⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
Logic-in-Frames: Dynamic Keyframe Search via Visual Semantic-Logical Verification for Long Video Understanding
Authors:Weiyu Guo, Ziyang Chen, Shaoguang Wang, Jianxiang He, Yijie Xu, Jinhui Ye, Ying Sun, Hui Xiong
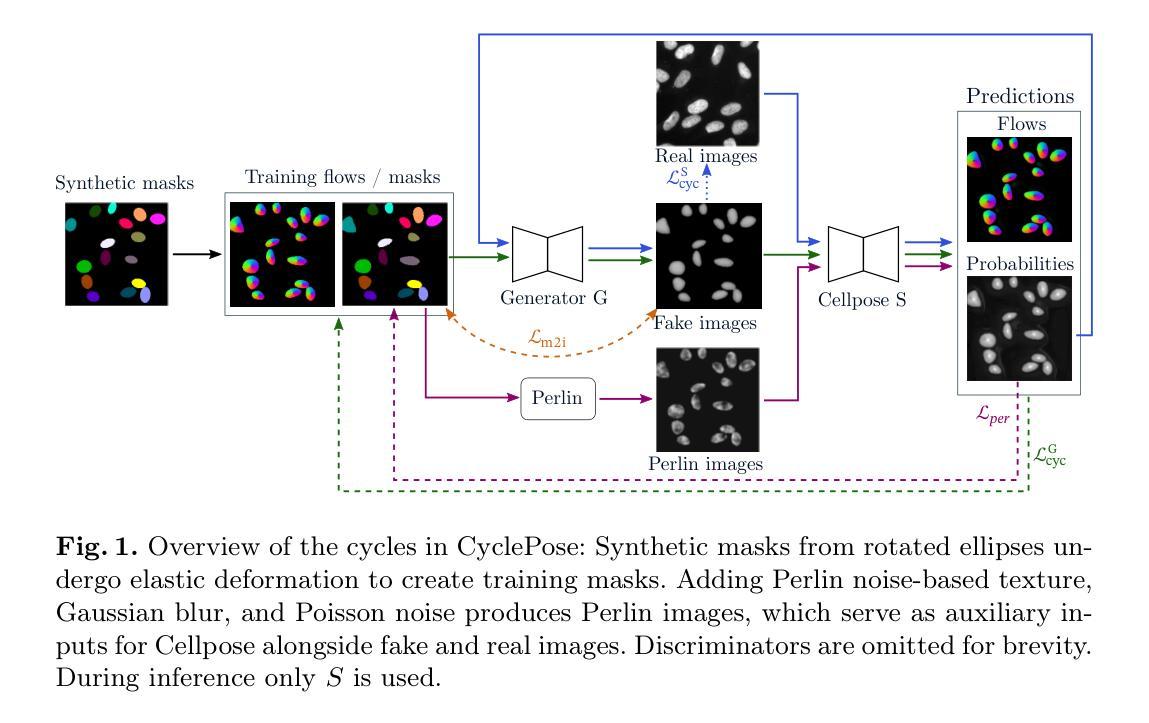
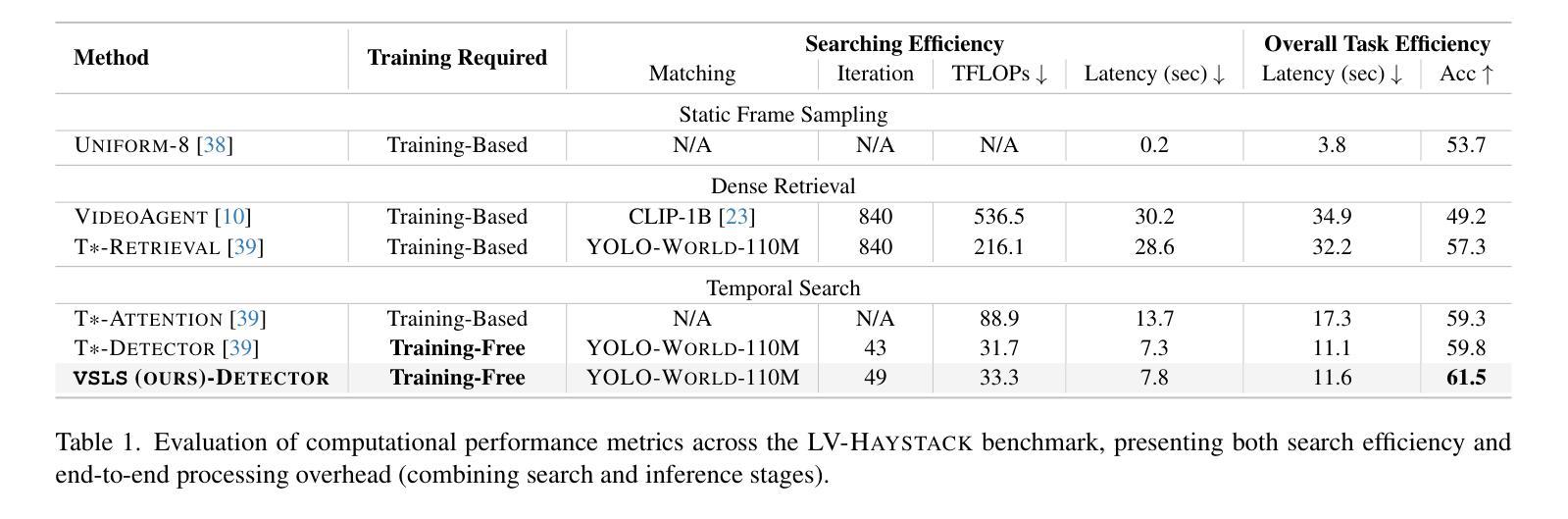
Understanding long video content is a complex endeavor that often relies on densely sampled frame captions or end-to-end feature selectors, yet these techniques commonly overlook the logical relationships between textual queries and visual elements. In practice, computational constraints necessitate coarse frame subsampling, a challenge analogous to ``finding a needle in a haystack.’’ To address this issue, we introduce a semantics-driven search framework that reformulates keyframe selection under the paradigm of Visual Semantic-Logical Search. Specifically, we systematically define four fundamental logical dependencies: 1) spatial co-occurrence, 2) temporal proximity, 3) attribute dependency, and 4) causal order. These relations dynamically update frame sampling distributions through an iterative refinement process, enabling context-aware identification of semantically critical frames tailored to specific query requirements. Our method establishes new SOTA performance on the manually annotated benchmark in key-frame selection metrics. Furthermore, when applied to downstream video question-answering tasks, the proposed approach demonstrates the best performance gains over existing methods on LongVideoBench and Video-MME, validating its effectiveness in bridging the logical gap between textual queries and visual-temporal reasoning. The code will be publicly available.
