⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
Exploring Disparity-Accuracy Trade-offs in Face Recognition Systems: The Role of Datasets, Architectures, and Loss Functions
Authors:Siddharth D Jaiswal, Sagnik Basu, Sandipan Sikdar, Animesh Mukherjee
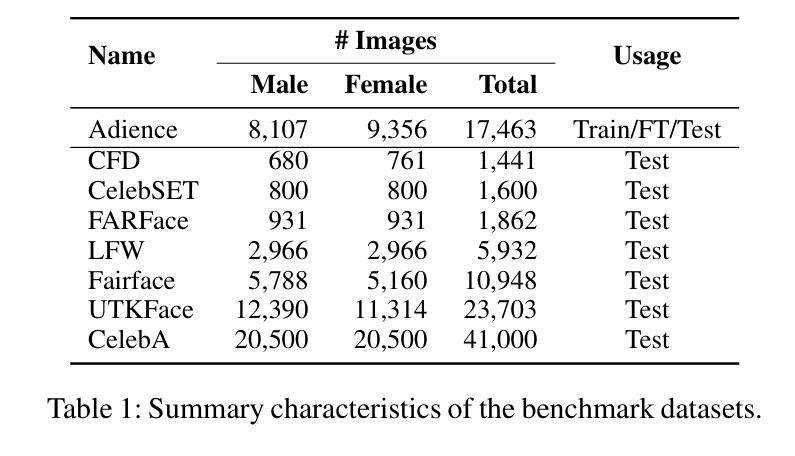
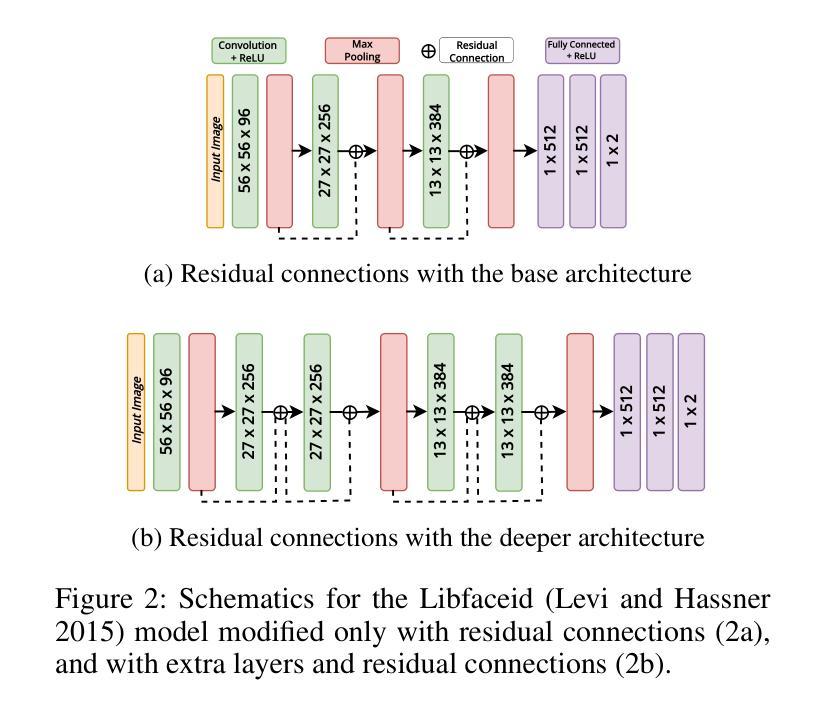
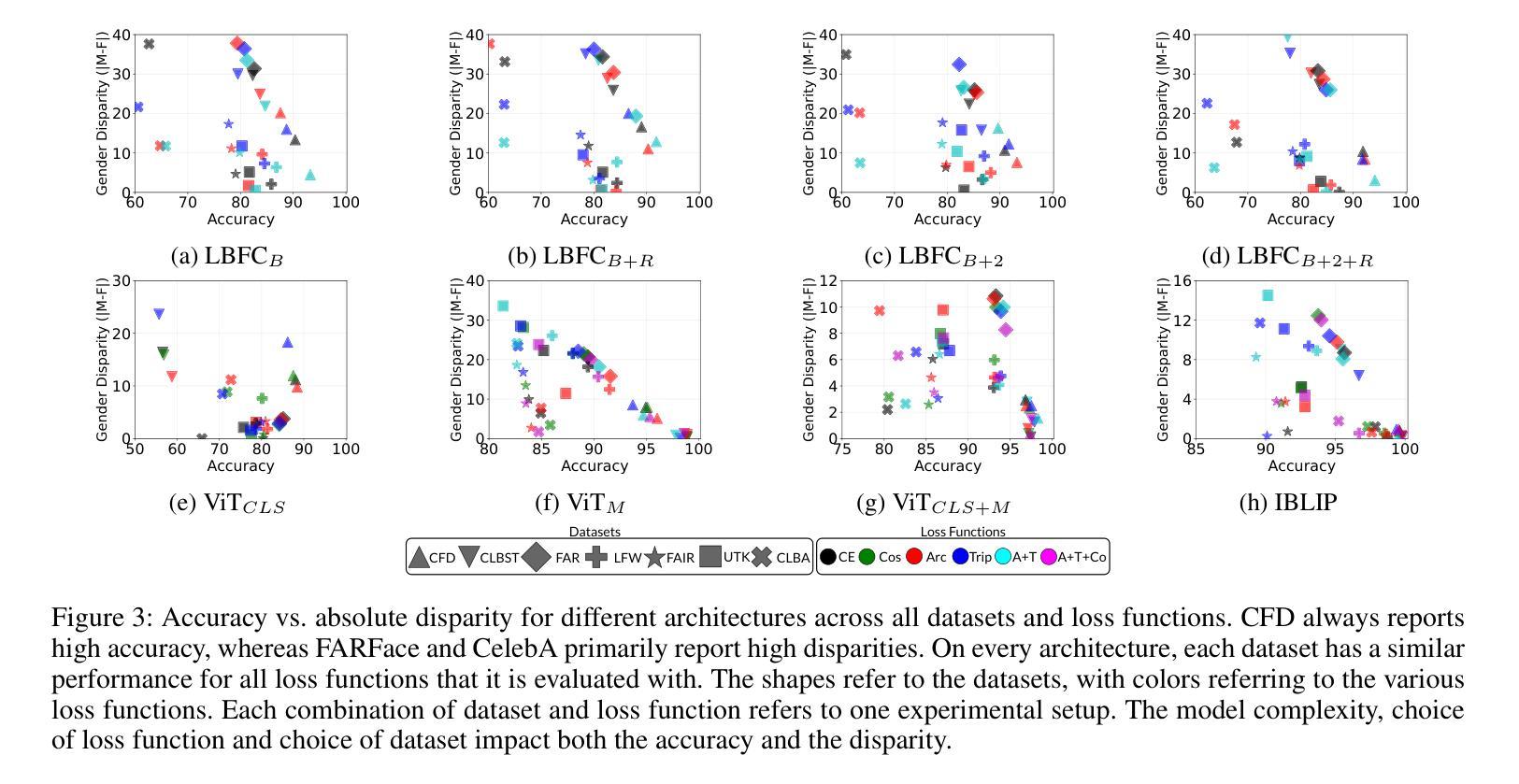
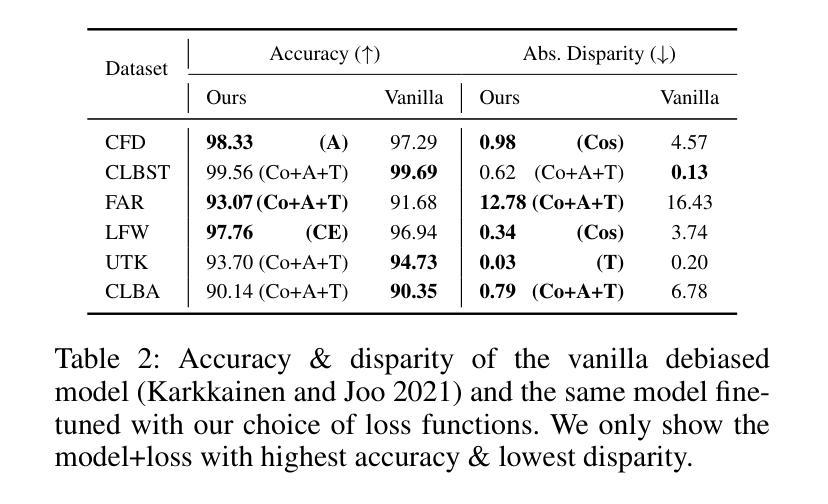
Automated Face Recognition Systems (FRSs), developed using deep learning models, are deployed worldwide for identity verification and facial attribute analysis. The performance of these models is determined by a complex interdependence among the model architecture, optimization/loss function and datasets. Although FRSs have surpassed human-level accuracy, they continue to be disparate against certain demographics. Due to the ubiquity of applications, it is extremely important to understand the impact of the three components – model architecture, loss function and face image dataset on the accuracy-disparity trade-off to design better, unbiased platforms. In