reasoning in Large Language Models for Mental Health Prediction via Online Text
Authors:Avinash Patil, Amardeep Kour Gedhu
Large Language Models (LLMs) have demonstrated potential in predicting mental health outcomes from online text, yet traditional classification methods often lack interpretability and robustness. This study evaluates structured reasoning techniques-Chain-of-Thought (CoT), Self-Consistency (SC-CoT), and Tree-of-Thought (ToT)-to improve classification accuracy across multiple mental health datasets sourced from Reddit. We analyze reasoning-driven prompting strategies, including Zero-shot CoT and Few-shot CoT, using key performance metrics such as Balanced Accuracy, F1 score, and Sensitivity/Specificity. Our findings indicate that reasoning-enhanced techniques improve classification performance over direct prediction, particularly in complex cases. Compared to baselines such as Zero Shot non-CoT Prompting, and fine-tuned pre-trained transformers such as BERT and Mental-RoBerta, and fine-tuned Open Source LLMs such as Mental Alpaca and Mental-Flan-T5, reasoning-driven LLMs yield notable gains on datasets like Dreaddit (+0.52% over M-LLM, +0.82% over BERT) and SDCNL (+4.67% over M-LLM, +2.17% over BERT). However, performance declines in Depression Severity, and CSSRS predictions suggest dataset-specific limitations, likely due to our using a more extensive test set. Among prompting strategies, Few-shot CoT consistently outperforms others, reinforcing the effectiveness of reasoning-driven LLMs. Nonetheless, dataset variability highlights challenges in model reliability and interpretability. This study provides a comprehensive benchmark of reasoning-based LLM techniques for mental health text classification. It offers insights into their potential for scalable clinical applications while identifying key challenges for future improvements.
