⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
Flow-NeRF: Joint Learning of Geometry, Poses, and Dense Flow within Unified Neural Representations
Authors:Xunzhi Zheng, Dan Xu
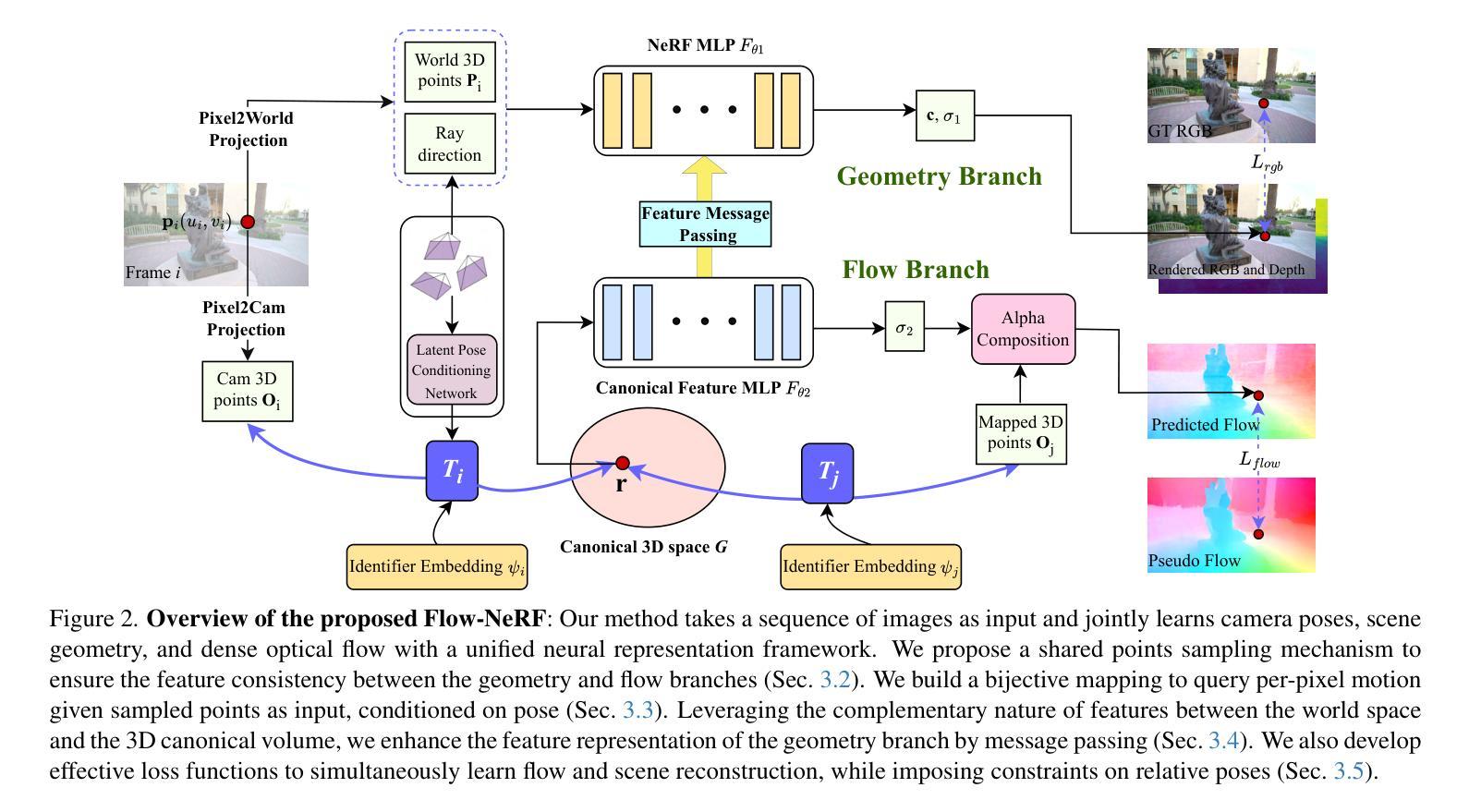
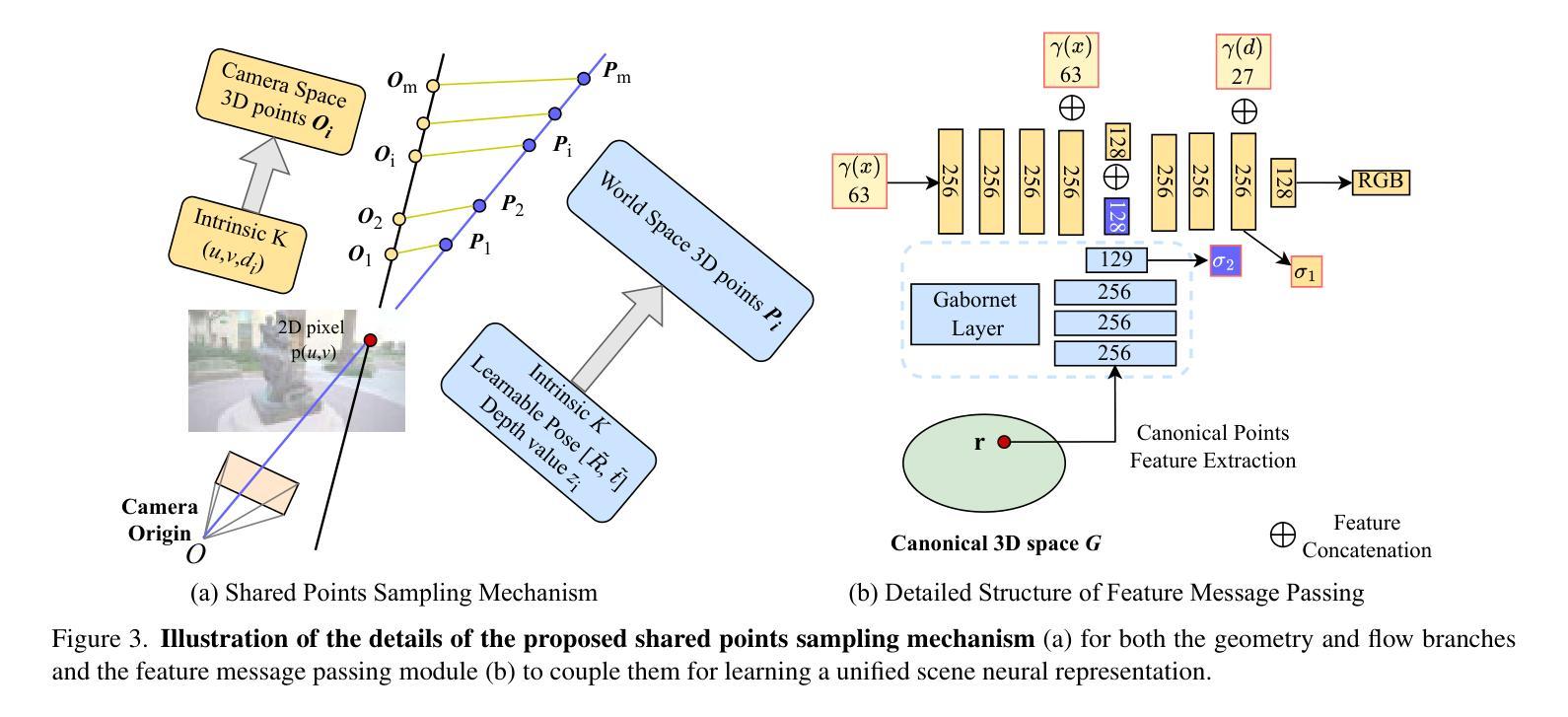
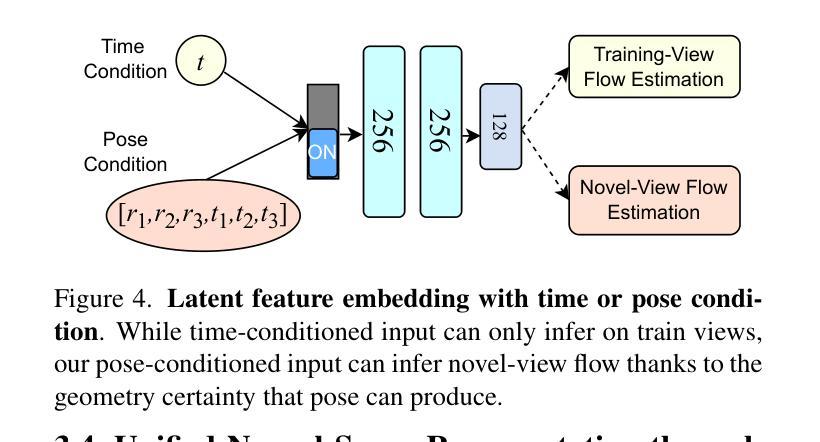
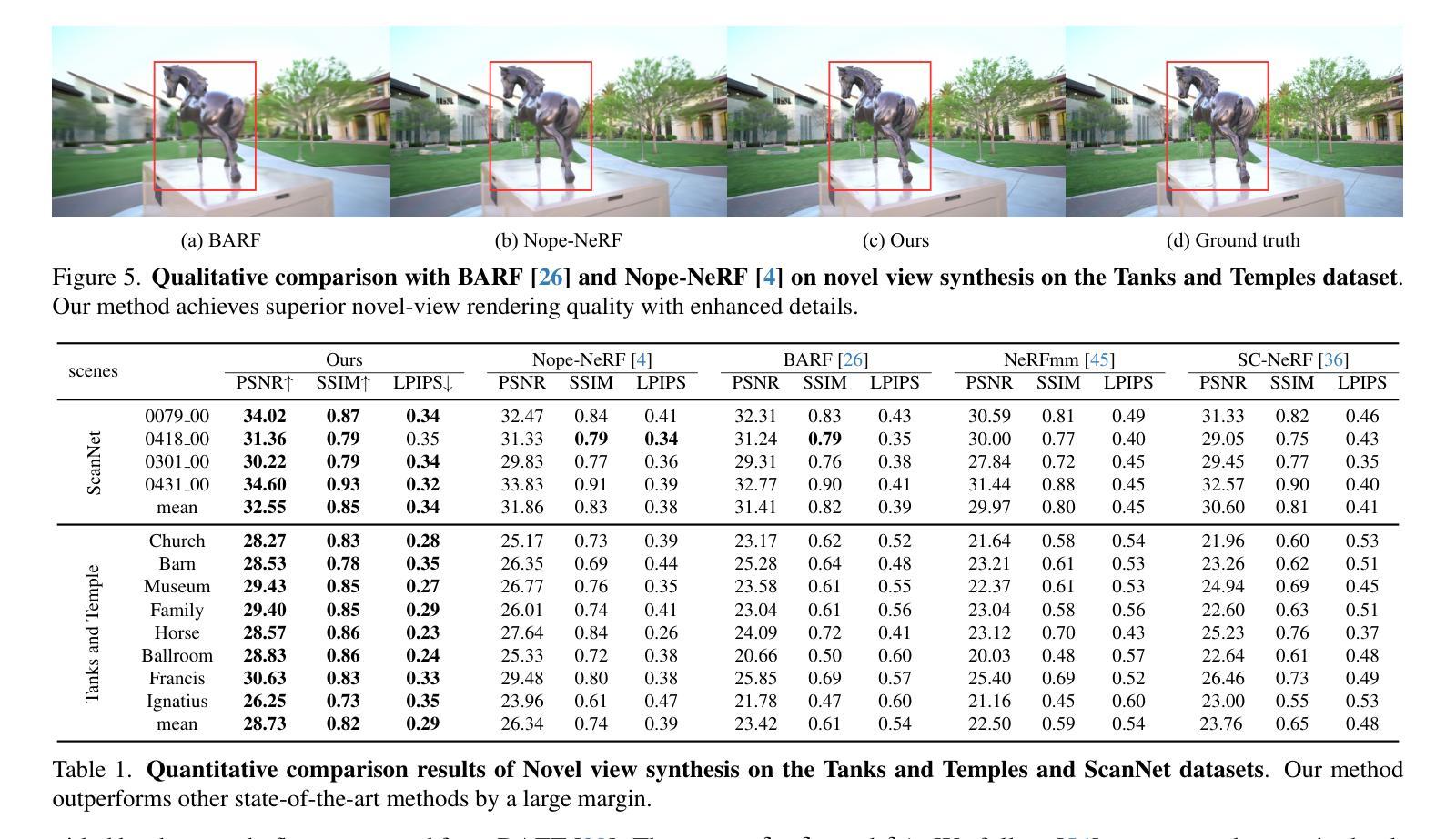
Learning accurate scene reconstruction without pose priors in neural radiance fields is challenging due to inherent geometric ambiguity. Recent development either relies on correspondence priors for regularization or uses off-the-shelf flow estimators to derive analytical poses. However, the potential for jointly learning scene geometry, camera poses, and dense flow within a unified neural representation remains largely unexplored. In this paper, we present Flow-NeRF, a unified framework that simultaneously optimizes scene geometry, camera poses, and dense optical flow all on-the-fly. To enable the learning of dense flow within the neural radiance field, we design and build a bijective mapping for flow estimation, conditioned on pose. To make the scene reconstruction benefit from the flow estimation, we develop an effective feature enhancement mechanism to pass canonical space features to world space representations, significantly enhancing scene geometry. We validate our model across four important tasks, i.e., novel view synthesis, depth estimation, camera pose prediction, and dense optical flow estimation, using several datasets. Our approach surpasses previous methods in almost all metrics for novel-view view synthesis and depth estimation and yields both qualitatively sound and quantitatively accurate novel-view flow. Our project page is https://zhengxunzhi.github.io/flownerf/.
