⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
RoGSplat: Learning Robust Generalizable Human Gaussian Splatting from Sparse Multi-View Images
Authors:Junjin Xiao, Qing Zhang, Yonewei Nie, Lei Zhu, Wei-Shi Zheng
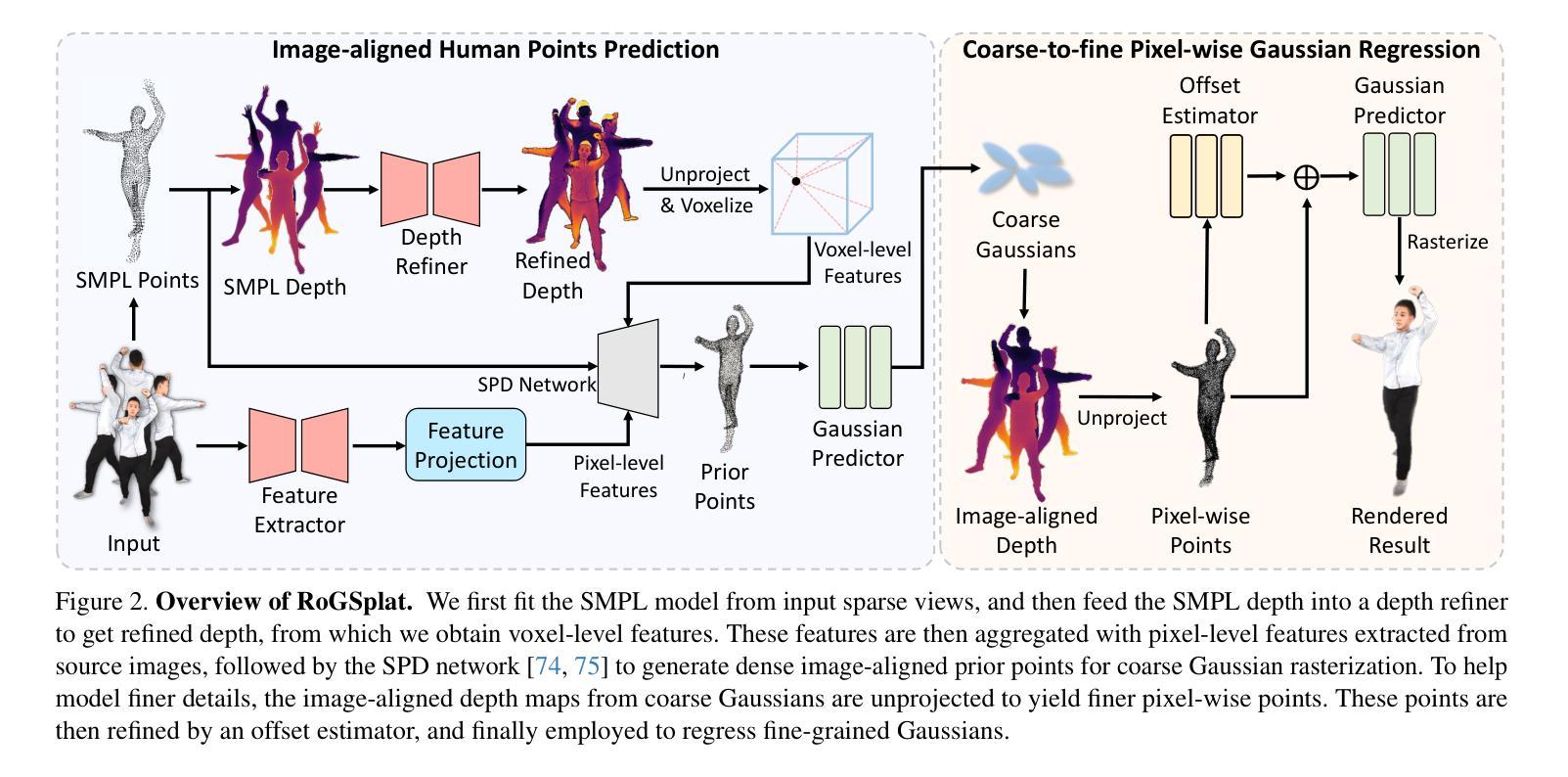
This paper presents RoGSplat, a novel approach for synthesizing high-fidelity novel views of unseen human from sparse multi-view images, while requiring no cumbersome per-subject optimization. Unlike previous methods that typically struggle with sparse views with few overlappings and are less effective in reconstructing complex human geometry, the proposed method enables robust reconstruction in such challenging conditions. Our key idea is to lift SMPL vertices to dense and reliable 3D prior points representing accurate human body geometry, and then regress human Gaussian parameters based on the points. To account for possible misalignment between SMPL model and images, we propose to predict image-aligned 3D prior points by leveraging both pixel-level features and voxel-level features, from which we regress the coarse Gaussians. To enhance the ability to capture high-frequency details, we further render depth maps from the coarse 3D Gaussians to help regress fine-grained pixel-wise Gaussians. Experiments on several benchmark datasets demonstrate that our method outperforms state-of-the-art methods in novel view synthesis and cross-dataset generalization. Our code is available at https://github.com/iSEE-Laboratory/RoGSplat.
