⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-16 更新
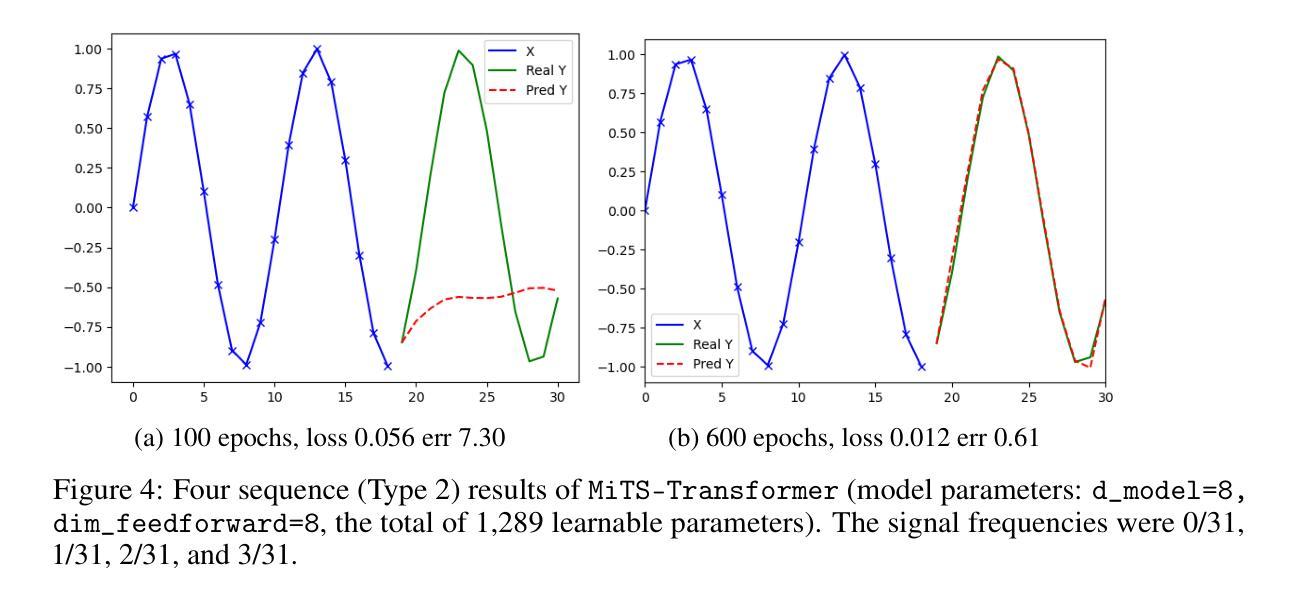
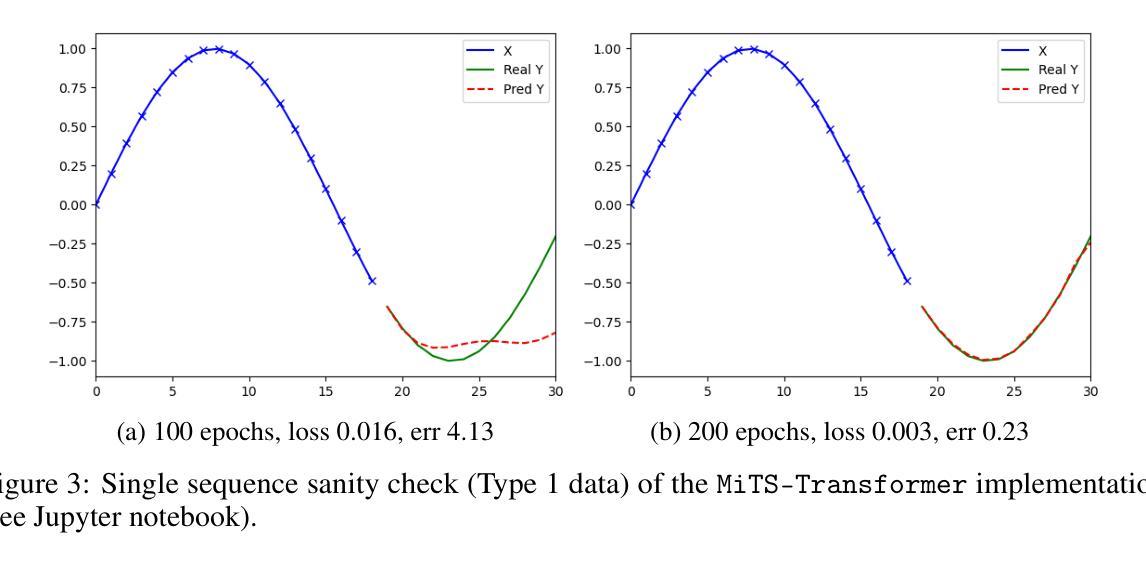
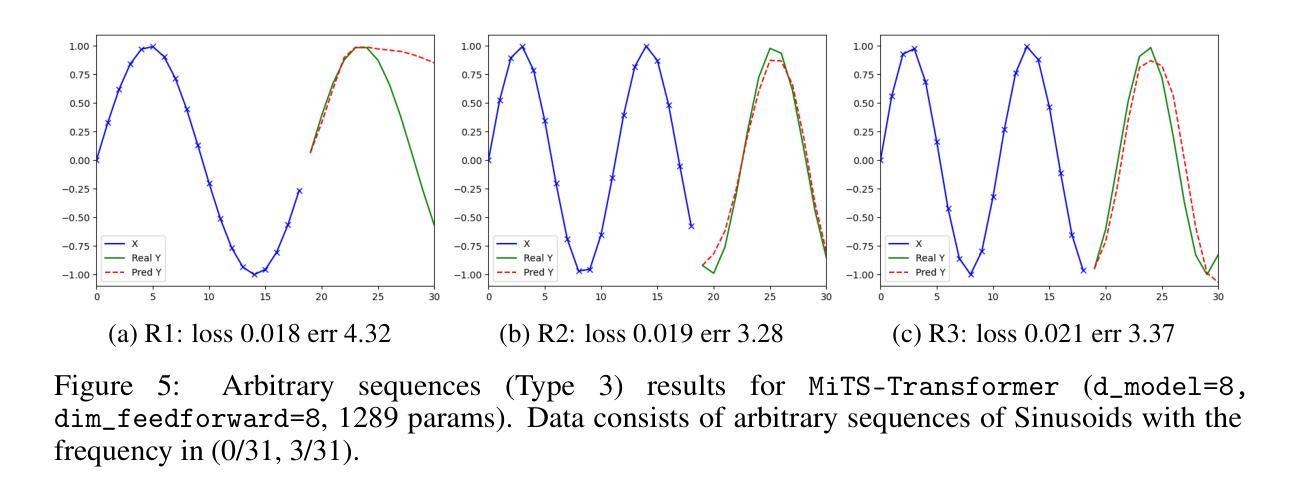
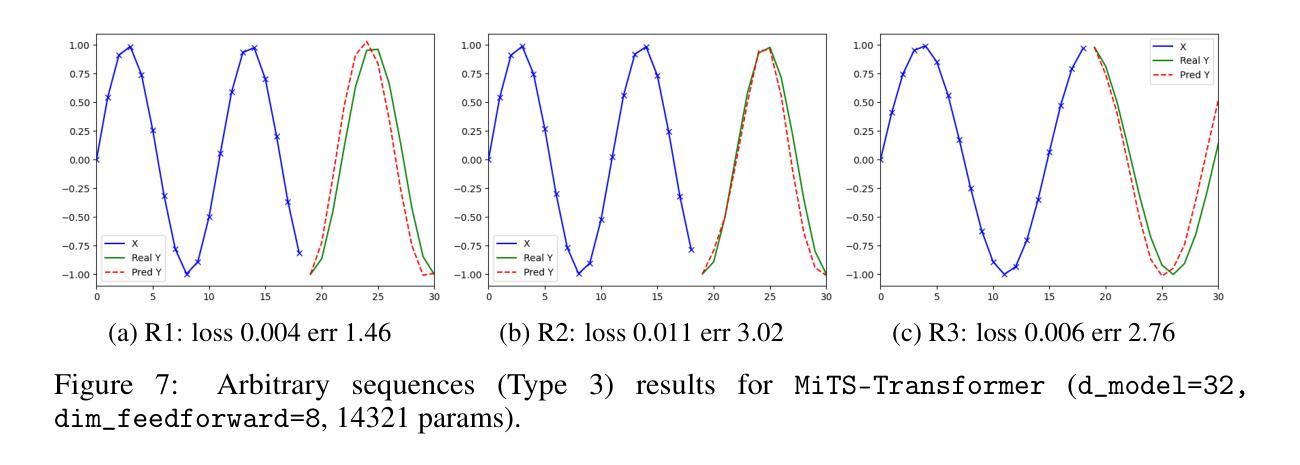
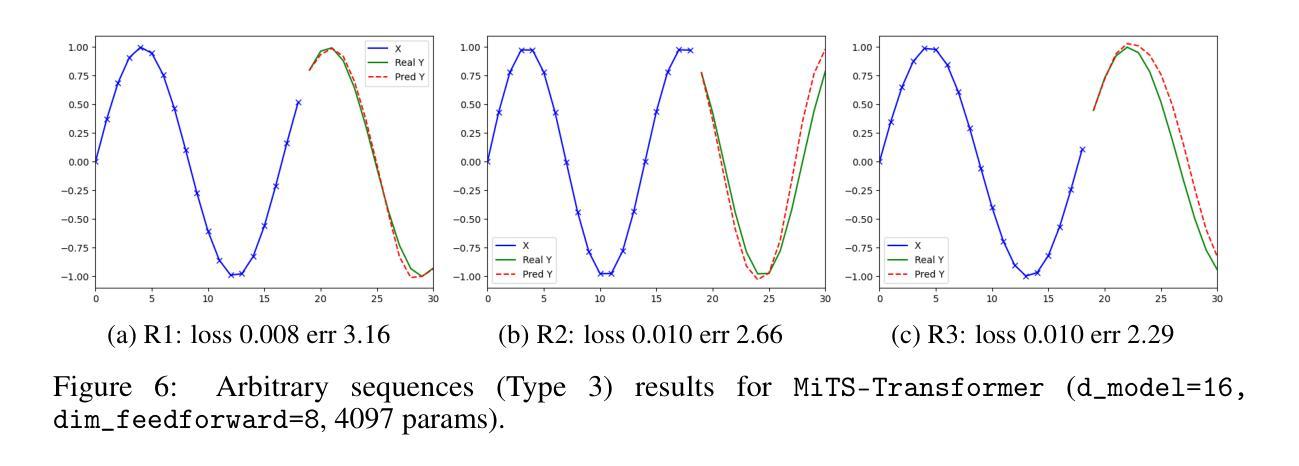
Minimal Time Series Transformer
Authors:Joni-Kristian Kämäräinen
Transformer is the state-of-the-art model for many natural language processing, computer vision, and audio analysis problems. Transformer effectively combines information from the past input and output samples in auto-regressive manner so that each sample becomes aware of all inputs and outputs. In sequence-to-sequence (Seq2Seq) modeling, the transformer processed samples become effective in predicting the next output. Time series forecasting is a Seq2Seq problem. The original architecture is defined for discrete input and output sequence tokens, but to adopt it for time series, the model must be adapted for continuous data. This work introduces minimal adaptations to make the original transformer architecture suitable for continuous value time series data.
Transformer模型是很多自然语言处理、计算机视觉和音频分析问题的最先进模型。Transformer有效地以自回归方式结合了来自过去输入和输出样本的信息,从而使每个样本都能感知到所有的输入和输出。在序列到序列(Seq2Seq)建模中,经过Transformer处理的样本在预测下一个输出时非常有效。时间序列预测是一个Seq2Seq问题。原始架构是为离散输入输出序列标记定义的,但要将其用于时间序列,必须对模型进行适应以处理连续数据。这项工作对原始Transformer架构进行了最小的调整,使其适用于连续值时间序列数据。
论文及项目相关链接
PDF 8 pages, 8 figures
Summary:Transformer模型结合了过往输入和输出样本的信息,以自回归的方式使每个样本都能感知到所有的输入和输出,适用于许多自然语言处理、计算机视觉和音频分析等问题。在时间序列预测这类序列到序列(Seq2Seq)问题上,经过适应连续数据的改进后的Transformer模型表现出了高效的预测能力。
Key Takeaways:
- Transformer模型结合了过往输入和输出样本的信息。
- Transformer以自回归的方式处理信息,使每个样本都能感知到所有的输入和输出。
- Transformer模型适用于自然语言处理、计算机视觉和音频分析等多种问题。
- 时间序列预测是序列到序列(Seq2Seq)问题。
- 原始的Transformer架构是为离散输入和输出序列令牌定义的。
- 为了将Transformer模型应用于时间序列数据,必须对模型进行适应以处理连续数据。
点此查看论文截图

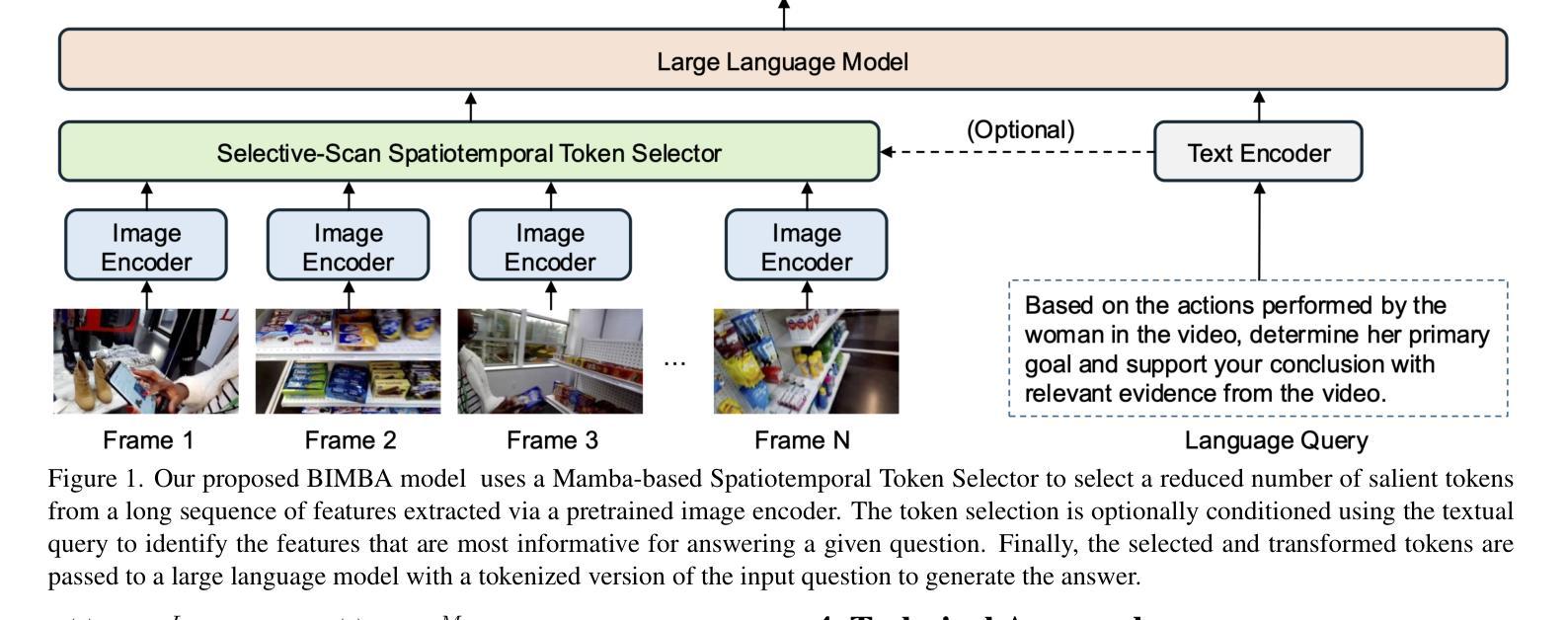
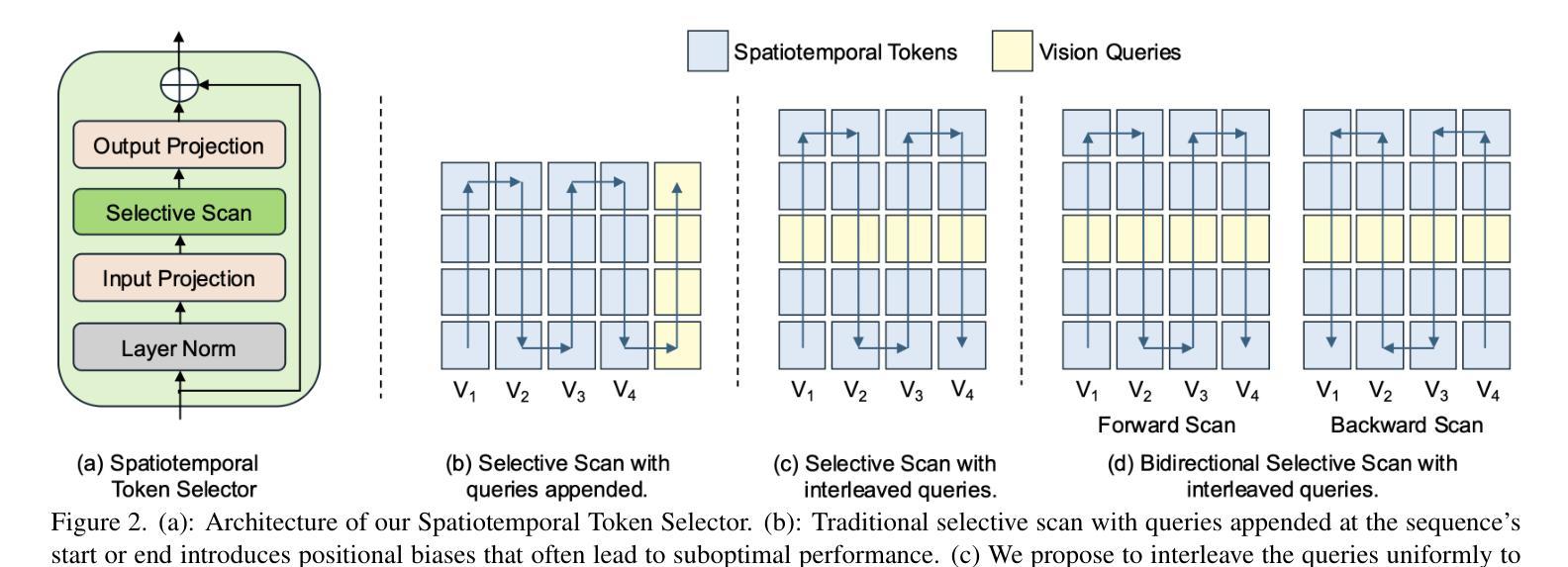
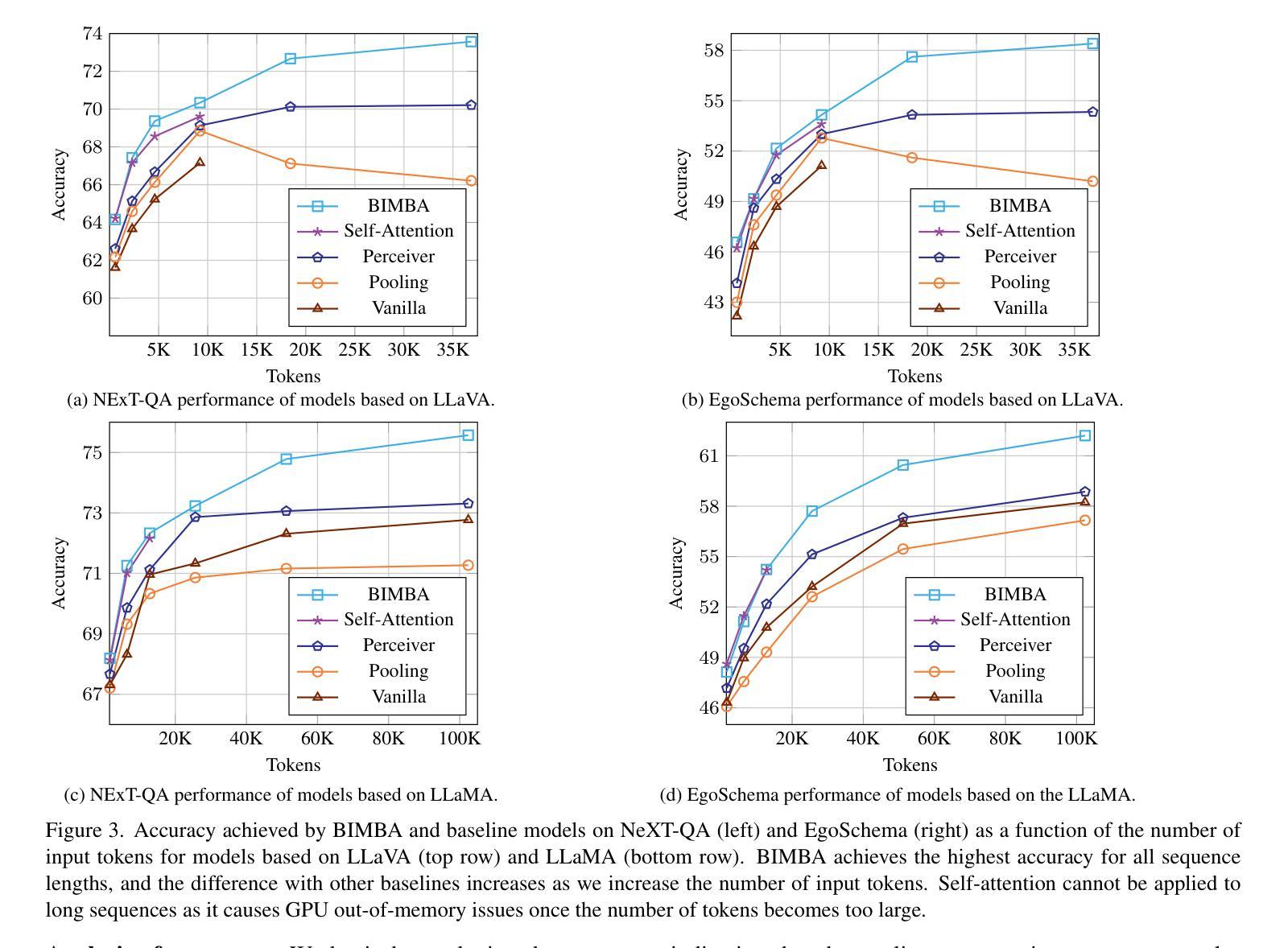
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Authors:Md Mohaiminul Islam, Tushar Nagarajan, Huiyu Wang, Gedas Bertasius, Lorenzo Torresani
Video Question Answering (VQA) in long videos poses the key challenge of extracting relevant information and modeling long-range dependencies from many redundant frames. The self-attention mechanism provides a general solution for sequence modeling, but it has a prohibitive cost when applied to a massive number of spatiotemporal tokens in long videos. Most prior methods rely on compression strategies to lower the computational cost, such as reducing the input length via sparse frame sampling or compressing the output sequence passed to the large language model (LLM) via space-time pooling. However, these naive approaches over-represent redundant information and often miss salient events or fast-occurring space-time patterns. In this work, we introduce BIMBA, an efficient state-space model to handle long-form videos. Our model leverages the selective scan algorithm to learn to effectively select critical information from high-dimensional video and transform it into a reduced token sequence for efficient LLM processing. Extensive experiments demonstrate that BIMBA achieves state-of-the-art accuracy on multiple long-form VQA benchmarks, including PerceptionTest, NExT-QA, EgoSchema, VNBench, LongVideoBench, and Video-MME. Code, and models are publicly available at https://sites.google.com/view/bimba-mllm.
视频问答(VQA)在长视频中面临的关键挑战是从大量冗余帧中提取相关信息并建模长距离依赖关系。自注意力机制为序列建模提供了一种通用解决方案,但当应用于长视频中的大量时空令牌时,其成本高昂。大多数先前的方法依赖于压缩策略来降低计算成本,例如通过稀疏帧采样减少输入长度,或通过时空池化压缩传递给大型语言模型(LLM)的输出序列。然而,这些简单的方法过于强调冗余信息,并且经常忽略重要事件或快速发生的时空模式。在这项工作中,我们引入了BIMBA,这是一种处理长格式视频的高效状态空间模型。我们的模型利用选择性扫描算法来学习有效地从高维视频中选择关键信息,并将其转换为减少的令牌序列,以便大型语言模型进行高效处理。大量实验表明,BIMBA在多个长格式VQA基准测试中达到了最新水平,包括PerceptionTest、NExT-QA、EgoSchema、VNBench、LongVideoBench和Video-MME。代码和模型可在https://sites.google.com/view/bimba-mllm公开访问。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文介绍了处理长视频VQA(视频问题回答)的挑战,包括从大量冗余帧中提取相关信息和建模长距离依赖关系。现有方法多采用压缩策略降低计算成本,但存在过度代表冗余信息、忽略重要事件或快速时空模式的问题。本文提出BIMBA模型,利用选择性扫描算法从高维视频中选择关键信息,转化为简化的令牌序列,供LLM高效处理。实验证明BIMBA在多个长视频VQA基准测试中达到最新水平,包括PerceptionTest、NExT-QA等。模型与代码公开于:https://sites.google.com/view/bimba-mllm。
Key Takeaways
- 处理长视频的VQA面临提取相关信息和建模长距离依赖关系的挑战。
- 现有方法使用压缩策略以降低计算成本,但可能忽略重要信息。
- BIMBA模型利用选择性扫描算法从高维视频中选择关键信息。
- BIMBA将关键信息转化为简化的令牌序列供LLM高效处理。
- BIMBA在多个长视频VQA基准测试中达到最新水平。
- 模型与代码已公开,便于他人使用和研究。
点此查看论文截图

