⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
LUCAS: Layered Universal Codec Avatars
Authors:Di Liu, Teng Deng, Giljoo Nam, Yu Rong, Stanislav Pidhorskyi, Junxuan Li, Jason Saragih, Dimitris N. Metaxas, Chen Cao
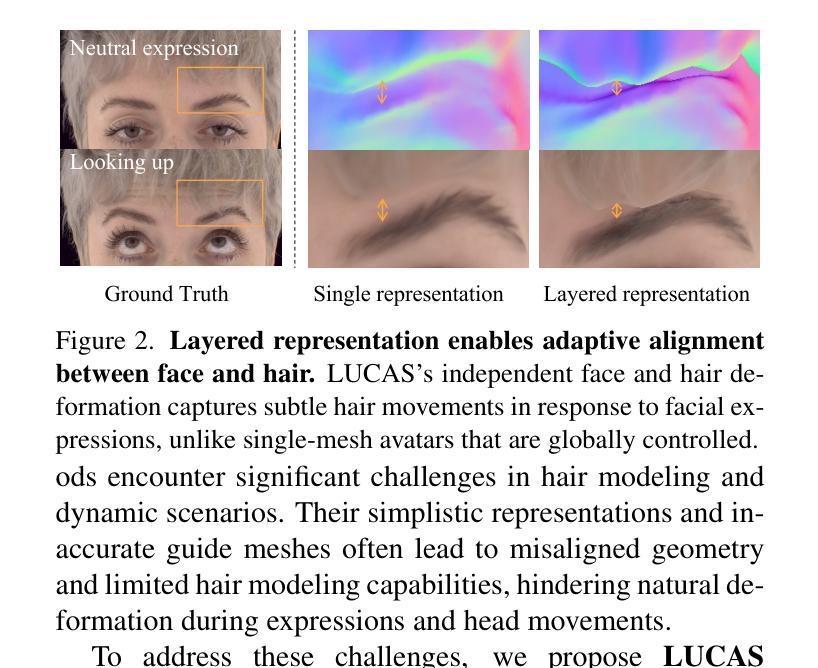
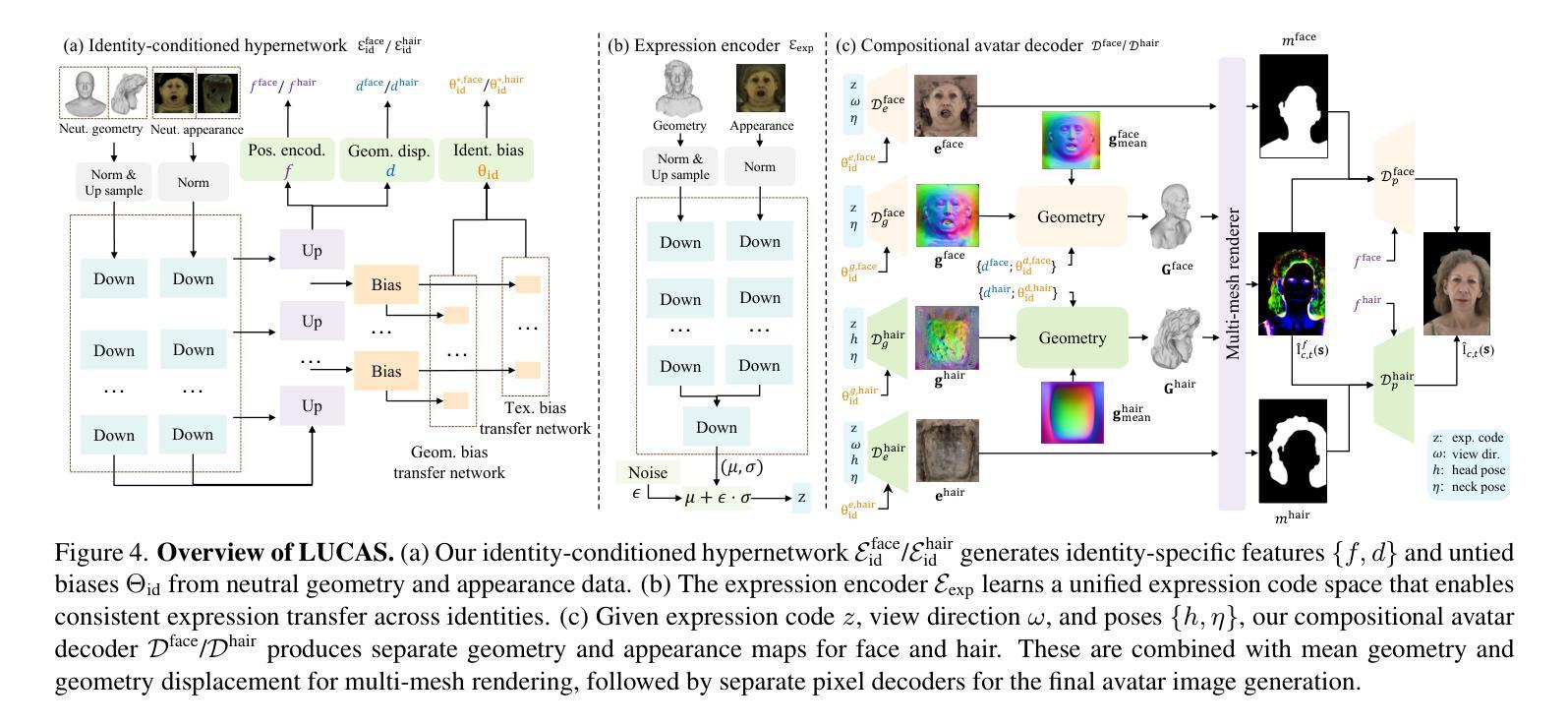
Photorealistic 3D head avatar reconstruction faces critical challenges in modeling dynamic face-hair interactions and achieving cross-identity generalization, particularly during expressions and head movements. We present LUCAS, a novel Universal Prior Model (UPM) for codec avatar modeling that disentangles face and hair through a layered representation. Unlike previous UPMs that treat hair as an integral part of the head, our approach separates the modeling of the hairless head and hair into distinct branches. LUCAS is the first to introduce a mesh-based UPM, facilitating real-time rendering on devices. Our layered representation also improves the anchor geometry for precise and visually appealing Gaussian renderings. Experimental results indicate that LUCAS outperforms existing single-mesh and Gaussian-based avatar models in both quantitative and qualitative assessments, including evaluations on held-out subjects in zero-shot driving scenarios. LUCAS