⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
One-Step Residual Shifting Diffusion for Image Super-Resolution via Distillation
Authors:Daniil Selikhanovych, David Li, Aleksei Leonov, Nikita Gushchin, Sergei Kushneriuk, Alexander Filippov, Evgeny Burnaev, Iaroslav Koshelev, Alexander Korotin
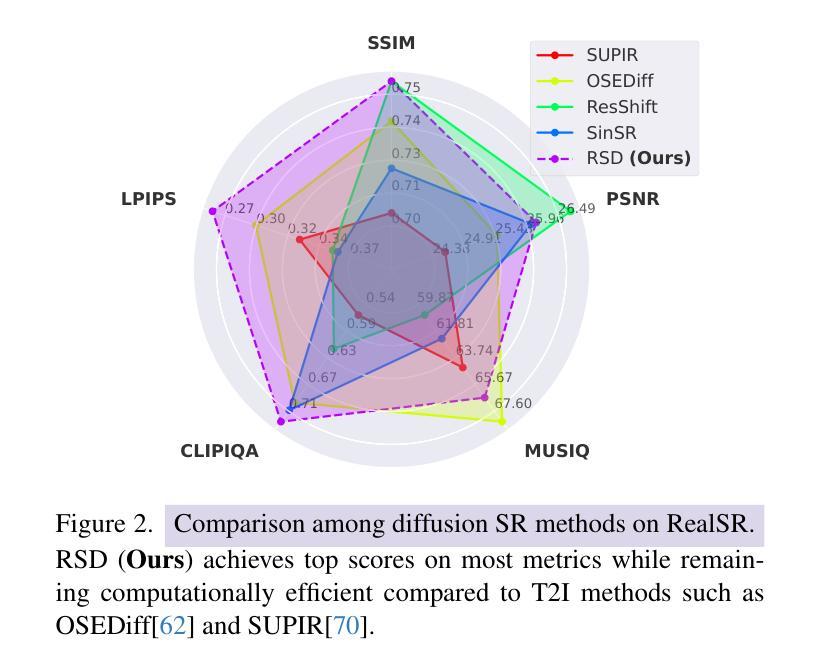
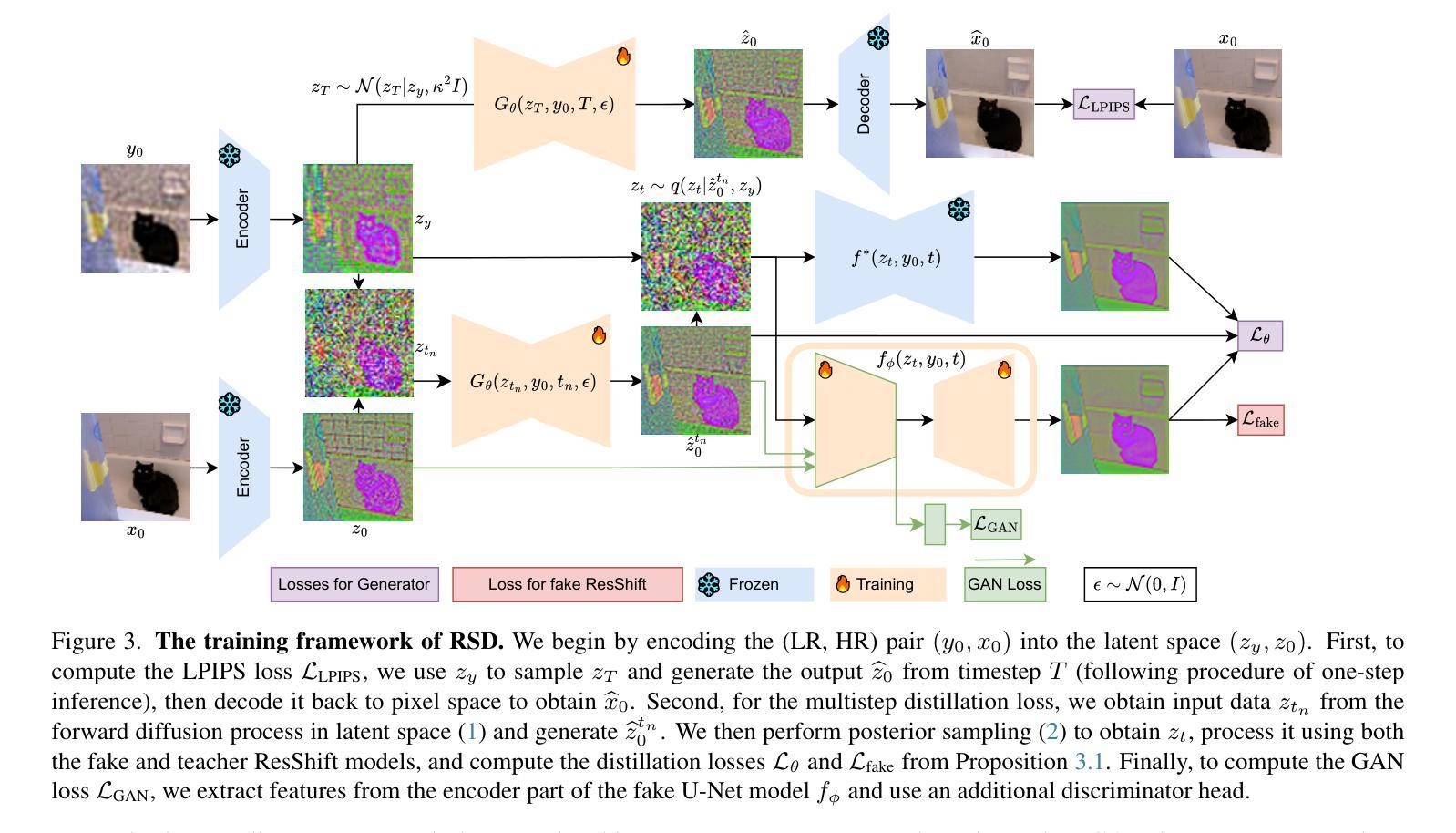
Diffusion models for super-resolution (SR) produce high-quality visual results but require expensive computational costs. Despite the development of several methods to accelerate diffusion-based SR models, some (e.g., SinSR) fail to produce realistic perceptual details, while others (e.g., OSEDiff) may hallucinate non-existent structures. To overcome these issues, we present RSD, a new distillation method for ResShift, one of the top diffusion-based SR models. Our method is based on training the student network to produce such images that a new fake ResShift model trained on them will coincide with the teacher model. RSD achieves single-step restoration and outperforms the teacher by a large margin. We show that our distillation method can surpass the other distillation-based method for ResShift - SinSR - making it on par with state-of-the-art diffusion-based SR distillation methods. Compared to SR methods based on pre-trained text-to-image models, RSD produces competitive perceptual quality, provides images with better alignment to degraded input images, and requires fewer parameters and GPU memory. We provide experimental results on various real-world and synthetic datasets, including RealSR, RealSet65, DRealSR, ImageNet, and DIV2K.
基于扩散模型的超分辨率(SR)技术能产生高质量的视觉效果,但需要巨大的计算成本。尽管已经开发了几种加速扩散SR模型的方法,但一些方法(例如SinSR)无法产生真实的感知细节,而其他方法(例如OSEDiff)可能会虚构不存在的结构。为了克服这些问题,我们提出了RSD,这是一种针对ResShift的新蒸馏方法,ResShift是顶级的扩散SR模型之一。我们的方法基于训练学生网络来生成图像,使得在这些图像上训练的新假ResShift模型与教师模型相符。RSD实现了单步恢复,并且大幅度超越了教师模型。我们展示我们的蒸馏方法可以超越ResShift的另一种蒸馏方法SinSR,使其与最先进的扩散SR蒸馏方法相媲美。与基于预训练文本到图像模型的SR方法相比,RSD产生的感知质量具有竞争力,提供的图像与退化输入图像的对齐性更好,并且需要的参数和GPU内存更少。我们在各种真实和合成数据集上提供了实验结果,包括RealSR、RealSet65、DRealSR、ImageNet和DIV2K。
论文及项目相关链接
Summary
扩散模型在超分辨率(SR)应用虽然可以生成高质量图像,但计算成本较高。虽然已有若干加速扩散模型的方法,但仍存在生成细节不真实或模拟不存在的结构的问题。本文提出了一种针对ResShift模型的全新蒸馏方法RSD。RSD训练学生网络生成图像,让新假ResShift模型对图像训练的结果与教师模型相符。RSD实现一步恢复并大幅度超越教师模型性能。实验结果显示,RSD超越其他基于蒸馏的ResShift模型SinSR,与最先进的扩散模型SR蒸馏方法表现相当。相较于基于预训练文本到图像的SR方法,RSD在感知质量方面更具竞争力,生成的图像更符合退化输入图像,同时参数和GPU内存需求更少。实验在RealSR、RealSet65、DRealSR、ImageNet和DIV2K等真实和合成数据集上进行了验证。
Key Takeaways
- 扩散模型在超分辨率应用中虽能生成高质量图像,但计算成本较高。
- 目前存在的加速扩散模型方法仍存在问题,如生成细节不真实或模拟不存在的结构。
- 本文提出一种针对ResShift模型的全新蒸馏方法RSD,实现一步恢复并大幅度提升模型性能。
- RSD通过训练学生网络生成图像,使新假ResShift模型与教师模型相符。
- RSD在多个数据集上的实验表现优于其他相关模型,包括SinSR和其他蒸馏方法。
- RSD相较于基于预训练文本到图像的SR方法更具竞争力,生成的图像更符合退化输入图像。
点此查看论文截图


Generative Gaussian Splatting: Generating 3D Scenes with Video Diffusion Priors
Authors:Katja Schwarz, Norman Mueller, Peter Kontschieder
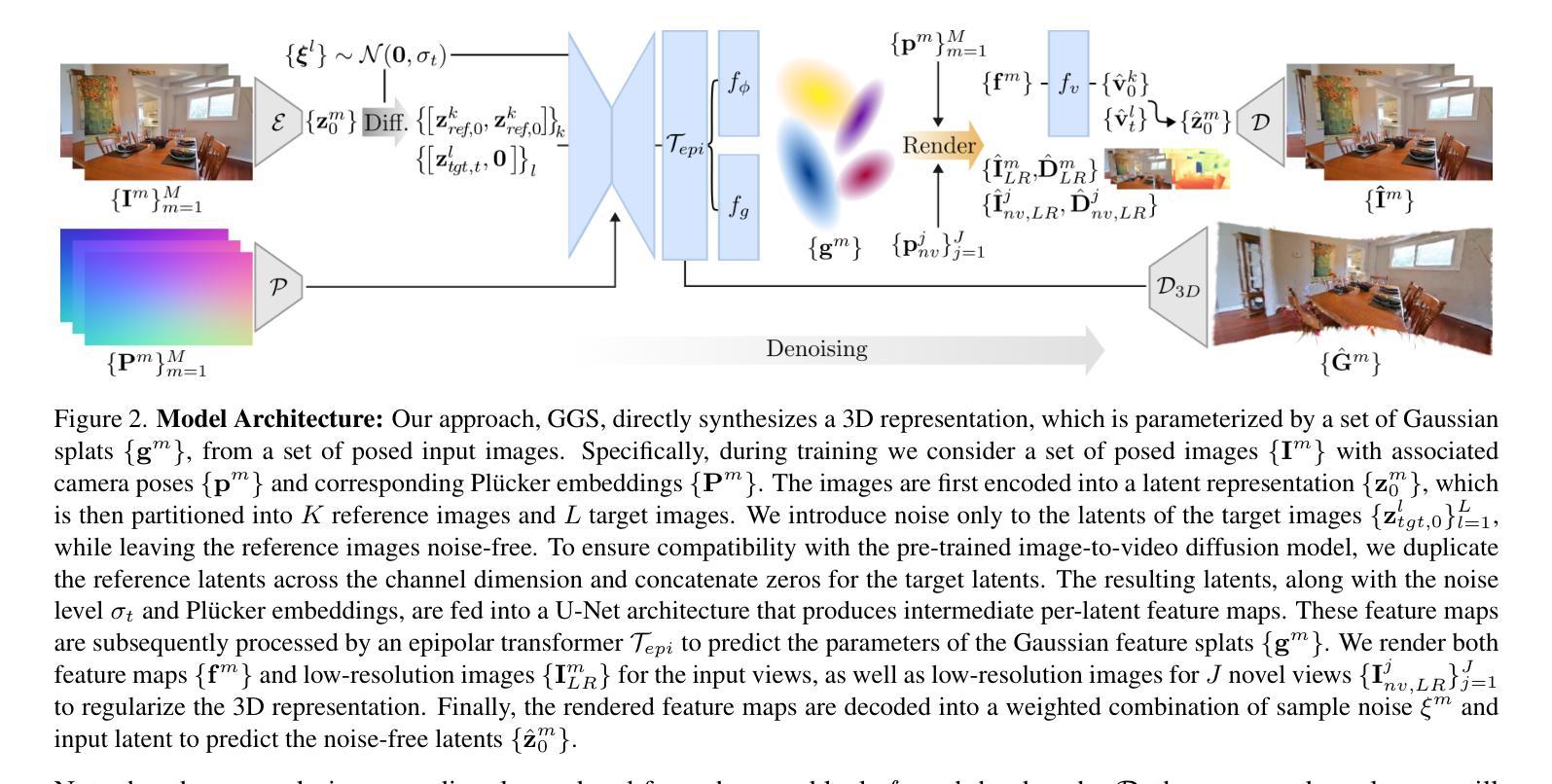
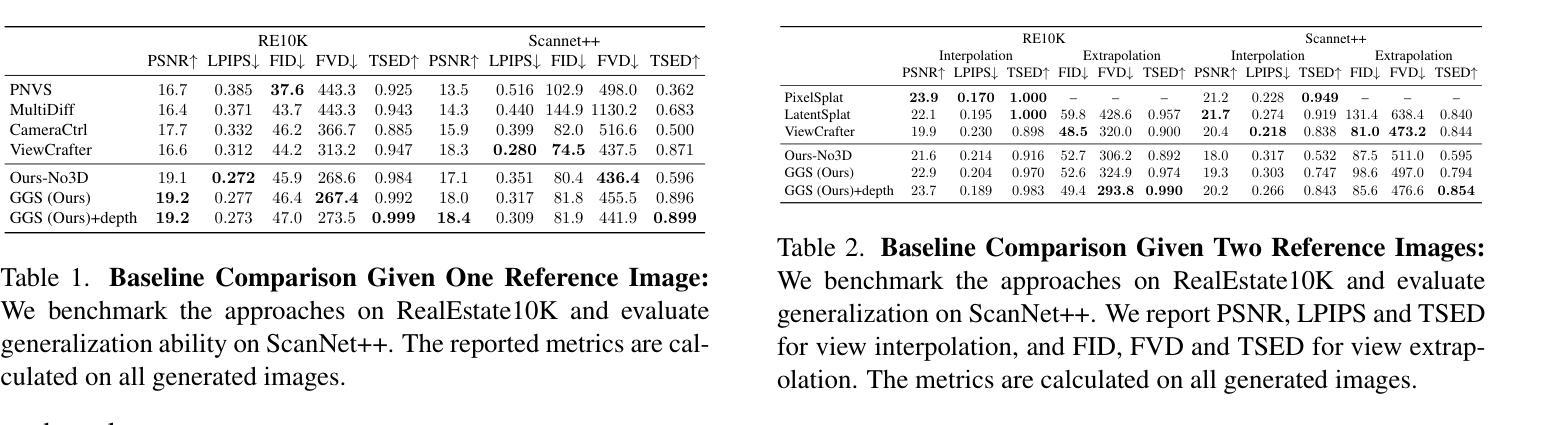
Synthesizing consistent and photorealistic 3D scenes is an open problem in computer vision. Video diffusion models generate impressive videos but cannot directly synthesize 3D representations, i.e., lack 3D consistency in the generated sequences. In addition, directly training generative 3D models is challenging due to a lack of 3D training data at scale. In this work, we present Generative Gaussian Splatting (GGS) – a novel approach that integrates a 3D representation with a pre-trained latent video diffusion model. Specifically, our model synthesizes a feature field parameterized via 3D Gaussian primitives. The feature field is then either rendered to feature maps and decoded into multi-view images, or directly upsampled into a 3D radiance field. We evaluate our approach on two common benchmark datasets for scene synthesis, RealEstate10K and ScanNet+, and find that our proposed GGS model significantly improves both the 3D consistency of the generated multi-view images, and the quality of the generated 3D scenes over all relevant baselines. Compared to a similar model without 3D representation, GGS improves FID on the generated 3D scenes by ~20% on both RealEstate10K and ScanNet+. Project page: https://katjaschwarz.github.io/ggs/
合成一致且逼真的3D场景是计算机视觉领域的一个开放性问题。视频扩散模型可以生成令人印象深刻的视频,但无法直接合成3D表示,即在生成的序列中缺乏3D一致性。此外,由于缺乏大规模的3D训练数据,直接训练生成式3D模型是一个挑战。在这项工作中,我们提出了生成式高斯喷溅(GGS)——一种将3D表示与预训练的潜在视频扩散模型相结合的新方法。具体来说,我们的模型通过3D高斯原始数据合成特征场。然后,该特征场要么被渲染为特征图并解码为多视图图像,要么直接上采样为3D辐射场。我们在场景合成的两个常用基准数据集RealEstate10K和ScanNet+上评估了我们的方法,发现所提出的GGS模型在生成的多视图图像的3D一致性和生成的3D场景的质量方面都有显著改善,优于所有相关基准。与没有3D表示的类似模型相比,GGS在RealEstate10K和ScanNet+上将生成的3D场景的FID提高了约20%。项目页面:https://katjaschwarz.github.io/ggs/
论文及项目相关链接
Summary
本文介绍了一种名为Generative Gaussian Splatting(GGS)的新方法,它将3D表示与预训练的潜在视频扩散模型相结合,用于合成3D场景。该方法通过合成以3D高斯原始数据为参数的特征场,然后将其渲染为特征图并解码为多视角图像或直接上采样为3D辐射场。在RealEstate10K和ScanNet+两个常用基准数据集上的评估结果表明,GGS模型显著提高了生成的多视角图像的3D一致性和生成的3D场景的质量。
Key Takeaways
- GGS是一种将3D表示与预训练潜在视频扩散模型结合的新方法。
- 通过合成以3D高斯原始数据为参数的特征场来实现3D场景的生成。
- 特征场可以渲染为特征图并解码为多视角图像或直接上采样为3D辐射场。
- 在RealEstate10K和ScanNet+数据集上的评估表明,GGS模型提高了生成的多视角图像的3D一致性和3D场景的质量。
- 与没有3D表示的类似模型相比,GGS模型在生成的3D场景上的FID得分提高了约20%。
- GGS模型通过整合3D表示,解决了视频扩散模型无法直接合成3D表示的问题。
点此查看论文截图

