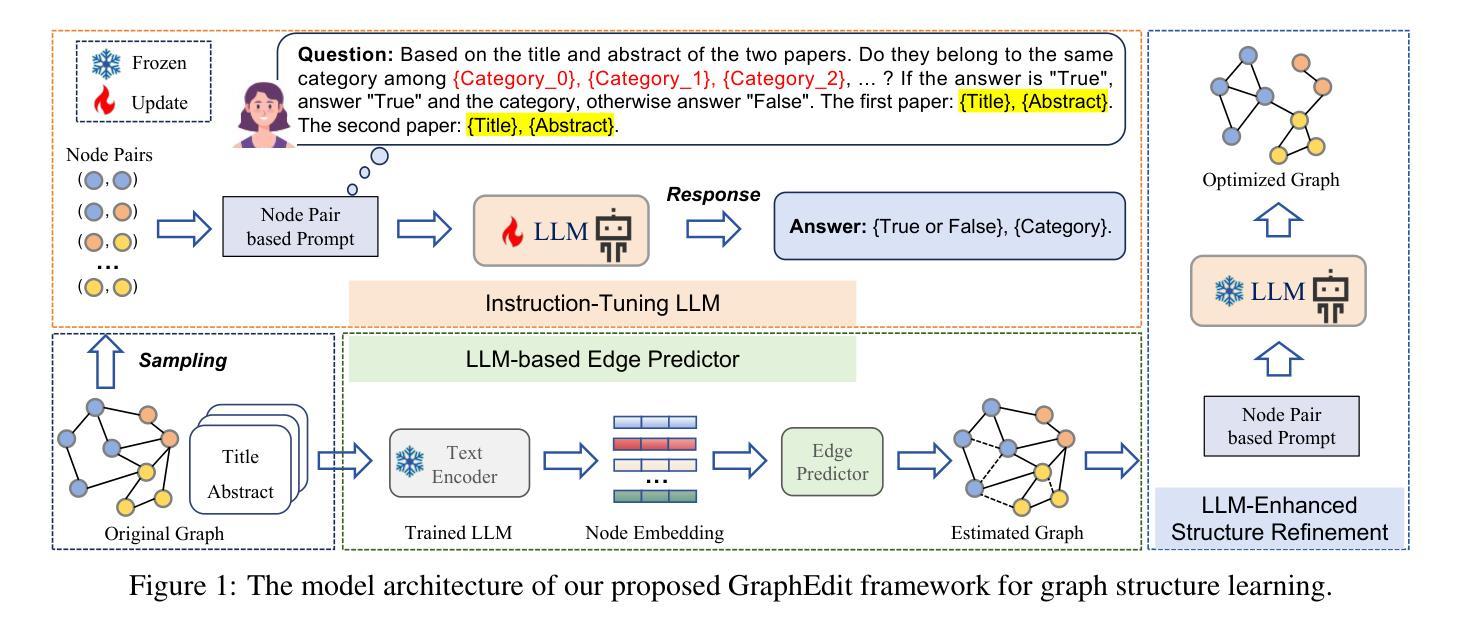
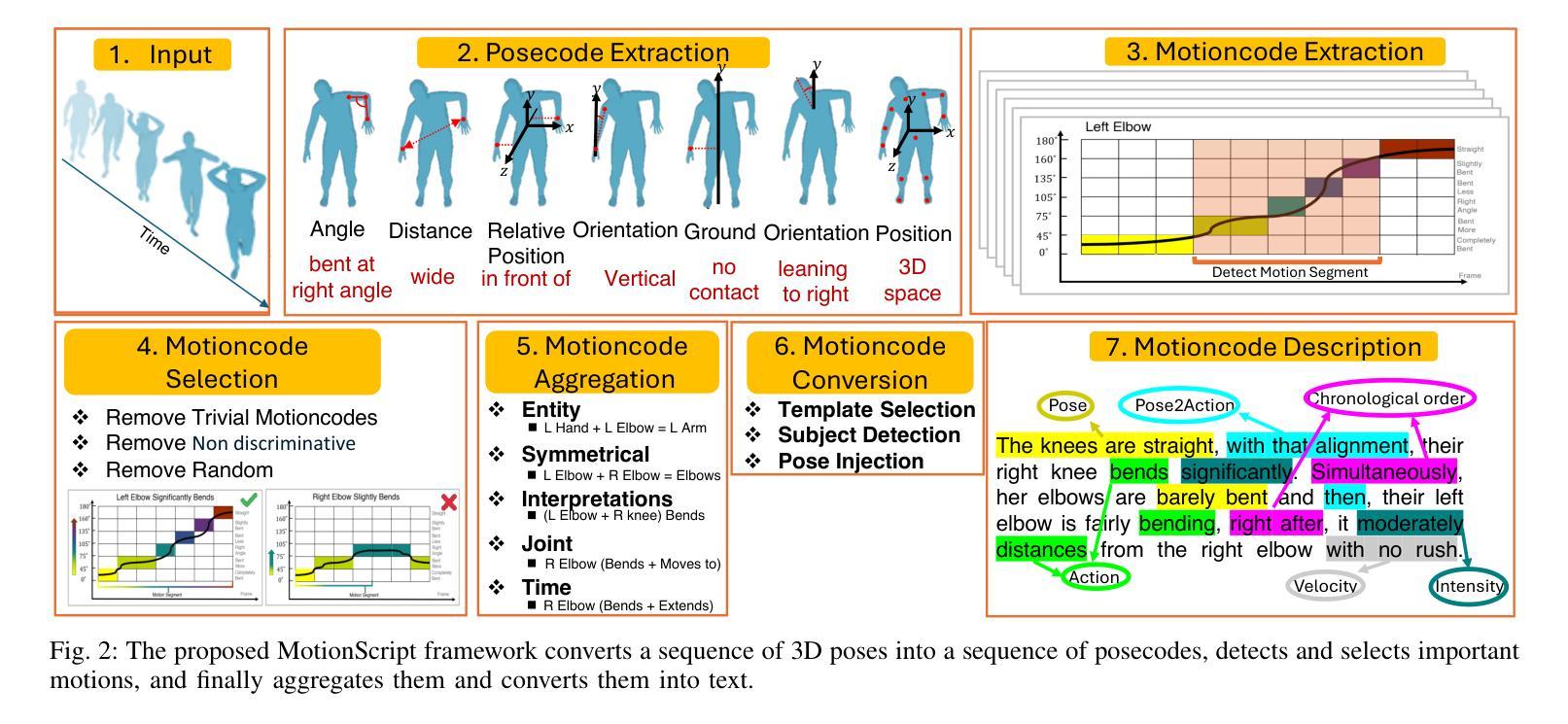
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-16 更新
GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing
Authors:Rongyao Fang, Chengqi Duan, Kun Wang, Linjiang Huang, Hao Li, Shilin Yan, Hao Tian, Xingyu Zeng, Rui Zhao, Jifeng Dai, Xihui Liu, Hongsheng Li
Current image generation and editing methods primarily process textual prompts as direct inputs without reasoning about visual composition and explicit operations. We present Generation Chain-of-Thought (GoT), a novel paradigm that enables generation and editing through an explicit language reasoning process before outputting images. This approach transforms conventional text-to-image generation and editing into a reasoning-guided framework that analyzes semantic relationships and spatial arrangements. We define the formulation of GoT and construct large-scale GoT datasets containing over 9M samples with detailed reasoning chains capturing semantic-spatial relationships. To leverage the advantages of GoT, we implement a unified framework that integrates Qwen2.5-VL for reasoning chain generation with an end-to-end diffusion model enhanced by our novel Semantic-Spatial Guidance Module. Experiments show our GoT framework achieves excellent performance on both generation and editing tasks, with significant improvements over baselines. Additionally, our approach enables interactive visual generation, allowing users to explicitly modify reasoning steps for precise image adjustments. GoT pioneers a new direction for reasoning-driven visual generation and editing, producing images that better align with human intent. To facilitate future research, we make our datasets, code, and pretrained models publicly available at https://github.com/rongyaofang/GoT.
当前图像生成和编辑方法主要将文本提示作为直接输入进行处理,而没有对视觉构图和明确操作进行推理。我们提出了“思维链生成”(Generation Chain-of-Thought,GoT)这一新型范式,它能够在输出图像之前,通过明确的语言推理过程实现图像的生成和编辑。这种方法将传统的文本到图像生成和编辑过程转变为一个以推理引导的分析框架,该框架能够分析语义关系和空间布局。我们定义了GoT的公式,并构建了大规模的GoT数据集,包含超过900万个样本,详细的推理链捕捉了语义-空间关系。为了利用GoT的优势,我们实现了一个统一框架,该框架集成了用于推理链生成的Qwen2.5-VL与端到端的扩散模型,并由我们新颖的语义-空间引导模块增强。实验表明,我们的GoT框架在生成和编辑任务上都表现出卓越的性能,显著优于基线方法。此外,我们的方法能够实现交互式视觉生成,让用户能够明确修改推理步骤以进行精确图像调整。GoT开创了一个以推理驱动视觉生成和编辑的新方向,生成的图像更好地符合人类意图。为了方便未来研究,我们在https://github.com/rongyaofang/GoT公开了我们的数据集、代码和预训练模型。
论文及项目相关链接
PDF Dataset and models are released in https://github.com/rongyaofang/GoT
Summary
文本提出了一种名为“思维链生成”(GoT)的新范式,它使图像生成和编辑能够通过在输出图像之前进行明确的逻辑推理过程来实现。该方法将传统的文本到图像生成和编辑转变为由推理引导的分析语义关系和空间排列的框架。实验表明,GoT框架在生成和编辑任务上都取得了出色的性能,并且与基线相比有显著改善。此外,GoT开启了推理驱动视觉生成和编辑的新方向,生成的图像更符合人类意图。
Key Takeaways
- GoT是一种新的图像生成和编辑方法,它通过明确的语言推理过程实现图像输出。
- GoT将文本到图像的生成和编辑转变为推理引导的框架,分析语义关系和空间排列。
- GoT框架包括大规模数据集,包含超过900万个样本的详细推理链,捕捉语义-空间关系。
- GoT框架集成了Qwen2.5-VL进行推理链生成,并通过端到端的扩散模型进行图像生成。
- GoT方法具有显著的性能提升,尤其在生成和编辑任务上。
- GoT方法允许用户显式修改推理步骤,实现精确的图像调整。
点此查看论文截图

