⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
The Power of Context: How Multimodality Improves Image Super-Resolution
Authors:Kangfu Mei, Hossein Talebi, Mojtaba Ardakani, Vishal M. Patel, Peyman Milanfar, Mauricio Delbracio
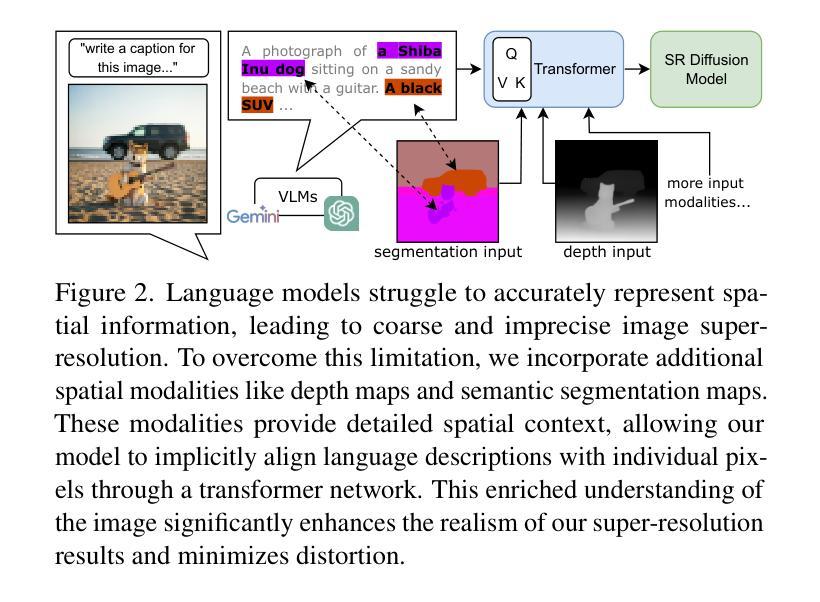
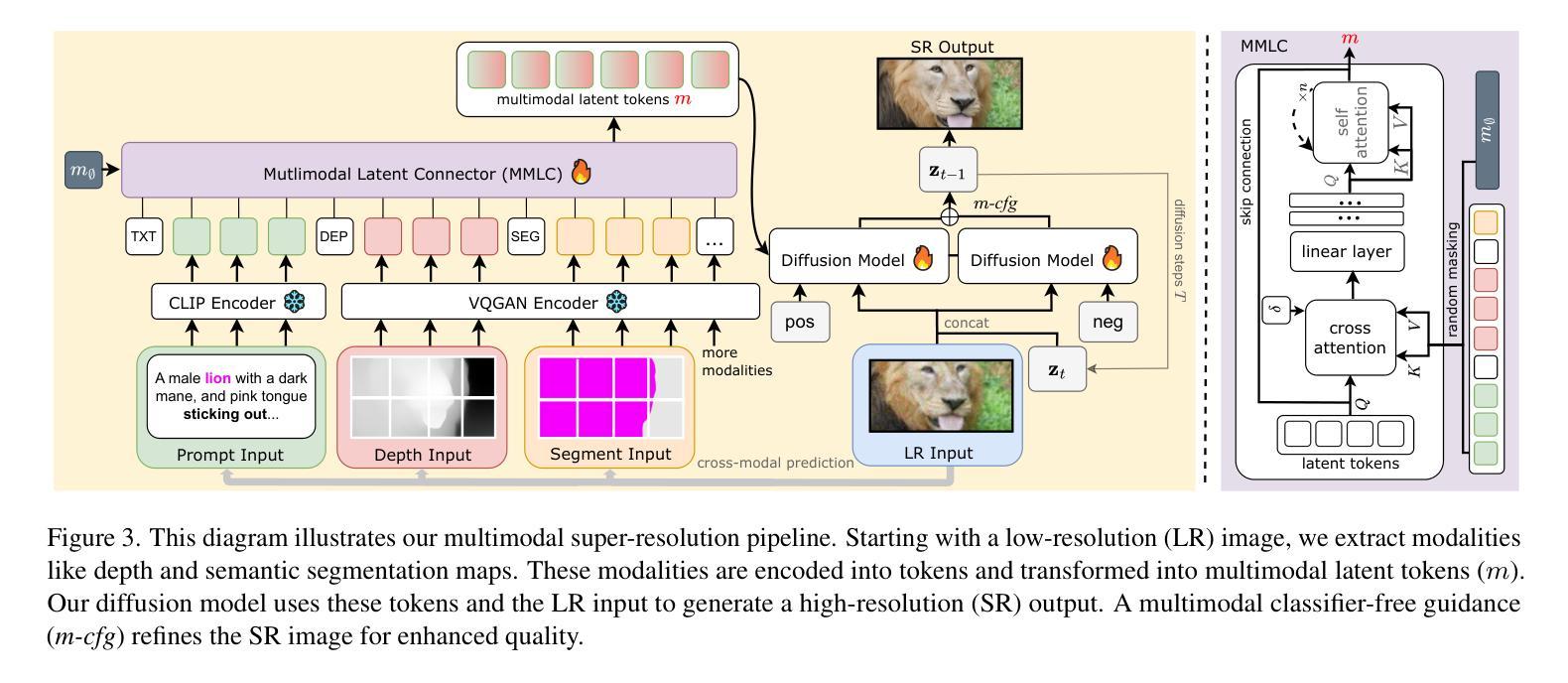
Single-image super-resolution (SISR) remains challenging due to the inherent difficulty of recovering fine-grained details and preserving perceptual quality from low-resolution inputs. Existing methods often rely on limited image priors, leading to suboptimal results. We propose a novel approach that leverages the rich contextual information available in multiple modalities – including depth, segmentation, edges, and text prompts – to learn a powerful generative prior for SISR within a diffusion model framework. We introduce a flexible network architecture that effectively fuses multimodal information, accommodating an arbitrary number of input modalities without requiring significant modifications to the diffusion process. Crucially, we mitigate hallucinations, often introduced by text prompts, by using spatial information from other modalities to guide regional text-based conditioning. Each modality’s guidance strength can also be controlled independently, allowing steering outputs toward different directions, such as increasing bokeh through depth or adjusting object prominence via segmentation. Extensive experiments demonstrate that our model surpasses state-of-the-art generative SISR methods, achieving superior visual quality and fidelity. See project page at https://mmsr.kfmei.com/.
单图像超分辨率(SISR)仍然是一个挑战,因为从低分辨率输入中恢复精细细节并保持感知质量具有固有的困难。现有方法往往依赖于有限的图像先验,导致结果不佳。我们提出了一种新方法,利用多种模式(包括深度、分割、边缘和文本提示)中可用的丰富上下文信息,在扩散模型框架内学习强大的生成先验,用于SISR。我们引入了一种灵活的网络架构,有效地融合了多模式信息,适应任意数量的输入模式,无需对扩散过程进行重大修改。关键的是,我们通过使用其他模态的空间信息来指导基于区域的文本条件化,减轻了由文本提示引起的幻觉。每种模态的引导强度也可以独立控制,从而引导输出朝向不同方向,例如通过深度增加散景或通过分段调整对象突出。大量实验表明,我们的模型超越了最先进的生成SISR方法,实现了卓越的可视质量和保真度。有关详细信息,请参见项目页面:https://mmsr.kfmei.com/。
论文及项目相关链接
PDF accepted by CVPR2025
Summary
本文提出了一种新的单图像超分辨率(SISR)方法,该方法利用扩散模型框架中的丰富上下文信息,包括深度、分割、边缘和文本提示,学习强大的生成先验。通过灵活的网络架构有效融合多模态信息,适应任意数量的输入模态,无需对扩散过程进行重大修改。利用其他模态的空间信息来指导基于文本的区域条件,缓解由文本提示引起的幻觉。实验表明,该模型超越了最先进的生成SISR方法,实现了优越的视觉质量和保真度。
Key Takeaways
- 引入多模态信息(深度、分割、边缘和文本提示)到扩散模型中,提高单图像超分辨率(SISR)的生成质量。
- 提出灵活网络架构,有效融合多模态信息,适应多种输入模态。
- 利用其他模态的空间信息来指导基于文本的区域条件,减少文本提示引起的幻觉。
- 每种模态的引导强度可以独立控制,使输出可以根据需要进行调整,如通过深度增加散景或通过分段调整对象突出程度。
- 方法的优越性通过广泛的实验得到验证,超越了最先进的生成SISR方法。
- 模型实现的高视觉质量和保真度。
点此查看论文截图




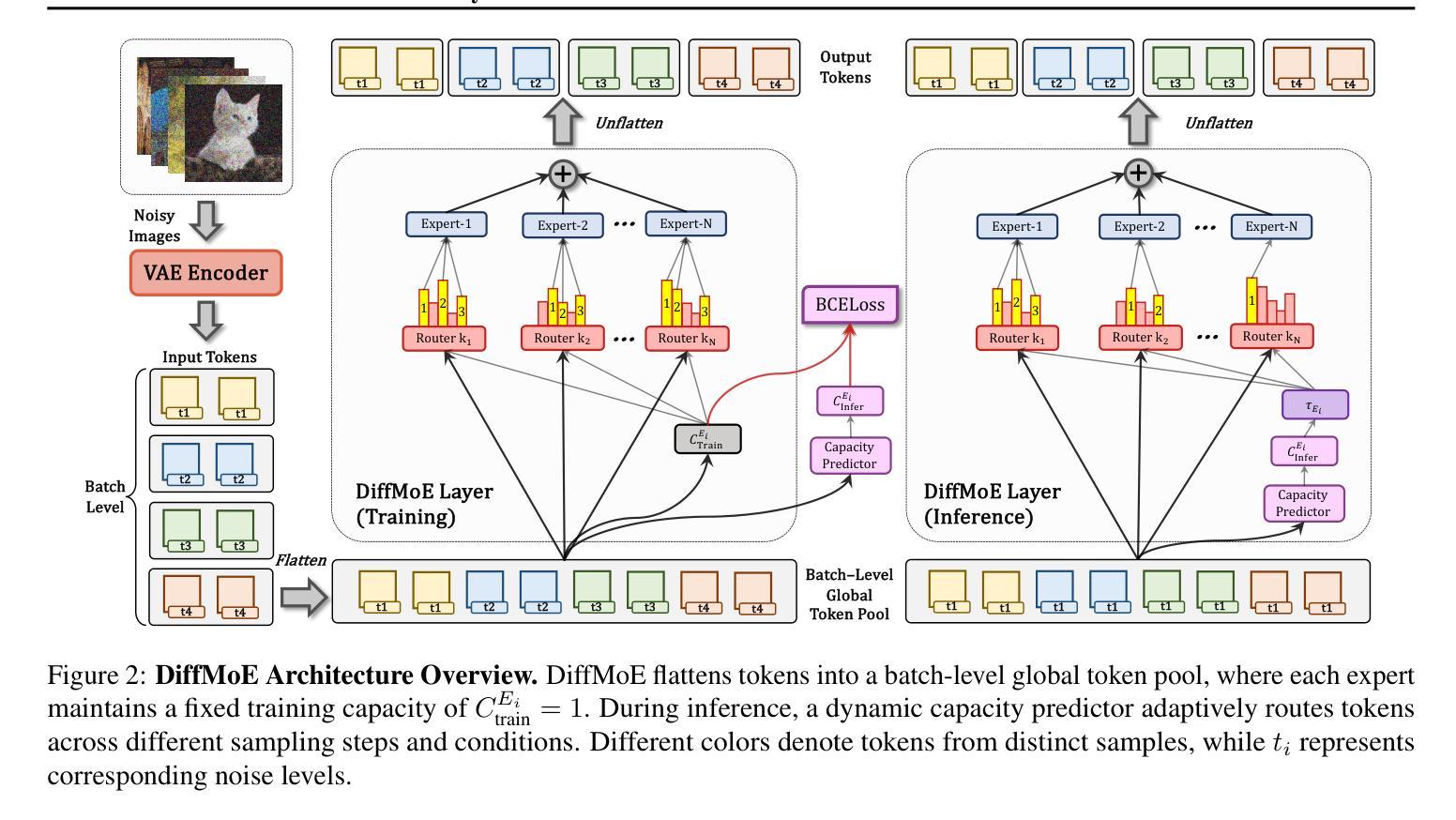
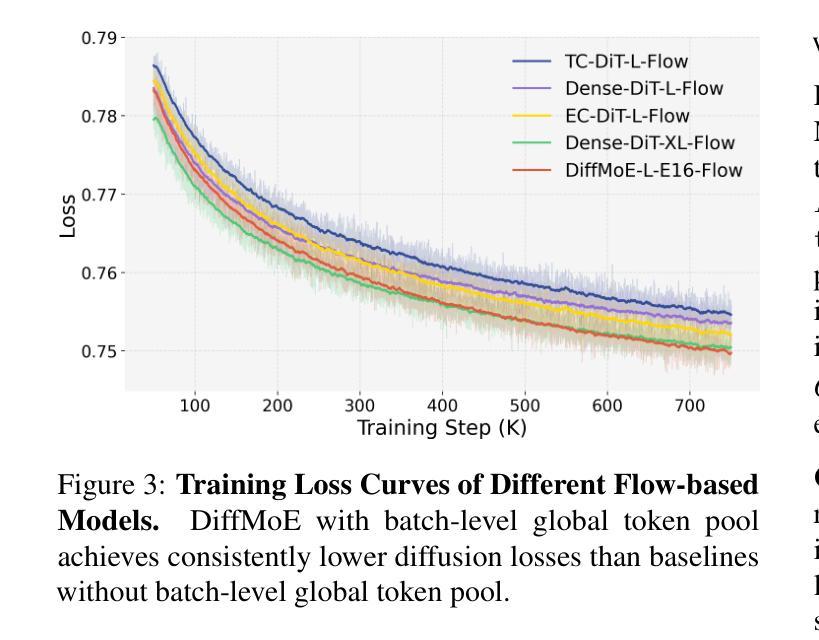
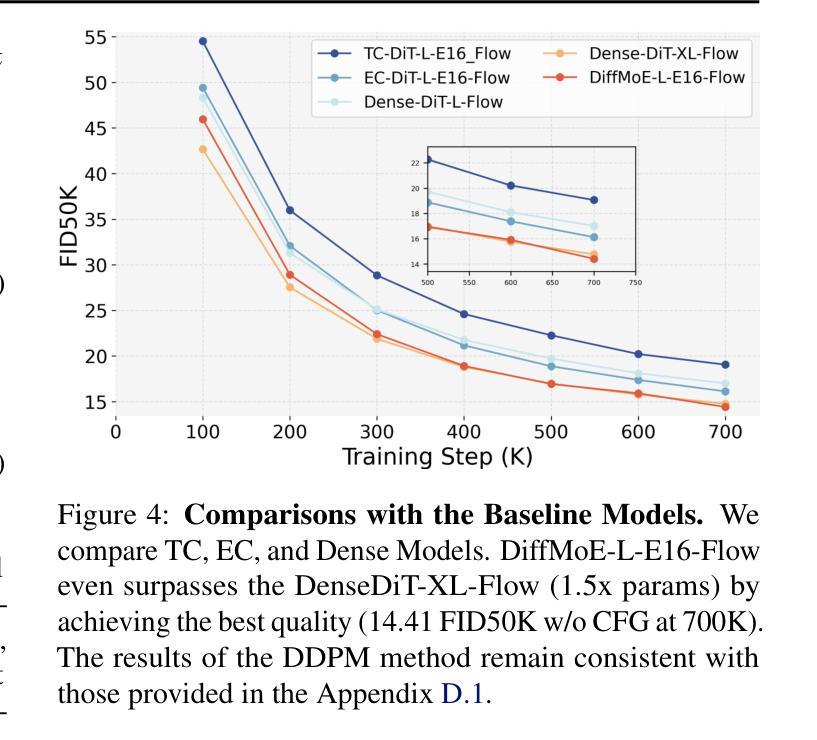
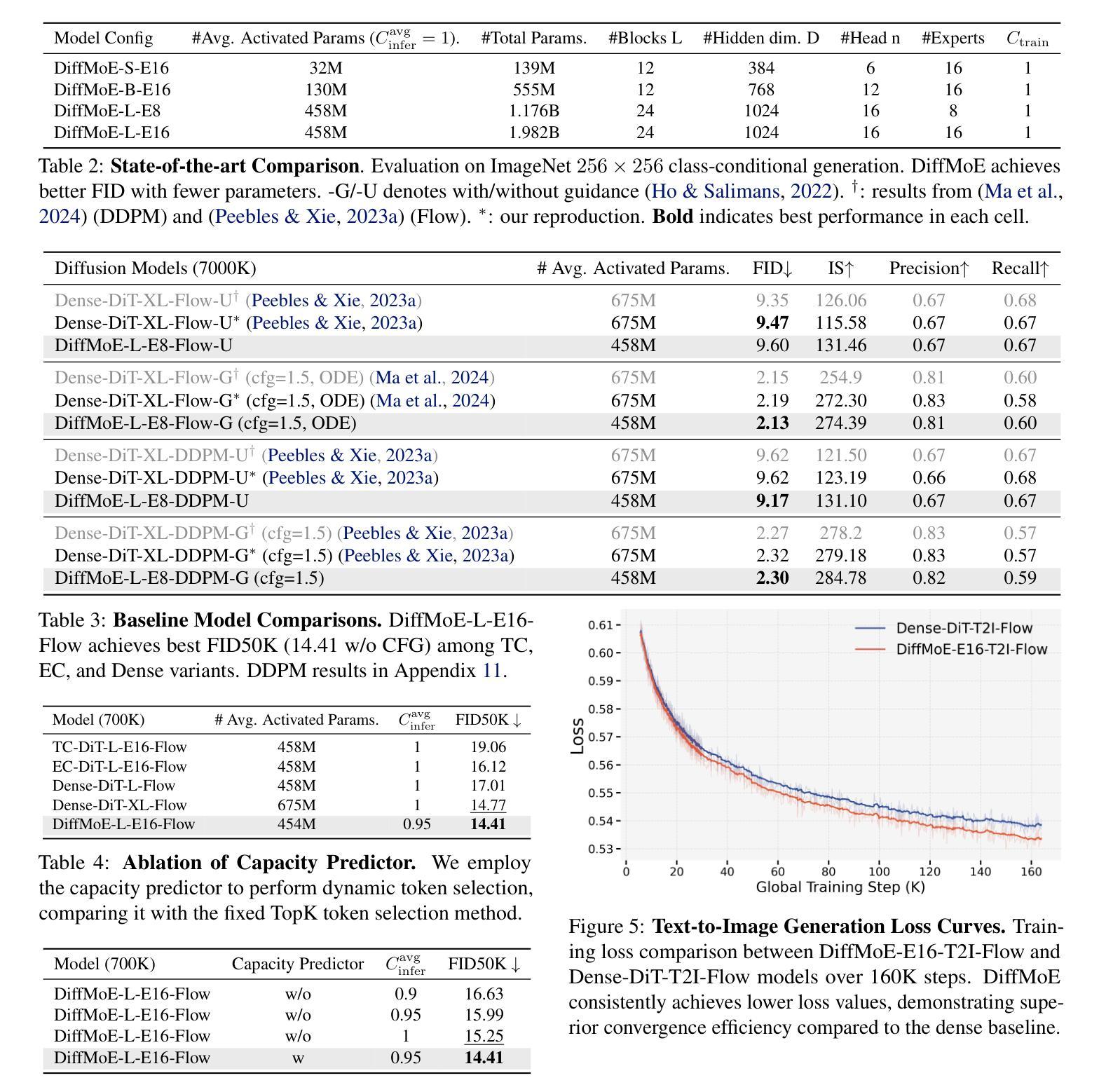
DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
Authors:Minglei Shi, Ziyang Yuan, Haotian Yang, Xintao Wang, Mingwu Zheng, Xin Tao, Wenliang Zhao, Wenzhao Zheng, Jie Zhou, Jiwen Lu, Pengfei Wan, Di Zhang, Kun Gai
Diffusion models have demonstrated remarkable success in various image generation tasks, but their performance is often limited by the uniform processing of inputs across varying conditions and noise levels. To address this limitation, we propose a novel approach that leverages the inherent heterogeneity of the diffusion process. Our method, DiffMoE, introduces a batch-level global token pool that enables experts to access global token distributions during training, promoting specialized expert behavior. To unleash the full potential of the diffusion process, DiffMoE incorporates a capacity predictor that dynamically allocates computational resources based on noise levels and sample complexity. Through comprehensive evaluation, DiffMoE achieves state-of-the-art performance among diffusion models on ImageNet benchmark, substantially outperforming both dense architectures with 3x activated parameters and existing MoE approaches while maintaining 1x activated parameters. The effectiveness of our approach extends beyond class-conditional generation to more challenging tasks such as text-to-image generation, demonstrating its broad applicability across different diffusion model applications. Project Page: https://shiml20.github.io/DiffMoE/
扩散模型在各种图像生成任务中取得了显著的成功,但其性能往往受到不同条件和噪声水平下输入统一处理方式的限制。为了解决这一局限性,我们提出了一种利用扩散过程固有异质性的新方法。我们的方法DiffMoE引入了一个批次级全局令牌池,使专家能够在训练过程中访问全局令牌分布,从而促进专业专家行为。为了释放扩散过程的全部潜力,DiffMoE融入了一个容量预测器,该预测器能够根据噪声水平和样本复杂性动态分配计算资源。通过全面评估,DiffMoE在ImageNet基准测试上实现了扩散模型中的最新技术性能,在保持1倍激活参数的同时,大幅超越了密集架构的模型(具有三倍激活参数)和现有的MoE方法。我们的方法的有效性不仅限于类别条件生成,而且适用于更具挑战性的任务,如文本到图像的生成,证明了其在不同扩散模型应用中的广泛适用性。项目页面:https://shiml20.github.io/DiffMoE/。
论文及项目相关链接
PDF Project Page: https://shiml20.github.io/DiffMoE/
Summary
扩散模型在各种图像生成任务中取得了显著的成功,但其性能往往受限于不同条件和噪声水平下输入的均匀处理。我们提出了一种利用扩散过程固有异质性的新方法DiffMoE。该方法引入了一个批处理级别的全局令牌池,使专家能够在训练过程中访问全局令牌分布,从而促进专业专家行为。为了释放扩散过程的潜力,DiffMoE结合了能力预测器,根据噪声水平和样本复杂性动态分配计算资源。经过全面评估,DiffMoE在ImageNet基准测试上实现了扩散模型的最佳性能,在保持1倍激活参数的同时,显著优于密集架构和现有MoE方法。我们的方法不仅适用于类别条件生成,还适用于更具挑战性的任务,如文本到图像生成,证明了其在不同扩散模型应用中的广泛适用性。
Key Takeaways
- 扩散模型在图像生成任务中表现优秀,但受限于不同条件和噪声水平下的输入处理。
- DiffMoE方法利用扩散过程的异质性,引入批处理级别的全局令牌池,促进专家行为。
- DiffMoE结合能力预测器,根据噪声水平和样本复杂性动态分配计算资源。
- DiffMoE在ImageNet基准测试上实现了扩散模型的最佳性能。
- DiffMoE在保持1倍激活参数的同时,优于密集架构和其他MoE方法。
- DiffMoE不仅适用于类别条件生成,还适用于文本到图像生成等更复杂的任务。
- DiffMoE方法具有广泛的应用性,可应用于不同的扩散模型应用。
点此查看论文截图

