⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-16 更新
Quenching and recovery of persistent X-ray emission during a superburst in 4U 1820$-$30
Authors:Zhijiao Peng, Zhaosheng Li, Yuanyue Pan, Tao Fu, Wenhui Yu, Yupeng Chen, Shu Zhang, Maurizio Falanga, Shuang-Nan Zhang
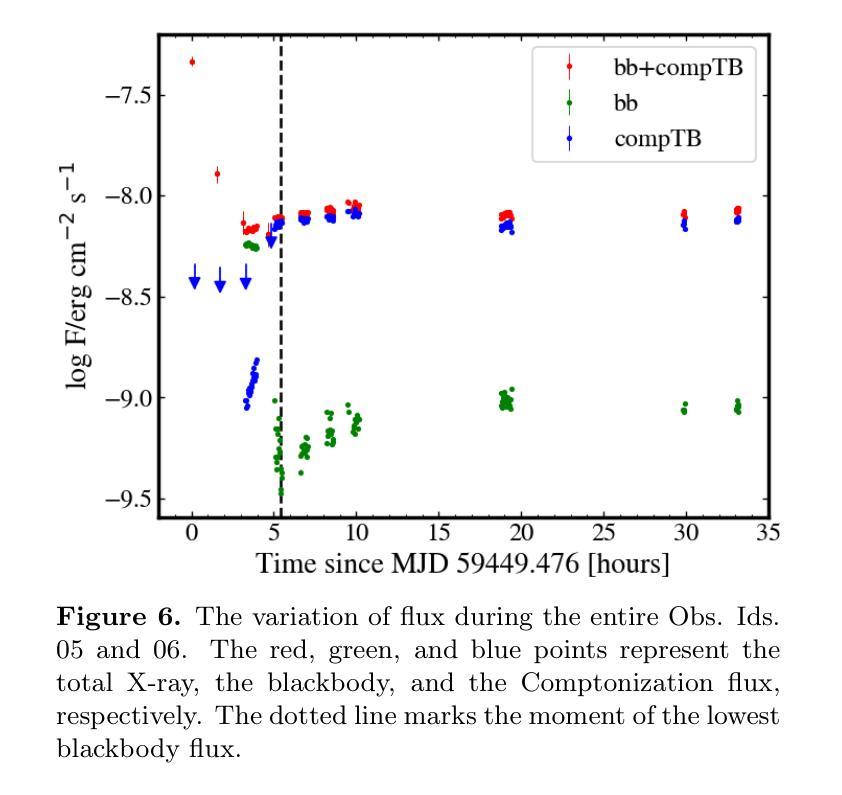
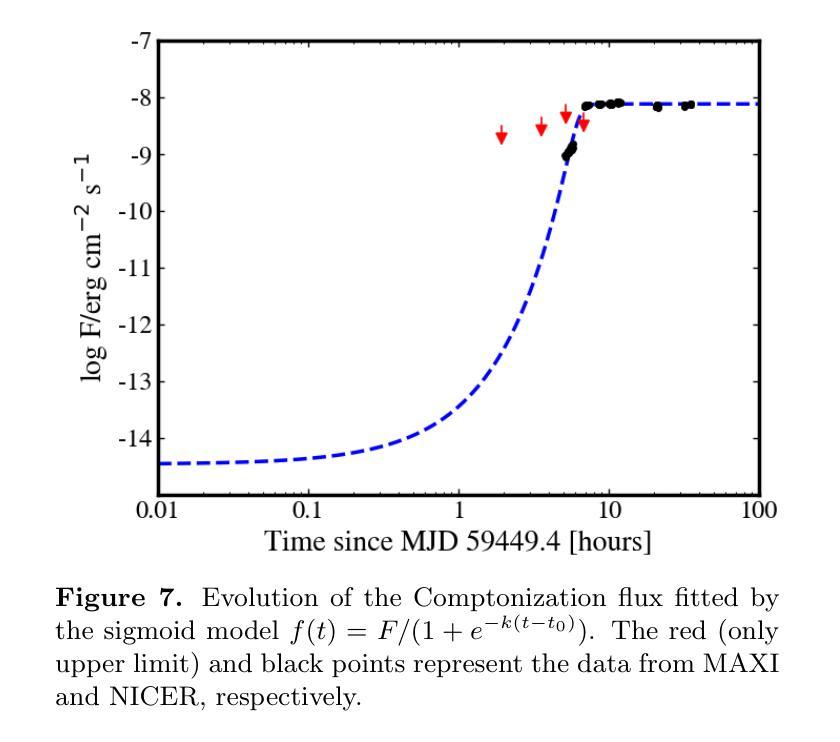
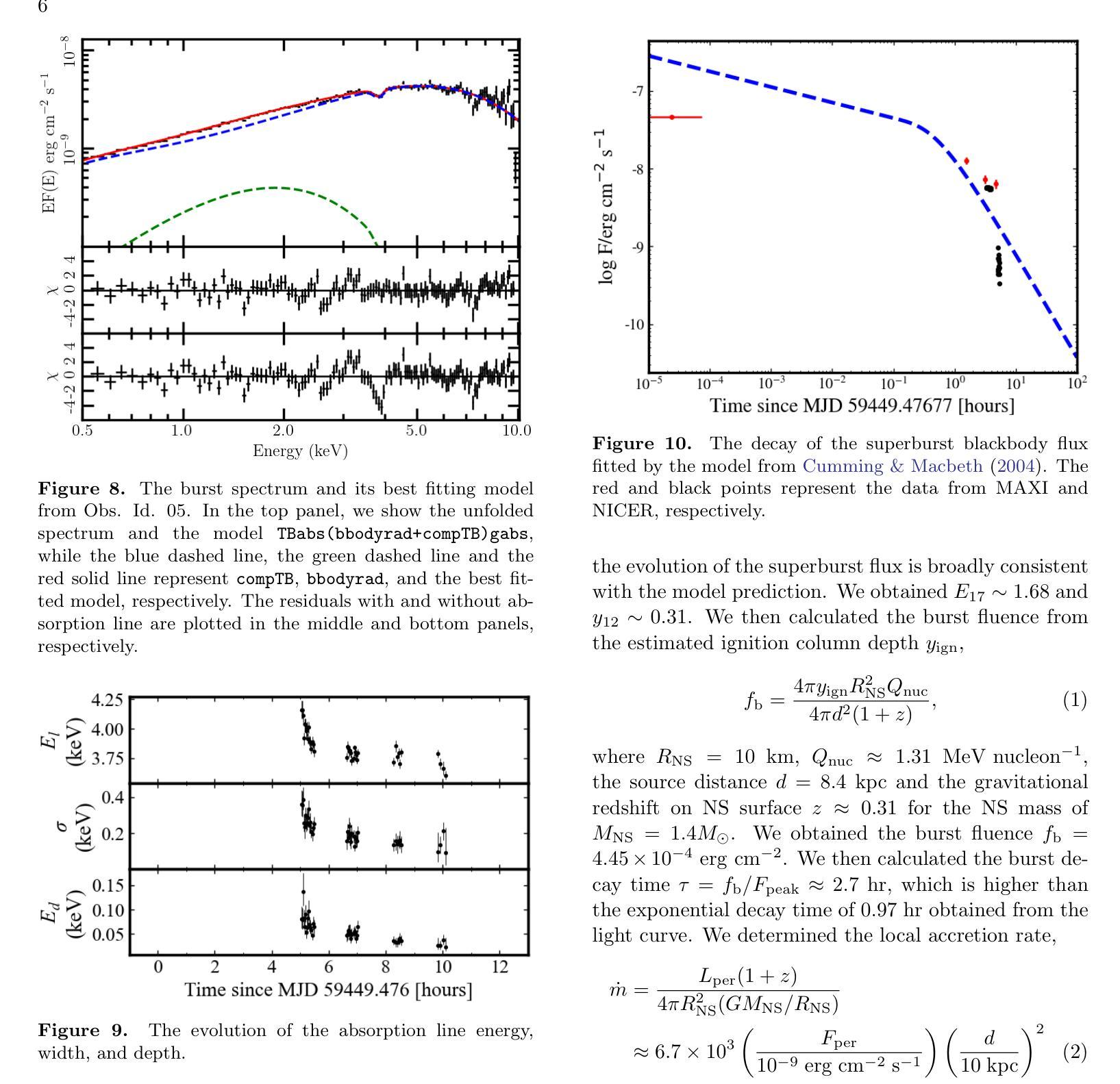
We report the superburst from 4U 1820–30 in 2021 observed by the Monitor of All-sky X-ray Image and Neutron star Interior Composition Explorer (NICER). During the tail of the superburst, we found that the NICER light curve unexpectedly increased from 1080 to 2204 ${\rm countss^{-1}}$ over 6.89 hr. From the time-resolved superburst spectra, we estimated the burst decay time of $\approx2.5$ hr, the ignition column depth of $\approx0.3\times 10^{12}{\rm g cm^{-2}}$, the energy release per unit mass of $\approx2.4\times 10^{17}{\rm ergg^{-1}}$, the fluence of $\approx4.1\times 10^{-4}{\rm ergcm^{-2}}$, and the total energy release of $\approx3.5\times10^{42}$ erg. Notably, we found a gradual increase in the Componization flux from $8.9\times 10^{-10}{\rm ergs^{-1}cm^{-2}}$ to the preburst level during the superburst. This increase can be interpreted as a consequence of superburst radiation depleting the inner accretion disk, leading to a near-complete quenching of the persistent emission. As the burst radiation decayed, the inner accretion disk gradually returned to its preburst state, as evidenced by the best-fit spectral parameters. Additionally, we observed a prominent absorption line that exhibited a gravitational redshift, shifting from 4.15 to 3.62 keV during the recovery phase of persistent emission. This absorption feature likely originates from the inner accretion disk rather than from burst emission on the neutron star (NS) surface. The observed changes in the absorption line energy suggest that the inner disk approached the NS to a distance as close as $\approx17$ km.
