⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
Efficient Multimodal 3D Object Detector via Instance-Level Contrastive Distillation
Authors:Zhuoqun Su, Huimin Lu, Shuaifeng Jiao, Junhao Xiao, Yaonan Wang, Xieyuanli Chen
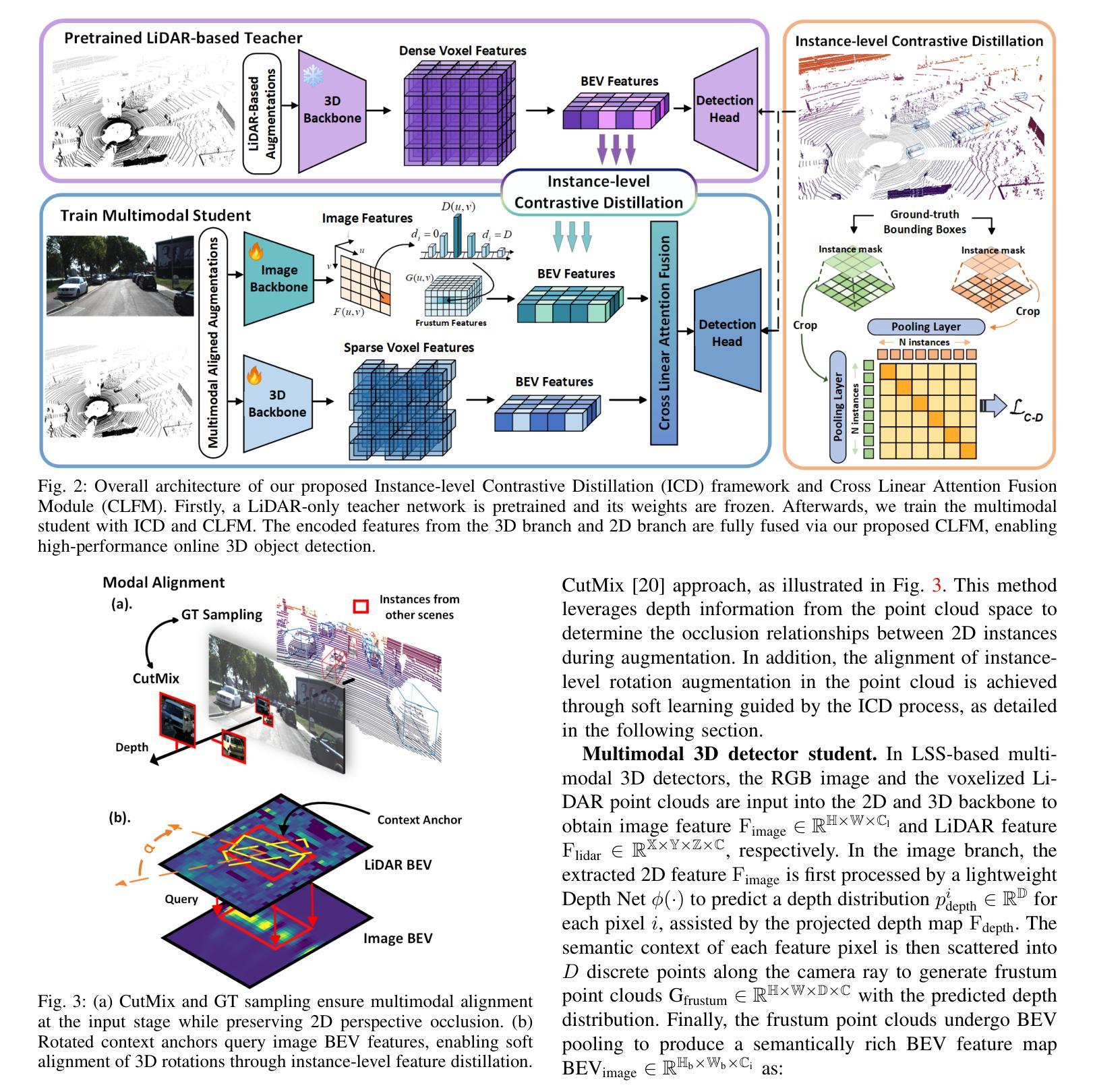
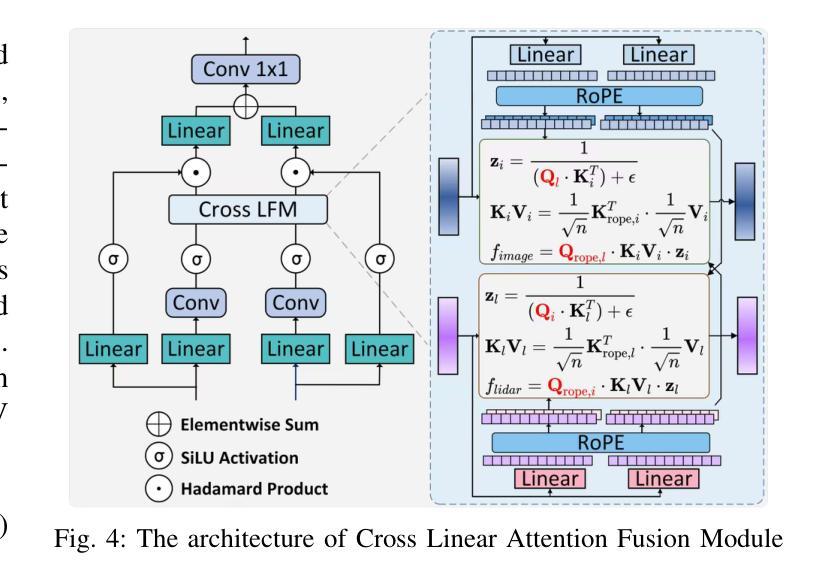
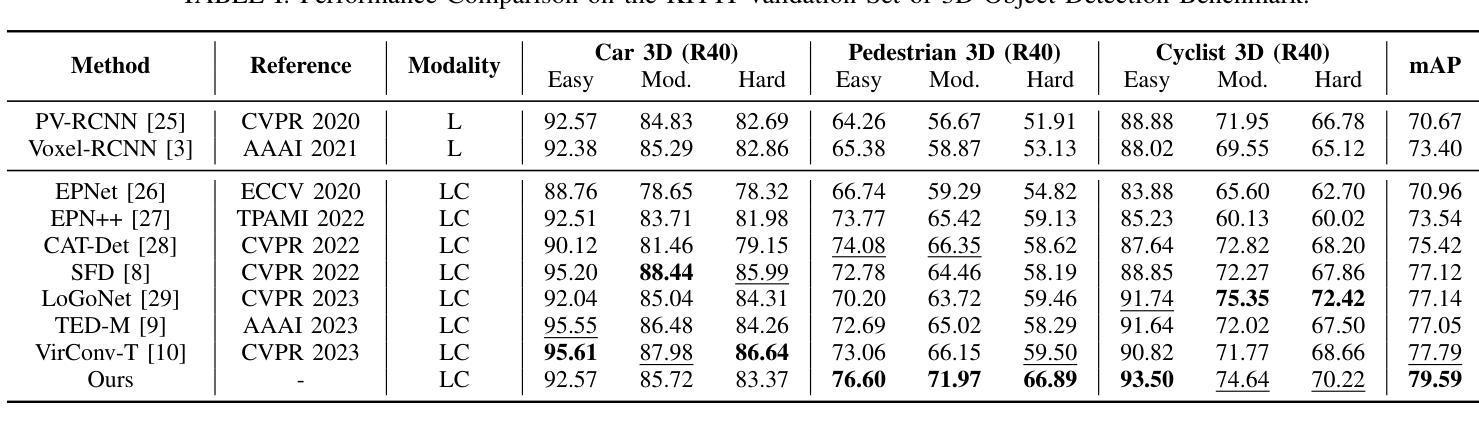
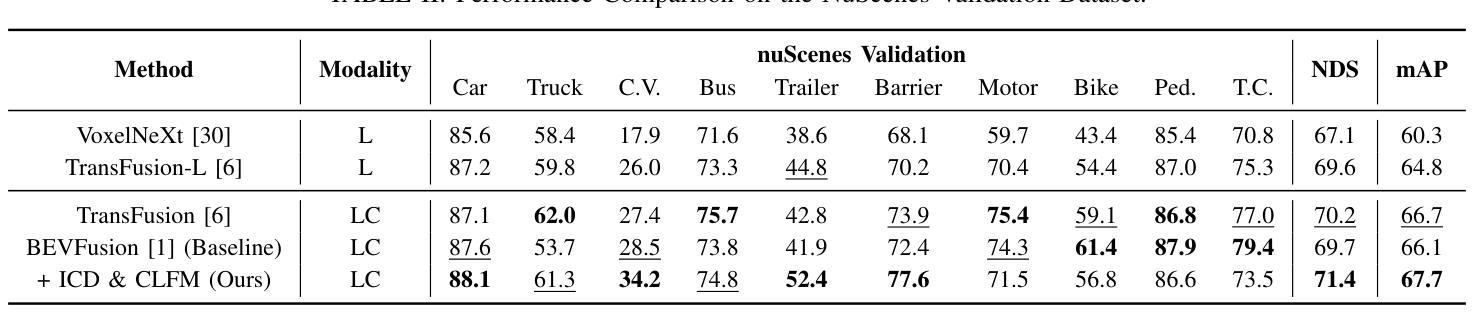
Multimodal 3D object detectors leverage the strengths of both geometry-aware LiDAR point clouds and semantically rich RGB images to enhance detection performance. However, the inherent heterogeneity between these modalities, including unbalanced convergence and modal misalignment, poses significant challenges. Meanwhile, the large size of the detection-oriented feature also constrains existing fusion strategies to capture long-range dependencies for the 3D detection tasks. In this work, we introduce a fast yet effective multimodal 3D object detector, incorporating our proposed Instance-level Contrastive Distillation (ICD) framework and Cross Linear Attention Fusion Module (CLFM). ICD aligns instance-level image features with LiDAR representations through object-aware contrastive distillation, ensuring fine-grained cross-modal consistency. Meanwhile, CLFM presents an efficient and scalable fusion strategy that enhances cross-modal global interactions within sizable multimodal BEV features. Extensive experiments on the KITTI and nuScenes 3D object detection benchmarks demonstrate the effectiveness of our methods. Notably, our 3D object detector outperforms state-of-the-art (SOTA) methods while achieving superior efficiency. The implementation of our method has been released as open-source at: https://github.com/nubot-nudt/ICD-Fusion.
多模态3D目标检测器利用几何感知激光雷达点云和语义丰富的RGB图像的优势,以提高检测性能。然而,这些模态之间的固有异质性,包括不平衡收敛和模态不匹配,带来了巨大的挑战。同时,面向检测的特征尺寸较大,也限制了现有的融合策略捕捉3D检测任务的长程依赖性。在这项工作中,我们引入了一种快速而有效的多模态3D目标检测器,结合了我们的实例级对比蒸馏(ICD)框架和交叉线性注意力融合模块(CLFM)。ICD通过对象感知对比蒸馏,将实例级图像特征与激光雷达表示对齐,确保精细的跨模态一致性。同时,CLFM提出了一种高效且可扩展的融合策略,可在大规模多模态BEV特征内增强跨模态全局交互。在KITTI和nuScenes 3D目标检测基准测试上的大量实验证明了我们方法的有效性。值得注意的是,我们的3D目标检测器在性能上超越了最新方法,同时实现了卓越的效率。我们的方法实现已经作为开源发布在:[https://github.com/nubot-nudt/ICD-Fusion。]
