⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-20 更新
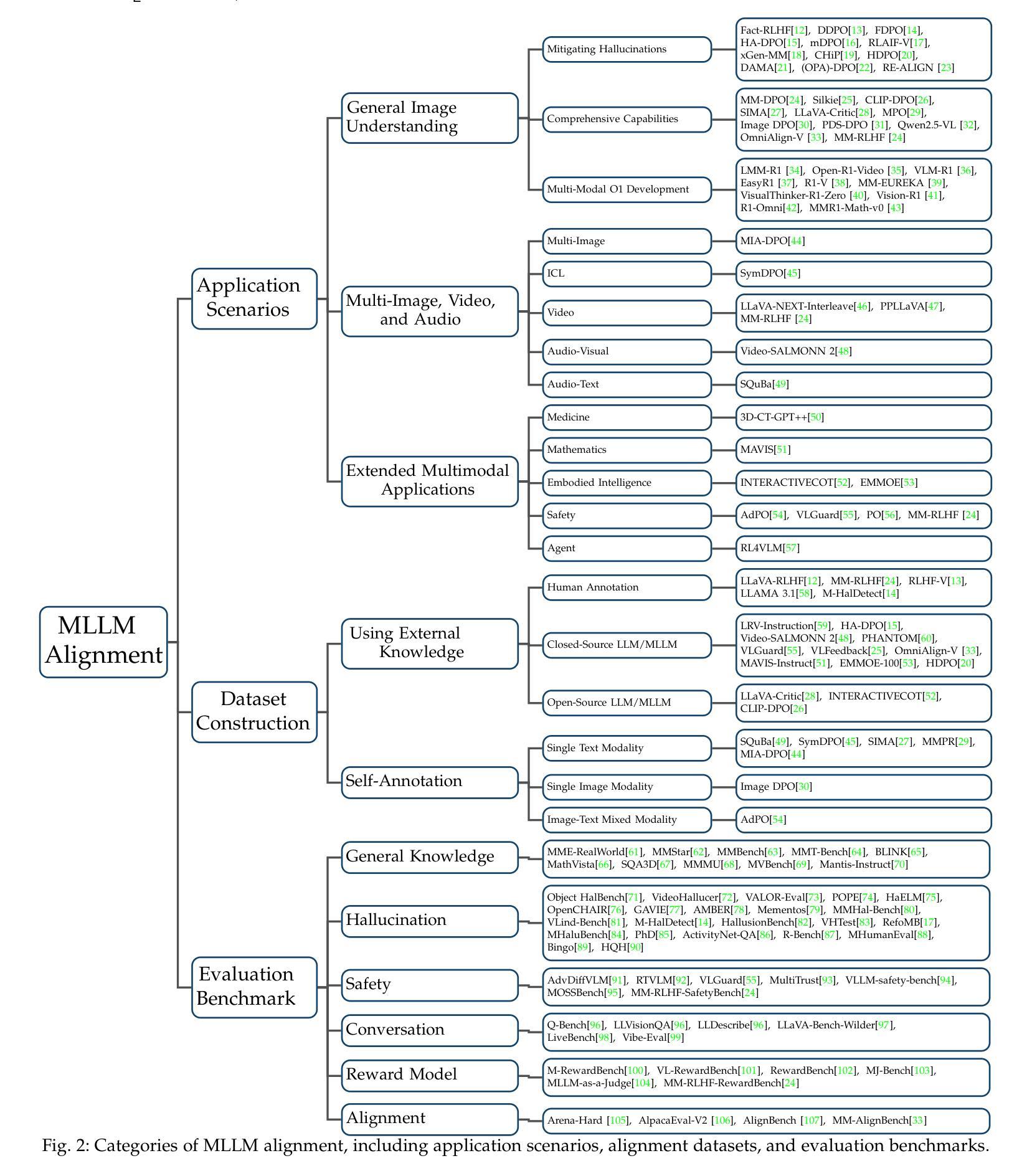
Aligning Multimodal LLM with Human Preference: A Survey
Authors:Tao Yu, Yi-Fan Zhang, Chaoyou Fu, Junkang Wu, Jinda Lu, Kun Wang, Xingyu Lu, Yunhang Shen, Guibin Zhang, Dingjie Song, Yibo Yan, Tianlong Xu, Qingsong Wen, Zhang Zhang, Yan Huang, Liang Wang, Tieniu Tan
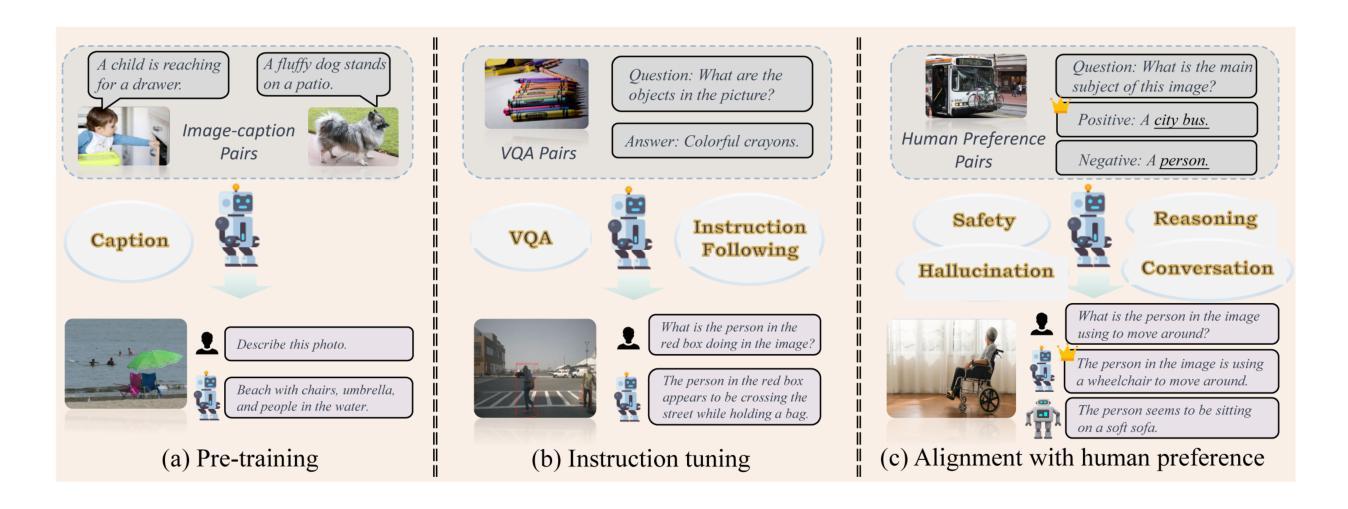
Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
大型语言模型(LLM)能够通过简单的提示处理多种一般任务,而无需特定任务训练。基于LLM的多模态大型语言模型(MLLM)在处理涉及视觉、听觉和文本数据的复杂任务时表现出了令人印象深刻的潜力。然而,与真实性、安全性、类似人类的推理和人类偏好对齐等相关的关键问题仍未得到足够重视。这一差距促使了各种对齐算法的涌现,每种算法都针对不同的应用场景和优化目标。最近的研究表明,对齐算法是解决上述挑战的有力方法。本文旨在全面系统地综述MLLM的对齐算法。具体来说,我们探讨了以下四个方面:(1)对齐算法所涵盖的应用场景,包括通用图像理解、多图像、视频和音频,以及扩展的多模态应用;(2)构建对齐数据集的核心因素,包括数据来源、模型响应和偏好注释;(3)用于评估对齐算法的基准测试;(4)对齐算法未来发展方向的探讨。这项工作旨在帮助研究人员整理该领域的最新进展并激发更好的对齐方法。本文的项目页面可在https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment找到。
论文及项目相关链接
PDF https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment
Summary
大型语言模型(LLM)具备处理各种通用任务的能力,而无需特定任务训练。基于LLM的多模态大型语言模型(MLLM)在处理涉及视觉、听觉和文本数据的复杂任务时展现出惊人的潜力。然而,关于真实性、安全性、类似人类的推理以及与人类偏好的对齐等问题尚未得到充分解决。为解决这些挑战,各种对齐算法应运而生,每种算法都针对不同的应用场景和优化目标。本文旨在全面系统地综述MLLM的对齐算法,包括应用情景、构建对齐数据集的核心因素、评估对齐算法的基准测试以及未来发展方向的讨论。
Key Takeaways
- LLMs具备处理多种通用任务的能力,无需特定任务训练。
- MLLMs在处理多模态数据(如视觉、听觉和文本)时展现出巨大潜力。
- LLMs和MLLMs面临真实性、安全性和与人类偏好对齐等关键挑战。
- 对齐算法用于解决上述挑战,并针对不同应用场景和优化目标进行发展。
- 本文综述了MLLM对齐算法的应用情景,包括图像理解、多图像、视频、音频以及扩展的多模态应用。
- 构建对齐数据集的核心因素包括数据来源、模型响应和偏好标注。
点此查看论文截图


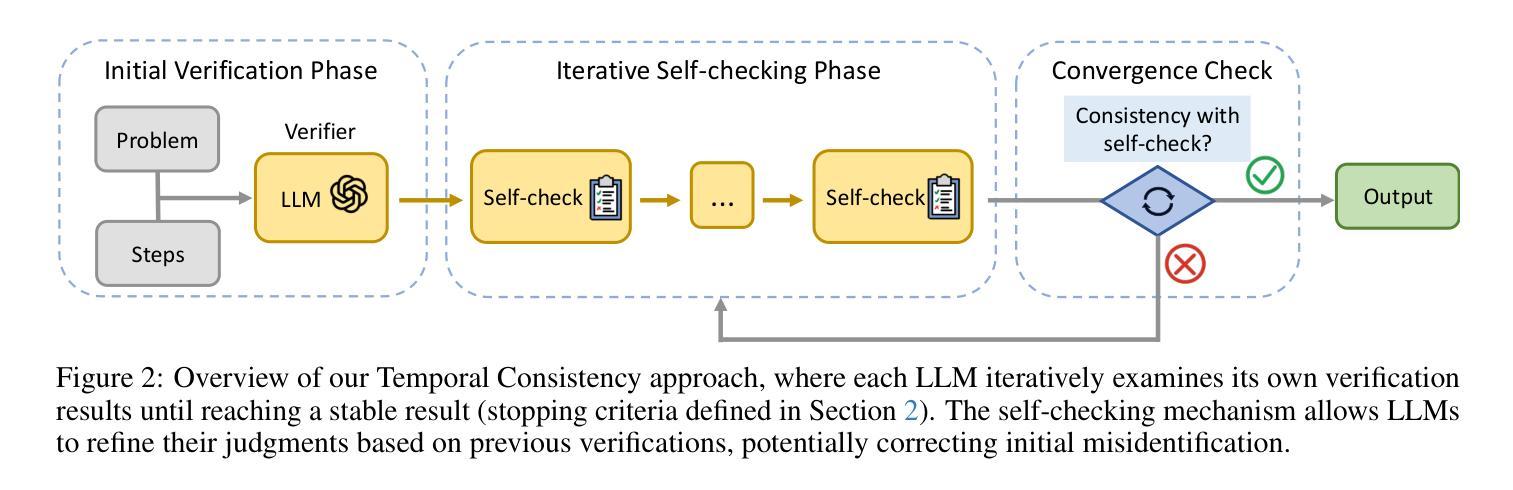
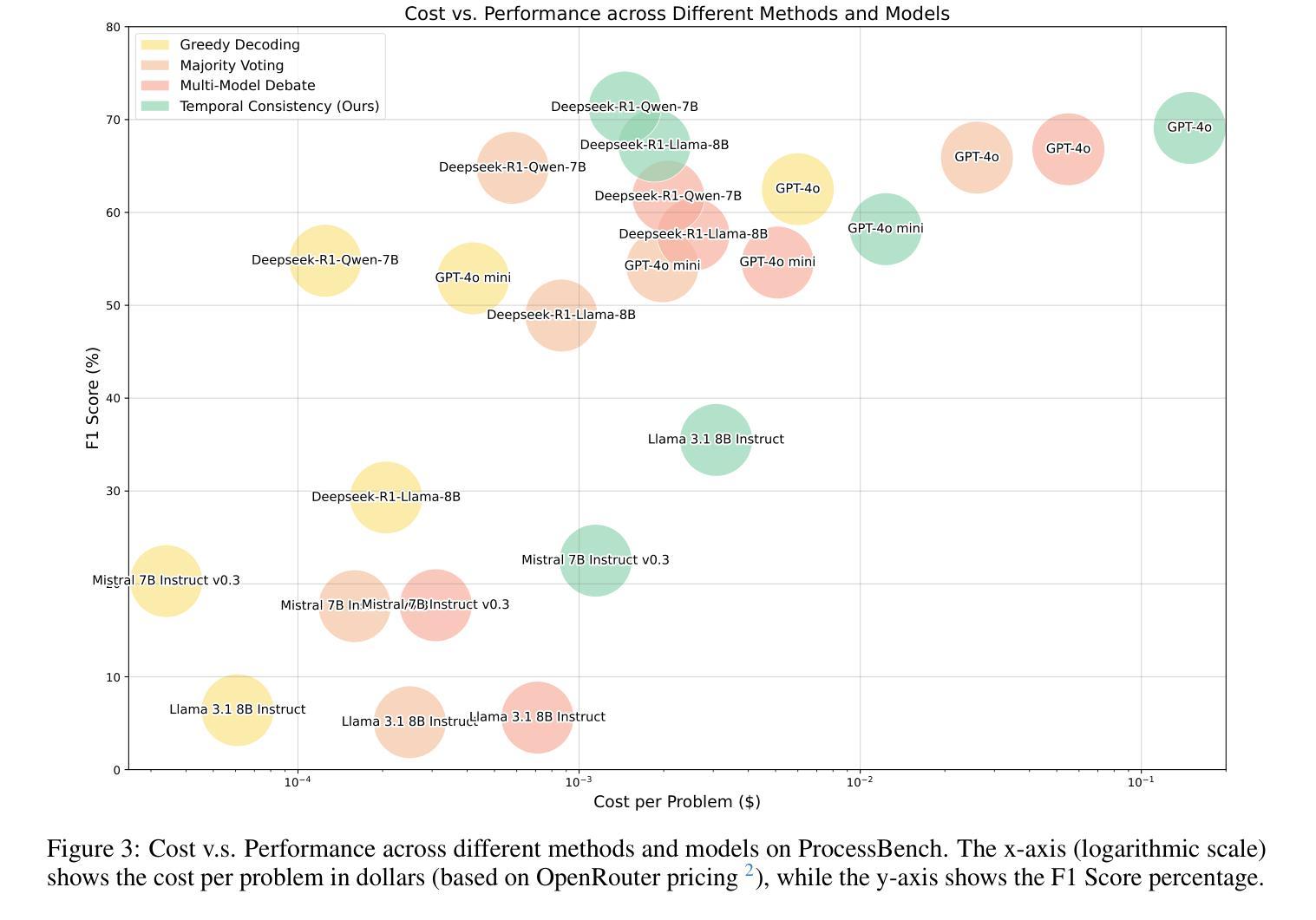
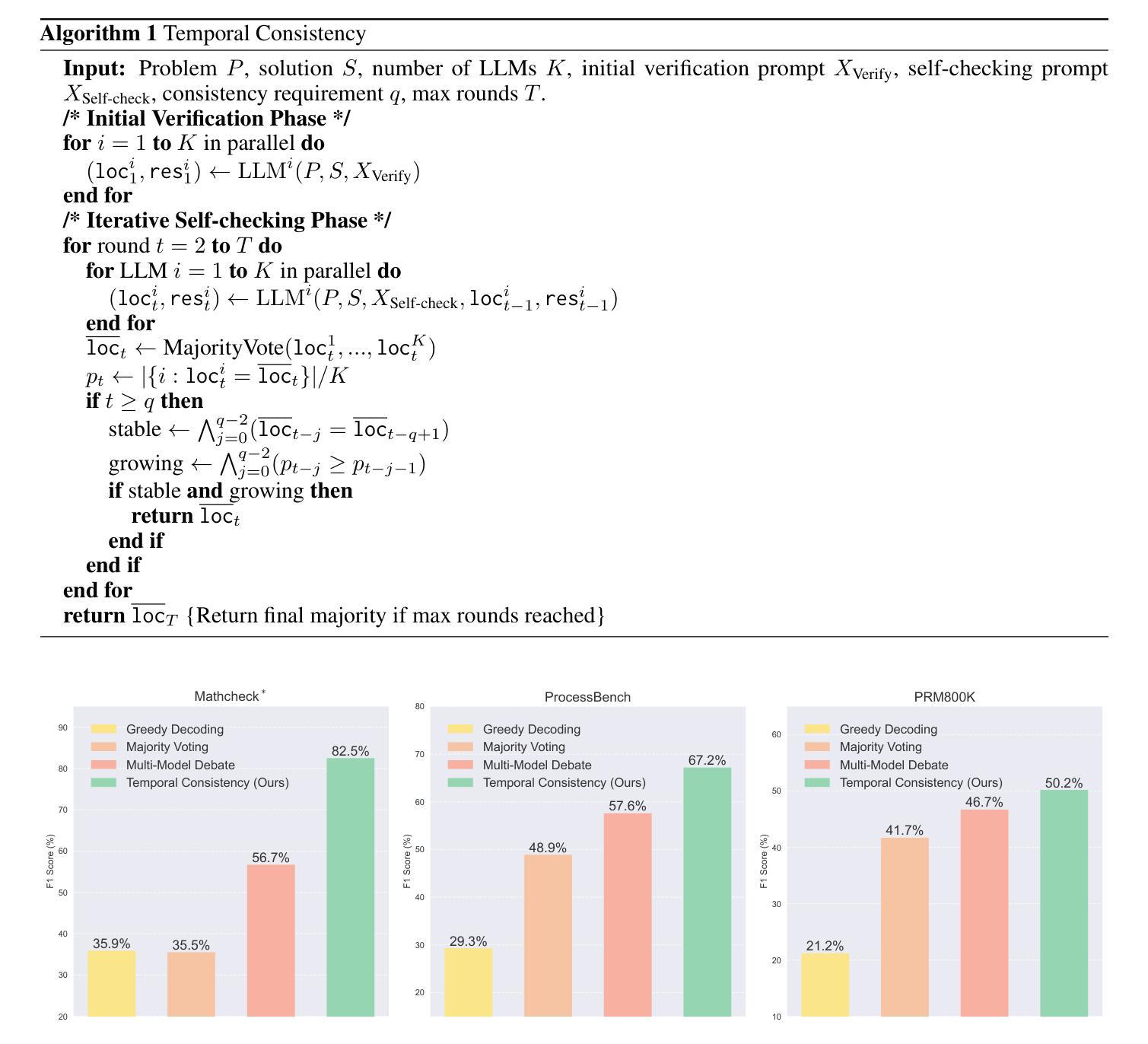
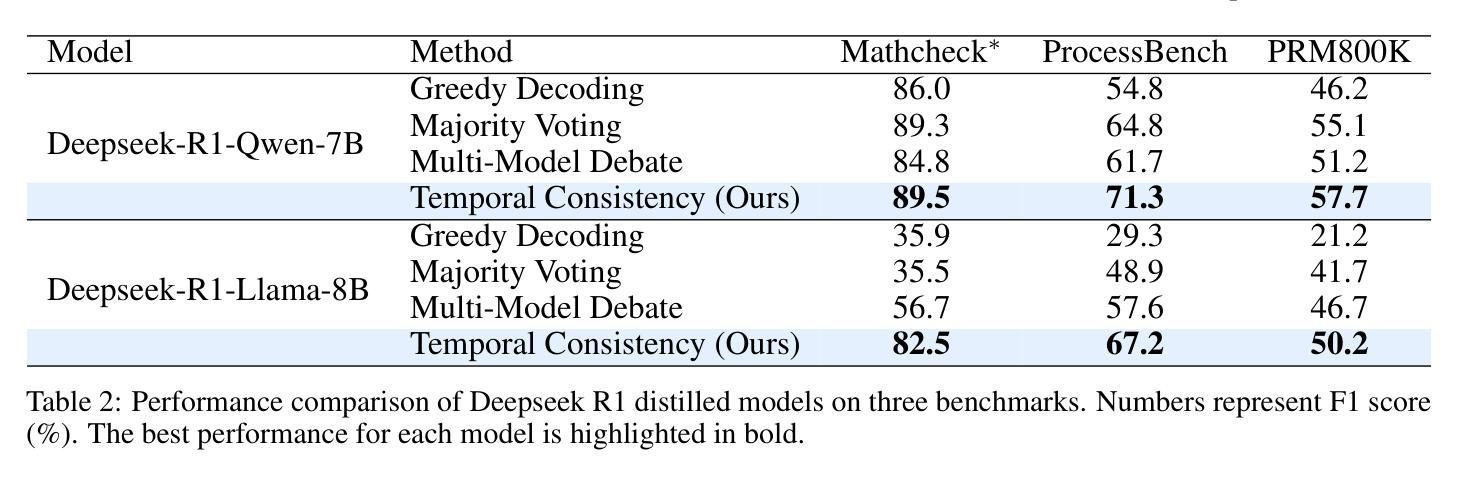
Temporal Consistency for LLM Reasoning Process Error Identification
Authors:Jiacheng Guo, Yue Wu, Jiahao Qiu, Kaixuan Huang, Xinzhe Juan, Ling Yang, Mengdi Wang
Verification is crucial for effective mathematical reasoning. We present a new temporal consistency method where verifiers iteratively refine their judgments based on the previous assessment. Unlike one-round verification or multi-model debate approaches, our method leverages consistency in a sequence of self-reflection actions to improve verification accuracy. Empirical evaluations across diverse mathematical process error identification benchmarks (Mathcheck, ProcessBench, and PRM800K) show consistent performance improvements over baseline methods. When applied to the recent DeepSeek R1 distilled models, our method demonstrates strong performance, enabling 7B/8B distilled models to outperform all 70B/72B models and GPT-4o on ProcessBench. Notably, the distilled 14B model with our method achieves performance comparable to Deepseek-R1. Our codes are available at https://github.com/jcguo123/Temporal-Consistency
验证对于有效的数学推理至关重要。我们提出了一种新的时序一致性方法,验证者可以根据之前的评估结果反复修正他们的判断。与一轮验证或多模型辩论方法不同,我们的方法利用一系列自我反思行为的连贯性来提高验证的准确性。在多种数学过程误差识别基准测试(Mathcheck、ProcessBench和PRM800K)上的经验评估表明,我们的方法在基准方法上实现了性能改进。当应用于最新的DeepSeek R1蒸馏模型时,我们的方法表现出强大的性能,使7B/8B蒸馏模型在ProcessBench上优于所有70B/72B模型和GPT-4o。值得注意的是,使用我们方法的14B蒸馏模型实现了与Deepseek-R1相当的性能。我们的代码位于https://github.com/jcguo123/Temporal-Consistency
论文及项目相关链接
Summary
本文提出了一种新的时序一致性验证方法,该方法通过验证者基于之前的评估进行迭代判断来提高验证的准确性。该方法在多种数学过程误差识别基准测试上的表现均优于基准方法,并且能显著提高蒸馏模型的性能。我们的代码已发布在GitHub上。
Key Takeaways
- 提出了基于时序一致性的新验证方法。
- 验证者通过迭代判断来完善自己的评估。
- 与其他验证方法相比,如一轮验证或多模型辩论方法,该方法利用一系列自我反思行动的一致性来提高验证准确性。
- 在多个数学过程误差识别基准测试中进行了实证评估,证明了该方法的有效性。
- 当应用于DeepSeek R1蒸馏模型时,该方法表现出强大的性能,使蒸馏模型在性能上超越了大型模型如GPT-4o。
- 使用该方法的蒸馏14B模型性能与Deepseek-R1相当。
点此查看论文截图



Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLM
Authors:Xinyu Fang, Zhijian Chen, Kai Lan, Shengyuan Ding, Yingji Liang, Xiangyu Zhao, Farong Wen, Zicheng Zhang, Guofeng Zhang, Haodong Duan, Kai Chen, Dahua Lin
Creativity is a fundamental aspect of intelligence, involving the ability to generate novel and appropriate solutions across diverse contexts. While Large Language Models (LLMs) have been extensively evaluated for their creative capabilities, the assessment of Multimodal Large Language Models (MLLMs) in this domain remains largely unexplored. To address this gap, we introduce Creation-MMBench, a multimodal benchmark specifically designed to evaluate the creative capabilities of MLLMs in real-world, image-based tasks. The benchmark comprises 765 test cases spanning 51 fine-grained tasks. To ensure rigorous evaluation, we define instance-specific evaluation criteria for each test case, guiding the assessment of both general response quality and factual consistency with visual inputs. Experimental results reveal that current open-source MLLMs significantly underperform compared to proprietary models in creative tasks. Furthermore, our analysis demonstrates that visual fine-tuning can negatively impact the base LLM’s creative abilities. Creation-MMBench provides valuable insights for advancing MLLM creativity and establishes a foundation for future improvements in multimodal generative intelligence. Full data and evaluation code is released on https://github.com/open-compass/Creation-MMBench.
创造力是智能的一个基本方面,涉及在不同情境中产生新颖且适当解决方案的能力。虽然大型语言模型(LLM)已经广泛评估了其创造力,但多模态大型语言模型(MLLM)在该领域的评估仍然很大程度上未被探索。为了弥补这一空白,我们引入了Creation-MMBench,这是一个专门设计用于评估多模态语言模型在现实世界中基于图像的任务的创造力能力的多模态基准测试。该基准测试包含765个测试用例,涵盖51个精细任务。为了确保严格的评估,我们为每个测试用例定义了特定的评估标准,指导对通用响应质量和与视觉输入的事实一致性的评估。实验结果表明,与专有模型相比,当前开源的MLLM在创造性任务中的表现明显较差。此外,我们的分析表明,视觉微调可能会负面影响基础LLM的创造力。Creation-MMBench为推进MLLM的创造力提供了宝贵的见解,并为未来改进多模态生成智能奠定了基础。完整的数据和评估代码已在https://github.com/open-compass/Creation-MMBench上发布。
论文及项目相关链接
PDF Evaluation Code and dataset see https://github.com/open-compass/Creation-MMBench
Summary
本文介绍了针对多模态大型语言模型(MLLMs)在真实世界图像任务中的创造性能力评估的多模态基准测试Creation-MMBench。该基准测试包含765个测试用例,涵盖51个精细任务,旨在评估MLLMs的创造性能力。实验结果显示,在创造性任务方面,当前开源的MLLMs与专有模型相比表现显著较差。此外,文章还指出视觉微调可能会对基础LLM的创造性能力产生负面影响。Creation-MMBench为推进MLLM的创造力提供了有价值的见解,并为未来多模态生成智能的改进奠定了基础。
Key Takeaways
- 多模态大型语言模型(MLLMs)的创造性能力评估是一个新兴领域。
- Creation-MMBench是一个专门用于评估MLLMs在真实世界图像任务中创造性能力的多模态基准测试。
- 该基准测试包含765个测试用例,涵盖51个精细任务,旨在全面评估MLLMs的表现。
- 实验结果显示,当前开源的MLLMs在创造性任务方面表现较差,与专有模型相比存在显著差距。
- 视觉微调可能会对基础LLM的创造性能力产生负面影响。
- Creation-MMBench为推进MLLM的创造力研究提供了有价值的见解。
点此查看论文截图