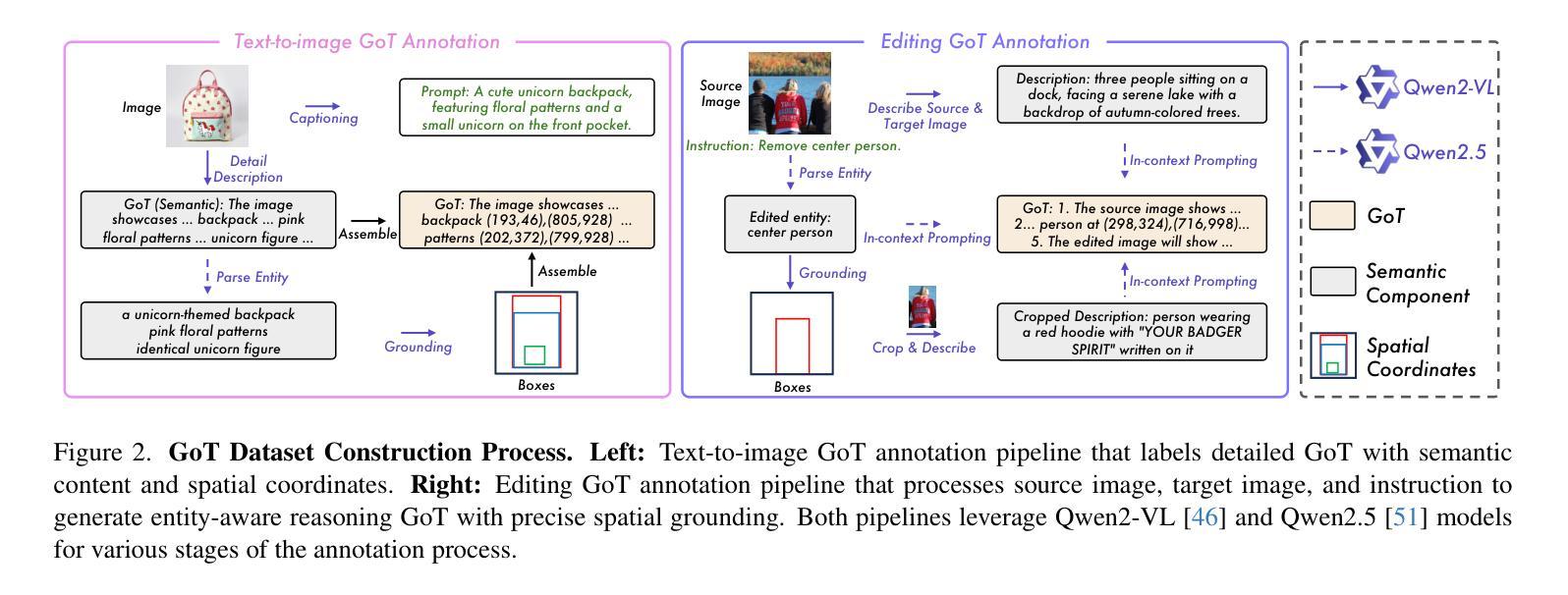
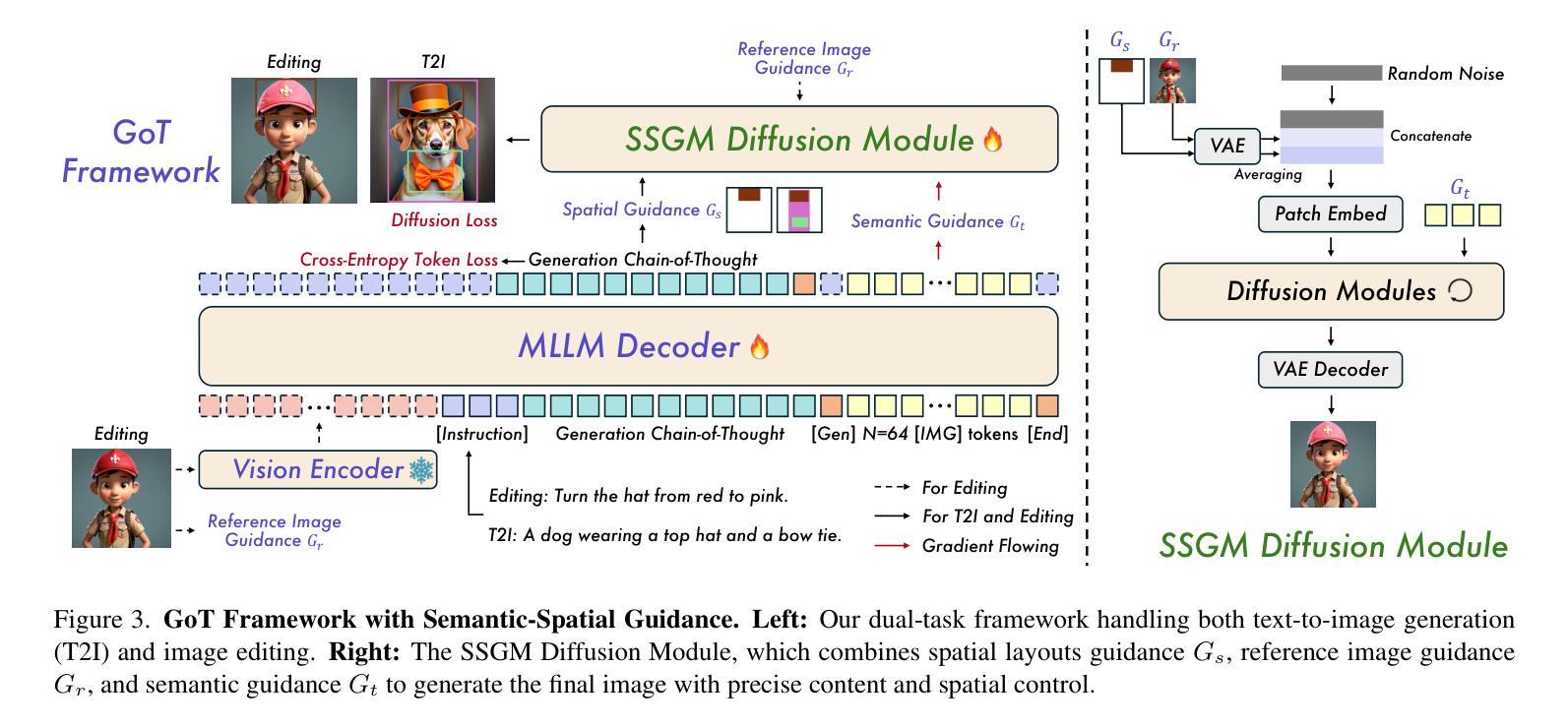
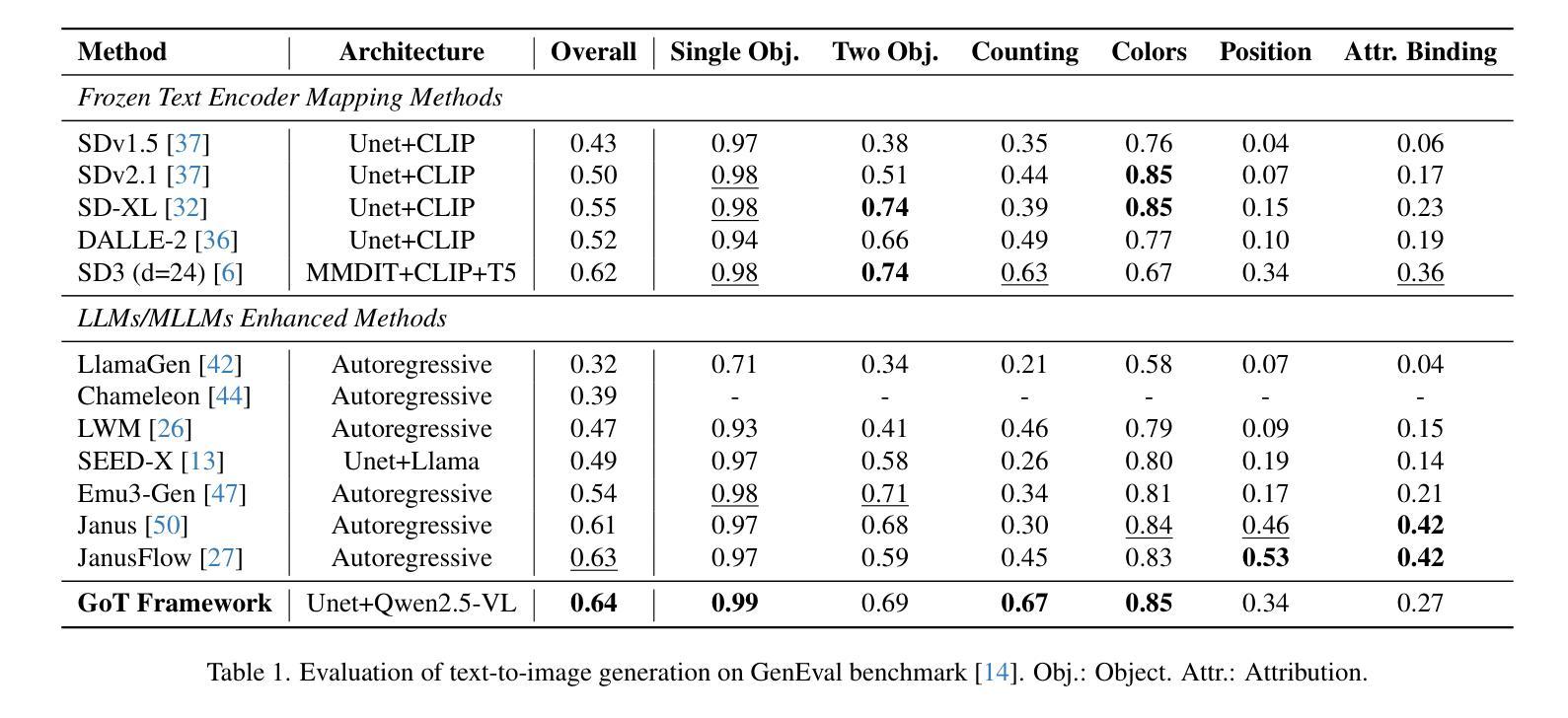
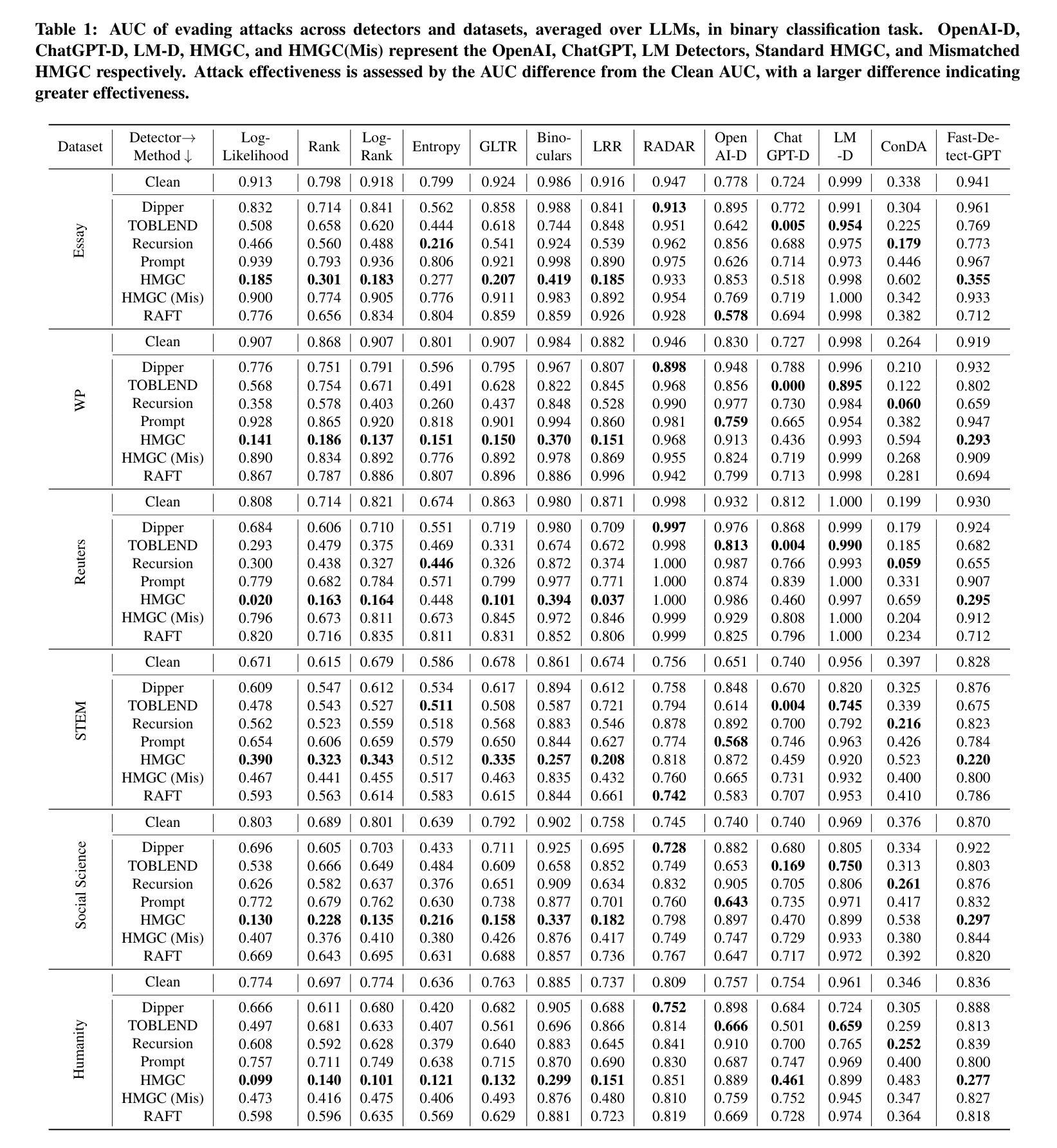
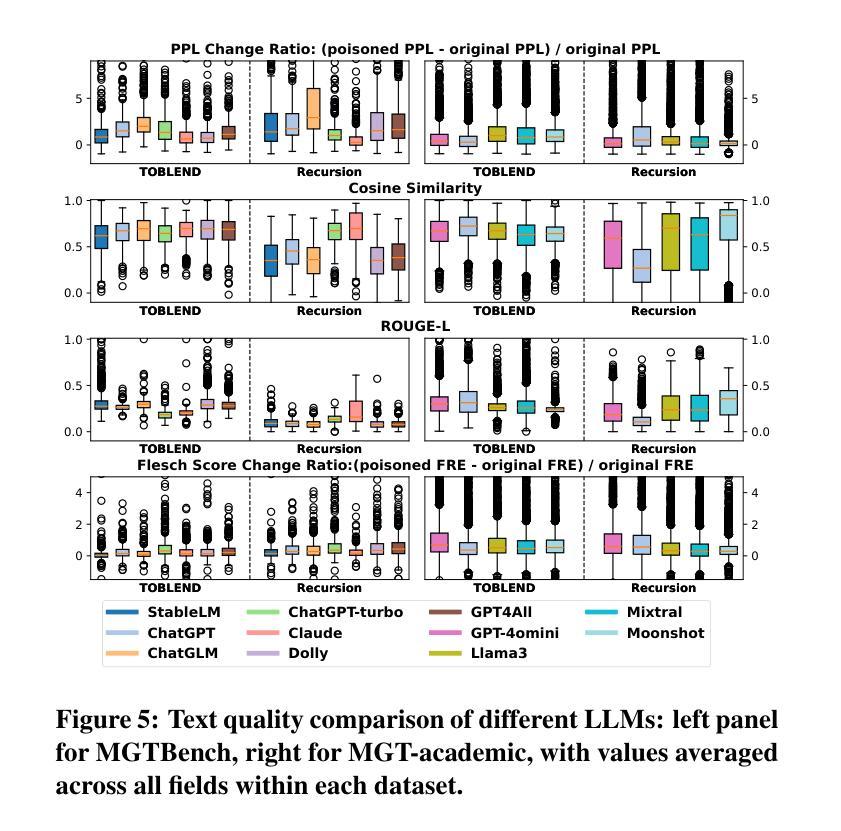
TH-Bench: Evaluating Evading Attacks via Humanizing AI Text on Machine-Generated Text Detectors
Authors:Jingyi Zheng, Junfeng Wang, Zhen Sun, Wenhan Dong, Yule Liu, Xinlei He
As Large Language Models (LLMs) advance, Machine-Generated Texts (MGTs) have become increasingly fluent, high-quality, and informative. Existing wide-range MGT detectors are designed to identify MGTs to prevent the spread of plagiarism and misinformation. However, adversaries attempt to humanize MGTs to evade detection (named evading attacks), which requires only minor modifications to bypass MGT detectors. Unfortunately, existing attacks generally lack a unified and comprehensive evaluation framework, as they are assessed using different experimental settings, model architectures, and datasets. To fill this gap, we introduce the Text-Humanization Benchmark (TH-Bench), the first comprehensive benchmark to evaluate evading attacks against MGT detectors. TH-Bench evaluates attacks across three key dimensions: evading effectiveness, text quality, and computational overhead. Our extensive experiments evaluate 6 state-of-the-art attacks against 13 MGT detectors across 6 datasets, spanning 19 domains and generated by 11 widely used LLMs. Our findings reveal that no single evading attack excels across all three dimensions. Through in-depth analysis, we highlight the strengths and limitations of different attacks. More importantly, we identify a trade-off among three dimensions and propose two optimization insights. Through preliminary experiments, we validate their correctness and effectiveness, offering potential directions for future research.
随着大型语言模型(LLM)的进步,机器生成文本(MGT)的流畅度、质量和信息量越来越高。现有的广泛MGT检测器旨在识别MGT,以防止抄袭和误导信息的传播。然而,攻击者试图使MGT人性化以躲避检测(称为躲避攻击),只需进行微小的修改就能绕过MGT检测器。然而,现有的攻击通常缺乏统一和全面的评估框架,因为它们的评估使用的是不同的实验设置、模型架构和数据集。为了填补这一空白,我们引入了文本人性化基准测试(TH-Bench),这是第一个全面评估针对MGT检测器的躲避攻击性能的基准测试。TH-Bench从三个关键维度评估攻击:躲避有效性、文本质量和计算开销。我们的大量实验评估了针对13种MGT检测器的6种最先进的攻击方法,跨越涵盖文本生成真实性的19个领域生成的由包含主流广泛使用的六种LLM生成。我们发现没有任何一种躲避攻击在所有三个维度上都表现出色。通过深入分析,我们突出了各种攻击的优势和局限性。更重要的是,我们发现了三个维度之间的权衡并提出了两个优化见解。通过初步实验,我们验证了它们的正确性和有效性,为未来研究提供了潜在方向。
论文及项目相关链接
Summary:随着大型语言模型(LLM)的进展,机器生成文本(MGT)的流畅性、质量和信息量不断提升。现有的广泛MGT检测器旨在防止抄袭和误导信息的传播。然而,攻击者试图通过使机器生成文本更具人性化以躲避检测(称为躲避攻击),仅需要微小修改即可绕过MGT检测器。为了填补现有研究缺少统一全面的评估框架的空白,我们推出了文本人性化基准测试(TH-Bench),这是第一个全面评估躲避攻击对MGT检测器影响的基准测试。TH-Bench从三个关键维度评估攻击:躲避效果、文本质量和计算开销。通过广泛实验,我们评估了6种最先进的攻击在13个MGT检测器上的表现,涉及6个数据集、涵盖19个领域并由11种广泛使用的LLM生成。我们的研究发现,没有任何一种躲避攻击能在所有三个维度上都表现出卓越性能。通过深入分析,我们突出了不同攻击的优势和局限性。更重要的是,我们发现了三个维度之间的权衡,并提出了两种优化见解。初步实验验证了它们的正确性和有效性,为未来的研究提供了潜在方向。
Key Takeaways:
- 大型语言模型(LLM)的进步使得机器生成文本(MGT)越来越流畅、高质量和富有信息量。
- 现有的MGT检测器旨在防止抄袭和误导信息的传播,但攻击者通过使MGT更具人性化以躲避检测。
- 文本人性化基准测试(TH-Bench)是首个全面评估躲避攻击对MGT检测器影响的基准,从躲避效果、文本质量和计算开销三个关键维度进行评估。
- 实验表明,没有一种躲避攻击能在所有维度上都表现最好。
- 不同攻击方法有其优势和局限性。
- 存在三个维度之间的权衡,需要优化以找到最佳解决方案。
点此查看论文截图