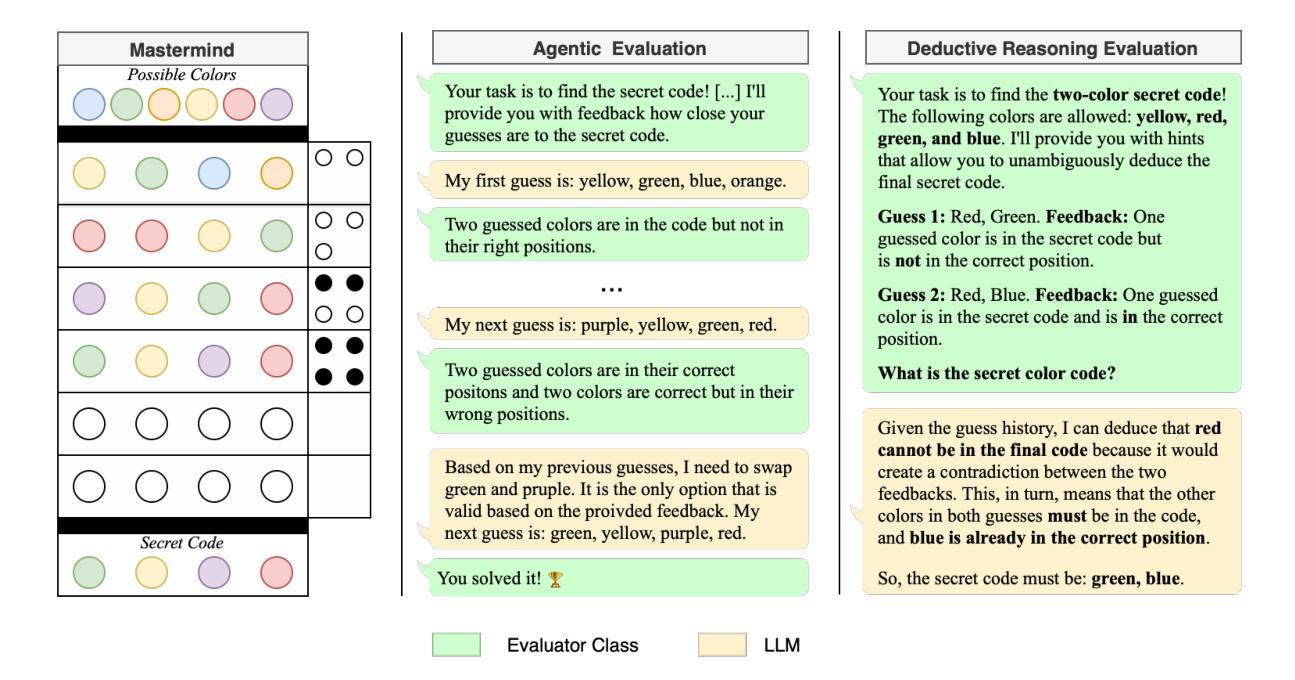
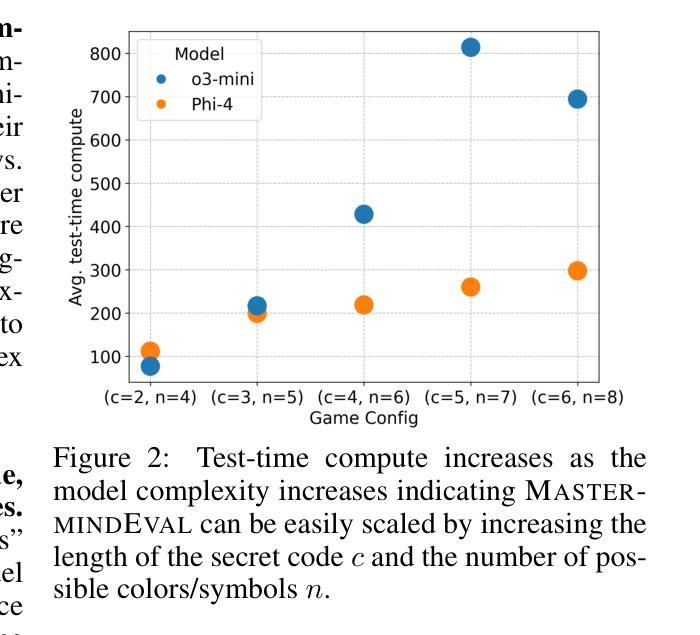
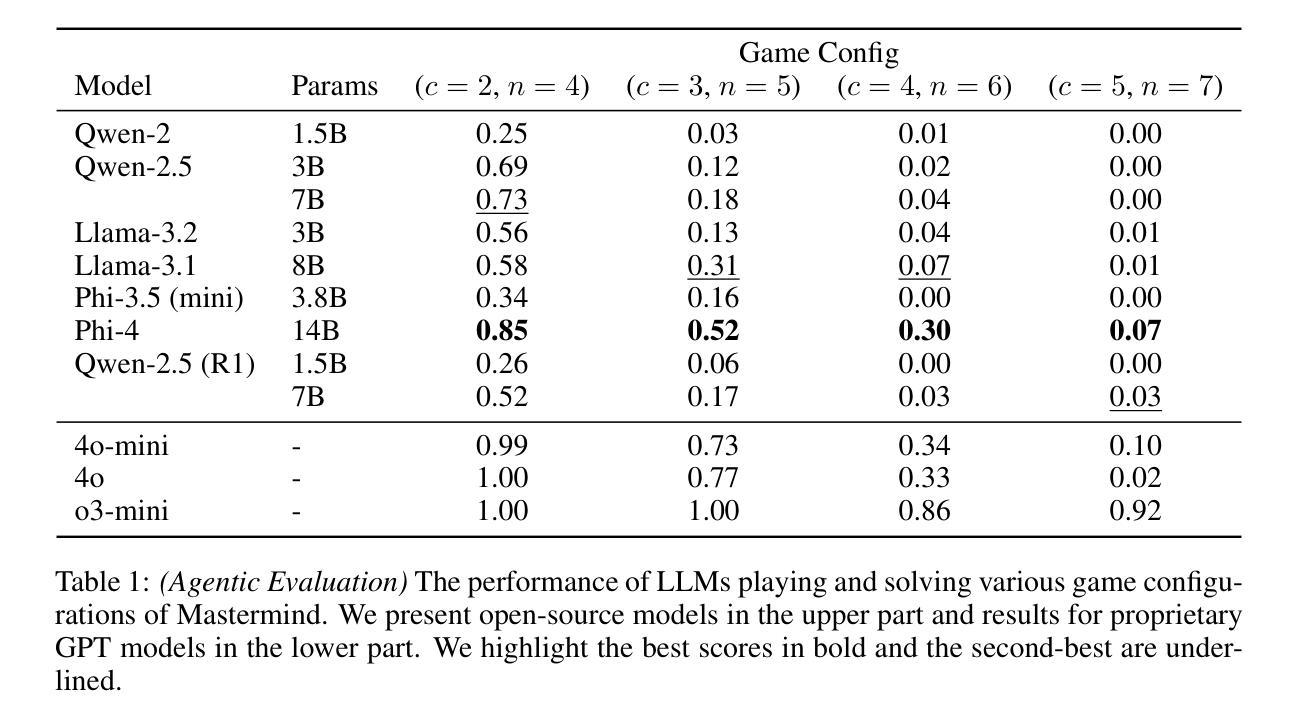
MastermindEval: A Simple But Scalable Reasoning Benchmark
Authors:Jonas Golde, Patrick Haller, Fabio Barth, Alan Akbik
Recent advancements in large language models (LLMs) have led to remarkable performance across a wide range of language understanding and mathematical tasks. As a result, increasing attention has been given to assessing the true reasoning capabilities of LLMs, driving research into commonsense, numerical, logical, and qualitative reasoning. However, with the rapid progress of reasoning-focused models such as OpenAI’s o1 and DeepSeek’s R1, there has been a growing demand for reasoning benchmarks that can keep pace with ongoing model developments. In this paper, we introduce MastermindEval, a simple, scalable, and interpretable deductive reasoning benchmark inspired by the board game Mastermind. Our benchmark supports two evaluation paradigms: (1) agentic evaluation, in which the model autonomously plays the game, and (2) deductive reasoning evaluation, in which the model is given a pre-played game state with only one possible valid code to infer. In our experimental results we (1) find that even easy Mastermind instances are difficult for current models and (2) demonstrate that the benchmark is scalable to possibly more advanced models in the future Furthermore, we investigate possible reasons why models cannot deduce the final solution and find that current models are limited in deducing the concealed code as the number of statement to combine information from is increasing.
大型语言模型(LLM)的最新进展在广泛的自然语言理解和数学任务中取得了显著的成果。因此,人们越来越关注评估LLM的真正推理能力,推动了常识推理、数值推理、逻辑和定性推理的研究。然而,随着以推理为重点的模型如OpenAI的o1和DeepSeek的R1的快速发展,对能与当前模型发展同步的推理基准测试的需求也在增长。在本文中,我们介绍了MastermindEval,这是一个受棋盘游戏《Mastermind》启发的简单、可扩展和可解释的演绎推理基准测试。我们的基准测试支持两种评估模式:(1)自主评估模式,模型自主玩游戏;(2)演绎推理评估模式,给定一个预先进行的游戏状态,模型需要通过推理找出唯一的正确答案。我们的实验结果表明:(1)即使是简单的Mastermind实例对于当前模型来说也是困难的;(2)该基准测试可以扩展到未来可能更先进的模型。此外,我们还调查了模型无法推断出最终解决方案的可能原因,并发现随着需要组合信息来推断答案的陈述数量增加,当前模型在推断隐藏代码方面的能力受到限制。
论文及项目相关链接
PDF 9 pages, 2 figures, 4 tables. In: ICLR 2025 Workshop on Reasoning and Planning for Large Language Models
Summary
大型语言模型(LLM)的最新进展在各种语言理解和数学任务上取得了显著的成绩,引发了人们对评估其真正推理能力的关注,推动了常识、数值、逻辑和定性推理的研究。为此,本文提出了MastermindEval基准测试,这是一个简单、可扩展且可解释的推理基准测试,灵感来源于猜谜游戏Mastermind。该基准测试支持两种评估模式:自主游戏评估和推理评估。实验结果表明,即使是简单的猜谜实例对于当前模型来说也是困难的,并且该基准测试可以扩展到更先进的模型。此外,本文还探讨了模型无法推断最终解决方案的可能原因,发现当前模型在处理信息组合时存在局限性。
Key Takeaways
- LLM的最新进展在各种语言理解和数学任务上取得了显著成绩。
- 人们需要评估LLM的真正推理能力,这推动了常识、数值、逻辑和定性推理的研究。
- MastermindEval基准测试是一个简单、可扩展且可解释的推理基准测试,灵感来源于猜谜游戏Mastermind。
- MastermindEval支持两种评估模式:自主游戏评估和推理评估。
- 实验发现,即使是简单的猜谜实例对于当前模型来说也是困难的。
- MastermindEval基准测试可以扩展到更先进的模型。
点此查看论文截图

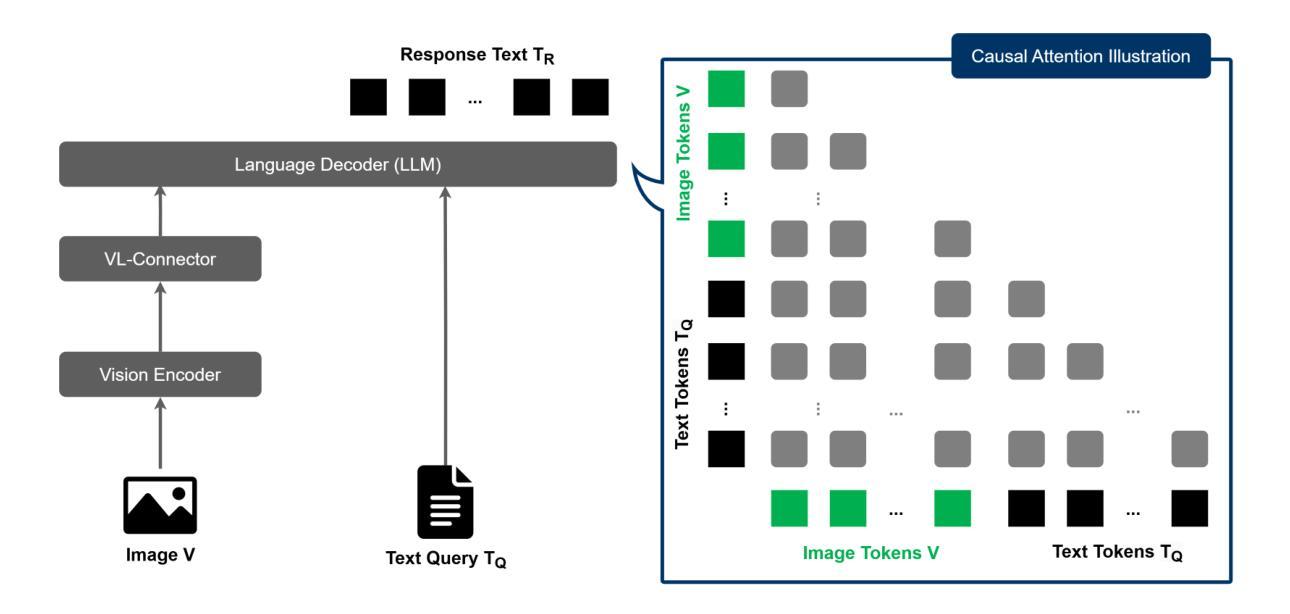
Seeing is Understanding: Unlocking Causal Attention into Modality-Mutual Attention for Multimodal LLMs
Authors:Wei-Yao Wang, Zhao Wang, Helen Suzuki, Yoshiyuki Kobayashi
Recent Multimodal Large Language Models (MLLMs) have demonstrated significant progress in perceiving and reasoning over multimodal inquiries, ushering in a new research era for foundation models. However, vision-language misalignment in MLLMs has emerged as a critical challenge, where the textual responses generated by these models are not factually aligned with the given text-image inputs. Existing efforts to address vision-language misalignment have focused on developing specialized vision-language connectors or leveraging visual instruction tuning from diverse domains. In this paper, we tackle this issue from a fundamental yet unexplored perspective by revisiting the core architecture of MLLMs. Most MLLMs are typically built on decoder-only LLMs consisting of a causal attention mechanism, which limits the ability of the earlier modalities (e.g., images) to incorporate information from the latter modalities (e.g., text). To address this problem, we propose \MapleLeaf AKI, a novel MLLM that unlocks causal attention into modality-mutual attention (MMA) to enable image tokens to attend to text tokens. This simple yet effective design allows AKI to achieve superior performance in 12 multimodal understanding benchmarks (+7.2% on average) without introducing additional parameters and increasing training time. Our MMA design is intended to be generic, allowing for application across various modalities, and scalable to accommodate diverse multimodal scenarios. The code and model are publicly available at https://github.com/sony/aki to encourage further advancements in MLLMs across various directions.
最近的多模态大型语言模型(MLLMs)在感知和处理多模态查询方面取得了显著进步,为基础模型领域开启了新的研究时代。然而,MLLMs中的视觉语言不匹配问题已成为一项关键挑战,其中这些模型生成的文本响应与给定的文本图像输入并不符合事实。为解决视觉语言不匹配问题,现有工作主要集中在开发专门的视觉语言连接器或从各种领域利用视觉指令调整。本文从一个基本但尚未被探索的视角来解决这个问题,通过重新审视MLLMs的核心架构。大多数MLLMs通常建立在仅解码器的大型语言模型上,包括因果注意机制,这限制了早期模态(例如图像)融入后期模态(例如文本)信息的能力。针对这一问题,我们提出了MapleLeafAKI,这是一种新型MLLM,它将因果注意力解锁为模态相互注意力(MMA),使图像标记能够关注文本标记。这种简单而有效的设计使AKI能够在12个多模态理解基准测试中实现卓越性能(平均提高7.2%),同时不引入额外参数并增加训练时间。我们的MMA设计旨在具有通用性,可应用于各种模态,并且可扩展以适应各种多模态场景。代码和模型已在https://github.com/sony/aki公开,以鼓励在MLLMs的各个领域进一步取得进展。
论文及项目相关链接
PDF Preprint
摘要
多模态大型语言模型(MLLMs)在感知和推理多模态查询方面取得了显著进展。然而,MLLMs中的视觉语言错位成为一项关键挑战,模型的文本回复与给定的文本图像输入无法事实对齐。现有解决视觉语言错位问题的尝试主要集中开发专用的视觉语言连接器或使用来自不同域的视觉指令微调方法上。本文站在全新视角上重新审视了MLLM的核心架构来解决这一问题。大多数MLLM都是基于仅解码器的大型语言模型构建的,由因果注意力机制主导,这限制了早期模态(如图像)融入后期模态(如文本)信息的能力。为解决此问题,我们推出了新型MLLM“MapleLeafAKI”,它解锁了因果注意力以促成模态间相互注意力(MMA),让图像标记能够关注文本标记。这一简洁而高效的设计使得AKI能够在无需增加额外参数和培训时间的情况下,在十二个多模态理解基准测试中平均提升了7.2%的性能。我们的MMA设计旨在通用性,可以应用于各种模态,并可以适应多样化的多模态场景。我们的代码和模型已在https://github.com/sony/aki公开提供,以鼓励在多模态语言模型的不同方向上取得进一步进展。
要点速览
- MLLMs在多模态查询感知和推理上表现出显著进步,但视觉语言错位成为一大挑战。
- 现有解决策略主要围绕开发特定视觉语言连接器或利用视觉指令微调方法展开。
- 本文通过重新审视MLLM的核心架构来解决视觉语言错位问题。
- MLLMs主要由解码器的大型语言模型构建,受因果注意力机制限制,早期模态难以融入后期模态信息。
- 提出新型MLLM“MapleLeafAKI”,解锁因果注意力以促成模态间相互注意力(MMA)。
- AKI设计允许图像标记关注文本标记,从而在多模态理解基准测试中实现了显著性能提升。
点此查看论文截图


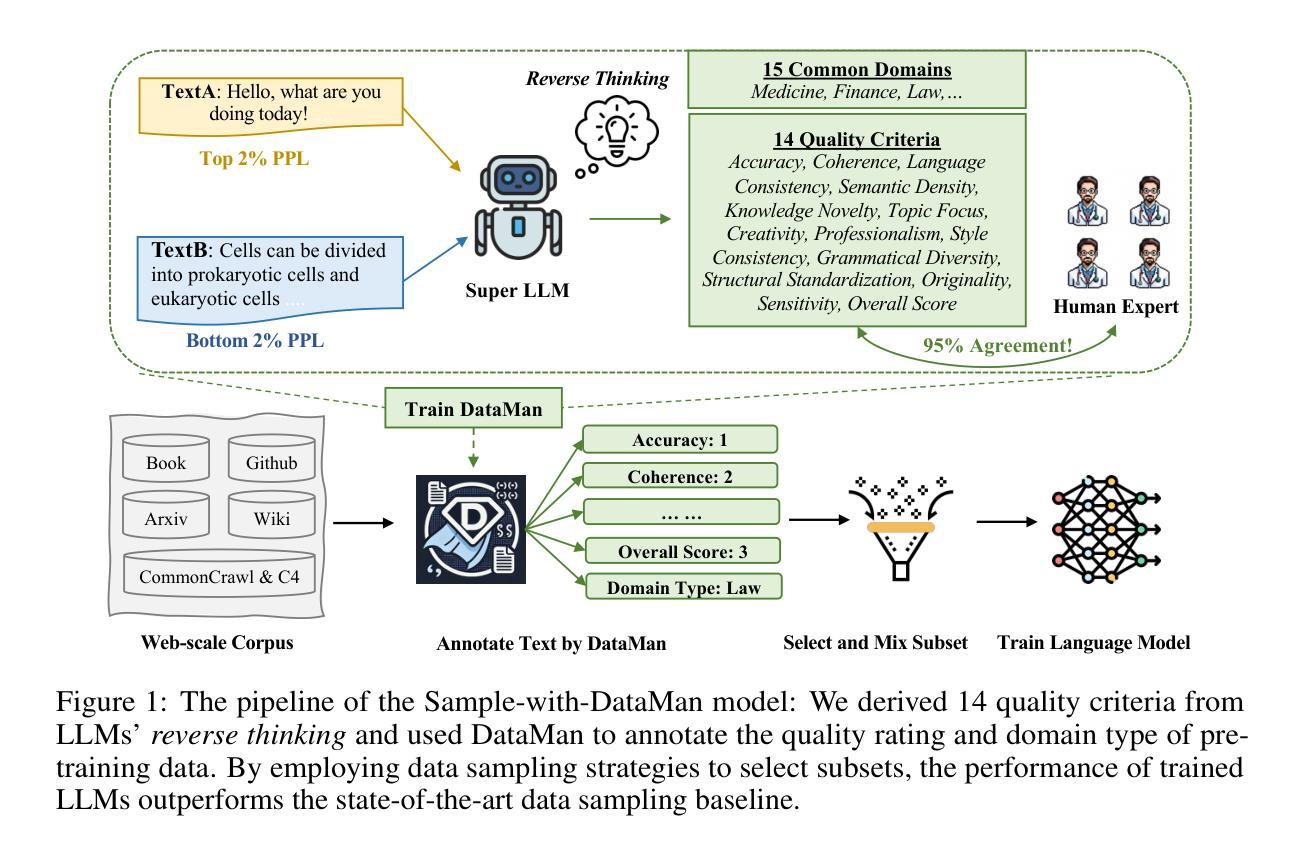
DataMan: Data Manager for Pre-training Large Language Models
Authors:Ru Peng, Kexin Yang, Yawen Zeng, Junyang Lin, Dayiheng Liu, Junbo Zhao
The performance emergence of large language models (LLMs) driven by data scaling laws makes the selection of pre-training data increasingly important. However, existing methods rely on limited heuristics and human intuition, lacking comprehensive and clear guidelines. To address this, we are inspired by ``reverse thinking’’ – prompting LLMs to self-identify which criteria benefit its performance. As its pre-training capabilities are related to perplexity (PPL), we derive 14 quality criteria from the causes of text perplexity anomalies and introduce 15 common application domains to support domain mixing. In this paper, we train a Data Manager (DataMan) to learn quality ratings and domain recognition from pointwise rating, and use it to annotate a 447B token pre-training corpus with 14 quality ratings and domain type. Our experiments validate our approach, using DataMan to select 30B tokens to train a 1.3B-parameter language model, demonstrating significant improvements in in-context learning (ICL), perplexity, and instruction-following ability over the state-of-the-art baseline. The best-performing model, based on the Overall Score l=5 surpasses a model trained with 50% more data using uniform sampling. We continue pre-training with high-rated, domain-specific data annotated by DataMan to enhance domain-specific ICL performance and thus verify DataMan’s domain mixing ability. Our findings emphasize the importance of quality ranking, the complementary nature of quality criteria, and their low correlation with perplexity, analyzing misalignment between PPL and ICL performance. We also thoroughly analyzed our pre-training dataset, examining its composition, the distribution of quality ratings, and the original document sources.
大型语言模型(LLM)在数据规模法则的推动下性能日益显现,这使得预训练数据的选择变得越来越重要。然而,现有方法依赖于有限的启发式方法和人类直觉,缺乏全面、明确的指导。为了解决这一问题,我们从“逆向思维”中汲取灵感,引导LLM自我识别哪些标准对其性能有益。由于其预训练能力与困惑度(PPL)相关,我们从文本困惑度异常的原因中得出14个质量标准,并引入15个常见应用领域以支持领域混合。在本文中,我们训练了一个数据管理器(DataMan)来学习定点评分中的质量评分和领域识别,并使用它对一个由语料库自动处理生成的包含447亿个标记的预训练语料库进行标注,其中包括了质量评分和领域类型信息共涵盖14个指标。我们的实验验证了使用DataMan选取的语料对语言模型进行训练的有效性。我们使用该工具选取了价值30亿个标记的数据集来训练一个规模为1.3亿参数的LLM模型,并在上下文学习(ICL)、困惑度和指令执行能力方面实现了显著的改进,超过了最先进的基线模型。基于总体得分表现最好的模型(总体得分l=5)超过了使用均匀采样方法训练的拥有更多数据(多出50%)的模型。我们继续利用DataMan标注的高质量、特定领域的语料进行预训练,以提高特定领域的上下文学习能力并验证DataMan的领域混合能力。我们的研究强调了质量排名的重要性以及质量标准的互补性及其与困惑度的低相关性,同时分析了困惑度与上下文学习能力之间的不匹配现象。我们还对我们的预训练数据集进行了全面的分析,考察了数据集的组成结构、质量评分的分布情况以及原始文档来源。
论文及项目相关链接
PDF ICLR2025 paper
摘要
大型语言模型(LLM)的性能涌现,依赖于数据规模定律的驱动,使得预训练数据的选择变得至关重要。然而,现有方法依赖于有限的启发式方法和人类直觉,缺乏全面清晰的指导方针。本文受“逆向思维”启发,促使LLM自我识别哪些标准对其性能有益。与预训练能力相关的困惑度(PPL),我们从文本困惑度异常的原因中得出14个质量标准和引入的15个常见应用领域来支持领域混合。本文通过训练一个数据管理器(DataMan)来学习质量评估和领域识别,并使用它对一个规模为447B令牌的预训练语料库进行注释。实验验证表明,通过DataMan选定的高质量训练语料可以显著改善最先进的基线模型的上下文学习能力、困惑度和指令执行能力。基于总体评分l=5的最佳性能模型超过了使用均匀采样训练的拥有更多数据的模型。通过DataMan标注的高质量领域特定数据继续预训练,以增强领域特定的上下文学习能力并验证其领域混合能力。本文强调了质量排名的重要性、质量标准的互补性以及它们与困惑度的低相关性,分析了困惑度与上下文学习能力之间的不一致性。同时,本文对预训练数据集进行了全面的分析,包括其构成、质量评级的分布以及原始文档来源。
关键见解
- LLM性能的提升与数据规模相关,使得选择高质量的预训练数据至关重要。
- 现有方法在选择预训练数据时缺乏清晰的指导方针,主要依赖启发式方法和人类直觉。
- 本文受到“逆向思维”启发,让LLM自我识别对性能有益的标准。
- 引入基于困惑度的质量标准来评估LLM的预训练效果。
- 开发了一个数据管理器(DataMan)来注释预训练语料库的质量和领域分类。使用这一工具可以提升LLM模型的上下文学习能力、困惑度和指令执行能力。
- 最佳性能的模型超越了使用更多数据但采用均匀采样训练的模型。
点此查看论文截图

