⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning
Authors:Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, Mike Zheng Shou
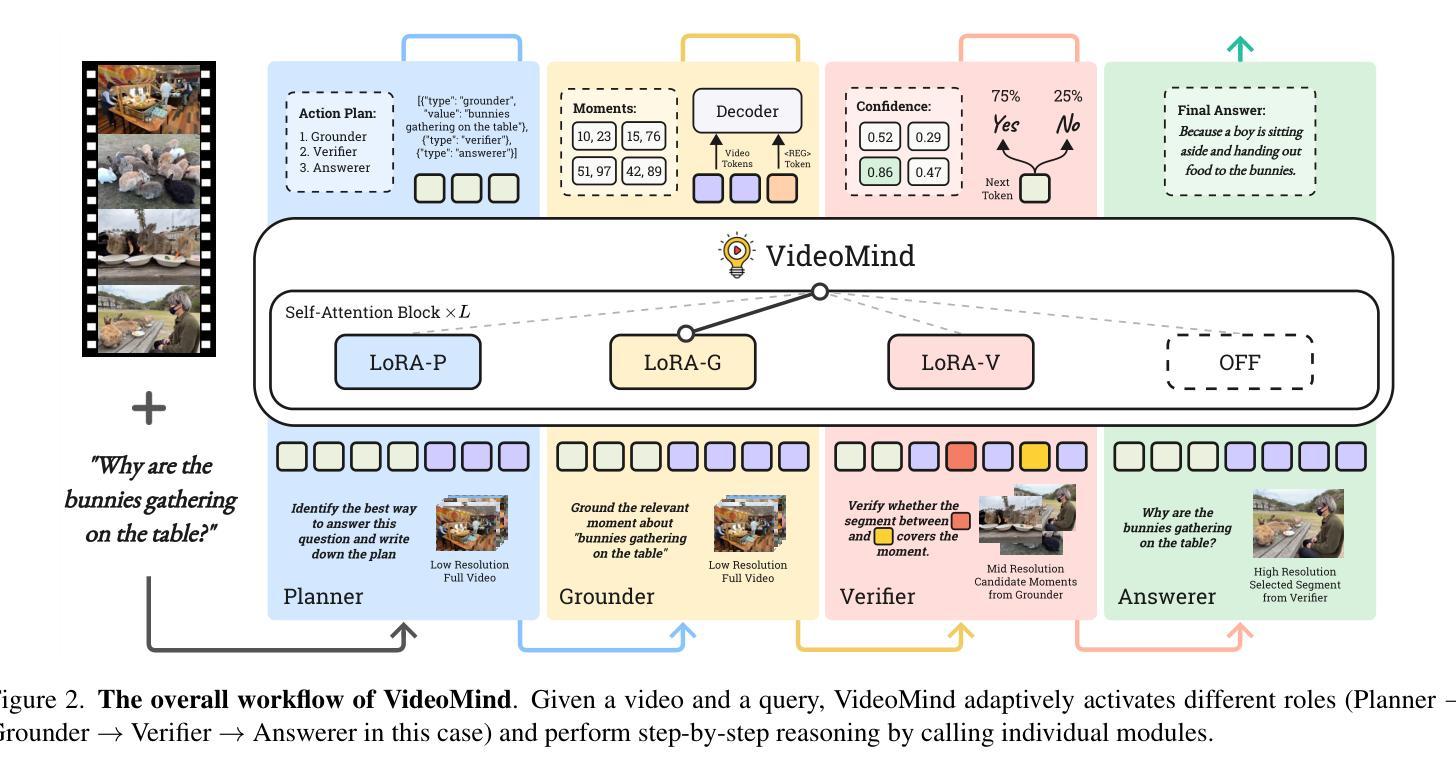
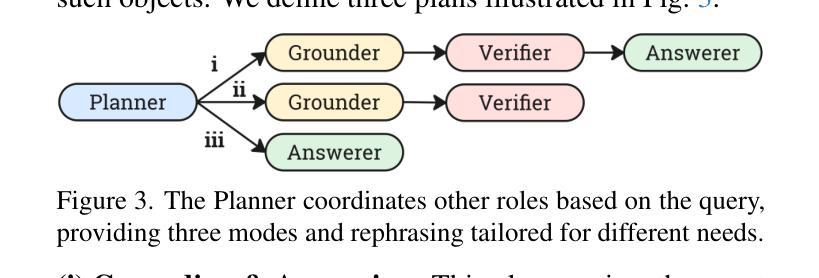
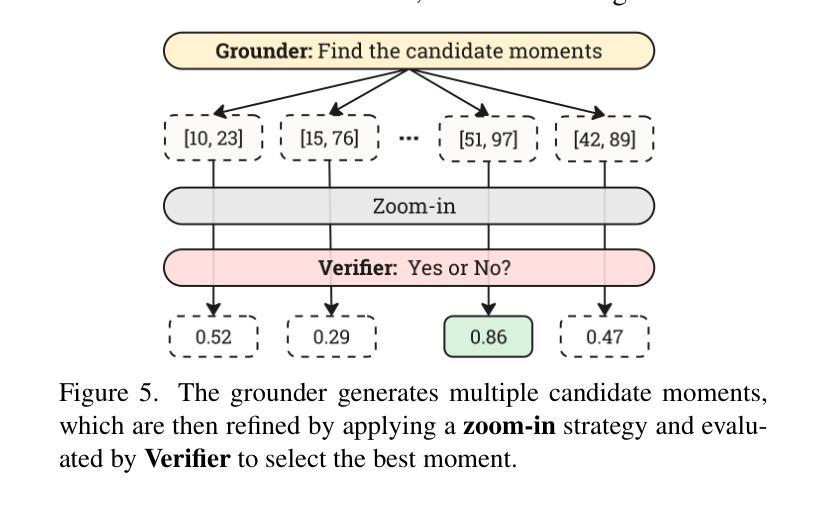
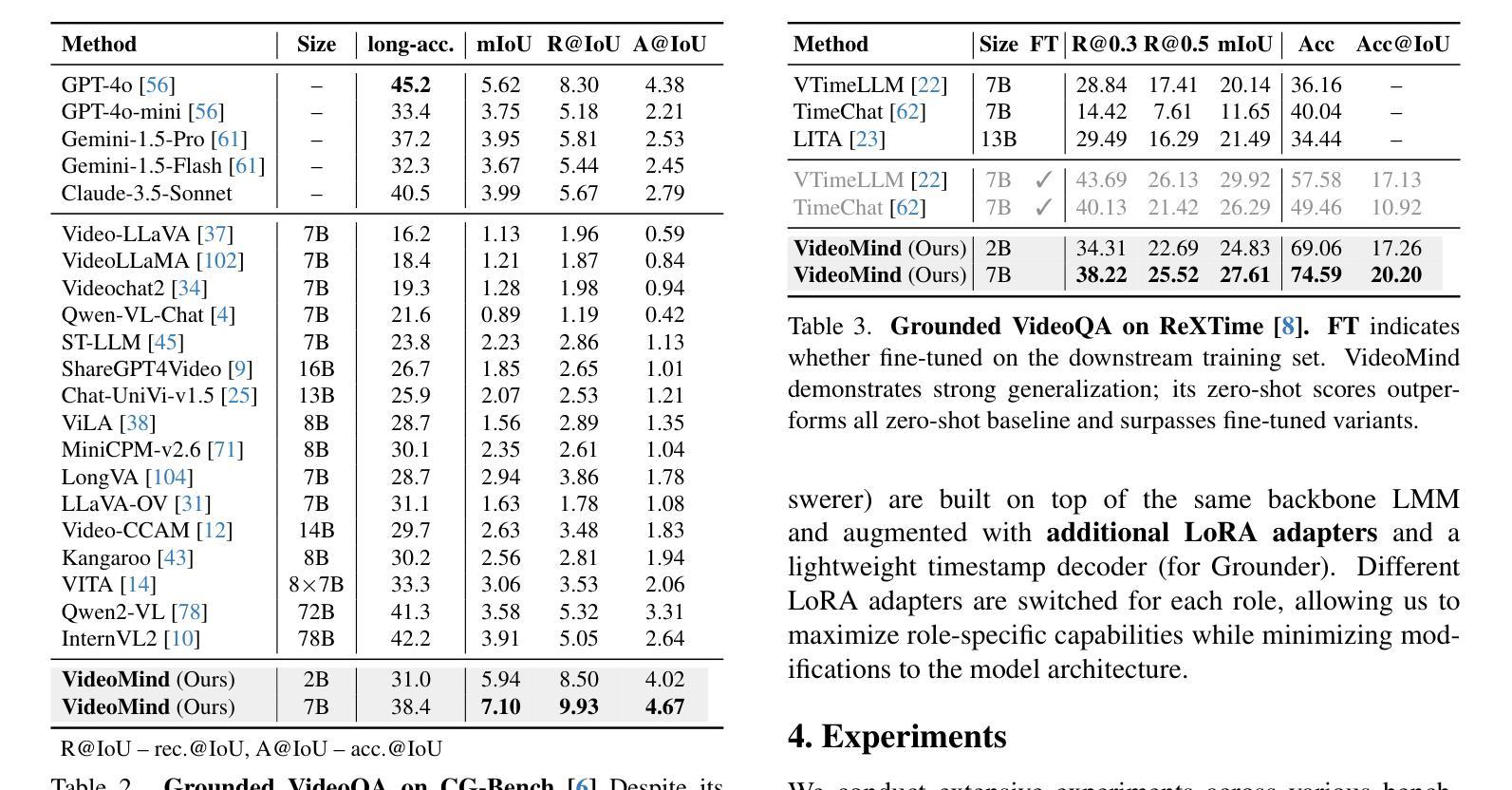
Videos, with their unique temporal dimension, demand precise grounded understanding, where answers are directly linked to visual, interpretable evidence. Despite significant breakthroughs in reasoning capabilities within Large Language Models, multi-modal reasoning - especially for videos - remains unexplored. In this work, we introduce VideoMind, a novel video-language agent designed for temporal-grounded video understanding. VideoMind incorporates two key innovations: (i) We identify essential capabilities for video temporal reasoning and develop a role-based agentic workflow, including a planner for coordinating different roles, a grounder for temporal localization, a verifier to assess temporal interval accuracy, and an answerer for question-answering. (ii) To efficiently integrate these diverse roles, we propose a novel Chain-of-LoRA strategy, enabling seamless role-switching via lightweight LoRA adaptors while avoiding the overhead of multiple models, thus balancing efficiency and flexibility. Extensive experiments on 14 public benchmarks demonstrate that our agent achieves state-of-the-art performance on diverse video understanding tasks, including 3 on grounded video question-answering, 6 on video temporal grounding, and 5 on general video question-answering, underscoring its effectiveness in advancing video agent and long-form temporal reasoning.
视频以其独特的时间维度而著称,需要精确且基于情境的理解,答案需直接与可视化、可解释的证据相关联。尽管大型语言模型的推理能力已经取得了重大突破,但多模态推理(特别是针对视频)仍然未被探索。在这项工作中,我们引入了VideoMind,这是一个为基于时间情境的视频理解设计的新型视频语言代理。VideoMind有两个关键的创新点:(i)我们确定了视频时间推理的核心能力,并基于角色设计了一个代理工作流程,包括一个协调不同角色的规划器、一个用于时间定位的定位器、一个评估时间间隔准确性的验证器,以及一个用于问答的回答者。(ii)为了有效地整合这些多样化的角色,我们提出了一种新型的Chain-of-LoRA策略,通过轻量级的LoRA适配器实现无缝角色切换,同时避免使用多个模型带来的开销,从而在效率和灵活性之间取得平衡。在14个公开基准测试上的广泛实验表明,我们的代理在多种视频理解任务上达到了最先进的性能,包括3个基于情境的视频问答任务、6个视频时间定位任务和5个通用视频问答任务,这突显了其在推进视频代理和长格式时间推理方面的有效性。
论文及项目相关链接
PDF Project Page: https://videomind.github.io/
Summary
本文介绍了一种新型的视频语言代理——VideoMind,专为时间基础视频理解而设计。它包含了两个主要创新点:一是确定了视频时间推理的关键能力,并基于这些能力设计了角色化的代理工作流程;二是提出了Chain-of-LoRA策略,高效整合不同角色,实现轻松的角色切换。VideoMind在多个公共基准测试上实现了卓越性能,表明其在推进视频代理和长形式时间推理方面的有效性。
Key Takeaways
- 视频由于其独特的时间维度,需要精确的时间基础理解,答案需直接与视觉、可解释的证据相关联。
- VideoMind是一种新型视频语言代理,专为时间基础视频理解而设计。
- VideoMind包含两个主要创新点:角色化的代理工作流程和Chain-of-LoRA策略。
- 角色化的代理工作流程包括规划、时间定位、时间区间精度评估和问题回答等多个角色。
- Chain-of-LoRA策略能够高效整合不同角色,实现轻松的角色切换,同时保持效率和灵活性。
- VideoMind在多个视频理解任务上实现了卓越性能,包括基于时间的视频问答、视频时间定位和一般视频问答等。
点此查看论文截图


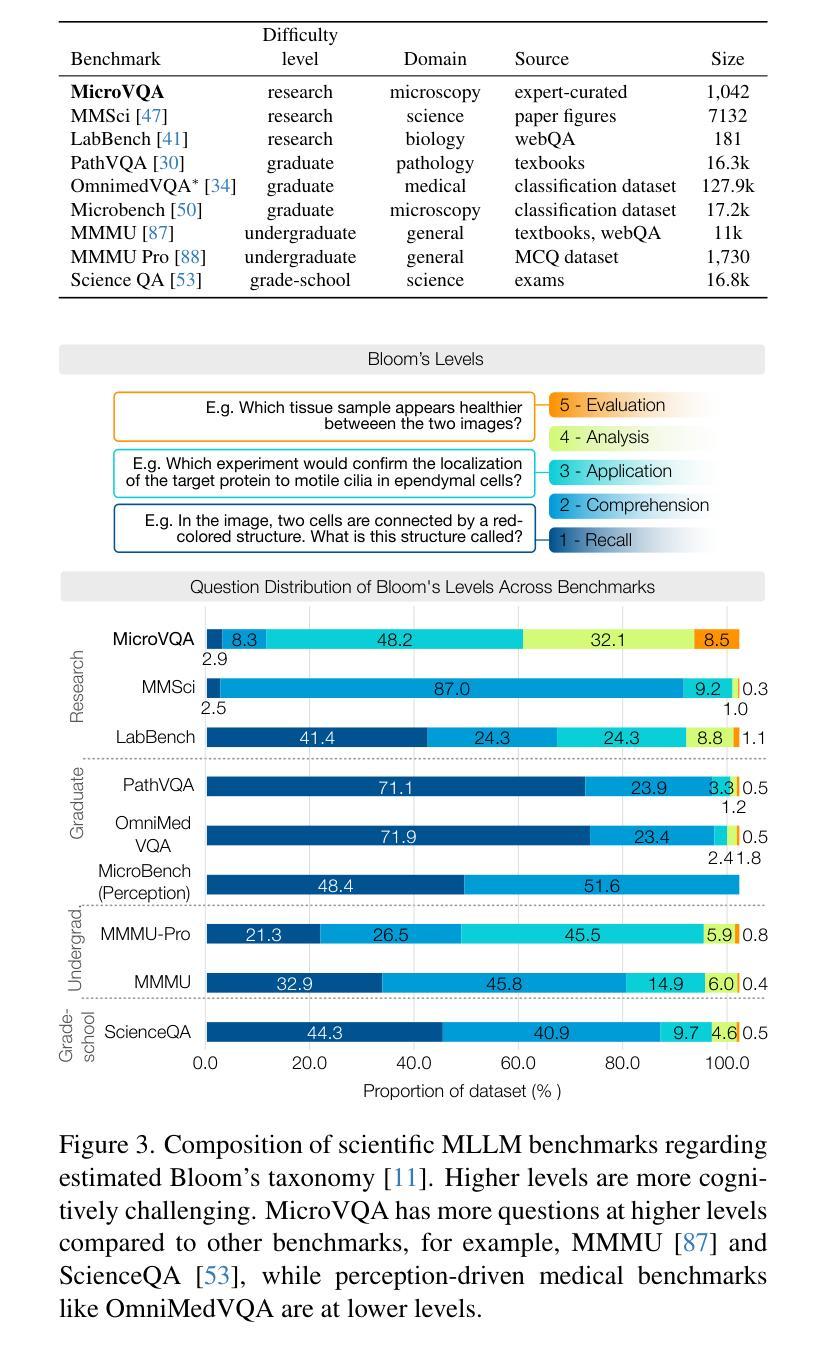
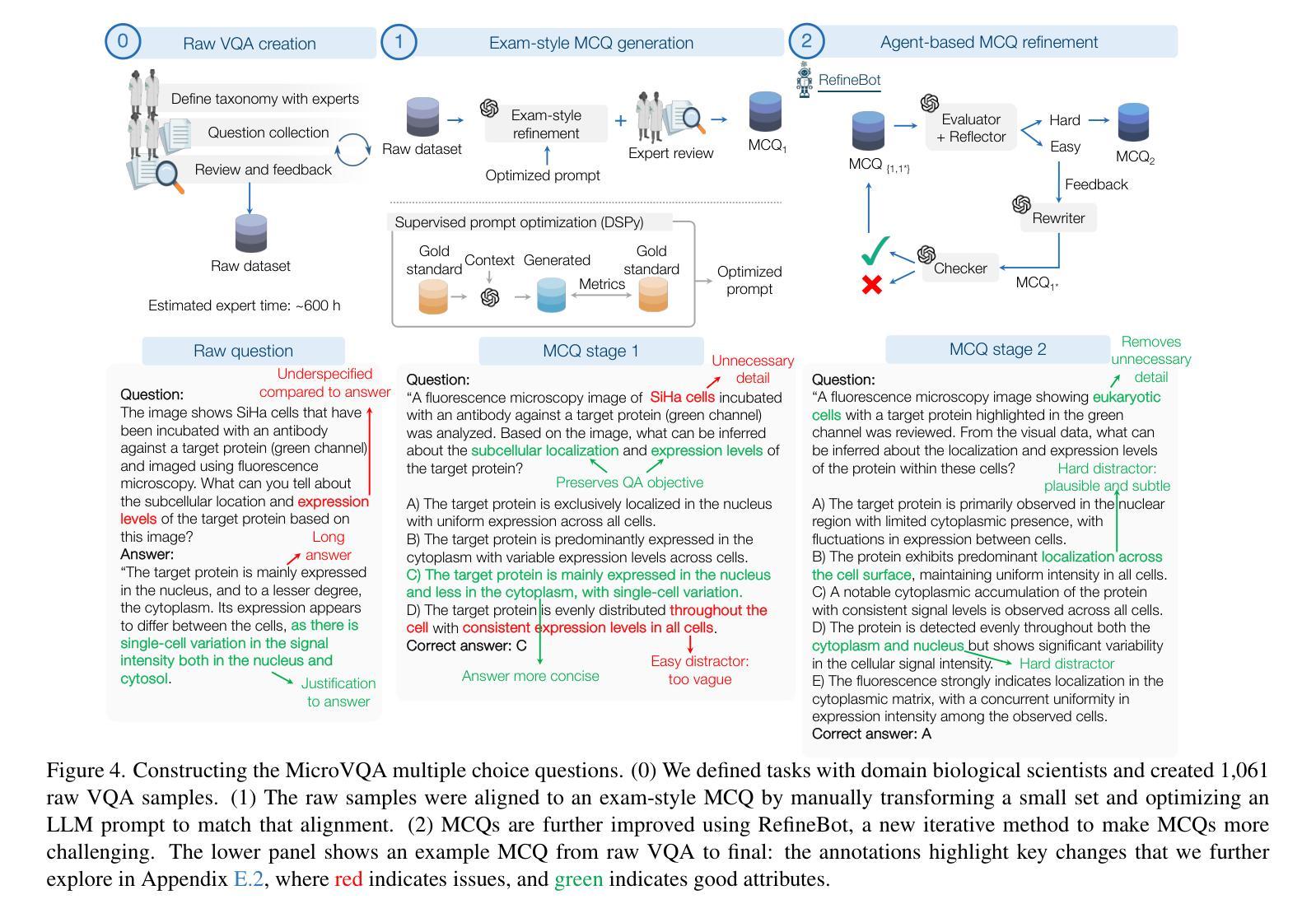
MicroVQA: A Multimodal Reasoning Benchmark for Microscopy-Based Scientific Research
Authors:James Burgess, Jeffrey J Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G. Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, Sarina M. Hasan, Alexandra Johannesson, William D. Leineweber, Malvika G Nair, Ridhi Yarlagadda, Connor Zuraski, Wah Chiu, Sarah Cohen, Jan N. Hansen, Manuel D Leonetti, Chad Liu, Emma Lundberg, Serena Yeung-Levy
Scientific research demands sophisticated reasoning over multimodal data, a challenge especially prevalent in biology. Despite recent advances in multimodal large language models (MLLMs) for AI-assisted research, existing multimodal reasoning benchmarks only target up to college-level difficulty, while research-level benchmarks emphasize lower-level perception, falling short of the complex multimodal reasoning needed for scientific discovery. To bridge this gap, we introduce MicroVQA, a visual-question answering (VQA) benchmark designed to assess three reasoning capabilities vital in research workflows: expert image understanding, hypothesis generation, and experiment proposal. MicroVQA consists of 1,042 multiple-choice questions (MCQs) curated by biology experts across diverse microscopy modalities, ensuring VQA samples represent real scientific practice. In constructing the benchmark, we find that standard MCQ generation methods induce language shortcuts, motivating a new two-stage pipeline: an optimized LLM prompt structures question-answer pairs into MCQs; then, an agent-based `RefineBot’ updates them to remove shortcuts. Benchmarking on state-of-the-art MLLMs reveal a peak performance of 53%; models with smaller LLMs only slightly underperform top models, suggesting that language-based reasoning is less challenging than multimodal reasoning; and tuning with scientific articles enhances performance. Expert analysis of chain-of-thought responses shows that perception errors are the most frequent, followed by knowledge errors and then overgeneralization errors. These insights highlight the challenges in multimodal scientific reasoning, showing MicroVQA is a valuable resource advancing AI-driven biomedical research. MicroVQA is available at https://huggingface.co/datasets/jmhb/microvqa, and project page at https://jmhb0.github.io/microvqa.
科学研究需要对多模态数据进行复杂的推理,这在生物学中尤为普遍。尽管近年来多模态大型语言模型(MLLMs)在AI辅助研究方面取得了进展,但现有的多模态推理基准测试仅针对大学水平的难度,而研究级基准测试则强调低级别的感知,无法达到科学发现所需的多模态复杂推理。为了弥补这一差距,我们引入了MicroVQA,这是一个视觉问答(VQA)基准测试,旨在评估研究工作流程中至关重要的三种推理能力:专家图像理解、假设生成和实验方案提出。MicroVQA包含由生物学专家跨多种显微镜模式整理的1042道选择题(MCQs),确保VQA样本代表真实的科学实践。在构建基准测试时,我们发现标准的选择题生成方法会导致语言上的捷径,这促使我们采用新的两阶段流程:优化的LLM提示结构将问题和答案配对成选择题;然后基于代理的RefineBot更新它们以消除捷径。在最新的MLLM上的基准测试显示,最高性能达到53%;使用较小LLM的模型性能略低于顶级模型,这表明基于语言的推理比多模态推理的挑战性较小;通过科学文章调整可增强性能。专家对思维链的响应分析显示,感知错误最为频繁,其次是知识错误,然后是过度概括错误。这些见解突出了多模态科学推理的挑战,表明MicroVQA是推动AI驱动生物医学研究的有价值的资源。MicroVQA可在https://huggingface.co/datasets/jmhb/microvqa获取,项目页面为https://jmhb0.github.io/microvqa。
论文及项目相关链接
PDF CVPR 2025 (Conference on Computer Vision and Pattern Recognition) Project page at https://jmhb0.github.io/microvqa Benchmark at https://huggingface.co/datasets/jmhb/microvqa
Summary
为填补科学研究中的多模态推理需求与现有基准测试之间的差距,提出MicroVQA基准测试,旨在评估生物学研究中的三大关键推理能力:专业图像理解、假设生成和实验提案。MicroVQA包含由生物学专家跨多种显微镜模式策划的1042道选择题,以确保视觉问答样本能真实反映科学实践。研究中发现标准选择题生成方法会引入语言捷径,因此研发了一个包含优化的大型语言模型提示结构和基于代理的RefineBot的选择题优化两阶段管道。在最新多模态大型语言模型上的基准测试显示,最佳性能为53%,且较小的语言模型性能略低于顶级模型,说明语言推理较之于多模态推理的挑战性较小。通过专家分析发现感知错误最为频繁,其次是知识错误和过度泛化错误。这些见解突显了多模态科学推理的困难,并证明了MicroVQA是推动人工智能驱动生物医学研究的宝贵资源。
Key Takeaways
- MicroVQA填补了科学研究中多模态推理需求的基准测试空白。
- MicroVQA旨在评估生物学研究中的三大关键推理能力:专业图像理解、假设生成和实验提案。
- MicroVQA包含由生物学专家在不同显微镜模式下策划的1042道选择题。
- 标准选择题生成方法存在引入语言捷径的问题,因此研发了两阶段管道进行优化。
- 在多模态大型语言模型上的基准测试显示最佳性能为53%,且较小的语言模型性能略低于顶级模型。
- 语言推理相较于多模态推理的挑战性较小。
点此查看论文截图