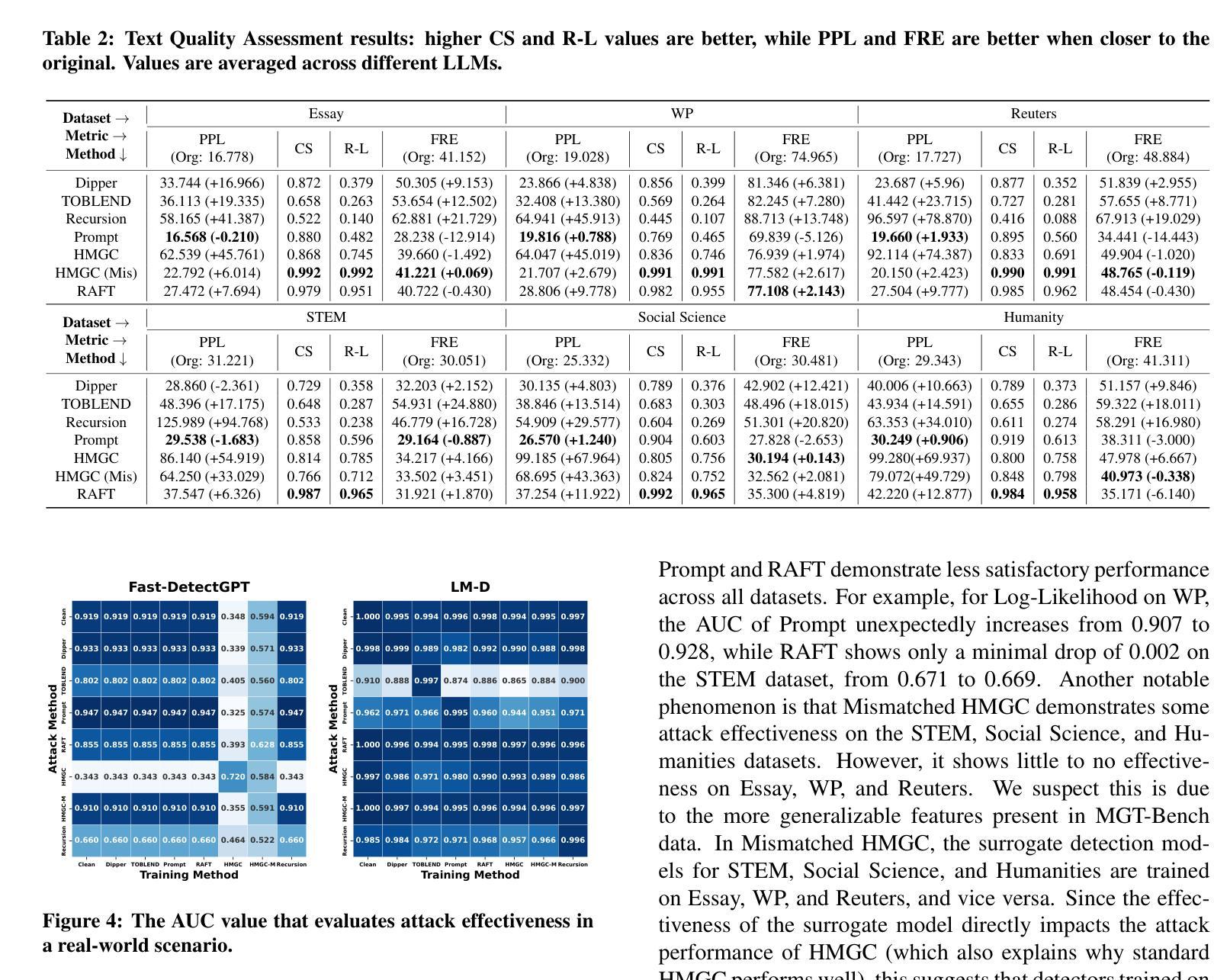
ProtTeX: Structure-In-Context Reasoning and Editing of Proteins with Large Language Models
Authors:Zicheng Ma, Chuanliu Fan, Zhicong Wang, Zhenyu Chen, Xiaohan Lin, Yanheng Li, Shihao Feng, Jun Zhang, Ziqiang Cao, Yi Qin Gao
Large language models have made remarkable progress in the field of molecular science, particularly in understanding and generating functional small molecules. This success is largely attributed to the effectiveness of molecular tokenization strategies. In protein science, the amino acid sequence serves as the sole tokenizer for LLMs. However, many fundamental challenges in protein science are inherently structure-dependent. The absence of structure-aware tokens significantly limits the capabilities of LLMs for comprehensive biomolecular comprehension and multimodal generation. To address these challenges, we introduce a novel framework, ProtTeX, which tokenizes the protein sequences, structures, and textual information into a unified discrete space. This innovative approach enables joint training of the LLM exclusively through the Next-Token Prediction paradigm, facilitating multimodal protein reasoning and generation. ProtTeX enables general LLMs to perceive and process protein structures through sequential text input, leverage structural information as intermediate reasoning components, and generate or manipulate structures via sequential text output. Experiments demonstrate that our model achieves significant improvements in protein function prediction, outperforming the state-of-the-art domain expert model with a twofold increase in accuracy. Our framework enables high-quality conformational generation and customizable protein design. For the first time, we demonstrate that by adopting the standard training and inference pipelines from the LLM domain, ProtTeX empowers decoder-only LLMs to effectively address diverse spectrum of protein-related tasks.
在分子科学领域,大型语言模型(LLM)在理解和生成功能性小分子方面取得了显著的进步。这一成功在很大程度上归功于分子标记策略的有效性。在蛋白质科学领域,氨基酸序列是LLM唯一的分词器。然而,蛋白质科学中的许多基本挑战本质上是结构依赖的。缺乏结构感知标记显著限制了LLM进行全面生物分子理解和多模式生成的能力。为了应对这些挑战,我们引入了一种新型框架ProtTeX,它将蛋白质序列、结构和文本信息标记为统一的离散空间。这种创新方法通过仅通过下一个标记预测范式来联合训练LLM,促进多模式蛋白质推理和生成。ProtTeX使通用LLM能够通过顺序文本输入感知和处理蛋白质结构,利用结构信息作为中间推理成分,并通过顺序文本输出生成或操作结构。实验表明,我们的模型在蛋白质功能预测方面取得了显著改进,优于最先进的领域专家模型,准确性提高了两倍。我们的框架能够实现高质量的结构生成和可定制的蛋白质设计。首次展示了通过采用LLM领域的标准训练和推理管道,ProtTeX使仅解码LLM能够有效地解决多样化的蛋白质相关任务。
论文及项目相关链接
PDF 26 pages, 9 figures
Summary
大型语言模型在分子科学领域取得了显著进展,尤其在理解和生成功能性小分子方面。本文提出一种新型框架ProtTeX,将蛋白质序列、结构和文本信息统一转化为离散空间,使语言模型能够感知和处理蛋白质结构,实现多模态蛋白质推理和生成。该框架实现了蛋白质结构的顺序文本输入和输出,提高了蛋白质功能预测的准确性,并实现了高质量的构象生成和可定制的蛋白质设计。
Key Takeaways
- 大型语言模型在分子科学领域取得显著进展,尤其在理解和生成功能性小分子方面。
- 蛋白质科学中的许多基本挑战与结构密切相关,但语言模型在结构感知方面存在局限性。
- ProtTeX框架将蛋白质序列、结构和文本信息统一转化为离散空间,解决语言模型的结构感知局限性。
- ProtTeX框架实现了多模态蛋白质推理和生成,通过顺序文本输入和输出来处理蛋白质结构。
- 该框架提高了蛋白质功能预测的准确性,并实现了高质量的构象生成和可定制的蛋白质设计。
- ProtTeX框架采用标准训练和推理管道,使解码器仅大型语言模型就能有效处理各种蛋白质相关任务。
点此查看论文截图

