⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
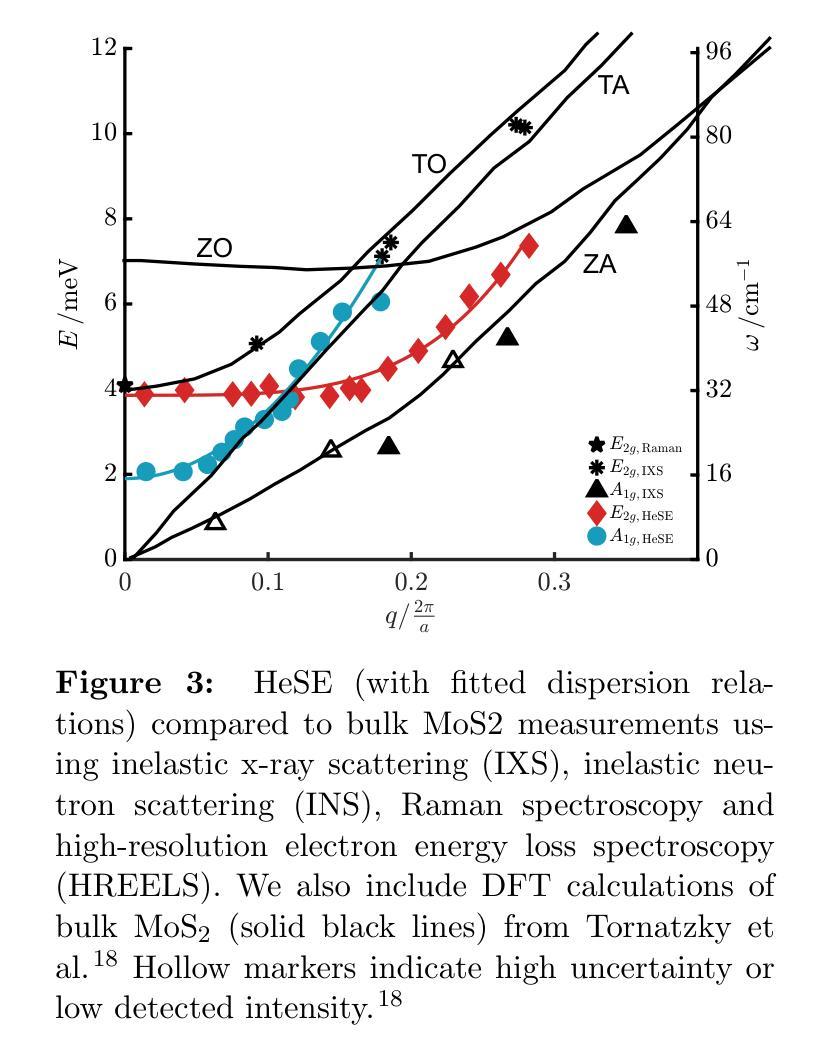
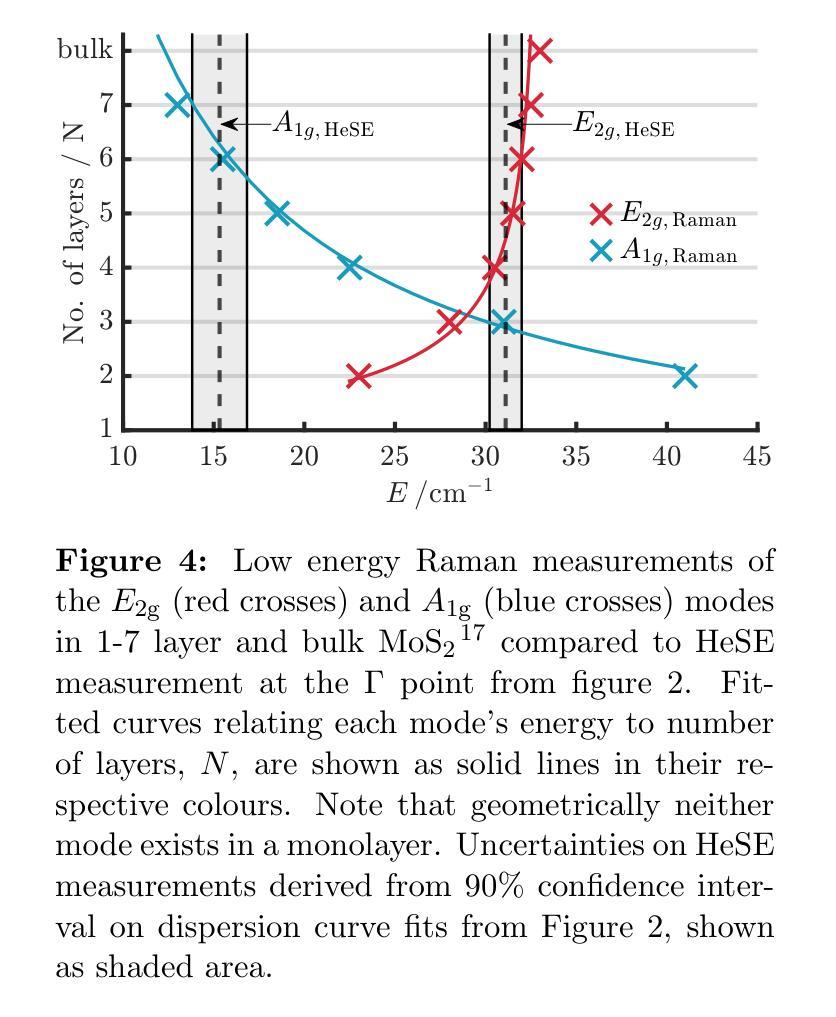
Surface phonons in MoS2
Authors:Aleksandar Radic, Boyao Liu, Andrew Jardine, Akshay Rao, Sam Lambrick
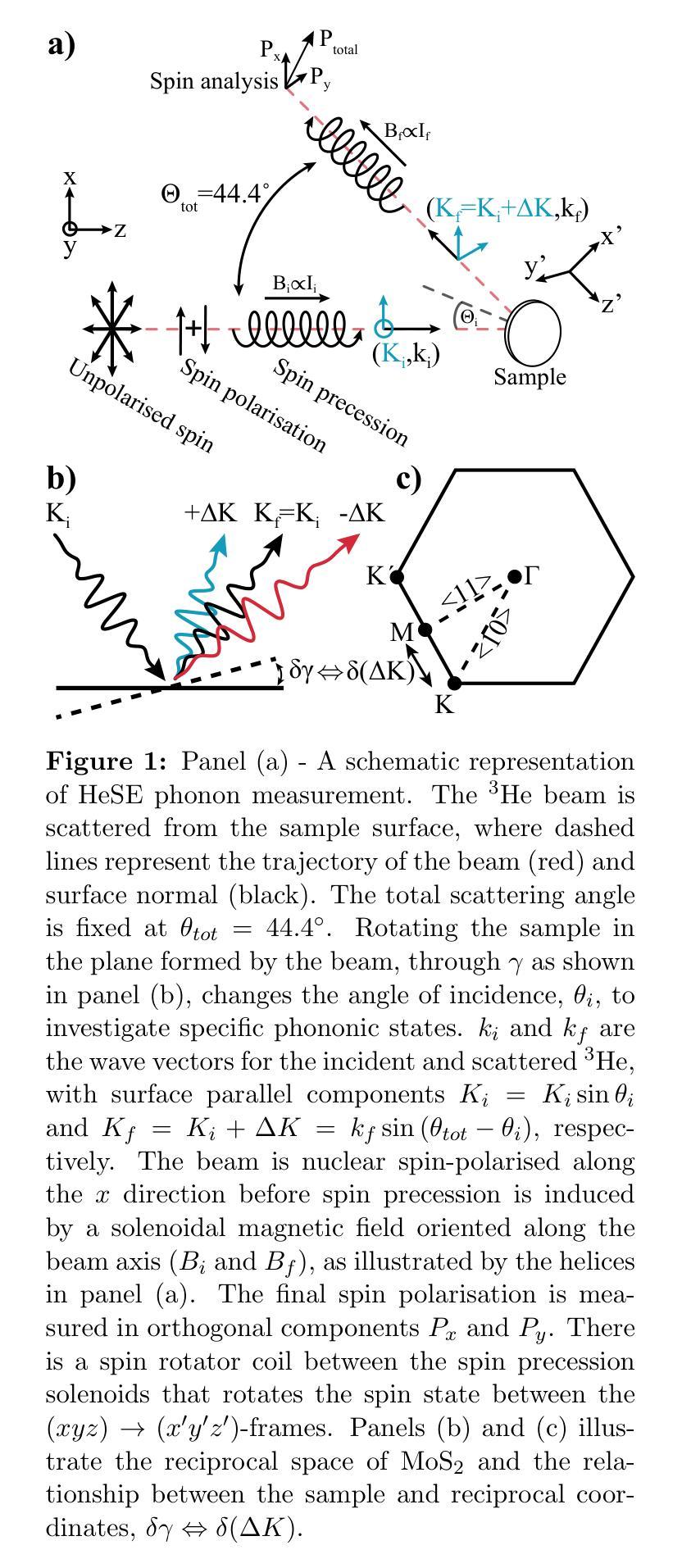
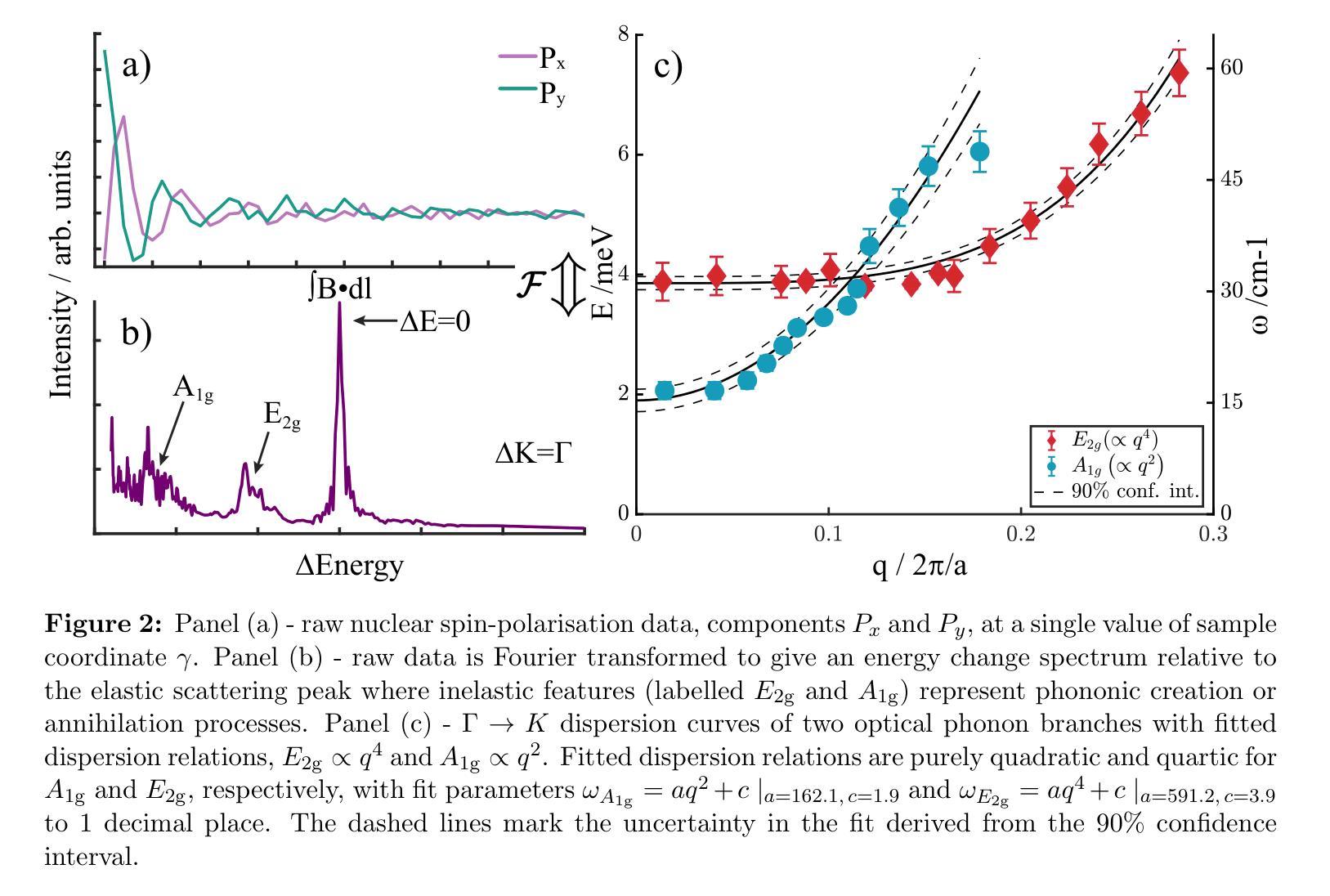
The thermal and electronic performance of atomically thin semiconductors is underpinned by their vibrational dynamics, yet surface phonons in layered materials remain poorly understood due to limitations in conventional experimental techniques. We employ helium-3 spin-echo (HeSE) spectroscopy to resolve the lowest energy (<10 meV) dispersions of surface phonons on bulk molybdenum disulfide (MoS\textsubscript{2}) with sub-meV energy resolution near $\Gamma$. We identify two low-energy optical modes, E_2g and A_1g, exhibiting unexpected quasi-acoustic dispersion, and crucially do not find evidence of an acoustic mode at the surface. A_1g follows a purely quadratic dispersion ((\omega_{A_{1g}} \propto q^2)), while (E_{2g}) displays quartic behaviour ((\omega_{E_{2g}} \propto q^4)), indicative of strong anharmonicity. These modes, absent in inelastic x-ray scattering (IXS) measurements and theoretical predictions of the bulk, exhibit finite-layer confinement equivalent to 4.5 and 6 layers, respectively. Their rapid dispersion yields substantial group velocities at small wavevectors, suggesting a dominant role in surface and few-layer thermal transport. This work establishes optical surface phonons as key drivers of thermal management in 2D materials and highlights the necessity of understanding surface phononics for designing next-generation optoelectronic devices.
原子级超薄半导体的热学和电子性能由其振动动力学支撑。然而,由于传统实验技术的局限性,层状材料中的表面声子仍了解不足。我们采用氦-3自旋回波(HeSE)光谱法,以亚毫电子伏特的能量分辨率,解决大块二硫化钼(MoS2)表面声子的最低能量(<10 meV)分散问题,接近于Γ。我们确定了两个低能光学模式,即E_2g和A_1g,它们表现出意外的准声学分散特征,并且关键的是,我们没有发现表面处的声学模式的证据。A_1g遵循纯二次分散((\omega_{A_{1g}} \propto q^2)),而E_2g表现出四次行为((\omega_{E_{2g}} \propto q^4)),表明具有强烈的非谐性。这些模式在弹性X射线散射(IXS)测量和大理论预测中均未发现,分别相当于4.5层和6层的有限层约束。它们快速的分散在小波矢下产生了可观的群速度,表明在表面和少层热输运中起着主导作用。这项工作确立了光学表面声子在二维材料热管理中的关键作用,并强调了了解表面声子学对于设计下一代光电子器件的必要性。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
该研究利用氦-3自旋回波光谱技术,解析了薄层二硫化钼表面声子的最低能量弥散关系。发现两种低能光学模式E_2g和A_1g具有意外的准声学弥散特性,并确定它们具有强烈的非线性行为。这些模式在光学特性上展现出有限的层限制,对表面和少层热传输起到重要作用。研究强调了光学表面声子在二维材料热管理中的重要性,为下一代光电子器件的设计提供了关键理解。
Key Takeaways
- 利用氦-3自旋回波光谱技术解析了薄层二硫化钼的表面声子弥散关系。
- 发现了两种低能光学模式E_2g和A_1g,具有准声学弥散特性。
- A_1g模式遵循纯粹的二次弥散,而E_2g模式显示四次行为,表明强烈的非谐性。
- 这些模式在弹性X射线散射测量中未被观察到,并且与理论预测不同。
- 观察到这些模式的有限层限制,相当于4.5和6层。
- 它们快速弥散产生较大的群速度,对表面和少层热传输起到重要作用。
- 研究强调了光学表面声子在二维材料热管理中的重要性。
点此查看论文截图

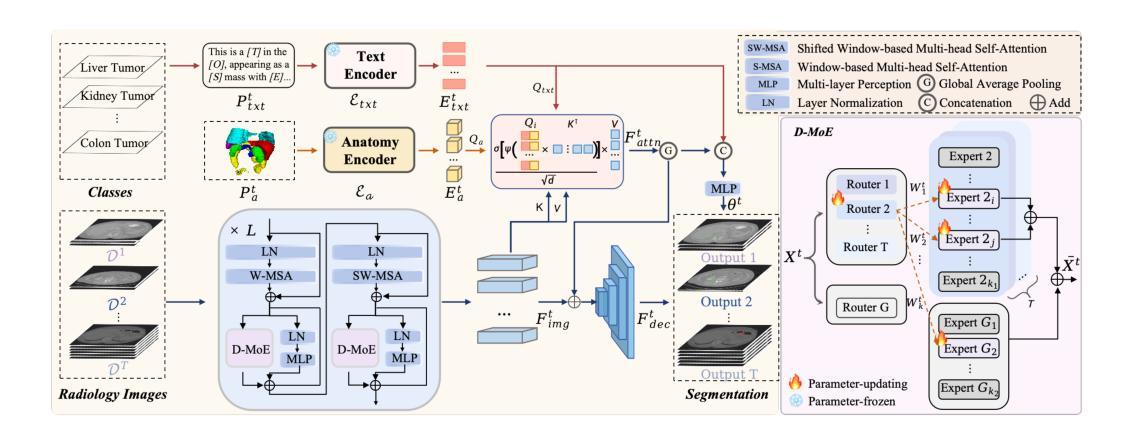
MAST-Pro: Dynamic Mixture-of-Experts for Adaptive Segmentation of Pan-Tumors with Knowledge-Driven Prompts
Authors:Runqi Meng, Sifan Song, Pengfei Jin, Yujin Oh, Lin Teng, Yulin Wang, Yiqun Sun, Ling Chen, Xiang Li, Quanzheng Li, Ning Guo, Dinggang Shen
Accurate tumor segmentation is crucial for cancer diagnosis and treatment. While foundation models have advanced general-purpose segmentation, existing methods still struggle with: (1) limited incorporation of medical priors, (2) imbalance between generic and tumor-specific features, and (3) high computational costs for clinical adaptation. To address these challenges, we propose MAST-Pro (Mixture-of-experts for Adaptive Segmentation of pan-Tumors with knowledge-driven Prompts), a novel framework that integrates dynamic Mixture-of-Experts (D-MoE) and knowledge-driven prompts for pan-tumor segmentation. Specifically, text and anatomical prompts provide domain-specific priors, guiding tumor representation learning, while D-MoE dynamically selects experts to balance generic and tumor-specific feature learning, improving segmentation accuracy across diverse tumor types. To enhance efficiency, we employ Parameter-Efficient Fine-Tuning (PEFT), optimizing MAST-Pro with significantly reduced computational overhead. Experiments on multi-anatomical tumor datasets demonstrate that MAST-Pro outperforms state-of-the-art approaches, achieving up to a 5.20% improvement in average DSC while reducing trainable parameters by 91.04%, without compromising accuracy.
准确的肿瘤分割对于癌症诊断和治疗至关重要。虽然基础模型已经推动了通用分割的进展,但现有方法仍然面临挑战:(1)医疗先验知识的有限融合;(2)通用和肿瘤特定特征之间的不平衡;(3)临床适应的高计算成本。为了解决这些挑战,我们提出了MAST-Pro(基于知识驱动提示的适应性强泛化肿瘤分割混合专家模型),这是一个集成了动态混合专家(D-MoE)和知识驱动提示的泛肿瘤分割新框架。具体来说,文本和解剖提示提供了特定领域的先验知识,指导肿瘤表示学习,而D-MoE则动态选择专家来平衡通用和肿瘤特定特征的学习,从而提高各种肿瘤类型的分割精度。为了提高效率,我们采用了参数高效微调(PEFT)技术,以显著降低计算开销来优化MAST-Pro。在多解剖肿瘤数据集上的实验表明,MAST-Pro超越了最先进的方法,平均DSC值提高了高达5.20%,同时减少了91.04%的可训练参数,且不影响准确性。
论文及项目相关链接
PDF 10 pages, 2 figures
Summary
本文提出了MAST-Pro框架,该框架集成了动态混合专家(D-MoE)和知识驱动提示,用于泛肿瘤分割。通过结合医学先验、平衡通用和肿瘤特异性特征学习,以及采用参数高效微调(PEFT)提高计算效率,MAST-Pro在多种肿瘤类型分割中实现了高精度和高效能。
Key Takeaways
- 肿瘤精准分割对癌症诊断和治疗至关重要。
- 当前方法在面对泛肿瘤分割时面临挑战,如缺乏医学先验的融入、通用与肿瘤特异性特征之间的不平衡以及高计算成本。
- MAST-Pro框架集成了动态混合专家(D-MoE)和知识驱动提示,以解决上述问题。
- 文本和解剖提示为领域特定先验提供了指导,引导肿瘤表示学习。
- D-MoE能够动态选择专家,以平衡通用和肿瘤特异性特征学习,提高分割精度。
- 参数高效微调(PEFT)技术用于优化MAST-Pro,显著减少计算开销。
点此查看论文截图

