⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
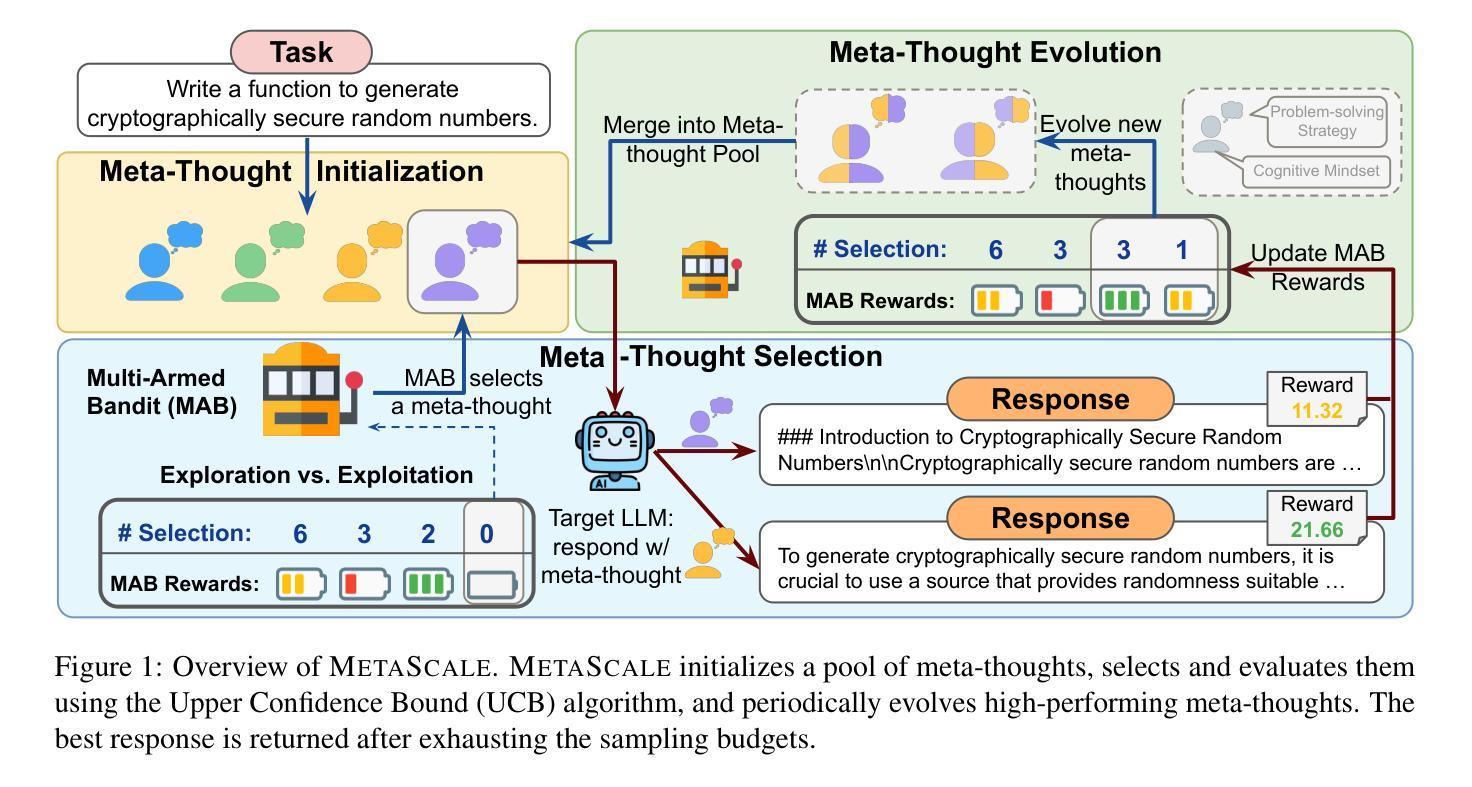
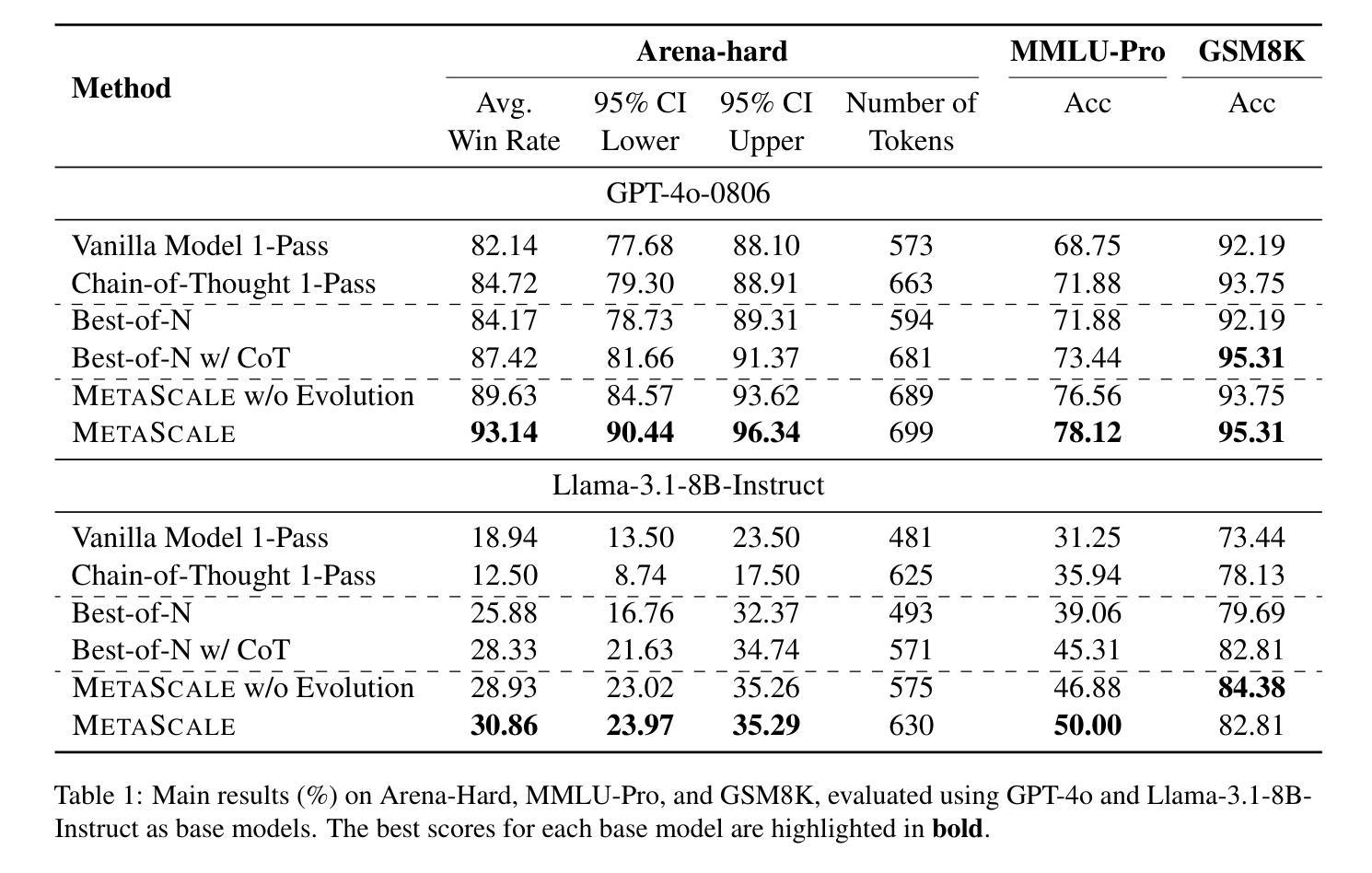
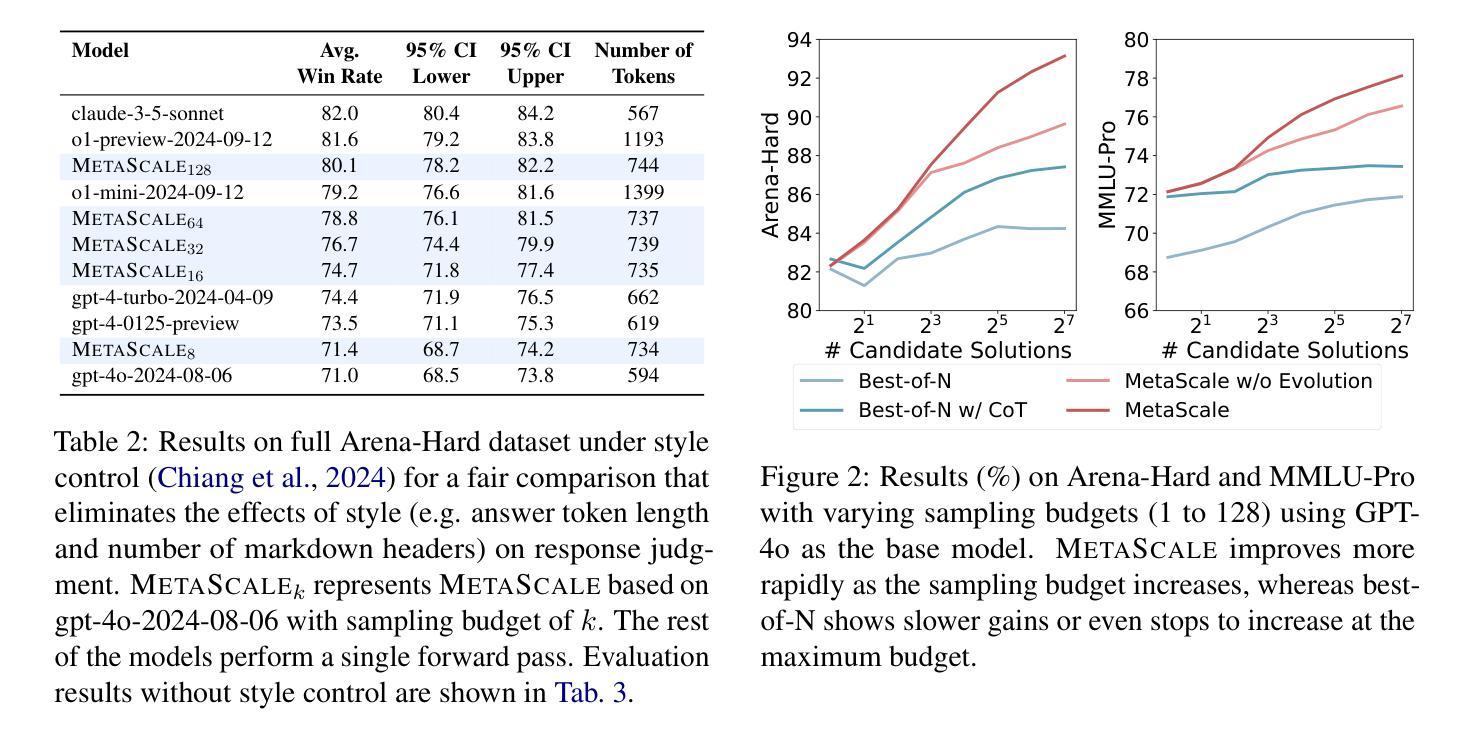
MetaScale: Test-Time Scaling with Evolving Meta-Thoughts
Authors:Qin Liu, Wenxuan Zhou, Nan Xu, James Y. Huang, Fei Wang, Sheng Zhang, Hoifung Poon, Muhao Chen
One critical challenge for large language models (LLMs) for making complex reasoning is their reliance on matching reasoning patterns from training data, instead of proactively selecting the most appropriate cognitive strategy to solve a given task. Existing approaches impose fixed cognitive structures that enhance performance in specific tasks but lack adaptability across diverse scenarios. To address this limitation, we introduce METASCALE, a test-time scaling framework based on meta-thoughts – adaptive thinking strategies tailored to each task. METASCALE initializes a pool of candidate meta-thoughts, then iteratively selects and evaluates them using a multi-armed bandit algorithm with upper confidence bound selection, guided by a reward model. To further enhance adaptability, a genetic algorithm evolves high-reward meta-thoughts, refining and extending the strategy pool over time. By dynamically proposing and optimizing meta-thoughts at inference time, METASCALE improves both accuracy and generalization across a wide range of tasks. Experimental results demonstrate that MetaScale consistently outperforms standard inference approaches, achieving an 11% performance gain in win rate on Arena-Hard for GPT-4o, surpassing o1-mini by 0.9% under style control. Notably, METASCALE scales more effectively with increasing sampling budgets and produces more structured, expert-level responses.
对于大型语言模型(LLM)进行复杂推理的一个关键挑战是,它们依赖于从训练数据中匹配推理模式,而不是主动选择最适当的认知策略来解决给定任务。现有方法强加固定的认知结构,这在特定任务中提高了性能,但缺乏在不同场景中的适应性。为了解决这一局限性,我们引入了METASCALE,这是一个基于元思维的测试时缩放框架——适应每个任务的思考策略。METASCALE首先初始化一组候选元思维,然后使用多臂匪徒算法和上限置信界选择进行迭代选择和评估,由奖励模型引导。为了进一步提高适应性,遗传算法对高奖励的元思维进行进化,随着时间的推移不断精炼和扩展策略池。通过在推理时动态提出和优化元思维,METASCALE提高了各种任务的准确性和泛化能力。实验结果表明,MetaScale始终优于标准推理方法,在GPT-4o的Arena-Hard上赢得了11%的性能提升率,在风格控制下超越了o1-mini 0.9%。值得注意的是,METASCALE在增加采样预算时更有效地扩展,并产生更结构化、专家级的回应。
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLM)在复杂推理方面的一个关键挑战是它们依赖于训练数据中的匹配推理模式,而不是主动选择最适当的认知策略来解决给定任务。为解决这个问题,本文提出一种基于元思维的任务自适应思考策略框架METASCALE。该框架通过初始化候选元思维池,使用多臂老虎机算法迭代选择和评估它们,并通过奖励模型进行引导。此外,遗传算法对高奖励的元思维进行进化,随时间推移优化和扩展策略池。METASCALE在多个任务上展现出更高的准确性和泛化能力。实验结果表明,与标准推理方法相比,MetaScale性能增益达11%,尤其在GPT-4o的Arena-Hard上表现尤为出色,并超过了o1-mini的风格控制表现。尤其值得一提的是,METASCALE在增加采样预算时更有效,并能产生更结构化、专家级的回应。
Key Takeaways
- 大型语言模型(LLM)在复杂推理时依赖训练数据中的匹配模式,缺乏适应不同任务的能力。
- METASCALE框架引入元思维概念,为不同任务提供自适应思考策略。
- METASCALE通过多臂老虎机算法选择和评估候选元思维,并由奖励模型引导。
- 遗传算法用于优化和扩展高奖励的元思维策略。
- METASCALE提高了准确性和泛化能力,特别是在多个任务上的表现。
- 实验结果表明,MetaScale性能优于标准推理方法,尤其在GPT-4o的Arena-Hard任务上表现突出。
点此查看论文截图


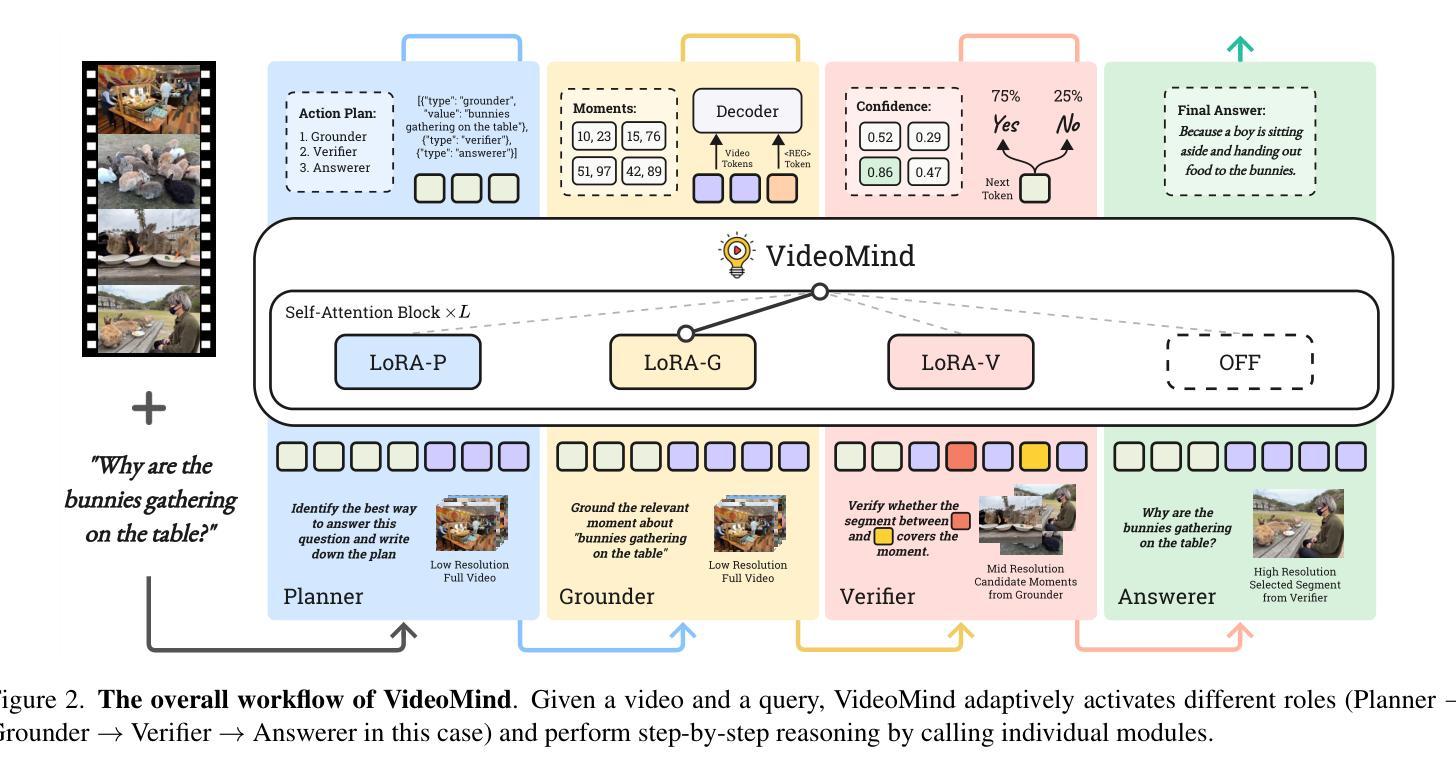
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning
Authors:Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, Mike Zheng Shou
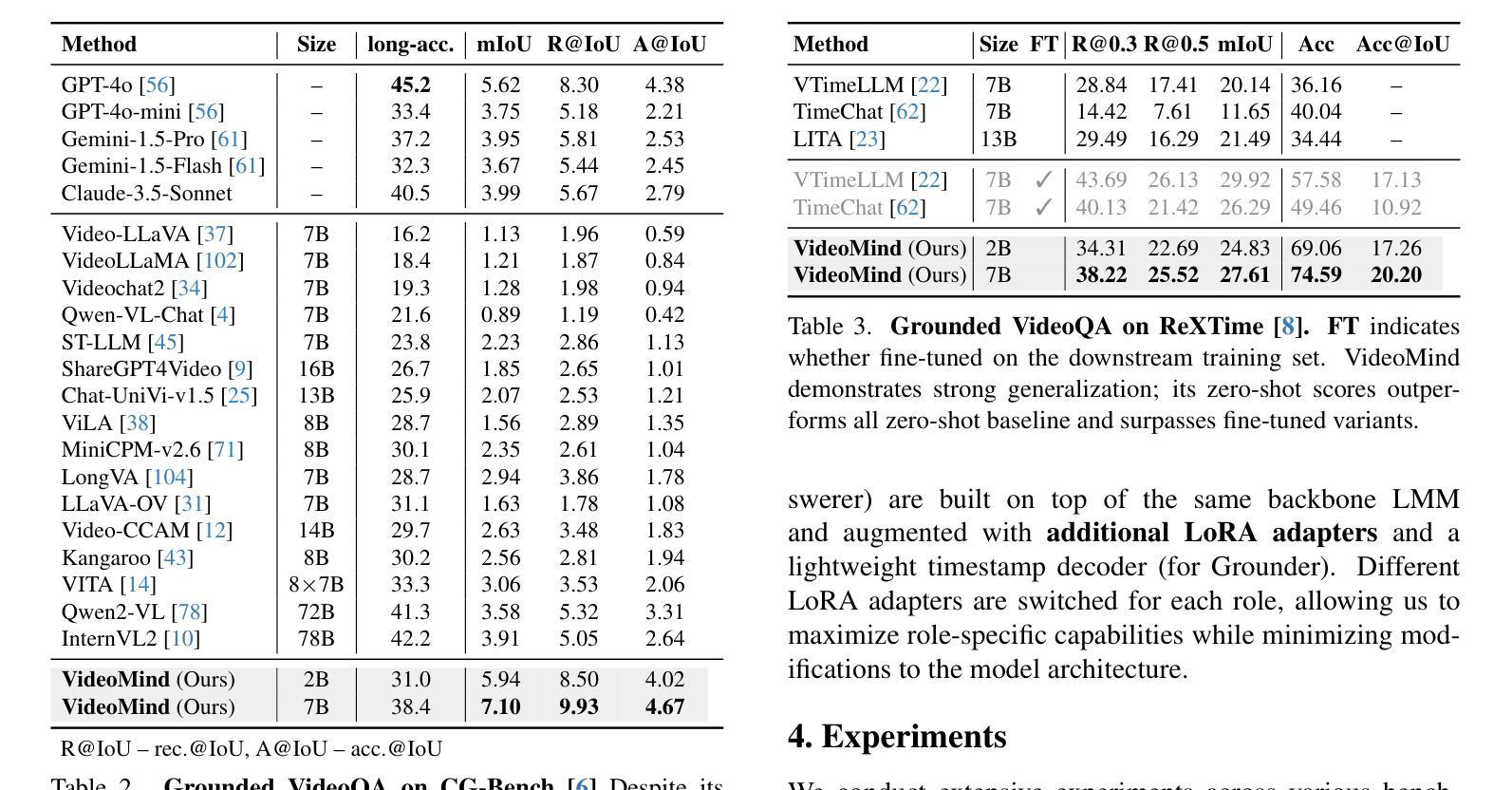
Videos, with their unique temporal dimension, demand precise grounded understanding, where answers are directly linked to visual, interpretable evidence. Despite significant breakthroughs in reasoning capabilities within Large Language Models, multi-modal reasoning - especially for videos - remains unexplored. In this work, we introduce VideoMind, a novel video-language agent designed for temporal-grounded video understanding. VideoMind incorporates two key innovations: (i) We identify essential capabilities for video temporal reasoning and develop a role-based agentic workflow, including a planner for coordinating different roles, a grounder for temporal localization, a verifier to assess temporal interval accuracy, and an answerer for question-answering. (ii) To efficiently integrate these diverse roles, we propose a novel Chain-of-LoRA strategy, enabling seamless role-switching via lightweight LoRA adaptors while avoiding the overhead of multiple models, thus balancing efficiency and flexibility. Extensive experiments on 14 public benchmarks demonstrate that our agent achieves state-of-the-art performance on diverse video understanding tasks, including 3 on grounded video question-answering, 6 on video temporal grounding, and 5 on general video question-answering, underscoring its effectiveness in advancing video agent and long-form temporal reasoning.
视频以其独特的时序维度为特色,要求精确且基于实际情境的理解,答案直接与视觉、可解释的证据相关联。尽管大型语言模型中的推理能力已经取得了重大突破,但多模态推理(尤其是视频)仍然未被充分探索。在这项工作中,我们引入了VideoMind,这是一个为时序视频理解设计的新型视频语言代理。VideoMind包含两个关键创新点:(i)我们确定了视频时序推理所需的核心能力,并基于角色设计了一个代理工作流程,包括一个协调不同角色的规划器、一个用于时序定位的定位器、一个评估时序间隔准确性的验证器,以及一个用于问答的回答者。(ii)为了有效地整合这些不同的角色,我们提出了一种新型的Chain-of-LoRA策略,该策略能够通过轻量级的LoRA适配器实现无缝角色切换,同时避免多个模型的开销,从而在效率和灵活性之间取得平衡。在14个公共基准测试上的广泛实验表明,我们的代理在多种视频理解任务上达到了最先进的性能,包括3个基于实际情境的视频问答任务、6个视频时序定位任务和5个一般视频问答任务,这突显了其在推进视频代理和长格式时序推理方面的有效性。
论文及项目相关链接
PDF Project Page: https://videomind.github.io/
Summary
视频由于其独特的时间维度,需要精确的理解,答案必须与视觉、可解释的证据直接相关。尽管大型语言模型在推理能力方面取得了重大突破,但多模态推理(尤其是视频)仍然未得到充分探索。在这项工作中,我们引入了VideoMind,这是一个为时间接地理解视频而设计的新型视频语言代理。VideoMind结合了两个关键创新点:首先,我们确定了视频时间推理的核心能力,并基于角色设计了一个代理工作流程,包括一个协调不同角色的规划器、一个用于时间定位的定标器、一个评估时间间隔准确性的验证器以及一个问答解答器。其次,为了有效地整合这些多样化的角色,我们提出了一种新型的Chain-of-LoRA策略,通过轻量级的LoRA适配器实现无缝的角色切换,避免了多个模型的开销,从而实现了效率和灵活性的平衡。在14个公共基准测试上的广泛实验表明,我们的代理在多种视频理解任务上达到了最先进的性能。
Key Takeaways
以下是论文中最显著的七个要点或关键洞见:
- 视频由于其独特的时间维度,对理解有精确要求,答案需与视觉证据直接相关。
- 尽管大型语言模型在推理方面有所突破,但多模态推理尤其是视频方面的多模态推理尚未充分探索。
- 引入了VideoMind这一新型视频语言代理来增强视频的时间感知理解能力。
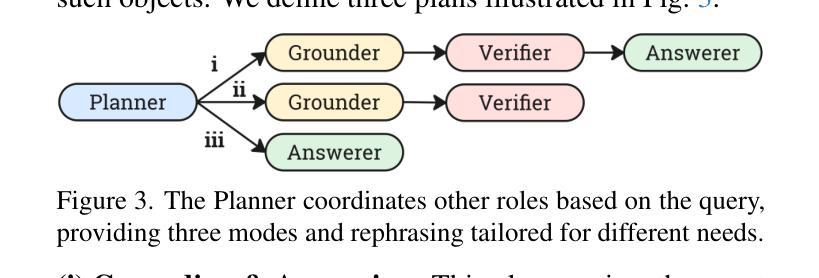
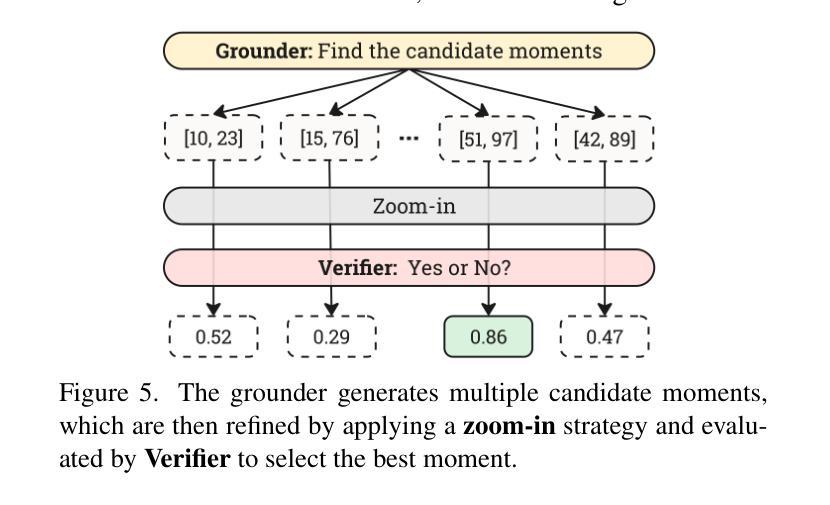
- VideoMind包含两个关键创新点:确定视频时间推理的核心能力并基于角色设计代理工作流程。
- VideoMind具有一个规划器来协调角色工作、一个用于时间定位的定标器以及一个评估时间间隔准确性的验证器等核心组件。
- 提出了一种新颖的Chain-of-LoRA策略以实现效率与灵活性的平衡。这种策略能无缝地在不同角色间切换并避免多个模型的开销。
点此查看论文截图


