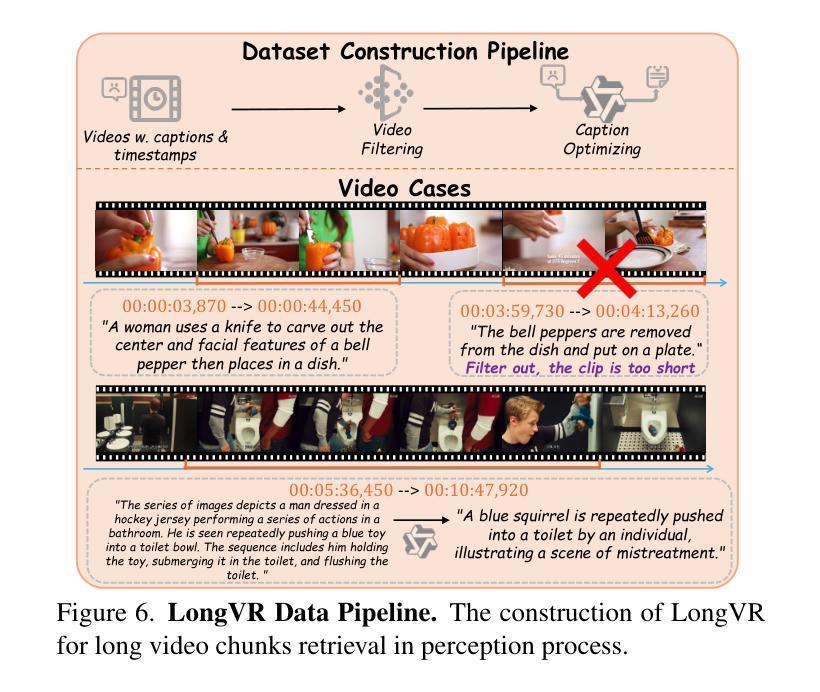
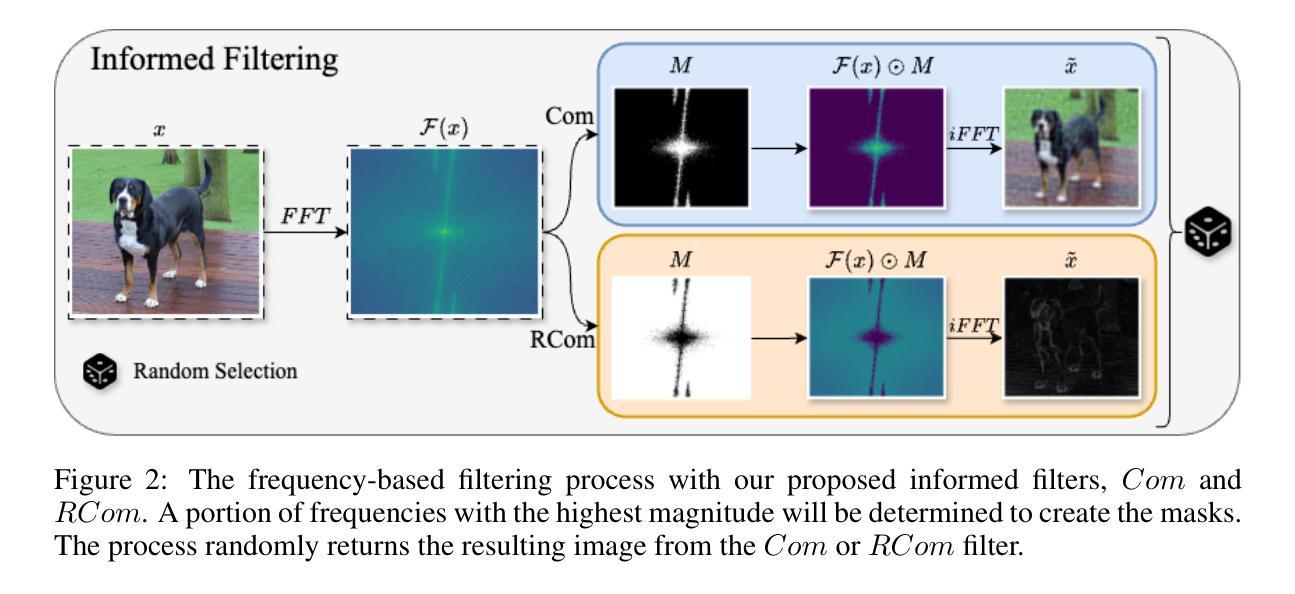
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
KUDA: Keypoints to Unify Dynamics Learning and Visual Prompting for Open-Vocabulary Robotic Manipulation
Authors:Zixian Liu, Mingtong Zhang, Yunzhu Li
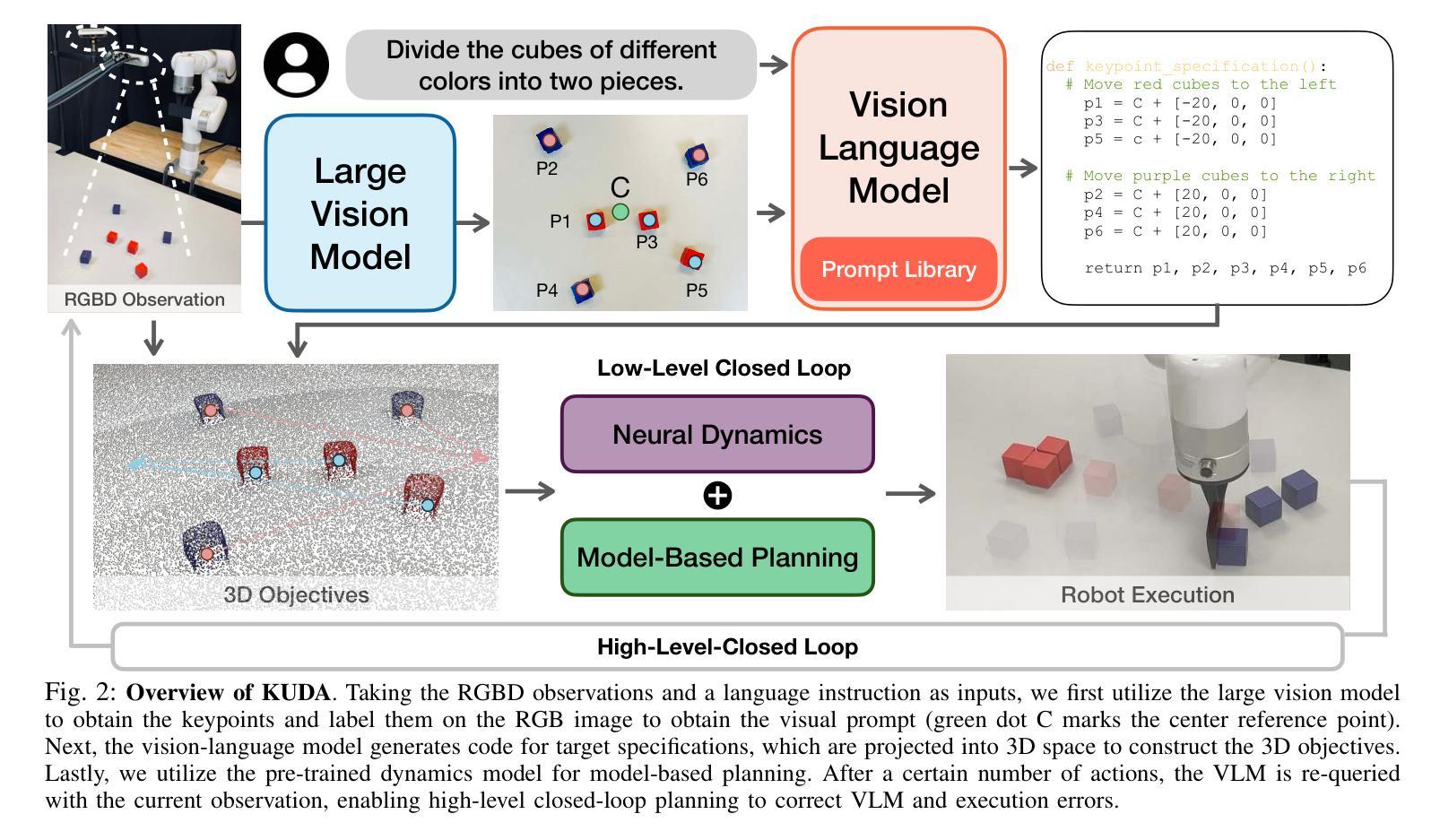
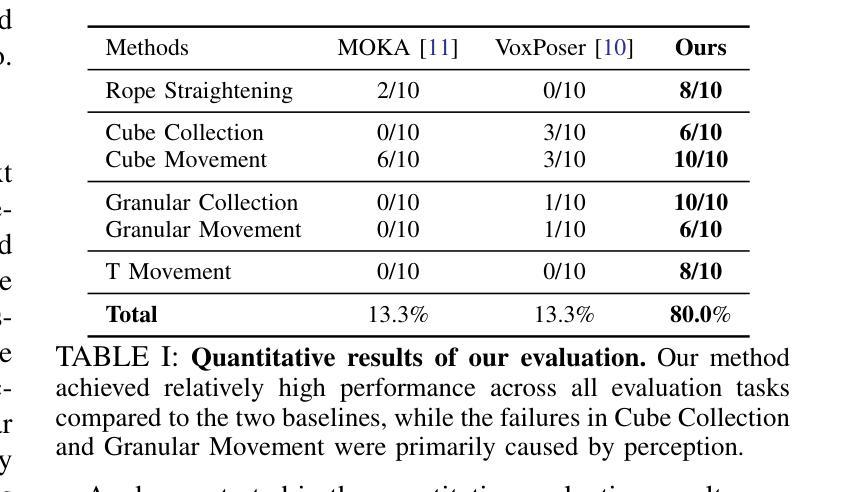
With the rapid advancement of large language models (LLMs) and vision-language models (VLMs), significant progress has been made in developing open-vocabulary robotic manipulation systems. However, many existing approaches overlook the importance of object dynamics, limiting their applicability to more complex, dynamic tasks. In this work, we introduce KUDA, an open-vocabulary manipulation system that integrates dynamics learning and visual prompting through keypoints, leveraging both VLMs and learning-based neural dynamics models. Our key insight is that a keypoint-based target specification is simultaneously interpretable by VLMs and can be efficiently translated into cost functions for model-based planning. Given language instructions and visual observations, KUDA first assigns keypoints to the RGB image and queries the VLM to generate target specifications. These abstract keypoint-based representations are then converted into cost functions, which are optimized using a learned dynamics model to produce robotic trajectories. We evaluate KUDA on a range of manipulation tasks, including free-form language instructions across diverse object categories, multi-object interactions, and deformable or granular objects, demonstrating the effectiveness of our framework. The project page is available at http://kuda-dynamics.github.io.