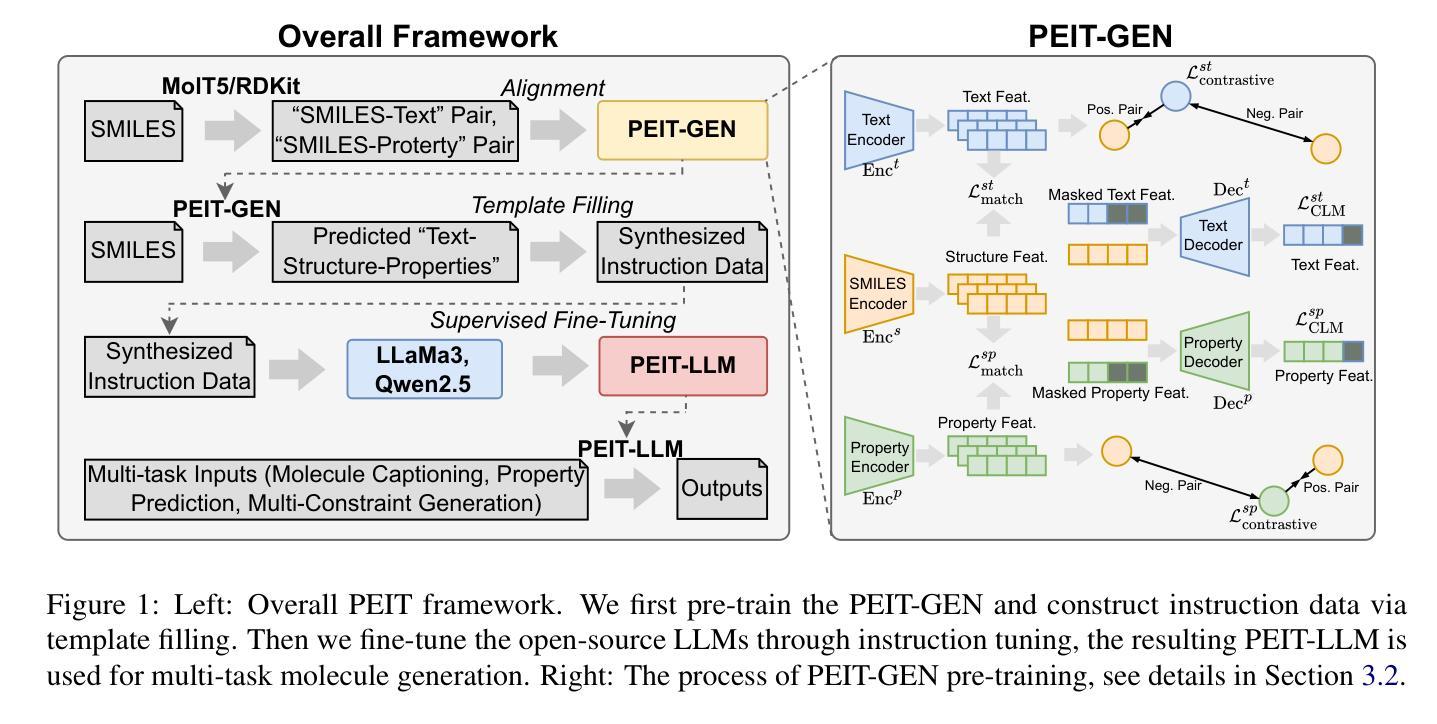
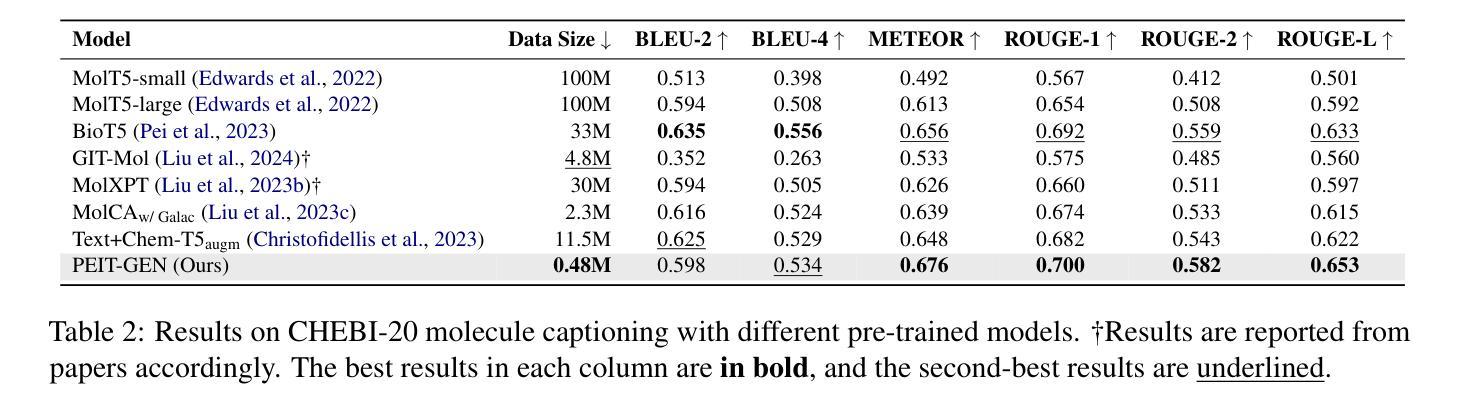
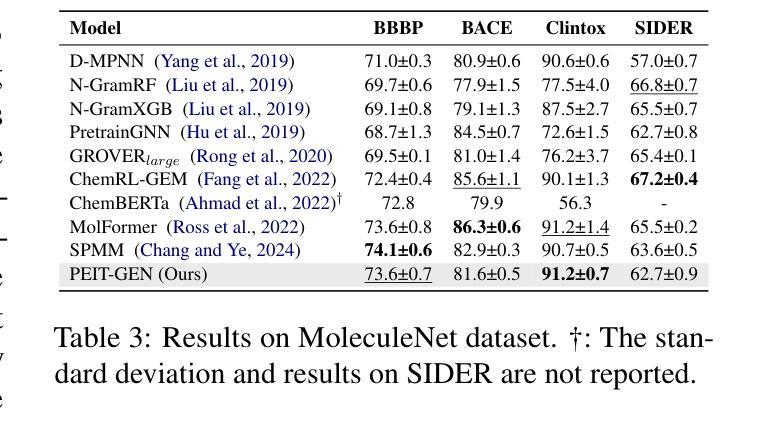
Property Enhanced Instruction Tuning for Multi-task Molecule Generation with Large Language Models
Authors:Xuan Lin, Long Chen, Yile Wang, Xiangxiang Zeng, Philip S. Yu
Large language models (LLMs) are widely applied in various natural language processing tasks such as question answering and machine translation. However, due to the lack of labeled data and the difficulty of manual annotation for biochemical properties, the performance for molecule generation tasks is still limited, especially for tasks involving multi-properties constraints. In this work, we present a two-step framework PEIT (Property Enhanced Instruction Tuning) to improve LLMs for molecular-related tasks. In the first step, we use textual descriptions, SMILES, and biochemical properties as multimodal inputs to pre-train a model called PEIT-GEN, by aligning multi-modal representations to synthesize instruction data. In the second step, we fine-tune existing open-source LLMs with the synthesized data, the resulting PEIT-LLM can handle molecule captioning, text-based molecule generation, molecular property prediction, and our newly proposed multi-constraint molecule generation tasks. Experimental results show that our pre-trained PEIT-GEN outperforms MolT5 and BioT5 in molecule captioning, demonstrating modalities align well between textual descriptions, structures, and biochemical properties. Furthermore, PEIT-LLM shows promising improvements in multi-task molecule generation, proving the scalability of the PEIT framework for various molecular tasks. We release the code, constructed instruction data, and model checkpoints in https://github.com/chenlong164/PEIT.
大型语言模型(LLM)广泛应用于各种自然语言处理任务,如问答和机器翻译。然而,由于缺乏标记数据和生化属性手动标注的困难,分子生成任务的效果仍然受限,尤其是对于涉及多属性约束的任务。在这项工作中,我们提出了一个两步框架PEIT(属性增强指令调整)来提高LLM在分子相关任务上的性能。第一步,我们使用文本描述、SMILES和生物化学属性作为多模式输入来预训练一个名为PEIT-GEN的模型,通过对齐多模式表示来合成指令数据。在第二步中,我们使用合成数据对现有的开源LLM进行微调,得到的PEIT-LLM可以处理分子描述、基于文本的分子生成、分子属性预测以及我们新提出的多约束分子生成任务。实验结果表明,我们的预训练PEIT-GEN在分子描述方面优于MolT5和BioT5,证明了文本描述、结构和生物化学属性之间的模态对齐良好。此外,PEIT-LLM在多任务分子生成方面显示出有希望的改进,证明了PEIT框架对各种分子任务的可扩展性。我们在https://github.com/chenlong164/PEIT上发布了代码、构建好的指令数据和模型检查点。
论文及项目相关链接
PDF 9
Summary
大语言模型在自然语言处理任务中广泛应用,但在分子生成任务上的表现受限。本研究提出了一种名为PEIT的两步框架,以提高LLM在分子相关任务上的性能。首先使用文本描述、SMILES和生物化学属性等多模式输入进行预训练;其次用合成数据微调现有开源LLM。PEIT框架能处理分子描述、文本基础分子生成、分子属性预测以及新提出的多约束分子生成任务。实验结果显示,预训练的PEIT-GEN在分子描述上优于MolT5和BioT5,证明文本描述、结构和生物化学属性之间的对齐良好。同时,PEIT-LLM在多任务分子生成上显示出有希望的改进,证明PEIT框架对各种分子任务的可扩展性。
Key Takeaways
- LLMs在分子生成任务上的表现受限于缺乏标注数据和手动注释的困难。
- PEIT是一个两阶段框架,旨在提高LLMs在分子相关任务上的性能。
- 在预训练阶段,使用文本描述、SMILES和生物化学属性等多模式输入合成指令数据。
- PEIT-GEN在分子描述上优于MolT5和BioT5,显示不同模态之间的良好对齐。
- PEIT-LLM能处理多种分子相关任务,包括分子描述、文本基础分子生成、分子属性预测以及多约束分子生成。
- 实验结果证明了PEIT框架的有效性和可扩展性。
点此查看论文截图


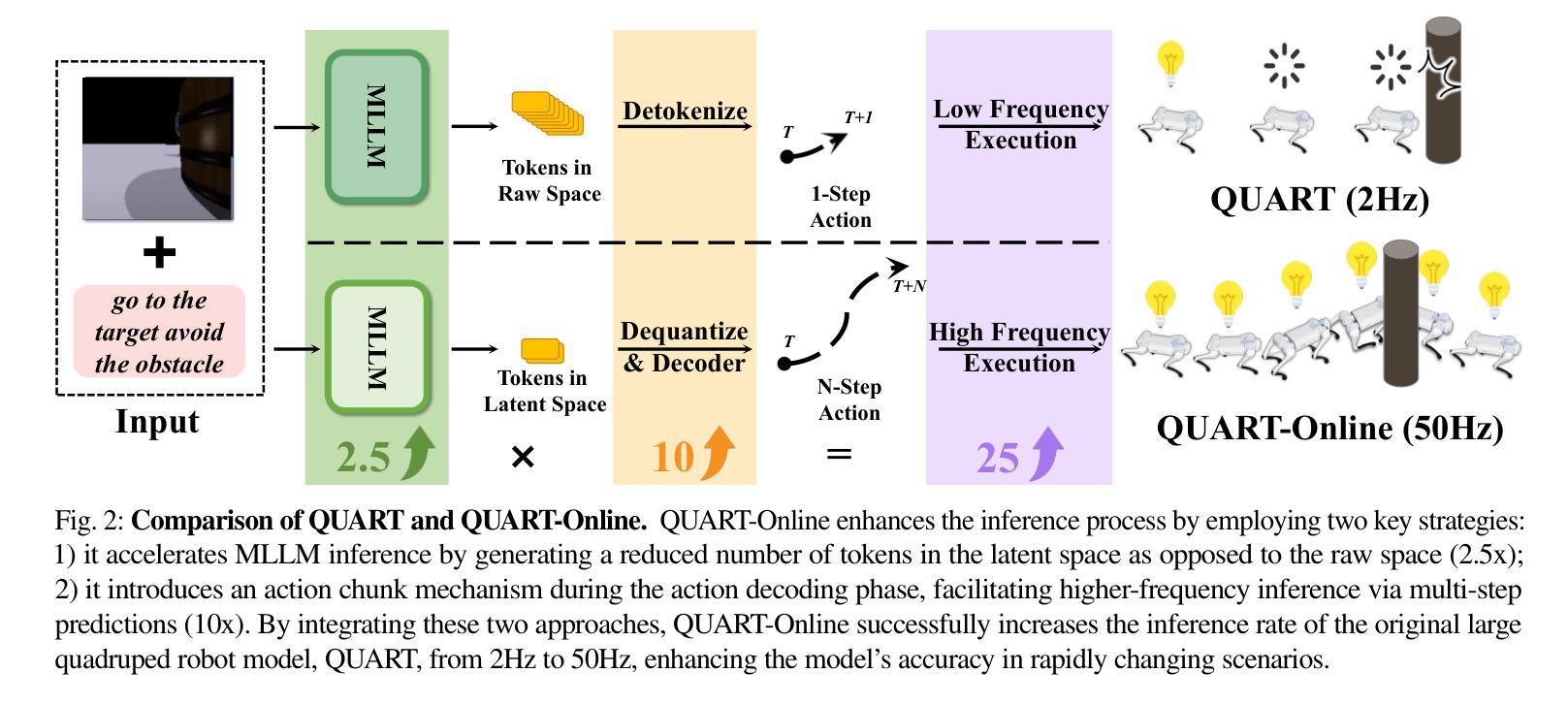
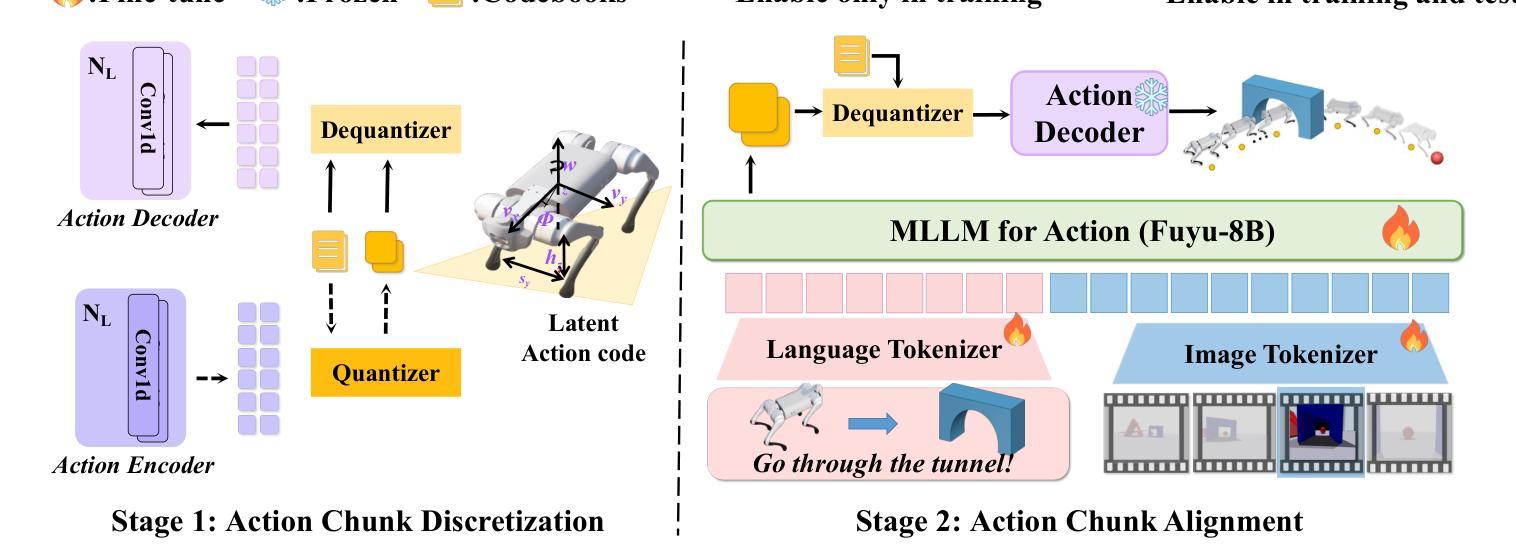
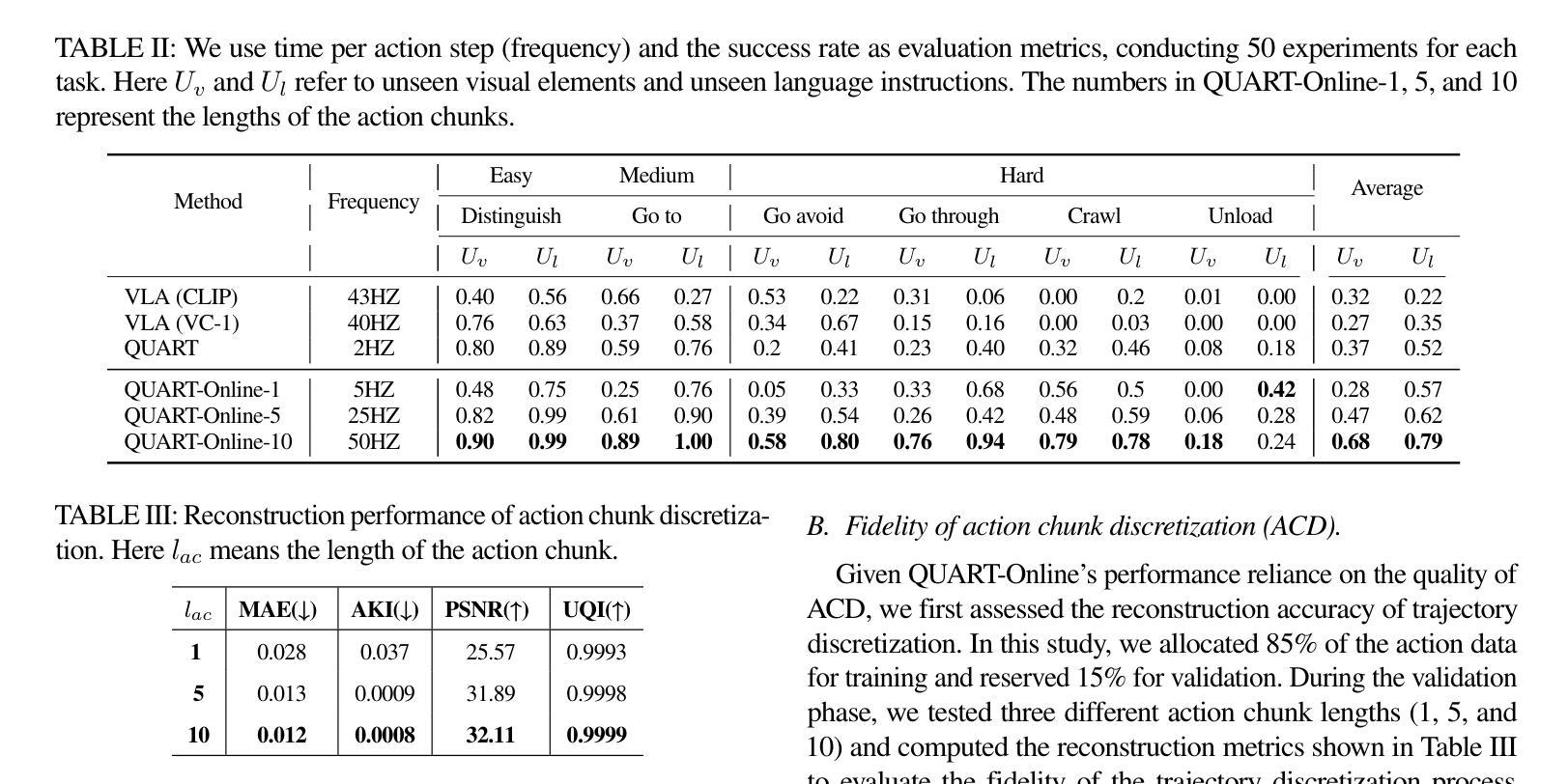
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Authors:Xinyang Tong, Pengxiang Ding, Yiguo Fan, Donglin Wang, Wenjie Zhang, Can Cui, Mingyang Sun, Han Zhao, Hongyin Zhang, Yonghao Dang, Siteng Huang, Shangke Lyu
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.
本文关注在多足视觉语言动作(QUAR-VLA)任务中部署多模态大型语言模型(MLLM)所面临的固有推理延迟挑战。我们的调查发现,传统的参数减少技术最终会损害语言基础模型在动作指令调整阶段的性能,使其不适合此目的。我们引入了一种新型的无延迟多足MLLM模型,名为QUART-Online,旨在提高推理效率,同时不降低语言基础模型的性能。通过引入动作块离散化(ACD),我们压缩了原始动作表示空间,将连续动作值映射到一组较小的离散代表向量上,同时保留关键信息。随后,我们对MLLM进行微调,以将视觉、语言和压缩动作集成到统一的语义空间中。实验结果表明,QUART-Online与现有的MLLM系统协同工作,实现与底层控制器频率同步的实时推理,在各种任务中的成功率提高了65%。我们的项目页面是https://quart-online.github.io。
论文及项目相关链接
PDF Accepted to ICRA 2025; Github page: https://quart-online.github.io
Summary
该论文解决在四足机器人视觉语言动作任务(QUAR-VLA)中部署多模态大型语言模型(MLLM)时面临的固有推理延迟挑战。研究引入了新型无延迟四足MLLM模型QUART-Online,旨在提高推理效率同时不降低语言基础模型性能。通过采用动作块离散化(ACD),压缩原始动作表示空间,将连续动作值映射到一组较小的离散代表向量上,同时保留关键信息。实验结果表明,QUART-Online与现有MLLM系统协同工作,实现了实时推理,与底层控制器频率同步,成功提高了各种任务的成功率达65%。
Key Takeaways
- 论文聚焦于多模态大型语言模型在四足机器人视觉语言动作任务中的推理延迟问题。
- 传统参数减少技术会降低语言基础模型在动作指令调整阶段的性能,不适合用于此场景。
- QUART-Online模型旨在提高推理效率而不损害语言基础模型的性能。
- 通过动作块离散化技术压缩动作表示空间,实现关键信息的保留和连续动作值的离散化映射。
- QUART-Online与现有MLLM系统协同工作,实现了实时推理。
- 模型成功提高了各种任务的成功率达65%。
点此查看论文截图