在神经辐射场(NeRF)中,没有姿态先验(pose priors)学习精确的场景重建具有挑战性,因为存在固有的几何模糊性。最近的研究要么依赖于对应先验进行正则化,要么使用现成的流量估计器来推导分析姿态。然而,在统一的神经网络表示中联合学习场景几何、相机姿态和密集流量的潜力尚未得到广泛探索。在本文中,我们提出了Flow-NeRF框架,该框架可实时优化场景几何、相机姿态和密集光流。为了在神经辐射场内学习密集流量,我们设计并实现了一种基于姿态的流量估计双向映射。为了使场景重建受益于流量估计,我们开发了一种有效的特征增强机制,将规范空间特征传递给世界空间表示,从而大大提高了场景几何。我们在四个重要任务上验证了我们的模型,即新视角合成、深度估计、相机姿态预测和密集光流估计,使用了几个数据集。我们的方法在几乎所有指标上都超越了以前的方法,用于新视角合成和深度估计,并在质量和数量上都准确的新视角光流。我们的项目页面是https://zhengxunzhi.github.io/flownerf/。
论文及项目相关链接
Summary
本文提出了一种名为Flow-NeRF的统一框架,能够同时优化场景几何、相机姿态和密集光流。通过设计基于姿态条件的密集光流映射,Flow-NeRF在神经辐射场中实现了光流学习。此外,为提高场景重建质量,开发了一种有效的特征增强机制,将规范空间特征传递给世界空间表示。经过四项重要任务验证,Flow-NeRF在新型视图合成、深度估计、相机姿态预测和密集光流估计方面均超越先前方法。
Key Takeaways
- Flow-NeRF是一个统一框架,能同时优化场景几何、相机姿态和密集光流。
- 通过设计基于姿态条件的映射,实现了在神经辐射场中的密集光流学习。
- 引入特征增强机制,将规范空间特征传递至世界空间表示,提升场景几何质量。
- 验证了Flow-NeRF在新型视图合成、深度估计、相机姿态预测和密集光流估计方面的表现。
- Flow-NeRF在多数指标上超越先前方法,尤其在新型视图合成和深度估计方面。
- 该方法不仅定性上健全,而且在定量上准确。
点此查看论文截图

SplatAD: Real-Time Lidar and Camera Rendering with 3D Gaussian Splatting for Autonomous Driving
Authors:Georg Hess, Carl Lindström, Maryam Fatemi, Christoffer Petersson, Lennart Svensson
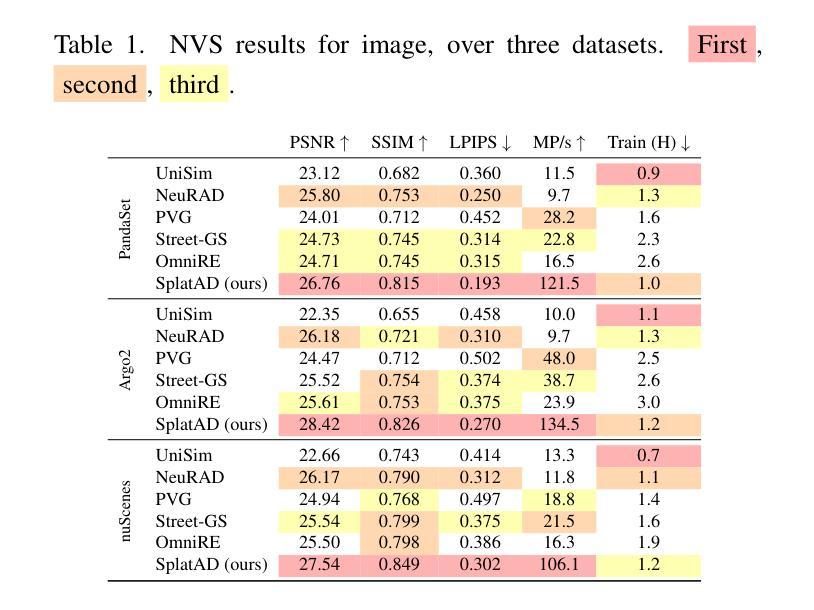
Ensuring the safety of autonomous robots, such as self-driving vehicles, requires extensive testing across diverse driving scenarios. Simulation is a key ingredient for conducting such testing in a cost-effective and scalable way. Neural rendering methods have gained popularity, as they can build simulation environments from collected logs in a data-driven manner. However, existing neural radiance field (NeRF) methods for sensor-realistic rendering of camera and lidar data suffer from low rendering speeds, limiting their applicability for large-scale testing. While 3D Gaussian Splatting (3DGS) enables real-time rendering, current methods are limited to camera data and are unable to render lidar data essential for autonomous driving. To address these