⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
HoloGest: Decoupled Diffusion and Motion Priors for Generating Holisticly Expressive Co-speech Gestures
Authors:Yongkang Cheng, Shaoli Huang
Animating virtual characters with holistic co-speech gestures is a challenging but critical task. Previous systems have primarily focused on the weak correlation between audio and gestures, leading to physically unnatural outcomes that degrade the user experience. To address this problem, we introduce HoleGest, a novel neural network framework based on decoupled diffusion and motion priors for the automatic generation of high-quality, expressive co-speech gestures. Our system leverages large-scale human motion datasets to learn a robust prior with low audio dependency and high motion reliance, enabling stable global motion and detailed finger movements. To improve the generation efficiency of diffusion-based models, we integrate implicit joint constraints with explicit geometric and conditional constraints, capturing complex motion distributions between large strides. This integration significantly enhances generation speed while maintaining high-quality motion. Furthermore, we design a shared embedding space for gesture-transcription text alignment, enabling the generation of semantically correct gesture actions. Extensive experiments and user feedback demonstrate the effectiveness and potential applications of our model, with our method achieving a level of realism close to the ground truth, providing an immersive user experience. Our code, model, and demo are are available at https://cyk990422.github.io/HoloGest.github.io/.
用整体的共语手势来驱动虚拟角色动画是一项充满挑战但至关重要的任务。以前的系统主要关注音频和手势之间微弱的关联,导致物理上不太自然的结果,从而降低了用户体验。为了解决这一问题,我们引入了HoleGest,这是一个基于解耦扩散和运动先验知识的新型神经网络框架,用于自动生成高质量、富有表现力的共语手势。我们的系统利用大规模人类运动数据集来学习一个稳健的先验模型,该模型具有较低的音频依赖性和较高的运动依赖性,能够实现稳定的全局运动和精细的手指动作。为了提高基于扩散模型的生成效率,我们将隐式关节约束与显式几何和条件约束相结合,在大步之间捕捉复杂的运动分布。这种结合显著提高了生成速度,同时保持了高质量的运动。此外,我们为手势转录文本对齐设计了一个共享嵌入空间,能够实现语义上正确的手势动作生成。大量的实验和用户反馈证明了我们模型的有效性和潜在应用,我们的方法达到了接近真实水平的逼真度,提供了沉浸式的用户体验。我们的代码、模型和演示作品可在https://cyk990422.github.io/HoloGest.github.io/找到。
论文及项目相关链接
PDF Accepted by 3DV 2025
Summary
本文提出一种基于解耦扩散和运动先验的神经网络框架HoleGest,用于自动生成高质量、表达性强的协同语音手势。该系统利用大规模人类运动数据集学习稳健的先验,实现稳定的全局运动和精细的手指动作,解决了音频与手势之间弱相关性的问题,提高了虚拟角色动画的自然性和用户沉浸感。
Key Takeaways
- HoleGest是一个基于解耦扩散和运动先验的神经网络框架,用于自动生成高质量协同语音手势。
- 系统利用大规模人类运动数据集学习稳健的先验,实现稳定的全局运动和精细的手指动作。
- HoleGest通过整合隐式关节约束、显式几何约束和条件约束,提高了扩散模型的生成效率,同时保持了高质量的运动。
- 设计了共享嵌入空间用于手势转录文本对齐,生成语义上正确的手势动作。
- 系统解决了音频与手势之间弱相关性的问题,提高了虚拟角色动画的自然性。
- 广泛的实验和用户反馈证明了该模型的有效性和潜在应用。
点此查看论文截图

FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Authors:Tong Lei, Qinwen Hu, Ziyao Lin, Andong Li, Rilin Chen, Meng Yu, Dong Yu, Jing Lu
The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
当前神经网络语音增强的主流方法主要依赖于使用模拟的远距离噪声混响语音(混合物)和清洁语音的配对进行纯监督深度学习。然而,这些训练好的模型对于真实记录的混合物往往表现出有限的泛化能力。为了解决这一问题,本研究致力于直接对真实混合物进行增强模型的训练。具体来说,我们重新审视单通道远距离到近距离语音增强(FNSE)任务,主要关注现实世界的数据特征,如低信噪比(SNR)、高混响和中高频衰减。我们提出了FNSE-SBGAN这一新型框架,它结合了基于Schrodinger Bridge(SB)的扩散模型与生成对抗网络(GANs)。我们的方法在各种指标和主观评估方面取得了最先进的性能,相较于远距离信号,字符错误率(CER)降低了高达14.58%。实验结果表明,FNSE-SBGAN保持了较高的主观质量,为现实世界的远距离语音增强建立了新的基准。此外,我们还引入了一种新的评估框架,利用时间频域中的矩阵秩分析,为模型性能提供了系统的见解,揭示了不同生成方法的优缺点。
论文及项目相关链接
PDF 13 pages, 6 figures
Summary
本文研究了基于真实混合物的语音增强模型训练问题,提出了一种新的FNSE-SBGAN框架,结合了基于Schrodinger Bridge的扩散模型和生成对抗网络。该框架在各项指标和主观评价上取得了最优性能,相比远场信号降低了高达14.58%的字符错误率,同时保留了优质的主观音质,为真实远场语音增强设立了新的基准。
Key Takeaways
- 当前神经网络语音增强主要依赖纯监督深度学习,使用模拟的远场带噪语音和干净语音对进行训练,但模型在真实录制混合物上的泛化能力有限。
- 为解决此问题,本研究直接对真实混合物进行增强模型训练。
- 研究重点为单通道远场到近场语音增强任务,针对低信噪比、高回声和中高频衰减的真实世界数据。
- 提出了一种新的FNSE-SBGAN框架,结合了Schrodinger Bridge扩散模型和生成对抗网络,实现了各项最优性能。
- FNSE-SBGAN框架显著降低了字符错误率,同时保持了优质的主观音质。
- 引入了一种新的评价框架,利用时频域矩阵秩分析,为模型性能提供了系统洞察,揭示了不同生成方法的优势和劣势。
- 研究结果为真实远场语音增强设立了新的基准。
点此查看论文截图

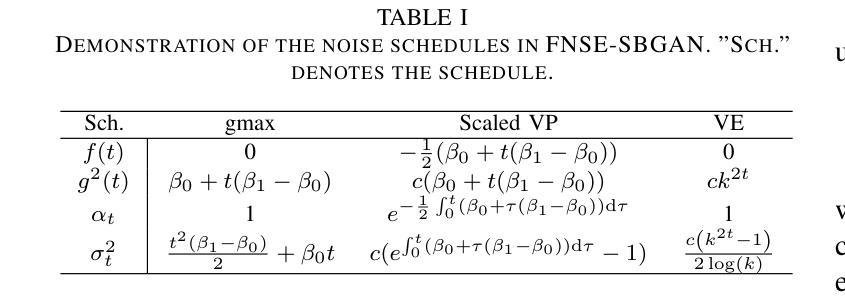
Prosody-Enhanced Acoustic Pre-training and Acoustic-Disentangled Prosody Adapting for Movie Dubbing
Authors:Zhedong Zhang, Liang Li, Chenggang Yan, Chunshan Liu, Anton van den Hengel, Yuankai Qi
Movie dubbing describes the process of transforming a script into speech that aligns temporally and emotionally with a given movie clip while exemplifying the speaker’s voice demonstrated in a short reference audio clip. This task demands the model bridge character performances and complicated prosody structures to build a high-quality video-synchronized dubbing track. The limited scale of movie dubbing datasets, along with the background noise inherent in audio data, hinder the acoustic modeling performance of trained models. To address these issues, we propose an acoustic-prosody disentangled two-stage method to achieve high-quality dubbing generation with precise prosody alignment. First, we propose a prosody-enhanced acoustic pre-training to develop robust acoustic modeling capabilities. Then, we freeze the pre-trained acoustic system and design a disentangled framework to model prosodic text features and dubbing style while maintaining acoustic quality. Additionally, we incorporate an in-domain emotion analysis module to reduce the impact of visual domain shifts across different movies, thereby enhancing emotion-prosody alignment. Extensive experiments show that our method performs favorably against the state-of-the-art models on two primary benchmarks. The demos are available at https://zzdoog.github.io/ProDubber/.
