⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
DARS: Dynamic Action Re-Sampling to Enhance Coding Agent Performance by Adaptive Tree Traversal
Authors:Vaibhav Aggarwal, Ojasv Kamal, Abhinav Japesh, Zhijing Jin, Bernhard Schölkopf
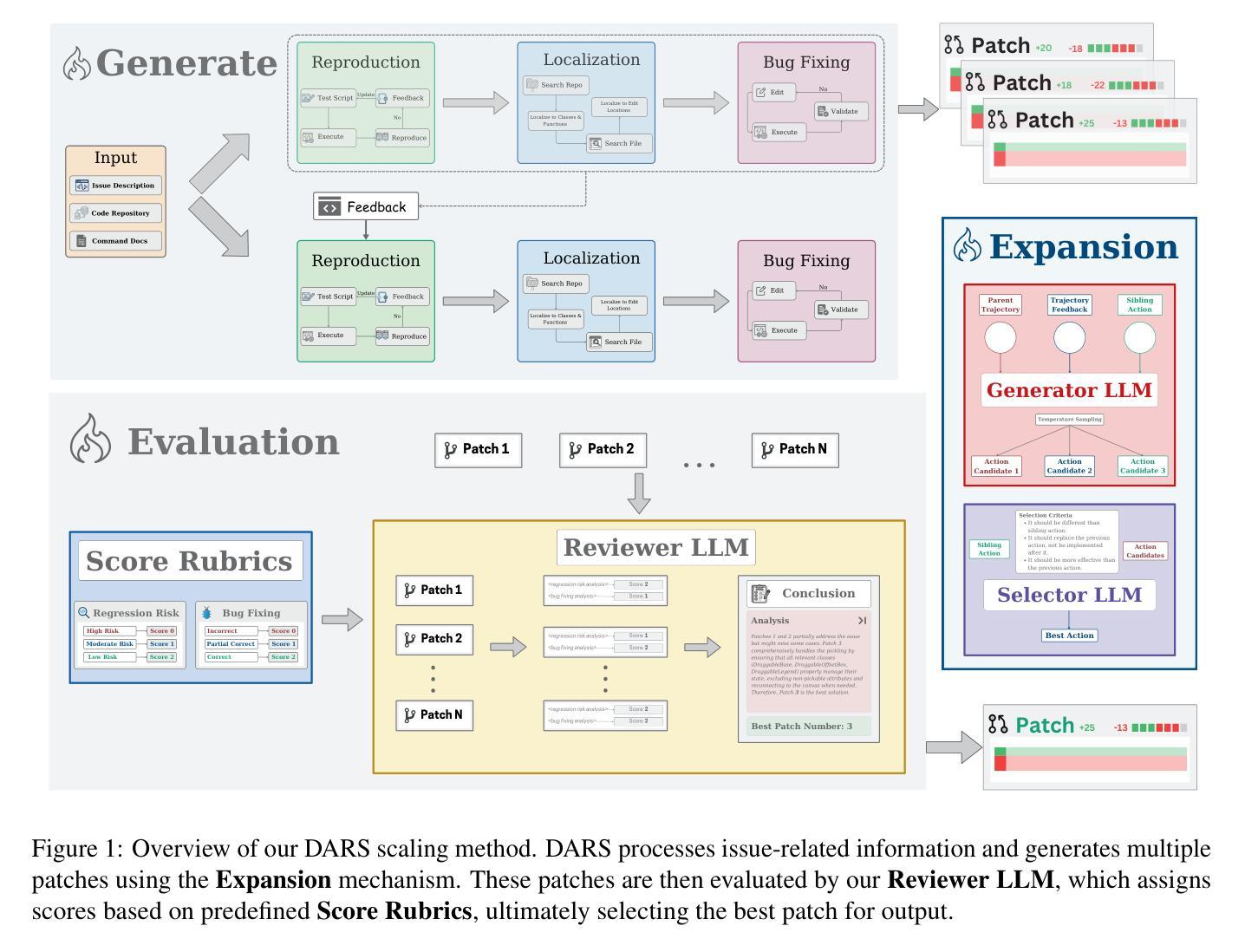
Large Language Models (LLMs) have revolutionized various domains, including natural language processing, data analysis, and software development, by enabling automation. In software engineering, LLM-powered coding agents have garnered significant attention due to their potential to automate complex development tasks, assist in debugging, and enhance productivity. However, existing approaches often struggle with sub-optimal decision-making, requiring either extensive manual intervention or inefficient compute scaling strategies. To improve coding agent performance, we present Dynamic Action Re-Sampling (DARS), a novel inference time compute scaling approach for coding agents, that is faster and more effective at recovering from sub-optimal decisions compared to baselines. While traditional agents either follow linear trajectories or rely on random sampling for scaling compute, our approach DARS works by branching out a trajectory at certain key decision points by taking an alternative action given the history of the trajectory and execution feedback of the previous attempt from that point. We evaluate our approach on SWE-Bench Lite benchmark, demonstrating that this scaling strategy achieves a pass@k score of 55% with Claude 3.5 Sonnet V2. Our framework achieves a pass@1 rate of 47%, outperforming state-of-the-art (SOTA) open-source frameworks.
大型语言模型(LLM)已经通过实现自动化,在多个领域(包括自然语言处理、数据分析和软件开发等)引发了革命。在软件工程领域,由LLM驱动的编码代理因具备自动化复杂开发任务、辅助调试和提高生产效率的潜力而备受关注。然而,现有方法常常面临决策不理想的困境,需要大量的人工干预或低效的计算扩展策略。为了提升编码代理的性能,我们提出了动态行为重采样(DARS),这是一种针对编码代理的新型推理时间计算扩展方法。与传统的代理相比,DARS在面临次优决策时,能够更快、更有效地恢复。传统的方法通常采用线性轨迹或随机采样进行计算扩展,而我们的DARS方法通过在关键决策点分支轨迹,根据轨迹历史和之前的执行反馈,采取替代行动。我们在SWE-Bench Lite基准测试上评估了我们的方法,结果显示,使用Claude 3.5 Sonnet V2时,该扩展策略达到了55%的pass@k得分。我们的框架实现了47%的pass@1率,超越了现有的开源先进框架。
论文及项目相关链接
Summary
大型语言模型(LLM)在多个领域引发革命性变革,软件工程领域尤为突出。LLM驱动的编码代理具备自动化复杂开发任务、辅助调试和提高生产效率的潜力。然而,现有方法常在决策制定上表现不佳,需要大量人工干预或低效的计算扩展策略。为改善编码代理性能,本文提出动态行为重采样(DARS)技术,这是一种新颖的推理时间计算扩展方法。相较于传统方法,DARS在关键决策点展开轨迹,结合历史轨迹和执行反馈,选择替代行动。实验表明,DARS在SWE-Bench Lite基准测试上表现优异,超越现有开源框架。
Key Takeaways
- 大型语言模型(LLM)在多个领域有广泛应用,包括自然语言处理、数据分析和软件开发。
- LLM在软件工程领域助力自动化复杂开发任务、辅助调试,提高生产效率。
- 现有编码代理方法在决策制定上表现欠佳,需改进。
- 提出动态行为重采样(DARS)技术,能在推理时间进行更有效的计算扩展。
- DARS在关键决策点展开轨迹,结合历史轨迹和执行反馈选择替代行动。
- DARS技术在SWE-Bench Lite基准测试上表现优异,pass@k得分达到55%。
点此查看论文截图


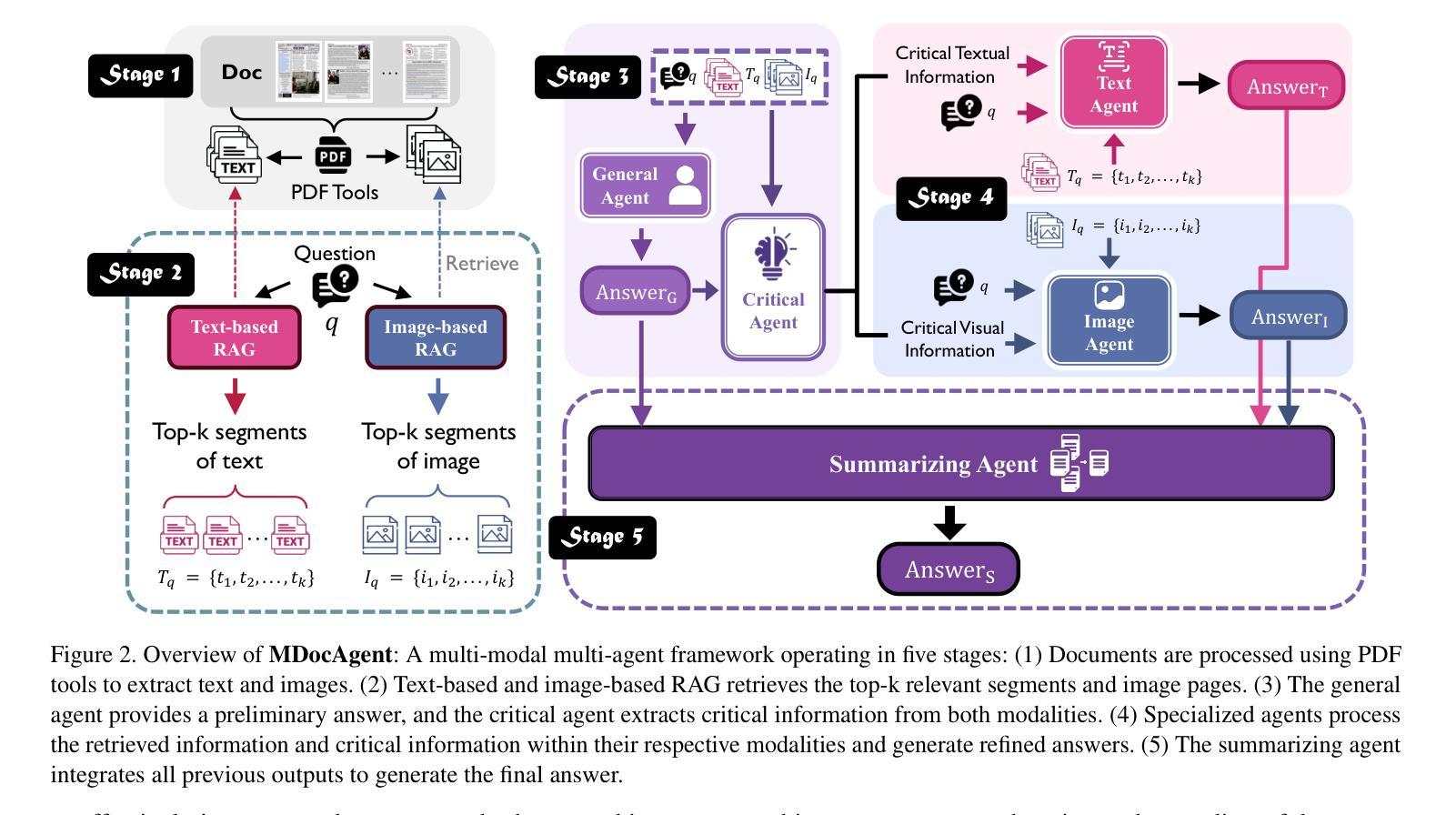
MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding
Authors:Siwei Han, Peng Xia, Ruiyi Zhang, Tong Sun, Yun Li, Hongtu Zhu, Huaxiu Yao
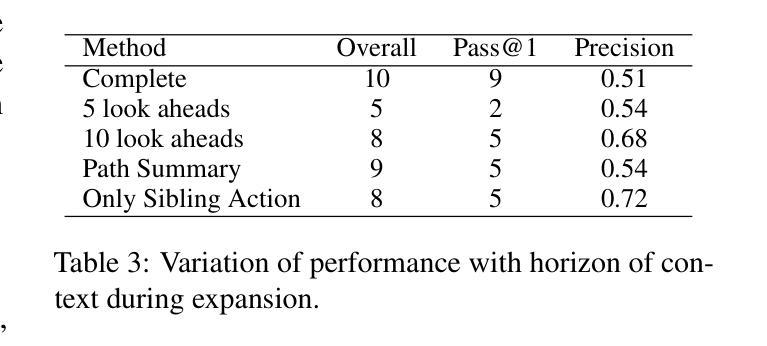
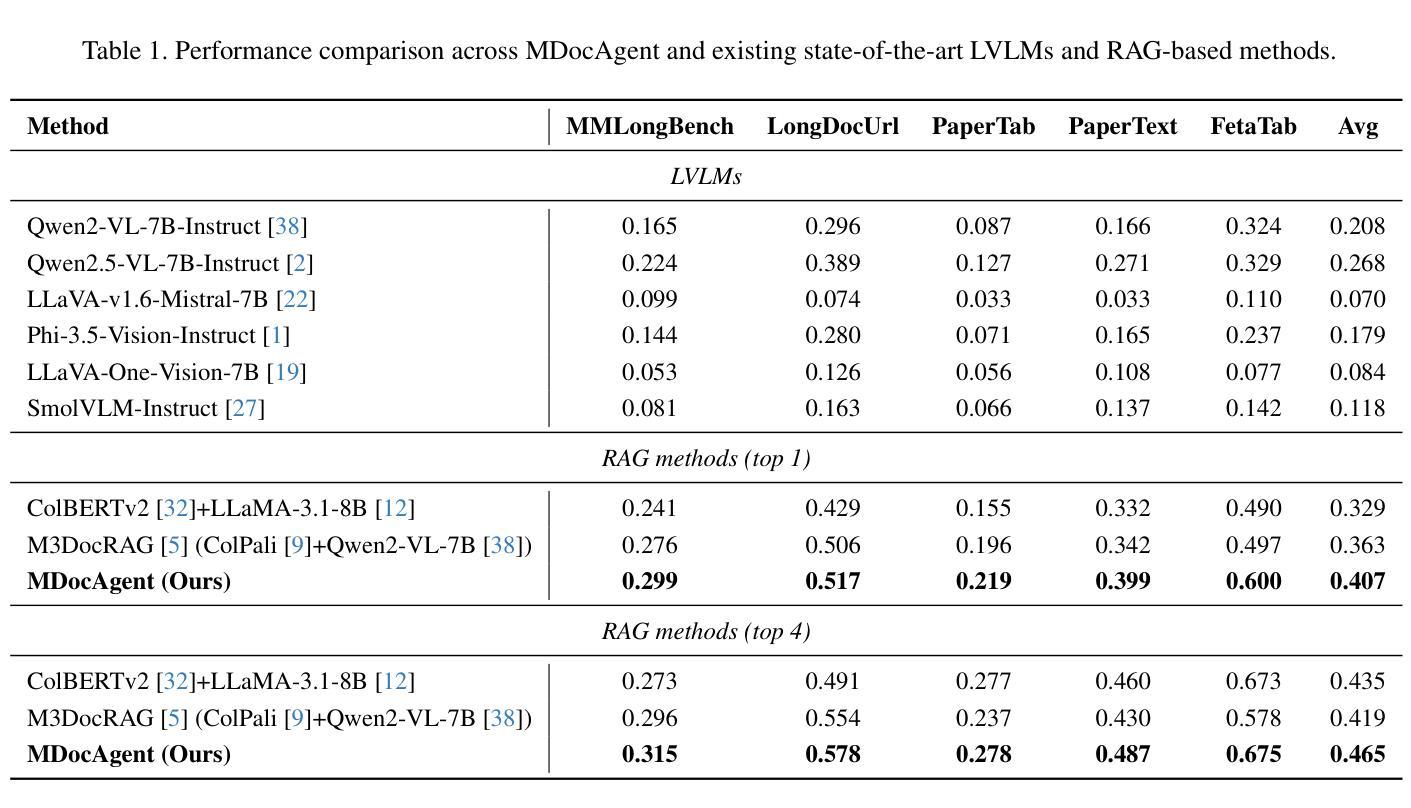
