⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
Beyond RGB: Adaptive Parallel Processing for RAW Object Detection
Authors:Shani Gamrian, Hila Barel, Feiran Li, Masakazu Yoshimura, Daisuke Iso
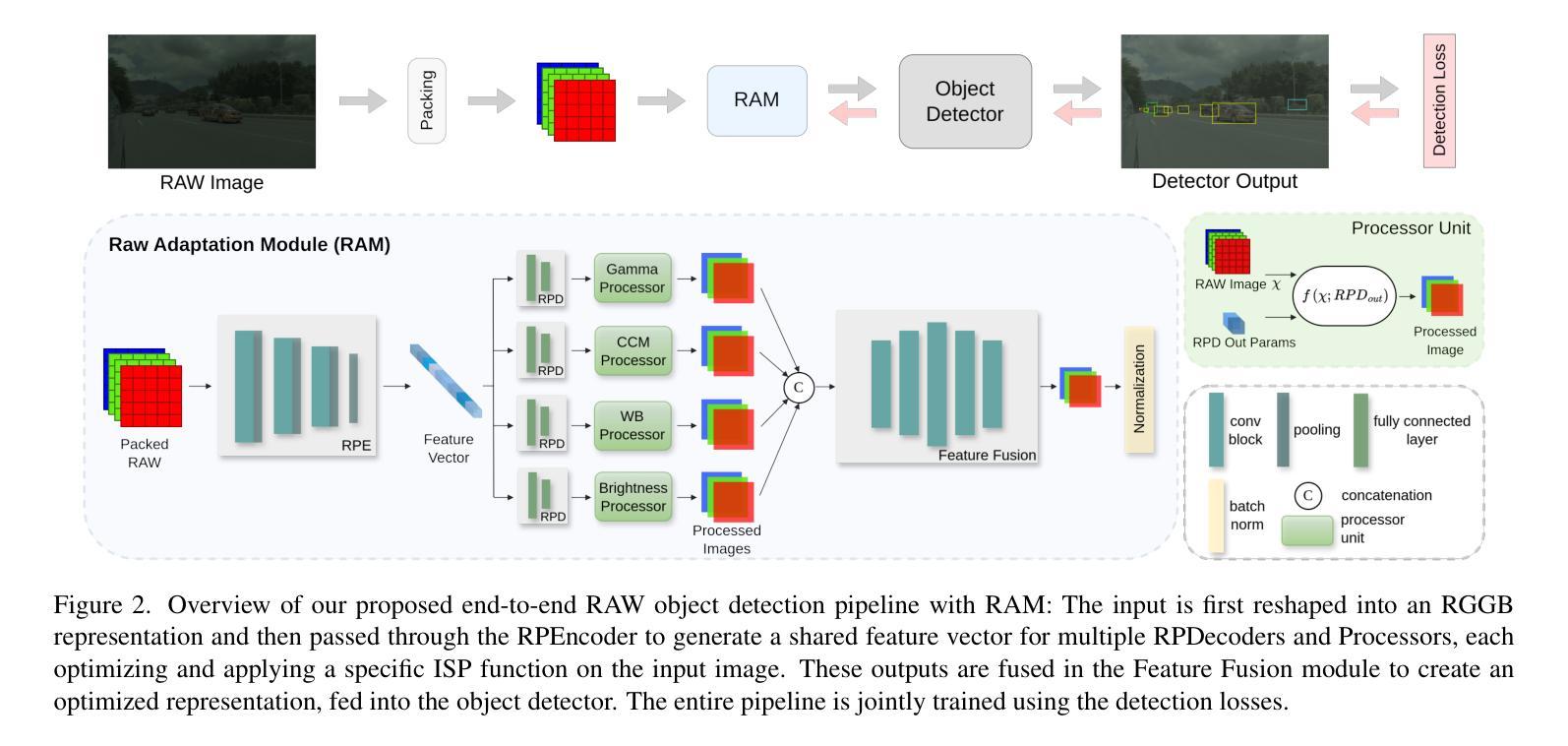
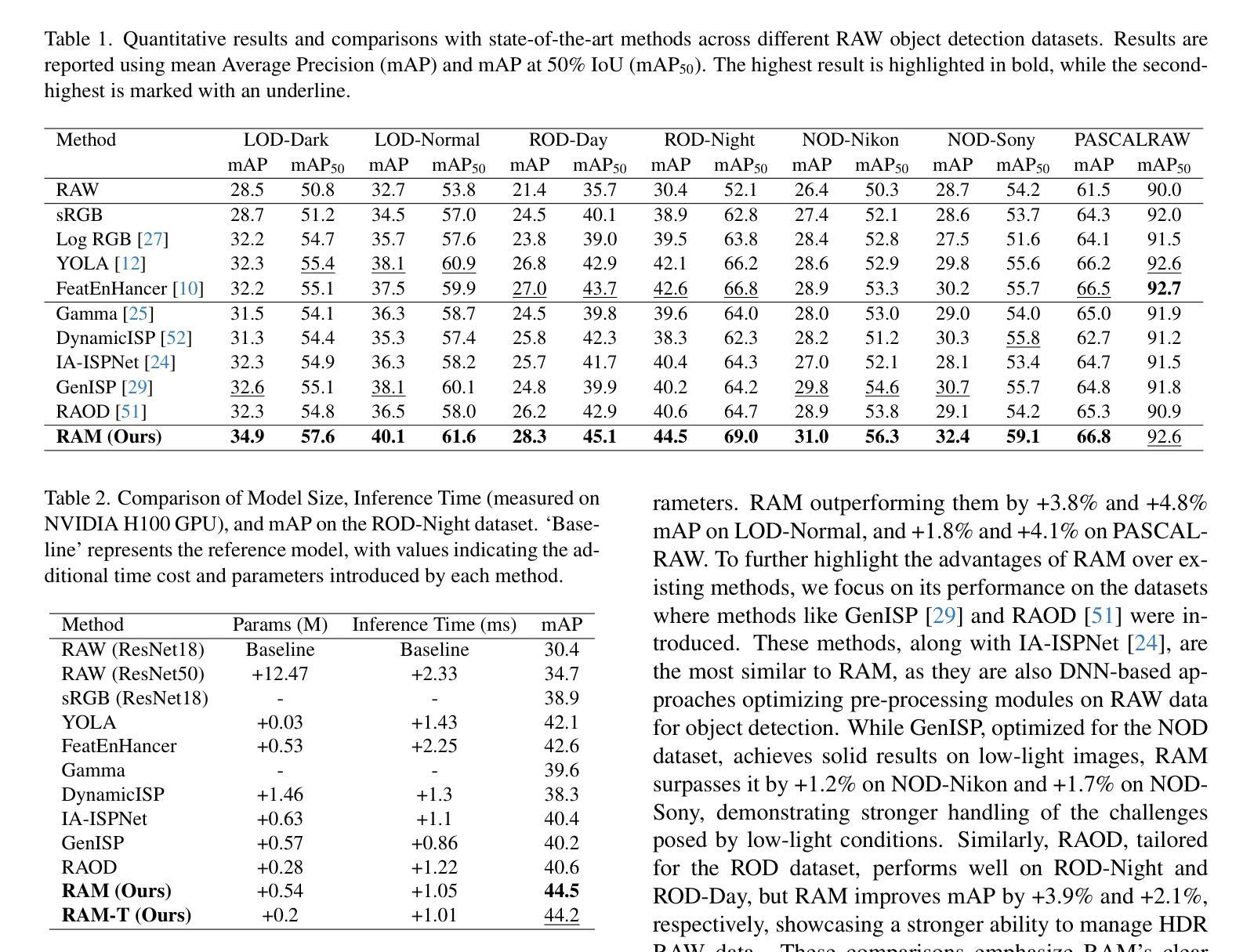
Object detection models are typically applied to standard RGB images processed through Image Signal Processing (ISP) pipelines, which are designed to enhance sensor-captured RAW images for human vision. However, these ISP functions can lead to a loss of critical information that may be essential in optimizing for computer vision tasks, such as object detection. In this work, we introduce Raw Adaptation Module (RAM), a module designed to replace the traditional ISP, with parameters optimized specifically for RAW object detection. Inspired by the parallel processing mechanisms of the human visual system, RAM departs from existing learned ISP methods by applying multiple ISP functions in parallel rather than sequentially, allowing for a more comprehensive capture of image features. These processed representations are then fused in a specialized module, which dynamically integrates and optimizes the information for the target task. This novel approach not only leverages the full potential of RAW sensor data but also enables task-specific pre-processing, resulting in superior object detection performance. Our approach outperforms RGB-based methods and achieves state-of-the-art results across diverse RAW image datasets under varying lighting conditions and dynamic ranges.
对象检测模型通常应用于通过图像信号处理(ISP)管道处理的标准RGB图像,这些管道旨在增强为增强人类视觉而捕获的传感器RAW图像。然而,这些ISP功能可能导致丢失对于优化计算机视觉任务(如对象检测)至关重要的关键信息。在这项工作中,我们引入了原始适配模块(RAM),这是一个旨在替代传统ISP的模块,其参数专为RAW对象检测优化。受人类视觉系统并行处理机制的启发,RAM通过与现有学习ISP方法不同的方式应用多个ISP功能并行而非顺序地应用,从而可以更全面地捕获图像特征。这些处理后的表示形式随后在一个专用模块中进行融合,该模块动态集成并优化针对目标任务的信息。这种新颖的方法不仅充分利用了RAW传感器的全部潜力,还实现了针对任务的预处理,从而实现了卓越的对象检测性能。我们的方法在多种RAW图像数据集上表现出优于基于RGB的方法,并在不同的照明条件和动态范围内达到了最新技术成果。
论文及项目相关链接
Summary:
本文介绍了在传统图像信号处理(ISP)管道中应用于标准RGB图像的对象检测模型可能会丢失关键信息,影响计算机视觉任务的优化。因此,研究提出了Raw Adaptation Module(RAM)模块,以替代传统的ISP,并针对RAW对象检测进行优化。RAM模块通过并行应用多个ISP功能,从原始传感器数据中提取更多特征信息,并动态集成和优化这些信息以完成目标检测任务。该方法不仅充分利用了RAW传感器数据的潜力,还实现了针对特定任务的预处理,从而获得卓越的对象检测性能。
Key Takeaways:
- 传统ISP管道设计主要面向人类视觉优化,可能丢失关键信息,影响计算机视觉任务的性能。
- 提出了Raw Adaptation Module(RAM)模块,替代传统ISP,针对RAW对象检测进行优化。
- RAM模块通过并行应用多个ISP功能,提取更多图像特征信息。
- RAM模块采用动态集成和优化信息的方式,以完成目标检测任务。
- 该方法充分利用RAW传感器数据的潜力。
- 实现针对特定任务的预处理,提高对象检测性能。
点此查看论文截图

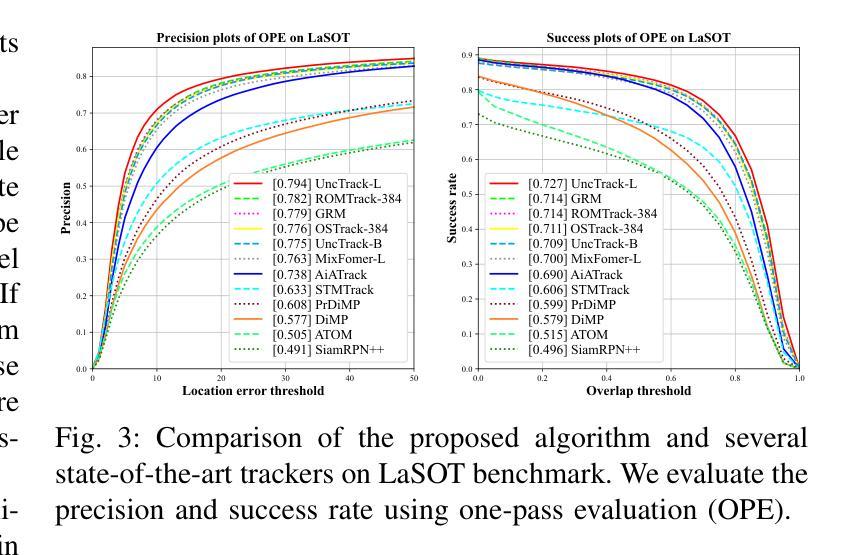
UncTrack: Reliable Visual Object Tracking with Uncertainty-Aware Prototype Memory Network
Authors:Siyuan Yao, Yang Guo, Yanyang Yan, Wenqi Ren, Xiaochun Cao
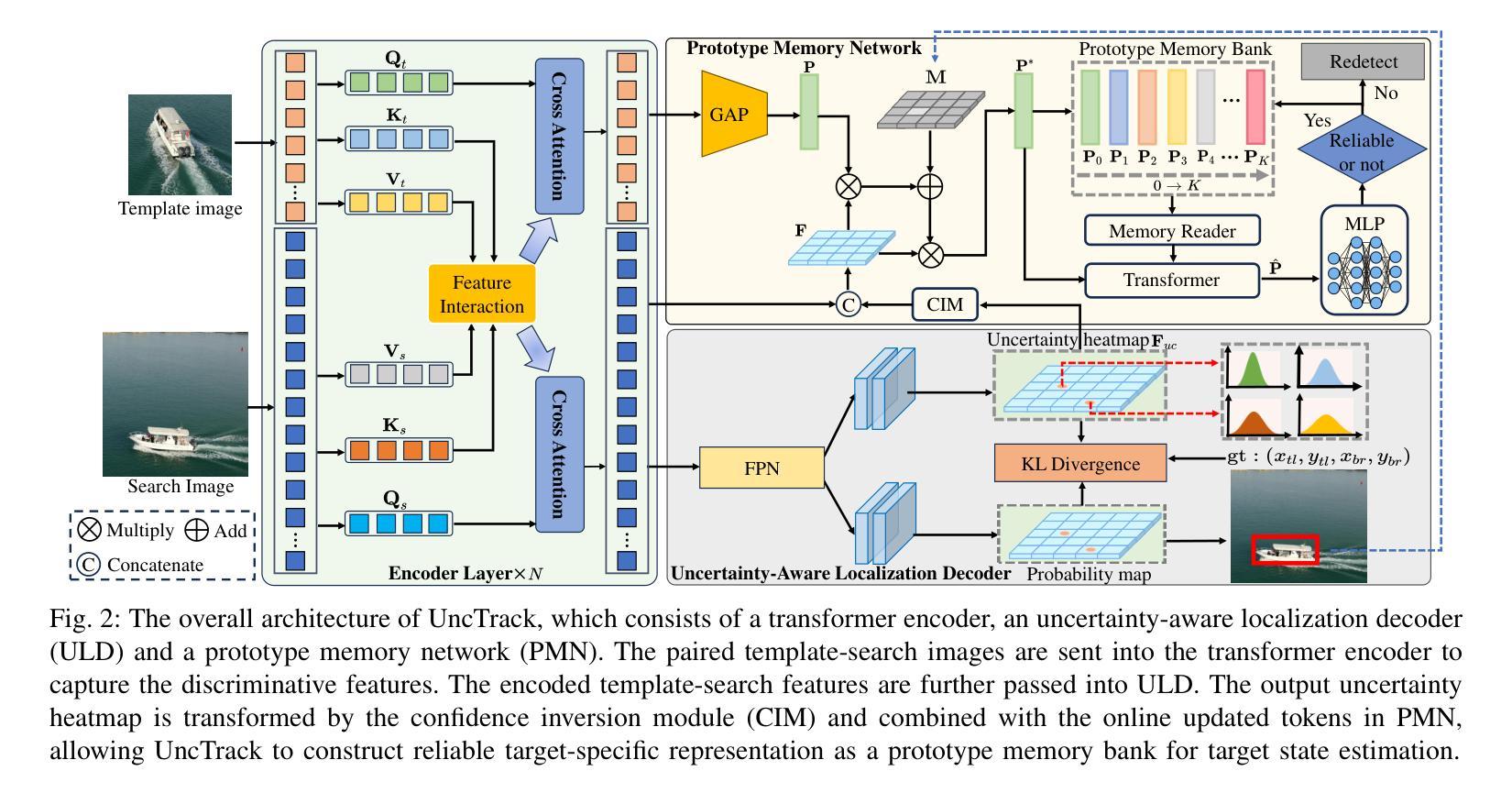
Transformer-based trackers have achieved promising success and become the dominant tracking paradigm due to their accuracy and efficiency. Despite the substantial progress, most of the existing approaches tackle object tracking as a deterministic coordinate regression problem, while the target localization uncertainty has been greatly overlooked, which hampers trackers’ ability to maintain reliable target state prediction in challenging scenarios. To address this issue, we propose UncTrack, a novel uncertainty-aware transformer tracker that predicts the target localization uncertainty and incorporates this uncertainty information for accurate target state inference. Specifically, UncTrack utilizes a transformer encoder to perform feature interaction between template and search images. The output features are passed into an uncertainty-aware localization decoder (ULD) to coarsely predict the corner-based localization and the corresponding localization uncertainty. Then the localization uncertainty is sent into a prototype memory network (PMN) to excavate valuable historical information to identify whether the target state prediction is reliable or not. To enhance the template representation, the samples with high confidence are fed back into the prototype memory bank for memory updating, making the tracker more robust to challenging appearance variations. Extensive experiments demonstrate that our method outperforms other state-of-the-art methods. Our code is available at https://github.com/ManOfStory/UncTrack.