我们报告了利用全天空X射线图像监视器和中子星内部结构探测器(NICER)观测到的来自4U 1820-30的超超爆发事件。在超爆发的尾部,我们发现NICER的光度曲线在长达6.89小时内意外从每秒的1080计数上升至每秒的2204计数。根据时间解析的超爆发光谱,我们估计了大约2.5小时的爆发衰减时间、大约深度为$0.3\times 10^{12}$克每立方厘米的点火柱、每单位质量的能量释放约为$2.4\times 10^{17}$尔格每克、流强度约为$4.1\times 成分流量的逐渐增加可解读为超爆发辐射耗尽了内盘积物质,导致持久性发射几乎完全熄灭。随着爆发辐射的衰减,内盘积物质逐渐恢复到爆发前的状态,最佳拟合光谱参数可以证明这一点。此外,我们观察到一条明显的吸收线展现出重力红移现象,在持久性发射的恢复阶段从4.15 keV降至3.62 keV。这一吸收特征可能源自内盘积物质而非中子星表面上的爆发发射。观察到的吸收线能量的变化表明内盘接近中子星至约17公里的距离。
论文及项目相关链接
PDF published in ApJ
Summary
文中报道了利用全天空X射线图像监视器和中子星内部结构探测器(NICER)观测到的来自4U 1820-30的超爆发事件。超爆发尾期出现意外的光变曲线增长,且光谱特征揭示了一系列重要参数和现象。包括超爆发的衰减时间、点火柱深度、单位质量的能量释放等参数的估算,以及持久发射逐渐被超级爆发辐射耗尽后的恢复过程,都展现了中子星及其环境的复杂行为。文中还观察到由重力红移产生的显著吸收线,其能量的变化表明内盘靠近中子星的距离达到了近似值。此超爆发事件揭示了中子星内部结构和物理过程的宝贵信息。
Key Takeaways
- 2021年利用Monitor of All-sky X-ray Image和NICER观测了来自4U 1820-30的超爆发事件。
- 超爆发尾期观察到NICER光变曲线意外增长。
- 通过时间解析超爆发光谱,估算了超爆发的衰减时间、点火柱深度等参数。
- 观察到持久发射在超爆发过程中逐渐减弱,并在超爆发后恢复期逐渐恢复的现象。
- 揭示了超爆发辐射可能耗尽内积盘,导致持久发射几乎完全熄灭的解释。
- 恢复阶段的显著吸收线展示重力红移,表明内盘可能靠近中子星至近距离。
点此查看论文截图

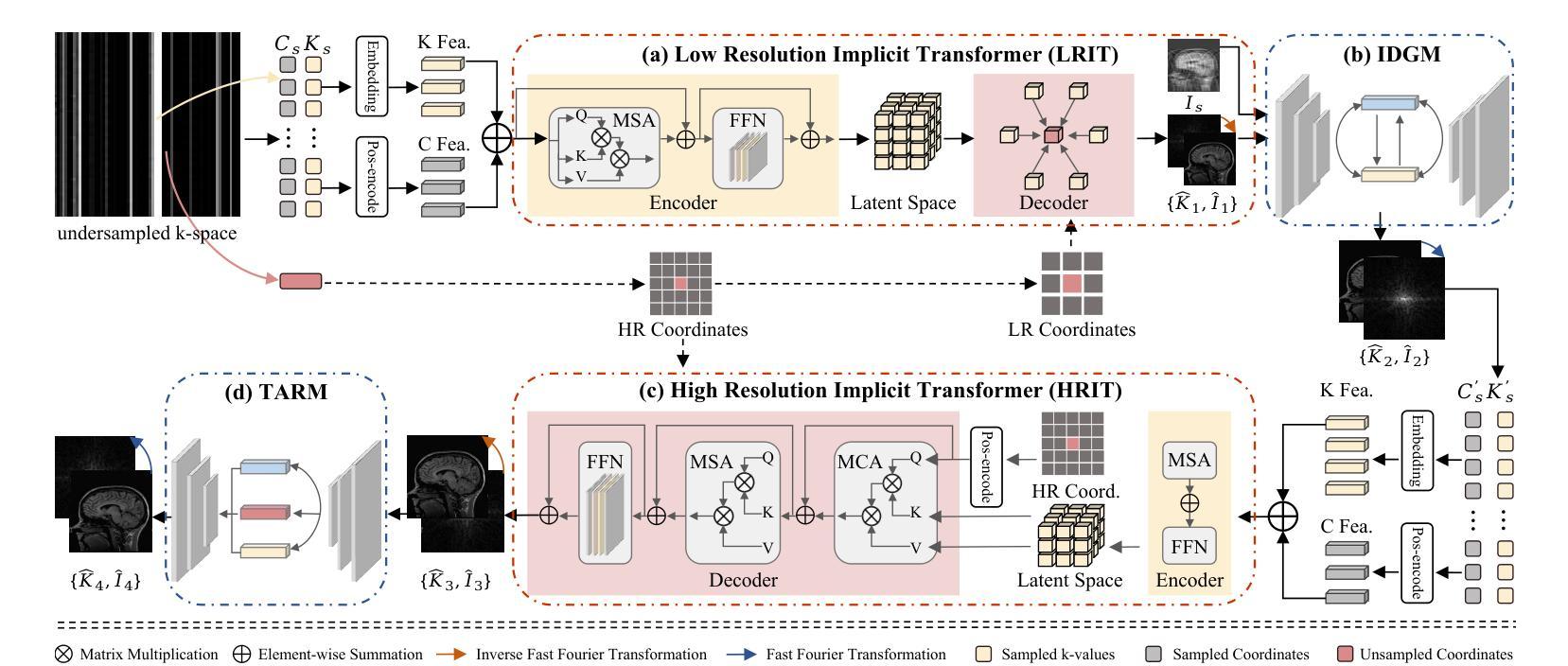
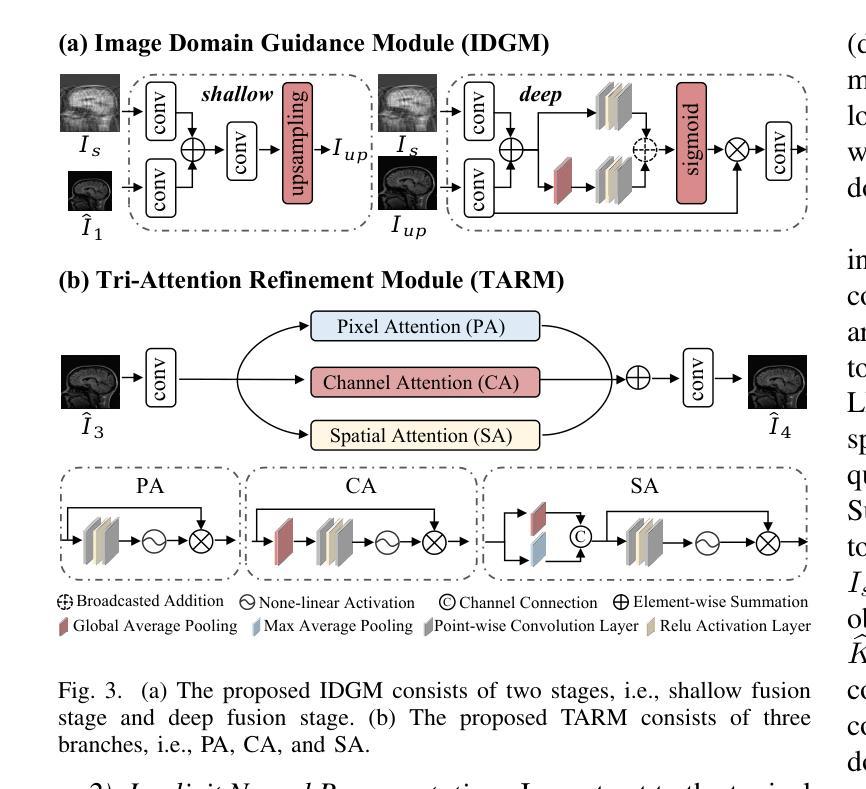
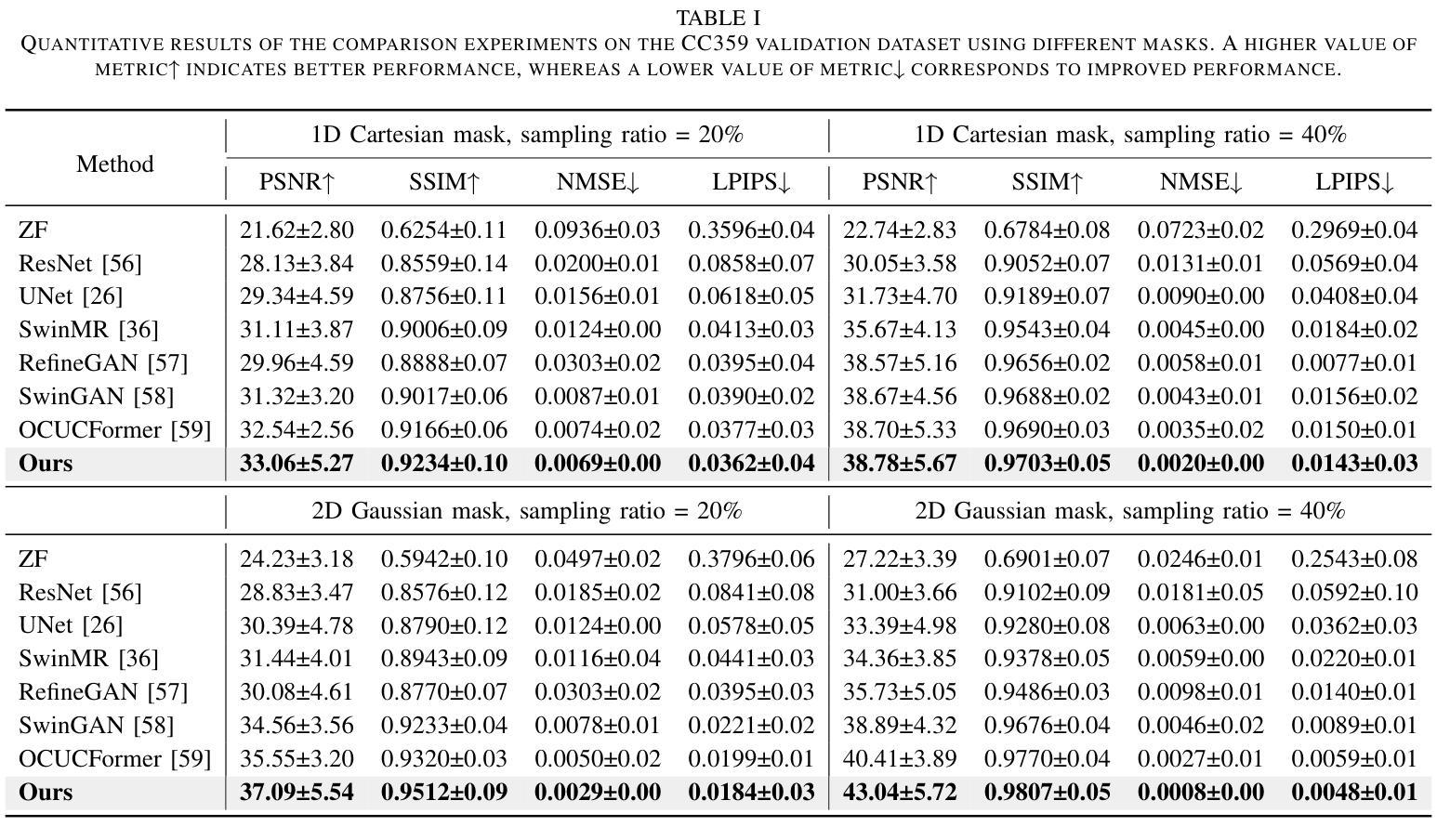
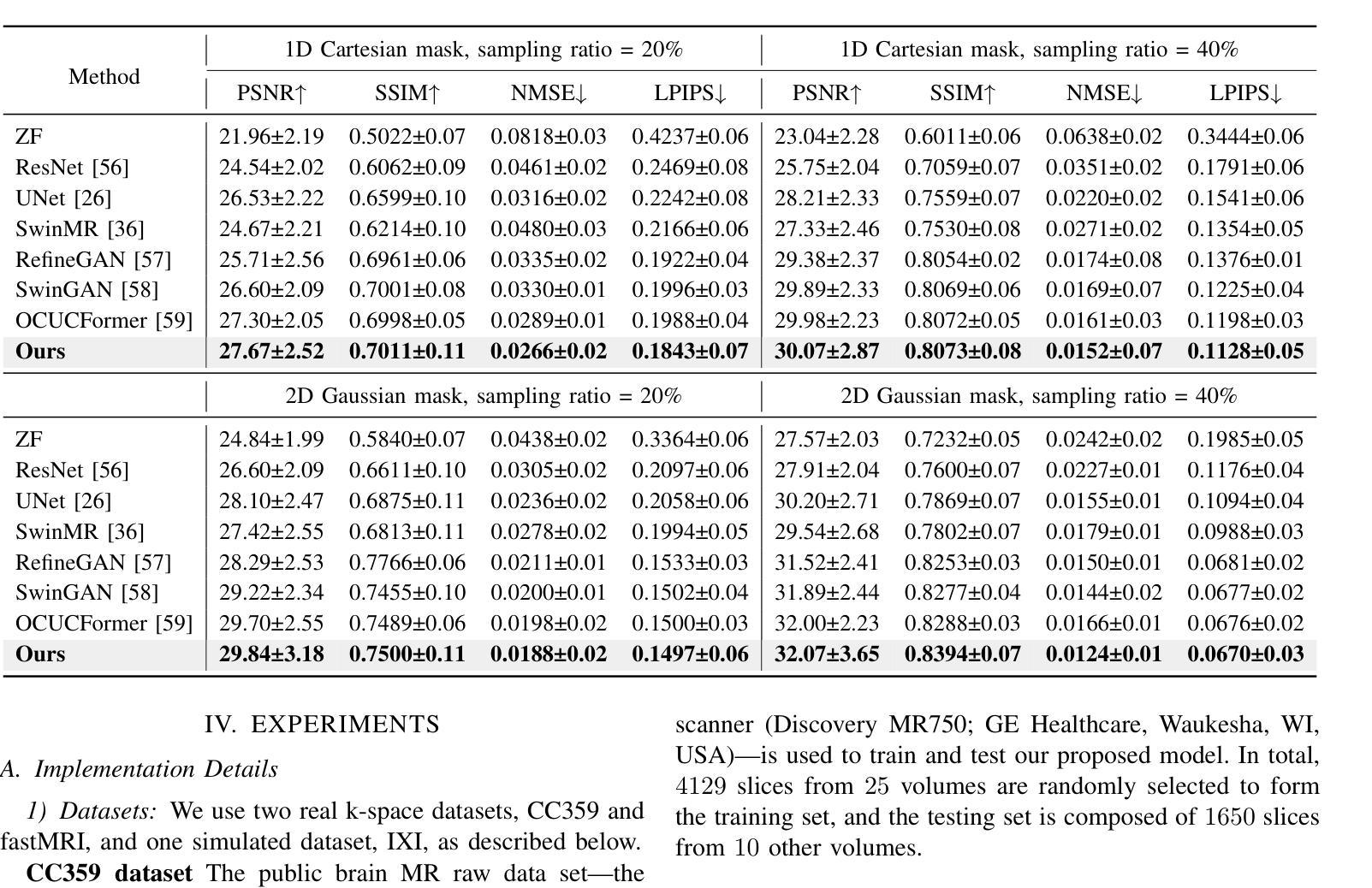
Continuous K-space Recovery Network with Image Guidance for Fast MRI Reconstruction
Authors:Yucong Meng, Zhiwei Yang, Minghong Duan, Yonghong Shi, Zhijian Song
Magnetic resonance imaging (MRI) is a crucial tool for clinical diagnosis while facing the challenge of long scanning time. To reduce the acquisition time, fast MRI reconstruction aims to restore high-quality images from the undersampled k-space. Existing methods typically train deep learning models to map the undersampled data to artifact-free MRI images. However, these studies often overlook the unique properties of k-space and directly apply general networks designed for image processing to k-space recovery, leaving the precise learning of k-space largely underexplored. In this work, we propose a continuous k-space recovery network from a new perspective of implicit neural representation with image domain guidance, which boosts the performance of MRI reconstruction. Specifically, (1) an implicit neural representation based encoder-decoder structure is customized to continuously query unsampled k-values. (2) an image guidance module is designed to mine the semantic information from the low-quality MRI images to further guide the k-space recovery. (3) a multi-stage training strategy is proposed to recover dense k-space progressively. Extensive experiments conducted on CC359, fastMRI, and IXI datasets demonstrate the effectiveness of our method and its superiority over other competitors.