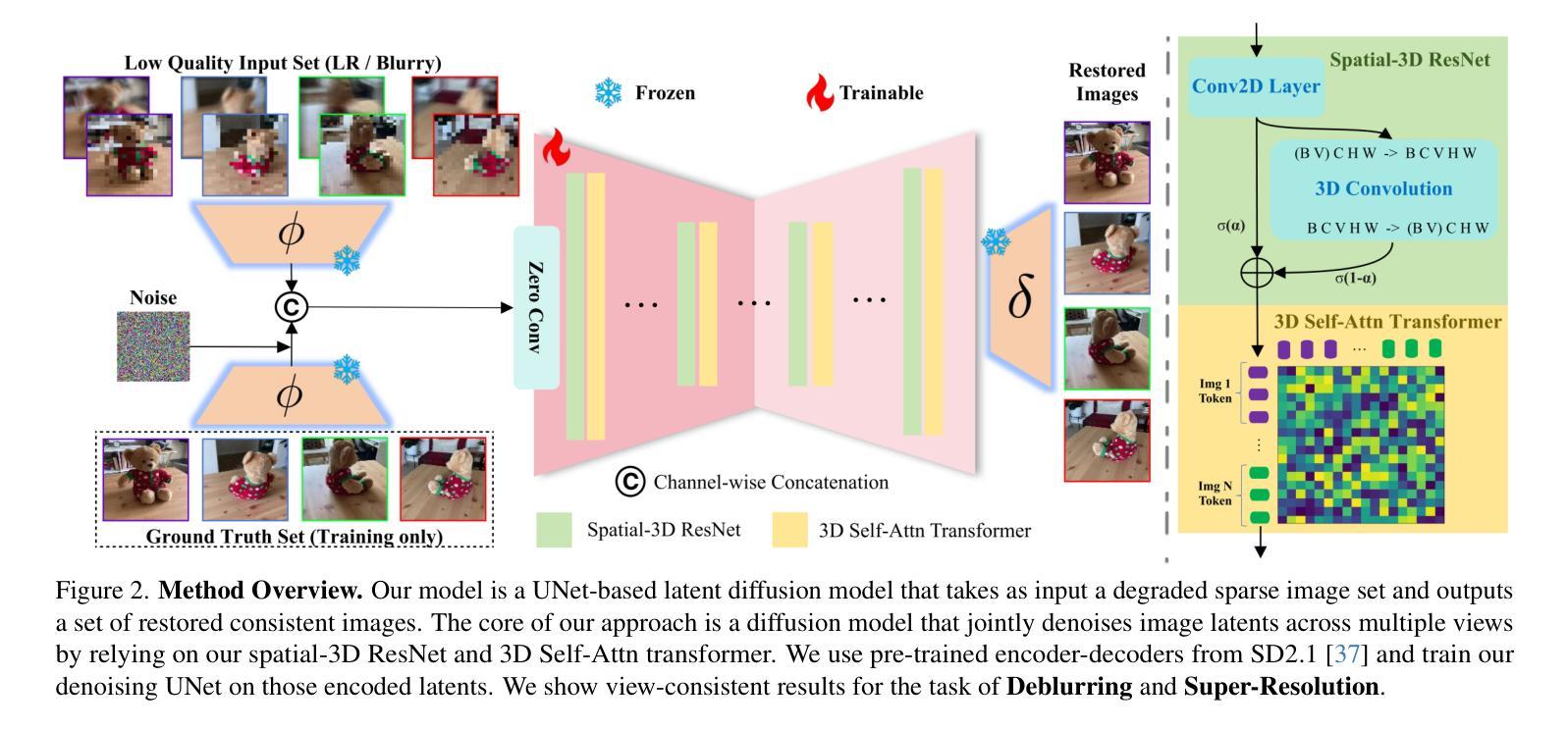
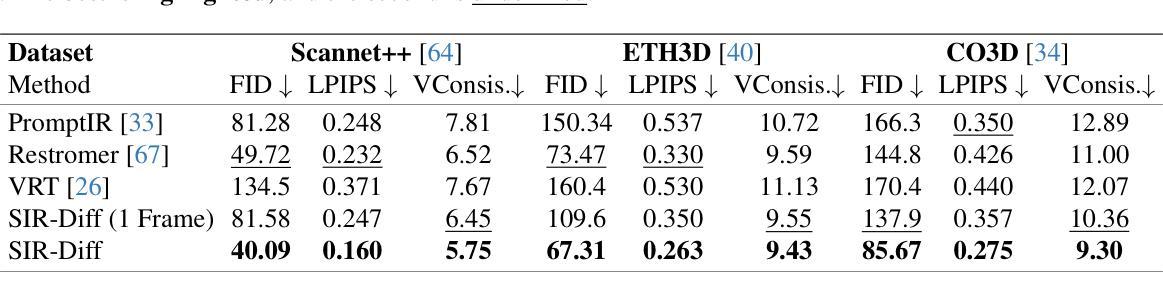
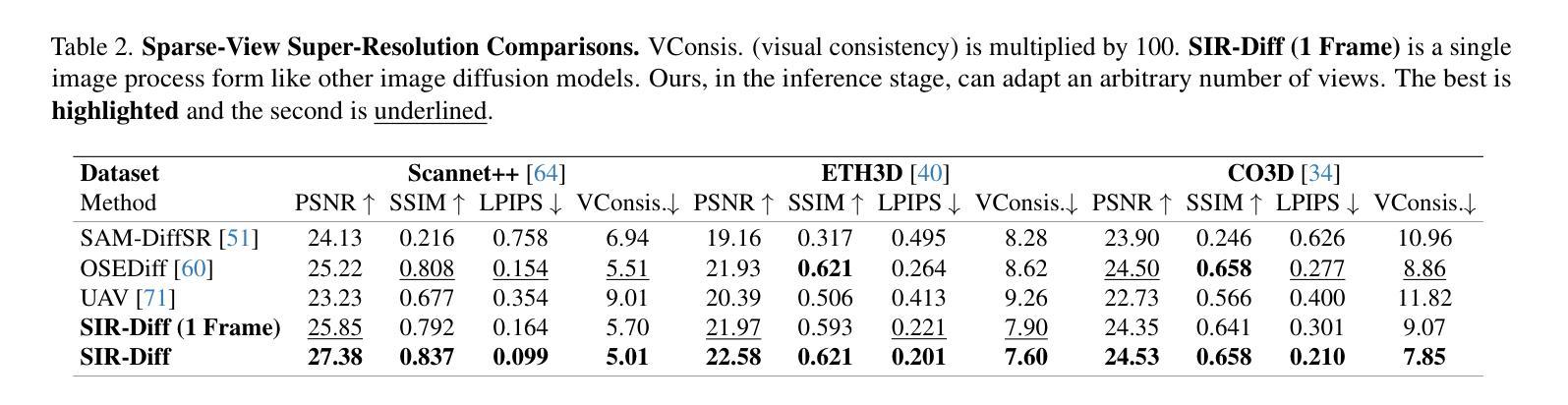
SIR-DIFF: Sparse Image Sets Restoration with Multi-View Diffusion Model
Authors:Yucheng Mao, Boyang Wang, Nilesh Kulkarni, Jeong Joon Park
The computer vision community has developed numerous techniques for digitally restoring true scene information from single-view degraded photographs, an important yet extremely ill-posed task. In this work, we tackle image restoration from a different perspective by jointly denoising multiple photographs of the same scene. Our core hypothesis is that degraded images capturing a shared scene contain complementary information that, when combined, better constrains the restoration problem. To this end, we implement a powerful multi-view diffusion model that jointly generates uncorrupted views by extracting rich information from multi-view relationships. Our experiments show that our multi-view approach outperforms existing single-view image and even video-based methods on image deblurring and super-resolution tasks. Critically, our model is trained to output 3D consistent images, making it a promising tool for applications requiring robust multi-view integration, such as 3D reconstruction or pose estimation.
计算机视觉领域已经开发了许多从单视图退化照片中数字恢复真实场景信息的技巧,这是一项重要但极度不适的任务。在这项工作中,我们通过联合去噪同一场景的多张照片,从不同的角度解决了图像恢复问题。我们的核心假设是,捕捉同一场景的退化图像包含互补信息,当这些信息结合时,可以更好地约束恢复问题。为此,我们实现了一个强大的多视图扩散模型,通过从多视图关系中提取丰富信息,联合生成未损坏的视图。我们的实验表明,我们的多视图方法在图像去模糊和超分辨率任务上优于现有的单视图图像甚至基于视频的方法。关键的是,我们的模型被训练输出三维一致的图像,使其成为适用于需要稳健多视图集成的应用的有前途的工具,例如三维重建或姿态估计。
论文及项目相关链接
Summary
本文提出了一种基于多视角扩散模型的方法,用于从多个同一场景的退化图像中提取丰富信息并联合去噪,从而恢复真实场景信息。该方法假设同一场景的多个退化图像包含互补信息,当这些信息结合时能更好地约束恢复问题。实验表明,该方法在图像去模糊和超分辨率任务上优于现有的单视图图像和视频方法,且模型训练可输出三维一致的图像,为三维重建或姿态估计等应用提供了有力工具。
Key Takeaways
- 本文提出了一种基于多视角扩散模型的图像恢复方法,联合处理多个同一场景的图像以提高恢复效果。
- 方法的核心假设是同一场景的多个退化图像包含互补信息,有助于更好地解决图像恢复这一病态问题。
- 通过实验验证,该方法在图像去模糊和超分辨率任务上表现优异,超越了许多现有的单视图及视频方法。
- 模型可以训练输出三维一致的图像,这对于需要多视角整合的应用(如三维重建、姿态估计等)具有重要意义。
- 该方法强调了多视角信息在图像恢复中的价值,并展示了其在实际应用中的潜力。
- 提出的扩散模型能够提取和整合多视角关系中的丰富信息,从而生成高质量的恢复图像。
点此查看论文截图


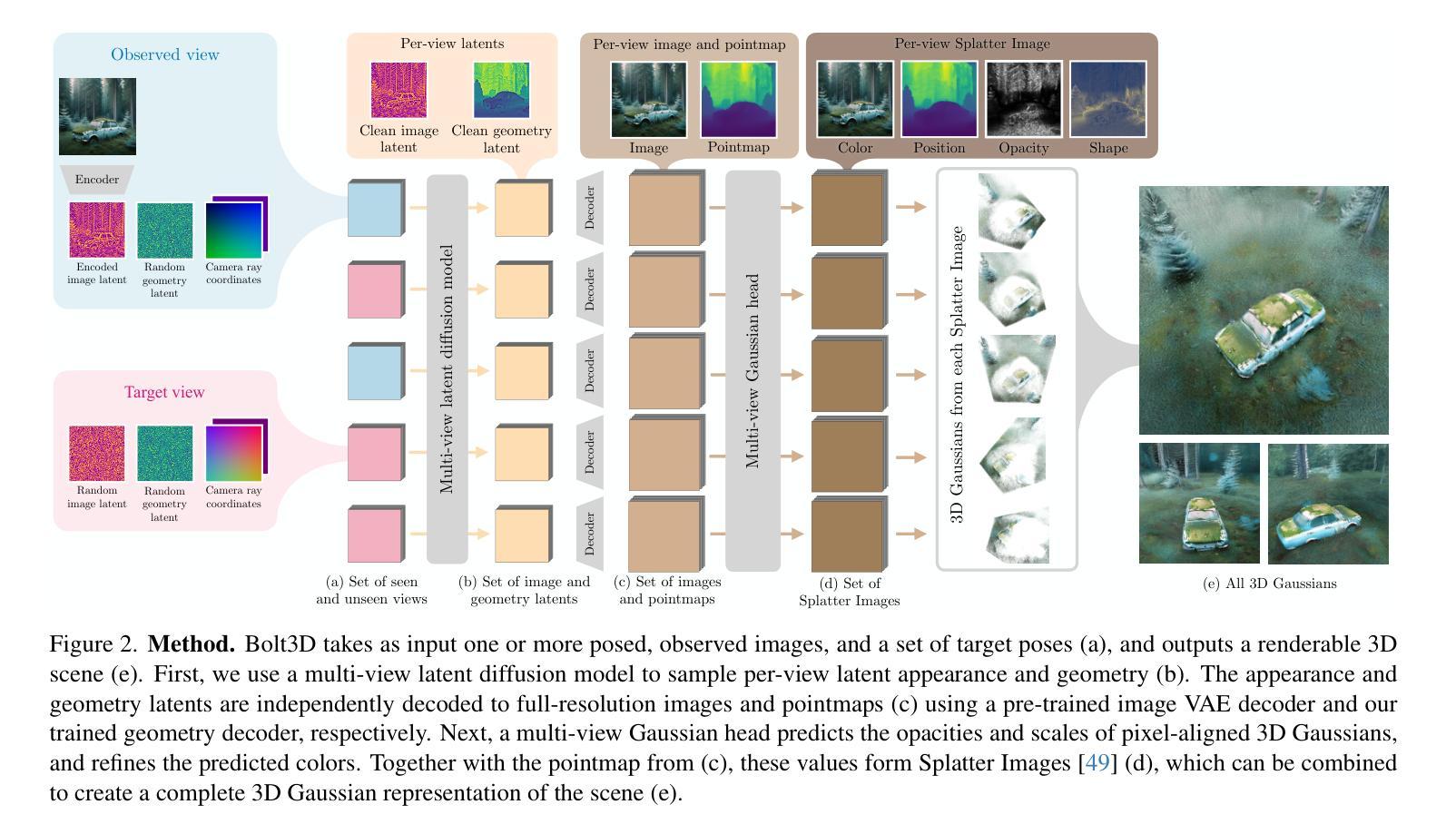
Bolt3D: Generating 3D Scenes in Seconds
Authors:Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, Aleksander Holynski, Ricardo Martin-Brualla, Jonathan T. Barron, Philipp Henzler
We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
我们提出了一种用于快速前馈3D场景生成的潜在扩散模型。给定一张或多张图像,我们的模型Bolt3D能够在单个GPU上不到七秒内直接采样3D场景表示。我们利用强大且可扩展的现有2D扩散网络架构来生成一致的高保真3D场景表示,从而实现了这一目标。为了训练此模型,我们通过将最新先进的密集3D重建技术应用于现有的多视角图像数据集,创建了一个大规模的多视角一致性的3D几何和外观数据集。与以前需要针对3D重建进行场景优化的多视角生成模型相比,Bolt3D将推理成本降低了高达30』【】倍。
论文及项目相关链接
PDF Project page: https://szymanowiczs.github.io/bolt3d
Summary
基于给定的一幅或多幅图像,Bolt3D模型能在单个GPU上实现快速的馈前三维场景生成。它借鉴现有的强大的二维扩散网络架构,生成一致的高保真三维场景表示。通过应用最新的密集三维重建技术到现有的多视角图像数据集,创建了大规模的多视角一致的三维几何和外观数据集以训练模型。相比于需要针对每个场景进行优化的先前的多视角生成模型,Bolt3D模型将推理成本降低了高达300倍。
Key Takeaways
- Bolt3D模型实现了基于图像的三维场景快速生成。
- 该模型能够在单个GPU上完成在七秒内直接采样三维场景表示。
- Bolt3D利用强大的二维扩散网络架构实现高保真三维场景生成。
- 创建大规模的多视角一致的三维几何和外观数据集用于训练模型。
- 模型采用最新的密集三维重建技术。
- Bolt3D模型将推理成本降低了高达300倍相比于其他多视角生成模型。
点此查看论文截图



RFMI: Estimating Mutual Information on Rectified Flow for Text-to-Image Alignment
Authors:Chao Wang, Giulio Franzese, Alessandro Finamore, Pietro Michiardi
Rectified Flow (RF) models trained with a Flow matching framework have achieved state-of-the-art performance on Text-to-Image (T2I) conditional generation. Yet, multiple benchmarks show that synthetic images can still suffer from poor alignment with the prompt, i.e., images show wrong attribute binding, subject positioning, numeracy, etc. While the literature offers many methods to improve T2I alignment, they all consider only Diffusion Models, and require auxiliary datasets, scoring models, and linguistic analysis of the prompt. In this paper we aim to address these gaps. First, we introduce RFMI, a novel Mutual Information (MI) estimator for RF models that uses the pre-trained model itself for the MI estimation. Then, we investigate a self-supervised fine-tuning approach for T2I alignment based on RFMI that does not require auxiliary information other than the pre-trained model itself. Specifically, a fine-tuning set is constructed by selecting synthetic images generated from the pre-trained RF model and having high point-wise MI between images and prompts. Our experiments on MI estimation benchmarks demonstrate the validity of RFMI, and empirical fine-tuning on SD3.5-Medium confirms the effectiveness of RFMI for improving T2I alignment while maintaining image quality.
使用流匹配框架训练的Rectified Flow(RF)模型在文本到图像(T2I)条件生成方面达到了最新技术水平。然而,多个基准测试显示,合成图像仍然可能因提示对齐不良而出现属性绑定错误、主题定位错误、数量计算等问题。虽然文献提供了许多改进T2I对齐的方法,但它们都只考虑扩散模型,并需要辅助数据集、评分模型和提示的语言分析。本文旨在解决这些空白。首先,我们介绍了RFMI,这是一种用于RF模型的新型互信息(MI)估计器,它使用预训练模型本身进行MI估计。然后,我们基于RFMI研究了一种无需除预训练模型以外的辅助信息的自我监督微调方法,用于改善T2I对齐。具体来说,通过选择从预训练的RF模型生成的合成图像,并具有较高的图像与提示之间的点对点互信息来构建微调集。我们在互信息估计基准测试上的实验验证了RFMI的有效性,在SD3.5-Medium上的经验微调证实了RFMI在保持图像质量的同时提高T2I对齐的有效性。
论文及项目相关链接
PDF to appear at ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy
Summary
本文旨在解决文本到图像生成中的对齐问题。提出了一种新的基于互信息的评估器RFMI,用于评估Rectified Flow模型的互信息,并利用此评估器进行自监督微调,以提高图像与文本提示的对齐度。该方法仅依赖预训练模型本身,无需额外的数据集、评分模型或语言分析。
Key Takeaways
- Rectified Flow (RF) models 在文本到图像生成领域取得了最先进的性能,但仍存在与提示对齐不良的问题。
- 现有方法大多专注于使用扩散模型改善对齐,并需要额外的数据集、评分模型和语言分析。
- 本文提出了一种新的互信息评估器RFMI,利用预训练模型自身进行互信息估计。
- 使用RFMI进行自监督微调,无需额外的辅助信息,仅依赖预训练模型本身。
- 通过选择高图像与提示点互信息的合成图像构建微调集。
- 实验结果表明RFMI的有效性,在MI估计基准测试和实际微调中均验证了其改善T2I对齐同时保持图像质量的能力。
点此查看论文截图