论文及项目相关链接
Summary
本文介绍了一种快速有效的多模态3D目标检测器,通过结合提出的实例级对比蒸馏(ICD)框架和交叉线性注意力融合模块(CLFM),解决了不同模态之间的不平衡收敛和模态不匹配问题。ICD框架通过对象感知对比蒸馏实现对实例级图像特征与激光雷达表示的匹配,确保了跨模态的精细一致性。CLFM提供了一种高效可扩展的融合策略,可在大型多模态BEV特征内增强跨模态全局交互。在KITTI和nuScenes 3D目标检测基准测试上的实验证明了该方法的有效性和优越性,其3D目标检测器在性能和效率方面都超过了当前先进水平。
Key Takeaways
- 多模态3D目标检测器结合了几何感知的LiDAR点云和语义丰富的RGB图像,以提高检测性能。
- 存在的挑战包括不同模态之间的内在异质性,如不平衡收敛和模态不匹配。
- 提出的实例级对比蒸馏(ICD)框架确保跨模态的精细一致性。
- 交叉线性注意力融合模块(CLFM)提供了一种高效且可扩展的融合策略,增强了跨模态全局交互。
- 在KITTI和nuScenes基准测试上的实验证明了该方法的有效性和优越性。
- 该检测器性能超过当前先进水平。
点此查看论文截图

A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Authors:Asifullah Khan, Laiba Asmatullah, Anza Malik, Shahzaib Khan, Hamna Asif
Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of “positive” and “negative” samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
自监督学习是一种机器学习的方法,它通过学习潜在的模式和从非标记数据中提取判别特征,生成隐含的标签,而无需人工标注。对比学习引入了“正样本”和“负样本”的概念,其中正样本对(例如,同一图像/对象的变体)在嵌入空间中聚集在一起,而负样本对(例如,来自不同图像/对象的视图)则被推开。这种方法在图像理解和图像文本分析方面取得了显著的改进,而且非常依赖标注数据。在本文中,我们针对文本图像模型的对比学习术语、最新发展及应用进行了全面的讨论。具体来说,我们概述了近年来文本图像模型中对比学习的方法。其次,我们根据不同的模型结构对这些方法进行了分类。第三,我们进一步介绍了该过程中使用的最新技术的进展,例如用于图像和文本的预文本任务、架构结构和关键趋势。最后,我们讨论了基于文本图像的最新最先进的自监督对比学习的应用。
