⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-18 更新
Towards Scalable Foundation Model for Multi-modal and Hyperspectral Geospatial Data
Authors:Haozhe Si, Yuxuan Wan, Minh Do, Deepak Vasisht, Han Zhao, Hendrik F. Hamann
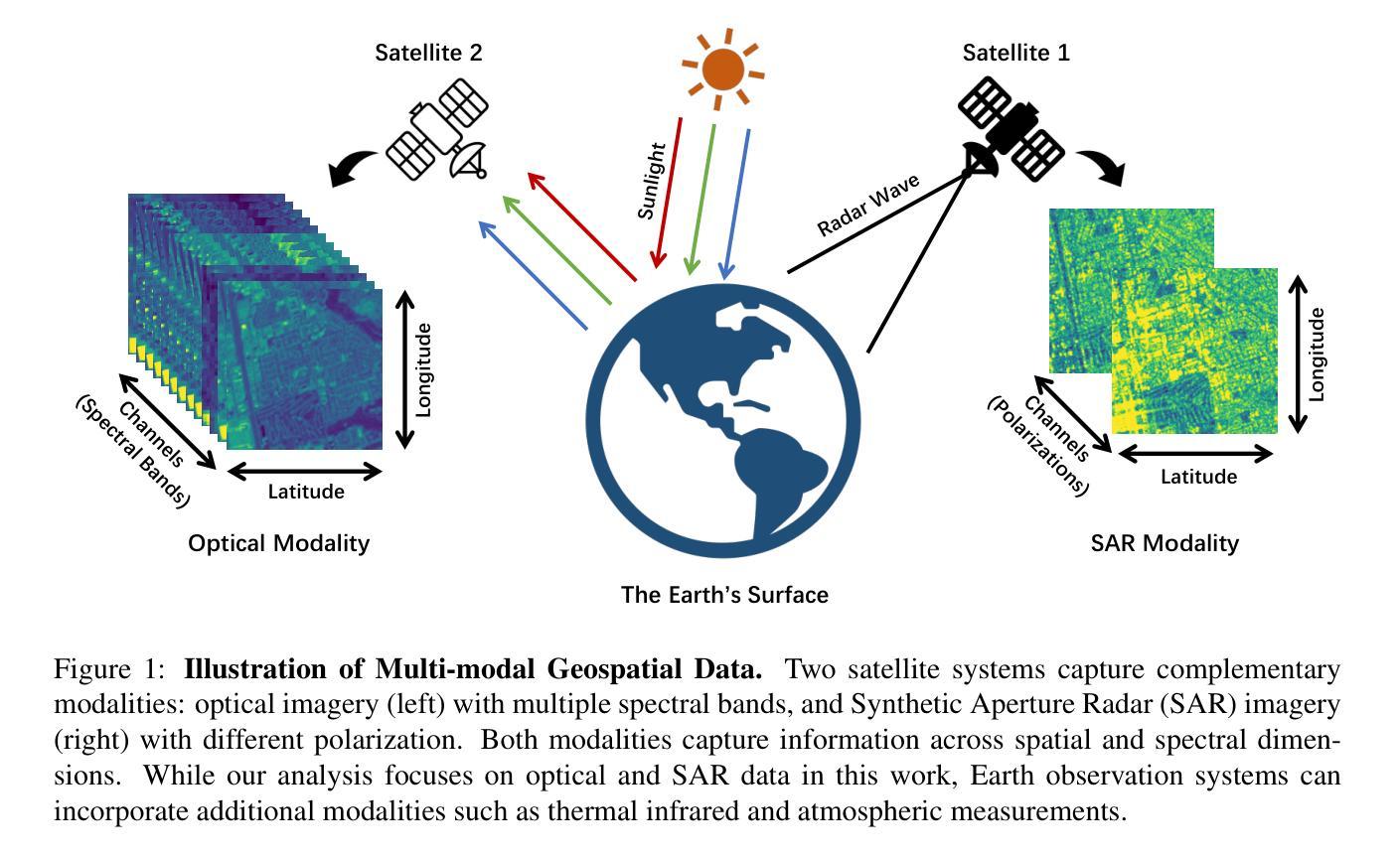
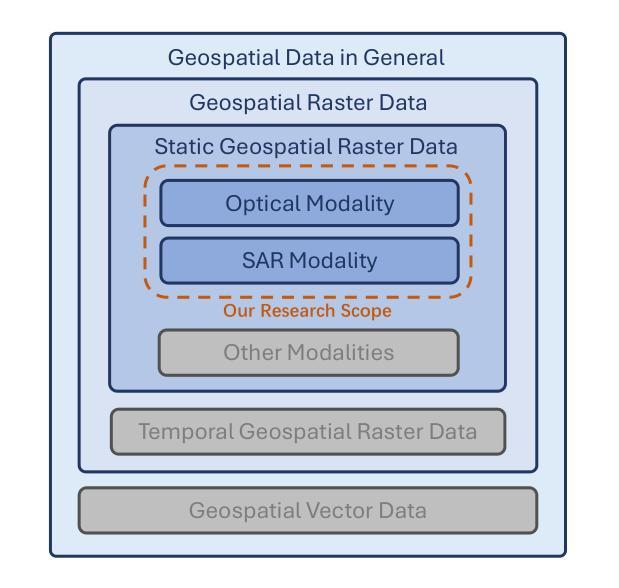
Geospatial raster (imagery) data, such as that collected by satellite-based imaging systems at different times and spectral bands, hold immense potential for enabling a wide range of high-impact applications. This potential stems from the rich information that is spatially and temporally contextualized across multiple channels and sensing modalities. Recent work has adapted existing self-supervised learning approaches for such geospatial data. However, they fall short of scalable model architectures, leading to inflexibility and computational inefficiencies when faced with an increasing number of channels and modalities. To address these limitations, we introduce Low-rank Efficient Spatial-Spectral Vision Transformer (LESS ViT) with three key innovations: i) the LESS Attention Block that approximates high-dimensional spatial-spectral attention through Kronecker’s product of the low-dimensional spatial and spectral attention components; ii) the Continuous Positional-Channel Embedding Layer that preserves both spatial and spectral continuity and physical characteristics of each patch; and iii) the Perception Field Mask that exploits local spatial dependencies by constraining attention to neighboring patches. To evaluate the proposed innovations, we construct a benchmark, GFM-Bench, which serves as a comprehensive benchmark for such geospatial raster data. We pretrain LESS ViT using a Hyperspectral Masked Autoencoder framework with integrated positional and channel masking strategies. Experimental results demonstrate that our proposed method surpasses current state-of-the-art multi-modal geospatial foundation models, achieving superior performance with less computation and fewer parameters. The flexibility and extensibility of our framework make it a promising direction for future geospatial data analysis tasks that involve a wide range of modalities and channels.
地理空间栅格(影像)数据,如由基于卫星的成像系统在不同时间和光谱波段所收集的,对于实现一系列高影响力应用具有巨大潜力。这种潜力来源于多个通道和感知模式之间在空间和时间上的丰富信息上下文。近期的工作已经对现有针对此类地理空间数据的自监督学习方法进行了改进。然而,它们缺乏可扩展的模型架构,在面对日益增长的通道和模式数量时,会导致灵活性不足和计算效率低下。为了克服这些局限性,我们引入了低秩高效空间光谱视觉转换器(LESS ViT),其中包括三项关键创新:一)LESS注意力块通过克罗内克乘积近似高维空间光谱注意力,该乘积是低维空间和光谱注意力组件的乘积;二)连续位置通道嵌入层保留了空间光谱的连续性以及每个补丁的物理特征;三)感知场掩膜通过限制注意力在相邻补丁上,利用局部空间依赖性。为了评估这些创新,我们构建了基准测试GFM-Bench,它是此类地理空间栅格数据的综合基准测试。我们使用具有集成位置和通道掩蔽策略的高光谱掩蔽自动编码器框架对LESS ViT进行预训练。实验结果表明,我们提出的方法超越了当前的多模态地理空间基础模型的最先进水平,在较少的计算和参数下实现了卓越的性能。我们框架的灵活性和可扩展性使其成为涉及广泛模式和通道的未来地理空间数据分析任务的有希望的方向。
论文及项目相关链接
Summary
本文介绍了针对地理空间栅格(影像)数据的新型自监督学习方法。针对现有模型在处理多通道和多模态数据时的不灵活性和计算效率低下问题,提出Low-rank Efficient Spatial-Spectral Vision Transformer(LESS ViT)。该模型包括三个关键创新点:LESS Attention Block、Continuous Positional-Channel Embedding Layer和Perception Field Mask。通过构建GFM-Bench基准测试集和采用Hyperspectral Masked Autoencoder框架进行预训练,实验结果表明该方法优于当前的多模态地理空间基础模型,具有更高的性能和更少的计算及参数需求。该框架具有灵活性和可扩展性,为涉及多种模态和通道的未来地理空间数据分析任务提供了有前景的研究方向。
Key Takeaways
- 地理空间栅格数据具有巨大的潜力,能够支持多种高影响力应用。
- 现有自监督学习方法在处理多通道和多模态的地理空间数据时存在局限性。
- 提出的Low-rank Efficient Spatial-Spectral Vision Transformer(LESS ViT)包含三个关键创新点:LESS Attention Block、Continuous Positional-Channel Embedding Layer和Perception Field Mask。
- GFM-Bench基准测试集用于评估模型性能。
- 采用Hyperspectral Masked Autoencoder框架进行预训练。
- 实验结果表明,该方法优于当前的多模态地理空间基础模型。
点此查看论文截图

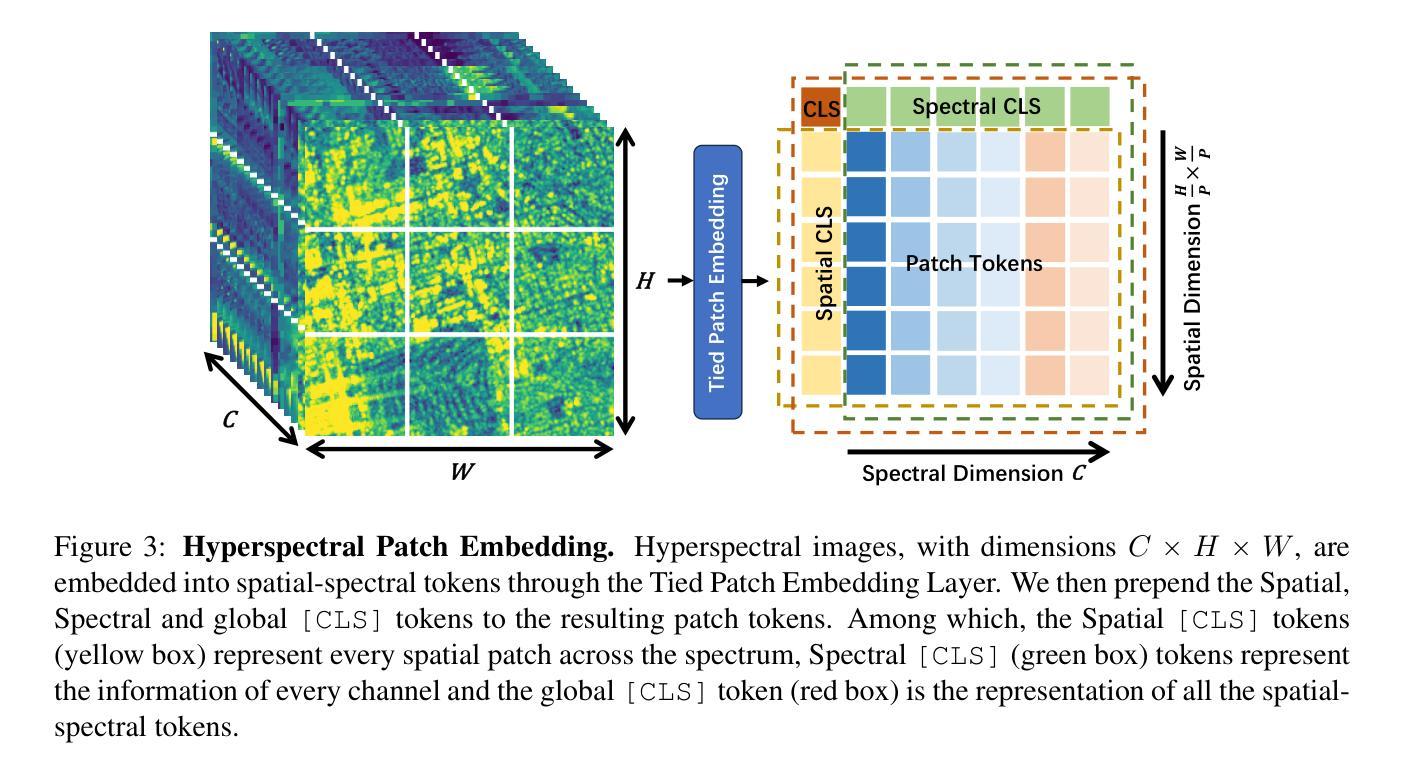
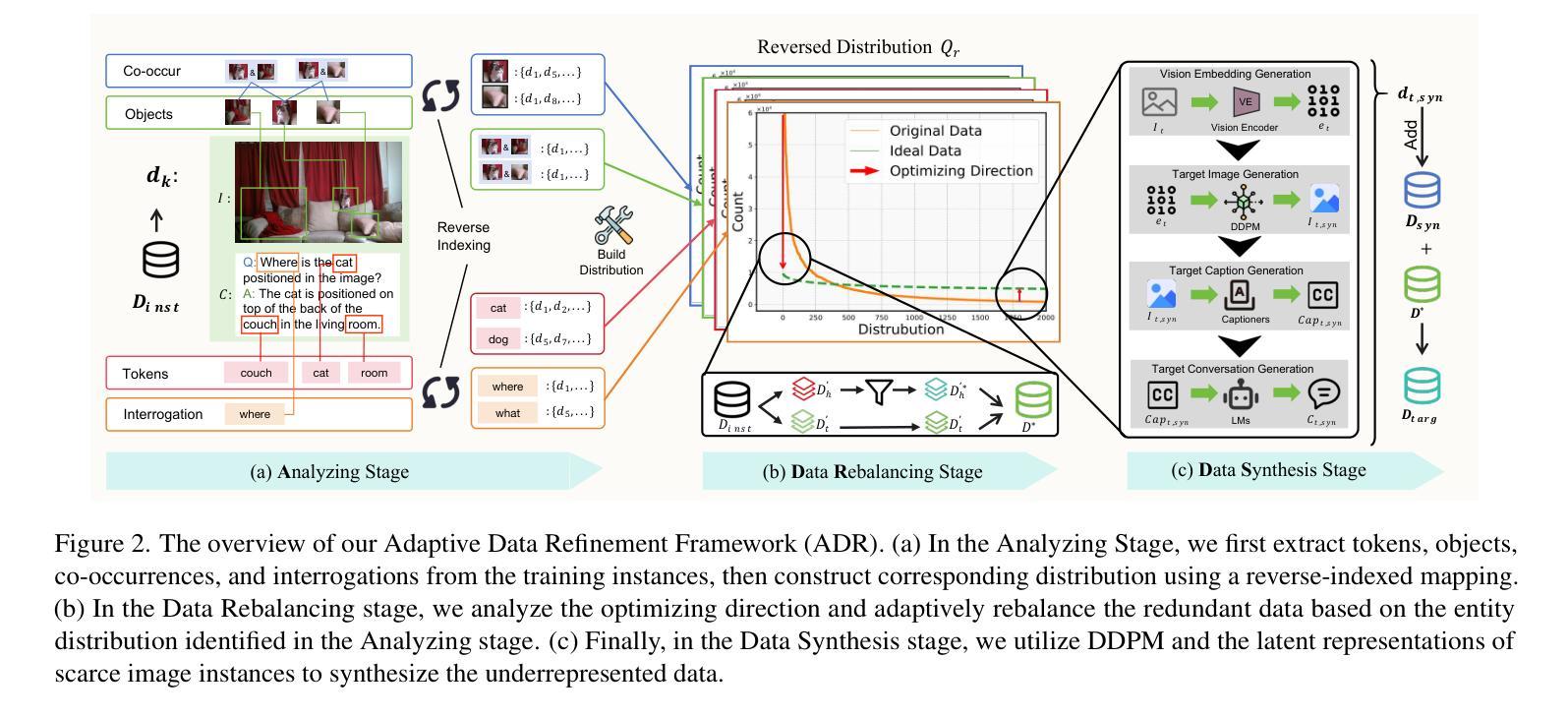
From Head to Tail: Towards Balanced Representation in Large Vision-Language Models through Adaptive Data Calibration
Authors:Mingyang Song, Xiaoye Qu, Jiawei Zhou, Yu Cheng
Large Vision-Language Models (LVLMs) have achieved significant progress in combining visual comprehension with language generation. Despite this success, the training data of LVLMs still suffers from Long-Tail (LT) problems, where the data distribution is highly imbalanced. Previous works have mainly focused on traditional VLM architectures, i.e., CLIP or ViT, and specific tasks such as recognition and classification. Nevertheless, the exploration of LVLM (e.g. LLaVA) and more general tasks (e.g. Visual Question Answering and Visual Reasoning) remains under-explored. In this paper, we first conduct an in-depth analysis of the LT issues in LVLMs and identify two core causes: the overrepresentation of head concepts and the underrepresentation of tail concepts. Based on the above observation, we propose an $\textbf{A}$daptive $\textbf{D}$ata $\textbf{R}$efinement Framework ($\textbf{ADR}$), which consists of two stages: $\textbf{D}$ata $\textbf{R}$ebalancing ($\textbf{DR}$) and $\textbf{D}$ata $\textbf{S}$ynthesis ($\textbf{DS}$). In the DR stage, we adaptively rebalance the redundant data based on entity distributions, while in the DS stage, we leverage Denoising Diffusion Probabilistic Models (DDPMs) and scarce images to supplement underrepresented portions. Through comprehensive evaluations across eleven benchmarks, our proposed ADR effectively mitigates the long-tail problem in the training data, improving the average performance of LLaVA 1.5 relatively by 4.36%, without increasing the training data volume.