Document Question Answering (DocQA) is a very common task. Existing methods using Large Language Models (LLMs) or Large Vision Language Models (LVLMs) and Retrieval Augmented Generation (RAG) often prioritize information from a single modal, failing to effectively integrate textual and visual cues. These approaches struggle with complex multi-modal reasoning, limiting their performance on real-world documents. We present MDocAgent (A Multi-Modal Multi-Agent Framework for Document Understanding), a novel RAG and multi-agent framework that leverages both text and image. Our system employs five specialized agents: a general agent, a critical agent, a text agent, an image agent and a summarizing agent. These agents engage in multi-modal context retrieval, combining their individual insights to achieve a more comprehensive understanding of the document’s content. This collaborative approach enables the system to synthesize information from both textual and visual components, leading to improved accuracy in question answering. Preliminary experiments on five benchmarks like MMLongBench, LongDocURL demonstrate the effectiveness of our MDocAgent, achieve an average improvement of 12.1% compared to current state-of-the-art method. This work contributes to the development of more robust and comprehensive DocQA systems capable of handling the complexities of real-world documents containing rich textual and visual information. Our data and code are available at https://github.com/aiming-lab/MDocAgent.
文档问答(DocQA)是一项非常常见的任务。现有方法主要使用大型语言模型(LLM)或大型视觉语言模型(LVLM)和检索增强生成(RAG),通常优先处理单一模态的信息,无法有效地整合文本和视觉线索。这些方法在处理复杂的跨模态推理时遇到困难,限制了它们在真实文档上的表现。我们提出了MDocAgent(面向文档理解的跨模态多代理框架),这是一个新的RAG和多代理框架,利用文本和图像信息。我们的系统采用五种专业代理:通用代理、关键代理、文本代理、图像代理和总结代理。这些代理参与多模态上下文检索,结合各自的见解,实现对文档内容更全面理解。这种协作方法允许系统综合文本和视觉组件的信息,从而提高问答的准确性。在MMLongBench、LongDocURL等五个基准测试上的初步实验表明,我们的MDocAgent的有效性,与当前最先进的相比,平均提高了12.1%。这项工作促进了更健壮、更全面的DocQA系统的发展,能够处理包含丰富文本和视觉信息的真实文档的复杂性。我们的数据和代码可在https://github.com/aiming-lab/MDocAgent上找到。
论文及项目相关链接
Summary
多模态文档理解的新方法MDocAgent通过结合文本和图像信息,使用五个专门代理(包括通用代理、关键代理、文本代理、图像代理和总结代理)进行多模态上下文检索,实现对文档内容的全面理解。初步实验表明,MDocAgent在五个基准测试上的表现优于当前最先进的模型,平均提高了12.1%。此工作为开发更稳健、全面的文档问答系统铺平了道路。
Key Takeaways
- MDocAgent是一个新的多模态多代理框架,用于文档理解。它利用文本和图像信息来增强文档理解。
- 该框架包含五个专门代理:通用代理、关键代理、文本代理、图像代理和总结代理。
- 这些代理进行多模态上下文检索,结合各自的见解,实现对文档内容的全面理解。
- 初步实验表明,MDocAgent在多个基准测试上的表现优于现有方法,平均提高了12.1%。
- MDocAgent的贡献在于为开发更稳健、全面的文档问答系统铺平了道路,特别是那些需要处理富含文本和图像信息的现实世界文档的系统。
- MDocAgent的数据和代码已公开,便于其他研究者使用和改进。
点此查看论文截图


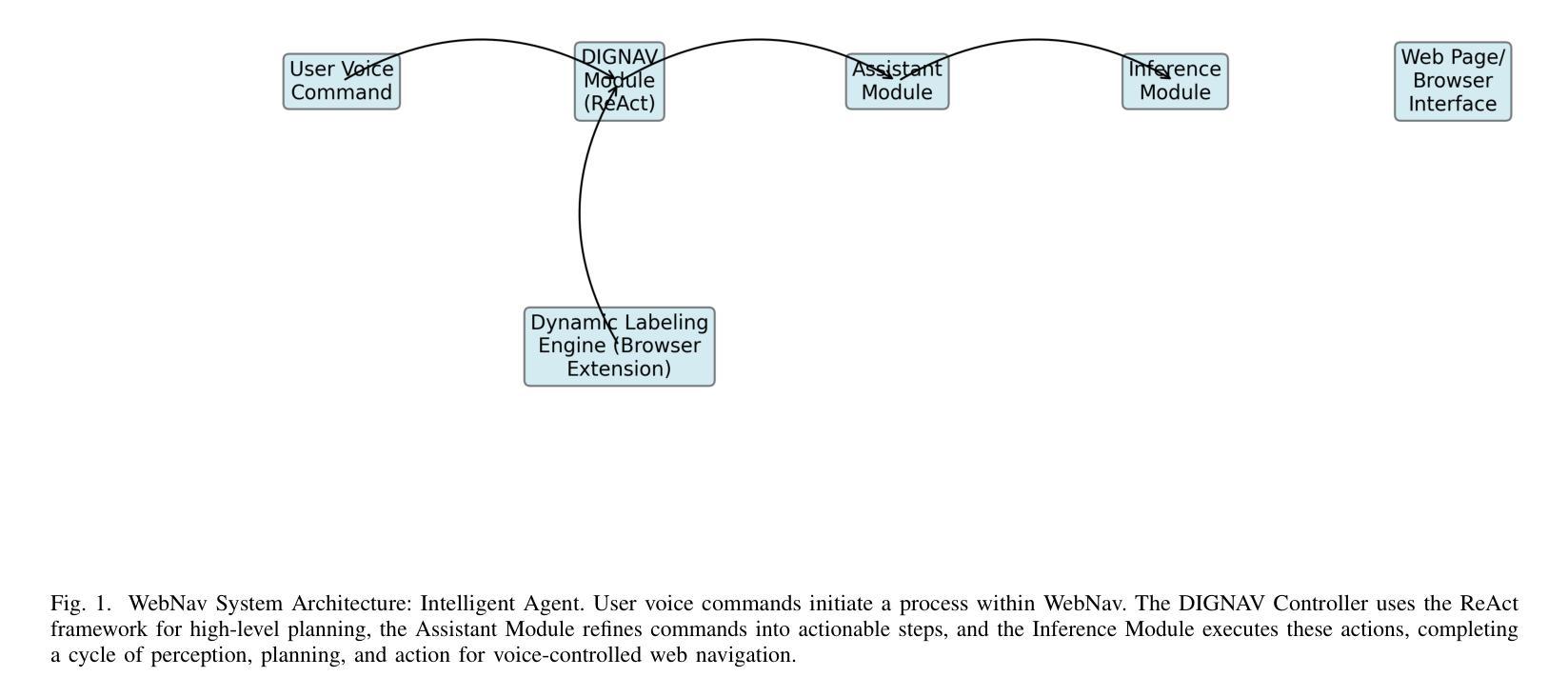
WebNav: An Intelligent Agent for Voice-Controlled Web Navigation
Authors:Trisanth Srinivasan, Santosh Patapati
The increasing reliance on web interfaces presents many challenges for visually impaired users, showcasing the need for more advanced assistive technologies. This paper introduces WebNav, a voice-controlled web navigation agent that leverages a ReAct-inspired architecture and generative AI to provide this framework. WebNav comprises of a hierarchical structure: a Digital Navigation Module (DIGNAV) for high-level strategic planning, an Assistant Module for translating abstract commands into executable actions, and an Inference Module for low-level interaction. A key component is a dynamic labeling engine, implemented as a browser extension, that generates real-time labels for interactive elements, creating mapping between voice commands and Document Object Model (DOM) components. Preliminary evaluations show that WebNav outperforms traditional screen readers in response time and task completion accuracy for the visually impaired. Future work will focus on extensive user evaluations, benchmark development, and refining the agent’s adaptive capabilities for real-world deployment.