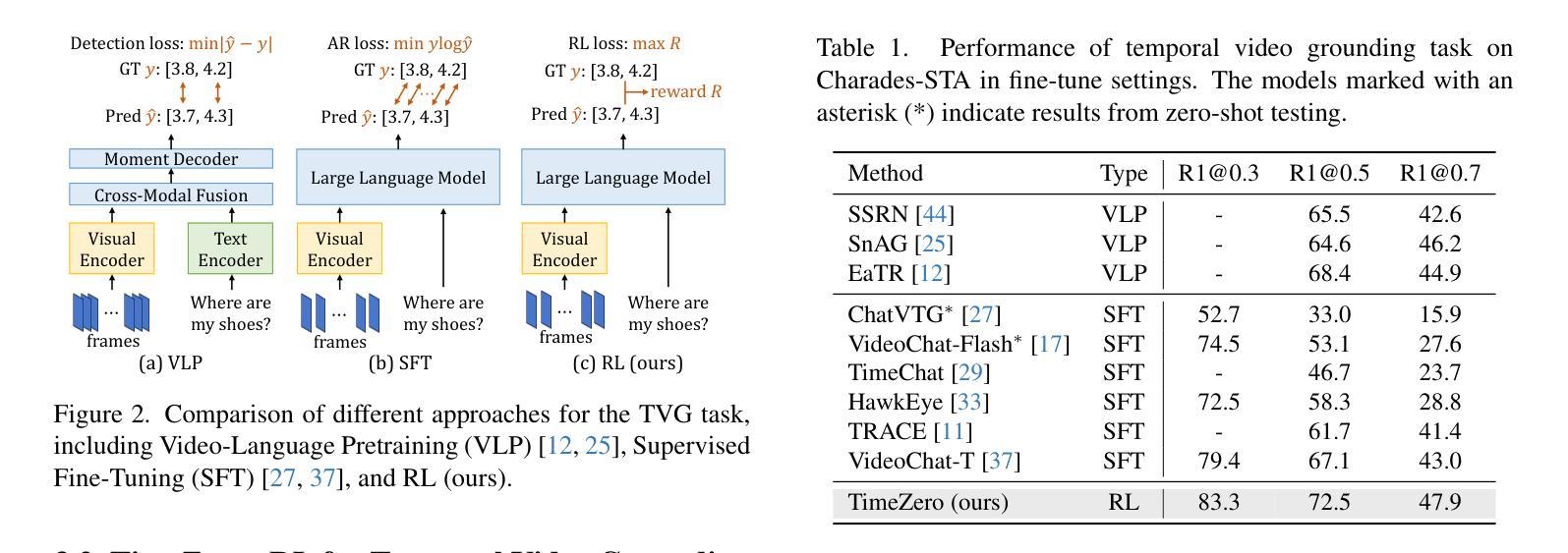
TimeZero: Temporal Video Grounding with Reasoning-Guided LVLM
Authors:Ye Wang, Boshen Xu, Zihao Yue, Zihan Xiao, Ziheng Wang, Liang Zhang, Dingyi Yang, Wenxuan Wang, Qin Jin
We introduce TimeZero, a reasoning-guided LVLM designed for the temporal video grounding (TVG) task. This task requires precisely localizing relevant video segments within long videos based on a given language query. TimeZero tackles this challenge by extending the inference process, enabling the model to reason about video-language relationships solely through reinforcement learning. To evaluate the effectiveness of TimeZero, we conduct experiments on two benchmarks, where TimeZero achieves state-of-the-art performance on Charades-STA. Code is available at https://github.com/www-Ye/TimeZero.
我们介绍了TimeZero,这是一种针对时序视频定位(TVG)任务设计的推理引导型LVVM。此任务需要在给定语言查询的基础上,在长视频中精确定位相关视频片段。TimeZero通过扩展推理过程来解决这一挑战,使模型能够仅通过强化学习对视频语言关系进行推理。为了评估TimeZero的有效性,我们在两个基准测试集上进行了实验,其中TimeZero在Charades-STA上取得了最新技术性能。代码可在https://github.com/www-Ye/TimeZero找到。
论文及项目相关链接
PDF Code: https://github.com/www-Ye/TimeZero
Summary
TimeZero是一种针对时序视频定位(TVG)任务的推理引导LVLM。该任务需要在长视频中精确定位与给定语言查询相关的视频片段。TimeZero通过扩展推理过程,使模型能够仅通过强化学习对视频语言关系进行推理,来解决这一挑战。在Charades-STA等两个基准测试集上进行的实验表明,TimeZero的性能达到了最新水平。相关代码已发布在链接。
Key Takeaways
- TimeZero是一种专为时序视频定位(TVG)任务设计的推理引导LVLM。
- TVG任务需要长视频中根据给定的语言查询精确定位相关视频片段。
- TimeZero通过强化学习进行推理,扩展了模型的推理过程来处理这一任务。
- TimeZero在Charades-STA基准测试集上取得了最新水平的性能表现。
- TimeZero模型具备强大的视频语言关系处理能力。
- TimeZero的代码已经公开,方便其他研究者使用和进一步开发。
点此查看论文截图


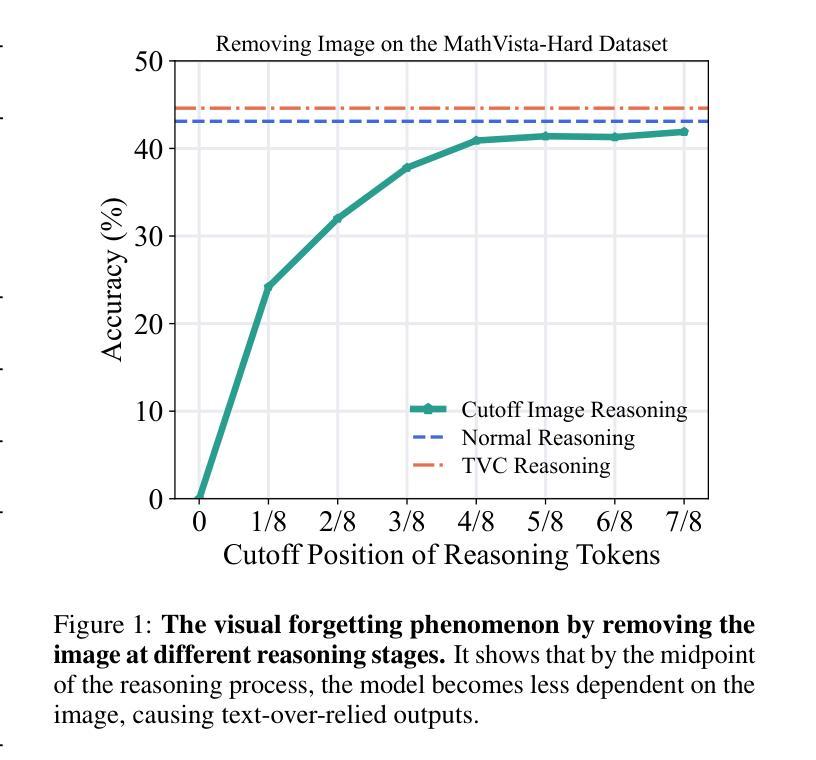
Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
Authors:Hai-Long Sun, Zhun Sun, Houwen Peng, Han-Jia Ye
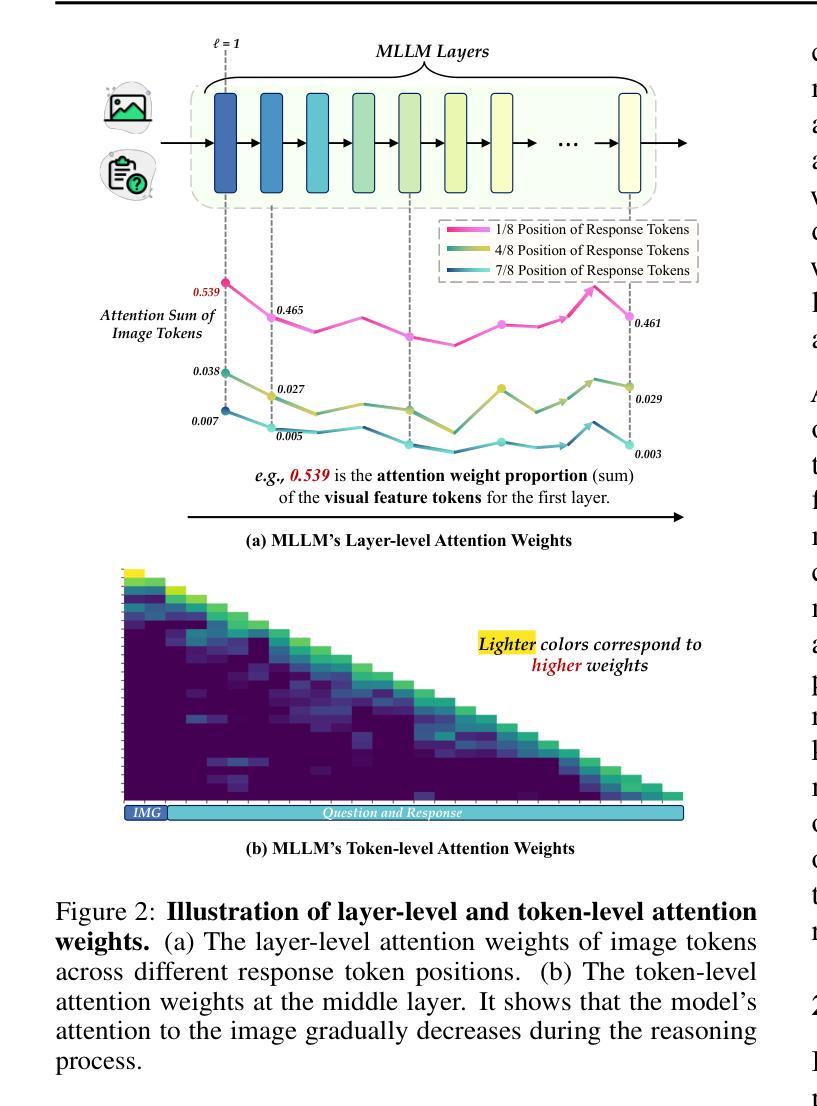
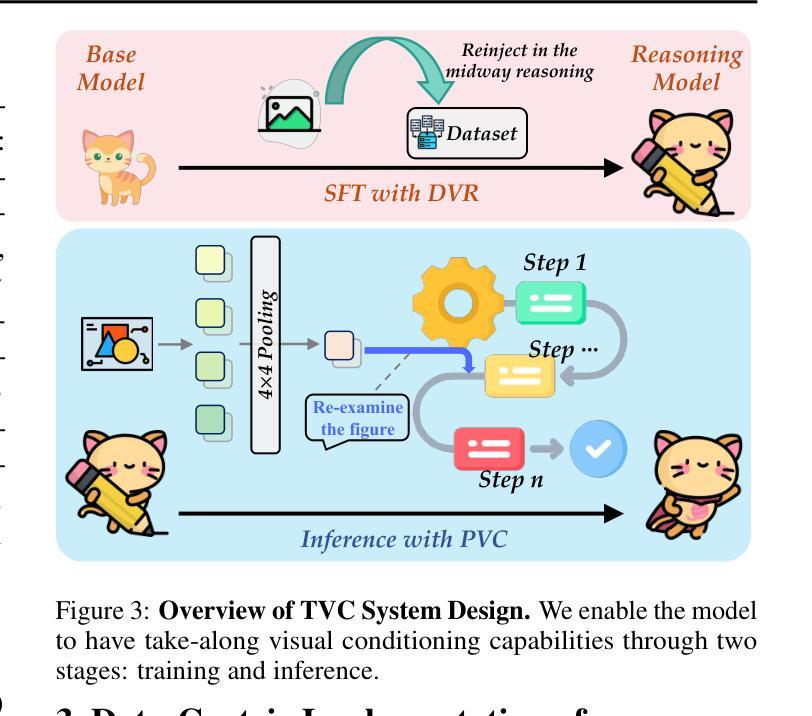
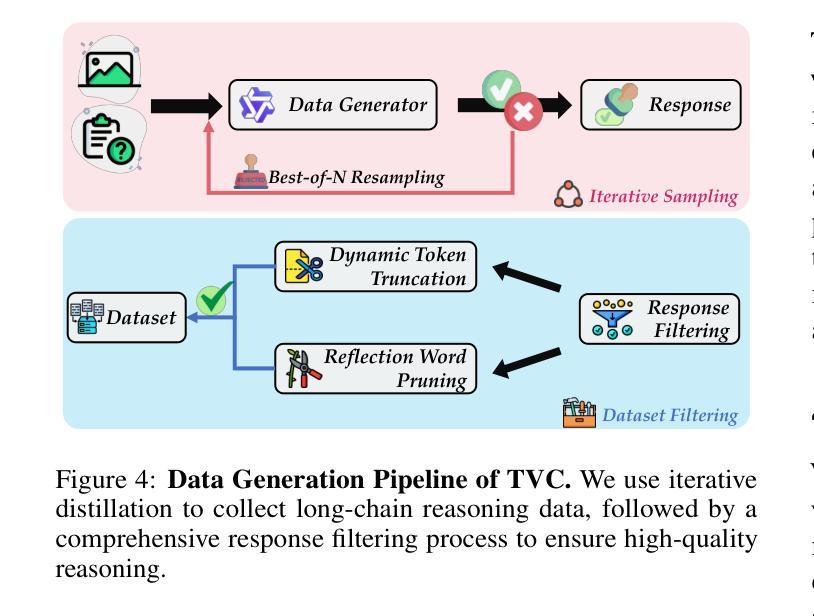
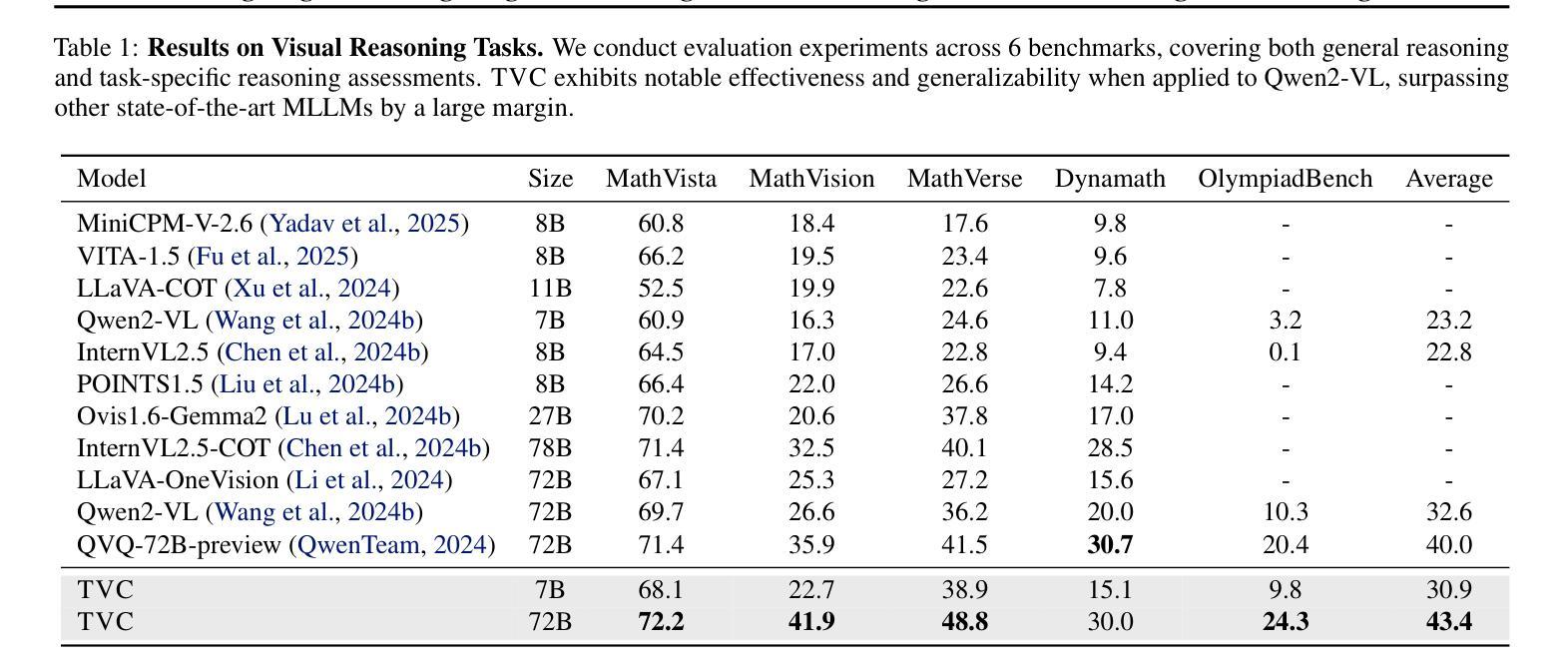
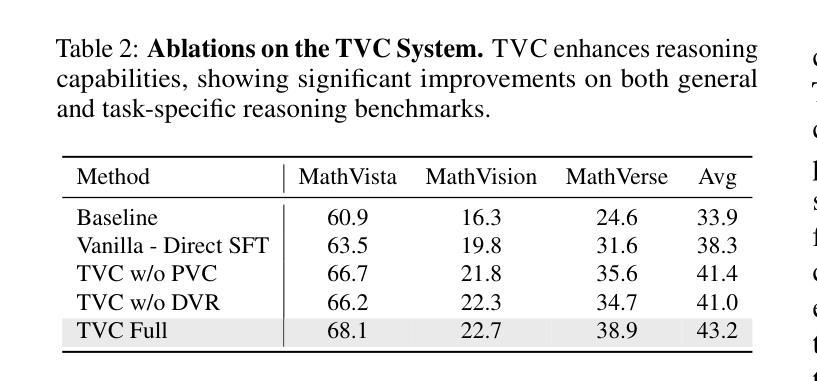
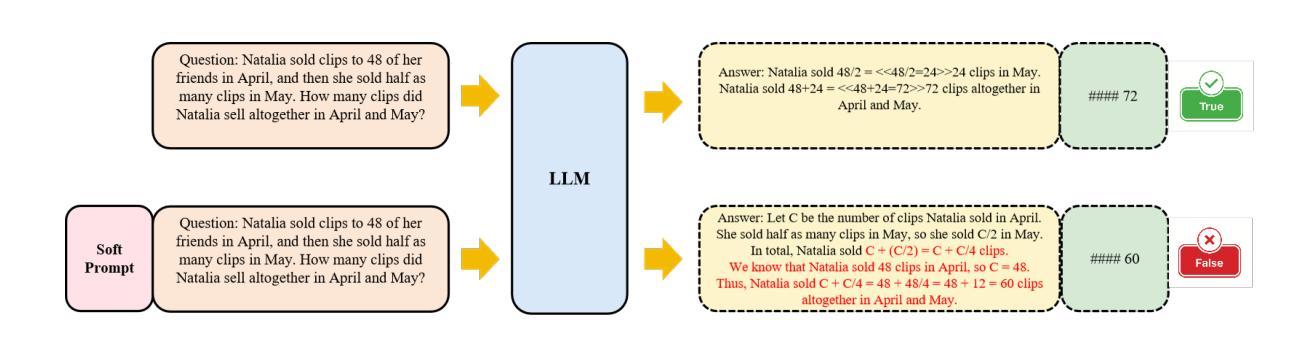
Recent advancements in Large Language Models (LLMs) have demonstrated enhanced reasoning capabilities, evolving from Chain-of-Thought (CoT) prompting to advanced, product-oriented solutions like OpenAI o1. During our re-implementation of this model, we noticed that in multimodal tasks requiring visual input (e.g., geometry problems), Multimodal LLMs (MLLMs) struggle to maintain focus on the visual information, in other words, MLLMs suffer from a gradual decline in attention to visual information as reasoning progresses, causing text-over-relied outputs. To investigate this, we ablate image inputs during long-chain reasoning. Concretely, we truncate the reasoning process midway, then re-complete the reasoning process with the input image removed. We observe only a ~2% accuracy drop on MathVista’s test-hard subset, revealing the model’s textual outputs dominate the following reasoning process. Motivated by this, we propose Take-along Visual Conditioning (TVC), a strategy that shifts image input to critical reasoning stages and compresses redundant visual tokens via dynamic pruning. This methodology helps the model retain attention to the visual components throughout the reasoning. Our approach achieves state-of-the-art performance on average across five mathematical reasoning benchmarks (+3.4% vs previous sota), demonstrating the effectiveness of TVC in enhancing multimodal reasoning systems.
最近,大型语言模型(LLM)的进展已经证明了其增强的推理能力,从思维链(CoT)提示发展到面向产品的高级解决方案,如OpenAI o1。在我们重新实现此模型的过程中,我们发现多模态任务需要视觉输入(例如几何问题),多模态LLM(MLLM)在维持对视觉信息的关注上遇到困难。换句话说,随着推理的进行,MLLM对视觉信息的关注逐渐下降,导致过度依赖文本输出。为了调查这个问题,我们在长链推理过程中消除图像输入。具体来说,我们在推理过程中中途截断,然后移除输入图像重新完成推理过程。我们在MathVista的硬测试子集上观察到仅约2%的准确率下降,这表明模型的文本输出主导了后续的推理过程。受此启发,我们提出了“携带式视觉条件”(TVC)策略,该策略将图像输入转移到关键的推理阶段,并通过动态修剪压缩冗余的视觉令牌。这种方法有助于模型在整个推理过程中保持对视觉成分的注意。我们的方法在五个数学推理基准测试上达到平均最先进的性能(比之前的最优性能高出3.4%),证明了TVC在增强多模态推理系统方面的有效性。
论文及项目相关链接
PDF The project page is available at https://sun-hailong.github.io/projects/TVC
Summary
大型语言模型(LLM)在推理能力方面取得显著进展,从链式思维(CoT)提示发展到面向产品的OpenAI等高级解决方案。在多模态任务中,多模态语言模型(MLLM)在处理视觉信息时面临注意力逐渐丧失的问题。研究发现,移除图像输入对长链推理过程仅造成约2%的准确率下降,表明模型主要依赖文本输出进行后续推理。因此,提出一种名为“带视觉条件”(TVC)的策略,将图像输入转移到关键推理阶段,并通过动态修剪压缩冗余视觉标记。此方法有助于模型在整个推理过程中保持对视觉成分的注意力,并在五个数学推理基准测试上取得平均最佳性能表现。
Key Takeaways
- 大型语言模型(LLM)已展现出增强的推理能力。
- 在多模态任务中,多模态语言模型(MLLM)在处理视觉信息时存在注意力逐渐丧失的问题。
- 移除图像输入对长链推理过程的影响较小,表明模型主要依赖文本输出。
- 提出带视觉条件(TVC)的策略,将图像输入转移到关键推理阶段。
- 通过动态修剪压缩冗余视觉标记,有助于模型保持对视觉成分的注意力。
- TVC策略在五个数学推理基准测试上取得了平均最佳性能表现。
点此查看论文截图