大型视觉语言模型(LVLMs)在结合视觉理解与语言生成方面取得了显著进展。然而,尽管取得了成功,LVLM的训练数据仍然面临长尾(LT)问题,即数据分布极度不平衡。之前的研究主要关注传统的VLM架构,例如CLIP或ViT,以及特定的任务,如识别和分类。然而,对于LVLM(例如LLaVA)和更一般的任务(例如视觉问答和视觉推理)的探索仍然不足。在本文中,我们首先对LVLM中的LT问题进行了深入分析,并确定了两个核心原因:头部概念的过度表示和尾部概念的表示不足。基于上述观察,我们提出了一个自适应数据细化框架(ADR),它分为两个阶段:数据再平衡(DR)和数据合成(DS)。在DR阶段,我们根据实体分布自适应地重新平衡冗余数据,而在DS阶段,我们利用去噪扩散概率模型(DDPMs)和稀缺图像来补充表示不足的部分。通过十一个基准的全面评估,我们提出的ADR有效地缓解了训练数据中的长尾问题,在不增加训练数据量的情况下,相对提高了LLaVA 1.5的平均性能4.36%。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文深入探讨了大型视觉语言模型(LVLMs)面临的Long-Tail(LT)问题,并指出其两大核心原因:头部概念的过度表示和尾部概念的表示不足。为此,本文提出了自适应数据优化框架(ADR),包括数据再平衡(DR)和数据合成(DS)两个阶段。通过全面评估,ADR框架有效地缓解了训练数据中的长尾问题,提高了LLaVA 1.5的平均性能。
Key Takeaways
- LVLMs虽在视觉理解和语言生成结合方面取得显著进展,但其训练数据仍面临Long-Tail(LT)问题,即数据分布极度不均衡。
- LT问题的两大核心原因是头部概念的过度表示和尾部概念的表示不足。
- 本文提出了自适应数据优化框架(ADR),包括数据再平衡(DR)和数据合成(DS)两个阶段,以解决LT问题。
- 在DR阶段,根据实体分布自适应地重新平衡数据。
- 在DS阶段,利用去噪扩散概率模型(DDPMs)和稀缺图像来补充表示不足的部分。
- 通过对十一个基准的全面评估,ADR框架有效地缓解了训练数据中的长尾问题。
点此查看论文截图

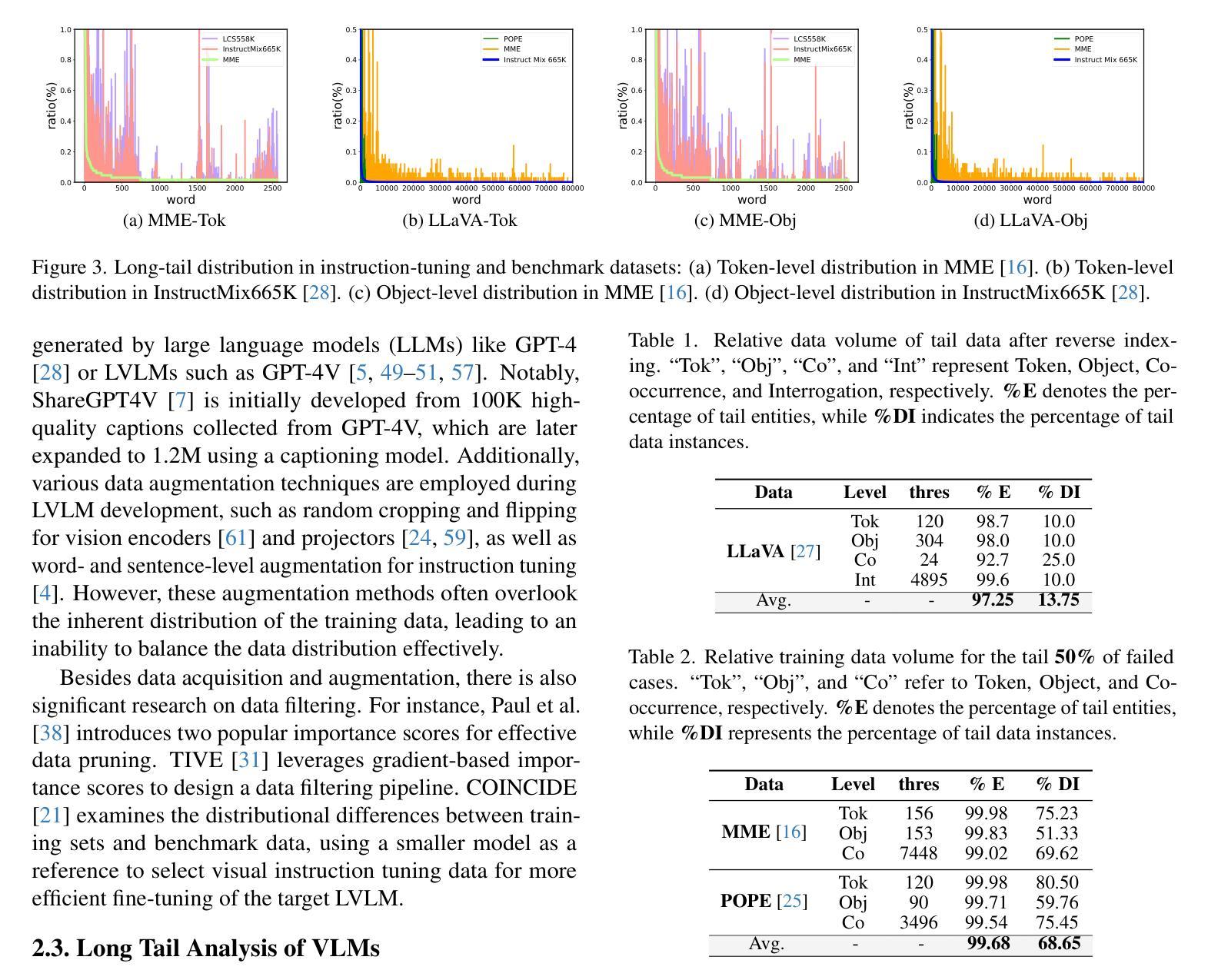
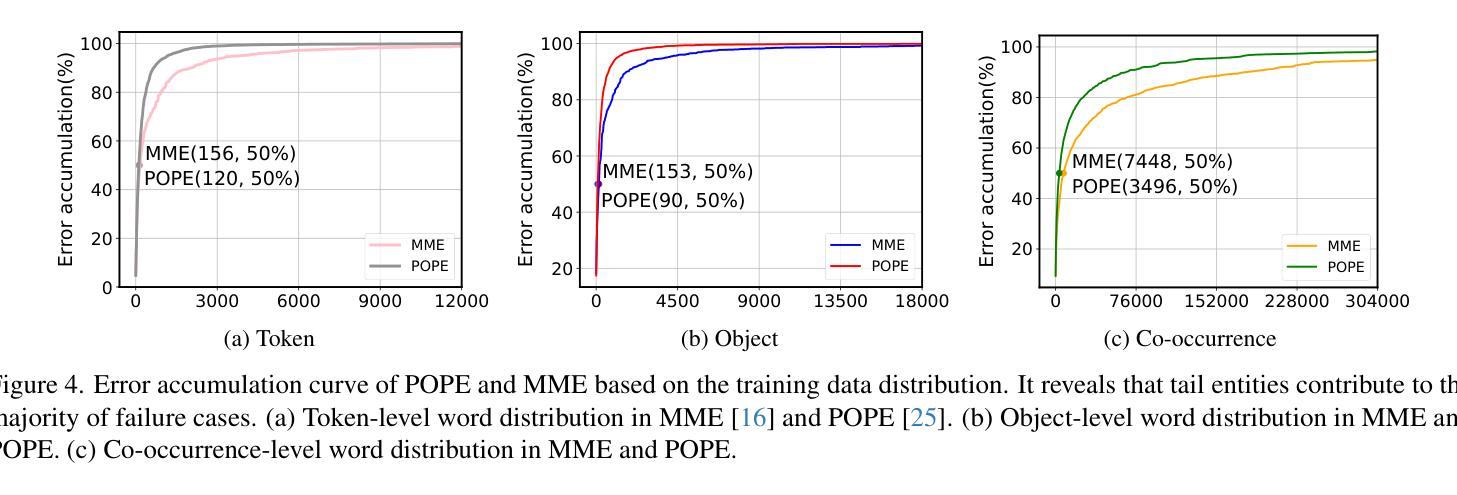
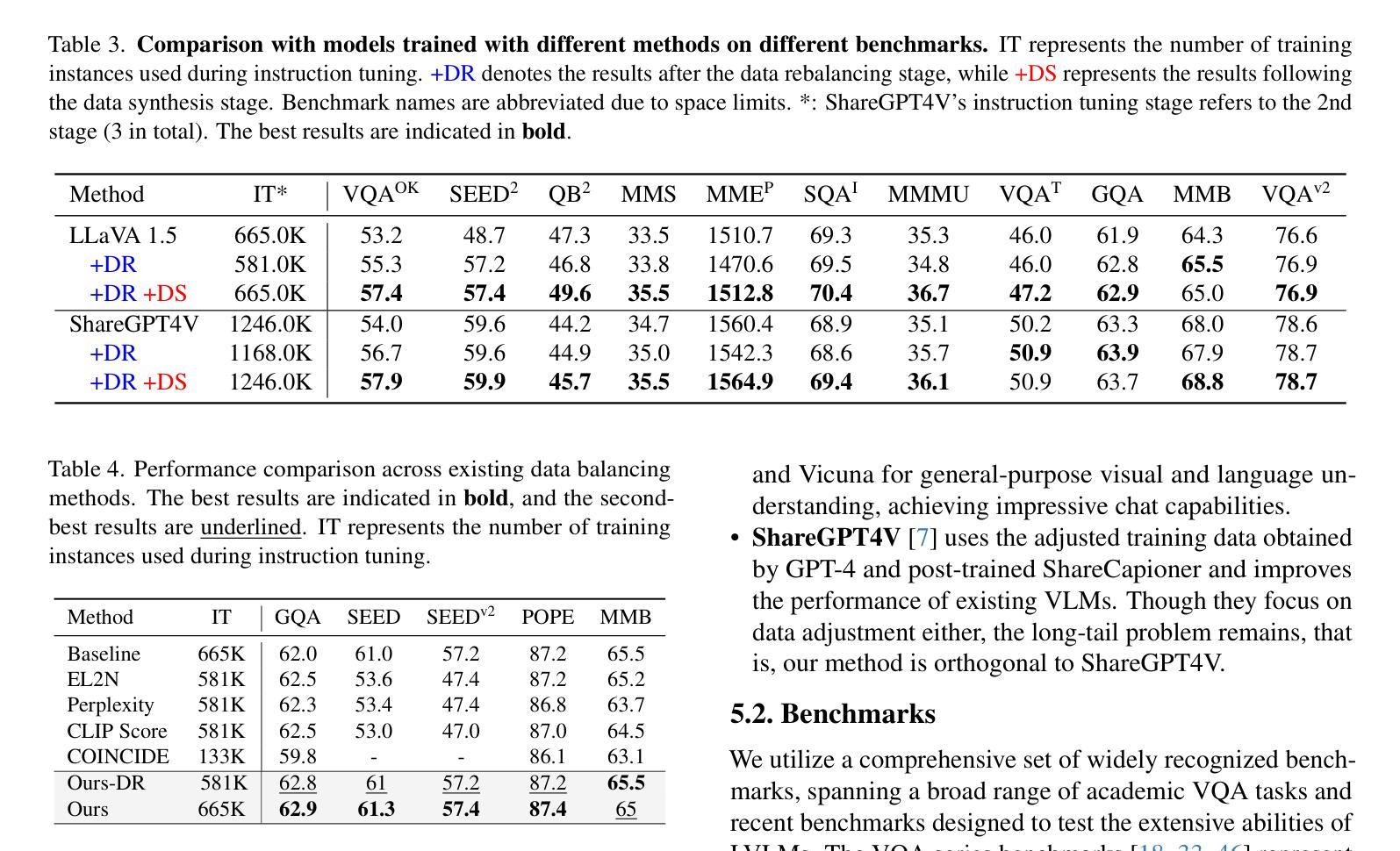
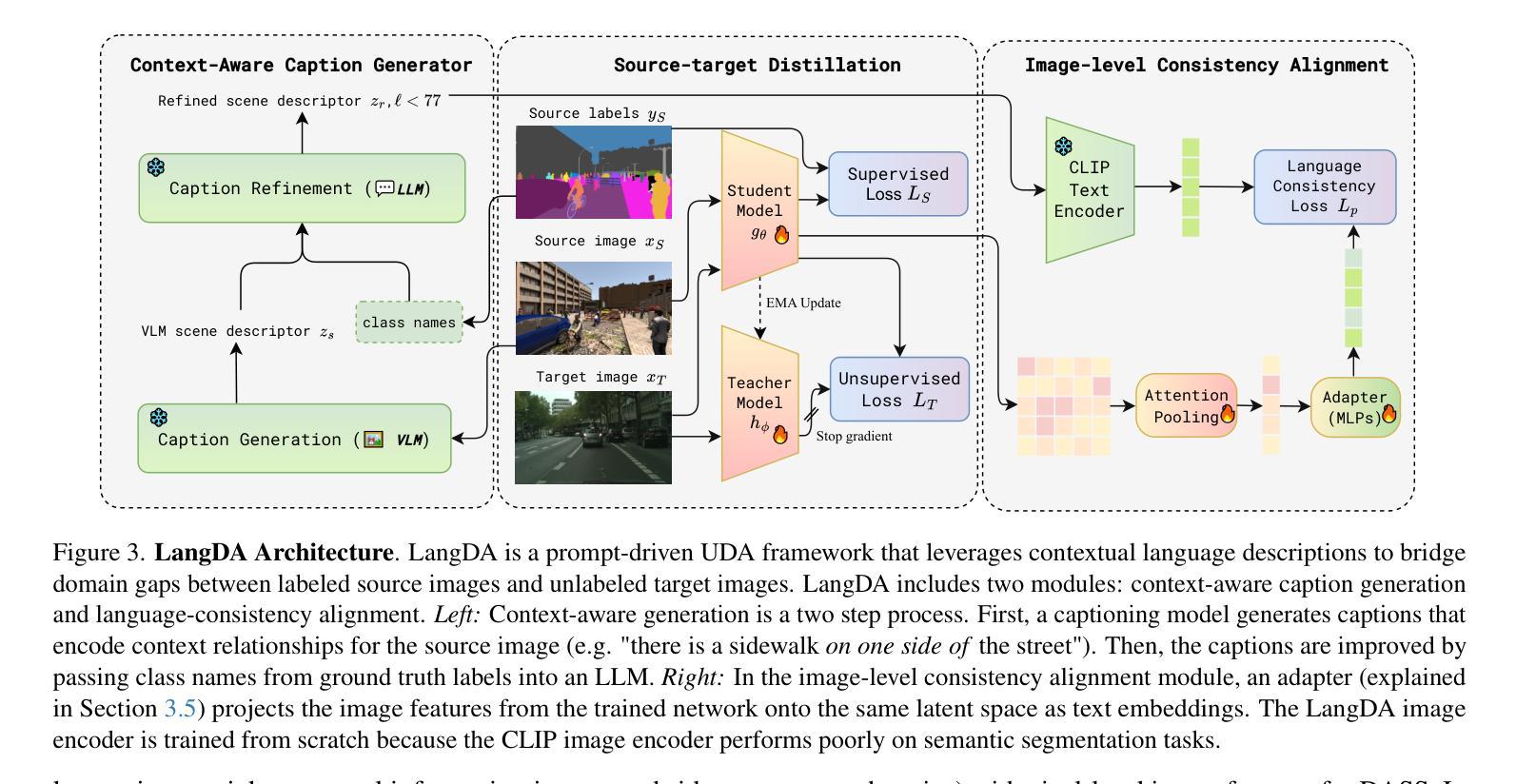
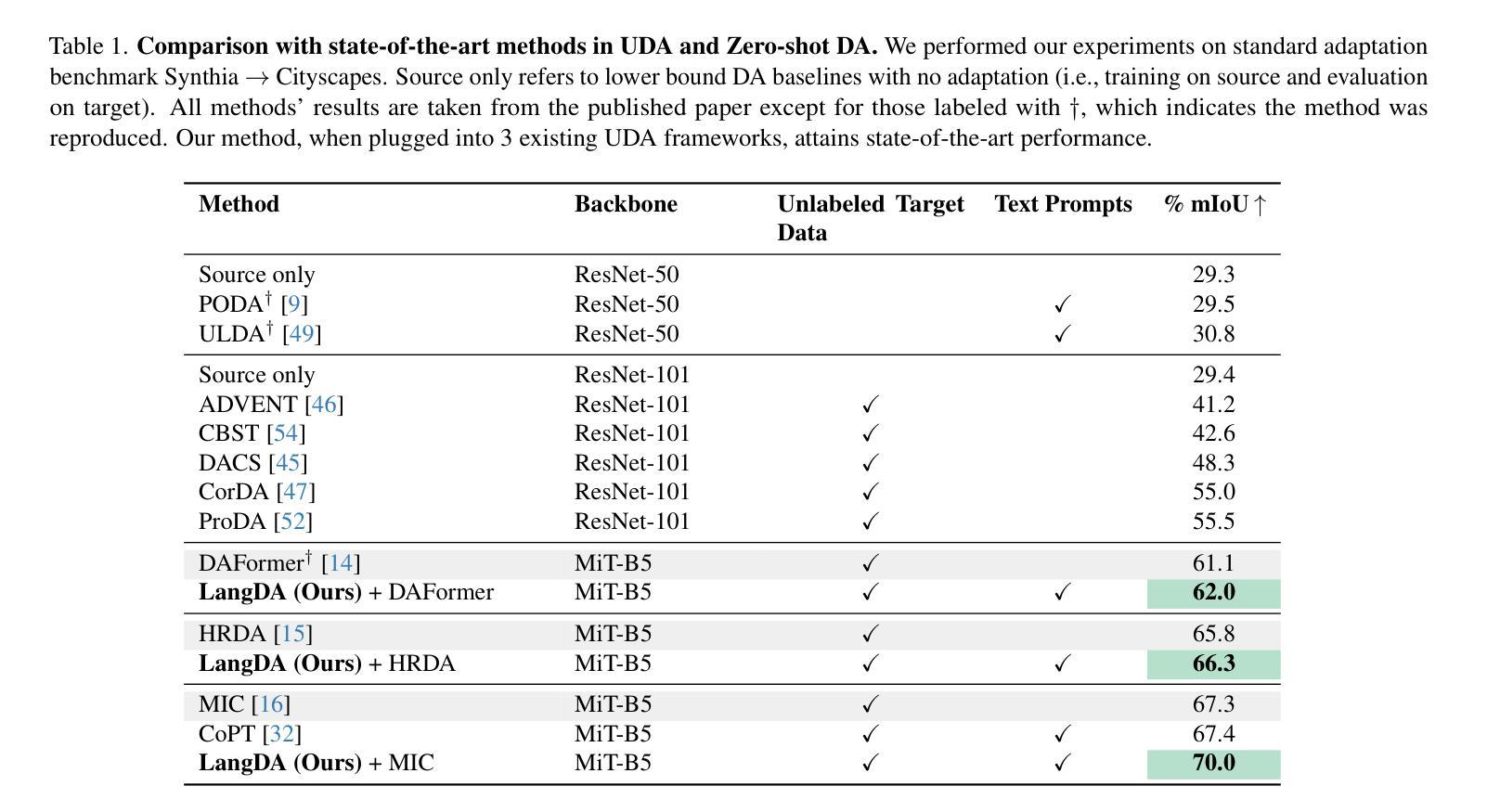
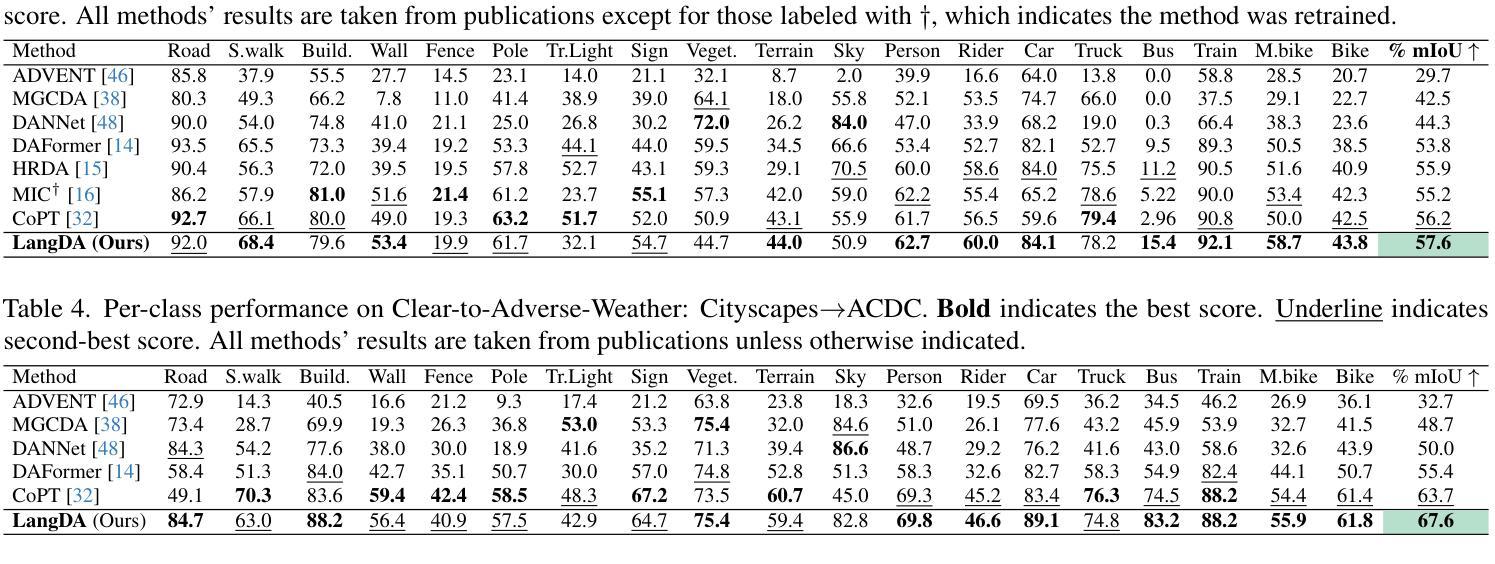
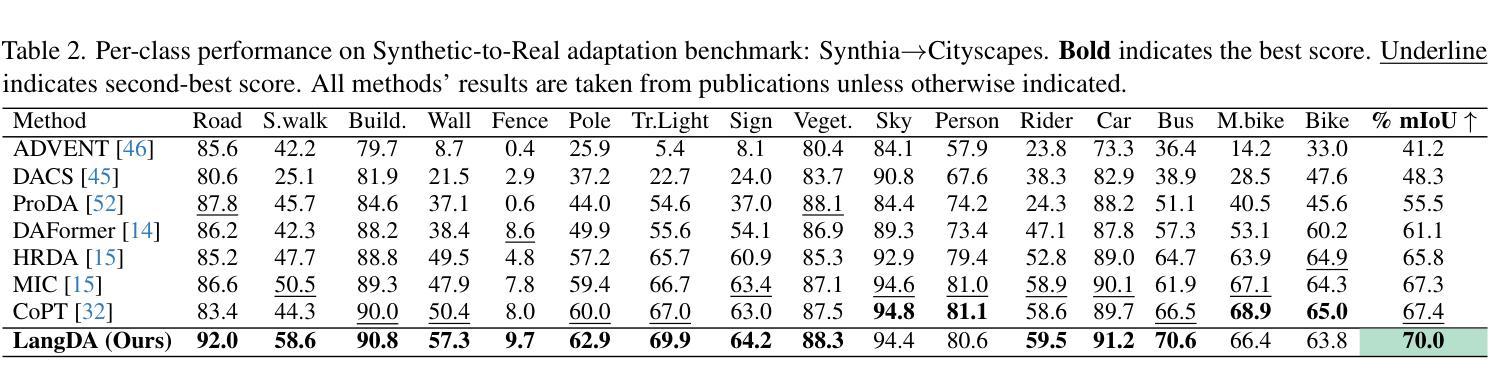
LangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Authors:Chang Liu, Bavesh Balaji, Saad Hossain, C Thomas, Kwei-Herng Lai, Raviteja Vemulapalli, Alexander Wong, Sirisha Rambhatla
Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. “a {snowy} photo of a {class}”). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects – key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. “a pedestrian is on the sidewalk, and the street is lined with buildings.”). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
无监督领域自适应语义分割(DASS)旨在将从标签丰富的源域转移知识到无标签的目标域。DASS中的两种主要方法是(1)仅使用视觉的方法,通过遮挡或多分辨率裁剪,以及(2)基于语言的方法,使用由目标域指导的通用类别提示(例如,“一个{雪覆盖的}照片中的{类别}”)。然而,前者容易受到偏向源域的噪声伪标签的影响。后者则没有完全捕捉到物体的复杂空间关系,这对于密集预测任务至关重要。为此,我们提出了LangDA。LangDA通过以下方式解决这些挑战:首先,通过VLM生成的场景描述学习物体之间的上下文关系(例如,“行人在人行道上,街道两旁是建筑物。”);其次,LangDA将整幅图像的特征与这种上下文感知的场景字幕的文本表示对齐,并通过文本学习通用表示。因此,LangDA在三个DASS基准测试中创下了新的最高纪录,较现有方法提高了2.6%、1.4%和3.9%。
