⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
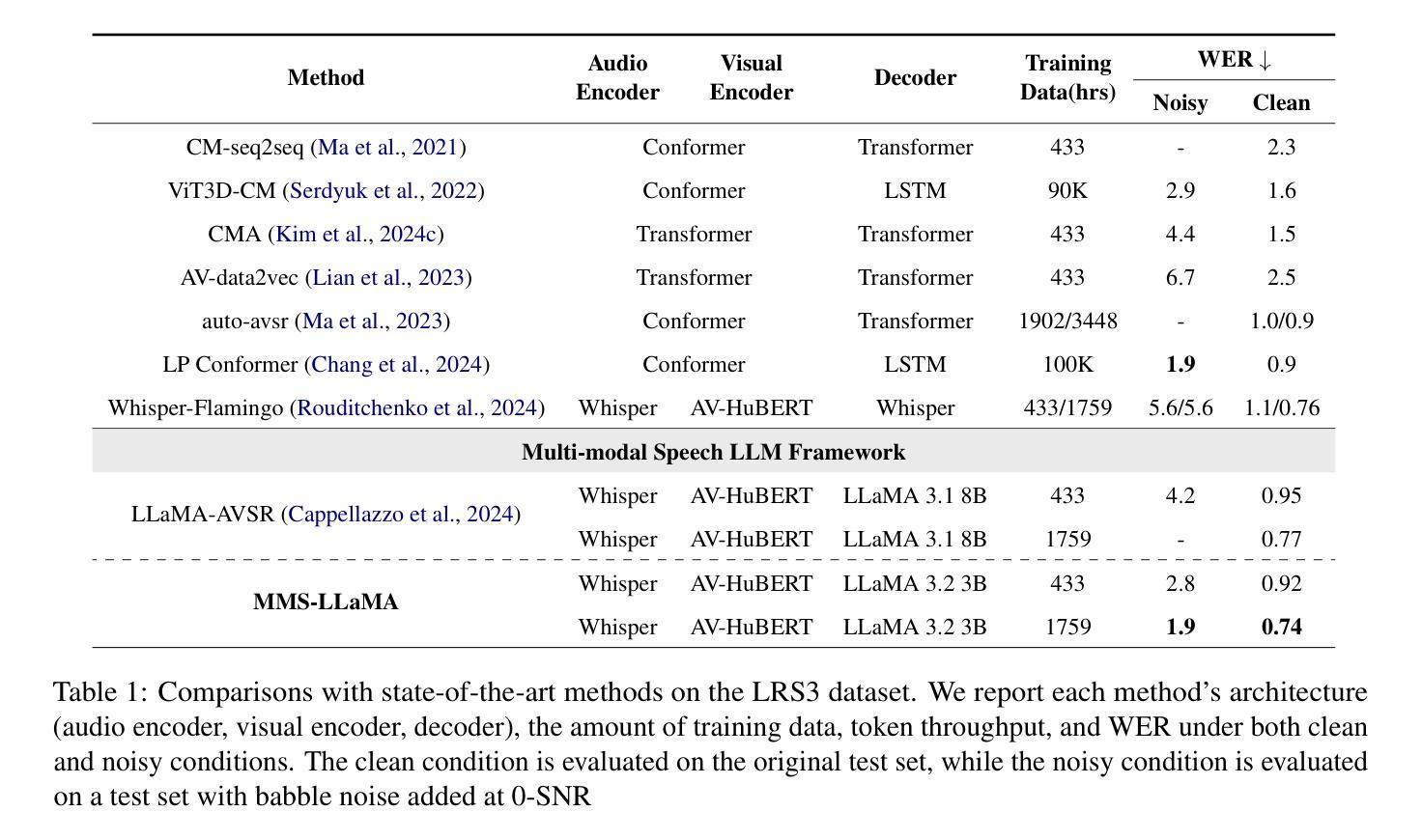
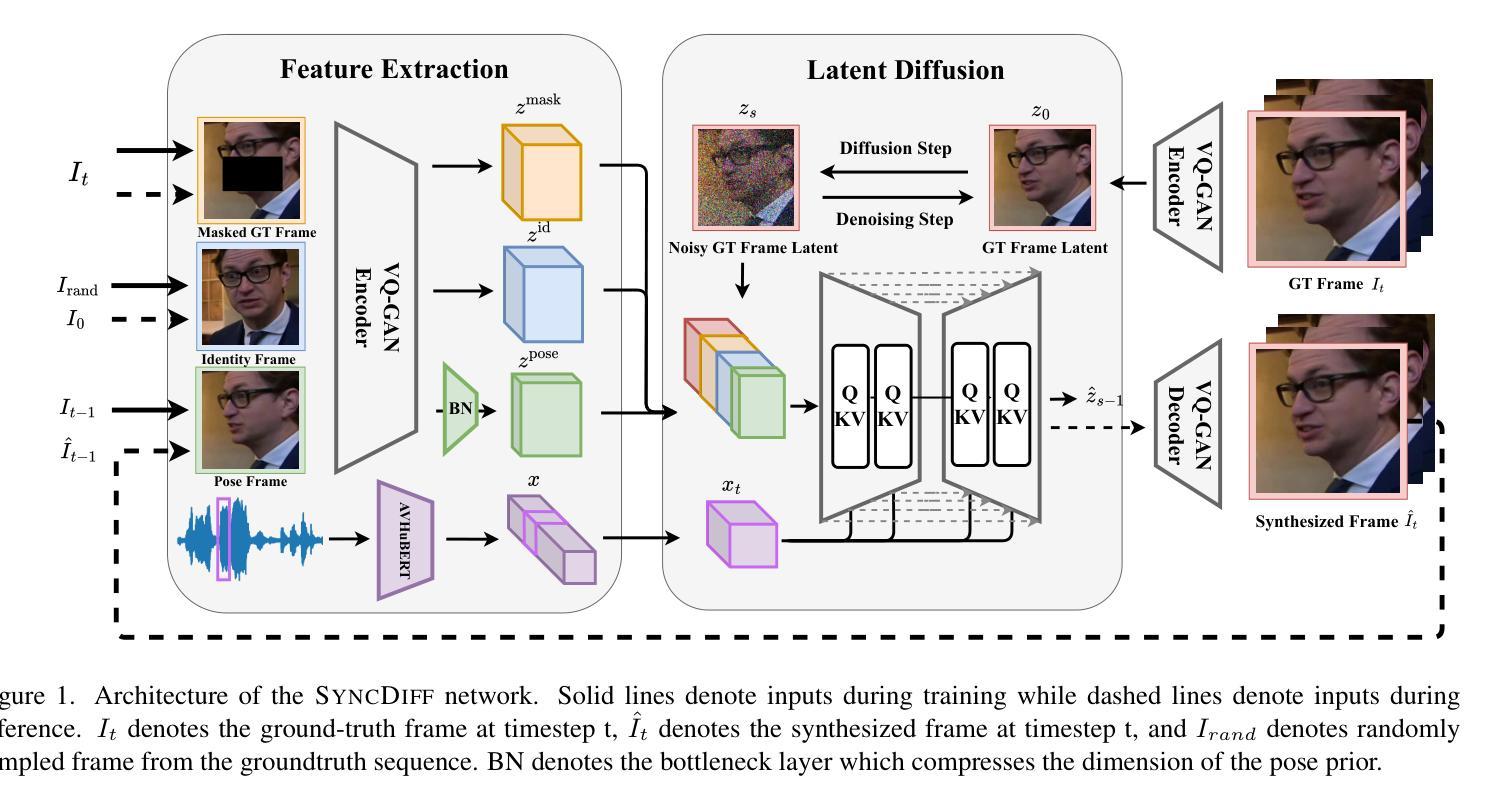
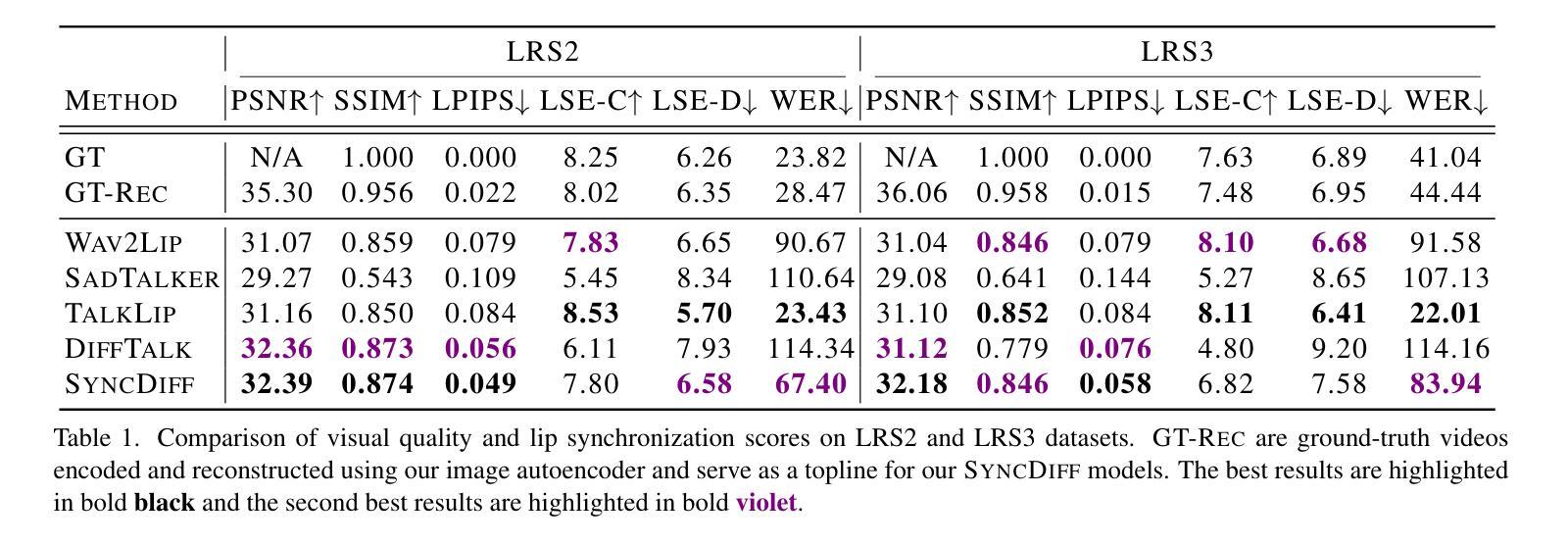
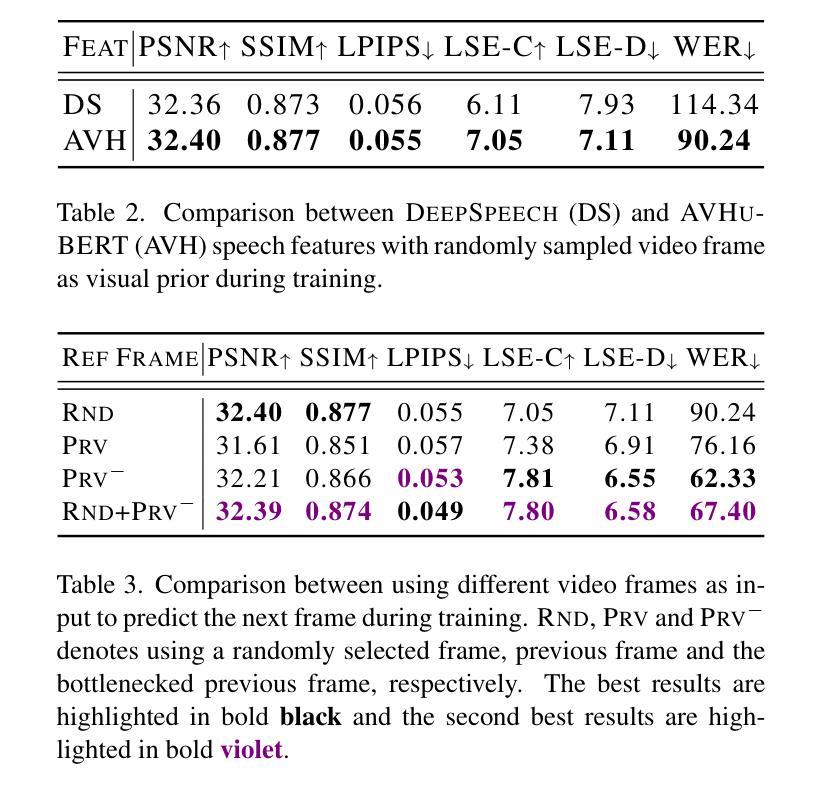
SyncDiff: Diffusion-based Talking Head Synthesis with Bottlenecked Temporal Visual Prior for Improved Synchronization
Authors:Xulin Fan, Heting Gao, Ziyi Chen, Peng Chang, Mei Han, Mark Hasegawa-Johnson
Talking head synthesis, also known as speech-to-lip synthesis, reconstructs the facial motions that align with the given audio tracks. The synthesized videos are evaluated on mainly two aspects, lip-speech synchronization and image fidelity. Recent studies demonstrate that GAN-based and diffusion-based models achieve state-of-the-art (SOTA) performance on this task, with diffusion-based models achieving superior image fidelity but experiencing lower synchronization compared to their GAN-based counterparts. To this end, we propose SyncDiff, a simple yet effective approach to improve diffusion-based models using a temporal pose frame with information bottleneck and facial-informative audio features extracted from AVHuBERT, as conditioning input into the diffusion process. We evaluate SyncDiff on two canonical talking head datasets, LRS2 and LRS3 for direct comparison with other SOTA models. Experiments on LRS2/LRS3 datasets show that SyncDiff achieves a synchronization score 27.7%/62.3% relatively higher than previous diffusion-based methods, while preserving their high-fidelity characteristics.
