⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-16 更新
StereoCrafter-Zero: Zero-Shot Stereo Video Generation with Noisy Restart
Authors:Jian Shi, Qian Wang, Zhenyu Li, Ramzi Idoughi, Peter Wonka
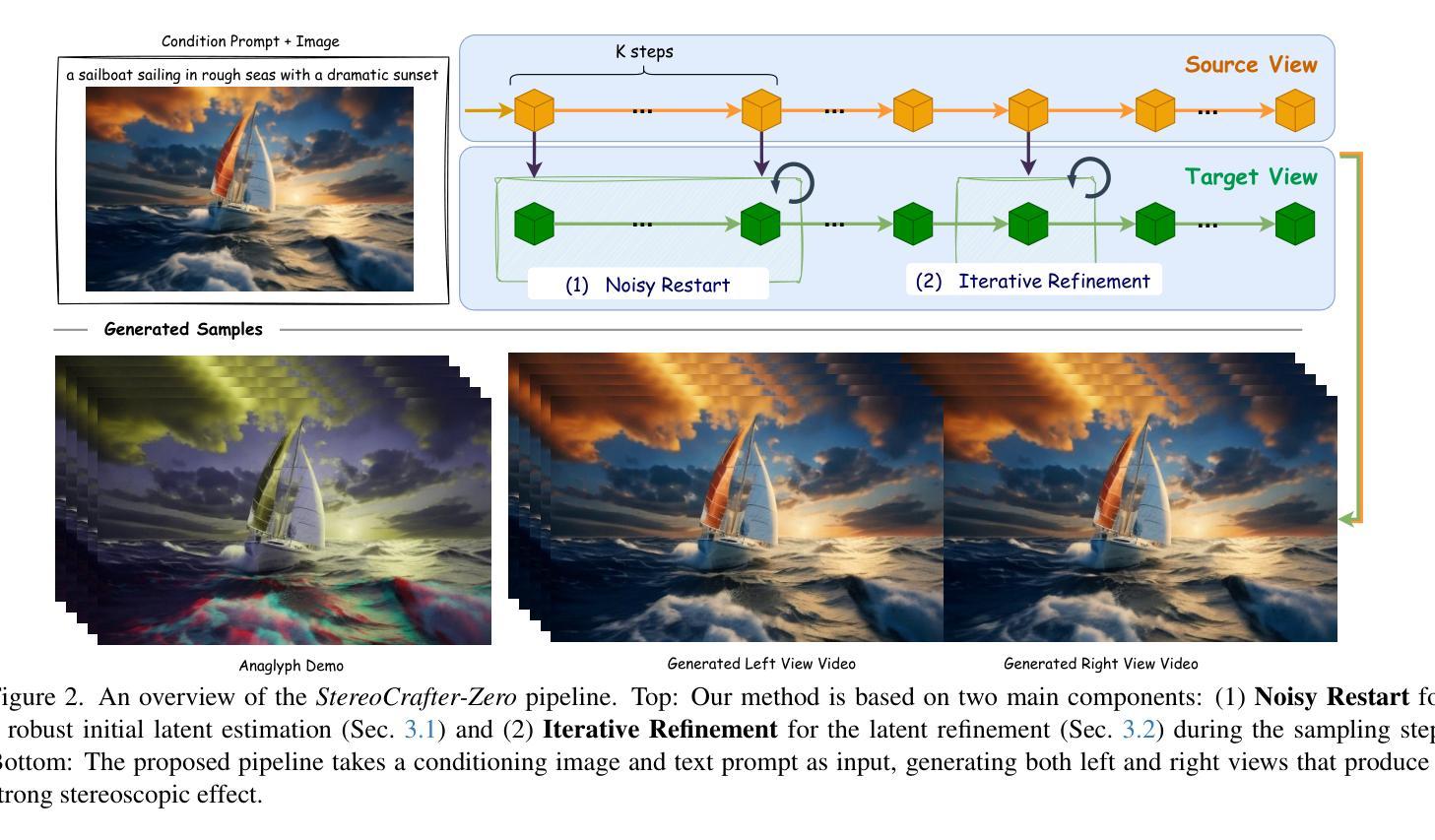
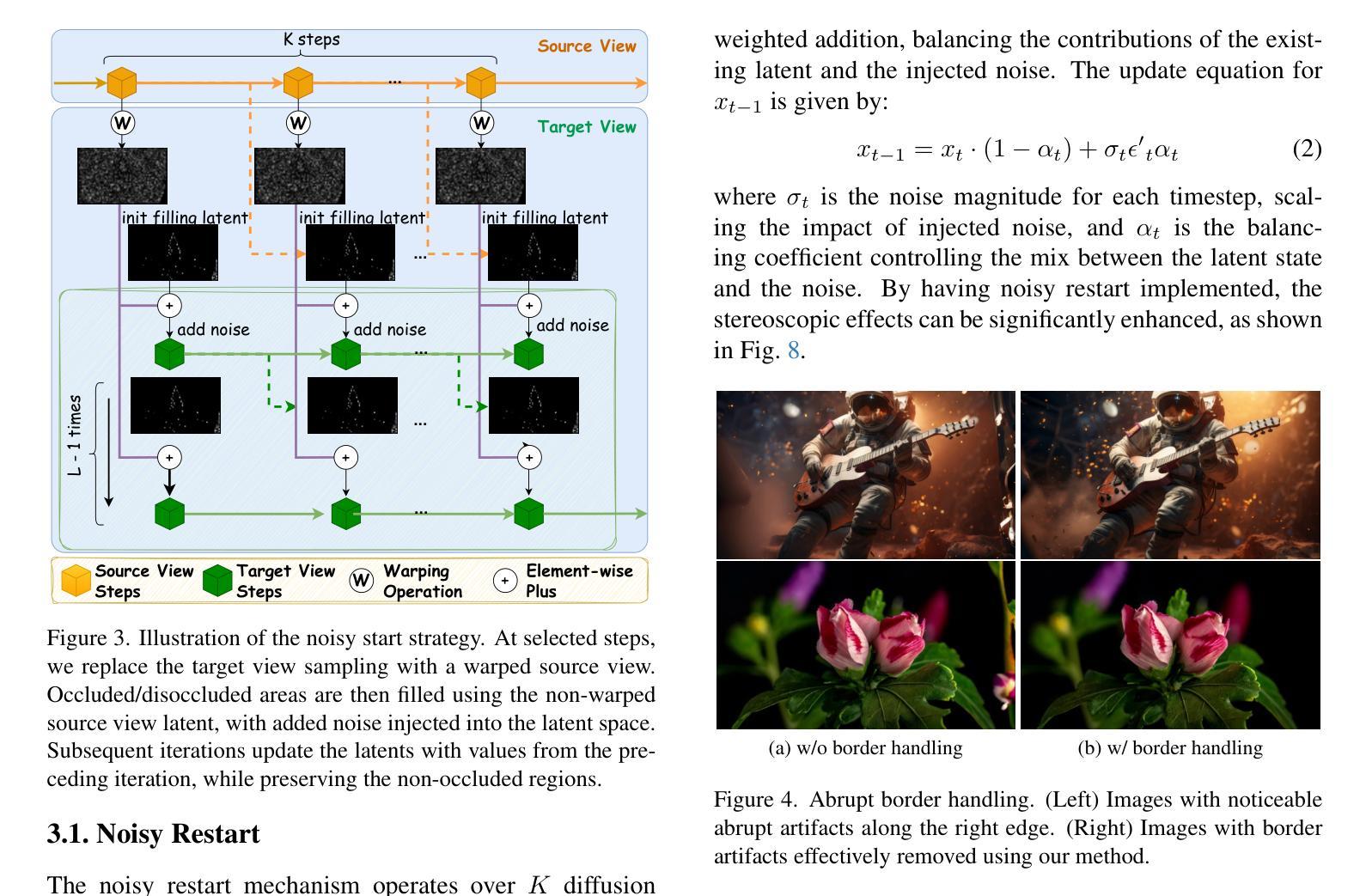
Generating high-quality stereo videos that mimic human binocular vision requires consistent depth perception and temporal coherence across frames. Despite advances in image and video synthesis using diffusion models, producing high-quality stereo videos remains a challenging task due to the difficulty of maintaining consistent temporal and spatial coherence between left and right views. We introduce StereoCrafter-Zero, a novel framework for zero-shot stereo video generation that leverages video diffusion priors without requiring paired training data. Our key innovations include a noisy restart strategy to initialize stereo-aware latent representations and an iterative refinement process that progressively harmonizes the latent space, addressing issues like temporal flickering and view inconsistencies. In addition, we propose the use of dissolved depth maps to streamline latent space operations by reducing high-frequency depth information. Our comprehensive evaluations, including quantitative metrics and user studies, demonstrate that StereoCrafter-Zero produces high-quality stereo videos with enhanced depth consistency and temporal smoothness, even when depth estimations are imperfect. Our framework is robust and adaptable across various diffusion models, setting a new benchmark for zero-shot stereo video generation and enabling more immersive visual experiences. Our code is in https://github.com/shijianjian/StereoCrafter-Zero.