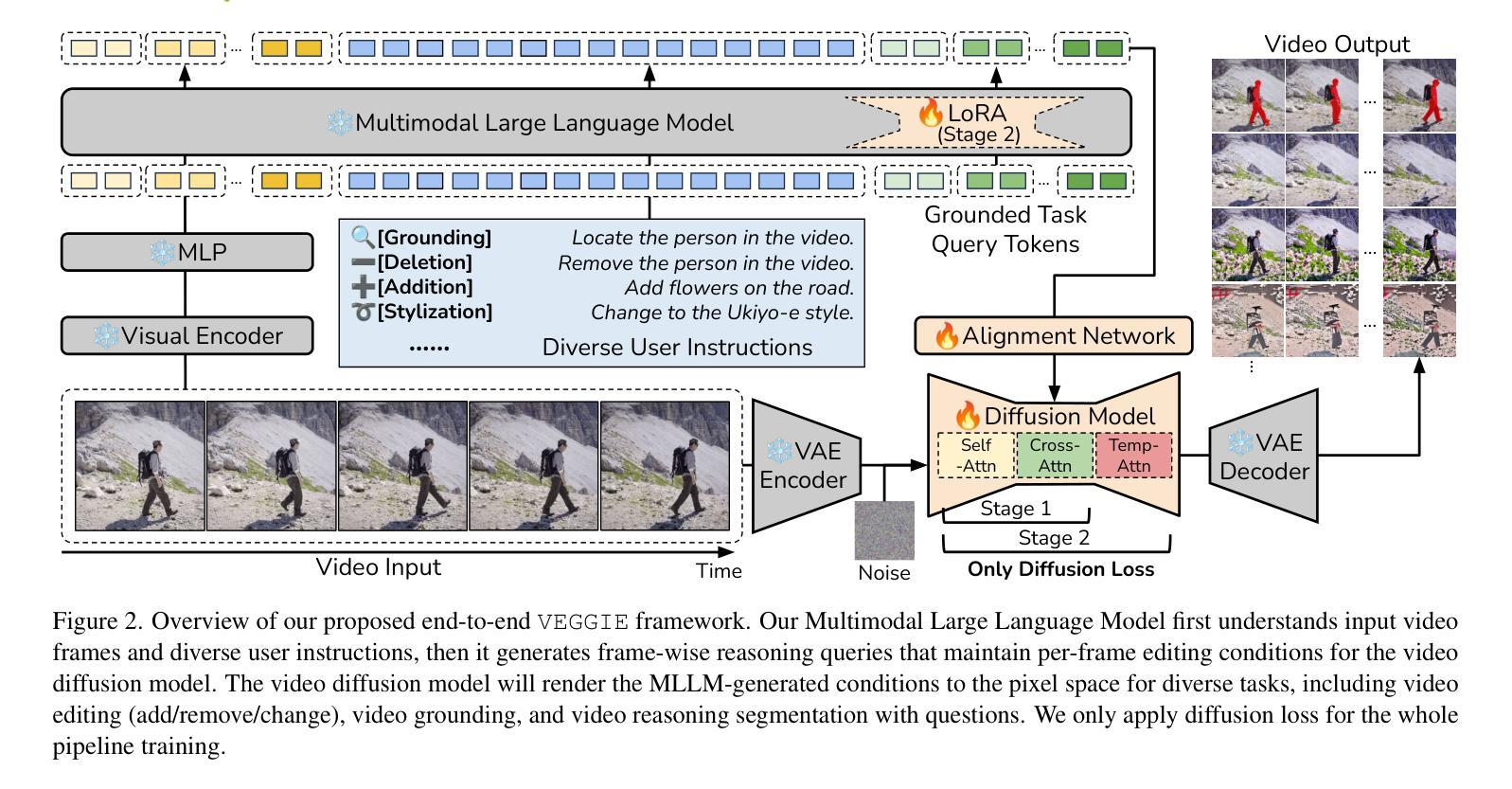
VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation
Authors:Shoubin Yu, Difan Liu, Ziqiao Ma, Yicong Hong, Yang Zhou, Hao Tan, Joyce Chai, Mohit Bansal
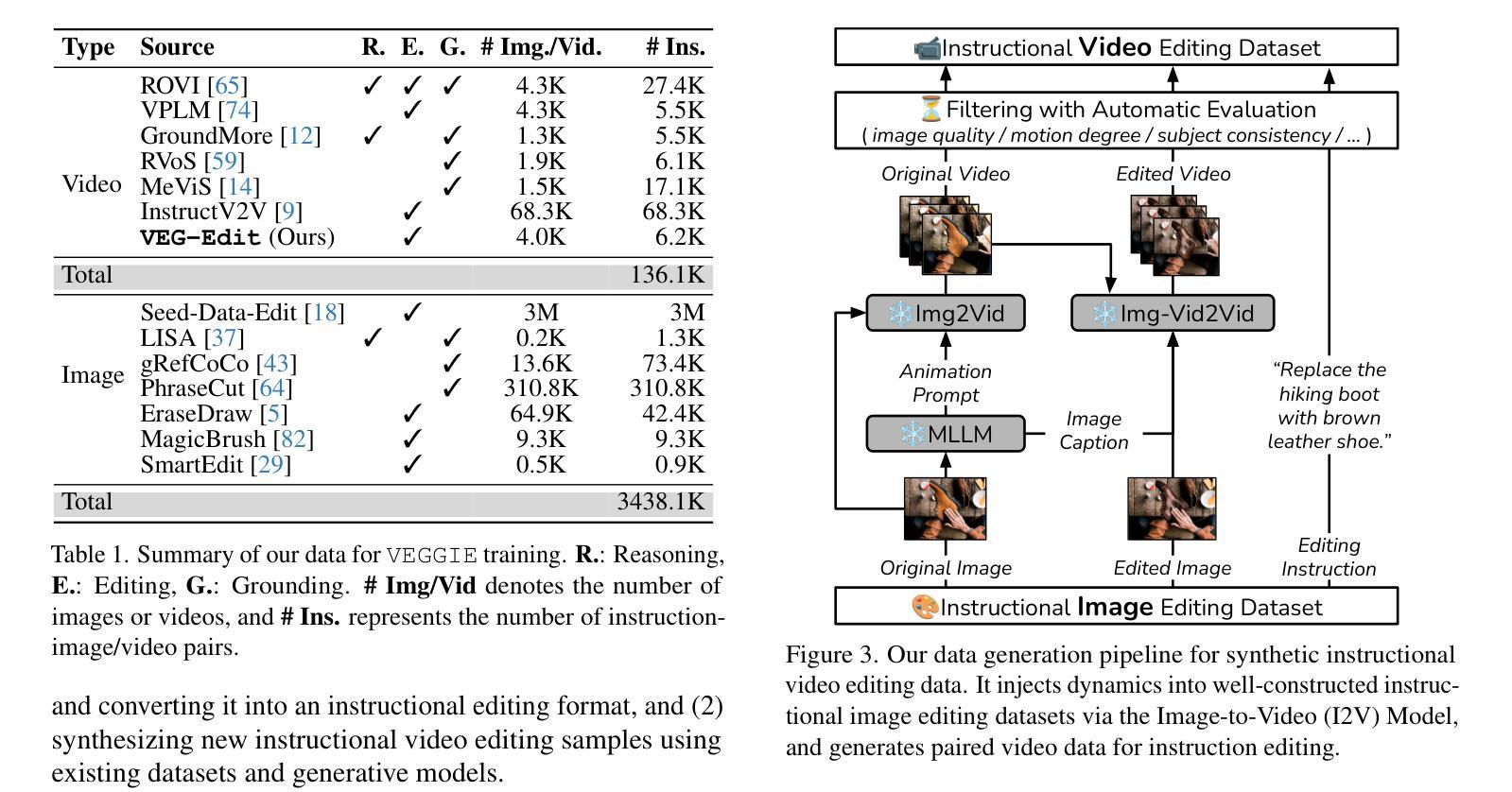
Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
近期,视频扩散模型已经提升了视频编辑的能力,但在统一框架内处理指令编辑和多样化任务(例如添加、删除、更改)仍然具有挑战性。在本文中,我们介绍了VEGGIE,一个基于指令的接地生成视频编辑器,这是一个简单端到端的框架,融合了视频概念编辑、接地和基于各种用户指令的推理。具体来说,给定一个视频和文本查询,VEGGIE首先利用MLLM来解释用户意图的指令,并将它们接地到视频上下文,为像素空间响应生成特定帧的接地任务查询。然后,扩散模型会呈现这些计划并生成符合用户意图的编辑视频。为了支持多样化的任务和复杂的指令,我们采用了一种课程学习策略:首先使用大规模的指令图像编辑数据来对齐MLLM和视频扩散模型,然后在高质量的多任务视频数据上进行端到端的微调。此外,我们还引入了一种新的数据合成管道,以生成用于模型训练的一对一指令视频编辑数据。它通过利用图像到视频的模型注入动态性,将静态图像数据转化为多样化、高质量的视频编辑样本。VEGGIE在具有不同编辑技能的指令视频编辑方面表现出强大的性能,作为一个通用模型,它超越了最佳指令基线,而其他模型在多任务处理方面则表现挣扎。VEGGIE在视频对象接地和推理分割方面也表现出色,而其他基线则未能做到。我们还进一步揭示了多个任务是如何相互帮助的,并强调了有前景的应用,如零射击多模式指令和在上下文中的视频编辑。
论文及项目相关链接
PDF First three authors contributed equally. Project page: https://veggie-gen.github.io/
Summary
本文介绍了VEGGIE,一款基于指令的通用视频编辑框架。该框架能解析用户指令并关联到视频上下文,生成特定帧的任务查询,再通过扩散模型生成符合用户意图的视频。为支持多样任务和复杂指令,采用课程学习策略,先在大规模指令图像编辑数据上对齐MLLM和扩散模型,再在高质多任务视频数据上进行端到端的微调。此外,引入了新型数据合成流程来生成配对指令视频编辑数据用于模型训练。实验表明,VEGGIE在指令视频编辑上表现优秀,其他模型难以胜任多任务处理时,VEGGIE展现出强大的通用性。同时,它在视频对象关联和推理分割方面也表现出卓越性能。
Key Takeaways
- VEGGIE是一个统一视频编辑、关联和基于指令的推理的框架。
- 通过MLLM解释用户指令并将其关联到视频上下文。
- 使用扩散模型生成符合用户意图的视频编辑。
- 采用课程学习策略支持多样任务和复杂指令的训练。
- 引入数据合成流程生成配对指令视频编辑数据。
- VEGGIE在指令视频编辑方面表现优秀,尤其是多任务处理和视频对象关联方面。
点此查看论文截图


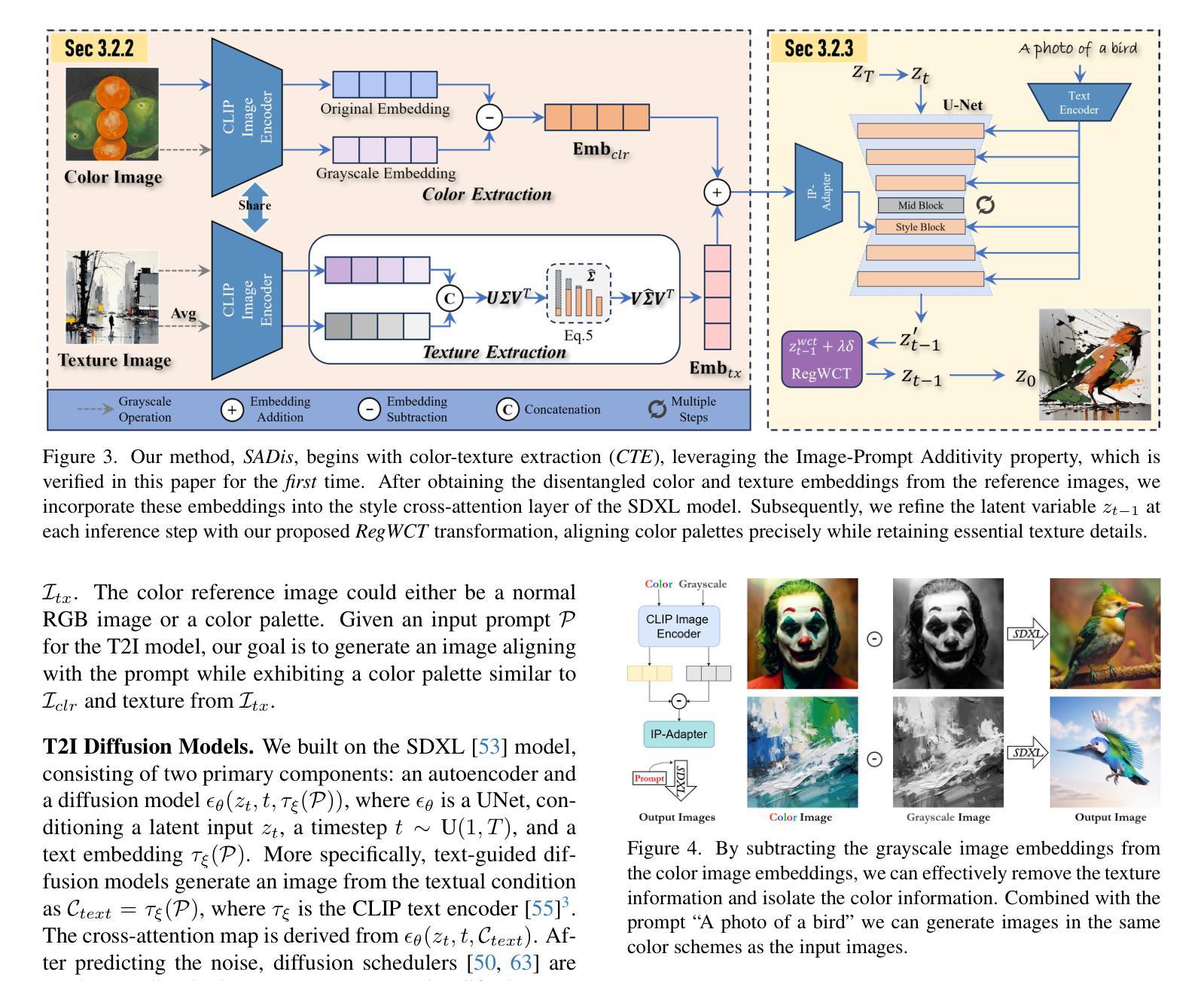
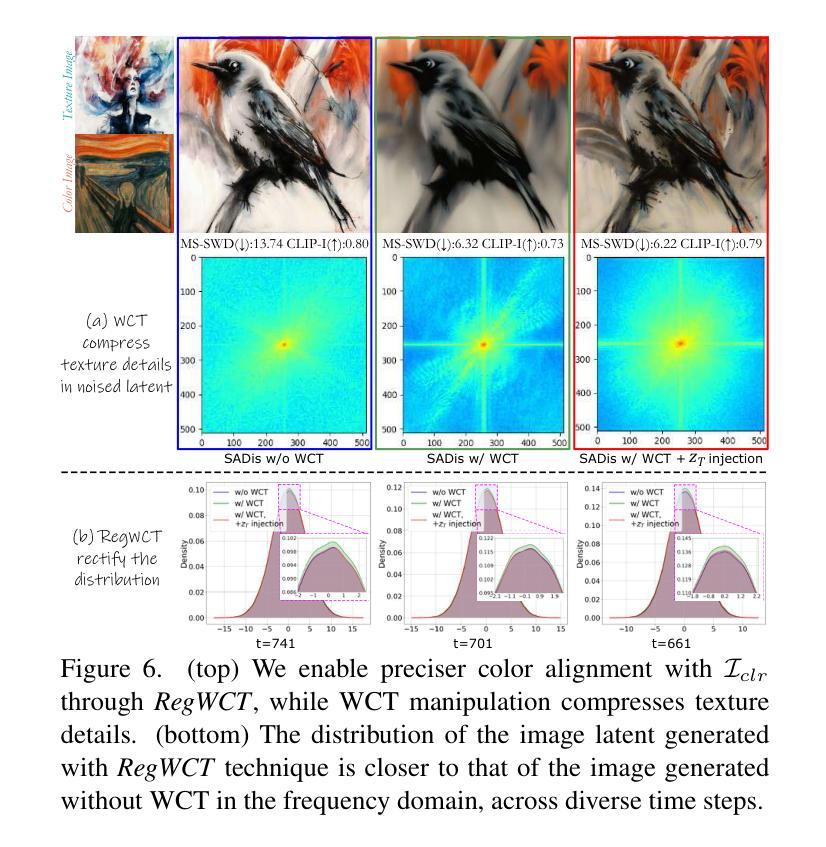
Free-Lunch Color-Texture Disentanglement for Stylized Image Generation
Authors:Jiang Qin, Senmao Li, Alexandra Gomez-Villa, Shiqi Yang, Yaxing Wang, Kai Wang, Joost van de Weijer
Recent advances in Text-to-Image (T2I) diffusion models have transformed image generation, enabling significant progress in stylized generation using only a few style reference images. However, current diffusion-based methods struggle with fine-grained style customization due to challenges in controlling multiple style attributes, such as color and texture. This paper introduces the first tuning-free approach to achieve free-lunch color-texture disentanglement in stylized T2I generation, addressing the need for independently controlled style elements for the Disentangled Stylized Image Generation (DisIG) problem. Our approach leverages the Image-Prompt Additivity property in the CLIP image embedding space to develop techniques for separating and extracting Color-Texture Embeddings (CTE) from individual color and texture reference images. To ensure that the color palette of the generated image aligns closely with the color reference, we apply a whitening and coloring transformation to enhance color consistency. Additionally, to prevent texture loss due to the signal-leak bias inherent in diffusion training, we introduce a noise term that preserves textural fidelity during the Regularized Whitening and Coloring Transformation (RegWCT). Through these methods, our Style Attributes Disentanglement approach (SADis) delivers a more precise and customizable solution for stylized image generation. Experiments on images from the WikiArt and StyleDrop datasets demonstrate that, both qualitatively and quantitatively, SADis surpasses state-of-the-art stylization methods in the DisIG task.
近期文本到图像(T2I)扩散模型的进展已经改变了图像生成领域,使得仅使用少数风格参考图像就能实现风格化生成方面的显著进展。然而,当前基于扩散的方法在控制多种风格属性(如颜色和纹理)方面面临挑战,因此在精细风格定制方面存在困难。本文引入了无需调整即可实现风格化T2I生成中的自由午餐颜色纹理分离的方法,解决了离散风格化图像生成(DisIG)问题中对独立控制风格元素的需求。我们的方法利用CLIP图像嵌入空间中的Image-Prompt Additivity属性,开发出了从单个颜色和纹理参考图像中分离和提取颜色纹理嵌入(CTE)的技术。为了确保生成图像的颜色调色板与颜色参考紧密对齐,我们应用了一种增白和着色变换以增强颜色一致性。此外,为了防止由于扩散训练中的信号泄漏偏差而导致的纹理损失,我们引入了一项噪声项,在正则化增白和着色变换(RegWCT)过程中保持纹理保真度。通过这些方法,我们的风格属性分离方法(SADis)为风格化图像生成提供了更精确和可定制化的解决方案。在WikiArt和StyleDrop数据集上的图像实验表明,无论是在定性还是定量上,SADis在DisIG任务中都超越了最先进的风格化方法。
论文及项目相关链接
Summary
本文介绍了针对文本到图像(T2I)扩散模型的最新进展,提出了一种无需调整的方法来实现风格化图像生成中的色彩纹理解纠缠。该方法利用CLIP图像嵌入空间中的图像提示添加性属性,从单个色彩和纹理参考图像中分离和提取色彩纹理嵌入(CTE)。通过白化和彩色转换增强颜色一致性,并通过引入噪声项在规则化白化和彩色转换(RegWCT)过程中保持纹理保真度,以防止由于扩散训练中的信号泄漏偏差而导致的纹理损失。实验表明,Style Attributes Disentanglement(SADis)方法在WikiArt和StyleDrop数据集上的风格化图像生成任务中,无论在定性还是定量方面都超越了最新风格化方法。
Key Takeaways
- 文本到图像(T2I)扩散模型的最新进展实现了基于少量风格参考图像的显著风格化生成。
- 当前扩散方法面临精细风格定制的挑战,难以控制多种风格属性,如色彩和纹理。
- 本文首次提出了无需调整的色彩纹理解纠缠方法,解决了独立控制风格元素的需求。
- 利用CLIP图像嵌入空间的图像提示添加性属性,实现色彩纹理嵌入(CTE)的分离和提取。
- 通过白化和彩色转换增强颜色一致性,确保生成图像的颜色调色板与颜色参考对齐。
- 引入噪声项以保持纹理保真度,防止因扩散训练中的信号泄漏偏差而导致的纹理损失。
点此查看论文截图