磁共振成像(MRI)是临床诊断中的重要工具,但同时也面临着扫描时间长这一挑战。为了缩短采集时间,快速MRI重建旨在从欠采样的k空间中恢复高质量图像。现有方法通常训练深度学习模型,将欠采样数据映射到无伪影的MRI图像。然而,这些研究往往忽视了k空间的独特属性,并直接使用为图像处理设计的通用网络进行k空间恢复,使得k空间的精确学习在很大程度上被忽视。在这项工作中,我们从隐式神经表示的新角度提出了一个连续的k空间恢复网络,并结合图像域指导提高了MRI重建的性能。具体来说,(1)基于隐式神经表示的编码器-解码器结构被定制为连续查询未采样的k值。(2)设计了一个图像引导模块,从低质量的MRI图像中提取语义信息,进一步指导k空间的恢复。(3)提出了一种多阶段训练策略,以逐步恢复密集的k空间。在CC359、fastMRI和IXI数据集上进行的广泛实验证明了我们的方法的有效性及其对其他竞争对手的优越性。
论文及项目相关链接
Summary
本研究提出了基于隐式神经表示的新视角的连续k-空间恢复网络,用于加速磁共振成像(MRI)重建。该网络结合图像域指导,提升了MRI重建性能。通过采用隐式神经表示编码器-解码器结构、设计图像指导模块以及采用多阶段训练策略,实现了对未采样k值的连续查询和密集k-空间的逐步恢复。在CC359、fastMRI和IXI数据集上的实验证明了该方法的有效性及优越性。
Key Takeaways
- 磁共振成像(MRI)面临长时间扫描的挑战,快速MRI重建旨在从欠采样的k-空间恢复高质量图像。
- 现有方法通常训练深度学习模型将欠采样数据映射到无伪影的MRI图像,但忽略了k-空间的独特属性。
- 本研究从隐式神经表示的新视角提出了连续k-空间恢复网络,可实现对未采样k值的连续查询。
- 设计中包含了图像域指导模块,挖掘低质量MRI图像中的语义信息以指导k-空间恢复。
- 研究采用多阶段训练策略,旨在逐步恢复密集k-空间。
- 在多个数据集上的实验证明了该方法的有效性及优越性。
点此查看论文截图

CAD-MLLM: Unifying Multimodality-Conditioned CAD Generation With MLLM
Authors:Jingwei Xu, Zibo Zhao, Chenyu Wang, Wen Liu, Yi Ma, Shenghua Gao
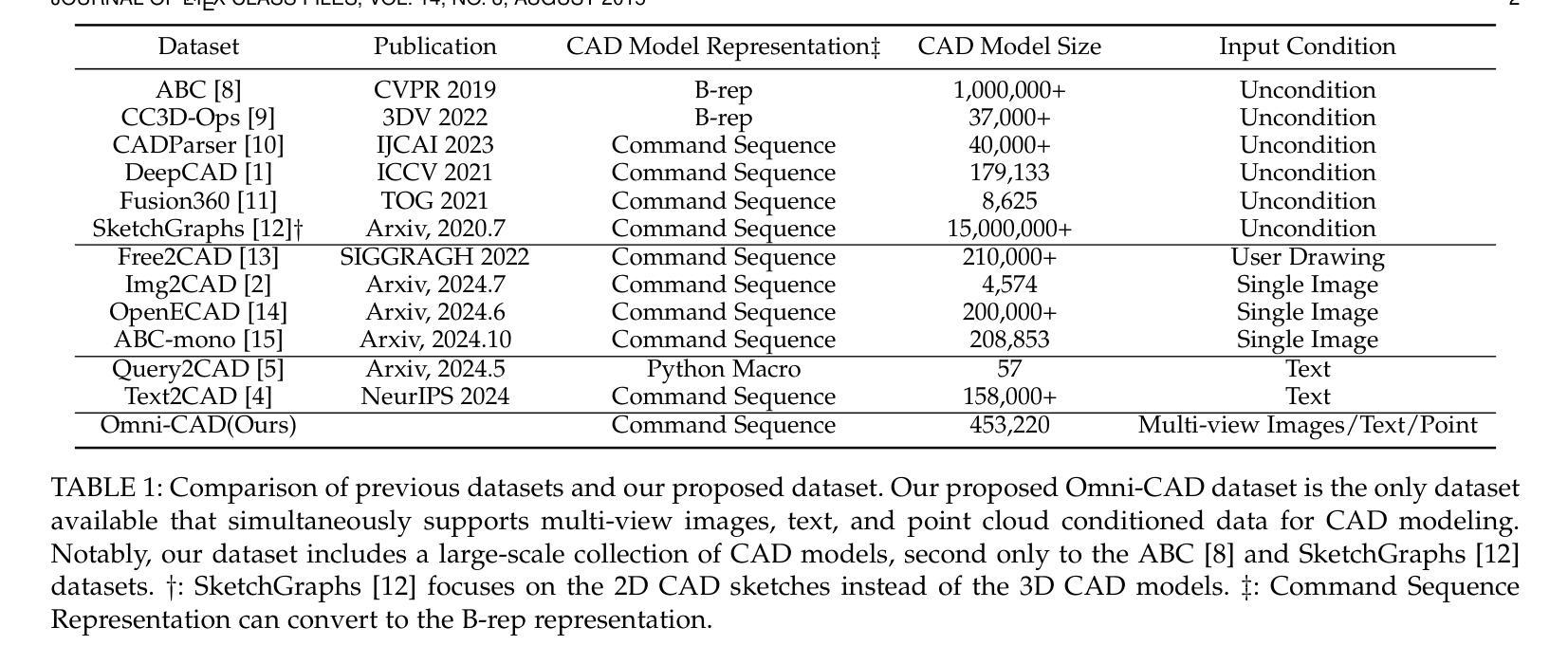
This paper aims to design a unified Computer-Aided Design (CAD) generation system that can easily generate CAD models based on the user’s inputs in the form of textual description, images, point clouds, or even a combination of them. Towards this goal, we introduce the CAD-MLLM, the first system capable of generating parametric CAD models conditioned on the multimodal input. Specifically, within the CAD-MLLM framework, we leverage the command sequences of CAD models and then employ advanced large language models (LLMs) to align the feature space across these diverse multi-modalities data and CAD models’ vectorized representations. To facilitate the model training, we design a comprehensive data construction and annotation pipeline that equips each CAD model with corresponding multimodal data. Our resulting dataset, named Omni-CAD, is the first multimodal CAD dataset that contains textual description, multi-view images, points, and command sequence for each CAD model. It contains approximately 450K instances and their CAD construction sequences. To thoroughly evaluate the quality of our generated CAD models, we go beyond current evaluation metrics that focus on reconstruction quality by introducing additional metrics that assess topology quality and surface enclosure extent. Extensive experimental results demonstrate that CAD-MLLM significantly outperforms existing conditional generative methods and remains highly robust to noises and missing points. The project page and more visualizations can be found at: https://cad-mllm.github.io/
本文旨在设计一个统一的计算机辅助设计(CAD)生成系统,该系统能够根据用户的文本描述、图像、点云或它们的组合等输入形式,轻松生成CAD模型。为实现这一目标,我们引入了CAD-MLLM系统,这是第一个能够根据多模式输入生成参数化CAD模型的系统。具体而言,在CAD-MLLM框架内,我们利用CAD模型的命令序列,然后采用先进的大型语言模型(LLM),以对齐这些多样化的多模式数据以及CAD模型的向量表示之间的特征空间。为了促进模型训练,我们设计了一个全面的数据构建和注释管道,为每个CAD模型配备相应的多模式数据。我们构建的数据集名为Omni-CAD,这是第一个多模式CAD数据集,包含每个CAD模型的文本描述、多视图图像、点和命令序列。它包含大约45万个实例及其CAD构建序列。为了全面评估我们生成的CAD模型的质量,我们超越了当前以重建质量为中心的评估指标,引入了其他评估拓扑质量和表面封闭程度的指标。大量的实验结果表明,CAD-MLLM显著优于现有的条件生成方法,并且对噪声和缺失点具有高度鲁棒性。项目页面和更多可视化内容可在:https://cad-mllm.github.io/找到。
论文及项目相关链接
PDF Project page: https://cad-mllm.github.io/
Summary
本文介绍了一个统一计算机辅助设计(CAD)生成系统,该系统能够根据用户的文本描述、图像、点云等多种输入形式,轻松生成CAD模型。为达成此目标,引入CAD-MLLM系统,该系统能够基于多模态输入生成参数化CAD模型。通过设计综合数据构建和标注管道,为每个CAD模型配备对应的多模态数据,创建名为Omni-CAD的多模态CAD数据集。此外,还引入了拓扑质量和表面封闭程度等评估指标来全面评估生成的CAD模型质量。实验结果表明,CAD-MLLM显著优于现有条件生成方法,对噪声和缺失点具有高度的鲁棒性。
Key Takeaways
- 该论文设计了一个统一的CAD生成系统,能够根据用户的多种输入形式(文本描述、图像、点云等)轻松生成CAD模型。
- 引入了CAD-MLLM系统,能够基于多模态输入生成参数化CAD模型。
- 创建了名为Omni-CAD的多模态CAD数据集,包含文本描述、多视角图像、点云和CAD模型的命令序列。
- 为评估生成的CAD模型质量,引入了拓扑质量和表面封闭程度的评估指标。
- CAD-MLLM系统显著优于现有的条件生成方法。
- CAD-MLLM系统对噪声和缺失点具有高度的鲁棒性。
点此查看论文截图


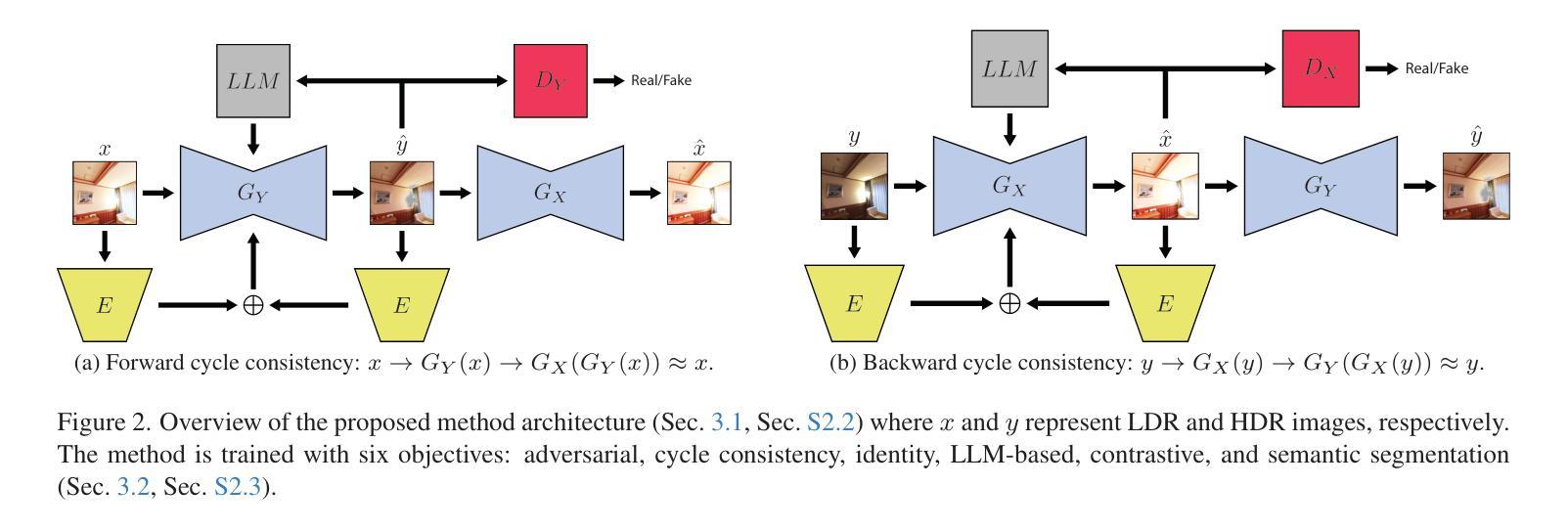
