⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
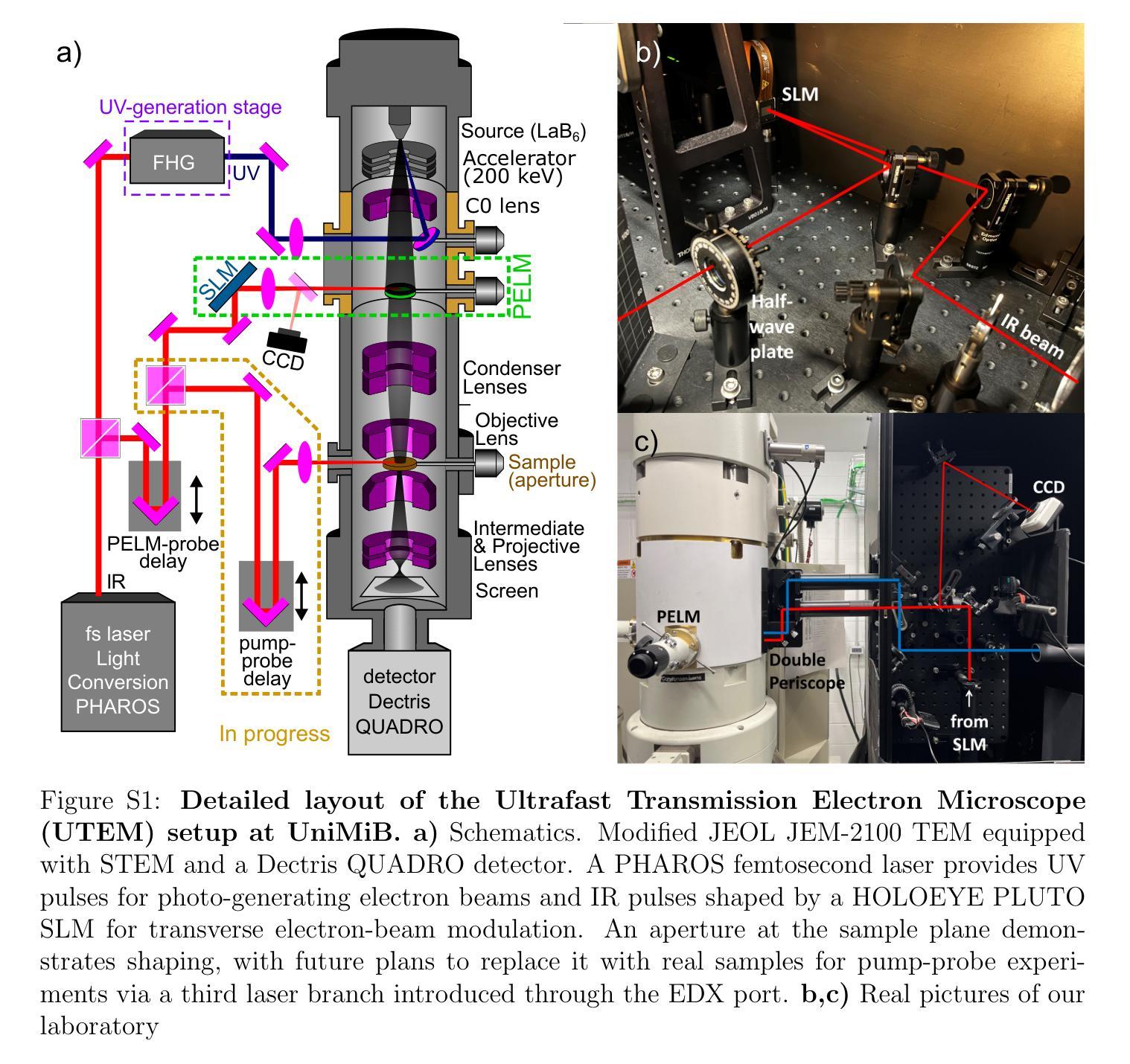
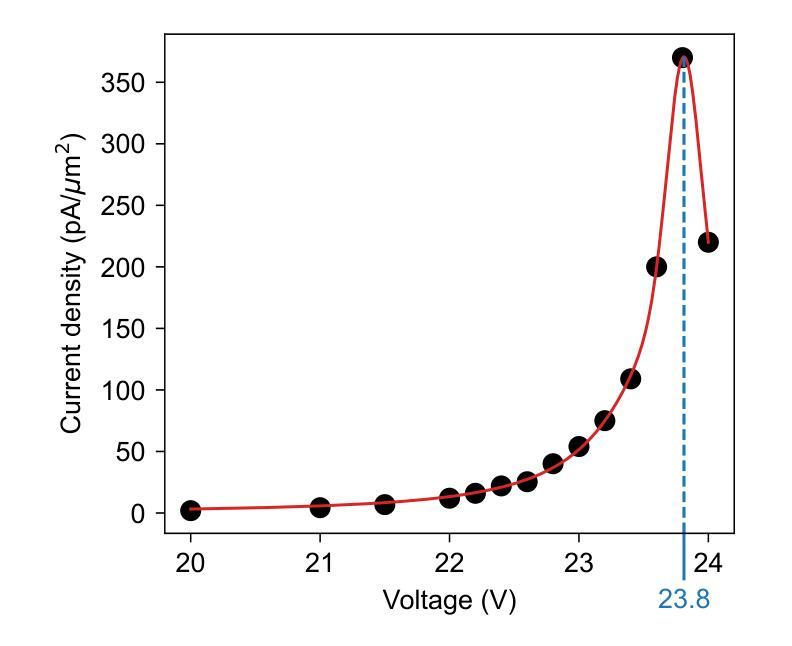
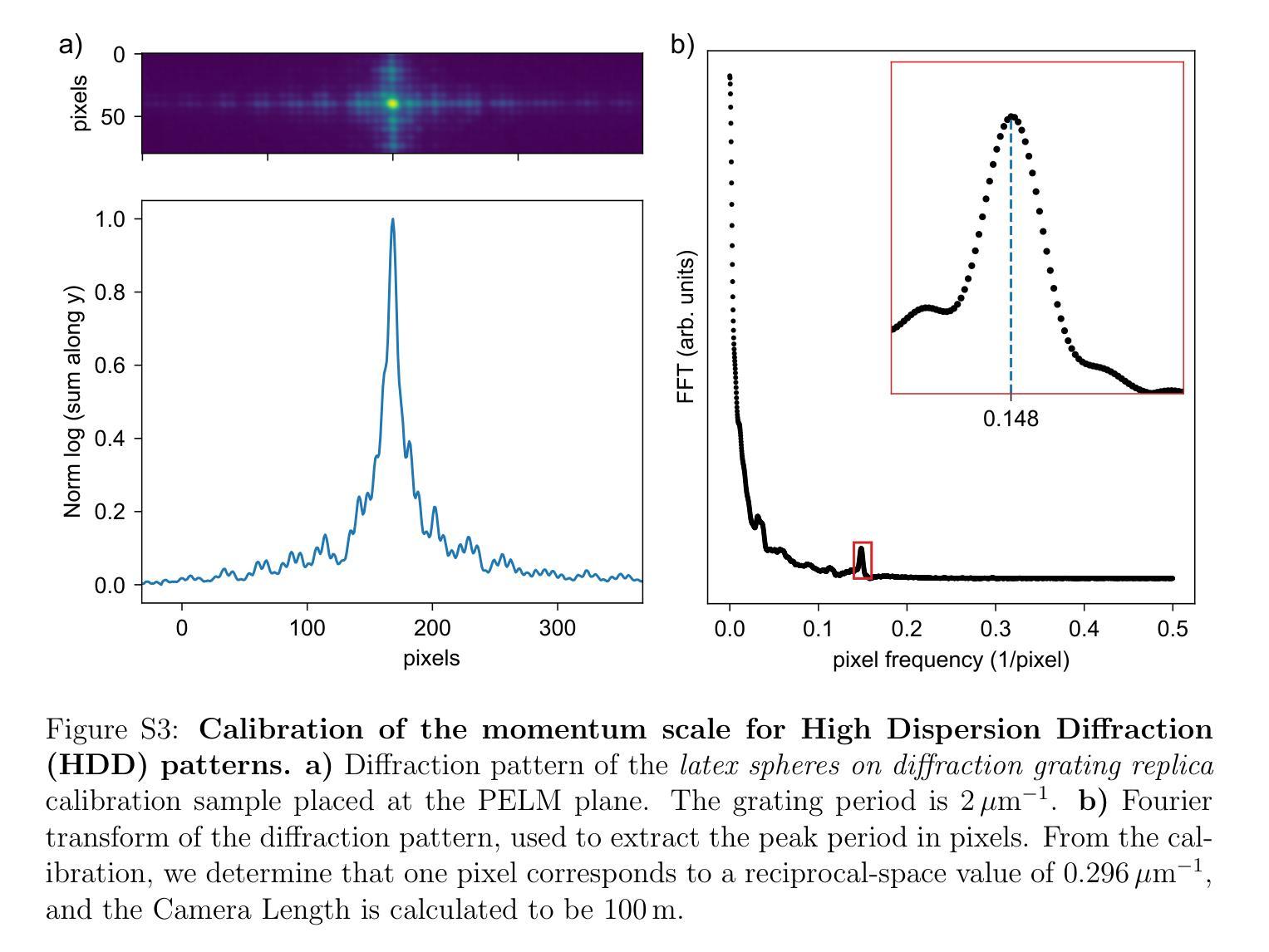
Realization of a Pre-Sample Photonic-based Free-Electron Modulator in Ultrafast Transmission Electron Microscopes
Authors:Beatrice Matilde Ferrari, Cameron James Richard Duncan, Michael Yannai, Raphael Dahan, Paolo Rosi, Irene Ostroman, Maria Giulia Bravi, Arthur Niedermayr, Tom Lenkiewicz Abudi, Yuval Adiv, Tal Fishman, Sang Tae Park, Dan Masiel, Thomas Lagrange, Fabrizio Carbone, Vincenzo Grillo, F. Javier García de Abajo, Ido Kaminer, Giovanni Maria Vanacore
Spatial and temporal light modulation is a well-established technology that enables dynamic shaping of the phase and amplitude of optical fields, significantly enhancing the resolution and sensitivity of imaging methods. Translating this capability to electron beams is highly desirable within the framework of a transmission electron microscope (TEM) to benefit from the nanometer spatial resolution of these instruments. In this work, we report on the experimental realization of a photonic-based free-electron modulator integrated into the column of two ultrafast TEMs for pre-sample electron-beam shaping. Electron-photon interaction is employed to coherently modulate both the transverse and longitudinal components of the electron wave function, while leveraging dynamically controlled optical fields and tailored design of electron-laser-sample interaction geometry. Using energy- and momentum-resolved electron detection, we successfully reconstruct the shaped electron wave function at the TEM sample plane. These results demonstrate the ability to manipulate the electron wave function before probing the sample, paving the way for the future development of innovative imaging methods in ultrafast electron microscopy.