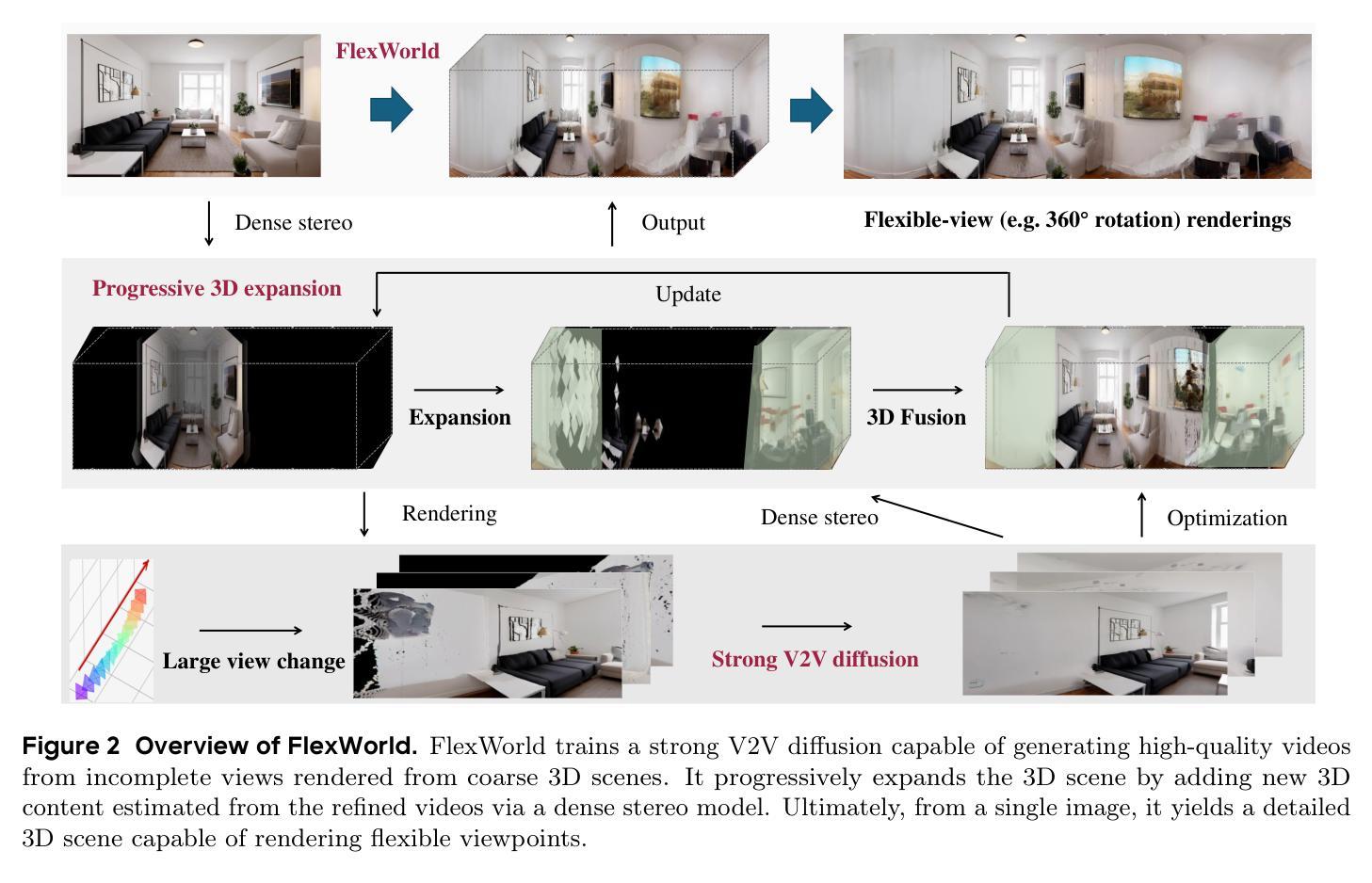
FlexWorld: Progressively Expanding 3D Scenes for Flexiable-View Synthesis
Authors:Luxi Chen, Zihan Zhou, Min Zhao, Yikai Wang, Ge Zhang, Wenhao Huang, Hao Sun, Ji-Rong Wen, Chongxuan Li
Generating flexible-view 3D scenes, including 360{\deg} rotation and zooming, from single images is challenging due to a lack of 3D data. To this end, we introduce FlexWorld, a novel framework consisting of two key components: (1) a strong video-to-video (V2V) diffusion model to generate high-quality novel view images from incomplete input rendered from a coarse scene, and (2) a progressive expansion process to construct a complete 3D scene. In particular, leveraging an advanced pre-trained video model and accurate depth-estimated training pairs, our V2V model can generate novel views under large camera pose variations. Building upon it, FlexWorld progressively generates new 3D content and integrates it into the global scene through geometry-aware scene fusion. Extensive experiments demonstrate the effectiveness of FlexWorld in generating high-quality novel view videos and flexible-view 3D scenes from single images, achieving superior visual quality under multiple popular metrics and datasets compared to existing state-of-the-art methods. Qualitatively, we highlight that FlexWorld can generate high-fidelity scenes with flexible views like 360{\deg} rotations and zooming. Project page: https://ml-gsai.github.io/FlexWorld.
生成包含360°旋转和缩放功能的灵活视角3D场景,从单张图像开始是一项挑战,因为缺乏3D数据。为此,我们引入了FlexWorld,这是一个由两个关键组件构成的新型框架:(1)强大的视频到视频(V2V)扩散模型,用于从由粗糙场景渲染的不完整输入生成高质量的新视角图像;(2)一个渐进的扩展过程来构建完整的3D场景。特别是,借助先进的预训练视频模型和精确的深度估计训练对,我们的V2V模型可以在大相机姿态变化下生成新视角。在此基础上,FlexWorld逐步生成新的3D内容,并通过几何感知场景融合将其集成到全局场景中。大量实验表明,FlexWorld在生成高质量新视角视频和灵活视角3D场景方面非常有效,从单张图像开始,在多个流行指标和数据集上与现有最先进的方法相比,实现了优越的视觉质量。从定性角度看,我们强调FlexWorld可以生成具有灵活视角的高保真场景,如360°旋转和缩放。项目页面:[https://ml-gsai.github.io/FlexWorld。]
论文及项目相关链接
Summary
本文介绍了一种名为FlexWorld的新型框架,用于从单一图像生成灵活的3D场景,包括360°旋转和缩放。该框架包含两个关键组件:一是强大的视频到视频(V2V)扩散模型,用于从粗略场景渲染的不完整输入生成高质量的新视角图像;二是渐进扩展过程,用于构建完整的3D场景。FlexWorld能够利用先进的预训练视频模型和精确的深度估计训练对,生成新型视角图像,并在大型相机姿态变化下表现出色。此外,FlexWorld逐步生成新的3D内容,并通过几何感知场景融合将其融入全局场景。实验证明,FlexWorld在生成高质量的新视角视频和灵活的3D场景方面效果显著,与现有最先进的方法相比,在多个流行的指标和数据集上实现了优越的视觉质量。
Key Takeaways
- FlexWorld是一种新型框架,用于从单一图像生成灵活的3D场景。
- 框架包含两个关键组件:视频到视频(V2V)扩散模型和渐进扩展过程。
- V2V模型利用预训练视频模型和深度估计训练对,能生成新型视角图像,应对大型相机姿态变化。
- 渐进扩展过程用于构建完整的3D场景,逐步生成新的3D内容并融入全局场景。
- FlexWorld生成的高质量新视角视频和灵活的3D场景在多个指标和数据集上表现出卓越性能。
- FlexWorld生成的场景具有高保真度,支持360°旋转和缩放等灵活视图。
点此查看论文截图




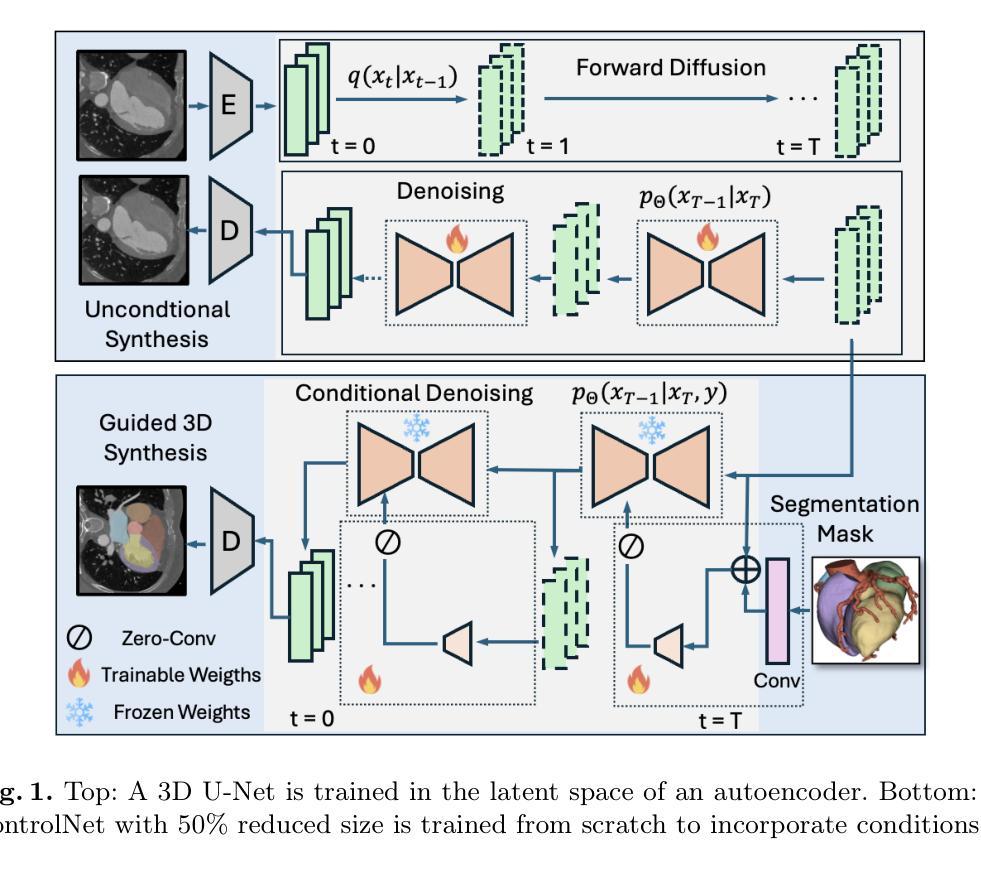
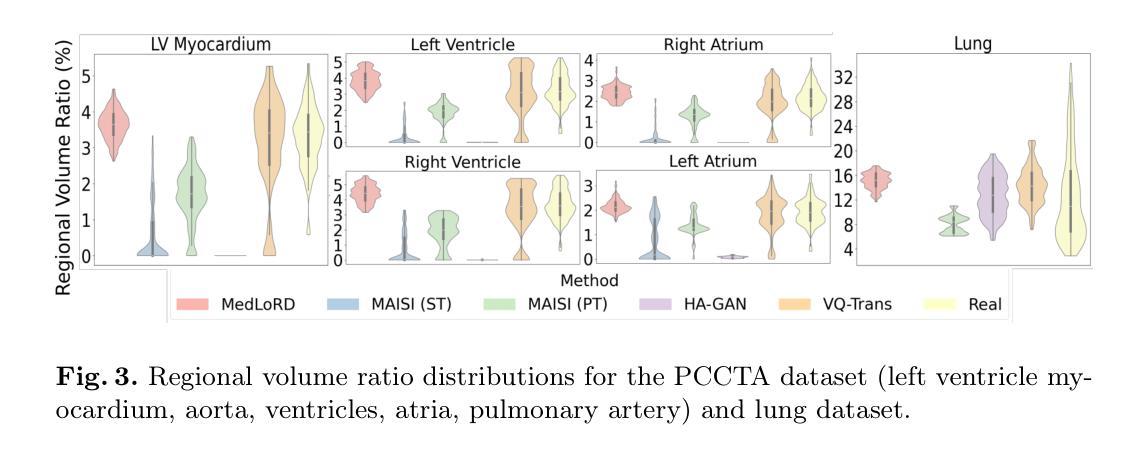
MedLoRD: A Medical Low-Resource Diffusion Model for High-Resolution 3D CT Image Synthesis
Authors:Marvin Seyfarth, Salman Ul Hassan Dar, Isabelle Ayx, Matthias Alexander Fink, Stefan O. Schoenberg, Hans-Ulrich Kauczor, Sandy Engelhardt
Advancements in AI for medical imaging offer significant potential. However, their applications are constrained by the limited availability of data and the reluctance of medical centers to share it due to patient privacy concerns. Generative models present a promising solution by creating synthetic data as a substitute for real patient data. However, medical images are typically high-dimensional, and current state-of-the-art methods are often impractical for computational resource-constrained healthcare environments. These models rely on data sub-sampling, raising doubts about their feasibility and real-world applicability. Furthermore, many of these models are evaluated on quantitative metrics that alone can be misleading in assessing the image quality and clinical meaningfulness of the generated images. To address this, we introduce MedLoRD, a generative diffusion model designed for computational resource-constrained environments. MedLoRD is capable of generating high-dimensional medical volumes with resolutions up to 512$\times$512$\times$256, utilizing GPUs with only 24GB VRAM, which are commonly found in standard desktop workstations. MedLoRD is evaluated across multiple modalities, including Coronary Computed Tomography Angiography and Lung Computed Tomography datasets. Extensive evaluations through radiological evaluation, relative regional volume analysis, adherence to conditional masks, and downstream tasks show that MedLoRD generates high-fidelity images closely adhering to segmentation mask conditions, surpassing the capabilities of current state-of-the-art generative models for medical image synthesis in computational resource-constrained environments.
人工智能在医学影像方面的进步具有巨大潜力。然而,其应用受到数据有限以及医疗中心因患者隐私担忧而不愿共享数据的制约。生成模型通过创建合成数据作为真实患者数据的替代品,呈现了一种有前景的解决方案。然而,医学图像通常是高维的,当前先进的技术方法在计算资源受限的医疗环境中通常不切实际。这些模型依赖于数据子采样,人们对它们的可行性和现实应用可行性提出质疑。此外,这些模型的评估往往依赖于定量指标,这单独评估生成的图像的质量和临床意义可能是误导的。为了解决这个问题,我们引入了MedLoRD,这是一种为计算资源受限环境设计的生成扩散模型。MedLoRD能够生成高维医学体积数据,分辨率高达512×512×256,仅利用24GB VRAM的GPU,这在标准台式工作站中很常见。MedLoRD在多模态评估中表现出色,包括冠状动脉计算机断层扫描血管造影和肺部计算机断层扫描数据集。通过放射学评估、相对区域体积分析、遵循条件掩膜和下游任务的广泛评估表明,MedLoRD生成的图像高度保真,紧密遵循分割掩膜条件,超越了当前先进生成模型在计算资源受限环境中医学图像合成的能力。
论文及项目相关链接
摘要
基于扩散模型的MedLoRD方法为解决医疗成像中数据受限及隐私保护问题提供了新的希望。该方法能在计算资源受限的环境下生成高质量医学图像,分辨率高达512×512×256,只需利用常见的桌面工作站配备的GPU(24GB VRAM)。经过多模态评估,包括冠状动脉计算机断层扫描和肺部计算机断层扫描数据集,证明MedLoRD生成的高保真图像紧密贴合分割掩膜条件,超越当前同类模型的能力。
关键见解
- 医疗成像中AI的进展具有巨大潜力,但数据可用性和隐私保护限制了其应用。
- 生成模型通过创建合成数据作为真实患者数据的替代品来解决这一问题。
- 医疗图像是高维度的,当前先进的方法对于计算资源受限的医疗环境来说通常不切实际。
- MedLoRD作为一种生成性扩散模型,旨在解决计算资源受限环境下的医疗图像生成问题。
- MedLoRD能够在标准桌面工作站常见的GPU(24GB VRAM)上生成高质量医学图像,分辨率高达512×512×256。
- MedLoRD在多模态评估中表现出优异性能,包括冠状动脉和肺部计算机断层扫描数据集。
- 通过多项评估证明,MedLoRD生成的图像质量高、临床意义重大,超越了现有模型的性能。
点此查看论文截图

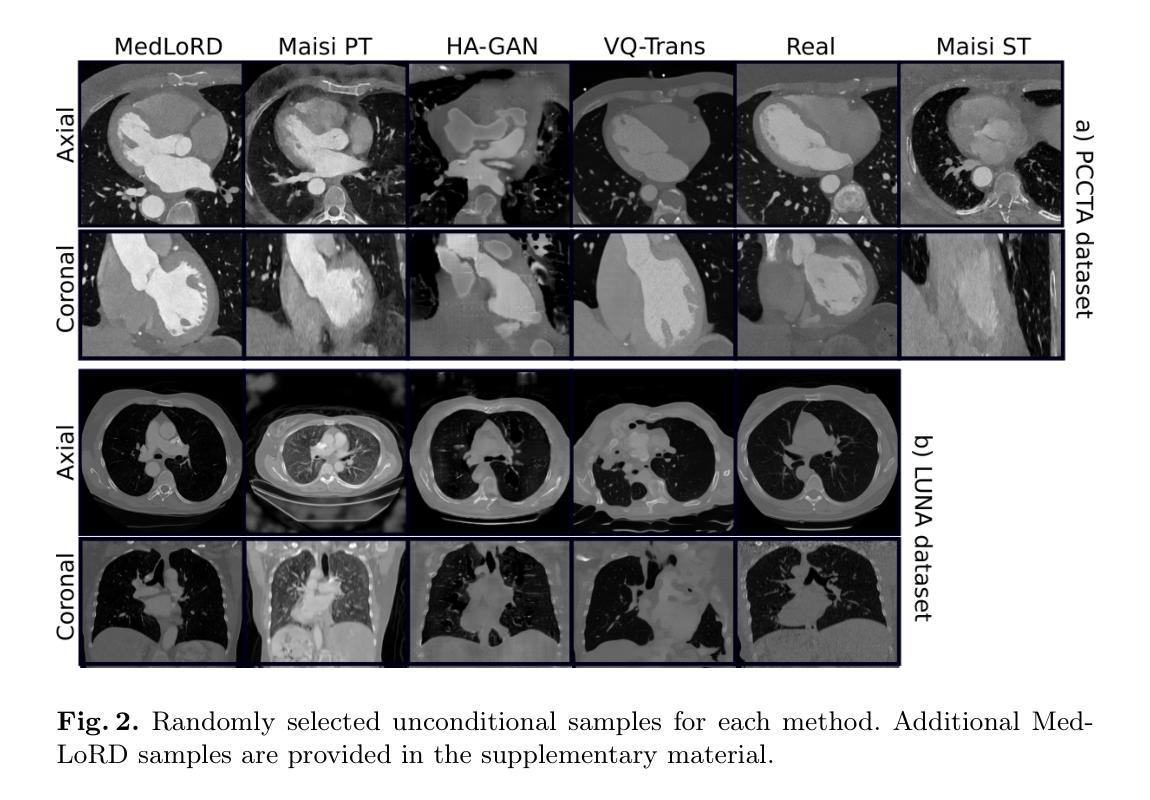
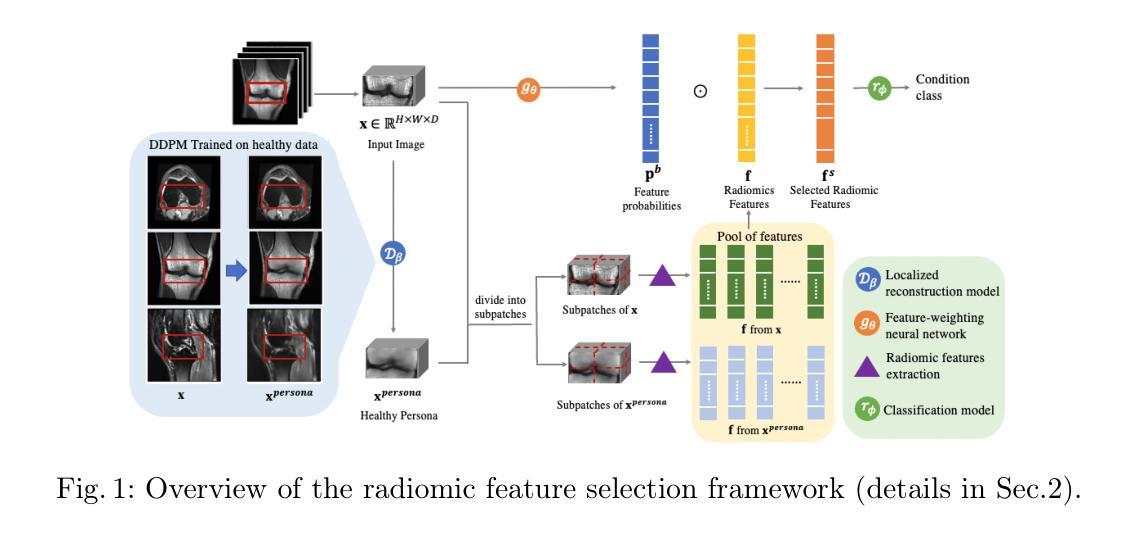
Patient-specific radiomic feature selection with reconstructed healthy persona of knee MR images
Authors:Yaxi Chen, Simin Ni, Aleksandra Ivanova, Shaheer U. Saeed, Rikin Hargunani, Jie Huang, Chaozong Liu, Yipeng Hu
Classical radiomic features have been designed to describe image appearance and intensity patterns. These features are directly interpretable and readily understood by radiologists. Compared with end-to-end deep learning (DL) models, lower dimensional parametric models that use such radiomic features offer enhanced interpretability but lower comparative performance in clinical tasks. In this study, we propose an approach where a standard logistic regression model performance is substantially improved by learning to select radiomic features for individual patients, from a pool of candidate features. This approach has potentials to maintain the interpretability of such approaches while offering comparable performance to DL. We also propose to expand the feature pool by generating a patient-specific healthy persona via mask-inpainting using a denoising diffusion model trained on healthy subjects. Such a pathology-free baseline feature set allows further opportunity in novel feature discovery and improved condition classification. We demonstrate our method on multiple clinical tasks of classifying general abnormalities, anterior cruciate ligament tears, and meniscus tears. Experimental results demonstrate that our approach achieved comparable or even superior performance than state-of-the-art DL approaches while offering added interpretability by using radiomic features extracted from images and supplemented by generating healthy personas. Example clinical cases are discussed in-depth to demonstrate the intepretability-enabled utilities such as human-explainable feature discovery and patient-specific location/view selection. These findings highlight the potentials of the combination of subject-specific feature selection with generative models in augmenting radiomic analysis for more interpretable decision-making. The codes are available at: https://github.com/YaxiiC/RadiomicsPersona.git
经典放射学特征被设计用于描述图像的外观和强度模式。这些特征是直接可解释的,很容易被放射科医生理解。与端到端的深度学习(DL)模型相比,使用这些放射学特征的低维参数模型提供增强的可解释性,但在临床任务中的比较性能较低。在研究中,我们提出了一种方法,即通过从候选特征池中学习选择针对个别患者的放射学特征来显著改进标准逻辑回归模型的性能。这种方法有潜力保持此类方法的可解释性,同时提供与深度学习相当的性能。我们还提议通过利用去噪扩散模型对健康受试者进行训练,通过掩膜修复法生成患者特定的健康人格来扩展特征池。这样的无病变基准特征集为进一步发现新特征和改进状况分类提供了更多机会。我们在分类一般异常、前交叉韧带撕裂和半月板撕裂等多个临床任务上展示了我们的方法。实验结果表明,我们的方法与最新深度学习技术相比取得了相当甚至更优的性能,同时通过提取图像中的放射学特征和补充生成健康人格,增加了可解释性。深入讨论了示例病例,以展示可解释性功能的实用性,如人类可解释的特征发现、患者特定位置/视图选择等。这些发现突出了结合主体特定特征选择和生成模型在增强放射学分析中的潜力,以做出更具可解释性的决策。相关代码可在:https://github.com/YaxiiC/RadiomicsPersona.git上找到。
论文及项目相关链接
Summary
本文提出一种基于逻辑回归模型的方法,通过选择患者个体化放射学特征来改进模型性能,特征池得到扩展,通过利用健康受试者的去噪扩散模型进行遮罩填充来生成患者特定的健康人格。该方法在维持模型可解释性的同时,实现了与深度学习模型相当或更优的性能,并在分类一般异常、前交叉韧带撕裂和半月板撕裂等多个临床任务中进行了验证。
Key Takeaways
- 经典放射学特征用于描述图像外观和强度模式,可直接被放射科医生解读。
- 与端到端的深度学习模型相比,低维参数模型虽然性能较低,但具有更高的可解释性。
- 提出一种改进逻辑回归模型的方法,通过选择个体化的放射学特征来提高性能。
- 通过利用健康受试者的扩散模型生成患者特定的健康人格来扩展特征池。
- 该方法在维持模型可解释性的同时,实现了与深度学习模型相当或更优的性能。
- 在多个临床任务中进行了实验验证,包括分类一般异常、前交叉韧带撕裂和半月板撕裂等。
点此查看论文截图

