⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Authors:Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, Yiqun Liu
This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
本文介绍了JuDGE(判决文书生成评估)这一新的基准测试,该测试旨在评估中文法律体系中判决文书生成的性能。我们将任务定义为根据给定的案件事实描述生成完整的法律判决书。为了促进这一基准测试,我们构建了一个综合数据集,其中包括来自真实法律案件的案件事实描述及其相应的完整判决书,这些判决书作为评估生成文档质量的真实标准。该数据集通过两个外部法律语料库进行扩充,为任务提供了额外的法律知识:一个包含法规和条例,另一个则包含大量过去的判决书。我们与法律专业人士合作,建立了一个全面的自动化评估框架,从多个维度评估生成的判决书的质量。我们评估了各种基线方法,包括小样本上下文学习、微调以及多源检索增强生成(RAG)方法,使用通用和法律领域的LLMs。实验结果表明,虽然RAG方法可以有效提高此任务性能,但仍存在很大的改进空间。所有代码和数据集均可在:https://github.com/oneal2000/JuDGE找到。
论文及项目相关链接
Summary
本文介绍了JuDGE(判决文书生成评估)基准测试,该测试旨在评估中文法律系统中判决文书生成系统的性能。该任务被定义为根据给定的案件事实描述生成完整的法律判决书。为支持此基准测试,构建了包含真实法律案例的事实描述以及与相应完整判决书配对的数据集,作为评估生成文档质量的基准。此外,还通过两个外部法律语料库提供额外的法律知识,包括法规和条例以及大量过去的判决书。与法务专业人士合作,建立了一个全面的自动化评估框架,以评估生成判决书的质量。评估了几种基线方法,包括少样本上下文学习、微调以及多源检索增强生成(RAG)方法,使用通用和法律领域的LLMs。实验结果表明,虽然RAG方法可以有效提高此任务性能,但仍存在很大的改进空间。
Key Takeaways
- JuDGE是一个针对中文法律系统判决文书生成的基准测试。
- 任务是基于案件事实描述生成完整的法律判决书。
- 构建了包含真实案例的事实描述和相应判决书的综合数据集。
- 利用外部法律语料库提供额外法律知识。
- 建立了一个全面的自动化评估框架来评估生成的判决书质量。
- 评估了几种基线方法,包括少样本学习和多源检索增强生成方法。
点此查看论文截图


Efficient Transfer Learning for Video-language Foundation Models
Authors:Haoxing Chen, Zizheng Huang, Yan Hong, Yanshuo Wang, Zhongcai Lyu, Zhuoer Xu, Jun Lan, Zhangxuan Gu
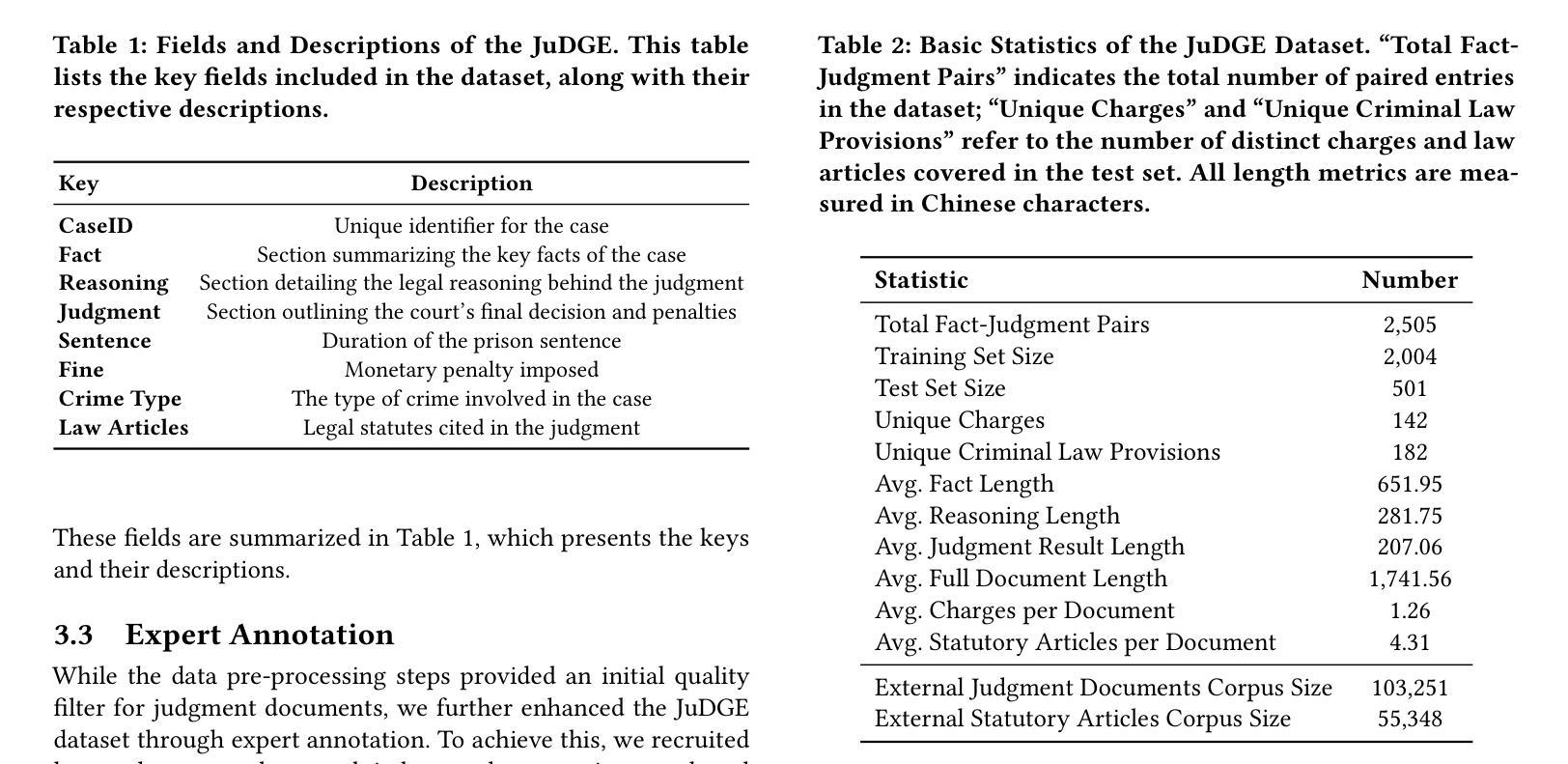
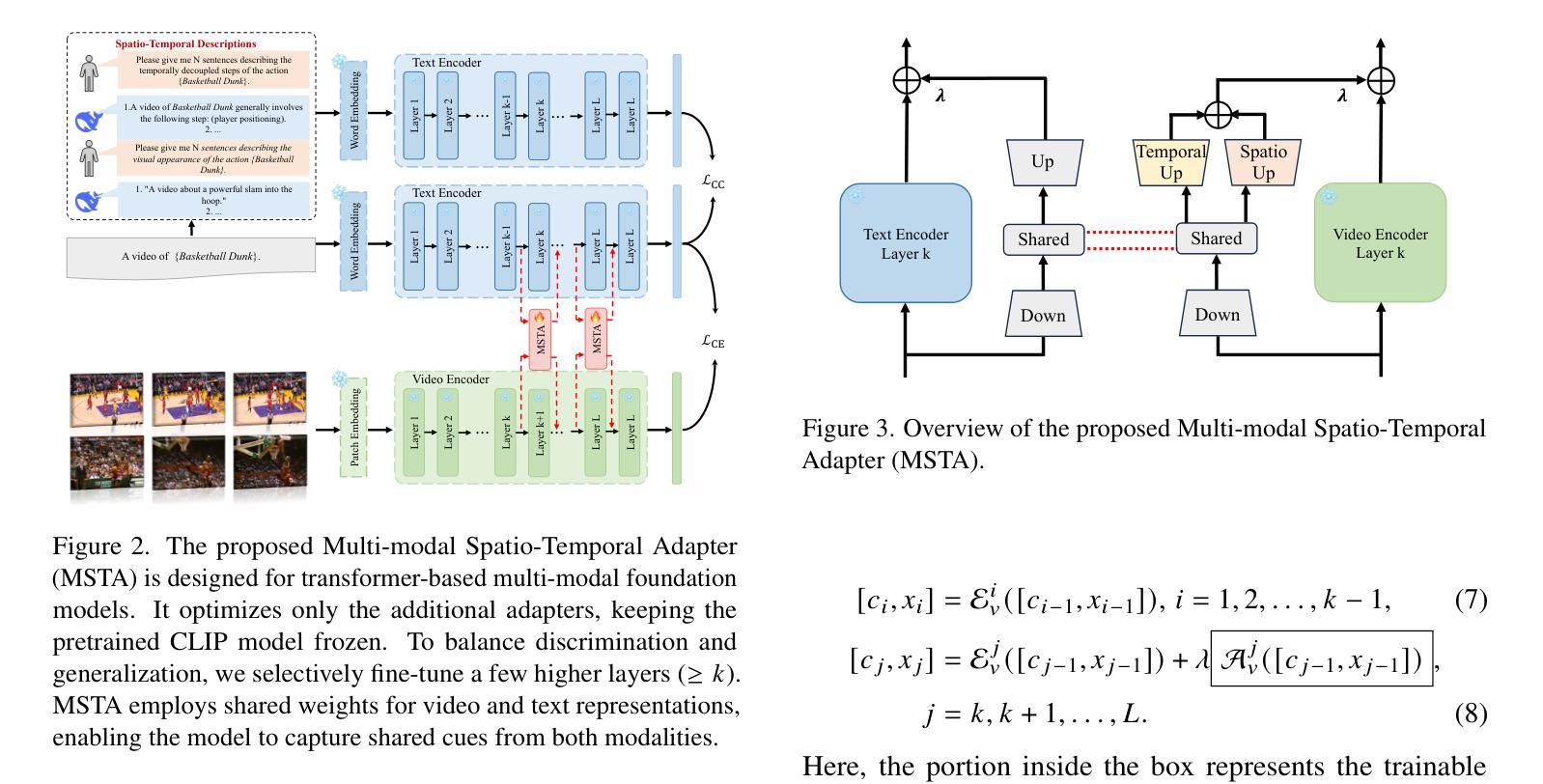
Pre-trained vision-language models provide a robust foundation for efficient transfer learning across various downstream tasks. In the field of video action recognition, mainstream approaches often introduce additional modules to capture temporal information. Although the additional modules increase the capacity of model, enabling it to better capture video-specific inductive biases, existing methods typically introduce a substantial number of new parameters and are prone to catastrophic forgetting of previously acquired generalizable knowledge. In this paper, we propose a parameter-efficient Multi-modal Spatio-Temporal Adapter (MSTA) to enhance the alignment between textual and visual representations, achieving a balance between generalizable knowledge and task-specific adaptation. Furthermore, to mitigate over-fitting and enhance generalizability, we introduce a spatio-temporal description-guided consistency constraint.This constraint involves providing template inputs (e.g., “a video of {\textbf{cls}}“) to the trainable language branch and LLM-generated spatio-temporal descriptions to the pre-trained language branch, enforcing output consistency between the branches. This approach reduces overfitting to downstream tasks and enhances the distinguishability of the trainable branch within the spatio-temporal semantic space. We evaluate the effectiveness of our approach across four tasks: zero-shot transfer, few-shot learning, base-to-novel generalization, and fully-supervised learning. Compared to many state-of-the-art methods, our MSTA achieves outstanding performance across all evaluations, while using only 2-7% of the trainable parameters in the original model.