电影配音是将剧本转化为与给定电影片段在时间和情感上相匹配的语音的过程,同时展示在简短参考音频片段中演示的说话人的声音。这项任务要求模型在角色表演和复杂的韵律结构之间建立联系,以构建高质量的与视频同步的配音轨道。电影配音数据集规模的有限性,以及音频数据所固有的背景噪音,阻碍了训练模型的声学建模性能。为了解决这些问题,我们提出了一种声学-韵律分解的两阶段方法,以实现高质量配音生成与精确韵律对齐。首先,我们提出一种韵律增强声学预训练方法,以发展稳健的声学建模能力。然后,我们冻结预训练的声学系统,设计一个分离的框架来建模韵律文本特征和配音风格,同时保持声学质量。此外,我们引入了一个领域内的情感分析模块,以减少不同电影之间视觉领域变化的影响,从而增强情感-韵律对齐。大量实验表明,我们的方法在两个主要基准测试上的表现优于最先进的模型。演示请访问:https://zzdoog.github.io/ProDubber/。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文介绍了电影配音的过程,即将剧本转化为与电影片段相匹配的声音,同时展示参考音频片段中的说话人的声音。电影配音任务需要模型在角色表演和复杂的韵律结构之间建立联系,以创建高质量的与视频同步的配音轨道。针对电影配音数据集规模有限及音频数据中的背景噪音问题,提出了一个声学韵律解耦的两阶段方法,以实现高质量的配音生成和精确的节奏对齐。首先,通过提出韵律增强的声学预训练来开发稳健的声学建模能力。然后,冻结预训练的声学系统,设计一个解耦框架来建模文本特征、配音风格和保持声学质量。此外,还融入了领域内的情感分析模块,以减少不同电影之间视觉域变化的影响,从而提高情感韵律的对齐度。实验证明,该方法在两个主要基准测试上的表现均优于现有模型。演示地址:链接地址。
Key Takeaways
- 电影配音是将剧本转化为与电影片段相匹配的声音的过程,需考虑角色表演和复杂韵律结构。
- 现有的电影配音数据集规模有限,且音频数据中的背景噪音影响声学建模性能。
- 提出一个声学韵律解耦的两阶段方法,以实现高质量的配音生成和精确的节奏对齐。
- 引入韵律增强的声学预训练来增强模型的声学建模能力。
- 通过冻结预训练的声学系统并设计解耦框架,同时建模文本特征、配音风格和保持声学质量。
- 融入领域内的情感分析模块以减少不同电影视觉域变化的影响,提高情感韵律的对齐度。
点此查看论文截图

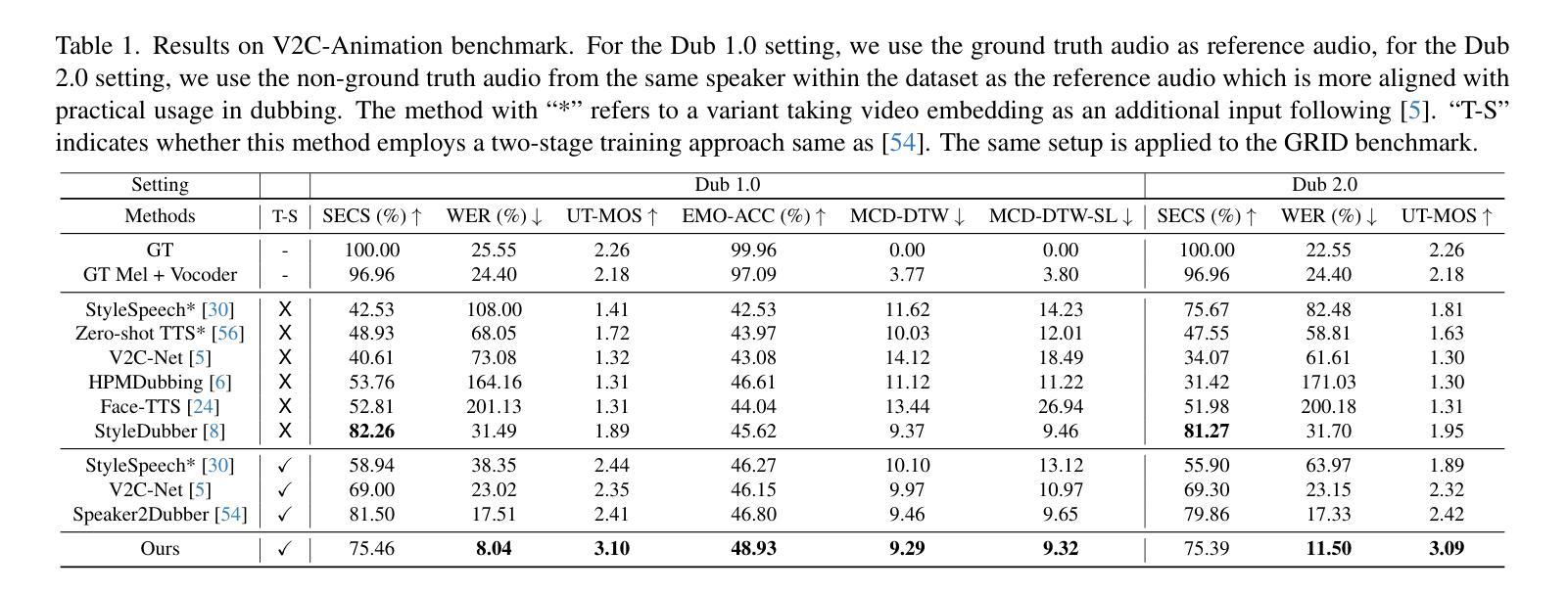
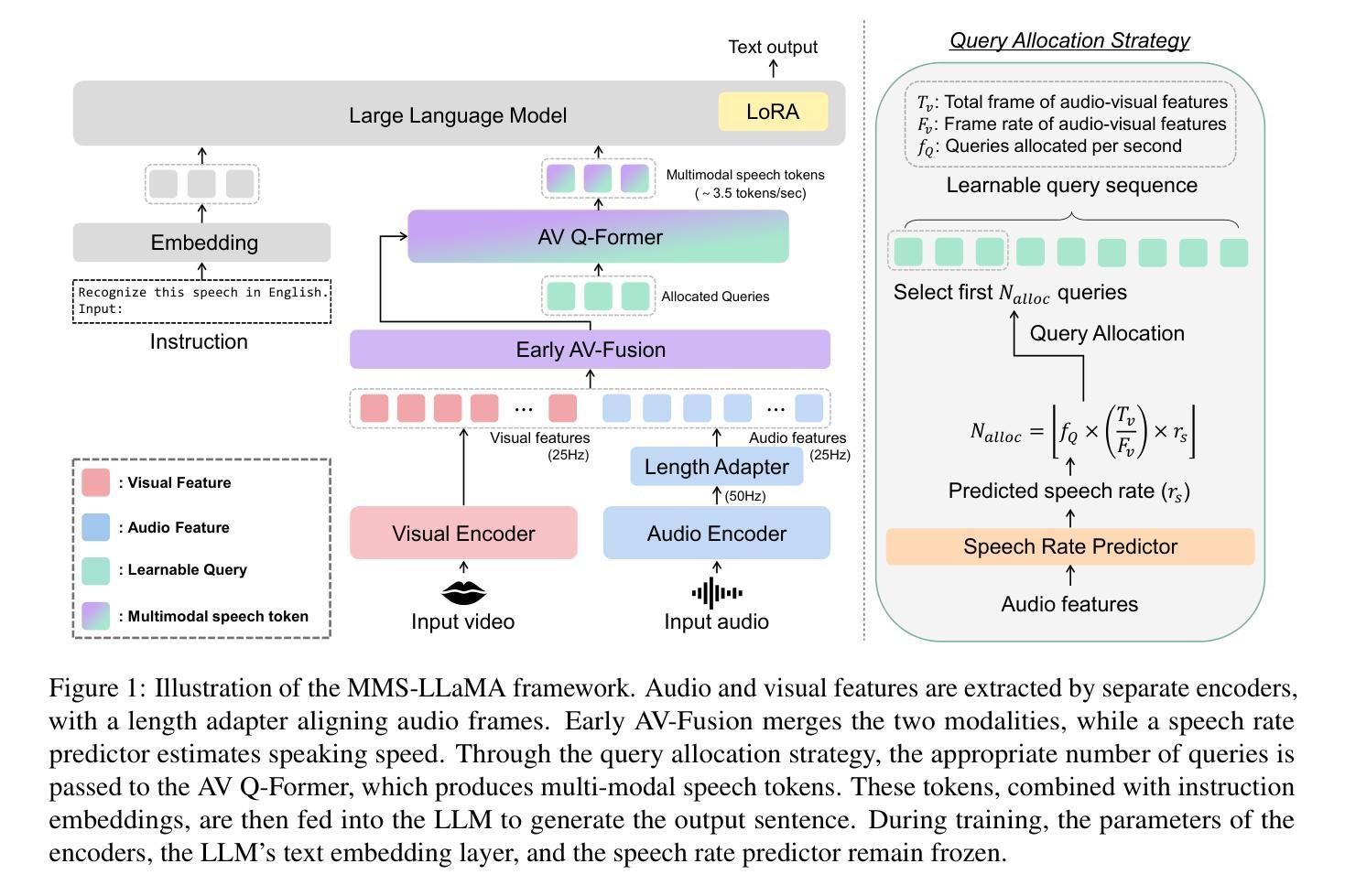
MMS-LLaMA: Efficient LLM-based Audio-Visual Speech Recognition with Minimal Multimodal Speech Tokens