大型语言模型(LLM)已显示出从在线文本预测心理健康结果的潜力,但传统分类方法往往缺乏可解释性和稳健性。本研究评估了链式思维(CoT)、自我一致性(SC-CoT)和树状思维(ToT)等结构化推理技术,以提高来自Reddit的多个心理健康数据集的分类精度。我们分析了以推理为核心的提示策略,包括零镜头CoT和少镜头CoT,使用平衡精度、F1分数和敏感性/特异性等关键性能指标。我们的研究结果表明,采用推理增强技术的分类性能优于直接预测,特别是在复杂情况下。与基线方法(如零镜头非CoT提示)以及微调过的预训练转换器(如BERT和Mental-RoBerta)以及微调过的开源LLM(如Mental Alpaca和Mental-Flan-T5)相比,以推理为核心的LLM在数据集上取得了显著的提升,如在Dreaddit上(较M-LLM提升0.52%,较BERT提升0.82%),SDCNL上(较M-LLM提升4.67%,较BERT提升2.17%)。然而,在抑郁症严重程度和CSSRS预测方面的性能下降表明,特定数据集存在局限性,这可能是由于我们使用了更广泛的测试集。在提示策略中,少镜头CoT表现最优秀且持续超越其他方法,这再次证明了以推理为核心的LLM的有效性。然而,数据集的变化性突显了模型可靠性和可解释性的挑战。本研究为基于推理的LLM技术在心理健康文本分类方面提供了全面的基准测试,为它们在可扩展的临床应用方面提供了见解,并指出了未来改进的关键挑战。
论文及项目相关链接
PDF 8 pages, 4 Figures, 3 tables
Summary
该文章研究了在多个心理健康数据集上应用的大型语言模型(LLMs)的预测效果,并评价了基于结构化推理技术的表现。通过Chain-of-Thought(CoT)、Self-Consistency(SC-CoT)和Tree-of-Thought(ToT)等技术提升分类精度。文章还探讨了基于推理的提示策略,包括Zero-shot CoT和Few-shot CoT,并在关键性能指标上进行了评估。结果表明,基于推理的技术在复杂情况下提高了分类性能。但与基准模型相比,这些技术在某些数据集上的表现仍有提升空间。此外,文章强调了不同提示策略之间的差异及其对不同数据集的适应性。总的来说,该文章提供了基于推理的大型语言模型在心理健康文本分类方面的全面基准测试,并指出了未来改进的关键挑战。
Key Takeaways
- 大型语言模型(LLMs)在预测心理健康结果方面展现潜力。
- 传统分类方法缺乏解释性和稳健性,而结构化推理技术(如Chain-of-Thought和Tree-of-Thought)能提高分类精度。
- 基于推理的提示策略(如Few-shot CoT)在复杂情况下表现更好。
- 与基准模型相比,推理驱动的大型语言模型在某些数据集上实现了显著的性能提升。
- 数据集差异对模型性能和解释性构成挑战。
- 研究提供了基于推理的LLMs在心理健康文本分类方面的全面基准测试。
点此查看论文截图


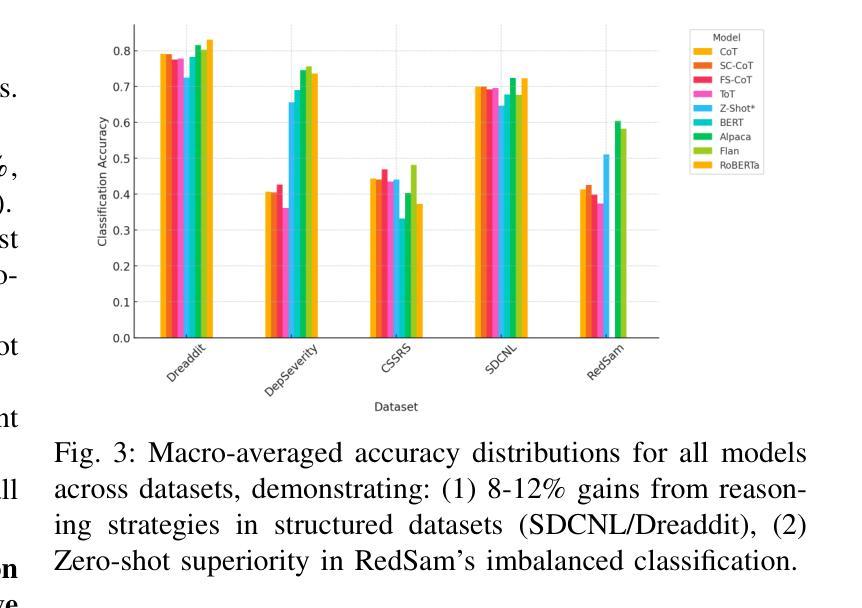
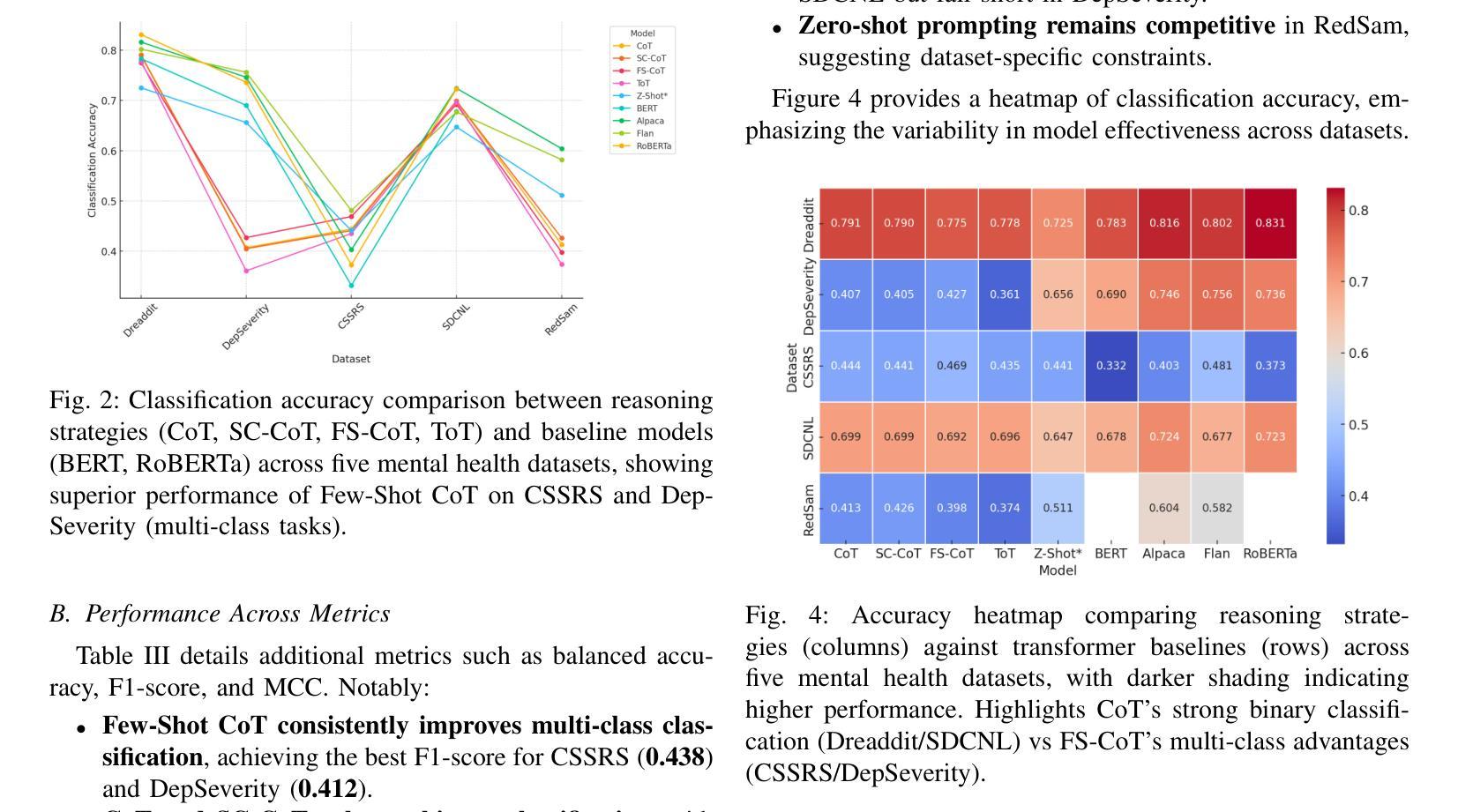
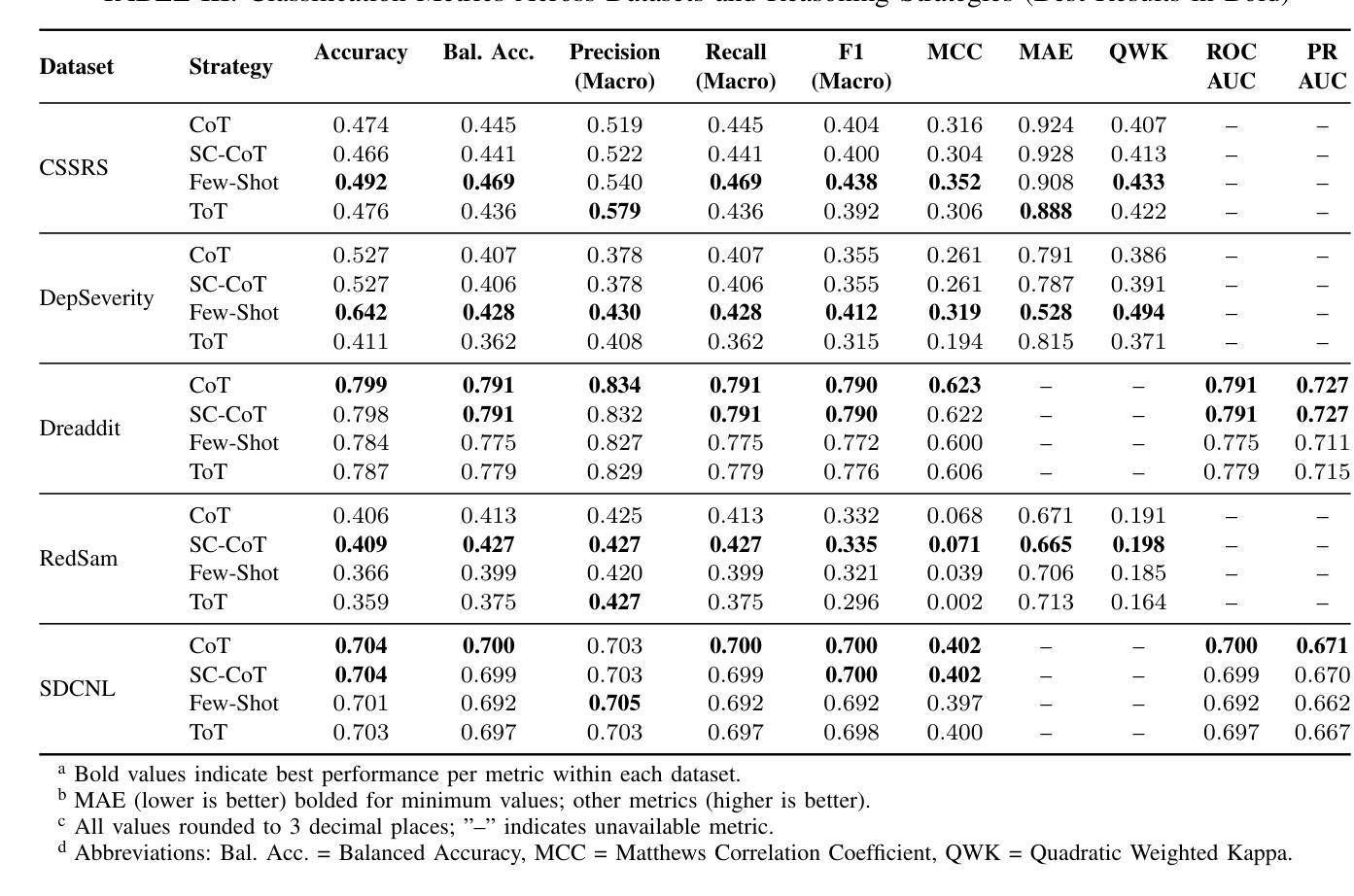
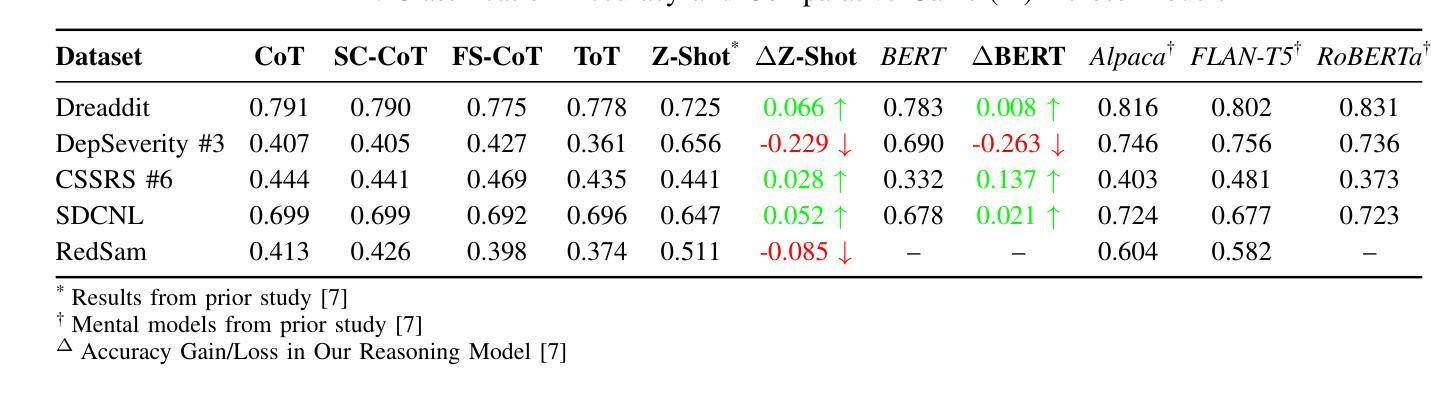
Take Off the Training Wheels Progressive In-Context Learning for Effective Alignment