LLM-HDR: Bridging LLM-based Perception and Self-Supervision for Unpaired LDR-to-HDR Image Reconstruction
Authors:Hrishav Bakul Barua, Kalin Stefanov, Lemuel Lai En Che, Abhinav Dhall, KokSheik Wong, Ganesh Krishnasamy
The translation of Low Dynamic Range (LDR) to High Dynamic Range (HDR) images is an important computer vision task. There is a significant amount of research utilizing both conventional non-learning methods and modern data-driven approaches, focusing on using both single-exposed and multi-exposed LDR for HDR image reconstruction. However, most current state-of-the-art methods require high-quality paired {LDR,HDR} datasets for model training. In addition, there is limited literature on using unpaired datasets for this task, that is, the model learns a mapping between domains, i.e., {LDR,HDR}. This paper proposes LLM-HDR, a method that integrates the perception of Large Language Models (LLM) into a modified semantic- and cycle-consistent adversarial architecture that utilizes unpaired {LDR,HDR} datasets for training. The method introduces novel artifact- and exposure-aware generators to address visual artifact removal and an encoder and loss to address semantic consistency, another under-explored topic. LLM-HDR is the first to use an LLM for the {LDR,HDR} translation task in a self-supervised setup. The method achieves state-of-the-art performance across several benchmark datasets and reconstructs high-quality HDR images. The official website of this work is available at: https://github.com/HrishavBakulBarua/LLM-HDR
从低动态范围(LDR)图像翻译到高动态范围(HDR)图像是一项重要的计算机视觉任务。许多研究都利用传统的非学习方法和现代的数据驱动方法,侧重于使用单曝光和多曝光的LDR进行HDR图像重建。然而,目前大多数最先进的方法都需要高质量配对的{LDR,HDR}数据集来进行模型训练。此外,关于使用未配对数据集进行此任务的文献很少,也就是说,模型学习域之间的映射,即{LDR,HDR}。本文提出了LLM-HDR方法,它将大型语言模型(LLM)的感知能力集成到一个经过修改的语义和循环一致的对抗性架构中,该架构利用未配对的{LDR,HDR}数据集进行训练。该方法引入了新型伪影和曝光感知生成器来解决视觉伪影去除问题,以及解决语义一致性这一尚未被深入探讨的话题的编码器和损失函数。LLM-HDR是第一个在自监督设置中使用LLM进行{LDR,HDR}翻译任务的方法。该方法在多个基准数据集上达到了最先进的性能,并重建了高质量的HDR图像。该工作的官方网站地址为:https://github.com/HrishavBakulBarua/LLM-HDR 。
论文及项目相关链接
Summary
本文提出一种名为LLM-HDR的方法,它将大型语言模型(LLM)感知融入修改后的语义和循环一致对抗架构中,利用无配对{LDR,HDR}数据集进行训练。该方法引入新型伪影和曝光感知生成器以解决视觉伪影去除问题,并解决了语义一致性的另一个未探讨话题。LLM-HDR是首个在自监督设置中利用LLM进行{LDR,HDR}翻译任务的方法。该方法在多个基准数据集上实现了最先进的性能,并能重建高质量HDR图像。
Key Takeaways
- LLM-HDR方法结合了大型语言模型(LLM)感知技术。
- 方法采用修改后的语义和循环一致对抗架构。
- 该方法利用无配对{LDR,HDR}数据集进行训练。
- LLM-HDR引入伪影和曝光感知生成器解决视觉伪影问题。
- 方法解决了语义一致性的未探讨话题。
- LLM-HDR是首个在自监督设置中应用LLM进行HDR图像翻译的方法。
点此查看论文截图


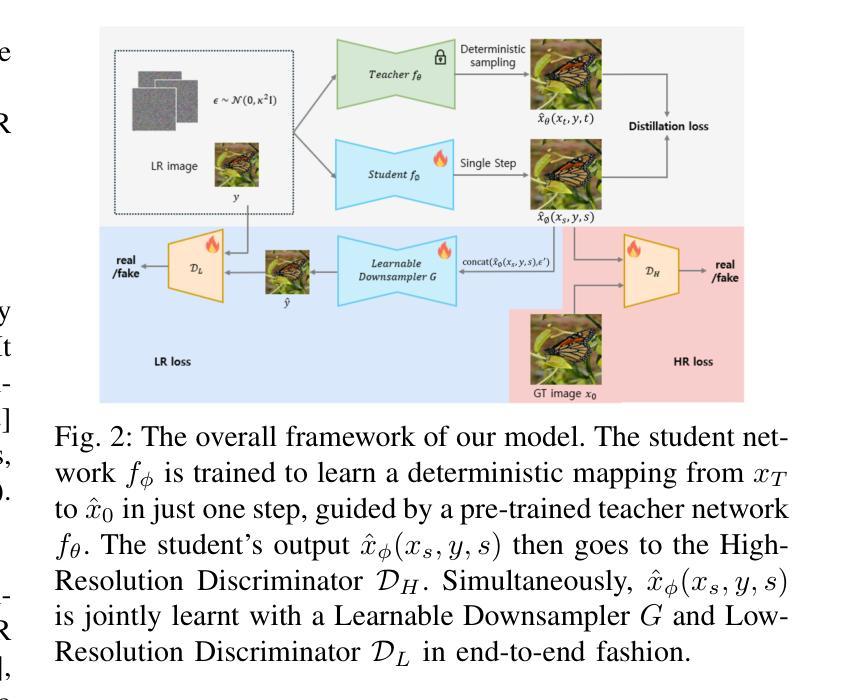
Co-learning Single-Step Diffusion Upsampler and Downsampler with Two Discriminators and Distillation
Authors:Sohwi Kim, Tae-Kyun Kim
Super-resolution (SR) aims to reconstruct high-resolution (HR) images from their low-resolution (LR) counterparts, often relying on effective downsampling to generate diverse and realistic training pairs. In this work, we propose a co-learning framework that jointly optimizes a single-step diffusion-based upsampler and a learnable downsampler, enhanced by two discriminators and a cyclic distillation strategy. Our learnable downsampler is designed to better capture realistic degradation patterns while preserving structural details in the LR domain, which is crucial for enhancing SR performance. By leveraging a diffusion-based approach, our model generates diverse LR-HR pairs during training, enabling robust learning across varying degradations. We demonstrate the effectiveness of our method on both general real-world and domain-specific face SR tasks, achieving state-of-the-art performance in both fidelity and perceptual quality. Our approach not only improves efficiency with a single inference step but also ensures high-quality image reconstruction, bridging the gap between synthetic and real-world SR scenarios.
