⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
Whisper Speaker Identification: Leveraging Pre-Trained Multilingual Transformers for Robust Speaker Embeddings
Authors:Jakaria Islam Emon, Md Abu Salek, Kazi Tamanna Alam
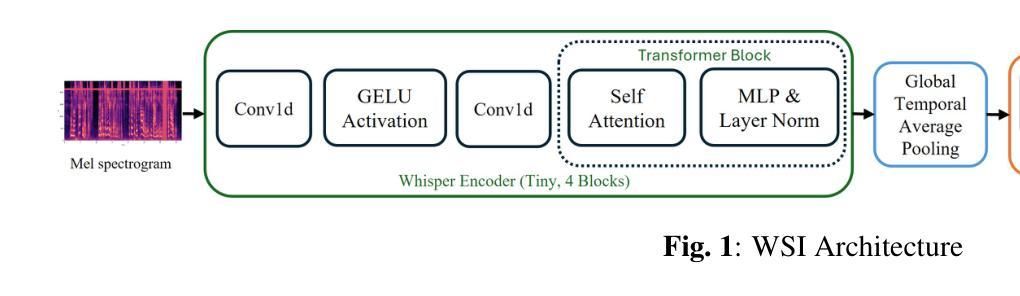
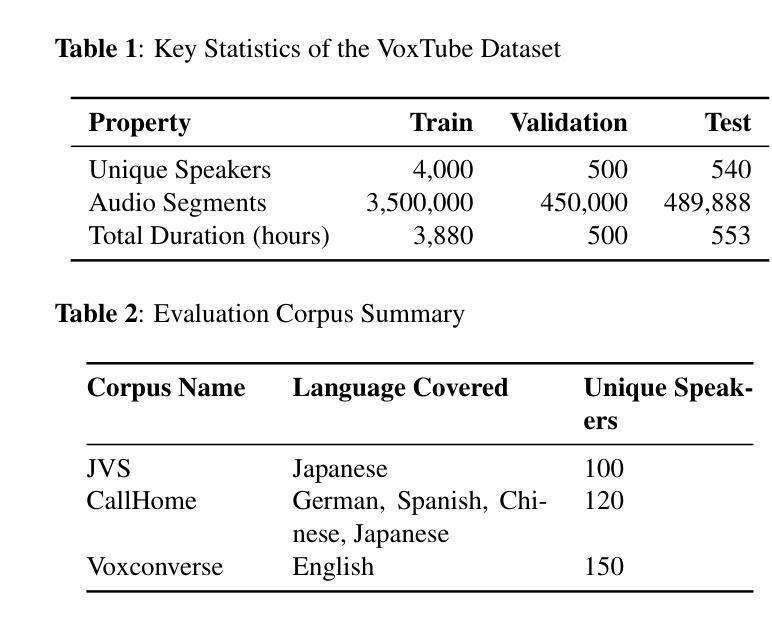
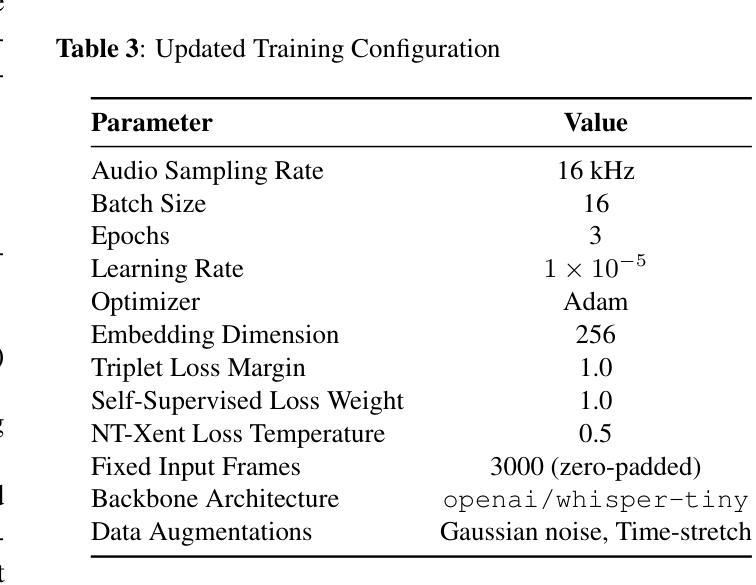
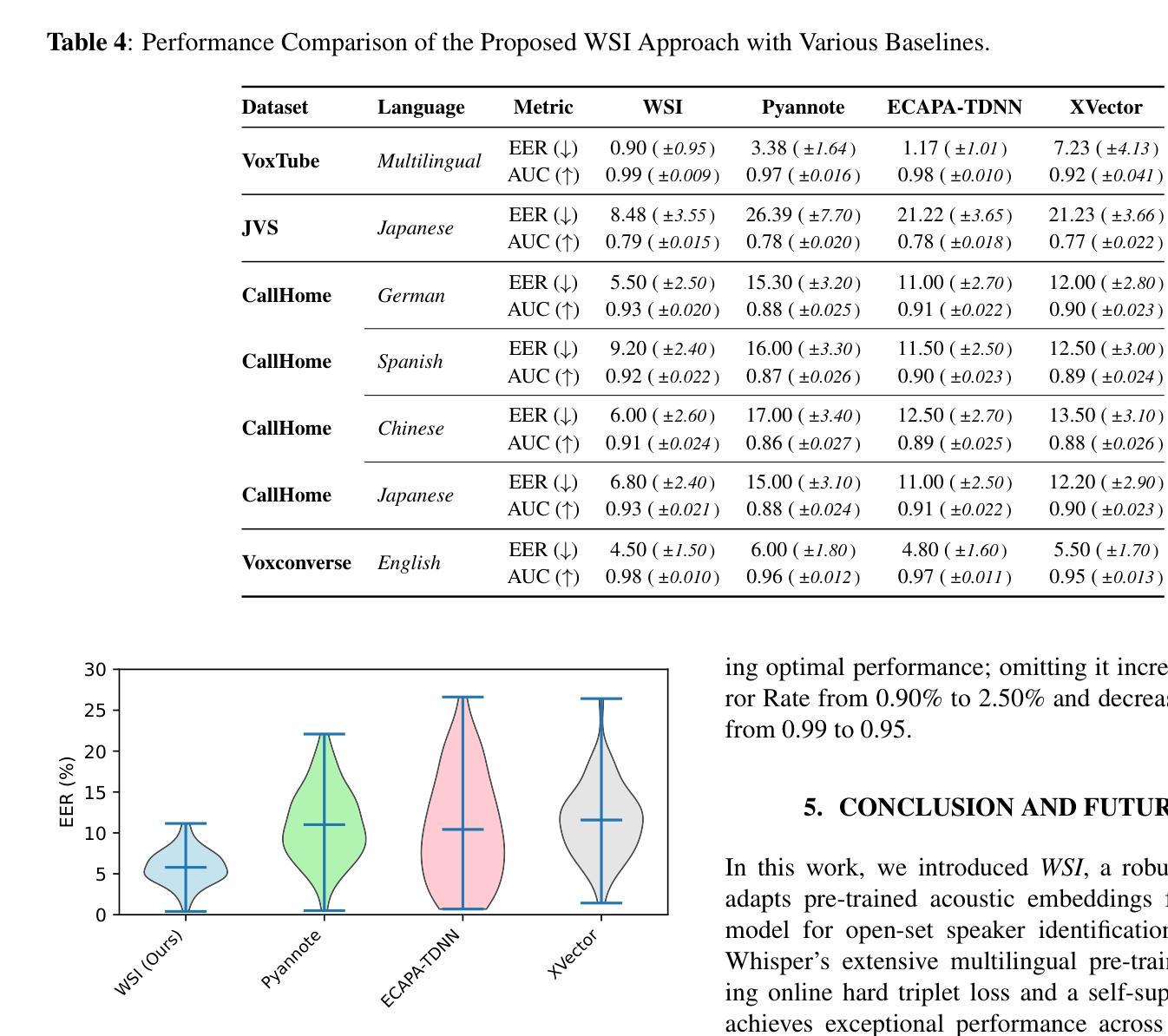
Speaker identification in multilingual settings presents unique challenges, particularly when conventional models are predominantly trained on English data. In this paper, we propose WSI (Whisper Speaker Identification), a framework that repurposes the encoder of the Whisper automatic speech recognition model pre trained on extensive multilingual data to generate robust speaker embeddings via a joint loss optimization strategy that leverages online hard triplet mining and self supervised Normalized Temperature-scaled Cross Entropy loss. By capitalizing on Whisper language-agnostic acoustic representations, our approach effectively distinguishes speakers across diverse languages and recording conditions. Extensive evaluations on multiple corpora, including VoxTube (multilingual), JVS (Japanese), CallHome (German, Spanish, Chinese, and Japanese), and Voxconverse (English), demonstrate that WSI consistently outperforms state-of-the-art baselines, namely Pyannote Embedding, ECAPA TDNN, and Xvector, in terms of lower equal error rates and higher AUC scores. These results validate our hypothesis that a multilingual pre-trained ASR encoder, combined with joint loss optimization, substantially improves speaker identification performance in non-English languages.
在多语言环境中进行说话人识别面临着独特的挑战,尤其是在使用主要基于英语数据训练的常规模型时。在本文中,我们提出了WSI(Whisper说话人识别),这是一个利用Whisper自动语音识别模型的编码器进行改造的框架,该编码器在大量多语言数据上进行预训练,通过联合损失优化策略生成稳健的说话人嵌入,该策略利用在线硬三元组挖掘和自监督的归一化温度比例交叉熵损失。通过利用Whisper的语言无关声音表示,我们的方法能够有效地区分不同语言和录制条件下的说话人。在多个语料库上的广泛评估,包括VoxTube(多语言)、JVS(日语)、CallHome(德语、西班牙语、中文和日语)和Voxconverse(英语),证明WSI在平等错误率和AUC分数方面始终优于最新基线技术,即Pyannote嵌入、ECAPA TDNN和Xvector。这些结果验证了我们的假设,即多语言预训练的ASR编码器与联合损失优化相结合,可以大大提高非英语语言的说话人识别性能。