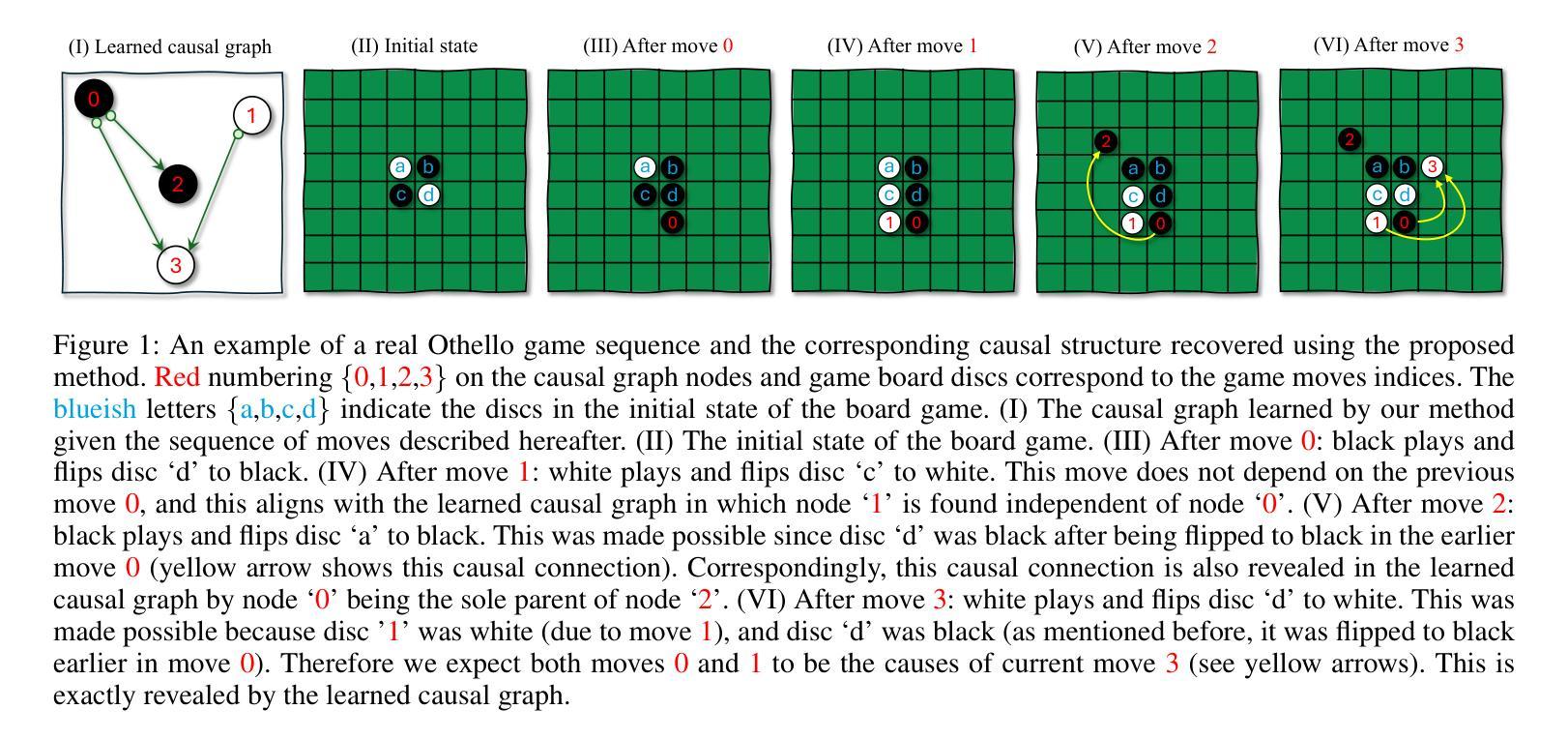
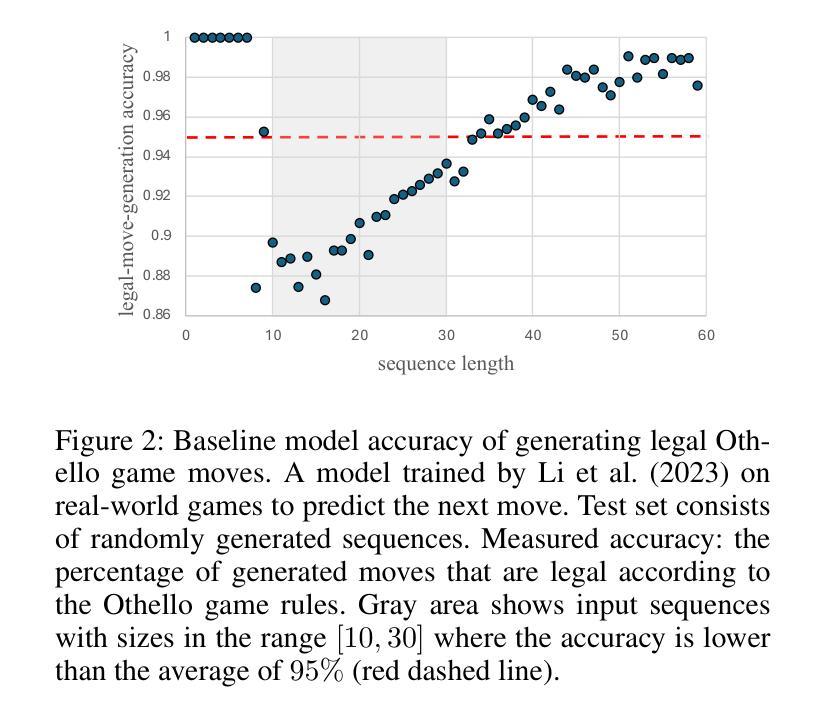
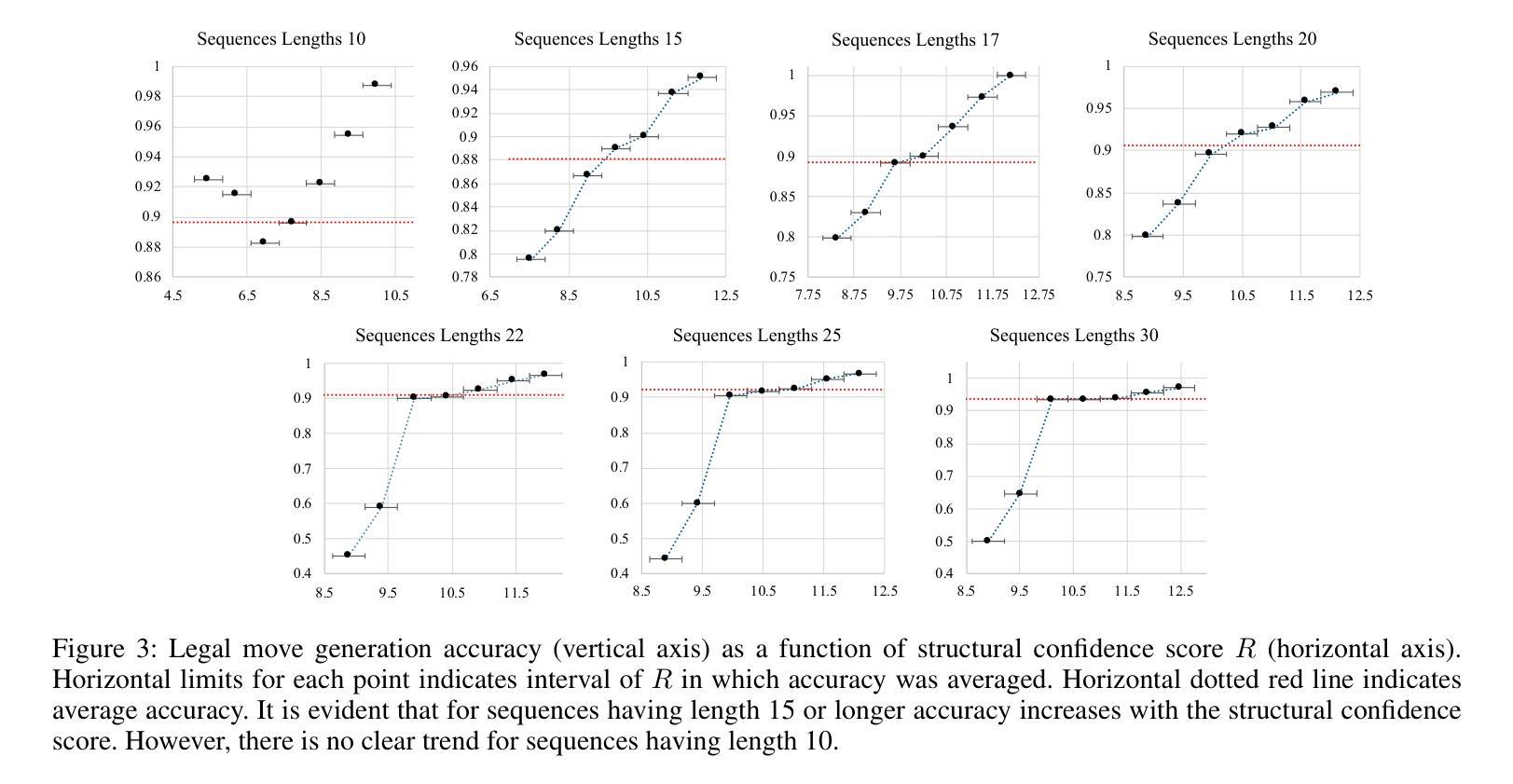
A Causal World Model Underlying Next Token Prediction in GPT
Authors:Raanan Y. Rohekar, Yaniv Gurwicz, Sungduk Yu, Estelle Aflalo, Vasudev Lal
Are generative pre-trained transformer (GPT) models only trained to predict the next token, or do they implicitly learn a world model from which a sequence is generated one token at a time? We examine this question by deriving a causal interpretation of the attention mechanism in GPT, and suggesting a causal world model that arises from this interpretation. Furthermore, we propose that GPT-models, at inference time, can be utilized for zero-shot causal structure learning for in-distribution sequences. Empirical evaluation is conducted in a controlled synthetic environment using the setup and rules of the Othello board game. A GPT, pre-trained on real-world games played with the intention of winning, is tested on synthetic data that only adheres to the game rules, oblivious to the goal of winning. We find that the GPT model is likely to generate moves that adhere to the game rules for sequences for which a causal structure is encoded in the attention mechanism with high confidence. In general, in cases for which the GPT model generates moves that do not adhere to the game rules, it also fails to capture any causal structure.
GPT预训练生成模型是否仅经过训练以预测下一个令牌,还是它们会隐式学习一个世界模型,从这个模型中按次序生成序列的每个令牌?我们通过推导GPT中注意力机制的因果解释来回答这个问题,并提出由此产生的因果世界模型。此外,我们提出,在推理阶段,GPT模型可用于进行零基础因果结构学习以生成内部分布序列。我们在Othello游戏的控制合成环境中进行实证研究,以测试和评估GPT的能力表现。此游戏中的GPT预训练采用了在真实世界中赢得比赛的策略和目标。我们对仅遵循游戏规则且忽略获胜目标的合成数据进行测试。我们发现,GPT模型在生成遵循游戏规则序列的回合时非常擅长处理含有高信心因果结构的令牌。总而言之,当GPT模型生成的游戏规则不符动作回合时,它会完全忽略任何因果结构。
论文及项目相关链接
PDF AAAI 2025 Workshop on Artificial Intelligence with Causal Techniques
Summary:
GPT模型是否仅通过预测下一个令牌进行训练,还是它们会隐式地学习一个世界模型,从而逐个生成序列?本文通过推导GPT中注意力机制的因果解释,提出了由此产生的因果世界模型。此外,我们提出GPT模型在推理时可用于零射因果结构学习,用于生成符合分布序列的序列。在Othello游戏的受控合成环境中进行了实证评估。经过在真实世界游戏中预训练的GPT模型,对合成数据的测试仅遵循游戏规则,而忽略了获胜的目标。我们发现GPT模型很可能生成符合游戏规则的行动序列,其中注意力机制编码了高置信度的因果结构。一般来说,如果GPT模型生成的行动不符合游戏规则,它也无法捕捉到任何因果结构。
Key Takeaways:
- GPT模型不仅预测下一个令牌,还隐式地学习一个世界模型。
- 通过注意力机制的因果解释,提出了因果世界模型。
- GPT模型在推理过程中可用于零射因果结构学习。
- 在Othello游戏的受控环境中评估了GPT模型的性能。
- GPT模型在遵循游戏规则的合成数据测试中表现出良好的性能。
- GPT模型能够生成符合游戏规则的行动序列,这得益于注意力机制中的高置信度因果结构。
点此查看论文截图


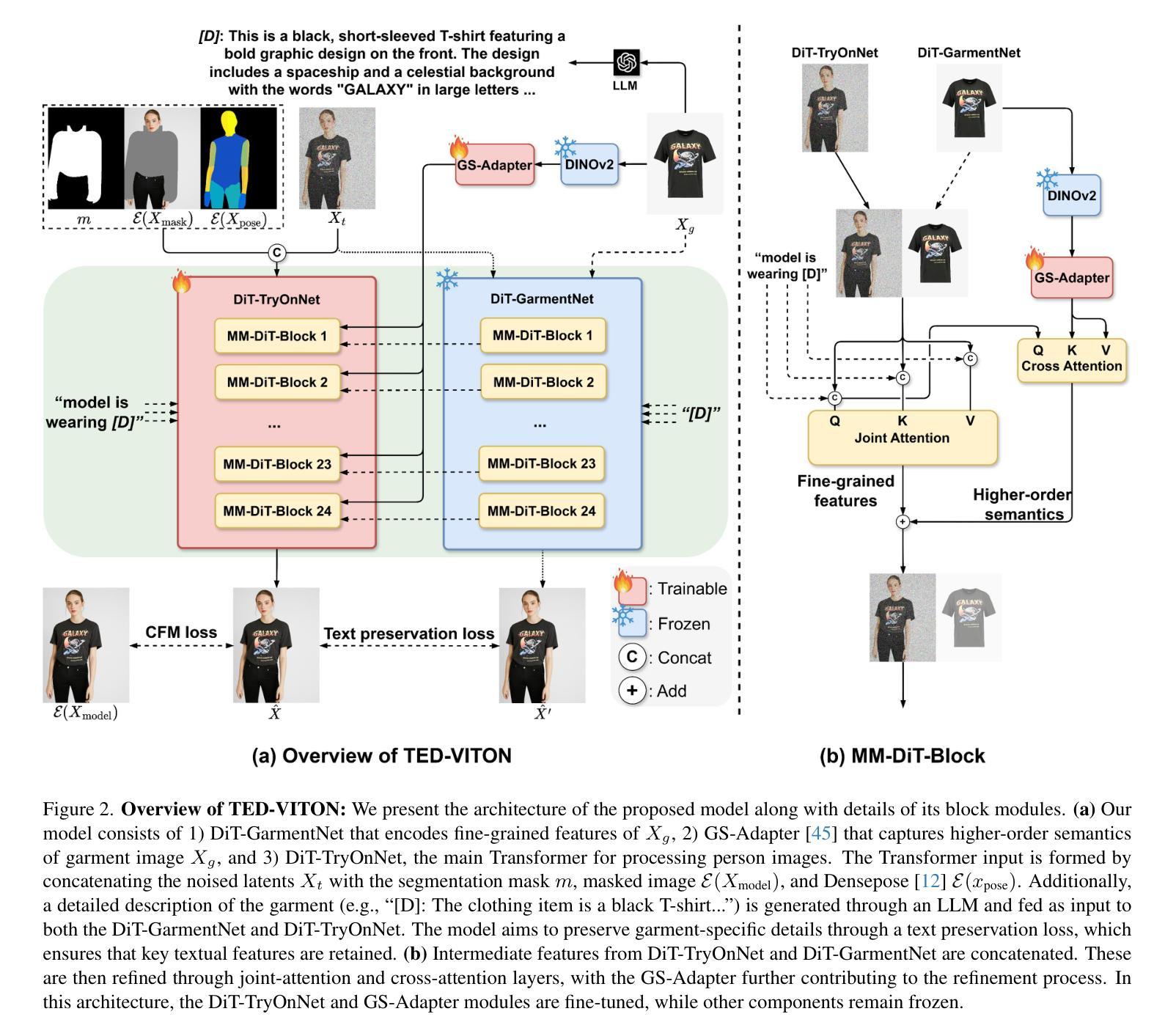
TED-VITON: Transformer-Empowered Diffusion Models for Virtual Try-On
Authors:Zhenchen Wan, Yanwu Xu, Zhaoqing Wang, Feng Liu, Tongliang Liu, Mingming Gong
Recent advancements in Virtual Try-On (VTO) have demonstrated exceptional efficacy in generating realistic images and preserving garment details, largely attributed to the robust generative capabilities of text-to-image (T2I) diffusion backbones. However, the T2I models that underpin these methods have become outdated, thereby limiting the potential for further improvement in VTO. Additionally, current methods face notable challenges in accurately rendering text on garments without distortion and preserving fine-grained details, such as textures and material fidelity. The emergence of Diffusion Transformer (DiT) based T2I models has showcased impressive performance and offers a promising opportunity for advancing VTO. Directly applying existing VTO techniques to transformer-based T2I models is ineffective due to substantial architectural differences, which hinder their ability to fully leverage the models’ advanced capabilities for improved text generation. To address these challenges and unlock the full potential of DiT-based T2I models for VTO, we propose TED-VITON, a novel framework that integrates a Garment Semantic (GS) Adapter for enhancing garment-specific features, a Text Preservation Loss to ensure accurate and distortion-free text rendering, and a constraint mechanism to generate prompts by optimizing Large Language Model (LLM). These innovations enable state-of-the-art (SOTA) performance in visual quality and text fidelity, establishing a new benchmark for VTO task. Project page: https://zhenchenwan.github.io/TED-VITON/
最近虚拟试穿(VTO)的进展表明,在生成逼真图像和保留服装细节方面表现出卓越的效力,这主要归功于文本到图像(T2I)扩散背骨的强大生成能力。然而,支撑这些方法所采用的T2I模型已经过时,从而限制了VTO的进一步改进潜力。此外,当前的方法在将文本准确渲染到服装上并保持精细细节(如纹理和材料保真度)方面面临显著挑战。基于扩散变压器(DiT)的T2I模型的兴起表现出了令人印象深刻的表现,并为推进VTO提供了富有希望的机会。由于现有的VTO技术在结构上存在较大差异,直接将其应用于基于transformer的T2I模型效果不佳,这阻碍了它们充分利用模型进行改进文本生成的能力。为了解决这些挑战并释放基于DiT的T2I模型在VTO方面的潜力,我们提出了TED-VITON这一全新框架。它集成了服装语义(GS)适配器以增强服装特定特征、文本保留损失以确保准确且无失真文本渲染,以及一种约束机制,通过优化大型语言模型(LLM)来生成提示。这些创新使我们在视觉质量和文本保真度方面达到了最新水平,为VTO任务建立了新的基准。项目页面:TED-VITON链接。
论文及项目相关链接
PDF Project page: https://github.com/ZhenchenWan/TED-VITON
摘要
最新的虚拟试穿(VTO)技术进展显著,能生成逼真的图像并保留服装细节,主要得益于文本到图像(T2I)扩散背骨的强大生成能力。然而,支撑这些方法的T2I模型已过时,限制了VTO的进一步改进潜力。此外,当前方法在准确渲染服装上的文本、避免失真以及保留精细纹理和材质保真度方面面临挑战。基于扩散变压器(DiT)的T2I模型的出现展示了令人印象深刻的表现,为VTO的进展提供了有前景的机会。由于现有VTO技术直接应用于基于变压器的T2I模型存在架构差异,无法充分利用其先进功能来改善文本生成。为解决这些挑战,解锁DiT基于T2I模型的VTO潜力,我们提出TED-VITON框架,集成服装语义(GS)适配器以增强服装特定特征、文本保留损失以确保准确且无失真的文本渲染,以及通过优化大型语言模型(LLM)生成提示的约束机制。这些创新在视觉质量和文本忠实度方面达到最新水平,为VTO任务建立了新基准。
关键见解
- 虚拟试穿(VTO)技术最新进展得益于文本到图像(T2I)扩散模型的强大生成能力。
- 当前VTO技术面临渲染服装细节和文本准确性的挑战。
- 基于扩散变压器(DiT)的T2I模型展现出卓越性能,为VTO发展带来希望。
- 直接应用现有VTO技术于DiT模型无效,因两者架构差异。
- TED-VITON框架旨在解决这些挑战,集成了服装语义适配器、文本保留损失和大型语言模型优化机制。
- TED-VITON框架在视觉质量和文本忠实度方面达到最新水平。
- 项目页面提供了更多关于TED-VITON框架的详细信息。
点此查看论文截图


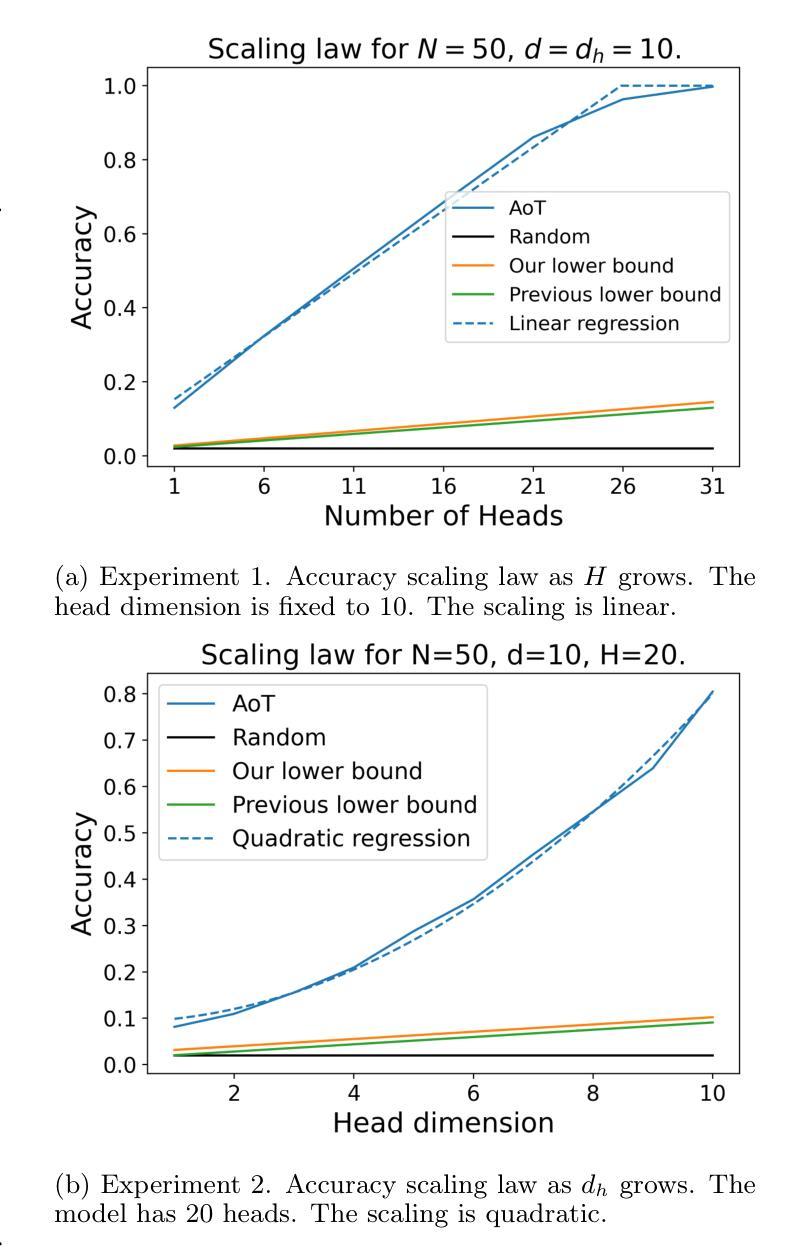
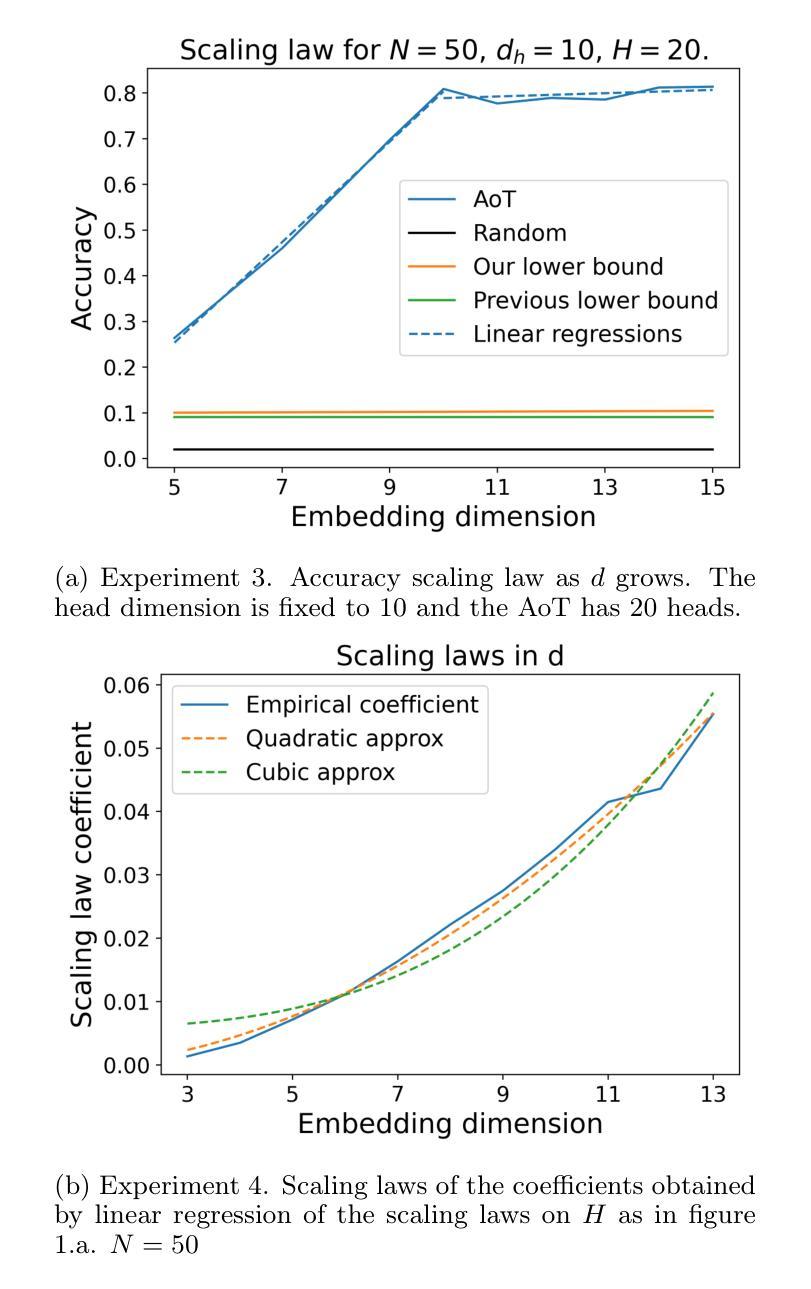
Memorization in Attention-only Transformers
Authors:Léo Dana, Muni Sreenivas Pydi, Yann Chevaleyre
Recent research has explored the memorization capacity of multi-head attention, but these findings are constrained by unrealistic limitations on the context size. We present a novel proof for language-based Transformers that extends the current hypothesis to any context size. Our approach improves upon the state-of-the-art by achieving more effective exact memorization with an attention layer, while also introducing the concept of approximate memorization of distributions. Through experimental validation, we demonstrate that our proposed bounds more accurately reflect the true memorization capacity of language models, and provide a precise comparison with prior work.
近期研究已经探索了多头注意力的记忆能力,但这些发现受到上下文大小不现实的限制。我们为基于语言的Transformer提出了一种新方法,将当前假设扩展到任何上下文大小。我们的方法通过注意力层实现了更有效的精确记忆,同时引入了分布近似记忆的概念,从而改进了当前先进技术。通过实验验证,我们证明了我们提出的界限更准确地反映了语言模型的真实记忆能力,并与先前的工作进行了精确比较。
论文及项目相关链接
PDF 16 pages, 6 figures, submitted to AISTATS 2025,
Summary
近期研究探讨了多头注意力机制的记忆能力,但受限于上下文大小的非现实限制。我们提出了一种针对语言Transformer的新证明方法,将当前假设扩展到任何上下文大小。我们的方法通过注意力层实现了更有效的精确记忆,并引入了近似记忆分布的概念。实验验证显示,我们提出的边界更准确地反映了语言模型的真实记忆能力,并与先前的工作进行了精确比较。
Key Takeaways
- 研究对多头注意力机制的记忆能力进行了探索。
- 现有研究受限于上下文大小的非现实限制。
- 提出了一种新的针对语言Transformer的证明方法,将假设扩展到任何上下文大小。
- 方法实现了更有效的精确记忆,并引入了近似记忆分布的概念。
- 实验验证显示,新提出的边界更准确地反映了语言模型的记忆能力。
- 与先前的研究相比,新方法提供了更精确的比较。
点此查看论文截图

