⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
LEGNet: Lightweight Edge-Gaussian Driven Network for Low-Quality Remote Sensing Image Object Detection
Authors:Wei Lu, Si-Bao Chen, Hui-Dong Li, Qing-Ling Shu, Chris H. Q. Ding, Jin Tang, Bin Luo
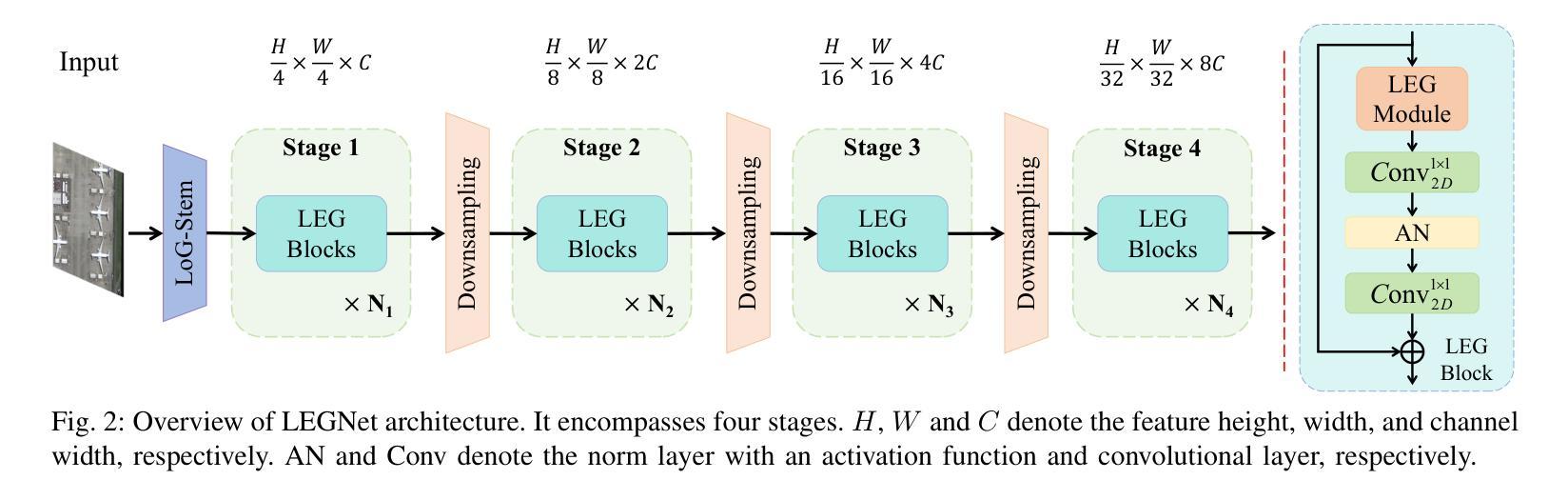
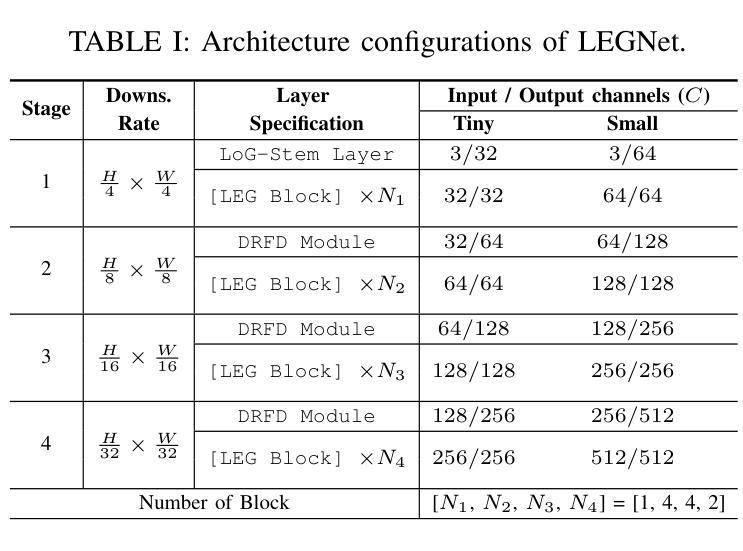
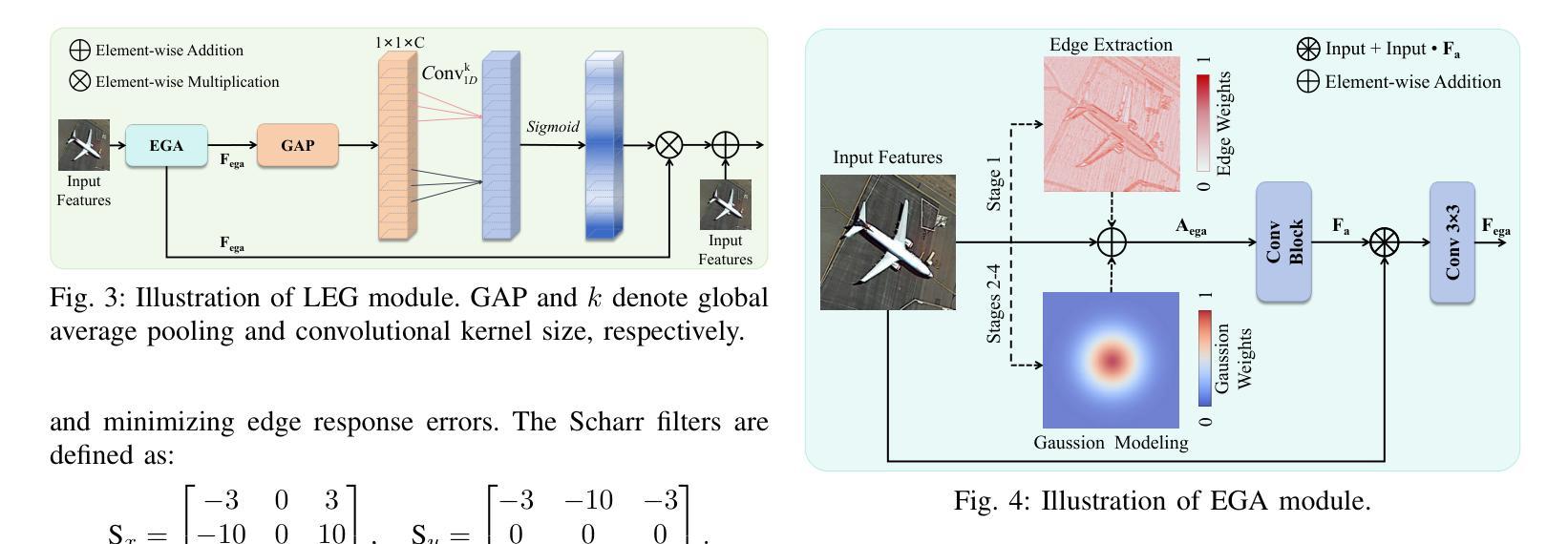
Remote sensing object detection (RSOD) faces formidable challenges in complex visual environments. Aerial and satellite images inherently suffer from limitations such as low spatial resolution, sensor noise, blurred objects, low-light degradation, and partial occlusions. These degradation factors collectively compromise the feature discriminability in detection models, resulting in three key issues: (1) reduced contrast that hampers foreground-background separation, (2) structural discontinuities in edge representations, and (3) ambiguous feature responses caused by variations in illumination. These collectively weaken model robustness and deployment feasibility. To address these challenges, we propose LEGNet, a lightweight network that incorporates a novel edge-Gaussian aggregation (EGA) module specifically designed for low-quality remote sensing images. Our key innovation lies in the synergistic integration of Scharr operator-based edge priors with uncertainty-aware Gaussian modeling: (a) The orientation-aware Scharr filters preserve high-frequency edge details with rotational invariance; (b) The uncertainty-aware Gaussian layers probabilistically refine low-confidence features through variance estimation. This design enables precision enhancement while maintaining architectural simplicity. Comprehensive evaluations across four RSOD benchmarks (DOTA-v1.0, v1.5, DIOR-R, FAIR1M-v1.0) and a UAV-view dataset (VisDrone2019) demonstrate significant improvements. LEGNet achieves state-of-the-art performance across five benchmark datasets while ensuring computational efficiency, making it well-suited for deployment on resource-constrained edge devices in real-world remote sensing applications. The code is available at https://github.com/lwCVer/LEGNet.