论文及项目相关链接
PDF 6 pages
Summary
本文提出了WSI(Whisper语音识别系统)框架,用于多语种环境下的说话人识别。该框架利用预训练于多语种数据的Whisper自动语音识别模型的编码器生成稳健的说话人嵌入,通过联合损失优化策略,结合在线硬三元组挖掘和自我监督的归一化温度尺度交叉熵损失,有效区分不同语言和录音条件下的说话人。在多个语料库上的评估表明,WSI在平等错误率和AUC得分方面均优于基线模型,如Pyannote嵌入、ECAPA TDNN和Xvector等最新技术。这验证了本文的假设:结合多语种预训练的ASR编码器和联合损失优化策略,可以显著提高非英语语言的说话人识别性能。
Key Takeaways
- WSI框架利用预训练的Whisper自动语音识别模型的编码器进行说话人识别。
- 该框架在多语种环境下表现出色,能有效区分不同语言和录音条件下的说话人。
- WSI采用联合损失优化策略,包括在线硬三元组挖掘和自我监督的归一化温度尺度交叉熵损失。
- 相较于其他基线模型,WSI在多个语料库上的评估结果表现更佳,体现在更低的平等错误率和更高的AUC得分。
点此查看论文截图


HSEmotion Team at ABAW-8 Competition: Audiovisual Ambivalence/Hesitancy, Emotional Mimicry Intensity and Facial Expression Recognition
Authors:Andrey V. Savchenko
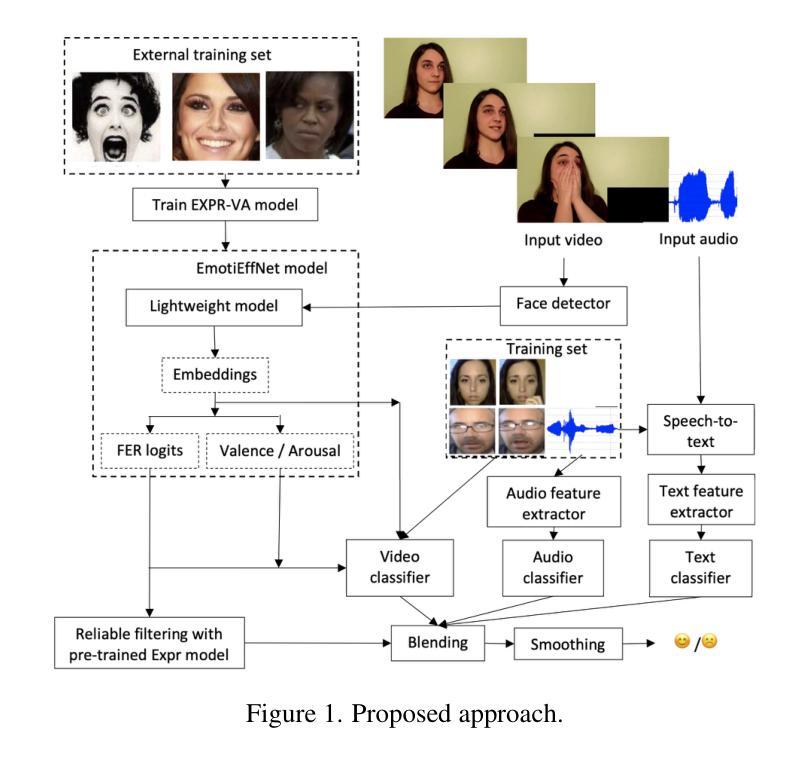
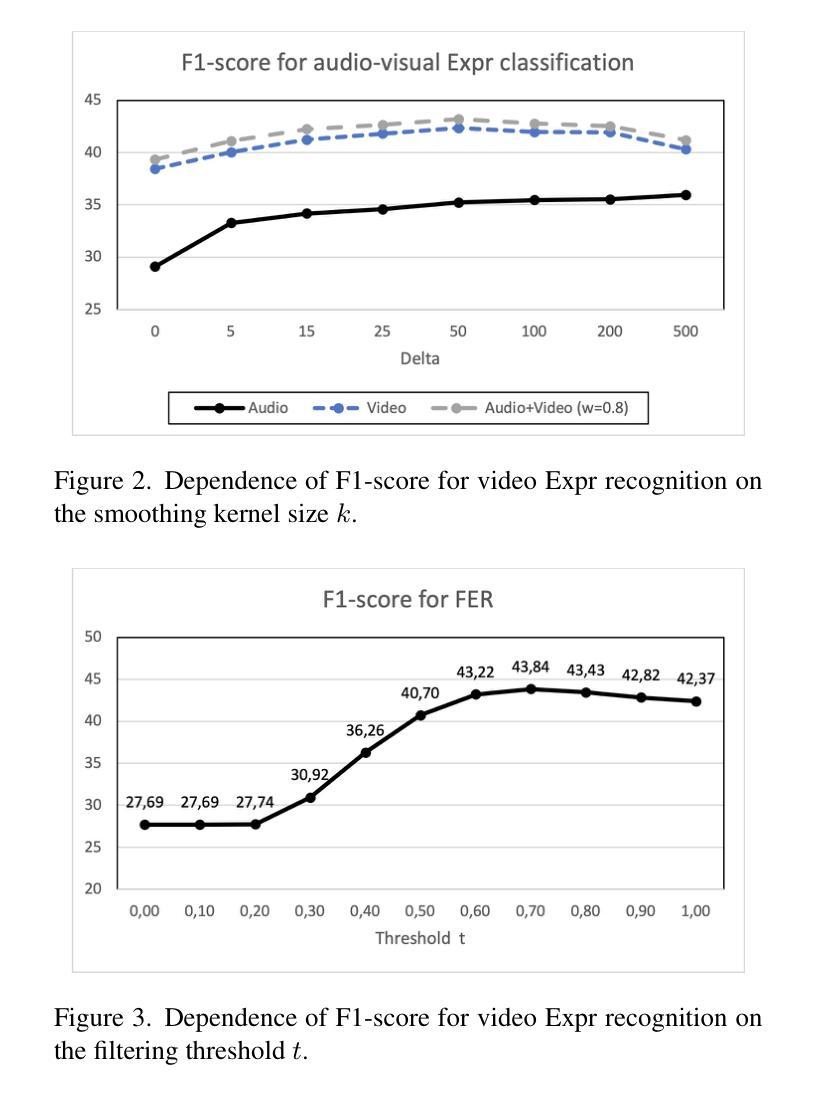
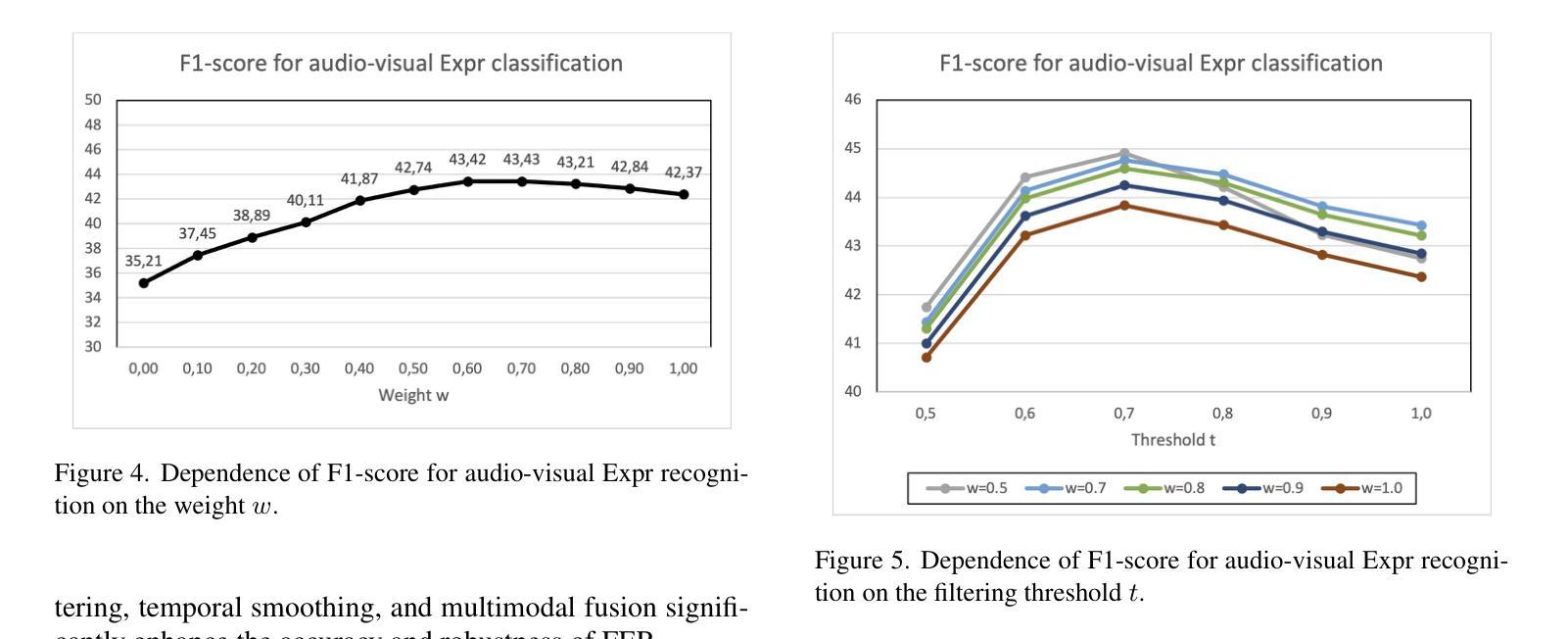
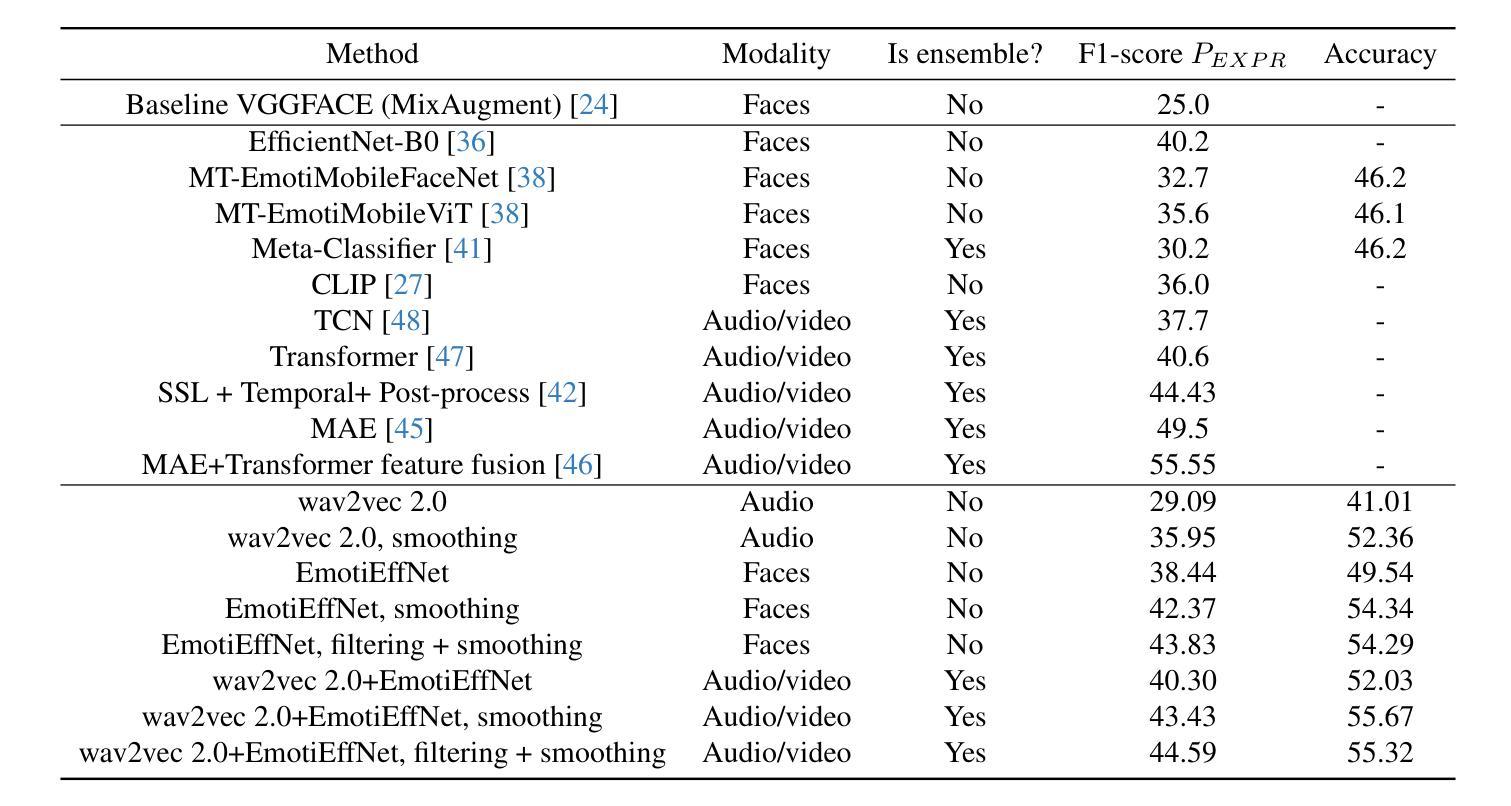
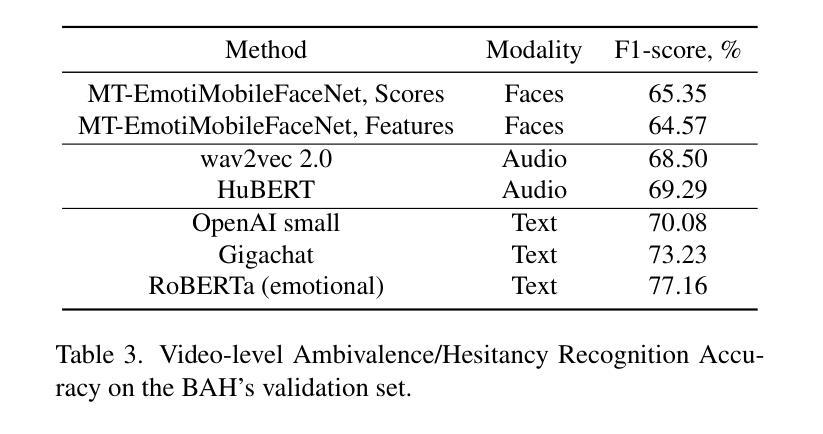
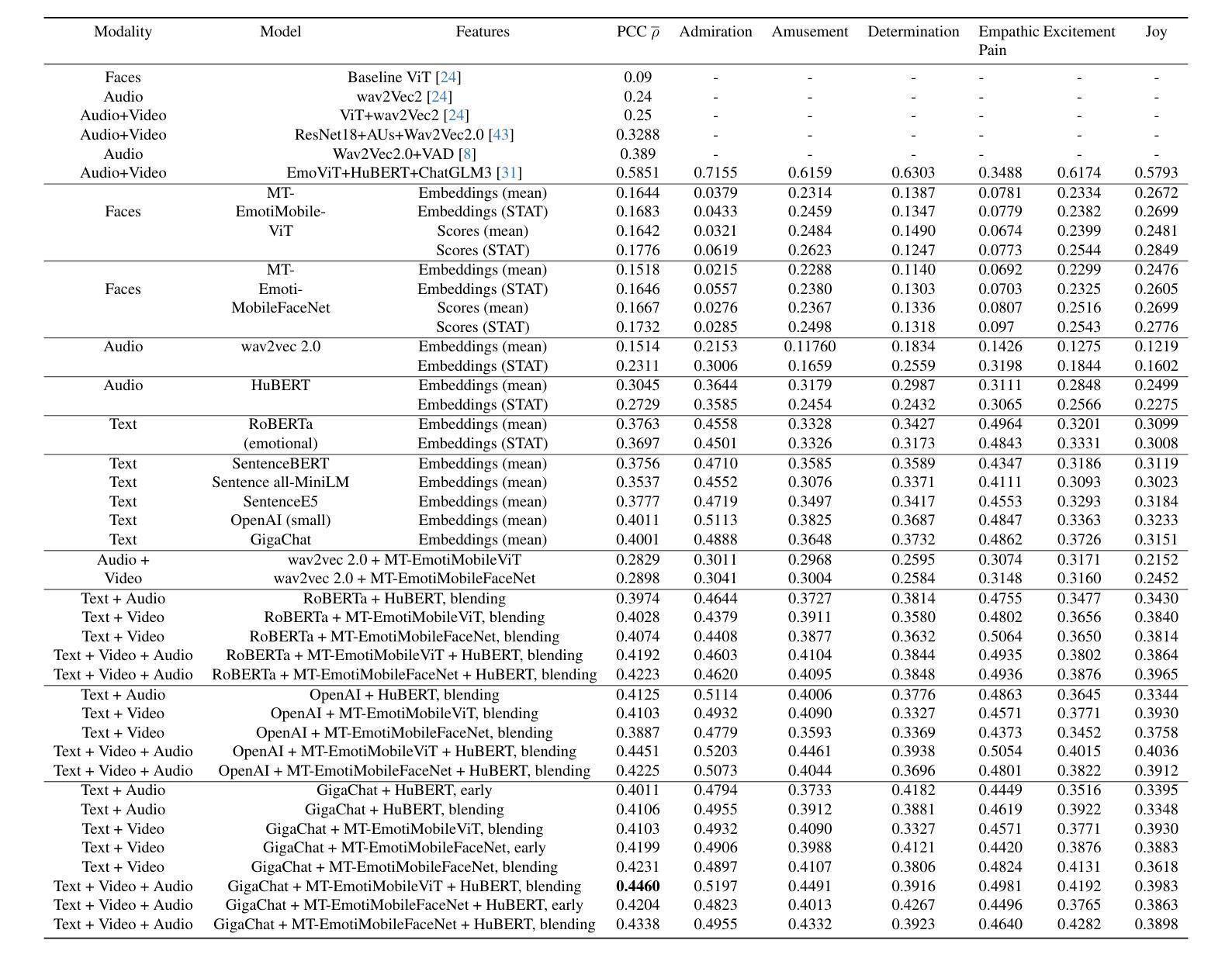
This article presents our results for the eighth Affective Behavior Analysis in-the-Wild (ABAW) competition. We combine facial emotional descriptors extracted by pre-trained models, namely, our EmotiEffLib library, with acoustic features and embeddings of texts recognized from speech. The frame-level features are aggregated and fed into simple classifiers, e.g., multi-layered perceptron (feed-forward neural network with one hidden layer), to predict ambivalence/hesitancy and facial expressions. In the latter case, we also use the pre-trained facial expression recognition model to select high-score video frames and prevent their processing with a domain-specific video classifier. The video-level prediction of emotional mimicry intensity is implemented by simply aggregating frame-level features and training a multi-layered perceptron. Experimental results for three tasks from the ABAW challenge demonstrate that our approach significantly increases validation metrics compared to existing baselines.
