⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-15 更新
KUDA: Keypoints to Unify Dynamics Learning and Visual Prompting for Open-Vocabulary Robotic Manipulation
Authors:Zixian Liu, Mingtong Zhang, Yunzhu Li
With the rapid advancement of large language models (LLMs) and vision-language models (VLMs), significant progress has been made in developing open-vocabulary robotic manipulation systems. However, many existing approaches overlook the importance of object dynamics, limiting their applicability to more complex, dynamic tasks. In this work, we introduce KUDA, an open-vocabulary manipulation system that integrates dynamics learning and visual prompting through keypoints, leveraging both VLMs and learning-based neural dynamics models. Our key insight is that a keypoint-based target specification is simultaneously interpretable by VLMs and can be efficiently translated into cost functions for model-based planning. Given language instructions and visual observations, KUDA first assigns keypoints to the RGB image and queries the VLM to generate target specifications. These abstract keypoint-based representations are then converted into cost functions, which are optimized using a learned dynamics model to produce robotic trajectories. We evaluate KUDA on a range of manipulation tasks, including free-form language instructions across diverse object categories, multi-object interactions, and deformable or granular objects, demonstrating the effectiveness of our framework. The project page is available at http://kuda-dynamics.github.io.
随着大型语言模型(LLMs)和视觉语言模型(VLMs)的快速发展,开放词汇机器人操作系统在开发方面取得了重大进展。然而,许多现有方法忽视了物体动力学的重要性,限制了它们在更复杂、动态的任务中的应用。在这项工作中,我们介绍了KUDA,这是一个开放词汇的操作系统,它通过关键点整合动力学学习和视觉提示,利用VLMs和基于学习的神经动力学模型。我们的关键见解是,基于关键点的目标规格可以同时被VLMs解释,并能有效地转化为基于模型的规划的成本函数。给定语言指令和视觉观察,KUDA首先将关键点分配给RGB图像并查询VLM以生成目标规格。这些抽象的基于关键点的表示然后被转换成成本函数,使用学习到的动力学模型进行优化以产生机器人轨迹。我们在一系列操作任务上评估了KUDA,包括跨不同对象类别的自由形式语言指令、多对象交互以及可变形或颗粒状物体,展示了我们的框架的有效性。项目页面可在[http://kuda-dynamics.github.io]上找到。