超分辨率(SR)旨在从低分辨率(LR)图像重建高分辨率(HR)图像,通常依赖于有效的下采样来生成多样且现实的训练对。在这项工作中,我们提出了一种联合优化一步扩散式上采样器和可学习下采样器的协同学习框架,它由两个鉴别器和循环蒸馏策略增强。我们的可学习下采样器旨在更好地捕捉现实的退化模式,同时保留低分辨率域中的结构细节,这对于提高超分辨率性能至关重要。通过利用基于扩散的方法,我们的模型在训练过程中生成多样的LR-HR对,使模型能够在各种退化情况下进行稳健学习。我们在一般的现实世界和特定领域的面部SR任务上都证明了我们的方法的有效性,在保真度和感知质量方面都达到了最新性能。我们的方法不仅通过一次推理步骤提高了效率,而且确保了高质量的图像重建,缩小了合成和现实世界SR场景之间的差距。
论文及项目相关链接
Summary
本文提出了一种联合优化单步扩散式上采样器和可学习下采样器的协同学习框架,通过两个鉴别器和循环蒸馏策略进行增强。可学习下采样器能够更好捕捉现实退化模式,同时在低分辨率领域保留结构细节,对提升超分辨率性能至关重要。利用扩散式方法,该模型在训练过程中生成多样的低分辨率-高分辨率图像对,使模型能够在各种退化情况下进行稳健学习。在通用现实世界和特定领域的面部超分辨率任务上,该方法取得了先进性能,在保真度和感知质量方面均表现优异。此方法不仅提高了效率,只需单步推理,而且保证了高质量图像重建,缩小了合成和真实世界超分辨率场景之间的差距。
Key Takeaways
- 提出了一个联合优化单步扩散式上采样器和可学习下采样器的协同学习框架。
- 可学习下采样器能捕捉现实退化模式并保留低分辨率领域的结构细节。
- 利用扩散式方法生成多样的低分辨率-高分辨率图像对,提升模型的稳健性。
- 在面部超分辨率任务上取得了先进性能。
- 方法提高了效率,只需单步推理。
- 保证了高质量图像重建。
点此查看论文截图



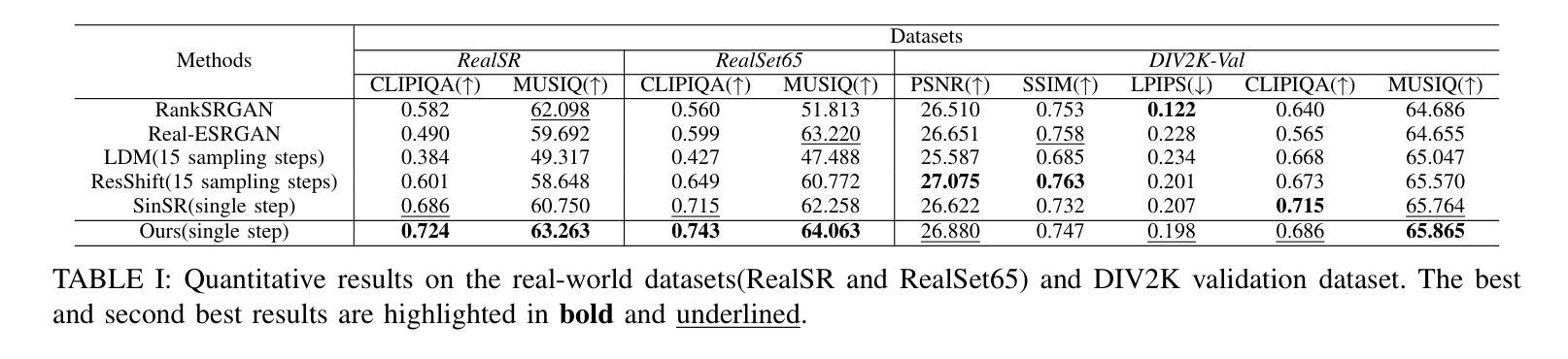

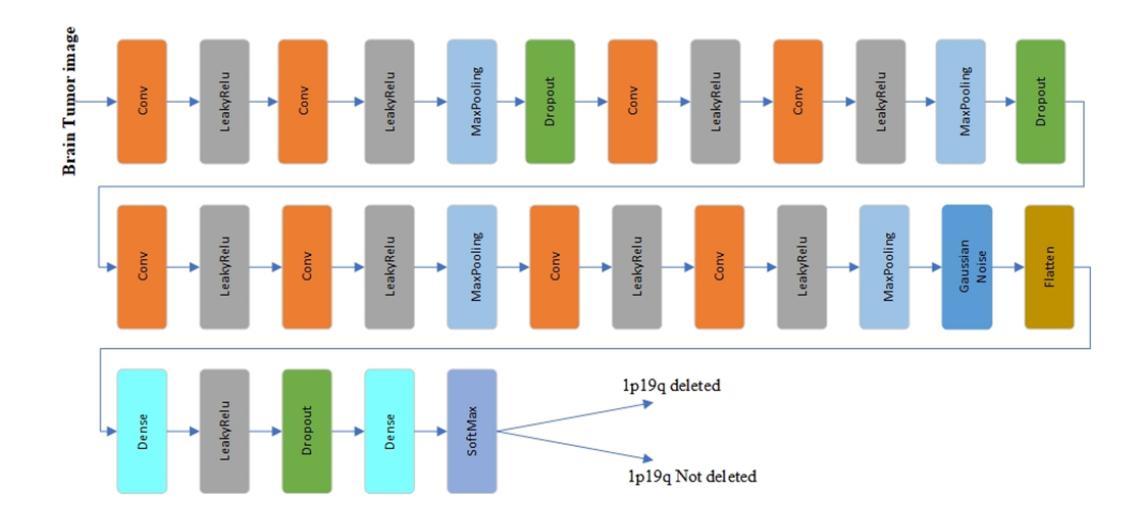
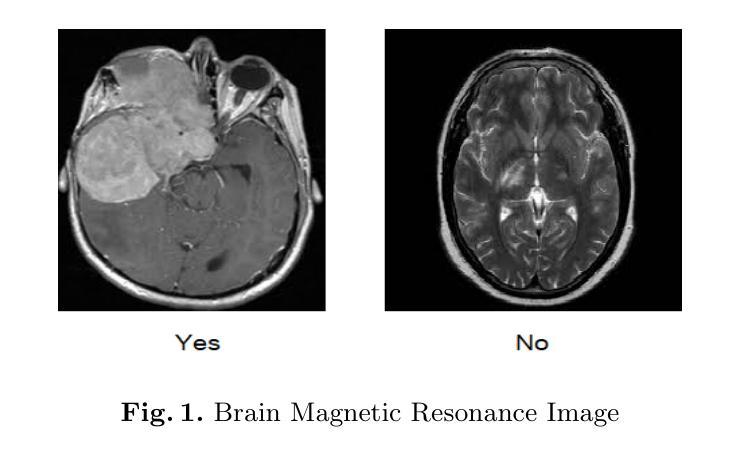
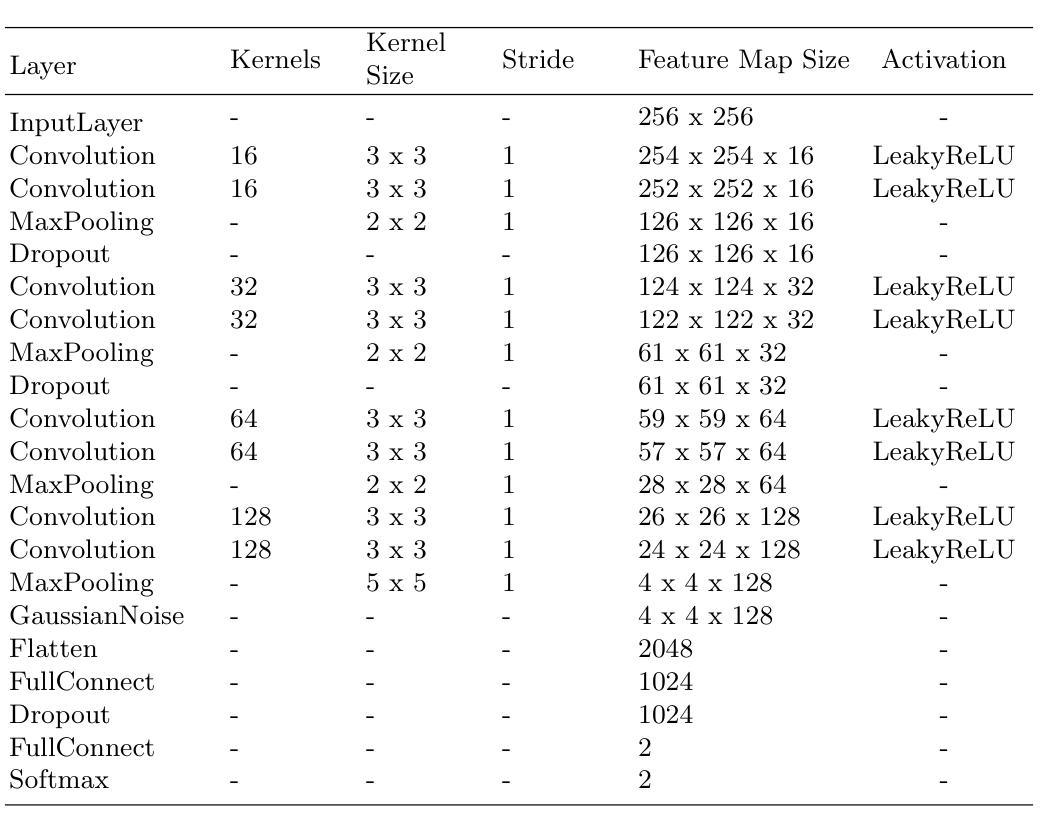
Brain Tumor Classification on MRI in Light of Molecular Markers
Authors:Jun Liu, Geng Yuan, Weihao Zeng, Hao Tang, Wenbin Zhang, Xue Lin, XiaoLin Xu, Dong Huang, Yanzhi Wang
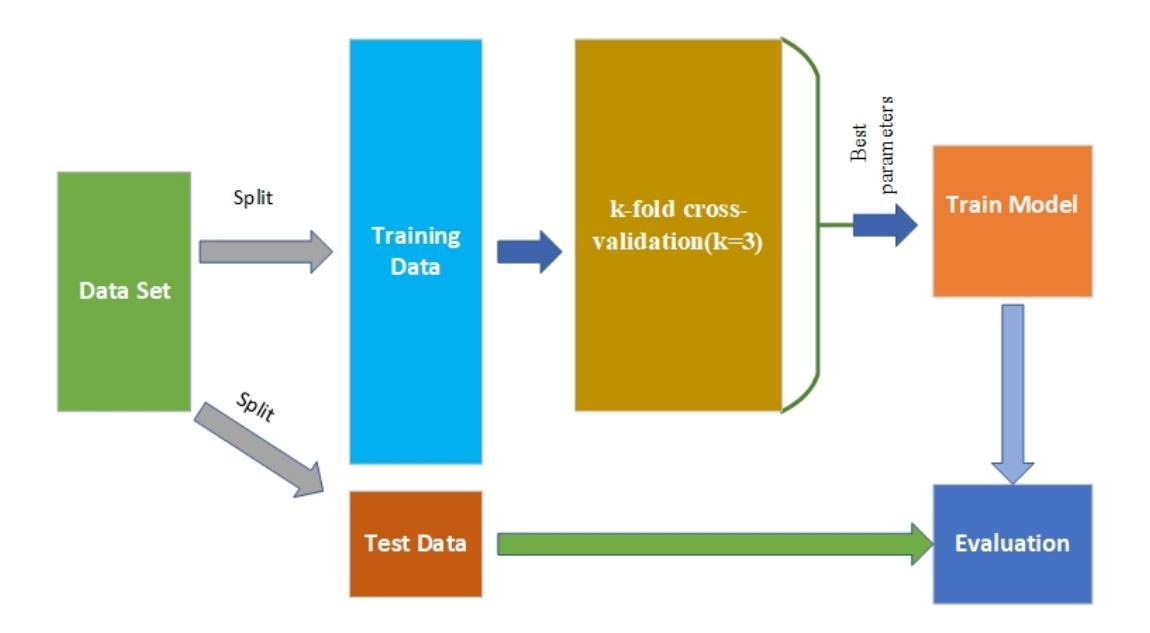
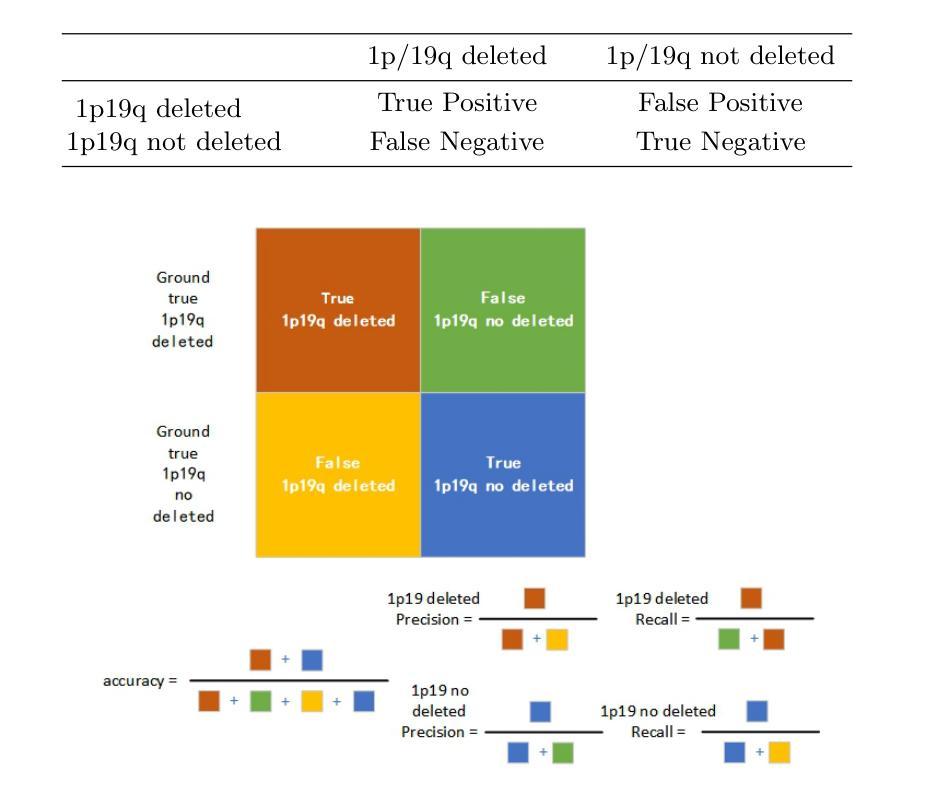
In research findings, co-deletion of the 1p/19q gene is associated with clinical outcomes in low-grade gliomas. The ability to predict 1p19q status is critical for treatment planning and patient follow-up. This study aims to utilize a specially MRI-based convolutional neural network for brain cancer detection. Although public networks such as RestNet and AlexNet can effectively diagnose brain cancers using transfer learning, the model includes quite a few weights that have nothing to do with medical images. As a result, the diagnostic results are unreliable by the transfer learning model. To deal with the problem of trustworthiness, we create the model from the ground up, rather than depending on a pre-trained model. To enable flexibility, we combined convolution stacking with a dropout and full connect operation, it improved performance by reducing overfitting. During model training, we also supplement the given dataset and inject Gaussian noise. We use three–fold cross-validation to train the best selection model. Comparing InceptionV3, VGG16, and MobileNetV2 fine-tuned with pre-trained models, our model produces better results. On an validation set of 125 codeletion vs. 31 not codeletion images, the proposed network achieves 96.37% percent F1-score, 97.46% percent precision, and 96.34% percent recall when classifying 1p/19q codeletion and not codeletion images.