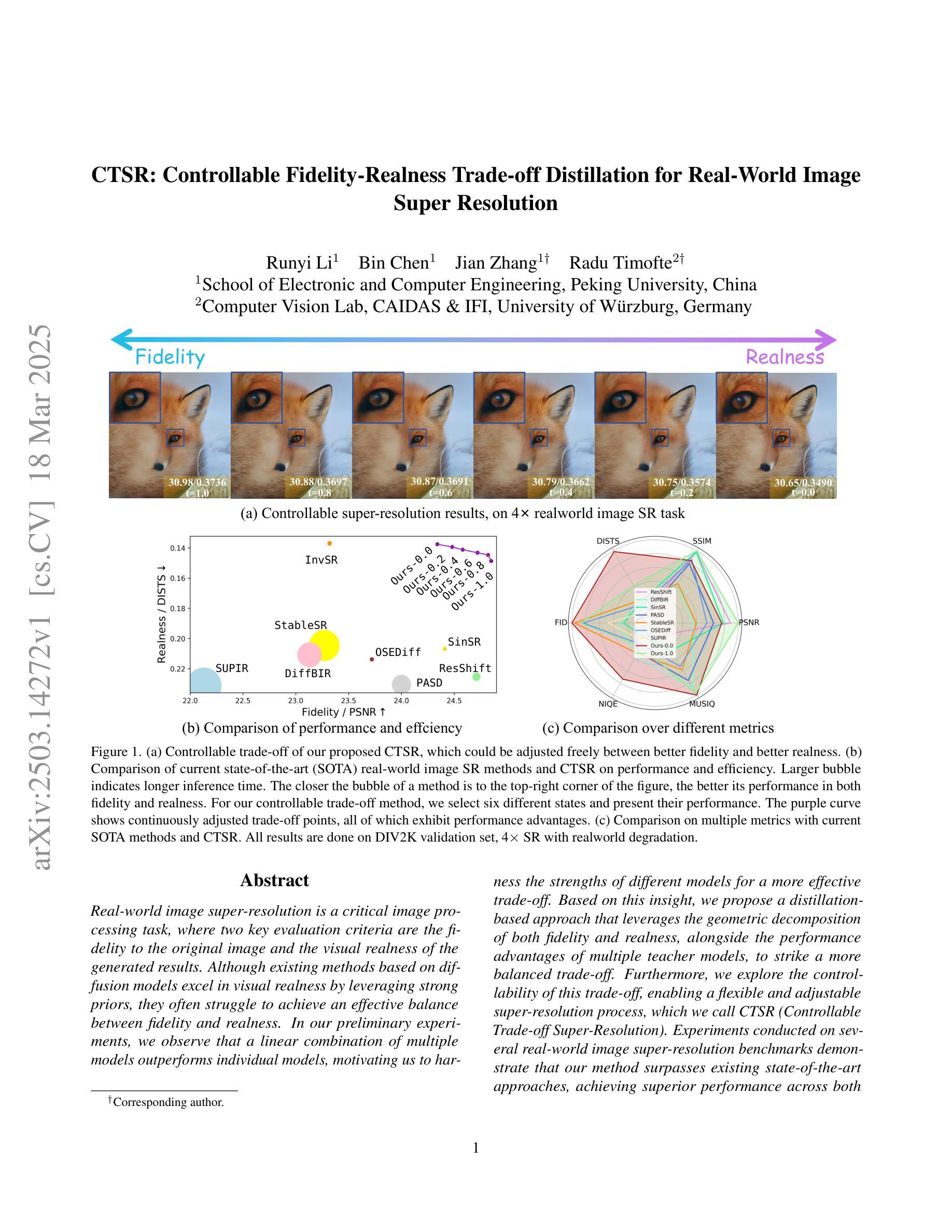
CTSR: Controllable Fidelity-Realness Trade-off Distillation for Real-World Image Super Resolution
Authors:Runyi Li, Bin Chen, Jian Zhang, Radu Timofte
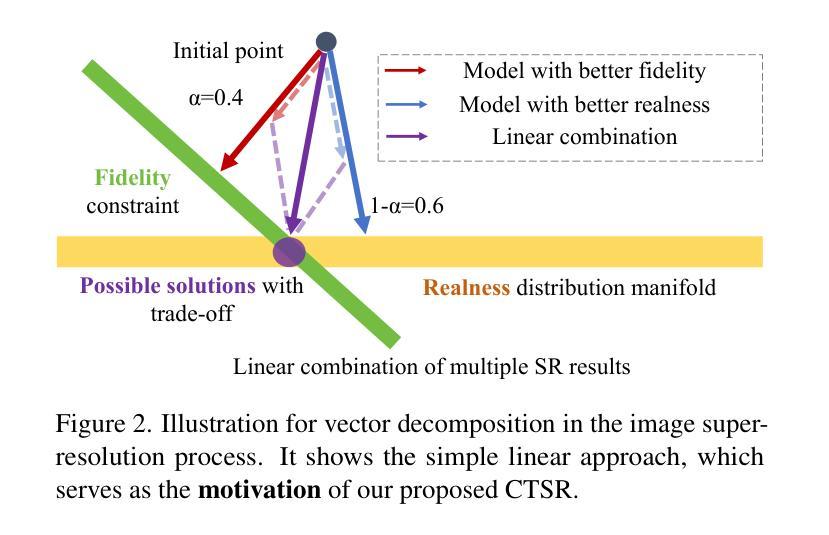
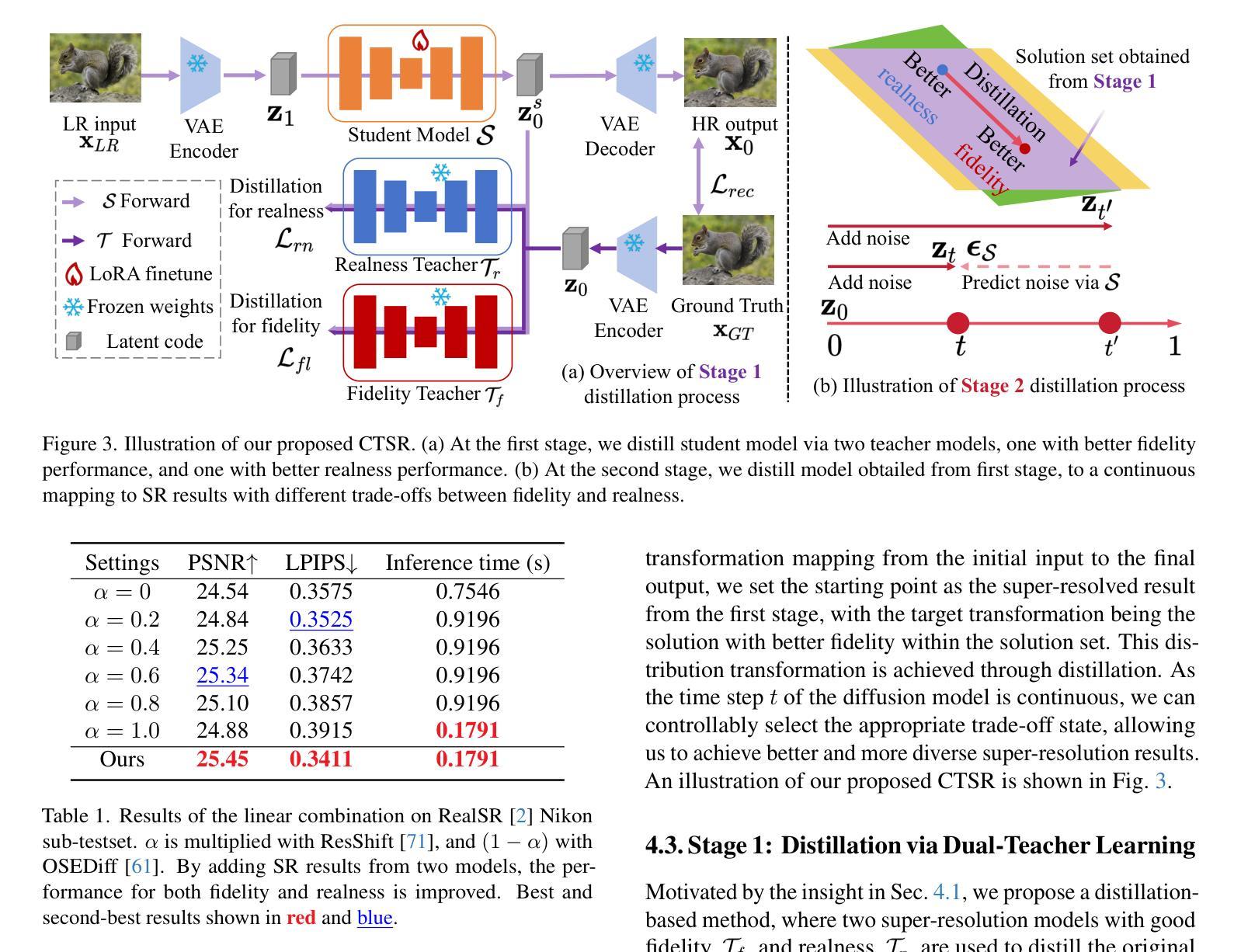
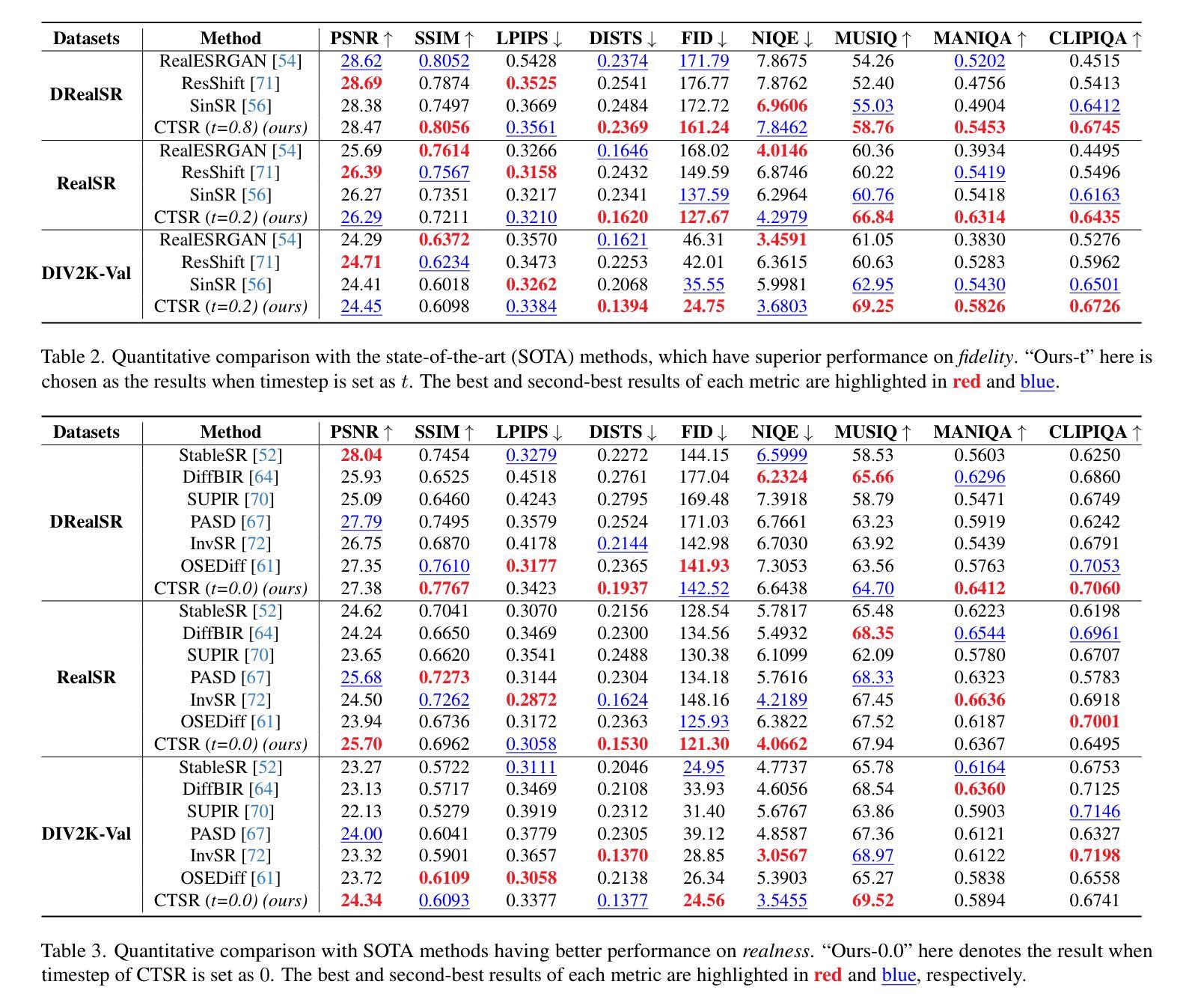
Real-world image super-resolution is a critical image processing task, where two key evaluation criteria are the fidelity to the original image and the visual realness of the generated results. Although existing methods based on diffusion models excel in visual realness by leveraging strong priors, they often struggle to achieve an effective balance between fidelity and realness. In our preliminary experiments, we observe that a linear combination of multiple models outperforms individual models, motivating us to harness the strengths of different models for a more effective trade-off. Based on this insight, we propose a distillation-based approach that leverages the geometric decomposition of both fidelity and realness, alongside the performance advantages of multiple teacher models, to strike a more balanced trade-off. Furthermore, we explore the controllability of this trade-off, enabling a flexible and adjustable super-resolution process, which we call CTSR (Controllable Trade-off Super-Resolution). Experiments conducted on several real-world image super-resolution benchmarks demonstrate that our method surpasses existing state-of-the-art approaches, achieving superior performance across both fidelity and realness metrics.
现实世界图像超分辨率处理是一项关键的图像处理任务,其两个关键的评估标准是对于原始图像的保真度和生成结果的视觉真实度。尽管基于扩散模型的现有方法在利用强大先验知识方面在视觉真实度上表现出色,但它们往往难以在保真度和真实度之间取得有效平衡。在我们的初步实验中,我们观察到多种模型的线性组合表现优于单个模型,这激励我们利用不同模型的优势来实现更有效的权衡。基于此见解,我们提出了一种基于蒸馏的方法,该方法利用保真度和真实度的几何分解,以及多个教师模型的性能优势,以实现更平衡的权衡。此外,我们探索了这种权衡的可控性,实现了一个灵活可调的超级分辨率过程,我们称之为可控权衡超级分辨率(CTSR)。在几个现实世界图像超分辨率基准测试上进行的实验表明,我们的方法超越了现有的最先进的方法,在保真度和真实度指标上均实现了卓越的性能。
论文及项目相关链接
Summary
基于扩散模型的现实图像超分辨率处理技术面临保持原始图像保真度和生成结果真实感的双重评价准则挑战。现有方法虽然擅长利用强先验信息提高真实感,但在保持保真和真实之间的平衡方面存在困难。本研究观察到多种模型的线性组合表现优于单一模型,因此提出一种基于蒸馏的方法,通过几何分解保真度和真实感,并结合多个教师模型的性能优势,实现更平衡的权衡。此外,本研究还探索了这种权衡的可控性,提出了一种灵活可调的超级分辨率过程,称为可控权衡超级分辨率(CTSR)。在多个现实图像超分辨率基准测试上的实验表明,该方法超越了现有先进技术,在保真度和真实感指标上均实现了卓越性能。
Key Takeaways
- 扩散模型在图像超分辨率处理中面临保持保真度和真实感的挑战。
- 现有方法虽然能提高真实感,但在保持两者平衡方面存在困难。
- 通过观察发现多种模型的线性组合通常表现更好。
- 提出一种基于蒸馏的方法,通过几何分解和结合多个教师模型实现更平衡的权衡。
- 引入了可控权衡的概念,使得超级分辨率过程更加灵活可调。
- 所提出的方法在多个现实图像超分辨率基准测试上超越了现有技术。
点此查看论文截图
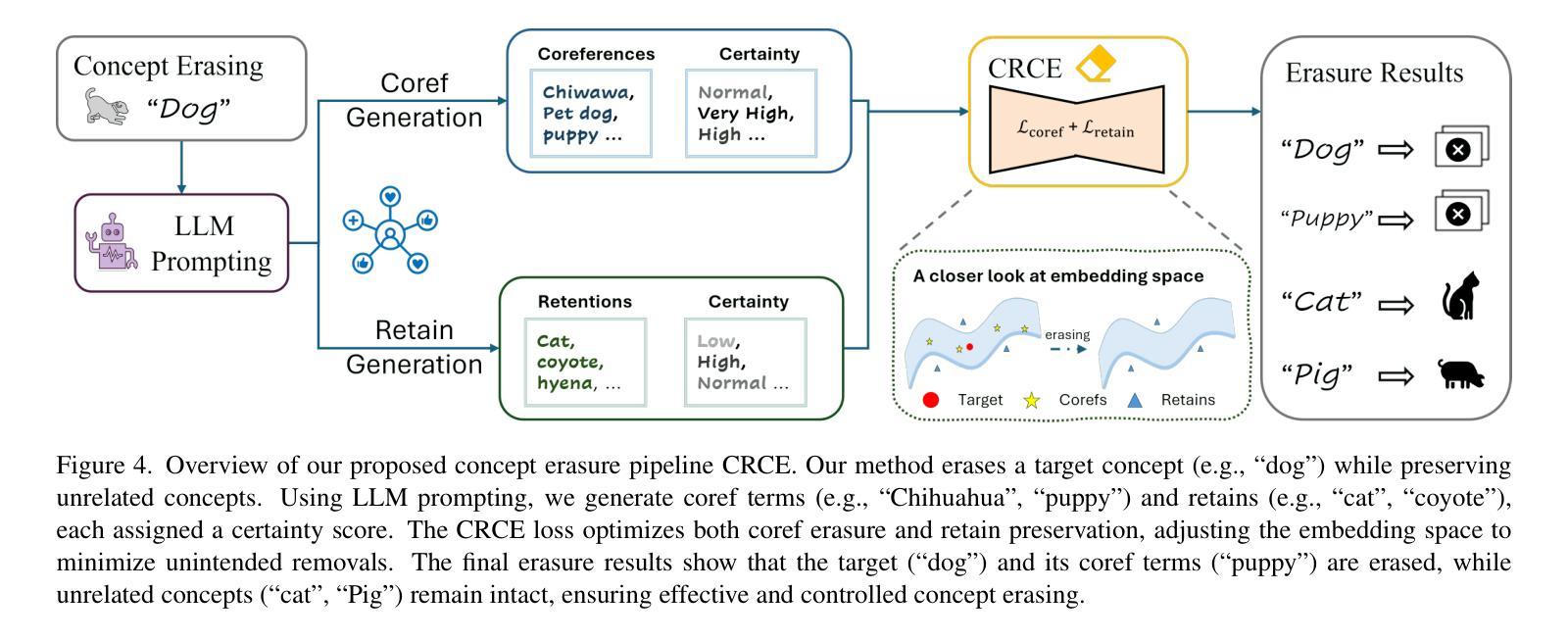
CRCE: Coreference-Retention Concept Erasure in Text-to-Image Diffusion Models
Authors:Yuyang Xue, Edward Moroshko, Feng Chen, Steven McDonagh, Sotirios A. Tsaftaris
Text-to-Image diffusion models can produce undesirable content that necessitates concept erasure techniques. However, existing methods struggle with under-erasure, leaving residual traces of targeted concepts, or over-erasure, mistakenly eliminating unrelated but visually similar concepts. To address these limitations, we introduce CRCE, a novel concept erasure framework that leverages Large Language Models to identify both semantically related concepts that should be erased alongside the target and distinct concepts that should be preserved. By explicitly modeling coreferential and retained concepts semantically, CRCE enables more precise concept removal, without unintended erasure. Experiments demonstrate that CRCE outperforms existing methods on diverse erasure tasks.
文本到图像的扩散模型会产生不需要的内容,这需要使用概念消除技术。然而,现有方法在消除方面存在困难,要么无法完全消除目标概念而留下残留痕迹,要么误删除与特定概念无关但视觉上相似的概念。为了克服这些局限性,我们引入了CRCE,这是一种新的概念消除框架,它利用大型语言模型来识别与目标概念同时应该消除的语义相关概念,以及应该保留的特有概念。通过明确地建立核心参照和保留概念的语义模型,CRCE能够实现更精确的概念去除,避免不必要的误删除。实验表明,CRCE在多种消除任务上的表现优于现有方法。
论文及项目相关链接
Summary:
文本介绍了针对文本到图像扩散模型生成的不理想内容的问题,提出了一个名为CRCE的新概念消除框架。该框架利用大型语言模型来识别应消除的目标概念以及与目标语义相关的概念,以及应保持的独特概念。CRCE能够更精确地移除概念,而不会造成意外消除。实验证明,CRCE在多种消除任务上的表现优于现有方法。
Key Takeaways:
- 文本到图像扩散模型会生成不理想的内容,需要概念消除技术来解决。
- 现有方法存在不足,如不完全消除或过度消除。
- CRCE框架被引入,利用大型语言模型来识别应消除和保留的概念。
- CRCE能够更精确地移除概念,避免意外消除。
- CRCE在多种消除任务上的表现优于现有方法。
- CRCE框架通过明确建模核心概念和保留概念的语义来实现其优势。
点此查看论文截图