论文及项目相关链接
PDF Project website: http://kuda-dynamics.github.io
Summary
本文介绍了KUDA这一开放词汇操作系统的研究进展,该系统结合了动力学学习和视觉提示的关键点技术,利用视觉语言模型和基于学习的神经动力学模型,实现了对复杂动态任务的广泛适用性。其核心在于将基于关键点的目标特定描述转换为抽象表示,并进一步转化为成本函数,用于基于模型的规划。系统通过语言指令和视觉观察进行工作,能在RGB图像上分配关键点并查询视觉语言模型生成目标特定描述。此外,KUDA在多种操作任务上进行了评估,包括自由形式的语言指令、多对象交互以及可变形或颗粒状物体等,展示了其框架的有效性。
Key Takeaways
- 该研究引入了KUDA这一开放词汇操作系统,该系统结合了动力学学习和视觉提示技术。
- KUDA利用视觉语言模型和基于学习的神经动力学模型来改进机器人操作能力。
- 该系统的核心在于通过关键点技术实现目标特定描述的可视化和理解,使机器人能够执行复杂动态任务。
- 系统通过语言指令和视觉观察进行工作,能在RGB图像上分配关键点并查询视觉语言模型生成目标描述。
- 基于关键点的抽象表示被转化为成本函数,用于优化机器人轨迹规划。
- KUDA在多种操作任务上进行了评估,包括自由形式语言指令、多对象交互以及处理可变形或颗粒状物体等场景。
点此查看论文截图



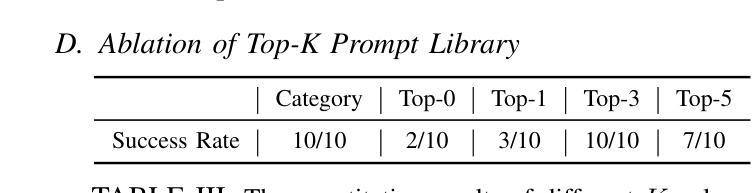
4D LangSplat: 4D Language Gaussian Splatting via Multimodal Large Language Models
Authors:Wanhua Li, Renping Zhou, Jiawei Zhou, Yingwei Song, Johannes Herter, Minghan Qin, Gao Huang, Hanspeter Pfister
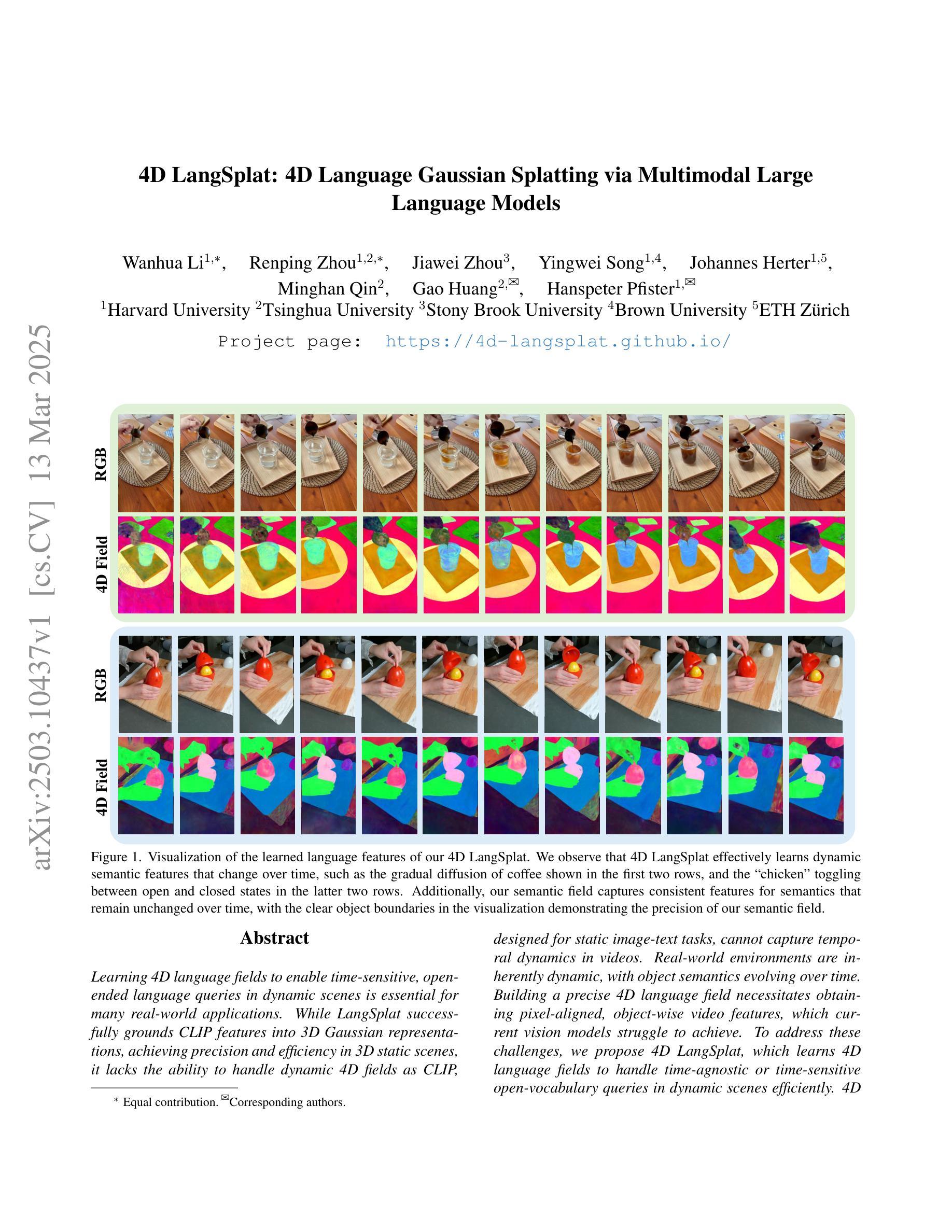
Learning 4D language fields to enable time-sensitive, open-ended language queries in dynamic scenes is essential for many real-world applications. While LangSplat successfully grounds CLIP features into 3D Gaussian representations, achieving precision and efficiency in 3D static scenes, it lacks the ability to handle dynamic 4D fields as CLIP, designed for static image-text tasks, cannot capture temporal dynamics in videos. Real-world environments are inherently dynamic, with object semantics evolving over time. Building a precise 4D language field necessitates obtaining pixel-aligned, object-wise video features, which current vision models struggle to achieve. To address these challenges, we propose 4D LangSplat, which learns 4D language fields to handle time-agnostic or time-sensitive open-vocabulary queries in dynamic scenes efficiently. 