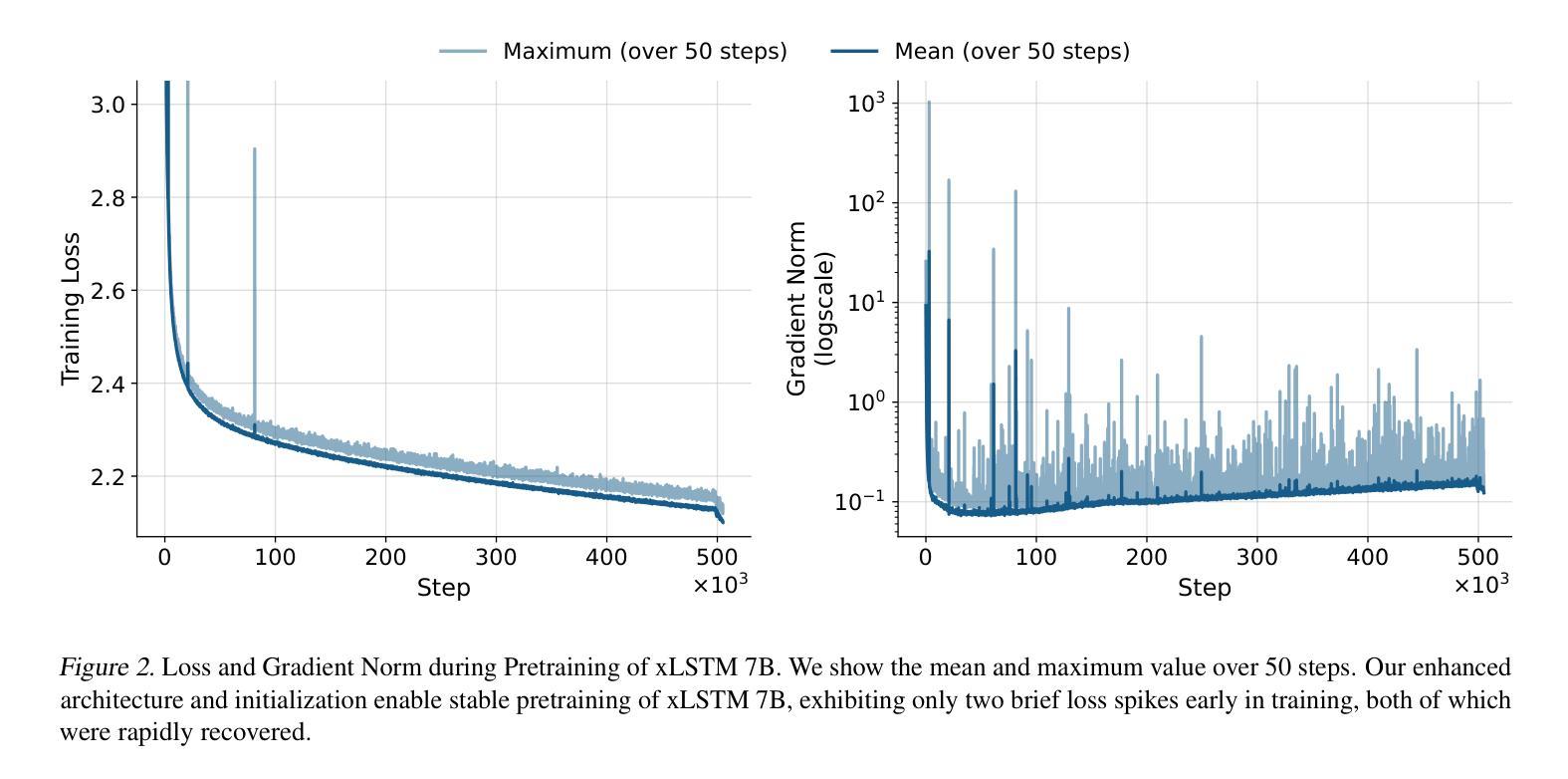
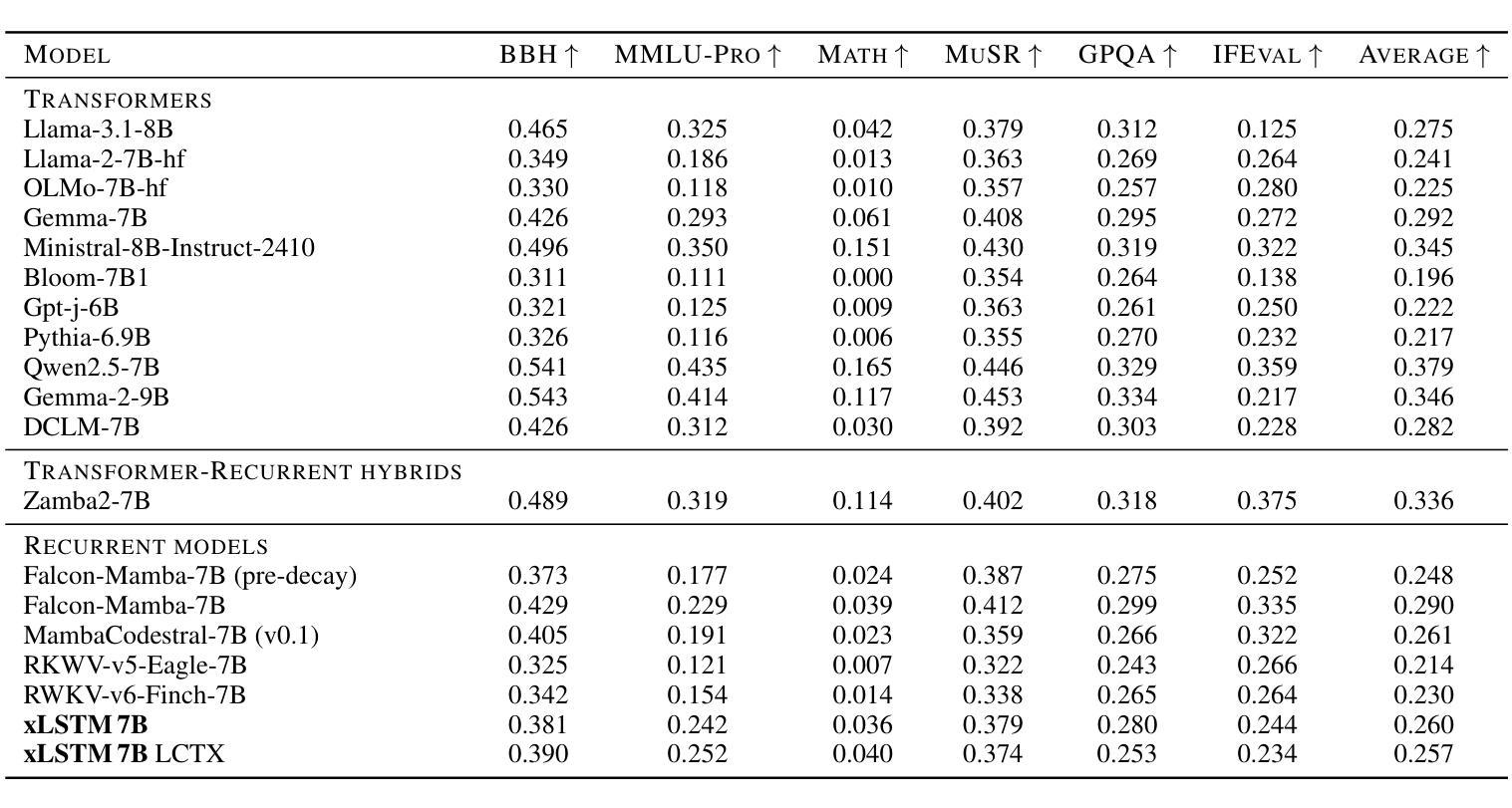
xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Authors:Maximilian Beck, Korbinian Pöppel, Phillip Lippe, Richard Kurle, Patrick M. Blies, Günter Klambauer, Sebastian Böck, Sepp Hochreiter
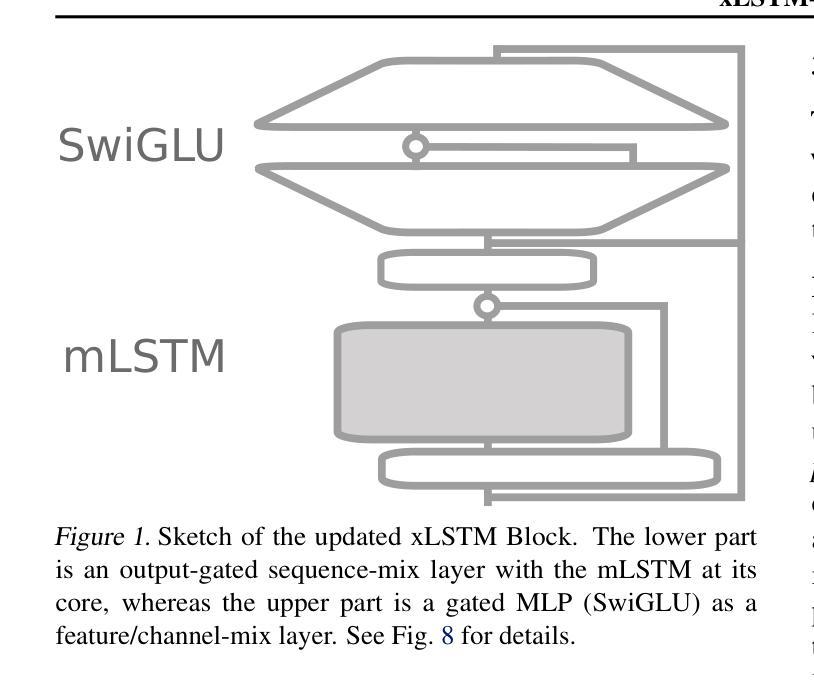
Recent breakthroughs in solving reasoning, math and coding problems with Large Language Models (LLMs) have been enabled by investing substantial computation budgets at inference time. Therefore, inference speed is one of the most critical properties of LLM architectures, and there is a growing need for LLMs that are efficient and fast at inference. Recently, LLMs built on the xLSTM architecture have emerged as a powerful alternative to Transformers, offering linear compute scaling with sequence length and constant memory usage, both highly desirable properties for efficient inference. However, such xLSTM-based LLMs have yet to be scaled to larger models and assessed and compared with respect to inference speed and efficiency. In this work, we introduce xLSTM 7B, a 7-billion-parameter LLM that combines xLSTM’s architectural benefits with targeted optimizations for fast and efficient inference. Our experiments demonstrate that xLSTM 7B achieves performance on downstream tasks comparable to other similar-sized LLMs, while providing significantly faster inference speeds and greater efficiency compared to Llama- and Mamba-based LLMs. These results establish xLSTM 7B as the fastest and most efficient 7B LLM, offering a solution for tasks that require large amounts of test-time computation. Our work highlights xLSTM’s potential as a foundational architecture for methods building on heavy use of LLM inference. Our model weights, model code and training code are open-source.
最近,通过推理时间的大量计算预算投入,利用大型语言模型(LLM)解决推理、数学和编码问题取得了突破。因此,推理速度成为LLM架构中最关键的属性之一,对高效快速的LLM推理需求日益增长。最近,基于xLSTM架构的LLM作为Transformer的强大替代方案而出现,它提供线性计算扩展和恒定内存使用,都是实现高效推理所期望的属性。然而,这样的基于xLSTM的LLM尚未扩展到更大的模型,并需要针对推理速度和效率进行评估和比较。在此工作中,我们介绍了xLSTM 7B,这是一个拥有7亿参数的LLM,它将xLSTM的架构优势与针对快速高效推理的优化相结合。我们的实验表明,xLSTM 7B在下游任务上的性能与其他类似规模的LLM相当,同时提供了更快的推理速度和更高的效率,与基于Llama和Mamba的LLM相比表现更优秀。这些结果确立了xLSTM 7B作为最快、最高效的7B LLM的地位,为解决需要大量测试时间计算的任务提供了解决方案。我们的工作突出了xLSTM作为基于大量使用LLM推理的方法的基础架构的潜力。我们的模型权重、模型代码和培训代码都是开源的。
论文及项目相关链接
PDF Code available at: https://github.com/NX-AI/xlstm and https://github.com/NX-AI/xlstm-jax
摘要
基于大规模语言模型(LLM)的推理、数学和编程问题解决方面的最新突破,得益于在推理时间投入了大量的计算预算。因此,推理速度成为LLM架构中最关键的属性之一,对于高效快速的LLM需求日益增长。基于xLSTM架构的LLM最近作为Transformer的有力替代而出现,具有线性计算扩展性和恒定内存使用等理想属性,有利于高效推理。然而,这样的xLSTM-based LLM尚未扩展到大型模型,并关于推理速度和效率进行评估和比较。在此工作中,我们介绍了xLSTM 7B,这是一个7亿参数的大型语言模型,结合了xLSTM的架构优势,并针对快速高效的推理进行了优化。实验表明,xLSTM 7B在下游任务上的性能与其他类似规模的大型语言模型相当,但推理速度更快,效率更高,与Lama和Mamba-based LLM相比表现更佳。这些结果确立了xLSTM 7B作为最快和最有效率的7B LLM的地位,为解决需要大量测试时间计算的任务提供了解决方案。我们的工作突出了xLSTM作为大量使用LLM推理方法的基础架构的潜力。我们的模型权重、模型代码和培训代码都是开源的。
关键见解
- 大型语言模型(LLM)在推理、数学和编程问题求解方面取得新突破。
- 推理速度是LLM架构的关键属性之一,对高效快速的LLM需求增加。
- xLSTM架构的LLM作为Transformer的有力替代出现,具有线性计算扩展性和恒定内存使用性。
- xLSTM 7B模型结合了xLSTM的架构优势并优化了推理速度和效率。
- xLSTM 7B在下游任务上的性能与类似规模的其他LLM相当。
- xLSTM 7B相比其他LLM具有更快的推理速度和更高的效率。
- xLSTM 7B的模型权重、模型和训练代码都是开源的。
点此查看论文截图

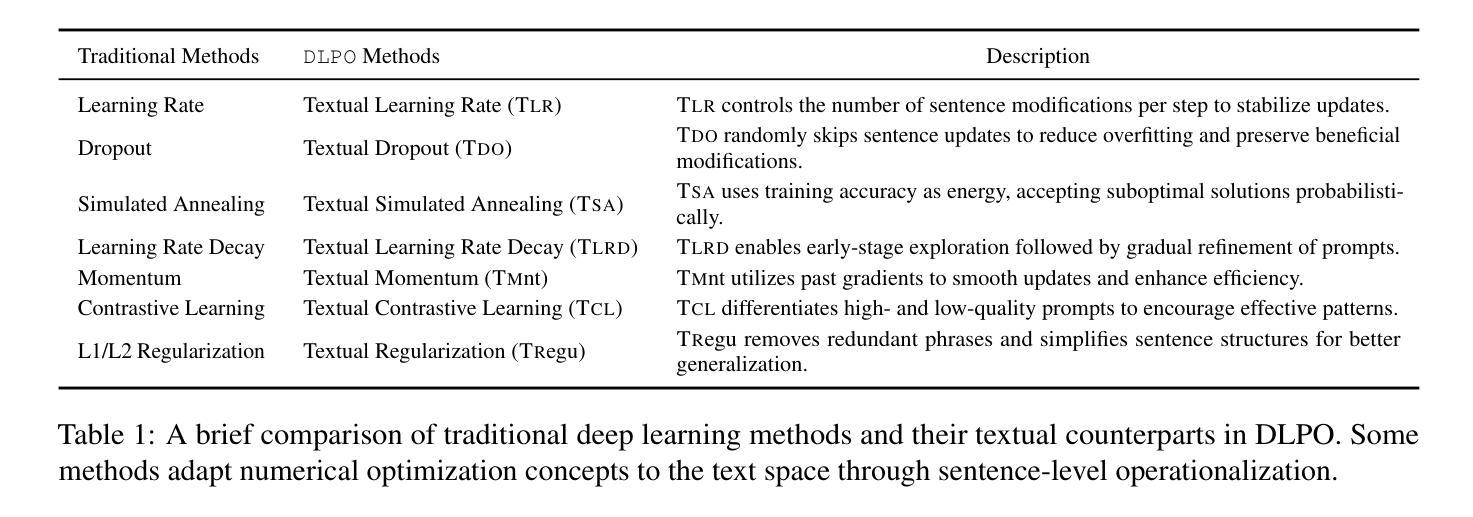
DLPO: Towards a Robust, Efficient, and Generalizable Prompt Optimization Framework from a Deep-Learning Perspective
Authors:Dengyun Peng, Yuhang Zhou, Qiguang Chen, Jinhao Liu, Jingjing Chen, Libo Qin
Large Language Models (LLMs) have achieved remarkable success across diverse tasks, largely driven by well-designed prompts. However, crafting and selecting such prompts often requires considerable human effort, significantly limiting its scalability. To mitigate this, recent studies have explored automated prompt optimization as a promising solution. Despite these efforts, existing methods still face critical challenges in robustness, efficiency, and generalization. To systematically address these challenges, we first conduct an empirical analysis to identify the limitations of current reflection-based prompt optimization paradigm. Building on these insights, we propose 7 innovative approaches inspired by traditional deep learning paradigms for prompt optimization (DLPO), seamlessly integrating these concepts into text-based gradient optimization. Through these advancements, we progressively tackle the aforementioned challenges and validate our methods through extensive experimentation. We hope our study not only provides valuable guidance for future research but also offers a comprehensive understanding of the challenges and potential solutions in prompt optimization. Our code is available at https://github.com/sfasfaffa/DLPO.
大型语言模型(LLM)在各项任务中取得了显著的成功,这很大程度上得益于精心设计的提示。然而,制作和选择这些提示通常需要大量的人工努力,这极大地限制了其可扩展性。为了缓解这一问题,近期的研究探索了自动提示优化作为一个有前景的解决方案。尽管付出了这些努力,现有方法仍然面临稳健性、效率和泛化方面的严峻挑战。为了系统地解决这些挑战,我们首先对基于当前反思的提示优化范式的局限性进行实证研究。基于这些见解,我们提出了7种创新方法,这些方法受到传统深度学习范式的启发,用于提示优化(DLPO),无缝集成这些概念到文本梯度优化中。通过这些进步,我们逐步解决了上述挑战,并通过广泛的实验验证了我们的方法。我们希望这项研究不仅为未来研究提供有价值的指导,而且全面了解了提示优化中的挑战和潜在解决方案。我们的代码可在https://github.com/sfasfaffa/DLPO访问。
论文及项目相关链接
PDF Preprint
Summary
大规模语言模型(LLM)的成功得益于巧妙的提示设计,但设计选择提示需要大量人力,限制了其可扩展性。为缓解这一问题,近期研究尝试自动化提示优化,但现有方法面临稳健性、效率和泛化能力的挑战。本研究通过实证分析了当前基于反射的提示优化范式的局限性,并提出7种受传统深度学习范式启发的提示优化方法(DLPO),将其无缝集成到文本梯度优化中。通过逐步解决前述挑战并通过大量实验验证方法的有效性,本研究为未来研究提供了有价值的指导,并全面理解了提示优化中的挑战和潜在解决方案。
Key Takeaways
- LLM的成功很大程度上归功于巧妙的提示设计,但人工设计提示限制了其可扩展性。
- 自动化提示优化是缓解这一问题的有效方法,但现有方法存在稳健性、效率和泛化能力的挑战。
- 本研究通过实证分析了当前基于反射的提示优化范式的局限性。
- 提出7种受传统深度学习范式启发的提示优化方法(DLPO)。
- DLPO方法无缝集成到文本梯度优化中,逐步解决前述挑战。
- 通过大量实验验证了DLPO方法的有效性。
点此查看论文截图

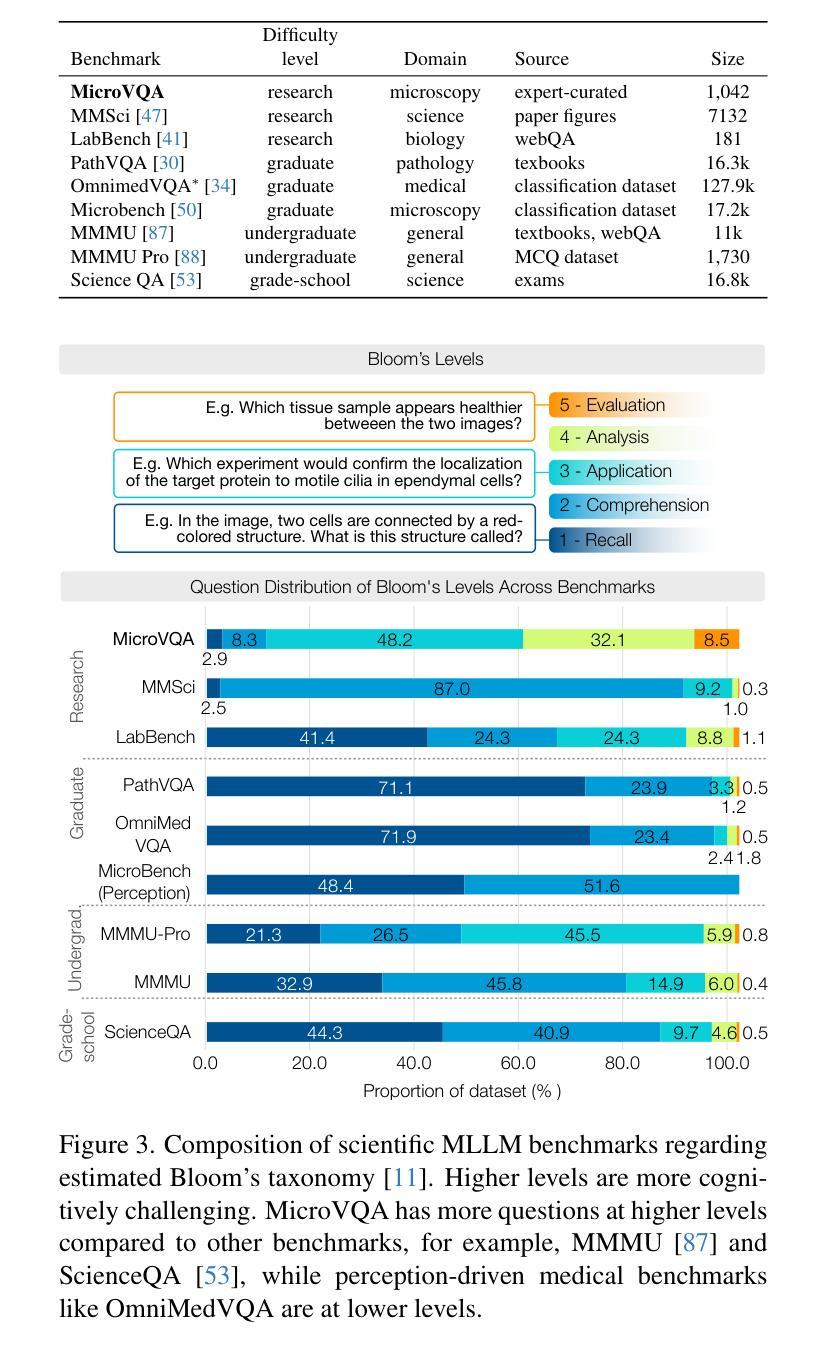
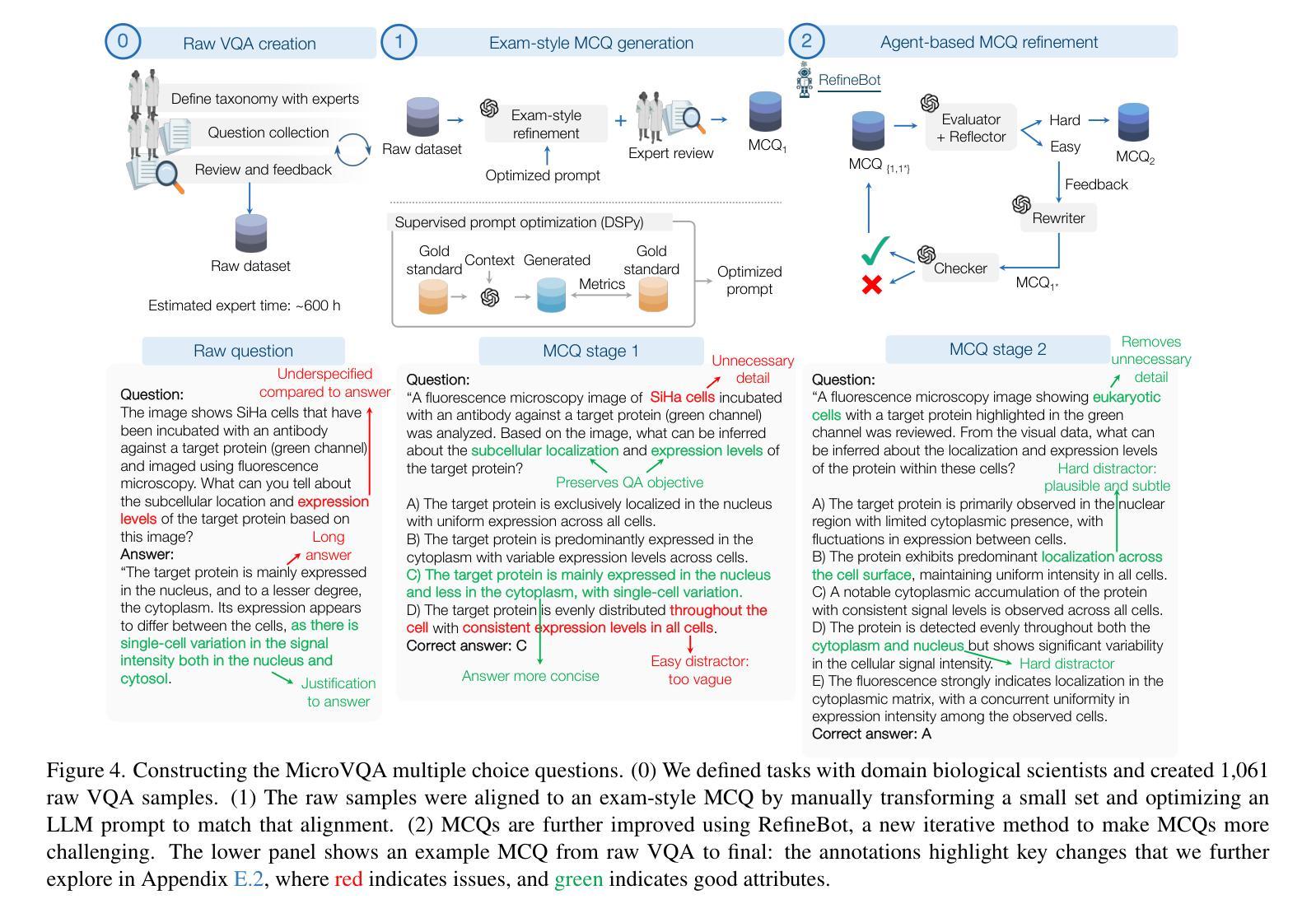
MicroVQA: A Multimodal Reasoning Benchmark for Microscopy-Based Scientific Research
Authors:James Burgess, Jeffrey J Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G. Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, Sarina M. Hasan, Alexandra Johannesson, William D. Leineweber, Malvika G Nair, Ridhi Yarlagadda, Connor Zuraski, Wah Chiu, Sarah Cohen, Jan N. Hansen, Manuel D Leonetti, Chad Liu, Emma Lundberg, Serena Yeung-Levy
Scientific research demands sophisticated reasoning over multimodal data, a challenge especially prevalent in biology. Despite recent advances in multimodal large language models (MLLMs) for AI-assisted research, existing multimodal reasoning benchmarks only target up to college-level difficulty, while research-level benchmarks emphasize lower-level perception, falling short of the complex multimodal reasoning needed for scientific discovery. To bridge this gap, we introduce MicroVQA, a visual-question answering (VQA) benchmark designed to assess three reasoning capabilities vital in research workflows: expert image understanding, hypothesis generation, and experiment proposal. MicroVQA consists of 1,042 multiple-choice questions (MCQs) curated by biology experts across diverse microscopy modalities, ensuring VQA samples represent real scientific practice. In constructing the benchmark, we find that standard MCQ generation methods induce language shortcuts, motivating a new two-stage pipeline: an optimized LLM prompt structures question-answer pairs into MCQs; then, an agent-based `RefineBot’ updates them to remove shortcuts. Benchmarking on state-of-the-art MLLMs reveal a peak performance of 53%; models with smaller LLMs only slightly underperform top models, suggesting that language-based reasoning is less challenging than multimodal reasoning; and tuning with scientific articles enhances performance. Expert analysis of chain-of-thought responses shows that perception errors are the most frequent, followed by knowledge errors and then overgeneralization errors. These insights highlight the challenges in multimodal scientific reasoning, showing MicroVQA is a valuable resource advancing AI-driven biomedical research. MicroVQA is available at https://huggingface.co/datasets/jmhb/microvqa, and project page at https://jmhb0.github.io/microvqa.
科学研究需要对多模态数据进行复杂推理,这在生物学中尤其普遍。尽管最近在多模态大型语言模型(MLLMs)方面取得了进展,为人工智能辅助研究提供了支持,但现有的多模态推理基准测试仅针对大学水平的难度,而研究级基准测试则强调较低级别的感知能力,远远达不到科学发现所需的多模态复杂推理能力。为了弥补这一差距,我们引入了MicroVQA,这是一个视觉问答(VQA)基准测试,旨在评估研究工作流程中至关重要的三种推理能力:专家图像理解、假设生成和实验方案提出。MicroVQA包含由生物学专家策划的1042道选择题(MCQs),涉及多种显微镜模态,确保VQA样本代表真实的科学实践。在构建基准测试时,我们发现标准的选择题生成方法会引发语言上的捷径,这促使我们采用新的两阶段流程:优化的LLM提示将问题答案对结构化为选择题;然后基于代理的“RefineBot”对其进行更新以消除捷径。在最新MLLMs上的基准测试显示,最佳性能达到53%;使用较小LLM的模型仅略微逊于顶级模型,这表明基于语言的推理不如多模态推理具有挑战性;使用科学文章进行调整可增强性能。专家对思维链式反应的分析表明,感知错误最为频繁,其次是知识错误,然后是过度概括错误。这些见解突出了多模态科学推理的挑战性,表明MicroVQA是推动人工智能驱动生物医学研究的有价值的资源。MicroVQA可通过https://huggingface.co/datasets/jmhb/microvqa访问,项目页面为https://jmhb0.github.io/microvqa。
论文及项目相关链接
PDF CVPR 2025 (Conference on Computer Vision and Pattern Recognition) Project page at https://jmhb0.github.io/microvqa Benchmark at https://huggingface.co/datasets/jmhb/microvqa
Summary
针对科学研究中的多模态数据推理需求,MicroVQA基准测试旨在评估图像理解、假设生成和实验方案提出等三项关键能力。该基准测试包含由生物学专家编写的千余道选择题,旨在反映真实科学实践中的挑战。研究发现,新的LLM提示和RefineBot能够减少语言捷径的产生。评估结果显示,目前顶尖模型的性能仅达到约53%,而使用科学文章进行微调可提升性能。感知错误是最常见的挑战。MicroVQA是推进AI驱动生物医学研究的重要资源。
Key Takeaways
- MicroVQA是一项视觉问答基准测试,针对科学研究领域的多模态推理能力进行评估。
- 它包括由生物学专家编制的1,042道选择题,涵盖多样的显微镜成像模式。
- 标准选择题生成方法会导致语言捷径的问题,因此引入LLM提示和RefineBot来优化问题设计。
- 当前顶尖模型的性能在MicroVQA上仅为约53%,显示多模态推理的挑战性。
- 使用科学文章进行微调可以提高模型性能。
- 专家分析显示感知错误是最常见的挑战,其次是知识错误和过度泛化错误。
点此查看论文截图