随着对网页界面的依赖日益增加,为视觉障碍用户带来了许多挑战,这凸显了需要更先进的辅助技术。本文介绍了WebNav,这是一个语音控制的网页导航代理,它利用受ReAct启发的架构和生成式人工智能来提供此框架。WebNav由分层结构组成:用于高级战略规划的数字导航模块(DIGNAV)、将抽象命令翻译为可执行操作的助理模块,以及用于低级交互的推理模块。一个关键组件是动态标签引擎,它作为浏览器扩展实现,为交互元素生成实时标签,创建语音命令与文档对象模型(DOM)组件之间的映射。初步评估表明,WebNav在响应时间和任务完成准确性方面优于传统的屏幕阅读器,对视觉受损者有很大帮助。未来的工作将侧重于广泛的用户评估、基准测试开发和细化代理的适应能力,以进行实际部署。
论文及项目相关链接
Summary
WebNav是一款基于语音控制的网页导航代理,它利用ReAct架构和生成式AI提供框架,旨在解决视觉障碍用户在使用网页界面时面临的挑战。WebNav包括数字导航模块、助理模块和推理模块三个层次结构,并通过动态标签引擎生成实时标签,为视觉障碍用户提供交互元素与语音命令之间的映射。初步评估显示,WebNav在响应时间、任务完成准确性等方面优于传统屏幕阅读器。未来的工作将重点放在广泛的用户评估、基准测试发展和进一步完善代理的自适应能力以适应实际部署环境。
Key Takeaways
- WebNav是一个为视觉障碍用户设计的语音控制的网页导航代理。
- 它采用ReAct架构和生成式AI技术实现。
- WebNav包括数字导航模块、助理模块和推理模块三个核心组成部分。
- 动态标签引擎是WebNav的关键组件,可以生成实时标签,为视觉障碍用户提供交互元素与语音命令之间的映射。
- 初步评估显示WebNav在响应时间、任务完成准确性等方面优于传统屏幕阅读器。
- 未来将进一步完善WebNav的用户适应性以及部署环境适应性。
点此查看论文截图


SagaLLM: Context Management, Validation, and Transaction Guarantees for Multi-Agent LLM Planning
Authors:Edward Y. Chang, Longling Geng
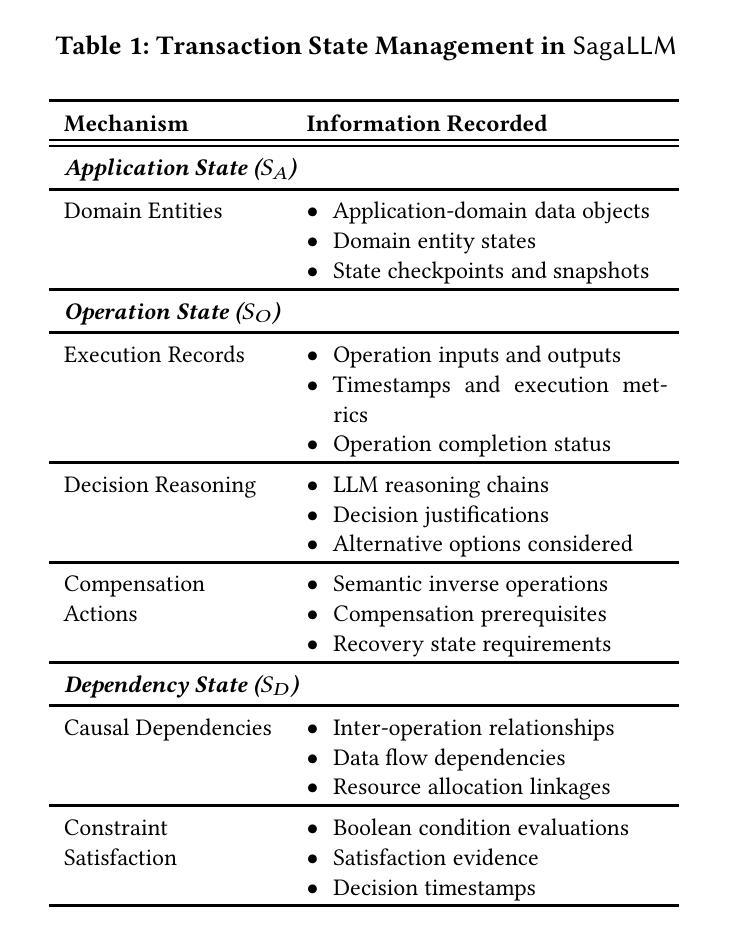
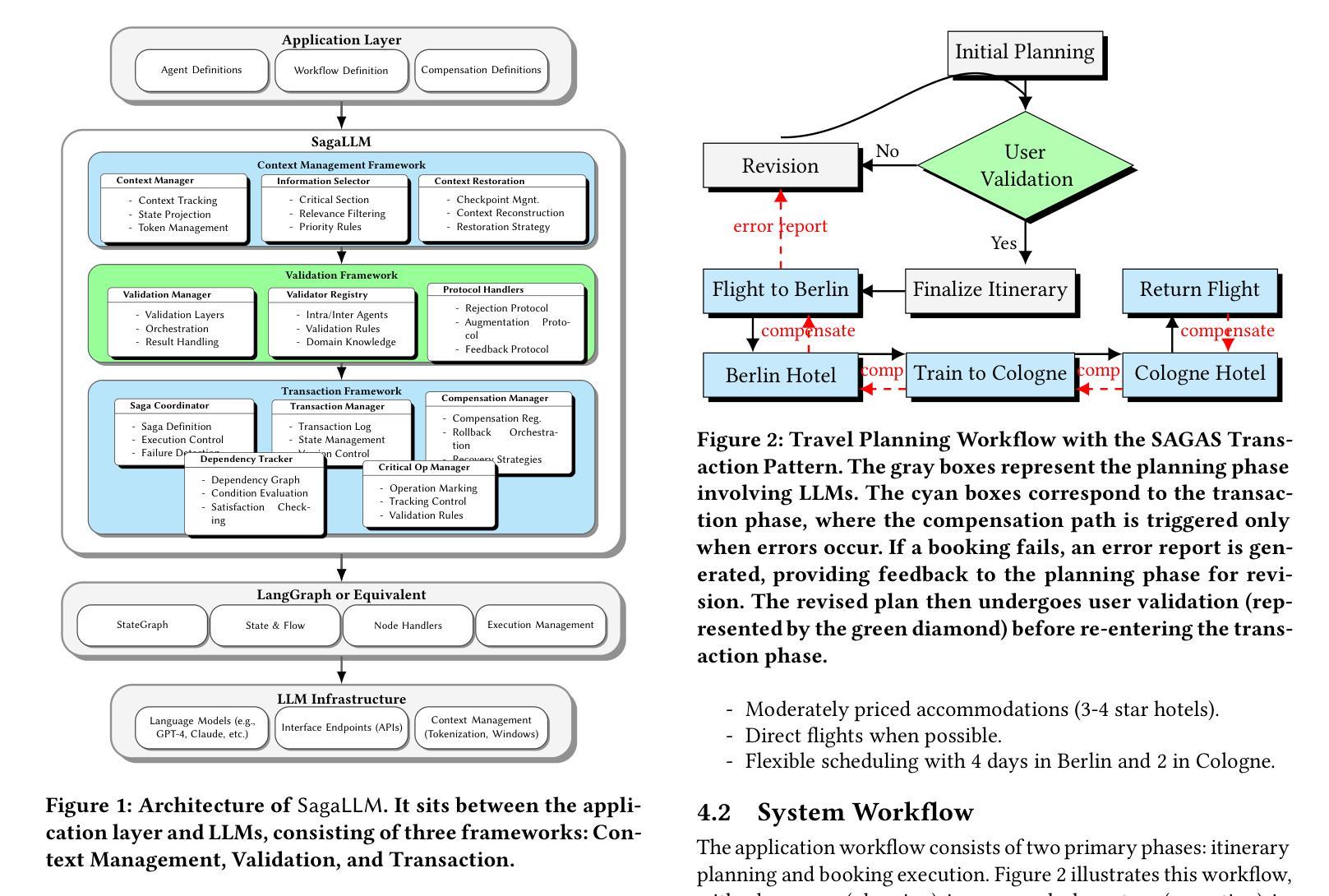
Recent LLM-based agent frameworks have demonstrated impressive capabilities in task delegation and workflow orchestration, but face significant challenges in maintaining context awareness and ensuring planning consistency. This paper presents SagaLLM, a structured multi-agent framework that addresses four fundamental limitations in current LLM approaches: inadequate self-validation, context narrowing, lacking transaction properties, and insufficient inter-agent coordination. By implementing specialized context management agents and validation protocols, SagaLLM preserves critical constraints and state information throughout complex planning processes, enabling robust and consistent decision-making even during disruptions. We evaluate our approach using selected problems from the REALM benchmark, focusing on sequential and reactive planning scenarios that challenge both context retention and adaptive reasoning. Our experiments with state-of-the-art LLMs, Claude 3.7, DeepSeek R1, GPT-4o, and GPT-o1, demonstrate that while these models exhibit impressive reasoning capabilities, they struggle with maintaining global constraint awareness during complex planning tasks, particularly when adapting to unexpected changes. In contrast, the distributed cognitive architecture of SagaLLM shows significant improvements in planning consistency, constraint enforcement, and adaptation to disruptions in various scenarios.