demonstrates superior dynamic performance in managing head pose changes, expression transfer, and hairstyle variations, thereby advancing the state-of-the-art in 3D head avatar reconstruction.
关于现实感的3D头像化模型重建面临着在建模动态人脸-头发交互和实现跨身份泛化方面的关键挑战,特别是在表情和头部动作中。我们提出了一种新型通用先验模型(UPM)的LUCAS系统,用于编解码人像建模,它通过分层表示将人脸和头发分开。与之前将头发视为头部一部分的通用先验模型不同,我们的方法将无毛发的头部和头发分为不同的分支进行建模。LUCAS是首个引入基于网格的通用先验模型,能在设备上实现实时渲染。我们的分层表示法还改进了锚点几何结构,以实现精确且视觉上吸引人的高斯渲染。实验结果表明,无论是在定量评估还是定性评估中,LUCAS都优于现有的单网格和基于高斯的人像模型,包括对未见过的受试者在零样本驾驶场景中的评估。LUCAS在应对头部姿态变化、表情转移和发型变化方面表现出了卓越的动态性能,从而推动了业界在虚拟头像重建领域的技术发展。
论文及项目相关链接
Summary
该文章介绍了LUCAS系统,一种用于三维头像重建的通用先验模型(UPM)。该系统通过分层表示法将脸部和头发分离建模,解决了动态面部与头发交互建模以及跨身份泛化的问题。相较于传统将头发视为头部整体一部分的UPM,LUCAS将其分为无发头部和头发两个独立分支进行处理。此外,LUCAS首次引入基于网格的UPM,便于在设备上实时渲染。其分层表示法还改进了锚点几何结构,以实现精确且视觉上吸引人的高斯渲染。实验结果显示,LUCAS在定量和定性评估中均优于现有单网格和基于高斯的方法,特别是在零样本驾驶场景中的测试主体评估上表现出色。其优势在于能动态应对头部姿态变化、表情传递和发型变化,推动了三维头像重建领域的最新技术。
Key Takeaways
- LUCAS系统是一种先进的通用先验模型(UPM),用于三维头像重建。
- LUCAS通过分层表示法解决了动态面部与头发交互建模的问题,将脸部和头发分离建模。
- 与传统UPM不同,LUCAS将无发头部和头发分为两个独立分支处理。
- LUCAS首次引入基于网格的UPM,支持实时渲染。
- 分层表示法改进了锚点几何结构,实现更精确和视觉吸引力的高斯渲染。
- LUCAS在多种评估中表现优异,包括定量和定性评估、零样本驾驶场景测试等。
点此查看论文截图



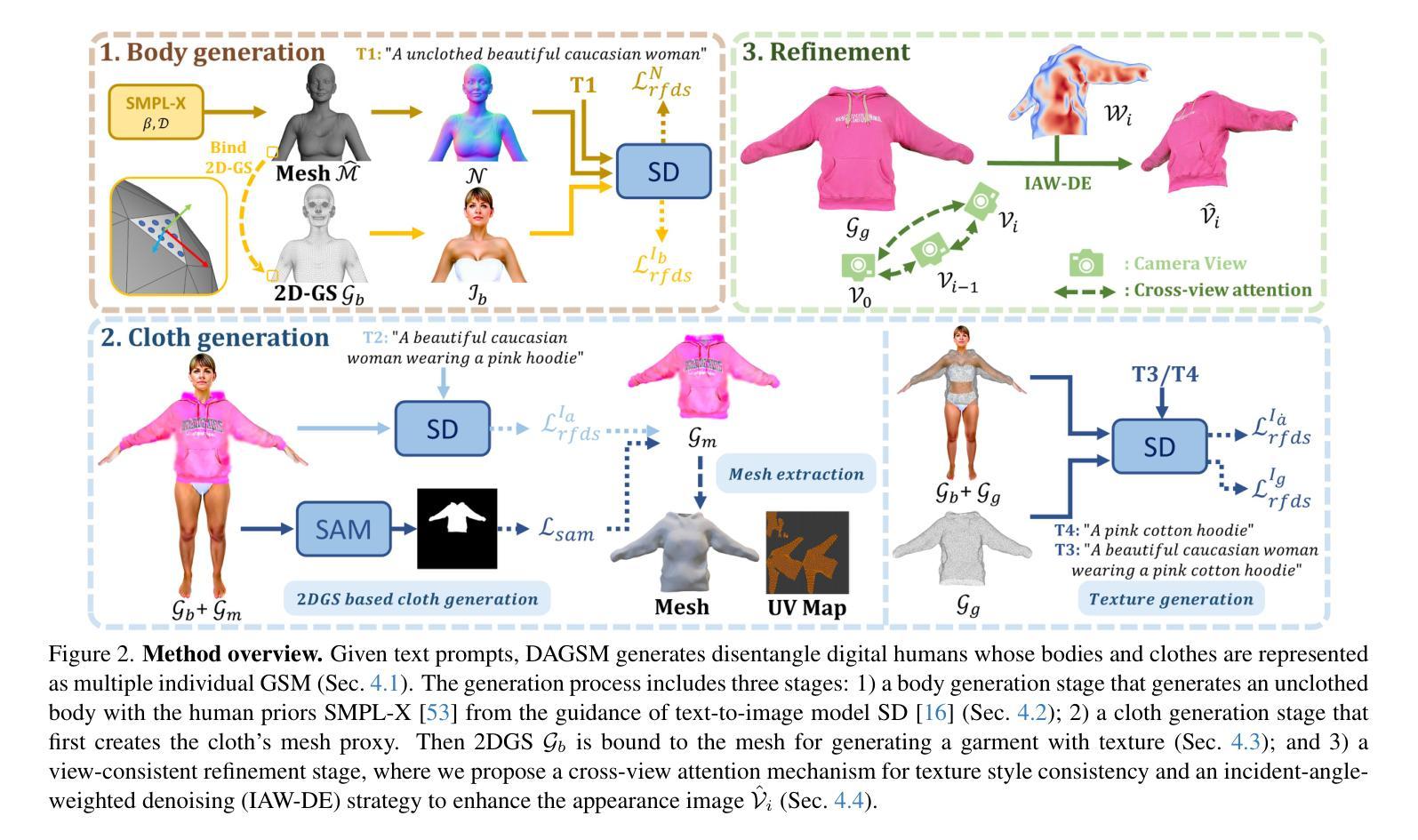
DAGSM: Disentangled Avatar Generation with GS-enhanced Mesh