遥感目标检测(RSOD)在复杂的视觉环境中面临着巨大的挑战。航空和卫星图像本质上存在诸如空间分辨率低、传感器噪声、目标模糊、低光退化和部分遮挡等局限性。这些退化因素集体影响了检测模型中的特征辨别力,导致三个关键问题:(1)对比度降低,妨碍前景背景分离;(2)边缘表示中的结构不连续;(3)由光照变化引起的特征响应模糊。这些共同削弱了模型的稳健性和部署的可行性。为了解决这些挑战,我们提出了LEGNet,这是一个轻量级网络,它融入了一个新型的边缘高斯聚合(EGA)模块,专门针对低质量的遥感图像设计。我们的关键创新在于将基于Scharr算子的边缘先验与不确定性感知高斯建模协同集成:(a)方向感知的Scharr滤波器以旋转不变性保留高频边缘细节;(b)不确定性感知的高斯层通过方差估计概率地优化低置信特征。这一设计既提高了精度,又保持了架构的简单性。在四个RSOD基准(DOTA-v1.0、v1.5、DIOR-R、FAIR1M-v1.0)和一个无人机视角数据集(VisDrone2019)上的全面评估表明,LEGNet取得了显著改进,在五个基准数据集上实现了最先进的性能,同时确保了计算效率,非常适合在资源受限的边缘设备上用于现实世界遥感应用部署。代码可通过https://github.com/lwCVer/LEGNet获取。
论文及项目相关链接
PDF 12 pages, 5 figures. Remote Sensing Image Object Detection
Summary
在复杂的视觉环境中,遥感目标检测面临严峻挑战。远程图像因低空间分辨率、传感器噪声、目标模糊、低光照退化和部分遮挡等固有缺陷,导致检测模型的特征辨别能力下降。这些问题集体造成对比减少、边缘断裂以及因光照变化产生的特征模糊,降低模型稳健性和部署可行性。为解决此问题,我们提出LEGNet网络,它结合了新颖的边缘高斯聚合模块,专为低质量遥感图像设计。主要创新在于结合基于Scharr算子的边缘先验与概率化高斯建模,既能保留边缘细节又能通过方差估计优化低置信度特征。在四个遥感目标检测基准测试中表现出卓越性能,同时保证计算效率,适用于资源受限的边缘设备进行遥感应用部署。代码已上传至GitHub供公众查阅。
Key Takeaways
- 遥感目标检测面临诸多挑战,包括图像低空间分辨率和模糊对象等问题。
- 上述缺陷降低检测模型的性能及识别特征的可靠性。
- LEGNet网络设计针对低质量遥感图像提出,包含新颖的边缘高斯聚合模块。
- 主要创新在于结合基于Scharr算子的边缘先验与概率化高斯建模。
点此查看论文截图

FrustumFusionNets: A Three-Dimensional Object Detection Network Based on Tractor Road Scene
Authors:Lili Yang, Mengshuai Chang, Xiao Guo, Yuxin Feng, Yiwen Mei, Caicong Wu
To address the issues of the existing frustum-based methods’ underutilization of image information in road three-dimensional object detection as well as the lack of research on agricultural scenes, we constructed an object detection dataset using an 80-line Light Detection And Ranging (LiDAR) and a camera in a complex tractor road scene and proposed a new network called FrustumFusionNets (FFNets). Initially, we utilize the results of image-based two-dimensional object detection to narrow down the search region in the three-dimensional space of the point cloud. Next, we introduce a Gaussian mask to enhance the point cloud information. Then, we extract the features from the frustum point cloud and the crop image using the point cloud feature extraction pipeline and the image feature