空间和时间光调制是一项成熟的技术,能够动态地改变光场的相位和振幅,极大地提高了成像方法的分辨率和灵敏度。在透射电子显微镜(TEM)的框架下,将该能力应用于电子束是非常理想的,以受益于这些仪器的纳米级空间分辨率。在这项工作中,我们报告了在两辆超快透射电子显微镜的列中集成基于光子学的自由电子调制器的实验实现,用于样品前的电子束整形。利用电子-光子相互作用,相干地调制电子波函数的横向和纵向分量,同时利用动态控制的光场和定制的电子-激光-样品相互作用几何结构。通过能量和动量解析的电子检测,我们成功地在透射电子显微镜样品平面上重建了整形的电子波函数。这些结果证明了在探测样品之前操纵电子波函数的能力,为未来在超快电子显微镜中开发创新成像方法铺平了道路。
论文及项目相关链接
PDF 14 pages, 5, figures, includes supplementary information, journal paper
Summary
空间和时间光调制是一项成熟的技术,能动态调整光学场的相位和振幅,显著提高成像方法的分辨率和灵敏度。将这一技术应用于透射电子显微镜(TEM)的电子束中,以利用这些仪器的纳米级空间分辨率,是非常理想的。本研究报道了将光子基自由电子调制器集成到两台超快TEM的列中进行预样本电子束形状的实验实现。电子-光子相互作用用于相干地调制电子波函数的横向和纵向分量,同时利用动态控制的光场和定制的电子-激光-样本相互作用几何设计。通过能量和动量解析的电子检测,我们在TEM样本平面上成功重建了形状的电子波函数。这些结果展示了在探测样品之前操作电子波函数的能力,为未来在超快电子显微镜中开发创新成像方法铺平了道路。
Key Takeaways
- 空间和时间光调制技术能够动态调整光学场的相位和振幅,增强成像方法的分辨率和灵敏度。
- 将此技术应用于透射电子显微镜的电子束中非常理想,以利用纳米级空间分辨率。
- 实验实现了光子基自由电子调制器的集成,用于预样本电子束形状的调整。
- 通过电子-光子相互作用,可以相干地调制电子波函数的横向和纵向分量。
- 利用动态控制的光场和定制的电子-激光-样本相互作用几何设计,实现了对电子波函数的有效操控。
- 通过能量和动量解析的电子检测,成功重建了形状的电子波函数在TEM样本平面上的表现。
点此查看论文截图

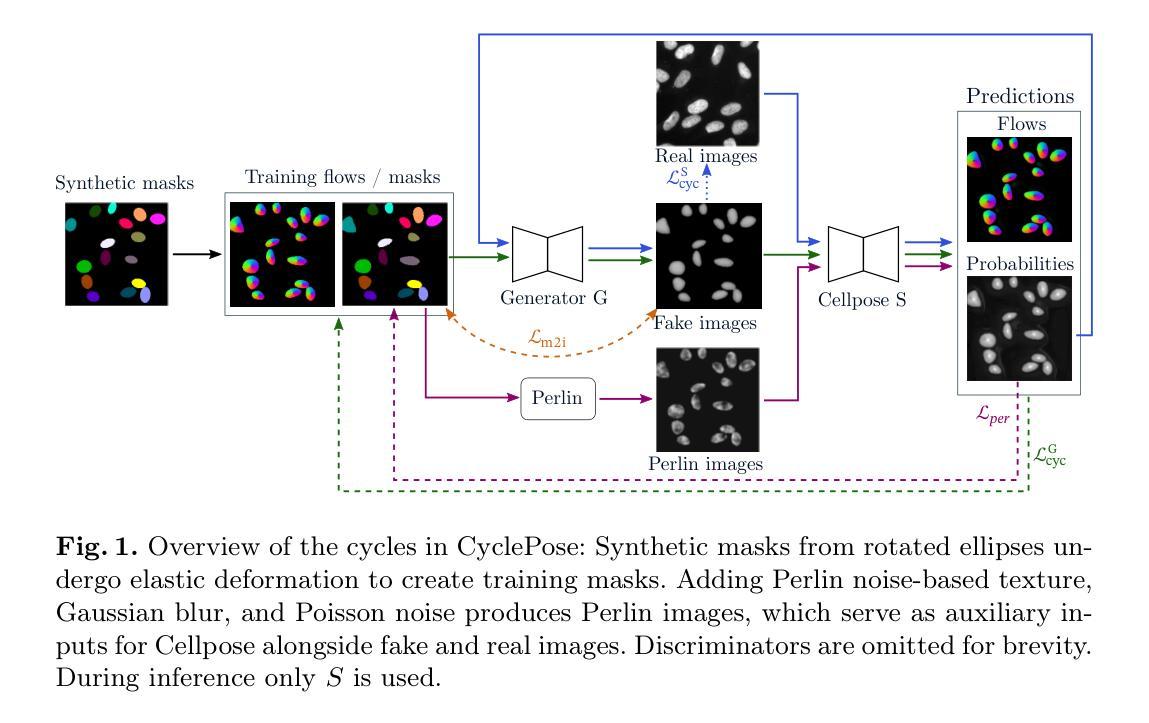
CyclePose – Leveraging Cycle-Consistency for Annotation-Free Nuclei Segmentation in Fluorescence Microscopy
Authors:Jonas Utz, Stefan Vocht, Anne Tjorven Buessen, Dennis Possart, Fabian Wagner, Mareike Thies, Mingxuan Gu, Stefan Uderhardt, Katharina Breininger
In recent years, numerous neural network architectures specifically designed for the instance segmentation of nuclei in microscopic images have been released. These models embed nuclei-specific priors to outperform generic architectures like U-Nets; however, they require large annotated datasets, which are often not available. Generative models (GANs, diffusion models) have been used to compensate for this by synthesizing training data. These two-stage approaches are computationally expensive, as first a generative model and then a segmentation model has to be trained. We propose CyclePose, a hybrid framework integrating synthetic data generation and segmentation training. CyclePose builds on a CycleGAN architecture, which allows unpaired translation between microscopy images and segmentation masks. We embed a segmentation model into CycleGAN and leverage a cycle consistency loss for self-supervision. Without annotated data, CyclePose outperforms other weakly or unsupervised methods on two public datasets. Code is available at https://github.com/jonasutz/CyclePose