Agents Play Thousands of 3D Video Games
Authors:Zhongwen Xu, Xianliang Wang, Siyi Li, Tao Yu, Liang Wang, Qiang Fu, Wei Yang
We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL’s effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead. Experiment results on the 3D video games are best viewed on https://zhongwen.one/projects/portal .
我们提出了PORTAL,这是一个新颖的框架,用于开发能够通过语言指导策略生成玩数千款3D视频游戏的人工智能代理。通过将决策问题转化为语言建模任务,我们的方法利用大型语言模型(LLM)来生成以领域特定语言(DSL)表示的行为树。这种方法消除了传统强化学习方法的计算负担,同时保持了战略深度和快速适应性。我们的框架引入了一种混合策略结构,结合了基于规则的节点和神经网络组件,能够实现高级战略推理和精确的低级控制。采用结合定量游戏指标和视觉语言模型分析的双重反馈机制,促进战术和战略层面的策略迭代改进。得到的策略可立即部署、人类可解释,并能够在各种游戏环境中进行推广。实验结果证明了PORTAL在数千款第一人称射击游戏(FPS)中的有效性,与传统方法相比,在开发效率、策略推广和行为多样性方面实现了显著改进。PORTAL在游戏人工智能开发方面代表了重大进展,为创建能够在数千款商业视频游戏中操作且开发成本较低的复杂代理提供了实用解决方案。关于3D视频游戏的实验结果,请访问 https://zhongwen.one/projects/portal 查看最佳效果。
论文及项目相关链接
Summary
基于语言指导策略生成,PORTAL框架能够实现人工智能代理在数千款三维视频游戏中的游戏能力。通过将决策问题转化为语言建模任务,利用大型语言模型生成行为树,实现战略深度和快速适应性的平衡。该框架引入混合政策结构,结合规则节点和神经网络组件,实现高级战略推理和精确低级控制。实验结果显示,该框架在数千款第一人称射击游戏中表现出显著的开发效率提升、政策推广和行为多样性优势。更多实验结果请访问:https://zhongwen.one/projects/portal。
Key Takeaways
- PORTAL是一个新型框架,可以开发能在数千款三维视频游戏中进行游戏的人工智能代理。
- 通过将决策问题转化为语言建模任务,利用大型语言模型生成行为树。
- 引入混合政策结构,结合规则节点和神经网络组件,实现战略和精确控制的平衡。
- 采用双反馈机制,结合定量游戏指标和视觉语言模型分析,促进战术和策略层面的政策改进。
- 实验结果显示,该框架在FPS游戏中显著提升开发效率、政策通用性和行为多样性。
- 生成的政策具有即时部署性、人类可解释性和跨不同游戏环境的泛化能力。
点此查看论文截图


Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Authors:Sinan Fan, Liang Xie, Chen Shen, Ge Teng, Xiaosong Yuan, Xiaofeng Zhang, Chenxi Huang, Wenxiao Wang, Xiaofei He, Jieping Ye
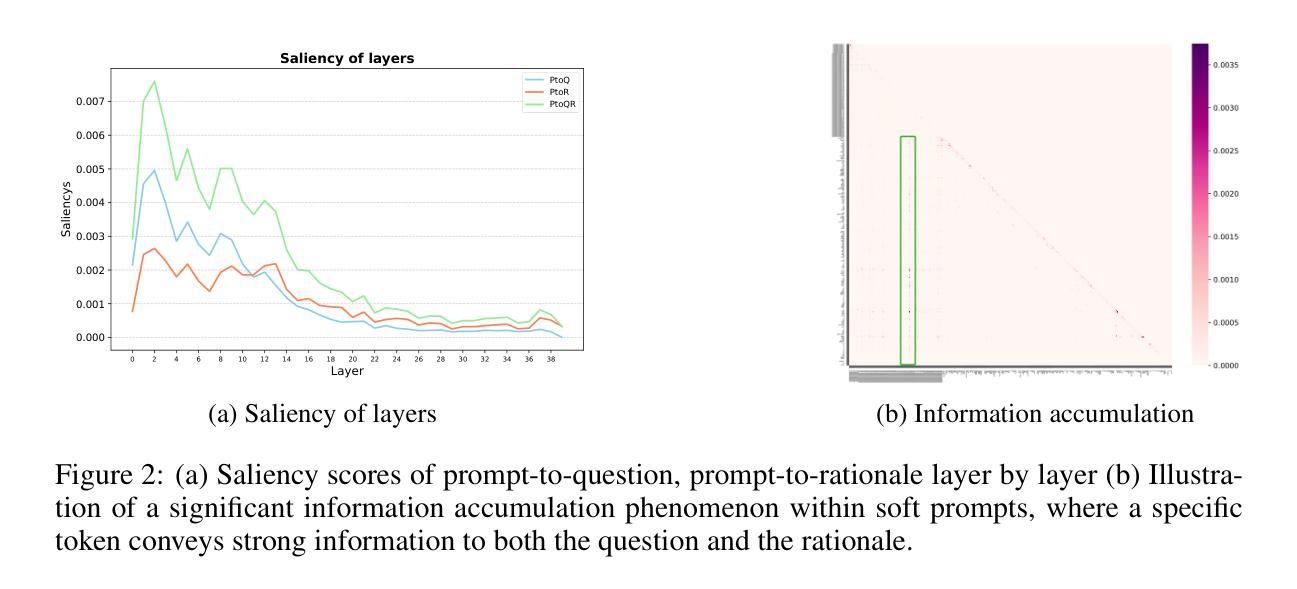
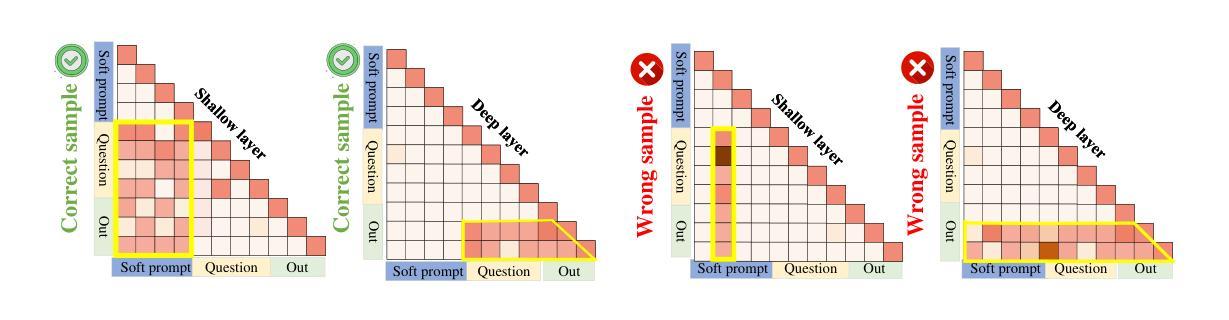
Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4%-8% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.
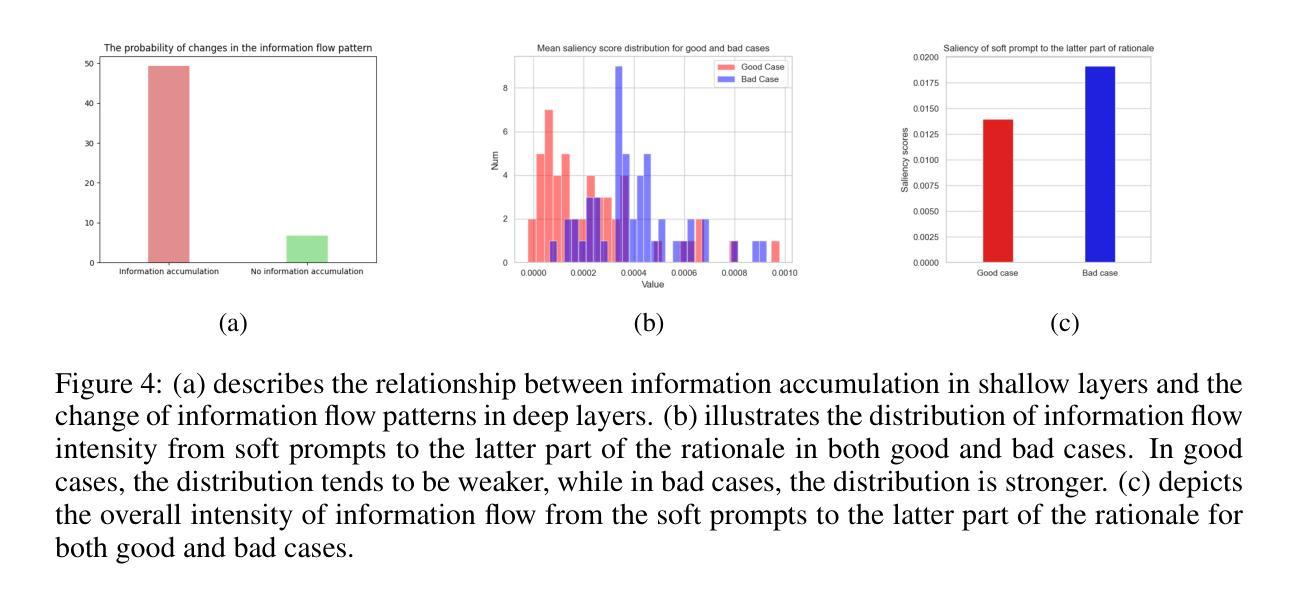
针对大型语言模型(LLM)的提示微调(PT)可以便于在各种传统的NLP任务中使用显著更少的可训练参数进行性能优化。然而,我们的调查表明,PT提供的改进非常有限,甚至可能会降低LLM在复杂的推理任务上的原始性能。这种现象表明,软提示可能会对某些实例产生积极影响,而对其他实例产生负面影响,特别是在推理的后期阶段。为了应对这些挑战,我们首先确定了软提示中的信息积累。通过详细分析,我们证明这种现象通常伴随着模型深层中错误的信息流模式,最终导致错误的推理结果。为了解决这一问题,我们提出了一种名为动态提示腐败(DPC)的新方法,以更好地利用软提示进行复杂的推理任务,该方法会根据软提示对推理过程的影响进行动态调整。具体来说,DPC分为两个阶段:动态触发和动态腐败。首先,动态触发会衡量软提示的影响,判断其是有益还是有害。然后,动态腐败通过有选择地掩盖干扰推理过程的关键令牌来减轻软提示的负面影响。我们通过在各种LLM和推理任务(包括GSM8K、MATH和AQuA)上进行的大量实验验证了所提出的方法。实验结果表明,DPC可以持续提高PT的性能,与简单的提示调整相比,实现了4%-8%的准确率提升,这凸显了我们方法的有效性及其在增强LLM复杂推理方面的潜力。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
大型语言模型通过微调软提示可优化各种常规自然语言处理任务的表现。但研究表明,对于复杂的推理任务,微调软提示提供的改进有限,甚至可能降低原始性能。为应对这一问题,本文提出了动态提示腐败(DPC)方法,通过动态调整软提示对推理过程的影响,有效提升了大型语言模型在复杂推理任务上的表现。该方法的两个阶段分别为动态触发和动态腐败,通过衡量软提示的影响,选择性屏蔽干扰推理过程的关键令牌来减轻软提示的负面影响。在多个大型语言模型和推理任务上的实验验证了该方法的有效性。
Key Takeaways
- 软提示对于大型语言模型在常规NLP任务上的性能优化有积极作用,但在复杂推理任务上的效果有限或可能产生负面影响。
- 在复杂推理任务中,软提示可能导致信息积累并伴随错误的信息流模式。
- 动态提示腐败(DPC)方法通过动态调整软提示的影响来解决上述问题,包括动态触发和动态腐败两个阶段。
- 动态触发用于衡量软提示的影响,判断其是否有利于推理过程。
- 动态腐败通过选择性屏蔽干扰推理过程的关键令牌来减轻软提示的负面影响。
- 实验结果显示,DPC方法能显著提升微调软提示的性能,与常规方法相比,准确率提升4%-8%。
点此查看论文截图

3DAxisPrompt: Promoting the 3D Grounding and Reasoning in GPT-4o
Authors:Dingning Liu, Cheng Wang, Peng Gao, Renrui Zhang, Xinzhu Ma, Yuan Meng, Zhihui Wang
Multimodal Large Language Models (MLLMs) exhibit impressive capabilities across a variety of tasks, especially when equipped with carefully designed visual prompts. However, existing studies primarily focus on logical reasoning and visual understanding, while the capability of MLLMs to operate effectively in 3D vision remains an ongoing area of exploration. In this paper, we introduce a novel visual prompting method, called 3DAxisPrompt, to elicit the 3D understanding capabilities of MLLMs in real-world scenes. More specifically, our method leverages the 3D coordinate axis and masks generated from the Segment Anything Model (SAM) to provide explicit geometric priors to MLLMs and then extend their impressive 2D grounding and reasoning ability to real-world 3D scenarios. Besides, we first provide a thorough investigation of the potential visual prompting formats and conclude our findings to reveal the potential and limits of 3D understanding capabilities in GPT-4o, as a representative of MLLMs. Finally, we build evaluation environments with four datasets, i.e., ScanRefer, ScanNet, FMB, and nuScene datasets, covering various 3D tasks. Based on this, we conduct extensive quantitative and qualitative experiments, which demonstrate the effectiveness of the proposed method. Overall, our study reveals that MLLMs, with the help of 3DAxisPrompt, can effectively perceive an object’s 3D position in real-world scenarios. Nevertheless, a single prompt engineering approach does not consistently achieve the best outcomes for all 3D tasks. This study highlights the feasibility of leveraging MLLMs for 3D vision grounding/reasoning with prompt engineering techniques.
多模态大型语言模型(MLLMs)在各种任务中展现出令人印象深刻的能力,尤其是当配备精心设计的视觉提示时。然而,现有研究主要集中在逻辑推理和视觉理解上,而MLLMs在3D视觉中有效操作的能力仍然是一个正在探索的领域。在本文中,我们介绍了一种新的视觉提示方法,称为3DAxisPrompt,以激发MLLMs在现实场景中的3D理解能力。更具体地说,我们的方法利用由Segment Anything Model(SAM)生成的3D坐标轴和掩码,为MLLMs提供明确的几何先验知识,然后将它们令人印象深刻的2D定位和推理能力扩展到现实世界的3D场景。此外,我们首次研究了潜在的视觉提示格式,并得出结论,以揭示GPT-4o等MLLMs的3D理解能力的潜力和局限性。最后,我们使用ScanRefer、ScanNet、FMB和nuScene四个数据集构建了评估环境,涵盖各种3D任务。在此基础上,我们进行了广泛的定量和定性实验,证明了所提出方法的有效性。总体而言,我们的研究表明,借助3DAxisPrompt,MLLMs可以有效地感知现实场景中物体的3D位置。然而,单一的提示工程方法并不总是对所有3D任务都能取得最佳效果。这项研究强调了利用提示工程技术进行MLLMs的3D视觉定位/推理的可行性。
论文及项目相关链接
Summary
本文介绍了一种名为3DAxisPrompt的新型视觉提示方法,旨在激发多模态大型语言模型(MLLMs)在现实场景中的3D理解能力。该方法利用由Segment Anything Model(SAM)生成的3D坐标轴和掩码,为MLLMs提供明确的几何先验信息,并将其在2D场景中的出色基础知识和推理能力扩展到现实世界的3D场景。文章还对视觉提示格式进行了深入研究,并得出结论,揭示了GPT-4o等MLLMs在3D理解能力方面的潜力和局限性。通过构建包含多种3D任务的评价环境,进行定量和定性的实验,验证了该方法的有效性。总的来说,该研究展示了MLLMs借助3DAxisPrompt有效感知物体在现实世界中的三维位置的能力。然而,单一的提示工程方法并不总是对所有3D任务产生最佳效果。该研究突显了利用提示工程技术将MLLMs用于3D视觉接地/推理的可行性。
Key Takeaways
- 多模态大型语言模型(MLLMs)在3D视觉理解方面展现出潜力,但仍是一个正在探索的领域。
- 引入了一种名为3DAxisPrompt的新型视觉提示方法,利用3D坐标轴和掩码来激发MLLMs的3D理解能力。
- 借助Segment Anything Model(SAM),为MLLMs提供明确的几何先验信息。
- 通过构建包含多种3D任务的评价环境,验证了该方法的有效性。
- MLLMs能有效感知物体在现实世界中的三维位置。
- 单一的提示工程方法并不总是对所有3D任务产生最佳效果,需要针对不同任务进行优化。
点此查看论文截图