理解长视频内容是一项复杂的任务,通常依赖于密集采样的帧字幕或端到端特征选择器,然而这些技术通常忽略了文本查询和视觉元素之间的逻辑关系。实际上,计算约束需要进行粗略的帧子采样,这类似于“在稻草中寻找针”的挑战。为了解决这一问题,我们引入了一个语义驱动搜索框架,该框架在视觉语义逻辑搜索的范式下重新制定关键帧选择。具体来说,我们系统地定义了四种基本逻辑依赖关系:1)空间共现,2)时间邻近,3)属性依赖,4)因果顺序。这些关系通过迭代优化过程动态更新帧采样分布,使上下文感知的语义关键帧识别能够针对特定查询要求进行定制。我们的方法在关键帧选择指标的手动注释基准测试上建立了新的最佳性能。此外,当应用于下游视频问答任务时,所提出的方法在LongVideoBench和Video-MME上的性能超过了现有方法,验证了其在弥合文本查询和视觉时间推理之间的逻辑差距方面的有效性。代码将公开可用。
论文及项目相关链接
PDF 18 pages, under review
Summary
本文提出了一种基于语义驱动的搜索框架,用于改进长视频内容理解中的关键帧选择问题。该框架通过定义四种基本逻辑依赖关系,包括空间共现、时间邻近、属性依赖和因果顺序,来动态更新帧采样分布,从而实现针对特定查询要求的上下文感知语义关键帧识别。该方法在关键帧选择指标上的性能达到了新的先进水平,并在视频问答等下游任务中显示出最佳的性能提升。
Key Takeaways
- 提出了一种语义驱动的搜索框架,用于改进长视频内容理解中的关键帧选择。
- 定义了四种基本逻辑依赖关系:空间共现、时间邻近、属性依赖和因果顺序。
- 通过迭代优化过程,这些逻辑依赖关系能够动态更新帧采样分布。
- 该方法实现了上下文感知的语义关键帧识别,适应于特定查询要求。
- 在关键帧选择指标上达到了新的先进水平。
- 在视频问答等下游任务中,该方法显示出最佳性能提升。
点此查看论文截图


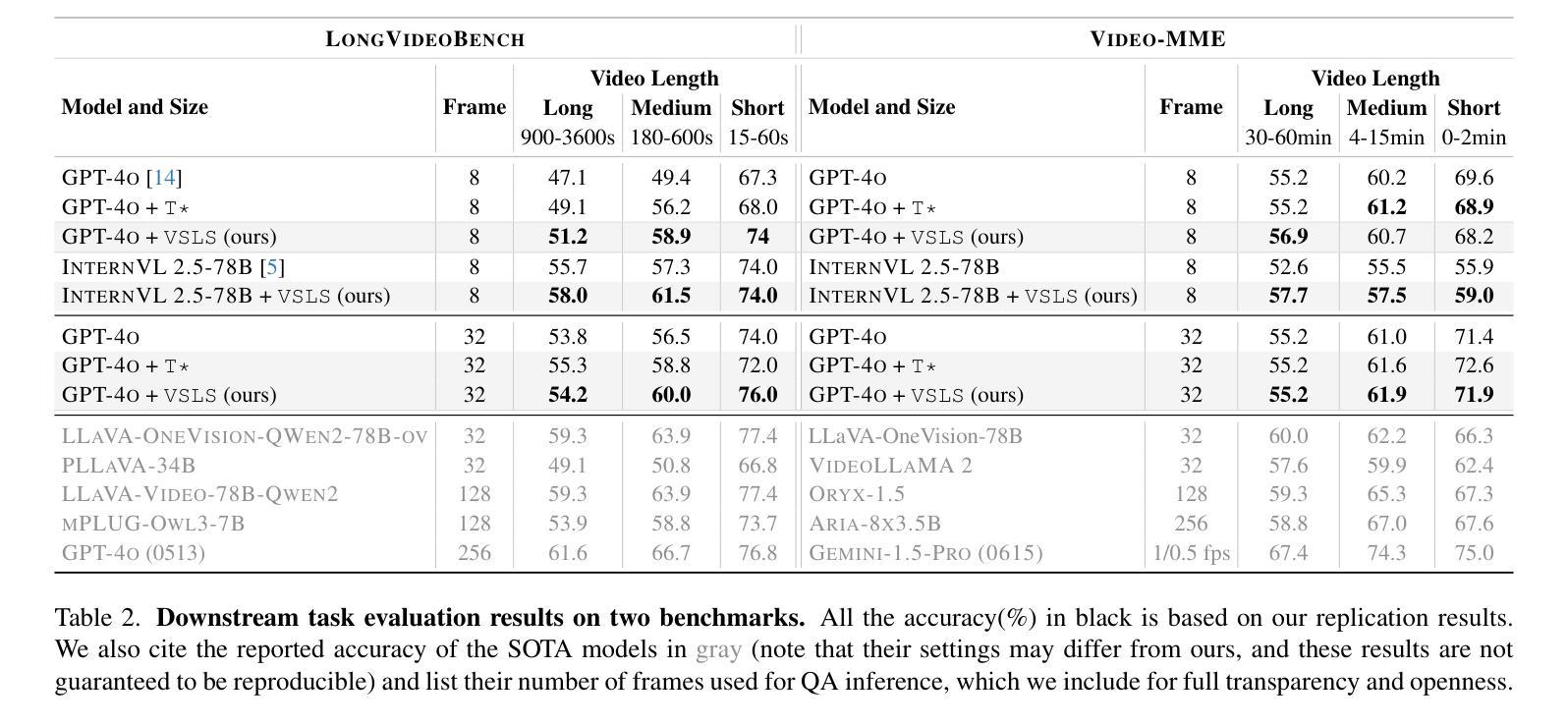
AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding
Authors:Xiao Wang, Qingyi Si, Jianlong Wu, Shiyu Zhu, Li Cao, Liqiang Nie
Multimodal Large Language Models (MLLMs) have revolutionized video understanding, yet are still limited by context length when processing long videos. Recent methods compress videos by leveraging visual redundancy uniformly, yielding promising results. Nevertheless, our quantitative analysis shows that redundancy varies significantly across time and model layers, necessitating a more flexible compression strategy. We propose AdaReTaKe, a training-free method that flexibly reduces visual redundancy by allocating compression ratios among time and layers with theoretical guarantees. Integrated into state-of-the-art MLLMs, AdaReTaKe improves processing capacity from 256 to 2048 frames while preserving critical information. Experiments on VideoMME, MLVU, LongVideoBench, and LVBench datasets demonstrate that AdaReTaKe outperforms existing methods by 2.3% and 2.8% for 7B and 72B models, respectively, with even greater improvements of 5.9% and 6.0% on the longest LVBench. Our code is available at https://github.com/SCZwangxiao/video-FlexReduc.git.
多模态大型语言模型(MLLMs)已经彻底改变了视频理解的方式,但在处理长视频时仍受到上下文长度的限制。最近的方法通过统一利用视觉冗余来压缩视频,取得了令人鼓舞的结果。然而,我们的定量分析表明,冗余性在时间和模型层之间有很大的变化,因此需要更灵活的压缩策略。我们提出了AdaReTaKe,这是一种无需训练的方法,它可以通过在时间和层之间分配压缩比来灵活地减少视觉冗余性,并有理论保证。将AdaReTaKe集成到最新MLLMs中,可以在保持关键信息的同时,将处理容量从256帧提高到2048帧。在VideoMME、MLVU、LongVideoBench和LVBench数据集上的实验表明,AdaReTaKe优于现有方法,对于7B和72B模型的性能分别提高了2.3%和2.8%,在最长LVBench上的性能甚至分别提高了5.9%和6.0%。我们的代码可在https://github.com/SCZwangxiao/video-FlexReduc.git上找到。
论文及项目相关链接
Summary