Toward Stable World Models: Measuring and Addressing World Instability in Generative Environments
Authors:Soonwoo Kwon, Jin-Young Kim, Hyojun Go, Kyungjune Baek
We present a novel study on enhancing the capability of preserving the content in world models, focusing on a property we term World Stability. Recent diffusion-based generative models have advanced the synthesis of immersive and realistic environments that are pivotal for applications such as reinforcement learning and interactive game engines. However, while these models excel in quality and diversity, they often neglect the preservation of previously generated scenes over time–a shortfall that can introduce noise into agent learning and compromise performance in safety-critical settings. In this work, we introduce an evaluation framework that measures world stability by having world models perform a sequence of actions followed by their inverses to return to their initial viewpoint, thereby quantifying the consistency between the starting and ending observations. Our comprehensive assessment of state-of-the-art diffusion-based world models reveals significant challenges in achieving high world stability. Moreover, we investigate several improvement strategies to enhance world stability. Our results underscore the importance of world stability in world modeling and provide actionable insights for future research in this domain.
我们针对提高世界模型中内容保存能力这一领域进行了一项新型研究,重点在于我们所称的“世界稳定性”这一属性。近期基于扩散的生成模型在合成沉浸式和逼真的环境方面取得了进展,这对于强化学习和交互式游戏引擎等应用至关重要。然而,尽管这些模型在质量和多样性方面表现出色,但它们往往忽视了随时间推移对先前生成场景的保留——这一缺陷可能会为代理学习引入噪声,并在安全关键设置中影响性能。在这项工作中,我们引入了一个评估框架,通过让世界模型执行一系列动作及其逆动作来返回到其初始观点,从而衡量世界稳定性,进而量化初始观测和最终观测之间的一致性。我们对最先进的基于扩散的世界模型的全面评估表明,实现高世界稳定性存在重大挑战。此外,我们还研究了多种改进策略来提高世界稳定性。我们的结果强调了世界稳定性在世界建模中的重要性,并为该领域的未来研究提供了可操作的见解。
论文及项目相关链接
PDF Preprint
Summary
世界模型内容保留能力提升研究的新成果,重点在于实现“世界稳定性”。现有的扩散式生成模型虽然能够合成沉浸式的真实环境,但对于维持先前生成的场景稳定性方面存在缺陷。本研究通过设计评估框架来量化世界稳定性,发现现有模型面临挑战。同时,研究提出多种提升世界稳定性的策略,强调了世界稳定性在世界模型中的重要性并为未来研究提供指导。
Key Takeaways
- 研究关注扩散式生成模型的世界模型内容保留能力提升。
- 提出“世界稳定性”作为衡量模型性能的重要指标。
- 设计评估框架来量化世界稳定性,通过让模型执行一系列动作再逆向执行以比较初始和最终观察结果的一致性。
- 发现现有扩散式世界模型在世界稳定性方面存在显著挑战。
- 提出多种增强世界稳定性的策略。
- 强调世界稳定性对世界模型的重要性。
点此查看论文截图


A General Framework to Evaluate Methods for Assessing Dimensions of Lexical Semantic Change Using LLM-Generated Synthetic Data
Authors:Naomi Baes, Raphaël Merx, Nick Haslam, Ekaterina Vylomova, Haim Dubossarsky
Lexical Semantic Change (LSC) offers insights into cultural and social dynamics. Yet, the validity of methods for measuring kinds of LSC has yet to be established due to the absence of historical benchmark datasets. To address this gap, we develop a novel three-stage evaluation framework that involves: 1) creating a scalable, domain-general methodology for generating synthetic datasets that simulate theory-driven LSC across time, leveraging In-Context Learning and a lexical database; 2) using these datasets to evaluate the effectiveness of various methods; and 3) assessing their suitability for specific dimensions and domains. We apply this framework to simulate changes across key dimensions of LSC (SIB: Sentiment, Intensity, and Breadth) using examples from psychology, and evaluate the sensitivity of selected methods to detect these artificially induced changes. Our findings support the utility of the synthetic data approach, validate the efficacy of tailored methods for detecting synthetic changes in SIB, and reveal that a state-of-the-art LSC model faces challenges in detecting affective dimensions of LSC. This framework provides a valuable tool for dimension- and domain-specific bench-marking and evaluation of LSC methods, with particular benefits for the social sciences.
词汇语义变化(LSC)提供了对文化和社会动态的洞察力。然而,由于缺乏历史基准数据集,衡量各种LSC方法的有效性尚未建立。为了弥补这一空白,我们开发了一种新的三阶段评估框架,包括:1)创建一种可扩展的、通用的方法,生成模拟跨时间理论驱动的LSC的合成数据集,利用上下文学习和词汇数据库;2)使用这些数据集来评估各种方法的有效性;3)评估它们在特定维度和领域的适用性。我们以心理学中的例子为基础,应用这一框架来模拟LSC关键维度的变化(SIB:情感、强度和广度),并评估所选方法对检测这些人为诱导变化的敏感性。我们的研究结果支持合成数据方法的实用性,验证了针对检测SIB中合成变化量身定制方法的有效性,并揭示最先进的LSC模型在检测LSC的情感维度方面面临挑战。该框架为特定维度和领域的基准测试和评估LSC方法提供了有价值的工具,对社会科学领域尤其有益。
论文及项目相关链接
PDF 36 pages, under review
Summary
文本讨论了词汇语义变化(LSC)的问题和挑战,尤其是缺少用于衡量LSC类型的有效方法和历史基准数据集的问题。为了解决这个问题,研究者开发了一种新型的三阶段评估框架,包括创建一种通用性较强的方法生成合成数据集,以模拟时间上的理论驱动的LSC变化;使用这些数据集评估各种方法的有效性;评估这些方法在不同维度和领域的适用性。研究者应用此框架模拟了心理学领域的关键维度变化,并发现某些方法能够很好地检测这些人为引起的变化。该框架为评估特定领域和特定维度的LSC方法提供了宝贵的工具。对于社会科学领域尤其具有实际意义。这一研究对于推进LSC领域的理论发展和实际应用具有重要意义。
Key Takeaways
- 缺乏历史基准数据集,导致无法确定衡量LSC的方法的有效性。针对这一问题,提出了一种新型的三阶段评估框架。
- 框架第一阶段利用语境学习和词汇数据库创建了通用的方法生成合成数据集来模拟时间驱动下的理论性LSC变化。这些合成数据集用于评估各种方法的性能。
- 第二阶段评估这些方法在不同维度和领域的适用性,包括情感、强度和广度等关键维度。在心理学领域的应用为例展示了这一点。
点此查看论文截图



Exploring Bias in over 100 Text-to-Image Generative Models
Authors:Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
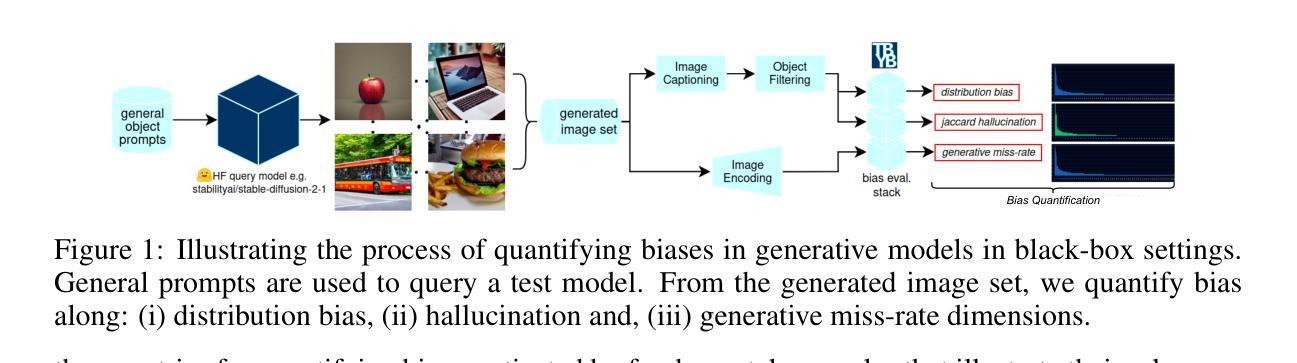
We investigate bias trends in text-to-image generative models over time, focusing on the increasing availability of models through open platforms like Hugging Face. While these platforms democratize AI, they also facilitate the spread of inherently biased models, often shaped by task-specific fine-tuning. Ensuring ethical and transparent AI deployment requires robust evaluation frameworks and quantifiable bias metrics. To this end, we assess bias across three key dimensions: (i) distribution bias, (ii) generative hallucination, and (iii) generative miss-rate. Analyzing over 100 models, we reveal how bias patterns evolve over time and across generative tasks. Our findings indicate that artistic and style-transferred models exhibit significant bias, whereas foundation models, benefiting from broader training distributions, are becoming progressively less biased. By identifying these systemic trends, we contribute a large-scale evaluation corpus to inform bias research and mitigation strategies, fostering more responsible AI development. Keywords: Bias, Ethical AI, Text-to-Image, Generative Models, Open-Source Models
我们研究了文本到图像生成模型中的偏见趋势随时间变化的情况,重点关注通过Hugging Face等开放平台日益普及的模型。这些平台虽然实现了人工智能的普及,但也促进了固有偏见模型的传播,这些模型往往通过特定任务的微调而形成。确保人工智能的伦理和透明部署需要强大的评估框架和可量化的偏见指标。为此,我们从三个关键维度评估偏见:(i)分布偏见,(ii)生成幻觉,(iii)生成错误率。通过分析超过100个模型,我们揭示了偏见模式随时间以及跨生成任务如何演变。我们的研究结果表明,艺术型和风格转换模型存在明显的偏见,而得益于更广泛的训练分布的基础模型则变得越来越少偏见。通过识别这些系统性趋势,我们为偏见研究和缓解策略提供了大规模评估语料库,促进了更负责任的人工智能发展。关键词:偏见、伦理人工智能、文本到图像、生成模型、开源模型。
论文及项目相关链接
PDF Accepted to ICLR 2025 Workshop on Open Science for Foundation Models (SCI-FM)
Summary
文本研究了文本到图像生成模型中的偏见趋势。随着Hugging Face等开放平台提供的模型越来越多,虽然民主化了人工智能,但也促进了固有偏见模型的传播。为确保人工智能的伦理和透明部署,需要强大的评估框架和可量化的偏见指标。文章对偏见进行了三个关键维度的评估:分布偏见、生成幻想和生成误报率。通过分析超过一百个模型,揭示了偏见模式随时间以及跨生成任务的发展变化。研究发现艺术型和风格转换模型存在显著偏见,而受益于更广泛训练分布的基础模型则变得越来越少偏见。关键词:偏见、伦理人工智能、文本到图像、生成模型、开源模型。
Key Takeaways
- 开放平台如Hugging Face促进了文本到图像生成模型的普及,但也带来了偏见模型的传播问题。
- 偏见趋势的研究是确保人工智能伦理和透明部署的关键。
- 三个关键维度用于评估偏见:分布偏见、生成幻想和生成误报率。
- 艺术型和风格转换模型存在显著偏见问题。
- 基础模型因受益于更广泛的训练分布,在偏见问题上表现逐渐改善。
- 文章贡献了一个大规模评估语料库,以推动偏见研究和缓解策略的制定。
点此查看论文截图


MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
Authors:Han Zhao, Wenxuan Song, Donglin Wang, Xinyang Tong, Pengxiang Ding, Xuelian Cheng, Zongyuan Ge
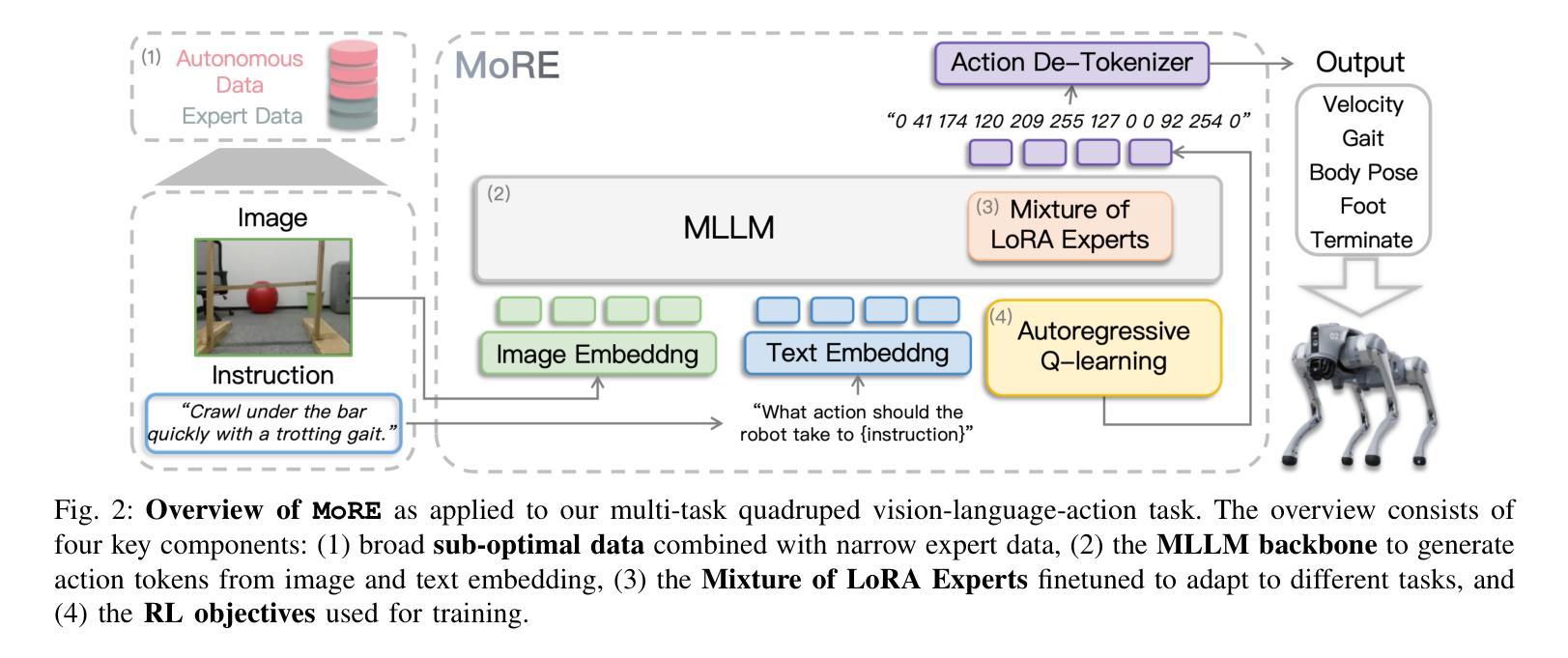
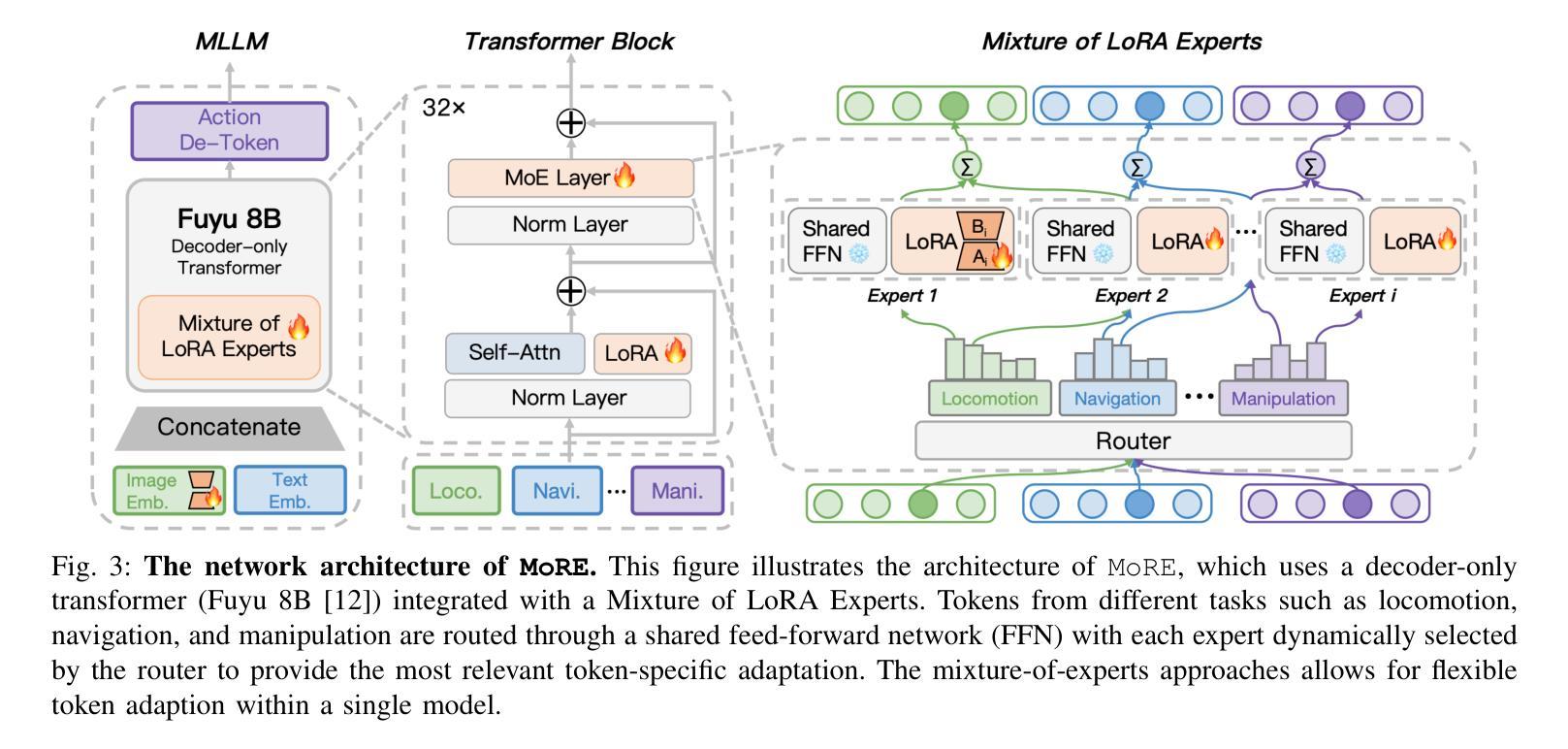
Developing versatile quadruped robots that can smoothly perform various actions and tasks in real-world environments remains a significant challenge. This paper introduces a novel vision-language-action (VLA) model, mixture of robotic experts (MoRE), for quadruped robots that aim to introduce reinforcement learning (RL) for fine-tuning large-scale VLA models with a large amount of mixed-quality data. MoRE integrates multiple low-rank adaptation modules as distinct experts within a dense multi-modal large language model (MLLM), forming a sparse-activated mixture-of-experts model. This design enables the model to effectively adapt to a wide array of downstream tasks. Moreover, we employ a reinforcement learning-based training objective to train our model as a Q-function after deeply exploring the structural properties of our tasks. Effective learning from automatically collected mixed-quality data enhances data efficiency and model performance. Extensive experiments demonstrate that MoRE outperforms all baselines across six different skills and exhibits superior generalization capabilities in out-of-distribution scenarios. We further validate our method in real-world scenarios, confirming the practicality of our approach and laying a solid foundation for future research on multi-task learning in quadruped robots.
开发能够在真实世界环境中流畅执行各种动作和任务的通用四足机器人仍然是一个巨大的挑战。本文介绍了一种用于四足机器人的新型视觉-语言-动作(VLA)模型,即机器人专家混合物(MoRE),旨在引入强化学习(RL)对大规模VLA模型进行微调,处理大量混合质量的数据。MoRE在密集的多模态大型语言模型(MLLM)中集成了多个低阶适应模块作为不同的专家,形成了一个稀疏激活的专家混合模型。这种设计使模型能够有效地适应各种下游任务。此外,我们在深入探索任务结构属性的基础上,采用基于强化学习的训练目标对模型进行Q函数训练。从自动收集的混合质量数据中有效学习提高了数据效率和模型性能。大量实验表明,MoRE在六种不同技能上超越了所有基线,并在超出分布的场景中表现出卓越的总括能力。我们进一步在现实场景中验证了我们的方法,证实了我们的方法的实用性,并为未来四足机器人多任务学习的研究奠定了坚实基础。
论文及项目相关链接
PDF Accepted by ICRA 2025
Summary
多足机器人面对实际环境执行任务存在挑战。本文提出一种新型的混合语言模型(MoRE),它集成了强化学习用于调整大规模模型以适应各种复杂数据,从而提升机器人的灵活性。MoRE模型设计灵活,能适应多种下游任务,并在实验环境中表现出卓越的性能和泛化能力。该模型在多足机器人领域具有实际应用价值,为未来多任务学习研究提供了坚实的基础。
Key Takeaways
- 介绍了一种针对多足机器人的新型混合语言模型(MoRE)。
- MoRE模型集成了强化学习进行大规模模型的精细调整,适应复杂数据。
- MoRE通过结合多个低阶适应模块作为专家,形成稀疏激活的专家混合模型,增强了模型的适应性。
- 采用强化学习训练目标进行模型训练,提高了模型的性能。
- MoRE模型在多种技能上表现出超越基准的性能,并在离群场景中展现出优秀的泛化能力。
- MoRE模型在真实世界场景中的应用验证了其实用性。
点此查看论文截图




AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
Authors:Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, Xinggang Wang
OpenAI o1 and DeepSeek R1 achieve or even surpass human expert-level performance in complex domains like mathematics and science, with reinforcement learning (RL) and reasoning playing a crucial role. In autonomous driving, recent end-to-end models have greatly improved planning performance but still struggle with long-tailed problems due to limited common sense and reasoning abilities. Some studies integrate vision-language models (VLMs) into autonomous driving, but they typically rely on pre-trained models with simple supervised fine-tuning (SFT) on driving data, without further exploration of training strategies or optimizations specifically tailored for planning. In this paper, we propose AlphaDrive, a RL and reasoning framework for VLMs in autonomous driving. AlphaDrive introduces four GRPO-based RL rewards tailored for planning and employs a two-stage planning reasoning training strategy that combines SFT with RL. As a result, AlphaDrive significantly improves both planning performance and training efficiency compared to using only SFT or without reasoning. Moreover, we are also excited to discover that, following RL training, AlphaDrive exhibits some emergent multimodal planning capabilities, which is critical for improving driving safety and efficiency. To the best of our knowledge, AlphaDrive is the first to integrate GRPO-based RL with planning reasoning into autonomous driving. Code will be released to facilitate future research.
OpenAI o1和DeepSeek R1在诸如数学和科学等复杂领域达到了甚至超越了人类专家的性能水平,强化学习(RL)和推理起到了至关重要的作用。在自动驾驶方面,最近的端到端模型在规划性能上有了很大的提高,但由于常识和推理能力的有限,仍然面临着长尾问题。一些研究将视觉语言模型(VLM)融入自动驾驶,但它们通常依赖于在驾驶数据上进行简单监督微调(SFT)的预训练模型,没有进一步探索针对规划的培训策略或优化。在本文中,我们提出了AlphaDrive,这是一个用于自动驾驶中VLM的RL和推理框架。AlphaDrive引入了四种针对规划设计的GRPO基于RL的奖励,并采用了一种两阶段规划推理培训策略,该策略结合了SFT与RL。因此,与仅使用SFT或没有推理的情况相比,AlphaDrive显著提高了规划性能和培训效率。此外,我们还发现,经过RL训练后,AlphaDrive表现出一些新兴的多元模式规划能力,这对于提高驾驶的安全性和效率至关重要。据我们所知,AlphaDrive是首个将基于GRPO的RL与规划推理集成到自动驾驶中的。我们将发布代码以促进未来的研究。
论文及项目相关链接
PDF Project Page: https://github.com/hustvl/AlphaDrive
Summary
OpenAI和DeepSeek在复杂领域如数学和科学方面达到了甚至超越了人类专家的水平,强化学习和推理在其中发挥了关键作用。在自动驾驶领域,尽管近期端到端模型提升了规划性能,但仍面临长尾问题。研究团队提出了一种结合强化学习和推理的视觉语言模型框架AlphaDrive,它通过定制化的奖励和两阶段规划推理训练策略,显著提高了规划性能和训练效率,并展现出多模式规划能力,提高了驾驶安全性和效率。AlphaDrive是首个将基于GRPO的强化学习与规划推理结合到自动驾驶中的技术。
Key Takeaways
- OpenAI和DeepSeek已在数学和科学等领域达到或超越人类专家水平,强化学习和推理起到关键作用。
- 自动驾驶中的端到端模型虽提升了规划性能,但仍面临长尾问题。
- AlphaDrive是一个结合强化学习和推理的视觉语言模型框架,针对自动驾驶中的规划问题。
- AlphaDrive通过定制化的奖励和两阶段规划推理训练策略,显著提高了规划性能和训练效率。
- AlphaDrive展现出多模式规划能力,这对于提高驾驶安全性和效率至关重要。
- AlphaDrive是首个将基于GRPO的强化学习与规划推理结合到自动驾驶的技术。
点此查看论文截图




Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Authors:Yuxiao Qu, Matthew Y. R. Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhutdinov, Aviral Kumar
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ‘’progress’’ made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.
训练模型以有效利用测试时的计算资源对于提高大型语言模型的推理性能至关重要。目前的方法大多是通过搜索痕迹进行微调或使用0/1结果奖励运行强化学习来实现,但这些方法是否有效地利用了测试时的计算资源?随着预算的提高,这些方法是否会继续扩展?在本文中,我们试图回答这些问题。我们将优化测试时计算的问题形式化为元强化学习(RL)问题,这为测试时计算提供了有原则的视角。这个视角使我们能够将大型语言模型的长期输出视为在测试时运行的多个片段,并引导我们使用输出标记的累积遗憾来衡量测试时计算的有效性。与强化学习算法在训练过程中如何最好地平衡探索和利用一样,最小化累积遗憾也将在标记流中提供探索和利用之间的最佳平衡。我们虽然表明,最先进的模型并没有最小化遗憾,但可以通过结合使用密集奖励奖金和结果0/1奖励强化学习来实现这一点。这一奖金是由输出流中每个后续块所取得的“进展”所量化的最终成功的可能性变化。基于这些见解,我们开发了元强化精细调整(MRT),这是一类新的精细调整方法,旨在优化测试时的计算。与结果奖励强化学习相比,MRT在数学推理方面实现了相对性能2-3倍的提升,以及大约1.5倍的标记效率提升。
论文及项目相关链接
Summary
该文针对大型语言模型(LLMs)的测试时间计算使用进行了优化研究。文章通过强化学习(RL)视角来解决测试时间计算优化问题,将长期输出流视为多个测试时的片段,并提出累积遗憾作为衡量测试时间计算效率的标准。文章指出当前主流方法并未最小化遗憾,并提出了结合密集奖励奖金和结果0/1奖励RL的方法来实现最小化遗憾。基于这些见解,文章开发了一种新的微调方法——元强化微调(MRT),用于优化测试时间计算。与结果奖励RL相比,MRT在推理性能上实现了相对2-3倍的增益,并在标记效率上实现了大约1.5倍的增益。
Key Takeaways
- 训练模型以有效利用测试时间计算对于提高大型语言模型的推理性能至关重要。
- 当前方法主要通过微调搜索痕迹或使用结果奖励强化学习来优化测试时间计算。
- 该文将测试时间计算优化问题形式化为一个元强化学习(RL)问题,提供了一种原则性的视角来分配测试时间计算资源。
- 累积遗憾是衡量测试时间计算效率的有效指标,旨在平衡探索与利用输出令牌之间的权衡。
- 当前最先进的模型并没有最小化累积遗憾,为此,文章提出了结合密集奖励奖金和结果奖励RL的方法来实现最小化遗憾。
- 基于上述见解,文章引入了一种新型的微调方法——元强化微调(MRT)。
点此查看论文截图