头部动作合成,也被称为语音唇动合成,会重建与给定音频轨迹对齐的面部动作。对于合成的视频,主要从两个方面进行评估,即唇语音同步和图像保真度。近期的研究表明,基于生成对抗网络(GAN)和扩散模型的算法在该任务上达到了最新技术水平(SOTA),其中扩散模型在图像保真度方面表现更优,但在同步方面相较于基于GAN的模型略逊一筹。为此,我们提出了SyncDiff方法,这是一种简单有效的基于扩散模型的改进方法,使用带有信息瓶颈的临时姿态帧和从AVHuBERT中提取的面部信息音频特征作为扩散过程的条件输入。我们在两个标准的头部动作数据集LRS2和LRS3上对SyncDiff进行了评估,以便与其他最新技术水平的模型进行直接比较。在LRS2/LRS3数据集上的实验表明,SyncDiff的同步得分相较于之前的扩散方法提高了27.7%/62.3%,同时保持了其高保真特性。
论文及项目相关链接
PDF Accepted to WACV 2025
Summary
基于生成对抗网络(GAN)和扩散模型的说话人头部合成技术已达成前沿水平。本文提出SyncDiff方法,利用时间姿态框架和面部信息音频特征,改善扩散模型的性能,使其在说话人头部合成任务中提升唇语音同步表现,同时保持高保真特性。
Key Takeaways
- 说话人头部合成(说话头合成)技术重建与音频轨迹对齐的面部动作。
- 主要评价指标包括唇语音同步和图像保真度。
- 近期研究表明,基于GAN和扩散模型的方法在该任务上达到前沿水平。
- 扩散模型在图像保真度上表现优异,但在同步方面较GAN模型低。
- SyncDiff方法通过结合时间姿态框架与信息瓶颈、提取面部信息音频特征,旨在改善扩散模型在说话头合成任务中的表现。
- 在两个经典数据集LRS2和LRS3上的实验表明,SyncDiff在同步得分上较之前扩散模型有所提升,并保持了高保真特性。
点此查看论文截图

RainScaleGAN: a Conditional Generative Adversarial Network for Rainfall Downscaling
Authors:Marcello Iotti, Paolo Davini, Jost von Hardenberg, Giuseppe Zappa
To this day, accurately simulating local-scale precipitation and reliably reproducing its distribution remains a challenging task. The limited horizontal resolution of Global Climate Models is among the primary factors undermining their skill in this context. The physical mechanisms driving the onset and development of precipitation, especially in extreme events, operate at spatio-temporal scales smaller than those numerically resolved, thus struggling to be captured accurately. In order to circumvent this limitation, several downscaling approaches have been developed over the last decades to address the discrepancy between the spatial resolution of models output and the resolution required by local-scale applications. In this paper, we introduce RainScaleGAN, a conditional deep convolutional Generative Adversarial Network (GAN) for precipitation downscaling. GANs have been effectively used in image super-resolution, an approach highly relevant for downscaling tasks. RainScaleGAN’s capabilities are tested in a perfect-model setup, where the spatial resolution of a precipitation dataset is artificially degraded from 0.25$^{\circ}\times$0.25$^{\circ}$ to 2$^{\circ}\times$2$^\circ$, and RainScaleGAN is used to restore it. The developed model outperforms one of the leading precipitation downscaling method found in the literature. RainScaleGAN not only generates a synthetic dataset featuring plausible high-resolution spatial patterns and intensities, but also produces a precipitation distribution with statistics closely mirroring those of the ground-truth dataset. Given that RainScaleGAN’s approach is agnostic with respect to the underlying physics, the method has the potential to be applied to other physical variables such as surface winds or temperature.