文本指出多模态大型语言模型(MLLMs)在视频理解领域具有革命性作用,但在处理长视频时受限于上下文长度。最近的方法通过利用视觉冗余进行视频压缩,但仍存在显著的时间与模型层间冗余变化,需要更灵活的压缩策略。提出一种名为AdaReTaKe的训练外方法,它通过分配时间与层间的压缩比率来灵活减少视觉冗余,并具有理论保证。集成到最先进的MLLMs中,AdaReTaKe将处理容量从256帧提高到2048帧,同时保留关键信息。在VideoMME、MLVU、LongVideoBench和LVBench数据集上的实验表明,AdaReTaKe在效率和性能上均优于现有方法。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视频理解上表现出强大能力,但处理长视频时受到上下文长度的限制。
- 现有视频压缩方法虽然能利用视觉冗余进行压缩,但未能充分适应时间与模型层间冗余的变化。
- AdaReTaKe是一种训练外方法,能够灵活减少视觉冗余,通过分配时间与层间的压缩比率来优化性能。
- AdaReTaKe显著提高了视频处理容量,从256帧提升至2048帧,同时保留关键信息。
- AdaReTaKe在多个数据集上的实验结果表明其性能优于现有方法。
- AdaReTaKe方法具有理论保证,稳定性与可靠性较高。
点此查看论文截图

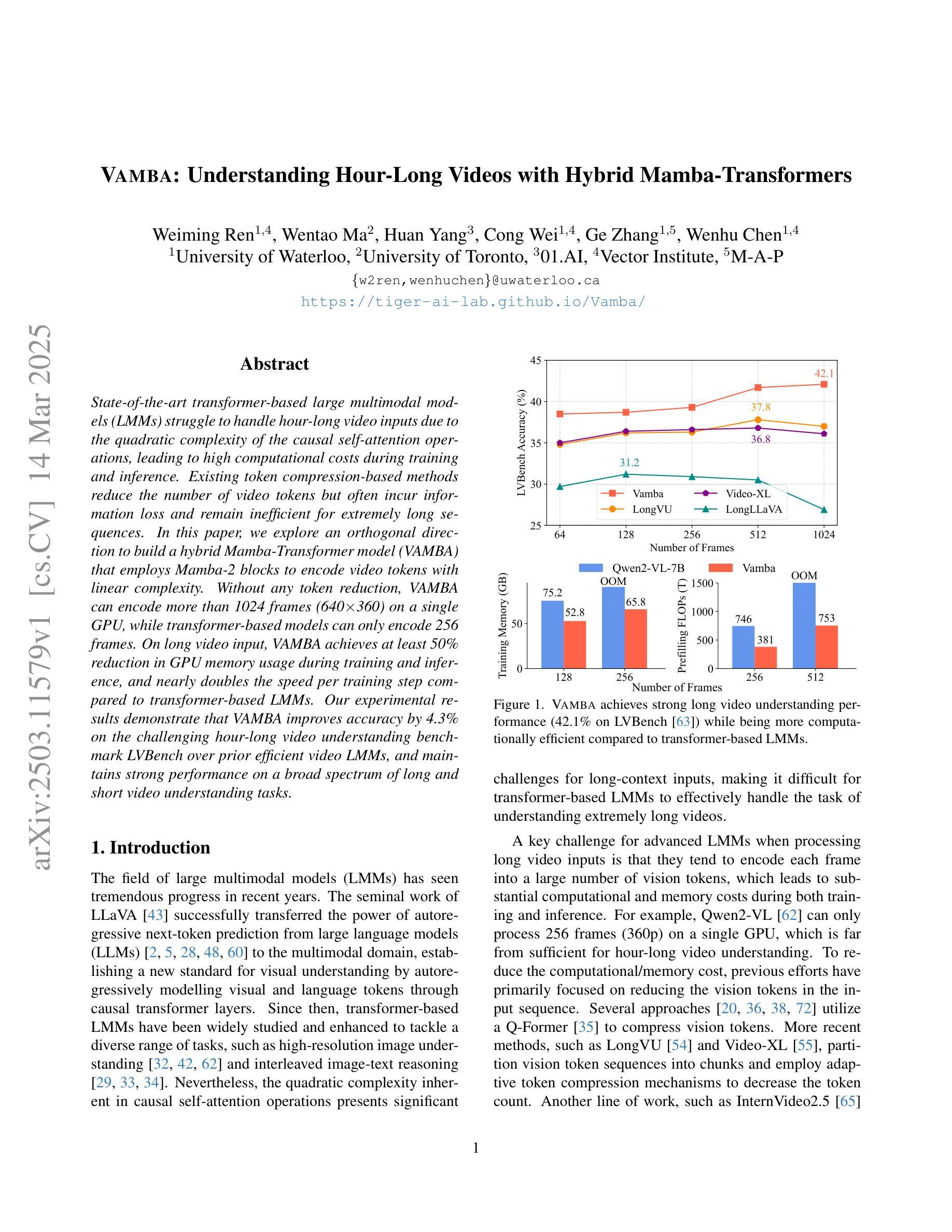
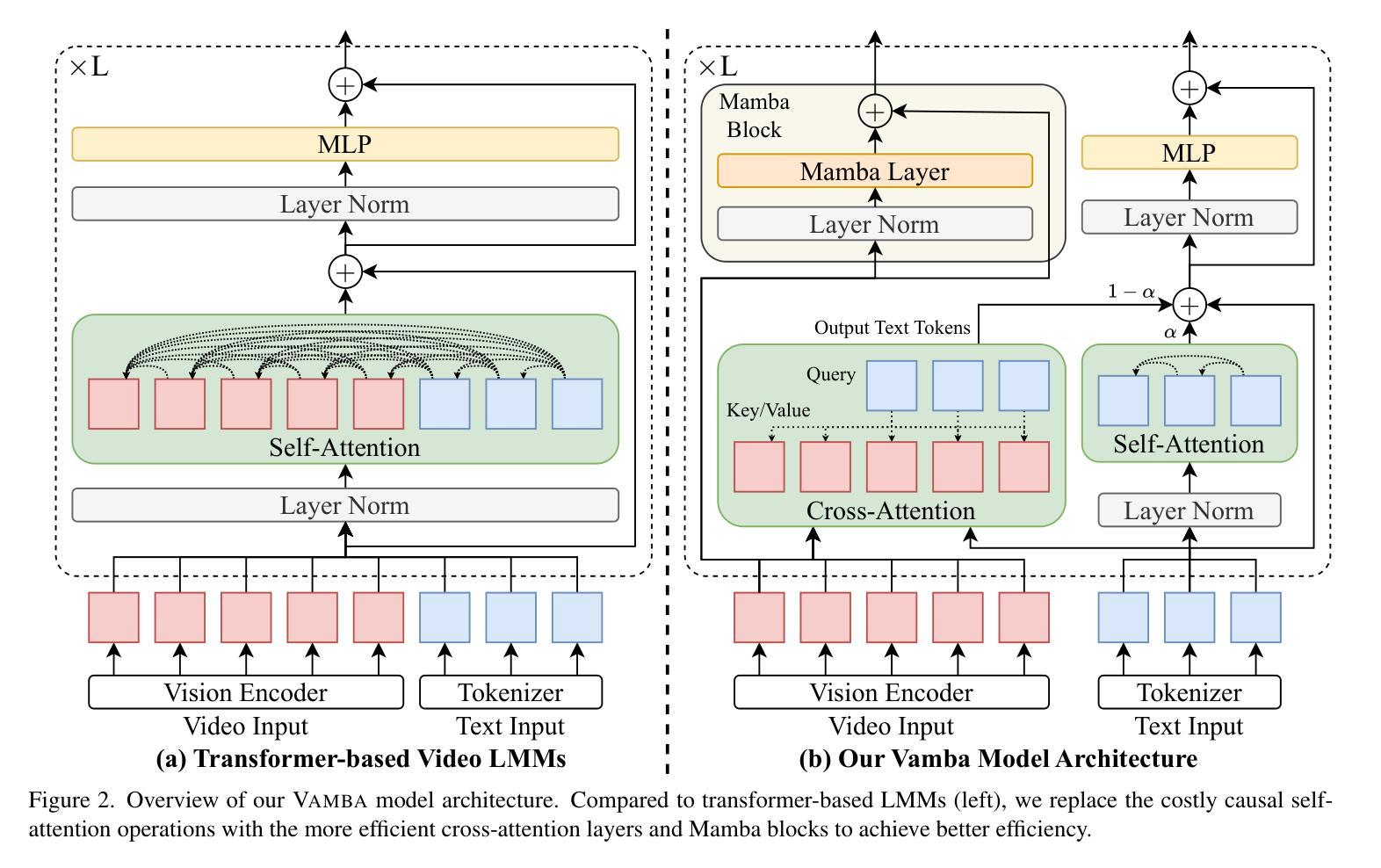
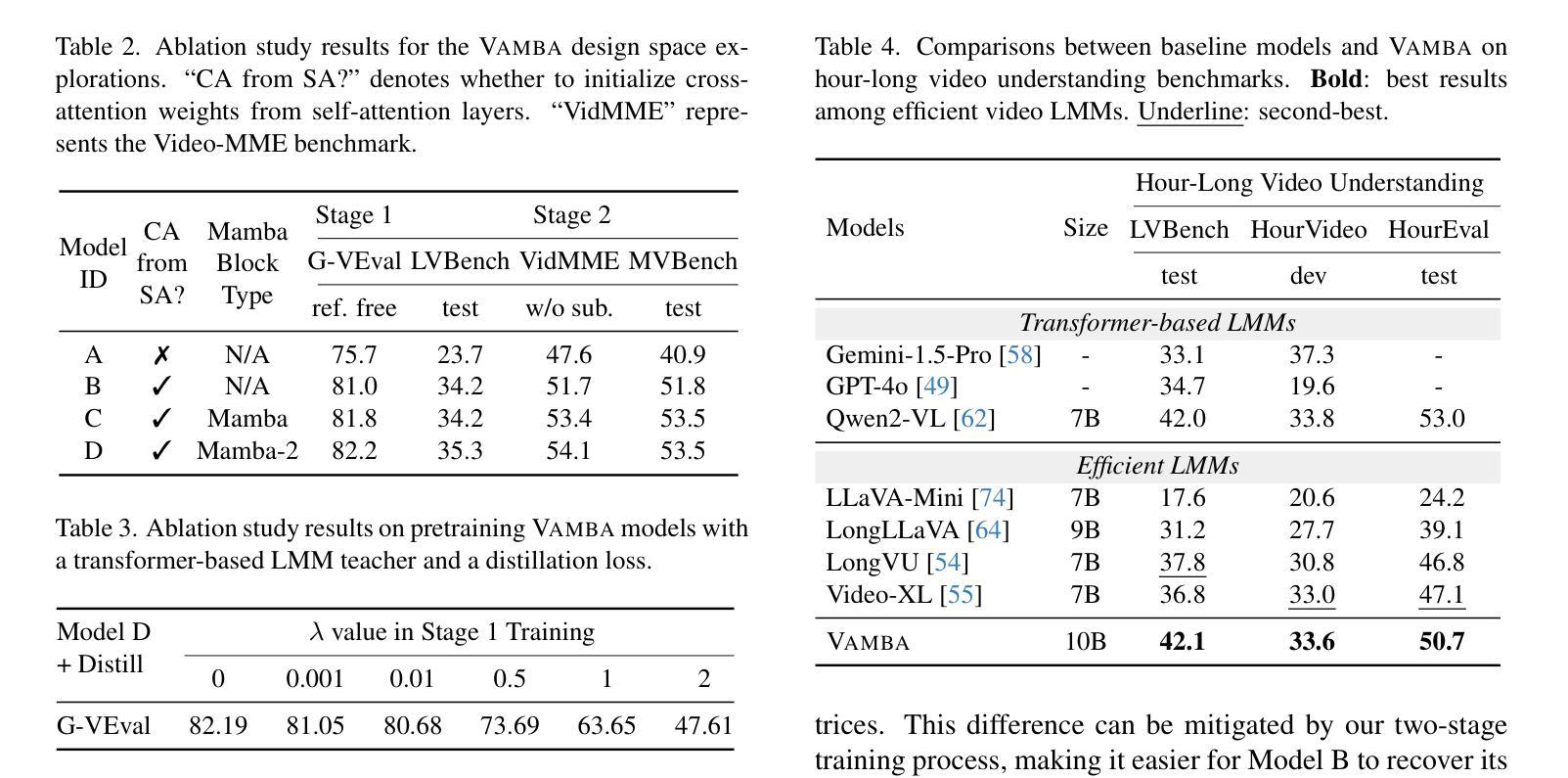
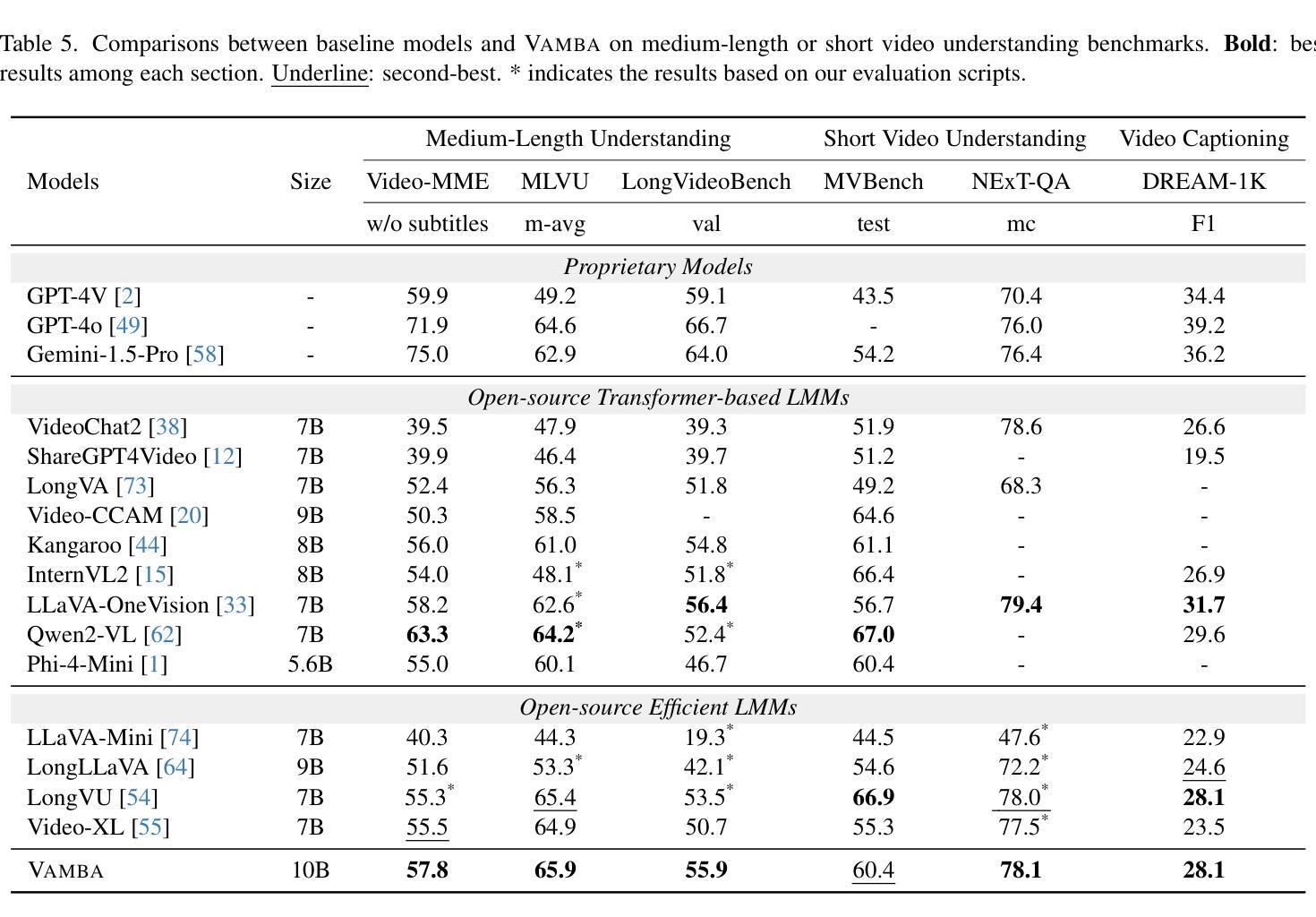
Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
Authors:Weiming Ren, Wentao Ma, Huan Yang, Cong Wei, Ge Zhang, Wenhu Chen
State-of-the-art transformer-based large multimodal models (LMMs) struggle to handle hour-long video inputs due to the quadratic complexity of the causal self-attention operations, leading to high computational costs during training and inference. Existing token compression-based methods reduce the number of video tokens but often incur information loss and remain inefficient for extremely long sequences. In this paper, we explore an orthogonal direction to build a hybrid Mamba-Transformer model (VAMBA) that employs Mamba-2 blocks to encode video tokens with linear complexity. Without any token reduction, VAMBA can encode more than 1024 frames (640$\times$360) on a single GPU, while transformer-based models can only encode 256 frames. On long video input, VAMBA achieves at least 50% reduction in GPU memory usage during training and inference, and nearly doubles the speed per training step compared to transformer-based LMMs. Our experimental results demonstrate that VAMBA improves accuracy by 4.3% on the challenging hour-long video understanding benchmark LVBench over prior efficient video LMMs, and maintains strong performance on a broad spectrum of long and short video understanding tasks.
最先进的基于transformer的大型多模态模型(LMMs)在处理长达数小时的视频输入时面临困难,原因在于因果自注意力操作的二次复杂性,导致训练和推理过程中的计算成本高昂。现有的基于令牌压缩的方法减少了视频令牌的数量,但往往会造成信息丢失,对于极长的序列仍然效率低下。在本文中,我们探索了一个与当前方法不同的方向,即构建混合Mamba-Transformer模型(VAMBA),该模型采用Mamba-2块以线性复杂度编码视频令牌。无需减少令牌,VAMBA可以在单个GPU上编码超过1024帧(640×360),而基于transformer的模型只能编码256帧。对于长视频输入,VAMBA在训练和推理期间实现了GPU内存使用至少减少50%,并且与基于transformer的LMM相比,每步训练速度几乎翻倍。我们的实验结果表明,在具有挑战性的长达一小时的视频理解基准测试LVBench上,VAMBA相较于先前的有效视频LMM提高了4.3%的准确率,并在广泛的长期和短期视频理解任务中保持了强劲的表现。
论文及项目相关链接
PDF Project Page: https://tiger-ai-lab.github.io/Vamba/
Summary