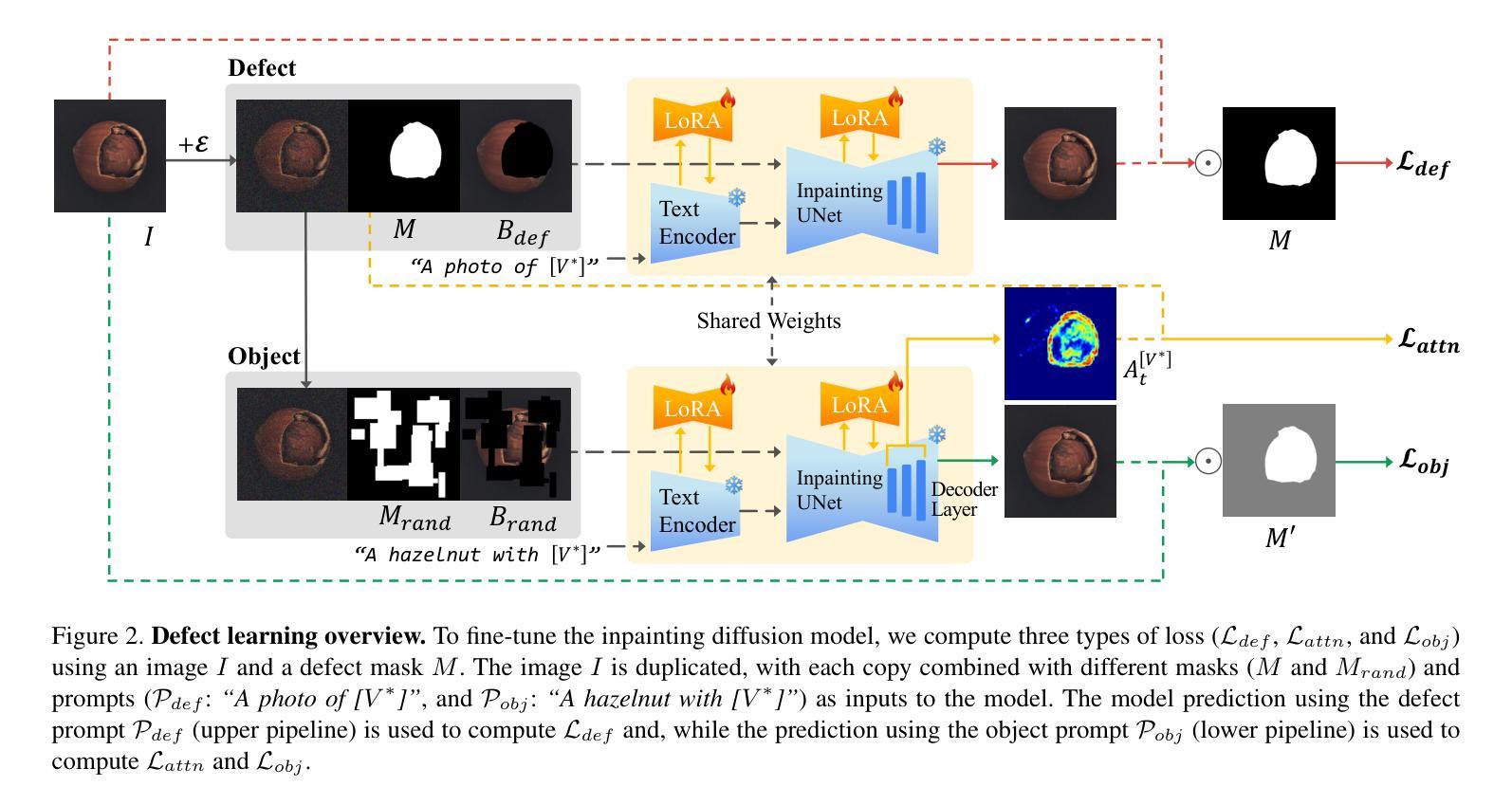
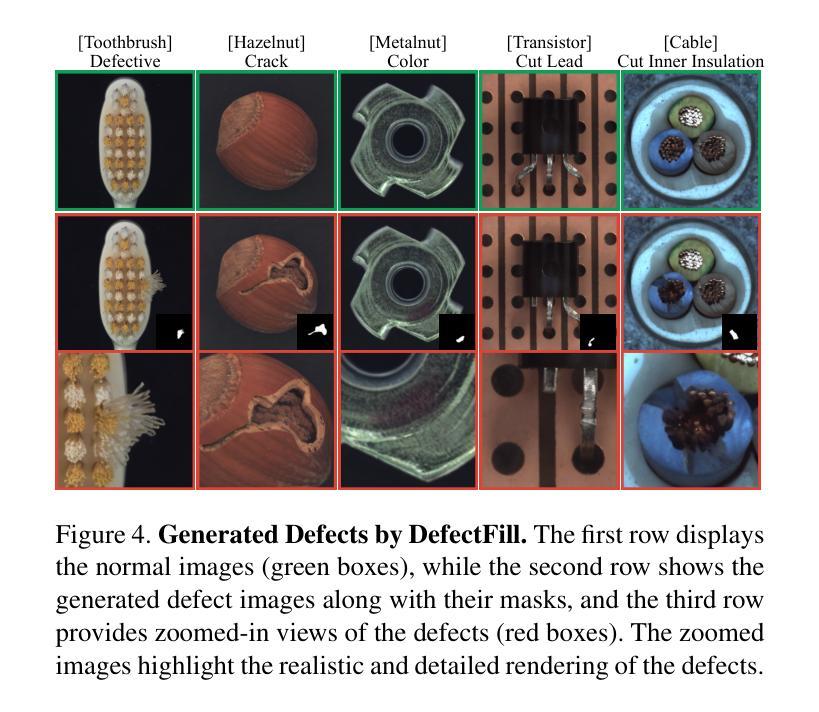
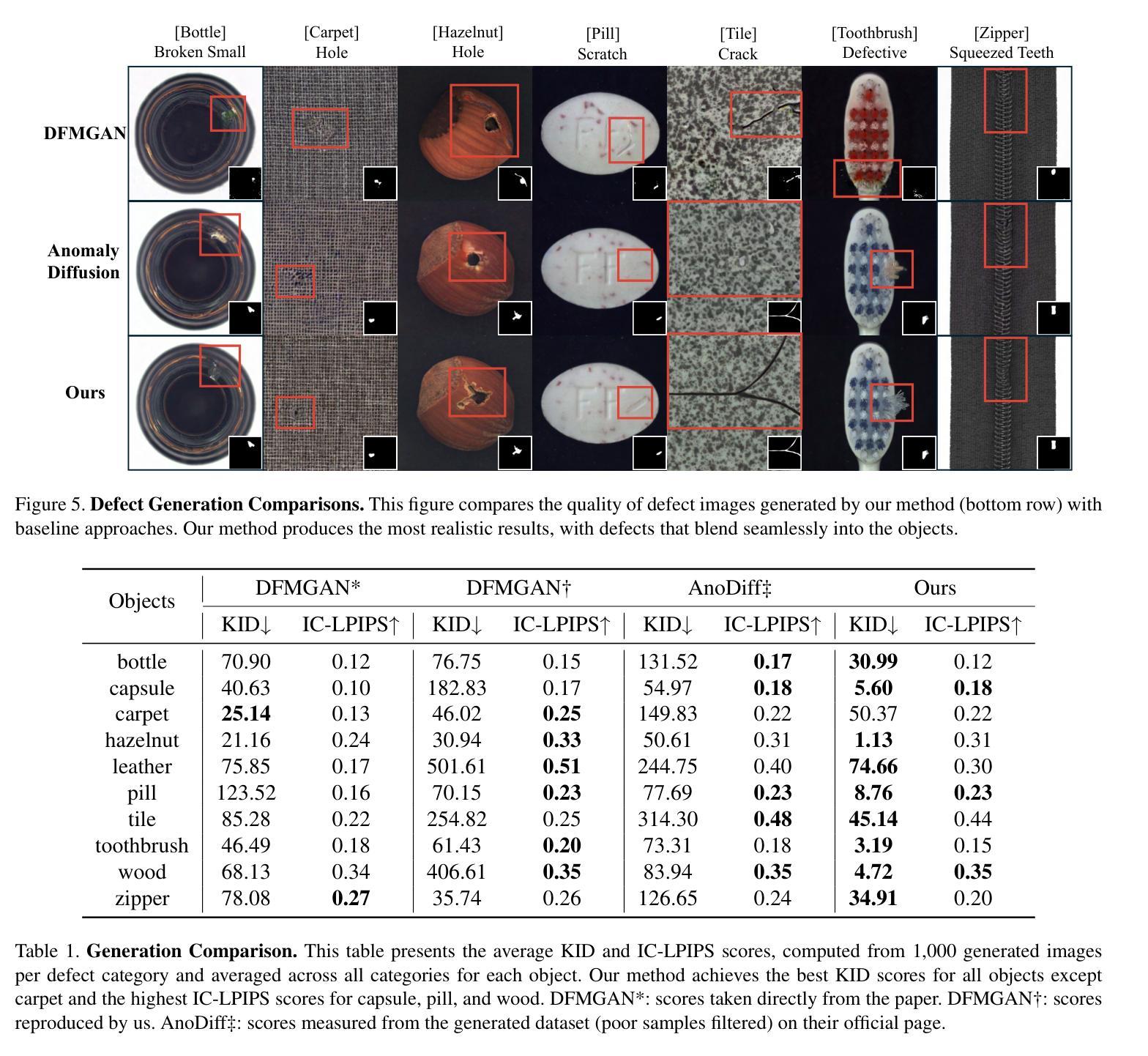
DefectFill: Realistic Defect Generation with Inpainting Diffusion Model for Visual Inspection
Authors:Jaewoo Song, Daemin Park, Kanghyun Baek, Sangyub Lee, Jooyoung Choi, Eunji Kim, Sungroh Yoon
Developing effective visual inspection models remains challenging due to the scarcity of defect data. While image generation models have been used to synthesize defect images, producing highly realistic defects remains difficult. We propose DefectFill, a novel method for realistic defect generation that requires only a few reference defect images. It leverages a fine-tuned inpainting diffusion model, optimized with our custom loss functions incorporating defect, object, and attention terms. It enables precise capture of detailed, localized defect features and their seamless integration into defect-free objects. Additionally, our Low-Fidelity Selection method further enhances the defect sample quality. Experiments show that DefectFill generates high-quality defect images, enabling visual inspection models to achieve state-of-the-art performance on the MVTec AD dataset.
开发有效的视觉检测模型仍然是一个挑战,主要是由于缺陷数据的稀缺性。虽然图像生成模型已被用于合成缺陷图像,但产生高度逼真的缺陷仍然很困难。我们提出了DefectFill,这是一种新型的现实缺陷生成方法,只需要少量的参考缺陷图像。它利用经过微调的内填扩散模型,通过结合缺陷、对象和注意力术语,对我们的自定义损失函数进行优化。它能够精确捕捉详细的局部缺陷特征,并将其无缝集成到无缺陷的对象中。此外,我们的低质量选择方法进一步提高了缺陷样本的质量。实验表明,DefectFill能够生成高质量的缺陷图像,使视觉检测模型在MVTec AD数据集上达到最新性能。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
基于缺陷数据稀缺的挑战,发展有效的视觉检测模型依然颇具难度。本文提出一种名为DefectFill的新型缺陷生成方法,仅需少量缺陷图像参考即可生成逼真的缺陷。该方法利用微调后的填充扩散模型,结合定制的损失函数和缺陷、物体以及注意力术语进行优化,能精准捕捉详细的局部缺陷特征,并将其无缝集成到无缺陷物体中。此外,本文的低保真选择方法进一步提升了缺陷样本质量。实验表明,DefectFill生成的缺陷图像质量高,能使视觉检测模型在MVTec AD数据集上达到最佳性能。
Key Takeaways
- 提出了DefectFill方法,用于基于少量参考缺陷图像生成逼真的缺陷。
- 利用微调后的填充扩散模型,结合定制的损失函数进行优化。
- 融合了缺陷、物体和注意力术语,能够精准捕捉局部缺陷特征。
- 提出低保真选择方法,提升了缺陷样本质量。
- DefectFill生成的缺陷图像质量高。
- 视觉检测模型在MVTec AD数据集上表现最佳。
点此查看论文截图


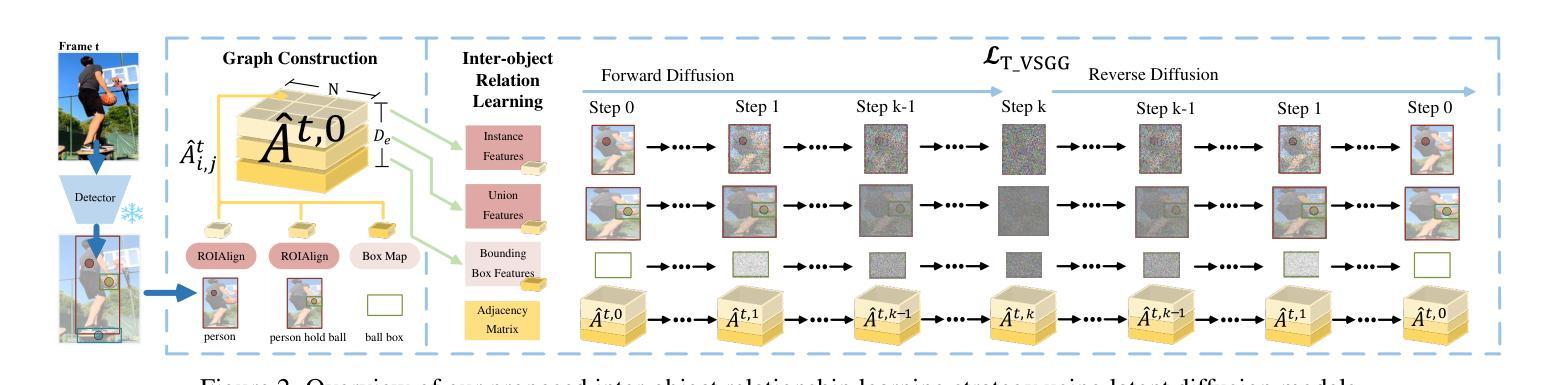
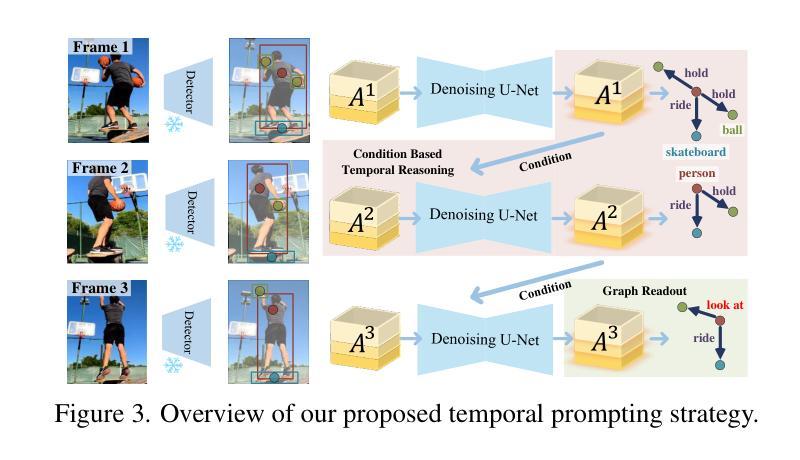
DIFFVSGG: Diffusion-Driven Online Video Scene Graph Generation
Authors:Mu Chen, Liulei Li, Wenguan Wang, Yi Yang
Top-leading solutions for Video Scene Graph Generation (VSGG) typically adopt an offline pipeline. Though demonstrating promising performance, they remain unable to handle real-time video streams and consume large GPU memory. Moreover, these approaches fall short in temporal reasoning, merely aggregating frame-level predictions over a temporal context. In response, we introduce DIFFVSGG, an online VSGG solution that frames this task as an iterative scene graph update problem. Drawing inspiration from Latent Diffusion Models (LDMs) which generate images via denoising a latent feature embedding, we unify the decoding of object classification, bounding box regression, and graph generation three tasks using one shared feature embedding. Then, given an embedding containing unified features of object pairs, we conduct a step-wise Denoising on it within LDMs, so as to deliver a clean embedding which clearly indicates the relationships between objects. This embedding then serves as the input to task-specific heads for object classification, scene graph generation, etc. DIFFVSGG further facilitates continuous temporal reasoning, where predictions for subsequent frames leverage results of past frames as the conditional inputs of LDMs, to guide the reverse diffusion process for current frames. Extensive experiments on three setups of Action Genome demonstrate the superiority of DIFFVSGG.
针对视频场景图生成(VSGG)的顶尖解决方案通常采用离线管道。尽管表现有前景,但它们仍无法处理实时视频流并消耗大量的GPU内存。此外,这些方法在时序推理方面不足,仅仅在时序上下文中对帧级预测进行聚合。为了应对这些问题,我们引入了DIFFVSGG,这是一个在线VSGG解决方案,将此项任务构建为迭代场景图更新问题。我们从潜在扩散模型(LDM)中汲取灵感,该模型通过去噪潜在特征嵌入来生成图像。我们统一了目标分类、边界框回归和图形生成这三个任务的解码工作,使用单一共享特征嵌入。给定包含对象对统一特征的嵌入后,我们在LDM中对其进行分步去噪处理,以获取清晰指示对象间关系的干净嵌入。然后,此嵌入作为目标分类、场景图生成等任务特定头的输入。DIFFVSGG进一步促进了连续的时序推理,后续帧的预测利用过去帧的结果作为LDM的条件输入,以指导当前帧的反向扩散过程。在Action Genome的三个设置上的广泛实验证明了DIFFVSGG的优越性。
论文及项目相关链接
PDF CVPR 2025, Code: https://github.com/kagawa588/DiffVsgg
Summary
基于扩散模型的在线视频场景图生成方案DIFFVSGG解决了传统离线管道在实时视频流处理方面的不足。通过统一特征嵌入解码物体分类、边界框回归和图生成三项任务,并采用基于潜在扩散模型的去噪步骤,DIFFVSGG能清晰表达物体间关系。此外,它支持连续时间推理,利用过去帧的预测结果指导当前帧的反扩散过程。在Action Genome的三个设置上的实验证明了DIFFVSGG的优越性。
Key Takeaways
- DIFFVSGG是一种在线视频场景图生成解决方案,解决了传统离线管道无法处理实时视频流的问题。
- 它通过统一特征嵌入解码物体分类、边界框回归和图生成任务。
- DIFFVSGG采用基于潜在扩散模型的去噪步骤,以表达物体间的清晰关系。
- 该方案支持连续时间推理,利用过去帧的预测结果指导当前帧的处理。
- DIFFVSGG在Action Genome的三个设置上进行了实验验证。
- 实验结果证明了DIFFVSGG在视频场景图生成任务中的优越性。
点此查看论文截图