Authors:Zhenyu Liu, Dongfang Li, Xinshuo Hu, Xinping Zhao, Yibin Chen, Baotian Hu, Min Zhang
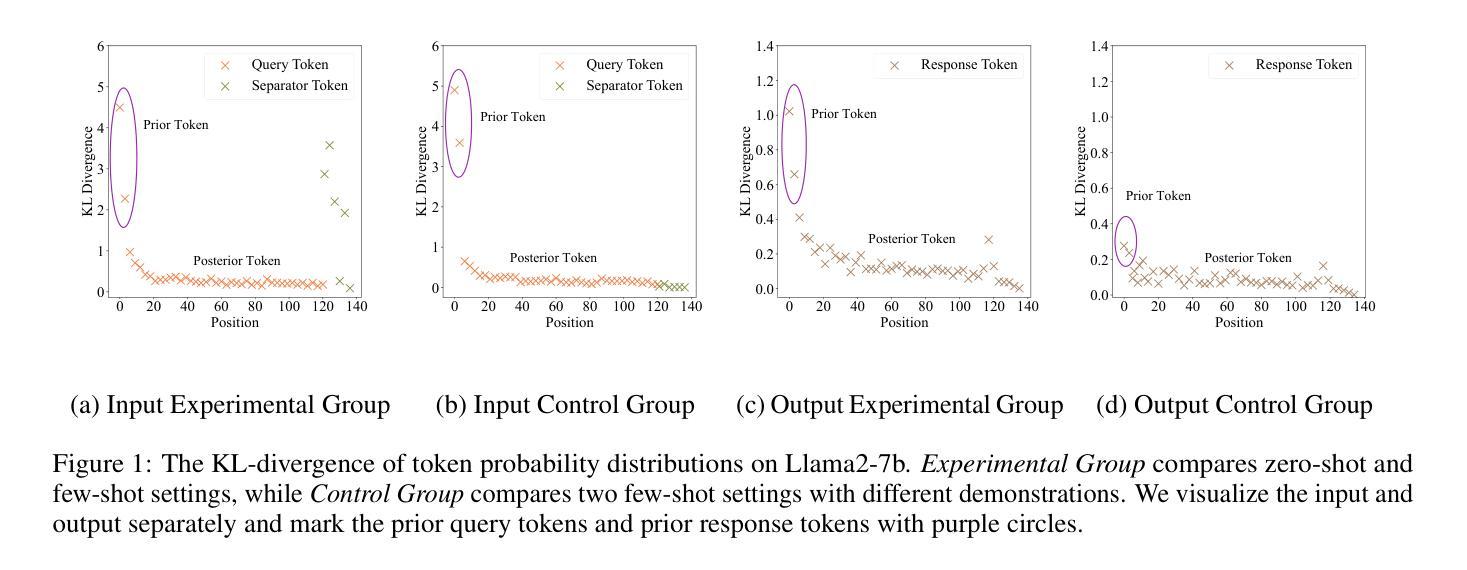
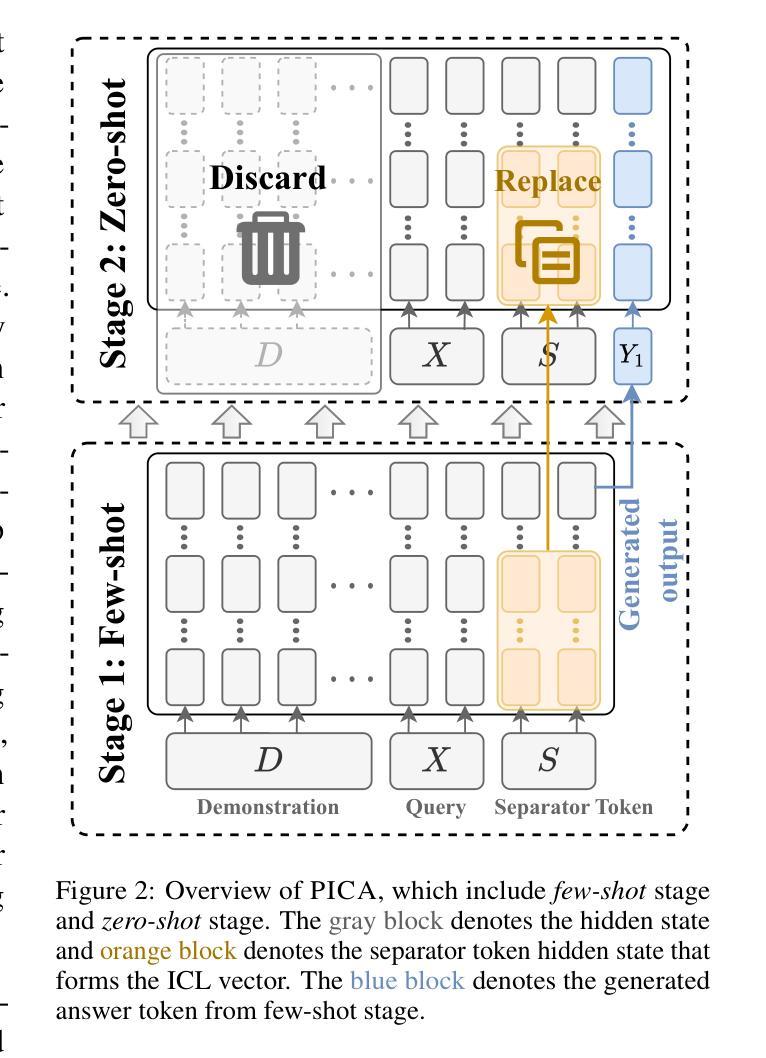
Recent studies have explored the working mechanisms of In-Context Learning (ICL). However, they mainly focus on classification and simple generation tasks, limiting their broader application to more complex generation tasks in practice. To address this gap, we investigate the impact of demonstrations on token representations within the practical alignment tasks. We find that the transformer embeds the task function learned from demonstrations into the separator token representation, which plays an important role in the generation of prior response tokens. Once the prior response tokens are determined, the demonstrations become redundant.Motivated by this finding, we propose an efficient Progressive In-Context Alignment (PICA) method consisting of two stages. In the first few-shot stage, the model generates several prior response tokens via standard ICL while concurrently extracting the ICL vector that stores the task function from the separator token representation. In the following zero-shot stage, this ICL vector guides the model to generate responses without further demonstrations.Extensive experiments demonstrate that our PICA not only surpasses vanilla ICL but also achieves comparable performance to other alignment tuning methods. The proposed training-free method reduces the time cost (e.g., 5.45+) with improved alignment performance (e.g., 6.57+). Consequently, our work highlights the application of ICL for alignment and calls for a deeper understanding of ICL for complex generations. The code will be available at https://github.com/HITsz-TMG/PICA.