视频理解领域的大型多模态模型在处理长达一小时的视频输入时面临计算成本高的问题。现有方法试图通过减少视频令牌数量来解决这一问题,但这样做会导致信息损失。本文提出了一种混合Mamba-Transformer模型(VAMBA),采用具有线性复杂度的Mamba-2块进行视频令牌编码,无需减少令牌数量即可在单个GPU上编码超过1024帧(640×360)。与基于Transformer的模型相比,VAMBA在训练和推理期间的GPU内存使用率降低了至少50%,且训练步骤速度提高了近一倍。实验结果证明了VAMBA在挑战性的长达一小时视频理解基准测试LVBench上的准确率提高了4.3%,并在广泛的长短视频理解任务上保持了出色的性能。
Key Takeaways
- 大型多模态模型处理长视频时面临计算成本高的问题。
- 现有方法通过减少视频令牌数量来降低计算成本,但会导致信息损失。
- VAMBA模型采用Mamba-2块进行视频令牌编码,具有线性复杂度,无需减少令牌数量。
- VAMBA在单个GPU上可编码更多的视频帧,相比基于Transformer的模型有优势。
- VAMBA降低了GPU内存使用率并提高了训练步骤速度。
- VAMBA在长达一小时的视频理解基准测试上提高了准确率。
点此查看论文截图

Watch and Learn: Leveraging Expert Knowledge and Language for Surgical Video Understanding
Authors:David Gastager, Ghazal Ghazaei, Constantin Patsch
Automated surgical workflow analysis is crucial for education, research, and clinical decision-making, but the lack of annotated datasets hinders the development of accurate and comprehensive workflow analysis solutions. We introduce a novel approach for addressing the sparsity and heterogeneity of annotated training data inspired by the human learning procedure of watching experts and understanding their explanations. Our method leverages a video-language model trained on alignment, denoising, and generative tasks to learn short-term spatio-temporal and multimodal representations. A task-specific temporal model is then used to capture relationships across entire videos. To achieve comprehensive video-language understanding in the surgical domain, we introduce a data collection and filtering strategy to construct a large-scale pretraining dataset from educational YouTube videos. We then utilize parameter-efficient fine-tuning by projecting downstream task annotations from publicly available surgical datasets into the language domain. Extensive experiments in two surgical domains demonstrate the effectiveness of our approach, with performance improvements of up to 7% in phase segmentation tasks, 8% in zero-shot phase segmentation, and comparable capabilities to fully-supervised models in few-shot settings. Harnessing our model’s capabilities for long-range temporal localization and text generation, we present the first comprehensive solution for dense video captioning (DVC) of surgical videos, addressing this task despite the absence of existing DVC datasets in the surgical domain. We introduce a novel approach to surgical workflow understanding that leverages video-language pretraining, large-scale video pretraining, and optimized fine-tuning. Our method improves performance over state-of-the-art techniques and enables new downstream tasks for surgical video understanding.