本文介绍了RoGSplat,这是一种从稀疏的多视角图像合成未见人物的高保真新视角的新方法,而无需进行繁琐的主体优化。与以往通常在视角稀疏、重叠较少的情况下表现挣扎并且在重建复杂人体几何方面效果较差的方法不同,所提出的方法在这种具有挑战性的条件下实现了稳健的重建。我们的核心思想是将SMPL顶点提升到密集且可靠的3D先验点,这些点表示准确的人体几何形状,然后根据这些点回归人体高斯参数。为了考虑SMPL模型与图像之间可能出现的错位对齐问题,我们提出了通过利用像素级特征和体素级特征来预测图像对齐的3D先验点的方法,并从这些点回归粗略的高斯参数。为了提高捕捉高频细节的能力,我们还从粗略的3D高斯渲染深度图,以帮助回归精细的像素级高斯参数。在几个基准数据集上的实验表明,我们的方法在新型视图合成和跨数据集泛化方面优于最先进的方法。我们的代码可以在https://github.com/iSEE-Laboratory/RoGSplat上找到。
论文及项目相关链接
PDF Accepted to CVPR2025
Summary
本文介绍了RoGSplat方法,该方法能从稀疏的多视角图像中合成高保真度的新视角人体图像,且无需对每个主题进行优化。该方法能够在仅有少量重叠的稀疏视角条件下实现稳健重建,通过提升SMPL顶点至密集可靠的3D先验点表示准确的人体几何结构,并基于此回归人体高斯参数。为解决SMPL模型与图像间可能的对齐问题,该方法预测图像对齐的3D先验点,同时利用像素级特征和体素级特征。为捕捉高频细节,该方法还从粗糙的3D高斯图中渲染深度图,以帮助回归精细的像素级高斯图。实验证明,该方法在新型视图合成和跨数据集泛化方面均优于现有技术。
Key Takeaways
- RoGSplat是一种从稀疏多视角图像合成高保真度新视角人体图像的新方法。
- 该方法无需对每个主题进行复杂的优化。
- RoGSplat能够在仅有少量重叠的稀疏视角条件下实现稳健重建。
- 方法通过提升SMPL顶点至密集可靠的3D先验点来表示准确的人体几何结构。
- 为解决SMPL模型与图像间的对齐问题,该方法利用像素级和体素级特征预测图像对齐的3D先验点。
- 通过从粗糙的3D高斯图中渲染深度图,增强捕捉高频细节的能力。
- 实验证明,该方法在新型视图合成和跨数据集泛化方面均优于现有技术。
点此查看论文截图


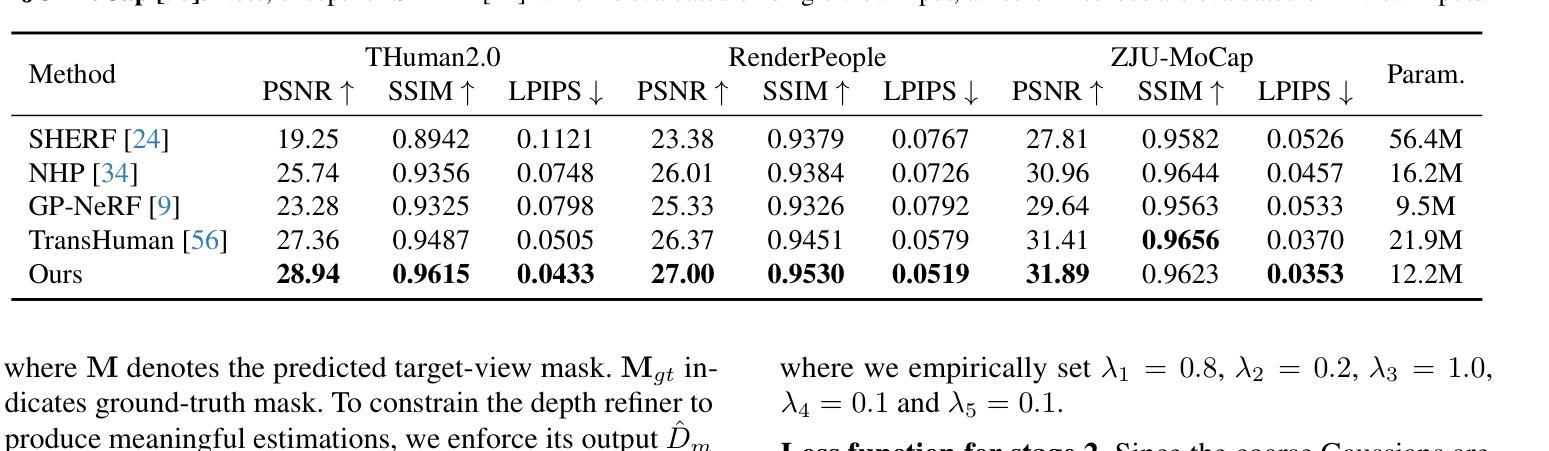

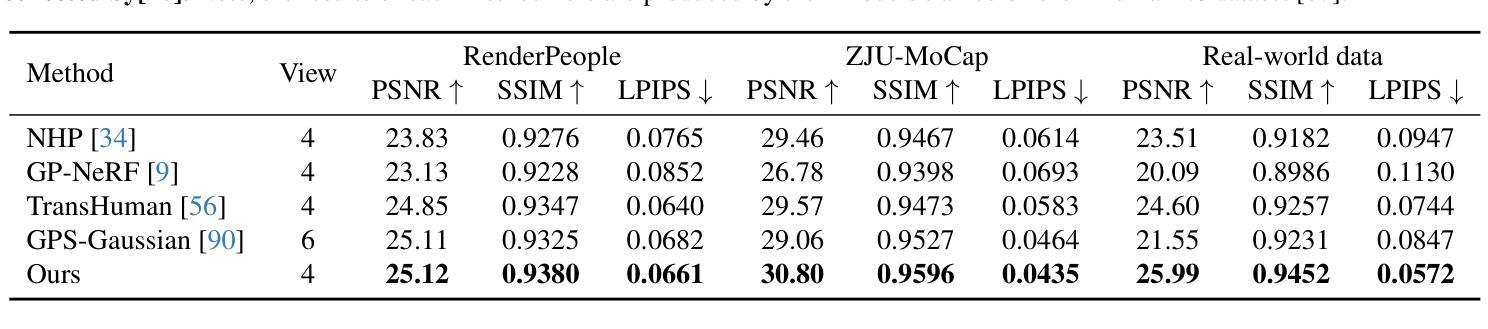
Rethinking End-to-End 2D to 3D Scene Segmentation in Gaussian Splatting
Authors:Runsong Zhu, Shi Qiu, Zhengzhe Liu, Ka-Hei Hui, Qianyi Wu, Pheng-Ann Heng, Chi-Wing Fu
Lifting multi-view 2D instance segmentation to a radiance field has proven to be effective to enhance 3D understanding. Existing methods rely on direct matching for end-to-end lifting, yielding inferior results; or employ a two-stage solution constrained by complex pre- or post-processing. In this work, we design a new end-to-end object-aware lifting approach, named Unified-Lift that provides accurate 3D segmentation based on the 3D Gaussian representation. To start, we augment each Gaussian point with an additional Gaussian-level feature learned using a contrastive loss to encode instance information. Importantly, we introduce a learnable object-level codebook to account for individual objects in the scene for an explicit object-level understanding and associate the encoded object-level features with the Gaussian-level point features for segmentation predictions. While promising, achieving effective codebook learning is non-trivial and a naive solution leads to degraded performance. Therefore, we formulate the association learning module and the noisy label filtering module for effective and robust codebook learning. We conduct experiments on three benchmarks: LERF-Masked, Replica, and Messy Rooms datasets. Both qualitative and quantitative results manifest that our Unified-Lift clearly outperforms existing methods in terms of segmentation quality and time efficiency. The code is publicly available at \href{https://github.com/Runsong123/Unified-Lift}{https://github.com/Runsong123/Unified-Lift}.