预训练视觉语言模型为各种下游任务的高效迁移学习提供了坚实的基础。在视频动作识别领域,主流方法通常引入额外的模块来捕获时间信息。虽然额外的模块增加了模型的容量,使其能够更好地捕捉视频特定的归纳偏见,但现有方法通常引入大量新参数,并容易遗忘先前获得的可推广知识。在本文中,我们提出了一种参数有效的多模态时空适配器(MSTA),以提高文本和视觉表示之间的对齐,在可推广知识和任务特定适应之间取得平衡。此外,为了缓解过拟合并增强泛化能力,我们引入了时空描述引导的一致性约束。该约束涉及向可训练的语言分支提供模板输入(例如,“一个包含{\textbf{cls}}的视频”),并向预训练的语言分支提供LLM生成的时空描述,强制两个分支之间的输出一致性。这种方法减少了下游任务的过度拟合,增强了可训练分支在时空语义空间中的可区分性。我们在四项任务上评估了我们的方法的有效性:零样本迁移、小样例学习、基础到新颖的泛化以及完全监督学习。与许多最新方法相比,我们的MSTA在所有评估中都取得了卓越的性能,同时只使用了原始模型中2-7%的可训练参数。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
预训练视觉语言模型为高效跨各种下游任务的迁移学习提供了坚实的基础。针对视频动作识别领域,主流方法通常引入额外的模块来捕获时间信息。本文提出了一种参数有效的多模态时空适配器(MSTA),增强了文本和视觉表示之间的对齐,实现了通用知识和任务特定适应之间的平衡。此外,为了减轻过拟合并增强泛化能力,引入了时空描述引导的一致性约束。该约束涉及向可训练的语言分支提供模板输入(例如,“一个包含{\textbf{cls}}的视频”),并向预训练的语言分支提供LLM生成的时空描述,强制两个分支之间的输出一致性。该方法减少了过度拟合下游任务的情况,增强了可训练分支在时空语义空间内的区分度。在零样本迁移、小样学习、基础到新颖的泛化和全监督学习四项任务中验证了MSTA的有效性。与许多最先进的方法相比,我们的MSTA在所有评估中都取得了出色的表现,同时使用的可训练参数仅为原始模型的2-7%。
Key Takeaways
- 预训练视觉语言模型为迁移学习提供了坚实的基础。
- 主流视频动作识别方法通过引入额外模块来捕获时间信息,但可能引入大量新参数并容易遗忘先前学到的通用知识。
- 提出了一种参数有效的多模态时空适配器(MSTA),以增强文本和视觉表示之间的对齐。
- 引入了时空描述引导的一致性约束,以提高模型的泛化能力并减少过度拟合。
- 该方法通过强制两个分支之间的输出一致性来优化模型性能。
- MSTA在四项任务中均表现出卓越性能,使用的可训练参数相对较少。
点此查看论文截图

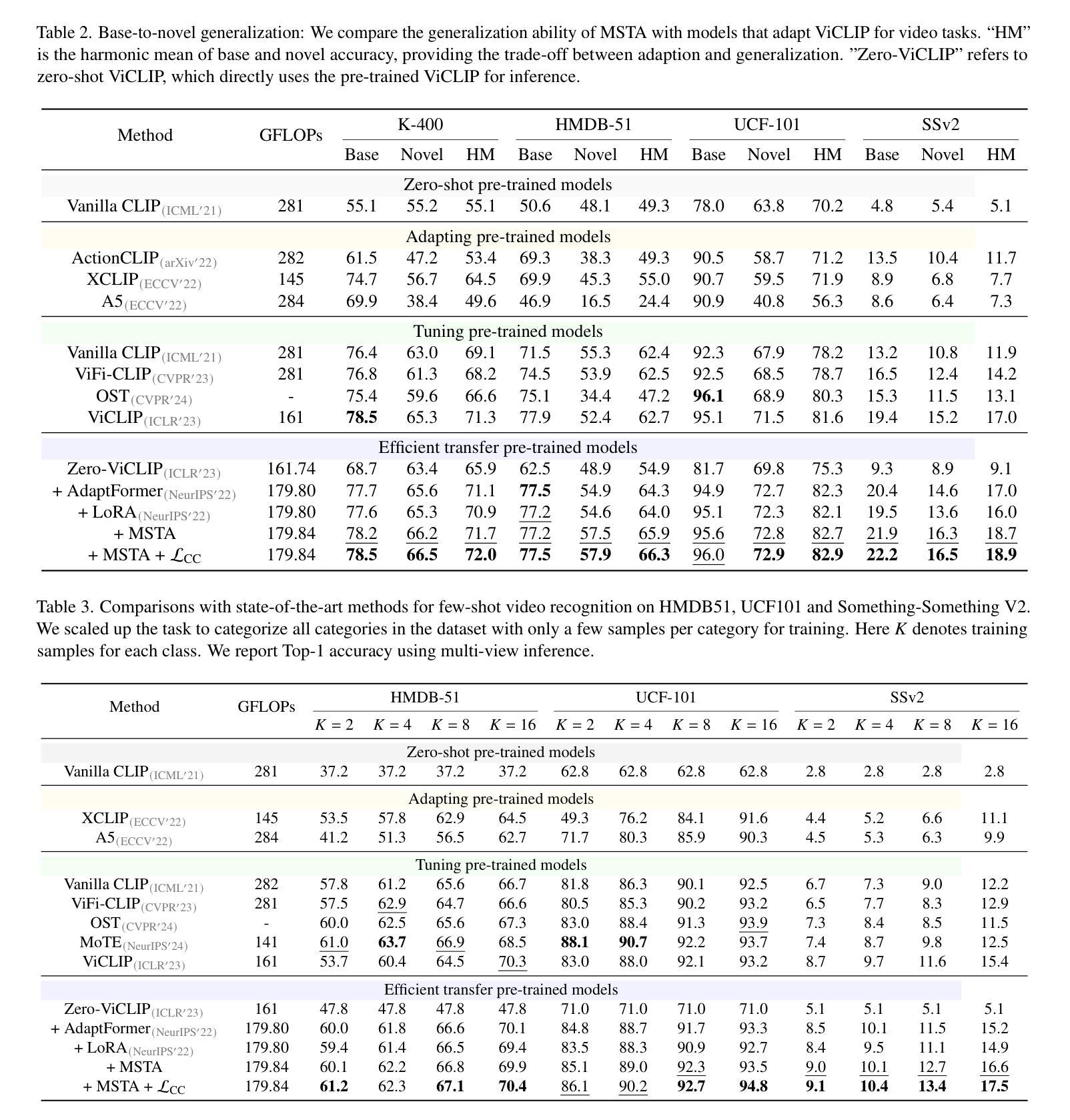
Zero-Shot Action Recognition in Surveillance Videos
Authors:Joao Pereira, Vasco Lopes, David Semedo, Joao Neves
The growing demand for surveillance in public spaces presents significant challenges due to the shortage of human resources. Current AI-based video surveillance systems heavily rely on core computer vision models that require extensive finetuning, which is particularly difficult in surveillance settings due to limited datasets and difficult setting (viewpoint, low quality, etc.). In this work, we propose leveraging Large Vision-Language Models (LVLMs), known for their strong zero and few-shot generalization, to tackle video understanding tasks in surveillance. Specifically, we explore VideoLLaMA2, a state-of-the-art LVLM, and an improved token-level sampling method, Self-Reflective Sampling (Self-ReS). Our experiments on the UCF-Crime dataset show that VideoLLaMA2 represents a significant leap in zero-shot performance, with 20% boost over the baseline. Self-ReS additionally increases zero-shot action recognition performance to 44.6%. These results highlight the potential of LVLMs, paired with improved sampling techniques, for advancing surveillance video analysis in diverse scenarios.