近期基于大型语言模型的代理框架在任务委派和工作流编排方面展示了令人印象深刻的能力,但在保持上下文意识和确保规划一致性方面面临重大挑战。本文提出了SagaLLM,这是一个结构化多代理框架,解决了当前大型语言模型方法中的四个基本局限性:自检不足、上下文狭窄、缺乏事务属性和代理间协调不足。通过实现专门的上文管理代理和验证协议,SagaLLM在复杂的规划过程中保持了关键的约束和状态信息,即使在中断情况下也能实现稳健和一致性的决策。我们使用REALM基准测试中的选定问题来评估我们的方法,侧重于序列和反应规划场景,这些场景对上下文保留和自适应推理都具有挑战性。我们与最新的大型语言模型进行的实验,包括Claude 3.7、DeepSeek R1、GPT-4o和GPT-o1,表明这些模型虽然具有令人印象深刻的推理能力,但在复杂的规划任务中保持全局约束意识方面存在困难,尤其是在适应意外变化时。相比之下,SagaLLM的分布式认知架构在规划一致性、约束执行和适应各种场景中的中断方面显示出显着改进。
论文及项目相关链接
PDF 13 pages, 8 tables, 5 figures
Summary
緩冡SagaLLM框架解决了大型语言模型(LLM)在任务委派、工作流编排方面的四个根本局限:缺乏自我验证、上下文狭窄、缺乏事务属性和跨代理协调不足。通过实施专门上下文管理代理和验证协议,SagaLLM能够在复杂的规划过程中保留关键约束和状态信息,从而实现稳健且一致的决策制定,即使面临干扰也是如此。相较于先进的大型语言模型(如GPT系列等),其在适应变化的情境中的规划和一致性方面具有显著改善。本文还提供了通过实际问题来验证上述方法的实用性研究证据。研究评估是基于现实环境中的复杂规划场景的REALM基准进行的。结果验证了新方法的潜力与实用性。使用特定的REALM问题集进行的研究表明,大型语言模型在处理复杂规划任务时,特别是在适应意外变化时,维持全局约束意识方面存在困难。相比之下,SagaLLM在规划一致性、约束执行和适应各种场景中的干扰方面表现出显著优势。该方法也展示出潜在的进步价值和应用潜力。经过实践检验与当下主流的模型和技术的对比和分析得出有效的研究成果。通过SagaLLM的结构化多代理框架解决了现有大型语言模型在处理复杂任务时的问题与缺陷,有望改进当前的模型和增强实践效能与理论效益。Key Takeaways:
关于所给文本的关键见解,总结如下:
点此查看论文截图

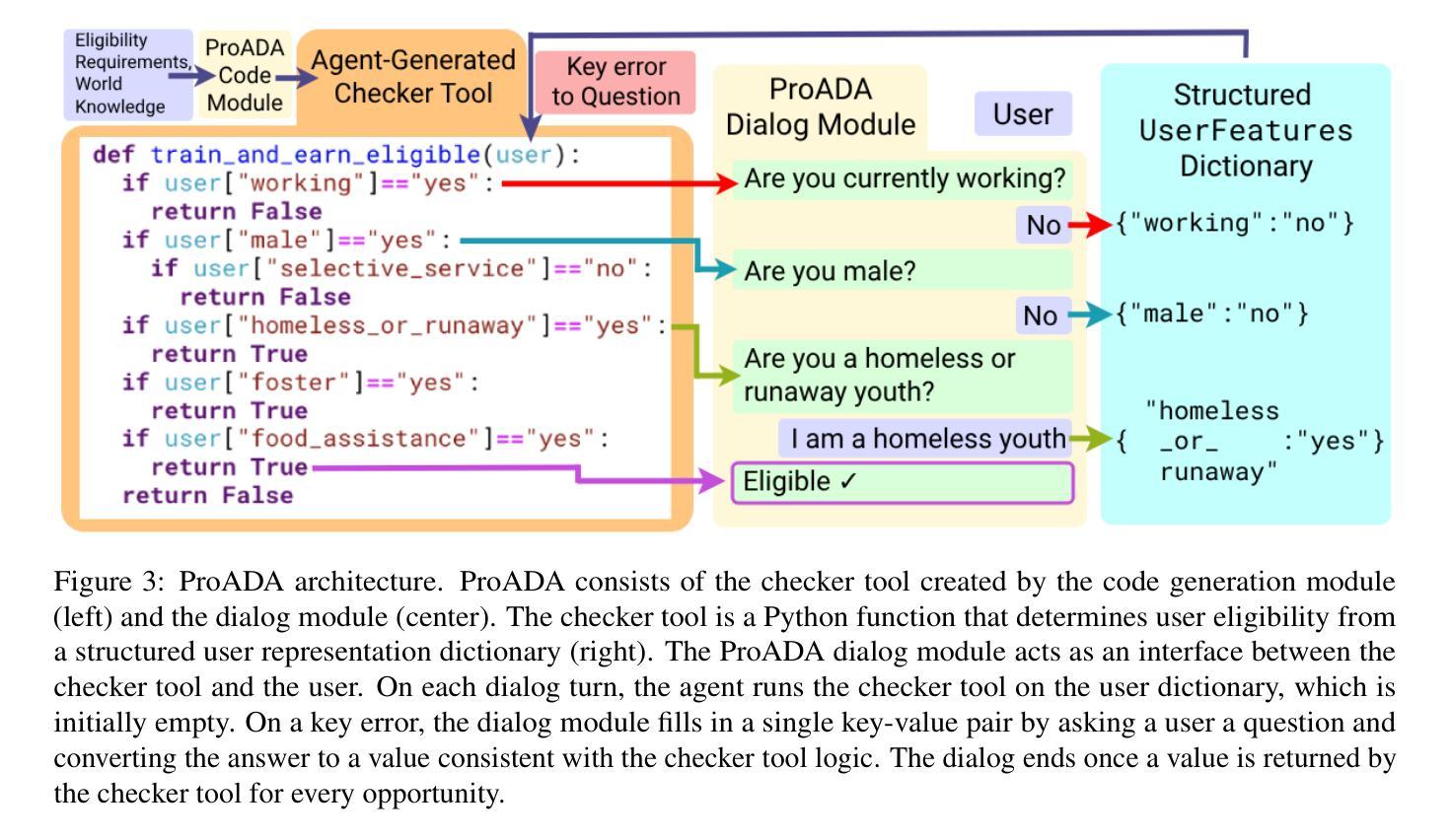
Program Synthesis Dialog Agents for Interactive Decision-Making
Authors:Matthew Toles, Nikhil Balwani, Rattandeep Singh, Valentina Giulia Sartori Rodriguez, Zhou Yu
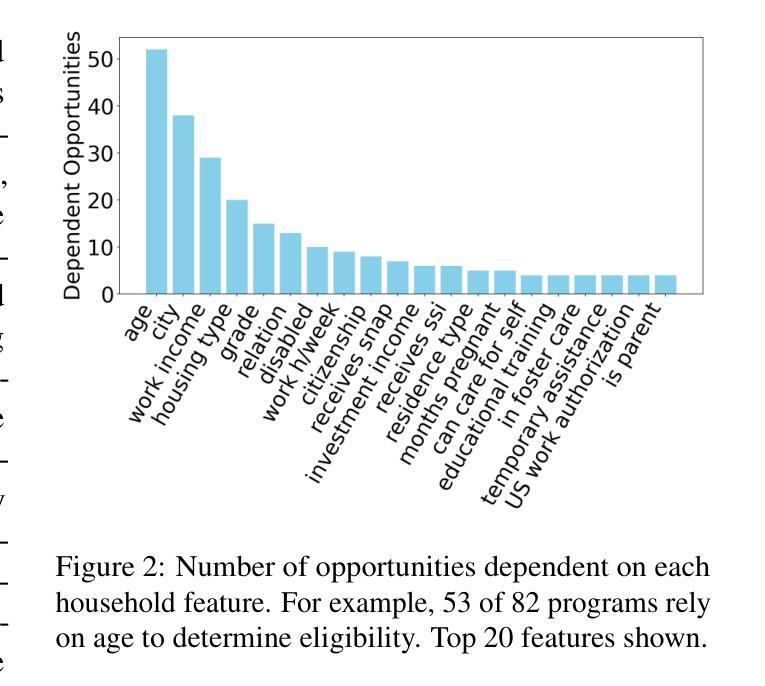
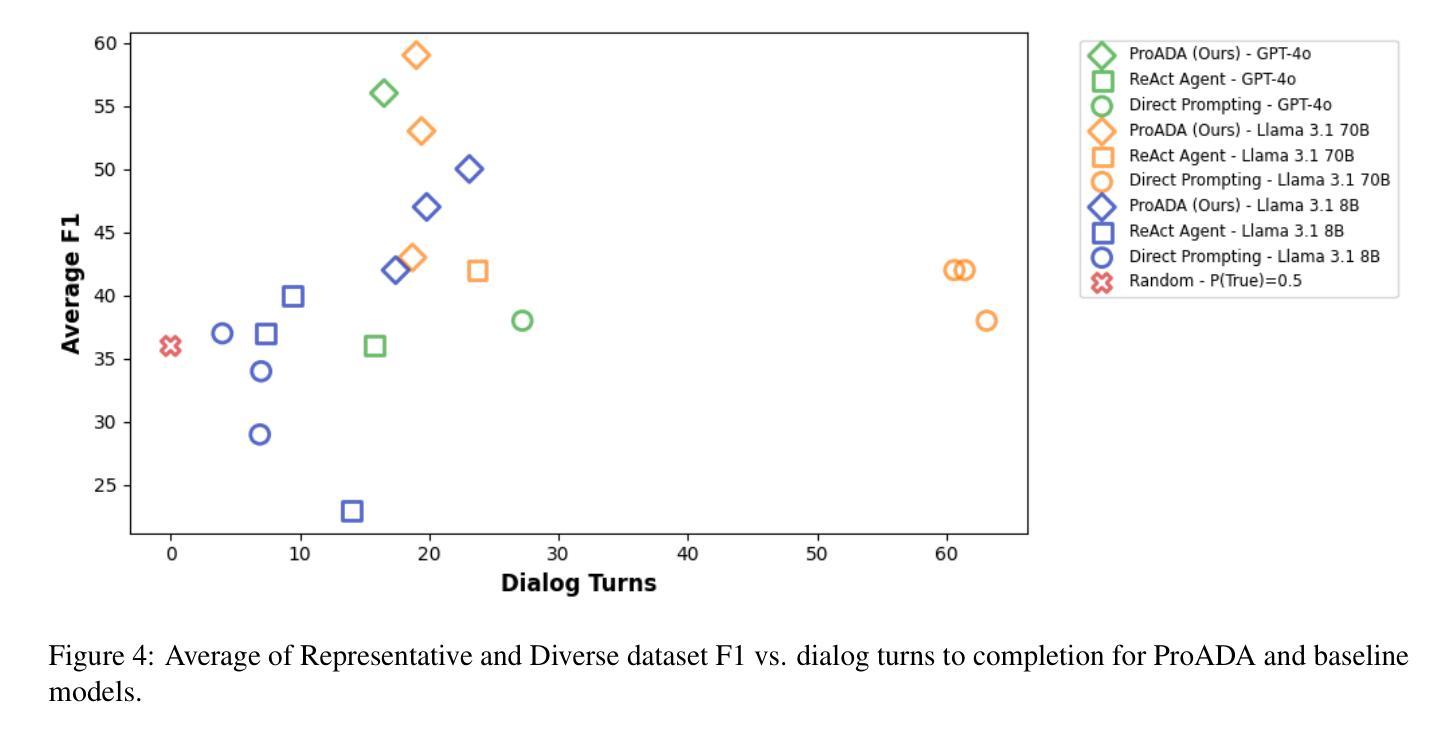
Many real-world eligibility problems, ranging from medical diagnosis to tax planning, can be mapped to decision problems expressed in natural language, wherein a model must make a binary choice based on user features. Large-scale domains such as legal codes or frequently updated funding opportunities render human annotation (e.g., web forms or decision trees) impractical, highlighting the need for agents that can automatically assist in decision-making. Since relevant information is often only known to the user, it is crucial that these agents ask the right questions. As agents determine when to terminate a conversation, they face a trade-off between accuracy and the number of questions asked, a key metric for both user experience and cost. To evaluate this task, we propose BeNYfits, a new benchmark for determining user eligibility for multiple overlapping social benefits opportunities through interactive decision-making. Our experiments show that current language models struggle with frequent hallucinations, with GPT-4o scoring only 35.7 F1 using a ReAct-style chain-of-thought. To address this, we introduce ProADA, a novel approach that leverages program synthesis to assist in decision-making by mapping dialog planning to a code generation problem and using gaps in structured data to determine the best next action. Our agent, ProADA, improves the F1 score to 55.6 while maintaining nearly the same number of dialog turns.