生成高质量立体视频,模仿人类双眼视觉,需要在各帧之间保持一致的深度感知和时间连贯性。尽管使用扩散模型的图像和视频合成取得了进展,但由于在左右视图之间保持时间和空间连贯性的困难,生成高质量立体视频仍然是一项具有挑战性的任务。我们引入了StereoCrafter-Zero,这是一种用于零样本立体视频生成的新型框架,它利用视频扩散先验,无需配对训练数据。我们的主要创新包括一种噪声重启策略,以初始化立体感知潜在表示,以及一个迭代细化过程,该过程逐步协调潜在空间,解决诸如时间闪烁和视图不一致等问题。此外,我们建议使用溶解深度图来简化潜在空间操作,通过减少高频深度信息。我们的全面评估,包括定量指标和用户研究,证明StereoCrafter-Zero即使在深度估计不完美的情况下,也能生成高质量立体视频,具有增强的深度一致性和时间平滑性。我们的框架在各种扩散模型中是稳健和可适应的,为零样本立体视频生成树立了新基准,并带来更沉浸式视觉体验。我们的代码位于https://github.com/shijianjian/StereoCrafter-Zero。
论文及项目相关链接
Summary
本文介绍了一种名为StereoCrafter-Zero的零样本立体视频生成框架,该框架利用视频扩散先验,无需配对训练数据。通过引入噪声重启策略和迭代细化过程,解决了立体视频生成中的深度一致性和时间连贯性问题。同时,利用溶解深度图简化潜在空间操作。评估和实验证明,StereoCrafter-Zero生成的高质量立体视频具有出色的深度一致性和时间平滑性,即使深度估计不完美也能表现出良好的性能。
Key Takeaways
- StereoCrafter-Zero是一个零样本立体视频生成框架,利用视频扩散先验。
- 框架引入了噪声重启策略,初始化立体感知的潜在表示。
- 通过迭代细化过程,逐步协调潜在空间,解决时间闪烁和视图不一致问题。
- 溶解深度图用于简化潜在空间操作,减少高频率深度信息。