this work, we perform an in-depth analysis of three FRSs for the task of gender prediction, with various architectural modifications resulting in ten deep-learning models coupled with four loss functions and benchmark them on seven face datasets across 266 evaluation configurations. Our results show that all three components have an individual as well as a combined impact on both accuracy and disparity. We identify that datasets have an inherent property that causes them to perform similarly across models, independent of the choice of loss functions. Moreover, the choice of dataset determines the model’s perceived bias – the same model reports bias in opposite directions for three gender-balanced datasets of in-the-wild'' face images of popular individuals. Studying the facial embeddings shows that the models are unable to generalize a uniform definition of what constitutes a female face’’ as opposed to a ``male face’’, due to dataset diversity. We provide recommendations to model developers on using our study as a blueprint for model development and subsequent deployment.
基于深度学习模型的自动人脸识别系统(FRSs)在全球范围内得到部署,用于身份验证和面部属性分析。这些模型的性能取决于模型结构、优化/损失函数和数据集之间的复杂相互依赖性。虽然FRS已经超越了人类水平的准确性,但它们对某些人口统计特征仍然存在差异。由于其应用的普遍性,了解模型架构、损失函数和人脸图像数据集对准确性差异权衡的影响对于设计更好、无偏见的平台至关重要。在这项工作中,我们对用于性别预测的三个FRS进行了深入分析,通过各种架构修改得到十个深度学习模型,结合四种损失函数,并在七个面部数据集上进行了超过266种评估配置的基准测试。我们的结果表明,所有这三个组成部分都对准确性和差异性都有各自和联合影响。我们发现数据集具有一种内在属性,使得它们在各种模型中的表现相似,与损失函数的选择无关。此外,数据集的选择决定了模型的感知偏见——同一模型针对野外流行人物的性别平衡数据集表现出相反方向的偏见。对面部嵌入的研究表明,由于数据集的多样性,模型无法概括什么是构成“女性面孔”相对于“男性面孔”的统一定义。我们向模型开发人员建议使用本研究作为模型开发和后续部署的蓝图。
论文及项目相关链接
PDF This work has been accepted for publication at AAAI ICWSM 2025
Summary
本文研究了使用深度学习模型开发的自动面部识别系统(FRSs),针对性别预测任务进行了深入的分析。实验涉及三种FRSs,进行了多种架构修改,形成十种深度学习模型,与四种损失函数一起,在七个面部数据集上进行评估。结果表明,模型架构、损失函数和面部图像数据集对准确性和差异均有个人和共同影响。数据集具有一种内在属性,使得它们在模型之间表现出相似的性能,与损失函数的选择无关。此外,数据集的选择决定了模型的感知偏见。研究面部嵌入显示,由于数据集的多样性,模型无法为“女性面孔”和“男性面孔”提供一个统一的定义。
Key Takeaways
- 自动面部识别系统(FRSs)用于身份验证和面部属性分析,其性能受模型架构、优化/损失函数和数据集之间的复杂相互依赖关系影响。
- FRSs在性别预测任务上表现出对特定人群的差异性。
- 实验研究了三种FRSs,形成十种深度学习模型,与四种损失函数在七个面部数据集上进行评估。
- 数据集具有内在属性,影响模型的性能,且与损失函数的选择独立。
- 数据集选择对模型的感知偏见有决定性影响。
- 研究发现,由于数据集的多样性,模型在定义“女性面孔”和“男性面孔”时存在困难。
点此查看论文截图