extraction pipeline, respectively. Finally, we concatenate and fuse the data features from both modalities to achieve three-dimensional object detection. Experiments demonstrate that on the constructed test set of tractor road data, the FrustumFusionNetv2 achieves 82.28% and 95.68% accuracy in the three-dimensional object detection of the two main road objects, cars and people, respectively. This performance is 1.83% and 2.33% better than the original model. It offers a hybrid fusion-based multi-object, high-precision, real-time three-dimensional object detection technique for unmanned agricultural machines in tractor road scenarios. On the Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) Benchmark Suite validation set, the FrustumFusionNetv2 also demonstrates significant superiority in detecting road pedestrian objects compared with other frustum-based three-dimensional object detection methods.
为了解决现有基于截锥体方法在道路三维目标检测中对图像信息利用不足的问题以及在农业场景研究方面的缺乏,我们构建了一个目标检测数据集,该数据集使用拖拉机道路场景中一台复杂的80线激光雷达和摄像机。在此基础上,我们提出了一种新的网络结构,称为FrustumFusionNets(FFNets)。首先,我们利用基于图像的两维目标检测结果来缩小点云的三维搜索区域。接下来,我们引入高斯掩膜以增强点云信息。然后,我们从截锥点云和作物图像中提取特征,分别使用点云特征提取管道和图像特征提取管道。最后,我们将两种模态的数据特征进行拼接和融合,以实现三维目标检测。实验表明,在构建的拖拉机道路测试集上,FrustumFusionNetv2针对主要道路目标车辆和行人,在三维目标检测方面的准确率分别达到82.28%和95.68%。这一性能比原始模型提高了1.83%和2.33%。它为无人驾驶农业机器在拖拉机道路上的场景中提供了一种基于混合融合的多目标、高精度、实时的三维目标检测技术。在KITTI基准套件验证集上,与其他的基于截锥体的三维目标检测方法相比,FrustumFusionNetv2在检测道路行人目标方面表现出显著的优越性。
论文及项目相关链接
Summary
针对现有基于Frustum的方法对图像信息利用不足的问题,以及农业场景研究缺乏的问题,我们构建了一个使用激光雷达和拖拉机道路场景相机的对象检测数据集,并提出了一个新的网络——FrustumFusionNets(FFNets)。首先,利用基于图像的二维对象检测结果缩小点云的三维搜索区域。接着,引入高斯掩膜增强点云信息。然后,分别从点云和农作物图像中提取特征,并通过拼接融合两种模态的数据特征来实现三维对象检测。实验表明,在构建的拖拉机道路测试集上,FrustumFusionNetv2对主要道路对象汽车和行人的三维对象检测准确率分别达到82.28%和95.68%,较原模型提升1.83%和2.33%。该模型为无人驾驶农业机械在拖拉机道路上的多对象、高精度、实时三维对象检测提供了混合融合技术。在KITTI基准套件验证集上,与其他的基于Frustum的三维对象检测方法相比,该模型在检测道路行人对象方面具有显著优势。
Key Takeaways
- 针对现有方法图像信息利用不足的问题,构建了基于激光雷达和相机的拖拉机道路场景对象检测数据集。
- 提出了一种新的网络结构——FrustumFusionNets(FFNets)。
- 利用二维图像检测结果缩小三维点云的搜索区域。
- 通过引入高斯掩膜增强点云信息。
- 实现了从点云和农作物图像中提取特征并进行三维对象检测。
- 在拖拉机道路测试集上,新模型较原模型有显著提升。
- 模型为无人驾驶农业机械提供了混合融合技术的多对象、高精度、实时三维对象检测方案。