本文介绍了我们在第八届野外情感行为分析(ABAW)竞赛的结果。我们将通过预训练模型提取的面部情感描述符(即我们的EmotiEffLib库)与从语音中识别的文本的声音特征和嵌入相结合。帧级特征被聚合并输入到简单的分类器中,例如多层感知器(具有一层隐藏层的前馈神经网络),以预测矛盾心理/犹豫和面部表情。在后一种情况下,我们还使用预训练的面部表情识别模型来选择高分数视频帧,并防止它们使用特定领域的视频分类器进行处理。通过简单地聚合帧级特征并训练多层感知器来实现情感模仿强度的视频级预测。来自ABAW挑战的三个任务的实验结果表明,我们的方法在提高验证指标方面明显优于现有基线。
论文及项目相关链接
PDF submitted to ABAW CVPR 2025 Workshop
Summary
本文介绍了在第八届情感行为分析竞赛(ABAW)中的研究结果。该研究结合了预训练模型提取的面部情感描述符、声学特征和从语音中识别的文本嵌入。框架级别的特征被聚合并输入到简单的分类器中,如多层感知器,以预测模棱两可/犹豫和面部表情。在预测面部表情时,还使用预训练的面部表情识别模型选择高分数视频帧,避免使用特定领域的视频分类器进行处理。通过简单聚合框架级别的特征并训练多层感知器,实现了情感模仿强度的视频级预测。在ABAW挑战中的三个任务的实验结果表明,该方法与现有基线相比,显著提高了验证指标。
Key Takeaways
- 本文介绍了在情感行为分析竞赛(ABAW)中的新研究成果。
- 使用了预训练的模型来提取面部情感描述符和文本嵌入。
- 结合了面部、声音和文本识别技术来预测情感表达。
- 采用多层感知器进行情感预测,并在预测面部表情时采用特定策略选择视频帧。
- 该方法通过简单聚合框架级别的特征实现了情感模仿强度的视频级预测。
- 在ABAW挑战的三个任务中,该方法显著提高了验证指标。
点此查看论文截图

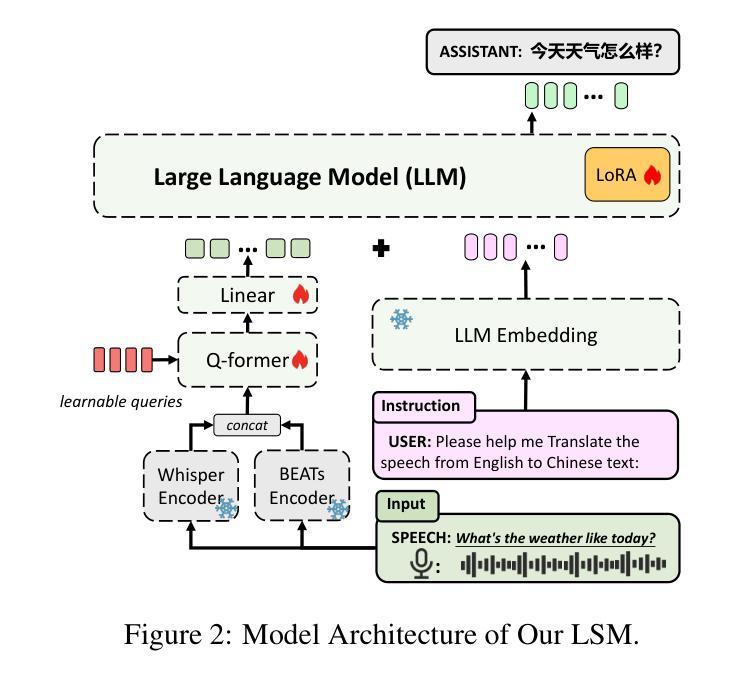
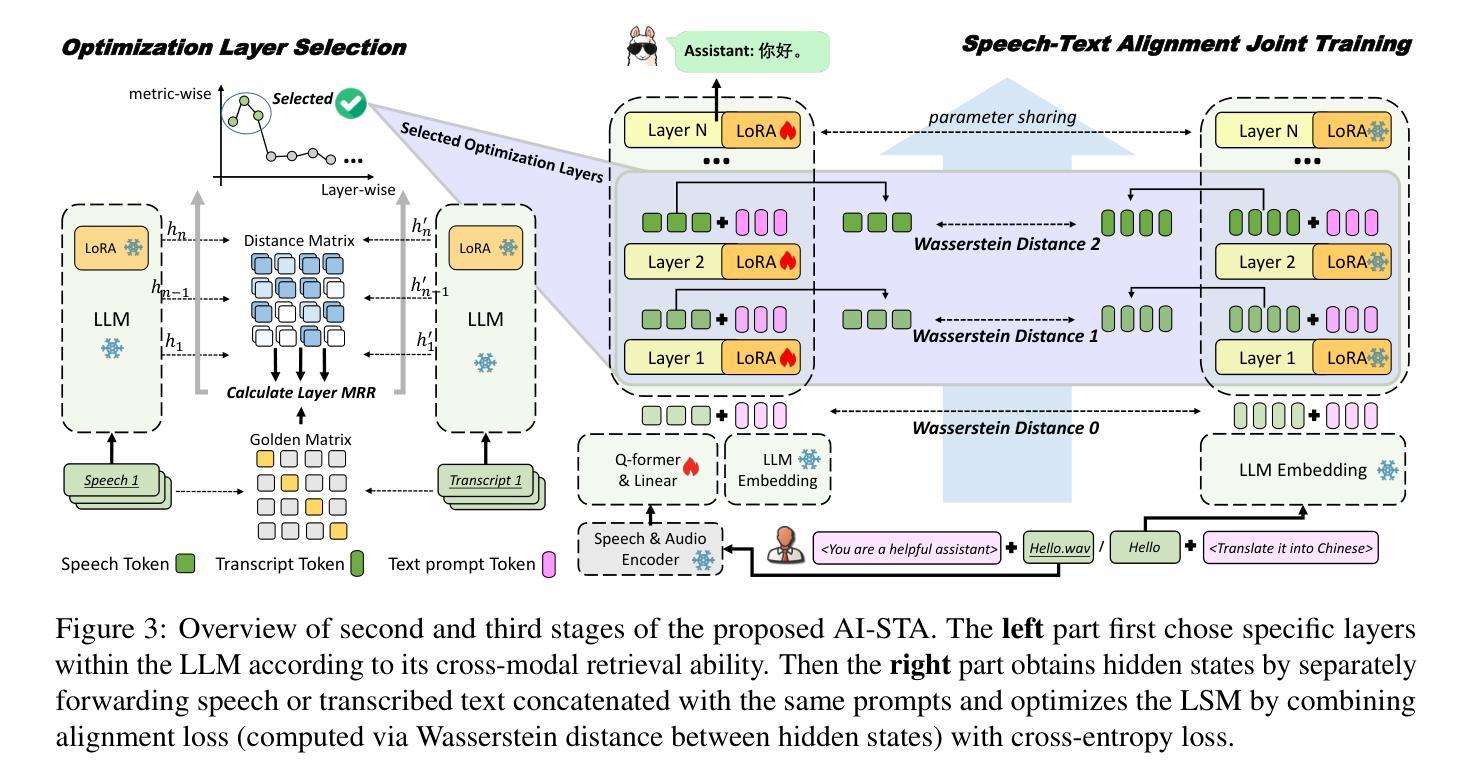
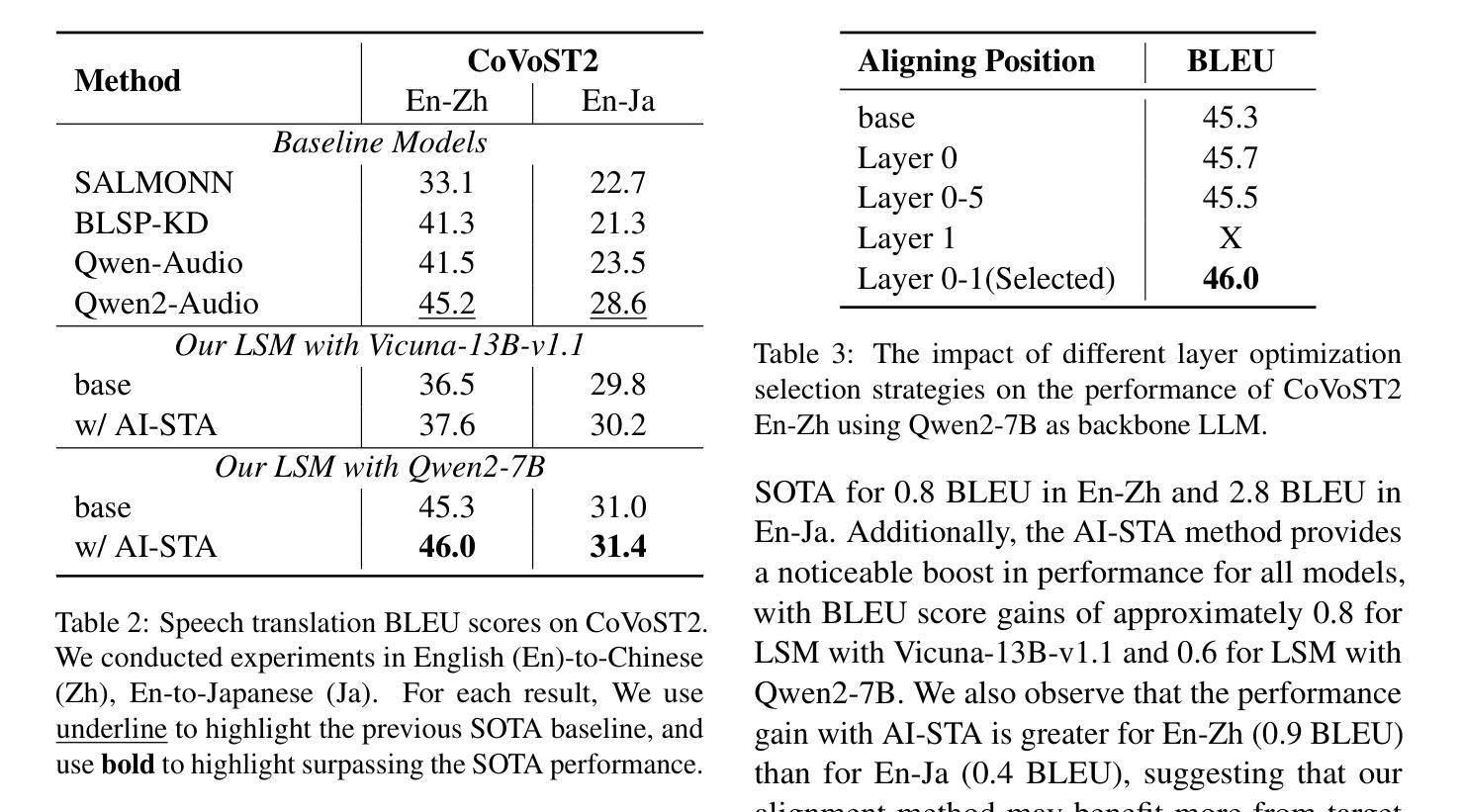
Adaptive Inner Speech-Text Alignment for LLM-based Speech Translation
Authors:Henglyu Liu, Andong Chen, Kehai Chen, Xuefeng Bai, Meizhi Zhong, Yuan Qiu, Min Zhang
Recent advancement of large language models (LLMs) has led to significant breakthroughs across various tasks, laying the foundation for the development of LLM-based speech translation systems. Existing methods primarily focus on aligning inputs and outputs across modalities while overlooking deeper semantic alignment within model representations. To address this limitation, we propose an Adaptive Inner Speech-Text Alignment (AI-STA) method to bridge the modality gap by explicitly aligning speech and text representations at selected layers within LLMs. To achieve this, we leverage the optimal transport (OT) theory to quantify fine-grained representation discrepancies between speech and text. Furthermore, we utilize the cross-modal retrieval technique to identify the layers that are best suited for alignment and perform joint training on these layers. Experimental results on speech translation (ST) tasks demonstrate that AI-STA significantly improves the translation performance of large speech-text models (LSMs), outperforming previous state-of-the-art approaches. Our findings highlight the importance of inner-layer speech-text alignment in LLMs and provide new insights into enhancing cross-modal learning.