论文及项目相关链接
Summary
本文介绍了无监督域自适应语义分割(DASS)的任务是将丰富的标签源域知识迁移到无标签的目标域中。文中提出两种关键方法:仅视觉的方法和基于语言的方法。然而,仅视觉的方法易受源域噪声伪标签的影响,而基于语言的方法无法完全捕捉对象的复杂空间关系,这对密集预测任务至关重要。为解决这些问题,本文提出了LangDA方法。它通过利用VLM生成的场景描述来学习对象之间的上下文关系,并通过与整个图像特征的文本表示对齐来学习通用表示。因此,LangDA在三个DASS基准测试中均达到了最新水平,分别比现有方法高出2.6%、1.4%和3.9%。
Key Takeaways
- DASS旨在从标签丰富的源域迁移到无标签的目标域。
- 当前两种方法——视觉方法和基于语言的方法——存在局限性。
- 视觉方法易受源域噪声伪标签影响。
- 基于语言的方法无法完全捕捉对象的复杂空间关系。
- LangDA方法通过学习对象间的上下文关系来解决这些问题。
- LangDA利用VLM生成的场景描述与图像特征对齐来学习通用表示。
点此查看论文截图


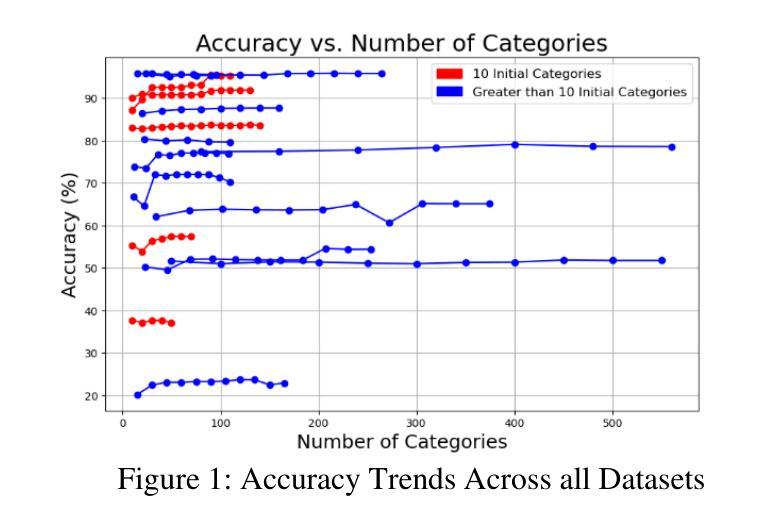
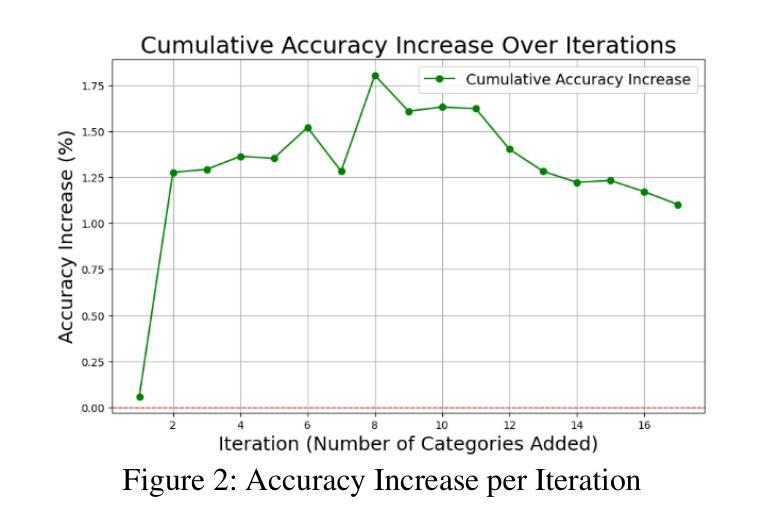
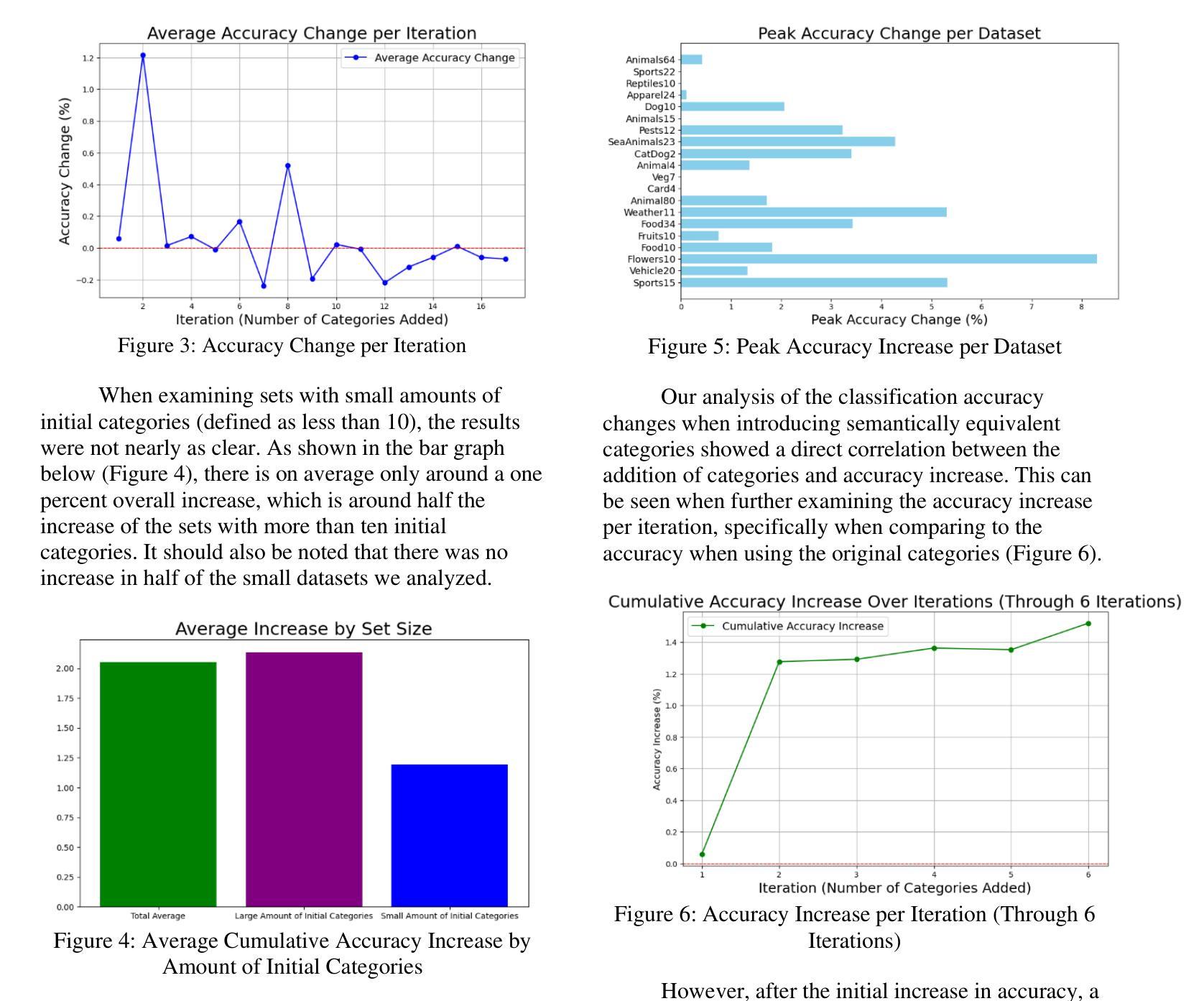
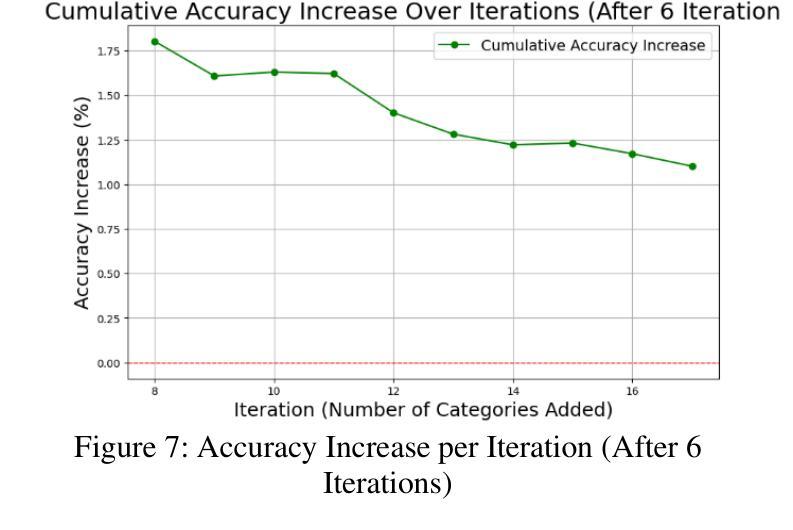
Scaling Semantic Categories: Investigating the Impact on Vision Transformer Labeling Performance
Authors:Anthony Lamelas, Harrison Muchnic
This study explores the impact of scaling semantic categories on the image classification performance of vision transformers (ViTs). In this specific case, the CLIP server provided by Jina AI is used for experimentation. The research hypothesizes that as the number of ground truth and artificially introduced semantically equivalent categories increases, the labeling accuracy of ViTs improves until a theoretical maximum or limit is reached. A wide variety of image datasets were chosen to test this hypothesis. These datasets were processed through a custom function in Python designed to evaluate the model’s accuracy, with adjustments being made to account for format differences between datasets. By exponentially introducing new redundant categories, the experiment assessed accuracy trends until they plateaued, decreased, or fluctuated inconsistently. The findings show that while semantic scaling initially increases model performance, the benefits diminish or reverse after surpassing a critical threshold, providing insight into the limitations and possible optimization of category labeling strategies for ViTs.