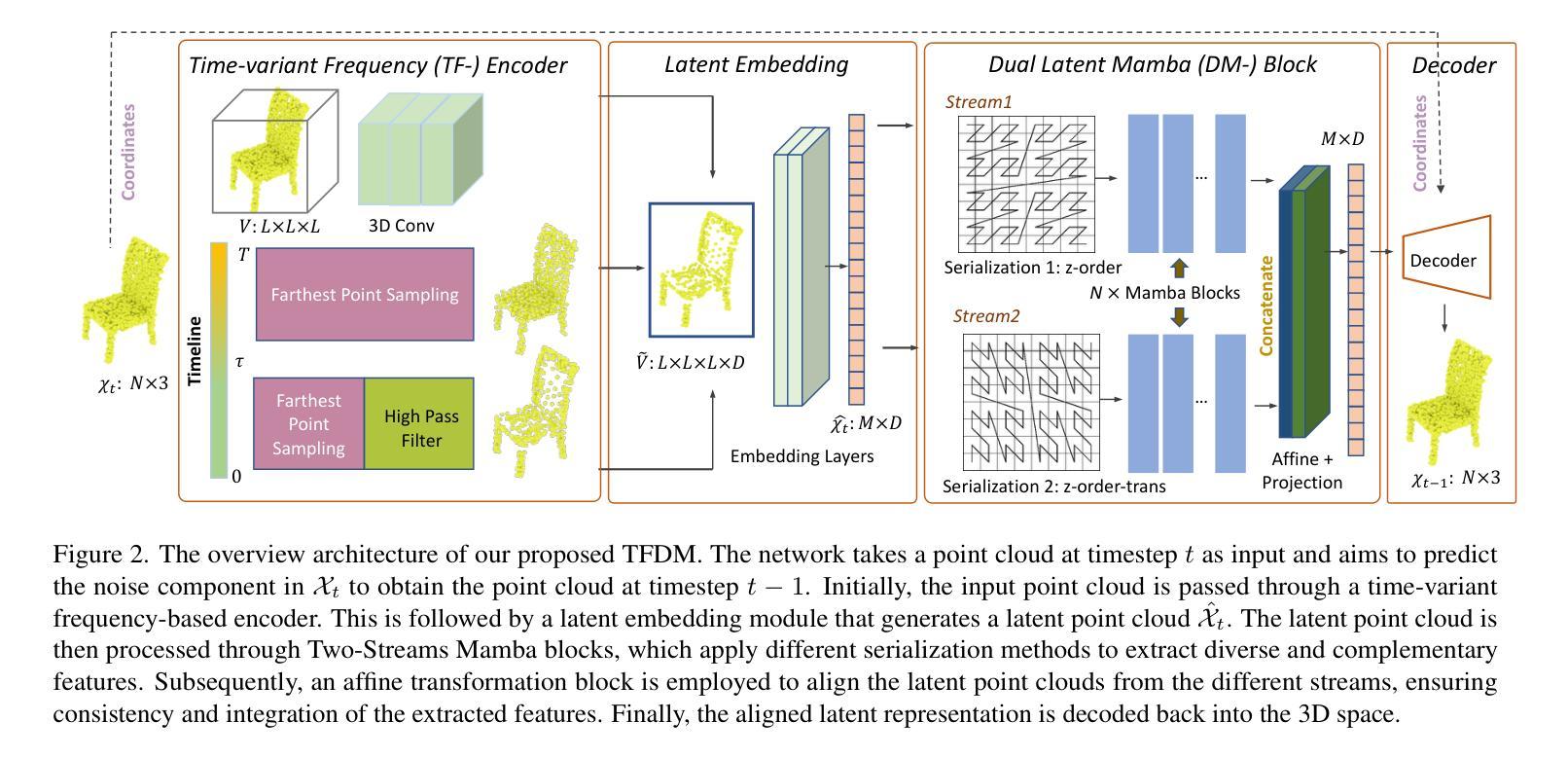
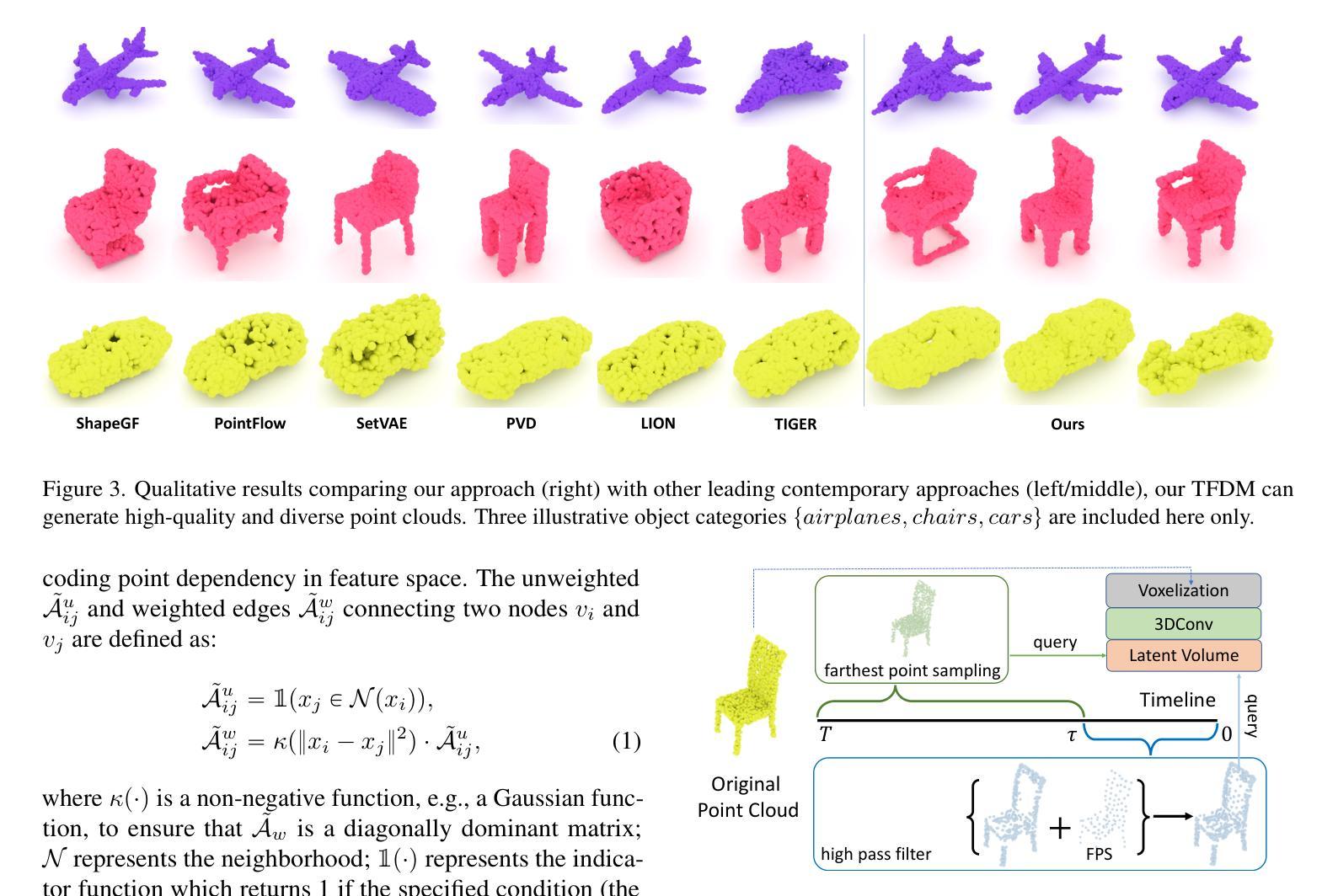
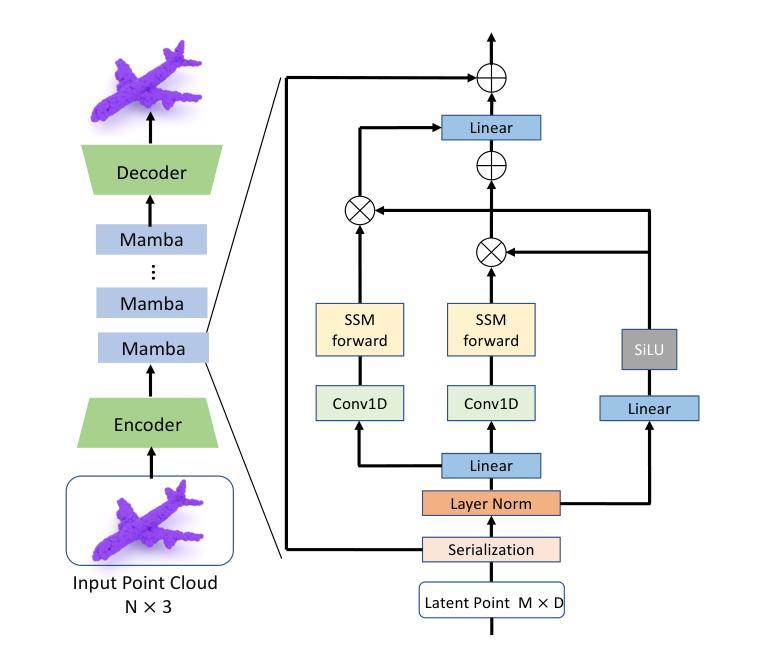
TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with Mamba
Authors:Jiaxu Liu, Li Li, Hubert P. H. Shum, Toby P. Breckon
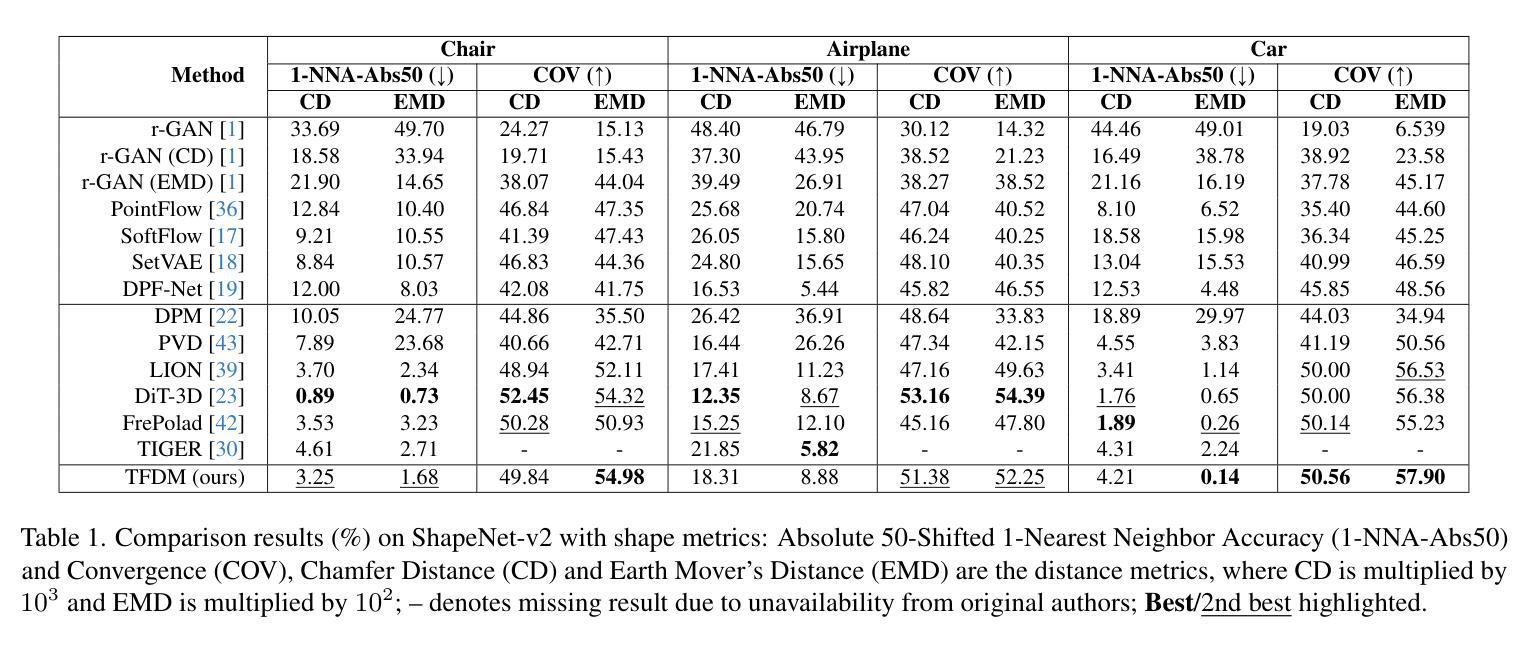
Diffusion models currently demonstrate impressive performance over various generative tasks. Recent work on image diffusion highlights the strong capabilities of Mamba (state space models) due to its efficient handling of long-range dependencies and sequential data modeling. Unfortunately, joint consideration of state space models with 3D point cloud generation remains limited. To harness the powerful capabilities of the Mamba model for 3D point cloud generation, we propose a novel diffusion framework containing dual latent Mamba block (DM-Block) and a time-variant frequency encoder (TF-Encoder). The DM-Block apply a space-filling curve to reorder points into sequences suitable for Mamba state-space modeling, while operating in a latent space to mitigate the computational overhead that arises from direct 3D data processing. Meanwhile, the TF-Encoder takes advantage of the ability of the diffusion model to refine fine details in later recovery stages by prioritizing key points within the U-Net architecture. This frequency-based mechanism ensures enhanced detail quality in the final stages of generation. Experimental results on the ShapeNet-v2 dataset demonstrate that our method achieves state-of-the-art performance (ShapeNet-v2: 0.14% on 1-NNA-Abs50 EMD and 57.90% on COV EMD) on certain metrics for specific categories while reducing computational parameters and inference time by up to 10$\times$ and 9$\times$, respectively. Source code is available in Supplementary Materials and will be released upon accpetance.
扩散模型目前在各种生成任务中表现出令人印象深刻的性能。关于图像扩散的最新工作突出了Mamba(状态空间模型)的强大能力,得益于其高效处理长程依赖关系和序列数据建模。然而,将状态空间模型与3D点云生成相结合的研究仍然有限。为了利用Mamba模型在3D点云生成方面的强大能力,我们提出了一种新的扩散框架,包含双潜伏Mamba块(DM-Block)和时间变量频率编码器(TF-Encoder)。DM-Block应用空间填充曲线对点进行排序,生成适合Mamba状态空间建模的序列,同时在潜在空间中进行操作,以减轻直接处理3D数据所产生的计算开销。同时,TF-Encoder利用扩散模型在后期恢复阶段细化细节的能力,在U-Net架构内优先处理关键点。这种基于频率的机制确保了生成最终阶段的细节质量得到提高。在ShapeNet-v2数据集上的实验结果表明,我们的方法在特定类别的某些指标上达到了最新技术性能(ShapeNet-v2:在1-NNA-Abs50 EMD上为0.14%,在COV EMD上为57.90%),同时减少了计算参数和推理时间,分别高达10倍和9倍。源代码包含在补充材料中,接受后将予以发布。
论文及项目相关链接
Summary
本文介绍了扩散模型在多种生成任务中的出色表现,特别是在图像扩散方面的能力。针对三维点云生成,提出一种新型扩散框架,包含双潜态Mamba块(DM-Block)和时变频率编码器(TF-Encoder)。DM-Block利用空间填充曲线将点重新排序,适合Mamba状态空间建模,并在潜在空间操作以减轻直接处理3D数据的计算负担。TF-Encoder则利用扩散模型在后期恢复阶段细化细节的能力,优先处理U-Net架构中的关键点。在ShapeNet-v2数据集上的实验结果显示,该方法在特定类别指标的某些度量上达到最新技术水平,同时减少计算参数和推理时间。
Key Takeaways
- 扩散模型在多种生成任务中表现优异,特别是在图像扩散方面。
- 针对三维点云生成,提出了包含DM-Block和TF-Encoder的新型扩散框架。
- DM-Block利用空间填充曲线处理点云数据,适合Mamba状态空间建模,并在潜在空间减轻计算负担。
- TF-Encoder利用扩散模型的细节优化能力,优先处理关键点。
- 在ShapeNet-v2数据集上的实验结果显示,该方法达到最新技术水平。
- 该方法在计算参数和推理时间上有所优化。
点此查看论文截图
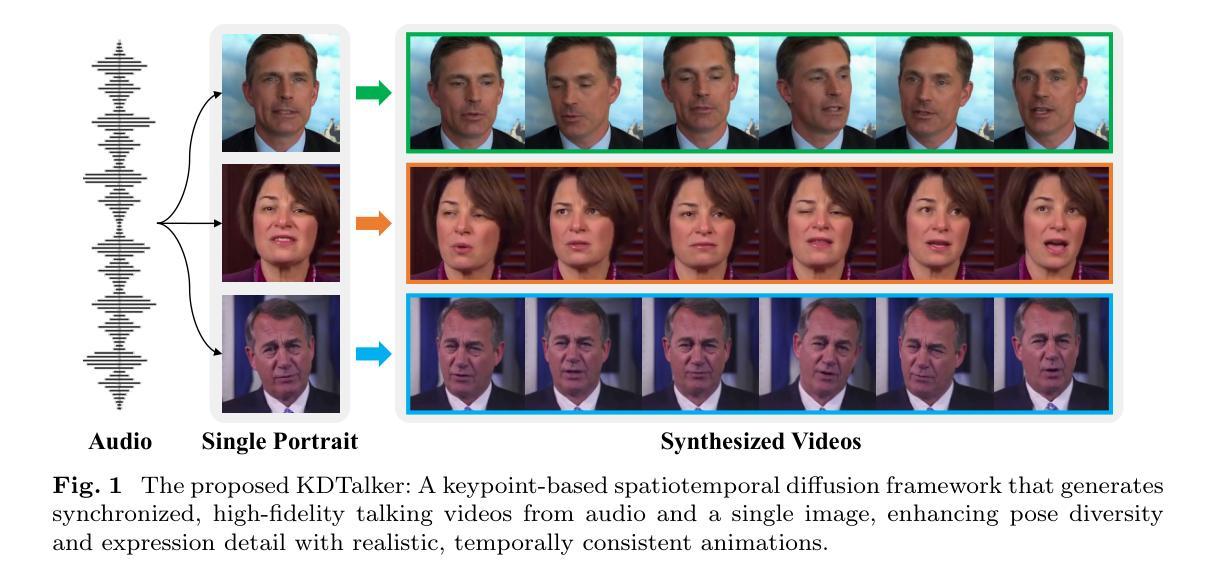
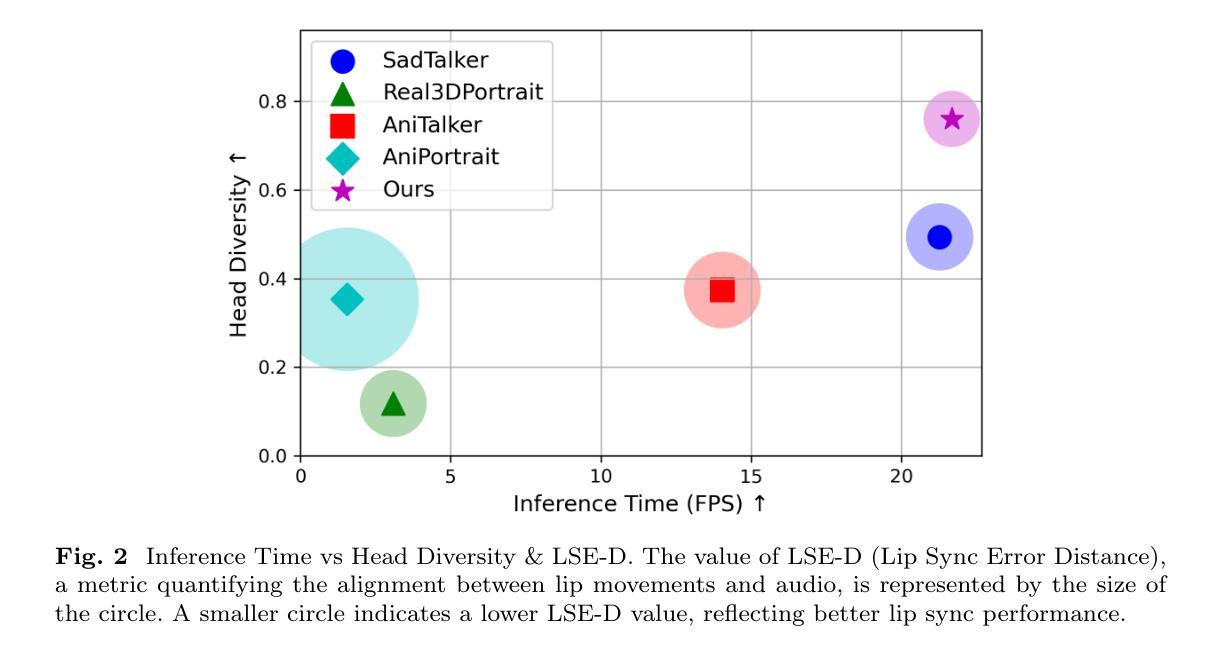
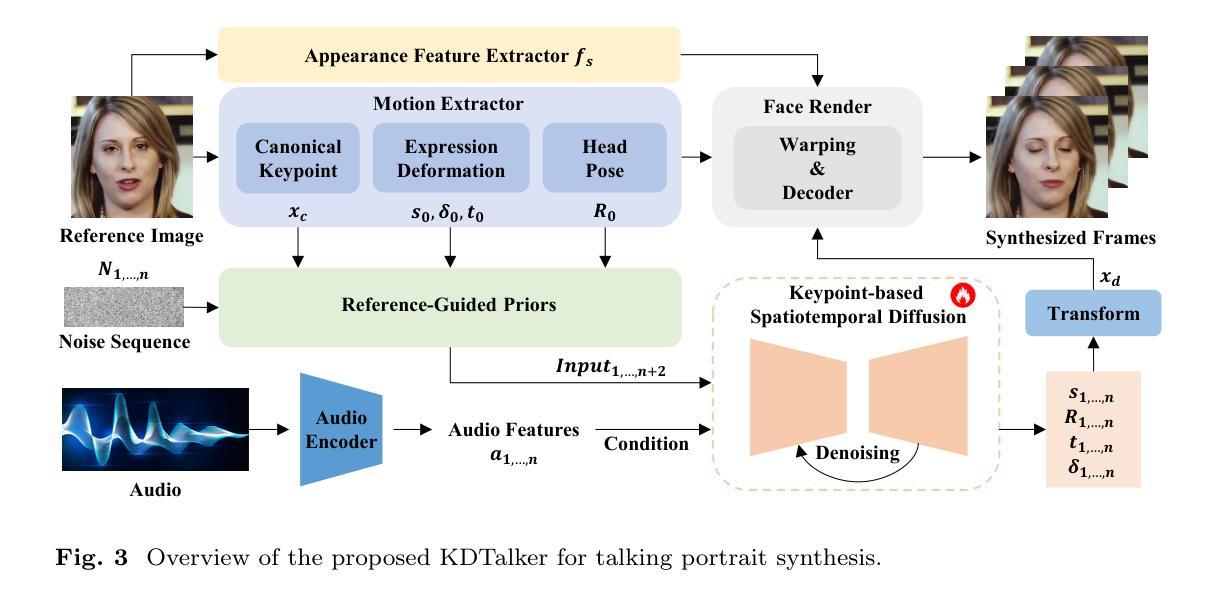
Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Authors:Chaolong Yang, Kai Yao, Yuyao Yan, Chenru Jiang, Weiguang Zhao, Jie Sun, Guangliang Cheng, Yifei Zhang, Bin Dong, Kaizhu Huang
Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
音频驱动的单图像说话肖像生成在虚拟现实、数字人类创建和电影制作中发挥着至关重要的作用。现有方法通常分为基于关键点的方法和基于图像的方法。基于关键点的方法能够有效地保留人物身份,但由于3D可变形模型的固定点限制,很难捕捉面部细节。此外,传统生成网络在有限数据集上建立音频和关键点之间的因果关系面临挑战,导致姿势多样性较低。相比之下,基于图像的方法使用扩散网络生成具有各种细节的高质量肖像,但会产生身份失真和昂贵的计算成本。在这项工作中,我们提出了KDTalker,这是第一个结合无监督隐式3D关键点与时空扩散模型的框架。利用无监督隐式3D关键点,KDTalker适应面部信息密度,使扩散过程能够灵活地模拟各种头部姿势并捕捉面部细节。定制的时空注意力机制确保了准确的唇部同步,产生时间上连贯、高质量动画,同时提高计算效率。实验结果表明,KDTalker在唇部同步准确性、头部姿势多样性和执行效率方面达到了最佳性能。我们的代码可在https://github.com/chaolongy/KDTalker找到。
论文及项目相关链接
Summary
本文介绍了一种名为KDTalker的音频驱动的单图像说话肖像生成框架,该框架结合了无监督隐式3D关键点及时空扩散模型。它采用隐式关键点,提高面部信息密度,使扩散过程能够灵活模拟各种头部姿态和捕捉面部细节。此外,定制的时空注意力机制确保了准确的唇同步,生成了时间连贯的高质量动画,同时提高了计算效率。KDTalker在唇同步准确性、头部姿态多样性和执行效率方面达到了领先水平。
Key Takeaways
- KDTalker是首个结合无监督隐式3D关键点和时空扩散模型的框架,用于音频驱动的单图像说话肖像生成。
- 隐式关键点技术提高了面部信息密度,使扩散过程能够灵活模拟各种头部姿态和捕捉面部细节。
- 定制的时空注意力机制确保了准确的唇同步,增强了动画的真实感。
- KDTalker生成了时间连贯的高质量动画,同时提高了计算效率。
- 该框架在唇同步准确性、头部姿态多样性和执行效率方面达到了领先水平。
- KDTalker框架可用于虚拟现实、数字人物创建和电影制作等领域。
点此查看论文截图