将多视角2D实例分割提升到辐射场已被证明是增强3D理解的有效方法。现有方法依赖于端到端的直接匹配提升,效果较差;或者采用两阶段解决方案,受限于复杂的预处理或后处理。在这项工作中,我们设计了一种新的端到端对象感知提升方法,名为Unified-Lift,它基于3D高斯表示提供准确的3D分割。首先,我们通过使用对比损失学习到的附加高斯级别特征来增强每个高斯点,以编码实例信息。重要的是,我们引入了一个可学习的对象级别代码本,以考虑场景中的单个对象,以进行明确的对象级别理解,并将编码的对象级别特征与高斯级别的点特征关联起来以进行分割预测。尽管前景充满希望,但实现有效的代码本学习并非易事,而简单的解决方案会导致性能下降。因此,我们制定了关联学习模块和噪声标签过滤模块,以实现有效的鲁棒性代码本学习。我们在三个基准测试:LERF-Masked、Replica和Messy Rooms数据集上进行了实验。定性和定量结果都表明,我们的Unified-Lift在分割质量和时间效率方面明显优于现有方法。代码公开在https://github.com/Runsong123/Unified-Lift。
论文及项目相关链接
PDF CVPR 2025. The code is publicly available at this https URL (https://github.com/Runsong123/Unified-Lift)
Summary
本文提出了一种新的端到端物体感知提升方法,名为Unified-Lift,用于基于3D高斯表示进行准确的多视角2D实例分割到辐射场的提升。通过引入可学习的物体级别代码本,实现场景中的个体物体明确理解,并将编码的物体级别特征与高斯级别的点特征相结合进行分割预测。该方法在多个数据集上的实验结果均优于现有方法,提高了分割质量和时间效率。
Key Takeaways
- 提出了一种新的端到端物体感知提升方法Unified-Lift,用于多视角2D实例分割到辐射场的提升。
- 利用高斯点附加高斯级别特征,通过对比损失进行实例信息编码。
- 引入可学习的物体级别代码本,实现场景中的个体物体明确理解。
- 结合物体级别特征和高斯级别点特征进行分割预测。
- 提出了关联学习模块和噪声标签过滤模块,以实现有效的代码本学习。
- 在多个数据集上的实验结果证明了Unified-Lift在分割质量和时间效率上的优越性。
点此查看论文截图

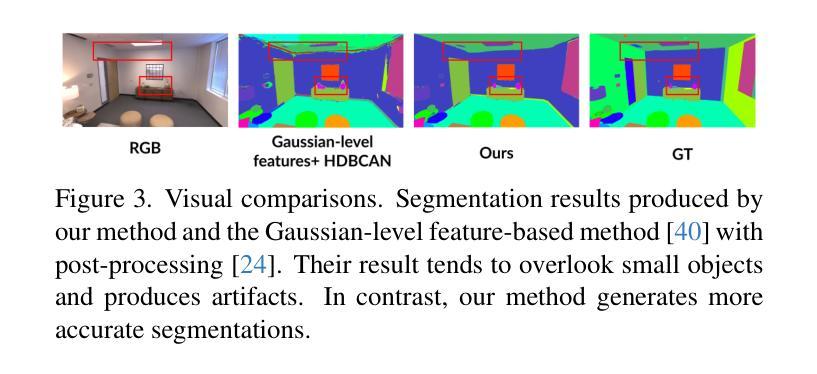
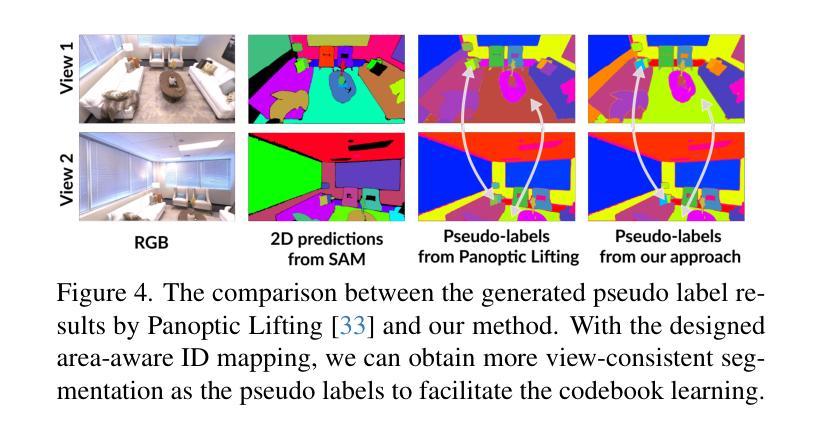

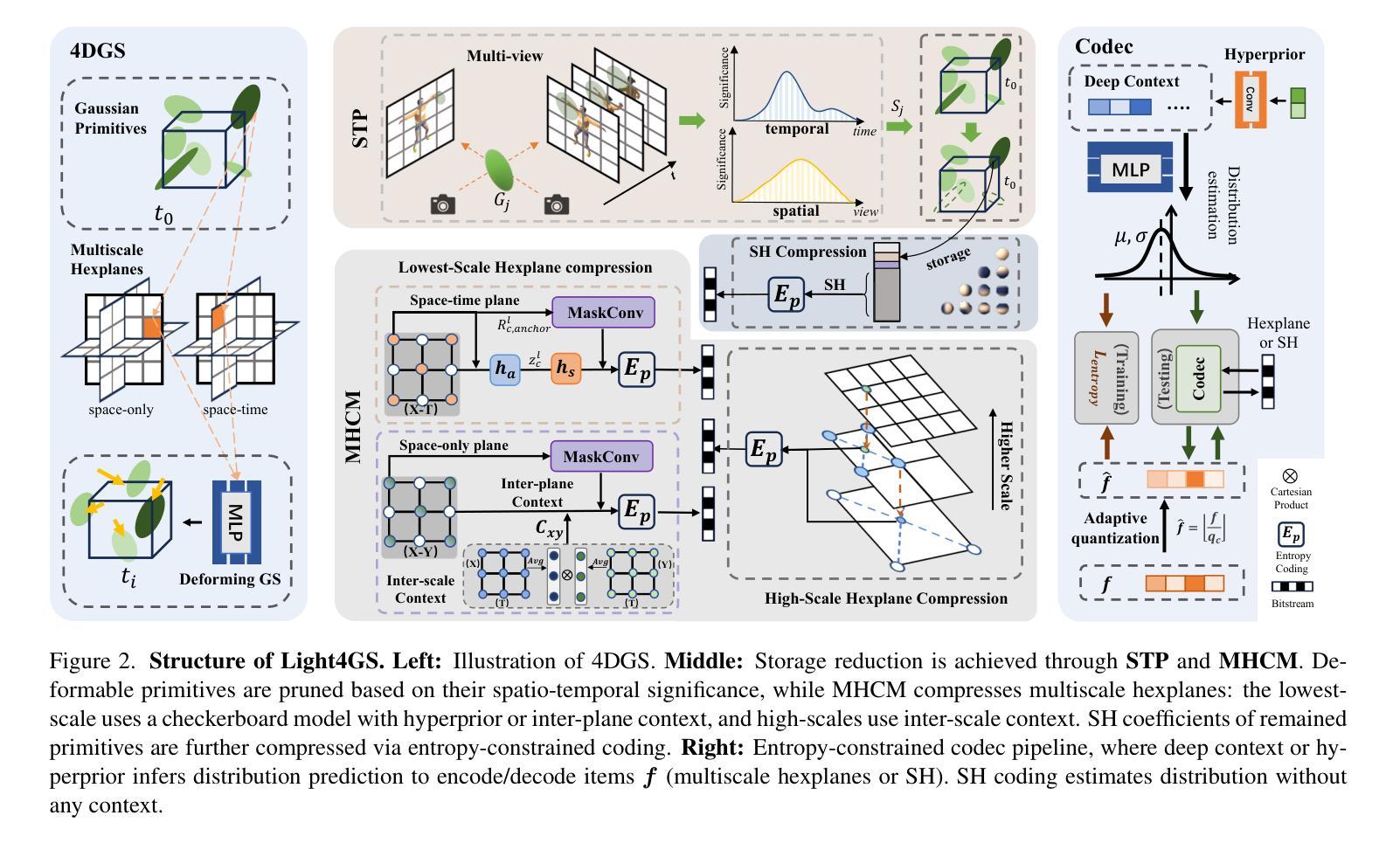
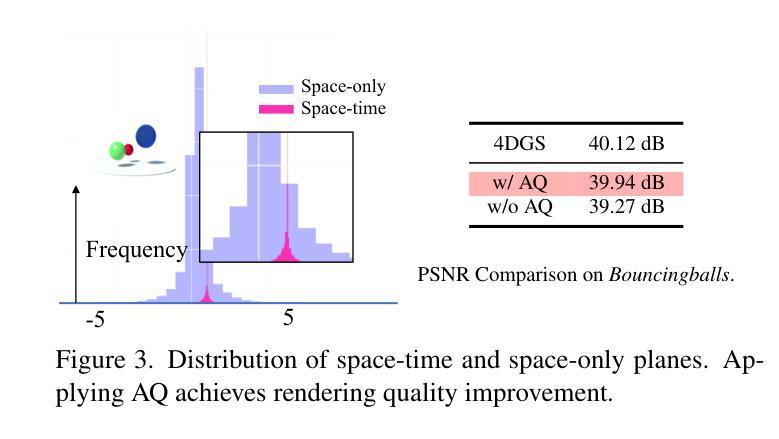
Light4GS: Lightweight Compact 4D Gaussian Splatting Generation via Context Model
Authors:Mufan Liu, Qi Yang, He Huang, Wenjie Huang, Zhenlong Yuan, Zhu Li, Yiling Xu