4D LangSplat bypasses learning the language field from vision features and instead learns directly from text generated from object-wise video captions via Multimodal Large Language Models (MLLMs). Specifically, we propose a multimodal object-wise video prompting method, consisting of visual and text prompts that guide MLLMs to generate detailed, temporally consistent, high-quality captions for objects throughout a video. These captions are encoded using a Large Language Model into high-quality sentence embeddings, which then serve as pixel-aligned, object-specific feature supervision, facilitating open-vocabulary text queries through shared embedding spaces. Recognizing that objects in 4D scenes exhibit smooth transitions across states, we further propose a status deformable network to model these continuous changes over time effectively. Our results across multiple benchmarks demonstrate that 4D LangSplat attains precise and efficient results for both time-sensitive and time-agnostic open-vocabulary queries.
学习4D语言场域以实现动态场景中的时间敏感型开放语言查询对于许多现实世界应用至关重要。虽然LangSplat成功地将CLIP特征嵌入到3D高斯表示中,在3D静态场景中实现了精度和效率,但它缺乏处理动态4D场域的能力,因为CLIP是为静态图像文本任务设计的,无法捕捉视频中的时间动态。现实世界的环境本质上是动态的,物体语义会随时间演变。构建精确的4D语言场域需要获得像素对齐的物体级视频特征,而当前视觉模型很难做到这一点。为了应对这些挑战,我们提出了4D LangSplat,它学习4D语言场域以高效地处理动态场景中的时间无关或时间敏感型开放式词汇查询。4D LangSplat绕过从视觉特征中学习语言场域的方法,而是直接从通过多媒体大型语言模型(MLLMs)生成的物体级视频字幕中学习。具体来说,我们提出了一种多媒体物体级视频提示方法,包括视觉和文本提示,引导MLLMs为视频中的对象生成详细、时间一致、高质量的字幕。这些字幕使用大型语言模型进行编码,以生成高质量句子嵌入,然后作为像素对齐的物体特定特征监督,通过共享嵌入空间实现开放式词汇文本查询。我们认识到4D场景中的对象在状态之间呈现出平滑过渡,因此进一步提出了状态可变形网络来有效模拟这些随时间变化的连续变化。我们在多个基准测试上的结果表明,4D LangSplat对于时间敏感型和时间无关型的开放式词汇查询都达到了精确而高效的结果。
论文及项目相关链接
PDF CVPR 2025. Project Page: https://4d-langsplat.github.io