论文及项目相关链接
Summary
无监督学习中的一种方法是自我监督学习,它通过学习潜在模式和从无标签数据中提取辨别特征来生成隐式标签,而无需手动标注。对比学习引入了“正样例”和“负样例”的概念,将正样例对(如同一图像/对象的变体)在嵌入空间中聚集在一起,而将负样例对(如来自不同图像/对象的视图)推开。这种方法在图像理解和图像文本分析方面取得了显著改进,对标签数据的依赖度较低。本文全面讨论了文本-图像模型的对比学习术语、最新发展及应用,概述了近年来的文本-图像模型对比学习的方法,按模型结构分类,并介绍了最新的技术进展,如图像和文本的预训练任务、架构结构和关键趋势等。
Key Takeaways
- 自我监督学习是通过学习潜在模式和提取无标签数据的辨别特征来生成隐式标签,无需手动标注。
- 对比学习在机器学习中引入“正样例”和“负样例”的概念,通过调整它们在嵌入空间中的位置来提高学习效果。
- 对比学习方法在图像理解和图像文本分析方面表现出显著效果,减少对标签数据的依赖。
- 文本-图像模型的对比学习方法被全面讨论,包括近年来的方法和按模型结构的分类。
- 文中介绍了最新的技术进展,包括图像和文本的预训练任务、模型架构结构和关键趋势等。
- 本文最后探讨了自我监督对比学习在文本-图像模型中的最新应用。
点此查看论文截图

Cyclic Contrastive Knowledge Transfer for Open-Vocabulary Object Detection
Authors:Chuhan Zhang, Chaoyang Zhu, Pingcheng Dong, Long Chen, Dong Zhang
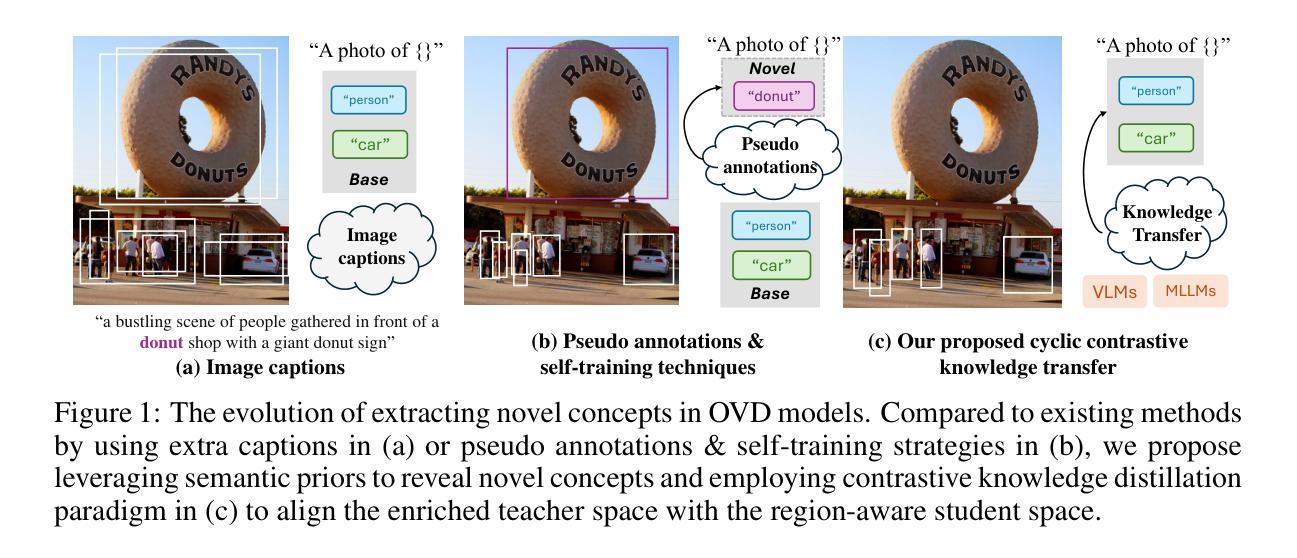
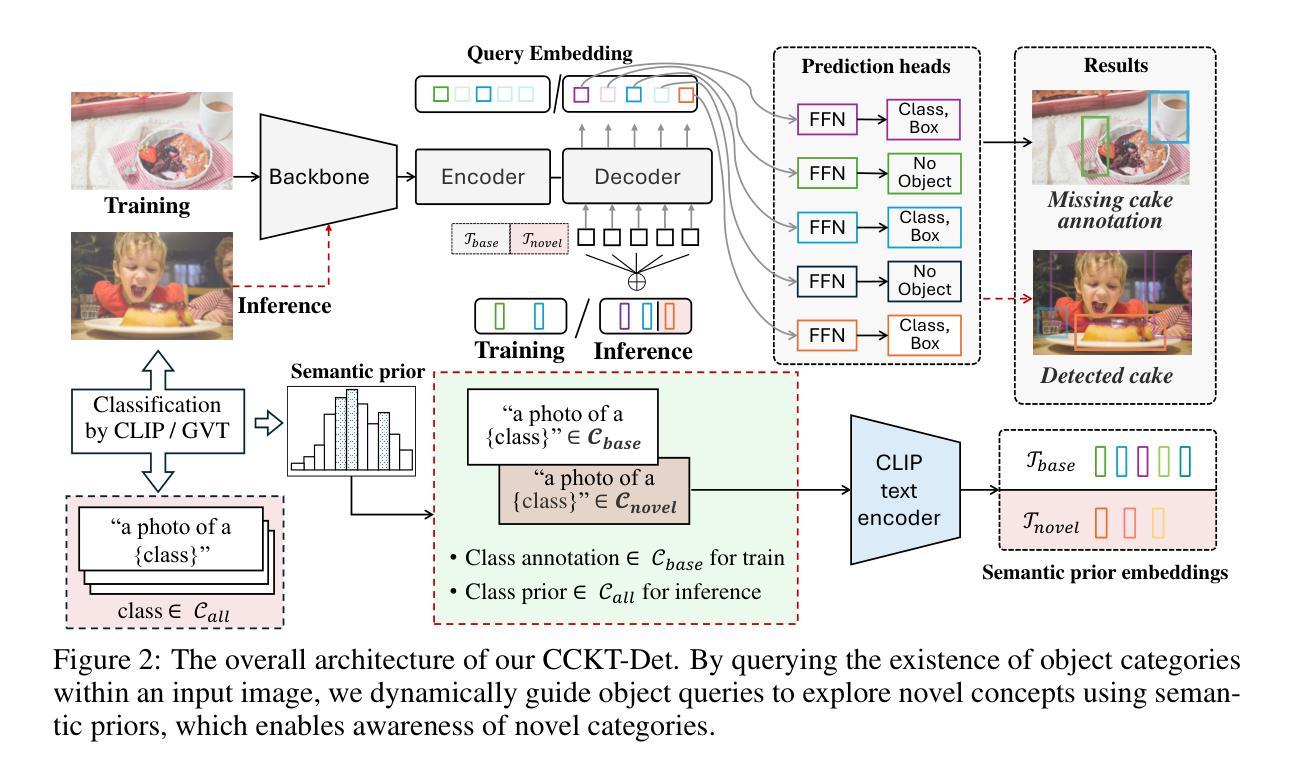
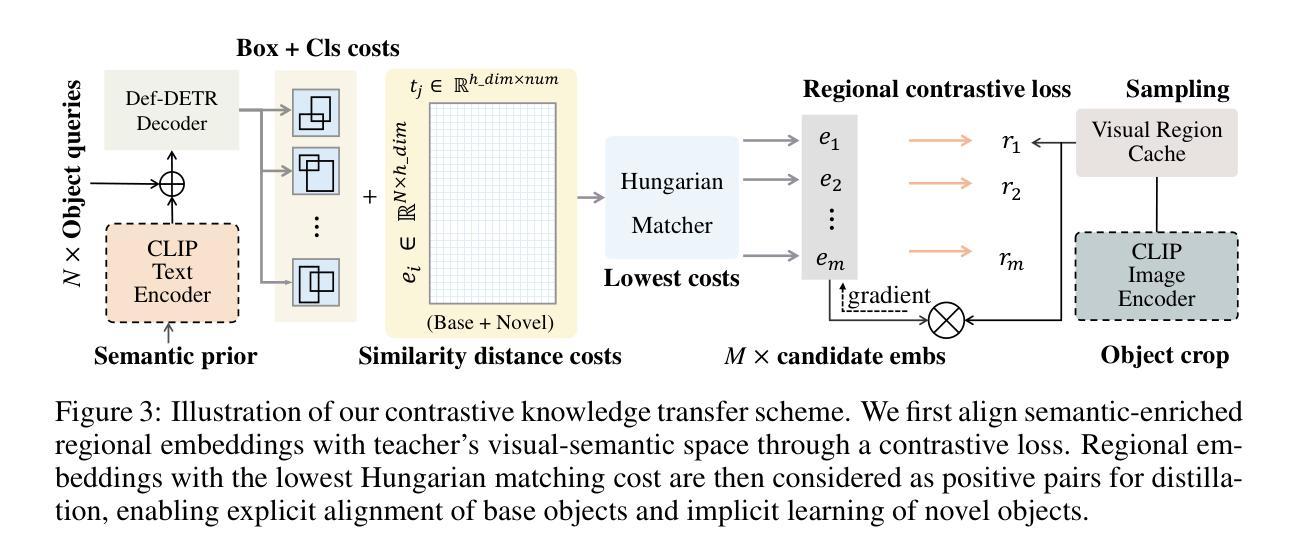