3D Gaussian Splatting (3DGS) has emerged as an efficient and high-fidelity paradigm for novel view synthesis. To adapt 3DGS for dynamic content, deformable 3DGS incorporates temporally deformable primitives with learnable latent embeddings to capture complex motions. Despite its impressive performance, the high-dimensional embeddings and vast number of primitives lead to substantial storage requirements. In this paper, we introduce a \textbf{Light}weight \textbf{4}D\textbf{GS} framework, called Light4GS, that employs significance pruning with a deep context model to provide a lightweight storage-efficient dynamic 3DGS representation. The proposed Light4GS is based on 4DGS that is a typical representation of deformable 3DGS. Specifically, our framework is built upon two core components: (1) a spatio-temporal significance pruning strategy that eliminates over 64% of the deformable primitives, followed by an entropy-constrained spherical harmonics compression applied to the remainder; and (2) a deep context model that integrates intra- and inter-prediction with hyperprior into a coarse-to-fine context structure to enable efficient multiscale latent embedding compression. Our approach achieves over 120x compression and increases rendering FPS up to 20% compared to the baseline 4DGS, and also superior to frame-wise state-of-the-art 3DGS compression methods, revealing the effectiveness of our Light4GS in terms of both intra- and inter-prediction methods without sacrificing rendering quality.