- 该框架生成的高质量立体视频具有优秀的深度一致性和时间平滑性。
- 即使深度估计不完美,也能表现出良好的性能。
点此查看论文截图


There and Back Again: On the relation between Noise and Image Inversions in Diffusion Models
Authors:Łukasz Staniszewski, Łukasz Kuciński, Kamil Deja
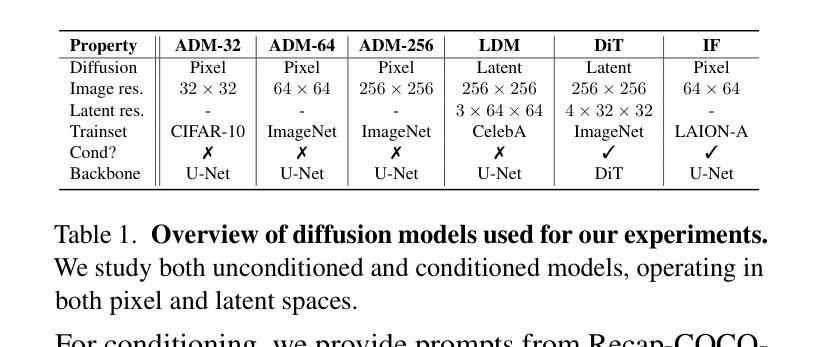
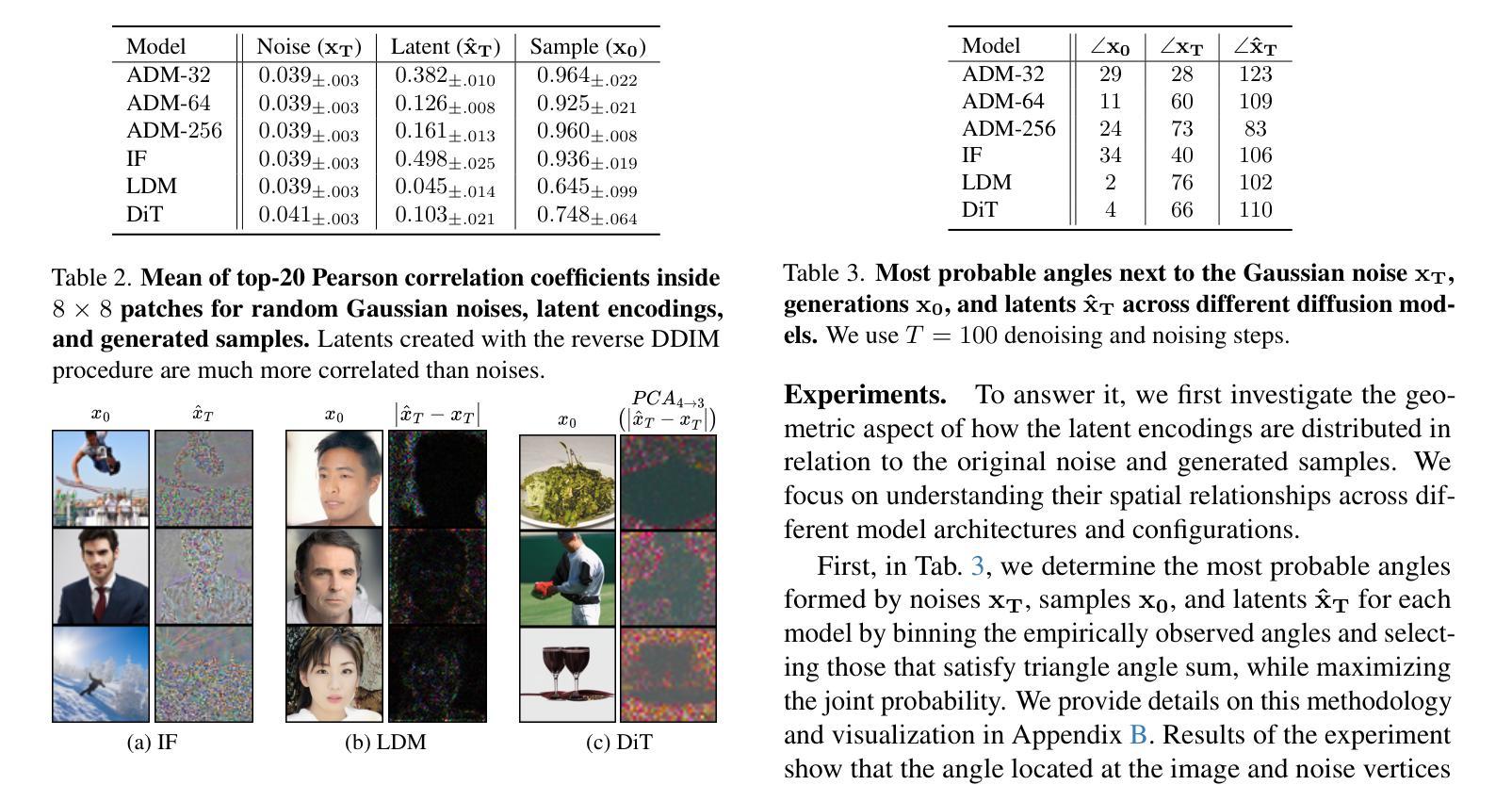
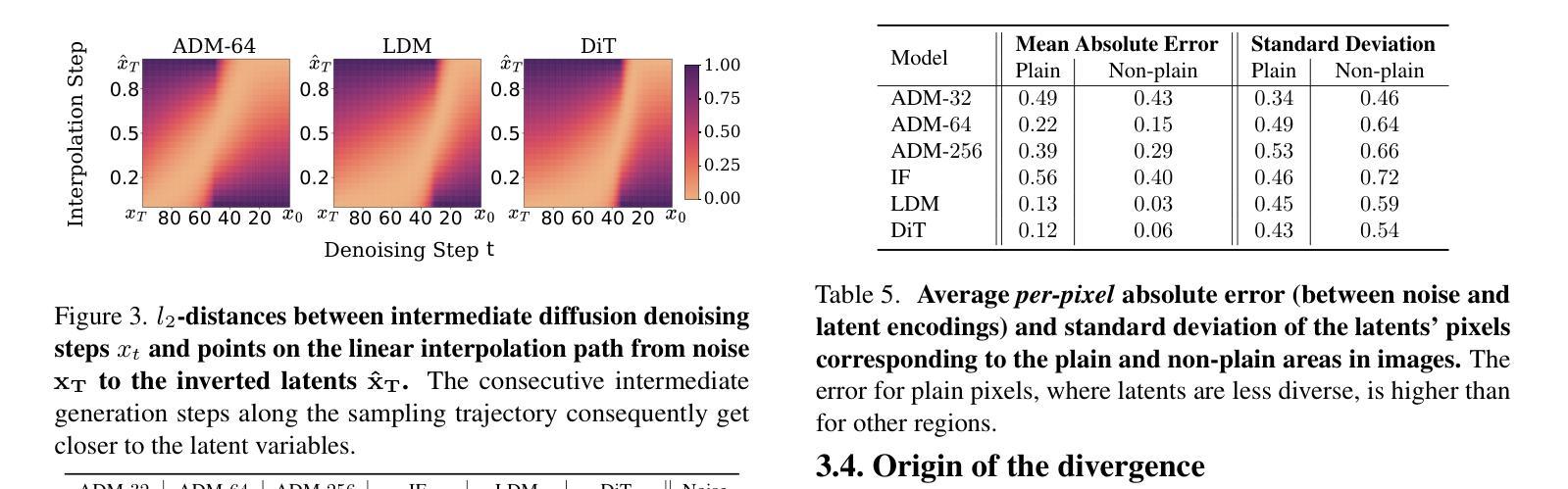
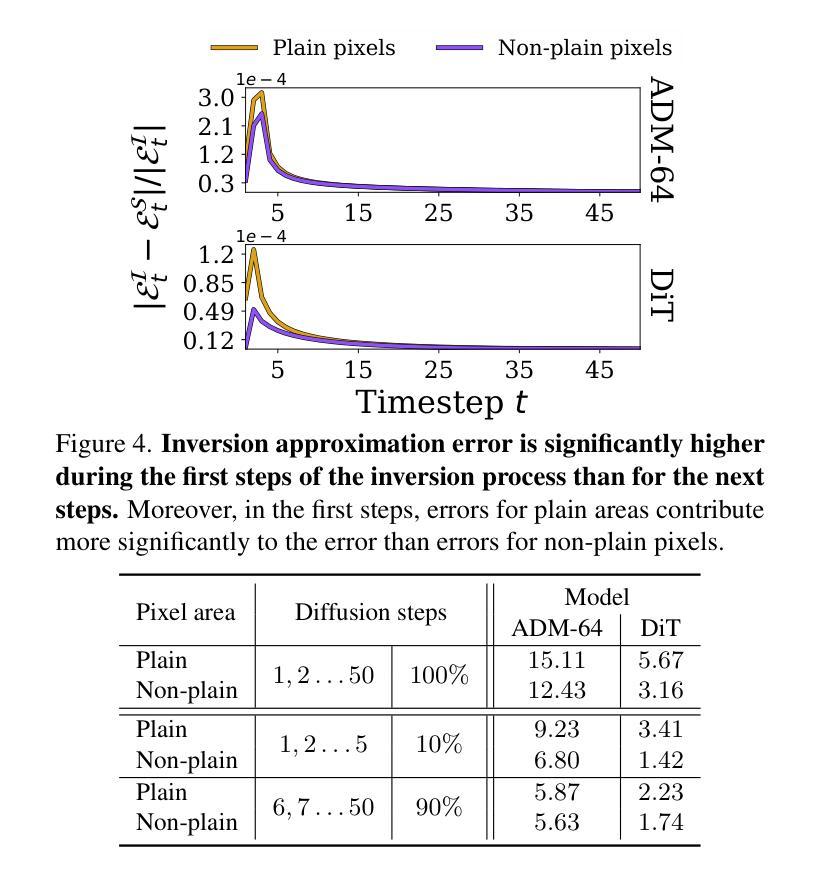
Diffusion Models achieve state-of-the-art performance in generating new samples but lack low-dimensional latent space that encodes the data into meaningful features. Inversion-based techniques try to solve this issue by reversing the denoising process and mapping images back to their approximated starting noise. In this work, we thoroughly analyze this procedure and focus on the relation between the initial Gaussian noise, the generated samples, and their corresponding