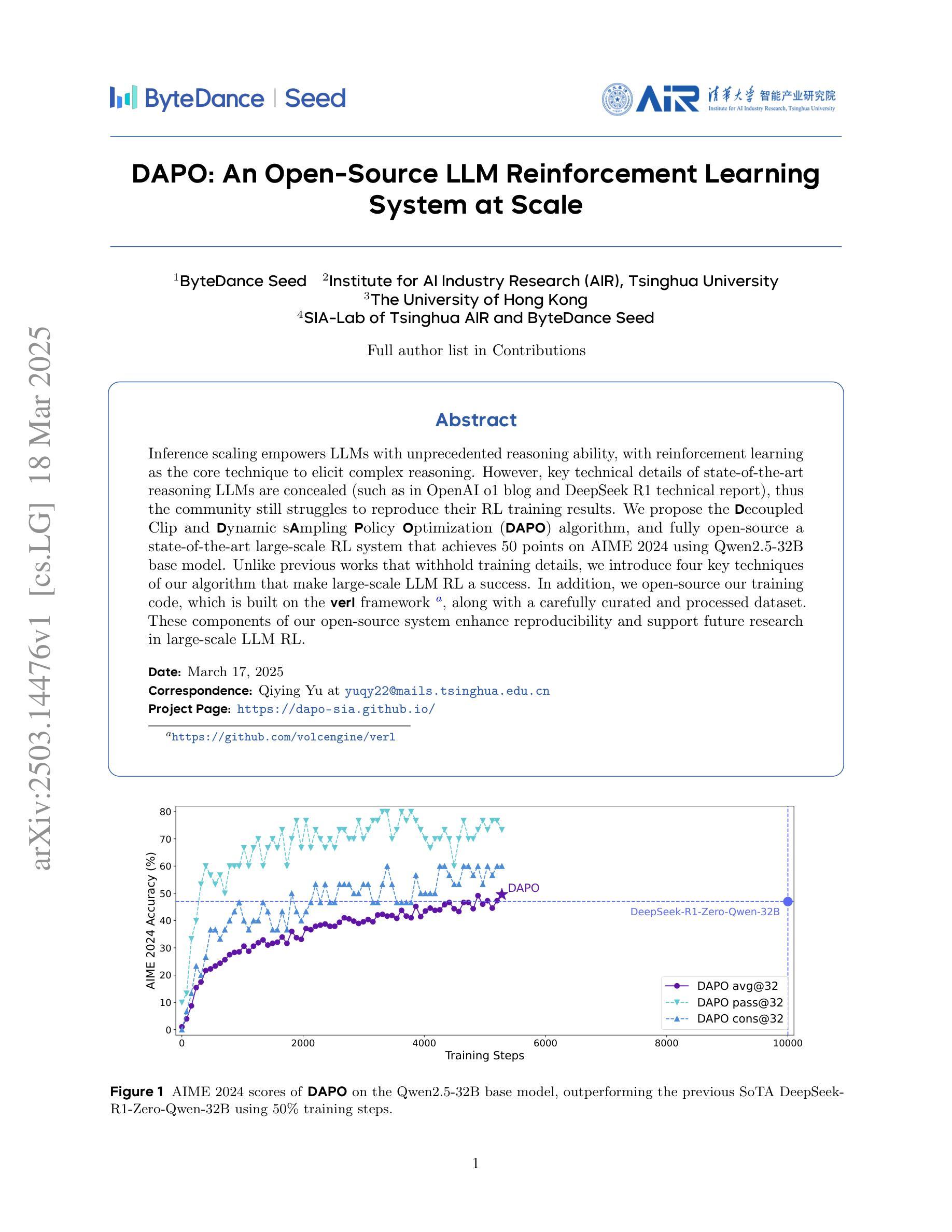
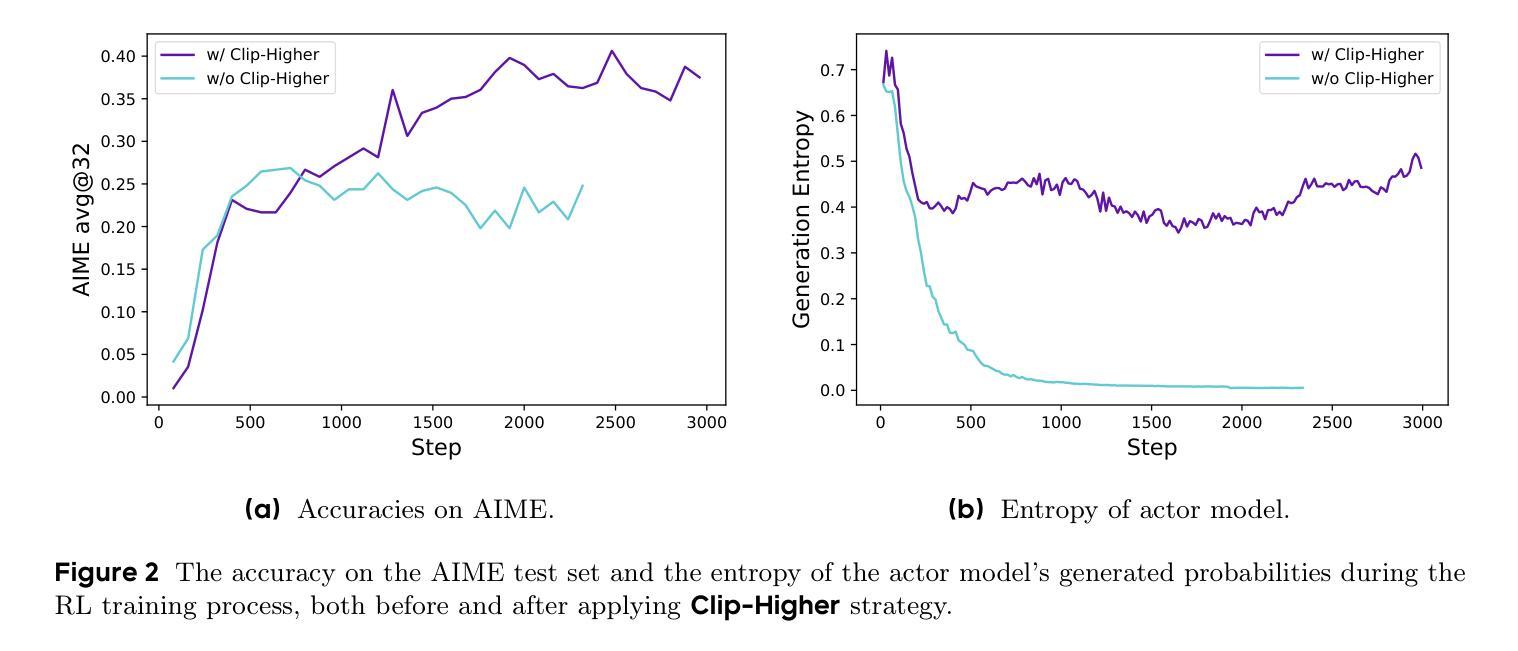
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Authors:Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Lin Yan, Mu Qiao, Yonghui Wu, Mingxuan Wang
Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
推理扩展赋予大型语言模型前所未有的推理能力,强化学习是激发复杂推理的核心技术。然而,最前沿推理大型语言模型的关键技术细节被隐藏(例如在OpenAI o1博客和DeepSeek R1技术报告中),因此社区仍难以复制其RL训练结果。我们提出了解耦的Clip和动态采样策略优化(DAPO)算法,并完全开源一个先进的大型RL系统,该系统使用Qwen2.5-32B基础模型在AIME 2024上实现了50分。不同于之前隐瞒训练细节的工作,我们介绍了算法中的四个关键技术,使大规模大型语言模型强化学习取得了成功。此外,我们在verl框架上开源了我们的训练代码,以及精心策划和处理过的数据集。我们开源系统的这些组件提高了可重复性,并支持未来在大型语言模型强化学习领域的研究。
论文及项目相关链接
PDF Project Page: https://dapo-sia.github.io/
Summary
基于推断扩展和强化学习的大型语言模型(LLM)具备前所未有的推理能力。尽管存在一些隐藏的技术细节,使得社区难以重现其强化学习训练结果,但仍存在一些问题值得关注和探索。本论文提出了一个新的算法“DAPO”,并且完全开源了一个最新的大型语言模型强化学习系统。与先前的研究不同,该系统对AIME 2024达到近五十点分的效果采用开源处理模式。此论文引入四项关键技术使大型语言模型强化学习取得成功,同时开源了训练代码和数据处理数据集。这将有助于提升系统的可重复性并支持未来的大型语言模型强化学习研究。
Key Takeaways
- 强化学习赋予大型语言模型前所未有的推理能力。然而,一些关键技术细节尚未公开,影响了技术的重现性。需要重点关注这些隐藏的详细信息以增强研究进展。
点此查看论文截图
EnvBench: A Benchmark for Automated Environment Setup
Authors:Aleksandra Eliseeva, Alexander Kovrigin, Ilia Kholkin, Egor Bogomolov, Yaroslav Zharov
Recent advances in Large Language Models (LLMs) have enabled researchers to focus on practical repository-level tasks in software engineering domain. In this work, we consider a cornerstone task for automating work with software repositories-environment setup, i.e., a task of configuring a repository-specific development environment on a system. Existing studies on environment setup introduce innovative agentic strategies, but their evaluation is often based on small datasets that may not capture the full range of configuration challenges encountered in practice. To address this gap, we introduce a comprehensive environment setup benchmark EnvBench. It encompasses 329 Python and 665 JVM-based (Java, Kotlin) repositories, with a focus on repositories that present genuine configuration challenges, excluding projects that can be fully configured by simple deterministic scripts. To enable further benchmark extension and usage for model tuning, we implement two automatic metrics: a static analysis check for missing imports in Python and a compilation check for JVM languages. We demonstrate the applicability of our benchmark by evaluating three environment setup approaches, including a simple zero-shot baseline and two agentic workflows, that we test with two powerful LLM backbones, GPT-4o and GPT-4o-mini. The best approach manages to successfully configure 6.69% repositories for Python and 29.47% repositories for JVM, suggesting that EnvBench remains challenging for current approaches. Our benchmark suite is publicly available at https://github.com/JetBrains-Research/EnvBench. The dataset and experiment trajectories are available at https://jb.gg/envbench.
近期大型语言模型(LLM)的进步使得研究人员能够关注软件工程领域中的实际仓库级任务。在这项工作中,我们考虑软件仓库自动化工作中的一个基石任务——环境设置,即在系统上配置特定于仓库的开发环境。关于环境设置的研究已经引入了创新的主动策略,但它们的评估通常基于小型数据集,可能无法捕捉到实践中遇到的配置挑战的全范围。为了弥补这一差距,我们引入了全面的环境设置基准测试EnvBench。它涵盖了329个Python和665个基于JVM(Java、Kotlin)的仓库,重点关注那些存在真实配置挑战的仓库,排除那些可以通过简单的确定性脚本完全配置的项目。为了实现基准测试的进一步扩展和模型调整的使用,我们实现了两项自动指标:Python中缺失导入的静态分析检查以及JVM语言的编译检查。我们通过评估三种环境设置方法来验证我们的基准测试的适用性,包括一个简单的零样本基准和两种主动工作流程,我们使用两个强大的LLM主干(GPT-4o和GPT-4o-mini)进行测试。最佳方法成功配置了6.69%的Python仓库和29.47%的JVM仓库,这表明EnvBench对当前方法仍然具有挑战性。我们的基准测试套件可在https://github.com/JetBrains-Research/EnvBench公开访问。数据集和实验轨迹可在https://jb.gg/envbench找到。
论文及项目相关链接
PDF Accepted at the DL4Code workshop at ICLR’25
Summary:
近期大型语言模型(LLM)的进步使得软件工程中仓库级别的任务得以实践。本文关注软件仓库环境设置的自动化任务,并引入了全面的环境设置基准测试EnvBench。该测试包含多种Python和JVM仓库,涵盖真实配置挑战。此外,我们还实现了两个自动度量指标以支持基准测试的扩展和模型调整。通过对三种环境设置方法的评估,发现当前模型仍需改进。我们的基准测试套件公开可用,并提供数据集和实验轨迹以供研究。
Key Takeaways:
- 大型语言模型(LLM)的进步推动了软件工程中仓库级别任务的实践。
- 环境设置是软件仓库自动化的核心任务之一。
- 现有研究虽提出创新性的代理策略,但其评估通常基于小数据集,无法全面反映实践中的配置挑战。
- 引入全面的环境设置基准测试EnvBench,包含多种Python和JVM仓库。
- EnvBench专注于具有真实配置挑战的仓库,排除可通过简单确定性脚本完全配置的项目。
- 实现两个自动度量指标以支持基准测试的扩展和模型调整:Python的静态分析检查缺失导入和JVM语言的编译检查。
点此查看论文截图


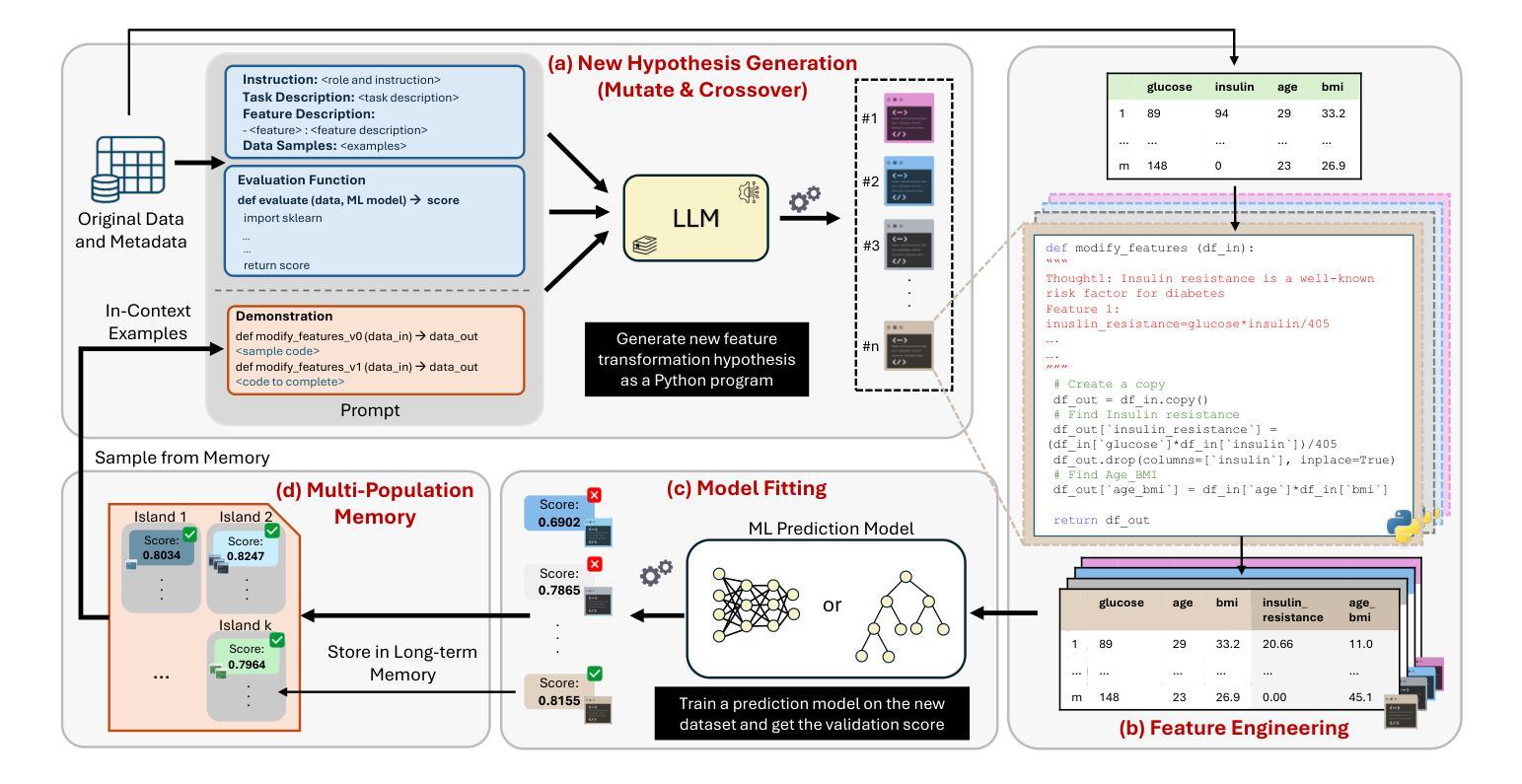
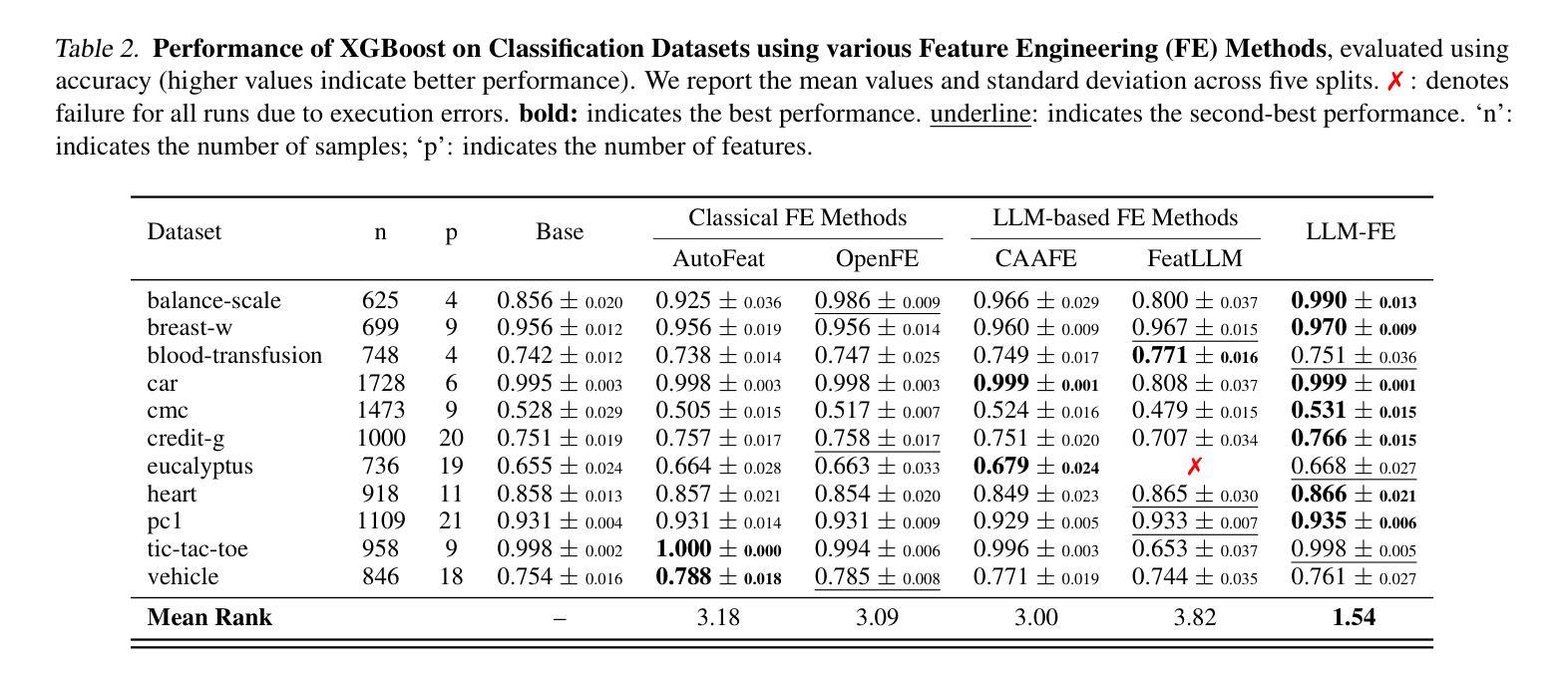
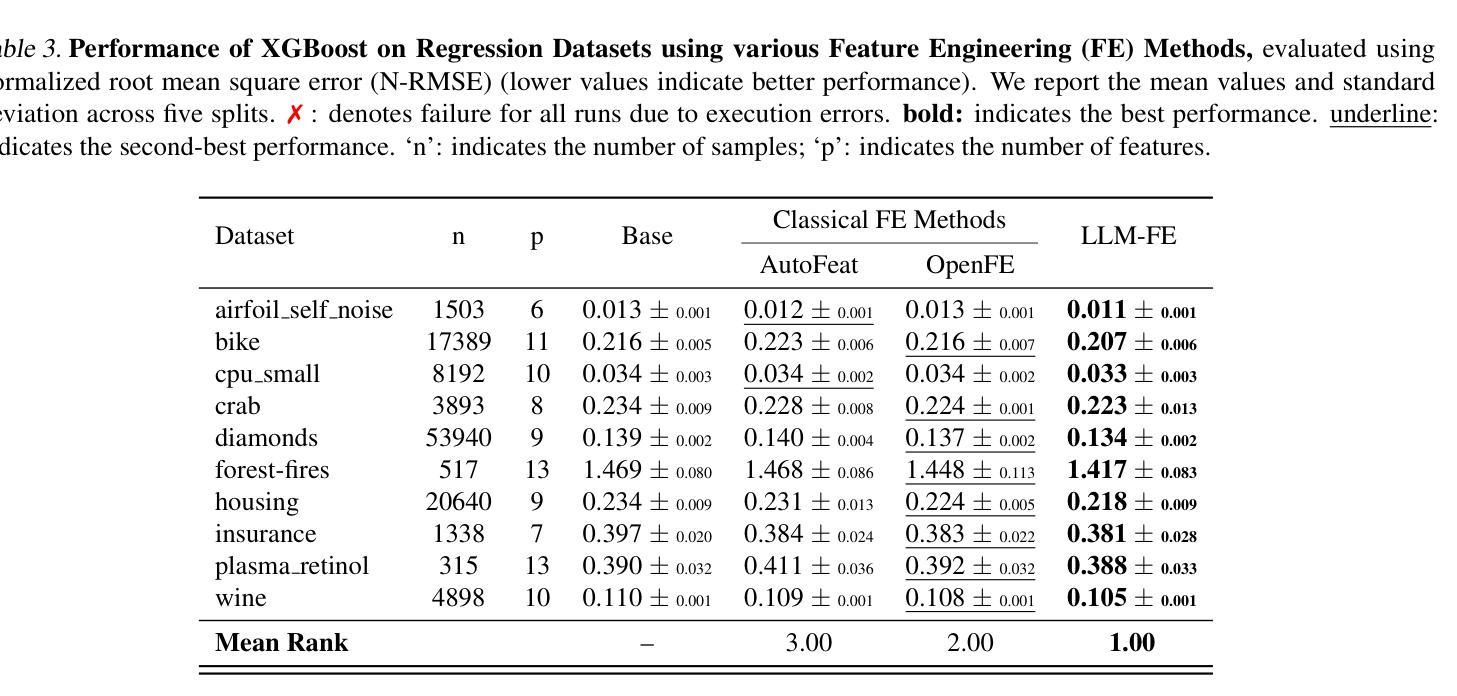
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Authors:Nikhil Abhyankar, Parshin Shojaee, Chandan K. Reddy
Automated feature engineering plays a critical role in improving predictive model performance for tabular learning tasks. Traditional automated feature engineering methods are limited by their reliance on pre-defined transformations within fixed, manually designed search spaces, often neglecting domain knowledge. Recent advances using Large Language Models (LLMs) have enabled the integration of domain knowledge into the feature engineering process. However, existing LLM-based approaches use direct prompting or rely solely on validation scores for feature selection, failing to leverage insights from prior feature discovery experiments or establish meaningful reasoning between feature generation and data-driven performance. To address these challenges, we propose LLM-FE, a novel framework that combines evolutionary search with the domain knowledge and reasoning capabilities of LLMs to automatically discover effective features for tabular learning tasks. LLM-FE formulates feature engineering as a program search problem, where LLMs propose new feature transformation programs iteratively, and data-driven feedback guides the search process. Our results demonstrate that LLM-FE consistently outperforms state-of-the-art baselines, significantly enhancing the performance of tabular prediction models across diverse classification and regression benchmarks.
自动化特征工程在改进表格学习任务的预测模型性能中起着至关重要的作用。传统的自动化特征工程方法受限于在固定、手动设计的搜索空间内预先定义的转换,往往忽略了领域知识。最近使用大型语言模型(LLM)的进步已经将领域知识集成到特征工程过程中。然而,现有的基于LLM的方法使用直接提示或仅依赖验证分数进行特征选择,未能利用先前特征发现实验中的见解或在特征生成和数据驱动性能之间建立有意义的推理。为了解决这些挑战,我们提出了LLM-FE,这是一个结合进化搜索和LLM的领域知识和推理能力,自动发现表格学习任务的有效特征的新型框架。LLM-FE将特征工程制定为程序搜索问题,其中LLM提出新的特征转换程序进行迭代,数据驱动的反馈引导搜索过程。我们的结果表明,LLM-FE持续超越最先进的基准测试,显著提高了各种分类和回归基准测试表的预测模型性能。
论文及项目相关链接
Summary
自动特征工程在改进表格学习任务的预测模型性能中扮演关键角色。传统的自动特征工程方法受限于固定的手动设计搜索空间内的预定义转换,常常忽视领域知识。最近使用大型语言模型(LLM)的进步使得领域知识可以融入特征工程过程。然而,现有的LLM方法通过直接提示或仅依赖验证分数进行特征选择,未能利用先前的特征发现实验中的见解或建立特征生成与数据驱动性能之间的有意义的关系。为了应对这些挑战,我们提出了LLM-FE这一新型框架,它结合了进化搜索、领域知识和LLMs的推理能力,自动为表格学习任务发现有效特征。LLM-FE将特征工程制定为程序搜索问题,其中LLMs迭代地提出新的特征转换程序,数据驱动的反馈引导搜索过程。我们的结果表明,LLM-FE持续优于最新基线,显著提高了不同分类和回归基准测试的表格预测模型性能。
Key Takeaways
- 自动化特征工程对于改进表格学习任务的预测模型性能至关重要。
- 传统方法因依赖固定的手动设计搜索空间和预定义转换而受限。
- 近期LLM的进步使得领域知识融入特征工程成为可能。
- 现有LLM方法主要依赖直接提示或验证分数,忽视先前实验中的见解和特征生成与数据驱动性能的关系。
- LLM-FE框架结合进化搜索、领域知识和LLMs的推理能力,自动发现表格学习的有效特征。
- LLM-FE将特征工程定义为程序搜索问题,LLMs提出迭代特征转换程序,并由数据驱动的反馈引导搜索。
点此查看论文截图