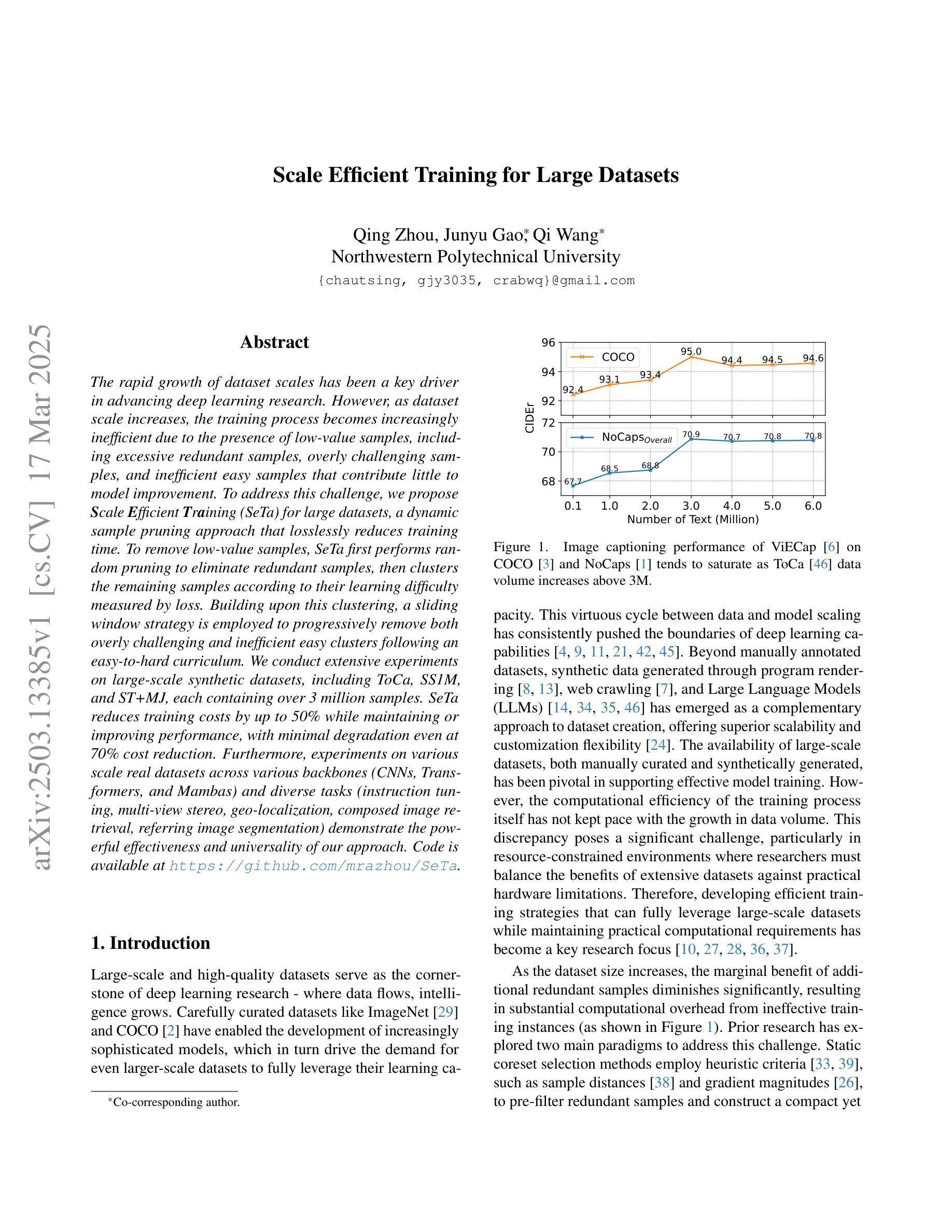
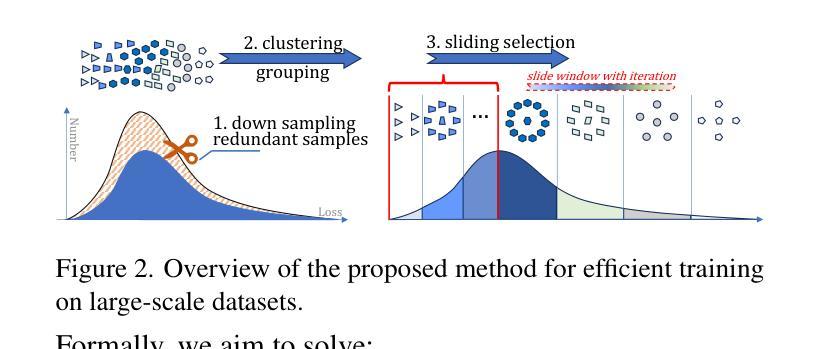
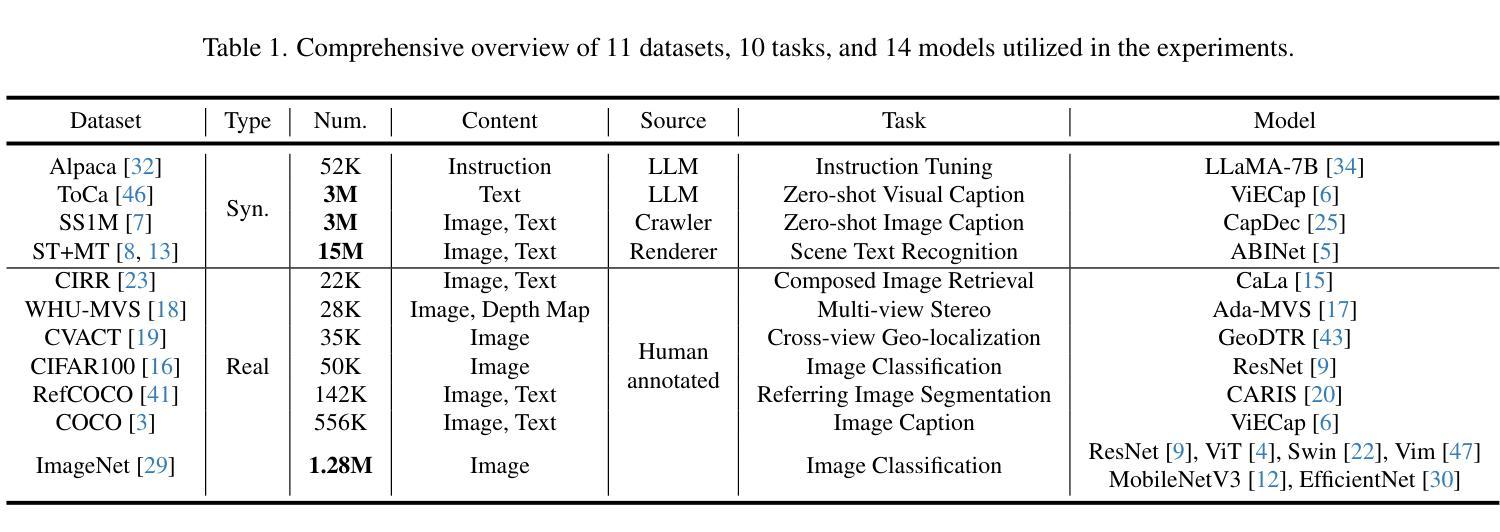
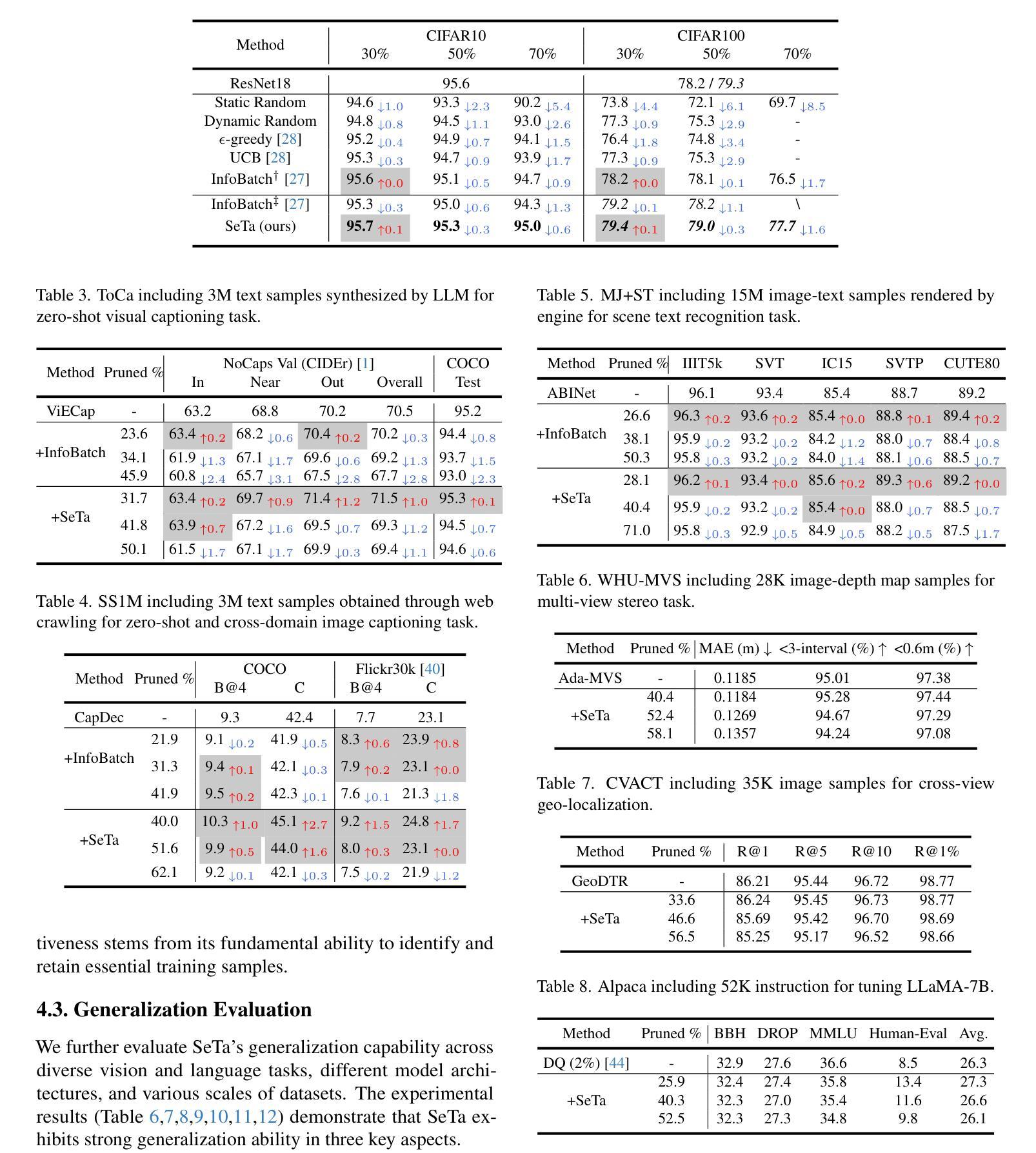
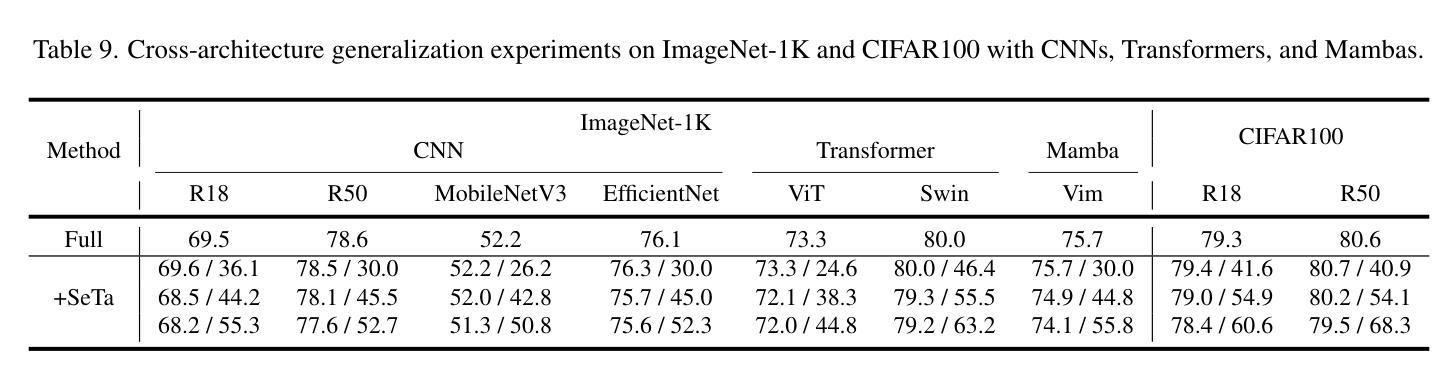
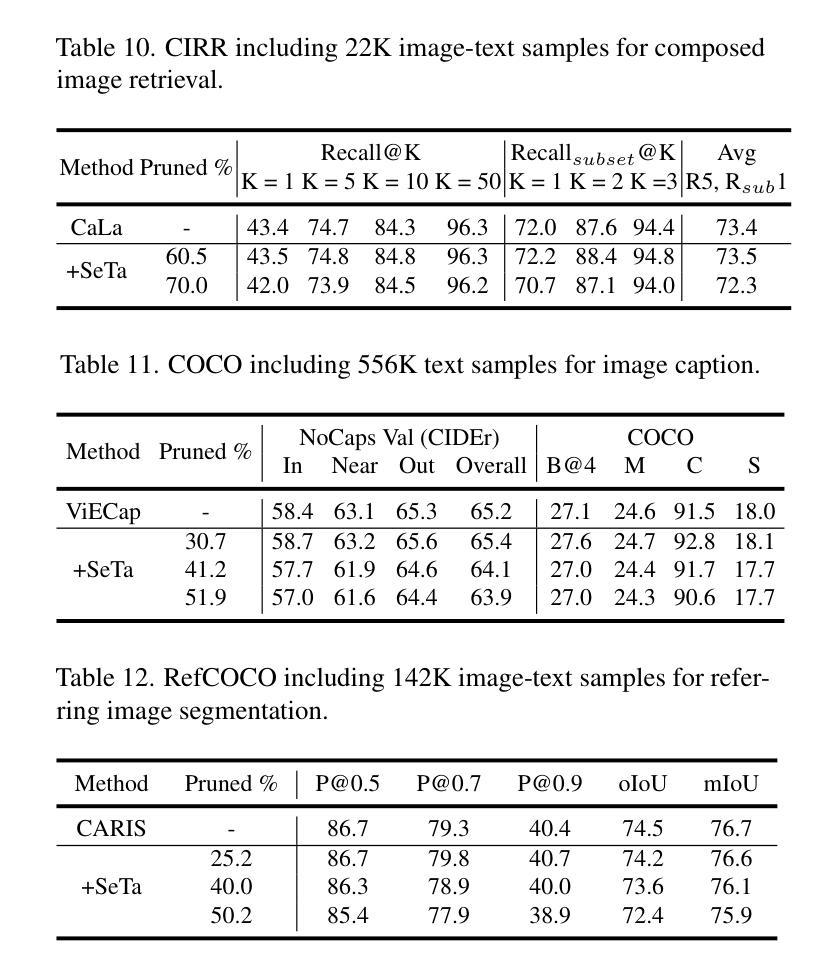
Scale Efficient Training for Large Datasets
Authors:Qing Zhou, Junyu Gao, Qi Wang
The rapid growth of dataset scales has been a key driver in advancing deep learning research. However, as dataset scale increases, the training process becomes increasingly inefficient due to the presence of low-value samples, including excessive redundant samples, overly challenging samples, and inefficient easy samples that contribute little to model improvement.To address this challenge, we propose Scale Efficient Training (SeTa) for large datasets, a dynamic sample pruning approach that losslessly reduces training time. To remove low-value samples, SeTa first performs random pruning to eliminate redundant samples, then clusters the remaining samples according to their learning difficulty measured by loss. Building upon this clustering, a sliding window strategy is employed to progressively remove both overly challenging and inefficient easy clusters following an easy-to-hard curriculum.We conduct extensive experiments on large-scale synthetic datasets, including ToCa, SS1M, and ST+MJ, each containing over 3 million samples.SeTa reduces training costs by up to 50% while maintaining or improving performance, with minimal degradation even at 70% cost reduction. Furthermore, experiments on various scale real datasets across various backbones (CNNs, Transformers, and Mambas) and diverse tasks (instruction tuning, multi-view stereo, geo-localization, composed image retrieval, referring image segmentation) demonstrate the powerful effectiveness and universality of our approach. Code is available at https://github.com/mrazhou/SeTa.
数据集规模的快速增长是推动深度学习研究进步的关键驱动力。然而,随着数据集规模的增加,由于存在大量低价值样本,包括过多的冗余样本、过于困难的样本以及对模型改进贡献甚微的高效简单样本,训练过程变得越来越低效。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
大规模数据集的增长推动了深度学习研究的进步,但其训练过程却变得愈发低效。针对此问题,本文提出了一种针对大规模数据集的动态样本裁剪方法——规模高效训练(SeTa),旨在无损减少训练时间。通过随机裁剪消除冗余样本,根据损失测量学习难度对剩余样本进行聚类。在此基础上,采用滑动窗口策略渐进移除过于复杂和效率较低的簇,遵循从易到难的课程模式。实验证明,SeTa在大型合成数据集上降低了50%的训练成本,同时保持或提高了性能,甚至在70%的成本降低下仍具有微小性能下降。此外,在各种规模的现实数据集、不同的骨干网络(CNN、Transformer和Mambas)以及多样化的任务(指令调优、多视图立体声、地理定位、组合图像检索、引用图像分割)上的实验展示了该方法的强大效果和普遍性。
Key Takeaways
- 大规模数据集的增长推动了深度学习研究的进步,但训练过程变得低效。
- SeTa是一种动态样本裁剪方法,旨在无损减少训练时间。
- SeTa通过随机裁剪消除冗余样本,然后根据损失测量学习难度进行样本聚类。
- SeTa采用滑动窗口策略,渐进移除过于复杂和效率较低的样本簇。
- SeTa在大型合成数据集上可降低训练成本,同时保持性能。
- SeTa在多种现实数据集、不同骨干网络和任务上的实验证明了其有效性和普遍性。
点此查看论文截图
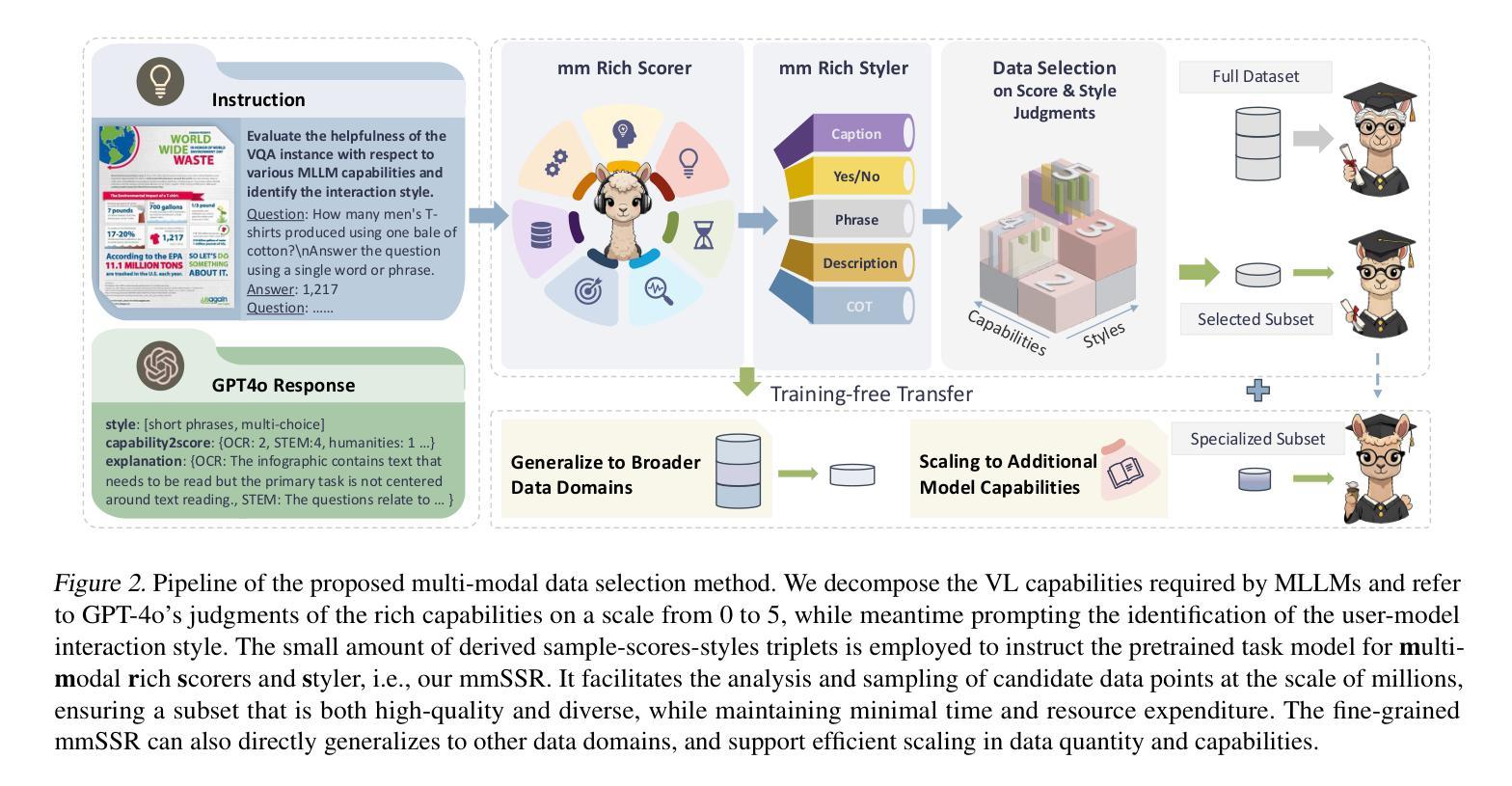
Cream of the Crop: Harvesting Rich, Scalable and Transferable Multi-Modal Data for Instruction Fine-Tuning
Authors:Mengyao Lyu, Yan Li, Huasong Zhong, Wenhao Yang, Hui Chen, Jungong Han, Guiguang Ding, Zhenheng Yang
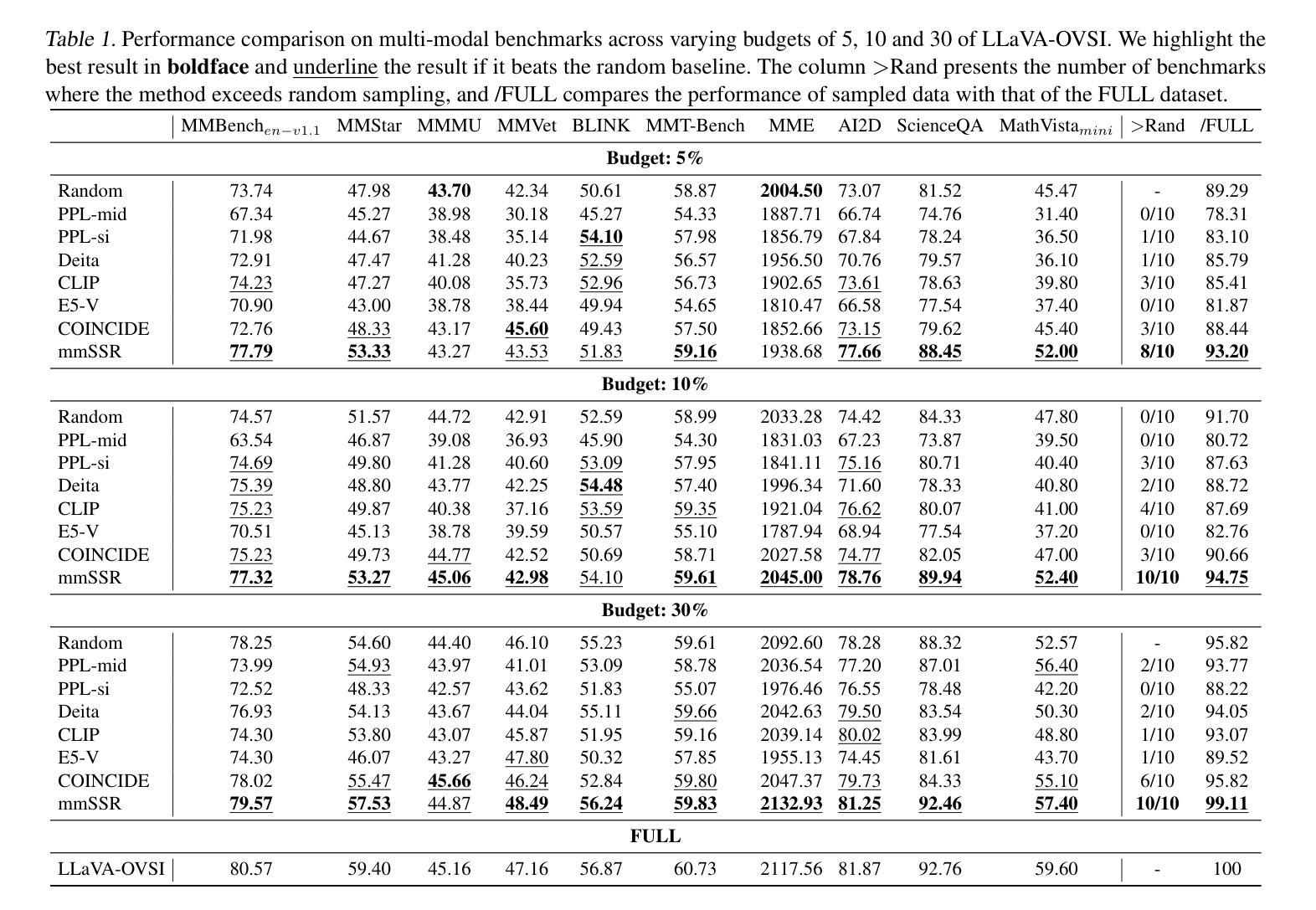
The hypothesis that pretrained large language models (LLMs) necessitate only minimal supervision during the fine-tuning (SFT) stage (Zhou et al., 2024) has been substantiated by recent advancements in data curation and selection research. However, their stability and generalizability are compromised due to the vulnerability to experimental setups and validation protocols, falling short of surpassing random sampling (Diddee & Ippolito, 2024; Xia et al., 2024b). Built upon LLMs, multi-modal LLMs (MLLMs), combined with the sheer token volume and heightened heterogeneity of data sources, amplify both the significance and complexity of data selection. To harvest multi-modal instructional data in a robust and efficient manner, we re-define the granularity of the quality metric by decomposing it into 14 vision-language-related capabilities, and introduce multi-modal rich scorers to evaluate the capabilities of each data candidate. To promote diversity, in light of the inherent objective of the alignment stage, we take interaction style as diversity indicator and use a multi-modal rich styler to identify data instruction patterns. In doing so, our multi-modal rich scorers and styler (mmSSR) guarantee that high-scoring information is conveyed to users in diversified forms. Free from embedding-based clustering or greedy sampling, mmSSR efficiently scales to millions of data with varying budget constraints, supports customization for general or specific capability acquisition, and facilitates training-free generalization to new domains for curation. Across 10+ experimental settings, validated by 14 multi-modal benchmarks, we demonstrate consistent improvements over random sampling, baseline strategies and state-of-the-art selection methods, achieving 99.1% of full performance with only 30% of the 2.6M data.
假设预训练大型语言模型(LLM)在微调(SFT)阶段只需要最小限度的监督(Zhou等人,2024年)的观点,最近的数据整理和选择研究方面的进展已经证实了这一点。然而,由于容易受到实验设置和验证协议的影响,其稳定性和泛化能力受到损害,未能超越随机抽样(Diddee和Ippolito,2024年;Xia等人,2024b)。基于LLM的多模态LLM(MLLM)结合了庞大的数据量和高度异质的数据源,放大了数据选择的重要性和复杂性。为了以稳健高效的方式收集多模态教学数据,我们重新定义了质量指标的粒度,将其分解为与视觉语言相关的14种能力,并引入多模态丰富评分者来评估每个数据候选者的能力。为了促进多样性,考虑到对齐阶段的固有目标,我们以交互风格作为多样性指标,并使用多模态丰富风格器来识别数据指令模式。通过这种方式,我们的多模态丰富评分器和风格器(mmSSR)确保以多样化的形式向用户传递高得分的信息。无需基于嵌入的聚类或贪婪采样,mmSSR可有效地扩展到数百万个不同预算约束的数据,支持通用或特定能力获取的定制,并促进无需培训的通用化到新领域进行整理。在10多个实验环境中,经过14个多模态基准验证,与随机抽样、基线策略和最先进的筛选方法相比,我们表现出了持续的优势,在仅使用260万数据的30%的情况下实现了99.1%的完全性能。
论文及项目相关链接
PDF update comparison with sota and analysis
Summary
本文探讨了基于大型预训练语言模型(LLM)的多模态LLM(MLLM)在数据选择和评价方面的挑战与创新。研究提出通过重新定义质量度量的粒度,将其分解为14种与视觉语言相关的能力,并引入多模态丰富评分器来评估每个数据候选者的能力。同时,为了促进多样性,研究采用交互风格作为多样性指标,并使用多模态丰富风格器来识别数据指令模式。通过这些方法,研究开发的mmSSR技术能够在不同预算约束下,有效扩展到数百万数据,支持通用或特定能力获取需求的定制,并促进对新领域的无训练泛化。实验结果显示,与随机采样、基准策略以及先进的选择方法相比,该方法在多个实验设置和14个多模态基准测试中表现一致地更好,以仅使用30%的260万数据实现了99.1%的完全性能。
Key Takeaways
- 预训练的大型语言模型(LLMs)在微调阶段只需要最少的监督。
- 数据选择和研究的最新进展证实了这一假设。
- 多模态LLM(MLLMs)在提高数据选择和重要性方面有更复杂的需求。
- 为了有效地收集多模式教学数据,重新定义了质量度量的粒度,并引入了多模态丰富评分器。
- 交互风格被视为数据多样性的一个重要指标。
- mmSSR技术能够在不同预算约束下有效扩展到大量数据,并表现出卓越的性能。
点此查看论文截图