Authors:Jeong Hun Yeo, Hyeongseop Rha, Se Jin Park, Yong Man Ro
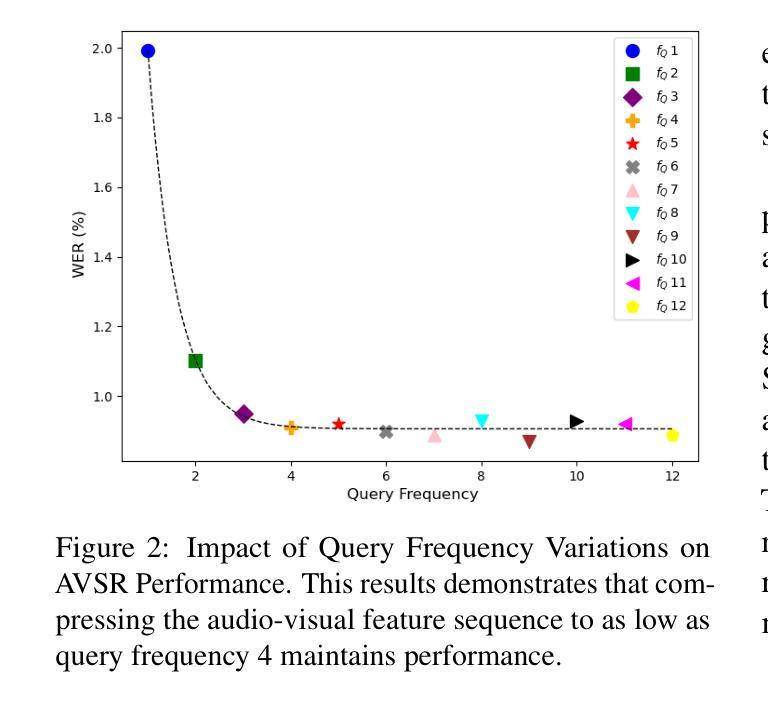
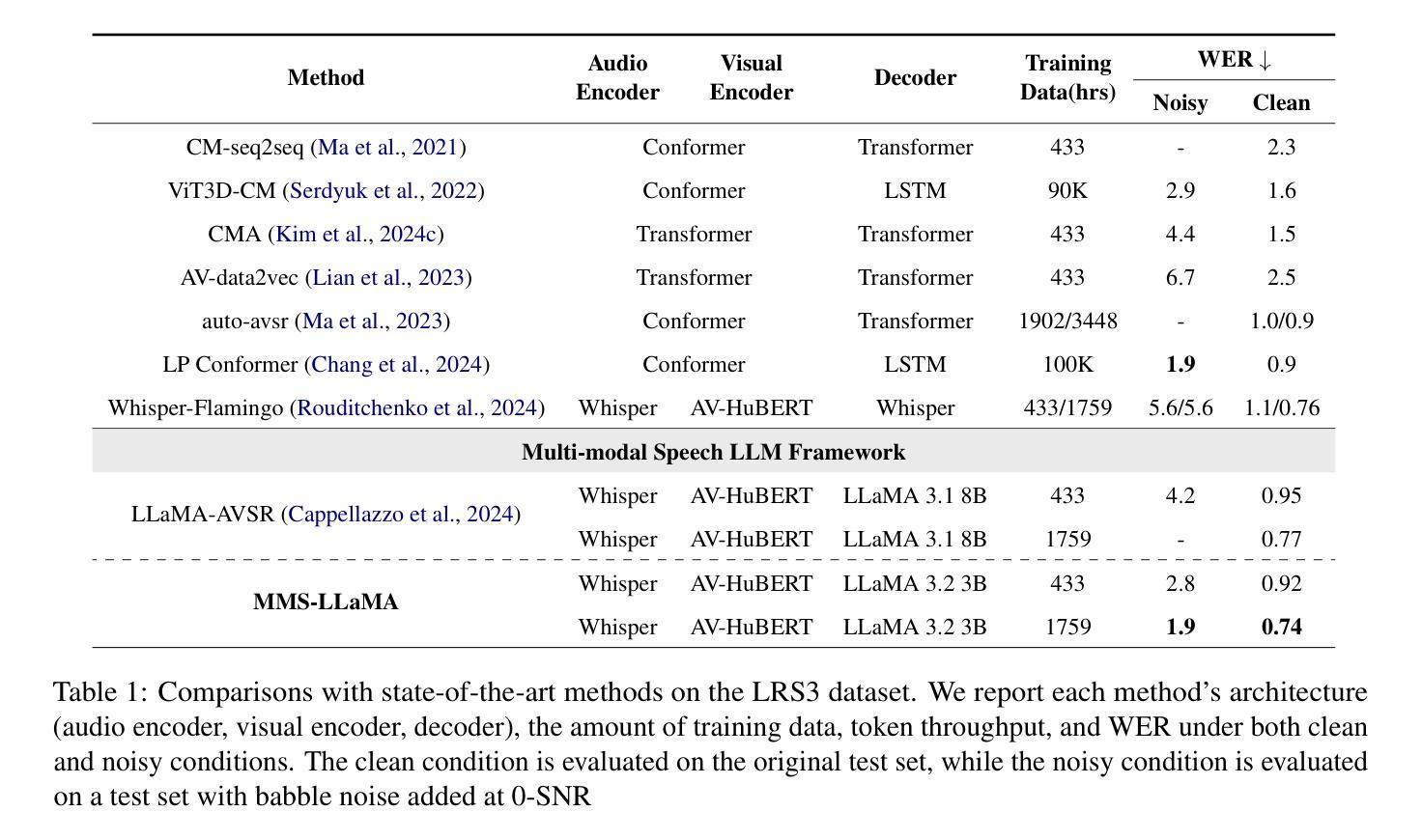
Audio-Visual Speech Recognition (AVSR) achieves robust speech recognition in noisy environments by combining auditory and visual information. However, recent Large Language Model (LLM) based AVSR systems incur high computational costs due to the high temporal resolution of audio-visual speech processed by LLMs. In this work, we introduce an efficient multimodal speech LLM framework that minimizes token length while preserving essential linguistic content. Our approach employs an early av-fusion module for streamlined feature integration, an audio-visual speech Q-Former that dynamically allocates tokens based on input duration, and a refined query allocation strategy with a speech rate predictor to adjust token allocation according to speaking speed of each audio sample. Extensive experiments on the LRS3 dataset show that our method achieves state-of-the-art performance with a WER of 0.74% while using only 3.5 tokens per second. Moreover, our approach not only reduces token usage by 86% compared to the previous multimodal speech LLM framework, but also improves computational efficiency by reducing FLOPs by 35.7%.