随着公共空间中监控需求的不断增长,由于人力资源短缺,这带来了重大挑战。当前基于人工智能的视频监控系统严重依赖于计算机视觉模型的核心技术,这需要大量的微调。然而,在监控环境中,由于数据集有限和设置困难(如观点、质量等),这尤其困难。在这项工作中,我们提议利用大型视觉语言模型(LVLMs)来解决监控中的视频理解任务,它们以强大的零样本和少样本泛化能力而闻名。具体来说,我们探索了最前沿的LVLM——VideoLLaMA2和改进的令牌级别采样方法——自我反射采样(Self-ReS)。我们在UCF-Crime数据集上的实验表明,VideoLLaMA2在零样本性能上实现了重大突破,比基线提高了20%。此外,Self-ReS将零样本动作识别性能提高了至44.6%。这些结果凸显了LVLMs与改进后的采样技术相结合在多种场景中推进监控视频分析的潜力。
论文及项目相关链接
Summary
AI在视频监控领域的应用面临人力资源短缺的挑战。本研究提出利用强大的零样本和少样本泛化能力的大型视觉语言模型(LVLMs)来解决视频监控中的理解任务。通过探索先进的LVLM——VideoLLaMA2和改进的token级别采样方法Self-Reflective Sampling(Self-ReS),在UCF-Crime数据集上的实验表明,VideoLLaMA2的零样本性能实现了显著的提升,相比基线有20%的提升。同时,Self-ReS将零样本动作识别性能提升至44.6%。这突显了LVLMs与改进采样技术在多种场景下的视频监控分析潜力。
Key Takeaways
- 公共空间的监控需求增长,但人力资源短缺,使得AI在视频监控领域的应用面临挑战。
- 当前AI视频监控系统主要依赖计算机视觉模型,需要大量微调,但在监控环境中由于数据集有限和设置复杂,这一任务尤为困难。
- 研究提出利用大型视觉语言模型(LVLMs)来解决视频理解任务,特别是VideoLLaMA2模型表现出强大的零样本和少样本泛化能力。
- VideoLLaMA2模型在UCF-Crime数据集上的零样本性能显著提升,相比基线有20%的提升。
- 研究的另一个亮点是提出的改进token级别采样方法——Self-Reflective Sampling(Self-ReS),它能进一步提高零样本动作识别性能至44.6%。
- LVLMs与改进采样技术的结合,为多种场景下的视频监控分析提供了巨大潜力。
点此查看论文截图

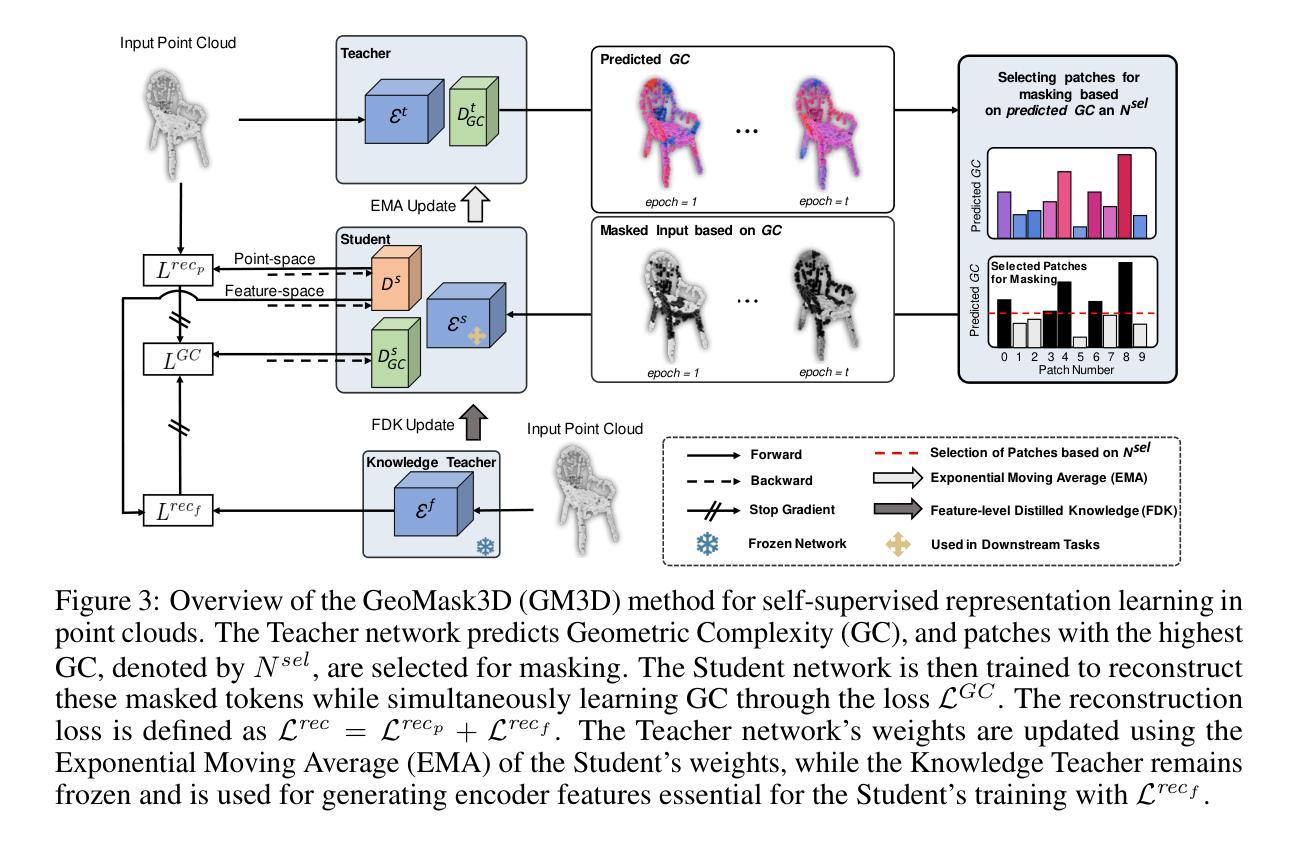
GeoMask3D: Geometrically Informed Mask Selection for Self-Supervised Point Cloud Learning in 3D
Authors:Ali Bahri, Moslem Yazdanpanah, Mehrdad Noori, Milad Cheraghalikhani, Gustavo Adolfo Vargas Hakim, David Osowiechi, Farzad Beizaee, Ismail Ben Ayed, Christian Desrosiers
We introduce a pioneering approach to self-supervised learning for point clouds, employing a geometrically informed mask selection strategy called GeoMask3D (GM3D) to boost the efficiency of Masked Auto Encoders (MAE). Unlike the conventional method of random masking, our technique utilizes a teacher-student model to focus on intricate areas within the data, guiding the model’s focus toward regions with higher geometric complexity. This strategy is grounded in the hypothesis that concentrating on harder patches yields a more robust feature representation, as evidenced by the improved performance on downstream tasks. Our method also presents a complete-to-partial feature-level knowledge distillation technique designed to guide the prediction of geometric complexity utilizing a comprehensive context from feature-level information. Extensive experiments confirm our method’s superiority over State-Of-The-Art (SOTA) baselines, demonstrating marked improvements in classification, and few-shot tasks.