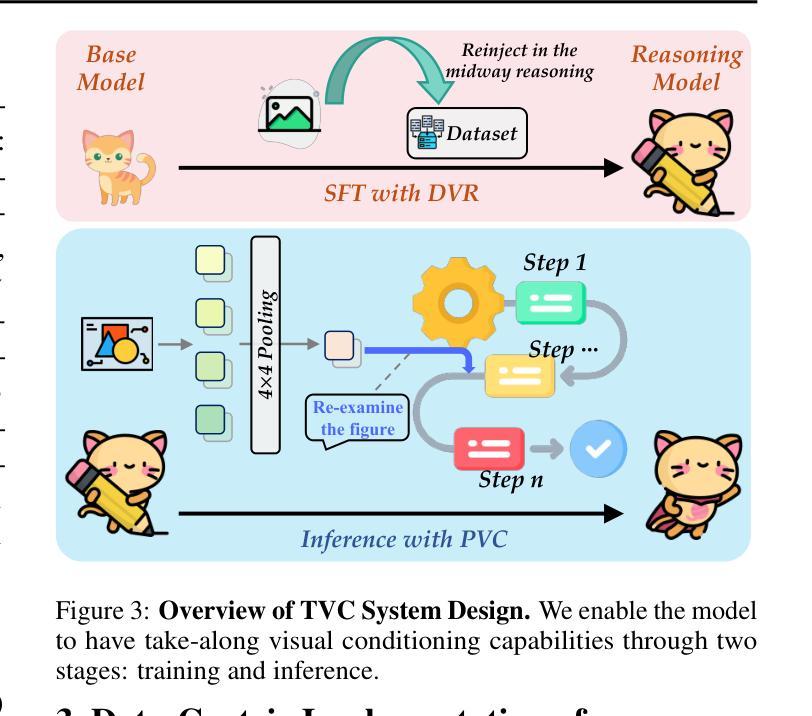
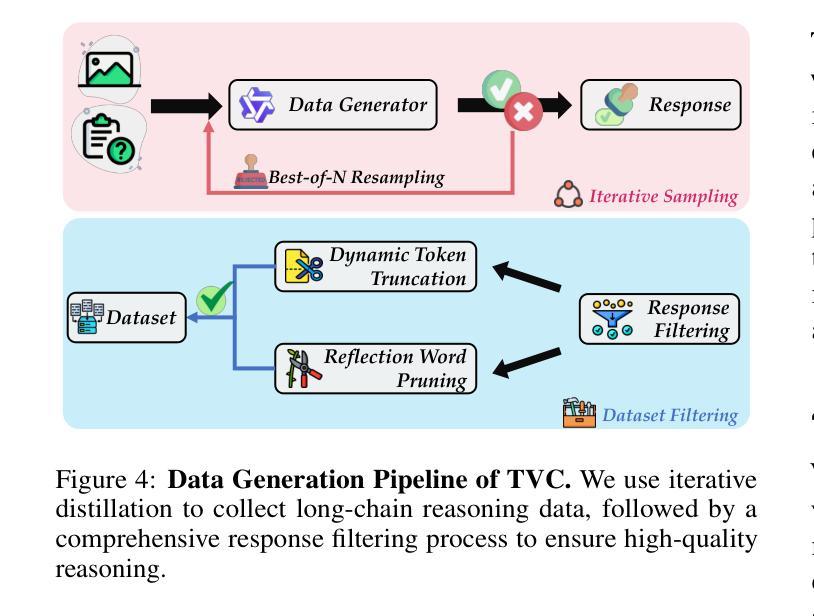
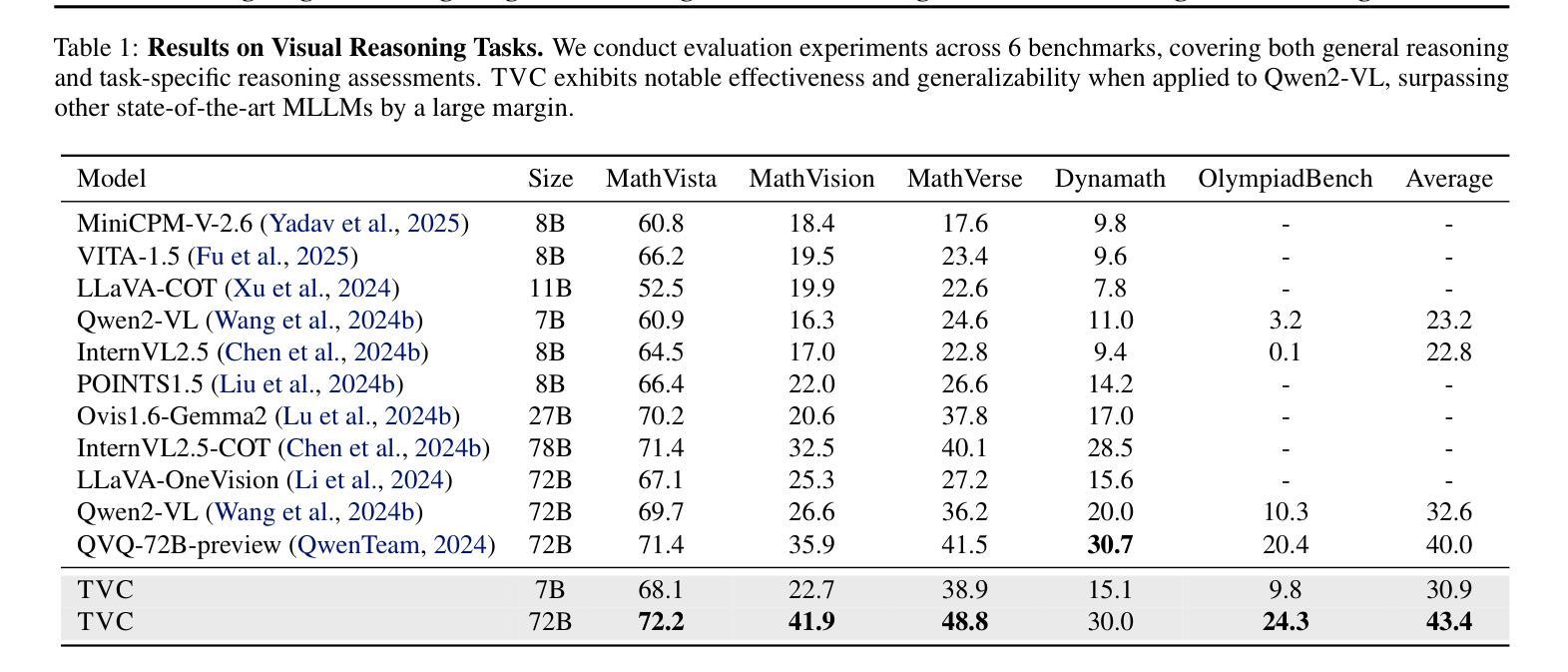
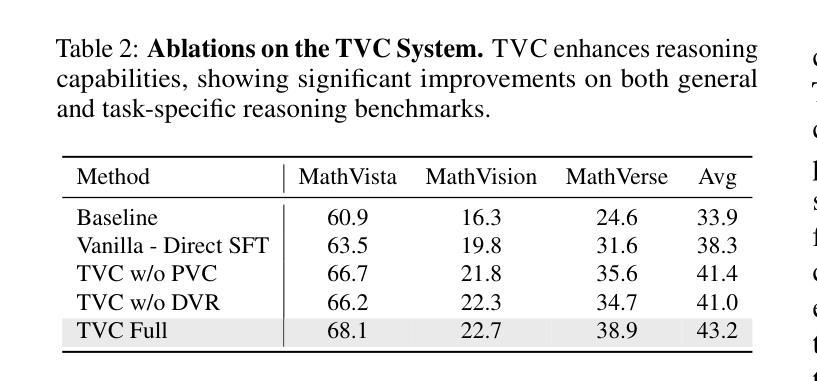
Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
Authors:Hai-Long Sun, Zhun Sun, Houwen Peng, Han-Jia Ye
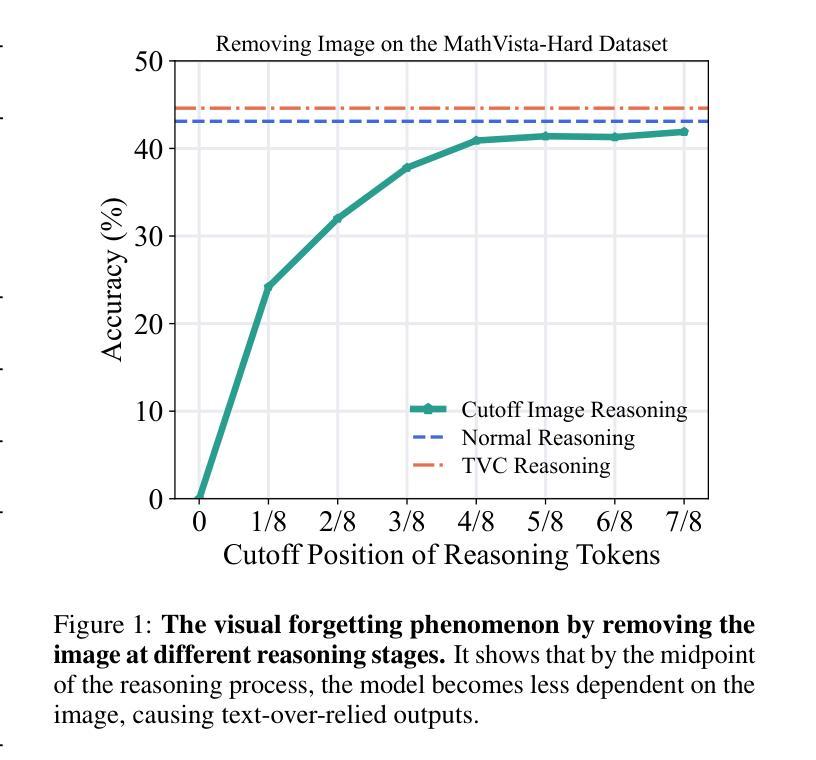
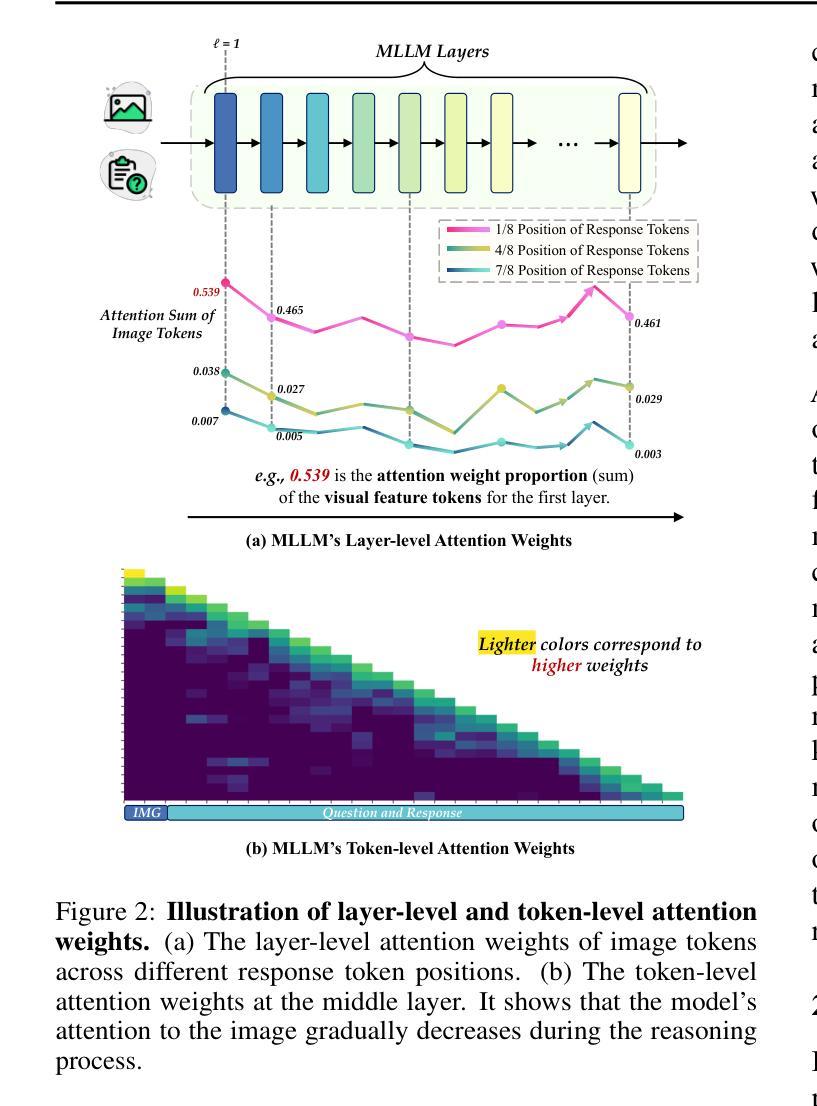
Recent advancements in Large Language Models (LLMs) have demonstrated enhanced reasoning capabilities, evolving from Chain-of-Thought (CoT) prompting to advanced, product-oriented solutions like OpenAI o1. During our re-implementation of this model, we noticed that in multimodal tasks requiring visual input (e.g., geometry problems), Multimodal LLMs (MLLMs) struggle to maintain focus on the visual information, in other words, MLLMs suffer from a gradual decline in attention to visual information as reasoning progresses, causing text-over-relied outputs. To investigate this, we ablate image inputs during long-chain reasoning. Concretely, we truncate the reasoning process midway, then re-complete the reasoning process with the input image removed. We observe only a ~2% accuracy drop on MathVista’s test-hard subset, revealing the model’s textual outputs dominate the following reasoning process. Motivated by this, we propose Take-along Visual Conditioning (TVC), a strategy that shifts image input to critical reasoning stages and compresses redundant visual tokens via dynamic pruning. This methodology helps the model retain attention to the visual components throughout the reasoning. Our approach achieves state-of-the-art performance on average across five mathematical reasoning benchmarks (+3.4% vs previous sota), demonstrating the effectiveness of TVC in enhancing multimodal reasoning systems.
近期大型语言模型(LLM)的进步已经展现出增强的推理能力,从思维链(CoT)提示发展到面向产品的先进解决方案,例如OpenAI o1。在我们重新实现此模型时,我们发现多模态任务需要视觉输入(例如几何问题),多模态LLM(MLLM)在维持对视觉信息的关注方面遇到困难。换句话说,随着推理的进行,MLLM对视觉信息的关注逐渐下降,导致过度依赖文本输出。为了调查这一点,我们在长链推理过程中消除图像输入。具体来说,我们在推理过程中中途截断,然后移除输入图像重新完成推理过程。我们在MathVista的硬测试子集上仅观察到约2%的准确率下降,表明模型的文本输出主导了后续的推理过程。受此启发,我们提出了“随行视觉条件”(TVC)策略,该策略将图像输入转移到关键的推理阶段,并通过动态剪枝压缩冗余的视觉标记。这种方法有助于模型在整个推理过程中保持对视觉成分的注意力。我们的方法平均在五个数学推理基准测试上达到最新水平(+3.4%对比之前的最优水平),证明了TVC在增强多模态推理系统方面的有效性。
论文及项目相关链接
PDF The project page is available at https://sun-hailong.github.io/projects/TVC
Summary
近期LLM在推理能力上的进步从Chain-of-Thought(CoT)提示发展到OpenAI o1等面向产品的先进解决方案。在重新实现此模型时发现,在多模态任务中,Multimodal LLMs(MLLMs)在推理过程中难以维持对视觉信息的关注,导致文本过度依赖输出。研究通过截断推理过程并移除图像输入进行观察,发现仅在MathVista的test-hard子集上准确率下降约2%,显示模型输出主要由文本驱动。为此,提出Take-along Visual Conditioning(TVC)策略,将图像输入转移到关键推理阶段,并通过动态剪枝压缩冗余视觉符号。该方法有助于模型在推理过程中保持对视觉成分的注意力。在五个数学推理基准测试中,该方法达到最新水平(+3.4%),证明TVC在提高多模态推理系统方面的有效性。
Key Takeaways
- LLMs在多模态任务中面临对视觉信息关注不足的问题。
- MLLMs在推理过程中会过度依赖文本输出。
- 通过截断并移除图像输入的实验观察,发现模型对视觉信息的关注度下降。
- 提出Take-along Visual Conditioning(TVC)策略,将图像输入转移到关键推理阶段。
- TVC策略通过动态剪枝压缩冗余视觉符号,帮助模型保持对视觉成分的注意力。
- 在五个数学推理基准测试中,TVC策略达到最新水平,性能提升显著。
点此查看论文截图

Agents Play Thousands of 3D Video Games
Authors:Zhongwen Xu, Xianliang Wang, Siyi Li, Tao Yu, Liang Wang, Qiang Fu, Wei Yang
We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL’s effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead. Experiment results on the 3D video games are best viewed on https://zhongwen.one/projects/portal .
我们推出了PORTAL,这是一个新型框架,用于开发能够通过语言指导策略生成玩数千款3D视频游戏的人工智能代理。通过将决策问题转变为语言建模任务,我们的方法利用大型语言模型(LLM)来生成以领域特定语言(DSL)表示的行为树。这种方法消除了传统强化学习方法的计算负担,同时保留了战略深度和快速适应性。我们的框架引入了一种混合策略结构,该结构结合了基于规则的节点和神经网络组件,能够实现高级战略推理和精确的低级控制。采用融合定量游戏指标和视觉语言模型分析的双重反馈机制,促进了战术和战略层面策略的迭代改进。所得到的策略可即时部署、人类可解释,并能够跨不同游戏环境进行推广。实验结果证明了PORTAL在数千款第一人称射击(FPS)游戏中的有效性,与传统方法相比,在开发效率、策略推广和行为多样性方面都有显著提高。PORTAL代表了游戏AI开发中的一项重大进展,为创建能够在数千款商业视频游戏中运行且开发成本极低的复杂代理提供了实用解决方案。有关3D视频游戏的实验结果请访问 https://zhongwen.one/projects/portal 查看效果最佳。
论文及项目相关链接
Summary
基于语言指导策略生成框架PORTAL,实现人工智能在三千维游戏中的应用。利用大语言模型将决策问题转化为语言建模任务,生成以领域特定语言表示的行为树,提升策略深度和快速适应性,同时降低计算负担。引入混合政策结构,结合规则节点和神经网络组件,实现高层战略推理和精确低级控制。通过结合定量游戏指标和视觉语言模型分析的双反馈机制,实现战术和战略层面的政策迭代改进。政策即时部署、人类可解释,可推广至不同游戏环境。在数千款第一人称射击游戏中验证了PORTA的有效性,相较于传统方法显著提高开发效率、政策推广和行为多样性。详情请访问 https://zhongwen.one/projects/portal 查看实验结果。
Key Takeaways
- PORTAL是一个支持多种游戏的AI开发框架,旨在解决游戏AI的开发效率和复杂性。
- 通过将决策问题转化为语言建模任务,利用大型语言模型(LLM)生成行为树。
- 引入混合政策结构以实现高级策略推理和低级精确控制相结合的能力。
点此查看论文截图


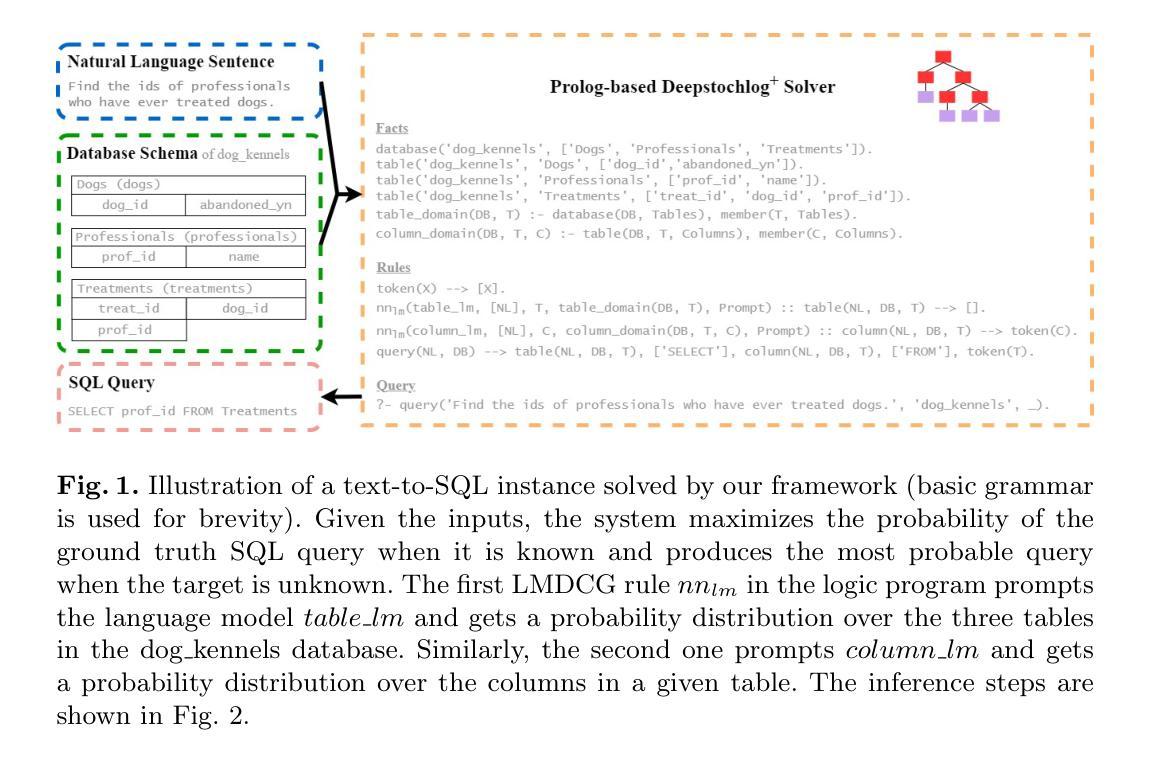
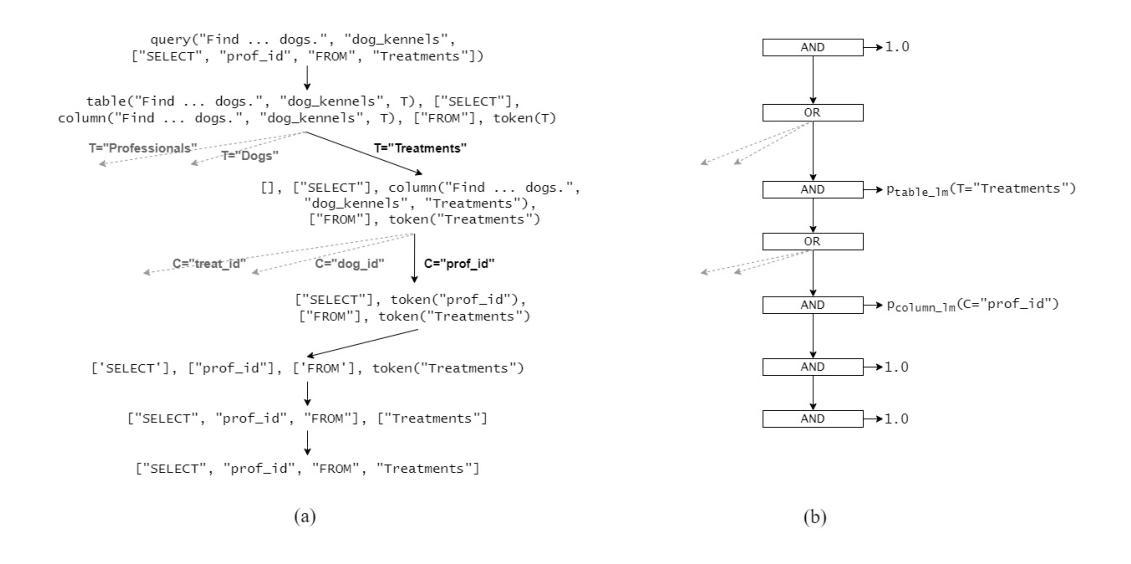
Valid Text-to-SQL Generation with Unification-based DeepStochLog
Authors:Ying Jiao, Luc De Raedt, Giuseppe Marra
Large language models have been used to translate natural language questions to SQL queries. Without hard constraints on syntax and database schema, they occasionally produce invalid queries that are not executable. These failures limit the usage of these systems in real-life scenarios. We propose a neurosymbolic framework that imposes SQL syntax and schema constraints with unification-based definite clause grammars and thus guarantees the generation of valid queries. Our framework also builds a bi-directional interface to language models to leverage their natural language understanding abilities. The evaluation results on a subset of SQL grammars show that all our output queries are valid. This work is the first step towards extending language models with unification-based grammars. We demonstrate this extension enhances the validity, execution accuracy, and ground truth alignment of the underlying language model by a large margin. Our code is available at https://github.com/ML-KULeuven/deepstochlog-lm.
大型语言模型已被用于将自然语言问题翻译为SQL查询。在不受语法和数据库模式严格约束的情况下,它们偶尔会生成无法执行的无效查询。这些失败限制了这些系统在现实场景中的使用。我们提出了一种神经符号框架,该框架通过基于统一的确定性子句语法来实施SQL语法和模式约束,从而确保生成有效的查询。我们的框架还建立了一个与语言模型的双向接口,以利用其自然语言理解能力。在SQL语法子集上的评估结果表明,我们输出的所有查询都是有效的。这项工作是基于统一的语法扩展语言模型的第一步。我们证明这种扩展大大提高了基础语言模型的有效性、执行准确性和与真实情况的匹配度。我们的代码可在https://github.com/ML-KULeuven/deepstochlog-lm获取。
论文及项目相关链接
Summary
大型语言模型用于将自然语言问题转换为SQL查询时,可能会因没有严格的语法和数据库模式约束而产生无效的查询。本文提出一种神经符号框架,采用基于统一的确定性子句语法对SQL语法和模式进行约束,确保生成有效的查询。该框架还构建了与语言模型的双向接口,利用其自然语言理解能力。评估结果显示,我们的输出查询均为有效。这项工作是在语言模型中引入基于统一的语法的重要尝试,显著提高语言模型的有效性、执行准确性和与真实数据的对齐程度。相关代码可通过链接访问。
Key Takeaways
- 大型语言模型在将自然语言转换为SQL查询时可能产生无效查询。
- 提出的神经符号框架通过引入SQL语法和模式约束确保生成有效查询。
- 该框架利用基于统一的确定性子句语法构建双向接口与语言模型交互。
- 评估结果显示所有输出查询均为有效。
- 与传统语言模型相比,此框架显著提高了模型的有效性、执行准确性和与真实数据的对齐程度。
- 该框架的实现在GitHub上有公开的代码可供访问。
点此查看论文截图