基于Transformer的跟踪器由于其准确性和高效性而取得了有前景的成功,并成为主导跟踪范式。尽管取得了重大进展,但大多数现有方法都将目标跟踪视为确定性坐标回归问题,而目标定位的不确定性却被大大忽视了,这阻碍了跟踪器在具有挑战性的场景中保持可靠的目标状态预测的能力。为了解决这一问题,我们提出了UncTrack,这是一种新型的不确定性感知Transformer跟踪器,它预测目标定位的不确定性,并将这种不确定性信息用于准确的目标状态推断。具体来说,UncTrack利用Transformer编码器执行模板图像和搜索图像之间的特征交互。输出特征被传递到不确定性感知定位解码器(ULD)中,以粗略预测基于角点的定位和相应的定位不确定性。然后,定位不确定性被发送到原型记忆网络(PMN)中,以挖掘有价值的历史信息来确定目标状态预测是否可靠。为了提高模板表示能力,高置信度的样本被反馈到原型记忆库中进行记忆更新,使跟踪器对挑战性的外观变化更加鲁棒。大量实验表明,我们的方法优于其他最先进的方法。我们的代码位于https://github.com/ManOfStory/UncTrack。
论文及项目相关链接
PDF 14 pages,11 figures,references added
Summary:
基于Transformer的跟踪器已成为目标跟踪的主流范式,因其准确性和高效性而受到广泛关注。然而,现有方法大多将目标跟踪视为确定性坐标回归问题,忽略了目标定位的不确定性,这在挑战场景下限制了跟踪器的可靠目标状态预测能力。为解决这一问题,我们提出了UncTrack,一种新型的不确定性感知Transformer跟踪器,它预测目标定位的不确定性,并结合这一不确定性信息进行准确的目标状态推断。
Key Takeaways:
- Transformer跟踪器已成为主流,因为它们既准确又高效。
- 现有方法主要关注确定性坐标回归,忽略了目标定位的不确定性。
- UncTrack是一种新型的不确定性感知Transformer跟踪器。
- UncTrack利用变压器编码器进行模板和搜索图像之间的特征交互。
- UncTrack有一个不确定性感知定位解码器(ULD),可粗略预测基于角落的定位和相应的定位不确定性。
- UncTrack使用原型记忆网络(PMN)来挖掘有价值的历史信息,以确定目标状态预测的可靠性。
点此查看论文截图

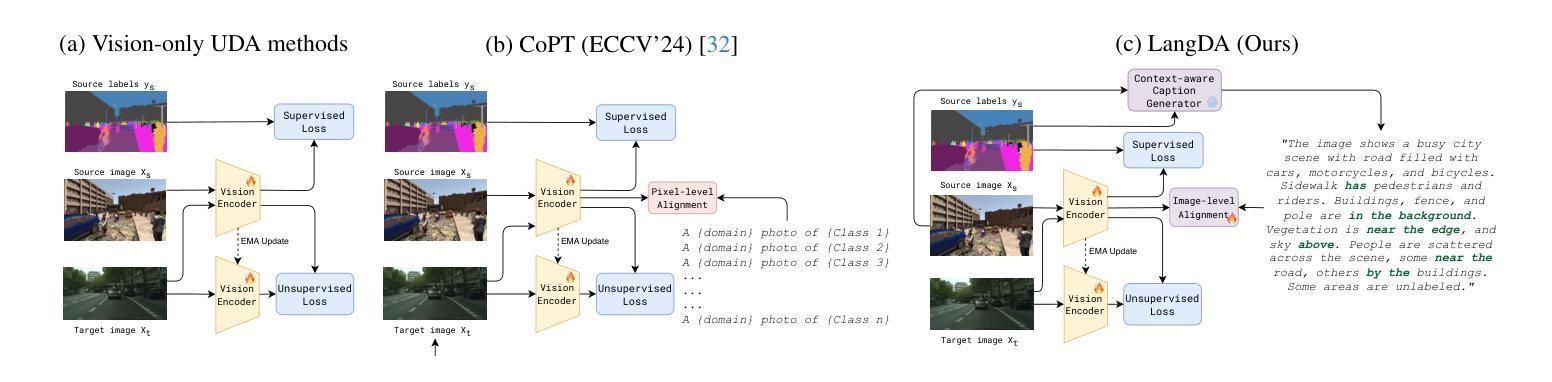
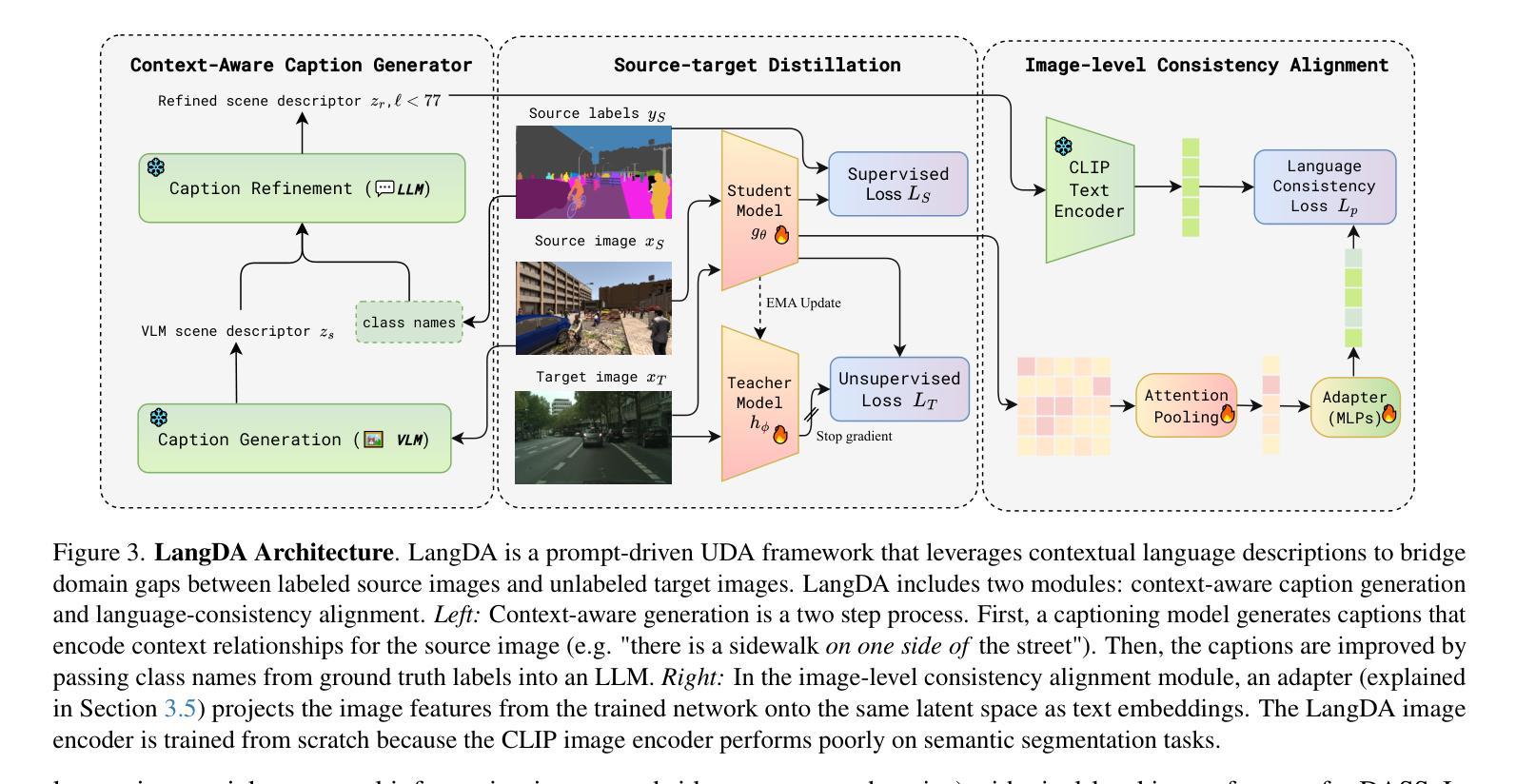
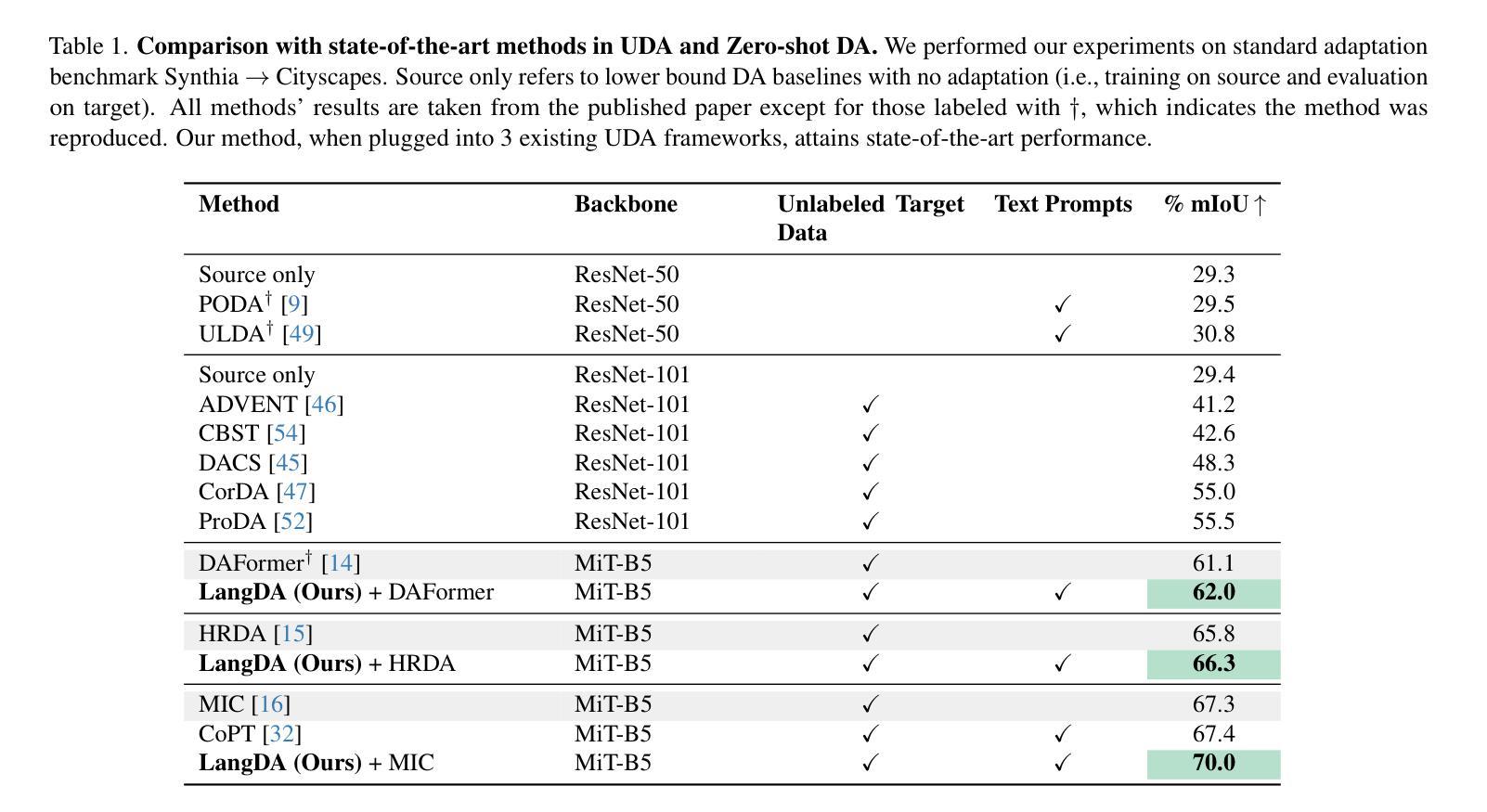
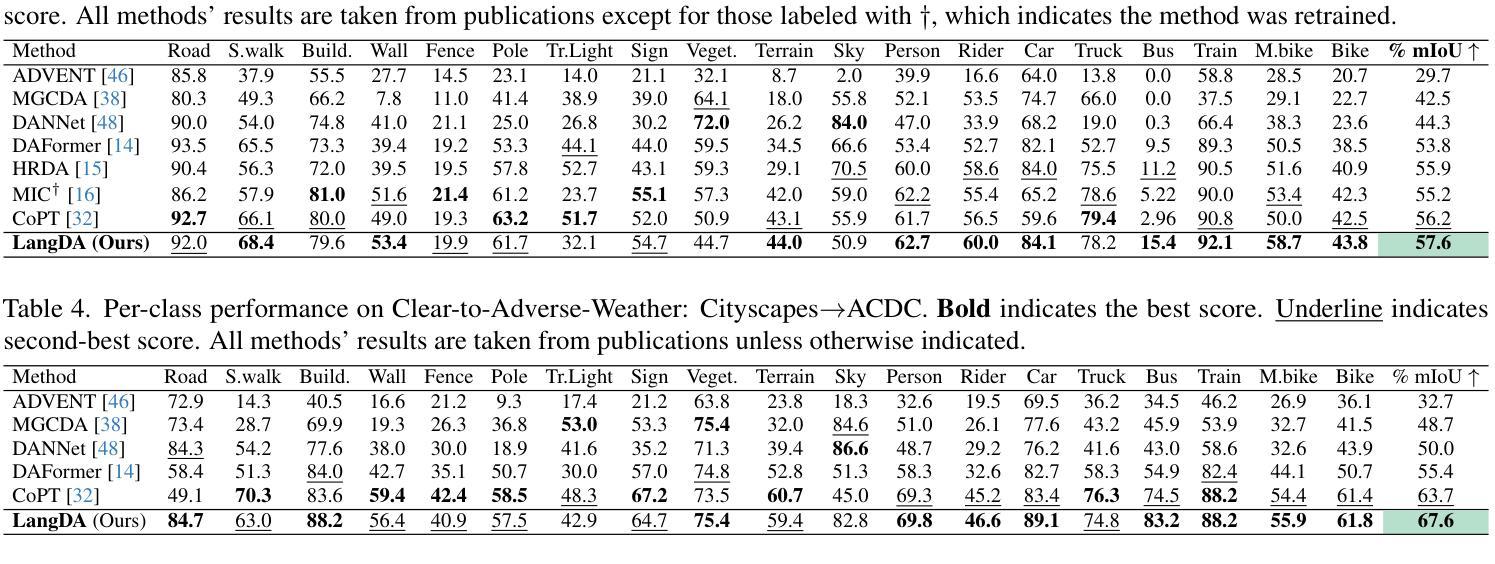
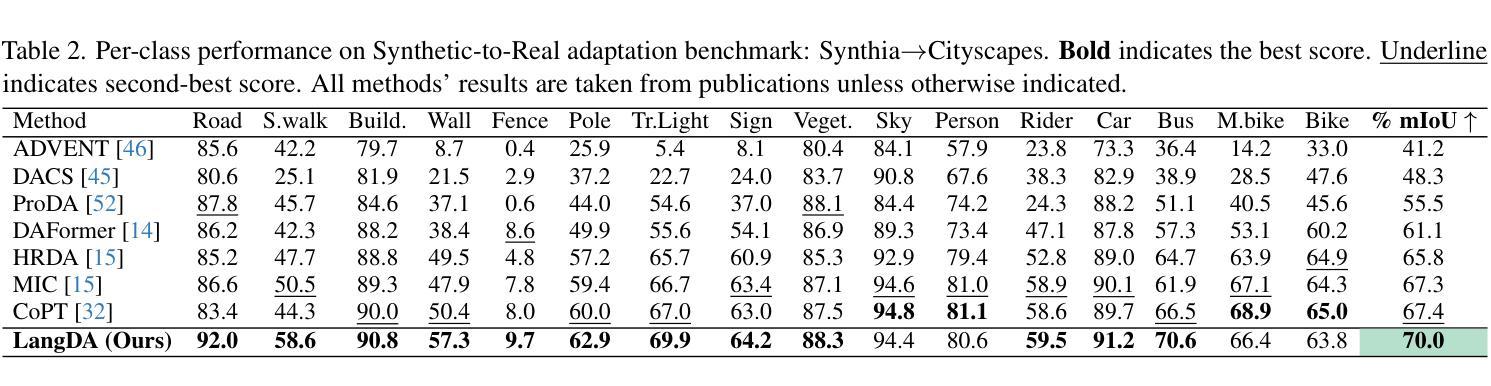
LangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Authors:Chang Liu, Bavesh Balaji, Saad Hossain, C Thomas, Kwei-Herng Lai, Raviteja Vemulapalli, Alexander Wong, Sirisha Rambhatla
Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. “a {snowy} photo of a {class}”). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects – key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. “a pedestrian is on the sidewalk, and the street is lined with buildings.”). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
无监督领域自适应语义分割(DASS)旨在将从标签丰富的源域转移的知识应用到无标签的目标域。DASS中的两种主要方法是(1)仅使用视觉的方法,采用遮挡或多分辨率裁剪,以及(2)基于语言的方法,使用由目标域信息指导的通用类别提示(例如,“一个{snowy}的{class}的照片”)。然而,前者容易受到偏向源域的噪声伪标签的影响。后者则无法完全捕获对象的复杂空间关系,这在密集预测任务中至关重要。为此,我们提出了LangDA方法。LangDA通过以下方式解决这些挑战:首先,通过VLM生成的场景描述学习对象之间的上下文关系(例如,“行人在人行道上,街道两旁都是建筑。”);其次,LangDA将整幅图像的特征与这种上下文感知的场景字幕的文本表示对齐,并通过文本学习通用表示。因此,LangDA在三个DASS基准测试中均达到最新水平,相较于现有方法分别提高了2.6%、1.4%和3.9%。
论文及项目相关链接
Summary
DASS采用无监督域自适应技术,将标签丰富的源域知识迁移到无标签的目标域。现有方法存在噪声伪标签偏向源域以及无法完全捕捉对象间复杂空间关系的问题。为此,提出LangDA方法。LangDA通过学习对象间的上下文关系并利用VLM生成的场景描述来解决这些问题,例如“行人在人行道上,街道两旁有建筑物。”此外,LangDA将整幅图像的特征与上下文感知的场景字幕文本表示进行对齐,并通过文本学习通用表示。这使LangDA在三个DASS基准测试中均创下新高,较现有方法提高了2.6%、1.4%和3.9%。