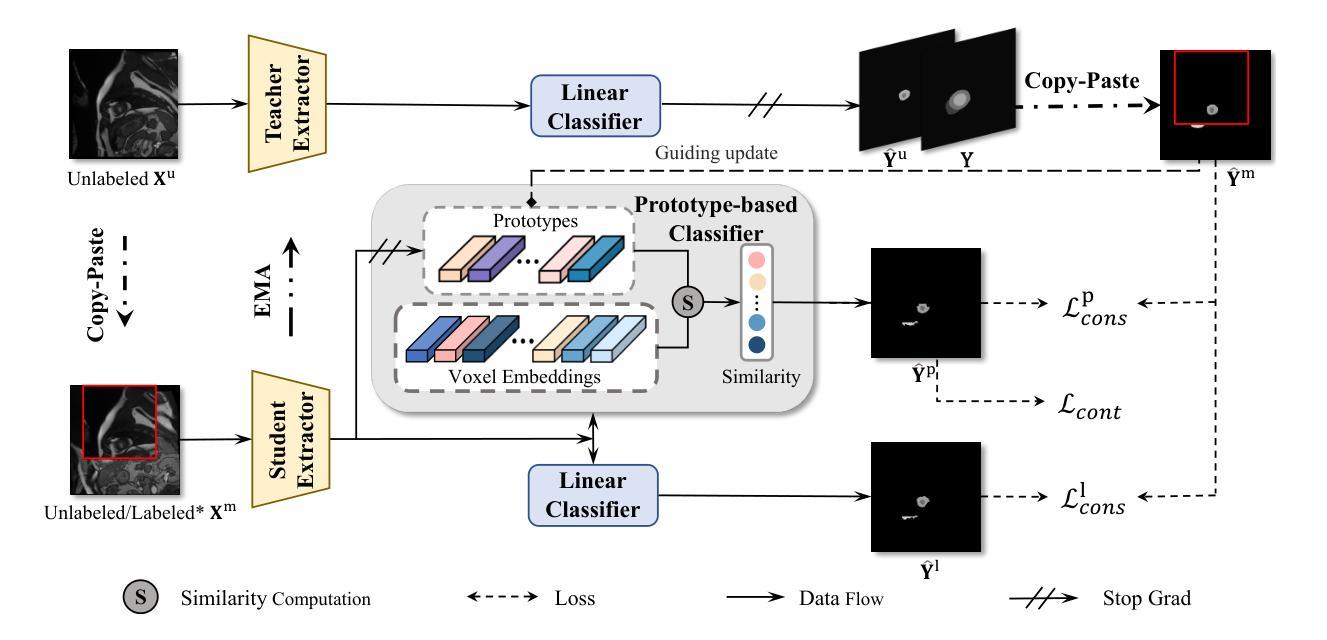
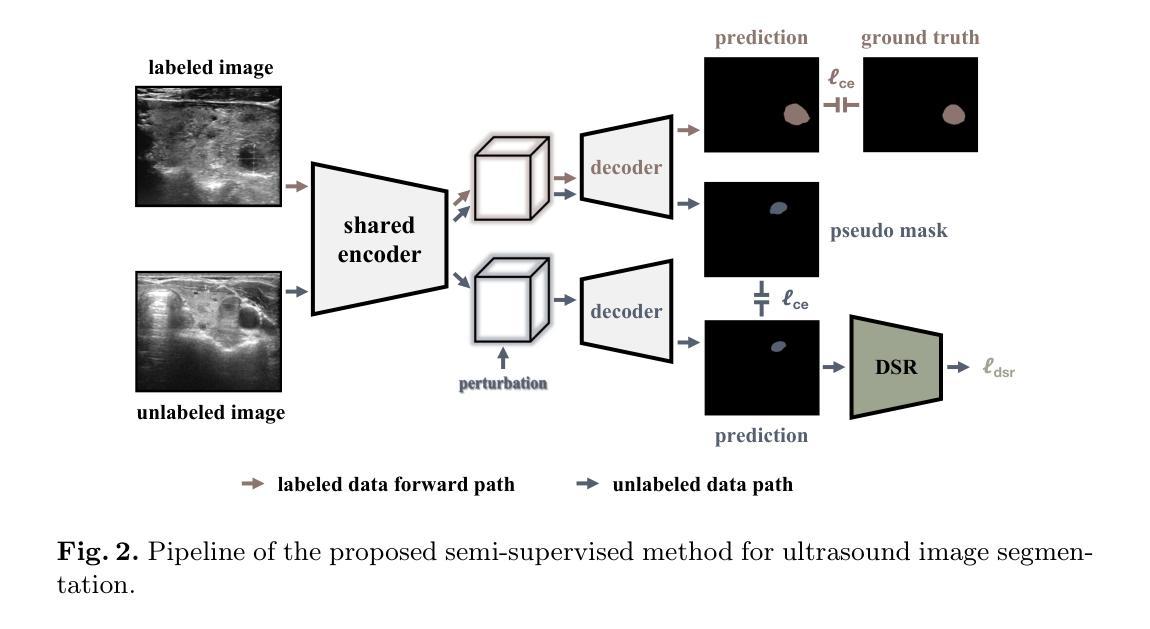
Multi-Prototype Embedding Refinement for Semi-Supervised Medical Image Segmentation
Authors:Yali Bi, Enyu Che, Yinan Chen, Yuanpeng He, Jingwei Qu
Medical image segmentation aims to identify anatomical structures at the voxel-level. Segmentation accuracy relies on distinguishing voxel differences. Compared to advancements achieved in studies of the inter-class variance, the intra-class variance receives less attention. Moreover, traditional linear classifiers, limited by a single learnable weight per class, struggle to capture this finer distinction. To address the above challenges, we propose a Multi-Prototype-based Embedding Refinement method for semi-supervised medical image segmentation. Specifically, we design a multi-prototype-based classification strategy, rethinking the segmentation from the perspective of structural relationships between voxel embeddings. The intra-class variations are explored by clustering voxels along the distribution of multiple prototypes in each class. Next, we introduce a consistency constraint to alleviate the limitation of linear classifiers. This constraint integrates different classification granularities from a linear classifier and the proposed prototype-based classifier. In the thorough evaluation on two popular benchmarks, our method achieves superior performance compared with state-of-the-art methods. Code is available at https://github.com/Briley-byl123/MPER.
医学图像分割旨在体素级别上识别解剖结构。分割精度依赖于区分体素差异的能力。相较于类间方差的研究进展,类内方差受到的关注较少。此外,传统线性分类器每类只有一个可学习的权重,难以捕捉这种更精细的区分。为了解决上述挑战,我们提出了一种基于多原型嵌入精化的半监督医学图像分割方法。具体来说,我们设计了一种基于多原型的分类策略,从体素嵌入的结构关系角度重新思考分割问题。我们通过聚类每类中的多个原型分布上的体素来探索类内变化。接下来,我们引入一致性约束来缓解线性分类器的局限性。该约束融合了线性分类器和所提出的基于原型的分类器之间的不同分类粒度。在两个流行基准的严格评估中,我们的方法与最先进的方法相比取得了优越的性能。代码可从https://github.com/Briley-byl123/MPER获得。
论文及项目相关链接
Summary
本文提出一种基于多原型嵌入精修的半监督医学图像分割方法。该方法设计了一种多原型分类策略,从像素嵌入的结构关系角度重新思考分割问题。通过聚类每个类中的多个原型分布来探索类内变化,并引入一致性约束来缓解线性分类器的局限性。该方法在两个流行基准测试上表现出卓越性能。
Key Takeaways
- 医学图像分割旨在以体素级别识别解剖结构。
- 分割准确性依赖于区分体素差异的能力。
- 传统线性分类器在捕捉类内细微差异方面存在局限性。
- 提出了一种基于多原型嵌入精修的半监督医学图像分割方法。
- 该方法通过聚类每个类别中的多个原型分布来探索类内变化。
- 引入一致性约束,结合线性分类器与原型分类器进行不同粒度分类。
点此查看论文截图

A Modular Edge Device Network for Surgery Digitalization
Authors:Vincent Schorp, Frédéric Giraud, Gianluca Pargätzi, Michael Wäspe, Lorenzo von Ritter-Zahony, Marcel Wegmann, John Garcia Henao, Dominique Cachin, Sebastiano Caprara, Philipp Fürnstahl, Fabio Carrillo
Future surgical care demands real-time, integrated data to drive informed decision-making and improve patient outcomes. The pressing need for seamless and efficient data capture in the OR motivates our development of a modular solution that bridges the gap between emerging machine learning techniques and interventional medicine. We introduce a network of edge devices, called Data Hubs (DHs), that interconnect diverse medical sensors, imaging systems, and robotic tools via optical fiber and a centralized network switch. Built on the NVIDIA Jetson Orin NX, each DH supports multiple interfaces (HDMI, USB-C, Ethernet) and encapsulates device-specific drivers within Docker containers using the Isaac ROS framework and ROS2. A centralized user interface enables straightforward configuration and real-time monitoring, while an Nvidia DGX computer provides state-of-the-art data processing and storage. We validate our approach through an ultrasound-based 3D anatomical reconstruction experiment that combines medical imaging, pose tracking, and RGB-D data acquisition.
未来的外科手术护理需求要求实时集成数据以支持做出明智的决策并改善患者结果。手术室内无缝高效的数据采集需求促使我们开发了一种模块化解决方案,以弥新兴机器学习技术与介入医学之间的差距。我们引入了一种边缘设备网络,称为数据中心(DHs),它通过光纤和集中式网络交换机互联各种医疗传感器、成像系统和机器人工具。每个数据中心都基于NVIDIA Jetson Orin NX构建,支持多个接口(HDMI、USB-C、以太网),并使用Isaac ROS框架和ROS2在Docker容器中封装设备特定驱动程序。集中式用户界面可实现简易配置和实时监控,而Nvidia DGX计算机则提供先进的数据处理和存储功能。我们通过基于超声的3D解剖重建实验验证了我们的方法,该实验结合了医学成像、姿态跟踪和RGB-D数据采集。
论文及项目相关链接
Summary
手术未来需求实时、整合数据以推动决策制定并改善患者结果。为解决手术室数据无缝高效采集的迫切需求,我们开发了一种模块化解决方案,该方案可桥接新兴机器学习技术与介入医学之间的差距。我们引入了边缘设备网络,称为数据中心(DHs),通过光纤和集中式网络交换机互联各种医疗传感器、成像系统和机器人工具。每个数据中心都基于NVIDIA Jetson Orin NX构建,支持多个接口(HDMI、USB-C、以太网),并使用Isaac ROS框架和ROS2封装设备特定驱动程序在Docker容器中。一个集中的用户界面可实现简易配置和实时监控,而Nvidia DGX计算机则提供先进的数据处理和存储功能。我们通过结合医学成像、姿态追踪和RGB-D数据采集的超声三维重建实验验证了我们的方法。
Key Takeaways
- 未来手术需求实时整合数据以提高决策效率和患者治疗效果。
- 介绍了边缘设备网络(数据中枢)作为手术室数据收集的模块化解决方案。
- 数据中枢可连接多样化的医疗传感器、成像系统和机器人工具。
- 数据中枢基于NVIDIA Jetson Orin NX构建,具有多种接口并支持多种设备驱动程序封装。
- 采用Isaac ROS框架和ROS2实现设备驱动的封装及高效数据处理。
- 集中化的用户界面提供简易配置和实时监控功能。
点此查看论文截图

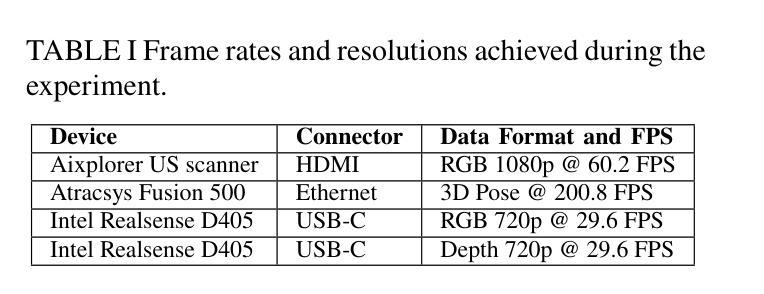
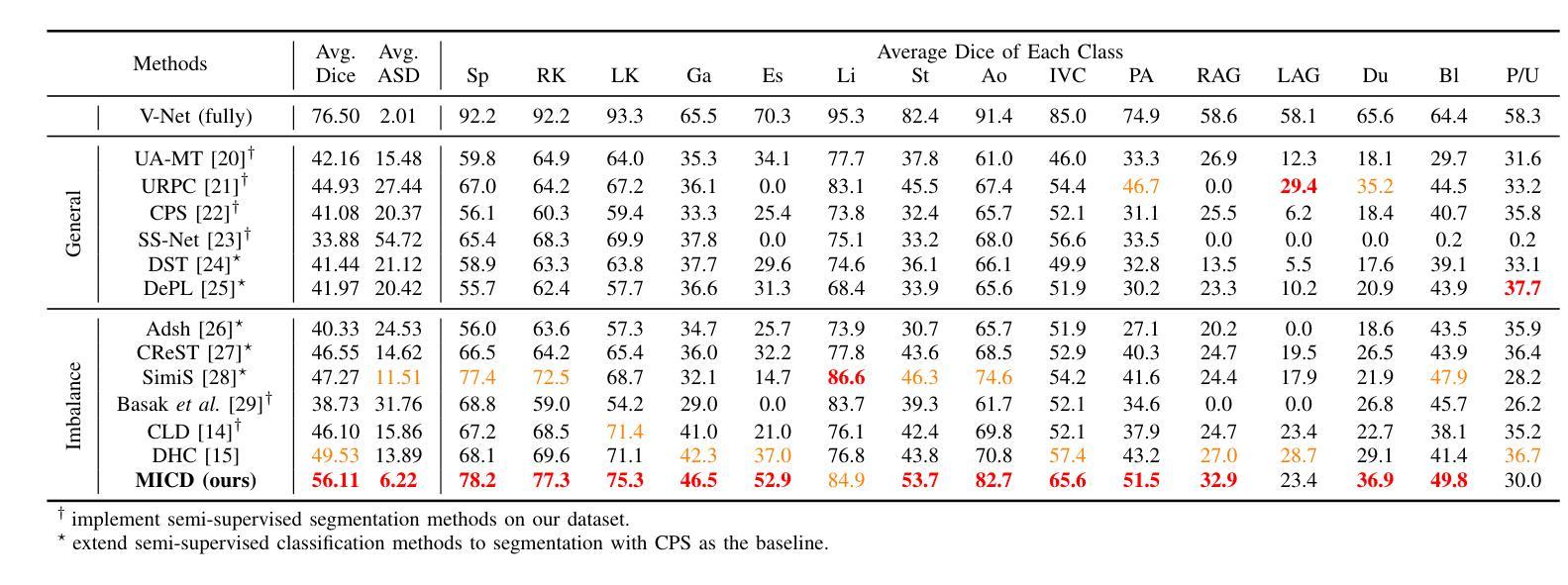
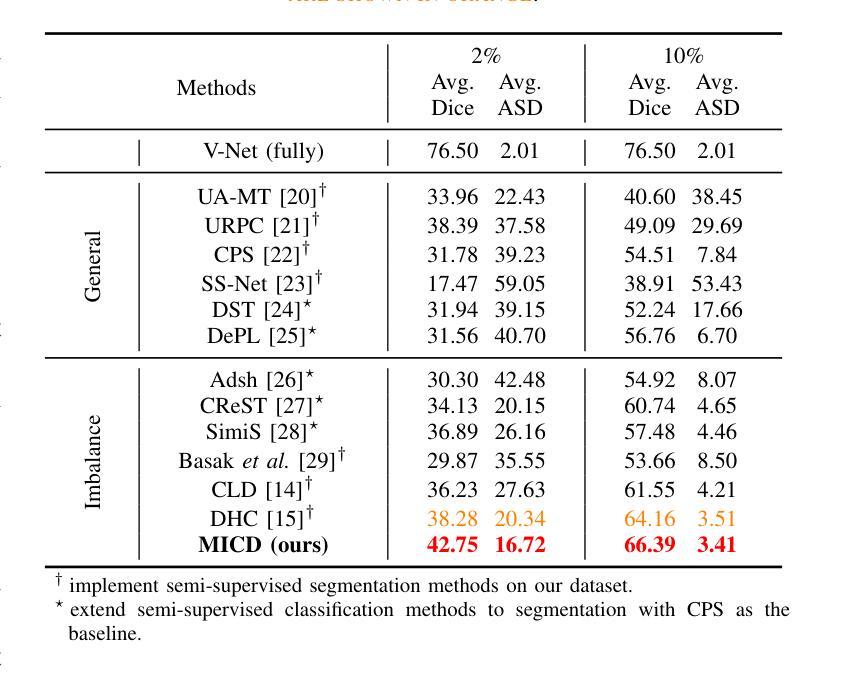
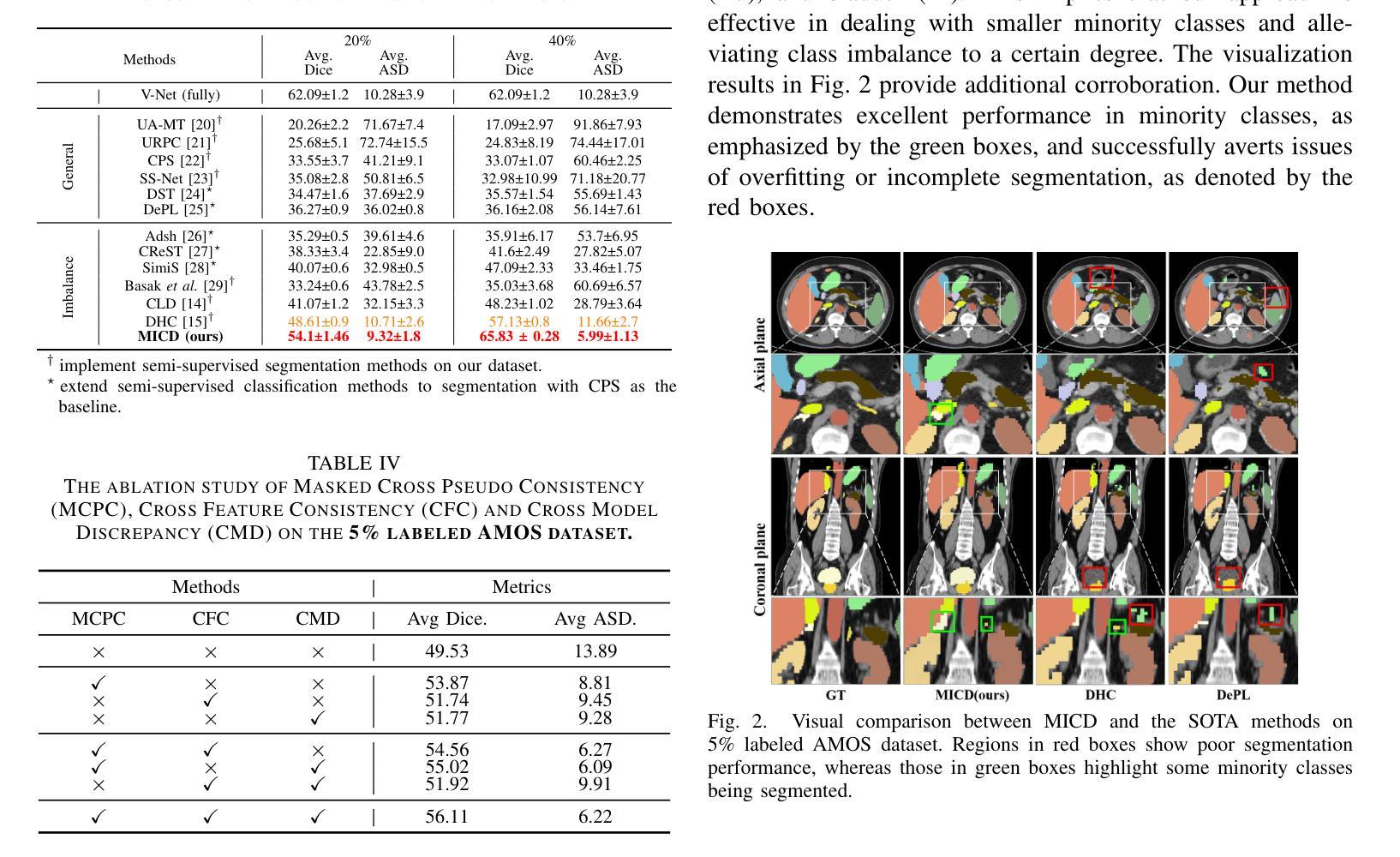
Boosting Semi-Supervised Medical Image Segmentation via Masked Image Consistency and Discrepancy Learning
Authors:Pengcheng Zhou, Lantian Zhang, Wei Li
Semi-supervised learning is of great significance in medical image segmentation by exploiting unlabeled data. Among its strategies, the co-training framework is prominent. However, previous co-training studies predominantly concentrate on network initialization variances and pseudo-label generation, while overlooking the equilibrium between information interchange and model diversity preservation. In this paper, we propose the Masked Image Consistency and Discrepancy Learning (MICD) framework with three key modules. The Masked Cross Pseudo Consistency (MCPC) module enriches context perception and small sample learning via pseudo-labeling across masked-input branches. The Cross Feature Consistency (CFC) module fortifies information exchange and model robustness by ensuring decoder feature consistency. The Cross Model Discrepancy (CMD) module utilizes EMA teacher networks to oversee outputs and preserve branch diversity. Together, these modules address existing limitations by focusing on fine-grained local information and maintaining diversity in a heterogeneous framework. Experiments on two public medical image datasets, AMOS and Synapse, demonstrate that our approach outperforms state-of-the-art methods.
在医学图像分割中,利用无标签数据进行半监督学习具有重要意义。在其策略中,协同训练框架尤为突出。然而,之前的协同训练研究主要集中在网络初始化差异和伪标签生成上,忽视了信息交换与模型多样性保持之间的平衡。在本文中,我们提出了带有三个关键模块的Masked Image Consistency and Discrepancy Learning (MICD)框架。其中,Masked Cross Pseudo Consistency (MCPC)模块通过跨掩码输入分支的伪标签丰富上下文感知和小样本学习。Cross Feature Consistency (CFC)模块通过确保解码器特征一致性,强化信息交换和模型稳健性。Cross Model Discrepancy (CMD)模块利用EMA教师网络来监督输出并保持分支多样性。这三个模块共同解决了现有问题,通过关注精细的局部信息并在异构框架中保持多样性。在公共医学图像数据集AMOS和Synapse上的实验表明,我们的方法优于最先进的方法。
论文及项目相关链接
摘要
医学图像分割中半监督学习利用未标注数据具有重要意义,其中协同训练框架尤为突出。然而,以往的协同训练研究主要集中在网络初始化差异和伪标签生成上,忽视了信息交换与模型多样性保持之间的平衡。本文提出带有三个关键模块的Masked Image Consistency and Discrepancy Learning(MICD)框架。其中,Masked Cross Pseudo Consistency(MCPC)模块通过跨掩膜输入分支的伪标签丰富上下文感知和小样本学习;Cross Feature Consistency(CFC)模块通过确保解码器特征一致性,强化信息交换和模型稳健性;Cross Model Discrepancy(CMD)模块利用EMA教师网络监督输出并保持分支多样性。这三个模块共同解决了现有限制,专注于精细的局部信息,并在异质框架中保持多样性。在公共医学图像数据集AMOS和Synapse上的实验表明,我们的方法优于最新技术。
关键见解
- 半监督学习在医学图像分割中利用未标注数据具有重要意义。
- 以往的协同训练研究主要关注网络初始化和伪标签生成,忽略了信息交换与模型多样性之间的平衡。
- 提出的MICD框架包括三个关键模块,旨在解决这些问题并改进医学图像分割的效果。
- MCPC模块通过伪标签丰富上下文感知和小样本学习。
- CFC模块强化信息交换和模型稳健性,确保解码器特征一致性。
- CMD模块利用EMA教师网络来监督输出并保持模型分支的多样性。
点此查看论文截图

