⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
StyleSpeaker: Audio-Enhanced Fine-Grained Style Modeling for Speech-Driven 3D Facial Animation
Authors:An Yang, Chenyu Liu, Pengcheng Xia, Jun Du
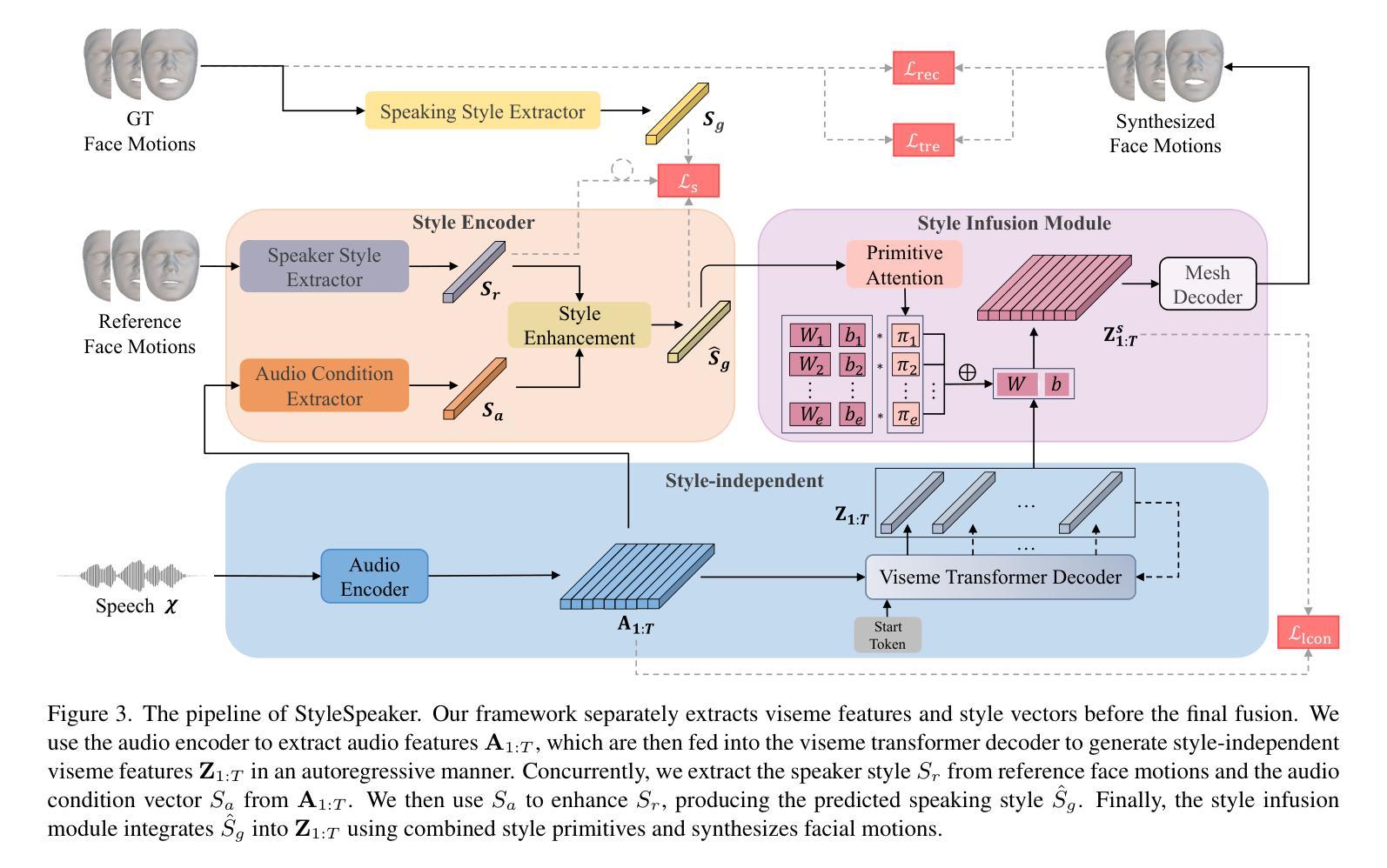
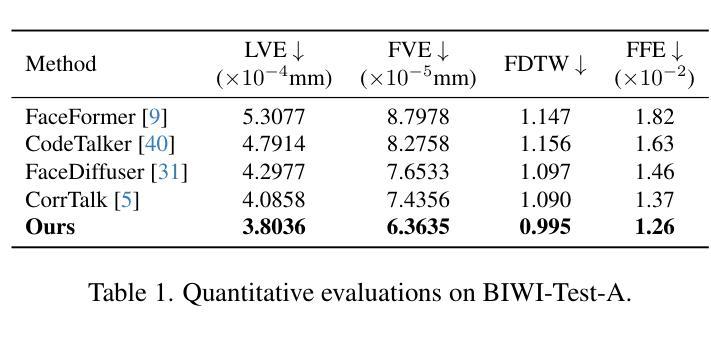
Speech-driven 3D facial animation is challenging due to the diversity in speaking styles and the limited availability of 3D audio-visual data. Speech predominantly dictates the coarse motion trends of the lip region, while specific styles determine the details of lip motion and the overall facial expressions. Prior works lack fine-grained learning in style modeling and do not adequately consider style biases across varying speech conditions, which reduce the accuracy of style modeling and hamper the adaptation capability to unseen speakers. To address this, we propose a novel framework, StyleSpeaker, which explicitly extracts speaking styles based on speaker characteristics while accounting for style biases caused