VisRL: Intention-Driven Visual Perception via Reinforced Reasoning
Authors:Zhangquan Chen, Xufang Luo, Dongsheng Li
Visual understanding is inherently intention-driven - humans selectively focus on different regions of a scene based on their goals. Recent advances in large multimodal models (LMMs) enable flexible expression of such intentions through natural language, allowing queries to guide visual reasoning processes. Frameworks like Visual Chain-of-Thought have demonstrated the benefit of incorporating explicit reasoning steps, where the model predicts a focus region before answering a query. However, existing approaches rely heavily on supervised training with annotated intermediate bounding boxes, which severely limits scalability due to the combinatorial explosion of intention-region pairs. To overcome this limitation, we propose VisRL, the first framework that applies reinforcement learning (RL) to the problem of intention-driven visual perception. VisRL optimizes the entire visual reasoning process using only reward signals. By treating intermediate focus selection as a internal decision optimized through trial-and-error, our method eliminates the need for costly region annotations while aligning more closely with how humans learn to perceive the world. Extensive experiments across multiple benchmarks show that VisRL consistently outperforms strong baselines, demonstrating both its effectiveness and its strong generalization across different LMMs. Our code is available at this URL.
视觉理解本质上是目标驱动的——人类会根据自己的目标选择性地关注场景中的不同区域。最近,大型多模态模型(LMMs)的进步能够通过自然语言灵活地表达意图,允许查询引导视觉推理过程。像“视觉思维链”这样的框架已经证明了加入明确推理步骤的好处,模型在回答查询之前会预测一个关注区域。然而,现有方法严重依赖于使用标注的中间边界框进行有监督训练,这由于意图区域对的组合爆炸而严重限制了可扩展性。为了克服这一局限性,我们提出了VisRL,这是第一个将强化学习(RL)应用于目标驱动视觉感知问题的框架。VisRL使用奖励信号优化整个视觉推理过程。通过将中间焦点选择视为通过试错优化的内部决策,我们的方法消除了对昂贵的区域标注的需求,同时更贴近人类感知世界的学习方式。在多个基准测试上的广泛实验表明,VisRL持续超越强大的基准测试,证明了其在不同LMMs中的有效性和强大的泛化能力。我们的代码可在URL获取。
论文及项目相关链接
PDF 18pages,11 figures
Summary
视觉理解本质上是目标驱动的,人类会根据目标有选择地关注场景的不同区域。最近的大型多模态模型(LMMs)的进步可以通过自然语言表达这种意图,通过查询引导视觉推理过程。VisRL是首个将强化学习(RL)应用于目标驱动视觉感知问题的框架。它通过奖励信号优化整个视觉推理过程,通过将中间焦点选择视为通过试错优化的内部决策,既消除了对昂贵的区域注释的需求,又更贴近人类感知世界的学习方式。
Key Takeaways
- 视觉理解是人类有目标的行为,人类会基于目标选择性关注场景的不同部分。
- 大型多模态模型(LMMs)的进步让人类意图的表达更灵活,可以通过查询引导视觉推理过程。
- 现有方法依赖标注的中间边界框进行训练,限制了可扩展性。
- VisRL框架首次将强化学习(RL)应用于目标驱动的视觉感知问题。
- VisRL优化整个视觉推理过程仅使用奖励信号。
- VisRL通过试错优化中间焦点选择,无需昂贵的区域标注。
点此查看论文截图




GRITHopper: Decomposition-Free Multi-Hop Dense Retrieval
Authors:Justus-Jonas Erker, Nils Reimers, Iryna Gurevych
Decomposition-based multi-hop retrieval methods rely on many autoregressive steps to break down complex queries, which breaks end-to-end differentiability and is computationally expensive. Decomposition-free methods tackle this, but current decomposition-free approaches struggle with longer multi-hop problems and generalization to out-of-distribution data. To address these challenges, we introduce GRITHopper-7B, a novel multi-hop dense retrieval model that achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks. GRITHopper combines generative and representational instruction tuning by integrating causal language modeling with dense retrieval training. Through controlled studies, we find that incorporating additional context after the retrieval process, referred to as post-retrieval language modeling, enhances dense retrieval performance. By including elements such as final answers during training, the model learns to better contextualize and retrieve relevant information. GRITHopper-7B offers a robust, scalable, and generalizable solution for multi-hop dense retrieval, and we release it to the community for future research and applications requiring multi-hop reasoning and retrieval capabilities.
基于分解的多跳检索方法依赖于许多自回归步骤来分解复杂查询,这破坏了端到端的可区分性,并且计算成本高昂。无分解的方法解决了这一问题,但当前的无分解方法在处理较长的多跳问题和泛化到分布外数据时面临困难。为了解决这些挑战,我们推出了GRITHopper-7B,这是一种新型的多跳密集检索模型,在分布内和分布外的基准测试中均实现了最先进的性能。GRITHopper通过集成因果语言建模与密集检索训练,调整了生成和代表性指令。通过对照研究,我们发现检索过程后融入额外的上下文——被称为后检索语言建模,能增强密集检索的性能。通过在训练中加入最后答案等元素,模型学会了更好地上下文化和检索相关信息。GRITHopper-7B为多跳密集检索提供了稳健、可扩展和通用的解决方案,我们将其发布给社区,以供未来研究和需要多跳推理和检索能力的应用使用。
论文及项目相关链接
PDF Under Review at ACL Rolling Review (ARR)
Summary
分解式多跳检索方法依赖于多个自回归步骤来分解复杂查询,这破坏了端到端的可区分性,并且计算成本高昂。无分解方法解决了这一问题,但当前的无分解方法在处理较长的多跳问题和泛化到分布外数据时遇到困难。为解决这些挑战,我们推出了GRITHopper-7B,这是一种新型的多跳密集检索模型,在内外分布基准测试上均实现了最先进的性能。GRITHopper通过整合因果语言建模与密集检索训练,实现了生成性和代表性指令调整。通过对照研究,我们发现,在检索过程后增加额外的上下文,即所谓的后检索语言建模,可以增强密集检索的性能。通过在训练中包含最终答案等元素,模型学会了更好地上下文化和检索相关信息。GRITHopper-7B为需要多跳推理和检索能力的未来研究与应用提供了稳健、可扩展和通用的解决方案。
Key Takeaways
- 多跳检索面临分解复杂查询的挑战和计算成本问题。
- 当前的无分解方法在处理长多跳问题和泛化到分布外数据时存在困难。
- GRITHopper-7B是一个新型的多跳密集检索模型,实现生成性和代表性指令调整。
- GRITHopper结合了因果语言建模和密集检索训练。
- 后检索语言建模(在检索过程后增加额外的上下文)增强了密集检索的性能。
- 在训练中包含最终答案等元素使模型能更好地上下文化和检索相关信息。
点此查看论文截图



Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Authors:Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, Shaohui Lin
DeepSeek-R1-Zero has successfully demonstrated the emergence of reasoning capabilities in LLMs purely through Reinforcement Learning (RL). Inspired by this breakthrough, we explore how RL can be utilized to enhance the reasoning capability of MLLMs. However, direct training with RL struggles to activate complex reasoning capabilities such as questioning and reflection in MLLMs, due to the absence of substantial high-quality multimodal reasoning data. To address this issue, we propose the reasoning MLLM, Vision-R1, to improve multimodal reasoning capability. Specifically, we first construct a high-quality multimodal CoT dataset without human annotations by leveraging an existing MLLM and DeepSeek-R1 through modality bridging and data filtering to obtain a 200K multimodal CoT dataset, Vision-R1-cold dataset. It serves as cold-start initialization data for Vision-R1. To mitigate the optimization challenges caused by overthinking after cold start, we propose Progressive Thinking Suppression Training (PTST) strategy and employ Group Relative Policy Optimization (GRPO) with the hard formatting result reward function to gradually refine the model’s ability to learn correct and complex reasoning processes on a 10K multimodal math dataset. Comprehensive experiments show our model achieves an average improvement of $\sim$6% across various multimodal math reasoning benchmarks. Vision-R1-7B achieves a 73.5% accuracy on the widely used MathVista benchmark, which is only 0.4% lower than the leading reasoning model, OpenAI O1. The datasets and code will be released in: https://github.com/Osilly/Vision-R1 .
DeepSeek-R1-Zero已成功展示了大语言模型通过强化学习(RL)出现推理能力。受此突破启发,我们探索了如何利用强化学习提高小语言模型的推理能力。然而,直接使用强化学习进行训练很难在小型语言模型中激活复杂的推理能力,如提问和反思,这是因为缺乏大量高质量的多模态推理数据。为了解决这一问题,我们提出了多模态小型语言模型——Vision-R1,以提升多模态推理能力。具体来说,我们首先利用现有的小型语言模型和DeepSeek-R1通过模态桥接和数据过滤构建了一个高质量的多模态因果推理数据集Vision-R1-cold数据集,其规模为二十万,无需人工标注,用作Vision-R1的冷启动初始化数据。为了缓解冷启动后过度思考带来的优化挑战,我们提出了渐进思考抑制训练(PTST)策略,并采用带有硬格式化结果奖励函数的群组相对策略优化(GRPO)来逐步改进模型在万级多模态数学数据集上学习正确且复杂推理过程的能力。全面的实验表明,我们的模型在各种多模态数学推理基准测试中平均提高了约6%。Vision-R1-7B在数学视野基准测试上的准确率为73.5%,仅比领先的推理模型OpenAI O1低0.4%。数据集和代码将在https://github.com/Osilly/Vision-R-发布。
论文及项目相关链接
Summary
深度强化学习(RL)已在LLMs中展现出推理能力。为解决缺乏高质量多模态推理数据的问题,提出了使用Vision-R1的模型以增强多模态推理能力。模型通过使用已存在的MLLM与DeepSeek-R1通过模态桥接和过滤技术构建了一个无人工标注的20万条多模态CoT数据集作为冷启动数据。采用渐进思考抑制训练(PTST)策略和群体相对策略优化(GRPO)技术提升模型的优化效率。在多种多模态数学推理测试中平均提升了约6%。该模型在MathVista基准测试上达到了73.5%的准确率,与领先的推理模型OpenAI O1相比仅低0.4%。数据集和代码将在GitHub上公开。
Key Takeaways
- DeepSeek-R1-Zero展示了通过强化学习使LLMs产生推理能力的新方法。
- RL直接训练在MLLM中激活复杂推理能力(如质疑和反思)存在挑战,主要由于缺乏高质量多模态推理数据。
- 提出Vision-R1模型以增强多模态推理能力。
- 利用现有MLLM和DeepSeek-R1构建了无人工标注的多模态CoT数据集Vision-R1-cold作为冷启动数据。
- 采用PTST策略和GRPO技术解决优化挑战并提升模型的推理能力。
- 模型在多个多模态数学推理测试中表现优异,平均提升约6%。
点此查看论文截图




CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Authors:Yuxuan Luo, Jiaqi Tang, Chenyi Huang, Feiyang Hao, Zhouhui Lian
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader’s \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader’s efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.
中国书法国粹,作为联合国教科文组织(UNESCO)遗产,仍然具有计算上的挑战性,因为存在视觉模糊和文化复杂性。现有的AI系统无法对其复杂的脚本进行语境化理解,这主要是因为标注数据有限以及视觉语义对齐不佳。我们提出了CalliReader,一个视觉语言模型(VLM),它通过三项创新解决了中文书法语境化(CC$^2$)问题:1)字符级切片进行精确字符提取和排序;2)CalliAlign进行视觉文本标记压缩和对齐;3)嵌入指令微调(e-IT)以提高对齐并解决数据稀缺问题。我们还建立了CalliBench,首个全页书法语境化的基准测试,解决了之前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅显和幻觉。进行了大量实验,包括用户研究,以验证我们的CalliReader在页级书法识别和解释方面优于其他最先进的方法甚至专业书法家,在提高准确性的同时减少了幻觉。与推理模型的比较突出了准确识别作为可靠理解先决条件的重要性。定量分析验证了CalliReader的效率;对文档和真实世界的基准测试评估证实了其稳健的泛化能力。
论文及项目相关链接
PDF 11 pages
Summary
本文介绍了中文书法这一联合国教科文组织遗产在计算上所面临的挑战,包括视觉模糊和文化复杂性。现有的人工智能系统因缺乏标注数据和视觉语义对齐不佳而无法适应复杂的书法文本。研究团队提出了CalliReader,这是一种解决中文书法上下文化问题的视觉语言模型。该模型通过三项创新技术:字符级切片进行精确字符提取和排序、CalliAlign进行视觉文本符号压缩和对齐以及嵌入指令调优改善对齐并应对数据稀缺问题。此外,研究团队还建立了CalliBench,首个全页书法上下文化的基准测试,解决了之前OCR和VQA方法中的三个关键问题:上下文碎片化、推理浅显和幻觉现象。经过大量实验和用户研究验证,CalliReader在页级书法识别和解释方面优于其他先进方法和专业人士,实现了更高的准确性和更低的幻觉现象。与推理模型的对比突显了准确识别作为可靠理解的前提的重要性。定量分析验证了CalliReader的效率,其在文档和真实世界的基准测试上的评估证明了其稳健的泛化能力。
Key Takeaways
- 中文书法作为联合国教科文组织遗产在计算上面临视觉模糊和文化复杂性的挑战。
- 现有AI系统在处理复杂书法文本时存在困难,主要由于标注数据有限和视觉语义对齐不佳。
- CalliReader是一种视觉语言模型,通过字符级切片、CalliAlign和嵌入指令调优等技术解决中文书法上下文化问题。
- CalliBench是全页书法上下文化的首个基准测试,解决了OCR和VQA方法中的三个关键问题。
- CalliReader在页级书法识别和解释方面优于其他先进方法和专业人士,具有高准确性和低幻觉现象。
- 准确识别是可靠理解的前提,与推理模型的对比突显了这一点。
点此查看论文截图






Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning
Authors:Shengyao Zhuang, Xueguang Ma, Bevan Koopman, Jimmy Lin, Guido Zuccon
In this paper, we introduce Rank-R1, a novel LLM-based reranker that performs reasoning over both the user query and candidate documents before performing the ranking task. Existing document reranking methods based on large language models (LLMs) typically rely on prompting or fine-tuning LLMs to order or label candidate documents according to their relevance to a query. For Rank-R1, we use a reinforcement learning algorithm along with only a small set of relevance labels (without any reasoning supervision) to enhance the reasoning ability of LLM-based rerankers. Our hypothesis is that adding reasoning capabilities to the rerankers can improve their relevance assessement and ranking capabilities. Our experiments on the TREC DL and BRIGHT datasets show that Rank-R1 is highly effective, especially for complex queries. In particular, we find that Rank-R1 achieves effectiveness on in-domain datasets at par with that of supervised fine-tuning methods, but utilizing only 18% of the training data used by the fine-tuning methods. We also find that the model largely outperforms zero-shot and supervised fine-tuning when applied to out-of-domain datasets featuring complex queries, especially when a 14B-size model is used. Finally, we qualitatively observe that Rank-R1’s reasoning process improves the explainability of the ranking results, opening new opportunities for search engine results presentation and fruition.
在这篇论文中,我们介绍了Rank-R1,这是一种基于大语言模型(LLM)的新型重排器(RERanker),在进行排名任务之前,它对用户查询和候选文档进行推理。基于大语言模型的现有文档重排方法通常依赖于提示或微调大语言模型,以根据其与查询的相关性对候选文档进行排序或标记。对于Rank-R1,我们仅使用一小套相关性标签(无需任何推理监督)结合强化学习算法,以提高基于LLM的重排器的推理能力。我们的假设是,向重排器添加推理功能可以提高其相关性评估和排名能力。我们在TREC DL和BRIGHT数据集上的实验表明,Rank-R1非常有效,尤其适用于复杂查询。特别是,我们发现Rank-R1在域内数据集上的效果与监督微调方法相当,但仅使用了微调方法所使用的18%的训练数据。我们还发现,该模型在具有复杂查询的域外数据集上的表现大大超过了零样本和监督微调,尤其是当使用14B大小模型时。最后,我们从本质上观察到,Rank-R1的推理过程提高了排名结果的可解释性,为搜索引擎结果的呈现和享受带来了新的机会。
论文及项目相关链接
Summary
本文介绍了Rank-R1,一种基于大语言模型(LLM)的新颖排序器。该排序器在用户查询和候选文档上进行推理,然后进行排序任务。与现有的基于LLM的文档排序方法不同,Rank-R1采用强化学习算法,仅使用少量相关性标签(无需推理监督)来提高LLM排序器的推理能力。实验表明,Rank-R1在复杂查询方面尤其有效,对于内部数据集几乎达到监督微调方法的效果,但仅使用其18%的训练数据。在外部数据集上,尤其是使用14B大小的模型时,该模型表现出显著的优势。此外,Rank-R1的推理过程提高了排名结果的可解释性,为搜索引擎结果的展示和用户体验提供了新的机会。
Key Takeaways
- Rank-R1是一种基于大语言模型的排序器,结合了强化学习算法进行文档排序。
- 与传统方法不同,Rank-R1仅使用少量相关性标签进行训练,无需推理监督。
- Rank-R1在复杂查询方面表现出色,对于内部数据集几乎达到监督微调的效果,但使用了较少的训练数据。
- 在外部数据集上,尤其是在使用大型模型时,Rank-R1显著优于零样本和监督微调方法。
- Rank-R1的推理过程提高了排名结果的可解释性,增强了搜索结果的呈现和用户体验。
- 该研究提供了一种有效的结合推理能力的大语言模型排序器的方法,为未来搜索引擎的发展提供了新的视角。
点此查看论文截图





MastermindEval: A Simple But Scalable Reasoning Benchmark
Authors:Jonas Golde, Patrick Haller, Fabio Barth, Alan Akbik
Recent advancements in large language models (LLMs) have led to remarkable performance across a wide range of language understanding and mathematical tasks. As a result, increasing attention has been given to assessing the true reasoning capabilities of LLMs, driving research into commonsense, numerical, logical, and qualitative reasoning. However, with the rapid progress of reasoning-focused models such as OpenAI’s o1 and DeepSeek’s R1, there has been a growing demand for reasoning benchmarks that can keep pace with ongoing model developments. In this paper, we introduce MastermindEval, a simple, scalable, and interpretable deductive reasoning benchmark inspired by the board game Mastermind. Our benchmark supports two evaluation paradigms: (1) agentic evaluation, in which the model autonomously plays the game, and (2) deductive reasoning evaluation, in which the model is given a pre-played game state with only one possible valid code to infer. In our experimental results we (1) find that even easy Mastermind instances are difficult for current models and (2) demonstrate that the benchmark is scalable to possibly more advanced models in the future Furthermore, we investigate possible reasons why models cannot deduce the final solution and find that current models are limited in deducing the concealed code as the number of statement to combine information from is increasing.
近年来,大型语言模型(LLM)的进展在各种语言理解和数学任务中取得了显著的成绩。因此,人们越来越关注评估LLM的真正推理能力,推动了常识推理、数值推理、逻辑和定性推理的研究。然而,随着以OpenAI的o1和DeepSeek的R1等为代表的推理重点模型的快速发展,对能够跟上当前模型发展节奏的推理基准测试的需求也在增长。在本文中,我们介绍了MastermindEval,这是一个简单、可扩展、可解释的以猜谜游戏Mastermind为灵感启发而诞生的演绎推理基准测试。我们的基准测试支持两种评估范式:(1)自主评估,模型自主玩游戏;(2)演绎推理评估,模型接收一个已经进行过的游戏状态,并只能推断出一个有效的代码。在我们的实验结果中,(1)我们发现即使是简单的猜谜实例对于当前模型来说也是困难的;(2)我们证明了该基准测试在未来可扩展至更先进的模型。此外,我们调查了模型无法推断出最终解决方案的可能原因,并发现随着结合信息所需陈述数量的增加,当前模型在推断隐藏代码方面的能力有限。
论文及项目相关链接
PDF 9 pages, 2 figures, 4 tables. In: ICLR 2025 Workshop on Reasoning and Planning for Large Language Models
Summary
大型语言模型(LLMs)的进步在各种语言理解和数学任务上取得了显著成效,引发了人们对模型推理能力的关注。为评估模型在常识推理、数值推理、逻辑和定性推理等方面的能力,人们设计了一种基于智力游戏的简单易懂的可扩展推理基准测试MastermindEval。初步实验发现即使是简单的Mastermind实例对现有的模型也有难度,该基准测试可扩展到更先进的模型。然而,模型在推导隐藏代码时存在局限性,当需要组合的信息量增加时,模型无法推断出最终解决方案。
Key Takeaways
- 大型语言模型(LLMs)的进步已显著提高了其在语言理解和数学任务上的表现。
- 随着模型的发展,对模型的推理能力评估需求日益增加,包括常识推理、数值推理、逻辑和定性推理等方面。
- MastermindEval作为一种基于智力游戏的推理基准测试,旨在评估模型的推理能力。
- MastermindEval支持两种评估模式:自主评估模式和逻辑推理评估模式。
- 实验发现,现有的模型在面对简单的Mastermind实例时都感到困难。
- MastermindEval基准测试具有可扩展性,可适用于未来更先进的模型。
点此查看论文截图




WritingBench: A Comprehensive Benchmark for Generative Writing
Authors:Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, Shaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, Fei Huang
Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework’s validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.
近期大型语言模型(LLM)的进步极大地提升了文本生成能力,但在生成写作中评估其性能仍然是一个挑战。现有的基准测试主要关注通用文本生成或有限的写作任务,无法捕捉跨不同领域高质量写作内容的多样化要求。为了弥补这一差距,我们推出了WritingBench,这是一个全面的基准测试,旨在评估LLM在6个核心写作领域和100个子领域中的表现,涵盖创造性、说服力、信息性和技术性写作。我们进一步提出了一个查询相关的评估框架,使LLM能够动态生成特定实例的评估标准。该框架通过微调后的批评模型进行标准感知评分,以风格、格式和长度为评估依据。该框架的有效性进一步体现在其数据整合能力上,使拥有7B参数的模型能够接近最佳(SOTA)性能。我们开源基准测试、评估工具和模块化框架组件,以促进写作领域LLM的发展。
论文及项目相关链接
Summary
大型语言模型(LLM)在文本生成能力上有了显著提升,但评估其生成写作性能仍具挑战。现有评估标准主要关注通用文本生成或有限写作任务,无法捕捉不同领域高质量内容的多样需求。为解决此问题,我们推出WritingBench,一个跨6大写作领域和100个子领域的综合性评估标准,涵盖创意、说服、信息和技术写作。我们还提出一个查询依赖评估框架,使LLM能够动态生成特定实例的评估标准。结合微调评论家模型进行标准感知评分,可在风格、格式和长度方面进行评估。该框架的有效性通过其数据整合能力得到进一步证明,使7B参数模型接近最新技术水平。我们开源此评估标准、评估工具和模块化框架组件,以促进写作领域LLM的发展。
Key Takeaways
- 大型语言模型(LLM)在文本生成方面取得了显著进展,但评估其写作性能仍然存在挑战。
- 现有评估标准主要集中在通用文本生成或有限的写作任务上,不能满足跨领域高质量内容的多样化需求。
- WritingBench是一个综合性的评估标准,覆盖创意、说服、信息和技术写作等多个领域。
- 引入查询依赖评估框架,使LLM能够动态生成具体的评估标准。
- 结合微调评论家模型进行标准感知评分,涵盖风格、格式和长度等方面的评估。
- 框架的有效性通过其数据整合能力得到验证,使模型性能接近最新技术水平。
点此查看论文截图







R1-Zero’s “Aha Moment” in Visual Reasoning on a 2B Non-SFT Model
Authors:Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, Cho-Jui Hsieh
Recently DeepSeek R1 demonstrated how reinforcement learning with simple rule-based incentives can enable autonomous development of complex reasoning in large language models, characterized by the “aha moment”, in which the model manifest self-reflection and increased response length during training. However, attempts to extend this success to multimodal reasoning often failed to reproduce these key characteristics. In this report, we present the first successful replication of these emergent characteristics for multimodal reasoning on only a non-SFT 2B model. Starting with Qwen2-VL-2B and applying reinforcement learning directly on the SAT dataset, our model achieves 59.47% accuracy on CVBench, outperforming the base model by approximately ~30% and exceeding both SFT setting by ~2%. In addition, we share our failed attempts and insights in attempting to achieve R1-like reasoning using RL with instruct models. aiming to shed light on the challenges involved. Our key observations include: (1) applying RL on instruct model often results in trivial reasoning trajectories, and (2) naive length reward are ineffective in eliciting reasoning capabilities. The project code is available at https://github.com/turningpoint-ai/VisualThinker-R1-Zero
最近,DeepSeek R1展示了如何通过基于简单规则的激励来应用强化学习,从而在大型语言模型中自主发展出复杂的推理能力,其特点是表现为“啊哈时刻”,在此过程中,模型在训练过程中表现出自我反思和响应长度的增加。然而,尝试将这种成功扩展到多模态推理时,往往无法重现这些关键特征。在本报告中,我们首次在仅对非SFT 2B模型进行多模态推理时成功复制了这些突发特征。我们以Qwen2-VL-2B为起点,直接在SAT数据集上应用强化学习,我们的模型在CVBench上达到了59.47%的准确率,比基础模型高出约30%,并比SFT设置高出约2%。此外,我们还分享了在使用RL进行指令模型以实现R1式推理的尝试中的失败经验和见解,以期阐明所涉及的挑战。我们的主要观察结果包括:(1)在指令模型上应用RL通常会导致微不足道的推理轨迹,(2)简单的长度奖励在激发推理能力方面无效。项目代码可在https://github.com/turningpoint-ai/VisualThinker-R1-Zero找到。
论文及项目相关链接
PDF 10 pages, 6 figures
Summary
本文介绍了DeepSeek R1如何通过强化学习与基于简单规则的激励实现大型语言模型的自主发展复杂推理的演示。研究中发现在多模态推理中,一些关键的特性未能复制成功。但报告提出首次成功复制这些特性用于非SFT 2B模型的多模态推理上,利用强化学习直接应用在SAT数据集上的Qwen2-VL-2B模型实现准确率为CVBench的59.47%,相比基础模型提高约30%,比SFT设置提高约2%。此外,报告还分享了尝试使用RL进行指令模型时的失败经验和观察结果,包括RL在指令模型上往往导致平庸的推理轨迹以及单纯长度奖励无法激发推理能力。项目代码可在https://github.com/turningpoint-ai/VisualThinker-R1-Zero找到。
Key Takeaways
- 通过强化学习和简单规则激励实现大型语言模型的自主发展复杂推理演示。
- 研究面临多模态推理的挑战,但成功复制某些特性在非SFT 2B模型上。
- Qwen2-VL-2B模型在SAT数据集上应用强化学习实现高准确率。
- 模型性能相较于基础模型提升约30%,相较于SFT设置提升约2%。
- 报告分享了使用RL进行指令模型的失败经验和观察结果。
- RL在指令模型上可能导致平庸推理轨迹的问题。
点此查看论文截图