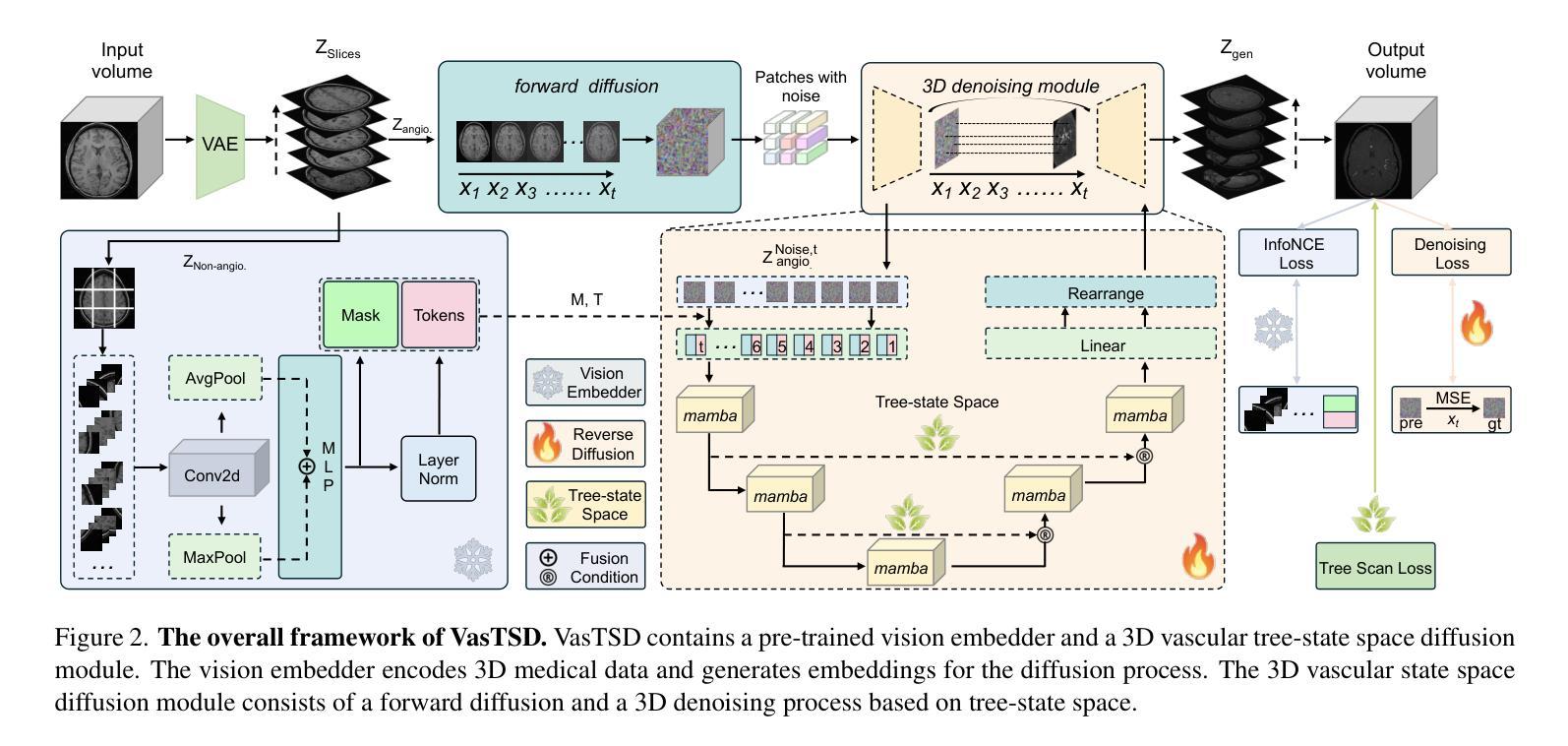
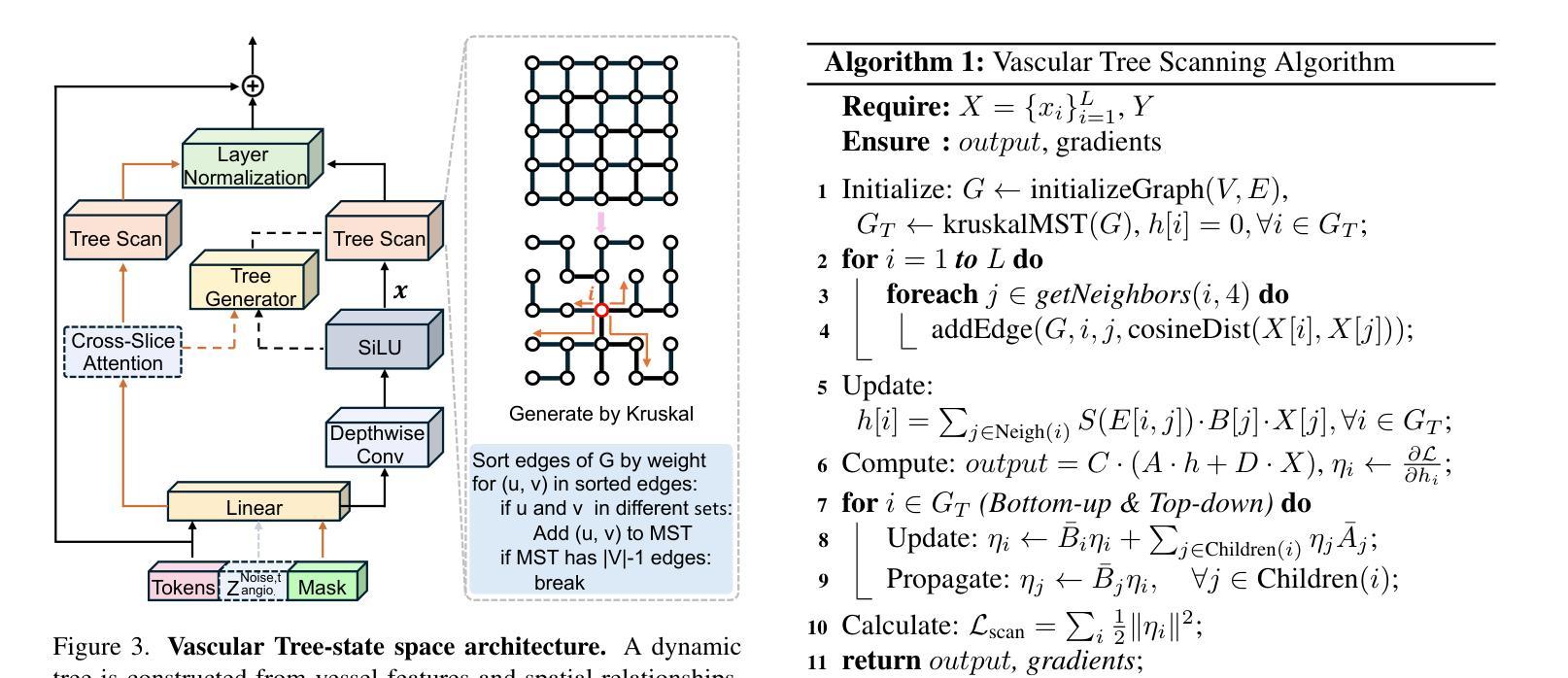
VasTSD: Learning 3D Vascular Tree-state Space Diffusion Model for Angiography Synthesis
Authors:Zhifeng Wang, Renjiao Yi, Xin Wen, Chenyang Zhu, Kai Xu
Angiography imaging is a medical imaging technique that enhances the visibility of blood vessels within the body by using contrast agents. Angiographic images can effectively assist in the diagnosis of vascular diseases. However, contrast agents may bring extra radiation exposure which is harmful to patients with health risks. To mitigate these concerns, in this paper, we aim to automatically generate angiography from non-angiographic inputs, by leveraging and enhancing the inherent physical properties of vascular structures. Previous methods relying on 2D slice-based angiography synthesis struggle with maintaining continuity in 3D vascular structures and exhibit limited effectiveness across different imaging modalities. We propose VasTSD, a 3D vascular tree-state space diffusion model to synthesize angiography from 3D non-angiographic volumes, with a novel state space serialization approach that dynamically constructs vascular tree topologies, integrating these with a diffusion-based generative model to ensure the generation of anatomically continuous vasculature in 3D volumes. A pre-trained vision embedder is employed to construct vascular state space representations, enabling consistent modeling of vascular structures across multiple modalities. Extensive experiments on various angiographic datasets demonstrate the superiority of VasTSD over prior works, achieving enhanced continuity of blood vessels in synthesized angiographic synthesis for multiple modalities and anatomical regions.
血管造影成像是一种利用造影剂提高体内血管可见度的医学成像技术。血管造影图像可以有效地辅助血管疾病的诊断。然而,造影剂可能会带来额外的辐射暴露,对具有健康风险的患者有害。为了缓解这些担忧,本文旨在利用并增强血管结构的固有物理特性,从非血管造影输入中自动生成血管造影。以往依赖于2D切片的血管造影合成方法在维持3D血管结构连续性方面存在困难,并且在不同成像模式之间的有效性有限。我们提出了VasTSD,这是一种用于从3D非血管造影体积合成血管造影的3D血管树状态空间扩散模型,采用了一种新型的状态空间序列化方法,动态构建血管树拓扑结构,并将其与基于扩散的生成模型相结合,确保在3D体积中生成解剖连续的血管。我们还采用预训练的视觉嵌入器来构建血管状态空间表示,实现在多个模态下对血管结构的一致建模。在各种血管造影数据集上的大量实验表明,VasTSD优于先前的工作,在多个模态和解剖区域的合成血管造影中实现了增强的血管连续性。
论文及项目相关链接
Summary
本文介绍了血管造影成像技术,该技术利用造影剂增强体内血管的可视性。然而,造影剂可能带来额外的辐射暴露,对患者健康构成风险。为减轻这一担忧,本文旨在通过利用和提升血管结构的固有物理特性,从非血管造影输入中自动生成血管造影。针对以往方法在维持三维血管结构连续性方面的不足,以及在不同成像模式之间效果的局限性,本文提出了一种名为VasTSD的三维血管树态空间扩散模型。该模型通过一种新的态空间序列化方法动态构建血管树拓扑结构,并与基于扩散的生成模型相结合,确保在三维体积中生成解剖连续的血管。采用预训练的视觉嵌入器构建血管状态空间表示,实现了跨多模态的血管结构一致建模。在多个血管造影数据集上的实验表明,VasTSD相较于以前的方法具有优越性,合成的血管造影中血管连续性增强,适用于多种模态和解剖区域。
Key Takeaways
- 血管造影成像技术利用造影剂增强血管可视化,有助于诊断血管疾病,但造影剂可能带来额外的辐射风险。
- 以往方法主要依赖二维切片基础的血管造影合成,难以维持三维血管结构的连续性,且在多模态成像之间效果有限。
- 提出了VasTSD模型,这是一种基于三维血管树态空间扩散的模型,用于从三维非血管造影体积中合成血管造影。
- VasTSD采用新的态空间序列化方法构建血管树拓扑结构,确保生成的血管在三维体积中解剖连续。
- 该模型结合预训练的视觉嵌入器,实现跨多模态的血管结构一致建模。
- 在多个数据集上的实验表明,VasTSD在合成的血管造影中表现出优越的连续性,适用于多种成像模态和解剖区域。
点此查看论文截图