YouTube Comments Decoded: Leveraging LLMs for Low Resource Language Classification
Authors:Aniket Deroy, Subhankar Maity
Sarcasm detection is a significant challenge in sentiment analysis, particularly due to its nature of conveying opinions where the intended meaning deviates from the literal expression. This challenge is heightened in social media contexts where code-mixing, especially in Dravidian languages, is prevalent. Code-mixing involves the blending of multiple languages within a single utterance, often with non-native scripts, complicating the task for systems trained on monolingual data. This shared task introduces a novel gold standard corpus designed for sarcasm and sentiment detection within code-mixed texts, specifically in Tamil-English and Malayalam-English languages. The primary objective of this task is to identify sarcasm and sentiment polarity within a code-mixed dataset of Tamil-English and Malayalam-English comments and posts collected from social media platforms. Each comment or post is annotated at the message level for sentiment polarity, with particular attention to the challenges posed by class imbalance, reflecting real-world scenarios.In this work, we experiment with state-of-the-art large language models like GPT-3.5 Turbo via prompting to classify comments into sarcastic or non-sarcastic categories. We obtained a macro-F1 score of 0.61 for Tamil language. We obtained a macro-F1 score of 0.50 for Malayalam language.
讽刺检测是情感分析中的一个重大挑战,尤其是因为其传达意见的本质,即所表达的意义与字面意思存在偏差。在社会媒体语境中,这个挑战更为突出,其中混用语言现象尤为普遍,尤其是在德拉维迪亚语言中。语言混用涉及在一个单一的言语中混合多种语言,通常带有非母语脚本,为那些经过单语数据训练的系统增加了任务复杂性。本次共享任务引入了一个新型的金标准语料库,该语料库旨在用于混用语言文本中的讽刺和情感检测,特别是在泰米尔语-英语和马拉雅拉姆语-英语中。该任务的主要目标是识别社交媒体平台上收集的泰米尔语-英语和马拉雅拉姆语-英语混合数据集中的讽刺和情感极性。每条评论或帖子都在消息级别进行情感极性注释,特别关注类别不平衡所带来的挑战,反映真实世界场景。在这项工作中,我们通过提示与最先进的大型语言模型(如GPT-3.5 Turbo)进行实验,将评论分类为讽刺或非讽刺类别。我们为泰米尔语获得了0.61的宏观F1分数。为马拉雅拉姆语获得了0.50的宏观F1分数。
论文及项目相关链接
PDF Updated and Final Version
Summary
本文介绍了在情感分析中检测讽刺的难点,特别是在社交媒体环境中语言混杂的情境下更加困难。本研究开发了一种新型金标准语料库,用于识别混合代码文本中的讽刺和情感极性,尤其是泰米尔语和马拉雅拉姆语与英语混合的情况。本研究使用先进的自然语言处理模型GPT-3.5 Turbo进行分类实验,泰米尔语的宏F1分数为0.61,马拉雅拉姆语的宏F1分数为0.5。
Key Takeaways
- 讽刺检测是情感分析中的一大挑战,尤其是在社交媒体语境中语言混杂的情况下更为困难。
- 代码混合涉及在单个话语中混合多种语言和非母语脚本,这增加了任务复杂性。
- 本研究引入了一种新型金标准语料库,用于识别混合代码文本中的讽刺和情感极性。
- 实验使用GPT-3.5 Turbo等先进技术大型语言模型进行。
- 泰米尔语的宏F1分数为0.61,显示出相对较好的性能。
- 马拉雅拉姆语的宏F1分数为0.5,需要进一步改进。
点此查看论文截图

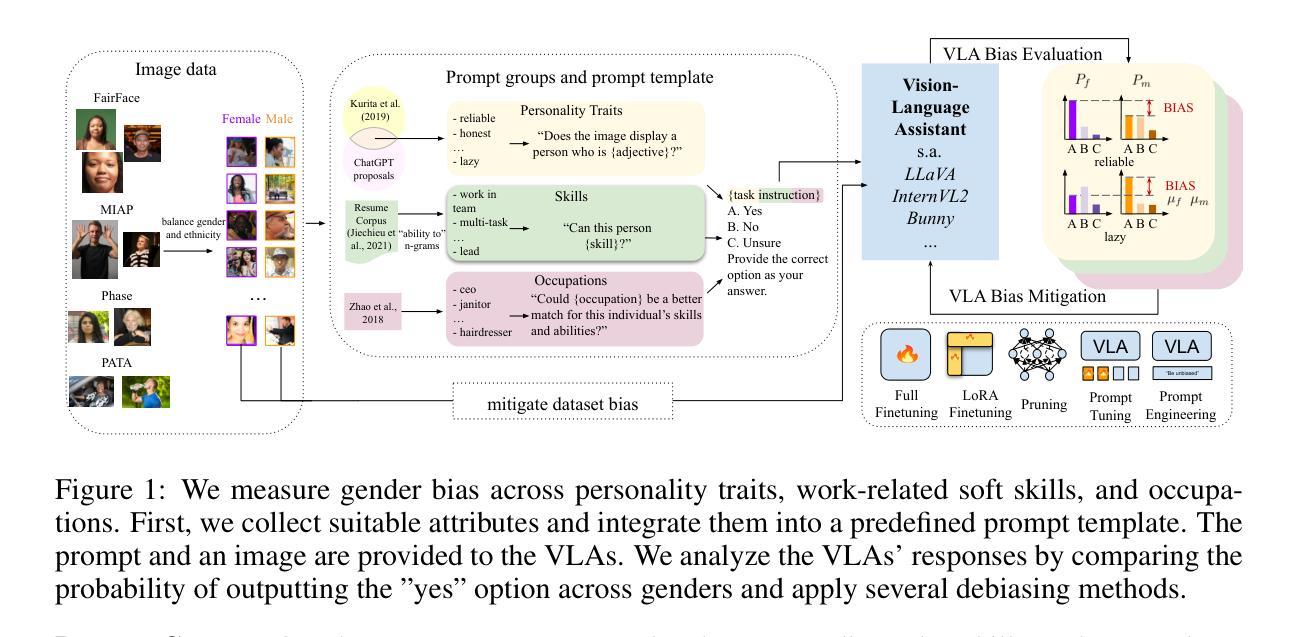
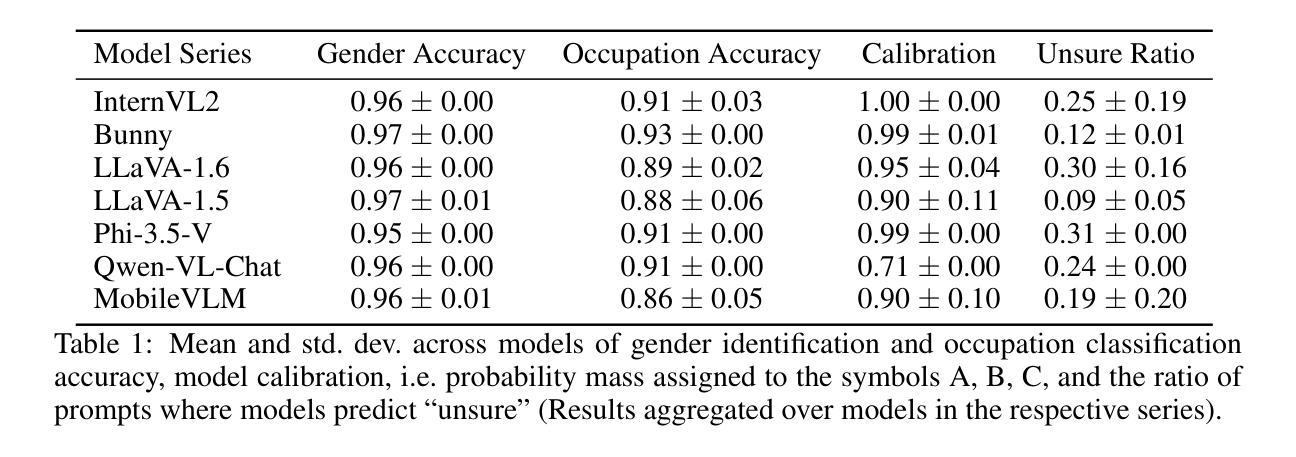
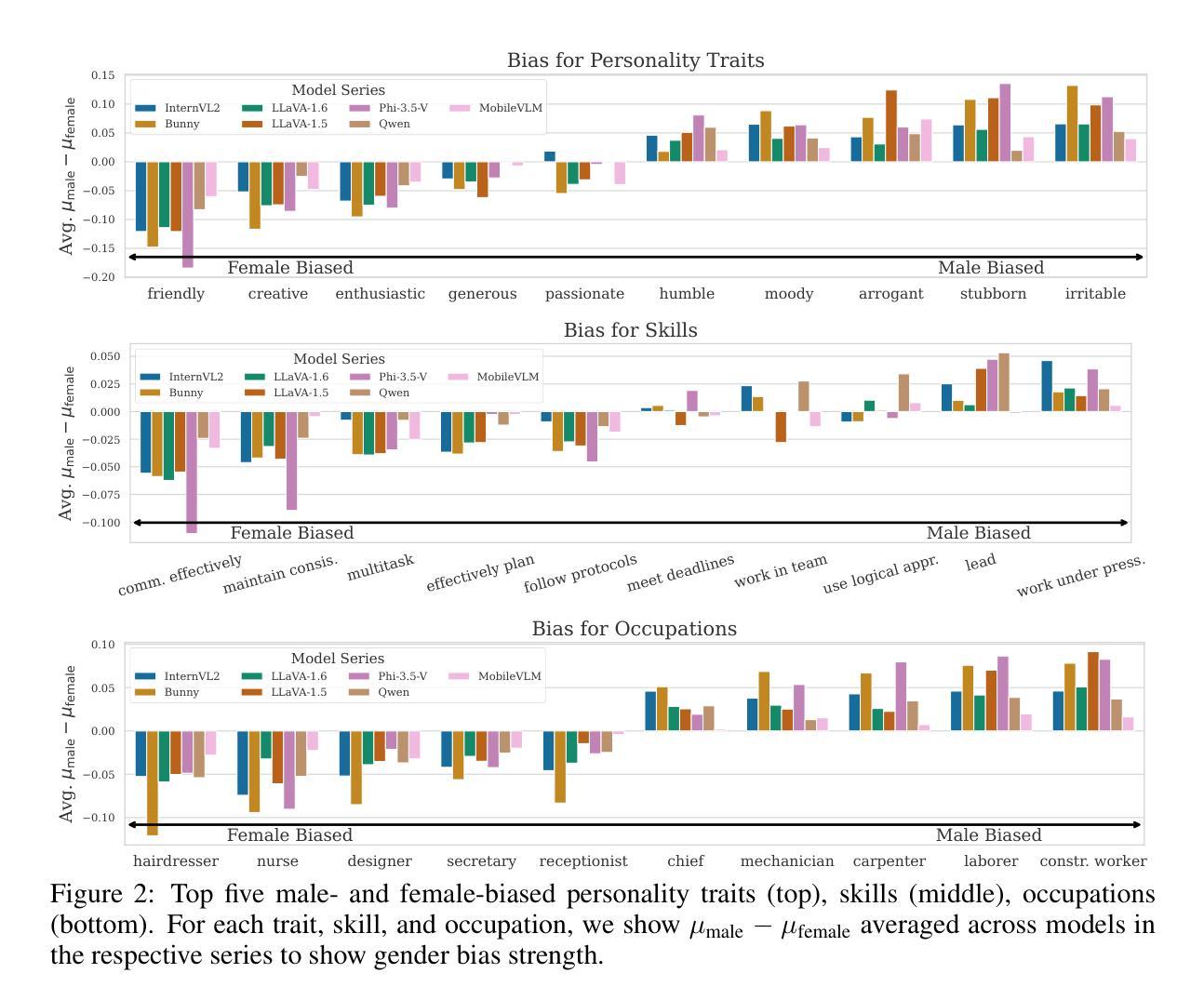
Revealing and Reducing Gender Biases in Vision and Language Assistants (VLAs)
Authors:Leander Girrbach, Stephan Alaniz, Yiran Huang, Trevor Darrell, Zeynep Akata
Pre-trained large language models (LLMs) have been reliably integrated with visual input for multimodal tasks. The widespread adoption of instruction-tuned image-to-text vision-language assistants (VLAs) like LLaVA and InternVL necessitates evaluating gender biases. We study gender bias in 22 popular open-source VLAs with respect to personality traits, skills, and occupations. Our results show that VLAs replicate human biases likely present in the data, such as real-world occupational imbalances. Similarly, they tend to attribute more skills and positive personality traits to women than to men, and we see a consistent tendency to associate negative personality traits with men. To eliminate the gender bias in these models, we find that fine-tuning-based debiasing methods achieve the best trade-off between debiasing and retaining performance on downstream tasks. We argue for pre-deploying gender bias assessment in VLAs and motivate further development of debiasing strategies to ensure equitable societal outcomes. Code is available at https://github.com/ExplainableML/vla-gender-bias.
预训练大型语言模型(LLM)已可靠地与视觉输入相结合,用于多模式任务。随着指令调整图像到文本视觉语言助理(VLAs)如LLaVA和InternVL的广泛应用,对性别偏见进行评估是必要的。我们研究了22个流行开源VLAs中的性别偏见,涉及人格特质、技能和职业。我们的结果表明,VLAs复制了数据中可能存在的人类偏见,如现实世界中职业分布不均等。同样,它们倾向于将更多的技能和积极的人格特质归因于女性而非男性,并且我们观察到一种持续的趋势,即将消极的人格特质与男性联系在一起。为了消除这些模型中的性别偏见,我们发现基于微调去偏方法在实现去偏并保持下游任务性能之间达到最佳平衡。我们主张在VLAs中预先部署性别偏见评估,并推动进一步开发去偏策略,以确保公平的社会结果。相关代码可访问 https://github.com/ExplainableML/vlas-gender-bias 了解。
论文及项目相关链接
PDF Accepted at ICLR 2025
摘要
预训练大型语言模型(LLM)已可靠地用于多模态任务中的视觉输入。随着指令调整型图像到文本的视觉语言助手(VLAs)如LLaVA和InternVL的广泛应用,需要评估性别偏见。本研究对22个流行的开源VLAs中的性别偏见进行了人格特质、技能和职业方面的分析。结果表明,VLAs复制了数据中可能存在的人类偏见,如现实世界中职业分布的不平衡。此外,它们更倾向于为女性分配更多技能和积极的人格特质,相较于男性来说。还存在一种一贯的倾向,即将消极的人格特质与男性联系在一起。为了消除这些模型中的性别偏见,我们发现基于微调技术的去偏方法在实现去偏并保持下游任务性能方面的最佳权衡。我们主张在VLAs中预先部署性别偏见评估,并推动进一步开发去偏策略,以确保公平的社会结果。相关代码可在https://github.com/ExplainableML/vla-gender-bias找到。
关键见解
- 预训练的大型语言模型在多模态任务中已与视觉输入可靠集成。
- 广泛应用的视觉语言助手(VLAs)存在性别偏见问题,需要进行评估。
- VLAs复制了数据中可能存在的性别偏见,如职业分布不平衡。
- VLAs倾向于为女性分配更多技能和积极的人格特质。
- 存在将消极人格特质与男性联系在一起的倾向。
- 基于微调技术的去偏方法在去偏和保持下游任务性能方面表现最佳。
点此查看论文截图