点此查看论文截图

HSOD-BIT-V2: A New Challenging Benchmarkfor Hyperspectral Salient Object Detection
Authors:Yuhao Qiu, Shuyan Bai, Tingfa Xu, Peifu Liu, Haolin Qin, Jianan Li
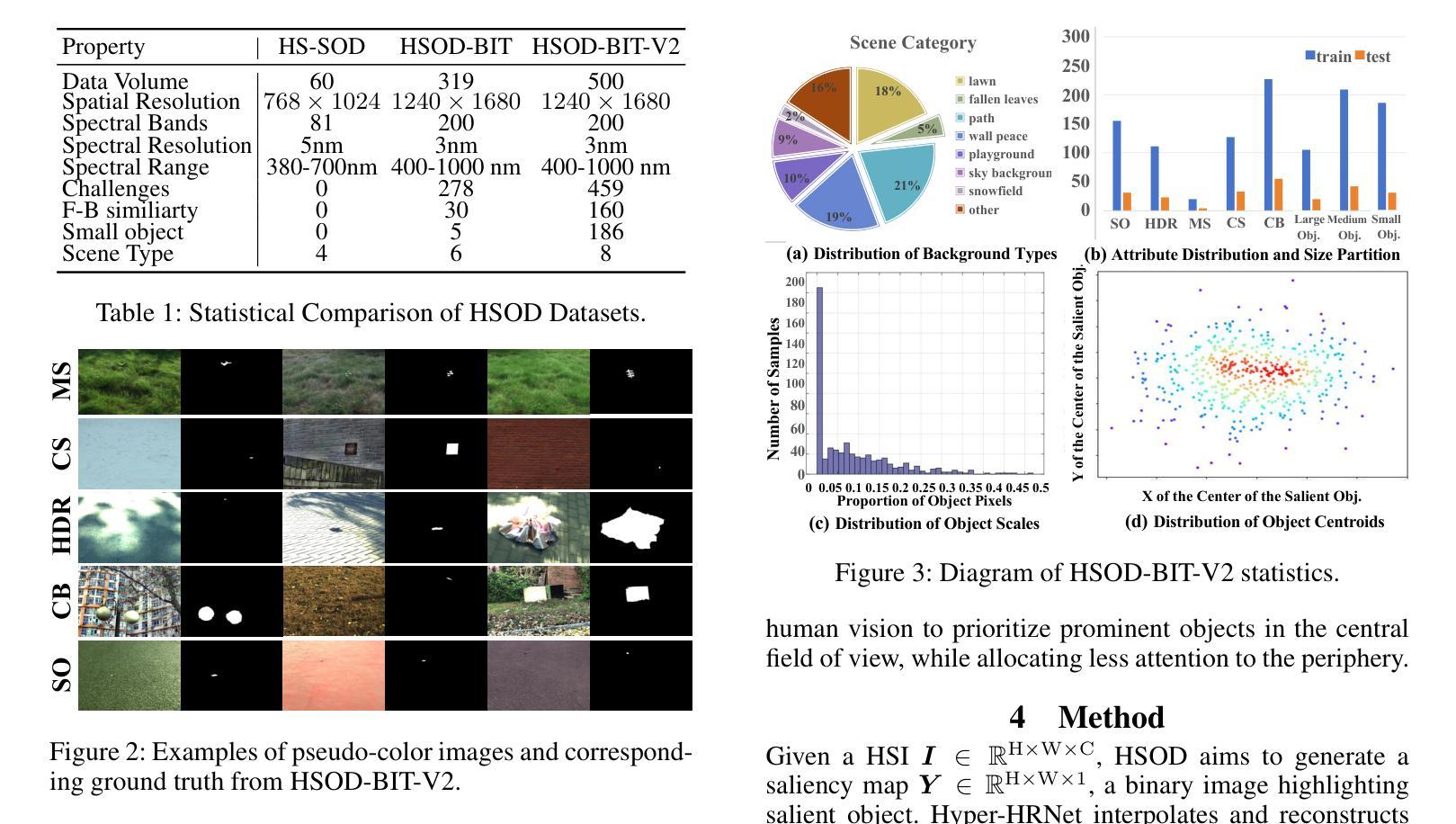
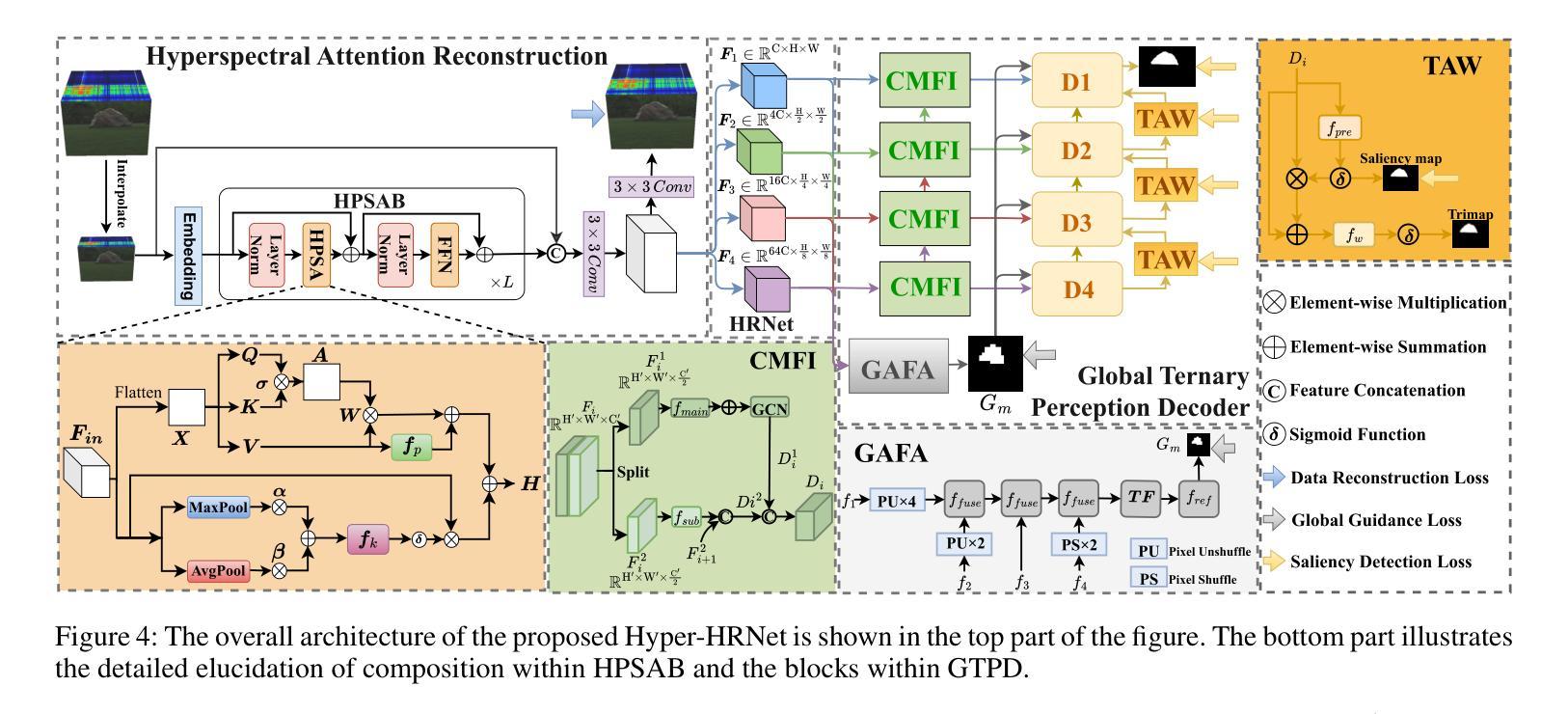
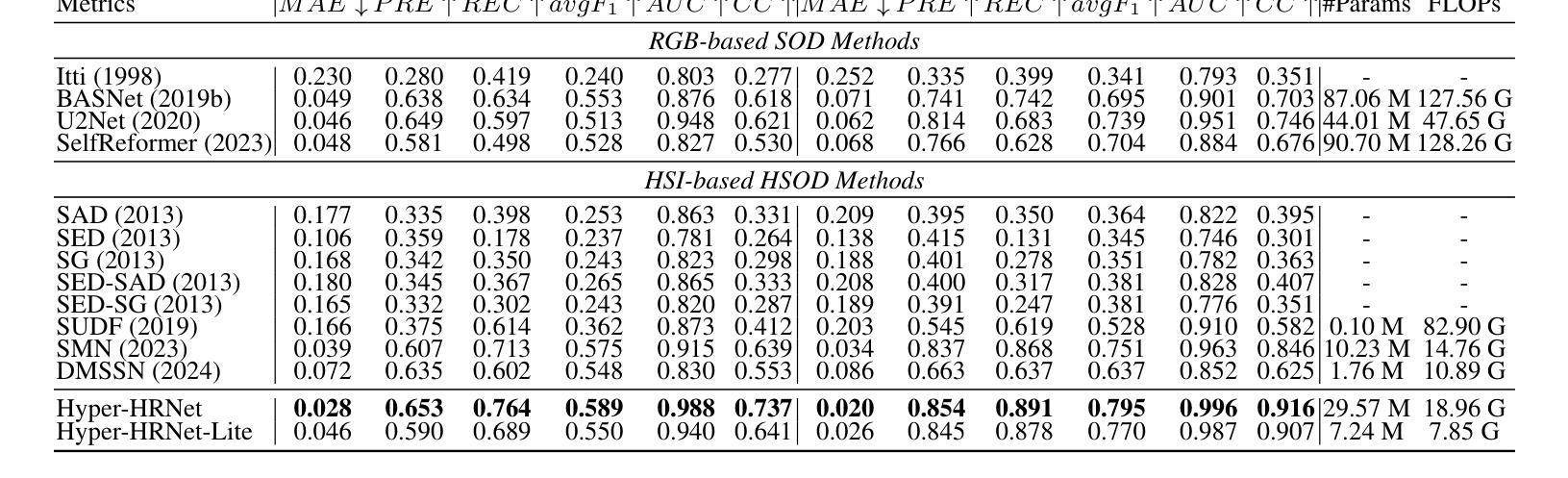
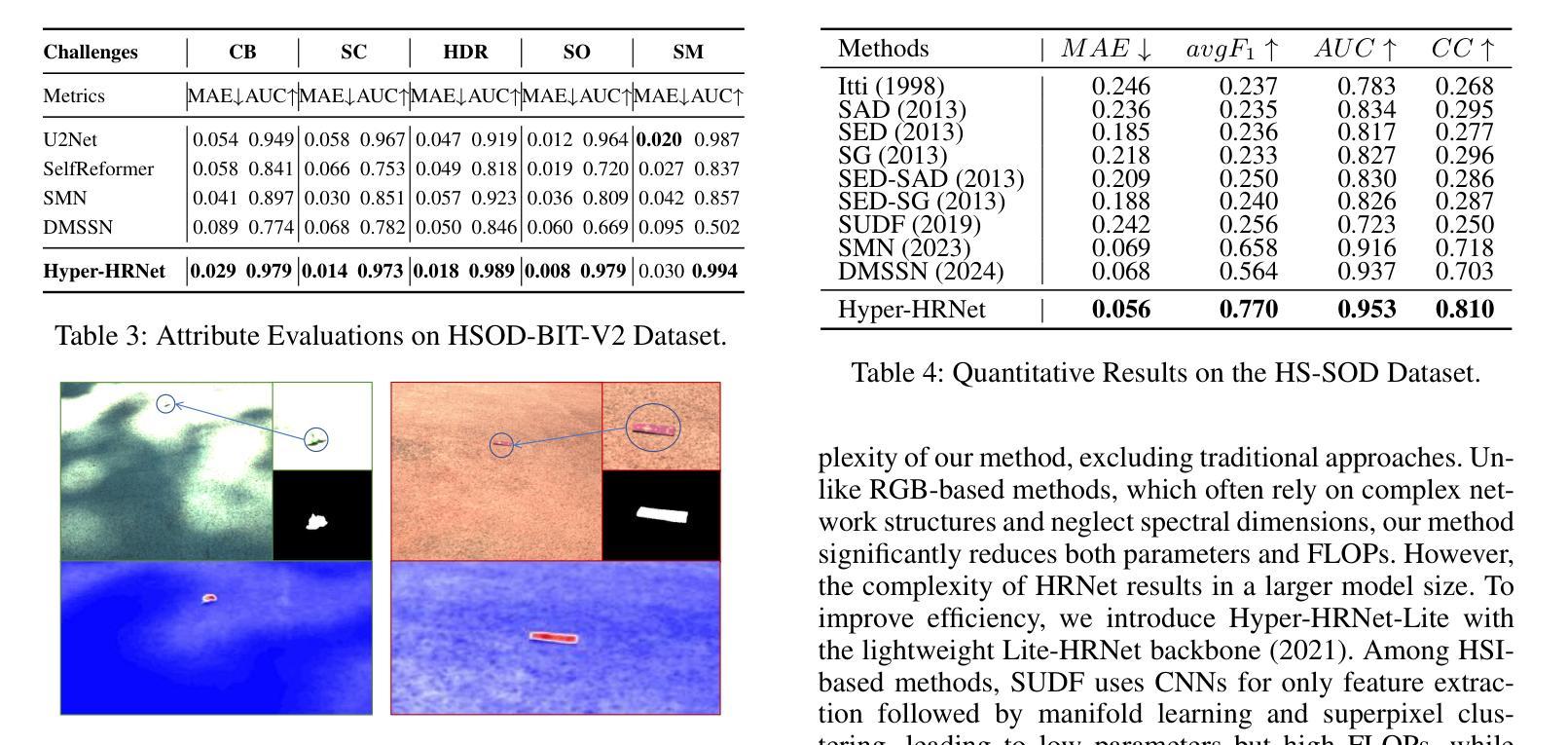
Salient Object Detection (SOD) is crucial in computer vision, yet RGB-based methods face limitations in challenging scenes, such as small objects and similar color features. Hyperspectral images provide a promising solution for more accurate Hyperspectral Salient Object Detection (HSOD) by abundant spectral information, while HSOD methods are hindered by the lack of extensive and available datasets. In this context, we introduce HSOD-BIT-V2, the largest and most challenging HSOD benchmark dataset to date. Five distinct challenges focusing on small objects and foreground-background similarity are designed to emphasize spectral advantages and real-world complexity. To tackle these challenges, we propose Hyper-HRNet, a high-resolution HSOD network. Hyper-HRNet effectively extracts, integrates, and preserves effective spectral information while reducing dimensionality by capturing the self-similar spectral features. Additionally, it conveys fine details and precisely locates object contours by incorporating comprehensive global information and detailed object saliency representations. Experimental analysis demonstrates that Hyper-HRNet outperforms existing models, especially in challenging scenarios.
显著性目标检测(SOD)在计算机视觉中至关重要,然而基于RGB的方法在具有挑战性的场景中,如小物体和相似颜色特征方面存在局限性。高光谱图像通过丰富的光谱信息为解决更准确的高光谱显著性目标检测(HSOD)问题提供了有前景的解决方案。然而,由于缺乏广泛可用的数据集,HSOD方法受到阻碍。在此背景下,我们介绍了迄今为止最大且最具挑战性的高光谱显著性目标检测数据集HSOD-BIT-V2。我们设计了五个独特挑战,重点关注小物体和前景背景相似性,以突出光谱优势和现实世界复杂性。为了解决这些挑战,我们提出了高分辨率高光谱显著性目标检测网络Hyper-HRNet。Hyper-HRNet能够有效地提取、集成和保留有效的光谱信息,通过捕获自相似光谱特征来降低维度。此外,它结合全面的全局信息和详细的对象显著性表示,传递了精细的细节并准确地对对象轮廓进行了定位。实验分析表明,Hyper-HRNet在具有挑战性的场景中表现优于现有模型。
论文及项目相关链接
PDF AAAI 2025
Summary