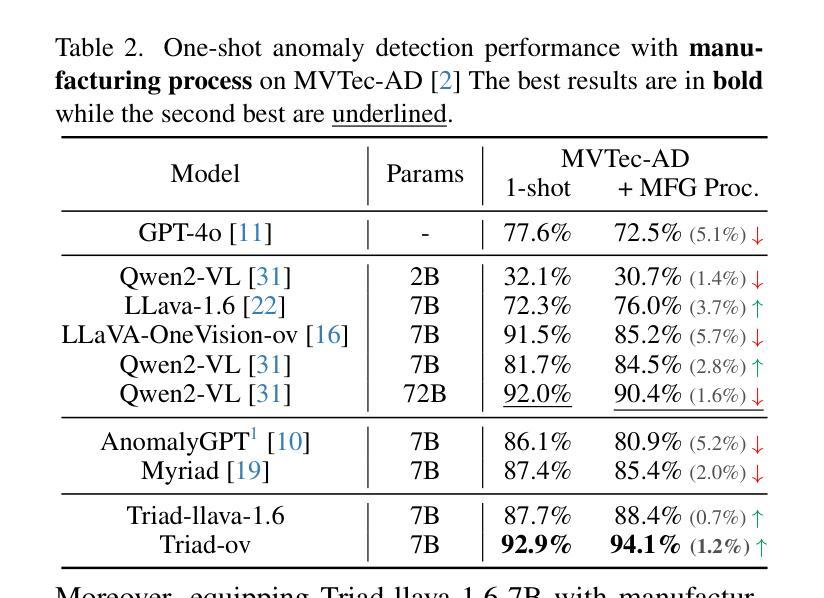
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Authors:Yuanze Li, Shihao Yuan, Haolin Wang, Qizhang Li, Ming Liu, Chen Xu, Guangming Shi, Wangmeng Zuo
Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
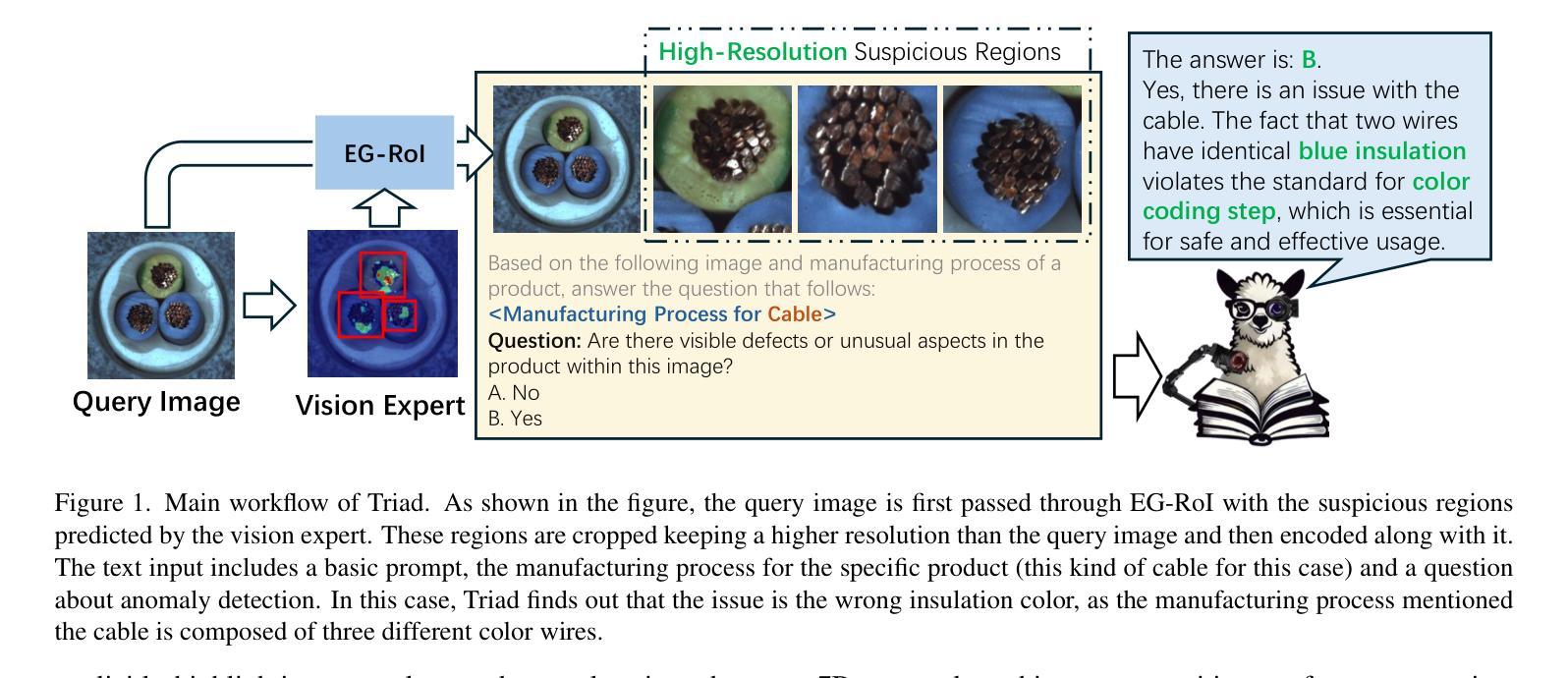
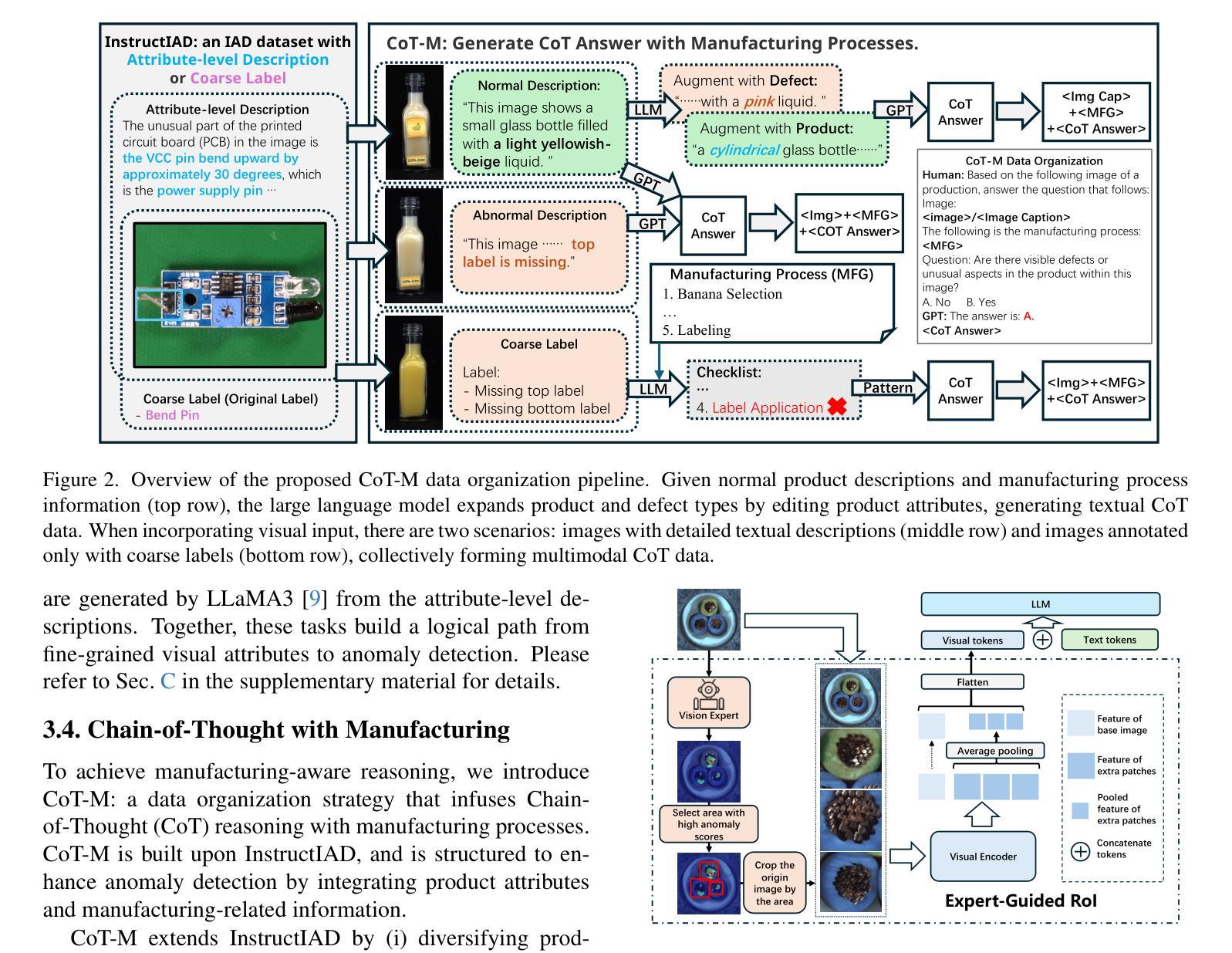
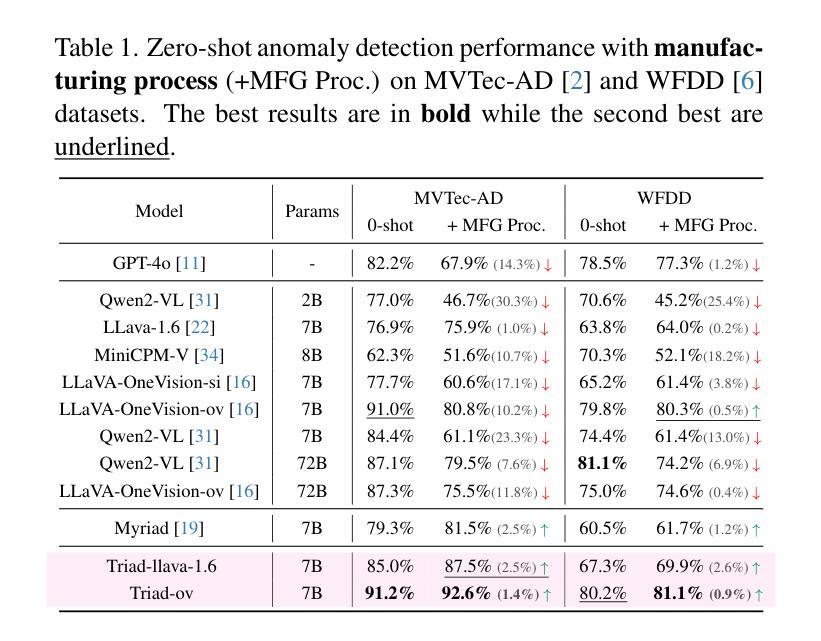
尽管最近的方法尝试将大型多模态模型(LMM)引入工业异常检测(IAD),但它们在IAD领域的泛化能力远远不如通用模型。我们将造成这种差距的主要原因总结为两个方面。首先,通用型LMM对视觉模态中的缺陷缺乏认知,因此无法充分关注缺陷区域。因此,我们提出修改LLaVA模型的AnyRes结构,将现有IAD模型识别的潜在异常区域提供给LMM。另一方面,现有方法主要侧重于通过学习缺陷模式或与正常样本进行比较来识别缺陷,但它们无法理解缺陷的原因。考虑到缺陷的产生与制造过程密切相关,我们提出了以制造为驱动的IAD范式。设计了用于IAD的指令调整数据集InstructIAD和用于Chain-of-Thought的制造数据组织方法CoT-M,以利用制造过程进行IAD。基于以上两个修改,我们提出了Triad,这是一种基于LMM的新方法,结合了专家引导的兴趣区域标记器和制造过程进行工业异常检测。大量实验表明,我们的Triad不仅与当前的LMM相比具有竞争力,而且在配备制造过程后还实现了更高的准确性。源代码、训练数据和预训练模型将在https://github.com/tzjtatata/Triad上公开。
论文及项目相关链接
Summary:
近期尝试将大型多模态模型(LMMs)引入工业异常检测(IAD)领域的方法虽然有所进展,但其泛化能力相较于通用领域仍有所不足。针对此问题,文章从两个方面进行了总结与分析。首先,通用的大型多模态模型在视觉模态上对缺陷的认知不足,无法充分关注缺陷区域。为此,文章提出对LLaVA模型的AnyRes结构进行修改,将现有IAD模型识别的潜在异常区域提供给LMMs。其次,现有方法主要通过学习缺陷模式或与正常样本进行比较来识别缺陷,缺乏对缺陷产生原因的深入理解。考虑到缺陷的产生与制造过程密切相关,文章提出了以制造过程驱动的IAD范式。为此,设计了针对IAD的指令调整数据集InstructIAD,以及适用于制造过程的Chain-of-Thought数据组织方法(CoT-M)。基于上述两个修改,文章提出了一种基于LMM的新方法Triad,结合专家引导的兴趣区域分词器和制造过程进行工业异常检测。实验表明,Triad不仅与当前LMMs相比具有竞争力,而且在配备制造过程后准确率进一步提高。
Key Takeaways:
- 大型多模态模型(LMMs)在工业异常检测(IAD)领域的泛化能力有待提高。
- 通用LMMs在视觉模态上对缺陷认知不足,需要关注缺陷区域。
- 现有方法主要关注缺陷的识别和比较,但缺乏对缺陷产生原因的理解。
- 缺陷产生与制造过程密切相关,提出以制造过程驱动的IAD范式。
- 设计了InstructIAD数据集和CoT-M数据组织方法以利用制造过程进行IAD。
- 基于上述改进,提出了LMMs为基础的新方法Triad,结合专家引导的兴趣区域分词器和制造过程。
点此查看论文截图

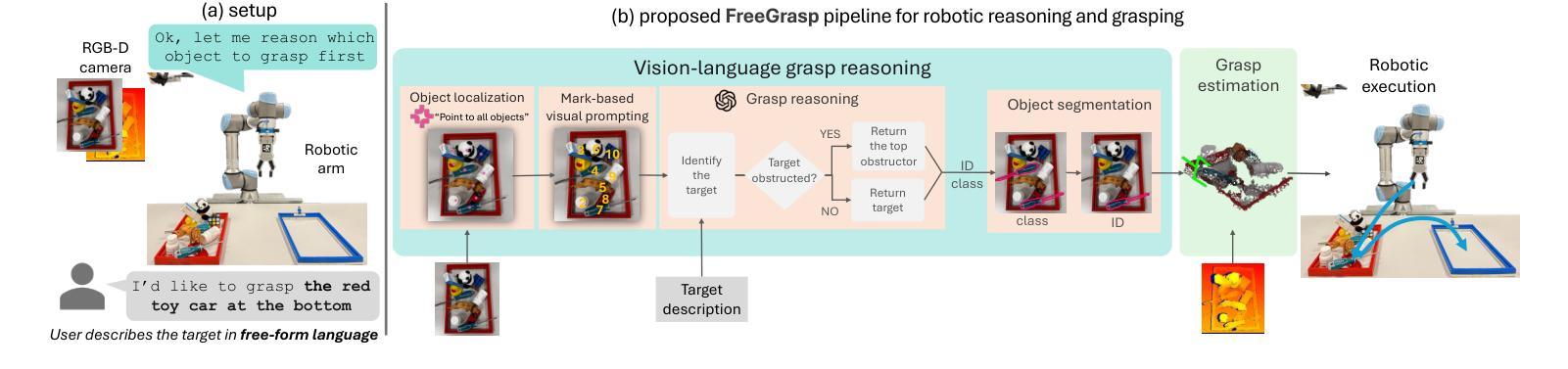
Free-form language-based robotic reasoning and grasping
Authors:Runyu Jiao, Alice Fasoli, Francesco Giuliari, Matteo Bortolon, Sergio Povoli, Guofeng Mei, Yiming Wang, Fabio Poiesi
Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs’ world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o’s zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution. Project website: https://tev-fbk.github.io/FreeGrasp/.
执行基于人类指令的从杂乱箱中抓取物体的机器人任务是一项具有挑战性的任务,因为它需要理解自由形式语言的细微差别以及物体之间的空间关系。在web级数据上训练的视觉语言模型(VLMs),如GPT-4o,在文本和图像方面都表现出了惊人的推理能力。但它们真的可以用于零样本设置中的这个任务吗?它们又存在哪些局限性呢?在本文中,我们通过基于自由形式语言的机器人抓取任务来探索这些研究问题,并提出了一种新方法FreeGrasp,它利用预训练的VLMs的世界知识来推理人类指令和物体的空间布局。我们的方法检测所有物体作为关键点,并使用这些关键点在图像上进行标注,旨在促进GPT-4o的零样本空间推理。这使得我们的方法能够确定所请求的对象是否可以直接抓取,或者是否必须先抓取并移除其他对象。由于没有现有的数据集是专门为这项任务设计的,我们通过扩展MetaGraspNetV2数据集,引入了包含人类注释指令和真实抓取序列的合成数据集FreeGraspData。我们进行了广泛的FreeGraspData分析以及与配备夹具的机器人手臂的真实世界验证,在抓取推理和执行方面均表现出卓越的性能。项目网站:https://tev-fbk.github.io/FreeGrasp/。
论文及项目相关链接
PDF Project website: https://tev-fbk.github.io/FreeGrasp/
Summary
该论文探索了在杂乱无章的箱子中进行基于人类指令的机器人抓取任务的挑战。通过利用预训练的跨文本和图像的视觉语言模型(VLMs),如GPT-4o,提出了一种新方法FreeGrasp。该方法能够利用VLMs的世界知识理解人类指令和物体空间布局,通过检测所有物体作为关键点并在图像上进行标注,以促进GPT-4o的零样本空间推理。新方法能够在无特定数据集的情况下,通过合成的FreeGraspData数据集进行训练,并在现实世界的验证中表现出卓越的性能。
Key Takeaways
- 论文探索了基于人类指令从杂乱无章的箱子中进行机器人抓取任务的挑战。
- 提出了利用预训练的视觉语言模型(VLMs)如GPT-4o进行机器人抓取的新方法FreeGrasp。
- FreeGrasp方法能够利用VLMs的世界知识理解人类指令和物体空间布局。
- 通过检测物体作为关键点并在图像上标注,促进GPT-4o的零样本空间推理。
- 论文引入了一个合成的FreeGraspData数据集,用于训练并验证FreeGrasp方法的性能。
- FreeGrasp方法在握持推理和执行方面表现出卓越的性能。
点此查看论文截图

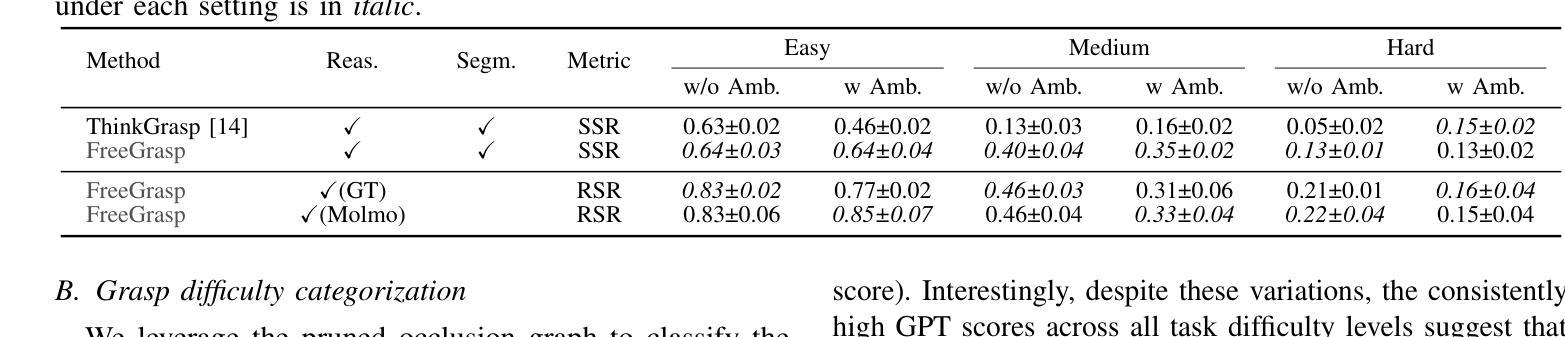

Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Authors:Henghui Du, Guangyao Li, Chang Zhou, Chunjie Zhang, Alan Zhao, Di Hu
In recent years, numerous tasks have been proposed to encourage model to develop specified capability in understanding audio-visual scene, primarily categorized into temporal localization, spatial localization, spatio-temporal reasoning, and pixel-level understanding. Instead, human possesses a unified understanding ability for diversified tasks. Therefore, designing an audio-visual model with general capability to unify these tasks is of great value. However, simply joint training for all tasks can lead to interference due to the heterogeneity of audiovisual data and complex relationship among tasks. We argue that this problem can be solved through explicit cooperation among tasks. To achieve this goal, we propose a unified learning method which achieves explicit inter-task cooperation from both the perspectives of data and model thoroughly. Specifically, considering the labels of existing datasets are simple words, we carefully refine these datasets and construct an Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning process (AV-UIE), which clarifies the cooperative relationship among tasks. Subsequently, to facilitate concrete cooperation in learning stage, an interaction-aware LoRA structure with multiple LoRA heads is designed to learn different aspects of audiovisual data interaction. By unifying the explicit cooperation across the data and model aspect, our method not only surpasses existing unified audio-visual model on multiple tasks, but also outperforms most specialized models for certain tasks. Furthermore, we also visualize the process of explicit cooperation and surprisingly find that each LoRA head has certain audio-visual understanding ability. Code and dataset: https://github.com/GeWu-Lab/Crab
近年来,为了鼓励模型发展理解音频视觉场景的能力,已经提出了许多任务,主要可分为时间定位、空间定位、时空推理和像素级理解。相比之下,人类具备对各种任务的统一理解能力。因此,设计一种具备统一这些任务的一般能力的视听模型是非常有价值的。然而,简单地对所有任务进行联合训练可能会导致由于视听数据的异质性和任务之间的复杂关系导致的干扰。我们认为这个问题可以通过任务之间的显式合作来解决。为了实现这一目标,我们提出了一种统一的学习方法,从数据和模型的视角实现任务的显式合作。具体来说,考虑到现有数据集的标签是简单的单词,我们精心地细化了这些数据集,构建了一个带有明确推理过程的视听统一指令调整数据集(AV-UIE),该数据集明确了任务之间的合作关系。随后,为了在学习阶段促进具体的合作,设计了一种具有多个LoRA头的信息交互感知LoRA结构。通过统一数据和模型方面的显式合作,我们的方法不仅在多个任务上超越了现有的统一视听模型,而且还在某些特定任务上超过了大多数专用模型。此外,我们还可视化了显式合作的过程,并惊讶地发现每个LoRA头都具有一定的音频视觉理解能力。代码和数据集地址:https://github.com/GeWu-Lab/Crab
论文及项目相关链接
Summary
本文提出了一种统一的视听学习方法,通过数据层面的细化处理和模型层面的创新设计,实现了不同视听任务间的显式合作。通过构建AV-UIE数据集和引入交互感知的LoRA结构,该方法在多个任务上超越了现有的视听模型,甚至在某些任务上超过了专门的模型。
Key Takeaways
- 视听场景理解的任务主要包括时间定位、空间定位、时空推理和像素级理解。
- 单纯联合训练所有任务会因视听数据的异质性和任务间复杂关系导致干扰。
- 本文提出了一种统一的学习方法,通过数据和模型两个层面的显式任务合作来解决这一问题。
- 构建了AV-UIE数据集,明确了任务间的合作关系。
- 引入了交互感知的LoRA结构,设计了多个LoRA头来学习视听数据的不同交互方面。
- 该方法不仅在多任务上超越了现有的视听模型,而且在某些任务上超过了专业模型。
点此查看论文截图

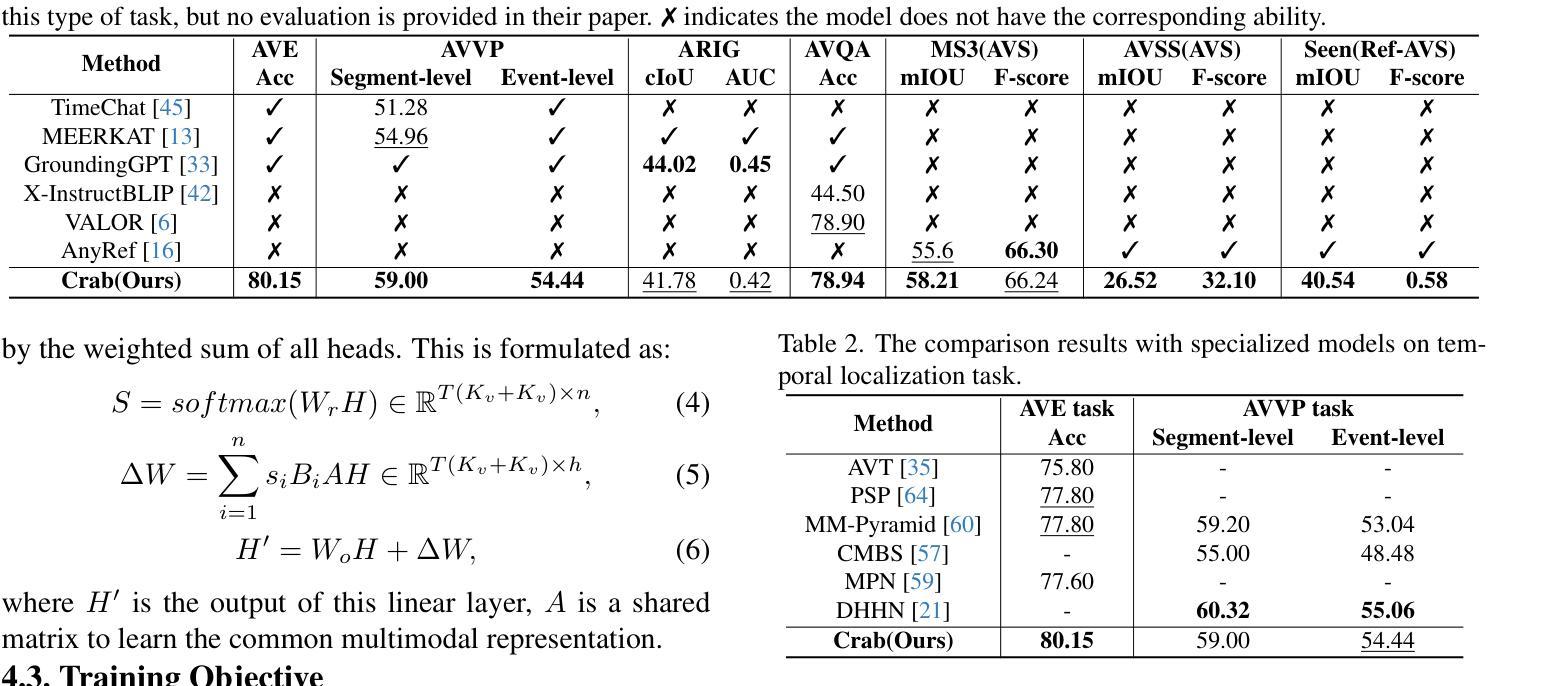
A Multi-Stage Framework with Taxonomy-Guided Reasoning for Occupation Classification Using Large Language Models
Authors:Palakorn Achananuparp, Ee-Peng Lim
Automatically annotating job data with standardized occupations from taxonomies, known as occupation classification, is crucial for labor market analysis. However, this task is often hindered by data scarcity and the challenges of manual annotations. While large language models (LLMs) hold promise due to their extensive world knowledge and in-context learning capabilities, their effectiveness depends on their knowledge of occupational taxonomies, which remains unclear. In this study, we assess the ability of LLMs to generate precise taxonomic entities from taxonomy, highlighting their limitations. To address these challenges, we propose a multi-stage framework consisting of inference, retrieval, and reranking stages, which integrates taxonomy-guided reasoning examples to enhance performance by aligning outputs with taxonomic knowledge. Evaluations on a large-scale dataset show significant improvements in classification accuracy. Furthermore, we demonstrate the framework’s adaptability for multi-label skill classification. Our results indicate that the framework outperforms existing LLM-based methods, offering a practical and scalable solution for occupation classification and related tasks across LLMs.
自动使用标准化职业对作业数据进行注释,这在职业分类中被称为分类,对于劳动力市场分析至关重要。然而,由于数据稀缺和手动注释的挑战,这一任务往往受阻。虽然大型语言模型(LLM)由于其丰富的世界知识和上下文学习能力而具有潜力,但其对职业分类知识的了解仍然不明确。本研究旨在评估LLM生成精确分类实体的能力。为了应对这些挑战,我们提出了一个包含推理、检索和重新排序阶段的多阶段框架,该框架融合了分类指导的推理示例,通过对齐输出和分类知识来提高性能。在大规模数据集上的评估显示,分类精度有了显著提高。此外,我们展示了该框架在多标签技能分类方面的适应性。我们的结果表明,该框架在职业分类和相关任务方面的表现优于现有的基于LLM的方法,为跨LLM的职业分类和相关任务提供了实用且可扩展的解决方案。
针对上述文本,其翻译为:
论文及项目相关链接
Summary:
自动标注职业数据并进行标准化职业分类对于劳动力市场分析至关重要。然而,由于数据稀缺性和手动标注的挑战,此任务往往受阻。大型语言模型(LLMs)由于其丰富的世界知识和上下文学习能力而具有潜力,但其对职业分类知识的了解尚不清楚。本研究评估了LLMs生成精确分类术语的能力,并强调了其局限性。为解决这些挑战,我们提出了一个包含推理、检索和重新排序阶段的多阶段框架,通过整合分类知识指导的推理示例来提高性能,使输出与分类知识相符。大规模数据集上的评估显示分类精度显著提高。此外,我们证明了该框架在多重标签技能分类中的适应性。我们的结果表明,该框架在职业分类和相关任务方面优于现有的LLM方法,为跨LLMs提供实用且可扩展的解决方案。
Key Takeaways:
- 自动标注职业数据并进行标准化职业分类是劳动力市场分析的关键。
- 大型语言模型(LLMs)在职业分类上具有潜力,但需提高其对于职业分类知识的了解。
- LLMs在生成精确分类术语方面存在局限性。
- 提出的多阶段框架包括推理、检索和重新排序阶段,旨在提高LLMs在职业分类任务中的性能。
- 框架集成了分类知识指导的推理示例,以对齐输出与分类知识。
- 在大规模数据集上的评估显示,该框架显著提高了分类精度。
点此查看论文截图