最近的大型语言模型(LLM)的进步为各项任务带来了重大突破,为基于LLM的语音翻译系统的发展奠定了基础。现有方法主要关注跨模态的输入输出对齐,而忽视了模型表示内的深层语义对齐。为了解决这一局限性,我们提出了一种自适应内部语音文本对齐(AI-STA)方法,通过明确对齐LLM中选定层上的语音和文本表示来缩小模态差距。为了实现这一点,我们利用最优传输(OT)理论来量化语音和文本表示之间的细粒度表示差异。此外,我们还利用跨模态检索技术来确定最适合对齐的层,并对这些层进行联合训练。在语音翻译(ST)任务上的实验结果表明,AI-STA显著提高了大型语音文本模型(LSM)的翻译性能,超越了之前的最先进方法。我们的研究强调了LLM内部层语音文本对齐的重要性,并为增强跨模态学习提供了新的见解。
论文及项目相关链接
PDF 12 pages, 7 figures
Summary
大型语言模型(LLM)的最新进展为基于LLM的语音识别系统的发展奠定了基础,带来了各项任务的显著突破。针对现有方法主要关注跨模态输入输出对齐而忽视模型表示中的深层语义对齐的问题,提出了一种自适应内部语音文本对齐(AI-STA)方法。该方法通过明确对齐LLM内选定层的语音和文本表示来缩小模态差距。利用最优传输(OT)理论来量化语音和文本表示之间的细微差异,并利用跨模态检索技术来确定最适合对齐的层,并对这些层进行联合训练。在语音识别任务上的实验结果表明,AI-STA显著提高了大型语音识别模型(LSM)的翻译性能,超越了现有先进方法。该研究强调了LLM内部层语音文本对齐的重要性,并为增强跨模态学习提供了新的见解。
Key Takeaways
- 大型语言模型(LLM)在语音识别领域取得显著进展。
- 现有方法主要关注跨模态输入输出对齐,忽视模型内部的深层语义对齐。
- 提出了一种自适应内部语音文本对齐(AI-STA)方法,以缩小模态差距。
- AI-STA方法通过明确对齐LLM内选定层的语音和文本表示来实现对齐。
- 利用最优传输(OT)理论量化语音和文本表示之间的差异。
- 使用跨模态检索技术确定最适合对齐的层,并对这些层进行联合训练。
点此查看论文截图


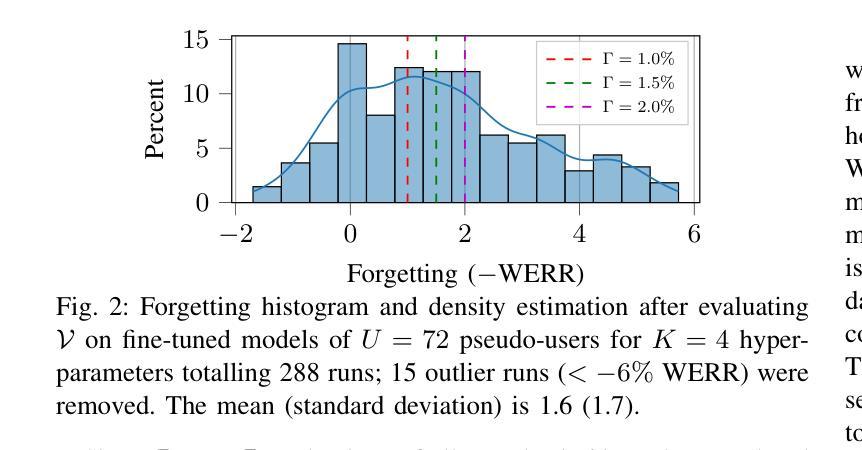
ValSub: Subsampling Validation Data to Mitigate Forgetting during ASR Personalization
Authors:Haaris Mehmood, Karthikeyan Saravanan, Pablo Peso Parada, David Tuckey, Mete Ozay, Gil Ho Lee, Jungin Lee, Seokyeong Jung
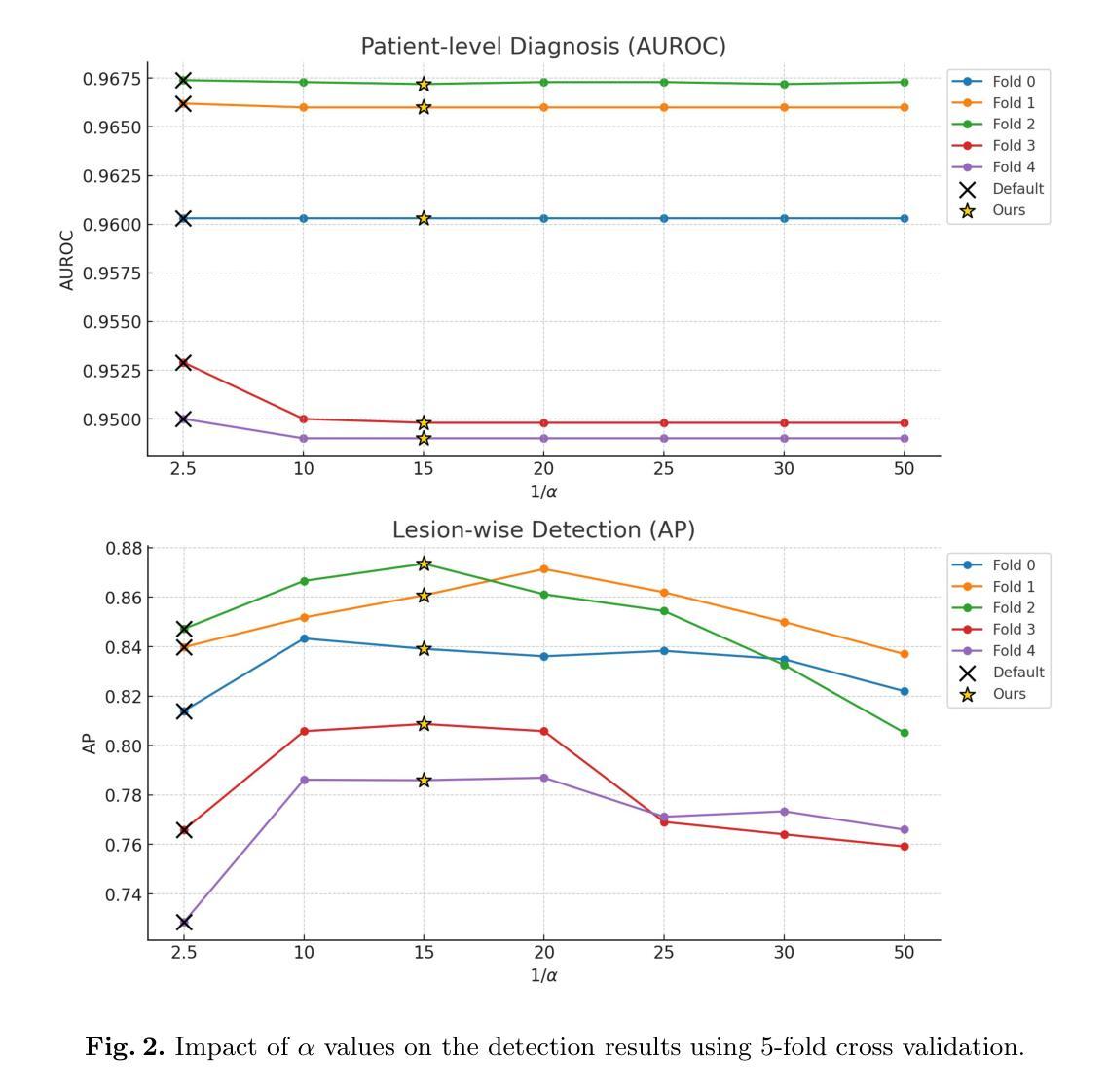
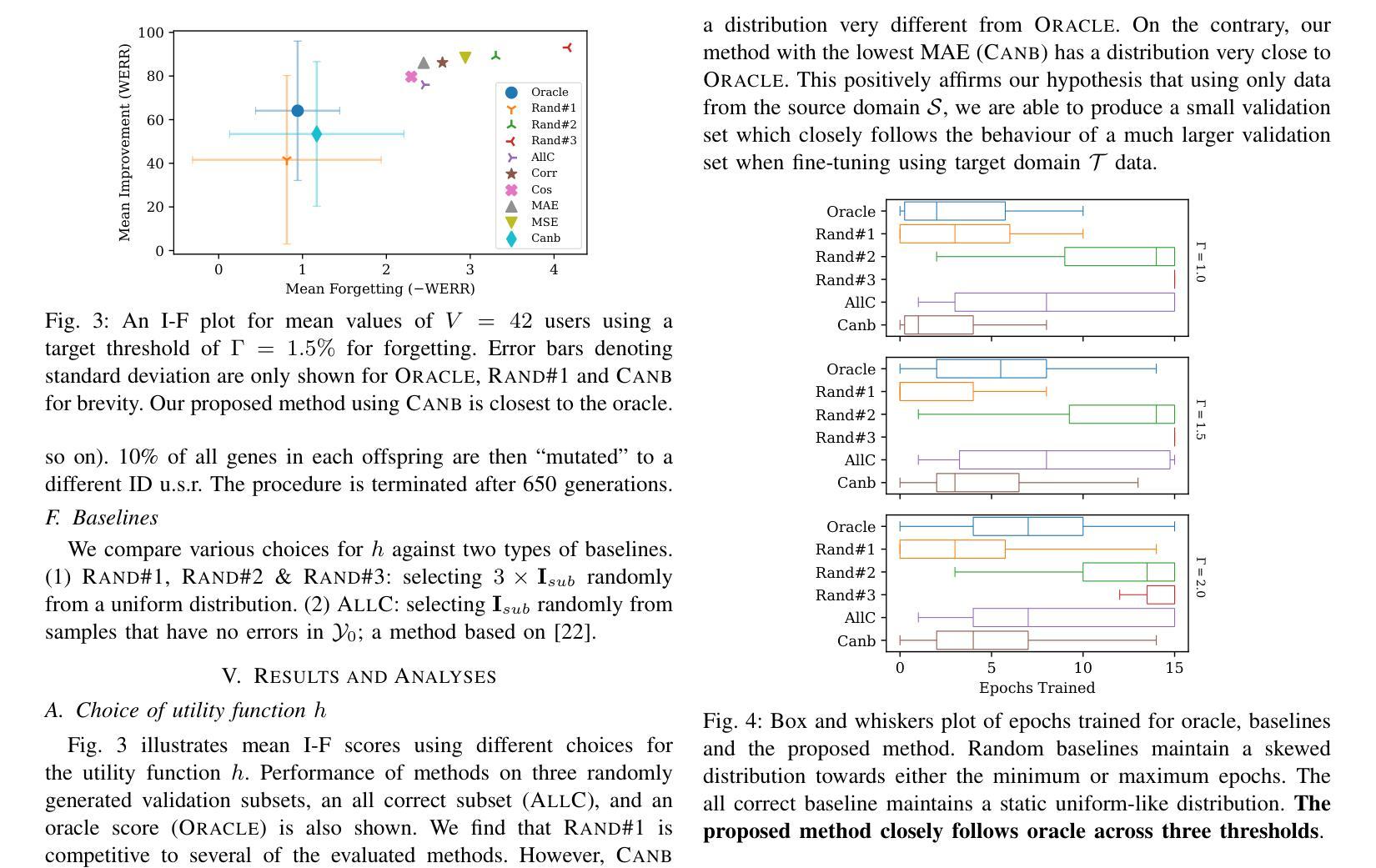
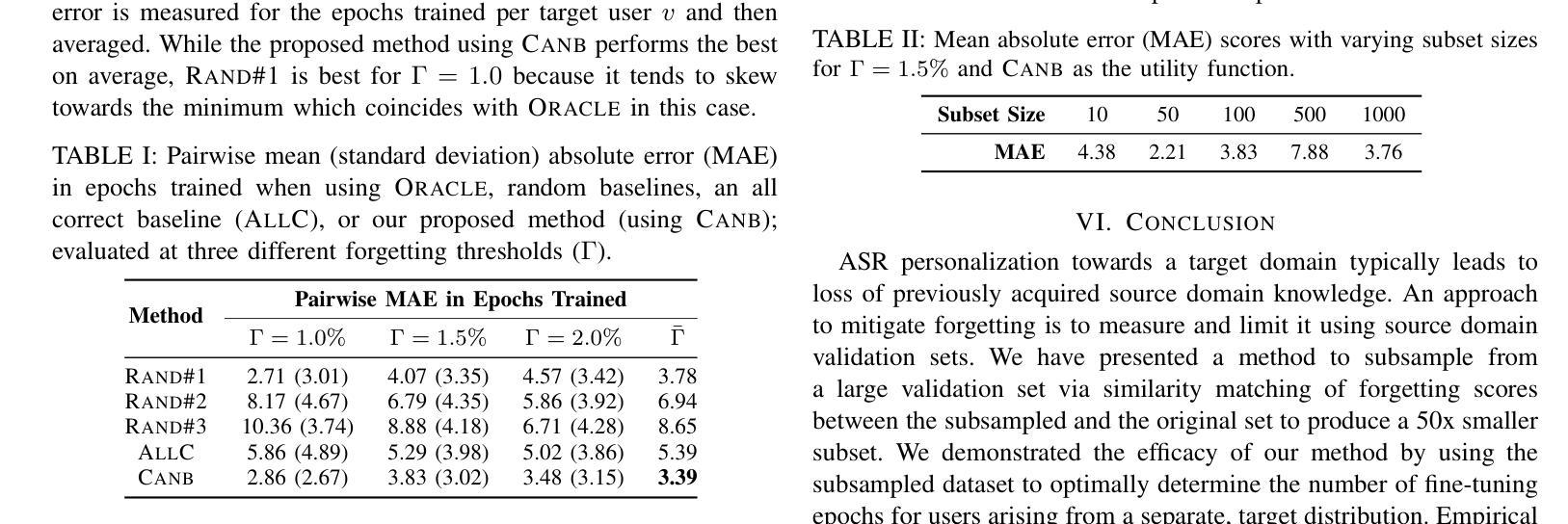
Automatic Speech Recognition (ASR) is widely used within consumer devices such as mobile phones. Recently, personalization or on-device model fine-tuning has shown that adaptation of ASR models towards target user speech improves their performance over rare words or accented speech. Despite these gains, fine-tuning on user data (target domain) risks the personalized model to forget knowledge about its original training distribution (source domain) i.e. catastrophic forgetting, leading to subpar general ASR performance. A simple and efficient approach to combat catastrophic forgetting is to measure forgetting via a validation set that represents the source domain distribution. However, such validation sets are large and impractical for mobile devices. Towards this, we propose a novel method to subsample a substantially large validation set into a smaller one while maintaining the ability to estimate forgetting. We demonstrate the efficacy of such a dataset in mitigating forgetting by utilizing it to dynamically determine the number of ideal fine-tuning epochs. When measuring the deviations in per user fine-tuning epochs against a 50x larger validation set (oracle), our method achieves a lower mean-absolute-error (3.39) compared to randomly selected subsets of the same size (3.78-8.65). Unlike random baselines, our method consistently tracks the oracle’s behaviour across three different forgetting thresholds.