我们介绍了一种用于点云的自我监督学习的开创性方法,采用了一种称为GeoMask3D(GM3D)的几何信息掩码选择策略,以提高掩码自动编码器(MAE)的效率。与传统的随机掩码方法不同,我们的技术采用师徒模型,专注于数据中的复杂区域,引导模型关注几何复杂性更高的区域。该策略基于假设,即关注更困难的补丁会产生更稳健的特征表示,如下游任务性能提高所证明的那样。我们的方法还提出了一种从全面到局部的特征级知识蒸馏技术,旨在利用特征级信息的全面上下文来指导几何复杂性的预测。大量实验证明我们的方法在最新技术基准上表现卓越,在分类和少镜头任务上表现出显着改进。
论文及项目相关链接
Summary
本文介绍了一种用于点云数据的自监督学习方法,采用名为GeoMask3D(GM3D)的几何信息掩码选择策略,提高Masked Auto Encoders(MAE)的效率。该方法利用教师-学生模型聚焦于数据中的复杂区域,假设关注较难的部分会得到更稳健的特征表示,并在下游任务中表现出更好的性能。此外,还提出了一种从全面特征信息中引导几何复杂度预测的全到部分特征级知识蒸馏技术。实验证明,该方法优于现有技术基线,在分类和少镜头任务中有显著改进。
Key Takeaways
- 引入了一种创新的自监督学习方法,用于点云数据的处理。
- 采用了名为GeoMask3D的几何信息掩码选择策略,提高Masked Auto Encoders的效率。
- 教师-学生模型聚焦于数据的复杂区域,以提高特征表示的稳健性。
- 假设关注较难的数据部分可以更好地在下游任务中表现。
- 提出了一种全到部分特征级别的知识蒸馏技术,用于从全面的特征信息中引导几何复杂度的预测。
- 实验证明该方法优于现有技术基线。
点此查看论文截图

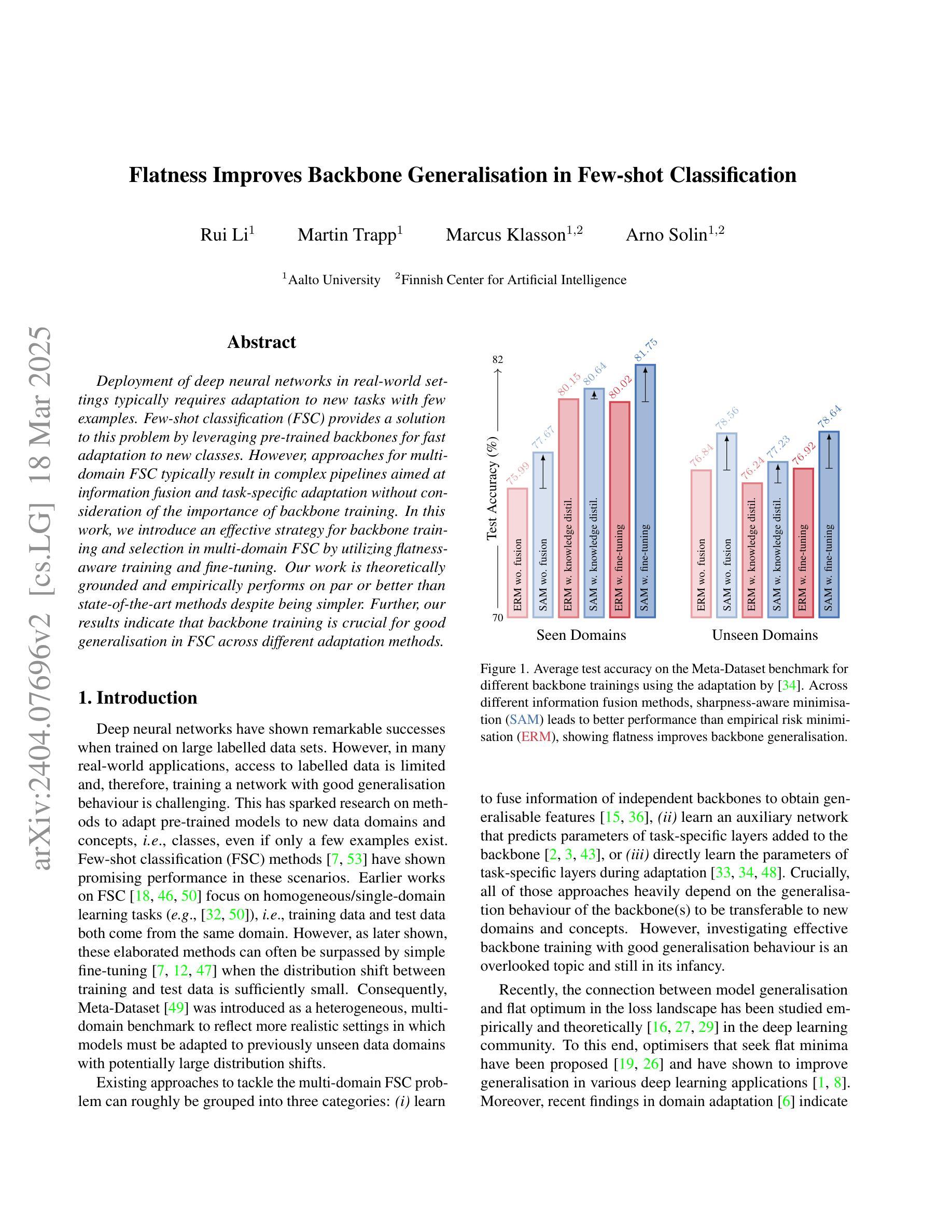
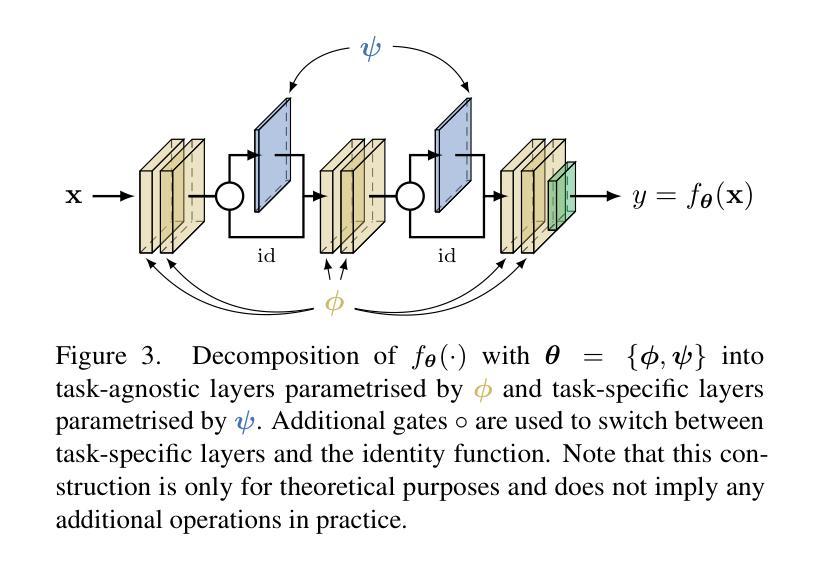
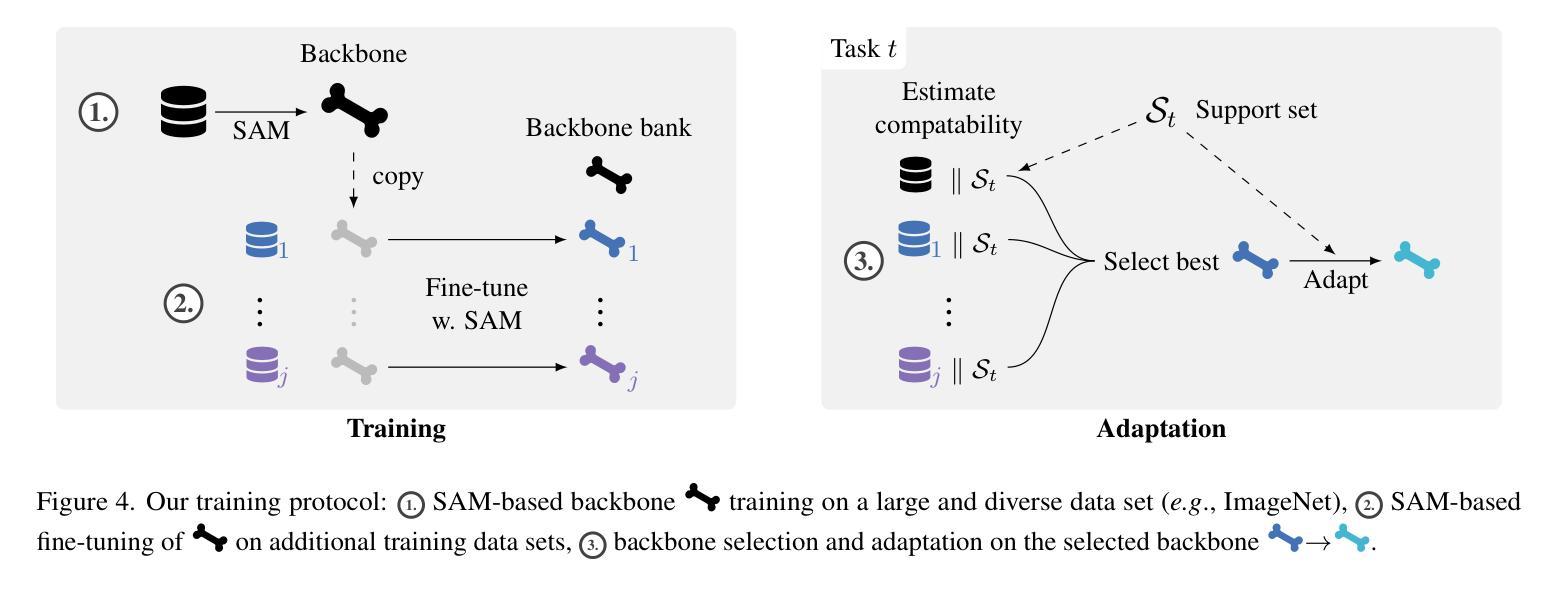
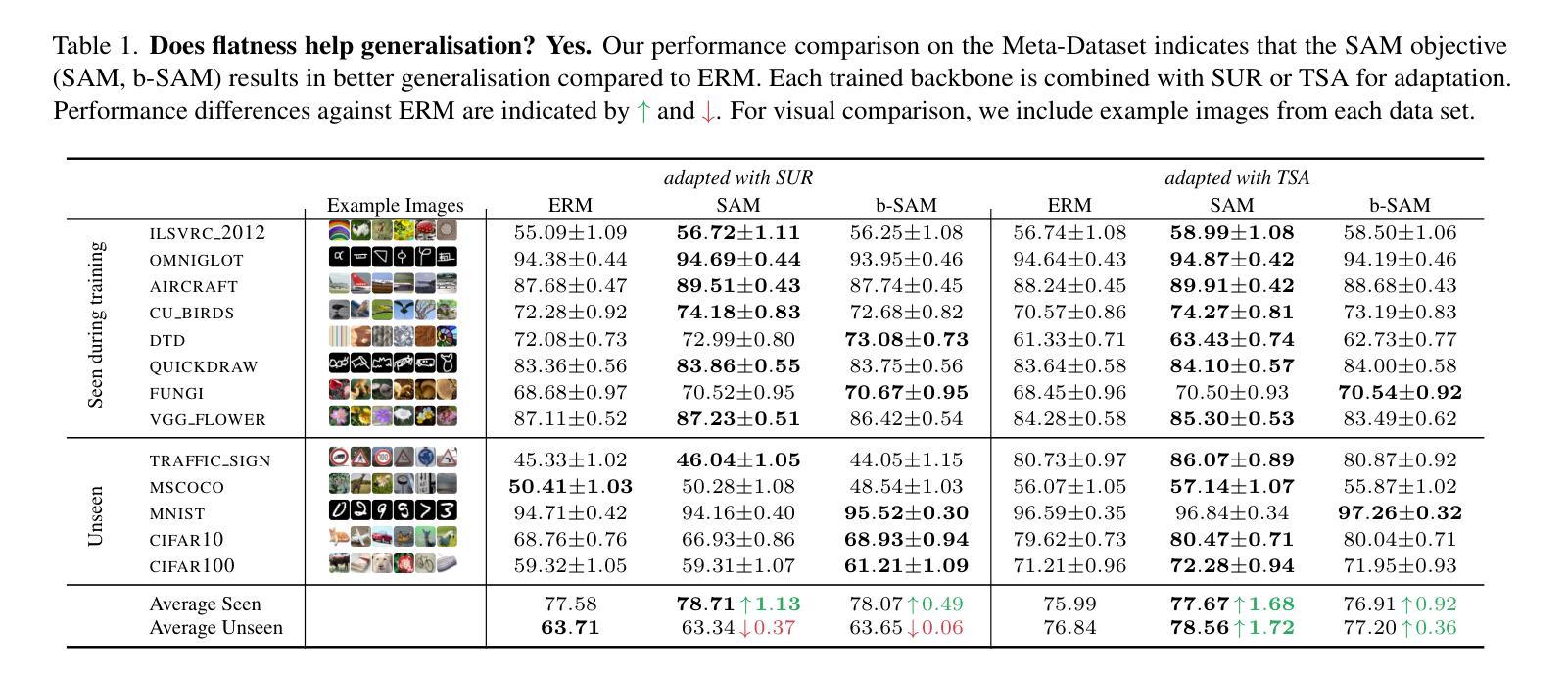
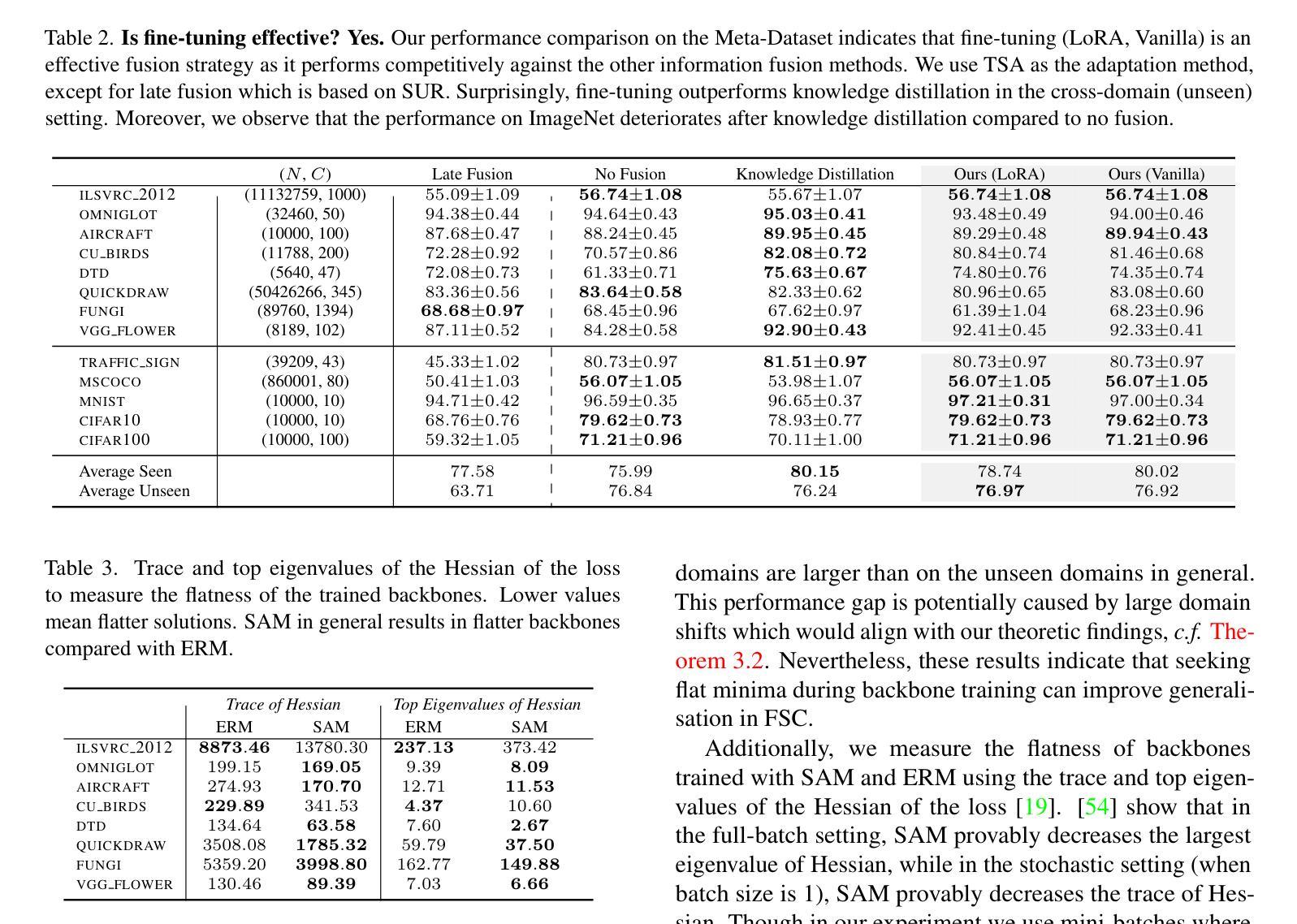
Flatness Improves Backbone Generalisation in Few-shot Classification
Authors:Rui Li, Martin Trapp, Marcus Klasson, Arno Solin
Deployment of deep neural networks in real-world settings typically requires adaptation to new tasks with few examples. Few-shot classification (FSC) provides a solution to this problem by leveraging pre-trained backbones for fast adaptation to new classes. However, approaches for multi-domain FSC typically result in complex pipelines aimed at information fusion and task-specific adaptation without consideration of the importance of backbone training. In this work, we introduce an effective strategy for backbone training and selection in multi-domain FSC by utilizing flatness-aware training and fine-tuning. Our work is theoretically grounded and empirically performs on par or better than state-of-the-art methods despite being simpler. Further, our results indicate that backbone training is crucial for good generalisation in FSC across different adaptation methods.
深度神经网络在实际环境中的部署通常需要适应具有少量示例的新任务。小样本分类(FSC)通过利用预训练的主干网络进行快速适应新类别来解决这个问题。然而,多域FSC的方法通常导致复杂的管道,旨在进行信息融合和任务特定适应,而没有考虑到主干训练的重要性。在这项工作中,我们介绍了一种利用平坦感知训练和微调的有效策略来进行多域FSC中的主干训练和选择。我们的工作是建立在理论基础上的,并且在实践中与最新方法的表现相当或更好,尽管它更简单。此外,我们的结果表明,主干训练对于不同适应方法在FSC中的良好泛化至关重要。
论文及项目相关链接
Summary
本文介绍了在多域小样本分类(FSC)中利用平坦感知训练和微调的有效策略进行骨干训练与选择的方法。该方法注重骨干训练的重要性,并在不同适应方法中实现良好的泛化性能。
