⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
RGBAvatar: Reduced Gaussian Blendshapes for Online Modeling of Head Avatars
Authors:Linzhou Li, Yumeng Li, Yanlin Weng, Youyi Zheng, Kun Zhou
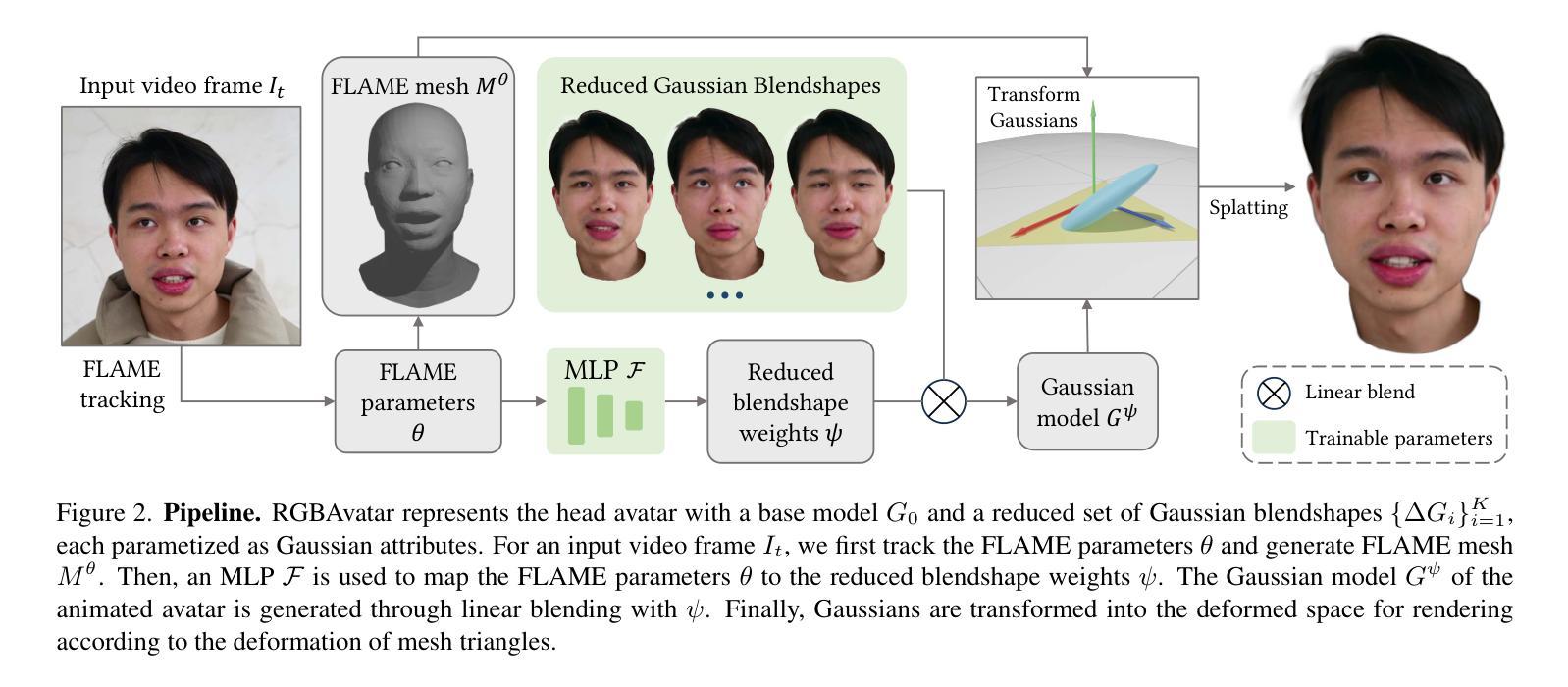
We present Reduced Gaussian Blendshapes Avatar (RGBAvatar), a method for reconstructing photorealistic, animatable head avatars at speeds sufficient for on-the-fly reconstruction. Unlike prior approaches that utilize linear bases from 3D morphable models (3DMM) to model Gaussian blendshapes, our method maps tracked 3DMM parameters into reduced blendshape weights with an MLP, leading to a compact set of blendshape bases. The learned compact base composition effectively captures essential facial details for specific individuals, and does not rely on the fixed base composition weights of 3DMM, leading to enhanced reconstruction quality and higher efficiency. To further expedite the reconstruction process, we develop a novel color initialization estimation method and a batch-parallel Gaussian rasterization process, achieving state-of-the-art quality with training throughput of about 630 images per second. Moreover, we propose a local-global sampling strategy that enables direct on-the-fly reconstruction, immediately reconstructing the model as video streams in real time while achieving quality comparable to offline settings. Our source code is available at https://github.com/gapszju/RGBAvatar.