迄今为止,准确模拟局部尺度的降水并可靠地再现其分布仍然是一项具有挑战性的任务。全球气候模型的有限水平分辨率是限制其在此背景下的能力的主要因素之一。驱动降水发生和发展的物理机制,特别是在极端事件中,其在时空尺度上的运作比数值解析的尺度更小,因此难以准确捕获。为了克服这一局限性,过去几十年已经开发了几种下标度方法来解决模型输出空间分辨率与局部尺度应用所需分辨率之间的差异。在本文中,我们介绍了RainScaleGAN,这是一种用于降水下标度的条件深度卷积生成对抗网络(GAN)。GAN已广泛应用于图像超分辨率,这与下标度任务高度相关。RainScaleGAN的能力是在完美模型设置中进行测试的,其中降水数据集的空间分辨率从0.25$^{\circ}\times$0.25$^{\circ}$人工降级到2$^{\circ}\times$2$^{\circ}$,然后使用RainScaleGAN进行恢复。所开发的模型表现优于文献中发现的一种领先的降水下标度方法。RainScaleGAN不仅生成了一个具有合理高分辨率空间模式和强度的人工数据集,而且产生的降水分布统计信息与真实数据集紧密对应。由于RainScaleGAN的方法对潜在物理学持不可知论态度,因此该方法有可能应用于其他物理变量,如地表风或温度。
论文及项目相关链接
PDF 38 pages, 16 figures
Summary
本文引入了一种基于条件深度卷积生成对抗网络(RainScaleGAN)的降水精细化方法。该方法旨在解决全球气候模型在模拟局部尺度降水分布时的水平分辨率限制问题。通过测试,RainScaleGAN在人为降低分辨率的降水数据集上表现出优异性能,能生成高分辨率的降水空间格局和强度,并接近真实数据的统计特征。此外,由于其不依赖于物理机制,RainScaleGAN还可应用于其他物理变量如地表风温的模拟。
Key Takeaways
- 准确模拟局部尺度降水及其分布是一个具有挑战的任务,全球气候模型的水平分辨率限制是主要原因之一。
- 降水特别是极端事件的发生和发展机制,在操作尺度上小于数值解析尺度,难以准确捕捉。
- 为解决模型输出分辨率与本地应用所需分辨率之间的差异,已开发多种降尺度方法。
- 本文介绍了RainScaleGAN,一种基于条件深度卷积生成对抗网络(GAN)的降水降尺度方法,在降水模拟中表现出优异性能。
- RainScaleGAN能够生成高分辨率的降水空间格局和强度,且统计特征接近真实数据。
- RainScaleGAN的方法对底层物理机制无特定要求,具有潜力应用于其他物理变量的模拟,如地表风和温度。
点此查看论文截图

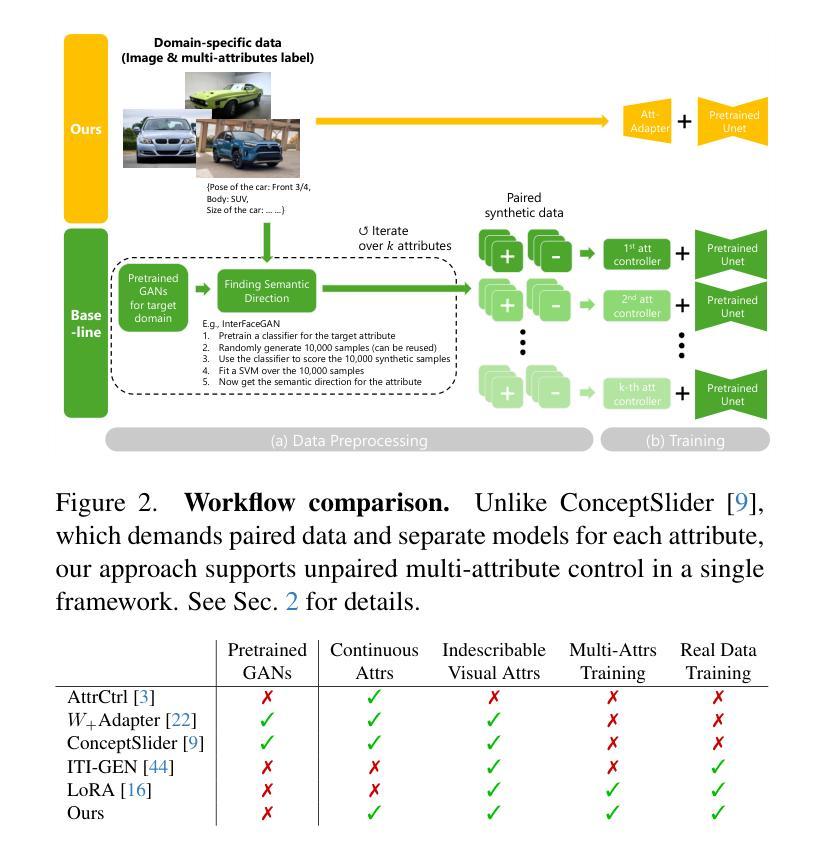
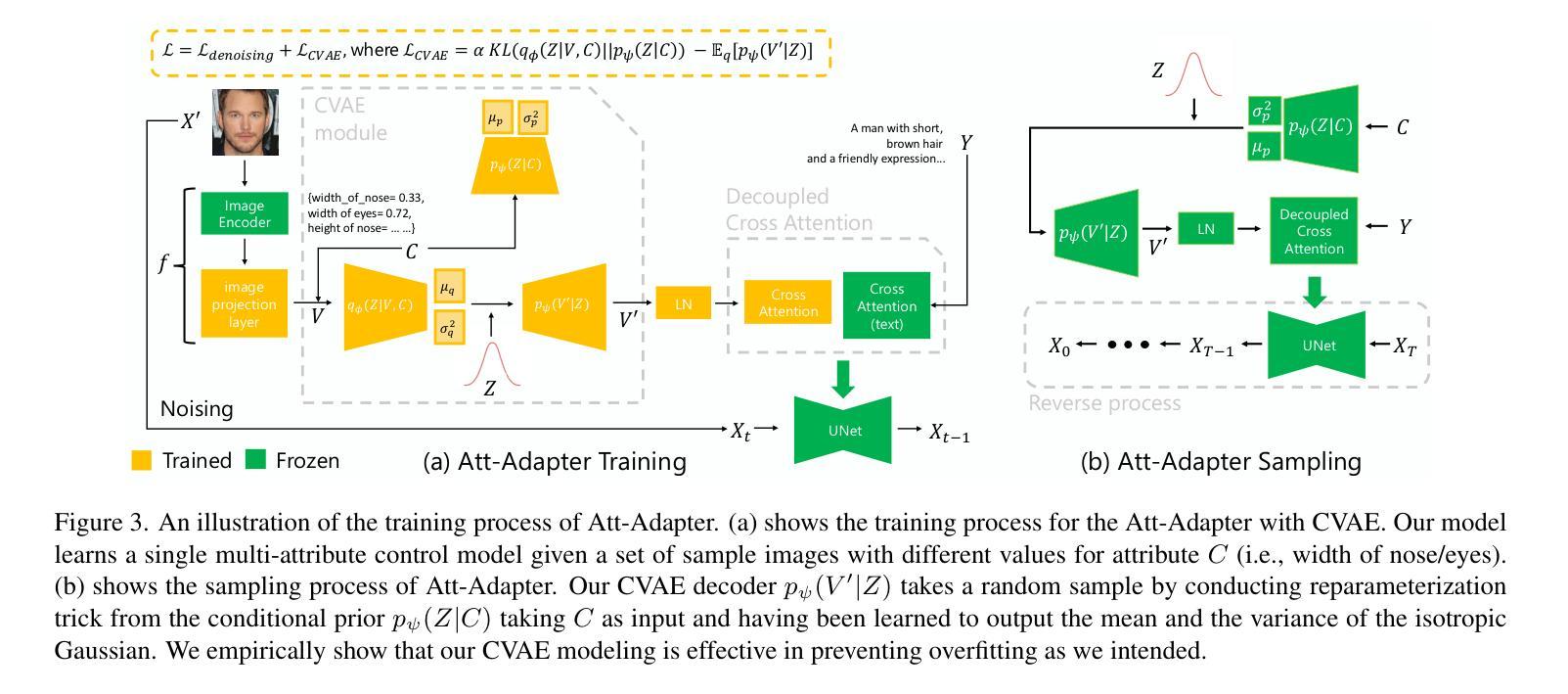
Att-Adapter: A Robust and Precise Domain-Specific Multi-Attributes T2I Diffusion Adapter via Conditional Variational Autoencoder
Authors:Wonwoong Cho, Yan-Ying Chen, Matthew Klenk, David I. Inouye, Yanxia Zhang
Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise control of continuous attributes, especially multiple attributes simultaneously, in a new domain (e.g., numeric values like eye openness or car width) with text-only guidance remains a significant challenge. To address this, we introduce the Attribute (Att) Adapter, a novel plug-and-play module designed to enable fine-grained, multi-attributes control in pretrained diffusion models. Our approach learns a single control adapter from a set of sample images that can be unpaired and contain multiple visual attributes. The Att-Adapter leverages the decoupled cross attention module to naturally harmonize the multiple domain attributes with text conditioning. We further introduce Conditional Variational Autoencoder (CVAE) to the Att-Adapter to mitigate overfitting, matching the diverse nature of the visual world. Evaluations on two public datasets show that Att-Adapter outperforms all LoRA-based baselines in controlling continuous attributes. Additionally, our method enables a broader control range and also improves disentanglement across multiple attributes, surpassing StyleGAN-based techniques. Notably, Att-Adapter is flexible, requiring no paired synthetic data for training, and is easily scalable to multiple attributes within a single model.