自动语音识别(ASR)在移动电话等消费设备中得到了广泛应用。最近,个性化或设备上的模型微调显示,针对目标用户语音的ASR模型适应性改进了其在罕见词汇或带口音语音方面的性能。尽管有这些收获,但在用户数据(目标域)上进行微调会使个性化模型忘记其原始训练分布(源域)的知识,即灾难性遗忘,导致通用的ASR性能下降。一种简单而有效的方法是通过代表源域分布的验证集来测量遗忘。然而,这样的验证集很大,对于移动设备来说不切实际。为此,我们提出了一种新方法,从大量验证集中抽样出较小的子集,同时保持估计遗忘的能力。我们通过在动态确定理想微调周期数时利用该数据集来证明此类数据集在缓解遗忘方面的有效性。当测量每个用户的微调周期与50倍大的验证集(理想情况)之间的偏差时,我们的方法实现了更低的平均绝对误差(3.39),与随机选择的相同大小的子集相比(3.78-8.65)。不同于随机基线方法,我们的方法始终跟踪理想情况下的行为表现,跨越三个不同的遗忘阈值。
论文及项目相关链接
PDF Accepted at ICASSP 2025
Summary
自动语音识别技术在手机等消费设备中得到广泛应用。用户模型微调提高了目标用户对ASR模型的适应性和对某些用户的罕见词汇或带口音语音的识别性能。然而,对用户数据进行微调可能使模型遗忘其原始训练分布的知识,导致一般ASR性能下降。一种解决灾难性遗忘的简单有效方法是使用代表原始训练分布的数据集来测量遗忘。然而,这样的验证集很大,不适用于移动设备。为此,我们提出了一种新方法,将较大的验证集缩减为较小的集合并仍然能够估计遗忘。我们证明了通过该数据集动态确定理想微调周期的有效性。与更大的验证集相比,我们的方法在衡量用户微调周期的偏差方面实现了更低的平均绝对误差。此外,我们的方法在不同的遗忘阈值下都能持续追踪验证集的走向。总的来说,本文提出了一种新型的ASR模型微调策略。通过对数据集进行智能采样来评估遗忘情况,从而实现更有效的模型调整并提升性能。同时确保即使在有限的资源条件下也能有效运行,为解决ASR面临的挑战提供了有效方法。此外还对有效性能表现提出了强有力的实证支持。这不仅可以优化消费设备的ASR技术还可以推广至其它语音识别应用或系统设计中并有助于更广泛实现高效的模型训练提升行业整体发展速度与成果普及广度。Key Takeaways
点此查看论文截图


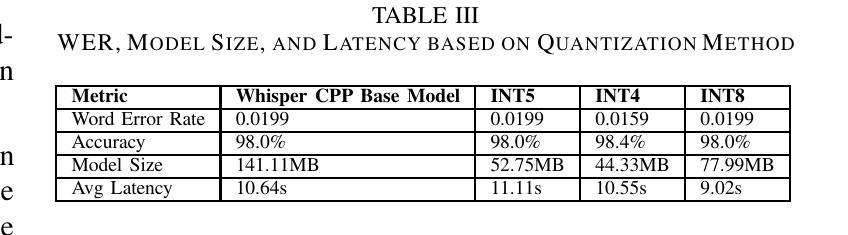
Quantization for OpenAI’s Whisper Models: A Comparative Analysis
Authors:Allison Andreyev
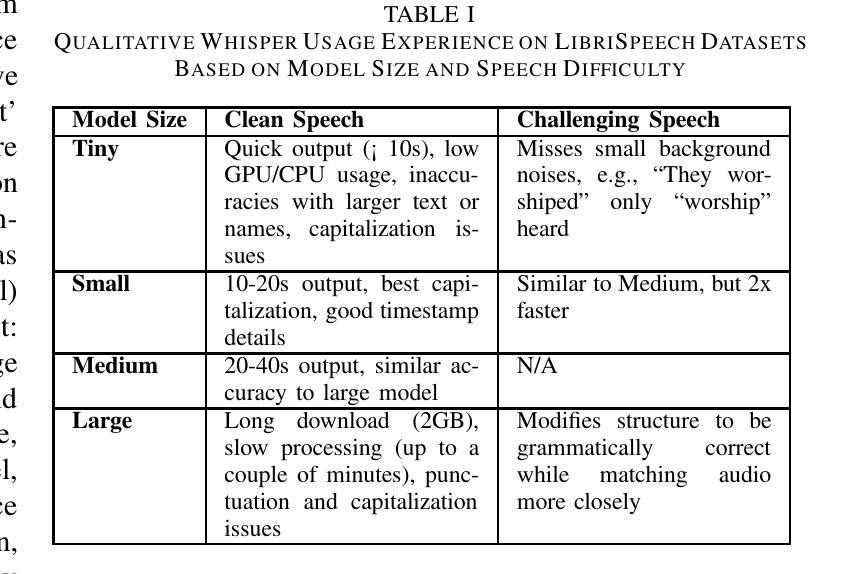
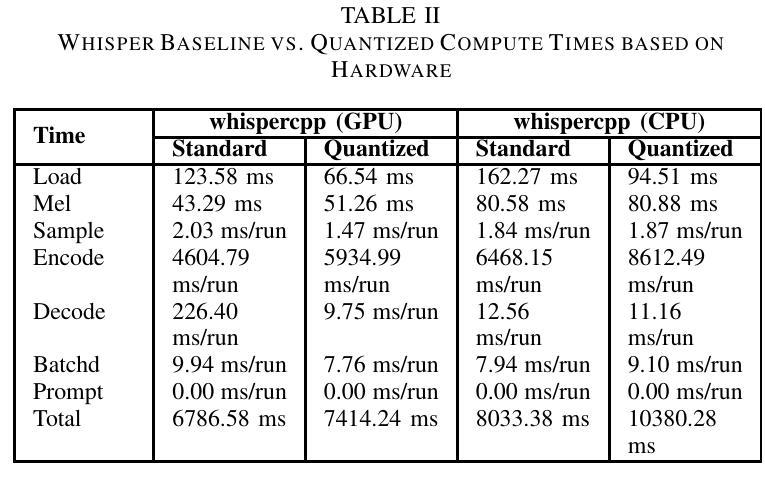
Automated speech recognition (ASR) models have gained prominence for applications such as captioning, speech translation, and live transcription. This paper studies Whisper and two model variants: one optimized for live speech streaming and another for offline transcription. Notably, these models have been found to generate hallucinated content, reducing transcription reliability. Furthermore, larger model variants exhibit increased latency and pose challenges for deployment on resource-constrained devices. This study analyzes the similarities and differences between three Whisper models, qualitatively examining their distinct capabilities. Next, this study quantifies the impact of model quantization on latency and evaluates its viability for edge deployment. Using the open source LibriSpeech dataset, this paper evaluates the word error rate (WER) along with latency analysis of whispercpp using 3 quantization methods (INT4, INT5, INT8). Results show that quantization reduces latency by 19% and model size by 45%, while preserving transcription accuracy. These findings provide insights into the optimal use cases of different Whisper models and edge device deployment possibilities. All code, datasets, and implementation details are available in a public GitHub repository: https://github.com/allisonandreyev/WhisperQuantization.git