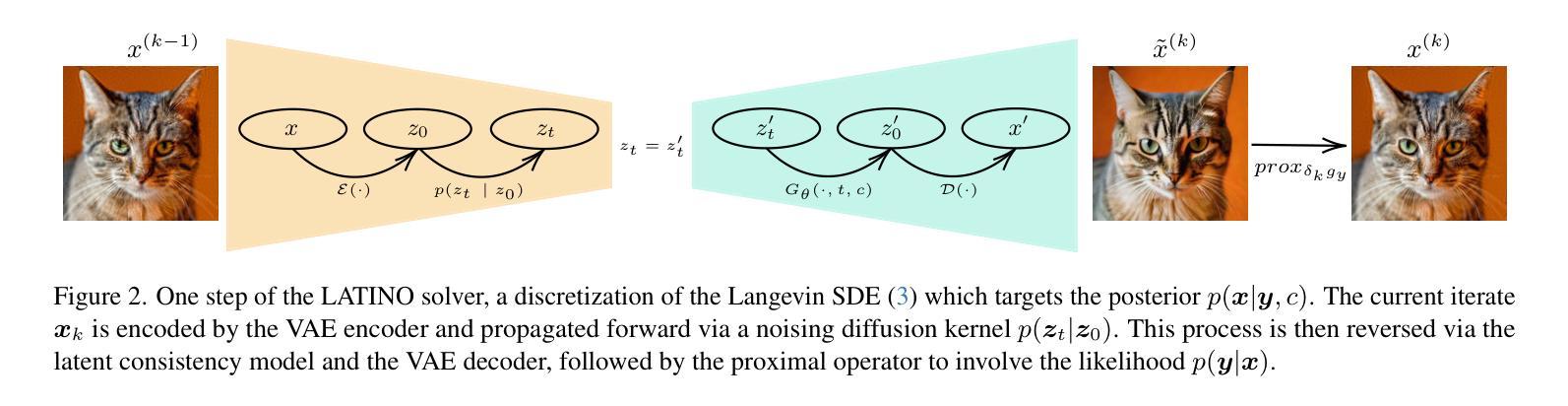
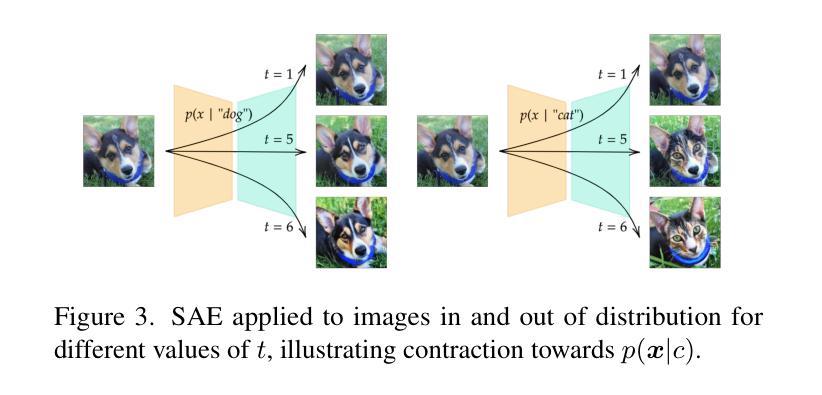
LATINO-PRO: LAtent consisTency INverse sOlver with PRompt Optimization
Authors:Alessio Spagnoletti, Jean Prost, Andrés Almansa, Nicolas Papadakis, Marcelo Pereyra
Text-to-image latent diffusion models (LDMs) have recently emerged as powerful generative models with great potential for solving inverse problems in imaging. However, leveraging such models in a Plug & Play (PnP), zero-shot manner remains challenging because it requires identifying a suitable text prompt for the unknown image of interest. Also, existing text-to-image PnP approaches are highly computationally expensive. We herein address these challenges by proposing a novel PnP inference paradigm specifically designed for embedding generative models within stochastic inverse solvers, with special attention to Latent Consistency Models (LCMs), which distill LDMs into fast generators. We leverage our framework to propose LAtent consisTency INverse sOlver (LATINO), the first zero-shot PnP framework to solve inverse problems with priors encoded by LCMs. Our conditioning mechanism avoids automatic differentiation and reaches SOTA quality in as little as 8 neural function evaluations. As a result, LATINO delivers remarkably accurate solutions and is significantly more memory and computationally efficient than previous approaches. We then embed LATINO within an empirical Bayesian framework that automatically calibrates the text prompt from the observed measurements by marginal maximum likelihood estimation. Extensive experiments show that prompt self-calibration greatly improves estimation, allowing LATINO with PRompt Optimization to define new SOTAs in image reconstruction quality and computational efficiency.
文本到图像的潜在扩散模型(LDM)最近作为强大的生成模型出现,在解决成像中的逆问题上具有巨大的潜力。然而,以Plug & Play(PnP)即插即用、零射击的方式利用这些模型仍然具有挑战性,因为这需要为未知的感兴趣图像确定合适的文本提示。此外,现有的文本到图像PnP方法计算量非常大。我们通过提出一种新型PnP推理范式来解决这些挑战,该范式专门设计用于将生成模型嵌入随机逆求解器中,特别关注潜在一致性模型(LCMs),它将LDM提炼为快速生成器。我们利用我们的框架提出了潜在一致性逆求解器(LATINO),这是第一个零射击PnP框架,使用LCMs编码的先验知识来解决逆问题。我们的调节机制避免了自动微分,并在仅8个神经网络函数评估中达到了最新技术水平。因此,LATINO提供了非常准确的解决方案,并且在内存和计算效率方面显著优于以前的方法。然后我们将LATINO嵌入经验贝叶斯框架中,通过边际最大似然估计自动校准文本提示来自观察到的测量值。大量实验表明,提示自我校准极大地提高了估计值,使带有提示优化的LATINO在图像重建质量和计算效率方面定义了新的最新技术。
论文及项目相关链接
PDF 27 pages, 20 figures
Summary
文本到图像潜在扩散模型(LDM)作为强大的生成模型,在解决成像中的逆问题上具有巨大潜力。然而,以Plug & Play(PnP)方式进行零样本应用仍具有挑战性,需要为未知图像选择合适的文本提示。现有文本到图像PnP方法计算成本高昂。本文提出一种为嵌入生成模型的随机逆求解器设计的PnP推理范式,特别关注潜在一致性模型(LCMs),它将LDMs简化为快速生成器。我们利用该框架提出LAtento consisTency INverse sOlver(LATINO),这是第一个零样本PnP框架,使用LCMs编码的先验知识解决逆问题。其调节机制避免了自动微分,在仅8个神经网络功能评估中达到最新质量。LATINO嵌入经验贝叶斯框架,通过边缘最大似然估计自动校准文本提示,从而提高估算质量。实验表明,带有提示优化的LATINO在图像重建质量和计算效率方面定义新标准。
Key Takeaways
- LDMs具有解决成像逆问题的潜力。
- PnP方式应用LDMs具有挑战性和高昂的计算成本。
- 提出一种针对生成模型的PnP推理范式,特别关注LCMs。
- 引入LATINO框架,能在零样本情况下解决逆问题并达到最新质量。
- LATINO调节机制避免自动微分,提高计算效率。
- LATINO嵌入经验贝叶斯框架,可自动校准文本提示,提高估算准确性。
- 实验显示,带有提示优化的LATINO在图像重建质量和计算效率上达到新的标准。
点此查看论文截图



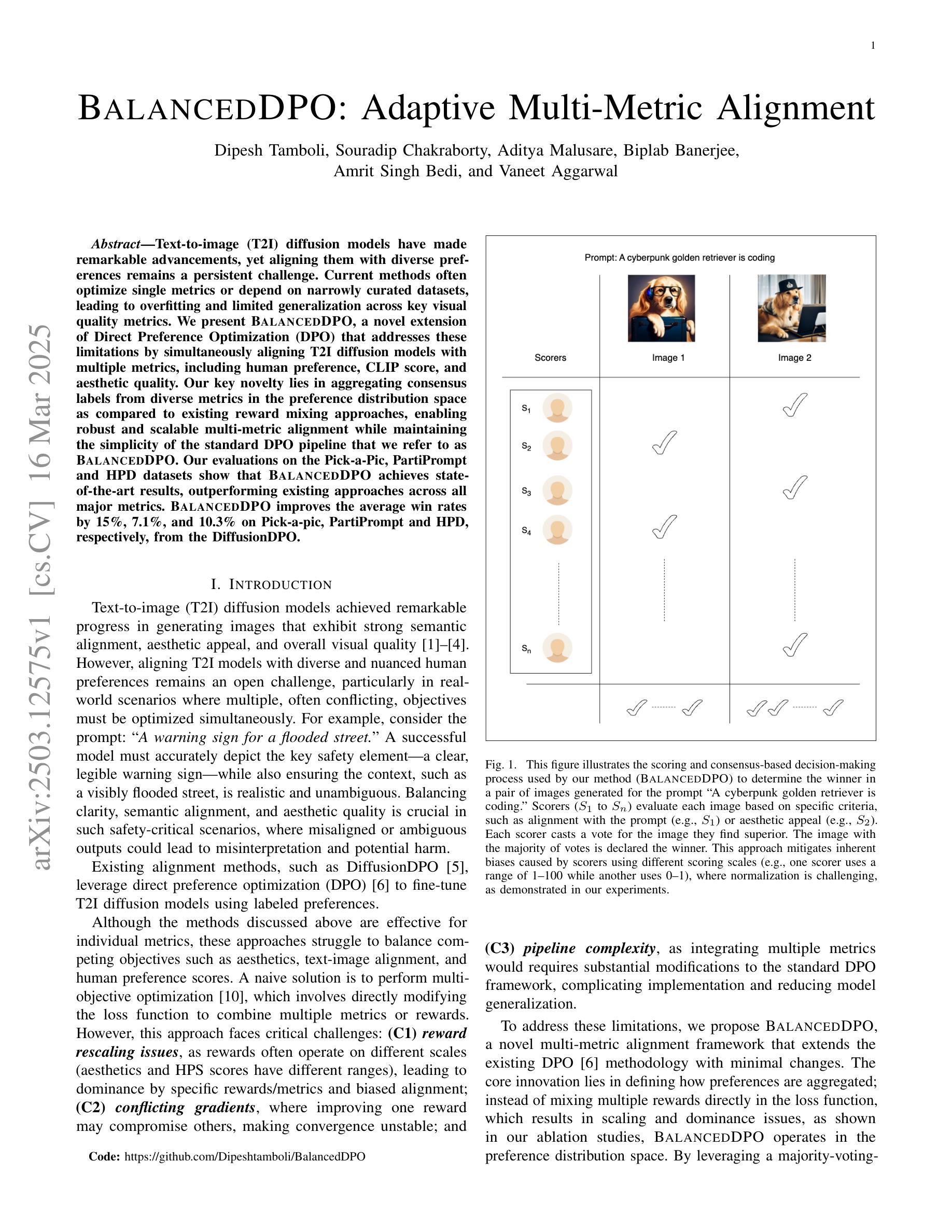
BalancedDPO: Adaptive Multi-Metric Alignment
Authors:Dipesh Tamboli, Souradip Chakraborty, Aditya Malusare, Biplab Banerjee, Amrit Singh Bedi, Vaneet Aggarwal
Text-to-image (T2I) diffusion models have made remarkable advancements, yet aligning them with diverse preferences remains a persistent challenge. Current methods often optimize single metrics or depend on narrowly curated datasets, leading to overfitting and limited generalization across key visual quality metrics. We present BalancedDPO, a novel extension of Direct Preference Optimization (DPO) that addresses these limitations by simultaneously aligning T2I diffusion models with multiple metrics, including human preference, CLIP score, and aesthetic quality. Our key novelty lies in aggregating consensus labels from diverse metrics in the preference distribution space as compared to existing reward mixing approaches, enabling robust and scalable multi-metric alignment while maintaining the simplicity of the standard DPO pipeline that we refer to as BalancedDPO. Our evaluations on the Pick-a-Pic, PartiPrompt and HPD datasets show that BalancedDPO achieves state-of-the-art results, outperforming existing approaches across all major metrics. BalancedDPO improves the average win rates by 15%, 7.1%, and 10.3% on Pick-a-pic, PartiPrompt and HPD, respectively, from the DiffusionDPO.
文本到图像(T2I)扩散模型已经取得了显著的进步,但如何将其与多种偏好进行匹配仍然是一个持续存在的挑战。当前的方法通常优化单一指标或依赖于精心策划的数据集,导致在关键视觉质量指标上过拟合和泛化能力有限。我们提出了BalancedDPO,它是Direct Preference Optimization(DPO)的新扩展,通过同时调整T2I扩散模型与包括人类偏好、CLIP分数和美学质量在内的多个指标,解决了这些限制。我们的关键创新之处在于,与现有的奖励混合方法相比,我们在偏好分布空间中聚合来自不同指标的共识标签,这使我们能够在保持标准DPO管道简单性的同时,实现稳健和可扩展的多指标匹配,我们将其称为BalancedDPO。我们在Pick-a-Pic、PartiPrompt和HPD数据集上的评估表明,BalancedDPO达到了最先进的成果,在所有主要指标上都优于现有方法。BalancedDPO在Pick-a-pic、PartiPrompt和HPD上分别提高了DiffusionDPO的平均胜率15%、7.1%和10.3%。
论文及项目相关链接
Summary
文本介绍了针对文本到图像(T2I)扩散模型的最新研究成果BalancedDPO。该模型解决了现有方法过度依赖单一度量标准或有限数据集导致的局限性问题,它通过直接偏好优化(DPO)方法的改进,能够在偏好分布空间中从多种度量标准中汇集共识标签,实现稳健且可扩展的多度量标准对齐。在多个数据集上的评估显示,BalancedDPO在主要指标上取得了最新成果,相对于DiffusionDPO平均提高了约15%、7.1%和10.3%的胜率。
Key Takeaways
以下是基于文本的主要发现点:
- BalancedDPO是一个针对文本到图像(T2I)扩散模型的新方法,解决了与多种偏好对齐的挑战。
- 通过直接偏好优化(DPO)的改进方法,BalancedDPO能在偏好分布空间中汇集多种度量标准的共识标签。
- BalancedDPO实现了稳健且可扩展的多度量标准对齐,克服了现有方法过度依赖单一度量标准或有限数据集的局限性。
- BalancedDPO在各种数据集上的评估结果均为业界最佳。
点此查看论文截图




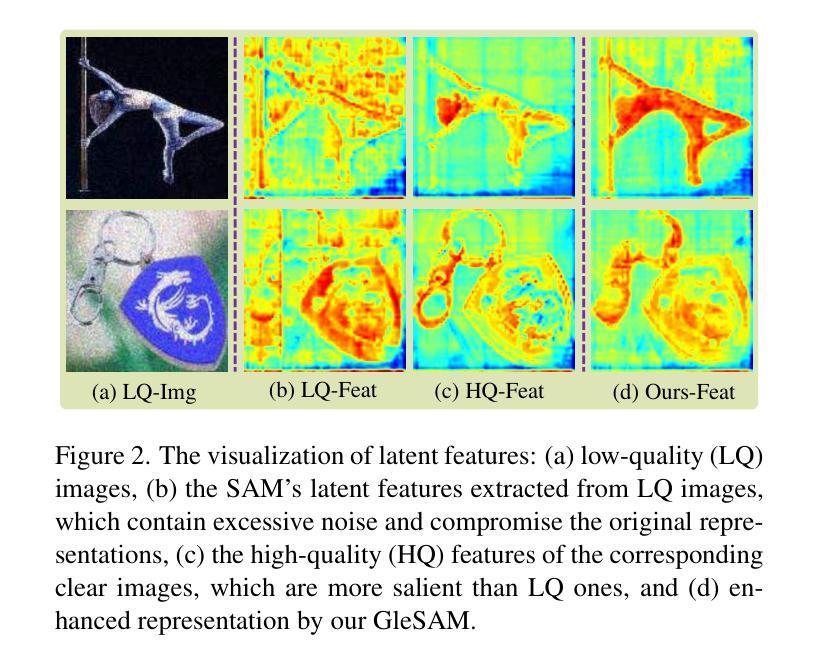
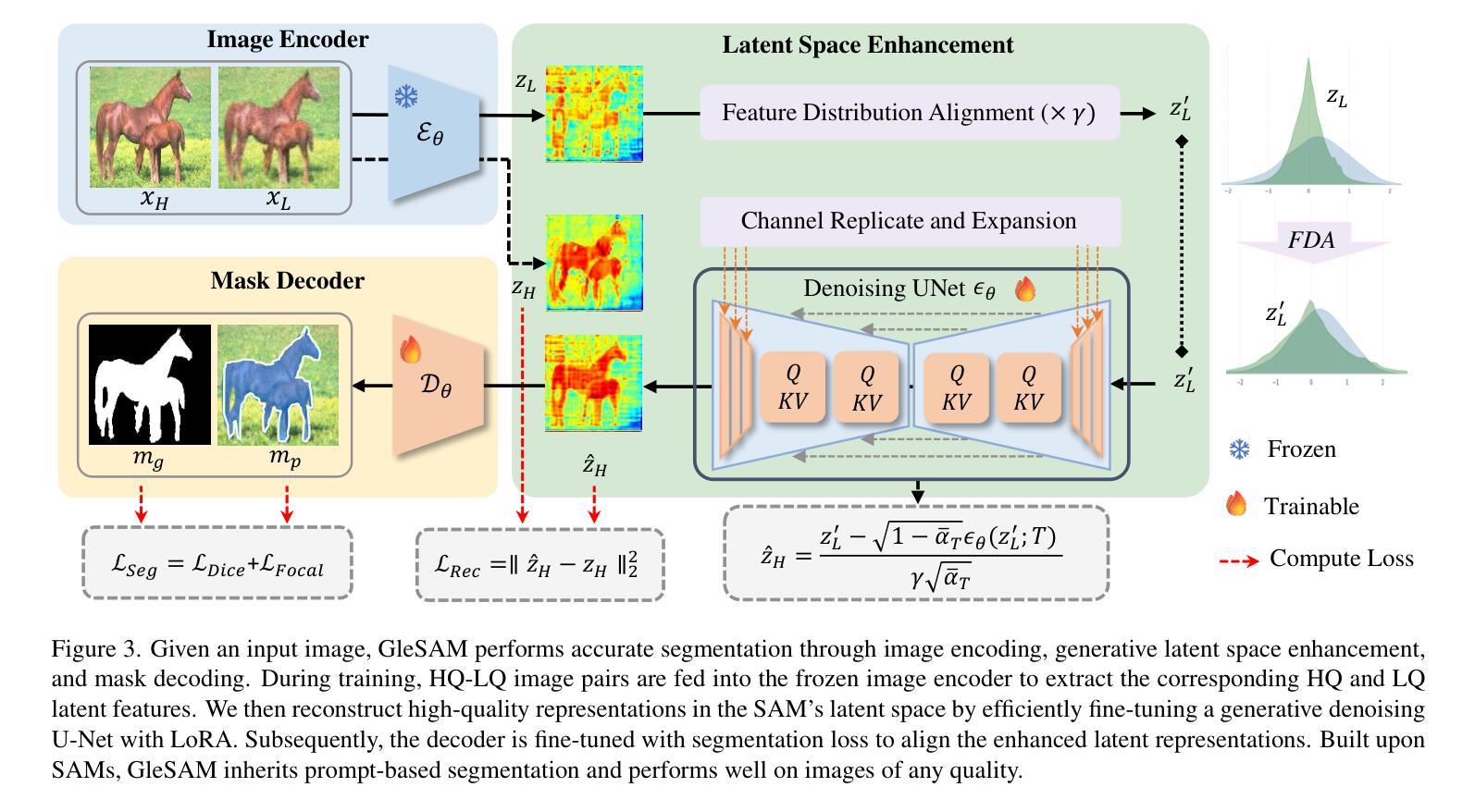
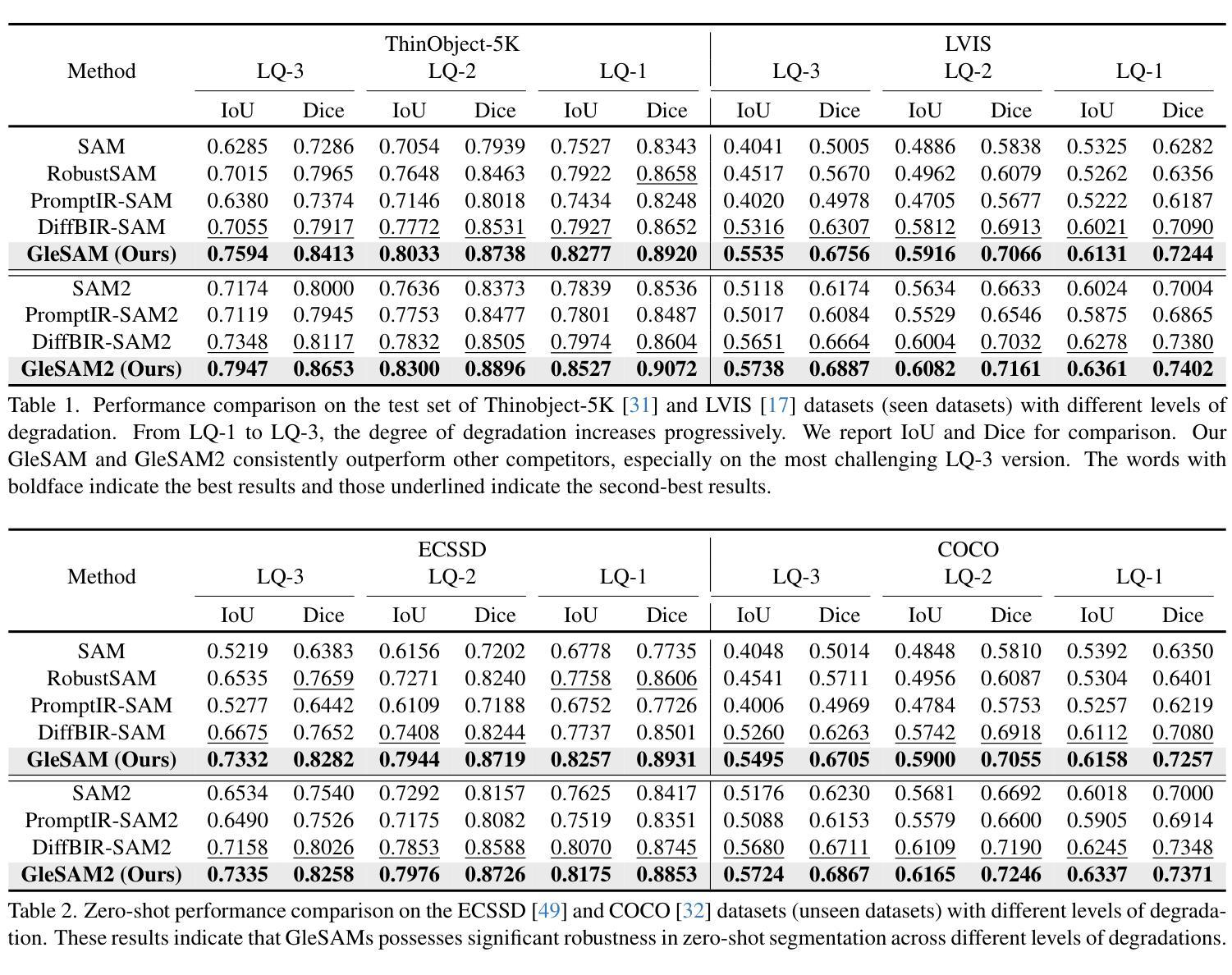
Segment Any-Quality Images with Generative Latent Space Enhancement
Authors:Guangqian Guo, Yoong Guo, Xuehui Yu, Wenbo Li, Yaoxing Wang, Shan Gao
Despite their success, Segment Anything Models (SAMs) experience significant performance drops on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Specifically, we adapt the concept of latent diffusion to SAM-based segmentation frameworks and perform the generative diffusion process in the latent space of SAM to reconstruct high-quality representation, thereby improving segmentation. Additionally, we introduce two techniques to improve compatibility between the pre-trained diffusion model and the segmentation framework. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. We also construct the LQSeg dataset with a greater diversity of degradation types and levels for training and evaluating the model. Extensive experiments demonstrate that GleSAM significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
尽管取得了成功,但Segment Anything Models(SAM)在严重退化、低质量的图像上会出现显著的性能下降,这限制了它们在现实场景中的有效性。为了解决这一问题,我们提出了GleSAM。它利用生成潜在空间增强技术来提高对低质量图像的稳健性,从而实现各种图像质量的泛化。具体来说,我们适应基于SAM的分割框架的潜在扩散概念,并在SAM的潜在空间中进行生成扩散过程,以重建高质量表示,从而提高分割效果。此外,我们还引入了两种技术来提高预训练扩散模型和分割框架之间的兼容性。我们的方法可以应用于预训练的SAM和SAM2,并且只需要很少的可学习参数,从而实现有效的优化。我们还构建了LQSeg数据集,包含更多类型和程度的退化类型,用于训练和评估模型。大量实验表明,GleSAM在复杂退化情况下显著提高分割稳健性,同时保持对清晰图像的泛化能力。此外,GleSAM在未见过的退化情况下也表现良好,这凸显了我们方法和数据集的通用性。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
SAM模型在低质量图像上性能显著下降,限制了其在现实场景中的应用。为解决这一问题,我们提出GleSAM,利用生成式潜在空间增强技术提高模型对低质量图像的稳健性,实现跨不同图像质量的泛化。我们在SAM分割框架中引入潜在扩散概念,在SAM的潜在空间中进行生成式扩散过程,重建高质量表示,从而提高分割性能。此外,我们还引入两种技术,提高预训练扩散模型与分割框架的兼容性。GleSAM可应用于预训练SAM和SAM2,仅需要少量额外的学习参数,实现高效优化。我们还构建了LQSeg数据集,包含更多类型的降解和水平,用于训练和评估模型。实验表明,GleSAM在复杂降解情况下显著提高分割稳健性,同时保持对清晰图像的泛化能力,并在未见过的降解情况下表现良好。
Key Takeaways
- SAM模型在低质量图像上性能受限。
- GleSAM通过利用生成式潜在空间增强技术提高模型稳健性。
- GleSAM引入潜在扩散概念至SAM分割框架中。
- 在SAM的潜在空间中进行生成式扩散过程以重建高质量表示。
- GleSAM引入两种技术提升预训练扩散模型与分割框架的兼容性。
- GleSAM可应用于预训练SAM和SAM2,且需要少量额外学习参数。
- LQSeg数据集用于训练和评估模型,包含多种降解类型和水平。
点此查看论文截图