近期研究已经探讨了上下文学习(In-Context Learning,ICL)的工作机制。然而,它们主要集中在分类和简单生成任务上,限制了其在实践中更复杂生成任务的更广泛应用。为了解决这一差距,我们研究了演示对实际对齐任务中令牌表示的影响。我们发现,transformer将从演示中学到的任务功能嵌入到分隔符令牌表示中,这在生成先前响应令牌时起到了重要作用。一旦确定了先前的响应令牌,演示就变得多余了。受此发现的启发,我们提出了一种高效渐进上下文对齐(Progressive In-Context Alignment,PICA)方法,分为两个阶段。在前几个镜头阶段,模型通过标准ICL生成几个先前的响应令牌,同时从分隔符令牌表示中提取存储任务功能的ICL向量。在接下来的零镜头阶段,这个ICL向量引导模型生成响应而无需进一步的演示。大量实验表明,我们的PICA不仅超越了基本的ICL,而且与其他对齐调整方法相比也取得了相当的性能。这种无需训练的方法不仅减少了时间成本(例如,5.45+),而且提高了对齐性能(例如,6.57+)。因此,我们的工作突出了ICL在对接中的应用,并呼吁对ICL在复杂生成中的更深理解。代码将在https://github.com/HITsz-TMG/PICA上提供。
论文及项目相关链接
PDF 15 pages, 9 figures, published in EMNLP2024
摘要
本研究探讨了In-Context Learning(ICL)的工作机制在复杂生成任务中的应用。研究发现,转换器将演示中学到的任务函数嵌入到分隔符令牌表示中,在生成先前响应令牌时起到重要作用。一旦确定了先前的响应令牌,演示就变得多余了。基于此发现,我们提出了一种高效的Progressive In-Context Alignment(PICA)方法,分为两个阶段。在初始的几次射击阶段,模型通过标准ICL生成几个先前的响应令牌,同时从分隔符令牌表示中提取存储任务函数的ICL向量。在接下来的零射击阶段,这个ICL向量引导模型在没有进一步演示的情况下生成响应。实验表明,我们的PICA不仅超越了原始的ICL,而且与其他对齐调整方法相比也取得了相当的性能。这种训练有素的方法减少了时间成本(例如,5.45+),提高了对齐性能(例如,6.57+)。因此,我们的工作突出了ICL在复杂生成任务中的应用,并呼吁对ICL进行更深入的了解。代码将在https://github.com/HITsz-TMG/PICA上提供。
关键见解
- 研究重点探索了In-Context Learning(ICL)在复杂生成任务中的应用机制。
- 发现转换器将演示中的任务函数嵌入到分隔符令牌的表示中。
- 提出了一种高效的Progressive In-Context Alignment(PICA)方法,包含两个阶段:few-shot阶段和zero-shot阶段。
- 在few-shot阶段,模型生成先前的响应令牌并提取存储任务函数的ICL向量。
- 在zero-shot阶段,使用ICL向量引导模型在没有进一步演示的情况下生成响应。
- 实验表明,PICA方法不仅超越了原始的ICL性能,而且在与其他对齐调整方法的比较中也取得了良好的性能。
点此查看论文截图

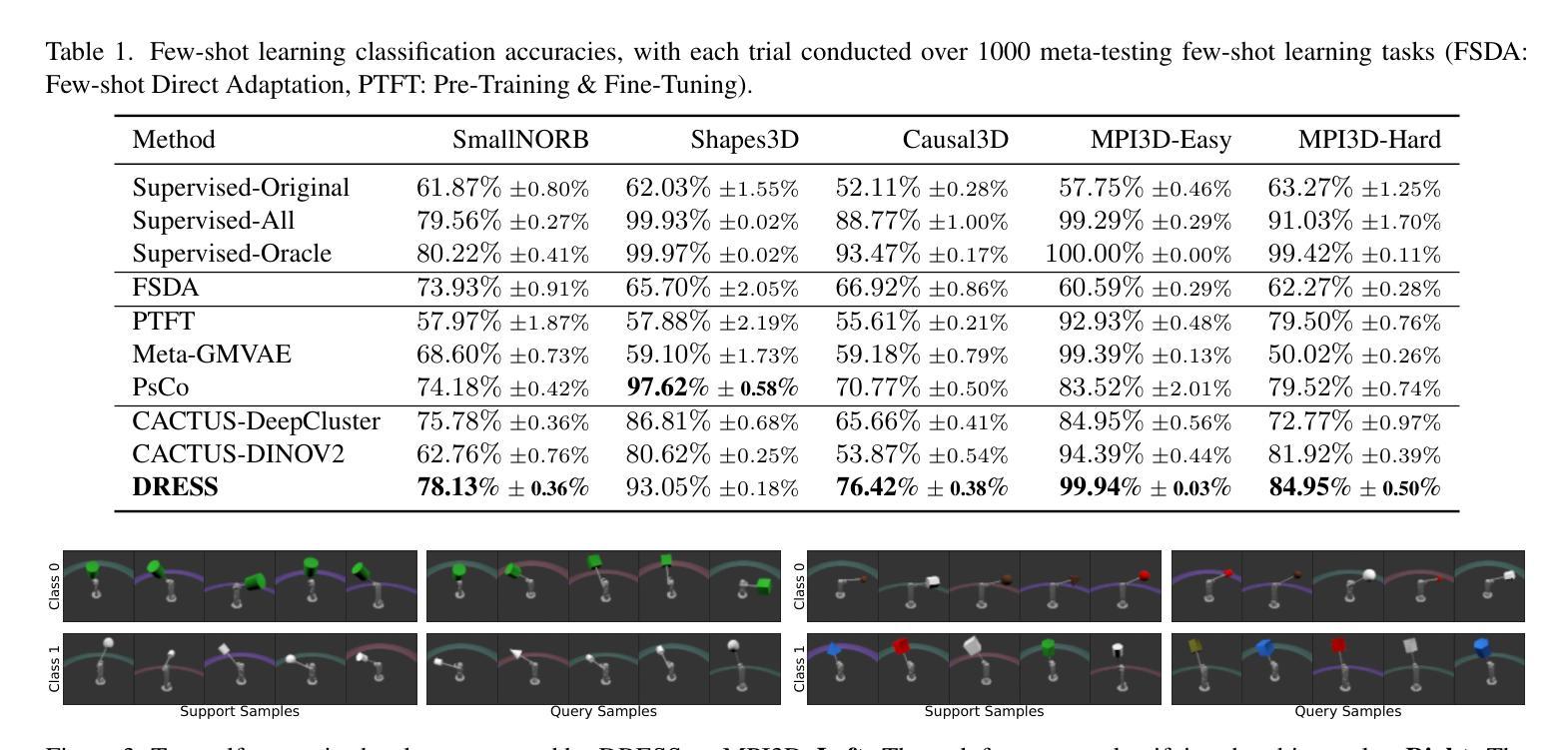
DRESS: Disentangled Representation-based Self-Supervised Meta-Learning for Diverse Tasks