Authors:Jingyu Zhuang, Di Kang, Linchao Bao, Liang Lin, Guanbin Li
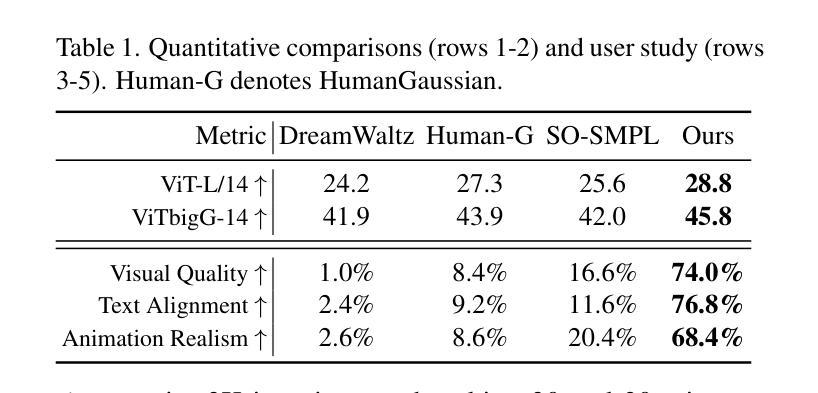
Text-driven avatar generation has gained significant attention owing to its convenience. However, existing methods typically model the human body with all garments as a single 3D model, limiting its usability, such as clothing replacement, and reducing user control over the generation process. To overcome the limitations above, we propose DAGSM, a novel pipeline that generates disentangled human bodies and garments from the given text prompts. Specifically, we model each part (e.g., body, upper/lower clothes) of the clothed human as one GS-enhanced mesh (GSM), which is a traditional mesh attached with 2D Gaussians to better handle complicated textures (e.g., woolen, translucent clothes) and produce realistic cloth animations. During the generation, we first create the unclothed body, followed by a sequence of individual cloth generation based on the body, where we introduce a semantic-based algorithm to achieve better human-cloth and garment-garment separation. To improve texture quality, we propose a view-consistent texture refinement module, including a cross-view attention mechanism for texture style consistency and an incident-angle-weighted denoising (IAW-DE) strategy to update the appearance. Extensive experiments have demonstrated that DAGSM generates high-quality disentangled avatars, supports clothing replacement and realistic animation, and outperforms the baselines in visual quality.
文本驱动的角色形象生成因其便利性而受到广泛关注。然而,现有方法通常将人体及其所有服装作为一个单一的3D模型进行建模,这限制了其可用性,例如服装更换,并降低了对生成过程的用户控制。为了克服上述局限性,我们提出了DAGSM,这是一种新型管道,可以从给定的文本提示生成解耦的人体和服装。具体来说,我们将人体的每个部分(例如身体、上下装)建模为一个GS增强的网格(GSM),这是一个传统的网格附加了2D高斯图以更好地处理复杂纹理(例如毛料、透明衣物)并产生逼真的服装动画。在生成过程中,我们首先创建裸体身体,然后基于身体生成一系列单独的服装,其中我们引入了一种基于语义的算法来实现更好的人衣和服装分离。为了提高纹理质量,我们提出了视图一致纹理优化模块,包括跨视图注意力机制以实现纹理风格的一致性以及基于入射角加权的去噪(IAW-DE)策略来更新外观。大量实验表明,DAGSM生成的高质量解耦角色形象支持服装更换和逼真动画,在视觉质量方面优于基线。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文提出一种名为DAGSM的新型文本驱动角色生成方法,克服了现有技术将人体与服装视为单一模型的局限性。该方法将人体各部分(如身体、上下衣物)分别建模为带有二维高斯增强的网格(GSM),以提高纹理处理能力和生成真实衣物动画的效果。通过先创建裸体,再基于身体生成一系列单独的衣物,引入语义算法实现人与衣物、衣物与衣物之间的更好分离。同时,通过跨视图纹理风格一致性机制和入射角加权去噪策略,改进纹理质量。实验证明,DAGSM能够生成高质量且相互独立的角色模型,支持换装和真实动画效果,在视觉质量上优于现有方法。
Key Takeaways
- DAGSM解决了现有文本驱动角色生成方法中的局限性,通过分别建模人体和服装来提高用户控制能力和实用性。
- 使用GS-增强网格(GSM)技术,将人体各部分以及服装作为独立模型处理,以处理复杂纹理和生成真实动画。
- 引入语义算法实现人与衣物、衣物与衣物之间的更好分离,提高生成角色的真实感。
- 提出跨视图纹理风格一致性机制和入射角加权去噪策略,改进纹理质量。
- DAGSM能够生成高质量且相互独立的角色模型,支持换装。
- 该方法在视觉质量上优于现有方法。
- DAGSM具有广泛的应用前景,如游戏、电影、虚拟现实等领域的角色生成和动画制作。
点此查看论文截图