Key Takeaways
- 少数样本分类(FSC)利用预训练骨干网快速适应新类别。
- 多域FSC的方法通常导致复杂的管道,侧重于信息融合和任务特定适应。
- 本文提出一种有效策略进行骨干训练与选择,利用平坦感知训练和微调。
- 该策略在理论上有依据,并在实证上表现良好,与现有先进技术相当或更好,同时更为简洁。
- 强调骨干训练在小样本分类中的重要性。
- 本文方法在不同适应方法中实现良好的泛化性能。
点此查看论文截图

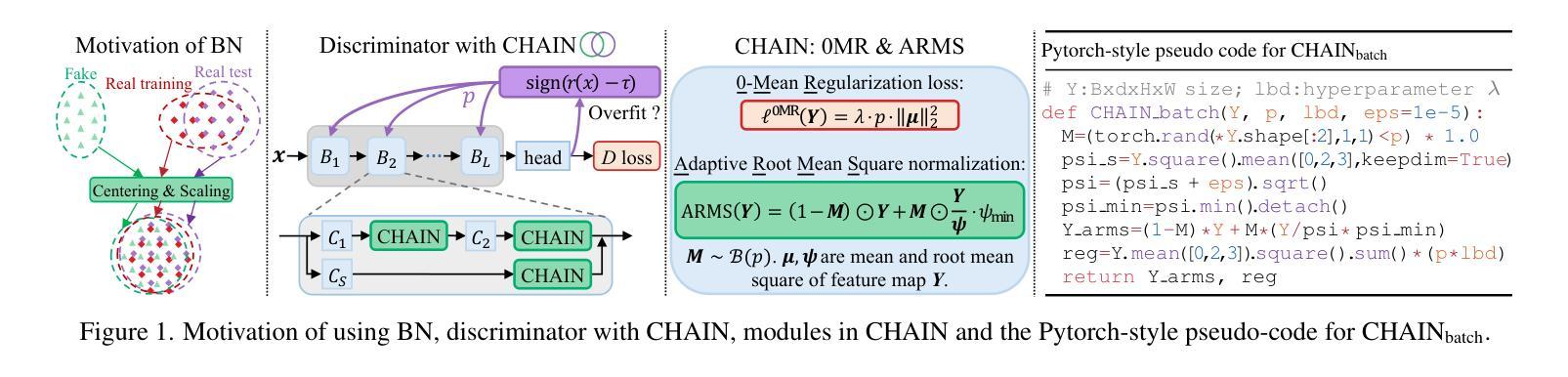
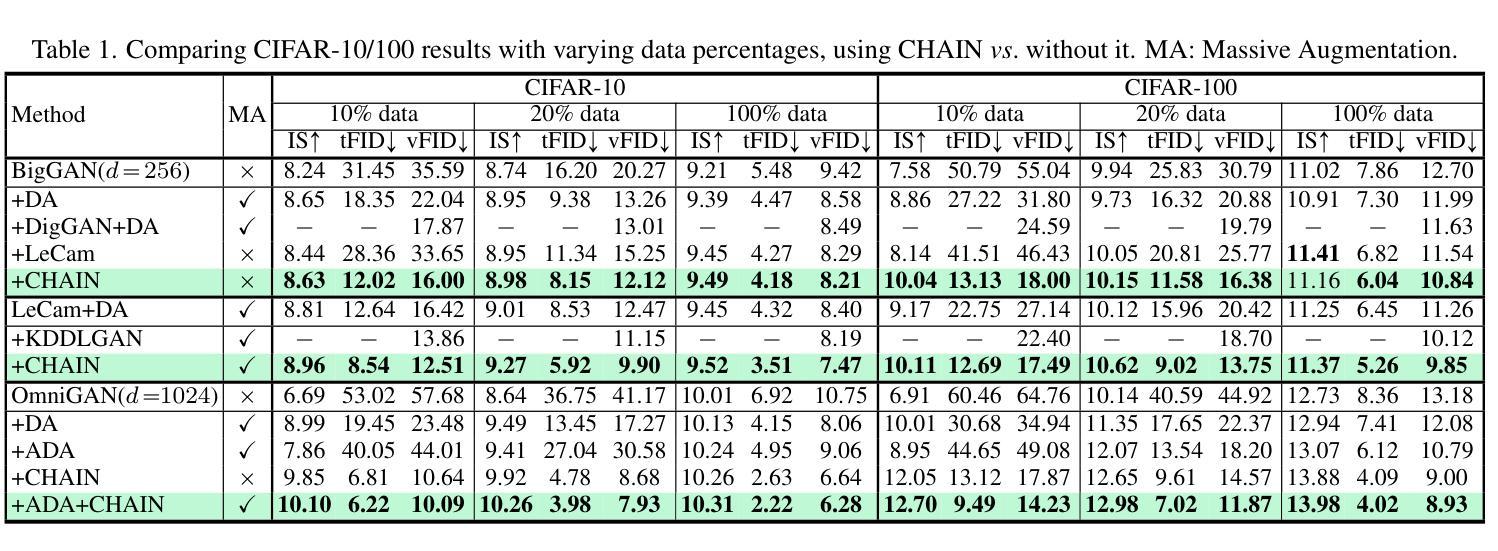
CHAIN: Enhancing Generalization in Data-Efficient GANs via lipsCHitz continuity constrAIned Normalization
Authors:Yao Ni, Piotr Koniusz
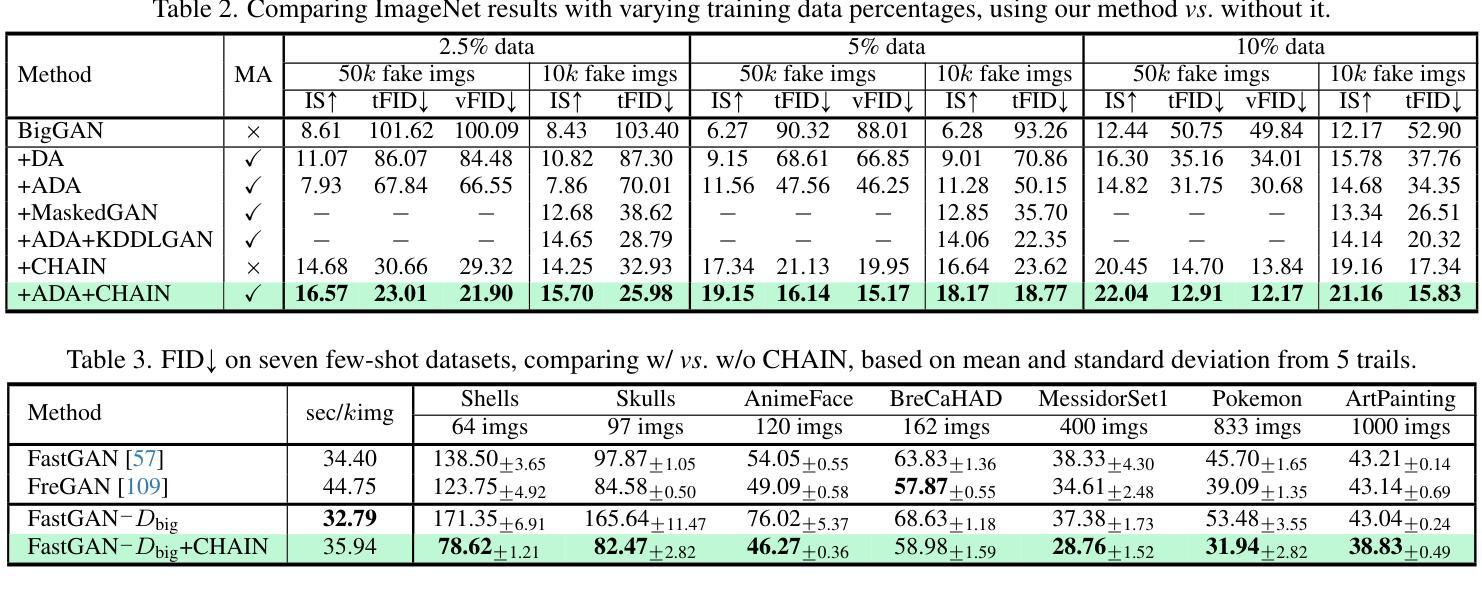
Generative Adversarial Networks (GANs) significantly advanced image generation but their performance heavily depends on abundant training data. In scenarios with limited data, GANs often struggle with discriminator overfitting and unstable training. Batch Normalization (BN), despite being known for enhancing generalization and training stability, has rarely been used in the discriminator of Data-Efficient GANs. Our work addresses this gap by identifying a critical flaw in BN: the tendency for gradient explosion during the centering and scaling steps. To tackle this issue, we present CHAIN (lipsCHitz continuity constrAIned Normalization), which replaces the conventional centering step with zero-mean regularization and integrates a Lipschitz continuity constraint in the scaling step. CHAIN further enhances GAN training by adaptively interpolating the normalized and unnormalized features, effectively avoiding discriminator overfitting. Our theoretical analyses firmly establishes CHAIN’s effectiveness in reducing gradients in latent features and weights, improving stability and generalization in GAN training. Empirical evidence supports our theory. CHAIN achieves state-of-the-art results in data-limited scenarios on CIFAR-10/100, ImageNet, five low-shot and seven high-resolution few-shot image datasets. Code: https://github.com/MaxwellYaoNi/CHAIN
生成对抗网络(GANs)在图像生成方面取得了重大进展,但其性能严重依赖于大量的训练数据。在数据有限的情况下,GANs经常面临判别器过拟合和训练不稳定的问题。尽管批标准化(BN)已知可以提高泛化和训练稳定性,但在数据高效GAN的判别器中很少使用。我们的工作通过识别BN中的关键缺陷来解决这一问题:在中心化和缩放步骤中梯度爆炸的倾向。为了解决这一问题,我们提出了CHAIN(受lipsCHitz连续性约束的归一化),它用零均值正则化替代了传统的中心化步骤,并在缩放步骤中集成了Lipschitz连续性约束。CHAIN通过自适应地插值归一化和未归一化的特征,有效地避免了判别器过拟合,进一步增强了GAN的训练。我们的理论分析有力地证明了CHAIN在降低潜在特征和权重梯度方面的有效性,提高了GAN训练的稳定性和泛化能力。经验证据支持我们的理论。在CIFAR-10/100、ImageNet、五个低镜头和七个高分辨率的小样本图像数据集上,CHAIN在数据有限的情况下实现了最新结果。代码:https://github.com/MaxwellYaoNi/CHAIN