by different speeches. Specifically, we utilize a style encoder to capture speakers’ styles from facial motions and enhance them according to motion preferences elicited by varying speech conditions. The enhanced styles are then integrated into the coarse motion features via a style infusion module, which employs a set of style primitives to learn fine-grained style representation. Throughout training, we maintain this set of style primitives to comprehensively model the entire style space. Hence, StyleSpeaker possesses robust style modeling capability for seen speakers and can rapidly adapt to unseen speakers without fine-tuning. Additionally, we design a trend loss and a local contrastive loss to improve the synchronization between synthesized motions and speeches. Extensive qualitative and quantitative experiments on three public datasets demonstrate that our method outperforms existing state-of-the-art approaches.
语音驱动的3D面部动画由于说话风格的多样性和3D视听数据的有限可用性而具有挑战性。语音主要决定唇部的粗略运动趋势,而特定风格则决定唇部运动的细节和整体面部表情。之前的研究在风格建模方面缺乏精细学习,没有充分考虑不同语音条件下的风格偏见,这降低了风格建模的准确性,并阻碍了对新说话者的适应能力。为了解决这一问题,我们提出了一种新的框架StyleSpeaker,它根据说话人的特点明确提取说话风格,同时考虑不同语音引起的风格偏见。具体来说,我们利用风格编码器从面部运动中捕捉说话人的风格,并根据不同语音条件引发的运动偏好进行增强。然后,将增强的风格通过风格注入模块集成到粗略运动特征中,该模块使用一组风格原始元素来学习精细的风格表示。在训练过程中,我们保持这组风格原始元素来全面建模整个风格空间。因此,StyleSpeaker具有对已知说话人的稳健风格建模能力,并且可以快速适应未知说话人而不进行微调。此外,我们设计了趋势损失和局部对比损失,以提高合成动作和语音之间的同步性。在三个公共数据集上进行的大量定性和定量实验表明,我们的方法优于现有的最先进方法。
论文及项目相关链接
Summary
本文提出了一个名为StyleSpeaker的新框架,用于解决语音驱动的三维面部动画中的风格建模问题。该框架能够基于面部运动提取说话人的风格特征,并考虑不同语音条件引起的风格偏差。通过风格编码器和风格融合模块,StyleSpeaker能够学习精细的风格表示,并在训练过程中保持对整个风格空间的全面建模。这使得StyleSpeaker对已知说话人的风格建模能力稳健,并能快速适应未见过的说话人。此外,还设计了趋势损失和局部对比损失以提高合成动作与语音的同步性。在三个公共数据集上的大量定性和定量实验表明,该方法优于现有先进技术。
Key Takeaways
- StyleSpeaker框架解决了语音驱动的三维面部动画中风格建模的挑战。
- 该框架能够提取并基于面部运动增强说话人的风格特征。
- StyleSpeaker通过风格编码器和风格融合模块学习精细的风格表示。
- 框架在训练过程中保持对整个风格空间的全面建模,适应不同说话人的风格。
- StyleSpeaker具有快速适应未见过的说话人的能力。
- 趋势损失和局部对比损失的设计提高了合成动作与语音的同步性。
点此查看论文截图

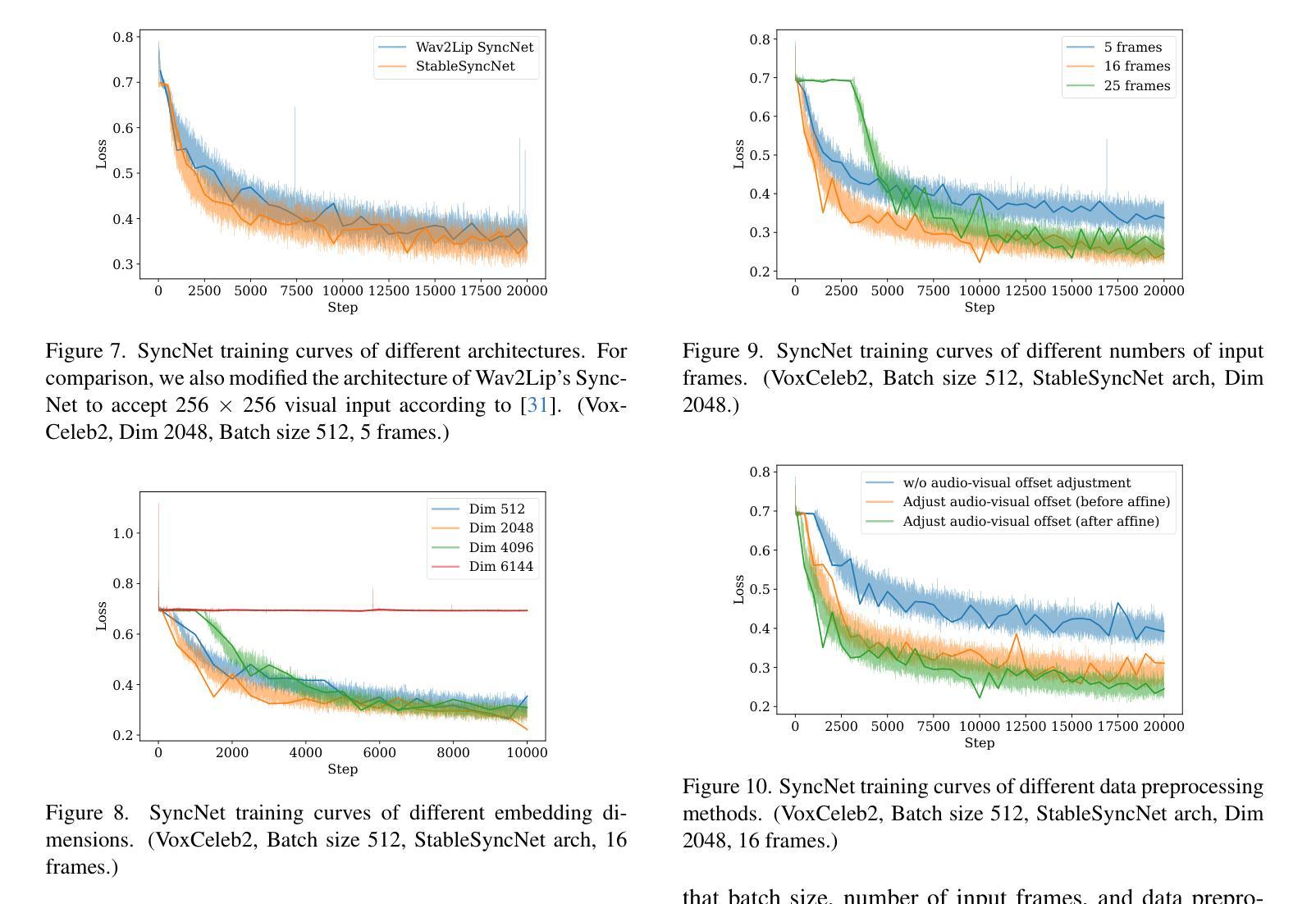
LatentSync: Taming Audio-Conditioned Latent Diffusion Models for Lip Sync with SyncNet Supervision