近年来,针对显微图像中的细胞核实例分割,已经推出了许多专门设计的神经网络架构。这些模型嵌入细胞核特异性先验知识,以超越通用架构(如U-Nets)。然而,它们需要大量标注数据集,而这些数据通常不可用。生成模型(GANs,扩散模型)已被用于通过合成训练数据来弥补这一缺陷。这两种两阶段的方法计算成本高昂,因为首先必须训练一个生成模型,然后训练一个分割模型。我们提出了CyclePose,这是一个混合框架,融合了合成数据生成和分割训练。CyclePose基于CycleGAN架构,允许显微图像和分割掩膜之间的无配对转换。我们将分割模型嵌入到CycleGAN中,并利用循环一致性损失进行自监督。无需标注数据,CyclePose在两个公共数据集上的表现优于其他弱监督或无监督方法。代码可在https://github.com/jonasutz/CyclePose找到。
论文及项目相关链接
PDF under review for MICCAI 2025
Summary
本文介绍了一种针对显微图像中细胞核实例分割的神经网络架构CyclePose。该框架集成了合成数据生成和分割训练,采用CycleGAN架构实现显微图像与分割掩膜之间的无配对转换。CyclePose在无需标注数据的情况下,在公共数据集上的表现优于其他弱监督或无监督方法。
Key Takeaways
- 近年针对显微图像中细胞核实例分割的神经网络架构逐渐增多,但通常需要大量标注数据。
- 生成模型(如GANs、扩散模型)已被用于合成训练数据,以弥补标注数据的不足。
- 两阶段方法(先训练生成模型再训练分割模型)计算成本较高。
- CyclePose是一种集成合成数据生成和分割训练的混合框架。
- CyclePose基于CycleGAN架构,实现显微图像与分割掩膜之间的无配对转换。
- CyclePose在无需标注数据的情况下,在公共数据集上的表现优于其他弱监督或无监督方法。
点此查看论文截图

Reangle-A-Video: 4D Video Generation as Video-to-Video Translation
Authors:Hyeonho Jeong, Suhyeon Lee, Jong Chul Ye
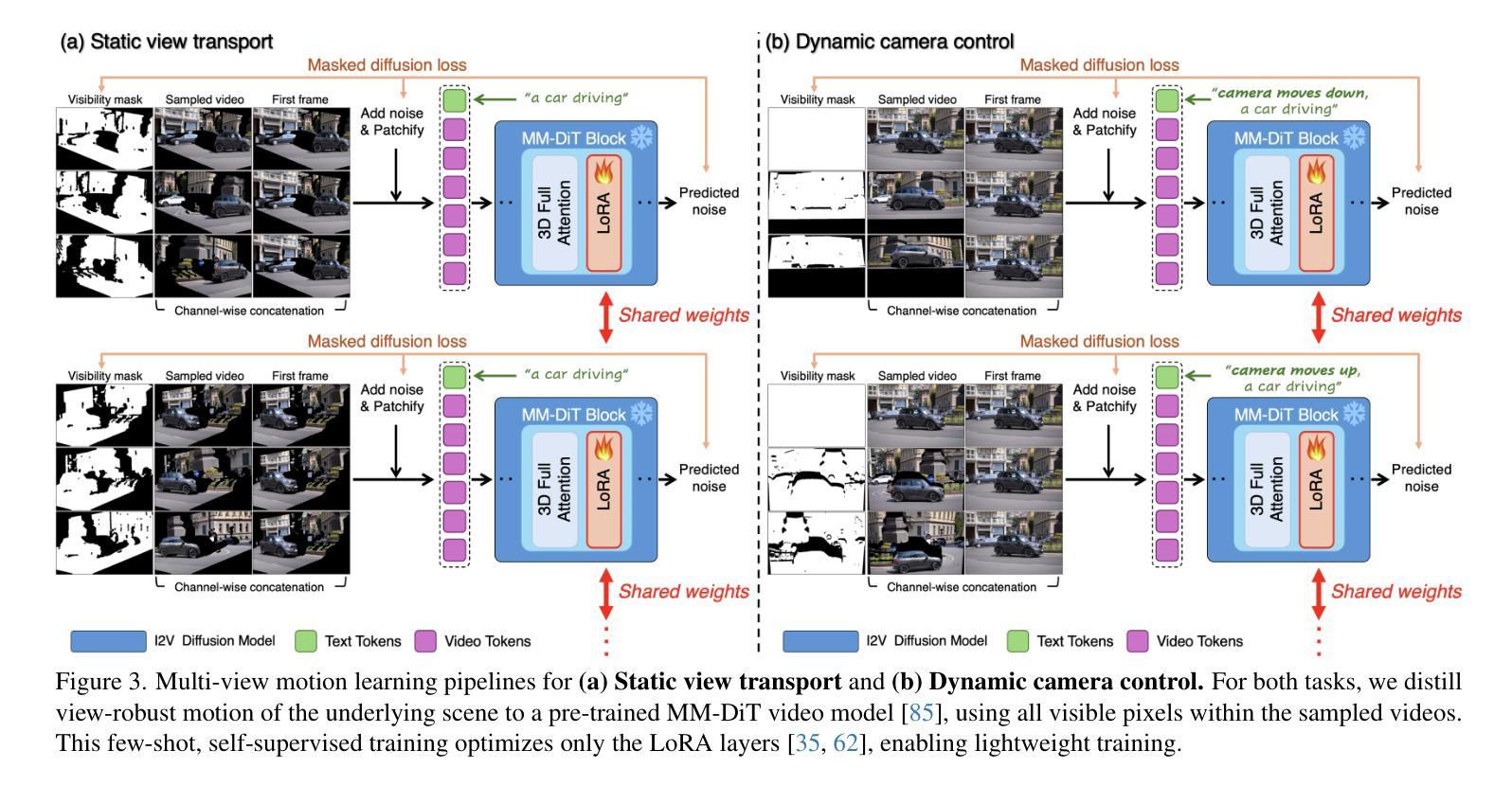
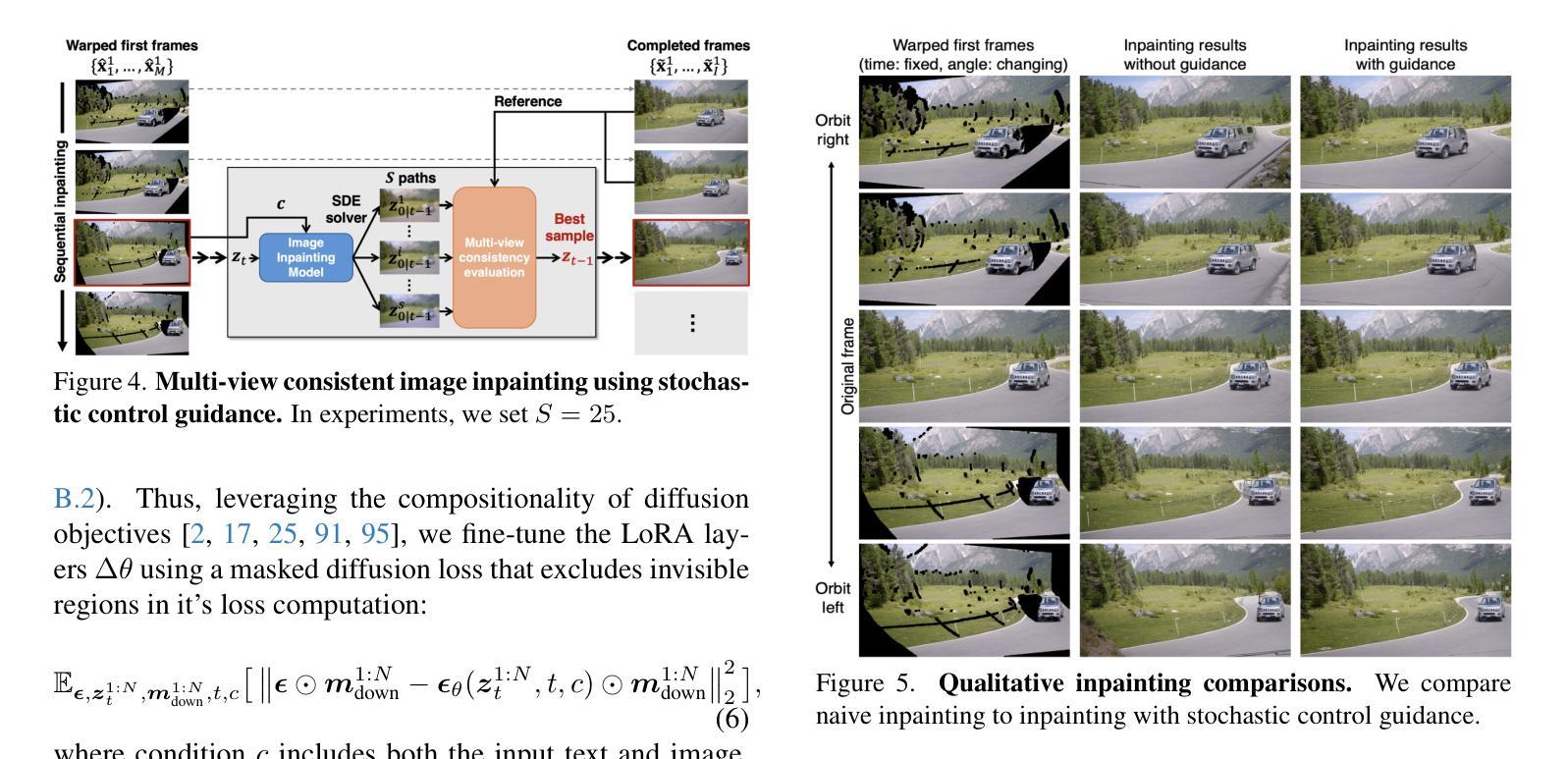
We introduce Reangle-A-Video, a unified framework for generating synchronized multi-view videos from a single input video. Unlike mainstream approaches that train multi-view video diffusion models on large-scale 4D datasets, our method reframes the multi-view video generation task as video-to-videos translation, leveraging publicly available image and video diffusion priors. In essence, Reangle-A-Video operates in two stages. (1) Multi-View Motion Learning: An image-to-video diffusion transformer is synchronously fine-tuned in a self-supervised manner to distill view-invariant motion from a set of warped videos. (2) Multi-View Consistent Image-to-Images Translation: The first frame of the input video is warped and inpainted into various camera perspectives under an inference-time cross-view consistency guidance using DUSt3R, generating multi-view consistent starting images. Extensive experiments on static view transport and dynamic camera control show that Reangle-A-Video surpasses existing methods, establishing a new solution for multi-view video generation. We will publicly release our code and data. Project page: https://hyeonho99.github.io/reangle-a-video/