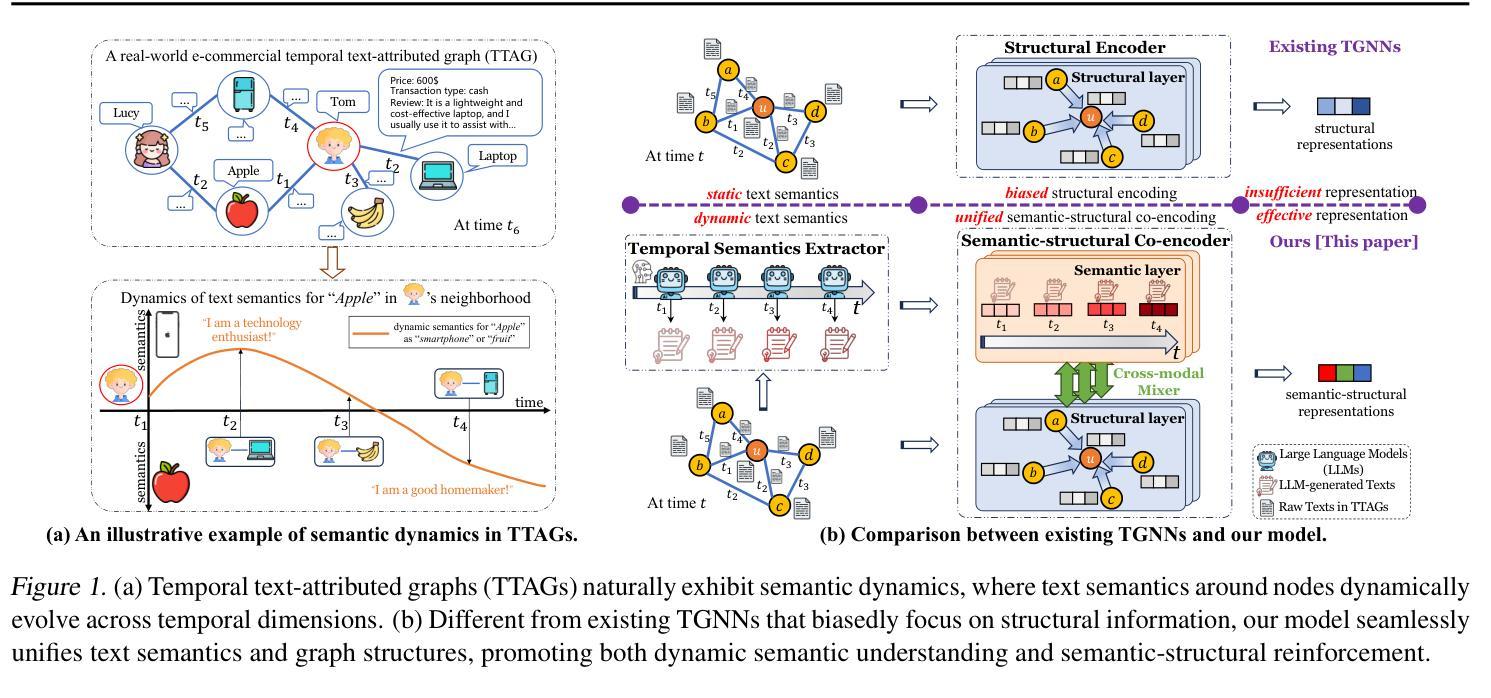
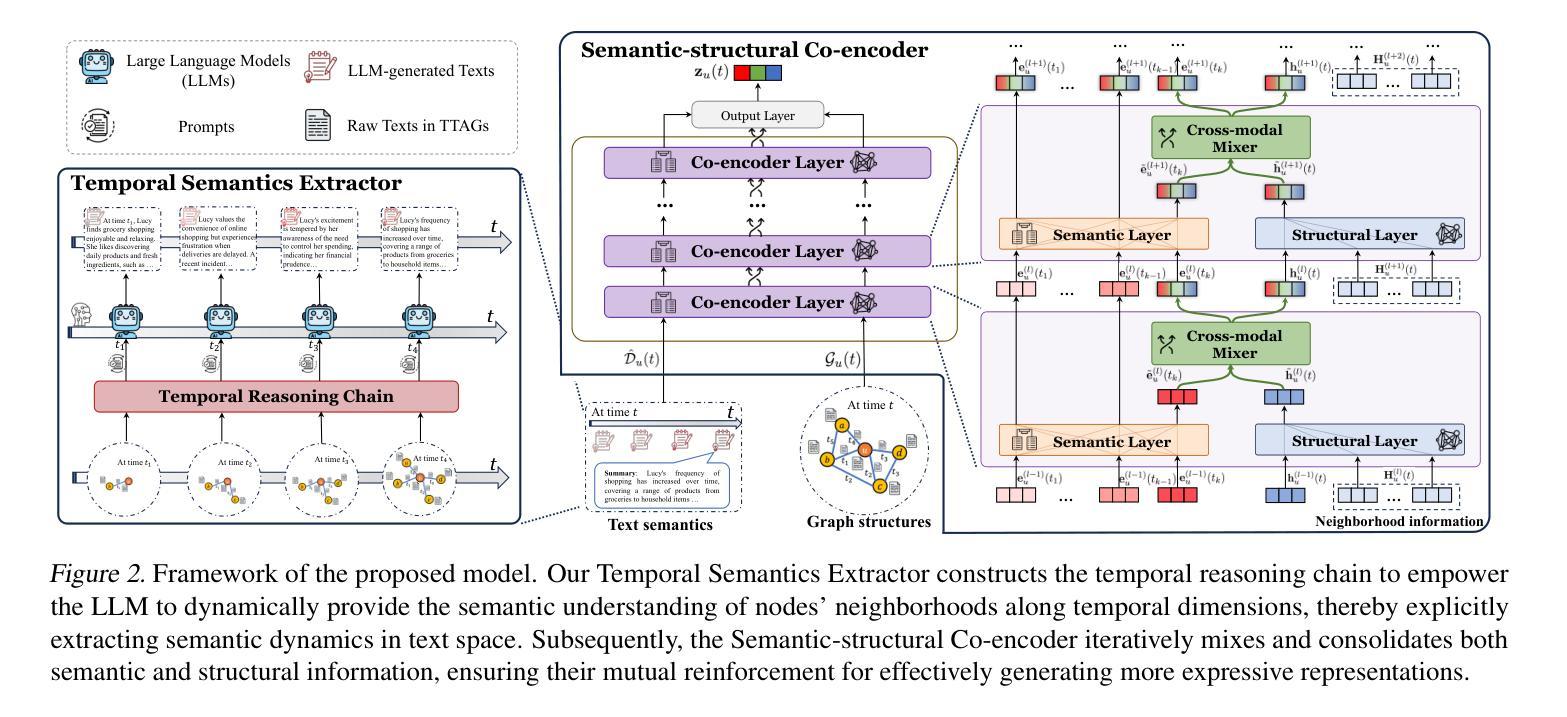
Unifying Text Semantics and Graph Structures for Temporal Text-attributed Graphs with Large Language Models
Authors:Siwei Zhang, Yun Xiong, Yateng Tang, Xi Chen, Zian Jia, Zehao Gu, Jiarong Xu, Jiawei Zhang
Temporal graph neural networks (TGNNs) have shown remarkable performance in temporal graph modeling. However, real-world temporal graphs often possess rich textual information, giving rise to temporal text-attributed graphs (TTAGs). Such combination of dynamic text semantics and evolving graph structures introduces heightened complexity. Existing TGNNs embed texts statically and rely heavily on encoding mechanisms that biasedly prioritize structural information, overlooking the temporal evolution of text semantics and the essential interplay between semantics and structures for synergistic reinforcement. To tackle these issues, we present \textbf, a novel framework that seamlessly extends existing TGNNs for TTAG modeling. The key idea is to employ the advanced large language models (LLMs) to extract the dynamic semantics in text space and then generate expressive representations unifying both semantics and structures. Specifically, we propose a Temporal Semantics Extractor in the {Cross} framework, which empowers the LLM to offer the temporal semantic understanding of node’s evolving contexts of textual neighborhoods, facilitating semantic dynamics. Subsequently, we introduce the Semantic-structural Co-encoder, which collaborates with the above Extractor for synthesizing illuminating representations by jointly considering both semantic and structural information while encouraging their mutual reinforcement. Extensive experimental results on four public datasets and one practical industrial dataset demonstrate {Cross}’s significant effectiveness and robustness.
时序图神经网络(TGNN)在时序图建模方面表现出卓越的性能。然而,现实世界的时序图通常具有丰富的文本信息,从而产生了时序文本属性图(TTAG)。动态文本语义和不断演变的图形结构的结合增加了复杂性。现有的TGNNs静态嵌入文本,并严重依赖于编码机制,这些机制偏向于优先处理结构信息,而忽略了文本语义的时空演变以及语义和结构之间的基本相互作用,以实现协同增强。为了解决这些问题,我们提出了一个名为“Cross”的新框架,无缝扩展现有的TGNN用于TTAG建模。主要思想是利用先进的大型语言模型(LLM)提取文本空间中的动态语义,然后生成统一语义和结构的表达性表示。具体来说,我们在“Cross”框架中提出了一个时序语义提取器,它赋予LLM对节点文本邻域上下文演变的理解能力,促进语义动态。随后,我们引入了语义结构协同编码器,它与上述提取器合作,通过联合考虑语义和结构信息来合成说明性表示,同时鼓励它们之间的相互促进。在四个公开数据集和一个实际工业数据集上的大量实验结果证明了“Cross”的有效性和稳健性。
论文及项目相关链接
PDF Submit to ICML2025
Summary
TGNN在处理带有丰富文本信息的动态时序图时面临挑战,提出了一个名为Cross的新框架来解决这一问题。该框架利用大型语言模型(LLM)提取文本中的动态语义信息,并生成统一语义和结构的表达性表示。通过Temporal Semantics Extractor和Semantic-structural Co-encoder两个核心组件,实现语义和结构的协同强化。实验证明,Cross在多个数据集上表现出显著的有效性和鲁棒性。
Key Takeaways
- TGNN在处理带有丰富文本信息的时序图时面临挑战。
- Cross框架旨在解决这一问题,通过结合大型语言模型(LLM)提取文本中的动态语义信息。
- Temporal Semantics Extractor是Cross框架的关键组件,使LLM能够理解节点文本邻域的语义的演变。
- Semantic-structural Co-encoder与Temporal Semantics Extractor协作,通过联合考虑语义和结构信息来生成表达性表示。
- Cross通过协同强化语义和结构信息,提高了模型的表达能力。
- 在多个数据集上的实验表明,Cross具有显著的有效性和鲁棒性。
点此查看论文截图

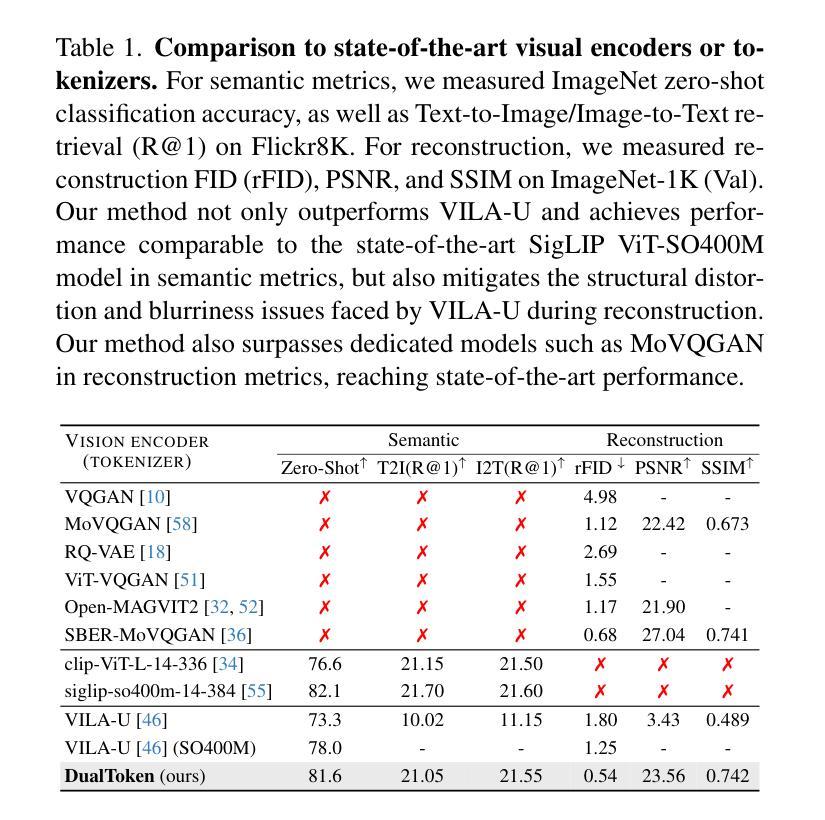
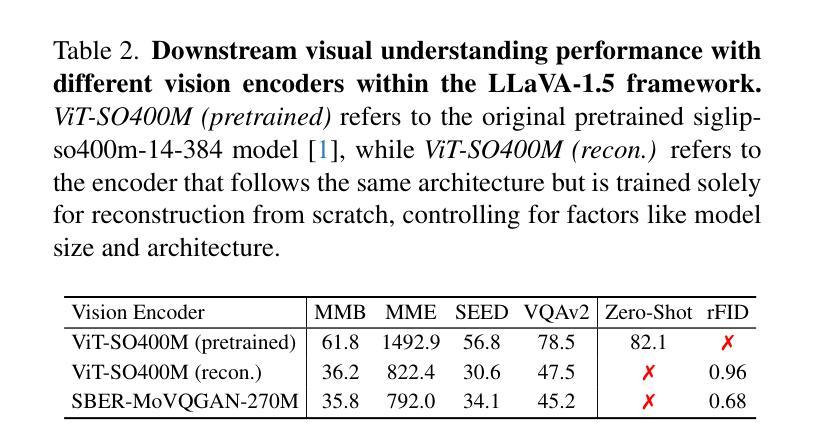
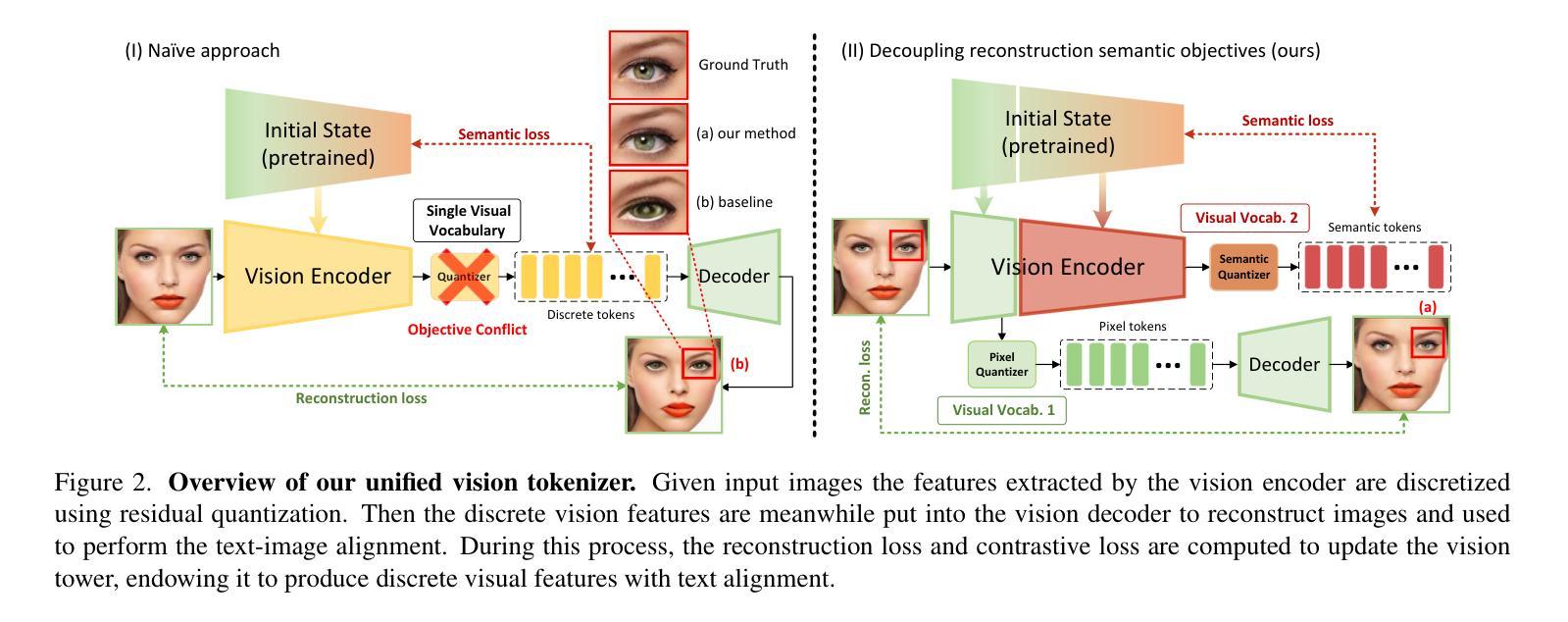
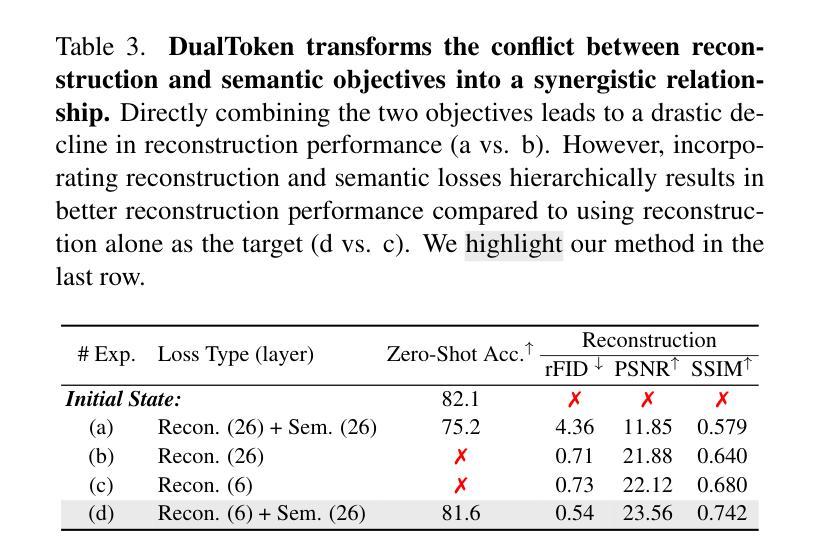
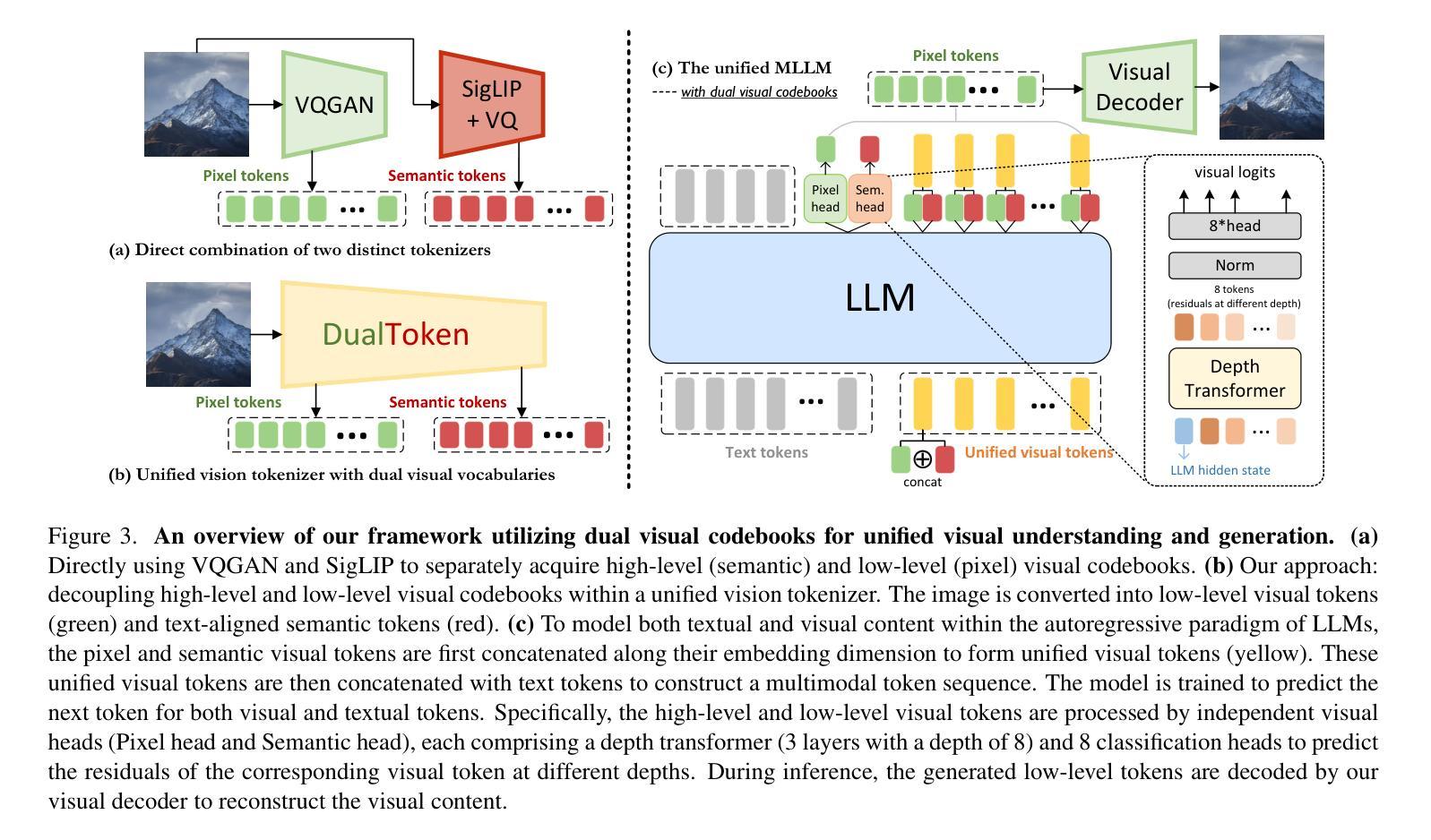
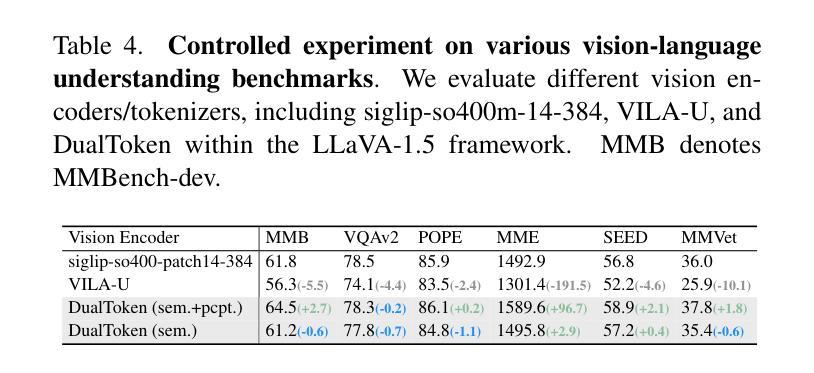
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Authors:Wei Song, Yuran Wang, Zijia Song, Yadong Li, Haoze Sun, Weipeng Chen, Zenan Zhou, Jianhua Xu, Jiaqi Wang, Kaicheng Yu
The differing representation spaces required for visual understanding and generation pose a challenge in unifying them within the autoregressive paradigm of large language models. A vision tokenizer trained for reconstruction excels at capturing low-level perceptual details, making it well-suited for visual generation but lacking high-level semantic representations for understanding tasks. Conversely, a vision encoder trained via contrastive learning aligns well with language but struggles to decode back into the pixel space for generation tasks. To bridge this gap, we propose DualToken, a method that unifies representations for both understanding and generation within a single tokenizer. However, directly integrating reconstruction and semantic objectives in a single tokenizer creates conflicts, leading to degraded performance in both reconstruction quality and semantic performance. Instead of forcing a single codebook to handle both semantic and perceptual information, DualToken disentangles them by introducing separate codebooks for high and low-level features, effectively transforming their inherent conflict into a synergistic relationship. As a result, DualToken achieves state-of-the-art performance in both reconstruction and semantic tasks while demonstrating remarkable effectiveness in downstream MLLM understanding and generation tasks. Notably, we also show that DualToken, as a unified tokenizer, surpasses the naive combination of two distinct types vision encoders, providing superior performance within a unified MLLM.
对于视觉理解和生成所需要的不同表示空间,在大型语言模型的自回归范式中统一它们构成了一项挑战。用于重建的愿景分词器擅长捕捉低级别的感知细节,非常适合于视觉生成,但缺乏高级语义表示,不适用于理解任务。相反,通过对比学习训练的视觉编码器与语言对齐良好,但在生成像素空间时难以解码。为了弥补这一差距,我们提出了DualToken方法,它在一个单一的分词器中统一了理解和生成的表示。然而,直接在分词器中整合重建和语义目标会产生冲突,导致重建质量和语义性能的下降。DualToken并没有强制单个代码本处理语义和感知信息,而是通过引入高级和低级特征的不同代码本来解决它们之间的冲突,将其固有的冲突转化为协同关系。因此,DualToken在重建和语义任务上达到了最先进的性能,同时在下游大型语言模型理解和生成任务中表现出了显著的有效性。值得注意的是,我们还表明,作为一个统一的分词器,DualToken超越了两种不同类型视觉编码器的简单组合,在统一的大型语言模型中提供了卓越的性能。
论文及项目相关链接
Summary
视觉理解和生成所需的不同表示空间给在大型语言模型的自回归范式中统一它们带来了挑战。一种用于重建的视觉分词器擅长捕捉低级别的感知细节,很适合于视觉生成,但缺乏高级语义表示,不足以完成理解任务。相反,通过对比学习训练的视觉编码器与语言对齐良好,但在生成任务中解码回像素空间时遇到困难。为了弥补这一差距,我们提出了DualToken方法,旨在在一个分词器中统一理解和表示。然而,在单一分词器中直接整合重建和语义目标会产生冲突,导致重建质量和语义性能的下降。DualToken通过引入用于高级和低级特征的不同代码本,解决这一冲突,将其转化为协同关系。因此,DualToken在重建和语义任务上实现了最先进的性能,并在下游大型语言模型的理解和生成任务中表现出了显著的有效性。值得注意的是,作为统一的分词器,DualToken的表现超越了两种不同类型视觉编码器的简单组合。
Key Takeaways
- 视觉理解和生成需要不同的表示空间,给统一带来了挑战。
- 重建的视觉分词器擅长捕捉低级别感知细节,适合视觉生成,但缺乏高级语义表示。
- 对比学习训练的视觉编码器与语言对齐良好,但在生成任务中解码回像素空间有困难。
- DualToken方法在一个分词器中统一理解和生成表示,实现先进性能。
- 直接整合重建和语义目标在单一分词器中会产生冲突,导致性能下降。
- DualToken通过引入不同代码本解决冲突,实现协同关系。
点此查看论文截图