latent encodings obtained through the DDIM inversion. First, we show that latents exhibit structural patterns in the form of less diverse noise predicted for smooth image regions. Next, we explain the origin of this phenomenon, demonstrating that, during the first inversion steps, the noise prediction error is much more significant for the plain areas than for the rest of the image. Finally, we present the consequences of the divergence between latents and noises by showing that the space of image inversions is notably less manipulative than the original Gaussian noise. This leads to a low diversity of generated interpolations or editions based on the DDIM inversion procedure and ill-defined latent-to-image mapping. Code is available at https://github.com/luk-st/taba.
扩散模型在生成新样本方面达到了最先进的性能,但缺乏将数据编码为有意义特征的低维潜在空间。基于反转的技术试图通过反转去噪过程,将图像映射回其近似初始噪声来解决这个问题。在这项工作中,我们彻底分析了这一过程,并重点关注初始高斯噪声、生成样本以及通过DDIM反转获得的相应潜在编码之间的关系。首先,我们展示潜伏因素在平滑图像区域预测的噪声形式表现出结构性的模式,即噪声多样性较低。接下来,我们解释了这一现象的起因,证明在最初的反转步骤中,对于平原地区的噪声预测误差比图像的其他部分要大的多。最后,我们通过展示图像反转空间明显比原始高斯噪声更不容易操控,来阐述潜伏与噪声之间分歧的后果。这导致基于DDIM反转程序的生成插值或编辑的多样性较低,潜伏到图像的映射定义不明确。代码可在https://github.com/luk-st/taba找到。
论文及项目相关链接
Summary
本文探讨了Diffusion Models在生成新样本时的性能,指出其缺乏低维潜在空间来编码数据为有意义的特征。研究者采用基于反演的技术来解决这一问题,通过反转去噪过程将图像映射回其近似初始噪声。本文详细分析了这一过程,并重点关注初始高斯噪声、生成样本及其通过DDIM反演获得的潜在编码之间的关系。研究发现,潜在空间在平滑图像区域的噪声预测展现出结构性模式,且这种现象起源于反演过程初期的噪声预测误差。此外,研究者展示了潜在与噪声之间的差异所带来的后果,即图像反演空间明显比原始高斯噪声更难以操控。这导致基于DDIM反演过程的生成插值或编辑的多样性较低,且潜在到图像的映射不明确。
Key Takeaways
- Diffusion Models生成样本性能先进,但缺乏低维潜在空间编码有意义特征。
- 基于反演的技术试图解决此问题,通过反转去噪过程将图像映射回初始噪声。
- 潜在空间在平滑图像区域的噪声预测展现结构性模式。
- 此现象起源于反演过程初期的噪声预测误差在图像平滑区域的显著较大。
- 潜在与噪声之间的差异导致图像反演空间比原始高斯噪声更难以操控。
- 基于DDIM反演过程的生成插值或编辑的多样性较低。
- 潜在到图像的映射不明确。
点此查看论文截图