现实世界中的许多资格问题,从医疗诊断到税务规划,都可以映射到以自然语言表达出的决策问题,其中模型必须基于用户特征进行二元选择。大规模领域(如法律编码或经常更新的资金机会)使得人工标注(例如网页表单或决策树)变得不切实际,这突显了需要能够自动协助决策的智能代理。由于相关信息通常只为用户所知,因此这些代理需要提出正确的问题至关重要。由于代理决定了何时终止对话,因此在准确性与所提问题的数量之间需要进行权衡,这是用户体验和成本的关键指标。为了评估此任务,我们提出了BeNYfits,这是一个新的基准测试,用于通过交互式决策来确定用户对于多个重叠的社会福利机会的资格。我们的实验表明,当前的语言模型经常出现错觉,GPT-4o在ReAct风格的思考链中使用时只有35.7的F1得分。为了解决这一问题,我们引入了ProADA,这是一种利用程序合成协助决策的新方法,通过将对话规划映射到代码生成问题并使用结构化数据中的空白来确定最佳下一步行动。我们的代理ProADA将F1得分提高到55.6,同时几乎保持了相同的对话轮次。
论文及项目相关链接
Summary
本文探讨了现实世界中从医疗诊断到税务规划等资格问题的决策难题。这些问题可以通过自然语言表达为决策问题,模型根据用户特征做出二元选择。大规模领域如法律编码或频繁更新的资助机会使得人工标注不切实际,需要能够自动协助决策的智能体。智能体需要提问关键信息,并面临何时结束对话的权衡,这对准确性和提问数量提出了挑战。为评估此任务,提出BeNYfits基准测试,通过交互决策确定用户对于多重社会福利机会的资格。实验表明当前语言模型存在频繁幻觉问题,GPT-4o的F1分数仅为35.7。为解决此问题,引入ProADA方法,通过程序合成协助决策,将对话规划映射为代码生成问题并利用结构化数据中的空白确定最佳下一步行动。ProADA提高了F1分数至55.6,同时保持对话轮次数量相近。
Key Takeaways
- 现实世界的许多资格问题可以通过自然语言转化为决策问题,需要智能体自动协助决策。
- 智能体需能够获取关键信息并作出二元选择。
- 大规模领域和频繁更新的信息使得人工标注不切实际,要求智能体具备自动决策能力。
- 智能体在对话过程中需权衡准确性和提问数量,关注用户体验和成本。
- BeNYfits基准测试用于评估智能体在用户资格决策方面的表现。
- 当前语言模型存在幻觉问题,需要新方法提高准确性。
点此查看论文截图


Collaborative Instance Object Navigation: Leveraging Uncertainty-Awareness to Minimize Human-Agent Dialogues
Authors:Francesco Taioli, Edoardo Zorzi, Gianni Franchi, Alberto Castellini, Alessandro Farinelli, Marco Cristani, Yiming Wang
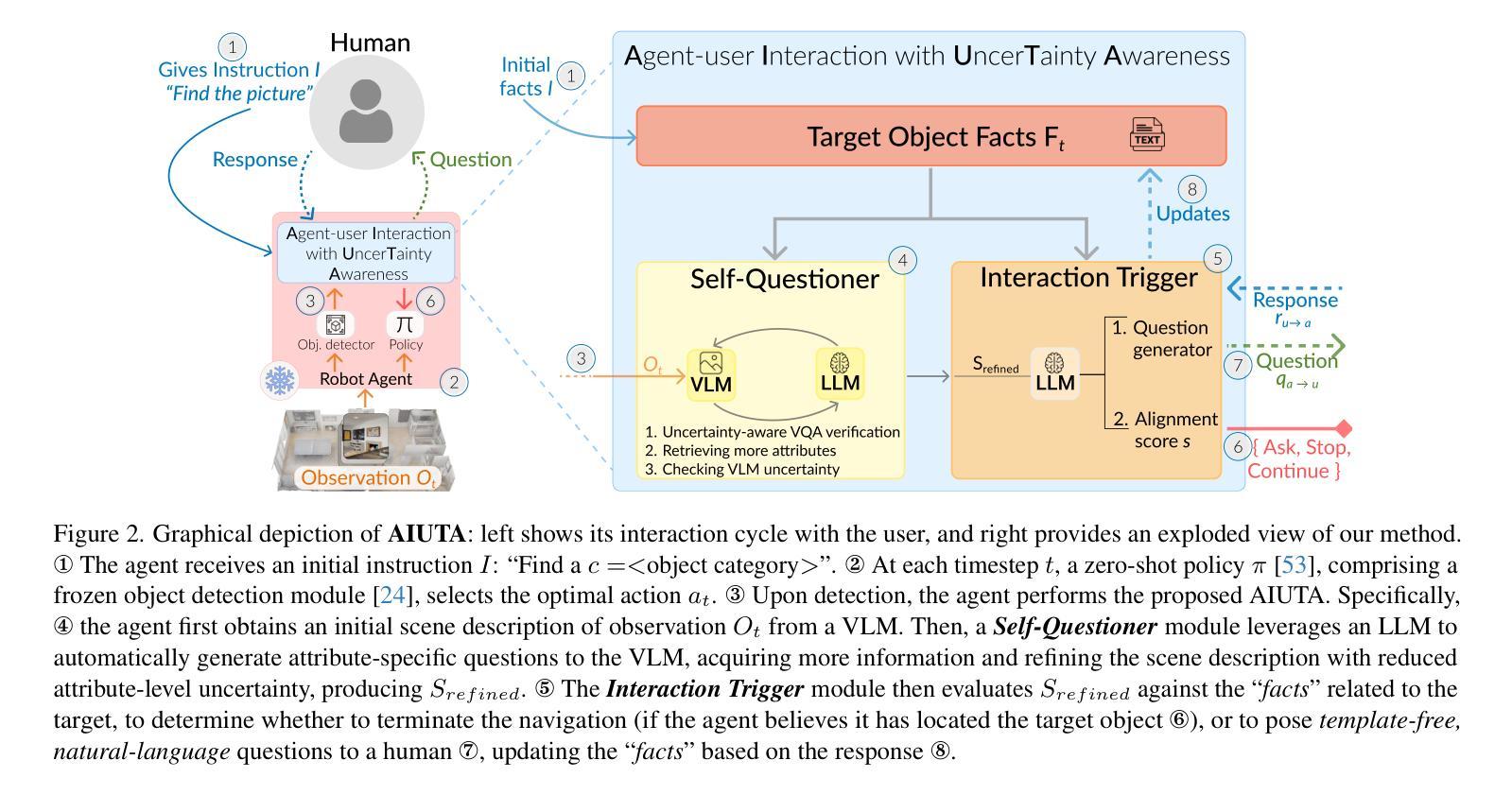
Language-driven instance object navigation assumes that human users initiate the task by providing a detailed description of the target instance to the embodied agent. While this description is crucial for distinguishing the target from visually similar instances in a scene, providing it prior to navigation can be demanding for human. To bridge this gap, we introduce Collaborative Instance object Navigation (CoIN), a new task setting where the agent actively resolve uncertainties about the target instance during navigation in natural, template-free, open-ended dialogues with human. We propose a novel training-free method, Agent-user Interaction with UncerTainty Awareness (AIUTA), which operates independently from the navigation policy, and focuses on the human-agent interaction reasoning with Vision-Language Models (VLMs) and Large Language Models (LLMs). First, upon object detection, a Self-Questioner model initiates a self-dialogue within the agent to obtain a complete and accurate observation description with a novel uncertainty estimation technique. Then, an Interaction Trigger module determines whether to ask a question to the human, continue or halt navigation, minimizing user input. For evaluation, we introduce CoIN-Bench, with a curated dataset designed for