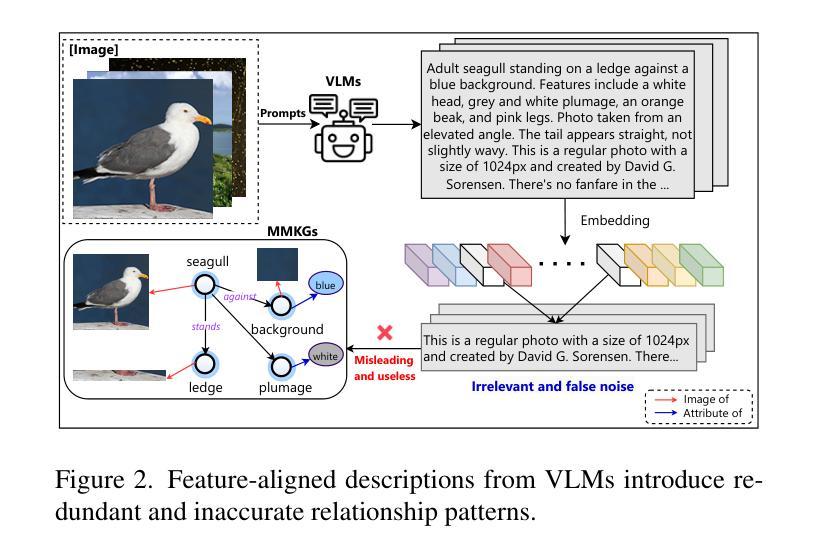
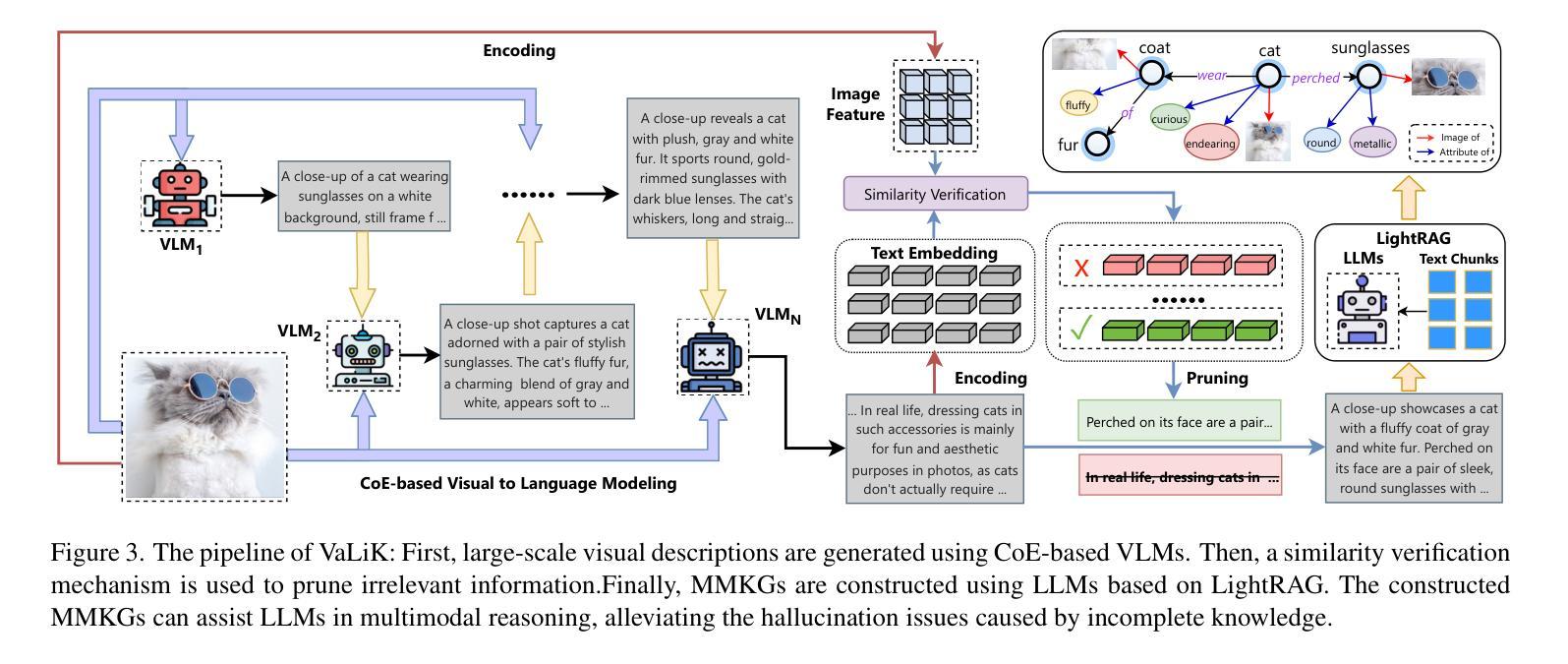
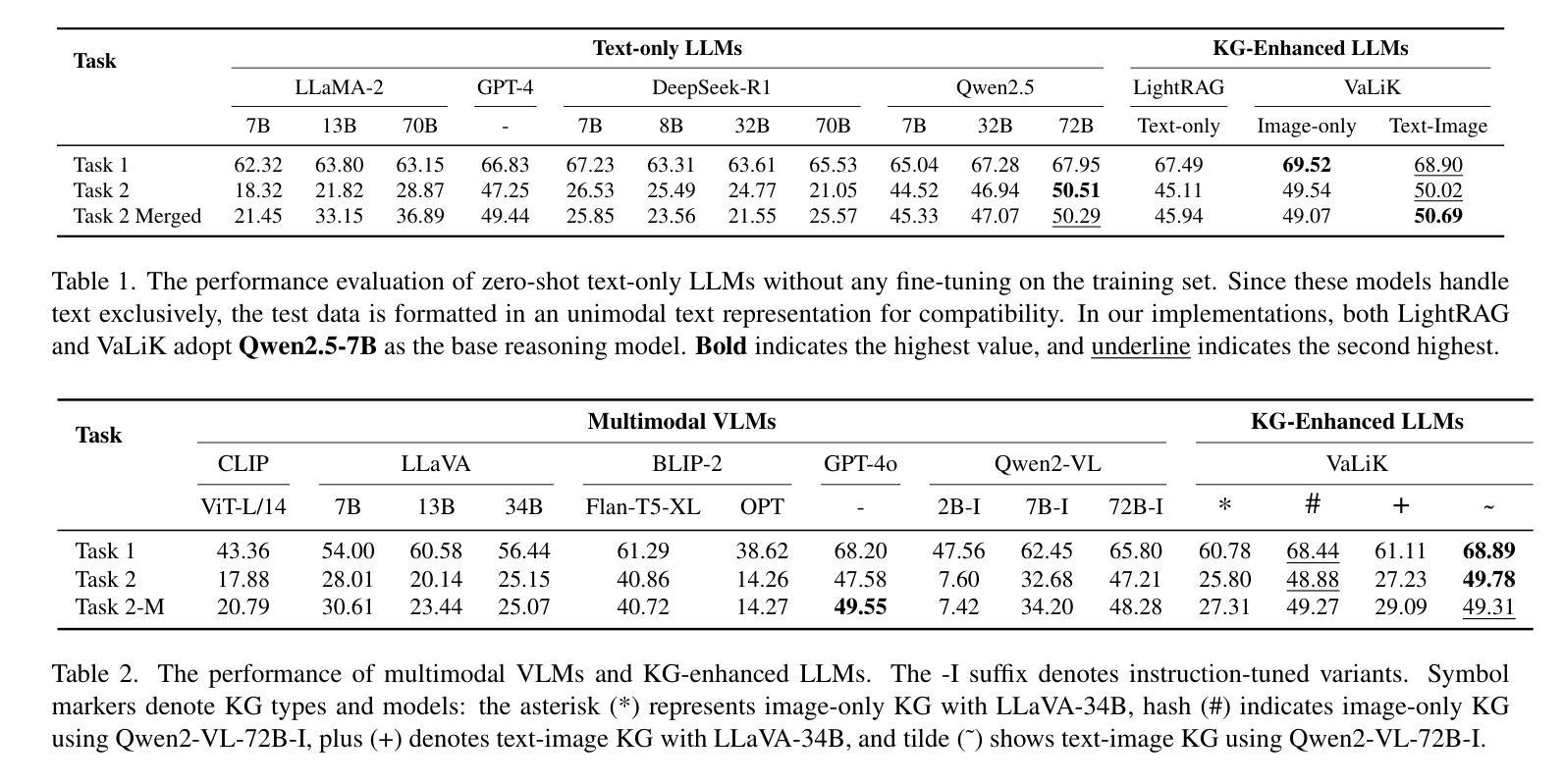
Aligning Vision to Language: Text-Free Multimodal Knowledge Graph Construction for Enhanced LLMs Reasoning
Authors:Junming Liu, Siyuan Meng, Yanting Gao, Song Mao, Pinlong Cai, Guohang Yan, Yirong Chen, Zilin Bian, Botian Shi, Ding Wang
Multimodal reasoning in Large Language Models (LLMs) struggles with incomplete knowledge and hallucination artifacts, challenges that textual Knowledge Graphs (KGs) only partially mitigate due to their modality isolation. While Multimodal Knowledge Graphs (MMKGs) promise enhanced cross-modal understanding, their practical construction is impeded by semantic narrowness of manual text annotations and inherent noise in visual-semantic entity linkages. In this paper, we propose Vision-align-to-Language integrated Knowledge Graph (VaLiK), a novel approach for constructing MMKGs that enhances LLMs reasoning through cross-modal information supplementation. Specifically, we cascade pre-trained Vision-Language Models (VLMs) to align image features with text, transforming them into descriptions that encapsulate image-specific information. Furthermore, we developed a cross-modal similarity verification mechanism to quantify semantic consistency, effectively filtering out noise introduced during feature alignment. Even without manually annotated image captions, the refined descriptions alone suffice to construct the MMKG. Compared to conventional MMKGs construction paradigms, our approach achieves substantial storage efficiency gains while maintaining direct entity-to-image linkage capability. Experimental results on multimodal reasoning tasks demonstrate that LLMs augmented with VaLiK outperform previous state-of-the-art models. Our code is published at https://github.com/Wings-Of-Disaster/VaLiK.
在多模态语言模型(LLM)中,处理不完整知识和幻觉效应面临困难。由于模态隔离的原因,文本知识图谱(KG)只能部分缓解这些挑战。虽然多模态知识图谱(MMKG)有望增强跨模态理解,但其实际构建受到手动文本注释的语义狭窄和视觉语义实体链接中的固有噪声的阻碍。在本文中,我们提出了Vision-align-to-Language集成知识图谱(VaLiK)这一构建MMKG的新方法,通过跨模态信息补充增强LLM推理能力。具体来说,我们将预训练的视觉语言模型(VLM)级联起来,将图像特征与文本对齐,将它们转换为包含图像特定信息的描述。此外,我们开发了一种跨模态相似性验证机制,以量化语义一致性,有效地过滤出在特征对齐过程中引入的噪声。即使没有手动注释的图像标题,经过提炼的描述也足以构建MMKG。与传统的MMKG构建范式相比,我们的方法在保持直接实体到图像链接能力的同时,实现了巨大的存储效率提升。在多模态推理任务上的实验结果表明,经过VaLiK增强的LLM性能优于先前最先进的模型。我们的代码已发布在:https://github.com/Wings-Of-Disaster/VaLiK。
论文及项目相关链接
PDF 14 pages, 7 figures, 6 tables
Summary
大型语言模型(LLM)的多模态推理面临知识不完整和幻觉伪像的问题,文本知识图谱(KG)由于模态隔离只能部分缓解这些问题。虽然多模态知识图谱(MMKG)承诺增强跨模态理解,但其实际构建受到手动文本注释的语义狭窄性和视觉语义实体链接中的固有噪声的阻碍。本文提出Vision-align-to-Language集成知识图谱(VaLiK)方法,通过跨模态信息补充增强LLM推理能力。该方法将预训练的视觉语言模型(VLM)级联,以将图像特征与文本对齐,并将其转换为包含图像特定信息的描述。此外,还开发了一种跨模态相似性验证机制,以量化语义一致性,有效地过滤出在特征对齐过程中引入的噪声。即使在没有手动注释的图像标题的情况下,经过优化的描述也足以构建MMKG。与常规MMKG构建范式相比,该方法在保持直接实体到图像链接能力的同时,实现了巨大的存储效率提升。在多模态推理任务上的实验结果表明,增强VaLiK的LLM优于以前的最先进模型。
Key Takeaways
- LLM的多模态推理面临知识不完整和幻觉伪像的挑战。
- 文本知识图谱只能部分解决这些挑战,因为其模态隔离。
- VaLiK是一种构建多模态知识图谱的新方法,通过跨模态信息补充增强LLM推理。
- VaLiK使用预训练的视觉语言模型将图像特征与文本对齐。
- VaLiK开发了一种跨模态相似性验证机制,以过滤掉特征对齐过程中的噪声。
- 即使在没有手动注释的图像标题的情况下,VaLiK也能构建MMKG。
点此查看论文截图