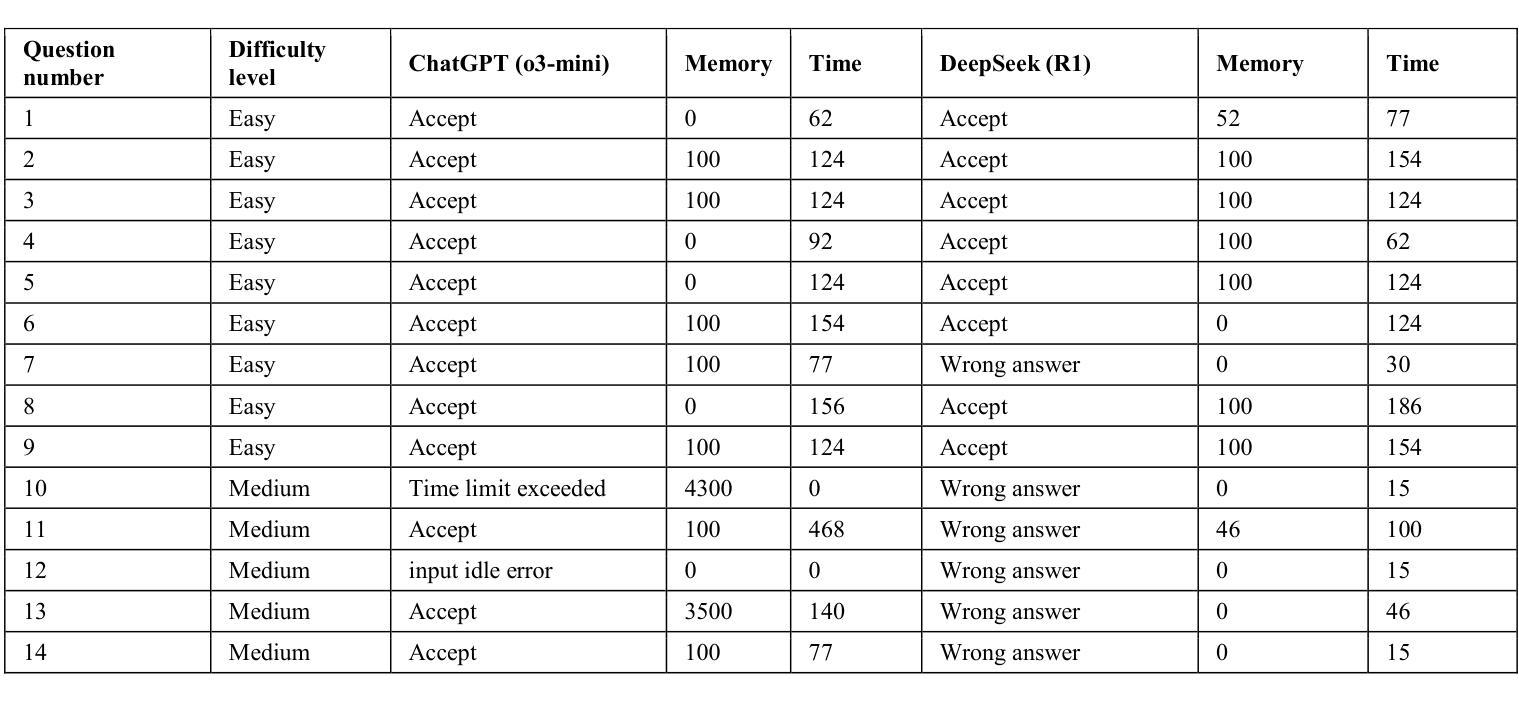
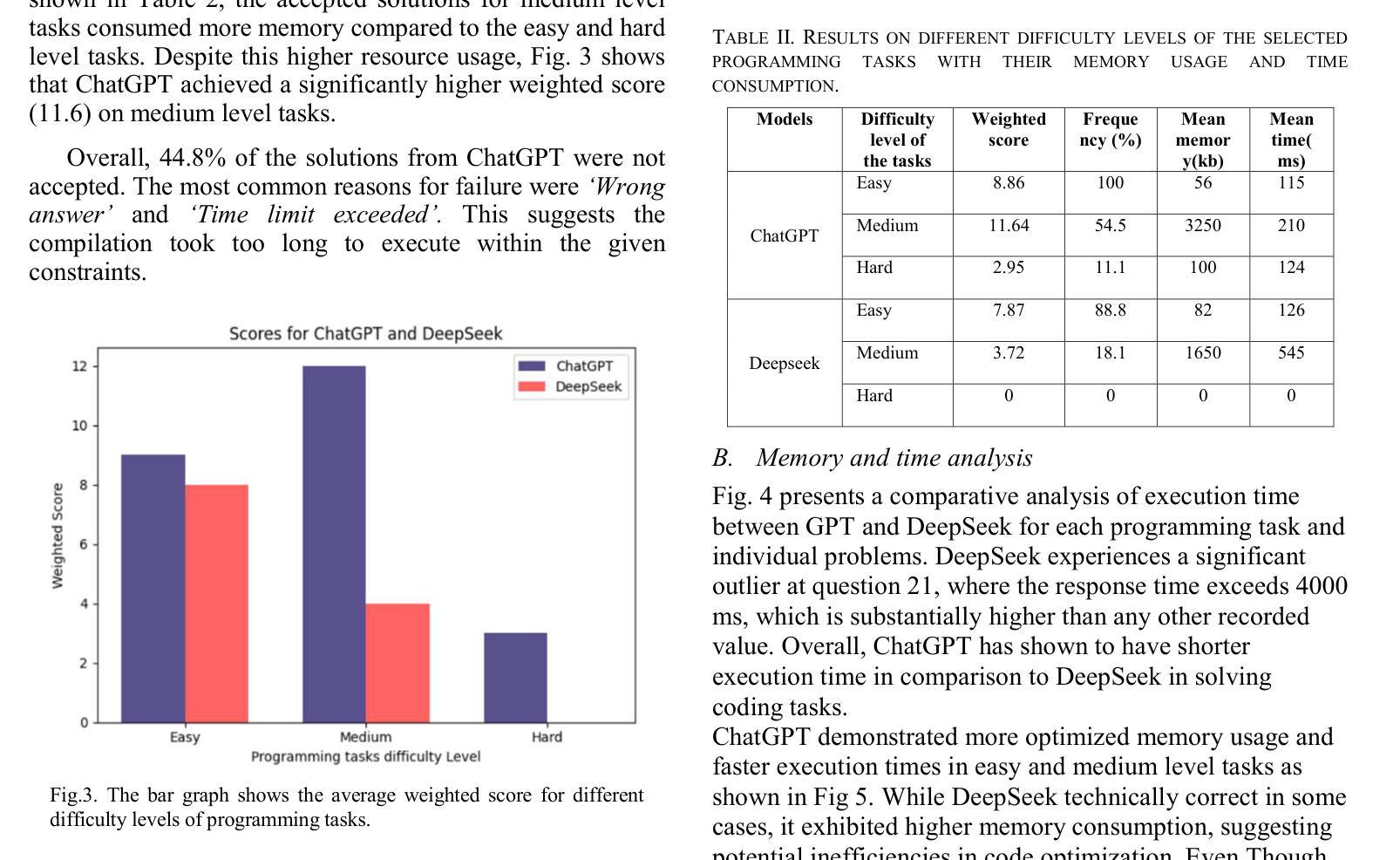
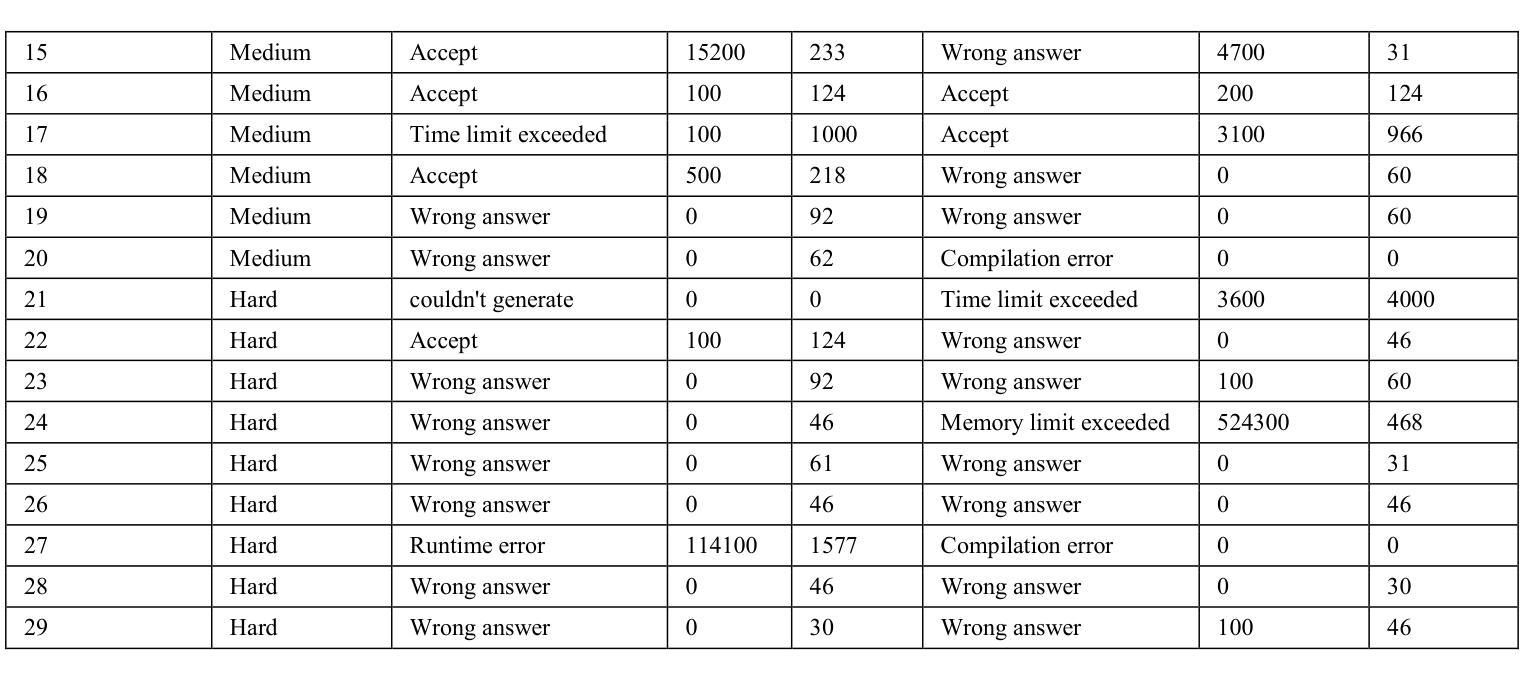
A Showdown of ChatGPT vs DeepSeek in Solving Programming Tasks
Authors:Ronas Shakya, Farhad Vadiee, Mohammad Khalil
The advancement of large language models (LLMs) has created a competitive landscape for AI-assisted programming tools. This study evaluates two leading models: ChatGPT 03-mini and DeepSeek-R1 on their ability to solve competitive programming tasks from Codeforces. Using 29 programming tasks of three levels of easy, medium, and hard difficulty, we assessed the outcome of both models by their accepted solutions, memory efficiency, and runtime performance. Our results indicate that while both models perform similarly on easy tasks, ChatGPT outperforms DeepSeek-R1 on medium-difficulty tasks, achieving a 54.5% success rate compared to DeepSeek 18.1%. Both models struggled with hard tasks, thus highlighting some ongoing challenges LLMs face in handling highly complex programming problems. These findings highlight key differences in both model capabilities and their computational power, offering valuable insights for developers and researchers working to advance AI-driven programming tools.
大型语言模型(LLM)的进步为AI辅助编程工具领域创造了竞争环境。本研究评估了两款领先模型:ChatGPT 03-mini和DeepSeek-R1,它们在解决Codeforces竞赛编程任务方面的能力。我们使用29个分为三个难度级别的编程任务,通过接受的解决方案、内存效率和运行时性能来评估两个模型的表现。我们的结果表明,虽然两个模型在简单任务上的表现相似,但在中等难度任务上,ChatGPT的表现优于DeepSeek-R1,成功率为54.5%,而DeepSeek的成功率为18.1%。两个模型在困难任务上都遇到了挑战,这突出了LLM在处理高度复杂的编程问题时面临的一些持续挑战。这些发现突出了两种模型在能力和计算能力方面的关键差异,为致力于开发AI驱动的编程工具的开发者和研究人员提供了宝贵的见解。
论文及项目相关链接
Summary
大型语言模型(LLM)的发展推动了AI辅助编程工具之间的竞争。本研究对比了两款领先模型:ChatGPT 03-mini和DeepSeek-R1,通过Codeforces的编程任务评估它们的性能。研究结果显示,在简单任务上两者表现相近,但在中等难度任务上,ChatGPT表现出更高的性能,成功率为54.5%,而DeepSeek的成功率为仅为18.1%。两者在复杂任务上都面临挑战,凸显出LLM在处理高度复杂编程问题上的局限。此研究为开发者和研究者提供了宝贵的信息,以推动AI驱动的编程工具的发展。
Key Takeaways
- 大型语言模型(LLM)在AI辅助编程工具领域具有竞争力。
- ChatGPT和DeepSeek-R1是两款领先的LLM模型。
- 在简单编程任务上,ChatGPT和DeepSeek-R1表现相近。
- 在中等难度任务上,ChatGPT优于DeepSeek-R1。
- 在复杂编程任务上,两者都面临挑战,显示出LLM的局限。
- 研究结果提供了关于两个模型的能力和计算能力的关键差异。
点此查看论文截图


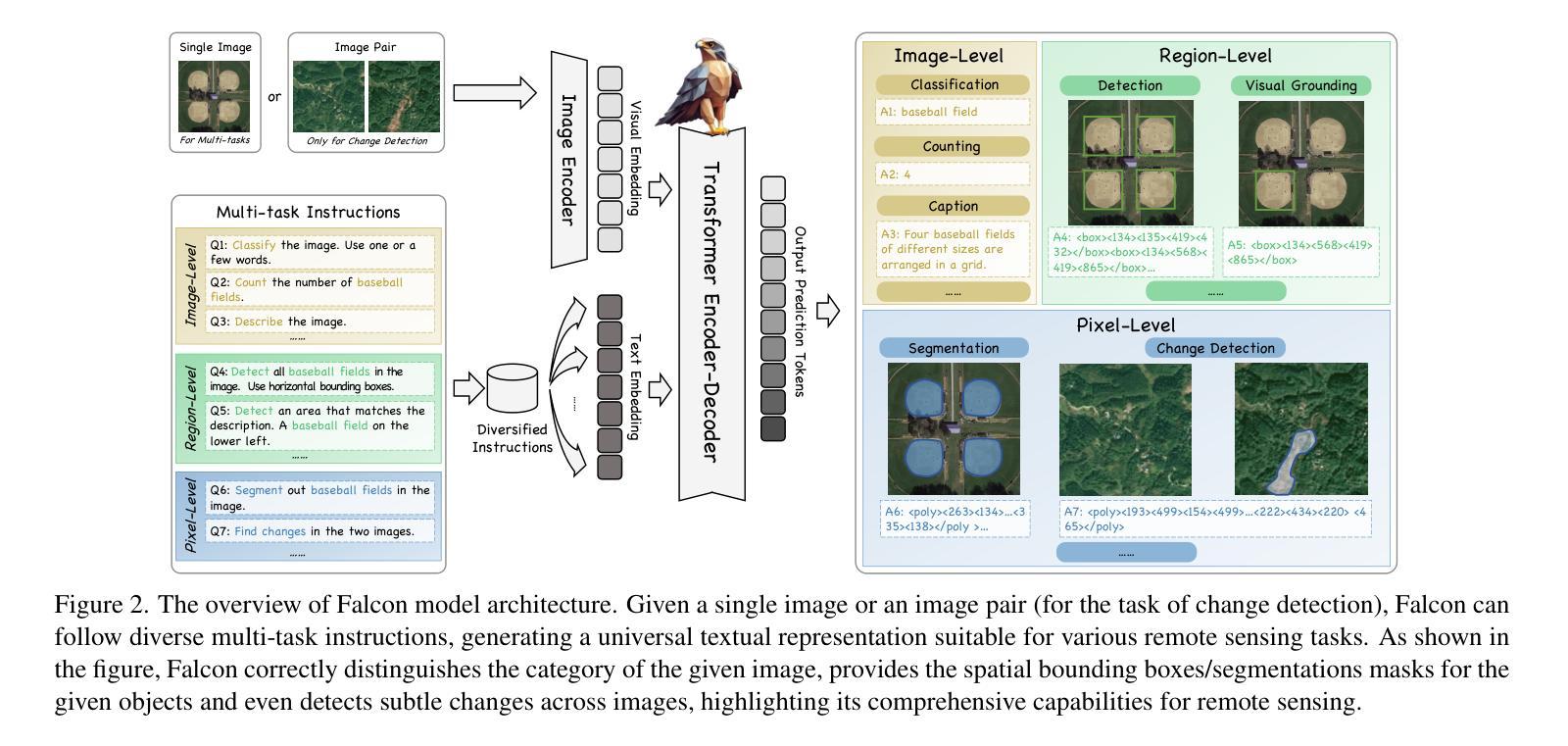
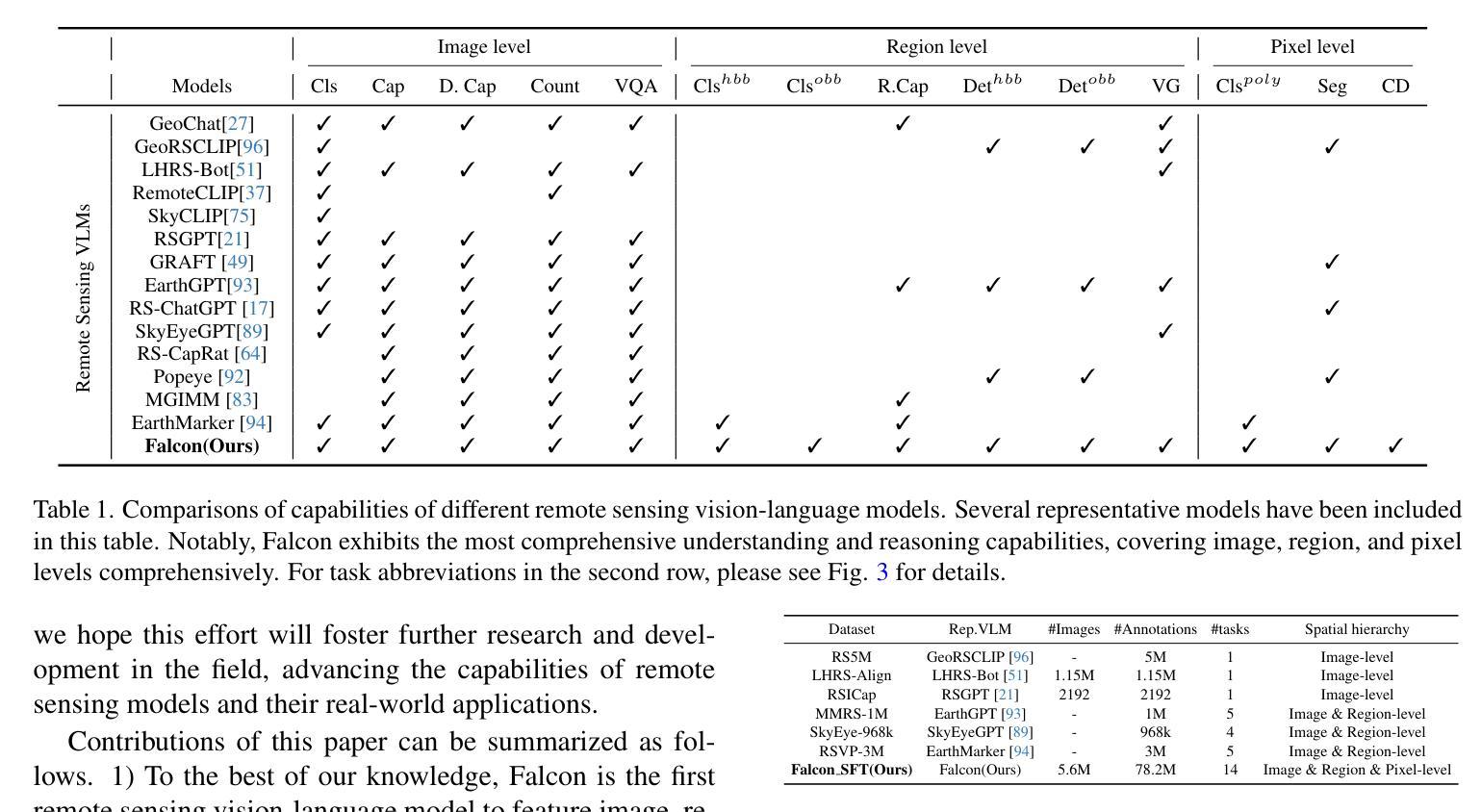
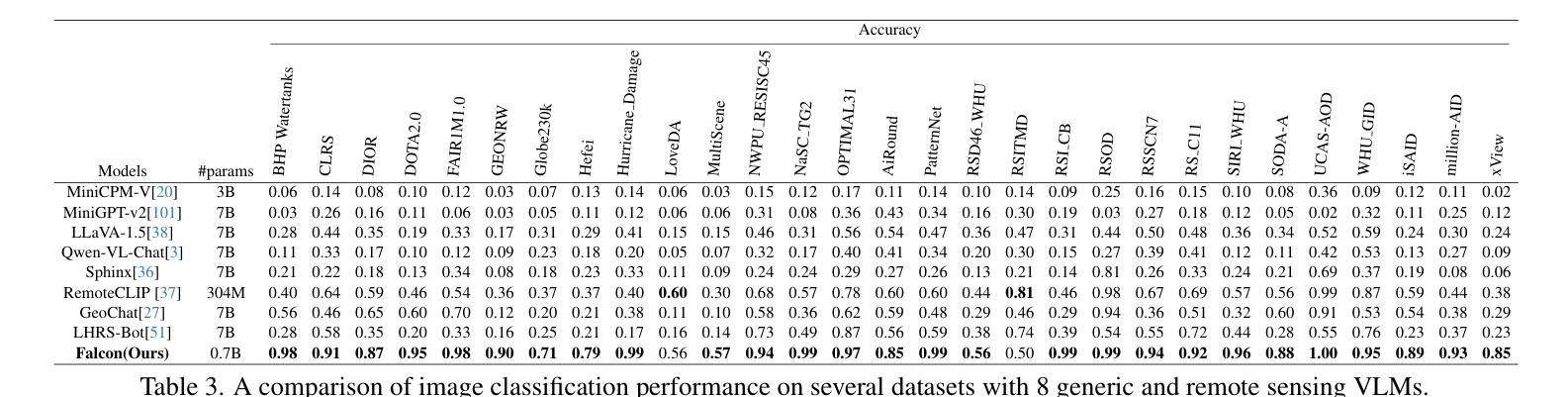
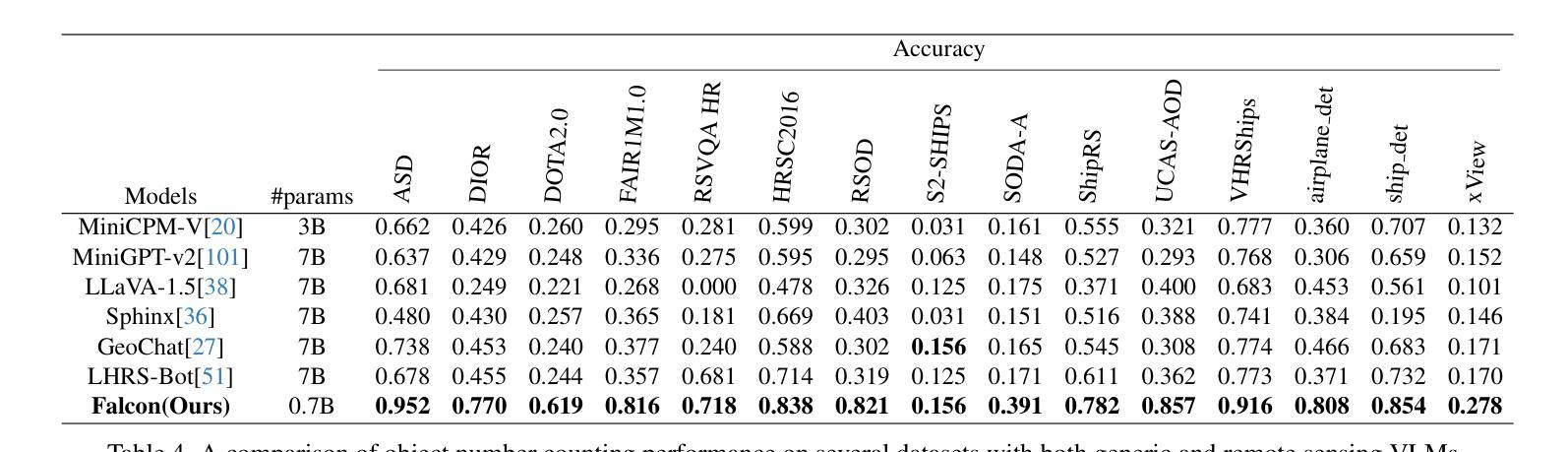
Falcon: A Remote Sensing Vision-Language Foundation Model
Authors:Kelu Yao, Nuo Xu, Rong Yang, Yingying Xu, Zhuoyan Gao, Titinunt Kitrungrotsakul, Yi Ren, Pu Zhang, Jin Wang, Ning Wei, Chao Li
This paper introduces a holistic vision-language foundation model tailored for remote sensing, named Falcon. Falcon offers a unified, prompt-based paradigm that effectively executes comprehensive and complex remote sensing tasks. Falcon demonstrates powerful understanding and reasoning abilities at the image, region, and pixel levels. Specifically, given simple natural language instructions and remote sensing images, Falcon can produce impressive results in text form across 14 distinct tasks, i.e., image classification, object detection, segmentation, image captioning, and etc. To facilitate Falcon’s training and empower its representation capacity to encode rich spatial and semantic information, we developed Falcon_SFT, a large-scale, multi-task, instruction-tuning dataset in the field of remote sensing. The Falcon_SFT dataset consists of approximately 78 million high-quality data samples, covering 5.6 million multi-spatial resolution and multi-view remote sensing images with diverse instructions. It features hierarchical annotations and undergoes manual sampling verification to ensure high data quality and reliability. Extensive comparative experiments are conducted, which verify that Falcon achieves remarkable performance over 67 datasets and 14 tasks, despite having only 0.7B parameters. We release the complete dataset, code, and model weights at https://github.com/TianHuiLab/Falcon, hoping to help further develop the open-source community.
本文介绍了一个专为遥感领域定制的全视觉语言基础模型,名为Falcon。Falcon提供了一个基于提示的统一范式,能够有效地执行全面复杂的遥感任务。Falcon在图像、区域和像素级别展现出强大的理解和推理能力。具体而言,给定简单的自然语言指令和遥感图像,Falcon可以在14个不同的任务中产生令人印象深刻的文本形式的结果,如图像分类、目标检测、分割、图像描述等。为了训练Falcon并增强其表示能力以编码丰富的空间语义信息,我们开发了遥感领域的大规模多任务指令调整数据集Falcon_SFT。Falcon_SFT数据集包含约7800万高质量数据样本,覆盖560万具有多种指令的多空间分辨率和多视角遥感图像。它采用分层注释并经过手动采样验证,以确保数据的高质量和可靠性。进行了广泛的对比实验,验证了在67个数据集和14个任务中,尽管只有0.7B参数,但Falcon取得了显著的性能。我们在https://github.com/TianHuiLab/Falcon上发布了完整的数据集、代码和模型权重,希望有助于进一步开发开源社区。
论文及项目相关链接
PDF Under Review
Summary
本文介绍了一款针对遥感领域的全新视觉语言基础模型——Falcon。它采用统一的提示式框架,能执行复杂多样的遥感任务,并具备强大的图像、区域和像素级别的理解与推理能力。通过简单的自然语言指令和遥感图像,Falcon能在14种不同任务中以文本形式生成令人印象深刻的结果。为训练Falcon并增强其表示能力以编码丰富的空间语义信息,团队开发了Falcon_SFT数据集。该数据集包含约7800万高质量数据样本,覆盖多空间分辨率和多视角的遥感图像,并提供多样化的指令。Falcon_SFT数据集具有层次化注释,并经过人工采样验证以确保数据质量和可靠性。实验表明,Falcon在67个数据集和14个任务上表现出卓越的性能,令人惊讶的是,它的参数规模仅有0.7B。
Key Takeaways
- Falcon是一个针对遥感领域的视觉语言基础模型,具备强大的理解和推理能力。
- Falcon采用提示式框架,能执行复杂多样的遥感任务。
- Falcon能通过自然语言指令和遥感图像,在多种任务中生成文本结果。
- 为训练Falcon,开发了大型多任务的Falcon_SFT数据集。
- Falcon_SFT数据集包含高质量数据样本,覆盖多种遥感图像,具有层次化注释和人工验证。
- Falcon在多个数据集和任务上表现出卓越性能,参数规模较小。
点此查看论文截图