我们介绍了Reangle-A-Video,这是一个从单个输入视频生成同步多视角视频的统一框架。不同于主流方法在大型4D数据集上训练多视角视频扩散模型,我们的方法将多视角视频生成任务重新构造成视频到视频的翻译,并利用可公开获取的图像和视频扩散先验。本质上,Reangle-A-Video分为两个阶段。(1)多视角运动学习:以自监督的方式同步微调图像到视频扩散转换器,从一组变形视频中提取视角不变运动。(2)多视角一致图像到图像翻译:输入视频的第一帧在推理时间跨视角一致性指导下被变形和填充到各种相机视角,生成多视角一致起始图像。对静态视角传输和动态摄像机控制的广泛实验表明,Reangle-A-Video超越了现有方法,为多视角视频生成建立了新的解决方案。我们将公开发布我们的代码和数据。项目页面:https://hyeonho99.github.io/reangle-a-video/
论文及项目相关链接
PDF Project page: https://hyeonho99.github.io/reangle-a-video/
Summary
基于单输入视频生成同步多视角视频的Reangle-A-Video统一框架介绍。不同于主流方法在大型4D数据集上训练多视角视频扩散模型,Reangle-A-Video将多视角视频生成任务重构为视频到视频的翻译任务,利用公众可获得的图像和视频扩散先验知识。
Key Takeaways
- Reangle-A-Video是一个统一框架,可以从单个输入视频生成同步多视角视频。
- 该方法通过视频到视频的翻译任务来重构多视角视频生成,而非在大型4D数据集上训练多视角视频扩散模型。
- 利用图像和视频扩散的先验知识。
- 该框架包含两个阶段:多视角运动学习(同步微调图像到视频扩散转换器以从一组变形视频中提取视角不变的运动)和多视角一致图像到图像翻译(将输入视频的第一帧在推理时间跨视角一致性指导下变形和填充,生成多视角一致起始图像)。
- 通过静态视角传输和动态相机控制的大量实验证明,Reangle-A-Video超越了现有方法,为多视角视频生成提供了新的解决方案。
- 该研究将公开代码和数据。
点此查看论文截图



Versatile Multimodal Controls for Whole-Body Talking Human Animation
Authors:Zheng Qin, Ruobing Zheng, Yabing Wang, Tianqi Li, Zixin Zhu, Minghui Yang, Ming Yang, Le Wang
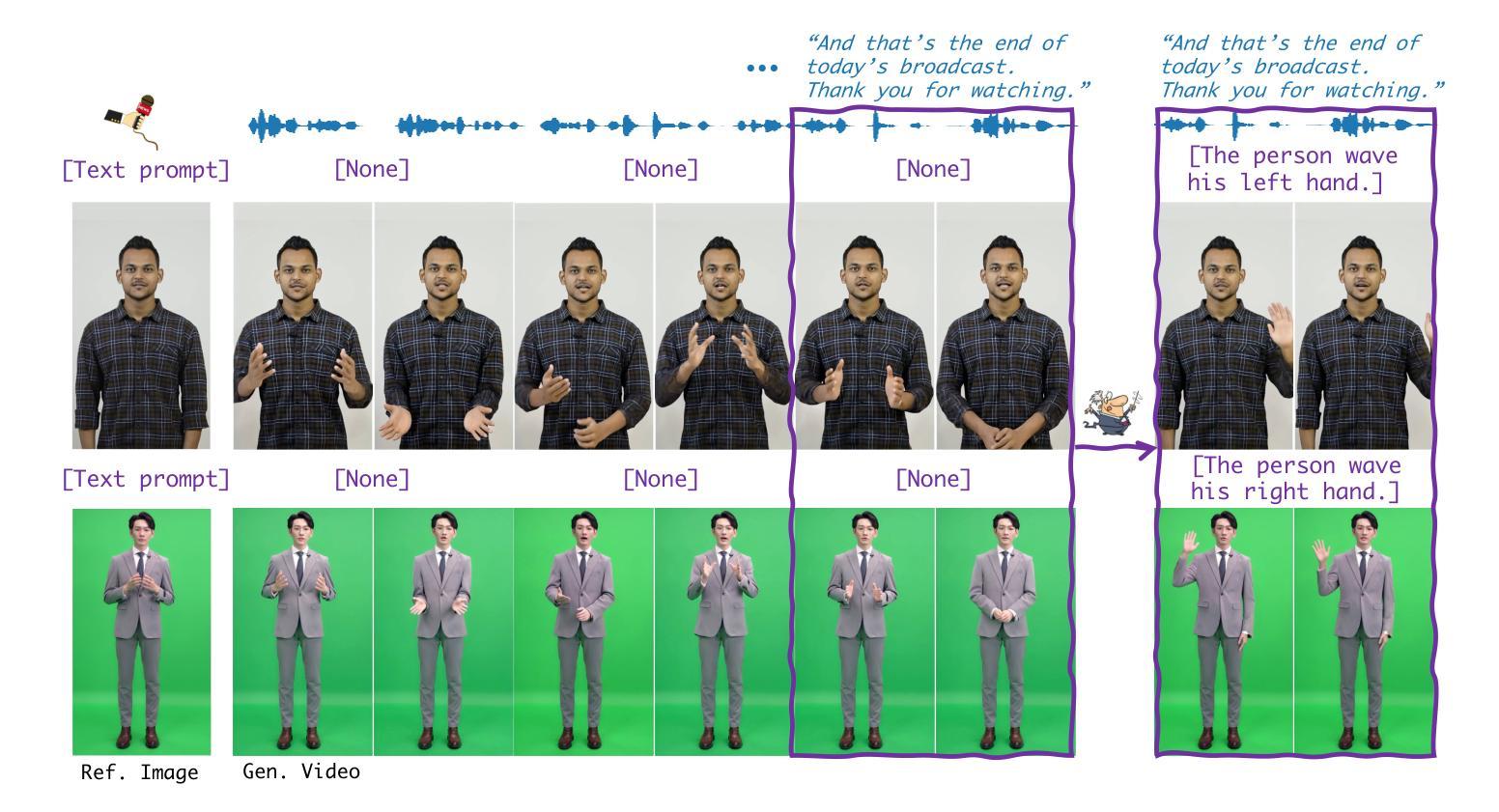
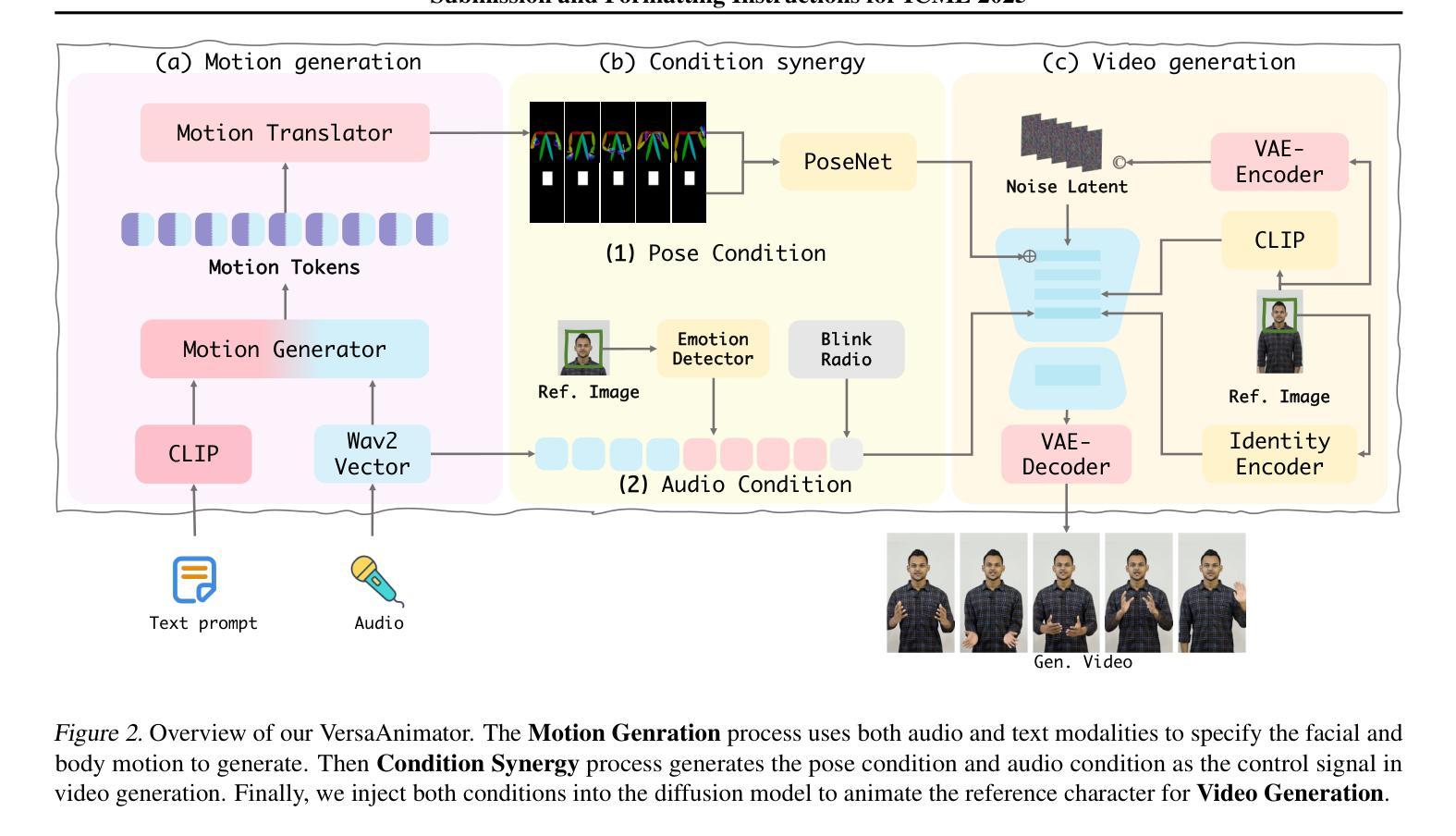
Human animation from a single reference image shall be flexible to synthesize whole-body motion for either a headshot or whole-body portrait, where the motions are readily controlled by audio signal and text prompts. This is hard for most existing methods as they only support producing pre-specified head or half-body motion aligned with audio inputs. In this paper, we propose a versatile human animation method, i.e., VersaAnimator, which generates whole-body talking human from arbitrary portrait images, not only driven by audio signal but also flexibly controlled by text prompts. Specifically, we design a text-controlled, audio-driven motion generator that produces whole-body motion representations in 3D synchronized with audio inputs while following textual motion descriptions. To promote natural smooth motion, we propose a code-pose translation module to link VAE codebooks with 2D DWposes extracted from template videos. Moreover, we introduce a multi-modal video diffusion that generates photorealistic human animation from a reference image according to both audio inputs and whole-body motion representations. Extensive experiments show that VersaAnimator outperforms existing methods in visual quality, identity preservation, and audio-lip synchronization.