Key Takeaways
- DASS旨在实现无监督域自适应技术,将知识从标签丰富的源域迁移到无标签的目标域。
- 当前两大关键方法分别为仅依赖视觉的方法和基于语言的方法。视觉方法易受噪声伪标签影响且易偏向源域,而基于语言的方法则无法完全捕捉对象的复杂空间关系。
- LangDA方法通过结合视觉和语言信息来解决上述问题。它利用VLM生成的场景描述来学习对象间的上下文关系。
- LangDA通过将整幅图像的特征与上下文感知的场景字幕文本表示进行对齐,实现图像和文本的匹配学习。
- LangDA方法在三个DASS基准测试中表现优异,显著优于现有方法。
- LangDA方法提高了语义分割的准确性和性能。
点此查看论文截图


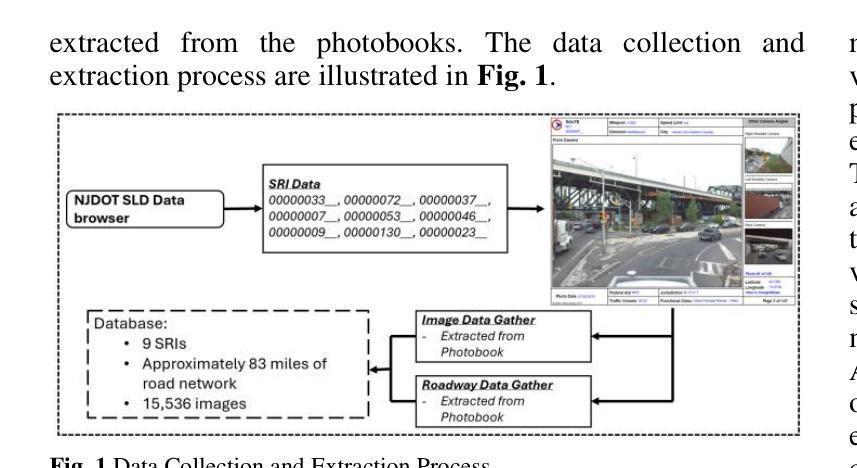
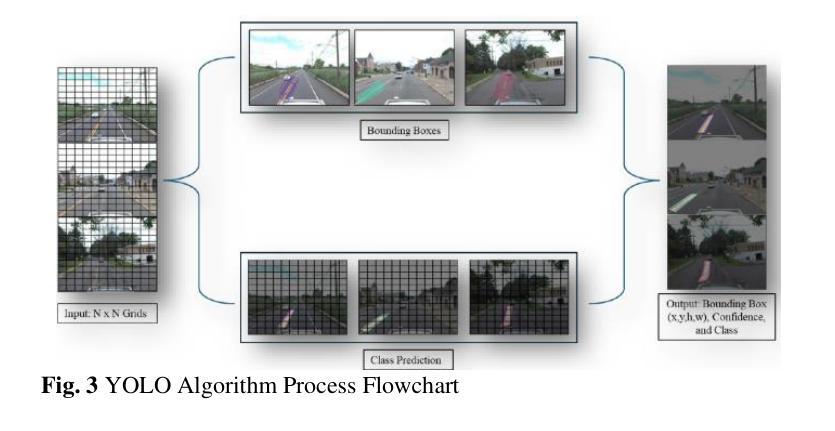
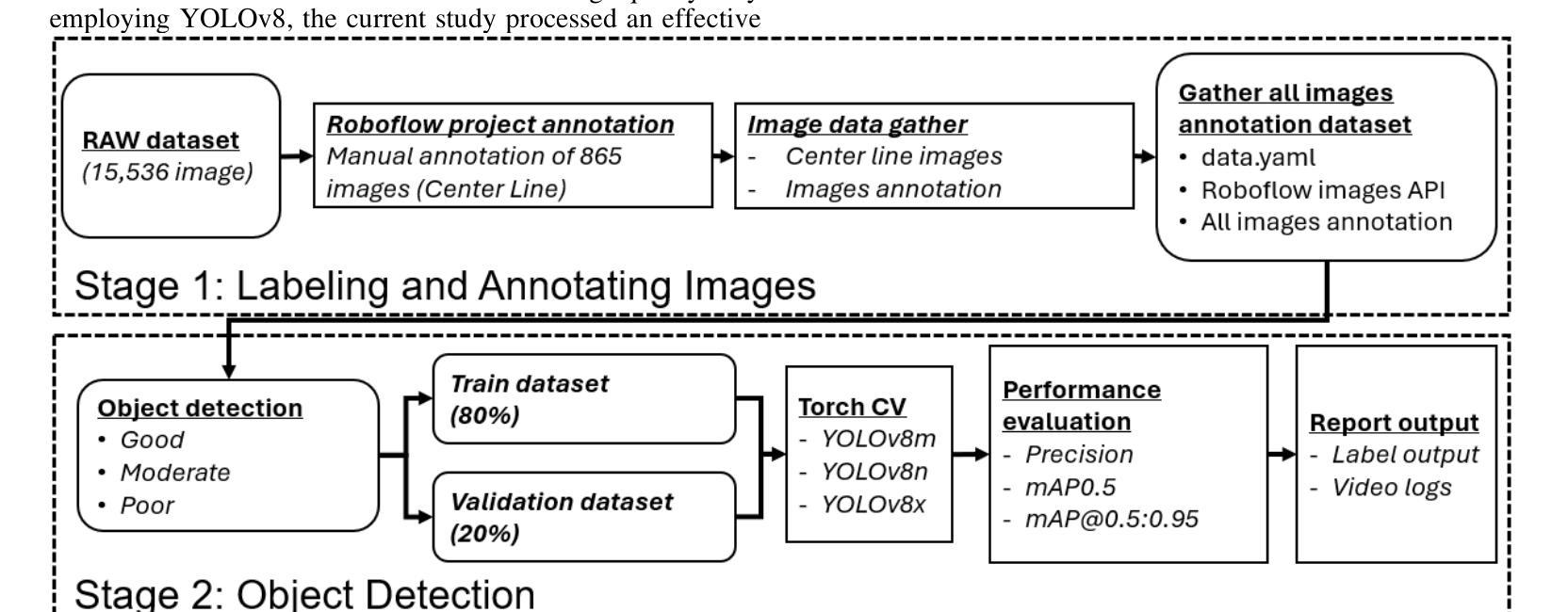
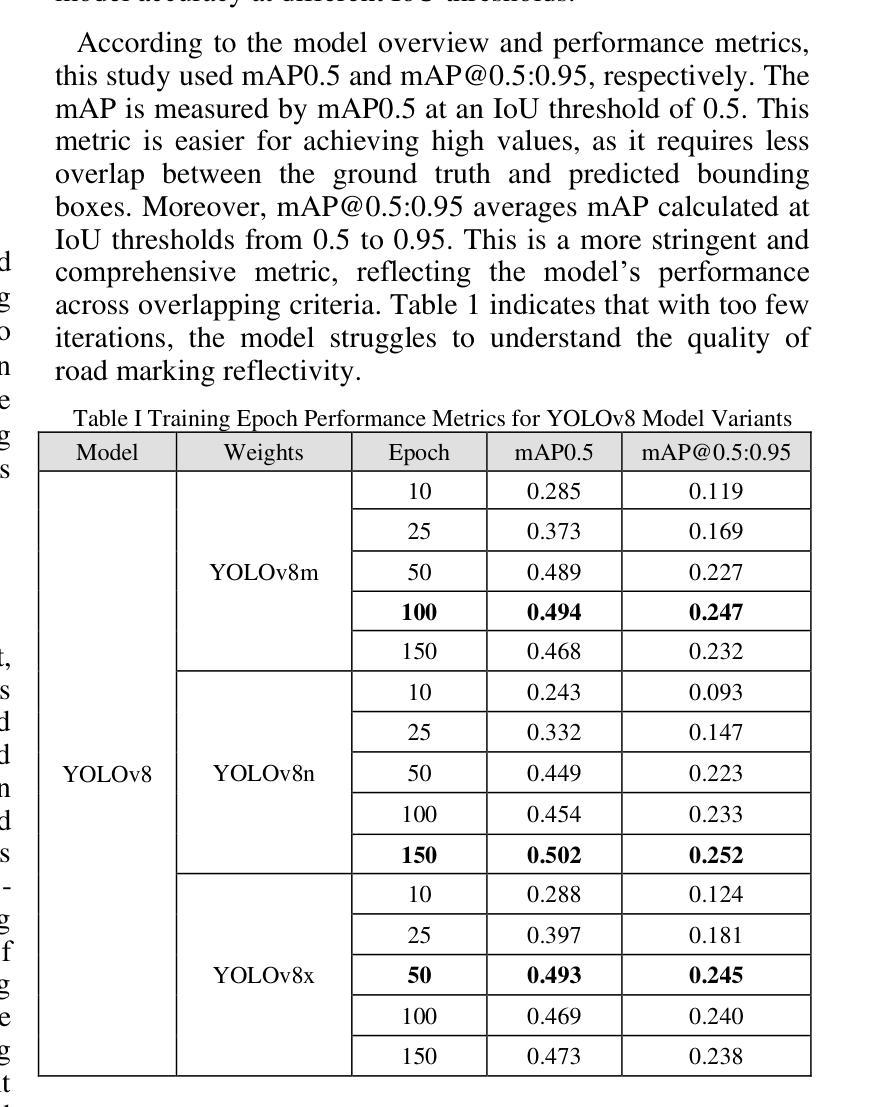
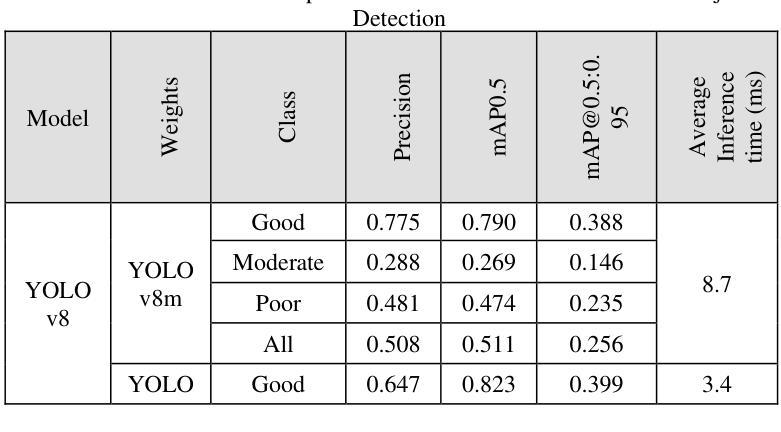
Comparative Analysis of Advanced AI-based Object Detection Models for Pavement Marking Quality Assessment during Daytime
Authors:Gian Antariksa, Rohit Chakraborty, Shriyank Somvanshi, Subasish Das, Mohammad Jalayer, Deep Rameshkumar Patel, David Mills
Visual object detection utilizing deep learning plays a vital role in computer vision and has extensive applications in transportation engineering. This paper focuses on detecting pavement marking quality during daytime using the You Only Look Once (YOLO) model, leveraging its advanced architectural features to enhance road safety through precise and real-time assessments. Utilizing image data from New Jersey, this study employed three YOLOv8 variants: YOLOv8m, YOLOv8n, and YOLOv8x. The models were evaluated based on their prediction accuracy for classifying pavement markings into good, moderate, and poor visibility categories. The results demonstrated that YOLOv8n provides the best balance between accuracy and computational efficiency, achieving the highest mean Average Precision (mAP) for objects with good visibility and demonstrating robust performance across various Intersections over Union (IoU) thresholds. This research enhances transportation safety by offering an automated and accurate method for evaluating the quality of pavement markings.
利用深度学习进行视觉对象检测在计算机视觉中起着至关重要的作用,在交通工程中有广泛的应用。本文重点研究在白天利用You Only Look Once(YOLO)模型检测路面标记质量,利用其先进的架构特性进行精确实时的评估,以提高道路安全。利用新泽西州的图像数据,本研究采用了三种YOLOv8变体:YOLOv8m、YOLOv8n和YOLOv8x。这些模型的评估基于它们对路面标记进行良好、中等和不良能见度分类的预测精度。结果表明,YOLOv8n在准确性和计算效率之间达到了最佳平衡,对于具有良好能见度的对象实现了最高的平均精度(mAP),并在各种交并比(IoU)阈值下表现出稳健的性能。本研究通过提供一种自动化、准确的方法来对路面标记质量进行评估,提高了交通运输安全。
论文及项目相关链接
PDF 6 pages, 3 figures, accepted at IEEE CAI 2025
Summary