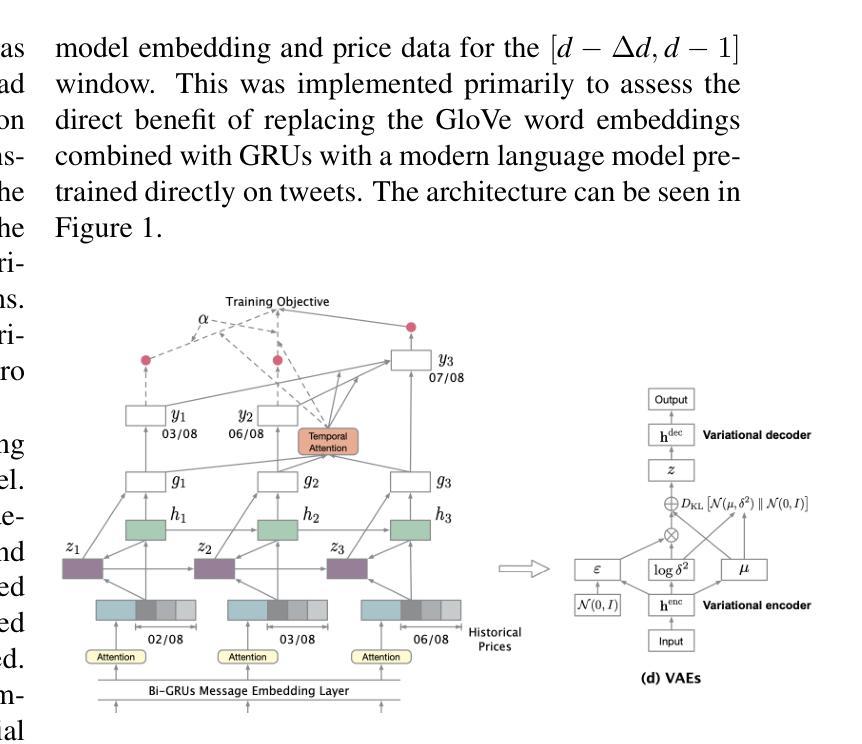
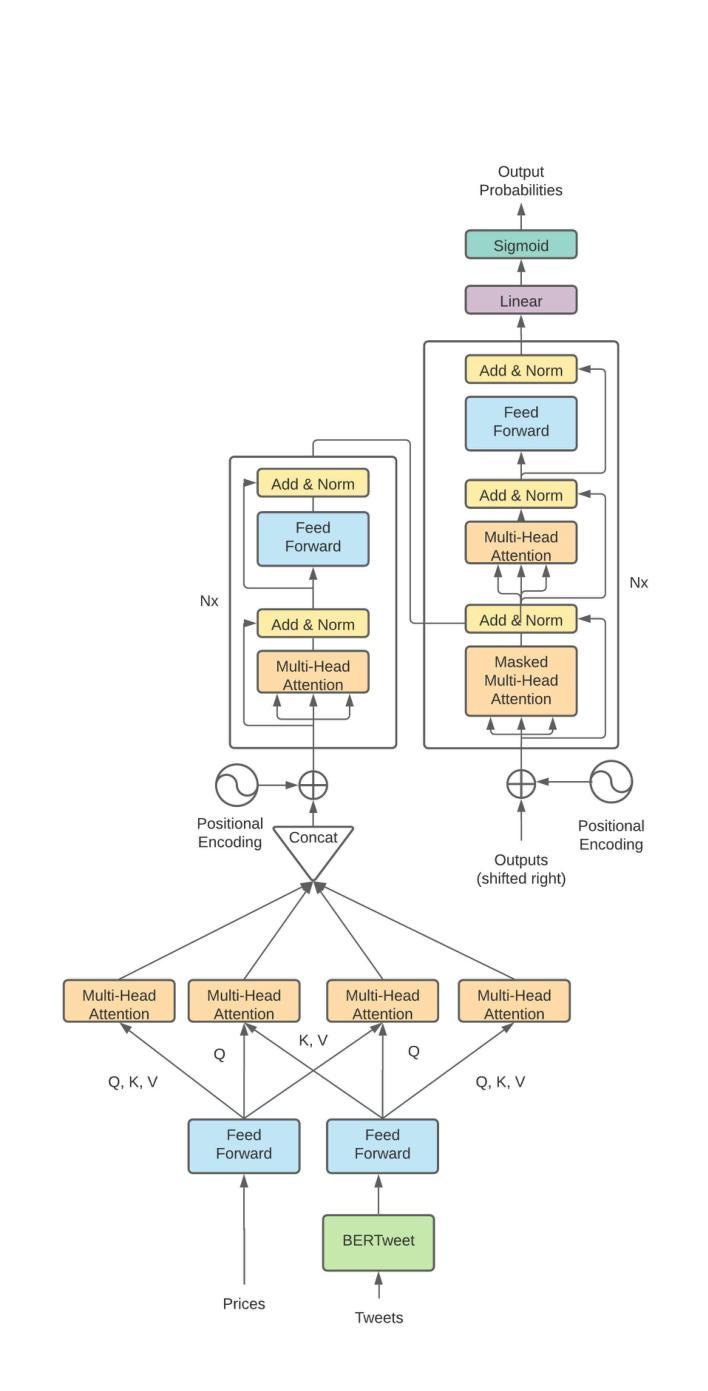
Predicting Stock Movement with BERTweet and Transformers
Authors:Michael Charles Albada, Mojolaoluwa Joshua Sonola
Applying deep learning and computational intelligence to finance has been a popular area of applied research, both within academia and industry, and continues to attract active attention. The inherently high volatility and non-stationary of the data pose substantial challenges to machine learning models, especially so for today’s expressive and highly-parameterized deep learning models. Recent work has combined natural language processing on data from social media to augment models based purely on historic price data to improve performance has received particular attention. Previous work has achieved state-of-the-art performance on this task by combining techniques such as bidirectional GRUs, variational autoencoders, word and document embeddings, self-attention, graph attention, and adversarial training. In this paper, we demonstrated the efficacy of BERTweet, a variant of BERT pre-trained specifically on a Twitter corpus, and the transformer architecture by achieving competitive performance with the existing literature and setting a new baseline for Matthews Correlation Coefficient on the Stocknet dataset without auxiliary data sources.
将深度学习计算智能应用于金融领域一直是学术界和工业界应用研究的热门领域,并且不断引起关注。数据的高内在波动性和非平稳性给机器学习模型带来了巨大的挑战,尤其是当今复杂且高度参数化的深度学习模型。近期的研究结合了社交媒体数据的自然语言处理,以扩充仅基于历史价格数据的模型,以提高性能,这一研究引起了特别的关注。先前的研究通过结合诸如双向GRU、变分自动编码器、单词和文档嵌入、自注意力、图注意力和对抗训练等技术,在此任务上取得了最先进的性能。在本文中,我们展示了BERTweet(一种在Twitter语料库上专门进行预训练的BERT变体)和基于Transformer架构的有效性,通过实现与现有文献具有竞争力的性能以及在不使用辅助数据源的情况下在Stocknet数据集上为 Matthews Correlation Coefficient设立新的基准线。
论文及项目相关链接
PDF 9 pages, 4 figures, 2 tables
Summary
深度学习及计算智能在金融领域的应用研究备受关注,特别是在学术界和工业界。金融数据的高波动性和非平稳性给机器学习模型带来挑战。最近的研究结合了社交媒体数据自然语言处理增强模型性能,在纯历史价格数据基础上取得了显著成果。本文展示了BERTweet模型的有效性,该模型在Twitter语料库上进行预训练,并通过变压器架构在Stocknet数据集上实现了与现有文献相当的竞争力表现,无需辅助数据源即可设置新的Matthews相关系数基准。
Key Takeaways
- 深度学习及计算智能在金融领域的应用是当前热门研究领域。
- 金融数据的高波动性和非平稳性给机器学习模型带来挑战。
- 结合社交媒体数据的自然语言处理可增强金融领域机器学习模型的性能。
- BERTweet模型在Twitter语料库上的预训练对于金融文本数据是有效的。
- 变压器架构在金融文本数据处理中表现出竞争力。
- 无需辅助数据源,BERTweet模型在Stocknet数据集上实现了新的Matthews相关系数基准。
点此查看论文截图

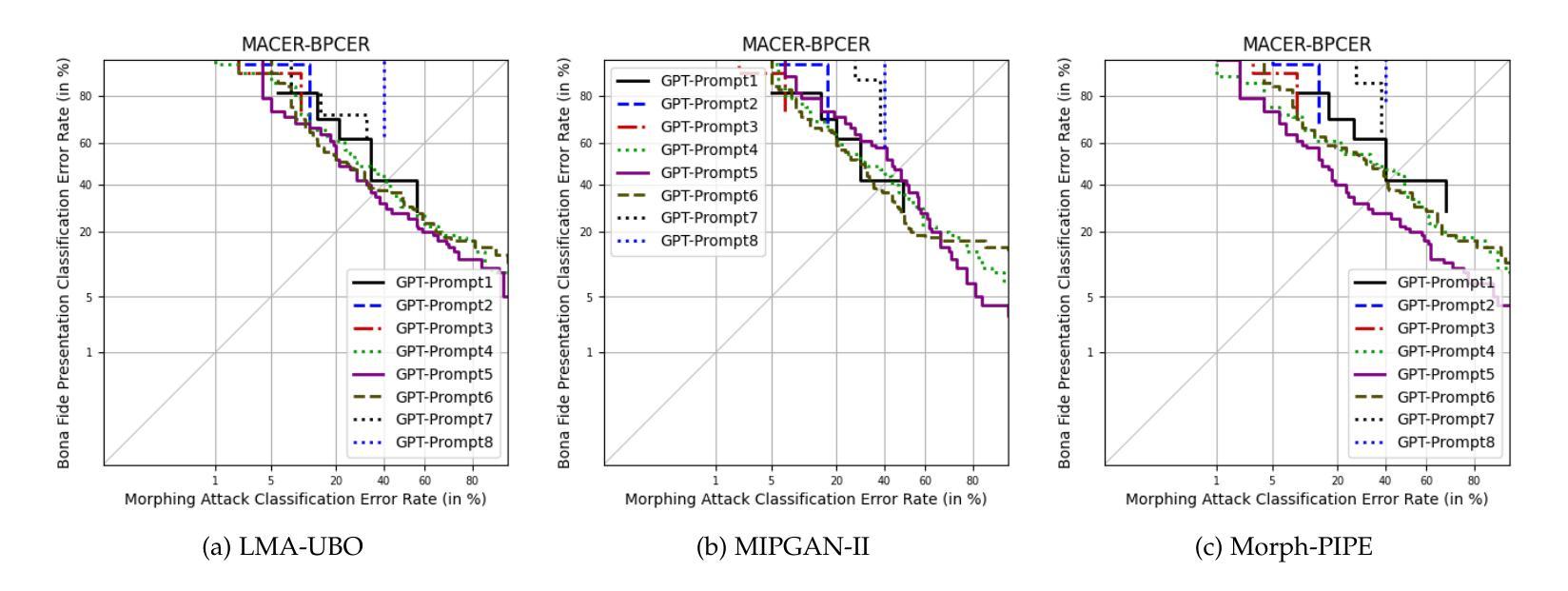
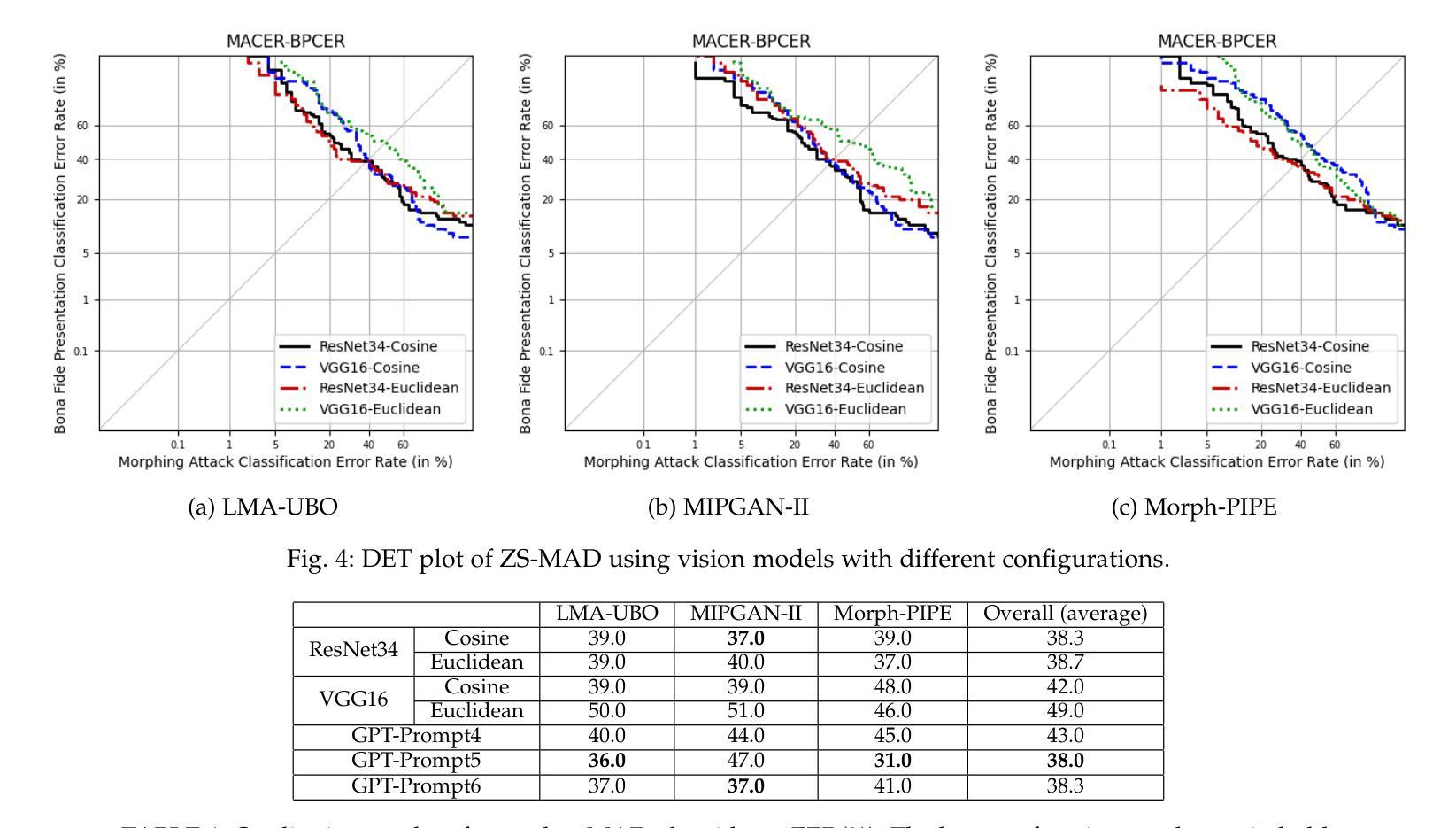
ChatGPT Encounters Morphing Attack Detection: Zero-Shot MAD with Multi-Modal Large Language Models and General Vision Models
Authors:Haoyu Zhang, Raghavendra Ramachandra, Kiran Raja, Christoph Busch
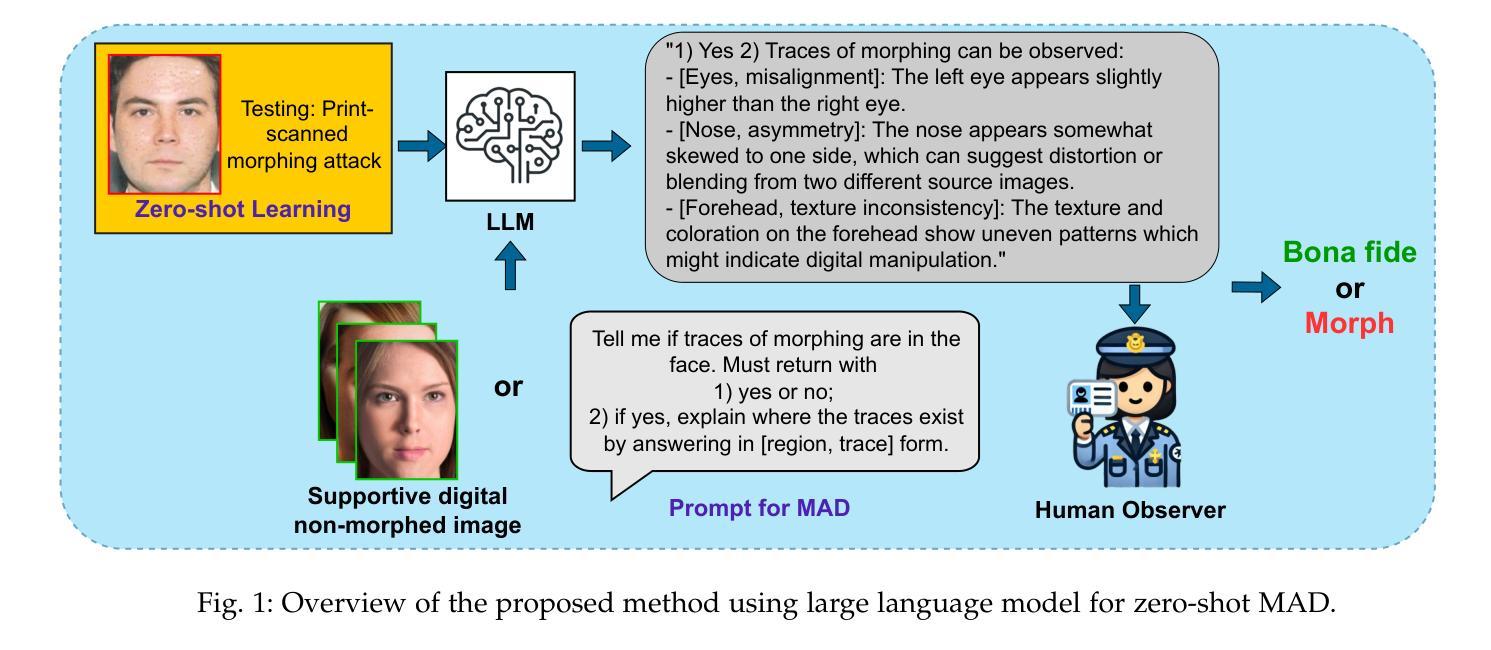
Face Recognition Systems (FRS) are increasingly vulnerable to face-morphing attacks, prompting the development of Morphing Attack Detection (MAD) algorithms. However, a key challenge in MAD lies in its limited generalizability to unseen data and its lack of explainability-critical for practical application environments such as enrolment stations and automated border control systems. Recognizing that most existing MAD algorithms rely on supervised learning paradigms, this work explores a novel approach to MAD using zero-shot learning leveraged on Large Language Models (LLMs). We propose two types of zero-shot MAD algorithms: one leveraging general vision models and the other utilizing multimodal LLMs. For general vision models, we address the MAD task by computing the mean support embedding of an independent support set without using morphed images. For the LLM-based approach, we employ the state-of-the-art GPT-4 Turbo API with carefully crafted prompts. To evaluate the feasibility of zero-shot MAD and the effectiveness of the proposed methods, we constructed a print-scan morph dataset featuring various unseen morphing algorithms, simulating challenging real-world application scenarios. Experimental results demonstrated notable detection accuracy, validating the applicability of zero-shot learning for MAD tasks. Additionally, our investigation into LLM-based MAD revealed that multimodal LLMs, such as ChatGPT, exhibit remarkable generalizability to untrained MAD tasks. Furthermore, they possess a unique ability to provide explanations and guidance, which can enhance transparency and usability for end-users in practical applications.
人脸识别系统(FRS)越来越容易受到人脸变形攻击的影响,这促使了变形攻击检测(MAD)算法的发展。然而,MAD的关键挑战在于其对未见数据的泛化能力有限,以及在实际应用环境(如注册站和自动边境控制系统)中缺乏可解释性。
意识到大多数现有的MAD算法都依赖于监督学习模式,这项工作探索了一种使用基于大型语言模型(LLM)的零射击学习的新方法来进行MAD。我们提出了两种类型的零射击MAD算法:一种利用通用视觉模型,另一种利用多模态LLM。对于通用视觉模型,我们通过计算独立支持集的均值支持嵌入来解决MAD任务,而不使用合成的图像。对于基于LLM的方法,我们采用了最先进的GPT-4 Turbo API和精心设计的提示。
论文及项目相关链接
摘要
人脸识别系统(FRS)易受面孔变形攻击影响,促使研发面向变形攻击检测的算法。但关键在于该检测方法的有限泛化能力与解释性的缺乏,对实战环境下如报到站、自动化边境控制系统等实际应用场景造成影响。本研究意识到多数现有的变形攻击检测算法依赖监督学习模式,于是探索采用基于零射击学习利用大型语言模型(LLM)的新方法。本研究提出两种零射击变形攻击检测算法:一种利用通用视觉模型,另一种则采用多模态LLM。对于通用视觉模型,我们通过计算独立支持集的均值支持嵌入来解决变形攻击检测任务,而不使用变形图像。对于基于LLM的方法,我们采用最先进的GPT-4 Turbo API与精心设计的提示词。为了评估零射击变形攻击检测的可行性以及所提出方法的有效性,我们构建了一个包含各种未见过的变形算法的面扫描打印变形数据集,模拟具有挑战性的现实应用场景。实验结果显示显著的检测准确性,验证了零射击学习在变形攻击检测任务中的适用性。此外,我们对基于LLM的变形攻击检测的研究表明,如ChatGPT等多模态LLM在未经训练的变形攻击检测任务中显示出非凡的泛化能力。而且,它们还具有提供解释和指导的独特能力,可以提高实际应用中对最终用户的透明度和可用性。
关键见解
- 人脸识别系统面临面孔变形攻击的风险,需要开发有效的变形攻击检测算法。
- 当前大多数变形攻击检测算法依赖于监督学习模式,存在泛化能力和解释性的局限性。
- 本研究首次探索了基于零射击学习的变形攻击检测新方法,利用大型语言模型进行识别。
- 提出两种零射击检测算法:基于通用视觉模型的方法和基于多模态LLM的方法。
- 通用视觉模型通过计算支持集的均值支持嵌入来检测变形攻击,无需使用变形图像。
- 使用GPT-4 Turbo API和精心设计的提示词进行LLM实验,证明了零射击检测的有效性。
点此查看论文截图