自动语音识别(ASR)模型在字幕、语音翻译和实时转录等领域的应用已经得到广泛关注。本文研究了Whisper和两种模型变体:一种适用于实时语音流,另一种适用于离线转录。值得注意的是,这些模型被发现会产生幻觉内容,降低了转录的可靠性。此外,较大的模型变体表现出更高的延迟,并在资源受限的设备上部署时带来挑战。本研究分析了三种Whisper模型的相似性和差异性,定性评估了它们各自的能力。接下来,本研究量化了模型量化对延迟的影响,并评估了其用于边缘设备的可行性。本研究使用开源LibriSpeech数据集,评估了whispercpp的单词错误率(WER),并对其使用三种量化方法(INT4、INT5、INT8)进行了延迟分析。结果表明,量化可以降低延迟19%,缩小模型体积45%,同时保持转录精度。这些发现提供了对不同Whisper模型的最佳用例和边缘设备部署可能性的深刻见解。所有代码、数据集和实施细节都可在公共GitHub仓库中找到:https://github.com/allisonandreyev/WhisperQuantization.git。
论文及项目相关链接
PDF 7 pages
Summary
本文主要探讨了自动语音识别(ASR)模型中的whisper与其两种变种模型在语音识别应用方面的表现和挑战。研究发现这些模型存在生成虚构内容的问题,降低了转录的可靠性。此外,大型模型表现出较高的延迟,在资源受限的设备上部署具有挑战性。该研究通过开源LibriSpeech数据集对whispercpp进行量化分析,探讨了三种量化方法对延迟和模型大小的影响,同时评估了其对边缘设备部署的可行性。结果显示,量化可降低延迟并减小模型大小,同时保持较高的转录精度。该研究的发现对于优化whisper模型在特定应用场景中的使用及其在边缘设备上的部署提供了重要见解。
Key Takeaways
- Whisper及其变种模型广泛应用于语音识别领域,如字幕、语音翻译和实时转录。
- 这些模型存在生成虚构内容的问题,影响转录的可靠性。
- 大型ASR模型具有更高的延迟,在资源受限的设备上部署具有挑战性。
- 研究通过LibriSpeech数据集对whispercpp进行量化分析,探讨了量化对延迟和模型大小的影响。
- 量化方法可降低延迟并减小模型大小约45%,同时保持较高的转录精度。
- 公共GitHub仓库提供了代码、数据集和实施细节。
点此查看论文截图

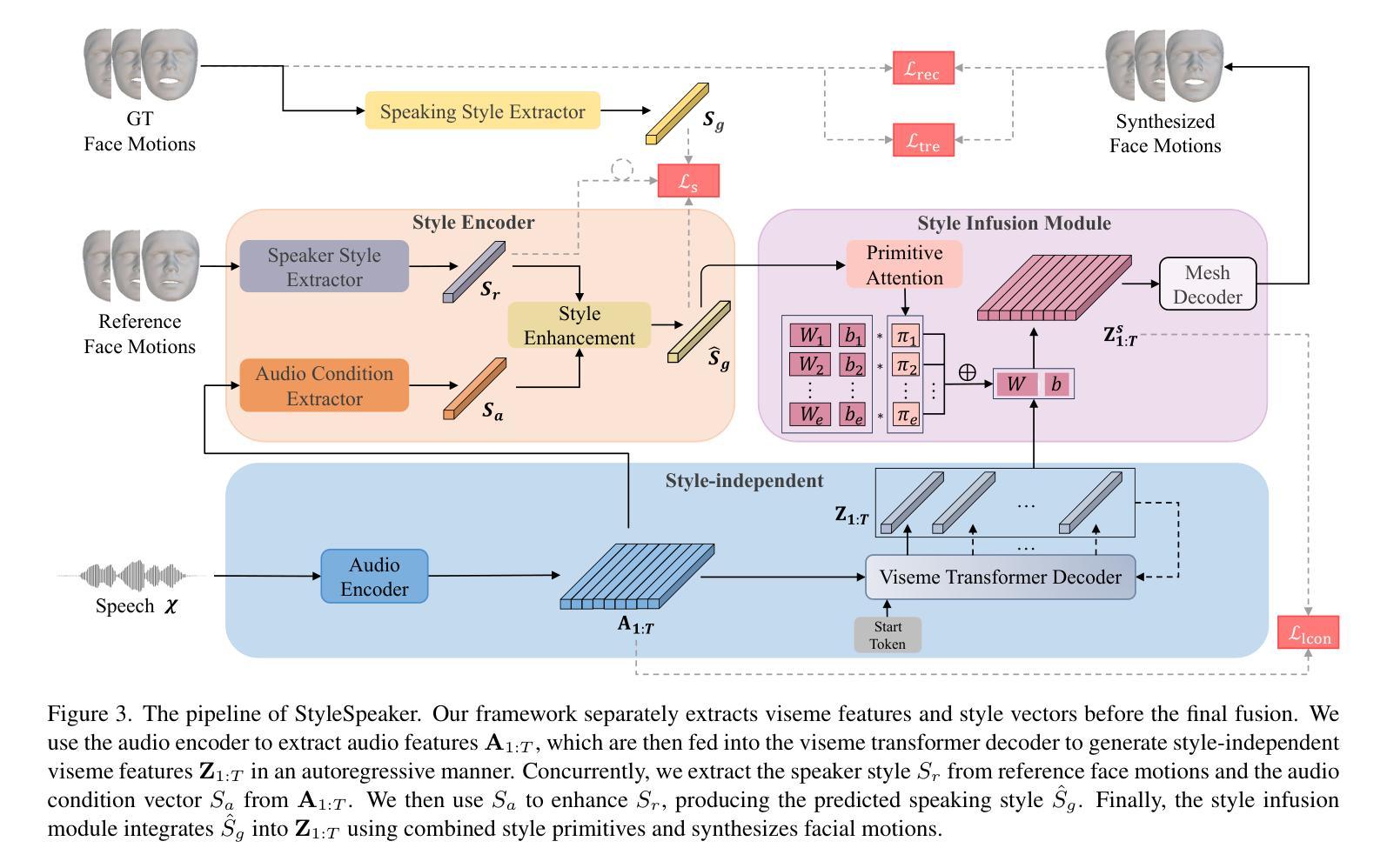
StyleSpeaker: Audio-Enhanced Fine-Grained Style Modeling for Speech-Driven 3D Facial Animation
Authors:An Yang, Chenyu Liu, Pengcheng Xia, Jun Du
Speech-driven 3D facial animation is challenging due to the diversity in speaking styles and the limited availability of 3D audio-visual data. Speech predominantly dictates the coarse motion trends of the lip region, while specific styles determine the details of lip motion and the overall facial expressions. Prior works lack fine-grained learning in style modeling and do not adequately consider style biases across varying speech conditions, which reduce the accuracy of style modeling and hamper the adaptation capability to unseen speakers. To address this, we propose a novel framework, StyleSpeaker, which explicitly extracts speaking styles based on speaker characteristics while accounting for style biases caused by different speeches. Specifically, we utilize a style encoder to capture speakers’ styles from facial motions and enhance them according to motion preferences elicited by varying speech conditions. The enhanced styles are then integrated into the coarse motion features via a style infusion module, which employs a set of style primitives to learn fine-grained style representation. Throughout training, we maintain this set of style primitives to comprehensively model the entire style space. Hence, StyleSpeaker possesses robust style modeling capability for seen speakers and can rapidly adapt to unseen speakers without fine-tuning. Additionally, we design a trend loss and a local contrastive loss to improve the synchronization between synthesized motions and speeches. Extensive qualitative and quantitative experiments on three public datasets demonstrate that our method outperforms existing state-of-the-art approaches.