本文利用深度学习中的YOLO模型对日间路面标记质量进行检测研究,以提高道路安全。通过对新泽西州的图像数据进行实验,发现YOLOv8n模型在分类路面标记为良好、中等和不良能见度类别时,实现了最高的平均精度(mAP),并且在不同的交并比(IoU)阈值下表现稳健。该研究为提高路面标记质量的自动评估提供了一种准确的方法,增强了交通运输的安全性。
Key Takeaways
- YOLO模型被用于检测日间路面标记质量,以增强道路安全。
- 研究使用了YOLOv8的三个变体:YOLOv8m、YOLOv8n和YOLOv8x。
- YOLOv8n模型在分类路面标记的预测精度上表现最佳,实现了最高的平均精度(mAP)。
- 研究使用新泽西州的图像数据进行实验。
- 该模型在检测不同能见度的路面标记时表现出稳健性能。
- 该研究为自动评估路面标记质量提供了一种准确的方法。
点此查看论文截图

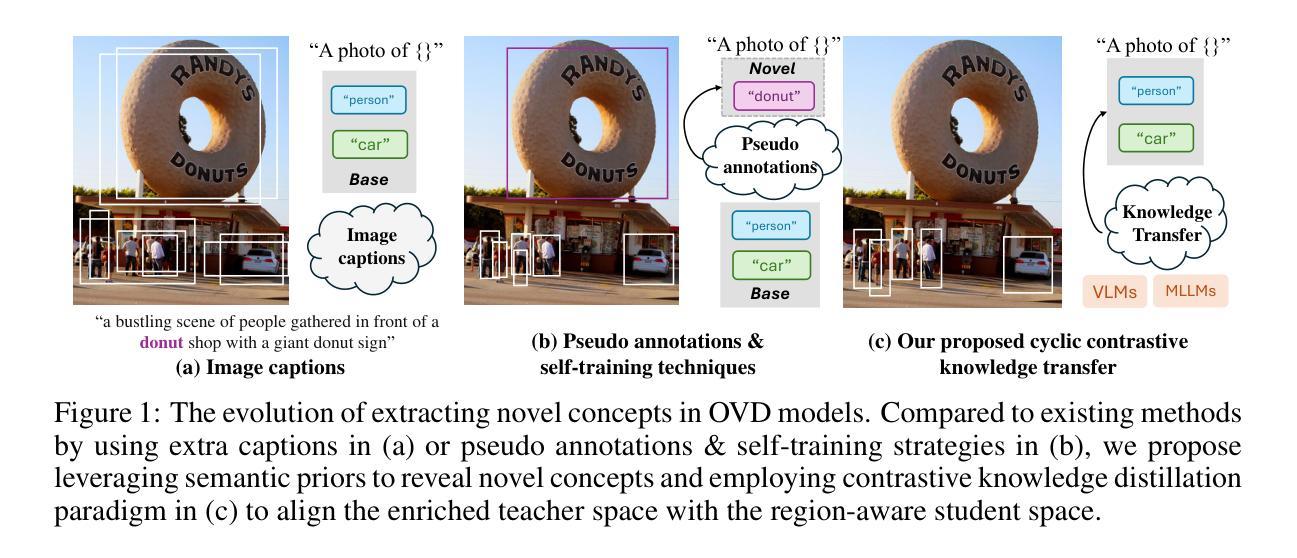
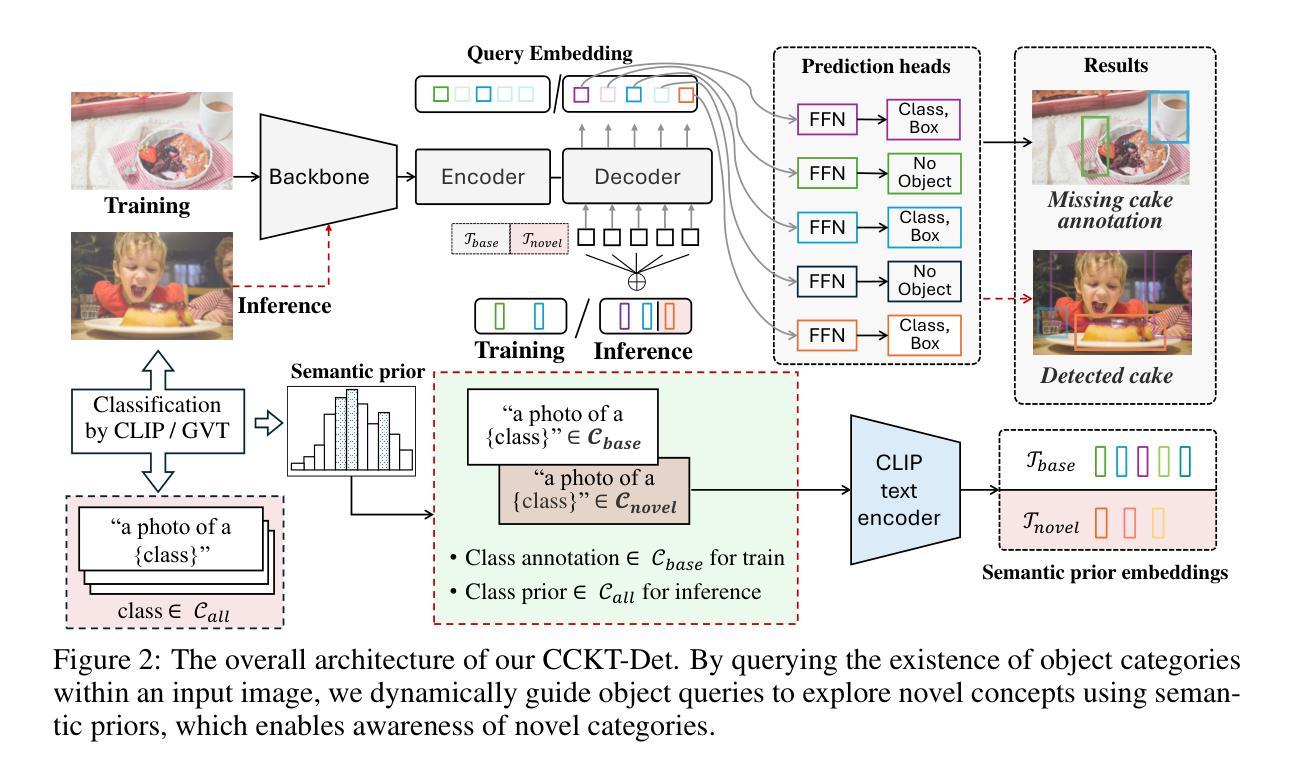
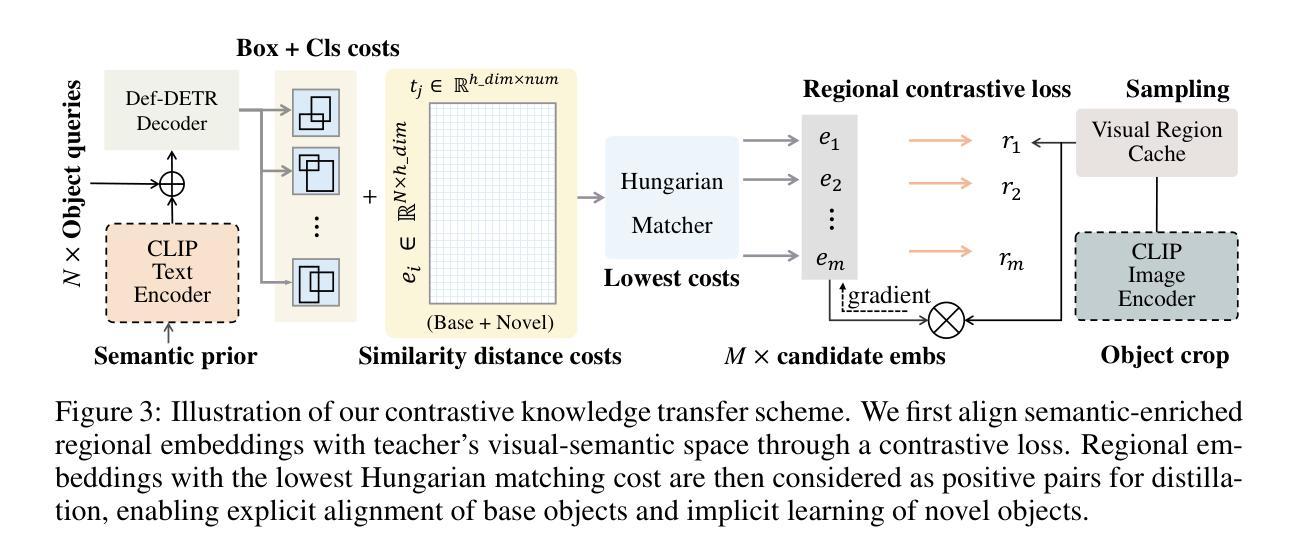
Cyclic Contrastive Knowledge Transfer for Open-Vocabulary Object Detection
Authors:Chuhan Zhang, Chaoyang Zhu, Pingcheng Dong, Long Chen, Dong Zhang
In pursuit of detecting unstinted objects that extend beyond predefined categories, prior arts of open-vocabulary object detection (OVD) typically resort to pretrained vision-language models (VLMs) for base-to-novel category generalization. However, to mitigate the misalignment between upstream image-text pretraining and downstream region-level perception, additional supervisions are indispensable, eg, image-text pairs or pseudo annotations generated via self-training strategies. In this work, we propose CCKT-Det trained without any extra supervision. The proposed framework constructs a cyclic and dynamic knowledge transfer from language queries and visual region features extracted from VLMs, which forces the detector to closely align with the visual-semantic space of VLMs. Specifically, 1) we prefilter and inject semantic priors to guide the learning of queries, and 2) introduce a regional contrastive loss to improve the awareness of queries on novel objects. CCKT-Det can consistently improve performance as the scale of VLMs increases, all while requiring the detector at a moderate level of computation overhead. Comprehensive experimental results demonstrate that our method achieves performance gain of +2.9% and +10.2% AP50 over previous state-of-the-arts on the challenging COCO benchmark, both without and with a stronger teacher model. The code is provided at https://github.com/ZCHUHan/CCKT-Det.
在追求检测无限制对象,这些对象超出预定类别的情况下,开放词汇表对象检测(OVD)的现有技术通常依赖于预训练的视觉语言模型(VLM)进行基础到新颖类别的推广。然而,为了减轻上游图像文本预训练和下游区域级别感知之间的不匹配,额外的监督是不可或缺的,例如,通过自训练策略生成的图像文本对或伪注释。在这项工作中,我们提出了无需任何额外监督的CCKT-Det。所提出的框架构建了从语言查询和从VLM提取的视觉区域特征之间的循环和动态知识转移,这迫使检测器紧密地对应于VLM的视觉语义空间。具体来说,1)我们预过滤并注入语义先验来指导查询学习,2)引入区域对比损失来提高查询对新对象的感知能力。随着VLM规模的增加,CCKT-Det可以持续提高性能,同时只需要适度的检测器计算开销。综合实验结果表明,我们的方法在具有挑战性的COCO基准测试上,相较于之前的最优水平,有无更强的教师模型分别实现了+2.9%和+10.2%的AP50性能提升。代码可在https://github.com/ZCHUHan/CCKT-Det找到。