在研究过程中发现,1p/19q基因的联合缺失与低级别胶质瘤的临床结果有关。预测1p19q状态对于治疗计划和患者随访至关重要。本研究旨在利用基于MRI的卷积神经网络进行脑癌检测。虽然RestNet和AlexNet等公共网络可以通过迁移学习有效地诊断脑癌,但模型中有很多权重与医学图像无关。因此,迁移学习模型的诊断结果不可靠。为了解决可信度问题,我们从零开始构建模型,而不是依赖于预训练模型。为了实现灵活性,我们将卷积堆叠与丢弃和完全连接操作相结合,通过减少过拟合提高了性能。在模型训练过程中,我们还补充了给定的数据集并注入了高斯噪声。我们使用三折交叉验证来训练最佳选择模型。将InceptionV3、VGG16和MobileNetV2与预训练模型微调相比,我们的模型产生了更好的结果。在125张代码缺失与31张非代码缺失图像的验证集上,所提出的网络在分类1p/19q代码缺失和非代码缺失图像时,达到了96.37%的F1分数、97.46%的精确度和96.34%的召回率。
论文及项目相关链接
PDF ICAI’22 - The 24th International Conference on Artificial Intelligence, The 2022 World Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE’22), Las Vegas, USA. The paper acceptance rate 17% for regular papers. The publication of the CSCE 2022 conference proceedings has been delayed due to the pandemic
Summary
该研究探讨了通过磁共振成像技术构建的卷积神经网络对低级胶质瘤进行诊断的方法。针对现有转移学习模型存在的可靠性问题,研究团队构建了全新的模型,该模型通过卷积堆叠、dropout操作和全连接操作相结合的方式提高了性能并降低了过拟合现象。在模型训练过程中,研究团队还补充了数据集并加入了高斯噪声以增强模型的灵活性。最终,该模型在验证集上取得了较高的分类性能。
Key Takeaways
- 研究发现共同缺失的1p/19q基因与低级别胶质瘤的临床结果有关。
- 预测1p/19q状态对治疗计划和患者随访至关重要。
- 研究旨在利用基于MRI的卷积神经网络进行脑癌检测。
- 虽然公共网络如RestNet和AlexNet可通过转移学习有效诊断脑癌,但其诊断结果存在可靠性问题。
- 为解决可靠性问题,研究团队构建了全新的模型,该模型结合了卷积堆叠、dropout和全连接操作来提高性能并降低过拟合现象。
- 在模型训练过程中,补充数据集并注入高斯噪声以增强模型的灵活性。
点此查看论文截图

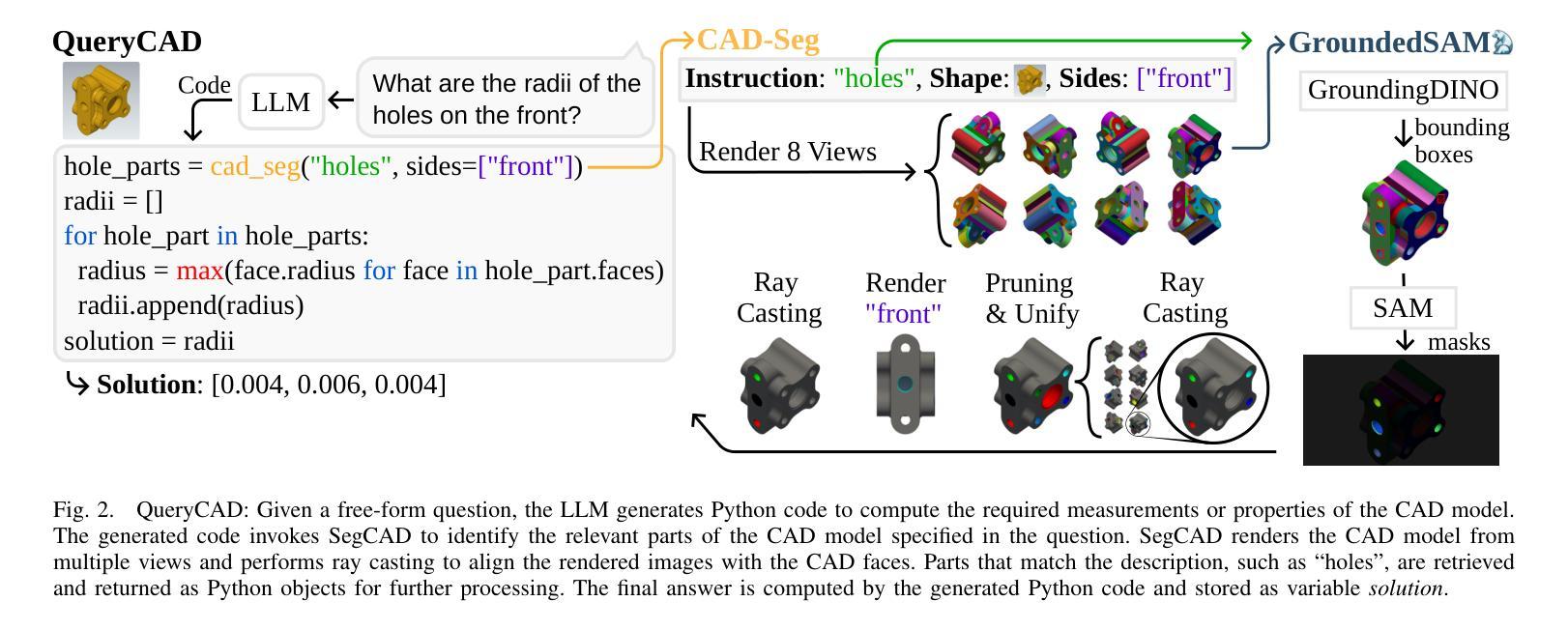
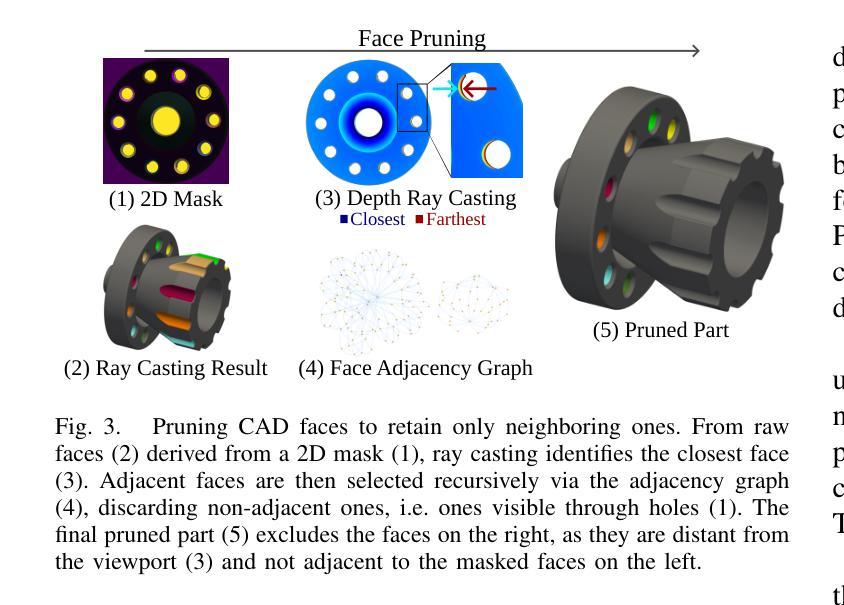
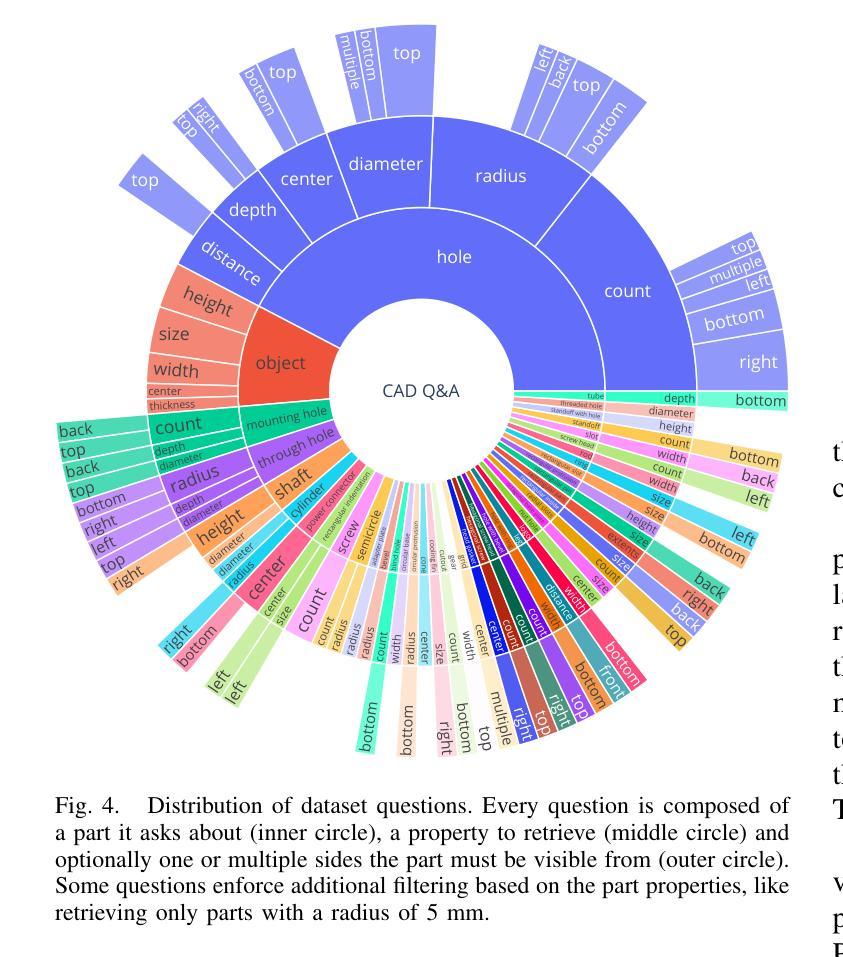
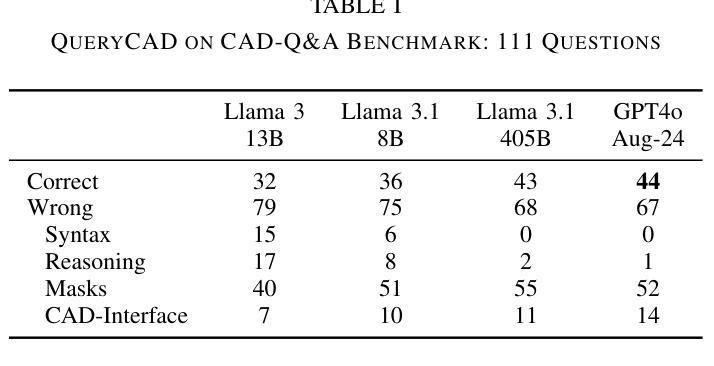
QueryCAD: Grounded Question Answering for CAD Models
Authors:Claudius Kienle, Benjamin Alt, Darko Katic, Rainer Jäkel, Jan Peters
CAD models are widely used in industry and are essential for robotic automation processes. However, these models are rarely considered in novel AI-based approaches, such as the automatic synthesis of robot programs, as there are no readily available methods that would allow CAD models to be incorporated for the analysis, interpretation, or extraction of information. To address these limitations, we propose QueryCAD, the first system designed for CAD question answering, enabling the extraction of precise information from CAD models using natural language queries. QueryCAD incorporates SegCAD, an open-vocabulary instance segmentation model we developed to identify and select specific parts of the CAD model based on part descriptions. We further propose a CAD question answering benchmark to evaluate QueryCAD and establish a foundation for future research. Lastly, we integrate QueryCAD within an automatic robot program synthesis framework, validating its ability to enhance deep-learning solutions for robotics by enabling them to process CAD models (https://claudius-kienle.github.com/querycad).