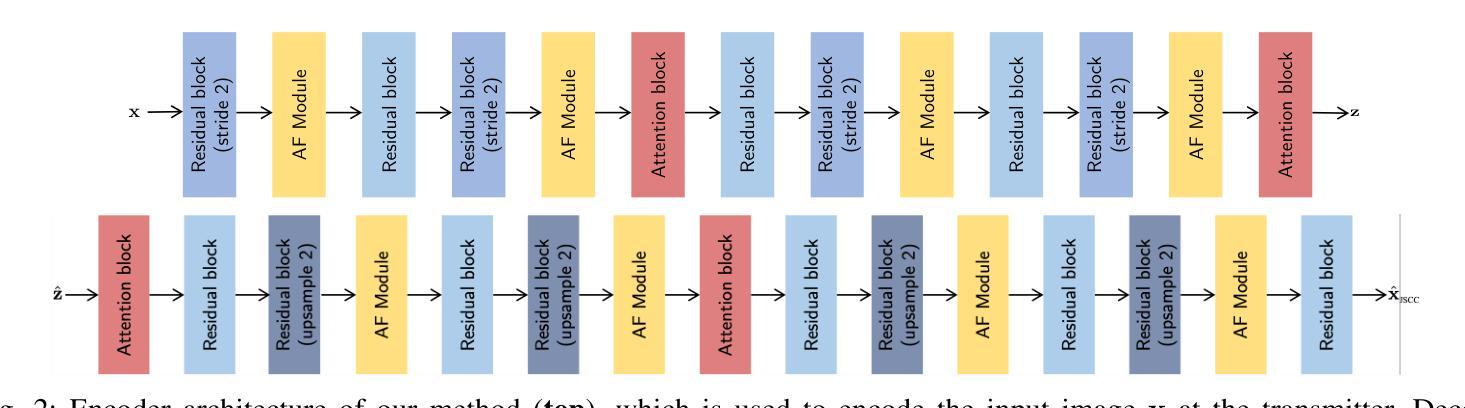
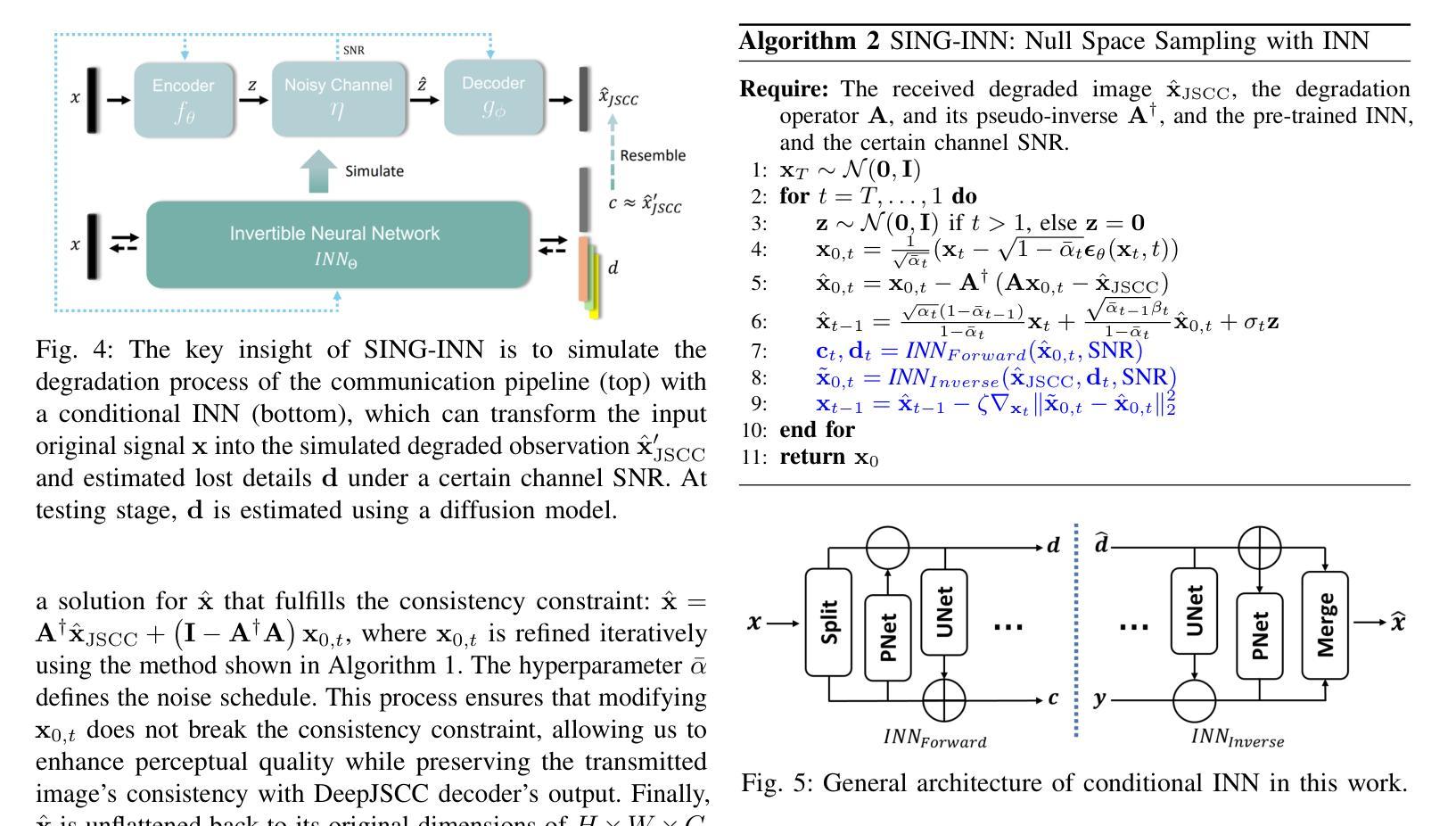
SING: Semantic Image Communications using Null-Space and INN-Guided Diffusion Models
Authors:Jiakang Chen, Selim F. Yilmaz, Di You, Pier Luigi Dragotti, Deniz Gündüz
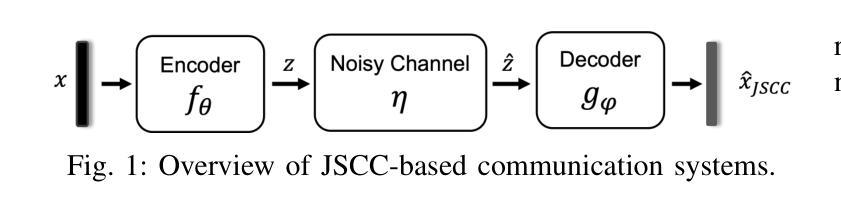
Joint source-channel coding systems based on deep neural networks (DeepJSCC) have recently demonstrated remarkable performance in wireless image transmission. Existing methods primarily focus on minimizing distortion between the transmitted image and the reconstructed version at the receiver, often overlooking perceptual quality. This can lead to severe perceptual degradation when transmitting images under extreme conditions, such as low bandwidth compression ratios (BCRs) and low signal-to-noise ratios (SNRs). In this work, we propose SING, a novel two-stage JSCC framework that formulates the recovery of high-quality source images from corrupted reconstructions as an inverse problem. Depending on the availability of information about the DeepJSCC encoder/decoder and the channel at the receiver, SING can either approximate the stochastic degradation as a linear transformation, or leverage invertible neural networks (INNs) for precise modeling. Both approaches enable the seamless integration of diffusion models into the reconstruction process, enhancing perceptual quality. Experimental results demonstrate that SING outperforms DeepJSCC and other approaches, delivering superior perceptual quality even under extremely challenging conditions, including scenarios with significant distribution mismatches between the training and test data.
基于深度神经网络的联合源信道编码系统(DeepJSCC)在无线图像传输中表现出了卓越的性能。现有的方法主要集中在最小化传输图像和接收端重建版本之间的失真,往往忽略了感知质量。这在极端条件下传输图像时,如低带宽压缩比(BCR)和低信噪比(SNR),可能会导致严重的感知质量下降。在这项工作中,我们提出了SING,这是一种新型的两阶段JSCC框架,它将从损坏的重建中恢复高质量源图像表述为一个反问题。根据接收端关于DeepJSCC编码器/解码器和信道的信息可用性,SING可以将随机退化近似为线性变换,或者利用可逆神经网络(INNs)进行精确建模。两种方法都能无缝地将扩散模型集成到重建过程中,提高感知质量。实验结果表明,即使在极具挑战性的条件下,包括训练和测试数据分布不匹配的情况,SING也优于DeepJSCC和其他方法,提供卓越的感知质量。
论文及项目相关链接
Summary
基于深度神经网络的联合源信道编码系统(DeepJSCC)在无线图像传输中展现出卓越性能。然而,现有方法主要关注传输图像与接收端重建版本之间的失真最小化,忽视了感知质量。本文提出一种新型的两阶段JSCC框架SING,将从损坏的重建中恢复高质量源图像表述为逆问题。根据接收器对DeepJSCC编码器/解码器和通道信息的可用性,SING可以将随机退化近似为线性变换,或利用可逆神经网络(INNs)进行精确建模。两种方法都能无缝集成扩散模型到重建过程中,提高感知质量。实验结果表明,即使在极具挑战性的条件下,SING的表现优于DeepJSCC和其他方法,包括训练和测试数据分布不匹配的场景。
Key Takeaways
- DeepJSCC在无线图像传输中有卓越性能表现。
- 现有方法主要关注图像传输失真,忽视了感知质量。
- 提出的新型框架SING将图像恢复表述为逆问题,以提高感知质量。
- 根据信息的可用性,SING可以采用线性变换或可逆神经网络建模。
- SING通过集成扩散模型增强重建过程。
- 实验结果显示,SING在多种条件下表现优越,包括低带宽压缩比和低信噪比环境。
点此查看论文截图


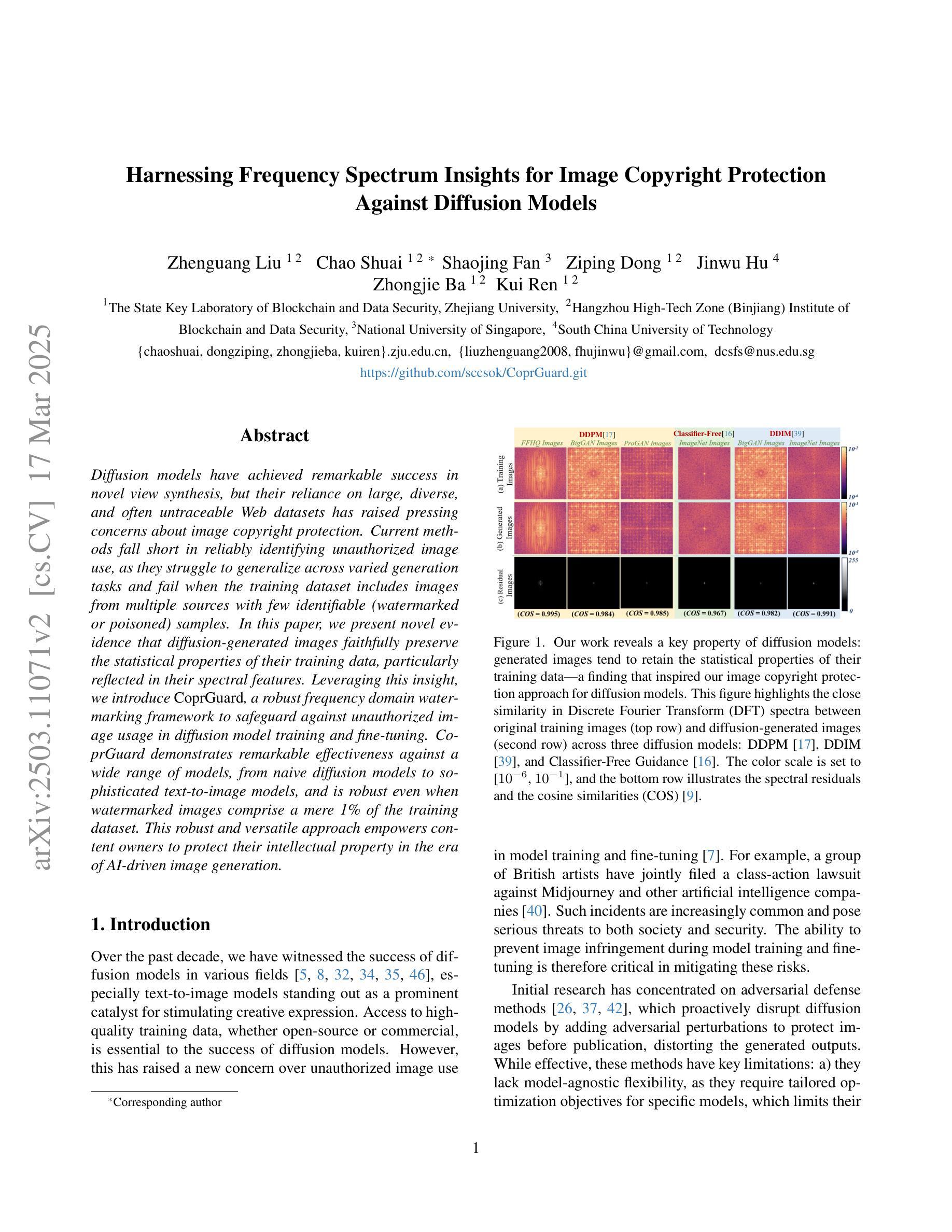
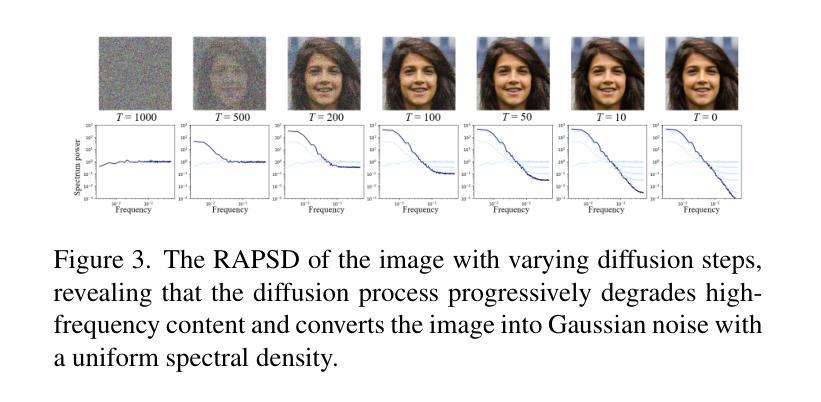
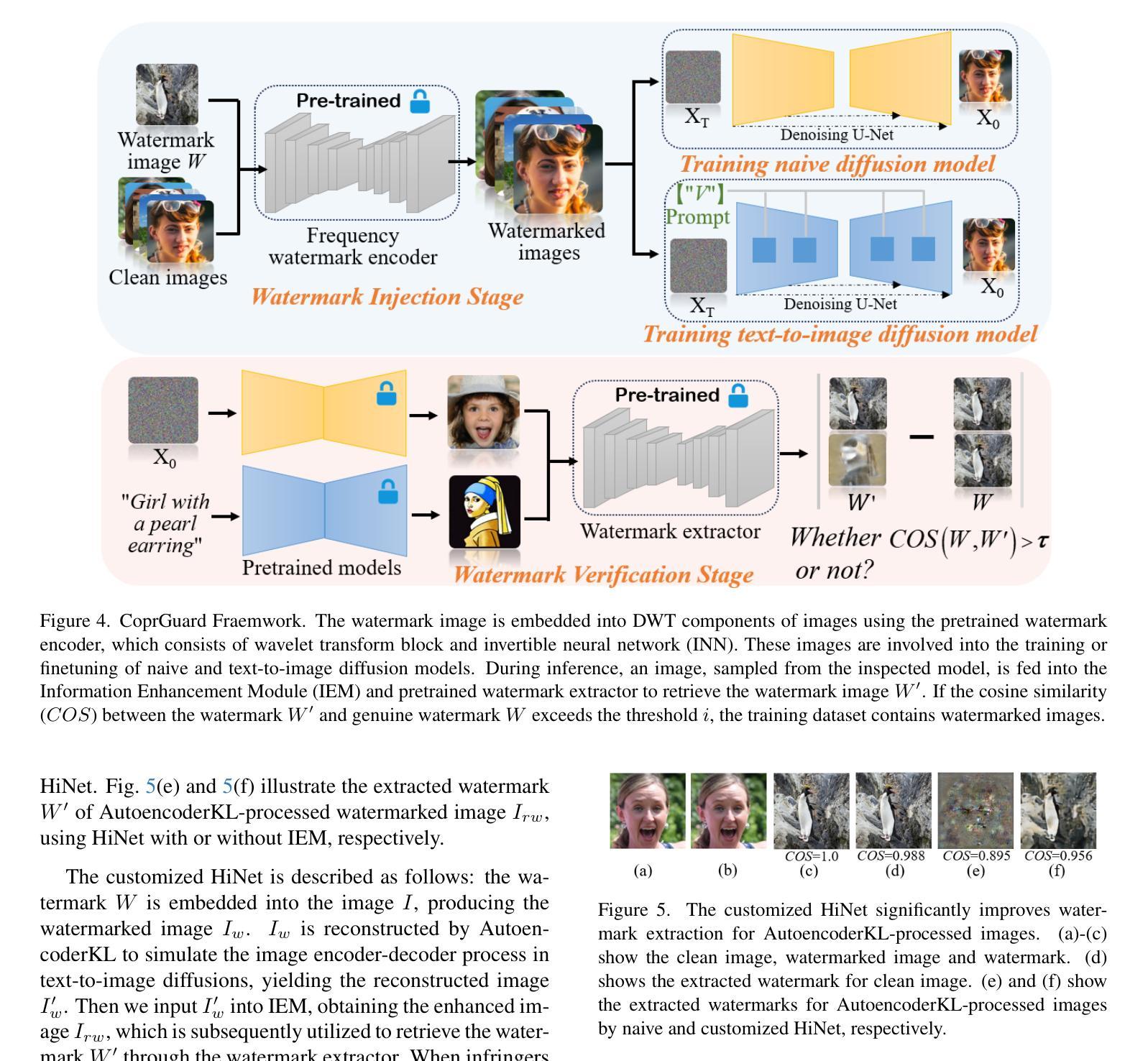
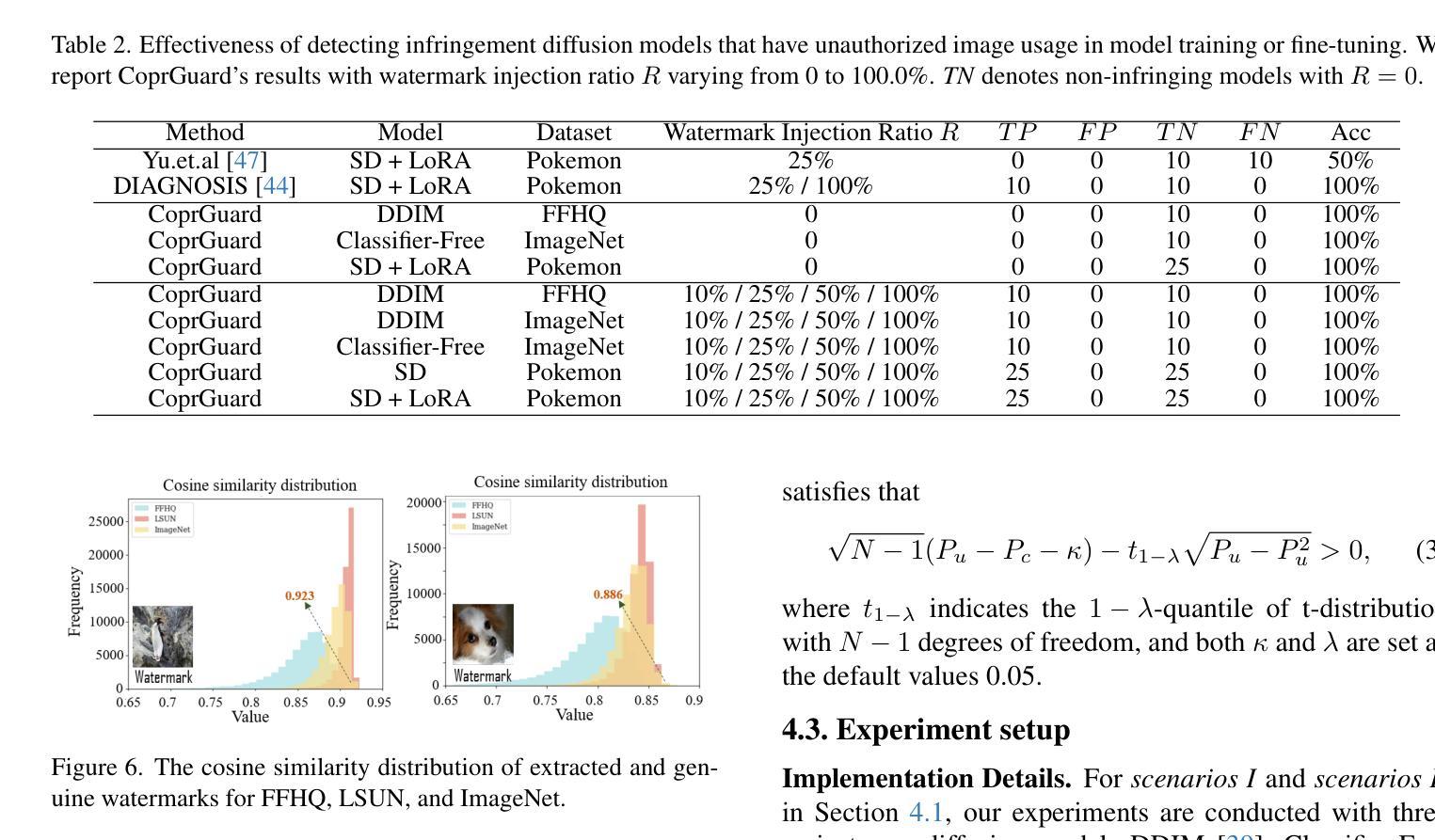
Harnessing Frequency Spectrum Insights for Image Copyright Protection Against Diffusion Models
Authors:Zhenguang Liu, Chao Shuai, Shaojing Fan, Ziping Dong, Jinwu Hu, Zhongjie Ba, Kui Ren
Diffusion models have achieved remarkable success in novel view synthesis, but their reliance on large, diverse, and often untraceable Web datasets has raised pressing concerns about image copyright protection. Current methods fall short in reliably identifying unauthorized image use, as they struggle to generalize across varied generation tasks and fail when the training dataset includes images from multiple sources with few identifiable (watermarked or poisoned) samples. In this paper, we present novel evidence that diffusion-generated images faithfully preserve the statistical properties of their training data, particularly reflected in their spectral features. Leveraging this insight, we introduce \emph{CoprGuard}, a robust frequency domain watermarking framework to safeguard against unauthorized image usage in diffusion model training and fine-tuning. CoprGuard demonstrates remarkable effectiveness against a wide range of models, from naive diffusion models to sophisticated text-to-image models, and is robust even when watermarked images comprise a mere 1% of the training dataset. This robust and versatile approach empowers content owners to protect their intellectual property in the era of AI-driven image generation.
扩散模型在新视角图像合成方面取得了显著的成功,但它们依赖于大量、多样且通常不可追溯的Web数据集,这引发了人们对图像版权保护的紧迫关注。当前的方法在可靠地识别未经授权的图像使用方面表现不足,因为它们在各种生成任务中难以实现通用化,并且在训练数据集中包含来自多个源头的图像时,只有少数可识别的(水印或中毒)样本会导致其失效。在本文中,我们提供了新的证据,证明扩散生成的图像忠实地保留了其训练数据的统计属性,特别是在光谱特征上。利用这一见解,我们引入了CoprGuard,这是一个稳健的频率域水印框架,旨在保护扩散模型训练和微调过程中防止图像被未经授权的使用。CoprGuard对抗一系列模型表现出了显著的有效性,从简单的扩散模型到复杂的文本到图像模型,即使在训练数据集中水印图像仅占1%时也能保持稳健。这种稳健且通用的方法使内容所有者在AI驱动图像生成的时代能够保护其知识产权。
论文及项目相关链接
PDF Received by CVPR 2025 (10 pages, 11 figures)
Summary
扩散模型在新型视图合成中取得了显著的成功,但其依赖于大量多样且难以追溯的Web数据集,引发了关于图像版权保护的紧迫关注。当前方法难以在多种生成任务中普遍识别未经授权的图像使用,且在训练数据集中包含多个来源的图像时,因可识别的水印或中毒样本较少而失效。本文提出扩散生成图像忠实保留其训练数据的统计特性,特别是在光谱特征上的体现。基于此,我们引入了CoprGuard,一个稳健的频率域水印框架,用于保护扩散模型训练和微调中的图像免受未经授权的使用。CoprGuard对从简单的扩散模型到先进的文本到图像模型等一系列模型均表现出显著的有效性,即使在水印图像仅占训练数据集的1%时仍具有稳健性。这一稳健且通用的方法赋予了内容所有者在AI驱动图像生成时代保护其知识产权的能力。
Key Takeaways
- 扩散模型在视图合成中表现优秀,但存在图像版权保护的问题。
- 当前方法难以在多种生成任务中识别未经授权的图像使用。
- 扩散生成图像保留训练数据的统计特性,特别是在光谱特征上。
- 引入CoprGuard框架,基于频率域水印保护图像免受未经授权使用。
- CoprGuard对各种扩散模型有效,包括从简单的到复杂的文本到图像模型。
- CoprGuard在训练数据集中水印图像占比很低时仍具有稳健性。
点此查看论文截图