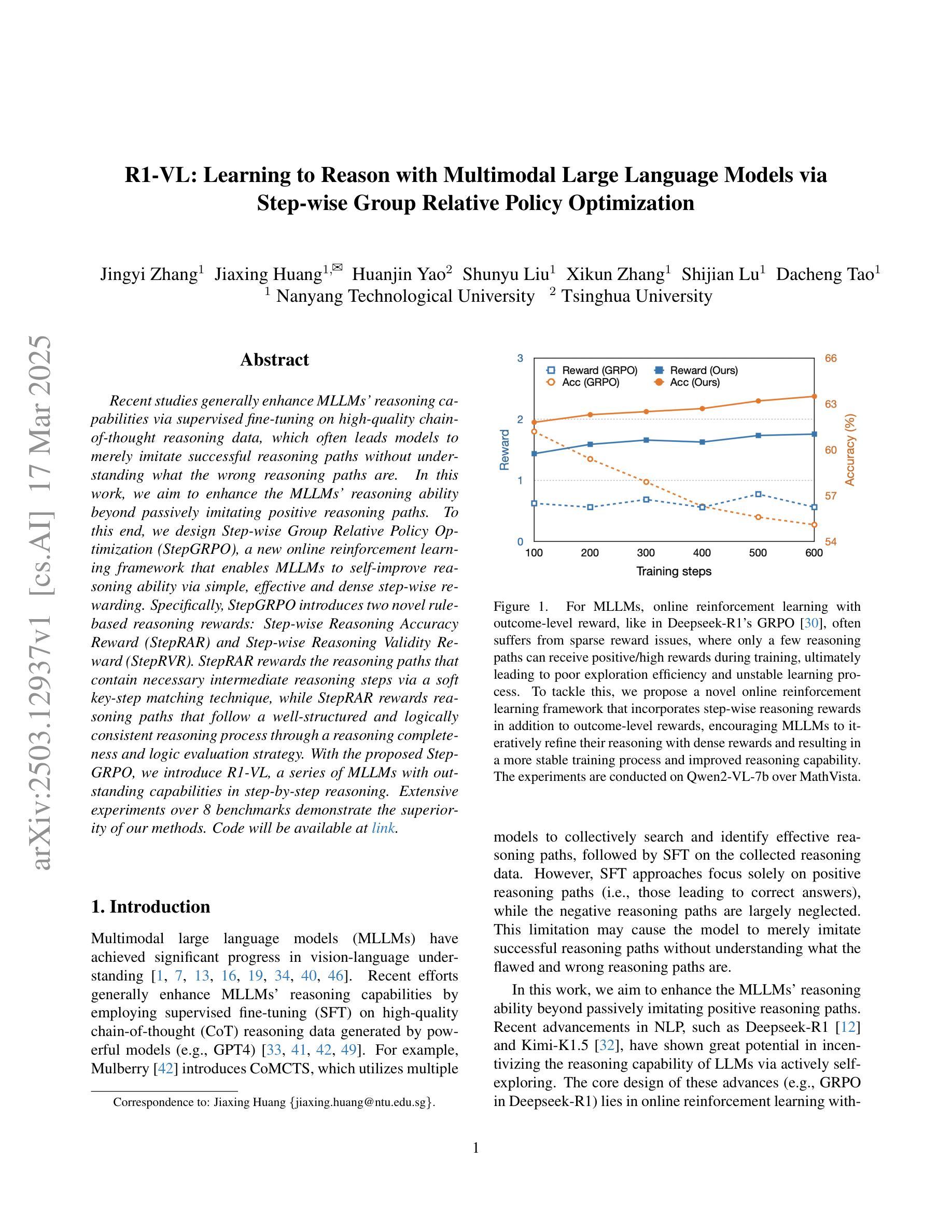
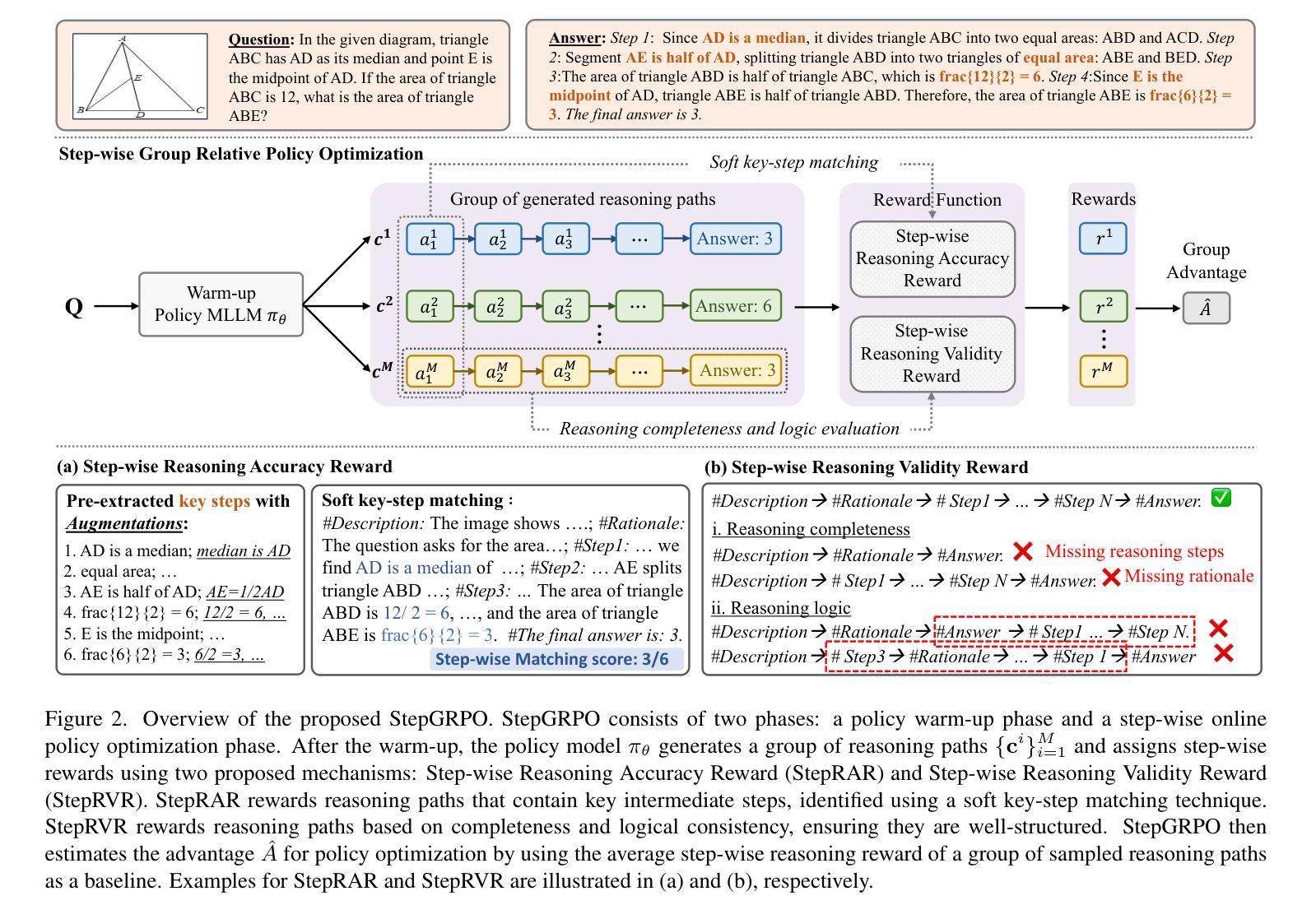
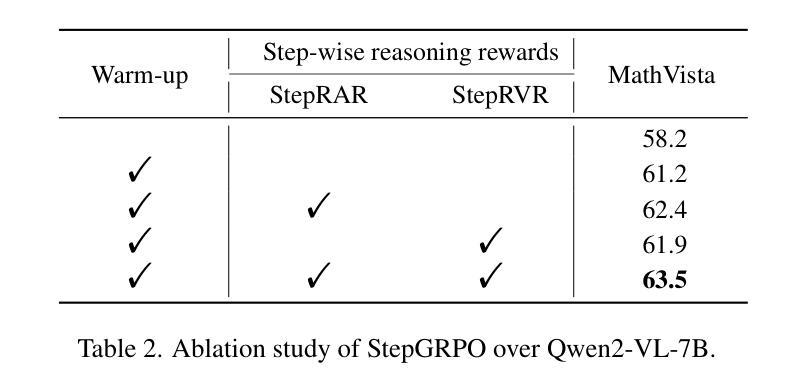
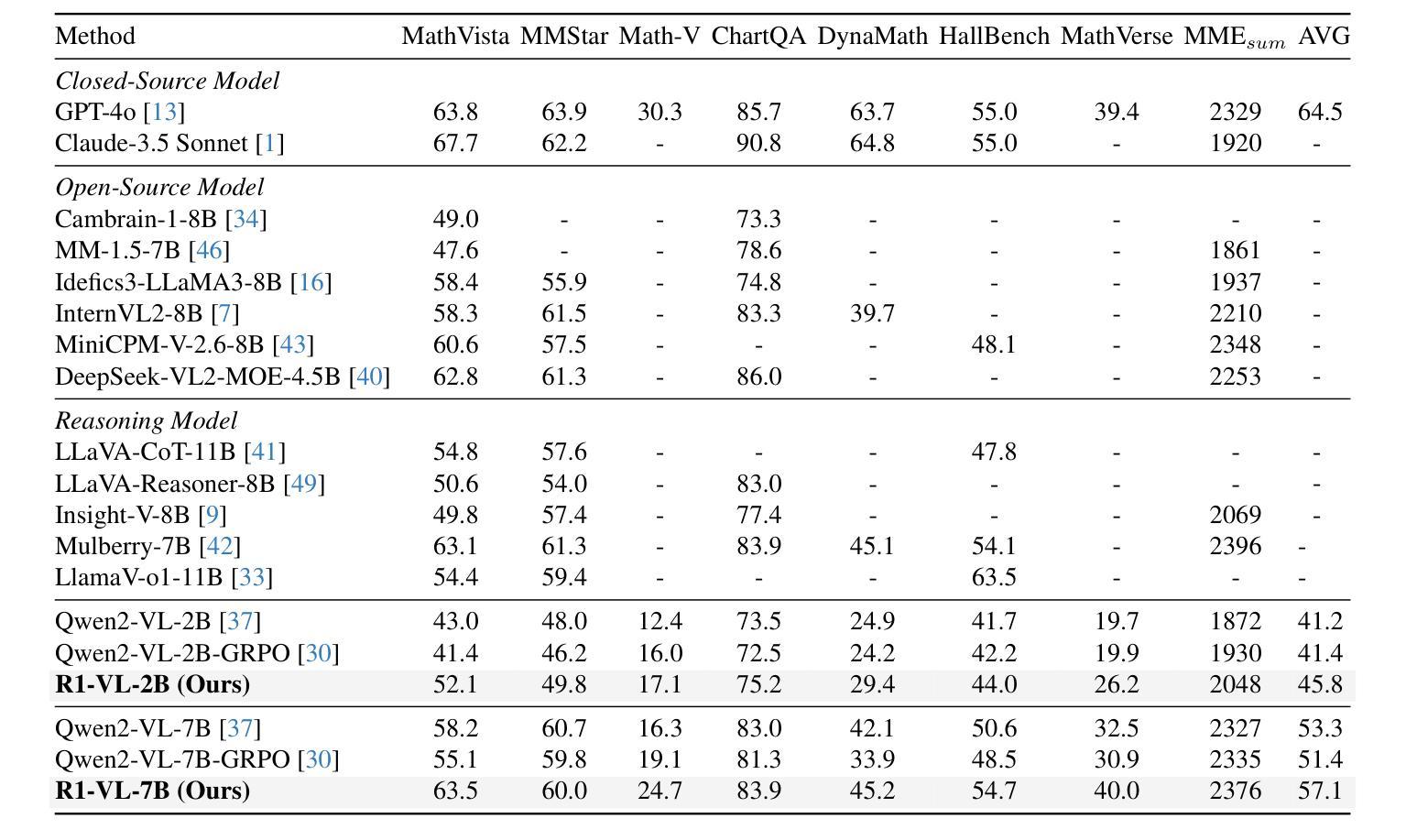
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization
Authors:Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, Dacheng Tao
Recent studies generally enhance MLLMs’ reasoning capabilities via supervised fine-tuning on high-quality chain-of-thought reasoning data, which often leads models to merely imitate successful reasoning paths without understanding what the wrong reasoning paths are. In this work, we aim to enhance the MLLMs’ reasoning ability beyond passively imitating positive reasoning paths. To this end, we design Step-wise Group Relative Policy Optimization (StepGRPO), a new online reinforcement learning framework that enables MLLMs to self-improve reasoning ability via simple, effective and dense step-wise rewarding. Specifically, StepGRPO introduces two novel rule-based reasoning rewards: Step-wise Reasoning Accuracy Reward (StepRAR) and Step-wise Reasoning Validity Reward (StepRVR). StepRAR rewards the reasoning paths that contain necessary intermediate reasoning steps via a soft key-step matching technique, while StepRAR rewards reasoning paths that follow a well-structured and logically consistent reasoning process through a reasoning completeness and logic evaluation strategy. With the proposed StepGRPO, we introduce R1-VL, a series of MLLMs with outstanding capabilities in step-by-step reasoning. Extensive experiments over 8 benchmarks demonstrate the superiority of our methods.
近期研究通常通过在高质量的思维链推理数据上进行监督微调,增强MLLMs的推理能力,这往往导致模型仅仅是模仿成功的推理路径,而没有理解错误的推理路径是什么。在这项工作中,我们的目标不仅仅是被动地模仿积极的推理路径来提升MLLMs的推理能力。为此,我们设计了逐步群体相对策略优化(StepGRPO),这是一种新的在线强化学习框架,它通过简单、有效和密集的逐步奖励,使MLLMs能够自我提升推理能力。具体来说,StepGRPO引入了两项基于规则的新推理奖励:逐步推理准确性奖励(StepRAR)和逐步推理有效性奖励(StepRVR)。StepRAR通过软关键步骤匹配技术奖励包含必要中间推理步骤的推理路径,而StepRVR则奖励遵循结构良好和逻辑一致的推理过程的推理路径,通过推理的完整性和逻辑评估策略来实现。通过提出的StepGRPO,我们推出了R1-VL系列MLLMs,在逐步推理方面展现出卓越的能力。在八个基准测试上的大量实验证明了我们的方法优越性。
论文及项目相关链接
Summary
本文介绍了如何通过一种名为StepGRPO的新型在线强化学习框架增强MLLMs的推理能力。该框架引入了两种基于规则的推理奖励:逐步推理准确性奖励(StepRAR)和逐步推理有效性奖励(StepRVR)。通过逐步奖励机制,MLLMs能够通过简单、有效且密集的逐步奖励自我提升推理能力,而不仅仅是被动模仿成功的推理路径。
Key Takeaways
- 研究现状:当前研究主要通过在高质量思维链数据上监督微调增强MLLMs的推理能力,但这种方式往往导致模型只是模仿成功的推理路径,缺乏对错误推理路径的理解。
- 目标:本研究旨在超越被动模仿正向推理路径,真正提升MLLMs的推理能力。
- 方法:引入新型在线强化学习框架StepGRPO,通过简单、有效且密集的逐步奖励,使MLLMs能够自我提升推理能力。
- StepGRPO特点:引入两种基于规则的推理奖励——StepRAR和StepRVR。
- StepRAR作用:奖励包含必要中间推理步骤的推理路径,通过软关键步骤匹配技术实现。
- StepRVR作用:奖励遵循结构良好、逻辑一致的推理过程的路径,通过推理完整性和逻辑评估策略实现。
点此查看论文截图
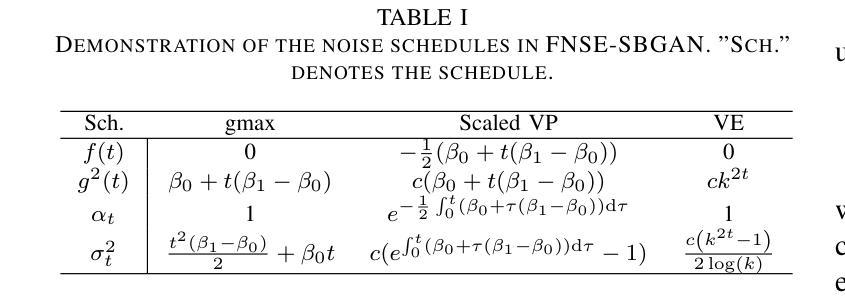
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Authors:Tong Lei, Qinwen Hu, Ziyao Lin, Andong Li, Rilin Chen, Meng Yu, Dong Yu, Jing Lu
The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
当前神经网络语音增强的主流方法主要依赖于使用模拟的远距离噪声混响语音(混合物)和清洁语音的配对进行纯监督深度学习。然而,这些训练好的模型在真实录音混合物上的泛化能力往往有限。为了解决这一问题,本研究探讨了直接在真实混合物上训练增强模型的方法。具体来说,我们重新审视单通道远距离到近距离语音增强(FNSE)任务,重点关注现实世界数据,其特点为低信噪比(SNR)、高混响、以及中高频衰减。我们提出了FNSE-SBGAN这一新型框架,它结合了基于Schrodinger Bridge(SB)的扩散模型与生成对抗网络(GANs)。我们的方法在各种指标和主观评估上达到了最先进的性能,与远距离信号相比,字符错误率(CER)降低了高达14.58%。实验结果表明,FNSE-SBGAN保持了卓越的主观质量,为现实世界中的远距离语音增强建立了新的基准。此外,我们还引入了一种新的评估框架,利用时频域的矩阵秩分析,为模型性能提供了系统的见解,并揭示了不同生成方法的优点和缺点。
论文及项目相关链接
PDF 13 pages, 6 figures
Summary
本文研究了基于真实混合物的语音增强模型训练问题,特别是针对低信噪比、高混响和中高频衰减的实际情况。提出FNSE-SBGAN框架,结合基于Schrodinger Bridge的扩散模型与生成对抗网络,实现前沿性能,显著降低字符错误率。同时,引入新的评估框架,利用时频域矩阵秩分析,深入洞察模型性能,揭示不同生成方法的优势和劣势。
Key Takeaways
- 当前神经网络语音增强主要依赖模拟的远距离含混响语音和干净语音的配对进行深度学习训练,但模型在真实录音混合物上的泛化能力有限。
- 研究者开始探索直接在真实混合物上训练语音增强模型的方法。
- FNSE-SBGAN框架结合了Schrodinger Bridge扩散模型和生成对抗网络,实现了先进性能。
- 该框架显著降低了字符错误率,达到最高达14.58%的降低。
- FNSE-SBGAN保留了出色的主观音质,为真实世界的远距离语音增强建立了新的基准。
- 引入新的评估框架,利用时频域矩阵秩分析,提供了对模型性能的深入理解。
点此查看论文截图

Lifelong Reinforcement Learning with Similarity-Driven Weighting by Large Models
Authors:Zhiyi Huang, Xiaohan Shan, Jianmin Li
Lifelong Reinforcement Learning (LRL) holds significant potential for addressing sequential tasks, but it still faces considerable challenges. A key difficulty lies in effectively preventing catastrophic forgetting and facilitating knowledge transfer while maintaining reliable decision-making performance across subsequent tasks in dynamic environments. To tackle this, we propose a novel framework, SDW (Similarity-Driven Weighting Framework), which leverages large-language-model-generated dynamic functions to precisely control the training process. The core of SDW lies in two functions pre-generated by large models: the task similarity function and the weight computation function. The task similarity function extracts multidimensional features from task descriptions to quantify the similarities and differences between tasks in terms of states, actions, and rewards. The weight computation function dynamically generates critical training parameters based on the similarity information, including the proportion of old task data stored in the Replay Buffer and the strategy consistency weight in the loss function, enabling an adaptive balance between learning new tasks and transferring knowledge from previous tasks. By generating function code offline prior to training, rather than relying on large-model inference during the training process, the SDW framework reduces computational overhead while maintaining efficiency in sequential task scenarios. Experimental results on Atari and MiniHack sequential tasks demonstrate that SDW significantly outperforms existing lifelong reinforcement learning methods.
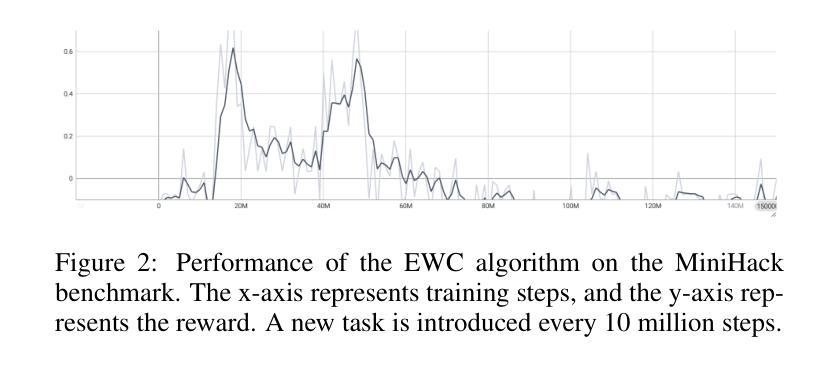
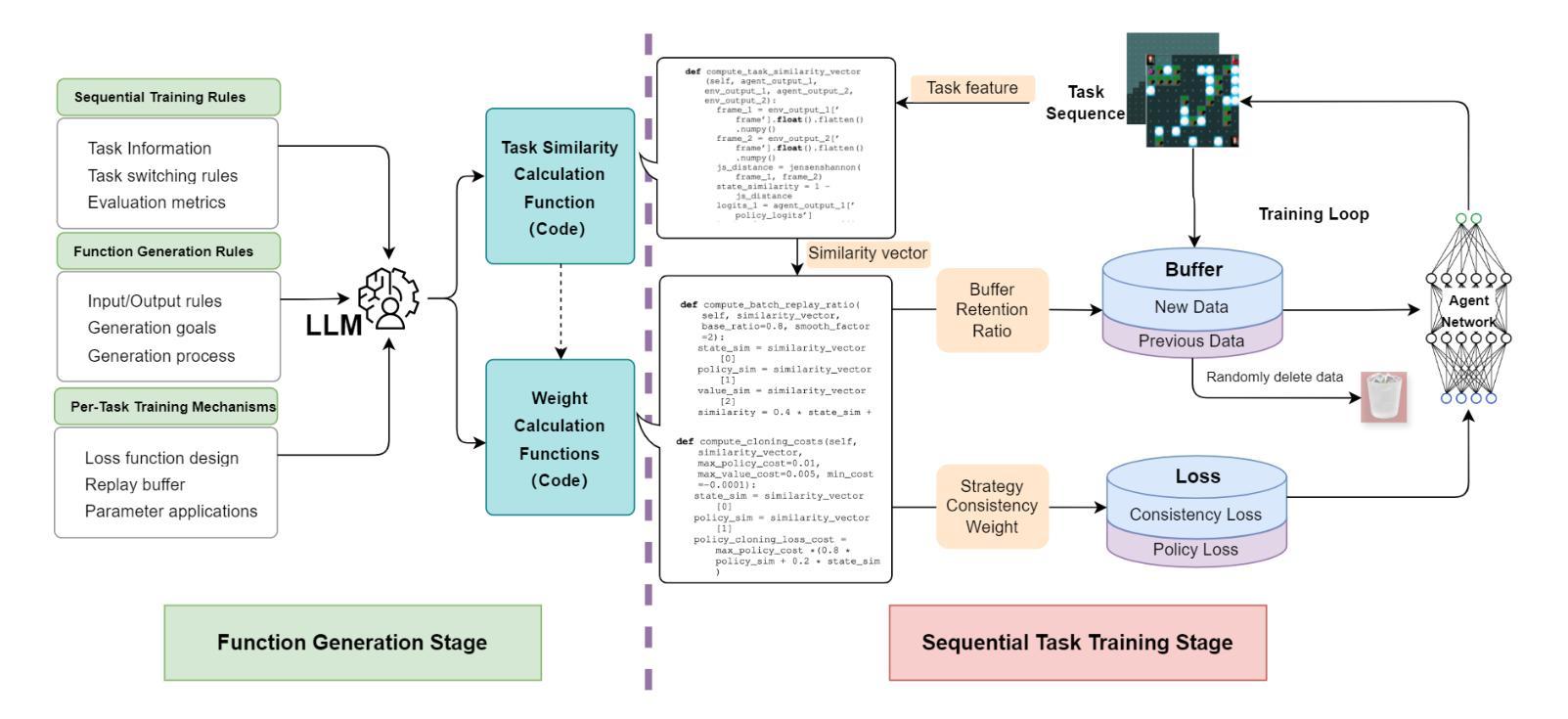
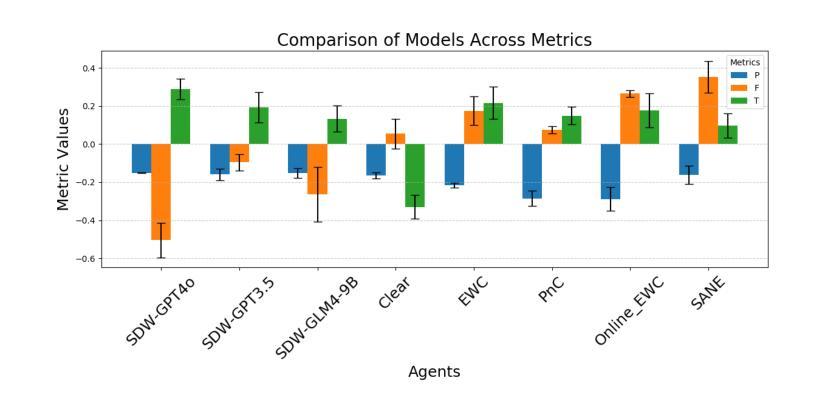
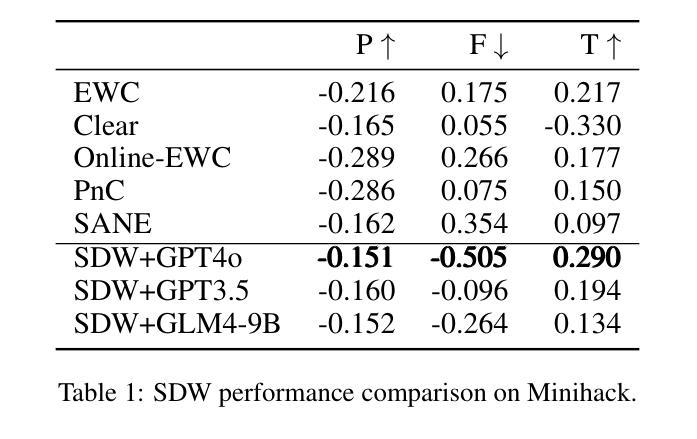
终身强化学习(LRL)在处理序列任务时具有显著潜力,但仍面临相当大的挑战。主要困难在于如何在动态环境中有效防止灾难性遗忘,促进知识迁移,同时保持后续任务的可靠决策性能。为了解决这一问题,我们提出了一种新型框架SDW(Similarity-Driven Weighting Framework),它利用大型语言模型生成的动态函数来精确控制训练过程。SDW的核心在于由大型模型预先生成的两个函数:任务相似度函数和权重计算函数。任务相似度函数从任务描述中提取多维特征,以量化任务在状态、动作和奖励方面的相似性和差异。权重计算函数根据相似度信息动态生成关键训练参数,包括存储在回放缓冲区中的旧任务数据比例和损失函数中的策略一致性权重,从而在学习新任务和从以前的任务中迁移知识之间实现自适应平衡。SDW框架在训练前离线生成函数代码,而不是在训练过程中依赖大型模型的推理,从而在保持序列任务场景效率的同时减少了计算开销。在Atari和MiniHack序列任务上的实验结果表明,SDW显著优于现有的终身强化学习方法。
论文及项目相关链接
Summary
基于终身强化学习(LRL)在处理序列任务时的潜力与挑战,提出了一种新的框架SDW(Similarity-Driven Weighting Framework)。该框架利用大型语言模型生成的动态函数精确控制训练过程,通过任务相似度函数和权重计算函数两个核心功能,实现任务间的相似度量化及训练参数的动态调整。SDW框架在减少计算开销的同时,保持了处理序列任务时的效率,并在Atari和MiniHack的序列任务实验中表现出显著优势。
Key Takeaways
- 终身强化学习(LRL)在处理序列任务时面临防止灾难性遗忘和促进知识迁移的挑战。
- SDW框架通过大型语言模型生成的动态函数精确控制训练过程。
- 任务相似度函数从任务描述中提取多维特征,量化任务间的相似性和差异。
- 权重计算函数根据相似度信息动态生成关键训练参数。
- SDW框架在减少计算开销的同时,保持了处理序列任务时的效率。
- 实验结果表明,SDW框架在Atari和MiniHack的序列任务中显著优于现有的终身强化学习方法。
点此查看论文截图