本研究探讨了扩展语义类别对视觉变压器(ViTs)图像分类性能的影响。在这个特定案例中,实验使用的是Jina AI提供的CLIP服务器。研究假设随着真实和人为引入的语义等价类别的数量增加,ViTs的标签精度会提高,直到达到理论上的最大值或极限。为了测试这个假设,选择了各种各样的图像数据集。这些数据集通过Python中的自定义函数进行处理,以评估模型的准确性,并对数据集格式差异进行了调整。通过指数方式引入新的冗余类别,实验评估了准确性趋势,直到它们达到平稳状态、下降或波动不一致。研究结果表明,虽然语义缩放最初提高了模型性能,但在超过临界阈值后,这些好处会减少或消失,这为理解ViTs类别标签策略的限制和可能的优化提供了洞见。
论文及项目相关链接
PDF 4 pages, 7 figures, submitted to CVPR (feedback pending)
Summary
本研究探讨了扩展语义类别对视觉转换器(ViTs)图像分类性能的影响。研究假设随着地面真实和人为引入的语义上等价类别的数量增加,ViTs的标签精度会提高,直到达到理论上的最大值或限制。实验结果显示,虽然语义缩放最初能提高模型性能,但在超过某个临界阈值后,其优势会减弱或逆转,这为ViTs类别标注策略的局限性和可能优化提供了见解。
Key Takeaways
- 研究探索了语义类别规模对视觉转换器(ViTs)图像分类性能的影响。
- 实验使用了Jina AI提供的CLIP服务器。
- 研究假设随着语义等价类别的增加,ViTs的标签精度会提高,直至达到某一理论极限。
- 使用了多种图像数据集进行测试,并通过自定义的Python函数来评估模型精度。
- 实验通过引入新的冗余类别来评估精度趋势,直至其达到平稳、下降或波动不一致的状态。
- 研究发现,语义缩放虽然最初能提高模型性能,但超过某个阈值后效果减弱或反转。
点此查看论文截图

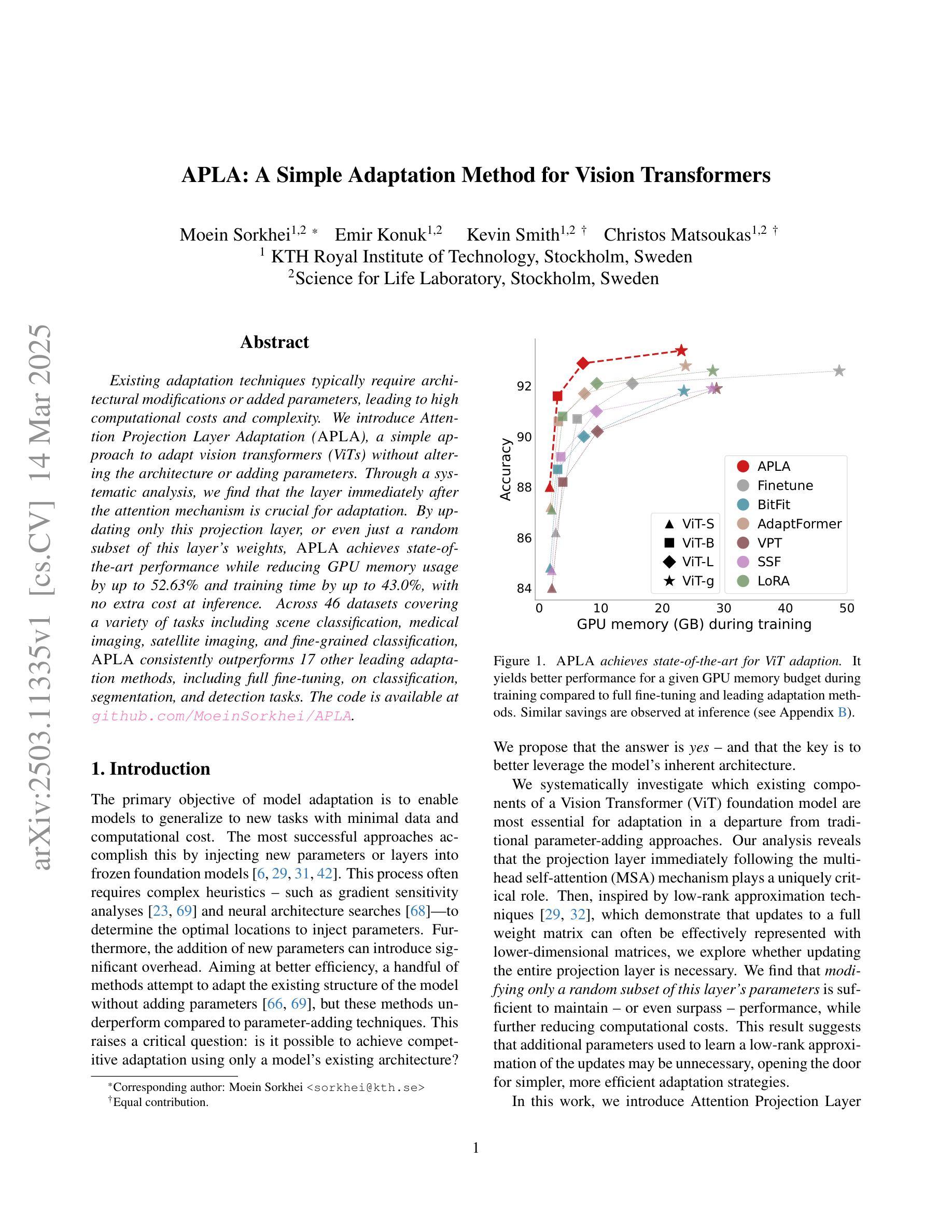
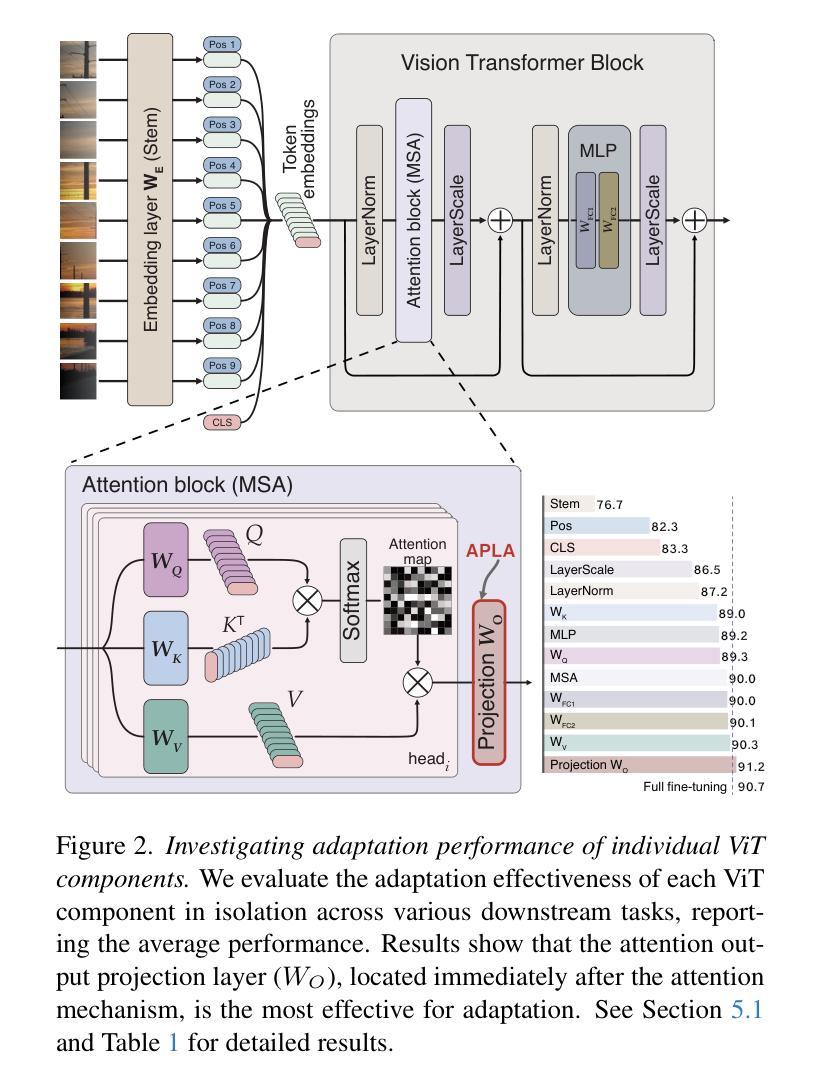
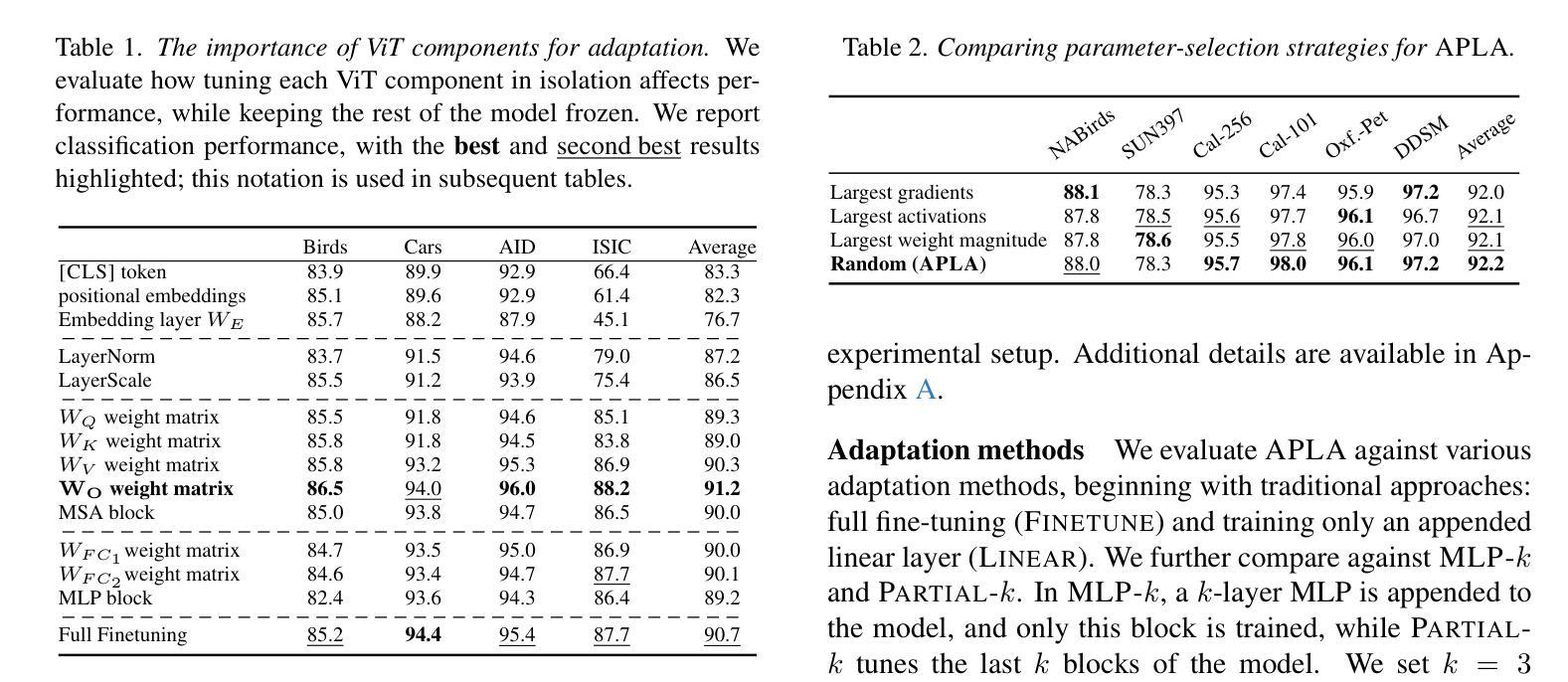
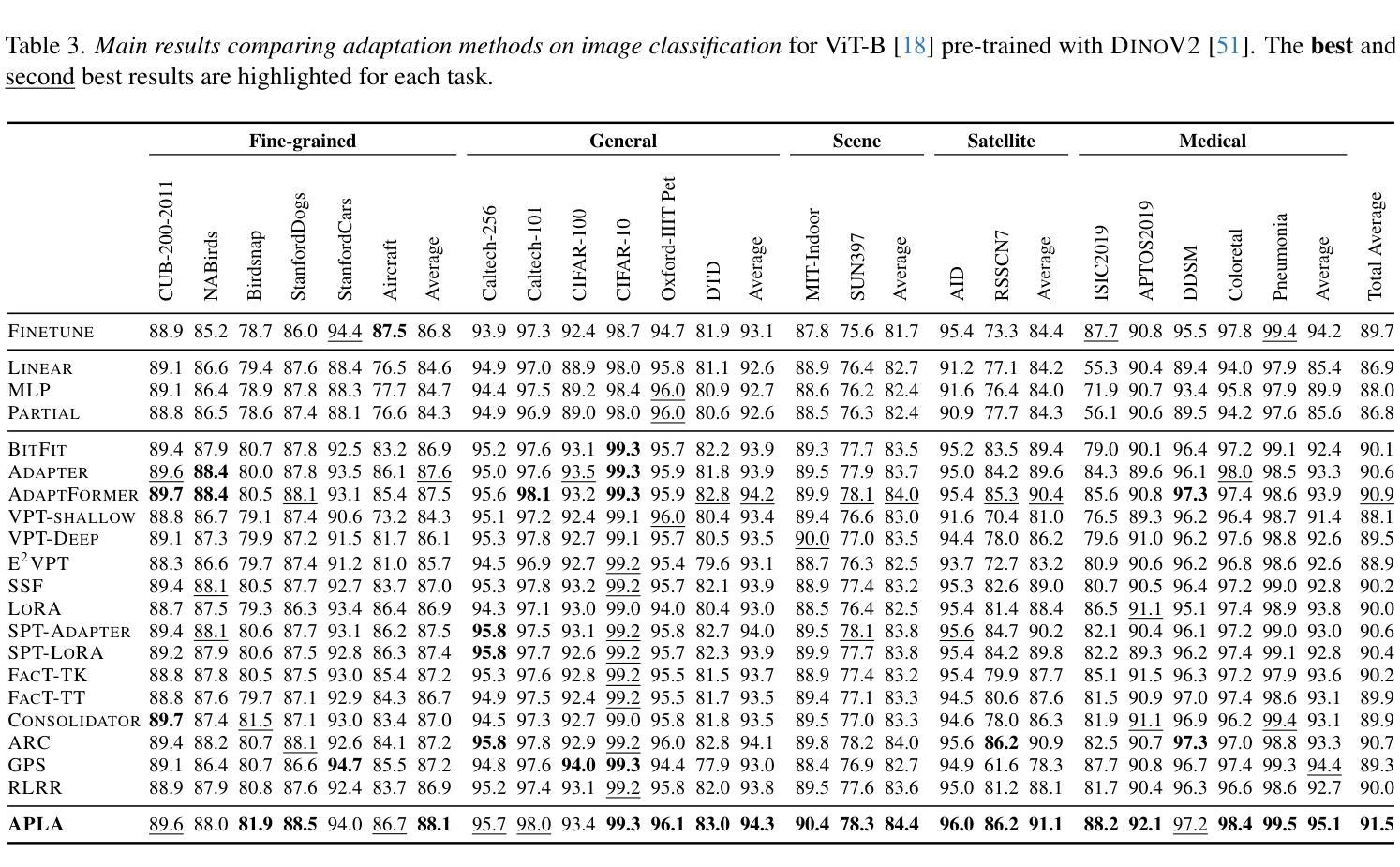
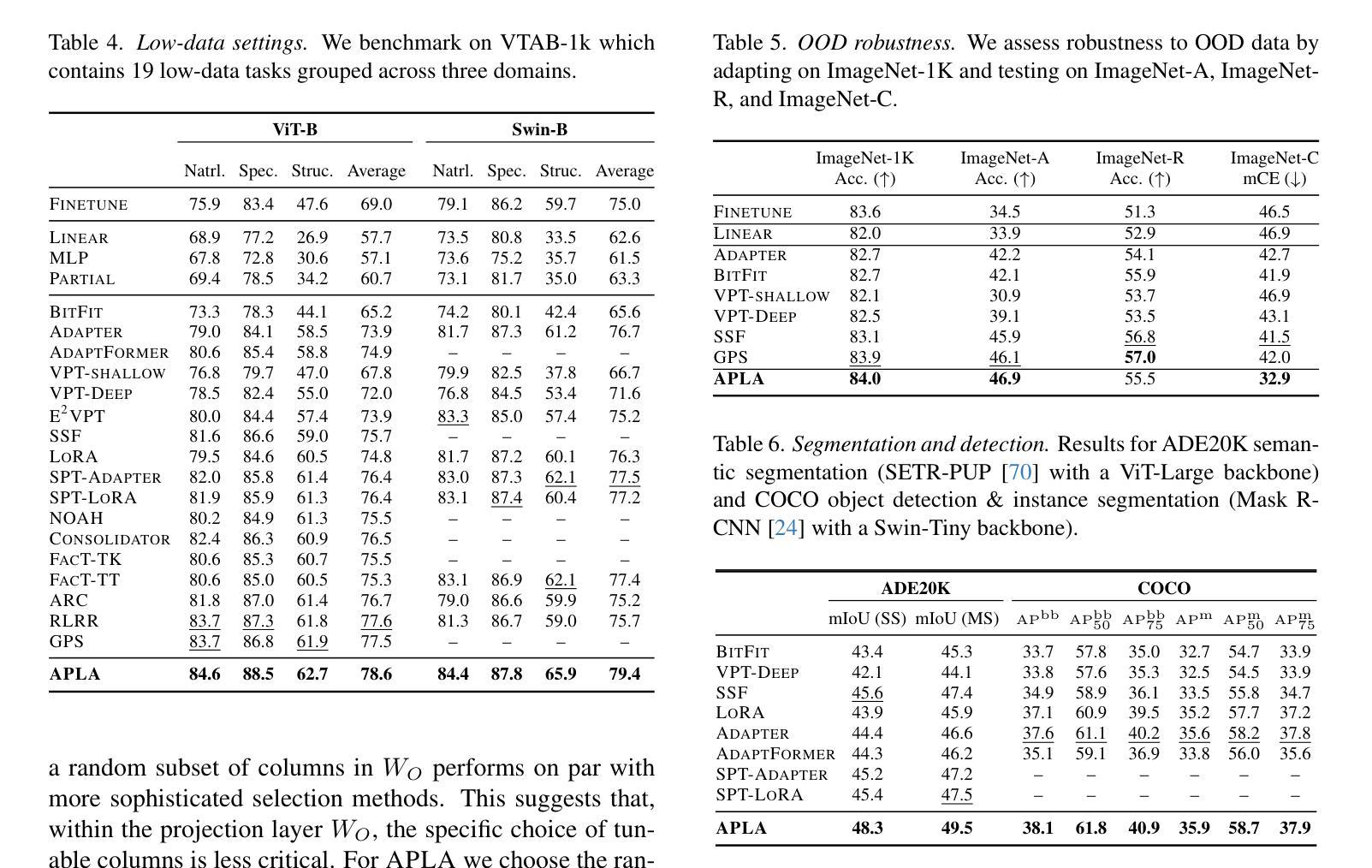
APLA: A Simple Adaptation Method for Vision Transformers
Authors:Moein Sorkhei, Emir Konuk, Kevin Smith, Christos Matsoukas
Existing adaptation techniques typically require architectural modifications or added parameters, leading to high computational costs and complexity. We introduce Attention Projection Layer Adaptation (APLA), a simple approach to adapt vision transformers (ViTs) without altering the architecture or adding parameters. Through a systematic analysis, we find that the layer immediately after the attention mechanism is crucial for adaptation. By updating only this projection layer, or even just a random subset of this layer’s weights, APLA achieves state-of-the-art performance while reducing GPU memory usage by up to 52.63% and training time by up to 43.0%, with no extra cost at inference. Across 46 datasets covering a variety of tasks including scene classification, medical imaging, satellite imaging, and fine-grained classification, APLA consistently outperforms 17 other leading adaptation methods, including full fine-tuning, on classification, segmentation, and detection tasks. The code is available at https://github.com/MoeinSorkhei/APLA.