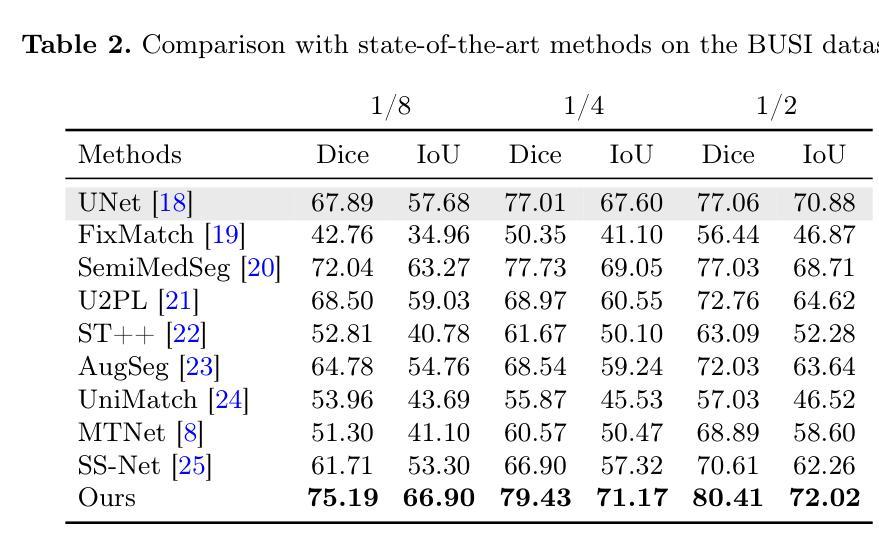
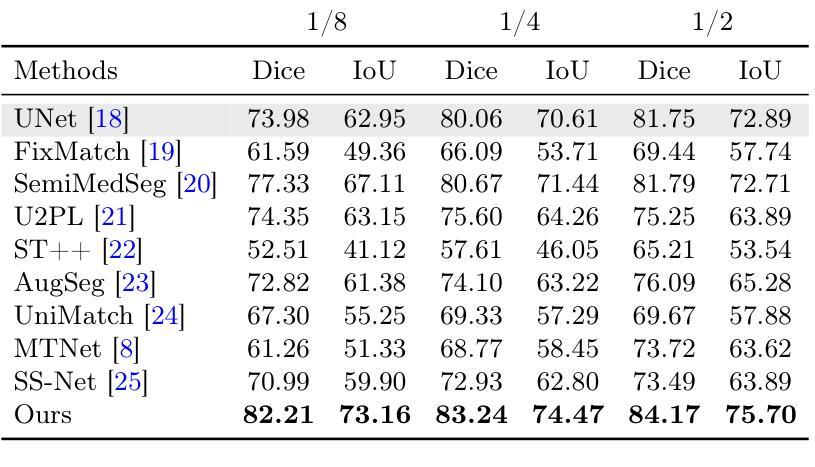
Striving for Simplicity: Simple Yet Effective Prior-Aware Pseudo-Labeling for Semi-Supervised Ultrasound Image Segmentation
Authors:Yaxiong Chen, Yujie Wang, Zixuan Zheng, Jingliang Hu, Yilei Shi, Shengwu Xiong, Xiao Xiang Zhu, Lichao Mou
Medical ultrasound imaging is ubiquitous, but manual analysis struggles to keep pace. Automated segmentation can help but requires large labeled datasets, which are scarce. Semi-supervised learning leveraging both unlabeled and limited labeled data is a promising approach. State-of-the-art methods use consistency regularization or pseudo-labeling but grow increasingly complex. Without sufficient labels, these models often latch onto artifacts or allow anatomically implausible segmentations. In this paper, we present a simple yet effective pseudo-labeling method with an adversarially learned shape prior to regularize segmentations. Specifically, we devise an encoder-twin-decoder network where the shape prior acts as an implicit shape model, penalizing anatomically implausible but not ground-truth-deviating predictions. Without bells and whistles, our simple approach achieves state-of-the-art performance on two benchmarks under different partition protocols. We provide a strong baseline for future semi-supervised medical image segmentation. Code is available at https://github.com/WUTCM-Lab/Shape-Prior-Semi-Seg.
医学超声成像技术非常普遍,但手动分析很难跟上其发展的步伐。虽然自动化分割技术可以辅助分析,但需要大量的标记数据集,而这些数据却很稀缺。利用无标签和有限标签数据的半监督学习是一种很有前景的方法。最先进的方法使用一致性正则化或伪标签技术,但模型日益复杂。若没有足够的标签,这些模型往往会依附于伪像或允许解剖上不可能的分割。在本文中,我们提出了一种简单有效的伪标签方法,利用对抗学习的形状先验来规范分割。具体来说,我们设计了一个编码器-孪生解码器网络,其中形状先验充当隐式形状模型,对解剖上不可能但并非偏离真实情况的预测进行惩罚。我们的简单方法在不同的分区协议下实现了两个基准测试的最先进性能,为未来半监督医学图像分割提供了强有力的基准。代码可在https://github.com/WUTCM-Lab/Shape-Prior-Semi-Seg找到。
论文及项目相关链接
PDF MICCAI 2024
Summary
医学超声成像广泛应用,但手动分析难以跟上速度。自动化分割可帮助但需求大量标记数据集,这些很稀缺。半监督学习利用无标签和有限标签数据是一个有前景的方法。当前方法使用一致性正则化或伪标签但越来越复杂。没有足够标签,这些模型常因附着于伪影或允许解剖上不合理分割。本文提出一种简单有效的伪标签方法与对抗训练形状先验分割方法相结合。特别地,我们设计了一种编码器和双胞胎解码器网络,其中形状先验充当隐性形状模型,以解剖不可能作为预测罚款基准但不应偏离真实值。我们的简单方法在两个基准测试下实现了业界领先性能,为未来的半监督医学图像分割提供了强有力的基线。代码公开于:链接地址。
Key Takeaways
- 医学超声成像广泛应用,但手动分析耗时耗力,寻求自动化解决方案成为研究热点。
- 自动化分割技术需要大量标记数据集,但实际中这些资源稀缺。
- 半监督学习方法能有效利用有限的标签数据和无标签数据,展现出良好的应用前景。
- 当前复杂模型方法容易出现解剖上不合理的分割结果。
- 本文提出了一种结合对抗性训练形状先验的伪标签方法,实现了医学图像分割的优异性能。
- 该方法设计了一种简单的编码器和双胞胎解码器网络结构,其中形状先验起到关键作用。
点此查看论文截图

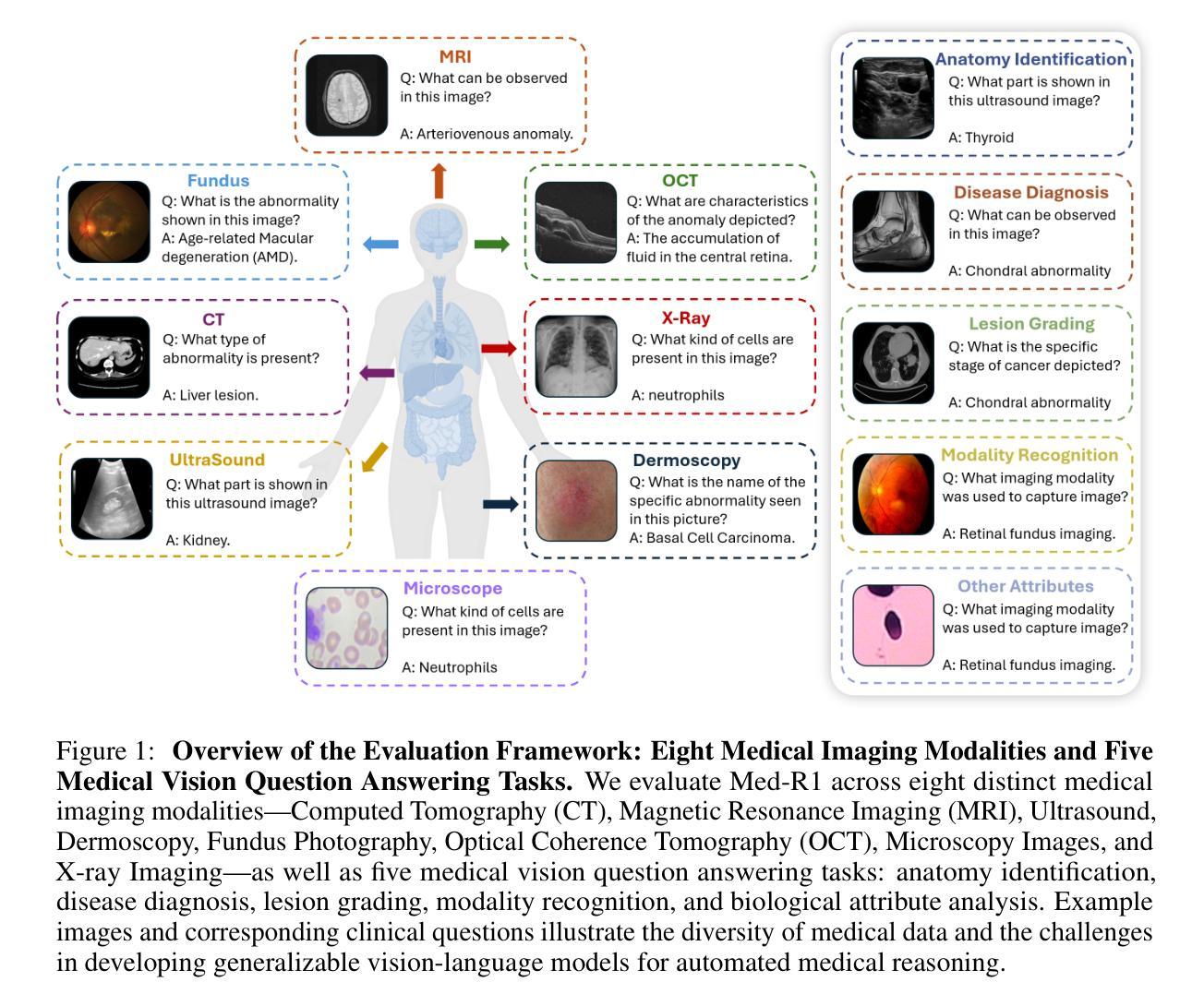
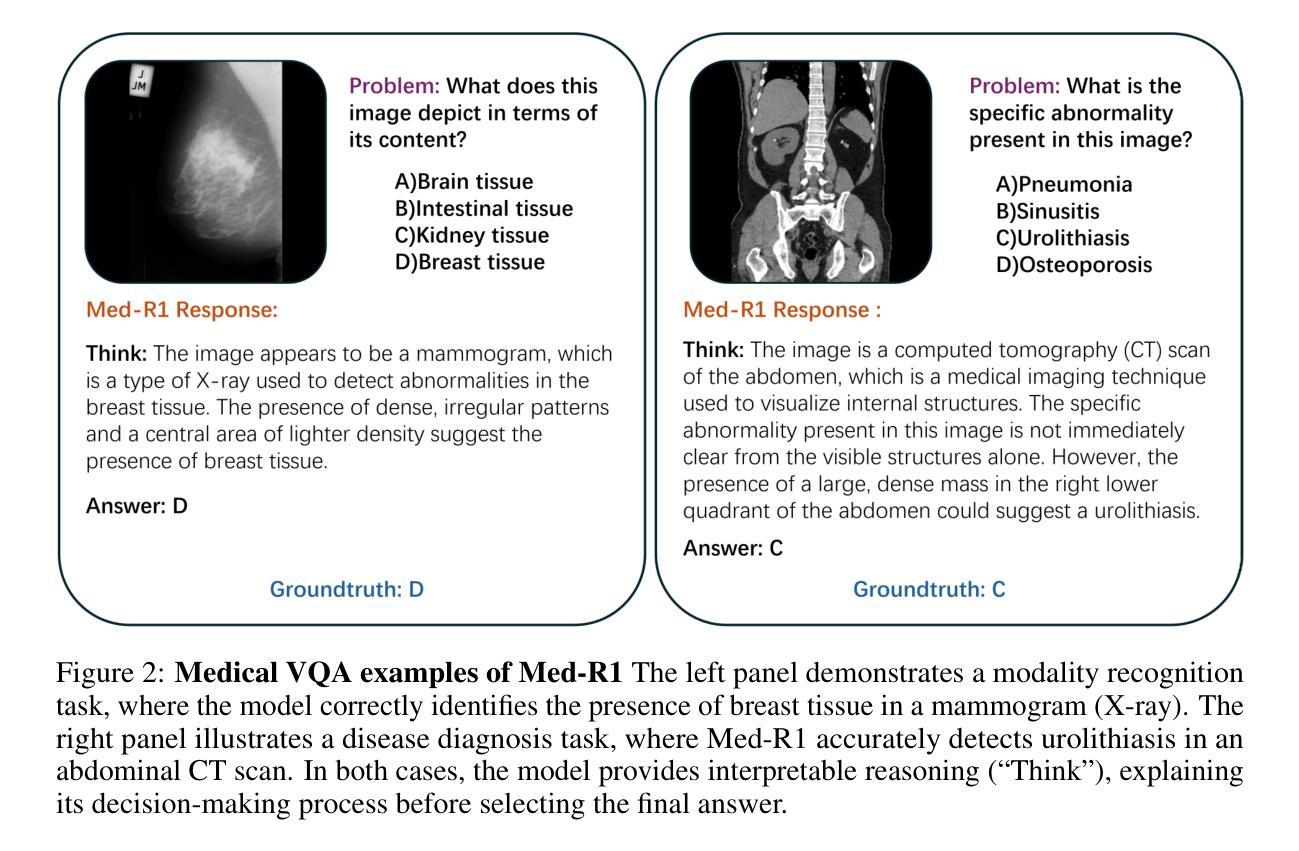
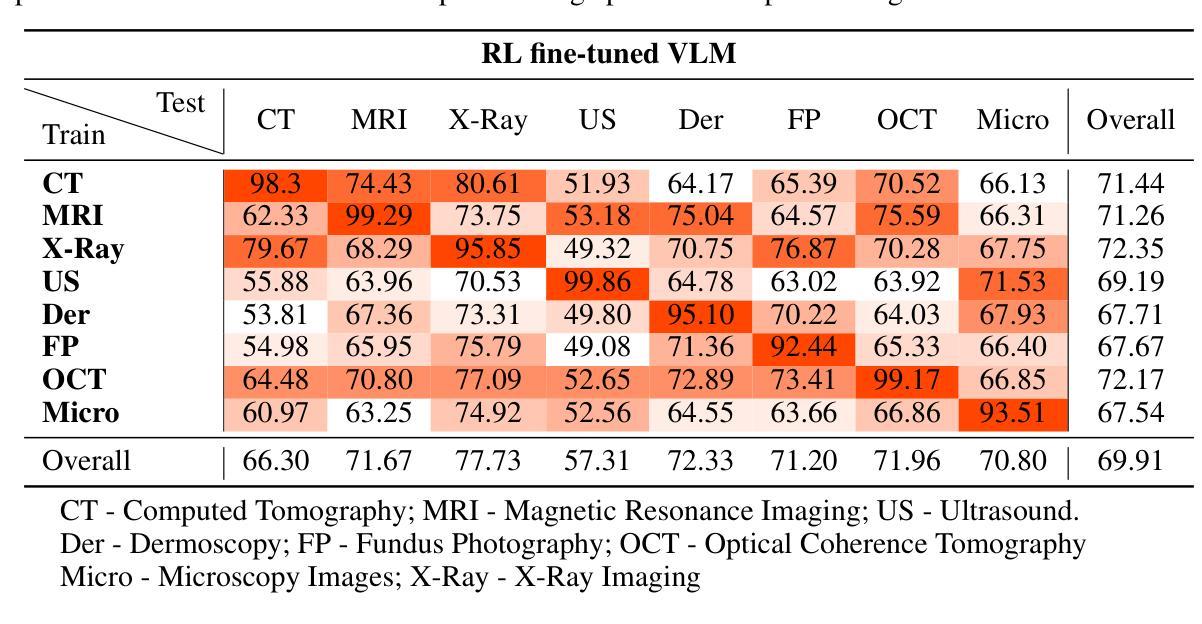
Med-R1: Reinforcement Learning for Generalizable Medical Reasoning in Vision-Language Models
Authors:Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Xiaofeng Yang
Vision-language models (VLMs) have advanced reasoning in natural scenes, but their role in medical imaging remains underexplored. Medical reasoning tasks demand robust image analysis and well-justified answers, posing challenges due to the complexity of medical images. Transparency and trustworthiness are essential for clinical adoption and regulatory compliance. We introduce Med-R1, a framework exploring reinforcement learning (RL) to enhance VLMs’ generalizability and trustworthiness in medical reasoning. Leveraging the DeepSeek strategy, we employ Group Relative Policy Optimization (GRPO) to guide reasoning paths via reward signals. Unlike supervised fine-tuning (SFT), which often overfits and lacks generalization, RL fosters robust and diverse reasoning. Med-R1 is evaluated across eight medical imaging modalities: CT, MRI, Ultrasound, Dermoscopy, Fundus Photography, Optical Coherence Tomography (OCT), Microscopy, and X-ray Imaging. Compared to its base model, Qwen2-VL-2B, Med-R1 achieves a 29.94% accuracy improvement and outperforms Qwen2-VL-72B, which has 36 times more parameters. Testing across five question types-modality recognition, anatomy identification, disease diagnosis, lesion grading, and biological attribute analysis Med-R1 demonstrates superior generalization, exceeding Qwen2-VL-2B by 32.06% and surpassing Qwen2-VL-72B in question-type generalization. These findings show that RL improves medical reasoning and enables parameter-efficient models to outperform significantly larger ones. With interpretable reasoning outputs, Med-R1 represents a promising step toward generalizable, trustworthy, and clinically viable medical VLMs.
视觉语言模型(VLMs)在自然场景中的推理能力已经得到提升,但它们在医学成像领域的应用仍然缺乏足够的探索。医学推理任务需要可靠的图像分析和合理的答案,由于医学图像的复杂性,这构成了挑战。透明度和可信度对于临床采用和法规合规至关重要。我们引入了Med-R1框架,探索强化学习(RL)以增强VLMs在医学推理中的通用性和可信度。利用DeepSeek策略,我们采用Group Relative Policy Optimization (GRPO)通过奖励信号引导推理路径。与通常导致过度拟合和缺乏泛化能力的监督微调(SFT)不同,强化学习促进稳健和多样化的推理。Med-R1在八种医学成像模式上进行了评估:CT、MRI、超声、皮肤镜检查、眼底摄影、光学相干断层扫描(OCT)、显微镜和X射线成像。与基准模型相比,Med-R1实现了29.94%的准确率提升,并超越了参数多出36倍的Qwen2-VL-72B。在五种问题类型(模态识别、解剖结构识别、疾病诊断、病变分级和生物属性分析)的测试上,Med-R1展现出卓越的泛化能力,相较于Qwen2-VL-2B提高32.06%,并在问题类型泛化上超越了Qwen2-VL-72B。这些发现表明,强化学习能提升医学推理能力,并使得参数效率模型能够超越规模更大的模型。Med-R1的可解释推理输出代表了一个有前景的步骤,朝着通用化、可信赖和临床上可行的医学VLMs迈进。
论文及项目相关链接
Summary
Med-R1框架通过强化学习(RL)技术提高了视觉语言模型(VLMs)在医疗推理中的通用性和信任度。通过DeepSeek策略并采用Group Relative Policy Optimization(GRPO)引导推理路径,该框架表现出优异的性能。与基准模型和大型模型相比,Med-R1在多种医学成像模态上的准确性显著提高,展示了解释性强、通用性强和值得信赖的医学VLMs的潜力。
Key Takeaways
- Med-R1框架首次探索了强化学习在医疗视觉语言模型中的应用,以提高其通用性和信任度。
- 通过DeepSeek策略和GRPO优化,Med-R1能够有效引导模型推理路径。
- 与传统的监督微调方法相比,强化学习有助于实现更稳健和多样化的推理。
- Med-R1在多种医学成像模态上进行了评估,证明了其广泛适用性。
- Med-R1在准确性上较基准模型有所提高,且优于大型模型。
- Med-R1在多种问题类型上表现出良好的泛化能力。
点此查看论文截图