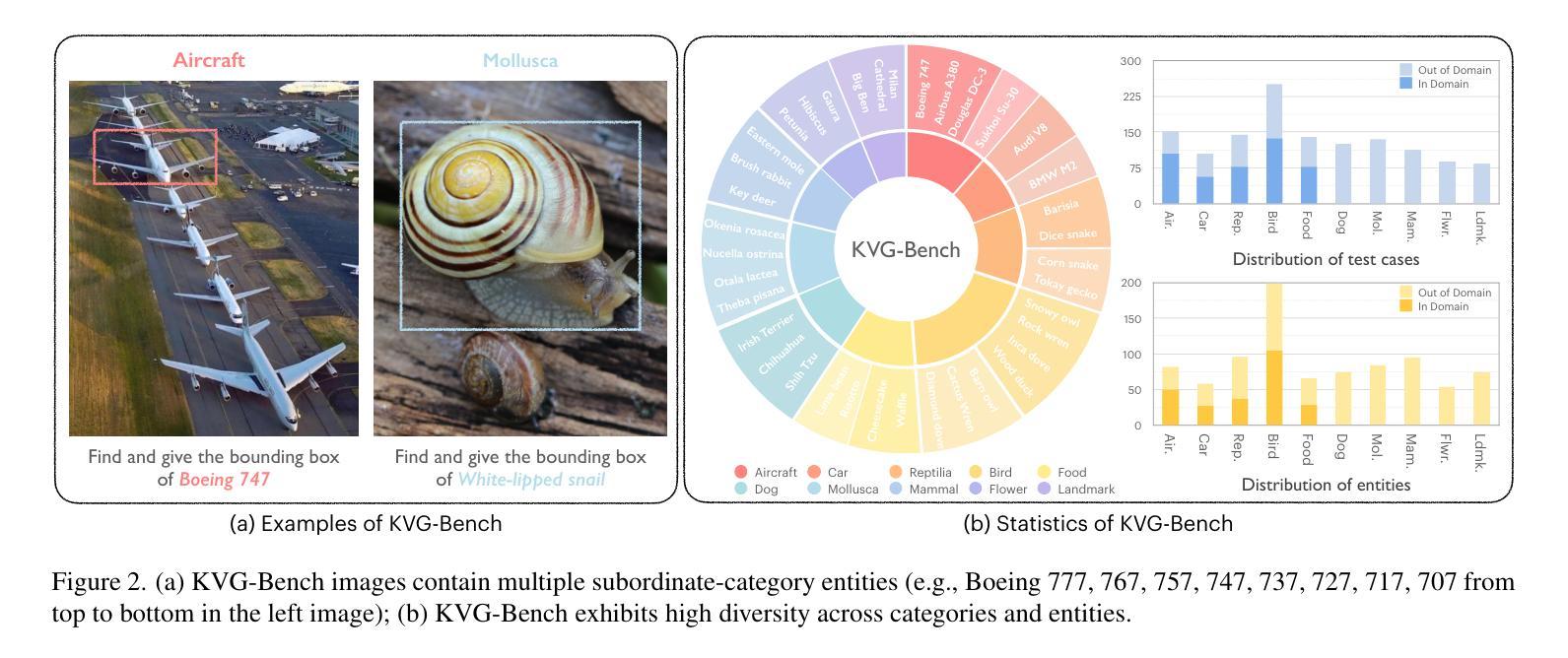
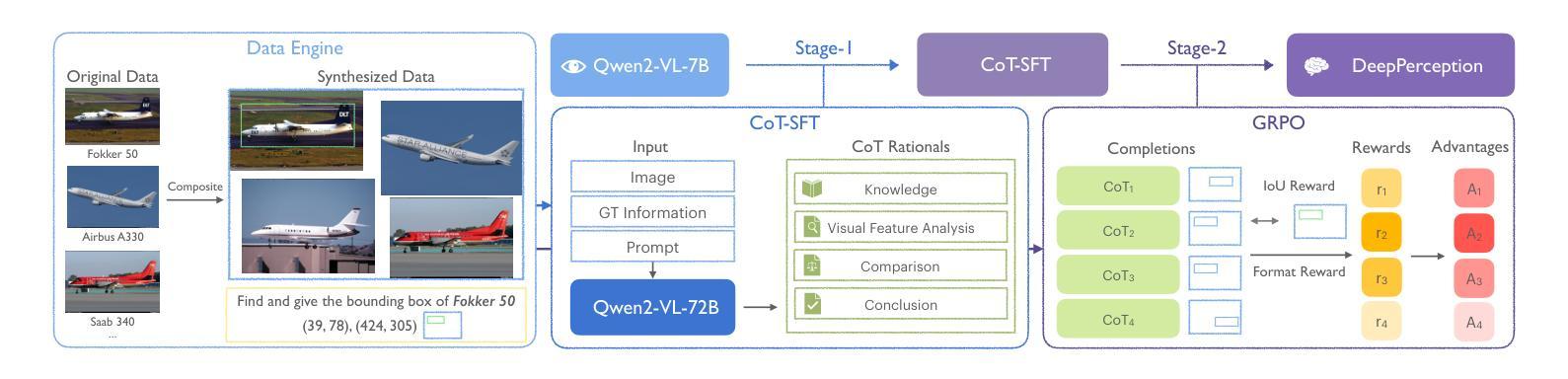
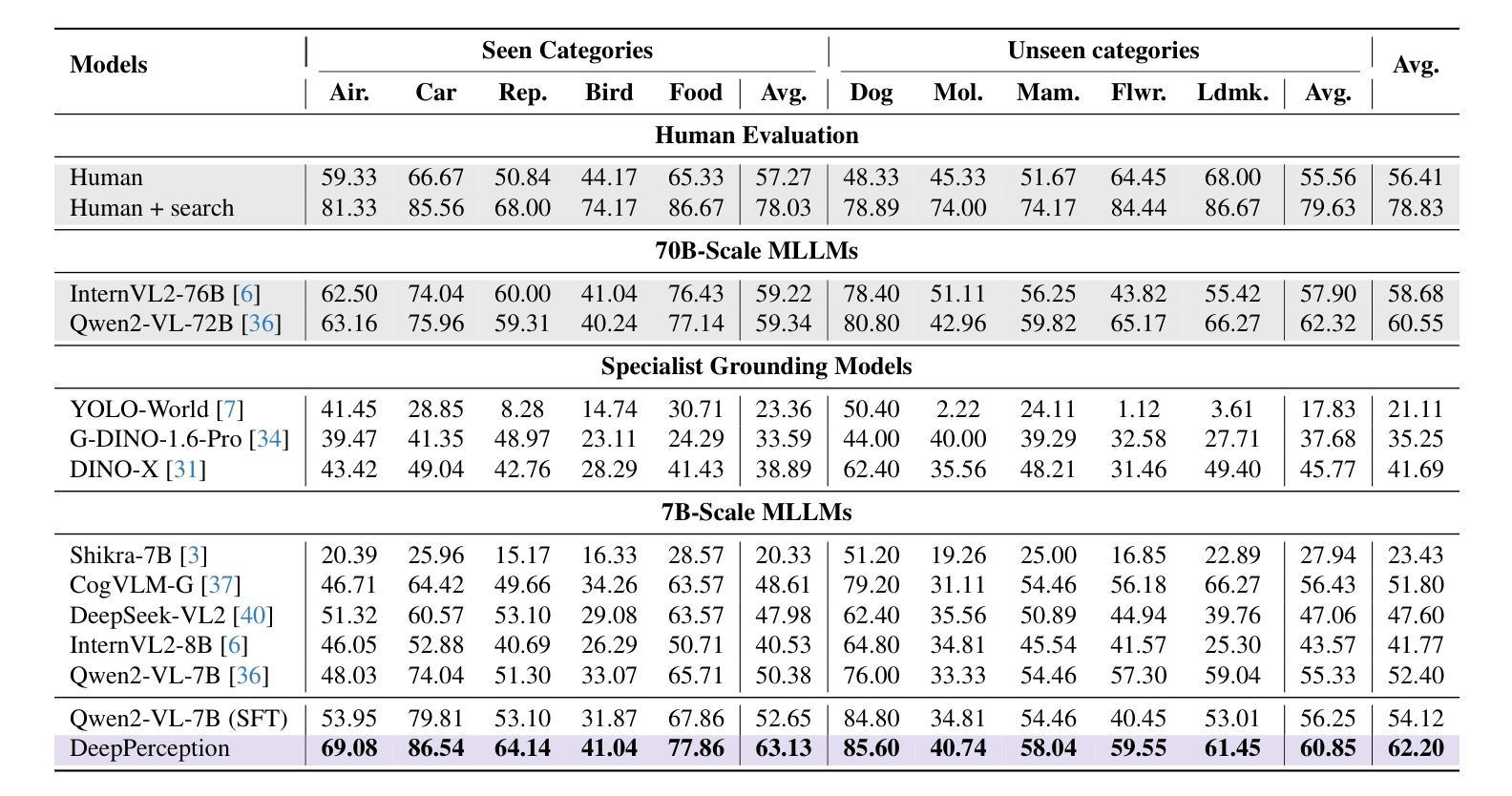
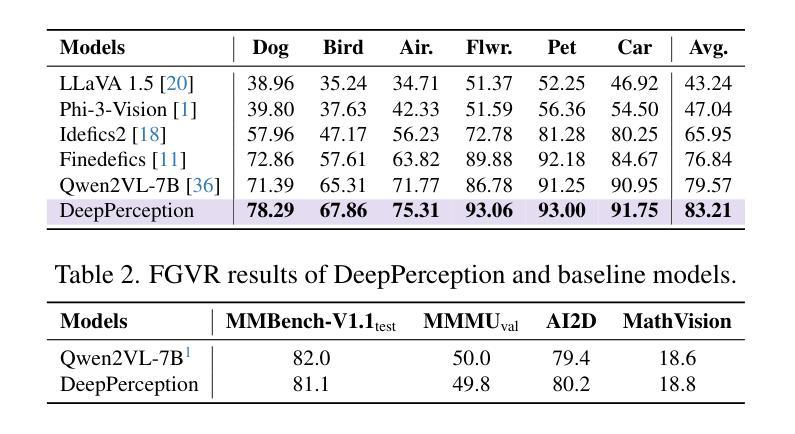
DeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding
Authors:Xinyu Ma, Ziyang Ding, Zhicong Luo, Chi Chen, Zonghao Guo, Derek F. Wong, Xiaoyi Feng, Maosong Sun
Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis. To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both fine-grained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases. Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08% accuracy improvements on KVG-Bench and exhibiting +4.60% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research. The data, codes, and models are released at https://github.com/thunlp/DeepPerception.
人类专家擅长通过利用领域知识来细化感知特征,进行精细化的视觉辨别,这是当前的多模态大型语言模型(MLLMs)中仍欠发展的能力。尽管拥有大量的专家级知识,MLLMs在将推理融入视觉感知时仍感到困难,经常产生直接的回应,而没有进行更深入的分析。为了弥补这一差距,我们引入了知识密集型视觉定位(KVG),这是一个需要精细感知和特定领域知识整合的新型视觉定位任务。为了应对KVG的挑战,我们提出了DeepPerception,这是一个增强型的多模态大型语言模型,具有认知视觉感知能力。我们的方法包括(1)一个自动化的数据合成管道,用于生成高质量、与知识对齐的训练样本;(2)一个两阶段的训练框架,结合监督微调用于认知推理的架构和强化学习优化感知与认知协同作用。为了评估性能,我们引入了KVG-Bench数据集,这是一个涵盖10个领域的综合数据集,包含1300个手动整理的测试案例。实验结果表明,DeepPerception显著优于直接微调方法,在KVG-Bench上准确率提高8.08%,在跨域概括方面比基线方法高出4.60%。我们的研究强调了将认知过程融入多模态大型语言模型的重要性,为类人视觉感知和多模态推理研究提供了新的方向。数据、代码和模型已发布在https://github.com/thunlp/DeepPerception。
论文及项目相关链接
Summary
本文介绍了当前多模态大型语言模型(MLLMs)在视觉感知方面的不足,特别是在精细粒度视觉辨识和领域知识整合方面的能力欠缺。为了弥补这一差距,提出了知识密集型视觉定位(KVG)这一新任务,并构建了DeepPerception模型以增强其认知视觉感知能力。通过引入自动化数据合成管道和两阶段训练框架,模型实现了在KVG任务上的优越性能。实验结果显示,DeepPerception在KVG-Bench数据集上的准确率提高了8.08%,并且在跨域泛化方面也表现出优于基准方法的能力。研究强调了将认知过程融入MLLMs的重要性,并为多模态推理研究指明了新方向。
Key Takeaways
- 当前多模态大型语言模型(MLLMs)在视觉感知方面存在不足,特别是在精细粒度辨识和领域知识整合方面。
- 知识密集型视觉定位(KVG)是一个新任务,要求模型具备精细粒度感知和领域知识整合能力。
- DeepPerception模型通过引入自动化数据合成管道,生成高质量的知识对齐训练样本。
- 采用两阶段训练框架,结合监督微调进行认知推理脚手架的构建和强化学习来优化感知与认知的协同。
- DeepPerception在KVG-Bench数据集上的准确率显著提高,并且展现出优于基准方法的跨域泛化能力。
- 研究强调了将认知过程融入MLLMs的重要性,以实现更人性化的视觉感知。
点此查看论文截图

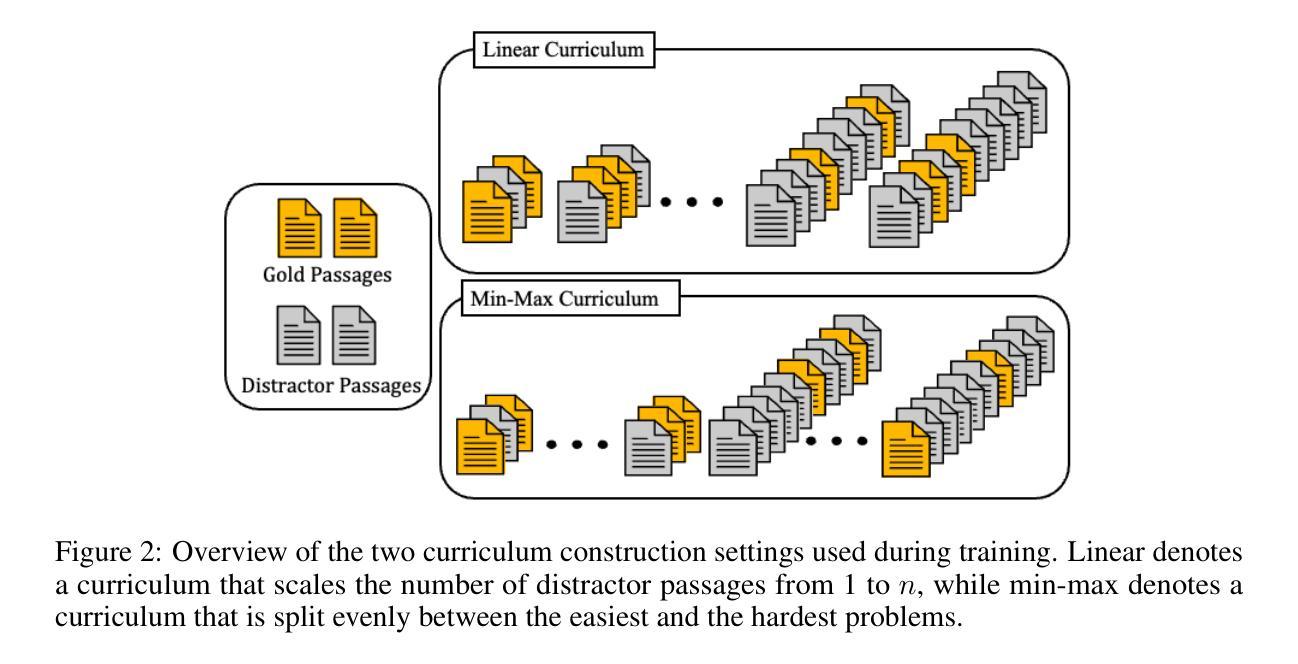
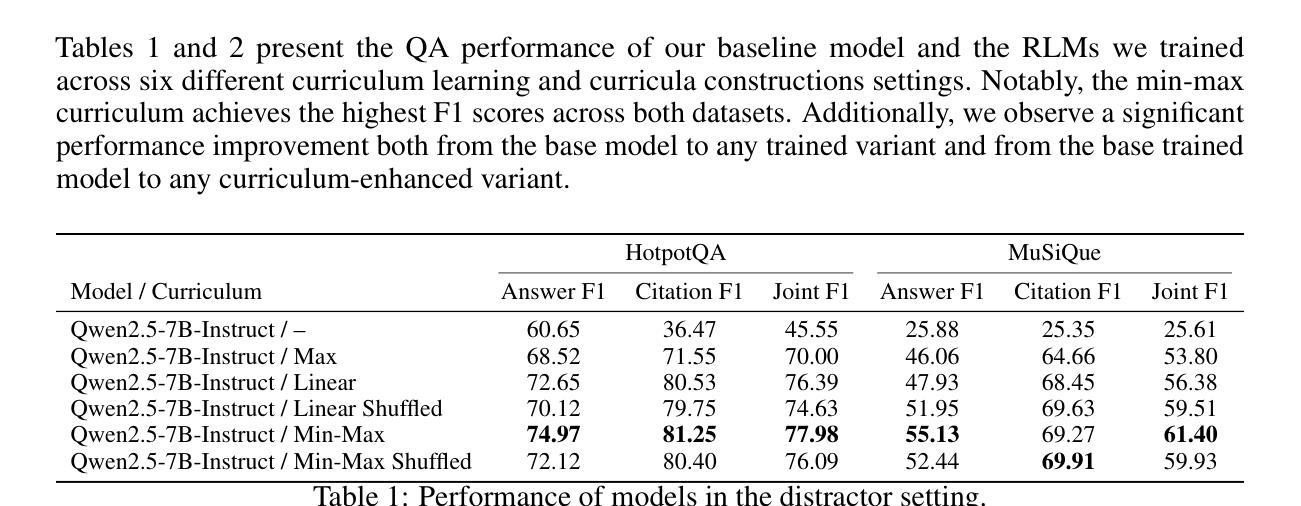
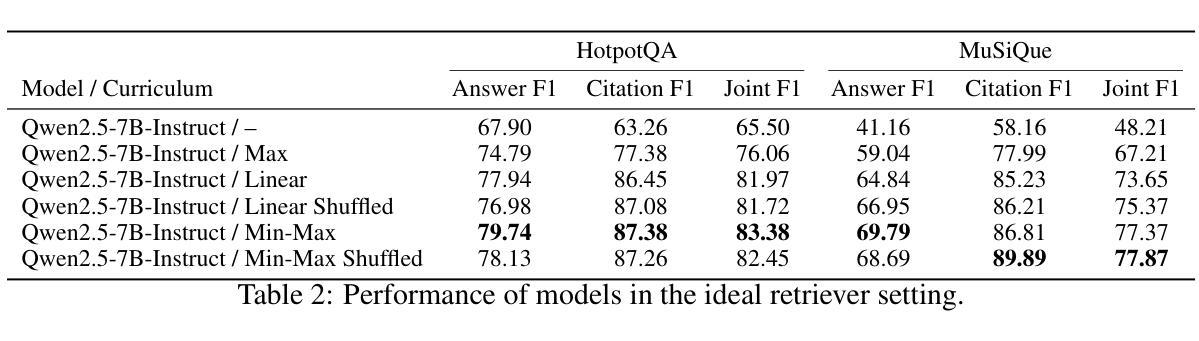
RAG-RL: Advancing Retrieval-Augmented Generation via RL and Curriculum Learning
Authors:Jerry Huang, Siddarth Madala, Risham Sidhu, Cheng Niu, Julia Hockenmaier, Tong Zhang
Recent research highlights the challenges retrieval models face in retrieving useful contexts and the limitations of generation models in effectively utilizing those contexts in retrieval-augmented generation (RAG) settings. To address these challenges, we introduce RAG-RL, the first reasoning language model (RLM) specifically trained for RAG. RAG-RL demonstrates that stronger answer generation models can identify relevant contexts within larger sets of retrieved information – thereby alleviating the burden on retrievers – while also being able to utilize those contexts more effectively. Moreover, we show that curriculum design in the reinforcement learning (RL) post-training process is a powerful approach to enhancing model performance. We benchmark our method on two open-domain question-answering datasets and achieve state-of-the-art results, surpassing previous SOTA generative reader models. In addition, we offers empirical insights into various curriculum learning strategies, providing a deeper understanding of their impact on model performance.
最近的研究强调了检索模型在检索有用上下文时所面临的挑战,以及生成模型在增强检索(RAG)设置中有效利用这些上下文时的局限性。为了解决这些挑战,我们引入了RAG-RL,这是专门为RAG训练的首个推理语言模型(RLM)。RAG-RL证明,更强大的答案生成模型能够在检索的大量信息中识别出相关的上下文,从而减轻检索器的负担,同时能够更有效地利用这些上下文。此外,我们还展示了在强化学习(RL)后训练过程中进行课程设计的增强模型性能的强大方法。我们在两个开放域问答数据集上对我们的方法进行了基准测试,取得了最先进的成果,超越了之前的最佳生成式阅读模型。此外,我们还提供了关于各种课程学习策略的实证见解,为深入了解它们对模型性能的影响提供了更深的了解。
论文及项目相关链接
PDF 11 Pages, 3 Figures, Preprint
Summary:近期研究发现检索模型在获取有用上下文方面存在挑战,生成模型在检索增强生成(RAG)设置中有效利用这些上下文也有限制。为应对这些挑战,我们推出了专为RAG设计的推理语言模型(RLM)RAG-RL。RAG-RL表明,更强大的答案生成模型能够在检索到的更大信息集中识别相关上下文,从而减轻检索器的负担,并更有效地利用这些上下文。此外,我们还展示了在强化学习(RL)后训练过程中进行课程设计的增强模型性能的强大方法。我们在两个开放域问答数据集上对我们的方法进行了基准测试,取得了超越之前最佳生成阅读模型的最新结果。此外,我们还提供了关于各种课程学习策略的经验见解,以深入了解它们对模型性能的影响。
Key Takeaways:
- 检索模型和生成模型在RAG设置中存在挑战,需要新的方法来解决。
- RAG-RL是首个专为RAG设计的推理语言模型(RLM),能有效识别相关上下文并减轻检索器的负担。
- RAG-RL在后训练过程中采用强化学习(RL)和课程设计,增强了模型性能。
- RAG-RL在开放域问答数据集上实现了最新结果,超越了之前的最佳生成阅读模型。
- RAG-RL提供了关于课程学习策略的经验见解。
- 课程设计策略对模型性能具有重要影响。
点此查看论文截图


AI Agents: Evolution, Architecture, and Real-World Applications
Authors:Naveen Krishnan
This paper examines the evolution, architecture, and practical applications of AI agents from their early, rule-based incarnations to modern sophisticated systems that integrate large language models with dedicated modules for perception, planning, and tool use. Emphasizing both theoretical foundations and real-world deployments, the paper reviews key agent paradigms, discusses limitations of current evaluation benchmarks, and proposes a holistic evaluation framework that balances task effectiveness, efficiency, robustness, and safety. Applications across enterprise, personal assistance, and specialized domains are analyzed, with insights into future research directions for more resilient and adaptive AI agent systems.
本文探讨了人工智能代理人的发展演变、架构和实际应用,从早期的基于规则的形式到现代复杂系统,这些系统将大型语言模型与用于感知、规划和工具使用的专用模块相结合。本文既强调理论基础,又关注现实应用,回顾了关键代理范式,讨论了当前评估基准的局限性,并提出了一个全面的评估框架,该框架平衡了任务的有效性、效率、稳健性和安全性。本文分析了在企业、个人助理和特殊领域的应用,并深入探讨了未来研究方向,旨在建立更具弹性和适应性的人工智能代理系统。
论文及项目相关链接
PDF 52 pages, 4 figures, comprehensive survey and analysis of AI agent evolution, architecture, evaluation frameworks, and applications
Summary:
本文介绍了人工智能代理人的演变、架构和实际应用,从早期的规则基础形式到现代集成大型语言模型的先进系统,包括感知、规划和工具使用等专用模块。文章强调理论基础和实际应用部署,回顾了关键代理范式,讨论了当前评估基准的局限性,并提出了一个全面的评估框架,该框架平衡了任务的有效性、效率、稳健性和安全性。文章还分析了在企业、个人助理和特殊领域的应用,并洞察了未来更具弹性和适应性的人工智能代理人系统的研究方向。
Key Takeaways:
- 人工智能代理人的演变:从早期的规则基础形式到现代集成大型语言模型的复杂系统。
- 人工智能代理人的架构:包括感知、规划和工具使用等模块。
- 人工智能代理人的实际应用:涉及企业、个人助理和特殊领域。
- 论文强调人工智能代理人的理论基础和实际应用部署。
- 当前评估基准的局限性及全面评估框架的介绍,包括任务有效性、效率、稳健性和安全性。
- 论文对关键代理范式的回顾。
点此查看论文截图