challenging multi-instance scenarios. CoIN-Bench supports both online evaluation with humans and reproducible experiments with simulated user-agent interactions. On CoIN-Bench, we show that AIUTA serves as a competitive baseline, while existing language-driven instance navigation methods struggle in complex multi-instance scenes. Code and benchmark will be available upon acceptance at https://intelligolabs.github.io/CoIN/
语言驱动的实例对象导航假设人类用户通过向实体代理提供目标实例的详细描述来启动任务。虽然这个描述对于从场景中的视觉上相似的实例中区分目标至关重要,但在导航之前提供它可能会对人类造成压力。为了弥补这一差距,我们引入了协作实例对象导航(COIN),这是一种新的任务设置,其中代理在与人类进行的无模板、开放式的自然对话过程中积极解决关于目标实例的不确定性。我们提出了一种新的无需训练的方法——具有不确定性感知的代理用户交互(AIUTA),它与导航策略独立,专注于利用视觉语言模型(VLMs)和大型语言模型(LLMs)进行的人机交互推理。首先,在对象检测后,自我提问模型会在代理内部发起一次自我对话,利用一种新的不确定性估计技术来获得完整准确的观察描述。然后,交互触发模块确定是否向人类提出问题、继续或停止导航,以最小化用户输入。为了评估性能,我们推出了COIN-Bench,其中包含专为具有挑战性的多实例场景设计的精选数据集。COIN-Bench支持与人类在线评估以及可重复的模拟用户与代理之间的交互实验。在COIN-Bench上,我们展示了AIUTA作为有竞争力的基准线,而现有的语言驱动实例导航方法在多实例复杂场景中表现挣扎。接受后,代码和基准测试将在https://intelligolabs.github.io/CoIN/上提供。
论文及项目相关链接
PDF https://intelligolabs.github.io/CoIN/
Summary
本文介绍了一种新的任务设置——协作式实例对象导航(CoIN),其中代理在与人进行自然、模板自由、开放式的对话过程中,主动解决关于目标实例的不确定性。提出了一种无需训练的方法——具有不确定性感知的代理用户交互(AIUTA),该方法独立于导航策略,专注于人类与代理交互推理,利用视觉语言模型(VLMs)和大型语言模型(LLMs)。通过对象检测和自我提问模型,AIUTA获得完整准确的观察描述,并引入互动触发模块来决定是否向人类提问、继续或停止导航。为评估此任务,推出了CoIN-Bench数据集,支持在线人类评估和可重复的模拟用户-代理互动实验。实验表明,AIUTA作为基准线表现有竞争力,而现有的语言驱动实例导航方法在复杂多实例场景中表现挣扎。
Key Takeaways
- 引入协作式实例对象导航(CoIN)任务设置,代理在导航过程中通过与人类对话解决目标实例的不确定性。
- 提出一种无需训练的方法——AIUTA,结合视觉语言模型和大型语言模型,处理人类与代理的交互推理。
- AIUTA通过自我提问模型获得准确观察描述,并引入互动触发模块以最小化用户输入。
- 推出CoIN-Bench数据集,支持在线人类评估和模拟用户-代理互动实验。
- AIUTA作为基准线表现有竞争力。
- 现行的语言驱动实例导航方法在复杂多实例场景中面临挑战。
点此查看论文截图

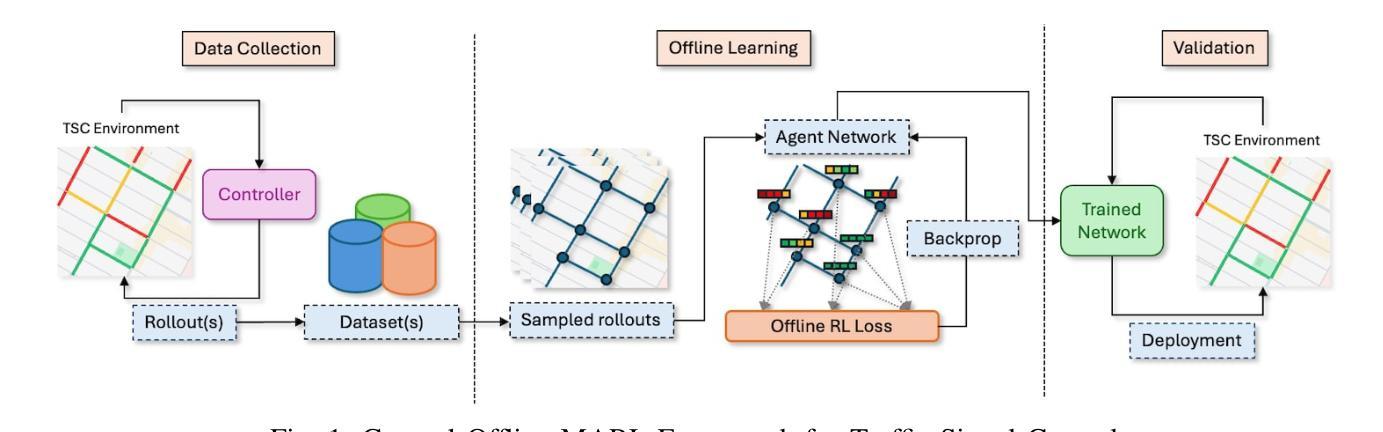
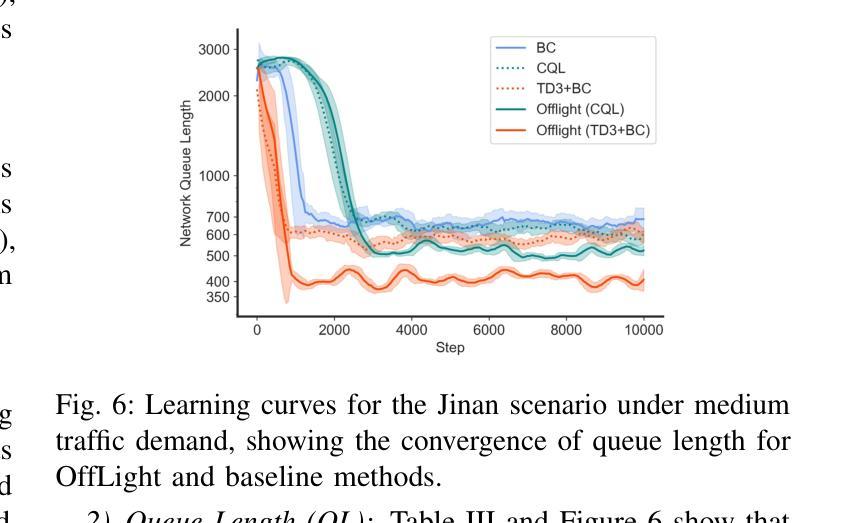
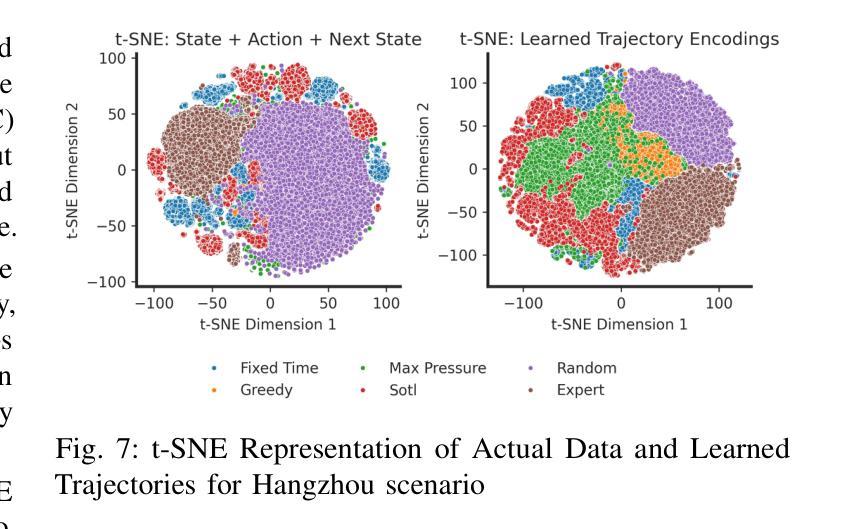
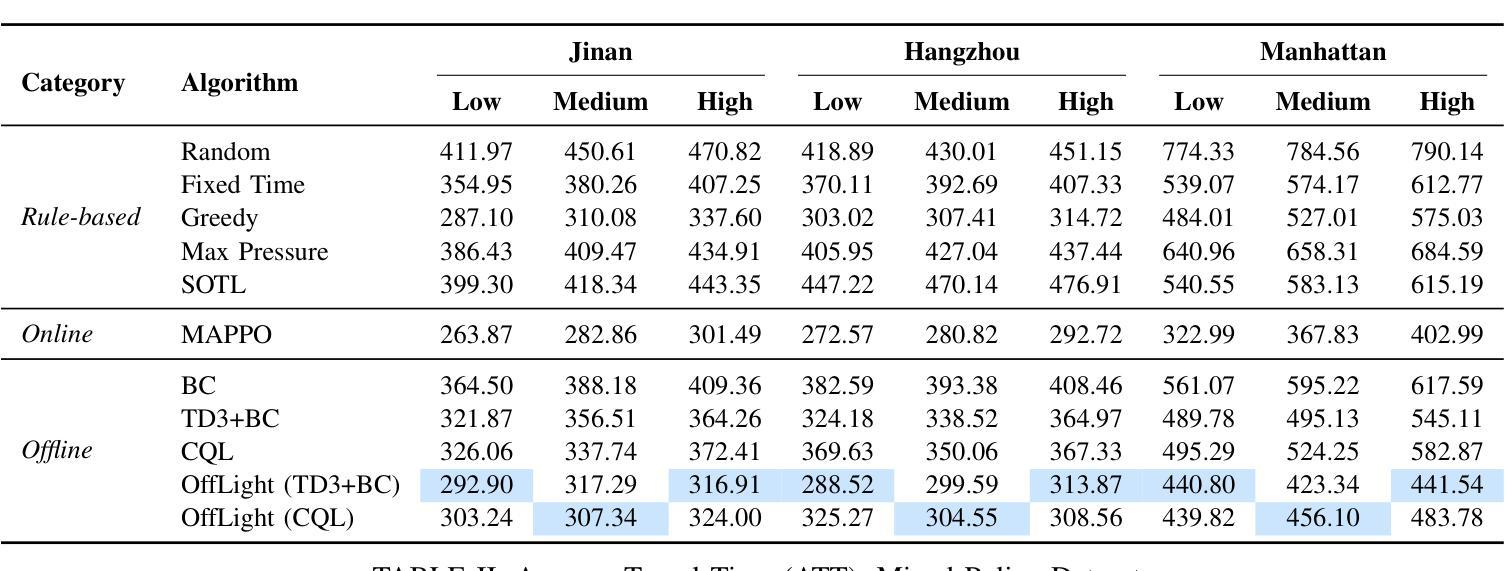
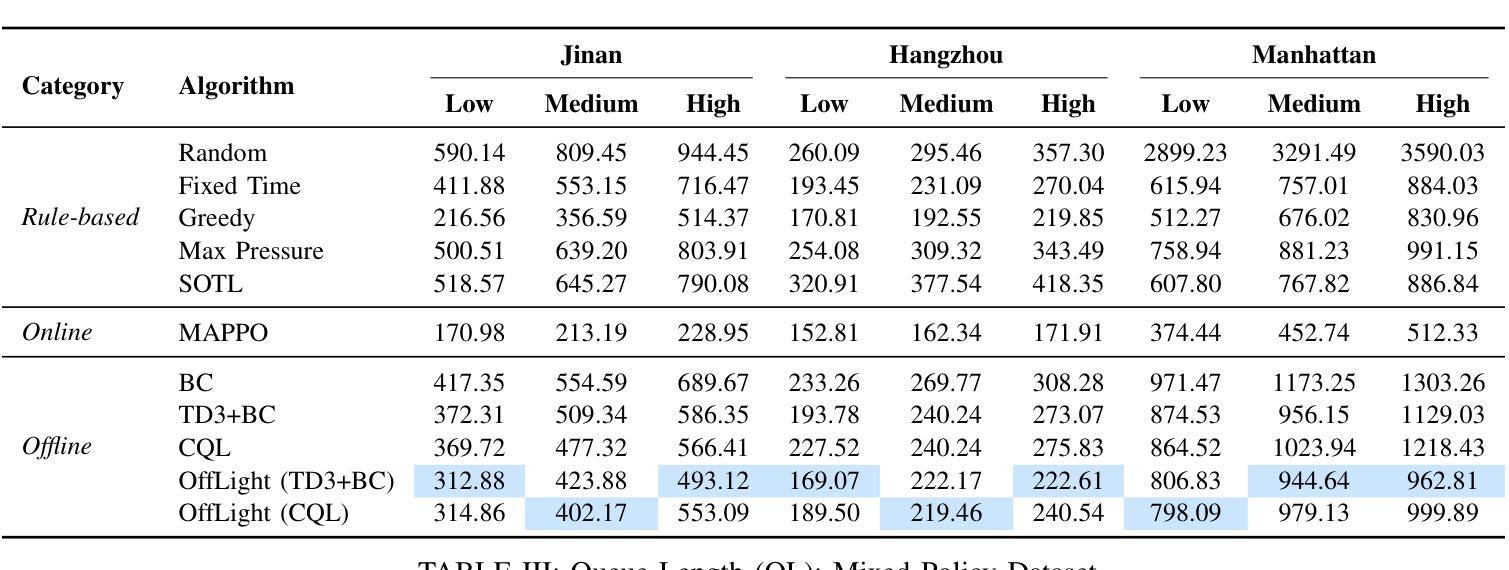
OffLight: An Offline Multi-Agent Reinforcement Learning Framework for Traffic Signal Control
Authors:Rohit Bokade, Xiaoning Jin
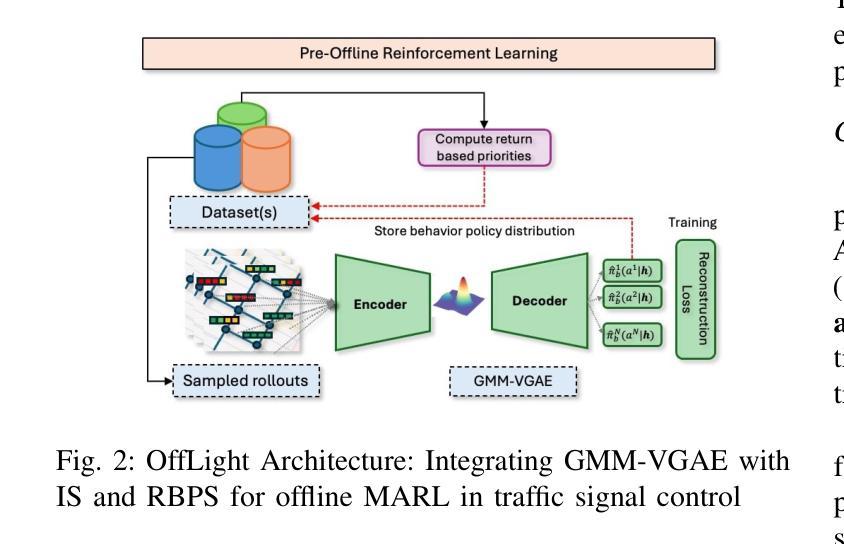
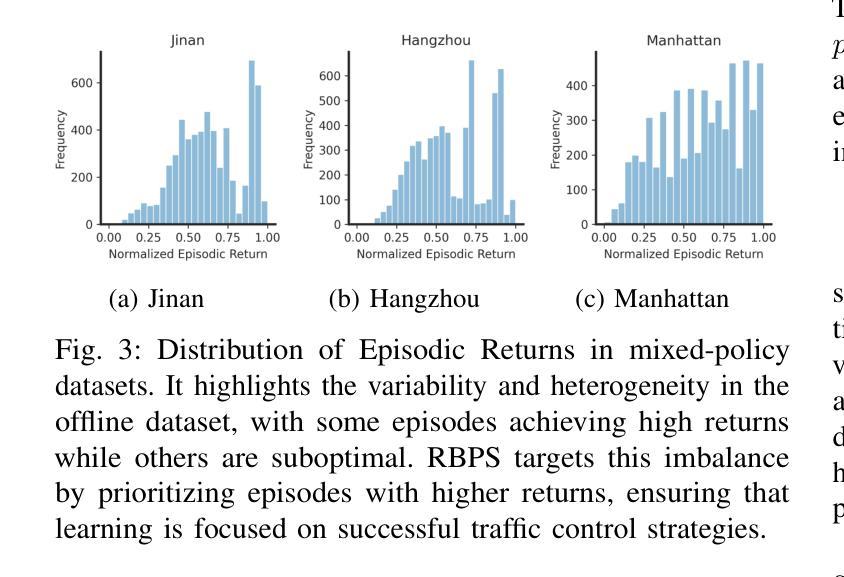
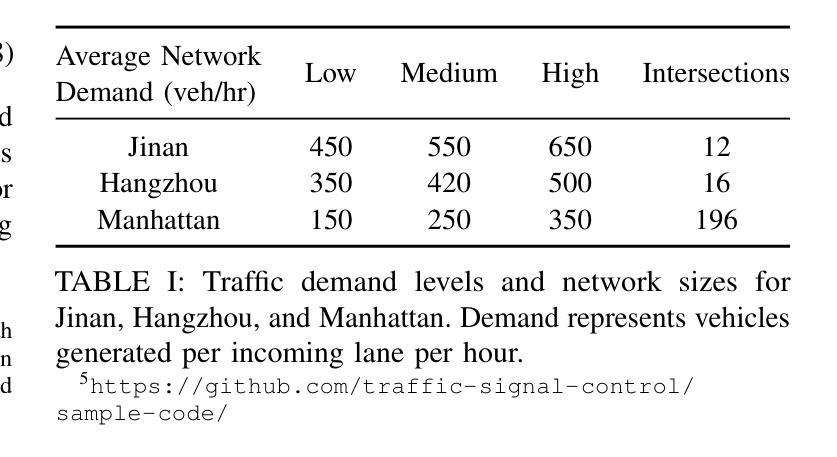
Efficient traffic control (TSC) is essential for urban mobility, but traditional systems struggle to handle the complexity of real-world traffic. Multi-agent Reinforcement Learning (MARL) offers adaptive solutions, but online MARL requires extensive interactions with the environment, making it costly and impractical. Offline MARL mitigates these challenges by using historical traffic data for training but faces significant difficulties with heterogeneous behavior policies in real-world datasets, where