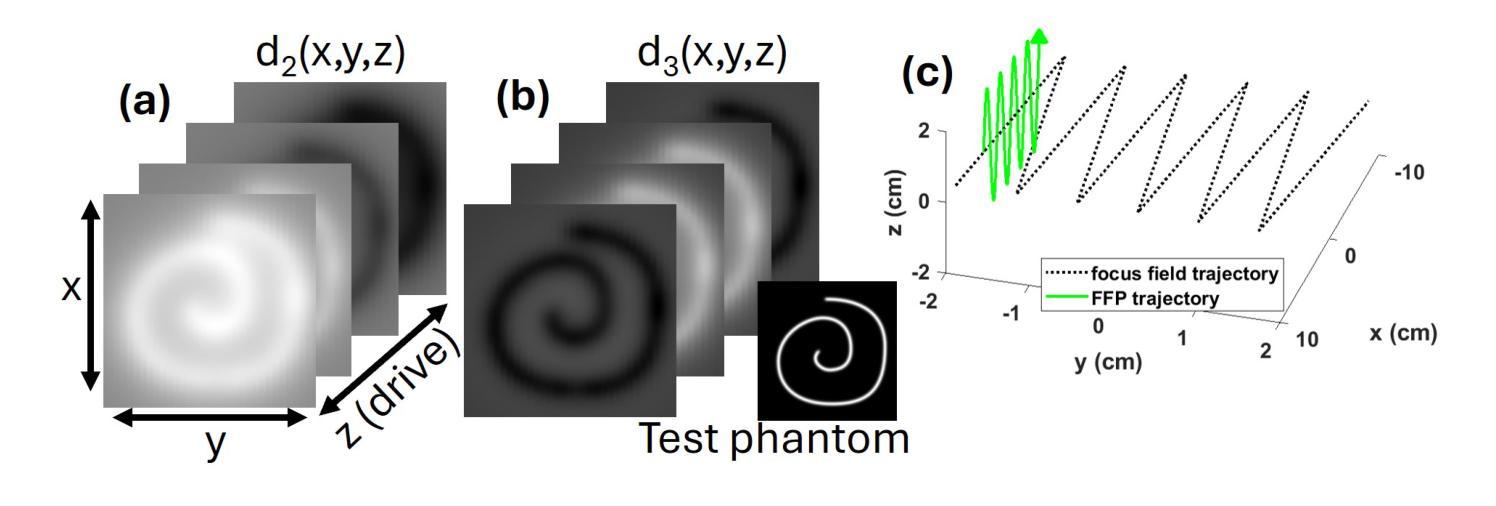
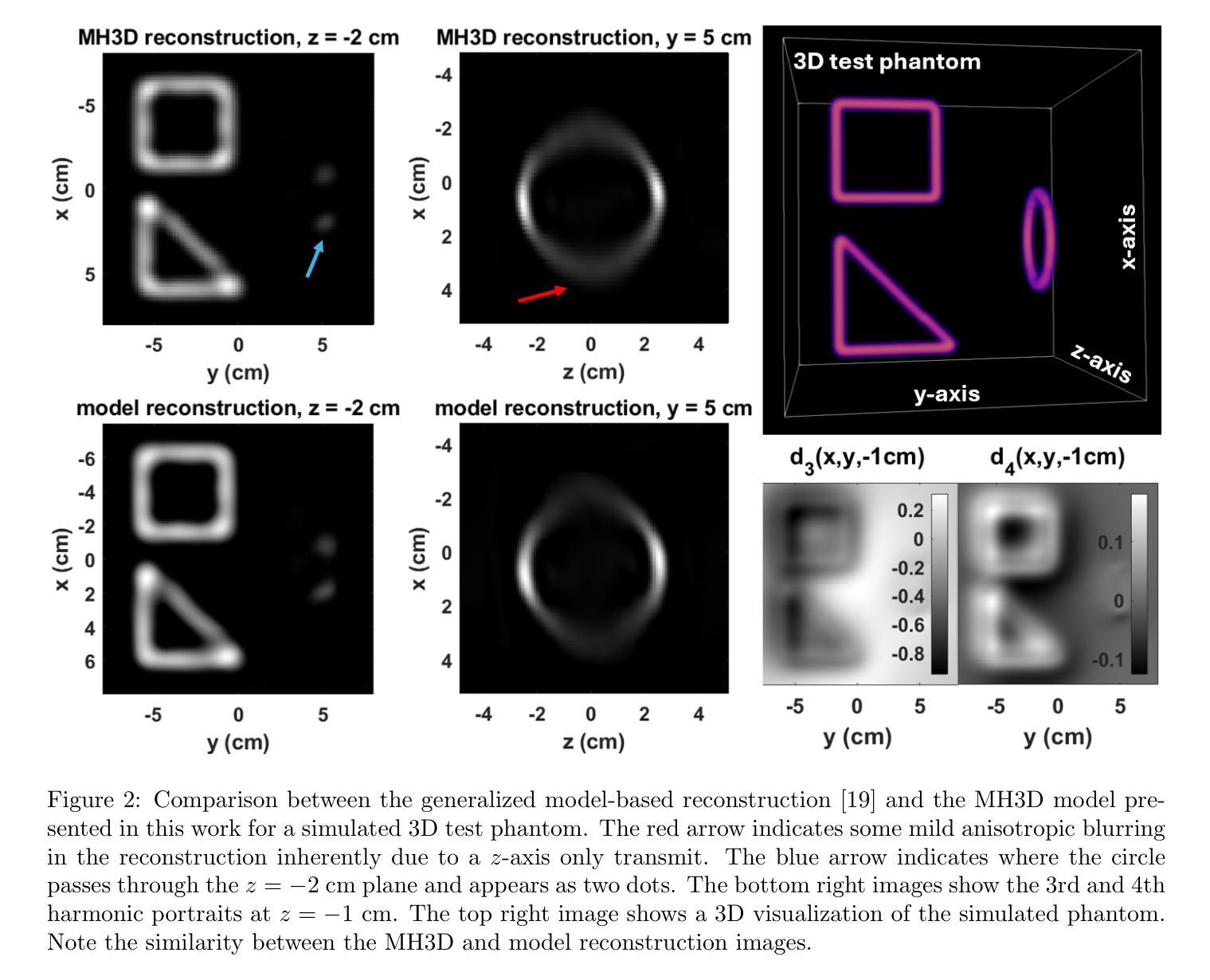
Multi-Harmonic Gridded 3D Deconvolution (MH3D) for Robust and Accurate Image Reconstruction in MPI for Single Axis Drive Field Scanners
Authors:Toby Sanders, Justin J. Konkle, Erica E. Mason, Patrick W. Goodwill
This article presents a new robust model for image reconstruction in magnetic particle imaging (MPI) for single-axis drive field scans, which is based on the deconvolution of gridded harmonic data. Gridded harmonic data, used commonly in MPI, does not map to underlying iron density but rather to the iron density convolved with the harmonic point-spread functions. We refer to the gridded harmonic data as harmonic portraits, since they only represent a portrait-like representation of the iron density, and a deconvolution method is implemented to reconstruct the true underlying density. The advantage of this new method is primarily in the intermediate data analysis that comes in the harmonic portrait domain, where we are able to perform artifact correction, parameter selection, and general data assessment and calibrations efficiently. Furthermore, we show with several examples that our new method closely compares qualitatively with current state-of-the-art image reconstruction models in MPI. While the general concept of gridding harmonic data in MPI is not new, the complete modeling and characterization in order to use the data for image reconstruction has remained an ongoing area of research. We provide detailed analysis, theoretical insights, and many nuanced techniques that make our new methodology and algorithm accurate and robust.
本文介绍了一种基于网格化谐波数据解卷积的单轴驱动场扫描磁粒子成像(MPI)图像重建新模型。网格化谐波数据在MPI中广泛使用,并不映射到底层的铁密度,而是映射到铁密度与谐波点扩散函数的卷积。我们将网格化谐波数据称为谐波肖像,因为它们只代表铁密度的肖像式表示,并实现了卷积方法来重建真正的底层密度。这种新方法的主要优点在于谐波肖像域中的中间数据分析,我们能够在此有效地执行伪影校正、参数选择以及一般的数据评估和校准。此外,通过几个例子,我们证明了我们的新方法在MPI图像重建模型方面与当前最先进技术进行了定性比较。虽然MPI中网格化谐波数据的一般概念并不新颖,但为了更好地使用数据进行图像重建,其完整建模和表征一直是研究领域的一个持续关注的主题。我们提供了详细的分析、理论见解和许多微妙的技术,使我们的新方法和算法更加准确和稳健。
论文及项目相关链接
Summary
本文介绍了一种基于网格化谐波数据解卷积的磁共振粒子成像(MPI)单轴驱动场扫描图像重建新模型。该模型在谐波肖像域进行中间数据分析,能够高效地进行伪影校正、参数选择以及数据评估和校准。通过多个实例对比,该新方法与当前先进的MPI图像重建模型在定性上非常接近。
Key Takeaways
- 文章提出了一种新的MPI图像重建模型,该模型基于网格化谐波数据的解卷积。
- 网格化谐波数据(称为谐波肖像)在MPI中用于表示铁密度的肖像式表示,需要通过解卷积方法重建真实的基础密度。
- 新方法的主要优势在于谐波肖像域中的中间数据分析,可高效进行伪影校正、参数选择以及数据评估和校准。
- 通过多个实例验证,新方法与现有先进MPI图像重建模型在定性上非常接近。
- 尽管网格化谐波数据在MPI中的概念并非全新,但将其用于图像重建的完整建模和表征仍是一个研究领域。
- 文章提供了详细的分析、理论见解和微妙技术,使新方法和算法更加准确和稳健。
点此查看论文截图

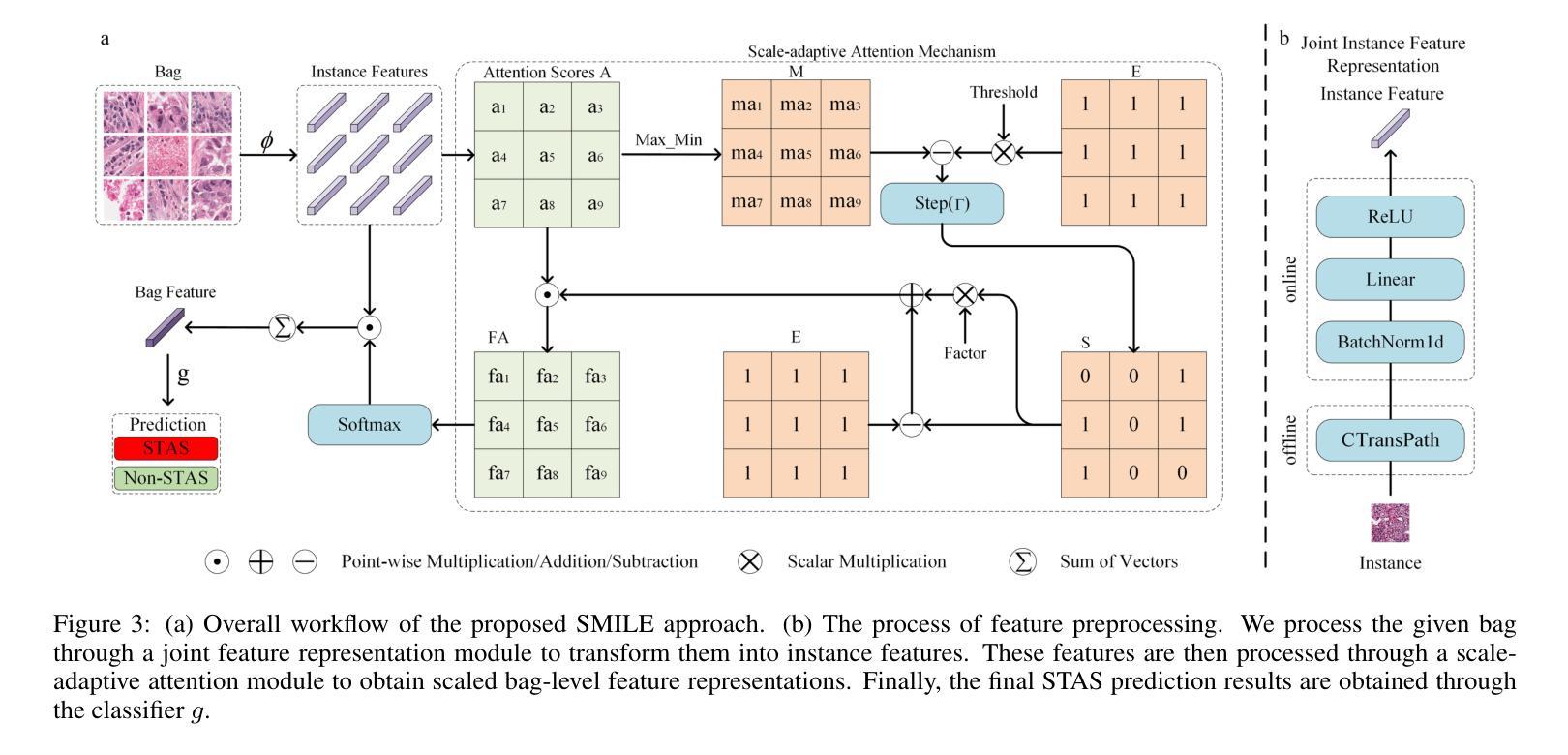
SMILE: a Scale-aware Multiple Instance Learning Method for Multicenter STAS Lung Cancer Histopathology Diagnosis
Authors:Liangrui Pan, Xiaoyu Li, Yutao Dou, Qiya Song, Jiadi Luo, Qingchun Liang, Shaoliang Peng
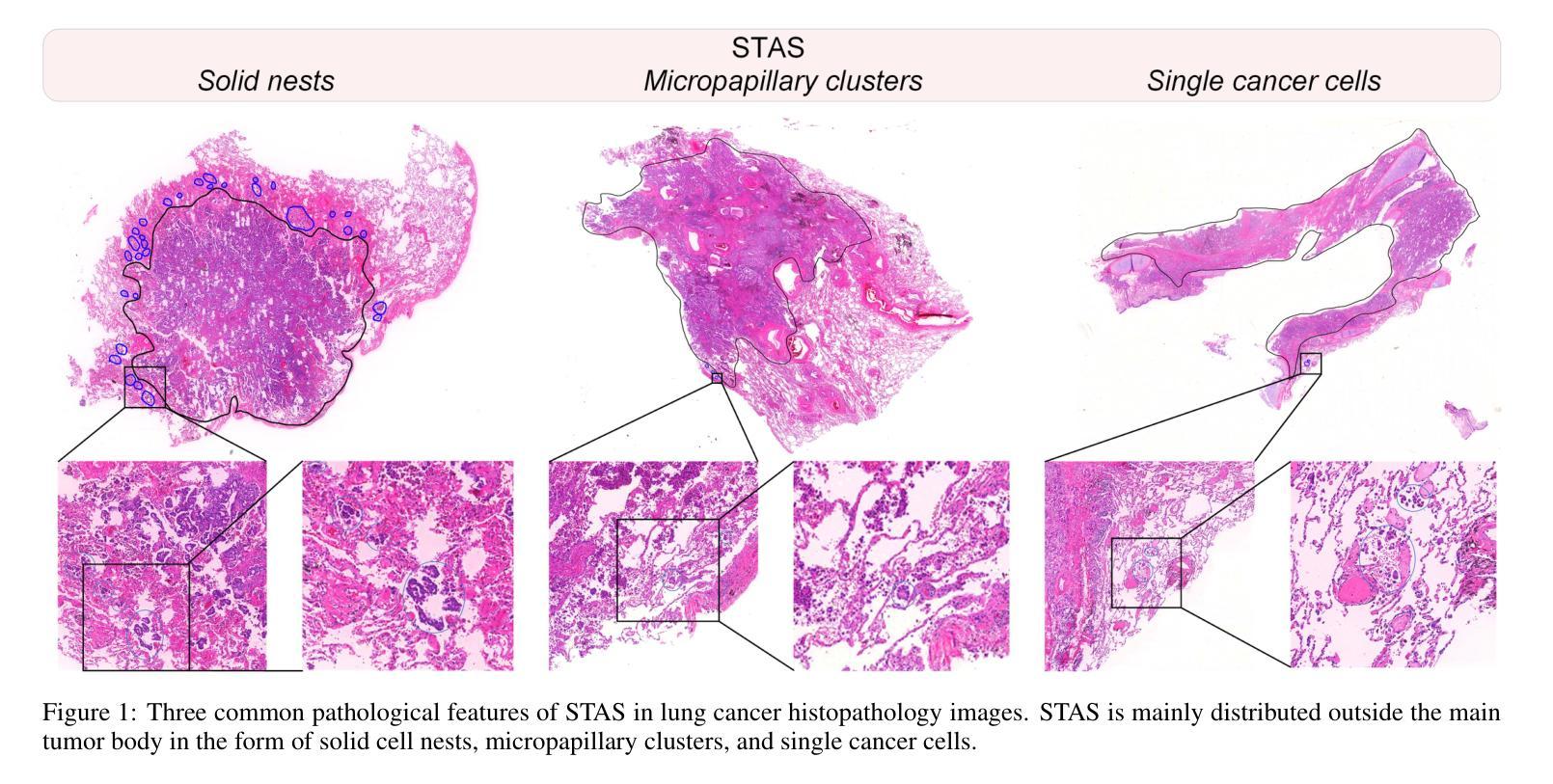
Spread through air spaces (STAS) represents a newly identified aggressive pattern in lung cancer, which is known to be associated with adverse prognostic factors and complex pathological features. Pathologists currently rely on time consuming manual assessments, which are highly subjective and prone to variation. This highlights the urgent need for automated and precise diag nostic solutions. 2,970 lung cancer tissue slides are comprised from multiple centers, re-diagnosed them, and constructed and publicly released three lung cancer STAS datasets: STAS CSU (hospital), STAS TCGA, and STAS CPTAC. All STAS datasets provide corresponding pathological feature diagnoses and related clinical data. To address the bias, sparse and heterogeneous nature of STAS, we propose an scale-aware multiple instance learning(SMILE) method for STAS diagnosis of lung cancer. By introducing a scale-adaptive attention mechanism, the SMILE can adaptively adjust high attention instances, reducing over-reliance on local regions and promoting consistent detection of STAS lesions. Extensive experiments show that SMILE achieved competitive diagnostic results on STAS CSU, diagnosing 251 and 319 STAS samples in CPTAC andTCGA,respectively, surpassing clinical average AUC. The 11 open baseline results are the first to be established for STAS research, laying the foundation for the future expansion, interpretability, and clinical integration of computational pathology technologies. The datasets and code are available at https://anonymous.4open.science/r/IJCAI25-1DA1.
通过空气传播的肺癌新病理模式(STAS)是一种新发现的侵袭性模式,与不良预后因素和复杂的病理特征有关。病理学家目前依赖于耗时的人工评估,这些评估具有很大的主观性和变化性。这突显了对自动化和精确诊断解决方案的迫切需求。我们对来自多个中心的2970张肺癌组织切片进行了重新诊断,并构建了三个公开的肺癌STAS数据集:STAS CSU(医院)、STAS TCGA和STAS CPTAC。所有STAS数据集都提供了相应的病理特征诊断和相关的临床数据。针对STAS的偏见、稀疏性和异质性,我们提出了一种尺度感知的多实例学习(SMILE)方法进行肺癌STAS诊断。通过引入尺度自适应注意力机制,SMILE可以自适应地调整高注意力实例,减少对局部区域的过度依赖,促进STAS病变的一致检测。大量实验表明,SMILE在STAS CSU上取得了具有竞争力的诊断结果,在CPTAC和TCGA中分别诊断了251例和319例STAS样本,超过了临床平均AUC值。这11个公开基准结果均为STAS研究的首次建立,为未来计算病理学技术的扩展、可解释性和临床整合奠定了基础。数据集和代码可通过https://anonymous.4open.science/r/IJCAI25-1DA1获取。
论文及项目相关链接
Summary
这是一项关于肺癌新发现的研究。研究中提出了一种名为SMILE的肺癌STAS诊断方法,针对目前病理学中手工评估时间长、主观性高等问题,该法具有自动化和精确性优势。研究者发布了三个肺癌STAS数据集并进行了测试,SMILE表现出良好的诊断效果,为计算病理学技术的未来扩展、解释和临床整合奠定了基础。
Key Takeaways
- 研究介绍了新发现的肺癌扩散模式——通过空气空间扩散(STAS),与不良预后因素和复杂病理特征相关。
- 当前病理学诊断主要依赖耗时且主观性高的手动评估,急需自动化和精确的诊断解决方案。
- 研究发布了三个肺癌STAS数据集:STAS CSU、STAS TCGA和STAS CPTAC,包含相应的病理特征诊断和相关的临床数据。
- 针对STAS的偏见、稀疏和异质性特点,研究提出了一种名为SMILE的诊断方法。
- SMILE通过引入尺度自适应注意力机制,能够自适应调整高注意力实例,减少局部区域的过度依赖,促进STAS病变的一致检测。
- 实验表明,SMILE在STAS CSU上取得了具有竞争力的诊断结果,并在CPTAC和TCGA中分别诊断出251和319个STAS样本,超过了临床平均AUC。
点此查看论文截图