现有的自适应技术通常需要修改架构或增加参数,导致计算成本较高且复杂性增加。我们引入了注意力投影层自适应(APLA)方法,这是一种无需改变架构或增加参数即可适应视觉变压器(ViTs)的简单方法。通过系统分析,我们发现注意力机制之后的那一层对于自适应至关重要。通过仅更新此投影层,甚至只是更新该层权重的随机子集,APLA在降低GPU内存使用率高达52.63%和训练时间高达43.0%的同时,实现了最先进的性能表现,且推理阶段无需额外成本。在涵盖场景分类、医学影像、卫星成像和细粒度分类等任务的46个数据集上,APLA在分类、分割和检测任务上均优于包括完全微调在内的其他17种主流自适应方法。相关代码可通过https://github.com/MoeinSorkhei/APLA访问。
论文及项目相关链接
Summary
本文提出了一种名为Attention Projection Layer Adaptation(APLA)的方法,可在不改变架构或增加参数的情况下适应视觉转换器(ViTs)。通过更新注意力机制后的关键层或该层权重的随机子集,APLA实现了卓越的性能,同时降低了GPU内存使用率和训练时间。在多个数据集上,APLA在分类、分割和检测任务上均优于其他17种主流适应方法。
Key Takeaways
- APLA是一种适应视觉转换器(ViTs)的新方法,无需修改架构或增加参数。
- 通过对注意力机制后的关键层进行系统分析,发现该层对于适应非常重要。
- 通过更新此关键投影层或其部分权重,APLA可实现卓越性能。
- APLA显著降低了GPU内存使用率和训练时间。
- APLA在多个数据集上的分类、分割和检测任务上均优于其他主流适应方法。
- APLA的代码已公开发布,便于其他研究者使用。
点此查看论文截图
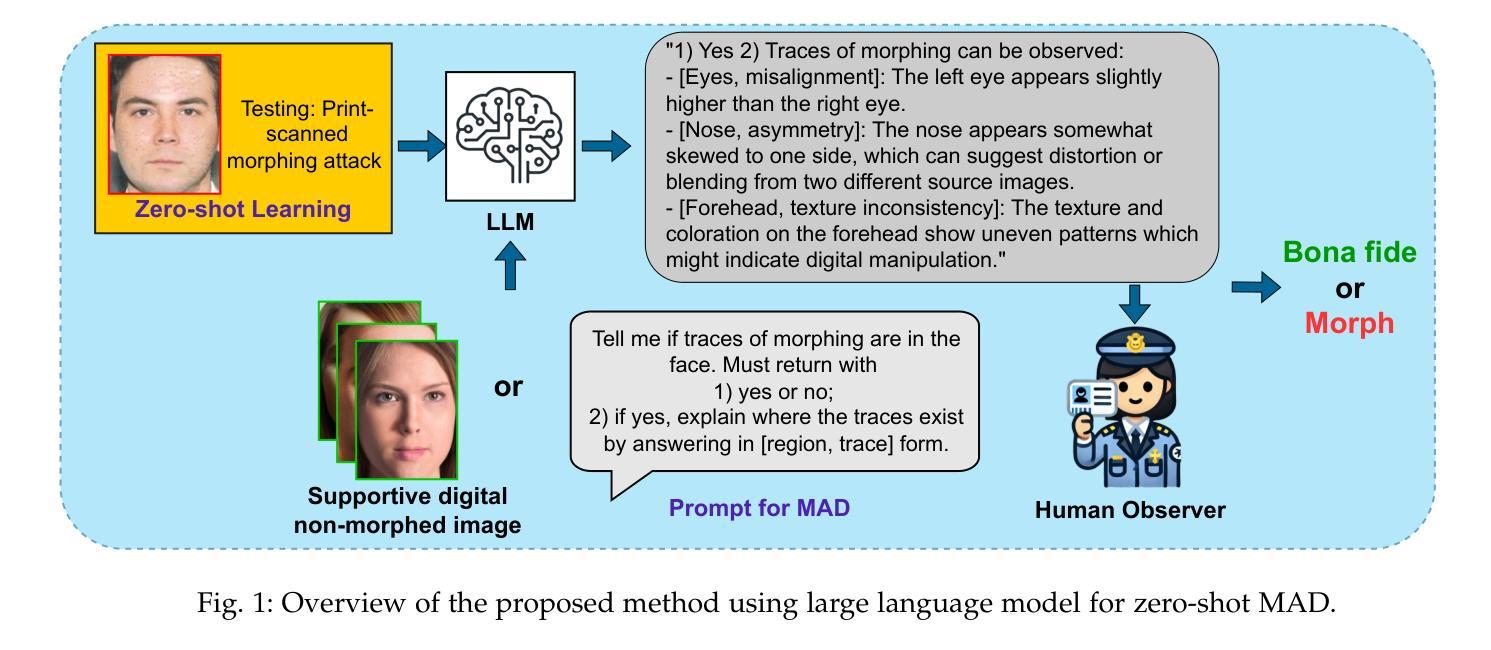
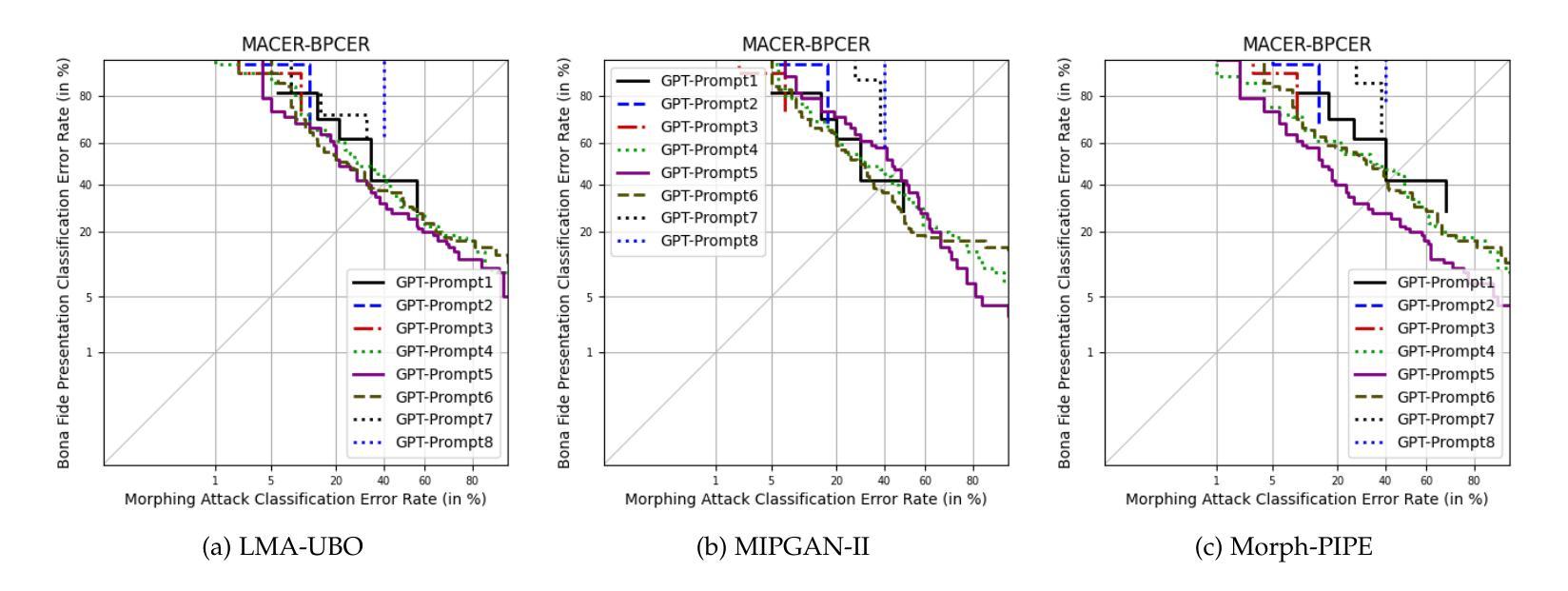
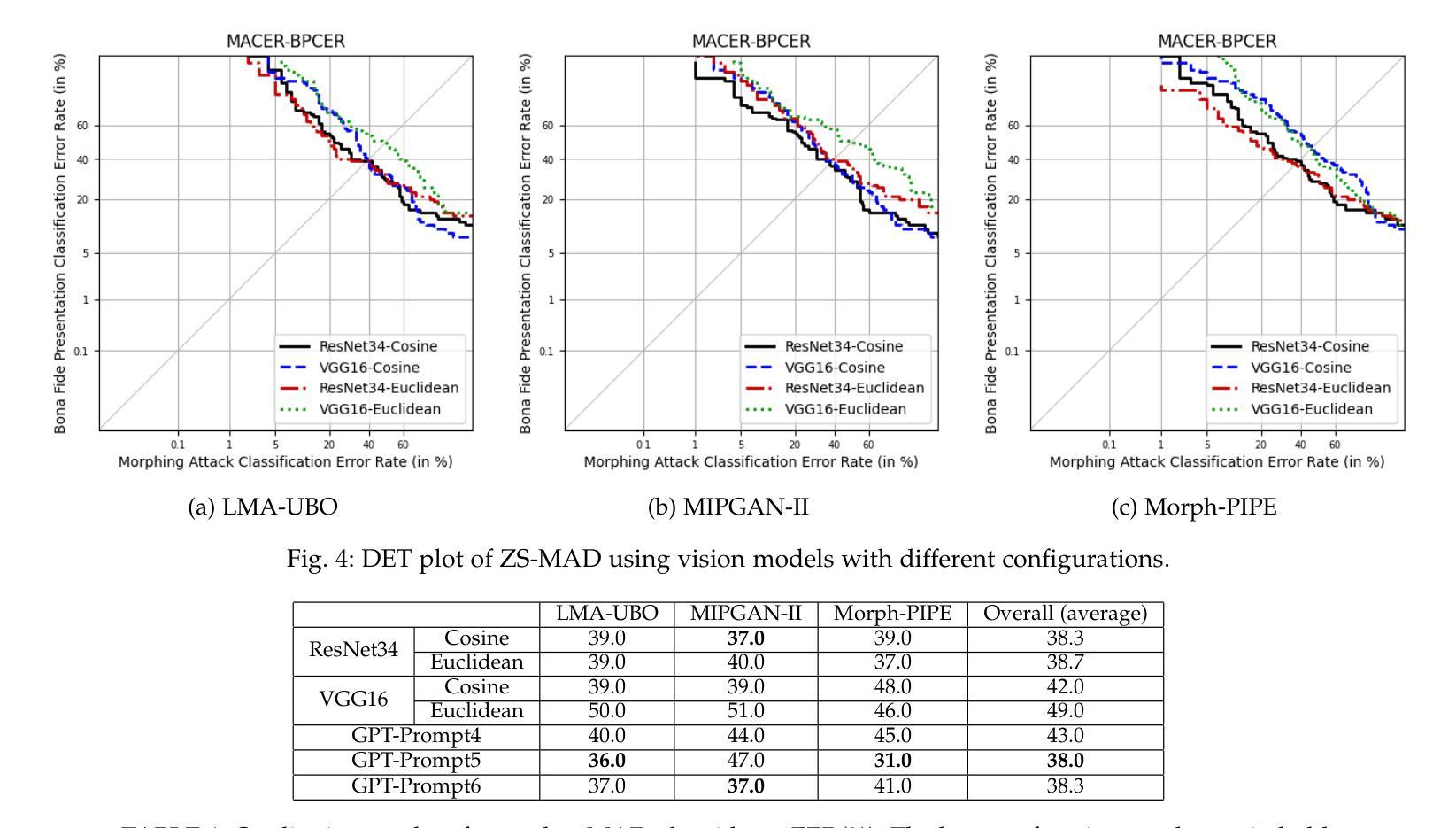
ChatGPT Encounters Morphing Attack Detection: Zero-Shot MAD with Multi-Modal Large Language Models and General Vision Models
Authors:Haoyu Zhang, Raghavendra Ramachandra, Kiran Raja, Christoph Busch
Face Recognition Systems (FRS) are increasingly vulnerable to face-morphing attacks, prompting the development of Morphing Attack Detection (MAD) algorithms. However, a key challenge in MAD lies in its limited generalizability to unseen data and its lack of explainability-critical for practical application environments such as enrolment stations and automated border control systems. Recognizing that most existing MAD algorithms rely on supervised learning paradigms, this work explores a novel approach to MAD using zero-shot learning leveraged on Large Language Models (LLMs). We propose two types of zero-shot MAD algorithms: one leveraging general vision models and the other utilizing multimodal LLMs. For general vision models, we address the MAD task by computing the mean support embedding of an independent support set without using morphed images. For the LLM-based approach, we employ the state-of-the-art GPT-4 Turbo API with carefully crafted prompts. To evaluate the feasibility of zero-shot MAD and the effectiveness of the proposed methods, we constructed a print-scan morph dataset featuring various unseen morphing algorithms, simulating challenging real-world application scenarios. Experimental results demonstrated notable detection accuracy, validating the applicability of zero-shot learning for MAD tasks. Additionally, our investigation into LLM-based MAD revealed that multimodal LLMs, such as ChatGPT, exhibit remarkable generalizability to untrained MAD tasks. Furthermore, they possess a unique ability to provide explanations and guidance, which can enhance transparency and usability for end-users in practical applications.
人脸识别系统(FRS)越来越容易受到人脸变形攻击的影响,这促使了变形攻击检测(MAD)算法的发展。然而,MAD面临的关键挑战在于其有限的未见数据泛化能力和缺乏解释性,这在入学注册站和自动化边境控制系统等实际应用环境中至关重要。
论文及项目相关链接
摘要
人脸识别系统(FRS)越来越容易受到人脸识别篡改攻击的影响,因此出现了篡改攻击检测(MAD)算法的发展。然而,MAD面临的关键挑战在于其对新数据的有限泛化能力以及缺乏解释性,这在入站站和自动化边境控制系统等实际应用环境中至关重要。鉴于大多数现有MAD算法都依赖于监督学习模式,本文探索了一种利用大型语言模型(LLM)的零样本学习来进行MAD的新方法。我们提出了两种零样本MAD算法:一种利用通用视觉模型,另一种利用多模态LLM。对于通用视觉模型,我们通过计算独立支持集的均值支持嵌入来解决MAD任务,而无需使用经过修改的图像。对于基于LLM的方法,我们采用了最先进的GPT-4 Turbo API并精心设计了提示。为了评估零样本MAD的可行性和所提方法的有效性,我们构建了一个包含各种未见过的篡改算法的打印扫描形态数据集,模拟具有挑战性的现实世界应用场景。实验结果表明检测精度显著,验证了零样本学习在MAD任务中的适用性。此外,我们对基于LLM的MAD的研究表明,如ChatGPT等多模态LLM在未经训练的MAD任务中展现出显著的可泛化能力。此外,它们具有对未训练用户提供解释和指导的独特能力,这可以增强实际应用中的透明度和用户友好性。
要点
- 人脸识别系统(FRS)面临人脸识别篡改攻击的风险,需要发展篡改攻击检测(MAD)算法。
- MAD算法面临对新数据泛化能力和解释性的挑战。
- 本文提出利用大型语言模型(LLM)的零样本学习来进行MAD的新方法。
- 通过利用通用视觉模型和多模态LLM实现了两种零样本MAD算法。
- 通过实验验证了零样本学习在MAD任务中的有效性。
- 多模态LLM如ChatGPT在未经训练的MAD任务中展现出良好的泛化能力。
- LLMs具有为用户提供解释和指导的独特能力,增强实际应用中的透明度和用户友好性。
点此查看论文截图


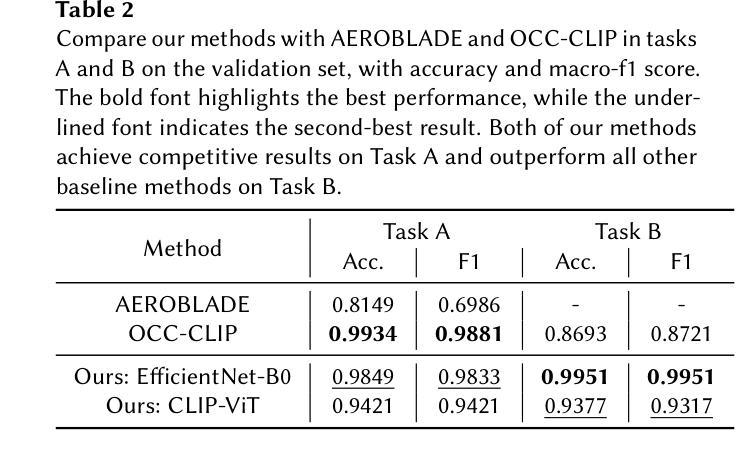
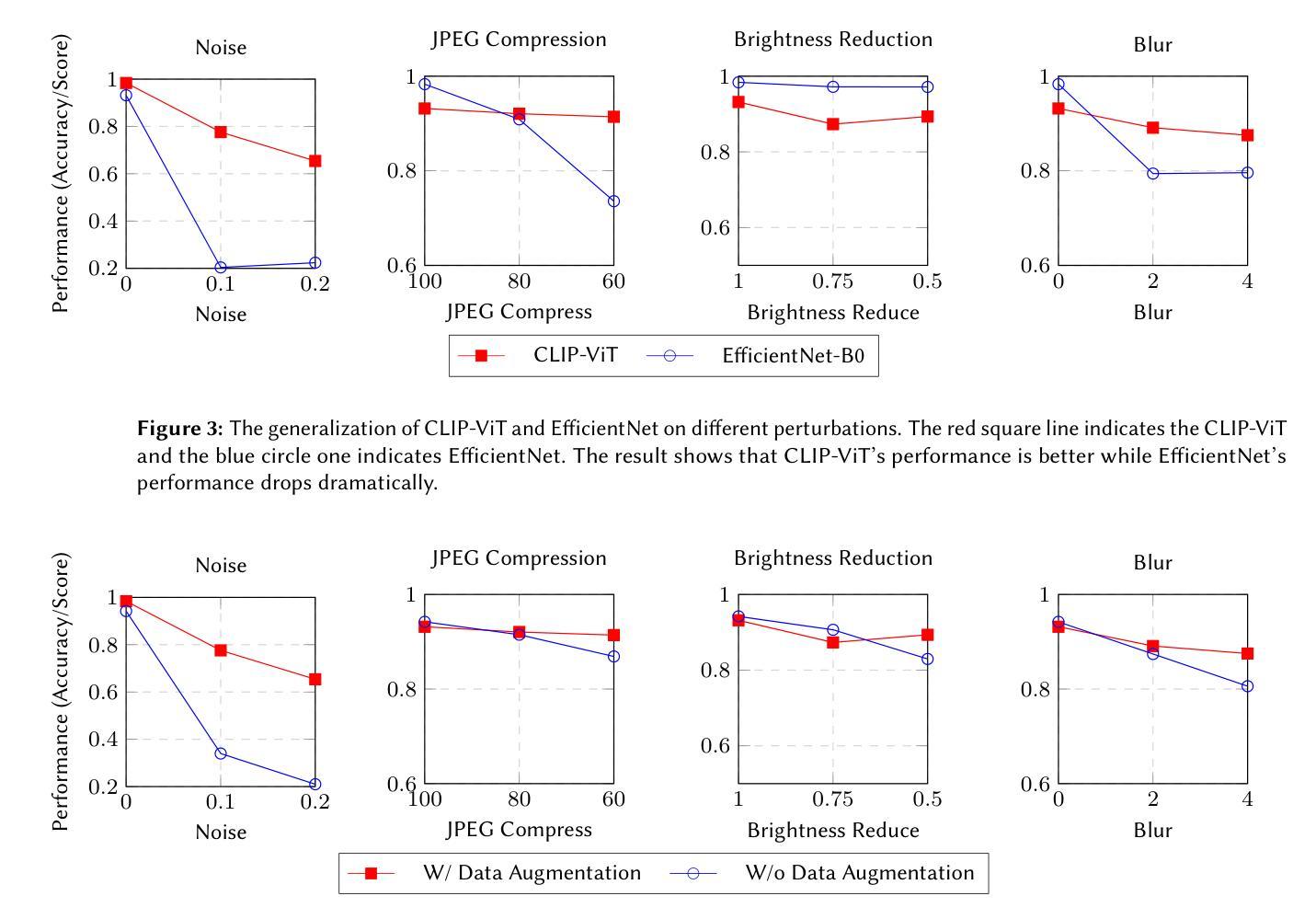
Team NYCU at Defactify4: Robust Detection and Source Identification of AI-Generated Images Using CNN and CLIP-Based Models
Authors:Tsan-Tsung Yang, I-Wei Chen, Kuan-Ting Chen, Shang-Hsuan Chiang, Wen-Chih Peng
With the rapid advancement of generative AI, AI-generated images have become increasingly realistic, raising concerns about creativity, misinformation, and content authenticity. Detecting such images and identifying their source models has become a critical challenge in ensuring the integrity of digital media. This paper tackles the detection of AI-generated images and identifying their source models using CNN and CLIP-ViT classifiers. For the CNN-based classifier, we leverage EfficientNet-B0 as the backbone and feed with RGB channels, frequency features, and reconstruction errors, while for CLIP-ViT, we adopt a pretrained CLIP image encoder to extract image features and SVM to perform classification. Evaluated on the Defactify 4 dataset, our methods demonstrate strong performance in both tasks, with CLIP-ViT showing superior robustness to image perturbations. Compared to baselines like AEROBLADE and OCC-CLIP, our approach achieves competitive results. Notably, our method ranked Top-3 overall in the Defactify 4 competition, highlighting its effectiveness and generalizability. All of our implementations can be found in https://github.com/uuugaga/Defactify_4
随着生成式AI的迅速发展,AI生成的图像越来越逼真,引发了关于创造力、误导信息和内容真实性的担忧。检测此类图像并识别其源模型,已成为确保数字媒体完整性的关键挑战。本文采用CNN和CLIP-ViT分类器检测AI生成的图像并识别其源模型。对于基于CNN的分类器,我们利用EfficientNet-B0作为骨干网,并输入RGB通道、频率特征和重建误差;而对于CLIP-ViT,我们采用预训练的CLIP图像编码器提取图像特征,并使用SVM进行分类。在Defactify 4数据集上评估,我们的方法在两项任务中都表现出强大的性能,CLIP-ViT对图像扰动表现出卓越的鲁棒性。与AEROBLADE和OCC-CLIP等基线相比,我们的方法取得了具有竞争力的结果。值得注意的是,我们的方法在Defactify 4竞赛中名列前茅,凸显了其有效性和通用性。所有实现均可访问 https://github.com/uuugaga/Defactify_4。