CAD模型在工业中得到了广泛应用,是机器人自动化流程中的关键。然而,在基于AI的新方法中,如机器人程序的自动合成,这些模型很少被考虑在内。因为没有现成的方法可以让CAD模型用于分析、解释或提取信息。为了解决这些局限性,我们提出了QueryCAD系统,这是首个为CAD问答设计的系统,通过自然语言查询能够从CAD模型中提取精确信息。QueryCAD集成了我们开发的SegCAD模型,这是一种开放式词汇实例分割模型,能够根据零件描述来识别和选择CAD模型中的特定部分。我们还提出了一个CAD问答基准测试来评估QueryCAD,并为未来的研究奠定了基础。最后,我们将QueryCAD集成到一个自动机器人程序合成框架中,验证了其通过处理CAD模型提升机器人深度学习能力的能力(https://claudius-kienle.github.com/querycad)。
论文及项目相关链接
Summary
CAD模型在工业中广泛应用,对机器人自动化流程至关重要。但在基于AI的自动机器人程序合成等新型方法中,CAD模型的应用受限,缺乏对其分析、解读或信息提取的方法。为解决此问题,提出QueryCAD系统,利用自然语言查询从CAD模型中提取精确信息。该系统包含SegCAD,一个基于开放词汇的实例分割模型,可基于部分描述识别并选择CAD模型的具体部分。此外,建立CAD问答基准测试评估QueryCAD并为未来研究奠定基础。最后,将QueryCAD集成到自动机器人程序合成框架中,验证其处理CAD模型的能力,从而提升机器人深度学习的解决方案。
Key Takeaways
- CAD模型在工业机器人自动化中占据重要地位,但在新型AI方法中的应用受限。
- QueryCAD系统填补这一空白,利用自然语言查询实现从CAD模型中提取精确信息。
- QueryCAD包含SegCAD实例分割模型,可识别并选择CAD模型中的特定部分。
- 建立CAD问答基准测试以评估QueryCAD的性能,并为未来研究提供基础。
- QueryCAD成功集成到自动机器人程序合成框架中。
- QueryCAD能增强深度学习的机器人解决方案,使其具备处理CAD模型的能力。
点此查看论文截图


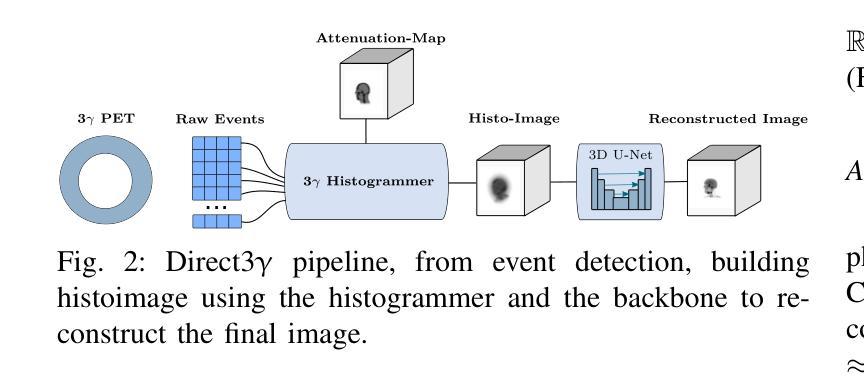
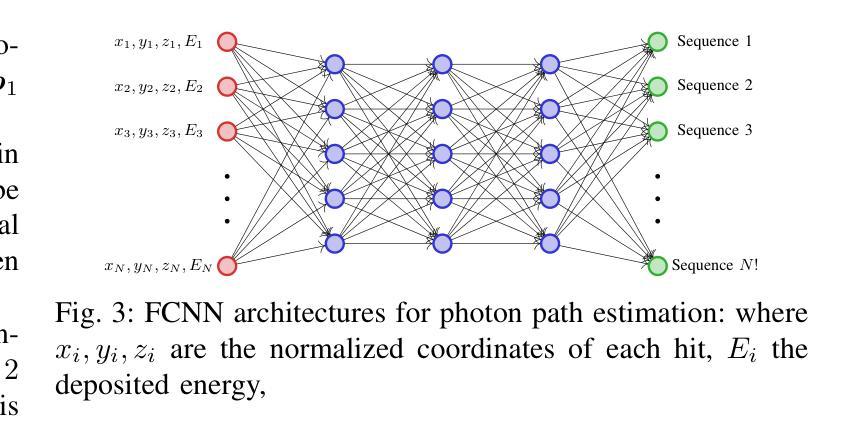
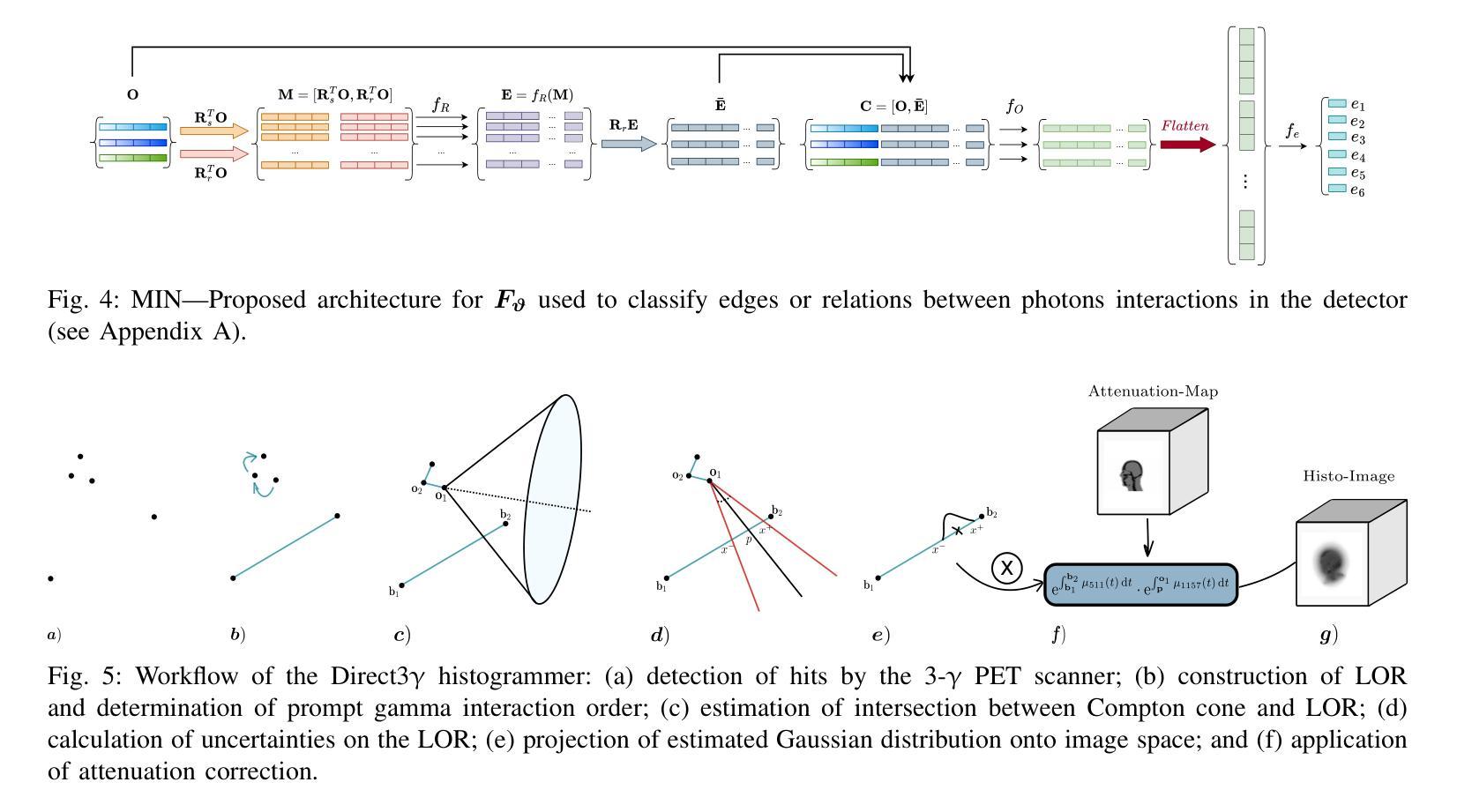
Direct3γ: A Pipeline for Direct Three-gamma PET Image Reconstruction
Authors:Youness Mellak, Alexandre Bousse, Thibaut Merlin, Debora Giovagnoli, Dimitris Visvikis
This paper presents a novel image reconstruction pipeline for three-gamma (3-{\gamma}) positron emission tomography (PET) aimed at improving spatial resolution and reducing noise in nuclear medicine. The proposed Direct3{\gamma} pipeline addresses the inherent challenges in 3-{\gamma} PET systems, such as detector imperfections and uncertainty in photon interaction points. A key feature of the pipeline is its ability to determine the order of interactions through a model trained on Monte Carlo (MC) simulations using the Geant4 Application for Tomography Emission (GATE) toolkit, thus providing the necessary information to construct Compton cones which intersect with the line of response (LOR) to provide an estimate of the emission point. The pipeline processes 3-{\gamma} PET raw data, reconstructs histoimages by propagating energy and spatial uncertainties along the LOR, and applies a 3-D convolutional neural network (CNN) to refine these intermediate images into high-quality reconstructions. To further enhance image quality, the pipeline leverages both supervised learning and adversarial losses, with the latter preserving fine structural details. Experimental results demonstrate that Direct3{\gamma} consistently outperforms conventional 200-ps time-of-flight (TOF) PET in terms of SSIM and PSNR.