自动化手术工作流程分析对医疗教育、研究和临床决策至关重要,但缺乏标注数据集阻碍了准确、全面的工作流程分析解决方案的发展。我们引入了一种新的方法来解决标注训练数据的稀缺和异质性,该方法受到人类观察专家并理解其解释的学习过程的启发。我们的方法利用在排列、去噪和生成任务上训练的视听语言模型来学习短期的时空和多模态表示。然后,使用特定任务的时序模型来捕捉整个视频的关系。为了实现手术领域全面的视听理解,我们引入了一种数据收集和过滤策略,从教育性质的YouTube视频中构建大规模预训练数据集。然后,我们通过将公开可用的手术数据集的下游任务注释投影到语言领域,实现了参数的精细调整。在两个手术领域的广泛实验表明,我们的方法非常有效,在阶段分割任务中的性能提高了高达7%,在零样本阶段分割中的性能提高了8%,并且在少量样本的情况下与完全监督的模型相比具有相当的能力。利用我们的模型进行远程时序定位和文本生成的能力,我们首次为手术视频提供了密集视频字幕(DVC)的全面解决方案,尽管手术领域缺乏现有的DVC数据集,我们仍解决了此任务。我们引入了一种新的手术工作流程理解方法,该方法利用视听语言预训练、大规模视频预训练和优化微调。我们的方法在最新技术的基础上提高了性能,并为手术视频理解启用了新的下游任务。
论文及项目相关链接
PDF 14 pages main manuscript with 3 figures; 6 pages supplementary material with 3 figures. To be presented at International Conference on Information Processing in Computer-Assisted Interventions (IPCAI 2025). To be published in International Journal of Computer Assisted Radiology and Surgery (IJCARS)
摘要
本文主要探讨手术工作流自动化分析在教育、研究和临床决策中的重要性。为解决标注数据集稀缺和多样性问题,提出一种新型解决方案。该方法基于人类观看专家并理解其解释的学习过程,利用视频语言模型进行训练,学习短期时空和多模态表示。通过特定任务的时间模型捕捉整个视频的关联。为在手术领域实现全面的视频语言理解,从教育YouTube视频中构建大规模预训练数据集。利用下游任务标注公开手术数据集,将其投影到语言领域进行微调优化。实验证明该方法有效,阶段分割任务性能提升高达7%,零阶段分割提升8%,在少样本设置中具有与全监督模型相当的实力。借助模型的长程时空定位和文本生成能力,本文提出首个针对手术视频的密集视频字幕(DVC)全面解决方案,解决手术领域缺乏现有DVC数据集的问题。本文提出一种基于视频语言预训练、大规模视频预训练和优化微调的新型手术工作流程理解方法。该方法提高了性能,并为手术视频理解开启了新的下游任务。
关键见解
- 自动化手术工作流分析在教育、研究和临床决策中具有重要性。
- 缺乏标注数据集限制了准确和全面的手术工作流分析解决方案的发展。
- 引入一种新型方法,基于人类学习观看专家并理解其解释的过程。
- 利用视频语言模型进行训练,学习短期时空和多模态表示。
- 采用特定任务的时间模型捕捉整个视频的关联。
- 构建大规模预训练数据集,从教育YouTube视频中实现全面的视频语言理解。
点此查看论文截图


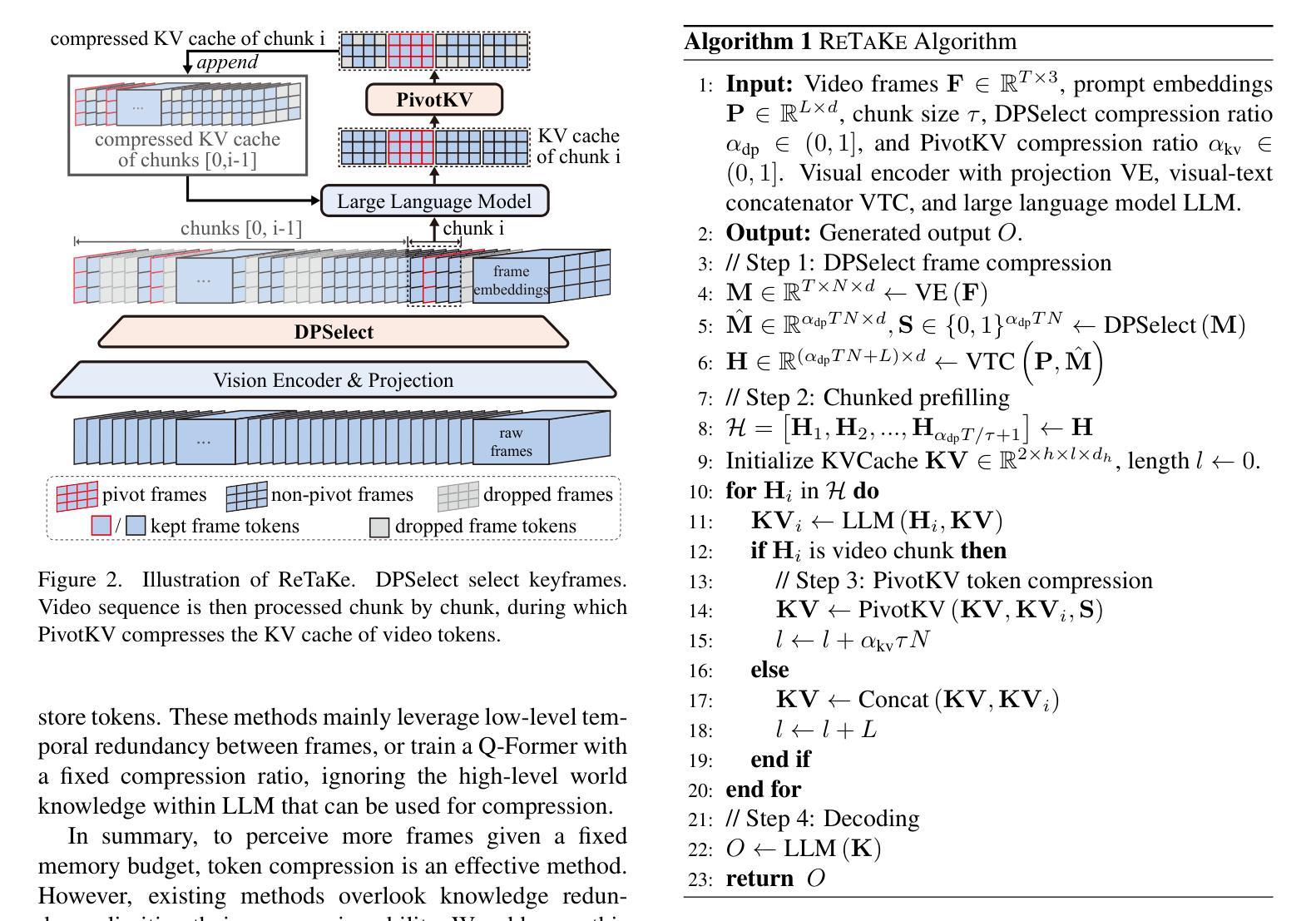
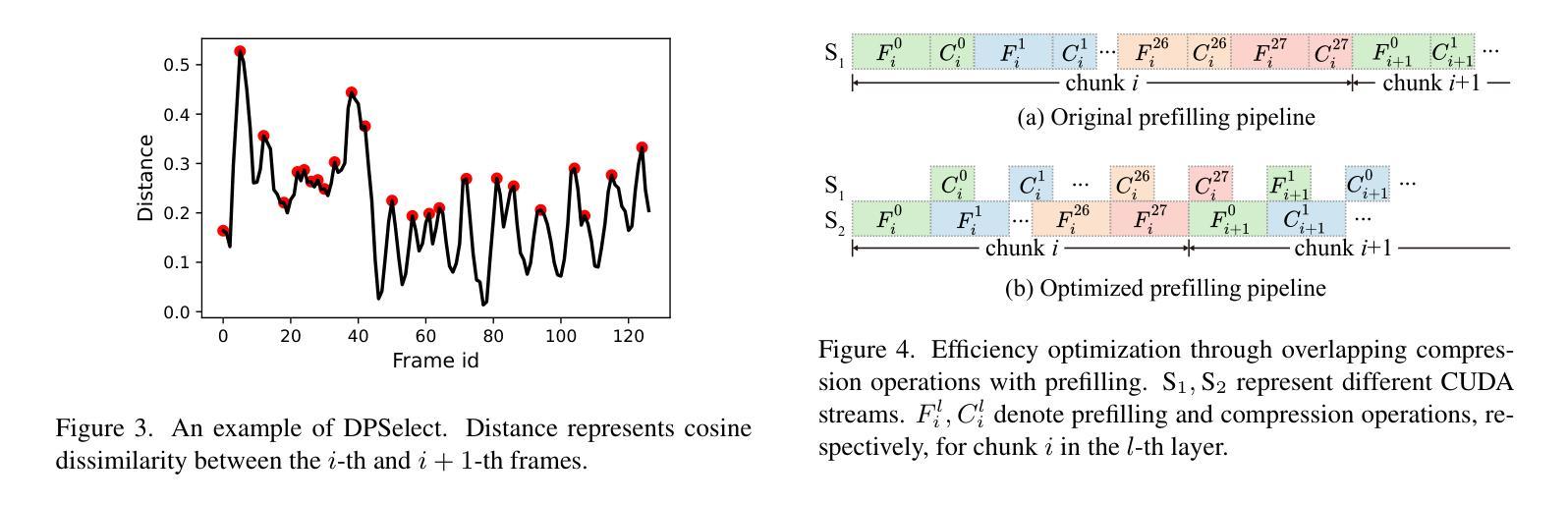