论文及项目相关链接
Summary
AI生成图像的检测与模型识别成为数字媒体完整性的关键挑战。本文使用CNN和CLIP-ViT分类器来解决这个问题,通过EfficientNet-B0作为CNN分类器的骨干并结合RGB通道、频率特征和重建误差来检测AI生成的图像;采用预训练的CLIP图像编码器提取图像特征并使用SVM进行模型识别。在Defactify 4数据集上评估,表现优秀,源码已上传至GitHub。
Key Takeaways
- AI生成的图像提高了检测其真实性的挑战,需关注数字媒体完整性。
- 本文利用CNN和CLIP-ViT分类器解决AI生成图像的检测与模型识别问题。
- EfficientNet-B0作为CNN分类器的骨干,结合多种特征进行检测。
- 采用预训练的CLIP图像编码器提取图像特征,并使用SVM进行分类。
- 在Defactify 4数据集上评估表现优秀,与基线方法相比具有竞争力。
- 方法在Defactify 4竞赛中位列前三,证明了其有效性和泛化能力。
点此查看论文截图


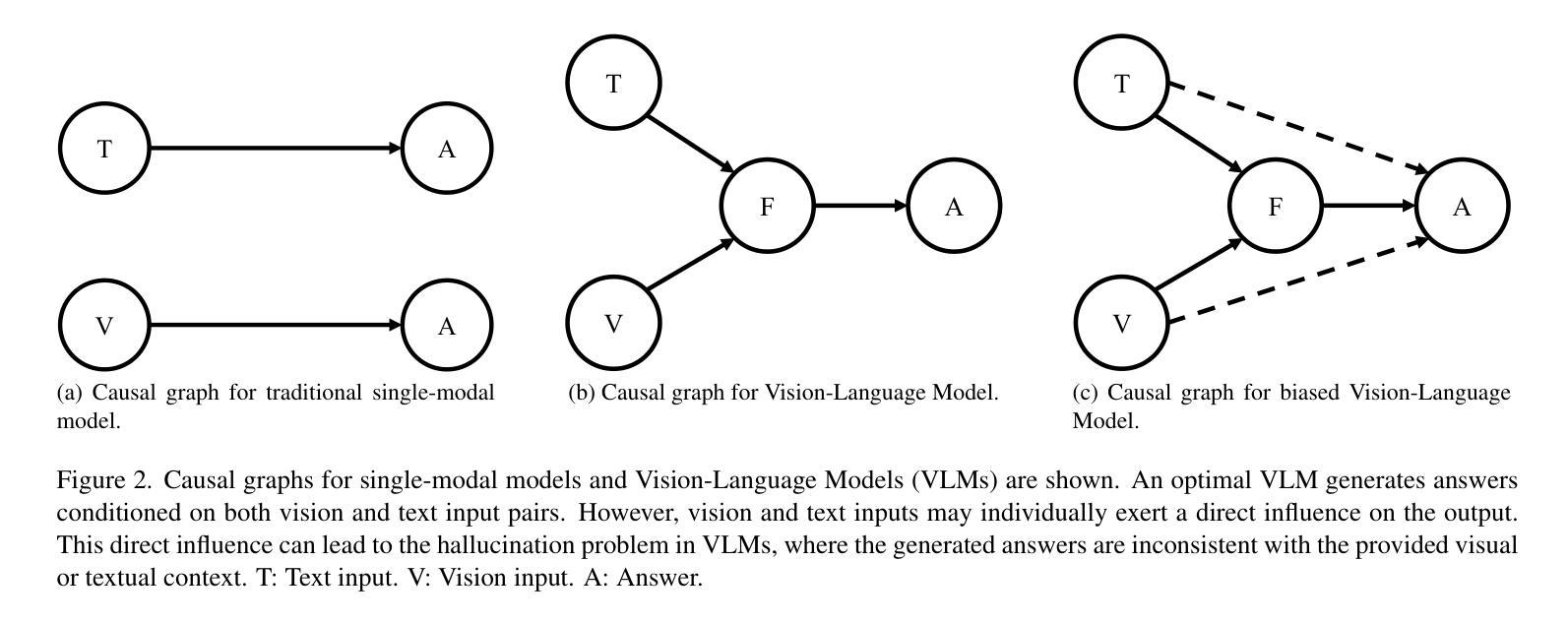
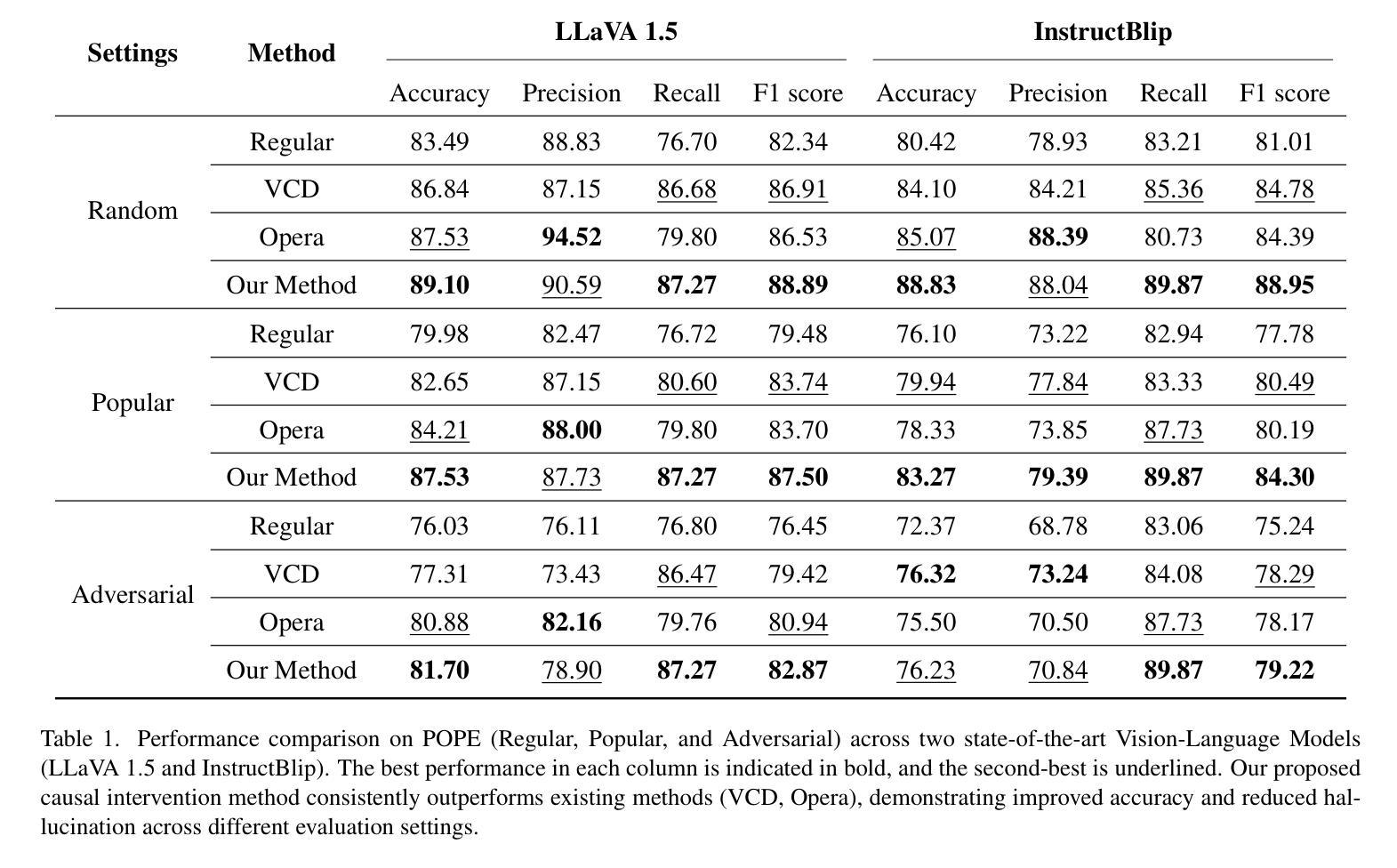
Treble Counterfactual VLMs: A Causal Approach to Hallucination
Authors:Shawn Li, Jiashu Qu, Yuxiao Zhou, Yuehan Qin, Tiankai Yang, Yue Zhao
Vision-Language Models (VLMs) have advanced multi-modal tasks like image captioning, visual question answering, and reasoning. However, they often generate hallucinated outputs inconsistent with the visual context or prompt, limiting reliability in critical applications like autonomous driving and medical imaging. Existing studies link hallucination to statistical biases, language priors, and biased feature learning but lack a structured causal understanding. In this work, we introduce a causal perspective to analyze and mitigate hallucination in VLMs. We hypothesize that hallucination arises from unintended direct influences of either the vision or text modality, bypassing proper multi-modal fusion. To address this, we construct a causal graph for VLMs and employ counterfactual analysis to estimate the Natural Direct Effect (NDE) of vision, text, and their cross-modal interaction on the output. We systematically identify and mitigate these unintended direct effects to ensure that responses are primarily driven by genuine multi-modal fusion. Our approach consists of three steps: (1) designing structural causal graphs to distinguish correct fusion pathways from spurious modality shortcuts, (2) estimating modality-specific and cross-modal NDE using perturbed image representations, hallucinated text embeddings, and degraded visual inputs, and (3) implementing a test-time intervention module to dynamically adjust the model’s dependence on each modality. Experimental results demonstrate that our method significantly reduces hallucination while preserving task performance, providing a robust and interpretable framework for improving VLM reliability. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/TREE985/Treble-Counterfactual-VLMs.
视觉语言模型(VLMs)在图像描述、视觉问答和推理等跨模式任务中取得了进展。然而,它们经常产生与视觉上下文或提示不一致的幻觉输出,从而限制了它们在自动驾驶和医学影像等关键应用中的可靠性。现有研究将幻觉与统计偏见、语言先验知识和有偏特征学习联系起来,但缺乏结构性的因果理解。在这项工作中,我们从因果角度来分析并缓解VLMs中的幻觉问题。我们假设幻觉的产生源于视觉或文本模态的意外直接影响,这些影响绕过了适当的跨模式融合。为解决这一问题,我们为VLMs构建了因果图,并应用反事实分析来估计视觉、文本及其跨模式交互对输出的自然直接影响(NDE)。我们系统地识别和缓解了这些意外的直接影响,以确保响应主要由真正的跨模式融合驱动。我们的方法分为三个步骤:(1)设计结构因果图,以区分正确的融合途径和虚假的模式捷径;(2)使用受干扰的图像表示、幻觉文本嵌入和退化视觉输入来估计模态特定和跨模态的NDE;(3)实现一个测试时间干预模块,以动态调整模型对各个模态的依赖。实验结果表明,我们的方法在减少幻觉的同时保持了任务性能,为提升VLM可靠性提供了一个稳健且可解释性的框架。为了增强可访问性和可重复性,我们的代码公开在https://github.com/TREE985/Treble-Counterfactual-VLMs。
论文及项目相关链接
Summary
本文探讨了视觉语言模型(VLMs)中的幻视问题,即模型在多模态任务中生成的输出常与视觉上下文或提示不符。作者引入因果视角来分析并缓解这一问题,通过构建因果图并估计各模态对输出的直接影响,系统地识别和缓解这些不必要的直接效应,确保响应主要由真正的多模态融合驱动。该方法包括设计结构因果图、估计模态特定和跨模态的自然直接效应,以及实施测试时间干预模块。实验结果证明该方法在减少幻视的同时保留了任务性能。
Key Takeaways
- 视觉语言模型(VLMs)在多模态任务中面临幻视问题,即输出与视觉上下文或提示不一致。
- 幻视问题可能与统计偏见、语言先验和偏差特征学习有关。
- 本文从因果角度分析了幻视的产生原因,认为其源于视觉或文本模态的意外直接影响,绕过了适当的多模态融合。
- 通过构建因果图和执行反事实分析,估计各模态对输出的自然直接效应(NDE)。
- 系统地识别和缓解这些不必要的直接效应,确保响应主要由真正的多模态融合驱动。
- 提出的方法包括设计结构因果图、估计模态特定和跨模态的NDE,以及实施测试时间干预模块来动态调整模型对各模态的依赖。
点此查看论文截图


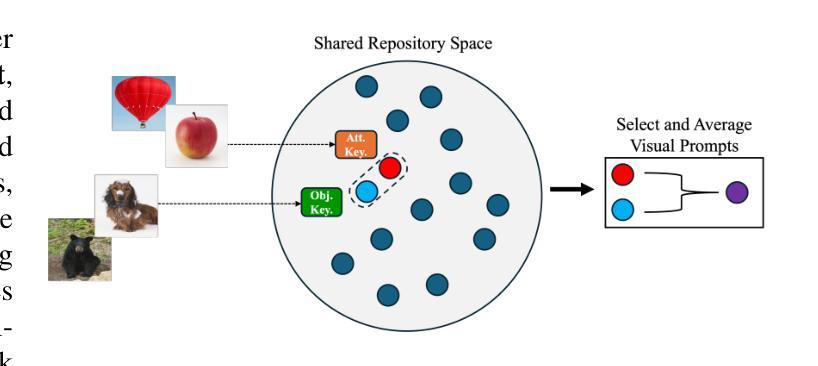
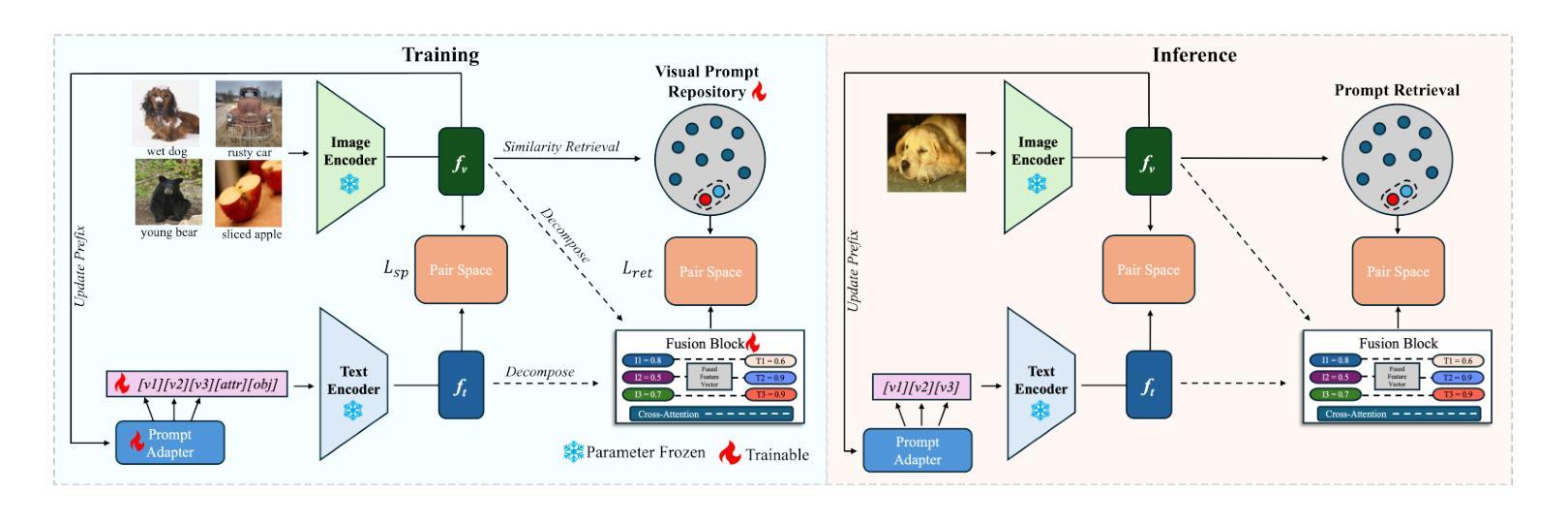
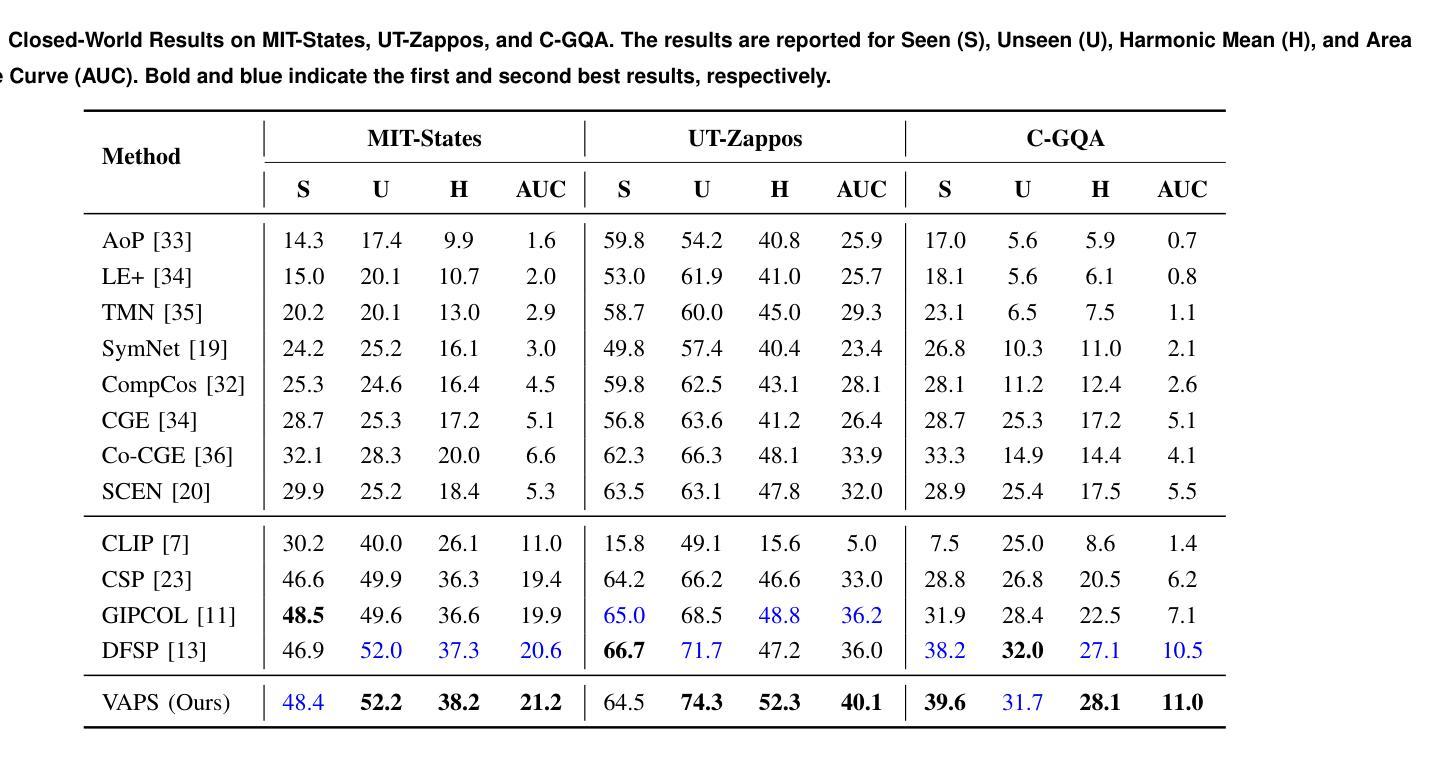
Visual Adaptive Prompting for Compositional Zero-Shot Learning
Authors:Kyle Stein, Arash Mahyari, Guillermo Francia, Eman El-Sheikh
Vision-Language Models (VLMs) have demonstrated impressive capabilities in learning joint representations of visual and textual data, making them powerful tools for tasks such as Compositional Zero-Shot Learning (CZSL). CZSL requires models to generalize to novel combinations of visual primitives-such as attributes and objects-that were not explicitly encountered during training. Recent works in prompting for CZSL have focused on modifying inputs for the text encoder, often using static prompts that do not change across varying visual contexts. However, these approaches struggle to fully capture varying visual contexts, as they focus on text adaptation rather than leveraging visual features for compositional reasoning. To address this, we propose Visual Adaptive Prompting System (VAPS) that leverages a learnable visual prompt repository and similarity-based retrieval mechanism within the framework of VLMs to bridge the gap between semantic and visual features. Our method introduces a dynamic visual prompt repository mechanism that selects the most relevant attribute and object prompts based on the visual features of the image. Our proposed system includes a visual prompt adapter that encourages the model to learn a more generalizable embedding space. Experiments on three CZSL benchmarks, across both closed and open-world scenarios, demonstrate state-of-the-art results.