From Pixels to Histopathology: A Graph-Based Framework for Interpretable Whole Slide Image Analysis
Authors:Alexander Weers, Alexander H. Berger, Laurin Lux, Peter Schüffler, Daniel Rueckert, Johannes C. Paetzold
The histopathological classification of whole-slide images (WSIs) is a fundamental task in digital pathology; yet it requires extensive time and expertise from specialists. While deep learning methods show promising results, they typically process WSIs by dividing them into artificial patches, which inherently prevents a network from learning from the entire image context, disregards natural tissue structures and compromises interpretability. Our method overcomes this limitation through a novel graph-based framework that constructs WSI graph representations. The WSI-graph efficiently captures essential histopathological information in a compact form. We build tissue representations (nodes) that follow biological boundaries rather than arbitrary patches all while providing interpretable features for explainability. Through adaptive graph coarsening guided by learned embeddings, we progressively merge regions while maintaining discriminative local features and enabling efficient global information exchange. In our method’s final step, we solve the diagnostic task through a graph attention network. We empirically demonstrate strong performance on multiple challenging tasks such as cancer stage classification and survival prediction, while also identifying predictive factors using Integrated Gradients. Our implementation is publicly available at https://github.com/HistoGraph31/pix2pathology
全切片图像(WSI)的组织病理学分类是数字病理学中的一项基本任务,但这需要专家的大量时间和专业知识。虽然深度学习方法显示出有希望的结果,但它们通常通过将WSI分割成人工补丁来处理,这固有地阻止网络从整个图像上下文中学习,忽略了自然组织结构并损害了可解释性。我们的方法通过基于图的新型框架来克服这一局限性,该框架构建WSI图表示。WSI图以紧凑的形式有效地捕获了关键的组织病理学信息。我们构建的组织表示(节点)遵循生物学边界,而不是任意补丁,同时提供可解释特征用于解释性。通过由学习嵌入引导的自适应图粗化,我们逐步合并区域,同时保持辨别局部特征并启用高效的全局信息交换。我们方法的最后一步是通过图注意力网络来解决诊断任务。我们在多个具有挑战性的任务上展示了强大的性能,例如癌症分期分类和生存预测,同时使用集成梯度识别预测因素。我们的实现可在 https://github.com/HistoGraph31/pix2pathology 中公开访问。
论文及项目相关链接
PDF 11 pages, 2 figures
Summary
本文提出了一种基于图的新方法,用于解决数字病理学中的全切片图像(WSI)的病理分类问题。该方法通过构建WSI图表示,有效地捕获了关键的组织病理学信息,提供了可解释的特征,并展示了强大的诊断性能。
Key Takeaways
- 传统深度学习方法在处理全切片图像(WSI)时,通常将其划分为人工补丁,这忽略了整个图像的上下文信息、自然组织结构以及解释性。
- 本文提出了一种新的基于图的方法,构建了WSI图表示,以克服这一限制。
- WSI图表示通过紧凑的形式有效地捕获了关键的组织病理学信息。
- 该方法构建的组织表示(节点)遵循生物边界而不是任意补丁,提供可解释的特征以增强解释性。
- 通过自适应图粗化引导学习嵌入,该方法能够逐步合并区域,同时保持鉴别局部特征并实现有效的全局信息交流。
- 该方法通过图注意力网络解决诊断任务,并在多个具有挑战性的任务上表现出强大的性能,如癌症分期分类和生存预测。
点此查看论文截图

A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Authors:Asifullah Khan, Laiba Asmatullah, Anza Malik, Shahzaib Khan, Hamna Asif
Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of “positive” and “negative” samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
自监督学习是一种机器学习的方法,它通过学习潜在的模式并从无标签数据中提取判别特征,从而生成隐式标签,而无需手动标注。对比学习引入了“正样本”和“负样本”的概念,其中正样本对(例如,同一图像/对象的变体)在嵌入空间中聚集在一起,而负样本对(例如,来自不同图像/对象的视图)则被推开。这种方法在图像理解和图像文本分析方面取得了显著的改进,而且不需要依赖大量的标注数据。在本文中,我们全面讨论了与文本-图像模型相关的对比学习的术语、最新发展以及应用。具体来说,我们概述了近年来文本-图像模型中对比学习的方法。其次,我们根据不同的模型结构对方法进行了分类。再次,我们进一步介绍和讨论了过程中使用的最新技术,例如图像和文本的预训练任务、架构结构和关键趋势。最后,我们讨论了基于文本-图像模型的自监督对比学习的最新应用。
论文及项目相关链接
Summary
自监督学习通过从非标记数据中学习潜在模式和提取判别特征,生成隐式标签,无需人工标注,便能实现机器学习。对比学习引入了“正样本”和“负样本”的概念,通过拉近正样本对(如同一图像/对象的变体)并在嵌入空间中推开负样本对(如来自不同图像/对象的视图),从而进行模型训练。该方法在图像理解和文本图像分析方面,大幅提高了模型的性能,且在依赖标注数据方面大大降低。本文全面探讨了文本图像模型中对比学习的术语、最新发展及应用,介绍了近年对比学习在文本图像模型中的方法,按模型结构分类,并深入介绍了图像和文本的预训练任务、架构结构和关键趋势的最新进展。
Key Takeaways
- 自监督学习通过非标记数据中的模式学习和特征提取生成隐式标签,无需人工标注。
- 对比学习通过区分正、负样本进行模型训练,提高图像理解和文本分析的性能。
- 对比学习在文本图像模型中有着广泛的应用和最新的研究进展。
- 模型方法可按结构进行分类。
- 预训练任务、架构结构和关键趋势的最新进展是对比学习的重点。
- 对比学习在依赖标注数据方面大幅降低。
点此查看论文截图

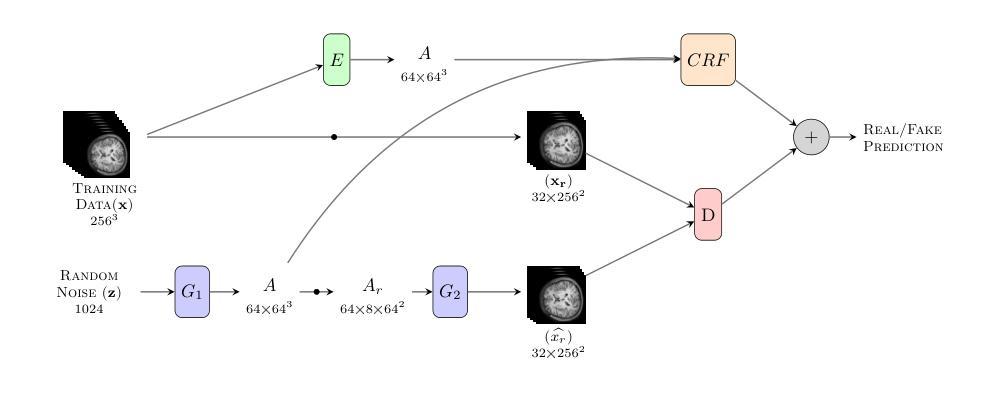
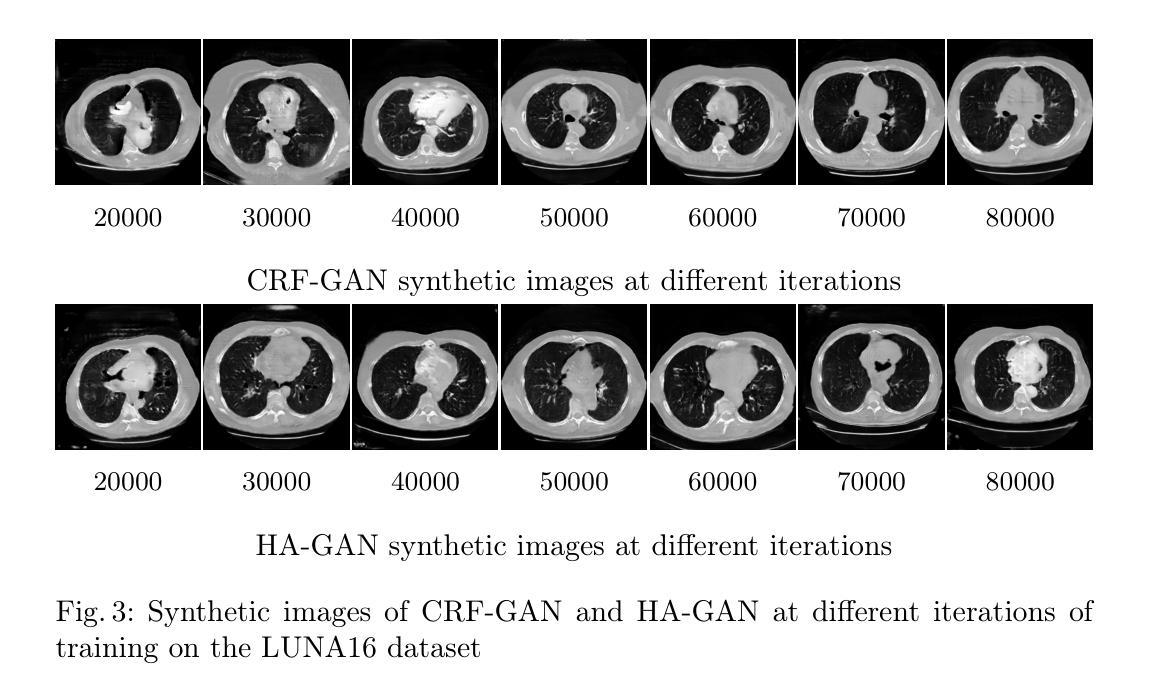
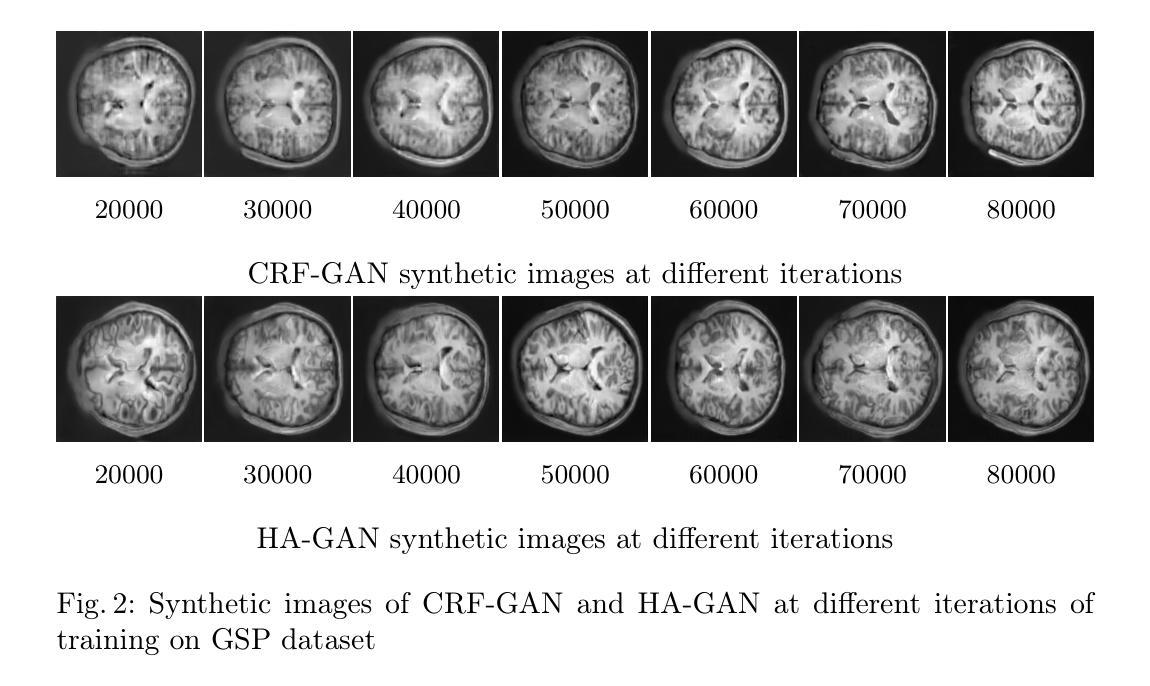
Memory-Efficient 3D High-Resolution Medical Image Synthesis Using CRF-Guided GANs
Authors:Mahshid Shiri, Alessandro Bruno, Daniele Loiacono
Generative Adversarial Networks (GANs) have many potential medical imaging applications. Due to the limited memory of Graphical Processing Units (GPUs), most current 3D GAN models are trained on low-resolution medical images, these models cannot scale to high-resolution or are susceptible to patchy artifacts. In this work, we propose an end-to-end novel GAN architecture that uses Conditional Random field (CRF) to model dependencies so that it can generate consistent 3D medical Images without exploiting memory. To achieve this purpose, the generator is divided into two parts during training, the first part produces an intermediate representation and CRF is applied to this intermediate representation to capture correlations. The second part of the generator produces a random sub-volume of image using a subset of the intermediate representation. This structure has two advantages: first, the correlations are modeled by using the features that the generator is trying to optimize. Second, the generator can generate full high-resolution images during inference. Experiments on Lung CTs and Brain MRIs show that our architecture outperforms state-of-the-art while it has lower memory usage and less complexity.
生成对抗网络(GANs)在医学成像应用方面拥有许多潜在可能性。由于图形处理单元(GPU)的内存有限,当前大多数3D GAN模型都是在低分辨率医学图像上训练的,这些模型无法扩展到高分辨率或容易出现斑块状伪影。在这项研究中,我们提出了一种端到端的新型GAN架构,该架构使用条件随机场(CRF)来建模依赖性,以生成一致的3D医学图像,而无需利用额外内存。为了达到这个目的,在训练过程中,生成器被分为两部分,第一部分生成中间表示,并对该中间表示应用CRF以捕获相关性。生成器的第二部分使用中间表示的一个子集来生成图像的随机子体积。这种结构有两个优点:首先,通过利用生成器试图优化的特征来建模相关性。其次,在推理过程中,生成器可以生成全高分辨率图像。对肺部CT和脑部MRI的实验表明,我们的架构在具有较低内存使用和较低复杂性的同时,优于最新技术。
论文及项目相关链接
PDF Accepted to Artificial Intelligence for Healthcare Applications, 3rd International Workshop ICPR 2024
Summary
本论文提出了一种新型的端到端GAN架构,利用条件随机场(CRF)进行依赖建模,旨在生成一致的3D医学图像,无需占用大量内存。该架构通过训练时分割生成器,利用中间表示和CRF捕捉相关性,同时生成随机的图像子体积,从而实现高效生成高质量图像的目标。实验结果表明,该架构在肺部CT和脑部MRI上表现出优异性能,同时内存占用更低、复杂度更小。
Key Takeaways
- GANs在医学成像中有广泛应用潜力。
- 当前3D GAN模型受限于GPU内存,通常只能处理低分辨率医学图像。
- 本研究提出了一种新型端到端GAN架构,利用CRF进行依赖建模。
- 该架构通过训练时分割生成器,利用中间表示和CRF捕捉相关性。
- 生成器可以生成完整的高分辨率图像。
- 实验结果表明该架构在肺部CT和脑部MRI上表现优异。
点此查看论文截图