3D高斯点云(3DGS)已经成为一种高效且高保真率的新型视图合成范式。为了适应动态内容,可变形3DGS结合了可学习的潜在嵌入和可变形原始数据,以捕捉复杂的运动。尽管其性能令人印象深刻,但高维嵌入和大量的原始数据需要大量的存储空间。在本文中,我们介绍了一种名为Light4GS的轻量级四维GS框架,该框架采用重要性裁剪和深度上下文模型来提供高效的动态存储压缩方法。所提出的Light4GS基于四维GS(是可变形体的典型代表)。具体来说,我们的框架建立在两个核心组件之上:(1)时空重要性裁剪策略,可以消除超过64%的可变形原始数据,然后对剩余部分应用熵约束球面谐波压缩;(2)深度上下文模型将帧内预测与帧间预测和超先验信息集成到粗到细的上下文结构中,以实现高效的多尺度潜在嵌入压缩。与基线四维GS相比,我们的方法实现了超过120倍的压缩率,并且渲染FPS提高了高达20%,同时也优于当前最先进的帧级三维GS压缩方法,证明了Light4GS在不影响渲染质量的情况下对于帧内和帧间预测的有效性。
论文及项目相关链接
Summary
本文介绍了Light4GS框架,该框架基于4DGS并采用时空重要性剪枝策略和深度上下文模型,旨在提供轻量级的存储高效动态3DGS表示。通过时空重要性剪枝策略,Light4GS能够消除超过64%的可变形原始数据,并对剩余数据进行熵约束球面谐波压缩。此外,其深度上下文模型结合了帧内和帧间预测与超先验,形成了一种从粗到细的上下文结构,实现了多尺度潜在嵌入的有效压缩。Light4GS框架相较于基线4DGS和其他先进的3DGS压缩方法,实现了超过120倍的压缩率提升和最高20%的渲染帧率提升,同时在渲染质量上不妥协。
Key Takeaways
- Light4GS框架采用时空重要性剪枝策略,消除多余的可变形原始数据,实现高效的存储和计算。
- 熵约束球面谐波压缩用于处理剩余数据,确保数据质量。
- 深度上下文模型结合了帧内和帧间预测与超先验,形成了一种从粗到细的上下文结构。
- Light4GS实现了多尺度潜在嵌入的有效压缩,提高了渲染效率。
- 与基线4DGS相比,Light4GS实现了超过120倍的压缩率提升和最高20%的渲染帧率提升。
- Light4GS在渲染质量上不妥协,表现出优异的性能。
点此查看论文截图


GS-I$^{3}$: Gaussian Splatting for Surface Reconstruction from Illumination-Inconsistent Images
Authors:Tengfei Wang, Yongmao Hou, Zhaoning Zhang, Yiwei Xu, Zongqian Zhan, Xin Wang
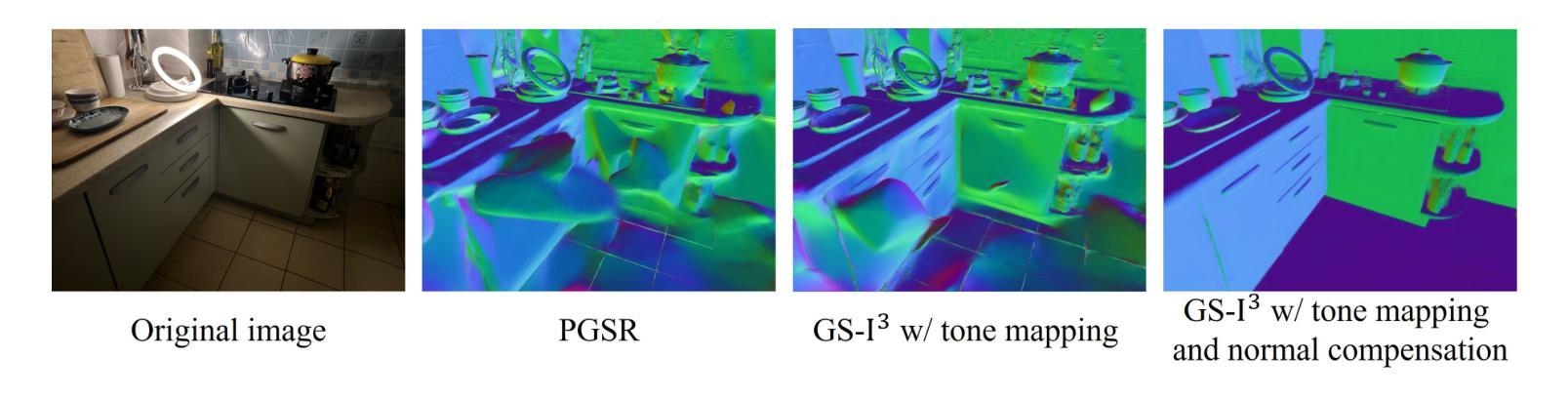
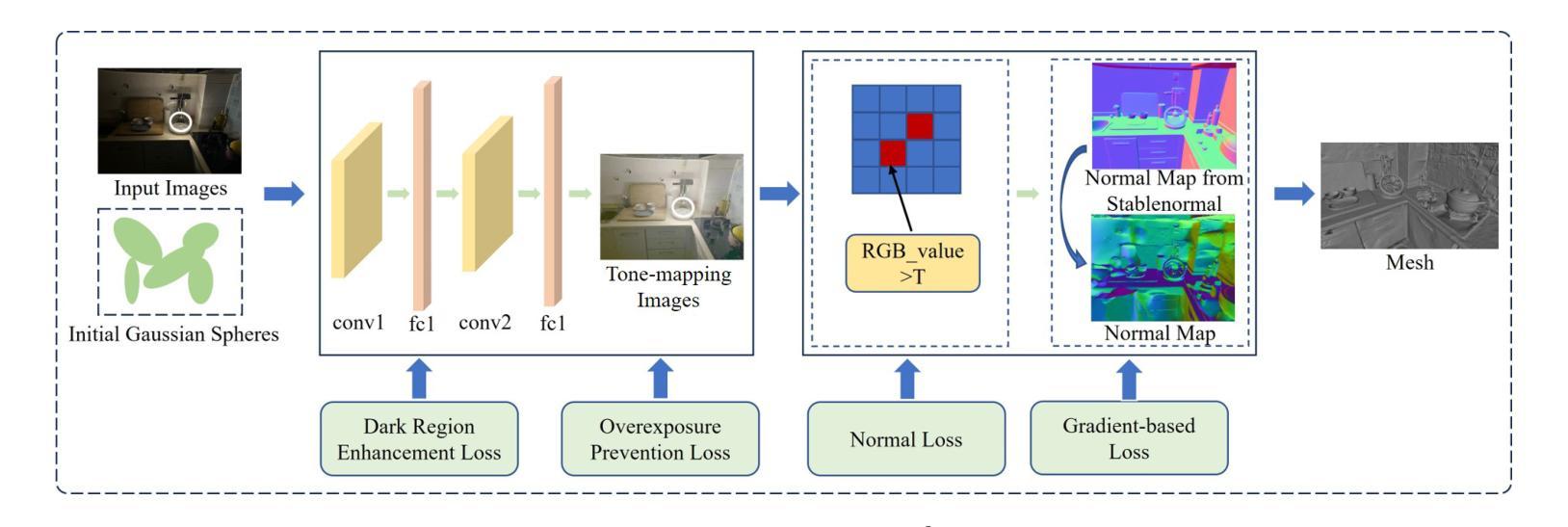
Accurate geometric surface reconstruction, providing essential environmental information for navigation and manipulation tasks, is critical for enabling robotic self-exploration and interaction. Recently, 3D Gaussian Splatting (3DGS) has gained significant attention in the field of surface reconstruction due to its impressive geometric quality and computational efficiency. While recent relevant advancements in novel view synthesis under inconsistent illumination using 3DGS have