Authors:Wei Cui, Tongzi Wu, Jesse C. Cresswell, Yi Sui, Keyvan Golestan
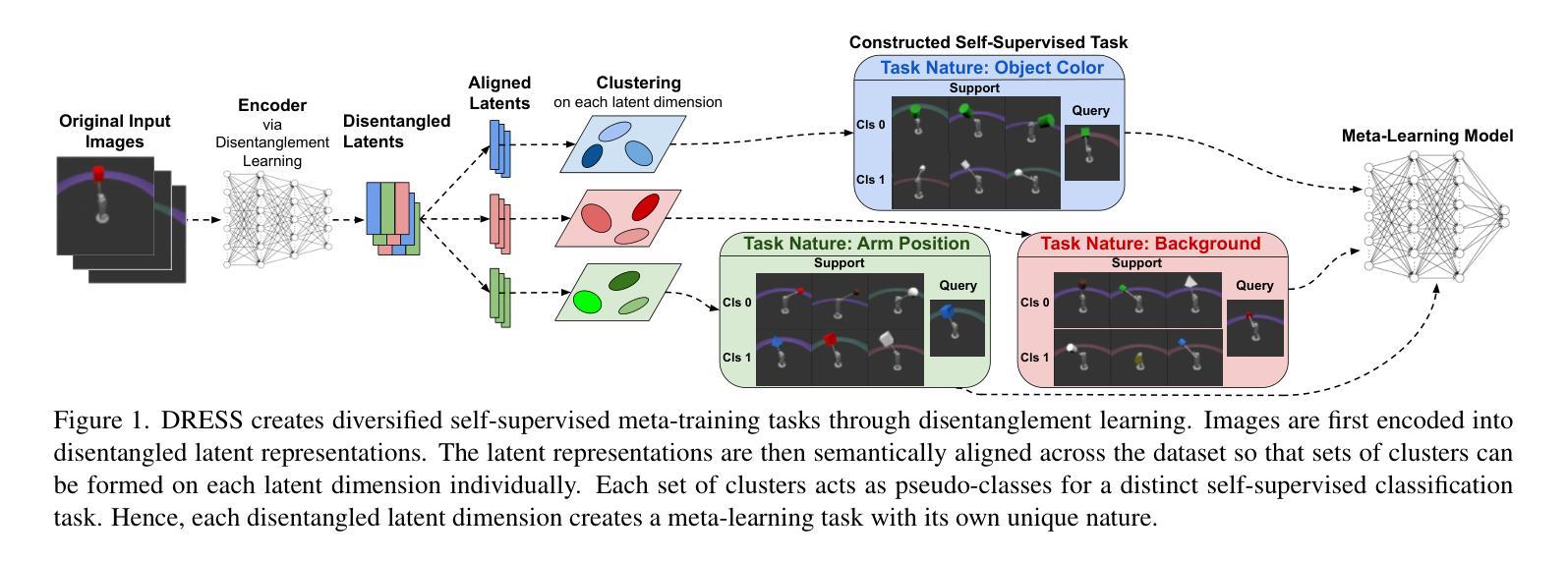
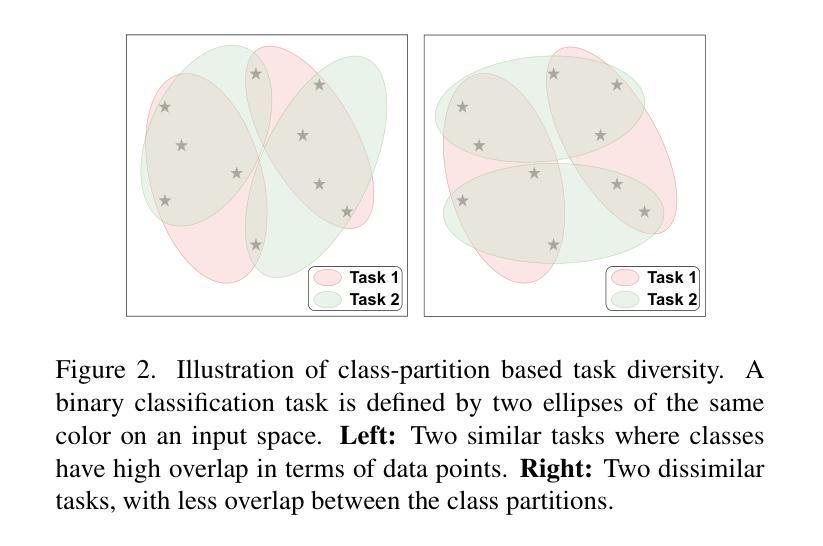
Meta-learning represents a strong class of approaches for solving few-shot learning tasks. Nonetheless, recent research suggests that simply pre-training a generic encoder can potentially surpass meta-learning algorithms. In this paper, we first discuss the reasons why meta-learning fails to stand out in these few-shot learning experiments, and hypothesize that it is due to the few-shot learning tasks lacking diversity. We propose DRESS, a task-agnostic Disentangled REpresentation-based Self-Supervised meta-learning approach that enables fast model adaptation on highly diversified few-shot learning tasks. Specifically, DRESS utilizes disentangled representation learning to create self-supervised tasks that can fuel the meta-training process. Furthermore, we also propose a class-partition based metric for quantifying the task diversity directly on the input space. We validate the effectiveness of DRESS through experiments on datasets with multiple factors of variation and varying complexity. The results suggest that DRESS is able to outperform competing methods on the majority of the datasets and task setups. Through this paper, we advocate for a re-examination of proper setups for task adaptation studies, and aim to reignite interest in the potential of meta-learning for solving few-shot learning tasks via disentangled representations.