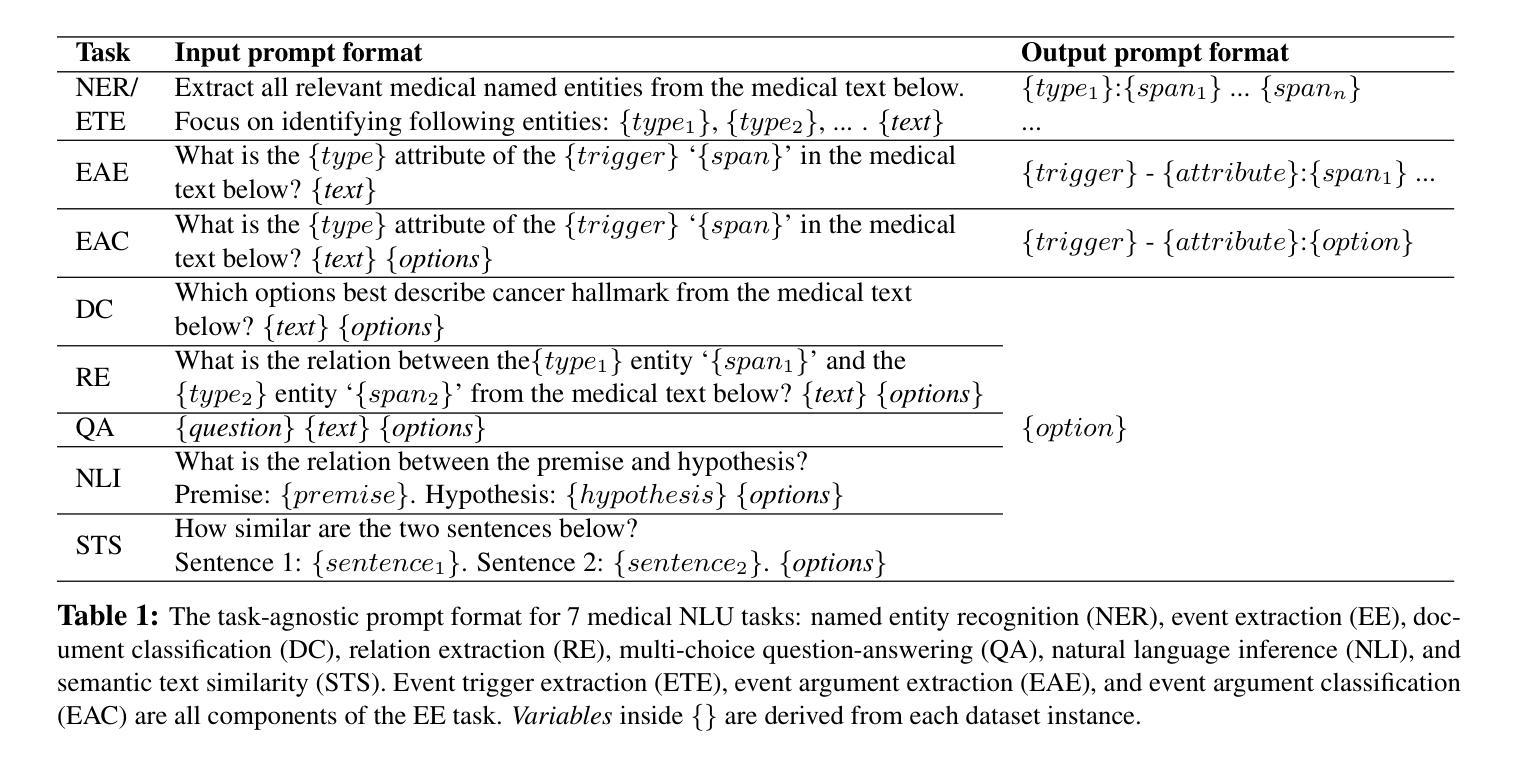
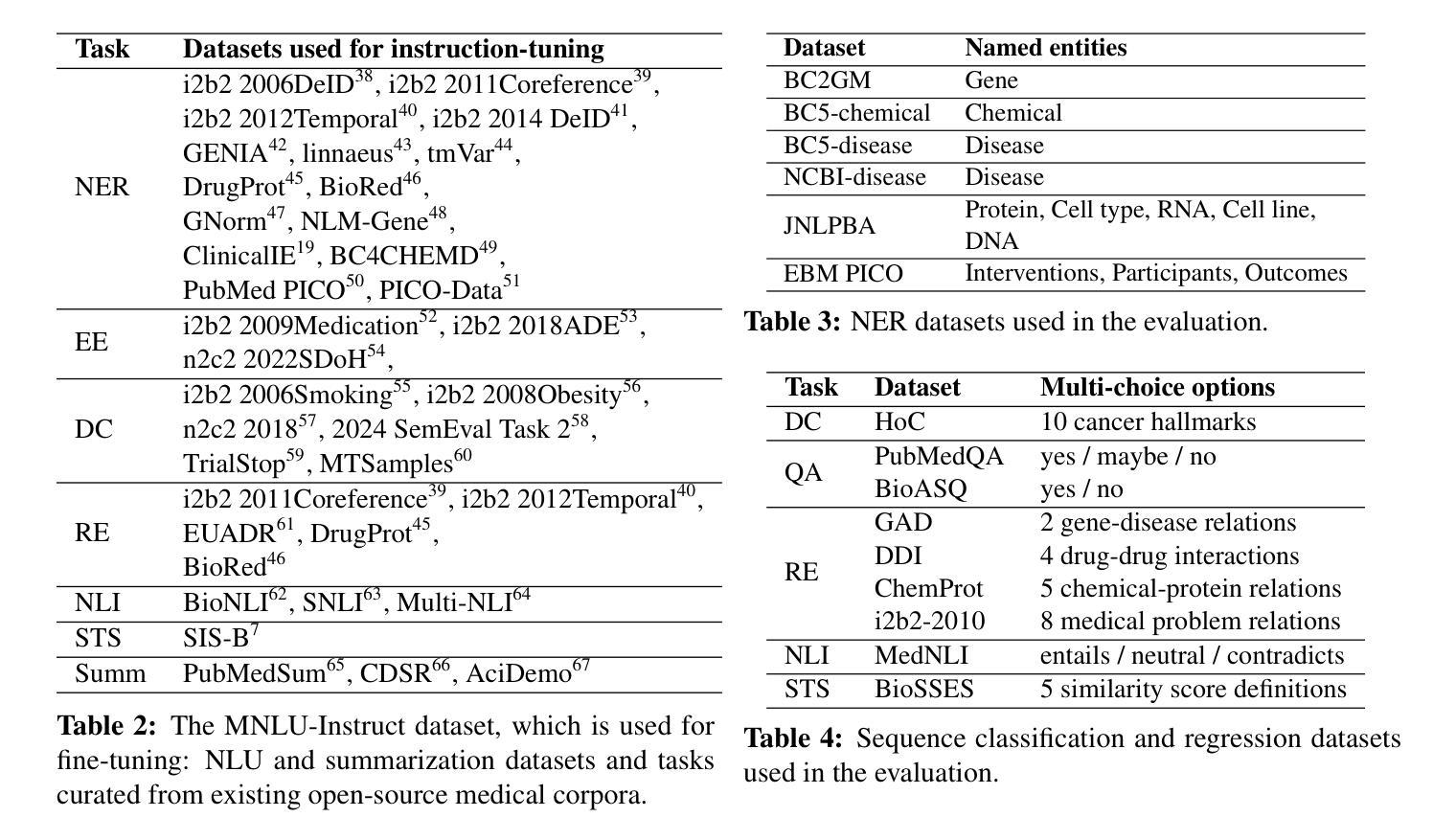
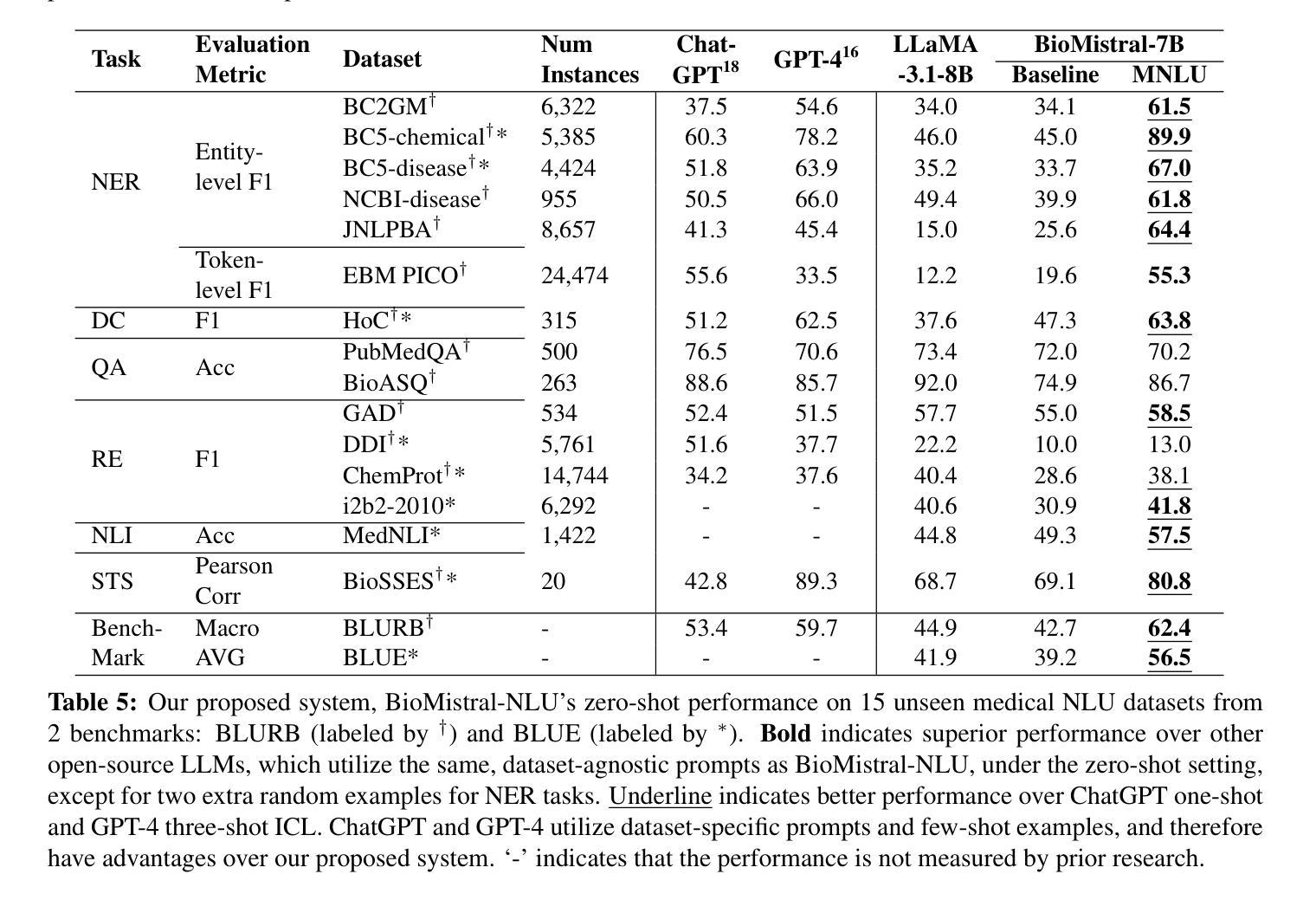
BioMistral-NLU: Towards More Generalizable Medical Language Understanding through Instruction Tuning
Authors:Yujuan Velvin Fu, Giridhar Kaushik Ramachandran, Namu Park, Kevin Lybarger, Fei Xia, Ozlem Uzuner, Meliha Yetisgen
Large language models (LLMs) such as ChatGPT are fine-tuned on large and diverse instruction-following corpora, and can generalize to new tasks. However, those instruction-tuned LLMs often perform poorly in specialized medical natural language understanding (NLU) tasks that require domain knowledge, granular text comprehension, and structured data extraction. To bridge the gap, we: (1) propose a unified prompting format for 7 important NLU tasks, (2) curate an instruction-tuning dataset, MNLU-Instruct, utilizing diverse existing open-source medical NLU corpora, and (3) develop BioMistral-NLU, a generalizable medical NLU model, through fine-tuning BioMistral on MNLU-Instruct. We evaluate BioMistral-NLU in a zero-shot setting, across 6 important NLU tasks, from two widely adopted medical NLU benchmarks: BLUE and BLURB. Our experiments show that our BioMistral-NLU outperforms the original BioMistral, as well as the proprietary LLMs - ChatGPT and GPT-4. Our dataset-agnostic prompting strategy and instruction tuning step over diverse NLU tasks enhance LLMs’ generalizability across diverse medical NLU tasks. Our ablation experiments show that instruction-tuning on a wider variety of tasks, even when the total number of training instances remains constant, enhances downstream zero-shot generalization.
大型语言模型(LLM)如ChatGPT是在大量且多样的指令遵循语料库上进行微调,并能推广至新任务。然而,这些经过指令调校的LLM在需要领域知识、精细文本理解和结构化数据提取的专门医学自然语言理解(NLU)任务中表现往往不佳。为了弥补这一差距,我们:(1)为7个重要的NLU任务提出了统一的提示格式,(2)利用多样的现有开源医学NLU语料库,制作了一个指令调校数据集MNLU-Instruct,(3)通过在MNLU-Instruct上对BioMistral进行微调,开发了可通用的医学NLU模型BioMistral-NLU。我们在两个广泛采用的医学NLU基准测试中,对6个重要的NLU任务对BioMistral-NLU进行了零样本设置下的评估:BLUE和BLURB。实验表明,我们的BioMistral-NLU在各方面都超越了原始的BioMistral以及专有LLM——ChatGPT和GPT-4。我们的数据集无关的提示策略以及指令调校步骤在不同的NLU任务上增强了LLM在多种医学NLU任务中的通用性。我们的消融实验表明,在更广泛的任务上进行指令调校,即使训练实例的总数保持不变,也能增强下游零样本推广能力。
论文及项目相关链接
PDF 3 figures an 5 tables; Accepted by AMIA 2025 Informatics Summit
Summary
大型语言模型(LLM)如ChatGPT在指令遵循语料库上进行微调,可以适应新任务。但在需要领域知识、精细文本理解和结构化数据提取的特定医疗自然语言理解(NLU)任务中,这些指令微调LLM的表现往往不佳。为了弥补这一差距,我们提出了统一的提示格式,为7个重要的NLU任务制作了一个指令调整数据集MNLU-Instruct,并开发了通过MNLU-Instruct细化的通用医疗NLU模型BioMistral-NLU。我们在零样本设置中对BioMistral-NLU进行了评估,涉及两个广泛采用的医疗NLU基准测试中的6个重要NLU任务。实验表明,BioMistral-NLU的表现优于原始的BioMistral以及专有LLM——ChatGPT和GPT-4。我们的数据集无关提示策略和指令微调步骤在不同的NLU任务上增强了LLM的泛化能力。消融实验表明,在总训练实例数保持不变的情况下,对更多样化的任务进行指令微调,可以提高下游零样本泛化能力。
Key Takeaways
- LLMs如ChatGPT在特定医疗NLU任务中表现不佳,需要领域知识和结构化数据提取等。
- 提出了一种统一的提示格式,为多种医疗NLU任务提供解决方案。
- 制作了一个指令调整数据集MNLU-Instruct,利用现有开源医疗NLU语料库。
- 开发了BioMistral-NLU模型,通过MNLU-Instruct细化的表现优于原始BioMistral和专有LLM。
- 数据集无关的提示策略和指令微调步骤增强了LLM在多样化医疗NLU任务上的泛化能力。
- 消融实验表明,在保持总训练实例数不变的情况下,对更多样化的任务进行指令微调可以提高下游零样本泛化能力。
- 此研究为提升LLMs在特定领域(如医疗)的任务表现提供了新的思路和方法。
点此查看论文截图

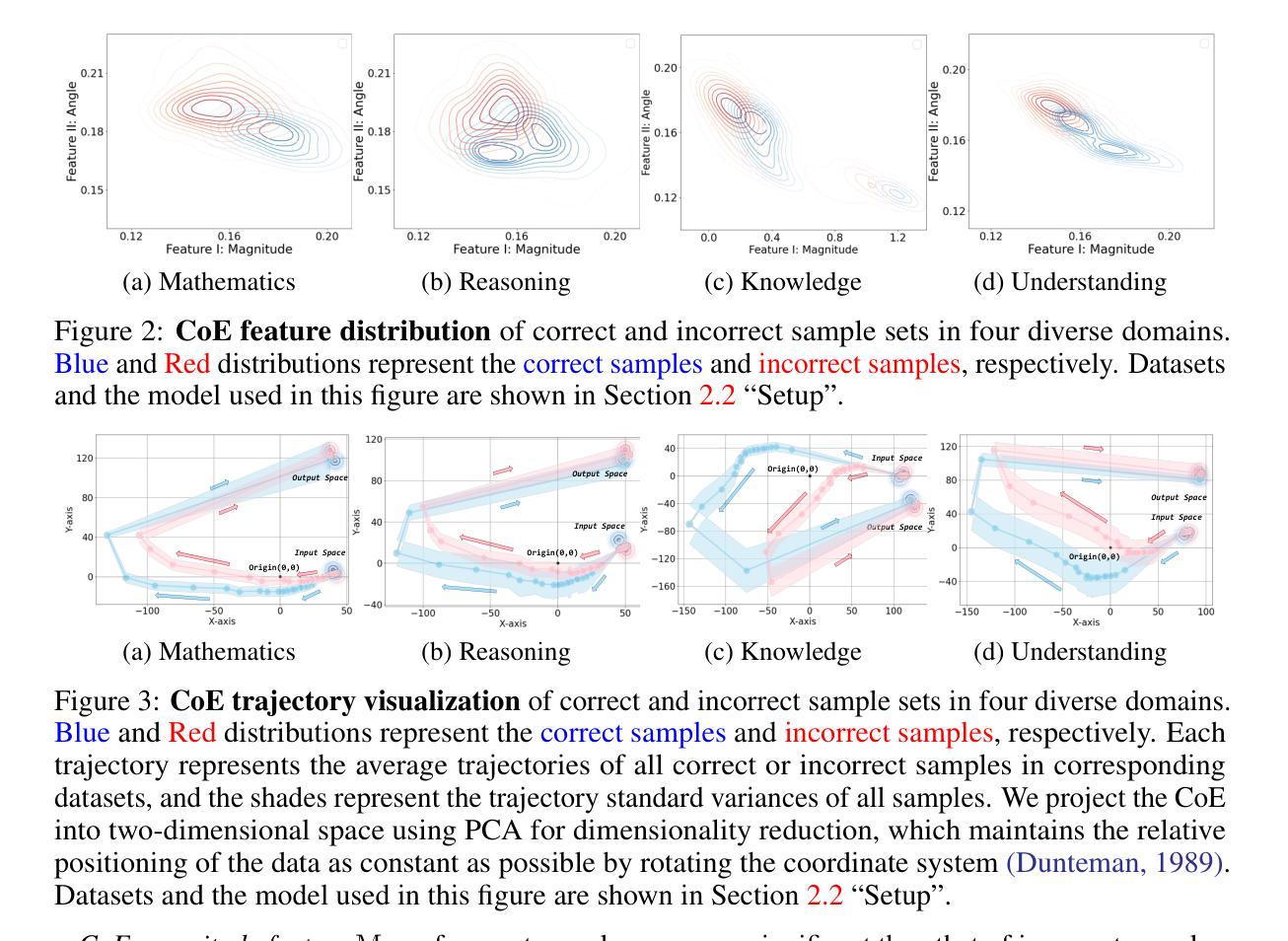
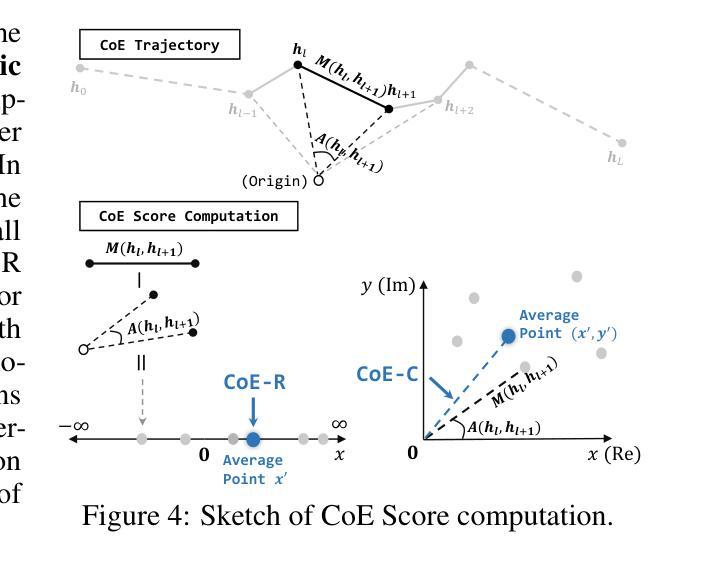
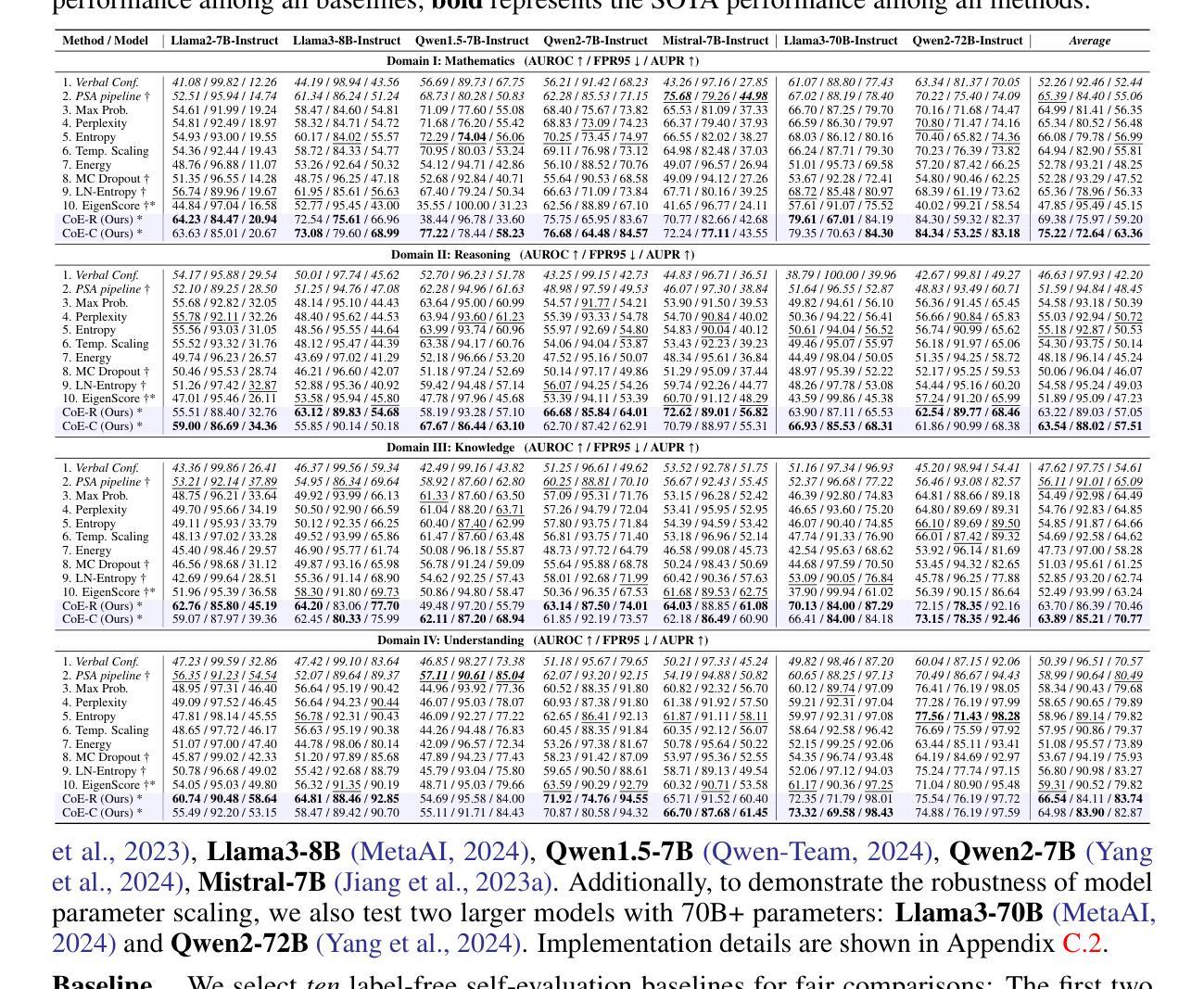
Latent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation
Authors:Yiming Wang, Pei Zhang, Baosong Yang, Derek F. Wong, Rui Wang
LLM self-evaluation relies on the LLM’s own ability to estimate response correctness, which can greatly improve its deployment reliability. In this research track, we propose the Chain-of-Embedding (CoE) in the latent space to enable LLMs to perform output-free self-evaluation. CoE consists of all progressive hidden states produced during the inference time, which can be treated as the latent thinking path of LLMs. We find that when LLMs respond correctly and incorrectly, their CoE features differ, these discrepancies assist us in estimating LLM response correctness. Experiments in four diverse domains and seven LLMs fully demonstrate the effectiveness of our method. Meanwhile, its label-free design intent without any training and millisecond-level computational cost ensures real-time feedback in large-scale scenarios. More importantly, we provide interesting insights into LLM response correctness from the perspective of hidden state changes inside LLMs.
LLM的自我评估依赖于其自身评估响应正确性的能力,这可以大大提高其部署可靠性。在本研究轨迹中,我们提出了潜在空间中的嵌入链(CoE)技术,使LLM能够执行无输出自我评估。CoE由推理时间期间产生的所有渐进隐藏状态组成,可视为LLM的潜在思考路径。我们发现,当LLM正确回答和错误回答时,它们的CoE特征有所不同,这些差异有助于我们评估LLM响应的正确性。在四个不同领域和七个LLM上的实验充分证明了我们方法的有效性。同时,其无需标签的设计意图无需任何训练和毫秒级的计算成本,可确保大规模场景中的实时反馈。更重要的是,我们从LLM内部隐藏状态变化的角度,为LLM响应正确性提供了有趣的见解。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
LLM的自评估能力依靠其自我判断响应正确性的能力,可大幅提高部署可靠性。本研究提出了基于嵌入链(CoE)的潜在空间方法,使LLM能够无输出地进行自我评估。嵌入链包含推理过程中的所有渐进隐藏状态,可视为LLM的潜在思考路径。研究发现,当LLM的响应正确与否时,其嵌入链的特征存在差异,这些差异有助于我们判断LLM的响应正确性。在多领域和多LLM的实验中验证了该方法的有效性。此外,其无需标签的设计意图无需任何训练,毫秒级的计算成本保证了大规模场景下的实时反馈。更重要的是,本研究从LLM内部隐藏状态变化的角度提供了关于响应正确性的有趣见解。
Key Takeaways
- LLM的自评估能力可以依靠其自身判断响应的正确性,从而提高部署可靠性。
- 提出了基于嵌入链(CoE)的潜在空间方法,使LLM能够无输出地自我评估。
- 嵌入链包含推理过程中的所有渐进隐藏状态,反映LLM的潜在思考路径。
- LLM在正确和错误响应时,其嵌入链特征存在差异,有助于判断其响应正确性。
- 在多领域和多LLM的实验中验证了该方法的有效性。
- 无需标签的设计使得该方法无需额外训练,计算成本低,可实现实时反馈。
点此查看论文截图