摘要
学习4D语言场域以处理动态场景中的时间敏感和非时间敏感的开放词汇查询对于许多实际应用至关重要。虽然LangSplat成功地将CLIP特性转化为3D高斯表示,但在处理动态4D场域方面仍有不足。本文提出4D LangSplat,通过直接从由对象级视频字幕生成的多模态大型语言模型(MLLMs)学习语言场域,以处理动态场景中的时间无关或时间敏感的开放词汇查询。具体而言,我们提出了一种多模态对象级视频提示方法,包括视觉和文本提示,引导MLLMs为视频中的对象生成详细、时间一致的高质量字幕。这些字幕通过大型语言模型编码为高质量的句子嵌入,作为像素对齐的对象特定特征监督,通过共享嵌入空间实现开放词汇文本查询。考虑到4D场景中对象状态变化的平滑过渡,我们进一步提出了状态可变形网络,以有效模拟这些随时间变化的连续变化。多项基准测试的结果表明,4D LangSplat对时间敏感和时间无关的开放词汇查询都能达到精确和高效的结果。
关键见解
- 学习4D语言场域对于处理动态场景中的语言查询至关重要。
- LangSplat在3D静态场景中具有精度和效率,但无法处理动态4D场域。
- 4D LangSplat通过直接从对象级视频字幕生成的多模态大型语言模型(MLLMs)学习语言场域。
- 提出了一种多模态对象级视频提示方法,包括视觉和文本提示,为视频中的对象生成高质量字幕。
- 通过大型语言模型将字幕编码为句子嵌入,作为对象特定特征监督。
- 共享嵌入空间实现了开放词汇文本查询。
点此查看论文截图
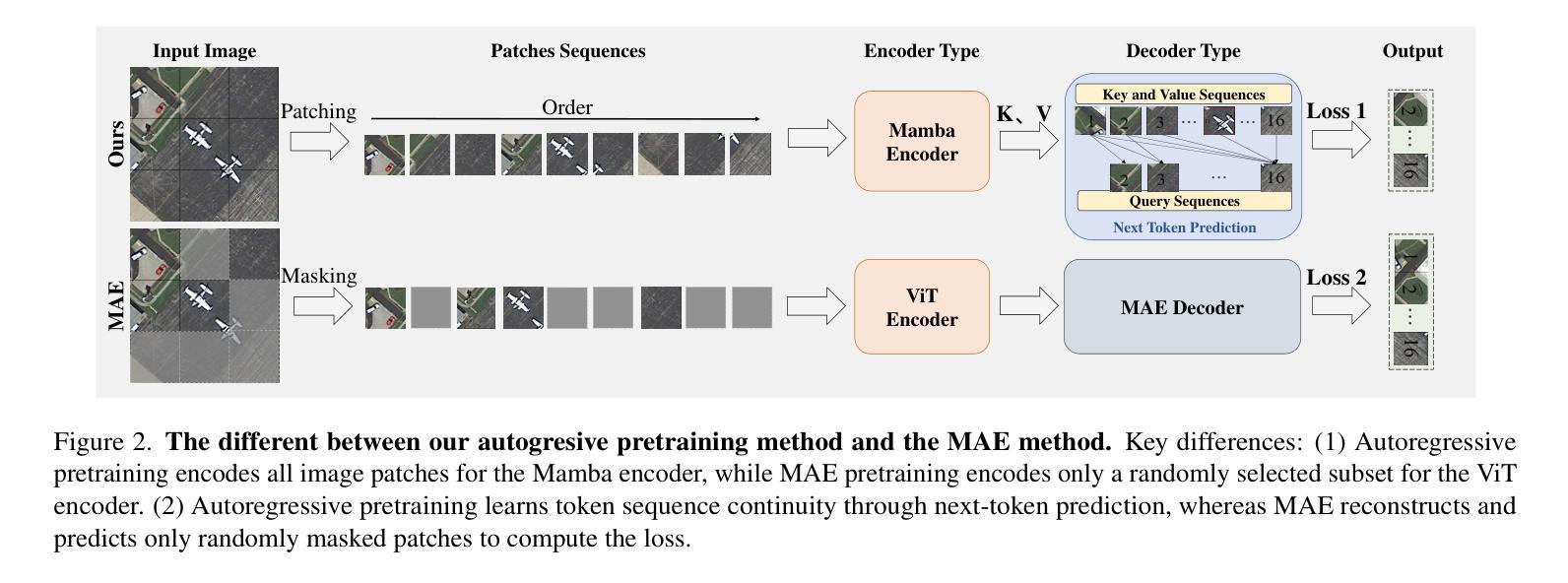
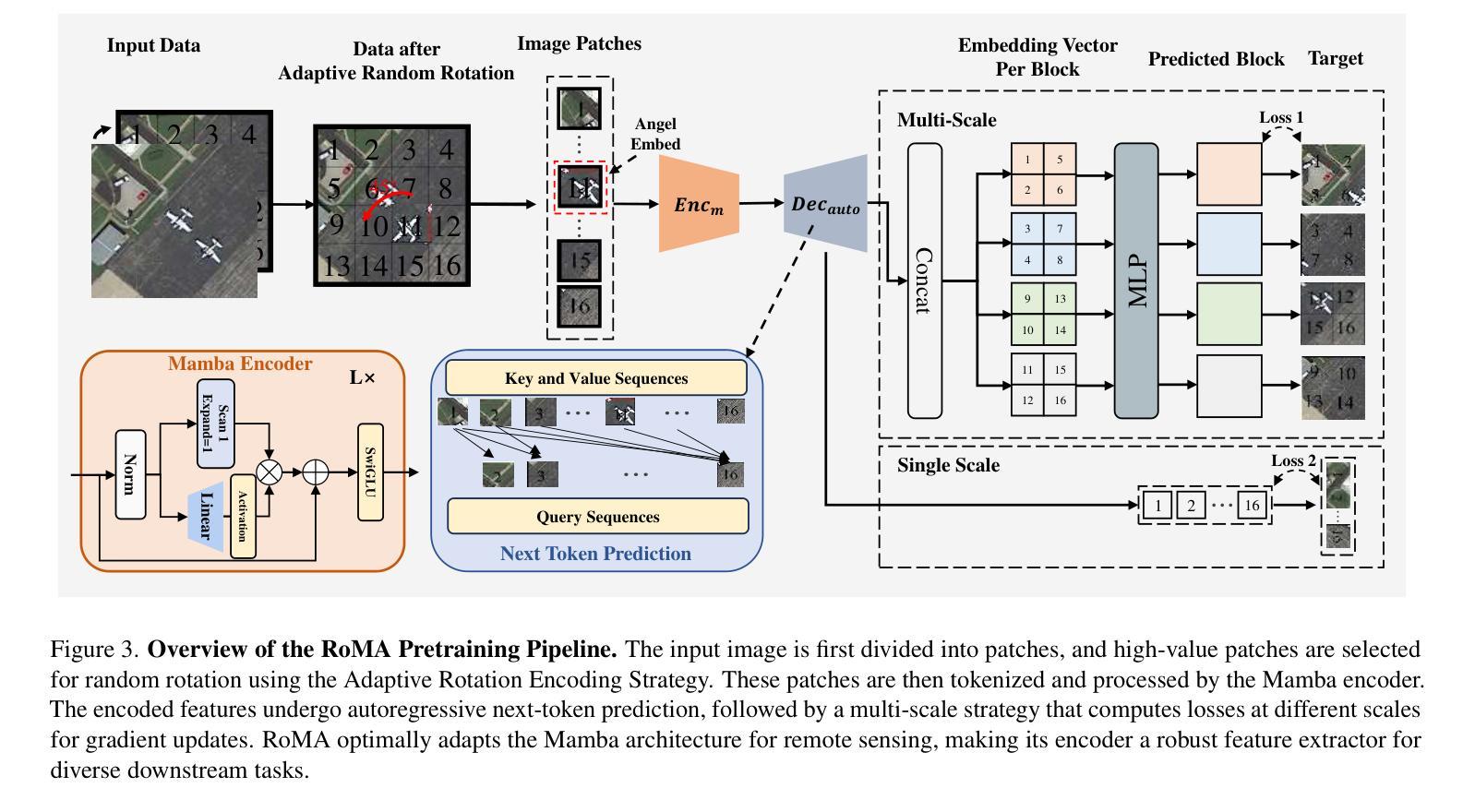
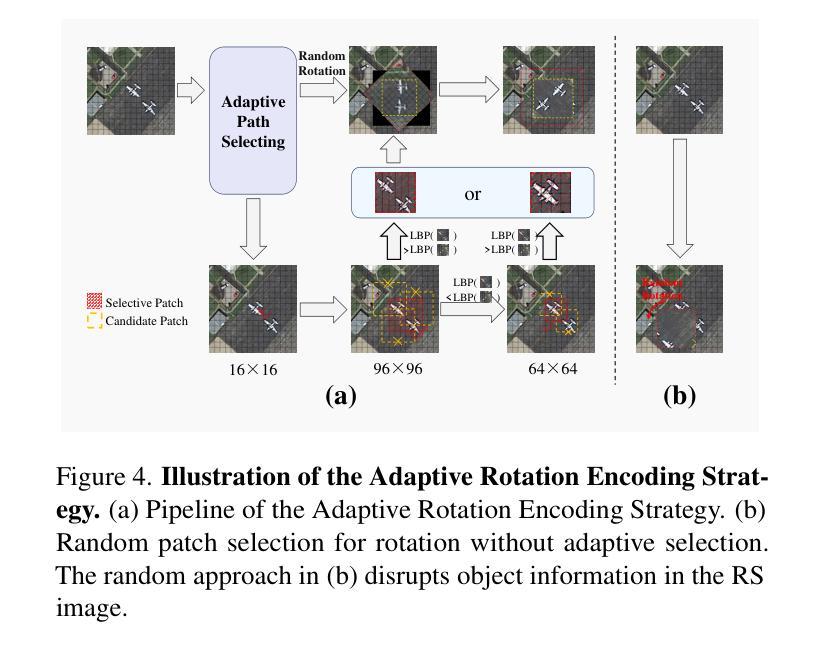
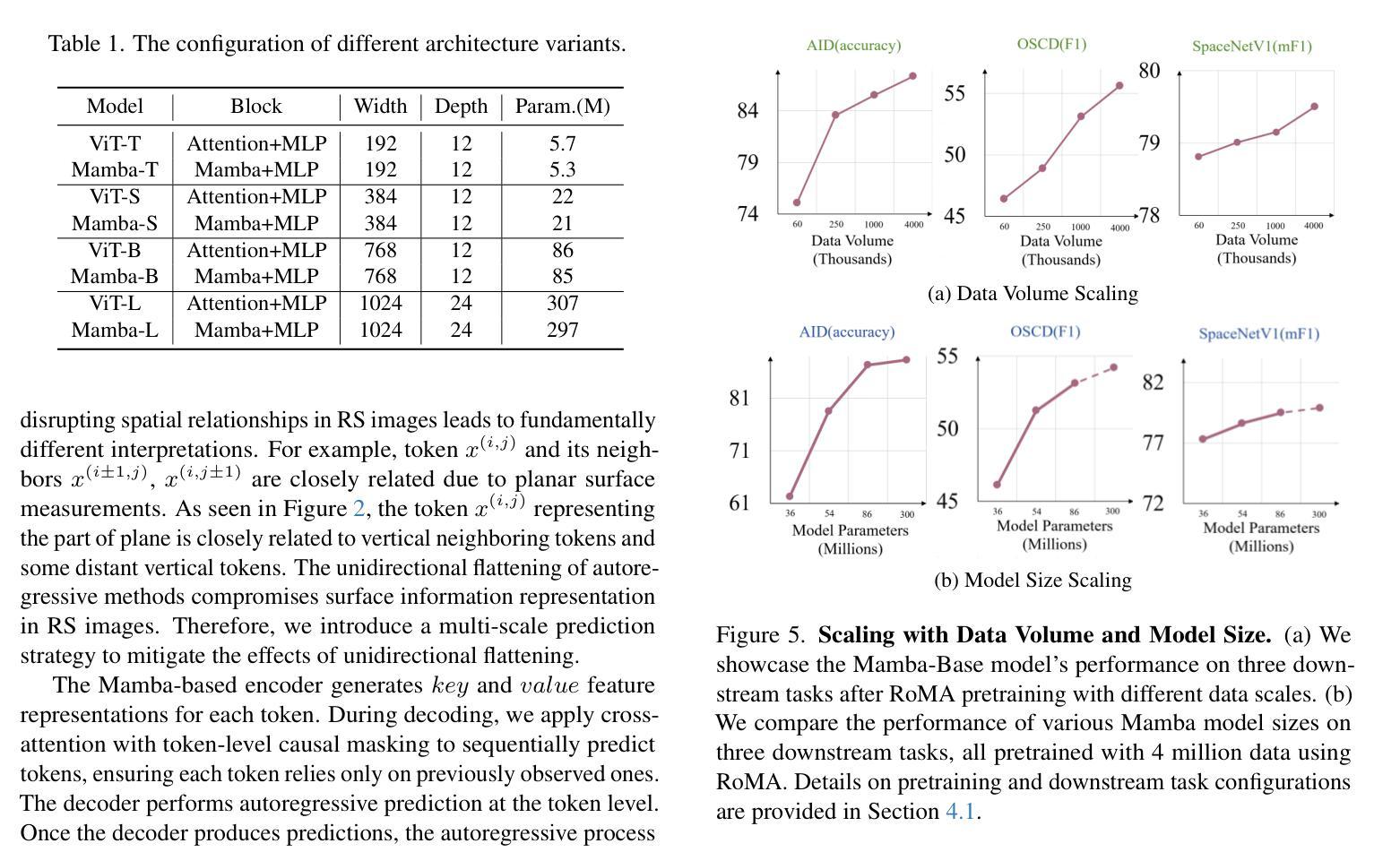
RoMA: Scaling up Mamba-based Foundation Models for Remote Sensing
Authors:Fengxiang Wang, Hongzhen Wang, Yulin Wang, Di Wang, Mingshuo Chen, Haiyan Zhao, Yangang Sun, Shuo Wang, Long Lan, Wenjing Yang, Jing Zhang
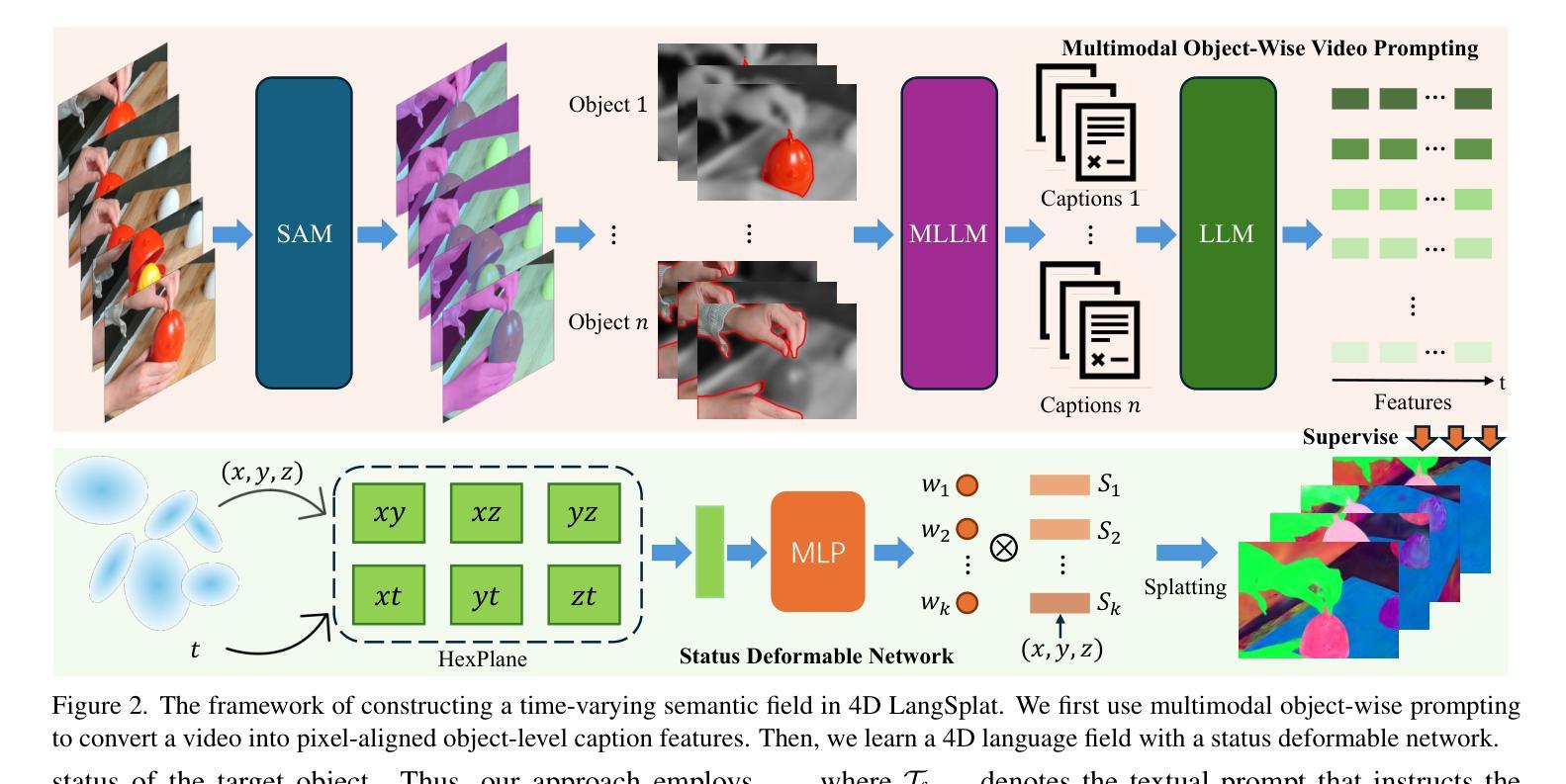
Recent advances in self-supervised learning for Vision Transformers (ViTs) have fueled breakthroughs in remote sensing (RS) foundation models. However, the quadratic complexity of self-attention poses a significant barrier to scalability, particularly for large models and high-resolution images. While the linear-complexity Mamba architecture offers a promising alternative, existing RS applications of Mamba remain limited to supervised tasks on small, domain-specific datasets. To address these challenges, we propose RoMA, a framework that enables scalable self-supervised pretraining of Mamba-based RS foundation models using large-scale, diverse, unlabeled data. RoMA enhances scalability for high-resolution images through