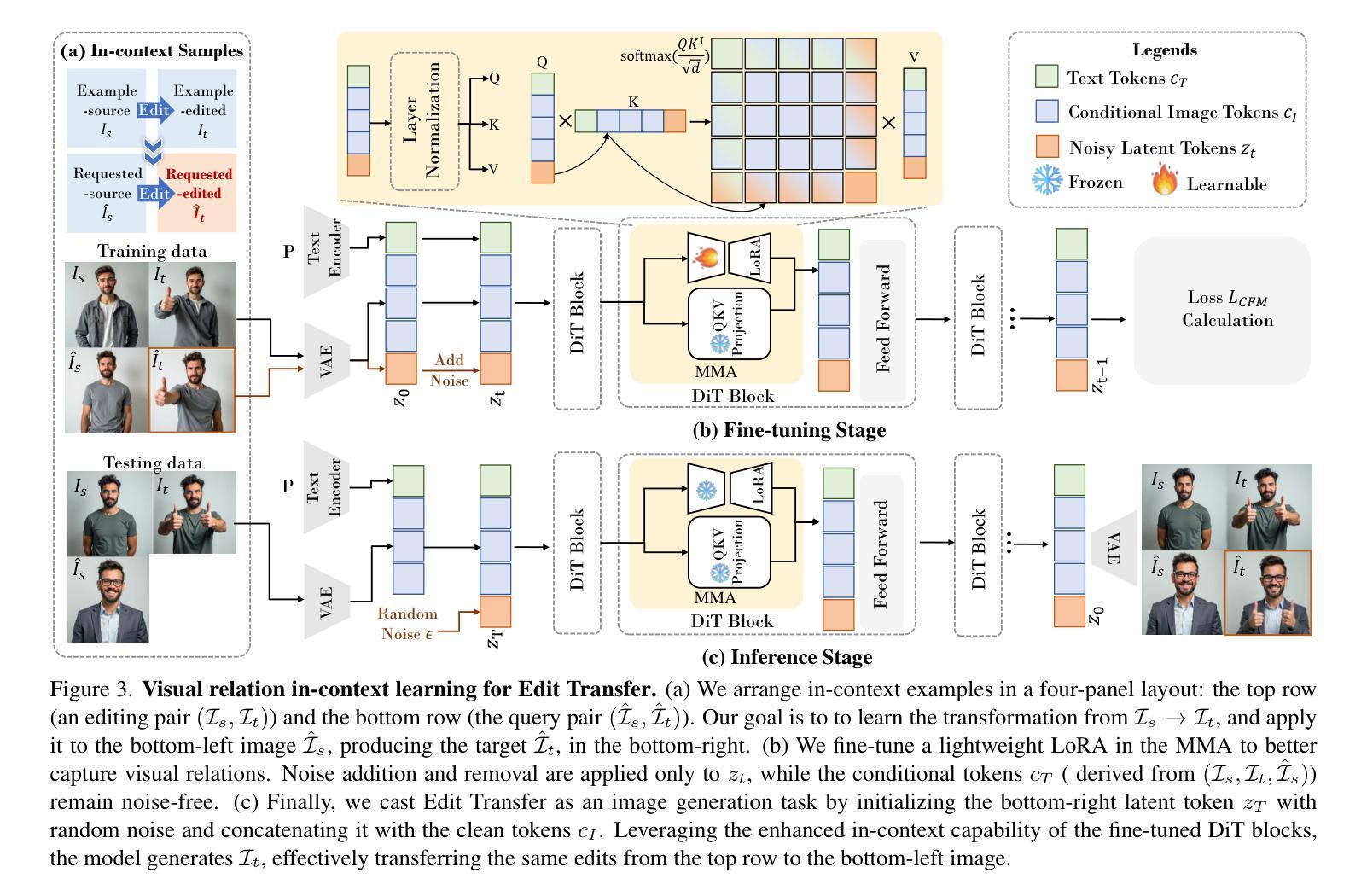
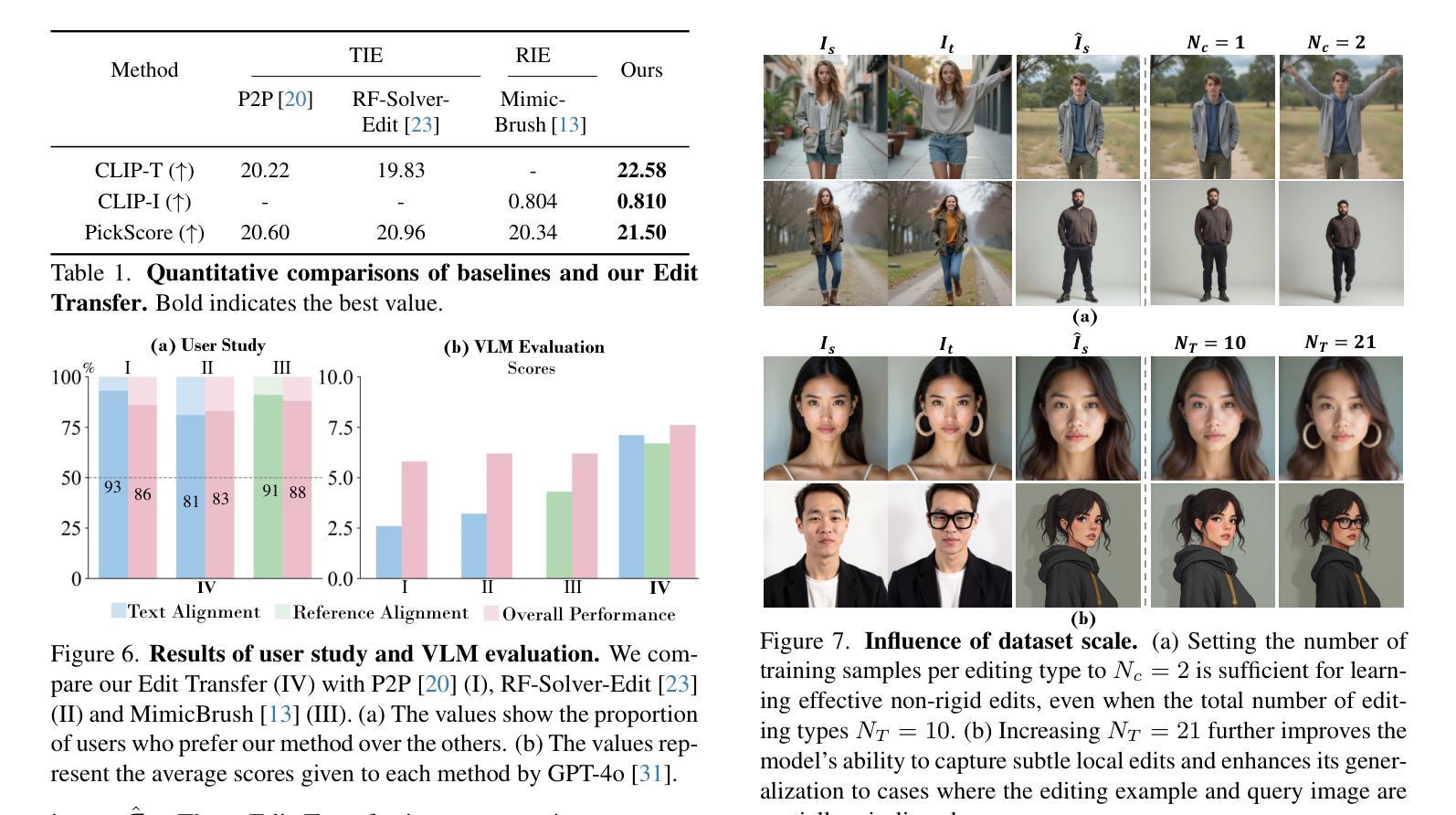
Edit Transfer: Learning Image Editing via Vision In-Context Relations
Authors:Lan Chen, Qi Mao, Yuchao Gu, Mike Zheng Shou
We introduce a new setting, Edit Transfer, where a model learns a transformation from just a single source-target example and applies it to a new query image. While text-based methods excel at semantic manipulations through textual prompts, they often struggle with precise geometric details (e.g., poses and viewpoint changes). Reference-based editing, on the other hand, typically focuses on style or appearance and fails at non-rigid transformations. By explicitly learning the editing transformation from a source-target pair, Edit Transfer mitigates the limitations of both text-only and appearance-centric references. Drawing inspiration from in-context learning in large language models, we propose a visual relation in-context learning paradigm, building upon a DiT-based text-to-image model. We arrange the edited example and the query image into a unified four-panel composite, then apply lightweight LoRA fine-tuning to capture complex spatial transformations from minimal examples. Despite using only 42 training samples, Edit Transfer substantially outperforms state-of-the-art TIE and RIE methods on diverse non-rigid scenarios, demonstrating the effectiveness of few-shot visual relation learning.
我们引入了一种新设置,名为“编辑传输”(Edit Transfer),在该设置中,模型仅从一个源目标示例中学习变换,并将其应用于新的查询图像。虽然基于文本的方法在通过文本提示进行语义操作方面表现出色,但它们通常对于精确的几何细节(例如姿势和视点变化)感到棘手。另一方面,基于参考的编辑通常侧重于风格或外观,而在非刚性变换方面表现不佳。通过从源目标对中学习编辑变换,Edit Transfer 缓解了仅使用文本和外观为中心的参考的限制。我们从大型语言模型中的上下文学习汲取灵感,提出了一种基于DiT的文本到图像模型的视觉关系上下文学习范式。我们将编辑示例和查询图像排列成统一的四面板组合,然后应用轻量级的LoRA微调,以从少量示例中学习复杂的空间变换。尽管只使用了42个训练样本,Edit Transfer在多种非刚性场景上大幅超越了最先进的TIE和RIE方法,证明了少量视觉关系学习的有效性。
论文及项目相关链接
Summary
该论文介绍了一种新的技术——Edit Transfer,该技术能够从单一源目标实例学习转换并应用于新查询图像。Edit Transfer弥补了纯文本和外观参考方法的局限性,通过从源到目标对显式学习编辑转换来实现。该技术受到大型语言模型中上下文学习的启发,建立在一个基于DiT的文本到图像模型之上。通过将编辑示例和查询图像组合成统一的四面板复合体,然后应用轻量级的LoRA微调来从少量示例中学习复杂的空间转换。尽管只使用了42个训练样本,但Edit Transfer在多样的非刚性场景上大幅超越了最新的TIE和RIE方法,证明了少数视觉关系学习的有效性。
Key Takeaways
- Edit Transfer技术能从单一源目标实例学习转换并应用于新查询图像。
- Edit Transfer弥补了文本方法和外观参考方法的局限性。
- 该技术通过从源到目标的显式学习来实现编辑转换。
- Edit Transfer受到大型语言模型中上下文学习的启发。
- 该技术建立在一个基于DiT的文本到图像模型之上。
- 通过将编辑示例和查询图像组合成四面板复合体来应用编辑转换。
点此查看论文截图




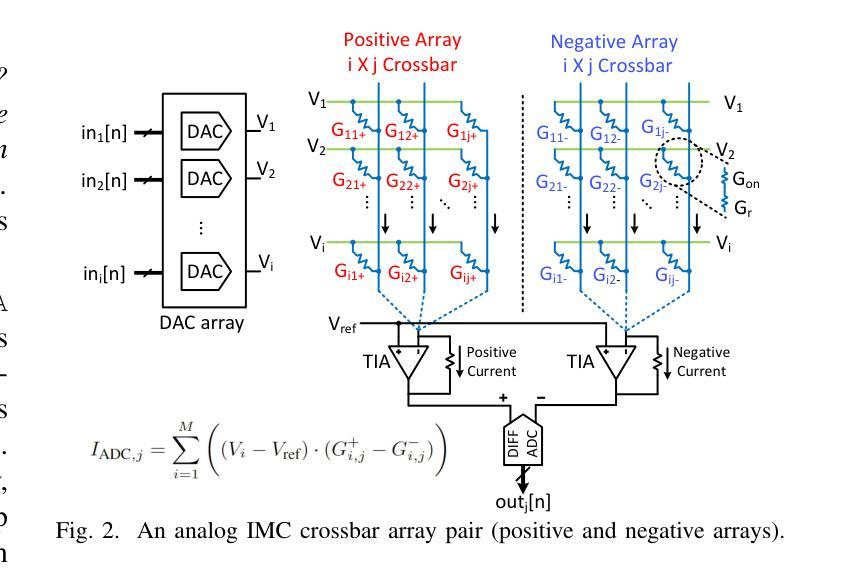
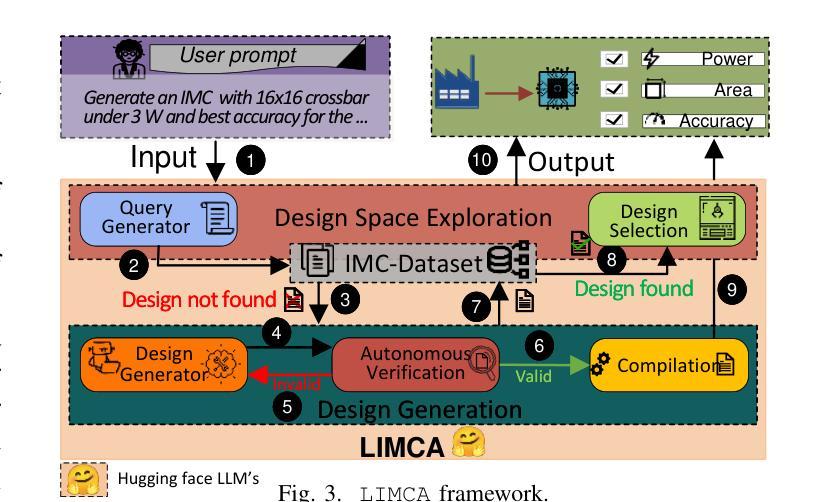
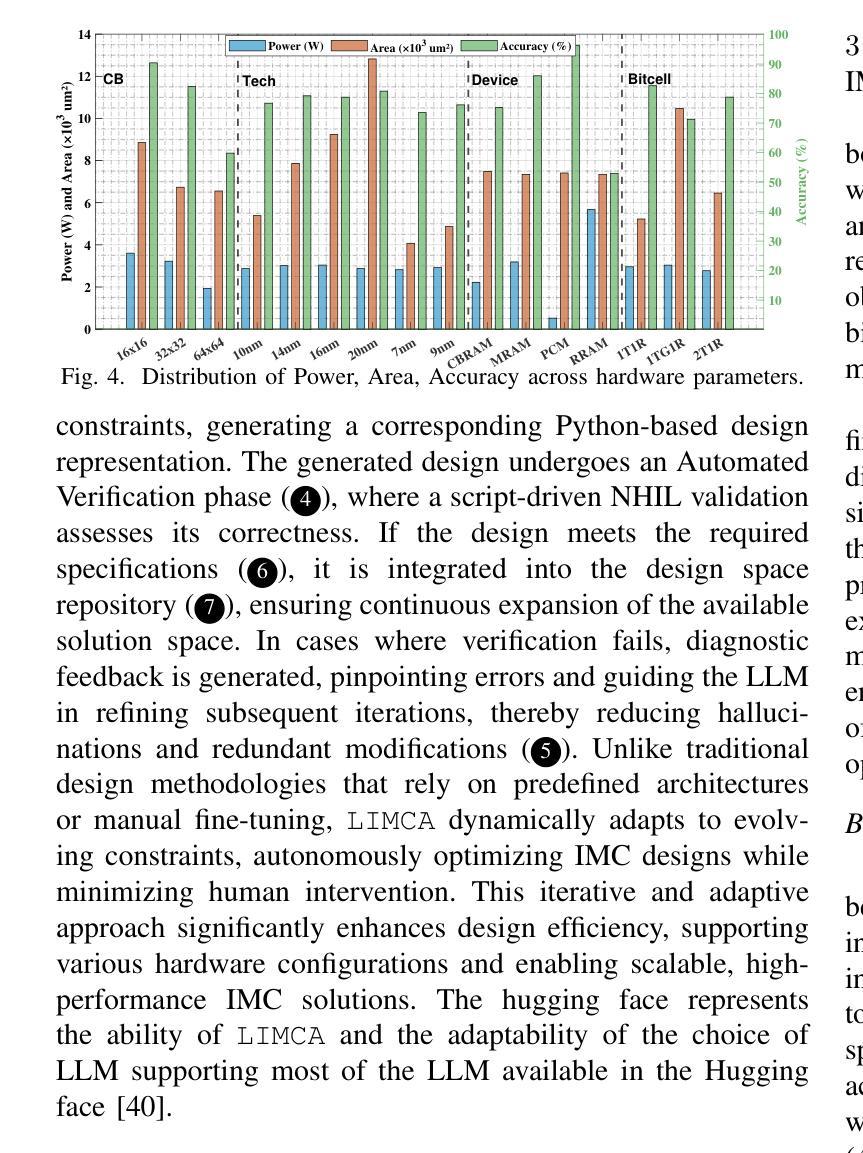
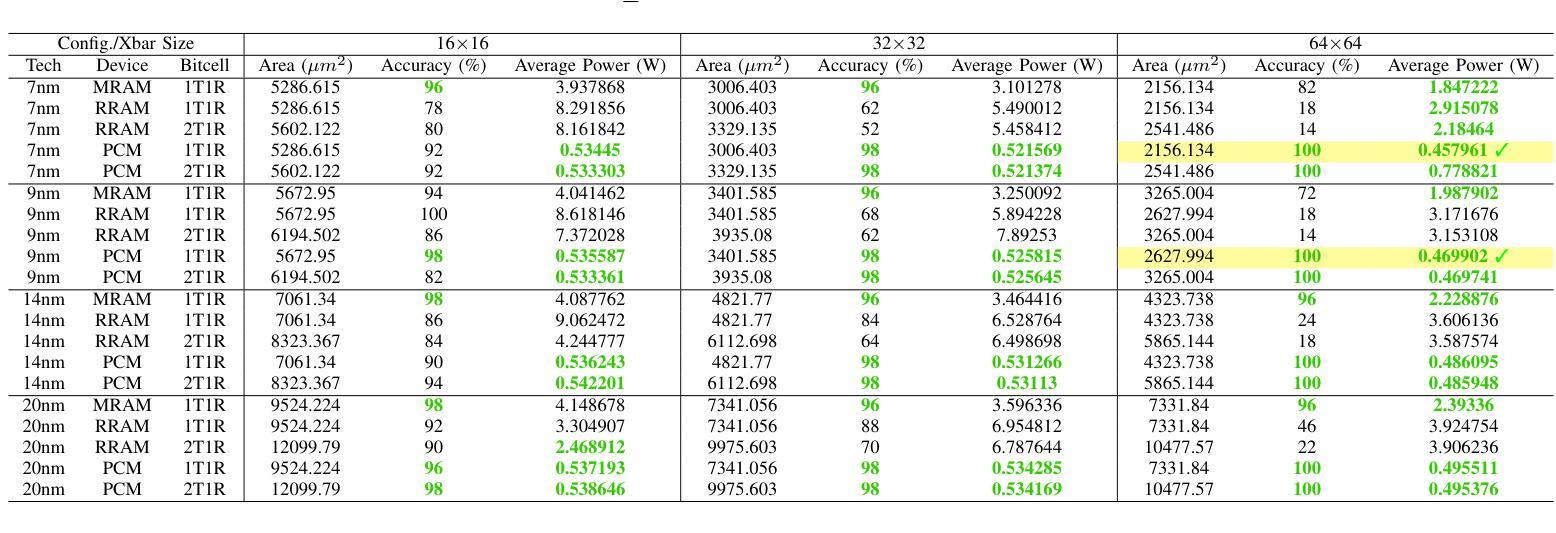
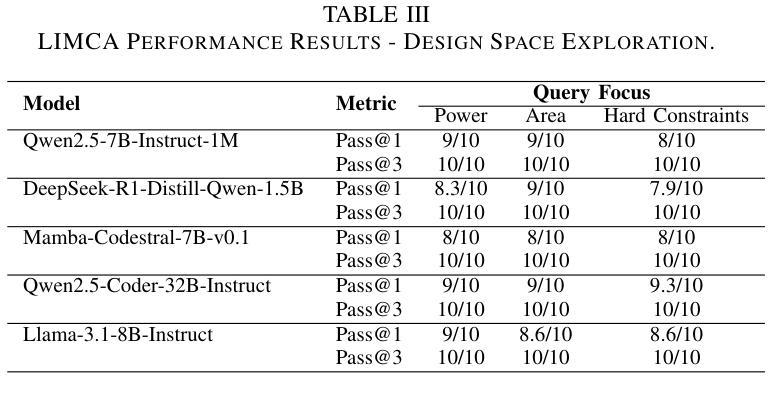
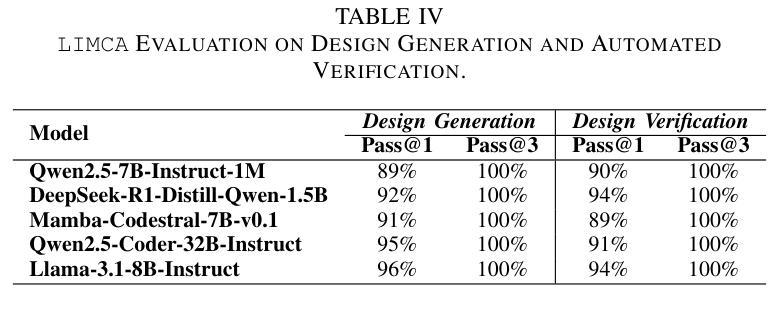
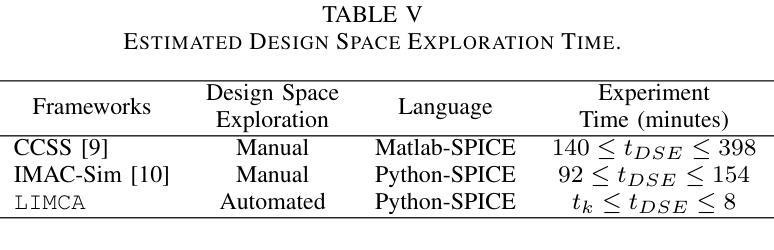
LIMCA: LLM for Automating Analog In-Memory Computing Architecture Design Exploration
Authors:Deepak Vungarala, Md Hasibul Amin, Pietro Mercati, Arnob Ghosh, Arman Roohi, Ramtin Zand, Shaahin Angizi
Resistive crossbars enabling analog In-Memory Computing (IMC) have emerged as a promising architecture for Deep Neural Network (DNN) acceleration, offering high memory bandwidth and in-situ computation. However, the manual, knowledge-intensive design process and the lack of high-quality circuit netlists have significantly constrained design space exploration and optimization to behavioral system-level tools. In this work, we introduce LIMCA, a novel fine-tune-free Large Language Model (LLM)-driven framework for automating the design and evaluation of IMC crossbar architectures. Unlike traditional approaches, LIMCA employs a No-Human-In-Loop (NHIL) automated pipeline to generate and validate circuit netlists for SPICE simulations, eliminating manual intervention. LIMCA systematically explores the IMC design space by leveraging a structured dataset and LLM-based performance evaluation. Our experimental results on MNIST classification demonstrate that LIMCA successfully generates crossbar designs achieving $\geq$96% accuracy while maintaining a power consumption $\leq$3W, making this the first work in LLM-assisted IMC design space exploration. Compared to existing frameworks, LIMCA provides an automated, scalable, and hardware-aware solution, reducing design exploration time while ensuring user-constrained performance trade-offs.
电阻式交叉结构为实现模拟内存计算(IMC)提供了有前景的架构,用于加速深度神经网络(DNN),提供高内存带宽和现场计算功能。然而,手动、知识密集型的设计流程以及缺乏高质量的电路网表,极大地限制了设计空间的探索和优化,使其仅适用于行为级系统工具。在此工作中,我们介绍了LIMCA,这是一种无需微调的大型语言模型(LLM)驱动框架,可自动化IMC交叉结构的设计评估。不同于传统方法,LIMCA采用无人工闭环(NHIL)自动化管道生成和验证SPICE模拟的电路网表,消除了人工干预。LIMCA通过利用结构化数据集和基于LLM的性能评估,系统地探索了IMC设计空间。我们在MNIST分类上的实验结果表明,LIMCA成功生成交叉结构设计,准确率≥96%,同时保持功耗≤3W,这是LLM辅助IMC设计空间探索的首次工作。与现有框架相比,LIMCA提供了自动化、可扩展和硬件感知的解决方案,减少了设计探索时间,同时确保用户限制的性能权衡。
论文及项目相关链接
PDF 4 Figures, 5 Tables
Summary
大型语言模型驱动的无人工干预的交叉条设计框架LIMCA,自动化实现内存计算(IMC)架构的设计和优化,提升神经网络加速性能。利用LLM进行性能评估,系统探索设计空间,生成电路网表进行SPICE仿真验证。在MNIST分类实验中,LIMCA成功生成准确度高且功耗低的交叉条设计。
Key Takeaways
- 大型语言模型(LLM)用于自动化设计内存计算(IMC)架构的交叉条,实现无人工干预的自动化设计。
- LLM用于性能评估和系统探索设计空间,提高设计效率。
- LIMCA框架通过生成电路网表进行SPICE仿真验证,确保设计的有效性。
- MNIST分类实验证明,LIMCA生成的交叉条设计达到96%以上的准确度。
- LIMCA设计在保持高性能的同时,实现了低功耗,功率消耗低于或等于3W。
- 与现有框架相比,LIMCA提供自动化、可扩展和硬件感知的解决方案,缩短了设计探索时间。
点此查看论文截图

3DAxisPrompt: Promoting the 3D Grounding and Reasoning in GPT-4o
Authors:Dingning Liu, Cheng Wang, Peng Gao, Renrui Zhang, Xinzhu Ma, Yuan Meng, Zhihui Wang
Multimodal Large Language Models (MLLMs) exhibit impressive capabilities across a variety of tasks, especially when equipped with carefully designed visual prompts. However, existing studies primarily focus on logical reasoning and visual understanding, while the capability of MLLMs to operate effectively in 3D vision remains an ongoing area of exploration. In this paper, we introduce a novel visual prompting method, called 3DAxisPrompt, to elicit the 3D understanding capabilities of MLLMs in real-world scenes. More specifically, our method leverages the 3D coordinate axis and masks generated from the Segment Anything Model (SAM) to provide explicit geometric priors to MLLMs and then extend their impressive 2D grounding and reasoning ability to real-world 3D scenarios. Besides, we first provide a thorough investigation of the potential visual prompting formats and conclude our findings to reveal the potential and limits of 3D understanding capabilities in GPT-4o, as a representative of MLLMs. Finally, we build evaluation environments with four datasets, i.e., ScanRefer, ScanNet, FMB, and nuScene datasets, covering various 3D tasks. Based on this, we conduct extensive quantitative and qualitative experiments, which demonstrate the effectiveness of the proposed method. Overall, our study reveals that MLLMs, with the help of 3DAxisPrompt, can effectively perceive an object’s 3D position in real-world scenarios. Nevertheless, a single prompt engineering approach does not consistently achieve the best outcomes for all 3D tasks. This study highlights the feasibility of leveraging MLLMs for 3D vision grounding/reasoning with prompt engineering techniques.
多模态大型语言模型(MLLMs)在各种任务中展现出令人印象深刻的能力,尤其是当配备精心设计的视觉提示时。然而,现有研究主要集中在逻辑理性和视觉理解上,而MLLM在3D视觉中有效操作的能力仍然是一个正在探索的领域。在本文中,我们介绍了一种新的视觉提示方法,称为3DAxisPrompt,以激发MLLM在现实场景中的3D理解能力。更具体地说,我们的方法利用由Segment Anything Model(SAM)生成的3D坐标轴和掩码,为MLLM提供明确的几何先验,然后将它们令人印象深刻的2D接地和推理能力扩展到现实世界的3D场景。此外,我们首次调查了潜在的视觉提示格式,并得出结论,以揭示GPT-4o作为MLLM代表在3D理解方面的潜力和局限性。最后,我们使用ScanRefer、ScanNet、FMB和nuScene四个数据集构建了评估环境,涵盖各种3D任务。在此基础上,我们进行了广泛的定量和定性实验,证明了所提出方法的有效性。总体而言,我们的研究表明,借助3DAxisPrompt的MLLM可以有效地感知现实场景中物体的3D位置。然而,单一的提示工程方法并不适用于所有3D任务都能取得最佳效果。这项研究强调了利用提示工程技术将MLLM应用于3D视觉接地/推理的可行性。
论文及项目相关链接
Summary
本文介绍了多模态大型语言模型(MLLMs)在3D视觉领域的潜力。通过引入名为3DAxisPrompt的新型视觉提示方法,MLLMs能够在真实世界场景中展现3D理解能力。该方法利用从Segment Anything Model(SAM)生成的3D坐标轴和遮罩,为MLLMs提供明确的几何先验信息,并将其在2D场景中的卓越推理能力扩展到真实世界的3D场景。研究通过多个数据集对MLLMs的潜力进行了全面调查,并发现虽然MLLMs能够有效感知物体在真实世界中的三维位置,但单一提示工程方法并不适用于所有任务。整体而言,该研究展示了MLLMs在结合提示工程技术进行3D视觉定位与推理方面的潜力。
Key Takeaways
- MLLMs在多模态任务中展现出强大的能力,尤其在配备精心设计的视觉提示时更是如此。
- 当前研究主要集中在逻辑理解和视觉认知上,而MLLMs在3D视觉领域的运用仍然是一个探索中的领域。
- 引入了一种新型的视觉提示方法——3DAxisPrompt,用于激发MLLMs在真实世界场景中的3D理解能力。
- 3DAxisPrompt利用SAM生成的3D坐标轴和遮罩为MLLMs提供几何先验信息。
- MLLMs能将其在2D场景中的优秀推理能力扩展到真实世界的3D场景。
- 研究通过多个数据集对MLLMs的潜力进行了全面调查,发现它们在感知物体在真实世界中的三维位置方面具有有效性。
点此查看论文截图