视听语音识别(AVSR)通过结合听觉和视觉信息,在嘈杂环境中实现了稳健的语音识别。然而,基于大型语言模型(LLM)的AVSR系统由于LLM处理视听语音的高时间分辨率而产生了较高的计算成本。在这项工作中,我们引入了一个高效的多模态语音LLM框架,该框架在保留基本语言内容的同时,最小化令牌长度。我们的方法采用早期av融合模块进行流线型特征集成,一个视听语音Q-Former,根据输入持续时间动态分配令牌,以及一种精细化的查询分配策略,配备一个语速预测器,根据每个音频样本的语速调整令牌分配。在LRS3数据集上的大量实验表明,我们的方法以0.74%的字错误率(WER)达到了最先进的性能,同时每秒仅使用3.5个令牌。此外,我们的方法不仅将令牌使用量减少了86%,与以前的多模态语音LLM框架相比,还提高了计算效率,减少了35.7%的浮点运算(FLOPs)。
论文及项目相关链接
PDF The code and models are available https://github.com/JeongHun0716/MMS-LLaMA
Summary
本文介绍了音频视觉语音识别(AVSR)在噪声环境下的稳健语音识别技术,结合了听觉和视觉信息。针对大型语言模型(LLM)在AVSR系统中处理高时空分辨率音频视觉语音时的高计算成本问题,提出了一种高效的多模态语音LLM框架。该框架通过最小化令牌长度同时保留基本语言内容、采用早期av融合模块进行功能整合、音频视觉语音Q-Former动态分配令牌以及使用精细查询分配策略与语速预测器调整每个音频样本的令牌分配,以实现性能优化。在LRS3数据集上的实验表明,该方法在词错误率为0.74%的情况下实现了最先进的性能,并且每秒仅使用3.5个令牌。此外,该方法不仅将令牌使用量减少了86%,而且通过降低浮点运算次数提高了计算效率。
Key Takeaways
- 音频视觉语音识别(AVSR)结合了听觉和视觉信息,提高了在噪声环境下的语音识别稳健性。
- 大型语言模型(LLM)处理高时空分辨率音频视觉语音时计算成本高昂。
- 高效多模态语音LLM框架旨在优化性能,减少计算成本。
- 该框架采用早期av融合、音频视觉语音Q-Former和查询分配策略与语速预测器的组合。
- 在LRS3数据集上的实验表明,该方法实现了先进的性能,词错误率低至0.74%。
- 与之前的多模态语音LLM框架相比,该方法显著减少了令牌使用量,并提高了计算效率。
点此查看论文截图

Joint Training And Decoding for Multilingual End-to-End Simultaneous Speech Translation
Authors:Wuwei Huang, Renren Jin, Wen Zhang, Jian Luan, Bin Wang, Deyi Xiong
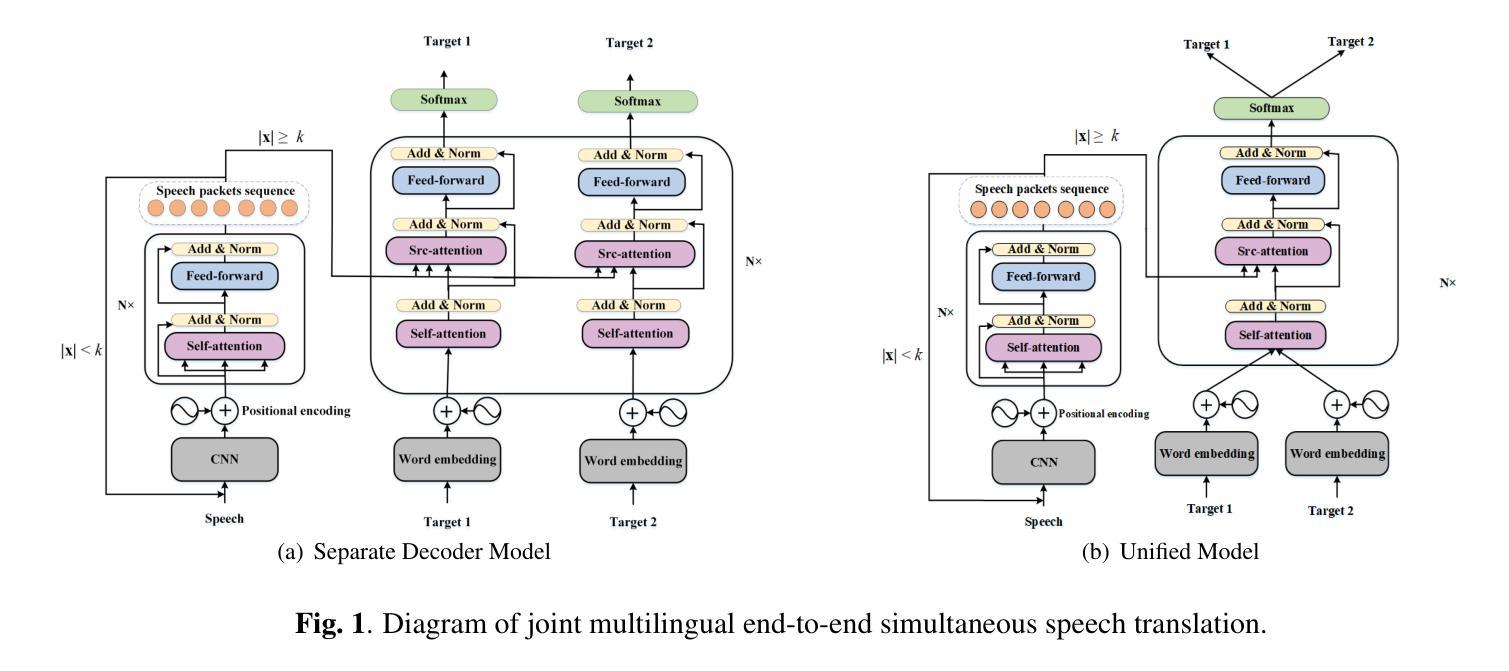
Recent studies on end-to-end speech translation(ST) have facilitated the exploration of multilingual end-to-end ST and end-to-end simultaneous ST. In this paper, we investigate end-to-end simultaneous speech translation in a one-to-many multilingual setting which is closer to applications in real scenarios. We explore a separate decoder architecture and a unified architecture for joint synchronous training in this scenario. To further explore knowledge transfer across languages, we propose an asynchronous training strategy on the proposed unified decoder architecture. A multi-way aligned multilingual end-to-end ST dataset was curated as a benchmark testbed to evaluate our methods. Experimental results demonstrate the effectiveness of our models on the collected dataset. Our codes and data are available at: https://github.com/XiaoMi/TED-MMST.
最近关于端到端语音翻译(ST)的研究促进了多语言端到端ST和端到端同步ST的探索。在本文中,我们在更接近实际应用场景的多种语言到多种语言的设置中,研究了端到端的实时语音翻译。我们在这个场景中探索了单独的解码器架构和联合同步训练的统一架构。为了进一步研究跨语言的知识转移,我们在统一的解码器架构上提出了异步训练策略。作为评估方法的基准测试平台,我们筛选了一个多路对齐的多语言端到端ST数据集。实验结果表明,我们的模型在收集的数据集上是有效的。我们的代码和数据集可在https://github.com/XiaoMi/TED-MMST上找到。
论文及项目相关链接
PDF ICASSP 2023
Summary
本文研究了端到端的多语言同步语音识别翻译技术,在真实场景应用中更具有实际意义。探讨了分别解码架构和联合同步训练统一架构的使用,并提出了异步训练策略来提升跨语言知识迁移。研究使用多语种对齐的多语种端到端语音识别翻译数据集作为评估模型性能的基准测试平台。实验结果表明模型的有效性。相关代码和数据可在GitHub上获取。
Key Takeaways
- 研究了端到端的多语言同步语音识别翻译技术,适用于真实场景应用。
- 分别探讨了分别解码架构和统一架构在联合同步训练中的应用。
- 提出了异步训练策略来提升跨语言知识迁移。
- 使用多语种对齐的多语种端到端语音识别翻译数据集作为评估模型性能的基准测试平台。
- 实验结果证明了模型的有效性。
- 相关代码和数据可在GitHub上获取。
点此查看论文截图

EmoDiffusion: Enhancing Emotional 3D Facial Animation with Latent Diffusion Models
Authors:Yixuan Zhang, Qing Chang, Yuxi Wang, Guang Chen, Zhaoxiang Zhang, Junran Peng
Speech-driven 3D facial animation seeks to produce lifelike facial expressions that are synchronized with the speech content and its emotional nuances, finding applications in various multimedia fields. However, previous methods often overlook emotional facial expressions or fail to disentangle them effectively from the speech content. To address these challenges, we present EmoDiffusion, a novel approach that disentangles different emotions in speech to generate rich 3D emotional facial expressions. Specifically, our method employs two Variational Autoencoders (VAEs) to separately generate the upper face region and mouth region, thereby learning a more refined representation of the facial sequence. Unlike traditional methods that use diffusion models to connect facial expression sequences with audio inputs, we perform the diffusion process in the latent space. Furthermore, we introduce an Emotion Adapter to evaluate upper face movements accurately. Given the paucity of 3D emotional talking face data in the animation industry, we capture facial expressions under the guidance of animation experts using LiveLinkFace on an iPhone. This effort results in the creation of an innovative 3D blendshape emotional talking face dataset (3D-BEF) used to train our network. Extensive experiments and perceptual evaluations validate the effectiveness of our approach, confirming its superiority in generating realistic and emotionally rich facial animations.