本文介绍了基于计算机视觉的显著性目标检测(SOD)的重要性,指出RGB方法在某些复杂场景中存在局限性。为解决这一问题,研究者引入超光谱图像作为解决方案,并推出迄今为止最大的超光谱显著性目标检测(HSOD)数据集HSOD-BIT-V2。针对超光谱图像的特点和实际应用场景中的复杂性,设计五个具有挑战性的小目标识别场景及五个背景识别挑战场景。此外,提出了基于Hyper-HRNet的超光谱高分辨率目标检测网络。该网络能有效提取、整合和保留有效的光谱信息,通过捕捉自相似光谱特征降低维度,同时结合全局信息和详细的对象显著性表示,精细地描绘出物体的轮廓。实验表明,Hyper-HRNet相较于现有模型性能更优,特别是在复杂场景下。
Key Takeaways
- RGB方法在处理某些复杂场景的显著性目标检测(SOD)时存在局限性。
- 超光谱图像提供了解决此问题的有前景的解决方案,拥有丰富的光谱信息以提高准确性。
- HSOD数据集HSOD-BIT-V2是目前最大的超光谱显著性目标检测数据集,包含五个具有挑战性的小目标识别场景和五个背景识别挑战场景。
点此查看论文截图


Biologically-inspired Semi-supervised Semantic Segmentation for Biomedical Imaging
Authors:Luca Ciampi, Gabriele Lagani, Giuseppe Amato, Fabrizio Falchi
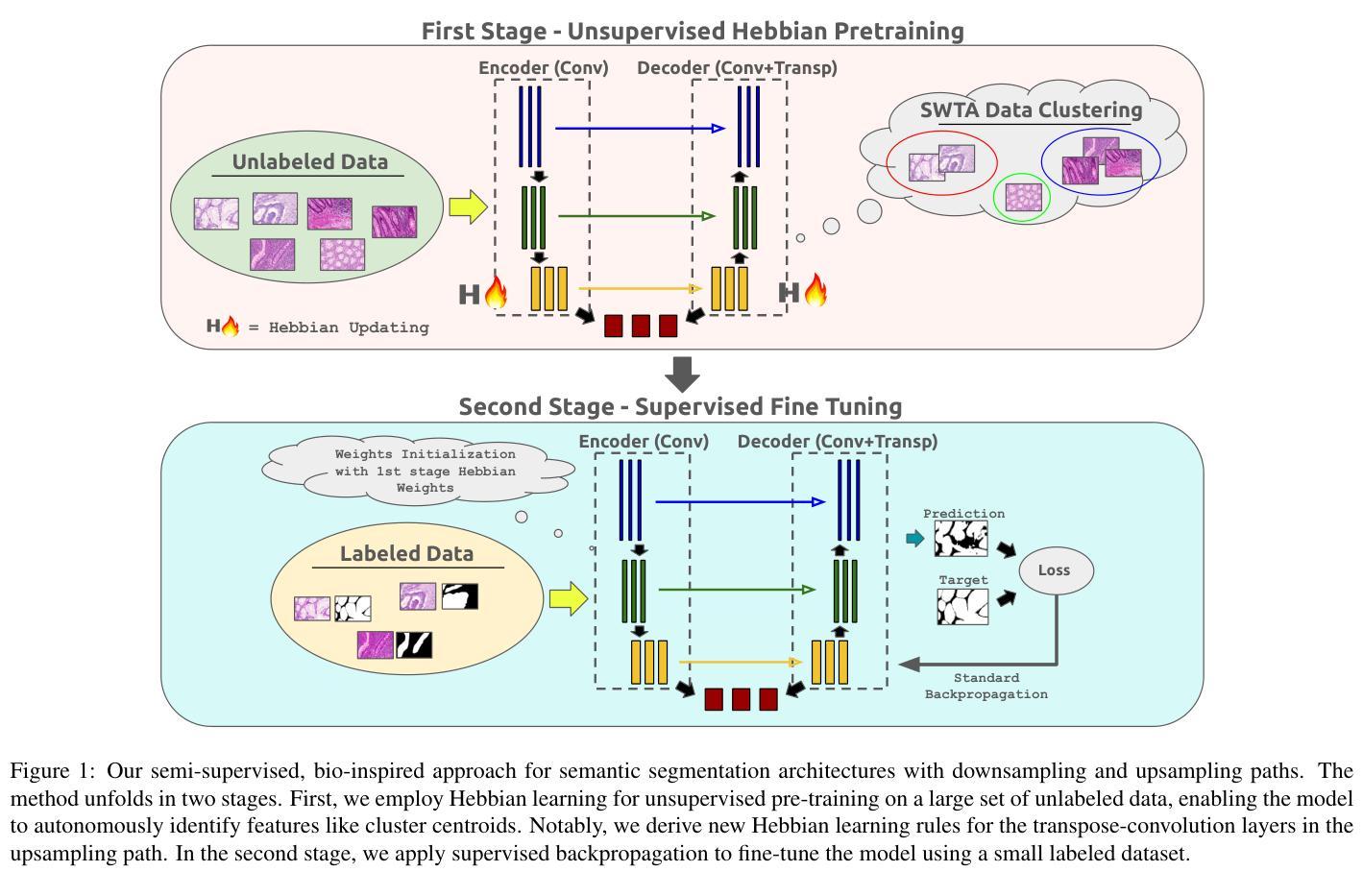
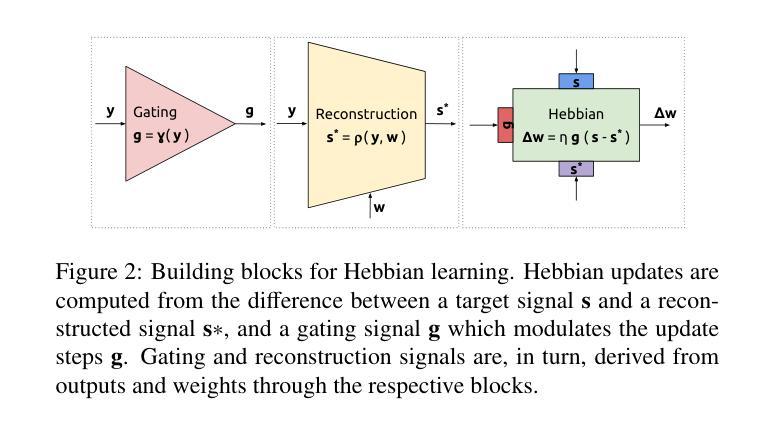
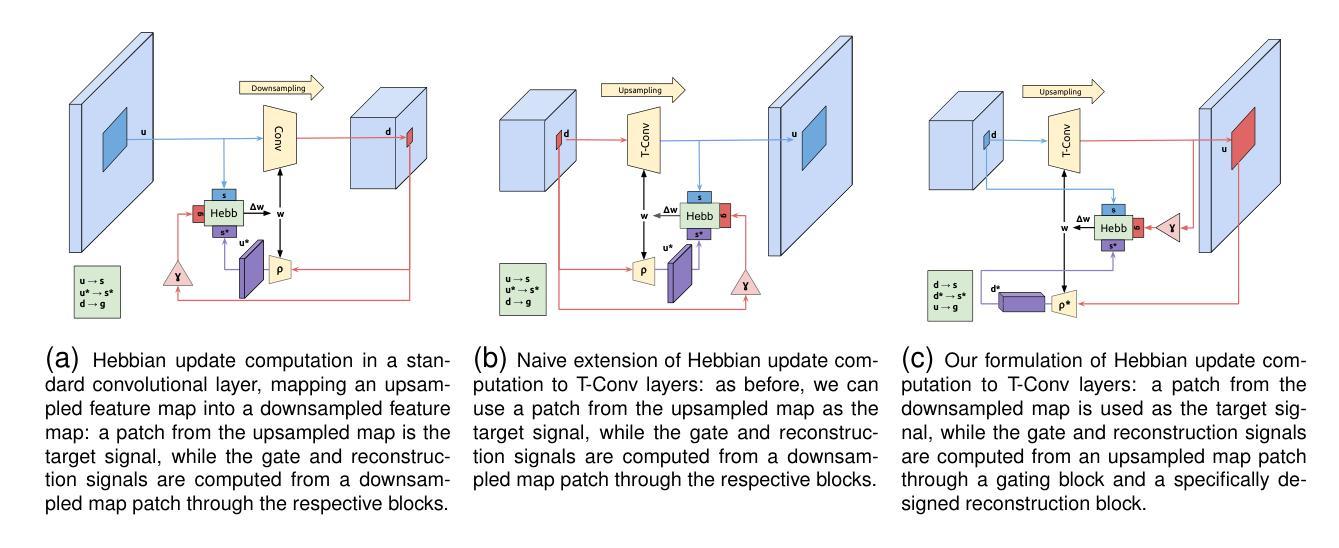
We propose a novel bio-inspired semi-supervised learning approach for training downsampling-upsampling semantic segmentation architectures. The first stage does not use backpropagation. Rather, it exploits the Hebbian principle ``fire together, wire together’’ as a local learning rule for updating the weights of both convolutional and transpose-convolutional layers, allowing unsupervised discovery of data features. In the second stage, the model is fine-tuned with standard backpropagation on a small subset of labeled data. We evaluate our methodology through experiments conducted on several widely used biomedical datasets, deeming that this domain is paramount in computer vision and is notably impacted by data scarcity. Results show that our proposed method outperforms SOTA approaches across different levels of label availability. Furthermore, we show that using our unsupervised stage to initialize the SOTA approaches leads to performance improvements. The code to replicate our experiments can be found at https://github.com/ciampluca/hebbian-bootstraping-semi-supervised-medical-imaging
我们提出了一种新型的生物启发半监督学习方法,用于训练下采样-上采样语义分割架构。第一阶段不使用反向传播。相反,它利用赫布原则“一起发射,一起连接”作为局部学习规则,以更新卷积层和转置卷积层的权重,从而实现数据特征的无监督发现。在第二阶段,模型使用标准反向传播对小部分标记数据进行微调。我们通过实验评估了我们的方法,实验是在几个广泛使用的生物医学数据集上进行的,我们认为这个领域在计算机视觉领域中至关重要,并且受到数据稀缺的显著影响。结果表明,我们的方法在标签可用性的不同层次上都优于最新技术方法。此外,我们还表明使用我们的无监督阶段来初始化最新技术方法可以提高性能。复制我们实验的代码可以在 https://github.com/ciampluca/hebbian-bootstraping-semi-supervised-medical-imaging 找到。