论文及项目相关链接
PDF 10 pages, 5 figures, Published as a conference paper at ICLR 2025
Summary
本文提出一种无需额外监督的CCKT-Det框架,用于开放词汇表对象检测。该框架通过构建循环和动态知识转移,从语言查询到视觉区域特征进行训练,促进检测器与视觉语言模型的视觉语义空间对齐。通过预筛选和注入语义先验来引导查询学习,引入区域对比损失提高查询对未知物体的识别能力。实验表明,该框架能在不同规模的视觉语言模型上持续提高性能,同时只需适度的计算开销。
Key Takeaways
- CCKT-Det利用循环和动态知识转移,实现语言查询到视觉区域特征的训练,促进检测器与视觉语言模型(VLMs)的视觉语义空间对齐。
- 通过预筛选和注入语义先验,引导查询学习,提高检测性能。
- 引入区域对比损失,提高检测器对未知物体的识别能力。
- CCKT-Det可在不同规模的VLMs上持续提高性能。
- 与现有技术相比,CCKT-Det在COCO基准测试上实现了显著的性能提升。
6.CCKT-Det的计算开销适中。
点此查看论文截图

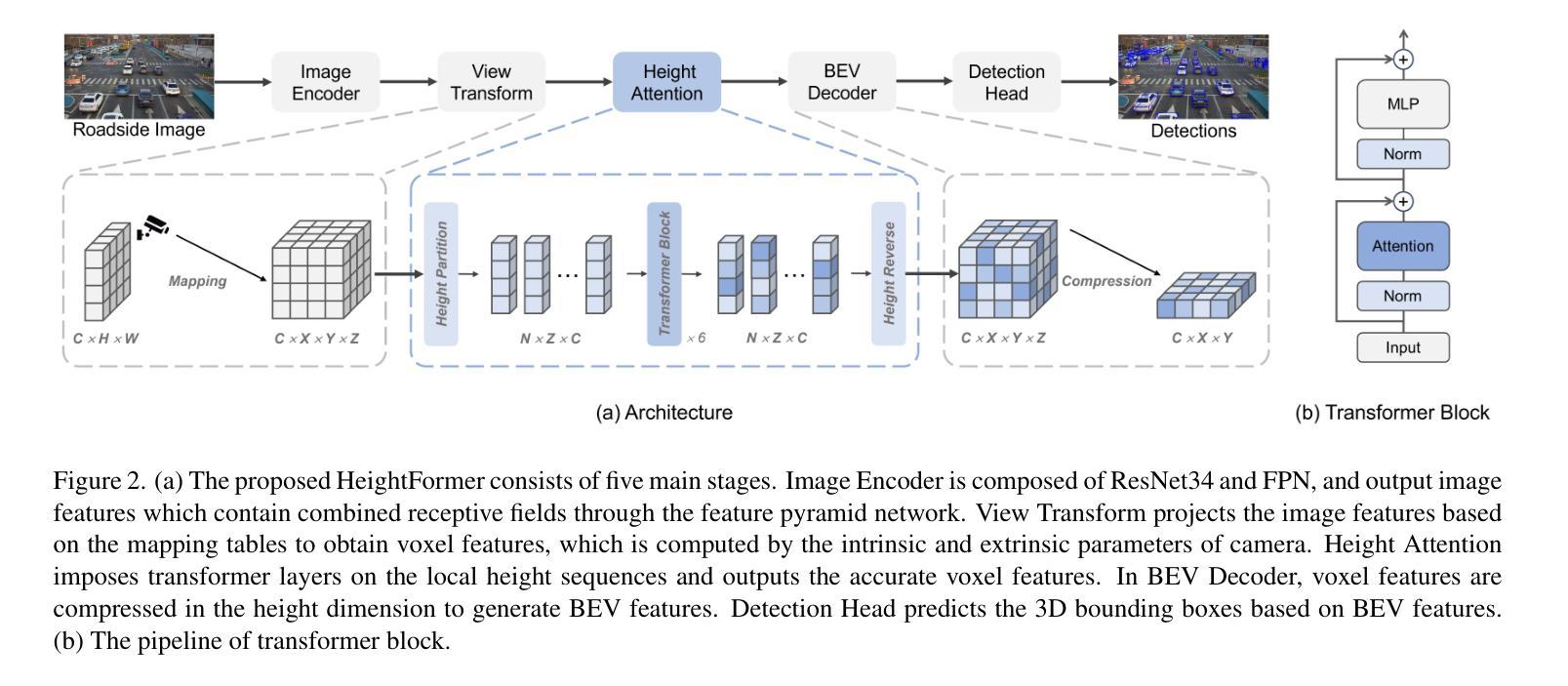
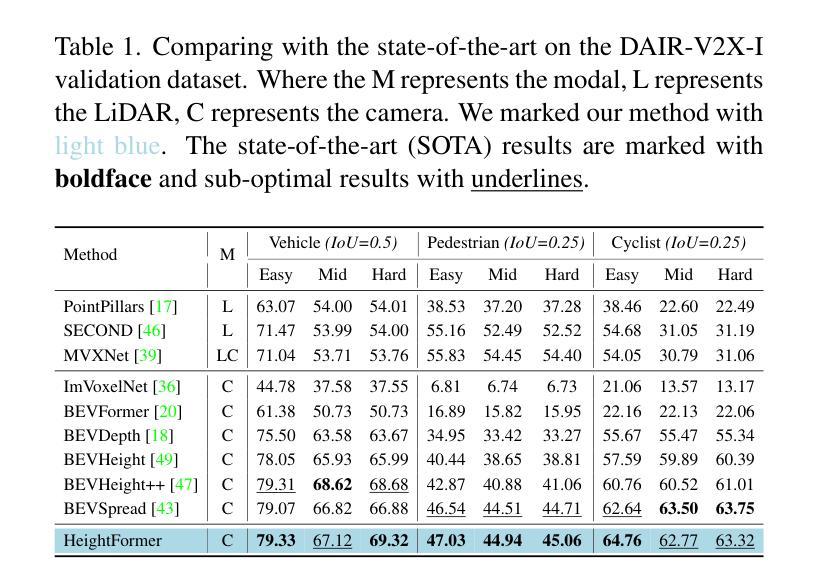
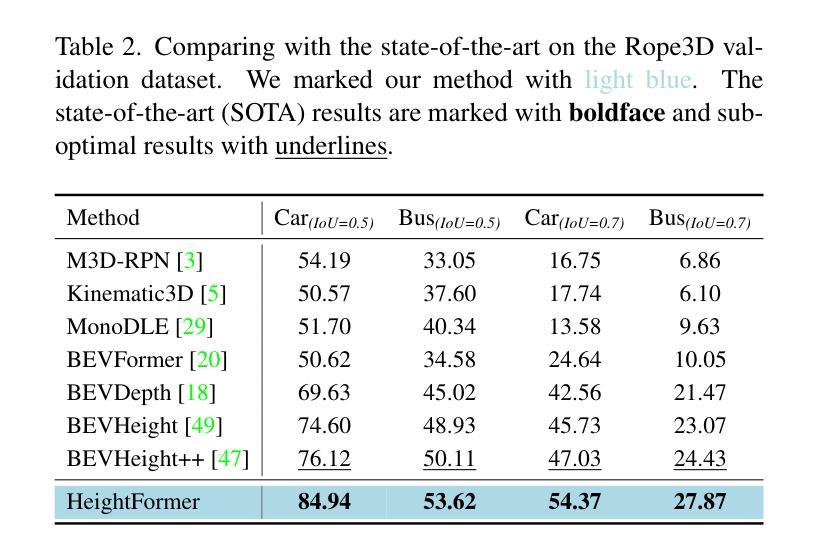
HeightFormer: Learning Height Prediction in Voxel Features for Roadside Vision Centric 3D Object Detection via Transformer
Authors:Zhang Zhang, Chao Sun, Chao Yue, Da Wen, Yujie Chen, Tianze Wang, Jianghao Leng
Roadside vision centric 3D object detection has received increasing attention in recent years. It expands the perception range of autonomous vehicles, enhances the road safety. Previous methods focused on predicting per-pixel height rather than depth, making significant gains in roadside visual perception. While it is limited by the perspective property of near-large and far-small on image features, making it difficult for network to understand real dimension of objects in the 3D world. BEV features and voxel features present the real distribution of objects in 3D world compared to the image features. However, BEV features tend to lose details due to the lack of explicit height information, and voxel features are computationally expensive. Inspired by this insight, an efficient framework learning height prediction in voxel features via transformer is proposed, dubbed HeightFormer. It groups the voxel features into local height sequences, and utilize attention mechanism to obtain height distribution prediction. Subsequently, the local height sequences are reassembled to generate accurate 3D features. The proposed method is applied to two large-scale roadside benchmarks, DAIR-V2X-I and Rope3D. Extensive experiments are performed and the HeightFormer outperforms the state-of-the-art methods in roadside vision centric 3D object detection task.