论文及项目相关链接
PDF Accepted by CVPR 2024. 26 pages. Code: https://github.com/MaxwellYaoNi/CHAIN
Summary
工作解决了Batch Normalization在GAN训练中的数据效率问题,提出了一种新的归一化方法CHAIN,通过改进Batch Normalization中的梯度爆炸问题,有效避免判别器过拟合,提高GAN在有限数据场景下的性能和稳定性。
Key Takeaways
- GANs在图像生成方面取得了显著进展,但在有限数据场景下表现不佳,面临判别器过拟合和训练不稳定的问题。
- Batch Normalization虽然能提高泛化和训练稳定性,但在数据效率高的GANs的判别器中很少使用。
- 工作发现Batch Normalization中存在梯度爆炸的问题。
- CHAIN方法提出用零均值正则化替代传统中心化步骤,并在缩放步骤中引入Lipschitz连续性约束。
- CHAIN通过自适应插值归一化和未归一化的特征,有效避免判别器过拟合。
- CHAIN在CIFAR-10/100、ImageNet、五个低分辨率和七个高分辨率的少量数据集上实现了最佳结果。
点此查看论文截图

Few-Shot Learning for Mental Disorder Detection: A Continuous Multi-Prompt Engineering Approach with Medical Knowledge Injection
Authors:Haoxin Liu, Wenli Zhang, Jiaheng Xie, Buomsoo Kim, Zhu Zhang, Yidong Chai, Sudha Ram
This study harnesses state-of-the-art AI technology for detecting mental disorders through user-generated textual content. Existing studies typically rely on fully supervised machine learning, which presents challenges such as the labor-intensive manual process of annotating extensive training data for each research problem and the need to design specialized deep learning architectures for each task. We propose a novel method to address these challenges by leveraging large language models and continuous multi-prompt engineering, which offers two key advantages: (1) developing personalized prompts that capture each user’s unique characteristics and (2) integrating structured medical knowledge into prompts to provide context for disease detection and facilitate predictive modeling. We evaluate our method using three widely prevalent mental disorders as research cases. Our method significantly outperforms existing methods, including feature engineering, architecture engineering, and discrete prompt engineering. Meanwhile, our approach demonstrates success in few-shot learning, i.e., requiring only a minimal number of training examples. Moreover, our method can be generalized to other rare mental disorder detection tasks with few positive labels. In addition to its technical contributions, our method has the potential to enhance the well-being of individuals with mental disorders and offer a cost-effective, accessible alternative for stakeholders beyond traditional mental disorder screening methods.