a tailored auto-regressive learning strategy, incorporating two key innovations: 1) a rotation-aware pretraining mechanism combining adaptive cropping with angular embeddings to handle sparsely distributed objects with arbitrary orientations, and 2) multi-scale token prediction objectives that address the extreme variations in object scales inherent to RS imagery. Systematic empirical studies validate that Mamba adheres to RS data and parameter scaling laws, with performance scaling reliably as model and data size increase. Furthermore, experiments across scene classification, object detection, and semantic segmentation tasks demonstrate that RoMA-pretrained Mamba models consistently outperform ViT-based counterparts in both accuracy and computational efficiency. The source code and pretrained models will be released at https://github.com/MiliLab/RoMA.
在Vision Transformers(ViTs)的自我监督学习方面最近的进展推动了遥感(RS)基础模型的突破。然而,自注意力的二次复杂性对可扩展性构成了重大障碍,特别是对于大型模型和高分辨率图像。虽然具有线性复杂度的Mamba架构提供了一个有前途的替代方案,但现有的Mamba遥感应用仅限于小规模特定领域的监督任务数据集。为了解决这些挑战,我们提出了RoMA框架,它使基于Mamba的RS基础模型能够利用大规模、多样化、无标签数据进行可扩展的自我监督预训练。RoMA通过定制的自回归学习策略增强了高分辨率图像的扩展性,其中包含两个关键创新点:1)一种结合自适应裁剪和角度嵌入的旋转感知预训练机制,用于处理具有任意方向稀疏分布的对象;2)多尺度令牌预测目标,解决遥感图像中对象尺度固有的极端变化问题。系统的实证研究验证了Mamba对遥感数据和参数缩放规律的遵循性,随着模型和数据规模的增加,性能可靠地扩展。此外,跨场景分类、对象检测和语义分割任务的实验表明,RoMA预训练的Mamba模型在准确性和计算效率方面始终优于基于ViT的同类模型。源代码和预训练模型将在https://github.com/MiliLab/RoMA发布。
论文及项目相关链接
Summary
本文介绍了针对遥感图像领域的自我监督学习,为大规模远程感知(RS)基础模型提出了一种新的框架RoMA。该框架通过自适应裁剪和角度嵌入的旋转感知预训练机制和多尺度令牌预测目标实现可伸缩的自我监督预训练。经过系统实验验证,RoMA在场景分类、目标检测和语义分割任务上均表现出优越性能。代码和预训练模型可在链接下载。
Key Takeaways
- RoMA框架实现了基于Mamba架构的遥感基础模型的自我监督预训练,解决了大规模图像和高分辨率图像的二次复杂性挑战。
- RoMA框架具有两种关键技术创新:旋转感知预训练机制和具有多尺度令牌预测目标的技术,这些技术可以解决遥感图像中的稀疏分布对象处理及对象尺度的极端变化问题。
- 系统实验表明,Mamba架构适用于遥感数据并具有参数缩放定律,性能和模型和数据规模增加成正比。
- RoMA预训练的Mamba模型在场景分类、目标检测和语义分割任务上均优于基于ViT的模型,表现出更高的准确性和计算效率。