Seeing is Understanding: Unlocking Causal Attention into Modality-Mutual Attention for Multimodal LLMs
Authors:Wei-Yao Wang, Zhao Wang, Helen Suzuki, Yoshiyuki Kobayashi
Recent Multimodal Large Language Models (MLLMs) have demonstrated significant progress in perceiving and reasoning over multimodal inquiries, ushering in a new research era for foundation models. However, vision-language misalignment in MLLMs has emerged as a critical challenge, where the textual responses generated by these models are not factually aligned with the given text-image inputs. Existing efforts to address vision-language misalignment have focused on developing specialized vision-language connectors or leveraging visual instruction tuning from diverse domains. In this paper, we tackle this issue from a fundamental yet unexplored perspective by revisiting the core architecture of MLLMs. Most MLLMs are typically built on decoder-only LLMs consisting of a causal attention mechanism, which limits the ability of the earlier modalities (e.g., images) to incorporate information from the latter modalities (e.g., text). To address this problem, we propose \MapleLeaf AKI, a novel MLLM that unlocks causal attention into modality-mutual attention (MMA) to enable image tokens to attend to text tokens. This simple yet effective design allows AKI to achieve superior performance in 12 multimodal understanding benchmarks (+7.2% on average) without introducing additional parameters and increasing training time. Our MMA design is intended to be generic, allowing for application across various modalities, and scalable to accommodate diverse multimodal scenarios. The code and model are publicly available at https://github.com/sony/aki to encourage further advancements in MLLMs across various directions.
最近的多模态大型语言模型(MLLMs)在感知和理解多模态查询方面取得了显著进展,为基础模型开启了新的研究时代。然而,MLLMs中的视觉语言错位问题已成为一项关键挑战,该挑战中,这些模型生成的文本回应与给定的文本图像输入在事实上并不对齐。为解决视觉语言错位问题,现有努力主要集中在开发专门的视觉语言连接器或从各种领域中利用视觉指令调整。本文从一个基本且未被探索的视角来解决这个问题,通过重新设计MLLMs的核心架构。大多数MLLMs通常建立在仅解码的LLMs上,由因果注意机制组成,这限制了早期模态(例如图像)融入后期模态(例如文本)信息的能力。针对这一问题,我们提出了MapleLeafAKI,这是一种新型MLLM,它将因果注意解锁为模态相互注意(MMA),使图像标记能够关注文本标记。这种简单而有效的设计使AKI能够在12个多模态理解基准测试中实现卓越性能(平均提高7.2%),同时不引入额外参数并增加训练时间。我们的MMA设计是通用的,可应用于各种模态,并且可扩展以适应各种多模态场景。代码和模型已在https://github.com/sony/aki公开,以鼓励在MLLMs的各个方面进一步取得进展。
论文及项目相关链接
PDF Preprint
Summary:最新多模态大型语言模型(MLLMs)在感知和推理多模态查询方面取得了显著进展,开启了基础模型的新研究时代。然而,MLLMs中的视觉语言不匹配问题已成为关键挑战,现有努力主要集中在开发专门的视觉语言连接器或利用不同领域的视觉指令调整。本文从一个基本但未被探索的视角出发,通过重新设计MLLM的核心架构来解决这一问题。大多数MLLMs都是建立在只解码的LLMs上,采用因果注意机制,这限制了早期模态(如图像)吸收后期模态(如文本)信息的能力。为解决此问题,我们提出“MapleLeafAKI”,一种新型MLLM,解锁因果注意力到模态相互注意力(MMA),使图像令牌能够关注文本令牌。这种简单而有效的设计使AKI在12个多模态理解基准测试中实现了卓越的性能(+7.2%的平均值),同时没有引入额外的参数并增加了训练时间。我们的MMA设计是通用的,可应用于各种模态,并可扩展以适应各种多模态场景。
Key Takeaways:
- MLLMs在多模态查询的感知和推理方面取得显著进步,但面临视觉语言不匹配的关键挑战。
- 现有解决方案主要关注开发专门的视觉语言连接器或利用不同领域的视觉指令调整。
- 本研究通过重新设计MLLM的核心架构来解决视觉语言不匹配问题,强调模态相互注意力(MMA)的重要性。
- 大多数MLLMs建立在只解码的LLMs上,采用因果注意机制,限制了不同模态间的信息交互。
- 提出的新型MLLM“MapleLeafAKI”通过解锁因果注意力到MMA,实现了图像令牌和文本令牌的互动。
- MapleLeafAKI在多个多模态理解基准测试中表现卓越,性能提升显著。
点此查看论文截图





Evaluating System 1 vs. 2 Reasoning Approaches for Zero-Shot Time-Series Forecasting: A Benchmark and Insights
Authors:Haoxin Liu, Zhiyuan Zhao, Shiduo Li, B. Aditya Prakash
Reasoning ability is crucial for solving challenging tasks. With the advancement of foundation models, such as the emergence of large language models (LLMs), a wide range of reasoning strategies has been proposed, including test-time enhancements, such as Chain-ofThought, and post-training optimizations, as used in DeepSeek-R1. While these reasoning strategies have demonstrated effectiveness across various challenging language or vision tasks, their applicability and impact on time-series forecasting (TSF), particularly the challenging zero-shot TSF, remain largely unexplored. In particular, it is unclear whether zero-shot TSF benefits from reasoning and, if so, what types of reasoning strategies are most effective. To bridge this gap, we propose ReC4TS, the first benchmark that systematically evaluates the effectiveness of popular reasoning strategies when applied to zero-shot TSF tasks. ReC4TS conducts comprehensive evaluations across datasets spanning eight domains, covering both unimodal and multimodal with short-term and longterm forecasting tasks. More importantly, ReC4TS provides key insights: (1) Self-consistency emerges as the most effective test-time reasoning strategy; (2) Group-relative policy optimization emerges as a more suitable approach for incentivizing reasoning ability during post-training; (3) Multimodal TSF benefits more from reasoning strategies compared to unimodal TSF. Beyond these insights, ReC4TS establishes two pioneering starting blocks to support future zero-shot TSF reasoning research: (1) A novel dataset, TimeThinking, containing forecasting samples annotated with reasoning trajectories from multiple advanced LLMs, and (2) A new and simple test-time scaling-law validated on foundational TSF models enabled by self-consistency reasoning strategy. All data and code are publicly accessible at: https://github.com/AdityaLab/OpenTimeR
推理能力对于解决具有挑战性的任务至关重要。随着基础模型的进步,如大型语言模型(LLMs)的出现,已经提出了多种推理策略,包括测试时的增强(如Chain-of-Thought)和训练后的优化(如DeepSeek-R1中所使用的)。虽然这些推理策略在各种具有挑战性的语言或视觉任务中已显示出其有效性,但它们在时间序列预测(TSF)中的应用及其对零样本TSF的影响在很大程度上尚未被探索。尤其是尚不清楚零样本TSF是否受益于推理,如果受益,那么哪些类型的推理策略最为有效。为了弥补这一空白,我们提出了ReC4TS,它是第一个系统地评估流行推理策略在零样本TSF任务上有效性的基准测试。ReC4TS在涵盖单模态和多模态以及短期和长期预测任务的八个领域的数据集上进行了全面的评估。更重要的是,ReC4TS提供了关键的见解:(1)自洽性被证明是最有效的测试时推理策略;(2)相对组策略优化是激励训练后推理能力的更合适方法;(3)多模态TSF比单模态TSF更能受益于推理策略。除了这些见解之外,ReC4TS建立了两个开创性的起点,以支持未来的零样本TSF推理研究:(1)一个新的数据集TimeThinking,其中包含被多个先进LLM的推理轨迹注释的预测样本;(2)通过自洽推理策略验证的基础TSF模型的新简单测试时间尺度定律。所有数据和代码均可公开访问:https://github.com/AdityaLab/OpenTimeR
论文及项目相关链接
Summary
本文探讨了推理能力在时间序列预测(TSF)中的重要作用,特别是零样本TSF。文章介绍了ReC4TS这一首个针对零样本TSF任务的推理策略评估基准测试,它在八个领域的数据集上进行了全面评估,并提供了一系列关键见解。同时,它还建立了两个支持未来零样本TSF推理研究的起点,包括一个新的数据集和时间测试的自洽推理策略的验证。ReC4TS的贡献公开可访问。
Key Takeaways
- 推理能力对于解决时间序列预测(TSF)的挑战性任务至关重要。
- ReC4TS是首个针对零样本TSF任务的推理策略评估基准测试。
- ReC4TS在八个领域的数据集上进行了全面评估,涵盖单模态和多模态,短期和长期预测任务。
- 自洽性被证明是最有效的测试时间推理策略。
- Group-relative政策优化是激励后训练阶段推理能力的更合适方法。
- 多模态TSF比单模态TSF更多地受益于推理策略。
- ReC4TS建立了一个新数据集TimeThinking,包含多个高级LLM的预测样本标注的推理轨迹。
点此查看论文截图








CE-U: Cross Entropy Unlearning
Authors:Bo Yang
Large language models inadvertently memorize sensitive data from their massive pretraining corpora \cite{jang2022knowledge}. In this work, we propose CE-U (Cross Entropy Unlearning), a novel loss function for unlearning. CE-U addresses fundamental limitations of gradient ascent approaches which suffer from instability due to vanishing gradients when model confidence is high and gradient exploding when confidence is low. We also unify standard cross entropy supervision and cross entropy unlearning into a single framework. Notably, on the TOFU benchmark for unlearning \cite{maini2024tofu}, CE-U achieves state-of-the-art results on LLaMA2-7B forgetting, even without the use of any extra reference model or additional positive samples. Our theoretical analysis further reveals that the gradient instability issues also exist in popular reinforcement learning algorithms like DPO \cite{rafailov2023direct} and GRPO \cite{Shao2024DeepSeekMath}, as they include a gradient ascent component. This suggests that applying CE-U principles to reinforcement learning could be a promising direction for improving stability and convergence.
大型语言模型无意中从其庞大的预训练语料库中记忆敏感数据\cite{jang2022knowledge}。在这项工作中,我们提出了CE-U(交叉熵遗忘)这一新型遗忘损失函数。CE-U解决了梯度上升方法的基本局限性,这些方法在模型置信度较高时因梯度消失而面临不稳定问题,在置信度较低时则面临梯度爆炸问题。我们还统一了标准交叉熵监督和交叉熵遗忘到一个单一框架中。值得注意的是,在遗忘的TOFU基准测试\cite{maini2024tofu}上,即使在未使用任何额外参考模型或额外正样本的情况下,CE-U在LLaMA2-7B的遗忘方面也取得了最新成果。我们的理论分析进一步揭示,梯度不稳定问题也存在于流行的强化学习算法中,如DPO\cite{rafailov2023direct}和GRPO\cite{Shao2024DeepSeekMath},因为它们包含梯度上升组件。这表明将CE-U原则应用于强化学习可能是提高稳定性和收敛性的一个有前途的方向。
论文及项目相关链接
Summary
大型语言模型在预训练语料库中无意间记忆敏感数据。本研究提出CE-U(交叉熵遗忘)作为新的遗忘损失函数。CE-U解决了梯度上升方法的基本局限,解决了模型信心高时梯度消失和信心低时梯度爆炸的问题。此外,我们将标准交叉熵监督和交叉熵遗忘统一到一个框架中。在TOFU遗忘基准测试中,CE-U在LLaMA2-7B的遗忘方面取得了最新成果,即使没有使用任何额外的参考模型或额外的正样本。我们的理论分析还表明,梯度不稳定问题也存在于流行的强化学习算法中,如DPO和GRPO,因为它们包含梯度上升成分。这表明将CE-U原则应用于强化学习可能是提高稳定性和收敛性的有前途的方向。
Key Takeaways
- 大型语言模型会无意中记忆预训练语料库中的敏感数据。
- 提出了CE-U(交叉熵遗忘)作为新的遗忘损失函数,解决了梯度上升方法的稳定性问题。
- CE-U将标准交叉熵监督和交叉熵遗忘结合到一个统一的框架中。
- 在TOFU基准测试中,CE-U在LLaMA模型遗忘方面取得最新成果。
- CE-U实现无需额外的参考模型或正样本。
- 梯度不稳定问题不仅存在于传统的机器学习算法中,也存在于强化学习算法如DPO和GRPO中。
点此查看论文截图