近年来,以道路为中心的3D物体检测得到了越来越多的关注。它扩展了自动驾驶车辆的感知范围,提高了道路安全性。之前的方法侧重于预测像素高度而非深度,在路边视觉感知方面取得了重大进展。然而,由于图像特征的近大远小的透视属性,网络难以理解物体在现实世界中的真实尺寸。与图像特征相比,BEV特征和体素特征展示了物体在真实世界中的真实分布。然而,BEV特征由于缺乏明确的高度信息而容易丢失细节,而体素特征的计算成本较高。受这一见解的启发,提出了一个高效的框架来学习通过Transformer进行体素特征的高度预测,称为HeightFormer。它将体素特征分组为局部高度序列,并利用注意力机制获得高度分布预测。随后,这些局部高度序列被重新组合以生成准确的3D特征。所提出的方法应用于两个大规模的路边基准测试DAIR-V2X-I和Rope3D。进行了大量的实验,HeightFormer在路边视觉为中心的3D物体检测任务中优于现有技术方法。
论文及项目相关链接
Summary
本文关注路边视觉为中心的3D目标检测问题,提出了HeightFormer框架,通过利用注意力机制预测物体高度序列信息来解决当前方法中BEV特征缺失细节和图像特征受透视效应影响的问题。HeightFormer将体素特征分为局部高度序列并生成准确的三维特征,在大型路边基准测试中表现优异。
Key Takeaways
- 路边视觉为中心的3D目标检测问题受到关注,旨在扩大自主车辆的感知范围并提高道路安全性。
- 传统方法主要预测像素高度,存在透视效应问题,导致网络难以理解真实的三维世界中的物体尺寸。
- BEV特征和体素特征能展示物体的真实三维分布,但BEV特征易丢失细节,体素特征计算成本高。
- HeightFormer框架通过利用注意力机制预测高度分布来解决上述问题。
- HeightFormer将体素特征分组为局部高度序列,然后重新组装以生成准确的三维特征。
- HeightFormer在大型路边基准测试中表现优越,优于现有技术。
点此查看论文截图


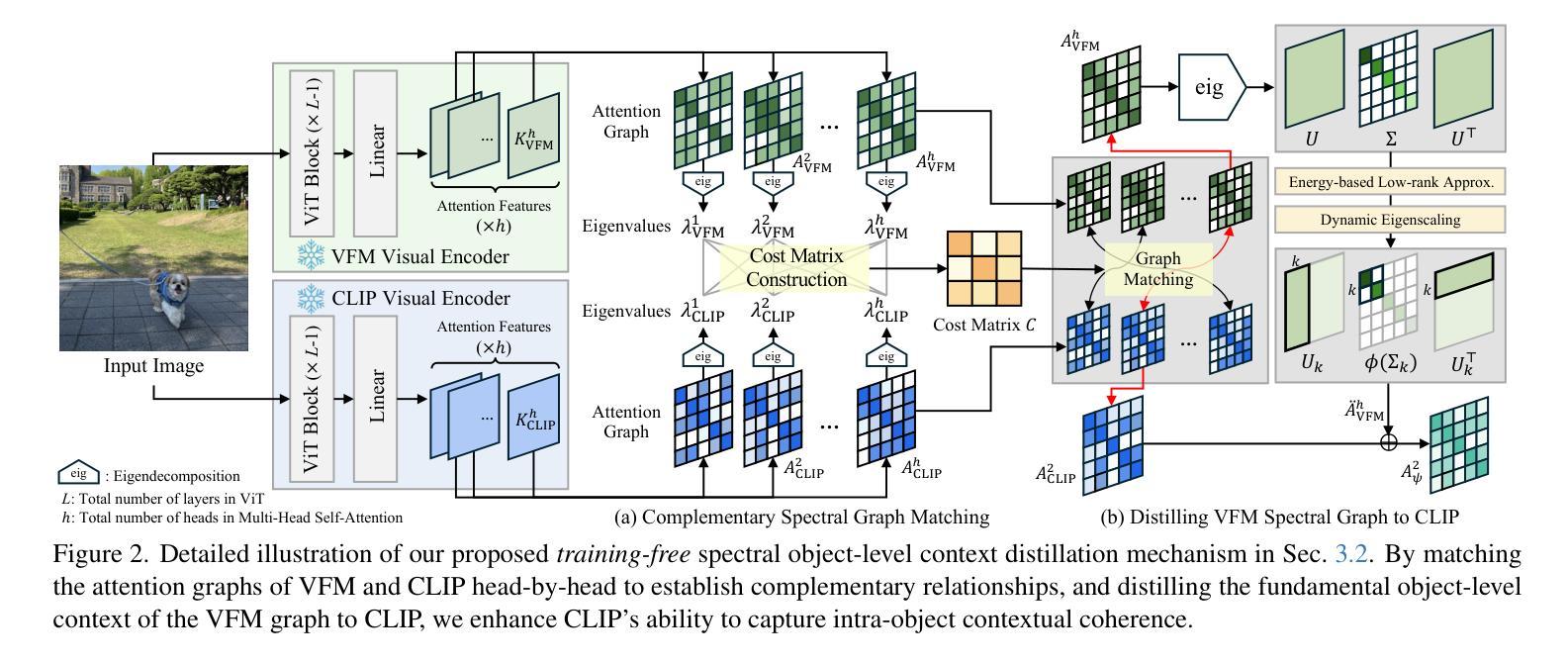
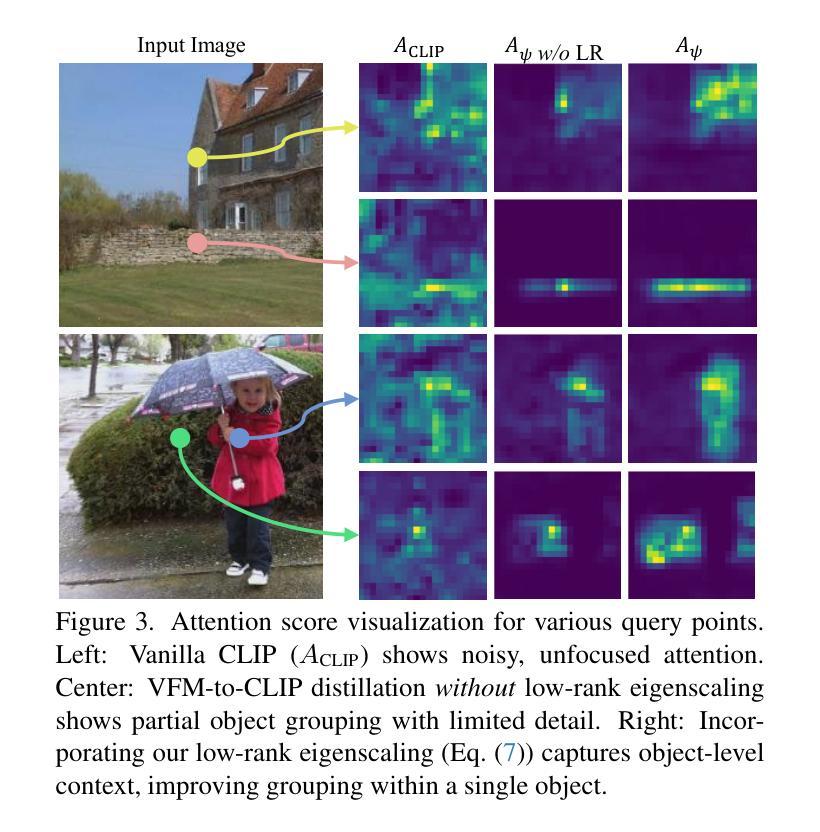
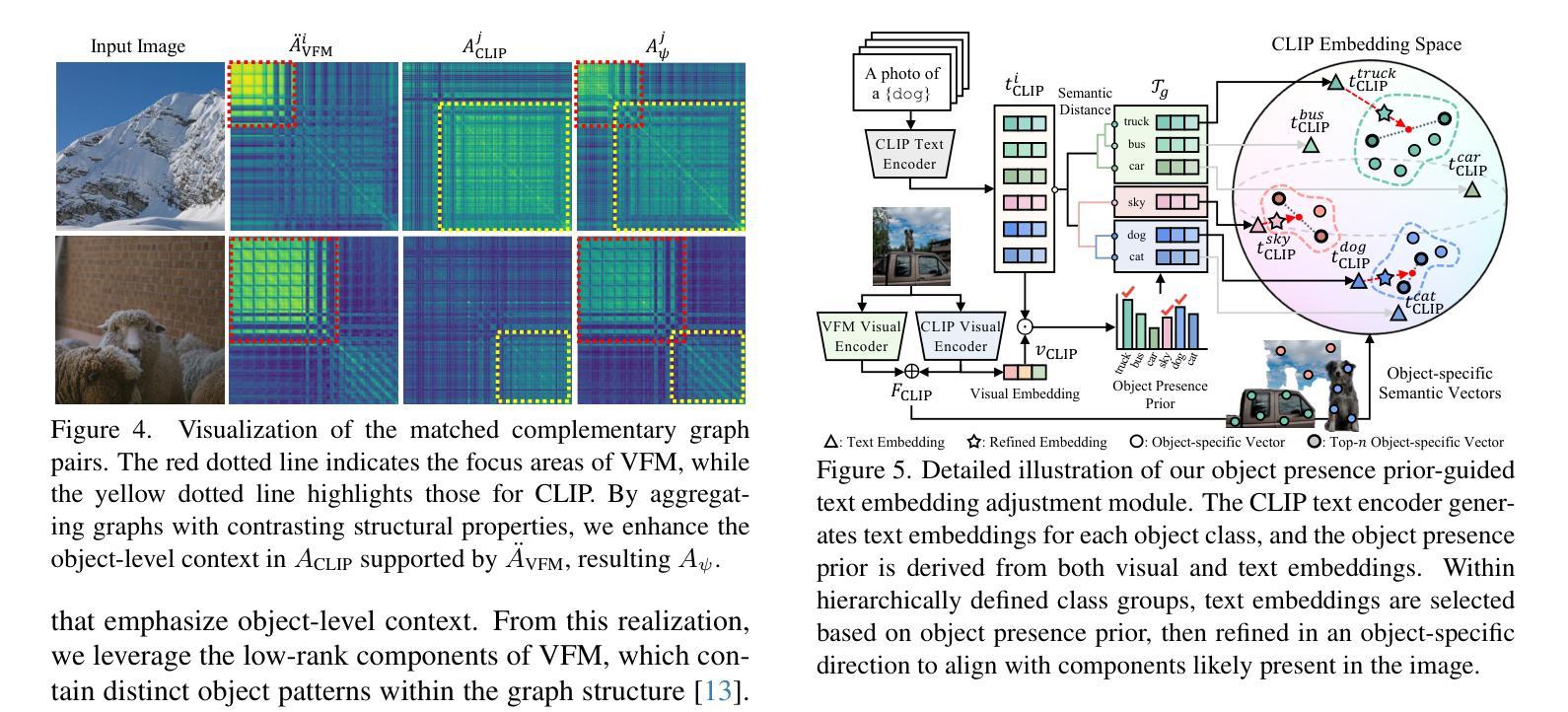
Distilling Spectral Graph for Object-Context Aware Open-Vocabulary Semantic Segmentation
Authors:Chanyoung Kim, Dayun Ju, Woojung Han, Ming-Hsuan Yang, Seong Jae Hwang
Open-Vocabulary Semantic Segmentation (OVSS) has advanced with recent vision-language models (VLMs), enabling segmentation beyond predefined categories through various learning schemes. Notably, training-free methods offer scalable, easily deployable solutions for handling unseen data, a key goal of OVSS. Yet, a critical issue persists: lack of object-level context consideration when segmenting complex objects in the challenging environment of OVSS based on arbitrary query prompts. This oversight limits models’ ability to group semantically consistent elements within object and map them precisely to user-defined arbitrary classes. In this work, we introduce a novel approach that overcomes this limitation by incorporating object-level contextual knowledge within images. Specifically, our model enhances intra-object consistency by distilling spectral-driven features from vision foundation models into the attention mechanism of the visual encoder, enabling semantically coherent components to form a single object mask. Additionally, we refine the text embeddings with zero-shot object presence likelihood to ensure accurate alignment with the specific objects represented in the images. By leveraging object-level contextual knowledge, our proposed approach achieves state-of-the-art performance with strong generalizability across diverse datasets.