文本到图像(T2I)扩散模型在生成高质量图像方面取得了显著的成绩。然而,在新的领域(如眼睛睁开程度或汽车宽度等数值)实现连续属性的精确控制,尤其是同时控制多个属性,仅通过文本指导仍然是一个巨大的挑战。为了解决这一问题,我们引入了属性(Att)适配器,这是一种新型即插即用模块,旨在在预训练的扩散模型中实现精细的、多属性控制。我们的方法从一组样本图像中学习单个控制适配器,这些图像可以是未配对的并且包含多个视觉属性。Att-Adapter利用解耦的交叉注意力模块,自然地协调多个域属性与文本条件。我们进一步将条件变分自编码器(CVAE)引入到Att-Adapter中,以减轻过拟合问题,适应视觉世界的多样性。在两个公共数据集上的评估表明,Att-Adapter在控制连续属性方面优于所有基于LoRA的方法。此外,我们的方法扩大了控制范围,并改善了多个属性之间的解纠缠,超越了基于StyleGAN的技术。值得注意的是,Att-Adapter非常灵活,无需配对合成数据进行训练,并且很容易在一个模型内扩展到多个属性。
论文及项目相关链接
Summary
文本至图像(T2I)扩散模型在生成高质量图像方面取得了显著成效,但在新领域实现连续属性,尤其是同时控制多个属性的精确性方面仍面临挑战。为解决这个问题,我们引入了属性适配器(Att-Adapter),这是一种新型即插即用模块,旨在在预训练扩散模型中实现精细的多属性控制。该方法通过从一组样本图像中学习单个控制适配器,能够实现对多个视觉属性的控制。此外,我们还引入了条件变分自编码器(CVAE)来减轻过拟合问题,以匹配视觉世界的多样性。在公开数据集上的评估表明,Att-Adapter在控制连续属性方面的表现优于所有基于LoRA的方法。此外,我们的方法具有更广泛的控制范围和更好的多属性解纠缠性能,超越了StyleGAN技术。值得一提的是,Att-Adapter训练无需配对合成数据,且能轻松扩展到单个模型中的多个属性。
Key Takeaways
- T2I扩散模型在生成高质量图像方面表现出色,但在新领域的多属性控制上仍有挑战。
- 引入属性适配器(Att-Adapter)来解决这个问题,这是一种新型的即插即用模块,可以精细控制多个属性。
- Att-Adapter通过从样本图像中学习单个控制适配器来实现多属性控制,这些图像可以是未配对的,并包含多个视觉属性。
- 引入条件变分自编码器(CVAE)来缓解过度拟合问题,以匹配视觉世界的多样性。
- 在公开数据集上的评估显示,Att-Adapter在控制连续属性方面优于其他方法。
- Att-Adapter具有更广泛的控制范围和更好的多属性解纠缠性能,超越了现有的StyleGAN技术。
点此查看论文截图


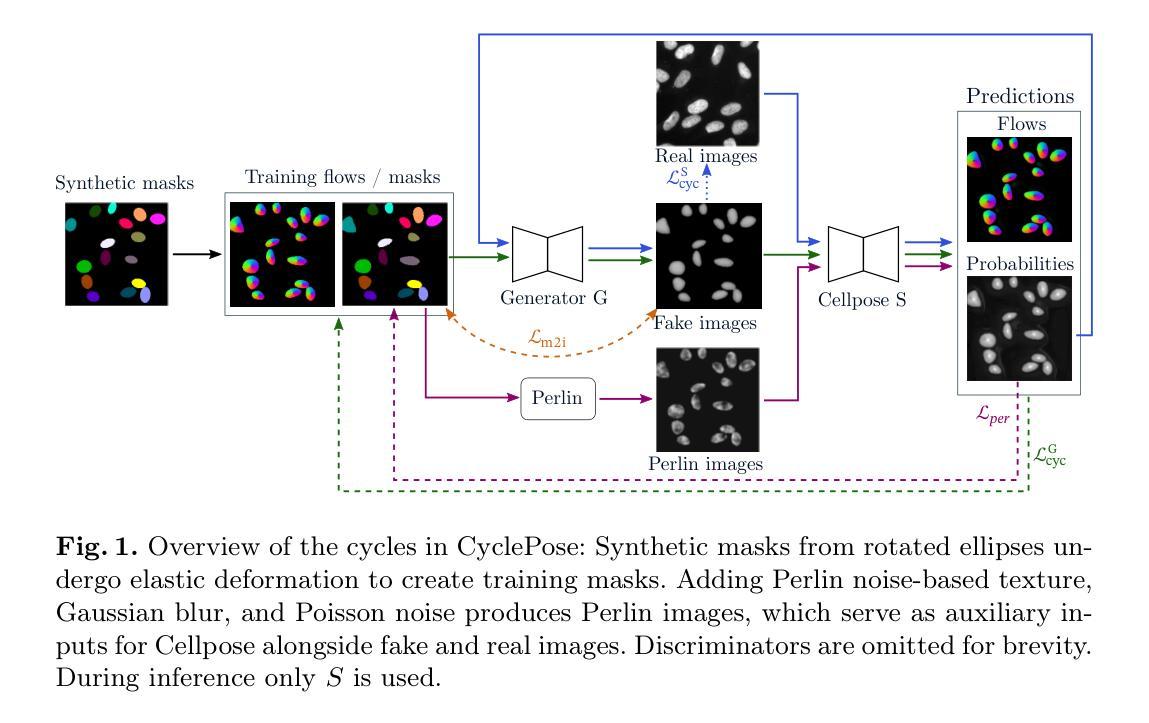
CyclePose – Leveraging Cycle-Consistency for Annotation-Free Nuclei Segmentation in Fluorescence Microscopy
Authors:Jonas Utz, Stefan Vocht, Anne Tjorven Buessen, Dennis Possart, Fabian Wagner, Mareike Thies, Mingxuan Gu, Stefan Uderhardt, Katharina Breininger
In recent years, numerous neural network architectures specifically designed for the instance segmentation of nuclei in microscopic images have been released. These models embed nuclei-specific priors to outperform generic architectures like U-Nets; however, they require large annotated datasets, which are often not available. Generative models (GANs, diffusion models) have been used to compensate for this by synthesizing training data. These two-stage approaches are computationally expensive, as first a generative model and then a segmentation model has to be trained. We propose CyclePose, a hybrid framework integrating synthetic data generation and segmentation training. CyclePose builds on a CycleGAN architecture, which allows unpaired translation between microscopy images and segmentation masks. We embed a segmentation model into CycleGAN and leverage a cycle consistency loss for self-supervision. Without annotated data, CyclePose outperforms other weakly or unsupervised methods on two public datasets. Code is available at https://github.com/jonasutz/CyclePose