本研究运用最先进的AI技术,通过用户生成的文本内容检测精神疾病。现有研究通常依赖于完全监督的机器学习方法,这带来了为每个研究问题对大量训练数据进行繁琐的手动标注以及为每个任务设计专门的深度学习架构的挑战。我们提出了一种新方法来解决这些挑战,该方法利用大型语言模型和连续的多提示工程,提供了两个主要优势:(1)开发个性化的提示,以捕捉每个用户的独特特征;(2)将结构化医学知识融入提示中,为疾病检测提供背景,促进预测建模。我们使用三种普遍存在的精神疾病作为研究案例来评估我们的方法。我们的方法显著优于现有方法,包括特征工程、架构工程和离散提示工程。同时,我们的方法在小样本学习方面取得了成功,即只需极少量的训练样本。此外,我们的方法可以推广到其他具有少量正面标签的罕见精神疾病检测任务。除了技术贡献外,我们的方法还有可能提高精神疾病患者的福祉,并为传统精神疾病筛查方法以外的利益相关者提供成本效益高、易于获得的替代方案。
论文及项目相关链接
Summary
本文利用先进的AI技术,通过用户生成的文本内容检测精神疾病。针对现有研究依赖全监督机器学习所面临的挑战,如为每个研究问题手动标注大量训练数据的劳动密集型过程和需要为每个任务设计专门的深度学习架构,我们提出了一种新方法。该方法利用大型语言模型和连续多提示工程,具有两个关键优势:一是开发能够捕捉每个用户独特特性的个性化提示,二是将结构化医学知识融入提示中,为疾病检测提供背景信息,促进预测建模。我们采用三种常见的精神疾病作为研究案例来评估我们的方法,结果显示该方法显著优于现有方法,包括特征工程、架构工程和离散提示工程。此外,该方法在少样本学习上取得了成功,即只需要极少量的训练样本。同时,我们的方法可以推广到其他具有少量阳性标签的罕见精神疾病检测任务。除了技术贡献外,该方法还有助于提高精神疾病的个体的福祉水平,并为传统精神疾病筛查方法之外的利益相关者提供成本效益高、易于访问的替代方案。
Key Takeaways
- 本研究使用先进的AI技术通过用户生成的文本内容检测精神疾病。
- 现有研究面临的挑战包括手动标注大量数据和设计专门架构的需求。
- 提出一种结合大型语言模型和连续多提示工程的新方法来解决这些挑战。
- 个性化提示能够捕捉用户的独特特性,同时融入医学知识以提高检测准确性。
- 该方法在三种常见精神疾病的检测上显著优于现有方法。
- 该方法在少样本学习上表现出优势,并有望推广到罕见精神疾病的检测任务。
点此查看论文截图

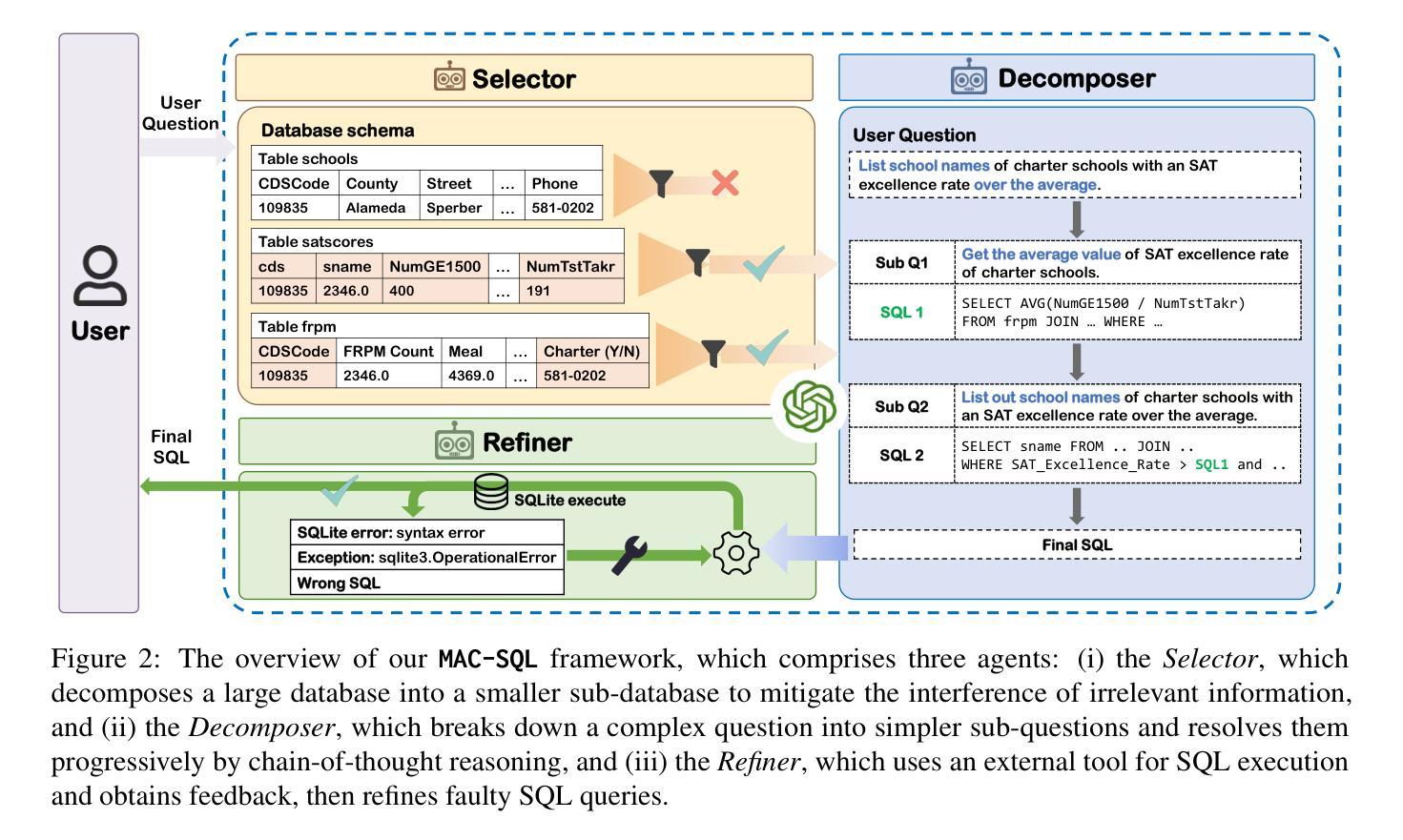
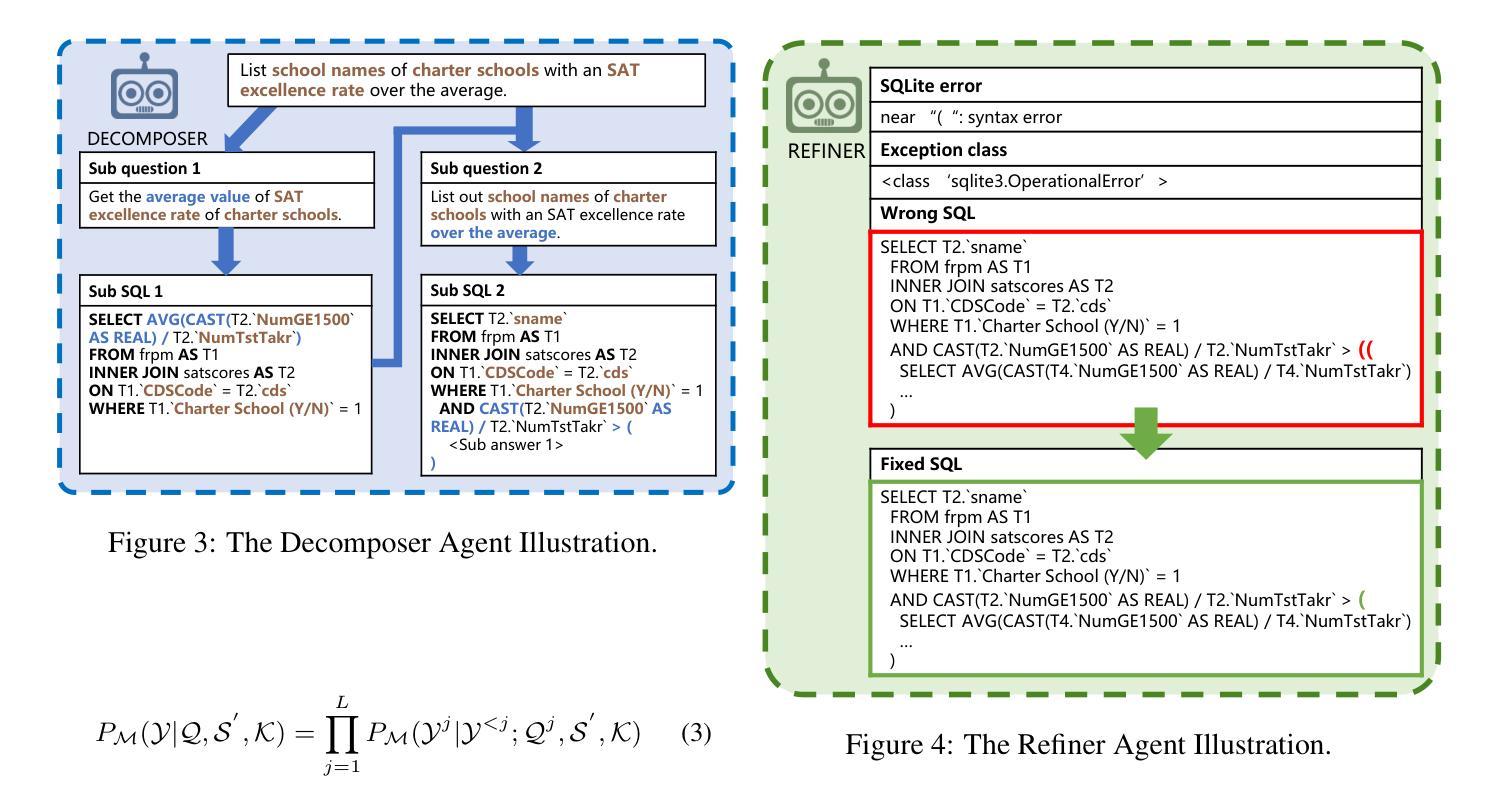
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Authors:Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, LinZheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, Zhoujun Li
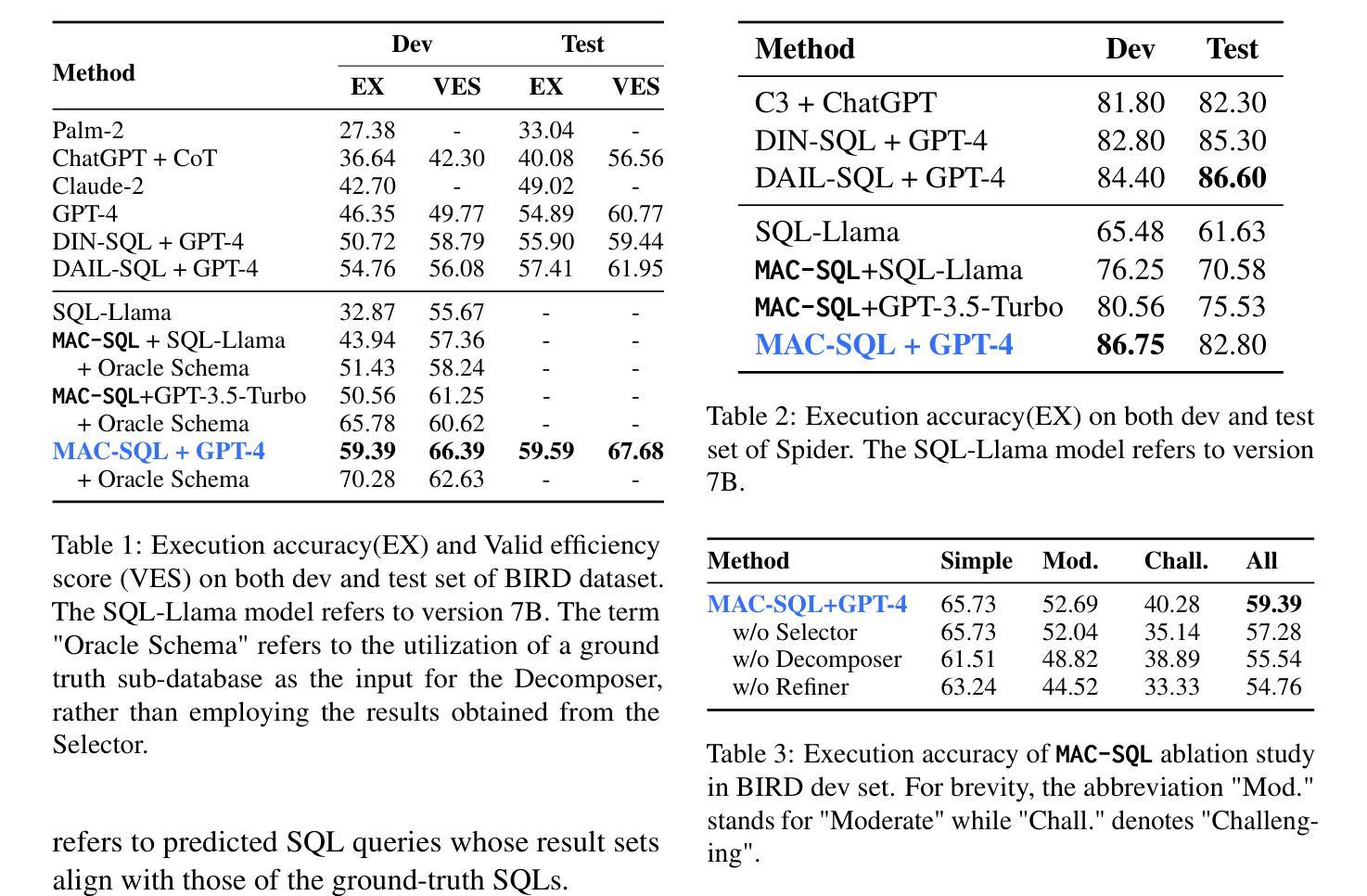
Recent LLM-based Text-to-SQL methods usually suffer from significant performance degradation on “huge” databases and complex user questions that require multi-step reasoning. Moreover, most existing methods neglect the crucial significance of LLMs utilizing external tools and model collaboration. To address these challenges, we introduce MAC-SQL, a novel LLM-based multi-agent collaborative framework. Our framework comprises a core decomposer agent for Text-to-SQL generation with few-shot chain-of-thought reasoning, accompanied by two auxiliary agents that utilize external