limitations, we propose SplatAD, the first 3DGS-based method for realistic, real-time rendering of dynamic scenes for both camera and lidar data. SplatAD accurately models key sensor-specific phenomena such as rolling shutter effects, lidar intensity, and lidar ray dropouts, using purpose-built algorithms to optimize rendering efficiency. Evaluation across three autonomous driving datasets demonstrates that SplatAD achieves state-of-the-art rendering quality with up to +2 PSNR for NVS and +3 PSNR for reconstruction while increasing rendering speed over NeRF-based methods by an order of magnitude. See https://research.zenseact.com/publications/splatad/ for our project page.
确保自主机器人(如自动驾驶汽车)的安全,需要在各种驾驶场景中进行广泛的测试。仿真是一种既经济又可扩展的用于进行此类测试的关键手段。神经渲染方法因其能够以数据驱动的方式从收集的日志中构建仿真环境而受到欢迎。然而,现有的用于相机和激光雷达数据传感器真实渲染的神经辐射场(NeRF)方法存在渲染速度低的问题,限制了其在大规模测试中的应用。虽然3D高斯拼贴(3DGS)可以实现实时渲染,但当前的方法仅限于相机数据,无法渲染对自动驾驶至关重要的激光雷达数据。为了解决这些限制,我们提出了SplatAD,这是基于3DGS的第一种用于相机和激光雷达数据的动态场景真实实时渲染方法。SplatAD使用专门构建的算法准确建模关键传感器特定现象,如滚动快门效应、激光雷达强度和激光雷达射线丢失,以优化渲染效率。在三个自动驾驶数据集上的评估表明,SplatAD实现了最先进的渲染质量,在NVS上提高了+2 PSNR,在重建上提高了+3 PSNR,同时比基于NeRF的方法提高了一个数量级的渲染速度。有关我们的项目页面,请参见https://research.zenseact.com/publications/splatad/。
论文及项目相关链接
Summary
为确保自主机器人(如自动驾驶车辆)的安全,需要在各种驾驶场景中进行广泛的测试。仿真是一种既经济又可扩展的测试方式。神经渲染方法因其能以数据驱动的方式从收集的日志中构建仿真环境而受到欢迎。然而,现有的神经辐射场(NeRF)方法在渲染相机和激光雷达数据时,存在渲染速度慢的问题,限制了其大规模测试的应用。虽然3D高斯贴图(3DGS)能够实现实时渲染,但当前方法仅限于相机数据,无法渲染对自动驾驶至关重要的激光雷达数据。为解决这些限制,我们提出SplatAD,这是基于3DGS的首个对相机和激光雷达数据的真实实时动态场景渲染方法。SplatAD准确模拟了关键传感器特定现象,如滚动快门效应、激光雷达强度和激光雷达射线丢失,并使用专用算法优化渲染效率。在三个自动驾驶数据集上的评估表明,SplatAD达到最先进的渲染质量,在NVS上提高了+2 PSNR,在重建上提高了+3 PSNR,同时较NeRF方法提高了渲染速度一个数量级。详情参见我们的项目页面:https://research.zenseact.com/publications/splatad/。
Key Takeaways
- 自主机器人的安全测试需要大量仿真场景以覆盖多种驾驶情况。
- 神经渲染方法在创建逼真的仿真环境中展现出优势。
- 现有的NeRF方法在渲染相机和激光雷达数据时存在速度瓶颈。
- 3DGS可以实现实时渲染但仅限于相机数据。
- SplatAD是第一种可以同时对相机和激光雷达数据进行真实实时渲染的方法。
- SplatAD能够模拟传感器特定现象如滚动快门效应和激光雷达射线丢失。
点此查看论文截图