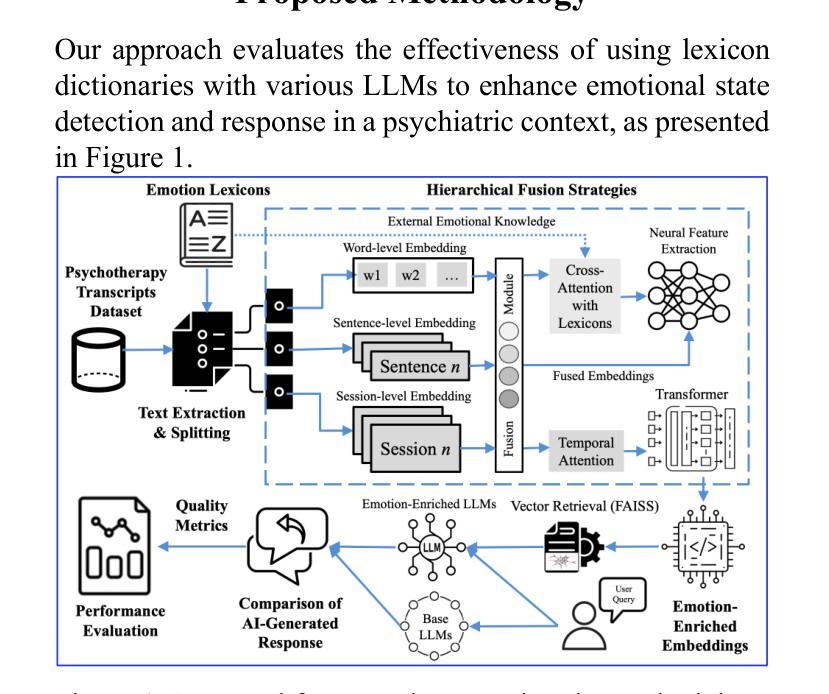
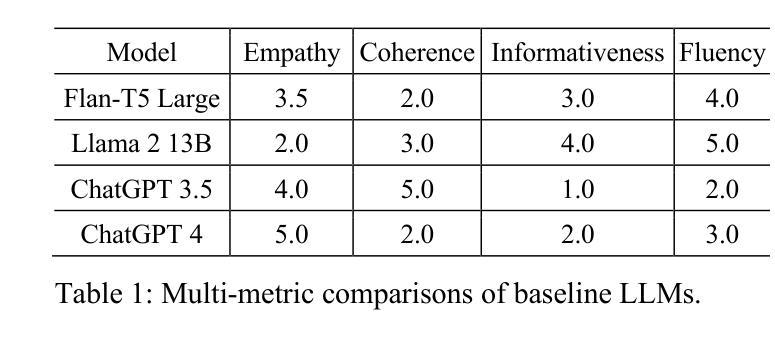
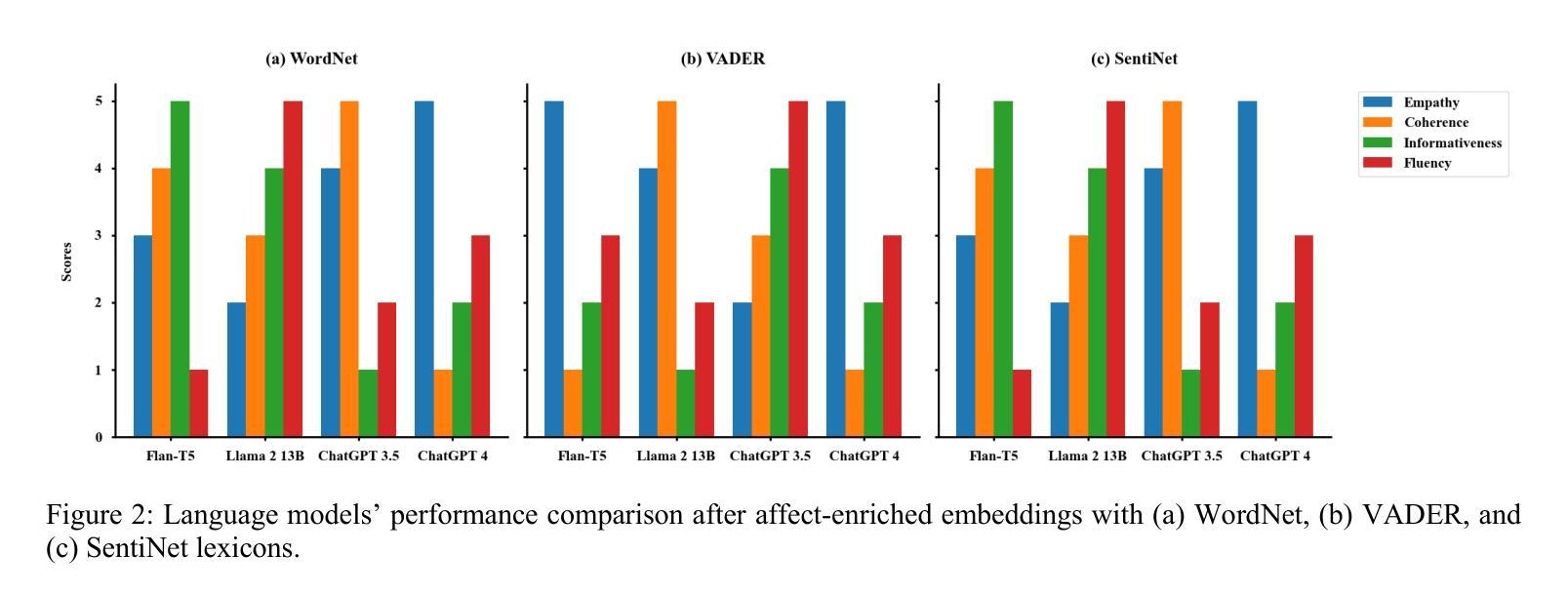
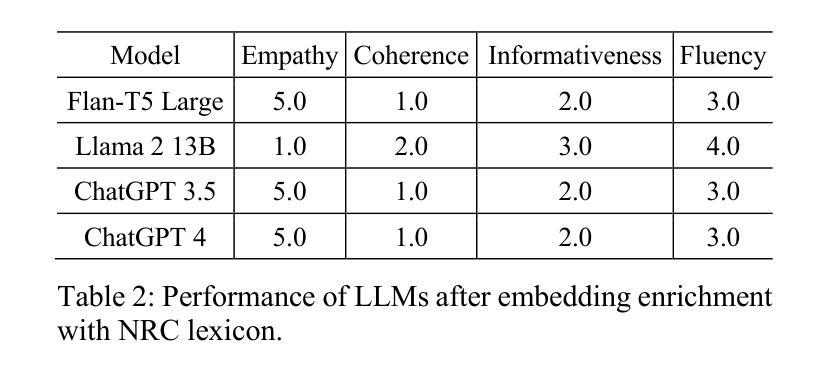
Emotion-Aware Embedding Fusion in LLMs (Flan-T5, LLAMA 2, DeepSeek-R1, and ChatGPT 4) for Intelligent Response Generation
Authors:Abdur Rasool, Muhammad Irfan Shahzad, Hafsa Aslam, Vincent Chan, Muhammad Ali Arshad
Empathetic and coherent responses are critical in auto-mated chatbot-facilitated psychotherapy. This study addresses the challenge of enhancing the emotional and contextual understanding of large language models (LLMs) in psychiatric applications. We introduce Emotion-Aware Embedding Fusion, a novel framework integrating hierarchical fusion and attention mechanisms to prioritize semantic and emotional features in therapy transcripts. Our approach combines multiple emotion lexicons, including NRC Emotion Lexicon, VADER, WordNet, and SentiWordNet, with state-of-the-art LLMs such as Flan-T5, LLAMA 2, DeepSeek-R1, and ChatGPT 4. Therapy session transcripts, comprising over 2,000 samples are segmented into hierarchical levels (word, sentence, and session) using neural networks, while hierarchical fusion combines these features with pooling techniques to refine emotional representations. Atten-tion mechanisms, including multi-head self-attention and cross-attention, further prioritize emotional and contextual features, enabling temporal modeling of emotion-al shifts across sessions. The processed embeddings, computed using BERT, GPT-3, and RoBERTa are stored in the Facebook AI similarity search vector database, which enables efficient similarity search and clustering across dense vector spaces. Upon user queries, relevant segments are retrieved and provided as context to LLMs, enhancing their ability to generate empathetic and con-textually relevant responses. The proposed framework is evaluated across multiple practical use cases to demonstrate real-world applicability, including AI-driven therapy chatbots. The system can be integrated into existing mental health platforms to generate personalized responses based on retrieved therapy session data.
在自动聊天机器人辅助的心理治疗(psychotherapy)中,体贴且连贯的回应至关重要。本研究旨在解决增强精神病学应用中的大型语言模型(LLM)的情感和上下文理解能力的挑战。我们引入了情感感知嵌入融合(Emotion-Aware Embedding Fusion)这一新型框架,该框架结合了层次融合和注意力机制,以优先处理治疗记录中的语义和情感特征。我们的方法结合了多个情感词典,包括NRC情感词典、VADER、WordNet和SentiWordNet,以及最先进的LLM,如Flan-T5、LLAMA 2、DeepSeek-R1和ChatGPT 4。治疗会话记录由超过两千个样本组成,它们通过神经网络分层划分到不同级别(如单词、句子和会话),而层次融合则使用池技术结合这些特征来优化情感表达。注意力机制包括多头自注意力机制和交叉注意力机制,它们进一步强调情感和上下文特征,实现跨会话的情感变化的时间建模。使用BERT、GPT-3和RoBERTa计算得到的处理过的嵌入存储在Facebook AI相似性搜索向量数据库中,这有助于在密集向量空间中实现高效相似性搜索和聚类。在用户查询时,相关片段被检索出来并提供给LLM作为上下文,从而增强它们生成体贴且上下文相关的响应的能力。所提出的框架经过多个实际应用案例的评估,证明了其在现实世界中的适用性,包括AI驱动的疗法聊天机器人。该系统可以集成到现有的心理健康平台中,根据检索到的治疗会话数据生成个性化响应。
论文及项目相关链接
Summary
在自动聊天机器人辅助的心理治疗中,共情和连贯的回应至关重要。本研究旨在提高大语言模型在心理治疗应用中的情感理解和语境理解能力。我们提出了情感感知嵌入融合框架,该框架结合了层次融合和注意力机制,以优先处理治疗记录中的语义和情感特征。该框架结合了多个情感词典,包括NRC情感词典、VADER、WordNet和SentiWordNet等,以及先进的LLM模型,如Flan-T5、LLAMA 2等。通过神经网络将治疗会话记录分段,利用层次融合和池化技术组合这些特征,以优化情感表达。注意力机制有助于优先处理情感和语境特征,实现跨会话的情感变化建模。该研究还使用了BERT、GPT-3和RoBERTa等模型生成的嵌入向量,并利用Facebook AI相似性搜索向量数据库进行高效相似性搜索和聚类。用户查询时,可检索相关片段作为上下文,增强LLM生成共情和语境相关响应的能力。该框架在多个实际应用场景中进行了评估,证明了其在现实世界的适用性,包括AI驱动的治疗聊天机器人。
Key Takeaways
- 情感感知嵌入融合框架用于增强大语言模型在心理治疗中的情感理解和语境理解能力。
- 框架结合了层次融合和注意力机制,以优先处理治疗记录中的语义和情感特征。
- 结合了多个情感词典和先进的LLM模型。
- 治疗会话记录被分段并优化情感表达。
- 注意力机制有助于跨会话的情感变化建模。
- 利用BERT、GPT-3和RoBERTa等模型生成的嵌入向量进行相似性搜索和聚类。
- 该框架适用于AI驱动的治疗聊天机器人,可生成个性化的响应。
点此查看论文截图

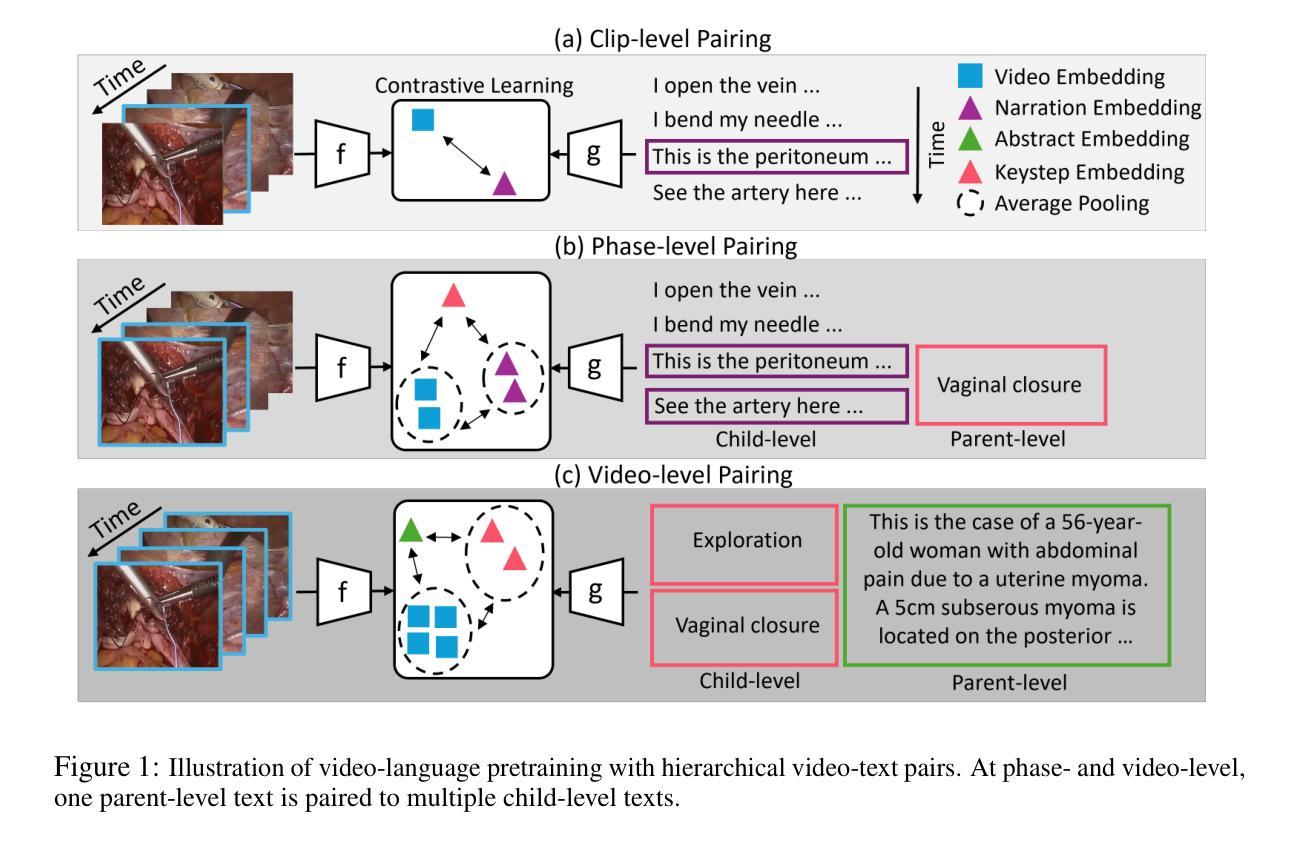
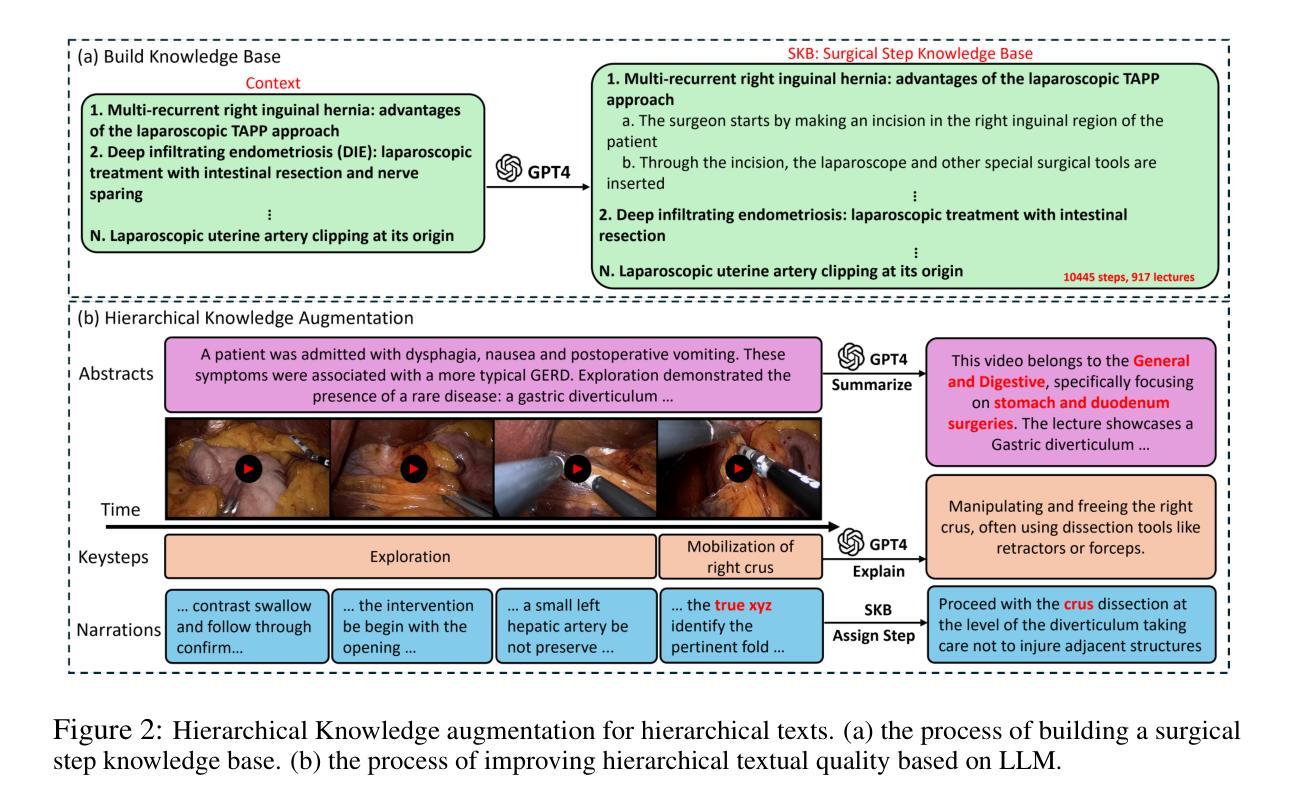
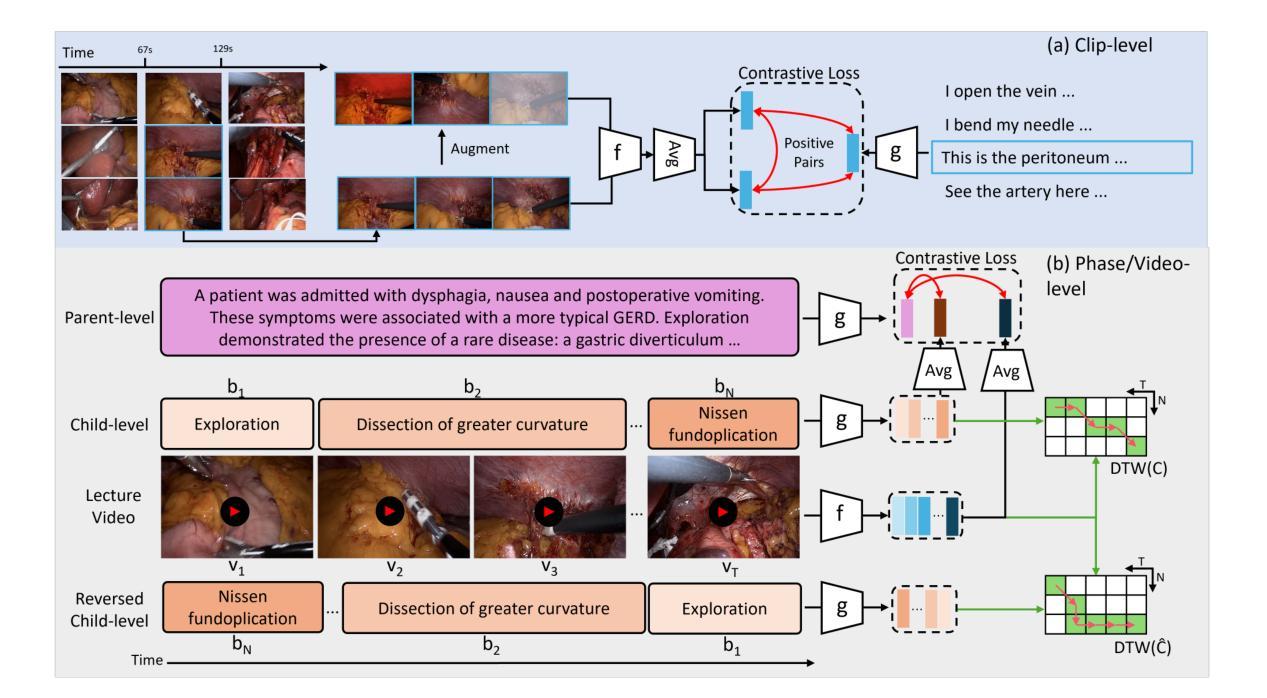
Procedure-Aware Surgical Video-language Pretraining with Hierarchical Knowledge Augmentation
Authors:Kun Yuan, Vinkle Srivastav, Nassir Navab, Nicolas Padoy
Surgical video-language pretraining (VLP) faces unique challenges due to the knowledge domain gap and the scarcity of multi-modal data. This study aims to bridge the gap by addressing issues regarding textual information loss in surgical lecture videos and the spatial-temporal challenges of surgical VLP. We propose a hierarchical knowledge augmentation approach and a novel Procedure-Encoded Surgical Knowledge-Augmented Video-Language Pretraining (PeskaVLP) framework to tackle these issues. The knowledge augmentation uses large language models (LLM) for refining and enriching surgical concepts, thus providing comprehensive language supervision and reducing the risk of overfitting. PeskaVLP combines language supervision with visual self-supervision, constructing hard negative samples and employing a Dynamic Time Warping (DTW) based loss function to effectively comprehend the cross-modal procedural alignment. Extensive experiments on multiple public surgical scene understanding and cross-modal retrieval datasets show that our proposed method significantly improves zero-shot transferring performance and offers a generalist visual representation for further advancements in surgical scene understanding.The code is available at https://github.com/CAMMA-public/SurgVLP
手术视频语言预训练(VLP)面临着知识域差距和多模态数据稀缺所带来的独特挑战。本研究旨在通过解决手术讲座视频中文本信息丢失以及手术VLP的时空挑战来弥补这一差距。我们提出了一种分层知识增强方法和一种新颖的手术编码知识增强视频语言预训练(PeskaVLP)框架来解决这些问题。知识增强利用大型语言模型(LLM)来提炼和丰富手术概念,从而为手术语言提供全面的监督,降低过拟合的风险。PeskaVLP结合了语言监督和视觉自监督,构建硬负样本并采用基于动态时间规整(DTW)的损失函数,以有效地理解跨模态过程对齐。在多个公共手术场景理解和跨模态检索数据集上的广泛实验表明,我们提出的方法显著提高了零样本迁移性能,并为手术场景理解的进一步进展提供了通用的视觉表示。代码可从 https://github.com/CAMMA-public/SurgVLP 获取。
论文及项目相关链接
PDF Accepted at the 38th Conference on Neural Information Processing Systems (NeurIPS 2024 Spolight)
Summary
针对手术视频语言预训练(VLP)中的知识域差距和多模态数据稀缺问题,本研究提出一种基于层次知识增强和新型手术知识编码的视频语言预训练框架(PeskaVLP)。利用大型语言模型(LLM)进行手术概念精细化和丰富化,提供全面的语言监督并降低过拟合风险。结合语言监督和视觉自监督,构建硬负样本并采用基于动态时间规整(DTW)的损失函数,实现跨模态过程对齐的有效理解。在多个公共手术场景理解和跨模态检索数据集上的实验表明,所提方法显著提高了零样本迁移性能,并为手术场景理解的进一步进展提供了通用的视觉表示。
Key Takeaways
- 手术视频语言预训练(VLP)面临知识域差距和多模态数据稀缺的挑战。
- 提出一种基于层次知识增强的方法,使用大型语言模型(LLM)来丰富手术概念。
- PeskaVLP框架结合了语言监督和视觉自监督,以改善跨模态对齐。
- 通过构建硬负样本和采用基于动态时间规整(DTW)的损失函数,提高了模型性能。
- 在多个数据集上的实验证明了该方法在零样本迁移性能上的显著提高。
- 所提方法为手术场景理解提供了通用的视觉表示。
点此查看论文截图

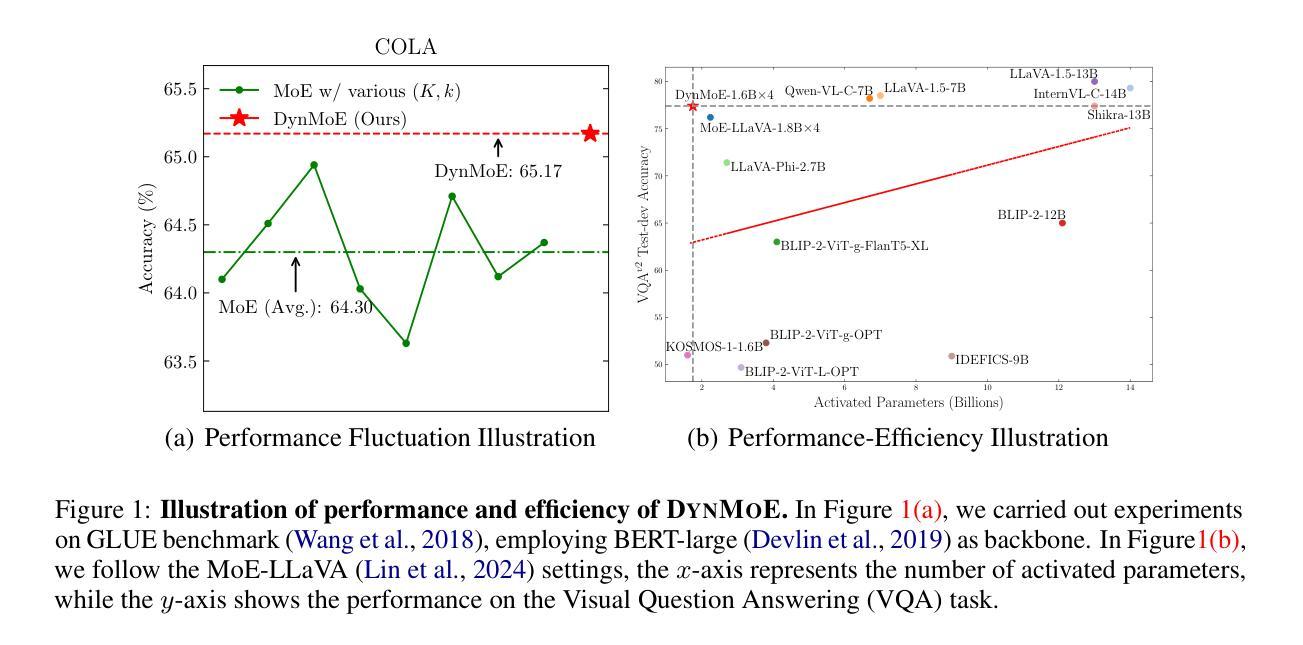
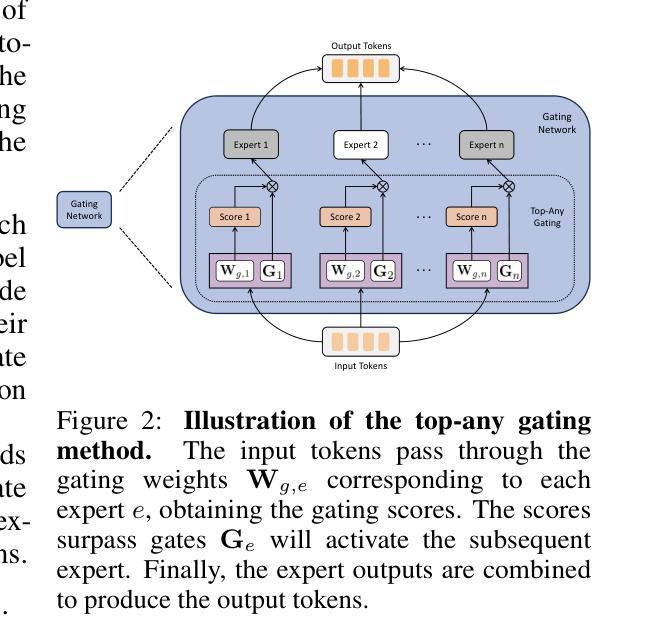
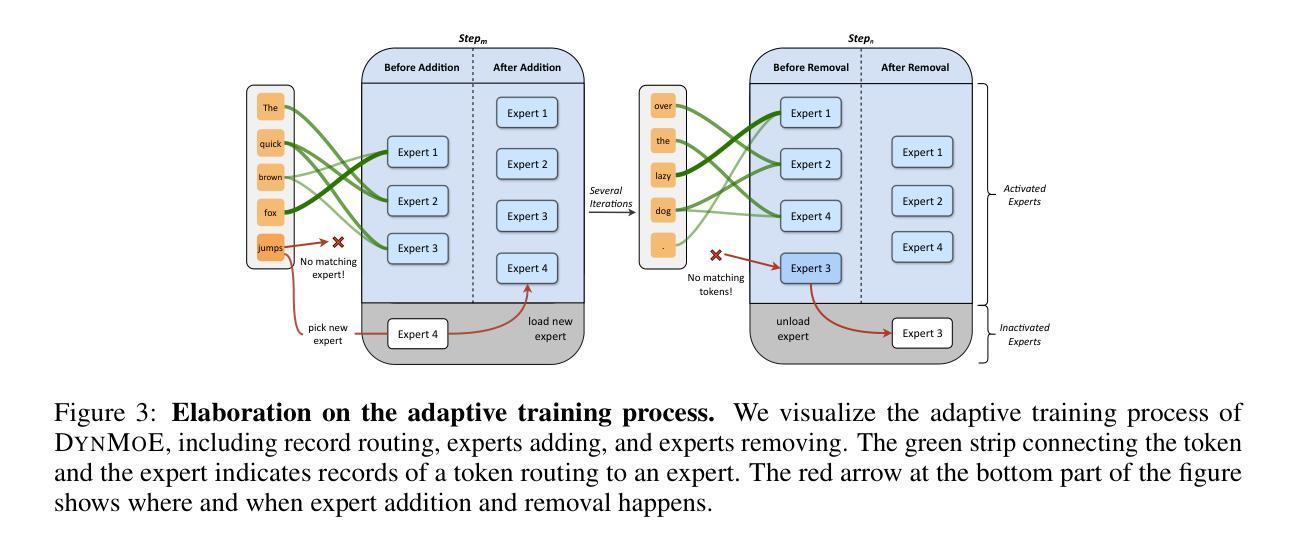
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
Authors:Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Zhaopeng Tu, Tao Lin
The Sparse Mixture of Experts (SMoE) has been widely employed to enhance the efficiency of training and inference for Transformer-based foundational models, yielding promising results.However, the performance of SMoE heavily depends on the choice of hyper-parameters, such as the number of experts and the number of experts to be activated (referred to as top-k), resulting in significant computational overhead due to the extensive model training by searching over various hyper-parameter configurations. As a remedy, we introduce the Dynamic Mixture of Experts (DynMoE) technique. DynMoE incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training. Extensive numerical results across Vision, Language, and Vision-Language tasks demonstrate the effectiveness of our approach to achieve competitive performance compared to GMoE for vision and language tasks, and MoE-LLaVA for vision-language tasks, while maintaining efficiency by activating fewer parameters. Our code is available at https://github.com/LINs-lab/DynMoE.
稀疏专家混合(SMoE)已被广泛应用于提高基于Transformer的基础模型的训练和推理效率,并产生了有前景的结果。然而,SMoE的性能在很大程度上取决于超参数的选择,如专家数量和要激活的专家数量(称为top-k),由于需要在各种超参数配置上进行广泛的模型训练,因此产生了巨大的计算开销。为了解决这个问题,我们引入了动态专家混合(DynMoE)技术。DynMoE结合了(1)一种新型的门控方法,使每个令牌能够自动确定要激活的专家数量。(2)一个自适应过程会在训练过程中自动调整专家数量。在视觉、语言和视觉语言任务上的大量数值结果表明,我们的方法在实现与GMoE在视觉和语言任务以及MoE-LLaVA在视觉语言任务上的竞争力同时,通过激活更少的参数来保持高效性。我们的代码位于https://github.com/LINs-lab/DynMoE。
论文及项目相关链接
PDF ICLR 2025
摘要
Sparse Mixture of Experts (SMoE)在提高基于Transformer的模型的训练和推理效率方面表现出色。然而,其性能高度依赖于超参数的选择,如专家数量和激活的专家数量(称为top-k),导致因搜索各种超参数配置而产生巨大的计算开销。为解决这一问题,我们引入了Dynamic Mixture of Experts (DynMoE)技术。DynMoE包括(1)一种新型的门控方法,使每个令牌能够自动确定要激活的专家数量;(2)一个自适应过程,可在训练过程中自动调整专家的数量。广泛的数值结果表明,我们的方法在视觉、语言和视觉语言任务上实现了与GMoE和MoE-LLaVA相比具有竞争力的性能,同时通过激活较少的参数来提高效率。我们的代码可在https://github.com/LINs-lab/DynMoE获取。
关键见解
- Sparse Mixture of Experts (SMoE)增强了Transformer模型训练和推理的效率。
- SMoE性能受超参数选择影响,如专家数量和激活的专家数量。
- 为解决SMoE的问题,提出了Dynamic Mixture of Experts (DynMoE)技术。
- DynMoE包含新型门控方法和自适应过程。
- 门控方法使每个令牌能自动确定激活的专家数量。
- 自适应过程在训练过程中自动调整专家数量。
点此查看论文截图