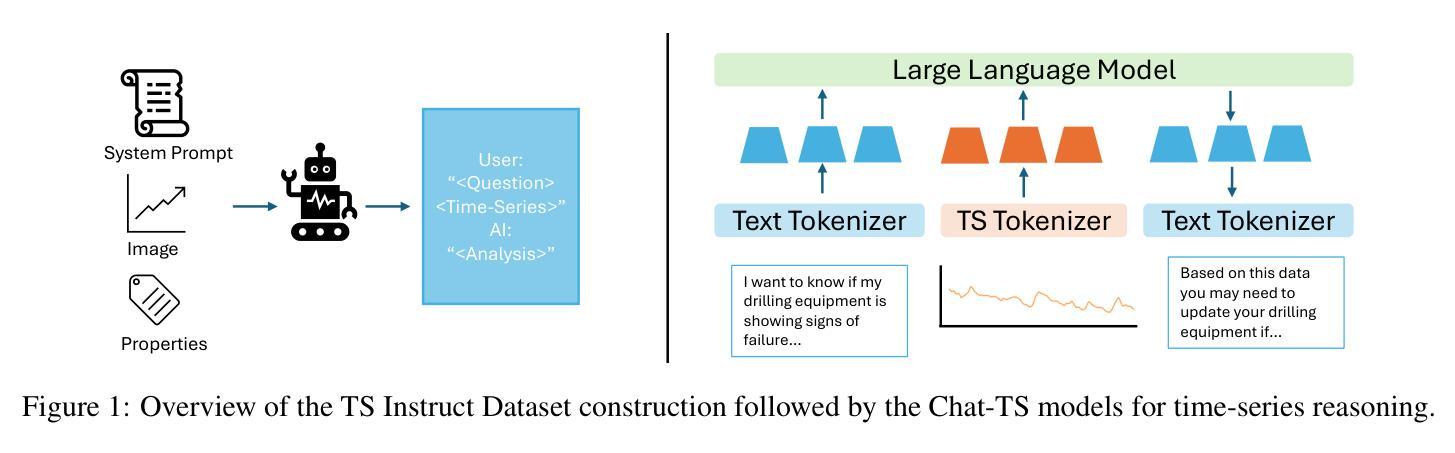
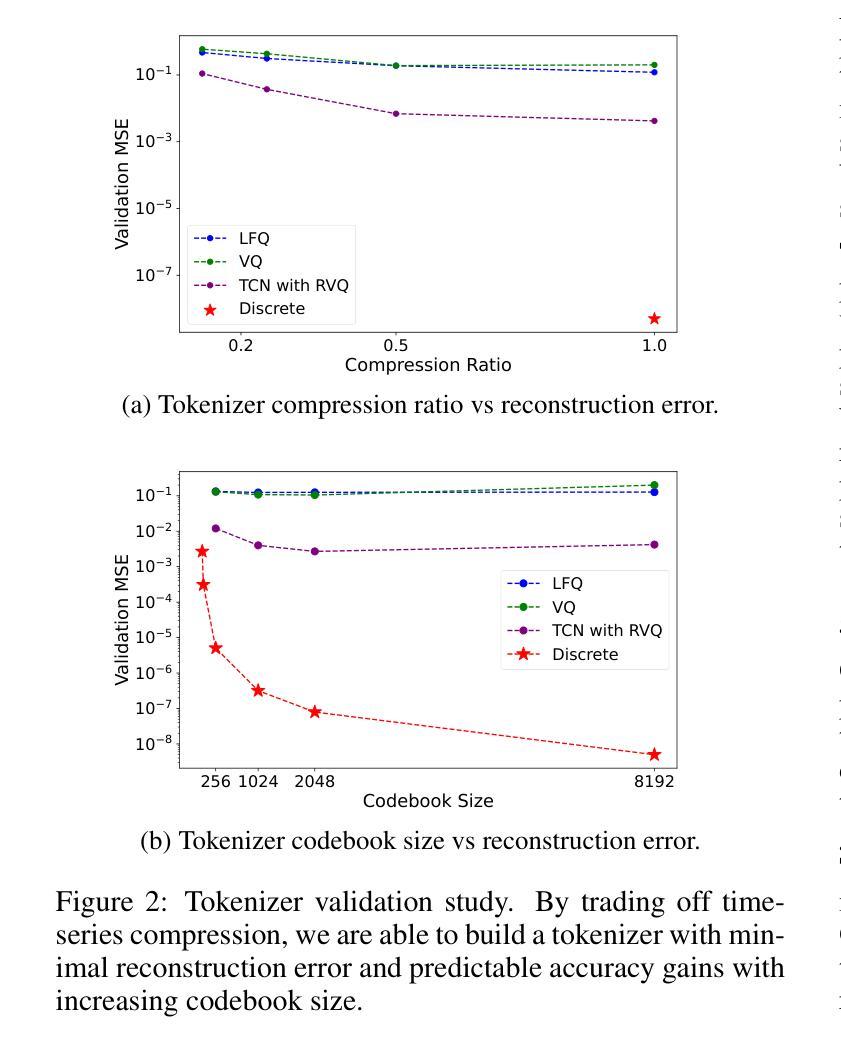
Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data
Authors:Paul Quinlan, Qingguo Li, Xiaodan Zhu
Time-series analysis is critical for a wide range of fields such as healthcare, finance, transportation, and energy, among many others. The practical applications often involve analyzing time-series data alongside contextual information in the form of natural language to support informed decisions. However, current time-series models are limited in their ability to perform reasoning that involves both time-series and their textual content. In this work, we address this gap by introducing \textit{Chat-TS}, a large language model (LLM) based framework, designed to support reasoning over time series and textual data. Unlike traditional models, Chat-TS integrates time-series tokens into LLMs’ vocabulary, enhancing its reasoning ability over both modalities without compromising the core natural language capabilities, enabling practical analysis and reasoning across modalities. To support learning and evaluation in this setup, we contribute new datasets: the \textit{TS Instruct Training Dataset} which pairs diverse time-series data with relevant text instructions and responses for instruction tuning, the \textit{TS Instruct Question and Answer (QA) Gold Dataset} which provides multiple-choice questions designed to evaluate multimodal reasoning, and a \textit{TS Instruct Quantitative Probing Set} which contains a small subset of the TS Instruct QA tasks alongside math and decision-making questions for LLM evaluation. We designed a training strategy to preserve the inherent reasoning capabilities of LLMs while augmenting them for time-series reasoning. Experiments show that Chat-TS achieves state-of-the-art performance in multi-modal reasoning tasks by maintaining strong natural language proficiency while improving time-series reasoning. ~\footnote{To ensure replicability and facilitate future research, all models, datasets, and code will be available at [\texttt{Github-URL}].}
时间序列分析在医疗保健、金融、交通、能源等众多领域具有广泛应用。实际应用中,常与自然语言形式的上下文信息一起分析时间序列数据,以支持决策。然而,当前的时间序列模型在涉及时间序列及其文本内容的推理方面存在局限性。在这项工作中,我们通过引入基于大型语言模型(LLM)的Chat-TS框架来解决这一差距。Chat-TS旨在支持时间序列和文本数据的推理。与传统模型不同,Chat-TS将时间序列标记集成到LLM词汇表中,在不损害核心自然语言功能的情况下,增强其在两种模式上的推理能力,从而实现跨模式的实用分析和推理。为了支持在此设置中的学习和评估,我们提供了新数据集:将多样化时间序列数据与相关文本指令和响应相匹配的TS Instruct训练数据集,用于指令微调;旨在评估多模式推理的TS Instruct问答黄金数据集;以及包含一小部分TS Instruct QA任务的TS Instruct定量探测集以及用于LLM评估的数学和决策问题。我们设计了一种训练策略,以保留LLM的固有推理能力并增强时间序列推理能力。实验表明,Chat-TS在多模式推理任务上达到了最新性能水平,在自然语言处理方面保持了强大能力的同时提高了时间序列推理能力。为确保可复制性和促进未来研究,所有模型、数据集和代码都将在GitHub上公开。
论文及项目相关链接
摘要
本文介绍了基于大型语言模型(LLM)的时间序列与文本数据推理框架Chat-TS。通过整合时间序列标记符号进LLM的词汇表中,Chat-TS增强了其在两种模态数据上的推理能力,同时不损害其核心的自然语言处理能力。为支持在这种设置下的学习和评估,本文贡献了新的数据集,并提出了一种训练策略,旨在保留LLM的内在推理能力的同时,增强它们的时间序列推理能力。实验表明,Chat-TS在多模态推理任务上达到了最先进的性能水平。
关键见解
- 时间序列分析在多个领域(如医疗保健、金融、交通和能源等)具有广泛应用,涉及时间序列数据与自然语言形式上下文信息的分析,以支持决策制定。
- 当前的时间序列模型在同时处理时间序列和文本内容的推理方面存在局限性。
- Chat-TS框架旨在支持时间序列和文本数据的推理,通过整合时间序列标记进LLM的词汇表中,增强了其在两种模态数据上的推理能力。
- 提出了新的数据集以支持Chat-TS框架的学习与评估,包括TS Instruct训练数据集、TS Instruct问答(QA)黄金数据集以及TS Instruct定量探测集。
- 设计了一种训练策略,旨在保留LLM的内在推理能力的同时增强其时间序列推理能力。
- 实验结果显示,Chat-TS在多模态推理任务上取得了最先进的性能,能够在保持强大的自然语言处理能力的同时提高时间序列推理能力。
点此查看论文截图



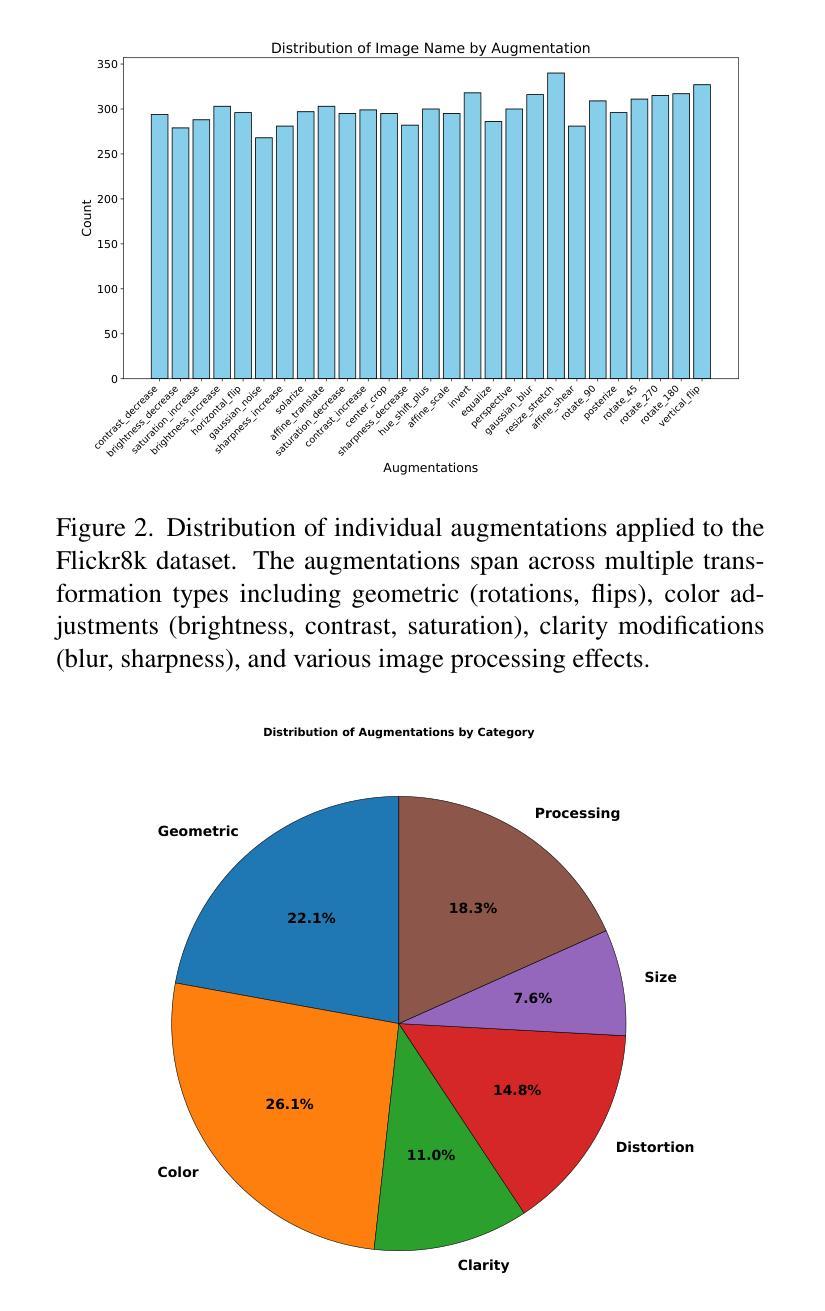
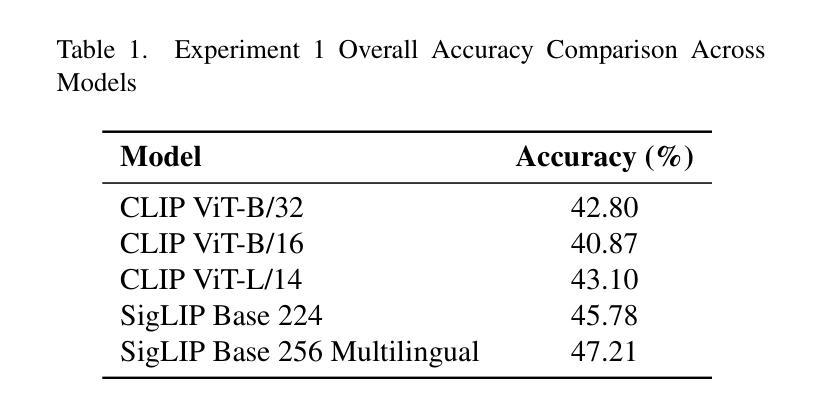
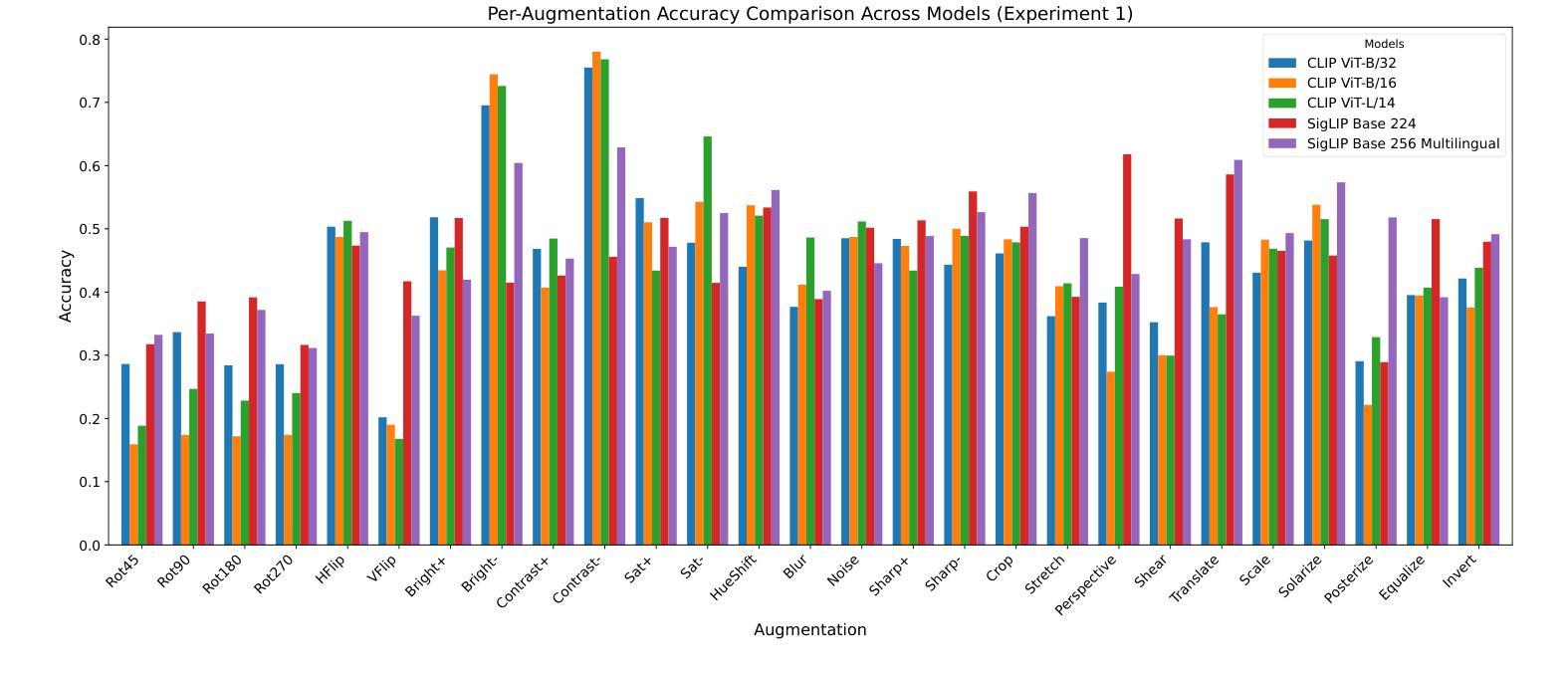
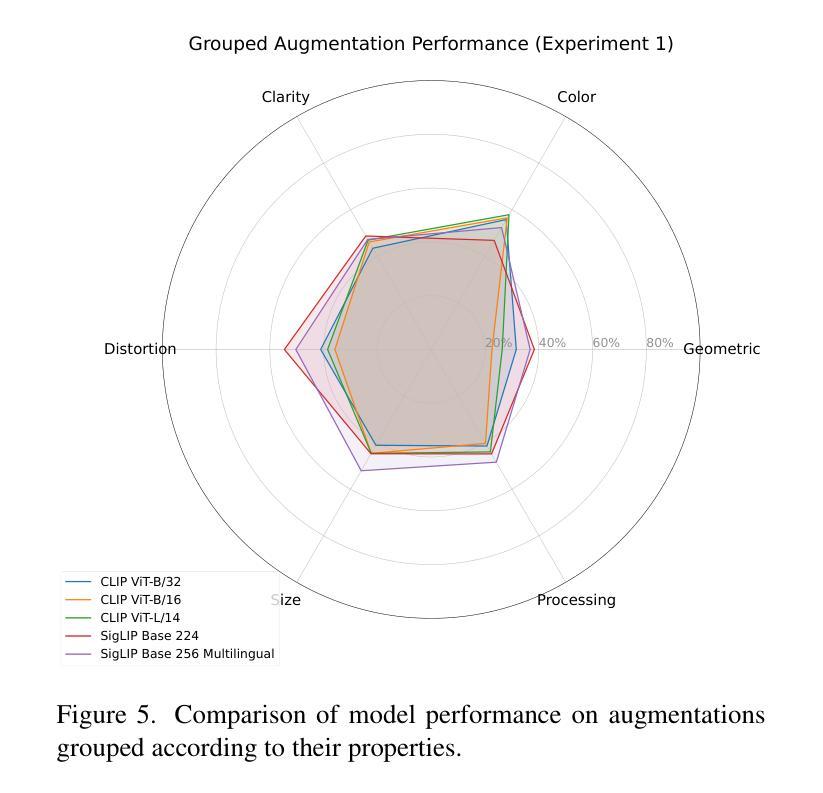
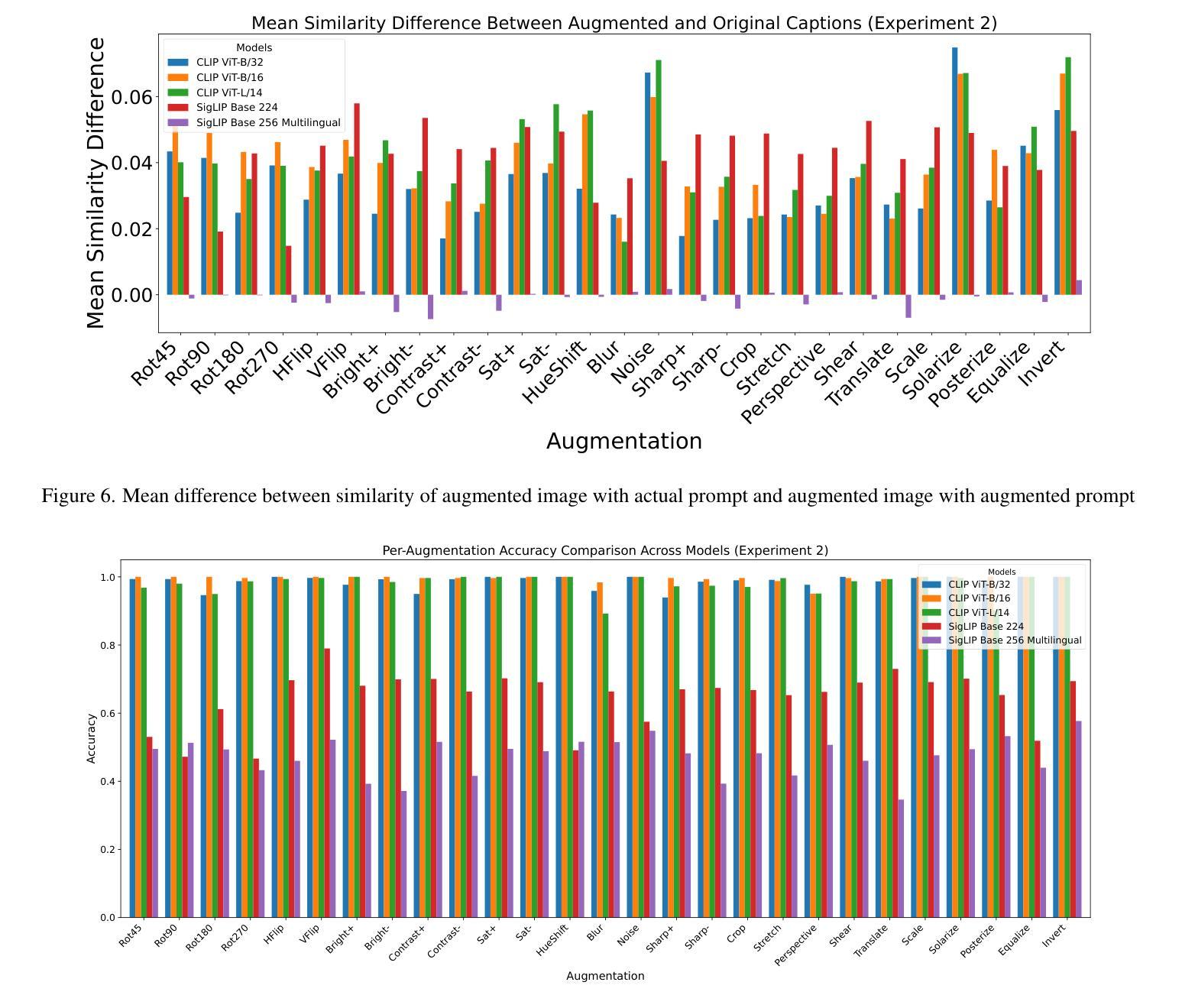
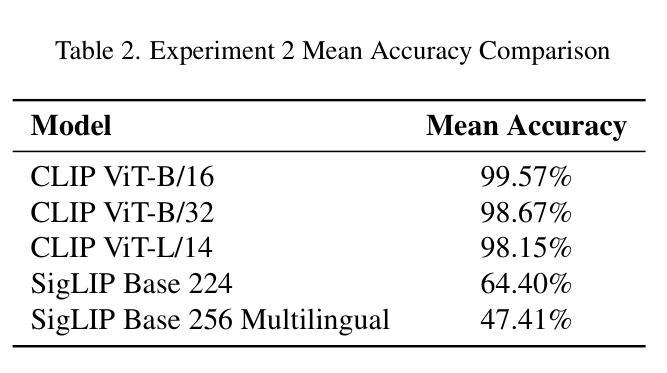
On the Limitations of Vision-Language Models in Understanding Image Transforms
Authors:Ahmad Mustafa Anis, Hasnain Ali, Saquib Sarfraz
Vision Language Models (VLMs) have demonstrated significant potential in various downstream tasks, including Image/Video Generation, Visual Question Answering, Multimodal Chatbots, and Video Understanding. However, these models often struggle with basic image transformations. This paper investigates the image-level understanding of VLMs, specifically CLIP by OpenAI and SigLIP by Google. Our findings reveal that these models lack comprehension of multiple image-level augmentations. To facilitate this study, we created an augmented version of the Flickr8k dataset, pairing each image with a detailed description of the applied transformation. We further explore how this deficiency impacts downstream tasks, particularly in image editing, and evaluate the performance of state-of-the-art Image2Image models on simple transformations.
视觉语言模型(VLMs)在各种下游任务中展现出了巨大的潜力,包括图像/视频生成、视觉问答、多模态聊天机器人和视频理解。然而,这些模型在基本的图像转换方面经常遇到困难。本文研究了VLMs的图像级别理解,特别是OpenAI的CLIP和Google的SigLIP。我们的研究发现,这些模型缺乏对图像级别增强的理解。为了推动这项研究,我们创建了Flickr8k数据集的增强版本,为每个图像提供了所应用转换的详细描述。我们还进一步探讨了这种缺陷对下游任务的影响,特别是在图像编辑方面,并评估了最新Image2Image模型在简单转换上的性能。
论文及项目相关链接
PDF 8 pages, 15 images
Summary
视觉语言模型(VLMs)在多个下游任务中展现出巨大潜力,包括图像/视频生成、视觉问答、多模态聊天机器人和视频理解。然而,这些模型在基本图像转换方面常常遇到困难。本文研究了VLMs的图像级别理解,特别是OpenAI的CLIP和Google的SigLIP。研究发现,这些模型缺乏对图像级别增强的理解。为了推动这项研究,我们创建了Flickr8k数据集的增强版本,为每个图像配备详细的转换描述。我们还探讨了这种缺陷对下游任务、尤其是图像编辑的影响,并评估了最先进的Image2Image模型在简单转换方面的性能。
Key Takeaways
- 视觉语言模型(VLMs)在多个下游任务中展现出潜力。
- VLMs在基本图像转换方面存在困难。
- 本文研究了VLMs的图像级别理解,特别是CLIP和SigLIP模型。
- 这些模型缺乏对图像级别增强的理解。
- 为了推动研究,创建了Flickr8k数据集的增强版本,包含图像转换描述。
- 这种缺陷影响下游任务,尤其是图像编辑。
点此查看论文截图