shown promise, the challenge of robust surface reconstruction under such conditions is still being explored. To address this challenge, we propose a method called GS-3I. Specifically, to mitigate 3D Gaussian optimization bias caused by underexposed regions in single-view images, based on Convolutional Neural Network (CNN), a tone mapping correction framework is introduced. Furthermore, inconsistent lighting across multi-view images, resulting from variations in camera settings and complex scene illumination, often leads to geometric constraint mismatches and deviations in the reconstructed surface. To overcome this, we propose a normal compensation mechanism that integrates reference normals extracted from single-view image with normals computed from multi-view observations to effectively constrain geometric inconsistencies. Extensive experimental evaluations demonstrate that GS-3I can achieve robust and accurate surface reconstruction across complex illumination scenarios, highlighting its effectiveness and versatility in this critical challenge. https://github.com/TFwang-9527/GS-3I
精确几何表面重建对于实现机器人的自我探索和交互至关重要,它为导航和操作任务提供了必要的环境信息。近期,由于其在几何质量和计算效率方面的出色表现,3D高斯贴图(3DGS)在表面重建领域引起了广泛关注。尽管使用3DGS在不一致照明下进行新颖视图合成的最新进展显示出希望,但在这种条件下的稳健表面重建挑战仍在探索中。为了应对这一挑战,我们提出了一种名为GS-3I的方法。具体来说,为了减轻由于单视图图像中曝光不足区域引起的3D高斯优化偏差,我们基于卷积神经网络(CNN)引入了一种色调映射校正框架。此外,由于相机设置和复杂场景照明的变化,多视图图像之间的照明不一致常常导致几何约束不匹配和重建表面的偏差。为了克服这一问题,我们提出了一种法线补偿机制,该机制将单视图图像中提取的参考法线与多视图观察计算得到的法线相结合,有效地约束了几何不一致性。广泛的实验评估表明,GS-3I可以在复杂的照明场景下实现稳健而准确的表面重建,突显了其在应对这一关键挑战中的有效性和通用性。相关代码链接:https://github.com/TFwang-9527/GS-3I
论文及项目相关链接
PDF Comments: This work has been submitted to the 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025) for possible publication
Summary