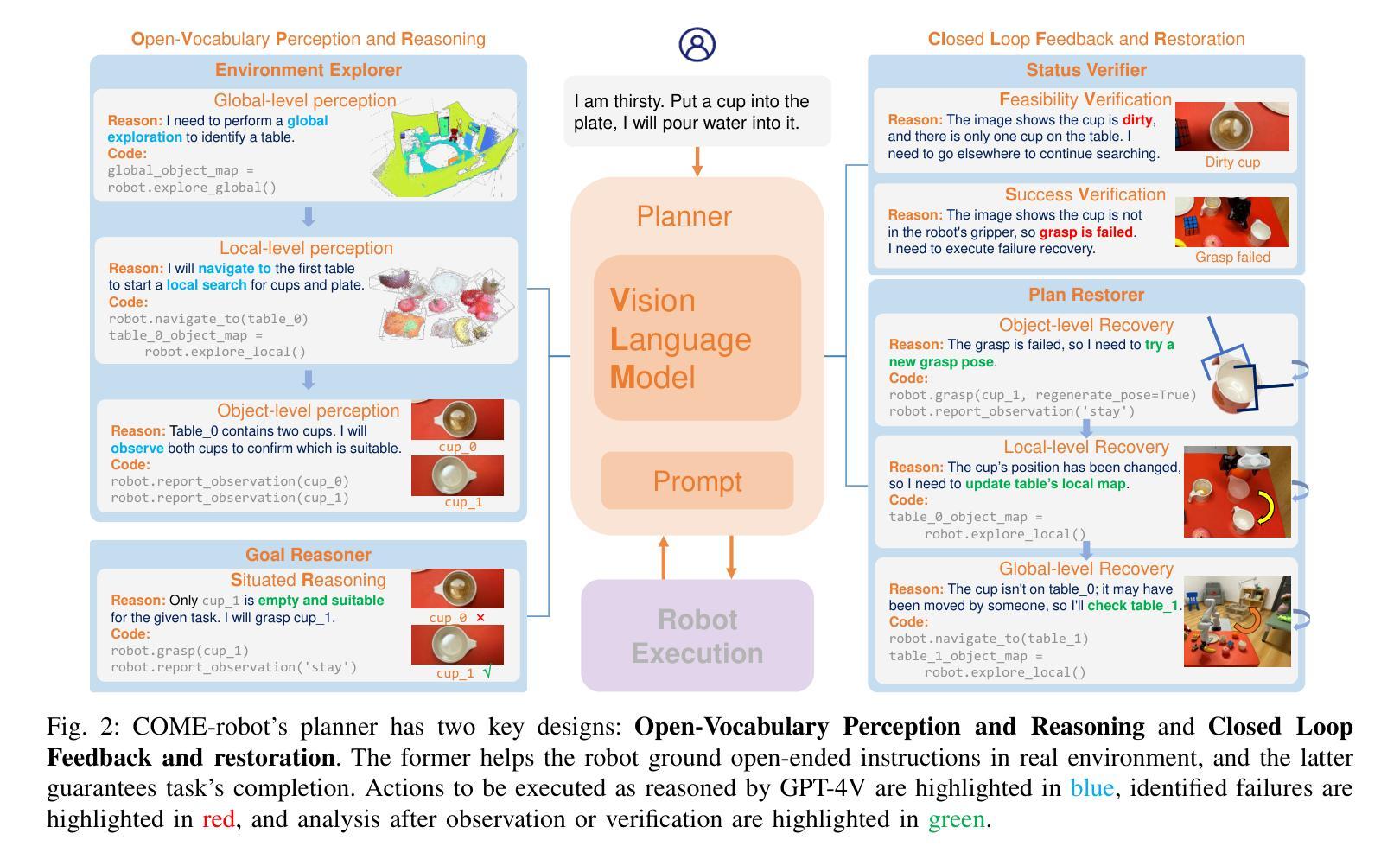
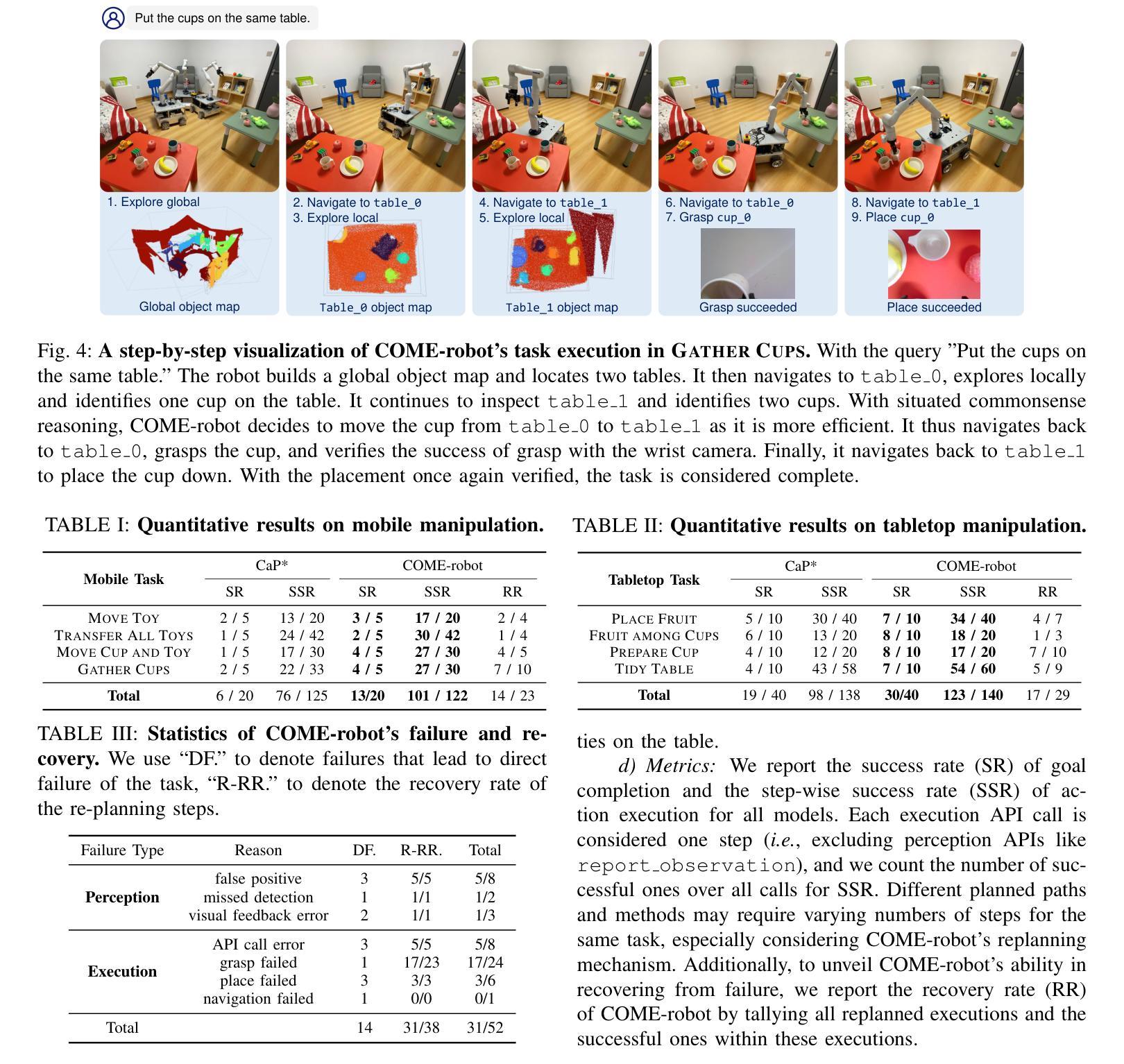
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Authors:Peiyuan Zhi, Zhiyuan Zhang, Yu Zhao, Muzhi Han, Zeyu Zhang, Zhitian Li, Ziyuan Jiao, Baoxiong Jia, Siyuan Huang
Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. In this work, we present COME-robot, the first closed-loop robotic system utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios.COME-robot incorporates two key innovative modules: (i) a multi-level open-vocabulary perception and situated reasoning module that enables effective exploration of the 3D environment and target object identification using commonsense knowledge and situated information, and (ii) an iterative closed-loop feedback and restoration mechanism that verifies task feasibility, monitors execution success, and traces failure causes across different modules for robust failure recovery. Through comprehensive experiments involving 8 challenging real-world mobile and tabletop manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~35%) compared to state-of-the-art methods. We further conduct comprehensive analyses to elucidate how COME-robot’s design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
自主机器人在开放环境中的导航和操控需要进行闭环反馈的推理和再规划。在这项工作中,我们推出了COME-robot,这是第一个利用GPT-4V视觉语言基础模型进行开放式推理和现实世界场景自适应规划的闭环机器人系统。COME-robot包含两个关键的创新模块:(i)多层次开放词汇感知和情境推理模块,利用常识知识和情境信息,实现有效的三维环境探索和目标对象识别;(ii)迭代闭环反馈和恢复机制,验证任务可行性,监控执行成功与否,并跟踪不同模块的失败原因,以实现稳健的故障恢复。通过对涉及8项具有挑战性的现实移动操作和桌面操控任务的全面实验,COME-robot与现有技术相比,在任务成功率方面取得了显著的提高(约35%)。我们还进行了全面的分析,以阐明COME-robot的设计如何促进故障恢复、自由形式的指令遵循和长期任务规划。
论文及项目相关链接
PDF 6 pages, Accepted at 2025 IEEE ICRA, website: https://come-robot.github.io/
Summary
基于GPT-4V视觉语言基础模型的闭环机器人系统COME-robot,实现了开放环境下的自主机器人导航和操控。该系统通过两级创新模块实现开放式词汇感知和情境推理,以及迭代式闭环反馈和恢复机制,有效提高了任务成功率。在包含多种挑战性移动和桌面操作任务的实验中,与现有技术相比,COME-robot的任务成功率显著提高约35%。
Key Takeaways
- COME-robot是首个利用GPT-4V视觉语言基础模型进行开放式推理和自适应规划的闭环机器人系统。
- COME-robot具有两级创新模块:一级是多级开放式词汇感知和情境推理模块,使机器人能够有效地探索三维环境并识别目标物体;另一级是迭代式闭环反馈和恢复机制,用于验证任务的可行性、监控执行成功情况并追踪不同模块的失败原因,从而实现稳健的故障恢复。
- COME-robot在多种挑战性移动和桌面操作任务中展示了显著的性能提升,任务成功率提高约35%。
- COME-robot的设计有助于故障恢复、自由形式指令跟随和长期任务规划。
- 多级开放式词汇感知和情境推理模块使得机器人能够利用常识知识和情境信息进行有效的环境探索和物体识别。
- 迭代式闭环反馈和恢复机制确保机器人在执行复杂任务时能够实时监控并调整,以实现更高的鲁棒性和适应性。
点此查看论文截图



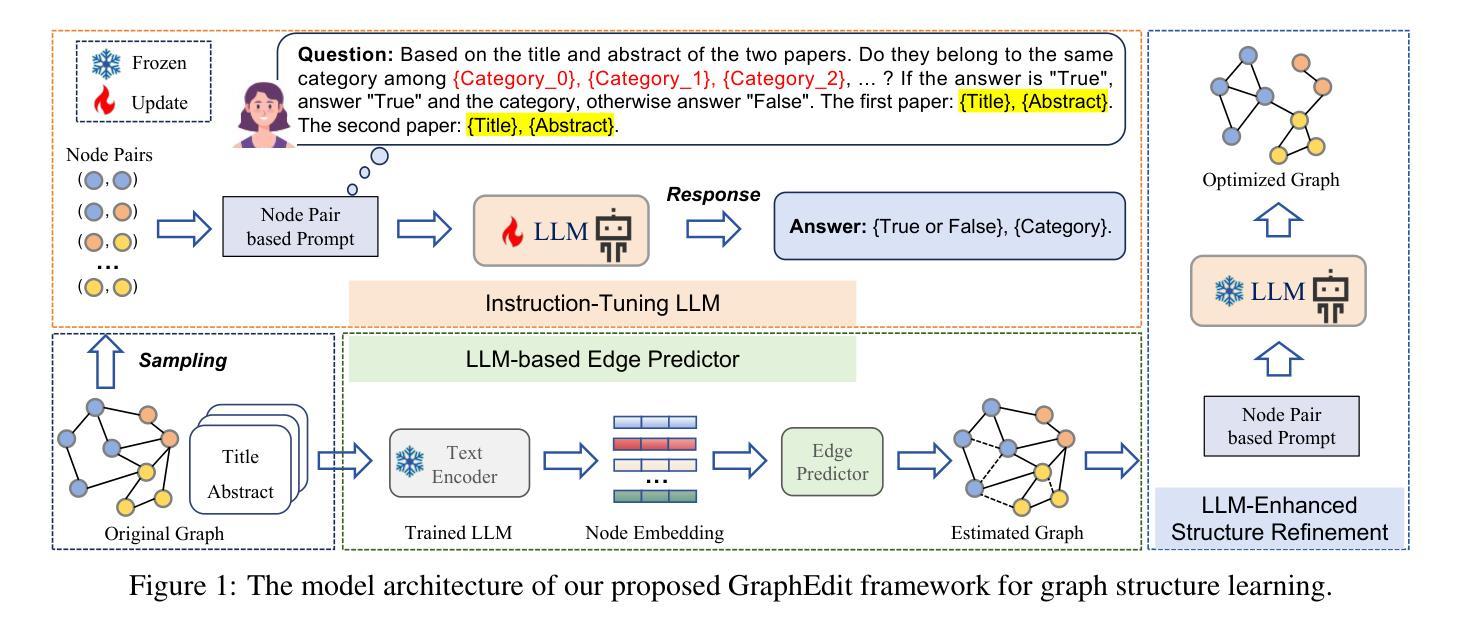
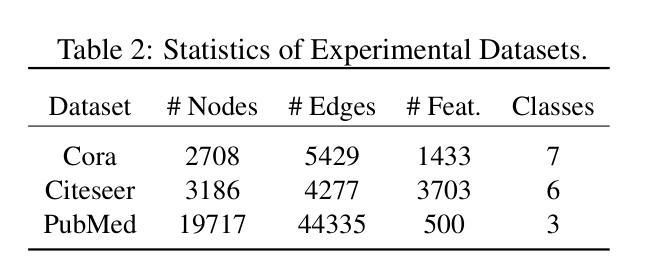
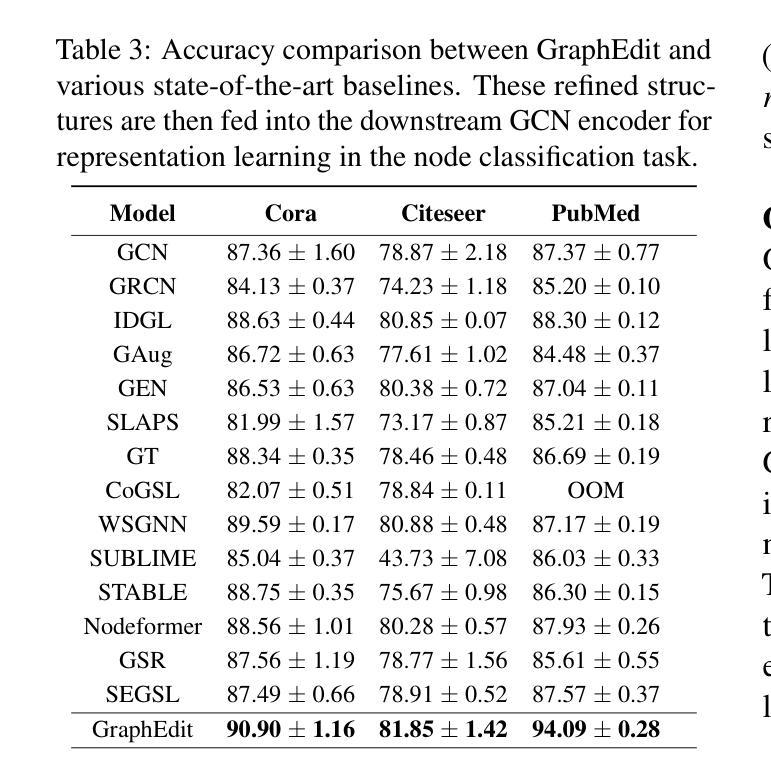
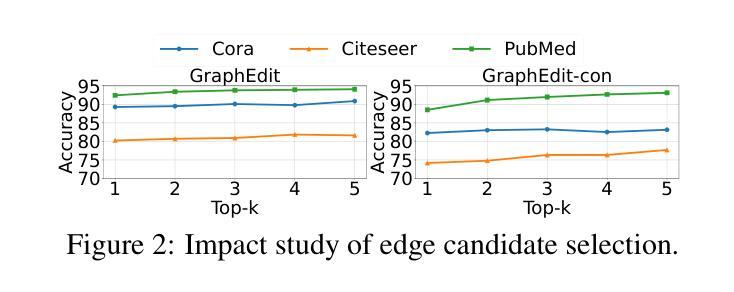
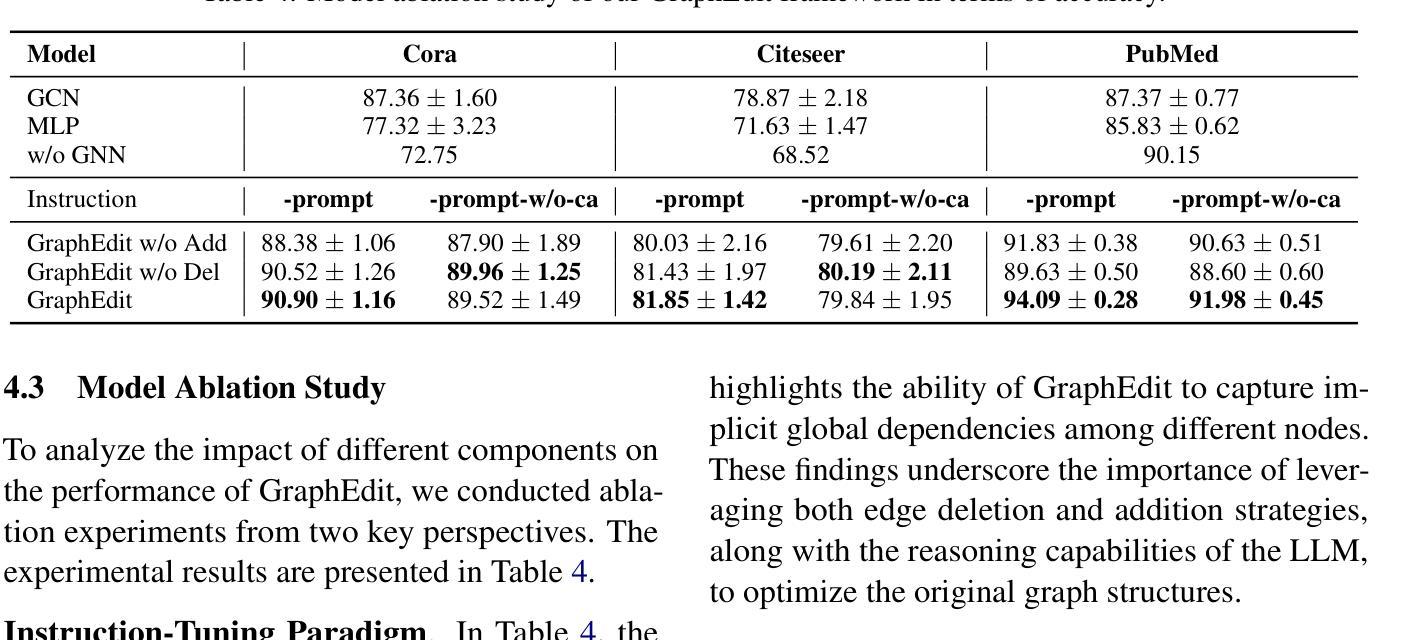
GraphEdit: Large Language Models for Graph Structure Learning
Authors:Zirui Guo, Lianghao Xia, Yanhua Yu, Yuling Wang, Kangkang Lu, Zhiyong Huang, Chao Huang
Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
图结构学习(GSL)旨在通过生成新的图结构来捕捉图结构数据中节点之间的内在依赖性和交互作用。图神经网络(GNNs)作为一种有前景的GSL解决方案出现,它利用递归消息传递来编码节点间的依赖性。然而,许多现有的GSL方法严重依赖于明确的图结构信息作为监督信号,这使得它们容易受到数据噪声和稀疏性等的挑战。在这项工作中,我们提出了GraphEdit方法,它利用大型语言模型(LLM)来学习图结构数据中的复杂节点关系。通过指令调优图结构增强LLM的推理能力,我们旨在克服与明确的图结构信息相关的局限性,提高图结构学习的可靠性。我们的方法不仅有效地消除了噪声连接,还从全局角度识别节点依赖关系,为图结构提供了全面的理解。我们在多个基准数据集上进行了广泛的实验,以证明GraphEdit在各种设置下的有效性和稳健性。我们的模型实现可在以下网址找到:https://github.com/HKUDS/GraphEdit。
论文及项目相关链接
Summary
GraphEdit利用大型语言模型(LLM)学习图结构数据中的复杂节点关系,通过指令调整增强LLM的推理能力,旨在克服与显式图结构信息相关的局限性,提高图结构学习的可靠性。此方法不仅能有效去除噪声连接,还能从全局角度识别节点依赖关系,为图结构提供全面的理解。
Key Takeaways
- GraphEdit专注于通过生成新型图结构来捕捉图结构数据中节点之间的内在依赖性和交互。
- 图神经网络(GNNs)作为图结构学习(GSL)的解决方法,通过递归消息传递来编码节点间的依赖性。
- 许多现有的GSL方法严重依赖于明确的图结构信息作为监督信号,这使其面临数据噪声和稀疏性挑战。
- GraphEdit利用大型语言模型(LLM)来学习复杂的节点关系,并旨在克服这些局限性。
- 通过指令调整增强LLM的推理能力,GraphEdit不仅能有效去除噪声连接,还能从全局角度理解图结构。
- GraphEdit在多个基准数据集上进行了广泛的实验,证明了其在不同设置下的有效性和稳健性。
点此查看论文截图