In pursuit of detecting unstinted objects that extend beyond predefined categories, prior arts of open-vocabulary object detection (OVD) typically resort to pretrained vision-language models (VLMs) for base-to-novel category generalization. However, to mitigate the misalignment between upstream image-text pretraining and downstream region-level perception, additional supervisions are indispensable, eg, image-text pairs or pseudo annotations generated via self-training strategies. In this work, we propose CCKT-Det trained without any extra supervision. The proposed framework constructs a cyclic and dynamic knowledge transfer from language queries and visual region features extracted from VLMs, which forces the detector to closely align with the visual-semantic space of VLMs. Specifically, 1) we prefilter and inject semantic priors to guide the learning of queries, and 2) introduce a regional contrastive loss to improve the awareness of queries on novel objects. CCKT-Det can consistently improve performance as the scale of VLMs increases, all while requiring the detector at a moderate level of computation overhead. Comprehensive experimental results demonstrate that our method achieves performance gain of +2.9% and +10.2% AP50 over previous state-of-the-arts on the challenging COCO benchmark, both without and with a stronger teacher model. The code is provided at https://github.com/ZCHUHan/CCKT-Det.
在追求检测无限制对象,这些对象超越了预定义类别,开放词汇表对象检测(OVD)的现有技术通常依赖于预训练的视觉语言模型(VLM)进行基础到新颖类别的推广。然而,为了缓解上游图像文本预训练和下游区域级别感知之间的不对齐,额外的监督是不可或缺的,例如通过自我训练策略生成的图像文本对或伪注释。在这项工作中,我们提出了无需任何额外监督的CCKT-Det。所提出的框架构建了从语言查询和从VLM提取的视觉区域特征之间的循环和动态知识转移,这迫使检测器紧密对齐VLM的视觉语义空间。具体来说,1)我们预过滤并注入语义先验来指导查询学习,2)引入区域对比损失来提高查询对新对象的意识。随着VLM规模的增长,CCKT-Det可以持续提高性能,同时只需适度增加检测器的计算开销。综合实验结果表明,我们的方法在具有挑战性的COCO基准测试上,较之前的最先进方法提高了2.9%和10.2%的AP50,无论是否使用更强的教师模型。代码提供在https://github.com/ZCHUHan/CCKT-Det。
论文及项目相关链接
PDF 10 pages, 5 figures, Published as a conference paper at ICLR 2025
Summary
本文提出了一种名为CCKT-Det的方法,用于无额外监督下的开放词汇表对象检测。该方法构建了从语言查询到视觉区域特征的循环和动态知识转移框架,通过预过滤和注入语义先验来指导查询学习,并引入区域对比损失来提高查询对新型对象的识别能力。CCKT-Det在不同规模的VLMs中都能持续提升性能,同时保持适度的计算开销。
Key Takeaways
- CCKT-Det是一种无需额外监督的开放词汇表对象检测方法。
- 该方法通过构建语言查询到视觉区域特征的循环和动态知识转移框架,实现了从VLMs的视觉语义空间对齐。
3.CCKT-Det通过预过滤和注入语义先验,以指导查询学习。 - 引入区域对比损失,提高查询对新型对象的识别能力。
- 随着VLMs规模的增长,CCKT-Det的性能可持续提升。