点此查看论文截图
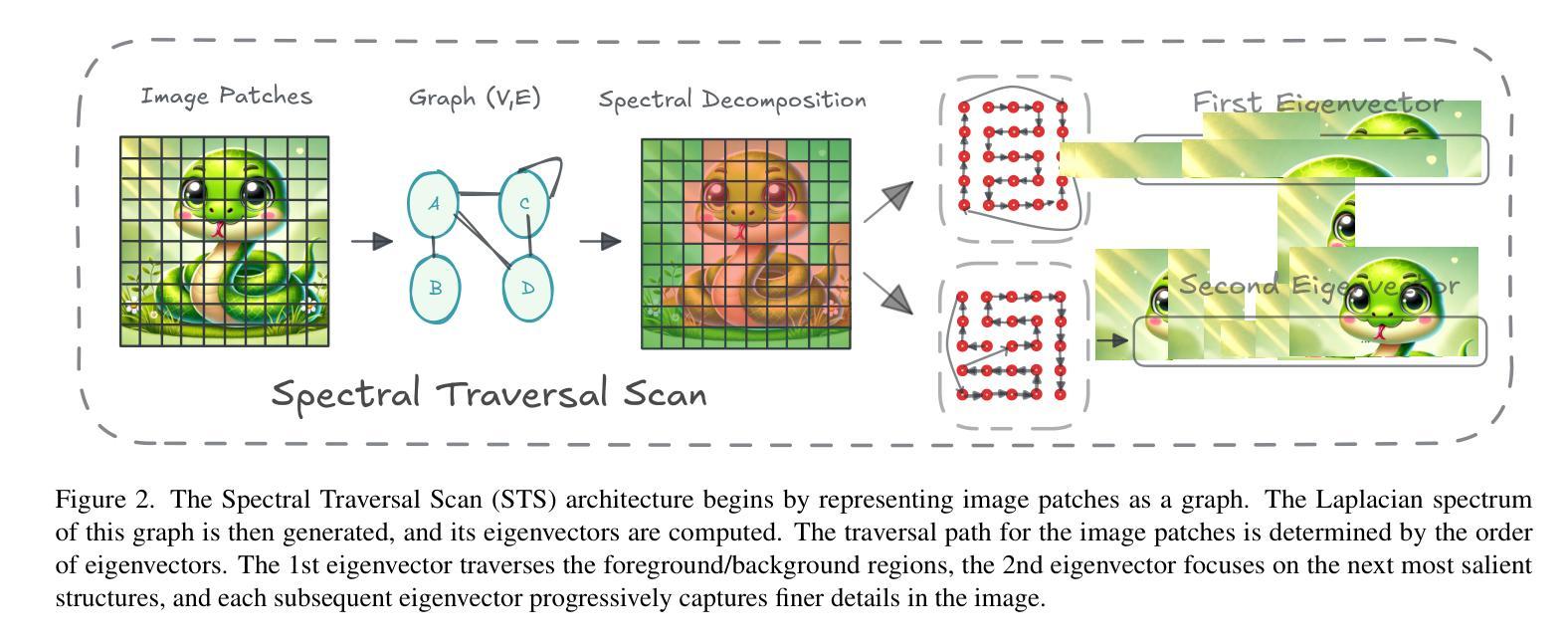
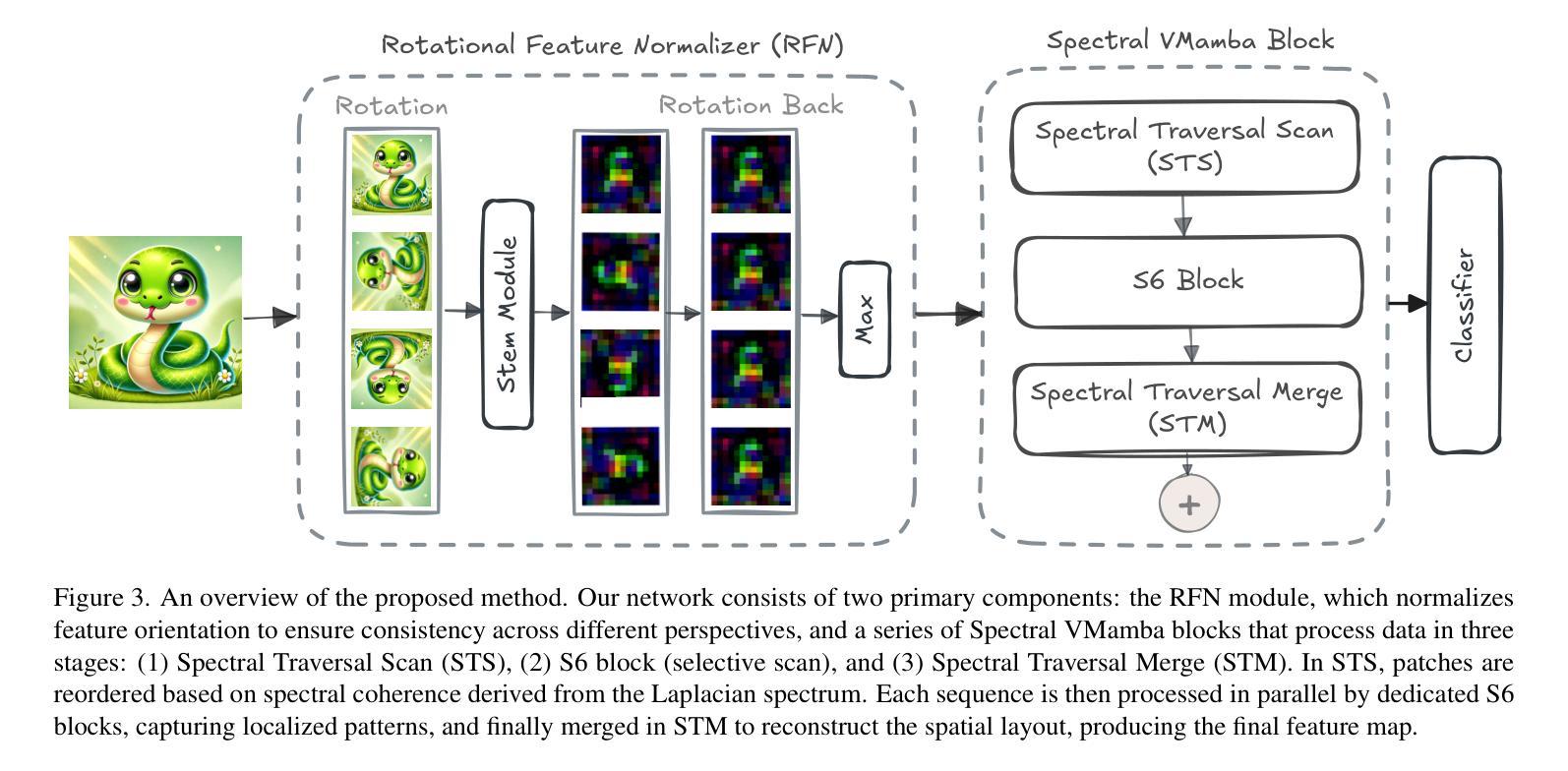
Spectral State Space Model for Rotation-Invariant Visual Representation Learning
Authors:Sahar Dastani, Ali Bahri, Moslem Yazdanpanah, Mehrdad Noori, David Osowiechi, Gustavo Adolfo Vargas Hakim, Farzad Beizaee, Milad Cheraghalikhani, Arnab Kumar Mondal, Herve Lombaert, Christian Desrosiers
State Space Models (SSMs) have recently emerged as an alternative to Vision Transformers (ViTs) due to their unique ability of modeling global relationships with linear complexity. SSMs are specifically designed to capture spatially proximate relationships of image patches. However, they fail to identify relationships between conceptually related yet not adjacent patches. This limitation arises from the non-causal nature of image data, which lacks inherent directional relationships. Additionally, current vision-based SSMs are highly sensitive to transformations such as rotation. Their predefined scanning directions depend on the original image orientation, which can cause the model to produce inconsistent patch-processing sequences after rotation. To address these limitations, we introduce Spectral VMamba, a novel approach that effectively captures the global structure within an image by leveraging spectral information derived from the graph Laplacian of image patches. Through spectral decomposition, our approach encodes patch relationships independently of image orientation, achieving rotation invariance with the aid of our Rotational Feature Normalizer (RFN) module. Our experiments on classification tasks show that Spectral VMamba outperforms the leading SSM models in vision, such as VMamba, while maintaining invariance to rotations and a providing a similar runtime efficiency.