语音驱动的3D面部动画由于说话风格的多样性和3D视听数据的有限可用性而具有挑战性。语音主要决定唇部的粗略运动趋势,而特定风格则决定唇部运动的细节和整体面部表情。之前的研究在风格建模方面缺乏精细学习,没有充分考虑不同语音条件下的风格偏见,这降低了风格建模的准确性,并阻碍了对未见说话者的适应能力。为了解决这一问题,我们提出了一种新型框架StyleSpeaker,该框架能够基于说话人特征明确提取说话风格,同时考虑不同语音引起的风格偏见。具体来说,我们利用风格编码器从面部运动中捕捉说话人的风格,并根据不同语音条件引发的运动偏好进行增强。增强后的风格然后通过风格注入模块融入到粗略运动特征中,该模块采用一系列风格原始元素来学习精细的风格表示。在训练过程中,我们保持这组风格原始元素来全面建模整个风格空间。因此,StyleSpeaker对已知说话人具有强大的风格建模能力,并且可以快速适应未见说话人而无需微调。此外,我们设计了趋势损失和局部对比损失来改善合成运动和语音之间的同步性。在三个公共数据集上的大量定性和定量实验表明,我们的方法优于现有的最先进的方法。
论文及项目相关链接
Summary
本文提出一种名为StyleSpeaker的新框架,用于基于说话风格的3D面部动画。该框架通过风格编码器捕捉说话人的风格特征,并考虑不同语音引起的风格偏见。通过风格融合模块将增强风格融入粗动作特征,学习精细的风格表示,并设计趋势损失和局部对比损失以提高动作与语音的同步性。实验证明,该方法在三个公共数据集上的性能优于现有技术。
Key Takeaways
- StyleSpeaker框架用于解决语音驱动的3D面部动画中的说话风格多样性和3D视听数据有限的问题。
- 框架通过风格编码器捕捉说话人的风格特征,并考虑不同语音条件引起的风格偏见。
- 利用风格融合模块将增强风格融入粗动作特征,学习精细的风格表示。
- 设计趋势损失和局部对比损失以提高动作与语音的同步性。
- StyleSpeaker具有稳健的风格建模能力,可快速适应未见过的说话人。
- 在三个公共数据集上进行的广泛实验证明,StyleSpeaker的性能优于现有技术。
点此查看论文截图

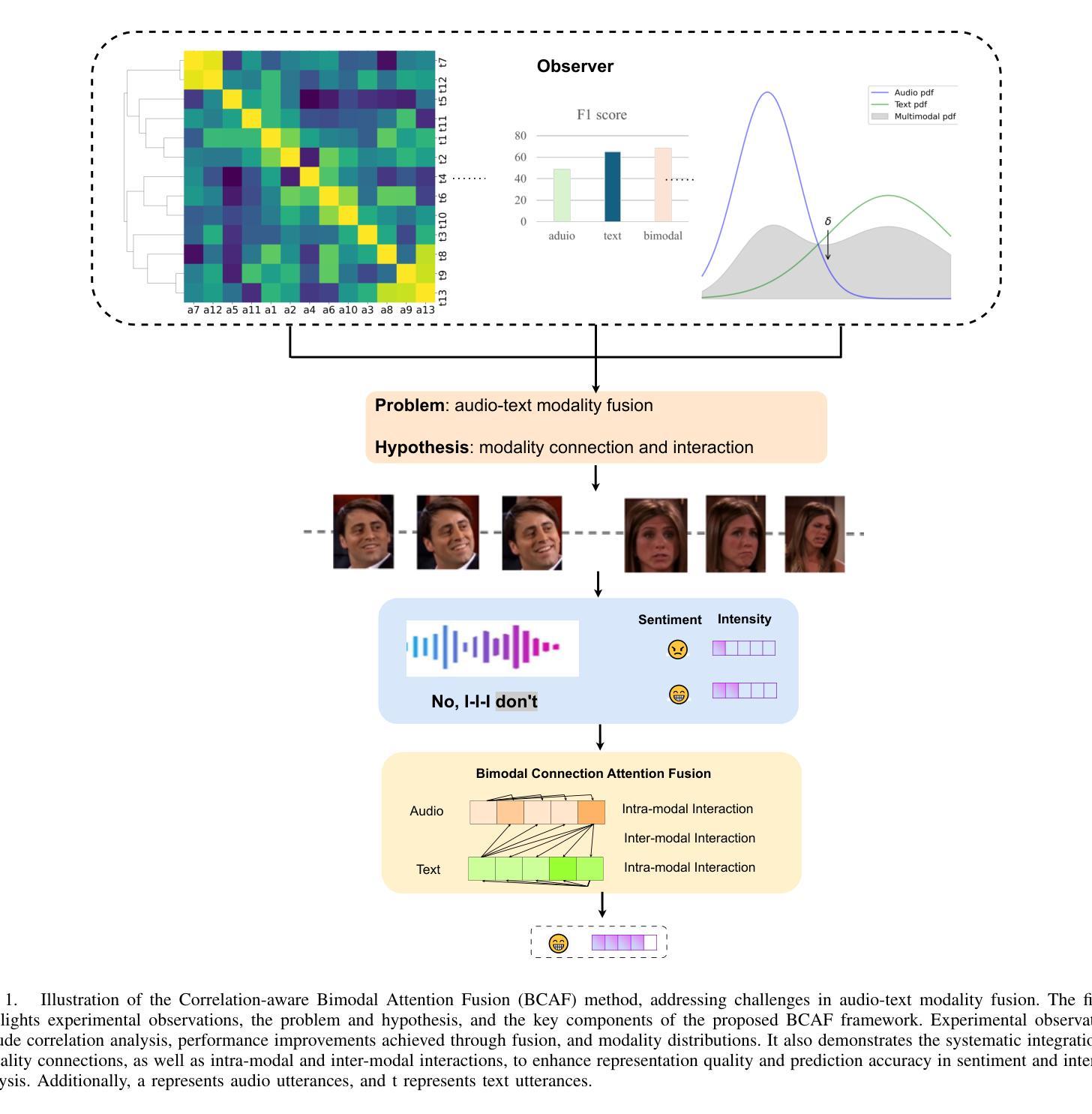
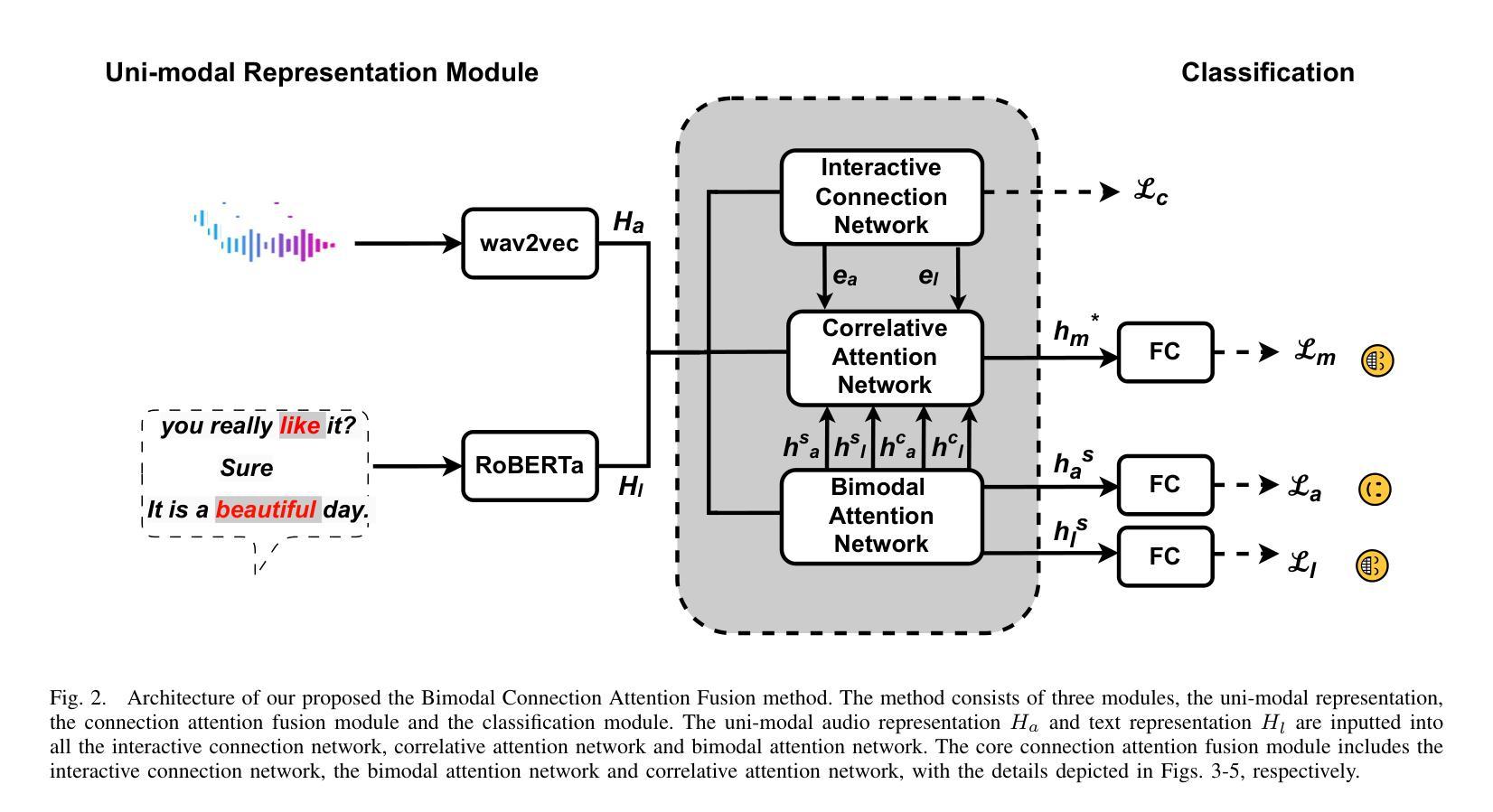
Bimodal Connection Attention Fusion for Speech Emotion Recognition
Authors:Jiachen Luo, Huy Phan, Lin Wang, Joshua D. Reiss
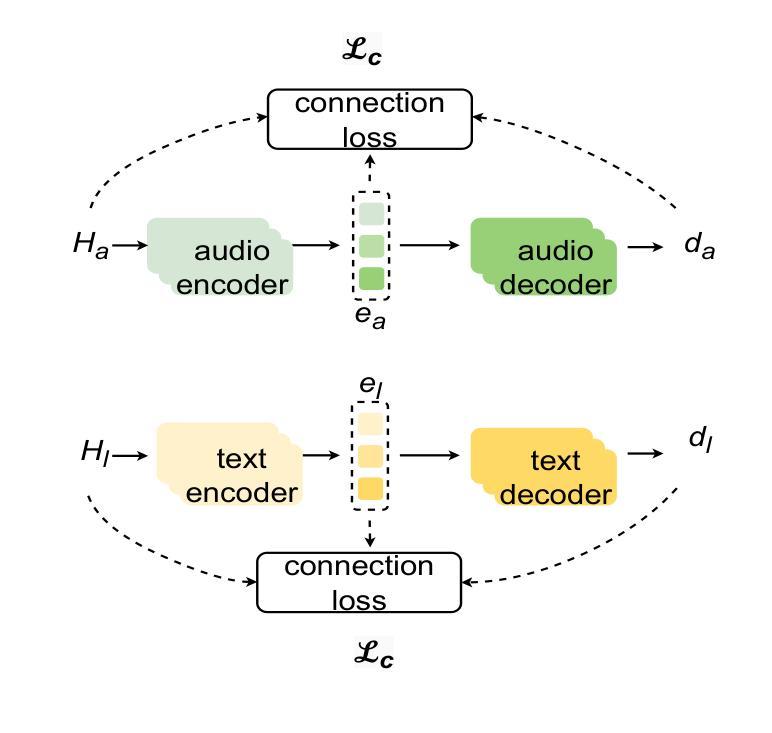
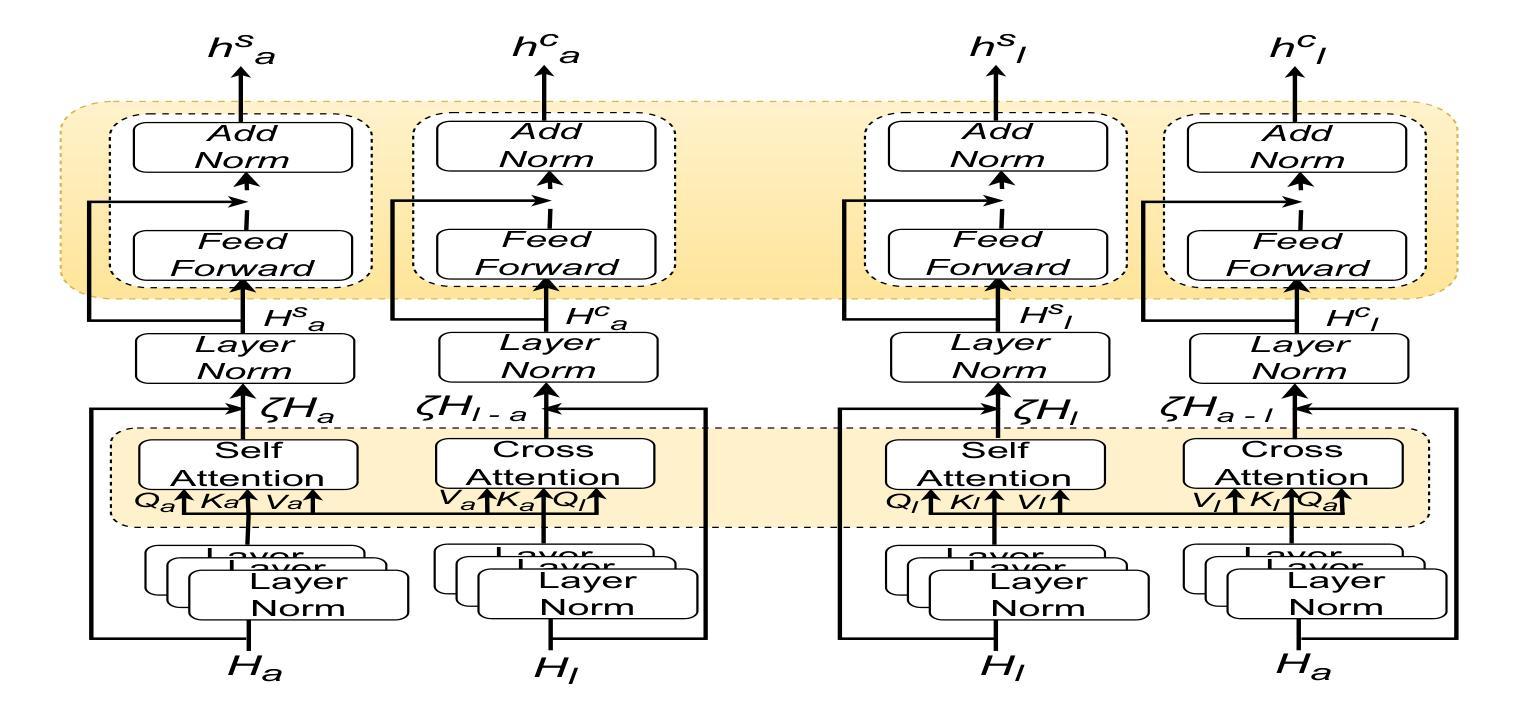
Multi-modal emotion recognition is challenging due to the difficulty of extracting features that capture subtle emotional differences. Understanding multi-modal interactions and connections is key to building effective bimodal speech emotion recognition systems. In this work, we propose Bimodal Connection Attention Fusion (BCAF) method, which includes three main modules: the interactive connection network, the bimodal attention network, and the correlative attention network. The interactive connection network uses an encoder-decoder architecture to model modality connections between audio and text while leveraging modality-specific features. The bimodal attention network enhances semantic complementation and exploits intra- and inter-modal interactions. The correlative attention network reduces cross-modal noise and captures correlations between audio and text. Experiments on the MELD and IEMOCAP datasets demonstrate that the proposed BCAF method outperforms existing state-of-the-art baselines.
多模态情感识别具有挑战性,其难点在于提取能够捕捉细微情感差异的特征。理解多模态交互和连接是构建有效的双模态语音情感识别系统的关键。在这项工作中,我们提出了双模态连接注意力融合(BCAF)方法,主要包括三个模块:交互连接网络、双模态注意力网络和相关性注意力网络。交互连接网络使用编码器-解码器架构来建模音频和文本之间的模态连接,同时利用模态特定特征。双模态注意力网络增强了语义互补性,并探索了模态内和模态间的交互。相关性注意力网络降低了跨模态噪声,并捕捉了音频和文本之间的相关性。在MELD和IEMOCAP数据集上的实验表明,所提出的BCAF方法优于现有的最新基线方法。
论文及项目相关链接
总结