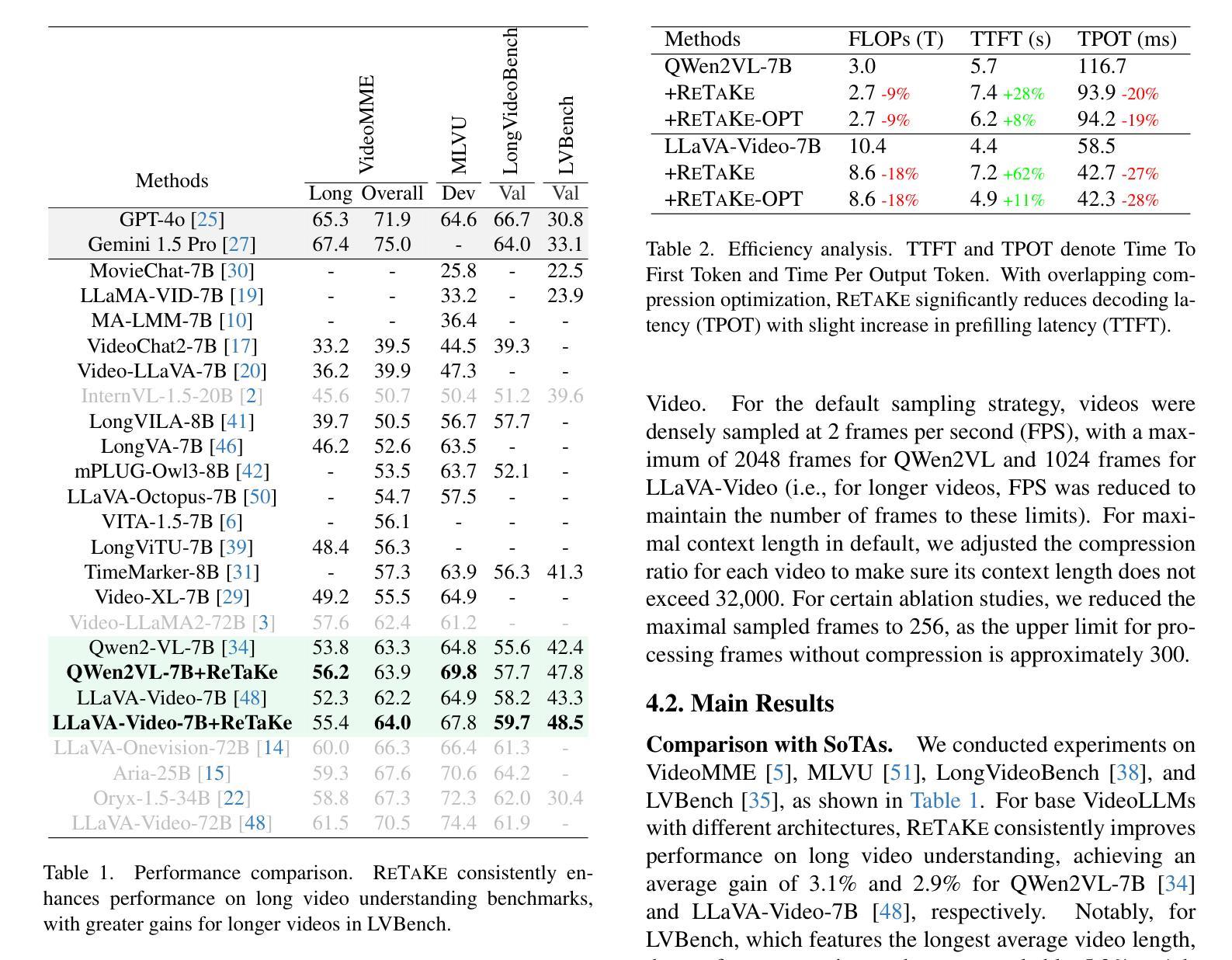
ReTaKe: Reducing Temporal and Knowledge Redundancy for Long Video Understanding
Authors:Xiao Wang, Qingyi Si, Jianlong Wu, Shiyu Zhu, Li Cao, Liqiang Nie
Video Large Language Models (VideoLLMs) have made significant strides in video understanding but struggle with long videos due to the limitations of their backbone LLMs. Existing solutions rely on length extrapolation, which is memory-constrained, or visual token compression, which primarily leverages low-level temporal redundancy while overlooking the more effective high-level knowledge redundancy. To address this, we propose $\textbf{ReTaKe}$, a training-free method with two novel modules DPSelect and PivotKV, to jointly reduce both temporal visual redundancy and knowledge redundancy for video compression. To align with the way of human temporal perception, DPSelect identifies keyframes based on inter-frame distance peaks. To leverage LLMs’ learned prior knowledge, PivotKV marks the keyframes as pivots and compress non-pivot frames by pruning low-attention tokens in their KV cache. ReTaKe enables VideoLLMs to process 8 times longer frames (up to 2048), outperforming similar-sized models by 3-5% and even rivaling much larger ones on VideoMME, MLVU, LongVideoBench, and LVBench. Moreover, by overlapping compression operations with prefilling, ReTaKe introduces only ~10% prefilling latency overhead while reducing decoding latency by ~20%. Our code is available at https://github.com/SCZwangxiao/video-ReTaKe.