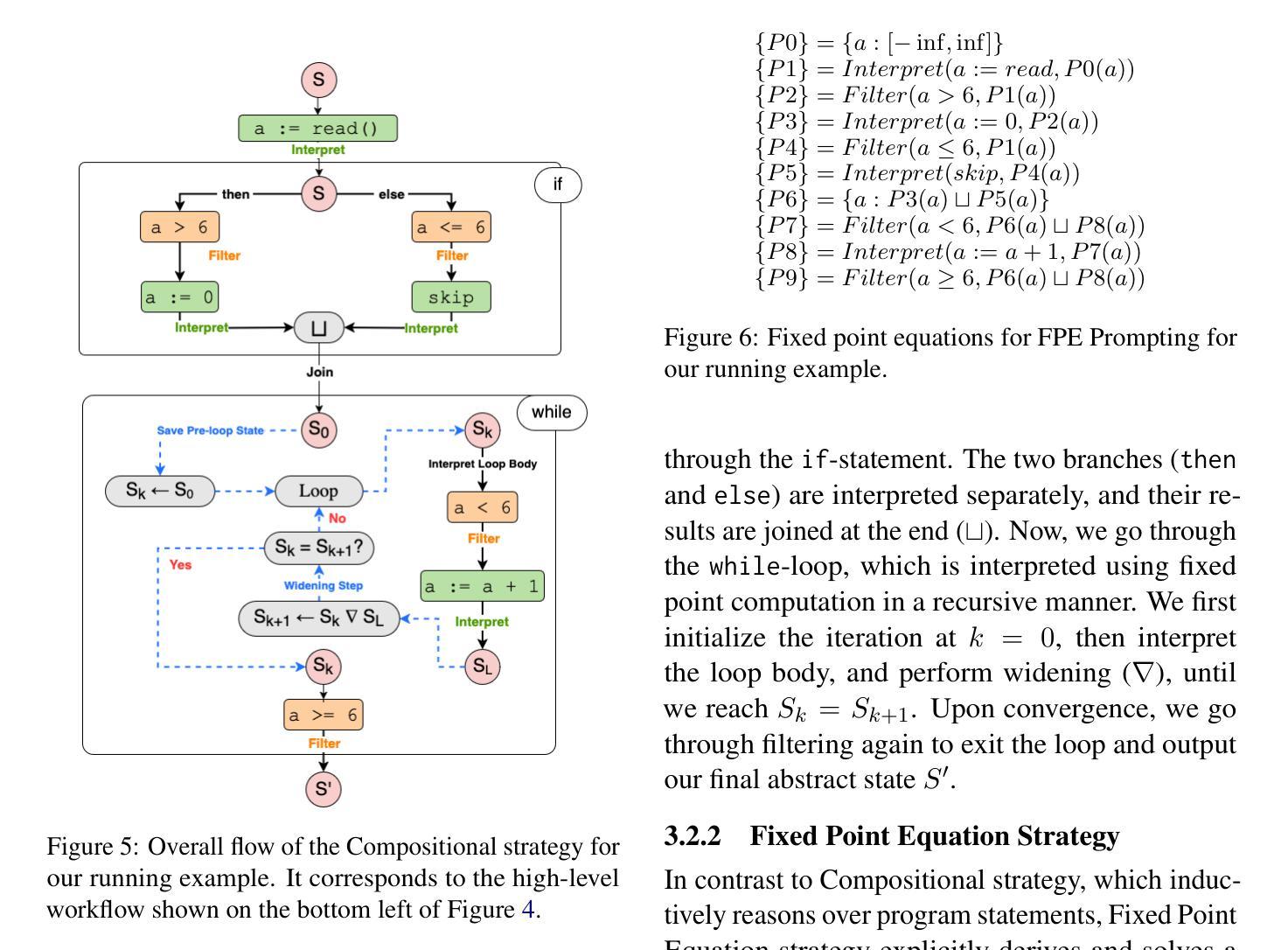
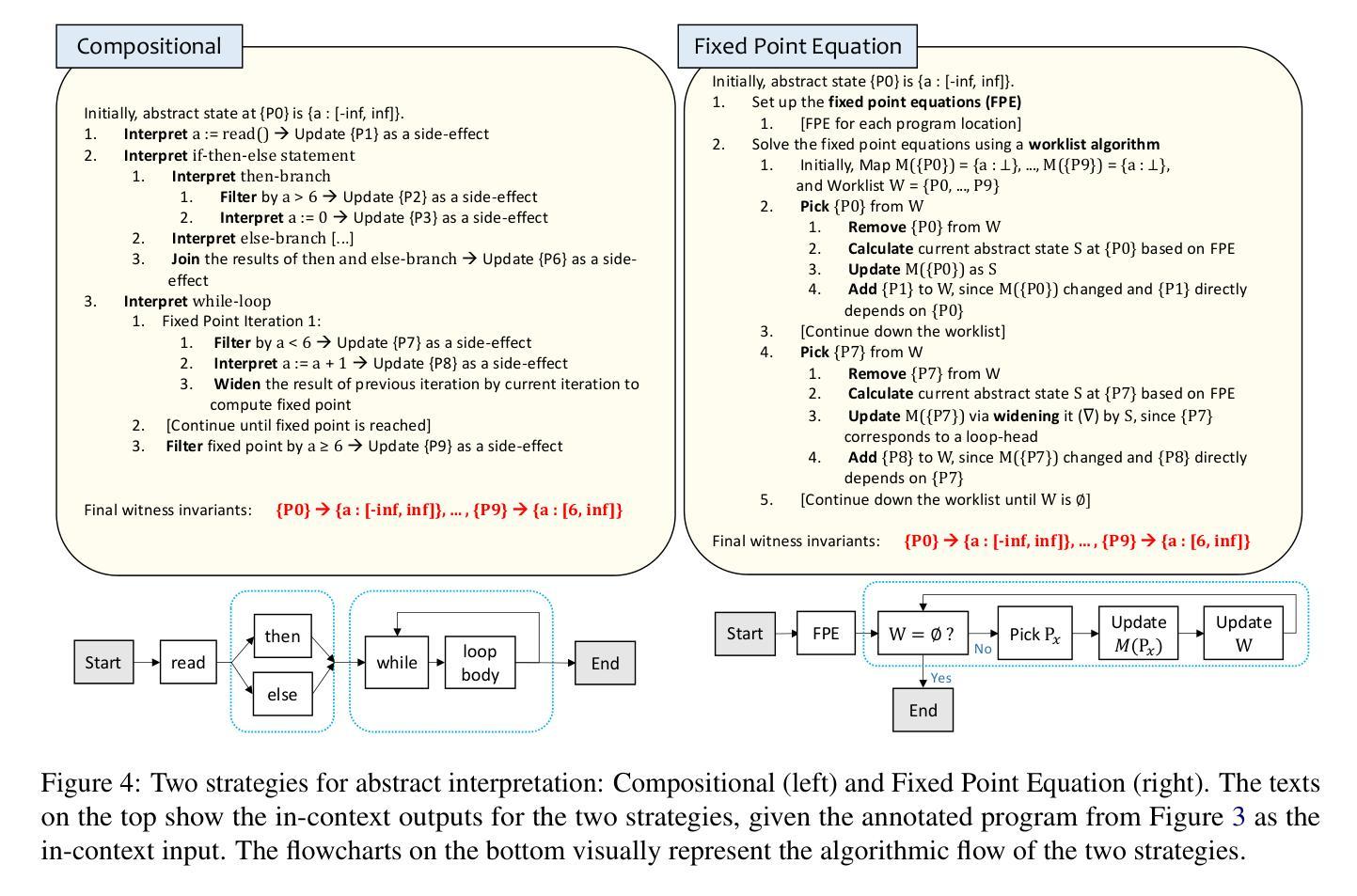
Can LLMs Formally Reason as Abstract Interpreters for Program Analysis?
Authors:Jacqueline L. Mitchell, Brian Hyeongseok Kim, Chenyu Zhou, Chao Wang
LLMs have demonstrated impressive capabilities in code generation and comprehension, but their potential in being able to perform program analysis in a formal, automatic manner remains under-explored. To that end, we systematically investigate whether LLMs can reason about programs using a program analysis framework called abstract interpretation. We prompt LLMs to follow two different strategies, denoted as Compositional and Fixed Point Equation, to formally reason in the style of abstract interpretation, which has never been done before to the best of our knowledge. We validate our approach using state-of-the-art LLMs on 22 challenging benchmark programs from the Software Verification Competition (SV-COMP) 2019 dataset, widely used in program analysis. Our results show that our strategies are able to elicit abstract interpretation-based reasoning in the tested models, but LLMs are susceptible to logical errors, especially while interpreting complex program structures, as well as general hallucinations. This highlights key areas for improvement in the formal reasoning capabilities of LLMs.
大型语言模型(LLMs)在代码生成和理解方面表现出了令人印象深刻的能力,但它们在正式、自动执行程序分析方面的潜力仍未得到充分探索。为此,我们系统地研究了LLMs是否可以使用名为抽象解释的程序分析框架来推理程序。我们提示LLMs采用两种不同策略,即组合策略和不动点方程策略,以抽象解释的方式进行正式推理,据我们所知,这是前所未有的。我们使用最先进的LLMs验证我们的方法,测试了来自软件验证竞赛(SV-COMP)2019数据集的22个具有挑战性的基准程序,广泛应用于程序分析领域。我们的结果表明,我们的策略能够在测试模型中激发基于抽象解释的推理,但LLMs容易犯逻辑错误,特别是在解释复杂的程序结构时,以及出现一般性的幻觉。这突出了提高LLMs形式推理能力的重要改进领域。
论文及项目相关链接
Summary
大型语言模型(LLMs)在代码生成和理解方面展现出令人印象深刻的能力,但其以正式、自动的方式进行程序分析方面的潜力尚未得到充分了解。本文系统地研究LLMs是否能利用抽象解释的程序分析框架进行程序推理。通过采用组合策略和不动点方程策略,本文首次利用抽象解释风格对LLMs进行正式推理研究。通过使用前沿的LLMs和大量来自软件验证竞赛(SV-COMP)2019数据集的基准程序进行验证,结果显示这两种策略能够激发基于抽象解释的推理能力,但LLMs在处理复杂程序结构和逻辑错误时易出现错误,以及出现一般性的幻觉。这为提升LLMs的正式推理能力提供了重要的改进方向。
Key Takeaways
- LLMs展现出强大的代码生成和理解能力,但在程序分析方面的潜力尚未得到充分探索。
- 本文首次尝试利用抽象解释框架来研究LLMs进行程序推理的能力。
- 通过组合策略和不动点方程策略,LLMs能够表现出基于抽象解释的推理能力。
- 在处理复杂程序结构和逻辑错误时,LLMs容易出现错误。
- LLMs在程序分析中的表现存在改进的空间和必要性。
- 抽象解释框架在提升LLMs的推理能力方面具有潜在应用价值。
点此查看论文截图



Focusing Robot Open-Ended Reinforcement Learning Through Users’ Purposes
Authors:Emilio Cartoni, Gianluca Cioccolini, Gianluca Baldassarre
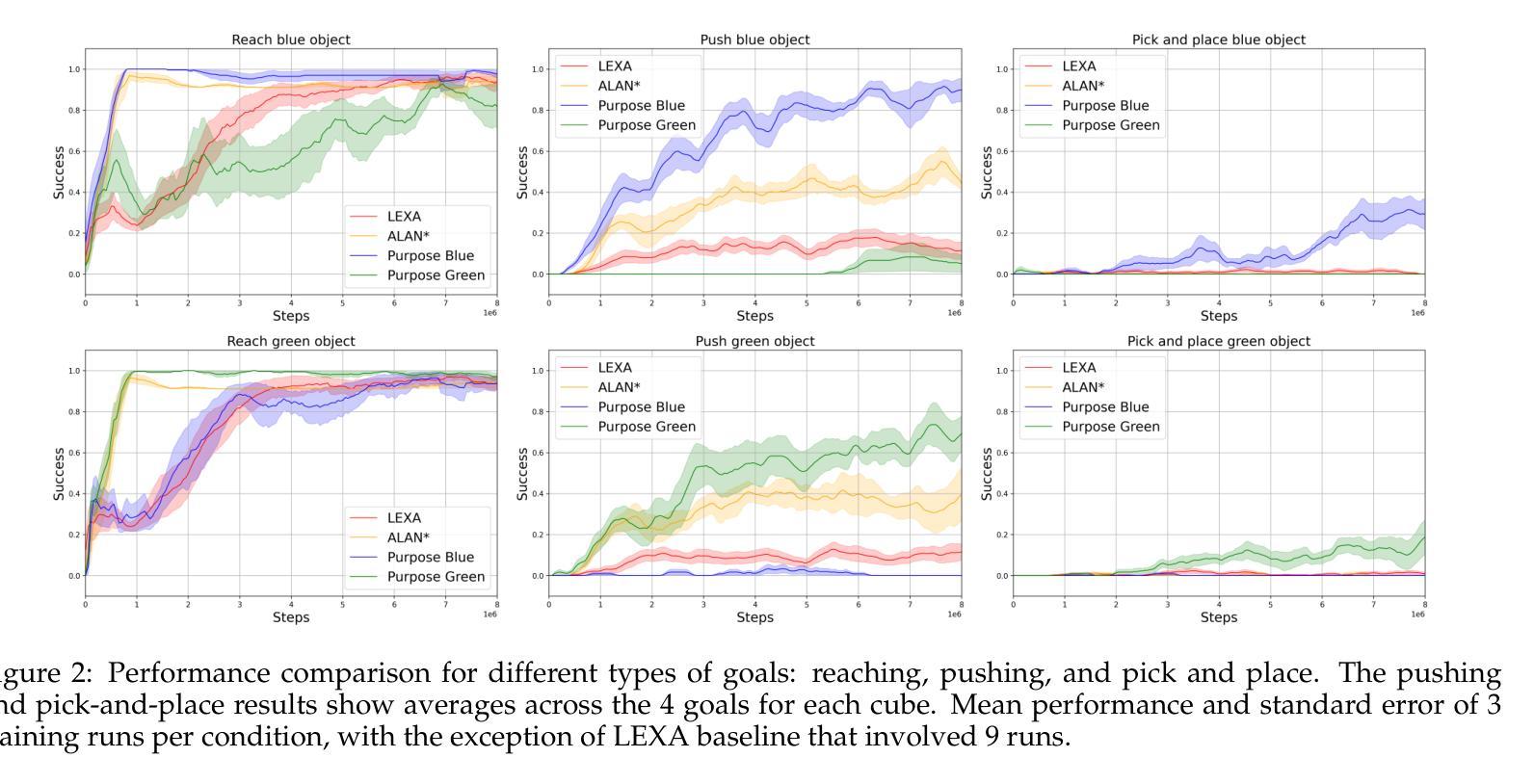
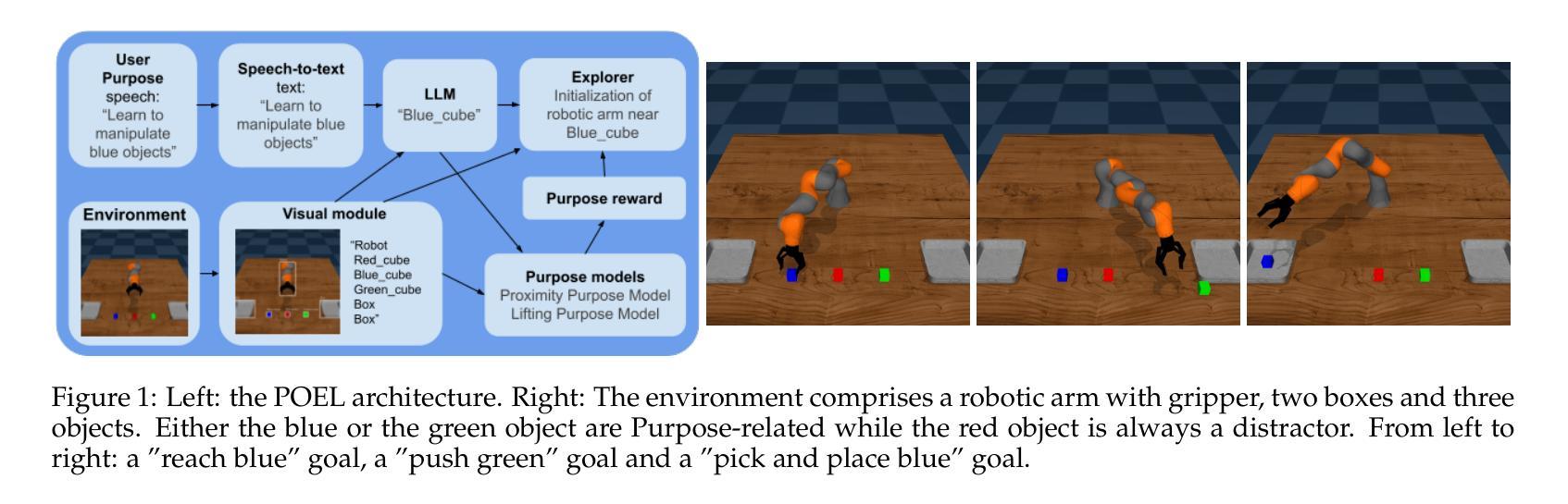
Open-Ended Learning (OEL) autonomous robots can acquire new skills and knowledge through direct interaction with their environment, relying on mechanisms such as intrinsic motivations and self-generated goals to guide learning processes. OEL robots are highly relevant for applications as they can autonomously leverage acquired knowledge to perform tasks beneficial to human users in unstructured environments, addressing challenges unforeseen at design time. However, OEL robots face a significant limitation: their openness may lead them to waste time learning information that is irrelevant to tasks desired by specific users. Here, we propose a solution called Purpose-Directed Open-Ended Learning' (POEL), based on the novel concept of purpose’ introduced in previous work. A purpose specifies what users want the robot to achieve. The key insight of this work is that purpose can focus OEL on learning self-generated classes of tasks that, while unknown during autonomous learning (as typical in OEL), involve objects relevant to the purpose. This concept is operationalised in a novel robot architecture capable of receiving a human purpose through speech-to-text, analysing the scene to identify objects, and using a Large Language Model to reason about which objects are purpose-relevant. These objects are then used to bias OEL exploration towards their spatial proximity and to self-generate rewards that favour interactions with them. The solution is tested in a simulated scenario where a camera-arm-gripper robot interacts freely with purpose-related and distractor objects. For the first time, the results demonstrate the potential advantages of purpose-focused OEL over state-of-the-art OEL methods, enabling robots to handle unstructured environments while steering their learning toward knowledge acquisition relevant to users.
开放式学习(OEL)自主机器人能够通过与其环境的直接互动获得新的技能和知识,依赖于内在动力和自我生成目标等机制来引导学习过程。OEL机器人在应用上具有很高的现实意义,因为它们可以自主地利用所获得的知识,在结构不良的环境中执行对人类用户有益的任务,应对设计时无法预见到的挑战。然而,OEL机器人面临一个重大局限:它们的开放性可能导致它们浪费时间学习特定用户不需要的任务的相关信息。在这里,我们提出了一种名为“目的导向的开放式学习”(POEL)的解决方案,这是基于先前工作中引入的“目的”这一新概念。目的指定了用户希望机器人实现的目标。这项工作的关键见解是,目的可以引导OEL学习自我生成的类别任务,这些任务虽然在自主学习中未知(如典型的OEL),但涉及与目的相关的对象。这个概念在一个能够接收人类目的并通过语音到文本的新型机器人架构中得以实施。该架构能够分析场景以识别物体,并使用大型语言模型来推断哪些物体与目的相关。这些物体随后被用来偏向OEL探索它们的空间邻近性并自我生成奖励,以鼓励与它们的互动。该解决方案在一个模拟场景中进行了测试,其中摄像机手臂抓手机器人可以自由地与与目的相关和无关的对象进行互动。结果首次展示了有目的导向的OEL相对于最先进的OEL方法的潜在优势,使机器人在处理结构不良环境时能够引导其学习,从而获取与用户相关的知识。
论文及项目相关链接
PDF 4 pages, 2 figures, accepted at RLDM 2025
Summary
开放学习(OEL)自主机器人可通过与环境直接互动获取新技能与知识,依赖内在动机和自我生成目标等机制来引导学习过程。对于应用而言,OEL机器人高度相关,因为它们可以自主利用获取的知识在结构化环境中执行对人类用户有益的任务,解决设计时无法预见到的挑战。然而,OEL机器人面临一个重大局限:其开放性可能导致它们浪费时间学习对特定用户任务无关的信息。为此,我们提出了基于先前工作中引入的“目的”概念的解决方案,即目的导向开放学习(POEL)。目的指定了用户希望机器人实现的目标。关键洞察力在于,目的可以引导OEL专注于学习自我生成的与目的相关的任务类别,这些任务在自主学习中是未知的,但涉及与目的相关的对象。我们在新型机器人架构中实现了这一概念,该架构能够通过语音到文本接收人类目的,分析场景以识别对象,并使用大型语言模型来推断哪些对象是目的相关的。这些对象然后用于偏向OEL探索其空间邻近性并自我生成奖励,以有利于与其的互动。解决方案在模拟场景中进行了测试,其中摄像机机械臂抓取机器人自由地与目的相关物体和干扰物体互动。结果表明,与最新OEL方法相比,以目的为中心的OEL具有潜在优势,使机器人在处理非结构化环境时能够将学习导向与用户相关的知识获取。
Key Takeaways
- 开放学习(OEL)自主机器人能通过与环境互动来习得新技能和知识。
- OEL机器人具有高度自主性,可以在非结构化环境中执行对人类有益的任务。
- OEL机器人可能因开放性而学习无关信息,导致时间浪费。
- 提出目的导向开放学习(POEL)解决方案,基于用户定义的目标来引导机器人的学习。
- POEL能够引导机器人学习自我生成的与目的相关的任务类别。
- 新型机器人架构通过识别目的相关物体来实施POEL,并据此偏向探索和生成奖励。
点此查看论文截图