最近,由于状态空间模型(SSMs)具有以线性复杂度对全局关系进行建模的独特能力,它作为视觉转换器(ViTs)的替代品崭露头角。SSMs专门设计用于捕获图像补丁的空间邻近关系。然而,它们无法识别概念上相关但并非相邻的补丁之间的关系。这一局限性源于图像数据的非因果性质,即缺乏固有的方向关系。此外,当前的基于视觉的SSMs对旋转等转换非常敏感。它们的预设扫描方向取决于原始图像的方向,这可能导致模型在旋转后产生不一致的补丁处理序列。为了解决这个问题,我们引入了Spectral VMamba,这是一种通过利用图像补丁图拉普拉斯算子得出的谱信息来有效捕获图像内全局结构的新方法。通过谱分解,我们的方法能够独立于图像方向地编码补丁关系,借助我们的旋转特征归一化器(RFN)模块实现旋转不变性。我们在分类任务上的实验表明,Spectral VMamba在视觉领域超越了领先的SSMs模型,如VMamba,同时保持对旋转的不变性并提供了类似的运行效率。
论文及项目相关链接
Summary
State Space Models(SSMs)具有线性复杂度的全局关系建模能力,但无法识别概念相关但非相邻的图像块之间的关系。为解决此局限性,提出Spectral VMamba方法,利用图像块的图拉普拉斯谱信息,实现全局结构捕捉,并通过谱分解实现旋转不变性。实验表明,Spectral VMamba在图像分类任务上优于领先的SSM模型,如VMamba,同时保持对旋转的不变性并维持相似的运行效率。
Key Takeaways
- State Space Models (SSMs) 能够以线性复杂度建模全局关系。
- SSMs 专门设计用于捕捉图像块的邻近关系,但无法识别概念相关但非相邻的图像块之间的关系。
- SSMs 对旋转等变换高度敏感,依赖于原始图像方向。
- Spectral VMamba方法利用图像块的图拉普拉斯谱信息,实现全局结构捕捉。
- 通过谱分解,Spectral VMamba实现了旋转不变性,借助Rotational Feature Normalizer (RFN)模块实现。
- 实验表明,Spectral VMamba在分类任务上优于其他领先的SSM模型。
点此查看论文截图

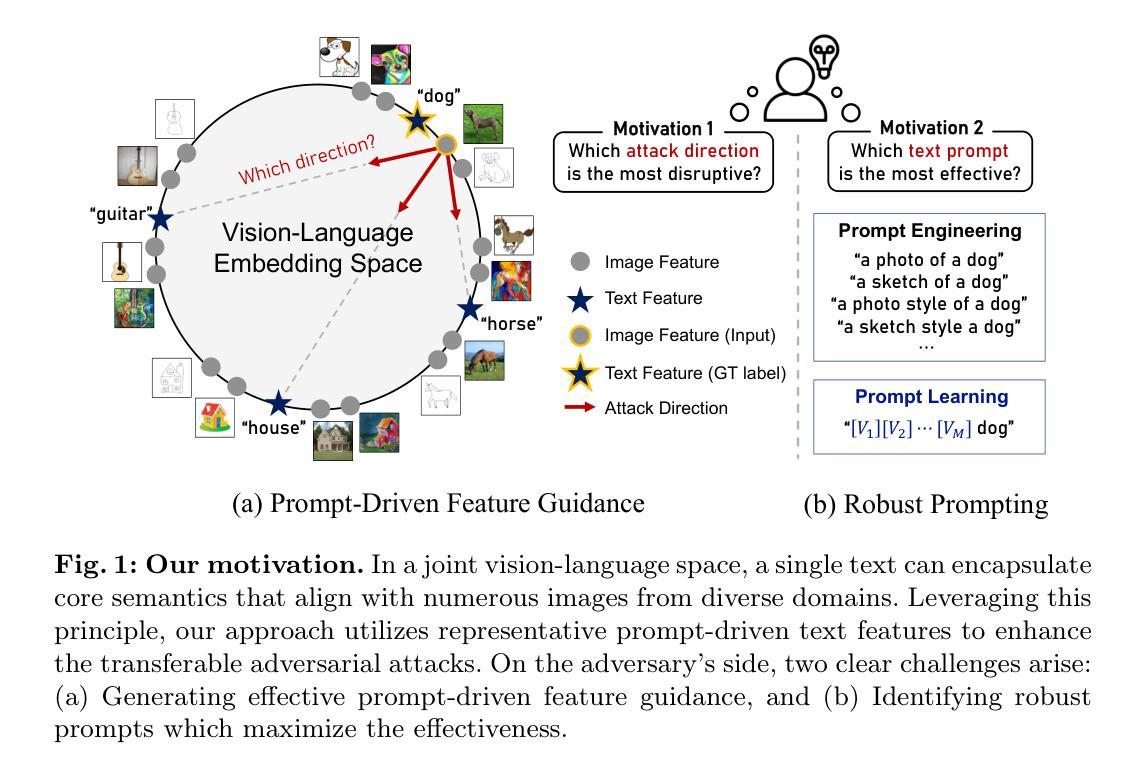
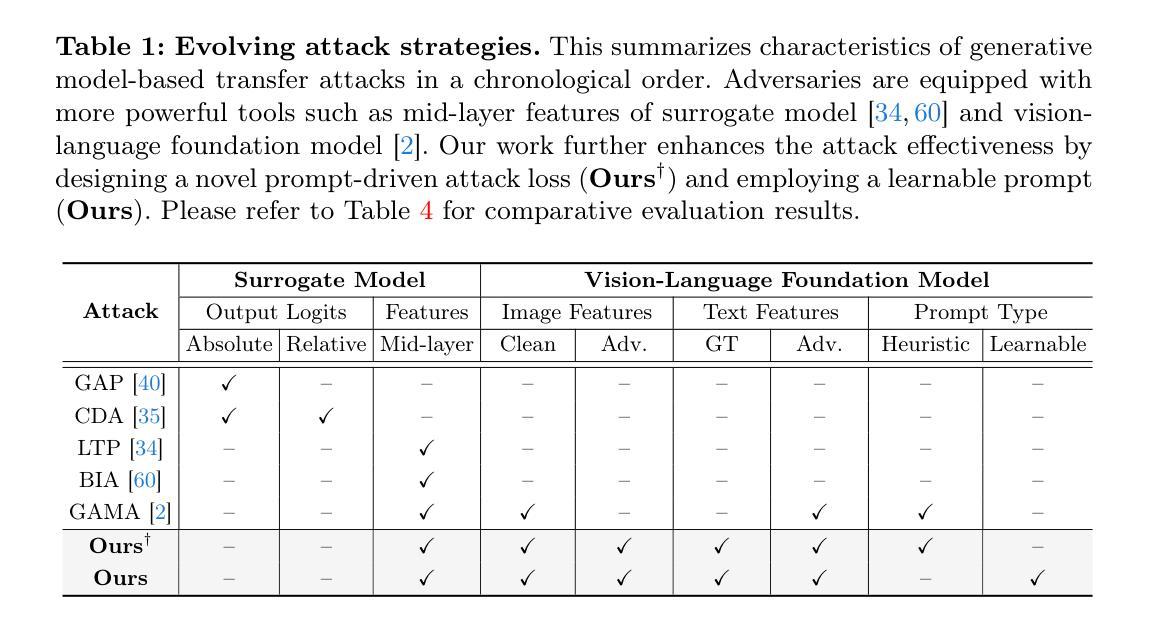
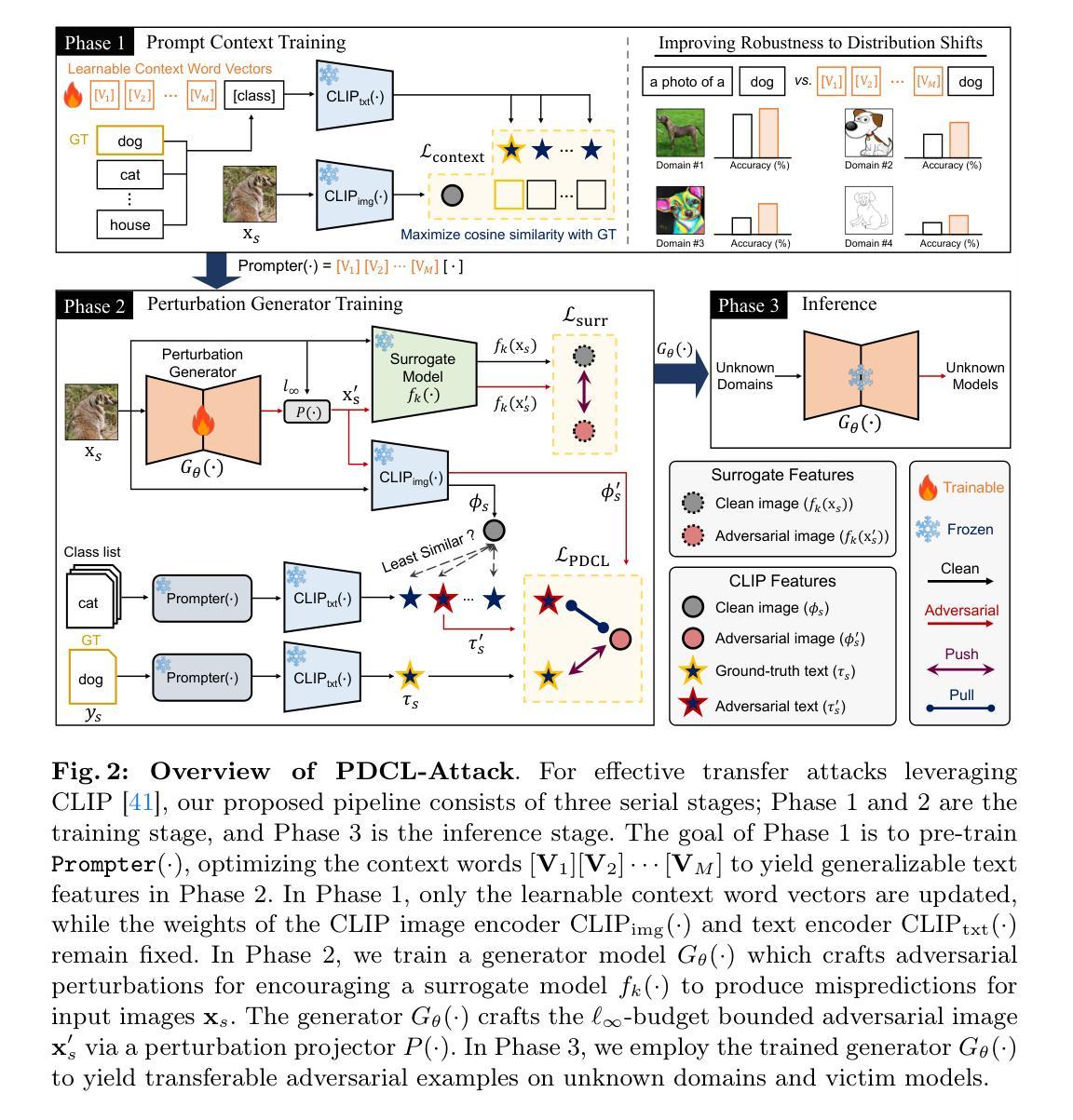
Prompt-Driven Contrastive Learning for Transferable Adversarial Attacks
Authors:Hunmin Yang, Jongoh Jeong, Kuk-Jin Yoon
Recent vision-language foundation models, such as CLIP, have demonstrated superior capabilities in learning representations that can be transferable across diverse range of downstream tasks and domains. With the emergence of such powerful models, it has become crucial to effectively leverage their capabilities in tackling challenging vision tasks. On the other hand, only a few works have focused on