视觉语言模型(VLMs)在学习视觉和文本数据的联合表示方面表现出了令人印象深刻的能力,使其成为用于组合零射击学习(CZSL)等任务的有力工具。CZSL要求模型能够推广到训练期间未明确遇到的新视觉原始数据的组合,例如属性和对象。关于CZSL的最近提示工作主要集中在修改文本编码器的输入,通常使用不会在变化的视觉上下文中改变的静态提示。然而,这些方法在捕捉变化的视觉上下文方面存在困难,因为它们侧重于文本适应,而不是利用视觉特征进行组合推理。为了解决这个问题,我们提出了视觉自适应提示系统(VAPS),该系统利用可学习的视觉提示存储库和基于相似性的检索机制,在视觉语言模型的框架内建立语义和视觉特征之间的桥梁。我们的方法引入了一个动态视觉提示存储库机制,该机制根据图像视觉特征选择最相关的属性和对象提示。我们提出的系统包括一个视觉提示适配器,鼓励模型学习一个更具泛化能力的嵌入空间。在三种CZSL基准测试上的实验,无论是在封闭还是开放世界场景中,都取得了最新技术成果。
论文及项目相关链接
Summary
视觉-语言模型(VLMs)在联合表示视觉和文本数据方面表现出强大的能力,特别是在组合零样本学习(CZSL)任务中。近期关于CZSL的提示方法主要关注文本编码器的输入修改,通常使用不随视觉上下文改变的静态提示。然而,这些方法难以充分捕捉变化的视觉上下文,因为他们关注的是文本适应而不是利用视觉特征进行组合推理。为解决这一问题,我们提出了视觉自适应提示系统(VAPS),该系统在VLMs的框架下,利用可学习的视觉提示仓库和基于相似性的检索机制来弥合语义和视觉特征之间的差距。我们的方法引入了一个动态视觉提示仓库机制,根据图像视觉特征选择最相关的属性和对象提示。我们的系统包括一个视觉提示适配器,鼓励模型学习一个更具通用性的嵌入空间。在三个CZSL基准测试中的封闭和开放世界场景下进行的实验均取得了最新结果。
Key Takeaways
- VLMs已经展现出强大的能力在学习视觉和文本数据的联合表示,特别是在CZSL任务中。
- 近期关于CZSL的提示方法主要关注文本编码器的输入修改,但难以捕捉变化的视觉上下文。
- 为解决这一问题,提出了视觉自适应提示系统(VAPS)。
- VAPS利用可学习的视觉提示仓库和基于相似性的检索机制来弥合语义和视觉特征之间的差距。
- VAPS通过动态选择最相关的属性和对象提示来适应视觉上下文。
- 系统包括一个视觉提示适配器,鼓励模型学习一个更具通用性的嵌入空间。
点此查看论文截图


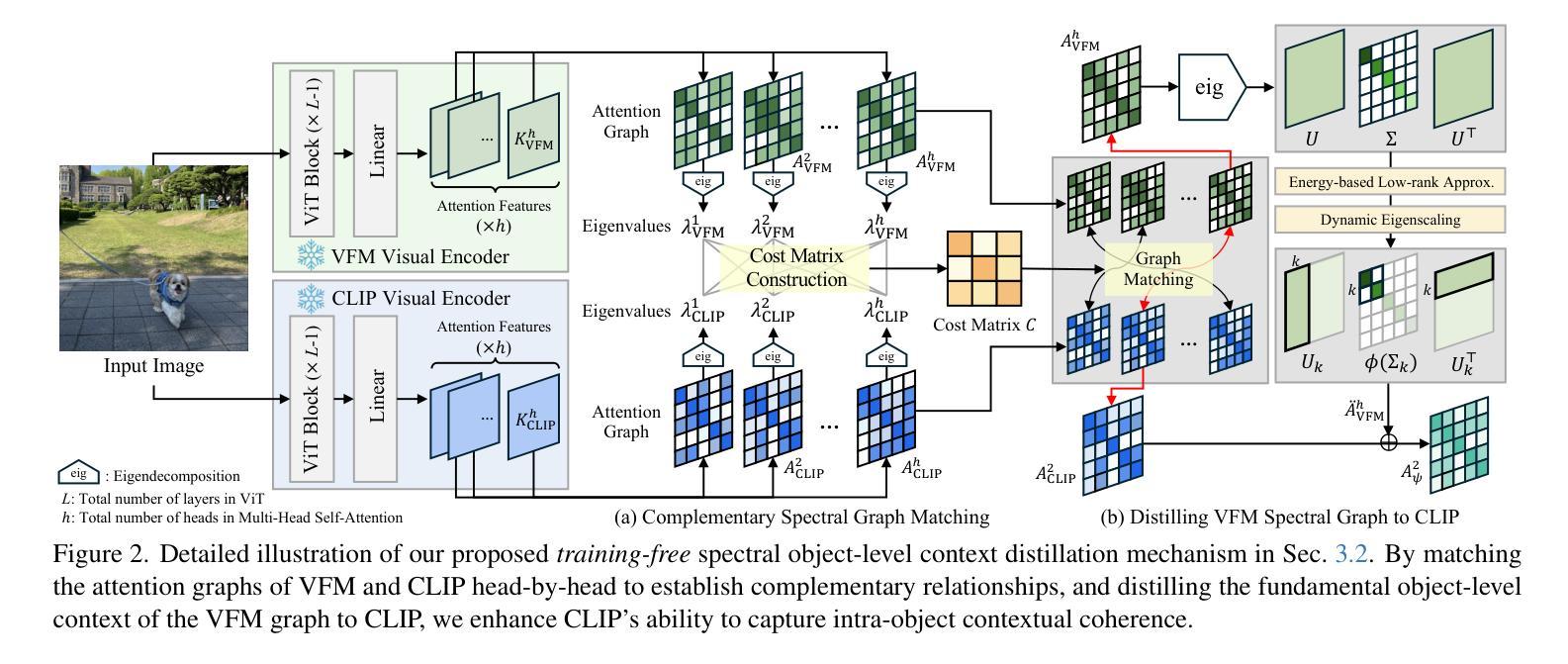
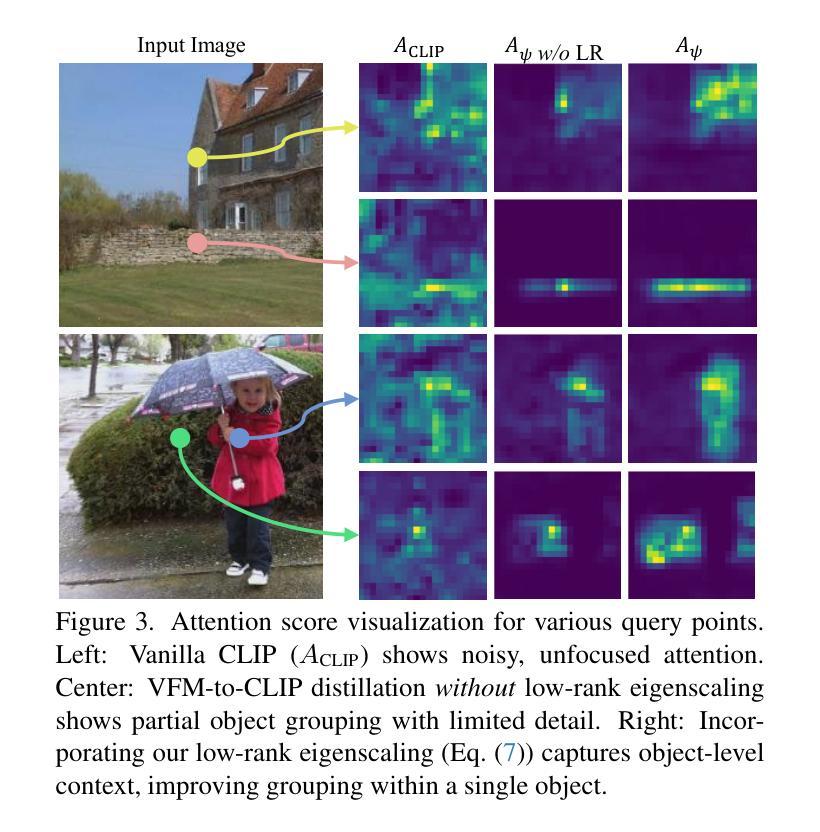
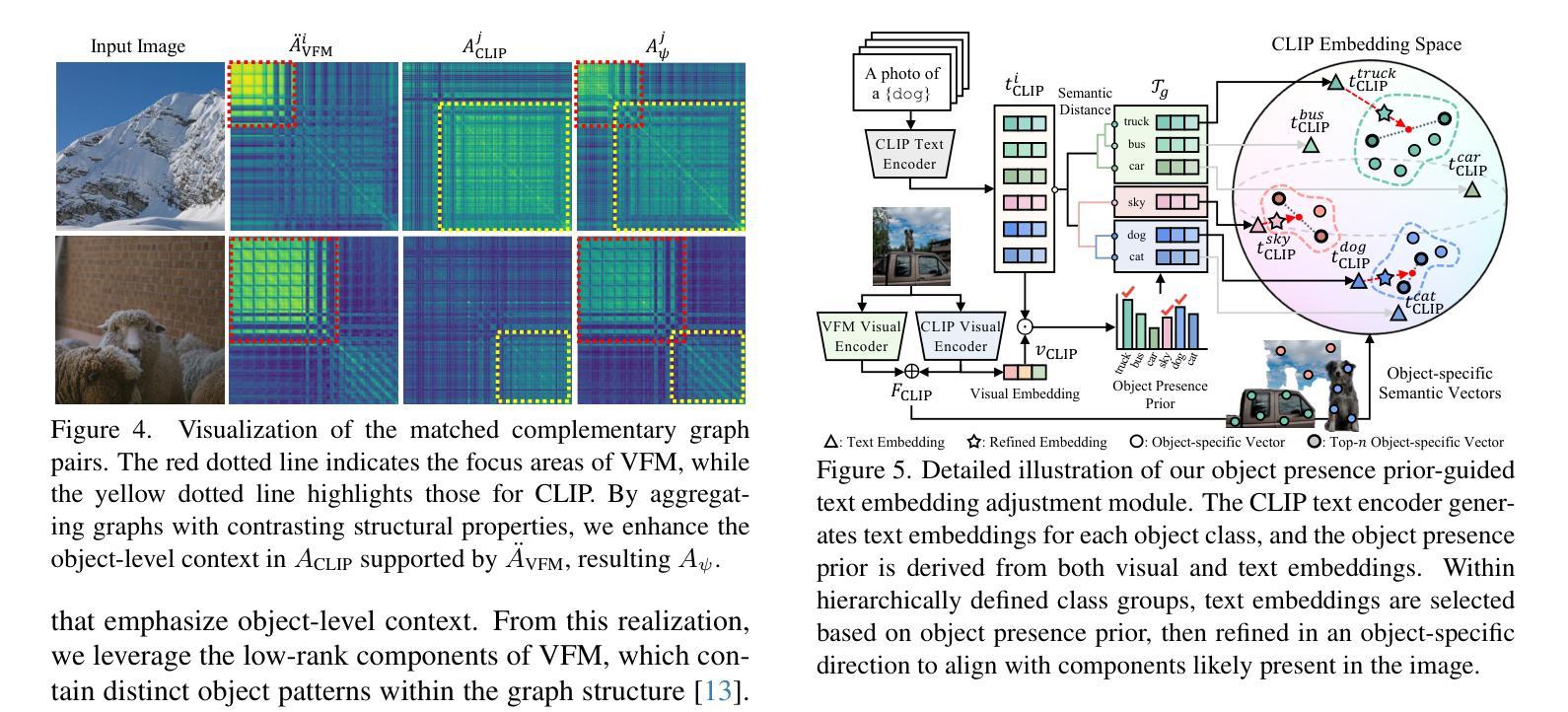
Distilling Spectral Graph for Object-Context Aware Open-Vocabulary Semantic Segmentation
Authors:Chanyoung Kim, Dayun Ju, Woojung Han, Ming-Hsuan Yang, Seong Jae Hwang
Open-Vocabulary Semantic Segmentation (OVSS) has advanced with recent vision-language models (VLMs), enabling segmentation beyond predefined categories through various learning schemes. Notably, training-free methods offer scalable, easily deployable solutions for handling unseen data, a key goal of OVSS. Yet, a critical issue persists: lack of object-level context consideration when segmenting complex objects in the challenging environment of OVSS based on arbitrary query prompts. This oversight limits models’ ability to group semantically consistent elements within object and map them precisely to user-defined arbitrary classes. In this work, we introduce a novel approach that overcomes this limitation by incorporating object-level contextual knowledge within images. Specifically, our model enhances intra-object consistency by distilling spectral-driven features from vision foundation models into the attention mechanism of the visual encoder, enabling semantically coherent components to form a single object mask. Additionally, we refine the text embeddings with zero-shot object presence likelihood to ensure accurate alignment with the specific objects represented in the images. By leveraging object-level contextual knowledge, our proposed approach achieves state-of-the-art performance with strong generalizability across diverse datasets.