基于深度学习和神经网络模型的图像光照补偿技术和基于视角校正和融合的深度补偿技术,对于实现机器人自我探索和交互中的精准几何表面重建至关重要。GS-3I方法通过引入基于卷积神经网络(CNN)的色调映射校正框架和融合单视角图像与多视角观察的正常补偿机制,解决了在复杂光照场景下表面重建的几何不一致性问题,实现了在复杂光照环境下的稳健和准确的表面重建。
Key Takeaways
- 几何表面重建对于机器人自我探索和交互至关重要,提供了导航和操作任务所需的环境信息。
- 3D高斯绘制(3DGS)由于其出色的几何质量和计算效率而受到广泛关注。
- GS-3I方法解决了光照不一致问题导致的稳健表面重建挑战。
- 通过引入基于卷积神经网络(CNN)的色调映射校正框架,GS-3I解决了由于单视角图像曝光不足导致的优化偏差问题。
- 为了解决多视角图像中的光照不一致问题,GS-3I引入了正常补偿机制,该机制融合了单视角图像和多视角观察的法线数据,有效地约束了几何不一致性。
点此查看论文截图



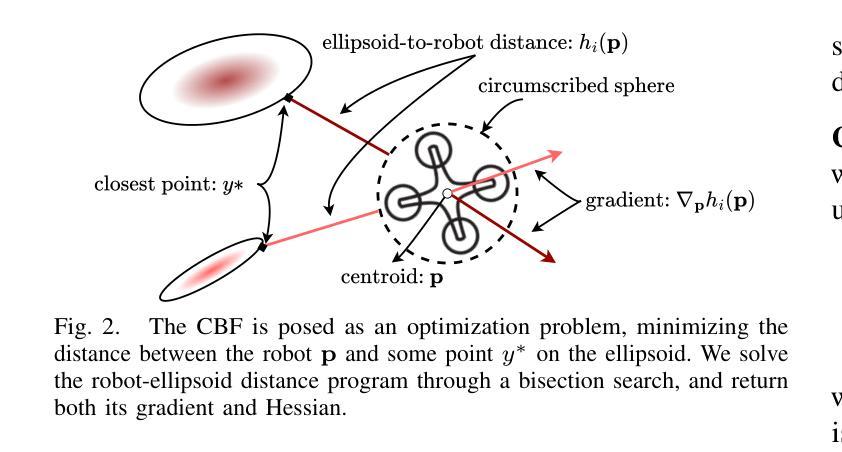
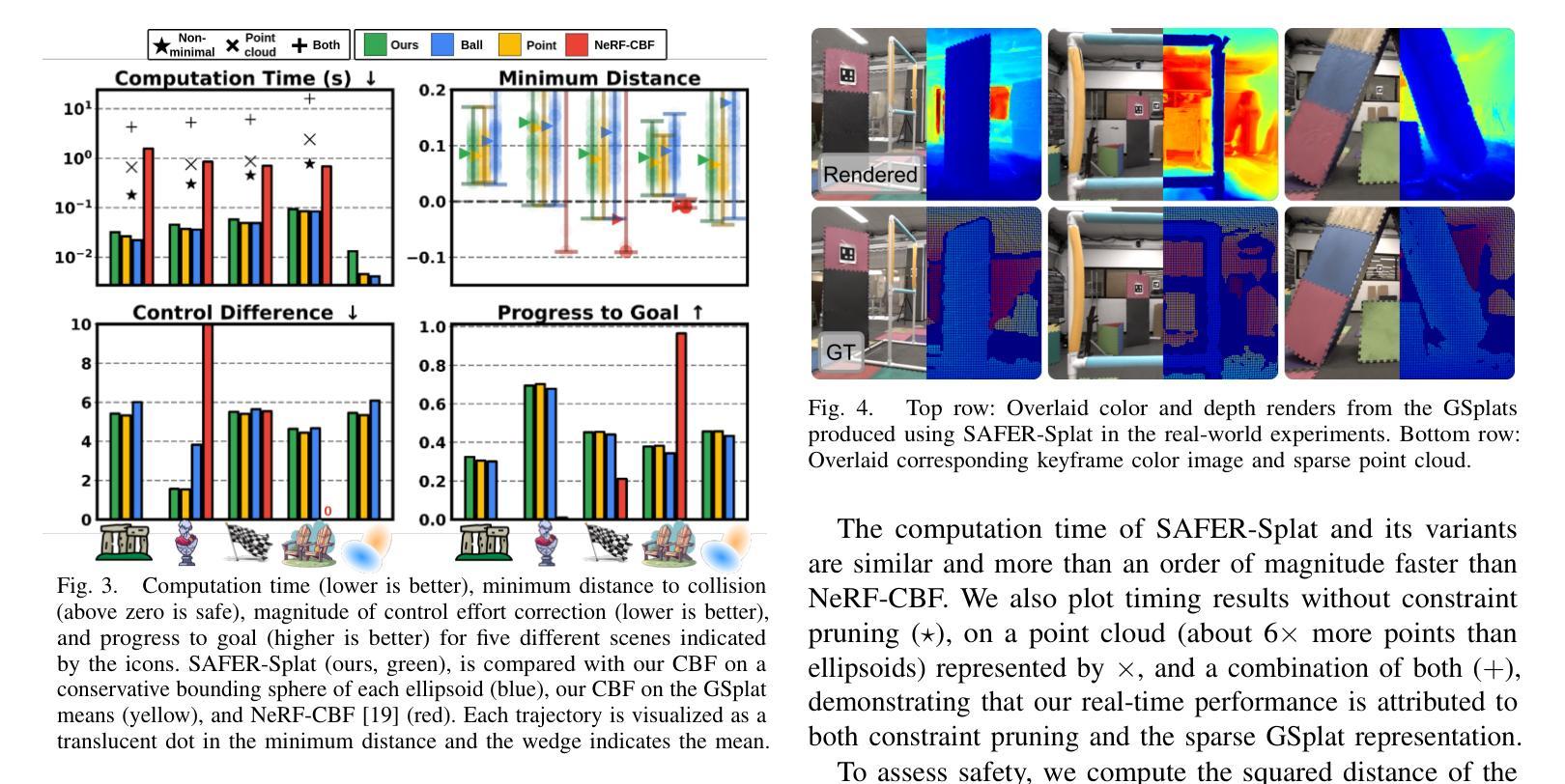
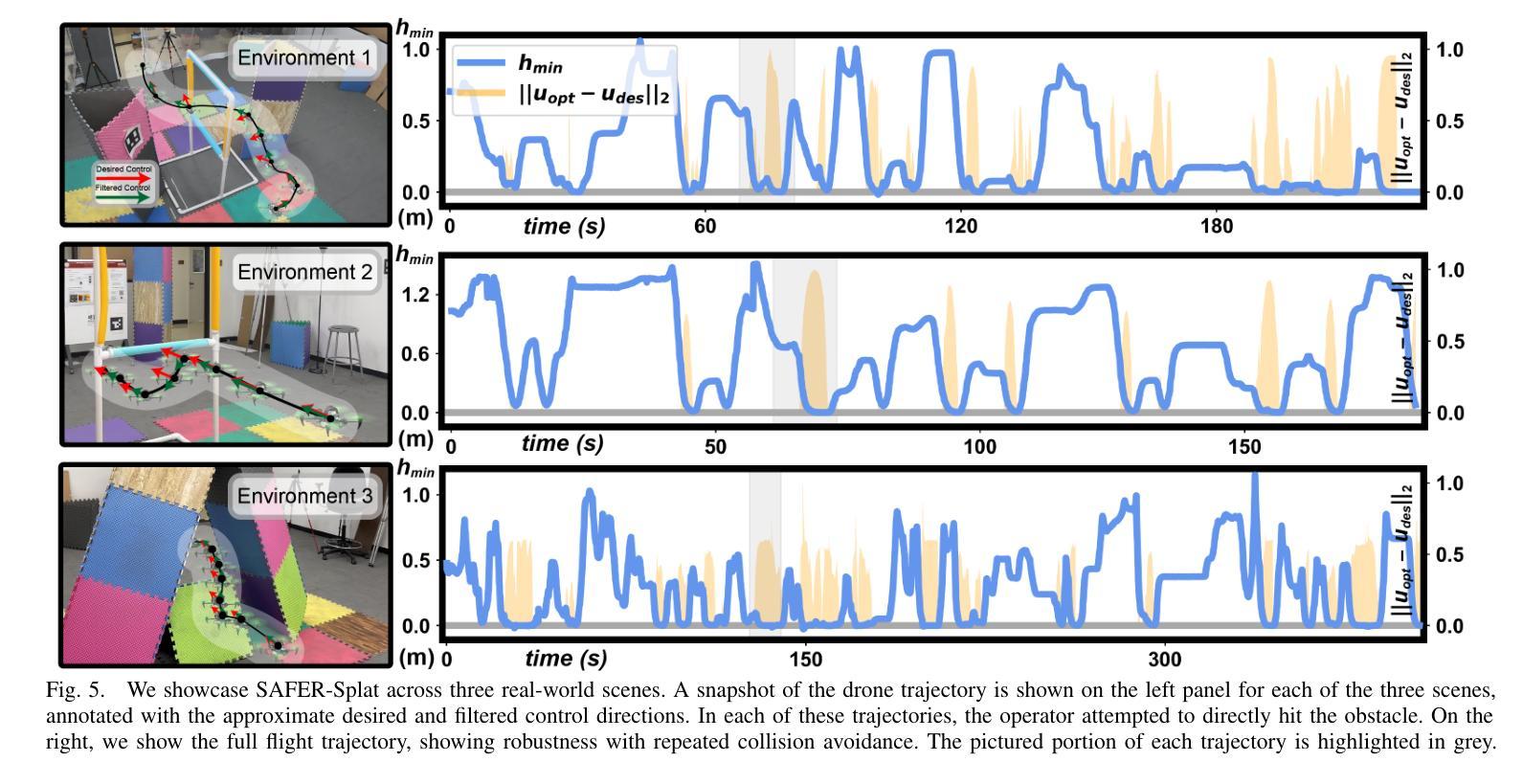
SAFER-Splat: A Control Barrier Function for Safe Navigation with Online Gaussian Splatting Maps
Authors:Timothy Chen, Aiden Swann, Javier Yu, Ola Shorinwa, Riku Murai, Monroe Kennedy III, Mac Schwager
SAFER-Splat (Simultaneous Action Filtering and Environment Reconstruction) is a real-time, scalable, and minimally invasive action filter, based on control barrier functions, for safe robotic navigation in a detailed map constructed at runtime using Gaussian Splatting (GSplat). We propose a novel Control Barrier Function (CBF) that not only induces safety with respect to all Gaussian primitives in the scene, but when synthesized into a controller, is capable of processing hundreds of thousands of Gaussians while maintaining a minimal memory footprint and operating at 15 Hz during online Splat training. Of the total compute time, a small fraction of it consumes GPU resources, enabling uninterrupted training. The safety layer is minimally invasive, correcting robot actions only when they are unsafe. To showcase the safety filter, we also introduce SplatBridge, an open-source software package built with ROS for real-time GSplat mapping for robots. We