近年来,针对显微图像中的细胞核实例分割,已经发布了大量专门设计的神经网络架构。这些模型嵌入细胞核特异性先验知识,以超越通用架构(如U-Nets)的表现;然而,它们需要大量标注数据集,而这些数据通常不可用。生成模型(GANs、扩散模型)已被用于通过合成训练数据来弥补这一缺陷。这两种分阶段的方法计算成本高昂,因为首先必须训练一个生成模型,然后训练一个分割模型。我们提出了CyclePose,这是一个混合框架,集成了合成数据生成和分割训练。CyclePose基于CycleGAN架构,允许显微镜图像和分割掩膜之间的非配对翻译。我们将分割模型嵌入到CycleGAN中,并利用循环一致性损失进行自监督。无需标注数据,CyclePose在两个公共数据集上的表现优于其他弱监督或无监督方法。代码可在https://github.com/jonasutz/CyclePose找到。
论文及项目相关链接
PDF under review for MICCAI 2025
Summary
近年来,针对显微图像中的细胞核实例分割,发布了多种神经网络架构。这些模型通过嵌入细胞核特异性先验知识来超越通用架构(如U-Net),但通常需要大量标注数据集,而这些数据通常不可用。为弥补这一不足,生成模型(GANs、扩散模型)被用于合成训练数据。这些两阶段方法计算成本高昂,因为首先需要训练一个生成模型,然后再训练一个分割模型。我们提出CyclePose,一个集成合成数据生成和分割训练的混合框架。CyclePose基于CycleGAN架构,允许显微镜图像和分割掩模之间的无配对转换。我们将分割模型嵌入CycleGAN中,并利用循环一致性损失进行自监督。无需标注数据,CyclePose在两项公开数据集上的表现优于其他弱监督或无监督方法。
Key Takeaways
- 近年针对显微图像细胞核实例分割发布了多种神经网络架构,这些模型通常超越通用架构但依赖大量标注数据。
- 生成模型(如GANs和扩散模型)被用于合成训练数据以弥补标注数据的不足。
- 当前的两阶段方法计算成本高昂,需先后训练生成模型和分割模型。
- CyclePose是一个混合框架,结合了合成数据生成和分割训练。
- CyclePose基于CycleGAN架构,允许显微镜图像和分割掩模之间的无配对转换。
- CyclePose将分割模型嵌入其中,并利用循环一致性损失进行自监督学习。
- 在无需标注数据的情况下,CyclePose在公开数据集上的表现优于其他弱监督或无监督方法。
点此查看论文截图

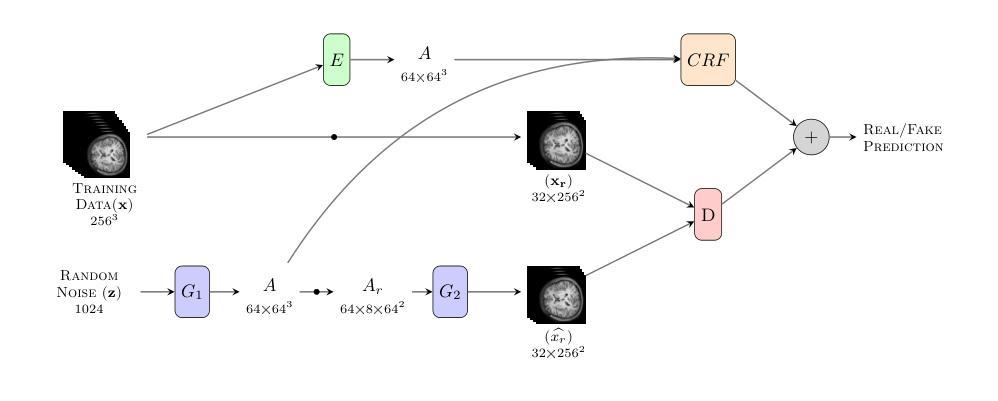
Memory-Efficient 3D High-Resolution Medical Image Synthesis Using CRF-Guided GANs
Authors:Mahshid Shiri, Alessandro Bruno, Daniele Loiacono
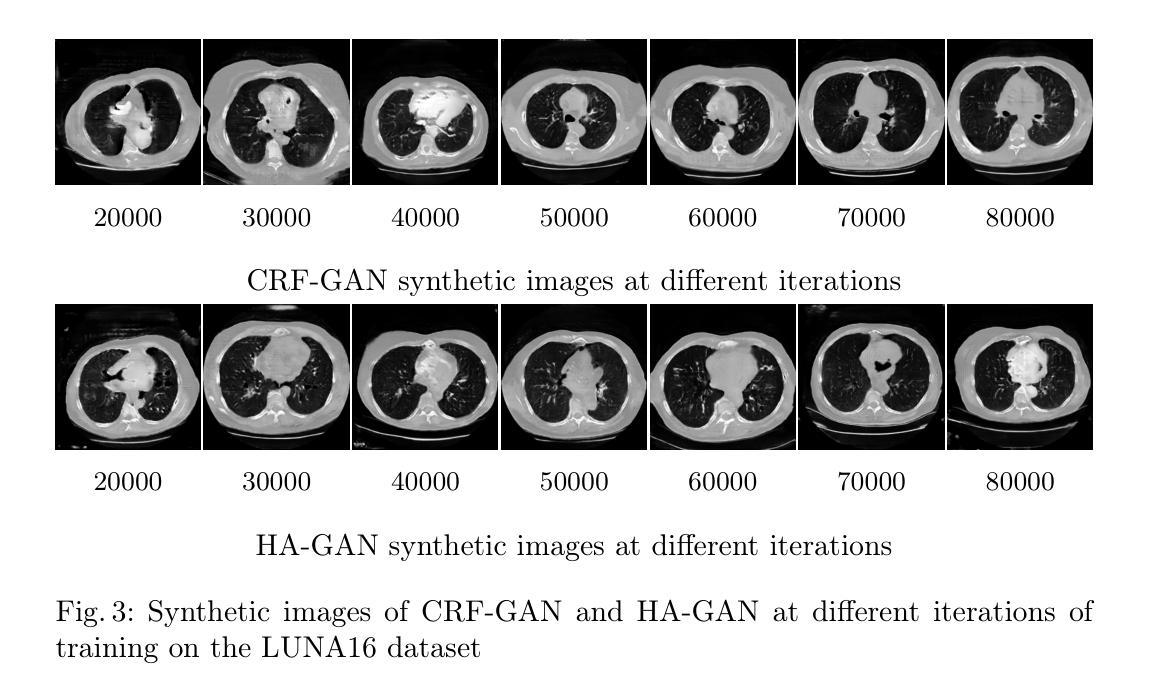
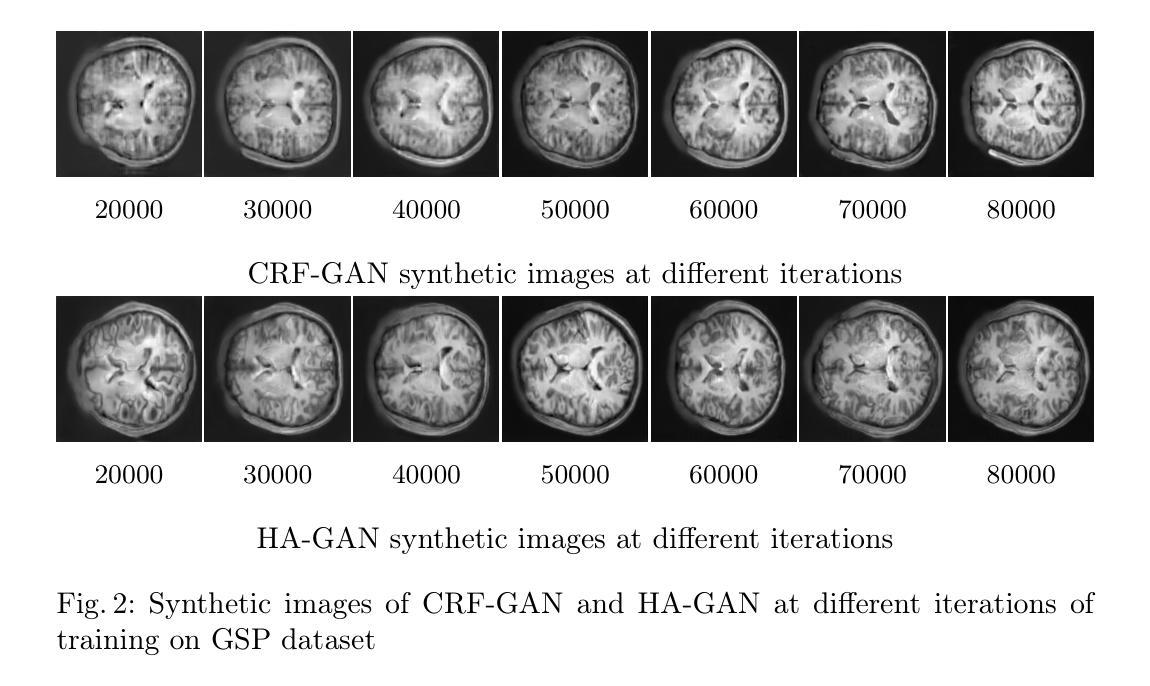
Generative Adversarial Networks (GANs) have many potential medical imaging applications. Due to the limited memory of Graphical Processing Units (GPUs), most current 3D GAN models are trained on low-resolution medical images, these models cannot scale to high-resolution or are susceptible to patchy artifacts. In this work, we propose an end-to-end novel GAN architecture that uses Conditional Random field (CRF) to model dependencies so that it can generate consistent 3D medical Images without exploiting memory. To achieve this purpose, the generator is divided into two parts during training, the first part produces an intermediate representation and CRF is applied to this intermediate representation to capture correlations. The second part of the generator produces a random sub-volume of image using a subset of the intermediate representation. This structure has two advantages: first, the correlations are modeled by using the features that the generator is trying to optimize. Second, the generator can generate full high-resolution images during inference. Experiments on Lung CTs and Brain MRIs show that our architecture outperforms state-of-the-art while it has lower memory usage and less complexity.