Authors:Chunyu Li, Chao Zhang, Weikai Xu, Jingyu Lin, Jinghui Xie, Weiguo Feng, Bingyue Peng, Cunjian Chen, Weiwei Xing
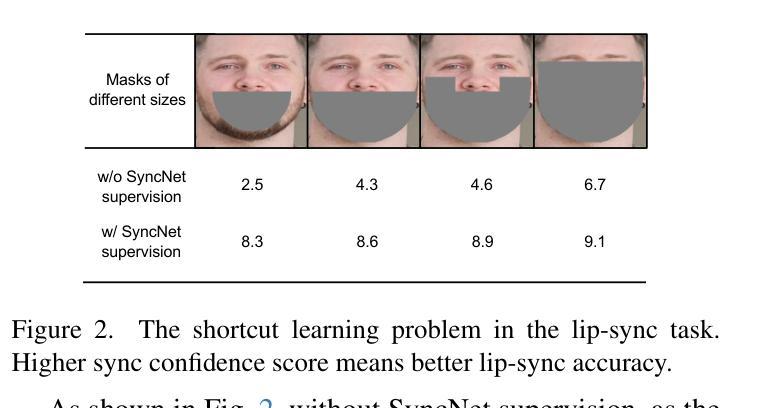
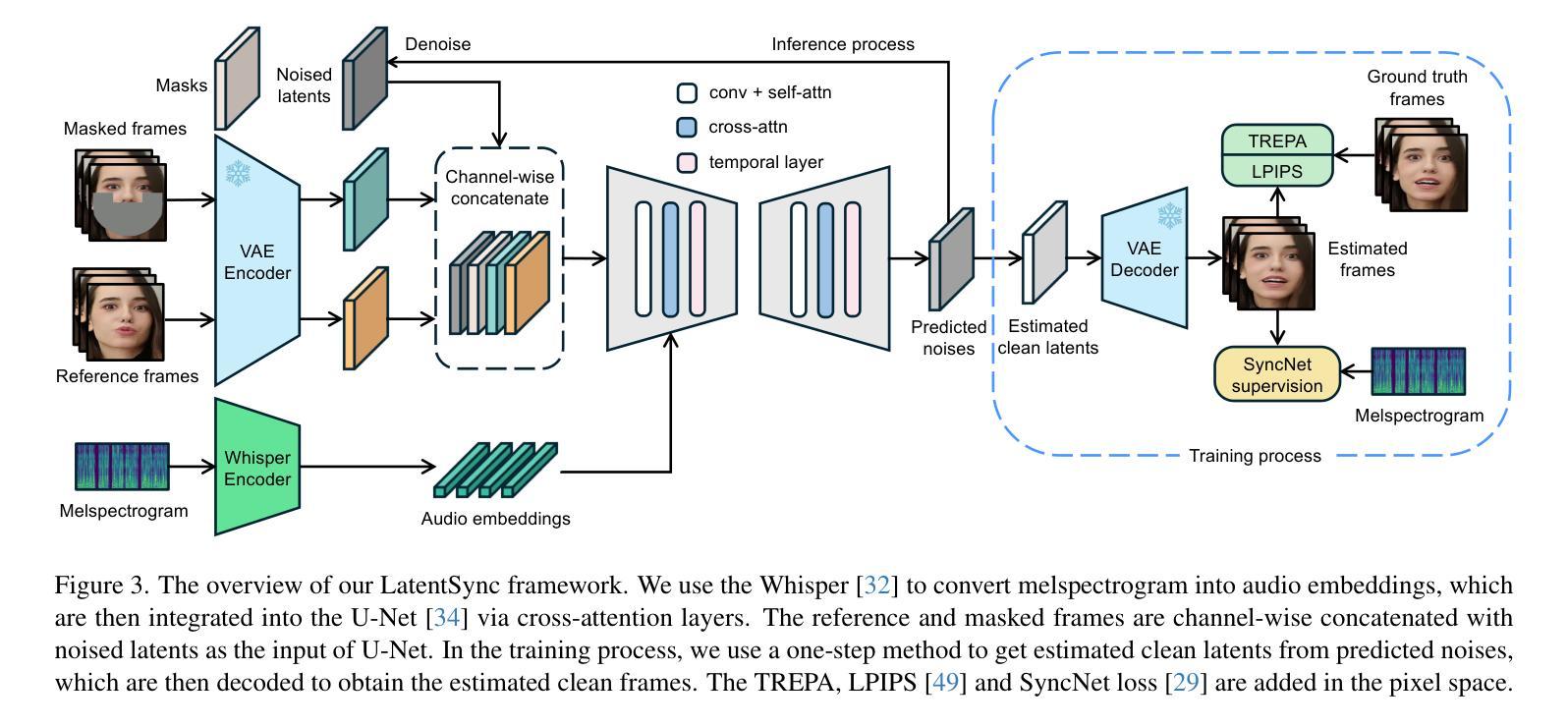
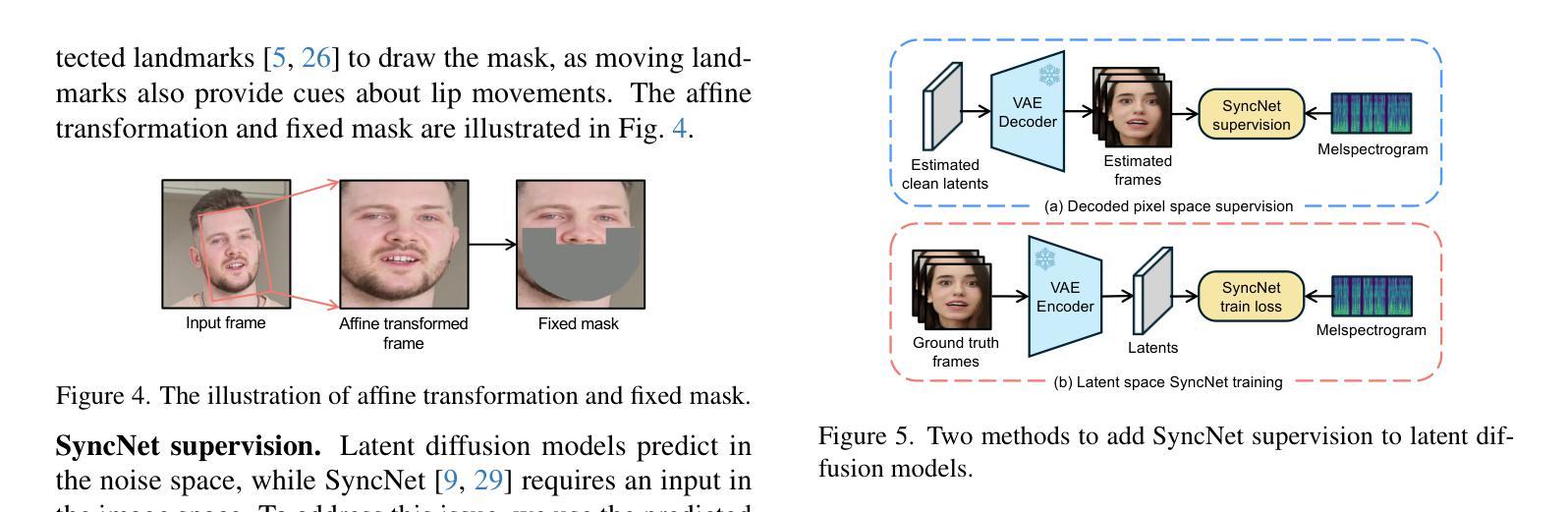
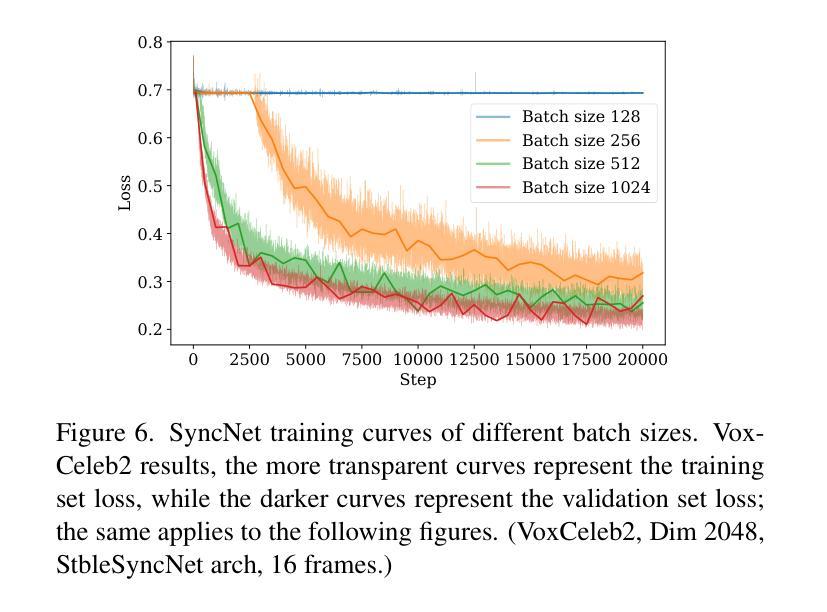
End-to-end audio-conditioned latent diffusion models (LDMs) have been widely adopted for audio-driven portrait animation, demonstrating their effectiveness in generating lifelike and high-resolution talking videos. However, direct application of audio-conditioned LDMs to lip-synchronization (lip-sync) tasks results in suboptimal lip-sync accuracy. Through an in-depth analysis, we identified the underlying cause as the “shortcut learning problem”, wherein the model predominantly learns visual-visual shortcuts while neglecting the critical audio-visual correlations. To address this issue, we explored different approaches for integrating SyncNet supervision into