元学习是解决小样本学习任务的一类强大方法。然而,最近的研究表明,简单地预训练一个通用编码器就有可能超越元学习算法。在本文中,我们首先讨论了在这些小样本学习实验中元学习未能脱颖而出的原因,并假设这是由于小样本学习任务缺乏多样性所导致的。我们提出了DRESS,这是一种基于任务无关解纠缠表示的自监督元学习方法,能够在高度多样化的小样本学习任务上实现快速模型适应。具体来说,DRESS利用解纠缠表示学习来创建可以推动元训练过程的自监督任务。此外,我们还提出了一种基于类别划分的度量标准,直接在输入空间上衡量任务多样性。我们在具有多种因素变化和不同复杂度的数据集上进行了实验,验证了DRESS的有效性。结果表明,DRESS在大多数数据集和任务设置上能够超越其他方法。本文通过提倡对任务适应研究的适当设置进行重新考察,旨在重新点燃通过解纠缠表示解决小样本学习任务的元学习的潜力。
论文及项目相关链接
PDF 9 pages, 6 figures. An earlier version of the paper has been presented at the Self-Supervised Learning workshop at the 2024 NeurIPS conference
Summary
预训练通用编码器可能超越元学习算法来解决小样本学习任务。本文探讨了元学习在这些任务中表现不佳的原因,假设是因为小样本学习任务缺乏多样性。为此,提出了基于解纠缠表示的元学习方法DRESS,能快速适应多样化的少样本学习任务。通过实验结果验证了DRESS在多个数据集和任务设置上的优越性。
Key Takeaways
- 元学习在小样本学习任务上的表现可能受到任务多样性的限制。
- DRESS是一种基于解纠缠表示的元学习方法,旨在解决少样本学习任务。
- DRESS通过自我监督任务来加速模型的适应过程。
- 提出了一种基于类划分的度量方法,用于直接在输入空间上量化任务多样性。
- DRESS在多个数据集和不同的任务设置上表现出优于其他方法的效果。
- 本文呼吁重新审查任务适应研究的适当设置。
点此查看论文截图

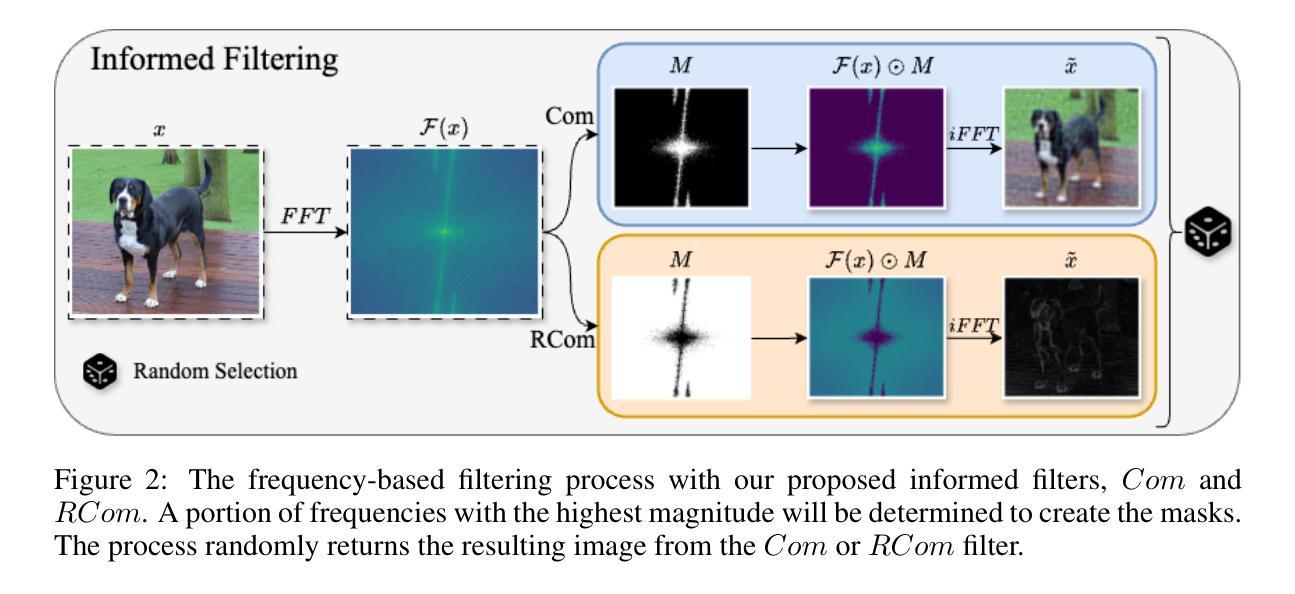
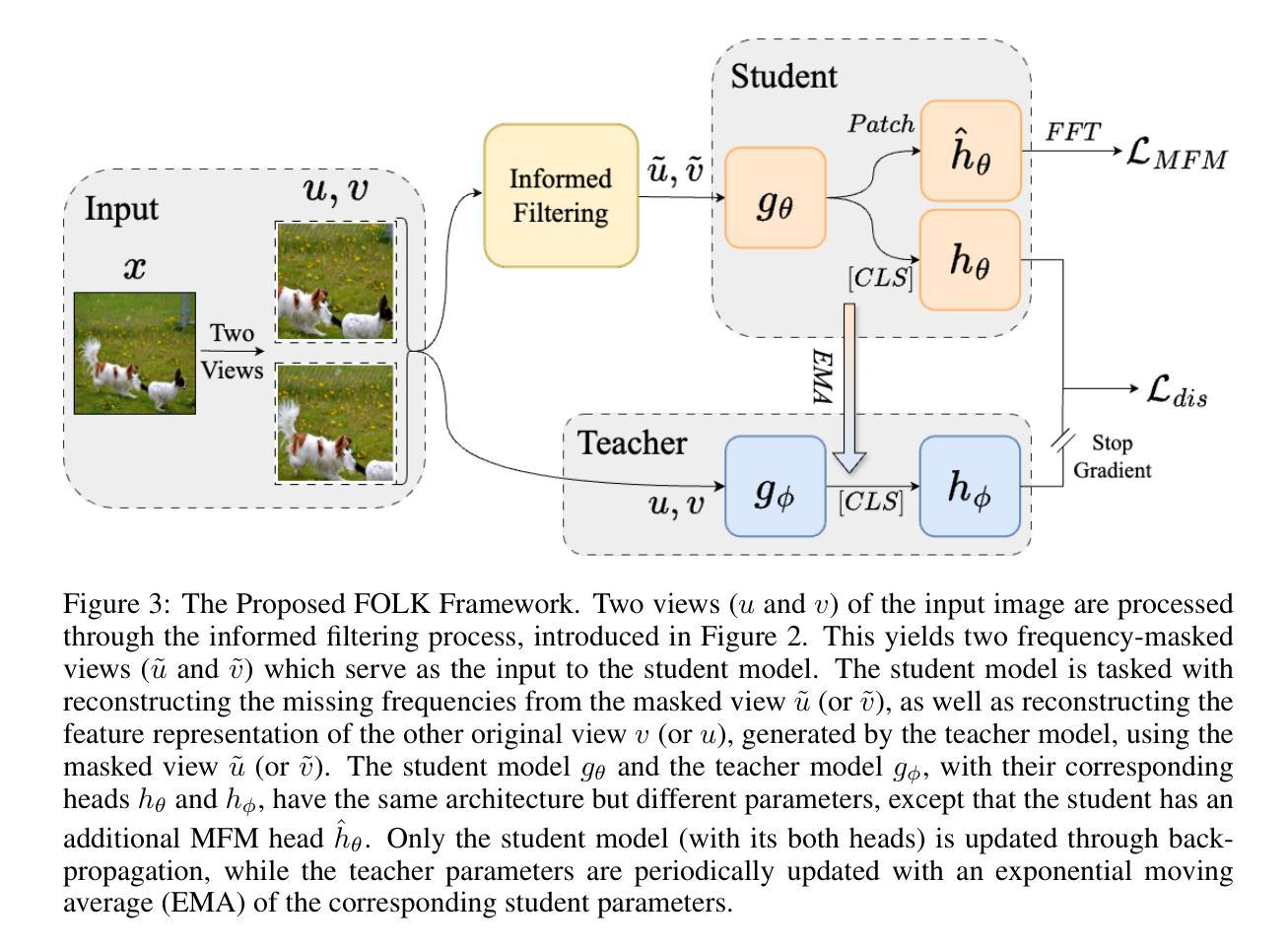
Frequency-Guided Masking for Enhanced Vision Self-Supervised Learning
Authors:Amin Karimi Monsefi, Mengxi Zhou, Nastaran Karimi Monsefi, Ser-Nam Lim, Wei-Lun Chao, Rajiv Ramnath
We present a novel frequency-based Self-Supervised Learning (SSL) approach that significantly enhances its efficacy for pre-training. Prior work in this direction masks out pre-defined frequencies in the input image and employs a reconstruction loss to pre-train the model. While achieving promising results, such an implementation has two fundamental limitations as identified in our paper. First, using pre-defined frequencies overlooks the variability of image frequency responses. Second, pre-trained with frequency-filtered images, the resulting model needs relatively more data to adapt to naturally looking images during fine-tuning. To address these drawbacks, we propose FOurier transform compression with seLf-Knowledge distillation (FOLK), integrating two dedicated ideas. First, inspired by image compression, we adaptively select the masked-out frequencies based on image frequency responses, creating more suitable SSL tasks for pre-training. Second, we employ a two-branch framework empowered by knowledge distillation, enabling the model to take both the filtered and original images as input, largely reducing the burden of downstream tasks. Our experimental results demonstrate the effectiveness of FOLK in achieving competitive performance to many state-of-the-art SSL methods across various downstream tasks, including image classification, few-shot learning, and semantic segmentation.