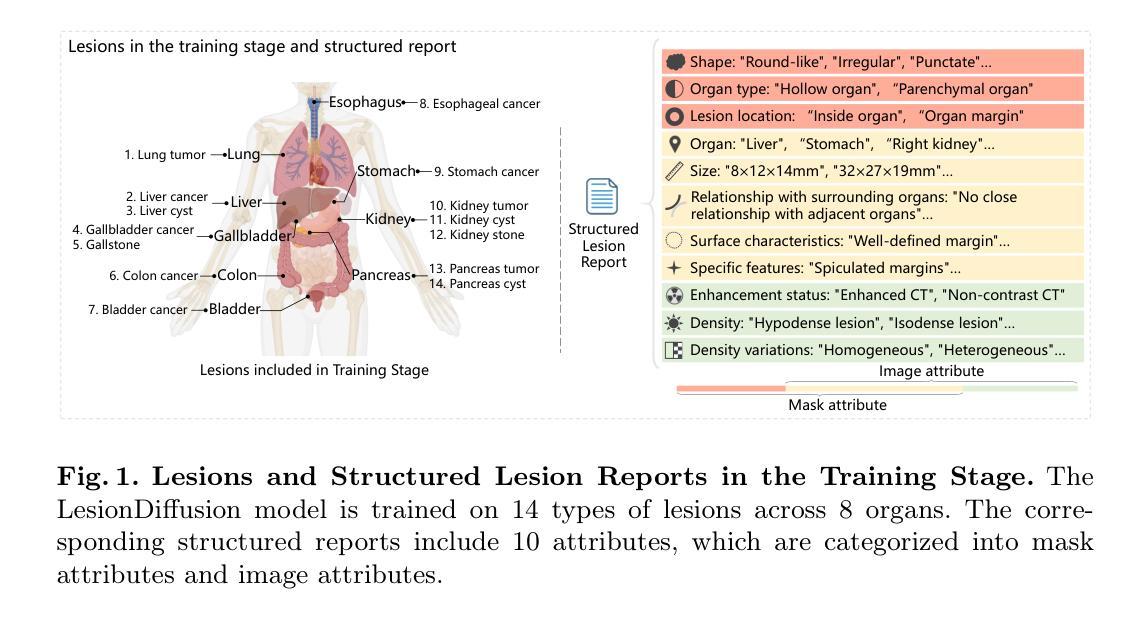
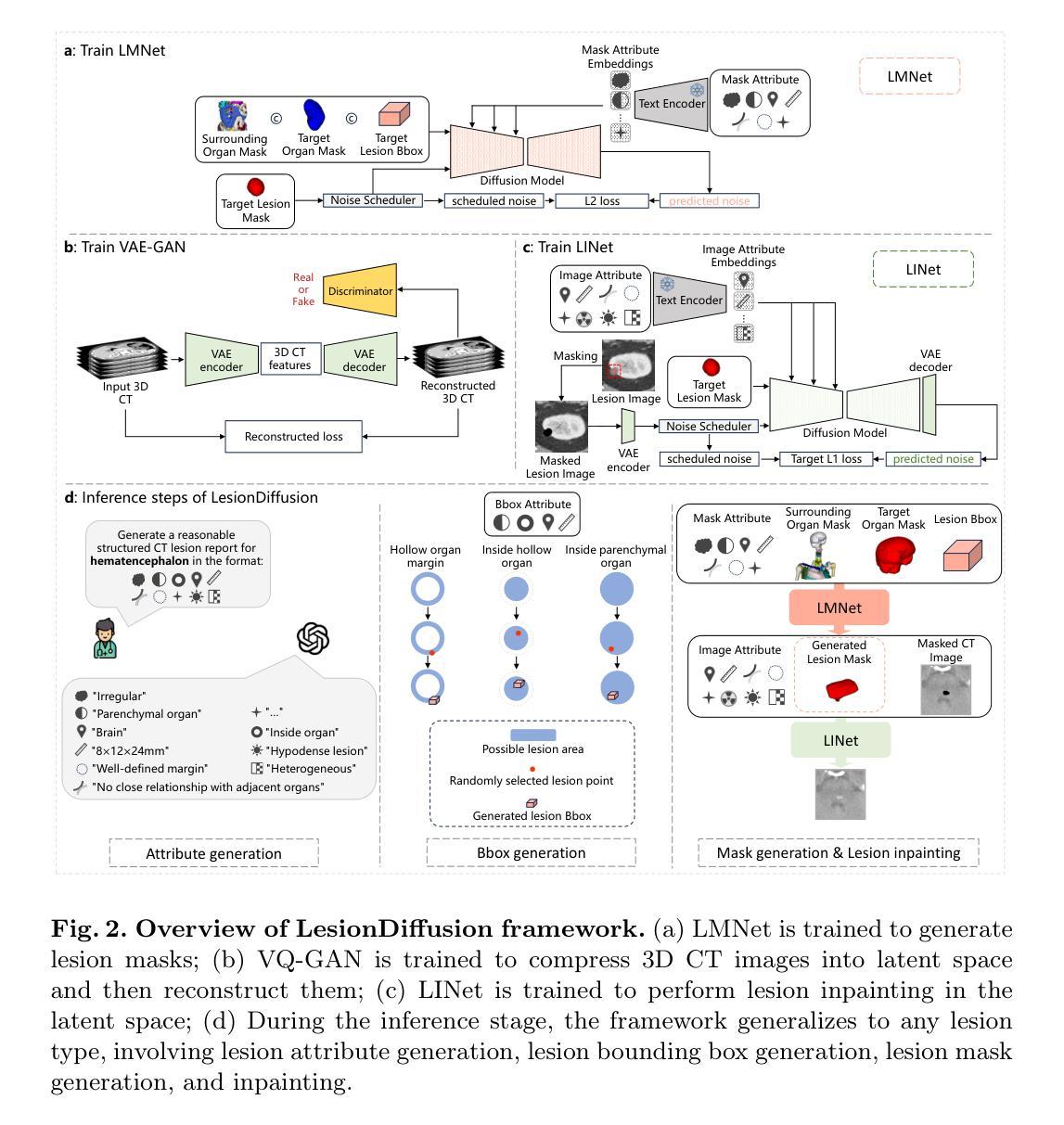
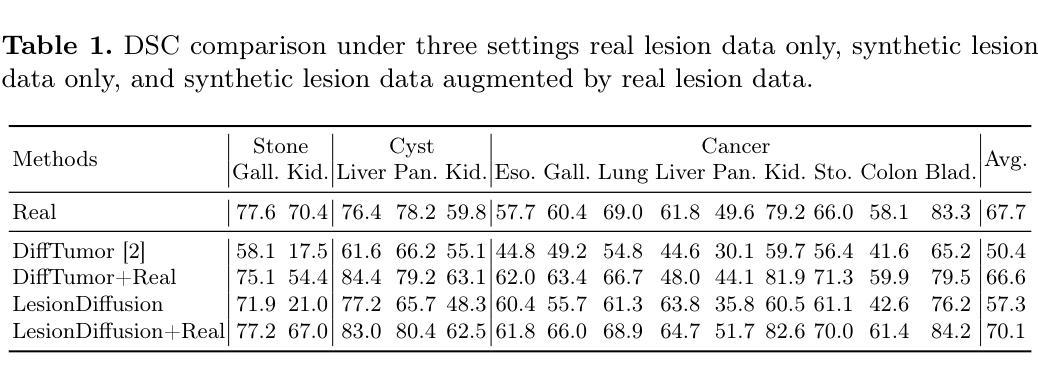
LesionDiffusion: Towards Text-controlled General Lesion Synthesis
Authors:Henrui Tian, Wenhui Lei, Linrui Dai, Hanyu Chen, Xiaofan Zhang
Fully-supervised lesion recognition methods in medical imaging face challenges due to the reliance on large annotated datasets, which are expensive and difficult to collect. To address this, synthetic lesion generation has become a promising approach. However, existing models struggle with scalability, fine-grained control over lesion attributes, and the generation of complex structures. We propose LesionDiffusion, a text-controllable lesion synthesis framework for 3D CT imaging that generates both lesions and corresponding masks. By utilizing a structured lesion report template, our model provides greater control over lesion attributes and supports a wider variety of lesion types. We introduce a dataset of 1,505 annotated CT scans with paired lesion masks and structured reports, covering 14 lesion types across 8 organs. LesionDiffusion consists of two components: a lesion mask synthesis network (LMNet) and a lesion inpainting network (LINet), both guided by lesion attributes and image features. Extensive experiments demonstrate that LesionDiffusion significantly improves segmentation performance, with strong generalization to unseen lesion types and organs, outperforming current state-of-the-art models. Code will be available at https://github.com/HengruiTianSJTU/LesionDiffusion.
在医学成像中,全监督病灶识别方法面临着依赖于大规模标注数据集的挑战,而这些数据集的收集既昂贵又困难。为解决这一问题,合成病灶生成已成为一种有前景的方法。然而,现有模型在可扩展性、病灶属性的精细控制以及复杂结构的生成方面遇到了困难。我们提出了LesionDiffusion,这是一个用于3D CT成像的文本可控病灶合成框架,能够生成病灶及其相应的掩膜。通过利用结构化病灶报告模板,我们的模型提供了对病灶属性更大的控制力,并支持更多种类的病灶。我们引入了一个包含1505个标注CT扫描的数据集,每个扫描都有配对的病灶掩膜和结构化报告,覆盖8个器官中的14种病灶类型。LesionDiffusion由两部分组成:病灶掩膜合成网络(LMNet)和病灶填充网络(LINet),两者均由病灶属性和图像特征引导。大量实验表明,LesionDiffusion显著提高了分割性能,对未见过的病灶类型和器官具有很强的泛化能力,超越了当前最先进的模型。代码将在https://github.com/HengruiTianSJTU/LesionDiffusion上提供。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
文本主要介绍了针对医学图像中病灶识别所面临的问题,提出了一种名为LesionDiffusion的文本可控病灶合成框架。该框架能够生成病灶及其对应的掩膜,利用结构化病灶报告模板,实现对病灶属性的更精细控制,并支持多种病灶类型。同时,引入了一个包含1,505个带病灶掩膜和结构化报告的标注CT扫描数据集。LesionDiffusion由两个组件构成:病灶掩膜合成网络(LMNet)和病灶修复网络(LINet),两者均受病灶属性和图像特征的引导。实验表明,LesionDiffusion在分割性能上有显著提升,对未见过的病灶类型和器官具有良好的泛化性能,优于当前最先进的模型。
Key Takeaways
- LesionDiffusion是一个用于3D CT成像的文本可控病灶合成框架,能够生成病灶及其对应的掩膜。
- 该框架利用结构化病灶报告模板,实现对病灶属性的更精细控制,并支持多种病灶类型。
- 引入了一个包含1,505个标注CT扫描数据集,其中包括配对病灶掩膜和结构化报告,覆盖8个器官的14种病灶类型。
- LesionDiffusion由LMNet和LINet两个组件构成,均受病灶属性和图像特征的引导。
- 实验表明LesionDiffusion在病灶分割性能上显著提升,且对未见过的病例具有良好的泛化性能。
- 该模型优于当前最先进的模型,具有潜在的临床应用价值。
点此查看论文截图

Learning of Patch-Based Smooth-Plus-Sparse Models for Image Reconstruction
Authors:Stanislas Ducotterd, Sebastian Neumayer, Michael Unser
We aim at the solution of inverse problems in imaging, by combining a penalized sparse representation of image patches with an unconstrained smooth one. This allows for a straightforward interpretation of the reconstruction. We formulate the optimization as a bilevel problem. The inner problem deploys classical algorithms while the outer problem optimizes the dictionary and the regularizer parameters through supervised learning. The process is carried out via implicit differentiation and gradient-based optimization. We evaluate our method for denoising, super-resolution, and compressed-sensing magnetic-resonance imaging. We compare it to other classical models as well as deep-learning-based methods and show that it always outperforms the former and also the latter in some instances.
我们旨在通过结合图像块的惩罚稀疏表示和无约束平滑表示来解决成像中的反问题。这使得重建过程更容易解释。我们将优化问题制定为双层问题。内层问题采用经典算法,外层问题通过监督学习优化字典和正则化参数。该过程通过隐式微分和基于梯度的优化来实现。我们评估了该方法在去噪、超分辨率和压缩感知磁共振成像方面的表现。我们将该方法与其他经典模型以及基于深度学习的方法进行了比较,并证明在多数情况下,该方法都优于前者,并且在某些情况下也优于后者。
论文及项目相关链接
Summary
结合惩罚稀疏图像补丁表示与无约束平滑表示,解决成像中的反问题。提出一种双层优化问题,内部问题采用经典算法,外部问题通过监督学习优化字典和正则化参数。通过隐式微分和基于梯度的优化实现这一过程。经去噪、超分辨率及磁共振成像压缩感知评估,该方法在某些情况下优于经典模型和深度学习方法。
Key Takeaways
- 整合惩罚稀疏图像补丁和无约束平滑表示以解决成像中的反问题。
- 优化问题被表述为双层结构,其中内部问题运用经典算法,外部问题侧重于优化字典和正则化参数。
- 通过隐式微分和基于梯度的优化实现流程。
- 方法在去噪、超分辨率及磁共振成像压缩感知方面进行了评估。
- 与经典模型相比,此方法表现出优越性能。
- 在某些情况下,该方法甚至超越了深度学习方法。
点此查看论文截图


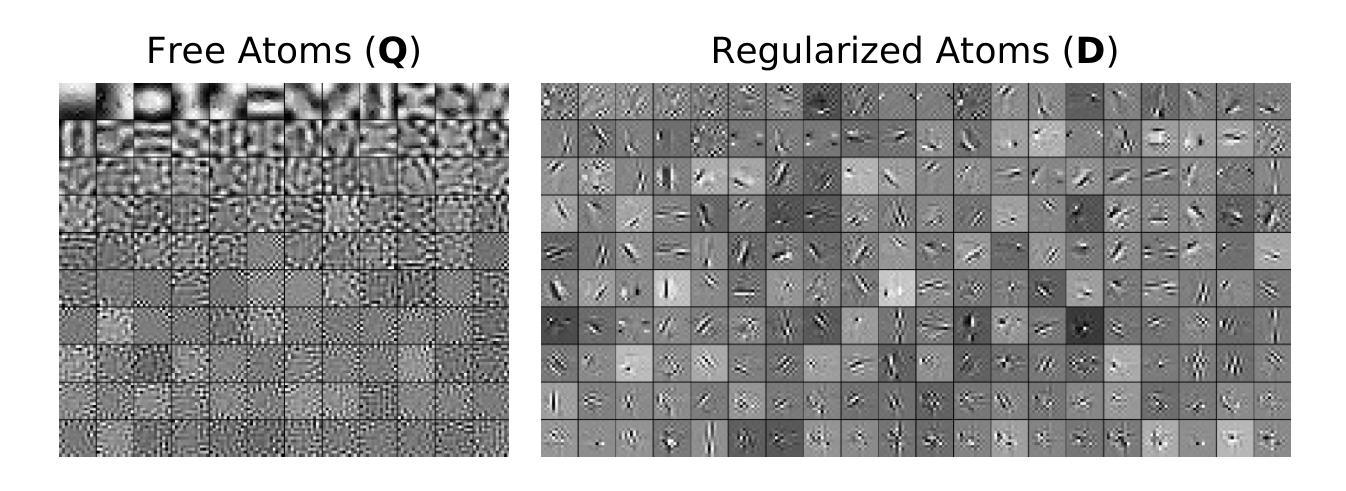
Semantic Consistency-Based Uncertainty Quantification for Factuality in Radiology Report Generation
Authors:Chenyu Wang, Weichao Zhou, Shantanu Ghosh, Kayhan Batmanghelich, Wenchao Li
Radiology report generation (RRG) has shown great potential in assisting radiologists by automating the labor-intensive task of report writing. While recent advancements have improved the quality and coherence of generated reports, ensuring their factual correctness remains a critical challenge. Although generative medical Vision Large Language Models (VLLMs) have been proposed to address this issue, these models are prone to hallucinations and can produce inaccurate diagnostic information. To address these concerns, we introduce a novel Semantic Consistency-Based Uncertainty Quantification framework that provides both report-level and sentence-level uncertainties. Unlike existing approaches, our method does not require modifications to the underlying model or access to its inner state, such as output token logits, thus serving as a plug-and-play module that can be seamlessly integrated with state-of-the-art models. Extensive experiments demonstrate the efficacy of our method in detecting hallucinations and enhancing the factual accuracy of automatically generated radiology reports. By abstaining from high-uncertainty reports, our approach improves factuality scores by $10$%, achieved by rejecting $20$% of reports using the \texttt{Radialog} model on the MIMIC-CXR dataset. Furthermore, sentence-level uncertainty flags the lowest-precision sentence in each report with an $82.9$% success rate. Our implementation is open-source and available at https://github.com/BU-DEPEND-Lab/SCUQ-RRG.
放射学报告生成(RRG)在通过自动化报告写作这一劳动密集型任务来辅助放射科医生方面显示出巨大潜力。虽然最近的进展提高了生成报告的质量和连贯性,但确保事实正确性仍是关键挑战。虽然已提出生成式医学视觉大型语言模型(VLLM)来解决这个问题,但这些模型容易产生幻觉并可能产生不准确的诊断信息。为了解决这些担忧,我们引入了一种新型的基于语义一致性的不确定性量化框架,该框架提供报告级和句子级的不确定性。与现有方法不同的是,我们的方法不需要对底层模型进行修改,也不需要访问其内部状态,如输出令牌对数几率,因此可以作为即插即用模块无缝集成到最新模型中。大量实验证明了我们方法在检测幻觉和提高自动生成的放射学报告的事实准确性方面的有效性。通过避免高不确定性的报告,我们的方法在MIMIC-CXR数据集上使用“Radialog”模型拒绝20%的报告,提高了事实得分10%。此外,句子级不确定性以82.9%的成功率标记了每个报告中的最低精度句子。我们的实现是开源的,可在https://github.com/BU-DEPEND-Lab/SCUQ-RRG获取。
论文及项目相关链接
Summary
本文介绍了一种新型的语义一致性基于不确定性的量化框架,用于提高放射学报告生成(RRG)的准确性和事实真实性。该框架能在无需修改底层模型或获取其内部状态的前提下,提供报告级别和句子级别的不确定性,从而检测出可能出现的幻觉,提高自动生成的放射学报告的事实准确性。通过拒绝高不确定性的报告,该方法的实际效果是在MIMIC-CXR数据集上,使用Radialog模型实现的报告事实性得分提高了10%,同时拒绝了大约20%的报告。此外,句子级别的不确定性成功标注了每个报告中的最低精度句子,成功率为82.9%。我们的实现是开源的,可在我们的GitHub仓库找到:https://github.com/BU-DEPEND-Lab/SCUQ-RRG。
Key Takeaways
- 该框架针对生成式医疗视觉大语言模型(VLLMs)存在的幻觉问题进行了优化,确保报告的准确性。
- 无需修改底层模型或访问其内部状态,作为即插即用模块无缝集成到最新模型中。
- 通过报告级别的不确定性检测,提高了报告的准确性。拒绝高不确定性报告后,报告的准确性得分提高了10%。
- 该框架具有开源实现,方便其他研究者使用和改进。
- 句子级别的不确定性成功标注了报告的最低精度句子,成功率为82.9%。
- 该框架适用于MIMIC-CXR数据集上的Radialog模型,未来可应用于其他数据集和模型。
点此查看论文截图