论文及项目相关链接
Summary
本文提出了一种新型的生物启发半监督学习方法,用于训练下采样-上采样语义分割架构。该方法分为两个阶段,第一阶段不采用反向传播,而是利用赫布原理(一起放电,一起连接)作为局部学习规则来更新卷积和转置卷积层的权重,实现数据特征的无监督发现。第二阶段使用标准反向传播对模型进行微调,仅使用少量标记数据进行训练。在多个广泛使用的生物医学数据集上进行的实验表明,该方法在不同标签可用性级别上均优于现有技术。此外,使用我们的无监督阶段初始化现有技术还可以提高性能。
Key Takeaways
- 提出了一种新的半监督学习方法,用于训练语义分割架构。
- 方法分为两个阶段:第一阶段利用赫布原理进行无监督学习,更新权重。
- 第二阶段使用标准反向传播进行微调,使用少量标记数据。
- 实验在多个生物医学数据集上进行,显示方法在不同标签可用性级别上优于现有技术。
- 该方法有助于提高现有技术的性能,通过无监督阶段进行初始化。
- 该方法对于数据稀缺领域(如生物医学图像)特别有影响。
点此查看论文截图

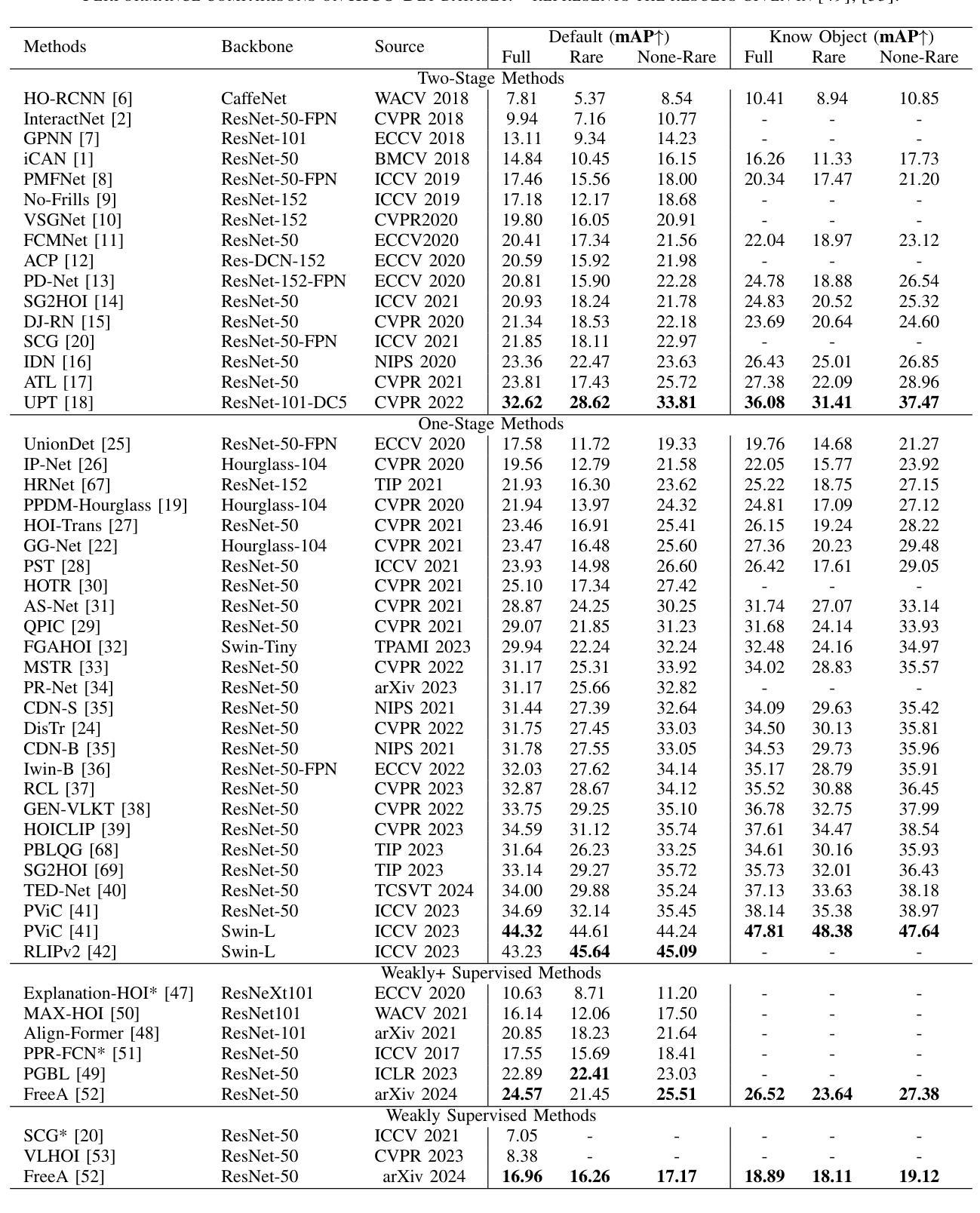
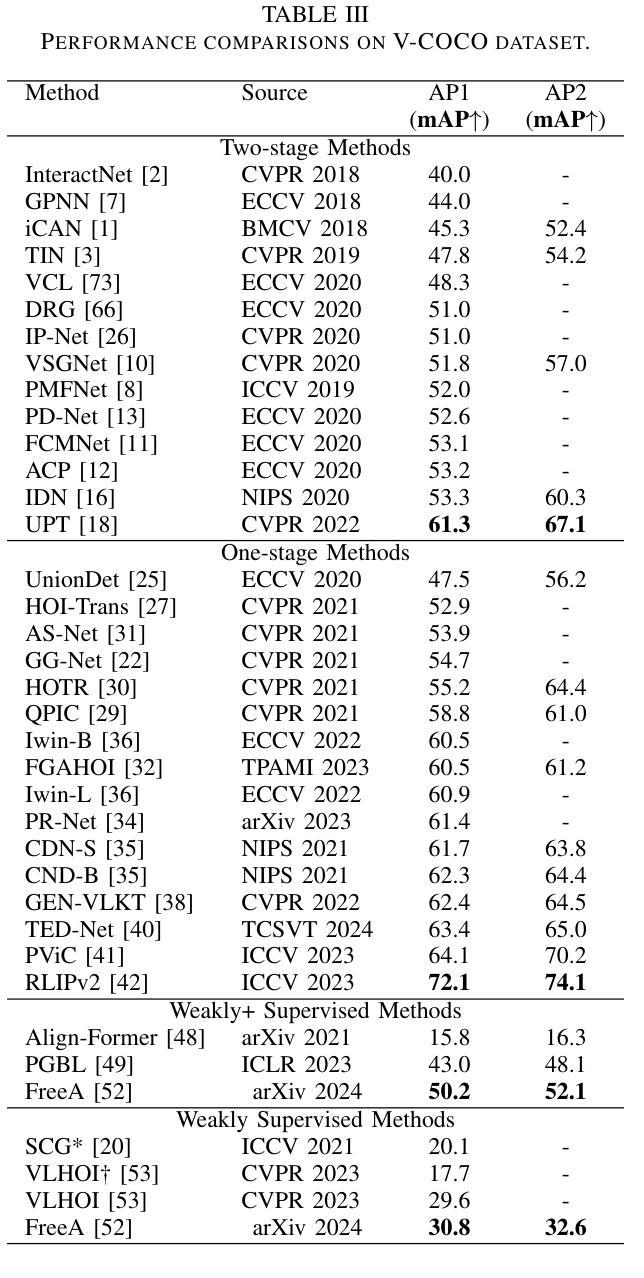
A Review of Human-Object Interaction Detection
Authors:Yuxiao Wang, Yu Lei, Li Cui, Weiying Xue, Qi Liu, Zhenao Wei
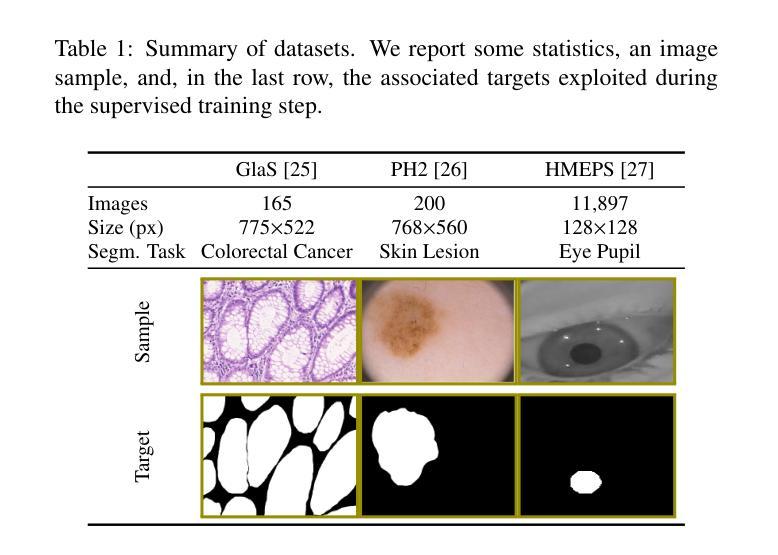
Human-object interaction (HOI) detection plays a key role in high-level visual understanding, facilitating a deep comprehension of human activities. Specifically, HOI detection aims to locate the humans and objects involved in interactions within images or videos and classify the specific interactions between them. The success of this task is influenced by several key factors, including the accurate localization of human and object instances, as well as the correct classification of object categories and interaction relationships. This paper systematically summarizes and discusses the recent work in image-based HOI detection. First, the mainstream datasets involved in HOI relationship detection are introduced. Furthermore, starting with two-stage methods and end-to-end one-stage detection approaches, this paper comprehensively discusses the current developments in image-based HOI detection, analyzing the strengths and weaknesses of these two methods. Additionally, the advancements of zero-shot learning, weakly supervised learning, and the application of large-scale language models in HOI detection are discussed. Finally, the current challenges in HOI detection are outlined, and potential research directions and future trends are explored.