随着大型语言模型(LLM)和视觉语言模型(VLM)的快速发展,开放词汇机器人操纵系统在开发方面取得了重大进展。然而,许多现有方法忽视了物体动力学的重要性,限制了它们在更复杂、动态的任务中的应用。在这项工作中,我们介绍了KUDA,这是一个开放词汇的操纵系统,它通过关键点整合动力学学习和视觉提示,利用VLM和基于学习的神经动力学模型。我们的关键见解是,基于关键点的目标规格可以同时被VLM解释,并能有效地转化为基于模型的规划的成本函数。给定语言指令和视觉观察,KUDA首先为RGB图像分配关键点,并查询VLM以生成目标规格。这些抽象的基于关键点的表示然后被转换成成本函数,使用学习到的动力学模型进行优化,以产生机器人轨迹。我们在各种操作任务上评估了KUDA,包括跨不同对象类别的自由形式语言指令、多对象交互以及可变形或颗粒状物体,证明了我们的框架的有效性。项目页面可在http://kuda-dynamics.github.io查看。
论文及项目相关链接
PDF Project website: http://kuda-dynamics.github.io
Summary
基于大型语言模型(LLM)和视觉语言模型(VLM)的快速发展,开放词汇机器人操作系统在开发方面取得了显著进展。然而,许多现有方法忽视了物体动力学的重要性,限制了它们在更复杂、动态的任务中的应用。本研究介绍了KUDA,一个集成动力学学习和视觉提示的关键点开放词汇操作体系,它利用VLM和学习型神经动力学模型。我们的关键见解是,基于关键点的目标规格可以同时被VLM解读,并能有效地转化为基于模型的规划的成本函数。给定语言指令和视觉观察,KUDA首先将关键点分配给RGB图像并查询VLM以生成目标规格。这些抽象的基于关键点的表示然后被转换成成本函数,使用学习到的动力学模型进行优化以产生机器人轨迹。我们在一系列操作任务上评估了KUDA的有效性,包括跨不同对象类别的自由形式语言指令、多对象交互以及可变形或颗粒状对象。
Key Takeaways
- 大型语言模型和视觉语言模型的进步推动了开放词汇机器人操作系统的发展。
- 现有方法忽略了物体动力学,限制了其在复杂、动态任务中的应用。
- KUDA是一个开放词汇操作体系,集成了动力学学习和视觉提示。
- KUDA利用VLM和学习型神经动力学模型,通过关键点进行目标规格解读和成本函数转化。
- KUDA将语言指令和视觉观察结合,通过分配关键点生成目标规格。
- 基于关键点的表示被转换成成本函数,优化后产生机器人轨迹。