从单一参考图像进行的人物动画应当能够灵活地合成头部或全身肖像的全身运动,这些运动可以通过音频信号和文字提示轻松控制。对于大多数现有方法而言,这很难实现,因为它们仅支持生成与音频输入对齐的预设头部或半身运动。在本文中,我们提出了一种通用的人物动画方法,即VersaAnimator。它可以从任意肖像图像生成全身说话的人物,不仅由音频信号驱动,还可以灵活地由文字提示控制。具体来说,我们设计了一个文本控制、音频驱动的运动生成器,它产生与音频输入同步的全身运动表示(3D),同时遵循文本运动描述。为了促进自然流畅的运动,我们提出了一个代码姿势翻译模块,将VAE代码本与从模板视频中提取的2DDW姿势联系起来。此外,我们引入了一种多模态视频扩散方法,根据音频输入和全身运动表示从参考图像生成逼真的人物动画。大量实验表明,VersaAnimator在视觉质量、身份保留和音频-嘴唇同步方面优于现有方法。
论文及项目相关链接
Summary
基于单张参考图像的人体动画能灵活地合成全身动作,无论是头部特写还是全身肖像,这些动作都能通过音频信号和文字提示轻易控制。现有的多数方法仅支持根据音频输入生成预设的头部或半身动作。本文提出了一种通用的人体动画方法,即VersaAnimator,不仅能由音频信号驱动,还能通过文字提示灵活控制,从任意肖像图像生成全身动作。此方法设计了文本控制的音频驱动运动生成器,在三维空间中生成与音频输入同步的全身动作表示,并遵循文本动作描述以产生自然流畅的运动。此外,通过连接变自动编码器代码本与从模板视频提取的二维动态姿势,提出了代码姿势翻译模块。再结合多模态视频扩散技术,根据参考图像、音频输入和全身动作表示生成逼真的人体动画。实验表明,VersaAnimator在视觉质量、身份保留和音频唇同步方面优于现有方法。
Key Takeaways
- VersaAnimator能够从单张参考图像生成全身动画。
- 该方法支持通过音频信号和文字提示控制动画。
- VersaAnimator设计了文本控制的音频驱动运动生成器,生成与音频同步的全身动作表示。
- 通过代码姿势翻译模块连接变自动编码器代码本和二维动态姿势。
- 多模态视频扩散技术用于生成逼真的人体动画。
- VersaAnimator在视觉质量、身份保留和音频唇同步方面表现优异。
- 当前方法相对于现有方法的优势。
点此查看论文截图

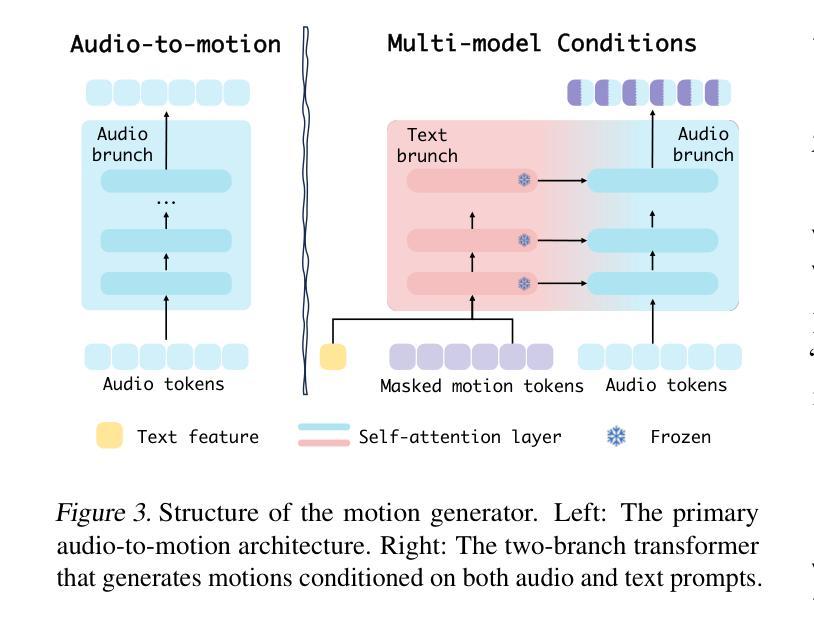

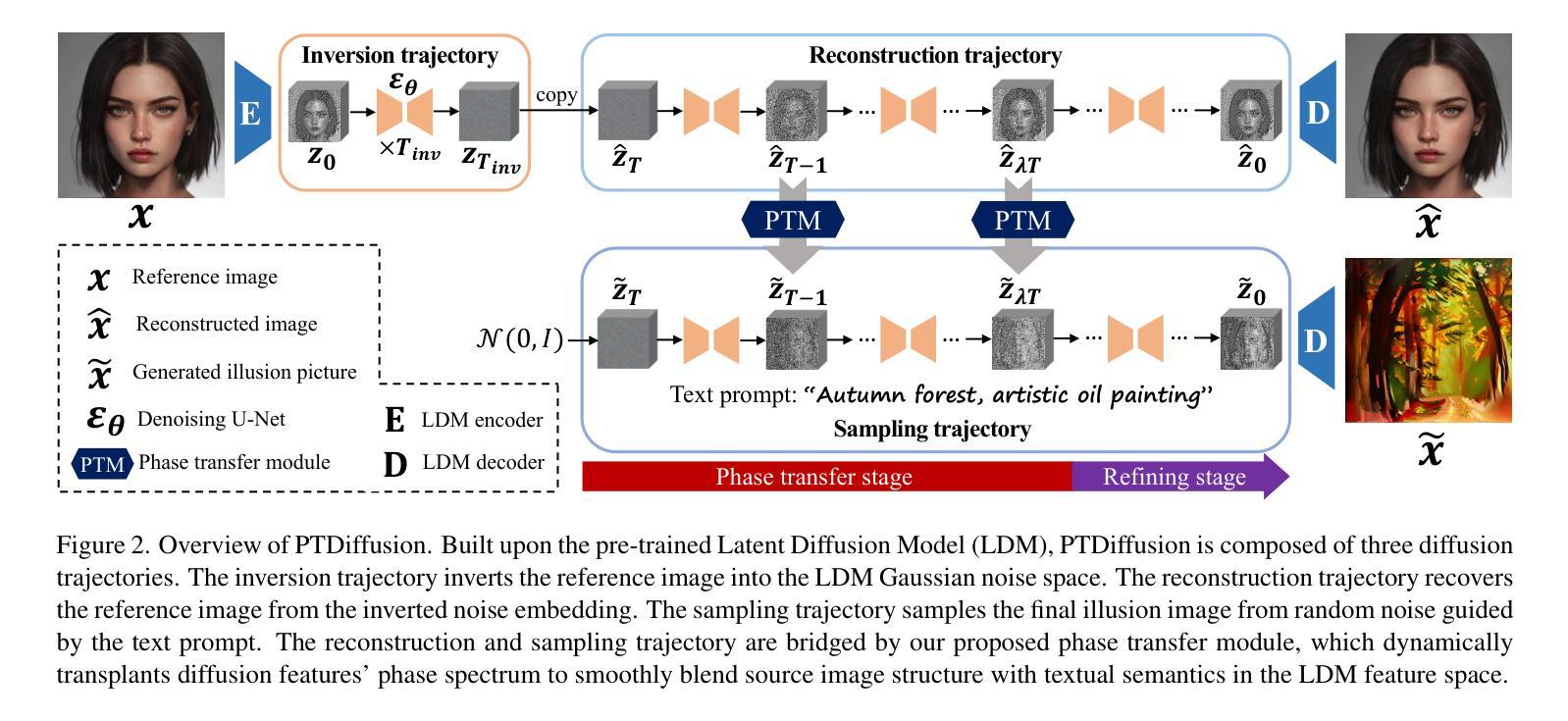
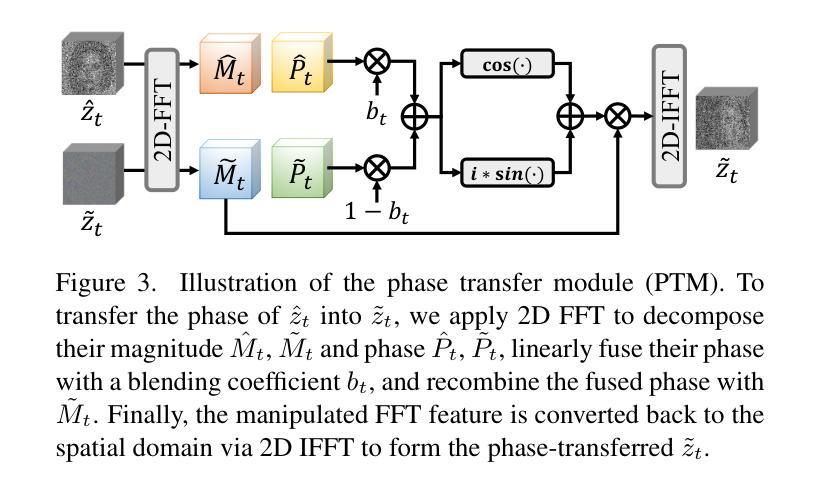
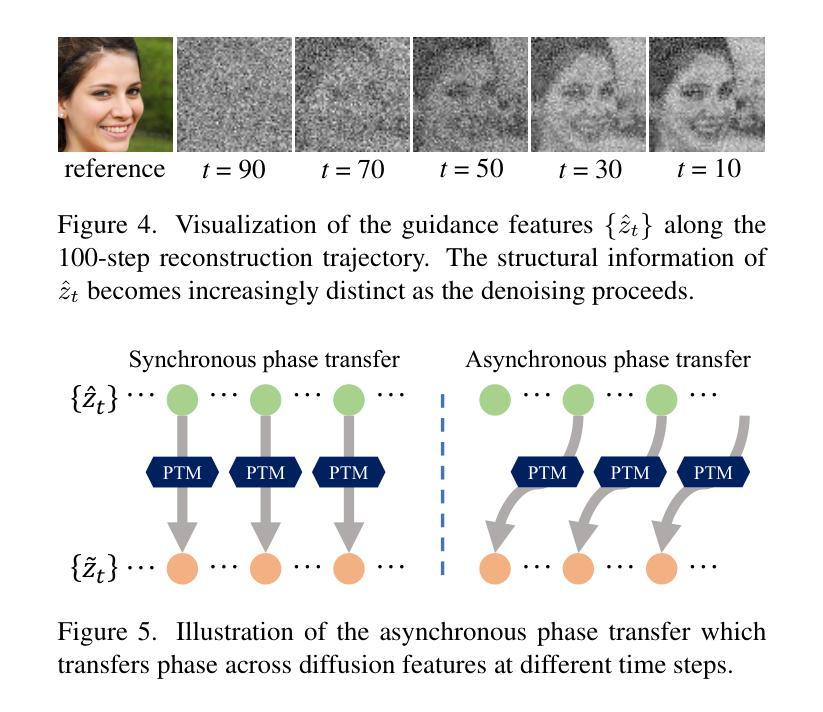
PTDiffusion: Free Lunch for Generating Optical Illusion Hidden Pictures with Phase-Transferred Diffusion Model
Authors:Xiang Gao, Shuai Yang, Jiaying Liu
Optical illusion hidden picture is an interesting visual perceptual phenomenon where an image is cleverly integrated into another picture in a way that is not immediately obvious to the viewer. Established on the off-the-shelf text-to-image (T2I) diffusion model, we propose a novel training-free text-guided image-to-image (I2I) translation framework dubbed as \textbf{P}hase-\textbf{T}ransferred \textbf{Diffusion} Model (PTDiffusion) for hidden art syntheses. PTDiffusion embeds an input reference image into arbitrary scenes as described by the text prompts, while exhibiting hidden visual cues of the reference image. At the heart of our method is a plug-and-play phase transfer mechanism that dynamically and progressively transplants diffusion features’ phase spectrum from the denoising process to reconstruct the reference image into the one to sample the generated illusion image, realizing harmonious fusion of the reference structural information and the textual semantic information. Furthermore, we propose asynchronous phase transfer to enable flexible control to the degree of hidden content discernability. Our method bypasses any model training and fine-tuning, all while substantially outperforming related methods in image quality, text fidelity, visual discernibility, and contextual naturalness for illusion picture synthesis, as demonstrated by extensive qualitative and quantitative experiments.