语音驱动的3D面部动画旨在产生与语音内容及其情感细微差别同步的逼真面部表情,在多媒体领域具有广泛的应用。然而,传统方法往往会忽略情感面部表情或无法有效地从语音内容中将其分离出来。为了应对这些挑战,我们提出了EmoDiffusion这一新方法,它通过分解语音中的不同情感来生成丰富的3D情感面部表情。具体来说,我们的方法采用两个变分自动编码器(VAEs)分别生成面部上区域和嘴巴区域,从而学习更精细的面部表情序列表示。不同于传统方法使用扩散模型将面部表情序列与音频输入连接起来,我们在潜在空间执行扩散过程。此外,我们引入了一个情感适配器来准确评估面部上部的运动。鉴于动画行业缺乏3D情感对话面部数据,我们在动画专家的指导下使用iPhone上的LiveLinkFace捕获面部表情,成功创建了一个创新的3D混相情绪对话面部数据集(3D-BEF),用于训练我们的网络。大量的实验和感知评估验证了我们的方法的有效性,证实其在生成真实且情感丰富的面部动画方面的优越性。
论文及项目相关链接
Summary
该文介绍了Speech-driven 3D面部动画面临的挑战及其应用于多媒体领域的价值。为解决以往方法忽视情感面部表情或无法有效从语音内容中分离情感的问题,提出一种名为EmoDiffusion的新方法。该方法利用变分自编码器(VAEs)分别生成面部上区和口部区域,并在潜在空间进行扩散过程,从而更精细地表示面部序列。此外,引入情感适配器准确评估面部上区的运动。为解决动画行业中缺乏3D情感说话面部数据的问题,使用LiveLinkFace在iPhone上采集面部表情数据,创建创新的3D blendshape情感说话面部数据集(3D-BEF)用于训练网络。实验和感知评估验证了该方法的优越性,能够在生成真实且情感丰富的面部动画方面表现出色。
Key Takeaways
- Speech-driven 3D面部动画旨在实现与语音内容及其情感细微差别同步的逼真面部表情。
- 现有方法忽视了情感面部表情或无法有效地从语音内容中分离情感。
- EmoDiffusion是一种新颖的方法,它通过变分自编码器(VAEs)生成面部上区和口部区域,以更精细的方式表示面部序列。
- EmoDiffusion在潜在空间进行扩散过程,并引入情感适配器以更准确地评估面部上区的运动。
- 为训练网络,创建了3D blendshape情感说话面部数据集(3D-BEF),该数据集是通过使用LiveLinkFace在iPhone上采集面部表情数据制成的。
- 广泛实验证明了EmoDiffusion方法的有效性,能够生成真实且情感丰富的面部动画。
点此查看论文截图

SPES: Spectrogram Perturbation for Explainable Speech-to-Text Generation
Authors:Dennis Fucci, Marco Gaido, Beatrice Savoldi, Matteo Negri, Mauro Cettolo, Luisa Bentivogli
Spurred by the demand for interpretable models, research on eXplainable AI for language technologies has experienced significant growth, with feature attribution methods emerging as a cornerstone of this progress. While prior work in NLP explored such methods for classification tasks and textual applications, explainability intersecting generation and speech is lagging, with existing techniques failing to account for the autoregressive nature of state-of-the-art models and to provide fine-grained, phonetically meaningful explanations. We address this gap by introducing Spectrogram Perturbation for Explainable Speech-to-text Generation (SPES), a feature attribution technique applicable to sequence generation tasks with autoregressive models. SPES provides explanations for each predicted token based on both the input spectrogram and the previously generated tokens. Extensive evaluation on speech recognition and translation demonstrates that SPES generates explanations that are faithful and plausible to humans.