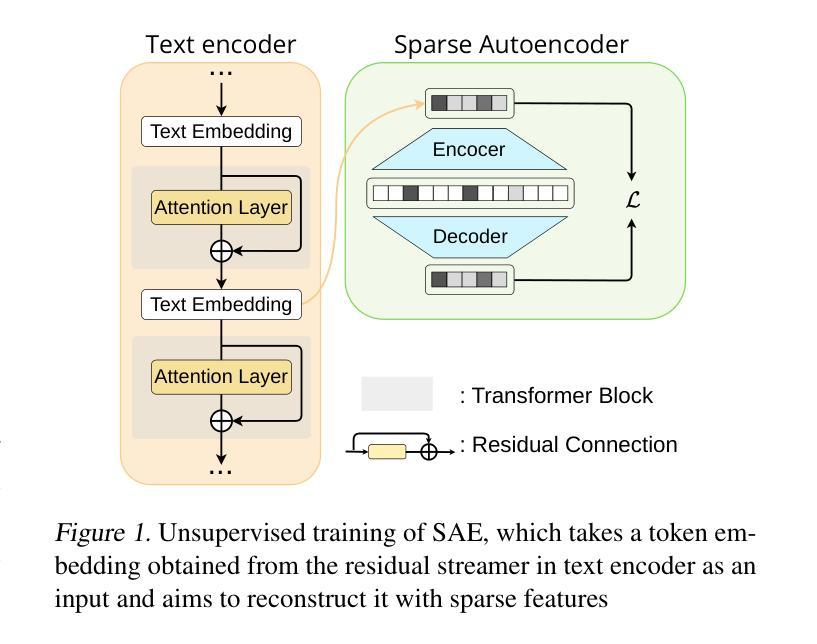
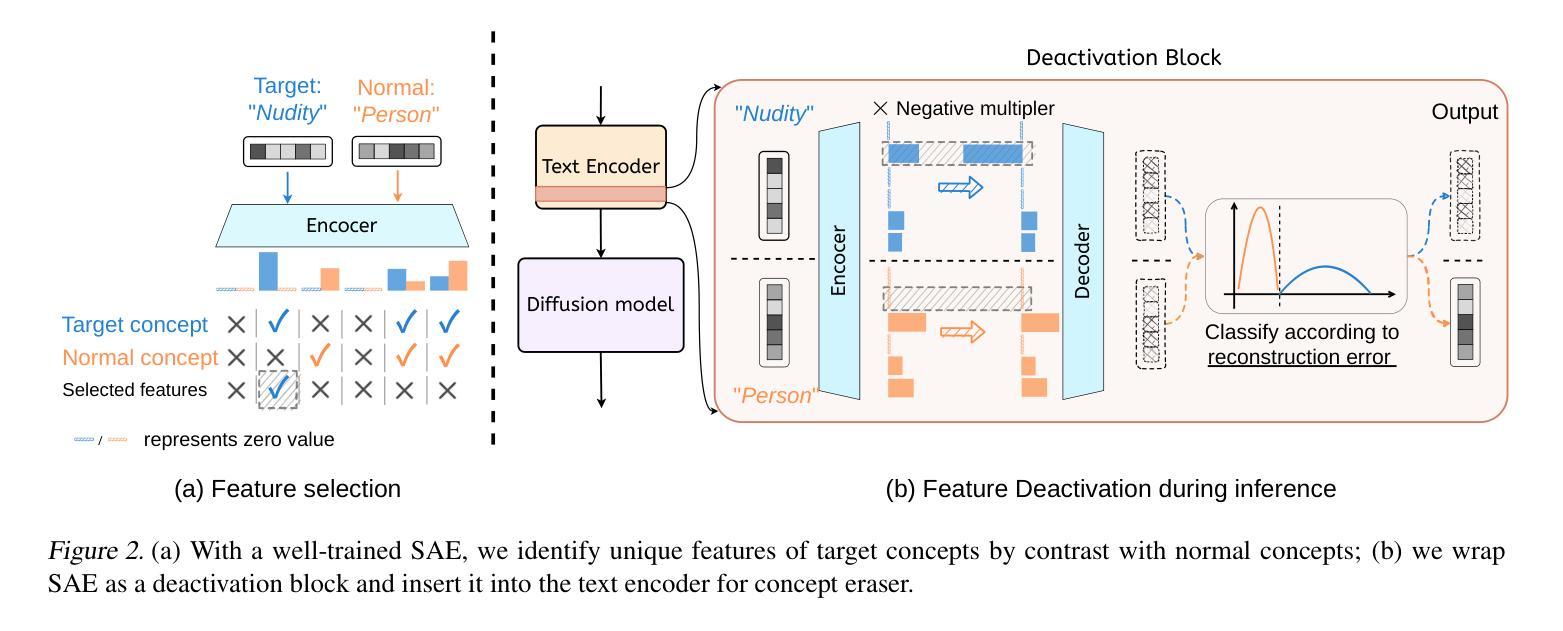
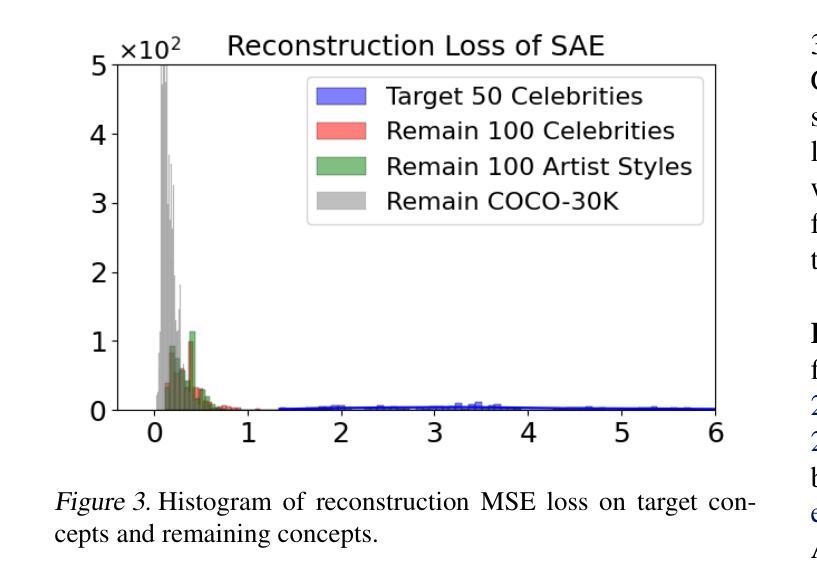
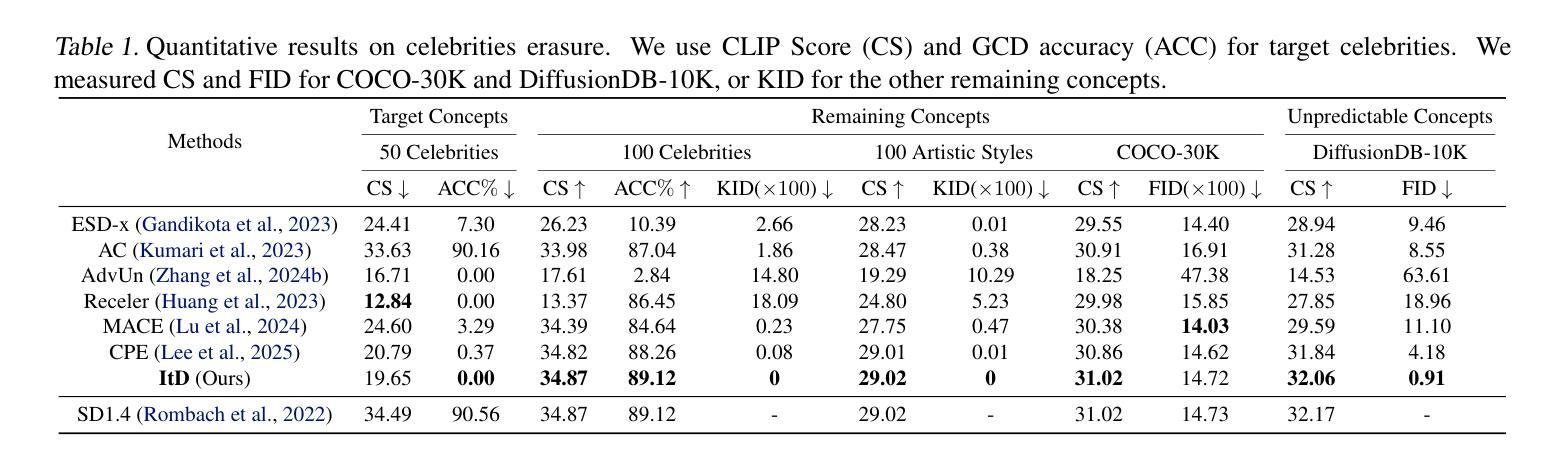
Sparse Autoencoder as a Zero-Shot Classifier for Concept Erasing in Text-to-Image Diffusion Models
Authors:Zhihua Tian, Sirun Nan, Ming Xu, Shengfang Zhai, Wenjie Qu, Jian Liu, Kui Ren, Ruoxi Jia, Jiaheng Zhang
Text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images but also raise people’s concerns about generating harmful or misleading content. While extensive approaches have been proposed to erase unwanted concepts without requiring retraining from scratch, they inadvertently degrade performance on normal generation tasks. In this work, we propose Interpret then Deactivate (ItD), a novel framework to enable precise concept removal in T2I diffusion models while preserving overall performance. ItD first employs a sparse autoencoder (SAE) to interpret each concept as a combination of multiple features. By permanently deactivating the specific features associated with target concepts, we repurpose SAE as a zero-shot classifier that identifies whether the input prompt includes target concepts, allowing selective concept erasure in diffusion models. Moreover, we demonstrate that ItD can be easily extended to erase multiple concepts without requiring further training. Comprehensive experiments across celebrity identities, artistic styles, and explicit content demonstrate ItD’s effectiveness in eliminating targeted concepts without interfering with normal concept generation. Additionally, ItD is also robust against adversarial prompts designed to circumvent content filters. Code is available at: https://github.com/NANSirun/Interpret-then-deactivate.
文本到图像(T2I)扩散模型在生成高质量图像方面取得了显著的进步,但也引发了人们对生成有害或误导性内容的担忧。虽然已有许多方法被提出来消除不需要的概念,而无需从头开始重新训练,但它们无意中会降低正常生成任务上的性能。在这项工作中,我们提出了“解释然后停用”(ItD)这一新框架,能够在T2I扩散模型中实现精确的概念移除,同时保留整体性能。ItD首先采用稀疏自动编码器(SAE)来解释每个概念是多个特征的组合。通过永久停用与目标概念相关的特定特征,我们将SAE重新定位为一种零射击分类器,可以识别输入提示是否包含目标概念,从而在扩散模型中实现选择性概念删除。此外,我们证明ItD可以很容易地扩展到删除多个概念,而无需进一步训练。在名人身份、艺术风格和明确内容方面的综合实验证明了ItD在消除目标概念方面的有效性,而不会干扰正常的概念生成。此外,ItD对于设计用于规避内容过滤器的对抗性提示也很稳健。代码可在:https://github.com/NANSirun/Interpret-then-deactivate找到。
论文及项目相关链接
PDF 25 pages
Summary
文本到图像(T2I)扩散模型在生成高质量图像方面取得了显著进展,但也引发了人们对生成有害或误导性内容的担忧。尽管已经提出了许多方法来消除不需要的概念,而无需从头进行再训练,但它们会无意中降低正常生成任务的性能。在这项工作中,我们提出了“解释后停用”(ItD)这一新型框架,能够在T2I扩散模型中实现精确的概念移除,同时保留整体性能。ItD首先使用稀疏自动编码器(SAE)来解释每个概念是多个特征的组合。通过永久停用与目标概念相关的特定特征,我们重新将SAE用作零样本分类器,以识别输入提示是否包含目标概念,从而在扩散模型中实现选择性概念删除。此外,我们证明ItD可以轻松地扩展到删除多个概念,无需进一步训练。在名人身份、艺术风格和明确内容方面的综合实验表明,ItD在消除目标概念方面非常有效,而不会干扰正常的概念生成。此外,ItD还能对抗旨在绕过内容过滤器的对抗性提示。相关代码可访问于:网址链接。
Key Takeaways
- T2I扩散模型虽能生成高质量图像,但存在生成有害或误导内容的风险。
- 当前方法在去除非必要概念时可能影响模型在常规任务上的表现。
- 提出了“解释后停用”(ItD)框架,能够在精确移除有害概念的同时保持整体性能。
- ItD利用稀疏自动编码器(SAE)解释概念并停用特定特征,实现选择性概念删除。
- ItD可轻松扩展到删除多个概念,无需额外训练。
- 实验证明ItD在消除特定概念方面效果显著,不影响正常概念生成。
点此查看论文截图

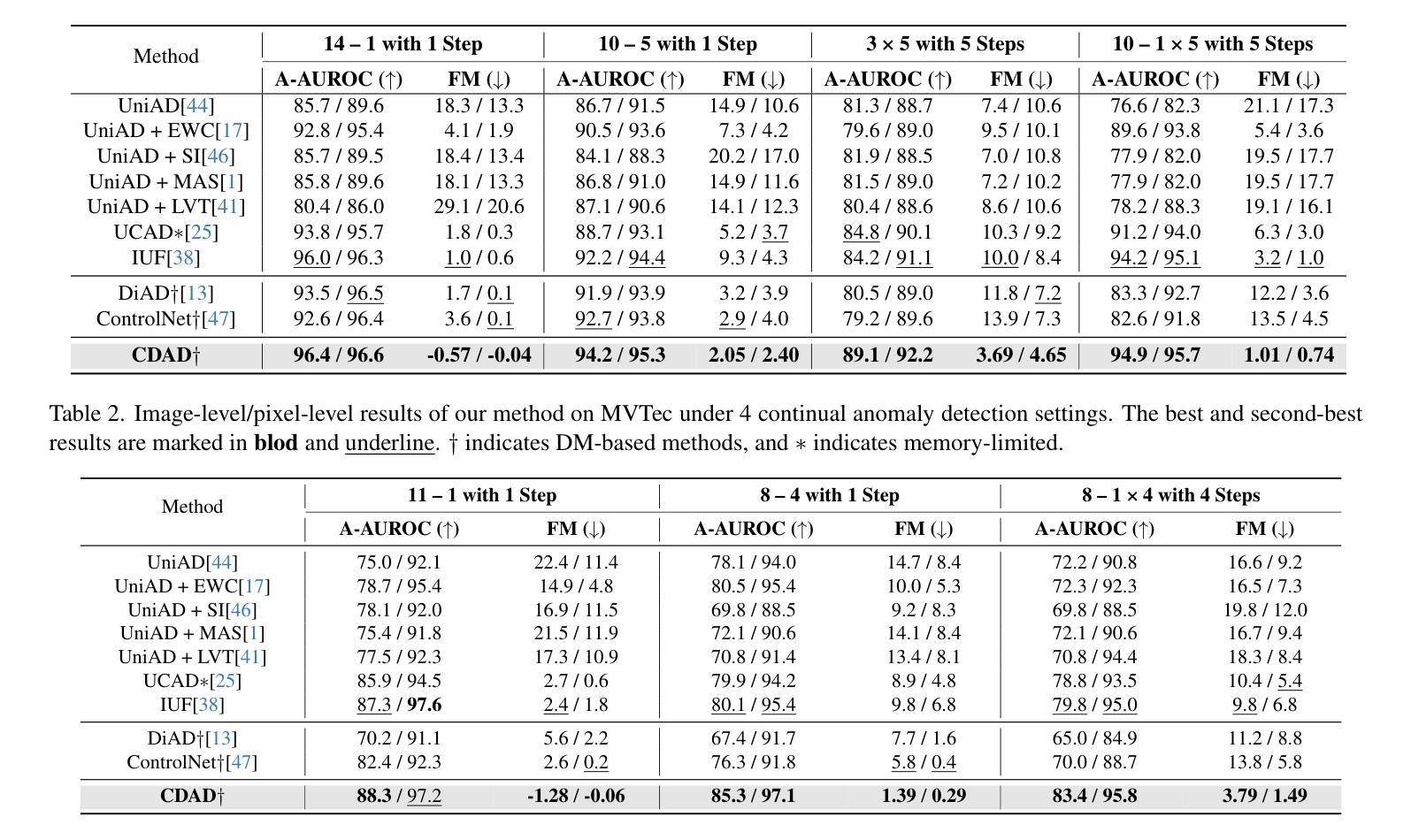
One-for-More: Continual Diffusion Model for Anomaly Detection
Authors:Xiaofan Li, Xin Tan, Zhuo Chen, Zhizhong Zhang, Ruixin Zhang, Rizen Guo, Guanna Jiang, Yulong Chen, Yanyun Qu, Lizhuang Ma, Yuan Xie
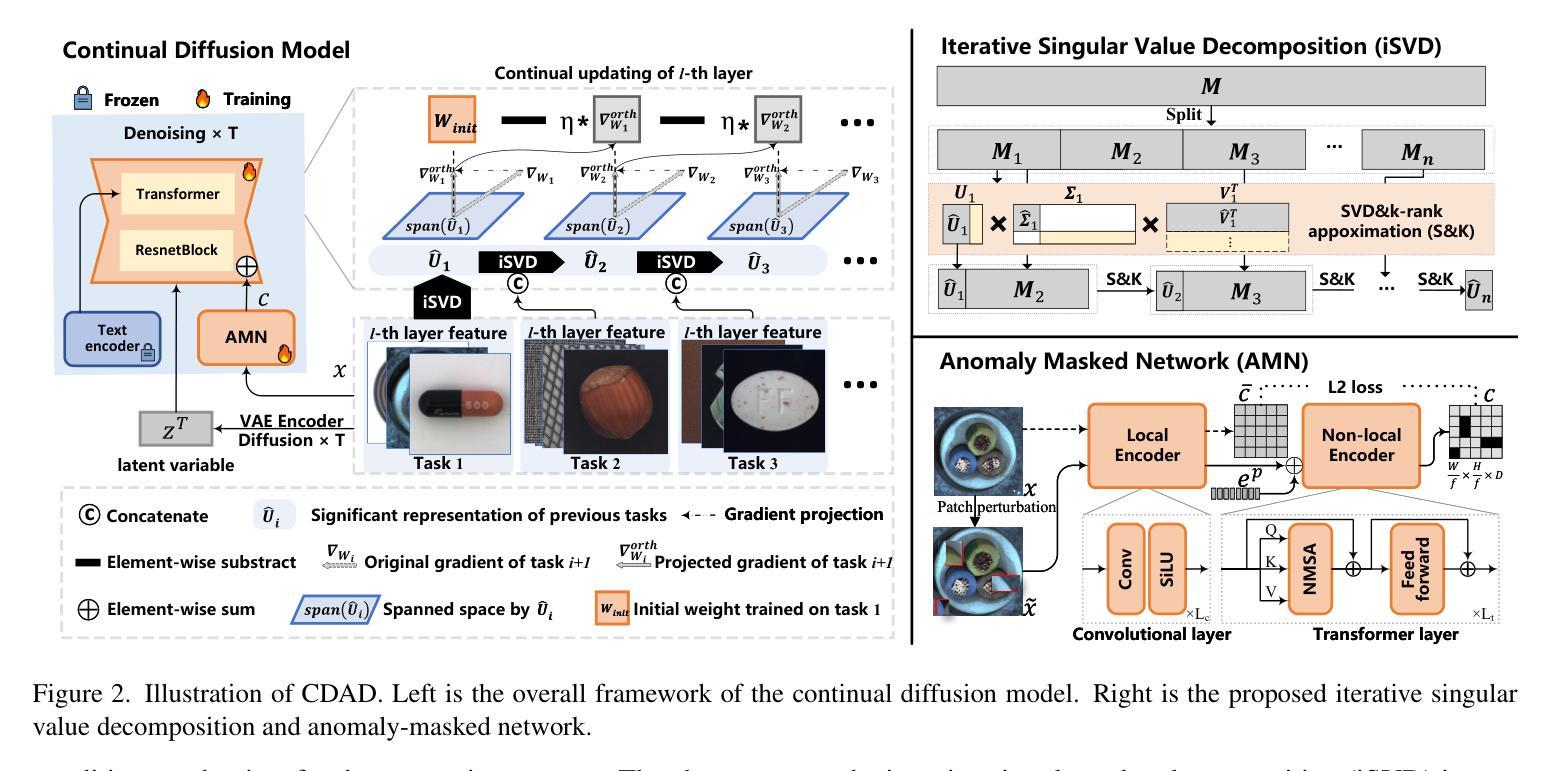
With the rise of generative models, there is a growing interest in unifying all tasks within a generative framework. Anomaly detection methods also fall into this scope and utilize diffusion models to generate or reconstruct normal samples when given arbitrary anomaly images. However, our study found that the diffusion model suffers from severe faithfulness hallucination'' and catastrophic forgetting’’, which can’t meet the unpredictable pattern increments. To mitigate the above problems, we propose a continual diffusion model that uses gradient projection to achieve stable continual learning. Gradient projection deploys a regularization on the model updating by modifying the gradient towards the direction protecting the learned knowledge. But as a double-edged sword, it also requires huge memory costs brought by the Markov process. Hence, we propose an iterative singular value decomposition method based on the transitive property of linear representation, which consumes tiny memory and incurs almost no performance loss. Finally, considering the risk of ``over-fitting’’ to normal images of the diffusion model, we propose an anomaly-masked network to enhance the condition mechanism of the diffusion model. For continual anomaly detection, ours achieves first place in 17/18 settings on MVTec and VisA. Code is available at https://github.com/FuNz-0/One-for-More
随着生成模型的发展,越来越有兴趣在生成框架内统一所有任务。异常检测方法是其中的一部分,在给定的任意异常图像中利用扩散模型生成或重建正常样本。然而,我们的研究发现扩散模型存在严重的“忠实幻觉”和“灾难性遗忘”,无法满足不可预测的模式增量。为了缓解上述问题,我们提出了一种持续扩散模型,采用梯度投影实现稳定的持续学习。梯度投影通过在模型更新过程中部署正则化,修改梯度以保护所学知识方向。然而,它就像一把双刃剑,还需要马尔可夫过程带来的巨大内存成本。因此,我们提出了一种基于线性表示传递属性的迭代奇异值分解方法,这种方法消耗内存小且几乎不会造成性能损失。最后,考虑到扩散模型对正常图像的“过度拟合”风险,我们提出了一种异常掩码网络来增强扩散模型的条件机制。对于持续的异常检测,我们的方法在MVTec和VisA的17/18设置上排名第一。代码可在https://github.com/FuNz-0/One-for-More找到。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文探讨了生成模型在异常检测中的应用,尤其是扩散模型。针对扩散模型存在的“忠实度幻觉”和“灾难性遗忘”问题,提出了持续扩散模型。该模型通过梯度投影实现稳定持续学习,并采用基于线性表示传递属性的迭代奇异值分解方法降低内存消耗。为增强扩散模型的条件机制,还提出了异常掩膜网络。在MVTec和VisA的17/18设置上,该方法在持续异常检测中取得第一名。
Key Takeaways
- 扩散模型在异常检测中受到“忠实度幻觉”和“灾难性遗忘”的挑战。
- 持续扩散模型通过梯度投影实现稳定持续学习,缓解上述问题。
- 梯度投影通过修改模型更新时的梯度来保护已学知识。
- 扩散模型存在大量内存消耗,为此提出了基于线性表示传递属性的迭代奇异值分解方法降低内存消耗。
- 异常掩膜网络用于增强扩散模型的条件机制。
- 方法在MVTec和VisA的异常检测任务中表现优异。
点此查看论文截图