- 在具有挑战性的COCO基准测试中,与先前最先进的相比,CCKT-Det的性能提升显著,平均准确率为+2.9%和+10.2%,且在不同模型(包括更强大的教师模型)下均表现优异。
点此查看论文截图

AI-assisted Early Detection of Pancreatic Ductal Adenocarcinoma on Contrast-enhanced CT
Authors:Han Liu, Riqiang Gao, Sasa Grbic
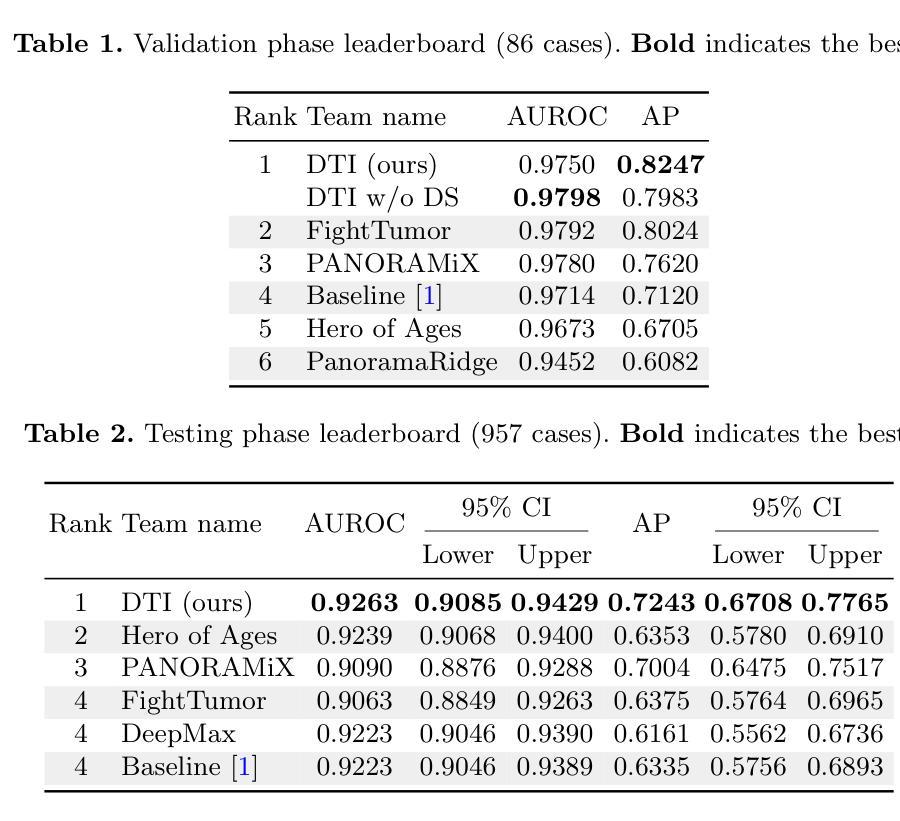
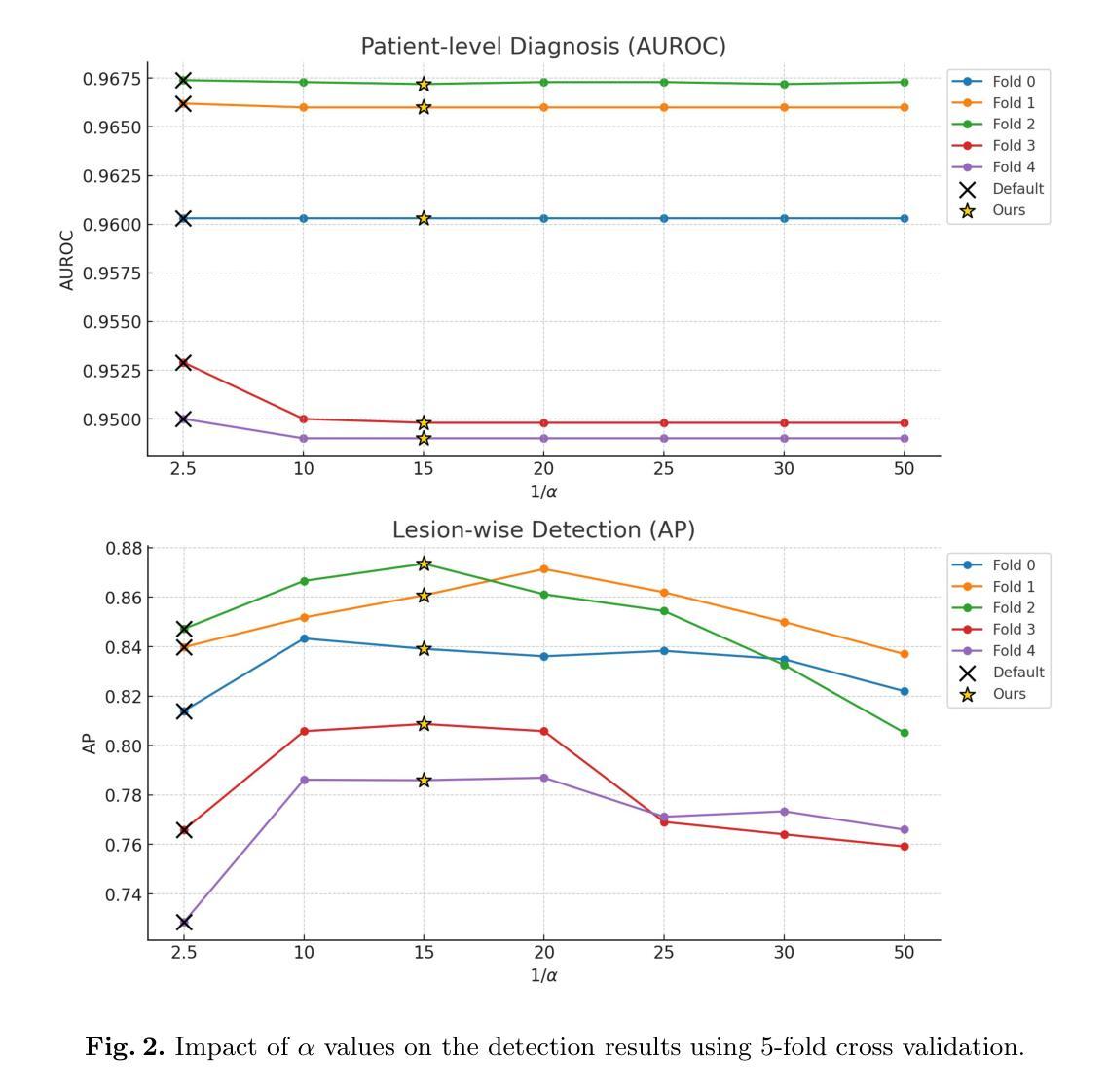
Pancreatic ductal adenocarcinoma (PDAC) is one of the most common and aggressive types of pancreatic cancer. However, due to the lack of early and disease-specific symptoms, most patients with PDAC are diagnosed at an advanced disease stage. Consequently, early PDAC detection is crucial for improving patients’ quality of life and expanding treatment options. In this work, we develop a coarse-to-fine approach to detect PDAC on contrast-enhanced CT scans. First, we localize and crop the region of interest from the low-resolution images, and then segment the PDAC-related structures at a finer scale. Additionally, we introduce two strategies to further boost detection performance: (1) a data-splitting strategy for model ensembling, and (2) a customized