开放词汇语义分割(OVSS)随着最新的视觉语言模型(VLMs)的发展而进步,通过各种学习方案实现了超出预定类别的分割。值得注意的是,无训练方法为处理未见数据提供了可扩展、易于部署的解决方案,这是OVSS的关键目标。然而,一个关键问题依然存在:在OVSS的挑战环境中,基于任意查询提示对复杂对象进行分割时,缺乏对象级别的上下文考虑。这一疏忽限制了模型在对象内部分组语义一致元素的能力,并精确地将其映射到用户定义的任意类别。在这项工作中,我们介绍了一种通过融入图像内的对象级别上下文知识来克服这一限制的新方法。具体来说,我们的模型通过蒸馏视觉基础模型的频谱驱动特征到视觉编码器的注意力机制中,增强了对象内部的一致性,使得语义一致的组件能够形成单个对象掩膜。此外,我们还通过零射对象存在可能性来优化文本嵌入,以确保与图像中表示的具体对象准确对齐。通过利用对象级别的上下文知识,我们提出的方法在多个数据集上实现了最先进的性能,并具有很强的泛化能力。
论文及项目相关链接
Summary
本文介绍了基于开放词汇语义分割(OVSS)的最新研究,通过引入对象级别的上下文知识来解决模型在复杂环境中对任意查询提示的分割限制。该研究通过蒸馏视觉基础模型的频谱驱动特征到视觉编码器的注意力机制中,增强了对象内部的一致性,并改进了文本嵌入,确保与图像中特定对象的准确对齐。该方法实现了跨多个数据集的卓越性能,具有强大的泛化能力。
Key Takeaways
- 开放词汇语义分割(OVSS)能够通过最新的视觉语言模型(VLMs)进行更广泛的分割,包括预定义类别之外的内容。
- 训练免费的方法为处理未见数据提供了可扩展和易于部署的解决方案,这是OVSS的关键目标之一。
- 当前工作中一个关键问题是缺乏对象级别的上下文考虑,在基于任意查询提示的OVSS环境中分割复杂对象时,这一点尤为重要。
- 新型方法通过整合图像中的对象级别上下文知识来解决此问题。
- 该方法通过蒸馏视觉基础模型的频谱驱动特征到视觉编码器的注意力机制中,增强了对象内部的一致性。
- 研究还改进了文本嵌入,通过零镜头对象存在可能性来确保与图像中特定对象的准确对齐。
点此查看论文截图


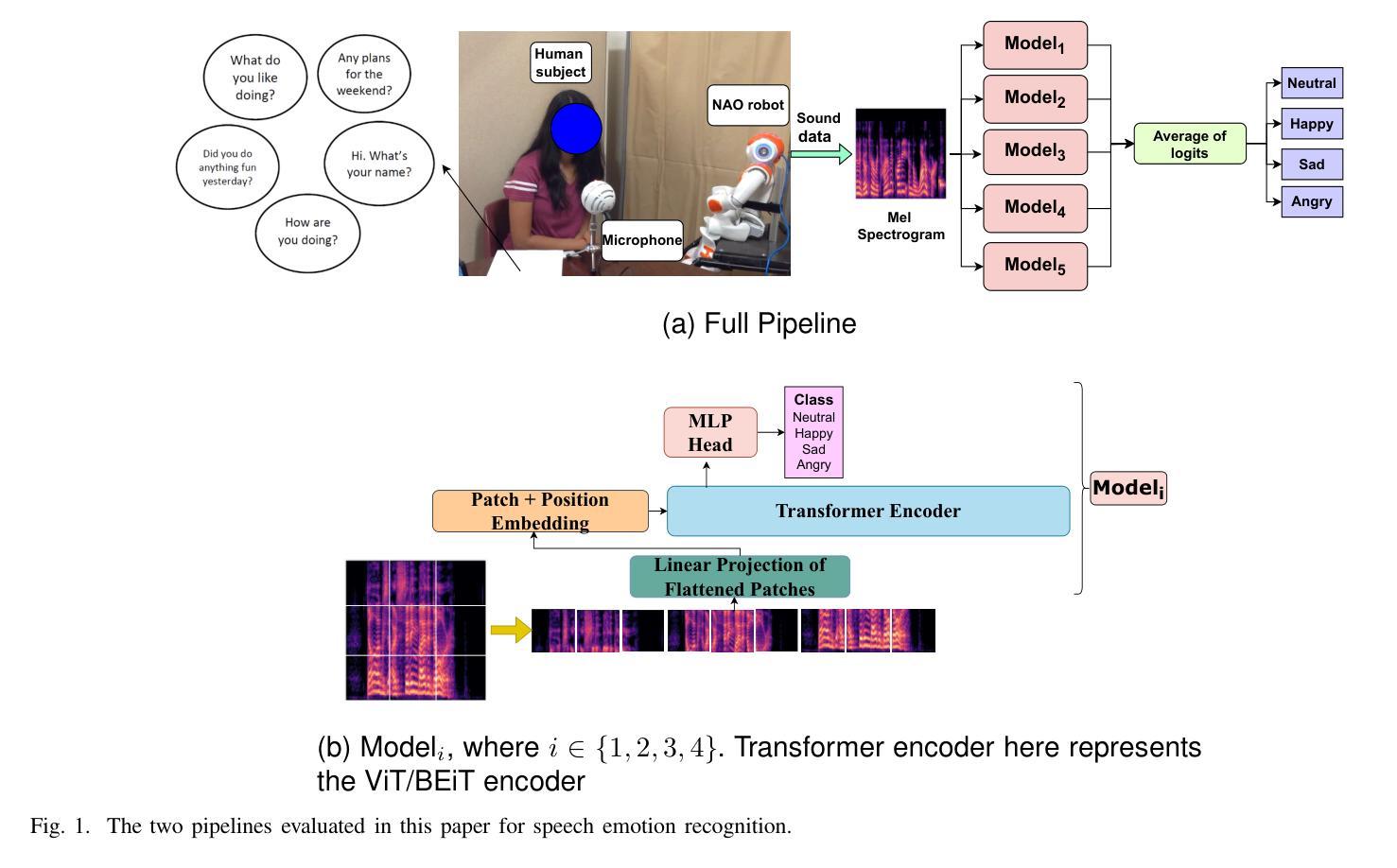
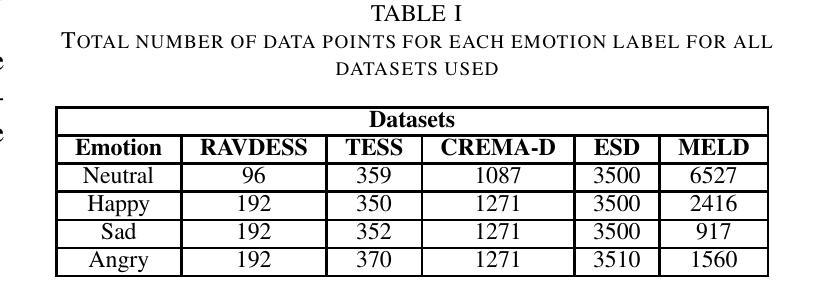
Personalized Speech Emotion Recognition in Human-Robot Interaction using Vision Transformers
Authors:Ruchik Mishra, Andrew Frye, Madan Mohan Rayguru, Dan O. Popa
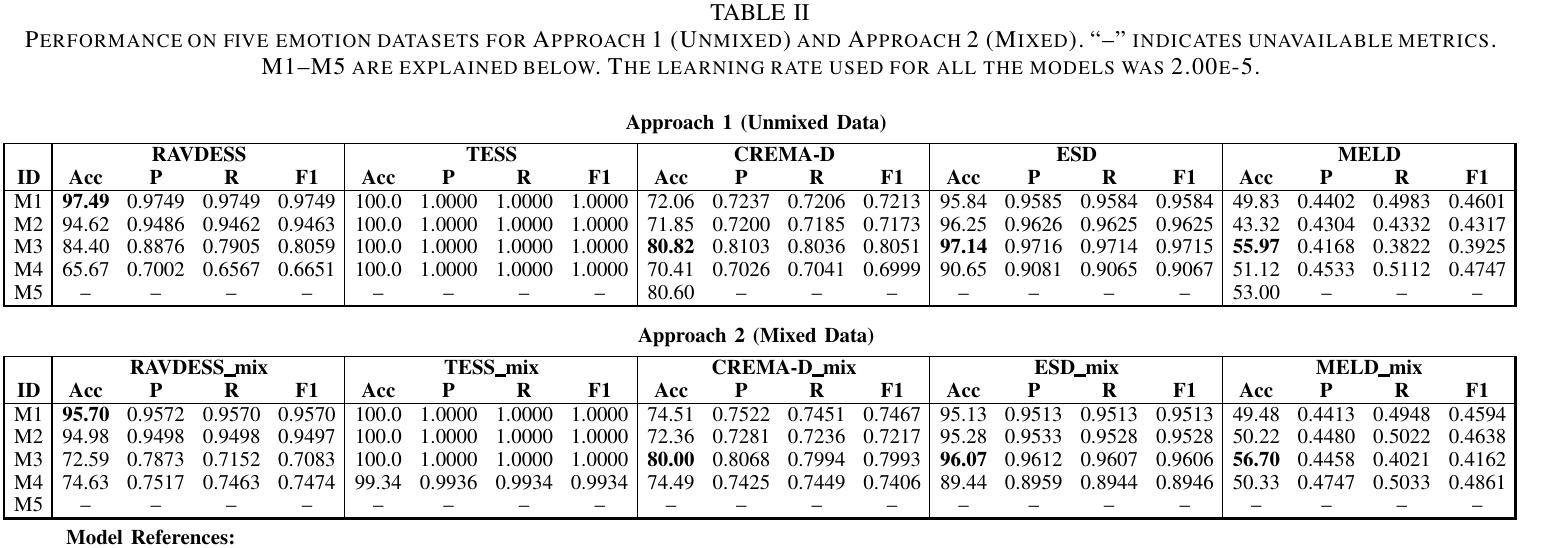
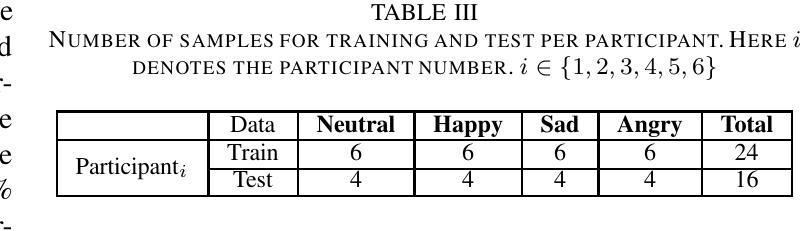
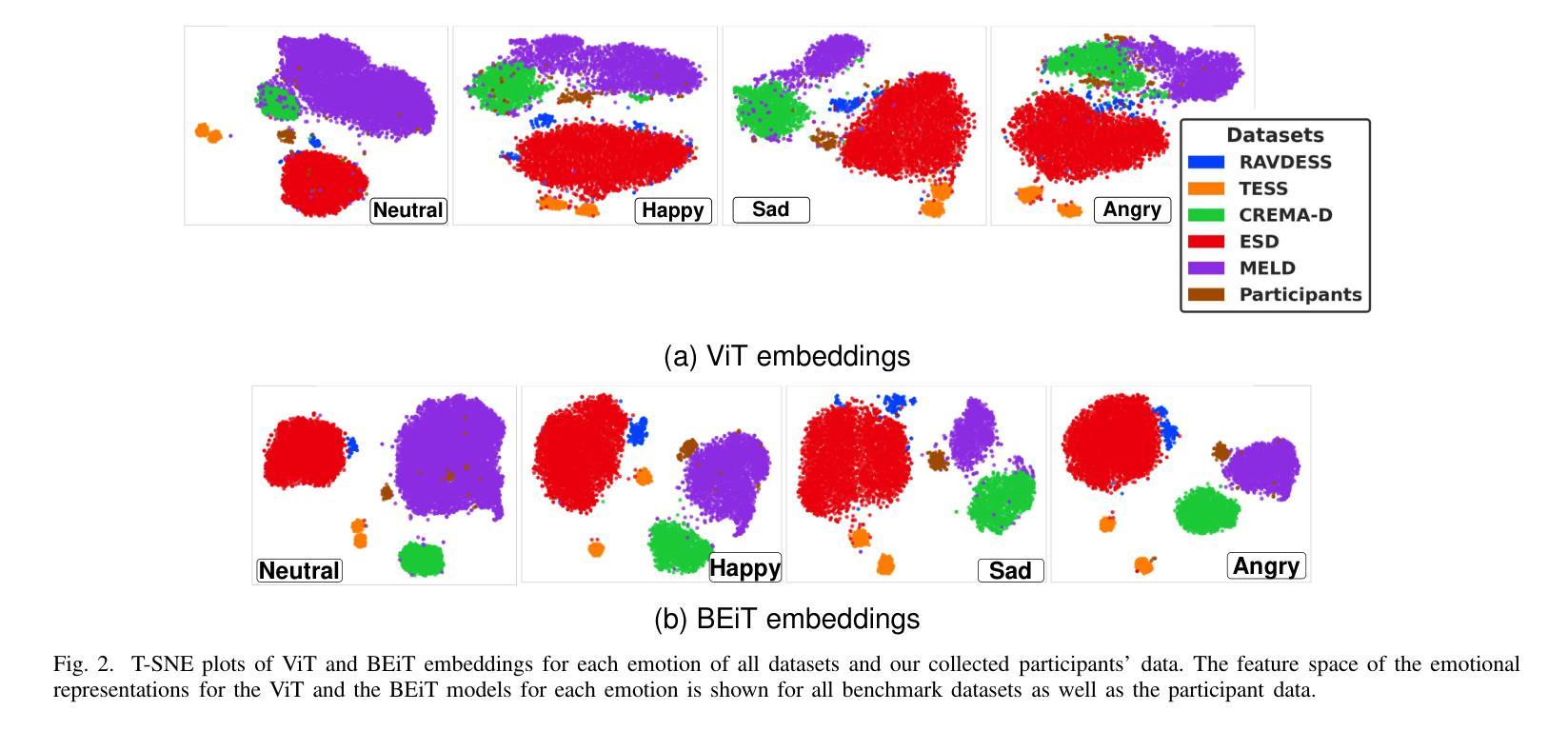
Emotions are an essential element in verbal communication, so understanding individuals’ affect during a human-robot interaction (HRI) becomes imperative. This paper investigates the application of vision transformer models, namely ViT (Vision Transformers) and BEiT (BERT Pre-Training of Image Transformers) pipelines, for Speech Emotion Recognition (SER) in HRI. The focus is to generalize the SER models for individual speech characteristics by fine-tuning these models on benchmark datasets and exploiting ensemble methods. For this purpose, we collected audio data from different human subjects having pseudo-naturalistic conversations with the NAO robot. We then fine-tuned our ViT and BEiT-based models and tested these models on unseen speech samples from the participants. In the results, we show that fine-tuning vision transformers on benchmark datasets and and then using either these already fine-tuned models or ensembling ViT/BEiT models gets us the highest classification accuracies per individual when it comes to identifying four primary emotions from their speech: neutral, happy, sad, and angry, as compared to fine-tuning vanilla-ViTs or BEiTs.
情感是口头交流的重要组成部分,因此在人机互动(HRI)中理解个体的情感变得至关重要。本文研究了视觉转换器模型(即ViT(视觉转换器)和Beit(图像转换器的BERT预训练))在人机互动中的语音情感识别(SER)应用。重点是通过在基准数据集上微调这些模型并利用集成方法,使SER模型适应个人的语音特征。为此,我们从与NAO机器人进行伪自然对话的不同人类受试者收集了音频数据。然后我们对基于ViT和Beit的模型进行了微调,并在来自参与者的未见语音样本上测试了这些模型。在结果中,我们显示,在基准数据集上微调视觉转换器,然后使用已经微调过的这些模型或集成ViT/BEiT模型,在识别四种主要情绪(中性、快乐、悲伤和愤怒)时,针对个人获得了最高的分类准确率,这与微调普通ViTs或BEITs相比效果更好。
论文及项目相关链接
PDF This work has been accepted for the IEEE Robotics and Automation Letters (RA-L)
Summary
本文研究了情绪在人机互动中的重要性,并探讨了如何利用视觉Transformer模型(如ViT和BEiT)进行语音情感识别(SER)。通过对基准数据集进行微调并采用集成方法,实现了针对个人语音特征的模型通用化。实验结果显示,对视觉Transformer模型进行微调并在识别四种主要情绪(中性、快乐、悲伤和愤怒)时,使用已调模型或集成ViT/BEiT模型可获得最高的个体分类准确率。
Key Takeaways
- 情绪在人机互动中的重要性。
- 视觉Transformer模型(ViT和BEiT)被应用于语音情感识别(SER)。
- 通过对基准数据集进行微调,实现了针对个人语音特征的模型通用化。
- 收集来自与NAO机器人进行伪自然对话的不同人类的音频数据。
- 视觉Transformer模型在识别四种主要情绪(中性、快乐、悲伤和愤怒)时表现出较高的性能。
- 已调模型或集成ViT/BEiT模型在个体分类准确率上表现最佳。
点此查看论文截图

Rethinking model prototyping through the MedMNIST+ dataset collection
Authors:Sebastian Doerrich, Francesco Di Salvo, Julius Brockmann, Christian Ledig
The integration of deep learning based systems in clinical practice is often impeded by challenges rooted in limited and heterogeneous medical datasets. In addition, the field has increasingly prioritized marginal performance gains on a few, narrowly scoped benchmarks over clinical applicability, slowing down meaningful algorithmic progress. This trend often results in excessive fine-tuning of existing methods on selected datasets rather than fostering clinically relevant innovations. In response, this work introduces a comprehensive benchmark for the MedMNIST+ dataset collection, designed to diversify the evaluation landscape across several imaging modalities, anatomical regions, classification tasks and sample sizes. We systematically reassess commonly used Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) architectures across distinct medical datasets, training methodologies, and input resolutions to validate and refine existing assumptions about model effectiveness and development. Our findings suggest that computationally efficient training schemes and modern foundation models offer viable alternatives to costly end-to-end training. Additionally, we observe that higher image resolutions do not consistently improve performance beyond a certain threshold. This highlights the potential benefits of using lower resolutions, particularly in prototyping stages, to reduce computational demands without sacrificing accuracy. Notably, our analysis reaffirms the competitiveness of CNNs compared to ViTs, emphasizing the importance of comprehending the intrinsic capabilities of different architectures. Finally, by establishing a standardized evaluation framework, we aim to enhance transparency, reproducibility, and comparability within the MedMNIST+ dataset collection. Code is available at https://github.com/sdoerrich97/rethinking-model-prototyping-MedMNISTPlus .
将深度学习系统整合到临床实践经常会受到有限的医学数据集和异构性的挑战所阻碍。此外,该领域越来越重视在狭窄范围基准测试中获得的一些微不足道的性能增益,而忽略了其在临床治疗中的应用价值,导致算法的有效进展变得缓慢。这一趋势通常导致在选定数据集上对现有方法的过度微调,而不是促进与临床实践相关的创新。为了应对这一问题,这项工作引入了针对MedMNIST+数据集集合的全面基准测试,旨在通过多种成像模式、解剖区域、分类任务和样本量来丰富评估景观。我们系统地重新评估了常用的卷积神经网络(CNN)和视觉转换器(ViT)架构在不同医学数据集、训练方法和输入分辨率上的表现,以验证和精炼关于模型有效性和发展的现有假设。我们的研究结果表明,计算效率高的训练方案和现代基础模型为昂贵的端到端训练提供了可行的替代方案。此外,我们发现图像分辨率并不总是在超过一定阈值后就能持续提高性能。这突出了使用较低分辨率的潜在优势,特别是在原型开发阶段,以减少计算需求而不牺牲准确性。值得注意的是,我们的分析再次证明了CNN与ViT相比的竞争力,强调了理解不同架构的内在能力的重要性。最后,通过建立一个标准化的评估框架,我们旨在提高MedMNIST+数据集集合中的透明度、可重复性和可比性。代码可在https://github.com/sdoerrich97/rethinking-model-prototyping-MedMNISTPlus中找到。
论文及项目相关链接
Summary
本文介绍了深度学习系统在临床应用中的挑战,包括医疗数据集有限和异质性问题。为应对这些挑战,文章提出了一套全面的基准测试标准,用于评估MedMNIST+数据集集合,涵盖多种成像模式、解剖区域、分类任务和样本量。文章评估了卷积神经网络(CNN)和视觉转换器(ViT)架构在医疗数据集上的表现,并发现计算效率高的训练方案和现代化基础模型具有可行性。此外,文章指出更高的图像分辨率并不总是能提高性能,并强调在原型制作阶段使用较低分辨率以减少计算需求而不牺牲准确性的潜力。最后,文章通过建立一个标准化的评估框架,旨在提高MedMNIST+数据集集合的透明度、可重复性和可比性。
Key Takeaways
- 深度学习系统在临床应用面临医疗数据集有限和异质性的挑战。
- MedMNIST+数据集评估标准被提出以全面评估不同成像模式、解剖区域、分类任务和样本量的表现。
- 对CNN和ViT架构的评估发现计算效率高的训练方案和现代化基础模型具有可行性。
- 更高的图像分辨率并不一定提高性能,使用较低分辨率在原型制作阶段具有潜力。
- CNN与ViT的竞争性分析强调了理解不同架构内在能力的重要性。
- 标准化评估框架提高了MedMNIST+数据集集合的透明度、可重复性和可比性。
点此查看论文截图




Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Authors:Amin Karimi Monsefi, Payam Karisani, Mengxi Zhou, Stacey Choi, Nathan Doble, Heng Ji, Srinivasan Parthasarathy, Rajiv Ramnath
Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet’s superior performance in both inference time and accuracy.
标准现代机器学习成像方法在音乐应用在医疗领域上面临诸多挑战,这主要是因为数据集建设成本高昂导致了可用标注训练数据的数量受限。此外,在实际部署过程中,这些方法通常用于每日处理大量数据,给医疗机构带来了高昂的维护成本。在本文中,我们引入了一种新型神经网络架构,名为LoGoNet,它采用定制的自监督学习方法来缓解这些挑战。LoGoNet在一个U型架构中集成了一种新型特征提取器,借助大内核注意力(LKA)和双编码策略来巧妙地捕获长短距离特征依赖关系。这与现有方法不同,后者依赖于增加网络容量来提升特征提取能力。模型中结合的新型技术特别有益于医学图像分割,考虑到学习复杂且通常不规则的器官形状(如脾脏)的难度。此外,我们针对三维图像提出了一种新型自监督学习方法来弥补大型标注数据集的不足。该方法在多任务学习框架内结合了掩码和对比学习技术,并与Vision Transformer(ViT)和CNN模型兼容。我们在两个标准数据集(即BTCV和MSD)的多个任务上展示了我们的方法的有效性。与八种最新模型的基准对比测试突显了LoGoNet在推理时间和准确性方面的卓越性能。
论文及项目相关链接
Summary
本文提出了一种新型的神经网络架构LoGoNet,配合定制的自监督学习方法,以解决医学应用中现代机器学习成像方法面临的挑战。LoGoNet采用U型架构并结合大型内核注意力机制与双重编码策略,能捕捉长短距离特征依赖关系,弥补了现有方法的不足。针对医学图像分割中复杂的器官形状学习难题,如脾脏,该模型具有独特优势。同时,为弥补缺乏大规模标注数据集的问题,本文提出了一种针对三维图像的新型自监督学习方法,结合了掩蔽和对比学习技术,并兼容Vision Transformer和CNN模型。在标准数据集BTCV和MSD上的多项任务实验中,与八种先进模型的基准对比结果显示,LoGoNet在推理时间和准确度上均表现出卓越性能。
Key Takeaways
- LoGoNet是一种新型的神经网络架构,结合了U型架构、大型内核注意力机制和双重编码策略,能有效捕捉医学图像中的特征依赖关系。
- LoGoNet通过自监督学习方法解决医学应用中数据集的构建成本高和标注数据有限的问题。
- 针对医学图像分割中复杂的器官形状学习难题,如脾脏,LoGoNet具有独特优势。
- 提出了一种针对三维图像的新型自监督学习方法,结合了掩蔽和对比学习技术,提高了模型在医学图像分割任务中的性能。
- 该方法兼容Vision Transformer和CNN模型,可广泛应用于多种医学图像任务。
- 在标准数据集BTCV和MSD上的实验结果显示,LoGoNet在推理时间和准确度上均优于其他先进模型。
点此查看论文截图