audio-conditioned LDMs to explicitly enforce the learning of audio-visual correlations. Since the performance of SyncNet directly influences the lip-sync accuracy of the supervised model, the training of a well-converged SyncNet becomes crucial. We conducted the first comprehensive empirical studies to identify key factors affecting SyncNet convergence. Based on our analysis, we introduce StableSyncNet, with an architecture designed for stable convergence. Our StableSyncNet achieved a significant improvement in accuracy, increasing from 91% to 94% on the HDTF test set. Additionally, we introduce a novel Temporal Representation Alignment (TREPA) mechanism to enhance temporal consistency in the generated videos. Experimental results show that our method surpasses state-of-the-art lip-sync approaches across various evaluation metrics on the HDTF and VoxCeleb2 datasets.
端到端的音频条件潜在扩散模型(LDM)已被广泛应用于音频驱动的肖像动画,证明了其在生成逼真、高分辨率的说话视频方面的有效性。然而,直接将音频条件的LDM应用于唇部同步(唇同步)任务会导致唇部同步精度不佳。通过深入分析,我们将根本原因识别为“捷径学习问题”,即模型主要学习视觉-视觉捷径,而忽视关键的音频-视觉关联。为了解决这一问题,我们探索了将SyncNet监督集成到音频条件LDM中的不同方法,以明确强制学习音频-视觉关联。由于SyncNet的性能直接影响监督模型的唇部同步精度,因此训练一个良好收敛的SyncNet变得至关重要。我们进行了首次全面的实证研究,以确定影响SyncNet收敛的关键因素。基于我们的分析,我们引入了StableSyncNet,其架构旨在实现稳定收敛。我们的StableSyncNet在HDTF测试集上的准确率从91%显著提高到94%。此外,我们引入了一种新的时间表示对齐(TREPA)机制,以提高生成视频的时间一致性。实验结果表明,我们的方法在HDTF和VoxCeleb2数据集的各种评估指标上超越了最先进的唇部同步方法。
论文及项目相关链接
Summary
本文探讨了音频驱动的肖像动画中的端对端音频条件潜在扩散模型(LDMs)。尽管LDM在生成高质量视频方面表现出色,但在唇同步任务中直接应用时,其唇同步精度并不理想。研究发现,模型主要学习视觉快捷方式而忽视关键的音视频关联,导致“捷径学习问题”。为解决此问题,本文探索将SyncNet监督方法融入音频条件LDM中,以强制学习音视频关联。本文还进行了开创性的实证研究,确定了影响SyncNet收敛的关键因素,并基于此引入了StableSyncNet架构以提高收敛稳定性。此外,为提高生成视频的时空一致性,引入了一种新颖的Temporal Representation Alignment(TREPA)机制。实验结果证明,该方法在HDTF和VoxCeleb2数据集上超越了现有唇同步方法。
Key Takeaways
- 音频条件潜在扩散模型(LDMs)广泛应用于音频驱动的肖像动画,但在唇同步任务中直接应用时存在精度问题。
- 问题的根源在于模型的“捷径学习问题”,即模型主要学习视觉快捷方式而忽视关键的音视频关联。
- 提出将SyncNet监督方法融入音频条件LDM中,以强制学习音视频关联,从而提高唇同步精度。
- 进行了开创性的实证研究,确定了影响SyncNet收敛的关键因素。
- 基于分析引入了StableSyncNet架构,实现了显著的唇同步精度提升。
- 引入Temporal Representation Alignment(TREPA)机制,提高了生成视频的时空一致性。
点此查看论文截图