demonstrate the safety and robustness of our pipeline first in simulation, where our method is 20-50x faster, safer, and less conservative than competing methods based on neural radiance fields. Further, we demonstrate simultaneous GSplat mapping and safety filtering on a drone hardware platform using only on-board perception. We verify that under teleoperation a human pilot cannot invoke a collision. Our videos and codebase can be found at https://chengine.github.io/safer-splat.
SAFER-Splat(同时动作过滤和环境重建)是一种基于控制屏障功能的实时、可扩展、微创性动作过滤器,用于在运行时使用高斯拼贴(GSplat)构建的细节地图中进行安全机器人导航。我们提出了一种新型的控制屏障功能(CBF),它不仅会对场景中的所有高斯原始数据产生安全影响,而且当被合成到控制器中时,能够处理数十万的高斯数据,同时保持较小的内存占用,并在在线拼贴训练时以1 结速运行。在总计算时间中,只有一小部分消耗GPU资源,从而实现不间断的训练。安全层是微创性的,仅在机器人动作不安全时进行纠正。为了展示安全过滤器,我们还推出了SplatBridge,这是一款用ROS构建的开源软件包,用于机器人的实时GSplat映射。我们首先在模拟中展示了我们的管道的安全性和稳健性,在这里,我们的方法比基于神经辐射场的方法快20-50倍,更安全,并且不那么保守。此外,我们在无人机硬件平台上展示了同时进行的GSplat映射和安全过滤,仅使用机载感知。我们验证了在遥操作下,人类飞行员无法造成碰撞。我们的视频和代码库可在https://chengine.github.io/safer-splat找到。
论文及项目相关链接
PDF Accepted to International Conference on Robotics and Automation
摘要
SAFER-Splat是一种基于控制屏障函数的实时、可扩展、侵入性较小的行动过滤器,用于在通过高斯拼贴法构建的详细地图上进行安全机器人导航。它提出了一种新型控制屏障函数,不仅可对场景中的所有高斯原始数据进行安全诱导,而且当合成控制器时,能够处理数十万高斯数据,同时保持较小的内存占用并以15Hz的频率进行在线Splat训练。其计算时间中只有一小部分消耗GPU资源,可实现不间断的训练。安全层具有较小的侵入性,仅在机器人行动不安全时进行校正。为了展示安全过滤器,我们还推出了SplatBridge,这是一款用ROS构建的开源软件包,用于机器人的实时GSplat映射。我们在模拟环境中展示了管道的安全性和稳健性,我们的方法比基于神经辐射场的方法快20-50倍,更加安全和保守。此外,我们在仅使用机载感知的无人机硬件平台上展示了同时进行的GSplat映射和安全过滤。我们验证了在遥操作情况下,人类飞行员无法造成碰撞。更多视频和代码可在https://chengine.github.io/safer-splat找到。
要点
- SAFER-Splat是一种基于控制屏障函数的实时行动过滤器,用于机器人导航。
- 它能够处理大量高斯数据,保持低内存占用,并具备实时训练能力。
- 安全层仅在必要时进行侵入性校正。
- SplatBridge是一个开源软件,用于机器人的实时GSplat映射。
- 在模拟环境中验证了管道的安全性和稳健性,表现优于其他方法。
- 实现了在无人机硬件平台上的同时GSplat映射和安全过滤。
点此查看论文截图