本文提出了多模态情感识别的挑战,关键在于提取捕捉细微情感差异的特征。为了构建有效的双模态语音情感识别系统,理解多模态交互和连接是关键。为此,本文提出了双模态连接注意力融合(BCAF)方法,包括三个主要模块:交互连接网络、双模态注意力网络和相关性注意力网络。该方法通过利用模态间的交互关系和信息来建模音频和文本之间的模态连接,同时采用编码器-解码器架构进行建模。双模态注意力网络增强了语义互补性,并利用了模态内的交互性。相关性注意力网络减少了跨模态噪声,并捕捉了音频和文本之间的相关性。在MELD和IEMOCAP数据集上的实验表明,所提出的BCAF方法优于现有的先进基线方法。
关键见解
- 多模态情感识别面临提取捕捉细微情感差异特征的挑战。
- 理解多模态交互和连接是构建有效双模态语音情感识别系统的关键。
- 本文提出了BCAF方法,包含三个主要模块来处理多模态数据。
- 交互连接网络利用编码器-解码器架构建模音频和文本之间的模态连接。
- 双模态注意力网络增强语义互补性并捕捉模态内的交互性。
- 相关性注意力网络减少跨模态噪声并捕捉音频和文本之间的相关性。
点此查看论文截图

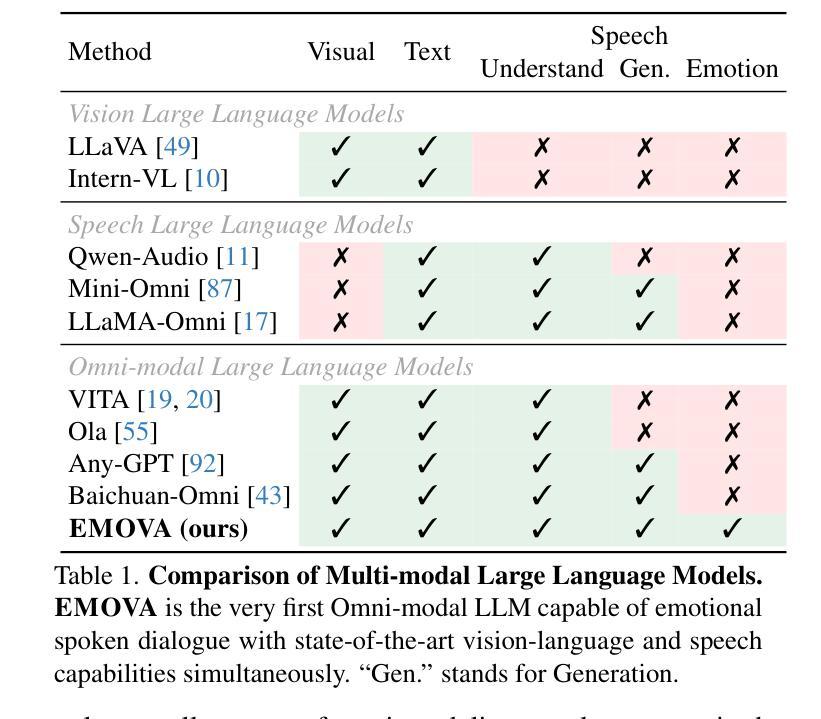
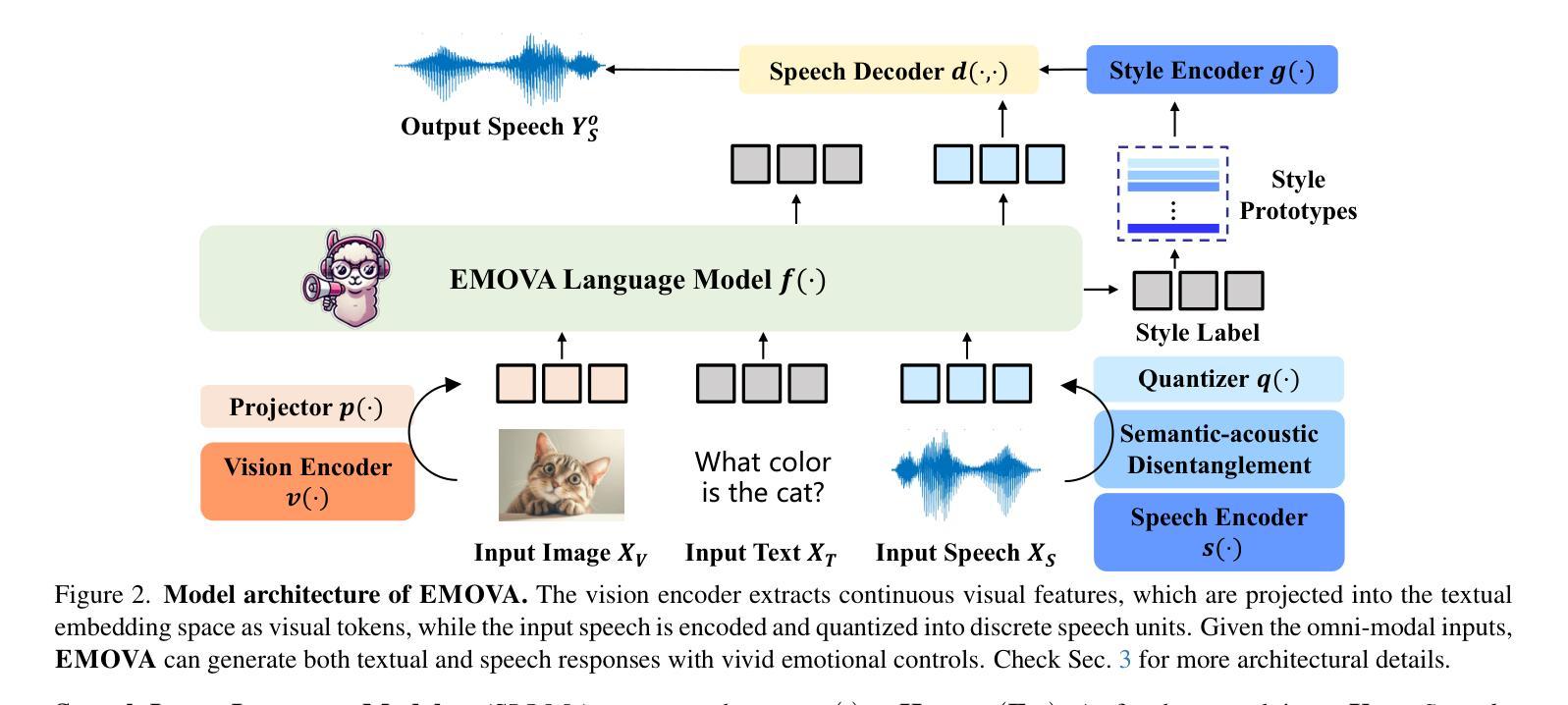
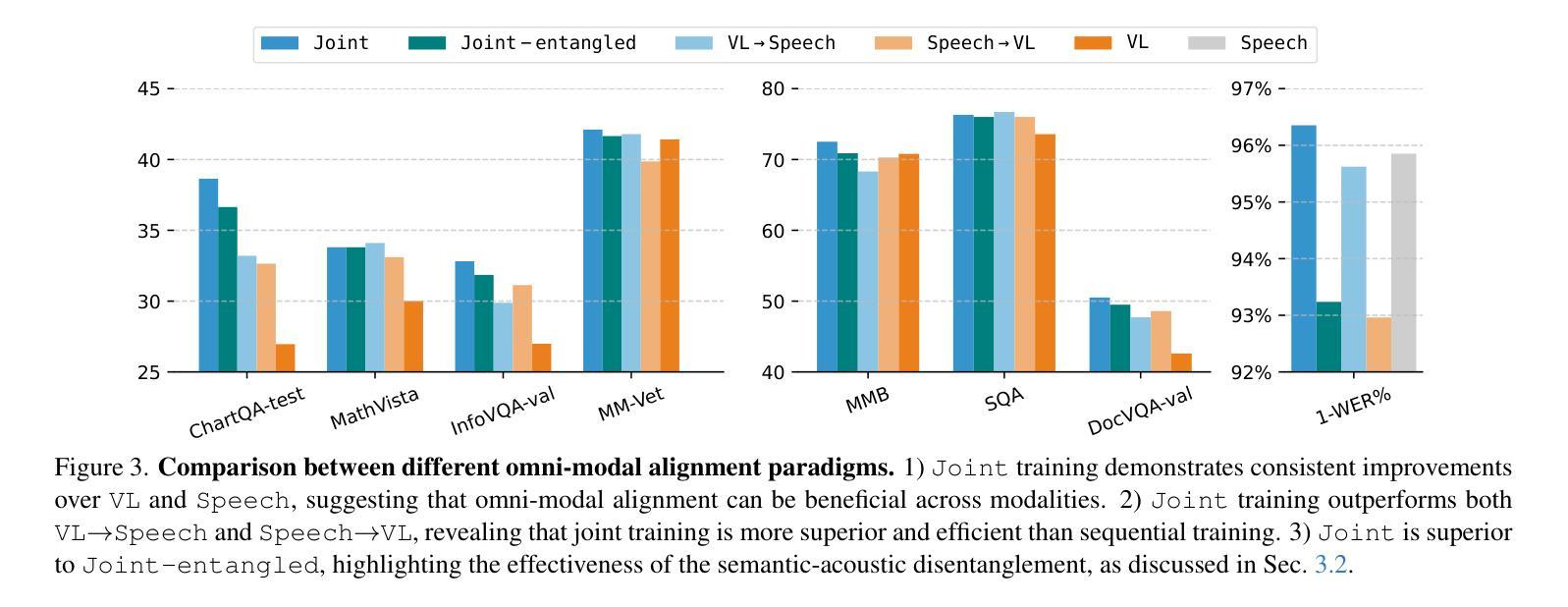
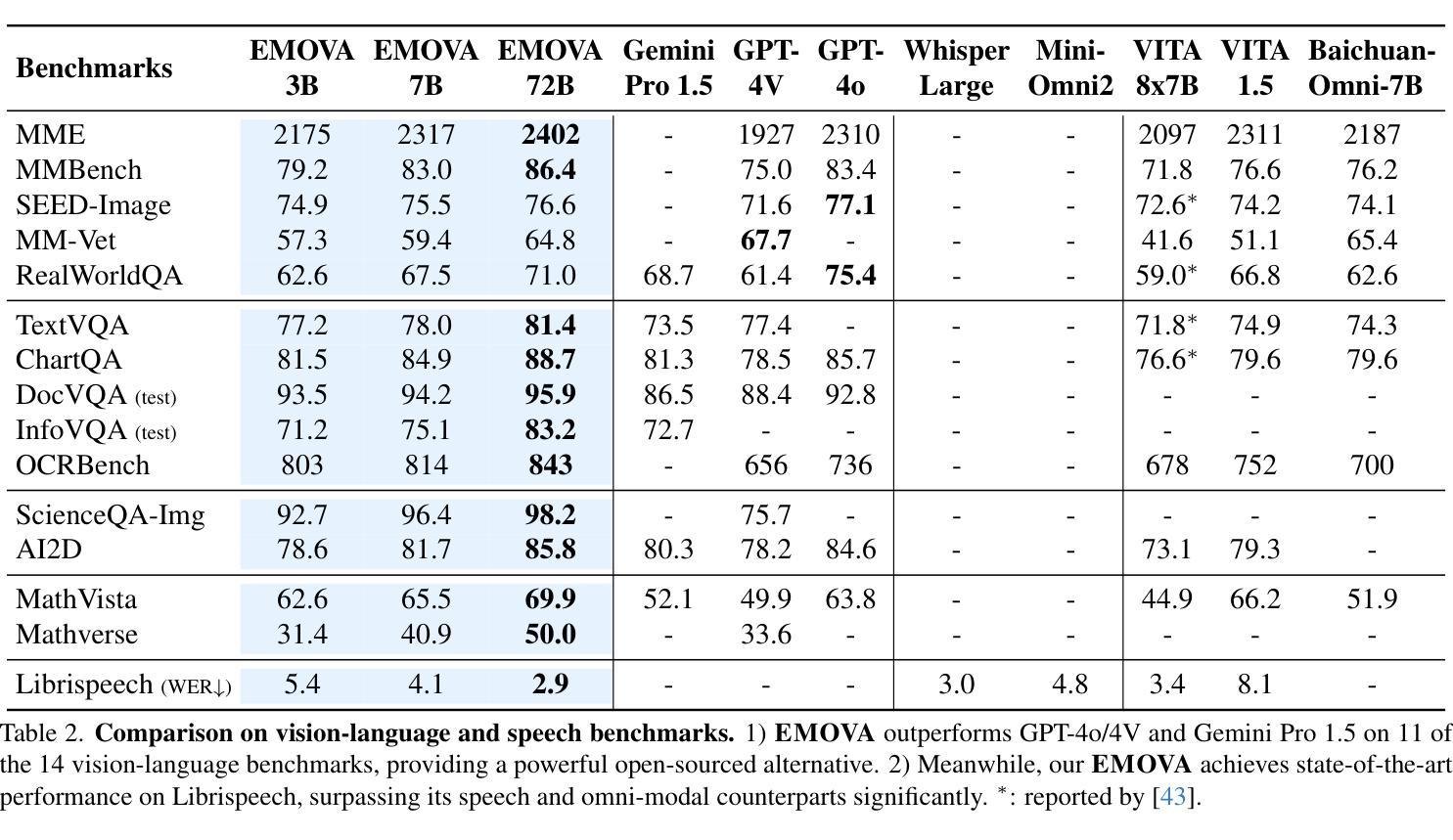
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Authors:Kai Chen, Yunhao Gou, Runhui Huang, Zhili Liu, Daxin Tan, Jing Xu, Chunwei Wang, Yi Zhu, Yihan Zeng, Kuo Yang, Dingdong Wang, Kun Xiang, Haoyuan Li, Haoli Bai, Jianhua Han, Xiaohui Li, Weike Jin, Nian Xie, Yu Zhang, James T. Kwok, Hengshuang Zhao, Xiaodan Liang, Dit-Yan Yeung, Xiao Chen, Zhenguo Li, Wei Zhang, Qun Liu, Jun Yao, Lanqing Hong, Lu Hou, Hang Xu
GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging for the open-source community. Existing vision-language models rely on external tools for speech processing, while speech-language models still suffer from limited or totally without vision-understanding capabilities. To address this gap, we propose the EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech abilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we surprisingly notice that omni-modal alignment can further enhance vision-language and speech abilities compared with the bi-modal aligned counterparts. Moreover, a lightweight style module is introduced for the flexible speech style controls including emotions and pitches. For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
GPT-4o是一款支持带有多种情感和语调的声音对话的跨模态模型,它为跨模态基础模型的发展树立了里程碑。然而,对于开源社区而言,利用大型语言模型感知和生成图像、文本和语音等端到端的数据仍然是一个挑战。现有的视觉语言模型依赖于外部工具进行语音处理,而语音语言模型仍然受到有限的或完全没有视觉理解能力的困扰。为了解决这一差距,我们提出了情感无处不在的语音助手(EMOVA),使大型语言模型具备端到端的语音能力,同时保持领先的视觉语言性能。通过语义声学分拆的语音标记器,我们发现跨模态对齐能进一步增强了视觉语言和语音的能力相比传统双模态对齐的方法。此外,我们还引入了一个轻量级风格模块,用于灵活的语音风格控制,包括情感和音调。首次实现了在视觉语言和语音基准测试上都达到了最佳表现,同时支持带有生动情感的跨模态口语对话。
论文及项目相关链接
PDF Accepted by CVPR 2025. Project Page: https://emova-ollm.github.io/
Summary
GPT-4o模型在支持跨模态对话中具有里程碑意义,能够支持多样化的情感和语调。然而,公开数据集中端到端感知和生成图像、文本和语音仍存在挑战。EMOVA模型旨在实现大型语言模型的端到端语音能力,同时保持领先的视觉语言性能。引入语义声学分离的语音分词器,发现多模态对齐能提高视觉语言和语音能力。此外,引入轻量级风格模块实现灵活的语音风格控制,包括情感和音调。EMOVA首次在视觉语言和语音基准测试中取得最先进的性能,并支持具有生动情感的跨模态语音对话。
Key Takeaways
- GPT-4o模型支持跨模态对话中具有多样化的情感和语调。
- EMOVA模型旨在实现大型语言模型的端到端语音能力。
- EMOVA模型引入语义声学分离的语音分词器以提高性能。
- 多模态对齐能提高视觉语言和语音能力。
- 轻量级风格模块实现灵活的语音风格控制,包括情感和音调控制。
- EMOVA在视觉语言和语音基准测试中表现先进。
点此查看论文截图