人机交互(HOI)检测在高层次视觉理解中扮演着关键角色,有助于深入理解人类活动。具体而言,HOI检测旨在定位图像或视频中涉及交互的人类和物体,并分类它们之间的特定交互。该任务的成功受到几个关键因素的影响,包括人类和物体实例的准确定位,以及物体类别和交互关系的正确分类。本文系统地总结和讨论了基于图像的HOI检测的最新工作。首先,介绍了HOI关系检测涉及的主流数据集。此外,本文综合讨论了基于图像的HOI检测的当前发展,包括两阶段方法和端到端的一阶段检测方案,分析了这两种方法的优缺点。另外,还讨论了零样本学习、弱监督学习以及大规模语言模型在HOI检测中的应用。最后,概述了HOI检测当前的挑战,并探讨了潜在的研究方向和未来趋势。
论文及项目相关链接
PDF Accepted by 2024 2nd International Conference on Computer, Vision and Intelligent Technology (ICCVIT)
Summary
本文综述了基于图像的HOI检测(人机交互检测)的最新工作。介绍了主流数据集,并详细讨论了当前的两阶段方法和端到端的一阶段检测方法的进展,分析了它们的优缺点。此外,还讨论了零样本学习、弱监督学习以及大规模语言模型在HOI检测中的应用,指出了当前挑战并探讨了未来研究方向。
Key Takeaways
- HOI检测是高级视觉理解中的关键任务,旨在识别图像或视频中的人类与物体的交互,并分类它们之间的交互。
- 主要数据集介绍。
- 当前的两阶段方法和一阶段检测方法的进展,以及它们的优缺点。
- 零样本学习、弱监督学习在HOI检测中的应用。
- 大规模语言模型在HOI检测中的使用正在增长。
- HOI检测当前面临的挑战。
点此查看论文截图

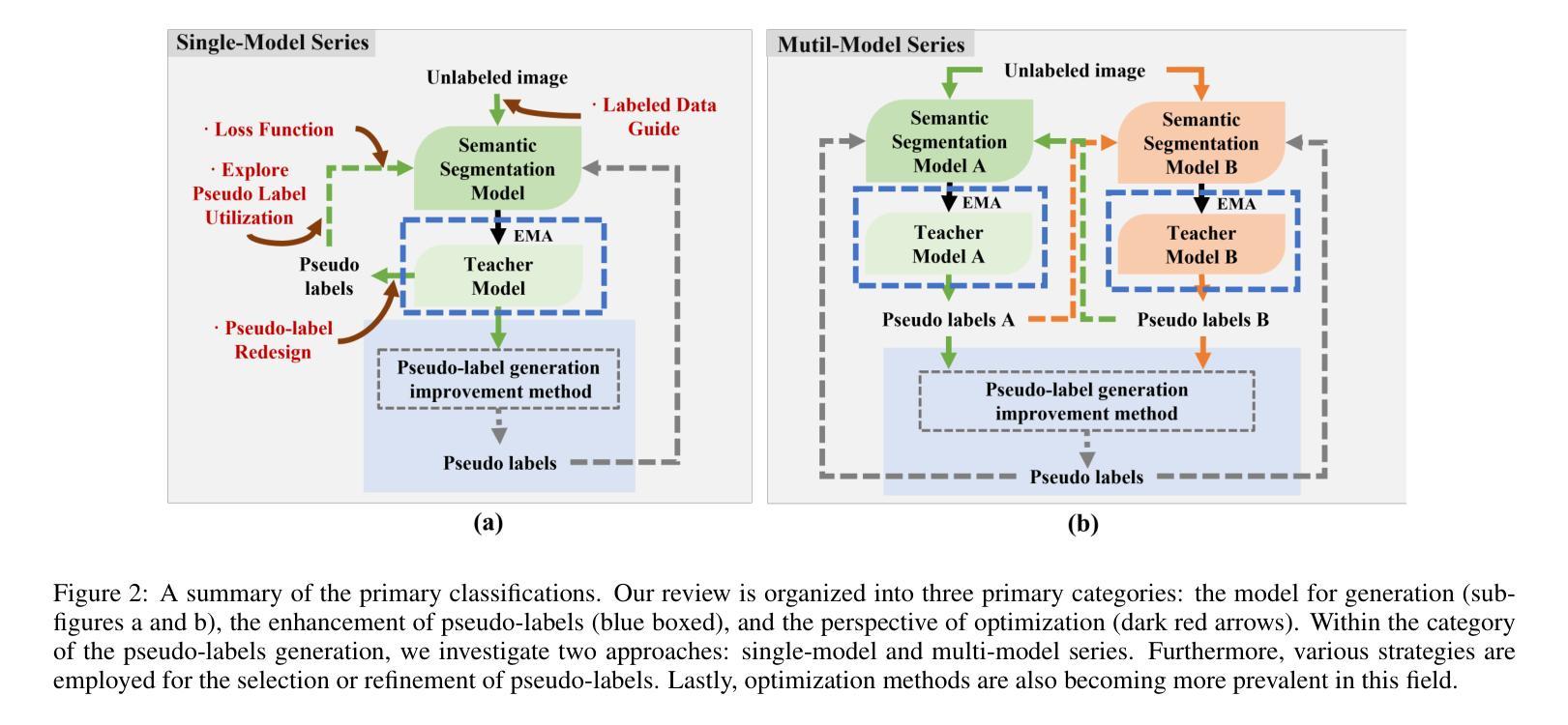
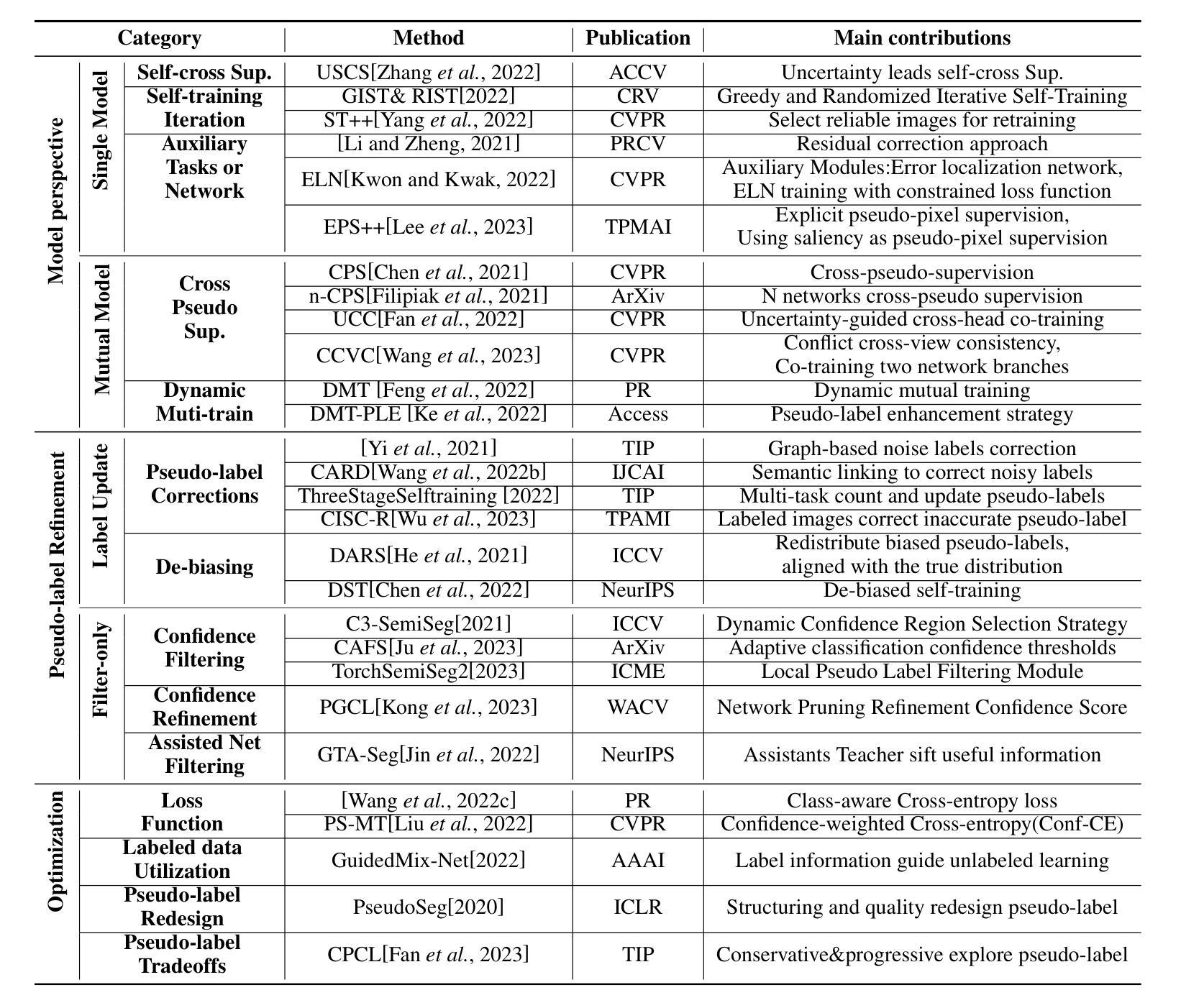
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Authors:Lingyan Ran, Yali Li, Guoqiang Liang, Yanning Zhang
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
语义分割是计算机视觉中一个重要且热门的研究领域,主要关注基于图像语义对像素进行分类。然而,深度学习的监督学习需要大量的数据来训练模型,逐个像素地标注图像既耗时又费力。这篇综述旨在全面、系统地介绍半监督语义分割领域伪标签方法的最新研究成果,从不同的角度对它们进行分类,并针对特定应用领域介绍具体方法。此外,我们还探讨了伪标签技术在医疗和遥感图像分割中的应用。最后,我们还提出了一些可行的未来研究方向,以应对现有挑战。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Circuits and Systems for Video Technology(TCSVT)
Summary
语义分割是计算机视觉中一个重要且热门的研究领域,主要对图像中的像素进行分类。然而,监督深度学习需要大量数据进行模型训练,逐像素标注图像的过程耗时费力。本文旨在提供伪标签方法在半监督语义分割领域的最新研究成果的首次全面概述,从不同角度分类并呈现特定应用领域的具体方法。此外,本文还探讨了伪标签技术在医疗和遥感图像分割中的应用,并提出解决现有挑战的可行的未来研究方向。
Key Takeaways
- 语义分割是计算机视觉中的重要研究领域,专注于基于像素语义对图像进行分类。
- 监督深度学习需要大量数据进行模型训练,标注过程耗时费力。
- 伪标签方法在半监督语义分割领域具有广泛的应用前景。
- 本文提供了伪标签方法的全面概述,包括从不同角度的分类以及特定领域的应用方法。
- 伪标签技术在医疗和遥感图像分割领域的应用得到了探讨。
- 当前存在挑战和问题需要解决,需要进一步的研究和探索。
点此查看论文截图

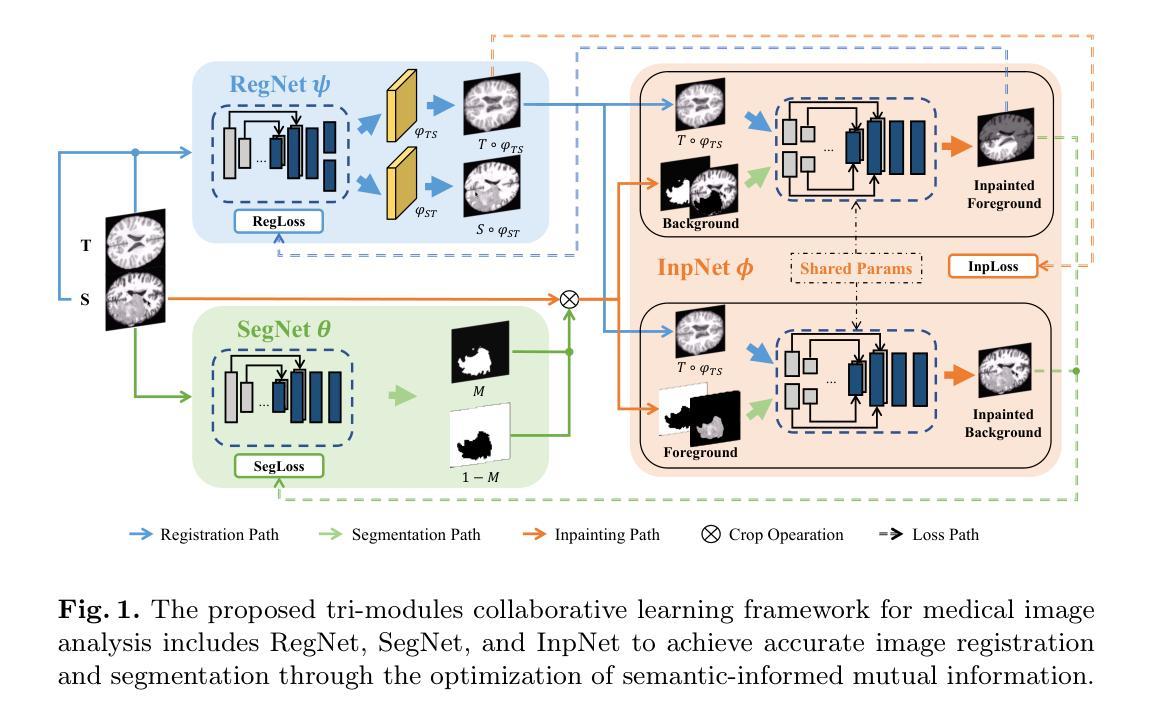
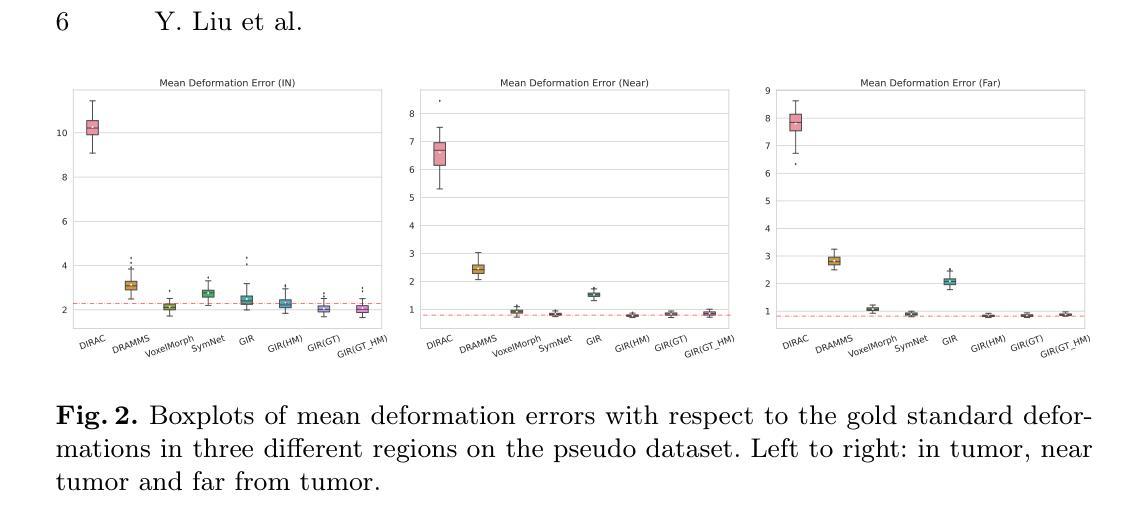
Co-Learning Semantic-aware Unsupervised Segmentation for Pathological Image Registration
Authors:Yang Liu, Shi Gu