生成对抗网络(GANs)在医疗成像领域具有许多潜在应用。由于图形处理单元(GPU)的内存有限,当前大多数3D GAN模型都是在低分辨率医学图像上训练的,这些模型无法扩展到高分辨率或容易出现斑驳的伪影。在这项研究中,我们提出了一种端到端的新型GAN架构,该架构使用条件随机场(CRF)来建模依赖关系,从而可以在不利用内存的情况下生成一致的3D医学图像。为了达到这个目的,在训练过程中,生成器被分为两部分,第一部分产生中间表示,并应用CRF到该中间表示来捕获相关性。生成器的第二部分使用中间表示的一个子集来产生图像的随机子体积。这种结构有两个优点:首先,通过使用生成器试图优化的特征来建模相关性。其次,在推理期间,生成器可以生成完整的高分辨率图像。对肺部CT和脑部MRI的实验表明,我们的架构在具有较低内存使用和较低复杂性的同时,优于最新技术。
论文及项目相关链接
PDF Accepted to Artificial Intelligence for Healthcare Applications, 3rd International Workshop ICPR 2024
Summary
生成对抗网络(GANs)在医学成像领域具有广泛的应用潜力。由于图形处理器(GPU)内存有限,当前大多数3D GAN模型仅在低分辨率医学图像上进行训练,无法扩展至高分辨率或易出现斑块状伪影。本研究提出了一种新型端到端的GAN架构,利用条件随机场(CRF)进行依赖建模,以生成连贯的3D医学图像而不占用额外内存。训练过程中,生成器分为两部分:第一部分生成中间表示,并应用CRF捕获相关性;第二部分则使用该中间表示的子集生成随机图像子体积。这种结构有两个优点:首先,通过生成器试图优化的特征来建模相关性;其次,在推理时可生成完整的高分辨率图像。在肺部CT和脑部MRI上的实验表明,该架构在具有较低内存使用率和更少复杂性的同时,优于现有技术。
Key Takeaways
- GANs在医学成像领域有广泛的应用潜力。
- 当前3D GAN模型受限于GPU内存,难以处理高分辨率图像或易出现伪影。
- 提出了一种新型端到端的GAN架构,利用CRF进行依赖建模,以生成连贯的3D医学图像。
- 生成器在训练过程中分为两部分:生成中间表示并应用CRF,以及使用该中间表示生成随机图像子体积。
- 该结构通过生成器优化的特征来建模相关性,并在推理时生成完整的高分辨率图像。
- 实验证明,该架构在肺部CT和脑部MRI上的表现优于现有技术。
点此查看论文截图

CHAIN: Enhancing Generalization in Data-Efficient GANs via lipsCHitz continuity constrAIned Normalization
Authors:Yao Ni, Piotr Koniusz
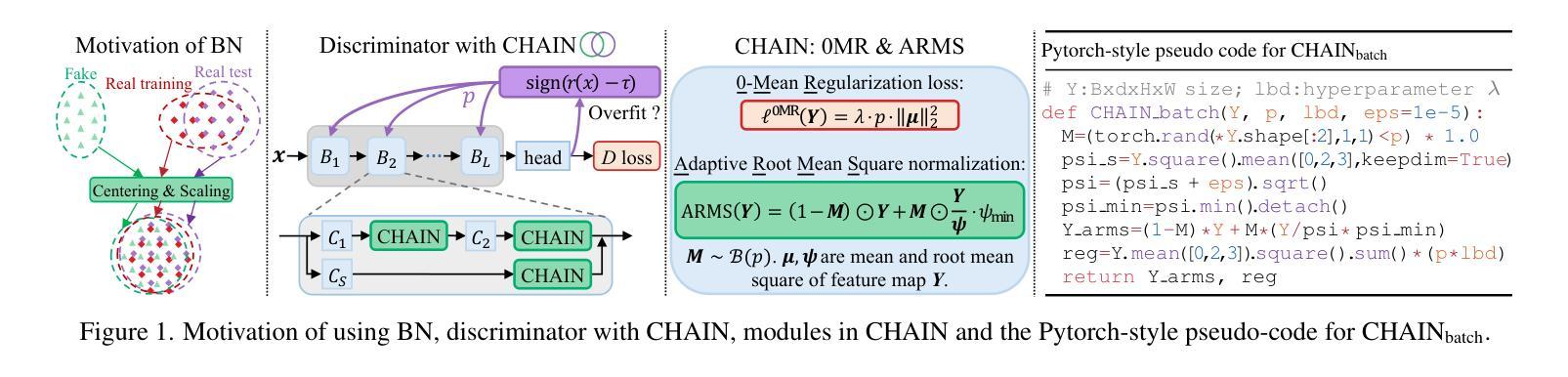
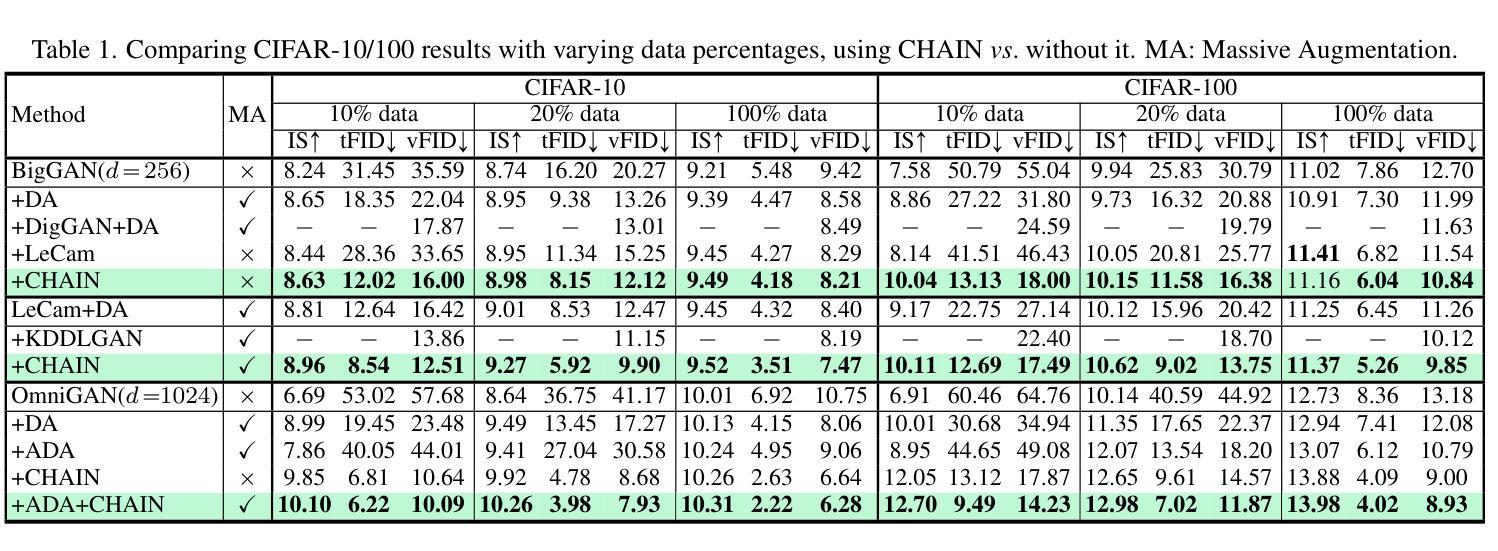
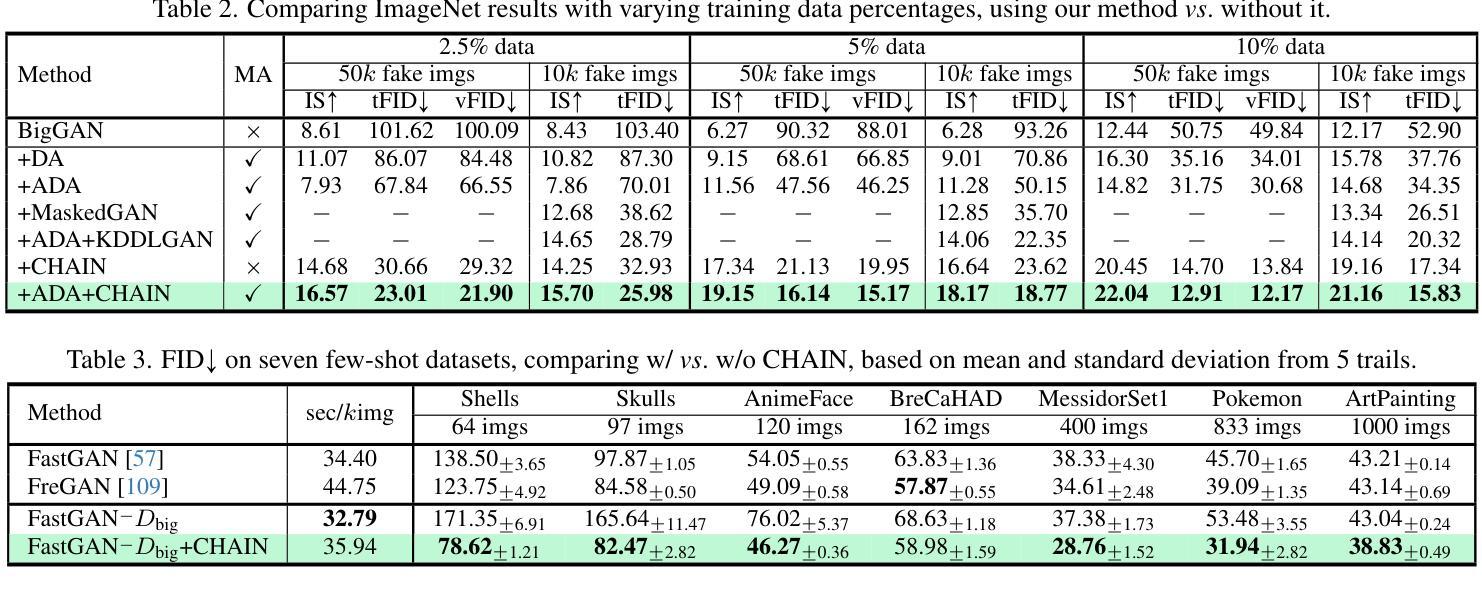
Generative Adversarial Networks (GANs) significantly advanced image generation but their performance heavily depends on abundant training data. In scenarios with limited data, GANs often struggle with discriminator overfitting and unstable training. Batch Normalization (BN), despite being known for enhancing generalization and training stability, has rarely been used in the discriminator of Data-Efficient GANs. Our work addresses this gap by identifying a critical flaw in BN: the tendency for gradient explosion during the centering and scaling steps. To tackle this