视频大语言模型(VideoLLMs)在视频理解方面取得了重大进展,但由于其主干LLMs的局限性,在处理长视频时面临困难。现有解决方案依赖于内存受限的长度扩展或视觉令牌压缩,后者主要利用低级别的时序冗余而忽视更有效的高级知识冗余。为了解决这一问题,我们提出了无需训练的ReTaKe方法,包含两个新颖模块DPSelect和PivotKV,以联合减少时序视觉冗余和知识冗余,从而实现视频压缩。为了与人类的时间感知方式保持一致,DPSelect根据帧间距离峰值识别关键帧。为了利用LLMs的先验知识,PivotKV将关键帧标记为枢轴点,并通过删除其KV缓存中的低关注令牌来压缩非枢轴帧。ReTaKe使VideoLLMs能够处理长达8倍的视频帧(最多可达2048帧),在VideoMME、MLVU、LongVideoBench和LVBench上的性能优于同类模型3-5%,甚至与更大的模型不相上下。此外,通过压缩操作与预填充的重叠,ReTaKe仅引入了约10%的预填充延迟开销,同时降低了约20%的解码延迟。我们的代码可在https://github.com/SCZwangxiao/video-ReTaKe找到。
论文及项目相关链接
PDF Rewrite the methods section. Add more ablation studies and results in LongVideoBench. Update metadata
Summary
视频大型语言模型(VideoLLMs)在视频理解方面取得了显著进展,但在处理长视频时因模型架构限制而面临挑战。现有解决方案主要通过长度推断或视觉令牌压缩来实现,但它们存在记忆受限或忽略高级知识冗余的问题。针对此,我们提出无需训练的ReTaKe方法,包含DPSelect和PivotKV两个新模块,旨在减少视频压缩中的时间视觉冗余和知识冗余。ReTaKe通过DPSelect基于帧间距离峰值识别关键帧,并利用LLMs的先验知识,通过PivotKV标记关键帧作为支点,压缩非支点帧通过删除低注意力令牌。ReTaKe使VideoLLMs能够处理长达八倍的视频帧(达2048帧),在VideoMME、MLVU、LongVideoBench和LVBench上表现优异。此外,通过压缩操作与预填充的重叠,ReTaKe仅引入约10%的预填充延迟开销,同时减少约20%的解码延迟。
Key Takeaways
- VideoLLMs在视频理解方面取得了显著进展,但在处理长视频时面临挑战。
- 现有解决方案主要依赖长度推断和视觉令牌压缩,但存在记忆受限和忽略高级知识冗余的问题。
- ReTaKe是一种无需训练的方法,旨在减少视频压缩中的时间视觉冗余和知识冗余。
- ReTaKe通过DPSelect识别关键帧,并利用PivotKV模块利用LLMs的先验知识。
- ReTaKe使VideoLLMs能够处理更长的视频帧,表现优于同类模型,甚至与更大的模型相当。
- ReTaKe通过压缩操作与预填充的重叠,有效管理延迟开销。
- ReTaKe的代码已公开可用。
点此查看论文截图


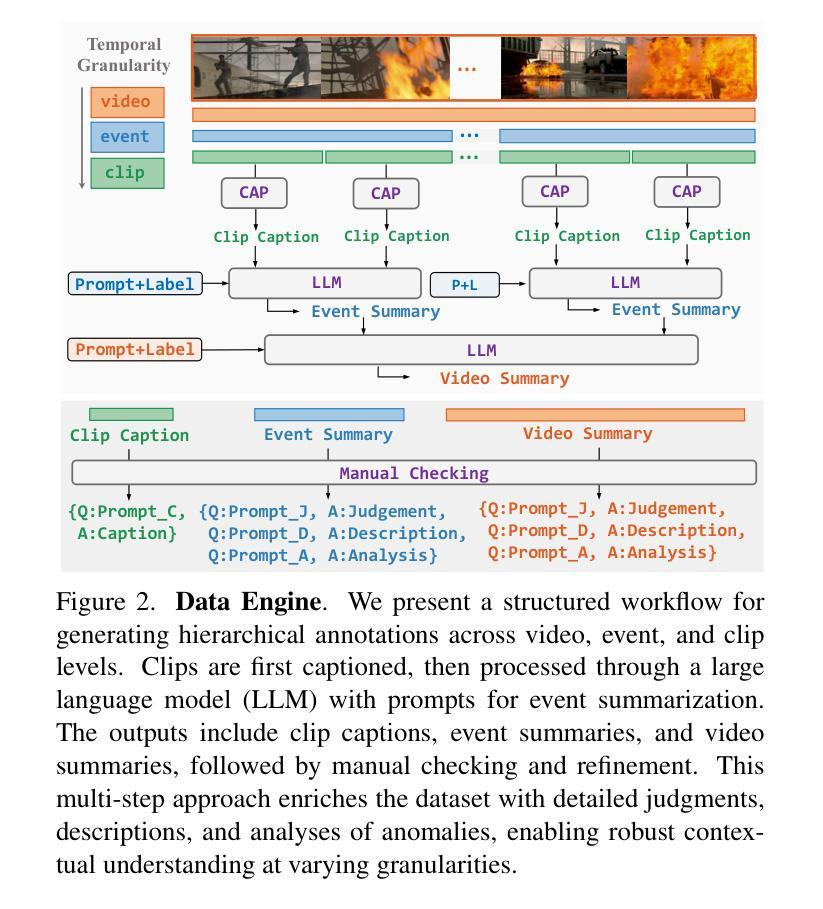
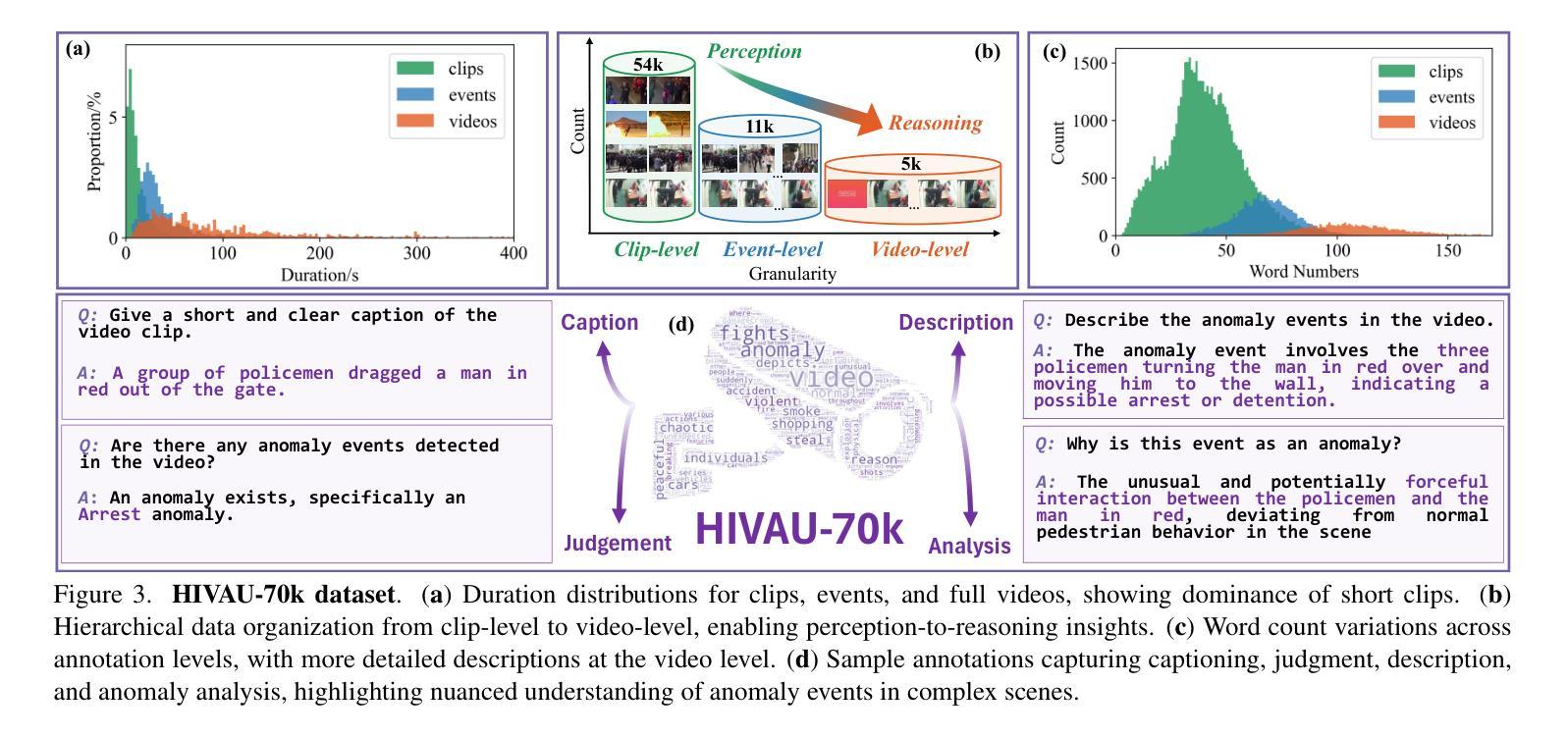
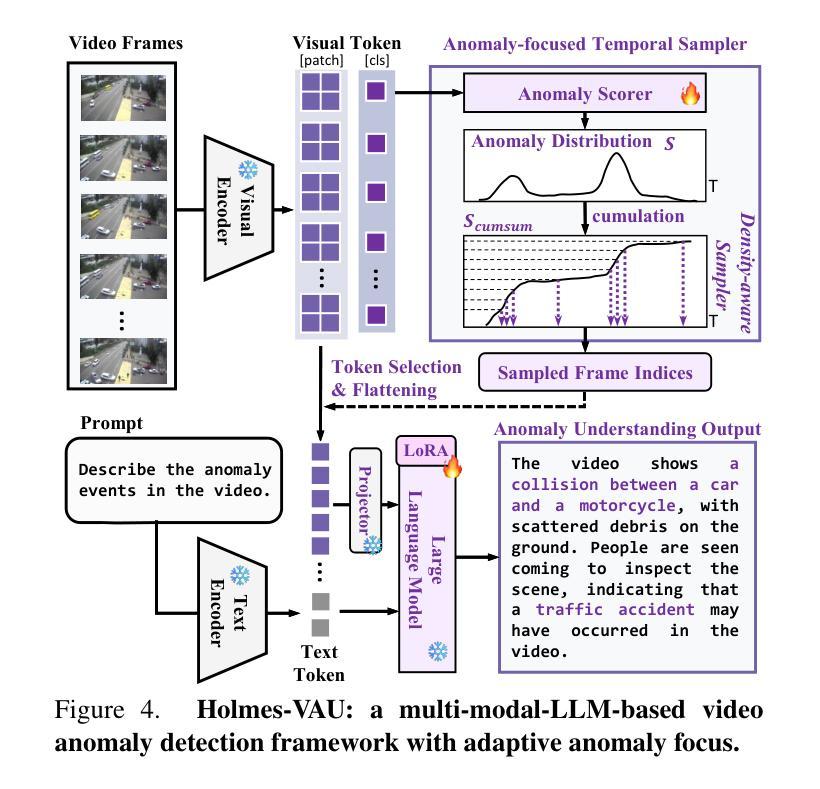
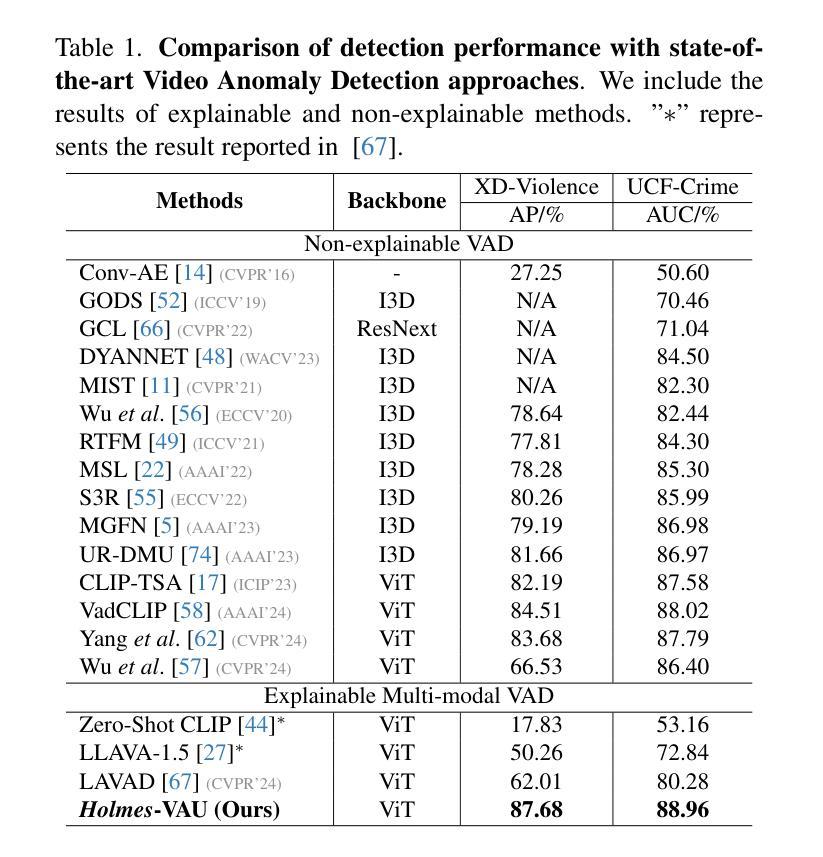
Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity
Authors:Huaxin Zhang, Xiaohao Xu, Xiang Wang, Jialong Zuo, Xiaonan Huang, Changxin Gao, Shanjun Zhang, Li Yu, Nong Sang
How can we enable models to comprehend video anomalies occurring over varying temporal scales and contexts? Traditional Video Anomaly Understanding (VAU) methods focus on frame-level anomaly prediction, often missing the interpretability of complex and diverse real-world anomalies. Recent multimodal approaches leverage visual and textual data but lack hierarchical annotations that capture both short-term and long-term