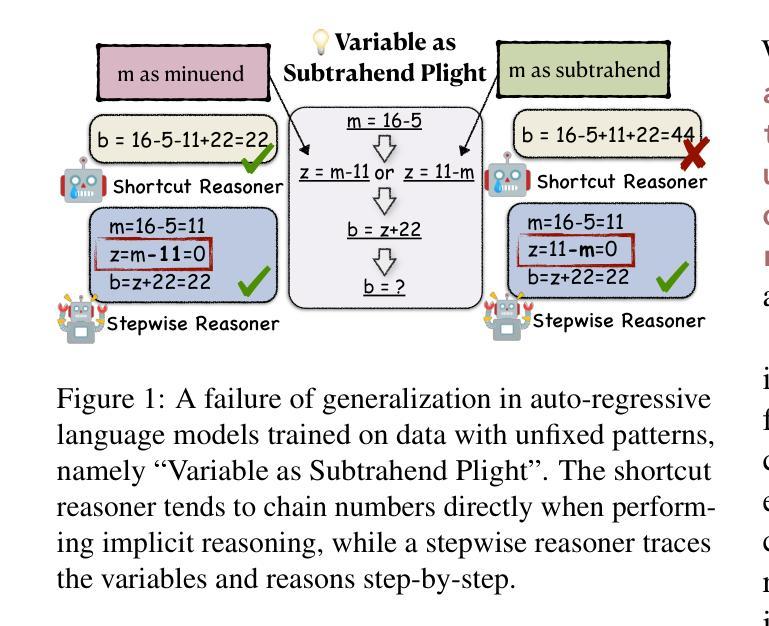
Implicit Reasoning in Transformers is Reasoning through Shortcuts
Authors:Tianhe Lin, Jian Xie, Siyu Yuan, Deqing Yang
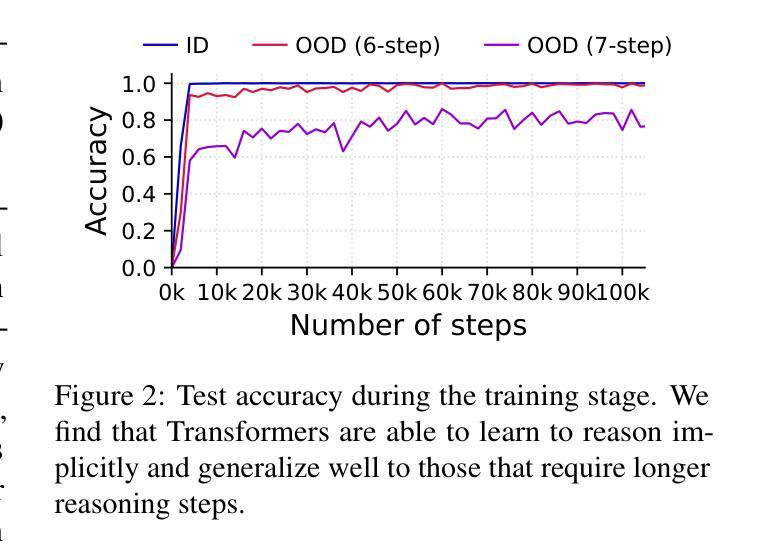
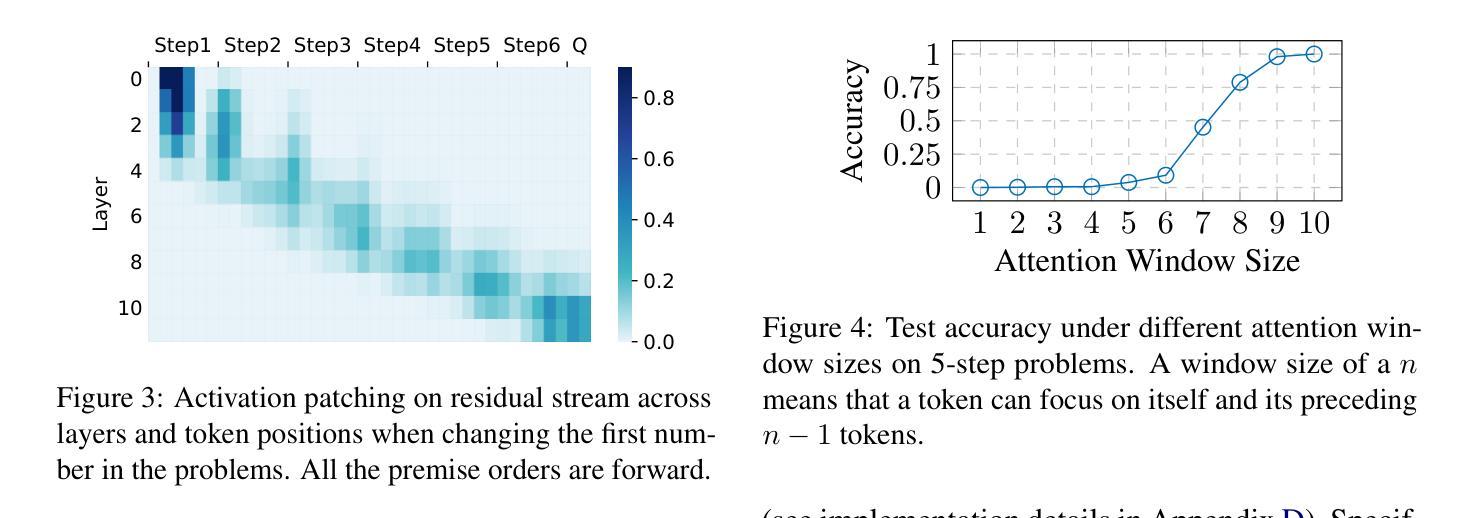
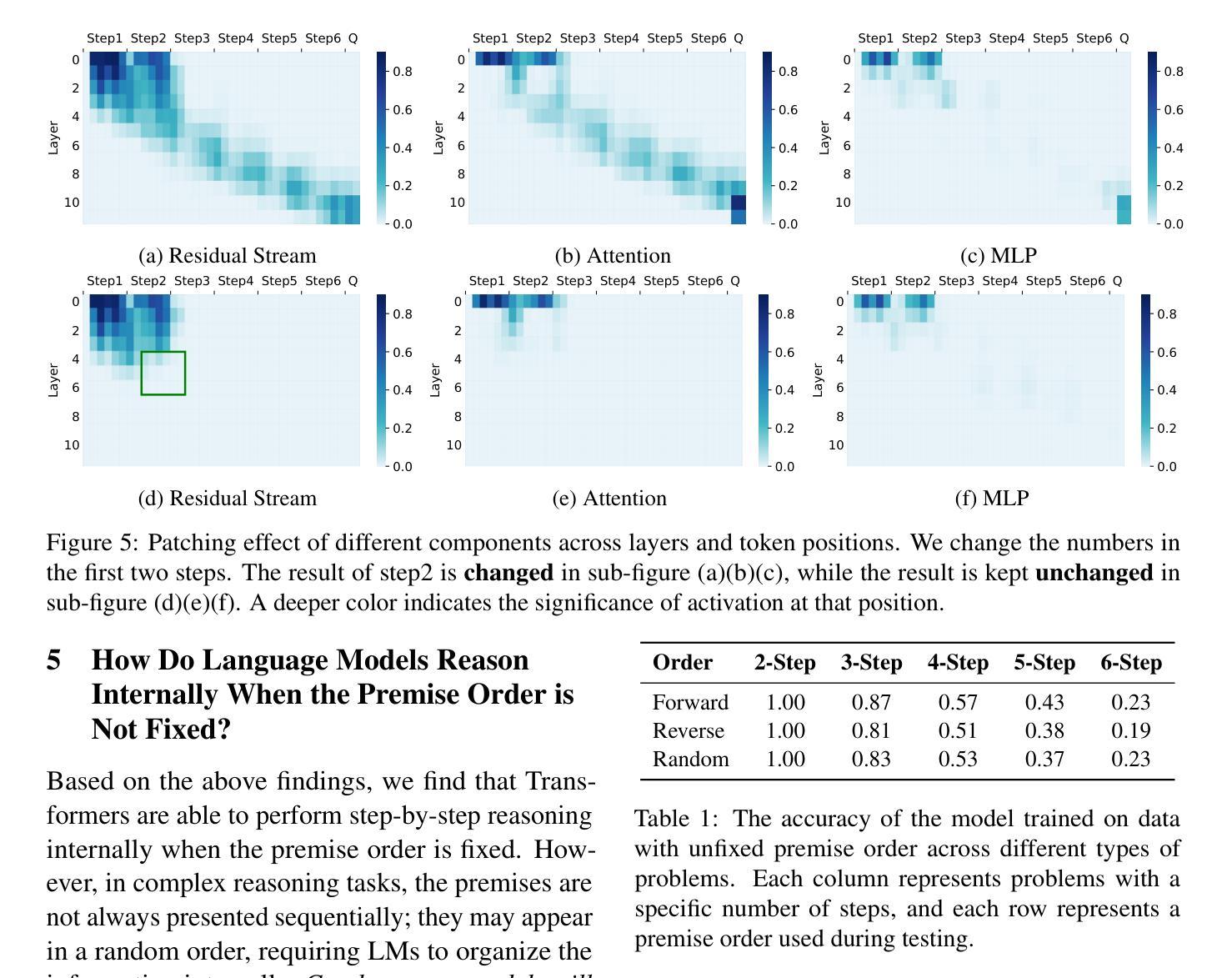
Test-time compute is emerging as a new paradigm for enhancing language models’ complex multi-step reasoning capabilities, as demonstrated by the success of OpenAI’s o1 and o3, as well as DeepSeek’s R1. Compared to explicit reasoning in test-time compute, implicit reasoning is more inference-efficient, requiring fewer generated tokens. However, why does the advanced reasoning capability fail to emerge in the implicit reasoning style? In this work, we train GPT-2 from scratch on a curated multi-step mathematical reasoning dataset and conduct analytical experiments to investigate how language models perform implicit reasoning in multi-step tasks. Our findings reveal: 1) Language models can perform step-by-step reasoning and achieve high accuracy in both in-domain and out-of-domain tests via implicit reasoning. However, this capability only emerges when trained on fixed-pattern data. 2) Conversely, implicit reasoning abilities emerging from training on unfixed-pattern data tend to overfit a specific pattern and fail to generalize further. Notably, this limitation is also observed in state-of-the-art large language models. These findings suggest that language models acquire implicit reasoning through shortcut learning, enabling strong performance on tasks with similar patterns while lacking generalization.
测试时的计算正成为增强语言模型复杂多步骤推理能力的新范式,OpenAI的o1和o3以及DeepSeek的R1的成功演示了这一点。与测试时计算中的显式推理相比,隐式推理的推理效率更高,生成的标记更少。然而,为什么先进的推理能力没有在隐式推理风格中出现?在这项工作中,我们从零开始训练GPT-2,在一个精选的多步数学推理数据集上进行实验分析,以研究语言模型如何在多步任务中进行隐式推理。我们的研究结果揭示了以下几点:1)语言模型可以通过隐式推理进行逐步推理,并在领域内外测试中实现高准确性。但这种能力仅在训练固定模式数据时出现。2)相反,从训练非固定模式数据中涌现的隐式推理能力往往倾向于过度适应特定模式,而无法进一步推广。值得注意的是,这一局限性也被观察到在最新的大型语言模型中。这些发现表明,语言模型通过捷径学习获得隐式推理能力,能够在具有相似模式的任务上表现出强大的性能,但缺乏泛化能力。
论文及项目相关链接
Summary
本文探讨了测试时计算(test-time compute)这一新兴范式在增强语言模型复杂多步推理能力方面的应用。通过对GPT-2进行训练和实验分析,发现语言模型可以通过隐式推理完成多步任务,并在固定模式数据上表现出高准确率。然而,当训练数据模式不固定时,隐式推理能力容易过度拟合特定模式,缺乏进一步的泛化能力。这表明语言模型的隐式推理是通过捷径学习获得的,能够在类似的任务上表现出色,但在泛化方面存在局限性。
Key Takeaways
- 测试时计算是增强语言模型多步推理能力的新兴范式。
- 隐式推理相比显式推理更推理高效,需要生成的标记更少。
- 语言模型可以通过隐式推理完成多步任务,并在固定模式数据上表现出高准确率。
- 在训练数据模式不固定的情况下,语言模型的隐式推理能力容易过度拟合特定模式。
- 隐式推理能力的泛化能力有限,即使在先进的大型语言模型中也是如此。
- 语言模型的隐式推理能力是通过捷径学习获得的。
点此查看论文截图

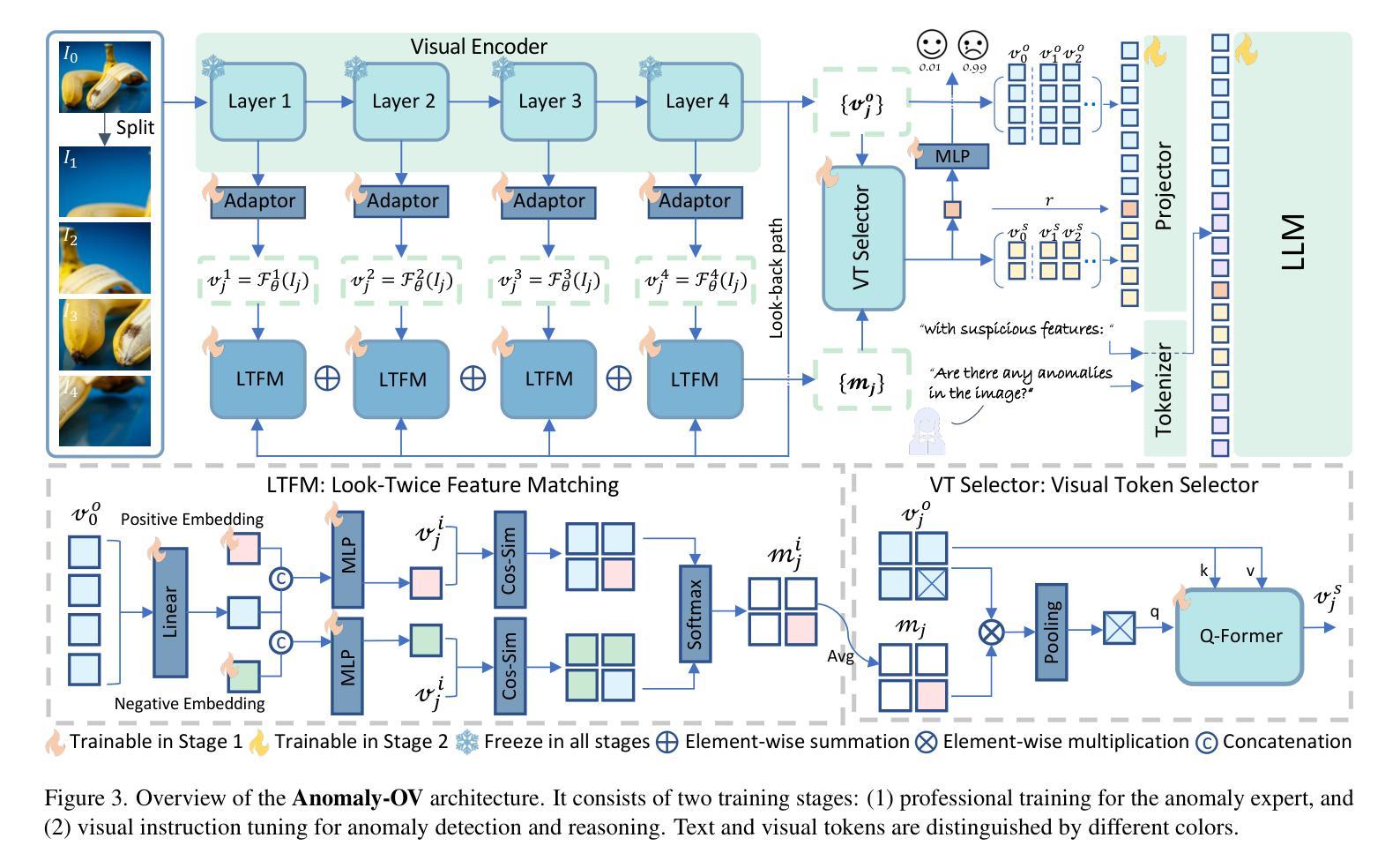
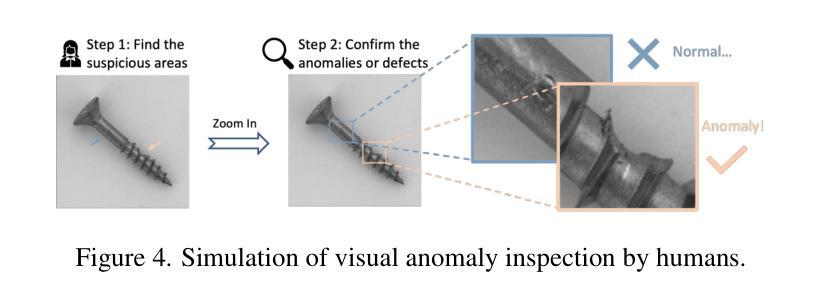
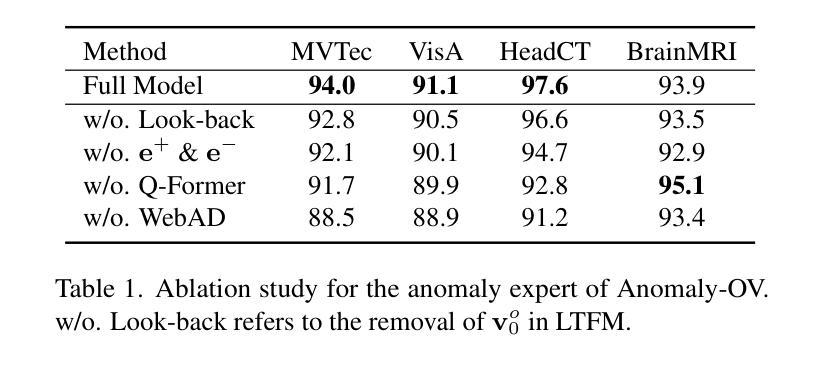
Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models
Authors:Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M. Patel, Isht Dwivedi
Zero-Shot Anomaly Detection (ZSAD) is an emerging AD paradigm. Unlike the traditional unsupervised AD setting that requires a large number of normal samples to train a model, ZSAD is more practical for handling data-restricted real-world scenarios. Recently, Multimodal Large Language Models (MLLMs) have shown revolutionary reasoning capabilities in various vision tasks. However, the reasoning of image abnormalities remains underexplored due to the lack of corresponding datasets and benchmarks. To facilitate research in AD & reasoning, we establish the first visual instruction tuning dataset, Anomaly-Instruct-125k, and the evaluation benchmark, VisA-D&R. Through investigation with our benchmark, we reveal that current MLLMs like GPT-4o cannot accurately detect and describe fine-grained anomalous details in images. To address this, we propose Anomaly-OneVision (Anomaly-OV), the first specialist visual assistant for ZSAD and reasoning. Inspired by human behavior in visual inspection, Anomaly-OV leverages a Look-Twice Feature Matching (LTFM) mechanism to adaptively select and emphasize abnormal visual tokens. Extensive experiments demonstrate that Anomaly-OV achieves significant improvements over advanced generalist models in both detection and reasoning. Extensions to medical and 3D AD are provided for future study. The link to our project page: https://xujiacong.github.io/Anomaly-OV/
零样本异常检测(ZSAD)是一种新兴的异常检测范式。不同于传统无监督异常检测需要大量正常样本进行模型训练,ZSAD在数据受限的现实场景中具有更实际的适用性。最近,多模态大型语言模型(MLLM)在各种视觉任务中展现出革命性的推理能力。然而,由于缺乏相应的数据集和基准测试,图像异常的推理仍然鲜有研究。为了促进异常检测和推理的研究,我们建立了首个视觉指令调整数据集Anomaly-Instruct-125k和评估基准VisA-D&R。通过我们的基准测试,我们发现当前的MLLM模型如GPT-4o无法准确检测和描述图像中的精细异常细节。为了解决这个问题,我们提出了Anomaly-OneVision(Anomaly-OV),这是第一个用于ZSAD和推理的专家视觉助手。Anomaly-OV借鉴了人类在视觉检查中的行为,利用二次特征匹配(LTFM)机制自适应选择和强调异常的视觉标记。大量实验表明,Anomaly-OV在检测和推理方面都实现了对先进通用模型的显著改进。此外,还为未来的研究提供了医学和三维异常检测的扩展。我们的项目页面链接为:链接。
论文及项目相关链接
PDF 19 pages, 10 figures, accepted by CVPR 2025
Summary
基于零样本异常检测(ZSAD)的新兴发展趋势,当前面临缺乏训练数据和实际应用场景的挑战。本文通过建立首个视觉指令调整数据集Anomaly-Instruct-125k和评估基准VisA-D&R,推动了对多模态大型语言模型(MLLMs)在异常检测和推理方面的应用。然而,当前MLLMs在图像异常检测方面存在不足,因此提出Anomaly-OneVision(Anomaly-OV)作为首个针对ZSAD和推理的专家视觉助手。Anomaly-OV采用看两次特征匹配(LTFM)机制,自适应选择和强调异常视觉标记,实现显著的性能提升。未来研究将扩展到医学和三维异常检测领域。更多信息请访问项目页面。
Key Takeaways
- ZSAD作为一种新兴异常检测(AD)范式,更适用于处理数据受限的实际情况。
- 多模态大型语言模型(MLLMs)在异常检测和推理方面具有革命性潜力。
- 当前图像异常检测研究中缺乏相应数据集和基准测试集,限制了研究发展。
- Anomaly-Instruct-125k数据集填补了这一空白,促进了AD和推理研究的进步。
- 当前MLLMs在图像异常检测方面存在准确性问题,无法准确捕捉细微的异常细节。
- Anomaly-OneVision(Anomaly-OV)通过自适应选择和强调异常视觉标记来提高检测性能。
- Anomaly-OV使用看两次特征匹配(LTFM)机制来模拟人类视觉检查的行为模式。
点此查看论文截图




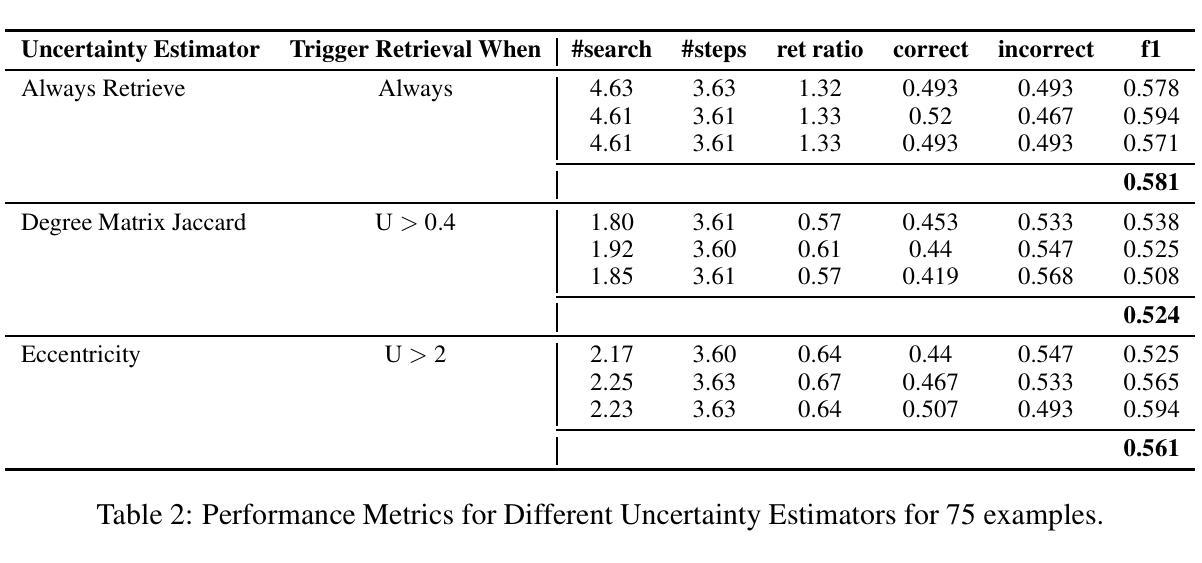
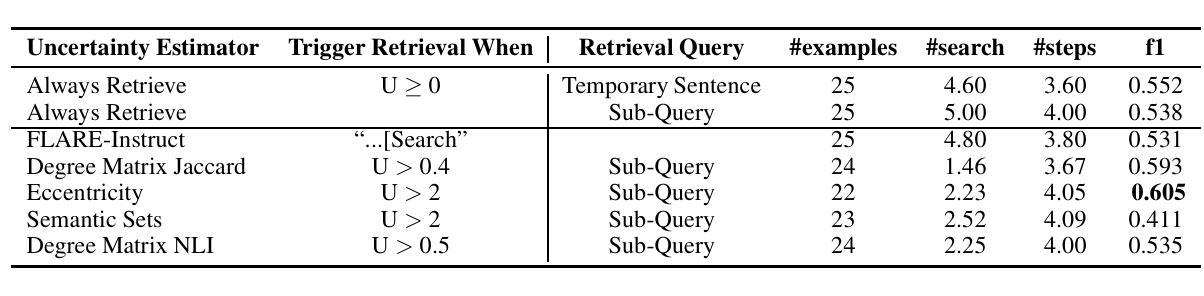
To Retrieve or Not to Retrieve? Uncertainty Detection for Dynamic Retrieval Augmented Generation
Authors:Kaustubh D. Dhole
Retrieval-Augmented Generation equips large language models with the capability to retrieve external knowledge, thereby mitigating hallucinations by incorporating information beyond the model’s intrinsic abilities. However, most prior works have focused on invoking retrieval deterministically, which makes it unsuitable for tasks such as long-form question answering. Instead, dynamically performing retrieval by invoking it only when the underlying LLM lacks the required knowledge can be more efficient. In this context, we delve deeper into the question, “To Retrieve or Not to Retrieve?” by exploring multiple uncertainty detection methods. We evaluate these methods for the task of long-form question answering, employing dynamic retrieval, and present our comparisons. Our findings suggest that uncertainty detection metrics, such as Degree Matrix Jaccard and Eccentricity, can reduce the number of retrieval calls by almost half, with only a slight reduction in question-answering accuracy.
检索增强生成技术为大型语言模型配备了检索外部知识的能力,从而通过融入模型自身能力之外的信息来抑制幻觉。然而,大多数早期工作都集中在确定性地调用检索上,这使得它不适用于长形式问答等任务。相反,仅在基础LLM缺乏所需知识时才动态执行检索会更加高效。在这种情况下,我们通过探索多种不确定性检测方法,深入探讨“是否进行检索?”的问题。我们对长形式问答任务评估这些方法,采用动态检索,并展示我们的比较结果。我们的研究结果表明,不确定性检测指标(如度矩阵雅卡尔和离心率)可以将检索调用次数减少近一半,而问答准确率只有轻微下降。
论文及项目相关链接
PDF 1st workshop of “Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI” at ICLR 2025
Summary:
大型语言模型通过检索增强生成技术,能够检索外部知识,从而融入模型本身不具备的信息,减少虚构内容。然而,之前的研究大多采用确定性检索方式,这不适用于长文本问答任务。本文通过探索多种不确定性检测方法来动态执行检索,只在语言模型缺乏所需知识时调用检索功能。实验表明,使用不确定性检测指标(如度数矩阵Jaccard和离心率)可以减少近一半的检索调用次数,同时仅略微降低问答准确性。
Key Takeaways:
- 检索增强生成技术使大型语言模型能够融入外部知识,减少虚构内容。
- 传统的确定性检索方式不适用于长文本问答任务。
- 通过动态执行检索可以提高效率。
- 不确定性检测方法是实现动态检索的关键。
- 实验中使用的不确定性检测指标如度数矩阵Jaccard和离心率可以有效减少检索调用次数。
- 在使用不确定性检测指标减少检索调用的同时,只略微影响问答准确性。
点此查看论文截图