mixed-quality data complicates learning. We introduce OffLight, a novel offline MARL framework designed to handle heterogeneous behavior policies in TSC datasets. To improve learning efficiency, OffLight incorporates Importance Sampling (IS) to correct for distributional shifts and Return-Based Prioritized Sampling (RBPS) to focus on high-quality experiences. OffLight utilizes a Gaussian Mixture Variational Graph Autoencoder (GMM-VGAE) to capture the diverse distribution of behavior policies from local observations. Extensive experiments across real-world urban traffic scenarios show that OffLight outperforms existing offline RL methods, achieving up to a 7.8% reduction in average travel time and 11.2% decrease in queue length. Ablation studies confirm the effectiveness of OffLight’s components in handling heterogeneous data and improving policy performance. These results highlight OffLight’s scalability and potential to improve urban traffic management without the risks of online learning.
高效的交通控制(TSC)对城市流动性至关重要,但传统系统在处理现实交通的复杂性方面面临困难。多智能体强化学习(MARL)提供自适应解决方案,但在线MARL需要与环境的大量交互,使其成本高昂且不切实际。离线MARL通过使用历史交通数据进行训练来缓解这些挑战,但面临现实数据集中异质行为策略的重大困难,混合质量的数据使学习复杂化。我们引入了OffLight,这是一个新型的离线MARL框架,旨在处理TSC数据集中的异质行为策略。为了提高学习效率,OffLight结合了重要性采样(IS)来纠正分布偏移和基于回报的优先采样(RBPS)来专注于高质量的经验。OffLight利用高斯混合变分图自动编码器(GMM-VGAE)来捕捉从局部观察中行为策略的多样分布。在真实世界城市交通场景的大量实验表明,OffLight的性能优于现有的离线RL方法,平均旅行时间减少了7.8%,队列长度减少了11.2%。消融研究证实了OffLight组件在处理异质数据和提高策略性能方面的有效性。这些结果突出了OffLight的可扩展性和在改善城市交通管理方面的潜力,并且没有在线学习的风险。
论文及项目相关链接
Summary
高效交通控制(TSC)对城市交通流动性至关重要,传统的交通控制系统难以应对现实世界的复杂性。多智能体强化学习(MARL)提供了适应性解决方案,但在线MARL需要大量与环境互动,成本高昂且实际操作中难以实现。离线MARL通过使用历史交通数据进行训练来缓解这些问题,但在面临现实世界中异质行为策略时面临挑战,混合质量的数据会复杂化学习过程。我们提出了OffLight这一新型离线MARL框架,专为处理TSC数据集中的异质行为策略而设计。OffLight通过重要性采样(IS)纠正分布转移,并借助基于回报的优先采样(RBPS)专注于高质量经验,以提高学习效率。OffLight利用高斯混合变分图自编码器(GMM-VGAE)从局部观测中捕获行为策略的多样分布。在真实世界城市交通场景的广泛实验表明,OffLight的表现优于现有离线RL方法,平均旅行时间减少了7.8%,排队长度减少了11.2%。消融研究证实了OffLight在处理异质数据和提升策略性能方面的有效性。这些结果突显了OffLight在处理城市智能交通管理方面的可扩展性和潜力,并降低了在线学习的风险。
Key Takeaways
- 高效交通控制对城市交通流动性至关重要,但传统系统难以应对现实世界的复杂性。
- 多智能体强化学习(MARL)为解决此问题提供适应性解决方案,但在线和离线MARL均面临挑战。
- 离线MARL通过使用历史交通数据进行训练,但面临处理现实世界中异质行为策略的挑战。
- OffLight框架采用重要性采样和基于回报的优先采样提高学习效率。
- OffLight利用高斯混合变分图自编码器处理异质数据,从局部观测中捕获行为策略的多样分布。
- 在真实世界城市交通场景的广泛实验表明,OffLight在平均旅行时间和排队长度方面表现优异。
点此查看论文截图


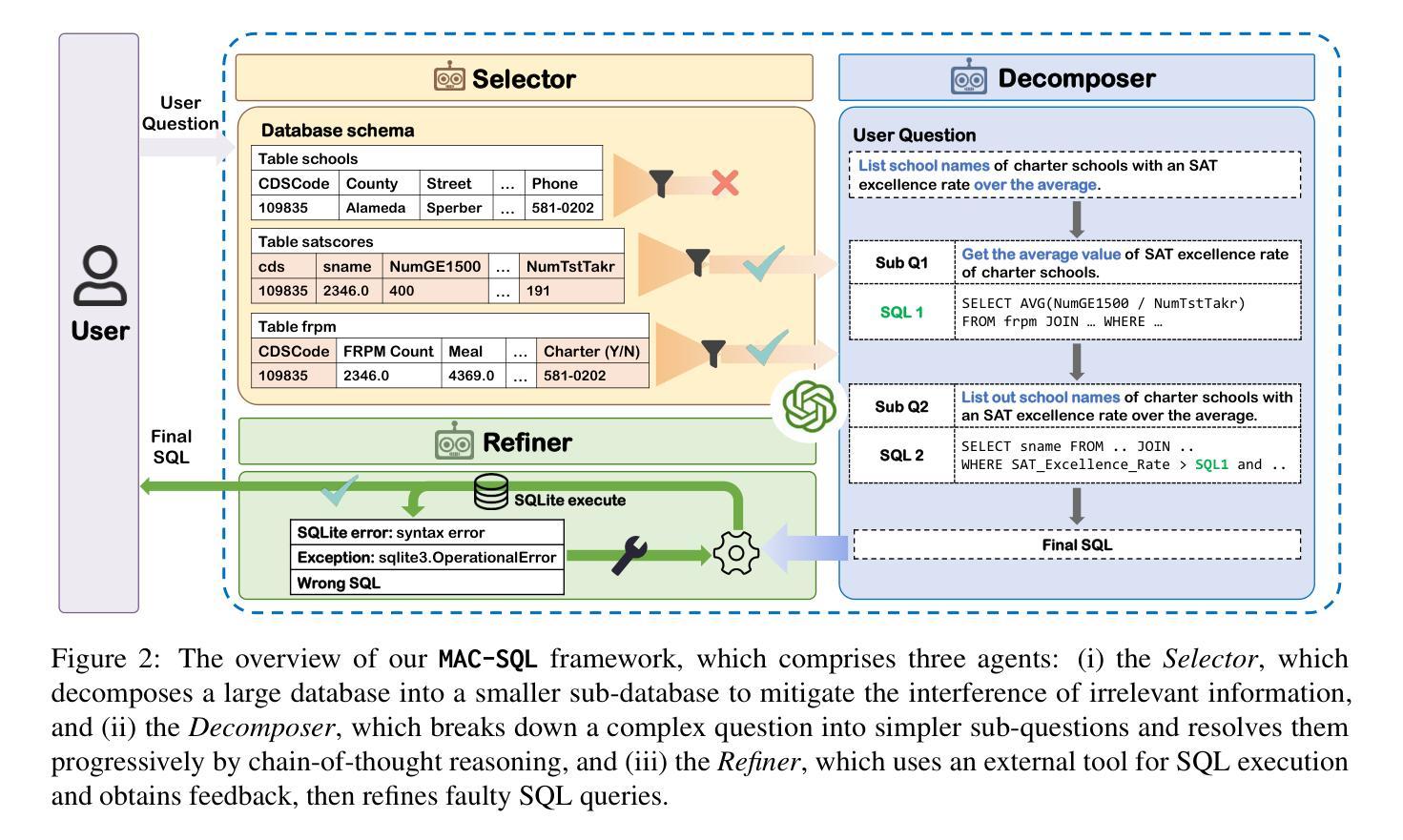
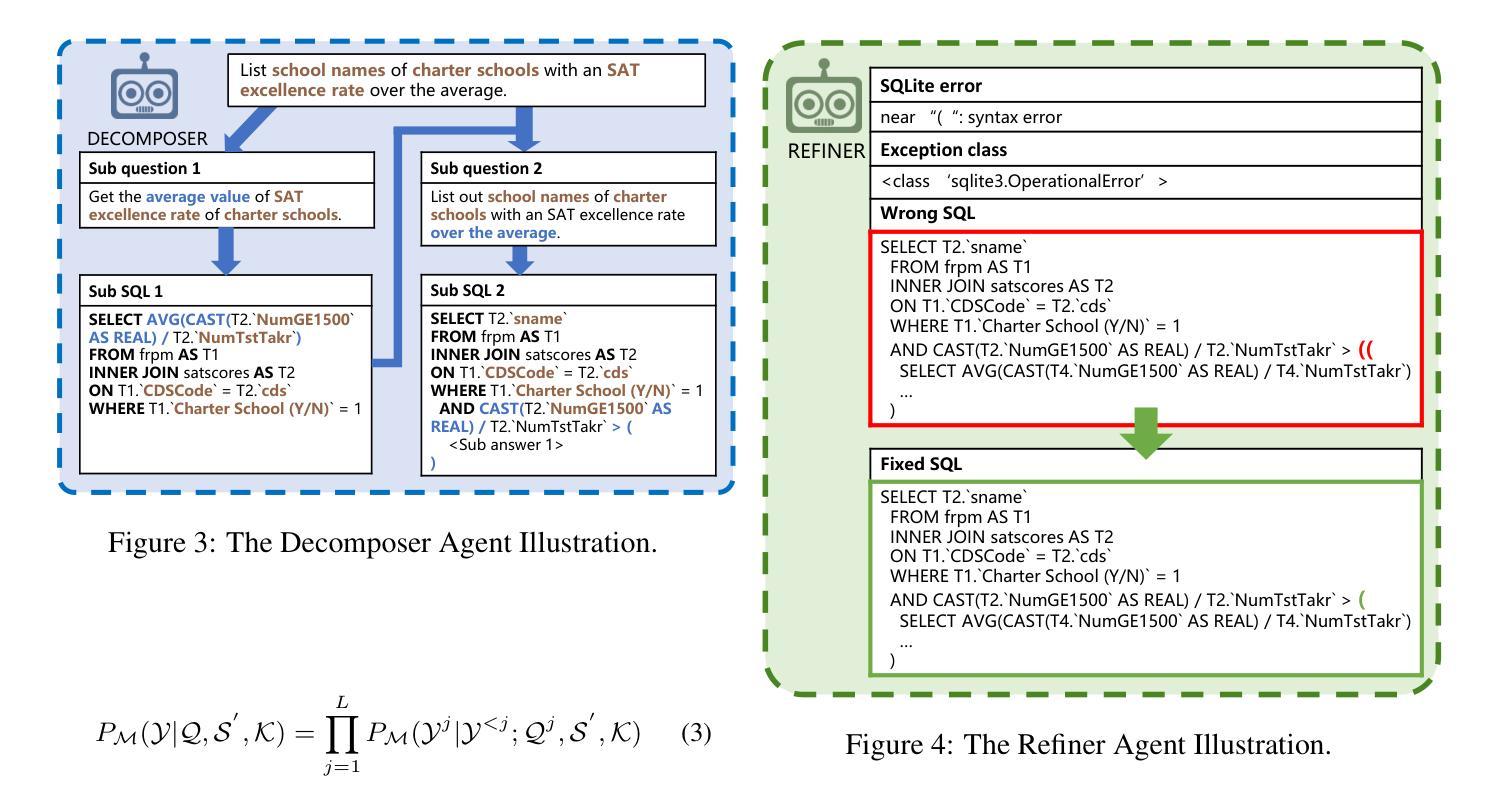
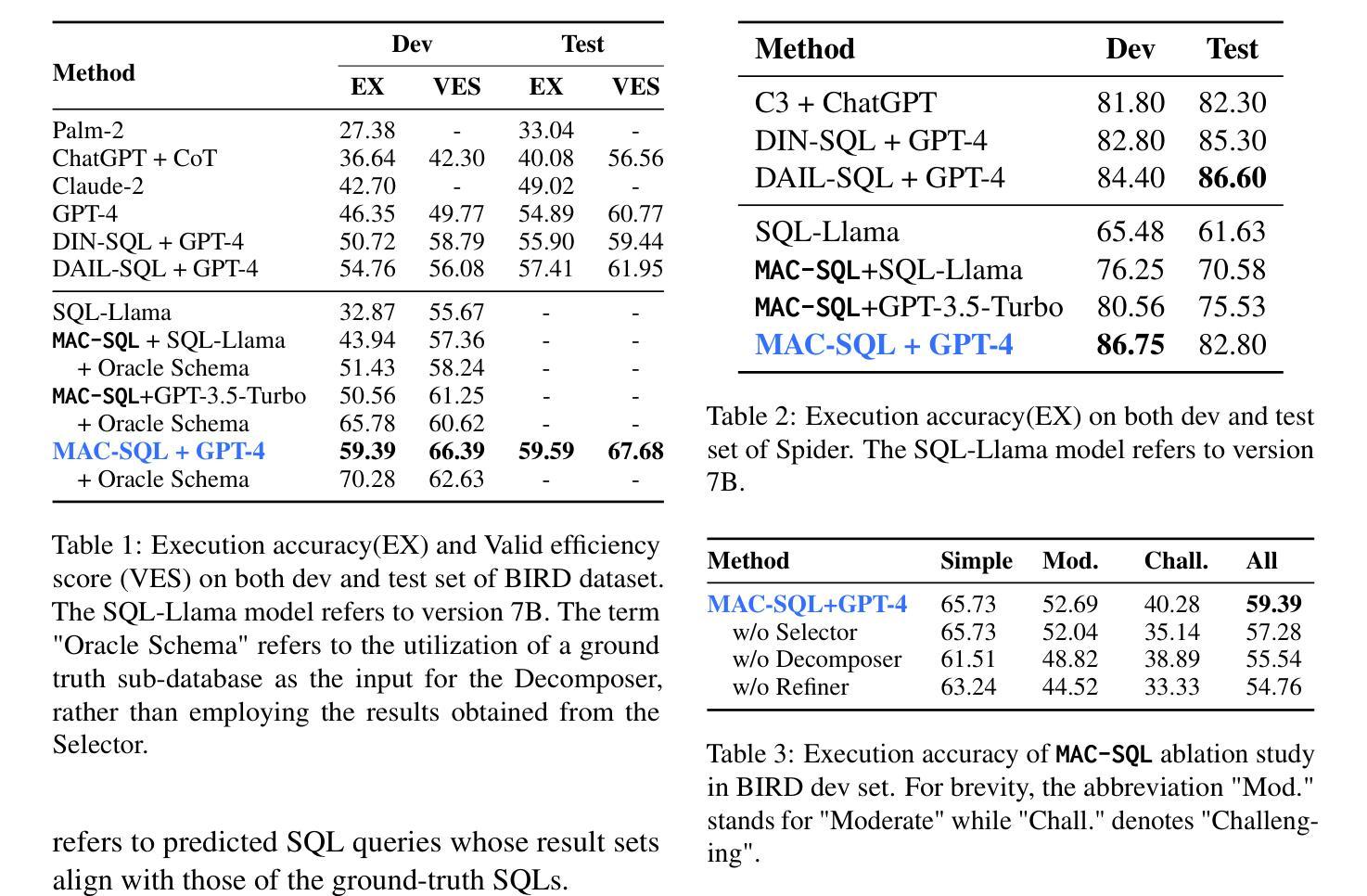
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Authors:Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, LinZheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, Zhoujun Li