点此查看论文截图



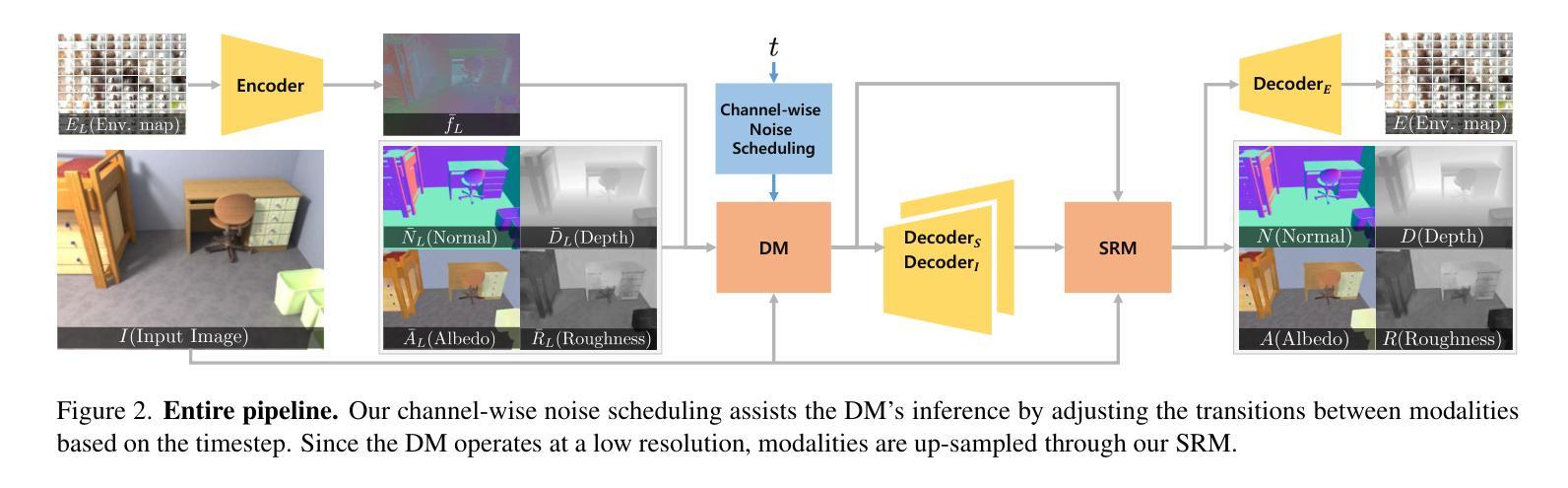
Channel-wise Noise Scheduled Diffusion for Inverse Rendering in Indoor Scenes
Authors:JunYong Choi, Min-Cheol Sagong, SeokYeong Lee, Seung-Won Jung, Ig-Jae Kim, Junghyun Cho
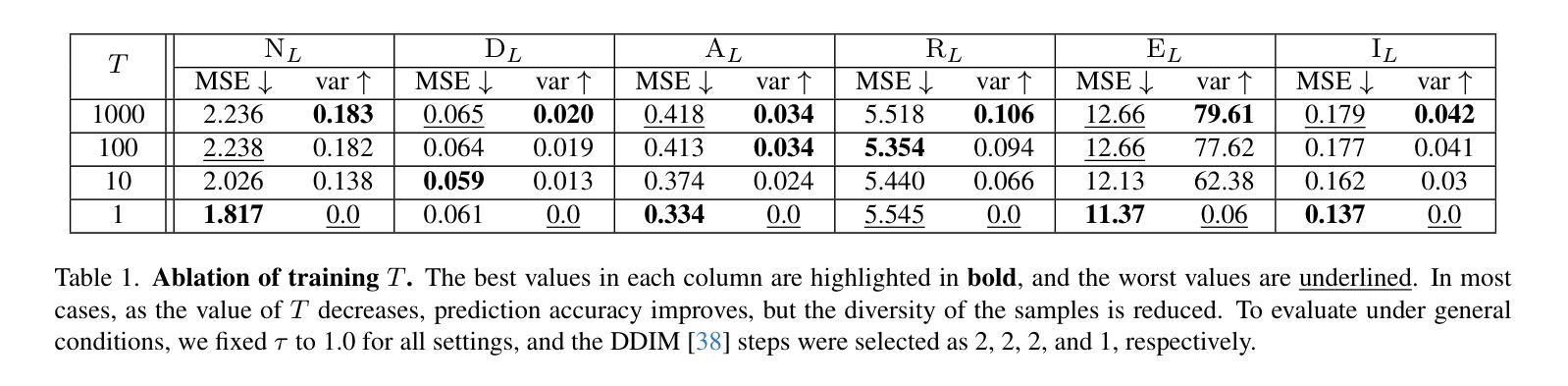
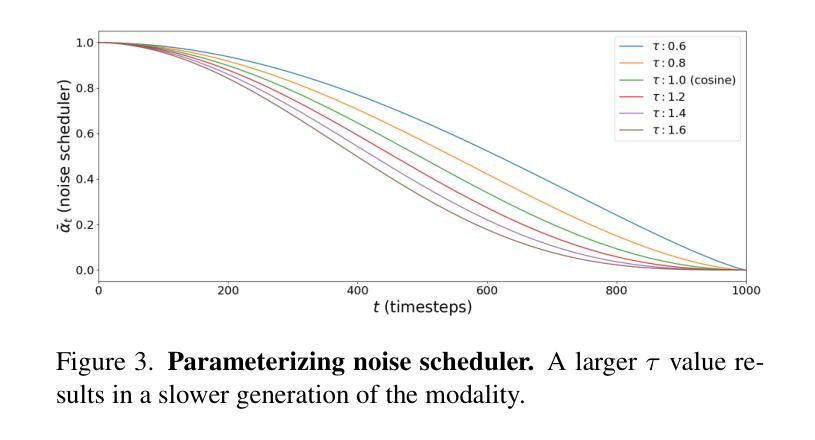
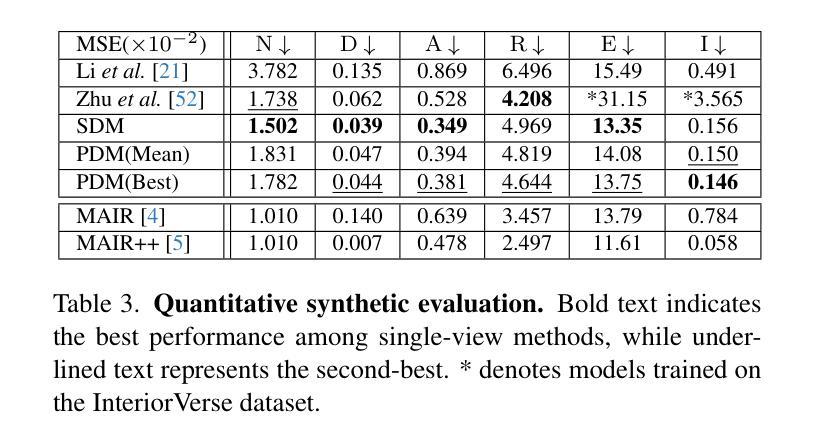
We propose a diffusion-based inverse rendering framework that decomposes a single RGB image into geometry, material, and lighting. Inverse rendering is inherently ill-posed, making it difficult to predict a single accurate solution. To address this challenge, recent generative model-based methods aim to present a range of possible solutions. However, finding a single accurate solution and generating diverse solutions can be conflicting. In this paper, we propose a channel-wise noise scheduling approach that allows a single diffusion model architecture to achieve two conflicting objectives. The resulting two diffusion models, trained with different channel-wise noise schedules, can predict a