光学错觉隐藏图像是一种有趣的视觉感知现象,其中图像被巧妙地集成到另一幅图像中,观众无法立即发现。我们基于现成的文本到图像(T2I)扩散模型,提出了一种无需训练的文字引导图像到图像(I2I)转换框架,称为Phase-Transferred Diffusion Model(PTDiffusion),用于合成隐藏艺术图像。PTDiffusion将输入参考图像嵌入到文本提示描述的任意场景中,同时显示参考图像的隐藏视觉线索。我们方法的核心是一个即插即用的相位转移机制,该机制动态且逐步地移植扩散特征的相位谱,从去噪过程中重建参考图像,并将其采样为生成的错觉图像,实现参考结构信息和文本语义信息的和谐融合。此外,我们提出了异步相位转移,以实现灵活控制隐藏内容的可识别程度。我们的方法避免了任何模型训练和微调,同时在图像质量、文本保真度、视觉可识别度和上下文自然度方面大大优于相关方法在错觉图像合成方面的表现,这已通过广泛的质量和数量实验得到证明。
论文及项目相关链接
PDF Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025)
Summary
光学错觉隐藏图像是一种有趣的视觉感知现象,其中图像被巧妙地融入另一幅画面中,观众无法立即察觉。基于现成的文本到图像(T2I)扩散模型,提出了一种无需训练、文本引导的图像到图像(I2I)转换框架——相位转移扩散模型(PTDiffusion),用于合成隐藏艺术图像。PTDiffusion可将输入参考图像嵌入到文本提示所描述的任意场景中,同时展示参考图像的隐藏视觉线索。该方法的核心是一个即插即用的相位转移机制,该机制动态且渐进地移植扩散特征的相位谱,从去噪过程中重建参考图像并采样生成错觉图像,实现参考结构信息和文本语义信息的和谐融合。此外,还提出了异步相位转移,以实现对隐藏内容辨识度的灵活控制。该方法无需任何模型训练和微调,在图像质量、文本保真度、视觉辨识度和上下文自然度方面均优于相关方法,大量定性和定量实验证明了这一点。
Key Takeaways
- 光学错觉隐藏图片是一种视觉感知现象,图像被巧妙地融入另一幅画面中。
- 提出了一种新的训练外文本引导的图像到图像(I2I)转换框架——相位转移扩散模型(PTDiffusion)。
- PTDiffusion可将参考图像嵌入任意场景,同时展示其隐藏视觉线索。
- 核心机制是相位转移,该机制能够动态地重建和融合参考图像和文本提示。
- 异步相位转移可实现隐藏内容辨识度的灵活控制。
- 该方法无需模型训练和微调。
点此查看论文截图


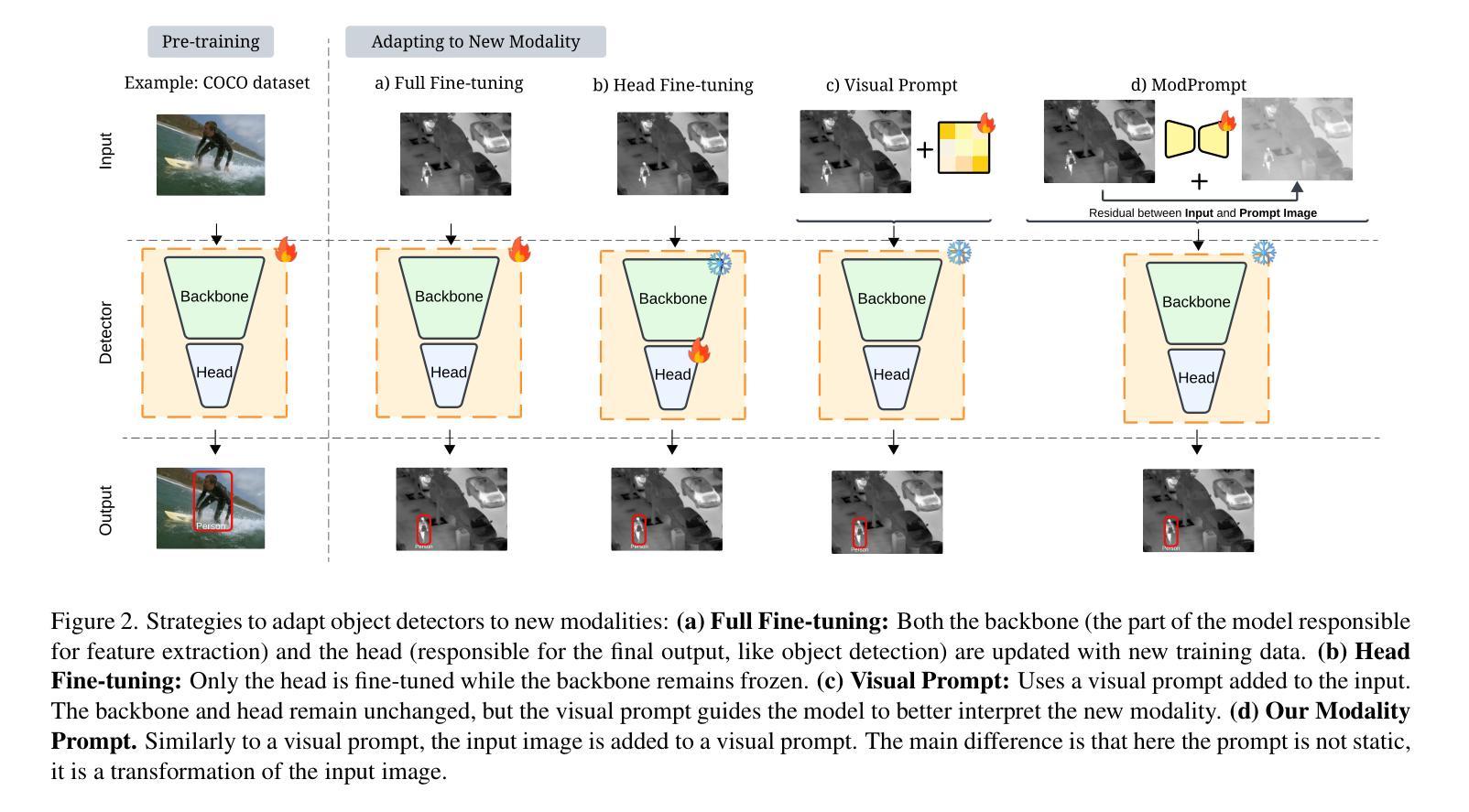
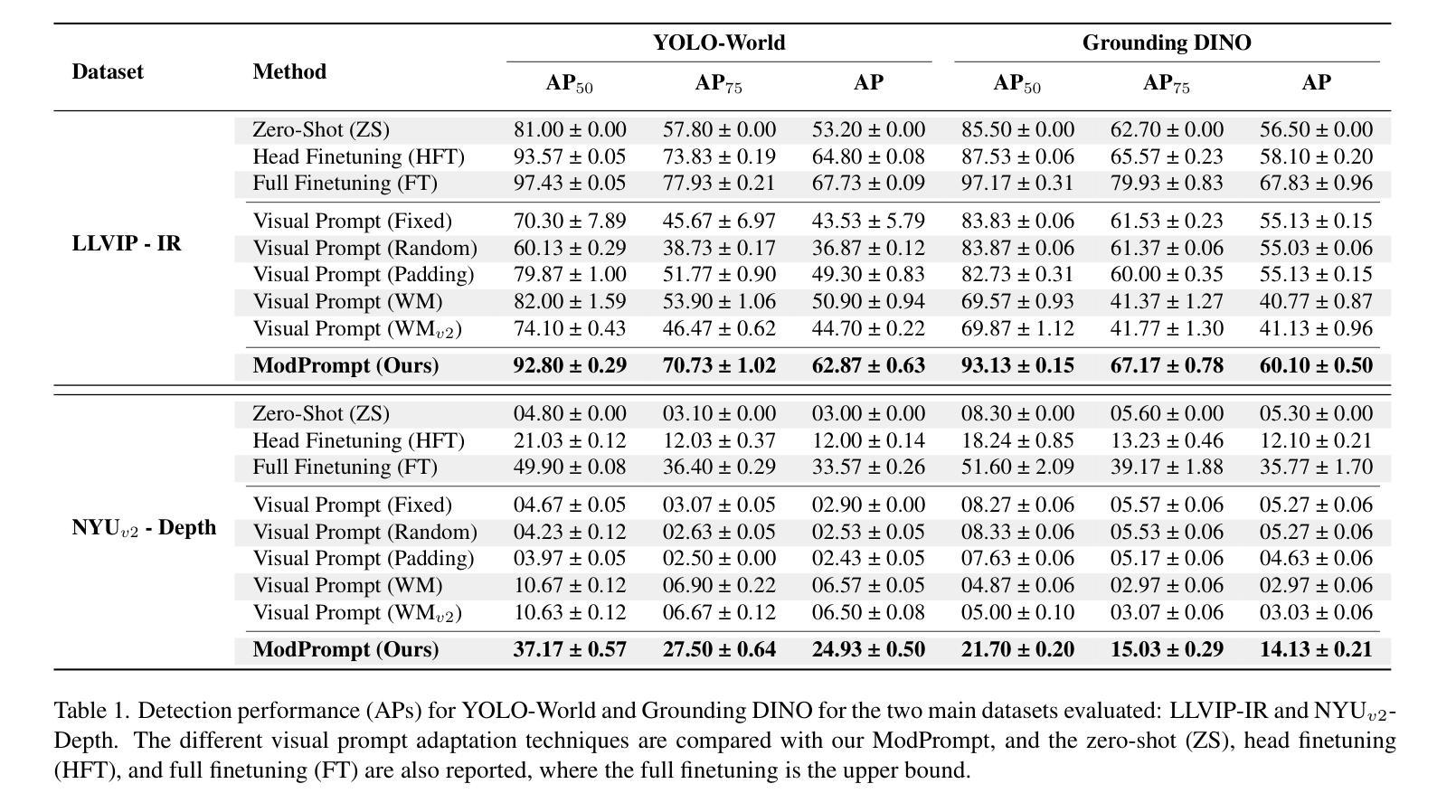
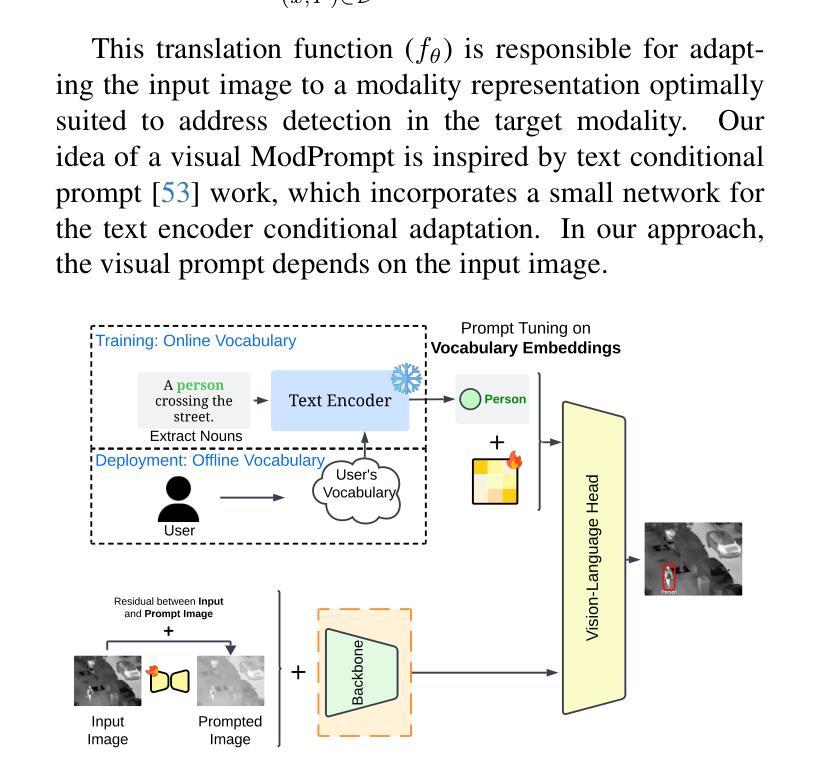
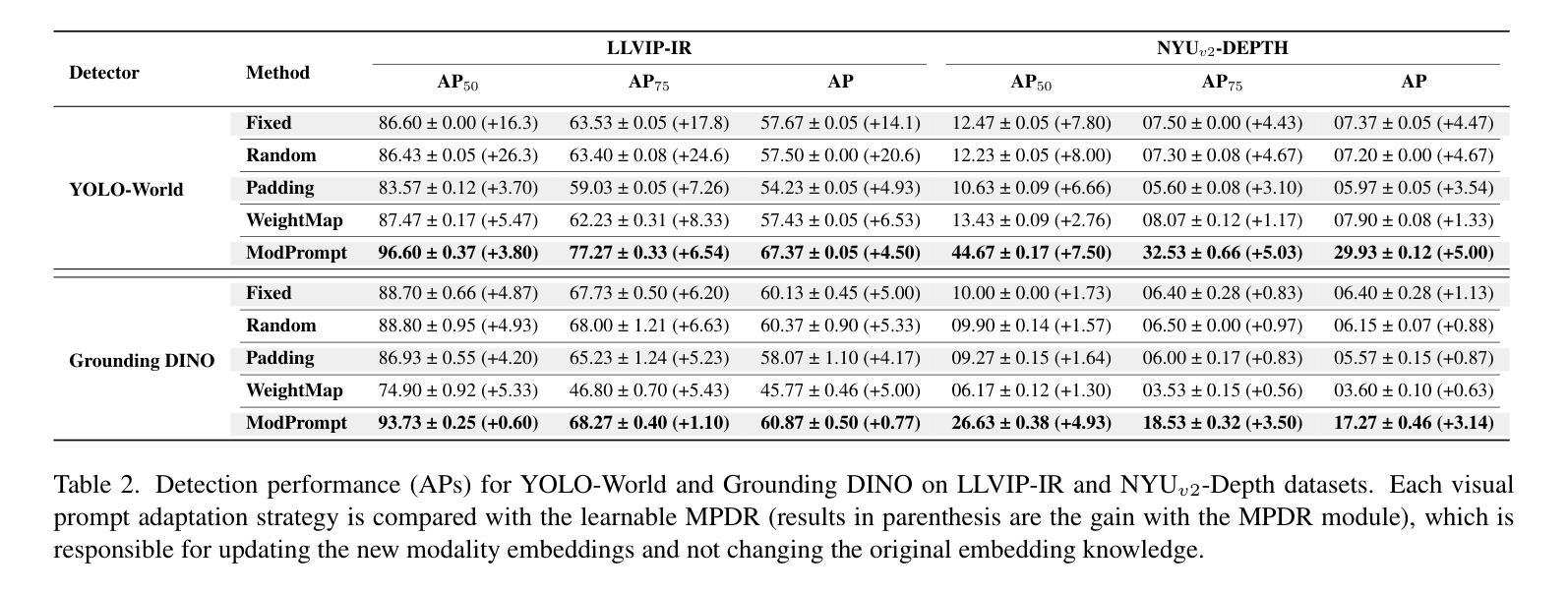
Visual Modality Prompt for Adapting Vision-Language Object Detectors
Authors:Heitor R. Medeiros, Atif Belal, Srikanth Muralidharan, Eric Granger, Marco Pedersoli
The zero-shot performance of object detectors degrades when tested on different modalities, such as infrared and depth. While recent work has explored image translation techniques to adapt detectors to new modalities, these methods are limited to a single modality and apply only to traditional detectors. Recently, vision-language detectors, such as YOLO-World and Grounding DINO, have shown promising zero-shot capabilities, however, they have not yet been adapted for other visual modalities. Traditional fine-tuning approaches compromise the zero-shot capabilities of the detectors. The visual prompt strategies commonly used for classification with vision-language models apply the same linear prompt translation to each image, making them less effective. To address these limitations, we propose ModPrompt, a visual prompt strategy to adapt vision-language detectors to new modalities without degrading zero-shot