受到可解释模型需求的影响,语言技术中的可解释人工智能研究经历了显著增长,特征归因方法已成为这一进步的核心。虽然自然语言处理中的先前工作已经探索了分类任务和文本应用中的这些方法,但解释能力与生成和语音的交集滞后,现有技术未能考虑到最先进模型的自回归性质,也无法提供精细粒度和音素意义上的解释。我们通过引入用于解释语音到文本生成的频谱扰动(SPES)来解决这一差距,SPES是一种适用于自回归模型的序列生成任务的特征归因技术。SPES基于输入频谱图和先前生成的标记为每个预测标记提供解释。在语音识别和翻译方面的广泛评估表明,SPES生成的解释对人类来说是忠实和可信的。
论文及项目相关链接
Summary
本文介绍了可解释的语音识别技术的最新进展。随着对可解释模型的需求增长,解释性人工智能在语言技术领域的研究已经取得了显著进展,特征归因方法已成为这一进展的核心。尽管先前的工作在NLP中探索了这些方法用于分类任务和文本应用,但解释性与生成和语音的交叉部分仍然滞后。为解决这一差距,本文引入了Spectrogram Perturbation for Explainable Speech-to-text Generation(SPES),这是一种适用于具有自回归模型的序列生成任务的特征归因技术。SPES基于输入频谱图和先前生成的标记为每个预测标记提供解释。在语音识别和翻译方面的广泛评估表明,SPES生成的解释对人类来说是忠实和可信的。
Key Takeaways
- 解释性人工智能在语言技术领域的研究正在增长,特征归因方法已成为核心。
- 在NLP中,尽管分类任务和文本应用的解释性研究已经取得进展,但生成任务和语音方面的解释性研究仍然滞后。
- 现有技术未能充分考虑到先进模型的自回归性质,无法提供精细粒度的、具有语音意义的解释。
- 引入Spectrogram Perturbation for Explainable Speech-to-text Generation(SPES)以填补空白。
- SPES是一种特征归因技术,适用于具有自回归模型的序列生成任务。
- SPES为每个预测标记提供基于输入频谱图和先前生成标记的解释。
点此查看论文截图

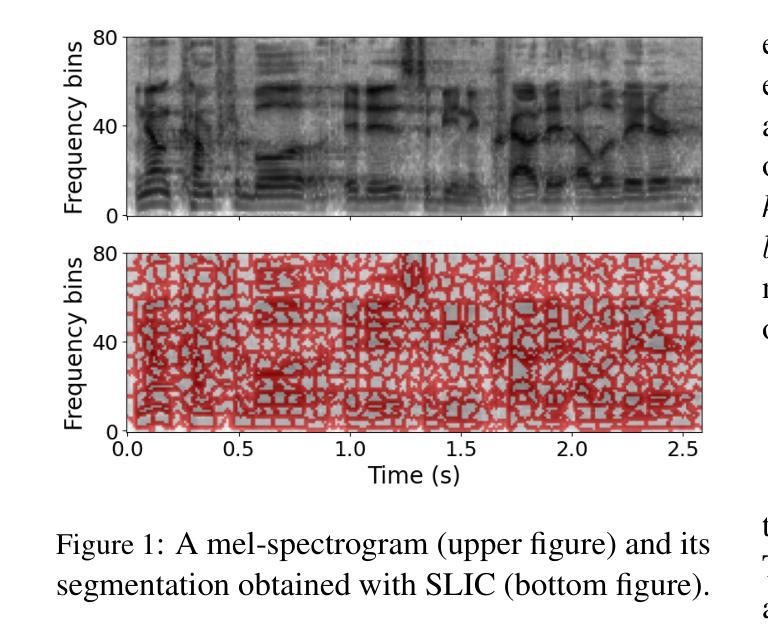
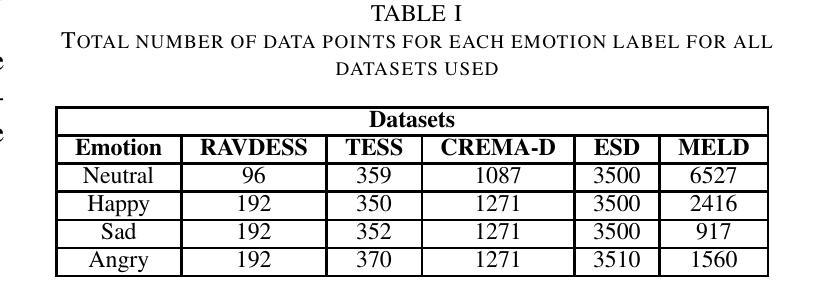
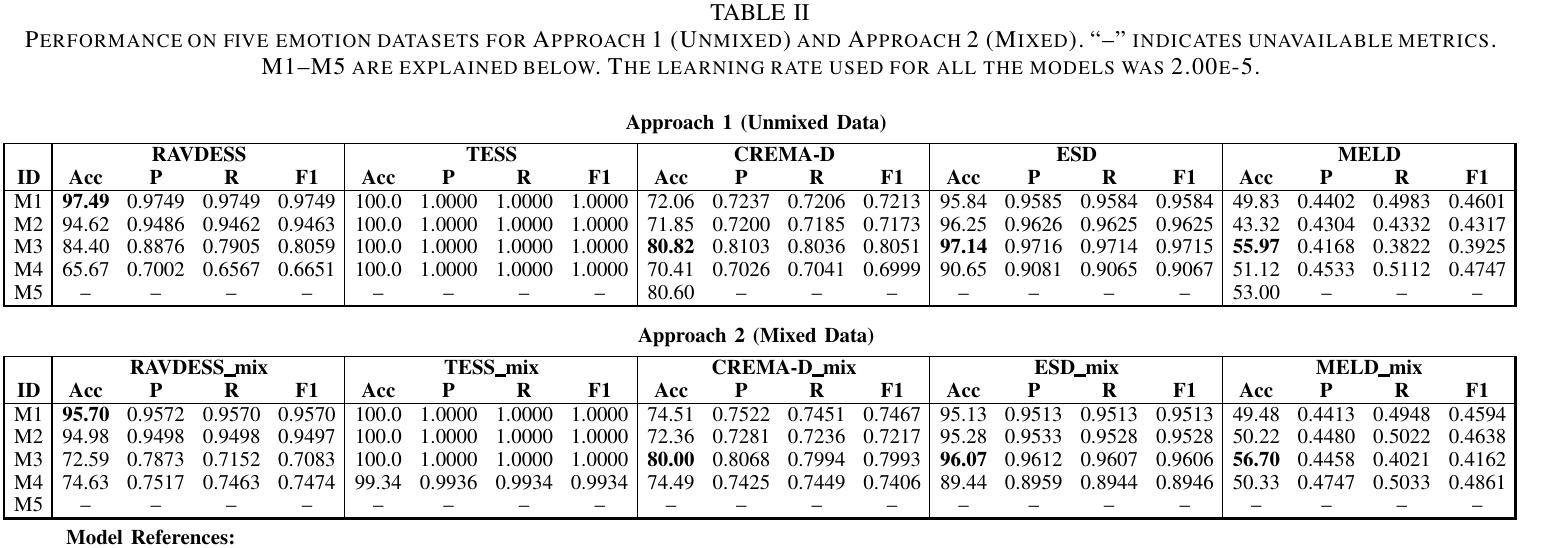
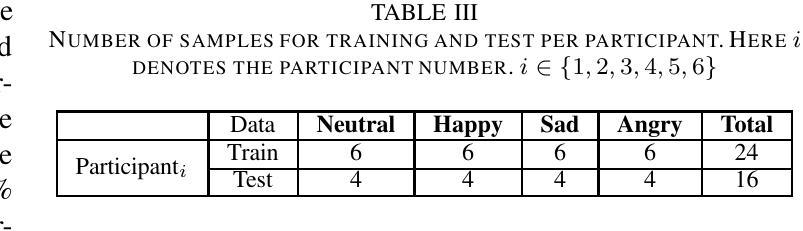
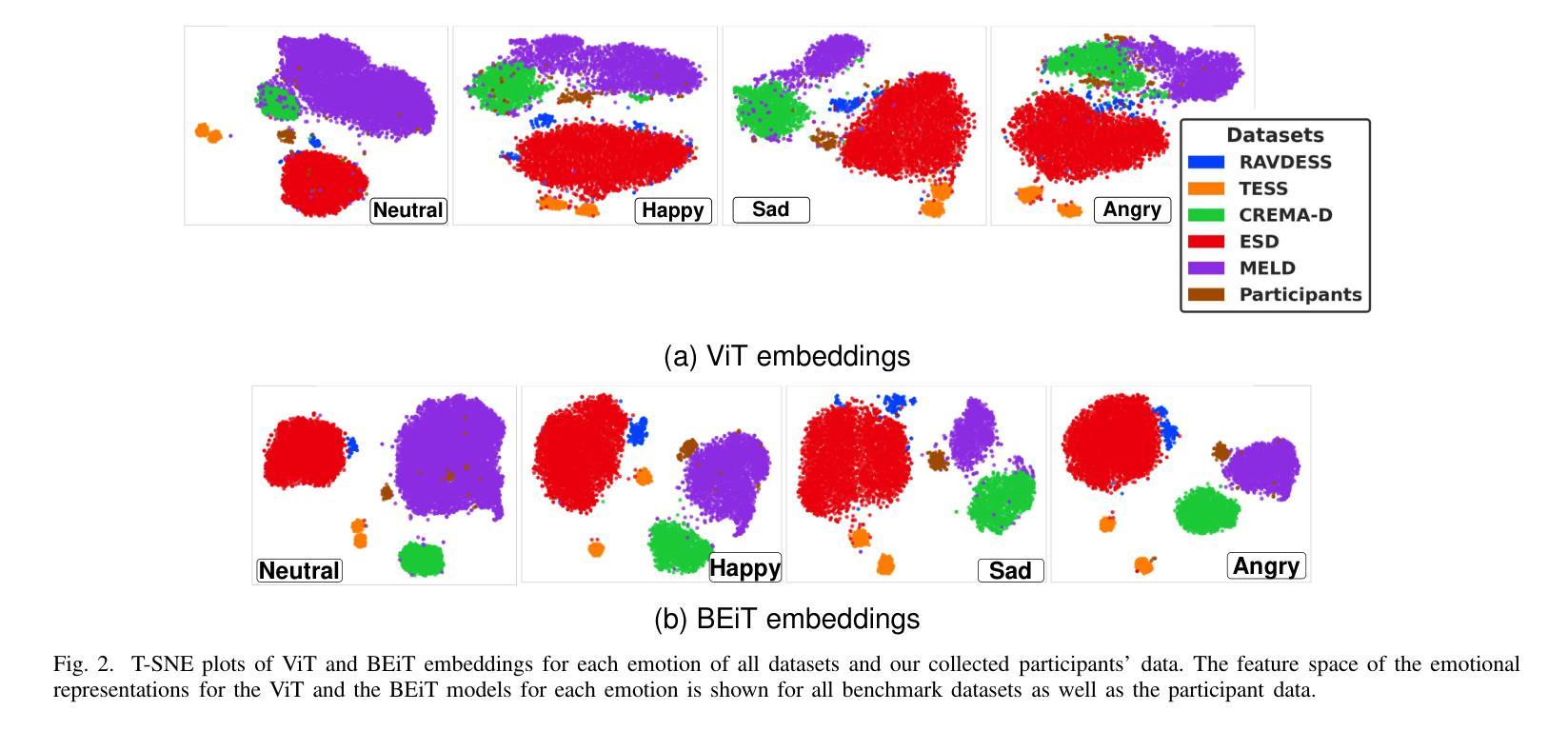
Personalized Speech Emotion Recognition in Human-Robot Interaction using Vision Transformers
Authors:Ruchik Mishra, Andrew Frye, Madan Mohan Rayguru, Dan O. Popa
Emotions are an essential element in verbal communication, so understanding individuals’ affect during a human-robot interaction (HRI) becomes imperative. This paper investigates the application of vision transformer models, namely ViT (Vision Transformers) and BEiT (BERT Pre-Training of Image Transformers) pipelines, for Speech Emotion Recognition (SER) in HRI. The focus is to generalize the SER models for individual speech characteristics by fine-tuning these models on benchmark datasets and exploiting ensemble methods. For this purpose, we collected audio data from different human subjects having pseudo-naturalistic conversations with the NAO robot. We then fine-tuned our ViT and BEiT-based models and tested these models on unseen speech samples from the participants. In the results, we show that fine-tuning vision transformers on benchmark datasets and and then using either these already fine-tuned models or ensembling ViT/BEiT models gets us the highest classification accuracies per individual when it comes to identifying four primary emotions from their speech: neutral, happy, sad, and angry, as compared to fine-tuning vanilla-ViTs or BEiTs.