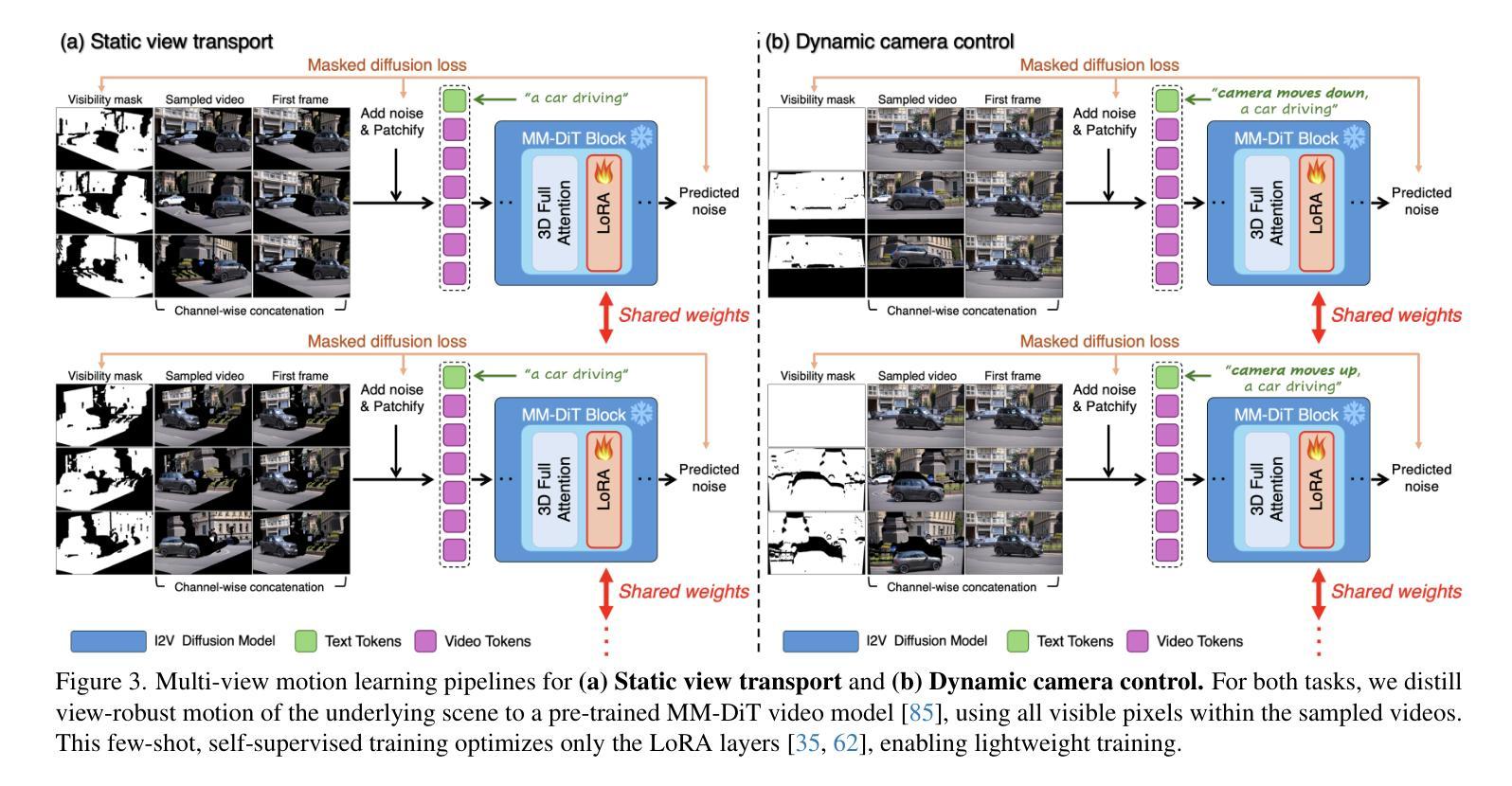
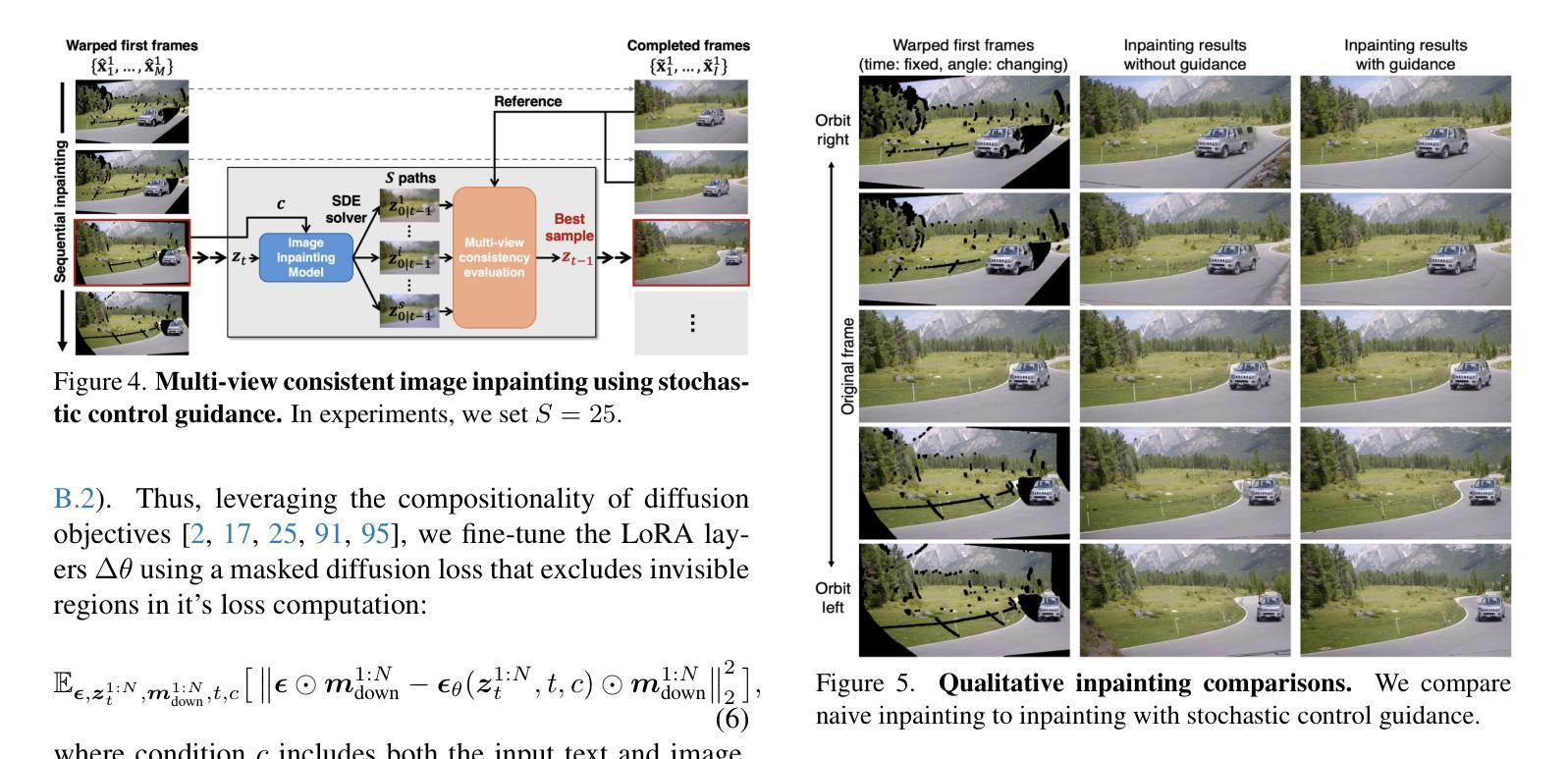
Reangle-A-Video: 4D Video Generation as Video-to-Video Translation
Authors:Hyeonho Jeong, Suhyeon Lee, Jong Chul Ye
We introduce Reangle-A-Video, a unified framework for generating synchronized multi-view videos from a single input video. Unlike mainstream approaches that train multi-view video diffusion models on large-scale 4D datasets, our method reframes the multi-view video generation task as video-to-videos translation, leveraging publicly available image and video diffusion priors. In essence, Reangle-A-Video operates in two stages. (1) Multi-View Motion Learning: An image-to-video diffusion transformer is synchronously fine-tuned in a self-supervised manner to distill view-invariant motion from a set of warped videos. (2) Multi-View Consistent Image-to-Images Translation: The first frame of the input video is warped and inpainted into various camera perspectives under an inference-time cross-view consistency guidance using DUSt3R, generating multi-view consistent starting images. Extensive experiments on static view transport and dynamic camera control show that Reangle-A-Video surpasses existing methods, establishing a new solution for multi-view video generation. We will publicly release our code and data. Project page: https://hyeonho99.github.io/reangle-a-video/
我们介绍了Reangle-A-Video,这是一个从单个输入视频生成同步多视角视频的统一框架。与主流方法在大型4D数据集上训练多视角视频扩散模型不同,我们的方法将多视角视频生成任务重新定位为视频到视频的翻译,利用公开可用的图像和视频扩散先验。本质上,Reangle-A-Video分为两个阶段。第一阶段是“多视角运动学习”:以自监督的方式同步微调图像到视频扩散转换器,从一组变形视频中提炼出视角不变的运动。第二阶段是“多视角一致图像到图像的翻译”:输入视频的第一帧在推理时间跨视角一致性指导下被变形和填充到各种相机视角,使用DUSt3R生成多视角一致的首帧图像。在静态视角转换和动态相机控制方面的大量实验表明,Reangle-A-Video超越了现有方法,为多视角视频生成提供了新的解决方案。我们将公开发布我们的代码和数据。项目页面:https://hyeonho99.github.io/reangle-a-video/
论文及项目相关链接
PDF Project page: https://hyeonho99.github.io/reangle-a-video/
Summary
Reangle-A-Video是一个统一框架,可以从单个输入视频生成同步多视角视频。它采用视频到视频的翻译方式,利用公开可用的图像和视频扩散先验知识,将多视角视频生成任务重新构建。该方法包括两个阶段:多视角运动学习和多视角一致图像到图像的翻译。通过同步微调图像到视频扩散转换器,从一组变形的视频中提炼出视图不变的运动;并在推理时间交叉视角一致性指导下,将输入视频的第一帧变形并填充为各种相机视角,生成多视角一致的开始图像。实验表明,Reangle-A-Video在静态视角转换和动态相机控制方面超越了现有方法,为多角度视频生成提供了新的解决方案。
Key Takeaways
- Reangle-A-Video是一个生成同步多视角视频的统一框架,可从单个输入视频进行生成。
- 该方法采用视频到视频的翻译方式,利用图像和视频扩散先验。
- Reangle-A-Video包括两个阶段:多视角运动学习和多视角一致图像到图像的翻译。
- 通过同步微调图像到视频扩散转换器,从变形的视频中提炼视图不变的运动。
- 在推理时间交叉视角一致性指导下,生成多视角一致的开始图像。
- Reangle-A-Video在静态视角转换和动态相机控制方面表现优越。
点此查看论文截图