post-processing function. We participated in the PANORAMA challenge and ranked 1st place for PDAC detection with an AUROC of 0.9263 and an AP of 0.7243. Our code and models are publicly available at https://github.com/han-liu/PDAC_detection.
胰腺癌导管腺癌(PDAC)是胰腺癌最常见且最具侵袭性的类型之一。然而,由于早期和特定疾病的症状缺乏,大多数PDAC患者在疾病晚期才被诊断出来。因此,早期发现PDAC对于改善患者的生活质量和扩大治疗选择至关重要。在这项工作中,我们开发了一种从粗到细的PDAC检测方法来检测增强型CT扫描结果。首先,我们从低分辨率图像中定位和裁剪感兴趣区域,然后在更精细的尺度上分割与PDAC相关的结构。此外,我们还引入了两种策略来进一步提高检测性能:(1)用于模型集成的数据拆分策略,(2)定制的后处理功能。我们参加了PANORAMA挑战赛,在PDAC检测方面获得第一名,AUROC为0.9263,AP为0.7243。我们的代码和模型可在https://github.com/han-liu/PDAC_detection公开访问。
论文及项目相关链接
PDF 1st place in the PANORAMA Challenge (Team DTI)
Summary
本文介绍了一种针对胰腺癌检测的早期诊断方法。该方法采用从粗到细的策略,在增强CT扫描上定位并裁剪感兴趣区域,然后在更精细的尺度上分割胰腺癌相关结构。此外,还引入两种策略进一步提升检测性能:模型集成使用的数据拆分策略和自定义的后处理功能。参与PANORAMA挑战赛并荣获胰腺癌检测第一名,性能指标为AUROC 0.9263和AP 0.7243。相关代码和模型已公开供查阅。
Key Takeaways
- 采用粗到细的策略进行胰腺癌检测,先定位并裁剪感兴趣区域,再进行精细分割。
- 利用增强CT扫描进行诊断。
- 引入两种策略提升检测性能:模型集成的数据拆分策略和自定义后处理功能。
- 参与PANORAMA挑战赛并荣获胰腺癌检测第一名。
- 检测性能指标包括AUROC 0.9263和AP 0.7243,显示了较高的检测准确性。
- 提供公开的代码和模型供查阅,便于其他研究者使用和改进。
点此查看论文截图