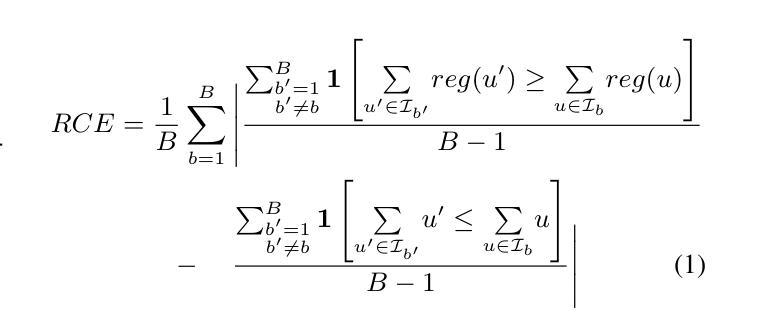
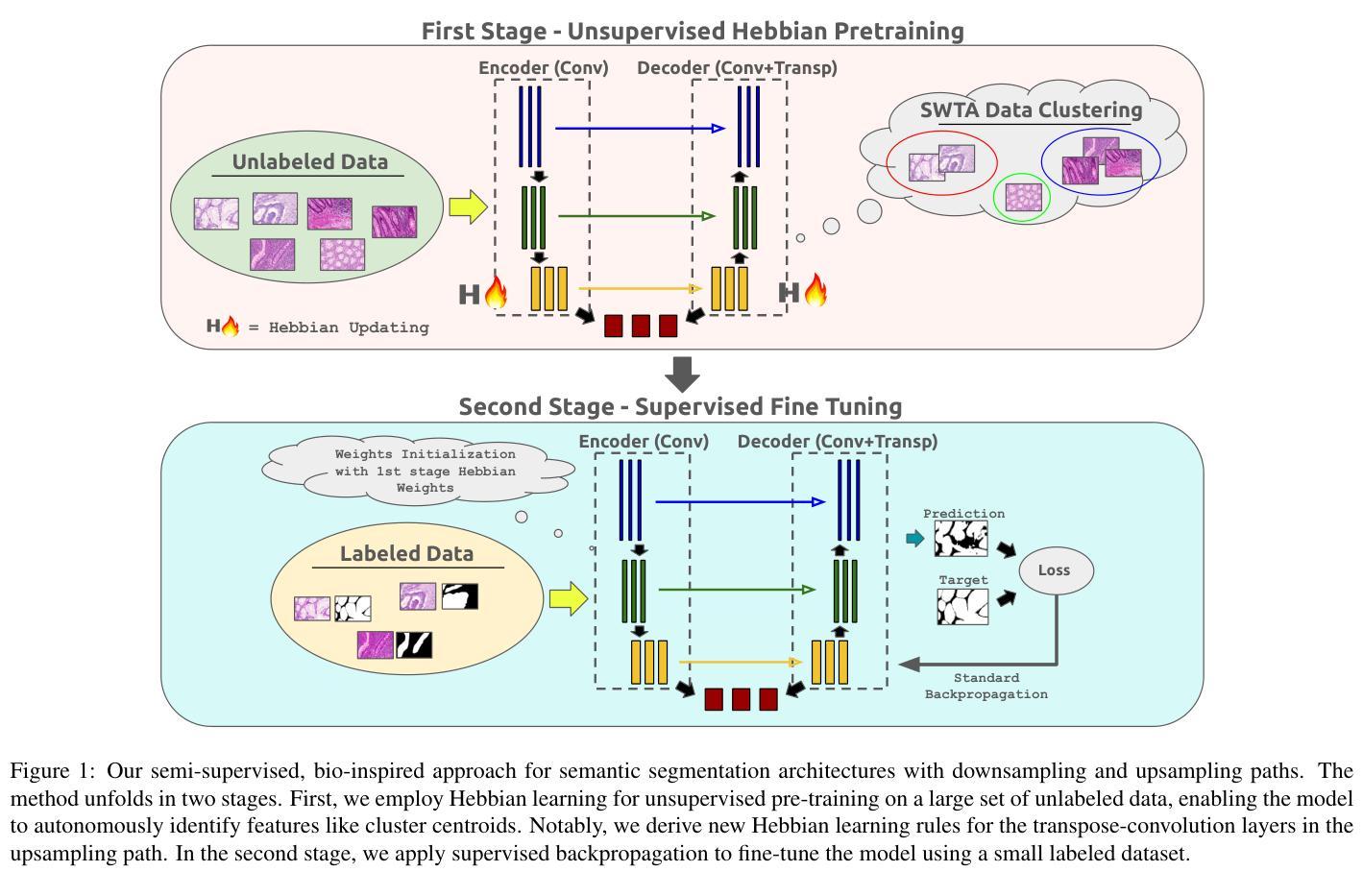
Biologically-inspired Semi-supervised Semantic Segmentation for Biomedical Imaging
Authors:Luca Ciampi, Gabriele Lagani, Giuseppe Amato, Fabrizio Falchi
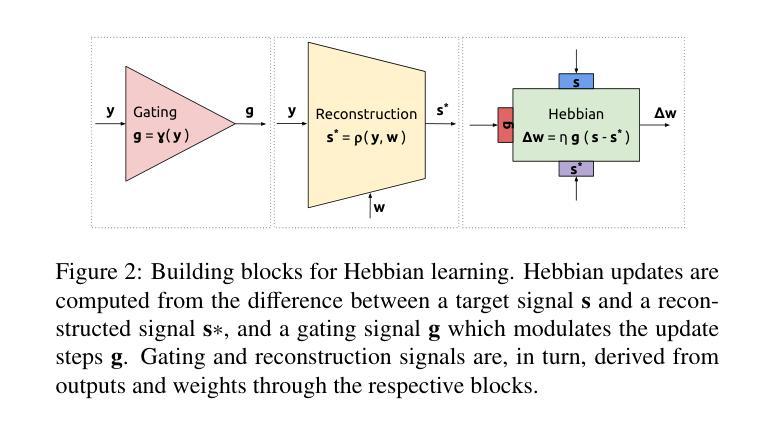
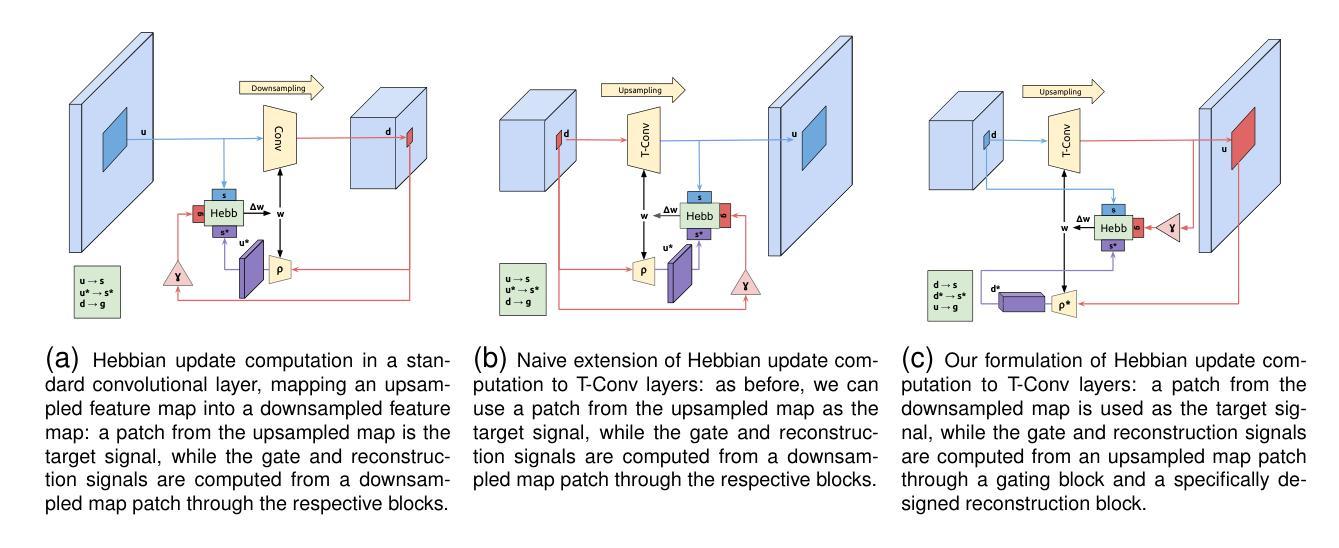
We propose a novel bio-inspired semi-supervised learning approach for training downsampling-upsampling semantic segmentation architectures. The first stage does not use backpropagation. Rather, it exploits the Hebbian principle ``fire together, wire together’’ as a local learning rule for updating the weights of both convolutional and transpose-convolutional layers, allowing unsupervised discovery of data features. In the second stage, the model is fine-tuned with standard backpropagation on a small subset of labeled data. We evaluate our methodology through experiments conducted on several widely used biomedical datasets, deeming that this domain is paramount in computer vision and is notably impacted by data scarcity. Results show that our proposed method outperforms SOTA approaches across different levels of label availability. Furthermore, we show that using our unsupervised stage to initialize the SOTA approaches leads to performance improvements. The code to replicate our experiments can be found at https://github.com/ciampluca/hebbian-bootstraping-semi-supervised-medical-imaging
我们提出了一种新型的生物启发半监督学习方法,用于训练下采样-上采样语义分割架构。第一阶段不使用反向传播。相反,它利用赫布原则“一起放电,一起连接”作为局部学习规则,以更新卷积层和转置卷积层的权重,从而实现数据特征的无监督发现。在第二阶段,模型使用标准反向传播对一小部分标记数据进行微调。我们通过几项广泛使用的生物医学数据集的实验评估了我们的方法,认为这一领域在计算机视觉领域至关重要,并且受到数据稀缺的显著影响。实验结果表明,我们的方法在标签可用性的不同级别上都优于最新技术方法。此外,我们还表明,使用我们的无监督阶段来初始化最新技术方法可以提高性能。复制我们实验的代码可以在https://github.com/ciampluca/hebbian-bootstraping-semi-supervised-medical-imaging找到。
论文及项目相关链接
Summary
一种基于生物启发的新型半监督学习方法应用于训练下采样-上采样语义分割架构。该方法分为两个阶段,第一阶段不使用反向传播,而是利用赫布原理“一起放电,一起连接”作为局部学习规则来更新卷积层和转置卷积层的权重,实现数据特征的无监督发现。第二阶段使用少量标记数据对模型进行微调,采用标准反向传播方法。在多个广泛使用的生物医学数据集上进行的实验表明,该方法在标签可用性的不同层次上都优于现有技术。此外,研究还显示,使用我们的无监督阶段初始化现有技术的方法能够提高性能。相关实验代码可访问:https://github.com/ciampluca/hebbian-bootstraping-semi-supervised-medical-imaging。
Key Takeaways
- 提出了一种基于生物启发的新型半监督学习方法用于训练语义分割架构。
- 方法分为两个阶段:无监督特征发现和基于标记数据的模型微调。
- 利用赫布原理进行无监督学习,更新卷积层与转置卷积层的权重。
- 在生物医学数据集上进行了实验验证,并显示了方法在各种标签可用性层次上的优越性。
- 与现有技术相比,该方法能够提高性能。
- 提供实验代码访问链接。
点此查看论文截图

Appearance Matching Adapter for Exemplar-based Semantic Image Synthesis in-the-Wild
Authors:Siyoon Jin, Jisu Nam, Jiyoung Kim, Dahyun Chung, Yeong-Seok Kim, Joonhyung Park, Heonjeong Chu, Seungryong Kim
Exemplar-based semantic image synthesis generates images aligned with semantic content while preserving the appearance of an exemplar. Conventional structure-guidance models like ControlNet, are limited as they rely solely on text prompts to control appearance and cannot utilize exemplar images as input. Recent tuning-free approaches address this by transferring local appearance via implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, prior works are often restricted to single-object cases or foreground object appearance transfer, struggling with complex scenes involving multiple objects. To overcome this, we propose AM-Adapter (Appearance Matching Adapter) to address exemplar-based semantic image synthesis in-the-wild, enabling multi-object appearance transfer from a single scene-level image. AM-Adapter automatically transfers local appearances from the scene-level input. AM-Adapter alternatively provides controllability to map user-defined object details to specific locations in the synthesized images. Our learnable framework enhances cross-image matching within augmented self-attention by integrating semantic information from segmentation maps. To disentangle generation and matching, we adopt stage-wise training. We first train the structure-guidance and generation networks, followed by training the matching adapter while keeping the others frozen. During inference, we introduce an automated exemplar retrieval method for selecting exemplar image-segmentation pairs efficiently. Despite utilizing minimal learnable parameters, AM-Adapter achieves state-of-the-art performance, excelling in both semantic alignment and local appearance fidelity. Extensive ablations validate our design choices. Code and weights will be released.: https://cvlab-kaist.github.io/AM-Adapter/
基于范例的语义图像合成能够生成与语义内容对齐的图像,同时保留范例的外观。传统的结构引导模型,如ControlNet,受限于仅依赖文本提示来控制外观,无法利用范例图像作为输入。最近的无需微调的方法通过预训练扩散模型的增强自注意机制中的隐式跨图像匹配来转移局部外观。然而,先前的工作通常局限于单对象情况或前景对象外观转移,对于涉及多个对象的复杂场景感到困扰。
为了克服这一局限性,我们提出了AM-Adapter(外观匹配适配器),解决基于范例的语义图像合成的野外问题,实现从单个场景级别图像进行多对象外观转移。AM-Adapter自动从场景级别的输入转移局部外观。AM-Adapter还提供可控性,将用户定义的对象细节映射到合成图像中的特定位置。我们通过学习框架,通过整合分割地图的语义信息,增强增强自注意机制内的跨图像匹配。为了解开生成和匹配,我们采用分阶段训练。我们首先训练结构引导和生成网络,然后训练匹配适配器,同时保持其他网络冻结。在推理过程中,我们引入了一种自动范例检索方法,以有效地选择范例图像-分割对。尽管使用了极少的学习参数,但AM-Adapter达到了最先进的性能,在语义对齐和局部外观保真度方面都表现出色。大量的消融实验验证了我们的设计选择。相关代码和权重已发布于:[https://cvlab-kaist.github.io/AM-Adapter/]
论文及项目相关链接
Summary
本文提出一种名为AM-Adapter的新方法,用于基于范例的语义图像合成。该方法能够克服现有技术中单对象案例或前景对象外观传递的限制,实现在复杂场景中多对象外观从单一场景级别图像的转移。通过集成分割地图中的语义信息,AM-Adapter提高了增强自我注意力中的跨图像匹配能力,并采用了分阶段训练方法。在推理阶段,引入自动范例检索方法高效选择范例图像-分割对。尽管使用较少的可学习参数,AM-Adapter在语义对齐和局部外观保真度方面达到最佳性能。
Key Takeaways
- AM-Adapter克服了依赖文本提示的现有结构引导模型的局限性,可以利用范例图像作为输入进行图像合成。
- AM-Adapter通过增强自我注意力机制中的跨图像匹配实现了局部外观的转移,适用于多对象复杂场景。
- 该方法集成了语义信息来提高跨图像匹配的效能,并通过分阶段训练来优化性能。
- AM-Adapter在自动范例检索方面表现出色,能高效选择范例图像和分割配对。
- 尽管参数较少,AM-Adapter在语义图像合成的性能和效率方面达到最佳状态。
- 该方法将在语义对齐和局部外观保真度方面展现出卓越性能,为图像合成领域提供新的解决方案。
点此查看论文截图





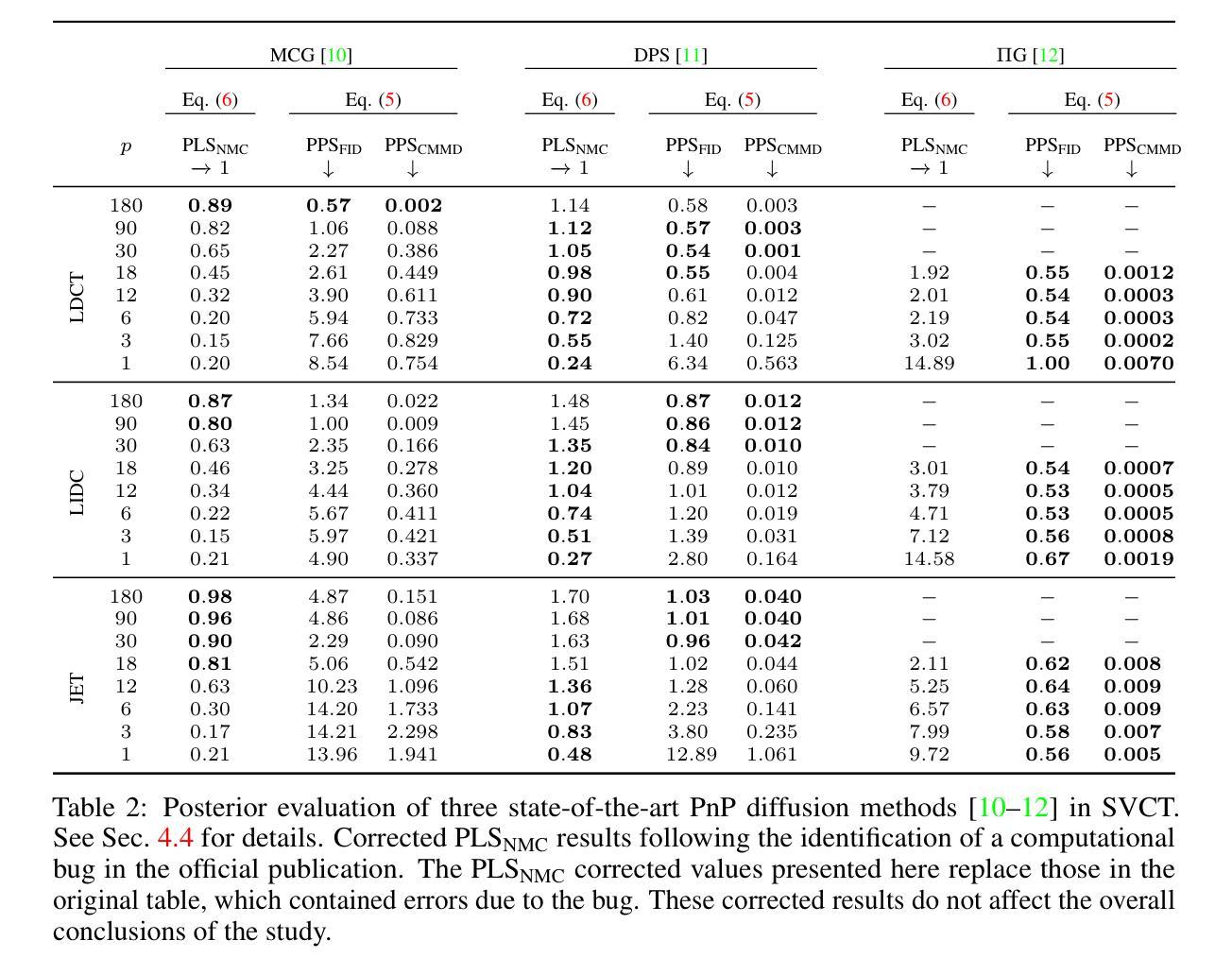
Evaluating the Posterior Sampling Ability of Plug&Play Diffusion Methods in Sparse-View CT
Authors:Liam Moroy, Guillaume Bourmaud, Frédéric Champagnat, Jean-François Giovannelli
Plug&Play (PnP) diffusion models are state-of-the-art methods in computed tomography (CT) reconstruction. Such methods usually consider applications where the sinogram contains a sufficient amount of information for the posterior distribution to be concentrated around a single mode, and consequently are evaluated using image-to-image metrics such as PSNR/SSIM. Instead, we are interested in reconstructing compressible flow images from sinograms having a small number of projections, which results in a posterior distribution no longer concentrated or even multimodal. Thus, in this paper, we aim at evaluating the approximate posterior of PnP diffusion models and introduce two posterior evaluation properties. We quantitatively evaluate three PnP diffusion methods on three different datasets for several numbers of projections. We surprisingly find that, for each method, the approximate posterior deviates from the true posterior when the number of projections decreases.
Plug&Play(PnP)扩散模型是目前计算机断层扫描(CT)重建领域的最前沿方法。这类方法通常应用于辛格拉姆图中包含足够信息,使得后验分布集中在单一模式的情况,因此它们是通过图像到图像的指标(如峰值信噪比/结构相似性度量)来评价的。相反,我们对从辛格拉姆图重建可压缩流动图像感兴趣,该辛格拉姆图具有少量的投影,导致后验分布不再集中,甚至是多模态的。因此,本文旨在评估PnP扩散模型的近似后验,并引入两个后验评估属性。我们在三个不同的数据集上定量评估了三种PnP扩散方法,进行了多次投影。令人惊讶的是,我们发现,对于每种方法,当投影数量减少时,近似后验与真实后验之间存在偏差。
论文及项目相关链接
Summary
PnP扩散模型在计算机断层扫描重建中是先进技术,但在投影数量较少的情况下重构可压缩流图像时,其近似后验分布会偏离真实后验分布。本文旨在评估PnP扩散模型的近似后验,并引入两种后验评估属性,对三种PnP扩散方法在不同数据集和不同投影数量上进行定量评估。
Key Takeaways
- PnP扩散模型在计算机断层扫描重建中是主流技术。
- 当投影数量较少时,重构可压缩流图像的近似后验分布会偏离真实后验分布。
- 本文的目标是评估PnP扩散模型的近似后验。
- 引入两种后验评估属性来评价PnP扩散模型性能。
- 在不同数据集和不同投影数量下,对三种PnP扩散方法进行定量评估。
- 发现每种方法的近似后验在投影数量减少时会偏离真实后验。
点此查看论文截图