The registration of pathological images plays an important role in medical applications. Despite its significance, most researchers in this field primarily focus on the registration of normal tissue into normal tissue. The negative impact of focal tissue, such as the loss of spatial correspondence information and the abnormal distortion of tissue, are rarely considered. In this paper, we propose GIRNet, a novel unsupervised approach for pathological image registration by incorporating segmentation and inpainting through the principles of Generation, Inpainting, and Registration (GIR). The registration, segmentation, and inpainting modules are trained simultaneously in a co-learning manner so that the segmentation of the focal area and the registration of inpainted pairs can improve collaboratively. Overall, the registration of pathological images is achieved in a completely unsupervised learning framework. Experimental results on multiple datasets, including Magnetic Resonance Imaging (MRI) of T1 sequences, demonstrate the efficacy of our proposed method. Our results show that our method can accurately achieve the registration of pathological images and identify lesions even in challenging imaging modalities. Our unsupervised approach offers a promising solution for the efficient and cost-effective registration of pathological images. Our code is available at https://github.com/brain-intelligence-lab/GIRNet.
病理图像的配准在医疗应用中扮演着重要角色。尽管其意义重大,但该领域的大多数研究者主要关注正常组织的配准到正常组织。很少考虑焦点组织的负面影响,如空间对应关系信息的丢失和组织异常扭曲。在本文中,我们提出了GIRNet,这是一种通过结合分割和修复的原则(生成、修复和配准(GIR))用于病理图像配准的新型无监督方法。配准、分割和修复模块以协同学习的方式进行训练,使得焦点区域的分割和修复对的配准可以协同改进。总体而言,病理图像的配准是在一个完全无监督的学习框架中实现的。在多个数据集上的实验结果,包括T1序列的磁共振成像(MRI),证明了我们提出的方法的有效性。我们的结果表明,我们的方法可以准确地实现病理图像的配准,即使在具有挑战性的成像模式下也能识别病变。我们的无监督方法为病理图像的有效和经济的配准提供了有前景的解决方案。我们的代码可在https://github.com/brain-intelligence-lab/GIRNet找到。
论文及项目相关链接
PDF 13 pages, 7 figures, published in Medical Image Computing and Computer Assisted Intervention (MICCAI) 2023
Summary
本文提出一种基于生成、修复和注册(GIR)原则的新型无监督病理图像注册方法GIRNet。该方法通过同时训练注册、分割和修复模块,实现了对病变区域的分割和对修复后图像的注册,提高了两者的协同性能。实验结果表明,该方法在多个数据集上可有效实现病理图像的注册和病变识别,为高效、经济的病理图像注册提供了有前途的解决方案。
Key Takeaways
- 病理图像注册在医疗应用中具有重要意义,但现有研究大多局限于正常组织的注册。
- 文章提出了一个名为GIRNet的新型无监督方法用于病理图像注册。
- GIRNet结合了分割和修复技术,通过生成、修复和注册的原则实现病理图像的精准注册。
- 该方法能够在无监督学习框架内实现对病变区域的分割以及对修复后图像的注册协同进步。
- 实验结果显示GIRNet在多个数据集上的表现良好,能有效实现病理图像的注册并识别病变。
- 所提出的代码在GitHub上开放供研究使用。
点此查看论文截图