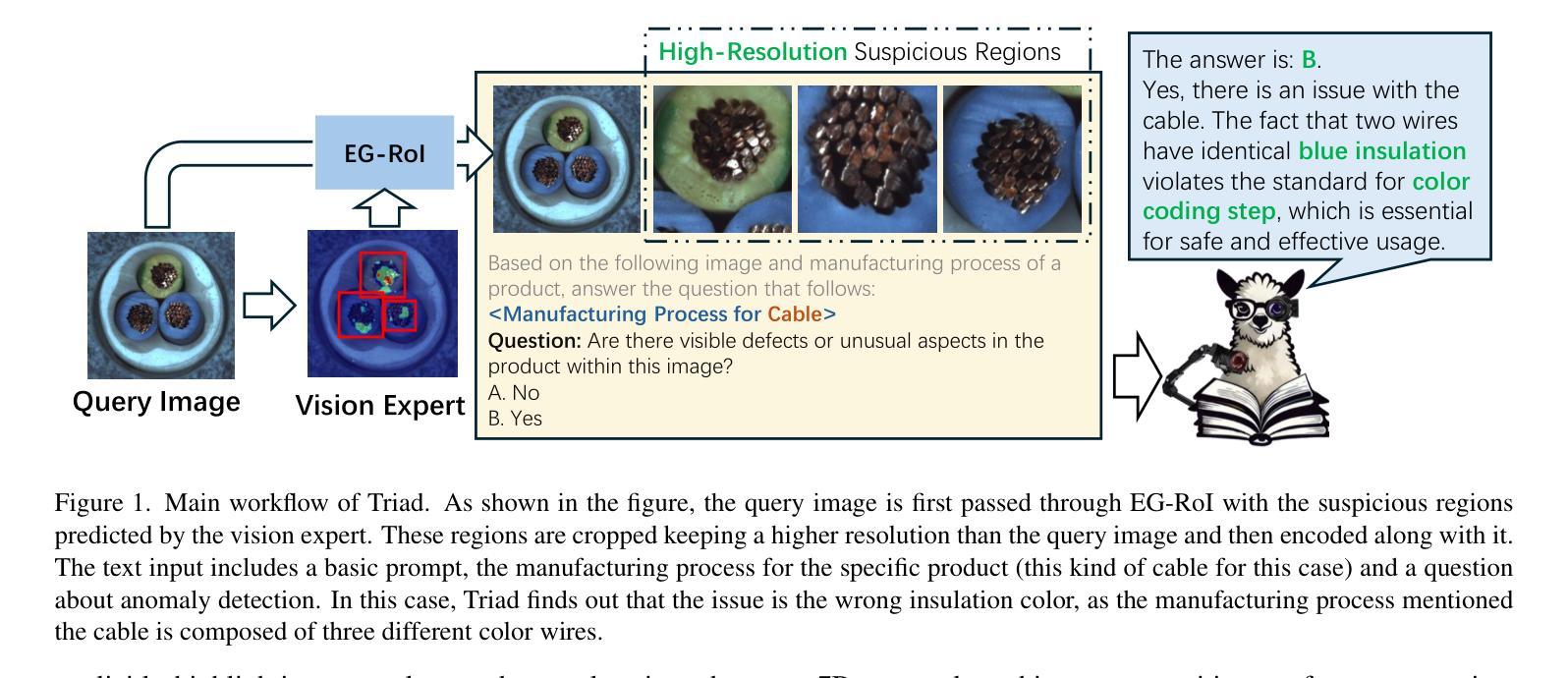
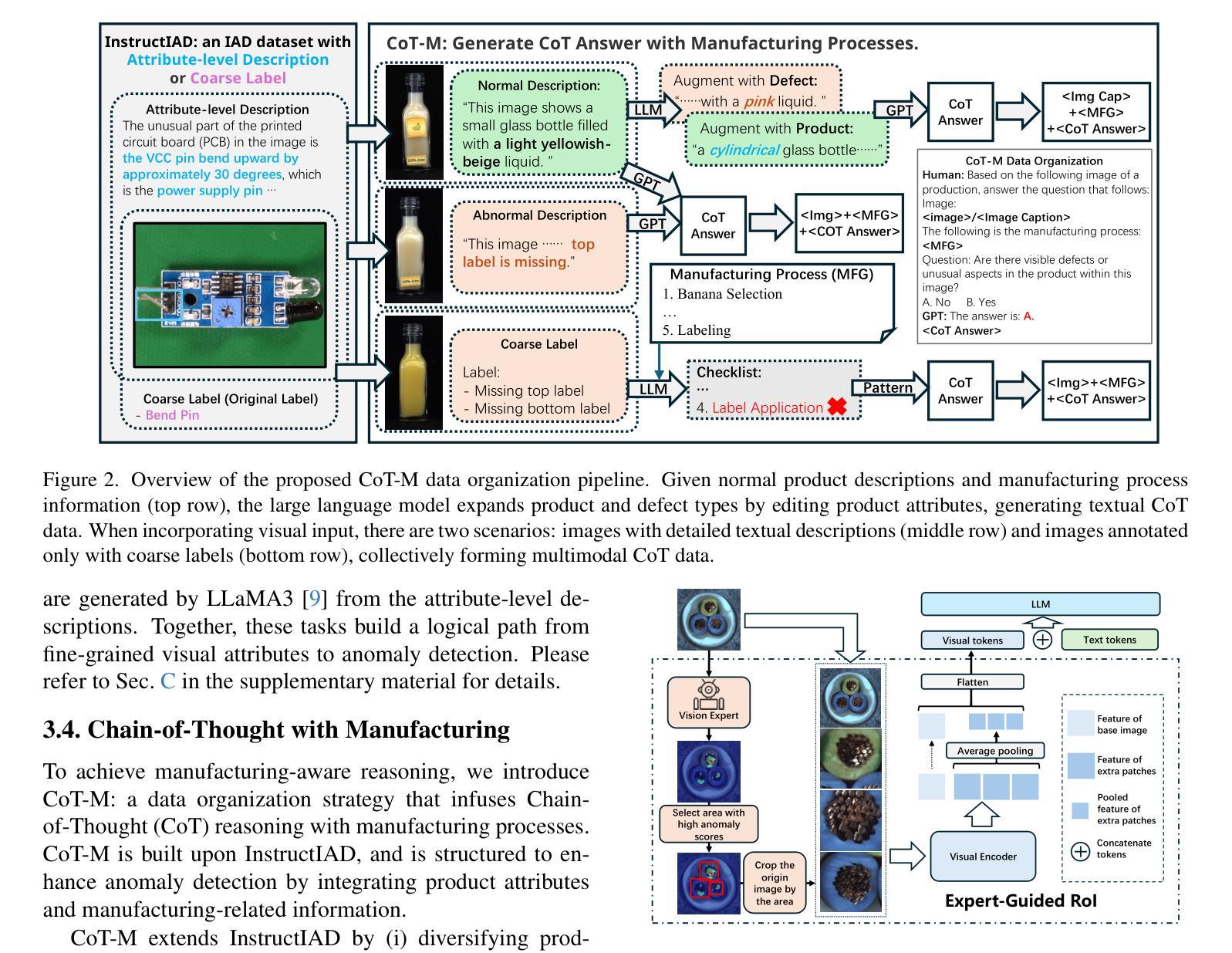
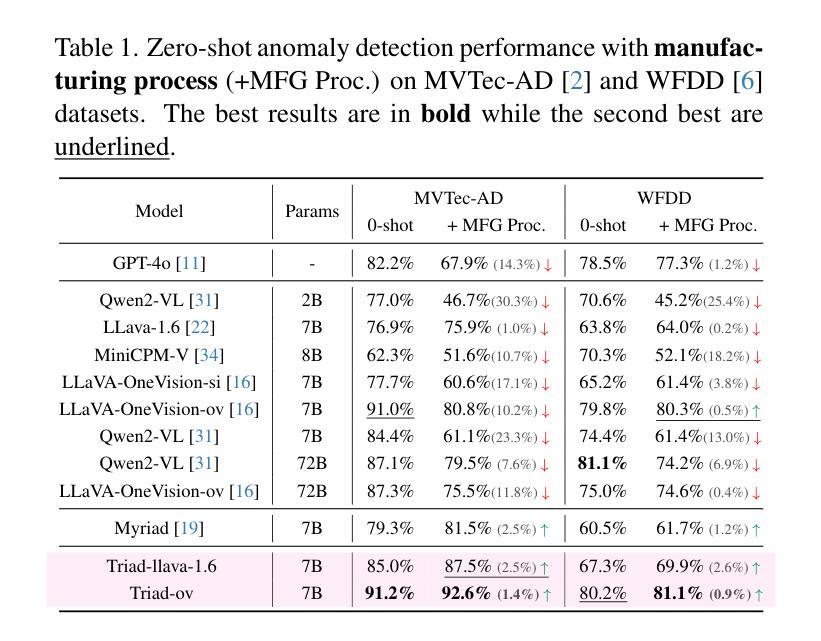
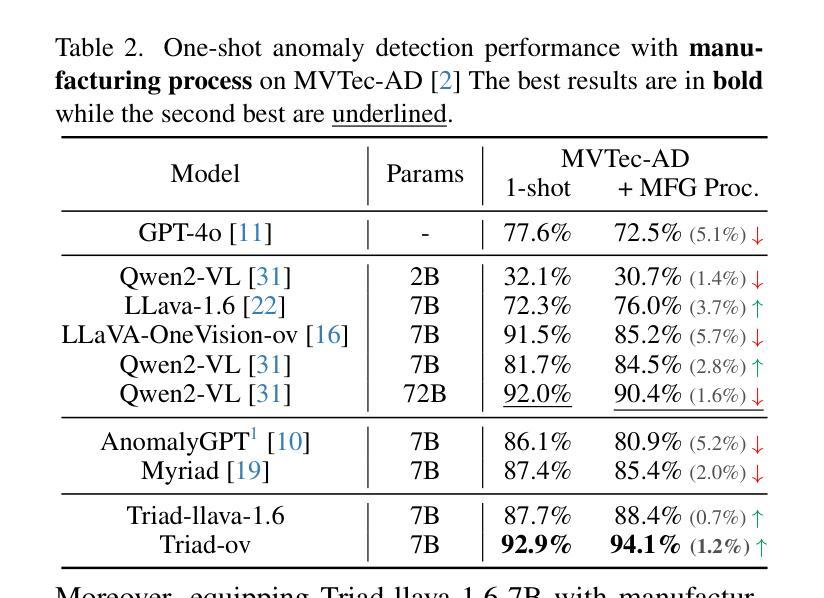
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Authors:Yuanze Li, Shihao Yuan, Haolin Wang, Qizhang Li, Ming Liu, Chen Xu, Guangming Shi, Wangmeng Zuo
Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
尽管最近的方法试图将大型多模态模型(LMM)引入工业异常检测(IAD),但它们在IAD领域的泛化能力远远不如通用模型。我们将造成这种差距的主要原因总结为两个方面。一方面,通用LMM缺乏对视觉模态缺陷的认知,因此无法充分关注缺陷区域。因此,我们提出修改LLaVA模型的AnyRes结构,向LMM提供现有IAD模型识别的潜在异常区域。另一方面,现有方法主要侧重于通过学习缺陷模式或与正常样本进行比较来识别缺陷,但它们缺乏对缺陷原因的理解。考虑到缺陷的产生与制造过程密切相关,我们提出了制造驱动型IAD范式。设计了用于IAD的指令调整数据集(InstructIAD)和结合制造的Chain-of-Thought数据组织方法(CoT-M),以利用制造过程进行IAD。基于上述两个修改,我们提出了Triad,这是一种基于LMM的新方法,结合了专家引导的兴趣区域分词器和制造过程进行工业异常检测。大量实验表明,我们的Triad不仅在与当前LMM的竞争中表现出良好的性能,而且在配备制造过程后实现了更高的准确性。源代码、训练数据和预训练模型将在https://github.com/tzjtatata/Triad上公开。
论文及项目相关链接
Summary:
近期尝试将大型多模态模型(LMMs)引入工业异常检测(IAD)领域的方法,在IAD领域的泛化能力不及通用领域。本文总结了造成这一差距的主要原因,并提出了相应的解决方案。一方面,通用LMMs缺乏对视觉模态缺陷的认知,无法充分关注缺陷区域。因此,我们提出修改LLaVA模型的AnyRes结构,将现有IAD模型识别的潜在异常区域提供给LMMs。另一方面,现有方法主要关注通过学习缺陷模式或与正常样本进行比较来识别缺陷,但缺乏对缺陷原因的理解。考虑到缺陷的产生与制造过程密切相关,我们提出了制造驱动IAD范式。为此设计了IAD指令调优数据集(InstructIAD)和制造过程的CoT-M数据组织方法。基于上述两个修改,我们提出了Triad这一新型基于LMM的方法,结合专家引导的兴趣区域分词器和制造过程进行工业异常检测。实验表明,Triad不仅与当前LMMs相比具有竞争力,而且在配备制造过程后实现了更高的准确性。
Key Takeaways:
- LMMs在IAD领域的泛化能力不及通用领域的原因主要包括缺乏对视觉模态缺陷的认知和缺乏对缺陷原因的理解。
- 为解决LMMs对视觉模态缺陷的认知不足,提出修改LLaVA模型的AnyRes结构,将潜在异常区域信息提供给LMMs。
- 现有IAD方法主要关注缺陷的识别和比较,但缺乏对缺陷产生原因的理解,为此提出制造驱动IAD范式。
- 为实现制造驱动IAD范式,设计了InstructIAD数据集和CoT-M数据组织方法,以利用制造过程进行IAD。
- 提出Triad这一新型基于LMM的方法,结合专家引导的兴趣区域分词器和制造过程进行工业异常检测。
- Triad在大量实验中表现出与当前LMMs相比的竞争力,并且在配备制造过程后实现了更高的准确性。
点此查看论文截图

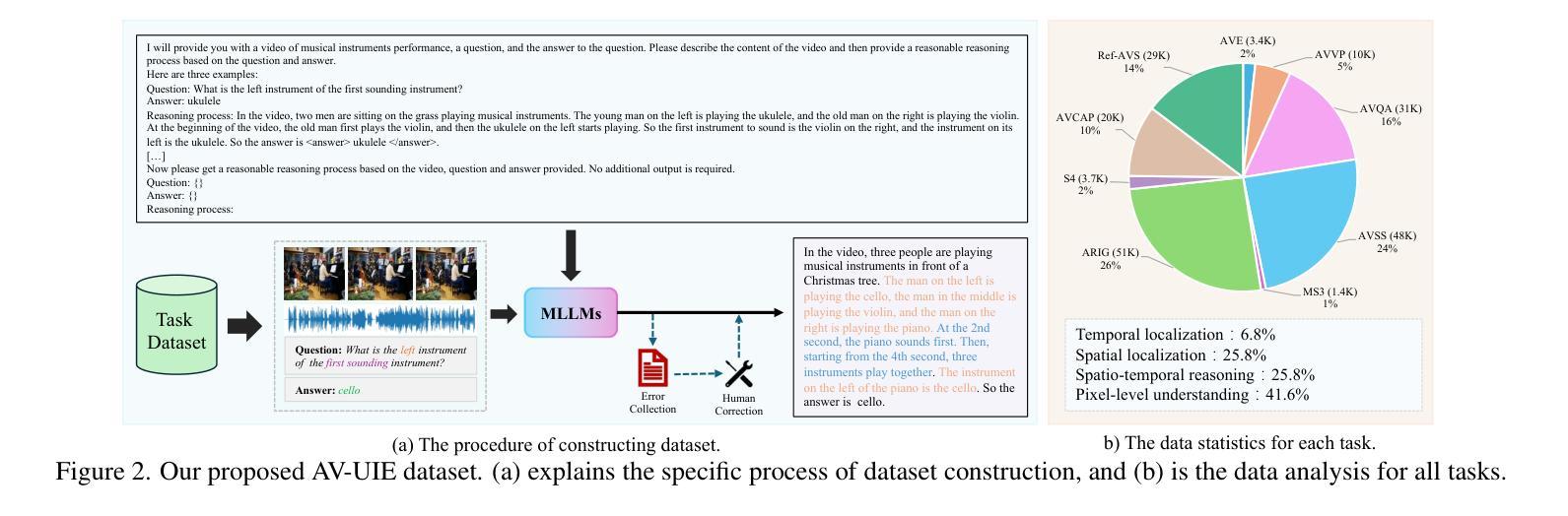
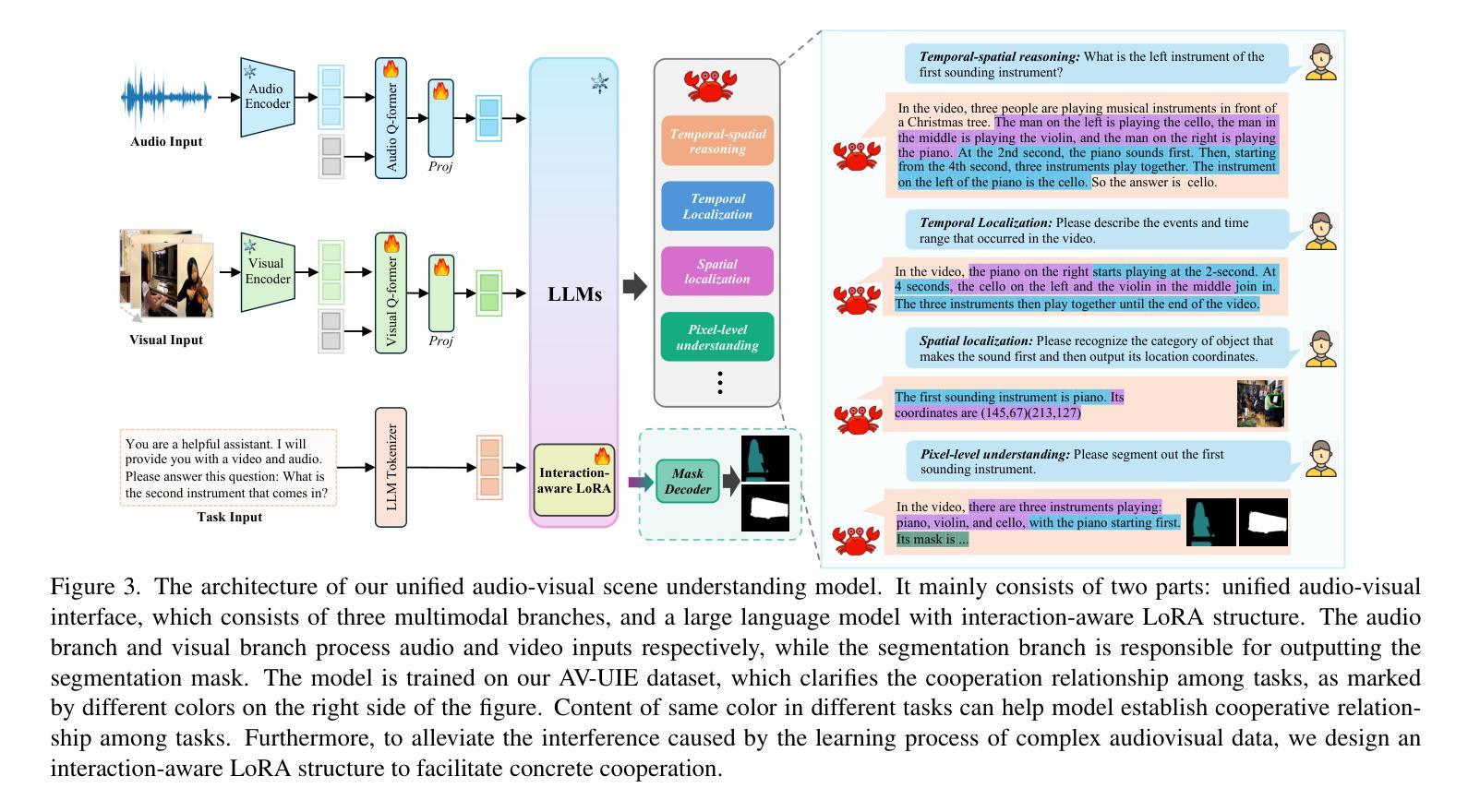
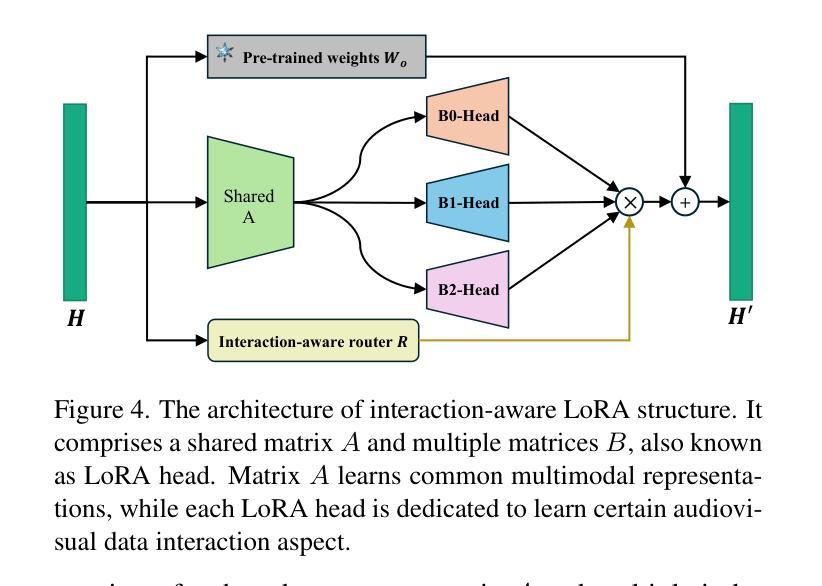
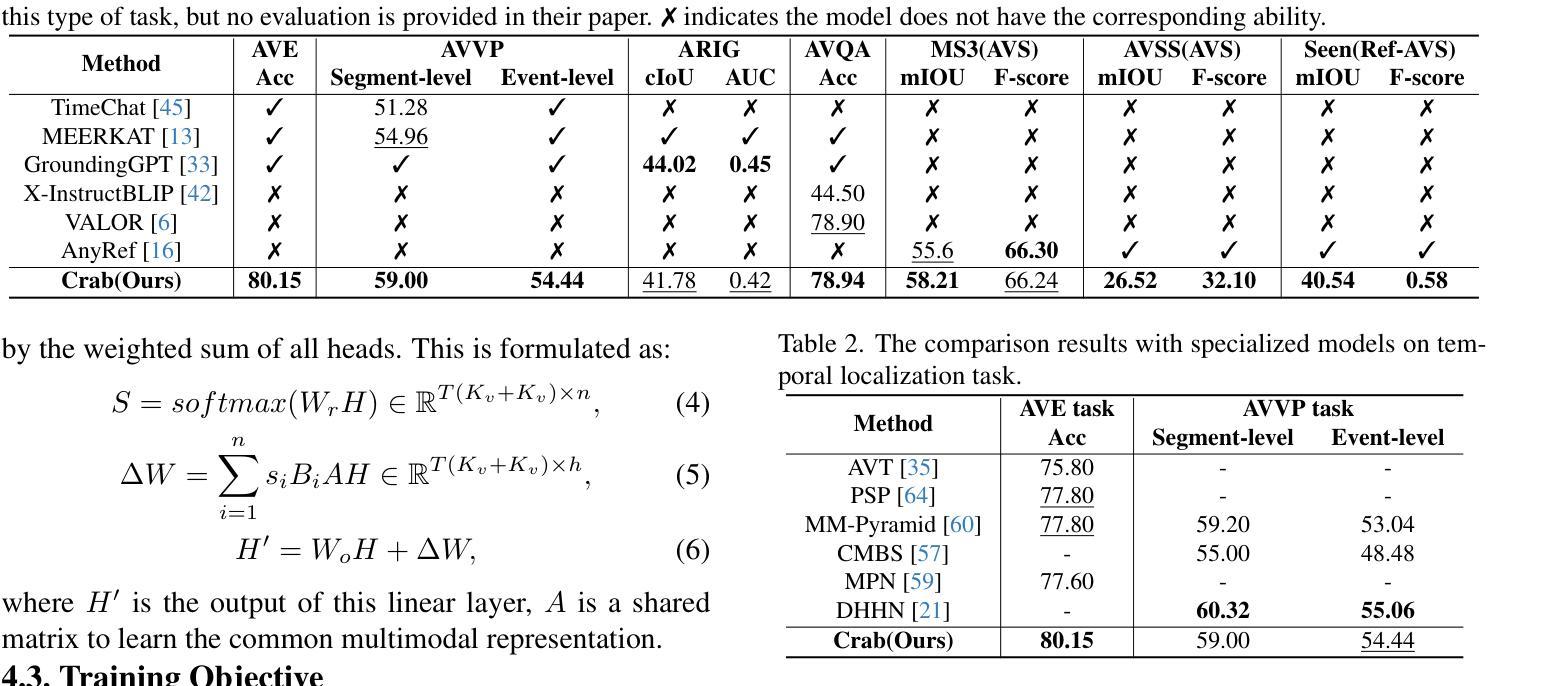
Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Authors:Henghui Du, Guangyao Li, Chang Zhou, Chunjie Zhang, Alan Zhao, Di Hu
In recent years, numerous tasks have been proposed to encourage model to develop specified capability in understanding audio-visual scene, primarily categorized into temporal localization, spatial localization, spatio-temporal reasoning, and pixel-level understanding. Instead, human possesses a unified understanding ability for diversified tasks. Therefore, designing an audio-visual model with general capability to unify these tasks is of great value. However, simply joint training for all tasks can lead to interference due to the heterogeneity of audiovisual data and complex relationship among tasks. We argue that this problem can be solved through explicit cooperation among tasks. To achieve this goal, we propose a unified learning method which achieves explicit inter-task cooperation from both the perspectives of data and model thoroughly. Specifically, considering the labels of existing datasets are simple words, we carefully refine these datasets and construct an Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning process (AV-UIE), which clarifies the cooperative relationship among tasks. Subsequently, to facilitate concrete cooperation in learning stage, an interaction-aware LoRA structure with multiple LoRA heads is designed to learn different aspects of audiovisual data interaction. By unifying the explicit cooperation across the data and model aspect, our method not only surpasses existing unified audio-visual model on multiple tasks, but also outperforms most specialized models for certain tasks. Furthermore, we also visualize the process of explicit cooperation and surprisingly find that each LoRA head has certain audio-visual understanding ability. Code and dataset: https://github.com/GeWu-Lab/Crab
近年来,为了鼓励模型发展特定的能力以理解视听场景,已经提出了许多任务,主要可分为时间定位、空间定位、时空推理和像素级理解。然而,人类具备对各种任务的统一理解能力。因此,设计一种具备统一这些任务的一般能力的视听模型是非常有价值的。然而,对所有任务进行联合训练可能会导致由于视听数据的异质性和任务之间的复杂关系而产生的干扰。我们认为,这个问题可以通过任务之间的明确合作来解决。为了实现这一目标,我们提出了一种统一的学习方法,从数据和模型的视角实现任务间的明确合作。具体来说,考虑到现有数据集的标签是简单的单词,我们精心地改进了这些数据集,并构建了一个视听统一指令调整数据集,具有明确的推理过程(AV-UIE),该数据集明确了任务之间的合作关系。随后,为了在学习阶段促进具体的合作,设计了一种具有多个LoRA头的交互感知LoRA结构来学习视听数据交互的不同方面。通过统一数据和模型方面的明确合作,我们的方法不仅在多个任务上超越了现有的统一视听模型,而且还在某些特定任务上超过了大多数专用模型。此外,我们还可视化了明确合作的过程,并惊讶地发现每个LoRA头都具有一定的视听理解能力。代码和数据集请见:https://github.com/GeWu-Lab/Crab。
论文及项目相关链接
Summary
本文提出一种统一的视听学习方法,通过数据和模型两个层面的显式任务间合作来解决视听数据的异质性和任务间的复杂关系问题。为解决现有数据集标签简单的问题,对数据集进行精细化处理,构建了视听统一指令调优数据集(AV-UIE),明确了任务间的合作关系。此外,设计了一种交互感知的LoRA结构,配备多个LoRA头,以学习视听数据交互的不同方面。此方法不仅超越了现有的多任务统一视听模型,而且在某些任务上的表现也优于大多数专项模型。
Key Takeaways
- 论文提出了一种统一的视听学习方法,旨在实现不同任务间的显式合作。
- 论文构建了视听统一指令调优数据集(AV-UIE),以解决现有数据集标签简单的问题。
- 论文明确了任务间的合作关系,有助于解决由于视听数据的异质性和任务间复杂关系导致的干扰问题。
- 设计了一种交互感知的LoRA结构,配备多个LoRA头,以学习视听数据交互的不同方面。
- 该方法不仅在多任务上超越了现有的统一视听模型,而且在某些任务上的表现超过了大多数专项模型。
- 论文提供了可视化显式合作过程的结果,发现每个LoRA头具有一定的音频视觉理解能力。
点此查看论文截图