issue, we present CHAIN (lipsCHitz continuity constrAIned Normalization), which replaces the conventional centering step with zero-mean regularization and integrates a Lipschitz continuity constraint in the scaling step. CHAIN further enhances GAN training by adaptively interpolating the normalized and unnormalized features, effectively avoiding discriminator overfitting. Our theoretical analyses firmly establishes CHAIN’s effectiveness in reducing gradients in latent features and weights, improving stability and generalization in GAN training. Empirical evidence supports our theory. CHAIN achieves state-of-the-art results in data-limited scenarios on CIFAR-10/100, ImageNet, five low-shot and seven high-resolution few-shot image datasets. Code: https://github.com/MaxwellYaoNi/CHAIN
生成对抗网络(GANs)在图像生成方面取得了重大进展,但其性能严重依赖于大量的训练数据。在数据有限的情况下,GANs经常面临判别器过拟合和训练不稳定的问题。尽管批标准化(BN)在增强通用性和训练稳定性方面已经为人所知,但在数据高效GAN的判别器中却很少使用。我们的工作解决了这个问题,通过识别BN中的一个关键缺陷:在中心化和缩放步骤中梯度爆炸的倾向。为了解决这个问题,我们提出了CHAIN(以lipsCHitz连续性约束归一化),它用零均值正则化替代了传统的中心化步骤,并在缩放步骤中集成了Lipschitz连续性约束。CHAIN通过自适应地插值归一化和未归一化的特征,进一步增强了GAN的训练,有效地避免了判别器的过拟合。我们的理论分析奠定了CHAIN在减少潜在特征和权重梯度方面的有效性,提高了GAN训练的稳定性和通用性。实证证据支持我们的理论。在CIFAR-10/100、ImageNet、五个低镜头和七个高分辨率的少量镜头图像数据集上,CHAIN在数据有限的情况下达到了最新水平的结果。代码地址:https://github.com/MaxwellYaoNi/CHAIN
论文及项目相关链接
PDF Accepted by CVPR 2024. 26 pages. Code: https://github.com/MaxwellYaoNi/CHAIN
Summary
基于生成对抗网络(GANs)在图像生成领域的显著进展,但在数据有限的情况下,其性能会受到诸如判别器过拟合和训练不稳定等问题的影响。针对批量归一化(BN)在数据高效GAN中的判别器使用中的不足,本文提出了一种新的方法CHAIN,它通过改进BN中的梯度爆炸问题,通过零均值正则化和Lipschitz连续性约束来增强GAN训练。CHAIN在数据有限的情况下取得了最佳效果,并在多个图像数据集上进行了实证验证。
Key Takeaways
- GANs在图像生成领域有显著进展,但在数据有限时面临挑战,如判别器过拟合和训练不稳定。
- 批量归一化(BN)在增强GAN的通用性和训练稳定性方面扮演重要角色,但在数据高效GAN的判别器中使用较少。
- CHAIN方法旨在解决BN中的梯度爆炸问题,通过改进标准化过程中的中心化和缩放步骤。
- CHAIN通过结合零均值正则化和Lipschitz连续性约束,增强GAN训练,有效避免判别器过拟合。
- CHAIN在多个数据集上的实证验证表明,它在数据有限的情况下具有最佳性能。
- CHAIN在CIFAR-10/100、ImageNet、五个低样本和七个高分辨率少样本图像数据集上实现了卓越的结果。
点此查看论文截图