本文提出了一种针对三伽马(3-γ)正电子发射断层扫描(PET)的新型图像重建流程,旨在提高核医学中的空间分辨率并降低噪声。所提出的Direct3γ流程解决了3-γ PET系统固有的挑战,如探测器缺陷和光子交互点的不确定性。该流程的一个关键功能是,它能够通过使用Geant4发射断层扫描应用程序(GATE)工具包进行蒙特卡洛(MC)模拟训练模型来确定交互的顺序,从而提供构建交于响应线(LOR)的康普顿锥所需的信息,以估计发射点。该流程处理3-γ PET原始数据,通过传播能量和空间不确定性沿LOR重建直方图像,并应用三维卷积神经网络(CNN)将这些中间图像精细化为高质量重建。为了进一步改善图像质量,该流程结合了监督学习和对抗性损失,后者能够保留精细的结构细节。实验结果表明,Direct3γ在结构相似性度量(SSIM)和峰值信噪比(PSNR)方面始终优于传统的200皮秒飞行时间(TOF)PET。
论文及项目相关链接
PDF 10 pages, 11 figures, 2 tables
Summary
本文提出了一种针对三伽马(3-γ)正电子发射断层扫描(PET)图像重建的新流程,旨在改善空间分辨率并减少核医学中的噪声。Direct3γ流程解决了3-γ PET系统的固有挑战,如探测器的不完美和光子交互点的不确定性。该流程通过训练模型使用蒙特卡洛(MC)模拟确定交互顺序,构建交于响应线(LOR)的康普顿锥以估算发射点。该流程处理3-γ PET原始数据,通过传播能量和空间不确定性沿LOR重建组织图像,并应用三维卷积神经网络(CNN)对中间图像进行高质量重建。为进一步改善图像质量,该流程结合了监督学习和对抗损失,后者保留了精细结构细节。实验结果表明,Direct3γ在结构相似性指数(SSIM)和峰值信噪比(PSNR)方面均优于传统的200皮秒飞行时间(TOF)PET。
Key Takeaways
- 该论文介绍了一种针对三伽马(3-γ)PET的新型图像重建流程。
- Direct3γ流程旨在提高空间分辨率并降低核医学中的噪声。
- 该流程解决了探测器不完美和光子交互点的不确定性等3-γ PET系统的固有挑战。
- 通过训练模型并使用蒙特卡洛模拟确定交互顺序,构建康普顿锥来估算发射点。
- 该流程利用CNN对图像进行高质量重建,并通过传播能量和空间不确定性沿LOR生成组织图像。
- Direct3γ流程结合了监督学习和对抗损失来改善图像质量,保留精细结构细节。
点此查看论文截图

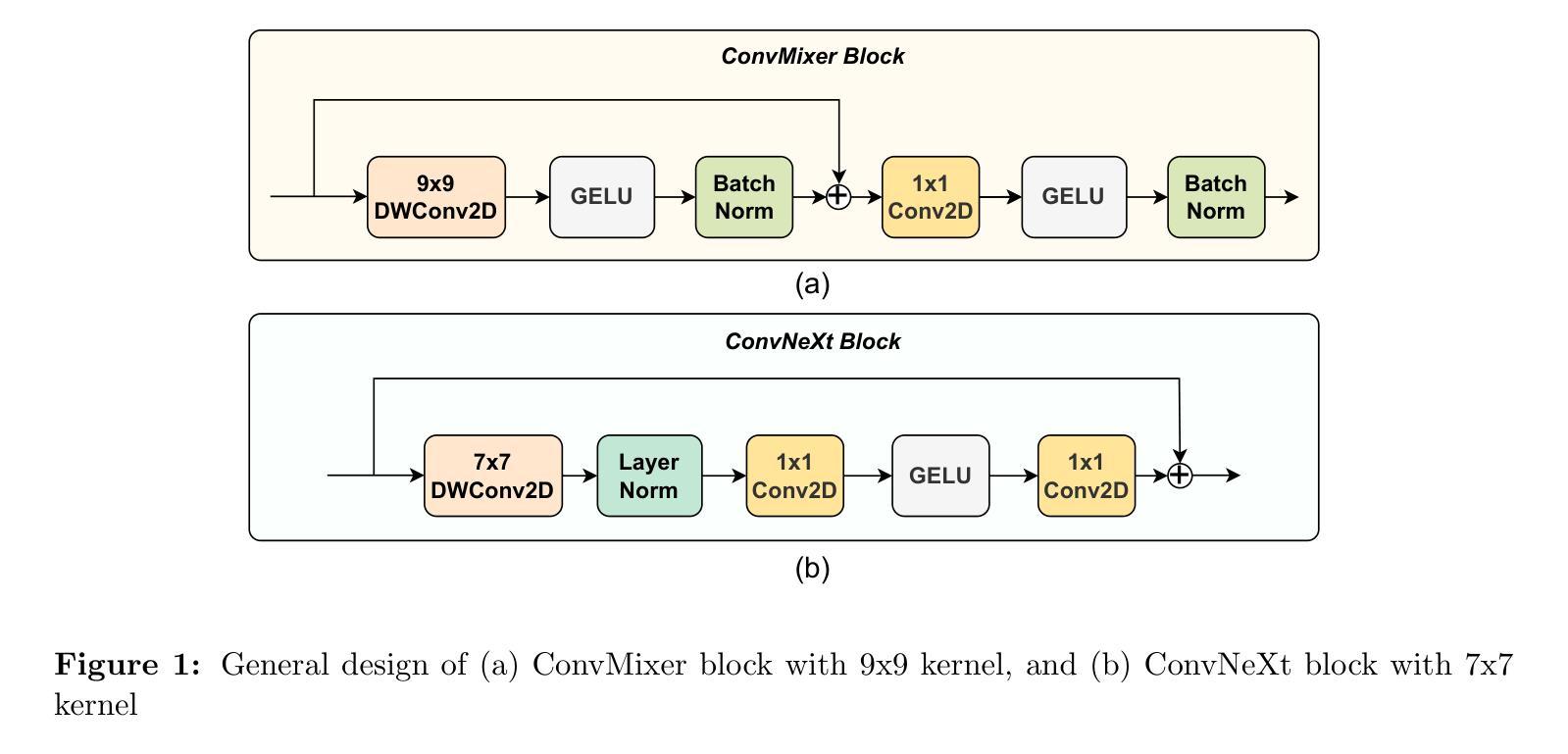
LiteNeXt: A Novel Lightweight ConvMixer-based Model with Self-embedding Representation Parallel for Medical Image Segmentation
Authors:Ngoc-Du Tran, Thi-Thao Tran, Quang-Huy Nguyen, Manh-Hung Vu, Van-Truong Pham
The emergence of deep learning techniques has advanced the image segmentation task, especially for medical images. Many neural network models have been introduced in the last decade bringing the automated segmentation accuracy close to manual segmentation. However, cutting-edge models like Transformer-based architectures rely on large scale annotated training data, and are generally designed with densely consecutive layers in the encoder, decoder, and skip connections resulting in large number of parameters. Additionally, for better performance, they often be pretrained on a larger data, thus requiring large memory size and increasing resource expenses. In this study, we propose a new lightweight but efficient model, namely LiteNeXt, based on convolutions and mixing modules with simplified decoder, for medical image segmentation. The model is trained from scratch with small amount of parameters (0.71M) and Giga Floating Point Operations Per Second (0.42). To handle boundary fuzzy as well as occlusion or clutter in objects especially in medical image regions, we propose the Marginal Weight Loss that can help effectively determine the marginal boundary between object and background. Additionally, the Self-embedding Representation Parallel technique is proposed as an innovative data augmentation strategy that utilizes the network architecture itself for self-learning augmentation, enhancing feature extraction robustness without external data. Experiments on public datasets including Data Science Bowls, GlaS, ISIC2018, PH2, Sunnybrook, and Lung X-ray data show promising results compared to other state-of-the-art CNN-based and Transformer-based architectures. Our code is released at: https://github.com/tranngocduvnvp/LiteNeXt.
随着深度学习技术的兴起,图像分割任务,尤其是医学图像分割,已经得到了极大的推进。过去十年中,已经引入了许多神经网络模型,使自动化分割的准确度接近手动分割。然而,最前沿的模型,如基于Transformer的架构,依赖于大规模标注的训练数据,并且通常具有编码器、解码器和跳过连接中的密集连续层,导致参数数量庞大。另外,为了获得更好的性能,它们通常需要在更大的数据上进行预训练,因此需要较大的内存并增加了资源开销。在本研究中,我们提出了一种新的轻量化但高效的模型,名为LiteNeXt,用于医学图像分割,该模型基于卷积和混合模块,并使用简化的解码器。该模型从零开始训练,参数较少(0.71M),并且每秒可进行0.42Giga浮点运算。为了处理医学图像区域中边界模糊以及对象遮挡或杂乱的情况,我们提出了边缘权重损失(Marginal Weight Loss),可以帮助有效地确定对象与背景之间的边缘边界。此外,还提出了自嵌入表示并行技术(Self-embedding Representation Parallel),这是一种创新的数据增强策略,利用网络架构本身进行自学习增强,提高特征提取的稳健性而无需外部数据。在公开数据集上的实验表明,与其他最先进的CNN和Transformer架构相比,我们的方法在Data Science Bowls、GlaS、ISIC2018、PH2、Sunnybrook和肺部X射线数据上均显示出有前景的结果。我们的代码已发布在:https://github.com/tranngocduvnvp/LiteNeXt。
解释:
论文及项目相关链接
PDF This manuscript has been accepted by Biomedical Signal Processing and Control
Summary
深度学习技术的出现推动了图像分割任务的发展,特别是在医学图像领域。一项新研究提出了一种轻量级但高效的模型LiteNeXt,用于医学图像分割。该模型基于卷积和混合模块,具有简化的解码器,可有效处理医学图像区域中边界模糊、遮挡或杂乱的问题。同时,该研究还提出了边际权重损失和自我嵌入表示并行等创新策略,实验结果显示其性能优异。
Key Takeaways
- 深度学习技术推动了医学图像分割的进展,许多神经网络模型提高了自动化分割的准确性。
- 最新模型如基于Transformer的架构需要大规模注释训练数据,并且参数较多。
- LiteNeXt模型是一个轻量级但高效的医学图像分割模型,基于卷积和混合模块,具有简化的解码器。
- LiteNeXt模型可处理医学图像中的边界模糊、遮挡或杂乱问题,通过边际权重损失有效确定物体与背景之间的边界。
- 自我嵌入表示并行是一种利用网络架构进行自我学习增强的创新数据增强策略,提高了特征提取的稳健性。
- 在公开数据集上的实验结果显示,LiteNeXt模型与其他先进的CNN和Transformer架构相比具有前景。
点此查看论文截图

DeepThalamus: A novel deep learning method for automatic segmentation of brain thalamic nuclei from multimodal ultra-high resolution MRI
Authors:Marina Ruiz-Perez, Sergio Morell-Ortega, Marien Gadea, Roberto Vivo-Hernando, Gregorio Rubio, Fernando Aparici, Mariam de la Iglesia-Vaya, Thomas Tourdias, Pierrick Coupé, José V. Manjón
The implication of the thalamus in multiple neurological pathologies makes it a structure of interest for volumetric analysis. In the present work, we have designed and implemented a multimodal volumetric deep neural network for the segmentation of thalamic nuclei at ultra-high resolution (0.125 mm3). Current tools either operate at standard resolution (1 mm3) or use monomodal data. To achieve the proposed objective, first, a database of semiautomatically segmented thalamic nuclei was created using ultra-high resolution T1, T2 and White Matter nulled (WMn) images. Then, a novel Deep learning based strategy was designed to obtain the automatic segmentations and trained to improve its robustness and accuaracy using a semisupervised approach. The proposed method was compared with a related state-of-the-art method showing competitive results both in terms of segmentation quality and efficiency. To make the proposed method fully available to the scientific community, a full pipeline able to work with monomodal standard resolution T1 images is also proposed.
丘脑在多种神经病理中的影响使其成为体积分析感兴趣的结构。在本研究中,我们设计并实现了一种多模态体积深度神经网络,用于超高分辨率(0.125 mm3)下的丘脑核分割。当前工具要么在标准分辨率(1 mm3)下运行,要么使用单模态数据。为了实现既定目标,首先使用超高分辨率的T1、T2和White Matter nulled(WMn)图像创建了半自动分割的丘脑核数据库。然后,设计了一种基于深度学习的新策略来获得自动分割,并使用半监督方法进行训练以提高其稳健性和准确性。所提出的方法与一种相关的高级方法进行了比较,在分割质量和效率方面都显示出具有竞争力的结果。为了使所提出的方法完全可供科学界使用,还提出了一种能够处理单模态标准分辨率T1图像的全流程。
论文及项目相关链接
Summary
本研究设计并实施了一种多模态体积深度神经网络,用于超高分辨率(0.125 mm³)丘脑核分割。当前工具操作于标准分辨率或使用单模态数据。本研究创建了一个半自动分割丘脑核数据库,使用超高分辨率T1、T2和白色物质空化(WMn)图像,然后设计了一种新型的基于深度学习的自动分割策略并进行了训练。本方法与相关领域的前沿方法相比在分割质量和效率方面展现了竞争力,并提出了适用于单模态标准分辨率T1图像的完整流程。
Key Takeaways
- 本研究探讨了丘脑在多种神经病理学中的作用,并对其进行体积分析。
- 设计并实施了一种多模态体积深度神经网络用于超高分辨率丘脑核分割。
- 当前工具存在操作于标准分辨率或使用单模态数据的局限。
- 通过创建半自动分割丘脑核数据库并使用超高分辨率图像进行训练,提高了方法的稳健性和准确性。
- 本方法与相关领域的前沿方法相比在分割质量和效率方面展现了竞争力。
- 研究提出了一种完整的流程,能够处理单模态标准分辨率T1图像。
点此查看论文截图