情感是口头交流的重要组成部分,因此在人机互动(HRI)中理解个体的情感变得至关重要。本文研究了视觉转换器模型在人机互动中的语音情感识别(SER)应用,重点关注使用ViT(视觉转换器)和BEiT(图像转换器的BERT预训练方法)管道。研究的重点是通过对基准数据集进行微调并利用集成方法,使SER模型适应个体语音特征。为此,我们从与NAO机器人进行伪自然对话的不同人类受试者中收集音频数据。然后我们对基于ViT和BEiT的模型进行微调,并在来自参与者的未见语音样本上测试这些模型。结果表明,在基准数据集上微调视觉转换器,然后使用已经微调过的模型或集成ViT/BEiT模型,在识别四种主要情绪(中性、快乐、悲伤和愤怒)时,针对个人的分类准确率最高,与微调普通ViTs或BEITs相比效果更佳。
论文及项目相关链接
PDF This work has been accepted for the IEEE Robotics and Automation Letters (RA-L)
Summary
本文探讨了将视觉转换器模型应用于人机互动中的语音情感识别。研究采用ViT和BEiT模型,通过对基准数据集进行微调并利用集成方法,实现对个体语音特性的通用化。通过对与NAO机器人进行伪自然对话的音频数据进行收集、微调模型并测试,发现对四种主要情绪——中性、快乐、悲伤和愤怒——的识别中,相较于微调普通的ViT或BEiT模型,使用已微调过的模型或集成ViT/BEiT模型可获得更高的个体分类准确率。
Key Takeaways
- 情感在人际交流中的重要性,特别是在人机互动中理解个体的情感变得至关重要。
- 研究采用视觉转换器模型(ViT和BEiT)进行语音情感识别。
- 通过微调基准数据集上的模型,实现对个体语音特性的通用化。
- 集成方法可以提高语音情感识别的准确率。
- 使用了与NAO机器人进行伪自然对话的音频数据来测试模型。
- 研究发现,使用已微调过的模型或集成ViT/BEiT模型在识别四种主要情绪时表现更佳。
点此查看论文截图

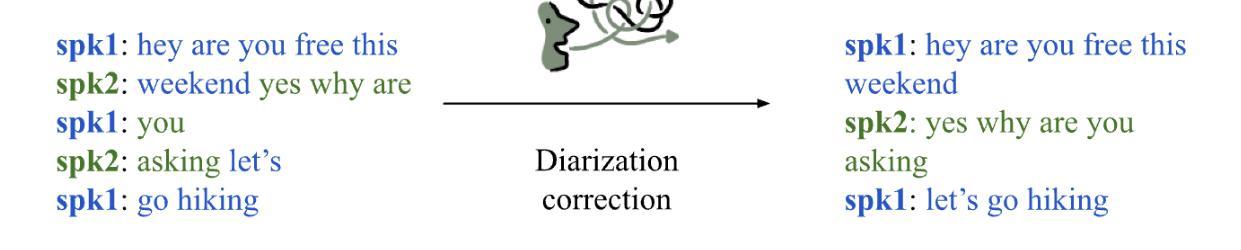
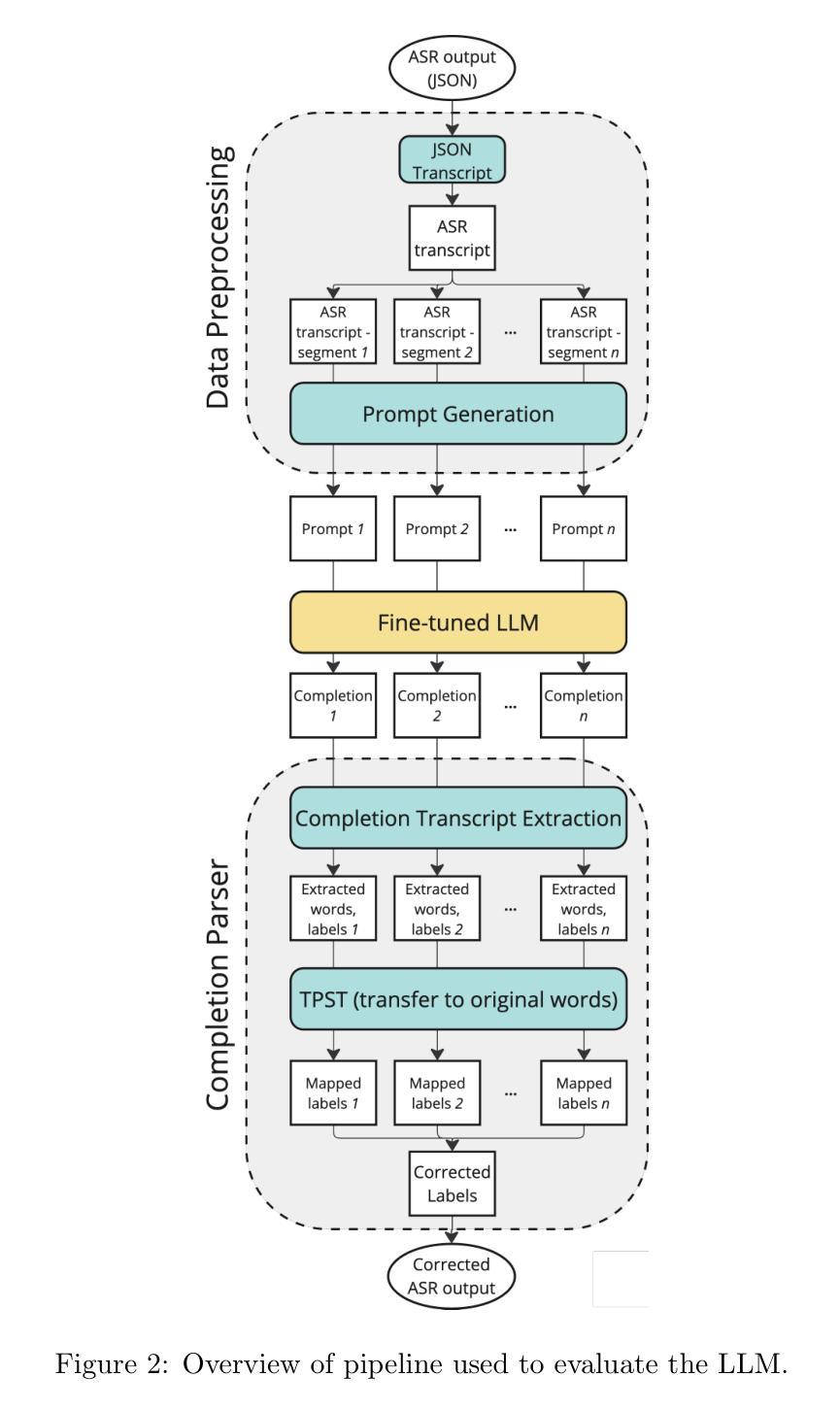
LLM-based speaker diarization correction: A generalizable approach
Authors:Georgios Efstathiadis, Vijay Yadav, Anzar Abbas
Speaker diarization is necessary for interpreting conversations transcribed using automated speech recognition (ASR) tools. Despite significant developments in diarization methods, diarization accuracy remains an issue. Here, we investigate the use of large language models (LLMs) for diarization correction as a post-processing step. LLMs were fine-tuned using the Fisher corpus, a large dataset of transcribed conversations. The ability of the models to improve diarization accuracy in a holdout dataset from the Fisher corpus as well as an independent dataset was measured. We report that fine-tuned LLMs can markedly improve diarization accuracy. However, model performance is constrained to transcripts produced using the same ASR tool as the transcripts used for fine-tuning, limiting generalizability. To address this constraint, an ensemble model was developed by combining weights from three separate models, each fine-tuned using transcripts from a different ASR tool. The ensemble model demonstrated better overall performance than each of the ASR-specific models, suggesting that a generalizable and ASR-agnostic approach may be achievable. We have made the weights of these models publicly available on HuggingFace at https://huggingface.co/bklynhlth.