我们提出了减少高斯混合体个性化角色(RGBAvatar)的方法,这是一种能够以足够快的速度重建用于实时重建的光照逼真的可动画头部个性化角色的方法。不同于以往使用三维形态模型(3DMM)的线性基元来构建高斯混合体的方法,我们的方法是通过多层感知机(MLP)将跟踪的3DMM参数映射到减少的混合体权重上,从而得到紧凑的混合体基元集。这种学习到的紧凑基元组合有效地捕捉了特定个体的面部细节,并且不依赖于3DMM的固定基元组合权重,从而提高了重建质量和效率。为了进一步加快重建过程,我们开发了一种新型的颜色初始化估算方法和批量并行高斯渲染过程,实现了每秒处理约630张图像的训练吞吐量,达到业界领先水平。此外,我们提出了一种局部全局采样策略,能够实现直接的实时重建,在实时视频流中立即重建模型,同时达到与离线设置相当的质量。我们的源代码可在https://github.com/gapszju/RGBAvatar找到。
论文及项目相关链接
Summary
提供实时重建的方法——Reduced Gaussian Blendshapes Avatar(RGBAvatar)。使用神经网络映射模型参数至简化版blendshape权重,实现紧凑的面部模型构建,提高重建质量和效率。配合色彩初始化估计和并行高斯渲染技术,实现每秒处理约630张图像的速度。同时提出局部全局采样策略,实现实时视频流的直接重建。
Key Takeaways
- RGBAvatar提供了一种构建逼真可动的头像的新方法,利用神经网络进行快速重建。
- RGBAvatar采用简化的blendshape权重方法代替了传统的基于3D形态模型的方法。
- 该技术采用一种新颖的色初值估算方法加速重建过程。
- RGBAvatar支持批量并行的高斯渲染,大幅提高图像处理速度。
- 本地全局采样策略实现了实时视频流的直接重建,与离线设置相比质量相当。
- RGBAvatar的代码已公开发布在GitHub上供研究使用。
点此查看论文截图



R3-Avatar: Record and Retrieve Temporal Codebook for Reconstructing Photorealistic Human Avatars
Authors:Yifan Zhan, Wangze Xu, Qingtian Zhu, Muyao Niu, Mingze Ma, Yifei Liu, Zhihang Zhong, Xiao Sun, Yinqiang Zheng
We present R3-Avatar, incorporating a temporal codebook, to overcome the inability of human avatars to be both animatable and of high-fidelity rendering quality. Existing video-based reconstruction of 3D human avatars either focuses solely on rendering, lacking animation support, or learns a pose-appearance mapping for animating, which degrades under limited training poses or complex clothing. In this paper, we adopt a “record-retrieve-reconstruct” strategy that ensures high-quality rendering from novel views while mitigating degradation in novel poses. Specifically, disambiguating timestamps record temporal appearance variations in a codebook, ensuring high-fidelity novel-view rendering, while novel poses retrieve corresponding timestamps by matching the most similar training poses for augmented appearance. Our R3-Avatar outperforms cutting-edge video-based human avatar reconstruction, particularly in overcoming visual quality degradation in extreme scenarios with limited training human poses and complex clothing.
我们提出了R3-Avatar,它结合了一个时间码簿,旨在克服人类虚拟形象既能动画化又能保持高质量渲染的难题。现有的基于视频的3D人类虚拟形象重建要么只专注于渲染,缺乏动画支持,要么学习姿势-外观映射进行动画处理,这在训练姿势有限或衣物复杂的情况下会出现性能下降。在本文中,我们采用了一种“记录-检索-重建”的策略,确保从新型视角进行高质量渲染,同时减轻新姿势下的性能下降问题。具体来说,通过时间戳消除模糊记录时间上的外观变化到码簿中,以确保从新颖视角的高保真渲染,同时新姿势通过匹配最相似的训练姿势来检索对应的时间戳以进行外观增强。我们的R3-Avatar在基于视频的先进人类虚拟形象重建技术中表现出色,特别是在面对训练人类姿势有限和衣物复杂的极端场景中克服视觉质量下降的问题。
论文及项目相关链接
Summary
实现了一种名为R3-Avatar的技术,采用时间编码本解决人类虚拟形象既需要可动画化又需要高质量渲染的问题。现有基于视频的3D人类虚拟形象重建技术要么只关注渲染,缺乏动画支持,要么学习姿势-外观映射进行动画,但在训练姿势有限或衣物复杂的情况下会降级。本研究采用“记录-检索-重建”策略,确保从新颖视角的高质量渲染,同时减轻新姿势下的降级问题。通过时间戳记录来消除模糊,保证高质量的新视角渲染,同时在新姿势下通过检索最相似的训练姿势来匹配对应的时间戳,增强外观表现。
Key Takeaways
- R3-Avatar技术结合了时间编码本,旨在解决人类虚拟形象在动画和高质量渲染方面的挑战。
- 现有技术要么缺乏动画支持,要么在特定情境下性能下降,特别是在训练姿势有限和衣物复杂的情况下。
- “记录-检索-重建”策略确保从新颖视角的高质量渲染,同时减轻新姿势下的性能下降问题。