performance. In particular, an encoder-decoder visual prompt strategy is proposed, further enhanced by the integration of inference-friendly modality prompt decoupled residual, facilitating a more robust adaptation. Empirical benchmarking results show our method for modality adaptation on two vision-language detectors, YOLO-World and Grounding DINO, and on challenging infrared (LLVIP, FLIR) and depth (NYUv2) datasets, achieving performance comparable to full fine-tuning while preserving the model’s zero-shot capability. Code available at: https://github.com/heitorrapela/ModPrompt.
对象检测器的零样本性能在不同的模态(如红外和深度)上进行测试时会下降。虽然近期的工作已经探索了图像翻译技术来适应新的模态检测器,但这些方法仅限于单一模态,仅适用于传统检测器。最近,视觉语言检测器,如YOLO-World和Grounding DINO,已经显示出有希望的零样本能力,然而,它们尚未适应其他视觉模态。传统的微调方法会损害检测器的零样本能力。视觉提示策略常用于与视觉语言模型一起进行分类任务,将相同的线性提示翻译应用于每个图像,使其效果较差。为了解决这些局限性,我们提出了ModPrompt,这是一种视觉提示策略,旨在适应新的模态视觉语言检测器,而不会降低零样本性能。特别是,我们提出了一种编码器-解码器视觉提示策略,通过引入推理友好的模态提示解耦残差进行增强,从而实现更稳健的适应。实证基准测试结果表明,我们的方法在两种视觉语言检测器YOLO-World和Grounding DINO上,以及在具有挑战性的红外(LLVIP、FLIR)和深度(NYUv2)数据集上进行模态适应的方法,在达到与完全微调相当的性能的同时,保持了模型的零样本能力。代码可在以下网址找到:https://github.com/heitorrapela/ModPrompt。
论文及项目相关链接
Summary
本文主要探讨零镜头目标检测器在处理不同模态如红外和深度时性能下降的问题。传统方法主要通过图像翻译技术或精细调整来适应新模态,但这种方法可能会损害零镜头性能。为此,本文提出了一种名为ModPrompt的视觉提示策略,该策略可适应新模态而无需对零镜头性能进行微调。该策略使用编码器解码器结构,并加入推理友好的模态提示分离残留物,实现更稳健的适应。在两种视觉语言检测器YOLO-World和Grounding DINO上进行的实验结果表明,该方法在红外和深度数据集上的性能与完全精细调整相当,同时保持了模型的零镜头能力。
Key Takeaways
- 零镜头目标检测器在不同模态下的性能会下降。
- 传统方法通过图像翻译或精细调整来适应新模态,但可能损害零镜头性能。
- ModPrompt策略旨在适应新模态而不损害零镜头性能。
- ModPrompt策略采用编码器解码器结构,加入推理友好的模态提示分离残留物。
- ModPrompt在YOLO-World和Grounding DINO等视觉语言检测器上表现良好。
- 在红外和深度数据集上的实验结果表明,ModPrompt性能与完全精细调整相当。
点此查看论文截图

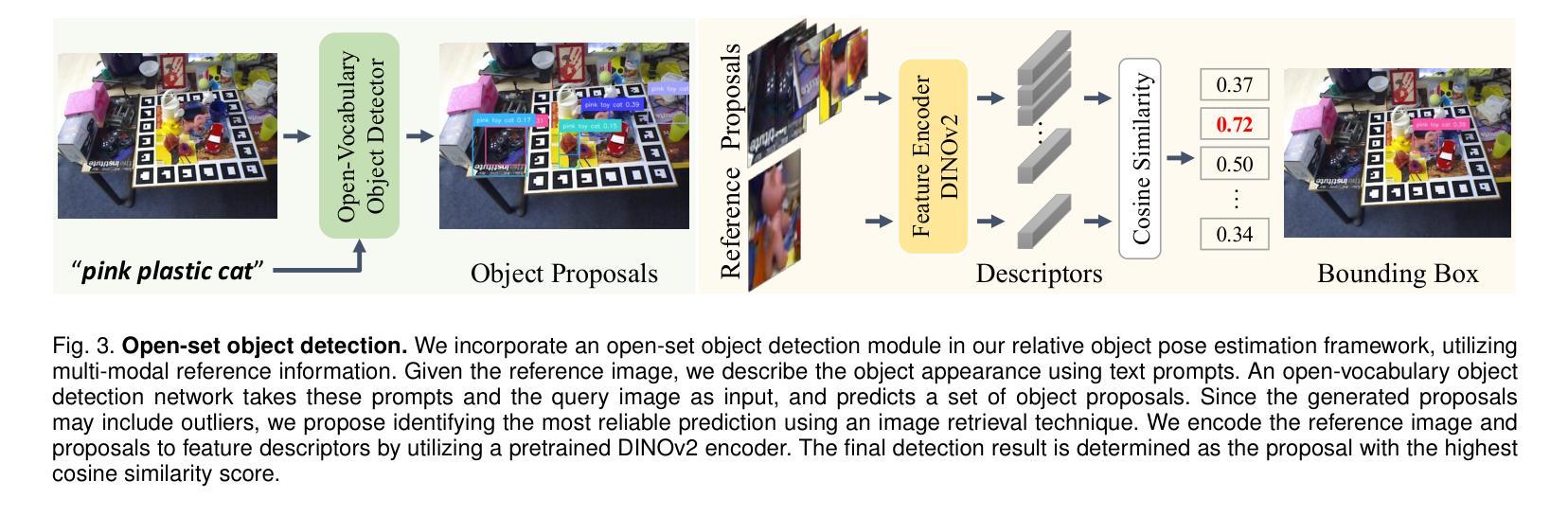
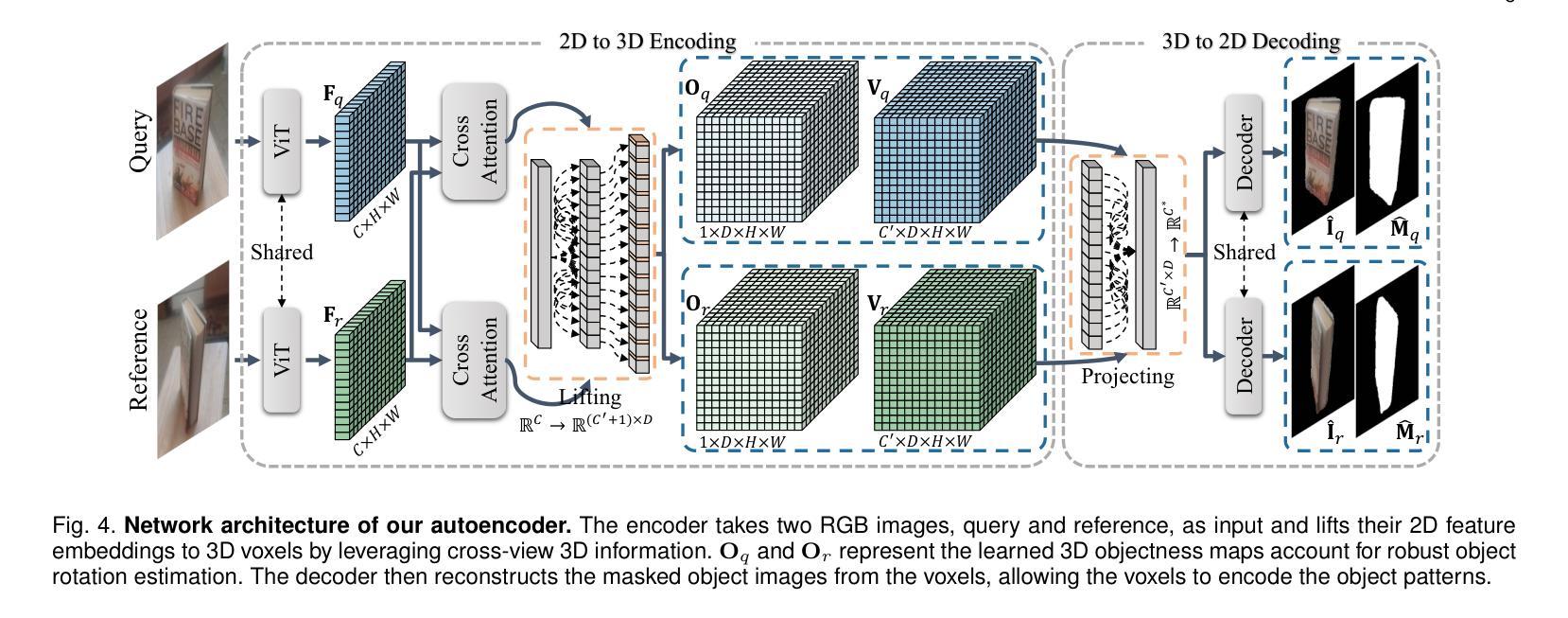
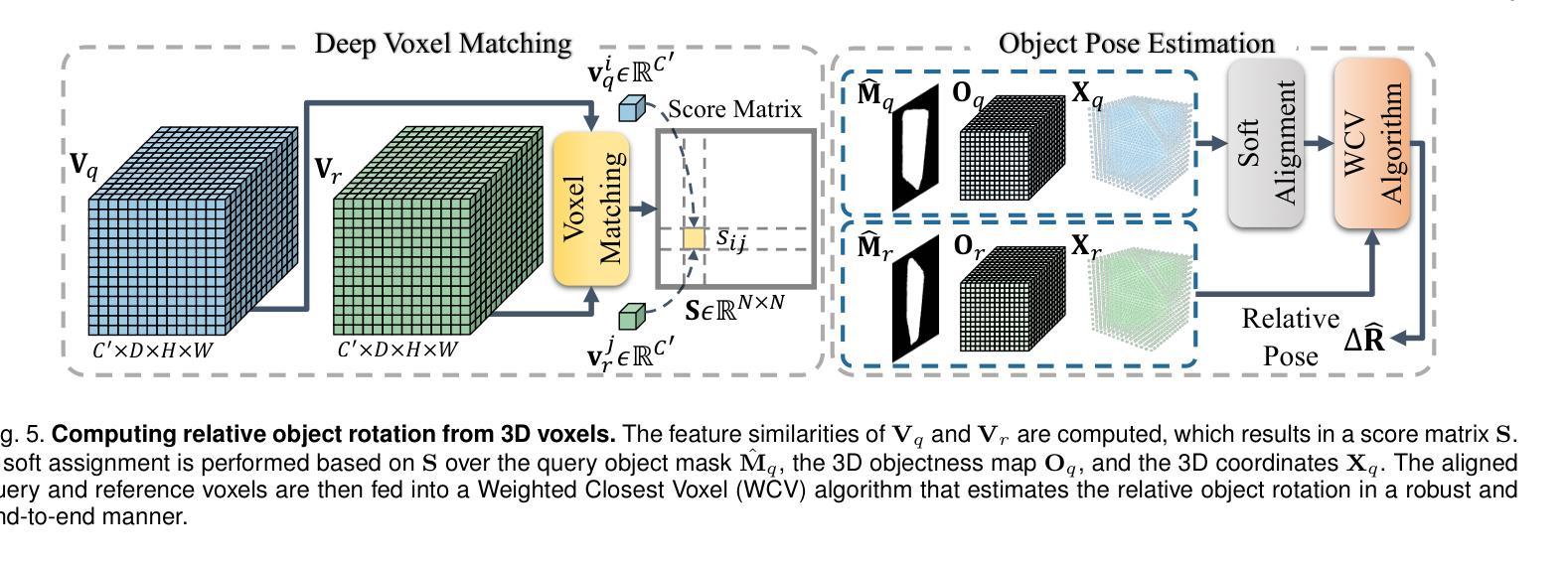
DVMNet++: Rethinking Relative Pose Estimation for Unseen Objects
Authors:Chen Zhao, Tong Zhang, Zheng Dang, Mathieu Salzmann
Determining the relative pose of a previously unseen object between two images is pivotal to the success of generalizable object pose estimation. Existing approaches typically predict 3D translation utilizing the ground-truth object bounding box and approximate 3D rotation with a large number of discrete hypotheses. This strategy makes unrealistic assumptions about the availability of ground truth and incurs a computationally expensive process