说话人识别是对使用自动语音识别(ASR)工具转录的对话进行解释的必要步骤。尽管识别方法有了显著的发展,但识别准确性仍然是一个问题。在这里,我们研究了大型语言模型(LLM)在作为后处理步骤的识别校正中的应用。这些LLM使用Fisher语料库(一个包含大量转录对话的数据集)进行了微调。我们测量了这些模型在提高Fisher语料库中的保留数据集以及独立数据集的识别准确性方面的能力。我们报告说,经过精细调整的LLM可以显著提高识别准确性。然而,模型的性能仅限于使用与微调时使用的相同ASR工具产生的转录本,从而限制了其通用性。为了解决这一限制,我们通过结合三个单独模型的权重,开发了一个集成模型,每个模型都使用来自不同ASR工具的转录本进行微调。集成模型的表现优于每个ASR特定模型的表现,这表明可能实现了通用和独立于ASR的方法。我们已在HuggingFace上公开了这些模型的权重:https://huggingface.co/bklynhlth。
论文及项目相关链接
Summary
使用大型语言模型(LLM)进行语音转文本的后处理步骤可以显著改善分置准确度。在研究中,通过对Fisher语料库的大型数据集进行微调训练LLM模型后,对其在Fisher语料库中的独立数据集和其他独立数据集上的表现进行了评估。报告指出,精细训练的LLM可以显著提高分置准确性,但模型性能仅限于使用与微调过程中相同的语音识别工具生成的转录文本,限制了其泛化能力。为解决此限制,通过结合三个独立模型的权重开发了集成模型,每个模型针对不同的语音识别工具进行微调。集成模型表现出优于单一ASR特定模型的性能,这表明可以实现一种通用且独立于ASR的方法。
Key Takeaways
- 大型语言模型(LLM)可以用于语音分置修正后处理,能显著提高分置准确度。
- LLM通过微调训练来适应特定的语音数据集。
- LLM的模型性能受限于与微调过程中使用的语音识别工具相同的转录文本。
- 集成模型通过将不同ASR工具生成的转录文本合并来优化模型性能。
- 集成模型表现优于单一ASR特定模型。
- 集成模型的权重已经公开提供在HuggingFace平台上。
点此查看论文截图

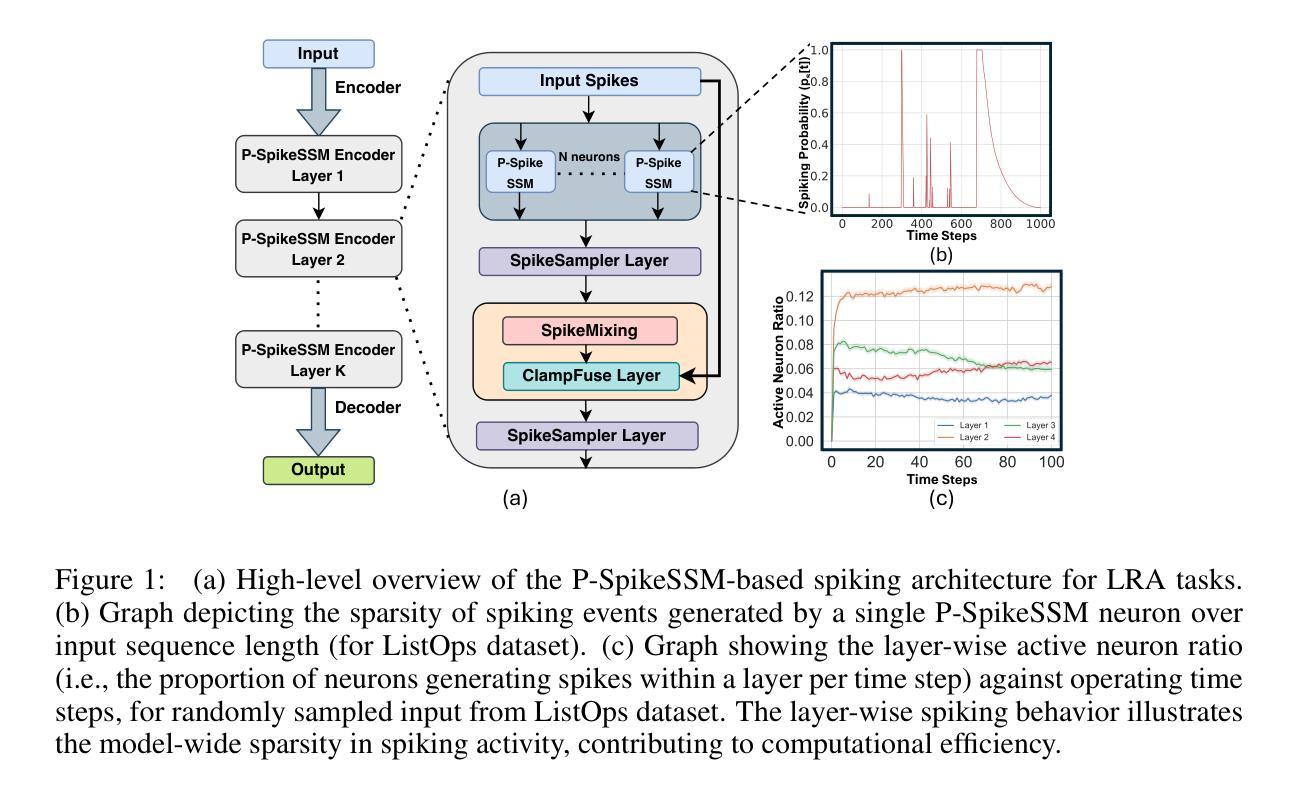
P-SpikeSSM: Harnessing Probabilistic Spiking State Space Models for Long-Range Dependency Tasks
Authors:Malyaban Bal, Abhronil Sengupta
Spiking neural networks (SNNs) are posited as a computationally efficient and biologically plausible alternative to conventional neural architectures, with their core computational framework primarily using the leaky integrate-and-fire (LIF) neuron model. However, the limited hidden state representation of LIF neurons, characterized by a scalar membrane potential, and sequential spike generation process, poses challenges for effectively developing scalable spiking models to address long-range dependencies in sequence learning tasks. In this study, we develop a scalable probabilistic spiking learning framework for long-range dependency tasks leveraging the fundamentals of state space models. Unlike LIF neurons that rely on the deterministic Heaviside function for a sequential process of spike generation, we introduce a SpikeSampler layer that samples spikes stochastically based on an SSM-based neuronal model while allowing parallel computations. To address non-differentiability of the spiking operation and enable effective training, we also propose a surrogate function tailored for the stochastic nature of the SpikeSampler layer. To enhance inter-neuron communication, we introduce the SpikeMixer block, which integrates spikes from neuron populations in each layer. This is followed by a ClampFuse layer, incorporating a residual connection to capture complex dependencies, enabling scalability of the model. Our models attain state-of-the-art performance among SNN models across diverse long-range dependency tasks, encompassing the Long Range Arena benchmark, permuted sequential MNIST, and the Speech Command dataset and demonstrate sparse spiking pattern highlighting its computational efficiency.
脉冲神经网络(SNNs)被提出作为传统神经网络架构的计算效率高且生物上合理的替代方案,其主要的计算框架主要使用泄漏积分和发射(LIF)神经元模型。然而,LIF神经元的隐藏状态表示有限,其特征在于标量膜电位和顺序脉冲生成过程,这为开发可扩展的脉冲模型以处理序列学习任务中的长距离依赖关系带来了挑战。在这项研究中,我们针对长距离依赖任务开发了一个可扩展的概率脉冲学习框架,该框架利用状态空间模型的基本原理。不同于依赖确定性海维赛德函数进行脉冲生成序列过程的LIF神经元,我们引入了SpikeSampler层,该层基于SSM神经元模型的随机性进行脉冲采样,同时允许并行计算。为了解决脉冲操作的不可微性和实现有效的训练,我们还为SpikeSampler层的随机性量身定制了替代函数。为了增强神经元之间的通信,我们引入了SpikeMixer块,该块整合了每层神经元群体的脉冲。随后是ClampFuse层,它结合了残差连接以捕捉复杂的依赖关系,使模型的可扩展性得以增强。我们的模型在不同类型的长距离依赖任务中达到了脉冲神经网络模型的最新性能水平,包括Long Range Arena基准测试、排列顺序的MNIST和语音命令数据集,并显示出稀疏的脉冲模式,突显了其计算效率。
论文及项目相关链接
PDF Accepted at ICLR 2025
Summary
本文研究了基于状态空间模型(SSM)的概率性脉冲学习框架,用于解决序列学习中的长程依赖问题。该研究引入了SpikeSampler层以随机采样脉冲,并利用SSM神经元模型实现并行计算。为解决脉冲操作不可微分的问题,研究提出了针对SpikeSampler层随机性的替代函数。此外,还引入了SpikeMixer块以增强神经元间的通信,并通过ClampFuse层结合残差连接捕捉复杂依赖关系,实现模型的扩展性。该模型在多种长程依赖任务上达到了脉冲神经网络模型的最新性能水平,包括Long Range Arena基准测试、顺序MNIST和语音命令数据集,并展示了其计算效率高的稀疏脉冲模式。
Key Takeaways
- SNNs作为一种计算高效且生物上可行的神经网络架构,面临长程依赖问题的挑战。
- 引入基于状态空间模型的SpikeSampler层以随机采样脉冲并实现并行计算。
- 提出替代函数以解决脉冲操作不可微分的问题,确保有效的训练。
- SpikeMixer块增强了神经元间的通信,而ClampFuse层则通过结合残差连接捕捉复杂依赖关系。
- 模型在多种长程依赖任务上实现了最新性能水平,包括Long Range Arena基准测试等。
- 模型展示了其计算效率高的稀疏脉冲模式。
点此查看论文截图