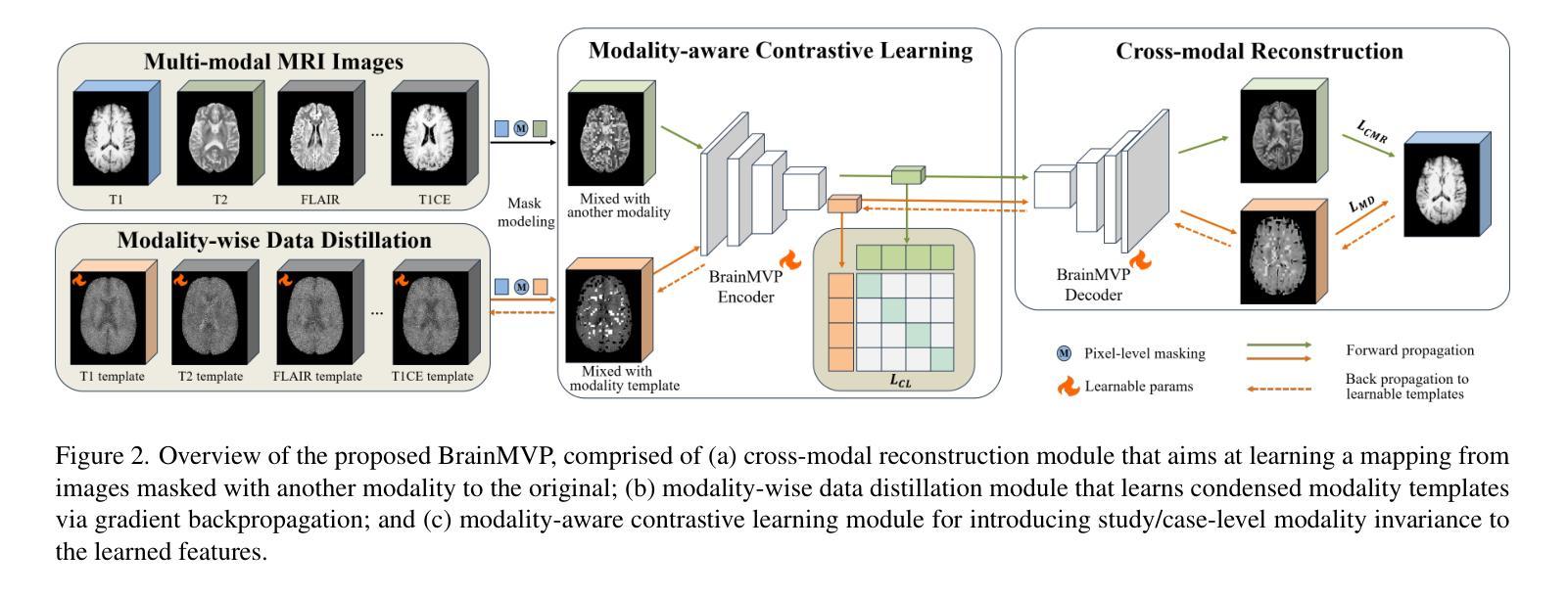
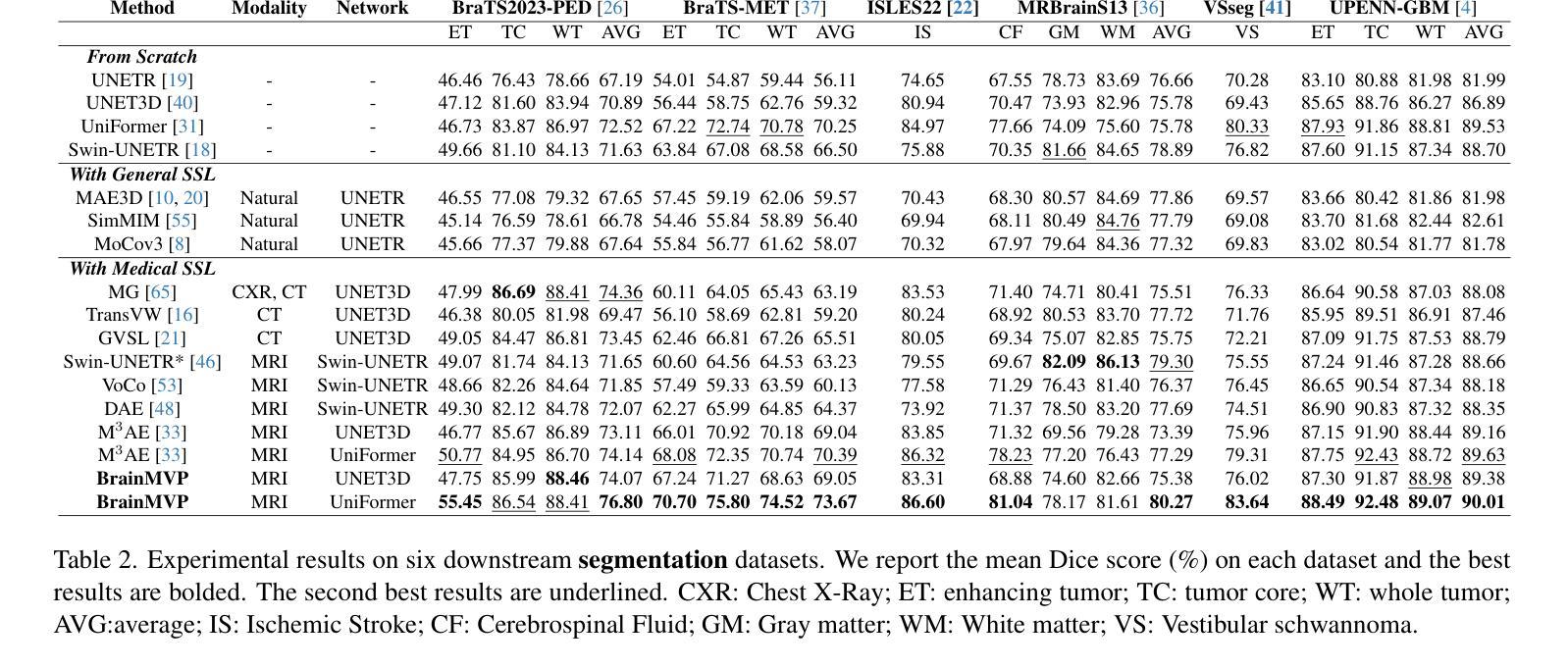
Multi-modal Vision Pre-training for Medical Image Analysis
Authors:Shaohao Rui, Lingzhi Chen, Zhenyu Tang, Lilong Wang, Mianxin Liu, Shaoting Zhang, Xiaosong Wang
Self-supervised learning has greatly facilitated medical image analysis by suppressing the training data requirement for real-world applications. Current paradigms predominantly rely on self-supervision within uni-modal image data, thereby neglecting the inter-modal correlations essential for effective learning of cross-modal image representations. This limitation is particularly significant for naturally grouped multi-modal data, e.g., multi-parametric MRI scans for a patient undergoing various functional imaging protocols in the same study. To bridge this gap, we conduct a novel multi-modal image pre-training with three proxy tasks to facilitate the learning of cross-modality representations and correlations using multi-modal brain MRI scans (over 2.4 million images in 16,022 scans of 3,755 patients), i.e., cross-modal image reconstruction, modality-aware contrastive learning, and modality template distillation. To demonstrate the generalizability of our pre-trained model, we conduct extensive experiments on various benchmarks with ten downstream tasks. The superior performance of our method is reported in comparison to state-of-the-art pre-training methods, with Dice Score improvement of 0.28%-14.47% across six segmentation benchmarks and a consistent accuracy boost of 0.65%-18.07% in four individual image classification tasks.
自监督学习通过减少对现实世界应用所需训练数据的要求,极大地促进了医学图像分析。当前的模式主要依赖于单模态图像数据内的自监督,从而忽略了跨模态图像表示有效学习所必需的跨模态关联。这一局限性对于自然分组的多模态数据尤为重要,例如,同一研究中患者接受多种功能成像协议的多参数MRI扫描。为了弥这一差距,我们采用了一种新型的多模态图像预训练方法,通过三个代理任务促进使用多模态脑MRI扫描(超过3755名患者的16,022次扫描中的超过240万张图像)的跨模态表示和关联的学习,即跨模态图像重建、模态感知对比学习和模态模板蒸馏。为了展示我们预训练模型的通用性,我们在各种基准测试上进行了广泛的实验,涉及十项下游任务。与最新的预训练方法相比,我们的方法在六个分割基准测试中报告了较高的性能提升,Dice得分提高了0.28%~14.47%,在四项单独的图像分类任务中准确率也持续提升了0.65%~18.07%。
论文及项目相关链接
Summary
自监督学习降低了医学图像分析对训练数据的要求,促进了其在现实世界应用中的发展。当前主流方法主要依赖单模态图像数据的自监督,忽略了跨模态图像表示学习中至关重要的跨模态关联。为解决这一问题,本文提出了一种新型多模态图像预训练方法,利用三种代理任务学习跨模态表示和关联,并使用多模态脑MRI扫描数据(超过2.4百万张图像)进行训练。实验表明,该方法在多个基准测试上的表现优于其他最新预训练方法,Dice Score在六个分割基准测试中提高了0.28%~14.47%,在四个独立图像分类任务中的准确率提高了0.65%~18.07%。
Key Takeaways
- 自监督学习降低了医学图像分析对训练数据的要求。
- 当前自监督学习方法主要依赖单模态图像数据的自监督,忽略了跨模态关联的重要性。
- 文中提出了一种新型的多模态图像预训练方法,利用三种代理任务学习跨模态表示和关联。
- 该方法使用多模态脑MRI扫描数据进行训练,包含超过2.4百万张图像。
- 实验表明该方法在多个基准测试上的表现优于其他最新预训练方法。
- 在六个分割基准测试中,该方法的Dice Score提高了0.28%~14.47%。
点此查看论文截图

Brain Tumor Classification on MRI in Light of Molecular Markers
Authors:Jun Liu, Geng Yuan, Weihao Zeng, Hao Tang, Wenbin Zhang, Xue Lin, XiaoLin Xu, Dong Huang, Yanzhi Wang
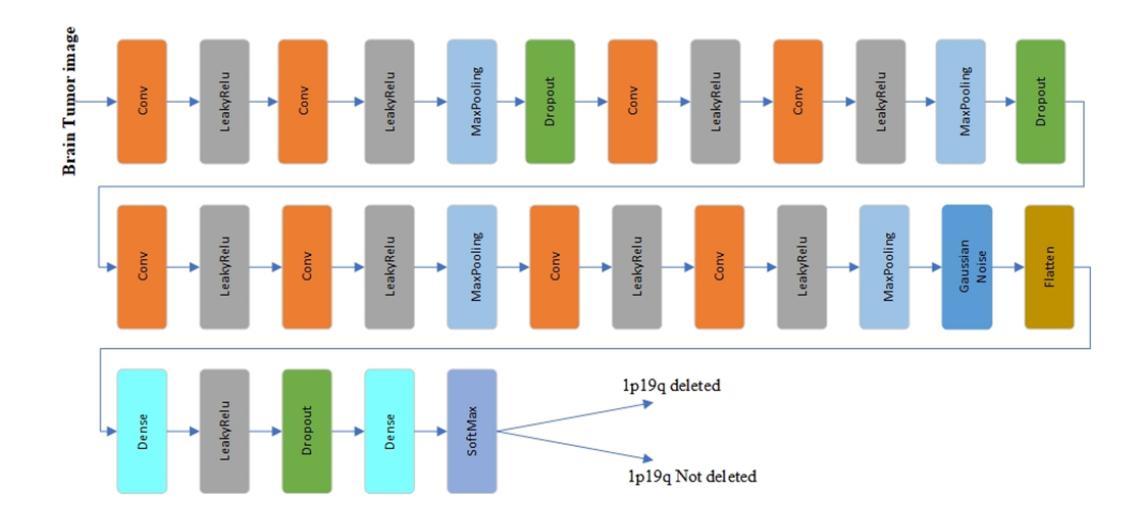
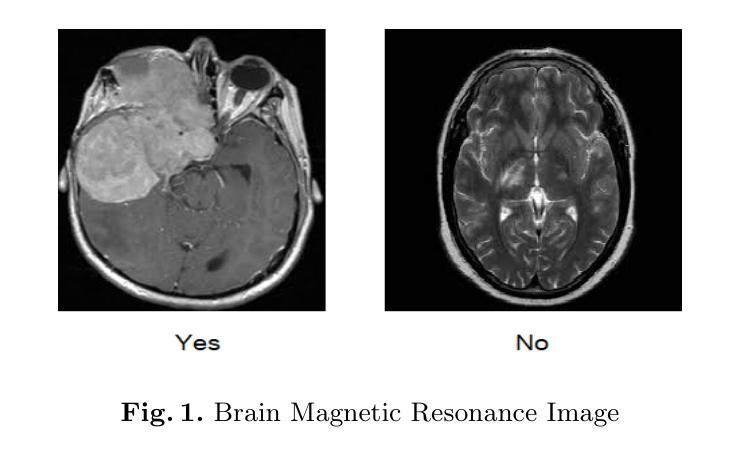
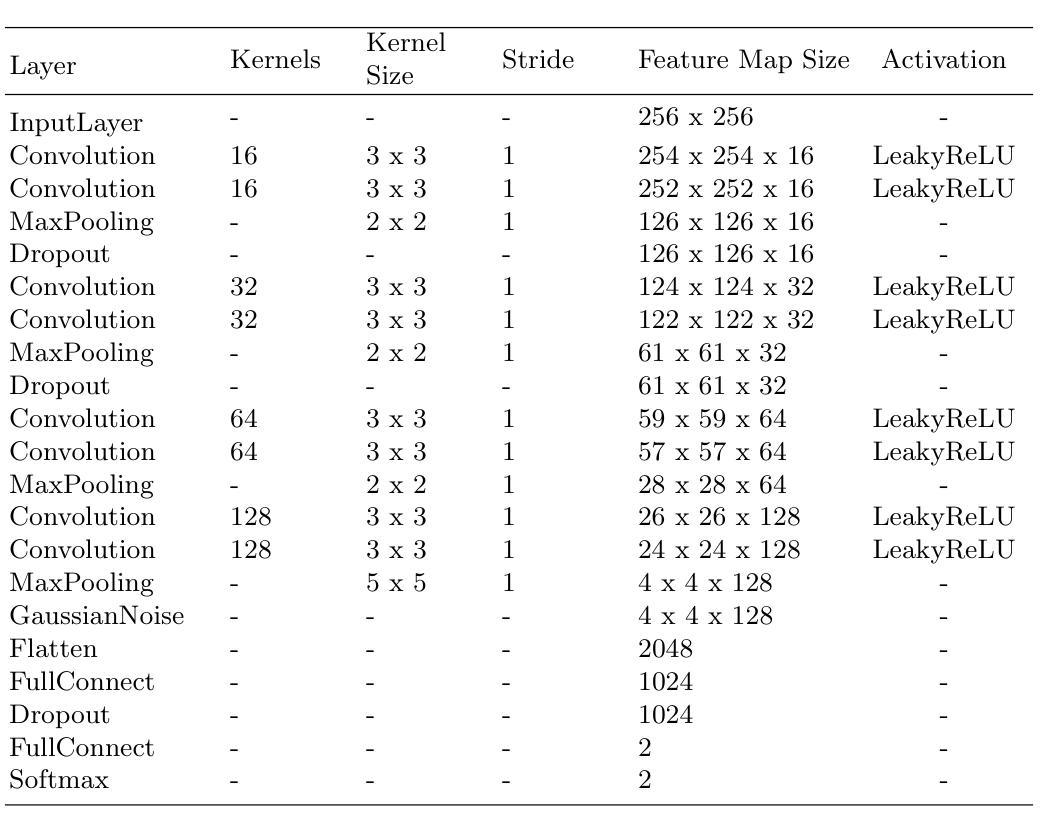
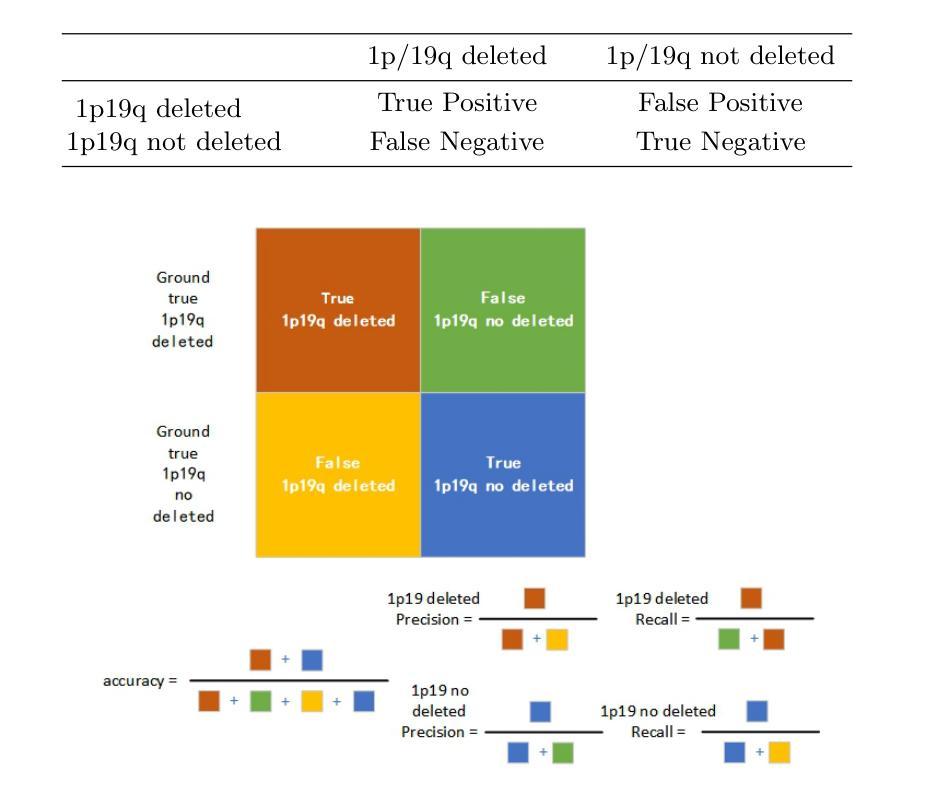
In research findings, co-deletion of the 1p/19q gene is associated with clinical outcomes in low-grade gliomas. The ability to predict 1p19q status is critical for treatment planning and patient follow-up. This study aims to utilize a specially MRI-based convolutional neural network for brain cancer detection. Although public networks such as RestNet and AlexNet can effectively diagnose brain cancers using transfer learning, the model includes quite a few weights that have nothing to do with medical images. As a result, the diagnostic results are unreliable by the transfer learning model. To deal with the problem of trustworthiness, we create the model from the ground up, rather than depending on a pre-trained model. To enable flexibility, we combined convolution stacking with a dropout and full connect operation, it improved performance by reducing overfitting. During model training, we also supplement the given dataset and inject Gaussian noise. We use three–fold cross-validation to train the best selection model. Comparing InceptionV3, VGG16, and MobileNetV2 fine-tuned with pre-trained models, our model produces better results. On an validation set of 125 codeletion vs. 31 not codeletion images, the proposed network achieves 96.37% percent F1-score, 97.46% percent precision, and 96.34% percent recall when classifying 1p/19q codeletion and not codeletion images.
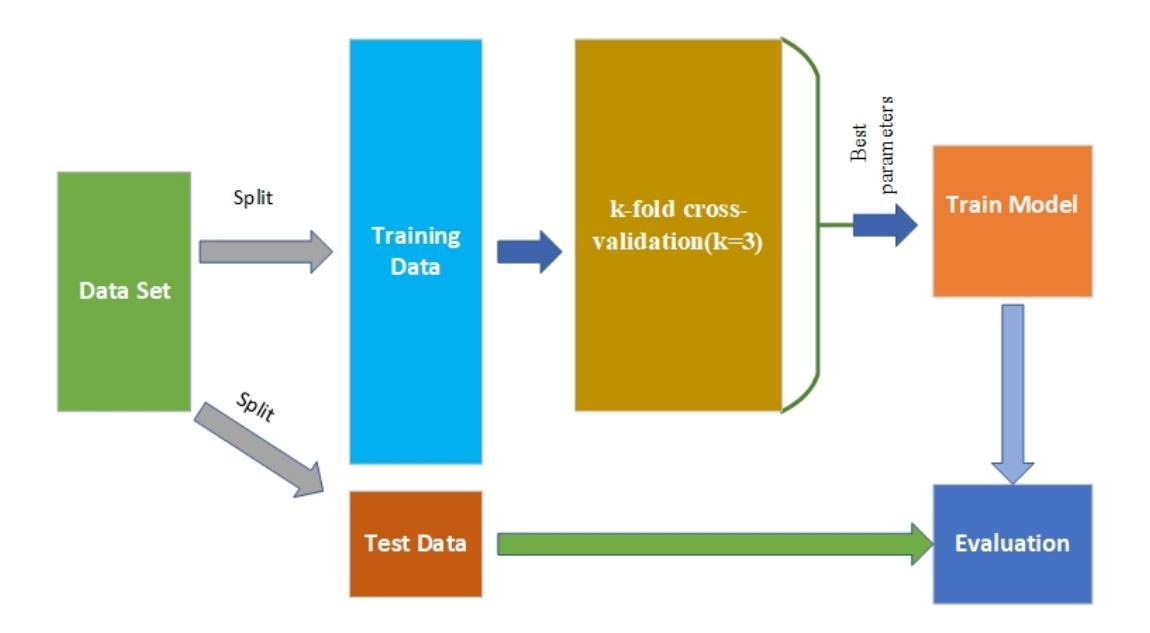
在研究过程中发现,1p/19q基因的联合缺失与低级别胶质瘤的临床结果有关。预测1p19q状态对于治疗计划和患者随访至关重要。本研究旨在利用基于MRI的卷积神经网络进行脑癌检测。虽然RestNet和AlexNet等公共网络可以通过迁移学习有效地诊断脑癌,但模型中包括许多与医学图像无关的权重。因此,迁移学习模型的诊断结果并不可靠。为了解决可靠性的问题,我们从零开始创建模型,而不是依赖于预训练模型。为了提高灵活性,我们将卷积堆叠与丢弃和全连接操作相结合,通过减少过拟合提高了性能。在模型训练过程中,我们还补充了给定的数据集并注入了高斯噪声。我们使用三折交叉验证来训练最佳选型模型。与预训练模型微调过的InceptionV3、VGG16和MobileNetV2相比,我们的模型取得了更好的结果。在125张codeletion与31张非codeletion图像的验证集上,所提出网络在分类1p/19q codeletion和非codeletion图像时,达到了96.37%的F1分数、97.46%的精确度和96.34%的召回率。
论文及项目相关链接
PDF ICAI’22 - The 24th International Conference on Artificial Intelligence, The 2022 World Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE’22), Las Vegas, USA. The paper acceptance rate 17% for regular papers. The publication of the CSCE 2022 conference proceedings has been delayed due to the pandemic
Summary
该研究探讨了通过MRI成像的卷积神经网络在低级别胶质瘤中的诊断应用,特别是关于涉及基因1p/19q联合缺失的预测。该研究提出了一种新型模型,其自主构建而非依赖预训练模型,并融合多种技术优化其性能和可信度,达到高准确度的诊断效果。实验显示其在特定的图像分类任务上表现出较高的性能指标。
Key Takeaways
- 研究发现基因1p/19q联合缺失与低级别胶质瘤的临床结果有关。预测此基因状态对治疗计划和患者随访至关重要。
- 该研究使用基于MRI的卷积神经网络进行脑癌检测。尽管公共网络如RestNet和AlexNet可通过迁移学习有效诊断脑癌,但它们在某些情况下存在诊断结果不可靠的问题。
- 为解决可靠性问题,研究团队自主构建模型,摒弃依赖预训练模型的方式。
- 结合卷积堆叠、丢弃操作和完全连接操作,以提高模型的性能并降低过拟合风险。
- 在模型训练过程中,对给定数据集进行了补充并添加了高斯噪声。
- 使用三折交叉验证训练最佳模型选择。对比InceptionV3、VGG16和MobileNetV2等预训练模型的微调结果,新模型表现出更好的性能。
点此查看论文截图