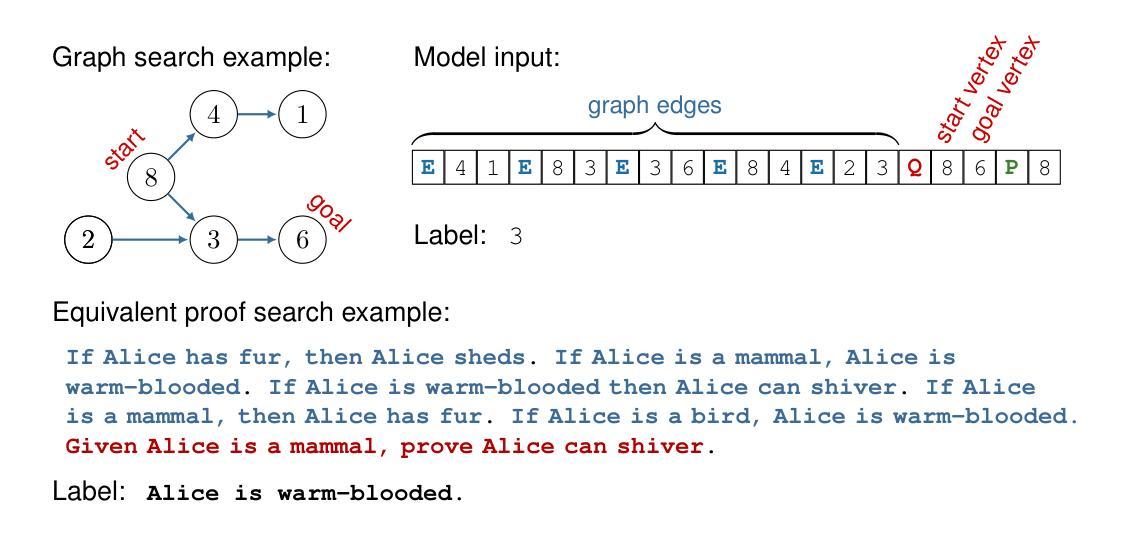
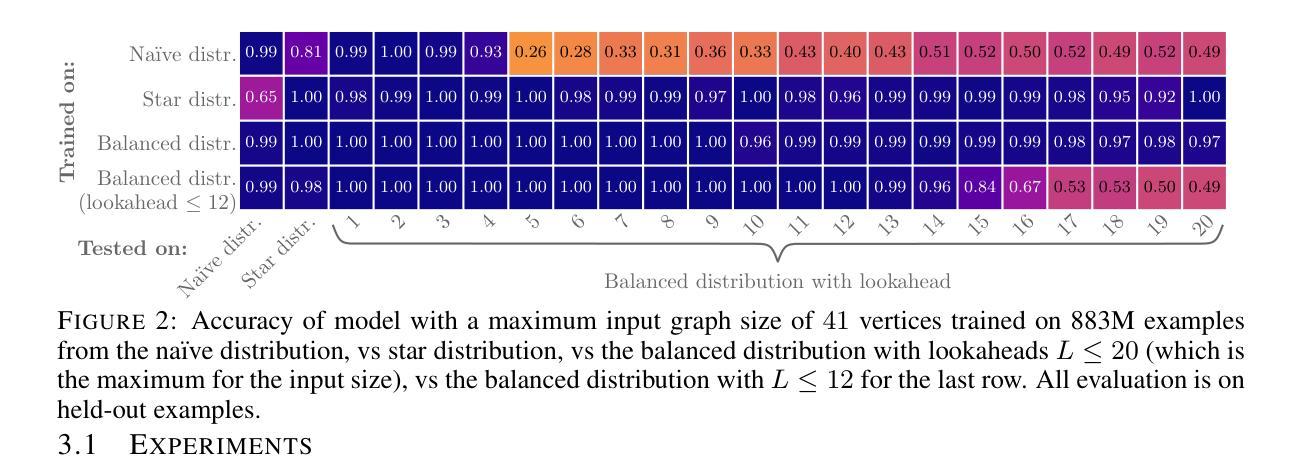
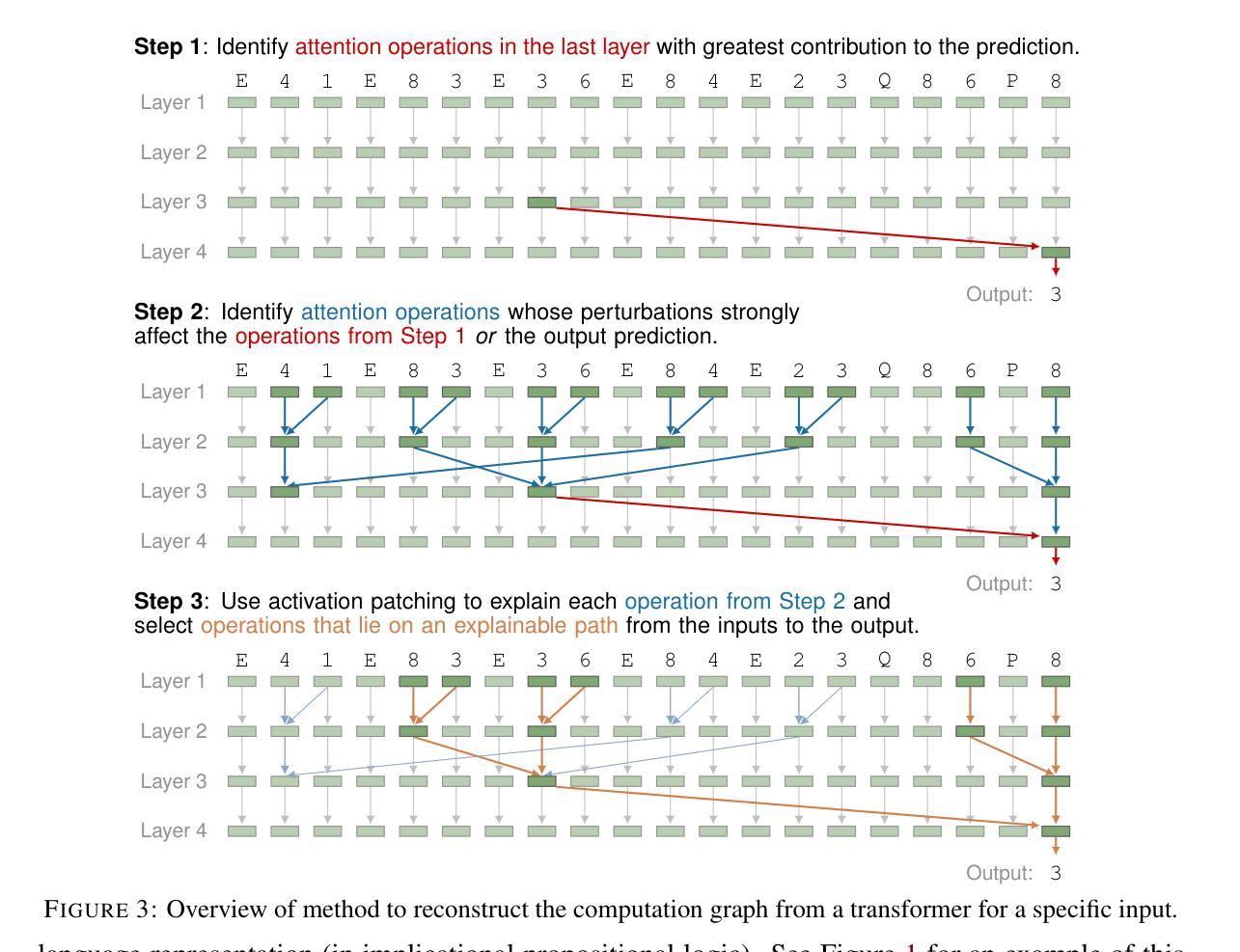
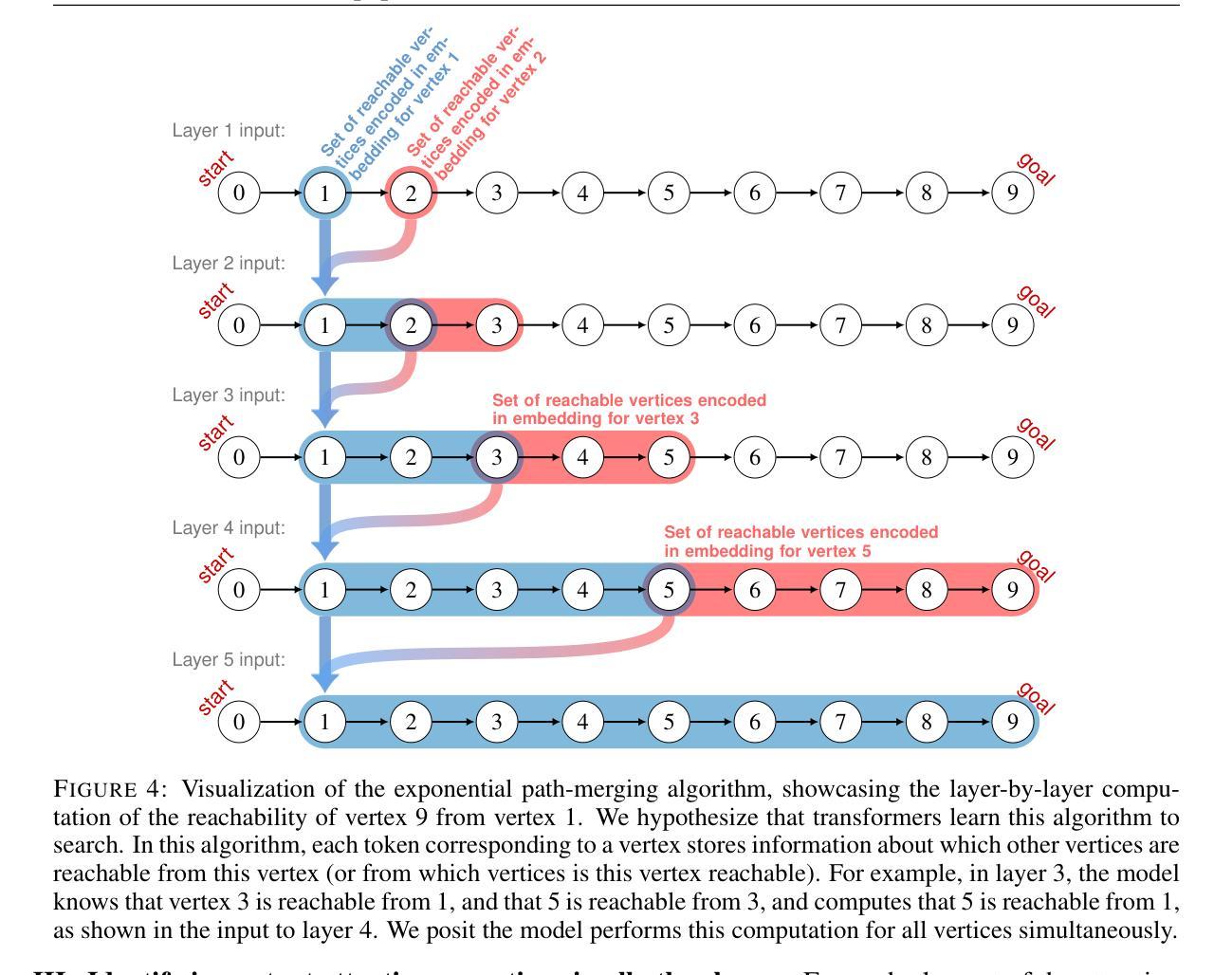
Transformers Struggle to Learn to Search
Authors:Abulhair Saparov, Srushti Pawar, Shreyas Pimpalgaonkar, Nitish Joshi, Richard Yuanzhe Pang, Vishakh Padmakumar, Seyed Mehran Kazemi, Najoung Kim, He He
Search is an ability foundational in many important tasks, and recent studies have shown that large language models (LLMs) struggle to perform search robustly. It is unknown whether this inability is due to a lack of data, insufficient model parameters, or fundamental limitations of the transformer architecture. In this work, we use the foundational graph connectivity problem as a testbed to generate effectively limitless high-coverage data to train small transformers and test whether they can learn to perform search. We find that, when given the right training distribution, the transformer is able to learn to search. We analyze the algorithm that the transformer has learned through a novel mechanistic interpretability technique that enables us to extract the computation graph from the trained model. We find that transformers perform search at every vertex in parallel: For each vertex in the input graph, transformers compute the set of vertices reachable from that vertex. Each layer then progressively expands these sets, allowing the model to search over a number of vertices exponential in $n_{\text{layers}}$. However, we find that as the input graph size increases, the transformer has greater difficulty in learning the task. This difficulty is not resolved even as the number of parameters is increased, suggesting that increasing model scale will not lead to robust search abilities. We also find that performing search in-context (i.e., chain-of-thought) does not resolve this inability to learn to search on larger graphs.
搜索是许多重要任务中的基础能力,最近的研究表明大型语言模型(LLM)在执行稳健搜索时遇到困难。目前尚不清楚这种无能是由于数据不足、模型参数不足,还是由于Transformer架构的根本限制。在这项工作中,我们以基础图连接问题作为测试平台,生成有效无限的高覆盖率数据来训练小型Transformer,并测试它们是否能学会搜索。我们发现,当给予正确的训练分布时,Transformer能够学会搜索。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
本文探讨了大型语言模型(LLM)在搜索任务上的表现,并指出其面临的挑战。研究通过利用基础图连接问题作为测试平台,生成大量数据进行训练,发现给予适当的训练分布,变压器模型能够学习进行搜索。通过新型机械解释技术,研究人员分析了模型算法,发现变压器在每个顶点并行执行搜索任务。然而,随着输入图形大小的增加,模型学习任务的难度也随之增加,即使增加参数数量也无法解决这一问题。这表明扩大模型规模并不一定能提高模型的搜索能力。同时,上下文搜索(即思维链)也无法解决大型图形上的搜索学习难题。
Key Takeaways
- 大型语言模型(LLM)在搜索任务上表现不佳的原因尚不清楚,可能涉及数据缺乏、模型参数不足或转换器架构的根本限制。
- 通过利用基础图连接问题作为测试平台,可以有效生成大量数据来训练小型转换器,使其学习搜索任务。
- 给予适当的训练分布,变压器模型能够学习进行搜索任务。
- 通过机械解释技术,研究人员发现变压器模型在每个顶点并行执行搜索任务。
- 随着输入图形大小的增加,模型学习任务的难度增加,增加参数数量也无法解决这一难题。
- 扩大模型规模并不一定能提高模型的搜索能力。
点此查看论文截图

CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation
Authors:Hui Zhang, Dexiang Hong, Yitong Wang, Jie Shao, Xinglong Wu, Zuxuan Wu, Yu-Gang Jiang
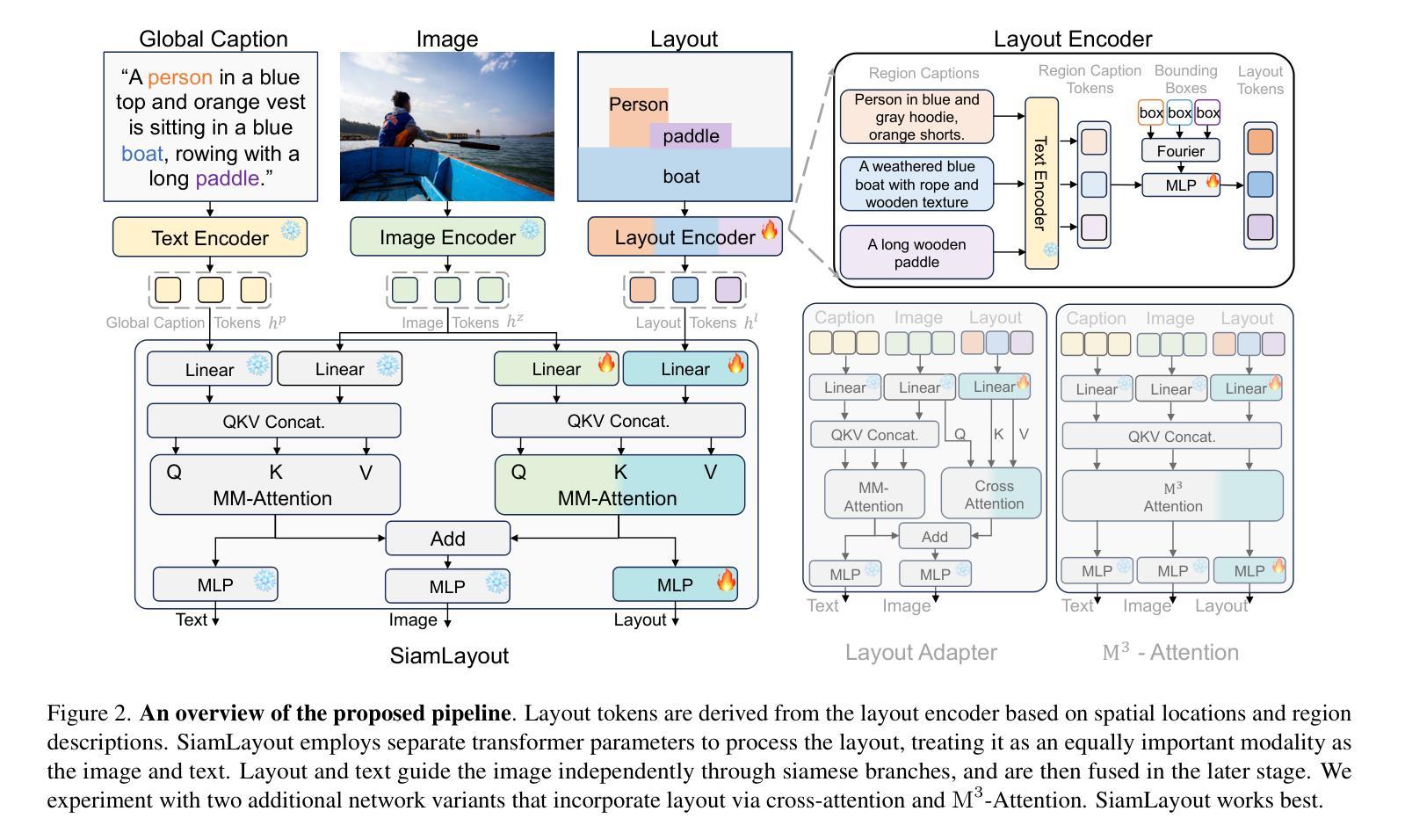
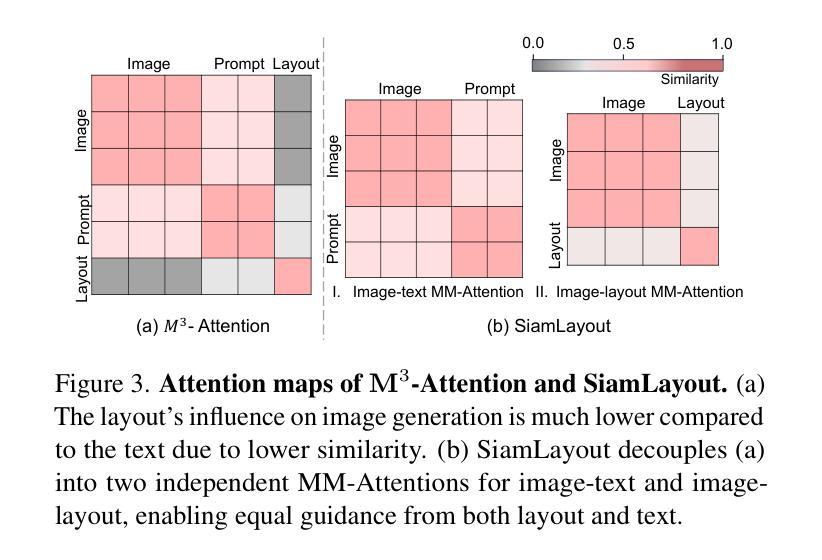
Diffusion models have been recognized for their ability to generate images that are not only visually appealing but also of high artistic quality. As a result, Layout-to-Image (L2I) generation has been proposed to leverage region-specific positions and descriptions to enable more precise and controllable generation. However, previous methods primarily focus on UNet-based models (e.g., SD1.5 and SDXL), and limited effort has explored Multimodal Diffusion Transformers (MM-DiTs), which have demonstrated powerful image generation capabilities. Enabling MM-DiT for layout-to-image generation seems straightforward but is challenging due to the complexity of how layout is introduced, integrated, and balanced among multiple modalities. To this end, we explore various network variants to efficiently incorporate layout guidance into MM-DiT, and ultimately present SiamLayout. To Inherit the advantages of MM-DiT, we use a separate set of network weights to process the layout, treating it as equally important as the image and text modalities. Meanwhile, to alleviate the competition among modalities, we decouple the image-layout interaction into a siamese branch alongside the image-text one and fuse them in the later stage. Moreover, we contribute a large-scale layout dataset, named LayoutSAM, which includes 2.7 million image-text pairs and 10.7 million entities. Each entity is annotated with a bounding box and a detailed description. We further construct the LayoutSAM-Eval benchmark as a comprehensive tool for evaluating the L2I generation quality. Finally, we introduce the Layout Designer, which taps into the potential of large language models in layout planning, transforming them into experts in layout generation and optimization. Our code, model, and dataset will be available at https://creatilayout.github.io.
扩散模型因其能够生成不仅视觉吸引力强而且艺术性高的图像而备受关注。因此,提出了Layout-to-Image(L2I)生成方法,利用特定区域的位置和描述来实现更精确和可控的生成。然而,之前的方法主要集中在基于UNet的模型(例如SD1.5和SDXL),对多模态扩散变压器(MM-DiT)的探索有限,而MM-DiT已显示出强大的图像生成能力。尽管使MM-DiT用于布局到图像生成看似简单,但由于引入、集成和平衡布局于多种模态之间的复杂性,实际上面临挑战。为此,我们探索了各种网络变体,以有效地将布局指导融入MM-DiT,并最终推出SiamLayout。为了继承MM-DiT的优点,我们使用一组独立的网络权重来处理布局,将其视为与图像和文本模态同等重要。同时,为了减轻模态之间的竞争,我们将图像布局交互解耦为与图像文本分支并列的孪生分支,并在后期进行融合。此外,我们贡献了一个大规模布局数据集LayoutSAM,其中包括270万张图像文本对和1070万个实体。每个实体都带有边界框和详细描述。我们还构建了LayoutSAM-Eval基准测试,作为评估L2I生成质量的综合工具。最后,我们推出了Layout Designer,它挖掘了大语言模型在布局规划中的潜力,将其转变为布局生成和优化的专家。我们的代码、模型和数据集将在https://creatilayout.github.io上提供。
论文及项目相关链接
Summary
本文探讨了Layout-to-Image(L2I)生成技术在图像生成领域的应用。文章指出,尽管现有的扩散模型已经能够生成高质量图像,但在引入布局指导方面仍存在挑战。文章介绍了如何利用多模态扩散转换器(MM-DiT)进行布局到图像的生成,并探讨了如何将布局指导有效地融入MM-DiT中的方法。此外,文章还贡献了一个大规模布局数据集LayoutSAM,包含大量带标注的图像文本对实体数据。同时推出了LayoutSAM-Eval评估工具以评价L2I生成质量,并引入了Layout Designer利用大型语言模型的潜力在布局规划方面的专家系统。最终的代码、模型和数据集将公开提供。
Key Takeaways
- 扩散模型在图像生成领域具有强大的能力,能够生成高质量且具有艺术感的图像。
- Layout-to-Image(L2I)生成技术利用区域特定位置和描述来实现更精确和可控的图像生成。
- 现有的方法主要关注UNet-based模型,而对Multimodal Diffusion Transformers(MM-DiT)的研究有限。
- MM-DiT融入布局指导面临复杂性挑战,需要探索有效的网络变体。
- SiamLayout通过采用分离的网络权重处理布局信息,实现了MM-DiT的优势,同时平衡了各模态之间的竞争。
- 推出了大规模布局数据集LayoutSAM,包含大量带标注的图像文本对实体数据,用于评估和改进L2I生成技术。
点此查看论文截图

Collaborative Instance Object Navigation: Leveraging Uncertainty-Awareness to Minimize Human-Agent Dialogues
Authors:Francesco Taioli, Edoardo Zorzi, Gianni Franchi, Alberto Castellini, Alessandro Farinelli, Marco Cristani, Yiming Wang
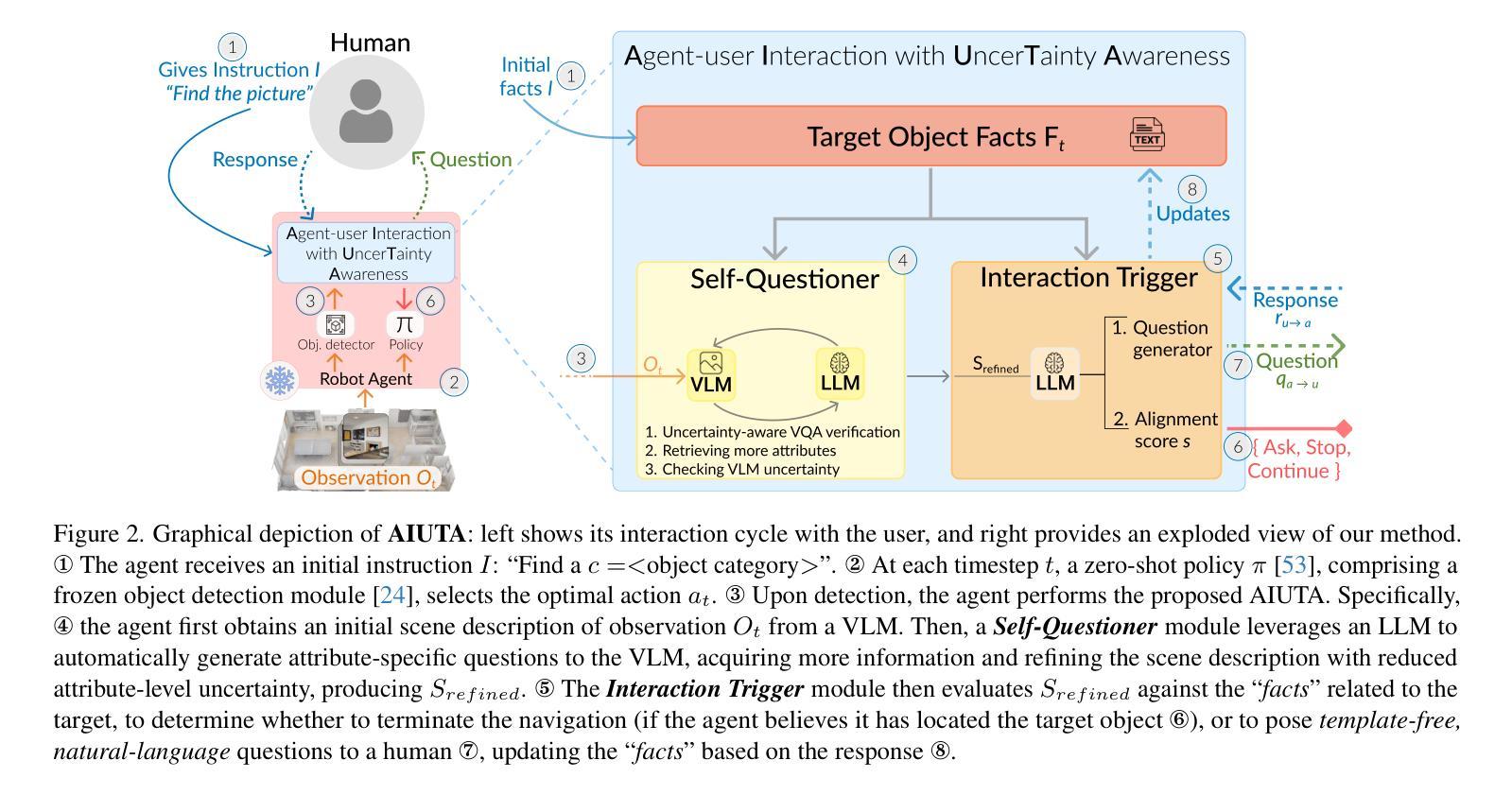
Language-driven instance object navigation assumes that human users initiate the task by providing a detailed description of the target instance to the embodied agent. While this description is crucial for distinguishing the target from visually similar instances in a scene, providing it prior to navigation can be demanding for human. To bridge this gap, we introduce Collaborative Instance object Navigation (CoIN), a new task setting where the agent actively resolve uncertainties about the target instance during navigation in natural, template-free, open-ended dialogues with human. We propose a novel training-free method, Agent-user Interaction with UncerTainty Awareness (AIUTA), which operates independently from the navigation policy, and focuses on the human-agent interaction reasoning with Vision-Language Models (VLMs) and Large Language Models (LLMs). First, upon object detection, a Self-Questioner model initiates a self-dialogue within the agent to obtain a complete and accurate observation description with a novel uncertainty estimation technique. Then, an Interaction Trigger module determines whether to ask a question to the human, continue or halt navigation, minimizing user input. For evaluation, we introduce CoIN-Bench, with a curated dataset designed for challenging multi-instance scenarios. CoIN-Bench supports both online evaluation with humans and reproducible experiments with simulated user-agent interactions. On CoIN-Bench, we show that AIUTA serves as a competitive baseline, while existing language-driven instance navigation methods struggle in complex multi-instance scenes. Code and benchmark will be available upon acceptance at https://intelligolabs.github.io/CoIN/
语言驱动的实例对象导航假设人类用户通过向实体代理提供目标实例的详细描述来启动任务。虽然这个描述对于从场景中的视觉相似实例中区分目标至关重要,但在导航之前提供它可能对人类来说是一种挑战。为了弥补这一差距,我们引入了协作实例对象导航(CoIN),这是一个新的任务设置,其中代理在与人类进行无模板、开放式的自然对话过程中,积极解决关于目标实例的不确定性。我们提出了一种新的无需训练的方法——具有不确定性意识的代理用户交互(AIUTA),它独立于导航策略,专注于利用视觉语言模型(VLM)和大型语言模型(LLM)的人类代理交互推理。首先,在对象检测后,自我提问模型会在代理内部发起一次自我对话,利用一种新型的不确定性估计技术来获得完整准确的观察描述。然后,交互触发模块确定是否向人类提问、继续或停止导航,以最小化用户输入。为了评估性能,我们推出了CoIN-Bench,它包含专为具有挑战性的多实例场景设计的精选数据集。CoIN-Bench支持与人类在线评估以及可重复的模拟用户代理交互实验。在CoIN-Bench上,我们展示了AIUTA作为一个有竞争力的基准线,而现有的语言驱动实例导航方法在复杂的多实例场景中表现挣扎。接受后,代码和基准线将在https://intelligolabs.github.io/CoIN/上可用。
论文及项目相关链接
PDF https://intelligolabs.github.io/CoIN/
Summary:
本文介绍了一种新的任务设置——协作式实例对象导航(CoIN),其中代理在导航过程中通过与用户的开放对话主动解决目标实例的不确定性问题。提出了一种无需训练的方法——具有不确定性感知的代理用户交互(AIUTA),该方法独立于导航策略,专注于利用视觉语言模型(VLM)和大型语言模型(LLM)进行人机交互推理。通过自我提问模型获得完整准确的观察描述,并引入交互触发模块来决定是否向用户提问、继续或停止导航。评估中引入了CoIN-Bench数据集,支持在线人类评估和可重复的模拟用户-代理交互实验。AIUTA在CoIN-Bench上表现有竞争力,而现有的语言驱动实例导航方法在复杂多实例场景中表现挣扎。
Key Takeaways:
- 引入新的任务设置:协作式实例对象导航(CoIN)。
- 提出一种无需训练的方法:AIUTA,用于解决导航过程中的不确定性问题。
- AIUTA利用视觉语言模型(VLM)和大型语言模型(LLM)进行人机交互推理。
- 通过自我提问模型获得对目标实例的完整准确观察描述。
- 引入交互触发模块以最小化用户输入,决定导航决策。
- 评估中使用了新的数据集CoIN-Bench,支持在线人类评估和模拟实验。
点此查看论文截图