开放词汇语义分割(OVSS)随着最近的视觉语言模型(VLMs)的发展而进步,通过各种学习方案实现了超出预定类别的分割。值得注意的是,无训练方法为处理未见数据提供了可扩展、易于部署的解决方案,这是OVSS的关键目标。然而,一个关键问题依然存在:在基于任意查询提示的OVSS的复杂环境中,对复杂对象进行分割时缺乏对象级别的上下文考虑。这一疏忽限制了模型在对象内组合语义一致元素的能力,并准确地将它们映射到用户定义的任意类别。在这项工作中,我们介绍了一种通过结合图像中的对象级上下文知识来克服这一限制的新方法。具体来说,我们的模型通过将从视觉基础模型提炼的谱驱动特征蒸馏到视觉编码器的注意力机制中,增强了对象内部的连贯性,使语义一致的组件能够形成单个对象掩码。此外,我们还通过零目标对象存在可能性来优化文本嵌入,以确保与图像中表示的特定对象的准确对齐。通过利用对象级的上下文知识,我们提出的方法在多个数据集上实现了最先进的性能,并具有较强的泛化能力。
论文及项目相关链接
Summary
文本描述了如何利用物体级别的上下文知识来提升Open-Vocabulary Semantic Segmentation模型的性能。为了解决传统模型中在分割复杂对象时缺乏对物体级别上下文考虑的局限性,提出了一种新的方法。该方法通过融合图像中的物体级别上下文知识,增强模型对物体内部的一致性,从而实现语义上连贯的组件形成单个物体掩膜。同时,通过改进文本嵌入和零样本物体存在概率,确保与图像中特定物体的准确对齐。该方法在多个数据集上取得了最先进的性能,并具有较强的泛化能力。
Key Takeaways
- Open-Vocabulary Semantic Segmentation (OVSS) 允许通过不同的学习方案进行超越预设类别的分割。
- 训练无关的方法为处理未见数据提供了可扩展、易于部署的解决方案,这是OVSS的关键目标。
- 当前工作中一个关键问题是缺乏物体级别的上下文考虑,在基于任意查询提示的OVSS环境中分割复杂对象时存在局限性。
- 新的方法通过融合图像中的物体级别上下文知识来解决这个问题,增强模型对物体内部的一致性。
- 该方法实现语义上连贯的组件形成单个物体掩膜,提高了模型的性能。
- 通过改进文本嵌入和零样本物体存在概率,确保与图像中特定物体的准确对齐。
点此查看论文截图

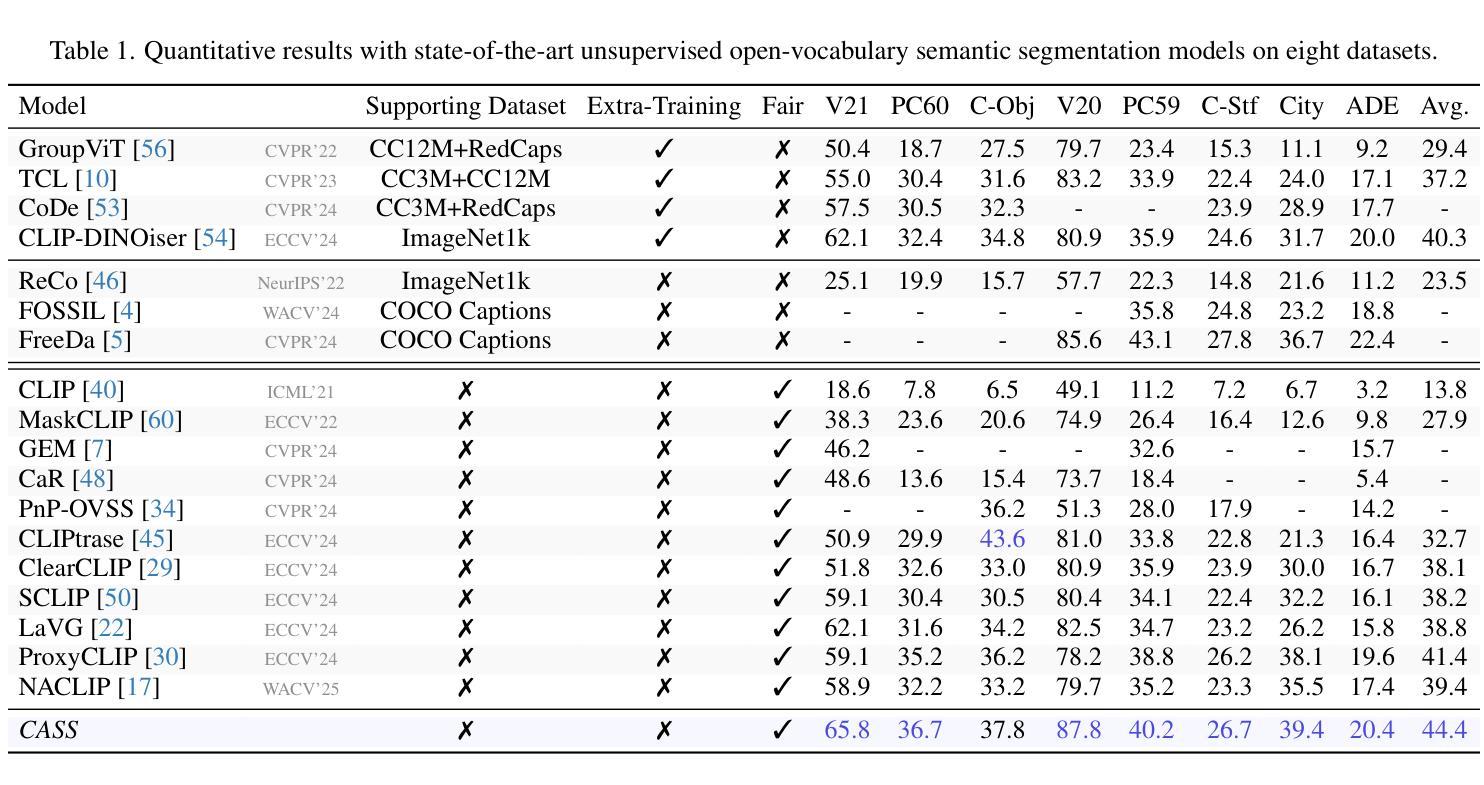
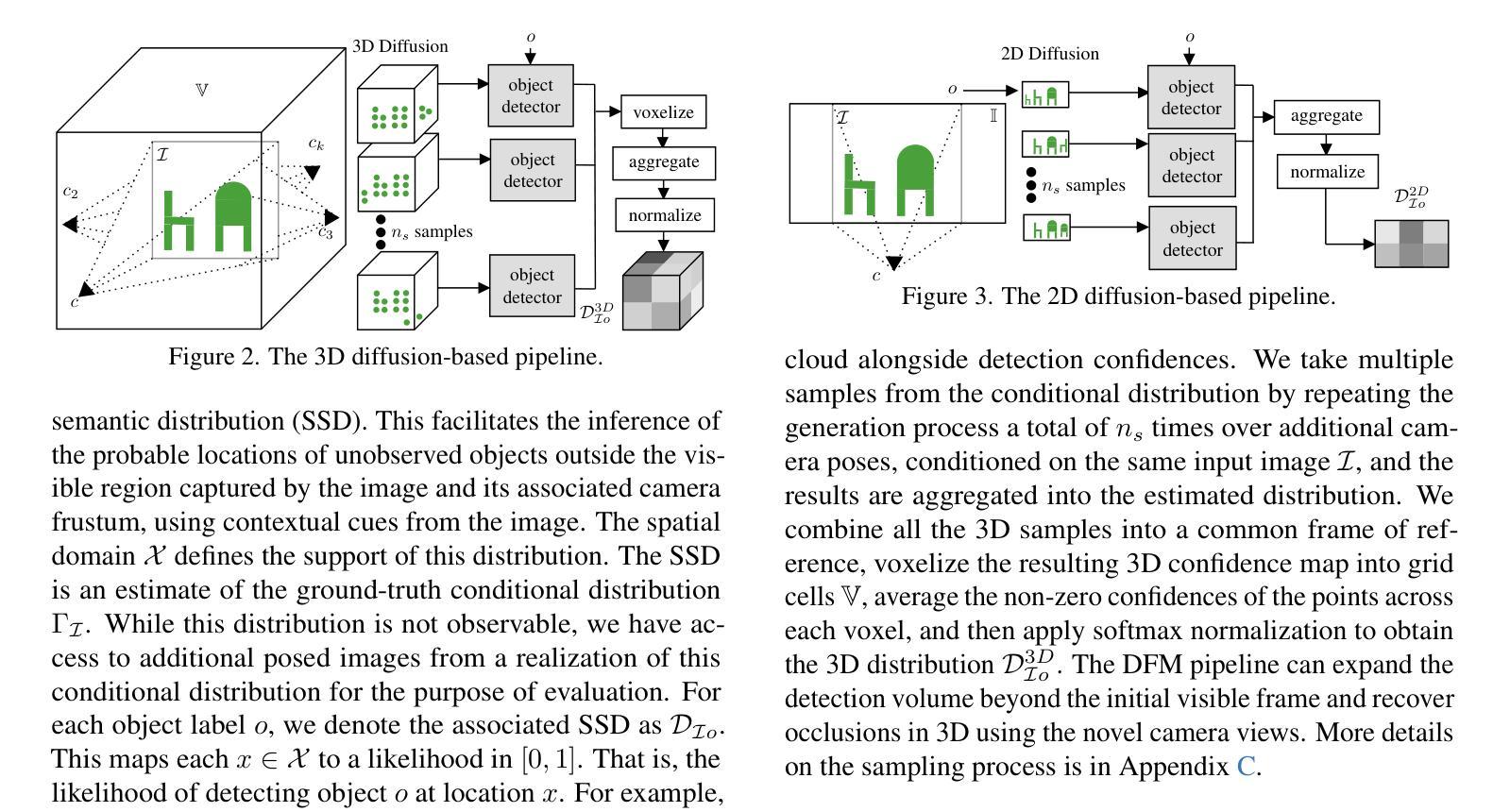
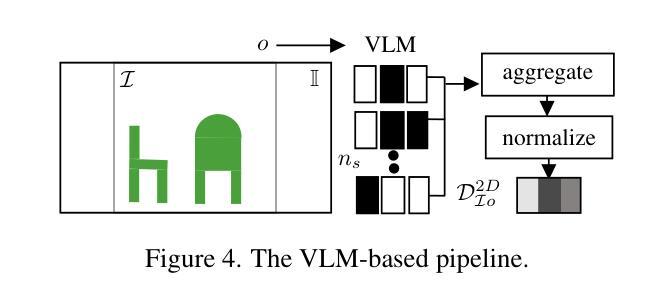
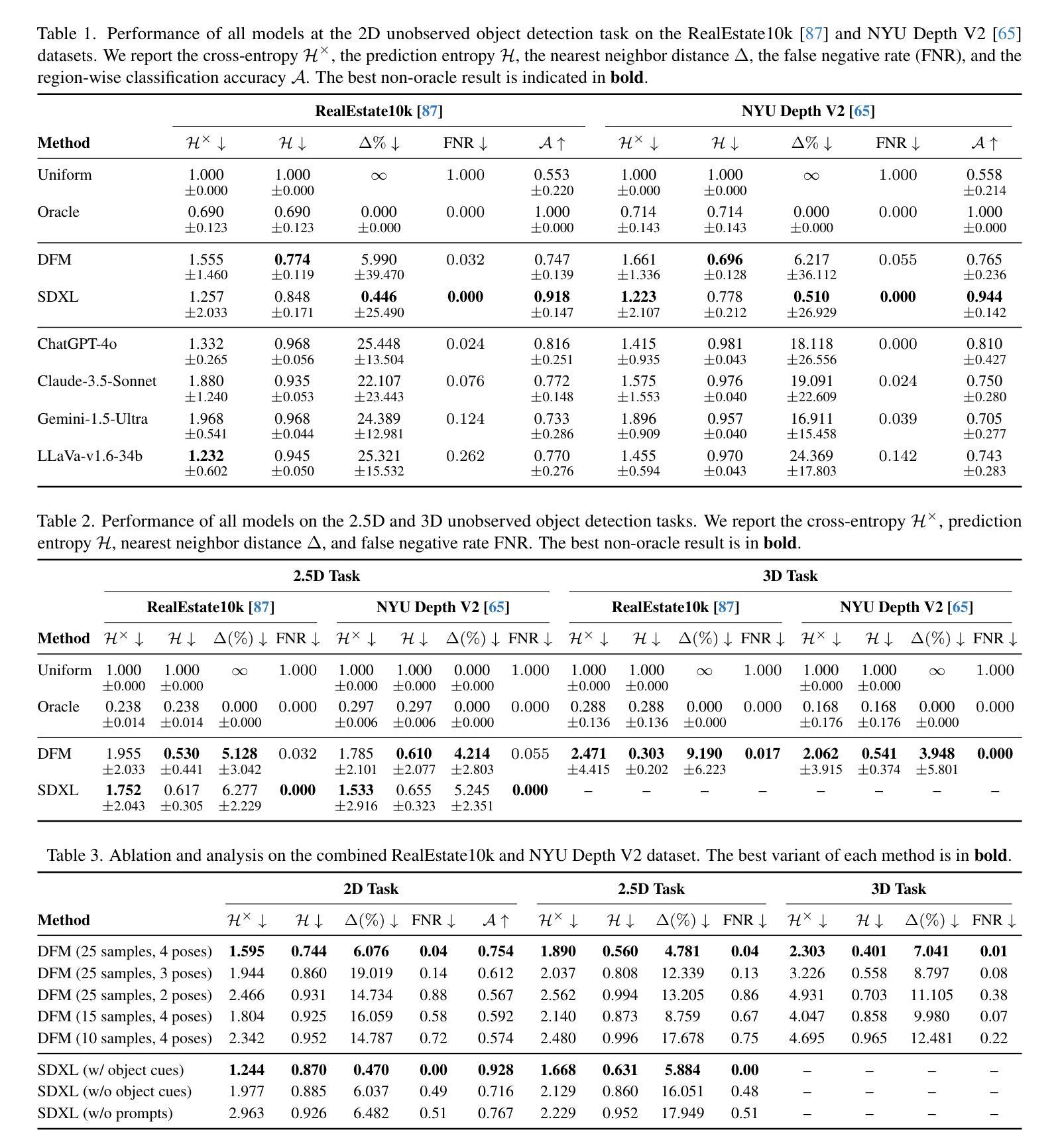
Believing is Seeing: Unobserved Object Detection using Generative Models
Authors:Subhransu S. Bhattacharjee, Dylan Campbell, Rahul Shome
Can objects that are not visible in an image – but are in the vicinity of the camera – be detected? This study introduces the novel tasks of 2D, 2.5D and 3D unobserved object detection for predicting the location of nearby objects that are occluded or lie outside the image frame. We adapt several state-of-the-art pre-trained generative models to address this task, including 2D and 3D diffusion models and vision-language models, and show that they can be used to infer the presence of objects that are not directly observed. To benchmark this task, we propose a suite of metrics that capture different aspects of performance. Our empirical evaluation on indoor scenes from the RealEstate10k and NYU Depth v2 datasets demonstrate results that motivate the use of generative models for the unobserved object detection task.