我们提出了一种基于频率的自监督学习(SSL)新方法,该方法显著提高了预训练的效果。之前的研究方向是在输入图像中掩盖预定义的频率,并采用重建损失来进行模型预训练。虽然取得了有前景的结果,但这种实现存在两个基本局限性,我们在论文中已经指出。首先,使用预定义的频率忽略了图像频率响应的变异性。其次,使用过滤后的频率图像进行预训练,得到的模型在微调时需要相对更多的数据来适应自然图像。为了解决这些缺点,我们提出了结合两种思想的傅里叶变换压缩与自我知识蒸馏(FOLK)。首先,受图像压缩的启发,我们根据图像频率响应自适应地选择掩蔽的频率,为预训练创建更合适的SSL任务。其次,我们采用由知识蒸馏赋能的双分支框架,使模型能够同时处理过滤后的图像和原始图像作为输入,大大减轻了下游任务的负担。我们的实验结果证明,FOLK在与许多最先进的SSL方法在各种下游任务上的竞争表现中,包括图像分类、小样本学习和语义分割,都是有效的。
论文及项目相关链接
Summary
基于频率的自我监督学习(SSL)是一种新型的预训练方法,它显著提高了模型的效果。以往的工作通常会在输入图像中预设频率屏蔽,并使用重建损失进行模型预训练。尽管这种方法取得了一定的成果,但它存在两个主要问题。首先,使用预设频率忽略了图像频率响应的多样性。其次,使用频率过滤的图像进行预训练得到的模型,在微调时适应自然图像所需的数据量相对较大。为了解决这些问题,我们提出了基于傅里叶变换压缩与自我知识蒸馏(FOLK)的方法。我们根据图像频率响应自适应选择屏蔽频率,创建更适用于预训练的SSL任务。同时,我们采用双分支框架和知识蒸馏技术,使模型可以同时处理过滤和原始图像作为输入,大大减轻了下游任务的负担。实验结果表明,FOLK在多个下游任务上实现了与许多最先进的SSL方法相当的性能,包括图像分类、小样本学习和语义分割。
Key Takeaways
- 提出了基于频率的自我监督学习(SSL)预训练方法,以提高模型效果。
- 识别了现有工作使用预设频率屏蔽的两个主要问题:忽略图像频率响应多样性和需要大量数据适应自然图像。
- 提出了FOLK方法来解决上述问题,包括自适应选择屏蔽频率和采用双分支框架和知识蒸馏技术。
- 实验结果表明,FOLK在多个下游任务上实现了与最先进的SSL方法相当的性能。
- 自适应屏蔽频率的方法是根据图像频率响应来选择的,为预训练创建了更合适的SSL任务。
- 双分支框架和知识蒸馏技术使模型能够同时处理过滤和原始图像,减轻了下游任务的负担。
点此查看论文截图


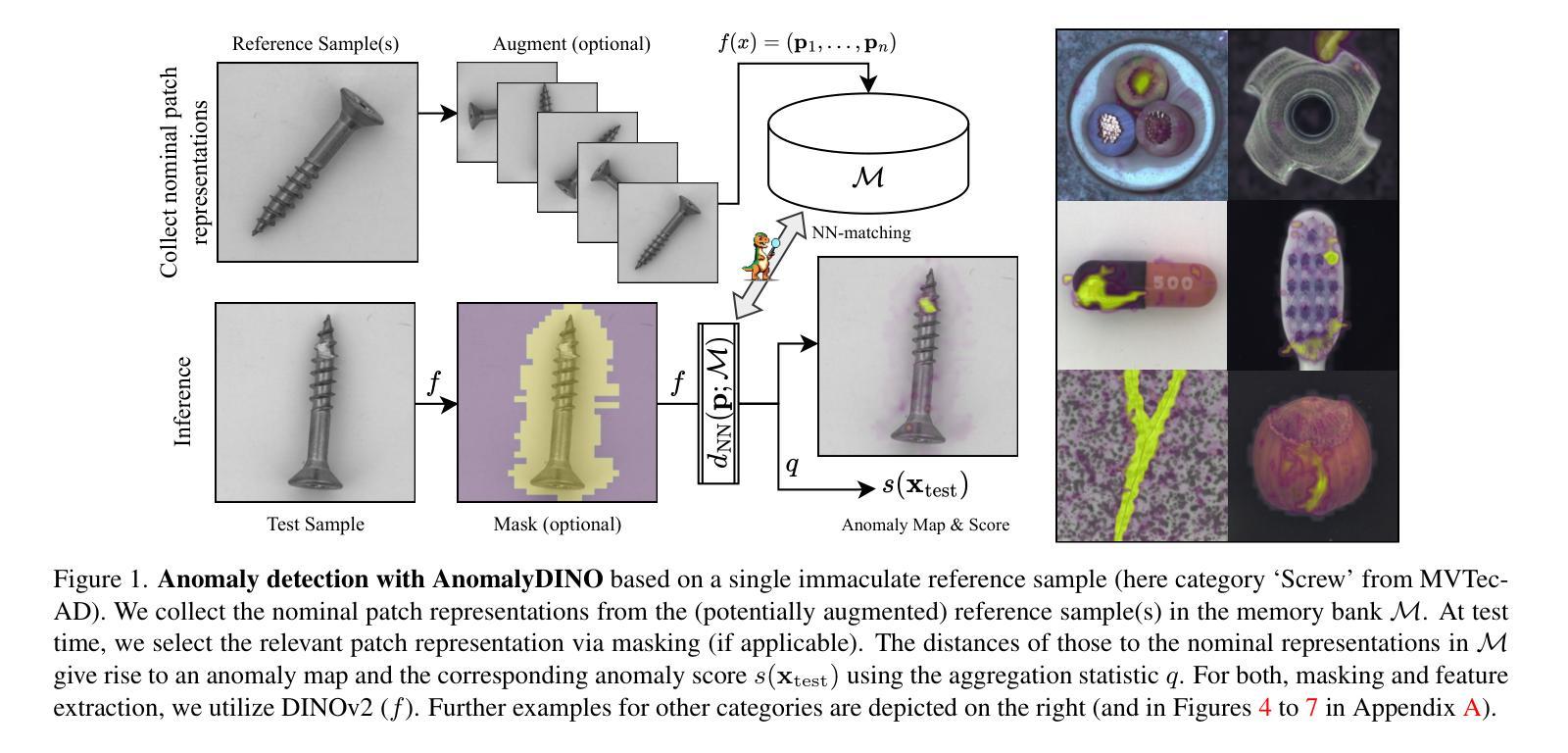
AnomalyDINO: Boosting Patch-based Few-shot Anomaly Detection with DINOv2
Authors:Simon Damm, Mike Laszkiewicz, Johannes Lederer, Asja Fischer
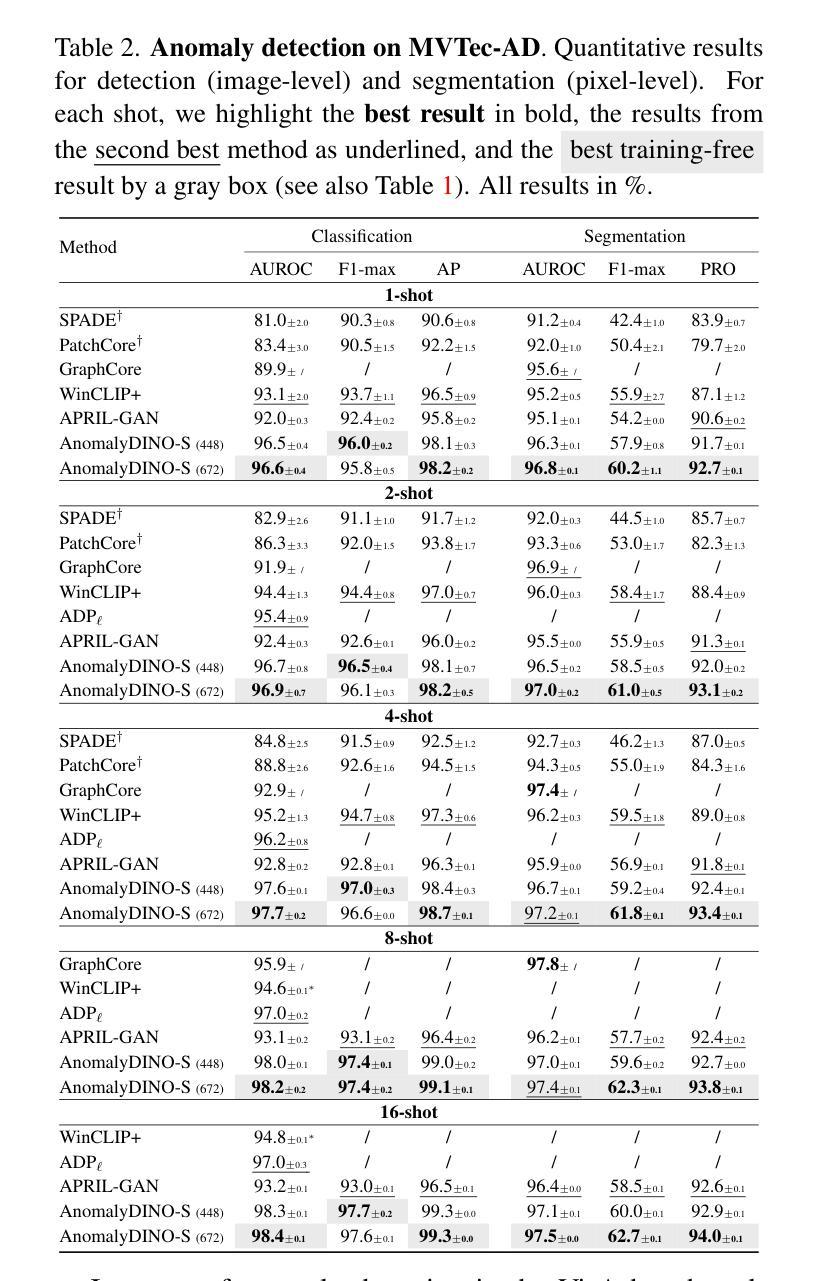
Recent advances in multimodal foundation models have set new standards in few-shot anomaly detection. This paper explores whether high-quality visual features alone are sufficient to rival existing state-of-the-art vision-language models. We affirm this by adapting DINOv2 for one-shot and few-shot anomaly detection, with a focus on industrial applications. We show that this approach does not only rival existing techniques but can even outmatch them in many