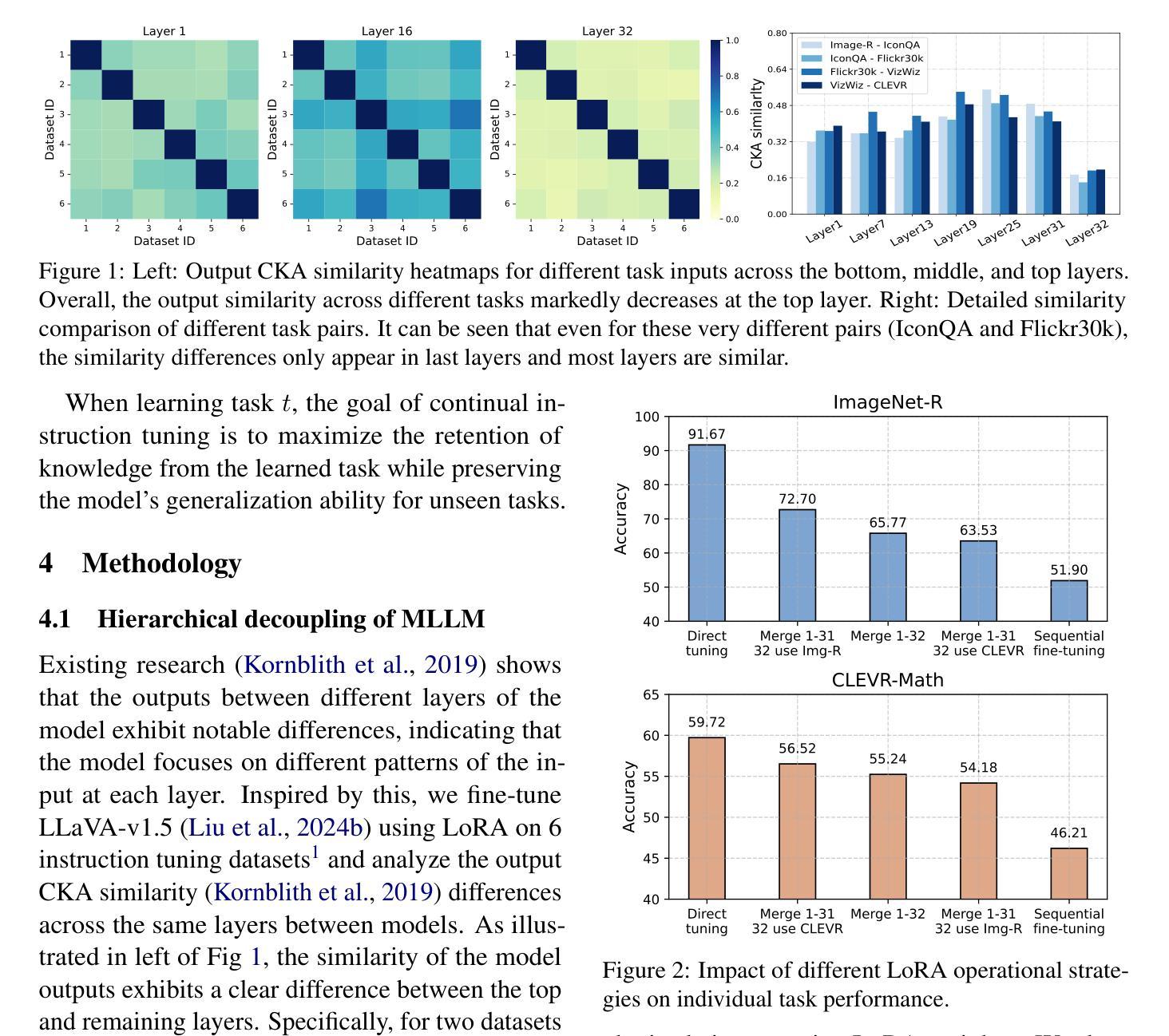
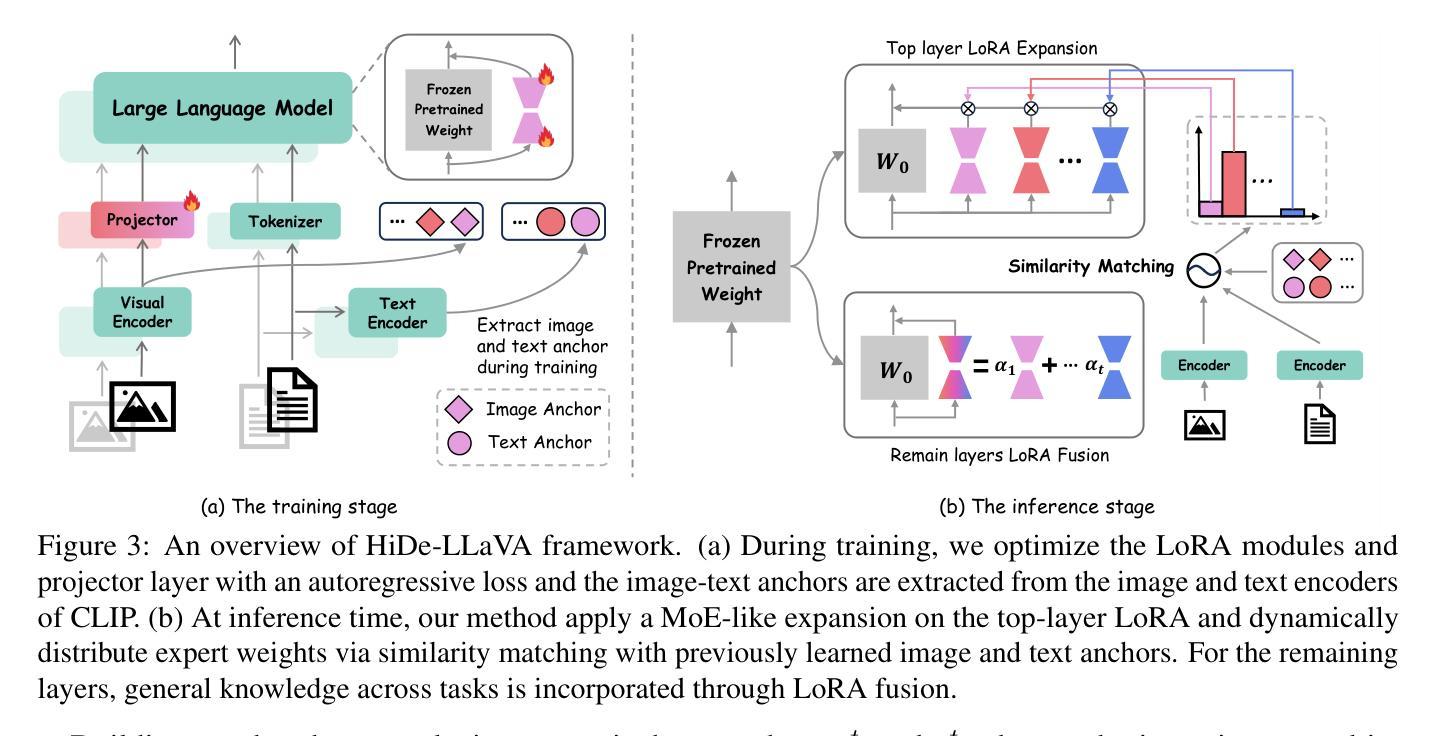
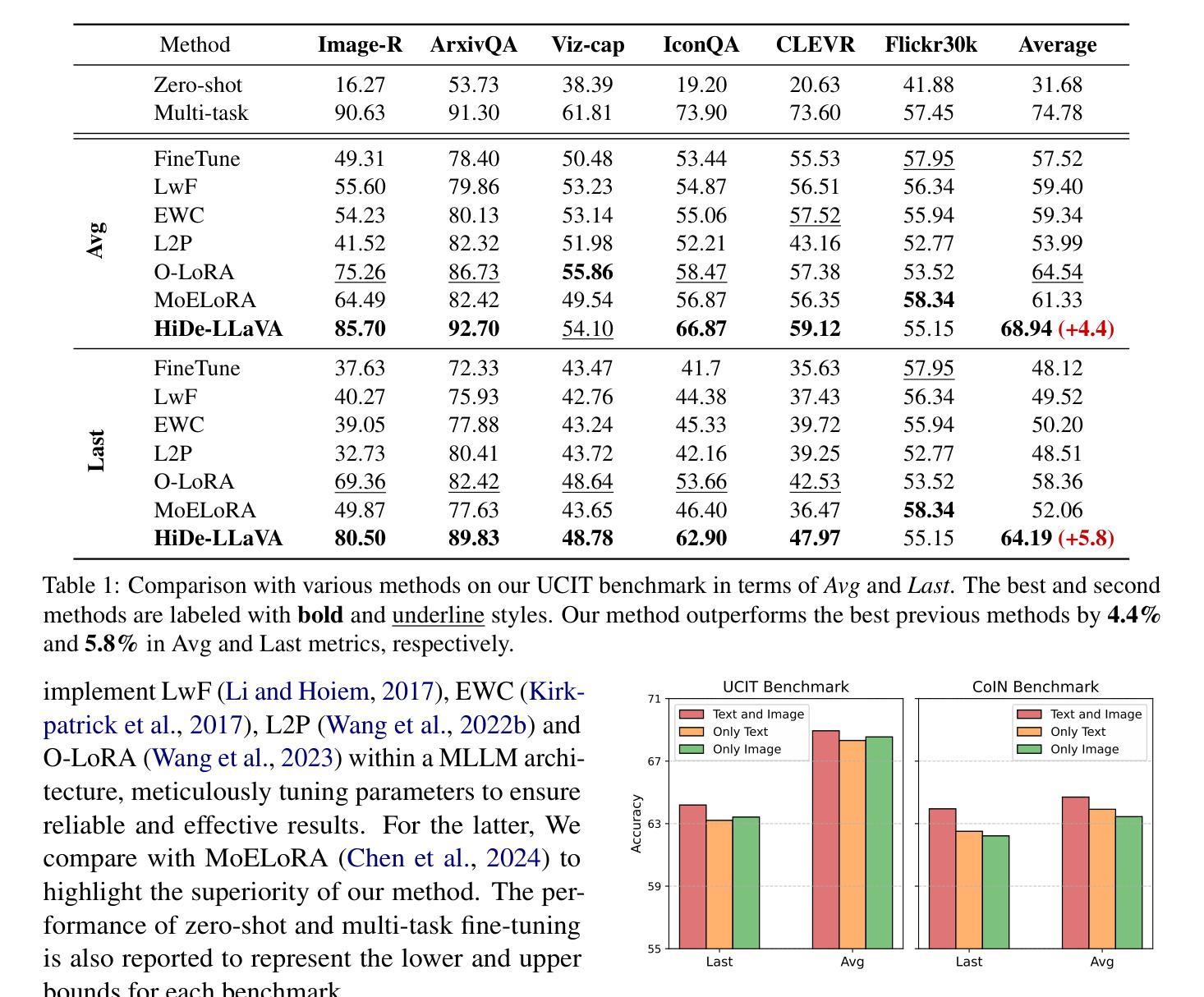
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Authors:Haiyang Guo, Fanhu Zeng, Ziwei Xiang, Fei Zhu, Da-Han Wang, Xu-Yao Zhang, Cheng-Lin Liu
Instruction tuning is widely used to improve a pre-trained Multimodal Large Language Model (MLLM) by training it on curated task-specific datasets, enabling better comprehension of human instructions. However, it is infeasible to collect all possible instruction datasets simultaneously in real-world scenarios. Thus, enabling MLLM with continual instruction tuning is essential for maintaining their adaptability. However, existing methods often trade off memory efficiency for performance gains, significantly compromising overall efficiency. In this paper, we propose a task-specific expansion and task-general fusion framework based on the variations in Centered Kernel Alignment (CKA) similarity across different model layers when trained on diverse datasets. Furthermore, we analyze the information leakage present in the existing benchmark and propose a new and more challenging benchmark to rationally evaluate the performance of different methods. Comprehensive experiments showcase a significant performance improvement of our method compared to existing state-of-the-art methods. Our code will be public available.
指令微调被广泛用于通过训练预训练的多模态大型语言模型(MLLM)在精选的任务特定数据集上来提高其性能,从而更好地理解人类指令。然而,在现实场景中同时收集所有可能的指令数据集是不可行的。因此,启用具有持续指令微调功能的MLLM对于保持其适应性至关重要。然而,现有方法往往以牺牲内存效率为代价来换取性能提升,从而严重损害整体效率。在本文中,我们提出了一种基于在不同数据集训练时不同模型层之间中心核对齐(CKA)相似性的变化的任务特定扩展和任务通用融合框架。此外,我们分析了现有基准测试中的信息泄露问题,并提出了一个新的更具挑战性的基准测试来合理评估不同方法的性能。综合实验表明,我们的方法与现有最先进的相比,性能有了显著的提升。我们的代码将公开可用。
论文及项目相关链接
PDF Preprint
Summary
本文介绍了如何通过指令微调提高预训练的多模态大型语言模型(MLLM)的性能。针对现实世界中无法同时收集所有可能的指令数据集的问题,本文提出了一种基于中心核对齐(CKA)相似度变化的特定任务扩展和通用任务融合框架。同时,本文分析了现有基准测试中的信息泄露问题,并提出了一种新的更具挑战性的基准测试来合理评估不同方法的性能。实验表明,与现有最先进的相比,该方法具有显著的性能改进。
Key Takeaways
- 指令微调用于提高预训练的多模态大型语言模型的性能。
- 现实世界中无法同时收集所有可能的指令数据集,因此持续指令微调对保持模型适应性至关重要。
- 现有方法往往以牺牲内存效率为代价来提高性能。
- 本文提出了一种基于中心核对齐(CKA)相似度变化的特定任务扩展和通用任务融合框架。
- 分析了现有基准测试中的信息泄露问题。
- 提出了一种新的更具挑战性的基准测试来合理评估不同方法的性能。
点此查看论文截图

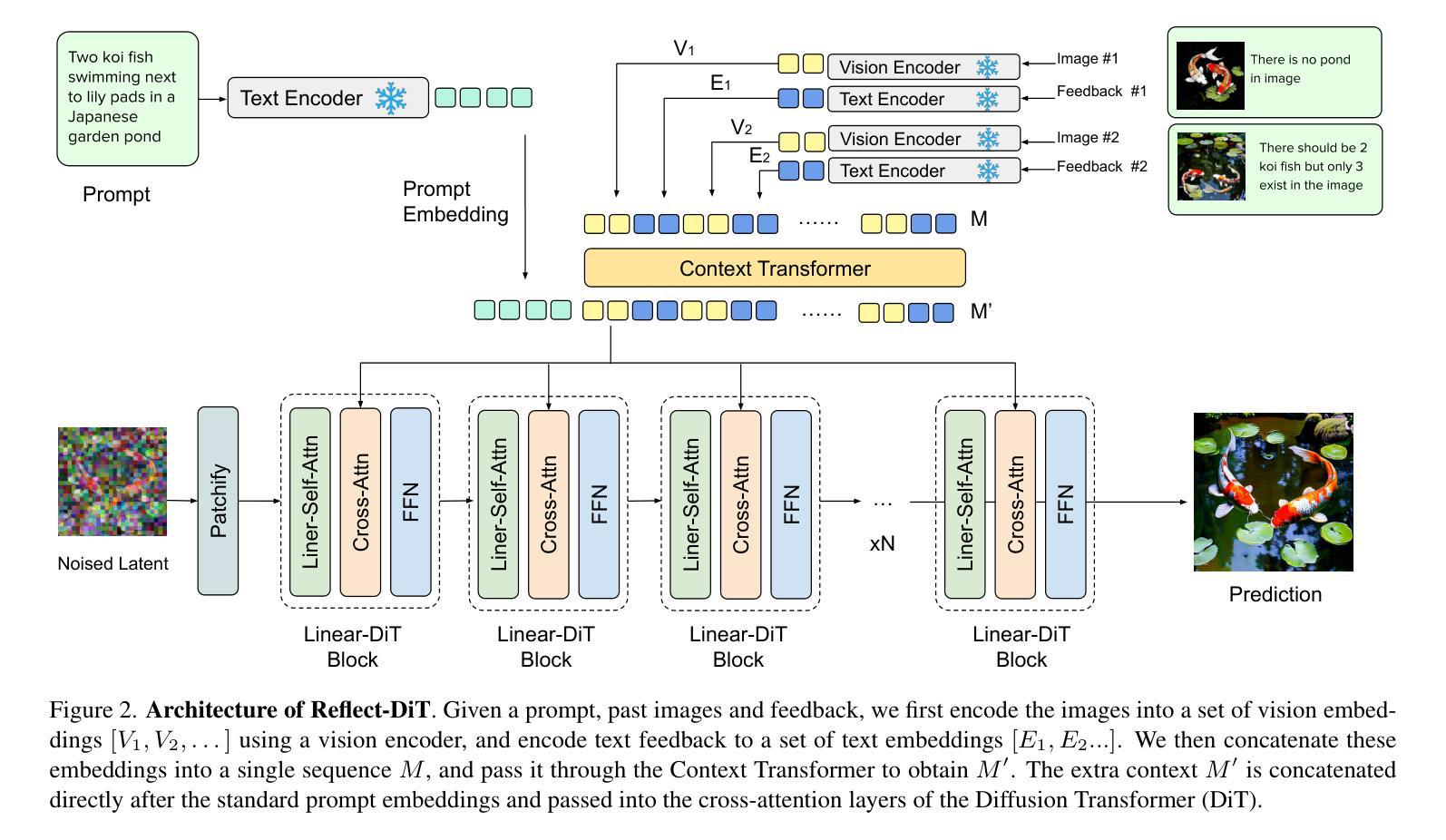
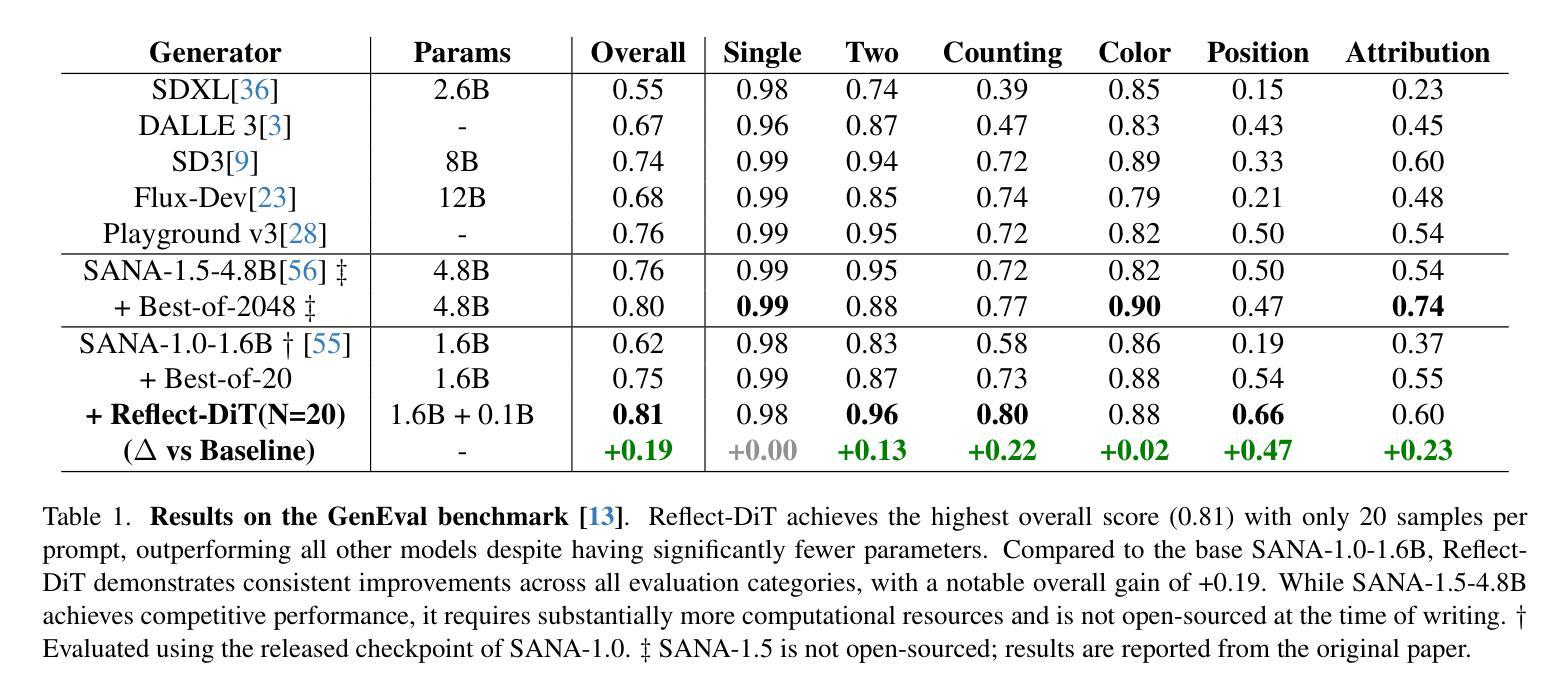
Reflect-DiT: Inference-Time Scaling for Text-to-Image Diffusion Transformers via In-Context Reflection
Authors:Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Arsh Koneru, Yusuke Kato, Kazuki Kozuka, Aditya Grover
The predominant approach to advancing text-to-image generation has been training-time scaling, where larger models are trained on more data using greater computational resources. While effective, this approach is computationally expensive, leading to growing interest in inference-time scaling to improve performance. Currently, inference-time scaling for text-to-image diffusion models is largely limited to best-of-N sampling, where multiple images are generated per prompt and a selection model chooses the best output. Inspired by the recent success of reasoning models like DeepSeek-R1 in the language domain, we introduce an alternative to naive best-of-N sampling by equipping text-to-image Diffusion Transformers with in-context reflection capabilities. We propose Reflect-DiT, a method that enables Diffusion Transformers to refine their generations using in-context examples of previously generated images alongside textual feedback describing necessary improvements. Instead of passively relying on random sampling and hoping for a better result in a future generation, Reflect-DiT explicitly tailors its generations to address specific aspects requiring enhancement. Experimental results demonstrate that Reflect-DiT improves performance on the GenEval benchmark (+0.19) using SANA-1.0-1.6B as a base model. Additionally, it achieves a new state-of-the-art score of 0.81 on GenEval while generating only 20 samples per prompt, surpassing the previous best score of 0.80, which was obtained using a significantly larger model (SANA-1.5-4.8B) with 2048 samples under the best-of-N approach.
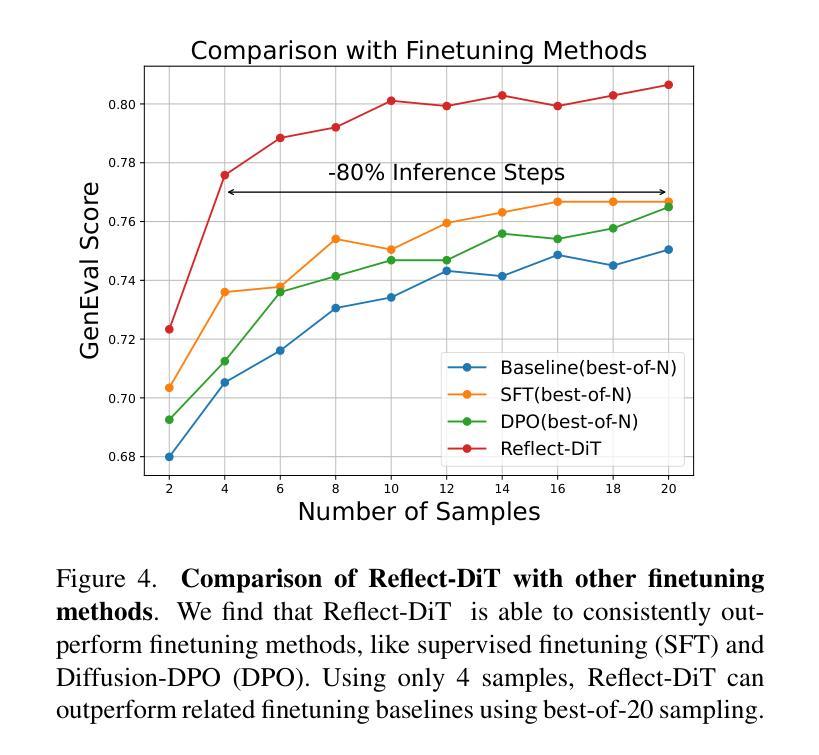
推进文本到图像生成的主要方法一直是训练时间尺度调整,即使用更大的计算资源在更多数据上训练更大的模型。虽然这种方法有效,但计算成本高昂,人们对提高性能的推理时间尺度调整方法越来越感兴趣。目前,文本到图像扩散模型的推理时间尺度调整主要局限于N选最优采样,即每次提示生成多个图像,并由选择模型选择最佳输出。受语言领域DeepSeek-R1等推理模型近期成功的启发,我们引入了一种替代N选最优采样的方法,即通过为文本到图像扩散转换器配备上下文内反射能力。我们提出了Reflect-DiT方法,它使扩散转换器能够利用以前生成的图像的上下文内示例和描述必要改进的文本反馈来改进其生成。Reflect-DiT明确针对需要增强的特定方面调整其生成,而不是被动地依赖随机采样并希望在将来的生成中获得更好的结果。实验结果表明,使用SANA-1.0-1.6B作为基准模型,Reflect-DiT在GenEval基准测试上的性能提高了(+0.19)。此外,它在仅生成20个样本的情况下达到了GenEval上的最新最高分数0.81,超过了之前使用更大的模型(SANA-1.5-4.8B)在N选最优方法下获得最高分数0.80(需要生成2048个样本)。
论文及项目相关链接
PDF 17 pages, 9 figures
摘要
本文主要介绍了一种提升文本到图像生成任务性能的新方法——Reflect-DiT。该方法通过赋予文本到图像扩散转换器上下文反思能力,改进了当前主要采用的基于大量数据和计算资源的训练时间缩放方法。Reflect-DiT允许扩散转换器利用先前生成的图像上下文示例和描述必要改进的文本反馈来优化其生成结果。相较于被动依赖随机采样和期望未来生成更好结果的方法,Reflect-DiT能够明确针对需要增强的特定方面调整其生成结果。实验结果表明,Reflect-DiT在GenEval基准测试上的性能有所提升(使用SANA-1.0-1.6B作为基准模型,+0.19),且在每提示仅生成20个样本的情况下达到了GenEval的新纪录得分0.81,超过了之前最佳得分的模型(SANA-1.5-4.8B)的得分(在最佳N方法下生成了高达2048个样本)。
关键见解
- 当前文本到图像生成的主要挑战在于计算资源的消耗,促使了对推理时间缩放的关注。
- 最佳N采样是目前推理时间缩放的主要方法,但存在局限性。
- 引入了一种名为Reflect-DiT的新方法,该方法结合了文本反馈和上下文图像示例来优化图像生成。
- Reflect-DiT允许扩散转换器针对需要改进的特定方面进行明确调整,而不是依赖随机采样。
- Reflect-DiT在GenEval基准测试上的表现优于传统方法,使用较小的模型即可达到新的记录得分。
- 实验结果表明,Reflect-DiT能够在仅生成少量样本的情况下实现高性能。
点此查看论文截图