在图像中不可见但位于相机附近的对象能否被检测出来?本研究引入了用于预测被遮挡或位于图像帧外的附近对象位置的二维、2.5维和三维未观测对象检测的新任务。我们适应了几种最先进的预训练生成模型来完成这项任务,包括二维和三维扩散模型以及视觉语言模型,并表明它们可用于推断未直接观察到的对象的存在。为了评估这项任务,我们提出了一套能够反映不同性能方面的指标。我们在RealEstate10k和NYU Depth v2数据集上的室内场景实证评估结果表明,使用生成模型进行未观测对象检测任务是可行的。
论文及项目相关链接
PDF IEEE/CVF Computer Vision and Pattern Recognition 2025; 22 pages
Summary
本文研究不可见物体的检测问题,探索了2D、2.5D和3D未观测物体检测的新任务。研究利用预训练的生成模型进行预测,包括2D和3D扩散模型以及视觉语言模型,并展示了在未直接观测物体的情况下进行推断的能力。为评估此任务性能,研究提出了一套评价指标。在RealEstate10k和NYU Depth v2数据集上的室内场景实证评估结果证明了生成模型在未观测物体检测任务中的实用性。
Key Takeaways
- 引入未观测物体检测的新任务,探索预测图像中不可见物体的位置。
- 利用预训练的生成模型(包括扩散模型和视觉语言模型)进行预测。
- 提出一套性能评价指标以评估未观测物体检测任务的效果。
- 研究涵盖从二维到三维的多种检测场景。
- 实证评估证明了生成模型在未观测物体检测任务中的有效性。
- 研究结果展示了推断未直接观测物体存在的能力。
点此查看论文截图

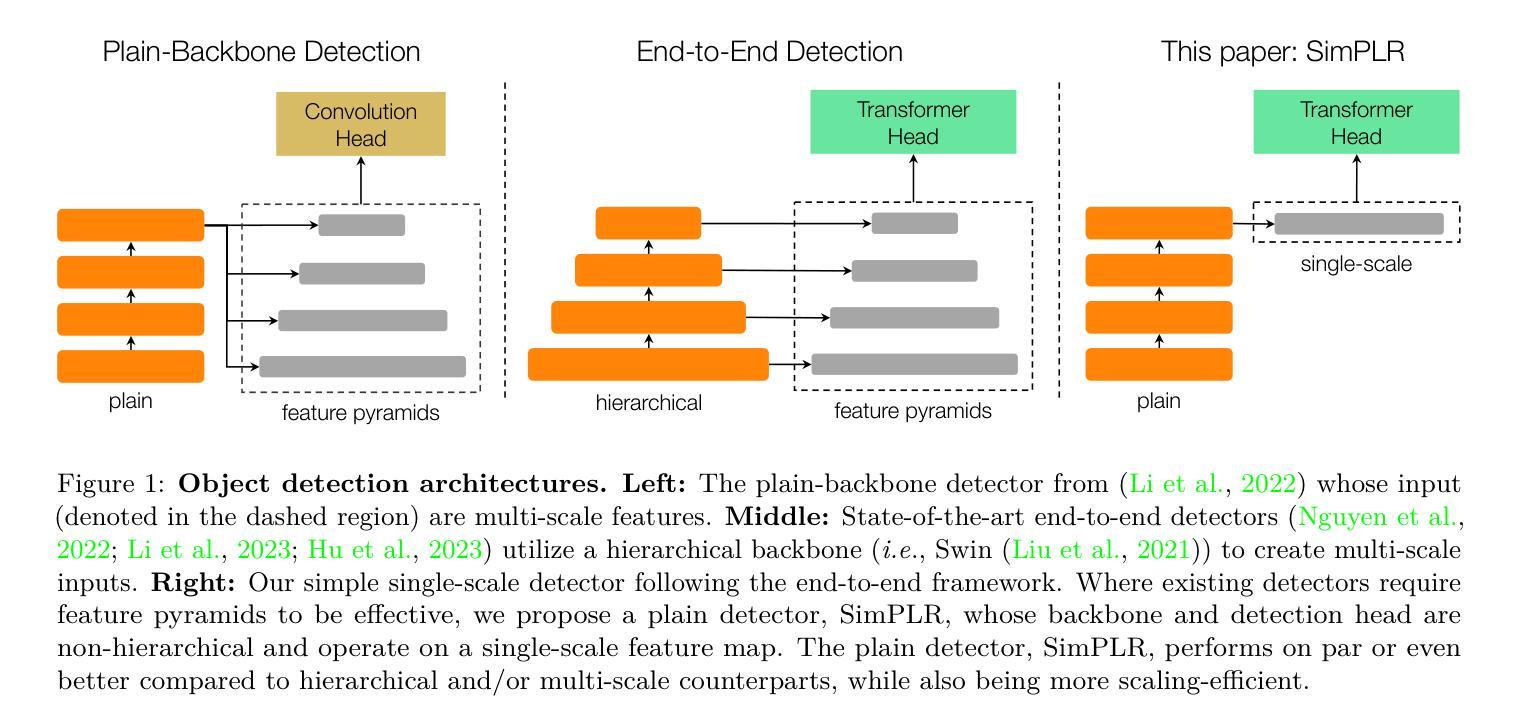
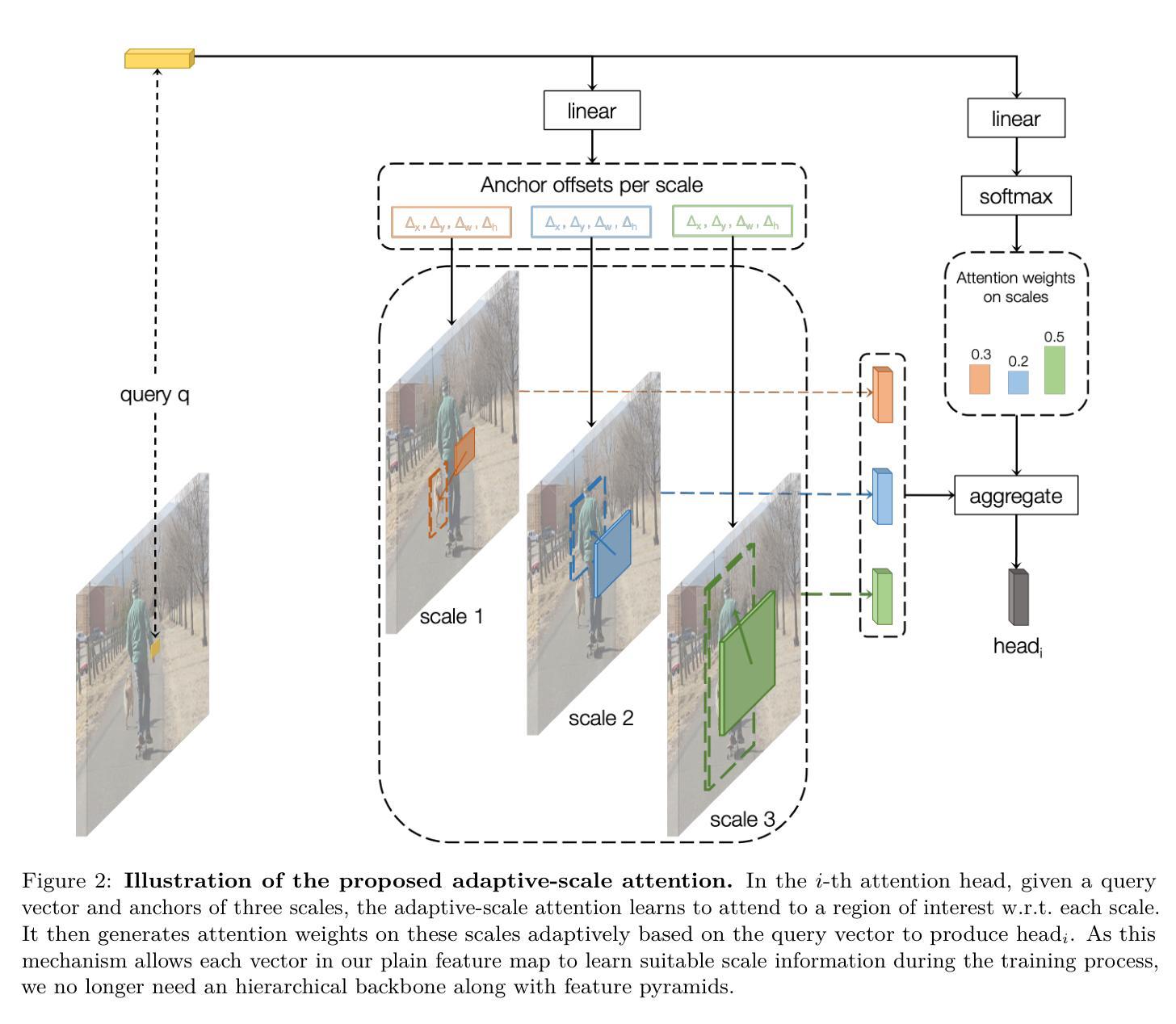
SimPLR: A Simple and Plain Transformer for Efficient Object Detection and Segmentation
Authors:Duy-Kien Nguyen, Martin R. Oswald, Cees G. M. Snoek
The ability to detect objects in images at varying scales has played a pivotal role in the design of modern object detectors. Despite considerable progress in removing hand-crafted components and simplifying the architecture with transformers, multi-scale feature maps and pyramid designs remain a key factor for their empirical success. In this paper, we show that shifting the multiscale inductive bias into the attention mechanism can work well, resulting in a plain detector `SimPLR’ whose backbone and detection head are both non-hierarchical and operate on single-scale features. We find through our experiments that SimPLR with scale-aware attention is plain and simple architecture, yet competitive with multi-scale vision transformer alternatives. Compared to the multi-scale and single-scale state-of-the-art, our model scales better with bigger capacity (self-supervised) models and more pre-training data, allowing us to report a consistently better accuracy and faster runtime for object detection, instance segmentation, as well as panoptic segmentation. Code is released at https://github.com/kienduynguyen/SimPLR.
在现代目标检测器设计中,能够在不同尺度上检测图像中的物体起着至关重要的作用。尽管在去除手工组件、简化架构方面以及使用transformer方面取得了很大进展,但多尺度特征映射和金字塔设计仍然是其经验成功的关键因素。在本文中,我们展示了将多尺度归纳偏置转移到注意力机制中可以很好地工作,从而得到了一个纯检测器SimPLR,其主干和检测头都是非分层的,并在单尺度特征上运行。我们通过实验发现,带有尺度感知注意力的SimPLR是一个简单明了的架构,但与多尺度视觉transformer替代方案相比仍具有竞争力。与多尺度和单尺度最新技术相比,我们的模型在更大容量(自监督)的模型和更多预训练数据的支持下表现更好,这使我们能够在目标检测、实例分割和全景分割方面报告更高的准确性和更快的运行时间。代码已发布在https://github.com/kienduynguyen/SimPLR。
论文及项目相关链接
PDF In Proceeding of TMLR’2025
Summary:
本文探讨了目标检测中的多尺度特征处理问题,提出了一种新的方法SimPLR,通过将多尺度归纳偏见转移到注意力机制中,实现了一种简单而有效的检测器。实验表明,SimPLR模型在目标检测、实例分割和全景分割任务上表现优异,特别是当使用更大容量和更多预训练数据时。代码已发布在GitHub上。
Key Takeaways:
- 多尺度特征处理在现代目标检测器设计中扮演重要角色。
- SimPLR通过将多尺度归纳偏见融入注意力机制来改进目标检测。
- SimPLR是一个简单且有效的非层次结构检测器,可在单尺度特征上操作。
- 实验表明SimPLR与多尺度视觉转换器相比具有竞争力。
- SimPLR在更大的容量模型和更多预训练数据下表现更佳。
- SimPLR在目标检测、实例分割和全景分割任务上表现优异。
点此查看论文截图