Appearance Matching Adapter for Exemplar-based Semantic Image Synthesis in-the-Wild
Authors:Siyoon Jin, Jisu Nam, Jiyoung Kim, Dahyun Chung, Yeong-Seok Kim, Joonhyung Park, Heonjeong Chu, Seungryong Kim
Exemplar-based semantic image synthesis generates images aligned with semantic content while preserving the appearance of an exemplar. Conventional structure-guidance models like ControlNet, are limited as they rely solely on text prompts to control appearance and cannot utilize exemplar images as input. Recent tuning-free approaches address this by transferring local appearance via implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, prior works are often restricted to single-object cases or foreground object appearance transfer, struggling with complex scenes involving multiple objects. To overcome this, we propose AM-Adapter (Appearance Matching Adapter) to address exemplar-based semantic image synthesis in-the-wild, enabling multi-object appearance transfer from a single scene-level image. AM-Adapter automatically transfers local appearances from the scene-level input. AM-Adapter alternatively provides controllability to map user-defined object details to specific locations in the synthesized images. Our learnable framework enhances cross-image matching within augmented self-attention by integrating semantic information from segmentation maps. To disentangle generation and matching, we adopt stage-wise training. We first train the structure-guidance and generation networks, followed by training the matching adapter while keeping the others frozen. During inference, we introduce an automated exemplar retrieval method for selecting exemplar image-segmentation pairs efficiently. Despite utilizing minimal learnable parameters, AM-Adapter achieves state-of-the-art performance, excelling in both semantic alignment and local appearance fidelity. Extensive ablations validate our design choices. Code and weights will be released.: https://cvlab-kaist.github.io/AM-Adapter/
基于范例的语义图像合成能够生成与语义内容对齐的图像,同时保留范例的外观。传统的结构引导模型,如ControlNet,受限于仅依赖文本提示来控制外观,无法利用范例图像作为输入。最近的无需微调的方法通过预训练扩散模型的增强自注意机制中的隐式跨图像匹配来传输局部外观。然而,先前的工作通常仅限于单对象情况或前景对象外观传输,对于涉及多个对象的复杂场景感到困扰。为了克服这一点,我们提出AM-Adapter(外观匹配适配器),解决基于范例的语义图像合成在野外的问题,支持从单个场景级图像进行多对象外观传输。AM-Adapter自动从场景级输入转移局部外观。AM-Adapter还提供可控性,将用户定义的对象细节映射到合成图像中的特定位置。我们的可学习框架通过整合分割图的语义信息,增强了增强自注意力机制中的跨图像匹配。为了分离生成和匹配,我们采用分阶段训练。我们首先训练结构引导和生成网络,然后冻结其他部分,只训练匹配适配器。在推理过程中,我们引入了一种自动范例检索方法,以有效地选择范例图像-分割对。尽管使用的可学习参数最少,但AM-Adapter仍达到了最先进的性能,在语义对齐和局部外观保真度方面都表现出色。大量的消融实验验证了我们的设计选择。[代码和权重将发布于]:https://cvlab-kaist.github.io/AM-Adapter/
论文及项目相关链接
Summary
基于示例的语义图像合成可以生成与语义内容对齐的图像,同时保留示例的外观。传统的结构指导模型如ControlNet存在局限性,仅依赖于文本提示来控制外观,无法利用示例图像作为输入。近期无需微调的方法通过预训练扩散模型的增强自注意力机制中的跨图像隐式匹配来转移局部外观。然而,先前的工作通常局限于单对象的情况或前景对象外观转移,面临涉及多个对象的复杂场景时感到困难。为克服此问题,我们提出AM-Adapter(外观匹配适配器),解决野生环境中的基于示例的语义图像合成问题,实现从单个场景级图像的多对象外观转移。AM-Adapter自动从场景级输入转移局部外观,并提供可控性,将用户定义的对象细节映射到合成图像中的特定位置。我们的可学习框架通过集成来自分割图的语义信息,增强增强自注意力中的跨图像匹配。为了分离生成和匹配,我们采用分阶段训练。首先训练结构指导和生成网络,然后冻结其他部分,仅训练匹配适配器。在推理过程中,我们引入自动示例检索方法,以有效地选择示例图像-分割对。尽管使用的可学习参数最少,但AM-Adapter仍达到最先进的性能,在语义对齐和局部外观保真度方面表现出色。
Key Takeaways
- 基于示例的语义图像合成结合了语义内容与示例的外观。
- 传统结构指导模型受限于仅使用文本提示,无法利用示例图像。
- 近期方法通过预训练扩散模型的增强自注意力来转移局部外观。
- AM-Adapter解决了涉及多个对象的复杂场景中的语义图像合成问题。
- AM-Adapter实现了从单个场景级图像的多对象外观转移。
- 框架通过集成分割图的语义信息增强了跨图像匹配。
点此查看论文截图





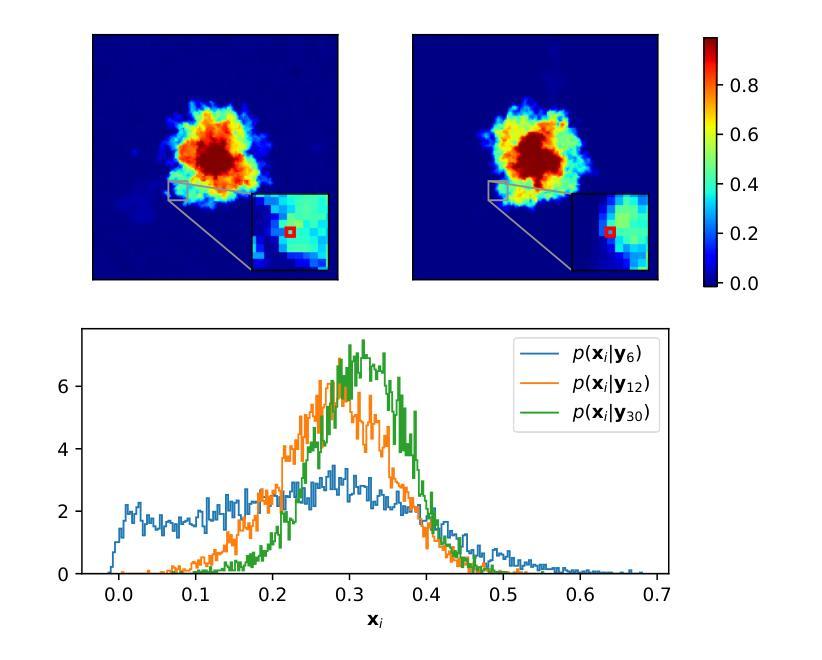
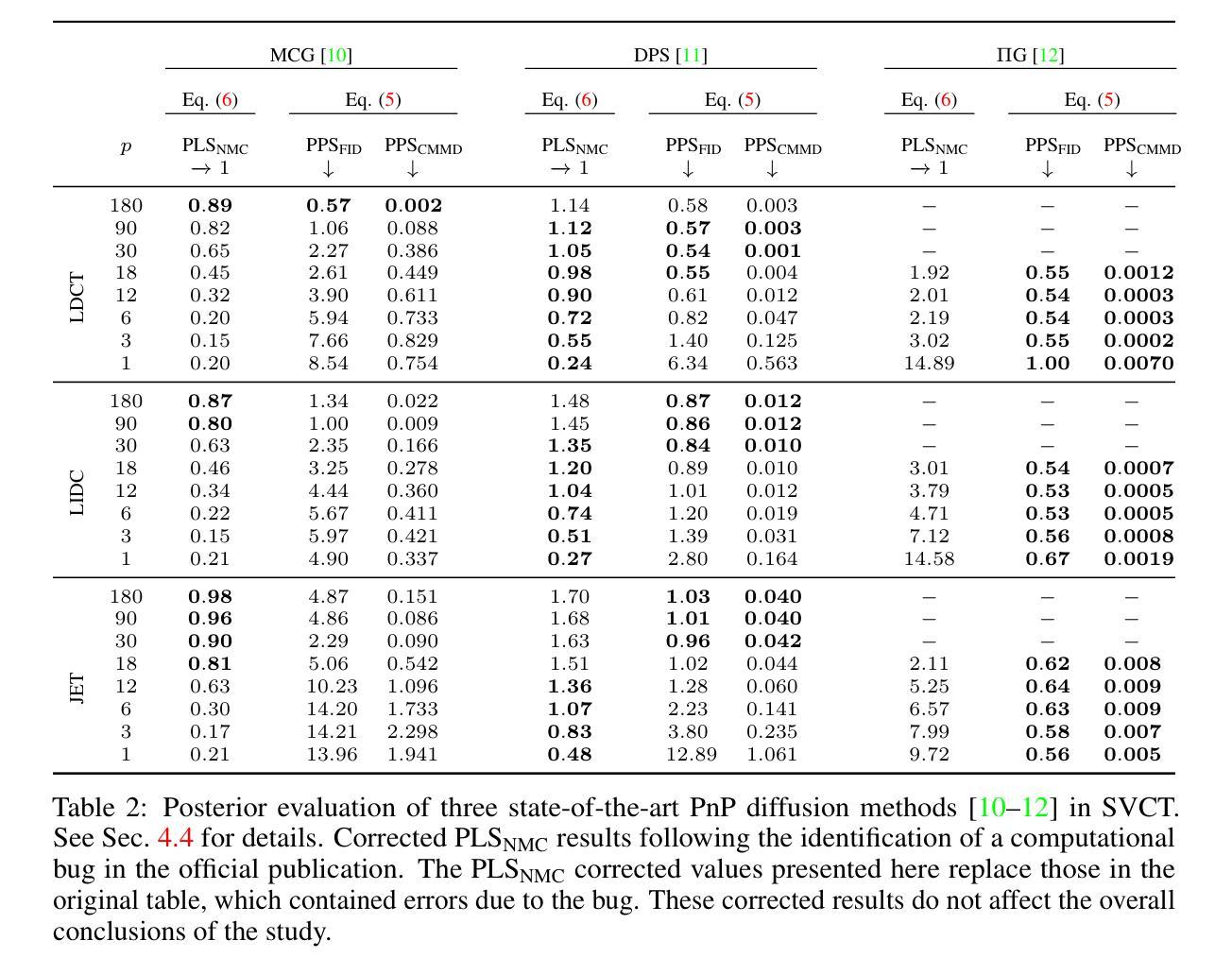
Evaluating the Posterior Sampling Ability of Plug&Play Diffusion Methods in Sparse-View CT
Authors:Liam Moroy, Guillaume Bourmaud, Frédéric Champagnat, Jean-François Giovannelli
Plug&Play (PnP) diffusion models are state-of-the-art methods in computed tomography (CT) reconstruction. Such methods usually consider applications where the sinogram contains a sufficient amount of information for the posterior distribution to be concentrated around a single mode, and consequently are evaluated using image-to-image metrics such as PSNR/SSIM. Instead, we are interested in reconstructing compressible flow images from sinograms having a small number of projections, which results in a posterior distribution no longer concentrated or even multimodal. Thus, in this paper, we aim at evaluating the approximate posterior of PnP diffusion models and introduce two posterior evaluation properties. We quantitatively evaluate three PnP diffusion methods on three different datasets for several numbers of projections. We surprisingly find that, for each method, the approximate posterior deviates from the true posterior when the number of projections decreases.
Plug&Play(PnP)扩散模型是计算机断层扫描(CT)重建领域的最前沿方法。这类方法通常应用于辛格尔图(sinogram)包含足够信息,使得后验分布集中在单一模式周围的情况。因此,它们通常使用图像到图像的指标(如PSNR/SSIM)进行评估。相反,我们对从辛格尔图重建可压缩流图像感兴趣,该辛格尔图具有较少的投影数,导致后验分布不再集中,甚至是多模态的。因此,本文旨在评估PnP扩散模型的近似后验概率,并引入两个后验评估属性。我们在三个不同的数据集上定量评估了三种PnP扩散方法的不同投影数量。令人惊讶的是,我们发现,对于每种方法,当投影数量减少时,近似后验分布都会偏离真实后验分布。
论文及项目相关链接
Summary
本文探讨了Plug&Play(PnP)扩散模型在计算层析成像(CT)重建中的最新应用。文章重点关注于从投影数量较少的辛克图(sinogram)重建可压缩流动图像的问题。由于投影数量减少,后验分布不再集中甚至呈现多模态。文章旨在评估PnP扩散模型的近似后验,并引入两个后验评估属性。通过对三种PnP扩散方法在三个不同数据集上进行定量评估,发现随着投影数量的减少,每种方法的近似后验都会偏离真实后验。
Key Takeaways
- PnP扩散模型在计算层析成像(CT)重建中处于前沿地位。
- 文章关注从投影数量较少的辛克图重建可压缩流动图像的问题。
- 由于投影数量减少,后验分布特性发生变化,不再集中甚至呈现多模态。
- 引入两个后验评估属性以评估PnP扩散模型的近似后验。
- 对三种PnP扩散方法在三个不同数据集上进行定量评估。
- 发现随着投影数量的减少,PnP扩散模型的近似后验会偏离真实后验。
点此查看论文截图


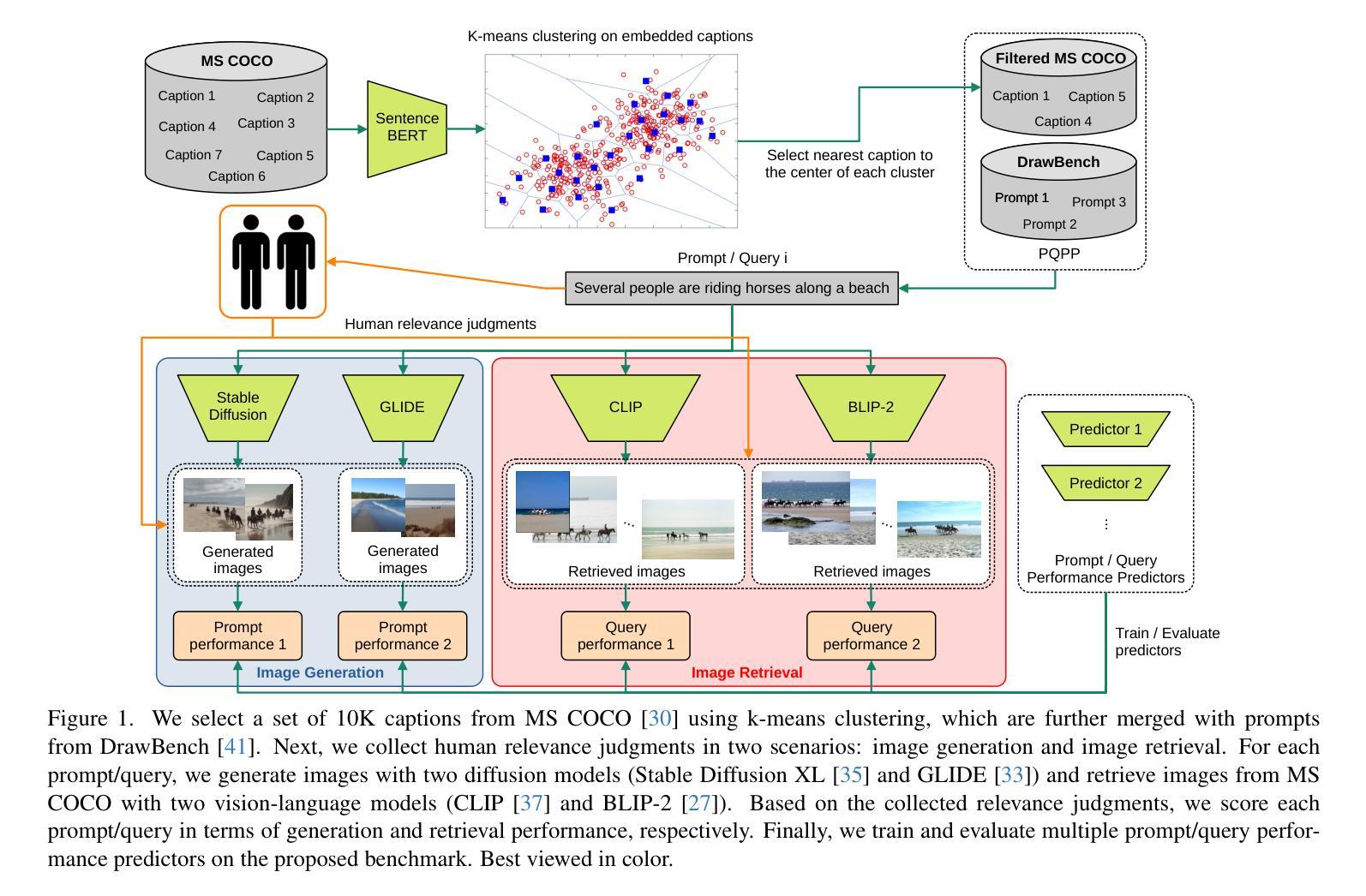
PQPP: A Joint Benchmark for Text-to-Image Prompt and Query Performance Prediction
Authors:Eduard Poesina, Adriana Valentina Costache, Adrian-Gabriel Chifu, Josiane Mothe, Radu Tudor Ionescu
Text-to-image generation has recently emerged as a viable alternative to text-to-image retrieval, driven by the visually impressive results of generative diffusion models. Although query performance prediction is an active research topic in information retrieval, to the best of our knowledge, there is no prior study that analyzes the difficulty of queries (referred to as prompts) in text-to-image generation, based on human judgments. To this end, we introduce the first dataset of prompts which are manually annotated in terms of image generation performance. Additionally, we extend these evaluations to text-to-image retrieval by collecting manual annotations that represent retrieval performance. We thus establish the first joint benchmark for prompt and query performance prediction (PQPP) across both tasks, comprising over 10K queries. Our benchmark enables (i) the comparative assessment of prompt/query difficulty in both image generation and image retrieval, and (ii) the evaluation of prompt/query performance predictors addressing both generation and retrieval. We evaluate several pre- and post-generation/retrieval performance predictors, thus providing competitive baselines for future research. Our benchmark and code are publicly available at https://github.com/Eduard6421/PQPP.
文本到图像生成作为一种可行的方法,已经逐渐崭露头角,成为文本到图像检索的一种替代方案,其背后驱动的是生成扩散模型的视觉令人印象深刻的结果。尽管查询性能预测在信息检索领域是一个热门的研究课题,但据我们所知,目前尚没有基于人类判断来分析文本到图像生成中的查询(称为提示)难度的研究。为此,我们引入了首个关于提示的手动标注数据集,这些提示是基于图像生成性能的。此外,我们还对这些评估进行了扩展,对文本到图像检索进行了手动标注,以代表检索性能。因此,我们建立了第一个针对图像生成和图像检索任务的提示和查询性能预测(PQPP)的联合基准测试,包含超过10万个查询。我们的基准测试可以进行:(i)对图像生成和图像检索中的提示/查询难度的比较评估;(ii)对同时处理生成和检索的提示/查询性能预测的评价。我们对多个预生成和生成后的性能预测器进行了评估,从而为未来的研究提供了竞争性的基准线。我们的基准测试和代码可在https://github.com/Eduard6421/PQPP公开访问。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
文本介绍了基于人类判断的首个针对文本到图像生成和文本到图像检索任务的查询性能预测数据集。该数据集包含超过10K个查询,旨在比较评估图像生成和图像检索中的查询难度,并评估针对这两个任务的查询性能预测器。此外,该研究还提供了一些预训练和后训练的查询性能预测器的竞争基线。该基准数据集和代码已公开发布在GitHub上。
Key Takeaways
- 文本介绍了基于人类判断的首个针对文本到图像生成和检索的查询性能预测数据集。
- 数据集包含超过10K个查询,旨在评估和比较文本到图像生成和检索中的查询难度。
- 数据集首次建立了一个联合基准测试平台,用于评估文本到图像生成和检索中的查询性能预测器。
- 该研究为未来的研究提供了预训练和后训练的查询性能预测器的竞争基线。
- 数据集可公开访问并提供代码示例。
- 该研究强调了评估文本到图像生成任务的重要性,尤其是查询性能的预测和分析。
点此查看论文截图