tools or models to acquire smaller sub-databases and refine erroneous SQL queries. The decomposer agent collaborates with auxiliary agents, which are activated as needed and can be expanded to accommodate new features or tools for effective Text-to-SQL parsing. In our framework, We initially leverage GPT-4 as the strong backbone LLM for all agent tasks to determine the upper bound of our framework. We then fine-tune an open-sourced instruction-followed model, SQL-Llama, by leveraging Code Llama 7B, to accomplish all tasks as GPT-4 does. Experiments show that SQL-Llama achieves a comparable execution accuracy of 43.94, compared to the baseline accuracy of 46.35 for vanilla GPT-4. At the time of writing, MAC-SQL+GPT-4 achieves an execution accuracy of 59.59 when evaluated on the BIRD benchmark, establishing a new state-of-the-art (SOTA) on its holdout test set (https://github.com/wbbeyourself/MAC-SQL).
当前基于大型语言模型(LLM)的文本到SQL方法在处理“庞大”数据库和需要多步骤推理的复杂用户问题时,通常会出现显著的性能下降。此外,大多数现有方法忽略了利用外部工具和模型协作在LLM中的关键作用。为了应对这些挑战,我们引入了MAC-SQL,这是一种基于LLM的新型多智能体协作框架。我们的框架包括一个用于文本到SQL生成的核心分解器智能体,它具有少镜头思维链推理能力,并配备两个辅助智能体,用于利用外部工具或模型获取较小的子数据库并修正错误的SQL查询。分解器智能体与辅助智能体进行协作,辅助智能体根据需要被激活,并且可以扩展以容纳新特性或工具,从而实现有效的文本到SQL解析。在我们的框架中,我们首先利用GPT-4作为所有智能体任务的主要LLM后盾,以确定我们框架的上限。然后,我们通过利用Code Llama 7B对开源的遵循指令模型SQL-Llama进行微调,以完成GPT-4完成的任务。实验表明,SQL-Llama的执行精度达到了与基准精度相当的43.94%,而GPT-4的基准精度为46.35%。在撰写本文时,MAC-SQL+GPT-4在BIRD基准测试集上的执行精度达到了59.59%,在其保留的测试集上创下了新的最先进的性能记录(https://github.com/wbbeyourself/MAC-SQL)。
论文及项目相关链接
PDF Accepted by COLING 2025 (Oral)
Summary
基于LLM的文本到SQL生成方法在大数据库和复杂用户问题上的性能下降显著,且忽视利用外部工具和模型协作的重要性。为解决这些问题,我们提出了MAC-SQL框架,该框架包含核心分解器、GPT-4等技术与辅助代理结合使用,以解决各种文本到SQL生成的问题。采用GPT-4作为基础LLM,精细化对开源的SQL指令进行编程来测试MAC-SQL的效力,初步证明了其效能。该框架已在BIRD基准测试集上实现了卓越的性能表现。有关最新成果详参GitHub地址。对于大量数据与高难度的推理问题处理更趋高效稳定,显示了卓越的未来潜力与应用前景。相关研究开辟了一条处理大规模复杂数据查询的便捷高效的新路径。利用智能与合作的结合,为自然语言处理领域带来革命性变革。更多信息参见GitHub链接。
Key Takeaways
- LLM-based Text-to-SQL方法在大数据库和复杂用户问题上性能受限,需解决多步骤推理挑战。
点此查看论文截图