settings. Our proposed vision-only approach, AnomalyDINO, follows the well-established patch-level deep nearest neighbor paradigm, and enables both image-level anomaly prediction and pixel-level anomaly segmentation. The approach is methodologically simple and training-free and, thus, does not require any additional data for fine-tuning or meta-learning. The approach is methodologically simple and training-free and, thus, does not require any additional data for fine-tuning or meta-learning. Despite its simplicity, AnomalyDINO achieves state-of-the-art results in one- and few-shot anomaly detection (e.g., pushing the one-shot performance on MVTec-AD from an AUROC of 93.1% to 96.6%). The reduced overhead, coupled with its outstanding few-shot performance, makes AnomalyDINO a strong candidate for fast deployment, e.g., in industrial contexts.
近期多模态基础模型的进展为少样本异常检测设定了新的标准。本文通过采用DINOv2进行单样本和少样本异常检测,专注于工业应用,探究高质量视觉特征是否足以与现有的最先进的视觉语言模型相抗衡。我们展示这种方法不仅与现有技术不相上下,而且在许多场景下甚至能够超越它们。我们提出的仅使用视觉的方法AnomalyDINO,遵循了成熟的补丁级别深度最近邻范式,能够实现图像级别异常预测和像素级别异常分割。该方法方法简单且无需训练,因此不需要任何额外数据进行微调或元学习。尽管方法简单,AnomalyDINO在单样本和少样本异常检测方面达到了最新水平的结果(例如,在MVTec-AD上将单样本检测的AUROC从93.1%提高到96.6%)。其减少的开销以及出色的少样本性能,使AnomalyDINO成为快速部署的强有力候选者,例如在工业环境中。
论文及项目相关链接
PDF Accepted at WACV 2025 (Oral)
Summary
本文探索了仅使用高质量视觉特征是否足以与现有的最先进的视觉语言模型相竞争,在少样本异常检测方面。通过适应DINOv2进行单样本和少样本异常检测,重点研究其在工业应用中的表现。实验结果表明,该方法不仅与现有技术相竞争,而且在许多设置中甚至超过了它们。本文提出的仅使用视觉的方法AnomalyDINO,遵循了成熟的补丁级别深度最近邻范式,能够进行图像级别的异常预测和像素级别的异常分割。该方法方法简单且无需训练,因此不需要任何额外的数据进行微调或元学习。尽管简单,AnomalyDINO在单样本和少样本异常检测方面达到了最新水平的结果。
Key Takeaways
- 多模态基础模型的最新进展为少样本异常检测设立了新标准。
- 高质量视觉特征在异常检测中的重要作用被强调。
- 通过适应DINOv2进行单样本和少样本异常检测,展示了视觉语言模型的强大竞争力。
- AnomalyDINO方法结合了现有的深度最近邻范式进行异常预测和分割。
- AnomalyDINO具有方法简单、无需训练的优势,省去了额外数据的需求。
- AnomalyDINO在一项工业应用中的快速部署具有潜力。
点此查看论文截图