- 通过记录时间戳来解决模糊问题,保证高质量渲染。
- 通过检索与新颖姿势最相似的训练姿势,并匹配对应的时间戳来增强外观表现。
- R3-Avatar技术超越了现有前沿的基于视频的人类虚拟形象重建技术。
点此查看论文截图




Snapmoji: Instant Generation of Animatable Dual-Stylized Avatars
Authors:Eric M. Chen, Di Liu, Sizhuo Ma, Michael Vasilkovsky, Bing Zhou, Qiang Gao, Wenzhou Wang, Jiahao Luo, Dimitris N. Metaxas, Vincent Sitzmann, Jian Wang
The increasing popularity of personalized avatar systems, such as Snapchat Bitmojis and Apple Memojis, highlights the growing demand for digital self-representation. Despite their widespread use, existing avatar platforms face significant limitations, including restricted expressivity due to predefined assets, tedious customization processes, or inefficient rendering requirements. Addressing these shortcomings, we introduce Snapmoji, an avatar generation system that instantly creates animatable, dual-stylized avatars from a selfie. We propose Gaussian Domain Adaptation (GDA), which is pre-trained on large-scale Gaussian models using 3D data from sources such as Objaverse and fine-tuned with 2D style transfer tasks, endowing it with a rich 3D prior. This enables Snapmoji to transform a selfie into a primary stylized avatar, like the Bitmoji style, and apply a secondary style, such as Plastic Toy or Alien, all while preserving the user’s identity and the primary style’s integrity. Our system is capable of producing 3D Gaussian avatars that support dynamic animation, including accurate facial expression transfer. Designed for efficiency, Snapmoji achieves selfie-to-avatar conversion in just 0.9 seconds and supports real-time interactions on mobile devices at 30 to 40 frames per second. Extensive testing confirms that Snapmoji outperforms existing methods in versatility and speed, making it a convenient tool for automatic avatar creation in various styles.
个性化头像系统的日益普及,如Snapchat的Bitmojis和Apple的Memojis,凸显了数字自我表示的需求增长。尽管它们得到了广泛使用,但现有的头像平台面临重大局限,包括由于预设资产导致的表达受限、繁琐的自定义流程或低效的渲染要求。针对这些不足,我们推出了Snapmoji,这是一个头像生成系统,可以立即从自拍中创建可动画的双风格化头像。我们提出了高斯域适应(GDA),它预训练于大规模高斯模型上,使用来自Objaverse等来源的3D数据,并通过2D风格转换任务进行微调,赋予其丰富的3D先验知识。这使得Snapmoji能够将自拍转化为像Bitmoji风格的主要风格化头像,并应用次要风格,如塑料玩具或外星风格,同时保持用户的身份和主要风格的完整性。我们的系统能够产生支持动态动画的3D高斯头像,包括准确的面部表情转移。为了效率而设计,Snapmoji只需0.9秒即可完成自拍到头像的转换,并支持以每秒30到40帧的速度在移动设备上实现实时交互。广泛测试证实,Snapmoji在通用性和速度方面优于现有方法,使其成为各种风格中自动创建头像的便捷工具。
论文及项目相关链接
PDF N/A
Summary
个性化头像系统日益流行,如Snapchat的Bitmojis和Apple的Memojis,凸显了数字自我表达的需求。现有平台存在表达受限、定制流程繁琐和渲染效率低下等缺陷。Snapmoji系统可立即从自拍创建动态双重风格头像,采用高斯域适应技术,融合3D和2D风格转移任务,生成个性化头像并支持动态动画。系统效率高,自拍到头像转换仅需0.9秒,支持移动设备实时互动。测试显示Snapmoji在多样性和速度上优于现有方法。
Key Takeaways
- 个性化头像系统需求增长:人们对数字自我表达的需求日益增强。
- 现有头像平台存在缺陷:表达受限、定制流程繁琐和渲染效率低下。
- Snapmoji系统特点:可快速创建双重风格动态头像,支持自拍到头像的快速转换(仅需0.9秒)。
- Snapmoji技术:采用高斯域适应技术和融合3D与2D风格转移任务实现丰富功能。
- 丰富的风格选项:支持多种风格转移,如Bitmoji风格、塑料玩具风格和外星风格等。
- 实时互动支持:在移动设备上支持实时互动,帧率达到每秒30至40帧。
点此查看论文截图