Recent LLM-based Text-to-SQL methods usually suffer from significant performance degradation on “huge” databases and complex user questions that require multi-step reasoning. Moreover, most existing methods neglect the crucial significance of LLMs utilizing external tools and model collaboration. To address these challenges, we introduce MAC-SQL, a novel LLM-based multi-agent collaborative framework. Our framework comprises a core decomposer agent for Text-to-SQL generation with few-shot chain-of-thought reasoning, accompanied by two auxiliary agents that utilize external tools or models to acquire smaller sub-databases and refine erroneous SQL queries. The decomposer agent collaborates with auxiliary agents, which are activated as needed and can be expanded to accommodate new features or tools for effective Text-to-SQL parsing. In our framework, We initially leverage GPT-4 as the strong backbone LLM for all agent tasks to determine the upper bound of our framework. We then fine-tune an open-sourced instruction-followed model, SQL-Llama, by leveraging Code Llama 7B, to accomplish all tasks as GPT-4 does. Experiments show that SQL-Llama achieves a comparable execution accuracy of 43.94, compared to the baseline accuracy of 46.35 for vanilla GPT-4. At the time of writing, MAC-SQL+GPT-4 achieves an execution accuracy of 59.59 when evaluated on the BIRD benchmark, establishing a new state-of-the-art (SOTA) on its holdout test set (https://github.com/wbbeyourself/MAC-SQL).
最近基于大型语言模型(LLM)的文本到SQL的方法在处理“大型”数据库和需要多步骤推理的复杂用户问题时通常会面临显著的性能下降。此外,大多数现有方法忽视了利用外部工具和模型协作的大型语言模型(LLM)的关键重要性。为了应对这些挑战,我们引入了MAC-SQL,这是一种基于LLM的新型多智能体协作框架。我们的框架包括一个用于文本到SQL生成的核心分解智能体,具有few-shot链式思维推理能力,以及两个利用外部工具或模型获取较小子数据库并优化错误SQL查询的辅助智能体。分解智能体与辅助智能体进行协作,辅助智能体根据需要被激活,并且可以扩展以容纳新特性或工具,从而实现有效的文本到SQL解析。在我们的框架中,我们首先利用GPT-4作为所有智能体任务的主干LLM,以确定我们框架的上限。然后,我们通过利用Code Llama 7B对开源的指令遵循模型SQL-Llama进行微调,以完成GPT-4所完成的任务。实验表明,SQL-Llama达到了与基线相当的执行准确率43.94%,而原始的GPT-4的准确率为46.35。在撰写本文时,MAC-SQL与GPT-4的组合在BIRD基准测试上的执行准确率为59.59%,在保留的测试集上创下了新的最新技术(https://github.com/wbbeyourself/MAC-SQL)。
论文及项目相关链接
PDF Accepted by COLING 2025 (Oral)
Summary
在大型数据库和复杂用户问题中,现有LLM文本到SQL的转换方法常常存在性能下降的问题。为了解决这些问题,引入了MAC-SQL多代理协作框架。框架包括一个核心分解器代理进行文本到SQL生成,辅以两个辅助代理利用外部工具或模型获取子数据库并修正错误SQL查询。框架首次使用GPT-4作为所有任务的基础模型,然后通过微调开源的指令遵循模型SQL-Llama实现所有任务。实验表明,SQL-Llama的执行精度与GPT-4相当,MAC-SQL在BIRD基准测试上的执行精度达到59.59%,达到新的最佳水平。
Key Takeaways
- LLM-based Text-to-SQL方法在大型数据库和复杂用户问题上存在性能下降的问题。
- MAC-SQL是一个新型的多代理协作框架,包括核心分解器代理和辅助代理。
- 核心分解器代理用于文本到SQL生成,辅助代理利用外部工具或模型优化过程。
- GPT-4作为框架的基础模型,SQL-Llama通过微调实现相同任务。
- SQL-Llama的执行精度与GPT-4相当。
- MAC-SQL在BIRD基准测试上的执行精度达到59.59%,为当前最佳水平。
点此查看论文截图