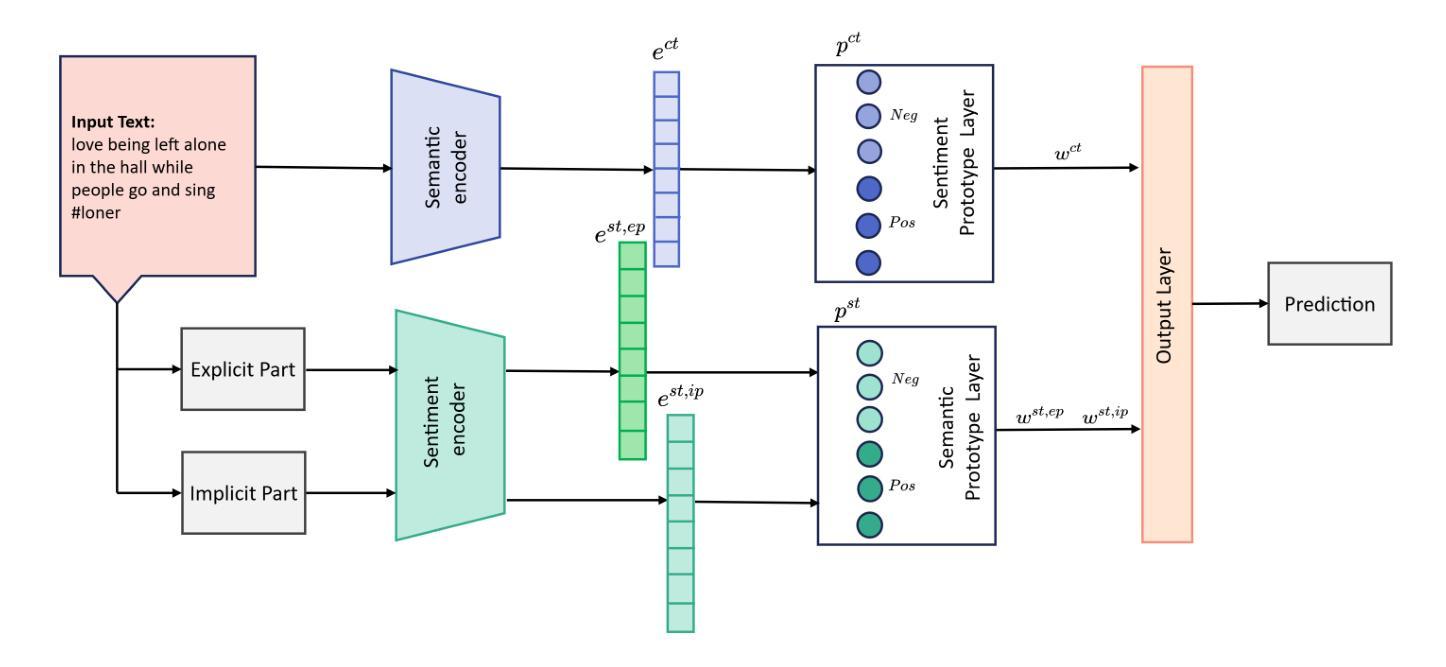
A Transformer and Prototype-based Interpretable Model for Contextual Sarcasm Detection
Authors:Ximing Wen, Rezvaneh Rezapour
Sarcasm detection, with its figurative nature, poses unique challenges for affective systems designed to perform sentiment analysis. While these systems typically perform well at identifying direct expressions of emotion, they struggle with sarcasm’s inherent contradiction between literal and intended sentiment. Since transformer-based language models (LMs) are known for their efficient ability to capture contextual meanings, we propose a method that leverages LMs and prototype-based networks, enhanced by sentiment embeddings to conduct interpretable sarcasm detection. Our approach is intrinsically interpretable without extra post-hoc interpretability techniques. We test our model on three public benchmark datasets and show that our model outperforms the current state-of-the-art. At the same time, the prototypical layer enhances the model’s inherent interpretability by generating explanations through similar examples in the reference time. Furthermore, we demonstrate the effectiveness of incongruity loss in the ablation study, which we construct using sentiment prototypes.
讽刺检测由于其比喻性质,对设计用于情感分析的情感系统提出了独特的挑战。虽然这些系统通常在识别直接情绪表达方面表现良好,但在处理讽刺中字面含义和意图情感之间的内在矛盾时却感到困难。由于基于变压器的语言模型(LMs)以其捕捉上下文含义的高效能力而闻名,我们提出了一种利用语言模型和基于原型的网络的方法,通过情感嵌入来进行可解释的讽刺检测。我们的方法本质上是可解释的,不需要额外的后续解释技术。我们在三个公共基准数据集上测试了我们的模型,结果表明我们的模型优于当前最先进的模型。同时,原型层通过参考时间中的相似例子生成解释,提高了模型的内在可解释性。此外,我们通过使用情感原型构建的消融研究证明了不一致损失的有效性。
论文及项目相关链接
PDF 8 pages, 2 figures
Summary
基于转化器语言模型的讽刺检测法结合了原型网络和情感嵌入技术,旨在解决情感分析中讽刺表达带来的挑战。该方法不仅高效捕捉语境意义,而且通过生成参考时间中的相似例子来解释模型预测,增强了模型的内在可解释性。在三个公共基准数据集上的测试表明,该方法优于当前最先进技术。同时,我们利用情感原型构建了不一致损失的消融研究,证明了其有效性。
Key Takeaways
- 讽刺检测对于情感系统是一个独特的挑战,因为讽刺表达在字面和意图情感之间存在内在矛盾。
- 转化器语言模型能够高效捕捉语境意义,是处理讽刺检测的关键技术之一。
- 提出的方法结合了语言模型、原型网络以及情感嵌入技术,进行可解释的讽刺检测。
- 模型在三个公共基准数据集上的表现优于当前最先进技术。
- 原型层通过生成参考时间中的相似例子来解释模型预测,增强了模型的内在可解释性。
- 消融研究证明了不一致损失的有效性。
- 该方法对于情感分析领域,特别是处理讽刺表达方面具有潜在的应用价值。
点此查看论文截图

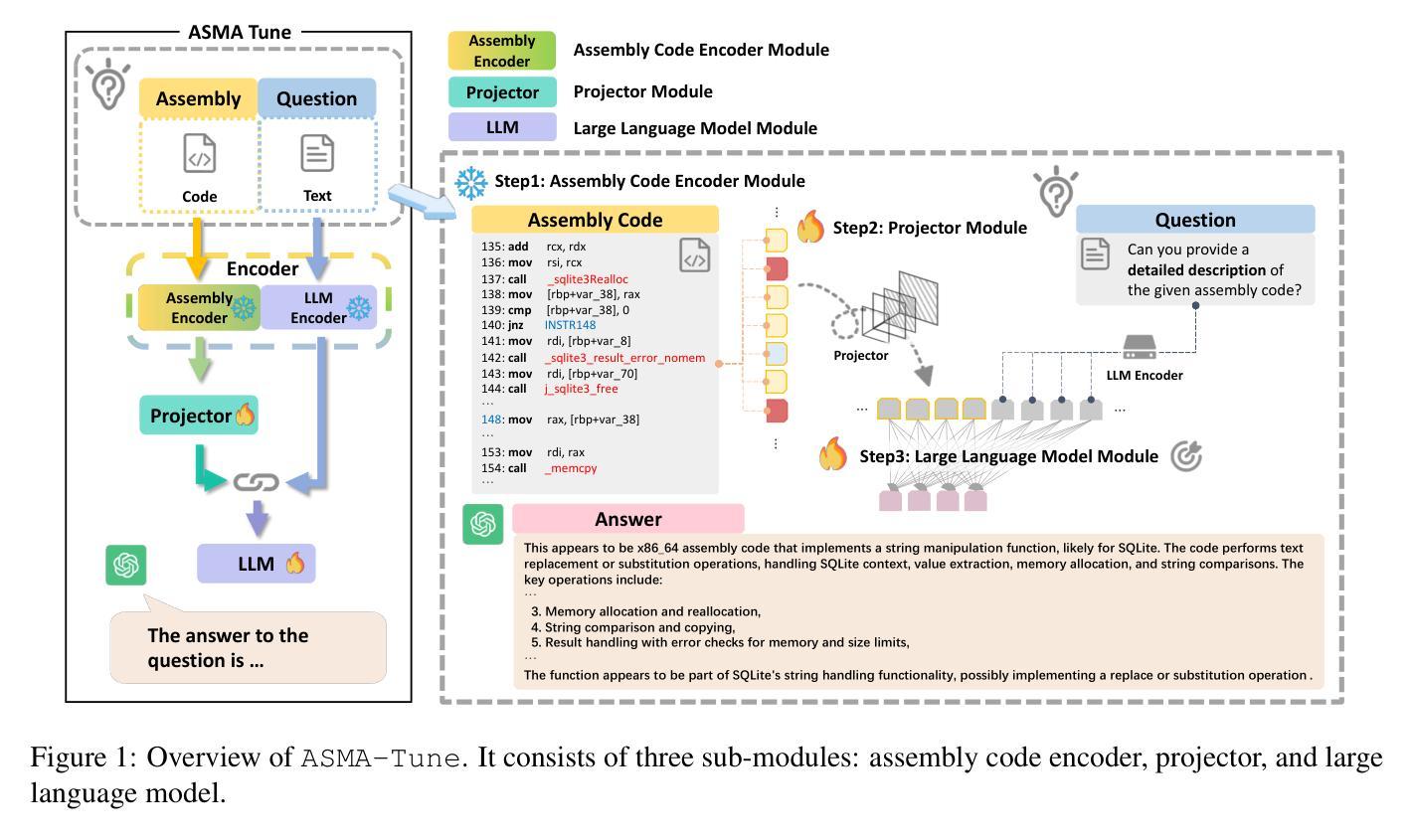
ASMA-Tune: Unlocking LLMs’ Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Authors:Xinyi Wang, Jiashui Wang, Peng Chen, Jinbo Su, Yanming Liu, Long Liu, Yangdong Wang, Qiyuan Chen, Kai Yun, Chunfu Jia
Analysis and comprehension of assembly code are crucial in various applications, such as reverse engineering. However, the low information density and lack of explicit syntactic structures in assembly code pose significant challenges. Pioneering approaches with masked language modeling (MLM)-based methods have been limited by facilitating natural language interaction. While recent methods based on decoder-focused large language models (LLMs) have significantly enhanced semantic representation, they still struggle to capture the nuanced and sparse semantics in assembly code. In this paper, we propose Assembly Augmented Tuning (ASMA-Tune), an end-to-end structural-semantic instruction-tuning framework. Our approach synergizes encoder architectures with decoder-based LLMs through projector modules to enable comprehensive code understanding. Experiments show that ASMA-Tune outperforms existing benchmarks, significantly enhancing assembly code comprehension and instruction-following abilities. Our model and dataset are public at https://github.com/wxy3596/ASMA-Tune.
分析和理解汇编代码在各种应用(如逆向工程)中至关重要。然而,汇编代码中信息密度低且缺乏明确的语法结构,这构成了重大挑战。基于掩码语言建模(MLM)的方法虽然促进了自然语言交互,但其在实践中的应用仍然有限。虽然最近基于解码器的大型语言模型(LLM)的方法显著增强了语义表示,但它们仍然难以捕捉汇编代码中细微且稀疏的语义。在本文中,我们提出了“汇编增强调优”(ASMA-Tune),这是一个端到端的结构语义指令调优框架。我们的方法通过投影仪模块协同编码器架构和基于解码器的LLM,以实现全面的代码理解。实验表明,ASMA-Tune优于现有基准测试,显著提高了汇编代码的理解和指令遵循能力。我们的模型和数据集公开在https://github.com/wxy3596/ASMA-Tune。
论文及项目相关链接
PDF 19 pages, multiple figures
Summary
基于自然语言模型在汇编代码分析方面的挑战,本文提出了Assembly Augmented Tuning(ASMA-Tune)框架,这是一个端到端的指令调优框架,融合了编码器的架构和基于解码器的语言模型。ASMA-Tune框架采用投影模块增强了汇编代码的综合理解能力,实验结果证明其在现有基准测试中表现优异。数据集和模型已在GitHub上公开。
Key Takeaways
- 汇编代码分析和理解在多个应用如逆向工程中非常重要。
- 当前的方法面临汇编代码信息密度低和缺乏明确句法结构的问题。
- 基于语言模型的汇编代码理解方法尚处于初级阶段,特别是解码器主导的LLM模型,存在捕捉语义的局限。
- 本文提出了Assembly Augmented Tuning(ASMA-Tune)框架,结合了编码器和解码器架构的优势。
- ASMA-Tune框架通过投影模块实现全面代码理解,提升了汇编代码的理解能力和指令执行能力。
- 实验结果表明,ASMA-Tune在现有基准测试中表现优越。
点此查看论文截图

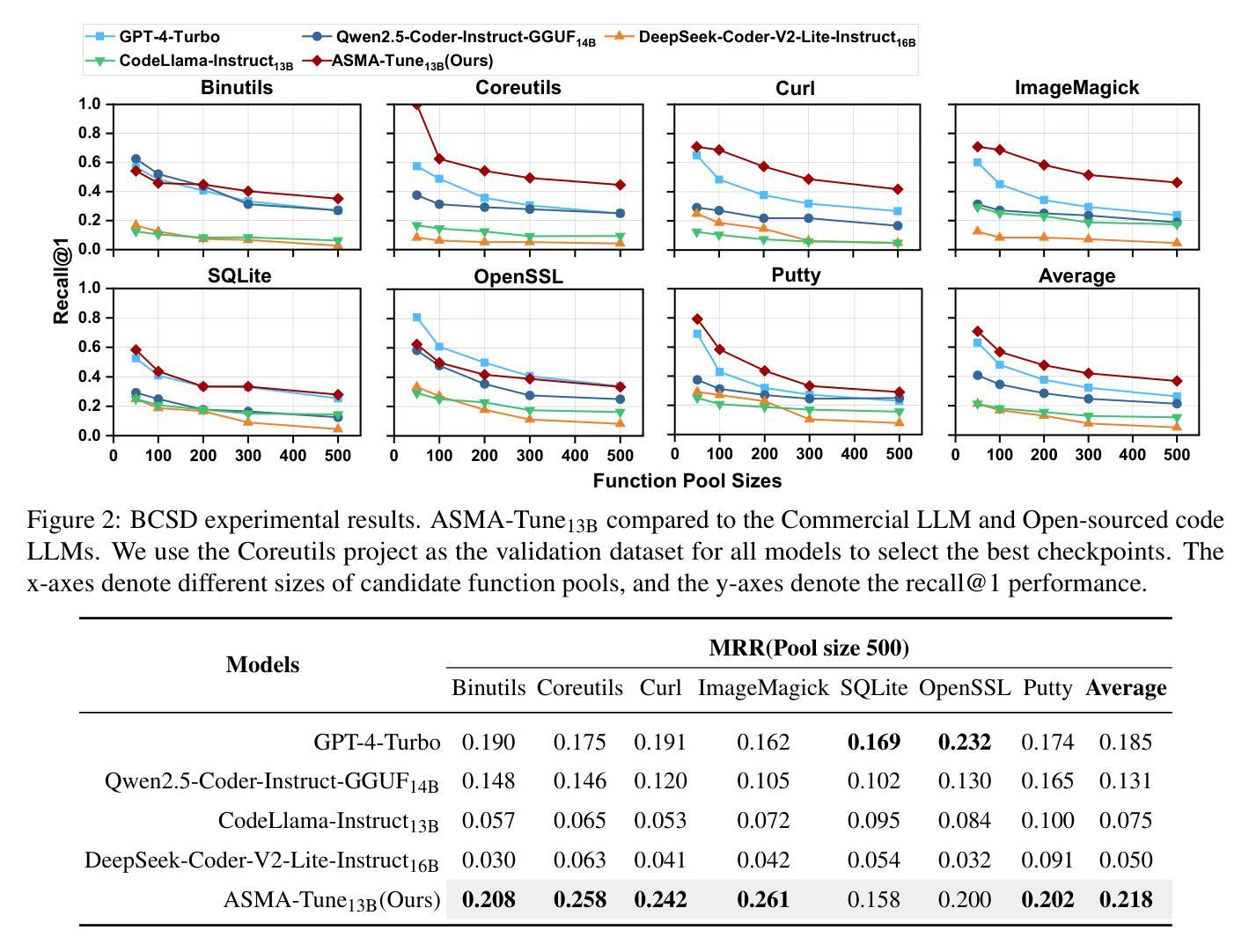
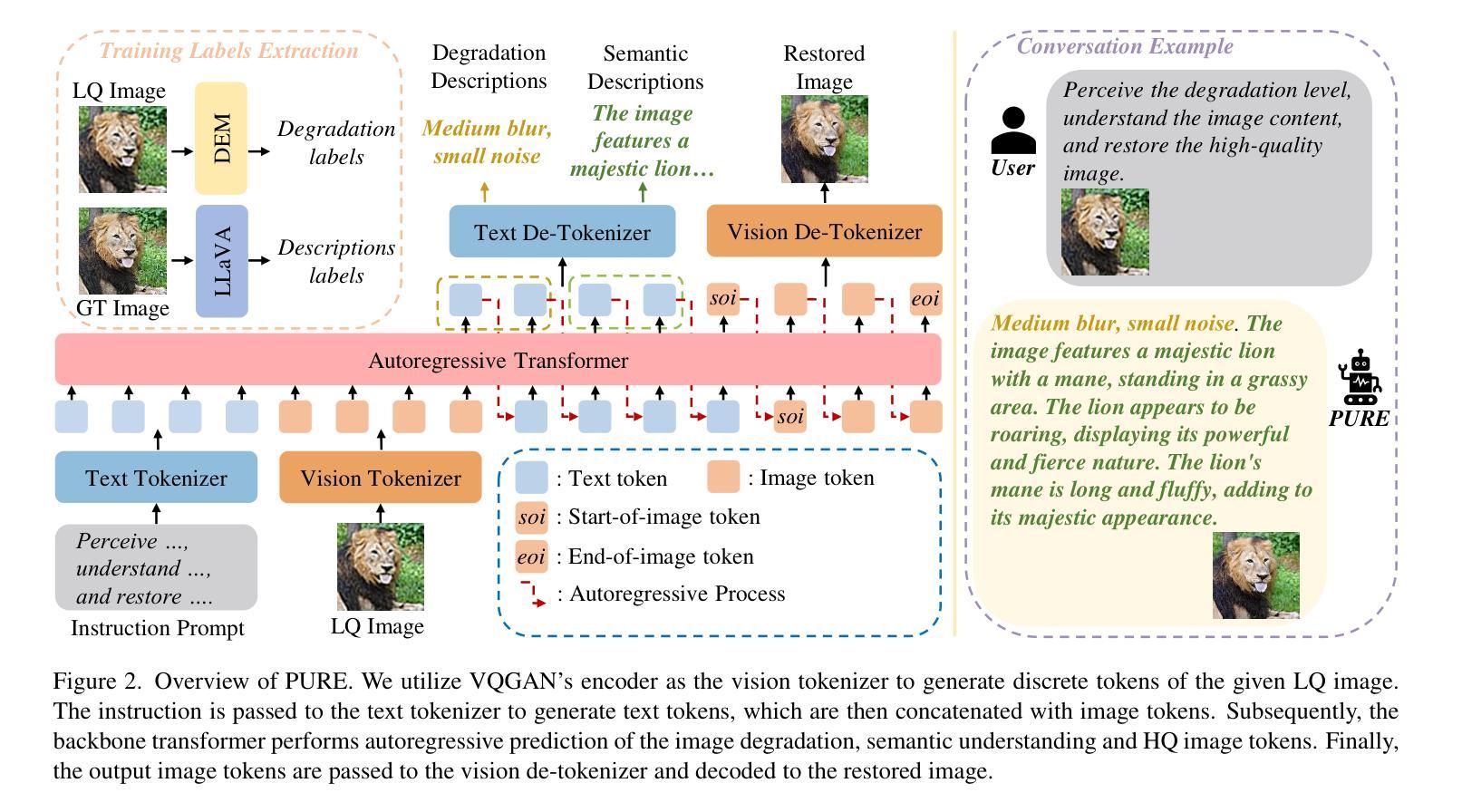
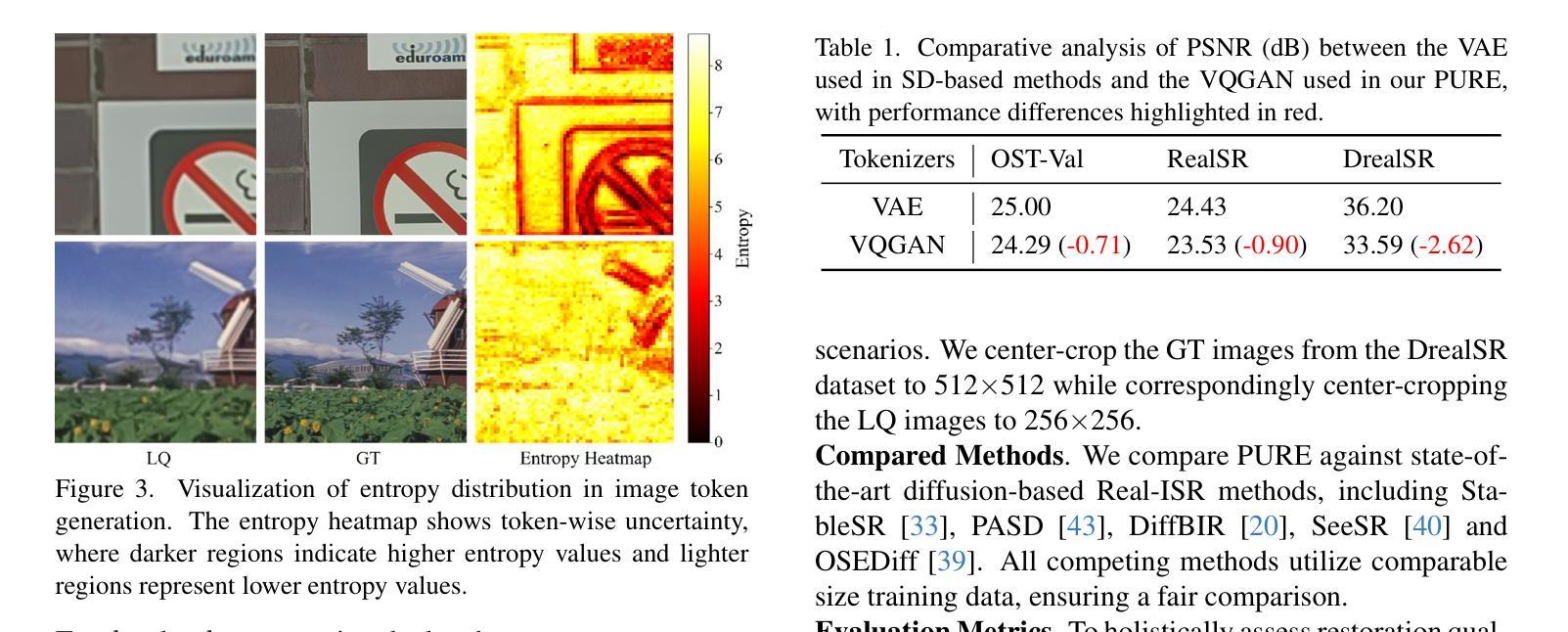
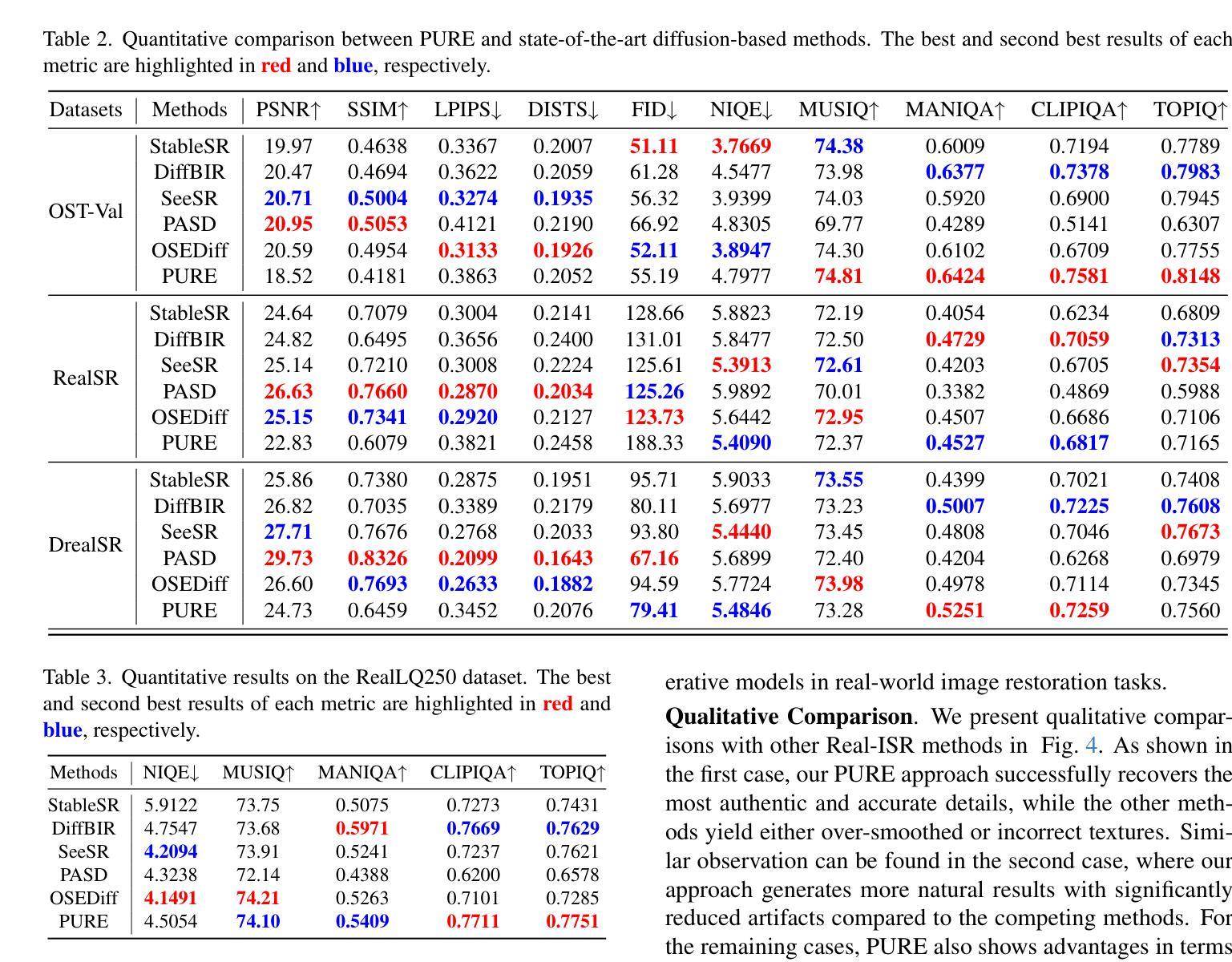
Perceive, Understand and Restore: Real-World Image Super-Resolution with Autoregressive Multimodal Generative Models
Authors:Hongyang Wei, Shuaizheng Liu, Chun Yuan, Lei Zhang
By leveraging the generative priors from pre-trained text-to-image diffusion models, significant progress has been made in real-world image super-resolution (Real-ISR). However, these methods tend to generate inaccurate and unnatural reconstructions in complex and/or heavily degraded scenes, primarily due to their limited perception and understanding capability of the input low-quality image. To address these limitations, we propose, for the first time to our knowledge, to adapt the pre-trained autoregressive multimodal model such as Lumina-mGPT into a robust Real-ISR model, namely PURE, which Perceives and Understands the input low-quality image, then REstores its high-quality counterpart. Specifically, we implement instruction tuning on Lumina-mGPT to perceive the image degradation level and the relationships between previously generated image tokens and the next token, understand the image content by generating image semantic descriptions, and consequently restore the image by generating high-quality image tokens autoregressively with the collected information. In addition, we reveal that the image token entropy reflects the image structure and present a entropy-based Top-k sampling strategy to optimize the local structure of the image during inference. Experimental results demonstrate that PURE preserves image content while generating realistic details, especially in complex scenes with multiple objects, showcasing the potential of autoregressive multimodal generative models for robust Real-ISR. The model and code will be available at https://github.com/nonwhy/PURE.
通过利用预训练的文本到图像扩散模型的生成先验知识,真实世界图像超分辨率(Real-ISR)已经取得了重大进展。然而,这些方法在复杂和/或严重退化的场景中往往会产生不准确和不自然的重建,主要是由于它们对输入的低质量图像的感知和理解能力有限。为了解决这些局限性,我们首次将预训练的自动回归多模式模型(如Lumina-mGPT)改编为稳健的Real-ISR模型,即PURE模型。该模型能够感知和理解输入的低质量图像,然后恢复其高质量对应图像。具体来说,我们对Lumina-mGPT进行了指令调整,以感知图像退化程度和先前生成的图像标记与下一个标记之间的关系,通过生成图像语义描述来理解图像内容,并使用收集的信息以自动回归的方式生成高质量图像标记来恢复图像。此外,我们发现图像标记熵反映了图像结构,并提出了一种基于熵的Top-k采样策略,以在推理过程中优化图像局部结构。实验结果表明,PURE在保留图像内容的同时生成了逼真的细节,特别是在具有多个对象的复杂场景中,展示了自动回归多模式生成模型在稳健Real-ISR中的潜力。模型和代码将在https://github.com/nonwhy/PURE上提供。
论文及项目相关链接
摘要
利用预训练的文本到图像扩散模型的生成先验,真实世界图像超分辨率(Real-ISR)取得了显著进展。然而,这些方法在复杂和/或严重退化的场景中往往会生成不准确和不自然的重建,主要是由于其对输入低质量图像的感知和理解能力有限。为解决这些问题,我们首次将预训练的自动回归多模式模型(如Lumina-mGPT)适应为稳健的Real-ISR模型,即PURE模型。该模型能够感知和理解输入的低质量图像,然后恢复其高质量对应物。具体来说,我们对Lumina-mGPT进行了指令调整,以感知图像退化程度和先前生成的图像标记与下一个标记之间的关系,通过生成图像语义描述来理解图像内容,并使用收集的信息以自动回归的方式生成高质量图像标记来恢复图像。此外,我们发现图像标记熵反映了图像结构,并提出了一种基于熵的Top-k采样策略,以在推理过程中优化图像局部结构。实验结果表明,PURE能够保留图像内容并生成逼真的细节,特别是在具有多个对象的复杂场景中,展示了自动回归多模式生成模型在稳健Real-ISR中的潜力。模型和代码将发布在https://github.com/nonwhy/PURE。
关键见解
- 利用预训练文本到图像扩散模型的生成先验在Real-ISR领域取得进展。
- 当前方法在处理复杂和严重退化的场景时存在不准确和不自然的重建问题。
- 首次将自动回归多模式模型(如Lumina-mGPT)适应为Real-ISR模型,形成PURE模型。
- 通过指令调整提升模型的感知和理解能力,生成高质量图像对应物。
- 提出基于熵的Top-k采样策略来优化推理过程中的图像局部结构。
- 实验结果表明,PURE模型能够保留图像内容并生成逼真的细节,尤其在复杂场景中表现优异。
点此查看论文截图