single highly accurate solution and present multiple possible solutions. The experimental results demonstrate the superiority of our two models in terms of both diversity and accuracy, which translates to enhanced performance in downstream applications such as object insertion and material editing.
我们提出了一种基于扩散的逆向渲染框架,该框架能够将单个RGB图像分解为几何、材质和光照。逆向渲染本质上是适定性问题,因此很难预测单个准确解。为了应对这一挑战,最近基于生成模型的方法旨在提出一系列可能的解决方案。然而,找到单个准确解和生成多种解决方案可能是矛盾的。在本文中,我们提出了一种通道噪声调度方法,允许单个扩散模型架构实现两个相互矛盾的目标。通过训练使用不同通道噪声调度的两个扩散模型,可以预测单个高度准确的解决方案并呈现多种可能的解决方案。实验结果表明,我们的两个模型在多样性和准确性方面都表现出卓越的性能,这转化为下游应用如对象插入和材料编辑的增强性能。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文提出了一种基于扩散的逆向渲染框架,该框架能够将单一RGB图像分解为几何、材质和光照。逆向渲染本质上是病态的,难以预测单一准确解。本文提出了一种通道噪声调度方法,允许单一扩散模型同时实现两个冲突目标:预测单一高度准确的解决方案并提供多种可能的解决方案。实验结果表明,这两种模型在多样性和准确性方面都表现出卓越性能,为下游应用如对象插入和材料编辑等提供了增强性能。
Key Takeaways
- 提出了一种基于扩散的逆向渲染框架,能够分解RGB图像为几何、材质和光照。
- 逆向渲染是病态的,难以获得单一准确解,近期基于生成模型的方法旨在提供一系列可能的解决方案。
- 通道噪声调度方法允许单一扩散模型同时实现两个冲突目标:预测高度准确的单一解和提供多种解决方案。
- 训练两种扩散模型,使用不同的通道噪声调度,以提高多样性和准确性。
- 实验结果表明,这两种模型在性能上优于传统方法。
- 该方法有助于下游应用如对象插入和材料编辑等。
点此查看论文截图