devising adversarial examples that transfer well to both unknown domains and model architectures. In this paper, we propose a novel transfer attack method called PDCL-Attack, which leverages the CLIP model to enhance the transferability of adversarial perturbations generated by a generative model-based attack framework. Specifically, we formulate an effective prompt-driven feature guidance by harnessing the semantic representation power of text, particularly from the ground-truth class labels of input images. To the best of our knowledge, we are the first to introduce prompt learning to enhance the transferable generative attacks. Extensive experiments conducted across various cross-domain and cross-model settings empirically validate our approach, demonstrating its superiority over state-of-the-art methods.
最近的视觉语言基础模型,如CLIP,已经显示出在学习表示方面的卓越能力,这些表示可以在各种下游任务和领域中转移。随着这种强大模型的出现,有效利用它们的能力来解决具有挑战性的视觉任务已经变得至关重要。另一方面,只有少数工作专注于设计能够在未知领域和模型架构中都良好转移的对抗性例子。在本文中,我们提出了一种新的转移攻击方法,称为PDCL-Attack,该方法利用CLIP模型来提高基于生成模型的攻击框架所产生的对抗性扰动的转移性。具体来说,我们通过利用文本语义表示能力,特别是输入图像的真实类别标签,制定了一种有效的提示驱动特征指导。据我们所知,我们是第一个将提示学习引入到增强可转移生成攻击中。在多种跨领域和跨模型设置下进行的广泛实验经验性地验证了我们的方法,证明了它在最新技术上的优越性。
论文及项目相关链接
PDF Accepted to ECCV 2024 (Oral), Project Page: https://PDCL-Attack.github.io
Summary
基于CLIP模型的强大表征学习能力,该文提出了一种新型的跨域转移攻击方法PDCL-Attack。该方法利用生成模型攻击框架生成对抗扰动,并通过文本语义表示引导增强对抗扰动的迁移性。通过引入提示学习技术,实现了在各种跨域和跨模型设置下的优越性能。
Key Takeaways
- CLIP等视觉语言基础模型在多种下游任务和领域中的表示学习能力强大。
- 对抗样本在未知领域和模型架构中的迁移能力受到关注。
- PDCL-Attack方法利用CLIP模型增强生成对抗扰动的迁移性。
- 通过文本语义表示引导,形成有效的提示驱动特征指导。
- 提示学习首次被引入以增强生成攻击的迁移性。
- 在多种跨域和跨模型设置下的实验验证了该方法的优越性。
点此查看论文截图