PLADIS: Pushing the Limits of Attention in Diffusion Models at Inference Time by Leveraging Sparsity
Authors:Kwanyoung Kim, Byeongsu Sim
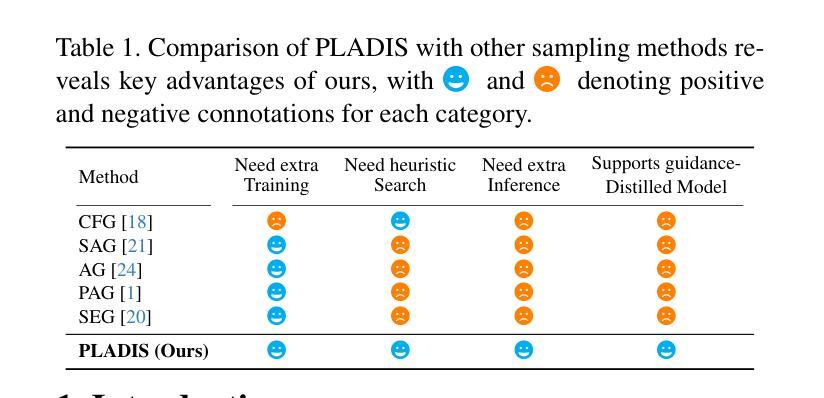
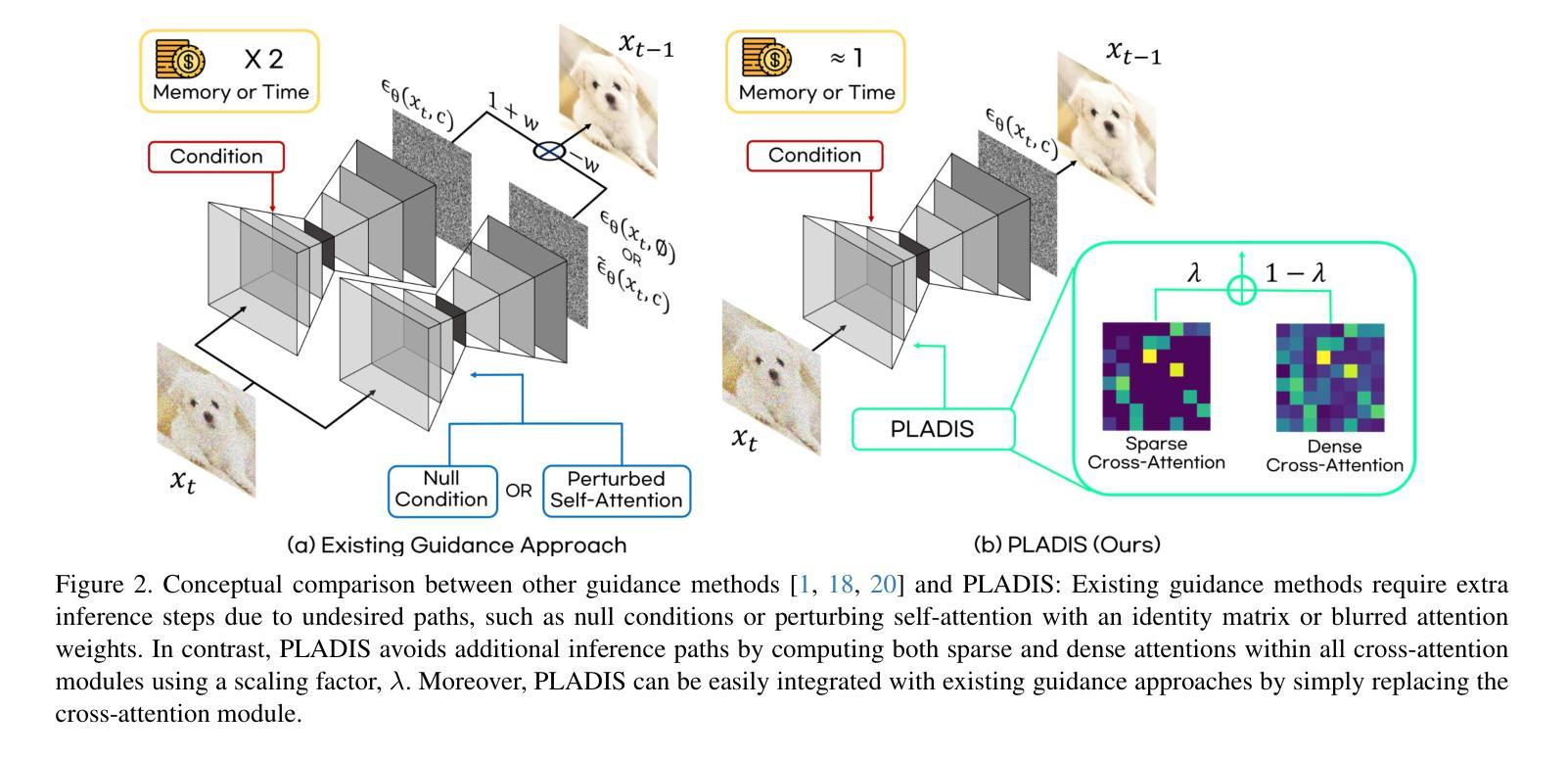
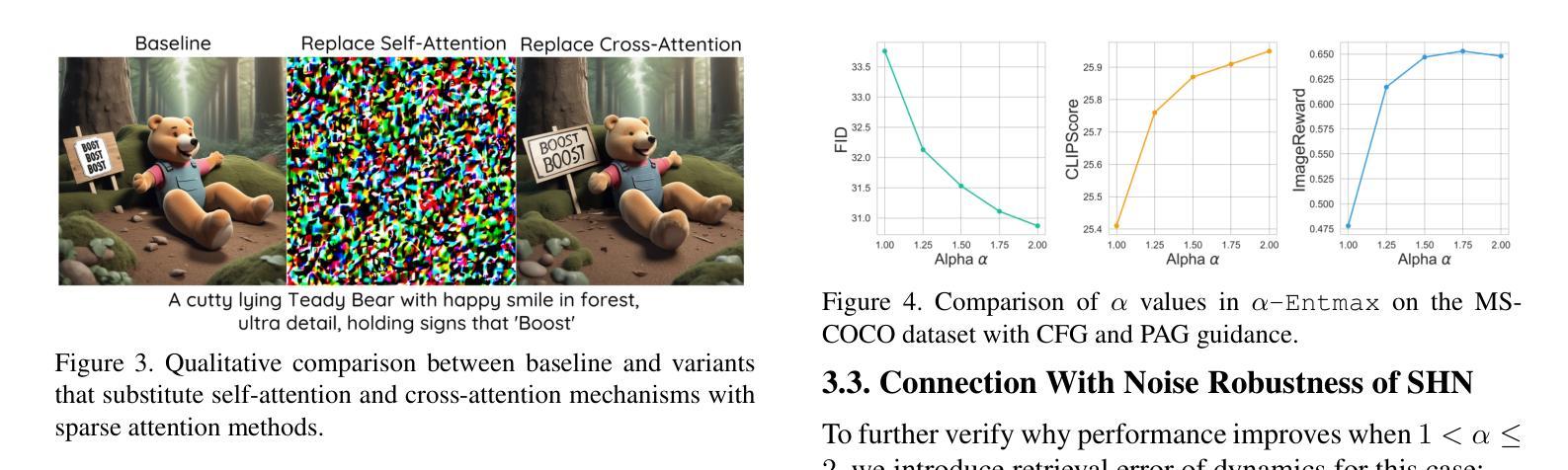
Diffusion models have shown impressive results in generating high-quality conditional samples using guidance techniques such as Classifier-Free Guidance (CFG). However, existing methods often require additional training or neural function evaluations (NFEs), making them incompatible with guidance-distilled models. Also, they rely on heuristic approaches that need identifying target layers. In this work, we propose a novel and efficient method, termed PLADIS, which boosts pre-trained models (U-Net/Transformer) by leveraging sparse attention. Specifically, we extrapolate query-key correlations using softmax and its sparse counterpart in the cross-attention layer during inference, without requiring extra training or NFEs. By leveraging the noise robustness of sparse attention, our PLADIS unleashes the latent potential of text-to-image diffusion models, enabling them to excel in areas where they once struggled with newfound effectiveness. It integrates seamlessly with guidance techniques, including guidance-distilled models. Extensive experiments show notable improvements in text alignment and human preference, offering a highly efficient and universally applicable solution. See Our project page : https://cubeyoung.github.io/pladis-proejct/
扩散模型利用指导技术(如无需分类器指导)生成高质量的条件样本,并取得了令人印象深刻的结果。然而,现有方法通常需要额外的训练或神经功能评估(NFE),使其与指导蒸馏模型不兼容。此外,它们依赖于启发式方法,需要识别目标层。在这项工作中,我们提出了一种新颖且高效的方法,称为PLADIS,它通过利用稀疏注意力来提升预训练模型(U-Net/Transformer)。具体来说,我们在推理过程中,利用交叉注意力层中的softmax及其稀疏对应物来推断查询-键相关性,无需额外的训练或NFE。通过利用稀疏注意力的噪声鲁棒性,我们的PLADIS释放了文本到图像扩散模型的潜在能力,使它们在以前挣扎的领域有了新的发现,并在文本对齐和人类偏好方面取得了显著的改进,提供了一个高效且普遍适用的解决方案。详见我们的项目页面:https://cubeyoung.github.io/pladis-proejct/
论文及项目相关链接
PDF 29 pages, 19 figures, project page : https://cubeyoung.github.io/pladis-proejct/
Summary
扩散模型利用指导技术如非分类指导(CFG)生成高质量的条件样本,取得了令人印象深刻的结果。然而,现有方法通常需要额外的训练或神经功能评估(NFEs),这与指导蒸馏模型不兼容。此外,它们依赖于启发式方法,需要识别目标层。本研究提出了一种新颖且高效的方法,名为PLADIS,它通过利用稀疏注意力来提升预训练模型(U-Net/Transformer)。在推理过程中,我们扩展了交叉注意力层中的查询-键相关性,使用softmax及其稀疏对应物,无需额外的训练或NFEs。通过利用稀疏注意力的噪声鲁棒性,PLADIS释放了文本到图像扩散模型的潜在能力,使它们在以前挣扎的领域有了新的发现,取得了显著的效果。它与指导技术无缝集成,包括指导蒸馏模型。大量的实验显示,它在文本对齐和人类偏好方面有了显著的改进,提供了一个高效且普遍适用的解决方案。
Key Takeaways
- 扩散模型通过使用指导技术如非分类指导(CFG)生成高质量条件样本,表现出强大的性能。
- 现有方法存在兼容性和效率问题,需要额外的训练或神经功能评估(NFEs),并且依赖于启发式方法来识别目标层。
- PLADIS方法通过利用稀疏注意力提升预训练模型(U-Net/Transformer),无需额外训练或NFEs。
- PLADIS在文本到图像扩散模型中释放了潜在能力,尤其在以前表现不佳的领域取得了显著改进。
- PLADIS方法与各种指导技术无缝集成,包括指导蒸馏模型。
- 实验结果表明,PLADIS在文本对齐和人类偏好方面有明显提升。
- PLADIS提供了一个高效且普遍适用的解决方案。
点此查看论文截图


TraSCE: Trajectory Steering for Concept Erasure
Authors:Anubhav Jain, Yuya Kobayashi, Takashi Shibuya, Yuhta Takida, Nasir Memon, Julian Togelius, Yuki Mitsufuji
Recent advancements in text-to-image diffusion models have brought them to the public spotlight, becoming widely accessible and embraced by everyday users. However, these models have been shown to generate harmful content such as not-safe-for-work (NSFW) images. While approaches have been proposed to erase such abstract concepts from the models, jail-breaking techniques have succeeded in bypassing such safety measures. In this paper, we propose TraSCE, an approach to guide the diffusion trajectory away from generating harmful content. Our approach is based on negative prompting, but as we show in this paper, a widely used negative prompting strategy is not a complete solution and can easily be bypassed in some corner cases. To address this issue, we first propose using a specific formulation of negative prompting instead of the widely used one. Furthermore, we introduce a localized loss-based guidance that enhances the modified negative prompting technique by steering the diffusion trajectory. We demonstrate that our proposed method achieves state-of-the-art results on various benchmarks in removing harmful content, including ones proposed by red teams, and erasing artistic styles and objects. Our proposed approach does not require any training, weight modifications, or training data (either image or prompt), making it easier for model owners to erase new concepts.
文本到图像扩散模型的最新进展使它们受到公众关注,日常用户也可以广泛访问和使用它们。然而,这些模型已显示出会生成有害内容,例如不适合工作场所(NSFW)的图像。虽然有人提出从模型中删除此类抽象概念的方法,但越狱技术已成功绕过这些安全措施。在本文中,我们提出TraSCE方法,通过引导扩散轨迹远离生成有害内容。我们的方法基于负提示,但正如我们在本文中所示,广泛使用的负提示策略并不是完整的解决方案,并且在某些特定情况下很容易被绕过。为了解决此问题,我们首先提出使用特定的负提示形式,而不是广泛使用的形式。此外,我们引入了一种基于局部损失的指导方法,通过引导扩散轨迹来增强改进后的负提示技术。我们证明,我们的方法在去除有害内容方面达到了最先进的结果,包括红队提出的各种基准测试,以及消除艺术风格和物体。我们提出的方法不需要任何训练、权重修改或训练数据(无论是图像还是提示),这使得模型所有者更容易消除新概念。
论文及项目相关链接
摘要
文本扩散模型最新进展广受公众关注,但生成有害内容(如不适合工作环境的图像)的问题也随之显现。现有方法试图从模型中消除此类抽象概念,但存在越狱技术绕过这些安全措施。本文提出TraSCE方法,通过负提示引导扩散轨迹避免生成有害内容。我们发现广泛使用的负提示策略并不完善,在某些情况下容易被绕过。因此,我们提出使用特定的负提示形式,并引入基于局部损失的指导,增强修改后的负提示技术,引导扩散轨迹。实验证明,该方法在去除有害内容、消除艺术风格和物体等方面达到最新水平,无需任何训练、权重修改或训练数据(无论是图像还是提示),使得模型所有者更容易消除新概念。
关键见解
- 文本扩散模型近期进展引发公众关注,但生成有害内容的问题突显。
- 现有方法试图从模型中消除有害内容,但存在技术能够绕过这些安全措施。
- TraSCE方法通过负提示引导扩散轨迹,避免生成有害内容。
- 广泛使用的负提示策略并不完善,需要在特定情况下进行改进。
- TraSCE使用特定的负提示形式,并结合局部损失指导增强技术效果。
- 实验证明TraSCE方法在去除有害内容方面达到最新水平。
点此查看论文截图





Video Depth without Video Models
Authors:Bingxin Ke, Dominik Narnhofer, Shengyu Huang, Lei Ke, Torben Peters, Katerina Fragkiadaki, Anton Obukhov, Konrad Schindler
Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth. However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range. An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs. We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various different frame rates back into a consistent video. RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models. Project page: rollingdepth.github.io.
视频深度估计通过推断每一帧的密集深度,将单目视频片段提升到3D。随着大型基础模型和合成训练数据的兴起,单图像深度估计方面的最新进展激发了人们对视频深度的重新关注。然而,盲目地将单图像深度估计器应用于视频的每一帧,会忽视时间的连续性,这不仅会导致闪烁,还可能在相机运动导致深度范围突然变化时出现问题。一个明显且基于原则的解决方案是建立视频基础模型,但这些模型也有其自身的局限性,包括昂贵的训练和推理成本、不完美的3D一致性以及固定长度(短)输出的拼接程序。我们退后一步,展示了如何将单图像潜在扩散模型(LDM)转化为最先进的视频深度估计器。我们的模型——RollingDepth,主要包括两个组成部分:(i)多帧深度估计器,它来源于单图像LDM,将非常短的视频片段(通常为三帧)映射到深度片段。(ii)一个稳健的、基于优化的注册算法,该算法能够最佳地将从不同帧率采样的深度片段重新组合成一致的视频。RollingDepth能够高效地处理长达数百帧的长视频,并提供比专用视频深度估计器和高性能单帧模型更准确的深度视频。项目页面:rollingdepth.github.io。
论文及项目相关链接
PDF Project page: rollingdepth.github.io
Summary
基于视频深度估算技术,将单眼视频剪辑提升为三维效果,通过每一帧推断出密集深度信息。近期随着大型基础模型和合成训练数据的兴起,单图像深度估算技术取得了进展,引发了人们对视频深度的重新关注。然而,简单地将单图像深度估算器应用于视频的每一帧会忽视时间的连续性,这不仅会导致闪烁,还可能在相机运动导致深度范围突然变化时失效。本文提出了一种将单图像潜在扩散模型(LDM)转化为最先进的视频深度估算器的方法。我们的模型——RollingDepth,包含两个主要成分:(i)从单图像LDM派生的多帧深度估算器,它将非常短的视频片段(通常为三帧)映射到深度片段;(ii)一种稳健的、基于优化的注册算法,它以最佳方式将不同帧率采样的深度片段重新组合成一致的视频。RollingDepth能够高效地处理长达数百帧的视频,并提供比专用视频深度估算器和高性能单帧模型更准确的深度视频。
Key Takeaways
- 视频深度估算技术能够将单眼视频转化为三维效果,通过每一帧的密集深度信息推断实现。
- 当前研究中单图像深度估算已取得了显著进展。
- 简单应用单图像深度估算于视频处理会忽略时间连续性,造成闪烁或深度范围突变时失效的问题。
- 提出了一种将单图像潜在扩散模型(LDM)转化为视频深度估算器的方法——RollingDepth。
- RollingDepth包含多帧深度估算器和基于优化的注册算法两个主要成分。
- 多帧深度估算器能将短视频片段映射到深度片段。
- 基于优化的注册算法能确保不同帧率采样的深度片段组合成一致的视频,提高处理长视频的效率和准确性。RollingDepth相比其他方法能提供更准确的深度视频。
点此查看论文截图




Classifier-Free Guidance inside the Attraction Basin May Cause Memorization
Authors:Anubhav Jain, Yuya Kobayashi, Takashi Shibuya, Yuhta Takida, Nasir Memon, Julian Togelius, Yuki Mitsufuji
Diffusion models are prone to exactly reproduce images from the training data. This exact reproduction of the training data is concerning as it can lead to copyright infringement and/or leakage of privacy-sensitive information. In this paper, we present a novel perspective on the memorization phenomenon and propose a simple yet effective approach to mitigate it. We argue that memorization occurs because of an attraction basin in the denoising process which steers the diffusion trajectory towards a memorized image. However, this can be mitigated by guiding the diffusion trajectory away from the attraction basin by not applying classifier-free guidance until an ideal transition point occurs from which classifier-free guidance is applied. This leads to the generation of non-memorized images that are high in image quality and well-aligned with the conditioning mechanism. To further improve on this, we present a new guidance technique, opposite guidance, that escapes the attraction basin sooner in the denoising process. We demonstrate the existence of attraction basins in various scenarios in which memorization occurs, and we show that our proposed approach successfully mitigates memorization.
扩散模型容易直接复制训练数据中的图像。这种对训练数据的精确复制会引发版权侵犯和/或隐私敏感信息泄露的担忧。在本文中,我们从新的角度看待记忆现象,并提出一种简单有效的缓解方法。我们认为记忆的产生是由于去噪过程中的吸引子盆地使得扩散轨迹朝向记忆中的图像。然而,可以通过在达到理想的过渡点之前不应用无分类器引导,将扩散轨迹从吸引子盆地中移开,从而缓解这一问题。这导致了生成非记忆图像,图像质量高且与调节机制吻合良好。为了进一步改进这一点,我们提出了一种新的引导技术——反向引导,该技术能够在去噪过程中更快地摆脱吸引子盆地。我们展示了在各种记忆现象发生的场景中吸引子盆地的存在,并证明我们提出的方法成功地缓解了记忆现象。
论文及项目相关链接
PDF CVPR 2025
Summary
本文指出扩散模型会重现训练数据中的图像,这可能导致版权侵犯和隐私泄露。文章提出了一个新的视角来解释这一现象,并建议了一种简单有效的方法来减轻其影响。文章认为记忆现象是由于去噪过程中的吸引盆地造成的,可以通过不应用分类器自由指导直至理想的过渡点,然后应用它来引导扩散轨迹远离吸引盆地。此外,文章还提出了一种新的指导技术,即反向指导,它能更早地从去噪过程中跳出吸引盆地。实验证明,该方法成功减轻了记忆现象。
Key Takeaways
- 扩散模型会重现训练数据中的图像,这可能会引发版权和隐私问题。
- 记忆现象的产生是因为去噪过程中的吸引盆地导致扩散轨迹导向记忆中的图像。
- 通过不应用分类器自由指导直至理想的过渡点,然后应用它来引导扩散轨迹远离吸引盆地,可以减轻记忆现象。
- 提出了一种新的指导技术——反向指导,能更早地从去噪过程中跳出吸引盆地。
- 文章展示了吸引盆地的存在,以及记忆现象发生时的各种情景。
- 本文的方法成功减轻了扩散模型的记忆现象,生成的图像质量高且与条件机制对齐。
点此查看论文截图





Believing is Seeing: Unobserved Object Detection using Generative Models
Authors:Subhransu S. Bhattacharjee, Dylan Campbell, Rahul Shome
Can objects that are not visible in an image – but are in the vicinity of the camera – be detected? This study introduces the novel tasks of 2D, 2.5D and 3D unobserved object detection for predicting the location of nearby objects that are occluded or lie outside the image frame. We adapt several state-of-the-art pre-trained generative models to address this task, including 2D and 3D diffusion models and vision-language models, and show that they can be used to infer the presence of objects that are not directly observed. To benchmark this task, we propose a suite of metrics that capture different aspects of performance. Our empirical evaluation on indoor scenes from the RealEstate10k and NYU Depth v2 datasets demonstrate results that motivate the use of generative models for the unobserved object detection task.
在图像中无法看到但位于相机附近的对象能被检测出来吗?本研究介绍了二维、二维半和三维非观测对象检测的新任务,旨在预测被遮挡或位于图像框外的附近对象的位置。我们适应了几种最新的预训练生成模型来解决此任务,包括二维和三维扩散模型以及视觉语言模型,并展示了这些模型可以用于推断未直接观察到的对象的存在。为了评估此任务,我们提出了一套指标,以捕捉性能的不同方面。我们在RealEstate10k和NYU Depth v2数据集上的室内场景实证评估结果表明,使用生成模型进行非观测对象检测任务是可行的。
论文及项目相关链接
PDF IEEE/CVF Computer Vision and Pattern Recognition 2025; 22 pages
Summary:
本研究探索了2D、2.5D和3D未观测物体检测的新任务,旨在预测图像中不可见但相机附近物体的位置。研究采用了几种先进的预训练生成模型来完成此任务,包括2D和3D扩散模型和视觉语言模型,并证明它们可用于推断未直接观察到的物体的存在。该研究还提出了用于评估此任务性能的指标,并在RealEstate10k和NYU Depth v2数据集上的室内场景进行了实证评估,证明了生成模型在未观测物体检测任务中的实用性。
Key Takeaways:
- 本研究引入了预测图像中未观测物体位置的新任务,这些物体可能因遮挡或位于图像范围之外而不可见。
- 研究采用先进的预训练生成模型,包括扩散模型和视觉语言模型,用于推断未直接观察到的物体的存在。
- 为了评估该任务性能,提出了多个性能指标,从不同角度衡量模型表现。
- 研究使用RealEstate10k和NYU Depth v2数据集进行实证评估,展示了生成模型在未观测物体检测任务中的实用性。
- 研究发现在室内场景中进行此类检测具有一定的可行性。
- 本研究推动了生成模型在未观测物体检测领域的进一步应用和发展。
点此查看论文截图