anomalies. To address this challenge, we introduce HIVAU-70k, a large-scale benchmark for hierarchical video anomaly understanding across any granularity. We develop a semi-automated annotation engine that efficiently scales high-quality annotations by combining manual video segmentation with recursive free-text annotation using large language models (LLMs). This results in over 70,000 multi-granular annotations organized at clip-level, event-level, and video-level segments. For efficient anomaly detection in long videos, we propose the Anomaly-focused Temporal Sampler (ATS). ATS integrates an anomaly scorer with a density-aware sampler to adaptively select frames based on anomaly scores, ensuring that the multimodal LLM concentrates on anomaly-rich regions, which significantly enhances both efficiency and accuracy. Extensive experiments demonstrate that our hierarchical instruction data markedly improves anomaly comprehension. The integrated ATS and visual-language model outperform traditional methods in processing long videos. Our benchmark and model are publicly available at https://github.com/pipixin321/HolmesVAU.
我们如何使模型能够理解发生在不同时间尺度和上下文中的视频异常?传统的视频异常理解(VAU)方法主要关注帧级异常预测,往往忽略了复杂和多样化的现实世界异常的解读性。最近的多模式方法利用视觉和文本数据,但缺乏能够捕捉短期和长期异常的层次化注释。为了解决这一挑战,我们推出了HIVAU-70k,这是一个用于任何粒度层次视频异常理解的大规模基准测试。我们开发了一个半自动注释引擎,通过结合手动视频分割和基于大型语言模型(LLM)的递归文本注释,有效地扩展了高质量注释。这产生了超过7万个多粒度注释,按剪辑级、事件级和视频级分段组织。为了实现长视频中高效的异常检测,我们提出了专注于异常的临时采样器(ATS)。ATS将异常评分者与密度感知采样器相结合,根据异常分数自适应地选择帧,确保多模式LLM专注于异常丰富的区域,这显著提高了效率和准确性。大量实验表明,我们的层次化指令数据显著提高了异常理解能力。我们的基准测试和模型与视觉语言模型集成的ATS在处理长视频时,其表现优于传统方法。我们的基准测试和模型在https://github.com/pipixin321/HolmesVAU公开可用。
论文及项目相关链接
PDF Accepted by CVPR2025
摘要
为解决模型对不同时间尺度和上下文视频异常理解的问题,引入HIVAU-70k大规模基准测试集,提出半自动注释引擎和Anomaly-focused Temporal Sampler(ATS)。该引擎结合手动视频分割和递归文本注释,实现高质量注释的高效扩展。ATS结合异常评分者和密度感知采样器,自适应选择关键帧进行异常检测。实验证明,新方法在处理长视频时显著提高了效率和准确性。基准测试和模型已公开。
要点
- 提出解决模型理解不同时间尺度和上下文视频异常的挑战。
- 引入HIVAU-70k大规模基准测试集,用于层次化视频异常理解。
- 开发半自动注释引擎,结合手动视频分割和递归文本注释。
- 提出Anomaly-focused Temporal Sampler(ATS),提高异常检测效率和准确性。
- 层次化指令数据显著改善异常理解。
- 公开基准测试和模型,便于公众访问和使用。
点此查看论文截图