of scoring each hypothesis at test time. By contrast, we rethink the problem of relative pose estimation for unseen objects by presenting a Deep Voxel Matching Network (DVMNet++). Our method computes the relative object pose in a single pass, eliminating the need for ground-truth object bounding boxes and rotation hypotheses. We achieve open-set object detection by leveraging image feature embedding and natural language understanding as reference. The detection result is then employed to approximate the translation parameters and crop the object from the query image. For rotation estimation, we map the two RGB images, i.e., reference and cropped query, to their respective voxelized 3D representations. The resulting voxels are passed through a rotation estimation module, which aligns the voxels and computes the rotation in an end-to-end fashion by solving a least-squares problem. To enhance robustness, we introduce a weighted closest voxel algorithm capable of mitigating the impact of noisy voxels. We conduct extensive experiments on the CO3D, Objaverse, LINEMOD, and LINEMOD-O datasets, demonstrating that our approach delivers more accurate relative pose estimates for novel objects at a lower computational cost compared to state-of-the-art methods. Our code is released at https://github.com/sailor-z/DVMNet/.
确定两个图像之间先前未见对象的相对姿态对于可泛化的对象姿态估计的成功至关重要。现有方法通常利用真实对象边界框预测3D平移,并用大量离散假设来近似3D旋转。这种策略对真实可用性的假设不现实,并且在测试时对每个假设进行评分的过程计算开销很大。相比之下,我们通过提出深度体素匹配网络(DVMNet++)来重新思考未见过对象的相对姿态估计问题。我们的方法在一次传递中计算相对对象姿态,无需真实对象边界框和旋转假设。我们利用图像特征嵌入和自然语言理解为参考来实现开放集对象检测。检测结果然后用于近似平移参数并从查询图像中裁剪出对象。对于旋转估计,我们将两个RGB图像(即参考和裁剪的查询)映射到其各自的体素化3D表示。得到的体素通过一个旋转估计模块,该模块对齐体素并通过解决最小二乘问题以端到端的方式计算旋转。为了提高稳健性,我们引入了一种加权最接近体素算法,能够减轻噪声体素的影响。我们在CO3D、Objaverse、LINEMOD和LINEMOD-O数据集上进行了大量实验,结果表明我们的方法以较低的计算成本为新型对象提供更准确的相对姿态估计,与最先进的方法相比。我们的代码已发布在https://github.com/sailor-z/DVMNet/。
论文及项目相关链接
Summary
本文提出一种基于深度体素匹配网络(DVMNet++)的方法,用于估计未见对象在两图像间的相对姿态。该方法无需使用真实对象边界框和旋转假设,通过一次计算即可得出相对对象姿态。通过图像特征嵌入和自然语言理解实现开放集对象检测,并据此近似翻译参数并从查询图像中裁剪对象。旋转估计则通过将两个RGB图像转换为各自的体素化三维表示,通过旋转估计模块对齐体素并计算旋转。实验结果表明,该方法在CO3D、Objaverse、LINEMOD和LINEMOD-O数据集上相比最新方法具有更高的相对姿态估计准确性和更低的计算成本。
Key Takeaways
- 提出了一种新的深度体素匹配网络(DVMNet++)用于估计未见对象在两图像间的相对姿态。
- 不需要使用真实对象边界框和旋转假设,简化了计算过程。
- 通过图像特征嵌入和自然语言理解实现开放集对象检测。
- 引入了一种加权最接近体素算法,以提高方法的稳健性。
- 在多个数据集上的实验表明,该方法相比最新方法具有更高的准确性和更低的计算成本。
- 公开了代码,便于他人使用和研究。
点此查看论文截图