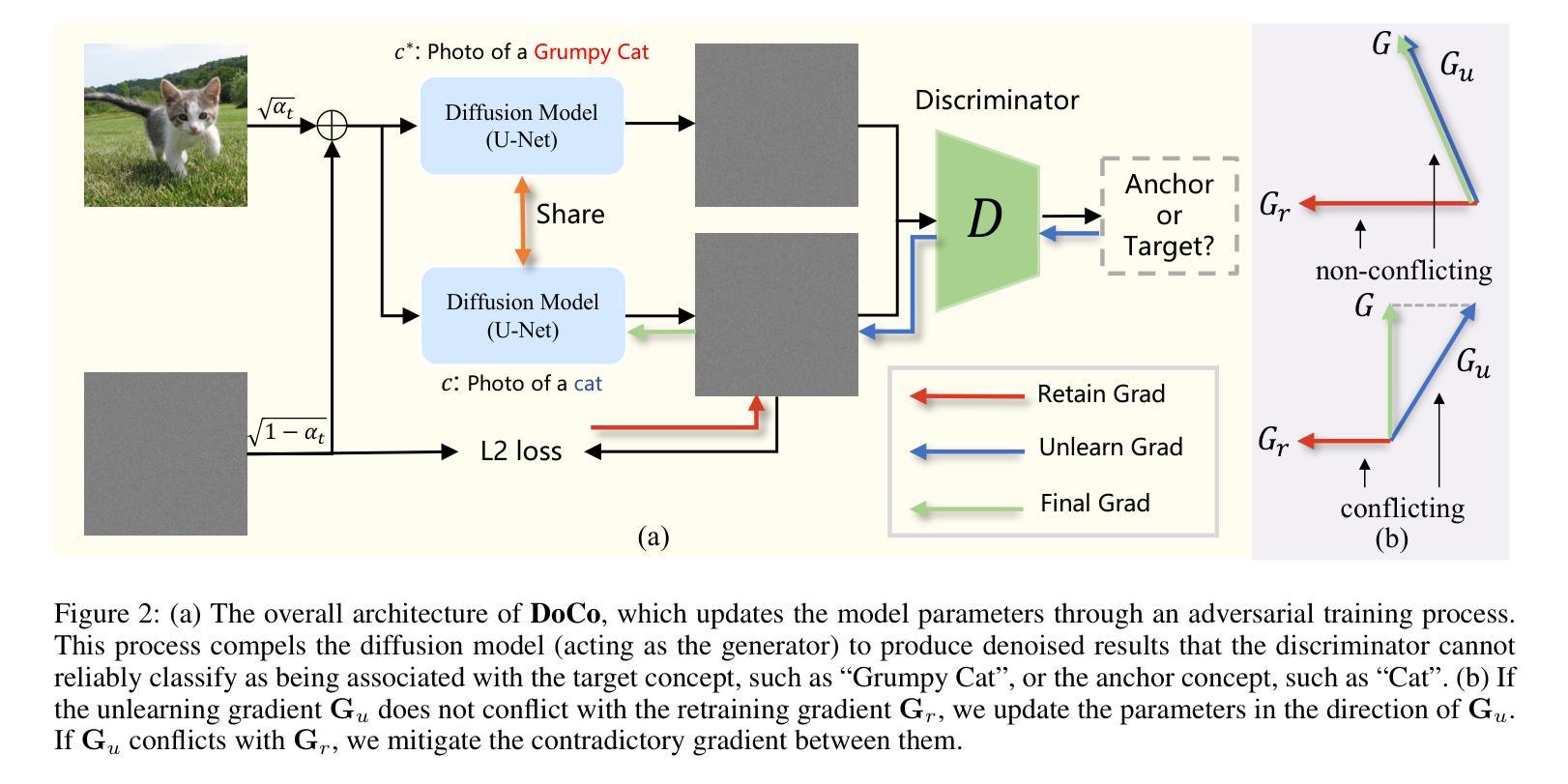
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
Authors:Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Heng Chang, Wenbo Zhu, Xinting Hu, Xiao Zhou, Xu Yang
Text-to-image diffusion models have achieved remarkable success in generating photorealistic images. However, the inclusion of sensitive information during pre-training poses significant risks. Machine Unlearning (MU) offers a promising solution to eliminate sensitive concepts from these models. Despite its potential, existing MU methods face two main challenges: 1) limited generalization, where concept erasure is effective only within the unlearned set, failing to prevent sensitive concept generation from out-of-set prompts; and 2) utility degradation, where removing target concepts significantly impacts the model’s overall performance. To address these issues, we propose a novel concept domain correction framework named \textbf{DoCo} (\textbf{Do}main \textbf{Co}rrection). By aligning the output domains of sensitive and anchor concepts through adversarial training, our approach ensures comprehensive unlearning of target concepts. Additionally, we introduce a concept-preserving gradient surgery technique that mitigates conflicting gradient components, thereby preserving the model’s utility while unlearning specific concepts. Extensive experiments across various instances, styles, and offensive concepts demonstrate the effectiveness of our method in unlearning targeted concepts with minimal impact on related concepts, outperforming previous approaches even for out-of-distribution prompts.
文本到图像的扩散模型在生成逼真图像方面取得了显著的成功。然而,预训练过程中敏感信息的包含带来了很大的风险。机器遗忘(MU)为从这些模型中消除敏感概念提供了有前景的解决方案。尽管潜力巨大,但现有的MU方法面临两个主要挑战:1)有限的泛化能力,概念消除只在未学习的集合中有效,未能防止来自集合外提示的敏感概念生成;2)效用降低,移除目标概念显著影响模型的总体性能。为了解决这些问题,我们提出了一种名为DoCo(领域修正)的新型概念域修正框架。通过对抗训练对齐敏感概念和锚概念的输出域,我们的方法确保了目标概念的全面遗忘。此外,我们引入了一种概念保留梯度手术技术,该技术减轻了冲突的梯度分量,从而在遗忘特定概念的同时保持模型的实用性。在各种实例、风格和冒犯概念方面的广泛实验表明,我们的方法在遗忘目标概念方面效果显著,对相关概念的影响最小,即使在离群提示的情况下也优于以前的方法。
论文及项目相关链接
PDF AAAI 2025 camera-ready version
Summary
文本到图像扩散模型在生成逼真图像方面取得了显著的成功,但在预训练过程中引入敏感信息存在重大风险。机器遗忘(MU)为解决这一问题提供了有前景的解决方案。然而,现有的MU方法面临两大挑战:一是通用性有限,仅在未学习的集合内有效,无法防止敏感概念从外部提示生成;二是效用降低,移除目标概念会影响模型的总体性能。为解决这些问题,我们提出了名为DoCo(领域修正)的新概念修正框架。通过对敏感概念和锚概念输出领域进行对齐,我们的方法确保了目标概念的全面遗忘。此外,我们引入了概念保留梯度手术技术,缓解冲突梯度成分,在遗忘特定概念的同时保留模型的实用性。广泛的实验表明,我们的方法在遗忘目标概念方面表现优越,对关联概念的影响最小,即使在超出分布范围的提示中也超过了以前的方法。
Key Takeaways
- 文本到图像扩散模型在生成逼真图像上表现出卓越的成功,但预训练中的敏感信息引入带来风险。
- 现有的机器遗忘(MU)方法存在两大挑战:有限通用性和效用降低。
- 提出名为DoCo的新概念修正框架,通过对敏感概念和锚概念输出领域进行对齐,确保目标概念的全面遗忘。
- 引入概念保留梯度手术技术,以缓解冲突梯度成分,从而在遗忘特定概念的同时保留模型的实用性。
- DoCo框架通过广泛的实验验证,表现优越于其他方法。
- DoCo框架能处理各种实例、风格和冒犯性概念,对目标概念的遗忘效果显著,对关联概念影响最小。
点此查看论文截图



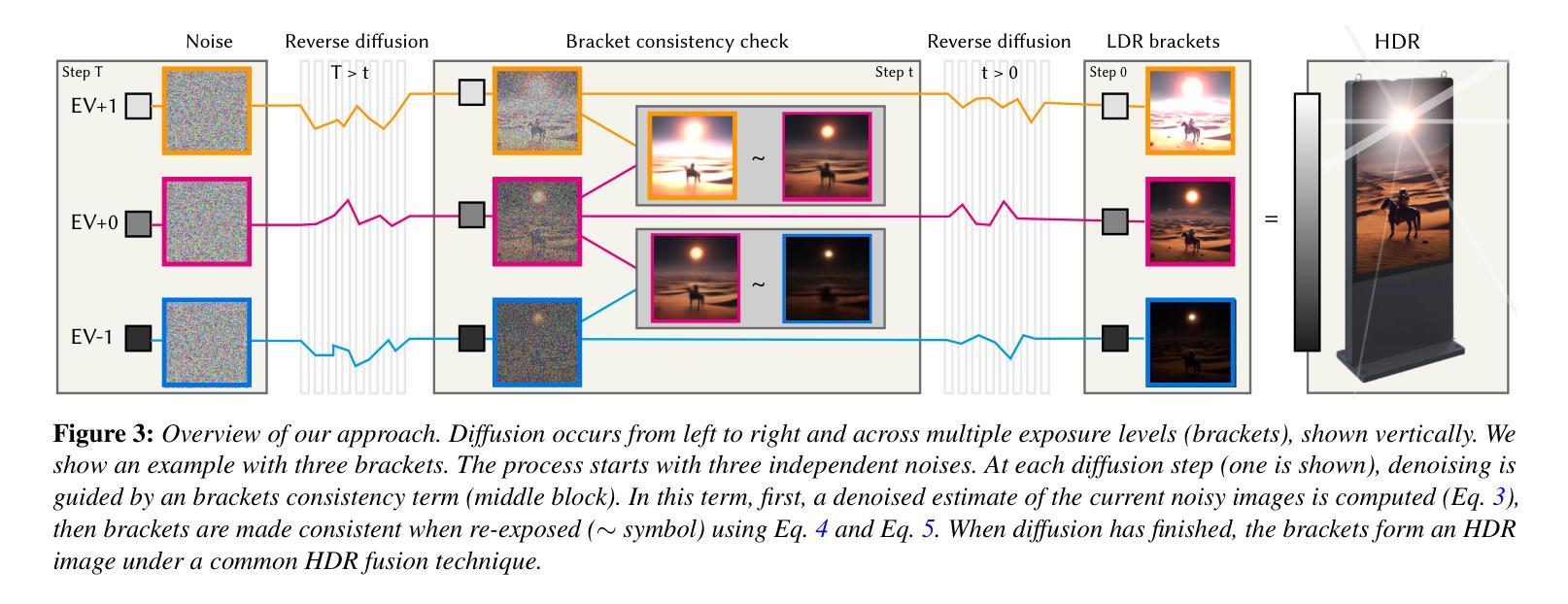
Bracket Diffusion: HDR Image Generation by Consistent LDR Denoising
Authors:Mojtaba Bemana, Thomas Leimkühler, Karol Myszkowski, Hans-Peter Seidel, Tobias Ritschel
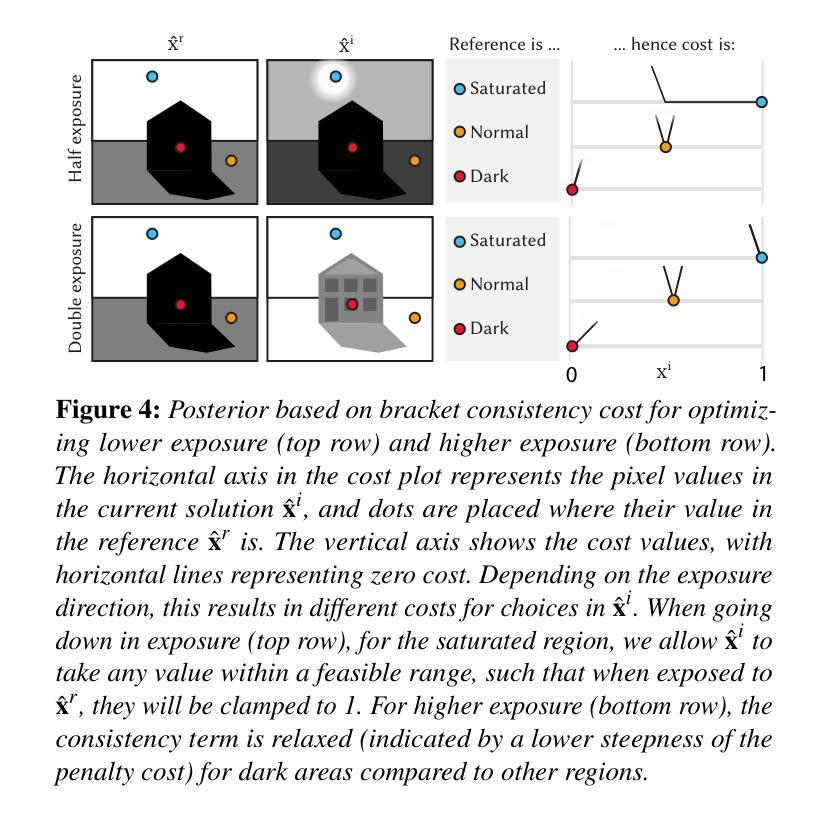
We demonstrate generating HDR images using the concerted action of multiple black-box, pre-trained LDR image diffusion models. Relying on a pre-trained LDR generative diffusion models is vital as, first, there is no sufficiently large HDR image dataset available to re-train them, and, second, even if it was, re-training such models is impossible for most compute budgets. Instead, we seek inspiration from the HDR image capture literature that traditionally fuses sets of LDR images, called “exposure brackets’’, to produce a single HDR image. We operate multiple denoising processes to generate multiple LDR brackets that together form a valid HDR result. The key to making this work is to introduce a consistency term into the diffusion process to couple the brackets such that they agree across the exposure range they share while accounting for possible differences due to the quantization error. We demonstrate state-of-the-art unconditional and conditional or restoration-type (LDR2HDR) generative modeling results, yet in HDR.
我们展示了如何利用多个预训练的LDR图像扩散模型的协同作用生成HDR图像。依赖预训练的LDR生成扩散模型至关重要,首先,目前没有足够大的HDR图像数据集可供重新训练,其次,即使有,大多数计算预算也无法重新训练这样的模型。相反,我们从HDR图像捕获文献中寻找灵感,该文献传统上将一组LDR图像(称为“曝光括号”)融合在一起,以产生单个HDR图像。我们执行多次去噪过程以生成多个LDR括号,这些括号共同形成一个有效的HDR结果。使这项工作成功的关键是向扩散过程引入一致性项,以耦合括号,使它们在共享的曝光范围内保持一致,同时考虑到由于量化误差可能导致的不同。我们展示了最先进的无条件和有条件的或恢复类型(LDR2HDR)生成建模结果,但仍然是HDR的。
论文及项目相关链接
PDF 11 pages, 14 figures, Accepted to Eurographics 2025, see https://bracketdiffusion.mpi-inf.mpg.de
摘要
我们展示了如何利用多个预训练的LDR图像扩散模型协同工作来生成HDR图像。由于目前尚没有足够大的HDR图像数据集可用于重新训练模型,且即使存在也难以承受大多数计算预算进行重训练,因此依赖预训练的LDR生成扩散模型至关重要。我们从HDR图像捕获的文献中获得灵感,这些文献通过融合一系列的LDR图像生成HDR图像。我们通过执行多次去噪过程生成多个LDR brackets来形成有效的HDR结果。该过程的关键在于在扩散过程中引入一致性术语,将不同曝光范围内的各个brackets组合起来,同时考虑可能的量化误差引起的差异。我们在HDR上展示了无条件和条件生成建模结果以及最先进的恢复型或重建型(LDR2HDR)结果。
关键见解
1. 利用多个预训练的LDR图像扩散模型协同生成HDR图像,无需大量数据重训模型。
2. HDR图像生成灵感来源于传统HDR图像捕获技术中的融合多个LDR图像的方法。
3. 通过执行多次去噪过程生成多个LDR brackets形成HDR结果。
4. 在扩散过程中引入一致性术语来组合不同曝光范围的brackets。考虑量化误差引起的差异。
5. HDR图像生成技术实现了无条件生成建模和条件生成建模(如恢复或重建型)。
6. 该方法对于解决当前缺乏足够大的HDR图像数据集的问题具有关键作用。即使存在数据集也难以承受大多数计算预算进行重训练的问题。
7. 此方法提高了从LDR图像生成HDR图像的建模性能和质量。
点此查看论文截图





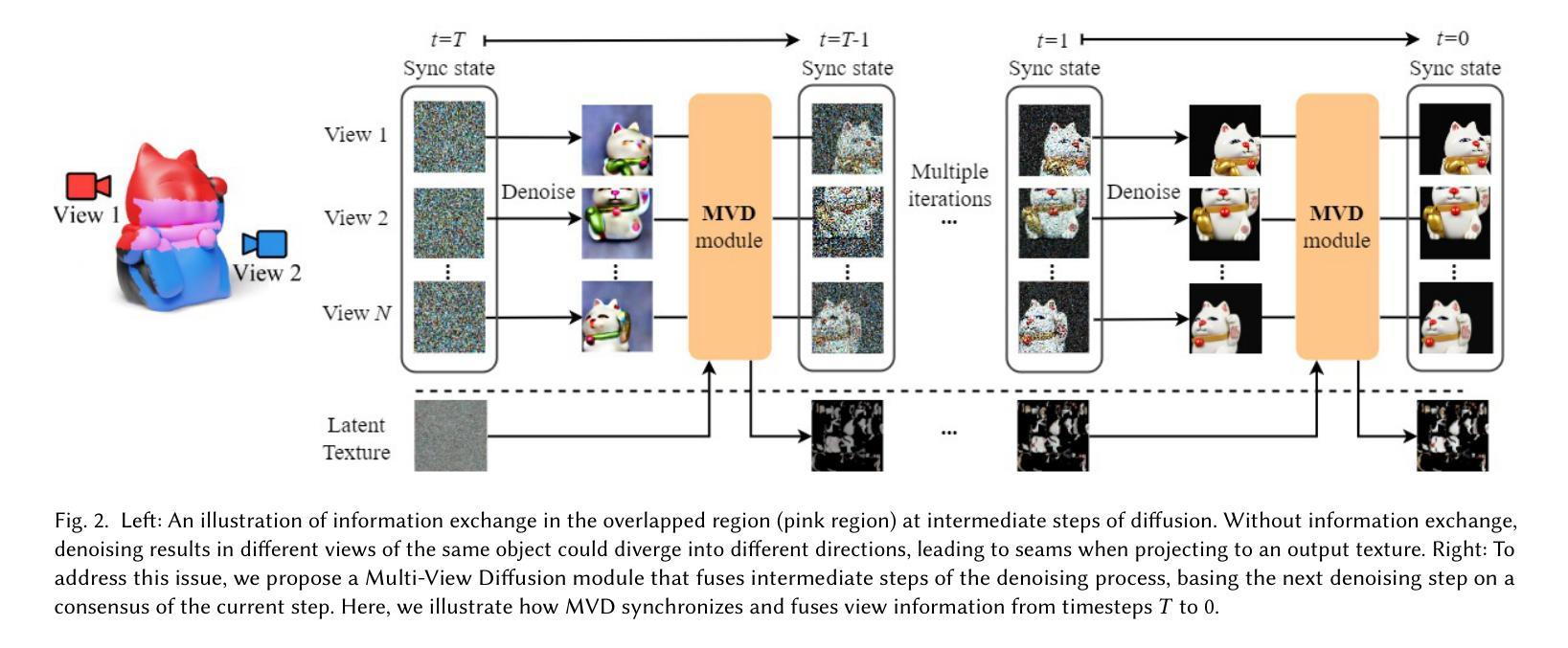
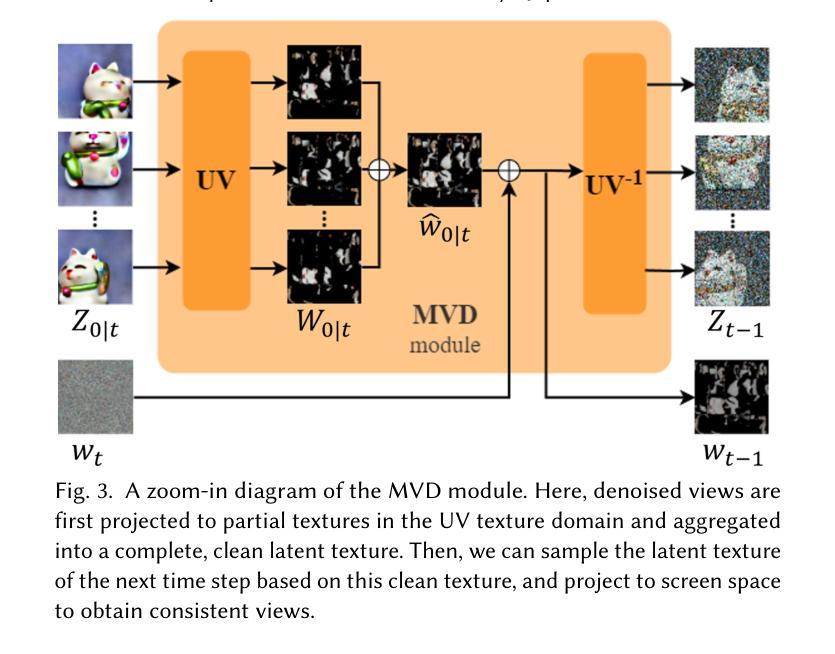
Text-Guided Texturing by Synchronized Multi-View Diffusion
Authors:Yuxin Liu, Minshan Xie, Hanyuan Liu, Tien-Tsin Wong
This paper introduces a novel approach to synthesize texture to dress up a given 3D object, given a text prompt. Based on the pretrained text-to-image (T2I) diffusion model, existing methods usually employ a project-and-inpaint approach, in which a view of the given object is first generated and warped to another view for inpainting. But it tends to generate inconsistent texture due to the asynchronous diffusion of multiple views. We believe such asynchronous diffusion and insufficient information sharing among views are the root causes of the inconsistent artifact. In this paper, we propose a synchronized multi-view diffusion approach that allows the diffusion processes from different views to reach a consensus of the generated content early in the process, and hence ensures the texture consistency. To synchronize the diffusion, we share the denoised content among different views in each denoising step, specifically blending the latent content in the texture domain from views with overlap. Our method demonstrates superior performance in generating consistent, seamless, highly detailed textures, comparing to state-of-the-art methods.
本文介绍了一种根据文本提示对给定3D对象进行纹理合成的新方法。基于预训练的文本到图像(T2I)扩散模型,现有方法通常采用投影和填充的方法,首先生成给定对象的视图,并将其扭曲到另一个视图进行填充。但由于多视图的异步扩散,这种方法往往会产生不一致的纹理。我们认为,这种异步扩散以及视图之间信息分享不足是不一致纹理的根源。本文提出了一种同步多视图扩散方法,允许不同视图的扩散过程在早期就达成共识,从而确保纹理的一致性。为了同步扩散,我们在每个去噪步骤中分享不同视图的去噪内容,特别是混合来自重叠视图的纹理域中的潜在内容。与最先进的方法相比,我们的方法在生成一致、无缝、高细节的纹理方面表现出卓越的性能。
论文及项目相关链接
PDF 11 pages, 11 figures, technical papers, “Text, Texturing, and Stylization”@SIGGRAPH Asia 2024
Summary
本文介绍了一种基于预训练文本到图像(T2I)扩散模型的新方法,用于根据文本提示合成纹理以装饰给定的3D对象。针对现有方法的不足,如异步扩散和信息共享不足导致的纹理不一致问题,本文提出了一种同步多视图扩散方法,通过在不同视图的扩散过程中实现早期内容共识,确保纹理一致性。该方法通过在每个去噪步骤中共享去噪内容,并特别融合来自重叠视图的纹理域潜在内容,展示了生成一致、无缝、高细节纹理的优越性能。
Key Takeaways
- 介绍了基于文本提示合成纹理以装饰3D对象的新方法。
- 现有方法采用投影和修复(project-and-inpaint)方式,但存在纹理不一致问题。
- 纹理不一致的根本原因是异步扩散和视图间信息分享不足。
- 提出了同步多视图扩散方法,确保不同视图在扩散过程中早期达成内容共识。
- 通过在每一步去噪过程中共享去噪内容,并融合重叠视图的潜在内容来提高性能。
- 该方法生成了更一致、无缝、高细节的纹理。
点此查看论文截图